كلمات مفتاحية:بحوث الذكاء الاصطناعي, علوم الحاسوب, التعلم التعزيزي, تطوير الأدوية, القيادة الذاتية, نماذج اللغة, المعالجة متعددة الوسائط, الخلية الافتراضية, معهد لود, معلمو التعلم التعزيزي (RLTs), منصة BioNeMo, تسلا روبوتاكسي, نموذج كيمي VL A3B للتفكير
🔥 الأضواء
تأسيس Laude Institute بتمويل أولي قدره 100 مليون دولار لدفع أبحاث علوم الحاسوب غير الربحية: أعلن Andy Konwinski عن إطلاق Laude Institute، وهي منظمة غير ربحية تهدف إلى تمويل أبحاث علوم الحاسوب غير التجارية ذات التأثير الكبير على العالم. انضم إلى مجلس الإدارة شخصيات بارزة مثل Jeff Dean و Joyia Pineau و Dave Patterson. حصل المعهد على التزام تمويل أولي بقيمة 100 مليون دولار، وسيدعم الباحثين في تحويل الأفكار إلى تأثير عملي من خلال التمويل ومشاركة الموارد وبناء المجتمع، مع التركيز بشكل خاص على الأبحاث المفتوحة والموجهة نحو التأثير. (المصدر: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

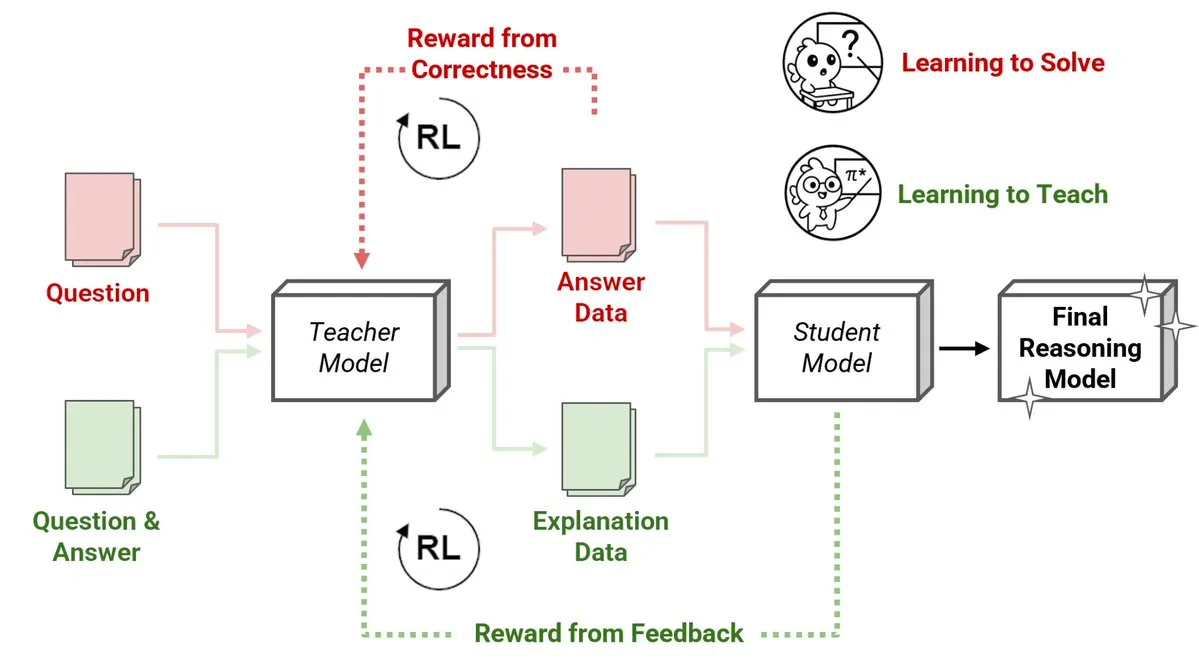
شركة Sakana AI تطلق طريقة جديدة لمعلمي التعلم المعزز (RLTs) حيث تقوم النماذج الصغيرة بتعليم النماذج الكبيرة الاستدلال: قدمت Sakana AI طريقة جديدة لمعلمي التعلم المعزز (RLTs)، والتي تغير طريقة تعليم الاستدلال للنماذج اللغوية الكبيرة (LLMs) من خلال التعلم المعزز (RL). يركز التعلم المعزز التقليدي على “تعلم الحل” للمشكلات، بينما يتم تدريب RLTs على إنشاء “تفسيرات” واضحة وتدريجية لتعليم النماذج الطلابية. أظهر RLT بمعلمات 7B فقط تفوقًا على LLMs أكبر منه بعدة مرات في مهام الاستدلال التنافسية وعلى مستوى الدراسات العليا عند تعليمه نموذجًا طلابيًا بمعلمات 32B. تضع هذه الطريقة معيارًا جديدًا للكفاءة في تطوير نماذج لغة الاستدلال باستخدام RL. (المصدر: cognitivecompai, AndrewLampinen)
Nvidia تتعاون مع Novo Nordisk لتسريع اكتشاف الأدوية باستخدام حاسوب فائق يعمل بالذكاء الاصطناعي: أعلنت Nvidia عن تعاونها مع شركة الأدوية الدنماركية العملاقة Novo Nordisk والمركز الوطني الدنماركي لابتكار الذكاء الاصطناعي، للاستفادة المشتركة من تقنية الذكاء الاصطناعي وأحدث حاسوب فائق في الدنمارك Gefion لتسريع تطوير الأدوية الجديدة. سيستخدم هذا التعاون منصة BioNeMo من Nvidia وسير عمل الذكاء الاصطناعي المتقدم، بهدف إحداث تحول في نماذج أبحاث وتطوير الأدوية. سيوفر حاسوب Gefion الفائق، الذي تم بناؤه بتقنيات من Eviden و Nvidia، دعمًا قويًا للحوسبة في مجالات مثل علوم الحياة، مما يدفع عجلة الطب الشخصي واكتشاف العلاجات الجديدة. (المصدر: nvidia)

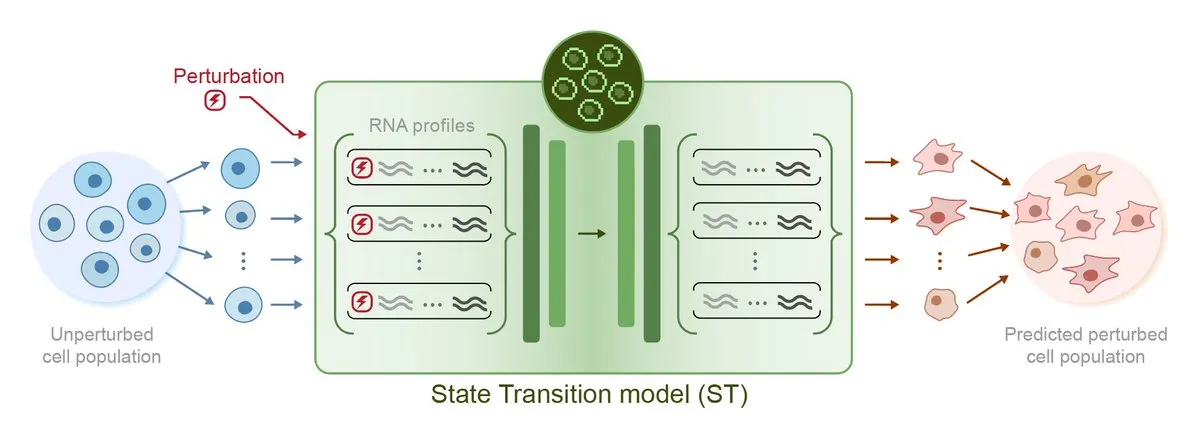
Arc Institute يطلق أول نموذج ذكاء اصطناعي للتنبؤ بالاضطرابات STATE، خطوة نحو هدف الخلية الافتراضية: أطلق Arc Institute أول نموذج ذكاء اصطناعي للتنبؤ بالاضطرابات STATE، وهو خطوة مهمة نحو تحقيق هدفه المتمثل في الخلية الافتراضية. يهدف نموذج STATE إلى تعلم كيفية استخدام الأدوية أو السيتوكينات أو الاضطرابات الجينية لتغيير حالة الخلية (على سبيل المثال، من “مريضة” إلى “سليمة”). يمثل إطلاق هذا النموذج تقدمًا جديدًا في فهم الذكاء الاصطناعي لسلوك الخلية والتنبؤ به، مما يفتح آفاقًا جديدة لعلاج الأمراض وتطوير الأدوية. تم توفير النماذج ذات الصلة على HuggingFace. (المصدر: riemannzeta, ClementDelangue)
Tesla Robotaxi تبدأ التشغيل التجريبي في أوستن، حلول الرؤية محط اهتمام، وتقليص كبير للكود الموروث من Karpathy: بدأت Tesla رسميًا خدمة Robotaxi التجريبية في أوستن، تكساس، الولايات المتحدة الأمريكية. تعتمد الدفعة الأولى من المركبات على طراز Model Y المعدل، وتستخدم حلول إدراك بصري خالص وبرنامج FSD. قاد Ashok Elluswamy، رئيس قسم الذكاء الاصطناعي وبرمجيات القيادة الذاتية في Tesla، الفريق لإجراء تغييرات تقنية كبيرة على النظام، حيث تم تقليص حوالي 330-340 ألف سطر من كود C++ الاستدلالي الموروث من فريق Andrej Karpathy بنسبة تقارب 90%، واستبداله بـ “شبكة عصبية عملاقة”. تهدف هذه الخطوة إلى التحول من “ترميز الخبرة البشرية” إلى “التدريب القائم على المعلمات”، من خلال تحسين النموذج ذاتيًا عبر كميات هائلة من البيانات ومحاكاة القيادة. الخدمة حاليًا في مرحلة تجريبية مبكرة، مما أثار نقاشًا واسعًا في الصناعة حول المسار التقني لـ Tesla وقدرتها على التوسع. (المصدر: 36氪, Ronald_vanLoon, kylebrussell)

