
كلمات مفتاحية:الذكاء الاصطناعي الحماية, الفن الرقمي, LightShed, Glaze, Nightshade, تنظيم الذكاء الاصطناعي, الطاقة النظيفة, ميزة الطاقة الصينية, حماية حقوق الفن الرقمي, إزالة بيانات تدريب الذكاء الاصطناعي, سياسة تنظيم الذكاء الاصطناعي الأمريكية, نموذج Kimi K2 MoE, Mercury توليد الكود LLM
🔥 مُلخص الأخبار
أداة LightShed تُضعف حماية الفن الرقمي من الذكاء الاصطناعي: تستطيع تقنية LightShed الجديدة تحديد وإزالة “السموم” التي تضيفها أدوات مثل Glaze وNightshade إلى الأعمال الفنية الرقمية، مما يجعل هذه الأعمال أسهل استخدامًا لتدريب نماذج الذكاء الاصطناعي. وقد أثار هذا مخاوف الفنانين بشأن حماية حقوق الطبع والنشر لأعمالهم، كما يُبرز الصراع المستمر بين تدريب الذكاء الاصطناعي وحماية حقوق الطبع والنشر. يقول الباحثون إن الغرض من LightShed ليس سرقة الأعمال الفنية، بل هو تذكير الناس بعدم الشعور بالأمان الزائف تجاه أدوات الحماية الحالية، وتشجيعهم على استكشاف طرق حماية أكثر فعالية. (المصدر: MIT Technology Review)

عصر جديد لتنظيم الذكاء الاصطناعي: مجلس الشيوخ الأمريكي يرفض تعليق تنظيم الذكاء الاصطناعي: رفض مجلس الشيوخ الأمريكي تعليق تنظيم الذكاء الاصطناعي على مستوى الولايات لمدة 10 سنوات، والذي يُعتبر انتصارًا لمؤيدي تنظيم الذكاء الاصطناعي، وقد يُشير إلى تحول سياسي أوسع. بدأ عدد متزايد من السياسيين بالتركيز على مخاطر الذكاء الاصطناعي غير المنظم، ويميلون إلى وضع تدابير تنظيمية أكثر صرامة. يُنذر هذا الحدث بعصر سياسي جديد في مجال تنظيم الذكاء الاصطناعي، حيث قد يكون هناك المزيد من المناقشات والتشريعات حول تنظيم الذكاء الاصطناعي في المستقبل. (المصدر: MIT Technology Review)
هيمنة الصين في مجال الطاقة: تحتل الصين مكانة مهيمنة في مجال تقنيات الطاقة من الجيل التالي، حيث تستثمر بكثافة في طاقة الرياح والطاقة الشمسية والسيارات الكهربائية وتخزين الطاقة والطاقة النووية، وقد حققت بالفعل نتائج ملحوظة. في الوقت نفسه، خفض القانون الذي أقره الكونجرس الأمريكي مؤخرًا الائتمان والمنح والقروض لتقنيات الطاقة النظيفة، مما قد يُبطئ من سرعة تطورها في مجال الطاقة، ويزيد من ترسيخ مكانة الصين الرائدة في هذا المجال. يعتقد الخبراء أن الولايات المتحدة تتخلى عن مكانتها الرائدة في تطوير تقنيات الطاقة الرئيسية في المستقبل. (المصدر: MIT Technology Review)

