كلمات مفتاحية:الحوسبة الكمية, التعلم المعزز, أخلاقيات الذكاء الاصطناعي, الترقية الذاتية للذكاء الاصطناعي, واجهة الدماغ والحاسوب, النماذج اللغوية الكبيرة, الحوسبة العصبية, إنشاء الفيديو بالذكاء الاصطناعي, معدل خطأ البت الكمي, التعلم الذاتي JEPA, تنسيق التكميم MLX, نموذج الفهم البصري PAM, إنشاء محتوى ASMR بالذكاء الاصطناعي
🔥 أبرز العناوين
جامعة أكسفورد تحقق معدل خطأ قياسي بنسبة 0.000015% في تجربة الحوسبة الكمومية (Quantum Computing): حقق فريق بحثي من جامعة أكسفورد (Oxford University) اختراقًا كبيرًا في تجربة الحوسبة الكمومية (quantum computing)، حيث تمكن من خفض معدل الخطأ في الكيوبتات الكمومية إلى 0.000015%، مسجلاً رقمًا قياسيًا عالميًا جديدًا. هذا التقدم حاسم لبناء حواسيب كمومية متسامحة مع الخطأ، حيث أن معدل الخطأ المنخفض للغاية هو شرط أساسي لتحقيق الخوارزميات الكمومية المعقدة وإطلاق العنان لإمكانات الحوسبة الكمومية. تُظهر هذه النتيجة تقدمًا ملحوظًا في تعزيز استقرار الكيوبتات الكمومية والتحكم الدقيق بها على مستوى الأجهزة، مما يضع أساسًا أكثر صلابة للتطبيقات المستقبلية التي تعتمد على قوة حوسبة هائلة في مجالات مثل الذكاء الاصطناعي (AI) وغيرها (المصدر: Ronald_vanLoon)

باحثون في معهد ماساتشوستس للتكنولوجيا (MIT) يجعلون الذكاء الاصطناعي يتعلم الترقية الذاتية والتحسين: حقق باحثون في معهد ماساتشوستس للتكنولوجيا (MIT) تقدمًا في مجال التحسين الذاتي للذكاء الاصطناعي، حيث طوروا طريقة جديدة تمكن أنظمة الذكاء الاصطناعي من التعلم المستقل وتحسين أدائها ذاتيًا. هذه القدرة تحاكي عملية التقدم المستمر للبشر من خلال الخبرة والتفكير، وهي حاسمة لتطوير ذكاء اصطناعي أكثر استقلالية وقدرة على التكيف. قد يمهد هذا البحث الطريق لتحسين نماذج الذكاء الاصطناعي بشكل مستمر بعد النشر، وتقليل الاعتماد على التدخل البشري، مما له تأثير عميق على تطوير وتطبيق الذكاء الاصطناعي على المدى الطويل (المصدر: TheRundownAI)

ذكاء اصطناعي “يقرأ الأفكار” يحول موجات دماغ المصابين بالشلل إلى كلام فوري: أظهر بحث ثوري كيف يمكن للذكاء الاصطناعي “قارئ الأفكار” تحويل موجات دماغ المرضى المصابين بالشلل إلى كلام واضح في الوقت الفعلي. تستخدم هذه التقنية واجهات دماغية-حاسوبية (BCI) متقدمة وخوارزميات ذكاء اصطناعي لفك تشفير الإشارات العصبية المتعلقة باللغة وتحويلها إلى مخرجات صوتية مفهومة. يوفر هذا وسيلة تواصل جديدة تمامًا للمرضى الذين فقدوا القدرة على الكلام بسبب اضطرابات حركية شديدة، ومن المتوقع أن يحسن بشكل كبير نوعية حياتهم، ويمثل تقدمًا كبيرًا للذكاء الاصطناعي في مجالات الرعاية الصحية المساعدة وعلوم الأعصاب (المصدر: Ronald_vanLoon)

تحقيق اختراق في معضلة رياضية فيزيائية عمرها قرن، وخريجو جامعة بكين يشاركون في حل مسألة هلبرت السادسة: حقق خريجو جامعة بكين دينغ يو (Deng Yu)، وما شياو (Ma Xiao) من دفعة الموهوبين بجامعة العلوم والتكنولوجيا الصينية، وزاهر هاني (Zaher Hani) تلميذ تيرنس تاو (Terence Tao) المتميز، اختراقًا كبيرًا في مسألة هلبرت السادسة “أكسيومة الفيزياء”. لقد أثبتوا لأول مرة بشكل صارم الانتقال الكامل من ميكانيكا نيوتن (مجهرية، قابلة للعكس زمنيًا) إلى معادلة بولتزمان (إحصائية عيانية، غير قابلة للعكس زمنيًا)، مما يسد الفجوة المنطقية بينهما، ويضع أساسًا رياضيًا أكثر صلابة للميكانيكا الإحصائية، ويجيب بشكل غير متوقع على “لغز سهم الزمن”. تُظهر هذه النتيجة، من خلال أدوات رياضية متقنة واستنتاجات مرحلية، المسار من النظرية الذرية إلى قوانين حركة الأوساط المستمرة (المصدر: 量子位)

🎯 اتجاهات
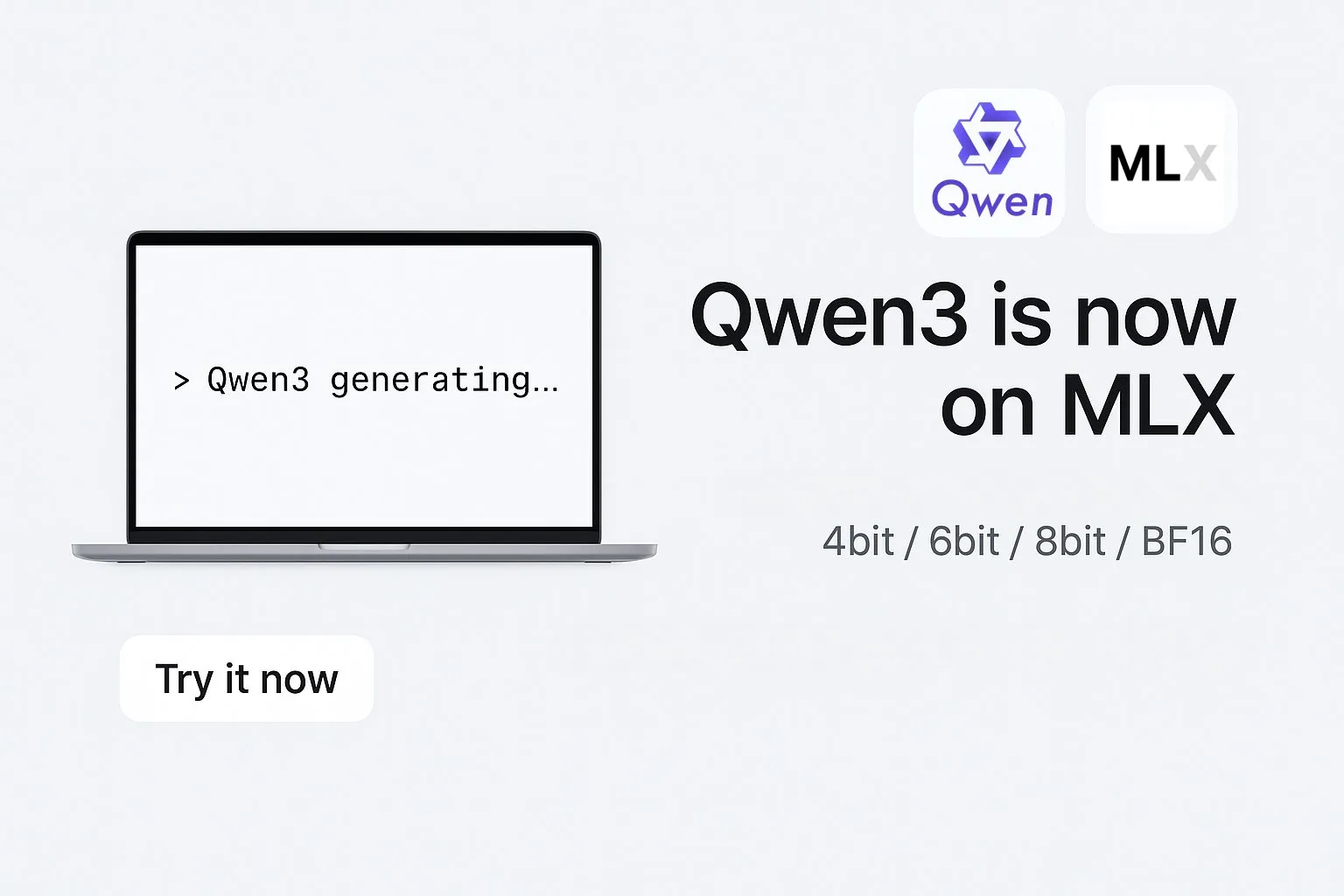
Alibaba تطلق إصدارات نماذج سلسلة Qwen3 بتنسيق MLX: أعلنت Alibaba أن نماذجها الكبيرة من سلسلة Qwen3 تدعم الآن تنسيق MLX، وتوفر أربعة مستويات تكميم: 4-bit، 6-bit، 8-bit، و BF16. MLX هو إطار تعلم آلي محسن من Apple لـ Apple Silicon، وهذا يعني أن نماذج Qwen3 ستعمل بكفاءة أكبر على أجهزة Apple، مما يقلل من عتبة نشر وتشغيل النماذج الكبيرة على الأجهزة الطرفية، ويساعد على تعزيز انتشار وتطبيق النماذج الكبيرة على الأجهزة الشخصية (المصدر: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google تطلق نموذج Gemma 3n، أداء عالٍ بمعلمات صغيرة: أطلقت Google نموذج Gemma 3n، الذي يحتوي على أقل من 10 مليارات معلمة، ولكنه تجاوز 1300 نقطة في تقييم LMArena، ليصبح أول نموذج صغير يحقق هذا الإنجاز. يثبت الأداء المتميز لـ Gemma 3n أنه يمكن تحقيق مستويات عالية من فهم اللغة وتوليدها بحجم معلمات أصغر، ويدعم التشغيل على الأجهزة الطرفية مثل الهواتف المحمولة، وهو أمر مهم لتعزيز انتشار تطبيقات الذكاء الاصطناعي وتقليل تكاليف الحوسبة (المصدر: osanseviero)
Tencent تطلق تقنية لإنشاء أصول ثلاثية الأبعاد (3D assets) بجودة سينمائية بواسطة الذكاء الاصطناعي: عرضت Tencent تقنية ذكاء اصطناعي جديدة قادرة على إنشاء أصول ثلاثية الأبعاد (3D assets) بجودة سينمائية. من المتوقع أن ترفع هذه التقنية بشكل كبير كفاءة وجودة إنشاء المحتوى ثلاثي الأبعاد في مجالات مثل تطوير الألعاب والإنتاج السينمائي، وتقليل تكاليف الإنتاج. يعد الإنشاء السريع للأصول ثلاثية الأبعاد عالية الجودة حلقة وصل رئيسية في تطوير صناعة الميتافيرس والمحتوى الرقمي (المصدر: TheRundownAI)
نموذج Kling 2.1 من Kuaishou يُظهر أداءً متميزًا في تحويل الصور إلى فيديو وتوليد الصوت والفيديو بشكل متزامن: تم تحديث نموذج Kling لتوليد الفيديو بالذكاء الاصطناعي التابع لـ Kuaishou إلى الإصدار 2.1، وأظهر قدرات قوية في تحويل الصور إلى فيديو. يُقال إن الإصدار الجديد يمكنه تحقيق توليد الفيديو والصوت بنقرة واحدة، دون الحاجة إلى تصميم مؤثرات صوتية لاحقة، لإنتاج محتوى متزامن صوتيًا ومرئيًا بجودة استوديو. يمثل هذا تقدمًا للذكاء الاصطناعي في توليد المحتوى متعدد الوسائط، وخاصة في مجال الفيديو، مما يبسط عملية الإنشاء ويحسن جودة التوليد (المصدر: Kling_ai, Kling_ai)
نموذج فيديو AI جديد “Kangaroo” قد يكون Minimax Hailuo 2.0، ويتحدى نماذج SOTA الحالية: ظهر في السوق نموذج غامض لتوليد الفيديو بالذكاء الاصطناعي يُدعى “Kangaroo”، وأظهر أداءً قويًا في ساحة منافسة الفيديو بالذكاء الاصطناعي، خاصة في تحويل الصور إلى فيديو. تشير التحليلات إلى أن هذا النموذج قد يكون إصدار Hailuo 2.0 من شركة Minimax. قد يغير ظهوره الترتيب الحالي لأداء نماذج تحويل النص إلى فيديو والصور إلى فيديو، على الرغم من أن قدراته في معالجة الصوت لا تزال بحاجة إلى تقييم (المصدر: TomLikesRobots)
MiniMax تطلق سلسلة نماذج M1، بقدرات معالجة نصوص طويلة متميزة: أصدرت MiniMaxAI سلسلة نماذج MiniMax-M1، وهو نموذج MoE (خليط الخبراء) يحتوي على 456 مليار معلمة. أظهرت هذه السلسلة من النماذج أداءً متميزًا في العديد من اختبارات الأداء القياسية، خاصة في معالجة السياقات الطويلة (مثل اختبار OpenAI-MRCR القياسي) حيث تجاوزت GPT-4.1، واحتلت المرتبة الثالثة في LongBench-v2. يُظهر هذا إمكاناتها في معالجة وفهم المستندات الطويلة، ولكن “ميزانية التفكير” (thinking budget) الكبيرة قد تتطلب موارد حوسبة عالية (المصدر: Reddit r/LocalLLaMA)

