
كلمات مفتاحية:معيار GDPval من OpenAI, Claude Opus 4.1, GPT-5, تقييم الذكاء الاصطناعي, أداء المهام الاقتصادية للذكاء الاصطناعي, تقييم تأثير نماذج الذكاء الاصطناعي على الاقتصاد, مقارنة بين Claude Opus 4.1 و GPT-5, اختبار معيار GDPval, قدرات الذكاء الاصطناعي التطبيقية العملية, مقارنة أداء الذكاء الاصطناعي عبر قطاعات متعددة
🔥 تركيز
إطلاق معيار OpenAI GDPval: أداء Claude Opus 4.1 يتفوق على GPT-5 : أطلقت OpenAI معيار GDPval الجديد لتقييم أداء نماذج الذكاء الاصطناعي في المهام الاقتصادية الفعلية عبر 9 صناعات و44 مهنة. أظهرت النتائج الأولية أن Claude Opus 4.1 من Anthropic وصل إلى مستوى الخبراء البشريين أو تجاوزه في ما يقرب من نصف المهام، متفوقًا على GPT-5. اعترفت OpenAI بتفوق Claude في الأداء الجمالي، بينما يتصدر GPT-5 في الدقة. يشير هذا إلى تحول في تقييم الذكاء الاصطناعي نحو قياس التأثير الاقتصادي الفعلي، ويكشف عن التقدم السريع في قدرات الذكاء الاصطناعي. (المصدر: OpenAI, menhguin, MillionInt, _sholtodouglas, polynoamial, menhguin, aidan_mclau, sammcallister, menhguin, andy_l_jones, tokenbender, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, alexwei_, scaling01, scaling01, scaling01, gdb, teortaxesTex, snsf, dilipkay, scaling01, scaling01, jachiam0, jachiam0, sama, ClementDelangue, AymericRoucher, shxf0072, Reddit r/artificial, 36氪, 36氪, 36氪)

الذكاء الاصطناعي وويكيبيديا: “دوامة الهلاك” للغات المهددة بالانقراض : تتعلم نماذج الذكاء الاصطناعي اللغات عن طريق جمع النصوص من الإنترنت، وغالبًا ما تكون ويكيبيديا أكبر مصدر للبيانات عبر الإنترنت للغات المهددة بالانقراض. ومع ذلك، فإن تدفق كميات كبيرة من المحتوى منخفض الجودة المترجم بواسطة الذكاء الاصطناعي إلى إصدارات ويكيبيديا الصغيرة هذه يؤدي إلى انتشار الأخطاء. يشكل هذا حلقة مفرغة من “المدخلات السيئة تؤدي إلى مخرجات سيئة”، مما قد يجعل ترجمة الذكاء الاصطناعي لهذه اللغات أقل موثوقية، وبالتالي تسريع تدهور اللغات المهددة بالانقراض. وقد اقتُرح إغلاق ويكيبيديا باللغة الغرينلاندية بسبب مشكلة “الكلام غير المفهوم” التي تسببت بها أدوات الذكاء الاصطناعي. يسلط هذا الضوء على التأثيرات السلبية المحتملة للذكاء الاصطناعي على التنوع الثقافي وحماية اللغة. (المصدر: MIT Technology Review, MIT Technology Review)

الباحث البارز في OpenAI سونغ يانغ ينتقل إلى Meta : انتقل سونغ يانغ، رئيس فريق الاستكشاف الاستراتيجي في OpenAI والمساهم الرئيسي في نماذج الانتشار، إلى فريق MSL في Meta، حيث سيرفع تقاريره إلى كبير العلماء تشاو شنغ جيا. سونغ يانغ هو عبقري شاب التحق بجامعة تسينغهوا في سن 16، واشتهر خلال فترة عمله في OpenAI بإنجازات مثل نماذج الاتساق، ويعتبره الصناعيون أحد “أقوى العقول”. يمثل هذا الانتقال حدثًا مهمًا آخر في استمرار Meta في جذب المواهب من OpenAI، مما أثار اهتمام الصناعة بالمنافسة على مواهب الذكاء الاصطناعي واتجاهات البحث. (المصدر: 36氪, dotey, jeremyphoward, teortaxesTex)

