
كلمات مفتاحية:نموذج اللغة الكبيرة, تقييم الذكاء الاصطناعي, نظام متعدد الوكلاء, قدرة الاستدلال, معالجة السياق, النماذج مفتوحة المصدر, توليد الفيديو بالذكاء الاصطناعي, البرمجة بالذكاء الاصطناعي, تقييم قدرة الاستدلال في نماذج اللغات الكبيرة, رد Claude Opus 4 على ورقة Apple البحثية, نموذج MiniMax-M1 المعتمد على الخبراء, نموذج البرمجة Kimi-Dev-72B, ميزة التفكير العميق في Gemini
🔥 أبرز العناوين
ورقة بحثية لـ Apple تشكك في قدرات الاستدلال للنماذج اللغوية الكبيرة (LLM) تواجه دحضًا، وورقة بحثية شارك في تأليفها Claude تشير إلى عيوب في تصميم التجربة: نشرت شركة Apple مؤخرًا ورقة بحثية بعنوان “وهم التفكير”، من خلال اختبارات على مسائل كلاسيكية مثل برج هانوي وعالم المكعبات، أشارت إلى أن النماذج اللغوية الكبيرة (LLM) السائدة تقدم أداءً ضعيفًا في مهام الاستدلال المعقدة، وأنها في جوهرها تعتمد على مطابقة الأنماط بدلاً من الفهم الحقيقي. ومع ذلك، قام الباحث المستقل Alex Lawsen بالاشتراك مع نموذج الذكاء الاصطناعي Claude Opus 4 بنشر ورقة بحثية بعنوان “وهم ‘وهم التفكير’ نفسه” لدحض ذلك، معتبرين أن تجربة Apple تحتوي على عيوب في التصميم: 1. عدم مراعاة الحد الأقصى لمخرجات الـ Token في LLM، مما يؤدي إلى الحكم على النموذج بالخطأ لعدم قدرته على إخراج الخطوات الطويلة جدًا بالكامل؛ 2. بعض حالات الاختبار (مثل بعض “مسائل عبور النهر”) ليس لها حل رياضيًا في ظل الظروف المعطاة، وعدم قدرة الذكاء الاصطناعي على تقديم “إجابة صحيحة” لا يعني نقصًا في القدرة؛ 3. عند تغيير طريقة التقييم، مثل مطالبة النموذج بإخراج برنامج لحل المشكلة بدلاً من الخطوات الكاملة، فإن أداء الذكاء الاصطناعي يكون ممتازًا. أثارت هذه الحادثة نقاشًا واسعًا حول قدرات الاستدلال الحقيقية للنماذج اللغوية الكبيرة ومنهجيات تقييمها، مما يسلط الضوء على أهمية تصميم خطط تقييم معقولة، ويذكر المطورين بضرورة الانتباه إلى تأثير عوامل مثل نافذة السياق (context window)، وميزانية الإخراج (output budget)، وصياغة المهام على أداء النموذج في التطبيقات العملية. (المصدر: 新智元, 大数据文摘)
الكشف عن خارطة طريق جوجل للذكاء الاصطناعي، تلميحات إلى أن بنية الذكاء الاصطناعي من الجيل التالي قد تتخلى عن آلية الانتباه الحالية: كشف Logan Kilpatrick، مسؤول المنتجات في جوجل، في معرض مهندسي الذكاء الاصطناعي العالمي (AI Engineer World’s Fair) عن الاتجاهات المستقبلية لنموذج Gemini، وكان أبرزها التطلع إلى تحقيق “سياق لا نهائي” (infinite context). وأشار إلى أنه باستخدام آلية الانتباه (attention mechanism) وطرق معالجة السياق الحالية، لا يمكن تحقيق سياق لا نهائي حقيقي، مما يشير إلى أن جوجل قد تكون بصدد دراسة بنية أساسية جديدة تمامًا للذكاء الاصطناعي. تتضمن خارطة الطريق أيضًا: قدرات متعددة الوسائط بالكامل (full-modality capability) (تدعم بالفعل الصور + الصوت، والفيديو هو المرحلة التالية)، تجارب مبكرة على Diffusion، قدرات Agent افتراضية (استدعاء واستخدام أدوات من الدرجة الأولى، وتطور النموذج تدريجيًا ليصبح وكيلًا ذكيًا)، قدرات استدلال متوسعة باستمرار، وإطلاق المزيد من النماذج الصغيرة. تشير هذه السلسلة من الخطط إلى أن جوجل تدفع بنشاط الذكاء الاصطناعي من الاستجابة السلبية إلى التطور نحو وكلاء أذكياء (intelligent agents)، وتلتزم باختراق الاختناقات التقنية الحالية، خاصة في معالجة السياق، مما قد يؤدي إلى تغيير كبير في بنية الذكاء الاصطناعي. (المصدر: 新智元)
شركة Sakana AI تطلق ALE-Agent، وتتفوق على 98% من المتسابقين البشر في مسابقة برمجة للمسائل الصعبة NP: أطلقت شركة Sakana AI، التي شارك في تأسيسها Llion Jones أحد مؤلفي Transformer، بالتعاون مع منصة مسابقات البرمجة اليابانية AtCoder، منصة ALE-Bench (معيار هندسة الخوارزميات)، والتي تركز على تقييم قدرات الذكاء الاصطناعي في الاستدلال طويل المدى والبرمجة الإبداعية للمسائل الصعبة NP (مثل تخطيط المسارات وجدولة المهام). وقد أظهر ALE-Agent الذي طورته الشركة، والمبني على Gemini 2.5 Pro، مع دمج توجيهات المعرفة المتخصصة واستراتيجيات البحث المتنوعة في فضاء الحلول، أداءً متميزًا في مسابقة AtCoder الاستكشافية، حيث احتل المرتبة 21 (أعلى 2%)، متجاوزًا عددًا كبيرًا من كبار المطورين البشر. يمثل هذا تقدمًا هامًا في قدرة الذكاء الاصطناعي على حل مشكلات التحسين المعقدة، وله أهمية كبيرة للتطبيقات العملية مثل الخدمات اللوجستية وتخطيط الإنتاج. على الرغم من أداء ALE-Agent المتميز في خوارزميات مثل التلدين المحاكى (simulated annealing)، لا يزال هناك مجال للتحسين في تصحيح الأخطاء، وتحليل التعقيد، وتجنب مآزق التحسين. (المصدر: 新智元, SakanaAILabs, hardmaru)
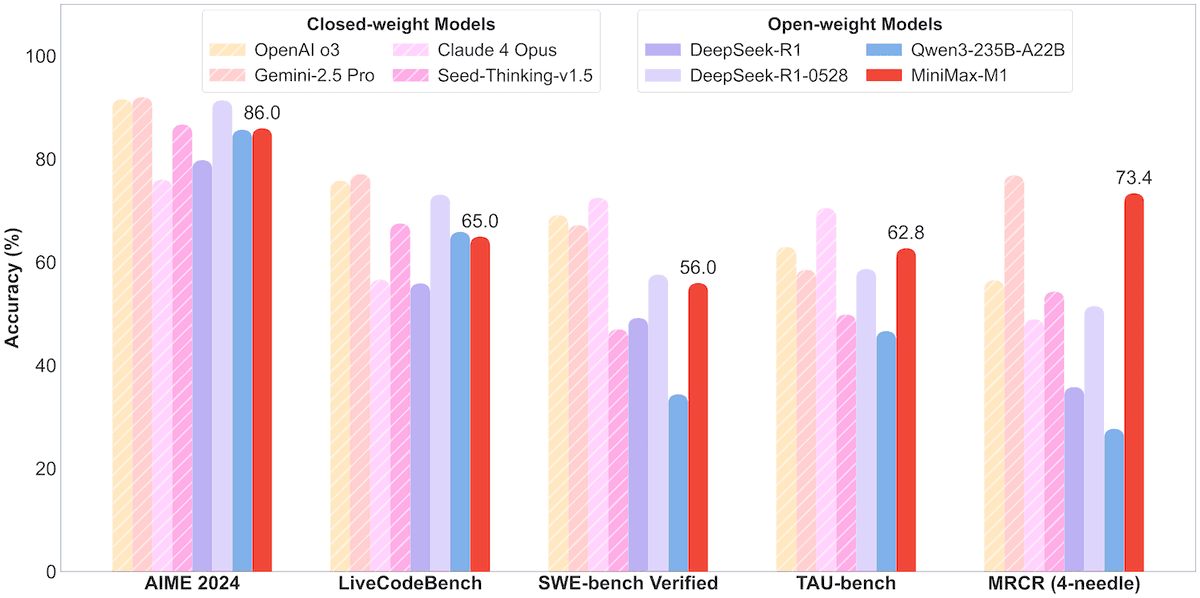
شركة MiniMax تطلق نموذج MoE مفتوح المصدر MiniMax-M1 بمعاملات 456B، يدعم سياق مليون Token ومخرجات 80 ألف Token: أعلنت شركة MiniMax عن إطلاق أول نموذج استدلال مفتوح المصدر واسع النطاق يعتمد على خليط الخبراء (MoE)، وهو MiniMax-M1. يبلغ حجم معاملات النموذج 45.6 مليار، ويقوم كل Token بتنشيط 4.59 مليار معامل، ويعتمد على بنية تجمع بين MoE وآلية الانتباه البرق (Lightning Attention). يدعم M1 أصلاً طول سياق يبلغ مليون Token، ويمكنه تحقيق مخرجات رائدة في الصناعة تصل إلى 80 ألف Token، ويتضمن نسختين بميزانية تفكير 40 ألف و 80 ألف. في اختبارات الأداء القياسية لمهام هندسة البرمجيات، واستخدام الأدوات، والسياق الطويل، تفوق M1 على نماذج مثل DeepSeek-R1 و Qwen3-235B، خاصة في استخدام أدوات Agent (مثل TAU-bench) حيث حقق نتائج بارزة. استغرقت مرحلة التعلم المعزز (reinforcement learning) ثلاث أسابيع فقط باستخدام 512 وحدة H800، بتكلفة تقارب 537,400 دولار أمريكي. نموذج M1 متاح مجانًا للاستخدام عبر تطبيق MiniMax وموقعه على الويب، ويتم توفيره أيضًا عبر API. (المصدر: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 اتجاهات
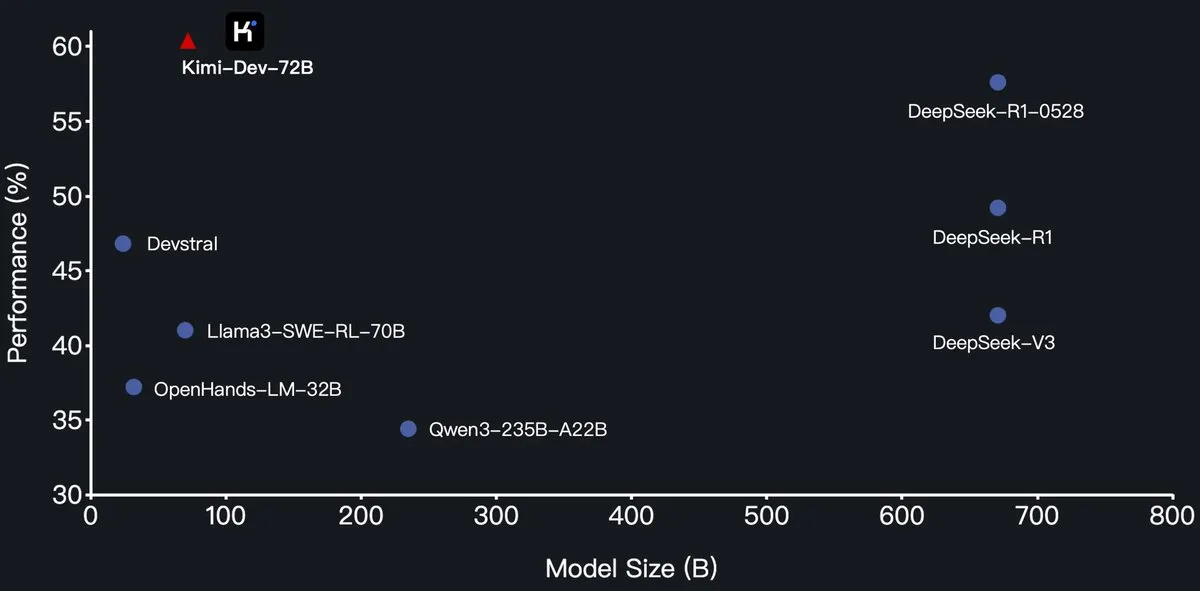
شركة Moonshot AI (月之暗面) تطلق نموذج البرمجة الكبير Kimi-Dev-72B مفتوح المصدر، ويتفوق على DeepSeek-R1 في SWE-Bench: أعلنت شركة Moonshot AI (月之暗面) عن إطلاق نموذجها اللغوي الكبير للبرمجة مفتوح المصدر الجديد Kimi-Dev-72B، والذي تم ضبطه بدقة (fine-tuned) بناءً على Qwen2.5-72B. يُقال إن Kimi-Dev-72B حقق معدل حل بنسبة 60.4% في اختبار SWE-bench Verified، متجاوزًا نماذج مثل DeepSeek-R1-0528 (57.6%) و Qwen3-235B-A22B، ليصبح من بين النماذج مفتوحة المصدر الرائدة. تم تدريب النموذج باستخدام التعلم المعزز (reinforcement learning)، مع التركيز على إصلاح مستودعات التعليمات البرمجية الحقيقية في بيئة Docker، ولم يحصل على مكافأة إلا عند اجتياز مجموعة الاختبارات الكاملة. صرح مسؤول تطوير Qwen بأنه لم يمنح إذنًا، لكن استخدام Kimi لترخيص MIT لإصدار نسخة مضبوطة بدقة يتوافق مع اللوائح. (المصدر: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
سلسلة نماذج Qwen3 تضيف دعمًا لتنسيق MLX، مما يحسن الاستدلال على شرائح Apple: أعلن فريق Tongyi Qianwen (通义千问) التابع لشركة Alibaba أن سلسلة نماذج Qwen3 تدعم الآن تنسيق MLX، وتوفر أربعة مستويات تكميم (quantization levels): 4bit، 6bit، 8bit، و BF16. تهدف هذه الخطوة إلى تحسين كفاءة تشغيل النماذج على إطار عمل MLX من Apple، مما يسهل على المطورين النشر المحلي والاستدلال على أجهزة Mac. يمكن للمستخدمين الحصول على النماذج ذات الصلة من HuggingFace و ModelScope. (المصدر: ClementDelangue, stablequan, jeremyphoward)

