
كلمات مفتاحية:جي بي تي-5, الحوسبة الكمية, تصميم المواد بالذكاء الاصطناعي, التعلم المعزز, نماذج اللغة الكبيرة, بنية تحتية للذكاء الاصطناعي, نماذج متعددة الوسائط, وكيل الذكاء الاصطناعي, مشاكل إن بي الكمية, شبكة عصبية بيانية للبلورات سي جي فورمر, إطار عمل التعلم المعزز آر إل إم تي, ديب سيك – الانتباه المتناثر دي إس إيه, يوني فيد – إطار عمل موحد لمهام الرؤية
🔥 تركيز
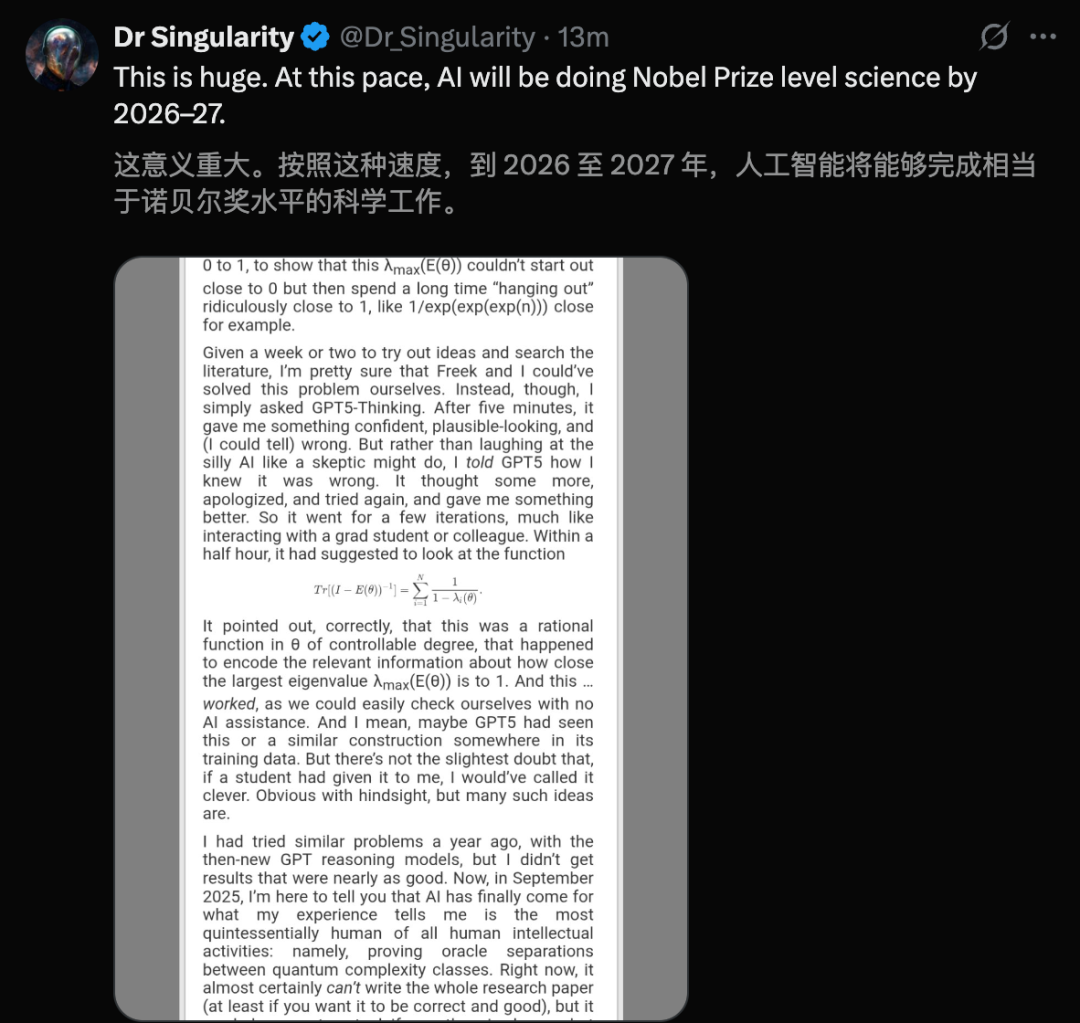
GPT-5 يحل “مشكلة NP الكمومية”: نشر خبير الحوسبة الكمومية Scott Aaronson لأول مرة ورقة بحثية تكشف عن الدور المساعد الرائد لـ GPT-5 في أبحاث نظرية التعقيد الكمومي. ساعد GPT-5 في حل خطوة استنتاجية رئيسية في “مشكلة NP الكمومية” في غضون 30 دقيقة، وهو ما يستغرق عادةً من البشر 1-2 أسبوع. يمثل هذا الإنجاز بداية لمس الذكاء الاصطناعي لعمل الاكتشافات العلمية الأساسية للذكاء البشري، وينذر بقفزة هائلة في إمكانات الذكاء الاصطناعي في مجال البحث العلمي. (المصدر: arXiv, scottaaronson.blog)
نموذج تصميم المواد الجديد CGformer: طور فريق البروفيسور Li Jinjin والبروفيسور Huang Fuqiang من جامعة Shanghai Jiao Tong نموذج تصميم مواد جديد يعتمد على الذكاء الاصطناعي، وهو CGformer، والذي يكسر قيود الشبكات العصبية التقليدية للرسوم البيانية البلورية من خلال دمج آليات الانتباه الشاملة لـ Graphormer مع CGCNN، ودمج ترميز المركزية والترميز المكاني. يمكن لهذا النموذج التقاط المعلومات الشاملة للهياكل البلورية المعقدة بالكامل، مما يحسن بشكل كبير دقة التنبؤ وكفاءة الفرز للمواد الجديدة مثل الإلكتروليتات الصلبة لأيونات الصوديوم عالية الإنتروبيا. (المصدر: Matter)

