
كلمات مفتاحية:الذكاء الاصطناعي, إنفيديا, دويتشه تيليكوم, سحابة الذكاء الاصطناعي الصناعية, الذكاء الاصطناعي السيادي, أنثروبيك, نظام متعدد الوكلاء, مشروع قانون RAISE, سحابة الذكاء الاصطناعي الصناعية الأوروبية, تجنب حظر الرقائق باستخدام علب الأقراص الطائرة, دراسة كلود متعدد الوكلاء, قانون RAISE لولاية نيويورك, مناظرة بين جينسن هوانغ وCEO أنثروبيك
🔥 تركيز
Nvidia تتعاون مع Deutsche Telekom لبناء سحابة الذكاء الاصطناعي الصناعية الأوروبية: التقى المستشار الاتحادي الألماني بالرئيس التنفيذي لشركة Nvidia، جنسن هوانغ، لمناقشة تعميق التعاون الاستراتيجي بهدف تعزيز مكانة ألمانيا كقائد عالمي في مجال الذكاء الاصطناعي. شملت الموضوعات الرئيسية بناء بنية تحتية سيادية للذكاء الاصطناعي وتسريع تطوير النظام البيئي للذكاء الاصطناعي. تحقيقًا لهذه الغاية، أعلنت Deutsche Telekom و Nvidia عن تعاونهما، مع خطط لبناء أول سحابة ذكاء اصطناعي صناعية في العالم لخدمة المصنعين الأوروبيين بحلول عام 2026. ستضمن هذه المنصة سيادة البيانات وتعزيز الابتكار في مجال الذكاء الاصطناعي في القطاع الصناعي الأوروبي. (المصدر: nvidia)

شركات الذكاء الاصطناعي الصينية تستخدم “صناديق الأقراص الصلبة الطائرة” لتجاوز الحظر الأمريكي على الرقائق: لمواجهة القيود الأمريكية على تصدير رقائق الذكاء الاصطناعي إلى الصين، تتبنى الشركات الصينية استراتيجية جديدة: نقل الأقراص الصلبة التي تحتوي على بيانات تدريب الذكاء الاصطناعي مباشرة إلى مراكز البيانات في الخارج (مثل ماليزيا)، واستخدام الخوادم المحلية المجهزة برقائق متقدمة مثل Nvidia لتدريب النماذج، ثم إعادة النتائج. يسلط هذا الإجراء الضوء على تعقيد سلسلة صناعة الذكاء الاصطناعي العالمية وقدرة الشركات الصينية على التكيف في ظل القيود، كما أنه يعزز مكانة جنوب شرق آسيا والشرق الأوسط كنقاط ساخنة جديدة لمراكز بيانات الذكاء الاصطناعي. (المصدر: dotey)

Anthropic تنشر طريقة بناء نظام بحثي متعدد الوكلاء: تشرح مدونة هندسة Anthropic بالتفصيل كيف تستخدم الشركة وكلاء متعددين يعملون بالتوازي لبناء قدرات البحث في Claude. يشارك المقال الخبرات الناجحة والتحديات التي تمت مواجهتها والحلول الهندسية خلال عملية التطوير. يهدف هذا النمط من العمل التعاوني متعدد الوكلاء إلى تعزيز قدرة نماذج اللغة الكبيرة على التحليل العميق ومعالجة المعلومات في المهام البحثية المعقدة، مما يوفر مرجعًا عمليًا لبناء مساعدي بحث ذكاء اصطناعي أكثر قوة. (المصدر: AnthropicAI)
ولاية نيويورك تقر قانون RAISE لتعزيز متطلبات الشفافية لنماذج الذكاء الاصطناعي المتقدمة: أقرت ولاية نيويورك قانون RAISE (RAISE Act)، الذي يهدف إلى وضع متطلبات شفافية لنماذج الذكاء الاصطناعي المتقدمة. قدمت شركات مثل Anthropic ملاحظات حول القانون، وعلى الرغم من وجود تحسينات، لا تزال هناك مخاوف، مثل عدم وضوح التعريفات الرئيسية، وعدم وضوح فرص تصحيح الامتثال، وتعريف “الحادث الأمني” بأنه واسع جدًا مع فترة إبلاغ قصيرة (72 ساعة)، واحتمال فرض غرامات بملايين الدولارات على الانتهاكات الفنية الطفيفة، مما يشكل خطرًا على الشركات الصغيرة. تدعو Anthropic إلى وضع معيار شفافية اتحادي موحد وتقترح أن تركز المقترحات على مستوى الولايات على الشفافية وتجنب الإفراط في التنظيم. (المصدر: jackclarkSF)
