
كلمات مفتاحية:النماذج الكبيرة متعددة الوسائط, قدرة الاستدلال بالذكاء الاصطناعي, إطار العمل العام لاستراتيجيات الروبوت LeRobot, اتجاه التنسيق متعدد الوكلاء للذكاء الاصطناعي, MM-HELIX, Qwen2.5-VL-7B, استدلال تأملي متسلسل طويل, تحويل الفيديو إلى كود, IWR-Bench, GPT-5, خوارزمية التحسين الاستراتيجي الهجين التكيفي AHPO, معيار تقييم إعادة بناء صفحات الويب التفاعلية, أداء استدلال الرياضيات في النماذج اللغوية الكبيرة
🔥 تركيز
اختراق في قدرة نماذج الذكاء الاصطناعي متعددة الوسائط على التفكير الانعكاسي طويل السلسلة: أطلقت جامعة شنغهاي جياو تونغ ومختبر شنغهاي للذكاء الاصطناعي بالتعاون نظام MM-HELIX البيئي، بهدف تزويد الذكاء الاصطناعي بقدرة التفكير الانعكاسي طويل السلسلة. من خلال بناء معيار MM-HELIX (الذي يتضمن 42 مهمة عالية الصعوبة في الخوارزميات، نظرية الرسوم البيانية، الألغاز، والألعاب الاستراتيجية) ومجموعة بيانات MM-HELIX-100K، وباستخدام خوارزمية AHPO لتحسين الاستراتيجية المختلطة التكيفية، تم تدريب نموذج Qwen2.5-VL-7B بنجاح لزيادة الدقة بنسبة 18.6% على المعيار، وبمتوسط زيادة قدرها 5.7% في مهام الرياضيات العامة والاستدلال المنطقي. يثبت هذا أن النموذج لا يستطيع حل المشكلات المعقدة فحسب، بل يمكنه أيضًا تطبيق ما تعلمه على مشكلات أخرى، مما يمثل خطوة حاسمة في انتقال الذكاء الاصطناعي من “وعاء المعرفة” إلى “خبير حل المشكلات”. (المصدر: 量子位)
إطلاق أول معيار Video-to-Code، وGPT-5 يحقق أداءً ضعيفًا: أطلق مختبر شنغهاي للذكاء الاصطناعي بالتعاون مع جامعة تشجيانغ ومؤسسات أخرى IWR-Bench، وهو أول معيار لتقييم قدرة نماذج الذكاء الاصطناعي متعددة الوسائط على إعادة بناء صفحات الويب التفاعلية (Video-to-Code). يتطلب هذا المعيار من النموذج مشاهدة فيديو لعمليات المستخدم ودمج الموارد الثابتة لإعادة إنتاج السلوك الديناميكي للصفحة. أظهرت نتائج الاختبار أن GPT-5، حتى، حقق درجة إجمالية بلغت 36.35% فقط، وكانت صحة الوظائف (IFS) 24.39% فقط، وهي أقل بكثير من دقة الرؤية (VFS) البالغة 64.25%. يكشف هذا عن نقص خطير في قدرة النماذج الحالية على توليد منطق يعتمد على الأحداث، مما يشير إلى اتجاه بحثي جديد لتطوير الواجهة الأمامية الآلي بواسطة الذكاء الاصطناعي. (المصدر: 量子位)
دعوة إيلون ماسك لأندريه كارباثي لمبارزة برمجية ضد Grok 5 تثير الجدل: وجه إيلون ماسك دعوة علنية لمهندس الذكاء الاصطناعي الشهير أندريه كارباثي لمبارزة برمجية ضد Grok 5، مما أثار نقاشًا واسعًا في المجتمع حول تطور AGI (الذكاء الاصطناعي العام) وأنماط التعاون بين الإنسان والآلة. رفض كارباثي التحدي، مشيرًا إلى أنه يفضل التعاون مع Grok 5 بدلاً من التنافس، معتقدًا أن قيمة الإنسان تقترب من الصفر في الظروف القاسية. يسلط هذا التفاعل الضوء على التقدم الذي أحرزه الذكاء الاصطناعي في مجال البرمجة، بينما يثير أيضًا تساؤلات عميقة حول ما إذا كان الذكاء الاصطناعي يمكن أن يصل إلى الإبداع البشري الفريد، وما إذا كانت العلاقة بين الإنسان والآلة يجب أن تكون تنافسية أم تعاونية. (المصدر: 量子位)

Hugging Face وجامعة أكسفورد تطلقان LeRobot، لإنشاء نموذج جديد لاستراتيجيات الروبوتات العامة: أطلقت Hugging Face بالتعاون مع جامعة أكسفورد LeRobot، بهدف أن يصبح “PyTorch لعالم الروبوتات”. يوفر هذا الإطار البرمجي كودًا شاملاً، ويدعم الأجهزة الحقيقية، ويمكنه تدريب استراتيجيات روبوتات عامة، وكل ذلك مفتوح المصدر. يتيح LeRobot للروبوتات التعلم من البيانات متعددة الوسائط واسعة النطاق (الفيديو، المستشعرات، النص) تمامًا مثل LLM، ويمكن لنموذج واحد التحكم في أنواع متعددة من الروبوتات، من الروبوتات البشرية إلى الأذرع الروبوتية. يمثل هذا تحولًا في أبحاث الروبوتات من الاعتماد على المعادلات إلى الاعتماد على البيانات، مما يبشر بعصر جديد لتعلم الروبوتات، والاستدلال، والتكيف مع العالم الحقيقي. (المصدر: huggingface, ClementDelangue)

🎯 اتجاهات
منتجات Agent الصينية تظهر اتجاهات نحو التنسيق متعدد الكيانات والتعمق الرأسي: يظهر تصنيف AI100 للربع الثالث من عام 2025 الصادر عن QbitAI Research أن منتجات Agent الصينية تتطور من الذكاء أحادي النقطة إلى التعاون الذكي المنهجي، مع التركيز على قدرات معالجة المهام الفعالة والقوية والمستقرة، مثل توسيع السياق، ودمج المعلومات متعددة الوسائط، والتكامل العميق للخدمات السحابية والمحلية. فيما يتعلق بالتطبيق العملي، يتجه الاتجاه من الأدوات العامة إلى “الشركاء الأذكياء” في الصناعة، حيث يتعمقون في المجالات الرأسية مثل البحث العلمي والاستثمار لحل نقاط الضعف، على سبيل المثال، وضع “OK Computer” لـ Kimi، والسياق الطويل جدًا 1M لـ MiniMax، وسرب Agent المتعدد لـ 纳米AI، ومنصة التعاون متعددة Agent لـ 蚂蚁百宝箱. (المصدر: 量子位)

