
كلمات مفتاحية:رقائق الذكاء الاصطناعي الضوئية, K2 Think, الذكاء المتجسد, Jupyter Agent, OpenPI, نموذج Claude, Qwen3-Next, Seedream 4.0, كفاءة الطاقة لرقائق الذكاء الاصطناعي الضوئية, سرعة استدلال النماذج الكبيرة مفتوحة المصدر, التعبير العاطفي للروبوتات البشرية, وكيل الذكاء الاصطناعي لعلوم البيانات LLM, نموذج الرؤية واللغة والحركة للروبوتات
🔥 تركيز
اختراق في كفاءة رقاقة AI الضوئية: طور فريق من المهندسين بجامعة فلوريدا رقاقة AI ضوئية جديدة تستخدم الفوتونات بدلاً من الكهرباء لإجراء عمليات الذكاء الاصطناعي مثل التعرف على الصور واكتشاف الأنماط. حققت الرقاقة دقة تصل إلى 98% في اختبارات التصنيف الرقمي، مع تحسين كفاءة الطاقة بما يصل إلى 100 مرة. يعد هذا الاختراق بتخفيض كبير في تكاليف وحجم استهلاك الطاقة لحوسبة الذكاء الاصطناعي، مما يدفع تطوير الذكاء الاصطناعي ليصبح أكثر صداقة للبيئة وقابلية للتوسع في مجالات تتراوح من الهواتف الذكية إلى أجهزة الكمبيوتر العملاقة، وينبئ بأن الرقائق الكهربائية الضوئية الهجينة ستعيد تشكيل مشهد أجهزة الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence)

K2 Think: إطلاق أسرع نموذج لغوي كبير مفتوح المصدر في العالم: أطلقت جامعة محمد بن زايد للذكاء الاصطناعي (MBZUAI) في الإمارات العربية المتحدة بالتعاون مع G42 AI نموذج K2 Think، وهو نموذج لغوي كبير مفتوح المصدر يعتمد على Qwen 2.5-32B، وبسرعة فعلية تتجاوز 2000 token/ثانية، أي أكثر من 10 أضعاف إنتاجية نشر GPU النموذجي. أظهر النموذج أداءً متميزًا في اختبارات المعايير الرياضية مثل AIME، وحقق ابتكارًا تقنيًا من خلال SFT التفكير طويل المدى، وRLVR المكافأة القابلة للتحقق، والتخطيط المسبق للاستدلال، وأخذ العينات Best-of-N، وفك التشفير التخميني، وتسريع أجهزة Cerebras WSE، مما يمثل مستوى جديدًا من الأداء لأنظمة استدلال الذكاء الاصطناعي مفتوحة المصدر. (المصدر: teortaxesTex, HuggingFace)

تطورات رائدة في الذكاء المتجسد والروبوتات البشرية: كشفت مناقشة مائدة مستديرة على Zhihu عن العديد من الاختراقات في مجال الذكاء المتجسد. عرض مختبر Air بجامعة تسينغهوا “الوجه الرشيق” Morpheus، الذي يستخدم محركًا هجينًا وتقنية الإنسان الرقمي لتحقيق تعابير وجه دقيقة وغنية، بهدف تعزيز القيمة العاطفية للروبوتات البشرية. في الوقت نفسه، فاز الروبوت Ultra من Beijing Tiangong بسباق 100 متر في بطولة العالم للروبوتات البشرية، مما يسلط الضوء على مزايا الخوارزميات والإدراك الذاتي. كما تناولت المناقشة قضايا رئيسية مثل تكلفة الروبوتات البشرية، والإنتاج الضخم، ونظرية التحكم، ودمج النماذج اللغوية الكبيرة، مما ينبئ بأن الذكاء المتجسد ينتقل من الاستكشاف التقني إلى التطبيقات العملية. (المصدر: ZhihuFrontier)

Jupyter Agent: تدريب LLM على استدلال علوم البيانات باستخدام Notebook: أطلقت Hugging Face مشروع Jupyter Agent، الذي يهدف إلى تمكين LLMs من حل مهام تحليل البيانات وعلوم البيانات في Jupyter Notebooks باستخدام أدوات تنفيذ التعليمات البرمجية. من خلال عملية تدريب متعددة المراحل تشمل تنظيف بيانات Kaggle Notebooks على نطاق واسع، وتقييم جودة التعليم، وتوليد QA، وتوليد مسارات تنفيذ التعليمات البرمجية، نجح المشروع في رفع أداء النماذج الصغيرة مثل Qwen3-4B في المهام السهلة ضمن معيار DABStep من 44.4% إلى 75%، مما يثبت أن النماذج الصغيرة يمكن أن تصبح وكلاء أقوياء لعلوم البيانات عند دمجها مع بيانات عالية الجودة وأطر عمل داعمة. (المصدر: HuggingFace Blog)
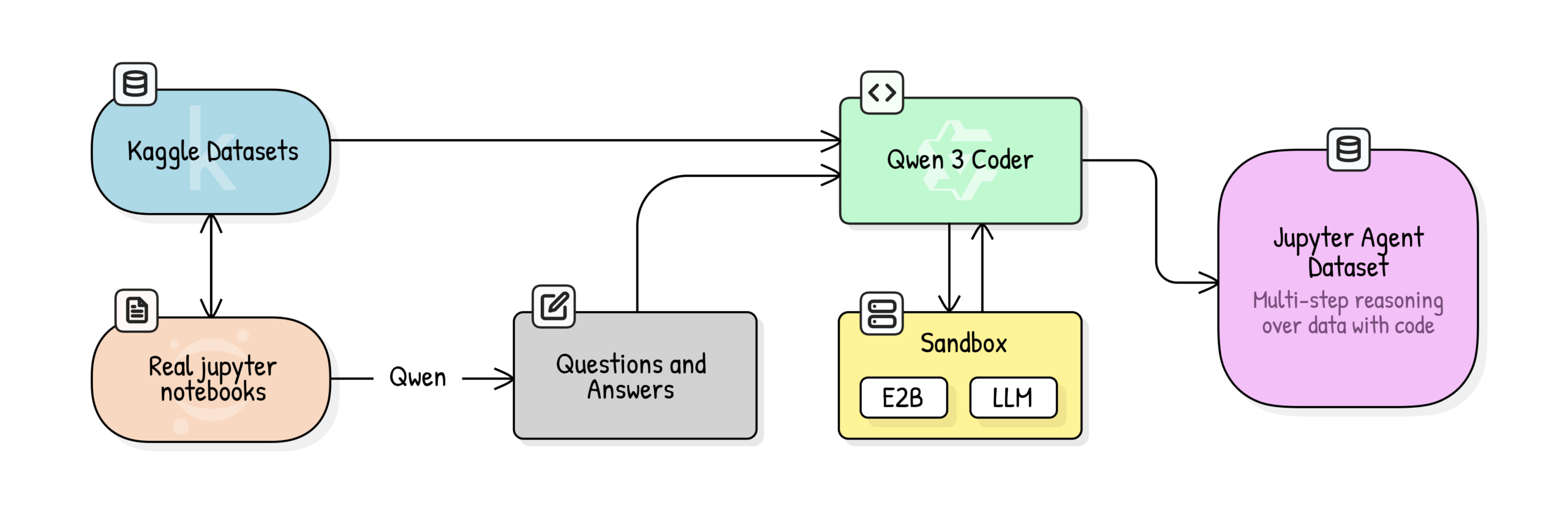
OpenPI: نماذج رؤية-لغة-حركة مفتوحة المصدر للروبوتات: أصدر فريق Physical Intelligence مكتبة OpenPI، التي تحتوي على نماذج VLA (الرؤية-اللغة-الحركة) مفتوحة المصدر مثل π₀ و π₀-FAST و π₀.₅. تم تدريب هذه النماذج مسبقًا على أكثر من 10 آلاف ساعة من بيانات الروبوتات، وتدعم PyTorch، وحققت أداء SOTA في معيار LIBERO. يوفر OpenPI نقاط فحص للنماذج الأساسية وأمثلة للضبط الدقيق، ويدعم الاستدلال عن بعد، ويهدف إلى تعزيز البحث والتطبيقات المفتوحة في مجال الروبوتات، خاصة في مهام مثل التعامل مع الأشياء على سطح المكتب والتقاطها. (المصدر: GitHub Trending)
🎯 اتجاهات
مايكروسوفت تتعاون مع Anthropic لدمج نموذج Claude في Office 365 Copilot: تدمج Microsoft نموذج Claude من Anthropic في Office 365 Copilot، خاصة في المجالات التي يتفوق فيها Claude، مثل حسابات دوال Excel وإنشاء شرائح PowerPoint. تهدف هذه الخطوة إلى تحسين وظائف Copilot المحددة في Word وExcel وPowerPoint، وتعزيز تجربة المستخدم، وتوسيع نطاق تطبيق Claude في أدوات الإنتاجية المؤسسية. (المصدر: dotey, alexalbert__, menhguin, TheRundownAI)

