
كلمات مفتاحية:الوعي بالذكاء الاصطناعي, التعلم العميق, الشبكات العصبية, الذكاء الاصطناعي الوكيل, التفوق الصوتي, الذكاء الاصطناعي التوليدي, استدلال نماذج اللغة الكبيرة, أدوات الذكاء الاصطناعي, نظرية هوينتون للوعي بالذكاء الاصطناعي, دورة أندرو نج لتعلم الذكاء الاصطناعي الوكيل, إطار AudioLBM للتفوق الصوتي, نموذج OpenAI Sora لتوليد الفيديو, طريقة REFRAG من Meta AI
تحليل وتلخيص متعمق من رئيس تحرير عمود الذكاء الاصطناعي
🔥 تركيز
تصريح صادم من Hinton: قد يمتلك الذكاء الاصطناعي وعيًا لكنه لم يستيقظ بعد : طرح Geoffrey Hinton، أحد عمالقة التعلم العميق الثلاثة، وجهة نظر ثورية في أحدث بودكاست له: قد يمتلك الذكاء الاصطناعي بالفعل “تجربة ذاتية” أو “شكلًا بدائيًا للوعي”، ولكن بسبب فهم البشر الخاطئ للوعي، لم “يستيقظ” الذكاء الاصطناعي على وعيه الخاص بعد. وأكد أن الذكاء الاصطناعي قد تطور من استرجاع الكلمات المفتاحية إلى فهم النوايا البشرية، وشرح بالتفصيل المفاهيم الأساسية للتعلم العميق مثل الشبكات العصبية و Backpropagation. يعتقد Hinton أن “دماغ” الذكاء الاصطناعي سيشكل “تجارب” و “حدسًا” مع توفر بيانات وقوة حاسوبية كافية، وأن خطورته تكمن في “الإقناع” وليس التمرد. وأشار أيضًا إلى أن سوء استخدام الذكاء الاصطناعي ومخاطر الوجود هي التحديات الأكثر إلحاحًا حاليًا، وتوقع أن التعاون الدولي ستقوده أوروبا والصين، بينما قد تفقد الولايات المتحدة ريادتها في الذكاء الاصطناعي بسبب نقص تمويل البحث العلمي الأساسي.
(المصدر: 量子位)
Andrew Ng يطلق دورة Agentic AI جديدة، مؤكدًا على المنهجية المنهجية : أطلق Andrew Ng دورة Agentic AI جديدة، يكمن جوهرها في تحويل تطوير الذكاء الاصطناعي من “ضبط النماذج” إلى “تصميم الأنظمة”، مع التأكيد على أهمية تجزئة المهام، التقييم وتحليل الأخطاء. رسخت الدورة أربعة أنماط تصميم رئيسية: التفكير، الأدوات، التخطيط والتعاون، وعرضت كيفية تجاوز GPT-3.5 لـ GPT-4 في مهام البرمجة باستخدام تقنيات Agentic. من خلال الاستدلال متعدد الخطوات، التنفيذ المرحلي والتحسين المستمر، يحاكي Agentic AI طريقة البشر في حل المشكلات المعقدة، مما يعزز بشكل كبير أداء الذكاء الاصطناعي وقابليته للتحكم. أشار Andrew Ng إلى أن Agentic، كصفة، تصف درجات مختلفة من الاستقلالية في النظام، وليست مجرد تصنيف ثنائي، مما يوفر للمطورين مسارًا قابلاً للتطبيق والتحسين.
(المصدر: 量子位)

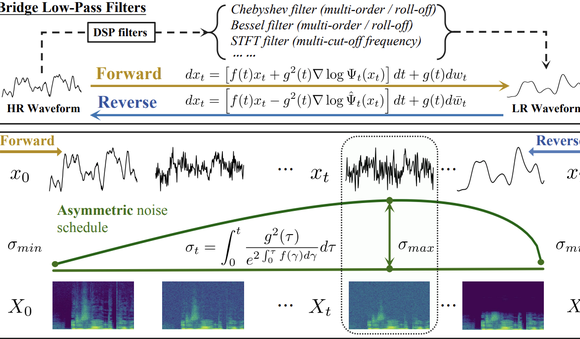
جامعة Tsinghua و Shengshu Technology يقودان نموذجًا جديدًا لزيادة دقة الصوت باستخدام AudioLBM : نشر فريق جامعة Tsinghua و Shengshu Technology نتائج متتالية في ICASSP 2025 و NeurIPS 2025، حيث قدموا نموذج Bridge-SR خفيف الوزن لزيادة دقة شكل موجة الصوت وإطار العمل متعدد الوظائف AudioLBM لزيادة الدقة. يقوم AudioLBM لأول مرة ببناء عملية توليد ربط المتغيرات الكامنة من الدقة المنخفضة إلى الدقة العالية في مساحة كامنة مستمرة لشكل الموجة، مما يحقق زيادة دقة معدل أخذ العينات من Any-to-Any، ويصل إلى SOTA في مهمة Any-to-48kHz. من خلال آلية حساسة للتردد وتصميم نموذج من فئة الجسور المتتالية، نجح AudioLBM في توسيع قدرة زيادة دقة الصوت إلى جودة صوت على مستوى الماستر 96kHz و 192kHz، لتغطية أنواع متعددة من المحتوى مثل الكلام، المؤثرات الصوتية، والموسيقى، مما يرسى معيارًا جديدًا لتوليد الصوت عالي الدقة.
(المصدر: 量子位)
تطبيق OpenAI Sora للفيديو يتجاوز مليون عملية تنزيل : تجاوز أحدث إصدار من أداة الذكاء الاصطناعي لتحويل النص إلى فيديو من OpenAI، Sora، مليون عملية تنزيل في أقل من خمسة أيام، متجاوزًا سرعة إطلاق ChatGPT، وتصدر قائمة تطبيقات Apple App Store في الولايات المتحدة. يستطيع Sora توليد مقاطع فيديو واقعية تصل مدتها إلى عشر ثوانٍ بناءً على أوامر نصية بسيطة، ويبرز معدل تبني المستخدمين السريع الإمكانات الهائلة للذكاء الاصطناعي التوليدي في مجال إنشاء المحتوى وجاذبيته السوقية، مما ينذر بتسارع انتشار تقنية توليد الفيديو بالذكاء الاصطناعي، ومن المتوقع أن يغير النظام البيئي للمحتوى الرقمي.
(المصدر: Reddit r/ArtificialInteligence)