جوجل Gemini ستطلق قريبًا ميزة “Deep Think” لتعزيز القدرة على معالجة المشكلات المعقدة: تستعد جوجل لتقديم ميزة جديدة تسمى “Deep Think” لنموذجها Gemini 2.5 Pro. تهدف هذه الميزة إلى معالجة المشكلات الأكثر تحديًا من خلال توفير قدرة حسابية إضافية، خاصة في المهام المتعلقة بالرياضيات، حيث من المتوقع أن يتحسن أداء Deep Think بنسبة تصل إلى 15% مقارنة بالإصدار العادي من Gemini 2.5 Pro. ستظهر هذه الميزة كخيار جديد في شريط الأدوات، وقد تستغرق عملية المعالجة بضع دقائق. وفي الوقت نفسه، ستشهد واجهة مستخدم Gemini تحديثًا أيضًا. (المصدر: op7418)
إطلاق نموذج جوجل Veo 3 لتوليد الفيديو رسميًا، وتوسيع نطاقه ليشمل أكثر من 70 سوقًا: أعلنت جوجل أن نموذجها لتوليد الفيديو بالذكاء الاصطناعي Veo 3 أصبح متاحًا رسميًا لمشتركي AI Pro و Ultra، ويغطي أكثر من 70 سوقًا حول العالم. يحظى Veo 3 باهتمام كبير بسبب مقاطع الفيديو الواقعية والإبداعية التي ينتجها، وقد استخدمه المستخدمون سابقًا لإنشاء محتوى ASMR مثل “تقطيع الفاكهة السحري” الذي حقق عشرات الملايين من المشاهدات على وسائل التواصل الاجتماعي، مما يوضح إمكاناته في مجال إنشاء المحتوى. سيمكن هذا الإطلاق الرسمي المزيد من المستخدمين من تجربة واستخدام Veo 3 لإنشاء الفيديو. (المصدر: Google, 新智元)
تعاون بين Hugging Face و Groq لتقديم خدمات استدلال LLM عالية السرعة: أعلنت Hugging Face عن شراكة مع شركة شرائح الذكاء الاصطناعي Groq، لدمج وحدة معالجة اللغة (LPU™) الخاصة بـ Groq في Hugging Face Playground و API. يمكن للمستخدمين الآن تجربة خدمات استدلال LLM المسرعة بواسطة أجهزة Groq مباشرة على منصة Hugging Face، مع دعم نماذج متعددة بما في ذلك Llama 4 و Qwen 3. تهدف هذه الخطوة إلى تزويد المطورين بخيارات استدلال نماذج الذكاء الاصطناعي أسرع وأكثر كفاءة، وهي مناسبة بشكل خاص لبناء الوكلاء (agents) والمساعدين وتطبيقات الذكاء الاصطناعي في الوقت الفعلي. (المصدر: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

منصة Hugging Face Hub تضيف ميزة تصفية النماذج حسب الحجم، لمساعدة المطورين على اختيار النموذج المناسب: أطلقت منصة Hugging Face ميزة جديدة تسمح للمستخدمين بتصفية النماذج بناءً على حجم النموذج (Size Range)، خاصة للنماذج التي تعمل على إطار عمل mlx / mlx-lm. يهدف هذا التحسين إلى مساعدة المطورين على إيجاد النماذج التي تتوافق مع متطلبات أجهزتهم وأدائهم المحددة بسهولة أكبر، مع التأكيد على أنه ليس بالضرورة أن يكون النموذج الأكبر هو الأفضل دائمًا، فالنماذج الصغيرة المتخصصة غالبًا ما تكون أفضل في سيناريوهات محددة. (المصدر: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

تحديث NVIDIA NCCL، يبدأ في استخدام تراكم FP32 لعمليات الاختزال (reduction ops) للمدخلات نصف الدقيقة: قدم أحدث إصدار من مكتبة الاتصالات الجماعية لـ NVIDIA (NCCL) (الالتزام 72d2432) تحديثًا هامًا: عند معالجة عمليات الاختزال (reduction ops) للمدخلات نصف الدقيقة (مثل FP16، BF16)، يبدأ في استخدام FP32 للتراكم. هذا التغيير حاسم للحفاظ على دقة الحساب ومنع تجاوز السعة (overflow)، خاصة في التدريب الموزع واسع النطاق. من المتوقع أن يتم دمج هذا الإصدار في PyTorch 2.8 والإصدارات الأحدث. (المصدر: StasBekman)

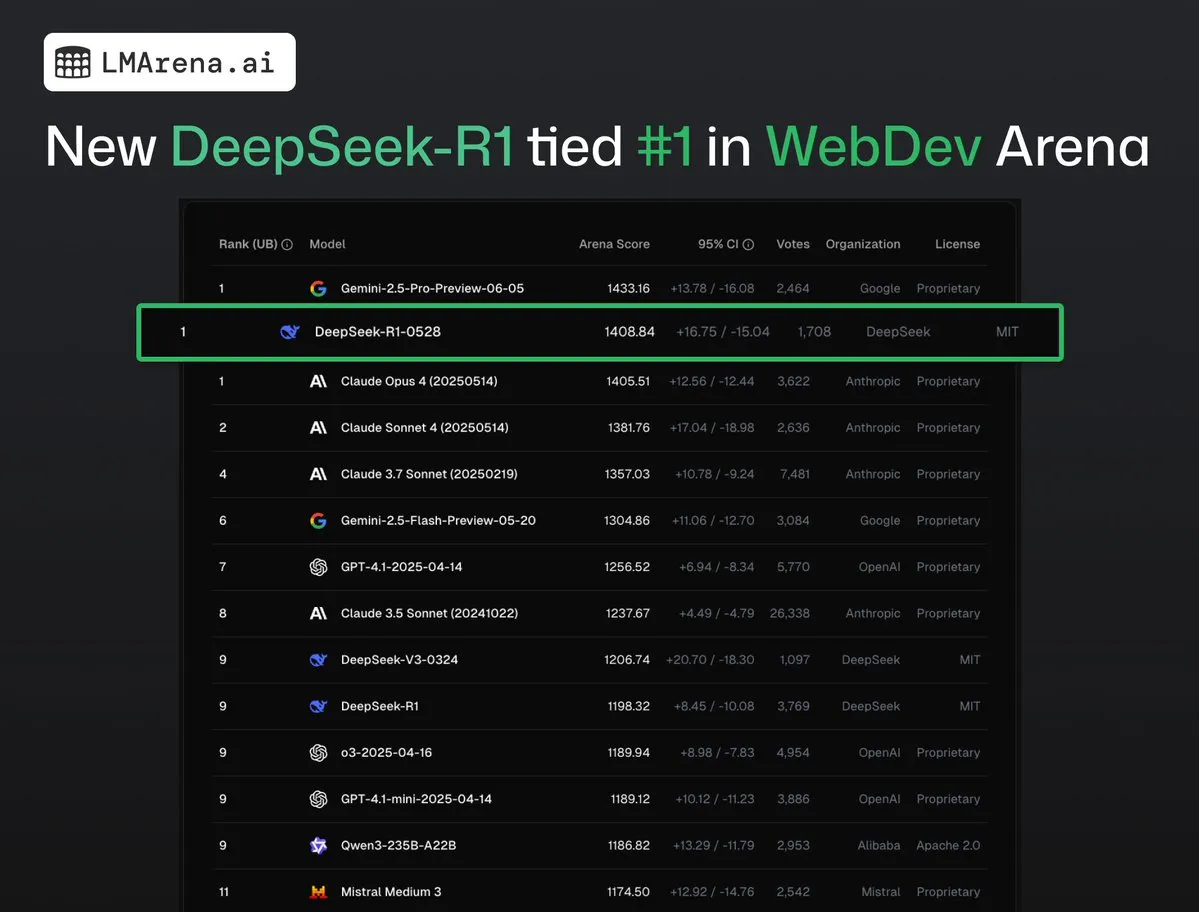
DeepSeek-R1 (0528) يحتل المرتبة الأولى بالاشتراك مع Claude Opus 4 في WebDev Arena: تظهر أحدث البيانات من lmarena.ai أن الإصدار الجديد من DeepSeek-R1 (0528) حقق أداءً متميزًا في اختبار WebDev Arena، حيث احتل المرتبة الأولى بالاشتراك مع Claude Opus 4. احتل هذا النموذج المرتبة السادسة بشكل عام في Text Arena، والمرتبة الثانية في قدرات البرمجة، والمرتبة الرابعة في التعامل مع التوجيهات الصعبة، والمرتبة الخامسة في القدرات الرياضية، وهو أفضل نموذج مفتوح المصدر مرخص بموجب MIT على لوحة الصدارة. يشير هذا إلى القدرة التنافسية القوية لـ DeepSeek في مهام التطوير والاستدلال المحددة. (المصدر: ClementDelangue, zizhpan)
بايت دانس تطلق نماذج الصور Seedream 3.0 والفيديو Seedance 1.0 Lite على منصة Poe: أطلقت أداة الإنشاء بالذكاء الاصطناعي التابعة لشركة بايت دانس تحديثًا على منصة Poe الخارجية، حيث أطلقت نموذج توليد الصور Seedream 3.0 من 即梦AI ونموذج توليد الفيديو Seedance 1.0 Lite. يهدف Seedream 3.0 إلى توليد صور واضحة وحيوية، بينما يمكن لـ Seedance 1.0 Lite توليد مقاطع فيديو ذات تأثيرات ديناميكية واقعية بسرعة. يمكن للمستخدمين في Poe استخدام Seedream أولاً لإنشاء الصور، ثم تحويلها إلى فيديو عن طريق الإشارة إلى @Seedance، مما يحقق سير عمل إبداعي متسلسل من صورة إلى فيديو. (المصدر: op7418)

