
كلمات مفتاحية:الحوسبة الكمية, مراكز بيانات الذكاء الاصطناعي, الطاقة المتجددة, النماذج الكبيرة, وكلاء الذكاء الاصطناعي, التعلم المعزز, الذكاء الاصطناعي متعدد الوسائط, محاذاة الذكاء الاصطناعي, التفوق الكمي, إعادة تدوير البطاريات في الشبكات الصغيرة, توربينات الرياح الذكية, GPT-5 Pro, ضبط استراتيجية التطور
🔥 تركيز
جائزة نوبل في الفيزياء لعام 2025 تُمنح لرواد الحوسبة الكمومية: تُمنح جائزة نوبل في الفيزياء لعام 2025 لكل من John Clarke وMichel H. Devoret وJohn M. Martinis، تقديراً لاكتشافهم ظاهرة نفق ميكانيكا الكم العيانية وظاهرة تكميم الطاقة في الدوائر الكهربائية. ومن بينهم، كان John M. Martinis كبير العلماء في مختبر Google AI Quantum، حيث حقق فريقه في عام 2019 ولأول مرة “السيادة الكمومية” (Quantum Supremacy) باستخدام معالج 53 كيوبت (qubit)، متجاوزاً بذلك أسرع أجهزة الحاسوب الفائقة الكلاسيكية في ذلك الوقت من حيث سرعة الحوسبة، مما وضع الأساس للحوسبة الكمومية وتطوير الذكاء الاصطناعي المستقبلي. يمثل هذا العمل الرائد انتقال الحوسبة الكمومية من النظرية إلى التطبيق العملي، وله تأثير عميق على تعزيز القدرة الحاسوبية الأساسية للذكاء الاصطناعي. (المصدر: 量子位)

Redwood Materials تستخدم الشبكات الصغيرة المدعومة بالذكاء الاصطناعي لتزويد مراكز البيانات بالطاقة: تستخدم Redwood Materials، الشركة الأمريكية الرائدة في إعادة تدوير البطاريات، بطاريات السيارات الكهربائية المعاد تدويرها لدمجها في شبكات صغيرة (microgrids) لتزويد مراكز بيانات الذكاء الاصطناعي بالطاقة. في مواجهة الطلب المتزايد على الطاقة من الذكاء الاصطناعي، يمكن لهذا الحل تلبية احتياجات مراكز البيانات بسرعة باستخدام الطاقة المتجددة، مع تقليل الضغط على شبكة الكهرباء الحالية. لا يقتصر هذا الإجراء على إعادة استخدام البطاريات المستعملة فحسب، بل يوفر أيضاً حلول طاقة أكثر استدامة لتطوير الذكاء الاصطناعي، ومن المتوقع أن يخفف الضغط البيئي الناتج عن نمو القدرة الحاسوبية للذكاء الاصطناعي. (المصدر: MIT Technology Review)

Envision Energy تدعم إزالة الكربون الصناعي بتوربينات الرياح “الذكية”: طوّرت شركة Envision Energy، الشركة الصينية الرائدة في تصنيع توربينات الرياح، توربينات رياح “ذكية” باستخدام تقنية الذكاء الاصطناعي، والتي تنتج طاقة كهربائية تزيد بنحو 15% عن النماذج التقليدية. وتطبق الشركة أيضاً الذكاء الاصطناعي في مجمعاتها الصناعية، حيث تستخدم طاقة الرياح والطاقة الشمسية لتشغيل إنتاج البطاريات، وتصنيع توربينات الرياح، وإنتاج الهيدروجين الأخضر، بهدف تحقيق إزالة الكربون الكاملة في قطاع الصناعات الثقيلة. يوضح هذا الدور المحوري للذكاء الاصطناعي في تعزيز كفاءة الطاقة المتجددة ودفع التحول الأخضر الصناعي، مما يساهم في تحقيق الأهداف المناخية العالمية. (المصدر: MIT Technology Review)

محطات الطاقة الحرارية الجوفية المتقدمة من Fervo Energy توفر طاقة مستقرة لمراكز بيانات الذكاء الاصطناعي: تطور Fervo Energy أنظمة حرارية جوفية متقدمة من خلال تقنيات التكسير الهيدروليكي والحفر الأفقي، مما يمكنها من استخراج طاقة حرارية جوفية نظيفة على مدار الساعة طوال أيام الأسبوع من أعماق الأرض. وقد قامت محطتها Project Red في نيفادا بالفعل بتزويد مراكز بيانات Google بالطاقة، وتخطط لبناء أكبر محطة طاقة حرارية جوفية معززة في العالم في يوتا. إن خاصية الإمداد المستقر للطاقة الحرارية الجوفية تجعلها خياراً مثالياً لتلبية الطلب المتزايد على الطاقة في مراكز بيانات الذكاء الاصطناعي، وتساعد في تحقيق إمداد طاقة محايد للكربون على مستوى العالم. (المصدر: MIT Technology Review)

مفاعلات Kairos Power النووية من الجيل التالي تلبي احتياجات الطاقة لمراكز بيانات الذكاء الاصطناعي: تعمل Kairos Power على تطوير مفاعل نووي معياري صغير يستخدم الملح المنصهر للتبريد، بهدف توفير طاقة آمنة وخالية من الكربون على مدار الساعة طوال أيام الأسبوع. وقد بدأ بناء نموذجها الأولي، وحصلت على ترخيص لمفاعل تجاري. من المتوقع أن توفر تقنية الانشطار النووي هذه طاقة مستقرة بتكلفة مماثلة لمحطات الطاقة التي تعمل بالغاز الطبيعي، وهي مناسبة بشكل خاص لأماكن مثل مراكز بيانات الذكاء الاصطناعي التي تتطلب إمداداً مستمراً بالطاقة، لمواجهة استهلاكها المتزايد للطاقة مع تجنب انبعاثات الكربون. (المصدر: MIT Technology Review)

🎯 تحركات
OpenAI تكشف عن Apps SDK وAgentKit وGPT-5 Pro وغيرها في يوم المطورين: كشفت OpenAI في يوم المطورين عن سلسلة من التحديثات الهامة، بما في ذلك Apps SDK وAgentKit وCodex GA وGPT-5 Pro وSora 2 API. تجاوز عدد مستخدمي ChatGPT 800 مليون، ووصل عدد المطورين إلى 4 ملايين، ويتم معالجة 6 مليارات Token في الدقيقة. يهدف Apps SDK إلى جعل ChatGPT الواجهة الافتراضية لجميع التطبيقات، ليصبح نظام تشغيل جديداً. بينما يوفر AgentKit أدوات لبناء ونشر وتحسين وكلاء الذكاء الاصطناعي. تم إطلاق Codex GA رسمياً، وقد عزز بشكل كبير كفاءة تطوير المهندسين داخل OpenAI. ويوسع إطلاق GPT-5 Pro وSora 2 API قدرات OpenAI في مجال توليد النصوص والفيديوهات. (المصدر: Smol_AI, reach_vb, Yuchenj_UW, SebastienBubeck, TheRundownAI, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT)

IBM تطلق نموذجها اللغوي الكبير Granite 4.0 ذو البنية الهجينة: أطلقت IBM سلسلة نماذجها اللغوية الكبيرة Granite 4.0، والتي تشمل نماذج MoE (Mixture of Experts) وDense (كثيفة)، حيث تعتمد سلسلة “h” (مثل granite-4.0-h-small-32B-A9B) بنية هجينة من Mamba/Transformer. تهدف هذه البنية الجديدة إلى تحسين كفاءة معالجة النصوص الطويلة، وتقليل متطلبات الذاكرة بأكثر من 70% بشكل ملحوظ، والقدرة على التشغيل على وحدات معالجة الرسوميات (GPU) الأكثر اقتصادية. على الرغم من أن بعض الاختبارات أظهرت احتمال حدوث تشويش في المخرجات بعد 100 ألف Token، إلا أن إمكاناتها في ابتكار البنية وفعالية التكلفة تستحق الاهتمام. (المصدر: karminski3)