China Telecom Tianyi AI تطلق مجموعة بيانات عالية الجودة تتجاوز 10 تريليون Tokens : أطلقت China Telecom Tianyi AI بيانات نموذج لغوي عام ضخمة بحجم تخزين إجمالي يبلغ 350 تيرابايت، وتتجاوز 10 تريليون Tokens، بالإضافة إلى مجموعات بيانات متخصصة تغطي 14 صناعة رئيسية. تم تصنيف وتحسين مجموعة البيانات هذه بعناية، وتتضمن بيانات صناعية متعددة الوسائط، بهدف تحسين أداء نماذج الذكاء الاصطناعي وقدرتها على التعميم. تؤكد China Telecom أن مجموعات البيانات عالية الجودة هي الوقود الأساسي لتطوير الذكاء الاصطناعي، وتعتمد على منصة Xingchen MaaS لبناء حلقة مغلقة من “البيانات – النموذج – الخدمة”، ملتزمة بتعزيز التنمية الشاملة للذكاء الاصطناعي والابتكار المحلي، وقد نجحت بالفعل في تدريب نموذج ضخم بمليارات المعلمات. (المصدر: 量子位)

China GuoXingYuHang تحقق أول كوكبة حوسبة فضائية تجارية دائمة في العالم : نجحت China GuoXingYuHang في إطلاق وتشغيل كوكبة الحوسبة الفضائية بشكل تجاري دائم، مما يمثل انتقال الحوسبة الفضائية من “الممكن” إلى “المتاح للاستخدام”. تتكون الكوكبة من الدفعة الأولى من أقمار “Xingsuan” الصناعية، وتهدف إلى بناء بنية تحتية للحوسبة الفضائية تتكون من 2800 قمر صناعي للحوسبة، بقدرة حوسبة إجمالية تتجاوز 100 ألف P، وتدعم تشغيل نماذج بمليارات المعلمات. وقد أدى هذا النجاح إلى نشر نموذج التعرف على الطرق على الأقمار الصناعية الموجودة في المدار، وإكمال العملية الكاملة من جمع الصور واستدلال النموذج إلى إعادة النتائج، مما حقق أول تشغيل لخوارزمية صناعة النقل على الأقمار الصناعية، ويوفر نموذجًا جديدًا للتوسع المكاني للبنية التحتية العالمية للذكاء الاصطناعي. (المصدر: 量子位)

الصين تقيد شراء شرائح Nvidia، وتسارع نحو الاكتفاء الذاتي في أشباه الموصلات : حظرت الصين على شركات التكنولوجيا الكبرى شراء شرائح Nvidia، مما يشير إلى أن الصين قد أحرزت تقدمًا كافيًا في مجال أشباه الموصلات لتتمكن من التخلص من الاعتماد على الشرائح المصممة أمريكيًا. يسلط هذا الضوء على ضعف الولايات المتحدة في تصنيع أشباه الموصلات في تايوان، بالإضافة إلى تعزيز قدرة الصين على الاكتفاء الذاتي. على سبيل المثال، تم تدريب نموذج DeepSeek-R1-Safe على 1000 شريحة Huawei Ascend. وقد أشار جينسن هوانغ من Nvidia أيضًا إلى أن 50% من باحثي الذكاء الاصطناعي في العالم يأتون من الصين. (المصدر: AndrewYNg, Plinz)

🎯 اتجاهات
إطلاق ChatGPT Pulse يفتتح عصر الذكاء الاستباقي : أطلقت OpenAI نسخة معاينة من ChatGPT Pulse لمستخدمي Pro، وهي ميزة تحول ChatGPT من أداة سلبية للإجابة على الأسئلة إلى مساعد ذكي استباقي. يقوم Pulse في الخلفية بإنشاء ملخصات يومية مخصصة على شكل بطاقات بناءً على سجل دردشة المستخدم وملاحظاته والتطبيقات المتصلة (مثل التقويم و Gmail)، بهدف توفير تجربة معلومات محددة الهدف وغير إدمانية. وصف سام ألتمان هذه الميزة بأنها “المفضلة لديه”، مما يشير إلى أن ChatGPT سيتجه نحو خدمات أكثر تخصيصًا واستباقية في المستقبل. (المصدر: Teknium1, openai, dejavucoder, natolambert, gdb, jam3scampbell, jam3scampbell, scaling01, sama, sama, scaling01, nickaturley, kevinweil, dotey, raizamrtn, BlackHC, op7418, 36氪, 36氪, 36氪, 36氪, 量子位)