الذكاء الاصطناعي يسرع البحث العلمي: الرسوم البيانية المعرفية والوكلاء المستقلون: عرضت MiniculeAI كيف يمكن للذكاء الاصطناعي تسريع الاكتشافات العلمية من خلال الرسوم البيانية المعرفية والوكلاء المستقلين. من خلال ربط الجينات والأدوية والنتائج في شبكات ديناميكية، يمكن للذكاء الاصطناعي الكشف عن روابط خفية يصعب اكتشافها في مستندات PDF. يمكن للوكلاء المستقلين مسح الأدبيات، واكتشاف الأنماط، وتقديم رؤى قابلة للتفسير، مما يقلص شهورًا من البحث التقليدي إلى دقائق، مع ضمان خصوصية البيانات على مستوى المؤسسات. (المصدر: Ronald_vanLoon)
سلسلة نماذج Qwen3-Next: تحسين السياق الطويل وكفاءة المعلمات: أطلق فريق Qwen سلسلة نماذج Qwen3-Next الأساسية، التي تركز على أطوال السياق القصوى وكفاءة المعلمات على نطاق واسع. تقدم هذه السلسلة العديد من الابتكارات المعمارية، بما في ذلك GatedAttention (لمعالجة القيم الشاذة) وGatedDeltaNet RNN (لتوفير ذاكرة التخزين المؤقت KV)، وتجمع بين بنية Sink+SWA الهجينة أو بنية Gated Attention+Linear RNN الهجينة، بهدف زيادة الأداء وتقليل تكاليف الحوسبة، مما ينبئ بنهاية عصر نماذج Attention النقية. (المصدر: tokenbender, SchmidhuberAI, teortaxesTex, ClementDelangue, andriy_mulyar)
إطلاق نموذج ByteDance Seedream 4.0 لتوليد وتحرير الصور: أطلقت ByteDance نموذج Seedream 4.0، الذي يوفر قدرات فائقة في توليد الصور وتحريرها. أفاد المستخدمون بأنه يتفوق في تلبية احتياجات المستخدمين، وتفضيلات RLHF الجمالية، والحفاظ على الذوق السائد. مقارنةً بـ Seedream 3.0، يضيف الإصدار 4.0 حبيبات فيلمية وتأثيرات عدسة، وتباينًا أعلى، وضربات فرشاة أكثر حدة في الأسلوب الأنمي، كما يظهر أداءً قويًا في فهم الدلالات الصينية والاتساق، مما يجعله مناسبًا للرسوم البيانية التوضيحية، والدروس التعليمية، وتصميم المنتجات. (المصدر: ZhihuFrontier, Reddit r/artificial, op7418, TomLikesRobots, dotey)
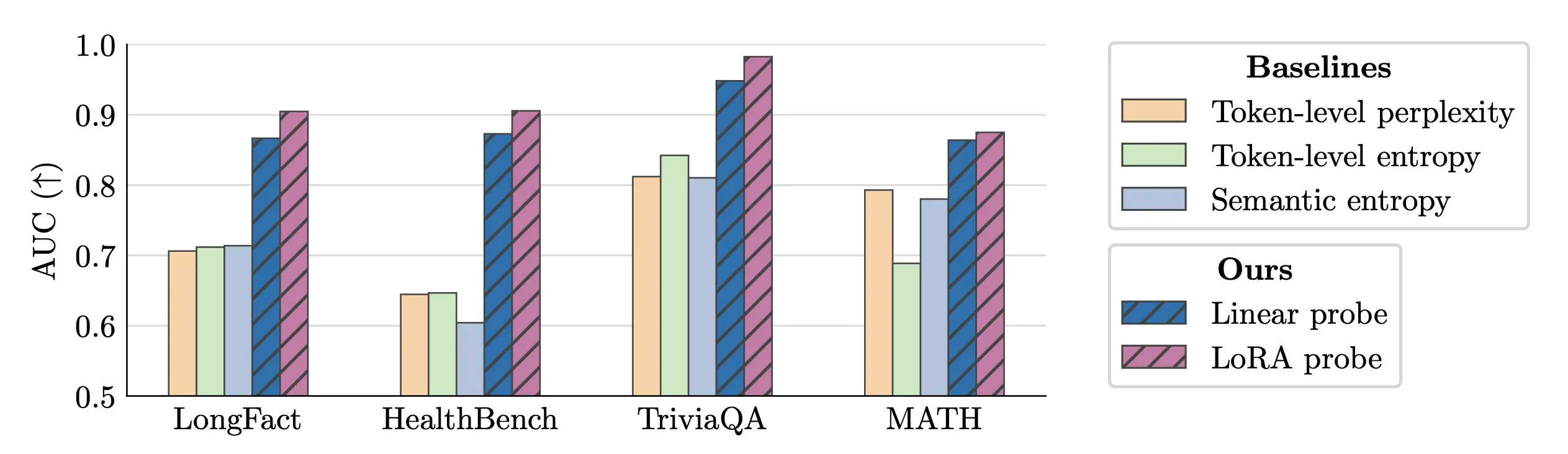
تقنية الكشف في الوقت الفعلي عن هلوسات LLM: اقترح الباحثون استخدام activation probes للكشف في الوقت الفعلي عن هلوسات LLM. أظهرت هذه الطريقة أداءً ممتازًا في تحديد الكيانات المزيفة في النصوص الطويلة، بقيم AUC تصل إلى 0.90، متفوقة بشكل كبير على طرق الانتروبيا الدلالية التقليدية. بالإضافة إلى ذلك، استكشفت الأبحاث الجديدة بعمق أصول الهلوسات في نماذج Transformer، مما يوفر أفكارًا جديدة لتعزيز موثوقية LLM. (المصدر: paul_cal, tokenbender)
Microsoft VibeVoice: توليد صوت عالي الدقة لفترات طويلة: حقق نموذج Microsoft VibeVoice تقدمًا ملحوظًا في مجال الصوت بالذكاء الاصطناعي، حيث يمكنه توليد صوت واقعي لمدة تتراوح بين 45 و 90 دقيقة، وبما يصل إلى 4 متحدثين، ودون الحاجة إلى التجميع. يتوفر النموذج للتجربة على Hugging Face Space، ويمكن للمستخدمين الاستفادة منه في استنساخ الصوت بجودة عالية، مما يفتح إمكانيات جديدة لتطبيقات مثل البودكاست والكتب الصوتية. (المصدر: Reddit r/LocalLLaMA)
mmBERT: معيار جديد للمشفرات متعددة اللغات: تم إطلاق نموذج mmBERT الجديد، ومن المتوقع أن يحل محل XLM-R الذي كان SOTA لمدة 6 سنوات. يعد mmBERT أسرع بـ 2-4 مرات من النماذج الحالية، وتفوق على o3 وGemini 2.5 Pro في مهام التشفير متعدد اللغات. سيقدم إطلاق هذا النموذج، المصحوب بنماذج مفتوحة وبيانات تدريب، أساسًا أكثر كفاءة وقوة لتطبيقات الذكاء الاصطناعي متعددة اللغات. (المصدر: code_star)