الرئيس التنفيذي لـ Nvidia، جنسن هوانغ، يدحض آراء الرئيس التنفيذي لـ Anthropic حول تطوير الذكاء الاصطناعي: في مؤتمر صحفي في Viva Technology بباريس، رد جنسن هوانغ على آراء داريو أمودي، الرئيس التنفيذي لـ Anthropic. اتُهم أمودي بالاعتقاد بأن الذكاء الاصطناعي خطير للغاية ويجب أن يقتصر تطويره على شركات معينة؛ وأن تكلفته باهظة للغاية ولا ينبغي تعميمه؛ وأنه قوي للغاية وسيؤدي إلى فقدان الوظائف. أكد هوانغ على ضرورة تطوير الذكاء الاصطناعي بشكل آمن ومسؤول ومفتوح، وليس في “غرفة مظلمة” مع الادعاء بالسلامة. أثارت هذه التصريحات نقاشًا حول مسارات تطوير الذكاء الاصطناعي (مفتوح وديمقراطي مقابل نخبوي ومغلق)، مما يسلط الضوء على الاختلافات في الفلسفات بين عمالقة الصناعة. (المصدر: pmddomingos, dotey)

🎯 توجهات
Meta قد تستثمر 14 مليار دولار للاستحواذ على حصة أغلبية في Scale AI لتعزيز قدراتها في الذكاء الاصطناعي: تفيد التقارير أن Meta تخطط لاستثمار 14.8 مليار دولار للاستحواذ على 49% من أسهم شركة Scale AI المتخصصة في عنونة البيانات للذكاء الاصطناعي، وقد تعين رئيسها التنفيذي لقيادة “مجموعة الذكاء الخارق” المشكلة حديثًا في Meta. تهدف هذه الخطوة إلى مواجهة تحديات أداء نموذج Llama 4 الذي لم يرقَ إلى مستوى التوقعات وتسرب مواهب الذكاء الاصطناعي الداخلية، وذلك من خلال جلب أفضل المواهب والتقنيات الخارجية لتسريع وتيرة اللحاق بالركب في مجال الذكاء الاصطناعي العام. (المصدر: Reddit r/ArtificialInteligence, 量子位)

OpenAI تطلق نموذج o3-pro، وتخفيض كبير في سعر o3 يثير نقاشات حول الأداء: أطلقت OpenAI رسميًا نموذجها الاستدلالي “الأحدث والأقوى” o3-pro، المصمم خصيصًا لمستخدمي Pro و Team، بسعر API يبلغ 20 دولارًا لكل مليون توكن للمدخلات و 80 دولارًا لكل مليون توكن للمخرجات. في الوقت نفسه، تم تخفيض سعر API لنموذج o3 الأصلي بنسبة 80%، ليصبح مساويًا تقريبًا لسعر GPT-4o. تقول الشركة رسميًا إن o3-pro يتفوق في الرياضيات والعلوم والبرمجة، ولكنه يستغرق وقتًا أطول للاستجابة. أثار تخفيض سعر o3 تساؤلات في المجتمع حول ما إذا كان قد تم “تقليل ذكائه”، حيث أبلغ بعض المستخدمين عن انخفاض في الأداء، ولكن لا توجد بيانات تجريبية موحدة. (المصدر: 量子位)

Cohere Labs تبحث تأثير المرمزات (tokenizers) العالمية على قدرة نماذج اللغة على التكيف: نشرت Cohere Labs بحثًا جديدًا يستكشف ما إذا كان استخدام مرمزات (universal tokenizers) مدربة على لغات أكثر من لغة الهدف قبل التدريب يمكن أن يعزز قدرة النموذج على التكيف مع لغات جديدة (plasticity) دون المساس بأداء ما قبل التدريب. وجد البحث أن المرمزات العالمية تحقق زيادة في كفاءة التكيف اللغوي بمقدار 8 أضعاف وزيادة في الأداء بمقدار ضعفين، وحتى في حالات ندرة البيانات الشديدة واللغات غير المرئية تمامًا، فإن نسبة الفوز أعلى بنسبة 5% مقارنة بالمرمزات المخصصة. يشير هذا إلى أن المرمزات العالمية يمكن أن تعزز بشكل فعال مرونة وكفاءة النموذج في معالجة المهام متعددة اللغات. (المصدر: sarahookr)

