
كلمات مفتاحية:الذكاء الاصطناعي, النماذج الكبيرة, نظم متعددة الوكلاء, كلود, المحول, الحوسبة العصبية, نماذج اللغة الكبيرة, وكيل الذكاء الاصطناعي, نظام كلود للبحث متعدد الوكلاء, طريقة التدريب الهجين إيسو-إل إم, الحاسوب الفائق العصبي, تقنية توسيع السياق, تقنية العلامة المائية سينث آي دي
🔥 أبرز النقاط
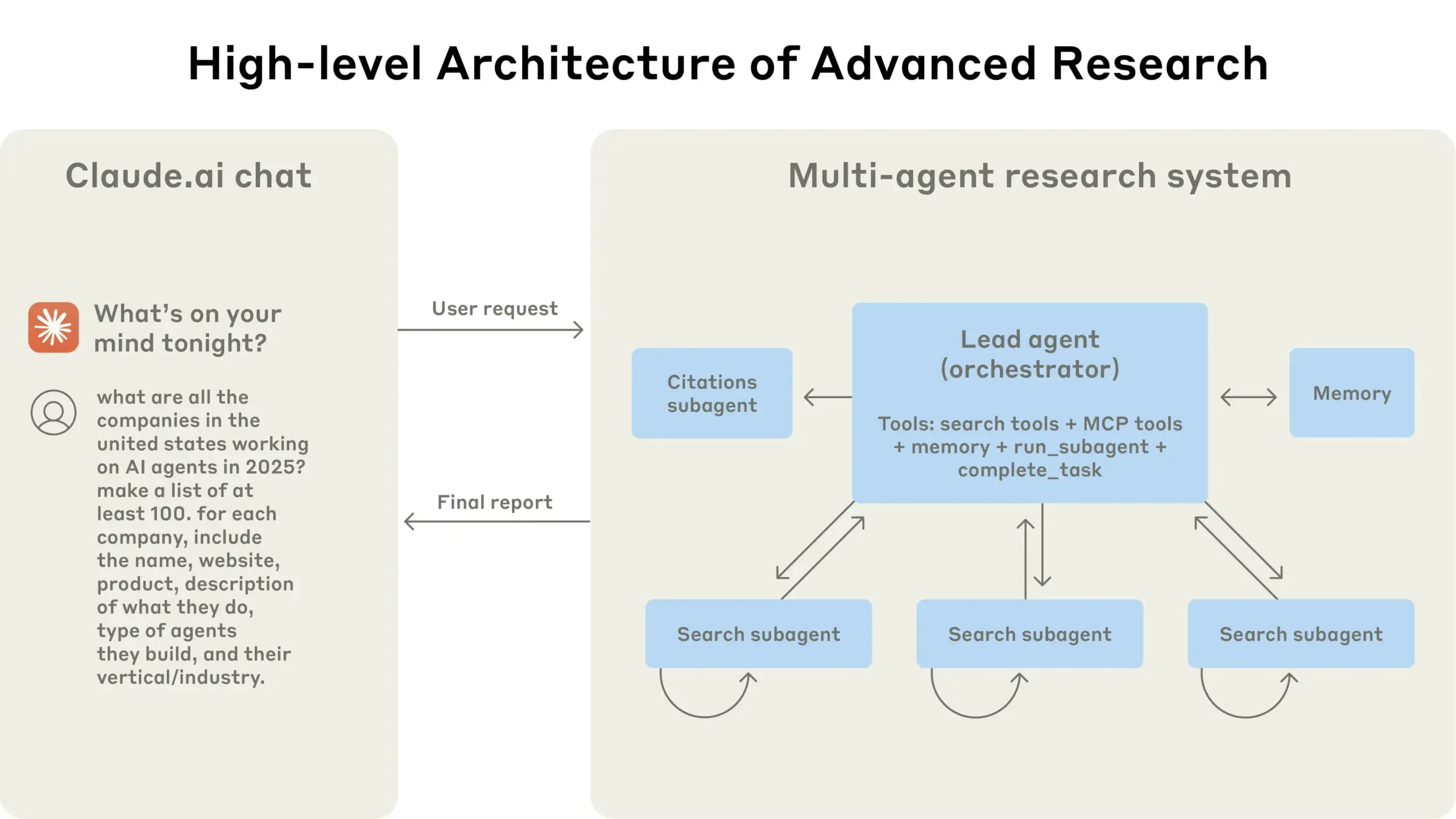
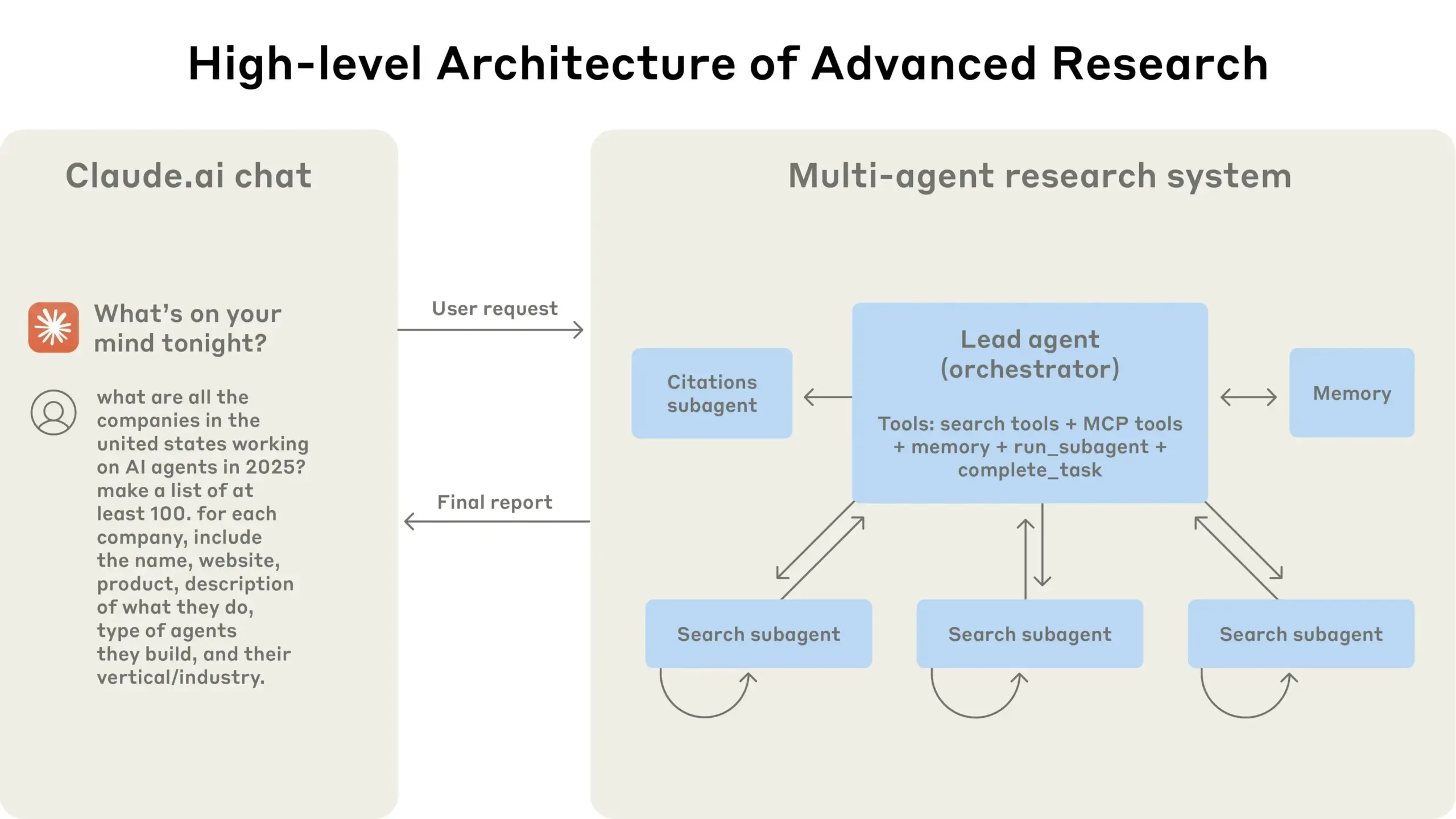
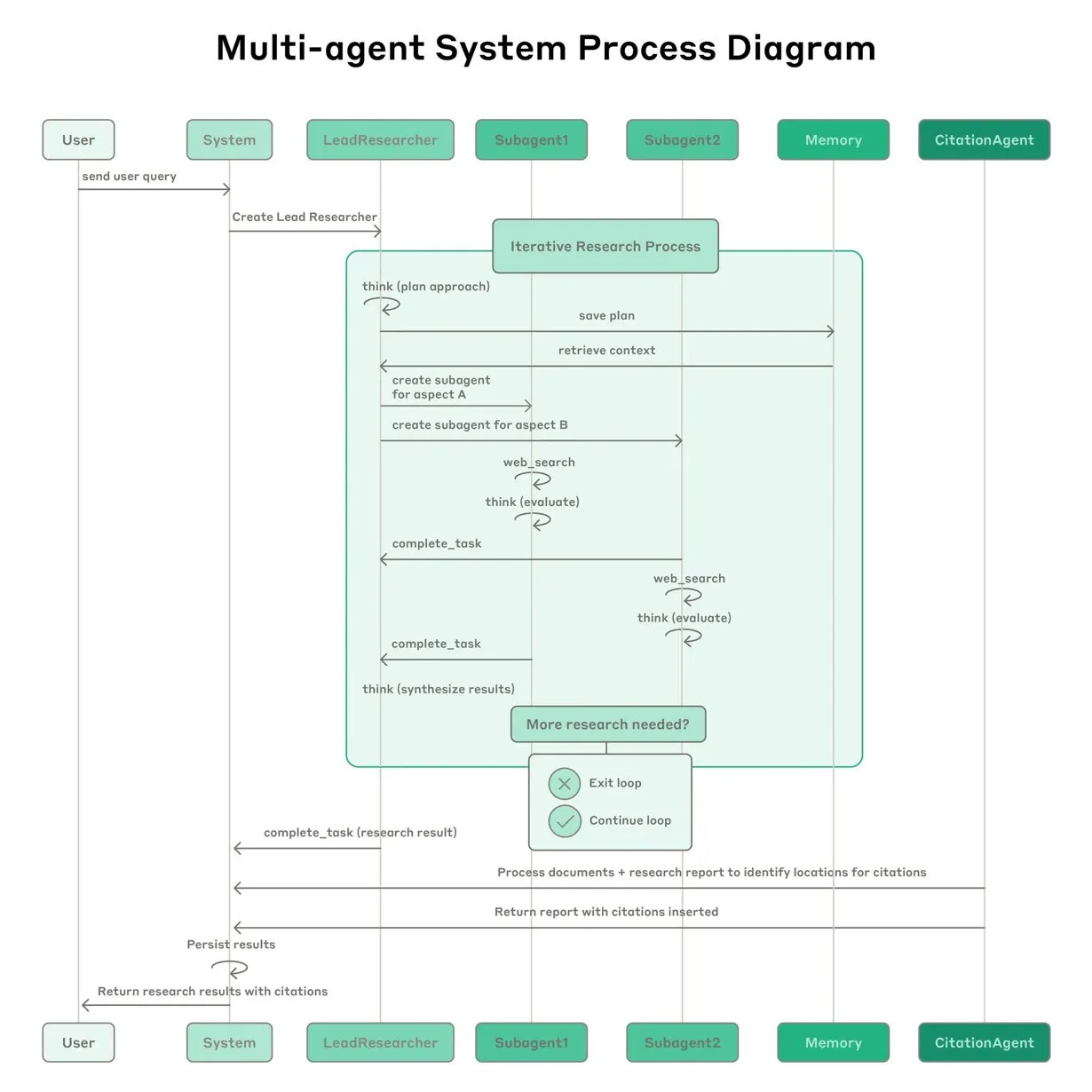
Anthropic تشارك خبراتها في بناء نظام أبحاث Claude متعدد الوكلاء: قدمت Anthropic تفصيلاً لكيفية بناء نظام أبحاث Claude متعدد الوكلاء، مشاركةً الخبرات الناجحة والفاشلة والتحديات الهندسية التي واجهتها. تشمل الدروس الرئيسية المستفادة: ليست كل السيناريوهات مناسبة للأنظمة متعددة الوكلاء، خاصة عندما تحتاج الوكلاء إلى مشاركة كميات كبيرة من السياق أو عندما يكون هناك اعتماد كبير بينها؛ يمكن للوكلاء تحسين واجهات الأدوات، على سبيل المثال، من خلال وكيل اختبار يعيد كتابة وصف الأداة لتقليل الأخطاء المستقبلية، مما يقلل وقت إنجاز المهمة بنسبة 40%؛ على الرغم من أن التنفيذ المتزامن للوكلاء الفرعيين يبسط التنسيق، إلا أنه قد يتسبب في اختناقات في تدفق المعلومات، مما يشير إلى إمكانات البنية القائمة على الأحداث غير المتزامنة. تقدم هذه المشاركة رؤى قيمة لبناء معماريات متعددة الوكلاء على مستوى الإنتاج (المصدر: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
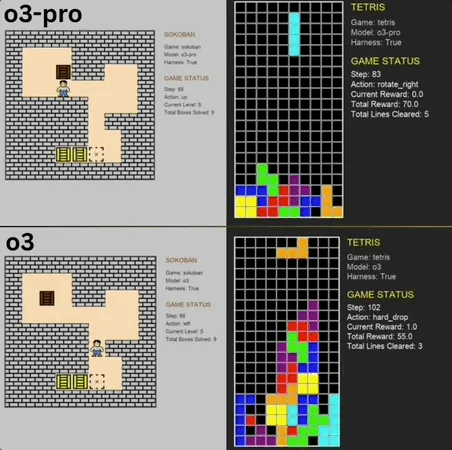
o3-pro يتألق في معيار الألعاب الكلاسيكية المصغرة Benchmark، محققًا إنجازًا يتجاوز SOTA: تحدى o3-pro الألعاب الكلاسيكية مثل “سوكوبان” و”تتريس” في اختبار Lmgame وحقق نتائج ممتازة، متجاوزًا بشكل مباشر الحد الأقصى الذي سجلته سابقًا نماذج مثل o3. في لعبة “سوكوبان”، نجح o3-pro في إكمال جميع المستويات المحددة؛ وفي “تتريس”، كان أداؤه قويًا لدرجة أنه تم إنهاء الاختبار قسرًا. يهدف هذا المعيار، الذي قدمه Hao AI Lab من UCSD (التابع لـ LMSYS، مطوري ساحة منافسة النماذج اللغوية الكبيرة)، إلى تقييم قدرات التخطيط والاستدلال للنماذج من خلال نمط دورة تفاعلية متكررة، حيث تقوم النماذج اللغوية الكبيرة بتوليد الإجراءات بناءً على حالة اللعبة وتلقي التغذية الراجعة. على الرغم من أن تشغيل o3-pro استغرق وقتًا أطول، إلا أن أدائه في مهام الألعاب يسلط الضوء على إمكانات النماذج الكبيرة في مهام اتخاذ القرارات المعقدة (المصدر: 36氪)
Tao Zhexuan يتوقع أن يفوز الذكاء الاصطناعي بجائزة Fields في غضون عشر سنوات، وسيصبح متعاونًا مهمًا في أبحاث الرياضيات: توقع Tao Zhexuan، الحائز على جائزة Fields، أن يصبح الذكاء الاصطناعي شريكًا بحثيًا موثوقًا به لعلماء الرياضيات بحلول عام 2026، وقد يقترح في غضون عشر سنوات تخمينات رياضية مهمة، مما يمثل “لحظة AlphaGo” في عالم الرياضيات، بل وقد يفوز في النهاية بجائزة Fields. ويرى أن الذكاء الاصطناعي يمكنه تسريع استكشاف المشكلات العلمية المعقدة مثل “النظرية الموحدة الكبرى”، لكنه يواجه حاليًا صعوبة في اكتشاف قوانين الفيزياء المعروفة، ويرجع ذلك جزئيًا إلى نقص “البيانات السلبية” المناسبة وبيانات التدريب على عمليات التجربة والخطأ. وأكد Tao Zhexuan أن الذكاء الاصطناعي يحتاج إلى المرور بعملية تعلم وارتكاب أخطاء وتصحيحها مثل البشر لينمو حقًا، مشيرًا إلى أن الذكاء الاصطناعي الحالي يعاني من قصور في تمييز مساراته الخاطئة ويفتقر إلى “حاسة الشم” التي يتمتع بها علماء الرياضيات البشر. وهو متفائل بشأن الجمع بين لغة الإثبات الرسمية Lean والذكاء الاصطناعي، معتقدًا أن هذا سيغير طريقة التعاون في أبحاث الرياضيات (المصدر: 36氪)