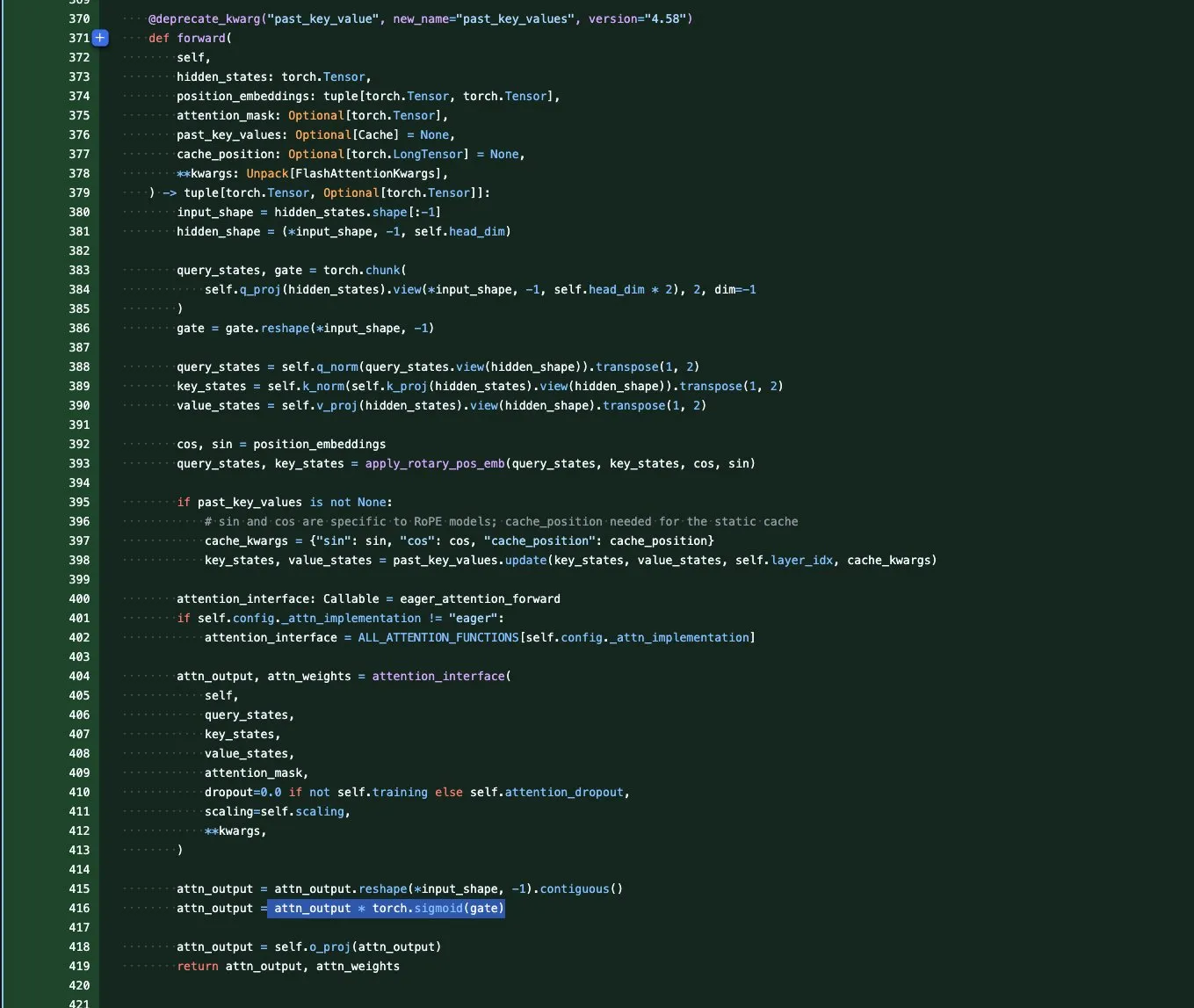
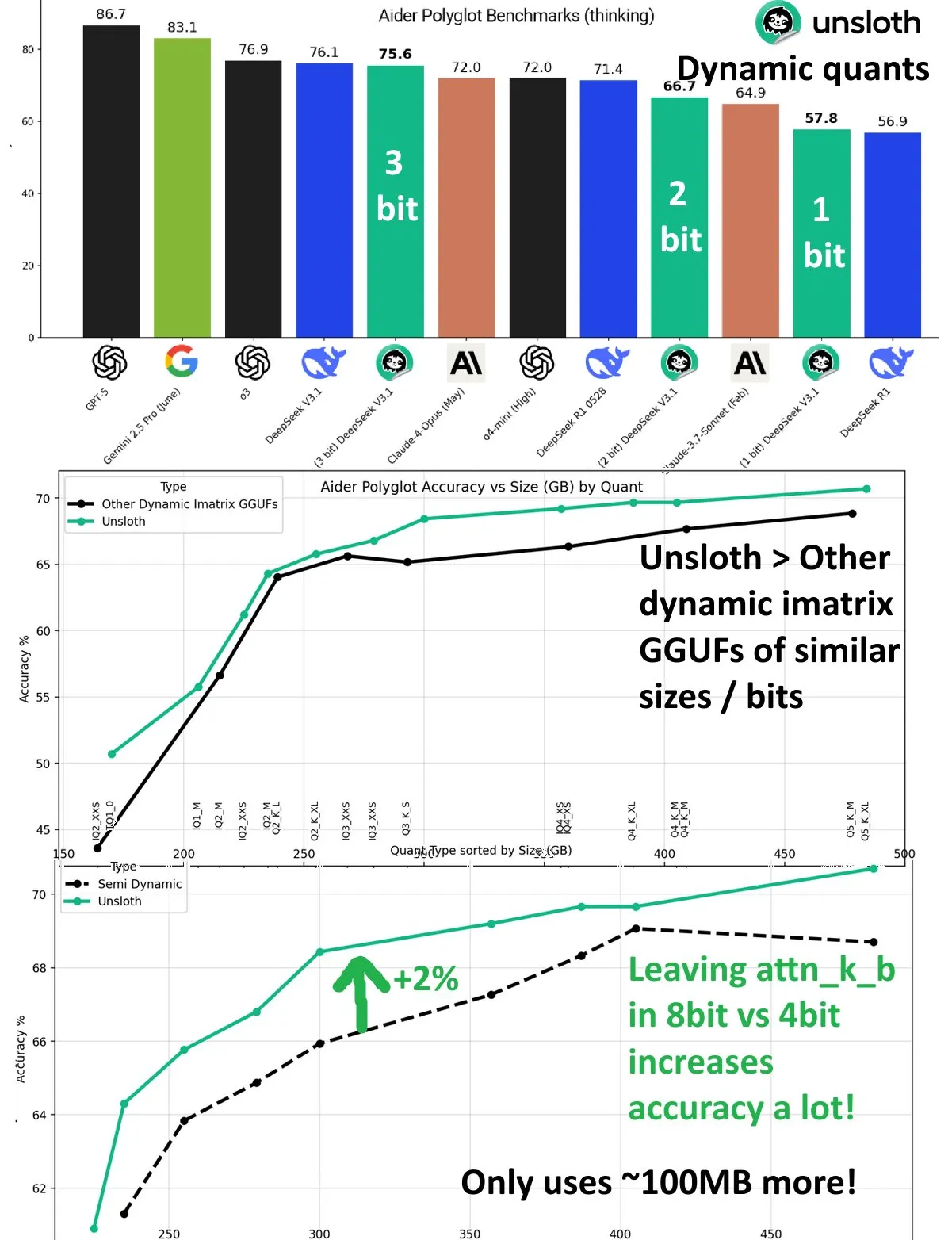
DeepSeek V3.1: تحسين الأداء من خلال التكميم الديناميكي: حقق نموذج DeepSeek V3.1 تحسينًا كبيرًا في الأداء من خلال تقنية التكميم الديناميكي في معيار Aider Polyglot لـ UnslothAI. اقترب التكميم بـ 3 بتات من دقة النموذج غير المكمم، وفي وضع الاستدلال، تجاوز التكميم الديناميكي بـ 1 بت الأداء الأصلي لـ DeepSeek R1. كشفت الأبحاث أن الحفاظ على طبقة attn_k_b بدقة 8 بت يمكن أن يزيد الدقة بنسبة 2% إضافية، مما يوضح إمكانات التكميم الفعال في الحفاظ على قدرات النموذج وتقليل تكاليف الحوسبة. (المصدر: danielhanchen)
SpikingBrain-1.0: نموذج لغوي كبير محلي تم تدريبه على وحدات معالجة الرسوميات المحلية: أصدر معهد أتمتة الأكاديمية الصينية للعلوم نموذجًا كبيرًا للذكاء الاصطناعي الشبيه بالدماغ القائم على النبضات، “SpikingBrain-1.0” (شونسى 1.0)، تم تدريبه واستدلاله على مجموعة GPU المحلية MuXi، مما قلل استهلاك الطاقة بنسبة 97.7% مقارنة بعمليات FP16 التقليدية. استخدم هذا النموذج 2% فقط من بيانات التدريب المسبق للنماذج الكبيرة السائدة، وحقق 90% من أداء Qwen2.5-7B، وأظهر أداءً متميزًا في مهام معالجة التسلسلات الطويلة جدًا، مع تسريع TTFT يصل إلى 26.5 مرة، مما يؤكد جدوى نظام بيئي للنماذج الكبيرة غير Transformer، محلي الصنع وذاتي التحكم. (المصدر: 36氪)
إطلاق Wenxin X1.1: تحسينات كبيرة في الواقعية، واتباع التعليمات، وقدرات الوكيل: تم إطلاق نموذج Baidu Wenxin X1.1 للتعلم العميق، مع تحسينات كبيرة في الواقعية (34.8%)، واتباع التعليمات (12.5%)، وقدرات الوكيل (9.6%) على التوالي. يتجاوز الأداء العام للنموذج DeepSeek R1-0528، ويضاهي GPT-5 وGemini 2.5 Pro، ويظهر قدرات وكيل قوية في المهام المعقدة طويلة المدى، حيث يمكنه تقسيم المهام تلقائيًا واستدعاء الأدوات. كما أطلقت Baidu نموذج ERNIE-4.5-21B-A3B-Thinking مفتوح المصدر ومجموعة تطوير ERNIEKit، مما يقلل من عوائق تطبيق الذكاء الاصطناعي. (المصدر: 量子位)

Huawei تطلق OpenPangu-Embedded-7B-v1.1 مفتوح المصدر: تبديل حر بين التفكير السريع والبطيء: أطلقت Huawei نموذج OpenPangu-Embedded-7B-v1.1، وهو نموذج مفتوح المصدر بـ 7 مليارات معلمة، يحقق لأول مرة التبديل الحر بين أوضاع التفكير السريع والبطيء، ويمكنه الاختيار التكيفي بناءً على صعوبة السؤال. من خلال الضبط الدقيق التدريجي واستراتيجية التدريب على مرحلتين، تحسنت دقة النموذج بشكل كبير في التقييمات العامة والرياضيات والتعليمات البرمجية، ومع الحفاظ على الدقة، انخفض متوسط طول سلسلة التفكير بنسبة 50% تقريبًا، مما يسد فجوة في النماذج الكبيرة مفتوحة المصدر في هذه القدرة، ويعزز الكفاءة والدقة. (المصدر: 量子位)

Tencent CodeBuddy Code: برمجة الذكاء الاصطناعي تدخل عصر L4: أطلقت Tencent أداة AI CLI CodeBuddy Code، وفتحت CodeBuddy IDE للاختبار العام، بهدف دفع برمجة الذكاء الاصطناعي إلى عصر “مهندس البرمجيات AI” من المستوى L4. يعتمد CodeBuddy Code على تثبيت npm، ويدعم دورة حياة التطوير والتشغيل الكاملة المدفوعة باللغة الطبيعية، مما يحقق أتمتة قصوى. تصبح هذه الأداة، من خلال الإدارة الموجهة بالوثائق، وضغط السياق، وتوسيع MCP، بنية تحتية أساسية لبرمجة الذكاء الاصطناعي على مستوى المؤسسات، مما يعزز كفاءة التطوير بشكل كبير. (المصدر: 量子位)

