
كلمات مفتاحية:أوبن إيه آي سورا 2, توليد الفيديو بالذكاء الاصطناعي, الذكاء الاصطناعي متعدد الوسائط, عالم الذكاء الاصطناعي, تصميم البروتين, واجهة برمجة تطبيقات سورا 2, تصميم البروتين PXDesign, إطار برومبت كوت 2.0, توليد منظور أول شخص إيغو توين, ليكيد إيه آي إل إف إم 2-أوديو
🔥 تركيز
إطلاق OpenAI Sora 2 وتأثيراته: أطلقت OpenAI رسميًا Sora 2، ووضعته كتطبيق اجتماعي على نظام iOS “شبيه بـ TikTok مدعوم بالذكاء الاصطناعي”، يدعم التوليد المتزامن للصوت والفيديو، مع تحسينات كبيرة في الالتزام بقوانين الفيزياء والتحكم. تشمل الميزات الجديدة “cameos” التي تسمح للمستخدمين بإدخال صورهم أو صور أصدقائهم في مقاطع الفيديو التي يولدها الذكاء الاصطناعي. أثارت وسائل التواصل الاجتماعي نقاشًا حادًا حول واقعيته المذهلة وقدرته الإبداعية، ولكن هناك أيضًا مخاوف بشأن انتشار محتوى “slop” (محتوى رديء)، وصعوبة التمييز بين الحقيقة والتزييف، والطلب المتزايد على وحدات معالجة الرسوميات (GPU)، وتوفر الخدمة إقليميًا (مثل عدم توفر Sora في المملكة المتحدة). رد الرئيس التنفيذي لـ OpenAI، Sam Altman، بأن Sora 2 يهدف إلى تمويل أبحاث AGI وتقديم منتجات جديدة وممتعة. تناولت مناقشات المجتمع أيضًا كيفية الحصول على رموز دعوة Sora 2، والتكهنات حول متطلبات الأجهزة (GPU)، والمخاوف بشأن جودة محتوى الفيديو المُولّد في المستقبل وسوء الاستخدام المحتمل. تخطط OpenAI لتوسيع دعوات Sora، ولكنها ستقلل من حدود التوليد اليومية، وكشفت عن خطط لإطلاق Sora 2 API.
(المصدر: 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs تطلق منصة عالم الذكاء الاصطناعي لتسريع الاكتشافات العلمية: حصلت Periodic Labs على تمويل بقيمة 300 مليون دولار، بهدف إنشاء علماء ذكاء اصطناعي لتسريع الاكتشافات العلمية الأساسية، خاصة في مجال تصميم المواد، من خلال أتمتة المختبرات والتجارب المدفوعة بالذكاء الاصطناعي. تهدف المنصة إلى اعتبار الكون المادي نظامًا حاسوبيًا، باستخدام الذكاء الاصطناعي لوضع الفرضيات وإجراء التجارب والتعلم، مما يبشر باختراقات في مجالات مثل الموصلات الفائقة عالية الحرارة. تؤكد هذه الرؤية على أهمية ربط الذكاء الاصطناعي بالعالم المادي، وتوليد بيانات عالية الجودة من خلال التجارب، متجاوزة النماذج التقليدية التي تعتمد فقط على البيانات المستقاة من الإنترنت.
(المصدر: dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

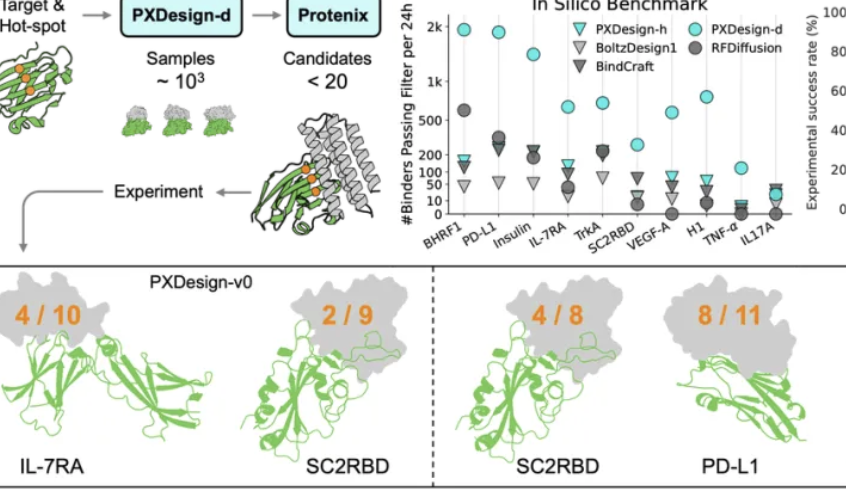
فريق ByteDance Seed يطلق PXDesign لتعزيز كفاءة تصميم البروتين: أطلق فريق ByteDance Seed أداة PXDesign، وهي طريقة قابلة للتطوير لتصميم البروتين بالذكاء الاصطناعي، قادرة على توليد مئات البروتينات المرشحة عالية الجودة في غضون 24 ساعة، مما يزيد الكفاءة بنحو 10 أضعاف مقارنة بالأساليب السائدة في الصناعة. حققت هذه الطريقة معدل نجاح في التجارب الرطبة يتراوح بين 20% و 73% على أهداف متعددة، وهو أعلى بكثير من AlphaProteo من DeepMind. يجمع PXDesign بين استراتيجية “التوليد + التصفية”، ويستخدم بنية شبكة DiT ونموذج Protenix للتنبؤ بالهيكل للفرز الفعال، ويوفر خدمة تصميم binder مجانية ومتاحة للجمهور عبر الإنترنت، بهدف تسريع الاستكشافات البحثية البيولوجية.