ريتشارد ساتون (Richard Sutton) الحائز على جائزة تورينغ: الذكاء الاصطناعي ينتقل من “عصر البيانات البشرية” إلى “عصر الخبرة”: أشار ريتشارد ساتون (Richard Sutton)، رائد التعلم المعزز، في مؤتمر بكين للمصادر المفتوحة للذكاء الاصطناعي (Beijing Zhiyuan Conference)، إلى أن نماذج الذكاء الاصطناعي الكبيرة الحالية التي تعتمد على البيانات البشرية تقترب من حدودها، حيث أن البيانات البشرية عالية الجودة قد استُنفدت، وفوائد توسيع نطاق النماذج تتضاءل. يعتقد أن مستقبل الذكاء الاصطناعي يكمن في دخول “عصر الخبرة”، أي أن الوكلاء الأذكياء يتعلمون من خلال التفاعل المباشر مع البيئة لتوليد خبرات مباشرة، بدلاً من تقليد النصوص القديمة. يتطلب هذا تشغيل الوكلاء الأذكياء بشكل مستمر في بيئات حقيقية أو محاكاة، واستخدام ردود الفعل البيئية كإشارات مكافأة، وتطوير نماذج عالمية وأنظمة ذاكرة، لتحقيق التعلم المستمر والابتكار الحقيقي (المصدر: 36氪)

نموذج PAM: معلمات 3B تحقق تكامل تجزئة الصور والفيديو والتعرف عليها وشرحها: قامت مؤسسات مثل MMLab في الجامعة الصينية في هونغ كونغ بإتاحة نموذج Perceive Anything Model (PAM) مفتوح المصدر، وهو نموذج بمعلمات 3B يمكنه إكمال تجزئة الكائنات في الصور ومقاطع الفيديو والتعرف عليها وتفسيرها ووصفها في نفس الوقت، وإخراج النصوص والأقنعة (Mask) بشكل متزامن. يحقق PAM تحويلاً فعالاً للميزات المرئية إلى رموز متعددة الوسائط من خلال إدخال Semantic Perceiver لربط هيكل تجزئة SAM2 و LLM. قام الفريق أيضًا ببناء مجموعة بيانات تدريب نصية وصورية واسعة النطاق وعالية الجودة. قام PAM بتحديث أو الاقتراب من حالة SOTA في العديد من معايير فهم الرؤية، ويتمتع بكفاءة استدلال أفضل (المصدر: 量子位)

الحوسبة العصبية الشكل (Neuromorphic Computing) قد تكون مفتاح الجيل القادم من الذكاء الاصطناعي، ومن المتوقع أن تعمل باستهلاك منخفض للطاقة: يستكشف العلماء بنشاط الحوسبة العصبية الشكل، التي تهدف إلى محاكاة بنية الدماغ البشري وطريقة عمله، لحل مشكلة استهلاك الطاقة العالية لنماذج الذكاء الاصطناعي الحالية. تعمل مؤسسات مثل المختبرات الوطنية الأمريكية على تطوير حواسيب عصبية الشكل بعدد خلايا عصبية يضاهي قشرة الدماغ البشري، وبسرعة تشغيل نظرية تتجاوز بكثير الدماغ البيولوجي، ولكن باستهلاك طاقة منخفض للغاية (مثل 20 واط لتشغيل ذكاء اصطناعي شبيه بالدماغ البشري). من المتوقع أن تحقق هذه التقنية، من خلال الاتصالات القائمة على الأحداث، والحوسبة في الذاكرة، والتعلم التكيفي، ذكاءً اصطناعيًا أكثر ذكاءً وكفاءة واستهلاكًا منخفضًا للطاقة، وتعتبر حلاً محتملاً لأزمة طاقة الذكاء الاصطناعي ومسارًا جديدًا لتطوير الذكاء الاصطناعي العام (AGI) (المصدر: 量子位)

محتوى ASMR المُنشأ بالذكاء الاصطناعي يحقق انتشارًا واسعًا على منصات الفيديو القصيرة، وتقنيات مثل Veo 3 تدفع هذا الاتجاه: انتشرت مقاطع فيديو ASMR (الاستجابة الحسية الذاتية للقنوات الحسية) المُنشأة بالذكاء الاصطناعي بسرعة على منصات مثل TikTok، حيث جذب أحد الحسابات ما يقرب من 100 ألف متابع في غضون 3 أيام، وحقق مقطع فيديو واحد لتقطيع الفاكهة أكثر من 16.5 مليون مشاهدة. تتميز هذه المقاطع بتأثيرات بصرية غريبة مُنشأة بالذكاء الاصطناعي (مثل الفاكهة ذات الملمس الزجاجي) مصحوبة بأصوات تقطيع وتصادم مقابلة، مما يخلق “إحساسًا بالإدمان” فريدًا. تُعتبر نماذج مثل Veo 3 من Google DeepMind، لقدرتها على إنشاء محتوى متزامن صوتيًا ومرئيًا مباشرة، تقنية رئيسية تدفع إنشاء هذا النوع من محتوى ASMR بالذكاء الاصطناعي، وتبسط العملية التي كانت تتطلب سابقًا إنتاج الصوت والفيديو بشكل منفصل ثم تجميعهما (المصدر: 量子位)

Meta AI تكشف عن سجلات البحث مما يثير الانتباه، و Google تختبر ملخصات صوتية بالذكاء الاصطناعي: كشفت شركة Meta عن سجلات بحث المستخدمين لوظيفة البحث بالذكاء الاصطناعي الخاصة بها، مما أثار اهتمام المستخدمين بشأن خصوصيتهم وشفافية استخدام البيانات. في الوقت نفسه، تختبر Google في مشاريعها المعملية ميزة جديدة، وهي توفير ملخصات صوتية شبيهة بالبودكاست مُنشأة بالذكاء الاصطناعي في أعلى نتائج البحث، بهدف تزويد المستخدمين بطريقة أكثر ملاءمة للحصول على المعلومات. يعكس هذان التطوران استكشاف عمالقة التكنولوجيا المستمر ومحاولات تحسين تجربة المستخدم في مجال البحث بالذكاء الاصطناعي وعرض المعلومات (المصدر: Reddit r/ArtificialInteligence)

فريق من سيدني يطور نموذج ذكاء اصطناعي للتعرف على الأفكار من خلال موجات الدماغ: طور فريق بحثي من سيدني، أستراليا، نموذج ذكاء اصطناعي جديد قادر على التعرف على محتوى أفكار الأفراد من خلال تحليل بيانات موجات الدماغ (EEG). تتمتع هذه التقنية بقيمة تطبيقية محتملة في مجالات علوم الأعصاب، والتفاعل بين الإنسان والآلة، والتواصل المساعد، مثل مساعدة الأشخاص غير القادرين على التواصل بالطرق التقليدية على التعبير عن نواياهم. يعزز هذا البحث تطوير تقنية واجهة الدماغ والحاسوب ويستكشف قدرة الذكاء الاصطناعي على تفسير نشاط الدماغ المعقد (المصدر: Reddit r/ArtificialInteligence)
كاليفورنيا تخطط لسن تشريعات لتقييد دور “الرؤساء الآليين” للذكاء الاصطناعي في قرارات التوظيف والفصل وغيرها: تعمل ولاية كاليفورنيا الأمريكية على دفع مشروع قانون يهدف إلى تقييد الشركات من اتخاذ قرارات التوظيف والفصل وغيرها من قرارات الموظفين الحاسمة بناءً على اقتراحات أنظمة الذكاء الاصطناعي فقط. يتطلب مشروع القانون من المديرين البشريين مراجعة ودعم أي اقتراحات من هذا القبيل من الذكاء الاصطناعي، لضمان الإشراف البشري والمساءلة. تعارض مجموعات الأعمال هذا، معتبرة أنه سيزيد من تكاليف الامتثال ويتعارض مع تقنيات التوظيف الحالية. تعكس هذه الخطوة الاهتمام المتزايد بأخلاقيات الذكاء الاصطناعي وتأثيراته الاجتماعية، خاصة في مجال اتخاذ القرارات الآلية في مكان العمل (المصدر: Reddit r/ArtificialInteligence)