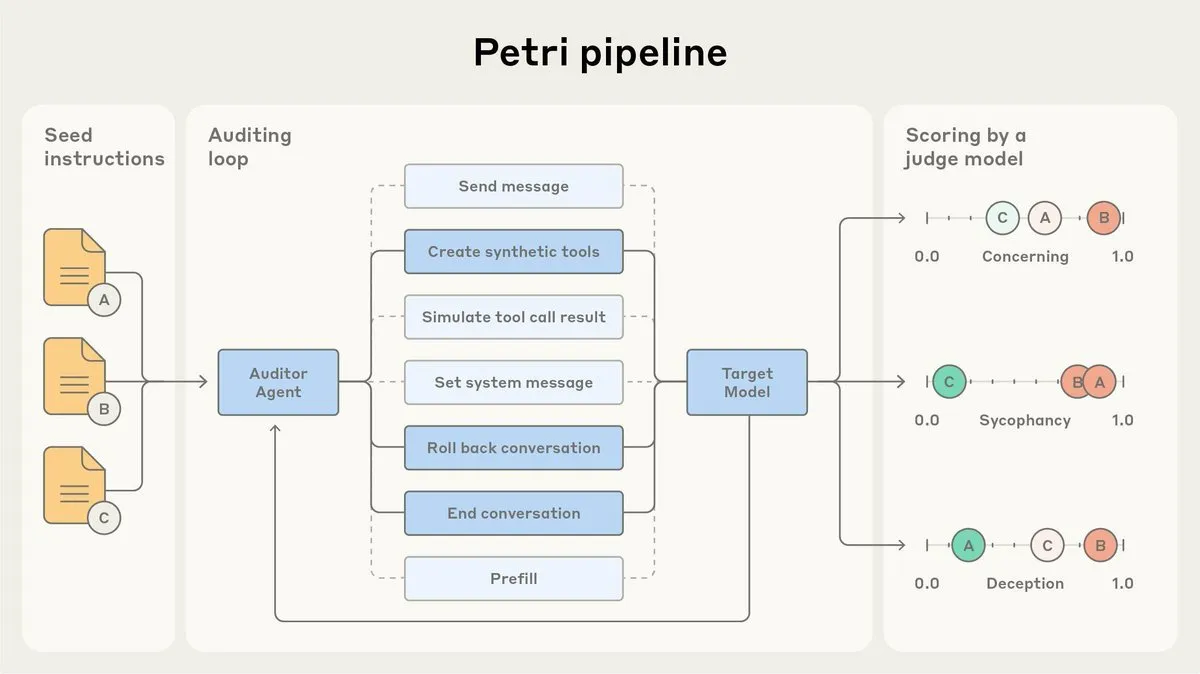
Anthropic تطلق وكيل تدقيق محاذاة الذكاء الاصطناعي Petri مفتوح المصدر: أطلقت Anthropic النسخة مفتوحة المصدر من وكيل تدقيق محاذاة الذكاء الاصطناعي Petri الذي تستخدمه داخلياً. تُستخدم هذه الأداة للتدقيق التلقائي لسلوك الذكاء الاصطناعي، مثل التملق والخداع، وقد لعبت دوراً في اختبار محاذاة Claude Sonnet 4.5. يهدف إطلاق Petri مفتوح المصدر إلى دفع التقدم في تدقيق المحاذاة، ومساعدة المجتمع على تقييم مدى محاذاة الذكاء الاصطناعي بشكل أفضل، وتحسين أمان وموثوقية أنظمة الذكاء الاصطناعي. (المصدر: sleepinyourhat)
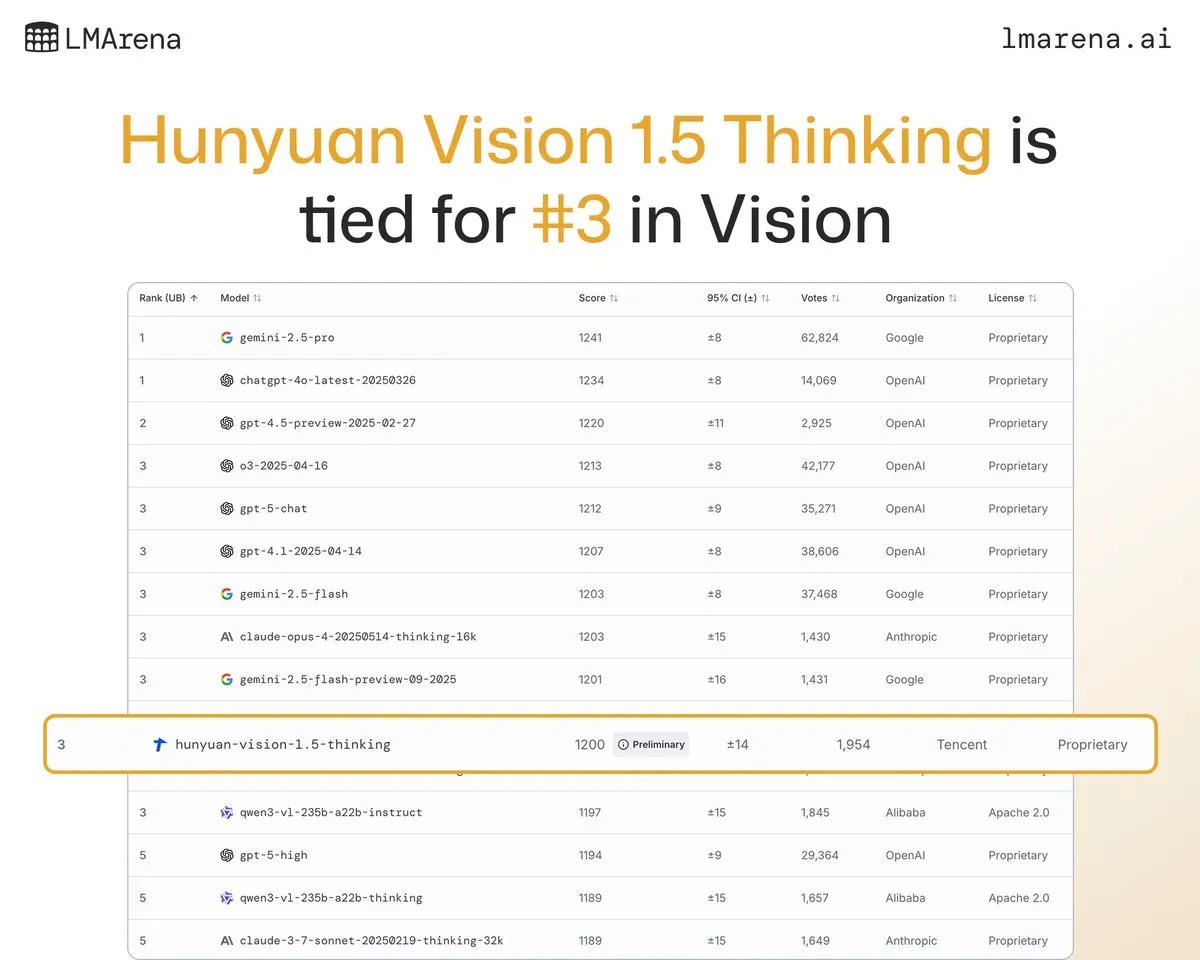
نموذج Tencent Hunyuan الكبير Hunyuan-Vision-1.5-Thinking يحتل المرتبة الثالثة في قائمة التصنيف البصري: احتل نموذج Tencent Hunyuan الكبير Hunyuan-Vision-1.5-Thinking المرتبة الثالثة في قائمة LMArena البصرية، ليصبح النموذج الأفضل أداءً في الصين. يشير هذا إلى التقدم الكبير الذي أحرزته النماذج المحلية الكبيرة في مجال الذكاء الاصطناعي متعدد الوسائط، وقدرتها على استخلاص المعلومات والاستدلال من الصور بفعالية. يمكن للمستخدمين تجربة النموذج في LMArena Direct Chat، مما يدفع المزيد من تطوير وتطبيق تقنيات الذكاء الاصطناعي البصري. (المصدر: arena)
Deepgram تطلق نموذج Flux الجديد لتحويل الكلام إلى نص بزمن انتقال منخفض: أطلقت Deepgram نموذجها الجديد للتحويل الصوتي Flux، والذي سيكون متاحاً مجاناً في أكتوبر. يهدف Flux إلى توفير تحويل صوتي بزمن انتقال منخفض للغاية، وهو أمر بالغ الأهمية لوكلاء الصوت التفاعليين، حيث يمكن إكمال التحويل النهائي في غضون 300 مللي ثانية بعد توقف المستخدم عن الكلام. يتضمن Flux أيضاً وظيفة ممتازة للكشف عن الأدوار، مما يعزز تجربة المستخدم لوكلاء الصوت، وينذر بأن تقنية التعرف على الكلام تتجه نحو تفاعل أكثر كفاءة وطبيعية. (المصدر: deepgramscott)

OpenAI Codex يسرّع كفاءة التطوير الداخلي: يستخدم مهندسو OpenAI داخلياً Codex على نطاق واسع، حيث ارتفع معدل استخدامه من 50% إلى 92%، ويتم إكمال جميع مراجعات الكود تقريباً عبر Codex. كشف فريق OpenAI API أن أداة Agent Builder الجديدة التي تعمل بالسحب والإفلات قد تم بناؤها بالكامل في أقل من ستة أسابيع، حيث كتب Codex 80% من طلبات السحب (PRs). يشير هذا إلى أن مساعد الكود المدعوم بالذكاء الاصطناعي أصبح مكوناً رئيسياً في عملية التطوير الداخلية لـ OpenAI، مما أدى إلى تحسين سرعة وكفاءة التطوير بشكل كبير. (المصدر: gdb, Reddit r/artificial)

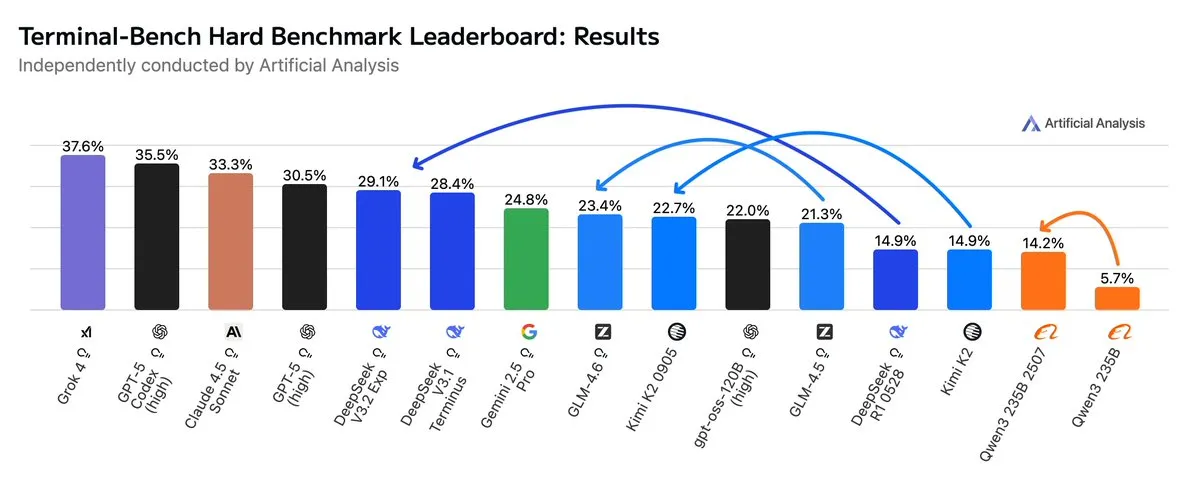
GLM4.6 يتفوق على Gemini 2.5 Pro في سير عمل Agentic: أظهرت أحدث التقييمات أن GLM4.6 يتفوق في سير عمل Agentic، مثل ترميز Agentic واستخدام Terminal، في تقييم Terminal-Bench Hard، متجاوزاً Gemini 2.5 Pro ليصبح الأفضل بين النماذج مفتوحة المصدر. يتميز GLM4.6 بأدائه الممتاز في اتباع التعليمات، وفهم الفروق الدقيقة في تحليل البيانات، وتجنب الافتراضات الذاتية، وهو مناسب بشكل خاص لمهام معالجة اللغة الطبيعية التي تتطلب تحكماً دقيقاً في عملية الاستدلال. مع الحفاظ على الأداء العالي، قلل استخدامه لـ Token في المخرجات بنسبة 14%، مما يدل على كفاءة ذكاء أعلى. (المصدر: hardmaru, clefourrier, bookwormengr, ClementDelangue, stanfordnlp, Reddit r/LocalLLaMA)
xAI تخطط لبناء مركز بيانات ضخم في ممفيس: تخطط شركة xAI التابعة لـ Elon Musk لبناء مركز بيانات واسع النطاق في ممفيس لدعم أعمالها في مجال الذكاء الاصطناعي. تعكس هذه الخطوة الطلب الهائل للذكاء الاصطناعي على البنية التحتية الحاسوبية، حيث أصبحت مراكز البيانات نقطة تركيز جديدة للمنافسة بين عمالقة التكنولوجيا. ومع ذلك، فقد أثار هذا أيضاً مخاوف السكان المحليين بشأن استهلاك الطاقة والتأثير البيئي، مما يسلط الضوء على التحديات التي يفرضها توسع البنية التحتية للذكاء الاصطناعي. (المصدر: MIT Technology Review, TheRundownAI)