إطار عمل UniVid للمهام البصرية الموحدة: UniVid هو إطار عمل مبتكر، يقوم بضبط نموذج Transformer لانتشار الفيديو المدرب مسبقًا، مما يتيح له التكيف مع مهام الصور والفيديو المتنوعة دون الحاجة إلى تعديلات خاصة بالمهام. تمثل هذه الطريقة المهام كعبارات بصرية، وتحدد المهام وأنماط الإخراج المتوقعة من خلال تسلسل السياق، مما يظهر الإمكانات الهائلة لنماذج توليد الفيديو المدربة مسبقًا كأساس موحد للنمذجة البصرية. (المصدر: HuggingFace Daily Papers)
RLMT يقلب التدريب اللاحق للنماذج الكبيرة: قدم فريق الأستاذ المساعد Chen Danqi من جامعة Princeton إطار عمل “التعلم المعزز القائم على التفكير بمكافأة النموذج” (RLMT)، والذي يسمح لـ LLM بإنشاء سلسلة تفكير طويلة قبل الرد، ويجمع بين نموذج المكافأة القائم على التفضيل لتحسين RL عبر الإنترنت. تعمل هذه الطريقة على تحسين قدرة LLM على الاستدلال والتعميم في المهام المفتوحة بشكل كبير، بل وتجعل نموذج 8B يتفوق على GPT-4o في الدردشة والكتابة الإبداعية. (المصدر: arXiv)

نموذج CHURRO للتعرف على النصوص التاريخية: CHURRO هو نموذج لغوي بصري مفتوح المصدر (VLM) بمعاملات 3B، مصمم خصيصًا للتعرف على النصوص التاريخية بدقة عالية وتكلفة منخفضة. تم تدريب هذا النموذج على مجموعة بيانات CHURRO-DS التي تحتوي على 99,491 صفحة من الوثائق التاريخية من 22 قرنًا و46 لغة، وتجاوز أداؤه نماذج VLM الحالية مثل Gemini 2.5 Pro، مما أدى إلى تحسين كبير في كفاءة أبحاث التراث الثقافي وحفظه. (المصدر: HuggingFace Daily Papers)
🎯 اتجاهات
Altman يتوقع الذكاء الاصطناعي الفائق وميزة Pulse: توقع Sam Altman أن يتجاوز الذكاء الاصطناعي الذكاء البشري بالكامل بحلول عام 2030، مشيرًا إلى السرعة المذهلة لتطور الذكاء الاصطناعي. أطلقت OpenAI ميزة Pulse “الوضع النشط” في ChatGPT، مما يشير إلى تحول الذكاء الاصطناعي من الاستجابة السلبية إلى التفكير الاستباقي للمستخدمين، والقدرة على تقديم معلومات ذات صلة بناءً على محادثات المستخدمين العادية، وتحقيق خدمة شخصية للغاية، مما ينذر بأن الذكاء الاصطناعي سيصبح استعانة بمصادر خارجية للوعي الباطن البشري. (المصدر: 36氪, )
Jensen Huang يدحض نظرية فقاعة الذكاء الاصطناعي واستراتيجية Nvidia: فند Jensen Huang في مقابلة معه نظرية “إمبراطورية فقاعة الذكاء الاصطناعي”، مؤكدًا على الدور المحوري للذكاء الاصطناعي في الاقتصاد، وتوقع أن تصبح Nvidia أول شركة تبلغ قيمتها السوقية 10 تريليونات دولار. وأشار إلى أن استدلال الذكاء الاصطناعي يخفي وراءه طلبًا هائلاً على قوة الحوسبة، وأن Nvidia، من خلال التصميم التعاوني الفائق، تطلق بنية جديدة كل عام، وتفتح نظامها البيئي، ولا تخشى موجة التطوير الذاتي، وتهدف إلى تشكيل النظام الاقتصادي للذكاء الاصطناعي ودفع “الذكاء الاصطناعي السيادي” ليصبح إجماعًا جديدًا. (المصدر: 36氪, )

DeepSeek تطلق V3.2-Exp مفتوح المصدر وآلية DSA: أطلقت DeepSeek الإصدار التجريبي V3.2-Exp مفتوح المصدر، والذي يحتوي على 685 مليار معلمة، ونشرت ورقة بحثية في نفس الوقت، تقدم تفصيلاً لآلية الانتباه المتفرقة الجديدة (DeepSeek Sparse Attention, DSA). يهدف DSA إلى استكشاف وتحسين كفاءة التدريب والاستدلال في سيناريوهات السياق الطويل، وقد أدى إلى تحسين كبير في كفاءة معالجة السياق الطويل مع الحفاظ على جودة مخرجات النموذج. (المصدر: 36氪, HuggingFace)

إطلاق GLM-4.6 قريبًا: من المتوقع إطلاق نموذج GLM-4.6 من Zhipu AI قريبًا، حيث تم تصنيف GLM-4.5 على موقع Z.ai الرسمي على أنه “النموذج الرائد للجيل السابق”، مما يشير إلى أن الإصدار الجديد قد يجلب تحسينات في طول السياق وجوانب أخرى، مما يثير اهتمام وتوقعات المجتمع. (المصدر: Reddit r/LocalLLaMA, karminski3)
استراتيجية Apple للذكاء الاصطناعي وروبوت الدردشة الداخلي Veritas: تم الكشف عن روبوت الدردشة AI الذي يحمل الاسم الرمزي “Veritas” والذي طورته Apple داخليًا، ويعمل كمدرب لـ Siri، ولديه القدرة على تنفيذ العمليات داخل التطبيقات. على الرغم من ذلك، لا تزال Apple تصر على عدم إطلاق روبوت دردشة للمستهلكين، وتركز على تكامل الذكاء الاصطناعي على مستوى النظام، وتخطط لتعميق تكامل نماذج الطرف الثالث من خلال محرك إجابات الذكاء الاصطناعي وواجهة MCP العامة، بدلاً من تطوير روبوتات الدردشة الخاصة بها. (المصدر: 36氪)

نمو سوق AI PC والاختناقات التقنية: من المتوقع أن تشهد شحنات سوق AI PC نموًا قويًا في 2025-2026، ولكن هذا النمو مدفوع بشكل أساسي بانتهاء دعم Windows 10 ودورة استبدال أجهزة الكمبيوتر، وليس بالثورة التكنولوجية للذكاء الاصطناعي. تعتبر وظائف الذكاء الاصطناعي الحالية في الغالب مكملة لأجهزة الكمبيوتر التقليدية، وتواجه تحديات مثل نقص قوة الحوسبة المحلية، والتفاعل السلبي، والنظام البيئي المغلق. تتطلب أجهزة الذكاء الاصطناعي الحقيقية تحقيق “قوة حوسبة محلية أساسية، وتكملة سحابية مساعدة” والإدراك النشط. (المصدر: 36氪)