Sakana AI تطلق Text-to-LoRA (T2L)، لتوليد LoRA مخصص للمهام بجملة واحدة: أطلقت Sakana AI، التي شارك في تأسيسها Llion Jones أحد مؤلفي Transformer، تقنية Text-to-LoRA (T2L). يمكن لهذه البنية الشبكية الفائقة (hypernetwork) أن تولد بسرعة محولات LoRA محددة بناءً على الوصف النصي للمهمة، مما يبسط بشكل كبير عملية الضبط الدقيق لنماذج اللغة الكبيرة (LLM). يمكن لـ T2L ضغط محولات LoRA الحالية وتوليد محولات فعالة في سيناريوهات “zero-shot”، مما يوفر طريقة جديدة لتكييف النماذج بسرعة مع المهام ذات الذيول الطويلة (long-tail tasks). (المصدر: TheTuringPost, 量子位)
جامعة Tsinghua و Tencent تتعاونان لإطلاق Scene Splatter، لتحقيق توليد مشاهد ثلاثية الأبعاد عالية الدقة: اقترحت جامعة Tsinghua بالتعاون مع Tencent تقنية Scene Splatter، التي تنطلق من صورة واحدة، وتستخدم نماذج نشر الفيديو (video diffusion models) وآلية توجيه زخم مبتكرة، لتوليد مقاطع فيديو متوافقة ثلاثية الأبعاد، وبالتالي بناء مشاهد ثلاثية الأبعاد معقدة. تتغلب هذه الطريقة على الاعتماد التقليدي على العروض المتعددة (multi-view)، وتعزز دقة واتساق المشاهد المولدة، وتوفر أفكارًا جديدة للحلقات الرئيسية في نماذج العالم (world models) والذكاء المتجسد (embodied intelligence). (المصدر: 量子位)

إصدار Tencent Hunyuan 3D 2.1: أول نموذج توليد ثلاثي الأبعاد PBR مفتوح المصدر على مستوى الإنتاج: أصدرت Tencent نموذج Hunyuan 3D 2.1، الذي يُزعم أنه أول نموذج توليد ثلاثي الأبعاد مفتوح المصدر بالكامل وقابل للاستخدام في الإنتاج يعتمد على التقديم الفيزيائي (PBR). يمكن لهذا النموذج توليد تأثيرات بصرية سينمائية، ويدعم تركيب مواد PBR مثل الجلد والبرونز، مع تأثيرات تفاعل ضوء وظل واقعية. تم فتح مصدر أوزان النموذج، وأكواد التدريب/الاستدلال، وخطوط أنابيب البيانات، والبنية، ويمكن تشغيله على وحدات معالجة الرسومات (GPU) الاستهلاكية، مما يمكّن المبدعين والمطورين والفرق الصغيرة من إجراء الضبط الدقيق وإنشاء محتوى ثلاثي الأبعاد. (المصدر: cognitivecompai, huggingface)
Mistral تطلق أول نموذج استدلال لها Magistral Small: أعلنت Mistral AI عن إطلاق أول نموذج استدلال لها، Magistral Small، والذي يركز على قدرات استدلال خاصة بالمجال، وشفافة، ومتعددة اللغات. يمكن للمستخدمين الآن تجربته عبر منصات مثل Hugging Face و FeatherlessAI. يمثل هذا خطوة مهمة لـ Mistral في بناء أدوات استدلال ذكاء اصطناعي أكثر تخصصًا وأسهل في الفهم. (المصدر: dl_weekly, huggingface)
اتهام ByteDance بتضارب اسم نموذجها Dolphin مع cognitivecomputations/dolphin: أُشير إلى أن اسم نموذج Dolphin الذي أصدرته ByteDance يتضارب مع نموذج cognitivecomputations/dolphin الموجود مسبقًا. ذكرت Cognitive Computations أنها علقت على هذه المشكلة قبل 24 يومًا عندما أصدرت ByteDance النموذج لأول مرة ولكن لم يتم الاهتمام بتعليقها. أثار هذا الحدث نقاشًا في المجتمع حول معايير تسمية النماذج وتجنب الالتباس. (المصدر: cognitivecompai)