🎯 التوجهات
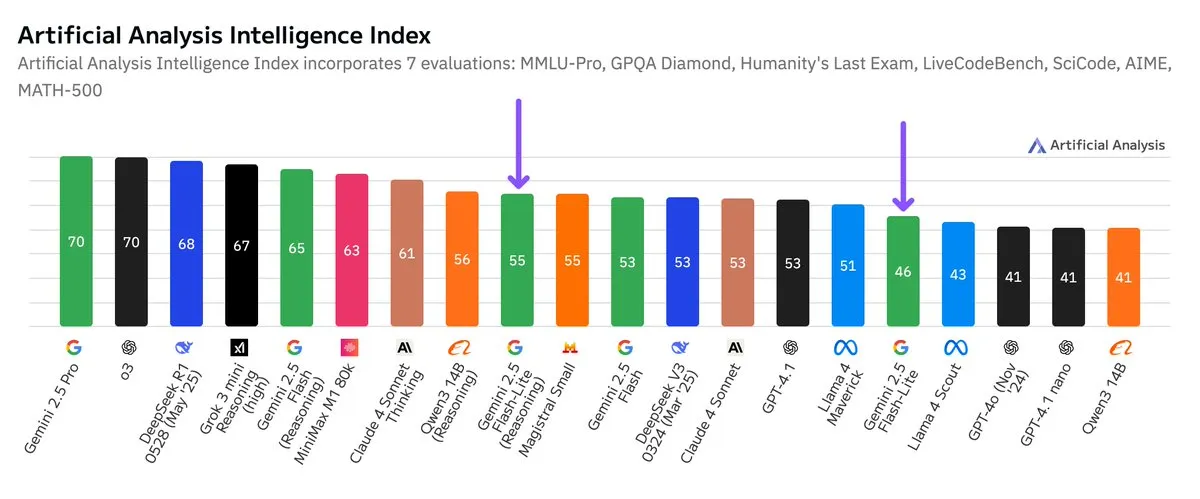
إصدار نتائج اختبار مستقل لـ Google Gemini 2.5 Flash-Lite، مع تحسين في نسبة الأداء إلى التكلفة: وفقًا لنتائج اختبار مستقلة نشرتها Artificial Analysis، فإن إصدار Google Gemini 2.5 Flash-Lite Preview (06-17) مقارنة بإصدار Flash العادي، شهد انخفاضًا في التكلفة بحوالي 5 أضعاف، وزيادة في السرعة بحوالي 1.7 مرة، ولكن مع انخفاض في مستوى الذكاء. هذا النموذج هو نسخة مطورة من Gemini 2.0 Flash-Lite الذي تم إصداره في فبراير 2025، وينتمي إلى النماذج الهجينة. يُظهر هذا التحديث جهود Google المستمرة في السعي لتحقيق كفاءة النموذج وفعالية التكلفة، وقد يكون موجهًا لسيناريوهات التطبيق التي تتطلب تكلفة وسرعة عالية. (المصدر: zacharynado)
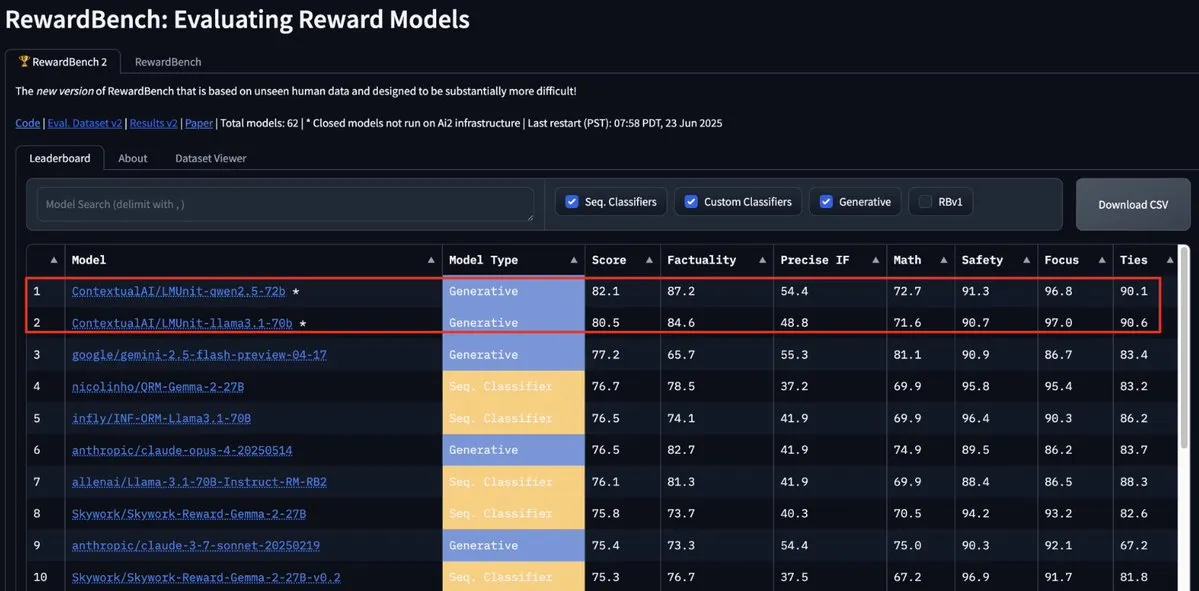
نموذج LMUnit من ContextualAI يتصدر RewardBench2 متجاوزًا Gemini و Claude 4 و GPT-4.1: احتل نموذج LMUnit من ContextualAI المرتبة الأولى في اختبار RewardBench2، متفوقًا على نماذج معروفة مثل Gemini و Claude 4 و GPT-4.1 بنسبة تزيد عن 5%. قد يُعزى هذا الإنجاز إلى طريقته التدريبية الفريدة، التي يُقال إنها تشبه طريقة “rubrics” التي استثمرت فيها OpenAI جهودًا كبيرة لتطويرها لنماذج o4 وما بعدها، وهي طريقة تساعد على تحقيق توسيع فعال لـ LLM كحكم (llm-as-a-judge) أثناء الاستدلال. (المصدر: natolambert, menhguin, apsdehal)
Arcee.ai تنجح في توسيع طول سياق نموذج AFM-4.5B من 4k إلى 64k: أعلنت Arcee.ai عن نجاحها في توسيع طول سياق نموذجها الأساسي الأول AFM-4.5B من 4k إلى 64k. حقق الفريق هذا الإنجاز من خلال التجارب النشطة، ودمج النماذج، والتقطير، وما يشار إليه مازحا بـ “كميات كبيرة من الحساء” (في إشارة إلى تقنية دمج النماذج). هذا التقدم حاسم لمعالجة مهام النصوص الطويلة، كما أثبتت تحسينات Arcee على نموذج GLM-32B-Base فعاليتها، حيث لم يقتصر الأمر على زيادة دعم السياق الطويل من 8k إلى 32k، بل شمل أيضًا تحسينات في جميع تقييمات النماذج الأساسية (بما في ذلك السياق القصير). (المصدر: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

تحديث واجهة برمجة تطبيقات Gemini من Google، لتحسين سرعة وقدرة معالجة الفيديو وملفات PDF: شهدت واجهة برمجة تطبيقات Gemini من Google تحديثًا هامًا في معالجة الفيديو وملفات PDF. تم تحسين وقت الاستجابة الأول (TTFT) لمقاطع الفيديو المخزنة مؤقتًا بمقدار 3 أضعاف، وزادت سرعة معالجة ملفات PDF المخزنة مؤقتًا بما يصل إلى 4 أضعاف. بالإضافة إلى ذلك، يدعم الإصدار الجديد المعالجة المجمعة لمقاطع فيديو متعددة، وأصبح أداء التخزين المؤقت الضمني قريبًا من التخزين المؤقت الصريح. تهدف هذه التحسينات إلى تعزيز كفاءة وتجربة المطورين عند استخدام واجهة برمجة تطبيقات Gemini لمعالجة محتوى الوسائط المتعددة. (المصدر: _philschmid)
Moonshot (Kimi) تحدث نموذج Kimi VL A3B Thinking لتعزيز قدرات المعالجة متعددة الوسائط: أصدرت Moonshot AI (Kimi) تحديثًا لنموذجها الصغير للغة المرئية (VLM) Kimi VL A3B Thinking، والذي يعتمد على ترخيص MIT. يستهلك الإصدار الجديد عددًا أقل من الـ tokens، ويقصر مسارات التفكير، وفي الوقت نفسه يدعم معالجة الفيديو ويمكنه التعامل مع صور عالية الدقة (1792×1792). حقق 65.2 نقطة على VideoMMMU، وتحسن MathVision بمقدار 20.1 نقطة ليصل إلى 56.9 نقطة، وتحسن MathVista بمقدار 8.4 نقطة ليصل إلى 80.1 نقطة، وتحسن MMMU-Pro بمقدار 3.2 نقطة ليصل إلى 46.3 نقطة، وأظهر أداءً متميزًا في الاستدلال البصري، وتحديد موقع وكيل واجهة المستخدم، ومعالجة الفيديو وملفات PDF، وقد تم توفيره كمصدر مفتوح على Hugging Face. (المصدر: mervenoyann)