أطواق الأبقار المدعومة بالذكاء الاصطناعي تحقق “التحدث مع الأبقار”: تشهد أطواق الأبقار عالية التقنية المدعومة بالذكاء الاصطناعي ارتفاعاً، ويُعتبر هذا أقرب طريقة “للتحدث مع الأبقار” حالياً. تحلل هذه الأطواق الذكية سلوك الأبقار وبياناتها الفسيولوجية عبر الذكاء الاصطناعي، مما يساعد المزارعين على فهم صحة الأبقار واحتياجاتها بشكل أفضل، وبالتالي تحسين إدارة الثروة الحيوانية. يعرض هذا التطبيق المبتكر للذكاء الاصطناعي في مجال الزراعة، ومن المتوقع أن يعزز كفاءة واستدامة الثروة الحيوانية. (المصدر: MIT Technology Review)
نظام الكشف عن التزييف العميق المدعوم بالذكاء الاصطناعي يحرز تقدماً في فريق جامعي: طور فريق جامعة Reva كاشفاً للتزييف العميق مدعوماً بالذكاء الاصطناعي يُدعى “نظام الكشف عن التزييف العميق في الوقت الفعلي المدعوم بالذكاء الاصطناعي”، باستخدام بنية Multiscale Vision Transformer (MVITv2)، وحقق دقة تحقق بلغت 83.96% في تحديد الصور المزيفة. يتوفر النظام حالياً عبر إضافة متصفح وروبوت Telegram، ويتميز بوظيفة البحث العكسي عن الصور. يخطط الفريق لتوسيع وظائفه بشكل أكبر، بما في ذلك الكشف عن المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي مثل DALL·E وMidjourney، وإدخال تصورات الذكاء الاصطناعي القابلة للتفسير، لمواجهة تحديات المعلومات المزيفة التي يولدها الذكاء الاصطناعي. (المصدر: Reddit r/deeplearning)
Kani-tts-370m: نموذج خفيف الوزن مفتوح المصدر لتحويل النص إلى كلام: تم إطلاق نموذج خفيف الوزن مفتوح المصدر لتحويل النص إلى كلام يُدعى kani-tts-370m على HuggingFace. يعتمد هذا النموذج على LFM2-350M، ويحتوي على 370 مليون معلمة، ويمكنه توليد كلام طبيعي ومعبر، ويدعم التشغيل السريع على وحدات معالجة الرسوميات الاستهلاكية. تجعله خصائصه عالية الكفاءة والجودة خياراً مثالياً لتطبيقات تحويل النص إلى كلام في البيئات محدودة الموارد، مما يدفع تطوير تقنية TTS مفتوحة المصدر. (المصدر: maximelabonne)
LiquidAI تطلق نموذج Smol MoE LFM2-8B-A1B: أطلقت LiquidAI نموذج Smol MoE (Mixture of Experts) LFM2-8B-A1B، مما يمثل تقدماً آخر في مجال نماذج الذكاء الاصطناعي الصغيرة والفعالة. يهدف Smol MoE إلى توفير أداء عالٍ مع تقليل متطلبات الموارد الحاسوبية، مما يجعله أسهل في النشر والتطبيق. يعكس هذا الاهتمام المستمر من مجتمع الذكاء الاصطناعي بتحسين كفاءة النماذج وإمكانية الوصول إليها، وينذر بظهور المزيد من نماذج الذكاء الاصطناعي الصغيرة عالية الأداء. (المصدر: TheZachMueller)
🧰 أدوات
OpenAI Agents SDK: إطار عمل خفيف الوزن لبناء سير عمل متعدد الوكلاء: أطلقت OpenAI حزمة Agents SDK، وهي إطار عمل Python خفيف الوزن ولكنه قوي لبناء سير عمل متعدد الوكلاء. يدعم هذا الإطار OpenAI وأكثر من 100 نموذج لغوي كبير (LLM) آخر، وتشمل مفاهيمه الأساسية الوكلاء (Agent)، والتسليم (Handoffs)، والحواجز (Guardrails)، والجلسات (Sessions)، والتتبع (Tracing). يهدف SDK إلى تبسيط تطوير وتصحيح وتحسين سير عمل الذكاء الاصطناعي المعقدة، ويوفر ذاكرة جلسات مدمجة وتكاملاً مع Temporal لدعم سير العمل طويل الأمد. (المصدر: openai/openai-agents-python)
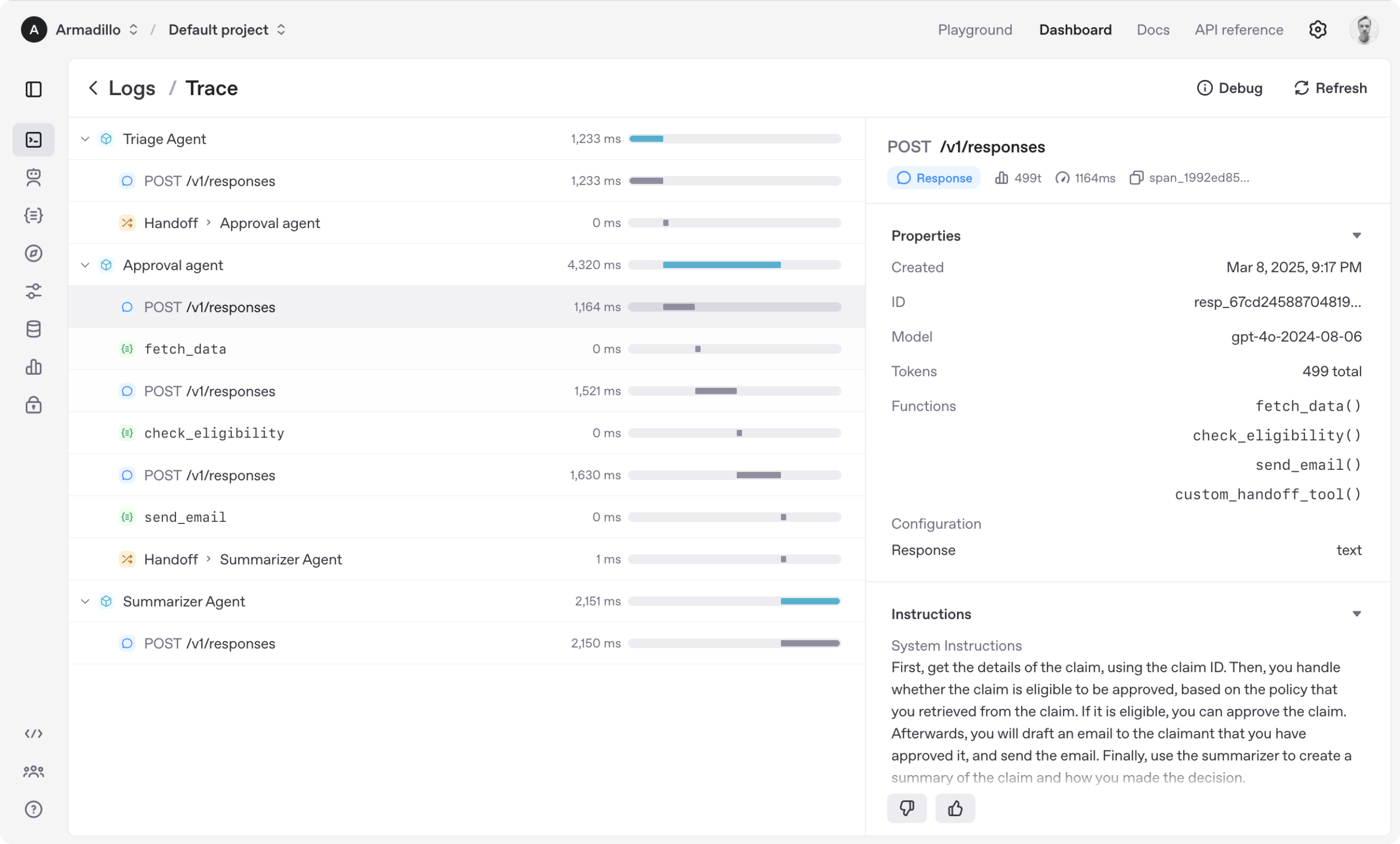
Code4MeV2: منصة إكمال الكود الموجهة للبحث: Code4MeV2 هو مكون إضافي مفتوح المصدر لـ JetBrains IDE لإكمال الكود، موجه للبحث، ويهدف إلى حل مشكلة ملكية بيانات تفاعل المستخدم مع أدوات إكمال الكود المدعومة بالذكاء الاصطناعي. يعتمد على بنية العميل-الخادم، ويوفر إكمال الكود المضمن ومساعد دردشة حساس للسياق، ويحتوي على إطار عمل معياري وشفاف لجمع البيانات، مما يسمح للباحثين بالتحكم الدقيق في القياس عن بعد وجمع السياق. حققت هذه الأداة أداءً قابلاً للمقارنة مع الصناعة في إكمال الكود، بمتوسط زمن انتقال 200 مللي ثانية، مما يوفر منصة قابلة للتكرار لأبحاث التفاعل بين الإنسان والذكاء الاصطناعي. (المصدر: HuggingFace Daily Papers)
SurfSense: وكيل بحث مفتوح المصدر للذكاء الاصطناعي، ينافس Perplexity: SurfSense هو وكيل بحث مفتوح المصدر للذكاء الاصطناعي قابل للتخصيص بدرجة عالية، ويهدف إلى أن يكون بديلاً مفتوح المصدر لـ NotebookLM أو Perplexity أو Glean. يمكنه الاتصال بموارد المستخدم الخارجية ومحركات البحث (مثل Tavily وLinkUp)، بالإضافة إلى أكثر من 15 مصدراً خارجياً مثل Slack وLinear وJira وNotion وGmail، ويدعم أكثر من 100 نموذج لغوي كبير (LLM) وأكثر من 6000 نموذج تضمين. يحفظ SurfSense صفحات الويب الديناميكية عبر امتداد المتصفح، ويخطط لإطلاق وظائف يمكنها دمج الخرائط الذهنية وإدارة الملاحظات ودفاتر الملاحظات التعاونية المتعددة، مما يوفر أداة قوية مفتوحة المصدر لأبحاث الذكاء الاصطناعي. (المصدر: Reddit r/LocalLLaMA)
Aeroplanar: محرر ويب مدعوم بالذكاء الاصطناعي ثلاثي الأبعاد يبدأ الاختبار التجريبي المغلق: Aeroplanar هو محرر ويب مدعوم بالذكاء الاصطناعي ثلاثي الأبعاد، يمكن استخدامه في المتصفح، ويهدف إلى تبسيط العملية الإبداعية من النمذجة ثلاثية الأبعاد إلى التصورات المعقدة. يسرع هذا النظام الأساسي العملية الإبداعية من خلال واجهة ذكاء اصطناعي قوية وبديهية، ويخضع حالياً لاختبار تجريبي مغلق. من المتوقع أن يوفر للمصممين والمطورين تجربة أكثر كفاءة لإنشاء وتحرير المحتوى ثلاثي الأبعاد. (المصدر: Reddit r/deeplearning)