تينسنت تطلق نموذج الغناء Levo، يدعم فصل المسارات واستنساخ الصوت بدون عينات (zero-sample voice cloning): أطلقت تينسنت نموذج غناء بالذكاء الاصطناعي يسمى Levo، يُقال إن أداءه يضاهي Suno V3.5. يدعم Levo فصل المسارات الصوتية (track separation) ووظيفة استنساخ الصوت بدون عينات (zero-shot voice cloning)، ويبدو أداؤه متميزًا بناءً على العروض التوضيحية والتقييمات المنشورة. يُظهر هذا التقدم قوة تينسنت في مجال توليد الموسيقى بالذكاء الاصطناعي. (المصدر: karminski3)
OpenAI تطلق ميزة توليد الصور بـ ChatGPT في WhatsApp: أعلنت OpenAI أنه يمكن للمستخدمين الآن استخدام ميزة توليد الصور في ChatGPT عبر خدمة 1-800-ChatGPT في WhatsApp. يتيح هذا التحديث لمجموعة أوسع من المستخدمين توليد صور بالذكاء الاصطناعي بسهولة مباشرة داخل تطبيق المراسلة الفورية. (المصدر: gdb, eliza_luth, iScienceLuvr)
تحديث SpatialLM إلى الإصدار 1.1، معززًا قدرات فهم وإعادة بناء المشاهد ثلاثية الأبعاد: أصدر نموذج الاستدلال المكاني SpatialLM الإصدار 1.1، ويدعم الإصدار الجديد أوضاع إدخال متعددة المصادر، بما في ذلك تحويل النص إلى مشهد ثلاثي الأبعاد (Text-to-3D)، وإعادة بناء الفيديو من كاميرا محمولة، وبيانات سحابة نقاط LiDAR (مثل ليزر iPhone Pro)، وعينات الشبكات الاصطناعية. تشمل الميزات الرئيسية المعالجة القوية لسحب النقاط غير المهيكلة، مما يتيح إعادة بناء معقولة حتى لو كانت بيانات المسح ثلاثي الأبعاد غير مكتملة. بالإضافة إلى ذلك، يحسن الإصدار الجديد الكشف بدون عينات (zero-shot detection) لمدخلات دفق الفيديو، ويحسن دقة تقدير التخطيط الداخلي، ويعزز تأثير اكتشاف الكائنات ثلاثية الأبعاد. تطبيقاته واسعة النطاق، وتشمل إعادة بناء مشاهد الواقع المعزز (AR)، وفهم الروبوتات للمكان، وسير عمل التصميم ثلاثي الأبعاد، وتطبيقات الكاميرا للمستهلكين. (المصدر: karminski3)
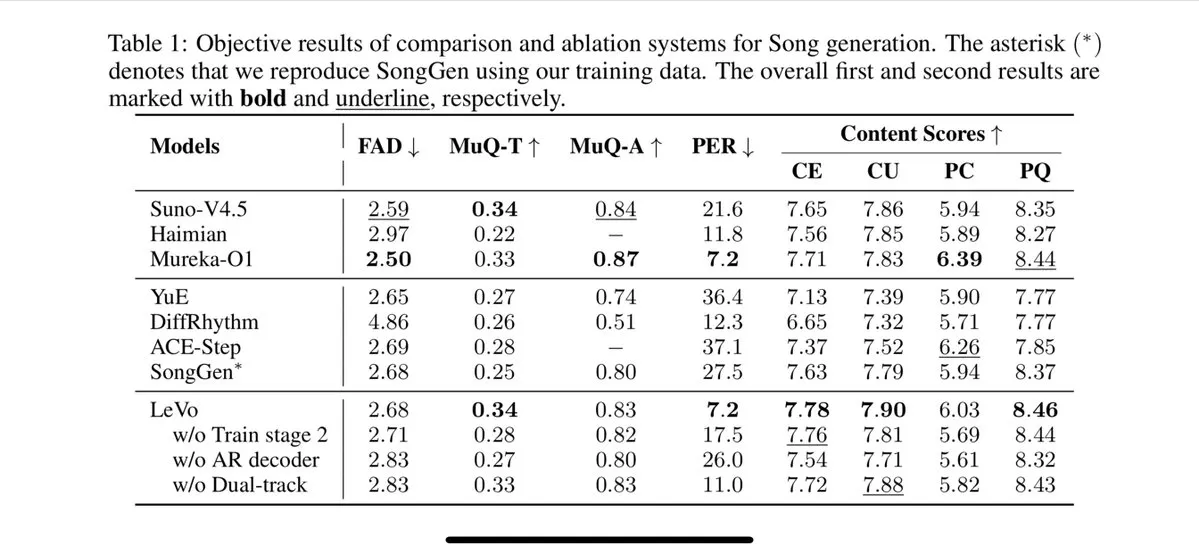
GitHub Copilot يطلق باقة بقيمة 39 دولارًا شهريًا، تدمج Claude Opus 4 ونماذج كبيرة أخرى: أضاف GitHub Copilot باقة اشتراك جديدة بقيمة 39 دولارًا شهريًا، لا توفر هذه الباقة وظيفة مساعد الترميز فحسب، بل تتيح للمستخدمين أيضًا الوصول إلى العديد من النماذج اللغوية القوية بما في ذلك Claude Opus 4 و o3 و GPT-4.5، ويمكنهم استخدام Coding agent. تهدف هذه الخطوة إلى تزويد المطورين بتجربة برمجة مساعدة بالذكاء الاصطناعي أكثر شمولاً. (المصدر: dotey)
تكلفة استدعاء نماذج الذكاء الاصطناعي الكبيرة تستمر في الانخفاض، وسعر سلسلة Doubao (豆包) 1.6 ينخفض بنسبة 63% أخرى: أطلقت Volcano Engine في مؤتمر Force Power سلسلة نماذج Doubao (豆包) الكبيرة 1.6، وأعلنت عن انخفاض تكلفتها الإجمالية بنسبة 63%. بالنسبة لنطاق الإدخال من 0 إلى 32 ألف token، وهو الأكثر استخدامًا من قبل معظم الشركات، يبلغ السعر 0.8 يوان لكل مليون token للإدخال و 8 يوانات للإخراج. يشير هذا إلى استمرار تصاعد حرب أسعار النماذج الكبيرة، بعد أن خفضت Alibaba Qianwen التكلفة في مارس من هذا العام إلى 1/10 من تكلفة DeepSeek R1. ستؤدي التكلفة المنخفضة إلى تعزيز تطبيق وانتشار تطبيقات مثل AI Agent. (المصدر: 字节必须再赢一次)
تحديث أداة تسريع توليد الفيديو Chipmunk، تدعم معماريات GPU متعددة والمزيد من النماذج مفتوحة المصدر: شهدت أداة Chipmunk من فريق Dan Fu تحديثًا، وهي تدعم الآن تسريع توليد الفيديو بدون فقدان بنسبة 1.4-3 أضعاف على معماريات NVIDIA GPU متعددة (sm_80, sm_89, sm_90، مثل A100s, 4090s, H100s). وفي الوقت نفسه، أضافت Chipmunk دعمًا لمزيد من نماذج الفيديو مفتوحة المصدر مثل Mochi و Wan، وقدمت دروسًا تعليمية للتكامل. تستفيد الأداة من تشتت قيم التنشيط في نماذج الفيديو (حيث تساهم 5-25% فقط من قيم التنشيط في أكثر من 90% من المخرجات) لتحقيق التسريع، دون الحاجة إلى إعادة تدريب النموذج. (المصدر: realDanFu)