الذكاء الاصطناعي يقتحم سوق تداول الطاقة: يُستخدم الذكاء الاصطناعي على نطاق واسع في سوق تداول الطاقة، حيث تقوم شركات مثل Qingpeng Intelligent بالتنبؤ بكميات توليد الطاقة الشمسية والرياح وطلب الكهرباء من خلال نماذج السلاسل الزمنية الكبيرة، مما يساعد في اتخاذ قرارات التداول. من المتوقع أن تزيد ميزة الذكاء الاصطناعي في معالجة كميات هائلة من البيانات من الأرباح، ولكنها قد تؤدي أيضًا إلى خسائر بسبب عدم نضج النماذج وتعقيد السوق، ولا يزال القطاع في مرحلة الاستكشاف. (المصدر: 36氪)
تحديث نماذج Alibaba Tongyi الكبيرة وخدمات الذكاء الاصطناعي الشاملة: قامت Alibaba Cloud بترقية نظام الذكاء الاصطناعي الشامل بشكل كبير في مؤتمر Apsara Conference، وأطلقت 6 نماذج جديدة بما في ذلك Qwen3-MAX وQwen3-Omni، لتضع نفسها كـ “مزود خدمة ذكاء اصطناعي شامل”. تلتزم Alibaba Cloud ببناء “Android لعصر الذكاء الاصطناعي” و”الجيل القادم من أجهزة الكمبيوتر”، وتقديم خدمات سحابية شاملة للذكاء الاصطناعي من النماذج الأساسية إلى البنية التحتية، لمواجهة تطور AI Agent من “الذكاء الناشئ” إلى “العمل المستقل”. (المصدر: 36氪)

تحليل معمق لهندسة NVIDIA Blackwell: سيتناول حدث التحليل المتعمق لهندسة NVIDIA Blackwell بنيتها وتحسيناتها وتطبيقها في سحابة GPU. يهدف هذا الحدث، الذي يقدمه خبراء من SemiAnalysis وNVIDIA، إلى الكشف عن كيفية دفع Blackwell GPU، باعتباره “GPU العقد القادم”، لتطوير قوة حوسبة الذكاء الاصطناعي ومستقبل سحابة GPU. (المصدر: TheTuringPost)

🧰 أدوات
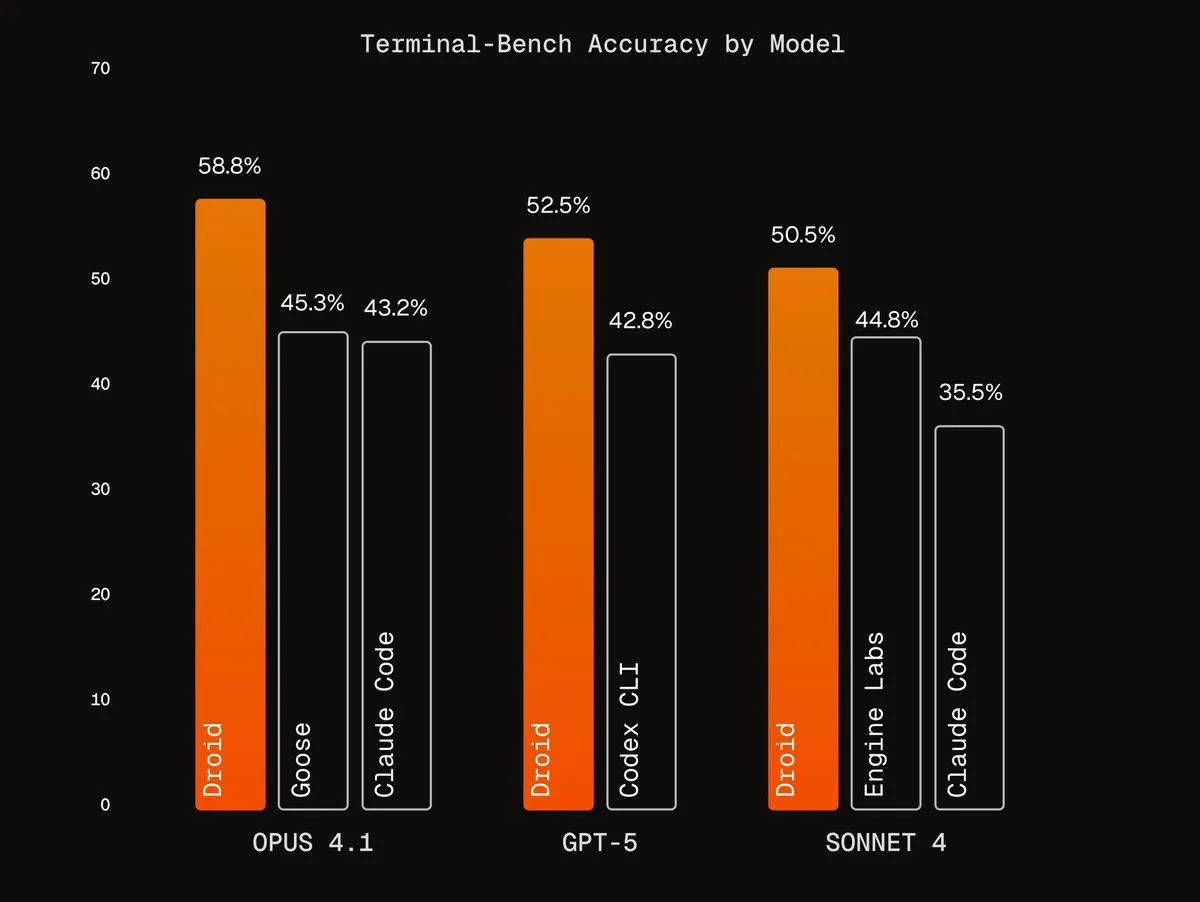
Agentic Harnesses من Factory AI: طورت Factory AI أدوات Agentic Harnesses عالمية المستوى، مما أدى إلى تحسين أداء النماذج الحالية بشكل كبير، وخاصة في مهام الترميز، حيث وصفها المستخدمون بأنها “رمز غش”. احتل وكيل Droids الخاص بها المرتبة الأولى في Terminal-Bench، وحقق إعادة هيكلة موثوقة للتعليمات البرمجية من خلال سير عمل التحقق متعدد الوكلاء. (المصدر: Vtrivedy10, matanSF, matanSF)
مكتبة RAGLight مفتوحة المصدر لـ RAG: أطلقت LangChainAI مكتبة RAGLight، وهي مكتبة Python خفيفة الوزن لبناء أنظمة RAG على مستوى الإنتاج. تتميز هذه المكتبة بخطوط أنابيب وكلاء مدفوعة بـ LangGraph، ودعم LLM متعدد المزودين، وتكامل GitHub مدمج، وأدوات CLI، وتهدف إلى تبسيط تطوير ونشر أنظمة RAG. (المصدر: LangChainAI, hwchase17)
نظام التشغيل الدلالي ArgosOS: ArgosOS هو تطبيق سطح مكتب يحقق البحث الذكي عن المستندات وتوحيد المحتوى من خلال بنية قائمة على العلامات بدلاً من قواعد بيانات المتجهات. يستخدم LLM لإنشاء علامات ذات صلة وتخزينها في قاعدة بيانات SQLite، وبالتالي معالجة الاستعلامات بذكاء، مثل تحليل فواتير التسوق، وتوفير حلول دقيقة وفعالة لإدارة المستندات للتطبيقات الصغيرة. (المصدر: Reddit r/MachineLearning)
أداة البحث عبر الويب من Ollama: يدعم Ollama الآن أدوات البحث عبر الويب، مما يسمح للمستخدمين بدمج وظيفة البحث عبر الويب في أحمال عمل Minions، وبالتالي إثراء معلومات السياق لتطبيقات الذكاء الاصطناعي، وتحسين قدرتها على معالجة المهام المعقدة. (المصدر: ollama)
Hyperlink لـ RAG متعدد الوسائط محليًا: يوفر Hyperlink وظيفة RAG متعددة الوسائط المحلية، مما يسمح للمستخدمين بالبحث وتلخيص لقطات الشاشة/مكتبات الصور دون اتصال بالإنترنت. من خلال تقنيات OCR والتضمين، يمكن لهذه الأداة تحويل بيانات الصور غير المهيكلة إلى محتوى قابل للاستعلام، مما يحقق إدارة مستندات واستخراج معلومات خاصة بالكامل وعلى الجهاز. (المصدر: Reddit r/LocalLLaMA)