جوجل تطلق سلسلة Gemini Robotics 1.5، محققة تعلم الروبوتات “عبر الأنواع” : أطلقت Google DeepMind سلسلة نماذج Gemini Robotics 1.5 (بما في ذلك Gemini Robotics 1.5 و Gemini Robotics-ER 1.5)، بهدف تزويد الروبوتات بقدرات أقوى على “التفكير قبل العمل” ومهارات التعلم عبر الأشكال المجسدة. يعمل Gemini Robotics-ER 1.5 كـ “دماغ” مسؤول عن التخطيط واتخاذ القرارات، بينما يقوم Gemini Robotics 1.5 كـ “مخيخ” بتنفيذ الحركات، ويعملان معًا بشكل متناسق. تُظهر هذه السلسلة من النماذج أداءً ممتازًا في الاستدلال المجسد والتعلم عبر الأشكال المجسدة، حيث يمكنها نقل الحركات المكتسبة من روبوت واحد إلى روبوت آخر، مما يبشر بتطوير الروبوتات العامة. (المصدر: Teknium1, nin_artificial, dejavucoder, crystalsssup, scaling01, jon_lee0, BlackHC, Google, demishassabis, shaneguML, demishassabis, JeffDean, 36氪, 36氪)

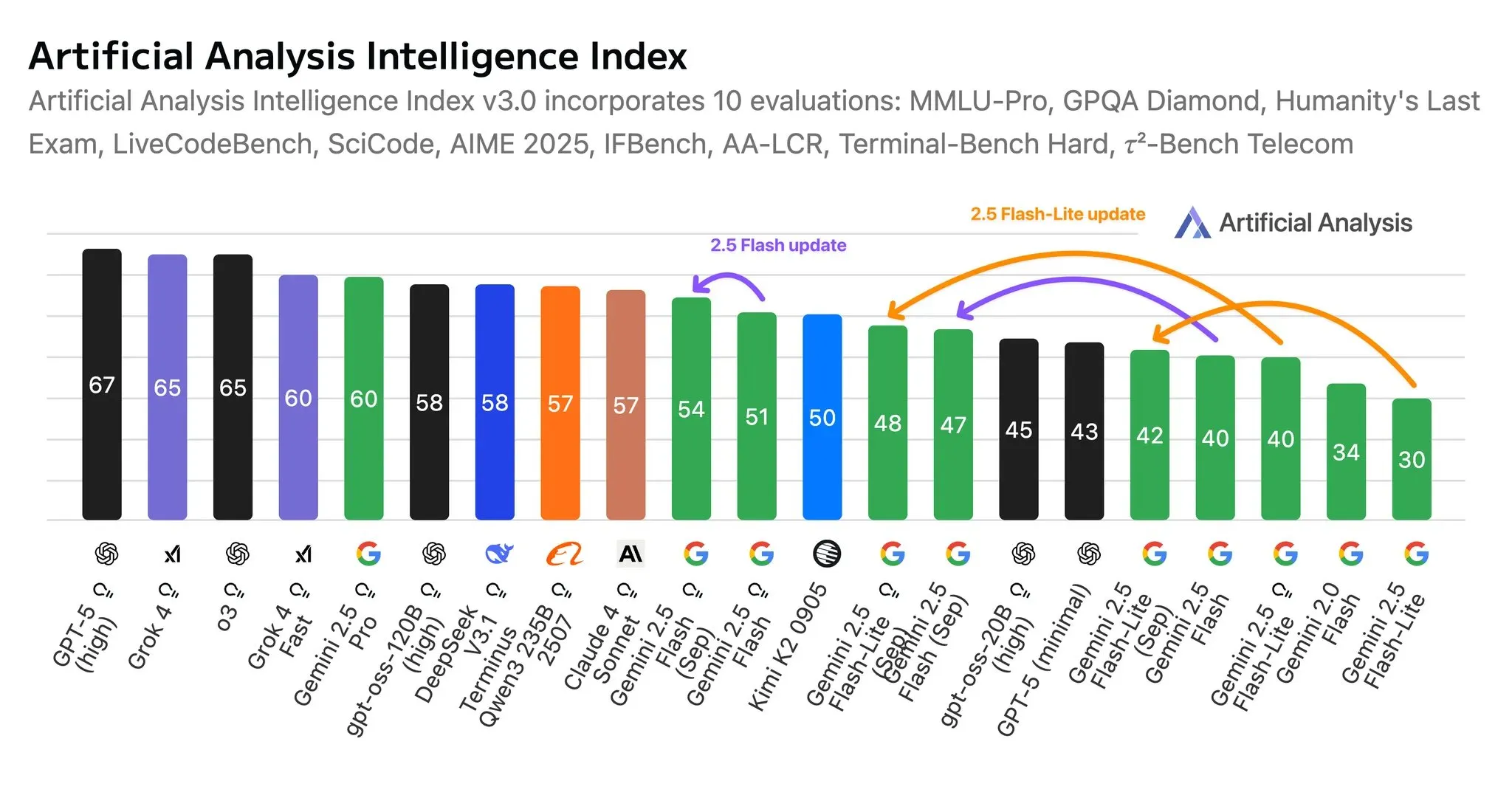
جوجل تطلق تحديثات لسلسلة نماذج Gemini 2.5 Flash : أطلقت جوجل أحدث التحديثات لنماذج Gemini 2.5 Flash و Flash-Lite، وقد شهدت هذه النماذج تحسينات في الذكاء، وفعالية التكلفة، وكفاءة الـ token. ارتفع مؤشر الذكاء لـ Flash-Lite بمقدار 8 نقاط في وضع الاستدلال، و12 نقطة في الوضع غير الاستدلالي، كما أصبح أكثر كفاءة في الـ token وأسرع في الاستدلال. تجعل هذه التحديثات النماذج أفضل في اتباع التعليمات، والفهم متعدد الوسائط، والترجمة، كما أن نماذج Flash أكثر كفاءة في استخدام أدوات Agent. (المصدر: scaling01, osanseviero, Google, osanseviero, andrew_n_carr)