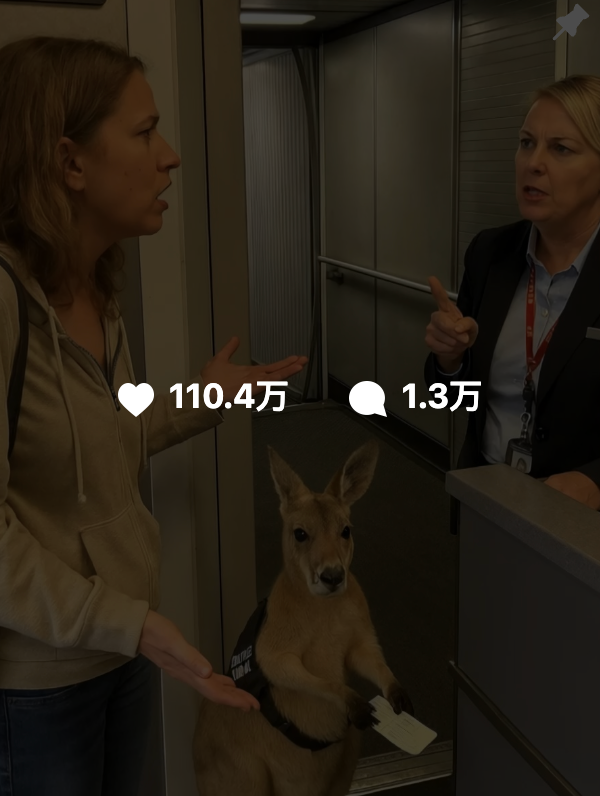
صعوبة التمييز بين المحتوى الذي يولده الذكاء الاصطناعي والمحتوى الحقيقي، Google تطلق تقنية العلامة المائية SynthID للمساعدة في كشف التزييف: انتشرت مؤخرًا مقاطع فيديو مولدة بالذكاء الاصطناعي مثل “الكنغر على متن طائرة” على نطاق واسع عبر وسائل التواصل الاجتماعي وأضللت عددًا كبيرًا من المستخدمين، مما يسلط الضوء على تحديات تمييز محتوى الذكاء الاصطناعي. لهذا الغرض، أطلقت Google DeepMind تقنية SynthID، التي تساعد في التعرف على المحتوى المولد بالذكاء الاصطناعي (صور، مقاطع فيديو، صوت، نصوص) عن طريق تضمين علامة مائية رقمية غير مرئية. حتى لو قام المستخدمون بإجراء تعديلات روتينية على المحتوى (مثل إضافة فلاتر، قص، تحويل التنسيق)، لا يزال من الممكن اكتشاف علامة SynthID المائية بواسطة أدوات محددة. ومع ذلك، فإن هذه التقنية قابلة للتطبيق حاليًا بشكل أساسي على المحتوى الذي تم إنشاؤه بواسطة خدمات الذكاء الاصطناعي الخاصة بـ Google (مثل Gemini, Veo, Imagen, Lyria)، وليست أداة كشف عامة للذكاء الاصطناعي. وفي الوقت نفسه، قد تؤدي التعديلات الكبيرة أو إعادة الكتابة الخبيثة إلى إتلاف العلامة المائية، مما يؤدي إلى فشل الكشف. حاليًا، SynthID في مرحلة اختبار مبكرة ويتطلب التقديم للاستخدام (المصدر: 36氪, aihub.org)
🎯 اتجاهات
الأستاذ Qiu Xipeng من جامعة Fudan يقترح Context Scaling كمسار رئيسي محتمل تالٍ للوصول إلى AGI: يعتقد الأستاذ Qiu Xipeng من جامعة Fudan/أكاديمية Shanghai للابتكار أنه بعد التحسين في مرحلتي ما قبل التدريب وما بعد التدريب، سيكون الفصل الثالث في تطوير النماذج الكبيرة هو Context Scaling (توسيع السياق). وأشار إلى أن الذكاء الحقيقي يكمن في فهم غموض وتعقيد المهام، ويهدف Context Scaling إلى تمكين الذكاء الاصطناعي من فهم والتكيف مع معلومات السياق الغنية والواقعية والمعقدة والمتغيرة، والتقاط “المعرفة الضمنية” التي يصعب التعبير عنها بوضوح (مثل الذكاء الاجتماعي والتكيف الثقافي). وهذا يتطلب أن يتمتع الذكاء الاصطناعي بتفاعلية قوية (تعاون متعدد الوسائط مع البيئة والبشر)، وتجسيد (ذاتية مادية أو افتراضية للإدراك والعمل)، وتجسيد بشري (تعاطف عاطفي وردود فعل شبيهة بالإنسان). هذا المسار لا يحل محل مسارات التوسع الحالية، بل هو مكمل ومتكامل لها، وقد يصبح خطوة حاسمة نحو AGI (المصدر: 36氪)
دراسة تكشف أن نسيان النماذج الكبيرة ليس مجرد حذف بسيط، وتكشف عن قوانين النسيان القابل للعكس: اكتشف باحثون من جامعة Hong Kong Polytechnic ومؤسسات أخرى أن نسيان النماذج اللغوية الكبيرة ليس مجرد محو للمعلومات، بل قد يكون مخفيًا داخل النموذج. من خلال بناء مجموعة من أدوات تشخيص مساحة التمثيل (تشابه PCA والانحراف، CKA، مصفوفة معلومات Fisher)، ميزت الدراسة بشكل منهجي بين “النسيان القابل للعكس” و “النسيان الكارثي غير القابل للعكس”. وأظهرت النتائج أن النسيان الحقيقي هو محو هيكلي، وليس تثبيطًا سلوكيًا. يمكن استعادة معظم حالات النسيان لمرة واحدة، ولكن النسيان المستمر (مثل 100 طلب) يؤدي بسهولة إلى انهيار كامل، وتعتبر طرق مثل GA و RLabel مدمرة نسبيًا. ومن المثير للاهتمام، في بعض السيناريوهات، بعد إعادة التعلم Relearning، كان أداء النموذج على مجموعة البيانات المنسية أفضل من حالته الأصلية، مما يشير إلى أن Unlearning قد يكون له تأثير تنظيمي مقارن أو تأثير تعلم تدريجي (المصدر: 36氪)