🧰 أدوات
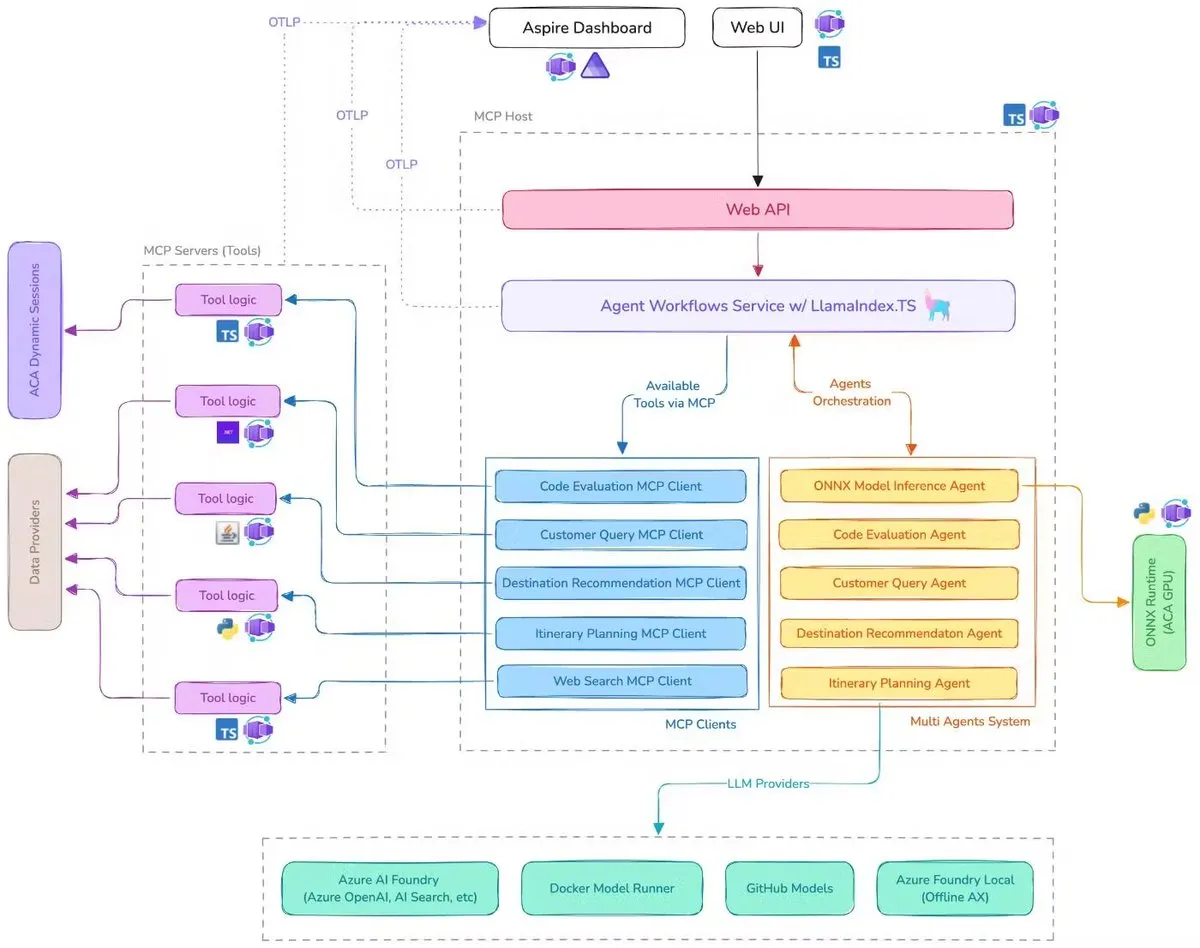
مايكروسوفت تصدر عرضًا توضيحيًا لمساعد السفر بالذكاء الاصطناعي، يدمج MCP و LlamaIndex.TS و Azure AI Foundry: عرضت مايكروسوفت عرضًا توضيحيًا لمساعد سفر يعمل بالذكاء الاصطناعي، يقوم هذا النظام بتنسيق العديد من وكلاء الذكاء الاصطناعي (بما في ذلك ستة وكلاء متخصصين في تصنيف الاستعلامات، وتوصيات الوجهات، وتخطيط الرحلات، وما إلى ذلك) لإكمال مهام تخطيط السفر المعقدة بشكل مشترك من خلال بروتوكول سياق النموذج (MCP) و LlamaIndex.TS و Azure AI Foundry. يحصل كل وكيل على بيانات وأدوات في الوقت الفعلي من خلال خوادم MCP مكتوبة بلغات Java و .NET و Python و TypeScript. يوضح هذا التطبيق كيف يمكن للوكلاء المتعددين على مستوى المؤسسات العمل بشكل تعاوني من خلال خدمات مصغرة متعددة اللغات، والاستفادة من نماذج Azure OpenAI و GitHub لتوفير قدرات الذكاء الاصطناعي، ويمكن تحقيق نشر بدون خادم قابل للتطوير من خلال Azure Container Apps. (المصدر: jerryjliu0, jerryjliu0)
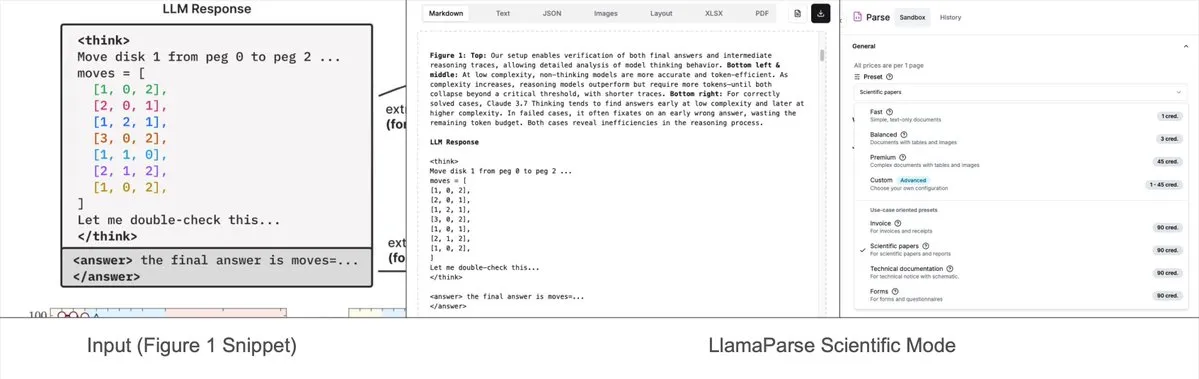
LlamaParse تضيف أوضاعًا محددة مسبقًا، يمكنها تحليل المخططات المعقدة إلى Mermaid أو Markdown: تم تحديث أداة LlamaParse من LlamaIndex مؤخرًا، حيث أضافت “أوضاعًا محددة مسبقًا” (preset-modes)، مما يمكنها من تحليل المخططات المعقدة في المستندات مثل تقارير البحث (مثل المخططات التي تحتوي على منحنيات وتعليقات متعددة)، وتحويلها إلى مخططات Mermaid منسقة أو جداول Markdown. تساعد هذه الميزة في التقاط السياق الكامل من الصفحة، ويمكن استخدام النص المهيكل الناتج لبناء تدفقات RAG أو لإجراء مزيد من استخراج البيانات الوصفية. (المصدر: jerryjliu0)
Prompt Optimizer: أداة تحسين للمساعدة في كتابة توجيهات عالية الجودة: Prompt Optimizer هي أداة تهدف إلى مساعدة المستخدمين على كتابة توجيهات AI أفضل، وبالتالي تحسين جودة مخرجات AI. تدعم شكلين: تطبيق ويب وملحق Chrome، وتوفر ميزات مثل التحسين الذكي، وتحسين التكرار متعدد الجولات، ومقارنة التوجيهات الأصلية والمحسّنة، وتكامل نماذج متعددة (OpenAI, Gemini, DeepSeek, 智谱AI, SiliconFlow، إلخ)، وتكوين معلمات متقدم، وتخزين مشفر محليًا. تعتمد الأداة على المعالجة من جانب العميل فقط، مما يضمن أمان البيانات والخصوصية. (المصدر: GitHub Trending)

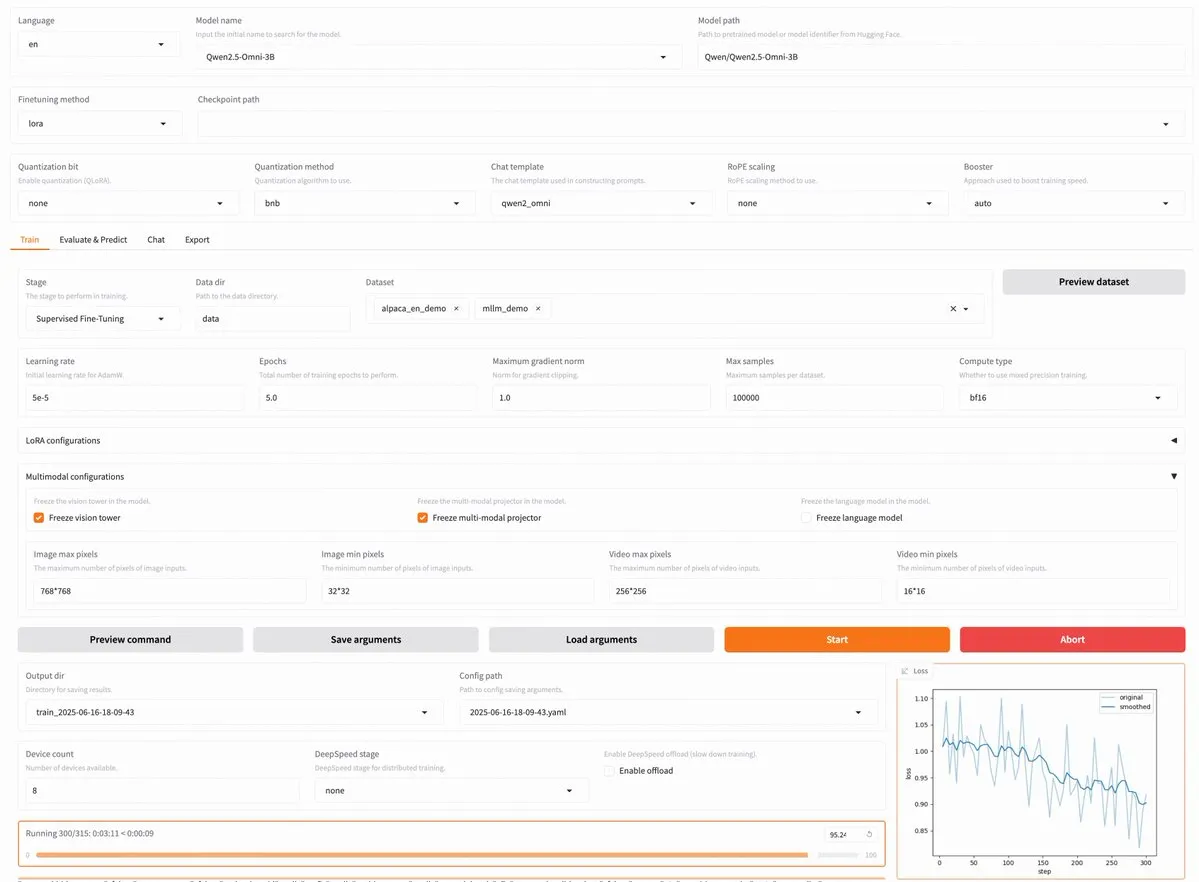
إصدار LLaMA Factory v0.9.3، يدعم الضبط الدقيق بدون كود لما يقرب من 300 نموذج بما في ذلك Qwen3 و Llama 4: أصدرت LLaMA Factory الإصدار v0.9.3، وهو منصة ضبط دقيق (fine-tuning) مفتوحة المصدر بالكامل تدعم واجهة مستخدم Gradio، ومناسبة لما يقرب من 300 نموذج، بما في ذلك أحدث النماذج مثل Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni وغيرها. يمكن للمستخدمين تثبيتها محليًا عبر صورة Docker، أو تجربتها على Hugging Face Spaces و Google Colab وكذلك على سحابة GPU الخاصة بـ Novita. (المصدر: _akhaliq)
Nanonets OCR: نموذج OCR متطور مفتوح المصدر يعتمد على Qwen 2.5 VL 3B: أصدرت Nanonets نموذج OCR جديد بمعاملات 3B – Nanonets OCR، يعتمد هذا النموذج على الشبكة الأساسية Qwen 2.5 VL 3B، ويتفوق أداؤه على Mistral OCR API، وهو مفتوح المصدر بموجب ترخيص Apache 2.0. يمكنه التعامل مع مهام OCR متعددة مثل التعرف على LaTeX، واكتشاف العلامات المائية والتوقيعات، واستخراج الجداول المعقدة. (المصدر: huggingface)
Perplexity Labs يُزعم أنها يمكن أن تحل محل العديد من الوظائف المتخصصة، مما يثير نقاشًا حول قدرات أدوات الذكاء الاصطناعي: ادعى مستخدم يُدعى GREG ISENBERG أنه استخدم Perplexity Labs ليحل محل عمل خمس وظائف: مندوب مبيعات، وكاتب إعلانات، ومخرج أفلام، ومدير وسائل تواصل اجتماعي، ومحلل مالي، معتبرًا أن قدرات أدوات الذكاء الاصطناعي “مجنونة بالفعل”. قام Arav Srinivas، الرئيس التنفيذي لشركة Perplexity، بإعادة تغريد المنشور وعلق بأنه أحد أفضل مقاطع الفيديو التي توضح كيفية تطبيق وكلاء الذكاء الاصطناعي في حالات الاستخدام الواقعية، مقارنًا Perplexity Labs بأدوات أخرى في السوق في مجالات التحليل المالي، والتسويق عبر وسائل التواصل الاجتماعي، والتوجيه الإبداعي، والمبيعات. يسلط هذا الضوء على إمكانات AI Agent في دمج وتنفيذ المهام المهنية متعددة المجالات. (المصدر: AravSrinivas, AravSrinivas)
Claude-Flow يصدر تحديثًا رئيسيًا v1.0.50، وينشط “وضع السرب” (Swarm Mode) لزيادة كفاءة أتمتة التعليمات البرمجية: أصدر Claude-Flow، وهو نظام وكيل متوازي للأدوات المجمعة يعتمد على Claude Code، الإصدار v1.0.50. يقدم الإصدار الجديد “وضع السرب” (Swarm Mode)، الذي يسمح للمستخدمين بإنشاء وإدارة وتنسيق مئات من وكلاء Claude للعمل بالتوازي في نفس الوقت، وذلك لبناء أو اختبار أو نشر أو دورات بحث متعددة المراحل. يُزعم أن الأداء قد تحسن بمقدار 20 مرة مقارنة بأتمتة Claude Code التسلسلية التقليدية. يمكن للمطورين تهيئته عبر npx claude-flow@latest init --sparc --force. (المصدر: Reddit r/ClaudeAI)