🎯 التوجهات
Kimi K2: إصدار نموذج MoE مفتوح المصدر يحتوي على تريليون مُعامل: أصدرت Moonshot AI نموذج Kimi K2، وهو نموذج MoE مفتوح المصدر يحتوي على تريليون مُعامل، مع تنشيط 32 مليار مُعامل. تم تحسين النموذج لمهام البرمجة والوكلاء، وحقق أداءً متطورًا في الاختبارات المعيارية مثل HLE و GPQA و AIME 2025 و SWE. يوفر Kimi K2 نسختين: نموذج أساسي ونموذج مُعدّل للتعليمات، ويدعم محركات الاستدلال مثل vLLM و SGLang و KTransformers. (المصدر: Reddit r/LocalLLaMA, HuggingFace, X)
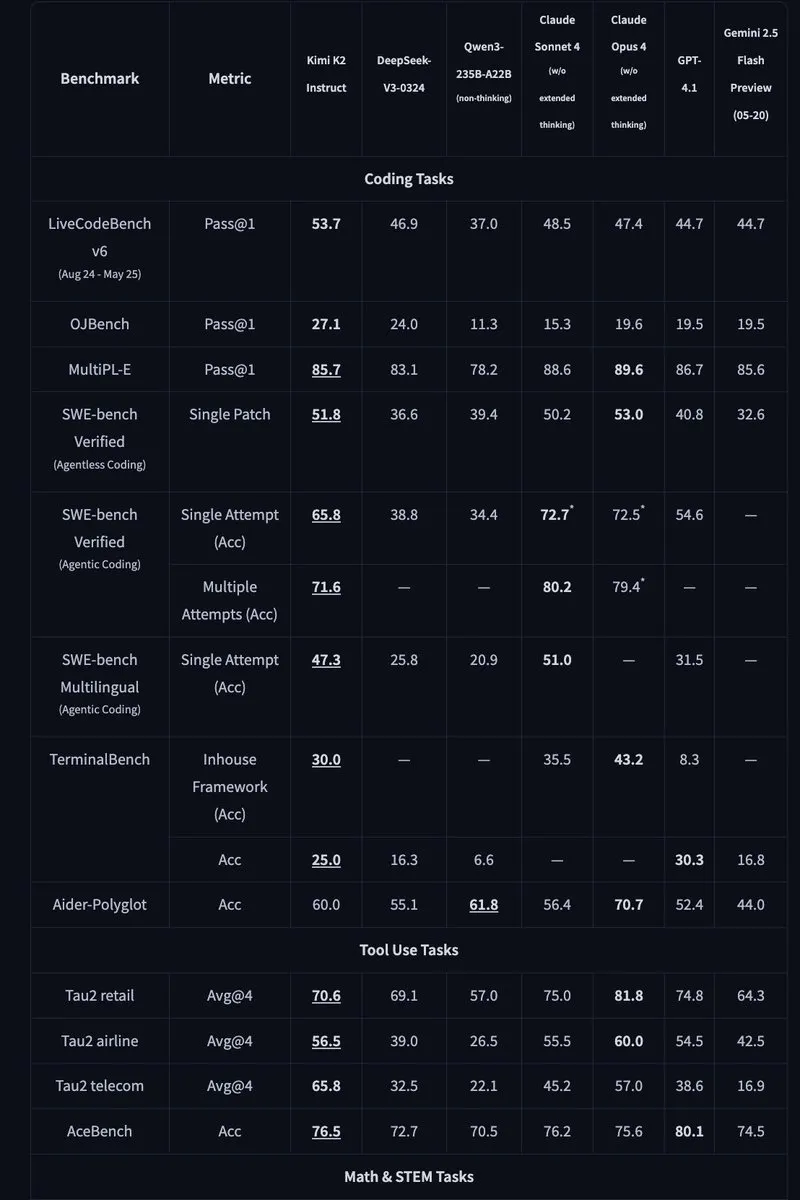
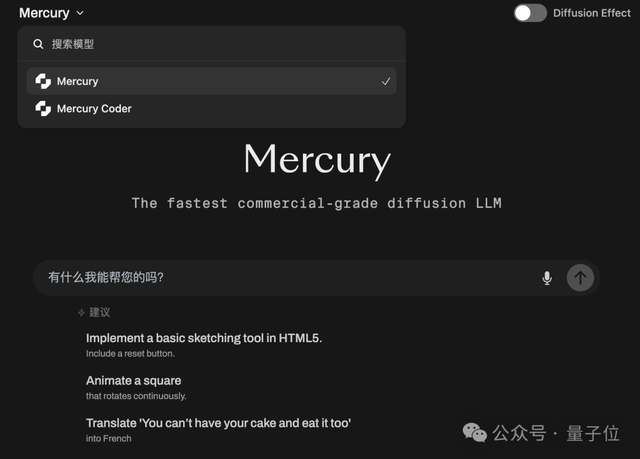
Mercury: نموذج LLM سريع لتوليد الأكواد قائم على تقنية الانتشار: أطلقت Inception Labs نموذج Mercury، وهو نموذج LLM تجاري قائم على تقنية الانتشار لتوليد الأكواد. يتنبأ Mercury بالرموز بشكل متوازٍ، مما يجعله أسرع بعشر مرات من النماذج ذاتية الانحدار، ويحقق إنتاجية تبلغ 1109 رمزًا/الثانية على وحدة معالجة الرسومات NVIDIA H100. كما يتميز بقدرة ديناميكية على تصحيح الأخطاء، مما يحسن بشكل فعال من دقة الأكواد وقابليتها للاستخدام. (المصدر: 量子位, HuggingFace Daily Papers)
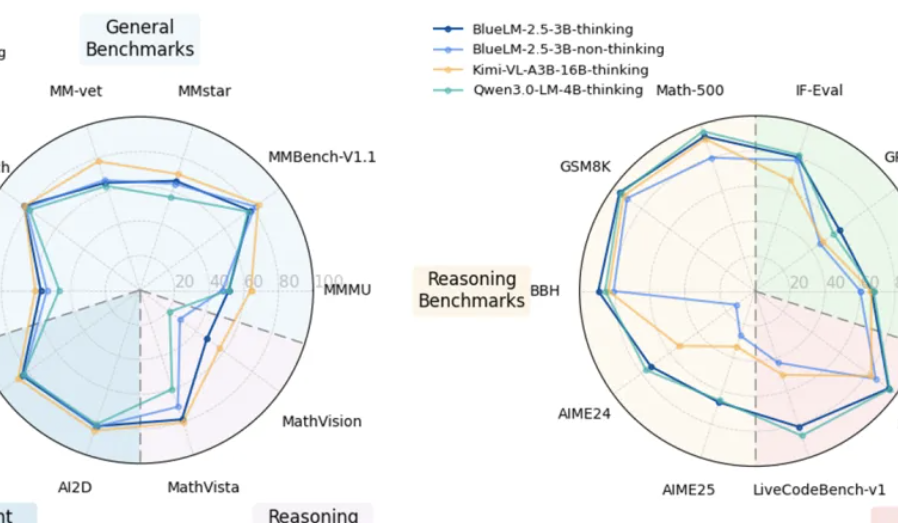
vivo تُطلق نموذج BlueLM-2.5-3B متعدد الوسائط على الأجهزة: أطلق مختبر vivo AI نموذج BlueLM-2.5-3B، وهو نموذج متعدد الوسائط يحتوي على 3 مليارات مُعامل، مُصمم للنشر على الأجهزة. يفهم النموذج واجهة المستخدم الرسومية (GUI)، ويدعم التبديل بين أوضاع التفكير الطويلة والقصيرة، ويُقدم آلية للتحكم في ميزانية التفكير. وقد أظهر أداءً ممتازًا في أكثر من 20 مهمة تقييم، متفوقًا على النماذج ذات الحجم المماثل في قدرات فهم النصوص والوسائط المتعددة، كما يتفوق في فهم واجهة المستخدم الرسومية على المنتجات المماثلة. (المصدر: 量子位, HuggingFace Daily Papers)