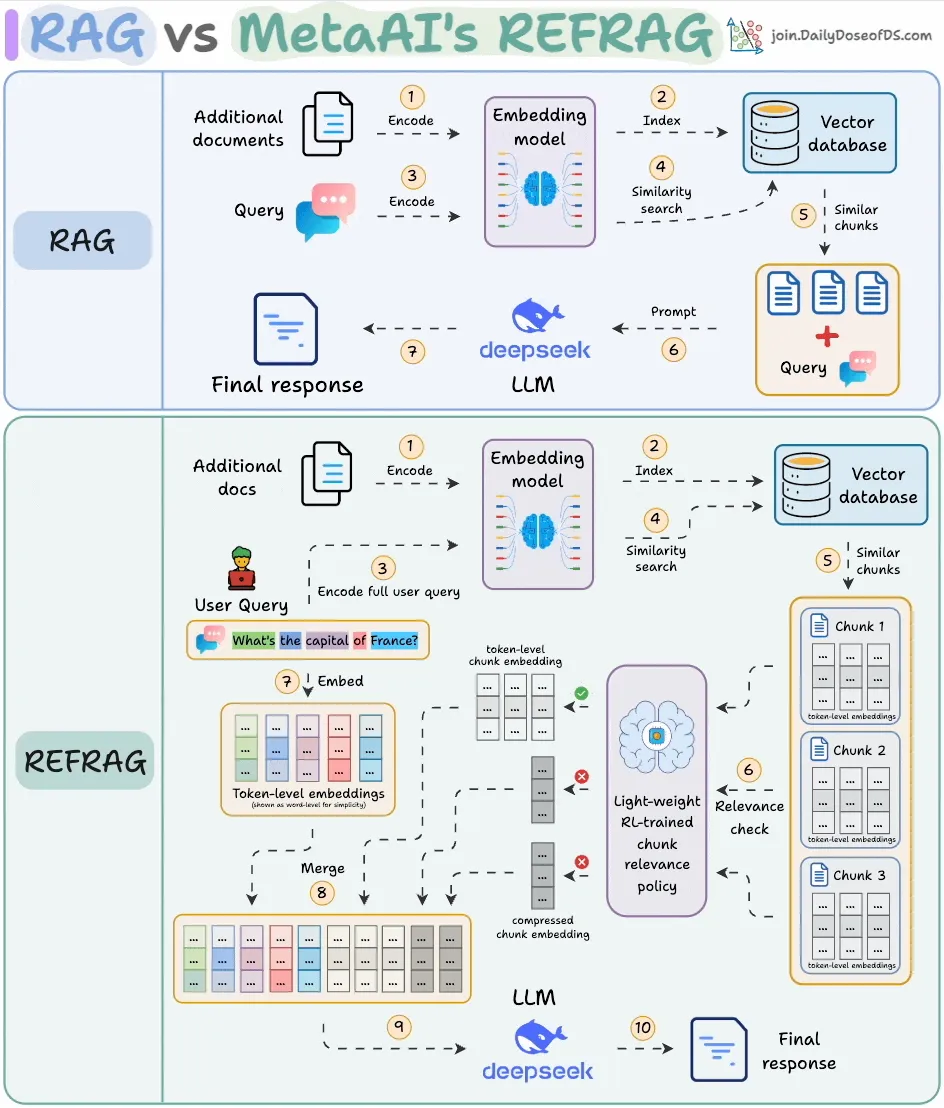
Meta AI تطلق REFRAG، مما يعزز كفاءة RAG بشكل كبير : أطلقت Meta AI طريقة جديدة لـ RAG (Retrieval-Augmented Generation) تسمى REFRAG، تهدف إلى حل مشكلة تكرار المحتوى المسترجع في RAG التقليدي. من خلال الضغط على مستوى المتجهات وتصفية السياق، حقق REFRAG وقتًا أسرع لتوليد الـ Token الأول بمقدار 30.85 مرة، ونافذة سياق أكبر بمقدار 16 مرة، بينما يستخدم 2-4 أضعاف أقل من Tokens للمفكك، دون فقدان الدقة في مهام RAG، التلخيص والمحادثة متعددة الأدوار. يكمن جوهرها في ضغط كل كتلة إلى تضمين واحد، واختيار الكتل الأكثر صلة من خلال استراتيجية مدربة بواسطة RL، وتوسيع انتقائي للكتل المختارة فقط، مما يحسن بشكل كبير كفاءة معالجة LLM وتكاليفها.
(المصدر: _avichawla)
🎯 اتجاهات
Tiny Recursive Model (TRM) يتفوق على LLMs العملاقة : تم اقتراح طريقة بسيطة وفعالة تسمى Tiny Recursive Model (TRM)، تستخدم شبكة صغيرة من طبقتين فقط، وتحسن إجاباتها بشكل متكرر. حقق TRM رقمًا قياسيًا جديدًا باستخدام 7M معامل فقط، متفوقًا على LLMs أكبر منه بـ 10,000 مرة في مهام مثل Sudoku-Extreme، Maze-Hard و ARC-AGI، مما يظهر إمكانية “القيام بالكثير بالقليل”، ويتحدى التصور التقليدي بأن حجم LLM يعادل الأداء.
(المصدر: TheTuringPost)
Amazon و KAIST يطلقان ToTAL، مما يعزز قدرة LLM على الاستدلال : تعاونت Amazon و KAIST لإطلاق ToTAL (Thoughts Meet Facts)، وهي طريقة جديدة لتعزيز قدرة LLM على الاستدلال من خلال “قوالب تفكير” قابلة لإعادة الاستخدام. تتفوق LCLMs (Large Context Language Models) في معالجة كميات كبيرة من السياق، لكنها لا تزال تعاني في الاستدلال. يحل ToTAL هذه المشكلة بفعالية من خلال توجيه الاستدلال متعدد الخطوات بأدلة منظمة، بالاشتراك مع وثائق الحقائق، مما يوفر اتجاهًا جديدًا لتحسين مهام الاستدلال المعقدة لـ LLM.
(المصدر: _akhaliq)
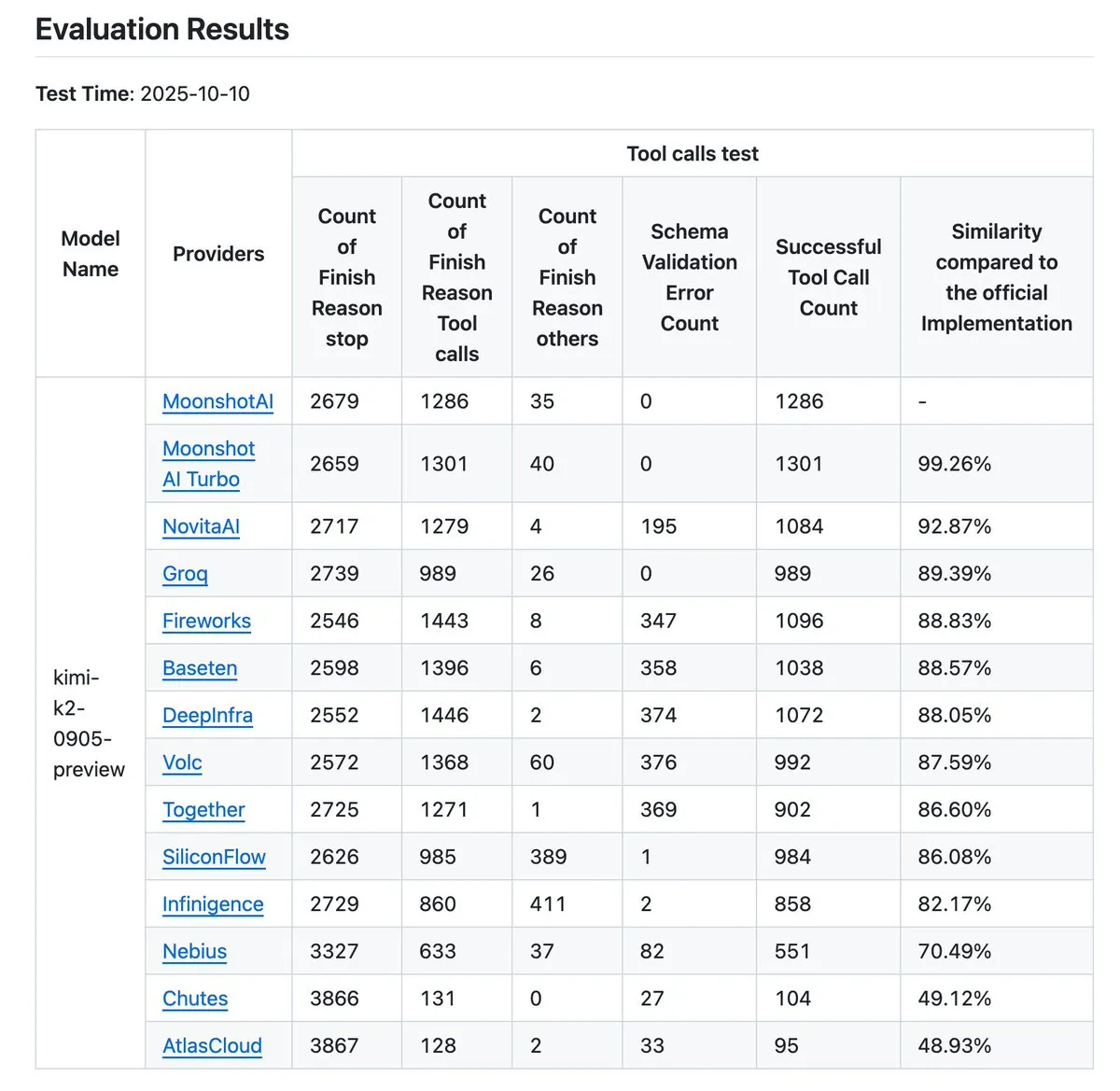
Kimi K2 Vendor Validator يتلقى تحديثًا، مما يعزز معيار دقة استدعاء الأدوات : قامت Kimi.ai بتحديث K2 Vendor Validator الخاص بها، وهي أداة تهدف إلى تصور الاختلافات في دقة استدعاء الأدوات بين مختلف الموردين. أدى هذا التحديث إلى زيادة عدد الموردين من 9 إلى 12، وأتاحت المزيد من إدخالات البيانات كمصدر مفتوح، مما يوفر للمطورين بيانات اختبار معيارية أكثر شمولاً، ويساعد في تقييم واختيار مزودي خدمة LLM المناسبين لسير عمل Agentic الخاص بهم.
(المصدر: JonathanRoss321)
Human3R يحقق إعادة بناء ثلاثية الأبعاد لكامل الجسم لعدة أشخاص ومزامنة المشهد من فيديو ثنائي الأبعاد : قدم بحث جديد يسمى Human3R إطار عمل موحدًا قادرًا على إعادة بناء نماذج ثلاثية الأبعاد لكامل الجسم لعدة أشخاص، ومشاهد ثلاثية الأبعاد، ومسارات الكاميرا في وقت واحد من فيديو ثنائي الأبعاد عشوائي، دون الحاجة إلى خط أنابيب متعدد المراحل. تتعامل هذه الطريقة مع إعادة بناء جسم الإنسان وإعادة بناء المشهد كمشكلة شاملة، مما يبسط العملية المعقدة، ويحقق تقدمًا كبيرًا في مجالات مثل الواقع الافتراضي، الرسوم المتحركة وتحليل الحركة.
(المصدر: nptacek)
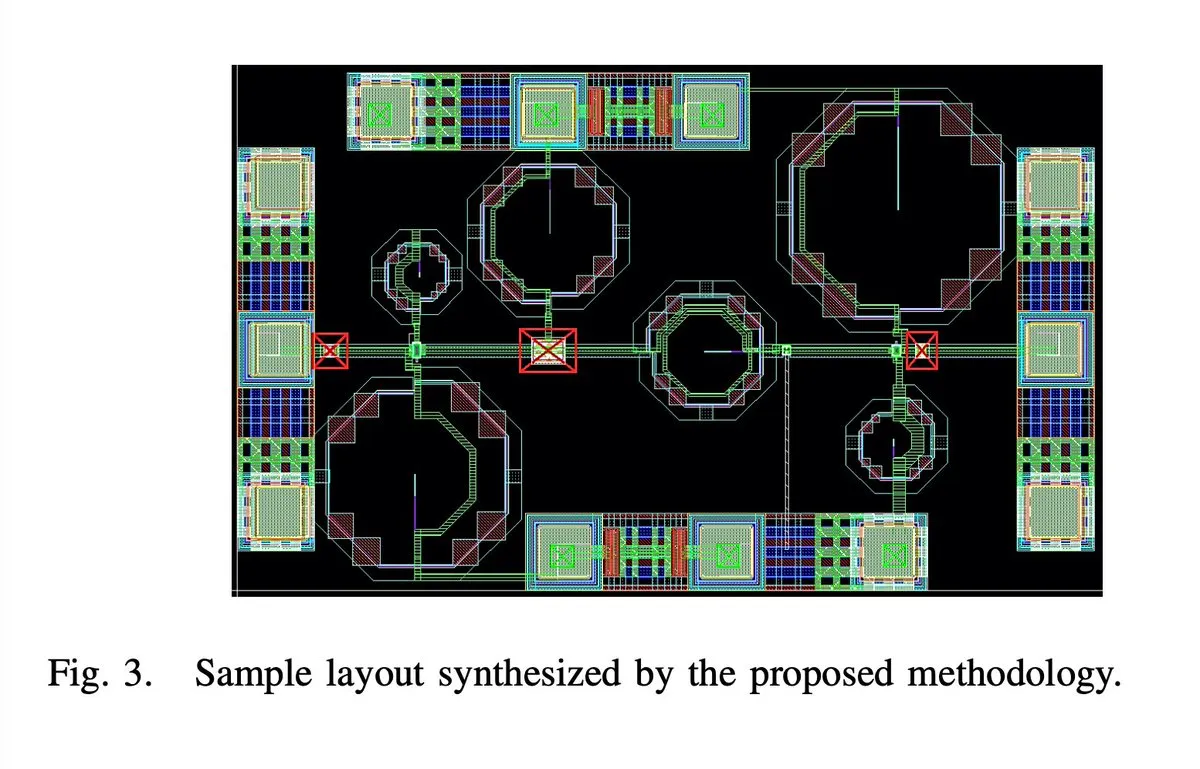
الذكاء الاصطناعي يصمم بالكامل شريحة مكبر صوت منخفض الضوضاء 65 نانومتر 28 جيجاهرتز 5G : تم تصميم شريحة مكبر صوت منخفض الضوضاء (LNA) 65 نانومتر 28 جيجاهرتز 5G، بالكامل بواسطة الذكاء الاصطناعي، بما في ذلك جميع الجوانب مثل التخطيط، المخطط التخطيطي و DRC (Design Rule Check). يدعي المؤلف أن هذا هو أول LNA بموجة مليمترية يتم توليفه تلقائيًا بالكامل، وقد تم تصنيع عينتين بنجاح، مما يمثل اختراقًا كبيرًا للذكاء الاصطناعي في مجال تصميم الدوائر المتكاملة، وينذر بقفزة في كفاءة تصميم الرقائق في المستقبل.
(المصدر: jpt401)
iPhone 17 Pro يشغل LLM بحجم 8B محليًا بسلاسة : تم تأكيد قدرة iPhone 17 Pro من Apple على تشغيل نموذج LLM بحجم 8B معامل، LFM2 8B A1B، بسلاسة، من خلال إطار عمل MLX على LocallyAIApp لتحقيق النشر على الجهاز. يشير هذا التقدم إلى أن Apple قد أعدت تصميم الأجهزة لتشغيل نماذج اللغة الكبيرة محليًا، ومن المتوقع أن يدفع انتشار تطبيقات الذكاء الاصطناعي على الأجهزة المحمولة وتحسين أدائها، مما يوفر للمستخدمين تجربة ذكاء اصطناعي أسرع وأكثر خصوصية.
(المصدر: Plinz, maximelabonne)
مشروع xAI MACROHARD يهدف إلى التصنيع غير المباشر المدفوع بالذكاء الاصطناعي : كشف Elon Musk أن مشروع “MACROHARD” التابع لـ xAI يهدف إلى إنشاء شركة قادرة على تصنيع المنتجات المادية بشكل غير مباشر، على غرار شركة Apple التي تنتج هواتفها من خلال شركات أخرى. هذا يعني أن هدف xAI هو تطوير أنظمة ذكاء اصطناعي قادرة على تصميم وتخطيط وتنسيق عمليات التصنيع المعقدة، بدلاً من المشاركة المباشرة في الإنتاج المادي، مما ينذر بتأثير هائل للذكاء الاصطناعي في الأتمتة الصناعية وإدارة سلسلة التوريد.
(المصدر: EERandomness, Yuhu_ai_)