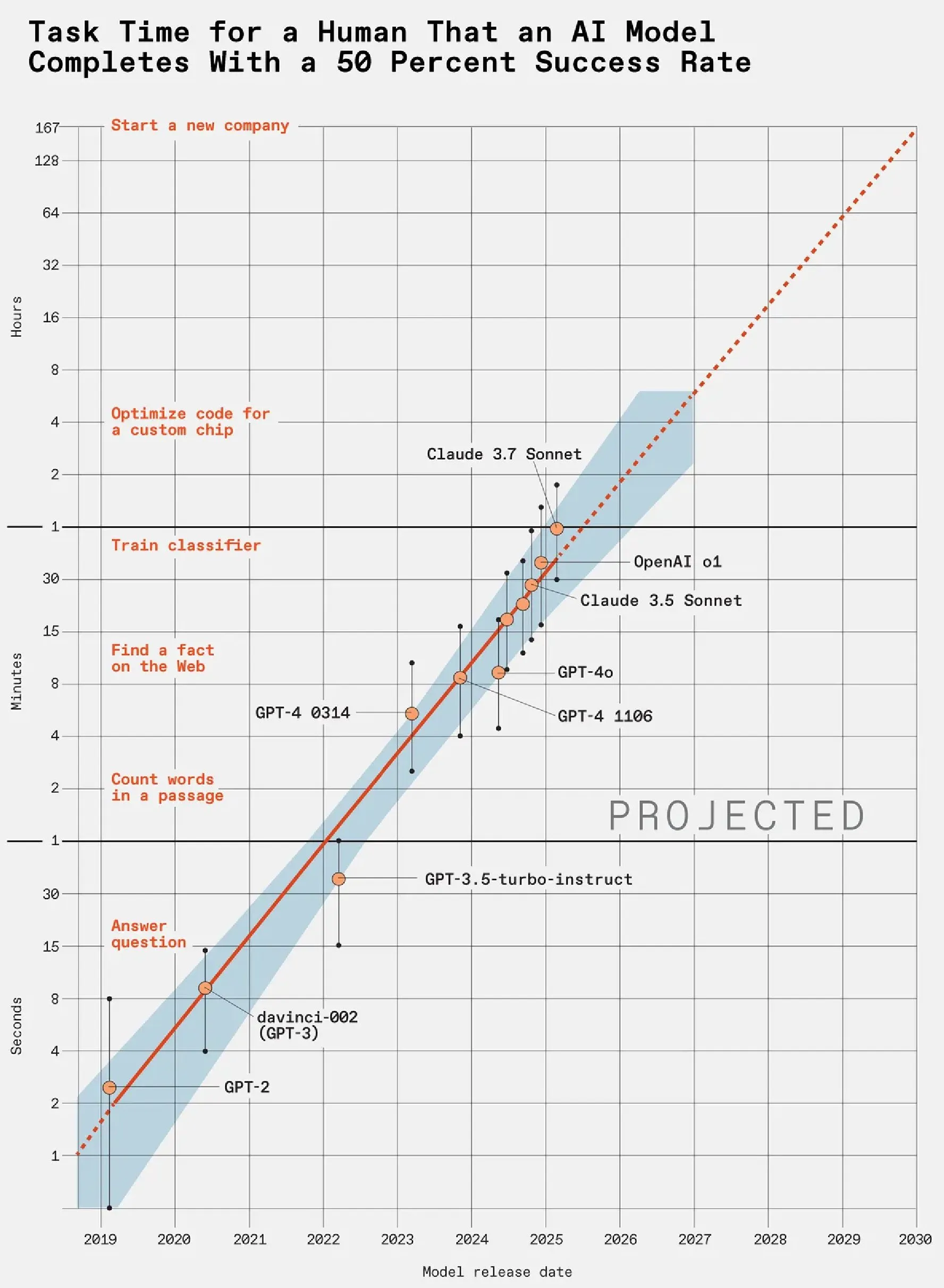
قدرات الذكاء الاصطناعي ترتفع بوتيرة مذهلة: قدرة LLM تتضاعف كل 7 أشهر : أظهرت دراسة معيارية لـ LLM نشرتها METR، من خلال قياس الوقت الذي تستغرقه LLM لإكمال المهام البشرية، أن قدرة LLM تتضاعف كل 7 أشهر. أصبح GPT-5 قادرًا على إكمال المهام المعقدة التي تتطلب ساعات من البشر بشكل مستقر، وبهذا الاتجاه، بحلول عام 2030، قد تتمكن LLM من معالجة الأعمال التي يستغرق البشر عامًا لإكمالها، مثل تأسيس شركات جديدة. هذا ينذر بتأثير مدمر للذكاء الاصطناعي على سوق العمل في السنوات القادمة. (المصدر: karminski3)
نماذج الفيديو تُظهر إمكانات الذكاء البصري العام : تشهد نماذج الفيديو “لحظة GPT”، حيث تُظهر قدرات عامة تتراوح من الإدراك البسيط إلى الاستدلال البصري. تتمتع نماذج مثل Veo3 بالفعل بقدرة “التعلم من الصفر” (zero-shot capability)، مما يمكنها من حل المهام المعقدة في مكدس الرؤية. تُشير الأبحاث إلى أن نماذج الفيديو هي “محركات استدلال زماني مكاني” عامة، ومن المتوقع أن تصبح المسار الرئيسي للذكاء البصري العام في المستقبل، خاصة في مجال الروبوتات، حيث يمكنها حل “أصعب” المشكلات مثل الدلالات والتخطيط والفطرة السليمة. (المصدر: shaneguML, BlackHC, AndrewLampinen, teortaxesTex)

