
كلمات مفتاحية:أوبن إيه آي, تنظيم الذكاء الاصطناعي, نماذج اللغة الكبيرة, أخلاقيات الذكاء الاصطناعي, ابتكار الذكاء الاصطناعي, تركيز سلطة الذكاء الاصطناعي, قانون أمان الذكاء الاصطناعي, حوكمة الذكاء الاصطناعي, تخويف أوبن إيه آي القانوني, إطار محاذاة جي تي ألاين, الاستدلال متعدد الوسائط آريس, نموذج العالم إكس إيه آي, تقنية التقسيم سام 3.0
🔥聚焦
الموضوع: اتهام OpenAI بترهيب منظمة غير ربحية: خلال مراجعة مشروع قانون سلامة الذكاء الاصطناعي في كاليفورنيا، تم الكشف عن قيام OpenAI بإصدار مذكرة استدعاء لمنظمة Encode غير الربحية، التي تضم ثلاثة موظفين فقط، مطالبة بجميع سجلاتها ومراسلاتها الخاصة، متهمة إياها دون دليل بأنها ممولة من قبل Musk. وقد أدانت Encode علنًا هذا الإجراء ووصفته بأنه ترهيب قانوني يهدف إلى قمع الانتقادات لمواقفها السياسية. أثارت هذه الحادثة انتقادات من موظفي OpenAI الحاليين وأعضاء مجلس الإدارة السابقين، مسلطة الضوء على الاستراتيجيات العدوانية التي تتبناها شركات AI الكبرى في مواجهة التنظيم، والتحديات التي تواجهها مجموعات المناصرة الصغيرة عند مواجهة العمالقة، على الرغم من أن مشروع قانون SB 53 قد تم تمريره في النهاية، والذي يطالب شركات AI بتقديم تقييمات للمخاطر وتقارير الشفافية. (المصدر: Reddit r/ArtificialInteligence)
الموضوع: تحذير من حائز على جائزة نوبل في الاقتصاد: تركيز قوة AI قد يخنق الابتكار: أشار فيليب أجيون، أحد الحائزين على جائزة نوبل في الاقتصاد لهذا العام، إلى أن تركيز قوة AI في أيدي عدد قليل من الشركات قد يعيق الابتكار والنمو الاقتصادي. ويرى أن الابتكار يعتمد على المنافسة، وأن احتكار موارد AI قد يؤدي إلى ركود التقدم، مما يجعل من الصعب على الشركات الناشئة تحدي العمالقة الحاليين. وقد أثار هذا نقاشًا حول حوكمة AI وأشكال التنظيم لمنع AI من أن يصبح عنق زجاجة للنمو بدلاً من أن يكون محركًا له. (المصدر: Reddit r/ArtificialInteligence)

الموضوع: GTAlign: إطار محاذاة مساعد LLM قائم على نظرية الألعاب: اقترح الباحثون GTAlign، وهو إطار محاذاة يدمج قرارات نظرية الألعاب في استدلال وتدريب LLM. يقوم الإطار بتقييم الرفاهية المشتركة لـ LLM والمستخدم من خلال بناء مصفوفة مكافآت، واختيار الإجراءات ذات المنفعة المتبادلة. أثناء التدريب، يتم إدخال مكافآت الرفاهية المتبادلة لتعزيز الاستجابات التعاونية. أظهرت التجارب أن GTAlign يعزز بشكل كبير كفاءة استدلال LLM وجودة الإجابات والرفاهية المشتركة في مهام متنوعة، مما يحل مشكلة الطرق التقليدية للمحاذاة حيث قد يؤدي الإفراط في الإسهاب إلى تقليل تجربة المستخدم. (المصدر: HuggingFace Daily Papers)
الموضوع: ARES: تحقيق الاستدلال التكيفي متعدد الوسائط من خلال تشكيل الانتروبيا المدرك للصعوبة: ARES هو إطار عمل موحد مفتوح المصدر يحل مشكلة عدم توازن الكفاءة في نماذج الاستدلال الكبيرة متعددة الوسائط (MLRMs) عند التعامل مع مهام مختلفة الصعوبة، وذلك من خلال التوزيع الديناميكي لجهود الاستكشاف. يستخدم هذا الإطار انتروبيا النافذة لتحديد لحظات الاستدلال الحاسمة، ومن خلال تدريب من مرحلتين (بدء تشغيل تكيفي بارد وتحسين سياسة الانتروبيا التكيفية)، يجعل النموذج يقلل من التفكير الزائد في المشكلات البسيطة ويزيد من الاستكشاف في المشكلات المعقدة. أظهر ARES أداءً متميزًا وكفاءة في الاستدلال في اختبارات الرياضيات والمنطق والمعايير متعددة الوسائط، مما قلل بشكل كبير من تكاليف الاستدلال. (المصدر: HuggingFace Daily Papers)
🎯动向
الموضوع: المسك وxAI يدخلان مجال نماذج العالم، ويستقطبان موظفين من NVIDIA لتطوير ألعاب AI: تعمل xAI بنشاط على تطوير نماذج العالم، وقد استقطبت العديد من كبار الباحثين من NVIDIA، وتخطط لإطلاق لعبة مولدة بواسطة AI ومدفوعة بنموذج العالم بحلول نهاية عام 2026. هدف xAI هو جعل AI يفهم جوهر الكون، وتطبيق نماذج العالم في ألعاب AI، والوكلاء، والقيادة الذاتية، والروبوتات الذكية المتجسدة، بهدف بناء نظام بيئي متكامل لـ AI. (المصدر: 量子位)

الموضوع: الكشف عن Meta “تقسيم كل شيء” 3.0: يقدم SAM 3.0 تجزئة المفاهيم القابلة للتوجيه (PCS)، ويدعم مهام التجزئة متعددة الحالات بناءً على عبارات أو أمثلة صورية. يتضمن تصميم البنية الجديدة كاشفًا يعتمد على DETR ووحدة Presence Head، مما يفصل التعرف على الكائنات عن تحديد المواقع، ويعزز دقة الكشف. من خلال محرك بيانات واسع النطاق واختبار SA-Co، حقق SAM 3.0 رقمًا قياسيًا جديدًا (SOTA) في مهام تجزئة المفردات المفتوحة، ويمكن دمجه مع النماذج الكبيرة متعددة الوسائط لحل مهام تجزئة الاستدلال المعقدة. (المصدر: 量子位)

الموضوع: تحديد موعد مؤتمر Baidu World 2025، ويركز على تطبيقات AI والنظام البيئي للنماذج الكبيرة: أعلنت Baidu أنها ستعقد مؤتمر Baidu World 2025 في 13 نوفمبر في بكين، تحت شعار “ظهور النتائج | AI in Action”. سيعرض المؤتمر بشكل شامل أحدث التطورات لـ Baidu في تطبيقات AI، والنماذج الكبيرة، والنظام البيئي لـ AI، والعولمة، بما في ذلك Wenxin iRAG، وWu Code Miaoda، وتقنية الإنسان الرقمي، والانتشار العالمي للقيادة الذاتية “Luobo Kuaipao”. سيوفر المؤتمر أيضًا أكثر من 40 محاضرة مفتوحة حول AI، لتمكين تطوير تطبيقات AI. (المصدر: 量子位)

الموضوع: Reflection AI: “DeepSeek الأمريكية” بقيمة 8 مليارات دولار قبل إطلاق المنتج: ارتفعت قيمة Reflection AI إلى 8 مليارات دولار قبل إطلاق أي منتج رسمي، وحصلت على تمويل بقيمة 2 مليار دولار من Nvidia، Sequoia Capital وغيرها. تأسست الشركة من قبل أعضاء أساسيين سابقين في Google DeepMind، وتهدف إلى أن تكون “DeepSeek الغربية”، وتقدم نماذج MoE عالية الأداء من خلال نموذج “الأوزان المفتوحة”، لسد الفجوة في السوق الغربية للنماذج مفتوحة المصدر غير الصينية، وتستهدف الشركات الكبيرة وأسواق AI السيادية. (المصدر: 36氪)