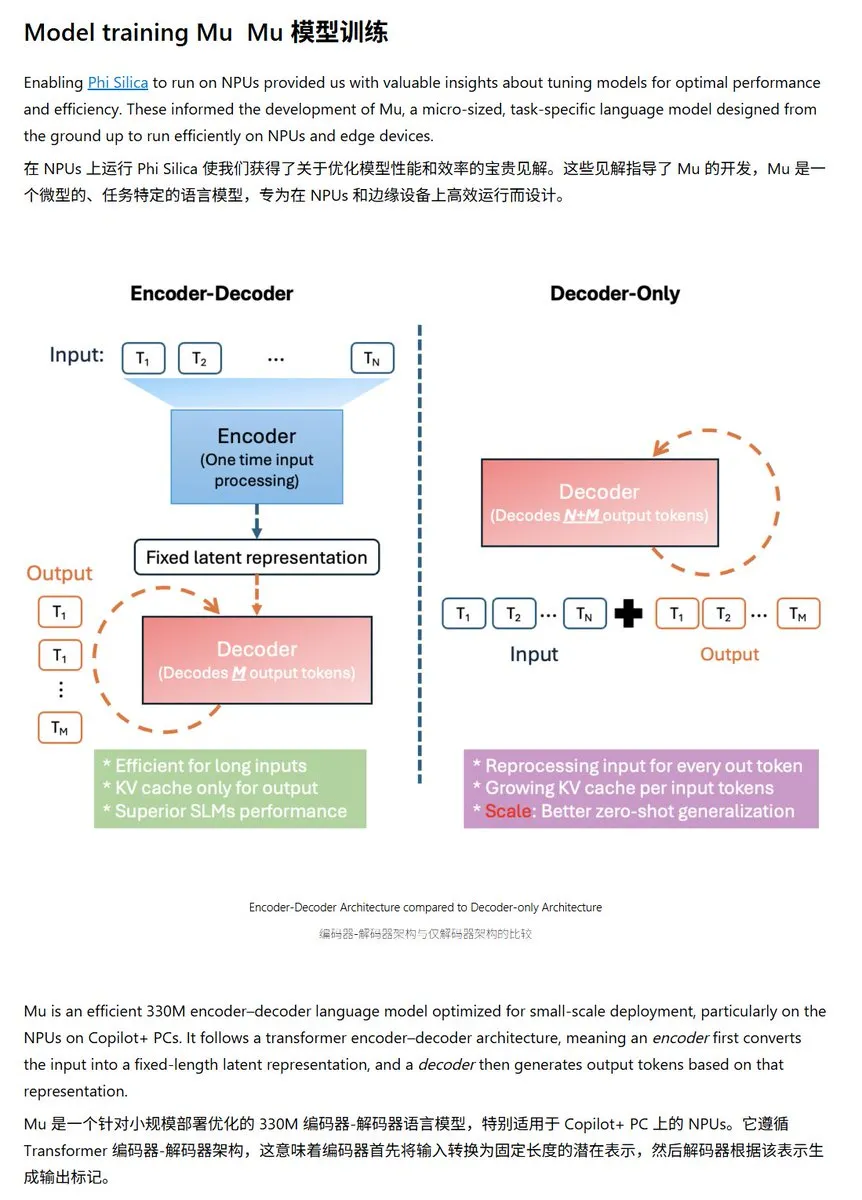
Microsoft تطلق نموذج اللغة الصغير Mu-330M، مُحسَّن خصيصًا لـ Windows NPU: قدمت Microsoft نموذج لغة صغيرًا جديدًا Mu-330M، مصممًا للتشغيل على NPU (وحدة المعالجة العصبية) لأجهزة الكمبيوتر الشخصية Windows Copilot+ PC، بهدف دعم وظائف Agent داخل نظام Windows. تم تحسين هذا النموذج لـ NPU، باستخدام تقنيات مثل تضمينات الموضع الدورانية، وانتباه الاستعلام المجمع، و LayerNorm مزدوج الطبقة، وذلك للعمل بكفاءة مع استهلاك منخفض للطاقة، مما يمثل خطوة إضافية لـ Microsoft في تطوير قدرات الذكاء الاصطناعي على الأجهزة الطرفية. (المصدر: karminski3)
DeepMind تنشر تقريرًا تقنيًا عن Mercury، مع التركيز على نماذج لغة الانتشار: نشرت Inception Labs (فريق مرتبط بـ DeepMind) تقريرًا تقنيًا عن نموذج لغة الانتشار Mercury. يفصل التقرير بنية نموذج Mercury وطرق تدريبه ونتائج التجارب، مما يوفر للباحثين رؤى متعمقة حول هذا النوع الناشئ من النماذج. حققت نماذج الانتشار نجاحًا ملحوظًا في مجال توليد الصور، ويعد تطبيقها على نماذج اللغة اتجاهًا رائدًا في أبحاث الذكاء الاصطناعي الحالية. (المصدر: andriy_mulyar)
Meta تتعاون مع Oakley لتوسيع مجموعة نظاراتها الذكية المدعومة بالذكاء الاصطناعي: تتعاون Meta مع علامة النظارات التجارية Oakley لتوسيع خط إنتاجها من النظارات الذكية المدعومة بالذكاء الاصطناعي. من المتوقع أن تدمج النظارات الذكية الجديدة تقنيات الذكاء الاصطناعي من Meta، مما يوفر وظائف تفاعلية أكثر ثراءً وتجربة مستخدم محسنة. يمثل هذا التعاون استثمار Meta المستمر في مجال أجهزة الذكاء الاصطناعي القابلة للارتداء، بهدف دمج الذكاء الاصطناعي بشكل أكثر سلاسة في الحياة اليومية. (المصدر: rowancheung, Ronald_vanLoon)
علي بابا كلاود تطلق إطار عمل تسريع تدريب واستدلال نماذج القيادة الذاتية PAI-TurboX، مما يقلل وقت التدريب بنسبة 50%: أطلقت علي بابا كلاود إطار عمل PAI-TurboX لتسريع تدريب واستدلال النماذج في مجال القيادة الذاتية. يهدف هذا الإطار إلى تحسين كفاءة تدريب واستدلال نماذج الإدراك والتخطيط والتحكم وحتى نماذج العالم، من خلال تحسين المعالجة المسبقة للبيانات متعددة الوسائط، وتقارب وحدة المعالجة المركزية، والترجمة الديناميكية، والتوازي عبر خطوط الأنابيب، وتوفير قدرات تحسين وتقدير المشغلات. أظهرت الاختبارات الفعلية أنه في مهام تدريب العديد من نماذج الصناعة مثل BEVFusion و MapTR و SparseDrive، يمكن لـ PAI-TurboX تقليل وقت التدريب بحوالي 50%. (المصدر: 量子位)
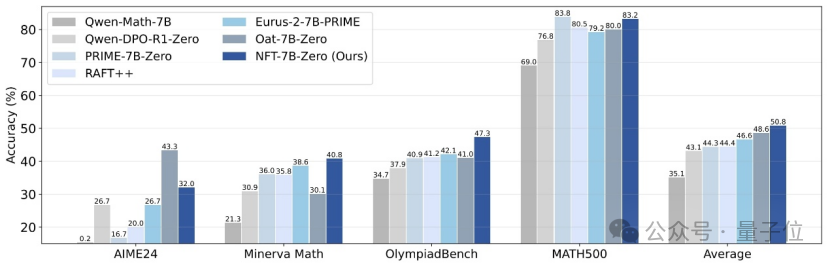
جامعة تسينغهوا و Nvidia وغيرهما يقترحون طريقة NFT لتمكين التعلم الخاضع للإشراف من “التفكير” في الأخطاء: اقترح باحثون من جامعة تسينغهوا و Nvidia وجامعة ستانفورد بشكل مشترك مخططًا جديدًا للتعلم الخاضع للإشراف يسمى NFT (Negative-aware FineTuning). تعتمد هذه الطريقة على خوارزمية RFT (Rejection FineTuning)، من خلال بناء “نموذج سلبي ضمني” لاستخدام البيانات السلبية في التدريب، أي “استراتيجية سلبية ضمنية”. تمكّن هذه الاستراتيجية التعلم الخاضع للإشراف من إجراء “تفكير ذاتي” كما هو الحال في التعلم المعزز، مما يسد الفجوة في بعض القدرات بين التعلم الخاضع للإشراف والتعلم المعزز، ويظهر تحسنًا كبيرًا في الأداء في مهام مثل الاستدلال الرياضي، وحتى في ظل ظروف On-Policy، فإن تدرج دالة الخسارة الخاصة به يعادل GRPO. (المصدر: 量子位)
إطلاق OmniGen2: نموذج تعديل صور متعدد الوظائف بدقة 8B، يدمج الفهم البصري وتوليد الصور: تم إطلاق نموذج جديد متعدد الوظائف لتعديل الصور يسمى OmniGen2، يجمع هذا النموذج بين الفهم البصري (المبني على Qwen-VL-2.5) وتوليد الصور (نموذج انتشار بمعلمات 4B)، بإجمالي عدد معلمات يبلغ حوالي 8B. يدعم OmniGen2 مهامًا متعددة مثل تحويل النص إلى صورة، وتحرير الصور، وفهم الصور، وتوليد السياق، ويهدف إلى توفير نموذج موحد يمكنه حل العديد من المشكلات المتعلقة بالرؤية ومناسب للتكامل على الأجهزة الطرفية. (المصدر: karminski3)

تحديث نموذج Chroma-8.9B-v39 لتوليد الصور من النصوص، مبني على FLUX.1-schnell، وقابل للاستخدام التجاري: تم إصدار تحديث لنموذج تحويل النص إلى صورة Chroma-8.9B-v39، مما يحسن الإضاءة والطبيعية في المهام. يعتمد هذا النموذج على FLUX.1-schnell، وتم ضغط عدد المعلمات من 12B إلى 8.9B، ويستخدم ترخيص Apache 2.0، مما يسمح بالاستخدام التجاري. يُزعم أن النموذج “أعاد تقديم المفاهيم التشريحية المفقودة، وهو خالٍ تمامًا من قيود المحتوى”، وتم تدريبه لاحقًا باستخدام مجموعة بيانات تحتوي على 5 ملايين من أعمال الأنمي والفروي والأعمال الفنية والصور. (المصدر: karminski3)