موصل Azure PostgreSQL لـ LangChain: أطلقت Microsoft موصل Azure PostgreSQL الأصلي، لتوحيد استمرارية الوكيل لنظام LangChain البيئي. يوفر هذا الموصل تخزينًا متجهًا على مستوى المؤسسات وإدارة الحالة، مما يبسط تعقيد بناء ونشر وكلاء الذكاء الاصطناعي في بيئة Azure. (المصدر: LangChainAI)
توحيد LLM API وبروتوكول MCP: ناقش المجتمع مشكلة تجزئة LLM API، مشيرًا إلى عدم التوافق في بنية الرسائل وأنماط استدعاء الأدوات وأسماء حقول الاستدلال بين مختلف المزودين، داعيًا إلى توحيد بروتوكول JSON API في الصناعة. في الوقت نفسه، أثار إدخال بروتوكول MCP (Model-Client Protocol) نقاشًا حول تأثيره على تطوير الوكلاء. (المصدر: AAAzzam, charles_irl)
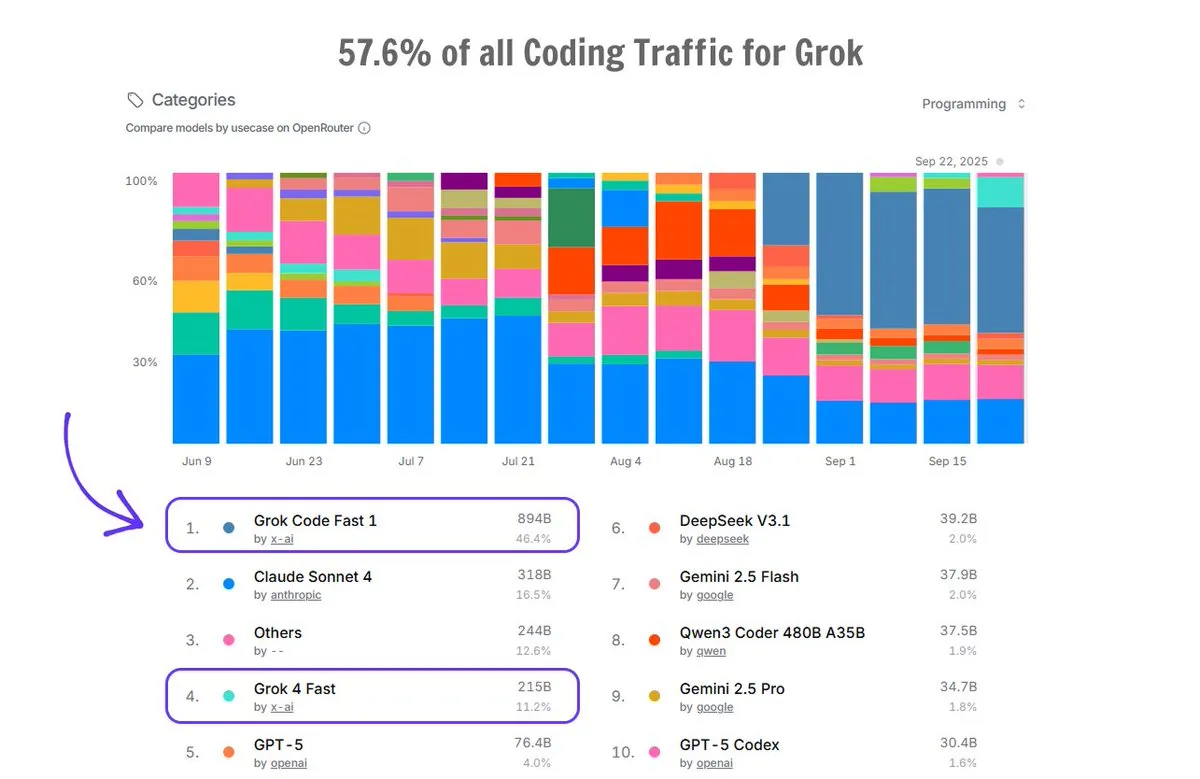
تطبيق Grok Code على OpenRouter: استحوذ Grok Code على 57.6% من حركة مرور الترميز على منصة OpenRouter، متجاوزًا مجموع جميع مولدات أكواد الذكاء الاصطناعي الأخرى، حيث احتل Grok Code Fast 1 المرتبة الأولى، مما يدل على أدائه القوي في السوق وتفضيل المستخدمين له في مجال توليد الأكواد. (المصدر: imjaredz)
📚 تعلم
دورة AI الأساسية Cursor Learn: أطلق Lee Robinson دورة Cursor Learn، وهي سلسلة فيديو مجانية من ستة أجزاء، تهدف إلى مساعدة المبتدئين على إتقان المفاهيم الأساسية للذكاء الاصطناعي مثل tokens وcontext وagents. تستغرق الدورة حوالي ساعة واحدة، وتوفر اختبارات وتجارب لنماذج الذكاء الاصطناعي، وهي مورد مناسب لتعلم أساسيات الذكاء الاصطناعي. (المصدر: crystalsssup)
كتاب مجاني عن هياكل البيانات في Python: نشر Donald R. Sheehy كتابًا مجانيًا بعنوان “A First Course on Data Structures in Python”، يغطي هياكل البيانات، والتفكير الخوارزمي، وتحليل التعقيد، والبرمجة التكرارية/الديناميكية، وطرق البحث، مما يوفر أساسًا متينًا للمتعلمين في مجالات الذكاء الاصطناعي والتعلم الآلي. (المصدر: TheTuringPost)