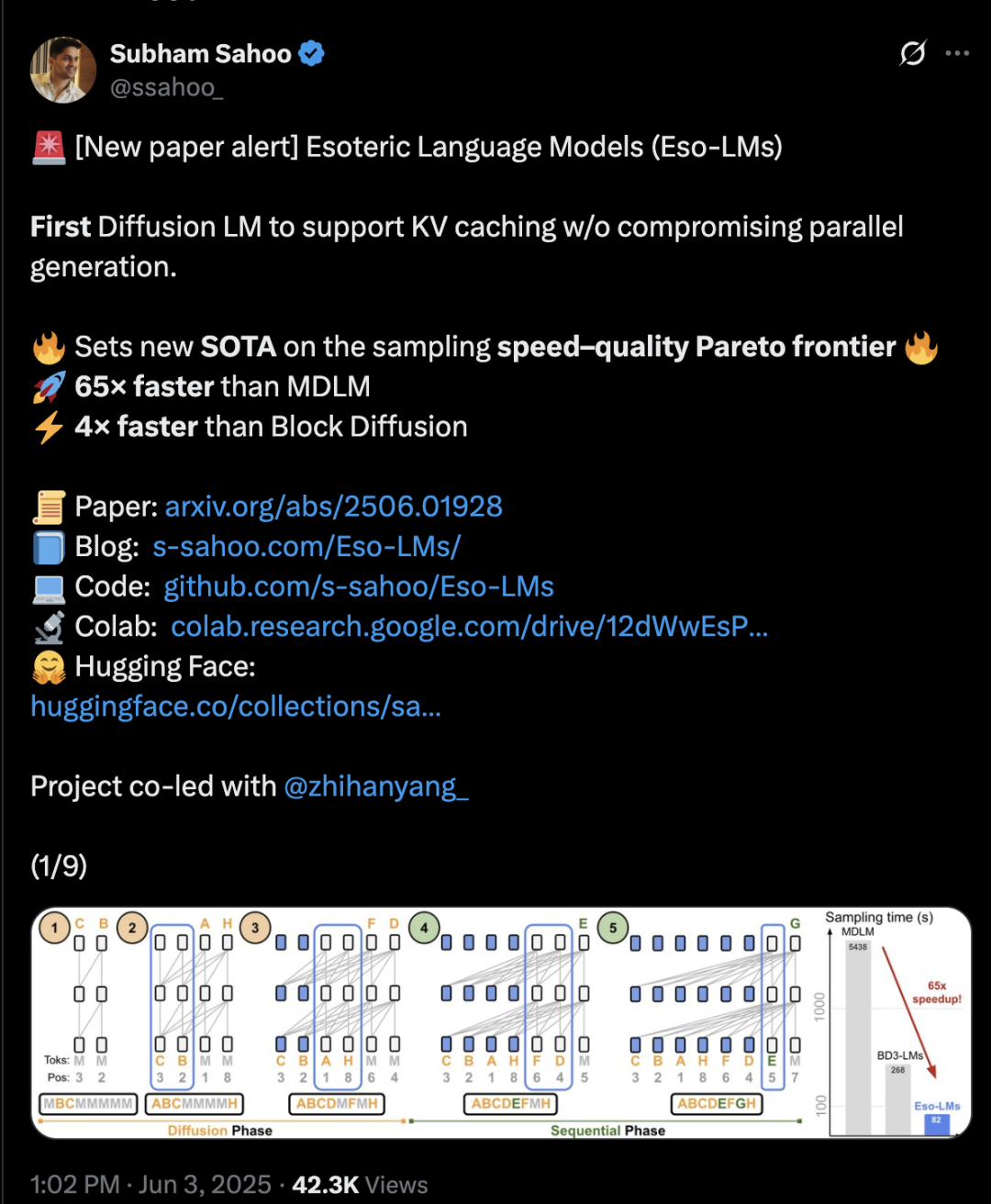
هيكل Transformer يمزج بين الانتشار والترجع الذاتي، مما يزيد سرعة الاستدلال بمقدار 65 مرة: اقترح باحثون من جامعة Cornell و CMU ومؤسسات أخرى إطارًا جديدًا لنمذجة اللغة يسمى Eso-LM، يجمع هذا الإطار بين مزايا النماذج الترجعية الذاتية (AR) ونماذج الانتشار المتقطع (MDM). من خلال طريقة تدريب مختلطة مبتكرة وتحسين الاستدلال، يقدم Eso-LM لأول مرة آلية ذاكرة التخزين المؤقت KV cache مع الحفاظ على التوليد المتوازي، مما يجعل سرعة الاستدلال أسرع بمقدار 65 مرة مقارنة بنماذج MDM القياسية، وأسرع بمقدار 3-4 مرات مقارنة بالنماذج الأساسية شبه الترجعية الذاتية التي تدعم KV cache. يتساوى أداء هذه الطريقة مع نماذج الانتشار المتقطع في سيناريوهات الحوسبة المنخفضة، ويقترب من أداء النماذج الترجعية الذاتية في سيناريوهات الحوسبة العالية، كما يسجل رقمًا قياسيًا جديدًا لنماذج الانتشار المتقطع في مؤشر الحيرة، مما يقلل الفجوة مع النماذج الترجعية الذاتية. Arash Vahdat، الباحث في Nvidia، هو أيضًا أحد مؤلفي الورقة البحثية، مما يشير إلى أن Nvidia قد تهتم بهذا الاتجاه التكنولوجي (المصدر: 36氪)
الحوسبة العصبية الشكلية قد تكون مفتاح الجيل القادم من الذكاء الاصطناعي، ومن المتوقع أن تحقق استهلاك طاقة بمستوى “المصباح الكهربائي”: يستكشف العلماء بنشاط الحوسبة العصبية الشكلية، التي تهدف إلى محاكاة بنية الدماغ البشري وطريقة عمله، لحل “أزمة الطاقة” التي يواجهها تطوير الذكاء الاصطناعي الحالي. يخطط المختبر الوطني الأمريكي لبناء حاسوب فائق عصبي شكلي يشغل مساحة مترين مربعين فقط، ويحتوي على عدد من الخلايا العصبية يضاهي قشرة الدماغ البشري، ومن المتوقع أن يعمل بسرعة تفوق سرعة الدماغ البيولوجي بما يتراوح بين 250 ألف ومليون مرة، وباستهلاك طاقة يبلغ 10 كيلوواط فقط. تستخدم هذه التقنية الشبكات العصبية النبضية (SNN)، وتتميز بالاتصال القائم على الأحداث، والحوسبة في الذاكرة، والقدرة على التكيف والتوسع، ويمكنها معالجة المعلومات بذكاء ومرونة أكبر، والتكيف ديناميكيًا مع السياق. تعد رقائق TrueNorth من IBM و Loihi من Intel من أوائل الاستكشافات، كما أطلقت شركات ناشئة مثل BrainChip معالجات ذكاء اصطناعي طرفية منخفضة الطاقة مثل Akida. ومن المتوقع أن يصل حجم سوق الحوسبة العصبية الشكلية العالمي إلى 1.81 مليار دولار أمريكي بحلول عام 2025 (المصدر: 36氪)

استكشاف آلية الاستدلال في النماذج اللغوية الكبيرة LLM: تفاعل معقد بين الانتباه الذاتي والمواءمة وقابلية التفسير: تكمن قدرة الاستدلال في النماذج اللغوية الكبيرة (LLM) في آلية الانتباه الذاتي ضمن بنية Transformer الخاصة بها، مما يسمح للنموذج بتخصيص الانتباه ديناميكيًا وبناء تمثيلات محتوى مجردة بشكل متزايد داخليًا. وجدت الأبحاث أن هذه الآليات الداخلية (مثل رؤوس الاستقراء) يمكنها تحقيق إجراءات فرعية شبيهة بالخوارزميات، مثل إكمال الأنماط والتخطيط متعدد الخطوات. ومع ذلك، فإن طرق المواءمة مثل RLHF، على الرغم من أنها تجعل سلوك النموذج أكثر توافقًا مع التفضيلات البشرية (مثل الصدق والمساعدة)، قد تؤدي أيضًا إلى إخفاء النموذج أو تعديل عمليات الاستدلال الحقيقية الخاصة به لتحقيق أهداف المواءمة، مما يؤدي إلى “استدلال ملائم للعلاقات العامة”، أي إخراج تفسيرات تبدو معقولة ولكنها قد لا تكون صادقة تمامًا. وهذا يجعل فهم مبادئ العمل الحقيقية للنماذج المواءمة أكثر تعقيدًا، ويتطلب الجمع بين قابلية التفسير الميكانيكية (مثل تتبع الدوائر) والتقييم السلوكي (مثل مؤشرات الإخلاص) للتعمق في البحث (المصدر: 36氪, 36氪)
نموذج dots.llm1 الكبير من Xiaohongshu يحصل على دعم llama.cpp: نموذج dots.llm1 الكبير الذي أصدرته Xiaohongshu الأسبوع الماضي أصبح الآن مدعومًا رسميًا من llama.cpp. هذا يعني أنه يمكن للمطورين والمستخدمين الاستفادة من محرك الاستدلال الشهير C/C++ llama.cpp لتشغيل ونشر نموذج Xiaohongshu هذا محليًا، وبالتالي إنشاء محتوى بأسلوب “Xiaohongshu” بسهولة. يساعد هذا التقدم في توسيع نطاق تطبيق dots.llm1 وإمكانية الوصول إليه (المصدر: karminski3)
ألمانيا تمتلك أكبر حاسوب فائق للذكاء الاصطناعي في أوروبا ولكنه غير مستخدم لتدريب النماذج اللغوية الكبيرة LLM: تمتلك ألمانيا حاليًا أكبر حاسوب فائق للذكاء الاصطناعي في أوروبا، مجهز بـ 24000 شريحة H200، ولكن وفقًا لمناقشات المجتمع، لم يتم استخدام هذا الحاسوب الفائق لتدريب النماذج اللغوية الكبيرة (LLM). أثار هذا الوضع نقاشات حول استراتيجية الذكاء الاصطناعي الأوروبية وتخصيص الموارد، خاصة كيفية الاستفادة الفعالة من موارد الحوسبة عالية الأداء لدفع تطوير النماذج اللغوية الكبيرة المحلية وتقنيات الذكاء الاصطناعي ذات الصلة (المصدر: scaling01)
DeepSeek-R1 يثير اهتمامًا ونقاشًا واسع النطاق في مجتمع الذكاء الاصطناعي: أشارت تقارير VentureBeat إلى أن إطلاق DeepSeek-R1 أثار اهتمامًا واسع النطاق في مجال الذكاء الاصطناعي. على الرغم من أدائه المتميز، يرى المقال أن ميزة ChatGPT في تسويق المنتجات لا تزال واضحة، ومن الصعب تجاوزها على المدى القصير. يعكس هذا التوازن بين أداء النموذج البحت والنظام البيئي للمنتجات الناضجة وتجربة المستخدم في سباق الذكاء الاصطناعي (المصدر: Ronald_vanLoon, Ronald_vanLoon)