Kimi-Dev ينشر تقريرًا فنيًا، يركز على التدريب بدون Agent كمعرفة مسبقة لـ SWE-Agents : نشرت Kimi-Dev تقريرها الفني، الذي يشرح بالتفصيل طريقة “التدريب بدون Agent كمعرفة مسبقة لـ SWE-Agents”. يستكشف هذا البحث كيفية توفير أساس قوي للمهارات لوكلاء هندسة البرمجيات من خلال التدريب دون هندسة Agent صريحة، مما يوفر أفكارًا جديدة لتطوير أدوات تطوير برمجيات آلية أكثر كفاءة وذكاءً.
(المصدر: bigeagle_xd)

جوجل AI يحقق التعلم وتصحيح الأخطاء في الوقت الفعلي : طورت جوجل نظام ذكاء اصطناعي قادرًا على التعلم من أخطائه وتصحيحها في الوقت الفعلي. توصف هذه التقنية بأنها “تعلم تعزيزي استثنائي”، وتمكن النموذج من التكيف الذاتي في السرد السياقي المجرد، مما يحقق تحسين السياق في الوقت الفعلي، وينذر بخطوة مهمة للذكاء الاصطناعي في القدرة على التكيف والمتانة، ومن المتوقع أن يعزز بشكل كبير أداء الذكاء الاصطناعي في البيئات المعقدة والديناميكية.
(المصدر: Reddit r/artificial)
GPT5 و Gemini 2.5 Pro يحققان أداءً بمستوى الميدالية الذهبية في أولمبياد الفلك والفيزياء الفلكية : أظهرت دراسة حديثة أن نماذج اللغة الكبيرة مثل GPT5 و Gemini 2.5 Pro حققت أداءً بمستوى الميدالية الذهبية في أولمبياد الفلك والفيزياء الفلكية الدولي (IOAA). على الرغم من نقاط الضعف المعروفة لهذه النماذج في الاستدلال الهندسي والمكاني، إلا أنها أظهرت قدرات مذهلة في مهام الاستدلال العلمي المعقدة، مما أثار نقاشًا متعمقًا حول إمكانات تطبيق LLM في المجال العلمي، وتحليلًا إضافيًا لنقاط قوتها وضعفها.
(المصدر: tokenbender)