نموذج OCR متعدد اللغات dots.ocr: أطلق Xiaohongshu Hi Lab نموذج dots.ocr، وهو نموذج OCR قوي متعدد اللغات يدعم 100 لغة، ويمكنه تحليل النصوص والجداول والصيغ والتخطيطات من البداية إلى النهاية (مع إخراج Markdown)، وهو متاح للاستخدام التجاري مجانًا. هذا النموذج صغير الحجم (1.7B VLM)، ولكنه يحقق أداء SOTA على OmniDocBench وdots.ocr-bench. (المصدر: mervenoyann)

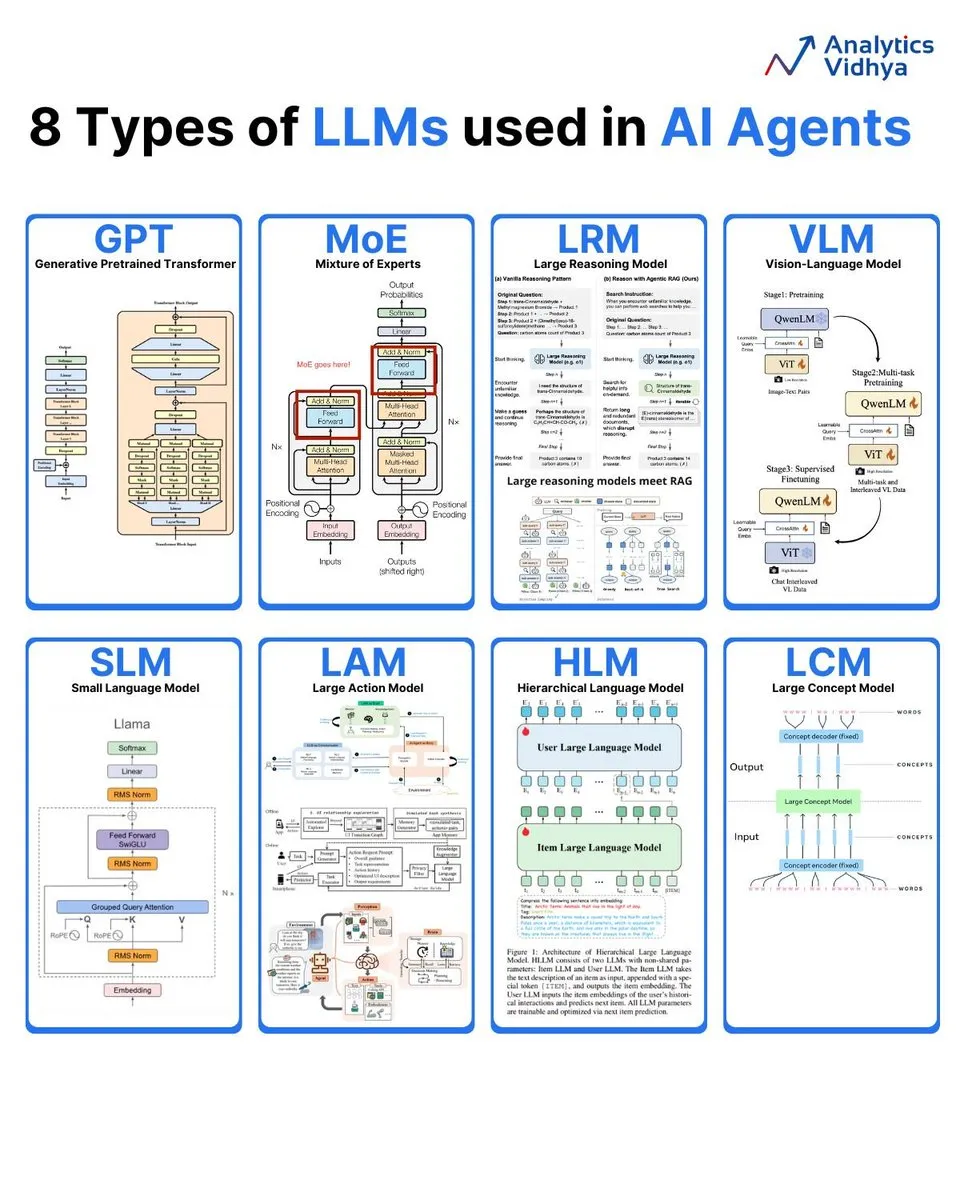
تحليل 8 أنواع من نماذج اللغة الكبيرة: لخصت Analytics Vidhya 8 أنواع رئيسية من نماذج اللغة الكبيرة، بما في ذلك GPT (Generative Pre-trained Transformer)، وMoE (Mixture of Experts)، وLRM (Large Reasoning Model)، وVLM (Vision Language Model)، وSLM (Small Language Model)، وLAM (Large Action Model)، وHLM (Hierarchical Language Model)، وLCM (Large Concept Model)، مع شرح مفصل لبنيتها وتطبيقاتها. (المصدر: karminski3)
نشرة AI الأسبوعية: ملخص أحدث الأوراق البحثية: نشرت DAIR.AI مختارات من أوراق بحثية للذكاء الاصطناعي لهذا الأسبوع (22-28 سبتمبر)، تغطي العديد من الأبحاث المتطورة مثل ATOKEN، وLLM-JEPA، وCode World Model، وTeaching LLMs to Plan، وAgents Research Environments، وLanguage Models that Think, Chat Better، وEmbodied AI: From LLMs to World Models، مما يوفر أحدث التطورات لباحثي الذكاء الاصطناعي. (المصدر: dair_ai)
نصائح للباحثين الشباب في عصر الذكاء الاصطناعي: شارك Jascha Sohl-Dickstein نصائح عملية للباحثين الشباب حول كيفية اختيار المشاريع البحثية واتخاذ القرارات المهنية في المرحلة الأخيرة من “الأنثروبوسين”. ناقش التأثير العميق لـ AGI على المسارات الأكاديمية، وشدد على الحاجة إلى إعادة التفكير في اتجاهات البحث والتطوير المهني في سياق أنظمة الذكاء الاصطناعي التي ستتجاوز الذكاء البشري. (المصدر: mlpowered)
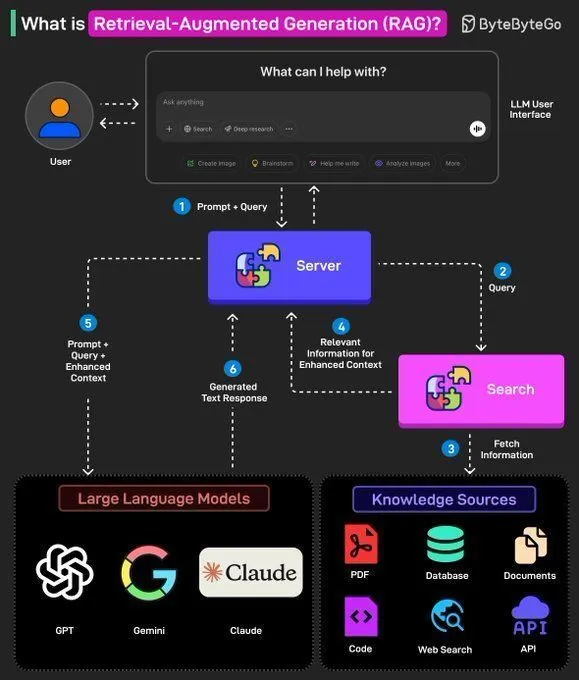
مفاهيم RAG وبناء AI Agent: شارك Ronald van Loon المفاهيم الأساسية لـ RAG (Retrieval Augmented Generation) وأهميتها في LLM، وقدم 8 خطوات رئيسية لبناء AI Agent. يغطي المحتوى مفاهيم AI Agent، ومكدسه، ومزاياه، وكيفية تقييمه من خلال الأطر، مما يوفر للمطورين في مجال الذكاء الاصطناعي إرشادات من النظرية إلى التطبيق. (المصدر: Ronald_vanLoon, Ronald_vanLoon)