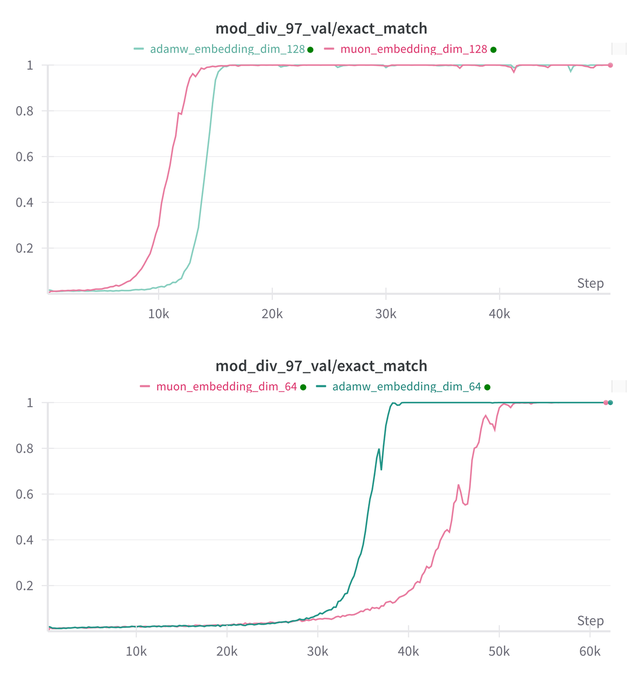
Essential AI تحدث استنتاجات أبحاثها حول قدرات نموذجيها Muon و Adam في Grokking: شاركت Essential AI أحدث التطورات البحثية المتعلقة بقدرات نموذجيها Muon و Adam في Grokking (ظاهرة حيث يظهر النموذج أداءً ضعيفًا في بداية التدريب ثم يفهم التعميم فجأة). قد تتعارض الفرضيات الأولية مع الملاحظات الفعلية، وقد كشف الفريق عن نتائج تجارب بحثية داخلية صغيرة، أظهرت أنه بعد توسيع مساحة البحث عن المعلمات الفائقة، لم يُظهر Muon أي ميزة عامة واضحة مقارنة بـ AdamW، حيث تفوق كل منهما على الآخر في سيناريوهات مختلفة. يشير هذا إلى أن AdamW لا يزال محسنًا قويًا وحتى SOTA في العديد من الحالات. (المصدر: eliebakouch, teortaxesTex, nrehiew_)
تحديث نموذج Ostris AI لتوليد الصور، مع التركيز على الإصدار بدون CFG وتحسين التفاصيل عالية التردد: تواصل Ostris AI تحديث نموذجها لتوليد الصور، وتركز حاليًا على تطوير الإصدار بدون CFG (Classifier-Free Guidance)، نظرًا لسرعة تقاربه الأسرع. في تحديث Day 7 الأخير، أضاف الفريق تقنيات تدريب جديدة لمعالجة التفاصيل عالية التردد بشكل أفضل، ويعملون جاهدين على إزالة التشوهات الناتجة عن التفاصيل العالية. أظهر تحديث Day 4 السابق تحسنًا ملحوظًا في جودة الصور التي تم إنشاؤها باستخدام طرق جديدة بدون استخدام CFG. (المصدر: ostrisai)

Ant Group والمعهد الصيني للعلوم وغيرهما يطلقون نموذج ViLaSR-7B مفتوح المصدر، لتحقيق استدلال مكاني “بالرسم أثناء التفكير”: أطلق معهد Ant Group للأبحاث التكنولوجية، ومعهد الأتمتة التابع للأكاديمية الصينية للعلوم، والجامعة الصينية في هونغ كونغ، نموذج ViLaSR-7B مفتوح المصدر. يمكّن هذا النموذج، من خلال نموذج “Drawing to Reason in Space”، النماذج اللغوية المرئية الكبيرة (LVLM) من رسم علامات مساعدة (مثل الخطوط المرجعية، والمربعات المحيطة) في الفضاء البصري للمساعدة في التفكير، وبالتالي تعزيز الإدراك المكاني وقدرات الاستدلال. يعتمد ViLaSR على إطار تدريب ثلاثي المراحل: التشغيل البارد، وأخذ عينات رفض التفكير، والتعلم المعزز. أظهرت التجارب أن هذا النموذج حقق تحسنًا متوسطًا بنسبة 18.4% في 5 معايير قياسية مثل التنقل في المتاهات، وفهم الصور، والاستدلال المكاني بالفيديو، وأظهر أداءً قريبًا من Gemini-1.5-Pro على VSI-Bench. (المصدر: 量子位)

🧰 الأدوات
SGLang يدعم الآن Hugging Face Transformers كواجهة خلفية، مما يعزز كفاءة الاستدلال: أعلنت SGLang عن دعمها لـ Hugging Face Transformers كواجهة خلفية. هذا يعني أنه يمكن للمستخدمين توفير خدمة استدلال سريعة وجاهزة للإنتاج لأي نموذج متوافق مع Transformers، دون الحاجة إلى دعم أصلي، أي أنه يعمل بمجرد التوصيل. يهدف هذا التكامل إلى تبسيط عملية نشر استدلال نماذج اللغة عالية الأداء، وتوسيع نطاق تطبيق SGLang وسهولة استخدامه. (المصدر: TheZachMueller, ClementDelangue)

إصدار MLX-LM-LORA v0.7.0 مع وظيفة RLHF مدمجة: تم إصدار MLX-LM-LORA v0.7.0، ويتضمن الإصدار الجديد وظيفة مدمجة للتعلم المعزز من ردود الفعل البشرية (RLHF). تدعم الأداة الآن التحميل بـ 4 بت و 6 بت و 8 بت، ووضع تدريب RLHF، ويمكنها دمج المهايئات (adapters) مباشرة في الأوزان الأساسية. هذا يجعل الضبط الدقيق لـ LoRA ضمن إطار عمل MLX أكثر ذكاءً وكفاءة، خاصة على أجهزة Apple Silicon. (المصدر: awnihannun)
إطلاق LlamaCloud، لتوفير مجموعة أدوات متوافقة مع MCP لسير عمل المستندات: تم إطلاق LlamaCloud الآن، كصندوق أدوات متوافق مع بروتوكول سياق النموذج (MCP)، يمكن استخدامه لأي سير عمل للمستندات. يمكن للمستخدمين توصيله بنماذج مثل Claude، لتحقيق عمليات معقدة لاستخراج المستندات ومقارنتها وما إلى ذلك. على سبيل المثال، يمكنه تحليل الأداء المالي لشركة Tesla خلال الأرباع الخمسة الماضية وإنشاء تقرير شامل، من خلال إنشاء أنماط موحدة ديناميكيًا وتشغيلها على جميع الملفات، ثم استخدام توليد الكود للوصول إلى النتيجة النهائية. يستطيع LlamaCloud تصحيح الأنماط غير الصحيحة ديناميكيًا، ويدعم ربط الملفات المباشر. (المصدر: jerryjliu0)
Georgi Gerganov يعلن عن مشروع LlamaBarn: نشر Georgi Gerganov (مبتكر llama.cpp) صورة على وسائل التواصل الاجتماعي، معلنًا عن مشروع جديد يسمى “LlamaBarn”. تُظهر الصورة واجهة تشبه لوحة التحكم، تحتوي على عناصر مثل اختيار النموذج، وتعديل المعلمات، مما يشير إلى أنه قد يكون أداة لإدارة أو تشغيل أو اختبار LLM محليًا. أعرب المجتمع عن ترقبه، معتقدًا أنه قد يصبح منافسًا قويًا للأدوات الحالية مثل Ollama. (المصدر: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor: مساعد برمجة جديد مفتوح المصدر يعمل بالذكاء الاصطناعي، يدعم MCP والنماذج المحلية: ظهر Void Editor كمساعد برمجة جديد مفتوح المصدر يعمل بالذكاء الاصطناعي، يهدف إلى أن يكون بديلاً لأدوات مثل Cursor. يدعم الإكمال التلقائي بعلامة التبويب، ووضع الدردشة، وبروتوكول سياق النموذج (MCP)، ووضع Agent. يمكن للمستخدمين الاتصال بأي واجهة برمجة تطبيقات لنموذج لغوي كبير أو تشغيل النماذج محليًا، مما يوفر للمطورين تجربة برمجة مرنة مدعومة بالذكاء الاصطناعي. (المصدر: karminski3)
Together AI تطلق أداة Which LLM للمساعدة في اختيار LLM مفتوح المصدر المناسب: أطلقت Together AI أداة مجانية تسمى “Which LLM”، تهدف إلى مساعدة المستخدمين على اختيار أنسب نموذج لغوي كبير مفتوح المصدر بناءً على حالات استخدام محددة، ومتطلبات الأداء، والاعتبارات الاقتصادية. مع التزايد الهائل في عدد LLMs مفتوحة المصدر، يمكن لمثل هذه الأدوات أن توفر مرجعًا قيمًا للمطورين والباحثين عند اختيار النماذج. (المصدر: vipulved)
Perplexity Finance تضيف ميزة تتبع الجدول الزمني لأسعار الأسهم: أعلنت Perplexity Finance أنه يمكن للمستخدمين الآن تتبع الجدول الزمني لتغيرات أسعار أي رمز سهم على منصتها. تهدف هذه الميزة الجديدة إلى تزويد المستخدمين بأداة تحليل معلومات السوق المالية أكثر سهولة ويسرًا، وبالاقتران مع قدرات الذكاء الاصطناعي لـ Perplexity، قد تجلب تجربة جديدة للاستعلام عن المعلومات المالية وتحليلها. (المصدر: AravSrinivas)