(المصدر: 量子位)
Ant Group وجامعة هونغ كونغ تطلقان PromptCoT 2.0، مع التركيز على تركيب المهام: أطلق فريق اللغة الطبيعية في مركز Ant Group للذكاء الاصطناعي العام بالتعاون مع فريق اللغة الطبيعية في جامعة هونغ كونغ إطار عمل PromptCoT 2.0، بهدف دفع استدلال النماذج الكبيرة وتطوير الوكلاء من خلال تركيب المهام. يستخدم هذا الإطار حلقة “Expectation-Maximization (EM)” بدلاً من التصميم اليدوي، ويقوم بتحسين سلسلة الاستدلال بشكل متكرر لتوليد أسئلة أكثر صعوبة وتنوعًا. يجمع PromptCoT 2.0 بين التعلم المعزز و SFT، مما يمكّن نموذج 30B-A3B من تحقيق SOTA في مهام استدلال الكود الرياضي، وقد تم فتح مصدر بيانات 4.77 مليون سؤال مركب، لتوفير موارد تدريب للمجتمع.
(المصدر: 量子位)

EgoTwin يحقق لأول مرة التوليد المتزامن للفيديو من منظور الشخص الأول وحركات الجسم البشري: أطلقت جامعة سنغافورة الوطنية، وجامعة نانيانغ التكنولوجية، وجامعة هونغ كونغ للعلوم والتكنولوجيا، ومختبر شنغهاي للذكاء الاصطناعي بشكل مشترك إطار عمل EgoTwin، الذي يحقق لأول مرة التوليد المشترك للفيديو من منظور الشخص الأول وحركات الجسم البشري. يعتمد هذا الإطار على نماذج الانتشار، ويستخدم التوليد المشترك ثلاثي الأنماط “نص-فيديو-حركة” للتغلب على تحديين رئيسيين: محاذاة المنظور والحركة، والاقتران السببي. تشمل الابتكارات الأساسية تمثيل الحركة المتمحور حول الرأس، وآلية التفاعل المستوحاة من علم التحكم الآلي، وإطار تدريب الانتشار غير المتزامن، ويمكن ترقية مقاطع الفيديو والحركات المُولّدة إلى مشاهد ثلاثية الأبعاد.
(المصدر: 量子位)

🎯 اتجاهات
إطلاق وتحديثات مكثفة لنماذج الذكاء الاصطناعي من الجيل الجديد: شهد مجال الذكاء الاصطناعي مؤخرًا إطلاق وتحديثات للعديد من النماذج والميزات الهامة، بما في ذلك DeepSeek-V3.2، Claude Sonnet 4.5، GLM 4.6، Sora 2، Dreamer 4، بالإضافة إلى ميزة الدفع الفوري في ChatGPT. تم تحسين DeepSeek-V3.2 على vLLM من خلال آلية الانتباه المتفرقة، مما حقق أداءً أعلى للسياقات الطويلة وكفاءة في التكلفة. أظهر Claude Sonnet 4.5 تعقيدًا في المحاذاة ونظرية العقل للمستخدم، وتفوق في الكتابة الإبداعية والكتابة الطويلة، لكن بعض المستخدمين أشاروا إلى أن جودة توليد الكود لا تزال بحاجة إلى تحسين. أظهر GLM-4.6 قدرة بارزة في كود الواجهة الأمامية، لكن التحسينات في لغات أخرى مثل Python لم تكن واضحة، وتم إطلاق نسخة GGUF الكمية لدعم النشر المحلي. أما Dreamer 4 فهو وكيل يتعلم حل مهام التحكم المعقدة ضمن نماذج عالمية قابلة للتوسع.
(المصدر: Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
نموذج الفيديو متعدد الوسائط Veo3 يظهر إمكانات الذكاء البصري العام: يُعتبر نموذج الفيديو Veo3 مسارًا محتملاً نحو الذكاء البصري العام، حيث يظهر قدرات التعلم والاستدلال بدون أمثلة (zero-shot learning)، ويمكنه حل مهام بصرية متنوعة، ويُعتقد أن له أهمية كبيرة في تقدم تكنولوجيا الروبوتات. في الوقت نفسه، أطلق فريق Qwen من Alibaba Cloud سلسلة نماذج اللغة الكبيرة متعددة الوسائط Qwen3-VL، والتي شهدت ترقيات شاملة في الوكلاء البصريين، والترميز البصري، والإدراك المكاني، وفهم السياقات الطويلة والفيديو، والاستدلال متعدد الوسائط، والتعرف البصري، و OCR، وقدمت إصدارات Instruct و Thinking. كما أطلقت Tencent نموذجي HunyuanImage 3.0 و Hunyuan3D-Part، اللذين حققا مستويات رائدة في مجالات تحويل النص إلى صورة وتوليد الأشكال ثلاثية الأبعاد على التوالي.
(المصدر: gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI تطلق LFM2-Audio ونماذج صغيرة متخصصة: أطلقت Liquid AI نموذج LFM2-Audio، وهو نموذج أساسي شامل للصوت والنص من طرف إلى طرف، يضم 1.5 مليار معلمة فقط، ويمكنه تحقيق محادثات سريعة الاستجابة في الوقت الفعلي على الأجهزة، وبسرعة استدلال أسرع 10 مرات من النماذج المماثلة. بالإضافة إلى ذلك، أطلقت Liquid AI أيضًا سلسلة نماذج LFM2 المُعدّلة، بما في ذلك متغيرات مختلفة مثل Tool و RAG و Extract، والتي تركز على مهام محددة بدلاً من السعي للعمومية، وهذا يتوافق مع وجهة نظر Nvidia في ورقتها البيضاء بأن النماذج المتخصصة الصغيرة هي الاتجاه المستقبلي للذكاء الاصطناعي الوكيلي (Agentic AI).