Meta تحل مشكلة عدم كفاءة استدلال LLM: كشفت أبحاث Meta عن مشكلة عدم كفاءة الاستدلال في LLM الناتجة عن العمل المتكرر في سلاسل التفكير الطويلة. اقترحوا ضغط الخطوات المتكررة إلى سلوكيات صغيرة مسماة، مما يسمح للنموذج باستدعاء هذه السلوكيات بدلاً من إعادة الاستدلال، وبالتالي تقليل استهلاك token، وتحسين كفاءة الاستدلال ودقته، مما يوفر أفكارًا جديدة لتحسين عملية استدلال LLM. (المصدر: ylecun)

ظهور قدرات الاستدلال البصري في Veo-3: أشار Lisan al Gaib إلى أن نموذج الفيديو Veo-3 يظهر قدرات استدلال (بصري) ناشئة مماثلة لـ GPT-3، مما ينذر بأن النماذج متعددة الوسائط الأصلية، بعد استغلال إمكاناتها بالكامل، ستجلب فهمًا بصريًا وفوائد استدلالية أكثر شمولاً. (المصدر: scaling01)

💼 أعمال
رهان OpenAI بمئات المليارات وفقاعة البنية التحتية للذكاء الاصطناعي: تنسج OpenAI شبكة عملاقة تمتد عبر الرقائق والحوسبة السحابية ومراكز البيانات بسرعة حرق الأموال، بما في ذلك استثمار Nvidia البالغ 100 مليار دولار والشراكة مع Oracle بقيمة 300 مليار دولار في مشروع “Stargate”. على الرغم من أن الإيرادات المتوقعة لعام 2025 تبلغ 13 مليار دولار فقط، إلا أن إدارة OpenAI تعتبر الاستثمار في البنية التحتية للذكاء الاصطناعي “فرصة لا تتكرر إلا مرة واحدة في القرن”، مما أثار جدلاً حول ما إذا كانت البنية التحتية للذكاء الاصطناعي تواجه فقاعة الإنترنت. (المصدر: 36氪)

Musk يقاضي OpenAI للمرة السادسة: رفعت شركة xAI التابعة لـ Elon Musk دعوى قضائية سادسة ضد OpenAI، متهمة إياها بالاستيلاء المنهجي على الموظفين، وسرقة الكود المصدري لنموذج Grok الكبير وخطط استراتيجية مراكز البيانات بشكل غير قانوني، وغيرها من الأسرار التجارية. تمثل هذه الدعوى القضائية دخول المنافسة بين عملاقي الذكاء الاصطناعي مرحلة حامية، حيث يرى Musk أن OpenAI قد انحرفت عن هدفها الأصلي غير الربحي، بينما نفت OpenAI الاتهامات، واصفة إياها بـ “المضايقة المستمرة”. (المصدر: 36氪)