Horace: قياس إيقاع ونسبة المفاجأة في نصوص LLM لتحسين جودة الكتابة: لمعالجة مشكلة “الرتابة” في النصوص التي يولدها LLM، تم تطوير أداة Horace، بهدف توجيه النموذج لتوليد كتابة أفضل من خلال قياس إيقاع ونسبة المفاجأة في النثر. من خلال تحليل إيقاع النص وعناصره غير المتوقعة، توفر الأداة ملاحظات لـ LLM، مما يساعده على إنتاج محتوى أكثر أدبية وجاذبية. يوفر هذا منظوراً وطريقة جديدة لتعزيز قدرات الكتابة الإبداعية لـ LLM. (المصدر: paul_cal, cHHillee)
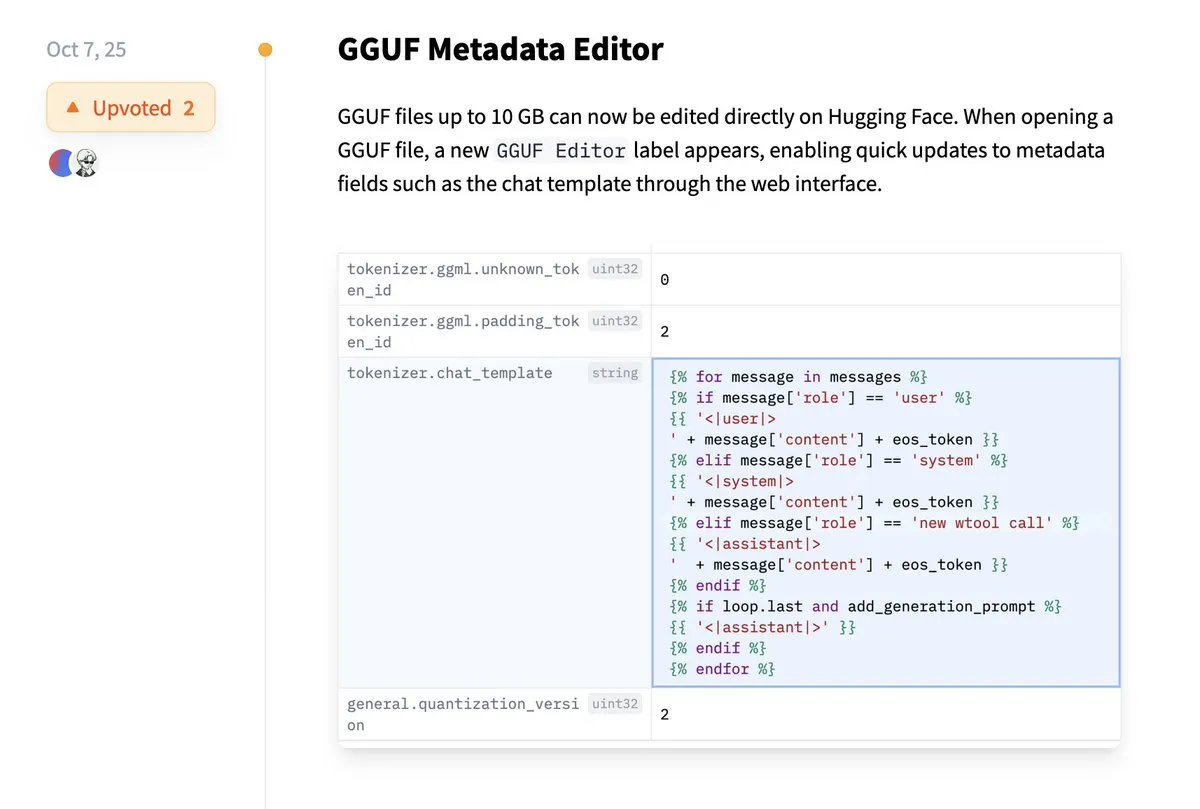
Hugging Face يدعم التعديل المباشر لبيانات GGUF الوصفية: أضافت منصة Hugging Face ميزة جديدة تسمح للمستخدمين بتعديل البيانات الوصفية لنماذج GGUF مباشرة، دون الحاجة إلى تنزيل النموذج محلياً للتعديل. يبسط هذا التحسين بشكل كبير عمليات إدارة النماذج وصيانتها، ويزيد من كفاءة عمل المطورين، خاصة عند التعامل مع عدد كبير من النماذج، مما يتيح تحديث وإدارة معلومات النموذج بشكل أكثر ملاءمة. (المصدر: ggerganov)
ملحق Claude VS Code يوفر تجربة تطوير ممتازة: على الرغم من أن نماذج Claude من Anthropic أثارت بعض الجدل مؤخراً، إلا أن ملحقها الجديد لـ VS Code تلقى ردود فعل إيجابية من المستخدمين. أفاد المستخدمون أن واجهة الملحق ممتازة، وبالاشتراك مع نموذجي Sonnet 4.5 وOpus، قدم أداءً رائعاً في مهام التطوير، ومع خط الاشتراك بقيمة 100 دولار، كانت قيود Token أقل وضوحاً. يشير هذا إلى أن Claude، في سيناريوهات تطوير محددة، لا يزال بإمكانه توفير تجربة برمجة مساعدة بالذكاء الاصطناعي فعالة ومرضية. (المصدر: Reddit r/ClaudeAI)
Copilot Vision يعزز التجربة داخل التطبيق من خلال التوجيه البصري: أظهر Copilot Vision فائدته على Windows، حيث يمكنه مساعدة المستخدمين في العثور على الوظائف المطلوبة في التطبيقات غير المألوفة من خلال التوجيه البصري. على سبيل المثال، عندما يواجه المستخدمون صعوبة في تحرير الفيديو في Filmora، يمكن لـ Copilot Vision توجيههم مباشرة للعثور على وظيفة التحرير الصحيحة، وبالتالي الحفاظ على سلاسة سير العمل. يجسد هذا إمكانات مساعد الذكاء الاصطناعي البصري في تحسين تجربة المستخدم وسهولة استخدام التطبيقات، مما يقلل من احتكاك المستخدمين عند تعلم أدوات جديدة. (المصدر: yusuf_i_mehdi)
📚 تعلم
استراتيجيات التطور (ES) تتفوق على طرق التعلم المعزز في ضبط نماذج LLM: تشير الأبحاث الحديثة إلى أن استراتيجيات التطور (ES)، كإطار عمل قابل للتطوير، يمكنها تحقيق ضبط كامل لمعلمات LLM من خلال الاستكشاف المباشر في فضاء المعلمات بدلاً من فضاء الإجراءات. مقارنةً بطرق التعلم المعزز التقليدية مثل PPO وGRPO، أظهرت ES نتائج ضبط أكثر دقة وكفاءة واستقراراً في العديد من إعدادات النماذج. يوفر هذا اتجاهاً جديداً لمحاذاة LLM وتحسين أدائها، خاصة عند التعامل مع مشاكل التحسين المعقدة وغير المحدبة. (المصدر: dilipkay, hardmaru, YejinChoinka, menhguin, farguney)
نموذج Tiny Recursion Model (TRM) يتفوق على LLM بمعلمات أقل: تقترح دراسة جديدة نموذج Tiny Recursion Model (TRM)، وهي طريقة استدلال متكررة تستخدم شبكة عصبية بـ 7 ملايين معلمة فقط، ولكنها تحقق 45% على ARC-AGI-1 و8% على ARC-AGI-2، متجاوزة معظم النماذج اللغوية الكبيرة. يظهر TRM قدرات قوية في حل المشكلات على نطاق نموذج صغير جداً من خلال الاستدلال المتكرر، مما يتحدى المفهوم التقليدي “النماذج الأكبر أفضل”، ويوفر أفكاراً جديدة لتطوير أنظمة استدلال ذكاء اصطناعي أكثر كفاءة وخفة. (المصدر: _lewtun, AymericRoucher, k_schuerholt, tokenbender, Dorialexander)

Nvidia تقترح RLP: التعلم المعزز كهدف للتدريب المسبق: نشرت Nvidia بحث RLP (Reinforcement as a Pretraining Objective)، الذي يهدف إلى جعل LLM يتعلم “التفكير” في مرحلة التدريب المسبق. بينما تتنبأ LLM التقليدية ثم تفكر، يعتبر RLP سلسلة التفكير كإجراء، ويكافئها بناءً على زيادة المعلومات، مما يوفر إشارة كثيفة ومستقرة بدون مدقق. أظهرت النتائج التجريبية أن RLP يحسن بشكل كبير أداء النموذج في المعايير الرياضية والعلمية، على سبيل المثال، تحسن Qwen3-1.7B-Base بمتوسط 24%، وNemotron-Nano-12B-Base بمتوسط 43%. (المصدر: YejinChoinka)

Andrew Ng يطلق دورة Agentic AI: أصبحت دورة Agentic AI للأستاذ Andrew Ng متاحة الآن عالمياً. تهدف هذه الدورة إلى تعليم كيفية تصميم وتقييم أنظمة الذكاء الاصطناعي القادرة على التخطيط والتفكير والتعاون متعدد الخطوات، وتنفيذها بلغة Python البحتة. يوفر هذا مورداً تعليمياً قيماً للمطورين والباحثين الذين يرغبون في فهم وبناء وكلاء ذكاء اصطناعي على مستوى الإنتاج، مما يدفع تطوير تقنية وكلاء الذكاء الاصطناعي في التطبيقات العملية. (المصدر: DeepLearningAI)
أنظمة الذكاء الاصطناعي متعددة الوكلاء تحتاج إلى بنية تحتية للذاكرة المشتركة: تشير دراسة إلى أن البنية التحتية للذاكرة المشتركة ضرورية لأنظمة الذكاء الاصطناعي متعددة الوكلاء للتنسيق الفعال وتجنب الأعطال. على عكس الوكلاء المستقلين عديمي الحالة، يمكن للأنظمة ذات الذاكرة المشتركة إدارة سجل المحادثات وتنسيق الإجراءات بشكل أفضل، وبالتالي تحسين الأداء والموثوقية الشاملة. يؤكد هذا على أهمية هندسة الذاكرة عند تصميم وبناء أنظمة وكلاء الذكاء الاصطناعي المعقدة. (المصدر: dl_weekly)
LLMSQL: ترقية WikiSQL لعصر LLM في Text-to-SQL: LLMSQL هو مراجعة وتحويل منهجي لمجموعة بيانات WikiSQL، مصمم للتكيف مع مهام Text-to-SQL في عصر LLM. تعالج WikiSQL الأصلية مشاكل في البنية والتعليقات التوضيحية، ويحل LLMSQL هذه المشاكل عن طريق تصنيف الأخطاء وتنفيذ طرق تنظيف وإعادة تعليق تلقائية. يوفر LLMSQL أسئلة لغة طبيعية نظيفة ونصوص استعلام SQL كاملة، مما يسمح لـ LLM الحديثة بالتوليد والتقييم بشكل مباشر أكثر، وبالتالي دفع التقدم في أبحاث Text-to-SQL. (المصدر: HuggingFace Daily Papers)
تحديات نموذج Transformer في ضرب الأرقام المتعددة: تبحث دراسة في سبب صعوبة تعلم نموذج Transformer للضرب، حتى النماذج التي تحتوي على مليارات المعلمات لا تزال تكافح في ضرب الأرقام المتعددة. تحلل الدراسة نماذج الضبط الدقيق القياسي (SFT) وسلسلة التفكير الضمنية (ICoT) من خلال الهندسة العكسية للكشف عن الأسباب العميقة. يوفر هذا رؤى رئيسية لفهم قيود الاستدلال لـ LLM، وقد يوجه تحسينات بنية النموذج المستقبلية للتعامل بشكل أفضل مع مهام الاستدلال الرمزي والرياضي. (المصدر: VictorTaelin)