(المصدر: ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
قواعد بيانات المتجهات تشهد “ربيعًا ثانيًا” وxAI تركز على البيانات عالية الجودة: يرى البعض أن قواعد بيانات المتجهات قد تشهد ذروة جديدة في التطور، لكن أنماط تطبيقها قد تختلف عن المتوقع. في الوقت نفسه، تعمل xAI على بناء نموذج جديد لمعالجة البيانات البشرية، مؤكدة على أهمية مرحلة ما بعد التدريب (post-training)، ومعتبرة أن البيانات عالية الجودة هي حجر الزاوية للوصول إلى AGI. تخطط xAI لتشكيل مجتمع يضم خبراء من مختلف المجالات لبناء أعلى نظام تقييم جودة.
(المصدر: _philschmid, Dorialexander, Yuhu_ai_)
🧰 أدوات
مولد الروايات بالذكاء الاصطناعي YILING0013/AI_NovelGenerator: مولد روايات متعدد الوظائف يعتمد على نماذج اللغة الكبيرة (LLM)، يدعم بناء العالم، وتحديد الشخصيات، وتخطيط الحبكة، وتوليد الفصول الذكي، وتتبع الحالة، وإدارة الخيوط السردية، والاسترجاع الدلالي، ودمج قواعد المعرفة، وآلية المراجعة التلقائية، ويوفر واجهة مستخدم رسومية (GUI) مرئية. تهدف هذه الأداة إلى إنشاء قصص طويلة متماسكة ومنطقية بكفاءة، وتدعم العديد من نماذج LLM وخدمات Embedding مثل OpenAI و DeepSeek و Ollama.
(المصدر: GitHub Trending)
تطور مستمر لأدوات البرمجة المدعومة بالذكاء الاصطناعي: يساعد GitHub Copilot المستخدمين على تحقيق أقصى استفادة من فعاليته في مختلف المجالات واللغات وحالات الاستخدام من خلال التعليمات والمطالبات وأنماط الدردشة التي يساهم بها المجتمع، ويوفر خادم MCP لتبسيط التكامل. أظهر Replit Agent قدرات قوية في ترحيل الكود وضمان الجودة (QA)، حيث يمكنه ترحيل مواقع Next.js الكبيرة بسرعة من Vercel، ويدعم تكامل المدفوعات داخل التطبيق. يمكن تشغيل نموذج Apriel-1.5-15b-Thinker من ServiceNow على وحدة معالجة رسوميات (GPU) واحدة، مما يوفر قدرات استدلال قوية. بالإضافة إلى ذلك، يُستخدم نموذج Moondream3-preview في مهام وكلاء واجهة المستخدم (UI) و RPA، ويدعم vLLM أيضًا نشر نماذج encoder-only.
(المصدر: github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)

ابتكارات الأدوات المدعومة بالذكاء الاصطناعي في مجالات تطبيق محددة: يمكن لـ pix2tex (LaTeX OCR) تحويل صور المعادلات الرياضية إلى كود LaTeX، مما يحسن الكفاءة بشكل كبير في مجالات البحث العلمي والتعليم. يستخدم BatonVoice قدرة LLM على اتباع التعليمات لتوفير معلمات منظمة لتوليد الكلام، مما يحقق TTS قابل للتحكم. يدمج نظام Hex وظائف الوكيل، مما يتيح لعدد أكبر من الأشخاص استخدام الذكاء الاصطناعي للقيام بعمل بيانات دقيق وموثوق. أدوات توليد الفيديو مثل Kling 2.5 Turbo و Lucid Origin تجعل إنشاء الفيديو أسهل من أي وقت مضى. أما Racine CU-1 فهو نموذج تفاعلي بواجهة مستخدم رسومية (GUI) يمكنه التعرف على مواقع النقر، وهو مناسب لعمليات وكلاء واجهة المستخدم (UI) ومهام RPA.
(المصدر: lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
نموذج إعادة ترتيب المستندات jina-reranker-v3: jina-reranker-v3 هو نموذج إعادة ترتيب مستندات متعدد اللغات بمعلمات 0.6B، يقدم آلية تفاعل جديدة “متأخرة ولكن ليست متأخرة جدًا” (last but not late interaction). تقوم هذه الطريقة بإجراء حساب الانتباه الذاتي السببي بين الاستعلام والمستندات، مما يحقق تفاعلات غنية عبر المستندات قبل استخراج التضمينات السياقية لكل مستند. حققت هذه البنية المدمجة أداء SOTA على BEIR، وهي أصغر بعشر مرات من نماذج إعادة ترتيب القوائم التوليدية.