🧰 أدوات
إصدار Augmentoolkit 3.0، لتعزيز توليد مجموعات البيانات وعمليات الضبط الدقيق: تم إصدار النسخة 3.0 من Augmentoolkit، وهي أداة لإنشاء مجموعات بيانات أسئلة وأجوبة (QA) من المستندات الطويلة (مثل النصوص التاريخية) وإجراء الضبط الدقيق للنماذج. يوفر الإصدار الجديد خط أنابيب على مستوى الإنتاج، يمكنه إنشاء بيانات التدريب وتدريب النماذج تلقائيًا، ويتضمن نماذج محلية تم ضبطها بدقة خصيصًا لإنشاء مجموعات بيانات QA عالية الجودة، ويوفر واجهة بدون كود. تهدف الأداة إلى تبسيط عملية الضبط الدقيق للنماذج الخاصة بمجالات معينة وتوليد بيانات التدريب، وتقليل العوائق التقنية (المصدر: Reddit r/LocalLLaMA)
Opius AI Planner: مخطط ذكاء اصطناعي لتحسين تجربة Cursor Composer: تم إصدار إضافة لـ Cursor تُدعى Opius AI Planner، تهدف إلى حل مشكلات Cursor Composer في فهم المتطلبات الغامضة. يمكن للأداة تحليل متطلبات المشروع، وإنشاء خارطة طريق مفصلة للتنفيذ، وإخراج مطالبات منظمة مُحسَّنة لـ Composer، مما يقلل من عدد التكرارات ويجعل نتائج المشروع أكثر توافقًا مع التصور الأولي. يعكس هذا الاتجاه نحو استخدام التخطيط المدعوم بالذكاء الاصطناعي لتعزيز فائدة أدوات توليد الأكواد بالذكاء الاصطناعي (المصدر: Reddit r/artificial)
إضافة Continue: تحقيق تكامل Copilot مفتوح المصدر محليًا مع MCP في VSCode: Continue هي إضافة لـ VSCode تسمح للمستخدمين بتكوين واستخدام نماذج لغوية كبيرة مفتوحة المصدر تعمل محليًا كمساعدين في البرمجة، ويمكنها دمج أدوات MCP (Model Control Protocol). يمكن للمستخدمين نشر النماذج محليًا من خلال خدمات مثل Llama.cpp أو LMStudio، والتفاعل معها من خلال Continue، مما يحقق التحكم الكامل والتخصيص لمساعدي البرمجة، مثل دمج أداة أتمتة المتصفح Playwright (المصدر: Reddit r/LocalLLaMA)

نموذج Doubao الكبير من ByteDance يتحد مع بروتوكول MCP من Volcano Engine لتبسيط نشر الخدمات السحابية وإنشاء الصفحات الشخصية: أظهر نموذج Doubao الكبير من ByteDance قدرة تكامل عميقة مع بروتوكول التحكم في النماذج (MCP) من Volcano Engine. يمكن للمستخدمين من خلال أوامر اللغة الطبيعية جعل نموذج Doubao الكبير يستدعي وظائف Volcano Engine (مثل veFaaS كخدمة دالة)، لإكمال مهام مثل إنشاء صفحة ويب دليل لوسائل التواصل الاجتماعي الشخصية ونشرها تلقائيًا عبر الإنترنت. يلغي هذا التكامل الخطوات المعقدة لتكوين البيئة السحابية يدويًا، ويقلل من عتبة استخدام الخدمات السحابية، ويُظهر إمكانات الذكاء الاصطناعي في تبسيط عمليات DevOps (المصدر: karminski3)
Figma تطلق ميزة AI جديدة: إنشاء مواقع ويب فورًا من مطالبات نصية: عرضت Figma ميزة جديدة مدفوعة بالذكاء الاصطناعي، قادرة على إنشاء نماذج أولية أو صفحات لمواقع الويب بسرعة بناءً على المطالبات النصية (prompt) التي يدخلها المستخدم. تهدف هذه الميزة إلى تسريع عمليات تصميم وتطوير الويب، مما يسمح للمصممين والمطورين بتحويل الأفكار بسرعة إلى تصميمات مرئية من خلال وصف اللغة الطبيعية، مما يعكس بشكل أكبر تغلغل الذكاء الاصطناعي التوليدي في مجال أدوات التصميم الإبداعي (المصدر: Ronald_vanLoon)
مركز نماذج Hugging Face يضيف ميزة التصفية حسب حجم النموذج: أضافت منصة Hugging Face ميزة عملية إلى مركز النماذج الخاص بها، تسمح للمستخدمين بالتصفية حسب حجم معلمات النماذج. يسهل هذا التحسين على المطورين والباحثين العثور على النماذج التي تتوافق مع موارد أجهزتهم المحددة أو متطلبات الأداء، مما يعزز كفاءة التنقل والاختيار في مكتبة النماذج الضخمة (المصدر: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
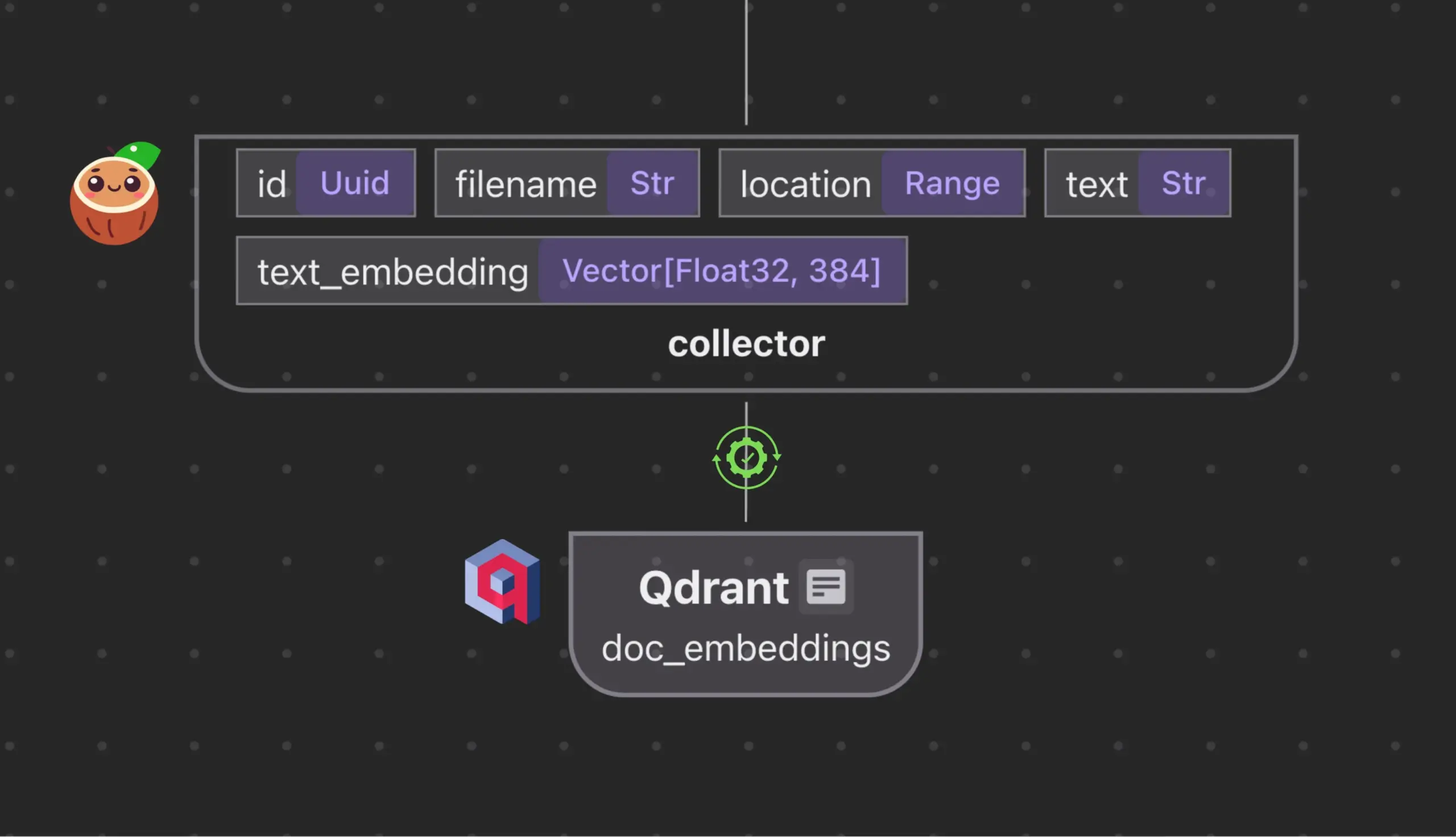
Cocoindex.io يتكامل مع Qdrant لإنشاء ومزامنة مجموعات قواعد بيانات المتجهات تلقائيًا: تدعم أداة تدفق البيانات مفتوحة المصدر Cocoindex.io الآن الإنشاء التلقائي لمجموعات قواعد بيانات المتجهات Qdrant. يحتاج المستخدمون فقط إلى تحديد تدفق البيانات، وستقوم الأداة باستنتاج مخطط Qdrant المناسب (بما في ذلك حجم المتجه، ومقياس المسافة، وهيكل الحمولة)، والحفاظ على مزامنة حقول المتجهات، وأنواع الحمولات، والمفاتيح الأساسية، ودعم التحديثات التزايدية. يبسط هذا تكوين وإدارة قواعد بيانات المتجهات، ويزيد من كفاءة فرق البيانات (المصدر: qdrant_engine)
Manus AI: أداة تطوير AI شاملة لا تكتب الأكواد فحسب، بل تنشرها تلقائيًا: Manus AI هي أداة تطوير AI شاملة يمكنها تحقيق عملية متكاملة من كتابة الأكواد إلى إعداد البيئة، وتثبيت التبعيات، والاختبار، وحتى النشر النهائي إلى عنوان URL عبر الإنترنت. تعتمد على بنية تعاونية متعددة الوكلاء (تخطيط، تطوير، اختبار، نشر)، ويمكنها حل مشكلات التبعيات وتصحيح الأخطاء بشكل مستقل. على الرغم من وجود نموذج تسعير قائم على نقاط الائتمان حاليًا، وكون الفريق المطور صينيًا (مما قد يثير اعتبارات تتعلق بالامتثال)، وقيود على دعم هياكل الشركات المعقدة للغاية، إلا أنها تُظهر إمكانات التحول من “مساعدة AI في البرمجة” إلى “تنفيذ AI للتطوير” (المصدر: Reddit r/artificial)

📚 موارد تعليمية
دليل نظريات الترجمة وتحسين مطالبات الترجمة بالذكاء الاصطناعي: بالجمع بين نظرية “الترجمة هي إعادة كتابة” من كتاب “أبحاث جديدة في الترجمة” (翻译新究) لـ سي جو (思果)، وآراء يو كوانغ تشونغ (余光中) في “الترجمة طريق عظيم” (翻译乃大道)، يناقش المقال مبادئ الترجمة عالية الجودة. يؤكد على أن الترجمة يجب أن تركز على التعبير الأصيل للغة الهدف، وليس التطابق الحرفي، وتحتاج إلى استخدام الترجمة الحرفية والترجمة بالمعنى بمرونة، والاهتمام بالاختلافات المنطقية بين اللغتين الصينية والغربية لإعادة صياغة الجمل. يناقش المقال أيضًا نقاء التعبير الصيني، ومعالجة المصطلحات، ويتأمل في قيود عملية “الترجمة الحرفية – التحليل – الترجمة بالمعنى” المكونة من ثلاث خطوات في الترجمة بالذكاء الاصطناعي، ويقترح اعتماد عملية “الفهم – التعبير – المراجعة – التحسين” أكثر تكاملاً، لرفع جودة الترجمة بالذكاء الاصطناعي، وجعلها أكثر توافقًا مع أسلوب الكتابة العلمية الشعبية باللغة الصينية (المصدر: dotey)