IdeaWeaver تطلق أول وكيل ذكاء اصطناعي لتصحيح أخطاء أداء النظام: أطلقت IdeaWeaver ما تدعي أنه أول وكيل ذكاء اصطناعي مصمم خصيصًا لتصحيح أخطاء مشكلات أداء النظام. تستخدم هذه الأداة إطار عمل CrewAI، ويمكنها تنفيذ أوامر النظام فعليًا لتشخيص المشكلات المتعلقة بوحدة المعالجة المركزية والذاكرة والإدخال/الإخراج والشبكة. تتميز بإعطاء الأولوية لاستخدام LLM محلي (عبر OLLAMA) لحماية الخصوصية، ولا تطلب مفتاح OpenAI API إلا عند عدم توفر النموذج المحلي، وتهدف إلى تطبيق قدرات الذكاء الاصطناعي في مجالات DevOps وإدارة النظام. (المصدر: Reddit r/artificial)
Kling AI يضيف دعم Live Photo، مما يسمح بحفظ مقاطع الفيديو التي تم إنشاؤها كخلفيات متحركة: أعلنت Kling AI أن وظيفة إنشاء الفيديو الخاصة بها تدعم الآن حفظ الأعمال كـ Live Photos (صور حية). يمكن للمستخدمين تعيين المحتوى الديناميكي المفضل لديهم الذي أنشأته Kling كخلفية لهواتفهم، مما يزيد من متعة وفائدة مقاطع الفيديو التي تم إنشاؤها بواسطة الذكاء الاصطناعي. (المصدر: Kling_ai)
Cognition AI تفتح مصدر Blockdiff، محققة زيادة في سرعة لقطات VM بمقدار 200 مرة: أعلنت Cognition AI عن فتح مصدر تنسيق ملف لقطات VM الخاص بها Blockdiff، والذي تم تطويره لـ Devin. نظرًا لأن إنشاء لقطات VM على EC2 يستغرق وقتًا طويلاً (أكثر من 30 دقيقة)، قام الفريق ببناء برنامج إدارة الأجهزة الافتراضية otterlink وتنسيق ملف Blockdiff بأنفسهم، مما أدى إلى زيادة سرعة إنشاء اللقطات بمقدار 200 مرة. تهدف هذه المساهمة مفتوحة المصدر إلى مساعدة المطورين على إدارة بيئات الأجهزة الافتراضية بكفاءة أكبر. (المصدر: karinanguyen_)

📚 مواد تعليمية
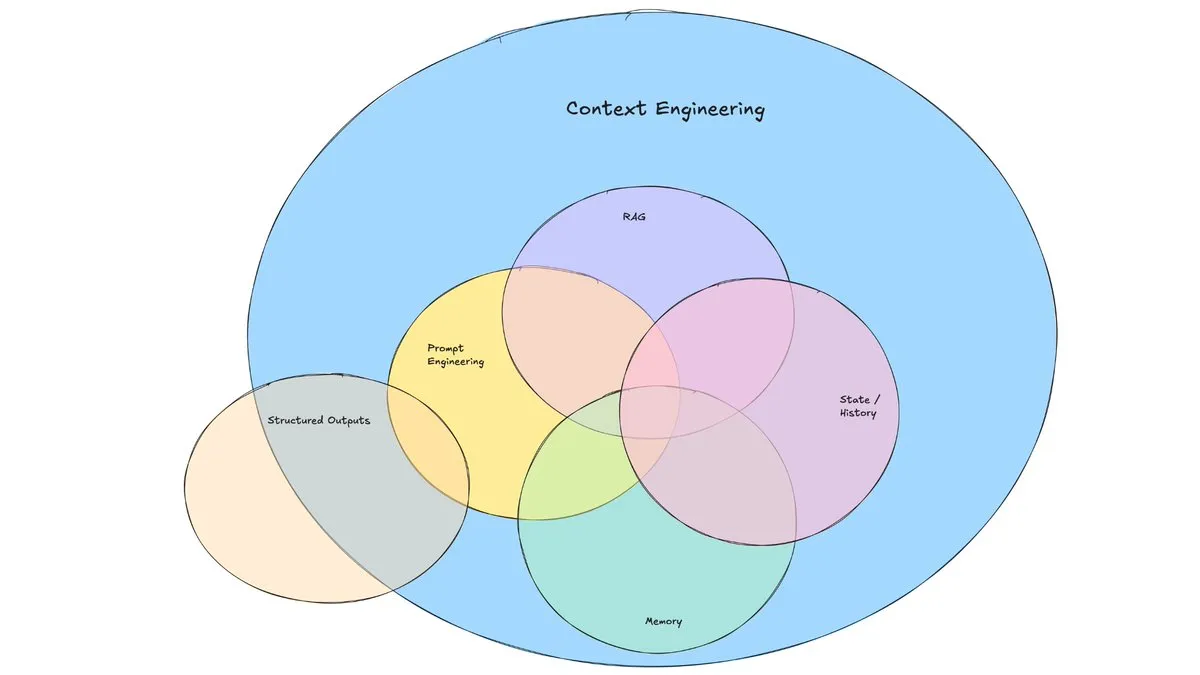
مدونة LangChain تناقش صعود “هندسة السياق”: نشرت LangChain تدوينة تناقش مصطلح “هندسة السياق” (Context Engineering) الذي يزداد شيوعًا. يعرّف المقال هذا المصطلح بأنه “بناء أنظمة ديناميكية لتوفير المعلومات والأدوات الصحيحة بالتنسيق الصحيح، مما يمكّن LLM من إكمال المهام بشكل معقول”. هذا ليس مفهومًا جديدًا تمامًا، فقد مارسه بناة الوكلاء (Agents) لفترة طويلة، كما تم إنشاء أدوات مثل LangGraph و LangSmith لهذا الغرض. يساعد طرح هذا المصطلح على جذب المزيد من الاهتمام للمهارات والأدوات ذات الصلة. (المصدر: hwchase17, Hacubu, yoheinakajima)
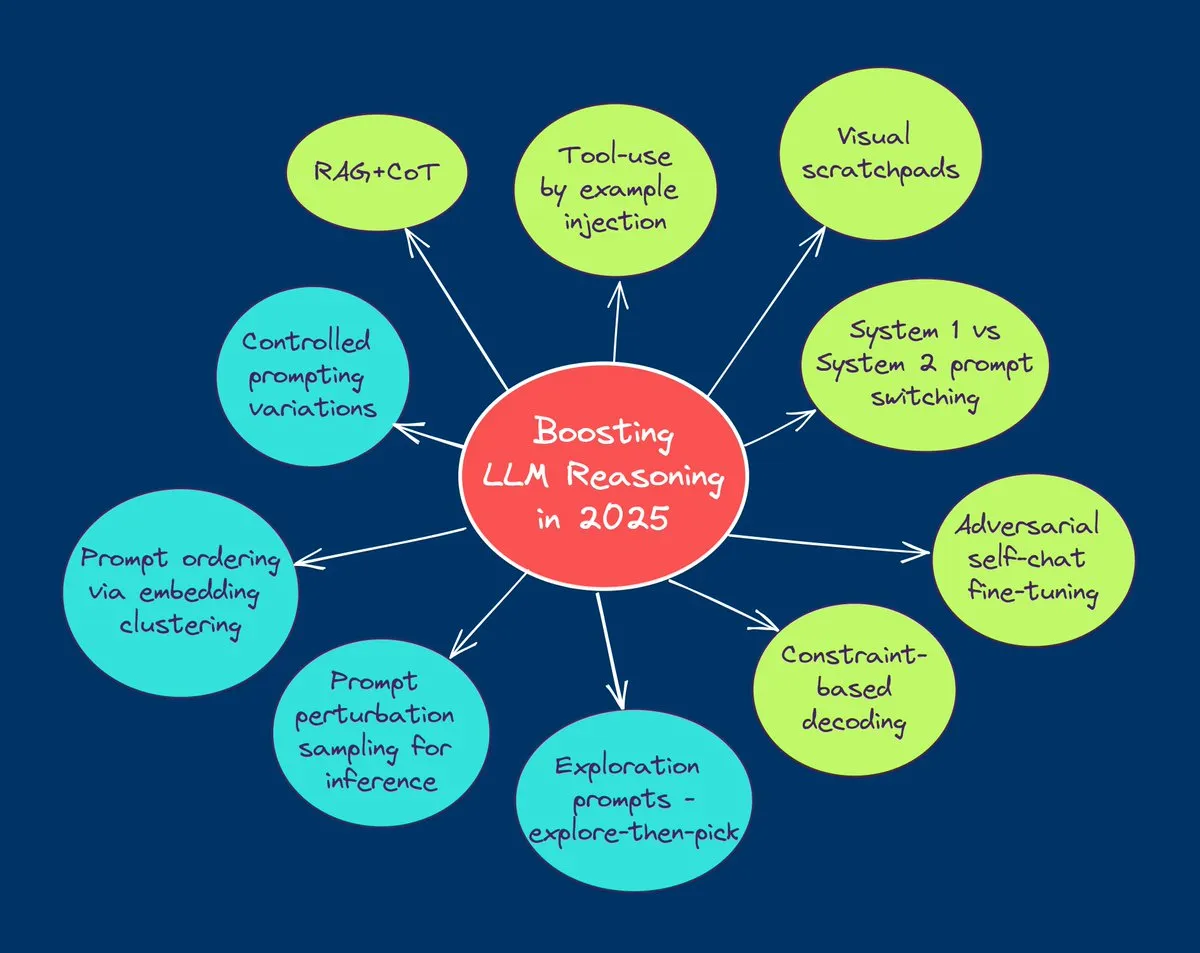
TuringPost تلخص أفضل 10 تقنيات لتعزيز قدرات استدلال LLM في عام 2025: شاركت TuringPost 10 تقنيات رئيسية تستخدم لتعزيز قدرات استدلال النماذج اللغوية الكبيرة (LLM) في عام 2025، وتشمل: سلسلة التفكير المعززة بالاسترجاع (RAG+CoT)، واستخدام الأدوات عن طريق حقن الأمثلة، والورق المرئي (دعم الاستدلال متعدد الوسائط)، والتبديل بين التوجيه بالنظام 1 والنظام 2، والضبط الدقيق الذاتي العدائي، وفك التشفير القائم على القيود، والتوجيه الاستكشافي (الاستكشاف أولاً ثم الاختيار)، وأخذ عينات اضطراب التوجيه للاستدلال، وترتيب التوجيه عن طريق تجميع التضمينات، ومتغيرات التوجيه المتحكم فيها. توفر هذه التقنيات مسارات متنوعة لتحسين أداء LLM في المهام المعقدة. (المصدر: TheTuringPost, TheTuringPost)
Cohere Labs تنظم مدرسة صيفية للتعلم الآلي لاستكشاف مستقبل التعلم الآلي: سينظم مجتمع العلوم المفتوحة في Cohere Labs مدرسة صيفية للتعلم الآلي (ML Summer School) في يوليو. سيجمع هذا الحدث أعضاء المجتمع العالمي لمناقشة مستقبل التعلم الآلي، وسيدعو متحدثين من الصناعة للمشاركة. من بين هؤلاء، ستقدم Katrina Lawrence محاضرة حول مراجعة رياضيات التعلم الآلي في 2 يوليو، تغطي مفاهيم أساسية مثل حساب التفاضل والتكامل، وحساب المتجهات، والجبر الخطي. (المصدر: sarahookr)