وكلاء الذكاء الاصطناعي ينتقلون من “المساعدين” إلى “المدبرين”، ويتغلغلون في العالم المادي : يتوقع عالم المستقبليات الشهير Bernard Marr أنه بحلول عام 2026، ستتحول وكلاء الذكاء الاصطناعي من مساعدين سلبيين إلى مدبرين استباقيين، قادرين على معالجة المهام اليومية وتنسيق المشاريع المعقدة بشكل مستقل. لن يقتصر الذكاء الاصطناعي على العالم الرقمي، بل سيندمج بعمق في العالم المادي من خلال القيادة الذاتية، والروبوتات الشبيهة بالبشر، وإنترنت الأشياء، مما يغير طريقة تفاعل البشر مع بيئتهم. كما تقوم الشركات الصينية الكبرى مثل Tencent و Alibaba و Baidu بنشاط بوضع خطط لوكلاء الذكاء الاصطناعي على مستوى الشركات، مؤكدة على قدرتها على تنفيذ المهام وتسليمها، وليس فقط قدرتها على المحادثة، بهدف جعلها نقطة نمو تجارية جديدة. (المصدر: 36氪, 36氪, omarsar0)
الروبوتات الصناعية تتحول من “العمل الفردي” إلى “فرق إنتاج فائقة” : تتوسع الروبوتات الصناعية الذكية المجسدة من العمليات الفردية إلى التعاون الشامل في جميع مراحل الإنتاج، لتشكل “فرق إنتاج فائقة”. على سبيل المثال، خط إنتاج مكون من 8 روبوتات صناعية ذكية مجسدة من Weiyi Zhizao يمكنه إنتاج 4 أنواع مختلفة من المنتجات، مع تبديل في دقائق وتعديلات في ساعات. تستطيع هذه الروبوتات التفكير مثل البشر، وتولي المهام، مما يعزز كفاءة الإنتاج ومرونته. أصبحت تقنية الرؤية بالذكاء الاصطناعي القوة الدافعة الأساسية، مما يدفع الروبوتات الصناعية للتطور من “أدوات تنفيذ” إلى “ذكاء مجسد”، ويوفر حلولًا صينية للتحول الرقمي والذكي في قطاع التصنيع. (المصدر: 36氪)