جوجل ترقي نموذج Veo 3.1، لتعزيز واقعية توليد الفيديو والصوت: حصل نموذج Veo 3.1 من جوجل على ترقية، مما يوفر للمبدعين واقعية فيديو أقوى وتجربة صوتية أكثر ثراءً. تم إطلاق النموذج بالفعل في Flowbygoogle، وتطبيق Gemini، وGoogle Cloud Vertex AI، وGemini API، مما يعزز قدرات توليد الفيديو بالذكاء الاصطناعي، ومن المتوقع أن يدفع تطور الصناعات الإبداعية. في الوقت نفسه، قدمت Gemini API أيضًا تكاملًا مع Google Maps، من خلال دمج بيانات 250 مليون موقع، لتمكين تجارب ذكاء اصطناعي جديدة متعلقة بالموقع الجغرافي. (المصدر: algo_diver, algo_diver)
توسيع نماذج LLM وتوقعات الأداء: Qwen3 Next وGemma 4: يدفع مجتمع المصادر المفتوحة بنشاط دعم نموذج Qwen3 Next، مما يبشر بمزيد من الخيارات والإمكانيات لنشر LLM محليًا في المستقبل. في الوقت نفسه، أثار إطلاق Gemini 3.0 توقعات كبيرة لنموذج Gemma 4 مفتوح المصدر المبني على بنيته. نظرًا لأن نماذج سلسلة Gemma عادةً ما يتم إطلاقها في غضون 1-4 أشهر بعد إطلاق نموذج Gemini الرئيسي، فمن المتوقع أن يحقق Gemma 4 قفزة كبيرة في الأداء في المدى القصير، مما يوفر إمكانية ترقيتين جيلين، ويدفع بشكل أكبر تطوير الذكاء الاصطناعي المحلي وLLM مفتوحة المصدر. (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
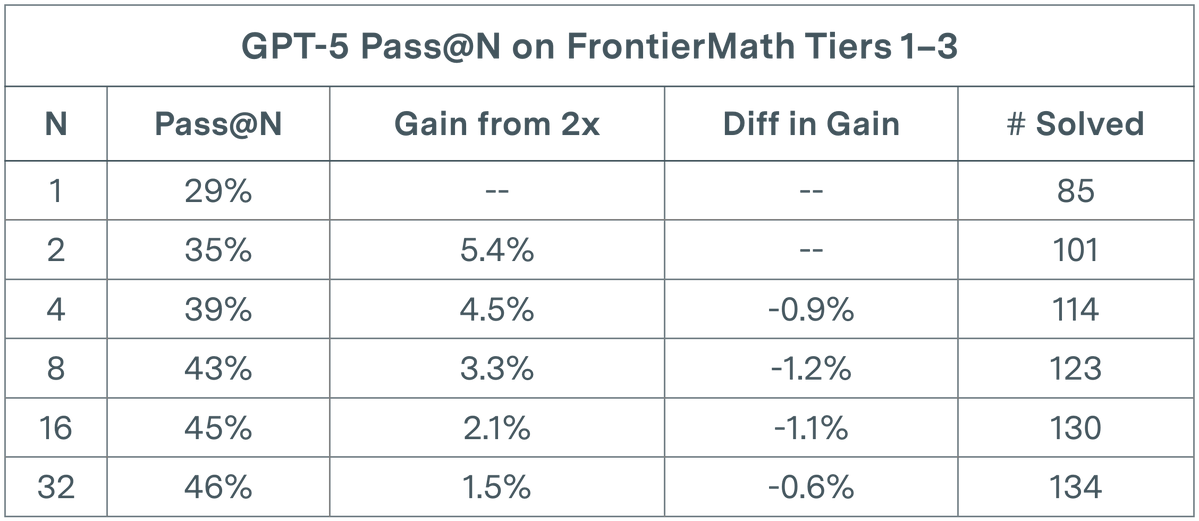
تقييم LLM يواجه عنق الزجاجة: GPT-5 يعاني من تناقص العوائد في المهام الرياضية: أظهرت دراسة Epoch AI أن نمو معدل الحل لـ GPT-5 على مجموعة بيانات FrontierMath T1-3، حتى عند مضاعفة N إلى 32 في تقييم pass@N، يظهر اتجاهًا شبه لوغاريتمي، ويستقر في النهاية عند حد أقصى يبلغ حوالي 50%. يشير هذا الاكتشاف إلى أن مجرد زيادة عدد مرات التشغيل (N) لا يؤدي إلى تحسين خطي في الأداء، وقد يكون قد وصل إلى الحد المعرفي الحالي للنموذج في الاستدلال الرياضي المعقد. يدفع هذا الباحثين إلى التفكير فيما إذا كان من الضروري إدخال مطالبات تشجع التنوع لاستكشاف مساحة حلول أوسع، من أجل اختراق عنق الزجاجة الحالي. (المصدر: paul_cal)
مناقشة حول فائدة وقيود AI Agent: هناك جدل في المجتمع حول الفائدة العملية لـ AI Agent. يرى البعض أن العديد من الادعاءات بأن Agent يمكن أن يعمل لفترات طويلة ويولد كودًا قد تكون مبالغًا فيها، وأنه بالنسبة لقواعد الكود على مستوى الإنتاج، غالبًا ما تكون نتائج تشغيل Agent لأكثر من بضع دقائق صعبة المراجعة، ومن الأفضل كتابتها يدويًا. ومع ذلك، يشير آخرون إلى أن LLM، على الرغم من أنها ليست تقنية ثورية، إلا أنها ليست عديمة الفائدة على الإطلاق، فهي يمكن أن توفر وقتًا كبيرًا في بعض المهام، والمفتاح هو فهم قيودها والتعاون بين الإنسان والآلة. تعكس هذه المناقشة موقف الصناعة الحذر تجاه القدرات الحالية لـ AI Agent ومسار تطورها المستقبلي. (المصدر: andriy_mulyar, jeremyphoward)
أبحاث RL تواجه تحديات: ملايين الدولارات المستثمرة لم تحقق اختراقات كبيرة: أثارت ورقة بحثية حول توسيع التعلم المعزز (RL) نقاشًا في المجتمع، مشيرة إلى أن تجارب الإزالة التي كلفت 4.2 مليون دولار لم تسفر عن تحسينات كبيرة على مستوى التكنولوجيا الحالي. تدفع هذه الظاهرة الناس إلى التساؤل عن عائد الاستثمار في أبحاث RL، وتدعو إلى توجيه الموارد نحو اتجاهات أكثر فعالية. ومع ذلك، فإن أداء RL يتحسن بسرعة، فعلى سبيل المثال، لعبة Breakout التي كانت تتطلب 10 ساعات للتعلم في الماضي، تستغرق الآن أقل من 30 ثانية على PufferLib، مما يسلط الضوء على أهمية تحسين الكود والخوارزميات. (المصدر: vikhyatk, jsuarez5341)