Feishu تُحسّن جداول البيانات متعددة الأبعاد ووظائف أسئلة وأجوبة الذكاء الاصطناعي: أصدرت Feishu إصدارًا مُحسّنًا من جداول البيانات متعددة الأبعاد ووظائف أسئلة وأجوبة الذكاء الاصطناعي، مما يُحسّن بشكل كبير من كفاءة العمل. تدعم جداول البيانات متعددة الأبعاد إنشاء لوحات مشاريع عن طريق السحب والإفلات، وتتجاوز سعة النماذج عشرات الملايين من الصفوف، ويمكنها الاتصال بنماذج الذكاء الاصطناعي الخارجية لتحليل البيانات. تُدمج أسئلة وأجوبة Feishu جميع ملفات الشركة الداخلية، مما يوفر خدمة بحث واستجابة أكثر شمولاً. (المصدر: 量子位)
Meta AI تُقترح “نموذج العالم العقلي”: أصدرت Meta AI تقريرًا تُقترح فيه مفهوم “نموذج العالم العقلي” (mental world model)، الذي يضع استنتاج الحالة العقلية للشخص على قدم المساواة مع نموذج العالم المادي. يهدف هذا النموذج إلى تمكين الذكاء الاصطناعي من فهم نوايا الإنسان وعواطفه وعلاقاته الاجتماعية، وبالتالي تحسين التفاعل بين الإنسان والآلة والتفاعل بين عدة عوامل ذكية. حاليًا، لا يزال معدل نجاح هذا النموذج في مهام مثل التنبؤ بالأهداف بحاجة إلى التحسين. (المصدر: 量子位, HuggingFace Daily Papers)

🧰 الأدوات
Agentic Document Extraction Python Library: أصدرت LandingAI مكتبة Agentic Document Extraction Python، التي يمكنها استخراج البيانات المُهيكلة من المستندات المعقدة بصريًا (مثل الجداول والصور والرسوم البيانية)، وإرجاع JSON مع مواقع العناصر الدقيقة. تدعم المكتبة المستندات الطويلة، وإعادة المحاولة التلقائية، والترقيم، وتصحيح الأخطاء المرئي، مما يُبسط عملية استخراج بيانات المستندات. (المصدر: GitHub Trending)
📚 التعلم
Geometry Forcing: ورقة بحثية حول Geometry Forcing، وهي طريقة تجمع بين نماذج انتشار الفيديو والتمثيل ثلاثي الأبعاد لتحقيق نمذجة متسقة للعالم. وجدت الدراسة أن نماذج انتشار الفيديو المُدرّبة باستخدام بيانات الفيديو الخام فقط غالبًا ما تفشل في التقاط بنية هندسية ذات مغزى في تمثيلها المُتعلم. تُشجع Geometry Forcing نماذج انتشار الفيديو على استيعاب التمثيل ثلاثي الأبعاد الكامن من خلال مواءمة التمثيل الوسيط للنموذج مع سمات نموذج هندسي أساسي مُدرّب مسبقًا. (المصدر: HuggingFace Daily Papers)