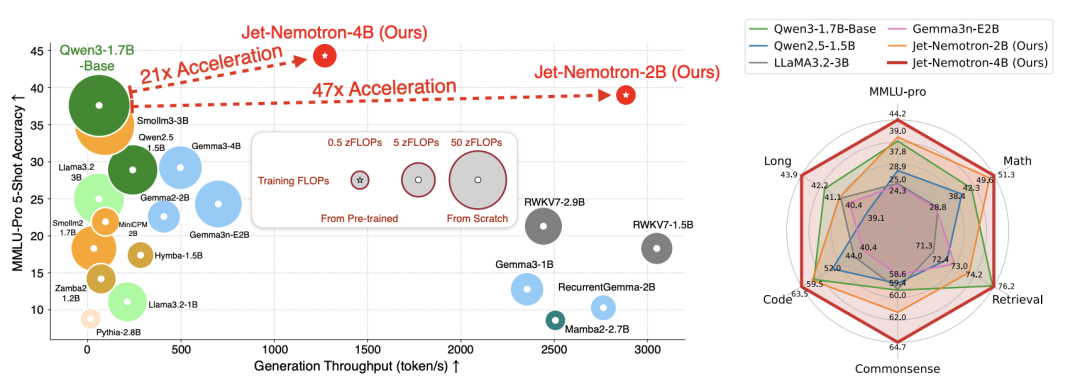
تحسين كفاءة Grok-4-fast قد يكون مرتبطًا بخوارزمية NVIDIA Jet-Nemotron : قد يكون الأداء المذهل لـ Grok-4-fast في تقليل التكاليف وزيادة الكفاءة مرتبطًا بخوارزمية NVIDIA Jet-Nemotron. تعمل هذه الخوارزمية، من خلال إطار عمل PortNAS، على تحسين آليات الانتباه بدءًا من نموذج الانتباه الكامل المدرب مسبقًا، مما يحقق زيادة في سرعة استدلال LLM بحوالي 53 مرة، مع الحفاظ على أداء مماثل لأفضل النماذج مفتوحة المصدر. يتمتع Jet-Nemotron-2B بدقة أعلى من Qwen3-1.7B-Base على MMLU-Pro، وهو أسرع بـ 47 مرة، ويتطلب ذاكرة أقل، مما يبشر بانخفاض كبير في تكلفة النماذج. (المصدر: 36氪)
تجاوز عدد تنزيلات نموذج NVIDIA Cosmos Reason مليون مرة : تجاوز عدد تنزيلات نموذج NVIDIA Cosmos Reason على HuggingFace مليون مرة، ويتصدر قوائم الترتيب في الاستدلال الفيزيائي. يهدف هذا النموذج إلى تعليم وكلاء الذكاء الاصطناعي والروبوتات التفكير مثل البشر، ويتم توفيره في شكل خدمات مصغرة سهلة النشر، مما يمثل إنجازًا مهمًا لـ NVIDIA في دفع تطوير وكلاء الذكاء الاصطناعي وتقنيات الروبوتات. (المصدر: huggingface, ClementDelangue)