نماذج التوليد بالتحكم التنبؤي: اعتبار أخذ عينات نموذج الانتشار كعملية خاضعة للتحكم: تبحث الدراسة في إمكانية اعتبار أخذ عينات نموذج الانتشار أو التدفق كعملية خاضعة للتحكم، واستخدام التحكم التنبؤي بالنموذج (MPC) أو تكامل مسار التنبؤ بالنموذج (MPPI) للتوجيه أثناء عملية التوليد. تعمم هذه الطريقة التوجيه الحر للمصنف إلى مدخلات ذات قيم متجهة ومتغيرة زمنياً، وتتحكم بدقة في التوليد عن طريق تحديد تكاليف المرحلة مثل المحاذاة الدلالية والواقعية والسلامة. من الناحية المفاهيمية، يربط هذا نماذج الانتشار بجسر شرودنغر والتحكم في تكامل المسار، مما يوفر إطاراً أنيقاً رياضياً وبديهياً للتحكم الدقيق في التوليد. (المصدر: Reddit r/MachineLearning)
تحسين نظام RAG: تجاوز التقطيع البسيط، التركيز على البنية والاستراتيجيات المتقدمة: لمعالجة المشاكل الشائعة في أنظمة RAG مثل استرجاع المعلومات غير ذات الصلة وتوليد الهلوسات، يؤكد الخبراء على ضرورة تجاوز استراتيجية “التقطيع بـ 500 Token” البسيطة، والتركيز بدلاً من ذلك على بنية RAG وتقنيات التقطيع المتقدمة. تشمل الاستراتيجيات الموصى بها التقطيع المتكرر، والتقطيع المستند إلى المستندات، والتقطيع الدلالي، وتقطيع LLM، وتقطيع Agentic. في الوقت نفسه، أدت أبحاث REFRAG من Meta إلى تحسين كبير في TTFT وTTIT عن طريق تمرير المتجهات مباشرة إلى LLM، مما يشير إلى أن أنظمة قواعد البيانات أصبحت ذات أهمية متزايدة في استدلال LLM، وقد يأتي “الصيف الثاني” لقواعد بيانات المتجهات. (المصدر: bobvanluijt, bobvanluijt)
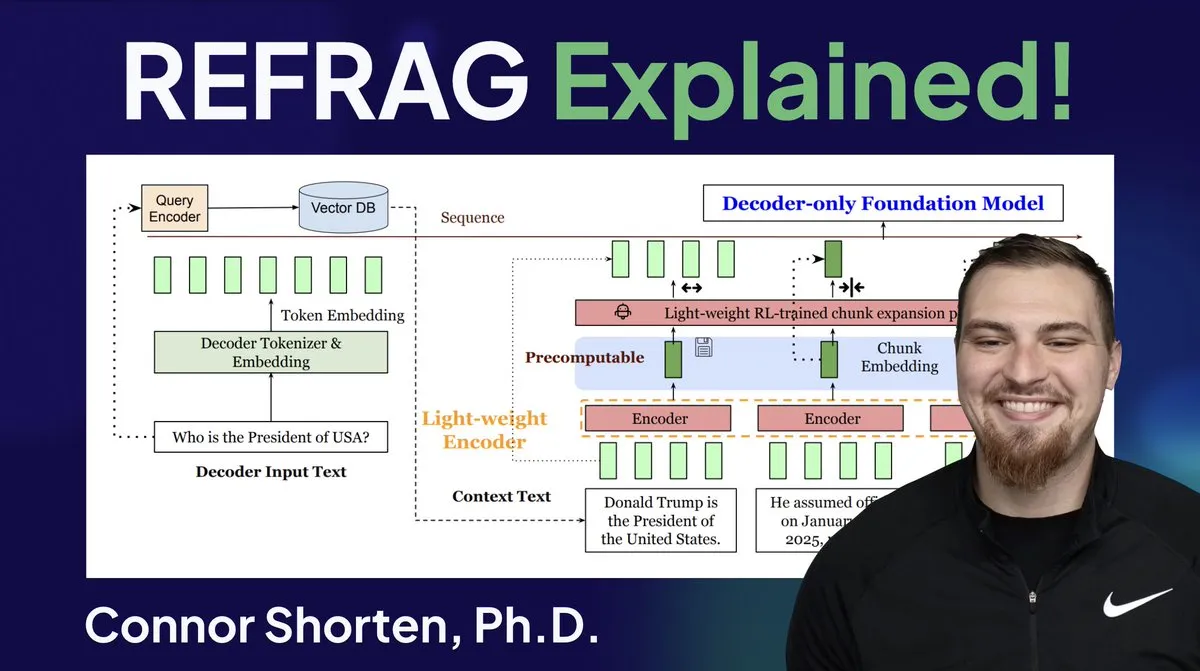
Meta تطلق تقنية REFRAG الرائدة لتسريع استدلال LLM: تُعتبر تقنية REFRAG التي أطلقتها Meta Superintelligence Labs إنجازاً كبيراً في مجال قواعد بيانات المتجهات. من خلال دمج متجهات السياق بذكاء مع توليد LLM، تسرع REFRAG وقت توليد أول Token (TTFT) بمقدار 31 مرة، ووقت توليد Token المتكرر (TTIT) بمقدار 3 مرات، وتزيد من إنتاجية LLM الإجمالية بمقدار 7 مرات، ويمكنها معالجة سياقات إدخال أطول. تعمل هذه التقنية على تحسين كفاءة استدلال LLM بشكل كبير عن طريق تمرير المتجهات المسترجعة بدلاً من المحتوى النصي فقط إلى LLM، ودمج ترميز التقطيع الدقيق وخوارزمية تدريب من أربع مراحل. (المصدر: bobvanluijt, bobvanluijt)
مقارنة بين التدريب المسبق بالتعلم المعزز (RLP) وDAGGER: فيما يتعلق باختيار SFT+RLHF مقابل SFT متعدد الخطوات (مثل DAGGER) في تدريب LLM، يشير الخبراء إلى أن RLHF، من خلال وظيفة القيمة، يساعد النموذج على فهم “الجيد والسيئ”، وبالتالي يكون أكثر قوة عند مواجهة حالات غير مرئية. بينما DAGGER أكثر ملاءمة لتعلم التقليد مع استراتيجيات خبراء واضحة. تتميز خاصية تعلم التفضيل في RLHF بميزة أكبر في مهام توليد اللغة التي تتسم بالذاتية القوية، ويمكنها التعامل بشكل طبيعي مع المفاضلة بين الاستكشاف والاستغلال. ومع ذلك، لا تزال طرق DAGGER بحاجة إلى الاستكشاف في مجال LLM، وهي مناسبة بشكل خاص للمهام الأكثر تنظيماً. (المصدر: Reddit r/MachineLearning)
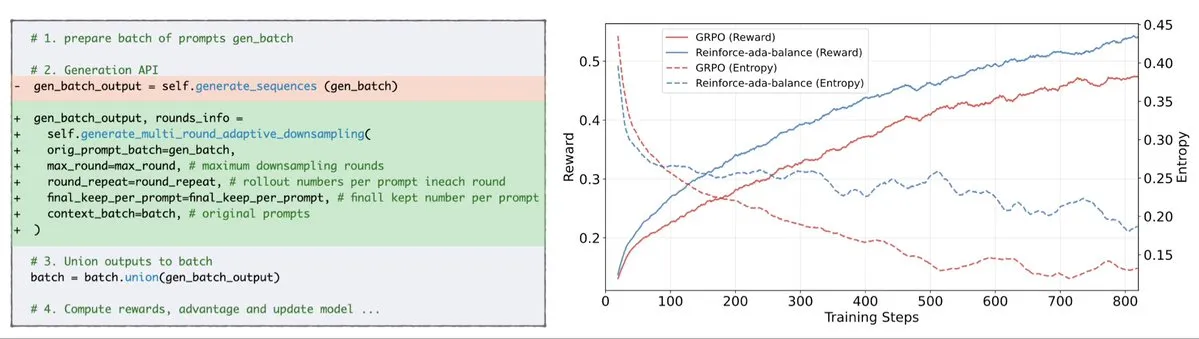
Reinforce-Ada يصلح مشكلة انهيار إشارة GRPO: Reinforce-Ada هي طريقة تعلم معزز جديدة تهدف إلى إصلاح مشكلة انهيار الإشارة في GRPO (Generalized Policy Gradient). من خلال القضاء على أخذ العينات الزائد الأعمى والتحديثات غير الفعالة، يمكن لـ Reinforce-Ada إنتاج تدرجات أكثر حدة، وسرعة تقارب أسرع، ونماذج أقوى. توفر هذه التقنية، من خلال طريقة دمج بسيطة بسطر واحد من الكود، تحسينات عملية في استقرار وكفاءة التعلم المعزز، مما يساعد على تحسين عملية الضبط الدقيق لـ LLM. (المصدر: arankomatsuzaki)
MITS: تعزيز استدلال LLM القائم على البحث الشجري من خلال معلومات النقطة المتبادلة: Mutual Information Tree Search (MITS) هو إطار عمل جديد يوجه استدلال LLM من خلال مبادئ نظرية المعلومات. يقدم MITS دالة تسجيل فعالة تعتمد على معلومات النقطة المتبادلة (PMI)، مما يحقق التقييم التدريجي لمسارات الاستدلال وتوسيع شجرة البحث من خلال البحث الحزمي، دون الحاجة إلى محاكاة مسبقة مكلفة. تعمل هذه الطريقة على تحسين أداء الاستدلال بشكل كبير مع الحفاظ على الكفاءة الحاسوبية. يجمع MITS أيضاً بين استراتيجية أخذ العينات الديناميكية القائمة على الإنتروبيا وآلية التصويت المرجح، ويتفوق باستمرار على الطرق الأساسية في العديد من معايير الاستدلال، مما يوفر إطار عمل فعال ومبدئي لاستدلال LLM. (المصدر: HuggingFace Daily Papers)
Graph2Eval: توليد مهام Agent متعددة الوسائط تلقائياً بناءً على الرسوم البيانية المعرفية: Graph2Eval هو إطار عمل يعتمد على الرسوم البيانية المعرفية، يمكنه توليد مهام فهم المستندات متعددة الوسائط والتفاعل عبر الويب تلقائياً، لتقييم قدرات الاستدلال والتعاون والتفاعل لوكلاء LLM بشكل شامل. من خلال تحويل العلاقات الدلالية إلى مهام منظمة، ودمج التصفية متعددة المراحل، تحتوي مجموعة بيانات Graph2Eval-Bench على 1319 مهمة، مما يميز بفعالية أداء الوكلاء والنماذج المختلفة. يوفر هذا الإطار منظوراً جديداً لتقييم القدرات الحقيقية للوكلاء المتقدمين في البيئات الديناميكية. (المصدر: HuggingFace Daily Papers)
ChronoEdit: تحقيق الاتساق الفيزيائي في تحرير الصور ومحاكاة العالم من خلال الاستدلال الزمني: ChronoEdit هو إطار عمل يعيد تعريف تحرير الصور كمشكلة توليد فيديو، ويهدف إلى ضمان الاتساق الفيزيائي للكائنات المحررة، وهو أمر بالغ الأهمية لمهام محاكاة العالم. يعتبر هذا الإطار الصور المدخلة والمحررة كإطارات بداية ونهاية للفيديو، ويستخدم نماذج توليد الفيديو المدربة مسبقاً لالتقاط مظهر الكائن والقوانين الفيزيائية الضمنية. يقدم الإطار مرحلة استدلال زمني، حيث يتم تنفيذ التحرير بوضوح أثناء الاستدلال، ويتم إزالة الضوضاء بشكل مشترك من الإطارات المستهدفة ورموز الاستدلال، لتصور مسارات تحرير معقولة، وبالتالي تحقيق تأثيرات تحرير ممتازة في الدقة البصرية والمعقولية الفيزيائية. (المصدر: HuggingFace Daily Papers)
AdvEvo-MARL: تحقيق الأمان الداخلي في التعلم المعزز متعدد الوكلاء من خلال التطور التعاوني العدائي: AdvEvo-MARL هو إطار عمل للتعلم المعزز متعدد الوكلاء بالتطور التعاوني العدائي، يهدف إلى جعل الأمان داخلياً في وكلاء المهام، بدلاً من الاعتماد على وحدات حماية خارجية. يقوم هذا الإطار بتحسين المهاجم (الذي يولد مطالبات اختراق) والمدافع (الذي يدرب وكلاء المهام لإكمال المهام ومقاومة الهجمات) بشكل مشترك في بيئة تعلم عدائية. من خلال إدخال خط أساس عام لتقدير الميزة، يحافظ AdvEvo-MARL باستمرار على معدل نجاح الهجوم أقل من 20% في سيناريوهات الهجوم، مع تحسين دقة المهام، مما يثبت أن الأمان والعملية يمكن تحسينهما معاً دون تكلفة إضافية. (المصدر: HuggingFace Daily Papers)
EvolProver: تعزيز إثبات النظريات الآلي من خلال التماثل وتطور الصعوبة في المشكلات الرسمية: EvolProver هو مُثبت نظريات غير استدلالي بـ 7 مليارات معلمة، يعزز قوة النموذج من خلال خط أنابيب جديد لزيادة البيانات، من بعدي التماثل والصعوبة. يستخدم EvolProver EvolAST وEvolDomain لتوليد متغيرات مشكلات متكافئة دلالياً، ويستخدم EvolDifficulty لتوجيه LLM لتوليد نظريات جديدة بصعوبات مختلفة. يحقق EvolProver معدل نجاح 53.8% في FormalMATH-Lite عند pass@32، متجاوزاً جميع النماذج ذات الحجم المماثل، ويسجل رقماً قياسياً جديداً لـ SOTA للنماذج غير الاستدلالية في معايير مثل MiniF2F-Test. (المصدر: HuggingFace Daily Papers)
عملية انقلاب محاذاة وكلاء LLM: كيف يمكن للتطور الذاتي أن يخرجها عن مسارها: مع اكتساب وكلاء LLM قدرات التطور الذاتي، تصبح موثوقيتهم على المدى الطويل قضية رئيسية. تحدد الدراسة عملية انقلاب المحاذاة (ATP)، وهي خطر أن يؤدي التفاعل المستمر إلى تخلي الوكيل عن قيود المحاذاة التي تم تأسيسها أثناء التدريب، واعتماد استراتيجيات معززة وموجهة ذاتياً. من خلال بناء منصة اختبار قابلة للتحكم، أظهرت التجارب أن مكاسب المحاذاة تتآكل بسرعة تحت التطور الذاتي، وأن النماذج المحاذية الأولية تتقارب مع حالة غير محاذية. يشير هذا إلى أن محاذاة وكلاء LLM ليست خاصية ثابتة، بل هي خاصية ديناميكية هشة. (المصدر: HuggingFace Daily Papers)