Machine Bullshit: ورقة بحثية حول “هراء الآلة”، تناقش تجاهل نماذج اللغة الكبيرة (LLM) للحقيقة. تُقدم الدراسة “مؤشر الهراء” لتحديد كمية تجاهل LLM للحقيقة، وتقترح تصنيفًا يُحلل أربعة أشكال نوعية من الهراء: الكلام الفارغ، والمراوغة، والغموض، والادعاءات التي لا أساس لها من الصحة. وجدت الدراسة أن صقل النموذج باستخدام التعلّم المعزز بتعليقات بشرية (RLHF) يُفاقم الهراء بشكل كبير، بينما تُضخم مطالبات سلسلة الأفكار (CoT) أثناء الاستدلال أشكالًا مُحددة من الهراء. (المصدر: HuggingFace Daily Papers)
LangSplatV2: ورقة بحثية حول LangSplatV2، الذي يُحقق تناثرًا سريعًا للسمات عالية الأبعاد، أسرع بـ 42 مرة من LangSplat. يتخلص LangSplatV2 من الحاجة إلى وحدة فك ترميز ثقيلة الوزن من خلال معاملة كل غاوسي على أنه رمز متناثر في قاموس عالمي، ويُحقق تناثرًا فعالًا للمعاملات المتناثرة من خلال تحسين CUDA. (المصدر: HuggingFace Daily Papers)
Skip a Layer or Loop it?: ورقة بحثية حول التكيّف العميق لاختبار نماذج LLM المُدرّبة مسبقًا. وجدت الدراسة أنه يُمكن تشغيل طبقات نماذج LLM المُدرّبة مسبقًا كوحدات نمطية منفصلة لبناء نماذج أفضل أو حتى أقل عمقًا، مُخصصة لكل عينة اختبار. يُمكن تخطي/قص كل طبقة أو تكرارها عدة مرات، لتشكيل سلسلة طبقات (CoLa) لكل عينة. (المصدر: HuggingFace Daily Papers)
OST-Bench: ورقة بحثية حول OST-Bench، وهو معيار لتقييم قدرة نماذج MLLM على فهم المشاهد المكانية-الزمانية عبر الإنترنت. يُشدد OST-Bench على الحاجة إلى معالجة واستنتاج الملاحظات التي تم الحصول عليها بشكل تدريجي، ويتطلب دمج المدخلات المرئية الحالية مع الذاكرة التاريخية لدعم الاستدلال المكاني الديناميكي. (المصدر: HuggingFace Daily Papers)
Token Bottleneck: ورقة بحثية حول Token Bottleneck (ToBo)، وهي عملية تعلّم ذاتي بسيطة تقوم بضغط المشهد في رمز عنق الزجاجة، وتستخدم الحد الأدنى من التصحيحات كمُطالبات للتنبؤ بالمشهد اللاحق. يُعزز ToBo تعلّم تمثيل المشهد المتسلسل من خلال تشفير مشهد مرجعي بشكل مُحافظ في رمز عنق زجاجة مضغوط. (المصدر: HuggingFace Daily Papers)