Meta تطلق Code World Model (CWM) لدفع أبحاث توليد الأكواد : أطلقت Meta FAIR نموذج Code World Model (CWM)، وهو نموذج بحثي بـ 32 مليار معلمة، يهدف إلى استكشاف كيف يمكن لنماذج العالم أن تغير توليد الأكواد والاستدلال عليها. تم فتح CWM بترخيص بحثي، مما يشجع المجتمع على التطوير بناءً عليه، وينذر باتجاهات بحثية جديدة في مجال توليد الأكواد. (المصدر: ylecun)
جوجل تطلق EmbeddingGemma، نموذج تضمين النصوص الخفيف الوزن : أطلقت جوجل EmbeddingGemma، وهو نموذج تضمين نصوص خفيف الوزن ومفتوح المصدر، يبلغ عدد معلماته 300M فقط، ولكنه حقق أداء SOTA في اختبارات MTEB المعيارية. لقد تجاوز النماذج التي تبلغ ضعف حجمه، وهو مناسب جدًا لتطبيقات الذكاء الاصطناعي السريعة والفعالة على الأجهزة. (المصدر: _akhaliq)

علي بابا Tongyi Qianwen تكشف عن خارطة طريق للنماذج متعددة الوسائط والتوسع الهائل : كشفت علي بابا Tongyi Qianwen عن خارطة طريق طموحة، تركز على النماذج الموحدة متعددة الوسائط والتوسع الهائل. تشمل الأهداف توسيع طول السياق من 1M إلى 100M tokens، وعدد المعلمات ليصل إلى تريليونات أو حتى عشرات التريليونات، وتوسيع حساب وقت الاختبار إلى 1M، وحجم البيانات ليصل إلى 100 تريليون tokens. بالإضافة إلى ذلك، ستدفع الشركة نحو توليد بيانات اصطناعية بحجم لا نهائي وتوسيع قدرات Agent، مما يجسد مفهوم “الحجم هو كل شيء”. (المصدر: menhguin, karminski3)

الذكاء الاصطناعي المساعد في الطب يدخل مرحلة التطبيق السريري : تتحول تطبيقات الذكاء الاصطناعي في المجال الطبي من أدوات تجريبية متطورة إلى أدوات روتينية. على سبيل المثال، أطلقت JD Health “AI hospital 1.0” وحدثت نموذجها الطبي الكبير “Jingyi Qianxun 2.0”، محققة خدمة “الفحص والتشخيص والعلاج والأدوية” المدفوعة بالذكاء الاصطناعي، والتي تغطي الإرشاد والاستشارة والفحص وشراء الأدوية وإدارة الصحة. أصبح سماعة الطبيب الذكية المدعومة بالذكاء الاصطناعي قادرة على المساعدة في تشخيص أمراض القلب، وحققت قراءة الصور الطبية بالذكاء الاصطناعي اختراقات في مجالات مثل عقيدات الرئة والنزيف الدماغي، بدقة تشخيص تتجاوز 96%. يدخل الذكاء الاصطناعي الآن التطبيقات السريرية بشكل كامل، مما يعزز كفاءة الخدمات الطبية ودقتها. (المصدر: 36氪, 36氪, 量子位, Ronald_vanLoon, Reddit r/ArtificialInteligence)

تطبيق Meta AI يطلق ميزة “Vibes” لمقاطع الفيديو القصيرة التي يولدها الذكاء الاصطناعي : أطلق تطبيق Meta AI ميزة جديدة تسمى “Vibes”، وهي موجز ديناميكي يركز على مقاطع الفيديو القصيرة التي يولدها الذكاء الاصطناعي. تمثل هذه الخطوة توسعًا إضافيًا لـ Meta في مجال إنشاء المحتوى بالذكاء الاصطناعي، وتهدف إلى تزويد المستخدمين بتجربة جديدة لمقاطع الفيديو القصيرة المدعومة بالذكاء الاصطناعي. (المصدر: dejavucoder, _tim_brooks, EigenGender)
اختراق في الجينومات المولدة بالذكاء الاصطناعي : نشر Arc Institute ثلاثة اكتشافات جديدة، بما في ذلك أول جينوم وظيفي مولد بالذكاء الاصطناعي في العالم. يستفيد هذا الاختراق من نموذج التعلم الآلي البيولوجي Evo 2 الذي أطلقه Arc بالتعاون مع NVIDIA، حيث يتمكن العلماء من تصميم وكتابة تغييرات واسعة النطاق في الجينوم البشري، وتصحيح تكرارات الحمض النووي التي تسبب الأمراض الوراثية، مما يبشر بتسريع العلاج الجيني وأبحاث المواد البيولوجية. (المصدر: dwarkesh_sp, riemannzeta, zachtratar, kevinweil, Reddit r/artificial)
Apple تطلق SimpleFold، ذكاء اصطناعي خفيف الوزن لتوقع طي البروتينات : طور باحثو Apple SimpleFold، وهو ذكاء اصطناعي جديد يعتمد على نموذج مطابقة التدفق لتوقع طي البروتينات. يتخلى هذا النموذج عن المكونات المكلفة حسابيًا في طرق الانتشار التقليدية، ويستخدم فقط كتل Transformer عامة، مما يمكنه من تحويل الضوضاء العشوائية مباشرة إلى توقعات لهياكل البروتينات. أظهر SimpleFold-3B أداءً ممتازًا في الاختبارات المعيارية القياسية، حيث وصل أداؤه إلى 95% من أداء النماذج الرائدة، كما أنه أكثر كفاءة في النشر والاستدلال، مما يبشر بخفض العبء الحسابي لتوقع هياكل البروتينات وتسريع اكتشاف الأدوية. (المصدر: Reddit r/ArtificialInteligence, HuggingFace Daily Papers)