(المصدر: HuggingFace Daily Papers)
📚 تعلم
أحدث التطورات البحثية في استدلال نماذج الذكاء الاصطناعي ومحاذاتها: كشفت الأبحاث أن الاستدلال متعدد الوسائط، بينما يعزز الاستدلال المنطقي، قد يضر بالأسس الإدراكية، مما يؤدي إلى النسيان البصري. تم اقتراح طريقة Vision-Anchored Policy Optimization (VAPO) لتوجيه عملية الاستدلال للتركيز بشكل أكبر على الأسس البصرية. تمت مناقشة أسباب تفوق المحاذاة عبر الإنترنت (مثل GRPO) على المحاذاة دون اتصال (مثل DPO)، وتم اقتراح متغير Humanline، الذي يحقق أداء المحاذاة عبر الإنترنت حتى مع التدريب على البيانات دون اتصال، من خلال محاكاة التحيزات الإدراكية البشرية. إطار عمل Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) وخوارزمية Optimum-Referenced One-Step Adaptation (ROSA)، يستخدمان ملاحظات المستخدم لإجراء تعديلات فعالة في الوقت الفعلي على معلمات النموذج، مما يعزز قدرة LLM على التصحيح الذاتي في المحادثات متعددة الأدوار. تعمل طريقة NuRL (Nudging method) على تقليل صعوبة المشكلات من خلال المطالبات المولدة ذاتيًا، مما يمكّن النموذج من التعلم من المشكلات التي كانت “غير قابلة للحل” في الأصل، وبالتالي رفع الحد الأقصى لقدرة استدلال LLM. يقدم RLP (Reinforcement Learning Pre-training) التعلم المعزز إلى مرحلة ما قبل التدريب، حيث يعتبر سلسلة الأفكار بمثابة أفعال، ويكافئها من خلال مكاسب المعلومات، لتعزيز قدرة النموذج على الاستدلال في مرحلة ما قبل التدريب. Exploratory Iteration (ExIt) هي طريقة منهجية تلقائية تعتمد على RL، تعمل على تحسين حلول LLM بشكل متكرر أثناء الاستدلال، مما يعزز بشكل فعال أداء النموذج في مهام الدور الواحد والمتعدد. يهدف بحث TruthRL إلى حل مشكلة هلوسة النموذج من خلال تحفيز LLM على توليد معلومات حقيقية باستخدام التعلم المعزز. كشفت الأبحاث أن “نافذة السياق الفعالة القصوى” (MECW) لـ LLM أصغر بكثير من “نافذة السياق القصوى” (MCW) المُبلغ عنها، وأن MECW تتغير مع نوع المشكلة، مما يكشف عن القيود العملية لـ LLM في معالجة السياقات الطويلة. يمكن لهجوم Bias-Inversion Rewriting Attack (BIRA) نظريًا أن يتجنب علامات LLM المائية بفعالية، من خلال تثبيط logits للرموز التي قد يتم وضع علامة مائية عليها، مما يحقق معدل تجنب يزيد عن 99% مع الحفاظ على المحتوى الدلالي، مما يسلط الضوء على ضعف تقنيات العلامات المائية.
(المصدر: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
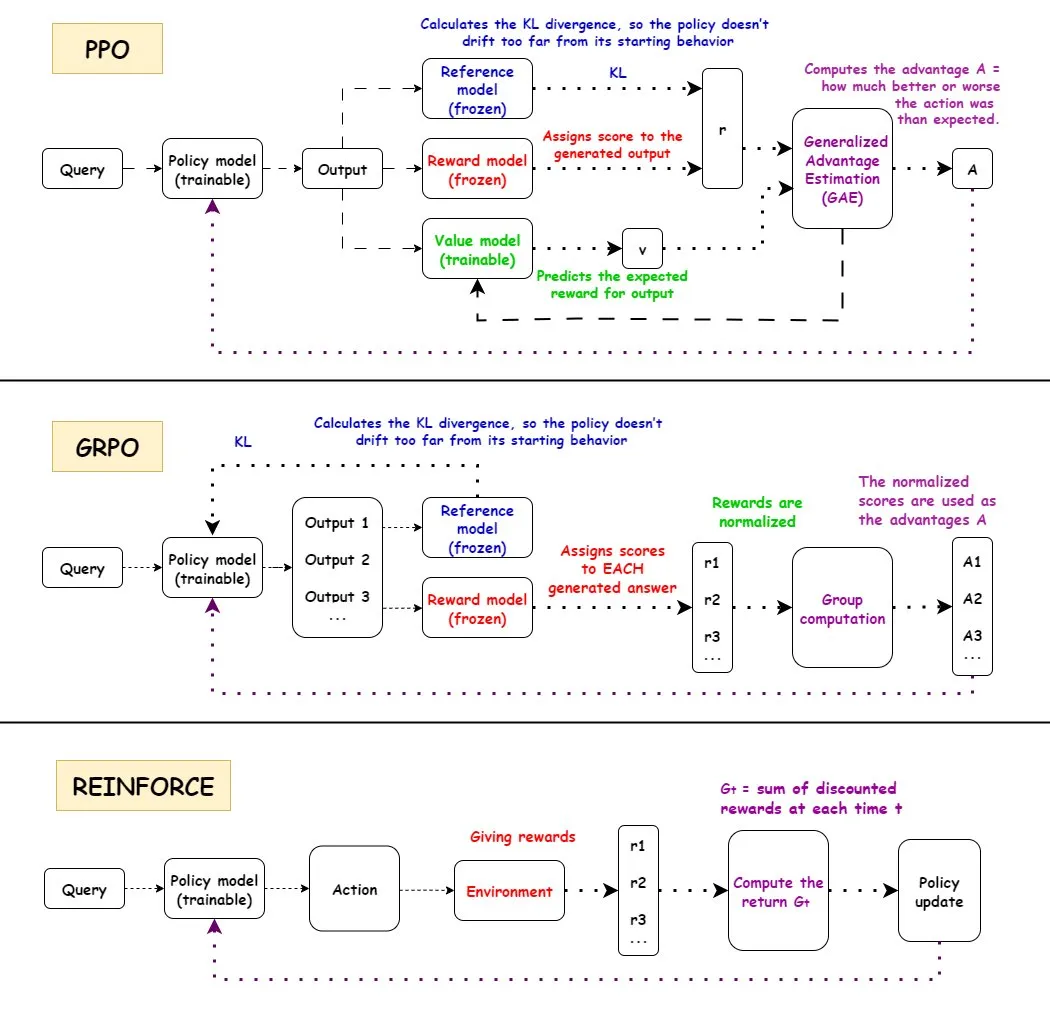
تحليل متعمق لخوارزميات التعلم المعزز (RL): تم تقديم شرح مفصل لسير عمل خوارزميات التعلم المعزز الرئيسية الثلاث: PPO و GRPO و REINFORCE، بالإضافة إلى مزاياها وعيوبها وسيناريوهات تطبيقها. تُستخدم PPO على نطاق واسع في مجال الذكاء الاصطناعي نظرًا لاستقرارها، و GRPO لآلية المكافأة النسبية، و REINFORCE كخوارزمية أساسية. تشير الأبحاث إلى أن التعلم المعزز يمكنه تدريب النماذج على تجميع المهارات الذرية وتحقيق التعميم في عمق التجميع، مما يدل على إمكانات RL في تعلم مهارات جديدة. وُجد أن أكثر من نصف تحسين الأداء في مسارات RL لا يأتي من تحسينات متعلقة بالتعلم الآلي (ML)، بل من تحسينات هندسية مثل تعدد الخيوط. تمت مناقشة مشكلة كمية المعلومات في كل حلقة تدريب RL، وتكافؤ المعلومات للمسارات المختلفة تحت نفس المكافأة النهائية. أجرى المجتمع مناقشات حول تعريف وفعالية التدريب المسبق لـ RL، مشيرًا إلى المشكلات المحتملة التي قد تنجم عن فرض التنوع الاصطناعي، وداعيًا إلى الاهتمام بتدهور الاتساق. بالنسبة للروبوت البشري ذي الذراعين والخمسة أصابع، تم تحسين استراتيجية استنساخ السلوك بشكل دقيق من خلال التعلم المعزز المتبقي خارج السياسة (ROSA)، مما أدى إلى تحسين كفاءة العينة بشكل كبير، وتحقيق تعديل دقيق للاستراتيجية مباشرة على الأجهزة.