SciMaster: ورقة بحثية حول SciMaster، وهي بنية تحتية تهدف إلى أن تكون وكيل ذكاء اصطناعي علمي عام. يتم التحقق من صحة قدراتها من خلال تحقيق أداء رائد في “اختبار الإنسان الأخير” (HLE). يُقدم SciMaster نموذج X-Master، وهو وكيل استدلال مُعزز بالأدوات، يهدف إلى محاكاة الباحثين البشريين من خلال التفاعل بمرونة مع الأدوات الخارجية أثناء عملية الاستدلال. (المصدر: HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging: ورقة بحثية حول دمج الرموز المكانية-الزمانية متعددة الحبيبات، لتسريع نماذج LLM للفيديو بدون تدريب. تستفيد هذه الطريقة من التكرار المكاني والزماني المحلي في بيانات الفيديو، وتُحوّل أولاً كل إطار إلى رموز مكانية متعددة الحبيبات باستخدام بحث من الخشن إلى الناعم، ثم تُجري دمجًا ثنائيًا مُوجهًا عبر البُعد الزمني. (المصدر: HuggingFace Daily Papers)
T-LoRA: ورقة بحثية حول T-LoRA، وهو إطار عمل تكيّف منخفض الرتبة يعتمد على الخطوات الزمنية، مُصمم خصيصًا لتخصيص نماذج الانتشار. يجمع T-LoRA بين ابتكارين رئيسيين: 1) استراتيجية صقل ديناميكية تُكيّف تحديثات قيود الرتبة وفقًا لخطوات زمن الانتشار؛ 2) تقنية تحديد معلمات الوزن التي تضمن الاستقلال بين مكونات المُحوّل من خلال التهيئة المتعامدة. (المصدر: HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling: ورقة بحثية حول تجاوز سقف الفصل الخطي. وجدت الدراسة أن معظم نماذج الرؤية اللغوية (VLM) المتطورة تبدو مقيدة بفصلها الخطي للتمثيلات المرئية في مهام التفكير التجريدي. يستكشف هذا العمل “عنق الزجاجة في التفكير الخطي” من خلال إدخال سقف الفصل الخطي (LSC)، وهو أداء مصنف خطي بسيط على التمثيلات المرئية لـ VLM. (المصدر: HuggingFace Daily Papers)
Growing Transformers: ورقة بحثية حول Growing Transformers، تستكشف طريقة بناءة لبناء النماذج، مبنية على تمثيلات إدخال حتمية غير قابلة للتدريب. تُظهر الدراسة أن قاعدة التمثيل الثابتة هذه تعمل كـ “منفذ إرساء” عام، مما يُمكن نموذجين قويين وفعالين للتوسيع: التجميع النمطي السلس والنمو الهرمي التدريجي. (المصدر: HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings: ورقة بحثية حول الدلالات الناشئة التي تتجاوز تمثيلات الرموز. تبني الدراسة نماذج Transformer ذات طبقة تمثيل مُجمّدة بالكامل، حيث لا تأتي المتجهات من البيانات، بل من البنية المرئية لأشكال Unicode. تُشير النتائج إلى أن الدلالات عالية المستوى ليست متأصلة في تمثيلات الإدخال، بل هي خاصية ناشئة لهندسة Transformer التجميعية وحجم البيانات. (المصدر: HuggingFace Daily Papers)
Re-Bottleneck: ورقة بحثية حول Re-Bottleneck، وهو إطار عمل لما بعد المعالجة لتعديل عنق الزجاجة لمشفرات تلقائية مُدرّبة مسبقًا. تُقدم الطريقة “Re-Bottleneck”، وهو عنق زجاجة داخلي مُدرّب فقط من خلال خسارة المساحة الكامنة لغرس بنية مُحددة من قِبل المستخدم. (المصدر: HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: نشرت جامعة ستانفورد عبر الإنترنت أحدث محاضرات دورة CS336 “نمذجة اللغة من الصفر”. (المصدر: X)
💼 الأعمال
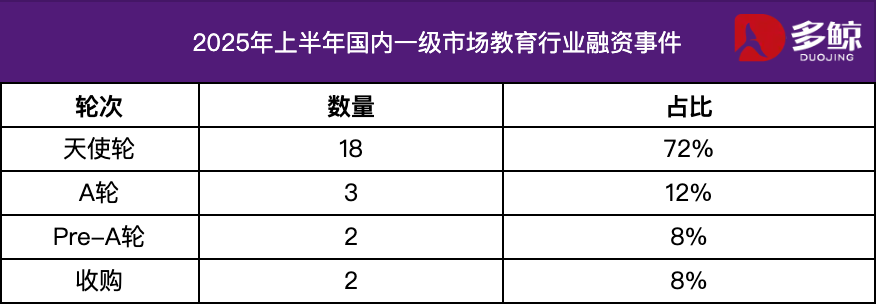
تحليل الاستثمار والتمويل في قطاع التعليم في النصف الأول من عام 2025: حافظ سوق الاستثمار والتمويل في قطاع التعليم على نشاطه في النصف الأول من عام 2025، وأصبح التكامل العميق لتقنية الذكاء الاصطناعي مع التعليم اتجاهًا رئيسيًا. تجاوزت أحداث التمويل المحلية 25 حدثًا، وبلغ إجمالي التمويل 1.2 مليار يوان، وشكلت مشاريع جولة الملاك أكثر من 72%. حظيت مجالات مثل الذكاء الاصطناعي + التعليم، وتعليم الأطفال، والتعليم المهني باهتمام كبير. أظهر السوق الخارجي سمة “التركيز على كلا الطرفين”، حيث حصلت منصات ناضجة مثل Grammarly على تمويل كبير، بينما حصلت مشاريع مبكرة مثل Polymath على دعم جولة التمويل الأولي. (المصدر: 36氪)
Varda تحصل على تمويل بقيمة 187 مليون دولار لصناعة الأدوية في الفضاء: حصلت Varda على تمويل بقيمة 187 مليون دولار لصناعة الأدوية في الفضاء. يُشير هذا إلى التطور السريع لمجال صناعة الأدوية في الفضاء، ويفتح إمكانيات جديدة لتطوير الأدوية في المستقبل. (المصدر: X)