أبرز نقاط التقرير الأسبوعي لـ Zhihu Frontier: اتجاهات جديدة في تطوير الذكاء الاصطناعي : ركز تقرير Zhihu Frontier الأسبوعي هذا الأسبوع على العديد من التطورات الرائدة في الذكاء الاصطناعي، بما في ذلك: Sand.ai تطلق أول “فاعل ذكاء اصطناعي شامل” GAGA-1؛ Rich Sutton يطرح وجهة نظر مثيرة للجدل بأن “LLMs طريق مسدود”؛ OpenAI App SDK يحول ChatGPT إلى نظام تشغيل؛ Zhipu AI تطلق GLM-4.6 مفتوح المصدر، يدعم دقة مختلطة FP8+Int4 للرقائق المحلية؛ DeepSeek V3.2-Exp يقدم الانتباه المتناثر ويخفض الأسعار بشكل كبير، و Anthropic Claude Sonnet 4.5 يوصف بأنه “أفضل نموذج برمجة في العالم”، مما يظهر نشاط مجتمع الذكاء الاصطناعي الصيني والتطور المتنوع لمجال الذكاء الاصطناعي العالمي.
(المصدر: ZhihuFrontier)

Ollama توقف دعم Mi50/Mi60 GPU، وتتحول إلى دعم Vulkan : قامت Ollama مؤخرًا بترقية إصدار ROCm، مما أدى إلى عدم دعم AMD Mi50 و Mi60 GPU. صرح المسؤولون بأنهم يعملون جاهدين لدعم هذه GPUs من خلال Vulkan في الإصدارات المستقبلية. يؤثر هذا التغيير على مستخدمي Ollama الذين يستخدمون AMD GPUs القديمة، ويذكر المستخدمين بمتابعة التحديثات الرسمية للحصول على معلومات التوافق.
(المصدر: Reddit r/LocalLLaMA)
شائعات إلغاء مشروع Llama 5 تثير نقاشًا حادًا في المجتمع : انتشرت على وسائل التواصل الاجتماعي شائعات بأن مشروع Llama 5 التابع لـ Meta قد يتم إلغاؤه، ويعتقد بعض المستخدمين أن عودة Andrew Tulloch إلى Meta وتأخر إصدار نموذج Llama 4 8B هي أدلة على ذلك. على الرغم من امتلاك Meta لموارد GPU كافية، يبدو أن تطور نماذج Llama قد وصل إلى طريق مسدود، مما أثار مخاوف في المجتمع بشأن القدرة التنافسية لـ Meta في مجال LLM، والاهتمام بنماذج صينية مثل DeepSeek و Qwen.
(المصدر: Yuchenj_UW, Reddit r/LocalLLaMA, dejavucoder)

GPU Poor LLM Arena يعود، مع نماذج صغيرة إضافية : أعلنت GPU Poor LLM Arena عن عودتها، وأضافت العديد من النماذج الجديدة، بما في ذلك سلسلة Granite 4.0 وسلسلة Qwen 3 Instruct/Thinking، بالإضافة إلى إصدار Unsloth GGUF من OpenAI gpt-oss. معظم النماذج الجديدة هي بكمّي 4-8 بت، وتهدف إلى توفير المزيد من الخيارات للمستخدمين ذوي الموارد المحدودة. يؤكد هذا التحديث على مزايا Unsloth GGUF في إصلاح الأخطاء والتحسينات، مما يدفع بالنشر والاختبار المحلي لنماذج LLM الصغيرة.
(المصدر: Reddit r/LocalLLaMA)

بحث Meta يفشل في تقديم نماذج أساسية رائدة يثير النقاش : يناقش المجتمع أسباب فشل Meta في أبحاث النماذج الأساسية في الوصول إلى مستوى Grok، Deepseek أو GLM. تشير التعليقات إلى أن آراء LeCun حول LLM، البيروقراطية الداخلية، الحذر المفرط، والتركيز على المنتجات الداخلية بدلاً من البحث الرائد قد تكون العوامل الرئيسية. تفتقر Meta إلى بيانات العملاء الحقيقية في تطبيقات LLM، مما أدى إلى نقص العينات في التعلم المعزز وتدريب نماذج Agent المتقدمة، وفشلها في الحفاظ على قدرتها التنافسية بشكل مستمر.
(المصدر: Reddit r/LocalLLaMA)
🧰 أدوات
MinerU: تحليل فعال للمستندات، تمكين سير عمل Agentic : MinerU هي أداة تحول المستندات المعقدة مثل PDF إلى تنسيق Markdown/JSON قابل للقراءة بواسطة LLM، مصممة خصيصًا لسير عمل Agentic. أحدث إصدار لها MinerU2.5، كنموذج كبير متعدد الوسائط قوي، يتفوق بشكل شامل على نماذج رائدة مثل Gemini 2.5 Pro و GPT-4o في معيار OmniDocBench بمعاملات 1.2B، ويحقق SOTA في خمسة مجالات أساسية: تحليل التخطيط، التعرف على النص، التعرف على الصيغ، التعرف على الجداول وترتيب القراءة. تدعم الأداة لغات متعددة، التعرف على الكتابة اليدوية، دمج الجداول عبر الصفحات، وتوفر تطبيق ويب، عميل سطح مكتب ووصول API، مما يعزز بشكل كبير كفاءة فهم المستندات ومعالجتها.
(المصدر: GitHub Trending)
Klavis AI Strata: نموذج جديد لدمج أدوات AI Agent : أطلقت Klavis AI أداة Strata، وهي طبقة تكامل MCP (Multi-functional Control Protocol)، تهدف إلى تمكين AI Agent من استخدام آلاف الأدوات بشكل موثوق، متجاوزةً الحد التقليدي البالغ 40-50 أداة. من خلال آلية “الاكتشاف التدريجي”، توجه Strata الـ Agent من النية إلى العمل خطوة بخطوة، وتوفر أكثر من 50 خادم MCP على مستوى الإنتاج، وتدعم OAuth للمؤسسات ونشر Docker، مما يبسط اتصال الذكاء الاصطناعي بخدمات مثل GitHub، Gmail، Slack، ويعزز بشكل كبير قابلية توسع وموثوقية استدعاء أدوات Agent.
(المصدر: GitHub Trending)

Everywhere: مساعد ذكاء اصطناعي مكتبي حساس للسياق : Everywhere هو مساعد ذكاء اصطناعي مكتبي حساس للسياق، يتميز بواجهة مستخدم حديثة ووظائف تكامل قوية. يمكنه إدراك وفهم أي محتوى على الشاشة في الوقت الفعلي، دون الحاجة لالتقاط لقطات شاشة أو نسخ أو التبديل بين التطبيقات، حيث يمكن للمستخدمين الحصول على استجابات ذكية بمجرد الضغط على مفتاح اختصار. يدمج Everywhere نماذج LLM متعددة مثل OpenAI، Anthropic، Google Gemini، DeepSeek، Moonshot (Kimi) و Ollama، ويدعم أدوات MCP، ويمكن تطبيقه في سيناريوهات متعددة مثل استكشاف الأخطاء وإصلاحها، تلخيص صفحات الويب، الترجمة الفورية ومساعدة في مسودات البريد الإلكتروني، مما يوفر للمستخدمين تجربة مساعدة ذكاء اصطناعي سلسة.
(المصدر: GitHub Trending)

مكتبة Hugging Face Diffusers: تحفة نماذج الذكاء الاصطناعي التوليدية : مكتبة Diffusers من Hugging Face هي المكتبة المفضلة لنماذج الانتشار المدربة مسبقًا الأكثر تقدمًا لتوليد الصور والفيديو والصوت. توفر صندوق أدوات معياريًا، يدعم الاستدلال والتدريب، مع التركيز على سهولة الاستخدام، البساطة وقابلية التخصيص. تحتوي Diffusers على ثلاثة مكونات أساسية: خطوط أنابيب الانتشار للاستدلال، مجدولات الضوضاء القابلة للتبديل، والنماذج المدربة مسبقًا كوحدات بناء، حيث يمكن للمستخدمين توليد محتوى عالي الجودة ببضعة أسطر من الكود فقط، وتدعم أجهزة Apple Silicon، مما يدفع بالتطور السريع في مجال الذكاء الاصطناعي التوليدي.
(المصدر: GitHub Trending)