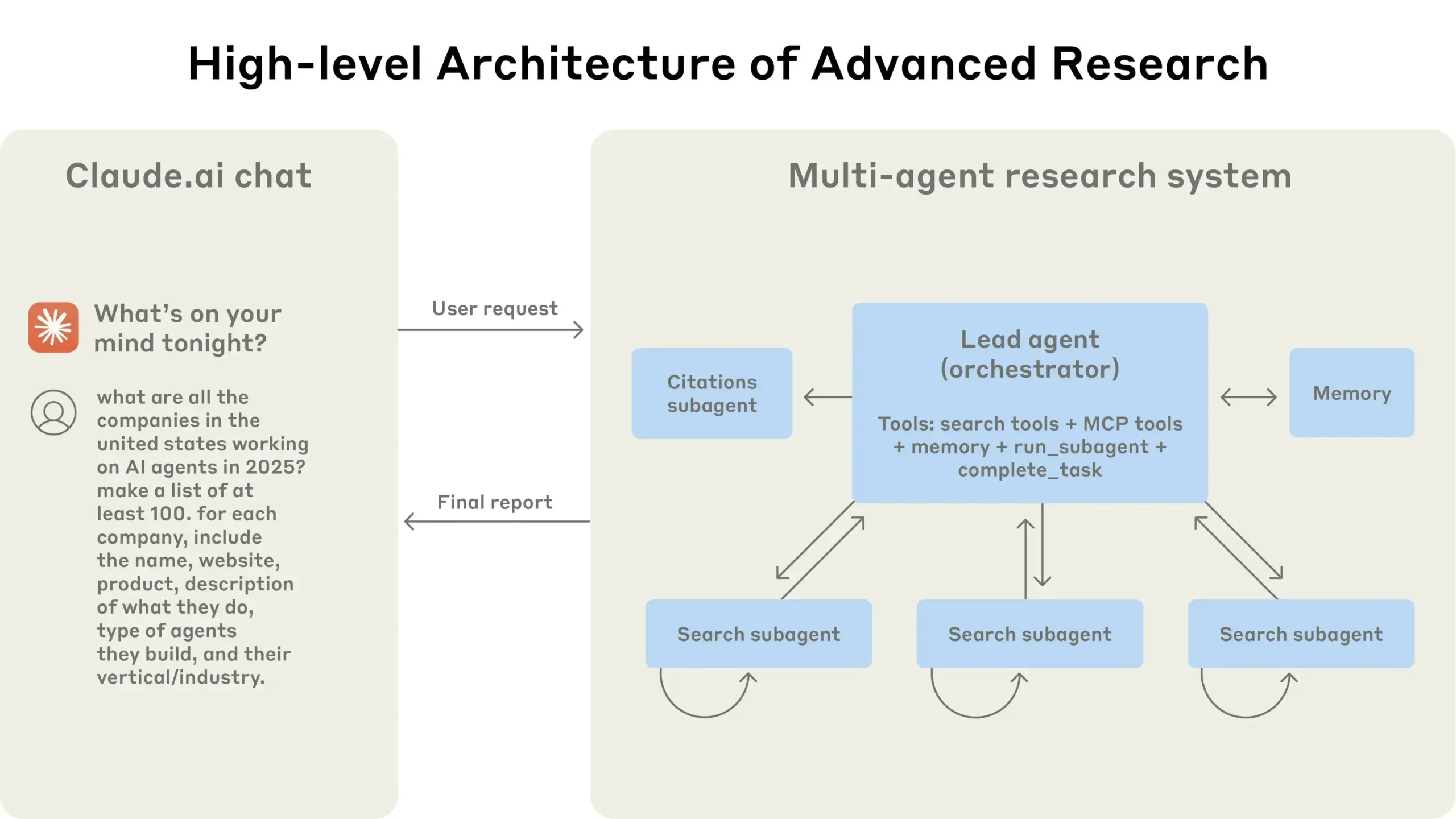
Anthropic تشارك خبرتها في بناء نظام أبحاث متعدد الوكلاء: نشرت AnthropicAI دليلاً مجانيًا يشرح بالتفصيل كيف قاموا ببناء نظام أبحاثهم متعدد الوكلاء. يتضمن المحتوى كيفية عمل بنية النظام، وطرق هندسة المطالبات والاختبار، والتحديات التي تواجه الإنتاج، ومزايا الأنظمة متعددة الوكلاء. يوفر هذا الدليل خبرة عملية ورؤى قيمة للباحثين والمطورين المهتمين بالأنظمة متعددة الوكلاء (المصدر: TheTuringPost, TheTuringPost)
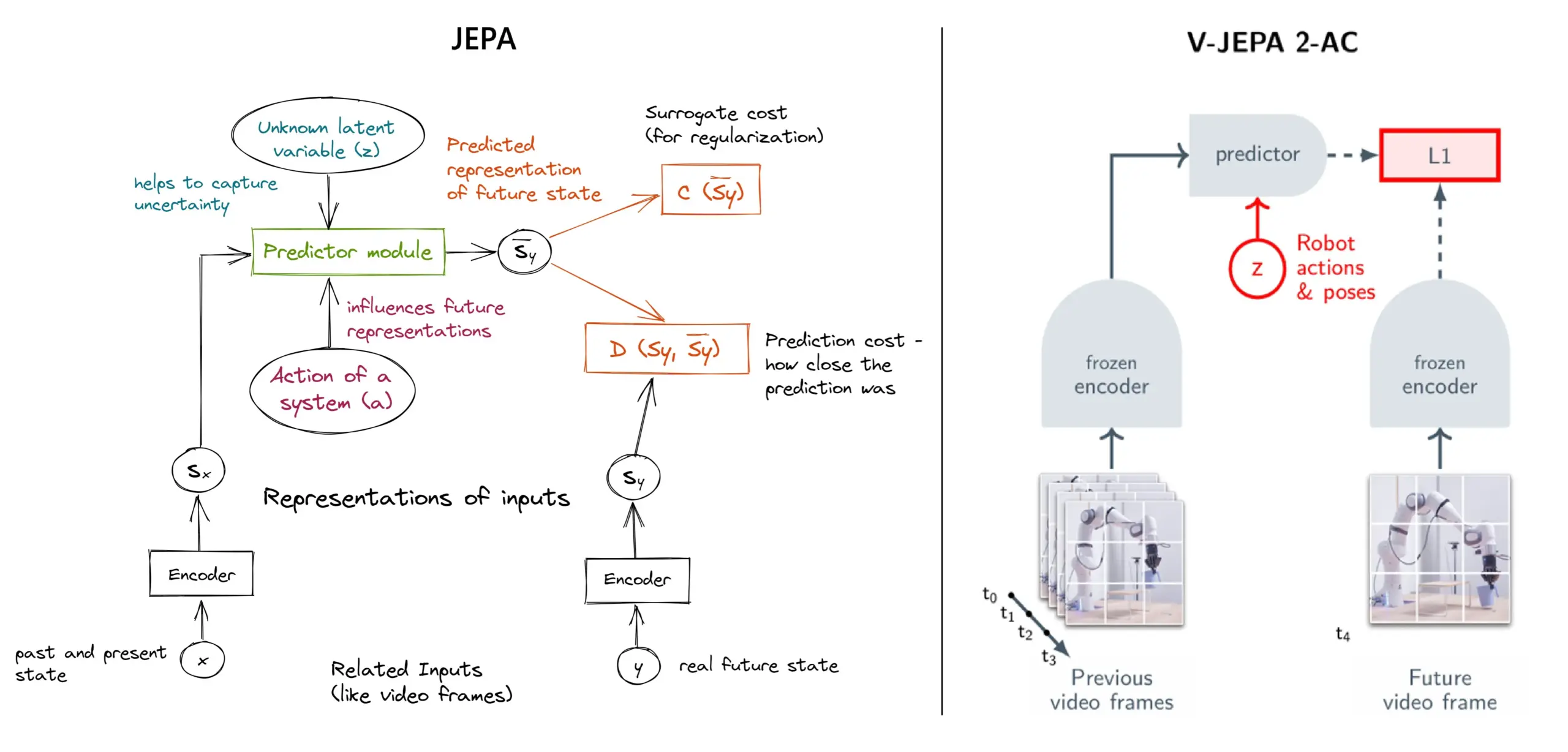
شرح مفصل لإطار التعلم الذاتي الإشرافي JEPA: نظرة عامة على 11 نوعًا: JEPA (Joint Embedding Predictive Architecture)، الذي اقترحه باحثون مثل يان لوكون (Yann LeCun) من Meta، هو إطار تعلم ذاتي إشرافي يتعلم من خلال التنبؤ بالتمثيلات الكامنة للأجزاء المفقودة من بيانات الإدخال. يقدم المقال 11 نوعًا مختلفًا من JEPA، بما في ذلك V-JEPA 2، TS-JEPA، D-JEPA وغيرها، ويوفر مزيدًا من المعلومات وروابط لموارد ذات صلة، مما يساعد على فهم هذه الطريقة المتطورة للتعلم الذاتي الإشرافي (المصدر: TheTuringPost, TheTuringPost)
إطار DSPy: فصل المهام عن LLM، وتحسين قابلية صيانة الكود: يشير مقال تحليلي حول إطار DSPy إلى أن إطار DSPy يقلل من تعقيد استخدام النماذج اللغوية الكبيرة (LLM) عن طريق فصل المهام عن LLM. حتى قبل التحسين، يمكن لـ DSPy مساعدة المطورين على بدء المشاريع بشكل أسرع، وإنشاء كود أسهل في الصيانة والتوسيع. هذا له قيمة مهمة للمشاريع التي تحتاج إلى التعامل مع هندسة المطالبات المعقدة وتكامل LLM (المصدر: lateinteraction, stanfordnlp)

مناقشة ورقة بحثية: محولات الرؤية لا تحتاج إلى سجلات مدربة مسبقًا (Vision Transformers Don’t Need Trained Registers): تستكشف ورقة بحثية جديدة آلية ظهور التشوهات في خرائط الانتباه وخرائط الميزات في Vision Transformer، وهي ظاهرة موجودة أيضًا في النماذج اللغوية الكبيرة. تقترح الورقة طريقة لا تحتاج إلى تدريب للتخفيف من هذه التشوهات، بهدف تحسين أداء Vision Transformer وقابليته للتفسير. هذا البحث له قيمة مرجعية لفهم وتحسين بنية Transformer في تطبيقات المهام البصرية (المصدر: Reddit r/MachineLearning)
مشاركة تعليمية: بناء سلسلة DeepSeek من الصفر (إجمالي 29 حلقة فيديو): نشر منشئ محتوى سلسلة دروس فيديو تعليمية بعنوان “كيفية بناء DeepSeek من الصفر”، تتكون من 29 حلقة. يغطي المحتوى أساسيات نموذج DeepSeek، وتفاصيل البنية (مثل آلية الانتباه، والانتباه متعدد الرؤوس، وذاكرة التخزين المؤقت KV، و MoE)، وترميز الموضع، والتنبؤ متعدد الرموز، والتكميم وغيرها من التقنيات الرئيسية. توفر هذه السلسلة التعليمية موارد فيديو قيمة للمتعلمين الذين يرغبون في فهم متعمق لكيفية عمل DeepSeek والنماذج الكبيرة المماثلة (المصدر: Reddit r/LocalLLaMA)