📚 موارد تعليمية
Awesome Machine Learning: قائمة شاملة بموارد تعلم الآلة: مشروع “awesome-machine-learning” على GitHub هو قائمة منسقة بعناية لأطر عمل تعلم الآلة والمكتبات والبرامج، مصنفة حسب لغة البرمجة. كما يحتوي على روابط لكتب تعلم الآلة المجانية، والفعاليات المهنية، والدورات التدريبية عبر الإنترنت، والمدونات الإخبارية، واللقاءات المحلية، مما يوفر دليلًا قيمًا لمتعلمي وممارسي تعلم الآلة. (المصدر: GitHub Trending)
Anthropic و Cognition AI تنشران مقالات مدونة حول بناء أنظمة متعددة الوكلاء، و LangChain تلخصها: نشرت كل من Anthropic و Cognition AI مؤخرًا مقالات مدونة حول بناء (أو عدم بناء) أنظمة متعددة الوكلاء. شاركت Anthropic تجربتها في بناء نظامها البحثي متعدد الوكلاء، بينما طرحت Cognition AI وجهة نظر “لا تبنِ أنظمة متعددة الوكلاء”. قام Harrison Chase من LangChain بتلخيص ذلك، مشيرًا إلى أنه على الرغم من أن وجهات النظر تبدو مختلفة ظاهريًا، إلا أن المقالتين تشتركان في الكثير من المبادئ التوجيهية والاقتراحات، وربط ذلك بجهود LangChain في مجال الأنظمة متعددة الوكلاء. (المصدر: hwchase17, Hacubu)
قبول ورقة بحثية بعنوان “Recent Advances in Speech Language Models: A Survey” في المؤتمر الرئيسي لـ ACL 2025: تم قبول ورقة المراجعة حول نماذج لغة الكلام (SpeechLM) بعنوان “Recent Advances in Speech Language Models: A Survey”، التي أعدها فريق من الجامعة الصينية في هونغ كونغ، في المؤتمر الرئيسي لـ ACL 2025. تعد هذه الورقة أول مراجعة شاملة ومنهجية في هذا المجال، حيث تحلل بعمق البنية التقنية لـ SpeechLM (مجزئات الكلام speech tokenizers، نماذج اللغة language models، مولدات الصوت vocoders)، واستراتيجيات التدريب (التدريب المسبق pre-training، الضبط الدقيق بالتعليمات instruction fine-tuning، المواءمة اللاحقة post-alignment)، ونماذج التفاعل (النمذجة ثنائية الاتجاه الكاملة full-duplex modeling)، وسيناريوهات التطبيق (الدلالات semantics، المتحدث speaker، علم اللغة المصاحب paralinguistics)، ونظام التقييم. تؤكد الورقة على إمكانات SpeechLM في تحقيق تفاعل صوتي طبيعي بين الإنسان والآلة، وتشير إلى التحديات القائمة والاتجاهات المستقبلية. (المصدر: 36氪)

دراسة جديدة تعزز قدرة النماذج الصغيرة على الاستدلال عبر المجالات من خلال تعلم الألعاب المرئية (ViGaL)، وأداء نموذج 7B في الرياضيات يتجاوز GPT-4o: اقترح فريق بحثي من جامعة رايس وجامعة جونز هوبكنز و Nvidia نموذجًا جديدًا للتدريب اللاحق (post-training paradigm) يسمى ViGaL (Visual Game Learning). من خلال جعل نموذج متعدد الوسائط بمعاملات 7B (Qwen2.5-VL-7B) يلعب ألعابًا بسيطة مثل لعبة الثعبان والدوران ثلاثي الأبعاد، لم يحسن النموذج مهاراته في اللعب فحسب، بل أظهر أيضًا تحسنًا ملحوظًا في القدرة على الاستدلال عبر المجالات في مهام معقدة مثل الرياضيات (MathVista) والإجابة على الأسئلة متعددة التخصصات (MMMU)، حتى أنه تجاوز في بعض الجوانب نماذج رائدة مثل GPT-4o. تشير الدراسة إلى أن تدريب الألعاب يمكن أن ينمي قدرات معرفية عامة لدى النموذج مثل الفهم المكاني والتخطيط التسلسلي، وأن الألعاب المختلفة يمكن أن تعزز جوانب مختلفة من مهارات الاستدلال. تحافظ هذه الطريقة على القدرات البصرية العامة للنموذج مع تحسين قدرات الاستدلال. (المصدر: 新智元)

مختبر شنغهاي للذكاء الاصطناعي وآخرون يقترحون إطار MathFusion لتعزيز قدرة LLM على حل المسائل الرياضية من خلال دمج التعليمات: اقترح مختبر شنغهاي للذكاء الاصطناعي وكلية الذكاء الاصطناعي Gaoling بجامعة رنمين الصينية ومؤسسات أخرى بشكل مشترك إطار MathFusion، الذي يهدف إلى تعزيز قدرة النماذج اللغوية الكبيرة (LLM) على حل المسائل الرياضية من خلال دمج تعليمات اصطناعية أكثر تنوعًا في هيكل توليد المسائل الرياضية المختلفة وأكثر تعقيدًا من الناحية المنطقية. يتضمن هذا الإطار ثلاث استراتيجيات دمج: الدمج التسلسلي، والدمج المتوازي، والدمج الشرطي، والتي يمكنها التقاط الروابط العميقة بين المسائل بشكل فعال. أظهرت التجارب أنه باستخدام 45 ألف تعليمة اصطناعية فقط، وبعد الضبط الدقيق (fine-tuning) على نماذج مثل DeepSeekMath-7B و Llama3-8B و Mistral-7B، ارتفع متوسط الدقة لـ MathFusion في العديد من اختبارات الرياضيات القياسية بمقدار 18.0 نقطة مئوية، مما يدل على كفاءة عالية في البيانات والأداء. (المصدر: 量子位)

مختبر شنغهاي للذكاء الاصطناعي وآخرون يقترحون إطار GRA، حيث تتعاون النماذج الصغيرة لتوليد بيانات عالية الجودة، بأداء يضاهي نماذج 72B: اقترح مختبر شنغهاي للذكاء الاصطناعي بالتعاون مع جامعة رنمين الصينية إطار GRA (Generator–Reviewer–Adjudicator)، الذي يحاكي آلية تقديم الأوراق البحثية ومراجعة الأقران، مما يسمح لعدة نماذج لغوية صغيرة (بمعاملات 7-8B) بالتعاون لتوليد بيانات تدريب عالية الجودة. في هذا الإطار، يكون الـ Generator مسؤولاً عن التوليد، ويقوم الـ Reviewer بمراجعة وتقييم متعدد الجولات، ويتخذ الـ Adjudicator القرار النهائي في حالة تضارب المراجعات. أظهرت التجارب أن تدريب نماذج أساسية مثل LLaMA-3.1-8B و Qwen-2.5-7B باستخدام البيانات المولدة بواسطة GRA، حقق أداءً يضاهي أو يتجاوز أداء البيانات المولدة عن طريق تقطير نماذج كبيرة مثل Qwen-2.5-72B-Instruct، وذلك في 10 مجموعات بيانات رئيسية تشمل الرياضيات، والتعليمات البرمجية، والاستدلال المنطقي. يوفر هذا أفكارًا جديدة لتوليد البيانات بتكلفة منخفضة وكفاءة عالية. (المصدر: 量子位)

ورقة بحثية تناقش الوضع الحالي ومستقبل قابلية تفسير النماذج الكبيرة، مؤكدة على أهميتها لنشر الذكاء الاصطناعي بأمان: نشر معهد أبحاث تينسنت مقالًا يناقش بعمق الوضع الحالي لقابلية تفسير النماذج اللغوية الكبيرة (LLM)، والمسارات التقنية، والتحديات المستقبلية. يشير المقال إلى أن فهم الآليات الداخلية لـ LLM أمر بالغ الأهمية للوقاية من الانحرافات القيمية، وتصحيح الأخطاء وتحسين النماذج، ومنع إساءة الاستخدام، ودفع التطبيقات في السيناريوهات عالية المخاطر. تشمل المسارات التقنية الحالية التفسير الآلي (نماذج كبيرة تفسر نماذج صغيرة)، وتصور الميزات (مثل المشفرات التلقائية المتناثرة sparse autoencoders)، ومراقبة سلسلة الأفكار (chain-of-thought monitoring)، وقابلية التفسير الآلية (mechanistic interpretability) (مثل “مجهر الذكاء الاصطناعي” لـ Anthropic و Tracr لـ DeepMind). ومع ذلك، لا تزال الدلالات المتعددة للخلايا العصبية، وعمومية قوانين التفسير، والقيود المعرفية البشرية تمثل تحديات رئيسية. يدعو المقال إلى تعزيز الاستثمار في أبحاث قابلية التفسير، ويقترح في المرحلة الحالية اعتماد قواعد قانونية مرنة تشجع على التنظيم الذاتي للصناعة، لضمان تطوير تكنولوجيا الذكاء الاصطناعي بشكل آمن وشفاف وم以人为本 (يركز على الإنسان). (المصدر: 腾讯研究院)