(المصدر: TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
علماء الذكاء الاصطناعي والاكتشافات العلمية: DeepScientist هو نظام اكتشاف علمي موجه نحو الهدف ومستقل تمامًا، يدفع الاكتشافات العلمية الرائدة على مدى أشهر من خلال التحسين البايزي وعملية التقييم الهرمي. لقد تجاوز هذا النظام طرق SOTA البشرية في ثلاث مهام رائدة للذكاء الاصطناعي، وتم فتح مصدر جميع سجلات التجارب وكود النظام. تقوم OpenAI بتوظيف علماء أبحاث بهدف بناء الجيل القادم من الأدوات العلمية – منصة مدفوعة بالذكاء الاصطناعي لتسريع الاكتشافات العلمية.
(المصدر: HuggingFace Daily Papers, mcleavey)
تقنيات الضبط الدقيق والتحسين لـ LLM: كشفت الأبحاث أن LoRA في التعلم المعزز يمكن أن يطابق تمامًا أداء التعلم للضبط الدقيق الكامل (FullFT)، وحتى في حالات الرتبة المنخفضة، فإنه كافٍ لاستيعاب المعلومات من تدريب RL. يعمل إطار عمل Quadrant-based Tuning (Q-Tuning) على تحسين كفاءة البيانات بشكل كبير في الضبط الدقيق الخاضع للإشراف (SFT) من خلال تقليم العينات والرموز المشتركة، بل ويتجاوز التدريب على البيانات الكاملة في بعض الحالات. يتفوق مُحسّن Muon باستمرار على Adam في تدريب LLM،尤其在尾部关联记忆学习方面، من خلال طيف فردي أكثر تجانسًا وتحسين فعال للبيانات ذات الذيل الثقيل، مما يحل فوارق التعلم لـ Adam على البيانات غير المتوازنة. تم إجراء بحث حول التقدير التقاربي لـ RMS الأوزان في مُحسّن AdamW. تم تحليل مفصل لآلية عمل نواة CUDA لـ Flash Attention 4، وكشف عن ابتكاراتها في خطوط الأنابيب غير المتزامنة، و softmax البرمجي (تقريب مكعب)، وإعادة التحجيم الفعالة، مما يفسر أداءها الأسرع من cuDNN.
(المصدر: ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
موارد تعلم الذكاء الاصطناعي وأدوات البحث: تم مشاركة شرائح عرض تقديمي حول الذكاء الاصطناعي متعدد الوسائط تغطي الاتجاهات والنماذج مفتوحة المصدر وأدوات التخصيص/النشر والموارد الإضافية. تم الإعلان عن مؤتمرات مثل AI Engineer Europe 2026 و AI Engineer Paris، لتوفير منصات لمهندسي الذكاء الاصطناعي للتبادل المعرفي. تم التوصية بسلسلة “Let’s build GPT” لـ Karpathy وورقة Qwen، مع التأكيد على أهمية بيانات تدريب CTF عالية الجودة وموارد الحوسبة لتدريب LLM. تمت مناقشة إمكانات مُحسّن DSPyOSS في تحقيق تحسين “متدرج” في حالات استخدام B2B AI، لمواجهة ندرة البيانات. يهدف Axiom Math AI إلى بناء مُستدِل فائق الذكاء ذاتي التحسين، بدءًا من عالم رياضيات الذكاء الاصطناعي، في مجال الرياضيات الرسمية. بحث في تطبيق نماذج اللغة التراجعية في توليد الكود وفهمه. مناقشة حول ما إذا كان التعلم المعزز كافيًا لتحقيق AGI. استكشاف مخترع التعلم المتبقي العميق (Deep Residual Learning) والجدول الزمني لتطوره. شرح يورغن شميدهوبر في عام 2016 الوعي الاصطناعي، ونماذج العالم، والترميز التنبؤي، والعلم كضغط للبيانات، مؤكدًا على مساهماته المبكرة في مجال الذكاء الاصطناعي. تحليل استكشافي لممارسات التعاون المفتوح والدوافع والحوكمة لـ 14 مشروعًا لنموذج لغة كبير مفتوح المصدر، يكشف عن تنوع وتحديات نظام LLM البيئي مفتوح المصدر. Dragon Hatchling (BDH) هي بنية LLM تعتمد على شبكة شبيهة بالدماغ، تهدف إلى ربط Transformer بنماذج الدماغ، لتحقيق قابلية التفسير وأداء شبيه بـ Transformer. يعمل إطار عمل d^2Cache على تحسين كفاءة الاستدلال وجودة التوليد لنماذج اللغة المنتشرة (dLLMs) بشكل كبير من خلال التخزين المؤقت التكيفي المزدوج. يقدر إطار عمل TimeTic قابلية نقل نماذج الأساس للسلاسل الزمنية (TSFMs) من خلال التعلم السياقي، لاختيار أفضل نموذج للضبط الدقيق اللاحق بكفاءة. يمكن