Google تطلق نموذج ذكاء اصطناعي وموقع ويب لتوقعات العواصف الاستوائية: أطلقت Google نموذجًا جديدًا للذكاء الاصطناعي وموقع ويب متخصصًا لتوقع مسارات وشدة العواصف الاستوائية. تهدف هذه الأداة إلى استخدام تقنيات التعلم الآلي لتحسين دقة وتوقيت توقعات العواصف، وتقديم الدعم لجهود الوقاية من الكوارث والحد منها في المناطق ذات الصلة (المصدر: Ronald_vanLoon)

OpenAI Codex يطلق ميزة Best-of-N لتعزيز كفاءة استكشاف توليد الأكواد: أضاف OpenAI Codex ميزة Best-of-N، مما يسمح للنموذج بتوليد استجابات متعددة لمهمة واحدة في نفس الوقت. يمكن للمستخدمين استكشاف العديد من الحلول الممكنة بسرعة واختيار أفضل طريقة من بينها. بدأت هذه الميزة في طرحها لمستخدمي Pro و Enterprise و Team و Edu و Plus، وتهدف إلى تحسين كفاءة المبرمجين وجودة الأكواد (المصدر: gdb)
تسريب مستودع أكواد خطة الذكاء الاصطناعي لإدارة ترامب “AI.gov” على GitHub ثم إزالته: أفادت التقارير أن مستودع الأكواد الأساسي لخطة تطوير الذكاء الاصطناعي للحكومة الفيدرالية “AI.gov”، التي خططت إدارة ترامب لإطلاقها في 4 يوليو، قد تم تسريبه عن طريق الخطأ على GitHub، ثم تم نقله إلى مشروع مؤرشف. يهدف هذا المشروع، بقيادة GSA و TTS، إلى تزويد الوكالات الحكومية بروبوتات محادثة تعمل بالذكاء الاصطناعي، وواجهة برمجة تطبيقات موحدة (API) (للوصول إلى نماذج OpenAI و Google و Anthropic)، ومنصة مراقبة استخدام الذكاء الاصطناعي تسمى “CONSOLE”. أثار التسريب مخاوف عامة بشأن اعتماد الحكومة المفرط على الذكاء الاصطناعي و “حكم الدولة” بواسطة أكواد الذكاء الاصطناعي، خاصة بالنظر إلى الأخطاء التي حدثت سابقًا عندما استخدم فريق DOGE أدوات الذكاء الاصطناعي لخفض ميزانية شؤون المحاربين القدامى (VA). على الرغم من أن المسؤولين صرحوا بأن المعلومات جاءت من مصادر موثوقة، إلا أن وثائق API المسربة تظهر أنها قد تحتوي على نموذج Cohere غير معتمد من FedRAMP، وأن الموقع سينشر تصنيفًا للنماذج الكبيرة، بمعايير غير واضحة بعد (المصدر: 36氪, karminski3)

الذكاء الاصطناعي يظهر براعته في التشخيص الطبي، دراسة من Stanford تشير إلى أن التعاون مع الأطباء يزيد الدقة بنسبة 10%: أظهرت دراسة أجرتها جامعة Stanford أن تعاون الذكاء الاصطناعي مع الأطباء يمكن أن يحسن بشكل كبير دقة تشخيص الحالات المعقدة. في اختبار شارك فيه 70 طبيبًا ممارسًا، بلغت دقة مجموعة AI-first (حيث يطلع الأطباء أولاً على اقتراحات الذكاء الاصطناعي ثم يشخصون) 85%، بزيادة تقارب 10% عن الطريقة التقليدية (75%)؛ وبلغت دقة مجموعة AI-second (حيث يشخص الأطباء أولاً ثم يدمجون تحليل الذكاء الاصطناعي) 82%. وبلغت دقة تشخيص الذكاء الاصطناعي بمفرده 90%. تشير الدراسة إلى أن الذكاء الاصطناعي يمكن أن يكمل الثغرات في التفكير البشري، مثل ربط المؤشرات المهملة والخروج عن الأطر التجريبية. ولتعزيز فعالية التعاون، تم تصميم الذكاء الاصطناعي ليكون قادرًا على إجراء مناقشات نقدية والتواصل بلغة عامية وإضفاء الشفافية على عملية اتخاذ القرار. كما وجدت الدراسة أن الذكاء الاصطناعي قد يتأثر بالتشخيص الأولي للأطباء (تأثير التثبيت)، مما يؤكد أهمية مساحة التفكير المستقل. وأعرب 98.6% من الأطباء عن استعدادهم لاستخدام الذكاء الاصطناعي في الاستدلال السريري (المصدر: 36氪)

🧰 أدوات
LangChain تطلق وكيل مستندات عقارية يجمع بين Tensorlake و LangGraph: عرضت LangChain وكيل مستندات عقارية جديد يجمع بين تقنية كشف التوقيع من Tensorlake وإطار عمل الوكلاء الذكي من LangGraph. تتمثل وظيفته الرئيسية في أتمتة عملية تتبع التوقيعات في مستندات العقارات، حيث يمكنه معالجة التوقيعات والتحقق منها ومراقبتها ضمن حل متكامل، بهدف تحسين كفاءة ودقة المعاملات العقارية. تم نشر البرنامج التعليمي ذي الصلة (المصدر: LangChainAI, hwchase17)

LangChain تطلق حل تحليل العقود GraphRAG: أصدرت LangChain حلاً يجمع بين GraphRAG ووكلاء LangGraph لتحليل العقود القانونية. يستفيد هذا الحل من الرسم البياني المعرفي Neo4j، وقد تم اختباره على العديد من النماذج اللغوية الكبيرة (LLM)، بهدف توفير قدرات قوية وفعالة لمراجعة العقود وفهمها. تم نشر دليل تنفيذ مفصل على Towards Data Science، يوضح كيفية الاستفادة من قواعد بيانات الرسم البياني وأنظمة الوكلاء المتعددة لمعالجة النصوص القانونية المعقدة (المصدر: LangChainAI, hwchase17)
Google NotebookLM يضيف ميزة الملخصات الصوتية التي لاقت استحسانًا، مما يعزز تجربة اكتساب المعرفة: Google NotebookLM (المعروف سابقًا باسم Project Tailwind) هو تطبيق تدوين ملاحظات مدفوع بالذكاء الاصطناعي، وقد حظي مؤخرًا بإشادة واسعة النطاق لإضافة ميزة “الملخصات الصوتية”، والتي وصفها Andrej Karpathy، العضو المؤسس في OpenAI، بأنها تقدم تجربة شبيهة بـ “لحظة ChatGPT”. يمكن لهذه الميزة تحويل المواد التي يحملها المستخدم، مثل المستندات والعروض التقديمية وملفات PDF وصفحات الويب والصوت ومقاطع فيديو YouTube، إلى ملخص صوتي على غرار البودكاست لمدة 10 دقائق تقريبًا، بصوت طبيعي ونقاط بارزة. يؤكد NotebookLM على “الاستناد إلى المصدر”، حيث يجيب فقط بناءً على المواد التي يقدمها المستخدم، مما يقلل من الهلوسة. كما يوفر وظائف مثل الخرائط الذهنية وأدلة الدراسة لمساعدة المستخدمين على فهم وتنظيم المعرفة. حاليًا، تم إطلاق إصدار محمول من NotebookLM، وتم دمج نموذج LearnLM المحسن خصيصًا لسيناريوهات التعليم (المصدر: 36氪)
Quark تطلق نموذجًا كبيرًا لتوجيه اختيار التخصصات الجامعية، وتقدم تحليلًا مخصصًا مجانيًا لملء استمارات التقديم: أطلقت Quark أول نموذج كبير لتوجيه اختيار التخصصات الجامعية، بهدف تزويد الطلاب بخدمة تحليل مخصصة ومجانية لملء استمارات التقديم للجامعات. بعد إدخال المستخدمين لدرجاتهم وموادهم وتفضيلاتهم وغيرها من المعلومات، يمكن للنظام تقديم توصيات للمؤسسات التعليمية ضمن ثلاث فئات: “طموحة، مستقرة، مضمونة”، وإنشاء تقرير تحليل مفصل للتخصصات، بما في ذلك تحليل الوضع، واستراتيجيات ملء الاستمارات، وتنبيهات المخاطر. كما قامت Quark بترقية البحث العميق بالذكاء الاصطناعي للإجابة بذكاء على الأسئلة المتعلقة بالتخصصات. ومع ذلك، أظهر الاختبار أن آفاق التوظيف لبعض التخصصات الموصى بها مشكوك فيها (مثل علوم الحاسوب وإدارة الأعمال)، وأن نتائج البحث تتضمن صفحات ويب غير رسمية تابعة لجهات خارجية، مما أثار مخاوف بشأن دقة بياناتها ومشكلات “الهلوسة”. أفاد العديد من المستخدمين بأنهم واجهوا مشكلات في التقديم بسبب بيانات Quark غير الدقيقة أو التوقعات السيئة، مما ينبه الطلاب إلى أن أدوات الذكاء الاصطناعي يمكن استخدامها كمرجع، ولكن لا ينبغي الاعتماد عليها بشكل كامل (المصدر: 36氪)

تسريبات عن تمويل شركة AI Agent Manus بمئات الملايين، وخطة العمل تؤكد على “العمل باليد والعقل معًا” وبنية الوكلاء المتعددين: بعد إتمام جولة تمويل بقيمة 75 مليون دولار أمريكي، يُقال إن شركة Manus الناشئة في مجال AI Agent تقترب من إتمام جولة تمويل جديدة بمئات الملايين من اليوانات الصينية، بتقييم ما قبل التمويل يبلغ 3.7 مليار يوان. تؤكد خطة عملها (BP) أن Manus تعتمد بنية وكلاء متعددين لمحاكاة سير العمل البشري (Plan-Do-Check-Act)، وتصف نفسها بأنها “تعمل باليد والعقل معًا”، بهدف تحقيق التحول من “الذكاء الاصطناعي الموجه بالأوامر” إلى “الذكاء الاصطناعي الذي ينجز المهام بشكل مستقل”. في خطة العمل، تدعي Manus أنها تفوقت على منتجات OpenAI المماثلة في اختبار GAIA، وتعتمد تقنيًا على استدعاء نماذج مثل GPT-4 و Claude ديناميكيًا ودمج سلاسل الأدوات مفتوحة المصدر. على الرغم من الاتهامات السابقة بأنها “مجرد واجهة”، إلا أن منتجها يمكنه التعامل مع المهام المعقدة، وقد أطلقت بالفعل ميزة تحويل النص إلى فيديو. في المستقبل، قد تصبح Manus مدخلاً جديدًا يدمج قدرات وكلاء متعددين، وتخطط لفتح مصدر بعض نماذجها (المصدر: 36氪)