DeepLearning.AI تتعاون مع Meta لإطلاق دورة مجانية بعنوان “Building with Llama 4”: أطلقت DeepLearning.AI بالتعاون مع Meta دورة مجانية بعنوان “Building with Llama 4”. يتضمن محتوى الدورة: التدريب العملي على نماذج سلسلة Llama 4، وفهم بنيتها القائمة على خليط الخبراء (MOE)، وكيفية بناء التطبيقات باستخدام واجهة برمجة التطبيقات الرسمية؛ تطبيق Llama 4 للاستدلال متعدد الصور، وتحديد مواقع الصور (التعرف على الكائنات ومربعاتها المحيطة)، ومعالجة استعلامات النصوص ذات السياق الطويل التي تصل إلى مليون توكن؛ استخدام أدوات تحسين التوجيه في Llama 4 لتحسين توجيهات النظام تلقائيًا، والاستفادة من مجموعة أدوات البيانات الاصطناعية الخاصة بها لإنشاء مجموعات بيانات عالية الجودة للضبط الدقيق. (المصدر: DeepLearningAI)
قناة EleutherAI على YouTube تقدم محتوى بحثيًا غنيًا في مجال الذكاء الاصطناعي: تجمع قناة EleutherAI على YouTube تسجيلات فيديو لنوادي القراءة وسلسلة المحاضرات الخاصة بها، يتجاوز محتواها 100 ساعة. تغطي الموضوعات قابلية التوسع والأداء في التعلم الآلي، والتحليل الوظيفي، بالإضافة إلى البودكاست والمقابلات مع أعضاء الفريق. توفر هذه القناة مصدرًا تعليميًا غنيًا للباحثين والمتحمسين للذكاء الاصطناعي. أطلقت EleutherAI أيضًا سلسلة محاضرات جديدة، يتحدث في أولى حلقاتها @linguist_cat عن أدوات التقطيع (tokenizers) وقيودها. (المصدر: BlancheMinerva, BlancheMinerva)
ورقة بحثية تناقش تعزيز الاستدلال متعدد الوسائط من خلال الرموز المرئية الكامنة (Machine Mental Imagery): تقترح ورقة بحثية جديدة بعنوان “Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens” إطار عمل Mirage، الذي يعزز الاستدلال متعدد الوسائط من خلال إضافة رموز مرئية كامنة (بدلاً من إنشاء صور كاملة) أثناء عملية فك تشفير VLM، محاكاةً للتصور الذهني البشري. تشرف هذه الطريقة أولاً على الرموز الكامنة من خلال تقطير تضمينات الصور الحقيقية، ثم تنتقل إلى الإشراف النصي البحت لمواءمة المسارات الكامنة مع أهداف المهمة، وتعزز القدرات بشكل أكبر من خلال التعلم المعزز. أثبتت التجارب أن Mirage يمكنه تحقيق استدلال متعدد الوسائط أقوى دون إنشاء صور واضحة. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح إطار عمل Vision as a Dialect لتوحيد الفهم والتوليد البصري من خلال تمثيلات متوافقة مع النص: ورقة بحثية بعنوان “Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations”، تقدم إطار عمل LLM متعدد الوسائط يسمى Tar. يستخدم هذا الإطار أداة تقطيع متوافقة مع النص (TA-Tok) لتحويل الصور إلى رموز منفصلة، ويستفيد من كتاب رموز متوافق مع النص مُسقط من مفردات LLM، وبالتالي يوحد الرؤية والنص في تمثيل دلالي منفصل مشترك. يحقق Tar إدخالًا وإخراجًا عبر الوسائط من خلال واجهة مشتركة، دون الحاجة إلى تصميم خاص بالوسائط، ويعتمد على برنامج ترميز وفك ترميز متكيف مع الحجم وأداة فك تقطيع توليدية لتحقيق التوازن بين الكفاءة والتفاصيل المرئية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح ReasonFlux-PRM: نموذج PRM مدرك للمسار لاستدلال سلسلة التفكير الطويلة في LLM: تقدم الورقة البحثية “ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs” نموذج مكافأة عملية (PRM) جديدًا مدركًا للمسار، مصمم خصيصًا لتقييم آثار الاستدلال من نوع المسار-الاستجابة التي تم إنشاؤها بواسطة نماذج الاستدلال المتطورة مثل DeepSeek-R1. يجمع ReasonFlux-PRM بين الإشراف على مستوى الخطوة ومستوى المسار، مما يحقق تخصيصًا دقيقًا للمكافآت يتماشى مع بيانات سلسلة التفكير المنظمة، ويحقق تحسينات في الأداء في سيناريوهات مثل SFT و RL و BoN عند التوسع في وقت الاختبار. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تدرس طرق تقييم حواجز الحماية من اختراق النماذج اللغوية الكبيرة: ورقة بحثية بعنوان “SoK: Evaluating Jailbreak Guardrails for Large Language Models” تقدم استعراضًا منهجيًا للمعرفة حول هجمات اختراق النماذج اللغوية الكبيرة (LLMs) وحواجز الحماية الخاصة بها (Guardrails). تقترح الورقة تصنيفًا جديدًا متعدد الأبعاد، يصنف حواجز الحماية من ستة أبعاد رئيسية، وتقدم إطار تقييم للأمان والكفاءة والفائدة لتقييم فعاليتها الفعلية. من خلال التحليل والتجارب المكثفة، تشير الورقة إلى مزايا وعيوب طرق حواجز الحماية الحالية، وتناقش مدى ملاءمتها لأنواع مختلفة من الهجمات، وتقدم رؤى لتحسين مجموعات الدفاع. (المصدر: HuggingFace Daily Papers)
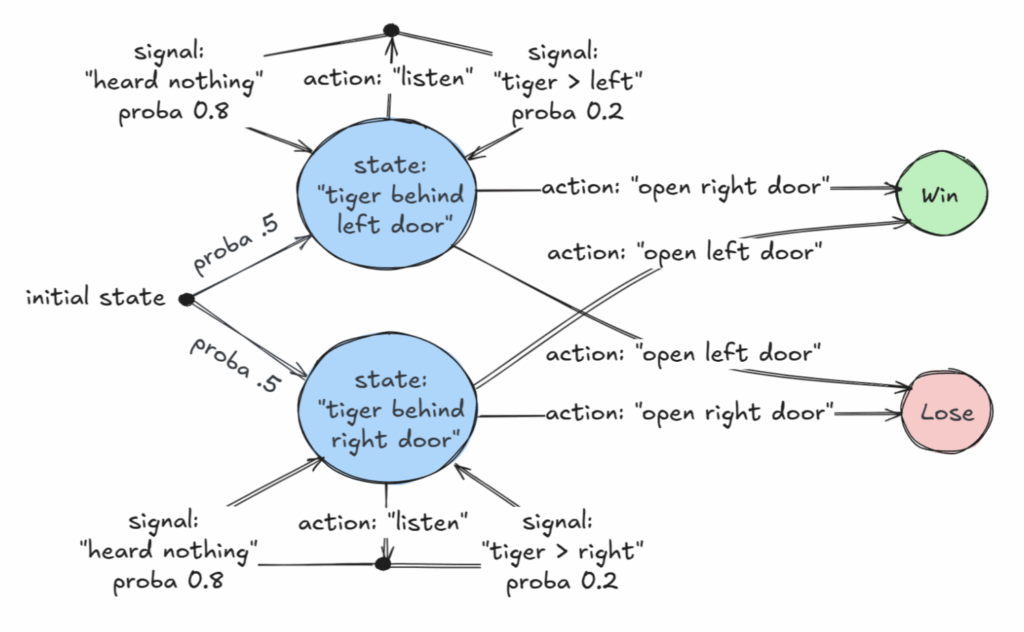
ورقة بحثية متميزة في AAAI 2025 تناقش الفئات القابلة للتقرير لعمليات ماركوف لاتخاذ القرار جزئية الملاحظة (POMDP): حصلت ورقة بحثية بعنوان “Revelations: A Decidable Class of POMDP with Omega-Regular Objectives” على جائزة الورقة المتميزة في AAAI 2025. تحدد هذه الدراسة فئة قابلة للتقرير من عمليات ماركوف لاتخاذ القرار (MDP): مشكلات اتخاذ القرار ذات “الكشف القوي”، أي أنه في كل خطوة هناك احتمال غير صفري للكشف عن الحالة الدقيقة للعالم. تقدم الورقة أيضًا نتائج قابلية التقرير لـ “الكشف الضعيف”، حيث يُضمن الكشف عن الحالة الدقيقة في النهاية، ولكن ليس بالضرورة في كل خطوة. توفر هذه الدراسة أساسًا نظريًا جديدًا لاتخاذ القرارات المثلى في ظل عدم اكتمال المعلومات. (المصدر: aihub.org)
ورقة بحثية تقترح CommVQ: تكميم متجه تبادلي لضغط ذاكرة التخزين المؤقت KV: تقترح ورقة بحثية بعنوان “CommVQ: Commutative Vector Quantization for KV Cache Compression” طريقة تسمى CommVQ، تقوم بضغط ذاكرة التخزين المؤقت KV من خلال التكميم الإضافي ومشفّر خفيف الوزن وكتاب رموز، لتقليل استهلاك الذاكرة في استدلال LLM ذي السياق الطويل. لتقليل تكلفة حساب فك التشفير، تم تصميم كتاب الرموز ليكون قابلاً للتبادل مع تضمينات الموضع الدورانية (RoPE)، ويتم تدريبه باستخدام خوارزمية EM. أظهرت التجارب أن هذه الطريقة يمكن أن تقلل حجم ذاكرة التخزين المؤقت FP16 KV بنسبة 87.5% عند تكميم 2 بت، وتتفوق على طرق تكميم ذاكرة التخزين المؤقت KV الحالية، بل ويمكنها تحقيق تكميم ذاكرة التخزين المؤقت KV بمقدار 1 بت مع خسارة دقة ضئيلة للغاية. (المصدر: HuggingFace Daily Papers)
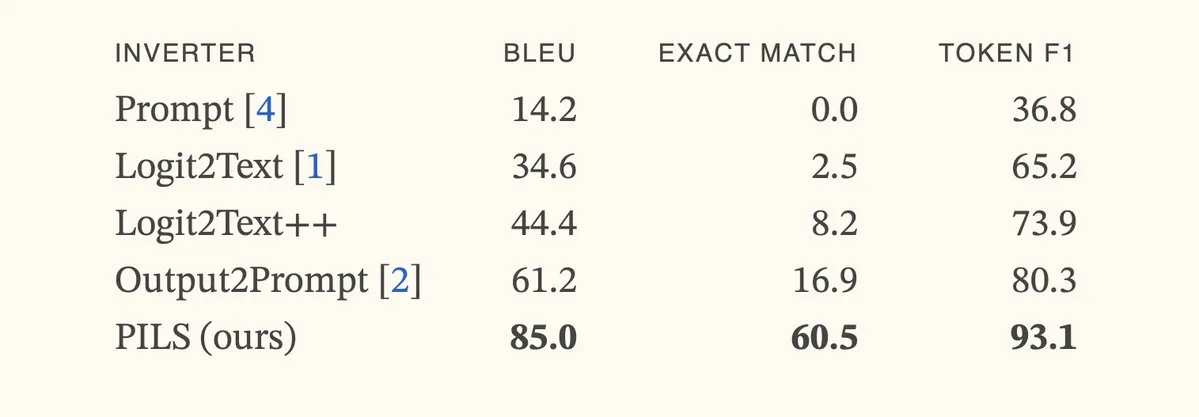
ورقة بحثية تقترح طريقة PILS لتحسين عكس نموذج اللغة من خلال تمثيل توزيع الرمز التالي بشكل مضغوط: تقترح ورقة بحثية بعنوان “Better Language Model Inversion by Compactly Representing Next-Token Distributions” طريقة جديدة لعكس نموذج اللغة تسمى PILS (Prompt Inversion from Logprob Sequences). تستعيد هذه الطريقة المطالبات المخفية من خلال تحليل احتمالات الرمز التالي للنموذج في خطوات توليد متعددة. يكمن جوهرها في اكتشاف أن متجهات إخراج نموذج اللغة تشغل فضاءًا فرعيًا منخفض الأبعاد، وبالتالي يمكن ضغط توزيع احتمالات الرمز التالي دون فقدان من خلال تعيين خطي، لاستخدامه في عكس أكثر فعالية. أظهرت التجارب أن PILS تتفوق بشكل كبير على طرق SOTA السابقة في استعادة المطالبات المخفية. (المصدر: HuggingFace Daily Papers, jxmnop)
ورقة بحثية تقترح Phantom-Data: مجموعة بيانات عامة لتوليد الفيديو المتسق مع الموضوع: تقدم ورقة بحثية بعنوان “Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset” مجموعة بيانات جديدة تسمى Phantom-Data، تهدف إلى حل مشكلة “النسخ واللصق” المنتشرة في نماذج توليد الفيديو من الموضوع الحالية (أي التشابك المفرط لهوية الموضوع مع سمات الخلفية والسياق). Phantom-Data هي أول مجموعة بيانات عامة لتناسق الفيديو من الموضوع عبر الأزواج، تحتوي على حوالي مليون زوج متسق الهوية عبر فئات مختلفة. تم بناء مجموعة البيانات هذه من خلال عملية ثلاثية المراحل، تشمل اكتشاف الموضوع، واسترجاع الموضوع عبر السياقات على نطاق واسع، والتحقق من الهوية الموجه مسبقًا. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح LongWriter-Zero: إتقان توليد النصوص الطويلة جدًا عبر التعلم المعزز: تقترح ورقة بحثية بعنوان “LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning” طريقة قائمة على الحوافز، تستخدم التعلم المعزز (RL) من الصفر لتنمية قدرة LLM على توليد نصوص طويلة جدًا وعالية الجودة، دون الحاجة إلى أي بيانات مشروحة أو اصطناعية. تبدأ هذه الطريقة من نموذج أساسي، وتوجهه من خلال RL لتحسين عمليات التخطيط والكتابة، وتستخدم نموذج مكافأة متخصص للتحكم في الطول وجودة الكتابة والتنسيق الهيكلي. أظهرت التجارب أن LongWriter-Zero، المدرب من Qwen2.5-32B، يتفوق على طرق SFT التقليدية في مهام كتابة النصوص الطويلة، ويحقق مستوى SOTA في العديد من اختبارات القياس. (المصدر: HuggingFace Daily Papers)
💼 أعمال
شركة Harvey للذكاء الاصطناعي القانوني تعلن عن إتمام جولة تمويل من الفئة E بقيمة 300 مليون دولار، وتقييم يصل إلى 5 مليارات دولار: أعلنت شركة Harvey الناشئة في مجال الذكاء الاصطناعي القانوني عن إتمام جولة تمويل من الفئة E بقيمة 300 مليون دولار بقيادة مشتركة من Kleiner Perkins و Coatue، ليصل تقييم الشركة إلى 5 مليارات دولار. ومن بين المستثمرين الآخرين Sequoia Capital و GV و DST Global و Conviction و Elad Gil و OpenAI Startup Fund و Elemental و SV Angel و Kris Fredrickson و REV. سيساعد هذا التمويل Harvey على مواصلة تطوير وتوسيع تطبيقاتها في مجال الذكاء الاصطناعي في القطاع القانوني. (المصدر: saranormous)
خدمة Hyperbolic السحابية لوحدات معالجة الرسومات حسب الطلب تحقق إيرادات سنوية متكررة بقيمة مليون دولار في 7 أيام: أعلن Yuchenj_UW أن خدمة Hyperbolic السحابية لوحدات معالجة الرسومات حسب الطلب، التي أطلقت الأسبوع الماضي، حققت نموًا في الإيرادات السنوية المتكررة (ARR) من 0 إلى مليون دولار في غضون 7 أيام، وذلك من خلال حملة تسويقية بسيطة عبر تغريدة واحدة فقط. يقدمون للمطورين رصيدًا تجريبيًا مجانيًا لعقدة 8xH100، مما يدل على الطلب القوي في السوق على خدمات سحابية لوحدات معالجة الرسومات عالية الأداء. (المصدر: Yuchenj_UW)
Replit تعلن عن تجاوز إيراداتها السنوية المتكررة (ARR) حاجز 100 مليون دولار: أعلنت Replit، منصة بيئة التطوير المتكاملة (IDE) والحوسبة السحابية عبر الإنترنت، عن تجاوز إيراداتها السنوية المتكررة (ARR) حاجز 100 مليون دولار، محققة نموًا كبيرًا مقارنة بـ 10 ملايين دولار في نهاية عام 2024. ذكرت الشركة أنه بعد إتمام آخر جولة تمويل لها في عام 2023 بتقييم 1.1 مليار دولار، لا يزال لديها أكثر من نصف الأموال في البنك. يعود نمو Replit إلى استخدام منصتها من قبل المستخدمين من الشركات (مثل Zillow و HubSpot) والمطورين المستقلين، وتقوم حاليًا بالتوظيف بنشاط. (المصدر: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 المجتمع
نموذج جديد لبرمجة الذكاء الاصطناعي: التصميم أولاً ثم التوجيه، مع تحسين تكراري لتوليد الكود: ناقش dotey و宝玉 التحول في نماذج تطوير البرمجيات الذي أحدثته برمجة الذكاء الاصطناعي. الجدل التقليدي حول “التصميم أولاً ثم الترميز” مقابل “التنفيذ أولاً ثم إعادة الهيكلة” يجد اندماجًا في عصر الذكاء الاصطناعي. يقلل الذكاء الاصطناعي بشكل كبير من تكلفة ووقت الانتقال من التصميم إلى الترميز، مما يسمح للمطورين بتنفيذ إصدارات بسرعة حتى عندما لا يكون التصميم واضحًا تمامًا، وتحسين التصميم والمطالبات بشكل تكراري من خلال التحقق من النتائج. تلعب المطالبات دور “وثائق التصميم التفصيلية” السابقة، ولكن بشكل مبسط. في هذا النموذج، يجب على المطورين التركيز بشكل أكبر على تصميم النظام، وتوليد الكود على دفعات صغيرة، واستخدام إدارة الكود المصدري، ومراجعة واختبار الكود الذي تم إنشاؤه بواسطة الذكاء الاصطناعي. بالنسبة للمبرمجين ذوي الخبرة، يعد تغيير طريقة التفكير وعادات التطوير أمرًا أساسيًا لتبني برمجة الذكاء الاصطناعي. (المصدر: dotey)
Claude Code يحظى بتفضيل المطورين لقدرته القوية على معالجة قواعد البيانات البرمجية الكبيرة وكفاءة السياق: يشهد مجتمع Reddit r/ClaudeAI نقاشًا حادًا حول الأداء المتميز لـ Claude Code في معالجة قواعد البيانات البرمجية الكبيرة. أفاد المستخدمون بقدرته الجيدة على فهم قواعد بيانات برمجية تتجاوز 200 ألف توكن وإجراء تعديلات عليها. يعتقد النقاش أن Claude Code قد يحقق معالجة سياق فعالة من خلال استراتيجيات مشابهة للقراءة البشرية (قراءة الأجزاء الرئيسية فقط)، واستخدام أدوات مثل grep لاسترجاع السياق (بدلاً من الاعتماد الكامل على ضغط المتجهات في RAG)، ومزايا تكامل نماذج الطرف الأول. شارك المستخدمون العديد من قصص النجاح في استخدام Claude Code لإصلاح مشكلات النظام، وبناء متتبع مالي شخصي، وتطوير تطبيقات أندرويد (حتى بدون خبرة في تطوير أندرويد)، وإنشاء نصوص Obsidian DataviewJS، مما أدى إلى تحسين كبير في كفاءة العمل. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