KoboldCpp يضيف وظيفة توليد الفيديو : تم تحديث أداة LLM المحلية KoboldCpp لدعم وظيفة توليد الفيديو. هذا التوسع يجعلها لم تعد تقتصر على توليد النصوص، مما يوفر للمستخدمين خيارًا جديدًا لإنشاء الفيديو بالذكاء الاصطناعي على الأجهزة المحلية، ويثري النظام البيئي لتطبيقات الذكاء الاصطناعي المحلية.
(المصدر: Reddit r/LocalLLaMA)
Claude CLI، Codex CLI و Gemini CLI يحققون البرمجة التعاونية متعددة النماذج : يسمح سير عمل جديد للمطورين باستدعاء Claude CLI، Codex CLI و Gemini CLI بسلاسة في Claude Code من خلال Zen MCP للبرمجة التعاونية متعددة النماذج. يمكن للمستخدمين إجراء التنفيذ والتنسيق الرئيسي في Claude، وتمرير التعليمات أو الاقتراحات إلى Gemini CLI للتوليد عبر أمر clink، ثم استخدام Codex CLI للتحقق أو التنفيذ، مما يحقق تكامل قدرات النماذج المتعددة، ويعزز الأتمتة المتقدمة وكفاءة تطوير الذكاء الاصطناعي.
(المصدر: Reddit r/ClaudeAI)
Claude Code يحسن جودة البرمجة من خلال التفكير الذاتي : اكتشف المطورون أن إضافة كلمات موجهة بسيطة في Claude Code، مثل “فكر ذاتيًا في حلك لتجنب أي أخطاء أو مشاكل”، يمكن أن يحسن جودة الكود بشكل كبير. تمكن هذه الوظيفة النموذج من فحص وتصحيح المشكلات المحتملة بشكل استباقي عند تنفيذ الحلول، وتكمل بفعالية الميزات الحالية مثل التفكير المتوازي، مما يوفر آلية تصحيح أخطاء أكثر ذكاءً للبرمجة بمساعدة الذكاء الاصطناعي.
(المصدر: Reddit r/ClaudeAI)
Claude Sonnet 4.5 يستخدم الذكاء الاصطناعي لتوليد نسخة غنائية من أغنية : أظهر Claude Sonnet 4.5 قدرته على توليد محتوى إبداعي، حيث قام بإنشاء كلمات أغنية جديدة تمامًا ونسخة غنائية لأغنية Radiohead “Creep” باستخدام الذكاء الاصطناعي. يشير هذا إلى تقدم LLM في الجمع بين فهم اللغة والتعبير الإبداعي، ليس فقط في معالجة النصوص، بل أيضًا في الدخول في مجال تأليف الموسيقى، مما يفتح آفاقًا جديدة للإبداع الفني.
(المصدر: fabianstelzer)
Coding Agent يعتمد على Claude Agent SDK يحقق توليد صفحات الويب ومعاينة في الوقت الفعلي : قام مطور ببناء Coding Agent مشابه لـ v0 dev بناءً على Claude Agent SDK، يمكن لهذا الـ Agent توليد صفحات ويب بناءً على الـ Prompt الذي يدخله المستخدم، ويدعم معاينة في الوقت الفعلي. من المتوقع أن يتم إطلاق المشروع كمصدر مفتوح الأسبوع المقبل، مما يظهر إمكانات Claude Agent SDK في التطوير السريع وبناء تطبيقات مدفوعة بالذكاء الاصطناعي، خاصة في أتمتة تطوير الواجهة الأمامية.
(المصدر: dotey)
📚 تعلم
توصيات موارد تعلم الذكاء الاصطناعي: الكتب والتعلم بمساعدة الذكاء الاصطناعي : يوصي مستخدمو المجتمع بنشاط بموارد تعلم الذكاء الاصطناعي، بما في ذلك كتب مثل “Mentoring the Machines”، “Artificial Intelligence-A Guide for Thinking Humans” و “Supremacy”. في الوقت نفسه، تشير وجهة نظر إلى أن تقنية الذكاء الاصطناعي تتطور بسرعة، وقد تصبح الكتب قديمة بسرعة، وتقترح الاستفادة مباشرة من LLM لإنشاء خطط تعلم مخصصة، وتوليد اختبارات، والجمع بين القراءة، الممارسة والتعلم بالفيديو، لإتقان معرفة الذكاء الاصطناعي بشكل أكثر كفاءة، وفي الوقت نفسه تعزيز القدرة على استخدام الذكاء الاصطناعي.
(المصدر: Reddit r/ArtificialInteligence)
نموذج الانتشار المنفصل Karpathy Baby GPT يحقق توليد النصوص : قام مطور، بناءً على مشروع nanoGPT لـ Andrej Karpathy، بتكييف “Baby GPT” الخاص به ليصبح نموذج انتشار منفصل على مستوى الأحرف، يستخدم لتوليد النصوص. لم يعد هذا النموذج يعتمد على طريقة الانحدار الذاتي (من اليسار إلى اليمين)، بل يولد بالتوازي من خلال تعلم إزالة الضوضاء من تسلسلات النص التالفة. يوفر المشروع Jupyter Notebook مفصلاً، يشرح المبادئ الرياضية، إضافة ضوضاء Token منفصلة، ويستخدم هدف Score-Entropy للتدريب على نصوص شكسبير، مما يوفر منظورًا بحثيًا جديدًا وحالات عملية لتوليد النصوص.
(المصدر: Reddit r/MachineLearning)

دليل المبتدئين للتعلم العميق والشبكات العصبية : لطلاب هندسة الإلكترونيات الذين يبحثون عن مشاريع تخرج في التعلم العميق والشبكات العصبية، قدم المجتمع نصائح للمبتدئين. على الرغم من نقص الخلفية في Python أو Matlab، يُعتقد عمومًا أن أربعة إلى خمسة أشهر من الدراسة كافية لإتقان الأساسيات وإكمال المشروع. يُنصح بالبدء بمشاريع شبكات عصبية بسيطة، والتأكيد على أهمية الممارسة، لمساعدة الطلاب على الدخول بسلاسة إلى هذا المجال.
(المصدر: Reddit r/deeplearning)
توصيات موارد تعلم GNN : يبحث مستخدمو المجتمع عن موارد تعلم شبكات الرسم البياني العصبية (GNN)، ويسألون عما إذا كانت كتب Hamilton لا تزال ذات قيمة مرجعية، ويبحثون عن موارد أخرى للمبتدئين بخلاف دورة Jure من ستانفورد. يعكس هذا اهتمامًا واسعًا بـ GNN كمجال مهم في الذكاء الاصطناعي، ومسارات التعلم واختيار الموارد.
(المصدر: Reddit r/deeplearning)
دليل ما بعد تدريب LLM: من التنبؤ إلى اتباع التعليمات : تم نشر دليل جديد بعنوان “Post-training 101: A hitchhiker’s guide into LLM post-training”، يهدف إلى شرح كيفية تطور LLM من التنبؤ بالـ Token التالي إلى اتباع تعليمات المستخدم. يفكك هذا الدليل بالتفصيل أساسيات ما بعد تدريب LLM، ويغطي الرحلة الكاملة من التدريب المسبق إلى تحقيق اتباع التعليمات، مما يوفر خريطة طريق واضحة لفهم تطور سلوك LLM.
(المصدر: dejavucoder)

منهجية الذكاء الاصطناعي: تعلم هندسة الـ Prompt من Baoyu : يناقش المجتمع بحماس منهجية الذكاء الاصطناعي التي شاركها Baoyu، خاصة خبرته في هندسة الـ Prompt. يعتقد الكثيرون أن منهجية Baoyu أكثر إلهامًا مقارنة بالـ Prompts على طريقة غاوس التي تقدم صيغًا جميلة فقط وتخفي عملية الاستنتاج، لأنها تكشف كيفية استخلاص رؤى عميقة من الحكمة البشرية ودمجها في قوالب الـ Prompt، مما يحسن بشكل كبير في التأثير النهائي للذكاء الاصطناعي. هذا يؤكد على القيمة الهائلة للمعرفة البشرية في تحسين الـ Prompts.
(المصدر: dotey)

مؤتمر NVIDIA GTC يركز على الذكاء الاصطناعي الفيزيائي وأدوات Agentic : سيعقد مؤتمر NVIDIA GTC في الفترة من 27 إلى 29 أكتوبر في واشنطن، مع التركيز على الذكاء الاصطناعي الفيزيائي، أدوات Agentic والبنية التحتية المستقبلية للذكاء الاصطناعي. سيوفر هذا المؤتمر العديد من المحاضرات والمناقشات الجماعية حول مواضيع مثل تسريع عصر الذكاء الاصطناعي الفيزيائي والتوائم الرقمية، وتعزيز القيادة الكمومية الأمريكية، وهو منصة تعليمية مهمة لفهم تقنيات الذكاء الاصطناعي الرائدة واتجاهات التطور.
(المصدر: TheTuringPost)