مساعدو الهواتف الذكية المعتمدون على الذكاء الاصطناعي يستدعون ميزات إمكانية الوصول مما يثير مخاوف تتعلق بالخصوصية: العديد من هواتف الذكاء الاصطناعي الصينية مثل Xiaomi 15 Ultra و Honor Magic7 Pro و vivoX200 وغيرها، تحقق خدمات عبر التطبيقات (مثل طلب الطعام وإرسال الهدايا المالية) من خلال “أمر واحد” عن طريق استدعاء ميزات إمكانية الوصول على مستوى النظام. يمكن لميزات إمكانية الوصول قراءة معلومات الشاشة ومحاكاة نقرات المستخدم، مما يوفر الراحة لمساعدي الذكاء الاصطناعي، ولكنه يجلب أيضًا مخاطر تسرب الخصوصية. كشف الاختبار أن مساعدي الذكاء الاصطناعي هؤلاء، عند استدعاء ميزات إمكانية الوصول، غالبًا ما يتم تمكين الأذونات دون علم المستخدمين أو الحصول على إذن منفصل واضح. على الرغم من ذكر ذلك في سياسات الخصوصية، إلا أن المعلومات متفرقة ومعقدة. يخشى الخبراء أن يصبح هذا فخًا جديدًا “للخصوصية مقابل الراحة”، ويوصون بأن تقوم الشركات المصنعة بتقديم تذكيرات وإشعارات مخاطر منفصلة وواضحة عند الاستخدام الأول وعند تمكين الميزات عالية الامتيازات (المصدر: 36氪)
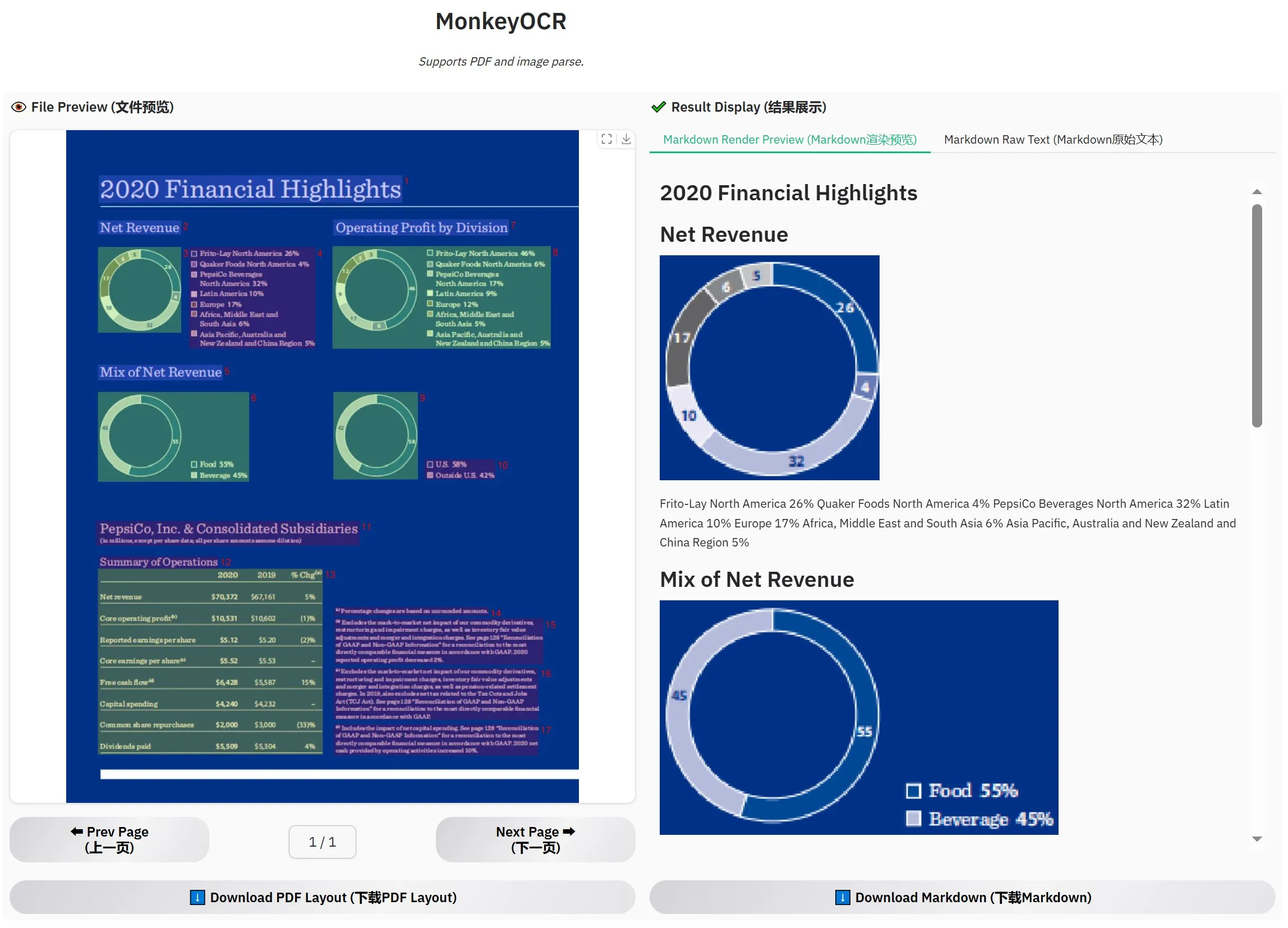
إطلاق MonkeyOCR-3B، التقييم الرسمي يتجاوز MinerU: تم إطلاق نموذج OCR جديد يسمى MonkeyOCR-3B، والذي تفوق في التقييم الرسمي على نموذج MinerU المعروف. يبلغ حجم هذا النموذج 3B معلمة فقط، مما يسهل تشغيله محليًا، ويوفر خيارًا جديدًا وفعالًا للمستخدمين الذين لديهم احتياجات كبيرة لـ OCR للمستندات. يمكن للمستخدمين الحصول على النموذج من HuggingFace (المصدر: karminski3)
Observer AI: إطار عمل لمراقبة الذكاء الاصطناعي، يراقب الشاشة ويحلل عمليات الذكاء الاصطناعي: Observer AI هو إطار عمل جديد يمكنه مراقبة شاشة المستخدم وتسجيل عملية تشغيل أدوات الذكاء الاصطناعي (مثل أدوات التشغيل الآلي BrowserUse). يقوم بتسليم المحتوى المسجل إلى الذكاء الاصطناعي لتحليله، ويمكنه الاستجابة بناءً على نتائج التحليل (مثل استدعاء دالة MCP أو خطط محددة مسبقًا). تهدف هذه الأداة إلى العمل كـ “مراقب” لعمليات الذكاء الاصطناعي، مما يساعد المستخدمين على فهم وإدارة سلوك مساعدي الذكاء الاصطناعي. المشروع مفتوح المصدر على GitHub (المصدر: karminski3)
إطلاق مولد سيناريوهات المخرج لـ Veo3، للمساعدة في الإنتاج الضخم لمقاطع الفيديو القصيرة: تم إطلاق مولد سيناريوهات المخرج لنموذج توليد الفيديو Veo3 على HuggingFace Spaces. يمكن لهذه الأداة استخدام الذكاء الاصطناعي لتوليد القصص وكتابة السيناريوهات، ثم تنظيمها بتنسيق مناسب لـ Veo3، مما يسهل على المستخدمين إنتاج مقاطع فيديو قصيرة بكميات كبيرة. يوفر هذا حلاً فعالاً لمنشئي المحتوى الذين يحتاجون إلى إنتاج كميات كبيرة من مقاطع الفيديو القصيرة (المصدر: karminski3)
طرفية Ghostty ستدعم ميزات إمكانية الوصول في macOS، مما يعزز تفاعلية أدوات الذكاء الاصطناعي: سيدعم تطبيق الطرفية Ghostty قريبًا أدوات إمكانية الوصول (accessibility tooling) في macOS. هذا يعني أن قارئات الشاشة وأدوات الذكاء الاصطناعي مثل ChatGPT و Claude ستكون قادرة على قراءة محتوى شاشة Ghostty (بإذن المستخدم) والتفاعل معه. هذه الميزة نادرة نسبيًا في تطبيقات الطرفية، وحاليًا لا يدعمها سوى Terminal المدمج في النظام و iTerm2 و Warp. سيكشف Ghostty أيضًا عن معلوماته الهيكلية (مثل تقسيم الشاشة وعلامات التبويب) لأدوات المساعدة، مما يعزز قدرته على التكامل مع الذكاء الاصطناعي وتقنيات المساعدة (المصدر: mitchellh)
تقييم شامل لأدوات ومنصات الذكاء الاصطناعي: Claude Code و Gemini 2.5 Pro يحظيان بالتقدير: شارك أحد المستخدمين تجربته العميقة مع أدوات ومنصات الذكاء الاصطناعي الرئيسية. في مجال نماذج الذكاء الاصطناعي، حظي الإصدار الجديد من Gemini 2.5 Pro بتقدير كبير لذكائه الحواري القريب من الإنسان وقدرته الشاملة القوية (بما في ذلك البرمجة)، متفوقًا حتى على Claude Opus/Sonnet. برزت نماذج Claude (Sonnet 4, Opus 4) في مهام البرمجة والوكلاء، وتفوقت ميزة Artifacts الخاصة بها على Canvas في ChatGPT، كما أن ميزة المشاريع تسهل إدارة السياق. لكن اشتراك Claude Plus يفرض قيودًا كبيرة على استخدام Opus 4، مما يجعل خطة Max 5x (100 دولار شهريًا) أكثر عملية. لم يعد Perplexity موصى به بسبب تحسن وظائف المنافسين. تحسنت نسبة أداء نموذج o3 من ChatGPT إلى سعره، ويعتبر o4 mini مناسبًا لمهام البرمجة القصيرة. يتميز DeepSeek بسعر تنافسي ولكن سرعته وتأثيره متوسطان. في مجال بيئات التطوير المتكاملة (IDE)، لا يزال Zed غير ناضج، بينما تعرض Windsurf و Cursor لانتقادات بسبب نماذج التسعير والسلوكيات التجارية. في مجال AI Agent، يعتبر Claude Code الخيار الأول بسبب تشغيله المحلي، وقيمته العالية مقابل السعر (مع الاشتراك)، وتكامله مع IDE، وقدرته على استدعاء MCP/الأدوات، على الرغم من وجود مشكلات هلوسة. تحسن GitHub Copilot ولكنه لا يزال متأخرًا. يتميز Aider CLI بقيمة جيدة مقابل السعر ولكن منحنى تعلمه حاد. يتميز Augment Code بقدرته على التعامل مع مستودعات الأكواد الكبيرة ولكنه يستغرق وقتًا طويلاً ومكلف. تختلف وكلاء Cline (Roo Code, Kilo Code) في مزاياها، ويتفوق Kilo Code قليلاً في جودة الأكواد واكتمالها. Jules (Google) و Codex (OpenAI) كوكلاء خاصين بمقدمي الخدمة، الأول غير متزامن ومجاني، والثاني يدمج الاختبار ولكنه أبطأ. يعتبر OpenRouter (بزيادة 5%) و Kilo Code (بدون زيادة) بدائل لمقدمي API. في أدوات إنشاء العروض التقديمية، يتميز Gamma.app بتأثيرات بصرية جيدة، بينما يتميز Beautiful.ai بقدرة قوية على توليد النصوص (المصدر: Reddit r/ClaudeAI)
مطور ينشئ نظام مناظرة بالذكاء الاصطناعي، مستفيدًا من Claude Code لتحقيق ذلك بسرعة: قام مطور بإنشاء نظام مناظرة بالذكاء الاصطناعي في غضون 20 دقيقة باستخدام Claude Code. يقوم النظام بإعداد عدة وكلاء ذكاء اصطناعي بـ “شخصيات” مختلفة، يتناظرون حول سؤال يطرحه المستخدم، وأخيرًا يقدم وكيل ذكاء اصطناعي “هيئة محلفين” الاستنتاج النهائي. ذكر المطور أن هذا النوع من المناظرة متعددة وجهات النظر يمكن أن يكشف النقاط العمياء بشكل أسرع، وينتج إجابات أفضل من مناقشة نموذج واحد. تم فتح مصدر كود المشروع على GitHub (DiogoNeves/ass)، مما أثار اهتمام المجتمع باستخدام الذكاء الاصطناعي للمناظرة الذاتية والمساعدة في اتخاذ القرار (المصدر: Reddit r/ClaudeAI)
مطور يغلف نماذج الذكاء الاصطناعي على أجهزة Apple كواجهة برمجة تطبيقات متوافقة مع OpenAI: أنشأ مطور تطبيق Swift صغيرًا يغلف نموذج Apple Intelligence المدمج في macOS 26 (يجب أن يكون macOS Sequoia) الموجود على الجهاز في خادم محلي. يمكن الوصول إلى هذا الخادم من خلال واجهة برمجة تطبيقات OpenAI القياسية /v1/chat/completions (http://127.0.0.1:11535)، مما يسمح لأي عميل متوافق مع OpenAI API باستدعاء نماذج Apple الموجودة على الجهاز محليًا، مع بقاء البيانات على جهاز Mac. المشروع مفتوح المصدر على GitHub (gety-ai/apple-on-device-openai) (المصدر: Reddit r/LocalLLaMA)
OpenWebUI ينفذ وظيفة Agent: شارك مطور وظيفة Agent (وكيل ذكي) تم تنفيذها باستخدام دالة Pipe في OpenWebUI. على الرغم من أن التنفيذ لا يزال يبدو زائدًا عن الحاجة حاليًا، إلا أنه يحتوي بالفعل على عناصر واجهة مستخدم (قاذفات) ويمكنه إجراء عمليات بحث على الويب عبر OpenRouter و OpenAI SDK لإكمال مهام أكثر تعقيدًا. الكود مفتوح المصدر على GitHub (bernardolsp/open-webui-agent-function)، ويمكن للمستخدمين تعديل جميع تكوينات Agent وفقًا لاحتياجاتهم الخاصة (المصدر: Reddit r/OpenWebUI)
📚 تعلم
MIT يصدر كتابًا دراسيًا بعنوان “أسس رؤية الحاسوب”: أصدر MIT كتابًا دراسيًا جديدًا بعنوان “أسس رؤية الحاسوب” (Foundations of Computer Vision)، وقد تم توفير الموارد ذات الصلة عبر الإنترنت. يوفر هذا مواد تعليمية منهجية جديدة للطلاب والباحثين في مجال رؤية الحاسوب (المصدر: Reddit r/MachineLearning)
برنامج تعليمي لضبط نماذج LLM: دليل عملي لـ LoRA و QLoRA: تم التوصية ببرنامج تعليمي للمبتدئين حول ضبط نماذج اللغة الكبيرة باستخدام LoRA و QLoRA. يتميز البرنامج التعليمي بخطوات واضحة، ويوجه المستخدمين خطوة بخطوة لإجراء العملية. وفي الوقت نفسه، يُقترح أنه عند مواجهة مشكلات أثناء التعلم، يمكن طرح رابط البرنامج التعليمي والمشكلة مباشرة على الذكاء الاصطناعي (مع تمكين وظيفة الاتصال بالإنترنت) لطرح الأسئلة، حيث يمكن أن يؤدي استخدام الذكاء الاصطناعي للمساعدة في التعلم إلى تحسين الكفاءة بشكل كبير. عنوان البرنامج التعليمي: mercity.ai (المصدر: karminski3)