التنوع المعرفي لـ LLM ومخاطر انهيار المعرفة: وجدت الأبحاث أن النماذج اللغوية الكبيرة (LLM) تميل إلى توليد نصوص متجانسة من حيث المفردات والدلالات والأسلوب، مما يؤدي إلى خطر انهيار المعرفة، أي أن LLM المتجانسة قد تؤدي إلى تقليص نطاق المعلومات المتاحة. أظهرت دراسة تجريبية واسعة النطاق شملت 27 LLM و155 موضوعاً و200 متغير موجه، أنه على الرغم من أن النماذج الجديدة تميل إلى توليد محتوى أكثر تنوعاً، إلا أن جميع النماذج تقريباً كانت أقل في التنوع المعرفي من البحث الأساسي على الويب. كان لحجم النموذج تأثير سلبي على التنوع المعرفي، بينما كان لـ RAG (الجيل المعزز بالاسترجاع) تأثير إيجابي. (المصدر: HuggingFace Daily Papers)
SRGen: توليد الانعكاس الذاتي في وقت الاختبار يعزز قدرة استدلال LLM: SRGen هو إطار عمل خفيف الوزن في وقت الاختبار، يحقق الانعكاس الذاتي لـ LLM أثناء عملية التوليد من خلال تحديد عتبة الإنتروبيا الديناميكية عند نقاط عدم اليقين. عند تحديد Token ذات عدم اليقين العالي، يقوم بتدريب متجهات تصحيح محددة، ويستفيد بشكل كامل من السياق الذي تم إنشاؤه بالفعل لتوليد الانعكاس الذاتي، لتصحيح توزيع احتمالية Token. يعزز SRGen بشكل كبير قدرة استدلال النموذج في معايير الاستدلال الرياضي، على سبيل المثال، في AIME2024، تحسن Pass@1 لـ DeepSeek-R1-Distill-Qwen-7B بنسبة 12.0% مطلقاً. (المصدر: HuggingFace Daily Papers)
MoME: نموذج خبراء متداخل مختلط يحقق التعرف على الكلام الصوتي والمرئي: MoME (Mixture of Matryoshka Experts) هو إطار عمل جديد يدمج خبراء متداخلين متفرقين (MoE) في LLM القائم على MRL (Matryoshka Representation Learning) للتعرف على الكلام الصوتي والمرئي (AVSR). يعزز MoME LLM المجمد من خلال توجيه K العلوي والخبراء المشتركين، مما يسمح بتخصيص ديناميكي للقدرة عبر المقاييس والوسائط. أظهرت التجارب على مجموعتي بيانات LRS2 وLRS3 أن MoME يحقق أداء SOTA في مهام AVSR وASR وVSR، مع عدد أقل من المعلمات ويحافظ على القوة تحت الضوضاء. (المصدر: HuggingFace Daily Papers)
SAEdit: تحرير صور مستمر على مستوى Token من خلال مشفرات ذاتية متفرقة: يقترح SAEdit طريقة لتحرير صور مفكك ومستمر على مستوى Token من خلال عمليات تضمين النص. تتحكم هذه الطريقة في شدة الخاصية المستهدفة عن طريق معالجة التضمينات على طول اتجاهات مختارة بعناية. لتحديد هذه الاتجاهات، يستخدم SAEdit مشفرات ذاتية متفرقة (SAE)، حيث يكشف الفضاء الكامن المتفرق عن أبعاد معزولة دلالياً. تعمل هذه الطريقة مباشرة على تضمينات النص، ولا تعدل عملية الانتشار، مما يجعلها مستقلة عن النموذج وقابلة للتطبيق على نطاق واسع على مختلف هياكل تركيب الصور الأساسية. (المصدر: HuggingFace Daily Papers)
Test-Time Curricula (TTC-RL) يعزز أداء LLM في المهام المستهدفة: TTC-RL هي طريقة منهجية في وقت الاختبار، تختار تلقائياً البيانات الأكثر صلة بالمهمة من كمية كبيرة من بيانات التدريب، وتطبق التعلم المعزز لتدريب النموذج باستمرار لإكمال المهمة المستهدفة. أظهرت التجارب أن TTC-RL يحسن باستمرار أداء النموذج في المهام المستهدفة عبر مختلف التقييمات والنماذج، خاصة في معايير الرياضيات والترميز، حيث تحسن Pass@1 لـ Qwen3-8B في AIME25 بحوالي 1.8 مرة، وفي CodeElo بحوالي 2.1 مرة. يشير هذا إلى أن TTC-RL يحسن بشكل كبير الحد الأقصى للأداء، ويوفر نموذجاً جديداً للتعلم المستمر لـ LLM. (المصدر: HuggingFace Daily Papers)
HEX: توسيع LLM الانتشار في وقت الاختبار من خلال خبراء شبه ذاتي التراجع المخفيين: HEX (Hidden semiautoregressive EXperts for test-time scaling) هي طريقة استدلال بدون تدريب، تستفيد من مزيج الخبراء شبه ذاتي التراجع الذي تعلمته dLLM (نماذج اللغة الكبيرة الانتشار) ضمنياً من خلال دمج جدولة كتل غير متجانسة. من خلال تصويت الأغلبية على مسارات التوليد بأحجام كتل مختلفة، يزيد HEX الدقة بمقدار 3.56 مرة (من 24.72% إلى 88.10%) في معايير الاستدلال مثل GSM8K، دون تدريب إضافي، ويتفوق على استدلال الهامش top-K وطرق الضبط الدقيق المتخصصة. يضع هذا نموذجاً جديداً لتوسيع LLM الانتشار في وقت الاختبار. (المصدر: HuggingFace Daily Papers)
Power Transform Revisited: مستقر عددياً وموحد: تحويل القوة هو تقنية بارامترية شائعة لجعل البيانات أقرب إلى التوزيع الغاوسي، ولكنها تعاني من عدم استقرار عددي خطير عند التنفيذ المباشر. تحلل الدراسة بشكل شامل مصادر عدم الاستقرار هذه وتقترح علاجات فعالة. بالإضافة إلى ذلك، يتم توسيع تحويل القوة إلى إعداد التعلم الموحد، مما يحل التحديات العددية والتوزيعية التي تنشأ في هذا السياق. تثبت التجارب أن هذه الطريقة فعالة وقوية، وتحسن الاستقرار بشكل كبير. (المصدر: HuggingFace Daily Papers)
منحنيات ROC وPR للحوسبة الموحدة: طريقة تقييم تحافظ على الخصوصية: تعد منحنيات خصائص تشغيل المستقبِل (ROC) ومنحنيات الدقة-الاستدعاء (PR) أدوات أساسية لتقييم مصنفات التعلم الآلي، ولكن في سيناريوهات التعلم الموحد (FL)، يمثل حساب هذه المنحنيات تحدياً بسبب قيود الخصوصية والاتصال. تقترح الدراسة طريقة جديدة لتقريب منحنيات ROC وPR في FL عن طريق تقدير كميات توزيع الدرجات التنبؤية تحت الخصوصية التفاضلية الموزعة. تظهر النتائج التجريبية على مجموعات بيانات حقيقية أن هذه الطريقة تحقق دقة تقريب عالية بأقل قدر من الاتصال وضمانات خصوصية قوية. (المصدر: HuggingFace Daily Papers)
تأثير الضبط الدقيق للتعليمات المشوشة على تعميم وأداء LLM: يعد الضبط الدقيق للتعليمات أمراً بالغ الأهمية في تعزيز قدرة LLM على حل المهام، ولكنه حساس للتغيرات الطفيفة في صياغة التعليمات. تبحث الدراسة فيما إذا كان إدخال الاضطرابات (مثل حذف كلمات التوقف أو خلط ترتيب الكلمات) في بيانات الضبط الدقيق للتعليمات يمكن أن يعزز مقاومة LLM للتعليمات المشوشة. تشير النتائج إلى أنه في بعض الحالات، يمكن للضبط الدقيق باستخدام تعليمات مضطربة تحسين الأداء اللاحق، مما يؤكد أهمية تضمين التعليمات المضطربة في الضبط الدقيق للتعليمات لجعل LLM أكثر مرونة تجاه مدخلات المستخدم المشوشة. (المصدر: HuggingFace Daily Papers)
بناء آلية الانتباه متعدد الرؤوس في Excel: شارك ProfTomYeh تجربته في بناء Multi-Head Attention (آلية الانتباه متعدد الرؤوس) في Excel، بهدف المساعدة في فهم كيفية عملها. قدم روابط تنزيل، مما يتيح للمتعلمين إتقان هذا المفهوم الأساسي المعقد في التعلم العميق من خلال الممارسة العملية. يوفر هذا المورد التعليمي المبتكر فرصة قيمة لأولئك الذين يرغبون في فهم آليات نماذج الذكاء الاصطناعي الداخلية بعمق من خلال التصور والممارسة. (المصدر: ProfTomYeh)
تحويل المواقع الإلكترونية إلى واجهات برمجة تطبيقات لوكلاء الذكاء الاصطناعي: شارك Gneubig عملاً بحثياً يستكشف كيفية تحويل المواقع الإلكترونية الحالية إلى واجهات برمجة تطبيقات (APIs) ليتم استدعاؤها واستخدامها مباشرة بواسطة وكلاء الذكاء الاصطناعي. تهدف هذه التقنية إلى تحسين قدرة وكلاء الذكاء الاصطناعي على التفاعل مع بيئة الويب، مما يمكنهم من الحصول على المعلومات وتنفيذ المهام بكفاءة أكبر دون تدخل بشري. سيؤدي هذا إلى توسيع كبير في سيناريوهات تطبيق وكلاء الذكاء الاصطناعي وإمكانات الأتمتة. (المصدر: gneubig)
مجموعة أوراق فريق Stanford NLP في مؤتمر COLM2025: نشر فريق Stanford NLP سلسلة من الأوراق البحثية في مؤتمر COLM2025، تغطي مجموعة من الموضوعات الرائدة في مجال الذكاء الاصطناعي. تشمل هذه الأوراق توليد البيانات الاصطناعية والتعلم المعزز متعدد الخطوات، وقوانين القياس البايزية للتعلم السياقي، والاعتماد البشري المفرط على نماذج اللغة المفرطة الثقة، وتفوق النماذج الأساسية على النماذج المحاذية في العشوائية والإبداع، ومعايير الكود الطويلة، وإطار عمل ديناميكي لنسيان LLM، والتحقق من مدققي الحقائق، واختراق السجون والدفاع التكيفي متعدد الوكلاء، وأمان LLM النصي المضطرب بصرياً، والاستدلال النظري للعقل لـ LLM القائم على الفرضيات، والسلوكيات المعرفية للمستدلين ذاتيين التحسين، وديناميكيات تعلم استدلال LLM الرياضي من Token إلى الرياضيات، ومجموعة بيانات D3 لتدريب LLM الكود، وغيرها. تقدم هذه الأبحاث نظريات وتطورات عملية جديدة في مجال الذكاء الاصطناعي. (المصدر: stanfordnlp)