مفهوم “هندسة السياق” يثير الاهتمام، مؤكدًا على بناء أنظمة ديناميكية لتمكين LLM: طرح Harrison Chase من LangChain مفهوم “هندسة السياق” (Context Engineering) باعتباره العمل الأساسي الذي يقوم به مهندسو الذكاء الاصطناعي في بناء الأنظمة. يُعرَّف بأنه “بناء أنظمة ديناميكية لتوفير المعلومات والأدوات الصحيحة بالتنسيق الصحيح، مما يمكّن LLM من إكمال المهام بشكل معقول”. يؤكد هذا المفهوم على أهمية كيفية تنظيم وتوفير معلومات السياق بشكل فعال لأداء النموذج في تطبيقات LLM، وهو أساس مجالات مثل بناء الوكلاء (Agents). (المصدر: hwchase17, Hacubu, yoheinakajima)
مؤسس Meta مارك زوكربيرغ يقوم شخصيًا بتوظيف مواهب الذكاء الاصطناعي، مما يثير اهتمام المجتمع: أفادت أنباء على وسائل التواصل الاجتماعي بأن مؤسس Meta مارك زوكربيرغ يشارك شخصيًا في عملية توظيف المواهب لمختبره للذكاء الفائق، حيث يتصل مباشرة بمئات المرشحين المحتملين ويدعو المستجيبين لتناول العشاء. تُفسر هذه الخطوة على أنها دليل على تصميم Meta وقوتها في مجال الذكاء الاصطناعي، وخاصة في الذكاء الاصطناعي العام (AGI) أو الذكاء الفائق، مما يُظهر المنافسة الشرسة بين كبرى شركات التكنولوجيا على أفضل مواهب الذكاء الاصطناعي. (المصدر: reach_vb, andrew_n_carr)