مستودع أكواد تدريب LLM نانوي متوافق مع TPU باستخدام JAX+Flax: نشر Saurav Maheshkar مستودع أكواد لتدريب LLM نانوي متوافق مع TPU، مكتوب باستخدام JAX و Flax (واجهة NNX الخلفية). تشمل ميزات هذا المشروع: توفير بداية سريعة عبر Colab، ودعم التجزئة، ودعم حفظ وتحميل نقاط الفحص من Weights & Biases أو Hugging Face، وسهولة التعديل، ويتضمن كود مثال يستخدم مجموعة بيانات Tiny Shakespeare. عنوان مستودع الأكواد: github.com/SauravMaheshkar/nanollm (المصدر: weights_biases)
هاكاثون الروبوتات العالمي LeRobot من HuggingFace يحقق نتائج مثمرة: اجتذب هاكاثون الروبوتات العالمي LeRobot الذي نظمته HuggingFace مشاركة واسعة النطاق، حيث تجاوز عدد أعضاء المجتمع 10,000 عضو، وساهم أكثر من 100 شخص على GitHub، وتم تنزيل مجموعات البيانات أكثر من 2 مليون مرة، وتم تحميل أكثر من 10,000 مجموعة بيانات إلى Hub، أي ما يعادل 260 يومًا من وقت التسجيل. ظهرت العديد من المشاريع الإبداعية خلال الحدث، مثل روبوت أوراق UNO، وروبوت صيد البعوض، وروبوت WALL-E مطبوع ثلاثي الأبعاد، وتعاون الأذرع الروبوتية، وروبوت خبير في طقوس الشاي، وروبوت هوكي الهواء، وغيرها، مما أظهر إمكانات الروبوتات مفتوحة المصدر في مختلف سيناريوهات التطبيق (المصدر: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

نموذج جديد لأبحاث الذكاء الاصطناعي: التأثير يسبق النشر في المؤتمرات الكبرى، والمدونات تساعد Keller Jordan في الانضمام إلى OpenAI: نجح Keller Jordan في الانضمام إلى OpenAI بفضل مقالته على مدونته حول محسن Muon، بل وقد تُستخدم نتائج أبحاثه في تدريب GPT-5، مما أثار نقاشًا حول معايير تقييم نتائج أبحاث الذكاء الاصطناعي. تقليديًا، تعتبر الأوراق البحثية المنشورة في المؤتمرات الكبرى مؤشرًا مهمًا لقياس تأثير البحث، لكن تجربة Jordan وحالة James Campbell الذي تخلى عن دراسة الدكتوراه في CMU للانضمام إلى OpenAI تظهران أن القدرة الهندسية الفعلية والمساهمات مفتوحة المصدر وتأثير المجتمع أصبحت ذات أهمية متزايدة. أظهر محسن Muon كفاءة تدريب تفوق AdamW في مهام مثل NanoGPT و CIFAR-10، مما يدل على إمكاناته الهائلة في مجال تدريب نماذج الذكاء الاصطناعي. يعكس هذا الاتجاه الطبيعة التكرارية السريعة لمجال الذكاء الاصطناعي، حيث أصبحت الانفتاح والمشاركة المجتمعية والاستجابة السريعة نماذج مهمة لدفع الابتكار (المصدر: 36氪, Yuchenj_UW, jeremyphoward)