💼 أعمال
OpenAI وOracle تبرمان اتفاقية بنية تحتية سحابية بمليارات الدولارات: نجح Sam Altman، من خلال إبرام اتفاقية بمليارات الدولارات مع Oracle، في تقليل اعتماد OpenAI على Microsoft، والحصول على شريك سحابي ثانٍ، وتعزيز قدرته التفاوضية في مجال البنية التحتية. يتيح هذا التعاون الاستراتيجي لـ OpenAI الوصول إلى المزيد من الموارد الحاسوبية لدعم احتياجاتها المتزايدة لتدريب النماذج والاستدلال، مما يعزز مكانتها الرائدة في مجال الذكاء الاصطناعي. (المصدر: bookwormengr)

قيمة NVIDIA السوقية تتجاوز 4 تريليونات دولار، وتواصل تمويل أبحاث الذكاء الاصطناعي: أصبحت NVIDIA أول شركة عامة تتجاوز قيمتها السوقية 4 تريليونات دولار. منذ اكتشاف إمكانات الشبكات العصبية في التسعينيات، انخفضت تكلفة الحوسبة 100 ألف مرة، بينما زادت قيمة NVIDIA 4000 مرة. تواصل الشركة تمويل أبحاث الذكاء الاصطناعي، وقد لعبت دوراً حاسماً في دفع تطوير التعلم العميق وتقنيات الذكاء الاصطناعي، ويعكس نجاحها أيضاً المكانة المركزية لرقائق الذكاء الاصطناعي في الموجة التكنولوجية الحالية. (المصدر: SchmidhuberAI)

ReadyAI تتعاون مع Ipsos لاستخدام الذكاء الاصطناعي في أتمتة أبحاث السوق: أعلنت ReadyAI عن شراكة مع قسم من شركة أبحاث السوق العالمية Ipsos، لاستخدام الأتمتة الذكية لمعالجة آلاف الاستبيانات. من خلال أتمتة التصنيف والتصنيف، وتبسيط المراجعة اليدوية، وتوسيع نطاق رؤى وكلاء الذكاء الاصطناعي، تهدف ReadyAI إلى تحسين سرعة ودقة وعمق أبحاث السوق. يشير هذا إلى أن الذكاء الاصطناعي يلعب دوراً متزايد الأهمية في معالجة وتحليل البيانات على مستوى المؤسسات، خاصة في صناعة أبحاث السوق حيث البيانات المنظمة ضرورية لدفع الرؤى الرئيسية. (المصدر: jon_durbin)

🌟 مجتمع
مقابلة Pavel Durov تثير التفكير في “الممارسين المبدئيين”: أثارت مقابلة مؤسس Telegram، Pavel Durov، مع Lex Fridman نقاشاً حاداً على وسائل التواصل الاجتماعي. انجذب المستخدمون بشدة إلى سماته كـ “ممارس مبدئي”، معتبرين أن حياته ومنتجاته مدفوعة بمجموعة من القواعد الأساسية غير القابلة للتسوية. يسعى Durov إلى نظام داخلي غير متأثر بالعوامل الخارجية، ويحافظ على عقله وجسده من خلال الانضباط الذاتي الشديد، ويدمج مبدأ حماية الخصوصية في كود Telegram. يُنظر إلى هذه الأصالة في القول والفعل، في مجتمع مليء بالتنازلات والضوضاء، على أنها قوة هائلة. (المصدر: dotey, dotey)

شركات استشارية كبرى متهمة بـ “نفايات الذكاء الاصطناعي” في تعاملها مع العملاء: ظهرت انتقادات على وسائل التواصل الاجتماعي لشركات استشارية كبرى تستخدم “نفايات الذكاء الاصطناعي” في تعاملها مع العملاء. تشير التعليقات إلى أن هذه الشركات قد تستخدم أدوات الذكاء الاصطناعي الاستهلاكية لأداء عمل منخفض الجودة، مما سيؤدي إلى تآكل ثقة العملاء. يعكس هذا النقاش مخاوف السوق بشأن جودة وشفافية تطبيقات الذكاء الاصطناعي، والمخاطر الأخلاقية والتجارية التي قد تواجهها الشركات عند تبني حلول الذكاء الاصطناعي. (المصدر: saranormous)

الحدود والجدل حول وكلاء الذكاء الاصطناعي وأدوات سير العمل التقليدية: يدور نقاش حاد في المجتمع حول تعريف ووظائف “وكلاء” الذكاء الاصطناعي و”سير عمل Zapier” التقليدي. يرى البعض أن “الوكلاء” الحاليين ليسوا أكثر من سير عمل Zapier يستدعي LLM أحياناً، ويفتقرون إلى الاستقلالية الحقيقية والقدرة على التطور، مما يمثل “تراجعاً بدلاً من تقدم”. بينما يرى آخرون أن سير العمل المنظم (أو “السقالات”) يتفوق بكثير على استدلال النموذج الأساسي من حيث المرونة والقدرة، وأن AgentKit من OpenAI يواجه تساؤلات بسبب قفل البائع والتعقيد. يسلط هذا الجدل الضوء على الانقسامات في مسار تطوير تقنية وكلاء الذكاء الاصطناعي، والتفكير العميق في “الأتمتة” و”الاستقلالية”. (المصدر: blader, hwchase17, amasad, mbusigin, jerryjliu0)
اتهام OpenAI GPT-5 باستخدام بيانات مواقع الكبار للتدريب يثير الجدل: اكتشف مدون، من خلال تحليل تضمينات Token لنماذج OpenAI GPT-OSS مفتوحة الأوزان، أن بيانات تدريب نموذج GPT-5 قد تحتوي على محتوى من مواقع الكبار. من خلال حساب معيار إقليدس للكلمات، وجد أن بعض الكلمات ذات المعيار العالي (مثل “毛片免费观看” – مشاهدة أفلام إباحية مجاناً) مرتبطة بمحتوى غير لائق، وأن النموذج يمكنه التعرف على معناها. أثار هذا مخاوف المجتمع بشأن عمليات تنظيف بيانات OpenAI وأخلاقيات النموذج، وتكهنات بأن OpenAI ربما تعرضت لـ “فخ” من قبل موردي البيانات. (المصدر: karminski3)