علماء OpenAI الأساسيون: الثنائي البولندي يدفع GPT-4 واختراقات الاستدلال: أشاد سام ألتمان بشدة بالعالم الرئيسي في OpenAI، Jakub Pachocki، والباحث التقني Szymon Sidor، لمساهماتهما الحاسمة في مشروع Dota، والتدريب المسبق لـ GPT-4، ودفع اختراقات الاستدلال. اجتمع الاثنان في OpenAI بعد أن كانا زميلين في المدرسة الثانوية، وأصبحا قوة لا غنى عنها في OpenAI من خلال نموذج يجمع بين التفكير العميق والتجارب العملية، بل ودعما بقوة عودة ألتمان خلال أزمة الاضطرابات الداخلية في عام 2023. (المصدر: 量子位)

قمة البيت الأبيض للذكاء الاصطناعي تركز على المواهب والأمن والتحديات الوطنية: ترأست ميلانيا ترامب اجتماعًا حول الذكاء الاصطناعي في البيت الأبيض، دعت إليه عمالقة التكنولوجيا مثل Google وIBM وMicrosoft، مع التركيز على تنمية المواهب، وضمان الأمن، والتحديات على المستوى الوطني في مجال الذكاء الاصطناعي. تظهر هذه الخطوة أن الحكومة الأمريكية تدفع بنشاط استراتيجية الذكاء الاصطناعي، بهدف مواجهة الفرص والتحديات التي يجلبها تطور الذكاء الاصطناعي، وضمان ريادة البلاد في هذا المجال. (المصدر: TheTuringPost, Reddit r/artificial)

Neuromorphic Computing: تجاوز الشبكات العصبية التقليدية: تعيد الحوسبة العصبية (Neuromorphic Computing) تعريف الذكاء، مستوحاة من بنية الدماغ البيولوجي ومبادئ عمله. تهدف هذه التقنية إلى تطوير أجهزة AI أكثر كفاءة واستهلاكًا أقل للطاقة، من خلال محاكاة قدرات المعالجة المتوازية للخلايا العصبية والمشابك، لتحقيق أنماط حوسبة تتجاوز بنية فون نيومان التقليدية، مما يوفر أساسًا أقوى لأنظمة الذكاء الاصطناعي المستقبلية. (المصدر: Reddit r/artificial)
MEGS²: تقنية Gaussian Splatting ذات كفاءة عالية في استخدام الذاكرة: MEGS² (Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning) هي تقنية Gaussian Splatting ثلاثية الأبعاد (3DGS) ذات كفاءة عالية في استخدام الذاكرة. من خلال استبدال التوافقيات الكروية التي تمثل الألوان بدوال غاوسية كروية ذات اتجاهات عشوائية، وإدخال إطار عمل موحد للتقليم الناعم، قللت هذه الطريقة بشكل كبير عدد المعلمات لكل عنصر بدائي أصلي، مما حقق ضغطًا لـ VRAM الثابت بمقدار 8 أضعاف وضغطًا لـ VRAM العرض بما يقرب من 6 أضعاف، مع الحفاظ على جودة العرض أو تحسينها، وهو أمر ذو أهمية كبيرة للرسومات ثلاثية الأبعاد والعرض في الوقت الفعلي. (المصدر: janusch_patas)

🧰 أدوات
LangChain 1.0 يقدم Middleware: نموذج جديد للتحكم في سياق الوكيل: أطلقت LangChain 1.0 ميزة Middleware، مما يوفر طبقة تجريدية جديدة لوكلاء الذكاء الاصطناعي، ويتيح للمطورين التحكم الكامل في هندسة السياق. تعزز هذه الميزة مرونة الوكلاء وقابليتهم للتركيب والتكيف، وتدعم تنفيذ معماريات وكلاء مختلفة مثل الانعكاس، والمجموعات، والمشرفين، مما يوفر أساسًا قويًا لبناء تطبيقات AI أكثر تعقيدًا. (المصدر: hwchase17, hwchase17, Hacubu)
MaxKB: منصة وكلاء مؤسسية مفتوحة المصدر: MaxKB هو منصة وكلاء مؤسسية مفتوحة المصدر قوية وسهلة الاستخدام، تدمج خط أنابيب RAG (الجيل المعزز بالاسترجاع)، ومحرك سير عمل قوي، وقدرات استخدام أدوات MCP. تدعم المنصة تحميل المستندات، والزحف التلقائي، وتقسيم النصوص، وتحويلها إلى متجهات، مما يقلل بفعالية من هلوسات النماذج الكبيرة، وتدعم العديد من النماذج الكبيرة الخاصة والعامة، وتوفر مدخلات ومخرجات متعددة الوسائط، وتستخدم على نطاق واسع في سيناريوهات مثل خدمة العملاء الذكية وقواعد المعرفة المؤسسية. (المصدر: GitHub Trending)

BlenderMCP: تكامل عميق بين Claude AI وBlender: حقق BlenderMCP تكاملاً عميقًا بين Claude AI وBlender، مما يسمح لـ Claude بالتحكم المباشر في Blender لإجراء نمذجة ثلاثية الأبعاد، وإنشاء المشاهد، والعمليات من خلال Model Context Protocol (MCP). تدعم هذه الأداة الاتصال ثنائي الاتجاه، ومعالجة الكائنات، والتحكم في المواد، وفحص المشاهد، وتنفيذ التعليمات البرمجية، ويمكنها دمج أصول Poly Haven وHyper3D Rodin، مما يعزز بشكل كبير كفاءة وإمكانيات إنشاء المحتوى ثلاثي الأبعاد بمساعدة الذكاء الاصطناعي. (المصدر: GitHub Trending)

AI Sheets: أداة بدون تعليمات برمجية لبناء وتحويل مجموعات بيانات الذكاء الاصطناعي: أطلقت Hugging Face أداة AI Sheets، وهي أداة مفتوحة المصدر بدون تعليمات برمجية، تستخدم لبناء مجموعات البيانات وإثرائها وتحويلها باستخدام نماذج الذكاء الاصطناعي. يمكن نشر هذه الأداة محليًا أو تشغيلها على Hub، وتدعم الوصول إلى آلاف النماذج مفتوحة المصدر على Hugging Face Hub (بما في ذلك gpt-oss)، ويمكن تشغيلها بسرعة عبر Docker أو pnpm، مما يبسط عمليات معالجة البيانات، وهي مناسبة بشكل خاص لتوليد مجموعات بيانات واسعة النطاق. (المصدر: GitHub Trending)