الموضوع: إطلاق نموذج Dolphin X1 8B: نسخة Llama3.1 8B المعدلة لإزالة الرقابة: تم إطلاق Dolphin X1 8B على Hugging Face، وهو نسخة معدلة من Llama3.1 8B Instruct، ويهدف إلى إزالة قيود الرقابة عن النموذج إلى أقصى حد ممكن دون المساس بالقدرات الأخرى. يستخدم النموذج تدريب SFT+RL، ونتائج الاختبارات المعيارية مماثلة أو أعلى من Llama3.1 8B Instruct، وتم إطلاق إصدارات GGUF وFP8 وexl2 برعاية Deepinfra. (المصدر: Reddit r/LocalLLaMA)
الموضوع: تطور مسارات RAG مفتوحة المصدر المتنوعة: تتفرع حلول RAG (الجيل المعزز بالاسترجاع) مفتوحة المصدر مثل MiniRAG وAgent-UniRAG وSymbioticRAG، وتقدم مفاهيم تصميم مختلفة. يسعى MiniRAG إلى الخفة والتشغيل المحلي، بينما يدمج Agent-UniRAG الاسترجاع والاستدلال في خط أنابيب وكيل مستمر، ويؤكد SymbioticRAG على التعاون بين الإنسان والآلة والتعلم القائم على التغذية الراجعة، بينما توفر مجموعات الأدوات مثل LangChain مكونات معيارية. عند الاختيار، يحتاج المستخدمون إلى الموازنة بين الدقة والسرعة والتحكم، والانتباه إلى المشكلات الشائعة مثل الهلوسة وفقدان السياق. (المصدر: Reddit r/LocalLLaMA)
الموضوع: LLM4Cell: مراجعة شاملة لنماذج اللغة الكبيرة ونماذج الوكلاء في مجال بيولوجيا الخلية الواحدة: يقدم LLM4Cell لأول مرة مراجعة موحدة لـ 58 نموذجًا أساسيًا ونموذج وكيل مطبق في أبحاث الخلية الواحدة، تغطي RNA وATAC والوسائط المتعددة والوسائط المكانية. يقسم البحث هذه الطرق إلى خمس فئات رئيسية، ويربطها بثماني مهام تحليل رئيسية. من خلال تحليل أكثر من 40 مجموعة بيانات عامة، تم تقييم قابلية تطبيق النماذج، وتنوع البيانات، والأخلاقيات، وقابلية التوسع، وتم تحديد التحديات في قابلية التفسير، والتوحيد القياسي، وتطوير النماذج الموثوقة. (المصدر: HuggingFace Daily Papers)
الموضوع: KORMo: نموذج الاستدلال الكوري المفتوح للجميع: KORMo-10B هو أول نموذج لغوي كبير ثنائي اللغة كوري-إنجليزي تم تدريبه بشكل أساسي على بيانات اصطناعية. يمتلك النموذج 10.8 مليار معلمة، و68.74% من الجزء الكوري عبارة عن بيانات اصطناعية. أثبتت التجارب أن البيانات الاصطناعية المنسقة بعناية لا تؤدي إلى عدم استقرار أو تدهور في الأداء أثناء التدريب المسبق للنموذج على نطاق واسع، وأن أداء النموذج في اختبارات الاستدلال والمعرفة واتباع التعليمات المعيارية يضاهي أداء النماذج متعددة اللغات مفتوحة المصدر الحالية. قام هذا المشروع بفتح البيانات والتعليمات البرمجية وخطط التدريب بالكامل، مما يوفر إطارًا شفافًا لتطوير النماذج المفتوحة المدفوعة بالبيانات الاصطناعية في بيئات الموارد المنخفضة. (المصدر: HuggingFace Daily Papers)
الموضوع: UML: تعزيز النماذج أحادية الوسائط باستخدام بيانات متعددة الوسائط غير المقترنة: UML (Unpaired Multimodal Learner) هو نموذج تدريب جديد مستقل عن الوسائط، حيث يقوم النموذج بمعالجة المدخلات من وسائط مختلفة بالتناوب ومشاركة المعلمات، مستفيدًا من الهيكل متعدد الوسائط لتعزيز تعلم التمثيل أحادي الوسائط، دون الحاجة إلى مجموعات بيانات مقترنة صراحةً. أظهرت النظرية والتجارب أن استخدام بيانات غير مقترنة من وسائط مساعدة (مثل النص والصوت والصورة) يمكن أن يحسن باستمرار أداء المهام أحادية الوسائط اللاحقة مثل الصور والصوت. (المصدر: HuggingFace Daily Papers)
الموضوع: إعلان عن كتاب جديد: “دليل مصور لوكلاء AI”: سيصدر قريبًا كتاب جديد بعنوان “دليل مصور لوكلاء AI” من تأليف Jay Alammar وMaarten Gr، ونشره O’Reilly Media. سيتناول الكتاب بعمق المفاهيم الأساسية لفهم وبناء وكلاء AI، ويغطي مواضيع متقدمة مثل الأدوات، والذاكرة، وتوليد الكود، والاستدلال، والوسائط المتعددة، وRLVR/GRPO، ويهدف إلى أن يكون المشروع المرئي الأكثر ثراءً في مجال وكلاء AI. (المصدر: JayAlammar, MaartenGr)

الموضوع: SEAL: نماذج اللغة ذاتية التكيف لتحقيق التعلم المستمر: تصف دراسة جديدة بعنوان SEAL (Self-Adapting Language Models) كيف يمكن لنماذج AI أن تتعلم باستمرار بعد النشر، وتطور تمثيلاتها الداخلية دون الحاجة إلى إعادة التدريب. تتيح بنية SEAL للنموذج التعلم من البيانات الجديدة في الوقت الفعلي، وإصلاح المعرفة المتدهورة ذاتيًا، وتكوين “ذاكرة” دائمة عبر الجلسات. إذا تم دمج هذه التقنية في GPT-6، فسيحقق ذلك AI ذاتي التعلم المستمر، مودعًا عصر “الأوزان المجمدة”. (المصدر: yoheinakajima)