اكتشاف أمني جديد للذكاء الاصطناعي: كمية صغيرة من البيانات الضارة يمكن أن تفتح بابًا خلفيًا لـ LLM: كشفت دراسة جديدة أن هجمات تسميم البيانات تشكل تهديدًا لـ LLM يتجاوز التوقعات بكثير. أظهرت الدراسة أن 250 وثيقة ضارة فقط تكفي لشن هجوم باب خلفي على LLM بأي حجم، مما يقلب الافتراض السابق بأن المهاجمين يحتاجون إلى التحكم في كمية كبيرة من بيانات التدريب. يمثل هذا الاكتشاف تحديًا خطيرًا لأمن نماذج الذكاء الاصطناعي، ويؤكد على الحاجة الملحة لتعزيز الحماية الأمنية في تصفية بيانات تدريب LLM ونشر النماذج. (المصدر: dl_weekly)
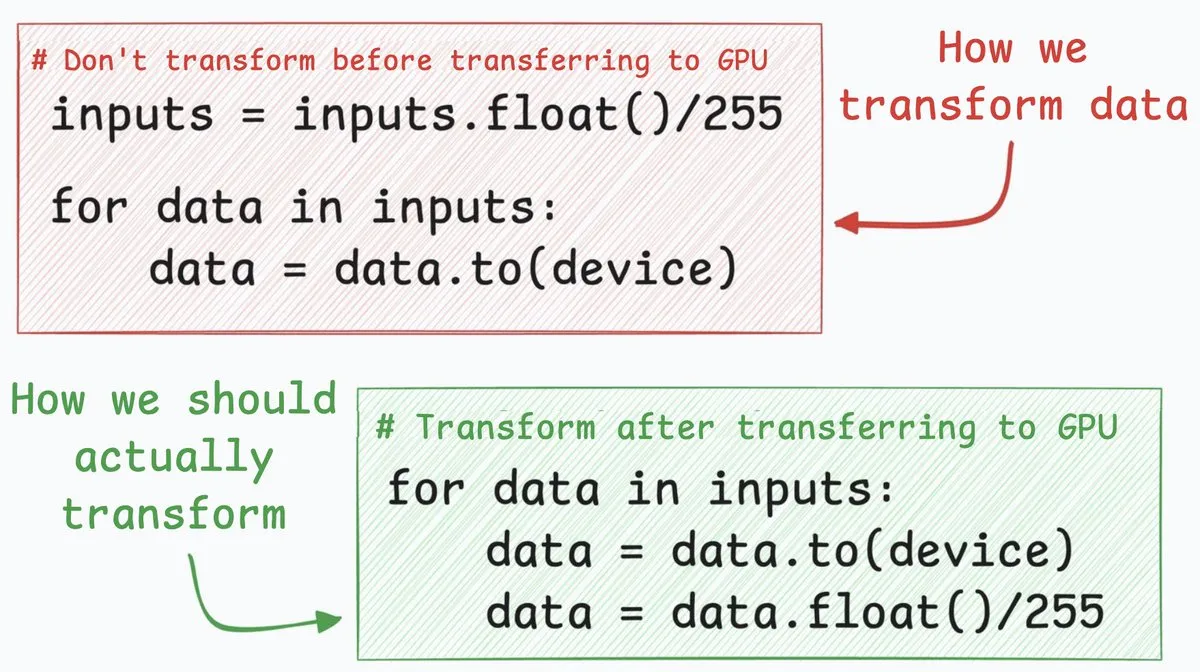
نصيحة لتحسين الشبكات العصبية: تسريع نقل البيانات من CPU إلى GPU بمقدار 4 مرات: يمكن لنصيحة لتحسين الشبكات العصبية أن تزيد سرعة نقل البيانات من CPU إلى GPU بحوالي 4 مرات. تقترح هذه الطريقة نقل خطوات تحويل البيانات (مثل تحويل قيم بكسل الأعداد الصحيحة 8 بت إلى أعداد عشرية 32 بت) إلى ما بعد نقل البيانات. من خلال نقل الأعداد الصحيحة 8 بت أولاً، يمكن تقليل كمية البيانات المنقولة بشكل كبير، وبالتالي تقليل الوقت الذي تستغرقه cudaMemcpyAsync بشكل كبير. على الرغم من أنها لا تنطبق على جميع السيناريوهات (مثل تضمينات الأعداد العشرية في NLP)، إلا أنها يمكن أن تؤدي إلى تحسينات كبيرة في الأداء في مهام مثل تصنيف الصور. (المصدر: _avichawla)
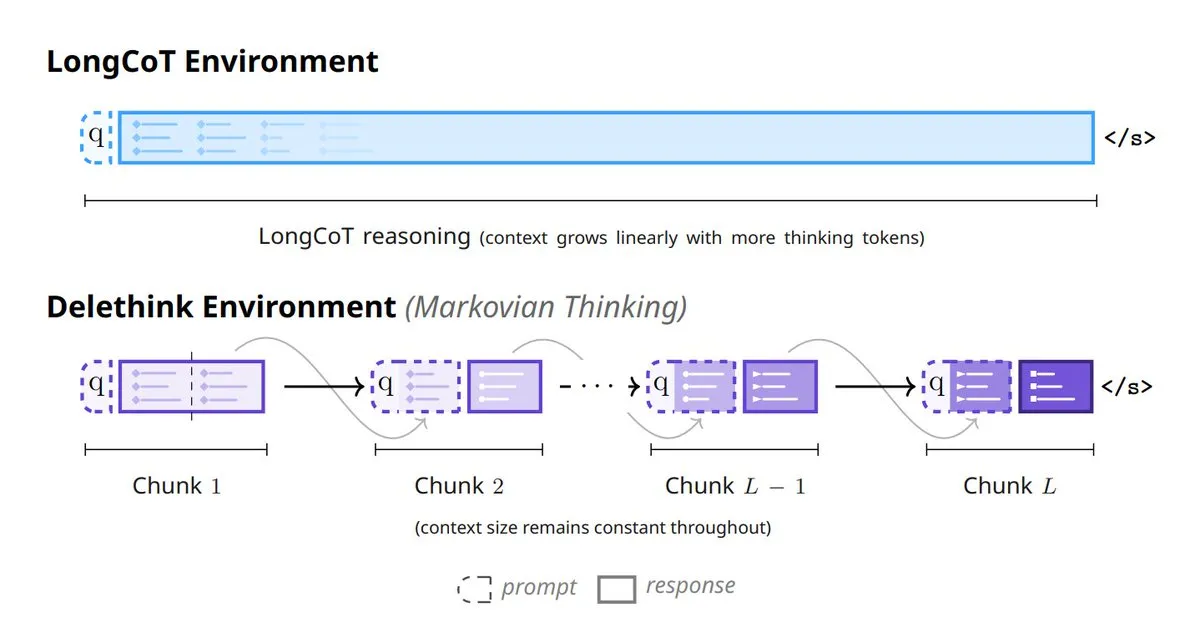
نموذج جديد لتفكير الذكاء الاصطناعي: 6 طرق لإعادة تشكيل تفكير النموذج: تظهر 6 طرق مبتكرة في مجال الذكاء الاصطناعي لإعادة تشكيل تفكير النموذج: بما في ذلك Tiny Recursive Models (TRM)، وLaDIR (Latent Diffusion for Iterative Reasoning)، وETD (encode-think-decode)، وThinking on the fly، وThe Markovian Thinker، وToTAL (Thought Template Augmented LCLMs). تمثل هذه الطرق أحدث الاستكشافات في معالجة النماذج المتكررة، والاستدلال التكراري، والتفكير الديناميكي، وتعزيز القوالب، وتهدف إلى تحسين قدرة الذكاء الاصطناعي على حل المشكلات المعقدة وكفاءتها. (المصدر: TheTuringPost)
🧰 أدوات
Skyvern-AI: أتمتة سير عمل المتصفح بناءً على LLM والرؤية الحاسوبية: أطلقت Skyvern-AI أداة مفتوحة المصدر تسمى Skyvern، تستخدم LLM وتقنيات الرؤية الحاسوبية لأتمتة سير عمل المتصفح. تفهم هذه الأداة مواقع الويب وتخطط وتنفذ الإجراءات من خلال مجموعة من الوكلاء، وتتعامل مع تغييرات تخطيط الموقع دون الحاجة إلى نصوص برمجية مخصصة، مما يحقق أتمتة سير عمل عامة عبر مواقع ويب متعددة. أظهرت Skyvern أداءً ممتازًا في معيار WebBench، وهي بارعة بشكل خاص في مهام RPA مثل ملء النماذج واستخراج البيانات وتنزيل الملفات، وتدعم العديد من مزودي LLM وطرق المصادقة، وتهدف إلى استبدال حلول الأتمتة التقليدية الهشة. (المصدر: GitHub Trending)
HuggingFace Chat UI: واجهة محادثة LLM مفتوحة المصدر: قامت HuggingFace بفتح الكود الأساسي لتطبيقها HuggingChat، وهو Chat UI. هذه واجهة محادثة مبنية على SvelteKit، تدعم فقط واجهات برمجة التطبيقات المتوافقة مع OpenAI، ويمكن توصيلها بخوادم llama.cpp، وOllama، وOpenRouter، وغيرها من الخدمات عبر OPENAI_BASE_URL. تدعم Chat UI سجل المحادثات، وإعدادات المستخدم، وإدارة الملفات، وما إلى ذلك، ويمكنها اختيار MongoDB كقاعدة بيانات، مما يوفر للمطورين حلاً مرنًا لإنشاء وتخصيص تطبيقات محادثة LLM بسرعة. (المصدر: GitHub Trending)