درس تعليمي: بناء خط أنابيب RAG لتلخيص منشورات Hacker News: شاركت Haystack by deepset درسًا تعليميًا خطوة بخطوة يرشد المستخدمين حول كيفية بناء خط أنابيب توليد معزز بالاسترجاع (RAG). يمكن لخط الأنابيب هذا الحصول على منشورات Hacker News في الوقت الفعلي، واستخدام نقطة نهاية لنموذج لغوي كبير (LLM) يعمل محليًا لتلخيص هذه المنشورات. يوفر هذا حالة استخدام عملية للمطورين الذين يرغبون في الاستفادة من تقنية RAG لمعالجة تدفقات المعلومات في الوقت الفعلي وإجراء معالجة محلية (المصدر: dl_weekly)
ملخصات الأوراق البحثية: مجموعة بيانات InterSyn ونموذج تقييم SynJudge لتوليد النصوص والصور المتداخلة: لمعالجة أوجه القصور الحالية في نماذج LMM في توليد مخرجات نصية وصورية متداخلة بشكل وثيق (والتي تنبع بشكل أساسي من الحجم المحدود وجودة وثراء التعليمات في مجموعات بيانات التدريب)، قدم الباحثون InterSyn، وهي مجموعة بيانات متعددة الوسائط واسعة النطاق تم بناؤها باستخدام طريقة SEIR (التقييم الذاتي والتحسين التكراري). تحتوي InterSyn على حوارات متعددة الأدوار ومدفوعة بالتعليمات، مع تداخل وثيق بين النصوص والصور في الاستجابات. في الوقت نفسه، لتقييم مثل هذه المخرجات، اقترح الباحثون أيضًا نموذج التقييم التلقائي SynJudge، الذي يقيم من أربعة أبعاد: محتوى النص، ومحتوى الصورة، وجودة الصورة، والتآزر بين النص والصورة. أظهرت التجارب أن نماذج LMM المدربة على InterSyn أظهرت تحسنًا في جميع مقاييس التقييم (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: توليد صور وهندسة من منظور جديد متوائم من خلال تقطير الانتباه عبر الوسائط: اقترح الباحثون إطارًا قائمًا على الانتشار يُدعى MoAI، يحقق توليد صور وهندسة من منظور جديد متوائم من خلال طريقة “التشويه ثم الإصلاح” (warping-and-inpainting). تستخدم هذه الطريقة أدوات تنبؤ هندسية جاهزة للتنبؤ بجزء من شكل هندسي للصورة المرجعية، وتوليف المنظور الجديد كمهمة إصلاح للصور والهندسة. لضمان التوافق الدقيق بين الصور والهندسة، تقترح الورقة تقطير الانتباه عبر الوسائط، حيث يتم حقن خرائط الانتباه من فرع انتشار الصور في فرع انتشار الهندسة الموازي أثناء التدريب والاستدلال. تحقق هذه الطريقة توليف منظورات مستنبطة عالية الدقة في العديد من المشاهد غير المرئية (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: ضبط التفضيلات القابل للتكوين (CPT) بناءً على بيانات مُصنَّعة موجهة بالقواعد: لمعالجة مشكلة تصلب التفضيلات ومحدودية القدرة على التكيف في نماذج التغذية الراجعة البشرية مثل DPO، اقترح الباحثون إطار ضبط التفضيلات القابل للتكوين (CPT). يستخدم CPT مطالبات نظامية قائمة على قواعد دقيقة منظمة (تحدد السمات المرغوبة مثل أسلوب الكتابة) لتوليد بيانات تفضيلات مُصنَّعة. من خلال الضبط الدقيق باستخدام هذه التفضيلات الموجهة بالقواعد، يمكن لـ LLM تعديل مخرجاتها ديناميكيًا بناءً على مطالبات النظام في وقت الاستدلال، دون الحاجة إلى إعادة التدريب، مما يحقق تحكمًا أكثر دقة وسياقية في التفضيلات (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: ازدواجية الانتشار (The Diffusion Duality): اقترح الباحثون طريقة Duo، من خلال الكشف عن أن عمليات الانتشار المنفصلة للحالات المنتظمة تنشأ من انتشار غاوسي كامن، لنقل التقنيات القوية للانتشار الغاوسي إلى نماذج الانتشار المنفصلة، بهدف تحسين أدائها. يشمل ذلك تحديدًا: 1) إدخال استراتيجية تعلم منهجي موجهة بالعملية الغاوسية، لتقليل التباين، ومضاعفة سرعة التدريب، وتجاوز النماذج ذاتية الانحدار في العديد من اختبارات الأداء القياسية. 2) اقتراح تقطير التناسق المنفصل، لتكييف تقطير التناسق المستمر مع الإعداد المنفصل، من خلال تسريع أخذ العينات بمقدارين أسيين، لتحقيق توليد نماذج لغة الانتشار بخطوات قليلة (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: SkillBlender – التحكم في حركة الجسم بالكامل للروبوتات البشرية متعددة الوظائف من خلال دمج المهارات: لمعالجة القيود الحالية في طرق التحكم في الروبوتات البشرية من حيث التعميم على مهام متعددة وقابلية التوسع، اقترح الباحثون SkillBlender، وهو إطار تعلم معزز هرمي. يقوم هذا الإطار أولاً بتدريب مسبق لمهارات أولية موجهة نحو الهدف ومستقلة عن المهمة، ثم يدمج هذه المهارات ديناميكيًا عند تنفيذ مهام تحكم حركي معقدة، مع الحاجة إلى الحد الأدنى من هندسة المكافآت الخاصة بالمهمة. في الوقت نفسه، تم إطلاق معيار المحاكاة SkillBench للتقييم. أظهرت التجارب أن هذه الطريقة يمكن أن تحسن بشكل كبير دقة وجدوى العديد من مهام التحكم الحركي (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: إطار U-CoT+ – فصل الفهم واستدلال CoT الموجه لاكتشاف الميمات الضارة: لمواجهة تحديات كفاءة الموارد والمرونة وقابلية التفسير في اكتشاف الميمات الضارة، اقترح الباحثون إطار U-CoT+. يقوم هذا الإطار أولاً بتحويل الميمات المرئية إلى أوصاف نصية تحتفظ بالتفاصيل من خلال عملية تحويل ميم إلى نص عالية الدقة، وبالتالي فصل تفسير الميمات عن التصنيف، مما يمكّن النماذج اللغوية الكبيرة العامة (LLM) من إجراء اكتشاف فعال من حيث الموارد. بعد ذلك، بالاقتران مع إرشادات قابلة للتفسير موضوعة يدويًا، يتم توجيه استدلال النموذج تحت مطالبات CoT بدون أمثلة (zero-shot)، مما يعزز القدرة على التكيف مع المنصات المختلفة والتغيرات الزمنية وقابلية التفسير (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: CRAFT – اختبار الفريق الأحمر الفعال للوكلاء الملتزمين بالسياسات:針對 مشكلة التزام وكلاء LLM الموجهين نحو المهام بالسياسات الصارمة (مثل أهلية استرداد الأموال)، اقترح الباحثون نموذج تهديد جديد، يركز على المستخدمين العدائيين الذين يحاولون استغلال الوكلاء الملتزمين بالسياسات لتحقيق مكاسب شخصية. لهذا الغرض، طوروا CRAFT، وهو نظام اختبار فريق أحمر متعدد الوكلاء، يستخدم استراتيجيات إقناع مدركة للسياسات لمهاجمة الوكلاء الملتزمين بالسياسات في سيناريوهات خدمة العملاء، ويتفوق تأثيره على طرق كسر الحماية التقليدية. في الوقت نفسه، تم إطلاق معيار tau-break، لتقييم مدى قوة الوكلاء ضد مثل هذه السلوكيات التلاعبية (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: فشل المسترجعات الكثيفة في الاستعلامات البسيطة ومعضلة دقة التضمينات: يكشف البحث عن قصور في مشفرات النصوص: قد لا تتعرف التضمينات على الكيانات أو الأحداث الدقيقة داخل المعنى الدلالي، مما يؤدي إلى فشل الاسترجاع الكثيف حتى في الحالات البسيطة. لدراسة هذه الظاهرة، تقدم الورقة مجموعة بيانات تقييم صينية CapRetrieval (الفقرات هي تسميات توضيحية للصور، والاستعلامات هي عبارات كيانات/أحداث). يُظهر التقييم بدون أمثلة (zero-shot) أن المشفرات قد يكون أداؤها ضعيفًا في المطابقة الدقيقة. يمكن أن يؤدي ضبط المشفرات بدقة باستخدام استراتيجية توليد البيانات المقترحة إلى تحسين الأداء، ولكنه يكشف أيضًا عن “معضلة الدقة”، أي أن التضمينات تجد صعوبة في التوافق مع المعنى الدلالي الكلي أثناء التعبير عن الأهمية الدقيقة (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: pLSTM – شبكة تحويل مصدر خطي قابلة للتوازي: لمعالجة القيود المفروضة على البنى التكرارية الحالية (مثل xLSTM, Mamba) التي تكون مناسبة بشكل أساسي للبيانات التسلسلية أو تتطلب معالجة متسلسلة للبيانات متعددة الأبعاد، اقترح الباحثون pLSTM (شبكة تحويل مصدر خطي قابلة للتوازي). يوسع pLSTM التعددية الأبعاد إلى RNNs الخطية، باستخدام بوابات المصدر والتحويل والعلامة التي تعمل على الرسم البياني الخطي لـ DAG (الرسم البياني الموجه غير الدوري) العام، مما يحقق توازيًا مشابهًا لمسح الارتباط المتوازي وأشكال التكرار المجمعة. أظهرت هذه الطريقة قدرة جيدة على الاستقراء والأداء في مهام الرؤية الحاسوبية الاصطناعية ومعايير الرسوم البيانية الجزيئية والرؤية الحاسوبية (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: DeepVideo-R1 – ضبط دقيق معزز للفيديو من خلال انحدار GRPO المدرك للصعوبة: لمعالجة أوجه القصور في تطبيق التعلم المعزز على نماذج الفيديو اللغوية الكبيرة (Video LLM)، اقترح الباحثون DeepVideo-R1، وهو Video LLM تم تدريبه من خلال Reg-GRPO (GRPO الانحداري) المقترح واستراتيجية تعزيز البيانات المدركة للصعوبة. يعيد Reg-GRPO صياغة هدف GRPO كمهمة انحدار، ويتنبأ مباشرة بدالة الميزة في GRPO، مما يلغي الاعتماد على تدابير وقائية مثل الاقتصاص، وبالتالي توجيه السياسة بشكل مباشر أكثر. تعمل استراتيجية تعزيز البيانات المدركة للصعوبة على تعزيز عينات التدريب ديناميكيًا بمستويات صعوبة قابلة للحل. أظهرت التجارب أن DeepVideo-R1 يحسن بشكل كبير أداء استدلال الفيديو (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: إطار تنقية ذاتية لتعزيز ASR باستخدام بيانات مُصنَّعة بواسطة TTS: اقترح الباحثون إطار تنقية ذاتية يمكنه تحسين أداء التعرف التلقائي على الكلام (ASR) باستخدام مجموعة بيانات غير مُعلَّمة فقط. يقوم الإطار أولاً بإنشاء تسميات زائفة على الكلام غير المُعلَّم باستخدام نموذج ASR حالي، ثم يستخدم هذه التسميات الزائفة لتدريب نظام تحويل نص إلى كلام (TTS) عالي الدقة. بعد ذلك، تُستخدم أزواج الكلام والنص المُصنَّعة بواسطة TTS لتوجيه تدريب نظام ASR الأصلي، مما يشكل حلقة مغلقة من التحسين الذاتي. أظهرت التجارب على لغة الماندرين التايوانية أن هذه الطريقة يمكن أن تقلل بشكل كبير من معدلات الخطأ، وتوفر مسارًا عمليًا لتحسين أداء ASR منخفض الموارد أو الخاص بمجال معين (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: خرائط انتباه مخلصة متأصلة في محولات الرؤية (Visual Transformers): يقترح الباحثون طريقة قائمة على الانتباه تستخدم أقنعة انتباه ثنائية مُتعلَّمة، لضمان أن المناطق الصورية التي يتم التركيز عليها فقط هي التي تؤثر على التنبؤ. تهدف هذه الطريقة إلى معالجة التحيزات التي قد تنشأ عن السياق في إدراك الكائنات، خاصة عندما تظهر الكائنات في خلفيات غير موزعة. من خلال إطار من مرحلتين (المرحلة الأولى تكتشف أجزاء الكائن وتحدد المناطق ذات الصلة بالمهمة، والمرحلة الثانية تستخدم قناع انتباه الإدخال لتقييد مجال الاستقبال للتحليل المركز)، يتم تدريب النموذج بشكل مشترك لتحقيق تعزيز متانته ضد الارتباطات الزائفة والخلفيات غير الموزعة (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: ViCrit – مهام وكيل تعلم معزز قابلة للتحقق للإدراك البصري في VLM: لمعالجة مشكلة افتقار مهام الإدراك البصري في VLM إلى التحدي والقابلية للتحقق بشكل واضح في نفس الوقت، قدم الباحثون ViCrit (ناقد هلوسة التسميات التوضيحية المرئية). هذه مهمة وكيل RL تدرب VLM على تحديد موقع الهلوسات البصرية الدقيقة والمُصنَّعة التي تم حقنها في فقرات تسميات توضيحية للصور مكتوبة بواسطة الإنسان. من خلال حقن خطأ وصفي بصري دقيق واحد في تسمية توضيحية مكونة من حوالي 200 كلمة، ومطالبة النموذج بتحديد نطاق الخطأ بناءً على الصورة والتسمية التوضيحية المعدلة، توفر هذه المهمة مكافأة ثنائية سهلة الحساب وواضحة. أظهرت النماذج المدربة باستخدام ViCrit مكاسب كبيرة في العديد من معايير VL (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: ما وراء الانتباه المتجانس – LLM فعال من حيث الذاكرة يعتمد على ذاكرة تخزين مؤقت KV بتقريب فورييه: لمعالجة مشكلة زيادة متطلبات ذاكرة التخزين المؤقت KV في LLM مع زيادة طول السياق، اقترح الباحثون FourierAttention، وهو إطار لا يحتاج إلى تدريب. يستغل هذا الإطار الأدوار غير المتجانسة لأبعاد رأس Transformer: الأبعاد المنخفضة تعطي الأولوية للسياق المحلي، بينما تلتقط الأبعاد العالية التبعيات طويلة المدى. من خلال إسقاط الأبعاد غير الحساسة للسياق الطويل على قواعد فورييه المتعامدة، يقرب FourierAttention تطورها الزمني بمعاملات طيفية ذات طول ثابت. أظهر التقييم على نماذج LLaMA أن هذه الطريقة تحقق أفضل دقة سياق طويل على LongBench و NIAH، وحسنت الذاكرة من خلال نواة Triton مخصصة FlashFourierAttention (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: JAFAR – مُحسِّن عام لرفع دقة أي ميزة إلى أي دقة: لمعالجة مشكلة عدم قدرة الميزات المكانية منخفضة الدقة الناتجة عن مشفرات الرؤية الأساسية على تلبية متطلبات المهام اللاحقة، قدم الباحثون JAFAR، وهو مُحسِّن ميزات خفيف الوزن ومرن. يمكن لـ JAFAR رفع دقة الميزات المكانية المرئية لأي مشفر رؤية أساسي إلى أي دقة مستهدفة. يعتمد على وحدات قائمة على الانتباه، يتم تعديلها من خلال تحويل الميزات المكانية (SFT)، لتعزيز التوافق الدلالي بين الاستعلامات عالية الدقة المشتقة من ميزات الصور منخفضة المستوى والمفاتيح منخفضة الدقة الغنية دلاليًا. أظهرت التجارب أن JAFAR يمكنه استعادة التفاصيل المكانية الدقيقة بشكل فعال، ويتفوق على الطرق الحالية في العديد من المهام اللاحقة (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: SwS – توليف المشكلات مدفوعًا بنقاط الضعف المدركة ذاتيًا في التعلم المعزز: لمعالجة مشكلة ندرة مجموعات المشكلات عالية الجودة والقابلة للتحقق من الإجابات في RLVR (التعلم المعزز بمكافآت قابلة للتحقق) عند تدريب LLM على حل مهام الاستدلال المعقدة (مثل المشكلات الرياضية)، اقترح الباحثون إطار SwS (توليف المشكلات مدفوعًا بنقاط الضعف المدركة ذاتيًا). يحدد نظام SwS بشكل منهجي عيوب النموذج (المشكلات التي يفشل النموذج باستمرار في تعلمها أثناء تدريب RL)، ويستخلص المفاهيم الأساسية لهذه الحالات الفاشلة، ويصنع مشكلات جديدة لتعزيز نقاط ضعف النموذج في التدريب المعزز اللاحق. يمكّن هذا الإطار النموذج من التعرف على نقاط ضعفه في RL ومعالجتها ذاتيًا، وحقق تحسينات كبيرة في الأداء على العديد من معايير الاستدلال الرئيسية (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: تعلم رمز “متابعة التفكير” لتعزيز قدرة التوسع في وقت الاختبار: لتعزيز أداء النماذج اللغوية في توسيع خطوات الاستدلال من خلال حسابات إضافية في وقت الاختبار، استكشف الباحثون جدوى تعلم رمز مخصص “لمتابعة التفكير” (<|continue-thinking|>). قاموا بتدريب تضمين هذا الرمز فقط من خلال التعلم المعزز، مع الحفاظ على تجميد أوزان نموذج DeepSeek-R1 المقطر. أظهرت التجارب أن الرمز المتعلم حقق دقة أعلى في معايير الرياضيات القياسية مقارنة بالنماذج الأساسية وطرق التوسع في وقت الاختبار التي تستخدم رموزًا ثابتة (مثل “Wait”) لفرض الميزانية، خاصة في الحالات التي يمكن فيها للرموز الثابتة تحسين دقة النماذج الأساسية، حيث يمكن للرمز المتعلم أن يحقق تحسينًا أكبر (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: LoRA-Edit – تحرير فيديو موجه بالإطار الأول قابل للتحكم من خلال ضبط LoRA الدقيق المدرك للقناع: لمعالجة مشكلة اعتماد طرق تحرير الفيديو الحالية على تدريب مسبق واسع النطاق وعدم كفاية المرونة، اقترح الباحثون LoRA-Edit، وهي طريقة ضبط LoRA دقيقة قائمة على القناع، لتكييف نماذج تحويل الصور إلى فيديو (I2V) المدربة مسبقًا لتحقيق تحرير فيديو مرن. تحافظ هذه الطريقة على مناطق الخلفية، وفي الوقت نفسه، يمكنها نشر تأثيرات تحرير قابلة للتحكم، ودمج معلومات مرجعية أخرى (مثل وجهات نظر بديلة أو حالات المشهد) كنقاط ارتساء مرئية. من خلال استراتيجية تعديل LoRA المدفوعة بالقناع، يتعلم النموذج من فيديو الإدخال (البنية المكانية وإشارات الحركة) والصورة المرجعية (التوجيه المظهري)، لتحقيق تعلم خاص بالمنطقة (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: Infinity Instruct – توسيع اختيار التعليمات وتوليفها لتعزيز النماذج اللغوية: لسد الفجوة في مجموعات بيانات التعليمات مفتوحة المصدر الحالية التي تركز في الغالب على مجالات ضيقة (مثل الرياضيات والبرمجة)، مما يؤدي إلى قدرة تعميم محدودة، أطلق الباحثون Infinity-Instruct، وهي مجموعة بيانات تعليمات عالية الجودة تهدف إلى تعزيز القدرات الأساسية والمحادثية لـ LLM من خلال عملية من مرحلتين. في المرحلة الأولى، تم استخدام تقنيات اختيار البيانات المختلطة لتصفية 7.4 مليون تعليمة أساسية عالية الجودة من بين أكثر من 100 مليون عينة. في المرحلة الثانية، من خلال عملية من مرحلتين لاختيار التعليمات وتطويرها وتصفية التشخيص، تم توليف 1.5 مليون تعليمة محادثة عالية الجودة. أظهرت تجارب الضبط الدقيق على العديد من النماذج مفتوحة المصدر أن مجموعة البيانات هذه يمكن أن تحسن بشكل كبير أداء النماذج في المعايير الأساسية ومعايير اتباع التعليمات (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: الترشيح أولاً ثم التقطير – إطار المعلم والطالب لوضع العلامات على البيانات بواسطة LLM: لمعالجة مشكلة أن LLM قد يرتكب أخطاء بسبب عدم اليقين عند تحديد علامة ذهبية واحدة مباشرة في طرق وضع العلامات على البيانات الحالية بواسطة LLM، اقترح الباحثون نموذجًا جديدًا لوضع العلامات المرشحة: تشجيع LLM على إخراج جميع العلامات الممكنة عند عدم اليقين. لضمان حصول المهام اللاحقة على علامة فريدة، تم تطوير إطار المعلم والطالب CanDist، باستخدام نموذج لغوي صغير (SLM) لتقطير العلامات المرشحة. أثبتت النظرية أن تقطير العلامات المرشحة من LLM المعلم أفضل من استخدام علامة واحدة مباشرة. أثبتت التجارب فعالية هذه الطريقة (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: Med-PRM – نموذج استدلال طبي بمكافآت عملية التحقق التدريجي والموجه بالإرشادات: لمعالجة القيود التي تواجهها النماذج اللغوية الكبيرة في تحديد وتصحيح أخطاء خطوات الاستدلال المحددة في اتخاذ القرارات السريرية، قدم الباحثون Med-PRM، وهو إطار لنمذجة مكافآت العمليات. يستخدم هذا الإطار تقنيات التوليد المعزز بالاسترجاع للتحقق من كل خطوة استدلال مقابل قواعد المعرفة الطبية الراسخة (الإرشادات السريرية والأدبيات). من خلال هذه الطريقة الدقيقة لتقييم جودة الاستدلال بدقة، حقق Med-PRM أداءً متطورًا (SOTA) في العديد من معايير الأسئلة والأجوبة الطبية ومهام التشخيص المفتوحة، ويمكن دمجه بطريقة التوصيل والتشغيل مع نماذج سياسات قوية (مثل Meerkat)، مما أدى إلى تحسين دقة النماذج الصغيرة (8B معلمة) بشكل كبير (المصدر: HuggingFace Daily Papers)
ملخصات الأوراق البحثية: احتكاك التغذية الراجعة – صعوبة LLM في استيعاب التغذية الراجعة الخارجية بشكل كامل: يبحث النظام بشكل منهجي في قدرة LLM على استيعاب التغذية الراجعة الخارجية. في التجارب، يحاول نموذج الحل حل المشكلات، ثم يقدم مولد التغذية الراجعة الذي لديه إجابات حقيقية شبه كاملة تغذية راجعة مستهدفة، ثم يحاول نموذج الحل مرة أخرى. أظهرت النتائج أنه حتى في ظل ظروف شبه مثالية، أظهرت نماذج SOTA، بما في ذلك Claude 3.7، مقاومة للتغذية الراجعة، وهو ما يسمى “احتكاك التغذية الراجعة”. على الرغم من التحسن الطفيف عند اعتماد استراتيجيات مثل زيادة درجة الحرارة التدريجية ورفض الإجابات الخاطئة السابقة بشكل صريح، إلا أن النماذج لم تصل إلى الأداء المستهدف. استبعد البحث عوامل مثل الثقة المفرطة للنموذج وألفة البيانات، بهدف الكشف عن هذا العائق الأساسي أمام التحسين الذاتي لـ LLM (المصدر: HuggingFace Daily Papers)
💼 أعمال تجارية
Meta تستحوذ على 49% من أسهم Scale AI مقابل 14.3 مليار دولار، والمؤسس Alexandr Wang ينضم إلى فريق Meta للذكاء الفائق: أعلنت شركة Meta عن استحواذها على 49% من أسهم شركة Scale AI المتخصصة في عنونة البيانات للذكاء الاصطناعي، وذلك مقابل 14.3 مليار دولار أمريكي، وهي أسهم لا تمنح حق التصويت. سيستمر مؤسس Scale AI، العبقري الصيني الأمريكي البالغ من العمر 28 عامًا Alexandr Wang، كعضو في مجلس الإدارة، وسيقود فريقه الأساسي للانضمام إلى فريق Meta للذكاء الفائق الذي شكله مارك زوكربيرج شخصيًا. يُنظر إلى هذا الاستحواذ على أنه عملية استحواذ باهظة الثمن على المواهب من قبل Meta لتعزيز قدراتها في مجال الذكاء الاصطناعي بعد الأداء المخيب للآمال لـ Llama 4، بهدف دمج الذكاء الاصطناعي بعمق في جميع منتجاتها. بدأت Scale AI بتقديم خدمات عنونة بيانات بشرية واسعة النطاق وعالية الجودة، ومن بين عملائها Waymo و OpenAI وغيرهم. أثارت هذه الخطوة مخاوف بشأن حيادية منصتها وأمن البيانات، وقد يوقف عملاء مثل Google تعاونهم (المصدر: 36氪)