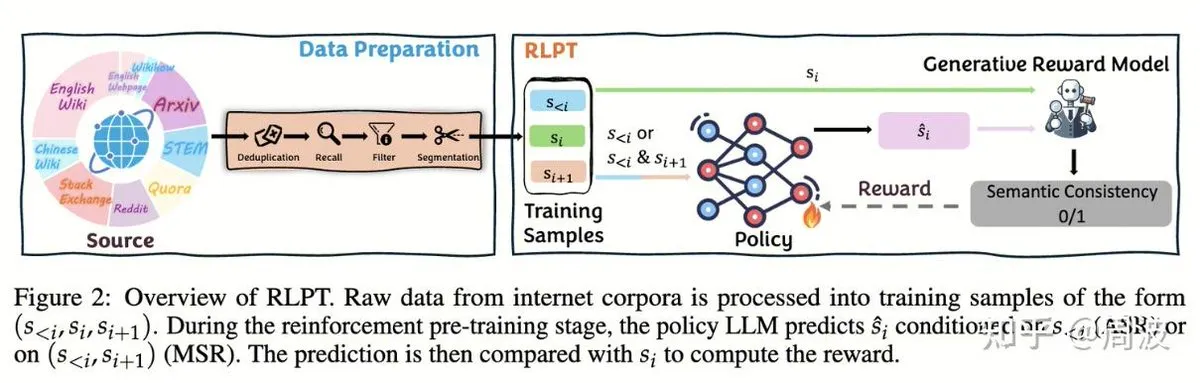
الموضوع: فريق Tencent Hunyuan يقترح طريقة جديدة لتعلم التعزيز لاستدلال LLM بدون بيانات مصنفة بشريًا: أطلق فريق Tencent Hunyuan للاستدلال والتدريب المسبق طريقة جديدة لتعلم التعزيز (RL)، تستبدل “توقع الرمز التالي” التقليدي بـ “توقع المقطع التالي” القائم على RL، مما يتيح توسيع قدرة استدلال LLM دون الحاجة إلى بيانات مصنفة بشريًا. تعمل هذه الطريقة، من خلال مهمتين من مهام RL وهما الاستدلال التراجعي للمقاطع (ASR) والاستدلال للمقاطع الوسيطة (MSR)، على تحسين أداء النموذج بشكل كبير في العديد من الاختبارات المعيارية في الرياضيات والمنطق وغيرها، مما يثبت أن توسيع الاستدلال لا يعني توسيع التكلفة. (المصدر: ZhihuFrontier, ZhihuFrontier)
🧰 أدوات
الموضوع: OpenAlex MCP Server: أداة OpenWebUI مخصصة للبحث العلمي: قام مطور بإنشاء OpenAlex MCP Server للبحث العلمي في OpenWebUI. تدمج هذه الخدمة فهرس OpenAlex العلمي المجاني، مما يسمح للمستخدمين بتصفية الأوراق البحثية حسب التاريخ وعدد الاستشهادات، مما يحل الحاجة التي لم تلبيها الأدوات الحالية، ويمكن دمجها بسهولة في OpenWebUI. (المصدر: Reddit r/OpenWebUI)
الموضوع: Claude ينجح في تشخيص وإصلاح مشكلة أداء جهاز كمبيوتر للمستخدم: شارك أحد المستخدمين كيف ساعده Claude AI في حل مشكلة أداء جهاز الكمبيوتر التي عانى منها لمدة ثلاث سنوات. من خلال توجيهات Claude، اكتشف المستخدم إعدادات أداء الطاقة المخفية في عمق لوحة التحكم، وقام بتعديلها من وضع “الصامت” إلى وضع الأداء العالي، مما رفع معدل إطارات الألعاب من 16 إطارًا في الثانية إلى 60 إطارًا في الثانية. يوضح هذا القيمة العملية لـ AI في تشخيص وإصلاح الأعطال التقنية المعقدة. (المصدر: Reddit r/ClaudeAI)
الموضوع: مايكروسوفت تطلق Copilot Benchmarks: تتبع استخدام الموظفين لـ AI يثير الجدل: أطلقت مايكروسوفت أداة تسمى Copilot Benchmarks، تسمح للمديرين بتتبع تكرار استخدام الموظفين لأدوات AI (مثل Copilot) في تطبيقات Office، ومقارنتها بمتوسط القسم و”الشركات الرائدة”. أثار هذا الإجراء مخاوف بشأن مراقبة مكان العمل وإساءة استخدام البيانات، حيث يرى الكثيرون أن هذا قد يؤدي إلى أن يصبح استخدام AI أساسًا لتقييم الأداء أو حتى التسريح من العمل، بدلاً من زيادة الإنتاجية الحقيقية. (المصدر: Reddit r/ArtificialInteligence)
الموضوع: MarkItDown: مايكروسوفت تطلق أداة تحويل مستندات خط أنابيب LLM إلى Markdown: أطلقت مايكروسوفت MarkItDown، وهي أداة Python يمكنها تحويل أنواع ملفات متعددة مثل PDF وWord وExcel وPowerPoint وHTML وCSV وJSON وXML والصور والصوت إلى تنسيق Markdown نظيف. نظرًا لأن Markdown هي “اللغة الأم” لـ LLM، فإن هذه الأداة مناسبة جدًا للمعالجة المسبقة للمستندات قبل إدخالها إلى النموذج، للحفاظ على العناوين والقوائم والجداول والروابط والبيانات الوصفية، مما يحسن كفاءة وجودة معالجة LLM للمستندات. (المصدر: TheTuringPost)
الموضوع: vLLM يتجاوز 60 ألف نجمة على GitHub، ويقود استدلال LLM الفعال: حصل مشروع vLLM على 60 ألف نجمة على GitHub، ليصبح قوة مهمة في مجال استدلال LLM. يدعم المشروع مجموعة متنوعة من الأجهزة مثل NVIDIA وAMD وIntel وApple وTPU، ويتوافق مع نماذج توليد النصوص السائدة مثل Llama وGPT-OSS وQwen وDeepSeek، بالإضافة إلى خطوط أنابيب RL مثل TRL وUnsloth، ويهدف إلى توفير حلول استدلال LLM فعالة وقابلة للتوسع ومفتوحة المصدر، لدفع تطوير النظام البيئي لـ AI. (المصدر: vllm_project)
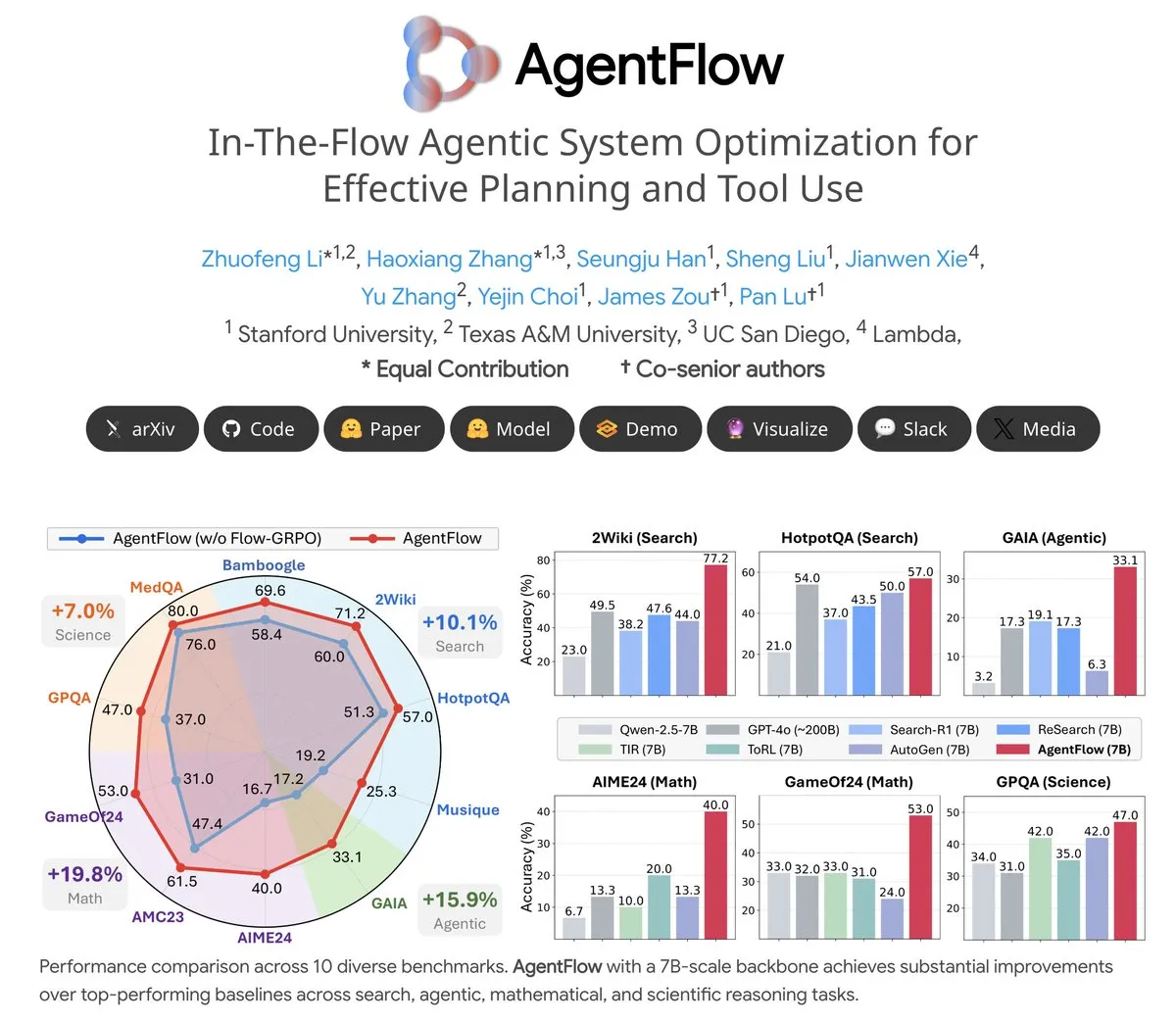
الموضوع: AgentFlow: نظام وكيل قابل للتدريب يحقق تطور البرامج المدفوع بـ LLM: AgentFlow هو نظام وكيل قابل للتدريب ومفتوح المصدر، من خلال التعاون الجماعي، يمكن للوكلاء تعلم التخطيط واستخدام الأدوات في سير عمل المهام. يقوم هذا النظام بتحسين وكيل Planner الخاص به مباشرةً من خلال طريقة Flow-GRPO، وفي العديد من الاختبارات المعيارية في البحث، والوكلاء، والرياضيات، والعلوم، أظهر AgentFlow (نموذج 7B) أداءً أفضل من Llama-3.1-405B وGPT-4o وغيرها من النماذج الكبيرة، مما يوضح الإمكانات الهائلة لـ LLM في استخدام الأدوات. (المصدر: NerdyRodent)
الموضوع: مشكلة تحديث Claude Code: المستخدمون يبلغون عن وجود أخطاء خطيرة في أحدث إصدار: أفاد مستخدمو مجتمع Reddit أن أحدث إصدار من Claude Code يحتوي على أخطاء خطيرة، بما في ذلك قيود نافذة السياق السريعة جدًا وحساب غير دقيق لاستخدام Token، مما يجعله غير قابل للاستخدام تقريبًا. أوصى العديد من المستخدمين بالرجوع فورًا إلى الإصدارات القديمة (مثل 1.0.88)، وتعطيل التحديثات التلقائية، لاستعادة الوظائف المستقرة. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
الموضوع: مشكلة استهلاك قرص Open WebUI Docker المرتفع جدًا: عند تشغيل Open WebUI في حاوية Docker، أبلغ المستخدمون عن استهلاك عالٍ جدًا للقرص، يتكون بشكل أساسي من cache/embedding/models وoverlay2 وcontainers وvector_db. يسعى المستخدمون إلى طرق آمنة لحذف ملفات التخزين المؤقت، وتقليل حجم overlay2، لحل مشكلة نقص مساحة القرص على Azure VM، مما يعكس الطلب على موارد التخزين وتحديات الإدارة عند نشر تطبيقات AI محليًا. (المصدر: Reddit r/OpenWebUI)
الموضوع: أداء Claude Sonnet 4.5 في مهام البرمجة يحظى بإشادة المستخدمين: على الرغم من الانتقادات السلبية الشائعة التي يواجهها Claude، إلا أن هناك مستخدمين أشادوا بأداء Sonnet 4.5 في مهام البرمجة. صرح المستخدمون أن Sonnet 4.5، بالاشتراك مع التحرير التلقائي ووضع التخطيط، حقق جودة كود مماثلة لـ Opus 4.1 Plan في تطوير Node.js وFlutter، بينما كان أسرع وأقل تكلفة، مما قلل بشكل كبير من تكرار الوصول إلى حدود الاستخدام، وقلل الاعتماد على ChatGPT. (المصدر: Reddit r/ClaudeAI)
📚 تعلم
الموضوع: CleanMARL: تطبيق مبسط لخوارزميات التعلم المعزز متعدد الوكلاء في PyTorch: CleanMARL هو مشروع مفتوح المصدر يوفر تطبيقًا مبسطًا وخاليًا من الملفات المتعددة لخوارزميات التعلم المعزز متعدد الوكلاء (MARL) في PyTorch، باتباع فلسفة تصميم CleanRL. يوفر المشروع أيضًا محتوى تعليميًا يغطي خوارزميات رئيسية مثل VDN وQMIX وCOMA وMADDPG وFACMAC وIPPO وMAPPO، ويدعم البيئات المتوازية وتدريب السياسات المتكررة، ويدمج تسجيل TensorBoard وWeights & Biases، ويهدف إلى مساعدة المستخدمين على فهم وتطبيق خوارزميات MARL. (المصدر: Reddit r/MachineLearning, Reddit r/deeplearning)