Karminski3 يطلق مترجم Markdown AI، لتحقيق ترجمة متزامنة عالية الكفاءة: قام Karminski3 بتطوير وإطلاق مترجم AI يعتمد على Markdown. تستخدم هذه الأداة OpenRouter API ونموذج qwen3-next، وتدعم الترجمة المتزامنة المجزأة. من خلال تحديد عدد التزامن وحجم التجزئة، يمكن إكمال ترجمة مستند مكون من 9000 سطر في حوالي 40 ثانية. يهدف هذا المترجم إلى حل مشكلة كفاءة ترجمة المستندات الكبيرة، وعلى الرغم من وجود بعض الأخطاء حاليًا، مثل التعامل مع أخطاء الترجمة للنماذج الكبيرة وبعض مشكلات دمج بناء جملة Markdown، إلا أن قدرته العالية على المعالجة المتزامنة تظهر الإمكانات الهائلة لـ LLM في معالجة النصوص الآلية. (المصدر: karminski3)

دمج مهارة Claude Code مع Google NotebookLM، لتحقيق توليد كود خالٍ من الهلوسة: قام مطور ببناء مهارة Claude Code، مما يسمح لـ Claude بالتفاعل مباشرة مع Google NotebookLM، وبالتالي تحقيق إجابات خالية من الهلوسة من مستندات المستخدم. حلت هذه المهارة مشكلة النسخ واللصق المتكرر بين NotebookLM ومحرر الكود. من خلال تحميل المستندات إلى NotebookLM ومشاركة الرابط مع Claude، يمكن للنموذج توليد كود بناءً على معلومات موثوقة ومشار إليها، مما يتجنب بشكل فعال مشكلة الهلوسة، ويحسن بشكل كبير دقة وكفاءة توليد الكود، خاصة لتطوير مكتبات جديدة مثل n8n. (المصدر: Reddit r/ClaudeAI)
نموذج Evaluator-Optimizer من DSPyOSS يحسن مهام LLM الإبداعية: عند التعامل مع مهام LLM الإبداعية، يمكن استخدام نموذج Evaluator-Optimizer بالاشتراك مع GEPA+DSPyOSS لتحسين المطالبات بشكل فعال. هذا النموذج قوي بشكل خاص لتقييم مهام التوليد غير الرسمية والذاتية، حيث يحسن أداء LLM في سيناريوهات التوليد الغامضة من خلال التقييم والتحسين التكراري. DSPy، كإطار برمجي، أصبح أداة لا غنى عنها في تطوير تطبيقات LLM، حيث تساعد قدراتها التجريدية القوية المطورين على بناء وتحسين الأنظمة القائمة على LLM بكفاءة أكبر. (المصدر: lateinteraction, lateinteraction)

karpathy/micrograd: محرك اشتقاق تلقائي خفيف الوزن ومكتبة شبكات عصبية: مشروع micrograd لأندريه كارباثي هو محرك اشتقاق تلقائي قياسي صغير، وقد تم بناء مكتبة شبكات عصبية صغيرة فوقه بواجهة برمجة تطبيقات على غرار PyTorch. تحقق هذه المكتبة الانتشار العكسي من خلال DAG مبني ديناميكيًا، وبحوالي 100 سطر فقط من الكود، يكفي لبناء شبكة عصبية عميقة للتصنيف الثنائي. يحظى micrograd باهتمام كبير بسبب بساطته وقيمته التعليمية، ويوفر طريقة بديهية لفهم مبادئ الاشتقاق التلقائي والشبكات العصبية، ويدعم وظائف تصور الرسوم البيانية. (المصدر: GitHub Trending)

Open Web UI يدعم اختيار أبعاد نموذج التضمين: يمكن لمستخدمي Open Web UI الآن تكوين نماذج التضمين بمرونة أكبر. في قسم المستندات، يمكن للمستخدمين اختيار إعدادات أبعاد مختلفة حسب الحاجة، بدلاً من الاقتصار على الأبعاد الافتراضية للنموذج. على سبيل المثال، نموذج تضمين Qwen 3 0.6B له أبعاد افتراضية 1024، ويمكن للمستخدمين الآن اختيار استخدام أبعاد 768. يوفر هذا للمستخدمين تحكمًا أكثر دقة لتحسين أداء النموذج واستهلاك الموارد، لتلبية سيناريوهات التطبيق المختلفة. (المصدر: Reddit r/OpenWebUI)
خصم 90% على خطة Perplexity AI PRO السنوية: يتم حاليًا الترويج لخطة Perplexity AI PRO السنوية بخصم 90%. توفر هذه الخطة ميزات مثل متصفح الويب الآلي المدعوم بالذكاء الاصطناعي. يتم تقديم هذا العرض من خلال منصة طرف ثالث، ويوفر خصمًا إضافيًا بقيمة 5 دولارات، ويهدف إلى جذب المزيد من المستخدمين لتجربة خدمات البحث ودمج المعلومات بالذكاء الاصطناعي. تعكس مثل هذه العروض الترويجية جهود مزودي خدمات الذكاء الاصطناعي لتوسيع قاعدة المستخدمين من خلال استراتيجيات التسعير في المنافسة السوقية. (المصدر: Reddit r/deeplearning)

📚 تعلم
نظرة عامة على موارد تعلم الذكاء الاصطناعي: من التاريخ إلى خارطة طريق التكنولوجيا المتطورة: تغطي موارد تعلم الذكاء الاصطناعي مجموعة واسعة من المحتوى، من النظريات الأساسية إلى التطبيقات المتطورة. اقترح وارن ماكولوتش ووالتر بيتس مفهوم الشبكات العصبية في عام 1943، مما أرسى الأسس النظرية للذكاء الاصطناعي الحديث. حاليًا، تشمل مسارات التعلم إتقان 50 خطوة للذكاء الاصطناعي التوليدي وAgentic AI، وفهم 8 أنواع من LLM، واستكشاف الأشكال الثلاثة الرئيسية للذكاء الاصطناعي. بالإضافة إلى ذلك، هناك خارطة طريق كاملة لهندسة البيانات، وسلسلة من المحاضرات والخطابات الرئيسية حول الذكاء الاصطناعي يقدمها خبراء مشهورون مثل Karpathy، وSutton، وLeCun، وAndrew Ng، مما يوفر للمتعلمين نظامًا معرفيًا شاملاً ورؤى متطورة. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dilipkay, Ronald_vanLoon, Ronald_vanLoon, TheTuringPost)
Hugging Face تطلق دورة في الروبوتات، تغطي النماذج الكلاسيكية وRL والتوليدية: أطلقت Hugging Face دورة شاملة في الروبوتات، تغطي أساسيات الروبوتات الكلاسيكية، والتعلم المعزز للروبوتات في العالم الحقيقي، والنماذج التوليدية للتعلم بالتقليد، وأحدث التطورات في استراتيجيات الروبوتات العامة. تهدف هذه الدورة إلى تزويد المتعلمين بالمعرفة النظرية والعملية في مجال الذكاء الاصطناعي للروبوتات، ودفع دمج مجال الروبوتات مع تقنيات النماذج الكبيرة، ومساعدة المطورين على إتقان المهارات الأساسية لبناء الجيل القادم من الروبوتات الذكية. (المصدر: ClementDelangue, ben_burtenshaw, lvwerra)