ورقة بحثية جديدة تناقش تطبيق وتطور نماذج الانتشار المتقطع في النماذج اللغوية الكبيرة والمتعددة الوسائط: تستعرض ورقة بحثية بعنوان “Discrete Diffusion in Large Language and Multimodal Models: A Survey” بشكل منهجي التقدم البحثي في نماذج لغة الانتشار المتقطع (dLLMs) ونماذج لغة الانتشار المتقطع متعددة الوسائط (dMLLMs). تعتمد هذه النماذج على فك التشفير المتوازي لعدة رموز (multi-Token parallel decoding) واستراتيجيات التوليد القائمة على إزالة الضوضاء (denoising-based generation strategy)، مما يحقق التوليد المتوازي، والتحكم الدقيق في المخرجات، وقدرات إدراك ديناميكية ومستجيبة، مع سرعة استدلال يمكن أن تصل إلى 10 أضعاف مقارنة بالنماذج ذاتية الانحدار (autoregressive models). تتتبع الورقة تاريخ تطورها، وتضفي الطابع الرسمي على الإطار الرياضي، وتصنف النماذج التمثيلية، وتحلل تقنيات التدريب والاستدلال الرئيسية، وتلخص التطبيقات في مجالات اللغة، واللغة البصرية، والأحياء، وأخيرًا تناقش اتجاهات البحث المستقبلية وتحديات النشر. (المصدر: HuggingFace Daily Papers)
بحث جديد يقترح Test3R: تحسين الدقة الهندسية لإعادة البناء ثلاثي الأبعاد من خلال التعلم في وقت الاختبار: تقنية جديدة تسمى Test3R، تعمل على تحسين الدقة الهندسية لإعادة البناء ثلاثي الأبعاد بشكل كبير من خلال التعلم في وقت الاختبار (test-time learning). تستخدم هذه الطريقة ثلاثيات صور (I_1,I_2,I_3)، وتولد نتائج إعادة بناء من أزواج الصور (I_1,I_2) و (I_1,I_3). الفكرة الأساسية هي تحسين الشبكة في وقت الاختبار من خلال هدف ذاتي الإشراف (self-supervised objective): تعظيم الاتساق الهندسي لهاتين النتيجتين لإعادة البناء بالنسبة للصورة المشتركة I_1. أظهرت التجارب أن Test3R يتفوق بشكل كبير على الطرق الحالية المتطورة (SOTA) في مهام إعادة البناء ثلاثي الأبعاد وتقدير العمق متعدد العروض، ويتميز بالعمومية والتكلفة المنخفضة، وسهولة التطبيق على نماذج أخرى، مع تكاليف تدريب في وقت الاختبار وعدد معلمات ضئيل للغاية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Mirage-1: وكيل واجهة مستخدم رسومية (GUI) بمهارات متعددة الوسائط هرمية، يعزز القدرة على معالجة المهام طويلة المدى: اقترح الباحثون Mirage-1، وهو وكيل واجهة مستخدم رسومية (GUI) متعدد الوسائط، ومتعدد المنصات، وقابل للتوصيل والتشغيل (plug-and-play)، يهدف إلى حل مشكلة نقص المعرفة وفجوة المجال بين البيئات غير المتصلة والمتصلة التي تواجهها وكلاء واجهة المستخدم الرسومية الحاليون عند معالجة المهام طويلة المدى في البيئات المتصلة. جوهر Mirage-1 هو وحدة المهارات متعددة الوسائط الهرمية (HMS)، التي تجرد المسارات تدريجيًا إلى مهارات تنفيذية، ومهارات أساسية، ومهارات فوقية (meta-skills)، مما يوفر هيكل معرفة هرمي لتخطيط المهام طويلة المدى. وفي الوقت نفسه، تستخدم خوارزمية بحث شجرة مونت كارلو المعززة بالمهارات (SA-MCTS) المهارات المكتسبة دون اتصال لتقليل مساحة بحث الإجراءات في استكشاف الشجرة عبر الإنترنت. في اختبارات AndroidWorld و MobileMiniWob++ و Mind2Web-Live ومعيار AndroidLH المبني حديثًا، أظهر Mirage-1 تحسنًا ملحوظًا في الأداء. (المصدر: HuggingFace Daily Papers)
ورقة بحثية بعنوان “Don’t Pay Attention” تقترح بنية تحتية جديدة للشبكات العصبية Avey، تتحدى Transformer: تقترح ورقة بحثية بعنوان “Don’t Pay Attention” بنية تحتية جديدة للشبكات العصبية تسمى Avey، تهدف إلى التخلص من الاعتماد على آليات الانتباه والتكرار. يتكون Avey من مُرتِّب (ranker) ومعالج عصبي ذاتي الانحدار (autoregressive neural processor)، يعملان معًا لتحديد ومعالجة الرموز الأكثر صلة بأي رمز معين فقط (بغض النظر عن موقعه في التسلسل) في سياقها. تفصل هذه البنية طول التسلسل عن عرض السياق، مما يتيح معالجة فعالة للتسلسلات ذات الطول التعسفي. أظهرت نتائج التجارب أن Avey يقدم أداءً مشابهًا لـ Transformer في اختبارات معالجة اللغة الطبيعية القياسية قصيرة المدى، ويتفوق بشكل خاص في التقاط التبعيات طويلة المدى. (المصدر: HuggingFace Daily Papers)
ورقة بحثية جديدة تناقش تحقيق التحقق من التعليمات البرمجية القابل للتطوير من خلال نماذج المكافأة، مع الموازنة بين الدقة والإنتاجية: تستكشف دراسة حديثة المفاضلة بين استخدام نماذج مكافأة النتائج (ORM) والمحققين الشاملين (مثل مجموعات الاختبار الكاملة) عند حل مهام الترميز بواسطة النماذج اللغوية الكبيرة (LLM). وجدت الدراسة أنه حتى في وجود محققين شاملين، تلعب ORM دورًا حاسمًا في توسيع نطاق التحقق من خلال التضحية ببعض الدقة مقابل السرعة. بشكل خاص في طريقة “التوليد-التقليم-إعادة الترتيب” (generate-prune-rerank)، فإن استخدام محقق أسرع ولكنه أقل دقة لإزالة الحلول الخاطئة مسبقًا يمكن أن يزيد سرعة النظام بمقدار 11.65 مرة، مع انخفاض الدقة بنسبة 8.33% فقط. تعمل هذه الطريقة عن طريق تصفية الحلول الخاطئة ولكن ذات الترتيب العالي، مما يوفر أفكارًا جديدة لتصميم أنظمة ترتيب برامج قابلة للتطوير ودقيقة. (المصدر: HuggingFace Daily Papers)
معيار جديد AbstentionBench يكشف: نماذج LLM الموجهة للاستدلال ضعيفة الأداء في الأسئلة غير القابلة للإجابة: لتقييم قدرة النماذج اللغوية الكبيرة (LLM) على اختيار الامتناع (أي رفض الإجابة بشكل صريح) عند مواجهة عدم اليقين، أطلق الباحثون AbstentionBench. يتضمن هذا الاختبار المعياري واسع النطاق 20 مجموعة بيانات مختلفة، تغطي أنواعًا متعددة من الأسئلة مثل الإجابات غير المعروفة، والمواصفات غير الكافية، والمقدمات الخاطئة، والتفسيرات الذاتية، والمعلومات القديمة. أظهر تقييم 20 نموذجًا من أحدث نماذج LLM أن الامتناع يمثل مشكلة لم يتم حلها بعد، وأن زيادة حجم النموذج لا تساعد كثيرًا في هذا الصدد. والمثير للدهشة أنه حتى نماذج LLM الموجهة للاستدلال والمدربة خصيصًا لمجالات الرياضيات والعلوم، أدى ضبطها الدقيق للاستدلال إلى خفض قدرتها على الامتناع بمعدل 24%. على الرغم من أن التوجيهات النظامية المصممة بعناية يمكن أن تحسن أداء الامتناع في الممارسة العملية، إلا أن هذا لا يحل العيوب الأساسية للنموذج في الاستدلال في ظل عدم اليقين. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح طريقة PatchInstruct القائمة على التوجيه والتحليل المستند إلى الرقع للاستفادة من LLM في التنبؤ بالسلاسل الزمنية: تستكشف دراسة جديدة استراتيجيات توجيه بسيطة ومرنة للاستفادة من النماذج اللغوية الكبيرة (LLM) في التنبؤ بالسلاسل الزمنية، دون الحاجة إلى إعادة تدريب مكثفة أو هياكل خارجية معقدة. من خلال الجمع بين تحليل السلاسل الزمنية، والترميز المستند إلى الرقع (patch-based tokenization)، والتعزيز بالجوار المستند إلى التشابه، وجد الباحثون أنه يمكن تحسين جودة تنبؤات LLM، مع الحفاظ على البساطة وتقليل المعالجة المسبقة للبيانات إلى الحد الأدنى. تمكن طريقة PatchInstruct المقترحة في هذه الدراسة LLM من إجراء تنبؤات دقيقة وفعالة. (المصدر: HuggingFace Daily Papers)
إصدار مجموعة بيانات جديدة MS4UI، تركز على التلخيص متعدد الوسائط لمقاطع الفيديو التعليمية لواجهة المستخدم: لمعالجة أوجه القصور في المعايير الحالية فيما يتعلق بتوفير تعليمات ورسوم توضيحية متدرجة وقابلة للتنفيذ، اقترح الباحثون مجموعة بيانات MS4UI (Multi-modal Summarization for User Interface Instructional Videos). تحتوي مجموعة البيانات هذه على 2413 مقطع فيديو تعليميًا لواجهة المستخدم، بإجمالي مدة تزيد عن 167 ساعة، وقد تم تقسيم مقاطع الفيديو يدويًا، وتلخيص النصوص، ووضع علامات على ملخصات الفيديو. تهدف إلى دفع البحث في طرق التلخيص متعدد الوسائط الموجزة والقابلة للتنفيذ لمقاطع الفيديو التعليمية لواجهة المستخدم. أظهرت التجارب أن الطرق الحالية المتطورة للتلخيص متعدد الوسائط لا تعمل بشكل جيد على MS4UI، مما يسلط الضوء على أهمية الطرق الجديدة في هذا المجال. (المصدر: HuggingFace Daily Papers)
DeepResearch Bench: اختبار معياري شامل لوكلاء البحث العميق (Deep Research Agents): لتقييم قدرات وكلاء البحث العميق (Deep Research Agents, DRAs) القائمة على LLM بشكل منهجي، أطلق الباحثون DeepResearch Bench. يتضمن هذا المعيار 100 مهمة بحثية على مستوى الدكتوراه صممها بعناية خبراء من 22 مجالًا مختلفًا. نظرًا لتعقيد وكثافة العمل في تقييم DRAs، اقترح الباحثون طريقتين جديدتين للتقييم تتوافقان بشكل كبير مع الحكم البشري: الأولى هي طريقة معيارية تكيفية قائمة على المرجع، لتقييم جودة تقارير البحث المولدة؛ والأخرى هي إطار عمل يقيم قدرة DRA على استرجاع وجمع المعلومات من خلال تقييم عدد الاستشهادات الفعالة ودقة الاستشهاد الإجمالية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح BridgeVLA: تحقيق تعلم فعال للعمليات ثلاثية الأبعاد من خلال محاذاة المدخلات والمخرجات: لتعزيز كفاءة استخدام الإشارات ثلاثية الأبعاد في تعلم عمليات الروبوتات بواسطة نماذج اللغة المرئية (VLM)، اقترح الباحثون BridgeVLA، وهو نموذج جديد للحركة اللغوية المرئية ثلاثية الأبعاد (VLA). يقوم BridgeVLA بإسقاط المدخلات ثلاثية الأبعاد على صور ثنائية الأبعاد متعددة، مما يضمن محاذاة المدخلات مع الشبكة الأساسية لـ VLM، ويستخدم خرائط حرارية ثنائية الأبعاد للتنبؤ بالحركة، وبالتالي توحيد المدخلات والمخرجات في مساحة صور ثنائية الأبعاد متسقة. بالإضافة إلى ذلك، تقترح هذه الدراسة طريقة تدريب مسبق قابلة للتطوير، تمكن الشبكة الأساسية لـ VLM من التنبؤ بالخرائط الحرارية ثنائية الأبعاد قبل تعلم السياسة النهائية. أظهرت التجارب أن BridgeVLA يقدم أداءً متميزًا في العديد من المعايير المحاكاة وتجارب الروبوتات الحقيقية، مما يعزز بشكل كبير كفاءة وفعالية تعلم العمليات ثلاثية الأبعاد، ويظهر كفاءة قوية في استخدام العينات وقدرة على التعميم. (المصدر: HuggingFace Daily Papers)
بحث جديد يركب ملايين التعليمات المعقدة والمتنوعة للمستخدمين (SynthQuestions) من خلال التأسيس المنسوب (Attributed Grounding): لمعالجة نقص البيانات التعليمية المتنوعة والمعقدة وواسعة النطاق اللازمة لمواءمة النماذج اللغوية الكبيرة (LLM)، اقترح الباحثون طريقة لتركيب التعليمات تعتمد على التأسيس المنسوب (attributed grounding). يتضمن هذا الإطار: 1) عملية إسناد من أعلى إلى أسفل، تربط التعليمات الحقيقية المختارة بمستخدمين سياقيين؛ 2) عملية تركيب من أسفل إلى أعلى، تستخدم مستندات الويب لتوليد السياقات أولاً، ثم توليد تعليمات ذات معنى. تم بناء مجموعة بيانات SynthQuestions التي تحتوي على مليون تعليمة باستخدام هذه الطريقة. أظهرت التجارب أن النماذج المدربة على مجموعة البيانات هذه تحقق أداءً رائدًا في العديد من المعايير الشائعة، وأن الأداء يستمر في التحسن مع زيادة مجموعة نصوص الويب. (المصدر: HuggingFace Daily Papers)
PersonaFeedback: إطلاق معيار تقييم شخصي واسع النطاق موسوم يدويًا: لتقييم قدرة النماذج اللغوية الكبيرة (LLM) على تقديم استجابات مخصصة عند إعطائها ملفات تعريف مستخدمين واستعلامات محددة مسبقًا، أطلق الباحثون معيار PersonaFeedback. يتضمن هذا المعيار 8298 حالة اختبار موسومة يدويًا، مصنفة إلى ثلاثة مستويات: سهل ومتوسط وصعب، بناءً على تعقيد سياق ملف تعريف المستخدم وصعوبة تمييز الاستجابات المخصصة. على عكس المعايير الحالية، يفصل PersonaFeedback استنتاج ملف التعريف عن التخصيص، ويركز على تقييم قدرة النموذج على توليد استجابات مخصصة لملفات تعريف واضحة. أظهرت نتائج التجارب أنه حتى نماذج LLM المتطورة تواجه تحديات في اختبارات المستوى الصعب، مما يشير إلى أن أطر العمل الحالية المعززة بالاسترجاع ليست الحل النهائي لمهام التخصيص. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش “جراحة اللغة” في النماذج اللغوية الكبيرة متعددة اللغات: تحقيق التحكم في اللغة وقت الاستدلال من خلال الحقن الكامن: تستكشف دراسة جديدة ظاهرة محاذاة التمثيل التي تحدث بشكل طبيعي في النماذج اللغوية الكبيرة (LLM) وأهميتها في فصل المعلومات الخاصة باللغة والمعلومات المستقلة عن اللغة. تؤكد الدراسة وجود هذه المحاذاة وتحلل مقارنة سلوكها مع نماذج المحاذاة المصممة بشكل صريح. بناءً على هذه النتائج، يقترح الباحثون طريقة التحكم في اللغة وقت الاستدلال (Inference-Time Language Control, ITLC)، التي تستخدم الحقن الكامن (latent injection) لتحقيق تحكم دقيق عبر اللغات وتخفيف مشكلة الخلط اللغوي في LLM. أثبتت التجارب أن ITLC تتمتع بقدرة قوية على التحكم عبر اللغات مع الحفاظ على السلامة الدلالية للغة الهدف، ويمكنها التخفيف بفعالية من مشكلة الخلط اللغوي التي لا تزال موجودة حتى في نماذج LLM واسعة النطاق الحالية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح طريقة NoWait: إزالة “رموز التفكير” لتعزيز كفاءة استدلال النماذج الكبيرة: أظهرت الأبحاث الحديثة أن نماذج الاستدلال الكبيرة، عند إجراء استدلال معقد متعدد الخطوات، غالبًا ما تؤدي إلى مخرجات زائدة عن الحاجة بسبب “التفكير” المفرط (مثل إخراج رموز “Wait” و “Hmm” وما إلى ذلك)، مما يؤثر على الكفاءة. تهدف طريقة NoWait المقترحة حديثًا إلى التحقق من ضرورتها للاستدلال المتقدم من خلال قمع رموز التفكير الذاتي الصريحة هذه أثناء الاستدلال. في عشرة اختبارات معيارية عبر مهام استدلال النصوص والصور والفيديو، قلصت NoWait طول مسارات سلسلة الأفكار (chain-of-thought) بنسبة 27%-51% في خمس سلاسل نماذج من طراز R1، دون المساس بفائدة النموذج. توفر هذه الطريقة حلاً جاهزًا للاستخدام لتحقيق استدلال متعدد الوسائط فعال مع الحفاظ على الفائدة. (المصدر: HuggingFace Daily Papers)
💼 أعمال
OpenAI تفوز بعقد دفاع أمريكي بقيمة 200 مليون دولار لتطوير قدرات عسكرية متطورة: وقعت OpenAI عقدًا مع وزارة الدفاع الأمريكية لمدة عام واحد بقيمة 200 مليون دولار، يهدف إلى تطوير أدوات ذكاء اصطناعي متقدمة للأمن القومي، مما يمثل أول عقد من هذا النوع مدرج للبنتاغون تحصل عليه OpenAI. سيتم العمل بشكل رئيسي في منطقة العاصمة الوطنية. كانت OpenAI قد تعاونت سابقًا مع شركة الدفاع Anduril، وتأتي هذه الخطوة في سياق حملة واسعة النطاق في قطاع الدفاع الأمريكي لتطبيق الذكاء الاصطناعي، حيث تتعاون منافستها Anthropic أيضًا مع Palantir و Amazon في هذا المجال. كان الرئيس التنفيذي لـ OpenAI، Sam Altman، قد أعرب علنًا عن دعمه لمشاريع الأمن القومي. (المصدر: Reddit r/ArtificialInteligence, code_star)