لمشفر الأساس البصري أن يعمل كـ tokenizer لنموذج الانتشار الكامن (LDM)، لتوليد مساحة كامنة غنية دلاليًا، وتحسين أداء توليد الصور. NVFP4 هو تنسيق تدريب مسبق جديد بـ 4 بت، من خلال التحجيم على مستويين، و RHT، والتقريب العشوائي، من المتوقع أن يحقق تحسينًا في الكفاءة بمقدار 6.8 مرة مع مطابقة أداء خط الأساس لـ FP8. DA^2 (Depth Anything in Any Direction) هو مقدر عمق بانورامي دقيق، يعمم بدون أمثلة، ومن طرف إلى طرف، يحقق SOTA في تقدير العمق البانورامي من خلال بيانات تدريب واسعة النطاق وبنية SphereViT. يحقق نموذج SAGANet توليدًا صوتيًا قابلاً للتحكم على مستوى الكائن من خلال الاستفادة من أقنعة التجزئة البصرية، ومقاطع الفيديو، وإشارات النص، مما يوفر تحكمًا دقيقًا لسير عمل Foley الاحترافي. Mem-α هو إطار عمل للتعلم المعزز، يحل مشكلة بناء الذاكرة وفقدان المعلومات لوكلاء LLM في فهم النصوص الطويلة من خلال تدريب الوكلاء على إدارة أنظمة الذاكرة الخارجية المعقدة بفعالية، ويظهر قدرة على التعميم على تسلسلات طويلة جدًا. يكتشف إطار عمل EntroPE (Entropy-Guided Dynamic Patch Encoder) نقاط التحول في السلاسل الزمنية ديناميكيًا من خلال الانتروبيا الشرطية، ويضع حدودًا للرقع للحفاظ على الهيكل الزمني، وتحسين دقة التنبؤ وكفاءته. BUILD-BENCH هو معيار أكثر تحديًا لتقييم قدرة وكلاء LLM على تجميع برامج مفتوحة المصدر في العالم الحقيقي، ويقترح OSS-BUILD-AGENT كخط أساس قوي. ProfVLM هو نموذج فيديو-لغة خفيف الوزن، يتنبأ بشكل مشترك بمستوى المهارة ويولد ملاحظات الخبراء من مقاطع الفيديو من منظور ذاتي وخارجي من خلال الاستدلال التوليدي. بحث في فعالية تدريب وقت الاختبار (TTT) في النماذج الأساسية، معتبرًا أن TTT من خلال التخصص في مهام الاختبار، يمكن أن يقلل بشكل كبير من خطأ الاختبار داخل التوزيع. CST هي بنية شبكة عصبية جديدة لمعالجة مجموعات الصور ذات الكاردينالية التعسفية، تعمل مباشرة على موترات الصور ثلاثية الأبعاد، وتجري استخراج الميزات ونمذجة السياق في نفس الوقت، وتتفوق في مهام مثل تصنيف المجموعات واكتشاف الشذوذ. يعتبر إطار عمل TTT3R إعادة البناء ثلاثي الأبعاد مشكلة تعلم عبر الإنترنت، ومن خلال الثقة في محاذاة حالة الذاكرة والملاحظة، يستنتج معدل التعلم، مما يعزز بشكل كبير قدرة التعميم على التسلسلات الطويلة.
(المصدر: tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
اكتشاف التزييف المدرك بشريًا في توليد الفيديو بالذكاء الاصطناعي: DeeptraceReward هي أول مجموعة بيانات معيارية دقيقة وحساسة للزمان والمكان، تُستخدم لتحديد علامات التزييف في مقاطع الفيديو المولدة التي يدركها البشر. تحتوي مجموعة البيانات هذه على 4.3K تعليق توضيحي مفصل على 3.3K مقطع فيديو عالي الجودة تم توليدها، وتم دمجها في 9 فئات رئيسية لعلامات التزييف. يدرب البحث نماذج لغوية متعددة الوسائط كنماذج مكافأة لمحاكاة الحكم البشري وتحديد المواقع، متفوقة على GPT-5 في تحديد وتحديد وتفسير أدلة التزييف.
(المصدر: HuggingFace Daily Papers)
التنقية العدائية وإعادة بناء المشاهد ثلاثية الأبعاد: MANI-Pure هو إطار عمل تنقية تكيفي يعتمد على السعة، يحقق أداء SOTA في الدفاع العدائي من خلال استخدام طيف سعة إشارة الإدخال لتوجيه عملية التنقية، وحقن ضوضاء غير متجانسة وموجهة بالتردد بشكل تكيفي، مما يثبط الاضطرابات عالية التردد بفعالية مع الحفاظ على المحتوى الدلالي المهم منخفض التتردد. أطلقت Nvidia نموذج Lyra، الذي يحقق إعادة بناء توليدية للمشاهد ثلاثية الأبعاد من خلال التقطير الذاتي لنموذج انتشار الفيديو، مما يمكن من توليد مشاهد ثلاثية ورباعية الأبعاد من صورة/فيديو واحد.