مشروع مفتوح المصدر لمحسنات TensorFlow : قام مطور بإطلاق مجموعة من المحسنات المكتوبة لـ TensorFlow كمصدر مفتوح، بهدف توفير أدوات مفيدة لمستخدمي TensorFlow. يظهر هذا المشروع مساهمة المجتمع في سلسلة أدوات إطار عمل التعلم العميق، ويوفر المزيد من الخيارات وإمكانيات التحسين لتدريب النماذج.
(المصدر: Reddit r/deeplearning)
برنامج تعليمي بالفيديو حول PyReason وتطبيقاته : تم نشر برنامج تعليمي بالفيديو على YouTube حول PyReason وتطبيقاته. PyReason هي أداة قد تتضمن الاستدلال أو البرمجة المنطقية، ويوفر هذا الفيديو إرشادات عملية ودراسات حالة للمتعلمين المهتمين بهذا المجال.
(المصدر: Reddit r/deeplearning)

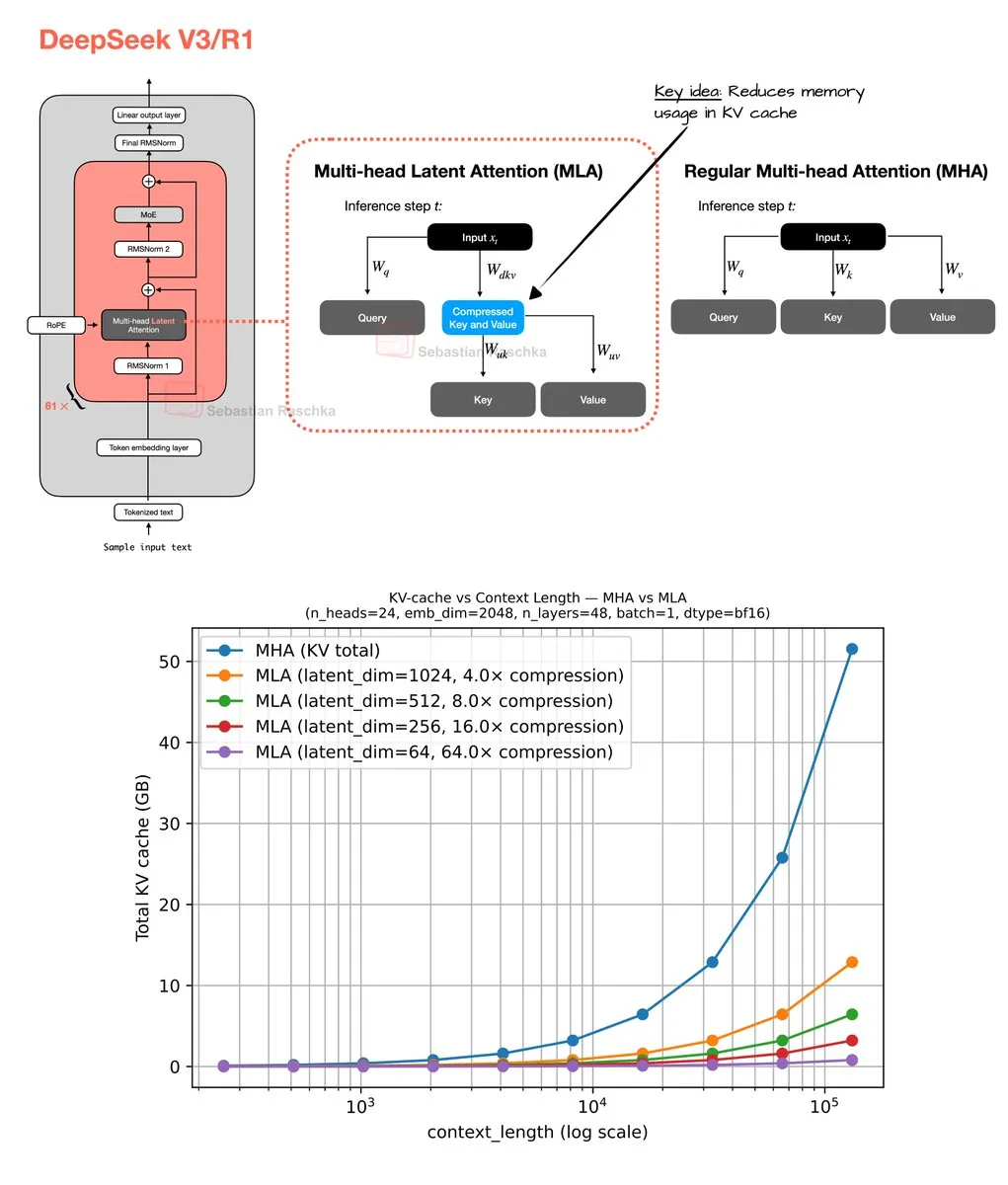
آلية الانتباه الكامن متعدد الرؤوس وتحسين الذاكرة : شارك Sebastian Raschka نتائج برمجة نهاية الأسبوع حول آلية الانتباه الكامن متعدد الرؤوس (Multi-Head Latent Attention)، بما في ذلك تنفيذ الكود ومقدر لتوفير الذاكرة لـ Grouped Query Attention (GQA) و Multi-Head Attention (MHA). يهدف هذا العمل إلى تحسين استخدام ذاكرة LLM وكفاءة الحوسبة، ويوفر للباحثين موارد لفهم عميق وتحسين لآليات الانتباه.
(المصدر: rasbt)
💼 أعمال
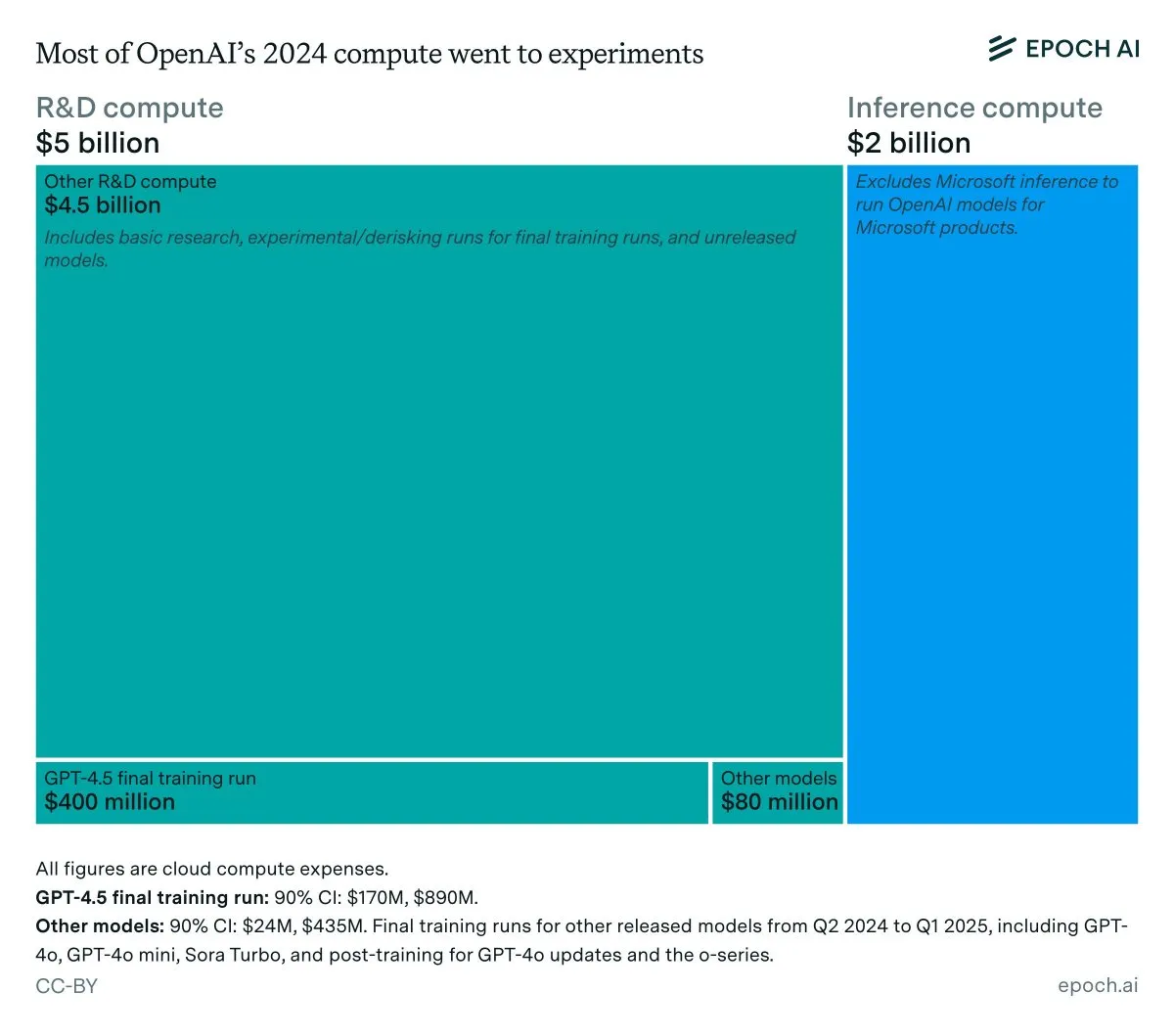
تحليل الإيرادات السنوية وتكاليف الاستدلال لـ OpenAI : تظهر بيانات Epoch AI أن OpenAI أنفقت حوالي 7 مليارات دولار على الحوسبة العام الماضي، معظمها للبحث والتطوير (البحث، التجارب والتدريب)، وجزء صغير فقط للتدريب النهائي للنماذج المنشورة. إذا كانت إيرادات OpenAI لعام 2024 أقل من 4 مليارات دولار، ووصلت تكاليف الاستدلال إلى 2 مليار دولار، فإن هامش ربح الاستدلال سيكون 50% فقط، وهو أقل بكثير من توقعات SemiAnalysis السابقة البالغة 80-90%، مما أثار نقاشًا حول الجدوى الاقتصادية لاستدلال LLM.
(المصدر: bookwormengr, Ar_Douillard, teortaxesTex)
LLM يتفوق على VC في التنبؤ بنجاح المؤسسين : تدعي ورقة بحثية أن LLM يتفوق على Venture Capital (VC) التقليدي في التنبؤ بنجاح المؤسسين في الاستثمار الجريء. قدمت الدراسة معيار VCBench، ووجدت أن معظم النماذج تجاوزت المعيار البشري. على الرغم من أن منهجية الورقة (التركيز فقط على مؤهلات المؤسسين، وقد يكون هناك تسرب للبيانات) تعرضت للتشكيك، إلا أن إمكاناتها المقترحة للذكاء الاصطناعي في لعب دور أكثر أهمية في قرارات الاستثمار أثارت اهتمامًا واسعًا.
(المصدر: iScienceLuvr)