Alta تجمع تمويلاً بقيمة 11 مليون دولار، بقيادة Menlo Ventures، مع التركيز على الذكاء الاصطناعي + الموضة: أعلنت شركة Alta الناشئة في مجال الموضة والذكاء الاصطناعي عن إتمام جولة تمويل بقيمة 11 مليون دولار بقيادة Menlo Ventures، وبمشاركة Benchstrength و Aglaé Ventures (صندوق رأس مال استثماري مدعوم من عائلة أرنو التابعة لمجموعة LVMH). ستنضم Amy Tong Wu إلى مجلس إدارة Alta. ستساعد هذه الجولة التمويلية Alta على مواصلة تطويرها في مجال دمج الذكاء الاصطناعي والموضة. (المصدر: ZhaiAndrew)
شركة Figure تعدل هيكلها التنظيمي، وتدمج قسم التحكم في Helix لتسريع خارطة طريق الذكاء الاصطناعي: أعلنت شركة الروبوتات البشرية Figure أن قسم التحكم (Controls) لم يعد موجودًا، وأن الفريق بأكمله قد تم دمجه في قسم Helix. تهدف هذه الخطوة إلى تسريع تطوير خارطة طريق الشركة في مجال الذكاء الاصطناعي، مما يشير إلى أن Figure تركز المزيد من الموارد والجهود على البحث والتطوير وتطبيق تكنولوجيا الذكاء الاصطناعي. (المصدر: adcock_brett)
🌟 مجتمع
نقاش حول AGI: لا داعي للقلق المفرط للمستخدمين العاديين، AGI يميل أكثر نحو الاستراتيجية وليس أداة يومية: أشار العديد من المشاركين في المجتمع إلى أنه بالنسبة لمستخدمي LLM العاديين، لا داعي للقلق المفرط بشأن وصول AGI (الذكاء الاصطناعي العام). تعريف AGI غامض ونظري للغاية، وحتى لو تحقق، فلن يظهر بشكل مباشر في نوافذ دردشة المستخدمين على المدى القصير، بل سيكون بمثابة أداة استراتيجية وبنية تحتية للدول أو المؤسسات الكبيرة، تُستخدم لمعالجة الشؤون المعقدة مثل المفاوضات بين الدول، وليس لمساعدة الأفراد في ترتيب الاجتماعات. (المصدر: farguney, farguney, farguney, farguney)
بناء أنظمة متعددة الوكلاء يتطلب تقييمًا بشريًا، مع التركيز على الحالات الهامشية وجودة المصادر: عند بناء أنظمة متعددة الوكلاء، يعد التقييم والاختبار البشري أمرًا بالغ الأهمية، حيث يمكنه اكتشاف الحالات الهامشية التي قد يتجاهلها التقييم الآلي. على سبيل المثال، في المراحل المبكرة، كانت الوكلاء تميل إلى اختيار مصادر المعلومات المحسّنة لمحركات البحث (SEO) من مزارع المحتوى (content farms) بدلاً من ملفات PDF الأكاديمية الموثوقة أو المدونات الشخصية. يساعد تضمين طرق استدلالية لجودة المصدر في التوجيهات على حل مثل هذه المشكلات. يشير هذا إلى أنه حتى في عصر التقييم الآلي، لا يزال الاختبار اليدوي ضروريًا لاكتشاف أعطال النظام، والتحيزات الدقيقة في اختيار المصدر، وما إلى ذلك. (المصدر: riemannzeta)