(المصدر: HuggingFace Daily Papers, _akhaliq)
💼 أعمال
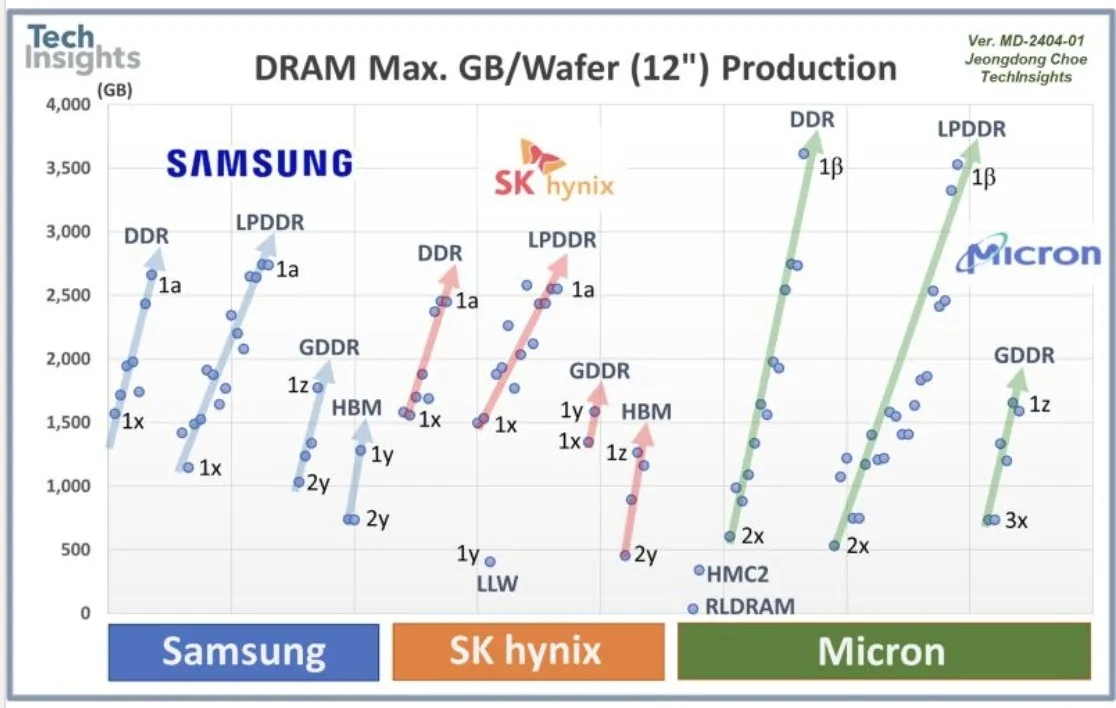
تعاون OpenAI مع سامسونج والطلب على DRAM: تتعاون OpenAI مع سامسونج لتطوير شريحة “Stargate”، وتتوقع الحاجة إلى 900 ألف رقاقة DRAM عالية الأداء شهريًا، مما يشير إلى خطط واستثمارات ضخمة في البنية التحتية للذكاء الاصطناعي في المستقبل، تتجاوز بكثير التوقعات الحالية للصناعة. أثار هذا الطلب الهائل نقاشات حول تكاليف حوسبة الذكاء الاصطناعي ودورة الذاكرة الفائقة.
(المصدر: bookwormengr, teortaxesTex, francoisfleuret)
تمويل الشركات الناشئة في مجال الذكاء الاصطناعي وتوجهات الصناعة: أطلقت Axiom Math AI مُستدِلًا فائق الذكاء ذاتي التحسين، بدءًا من عالم رياضيات الذكاء الاصطناعي، مما جذب اهتمام الصناعة. أكملت Modal جولة تمويل B بقيمة 87 مليون دولار، بتقييم 1.1 مليار دولار، بهدف دفع مستقبل البنية التحتية للحوسبة بالذكاء الاصطناعي. أكملت OffDeal جولة تمويل A بقيمة 12 مليون دولار، ملتزمة ببناء أول بنك استثماري يعتمد على الذكاء الاصطناعي في العالم. زار وزير الدفاع الياباني مكتب Sakana AI، مما يشير إلى تعاون محتمل للذكاء الاصطناعي في مجال الدفاع. شارك أحد المطورين تجربته في مواجهة نفاد التمويل بعد إنفاق 3000 دولار على بناء نماذج LLM مفتوحة المصدر، مما أثار نقاشًا مجتمعيًا حول استدامة مشاريع الذكاء الاصطناعي مفتوحة المصدر. أعلن مطورو Google AI عن الفائزين في Nano Banana Hackathon، وقدموا جوائز تزيد عن 400 ألف دولار، بهدف تشجيع الابتكار في تطبيقات الذكاء الاصطناعي.
(المصدر: shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 مجتمع
التأثيرات الاجتماعية والجدل الذي أثاره Sora 2: أثار إطلاق Sora 2 تأثيرات اجتماعية وجدلاً واسعًا. يخشى العديد من المستخدمين من انتشار محتوى “slop” (محتوى منخفض الجودة وعديم المعنى) الذي يولده الذكاء الاصطناعي، ويتساءلون عما إذا كانت أولويات OpenAI هي الترفيه بدلاً من حل مشكلات كبيرة مثل السرطان. في الوقت نفسه، هناك مخاوف من أن الواقعية الفائقة لـ Sora 2 قد تجعل من الصعب التمييز بين مقاطع الفيديو الحقيقية والمزيفة، أو حتى استخدامها بشكل ضار لتوليد معلومات كاذبة أو محتوى ضار “شبيه بالأسلحة البيولوجية”. أصبح Sam Altman، الرئيس التنفيذي لـ OpenAI، نفسه بطل الميمات المولدة بالذكاء الاصطناعي، وقد علق على ذلك بأنه “ليس غريبًا جدًا”، موضحًا أن تركيز OpenAI لا يزال على AGI والاكتشافات العلمية، وأن إطلاق المنتجات يهدف إلى تلبية الاحتياجات المالية. أبرزت القدرات القوية لـ Sora 2 مرة أخرى الطلب الهائل على وحدات معالجة الرسوميات (GPU)، مما أثار نقاشات حول التكاليف الباهظة للذكاء الاصطناعي، حتى أن البعض قارن تكلفة الذكاء الاصطناعي بتكلفة بناء نظام الطرق السريعة بين الولايات في الولايات المتحدة. يرى بعض المعلقين أن استراتيجية إطلاق Sora 2 “عادية” للغاية، وتفتقر إلى اختبارات الأداء ودعم المستخدمين المحترفين، وتفرض قيودًا على المحتوى الذي يولده المستخدمون المجانيون.