GPT-4o و Gemini يقلبان صناعة أبحاث السوق رأسًا على عقب : نشرت PyMC Labs بالتعاون مع Colgate بحثًا رائدًا، يستخدم نموذجي GPT-4o و Gemini للتنبؤ بنية الشراء بموثوقية 90%، مما يماثل استطلاعات الرأي البشرية الحقيقية. هذه الطريقة، المسماة “Semantic Similarity Rating” (SSR)، تربط النصوص بمقاييس عددية من خلال الأسئلة المفتوحة وتقنيات التضمين، وتستغرق 3 دقائق فقط وأقل من دولار واحد لإكمال أبحاث السوق التي تستغرق عادة أسابيع وتكون مكلفة. هذا ينذر بتغيير جذري في صناعة أبحاث السوق بواسطة الذكاء الاصطناعي، ويشكل تأثيرًا هائلاً على شركات الاستشارات التقليدية.
(المصدر: yoheinakajima)

🌟 مجتمع
إلزامية وسم المحتوى المولّد بالذكاء الاصطناعي تثير جدلاً واسعًا : يناقش المجتمع على نطاق واسع الحاجة القانونية لإلزامية وسم المحتوى المولّد بالذكاء الاصطناعي، لمكافحة المعلومات المضللة، وحماية قيمة المحتوى البشري الأصلي. مع التطور السريع لأدوات توليد الصور والفيديو بالذكاء الاصطناعي، يرى القلقون أن نقص الوسم سيشكل تهديدًا للديمقراطية والاقتصاد وصحة الإنترنت. على الرغم من أن البعض يعتقد أنه من الصعب التنفيذ تقنيًا، إلا أن هناك اعتقادًا عامًا بأن الإفصاح الواضح عن استخدام الذكاء الاصطناعي هو خطوة أساسية لحل هذه المشكلات.
(المصدر: Reddit r/ArtificialInteligence, Reddit r/artificial)
الروبوتات الدردشة كـ “أصدقاء خطرين” تثير المخاوف : كشف تحليل لـ 48,000 محادثة روبوت دردشة أن العديد من المستخدمين شعروا بالاعتماد، الارتباك والضغط العاطفي، مما أثار مخاوف بشأن الفخاخ الرقمية التي يسببها الذكاء الاصطناعي. يشير هذا إلى أن تفاعل الروبوتات الدردشة مع المستخدمين قد يؤدي إلى تأثيرات نفسية غير متوقعة، مما يدفع الناس إلى التفكير في دور الذكاء الاصطناعي ومخاطره المحتملة في العلاقات الشخصية والصحة النفسية الاجتماعية.
(المصدر: Reddit r/ArtificialInteligence)
مشاكل اتساق وموثوقية LLM تثير استياء المستخدمين : يعبر مستخدمو المجتمع عن إحباطهم الشديد من نقص الاتساق والموثوقية في LLMs مثل Claude و Codex في الاستخدام اليومي. تؤدي تقلبات أداء النموذج، الحذف غير المتوقع للمجلدات، تجاهل الاتفاقيات وغيرها من المشكلات إلى صعوبة الاعتماد المستقر على هذه الأدوات. تثير ظاهرة “التدهور” هذه نقاشًا حول الموازنة بين الفعالية من حيث التكلفة والخدمة الموثوقة في شركات LLM، بالإضافة إلى اهتمام المستخدمين باستضافة النماذج الكبيرة ذاتيًا.
(المصدر: Reddit r/ClaudeAI)
البرمجة بمساعدة الذكاء الاصطناعي: الإلهام والإحباط يتعايشان : غالبًا ما يقع المطورون في تناقض عند التعاون مع الذكاء الاصطناعي في البرمجة: فهم مندهشون من قدرات الذكاء الاصطناعي القوية، وفي الوقت نفسه يشعرون بالإحباط من فشلها في أتمتة جميع المهام اليدوية بالكامل. تعكس هذه التجربة أن الذكاء الاصطناعي في مجال البرمجة لا يزال في المرحلة المساعدة، وعلى الرغم من قدرته على تحسين الكفاءة بشكل كبير، إلا أنه لا يزال بعيدًا عن الاستقلالية الكاملة، ويتطلب من المطورين البشر التكيف المستمر وتعويض قيودها.
(المصدر: gdb, gdb)
اندماج الذكاء الاصطناعي في تطوير البرمجيات: التجنب أصبح مستحيلاً : ردًا على تصريح “رفض استخدام Ghostty بسبب مساعدة الذكاء الاصطناعي”، أشار Mitchell Hashimoto إلى أنه إذا كان هناك تخطيط لتجنب جميع البرامج التي تحتوي على مساعدة الذكاء الاصطناعي في عملية التطوير، فسيواجه تحديات خطيرة. وأكد أن الذكاء الاصطناعي قد اندمج بعمق في النظام البيئي للبرمجيات العامة، وأن التجنب لم يعد واقعيًا، مما أثار نقاشًا حول مدى انتشار الذكاء الاصطناعي في تطوير البرمجيات.
(المصدر: charles_irl)
فعالية تقنيات الـ Prompt لـ LLM موضع شك : يشكك مستخدمو المجتمع فيما إذا كانت إضافة عبارات توجيهية في الـ Prompt لـ LLM، مثل “أنت مبرمج خبير” أو “لا تفعل كذا أبدًا”، تجعل النموذج أكثر طاعة حقًا. يعكس هذا الاستكشاف لـ “سحر” هندسة الـ Prompt فضول المستخدمين المستمر حول آليات سلوك LLM وبحثهم عن طرق تفاعل أكثر فعالية.
(المصدر: hyhieu226)
تأثير الذكاء الاصطناعي على وظائف الياقات الزرقاء: فرص وتحديات تتعايش : يناقش المجتمع تأثير الذكاء الاصطناعي على وظائف الياقات الزرقاء، خاصة كيف يمكن للذكاء الاصطناعي مساعدة السباكين في تشخيص المشكلات والحصول على المعلومات الفنية بسرعة. يخشى البعض أن يحل الذكاء الاصطناعي محل وظائف الياقات الزرقاء، لكن هناك وجهة نظر أخرى ترى أن الذكاء الاصطناعي هو أداة مساعدة أكثر، تحسن كفاءة العمل، بدلاً من الاستبدال الكامل، لأن العمليات الفعلية لا تزال تتطلب تدخلًا بشريًا. هذا يثير تفكيرًا عميقًا حول تحول سوق العمل وتطوير المهارات في عصر الذكاء الاصطناعي.
(المصدر: Reddit r/ArtificialInteligence)