العالم البارز في الذكاء الاصطناعي Steven Hoi ينضم إلى Alibaba Tongyi: انضم عالم الذكاء الاصطناعي العالمي البارز وزميل IEEE، Steven Hoi، إلى مختبر Alibaba Tongyi، وسيتجه نحو البحث والتطوير الأساسي المتطور للنماذج الكبيرة متعددة الوسائط. يمتلك Steven Hoi أكثر من 20 عامًا من الخبرة في البحث والتطوير الصناعي والأكاديمي في مجال الذكاء الاصطناعي، وقد شغل سابقًا منصب نائب رئيس Salesforce وأسس HyperAGI. يمثل هذا الانضمام استثمارًا كبيرًا آخر من Alibaba في مجال النماذج الكبيرة متعددة الوسائط، بهدف تسريع كفاءة تكرار النموذج وتحقيق اختراقات في الابتكار متعدد الوسائط. (المصدر: 36氪)

🌟 مجتمع
تدهور أداء ChatGPT 4o ومشاعر المستخدمين: أفاد عدد كبير من مستخدمي ChatGPT بانخفاض أداء نموذج 4o، وظهور مشكلات “التقلص” و”التوجيه الآمن”، مما أدى إلى شعور المستخدمين بالإحباط والخداع. يشعر العديد من المستخدمين ذوي التنوع العصبي بالحزن بشكل خاص، معتبرين أن 4o كان “شريان الحياة” لهم في التواصل وفهم الذات. يشكك المستخدمون عمومًا في افتقار OpenAI للشفافية، ويدعونها إلى الوفاء بوعدها “بمعاملة المستخدمين البالغين”، ويعارضون آليات الرقابة غير الواضحة. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

جدل حول التوظيف والتسريح في عصر الذكاء الاصطناعي: يناقش المجتمع بشدة تأثير الذكاء الاصطناعي على سوق العمل، بما في ذلك الانخفاض الملحوظ في عدد الوظائف للمبتدئين، وتسريح الشركات للموظفين بالتوازي مع الاستثمار في الذكاء الاصطناعي، وصحة أسباب تسريح العمال بسبب الذكاء الاصطناعي. تشير المناقشات إلى اتجاه “استبدال الأشخاص الذين يفهمون الذكاء الاصطناعي بمن لا يفهمونه”، وتدعو الشركات إلى إعادة تصميم الوظائف للمبتدئين بدلاً من إلغائها ببساطة، لتدريب المواهب النادرة التي تتكيف مع متطلبات عصر الذكاء الاصطناعي. (المصدر: 36氪, 36氪, Reddit r/artificial)

تحديات وعقبات البحث في LLM: يناقش المجتمع بشدة ارتفاع عتبة البحث في التعلم الآلي، وصعوبة منافسة الباحثين الأفراد لعمالقة التكنولوجيا الكبار. في مواجهة تحديات مثل الكم الهائل من الأوراق البحثية، وقوة الحوسبة المكلفة، والنظريات الرياضية المعقدة، يجد الكثيرون صعوبة في البدء وتحقيق اختراقات، مما يثير مخاوف بشأن استدامة المجال. (المصدر: Reddit r/MachineLearning)
تأثير نماذج MoE على الاستضافة المحلية: يناقش المجتمع بعمق مزايا وعيوب نموذج MoE لاستضافة LLM المحلية. ترى الآراء أن نموذج MoE، على الرغم من استهلاكه المزيد من VRAM، إلا أنه يتميز بكفاءة حوسبة عالية، ويمكنه تشغيل نماذج أكبر من خلال تفريغ CPU، وهو مناسب بشكل خاص للأجهزة الاستهلاكية ذات الذاكرة الوفيرة ولكن GPU المحدود، مما يجعله وسيلة فعالة لتحسين أداء LLM. (المصدر: Reddit r/LocalLLaMA)
التطور السريع وتطبيقات AI Agents: يناقش المجتمع التطور السريع لـ AI Agents، حيث تحسنت قدراتها بسرعة من “غير قابلة للاستخدام تقريبًا” إلى “أداء جيد” في سيناريوهات محددة في أقل من عام، بل وحتى “بدأت الوكلاء العامون تصبح مفيدة”، متجاوزة سرعة تقدمها التوقعات. ومع ذلك، هناك أيضًا آراء تشير إلى أن وكلاء الترميز الحاليين متجانسون بشكل كبير ويفتقرون إلى اختلافات جوهرية. (المصدر: nptacek, HamelHusain)
اتجاهات بحث RL وجدل GRPO: يناقش المجتمع بعمق أحدث الاتجاهات في أبحاث التعلم المعزز (RL)، وخاصة مكانة وخلافات خوارزمية GRPO. ترى بعض الآراء أن أبحاث RL تتجه نحو التدريب المسبق/النمذجة، وأن GRPO هو تقدم مهم مفتوح المصدر، ولكن موظفي OpenAI يرون أنه متأخر بشكل كبير عن التقنيات المتطورة، مما أثار نقاشًا حادًا حول ابتكار الخوارزميات والأداء الفعلي. (المصدر: natolambert, MillionInt, cloneofsimo, jsuarez5341, TheTuringPost)