(المصدر: teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
تجربة المستخدم والجدل حول Claude Sonnet 4.5: يرى المستخدمون عمومًا أن Sonnet 4.5 قد تحسن بشكل ملحوظ في الاحتفاظ بالمعلومات، والحكم، واتخاذ القرارات، والكتابة الإبداعية، بل وأظهر “تغييرًا في الموقف” شبيهًا بالبشر، مثل أن يصبح أكثر احترافية بعد اكتشاف خلفية المستخدم، أو تصحيح المستخدم عندما “يهذي”. على الرغم من أدائه المميز في بعض الجوانب، لا يزال بعض المستخدمين ينتقدون جودة توليد الكود، مشيرين إلى “أخطاء إهمال وغبية”، وحتى مشكلة “المحادثة الطويلة جدًا” التي تمنع توليد الكود عند التعامل مع المحادثات الطويلة، معتبرين أنه لا يزال بعيدًا عن استبدال مهندسي البرمجيات البشر. بالإضافة إلى ذلك، نجح بعض المستخدمين في “كسر حماية” Sonnet 4.5، مما سمح له بتوليد وصفات خطيرة وكود برامج ضارة، مما أثار مخاوف جدية بشأن حواجز الأمان للنموذج.
(المصدر: teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
مستقبل لغات البرمجة في عصر الذكاء الاصطناعي وتراجع ثقافة المجتمع: أظهر تصنيف IEEE Spectrum 2025 للغات البرمجة أن Python احتلت المرتبة الأولى كأكثر اللغات شعبية لعشر سنوات متتالية، وتصدرت التصنيف العام، وسرعة النمو، والتوجه الوظيفي، وقد تعززت ميزتها بشكل أكبر في عصر الذكاء الاصطناعي. تراجع ترتيب JavaScript بشكل كبير، بينما لا تزال SQL ذات قيمة على الرغم من التحديات التي تواجهها. يشير التقرير إلى أن الذكاء الاصطناعي ينهي تنوع لغات البرمجة، ويتفاقم تأثير ماتيو للغات السائدة، بينما سيتم تهميش اللغات غير السائدة. في الوقت نفسه، تتراجع ثقافة مجتمع المبرمجين، حيث يميل المطورون إلى طلب المساعدة من النماذج الكبيرة بدلاً من طرح الأسئلة في المجتمع، مما غير طرق التعلم والعمل، وأثار نقاشات حول دور المبرمجين المستقبلي وأهمية القدرات الأساسية في تصميم البنية التحتية.
(المصدر: 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

فقاعة الذكاء الاصطناعي وآفاق تطور الصناعة: تدور نقاشات على وسائل التواصل الاجتماعي حول ما إذا كانت صناعة الذكاء الاصطناعي تشهد فقاعة، حيث يرى البعض أن حماس الاستثمار الحالي قد يؤدي إلى ظهور بعض المشاريع “الغبية”، لكن الأساسيات الصناعية لا تزال قوية، ويتزايد تبني الشركات للذكاء الاصطناعي بشكل مطرد. في الوقت نفسه، تشير بعض الأصوات إلى أن التكاليف الهائلة لحوسبة الذكاء الاصطناعي والطلب الضخم من OpenAI على DRAM ينذران بأن الصناعة لا تزال تتوسع بسرعة، ولم تصل بعد إلى مرحلة انفجار الفقاعة، لكن دخول رأس المال يتطلب الحذر أيضًا.
(المصدر: arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 أخرى
الروبوتات البشرية والأجهزة المساعدة بالذكاء الاصطناعي: عرضت شركة الروبوتات الصينية LimX Dynamics قدرات الروبوت البشري Oli على الحركة المستقلة، والانحناء، والرمي، دون الحاجة إلى التقاط الحركة أو التحكم عن بعد، مما يشير إلى أن الصين قد وصلت إلى مستوى مماثل لـ Figure/1X/Tesla في مجال الروبوتات البشرية. من المتوقع أن توفر Neural Band من Meta، التي تقرأ الإشارات العصبية عبر EMG، بالاشتراك مع نظارات Meta Rayban الذكية، طريقة تحكم ثورية للمبتورين، مما يتيح التحكم المتزامن في الأطراف الاصطناعية والواجهات الرقمية، وقد تصبح وحدة تحكم عالمية بدون استخدام اليدين. بالإضافة إلى ذلك، هناك تطبيقات متنوعة للذكاء الاصطناعي وتكنولوجيا الروبوتات في تعزيز التنقل، والاستكشاف، والإنقاذ، مثل الهياكل الخارجية الروبوتية الكهربائية، والحشرات الروبوتية التي يتم التحكم فيها لاسلكيًا، والروبوتات رباعية الأرجل، والروبوتات الثعبانية لمهام الإنقاذ.
(المصدر: Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
تطبيقات الذكاء الاصطناعي في تحرير الصور والتصميم الجرافيكي: LayerD هي طريقة لتحليل تصميمات الرسوم النقطية إلى طبقات، تهدف إلى تحقيق سير عمل إبداعي قابل لإعادة التحرير، من خلال استخراج طبقات المقدمة غير المحجوبة بشكل متكرر، والاستفادة من افتراض أن الطبقات عادة ما تظهر بمظهر موحد لتحسينها، وبالتالي تحقيق تحليل عالي الجودة. أما GeoRemover فيقدم إطار عمل من مرحلتين يراعي الهندسة، لإزالة الكائنات من الصور وما يترتب عليها من تشوهات بصرية (مثل الظلال والانعكاسات)، من خلال فصل الإزالة الهندسية عن عرض المظهر، وتقديم أهداف مدفوعة بالتفضيلات لتوجيه التعلم.
(المصدر: HuggingFace Daily Papers, HuggingFace Daily Papers)