تكامل vLLM Real-time Notebook مع Modal: تكاملت Modal Notebooks مع vLLM لتوفير بيئة تفاعلية في الوقت الفعلي وقابلة للمشاركة، مما يساعد المطورين على فهم الآليات الداخلية لـ vLLM بشكل أعمق. من خلال هذا التكامل، لا يحتاج المستخدمون إلى بناء تكاملات معقدة، ويمكنهم بسهولة تشغيل ومشاركة مهام الحوسبة المتوافقة مع CUDA في السحابة، مما يبسط بشكل كبير عملية تطوير وتعلم vLLM. (المصدر: charles_irl, vllm_project, charles_irl, charles_irl, charles_irl, charles_irl)
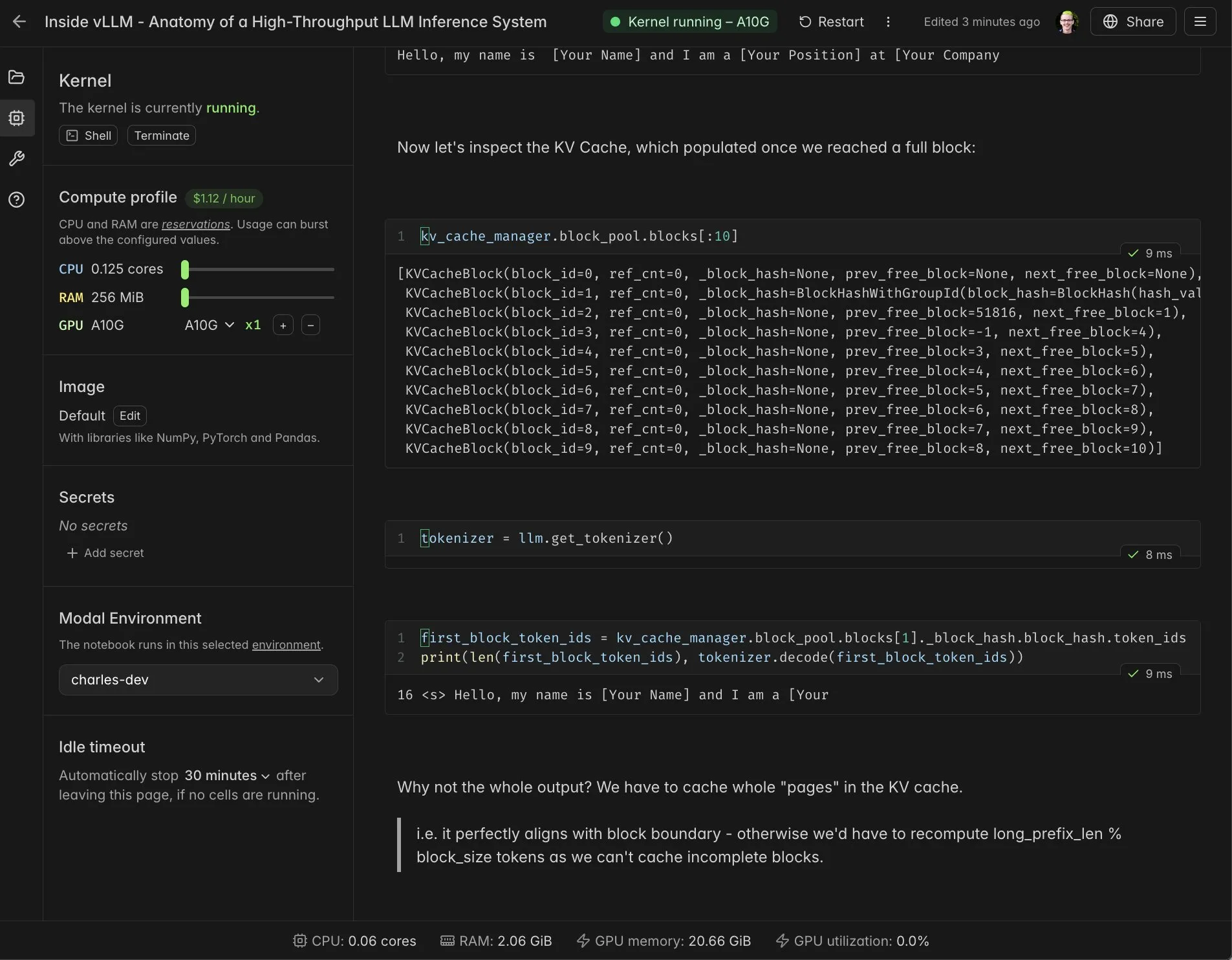
Docker يدعم Minions AI: أعباء عمل AI هجينة محلية: يدعم Minions AI الآن رسميًا Docker، مما يسمح للمستخدمين بفتح أحمال عمل الذكاء الاصطناعي الهجينة محليًا عبر مشغل نماذج Docker. يتيح هذا التعاون للمطورين نشر وإدارة Minions AI بسهولة أكبر في البيئات المحلية، بالاستفادة من مزايا Docker في الحاويات، مما يعزز مرونة وكفاءة تطوير تطبيقات الذكاء الاصطناعي. (المصدر: shishirpatil_)
Replit Agent 3: اختراق جديد في تطوير البرمجيات المستقل: أطلقت Replit وكيلها Agent 3، الذي يُوصف بأنه لحظة “القيادة الذاتية الكاملة” في تطوير البرمجيات، مع زيادة استقلالية الوكيل بمقدار 10 أضعاف عن ذي قبل. يمكن لهذا الوكيل إنشاء نماذج أولية للتطبيقات بشكل أعمق، ومواصلة التقدم عندما تواجه الوكلاء الآخرون عقبات، ويهدف إلى حل مراحل الاختبار والتصحيح وإعادة الهيكلة المستهلكة للوقت في تطوير البرمجيات، مما يعزز كفاءة التطوير بشكل كبير. (المصدر: amasad, amasad, pirroh)
Qwen3-Coder: نموذج برمجة مفتوح المصدر عالي الكفاءة من حيث التكلفة: أظهر Qwen3-Coder أداءً متميزًا وفعالية من حيث التكلفة على منصة Windsurf، حيث يتطلب 0.5 نقطة فقط للتشغيل، مما يجعله أكثر فائدة مقارنة بـ Claude 4 وGPT-5 High (التي تتطلب ضعف النقاط). يتفوق هذا النموذج في مهام البرمجة، وبصفته نموذجًا مفتوح المصدر، يوفر خيارًا قويًا لبرمجة الذكاء الاصطناعي للشركات الخاضعة للتنظيم ومنظمات القطاع العام دون الحاجة إلى الاعتماد على واجهات برمجة التطبيقات العامة، مما يساعد في حل قضايا سيادة البيانات ووضوحها. (المصدر: bookwormengr)
📚 تعلم
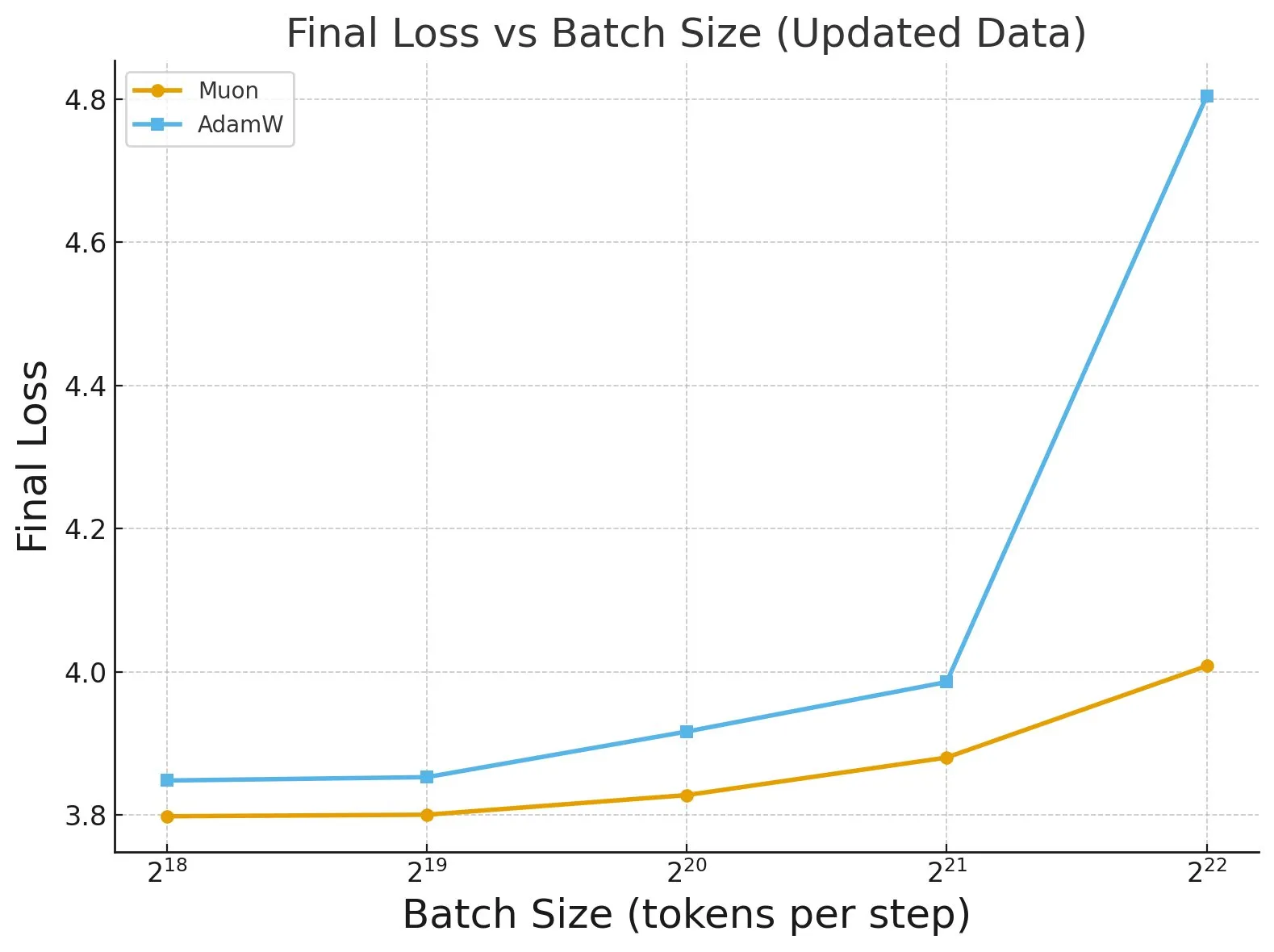
دراسة “Fantastic Pretraining Optimizers and Where to Find Them”: كشفت دراسة واسعة النطاق أجريت على أكثر من 4000 نموذج عن أداء مُحسِّنات التدريب المسبق. وجدت الدراسة أن بعض المُحسِّنات (مثل Muon) يمكن أن تحقق زيادة في السرعة تصل إلى 40% في النماذج صغيرة الحجم (أقل من 0.5 مليار معلمة)، ولكنها تحقق زيادة بنسبة 10% فقط في النماذج كبيرة الحجم (1.2 مليار معلمة). يؤكد هذا على ضرورة توخي الحذر من عدم كفاية ضبط الخط الأساسي وقيود الحجم عند تقييم المُحسِّنات، ويشير إلى تأثير حجم الدفعة على الفجوة في أداء المُحسِّن. (المصدر: tokenbender, code_star)
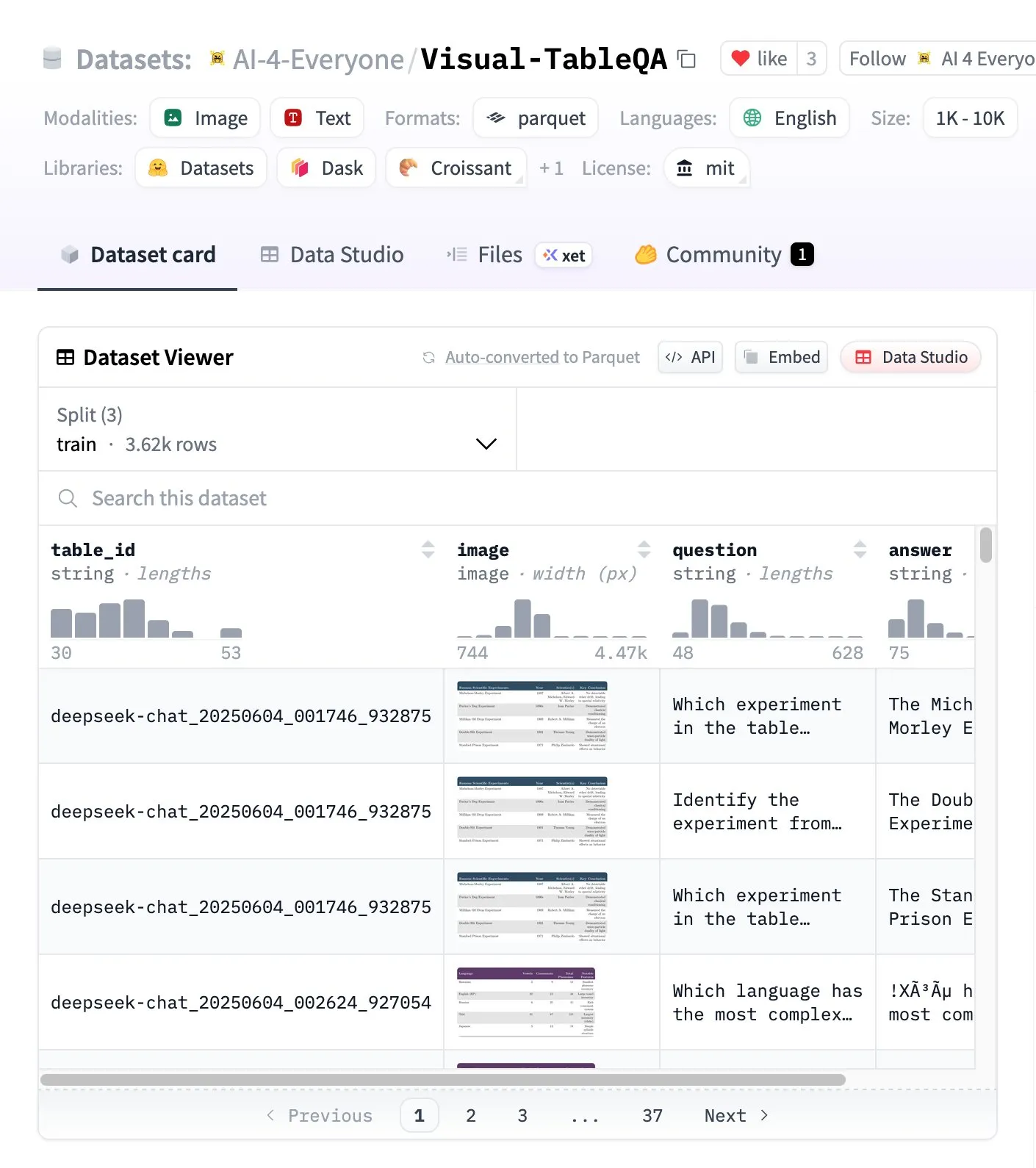
Visual-TableQA: معيار استدلال معقد للجدول: أطلقت Hugging Face معيار Visual-TableQA، وهو معيار استدلال معقد للجدول يحتوي على 2.5 ألف جدول و 6 آلاف زوج من الأسئلة والأجوبة. يركز هذا المعيار على الاستدلال متعدد الخطوات على البنية البصرية، وقد تم التحقق منه يدويًا بنسبة 92%، وبتكلفة توليد تقل عن 100 دولار. يوفر هذا المعيار موردًا عالي الجودة لتقييم وتحسين قدرة النماذج على فهم واستدلال البيانات الجدولية المعقدة. (المصدر: huggingface)
تحليل مفهومي AI Agents وAgentic AI: يوجد خلط شائع في المجتمع بين مفاهيم AI Agents وأنظمة Agentic AI. يشير AI Agents إلى برنامج مستقل واحد (LLM + أدوات) ينفذ مهامًا محددة، ويتصرف بشكل تفاعلي، وذاكرته محدودة. بينما يشير Agentic AI إلى نظام تعاوني متعدد الوكلاء (LLMs متعددة + تنسيق + ذاكرة مشتركة)، ويتصرف بشكل استباقي، وذاكرته دائمة. فهم الفرق بين الاثنين أمر بالغ الأهمية لقرارات التصميم المعماري، لتجنب بناء أنظمة معقدة لا داعي لها. (المصدر: Reddit r/deeplearning)