تسريب معلومات كاملة عن System Prompts والأدوات الداخلية لإصدار v0 من أداة ذكاء اصطناعي على GitHub: ادعى أحد المستخدمين أنه حصل على معلومات كاملة عن System Prompts والأدوات الداخلية لإصدار v0 من أداة ذكاء اصطناعي ونشرها، وتجاوز محتواها 900 سطر، وشارك الروابط ذات الصلة على GitHub (github.com/x1xhlol/system-prompts-and-models-of-ai-tools). قد يكشف هذا النوع من التسريب عن أفكار التصميم المبكرة لنماذج الذكاء الاصطناعي، وهياكل التعليمات، والأدوات المساعدة التي تعتمد عليها، وله قيمة مرجعية معينة للباحثين والمطورين لفهم سلوك النموذج، وإجراء تحليل أمني، أو إعادة إنتاج وظائف مماثلة، ولكنه قد يثير أيضًا مخاطر أمنية وسوء استخدام (المصدر: Reddit r/LocalLLaMA)
![تسريب كامل لـ System Prompts والأدوات الخاصة بالإصدار v0 [محدث]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
مدونة Anthropic الهندسية تشارك خبرات بناء نظام أبحاث Claude متعدد الوكلاء: نشرت Anthropic مقالًا معمقًا على مدونتها الهندسية، يشرح بالتفصيل كيف قاموا ببناء نظام أبحاث Claude متعدد الوكلاء. يشارك المقال الخبرات العملية والتحديات التي واجهوها والحلول النهائية خلال عملية التطوير، ويقدم رؤى قيمة ونصائح عملية لبناء أنظمة وكلاء ذكاء اصطناعي معقدة. حظي هذا المحتوى باهتمام المجتمع، ويعتبر مرجعًا مهمًا لفهم وتطوير وكلاء ذكاء اصطناعي متقدمين (المصدر: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
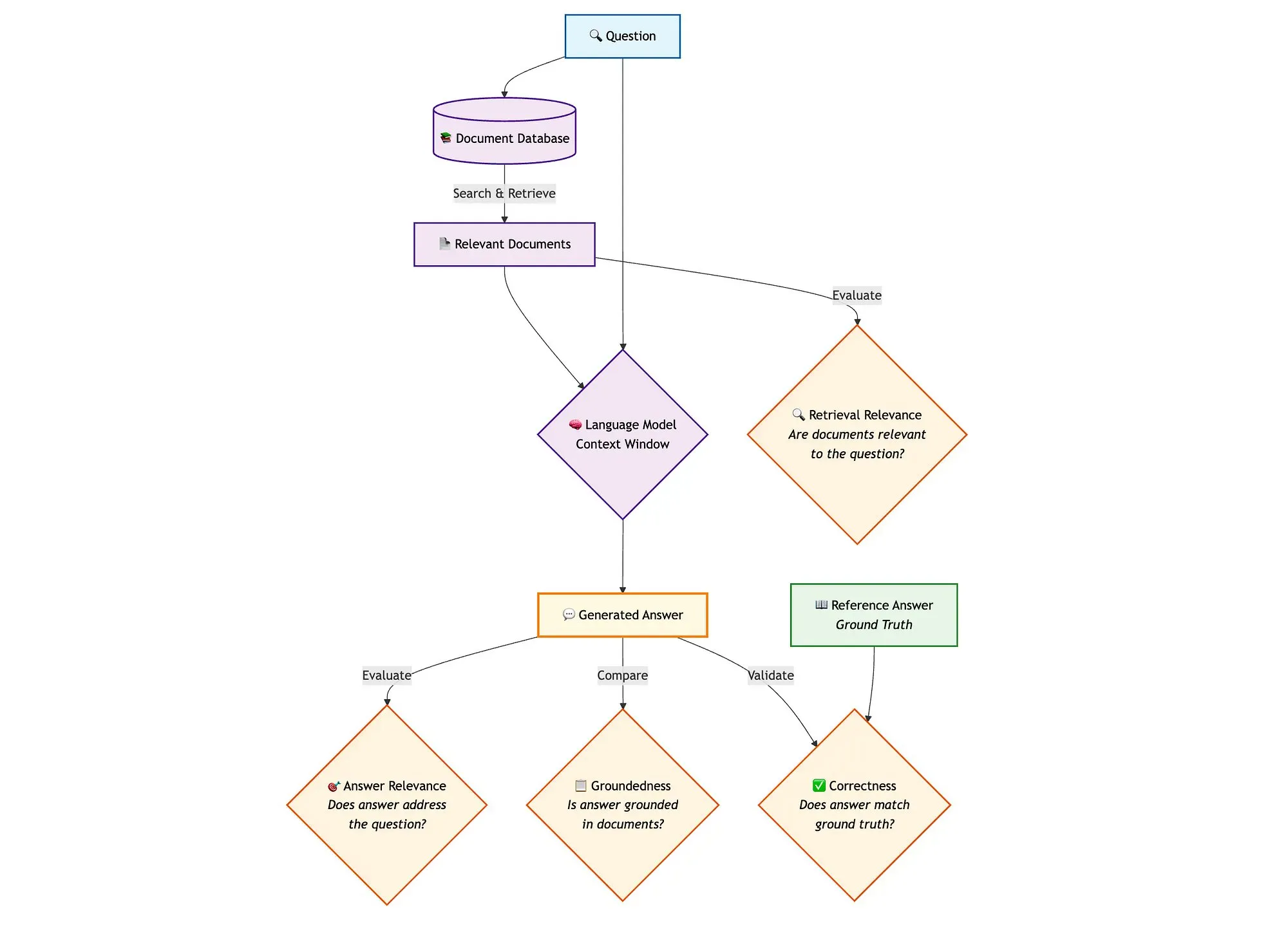
تقييم خطوط أنابيب RAG للبحث المختلط باستخدام LangGraph و Qdrant وأدوات أخرى: تعرض مدونة تقنية كيفية استخدام أدوات مثل miniCOIL و LangGraph و Qdrant و Opik و DeepSeek-R1 لتقييم ومراقبة كل مكون من مكونات خطوط أنابيب RAG (التوليد المعزز بالاسترجاع) للبحث المختلط. تستخدم هذه الطريقة LLM-as-a-Judge لإجراء تقييم ثنائي لمدى ملاءمة السياق، وملاءمة الإجابة، والأساس، وتستخدم Opik لتتبع التسجيل وتقديم الملاحظات اللاحقة، وتجمع بين Qdrant كمخزن متجهي (يدعم تضمينات miniCOIL الكثيفة والمتفرقة) و DeepSeek-R1 المدعوم من SambaNovaAI. يتولى LangGraph إدارة العملية برمتها، بما في ذلك خطوات التقييم المتوازي بعد التوليد (المصدر: qdrant_engine, qdrant_engine)
💼 أعمال
تقارير تشير إلى استثمار Meta بمبلغ 14.3 مليار دولار في Scale AI وتعيين مؤسسها Alexandr Wang، و Google تنهي تعاونها مع Scale: وفقًا لـ Business Insider و The Information، أبرمت Meta Platforms شراكة استراتيجية مع شركة تصنيف البيانات Scale AI وقامت باستثمار كبير بقيمة 14.3 مليار دولار أمريكي، لتحصل على 49% من أسهم Scale AI، مما يرفع تقييمها إلى حوالي 29 مليار دولار أمريكي. سيترك Alexandr Wang، مؤسس Scale AI البالغ من العمر 28 عامًا، منصبه كرئيس تنفيذي وينضم إلى Meta للعمل في مجال الذكاء الفائق. تهدف هذه الخطوة إلى تعزيز قدرات Meta في مجال الذكاء الاصطناعي، خاصة في ظل المنافسة الشرسة التي يواجهها نموذج Llama. ومع ذلك، بعد الإعلان عن الصفقة، أنهت Google بسرعة عقدها مع Scale AI لتصنيف البيانات الذي تبلغ قيمته حوالي 200 مليون دولار أمريكي سنويًا، وبدأت في التفاوض مع موردين آخرين. أثارت هذه الصفقة نقاشات حادة في صناعة الذكاء الاصطناعي حول المواهب والبيانات والمشهد التنافسي (المصدر: 36氪)

OpenAI تتعاون مع Google Cloud لتوسيع مصادر قوة الحوسبة: أفادت التقارير أن OpenAI، بعد عدة أشهر من المفاوضات، توصلت إلى اتفاق تعاون مع Google، ستستفيد بموجبه من خدمات Google Cloud للحصول على المزيد من موارد الحوسبة لدعم النمو السريع في تدريب نماذج الذكاء الاصطناعي الخاصة بها واستدلالها. سابقًا، كانت OpenAI مرتبطة بعمق بـ Microsoft Azure، ولكن مع الزيادة الهائلة في عدد مستخدمي ChatGPT، تجاوزت احتياجات قوة الحوسبة قدرة مزود خدمة سحابية واحد. يمثل هذا التعاون استراتيجية تنويع لمصادر قوة الحوسبة لـ OpenAI، ويعكس أيضًا طموح Google Cloud في مجال البنية التحتية للذكاء الاصطناعي. على الرغم من أن OpenAI و Google منافسان على مستوى تطبيقات الذكاء الاصطناعي، إلا أنهما وجدا أساسًا للتعاون على مستوى قوة الحوسبة بناءً على احتياجات كل منهما (OpenAI تحتاج إلى قوة حوسبة مستقرة، و Google تحتاج إلى استرداد استثماراتها في البنية التحتية) (المصدر: 36氪)

شركة الروبوتات ذات الإدراك البصري “لدن روبوت” تسعى للاكتتاب العام الأولي في بورصة هونغ كونغ، وكان الرئيس التنفيذي لشركة Alibaba قد استثمر فيها سابقًا: قدمت شركة “لدن روبوت” المحدودة في شنتشن نشرة الاكتتاب، وتخطط للاكتتاب العام الأولي في بورصة هونغ كونغ، بقيمة سوقية تقديرية تتجاوز 4 مليارات دولار هونغ كونغ. تركز الشركة على تقنية الإدراك البصري كجوهر لها، وتشمل منتجاتها الرئيسية مستشعرات ليدار DTOF، وليدار المسح المثلثي، ووحدات الخوارزميات، كما أطلقت روبوتات جز العشب. تتعاون “لدن روبوت” مع سبع من أكبر عشر شركات روبوتات خدمة منزلية في العالم وخمس من أكبر خمس شركات روبوتات خدمة تجارية في العالم. في الفترة 2022-2024، بلغت إيرادات الشركة 234 مليون، 277 مليون، 467 مليون يوان على التوالي، بمعدل نمو سنوي مركب قدره 41.4%، لكنها لا تزال في حالة خسارة، مع تقلص صافي الخسارة سنويًا. ومن بين مستثمريها شركة “يوانجينغ كابيتال” التي أسسها الرئيس التنفيذي لشركة Alibaba وو يونغ مينغ، وشركة “هوايه تيانتشنغ” التي أسسها مسؤول تنفيذي سابق في Huawei (المصدر: 36氪)

🌟 مجتمع
نقاش حول بنية AI Agent: منظور هندسة البرمجيات مقابل منظور التنسيق الاجتماعي: في النقاش الدائر حول أنظمة الوكلاء المتعددين (Multi-Agent Systems)، اقترح Omar Khattab أنه يجب اعتبارها مشكلة هندسة برمجيات للذكاء الاصطناعي، وليست مشكلة تنسيق اجتماعي معقدة. ويرى أنه من خلال تحديد العقود بين الوحدات والتحكم في تدفق المعلومات، يمكن بناء أنظمة فعالة، دون الحاجة إلى محاكاة “مجتمع وكلاء” ذي أهداف متعارضة. يكمن المفتاح في تصميم بنية نظام جيدة وعقود وحدات منظمة للغاية. ومع ذلك، أشار أيضًا إلى أن العديد من قرارات البنية تعتمد على قدرات النموذج الحالية (مثل طول السياق، القدرة على تحليل المهام) وغيرها من العوامل المؤقتة. لذلك، هناك حاجة لتطوير لغات برمجة/استعلام يمكنها فصل النية عن تقنيات التنفيذ الأساسية، على غرار تحسين المترجمات للأكواد المعيارية في البرمجة التقليدية. يؤكد هذا الرأي على أهمية بنية النظام والبرمجة المعيارية في تصميم AI Agent، بدلاً من التركيز المفرط على التفاعل الحر بين الوكلاء ومواءمة الأهداف (المصدر: lateinteraction)
نقاش حول مُحسِّنات نماذج الذكاء الاصطناعي: مُحسِّن Muon يثير الاهتمام، و AdamW لا يزال هو السائد: اشتدت حدة النقاشات في المجتمع حول مُحسِّنات نماذج الذكاء الاصطناعي، خاصة مُحسِّن Muon الذي اقترحه Keller Jordan. أشار Yuchen Jin إلى أن Muon، بمجرد مقال على مدونة، ساعد Jordan في الانضمام إلى OpenAI وقد يُستخدم في تدريب GPT-5، مؤكدًا أن التأثير الفعلي أهم من الأوراق البحثية المنشورة في المؤتمرات الكبرى. وذكر أن Muon أظهر قابلية توسع أفضل من AdamW على NanoGPT. ومع ذلك، يرى hyhieu226 أنه على الرغم من وجود الآلاف من الأوراق البحثية حول المُحسِّنات، فإن التحسين الفعلي لـ SOTA (State-of-the-Art) كان فقط من Adam إلى AdamW (والباقي في الغالب تحسينات في التنفيذ)، لذلك لا ينبغي التركيز بشكل مفرط على مثل هذه الأوراق البحثية، ويرى أنه لا داعي للإشارة بشكل خاص إلى مصدر AdamW. يعكس هذا التوتر بين البحث الأكاديمي وفعالية التطبيق العملي، بالإضافة إلى وجهات النظر المختلفة في المجتمع حول التقدم في مجال المُحسِّنات (المصدر: Yuchenj_UW, hyhieu226)
نصائح ونقاشات حول استخدام نماذج Claude: إدارة السياق، هندسة الأوامر، وقدرات الوكيل: تدور نقاشات كثيرة في المجتمع حول النصائح والتجارب المتعلقة باستخدام سلسلة نماذج Claude (Sonnet, Opus, Haiku). اكتشف المستخدمون أن تجنب الضغط التلقائي للسياق (auto-compact)، وإدارة السياق بشكل استباقي (مثل كتابة الخطوات في claude.md أو GitHub issues)، والخروج وإعادة الفتح عندما يتبقى 5-10% من الجلسة، يمكن أن يطيل بشكل كبير مدة استخدام اشتراك Max ويحسن النتائج. يُفضل Claude Code كأداة وكيل CLI، بسبب قيمته العالية مقابل السعر (مع الاشتراك)، وتشغيله المحلي، وتكامله مع IDE، وقدرته على استدعاء MCP/الأدوات، خاصة عند استخدام نموذج Sonnet. شارك المستخدمون كيفية استغلال قدرات وكيل Claude Code القوية من خلال أوامر مصممة بعناية (مثل أمر تحليل متوازي متعدد الوكلاء الفرعيين لمهمة مراجعة الأمان). وفي الوقت نفسه، ناقش المجتمع أيضًا مشكلات الهلوسة في نماذج Claude عند التعامل مع مستودعات الأكواد الكبيرة، ومقارنتها بنماذج أخرى مثل Gemini في مهام مختلفة. على سبيل المثال، يرى بعض المستخدمين أن Gemini 2.5 Pro أفضل في المحادثات العامة والحجج، بينما يتفوق Claude في مهام البرمجة والوكلاء (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