الموضوع: المفاهيم الأساسية ومسارات التعلم لـ AI/GenAI/ML/LLM: توفر العديد من الموارد أدلة تعلم في مجال AI من الأساسيات إلى المستويات المتقدمة. يغطي المحتوى مفاهيم Python اللازمة لإتقان AI، وخارطة طريق لتصبح خبيرًا في AI التوليدي، ومقدمة لوكلاء AI، و7 مستويات لهندسة نماذج AI، والفرق بين AI وAI التوليدي والتعلم الآلي، و20 مفهومًا أساسيًا لـ LLM، ومفاهيم وكلاء AI، ومسار وظيفي في علم البيانات. تهدف هذه الموارد إلى مساعدة المتعلمين على بناء نظام معرفي شامل لـ AI وتخطيط التطوير الوظيفي. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

الموضوع: نظام الأرقام اللوغاريتمية للتدريب منخفض الدقة: تستكشف مقالة مدونة نظام الأرقام اللوغاريتمية المستخدم للتدريب منخفض الدقة، وهو أمر بالغ الأهمية لتحسين نماذج التعلم الآلي في بيئات محدودة الموارد. تهدف هذه التقنية إلى زيادة كفاءة التدريب مع الحفاظ على دقة النموذج، وهي اتجاه تحسين مستمر في مجال التعلم العميق. (المصدر: Reddit r/deeplearning)
الموضوع: الأهمية المستمرة لـ OpenCV في مجال رؤية الكمبيوتر: ناقش المجتمع سبب استمرار استخدام OpenCV على نطاق واسع في عام 2025، على الرغم من انتشار أطر عمل التعلم العميق مثل PyTorch/TensorFlow. الرأي السائد هو أن OpenCV أكثر ثراءً وكفاءة في وظائف معالجة الصور والفيديو، خاصة مع تسريع CUDA، حيث تتفوق سرعة معالجته على PyTorch، لذلك غالبًا ما يستخدم للمعالجة المسبقة للصور/الفيديو، ثم يتم تمرير البيانات إلى PyTorch لمهام التعلم العميق. (المصدر: Reddit r/deeplearning)
الموضوع: متطلبات عرض أوراق NeurIPS في EurIPS: ناقش المجتمع قواعد عرض أوراق NeurIPS، مشيرًا إلى أن EurIPS لا يُحتسب كعرض ملصق لـ NeurIPS. إذا لم يتمكن المؤلفون من الحضور شخصيًا إلى SD أو مكسيكو سيتي للعرض، فغالبًا ما يتم سحب الورقة. ومع ذلك، يمكن لأي مؤلف أن يعرض نيابة عنهم، ويحتاج غير المؤلفين إلى الحصول على إذن من المنظمين. يوفر هذا إرشادات للباحثين لضمان نشر أوراقهم في ظروف خاصة. (المصدر: Reddit r/MachineLearning)
الموضوع: تحديات التدريب الموزع لبطاقتي GPU على Windows 11: يسعى أحد المستخدمين للحصول على نصيحة بشأن التدريب الموزع لـ PyTorch باستخدام بطاقتي رسومات NVIDIA A6000 على Windows 11. على الرغم من تمكين CUDA، لا يمكن حاليًا استخدام سوى بطاقة رسومات واحدة. تركز مناقشات المجتمع على كيفية تهيئة البيئة والكود للاستفادة الكاملة من موارد GPU المتعددة للتدريب الفعال للتعلم العميق. (المصدر: Reddit r/deeplearning)
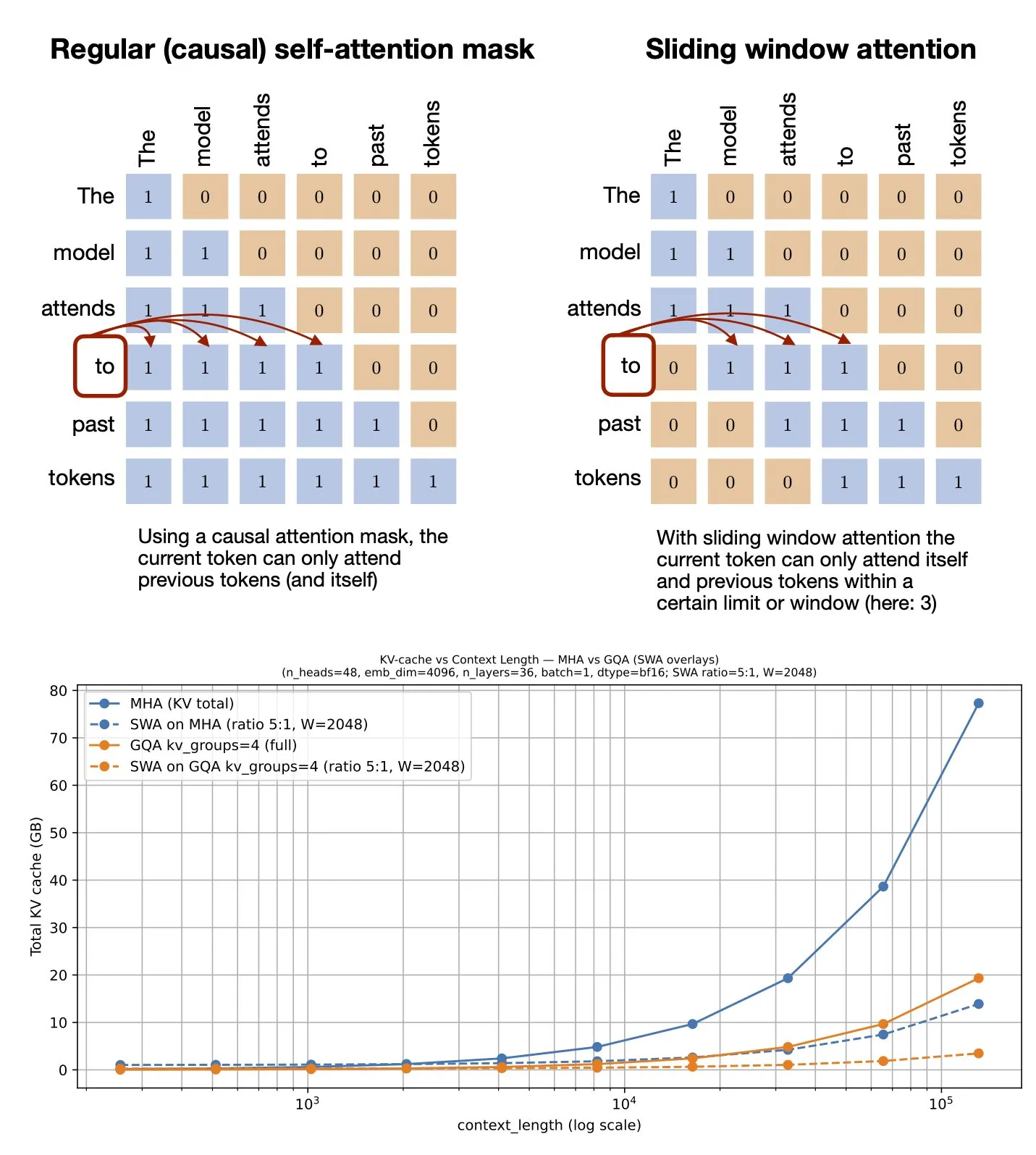
الموضوع: آلية الانتباه بالنافذة المنزلقة: مشاركة مورد GitHub: شارك Sebastian Raschka موردًا على GitHub حول آلية الانتباه بالنافذة المنزلقة (Sliding Window Attention). هذه الآلية هي تقنية تحسين في نماذج اللغة الكبيرة تستخدم لمعالجة المدخلات ذات التسلسلات الطويلة، عن طريق الحد من نطاق حساب الانتباه لتقليل التعقيد الحسابي واستهلاك الذاكرة، مع الحفاظ على فهم فعال للسياق. (المصدر: rasbt)
الموضوع: تحسين التلميحات متعددة الوسائط: استخدام الوسائط المتعددة لتعزيز أداء MLLM: قدمت دراسة طريقة تحسين التلميحات متعددة الوسائط (MPO)، تهدف إلى توسيع مساحة التلميحات إلى ما وراء النص، وتحسين التلميحات متعددة الوسائط بفعالية. تستخدم هذه الطريقة مزيجًا من الوسائط المتعددة (مثل الصور والنصوص) لتعزيز أداء نماذج اللغة الكبيرة متعددة الوسائط (MLLMs)، خاصة عند معالجة المهام المعقدة متعددة الوسائط، من خلال معلومات تلميح أكثر ثراءً لتحقيق فهم وتوليد أكثر دقة. (المصدر: _akhaliq)