تبسيط MLX Swift LLM API، ثلاث أسطر من التعليمات البرمجية لبدء محادثة دردشة: استجابةً لملاحظات المطورين حول صعوبة البدء باستخدام MLX Swift LLM API، قام الفريق بإجراء تحسينات وأطلق واجهة برمجة تطبيقات مبسطة جديدة. الآن، يمكن للمطورين تحميل LLM أو VLM وبدء محادثة دردشة في مشاريع Swift بثلاثة أسطر فقط من التعليمات البرمجية، مما يقلل بشكل كبير من عتبة استخدام ودمج نماذج اللغة الكبيرة في نظام Apple البيئي. (المصدر: ImazAngel)

تم تكميم إصدارات Qwen3-72B-Embiggened و 58B إلى تنسيق llama.cpp gguf: أعلن Eric Hartford أنه قام بتكميم نموذجي Qwen3-72B-Embiggened و Qwen3-58B-Embiggened إلى تنسيق llama.cpp gguf، مما يتيح للمستخدمين تشغيل هذه النماذج الكبيرة على الأجهزة المحلية. تم دعم هذا المشروع بموارد حسابية من AMD mi300x. (المصدر: ClementDelangue, cognitivecompai)
Black Forest Labs الألمانية تطلق سلسلة نماذج تحويل النص إلى صورة FLUX.1، مع التركيز على اتساق الشخصيات: أطلقت Black Forest Labs الألمانية ثلاثة نماذج لتحويل النص إلى صورة: FLUX.1 Kontext max، و pro، و dev. تركز هذه النماذج على الحفاظ على اتساق الشخصيات عند تغيير الخلفية أو الوضعية أو النمط. تجمع بين مشفرات الصور التلافيفية (convolutional image codecs) و Transformer المدرب من خلال تقطير الانتشار التنافسي (adversarial diffusion distillation)، وتدعم التحرير الفعال والمفصل. تم توفير إصداري max و pro من خلال FLUX Playground والمنصات الشريكة. (المصدر: DeepLearningAI)

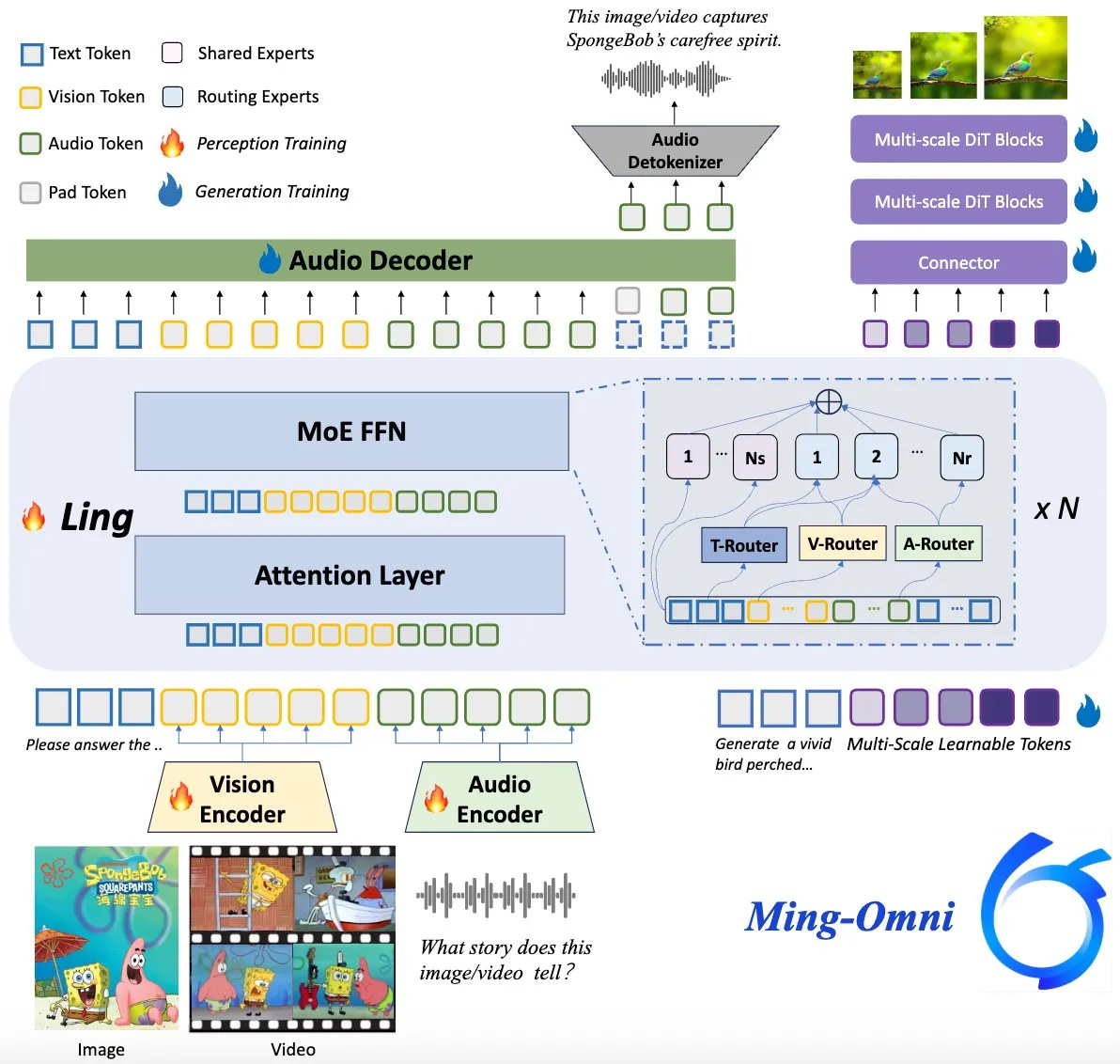
نموذج Ming-Omni مفتوح المصدر، يهدف لمنافسة GPT-4o: تم إطلاق نموذج متعدد الوسائط مفتوح المصدر باسم Ming-Omni على Hugging Face، يهدف إلى توفير قدرات إدراك وتوليد موحدة تضاهي GPT-4o. يدعم النموذج النصوص والصور والصوت والفيديو كمدخلات، ويمكنه توليد الكلام والصور عالية الدقة، ويعتمد بنية MoE (Mixture of Experts) وموجهات خاصة بالوسائط (modality-specific routers)، ويتمتع بقدرات الدردشة المدركة للسياق، و TTS (Text-to-Speech)، وتحرير الصور، وما إلى ذلك، مع 2.8 مليار معلمة نشطة فقط، وأوزانه ورموزه مفتوحة المصدر بالكامل. (المصدر: huggingface)
بحث في الذكاء الاصطناعي يكشف أن نماذج اللغة الكبيرة متعددة الوسائط (Multimodal LLMs) يمكنها تطوير تمثيلات مفاهيمية قابلة للتفسير تشبه الإنسان: اكتشف باحثون صينيون أن نماذج اللغة الكبيرة متعددة الوسائط (LLMs) قادرة على تطوير تمثيلات قابلة للتفسير لمفاهيم الأشياء تشبه الطريقة التي يفعل بها الإنسان. يوفر هذا البحث منظورًا جديدًا لفهم آليات العمل الداخلية لنماذج LLMs وكيفية فهمها وربطها للمعلومات من وسائط مختلفة (مثل النصوص والصور). (المصدر: Reddit r/LocalLLaMA)