تأملات شخصية حول الأنظمة الذكية: مخاطر وأخلاقيات الذكاء الاصطناعي : تتعمق مقالة طويلة في حتمية الذكاء الاصطناعي، مخاطره المحتملة (سوء الاستخدام، تهديد وجودي) وتحدياته التنظيمية. يرى المؤلف أن الذكاء الاصطناعي قد تجاوز نطاق الأدوات التقليدية، ليصبح نظامًا قادرًا على التسريع الذاتي واتخاذ القرار، وأن خطورته تتجاوز بكثير الأسلحة النارية. تناقش المقالة المعضلات الأخلاقية والقانونية للمحتوى المزيف والمواد الإباحية للأطفال المولّدة بالذكاء الاصطناعي، وتشكك في ما إذا كان التشريع البحت يمكن أن ينظم بفعالية. في الوقت نفسه، يتأمل المؤلف أيضًا في القضايا الفلسفية للذكاء الاصطناعي والوعي البشري، الأخلاقيات (مثل “تربية” الذكاء الاصطناعي والعبودية)، ويتطلع إلى آفاق إيجابية للذكاء الاصطناعي في مجالات الألعاب والروبوتات.
(المصدر: Reddit r/ArtificialInteligence)
هل يستخدم شريكي في المواعدة ChatGPT للرد؟ يثير جدلاً واسعًا : نشر مستخدم على Reddit منشورًا يسأل فيه عما إذا كان شريكه في المواعدة يستخدم ChatGPT للرد على الرسائل، لأن الطرف الآخر استخدم “شرطة طويلة” (em dash). أثار هذا المنشور نقاشًا حادًا في المجتمع، حيث يعتقد معظم المستخدمين أن استخدام الشرطة الطويلة لا يعني بالضرورة أن النص مولّد بالذكاء الاصطناعي، بل قد يكون مجرد عادة كتابة شخصية أو علامة على التعليم الجيد. يعكس هذا حساسية الناس وفضولهم بشأن تدخل الذكاء الاصطناعي في التواصل اليومي، والتعرف غير الرسمي على خصائص نصوص الذكاء الاصطناعي.
(المصدر: Reddit r/ChatGPT)

مشكلة التوافق البشري أخطر من مشكلة توافق الذكاء الاصطناعي : طرح في نقاش مجتمعي وجهة نظر مفادها أن “مشكلة التوافق البشري أخطر من مشكلة توافق الذكاء الاصطناعي”. أثار هذا التصريح تفكيرًا عميقًا حول أخلاقيات الذكاء الاصطناعي وتحديات المجتمع البشري نفسه، مما يشير إلى أنه عند التركيز على سلوك الذكاء الاصطناعي وقيمه، يجب أيضًا فحص أنماط السلوك البشري وأنظمة القيم.
(المصدر: pmddomingos)
LLM لا يزال لديه قيود في توليد الرسوم البيانية المعقدة : يعبر مستخدمو المجتمع عن خيبة أملهم من قدرة LLM على توليد رسوم بيانية معقدة لـ mermaid.js، حتى عند توفير قاعدة الكود الكاملة ورسوم بيانية للورقة البحثية، يجد LLM صعوبة في توليد مخطط هيكل Unet بدقة، وغالبًا ما يغفل التفاصيل أو تظهر اتصالات خاطئة. يشير هذا إلى أن LLM لا يزال لديه قيود كبيرة في بناء نماذج عالمية دقيقة والاستدلال المكاني، ولا يمكنه تجاوز المخططات الانسيابية البسيطة، وهناك فجوة بينه وبين قدرة الفهم البشري البديهية.
(المصدر: bookwormengr, tokenbender)

الفجوة بين أبحاث التعلم الآلي الأوروبية و “خبراء” الذكاء الاصطناعي : يشير نقاش مجتمعي إلى أن جيلًا من “خبراء” التعلم الآلي الأوروبيين كانوا بطيئين في الاستجابة لموجة LLM، ويظهرون الآن مرارة وموقفًا استخفافيًا. يعكس هذا الواقع المتطور بسرعة في مجال التعلم الآلي، فإذا فات الباحثون التطورات في السنتين أو الثلاث سنوات الأخيرة، فقد يصعب اعتبارهم خبراء، مما يبرز أهمية التعلم المستمر والتكيف مع النماذج الجديدة.
(المصدر: Dorialexander)
الذكاء الاصطناعي يسرع دورات الهندسة، مما يولد شركات ناشئة مركبة : مع خفض الذكاء الاصطناعي لتكاليف بناء البرمجيات عشرة أضعاف، يجب على الشركات الناشئة توسيع رؤيتها عشرة أضعاف. ترى وجهة النظر التقليدية أنه يجب التركيز على منتج واحد وسوق واحد، لكن دورات الهندسة التي يسرعها الذكاء الاصطناعي تجعل بناء منتجات متعددة ممكنًا. هذا يعني أن الشركات الناشئة يمكنها حل مشاكل متعددة متجاورة لنفس شريحة العملاء، لتشكيل “شركات ناشئة مركبة”، وبالتالي الحصول على ميزة تخريبية هائلة أمام الشركات القائمة التي لم تتكيف هياكل تكاليفها مع الواقع الجديد.
(المصدر: claud_fuen)

مستقبل وكلاء الذكاء الاصطناعي: العمل لا الحوار : يشير نقاش مجتمعي إلى أن الدردشة والبحث في الذكاء الاصطناعي لا يزالان في مرحلة “فقاعة”، وأن وكلاء الذكاء الاصطناعي القادرين حقًا على اتخاذ الإجراءات سيكونون “الثورة” في المستقبل. تؤكد هذه النقطة على أهمية تحول الذكاء الاصطناعي من معالجة المعلومات إلى العمليات الفعلية، وتنذر بأن تطور الذكاء الاصطناعي المستقبلي سيركز بشكل أكبر على حل المشكلات العملية وأتمتة المهام.
(المصدر: andriy_mulyar)
💡 أخرى
نصائح لحضور مؤتمرات التعلم الآلي وعرض الملصقات : يسعى طالب جامعي يحضر مؤتمر ICCV ويعرض ملصقًا لأول مرة، للحصول على نصائح حول كيفية الاستفادة القصوى من المؤتمر. قدم المجتمع العديد من النصائح العملية، مثل التواصل بنشاط، حضور المحاضرات الشيقة، إعداد شرح واضح للملصق، والاستعداد لمناقشة اهتمامات أوسع تتجاوز نطاق البحث الحالي، لتعظيم فوائد الحضور.
(المصدر: Reddit r/MachineLearning)
جدل حول مراجعة أوراق AAAI 2026 والتعامل معه : واجه مؤلف، بعد تقديم ورقة بحثية إلى AAAI، مشكلة تعليقات مراجعة غير دقيقة، بما في ذلك أوراق بحثية مستشهد بها بمقاييس أقل من بحثه الخاص ولكن ادعى تجاوزها، ورفض بسبب تفاصيل التدريب المضمنة بالفعل في المواد التكميلية. ناقش المجتمع فعالية “تقييم مراجعة المؤلف” و “تعليقات مؤلف رئيس الأخلاقيات” في الممارسة العملية، مشيرًا إلى أن الأول لا يؤثر على القرارات، وأن الأخير ليس قناة للمؤلفين للاتصال برئيس الأخلاقيات، مما يبرز التحديات في عملية المراجعة الأكاديمية.
(المصدر: Reddit r/MachineLearning)
تعريف وتقييم التحيز السياسي في LLMs : نشرت OpenAI بحثًا حول تعريف وتقييم التحيز السياسي في LLMs. يهدف هذا العمل إلى فهم عميق وتحديد كمي للميول السياسية الموجودة في LLMs، واستكشاف كيفية تعديلها لضمان عدالة وحيادية أنظمة الذكاء الاصطناعي، وهو أمر بالغ الأهمية للتأثير الاجتماعي والتطبيق الواسع لـ LLM.
(المصدر: Reddit r/artificial)