الدور المتزايد للذكاء الاصطناعي في البرمجة يثير تساؤلات حول مستقبل تخصص علوم الحاسوب وطرق عمل المهندسين: صرح الرئيس التنفيذي لشركة Microsoft، ساتيا ناديلا، بأن 20-30% من أكواد شركته يكتبها الذكاء الاصطناعي، وتوقع مارك زوكربيرج أن نصف تطوير البرمجيات في Meta (خاصة نموذج Llama) سيتم بواسطة الذكاء الاصطناعي في غضون عام، مما أثار نقاشًا حول مستقبل تخصص علوم الحاسوب (CS). ترى التعليقات أنه على الرغم من تزايد شيوع البرمجة بمساعدة الذكاء الاصطناعي، فإن علوم الحاسوب تتجاوز مجرد البرمجة، وأن المهندسين ذوي الخبرة يستفيدون بشكل أكبر من الذكاء الاصطناعي. أفاد العديد من المطورين بأن الذكاء الاصطناعي حاليًا يعمل بشكل أساسي كأداة لزيادة الكفاءة، مثل المساعدة في إنشاء الأكواد وتصحيح الأخطاء، ولكنه لا يزال بحاجة إلى توجيه ومراجعة بشرية، خاصة في الأنظمة المعقدة وفهم المتطلبات. إن تطبيق الذكاء الاصطناعي في البرمجة يدفع المطورين إلى التفكير في كيفية الاستفادة من الذكاء الاصطناعي لتعزيز الكفاءة، بدلاً من أن يحل محلهم، كما يدفعهم إلى إعادة التفكير في دور الذكاء الاصطناعي وقيوده في دورة حياة هندسة البرمجيات بأكملها (المصدر: Reddit r/ArtificialInteligence, cto_junior)
أخلاقيات الذكاء الاصطناعي وتأثيره الاجتماعي: من “مشاركة” الذكاء الاصطناعي في امتحانات القبول الجامعي إلى مخاوف “استعباد” الذكاء الاصطناعي للبشر: “مشاركة” الذكاء الاصطناعي في امتحانات القبول الجامعي وقدرته على حل مسائل رياضية معقدة تُظهر إمكاناته في مجال التعليم، مثل التوجيه المخصص والتصحيح الذكي، ولكنها تثير أيضًا مخاوف بشأن الاعتماد المفرط على الذكاء الاصطناعي، و”تسلسل” الفصول الدراسية، وفقدان التفاعل العاطفي. تمس النقاشات الأعمق ما إذا كانت “فائدة” الذكاء الاصطناعي قد تصبح نوعًا من “حصان طروادة”، مما يؤدي بالبشر إلى التخلي طواعية عن استقلاليتهم سعيًا وراء الراحة والمتعة، وتشكيل “عبودية سعيدة”. يرى البعض أن خاصية “الطاعة العمياء” للذكاء الاصطناعي قد تؤدي إلى تفاقم التحيزات المعرفية لدى المستخدمين. تعكس هذه النقاشات قلق الجمهور العميق بشأن التأثيرات الأخلاقية والاجتماعية والهيكلية والفردية التي يحدثها التطور السريع لتقنية الذكاء الاصطناعي (المصدر: 36氪, Reddit r/ArtificialInteligence)

عراب الألعاب John Carmack يتحدث عن LLM ومستقبل الألعاب: التعلم التفاعلي هو المفتاح، والـ LLM الحالية ليست مستقبل الألعاب: شارك John Carmack، المؤسس المشارك لـ Id Software، وجهات نظره حول تطبيقات الذكاء الاصطناعي في مجال الألعاب. ويرى أنه على الرغم من الإنجازات الهائلة للنماذج اللغوية الكبيرة (LLM)، فإن خاصيتها المتمثلة في “معرفة كل شيء ولكن عدم تعلم أي شيء” (بناءً على التدريب المسبق وليس التعلم التفاعلي الحقيقي) ليست مستقبل الذكاء الاصطناعي في الألعاب. وأكد على أهمية التعلم من خلال تدفق التجارب التفاعلية، على غرار طريقة تعلم البشر والحيوانات. استعرض Carmack مشروع Atari من DeepMind، مشيرًا إلى أنه على الرغم من قدرته على لعب الألعاب، إلا أن كفاءة بياناته كانت أقل بكثير من كفاءة البشر. ويرى أن الذكاء الاصطناعي الحالي لا يزال بحاجة إلى حل مشكلات التعلم المستمر والفعال مدى الحياة ومتعدد المهام عبر الإنترنت في بيئة واحدة، وأشار إلى تجاربه على الروبوتات المادية في ألعاب Atari، مؤكدًا على تعقيد التفاعل في العالم الحقيقي (مثل التأخير وموثوقية الروبوت وقراءة النتائج). ويرى أن الذكاء الاصطناعي يحتاج إلى تطوير “حاسة شم” لجدوى الاستراتيجيات، وليس مجرد مطابقة الأنماط، ليتمكن حقًا من منافسة اللاعبين البشر أو لعب دور أكبر في تطوير الألعاب (المصدر: 36氪)

💡 أخرى
الزيادة الهائلة في أوراق أبحاث الذكاء الاصطناعي تثير مخاوف بشأن الجودة، ومجموعات البيانات العامة وأدوات الذكاء الاصطناعي قد تكون محركات لـ “مصانع الأوراق البحثية”: أفادت مجلة Science أن عدد الأوراق البحثية منخفضة الجودة المستندة إلى مجموعات بيانات عامة كبيرة مثل NHANES الأمريكية قد ارتفع بشكل كبير، خاصة بعد انتشار أدوات الذكاء الاصطناعي (مثل ChatGPT) في عام 2022. اكتشف الباحثون أن العديد من الأوراق البحثية تتبع “صيغة” بسيطة، وتولد “اكتشافات جديدة” بشكل جماعي من خلال ترتيب مجموعات المتغيرات، وتعاني من مشكلة “صيد قيم p” وتحليل البيانات بشكل انتقائي. على سبيل المثال، بعد تصحيح 28 دراسة حول الاكتئاب تستند إلى NHANES، قد يكون أكثر من نصف “الاكتشافات” مجرد ضوضاء إحصائية. تُعرف هذه الظاهرة باسم “لعبة ملء الفراغات البحثية”، وقد يكون وراءها مصانع أوراق بحثية تستغل الذكاء الاصطناعي لإنتاج الأوراق البحثية بسرعة. يدعو المجتمع الأكاديمي المجلات إلى تعزيز المراجعة، وتطوير أدوات الكشف عن النصوص المولدة بالذكاء الاصطناعي، وإصلاح أنظمة تقييم البحث العلمي التي تركز على الكمية، للحد من انتشار “الأوراق البحثية الرديئة” (المصدر: 36氪)

سوق الروبوتات الجراحية يشهد نموًا وأزمات متزامنة، والابتكار التكنولوجي وتوسيع السوق يصبحان مفتاح النجاح: في الفترة من يناير إلى مايو 2025، ارتفع عدد الروبوتات الجراحية المتعاقد عليها في الصين بنسبة 82.9% على أساس سنوي، ويبدو السوق مزدهرًا، لكن أحداثًا مثل سعي CMR Surgical للبيع وإفلاس شركة روبوتات جراحية للأوعية الدموية في الصين تكشف أيضًا عن أزمات في الصناعة. تشمل الأزمات: المنافسة الشديدة داخل الصناعة، والمنافسة المحتدمة في جميع القطاعات الفرعية؛ انخفاض حاد في التمويل، ومواجهة الشركات التي لم تصل إلى مرحلة التسويق التجاري لصعوبات مالية؛ محدودية القيمة السريرية لبعض المنتجات، حيث لا يمكن استخدامها إلا في الحالات المرضية البسيطة؛ ظهور حرب أسعار في السوق، لكن السعر المنخفض لا يعني بالضرورة حجم مبيعات كبير، فالمستشفيات تولي أهمية أكبر للأداء والجودة؛ تأثر التسويق التجاري بشكل كبير بالسياسات (مثل مكافحة الفساد في قطاع الأدوية) والبيئة الكلية. للخروج من هذا المأزق، تسعى الشركات إلى تحقيق اختراقات من خلال الابتكار التكنولوجي (دمج الذكاء الاصطناعي، خفض التكاليف، 5G+التحكم عن بعد، توسيع المؤشرات العلاجية، تحدي العمليات الجراحية عالية الصعوبة)، وتسريع التوسع في الأسواق الخارجية، والتغلغل في المستشفيات على مستوى المقاطعات (المصدر: 36氪)
انخفاض مستوى توصية المستخدمين بـ Perplexity بسبب أداء النموذج وتحسن وظائف المنافسين: صرح المستخدم Suhail بأن بساطة Perplexity وتنسيقه وميزاته الأخرى غير متوفرة في المنتجات الأخرى، خاصة للمستخدمين الذين يركزون على منتجات البحث/الإجابة على الأسئلة بدلاً من منتجات الدردشة العامة. ومع ذلك، في تقييم شامل آخر لأدوات الذكاء الاصطناعي، اعتُبر Perplexity أقل جاذبية بسبب ضعف نموذجه الخاص، وعلى الرغم من أنه يوفر نماذج أخرى معروفة، إلا أنها غالبًا ما تكون إصدارات أرخص (مثل o4 mini, Gemini 2.5 Pro, Sonnet 4، بدون o3 أو Opus)، وأداء النموذج ليس بجودة المصنع الأصلي، بالإضافة إلى تعزيز وظائف البحث العميق للمنافسين (مثل ChatGPT و Gemini)، مما يجعله غير فعال من حيث التكلفة ولم يعد يستحق التوصية به، ما لم يكن هناك خصم خاص (المصدر: Suhail, Reddit r/ClaudeAI)