الاندماج العميق بين الذكاء الاصطناعي الصناعي والذكاء الاصطناعي الفيزيائي : تتعاون علي بابا مع NVIDIA لدمج حزمة برامج NVIDIA Physical AI الكاملة في منصة Alibaba Cloud. يهدف Physical AI إلى نقل الذكاء الاصطناعي من الشاشات إلى العالم المادي، من خلال دمج القوانين الفيزيائية لتحسين المحتوى الذي يولده الذكاء الاصطناعي، مما يجعله أكثر توافقًا مع المنطق الواقعي. تشمل تقنياته الأساسية نماذج العالم، ومحركات المحاكاة الفيزيائية، ووحدات التحكم الذكية المجسدة، بهدف تحقيق فهم كامل للذكاء الاصطناعي للمساحات ثلاثية الأبعاد، والحسابات الفيزيائية في الوقت الفعلي، والإجراءات المحددة. من المتوقع أن يدفع هذا التعاون التطبيق الواسع للذكاء الاصطناعي في صناعات مثل الروبوتات، والخدمات اللوجستية، والسيارات، والتصنيع، ويحول الذكاء الاصطناعي من أداة لمعالجة المعلومات إلى نظام ذكي قادر على فهم العالم المادي والتفاعل معه. (المصدر: 36氪)

إطلاق Hunyuan3D-Omni، إطار عمل لتوليد الأصول ثلاثية الأبعاد بالذكاء الاصطناعي : Hunyuan3D-Omni هو إطار عمل موحد لتوليد الأصول ثلاثية الأبعاد القابلة للتحكم، يعتمد على Hunyuan3D 2.1. لا يدعم فقط شروط الصور والنصوص، بل يقبل أيضًا سحابة النقاط، وحدات الفوكسل، وصناديق التحديد، ووضعيات الهيكل العظمي كإشارات شرطية، مما يحقق تحكمًا دقيقًا في الهندسة، والطبولوجيا، والوضعيات. يعتمد النموذج بنية واحدة متعددة الوسائط لتوحيد جميع الإشارات، ويتم تدريبه من خلال استراتيجية أخذ عينات تدريجية وحساسة للصعوبة، مما يحسن دقة التوليد وقوته. (المصدر: HuggingFace Daily Papers)
تنسنت تطلق Hunyuan Image 3.0، وتدعي أنه أقوى نموذج نص إلى صورة مفتوح المصدر : أعلنت تنسنت عن إطلاق Hunyuan Image 3.0 في 28 سبتمبر، مدعية أنه أقوى نموذج نص إلى صورة مفتوح المصدر في العالم. أثار هذا الإطلاق اهتمامًا وتوقعات واسعة في المجتمع، خاصة فيما يتعلق بآفاق تطبيقه في أدوات مثل ComfyUI. (المصدر: ostrisai, Reddit r/LocalLLaMA)

Llama.cpp يضيف دعمًا لـ Qwen3 reranker : دمج Llama.cpp دعمًا لـ Qwen3 reranker، وهي ميزة تعمل على تحسين أداء استرجاع بيانات البحث بشكل كبير في مسارات الاسترجاع مثل RAG، وذلك عن طريق إخراج درجات التشابه لأزواج الاستعلامات والمستندات عبر نموذج إعادة الترتيب (cross-encoder). يحتاج المستخدمون إلى استخدام ملف GGUF الجديد للحصول على النتائج الصحيحة. (المصدر: Reddit r/LocalLLaMA)