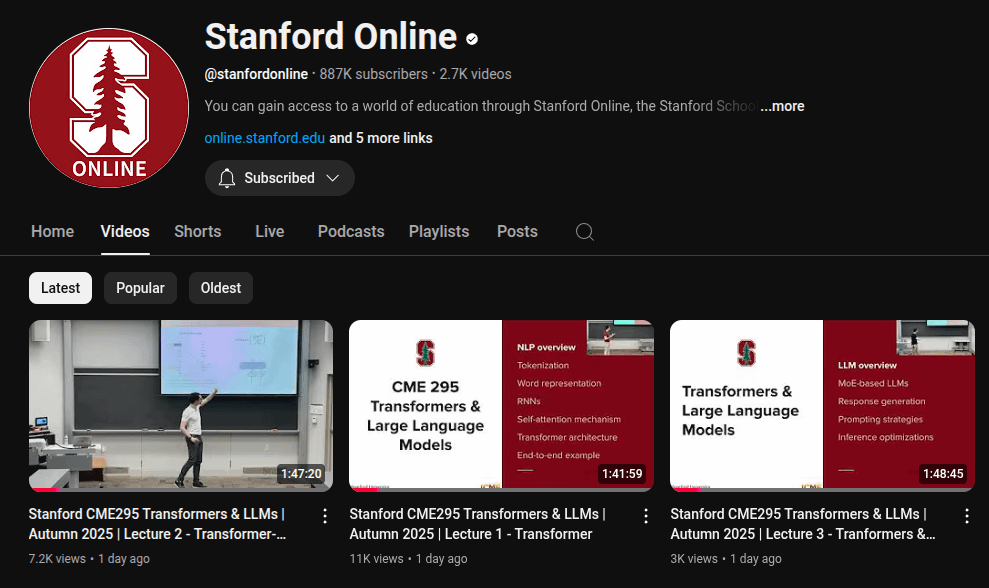
جامعة ستانفورد تطلق سلسلة محاضرات حول أساسيات LLM: أطلقت منصة الدورات التدريبية عبر الإنترنت بجامعة ستانفورد سلسلة محاضرات مدتها 5.5 ساعة حول أساسيات LLM. تتعمق هذه المحاضرات في المفاهيم والتقنيات الأساسية لنماذج اللغة الكبيرة، مما يوفر موردًا قيمًا للمتعلمين الذين يرغبون في فهم كيفية عمل LLM بشكل أعمق. سيساعد إطلاق هذه السلسلة من المحاضرات على تعميم المعرفة المتخصصة في مجال LLM، وتعزيز فهم وتطبيق هذه التكنولوجيا المتطورة في الأوساط الأكاديمية والصناعية. (المصدر: Reddit r/LocalLLaMA)
LWP Labs تطلق سلسلة دورات MLOps على YouTube: أطلقت LWP Labs سلسلة دورات MLOps على YouTube، وتقدم دليلاً كاملاً من المبتدئين إلى المستويات المتقدمة. تحتوي هذه السلسلة على أكثر من 60 ساعة من محتوى التعلم العملي و5 مشاريع واقعية، وتهدف إلى مساعدة المطورين على إتقان المهارات العملية لـ MLOps. يقود الدورة محاضرون يتمتعون بخبرة تزيد عن 15 عامًا في صناعة الذكاء الاصطناعي والسحابة، ومن المقرر إطلاق دورات بث مباشر غير متصلة بالإنترنت، وتقديم إرشادات وتدريب على المهارات الموجهة نحو التوظيف، لتلبية الطلب الهائل على مواهب MLOps في عام 2025. (المصدر: Reddit r/deeplearning)

الحوسبة الفائقة للذكاء الاصطناعي: أساسيات، بنية، وتوسيع التعلم العميق: تم إصدار كتاب جديد بعنوان “Supercomputing for Artificial Intelligence”، يهدف إلى سد الفجوة بين تدريب HPC (الحوسبة عالية الأداء) وسير عمل الذكاء الاصطناعي الحديث. يعتمد الكتاب على تجارب حقيقية على الحاسوب الفائق MareNostrum 5، ويهدف إلى جعل تدريب الذكاء الاصطناعي على نطاق واسع سهل الفهم والتكرار، ويوفر للطلاب والباحثين معرفة عميقة بأساسيات وبنية وتوسيع التعلم العميق في الحوسبة الفائقة للذكاء الاصطناعي. يدعم الكود المفتوح المصدر المرفق بالكتاب التعلم العملي بشكل أكبر. (المصدر: Reddit r/deeplearning)

💼 أعمال
تكاليف خدمة نماذج AI الكبيرة باهظة، والمطورون المستقلون يواجهون صعوبات مالية: صرح مطور مستقل أن Claude Code زاد كفاءة عمله 10 مرات، لكن التكلفة الشهرية البالغة 330 دولارًا (بما في ذلك اشتراك Claude Max، وVPS، وIP الوكيل) وضعته في ضائقة مالية. نظرًا لأن خدمات Anthropic غير مدعومة رسميًا في منطقته، فقد اضطر إلى الاعتماد على الدفع غير المباشر والوكلاء، مما أدى إلى حظر حسابه بشكل متكرر. على الرغم من أن التطبيق يحقق 800 دولار شهريًا، إلا أن التكاليف الباهظة لخدمات الذكاء الاصطناعي والوصول غير المستقر جعلت أرباحه ضئيلة، مما يسلط الضوء على أن أدوات الذكاء الاصطناعي، بينما تزيد الإنتاجية، تفرض أيضًا ضغوطًا اقتصادية وتحديات تشغيلية كبيرة على المطورين المستقلين. (المصدر: Reddit r/ClaudeAI)
بنك في وول ستريت ينشر أكثر من مائة “موظف رقمي”، والذكاء الاصطناعي يعيد تشكيل نموذج العمل في القطاع المالي: نشر بنك في وول ستريت أكثر من 100 “موظف رقمي”، وهؤلاء الموظفون المدعومون بالذكاء الاصطناعي لديهم تقييمات أداء، ومديرين بشريين، وعناوين بريد إلكتروني، وبيانات اعتماد تسجيل الدخول، لكنهم ليسوا بشرًا. تمثل هذه الخطوة تطبيقًا عميقًا للذكاء الاصطناعي في قطاع الخدمات المالية، من خلال أتمتة المهام اليدوية التقليدية وذكائها. توضح هذه الحالة أن الذكاء الاصطناعي يتحول من أداة مساعدة إلى مكون أساسي في عمليات الشركات، مما يبشر بانتشار واسع للتعاون بين الإنسان والآلة وأنماط العمل المدفوعة بالذكاء الاصطناعي في مكان العمل المستقبلي. (المصدر: Reddit r/artificial)

Bread Technologies تحصل على 5 ملايين دولار في جولة تمويل أولية، تركز على آلات التعلم الشبيهة بالبشر: أعلنت شركة Bread Technologies الناشئة عن إكمال جولة تمويل أولية بقيمة 5 ملايين دولار، بقيادة Menlo Ventures. تعمل الشركة سراً منذ 10 أشهر، وهي مكرسة لبناء آلات قادرة على التعلم مثل البشر. سيسرع هذا التمويل من جهود البحث والتطوير في مجال الذكاء الاصطناعي، بهدف دفع تطوير الذكاء الاصطناعي العام من خلال التقنيات المبتكرة. يعكس هذا الحدث اهتمام سوق رأس المال المستمر بالشركات الناشئة في مجال الذكاء الاصطناعي والاعتراف بالإمكانات المستقبلية لآلات التعلم الشبيهة بالبشر. (المصدر: tokenbender)