تطور الذكاء الاصطناعي يثير تفكيرًا عميقًا حول سوق العمل والهياكل الاقتصادية: حذر كلية هارفارد للأعمال والخبير الاقتصادي Anton Korinek من أن الذكاء الاصطناعي العام (AGI) قد يتحقق في غضون 2-5 سنوات، وإذا لم يتم إصلاح النظام الاقتصادي بشكل جذري، فقد يؤدي ذلك إلى الانهيار، مؤكدًا على ضرورة الدخل الأساسي الشامل. في الوقت نفسه، يعتقد النقاش المجتمعي أن الذكاء الاصطناعي سيقوم بأتمتة عدد كبير من المهام القابلة للقياس، مما يؤثر على وظائف ذوي الياقات الزرقاء والبيضاء، ويتطلب من الشركات إعادة هيكلة تنظيماتها للتكيف مع الذكاء الاصطناعي. يشبه Yuval Noah Harari ثورة الذكاء الاصطناعي بـ “موجة هجرة الذكاء الاصطناعي”، مما يثير نقاشًا حول استبدال الذكاء الاصطناعي للوظائف والسعي وراء السلطة. تشير هذه الآراء مجتمعة إلى التأثير التخريبي للذكاء الاصطناعي على الهياكل الاجتماعية والاقتصادية المستقبلية. (المصدر: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

أداء الذكاء الاصطناعي بارز في مسابقات البرمجة، ونتائج وكيل Sakana AI المتميزة تثير نقاشًا حادًا: احتل وكيل Sakana AI المرتبة 21 من بين أكثر من 1000 مبرمج بشري في مسابقة AtCoder للبرمجة الاستدلالية، ليحتل المرتبة 6.8% الأعلى بشكل عام. قام الذكاء الاصطناعي بتكرار حوالي 100 إصدار في 4 ساعات، وتوليد آلاف الحلول المحتملة، بينما عادة ما يختبر المتسابقون البشريون حوالي 12 حلاً فقط. استخدم الذكاء الاصطناعي Gemini 2.5 Pro، ودمج المعرفة المتخصصة مع خوارزميات البحث المنهجي (مثل التلدين المحاكى وبحث الحزمة) لحل مشكلات التحسين الفعلية. تباينت ردود فعل المجتمع على ذلك، حيث رأى البعض أن برمجة المسابقات تختلف عن الهندسة على مستوى الشركات، وأن فوز الذكاء الاصطناعي يشبه تفوق الكمبيوتر على البشر في الجمع والطرح. (المصدر: Reddit r/ArtificialInteligence)
💡 أخبار أخرى
استكشاف الذكاء الاصطناعي في مجال التعليم المهني: محاولات متنوعة في المقابلات والمعلمين وأجهزة التعلم: تستكشف شركات التعليم المهني الكبرى مثل Huatu و Fenbi و Zhonggong بنشاط تطبيقات الذكاء الاصطناعي، ولكن باتجاهات مختلفة. تركز Huatu على تقييم المقابلات بواسطة الذكاء الاصطناعي، بينما تتعمق Fenbi في التصحيح بواسطة الذكاء الاصطناعي والمعلمين المدعومين بالذكاء الاصطناعي (تجاوزت مبيعات فصول نظام حل الأسئلة بالذكاء الاصطناعي 14 مليون يوان)، أما Zhonggong فقد أطلقت جهاز تعلم للتوظيف يعمل بالذكاء الاصطناعي. الإجماع في الصناعة هو أن الذكاء الاصطناعي يجب أن يحسن نتائج التعلم وكفاءة التشغيل، بدلاً من السعي وراء علاوات سعرية عالية فحسب. انتقل تطبيق الذكاء الاصطناعي أيضًا من إثبات المفهوم إلى التعمق في السيناريوهات، مثل استخدام 51CTO للشخصيات الرقمية والنمذجة ثلاثية الأبعاد لإنشاء الدورات التدريبية، وإجراء تحليل مسارات التعلم وتوليد أسئلة الاختبار بواسطة الذكاء الاصطناعي. ومع ذلك، لا تزال معظم شركات التعليم تفتقر إلى القدرة على بناء نماذج كبيرة خاصة بها، وتميل أكثر إلى استدعاء واجهات برمجة تطبيقات تابعة لجهات خارجية. (المصدر: 36氪)
ديزني ويونيفرسال بيكتشرز تقاضيان شركة Midjourney الناشئة في مجال توليد الصور بالذكاء الاصطناعي بتهمة انتهاك حقوق النشر: رفعت شركتا الإنتاج السينمائي العملاقتان ديزني ويونيفرسال بيكتشرز دعوى قضائية مشتركة ضد شركة Midjourney لتوليد الصور بالذكاء الاصطناعي، متهمة إياها باستخدام كميات كبيرة من محتوى الملكية الفكرية المحمي بحقوق الطبع والنشر (مثل Iron Man و Minions وغيرها) لتدريب نماذج الذكاء الاصطناعي الخاصة بها، وتوليد صور شديدة الشبه. يطالب المدعون بحظر السلوك المخالف، وتعويض يصل إلى 150 ألف دولار عن كل عمل تم انتهاكه عمدًا. تسلط هذه القضية الضوء على تحديات حقوق النشر التي يواجهها الذكاء الاصطناعي التوليدي، وكان مؤسس Midjourney قد اعترف باستخدام بيانات دون الحصول على إذن. قد تهدف الدعوى إلى الدفع نحو إنشاء آلية لترخيص حقوق النشر وأنظمة لتصفية المحتوى. (المصدر: 36氪)

اتهام Apple بالتخلف في مجال الذكاء الاصطناعي، وقد تفكر في عمليات استحواذ لتعويض النقص، وشركة المدير التقني السابق لـ OpenAI محط اهتمام: تشير التقارير إلى أن Apple متخلفة نسبيًا في مجال الذكاء الاصطناعي، وأن قدراتها الذاتية في هذا المجال غير كافية، وأداء Siri ضعيف. لتعويض هذا النقص، قد تفكر Apple في إجراء عمليات استحواذ كبيرة، ويُشاع أنها أجرت اتصالات أولية مع Mira Murati، المديرة التقنية السابقة لـ OpenAI، بشأن شركتها الناشئة الجديدة Thinking Machines Lab. تاريخيًا، قامت Apple عدة مرات بالاستحواذ على شركات تكنولوجية صغيرة لتعزيز قدراتها (مثل Siri نفسها). حاليًا، تتخلف Apple كثيرًا عن عمالقة الصناعة من حيث حجم معلمات نماذج الذكاء الاصطناعي، وقد يساعدها الاستحواذ على شركات مثل Mistral في تحقيق اختراق في تطوير نماذجها اللغوية الكبيرة الخاصة. (المصدر: 36氪)