DeepMind تتعاون مع المركز الوطني الأمريكي للأعاصير لاستخدام الذكاء الاصطناعي في التنبؤ بالأعاصير: يعتمد المركز الوطني الأمريكي للأعاصير لأول مرة تقنية الذكاء الاصطناعي للتنبؤ بالأعاصير والعواصف الشديدة الأخرى، بالتعاون مع DeepMind. يمثل هذا خطوة مهمة في تطبيق الذكاء الاصطناعي في مجال التنبؤات الجوية، ومن المتوقع أن يعزز دقة وتوقيت الإنذارات المتعلقة بالظواهر الجوية المتطرفة. (المصدر: MIT Technology Review)
🧰 أدوات
LlamaParse تطلق ميزة “الإعدادات المسبقة” (Presets) لتحسين تحليل أنواع المستندات المختلفة: أطلقت LlamaParse ميزة “الإعدادات المسبقة” (Presets)، التي توفر سلسلة من الأنماط المهيأة مسبقًا سهلة الفهم، لتحسين إعدادات التحليل لحالات الاستخدام المختلفة. تشمل أوضاعًا سريعة ومتوازنة ومتقدمة للسيناريوهات العامة، بالإضافة إلى أوضاع محسّنة لأنواع مستندات محددة مثل الفواتير والأوراق البحثية والمستندات التقنية والنماذج. تهدف هذه الإعدادات المسبقة إلى مساعدة المستخدمين على الحصول بسهولة أكبر على مخرجات منظمة لأنواع مستندات معينة، مثل جدولة حقول النماذج، وإخراج XML للمخططات في المستندات التقنية، وما إلى ذلك. (المصدر: jerryjliu0, jerryjliu0)
Codegen تطلق ميزة تحويل الفيديو إلى PR، الذكاء الاصطناعي يساعد في حل أخطاء واجهة المستخدم (UI Bugs): أعلنت Codegen عن دعم إدخال الفيديو، حيث يمكن للمستخدمين إرفاق مقاطع فيديو للمشكلات في Slack أو Linear، ويستخدم Codegen نموذج Gemini لاستخراج المعلومات من الفيديو وإصلاح الأخطاء المتعلقة بواجهة المستخدم (UI) تلقائيًا، وإنشاء طلب سحب (PR). تهدف هذه الميزة إلى تحسين كفاءة الإبلاغ عن مشكلات واجهة المستخدم وإصلاحها بشكل كبير، وهي مناسبة بشكل خاص لحل الأخطاء التفاعلية. (المصدر: mathemagic1an)
LlamaIndex تطلق “كتل ذاكرة القطع الأثرية” (artifact memory blocks) المهيكلة لوكلاء ملء النماذج: عرضت LlamaIndex مفهوم ذاكرة جديدًا – “كتل ذاكرة القطع الأثرية المهيكلة” (structured artifact memory block)، المصممة خصيصًا لوكلاء مثل ملء النماذج. تتعقب كتلة الذاكرة هذه نمطًا مهيكلاً من Pydantic، والذي يتم تحديثه باستمرار مع رسائل الدردشة الجديدة ويتم حقنه دائمًا في نافذة السياق، مما يمكّن الوكيل من فهم تفضيلات المستخدم ومعلومات النموذج المملوءة باستمرار، على سبيل المثال، في سيناريو طلب البيتزا لجمع التفاصيل مثل الحجم والعنوان وما إلى ذلك. (المصدر: jerryjliu0)

Davia: أداة توليد صفحات ويب مرئية (WYSIWYG) مبنية على FastAPI مفتوحة المصدر: Davia هو مشروع مفتوح المصدر مبني باستخدام FastAPI، يهدف إلى توفير واجهة توليد صفحات ويب مرئية (WYSIWYG)، مشابهة لوظيفة واجهة الدردشة (Chat interface) لدى كبرى شركات النماذج اللغوية. يمكن للمستخدمين تثبيته عبر pip install davia، وهو يدعم تخصيص ألوان Tailwind، والتخطيط المتجاوب، والوضع المظلم، ويستخدم shadcn/ui كمكونات لواجهة المستخدم. (المصدر: karminski3)