الموضوع: كتاب جديد حول نماذج اللغة البصرية سيصدر قريبًا: ستصدر O’Reilly Media قريبًا كتابًا جديدًا حول نماذج اللغة البصرية، وقد تم فتح إشعارات إصدار الفصول بالفعل. يهدف الكتاب إلى تزويد القراء بدليل شامل في مجال نماذج اللغة البصرية، يغطي الأسس النظرية، وأحدث التطورات، والتطبيقات العملية، وهو مرجع مهم للباحثين والمطورين الذين يرغبون في التعمق في هذا المجال المتقاطع. (المصدر: mervenoyann)
الموضوع: nanochat: Andrej Karpathy يطلق خط أنابيب تدريب واستدلال مبسط لاستنساخ ChatGPT: أطلق Andrej Karpathy مستودع GitHub جديدًا باسم nanochat، وهو خط أنابيب تدريب/استدلال كامل ومبسط من الصفر، لبناء استنساخ بسيط لـ ChatGPT. على عكس nanoGPT السابق الذي غطى التدريب المسبق فقط، يوفر nanochat حلاً شاملاً من البداية إلى النهاية، مما يسهل على المطورين فهم وممارسة عملية بناء ChatGPT. (المصدر: dejavucoder)

الموضوع: nanosft: تطبيق ملف واحد لضبط نماذج الدردشة الدقيق على أساس PyTorch: nanosft هو تطبيق مبسط بملف واحد، لضبط النماذج المصممة للدردشة. يمكنه تحميل أوزان gpt2-124M على nanogpt، ويستخدم PyTorch فقط للضبط الدقيق تحت الإشراف. يهدف هذا المشروع إلى توفير أداة سهلة الفهم والاستخدام، لمساعدة المطورين على تخصيص وتحسين نماذج الدردشة. (المصدر: tokenbender, dejavucoder)
الموضوع: دليل مايكروسوفت Edge AI للمبتدئين: مورد قراءة موصى به: تمت التوصية بدليل مايكروسوفت Edge AI للمبتدئين كمورد تعليمي. قد يغطي هذا الدليل النظريات والأدوات والحالات العملية لنشر وتشغيل نماذج AI على الأجهزة الطرفية، وهو ذو قيمة إرشادية للمتعلمين الذين يرغبون في استكشاف تطبيقات Edge AI وتطويرها. (المصدر: hrishioa)
الموضوع: llama.cpp: ثورة الكفاءة في تشغيل LLM المحلي: ناقش المجتمع تجربة الانتقال من Ollama وLM Studio إلى llama.cpp لتشغيل نماذج اللغة الكبيرة المحلية (LLM)، حيث يرى الجميع أن llama.cpp يوفر تحسينًا كبيرًا في الكفاءة. وصفه المستخدمون بأنه أداة “تغير قواعد اللعبة تمامًا”، مما يشير إلى أن llama.cpp قد حقق تقدمًا مهمًا في تحسين أداء استدلال LLM المحلي. (المصدر: ggerganov)
الموضوع: RL-Guided KV Cache Compression: ضغط ذاكرة التخزين المؤقت للقيمة الرئيسية لاستدلال LLM: يقترح هذا البحث إطار عمل RLKV، الذي يحدد رؤوس الانتباه الحاسمة للاستدلال من خلال التعلم المعزز، ويحسن العلاقة بين استخدام ذاكرة التخزين المؤقت KV وجودة الاستدلال. يحصل RLKV على مكافآت من عينات التوليد الفعلية أثناء التدريب، ويحدد بفعالية رؤوس الانتباه المرتبطة باتساق سلسلة التفكير، مما يحقق تخفيضًا في ذاكرة التخزين المؤقت بنسبة 20-50%، مع الحفاظ على أداء شبه خالٍ من الفقدان، مما يحل مشكلة الأداء الضعيف للطرق الحالية على نماذج الاستدلال. (المصدر: HuggingFace Daily Papers)
الموضوع: Hybrid-depth: تجميع الميزات الهجينة لتقدير العمق أحادي العين بتوجيه لغوي: Hybrid-depth هو إطار عمل جديد، يدمج بشكل منهجي نماذج أساسية مثل CLIP وDINO، ويستخرج الأولويات البصرية والمعلومات السياقية من خلال التوجيه اللغوي المتباين، لتعزيز أداء تقدير العمق أحادي العين (MDE). تعمل هذه الطريقة، من خلال إطار تعلم تدريجي من الخشن إلى الدقيق، على تجميع الميزات متعددة المستويات وتحسين توقعات العمق، وتتفوق بشكل كبير على طرق SOTA في اختبارات KITTI المعيارية، وتفيد مهام إدراك BEV اللاحقة. (المصدر: HuggingFace Daily Papers)
الموضوع: ترسيم أسلوب السرد الشخصي: تحليل التجارب الذاتية من خلال نماذج اللغة: يقترح هذا البحث طريقة جديدة لترسيم أسلوب السرد الشخصي كأنماط لاختيار اللغة من قبل المؤلف عند نقل التجارب الذاتية. يجمع هذا الإطار بين اللغويات الوظيفية وعلوم الكمبيوتر والملاحظات النفسية، ويستخرج تلقائيًا الميزات اللغوية، مثل العمليات والمشاركين والسياقات. من خلال تحليل سرد الأحلام (بما في ذلك حالات قدامى المحاربين المصابين باضطراب ما بعد الصدمة)، كشف البحث عن العلاقة بين اختيار اللغة والحالة النفسية. (المصدر: HuggingFace Daily Papers)
الموضوع: ELMUR: ذاكرة الطبقة الخارجية للتعلم المعزز طويل المدى: ELMUR (External Layer Memory with Update/Rewrite) هو بنية Transformer مزودة بذاكرة خارجية منظمة، تحل مشكلة صعوبة الاحتفاظ بالاعتمادات طويلة المدى واستخدامها في التعلم المعزز طويل المدى في النماذج التقليدية. يوسع ELMUR مجال الرؤية الفعال إلى 100 ألف ضعف نافذة الانتباه، ويحقق معدل نجاح 100% في مهام T-Maze الاصطناعية، ويحسن الأداء بما يقرب من الضعف في مهام التشغيل ذات المكافآت المتفرقة، مما يثبت قابلية توسيع الذاكرة الخارجية المنظمة والمحلية للطبقات في اتخاذ القرارات القابلة للملاحظة جزئيًا. (المصدر: HuggingFace Daily Papers)
الموضوع: LightReasoner: كيف تعلم نماذج اللغة الصغيرة نماذج اللغة الكبيرة الاستدلال: يستخدم إطار عمل LightReasoner الاختلافات السلوكية بين النماذج الخبيرة (LLM) والنماذج الهواة (SLM) لتحديد لحظات الاستدلال الحاسمة وبناء أمثلة إشرافية، مما يمكن نماذج اللغة الصغيرة من تعليم نماذج اللغة الكبيرة الاستدلال بكفاءة. أدت هذه الطريقة إلى زيادة الدقة بنسبة تصل إلى 28.1% في سبعة اختبارات معيارية للرياضيات، مع تقليل استهلاك الوقت، وعينات المشكلات، واستخدام رموز الضبط الدقيق بنسبة 90% و80% و99% على التوالي، ودون الحاجة إلى تسميات حقيقية، مما يوفر طريقة فعالة من حيث الموارد لتوسيع استدلال LLM. (المصدر: HuggingFace Daily Papers)
الموضوع: MONKEY: محول تنشيط القيمة الرئيسية لنماذج الانتشار المخصصة: يقترح MONKEY طريقة تستخدم الأقنعة التي يتم إنشاؤها تلقائيًا بواسطة IP-Adapter، لإخفاء رموز الصور في مرحلة الاستدلال الثانية، وبالتالي حصر التخصيص في نماذج الانتشار على المناطق الموضوعية، مما يسمح للتلميحات النصية بالتركيز بشكل أفضل على بقية الصورة. عند وصف النص للمواقع والمشاهد، يمكن لهذه الطريقة توليد صور تصور الموضوع بدقة وتطابق التلميحات بوضوح، مما يحقق توافقًا عاليًا بين التلميحات والصور المصدر. (المصدر: HuggingFace Daily Papers)
الموضوع: Speculative Jacobi-Denoising Decoding: تسريع توليد النصوص إلى الصور التراجعية: يعمل إطار عمل SJD2 (Speculative Jacobi-Denoising Decoding) على تسريع استدلال نماذج توليد النصوص إلى الصور التراجعية من خلال دمج عملية إزالة الضوضاء في تكرار Jacobi، مما يتيح توليد الرموز المتوازية. تقدم هذه الطريقة نموذج “توقع الرمز النظيف التالي”، مما يسمح للنماذج المدربة مسبقًا بقبول تضمينات الرموز المشوشة، والتنبؤ بالرمز النظيف التالي من خلال ضبط دقيق منخفض التكلفة، وبالتالي تقليل عدد عمليات التمرير الأمامي للنموذج مع الحفاظ على الجودة البصرية للصور المولدة. (المصدر: HuggingFace Daily Papers)
الموضوع: ACE: تحرير المعرفة المتحكم فيه بالإسناد لتحقيق استدعاء الحقائق متعدد القفزات: يعمل إطار عمل ACE (Attribution-Controlled Knowledge Editing) على تحديد وتحرير مسارات الاستعلام-القيمة (Q-V) الرئيسية من خلال الإسناد على مستوى الخلايا العصبية، لتحقيق تحرير فعال للمعرفة في LLM. تتفوق هذه الطريقة بشكل كبير على طرق SOTA الحالية في مهام استدعاء الحقائق متعددة القفزات، حيث تزيد الأداء بنسبة 9.44% على GPT-J و37.46% على Qwen3-8B، مما يفتح آفاقًا جديدة لتحسين قدرات تحرير المعرفة بناءً على فهم آليات الاستدلال الداخلية. (المصدر: HuggingFace Daily Papers)
الموضوع: DISCO: تكثيف العينات المتنوعة لتحقيق تقييم فعال للنماذج: تحقق طريقة DISCO (Diversifying Sample Condensation) تقييمًا فعالًا لنماذج التعلم الآلي من خلال اختيار أفضل k عينة تختلف فيها النماذج بشكل أكبر. تستخدم هذه الطريقة إحصائيات على مستوى العينة الجشعة بدلاً من التجميع العالمي، وهي أبسط من الناحية المفاهيمية. نظريًا، يوفر الاختلاف بين النماذج قواعد اختيار جشعة مثالية من الناحية المعلوماتية. تتفوق DISCO على الطرق الحالية في التنبؤ بالأداء في اختبارات MMLU وHellaswag وWinogrande وARC المعيارية، وتحقق نتائج SOTA. (المصدر: HuggingFace Daily Papers)
الموضوع: D2E: التدريب المسبق للرؤية-الحركة من بيانات سطح المكتب، والانتقال إلى AI المتجسد: يثبت إطار عمل D2E (Desktop to Embodied AI) أن التفاعل المكتبي يمكن أن يكون أساسًا فعالًا للتدريب المسبق لمهام AI الروبوتية المتجسدة. يتضمن هذا الإطار مجموعة أدوات OWA (تفاعل مكتبي موحد)، وGeneralist-IDM (تعميم بدون أمثلة عبر الألعاب)، وVAPT (نقل تمثيلات التدريب المسبق المكتبي إلى العمليات المادية والتنقل). استخدم D2E أكثر من 1.3 ألف ساعة من البيانات، وحقق معدلات نجاح بلغت 96.6% في عمليات LIBERO و83.3% في تنقل CANVAS المعيارية. (المصدر: HuggingFace Daily Papers)
الموضوع: One Patch to Caption Them All: إطار عمل موحد لتسمية الصور بدون أمثلة: يقترح هذا البحث إطار عمل موحدًا لتسمية الصور بدون أمثلة، ينتقل من التركيز على الصورة إلى التركيز على الرقعة، ويمكنه تسمية أي منطقة دون الحاجة إلى إشراف على مستوى المنطقة. من خلال اعتبار رقعة واحدة كوحدة تسمية ذرية وتجميعها لوصف أي منطقة، تتفوق هذه الطريقة على الخطوط الأساسية الحالية وطرق SOTA في العديد من مهام التسمية القائمة على المنطقة، مما يسلط الضوء على فعالية تمثيلات الدلالات على مستوى الرقعة في توليد التسميات القابلة للتوسع. (المصدر: HuggingFace Daily Papers)
الموضوع: Adaptive Attacks on Trusted Monitors: قلب بروتوكولات التحكم في AI: يكشف هذا البحث عن نقطة عمياء رئيسية في بروتوكولات التحكم في AI: عندما يفهم النموذج غير الموثوق به البروتوكول ونموذج المراقبة، يمكن للهجمات التكيفية استغلال حقن التلميحات العلنية أو بدون أمثلة للتحايل على المراقبة وإكمال المهام الضارة. أظهرت التجارب أن النماذج الرائدة يمكنها باستمرار التحايل على مختلف أجهزة المراقبة، وإكمال المهام الضارة على معيارين رئيسيين للتحكم في AI، وحتى بروتوكول Defer-to-Resample يمكن أن يأتي بنتائج عكسية. (المصدر: HuggingFace Daily Papers)
الموضوع: Bridging Reasoning to Learning: الكشف عن الهلوسة من خلال تعميم Complexity OoD: يقترح هذا البحث إطار عمل التعميم خارج التوزيع (Complexity OoD) لتعريف وقياس قدرة AI على الاستدلال. عندما يحافظ النموذج على الأداء في حالات الاختبار التي تتجاوز تعقيد الحل (التمثيل أو الحساب) لأمثلة التدريب، فإنه يظهر تعميم Complexity OoD. يوحد هذا الإطار التعلم والاستدلال، ويقدم توصيات لتشغيل Complexity OoD، ويؤكد أن الاستدلال القوي يتطلب آليات معمارية وتدريبية تقوم بنمذجة الحساب وتخصيصه بشكل صريح. (المصدر: HuggingFace Daily Papers)
💼 أعمال
الموضوع: OpenAI تتعاون مع Broadcom لتصميم ونشر شرائح AI مخصصة: أعلنت OpenAI عن شراكة استراتيجية مع Broadcom لتصميم ونشر 10 جيجاوات من شرائح AI المخصصة. تهدف هذه الخطوة إلى توسيع شبكة شركاء OpenAI في مجال الأجهزة، لتلبية الطلب العالمي المتزايد على الحوسبة في AI، وتعزيز استثماراتها في بناء البنية التحتية لـ AI، بعد أن أقامت شراكات مع NVIDIA وAMD. (المصدر: aidan_mclau, gdb, scaling01, bookwormengr)