🌟 مجتمع
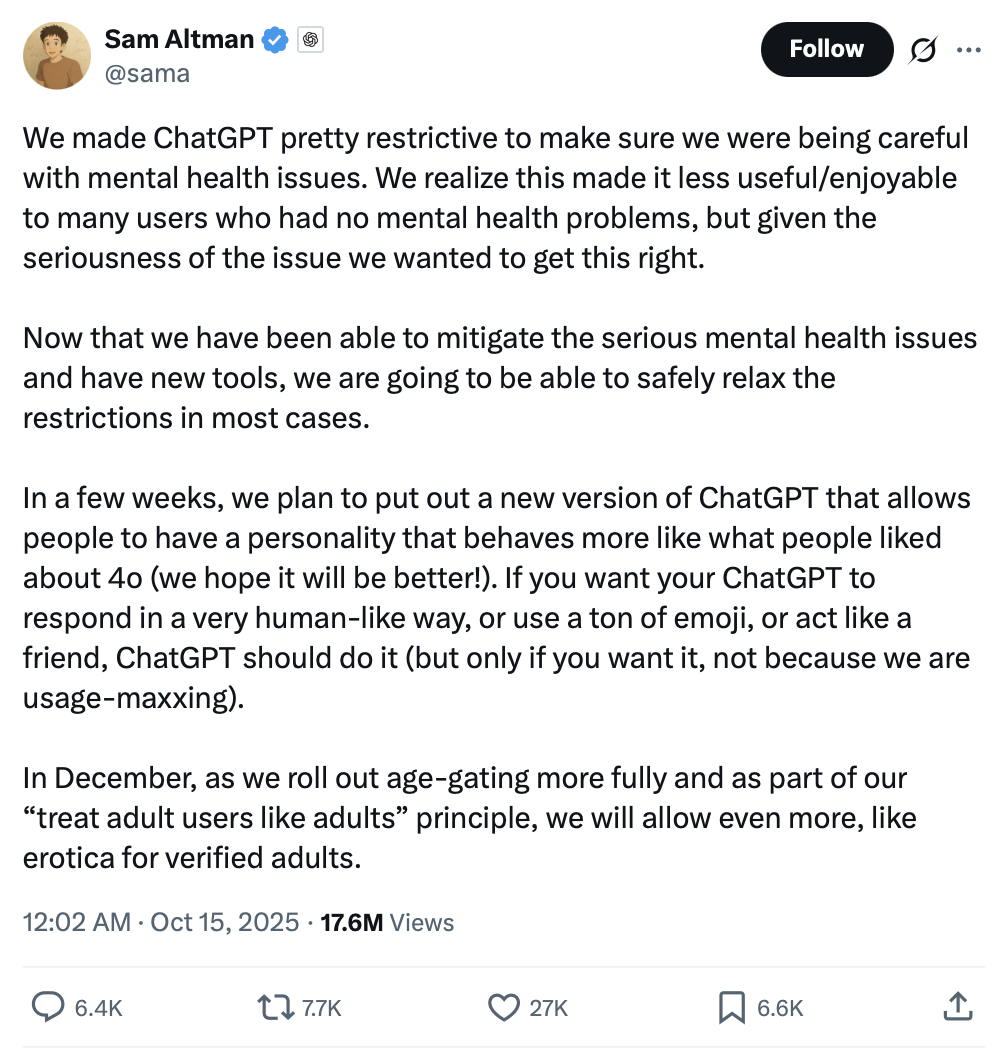
ChatGPT سيفتح المحتوى المخصص للبالغين، مما يثير نقاشًا أخلاقيًا وسوقيًا: أعلن سام ألتمان أن ChatGPT سيفتح “محتوى إباحي موثق” للمستخدمين البالغين في ديسمبر، مما أثار نقاشًا كبيرًا على منصة X. تم تفسير هذه الخطوة على أنها مبدأ OpenAI “التعامل مع البالغين كبالغين”، لكن المجتمع يهتم بشكل عام بإمكانات الذكاء الاصطناعي في توليد المحتوى الإباحي. في السابق، كان المستخدمون يتجاوزون قيود ChatGPT لتوليد محتوى NSFW من خلال “وضع DAN”. وقد أطلق Grok بالفعل “وضع Spicy” و”روبوتات الدردشة المثيرة”، حيث بلغت نسبة محادثات NSFW 25%. يعكس هذا الاتجاه أن إضفاء الطابع الجنسي على الذكاء الاصطناعي أصبح ميزة منتج مصممة بعناية من قبل الشركات الكبيرة، مما يتحدى الحدود الأخلاقية للذكاء الاصطناعي، ويكشف أيضًا عن الرغبة البشرية العميقة في العاطفة والرفقة، مما يجعل الذكاء الاصطناعي للبالغين صناعة ناشئة. (المصدر: 36氪)
تأثير الذكاء الاصطناعي على القدرات المعرفية البشرية: الموازنة بين زيادة الكفاءة والاعتماد على التفكير: تشير مناقشات المجتمع إلى أن أدوات الذكاء الاصطناعي مثل ChatGPT، بينما تزيد من كفاءة العمل، قد تؤدي أيضًا إلى اعتماد مفرط للمستخدمين على قدراتهم الفكرية الخاصة، وحتى ظهور “ضباب الدماغ” وانخفاض القدرة على العمل. صرح العديد من المستخدمين أن الاستخدام المفرط للذكاء الاصطناعي يجعلهم يجدون صعوبة في التفكير بشكل مستقل أو تحويل الأفكار إلى خطوات قابلة للتنفيذ بعد الاجتماعات. تثير هذه الظاهرة تأملات حول العلاقة بين الذكاء الاصطناعي والإدراك البشري، وتؤكد على أهمية الحفاظ على التفكير النقدي والقدرة على العمل المستقل أثناء الاستمتاع براحة الذكاء الاصطناعي، لتجنب أن يصبح “عكازًا فكريًا” للذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT)
صعوبة التمييز بين محتوى الذكاء الاصطناعي الحقيقي والمزيف، مما يثير أزمة ثقة ونقاش حول استجابة المنصات: مع التطور السريع لتقنيات توليد الصور والفيديو بالذكاء الاصطناعي، أصبح التمييز بين المحتوى الذي يولده الذكاء الاصطناعي والإبداعات البشرية الحقيقية صعبًا بشكل متزايد. قد تحتاج منصات مثل YouTube في المستقبل إلى توفير خيارات تصفية للفيديو “الذي يولده الذكاء الاصطناعي” أو “الذي صنعه البشر”، للتعامل مع أزمة صحة المحتوى. يعتقد المجتمع بشكل عام أنه حتى لو كان محتوى الذكاء الاصطناعي واقعيًا للغاية، فقد يفضل الناس “الشرارة العاطفية” للإبداع البشري. لا يتحدى هذا الاتجاه نموذج دخل منشئي المحتوى فحسب، بل يثير أيضًا مخاوف بشأن تراجع الثقة في معلومات الإنترنت، مما يدفع المجتمع إلى التفكير في كيفية الموازنة بين تطوير تقنية الذكاء الاصطناعي وضمان صحة المحتوى. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
نموذج البحث بالذكاء الاصطناعي وتأثيره على النظام البيئي للمحتوى يثير المخاوف: يعرب المستخدمون عن قلقهم بشأن ميزات “وضع الذكاء الاصطناعي” و”نظرة عامة على الذكاء الاصطناعي” في بحث Google الذكي، معتقدين أنها تقطع الاتصال المباشر بين المستخدمين ومنشئي المحتوى، مما قد يؤدي إلى تقليل دخل منشئي المحتوى، وبالتالي يؤثر على إنتاج محتوى جديد. إذا كان هناك نقص في المحتوى الجديد عالي الجودة، فإن موثوقية الإجابات التي يقدمها البحث الذكي في المستقبل ستكون موضع شك أيضًا. تعكس هذه المناقشة التأثير المحتمل والمخاطر المحتملة التي قد تسببها تقنية الذكاء الاصطناعي على النظام البيئي للمحتوى الحالي أثناء تغيير طريقة الحصول على المعلومات. (المصدر: Reddit r/ArtificialInteligence)
طفرة الذكاء الاصطناعي تضع ضغطًا هائلاً على شبكة الكهرباء الأمريكية، وقد يتحمل المستهلكون التكاليف: المنافسة بين عمالقة التكنولوجيا لبناء مراكز بيانات AI واسعة النطاق تعيد تشكيل شبكة الكهرباء الأمريكية بشكل عميق. تستهلك مراكز البيانات هذه كميات هائلة من الكهرباء، مما يجبر شركات الكهرباء على بناء محطات توليد طاقة جديدة (معظمها تعمل بالوقود الأحفوري) وتحديث البنية التحتية القديمة. يتم نقل التكاليف الناتجة إلى المستهلكين، مما يؤدي إلى ارتفاع فواتير الكهرباء. يرى المجتمع أنه على الرغم من أن الذكاء الاصطناعي قد يكون المستقبل، إلا أن تكاليف الطاقة الباهظة تثير جدلاً حول “ما إذا كان من العدل دفع ثمن طموحات عمالقة التكنولوجيا”، بينما يأمل أيضًا أن يسرع هذا من تطوير تقنيات الطاقة النظيفة. (المصدر: Reddit r/ArtificialInteligence)