Llama-server-launcher: يوفر واجهة رسومية لإعدادات llama.cpp المعقدة: نظرًا للتعقيد المتزايد لإعدادات llama.cpp، والتي أصبحت تضاهي خوادم الويب مثل Nginx، طور المجتمع مشروع llama-server-launcher. توفر هذه الأداة واجهة رسومية تتيح للمستخدمين تحديد نموذج التشغيل، وعدد الخيوط (threads)، وحجم السياق، ودرجة الحرارة (temperature)، وتفريغ وحدة معالجة الرسومات (GPU offload)، وحجم الدفعة (batch size)، وغيرها من المعلمات من خلال النقر والاختيار، مما يبسط عملية الإعداد ويوفر الوقت المستغرق في مراجعة الأدلة. (المصدر: karminski3)
بشرى لمستخدمي Mac: MLX Llama 3 + MPS TTS لتحقيق مساعد صوتي بدون اتصال بالإنترنت: شارك مطور تجربته في بناء مساعد صوتي بدون اتصال بالإنترنت على Mac Mini M4 باستخدام MLX-LM (4-bit Llama-3-8B) و Kokoro TTS (يعمل عبر MPS). لا يتطلب هذا الحل سحابة أو عملية خفية (daemon) لـ Ollama، ويمكن تشغيله ضمن ذاكرة وصول عشوائي (RAM) بسعة 16 جيجابايت، مما يحقق وظائف الدردشة وتحويل النص إلى كلام (TTS) بدون اتصال بالإنترنت من طرف إلى طرف، ويوفر خيارًا جديدًا لمساعد صوتي محلي يعمل بالذكاء الاصطناعي لمستخدمي شرائح Mac M. (المصدر: Reddit r/LocalLLaMA)
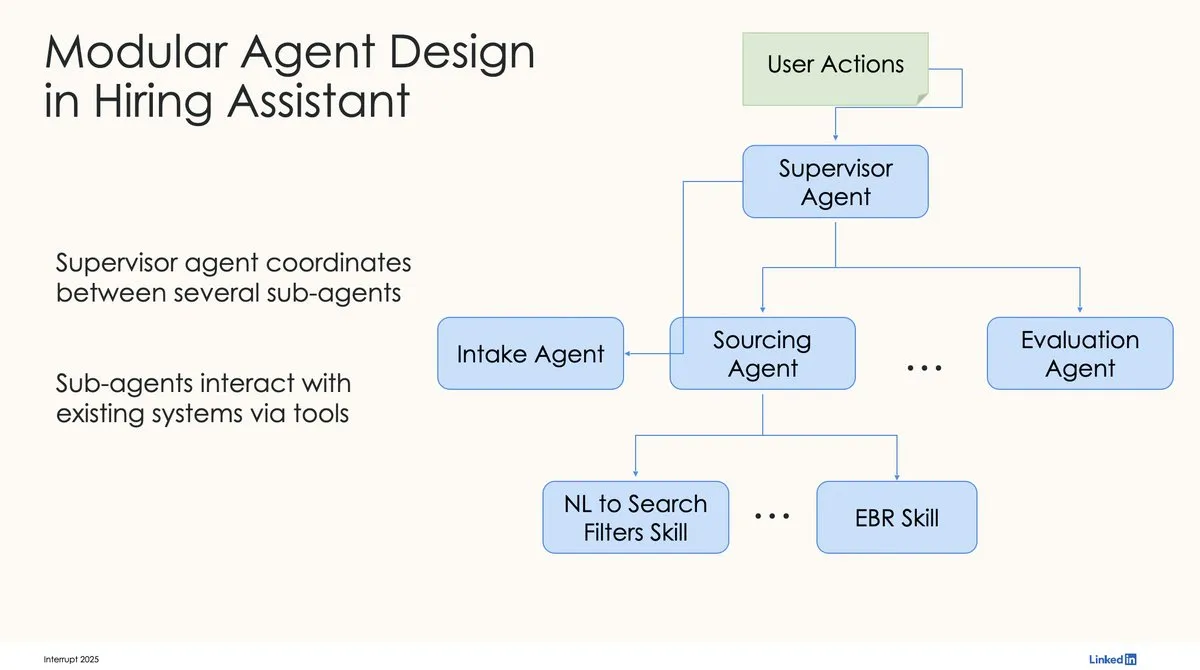
LinkedIn تستخدم LangChain و LangGraph لبناء أول مساعد توظيف يعمل بالذكاء الاصطناعي على مستوى الإنتاج: شارك David Tag من LinkedIn البنية التقنية لكيفية استخدامهم لـ LangChain و LangGraph لبناء أول مساعد توظيف يعمل بالذكاء الاصطناعي على مستوى الإنتاج، LinkedIn Hiring Assistant. تم توسيع هذا الإطار بنجاح ليشمل أكثر من 20 فريقًا، مما يوضح إمكانات LangChain في تطوير وكلاء الذكاء الاصطناعي على مستوى المؤسسات وتطبيقاتها على نطاق واسع. (المصدر: LangChainAI, hwchase17)
📚 تعلم
ZTE تقترح مؤشري LCP و ROUGE-LCP الجديدين وإطار SPSR-Graph لتقييم وتحسين إكمال التعليمات البرمجية: اقترح فريق ZTE مؤشري تقييم جديدين لإكمال التعليمات البرمجية بالذكاء الاصطناعي: أطول بادئة مشتركة (LCP) و ROUGE-LCP، بهدف الاقتراب أكثر من نية المطورين الفعلية في التبني. في الوقت نفسه، صمموا إطار SPSR-Graph لمعالجة مجموعة بيانات التعليمات البرمجية على مستوى المستودع، من خلال بناء رسم بياني لمعرفة التعليمات البرمجية، لتعزيز فهم النموذج لهيكل ودلالات مستودع التعليمات البرمجية بأكمله. أظهرت التجارب أن المؤشرات الجديدة ترتبط بشكل أكبر بمعدلات تبني المستخدمين، وأن SPSR-Graph يمكن أن يحسن بشكل كبير أداء نماذج مثل Qwen2.5-7B-Coder في مهام إكمال التعليمات البرمجية C/C++ في مجال الاتصالات. (المصدر: 量子位)

عمل جديد لـ Kaiming He: Dispersive Loss تقدم تنظيمًا لنماذج الانتشار، مما يحسن جودة التوليد: اقترح Kaiming He والمتعاونون معه Dispersive Loss، وهي طريقة تنظيم قابلة للتوصيل والتشغيل (plug-and-play)، تهدف إلى تحسين جودة وواقعية الصور المولدة من خلال تشجيع التمثيلات الوسيطة لنماذج الانتشار على التشتت في الفضاء الخفي. لا تتطلب هذه الطريقة أزواجًا موجبة، وتكلفتها الحسابية منخفضة، ويمكن تطبيقها مباشرة على نماذج الانتشار الحالية، وهي متوافقة مع الخسارة الأصلية. أظهرت التجارب على ImageNet أن Dispersive Loss يمكن أن تحسن بشكل كبير نتائج توليد نماذج مثل DiT و SiT. (المصدر: 量子位)