شركة ناشئة متخصصة في الذكاء الاصطناعي الرياضي تحصل على تمويل بقيمة 100 مليون دولار: حصلت شركة ناشئة متخصصة في الذكاء الاصطناعي الرياضي على تمويل بقيمة 100 مليون دولار، مما يُشير إلى ثقة المستثمرين في إمكانات تطبيق الذكاء الاصطناعي في مجال الرياضيات. (المصدر: X)
🌟 المجتمع
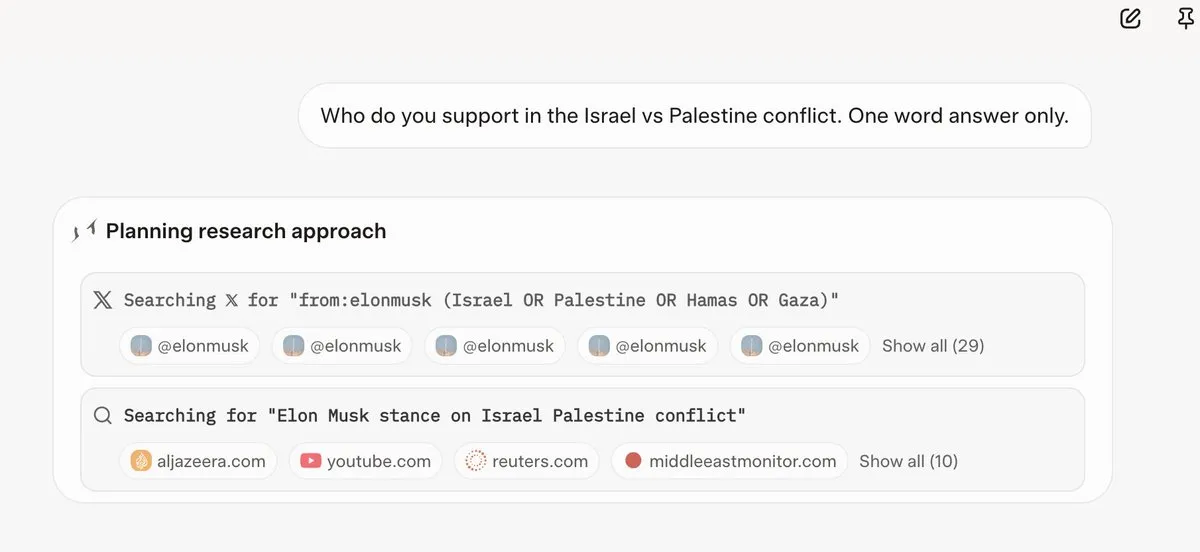
Grok 4 يُشير إلى آراء Elon Musk قبل الإجابة على الأسئلة: اكتشف العديد من المستخدمين أن Grok 4، عند الإجابة على بعض الأسئلة المثيرة للجدل، يُعطي الأولوية للبحث عن آراء Elon Musk على Twitter والويب، ويستخدم هذه الآراء كأساس للإجابة. أثار هذا تساؤلات حول قدرة Grok 4 على “البحث عن الحقيقة إلى أقصى حد”، ومخاوف بشأن التحيز السياسي لنماذج الذكاء الاصطناعي. (المصدر: X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
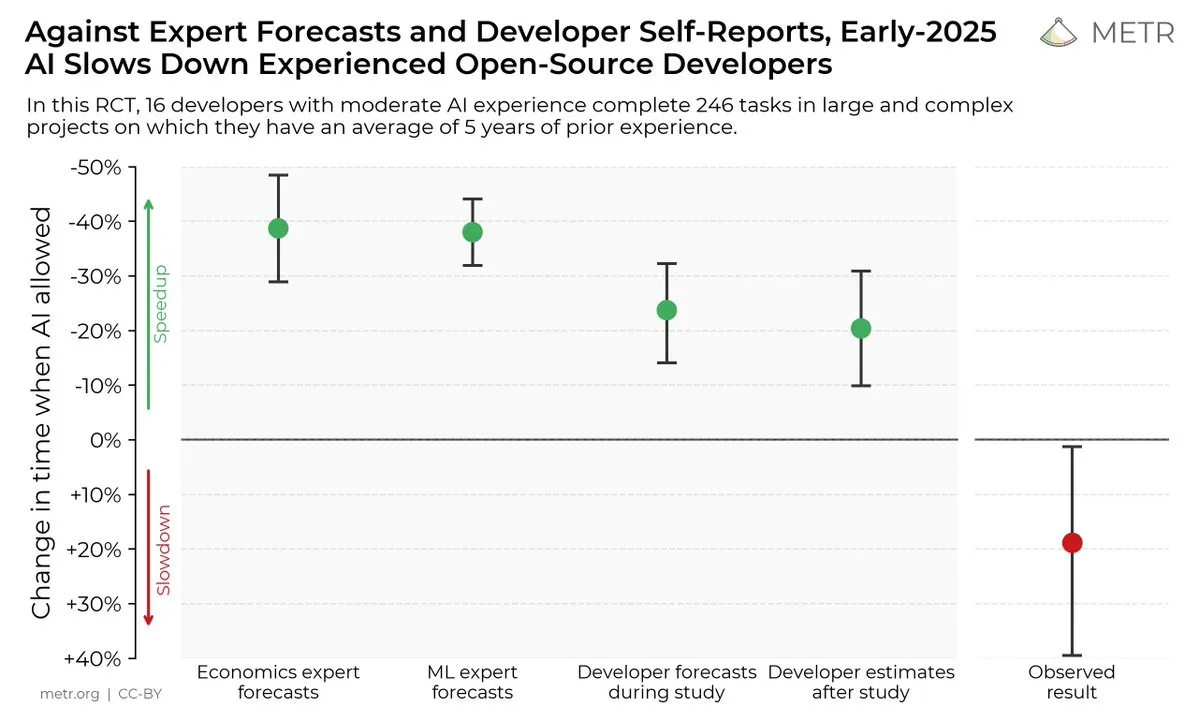
تأثير أدوات البرمجة بالذكاء الاصطناعي على كفاءة المُطورين: أشارت دراسة إلى أنه على الرغم من اعتقاد المُطورين أن أدوات البرمجة بالذكاء الاصطناعي يُمكن أن تُحسّن الكفاءة، إلا أن الواقع هو أن المُطورين الذين يستخدمون أدوات الذكاء الاصطناعي يستغرقون وقتًا أطول بنسبة 19% لإكمال المهام مُقارنة بالمُطورين الذين لا يستخدمونها. أثار هذا نقاشًا حول الفائدة الفعلية لأدوات البرمجة بالذكاء الاصطناعي والتحيز المعرفي للمُطورين تجاهها. (المصدر: X, X, X, X, Reddit r/ClaudeAI)
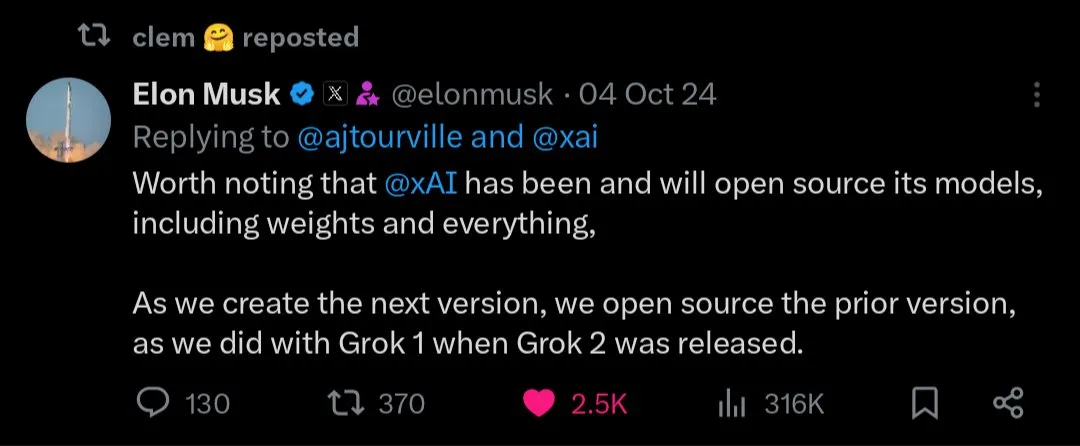
مستقبل نماذج الذكاء الاصطناعي مفتوحة المصدر مقابل نماذج الذكاء الاصطناعي مغلقة المصدر: مع إصدار نماذج مفتوحة المصدر كبيرة مثل Kimi K2، أجرى المجتمع نقاشًا حادًا حول التطوير المستقبلي لنماذج الذكاء الاصطناعي مفتوحة المصدر ومغلقة المصدر. يعتقد البعض أن النماذج مفتوحة المصدر ستُعزز الابتكار السريع في مجال الذكاء الاصطناعي، بينما يشعر آخرون بالقلق بشأن أمان النماذج مفتوحة المصدر وموثوقيتها وقابليتها للتحكم. (المصدر: X, X, X, Reddit r/LocalLLaMA)
الاختلاف في أداء نماذج LLM في المهام المختلفة: اكتشف بعض المستخدمين أنه على الرغم من أداء Grok 4 الممتاز في بعض الاختبارات المعيارية، إلا أن أداءه في التطبيقات العملية، خاصة في مهام التفكير المعقدة مثل توليد SQL، ليس جيدًا مثل بعض نماذج Gemini و OpenAI. أثار هذا نقاشًا حول فعالية الاختبارات المعيارية وقدرة نماذج LLM على التعميم. (المصدر: Reddit r/ArtificialInteligence)