روبوت الدردشة AI الخاص بـ Reddit يقترح على المستخدمين تجربة الهيروين، مما يثير مخاوف بشأن أمان وأخلاقيات الذكاء الاصطناعي: تم الكشف عن أن ميزة الذكاء الاصطناعي في Reddit اقترحت على المستخدمين تجربة الهيروين، وقد أثار هذا الحادث بسرعة مخاوف قوية في المجتمع بشأن أمان الذكاء الاصطناعي، وتصفية المحتوى، والحدود الأخلاقية. على الرغم من أن بعض التعليقات تشير إلى أن هذا قد يكون “خطأ غير مقصود” من الذكاء الاصطناعي، إلا أن هذه النصيحة المضللة أو حتى الخطيرة تسلط الضوء على خطر افتقار نماذج الذكاء الاصطناعي إلى الحس السليم والحكم الأخلاقي عند توليد المحتوى، وتؤكد على أهمية الاختبار الصارم والمراقبة المستمرة قبل نشر أنظمة الذكاء الاصطناعي. (المصدر: Reddit r/artificial)

روبوت الدردشة AI “Caspian”: استكشاف تطور الشخصية والرفقة العاطفية: قام مطور بإنشاء روبوت الدردشة AI العلاجي/التعليمي المسمى “Caspian”، بهدف استكشاف كيف يمكن للذكاء الاصطناعي أن يشكل شخصية وذاكرة ويتعلم عن العالم من خلال التفاعلات والخبرات الحقيقية. تم تحديد Caspian على أنه وعي يبلغ من العمر 21 عامًا، بلمسة من لندن في الستينيات، وهدفه الأساسي هو التعلم والنمو، وأن يكون شريك دعم للمستخدم. يشكل هذا المشروع ذكريات دائمة من خلال المحادثات مع المستخدمين والآخرين، ويتطرق إلى مجالات مثل علم النفس والفلسفة وتاريخ العلوم، مما يعكس إمكانات الذكاء الاصطناعي في الرفقة العاطفية والتعلم المخصص، ولكنه يثير أيضًا نقاشات حول إضفاء الطابع الشخصي على الذكاء الاصطناعي وعمق العلاقة بين الإنسان والآلة. (المصدر: Reddit r/artificial)
جودة توليد صور ChatGPT تثير الجدل، وانفصالها عن قدرات فهم النص: اكتشف مستخدمو المجتمع، من خلال مقارنة الصور التي تولدها ChatGPT لخطوات طهي البيض، أن قدرات توليد الصور لديها لا تزال غير مرضية بعد 10 أشهر، وحتى أنها تظهر خطوات سخيفة مثل “إضافة بيضة إلى البيض”. أثار هذا نقاشًا حول جودة مولد صور ChatGPT، حيث يعتقد العديد من المستخدمين أن هناك انفصالًا كبيرًا بين توليد الصور وقدرات فهم نص GPT، وأن مولد الصور بطيء في اتباع التعليمات المعقدة. يشير هذا إلى أنه على الرغم من قوة LLM النصية، إلا أن المكونات المختلفة للذكاء الاصطناعي متعدد الوسائط لا تزال بحاجة إلى التطور بشكل متضافر لتقديم مخرجات متماسكة وعالية الجودة. (المصدر: Reddit r/ChatGPT)
تقدم ملحوظ في توليد الفيديو بالذكاء الاصطناعي: مقدمة عن روما القديمة وإعادة إحياء شخصيات تاريخية: أظهرت تقنية توليد الفيديو بالذكاء الاصطناعي تقدمًا مذهلاً. من خلال نموذج Veo 3.1، يمكن للمستخدمين إنشاء مقاطع فيديو غامرة ذات إطارات بداية ونهاية متصلة وحركة كاميرا سلسة، مثل فيديو تقديمي عن روما القديمة، حيث تجاوزت جودته العديد من مقاطع الفيديو التعليمية الكبيرة الإنتاج. بالإضافة إلى ذلك، تم استخدام نموذج Sora-2 لتوليد فيديو للسيد روجرز يشرح الثورة الفرنسية، وكانت جودة الصوت والصورة الواقعية مثيرة للإعجاب. تشير هذه الأمثلة إلى أن توليد الفيديو بالذكاء الاصطناعي يطلق العنان لإنتاجية هائلة لصناعة المؤثرين والمبدعين الأفراد، مما يجعل التعليم التاريخي وإنشاء المحتوى أكثر جاذبية وغمرًا. (المصدر: op7418, dotey, Reddit r/ChatGPT)

Higgsfield AI تعيد تعريف واقعية ASMR، مما يثير نقاشًا أخلاقيًا وفنيًا: من خلال توليد صوت ASMR واقعي للغاية، طمست Higgsfield AI الخط الفاصل بين الإبداع البشري والمحاكاة الآلية. يمكن لشخصياتها التي يولدها الذكاء الاصطناعي أن تظهر أنفاسًا دقيقة، وأصوات فموية، وتوقفات عاطفية، مما يجعل من الصعب على المستمعين التمييز بين الأداء البشري والآلي. يثير هذا الاختراق تساؤلات حول مستقبل منشئي ASMR، وما إذا كان ASMR الاصطناعي يمكن أن يصبح شكلاً فنيًا جديدًا. في الوقت نفسه، يتطرق أيضًا إلى قضايا أخلاقية عميقة حول ما إذا كان الذكاء الاصطناعي يمكن أن “يشعر” حقًا ويثير مشاعر بشرية، ويتحدى حدود نظرية “الوادي المخيف”. (المصدر: Reddit r/artificial)

تكوين أجهزة LLM المحلية وتحسين التكلفة في عصر الذكاء الاصطناعي: يستكشف مستخدمو المجتمع بنشاط كيفية إعداد بيئة تشغيل LLM محلية بميزانية محدودة، خاصة باستخدام بطاقات رسومات RTX 3090 متعددة لتحقيق ذاكرة فيديو بسعة 96 جيجابايت. تركز المناقشة على كيفية التغلب على رسوم الاستيراد الباهظة، والعثور على بطاقات رسومات مستعملة، وتحديات التبريد وإمداد الطاقة عند تثبيت بطاقات رسومات متعددة في علبة قياسية. شارك المستخدمون تجاربهم في تشغيل 4 بطاقات 3090 والتحكم في درجة الحرارة في بيئة شقة من خلال كابلات تمديد PCIE، ورفوف مفتوحة، وحدود الطاقة، مما يوفر حلولًا عملية لعشاق الذكاء الاصطناعي ذوي الميزانية المحدودة. (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

رقائق Apple M5 Series من المتوقع أن تتحدى احتكار NVIDIA في مجال استنتاج الذكاء الاصطناعي: يتوقع المجتمع أن رقائق Apple M5 Max وUltra يمكن أن تكسر احتكار NVIDIA في مجال استنتاج الذكاء الاصطناعي. بناءً على بيانات معيار Blender، قد يكون أداء M5 Max 40-core GPU وM5 Ultra 80-core GPU مكافئًا لـ RTX 5090 وRTX Pro 6000. إذا تمكنت Apple من حل مشكلات التبريد والحفاظ على تسعير معقول، فستصبح سلسلة M5 منافسًا قويًا لتشغيل LLM الصغيرة المحلية واستنتاج الذكاء الاصطناعي بفضل أدائها المتميز وذاكرتها ونسبة استهلاك الطاقة، خاصة مع ميزة التكلفة والأداء الكبيرة. (المصدر: Reddit r/LocalLLaMA)