استراتيجية Kunlun Tech “الكل في الذكاء الاصطناعي” تؤدي إلى أول خسارة لها منذ عشر سنوات من الإدراج، وآفاق تسويق الذكاء الاصطناعي غير واضحة: منذ إعلان Kunlun Tech عن استراتيجيتها “الكل في AGI و AIGC”، قامت الشركة بنشاط بتخطيط نماذج كبيرة (نموذج Tiangong الكبير) وتطبيقات الذكاء الاصطناعي مثل موسيقى الذكاء الاصطناعي (Mureka)، والشبكات الاجتماعية بالذكاء الاصطناعي (Linky)، والفيديو بالذكاء الاصطناعي (SkyReels)، والمكاتب بالذكاء الاصطناعي (Skywork Super Agents)، واستثمرت في رقائق حوسبة الذكاء الاصطناعي. ومع ذلك، أدت التكاليف الباهظة للبحث والتطوير والتسويق إلى تكبد الشركة أول خسارة لها منذ عشر سنوات من الإدراج في عام 2024 (1.59 مليار يوان)، واستمرت الخسائر في الربع الأول من عام 2025. على الرغم من أن بعض تطبيقات الذكاء الاصطناعي مثل Mureka و Linky بدأت في تحقيق إيرادات، إلا أن الربحية الإجمالية لأعمال الذكاء الاصطناعي وقدرتها التنافسية في السوق لا تزال تواجه تحديات، وما إذا كان بإمكانها تحقيق “حلم الشركة الكبيرة” بمساعدة الذكاء الاصطناعي لا يزال ينتظر اختبار السوق (المصدر: 36氪)