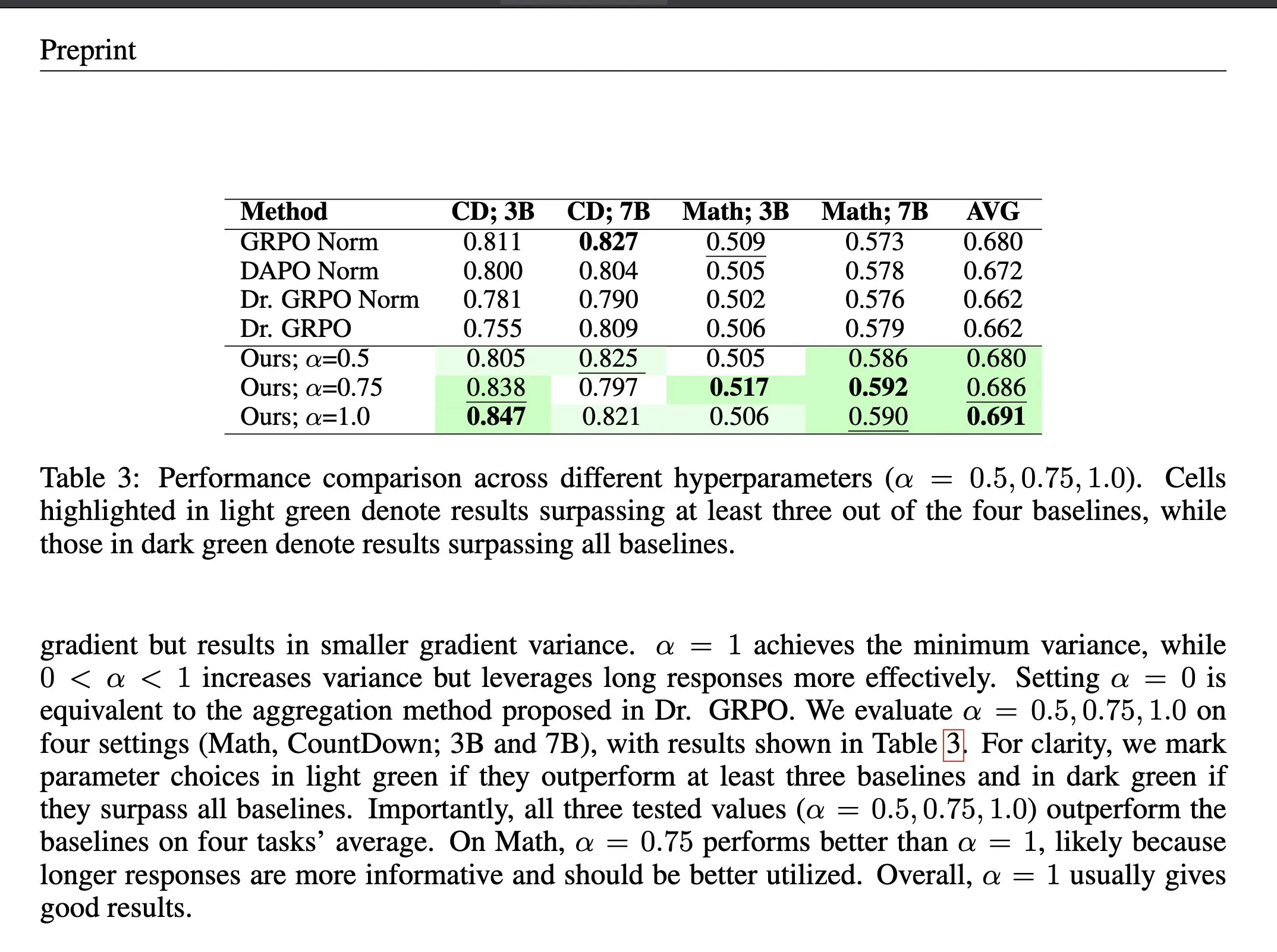
ΔL Normalization: طريقة تجميع الخسارة في التعلم المعزز: ΔL Normalization هي طريقة تجميع للخسارة مصممة خصيصًا لخاصية الطول المتولدة ديناميكيًا في التعلم المعزز بالمكافآت القابلة للتحقق (RLVR). تحلل هذه الطريقة تأثير الأطوال المختلفة على خسارة السياسة، وتعيد صياغة المشكلة لإيجاد مقدر غير متحيز بأقل تباين، مما يقلل تباين التدرج نظريًا. أثبتت التجارب أن ΔL Normalization تحقق نتائج ممتازة باستمرار عبر أحجام النماذج المختلفة، وأقصى الأطوال، والمهام، مما يحل تحديات التباين العالي للتدرج وعدم استقرار التحسين في RLVR. (المصدر: HuggingFace Daily Papers, teortaxesTex)
محاضرة فيديو مقارنة لبنى LLM: نشر Rasbt محاضرة فيديو تحليلية مقارنة لـ 11 بنية LLM لعام 2025، تغطي DeepSeek V3/R1 وOLMo 2 وGemma 3 وMistral Small 3.1 وLlama 4 وQwen3 وSmolLM3 وKimi 2 وGPT-OSS وGrok 2.5 وGLM-4.5. توفر هذه المحاضرة للمطورين والباحثين نظرة عامة شاملة على معماريات LLM، مما يساعد على فهم فلسفات التصميم وميزات الأداء للنماذج المختلفة. (المصدر: rasbt)
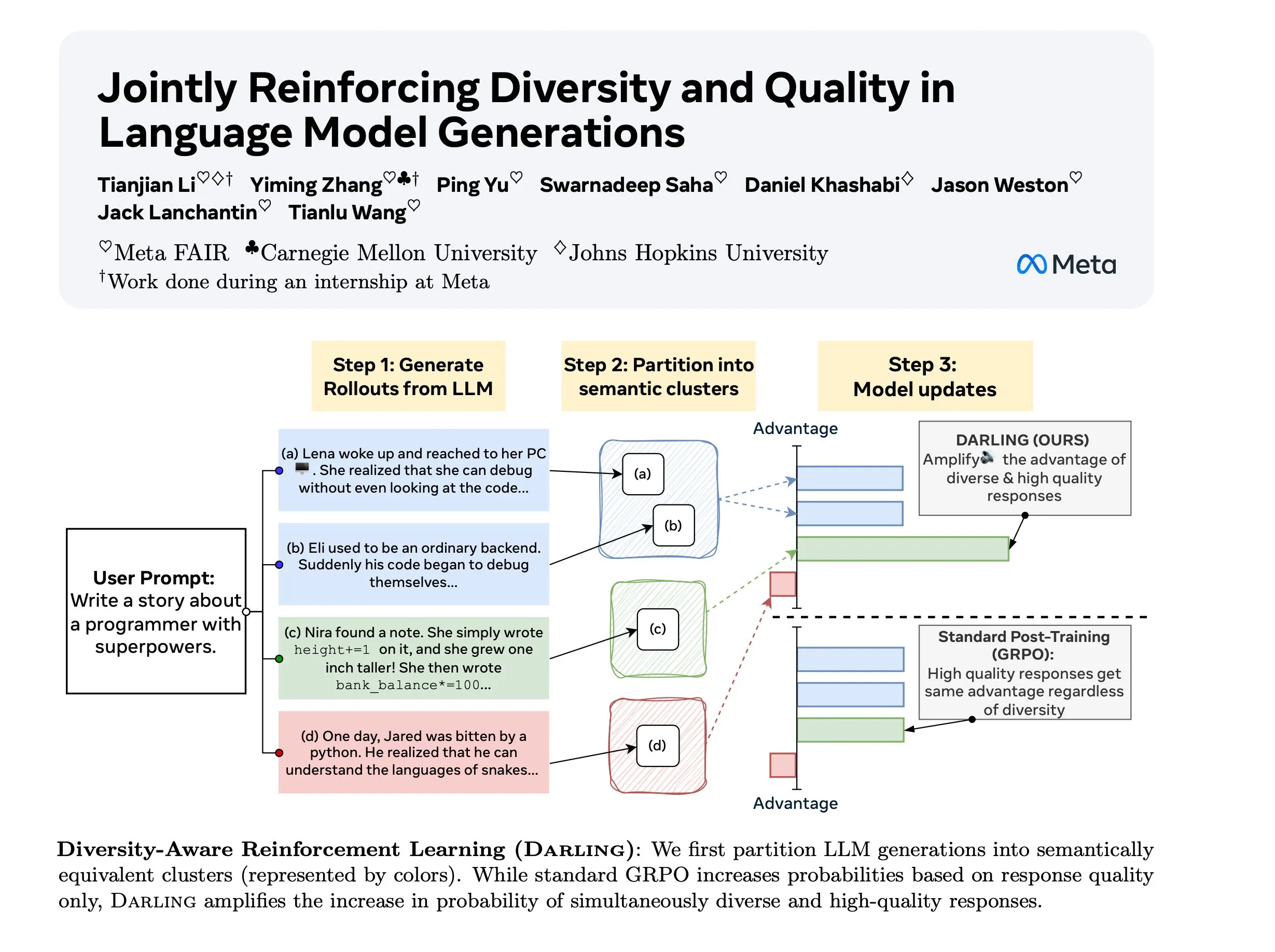
دراسة Diversity Aware RL (DARLING): DARLING (Diversity Aware RL) هي طريقة جديدة للتعلم المعزز، تعمل على تحسين الجودة والتنوع في آن واحد من خلال تعلم دالة التقسيم. تتفوق هذه الطريقة على التعلم المعزز القياسي في كل من مقاييس الجودة والتنوع، مثل pass@1/p@k أعلى، وهي قابلة للتطبيق على المهام غير القابلة للتحقق والقابلة للتحقق، مما يوفر سبيلاً جديدًا لتعزيز قدرة التعلم المعزز على التعميم في البيئات المعقدة. (المصدر: ylecun)
ستانفورد CS 224N: دورة التعلم العميق ومعالجة اللغة الطبيعية: تقدم دورة CS 224N بجامعة ستانفورد تعليمًا شاملاً في التعلم العميق ومعالجة اللغة الطبيعية (NLP). الدورة متاحة للجمهور عبر مقاطع فيديو على YouTube، مما يوفر موارد تعليمية عالية الجودة للذكاء الاصطناعي للمتعلمين حول العالم، وتغطي النظريات الأساسية لـ NLP، وأحدث النماذج، والتطبيقات العملية، وهي دورة تمهيدية مهمة لدخول مجال الذكاء الاصطناعي. (المصدر: stanfordnlp)
💼 أعمال
سياسة الخصوصية الجديدة لـ Anthropic تثير الجدل: عيب منهجي للمطورين المستقلين: تتطلب سياسة الخصوصية الجديدة لـ Anthropic من المستخدمين اختيار ما إذا كانوا سيسمحون لها باستخدام بيانات المحادثات لتدريب الذكاء الاصطناعي والاحتفاظ بها لمدة 5 سنوات قبل 28 سبتمبر، وإلا سيفقدون وظائف الذاكرة والتخصيص. انتقدت هذه الخطوة بأنها تخلق “نظامًا من مستويين”، مما يضع المطورين المستقلين أمام مفاضلة بين الخصوصية والوظائف، وقد تصبح رموزهم الخاصة بيانات تدريب للذكاء الاصطناعي للشركات، بينما يمكن لعملاء الشركات الاستمتاع بحلول مكلفة تجمع بين حماية الخصوصية والتخصيص، مما يثير مخاوف بشأن ديمقراطية الذكاء الاصطناعي واستخراج الابتكار. (المصدر: Reddit r/ClaudeAI)
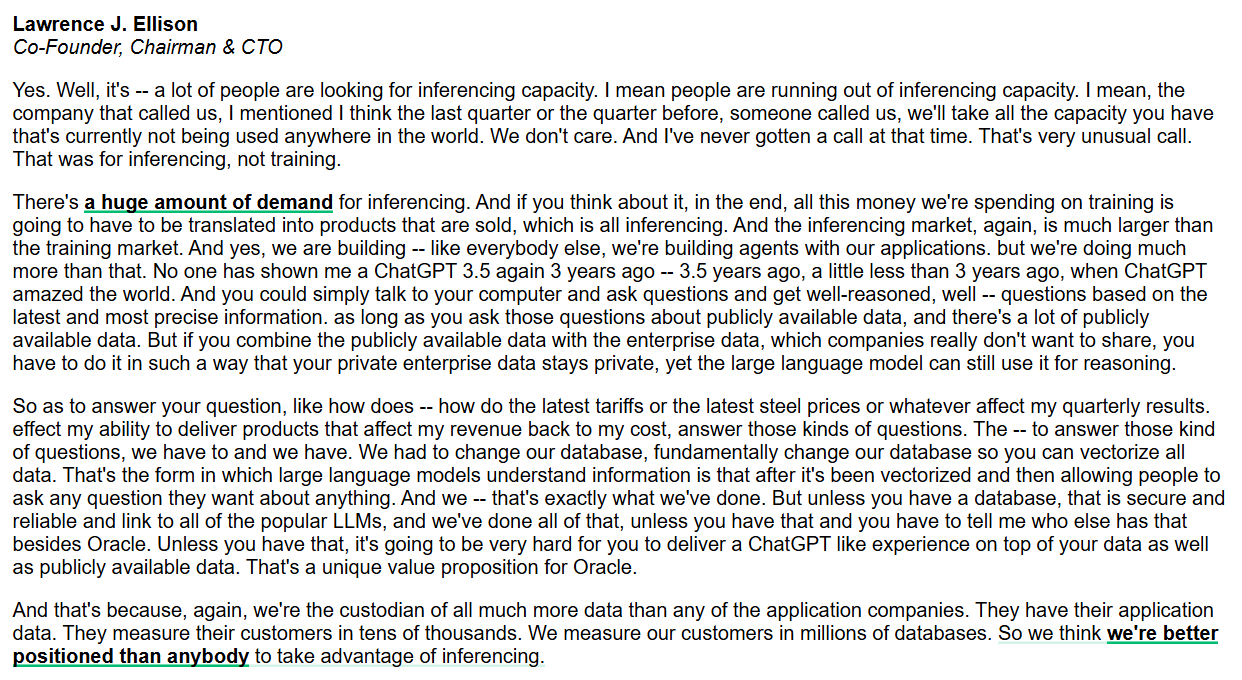
Oracle تركز على قدرات الاستدلال وقواعد بيانات AI على مستوى المؤسسات: أكد لاري إليسون، الرئيس التنفيذي لشركة Oracle، أن سوق قدرات الاستدلال أكبر بكثير من سوق التدريب، وأن الطلب عليه هائل. تغير Oracle قواعد البيانات بشكل جذري لتحويل جميع البيانات إلى متجهات، وتضمن أمانها وموثوقيتها، بهدف توفير تجربة شبيهة بـ ChatGPT تجمع بين البيانات العامة والخاصة بالمؤسسات. ترى Oracle أن لديها ميزة فريدة بصفتها مضيفًا للبيانات في تقديم خدمات استدلال الذكاء الاصطناعي على مستوى المؤسسات. (المصدر: JonathanRoss321)
معيار ترخيص محتوى الذكاء الاصطناعي الجديد RSL Standard: دفع شركات الذكاء الاصطناعي للدفع: تدعم العلامات التجارية الكبرى مثل Reddit وYahoo وQuora وwikiHow معيار Really Simple Licensing (RSL) Standard، وهو معيار ترخيص محتوى مفتوح، يهدف إلى تمكين ناشري الويب من تحديد شروط استخدام مطوري أنظمة الذكاء الاصطناعي لأعمالهم. يعتمد RSL على بروتوكول robots.txt، ويسمح للمواقع بإضافة شروط الترخيص والرسوم، ويطلب من زواحف الذكاء الاصطناعي الدفع مقابل بيانات التدريب (اشتراك أو دفع لكل عملية زحف/استدلال)، لضمان حصول مبدعي المحتوى على تعويض عادل. (المصدر: Reddit r/artificial)
🌟 مجتمع
التعايش بين الذكاء الاصطناعي والذكاء البشري وتعزيزه: يناقش المجتمع ما إذا كان الذكاء الاصطناعي سيعمل كـ “مصحح معرفي” يدعم الذكاء البشري (مثل المعداد)، أم كـ “منافس” يحل محل البشر (مثل الآلة الحاسبة). قدم فرانسوا شوليه استعارة “دراجة التفكير”، مؤكدًا أن التكنولوجيا يجب أن تضخم الجهود البشرية بدلاً من جعل الناس خاملين، مما أثار تأملات فلسفية حول العلاقة بين الذكاء الاصطناعي والذكاء البشري (IA) واتجاهات التطور المستقبلية. (المصدر: rao2z)
معضلة العلاقات العامة في صناعة الذكاء الاصطناعي والمشاعر السلبية للجمهور: على الرغم من أن منتجات الذكاء الاصطناعي يستخدمها مليارات الأشخاص ويستفيد منها الكثيرون، إلا أن صناعة الذكاء الاصطناعي تواجه بشكل عام مشاعر سلبية من الجمهور. يرى البعض أن هذا يرجع إلى فشل قادة الصناعة في التواصل بفعالية في حملاتهم الدعائية الخارجية، مما أدى إلى تحيز الجمهور ضد شركات الذكاء الاصطناعي. ويخمّن آخرون أن هذا قد يكون مقصودًا من قبل صناعة الذكاء الاصطناعي، بهدف تركيز التقنيات والمزايا الأساسية في أيدي عدد قليل من اللاعبين. (المصدر: Dorialexander)
تأثير نقاط الضعف في أنظمة LLM متعددة الوكلاء: تشير الأبحاث إلى أن استخدام النماذج اللغوية الصغيرة في أنظمة الوكلاء المتعددين ليس دائمًا الخيار الأمثل. في سيناريوهات مثل المناقشات بين الوكلاء المتعددين، غالبًا ما تتداخل وكلاء LLM الأضعف مع أداء الوكلاء الأقوى أو حتى تدمره، مما يؤدي إلى تدهور الأداء العام للنظام. يكشف هذا عن ضرورة النظر بعناية في اختلافات قدرات الوكلاء وتأثيرات التفاعل السلبية المحتملة عند تصميم ونشر أنظمة الوكلاء المتعددين. (المصدر: omarsar0)