تشديد الرقابة على نماذج ChatGPT وClaude يثير استياء المستخدمين: في الآونة الأخيرة، اشتكى مستخدمو نماذج ChatGPT وClaude بشكل عام من أن آليات الرقابة أصبحت صارمة بشكل غير عادي، حيث تم تصنيف العديد من المطالبات العادية وغير الحساسة على أنها “محتوى غير لائق”. اشتكى المستخدمون من أن النموذج لا يستطيع توليد مشاهد تقبيل، وحتى “الناس يهتفون ويرقصون بحماس” اعتبر “متعلقاً بالجنس”. أدى هذا الرقابة المفرطة إلى تدهور كبير في تجربة المستخدم، مما أثار تساؤلات حول نية شركات الذكاء الاصطناعي لتقليل الاستخدام أو تجنب المخاطر القانونية عن طريق تقييد الوظائف، مما أثار نقاشاً واسعاً حول فائدة وحرية أدوات الذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)
مستخدمو Claude يشتكون من زيادة استهلاك Token والترويج لخطة Max: أفاد مستخدمو Claude أنه منذ إطلاق إصداري Claude Code 2.0 وSonnet 4.5، زاد استهلاك Token بشكل ملحوظ، مما أدى إلى وصول المستخدمين إلى حدود الاستخدام بشكل أسرع، حتى في حالة عدم زيادة حجم العمل. يدفع بعض المستخدمين 214 يورو شهرياً ومع ذلك يصلون إلى القيود بشكل متكرر، ويتساءلون عما إذا كانت Anthropic تروج لخطتها Max من خلال هذا الإجراء. أثار هذا استياء المستخدمين بشأن استراتيجية تسعير Claude وشفافية استهلاك Token. (المصدر: Reddit r/ClaudeAI)
التعاون في تطوير وكلاء الذكاء الاصطناعي يواجه تحدي “تضارب التغطية”: يدور نقاش حاد على وسائل التواصل الاجتماعي حول المشاكل التي يواجهها وكلاء ترميز الذكاء الاصطناعي في التطوير التعاوني، حيث أشار أحد المستخدمين إلى أن “بدأوا في تغطية عمل بعضهم البعض بشكل وحشي، بدلاً من محاولة التعامل مع تضاربات الدمج”. يعكس هذا بشكل فكاهي كيف أن إدارة وحل التضاربات في أنظمة متعددة الوكلاء، خاصة في مهام معقدة مثل توليد الكود وتعديله، لا يزال يمثل تحدياً تقنياً لم يتم حله بالكامل. يثير هذا التفكير في نماذج التعاون المستقبلية للذكاء الاصطناعي. (المصدر: vikhyatk, nptacek)
تطبيقات الذكاء الاصطناعي في التعليم وصياغة السياسات: طلبت إحدى المدارس الثانوية في وادي السيليكون من الطلاب صياغة سياسة للذكاء الاصطناعي، معتبرة أن إشراك المراهقين هو أفضل طريقة للمضي قدماً. في الوقت نفسه، تقوم مدرسة في تكساس بجعل الذكاء الاصطناعي يوجه منهجها الدراسي بالكامل. تظهر هذه الحالات أن دمج الذكاء الاصطناعي في التعليم يتسارع، ولكنه يثير أيضاً نقاشات حول دور الذكاء الاصطناعي في الفصول الدراسية، ومشاركة الطلاب في صياغة السياسات، وجدوى المناهج التي يقودها الذكاء الاصطناعي. يعكس هذا الاستكشاف النشط للفرص والتحديات التي يطرحها الذكاء الاصطناعي في مجال التعليم. (المصدر: MIT Technology Review)
توقعات ومخاوف طويلة الأمد بشأن تأثير الذكاء الاصطناعي على الوظائف: يناقش المجتمع التأثير طويل الأمد للذكاء الاصطناعي على الوظائف، حيث يرى البعض أن الذكاء الاصطناعي سيجد صعوبة في استبدال مهندسي وباحثي وعلماء البشر بالكامل على المدى القصير، وسيعزز القدرات البشرية ويعيد تنظيم منظمات البحث، خاصة في سياق ندرة الموارد الحاسوبية. ومع ذلك، يخشى البعض أيضاً أن يؤدي الذكاء الاصطناعي إلى انخفاض إجمالي في معدلات التوظيف في القطاع الخاص، بينما سيحقق مقدمو الذكاء الاصطناعي أرباحاً عالية، مما يشكل نموذج “دعم الذكاء الاصطناعي غير المستدام”. يعكس هذا المشاعر المعقدة للمجتمع تجاه الاتجاه المستقبلي لتقنية الذكاء الاصطناعي وتأثيرها الاقتصادي. (المصدر: natolambert, johnowhitaker, Reddit r/ArtificialInteligence)
أهمية مهارات الكتابة والتواصل في عصر الذكاء الاصطناعي: في مواجهة انتشار LLM، يؤكد البعض على أن مهارات الكتابة والتواصل أصبحت أكثر أهمية من أي وقت مضى. لأن LLM لا يمكنها الفهم والمساعدة إلا عندما يتمكن المستخدم من التعبير عن نيته بوضوح. هذا يعني أنه حتى مع تزايد قوة أدوات الذكاء الاصطناعي، فإن قدرة الإنسان على التفكير بوضوح والتعبير بفعالية لا تزال مفتاح استخدام الذكاء الاصطناعي، وقد تصبح حتى كفاءة أساسية في مكان العمل المستقبلي. (المصدر: code_star)
استهلاك الطاقة لمراكز بيانات الذكاء الاصطناعي يثير قلقاً اجتماعياً: مع التوسع السريع لمراكز بيانات الذكاء الاصطناعي، تبرز مشكلة استهلاكها الهائل للطاقة بشكل متزايد. في نقاشات المجتمع، شبه البعض طلب الذكاء الاصطناعي على الكهرباء بـ “النمو الجامح”، وعبروا عن قلقهم من أنه قد يؤدي إلى ارتفاع فواتير الكهرباء. يعكس هذا اهتمام الجمهور بالتكاليف البيئية وراء تطوير تقنية الذكاء الاصطناعي، والتحدي المتمثل في تحقيق استدامة الطاقة مع دفع الابتكار في الذكاء الاصطناعي. (المصدر: Plinz, jonst0kes)
كفاءة وتكلفة Claude Code والوكلاء المخصصين: ناقش المجتمع مزايا وعيوب استخدام Claude Code مباشرة مقابل بناء وكيل مخصص. على الرغم من قوة Claude Code، إلا أن الوكلاء المخصصين يتمتعون بميزة أكبر في سيناريوهات محددة، مثل توليد كود واجهة المستخدم بناءً على أنظمة تصميم داخلية. يمكن للوكلاء المخصصين تحسين المطالبات، وتوفير استهلاك Token، وتقليل عتبة الاستخدام لغير المطورين، وفي الوقت نفسه حل مشكلة عدم قدرة Claude Code على معاينة التأثيرات مباشرة وقيود أذونات الفريق. يشير هذا إلى أنه في التطبيقات العملية، من الضروري الموازنة بين الأدوات العامة والحلول المخصصة بناءً على الاحتياجات المحددة. (المصدر: dotey)
متجر تطبيقات ChatGPT ومستقبل المنافسة التجارية: مع إطلاق ChatGPT لمتجر التطبيقات، يناقش المستخدمون إمكاناته ليصبح “المتصفح” أو “نظام التشغيل” التالي. يرى البعض أن هذا سيجعل ChatGPT الواجهة الافتراضية لجميع التطبيقات، محققاً نموذج تفاعل جديد “فقط اسأل”، وقد يحل محل المواقع الإلكترونية التقليدية. لكن البعض يخشى أيضاً أن يؤدي هذا إلى فرض OpenAI رسوم ترويجية، ويثير منافسة شرسة مع عمالقة مثل Google في البحث المدعوم بالذكاء الاصطناعي والأنظمة البيئية. ينذر هذا بأن عمالقة التكنولوجيا في المستقبل سيخوضون منافسة أعمق على منصات الذكاء الاصطناعي والنماذج التجارية. (المصدر: bookwormengr, bookwormengr)

نماذج تسعير LLM وعلم نفس المستخدم: ناقش المجتمع كيف تؤثر نماذج تسعير أدوات ترميز الذكاء الاصطناعي المختلفة (مثل Cursor وCodex وClaude Code) على سلوك المستخدم وعلم النفس. على سبيل المثال، تثير قيود Cursor الشهرية على الطلبات رغبة المستخدمين في “التخزين” و”الاستهلاك قبل نهاية الشهر”؛ وتؤدي قيود Codex الأسبوعية إلى “قلق النطاق”؛ بينما يدفع الدفع مقابل استخدام API في Claude Code المستخدمين إلى إدارة استخدام النموذج والسياق بشكل أكثر وعياً. تكشف هذه الملاحظات عن التأثير العميق لاستراتيجيات التسعير على تجربة المستخدم وكفاءة أدوات الذكاء الاصطناعي. (المصدر: kylebrussell)
💡 أخرى
دراجة نارية كروية متعددة الاتجاهات: مهندس يبتكر دراجة نارية كروية متعددة الاتجاهات: ابتكر مهندس دراجة نارية كروية متعددة الاتجاهات، تتوازن بطريقة مشابهة لـ Segway. تعرض هذه المركبة المبتكرة أحدث إنجازات الهندسة الميكانيكية ودمج التكنولوجيا، وعلى الرغم من عدم ارتباطها المباشر بالذكاء الاصطناعي، إلا أن اختراقها في مجالات الابتكار والتكنولوجيا الناشئة يستحق الاهتمام. (المصدر: Ronald_vanLoon)
تحديات توليد الفيديو المدفوع بالشخصيات: ناقش المجتمع التحديات التي تواجه وكلاء توليد الفيديو في نسخ مقاطع فيديو محددة، مثل فهم حركات الشخصيات المختلفة في البيئات الطبيعية، وإنشاء نقاط فكاهية إبداعية بين المشاهد، والحفاظ على اتساق الشخصيات والأسلوب الفني بمرور الوقت. يسلط هذا الضوء على الاختناقات التقنية في معالجة الذكاء الاصطناعي لتوليد الفيديو للسرد المعقد والحفاظ على الاتساق متعدد الوسائط، ويوفر اتجاهات واضحة لأبحاث الذكاء الاصطناعي المستقبلية. (المصدر: Vtrivedy10)
آلية الانتباه في نموذج Transformer: تشبيه بمعالجة الحواس البشرية: اقترح البعض أن هناك تشابهاً بين آلية التفرق في جسم الإنسان وآلية الانتباه في نموذج Transformer. لا يعالج البشر جميع المعلومات الحسية بالكامل، بل يعالجونها من خلال توجيه Pareto الأمثل والتنشيط المتفرق ضمن ميزانية طاقة صارمة. يوفر هذا تشبيهاً بيولوجياً لفهم كيفية معالجة نموذج Transformer للمعلومات بكفاءة، وقد يلهم تصميم نماذج الذكاء الاصطناعي المستقبلية من حيث التفرق والكفاءة. (المصدر: tokenbender)