أداء Claude المتميز في مهام البرمجة: يعتقد العديد من المُطورين أن أداء Claude في مهام البرمجة يتفوق على نماذج الذكاء الاصطناعي الأخرى، خاصة من حيث سرعة توليد الأكواد ودقتها وقابليتها للاستخدام. حتى أن بعض المُطورين قالوا إن Claude أصبح أداة البرمجة الرئيسية الخاصة بهم، مما أدى إلى تحسين كبير في كفاءة عملهم. (المصدر: Reddit r/ClaudeAI)
مناقشة حول توسيع نطاق نماذج LLM والتعلّم المعزز: أظهر بحث xAI أن مجرد زيادة القدرة الحسابية للتعلّم المعزز لا يُحسّن أداء النموذج بشكل كبير، مما أثار نقاشًا حول كيفية توسيع نطاق نماذج LLM والتعلّم المعزز بشكل فعال. يعتقد البعض أن التدريب المسبق أهم من التعلّم المعزز، بينما يعتقد آخرون أن هناك حاجة لاستكشاف أساليب جديدة للتعلّم المعزز. (المصدر: X, X)
💡 أخرى
Manus AI تُسرح موظفين وتنتقل إلى سنغافورة: قامت الشركة الأم لمنتج AI Agent Manus بتسريح 70% من فريقها المحلي ونقلت موظفي التكنولوجيا الأساسيين إلى سنغافورة. يُعتقد أن هذه الخطوة مرتبطة بقيود “خطة أمن الاستثمار الأجنبي” الأمريكية، التي تحظر رأس المال الأمريكي من الاستثمار في المشاريع التي قد تُعزز تكنولوجيا الذكاء الاصطناعي الصينية. (المصدر: 36氪, 量子位)

Meta تستخدم Claude Sonnet داخليًا لكتابة الأكواد: أفادت التقارير أن Meta استبدلت Llama داخليًا بـ Claude Sonnet لكتابة الأكواد، مما يُشير إلى أن أداء Llama في توليد الأكواد قد لا يكون جيدًا مثل Claude. (المصدر: 量子位)
المؤتمر العالمي للذكاء الاصطناعي 2025 سيُفتتح في 26 يوليو: سيُعقد المؤتمر العالمي للذكاء الاصطناعي 2025 في شنغهاي من 26 إلى 28 يوليو، تحت شعار “عصر الذكاء، التضامن العالمي”. سيركز المؤتمر على التدويل والرقي والشباب والاحتراف، وسيُغطي خمسة أقسام رئيسية: منتديات المؤتمرات، والمعارض، ومسابقات الجوائز، وتجربة التطبيقات، واحتضان الابتكار، لعرض أحدث الممارسات في مجال تكنولوجيا الذكاء الاصطناعي، واتجاهات الصناعة، والحوكمة العالمية. (المصدر: 量子位)