قيود البيانات الاصطناعية على تحقيق AGI: أشار Andrew Trask وFei-Fei Li إلى أن البيانات الاصطناعية هي استراتيجية ضعيفة لـ LLM لتحقيق AGI. لا يمكن للبيانات الاصطناعية إنشاء معلومات جديدة (مثل الكيانات التي لم يسمع بها النموذج من قبل)، بل يمكنها فقط الكشف عن الاستنتاجات الطبيعية للمعلومات الموجودة. على الرغم من أن البيانات الاصطناعية يمكنها حل مشكلات مثل “لعنة الانعكاس” من خلال التبديل المنطقي وتركيب الحقائق المعروفة، إلا أن عنق الزجاجة المعلوماتي يحد من إمكاناتها كـ “رصاصة فضية” لـ AGI، وقد يكمن الاختراق الحقيقي في الاسترجاع الفوري للذكاء العالمي والسياق. (المصدر: algo_diver, jpt401)
الذكاء الاصطناعي وسوق العمل البشري: حلقة مفرغة من السير الذاتية التي يكتبها الذكاء الاصطناعي ويفرزها الذكاء الاصطناعي: يُحدث الذكاء الاصطناعي حلقة مفرغة من “عدم التوظيف” في سوق العمل: يستخدم الباحثون عن عمل الذكاء الاصطناعي لكتابة السير الذاتية، ويستخدم مسؤولو الموارد البشرية الذكاء الاصطناعي لفرزها، مما يؤدي إلى “زيادة” في الكفاءة ولكن لا يتم توظيف أحد. تتنوع أسباب رفض السير الذاتية من قبل الذكاء الاصطناعي بشكل كبير، حتى أن مسؤولي الموارد البشرية يشتكون من أن السير الذاتية التي يولدها الذكاء الاصطناعي متشابهة. يسلط هذا الضوء على التحديات الجديدة التي يجلبها الذكاء الاصطناعي في التوظيف، وقد يؤدي إلى جمود عملية التوظيف وعدم القدرة على تحديد المواهب الحقيقية. (المصدر: 量子位)