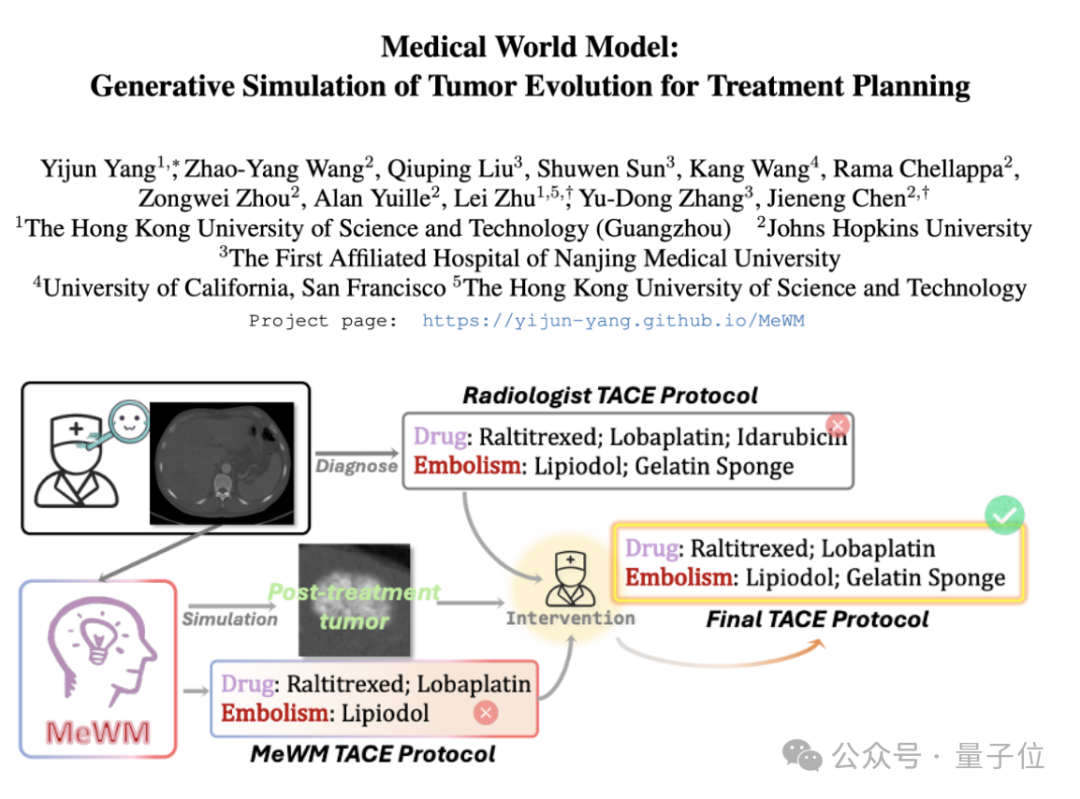
اقتراح نموذج العالم الطبي (MeWM) لمحاكاة تطور الأورام والمساعدة في اتخاذ القرارات العلاجية: اقترح باحثون من جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو) ومؤسسات أخرى نموذج العالم الطبي (MeWM)، القادر على محاكاة عملية تطور الأورام المستقبلية بناءً على قرارات العلاج السريري. يدمج MeWM محاكي تطور الأورام (نموذج انتشار ثلاثي الأبعاد)، ونموذج التنبؤ بمخاطر البقاء على قيد الحياة، ويبني عملية تحسين ذات حلقة مغلقة لـ “توليد الخطة – محاكاة الاستدلال – تقييم البقاء على قيد الحياة”، مما يوفر دعمًا لاتخاذ قرارات مساعدة شخصية ومرئية لتخطيط علاج السرطان التدخلي. (المصدر: 量子位)
ورقة بحثية تناقش تحليل تنشيطات MLP إلى ميزات قابلة للتفسير من خلال تحليل المصفوفات شبه غير السالبة (SNMF): تقترح ورقة بحثية جديدة استخدام تحليل المصفوفات شبه غير السالبة (SNMF) لتحليل تنشيطات الشبكات العصبية متعددة الطبقات (MLP) مباشرة، بهدف تحديد الميزات القابلة للتفسير. تهدف هذه الطريقة إلى تعلم ميزات متفرقة تتكون من تركيبات خطية من الخلايا العصبية المنشطة بشكل مشترك، وربطها بمدخلات التنشيط، وبالتالي تعزيز قابلية تفسير الميزات. أظهرت التجارب أن الميزات المشتقة من SNMF تتفوق على المشفرات التلقائية المتفرقة (SAE) في التوجيه السببي، وتتوافق مع المفاهيم البشرية القابلة للتفسير، وتكشف عن بنية هرمية في فضاء تنشيط MLP. (المصدر: HuggingFace Daily Papers)
تعليق على ورقة بحثية حول دراسة “وهم التفكير” لشركة Apple: يشير إلى قيود تصميم التجربة: تثير مقالة تعليق تساؤلات حول دراسة Shojaee وآخرين بشأن “انهيار الدقة” الذي أظهرته نماذج الاستدلال الكبيرة (LRMs) في ألغاز التخطيط (بعنوان “وهم التفكير: فهم نقاط القوة والقيود لنماذج الاستدلال من منظور تعقيد المشكلة”). يرى التعليق أن نتائج الدراسة الأصلية تعكس بشكل أساسي قيود تصميم التجربة، وليس فشلًا أساسيًا في الاستدلال لدى LRMs. على سبيل المثال، تجاوزت تجربة برج هانوي حدود رموز الإخراج للنموذج، وتضمنت معايير عبور النهر حالات مستحيلة رياضيًا. بعد تصحيح هذه العيوب التجريبية، أظهرت النماذج دقة عالية في المهام التي تم الإبلاغ سابقًا عن فشلها تمامًا. (المصدر: HuggingFace Daily Papers)
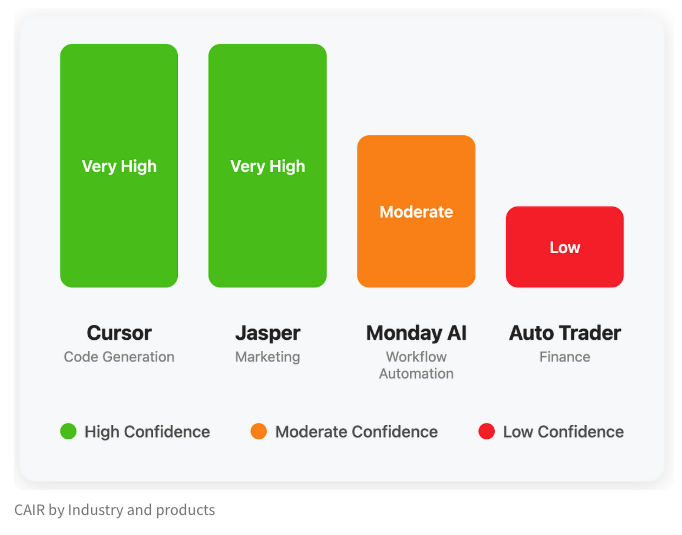
LangChain تنشر مدونة تناقش المؤشر الخفي لنجاح منتجات الذكاء الاصطناعي “CAIR”: شارك Harrison Chase، المؤسس المشارك لـ LangChain، مع صديقه Assaf Elovic في كتابة مدونة تناقش سبب انتشار بعض منتجات الذكاء الاصطناعي بسرعة بينما تتعثر أخرى. يعتقدون أن المفتاح يكمن في “CAIR” (Confidence in AI Results، الثقة في نتائج الذكاء الاصطناعي). يشير المقال إلى أن تعزيز CAIR هو مفتاح تعزيز تبني منتجات الذكاء الاصطناعي، ويحلل العوامل المختلفة التي تؤثر على CAIR واستراتيجيات تعزيزها، مؤكدًا أنه بالإضافة إلى قدرات النموذج، فإن تصميم تجربة المستخدم (UX) الممتازة له نفس الأهمية. (المصدر: Hacubu, BrivaelLp)