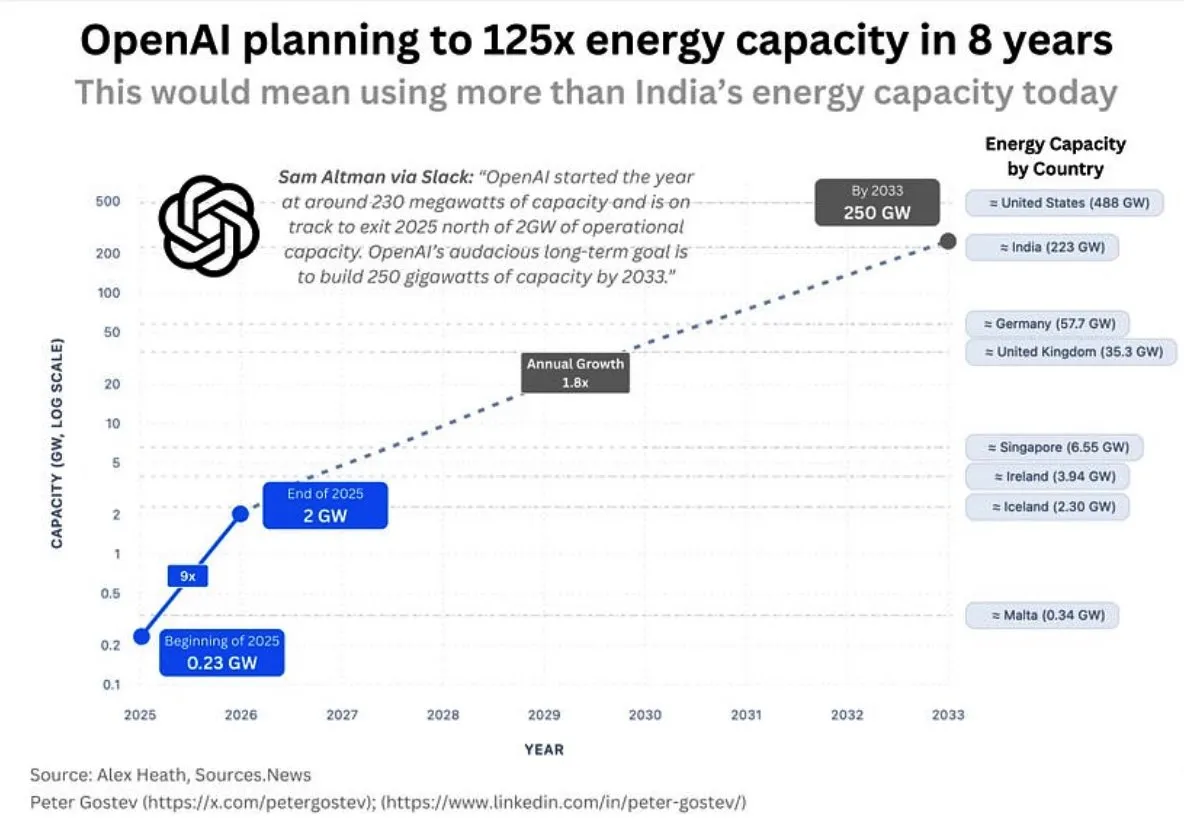
استهلاك OpenAI للطاقة والبنية التحتية للذكاء الاصطناعي: يناقش المجتمع الاحتياجات الهائلة لـ OpenAI من الطاقة في المستقبل، حيث من المتوقع أن تستهلك خلال خمس سنوات طاقة تتجاوز استهلاك المملكة المتحدة أو ألمانيا، وخلال ثماني سنوات تتجاوز استهلاك الهند، مما يثير مخاوف بشأن حجم بناء البنية التحتية للذكاء الاصطناعي، وإمدادات الطاقة، والتأثير البيئي. في الوقت نفسه، واجه اختيار Google لمواقع مراكز البيانات معارضة من السكان المحليين بسبب مشكلات استهلاك المياه. (المصدر: teortaxesTex, brickroad7)
درس Sutton المرير وتطور الذكاء الاصطناعي: يناقش المجتمع دلالات “الدرس المرير” لـ Richard Sutton على أبحاث الذكاء الاصطناعي، مؤكدًا على أن طرق الحوسبة العامة تتفوق على المعرفة البشرية المسبقة. تركز المناقشة حول العلاقة بين “التقليد ونماذج العالم”، معتبرة أن التقليد البسيط قد يؤدي إلى “عبادة البضائع”، وأن التقليد الذي يفتقر إلى الخبرة الحقيقية له قيود جوهرية. (المصدر: rao2z, jonst0kes)
💡 أخرى
الروبوت الحيوي BionicWheelBot: حقق الروبوت BionicWheelBot ميزة التنقل متعدد الوظائف على التضاريس المعقدة من خلال محاكاة حركة دحرجة العنكبوت العجلة. يُظهر هذا الابتكار إمكانات تطبيق علم المحاكاة الحيوية في تصميم الروبوتات، ويوفر حلولًا جديدة للروبوتات المستقبلية للتعامل مع البيئات المتغيرة. (المصدر: Ronald_vanLoon)
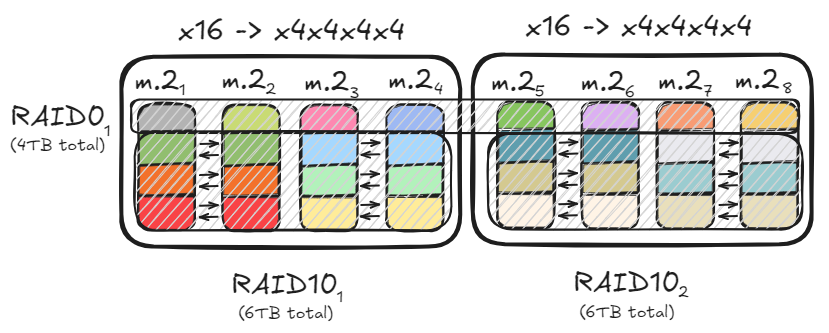
تحسين تخزين الكمبيوتر وتكوين RAID: شارك المستخدمون كيفية تحقيق معدل نقل بيانات يصل إلى 47 جيجابايت/ثانية من خلال تكوينات RAID0 وRAID10، باستخدام قنوات PCIe متعددة ومحركات أقراص M.2، لتسريع تحميل النماذج الكبيرة. يوازن هذا الحل الأمثل بين تلبية متطلبات القراءة والكتابة عالية السرعة، وسعة التخزين، وتكرار البيانات، مما يوفر أساسًا فعالًا للأجهزة لنشر نماذج الذكاء الاصطناعي المحلية. (المصدر: TheZachMueller)
افتتاح “منطقة Liangzhu Digital Habitat AI+ الصناعية”: افتتحت “منطقة Liangzhu Digital Habitat AI+ الصناعية” في Hangzhou رسميًا، مع التركيز على مجالات متطورة مثل الذكاء الاصطناعي، واقتصاد الرحالة الرقميين، والإبداع الثقافي. توفر هذه المنطقة، من خلال سياسات “Digital Habitat Eight Articles” الخاصة وتخطيط المساحات “الأربع”، دعمًا كاملاً للمستكشفين في مجال الذكاء الاصطناعي من مرحلة الفكرة الأولية إلى قيادة النظام البيئي، وتهدف إلى بناء نظام بيئي مبتكر يدمج التكنولوجيا والثقافة الإنسانية بعمق. (المصدر: 36氪)