OpenAI قد تختبر الإعلانات في ChatGPT، وضغوط الربحية تدفع لاستكشاف نماذج أعمال جديدة: أفاد بعض مستخدمي ChatGPT Plus المدفوعين بأنهم واجهوا إعلانات متقطعة أثناء استخدام وضع الصوت المتقدم، مما أثار نقاشًا حول ما إذا كانت OpenAI قد بدأت في اختبار الإعلانات بين المستخدمين المدفوعين. ذكرت تقارير سابقة أن OpenAI تفكر في إدخال الإعلانات لتوسيع مصادر الدخل. نظرًا للتكاليف التشغيلية الباهظة لنماذج الذكاء الاصطناعي الكبيرة وضغوط الربحية (من المتوقع أن تخسر 44 مليار دولار أمريكي بحلول عام 2029)، وعدم اليقين بشأن وقت تحقيق الذكاء الاصطناعي العام (AGI)، يُعتبر سعي OpenAI نحو نماذج تحقيق دخل جديدة مثل الإعلانات خيارًا حتميًا لاستدامتها التجارية، خاصة في ظل انخفاض معدل اختراق الاشتراكات المدفوعة نسبيًا (المصدر: 36氪)

🌟 مجتمع
إمكانات الذكاء الاصطناعي هائلة في مجال علوم البيانات، و Databricks توظف بنشاط: يعتقد ماتي زهاريا (Matei Zaharia) من Databricks أن زيادة الإنتاجية التي سيحققها الذكاء الاصطناعي في مجال علوم البيانات ستكون أكثر أهمية من المساعدة التي يقدمها الذكاء الاصطناعي في البرمجة. تقود Databricks هذا الاتجاه من خلال منتجات مثل Lakeflow Designer و Genie Deep Research، وتوظف بنشاط باحثين ومهندسين في هذا المجال، مما يدل على الأهمية الكبيرة التي يوليها القطاع للابتكار في علوم البيانات المدفوعة بالذكاء الاصطناعي (المصدر: matei_zaharia)
اختلاف “شخصية” نماذج LLM يؤثر على سلوك دوائر الوكلاء: لاحظ الباحث فابيان ستيلزر (Fabian Stelzer) وجود اختلافات في “شخصية” نماذج اللغات الكبيرة (LLM) المختلفة، مما يؤدي إلى اختلاف أدائها عند تنفيذ مهام دورية للوكلاء (agentic). على سبيل المثال، يميل Claude إلى تنفيذ الأدوات بشكل تسلسلي، بينما يفضل GPT-4.1 بشدة التنفيذ المتوازي، حتى أنه يتجاهل الطلبات التسلسلية؛ نموذج Haiku أكثر “عدوانية” في تشغيل الأدوات. تؤكد هذه الملاحظة على أهمية مراعاة خصائص LLM الأساسية والعواقب الوظيفية لـ “الحالة العاطفية” عند تصميم وتقييم أنظمة الوكلاء المتعددين (المصدر: fabianstelzer, menhguin)
“تفكير” LLM يعتمد على إخراج الرموز (Tokens)، وبدون إخراج لا يوجد تحليل فعال: نقل المستخدم dotey اكتشاف xincmm أثناء تصحيح أخطاء موجه ReAct: إذا كان من المتوقع أن يقوم LLM بالتحليل أولاً ثم تنفيذ عملية (مثل الرسم)، ولكن لم يُسمح له بإخراج رموز عملية التحليل، فقد يتخطى LLM خطوة التحليل مباشرة. هذا يؤكد أن عملية “تفكير” LLM تتحقق من خلال توليد الرموز، وأن “التحليل” المحدد في الموجه، إذا لم يكن له مخرج محتوى فعلي، فإن الذكاء الاصطناعي لم ينفذ هذا التحليل بالفعل. هذا له أهمية إرشادية لتصميم موجهات LLM فعالة (المصدر: dotey)

محدودية الذكاء الاصطناعي في مهام محددة: تيرنس تاو (Terence Tao) يقول إن الذكاء الاصطناعي يفتقر إلى “حاسة الشم الرياضية”: أشار عالم الرياضيات تيرنس تاو (Terence Tao) إلى أنه على الرغم من أن البراهين التي يولدها الذكاء الاصطناعي حاليًا تبدو مثالية ظاهريًا (تجتاز “اختبار العين المجردة”)، إلا أنها غالبًا ما تفتقر إلى “حاسة شم رياضية” دقيقة وخاصة بالبشر، وتميل إلى ارتكاب بعض الأخطاء غير البشرية. يعتقد أن الذكاء الحقيقي ليس مجرد المظهر الصحيح، بل يكمن في القدرة على “شم” ما هو حقيقي. هذا يكشف عن محدودية الذكاء الاصطناعي الحالي في الفهم العميق والحكم الحدسي (المصدر: ecsquendor)
تحديات المحتوى المُنشأ بالذكاء الاصطناعي وقوانين الفيزياء الواقعية: اكتشف المستخدم karminski3 عند استخدام Doubao Seed 1.6 و DeepSeek-R1 لتوليد الأكواد (محاكاة رسوم متحركة ثلاثية الأبعاد لهدم مدخنة بالمتفجرات) أنه على الرغم من قدرة النماذج على توليد الأكواد ومحاكاة الرسوم المتحركة، لا تزال هناك اختلافات ومجال للتحسين في استعادة العمليات الفيزيائية الحقيقية (مثل تأثيرات موجة الصدمة، وطريقة انهيار الهيكل). كان Doubao Seed 1.6 أقرب إلى الواقع في محاكاة تأثيرات الجسيمات وانهيار الهيكل، بينما كان أداء DeepSeek أفضل في تأثيرات الإضاءة والظل والدخان. يعكس هذا تحديات الذكاء الاصطناعي في فهم ومحاكاة الظواهر الفيزيائية المعقدة (المصدر: karminski3)
فصل مبرمج مخضرم بسبب اعتماده المفرط على الذكاء الاصطناعي في كتابة الأكواد، ورفضه التعديل اليدوي، وتخويف الموظفين الجدد بأن الذكاء الاصطناعي سيحل محلهم: يروي منشور على Reddit نقله موقع 36Kr قصة مبرمج يتمتع بخبرة 30 عامًا تم فصله من الشركة بسبب إفراطه في الاعتماد على الذكاء الاصطناعي (مثل الاعتماد الكامل على Copilot Agent لتقديم طلبات السحب PR، ورفض تعديل الأكواد يدويًا، واستغراق 5 أيام لإكمال مهمة تستغرق يومًا واحدًا، والترويج للمتدربين بأن الذكاء الاصطناعي سيحل محلهم). أثارت هذه الحادثة نقاشًا حول الحدود المعقولة لاستخدام الذكاء الاصطناعي في تطوير البرمجيات، وتأثير الذكاء الاصطناعي على القيمة المهنية للمطورين (المصدر: 36氪)
تأثير “التدفق الذهني” و”الشخصية” للذكاء الاصطناعي على تجربة المستخدم: المستخدمون يشكون من أن الذكاء الاصطناعي “متوافق بشكل مفرط”: ناقش مستخدمو مجتمع Reddit أنهم لاحظوا عند التفاعل مع الذكاء الاصطناعي (خاصة Claude)، يميل الذكاء الاصطناعي إلى التفاؤل المفرط والتوافق مع آراء المستخدمين، ويفتقر إلى التحدي الفعال وردود الفعل النقدية العميقة، مما يجعل المستخدمين يشعرون وكأنهم في “غرفة صدى”. هذا “إرهاق نبرة الذكاء الاصطناعي” يدفع المستخدمين إلى البحث عن طرق لجعل الذكاء الاصطناعي يتصرف بشكل أكثر حيادية ونقدية، على سبيل المثال من خلال توجيه مطالبات محددة. يعكس هذا تحديات الذكاء الاصطناعي الحالية في محاكاة حوار بشري حقيقي ومتعدد الأوجه وتقديم رؤى عميقة حقًا (المصدر: Reddit r/ClaudeAI)
في عصر الذكاء الاصطناعي، تبرز قيمة التغذية الراجعة البشرية، لكن منصات التفاعل البشري الحقيقية تواجه تغلغل محتوى الذكاء الاصطناعي: أشار مستخدمو Reddit إلى أنه في سياق تزايد المحتوى المُنشأ بالذكاء الاصطناعي، أصبحت التغذية الراجعة والآراء البشرية الحقيقية أكثر قيمة، وتحظى منصات مثل Reddit بالتقدير لخصائص تفاعلها البشري. ومع ذلك، تواجه هذه المنصات أيضًا تحدي تغلغل المحتوى المُنشأ بالذكاء الاصطناعي (مثل تعليقات الروبوتات، والمنشورات المكتوبة بمساعدة الذكاء الاصطناعي)، مما يجعل تمييز الآراء البشرية الحقيقية أكثر صعوبة، ويثير مخاوف بشأن صحة التواصل عبر الإنترنت في المستقبل (المصدر: Reddit r/ArtificialInteligence)
“أصدقاء” الذكاء الاصطناعي قد يصبحون أمرًا طبيعيًا؟ اتجاه ونقاش حول بناء المستخدمين لعلاقات عاطفية مع الذكاء الاصطناعي: ظهرت نقاشات حول رفقاء الذكاء الاصطناعي وأصدقاء الذكاء الاصطناعي على وسائل التواصل الاجتماعي ومجتمع Reddit. يعتقد بعض المستخدمين أنه نظرًا لخصائص الذكاء الاصطناعي غير المتحيزة والداعمة دائمًا، قد يصبح أصدقاء الذكاء الاصطناعي أمرًا طبيعيًا في غضون السنوات الخمس القادمة، وقد ظهر ذلك بالفعل في تطبيقات مثل Endearing AI و Replika و Character.ai. يشارك مستخدمون آخرون تجاربهم في بناء علاقات حوارية عميقة مع الذكاء الاصطناعي مثل ChatGPT، حتى أنهم يعتبرونه “أفضل صديق”. يثير هذا تفكيرًا واسع النطاق حول التفاعل العاطفي بين الإنسان والذكاء الاصطناعي، ودور الذكاء الاصطناعي في الدعم العاطفي، وتأثيراته الاجتماعية المحتملة (المصدر: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