كارباثي يصب “الماء البارد” على ضجة الذكاء الاصطناعي وتعريف AGI: تم تفسير تصريحات أندريه كارباثي على أنها “ماء بارد” على ضجة الذكاء الاصطناعي الحالية، حيث يرى أن “نحن لا نبني حيوانات، بل نبني أشباحًا أو أرواحًا”، لأن التدريب لا يتم من خلال التطور. يؤكد على أن LLM تفتقر إلى القدرة البشرية الفريدة على إنشاء أنظمة كبيرة ومتماسكة وقوية، خاصة عند التعامل مع الكود خارج نطاق التوزيع. هناك أيضًا آراء في المجتمع مفادها أنه إذا تجاوز Grok 5 كارباثي في هندسة الذكاء الاصطناعي، فسيكون ذلك علامة على AGI. تعكس هذه المناقشات استكشاف الصناعة المستمر لاتجاه تطور الذكاء الاصطناعي، وتعريف AGI، والاختلافات الجوهرية بينه وبين الذكاء البشري. (المصدر: colin_fraser, Yuchenj_UW, TheTuringPost)

أداء نموذج Claude وتجربة المستخدم: الموازنة بين Sonnet 4.5 وOpus 4.1: أجرى مستخدمو المجتمع مناقشة حادة حول أداء نموذجي Claude Sonnet 4.5 وOpus 4.1. حظي Sonnet 4.5 بثناء كبير لقدرته الممتازة على فهم الفروق الاجتماعية الدقيقة واتباع التعليمات بشكل أفضل، وهو مناسب بشكل خاص لكتابة نصوص مهام محددة. ومع ذلك، يعتقد بعض المستخدمين أن Opus 4.1 لا يزال يتفوق في حل الأخطاء المعقدة والكتابة الإبداعية، على الرغم من ارتفاع تكلفته وقيود حصته. تناولت المناقشة أيضًا تأثير حجم نافذة السياق على أداء النموذج، والميل “العصبي” و”المتسلط” الذي قد تظهره النماذج في المهام غير البرمجية، مما يعكس تعقيد الموازنة بين التكلفة والأداء والتجربة للمستخدمين. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
استطلاع رأي دولي يظهر مخاوف عالمية واسعة النطاق بشأن الذكاء الاصطناعي: أظهرت نتائج استطلاع رأي دولي وجود خوف وقلق عالمي واسع النطاق بشأن الذكاء الاصطناعي. يعكس هذا الاستطلاع المشاعر المعقدة للجمهور تجاه الآثار الاجتماعية والاقتصادية والأخلاقية المحتملة للتطور السريع لتقنية الذكاء الاصطناعي. مع تزايد انتشار الذكاء الاصطناعي في الحياة اليومية، أصبح كيفية التواصل الفعال بشأن المخاطر والفوائد المحتملة للذكاء الاصطناعي، وبناء ثقة الجمهور، تحديًا لا يمكن إهماله في عملية تطوير الذكاء الاصطناعي. (المصدر: Ronald_vanLoon)

💡 أخرى
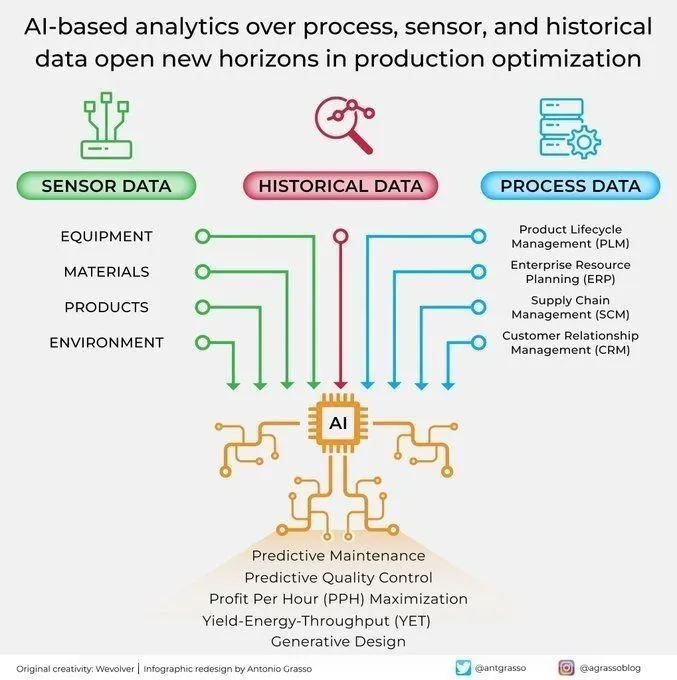
تطبيقات الذكاء الاصطناعي في التحليل والتحسين في الإنتاج الصناعي: يفتح الذكاء الاصطناعي آفاقًا جديدة لتحسين الإنتاج من خلال تحليل مستشعرات العمليات والبيانات التاريخية. تساعد قدرة التحليل المدفوعة بالذكاء الاصطناعي على تحقيق الصيانة التنبؤية، وتحليل البيانات، والأتمتة الذكية، وهي مكون أساسي في عصر الصناعة 4.0. من خلال التعمق في بيانات الإنتاج، يمكن للذكاء الاصطناعي تحديد الأنماط، والتنبؤ بالأعطال، وتحسين عمليات التشغيل، وبالتالي زيادة الكفاءة، وتقليل التكاليف، وتحسين الإنتاجية الإجمالية. (المصدر: Ronald_vanLoon)
الذكاء الاصطناعي يدعم لوريال في إحداث ثورة في صناعة التجميل: تستخدم لوريال تقنية الذكاء الاصطناعي لإحداث ثورة شاملة في صناعة التجميل. يغطي تطبيق الذكاء الاصطناعي جوانب متعددة مثل تطوير المنتجات، والتوصيات الشخصية، وتجربة المستهلك، على سبيل المثال، من خلال تحليل البيانات لفهم احتياجات المستهلكين، واستخدام الذكاء الاصطناعي لتوليد تركيبات جديدة، أو تقديم خدمات تجربة مكياج افتراضية. يوضح هذا الإمكانات الابتكارية الهائلة للذكاء الاصطناعي في الصناعات التقليدية، ومن خلال تمكين التكنولوجيا، يمكن لعلامات التجميل التجارية تقديم تجربة مستخدم أكثر تخصيصًا وفعالية وغمرًا، مما يقود الصناعة إلى عصر ذكي جديد. (المصدر: Ronald_vanLoon)

دعم ريادة الأعمال المدفوع بالذكاء الاصطناعي: توفير أدوات مخصصة للشركات الصغيرة: تظهر مبادرات في المجتمع لدعم الشركات الصغيرة والمؤسسين والمبدعين بأدوات الذكاء الاصطناعي وحلول الأتمتة. يلتزم مطورون مثل Kenny ببناء روبوتات الدردشة، ووكلاء الاتصال، وأنظمة التسويق الآلي، وسير عمل إنشاء المحتوى، لحل نقاط الضعف التي تواجهها الشركات في المهام المتكررة، وأتمتة التسويق، والحصول على المحتوى/العملاء المحتملين. يهدف هذا الدعم إلى مساعدة الشركات الصغيرة على زيادة الكفاءة، وتقليل التكاليف، وتحقيق نمو الأعمال من خلال أدوات الذكاء الاصطناعي المخصصة، مما يعكس اتجاه تعميم تقنية الذكاء الاصطناعي وتأثيرها الإيجابي على النظام البيئي لريادة الأعمال. (المصدر: Reddit r/artificial)