الموضوع: قسم الدفاع والفضاء في بوينغ يتعاون مع Palantir لتسريع تطبيقات AI: أعلن قسم الدفاع والفضاء في بوينغ عن شراكة مع Palantir، بهدف تسريع تبني وتكامل تقنيات AI. ستستفيد هذه الشراكة من خبرة Palantir في AI وتحليل البيانات، لتعزيز كفاءة عمليات بوينغ وقدراتها على اتخاذ القرار في مجالات الدفاع والفضاء، مما يشير إلى التطبيق العميق لـ AI في القطاعات الصناعية الحيوية. (المصدر: Reddit r/artificial)

الموضوع: Pinterest توسع بنيتها التحتية لـ ML عبر Ray، وتقلل التكاليف: نجحت Pinterest في توسيع بنيتها التحتية للتعلم الآلي (ML) إلى منصة Ray، مما أدى إلى تسريع تطوير الميزات وتقليل التكاليف بشكل كبير من خلال تحويل البيانات الأصلي، وIceberg bucket joins، واستمرارية البيانات. أدت هذه الخطوة إلى تحسين سير عمل ML الخاص بها، وضمان الاستخدام الفعال لوحدات معالجة الرسوميات (GPU) وإمكانية التنبؤ بالميزانية، مما يوفر مرجعًا للشركات الأخرى في تخزين بيانات AI وكفاءة الحوسبة. (المصدر: dl_weekly, TheTuringPost)

🌟 مجتمع
الموضوع: “استخدام AI بفعالية” و”إتقان العمل” في نقاشات AI: إحدى المشكلات الكبيرة في مناقشات AI على وسائل التواصل الاجتماعي هي وجود انفصال بين القدرة على “استخدام AI جيدًا” والقدرة على “إتقان العمل”. قد يتفوق العديد من الخبراء في تطبيقات AI، بينما لا يتفوق آخرون، مما يؤدي إلى صعوبة في الفهم المتبادل. يسلط هذا الاختلاف الضوء على الحاجة إلى دمج المهارات عبر المجالات في عصر AI. (المصدر: nptacek)
الموضوع: ملاحظات حول تحديث ChatGPT Pulse: المستخدمون يتطلعون إلى تلميحات الألعاب ودعم الميزات: ناقش المستخدمون بنشاط تحديث ChatGPT Pulse، وشاركوا التلميحات التي اعتبروها “تغير قواعد اللعبة”، وأشاروا إلى الميزات غير المدعومة حاليًا. تركز هذه المناقشات على كيفية تحسين تجربة ChatGPT، وتخصيص التفاعل، والتوقعات للميزات الجديدة وتحسينات الميزات الحالية، مما يعكس حاجة المستخدمين إلى تخصيص ودعم أعمق لمساعد AI. (المصدر: ChristinaHartW, _samirism, nickaturley)
الموضوع: تحذير: تجنب استخدام cairosvg في بيئات الإنتاج، بسبب خطر DoS: حذر أحد المطورين من عدم استخدام cairosvg في بيئات الإنتاج، لأنه قد يدخل في حلقة لا نهائية عند تحليل ملفات SVG غير الصحيحة التنسيق، وبالتالي يصبح ناقلًا لهجمات رفض الخدمة (DoS). يذكر هذا المطورين بأنه عند اختيار المكتبات، بالإضافة إلى الوظائف، يجب إيلاء اهتمام كبير لاستقرارها وأمانها في بيئات الإنتاج. (المصدر: vikhyatk)