الاختلافات بين LLM ونماذج الفيديو في آليات التنبؤ والتعلم تثير التفكير: أعاد Yann LeCun و Pedro Domingos نشر وجهة نظر Sergey Levine، التي تتساءل عن سبب تعلم النماذج اللغوية الكثير من التنبؤ بالرمز التالي (next Token prediction)، بينما تتعلم نماذج الفيديو أقل نسبيًا من التنبؤ بالإطار التالي (next frame prediction). يخمن Levine أن هذا قد يكون بسبب أن LLM تلعب دور “ماسح الدماغ” إلى حد ما، مما يشير إلى تفرد آليات تعلمها، أو أن LLM تعيش كما لو كانت في كهف أفلاطون، وتستنتج العالم الحقيقي من خلال ملاحظة تسلسل الظلال (النصوص). (المصدر: ylecun, pmddomingos, pmddomingos)

التأثير الإيجابي لوكلاء الذكاء الاصطناعي في مجال التعليم: تشجيع المتعلمين على الخروج من منطقة الراحة: يرى نقاش مجتمعي أن وكلاء الذكاء الاصطناعي ليس لهم تأثير إيجابي على الشركات فحسب، بل لديهم أيضًا إمكانات هائلة في مجال التعليم. من خلال التفاعل مع وكلاء الذكاء الاصطناعي، يمكن للمتعلمين الخروج من منطقة الراحة الخاصة بهم بشكل أكثر فعالية، مما يعزز نتائج التعلم. (المصدر: pirroh, amasad)
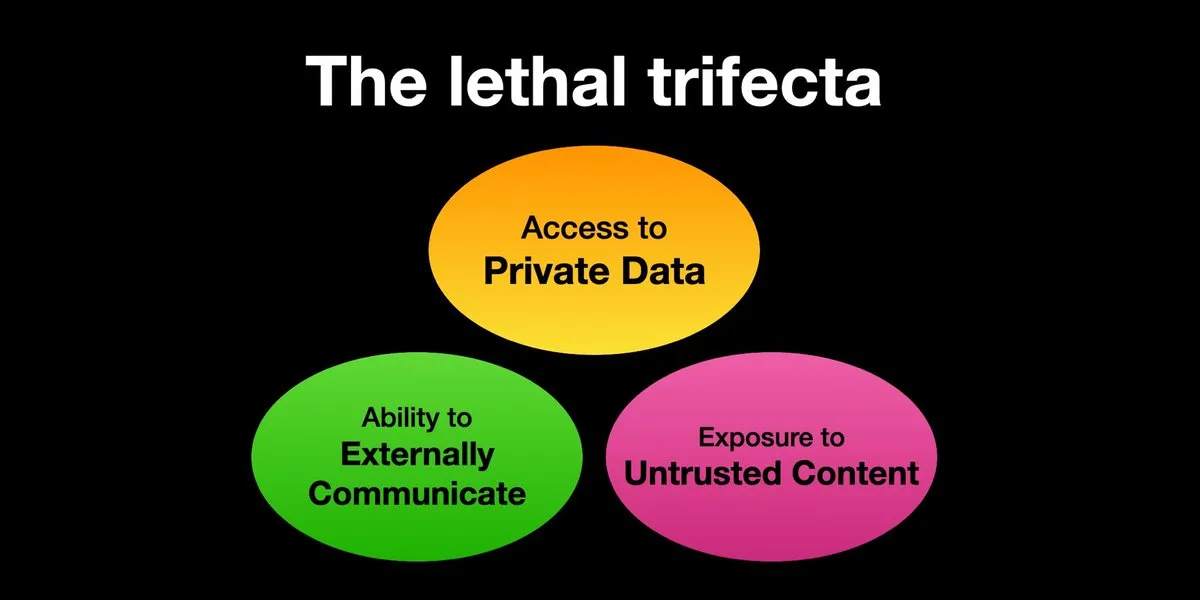
وكلاء الذكاء الاصطناعي يواجهون مخاطر هجمات حقن التوجيهات (prompt injection)، والحماية الأمنية بحاجة ماسة إلى التعزيز: أعاد Karpathy نشر تحذير Simon Willison بشأن المخاطر “الثلاثية القاتلة” (Lethal Trifecta) التي تواجه وكلاء الذكاء الاصطناعي، أي عندما يمتلك وكيل الذكاء الاصطناعي في نفس الوقت إمكانية الوصول إلى البيانات الخاصة، والتعرض لمحتوى غير موثوق به، والقدرة على الاتصال الخارجي، يمكن للمهاجمين خداع النظام لسرقة البيانات. هذا يذكرنا بعصر “الغرب المتوحش” لفيروسات الكمبيوتر المبكرة، فآليات الدفاع الحالية ضد التوجيهات الخبيثة لا تزال غير مكتملة، على سبيل المثال، الافتقار إلى نماذج أمان مشابهة لنواة نظام التشغيل/مساحة المستخدم لتقييد قدرة الوكيل على تنفيذ أي نصوص برمجية. هذا يجعل التبني المبكر لوكلاء LLM للحوسبة الشخصية أمرًا مثيرًا للقلق. (المصدر: karpathy, TheTuringPost)
في عصر الذكاء الاصطناعي، تصبح القدرة على التعلم السريع هي القدرة التنافسية الأساسية: أشار Mustafa Suleyman إلى أن أكبر مسرّع مهني في العقد القادم سيكون القدرة الفائقة على التعلم. ينصح الناس بتحديد أسلوب تعلمهم بوضوح، واستخدام الذكاء الاصطناعي لتحويل المواد إلى تنسيق مناسب (مثل البودكاست والاختبارات)، ثم تطبيق المعرفة وتكرار هذه العملية باستمرار، وبالتالي تحقيق التعلم والنمو السريع. (المصدر: mustafasuleyman)
واقعية المحتوى الذي يولده الذكاء الاصطناعي وأهميته: أهمية المحتوى قد تفوق واقعيته: شارك المستخدم imjaredz تجربته قائلاً إنه أرسل 2000 رسالة بريد إلكتروني توجيهية مولدة بواسطة الذكاء الاصطناعي، ولم يشتكِ أحد من أنها مكتوبة بواسطة الذكاء الاصطناعي، بل أعرب 5 أشخاص عن أن محتوى الرسالة “هو بالضبط ما كانوا يبحثون عنه”. أثار هذا نقاشًا حول ما إذا كانت أهمية المحتوى في التواصل تفوق “واقعيته” (أي ما إذا كان من صنع الإنسان). (المصدر: imjaredz)
نقاش حول قدرة LLM على “الفهم”: التقريب السلوكي لا يساوي الفهم الحقيقي: هناك وجهة نظر في المجتمع ترى أنه على الرغم من أن النماذج اللغوية الكبيرة تظهر قدرات تقريب سلوكية ومعرفية قوية، إلا أن هذا لا يعادل الفهم الحقيقي. يتطلب الفهم القدرة على التفسير، ومجرد إظهار السلوك ليس ذكاءً أو فهمًا. غالبًا ما يتم تجاهل هذا الاختلاف الأساسي. تؤكد وجهة النظر هذه على أنه قبل تسليم القرارات التي تنطوي على سلامة الأرواح إلى النماذج، يجب تقييم ما إذا كانت تقترب حقًا من الذكاء الاصطناعي العام بحذر، والحذر من المبالغة في الترويج لقدراتها. (المصدر: farguney)
وكلاء الذكاء الاصطناعي يقدمون أداءً لافتًا في اختبارات هندسة البرمجيات، ولكن هناك نقاش حول طبيعتهم “كوكلاء”: مع استمرار ارتفاع درجات الذكاء الاصطناعي في اختبارات هندسة البرمجيات مثل SWE-bench (حتى تجاوزت 50-60 نقطة)، ناقش المجتمع ما إذا كان “عصر ترميز الوكلاء” قد بدأ بالفعل. هناك وجهة نظر ترى أنه إذا كانت “الأطر الخالية من الوكلاء” (agentless frameworks) هي المستخدمة بشكل عام، بدلاً من السماح للنماذج اللغوية باستكشاف البيئة حقًا، فإن تسميتها “عصر ترميز الوكلاء” قد لا تكون دقيقة، على الرغم من أن هذه الأطر نفسها ذات قيمة. (المصدر: huybery, terryyuezhuo)
الحاجة إلى مراجعة محتوى الصور المولدة بالذكاء الاصطناعي: البحث عن حلول مفتوحة المصدر أو تجارية: مع انتشار تقنية توليد الصور بالذكاء الاصطناعي، بدأ المطورون في الصين في الاهتمام بمسألة امتثال المحتوى الناتج، وخاصة كيفية اكتشاف المحتوى الإباحي والحساس سياسيًا وما إلى ذلك. ظهرت في المجتمع نقاشات تبحث عن نماذج صغيرة مفتوحة المصدر أو منتجات تجارية متاحة لمراجعة المحتوى. (المصدر: dotey)
💡 أخرى
التخصيص المدفوع بالذكاء الاصطناعي وأهمية المحتوى: 2000 رسالة بريد إلكتروني من الذكاء الاصطناعي بدون تقييم سلبي، و5 أشخاص يقولون “هذا ما أحتاجه بالضبط”: شارك أحد المستخدمين أنه أرسل 2000 رسالة بريد إلكتروني توجيهية تم إنشاؤها بواسطة الذكاء الاصطناعي، ولم يشتك أي من المستلمين من أن الرسائل مكتوبة بواسطة الذكاء الاصطناعي. على العكس من ذلك، ذكر خمسة مستلمين أن محتوى الرسالة “هو بالضبط العمل الذي يقومون به حاليًا”. أثارت هذه الحالة نقاشًا حول ما إذا كانت الأهمية الكبيرة للمحتوى في الاتصال بمساعدة الذكاء الاصطناعي يمكن أن تتجاوز الاهتمام بـ “الواقعية” (أي ما إذا كانت مكتوبة بواسطة الإنسان)، مما يشير إلى إمكانات الذكاء الاصطناعي في إنشاء محتوى مخصص. (المصدر: imjaredz)
البشر يصبحون عنق الزجاجة في أنظمة الذكاء الاصطناعي، والحاجة إلى تجنب أو رفع كفاءة البشر: تشير وجهة نظر Charles Earl إلى أن تراكم رسائل البريد الإلكتروني في صندوق الوارد، بينما يكون صندوق الصادر فارغًا، يعكس أن البشر هم عنق الزجاجة في معالجة المعلومات والاستجابة لها. في عصر الذكاء الاصطناعي، يجب التفكير في كيفية تجنب عنق الزجاجة البشري، أو كيفية رفع كفاءة عمل البشر من خلال الذكاء الاصطناعي وتقنيات أخرى. (المصدر: charles_irl)
المخاطر المحتملة للتحكم في المنازل الذكية بواسطة الذكاء الاصطناعي: مستخدم يُحتجز في سرير ذكي بارد بسبب عطل في التطبيق: شارك أحد المستخدمين تجربته حيث لم يتمكن من تعديل درجة حرارة سريره الذكي الذي يتحكم فيه الذكاء الاصطناعي (Eight Sleep Pod3) بسبب عطل في التطبيق، مما أدى في النهاية إلى احتجازه في سرير بارد. نظرًا لأن هذا الطراز لا يحتوي على تحكم يدوي ويعتمد كليًا على التطبيق، فإن هذا العطل يسلط الضوء على الإزعاج والتجربة “الديستوبية” المحتملة التي قد تنجم عن الاعتماد المفرط على الذكاء الاصطناعي وتطبيقات التحكم في أجهزة المنزل الذكي. (المصدر: madiator)