التحديات التي يواجهها خبراء أخلاقيات الذكاء الاصطناعي: مع التطور السريع لتقنيات الذكاء الاصطناعي، يواجه خبراء أخلاقيات الذكاء الاصطناعي معضلة “الصراخ في الفراغ”. إن سباق الذكاء الاصطناعي المدفوع بالرأسمالية أدى إلى تهميش الاعتبارات الأخلاقية، وتجاوزت سرعة التقدم التكنولوجي بكثير سرعة دمج الأخلاقيات. يخشى الخبراء أنه إذا تم الانتظار حتى تظهر الأضرار على نطاق واسع لاتخاذ الإجراءات، فقد يكون الأوان قد فات، ويدعون الصناعة إلى دمج الضمانات الأخلاقية ضمن الاعتبارات الأساسية. (المصدر: Reddit r/ArtificialInteligence)

مستقبل الإنترنت: حركة مرور الروبوتات تتجاوز البشر: تشير الاتجاهات إلى أن التفاعلات المدفوعة بالروبوتات على الإنترنت ستتجاوز بكثير التفاعلات البشرية خلال السنوات الثلاث المقبلة، مما سيجعل الإنترنت “ميتًا”. وقد أشارت دراسات سابقة إلى أن حركة مرور الروبوتات تجاوزت بالفعل 50%. يثير هذا مخاوف بشأن كيفية التمييز بين الأصوات البشرية الحقيقية والمحتوى الذي يولده الذكاء الاصطناعي، وكذلك صحة المعلومات على الإنترنت، مما ينبئ بتحول جذري في النظام البيئي للشبكة. (المصدر: Reddit r/artificial)

تدهور أداء Claude Code وفقدان المستخدمين: أفاد مستخدمو Claude Code من Anthropic بانخفاض كبير في أداء النموذج مؤخرًا، ويتجلى ذلك في تدهور جودة التعليمات البرمجية، وتوليد تعليمات برمجية زائدة عن الحاجة، وانخفاض جودة الاختبارات، والإفراط في الهندسة، وضعف القدرة على الفهم. يفكر العديد من المستخدمين في التحول إلى بدائل مثل GPT-5 وGLM-4.5 وQwen3، ويدعون Anthropic إلى زيادة الشفافية، وشرح أسباب تراجع النموذج وإجراءات الإصلاح، وإلا ستواجه الشركة فقدان المستخدمين. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
💡 أخرى
إمكانات الذكاء الاصطناعي والواقع الافتراضي في إصلاح الجرائم: طُرحت فكرة مفادها أنه يمكن استخدام تقنيات الذكاء الاصطناعي والواقع الافتراضي (VR) الرخيصة لتوفير كبسولات VR إلزامية للمرضى النفسيين الجنائيين، لعزلهم عن المجتمع بتكلفة أقل من تكاليف الإقامة والطعام التقليدية. أثار هذا التصور الجذري نقاشًا حول دور الذكاء الاصطناعي في التحكم الاجتماعي، وأنظمة العقاب، والحدود الأخلاقية، وعلى الرغم من الجدل حول جدواه وإنسانيته، إلا أنه يكشف عن اتجاهات تطبيقية محتملة للتكنولوجيا في حل المشكلات الاجتماعية. (المصدر: gfodor, gfodor)
تصور لتطبيق Replit في السجون: اقترح أحد المستخدمين فكرة إدخال Replit (منصة برمجة عبر الإنترنت) إلى السجون، معتبرًا أن ذلك يمكن أن يحل محل مرافق الترفيه، ويسمح للسجناء بإنشاء منتجات ذات قيمة من خلال البرمجة. تستكشف هذه الفكرة الدور المحتمل للتكنولوجيا في إصلاح المجتمع، وتوفير التدريب على المهارات، وتعزيز إعادة دمج السجناء في المجتمع، مما أثار نقاشًا حول العدالة التعليمية والتمكين التكنولوجي. (المصدر: amasad)