الموضوع: أسلوب كتابة LLM و”انهيار النموذج”: انتقد المجتمع الاستخدام المفرط لـ LLM للعبارات البلاغية مثل “هذا ليس X، هذا Y”، معتبرين أن النموذج ينسخ الأنماط في غياب السياق، مما يؤدي إلى تدهور جودة الكتابة، وربطوا ذلك بظاهرة “انهيار النموذج”. تشير هذه الظاهرة إلى أن LLM لديه قيود في جودة بيانات التدريب وفهم الأنماط، مما قد يؤثر على أدائه في مهام الكتابة المعقدة. (المصدر: Reddit r/LocalLLaMA, Reddit r/artificial)
الموضوع: AI يفاقم “تأثير متى” في مكان العمل، ويزيد الفجوة بين الموظفين المتميزين والعاديين: تشير “وول ستريت جورنال” إلى أن AI سيزيد من الفجوة بين الموظفين المتميزين والموظفين العاديين. فالموظفون المتميزون، بفضل خبرتهم المهنية وعاداتهم الفعالة، يمكنهم الاستفادة من أدوات AI في وقت مبكر وبعمق أكبر، وبناء سير عمل فعال، ويمكنهم الحكم بشكل أفضل على اقتراحات AI. بينما يميل الموظفون العاديون إلى انتظار توجيهات واضحة، وغالبًا ما تُنسب نتائجهم المدعومة بـ AI إلى التكنولوجيا بدلاً من القدرة الشخصية، مما يزيد من “تأثير متى” في مكان العمل. (المصدر: dotey)

الموضوع: المستخدمون يتساءلون عما إذا كان AI يمكن أن يحل محل البشر بشكل هادف: أعرب بعض المستخدمين عن شكوكهم حول ما إذا كان AI يمكن أن يحل محل البشر بشكل هادف، على الرغم من أداء LLM المتميز في السرعة، إلا أنه لا يزال يعاني من أوجه قصور في اتباع تعليمات محددة، ومعالجة السياقات المعقدة، وتجنب الكتابة المجزأة. يرى المستخدمون أن البشر، في المتوسط، لا يزالون يتفوقون على AI في فهم السياق وتنفيذ التعليمات، وبالتالي يدعون إلى أن يركز تطوير AI بشكل أكبر على الموثوقية والاتساق. (المصدر: Reddit r/ClaudeAI)
الموضوع: Sora 2 يثير مخاوف بشأن مصداقية المحتوى المولّد بواسطة AI والجدل الأخلاقي: أعرب المجتمع عن قلقه بشأن انتشار أدوات توليد الفيديو بالذكاء الاصطناعي مثل Sora 2، معتبرين أن مخرجاتها الواقعية للغاية قد تستخدم لتصنيع معلومات كاذبة ومقالب، مما يضر بثقة الجمهور في AI. على سبيل المثال، انتشر مقطع فيديو حول “مقالب المشردين بالذكاء الاصطناعي” على وسائل التواصل الاجتماعي وحصل على عدد كبير من الإعجابات، مما يسلط الضوء على تحديات التحقق من صحة محتوى AI والآثار الاجتماعية السلبية المحتملة. (المصدر: Reddit r/artificial, Reddit r/artificial)
الموضوع: قضاة AI يثيرون جدلاً حول العدالة القضائية والأخلاقيات: استخدم قاضيان فيدراليان أمريكيان AI للمساعدة في صياغة أوامر المحكمة، مما أثار جدلاً حادًا حول دور AI في المجال القضائي. يرى المؤيدون أن AI يمكن أن يبسط عمل المحاكم ويزيد من إمكانية الوصول إلى الخدمات القانونية؛ بينما يحذر المنتقدون من أن AI قد يرتكب أخطاء، ويفتقر إلى “الإنسانية المشتركة” اللازمة للقضاء، مما يضر بالتعاطف والعدالة. أجرت الصين وإستونيا تجارب على قضاة AI، مما ينذر بتغييرات كبيرة محتملة في النظام القضائي المستقبلي. (المصدر: Reddit r/ArtificialInteligence)
الموضوع: مناقشة دعم ChatGPT للصحة النفسية للمستخدمين: شارك مستخدمو Reddit تجاربهم الشخصية مع ChatGPT كمنفذ إبداعي وأداة دعم عاطفي، خاصة عند مواجهة الصدمات والضيق النفسي. يرون أن AI يوفر مساحة آمنة وخاصة، تساعدهم على التعامل مع الوحدة والقلق، ويدعون شركات AI إلى مراعاة احتياجات المستخدمين البالغين المتنوعة في الصحة والاستخدامات الإبداعية عند وضع قيود المحتوى، لتجنب التأثير السلبي على المستخدمين بسبب القيود المفرطة. (المصدر: Reddit r/ChatGPT)
الموضوع: ChatGPT يقع في حلقة لا نهائية من الأخطاء: اكتشف المستخدمون وشاركوا أن ChatGPT يدخل في حلقة لا نهائية من التكرار والرجوع إلى الذات عند الإجابة على بعض الأسئلة المحددة (مثل “ما هو إيموجي فرس البحر؟”). أثارت هذه الظاهرة نقاشًا وردودًا فكاهية في المجتمع، وكشفت عن السلوكيات غير المتوقعة والقيود التي قد تظهر في نماذج AI عند معالجة بعض الأسئلة الغامضة أو المفتوحة. (المصدر: Reddit r/ChatGPT)

الموضوع: VChain: تعزيز الاتساق السببي لنماذج تحويل النص إلى الفيديو من خلال سلسلة التفكير البصري: يعمل VChain على تمكين نماذج تحويل النص إلى الفيديو من اتباع العلاقات السببية في العالم الحقيقي عن طريق حقن “سلسلة التفكير البصري” (سلسلة من الإطارات الرئيسية) أثناء الاستدلال. لا تتطلب هذه الطريقة إعادة تدريب كاملة، بل تتطلب فقط عددًا قليلاً من الإطارات الرئيسية أثناء الاستدلال وضبطًا دقيقًا، مما يحسن بشكل كبير الاتساق الفيزيائي والسببي للفيديو، ويحل مشكلة نماذج الفيديو الحالية التي تتميز بالنعومة العالية ولكنها تتجاهل النتائج السببية الرئيسية. (المصدر: connerruhl)

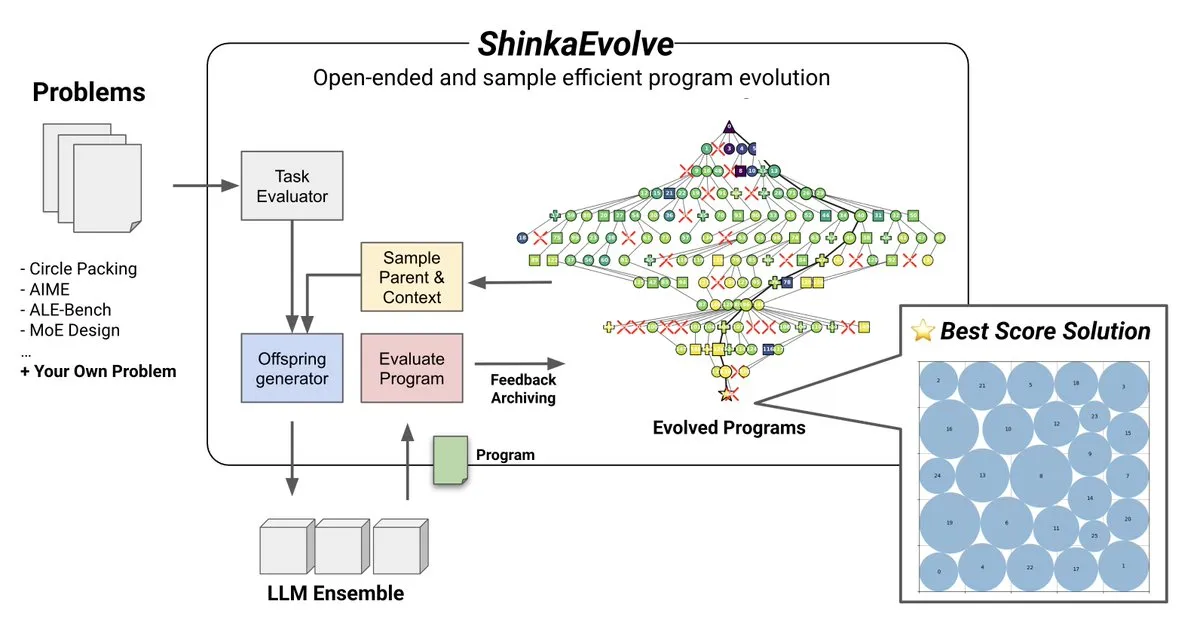
الموضوع: ShinkaEvolve: طريقة مفتوحة المصدر لتطور البرامج المدفوعة بـ LLM: أطلقت Sakana AI طريقة ShinkaEvolve، وهي طريقة مفتوحة المصدر وفعالة من حيث العينات لتطور البرامج المدفوعة بـ LLM، تهدف إلى حل التحديات الرئيسية في اكتشاف البرامج الفعالة في الاكتشاف المفتوح والفعال من حيث العينات. يستخدم هذا الإطار LLM كعامل إعادة تركيب ذكي، ويدفع تطور البرامج في الاكتشاف العلمي، وقد تم اختباره عمليًا، مما يوفر منظورًا جديدًا لطرق مثل AlphaEvolve. (المصدر: hardmaru)
الموضوع: جوجل تطلق تقنية توسيع النطاق الزمني للاختبار المدركة للذاكرة، لتعزيز كفاءة وكلاء AI: قدمت جوجل تقنية توسيع النطاق الزمني للاختبار المدركة للذاكرة (memory-aware test-time scaling)، لتحسين وكلاء AI ذاتيين التطور. تعمل هذه التقنية، من خلال الاستفادة من آليات الذاكرة المنظمة والتكيفية، على تحسين أداء الوكلاء بشكل كبير، متجاوزة آليات الذاكرة الأخرى، وتحل المشكلة الرئيسية المتمثلة في صعوبة إدارة الذاكرة بفعالية في وكلاء AI. (المصدر: omarsar0)