مستقبل الشركات الناشئة “المغلفة” للذكاء الاصطناعي يثير النقاش: ناقش مجتمع Reddit آفاق عدد كبير من الشركات الناشئة في مجال الذكاء الاصطناعي التي تعتمد على تغليف نماذج أساسية مثل GPT أو Claude (بإضافة واجهة مستخدم، أو سلاسل مطالبات، أو ضبط دقيق لمجالات محددة). شكك المشاركون في قدرة هذه التطبيقات “المغلفة” على الحفاظ على قدرتها التنافسية بعد تطور وظائف منصات النماذج الأساسية نفسها، وما إذا كان بإمكانها بناء خنادق حقيقية. ترى الآراء أن التركيز على مجالات رأسية محددة، وتجميع بيانات خاصة، وتجاوز التغليف البسيط قد يكون مسارها نحو التنمية المستدامة (المصدر: Reddit r/LocalLLaMA)
نقاش حول إمكانية استبدال الذكاء الاصطناعي في التشخيص الطبي وهندسة البرمجيات: ظهر نقاش في مجتمع Reddit يشير إلى أن سرعة استبدال الذكاء الاصطناعي للأطباء قد تكون أسرع من استبداله لمهندسي البرمجيات المتقدمين. السبب هو أن العديد من التشخيصات الطبية تتبع بروتوكولات محددة، والذكاء الاصطناعي بارع في تفسير نتائج الاختبارات وتحديد الأعراض؛ بينما تتضمن هندسة البرمجيات غالبًا كمية كبيرة من المعرفة الضمنية والتواصل المعقد للمتطلبات، والتي يصعب على الذكاء الاصطناعي إتقانها بالكامل. أثارت هذه النظرة مزيدًا من التفكير حول عمق تطبيق الذكاء الاصطناعي وإمكانية الاستبدال في مختلف المجالات المهنية، ولكنها قوبلت أيضًا بمعارضة من متخصصين مثل الأطباء، الذين أكدوا على تعقيد الممارسة الفعلية وأهمية الحكم البشري (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 أخبار أخرى
الشخصية الرقمية للو يونغهاو (Luo Yonghao) بالذكاء الاصطناعي تبث لأول مرة على منصة Baidu للتجارة الإلكترونية، وتحقق مبيعات تتجاوز 55 مليون يوان: قامت الشخصية الرقمية للو يونغهاو (Luo Yonghao) بالذكاء الاصطناعي بأول بث مباشر لبيع المنتجات على منصة Baidu للتجارة الإلكترونية، وجذبت أكثر من 13 مليون مشاهدة، وتجاوز إجمالي قيمة البضائع المباعة (GMV) 55 مليون يوان. تم إنشاء هذه الشخصية الرقمية بواسطة منصة “慧播星” (Huiboxing) التابعة لـ Baidu للتجارة الإلكترونية، بالاعتماد على نموذج Wenxin 4.5 الكبير، وهي قادرة على محاكاة نبرة صوت لو يونغهاو ولهجته وتعبيراته الدقيقة، والرد بذكاء. أظهر هذا البث المباشر إمكانات نموذج “الذكاء الاصطناعي + كبار المذيعين”، بالإضافة إلى تخطيط Baidu في تكنولوجيا “الشخصيات الرقمية عالية الإقناع” ومجال التجارة الإلكترونية بالذكاء الاصطناعي (المصدر: 36氪)

Baidu و Tencent وغيرها من الشركات تزيد من جهود توظيف مواهب الذكاء الاصطناعي، وتطلق خطط توظيف واسعة النطاق: أطلقت Baidu أكبر برنامج توظيف لمواهب الذكاء الاصطناعي المتميزة “AIDU Plan”، حيث زادت الوظائف الشاغرة بنسبة 60% على أساس سنوي، مع التركيز على المجالات المتطورة مثل خوارزميات النماذج الكبيرة والبنية التحتية الأساسية، وتقديم رواتب غير محدودة. وبالمثل، نظمت Tencent مسابقة خوارزميات “التوصية التوليدية متعددة الوسائط” (全模态生成式推荐)، وقدمت ملايين الجوائز وعروض التوظيف للخريجين، لجذب مواهب الذكاء الاصطناعي العالمية. تعكس هذه المبادرات حاجة عمالقة التكنولوجيا الصينيين الملحة للمواهب المتميزة وتخطيطهم الاستراتيجي في ظل المنافسة المحتدمة في مجال الذكاء الاصطناعي (المصدر: 量子位, 量子位)

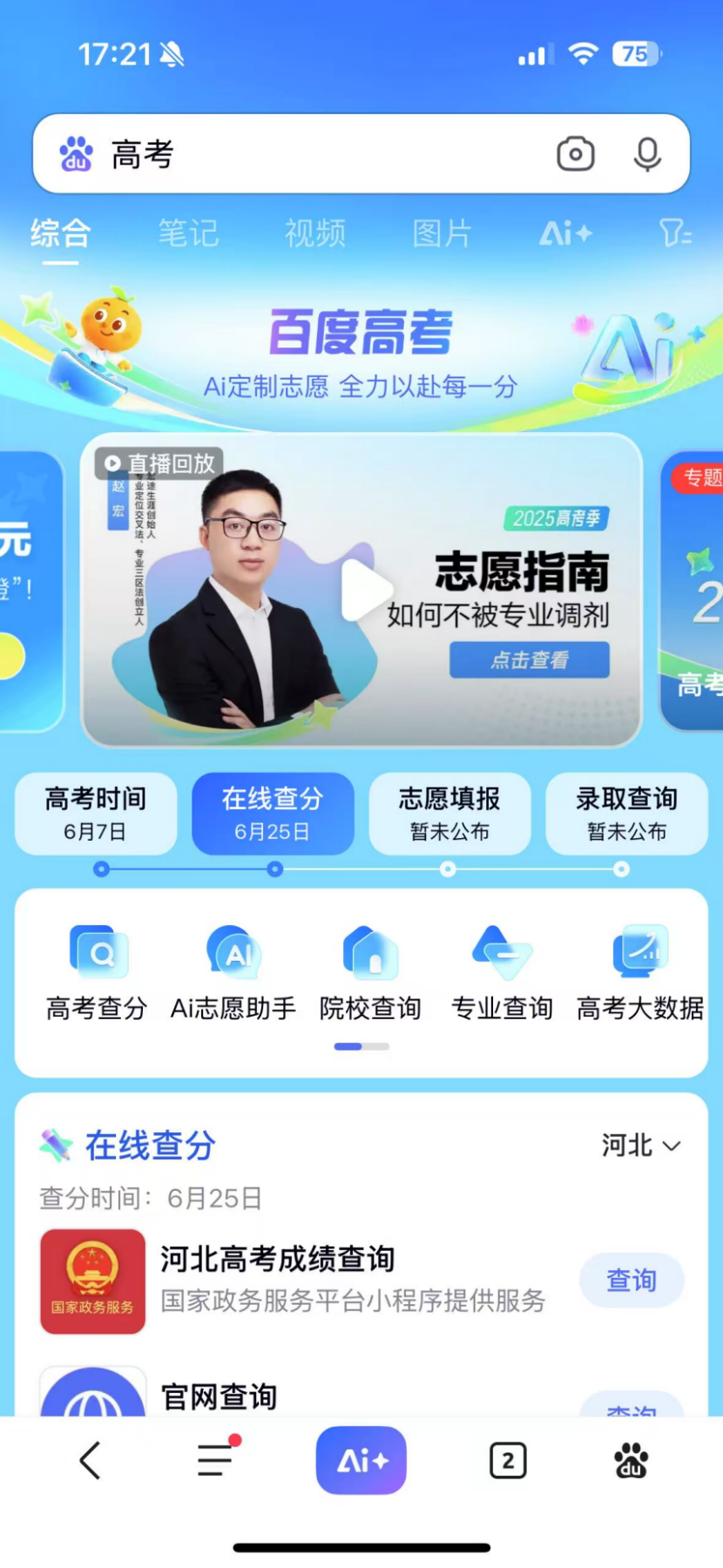
Baidu تطلق خدمة مساعدة شاملة لاختيار التخصصات الجامعية بالذكاء الاصطناعي، وتدمج نماذج متعددة وبيانات ضخمة: لمواجهة تعقيدات اختيار التخصصات الجامعية الناتجة عن إصلاحات امتحان القبول الجامعي الجديد، أطلقت Baidu أداة مساعدة مجانية لاختيار التخصصات الجامعية بالذكاء الاصطناعي. تتوفر هذه الخدمة مدمجة في صفحة “امتحان القبول الجامعي” (高考) في تطبيق Baidu، وتوفر “مساعد اختيار التخصص بالذكاء الاصطناعي” (AI志愿助手) للتوصية بالكليات والتخصصات وتحليل احتمالات القبول، وتدعم وكلاء “الدردشة حول التخصصات بالذكاء الاصطناعي” (AI聊志愿) من نماذج متعددة مثل Wenxin و DeepSeek R1 لتقديم استشارات مخصصة. بالإضافة إلى ذلك، تجمع الخدمة بين بيانات البحث الحصرية من Baidu لتقديم تحليل لآفاق التوظيف في التخصصات، وتقييم MBTI المهني، بالإضافة إلى موارد مساعدة بشرية مثل البث المباشر لمكاتب القبول في الجامعات، وأسئلة وأجوبة من طلاب الجامعات الحاليين، بهدف مساعدة المتقدمين على التعامل مع فجوة المعلومات واتخاذ خيارات تخصص أكثر ملاءمة (المصدر: 36氪)