الموضوع: جودة برنامج AMD ROCm تتحسن بشكل ملحوظ، وMI300X تنافسي في أحمال عمل الاستدلال: أفاد المجتمع أن جودة برنامج AMD ROCm قد شهدت “قفزة نوعية” منذ صيف 2024، مما أدى إلى تقليل كبير في تكرار الأخطاء. أظهرت الاختبارات المعيارية أن MI300X vLLM كان أقل بنسبة 5-10% في الأداء لكل TCO مقارنة بـ H100 vLLM في أحمال عمل استدلال Llama3 70B FP8، ولكنه كان تنافسيًا في مقارنة MI325X vLLM مع H200 vLLM وGPTOSS MX4 120B Mi355 مع B200. (المصدر: riemannzeta)

الموضوع: الديناميكيات المستقبلية لـ AI ذاتي التحسين التكراري: ناقش المجتمع كيف سيتطور وينتشر AI ذاتي التحسين التكراري بين المنظمات والمؤسسات والمشاركين والمجتمعات. يعتبر هذا السؤال الأكثر جوهرية حاليًا، ويتعلق بالآثار العميقة لتطور AI على الهياكل الاجتماعية وتوزيع السلطة، وكيفية التنبؤ بهذه التغييرات وإدارتها. (المصدر: ethanCaballero)
الموضوع: Nando de Freitas: إدراك الآلة التنبؤي هو بداية الوعي: اقترح Nando de Freitas من Google DeepMind أن الآلات القادرة على التنبؤ بما ستستشعره المستشعرات (اللمس، الكاميرا، لوحة المفاتيح، درجة الحرارة، الميكروفون، الجيروسكوب، إلخ) تمتلك بالفعل وعيًا وتجربة ذاتية، وأن هذا مجرد مسألة درجة. يرى أن المزيد من المستشعرات والبيانات والحوسبة والمهام ستؤدي بلا شك إلى ظهور “الأنا”، مما أثار نقاشًا حول متى يبدأ الوعي والوعي الذاتي. (المصدر: TheRealRPuri)
الموضوع: تأثير إغلاق بيانات الإنترنت على وكلاء البحث العميق لـ AI: هناك رأي مفاده أنه مع صعود LLM، أصبحت بيانات الإنترنت مغلقة بشكل متزايد، مما يجعل وجود وكلاء البحث العميق لـ AI أمرًا صعبًا. يتساءل الناس عما إذا كان وكيل LLM الذي لا يخزن المعرفة ولكنه بارع في استرجاع المعرفة يمكن أن يتحقق إذا كان الوصول إلى البيانات مقيدًا، مما يعكس المخاوف بشأن انفتاح البيانات وإمكانية الوصول إليها في تطوير AI. (المصدر: Teknium1)
الموضوع: وظائف DevRel تعود بقوة في مجال AI: توظف شركات AI مثل Anthropic موظفين علاقات المطورين (DevRel) برواتب عالية، مما يشير إلى انتعاش قوي لهذا المنصب في مجال AI. يعود الفضل في ذلك إلى الأهمية المتزايدة لهندسة التلميحات ومشاركة المجتمع في تقنيات AI، حيث يلعب متخصصو DevRel دورًا رئيسيًا في ربط المطورين، ودفع تبني المنتجات، وبناء الأنظمة البيئية. (المصدر: swyx)
الموضوع: Jonathan Blow: جودة الكود الذي ينتجه AI منخفضة ولا يفهمها AI: أشار المطور الشهير Jonathan Blow إلى أن جودة الكود الذي تنتجه أنظمة AI “منخفضة جدًا”، وأن AI نفسه لا يفهم هذا الكود. يرى أن حالات استخدام الكود الذي تنتجه AI تقتصر بشكل أساسي على السيناريوهات التي تتطلب كمية كبيرة من الكود منخفض الجودة، مما أثار نقاشًا حول القدرات والقيود الفعلية لـ AI في مجال البرمجة. (المصدر: aiamblichus, jeremyphoward, teortaxesTex)
الموضوع: انتقاد منشورات الترويج لـ AI: دعوة إلى الشفافية والمحتوى الجوهري: أعرب المجتمع عن استيائه من المنشورات الغامضة والمبالغ فيها حول تقدم AI، داعين الناشرين إلى تقديم محتوى أكثر تحديدًا وجوهرية، وحتى “التبليغ” عند وجود تطورات كبيرة قد تغير نمط الحياة. تعكس هذه المشاعر توقعات الجمهور لجودة المعلومات في مجال AI، والنفور من “الدعاية الغامضة” غير المسؤولة. (المصدر: aiamblichus, Teknium1)
الموضوع: تساؤلات وتوقعات حول NVIDIA DGX Spark: يشكك المجتمع في إطلاق “الكمبيوتر الفائق المكتبي لـ AI” من NVIDIA DGX Spark، ويتساءل عن إمكانية الوصول إليه وسعره وأدائه الفعلي، خاصة لتشغيل LLM المحلي. يرى الكثيرون أن الدعاية مبالغ فيها، وأن الأداء قد لا يكون كما هو متوقع، وأن تاريخ الإطلاق قد تأجل مرارًا وتكرارًا، مما دفع بعض المستخدمين إلى التحول إلى حلول أخرى. (المصدر: Reddit r/LocalLLaMA)
💡 أخرى
الموضوع: Yunpeng Technology تطلق منتجات AI+الصحة الجديدة، لتعزيز إدارة الصحة المنزلية الذكية: أطلقت Yunpeng Technology منتجات جديدة في مجال AI+الصحة بالتعاون مع ShuaiKang وSkyworth، بما في ذلك “مختبر المطبخ الذكي المستقبلي” وثلاجة ذكية مزودة بنموذج AI صحي كبير. توفر الثلاجة الذكية إدارة صحية مخصصة من خلال “مساعد الصحة Xiaoyun”، وتحسن تصميم المطبخ وعملياته. يشير هذا الإطلاق إلى اختراق AI في مجال إدارة الصحة اليومية، ومن المتوقع أن يحقق خدمات صحية مخصصة من خلال الأجهزة الذكية، مما يحسن جودة حياة السكان. (المصدر: 36氪)

الموضوع: مواد MOF الحائزة على جائزة نوبل تُصنع منها شرائح نانوية سائلة شبيهة بالدماغ: استخدم علماء جامعة موناش مواد MOF (Metal-Organic Framework) الحائزة على جائزة نوبل في الكيمياء، لإنشاء شريحة نانوية فائقة الصغر للسوائل. لا تستطيع هذه الشريحة إجراء العمليات الحسابية التقليدية فحسب، بل يمكنها أيضًا تذكر وتعلم التغيرات في الجهد الكهربائي السابقة مثل الخلايا العصبية في الدماغ، وتكوين ذاكرة قصيرة المدى. يحل هذا الإنجاز الرائد مشكلة نقص التطبيقات العملية لمواد MOF لفترة طويلة، ويوفر نموذجًا جديدًا لأجهزة الكمبيوتر من الجيل الجديد والحوسبة الشبيهة بالدماغ. (المصدر: 量子位)

الموضوع: تسارع الابتكار والتطبيق في تقنيات الروبوتات العالمية: يشهد مجال الروبوتات العديد من الابتكارات والاختراقات والتطبيقات الواسعة. تعمل روبوتات الأمن الذاتية من Knightscope على تغيير مجال الأمن، وأطلقت الصين روبوتات شرطة كروية عالية السرعة يمكنها القبض على المجرمين بشكل مستقل. أطلقت AgiBot الروبوت البشري Lingxi X2 بقدرات حركة شبه بشرية ومهارات متعددة الوظائف، وأنشأت أكبر مركز تدريب للروبوتات البشرية في العالم، لتسريع اندماجها وتطبيقها في المجتمع. بالإضافة إلى ذلك، أظهرت روبوتات تعزيز القوة القابلة للارتداء للعمال الصناعيين والروبوتات ذات الأربع أرجل التي يمكنها الركض لمسافة 100 متر في 10 ثوانٍ إمكانات تقنية الروبوتات في سيناريوهات مختلفة. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)