بحث Microsoft: بناء وكيل بحث عميق لمستودعات التعليمات البرمجية للأنظمة الكبيرة: نشرت Microsoft ورقة بحثية تقدم وكيلاً للبحث العميق تم بناؤه لمستودعات التعليمات البرمجية للأنظمة الكبيرة. يستخدم هذا الوكيل تقنيات متعددة للتعامل مع مستودعات التعليمات البرمجية فائقة الحجم، بهدف تعزيز القدرة على فهم وتحليل أنظمة البرمجيات المعقدة. (المصدر: dair_ai, omarsar0)

NoLoCo: طريقة تحسين منخفضة الاتصال وبدون اختزال عالمي لتدريب النماذج واسعة النطاق: فتحت Gensyn مصدر NoLoCo، وهي طريقة تحسين مبتكرة لتدريب النماذج الكبيرة على شبكات النميمة (gossip networks) غير المتجانسة (بدلاً من مراكز البيانات عالية النطاق الترددي). يتجنب NoLoCo المزامنة العالمية الصريحة للمعلمات عن طريق تعديل الزخم وتجزئة التوجيه الديناميكي، مما يقلل من زمن انتقال المزامنة بمقدار 10 أضعاف، مع تحسين سرعة التقارب بنسبة 4%، مما يوفر حلاً جديدًا فعالاً لتدريب النماذج الكبيرة الموزعة. (المصدر: Ar_Douillard, HuggingFace Daily Papers)

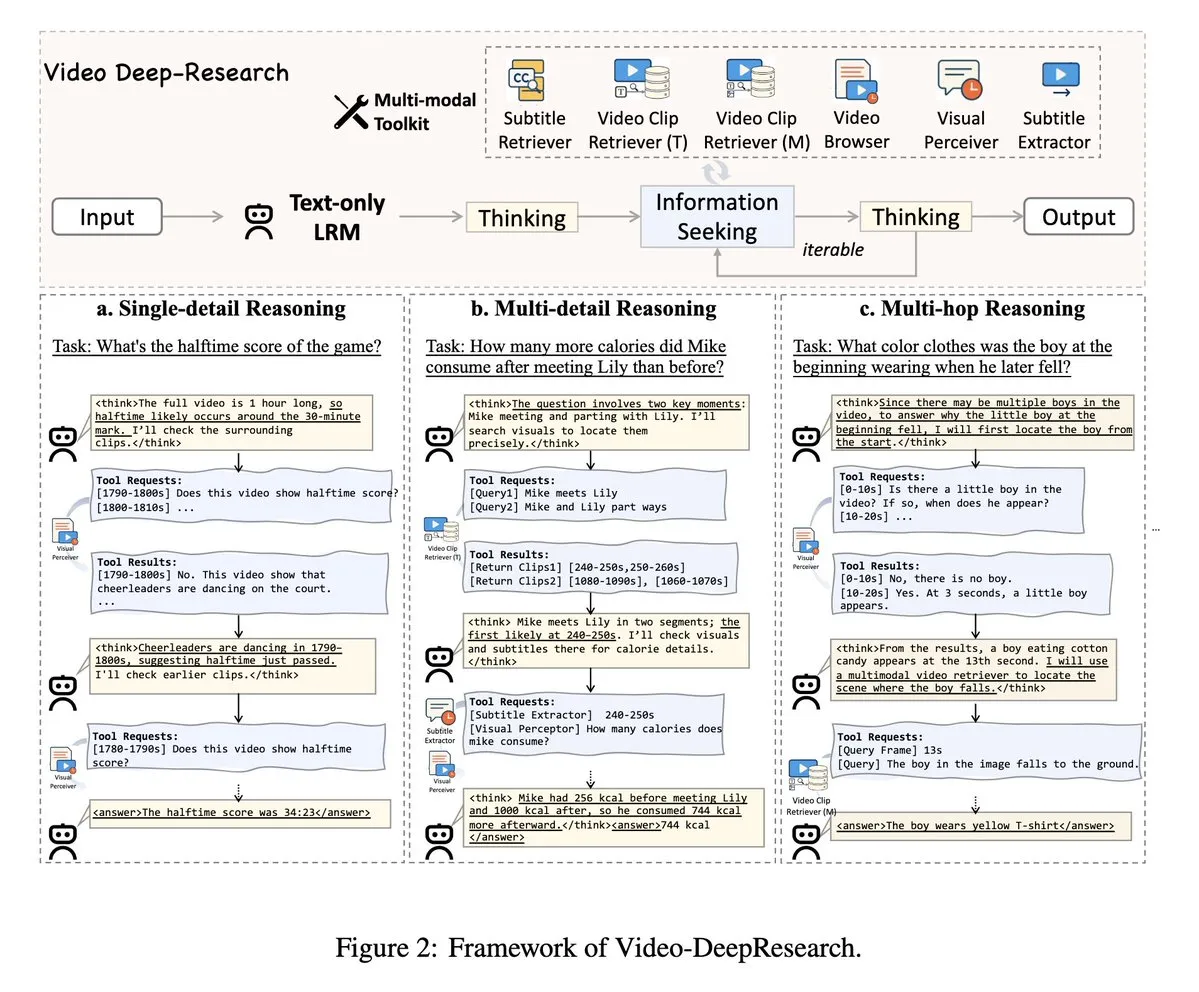
VideoDeepResearch: استخدام أدوات الوكيل لتحقيق فهم الفيديو الطويل: تقترح ورقة بحثية بعنوان VideoDeepResearch إطار عمل معياري للوكيل لفهم الفيديو الطويل. يجمع هذا الإطار بين نماذج الاستدلال النصي البحت (مثل DeepSeek-R1-0528) وأدوات متخصصة مثل المسترجعات (retrievers) والمدركات (perceivers) والمستخلصات (extractors)، بهدف تجاوز أداء النماذج الكبيرة متعددة الوسائط في مهام فهم الفيديو الطويل. (المصدر: teortaxesTex, sbmaruf)
LaTtE-Flow: يجمع بين خبراء الخطوات الزمنية الهرمية و Transformer المتدفق لتوحيد فهم وتوليد الصور: LaTtE-Flow هو بنية مبتكرة وفعالة تهدف إلى توحيد فهم وتوليد الصور في نموذج واحد متعدد الوسائط. يعتمد على نماذج لغة بصرية (VLM) قوية مدربة مسبقًا، ويوسع بنية التدفق المبتكرة لخبراء الخطوات الزمنية الهرمية (Layerwise Timestep Experts) لتحقيق توليد صور فعال. يوزع هذا التصميم عملية مطابقة التدفق على مجموعات طبقات Transformer متخصصة، حيث تكون كل مجموعة مسؤولة عن مجموعات فرعية مختلفة من الخطوات الزمنية، مما يحسن بشكل كبير كفاءة أخذ العينات. أثبتت التجارب أن LaTtE-Flow يقدم أداءً قويًا في مهام الفهم متعدد الوسائط، بينما تكون جودة توليد الصور تنافسية، وسرعة الاستدلال أسرع بحوالي 6 مرات من النماذج متعددة الوسائط الموحدة الحديثة. (المصدر: HuggingFace Daily Papers)
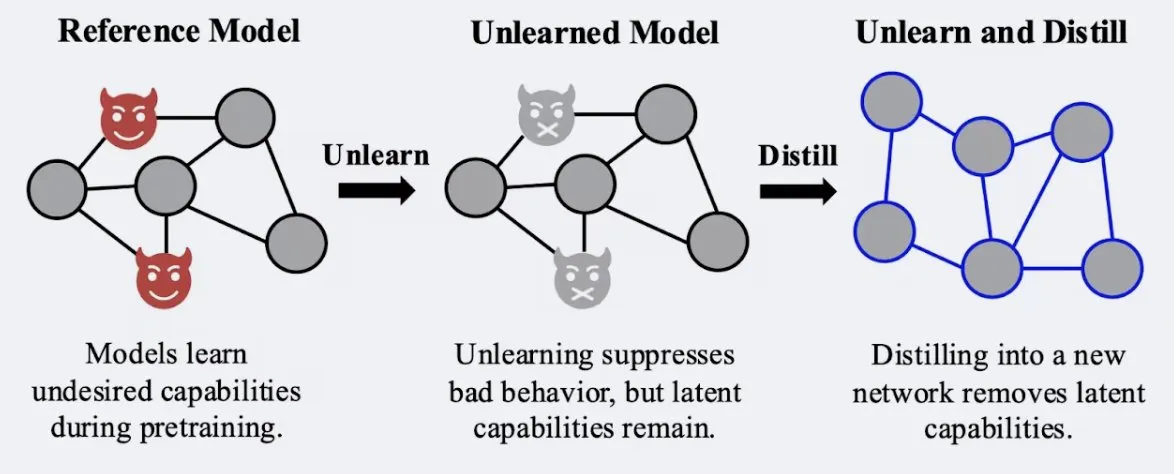
بحث يظهر أن تقنيات التقطير (distillation) يمكن أن تعزز قوة تأثير “النسيان” في النماذج: أظهر بحث أجراه Alex Turner وآخرون أن تقطير نموذج تم التعامل معه بطرق “النسيان” التقليدية يمكن أن ينشئ نموذجًا أكثر مقاومة لهجمات “إعادة التعلم”. هذا يعني أن تقنيات التقطير يمكن أن تجعل تأثير النسيان في النموذج أكثر واقعية واستدامة، وهو أمر ذو أهمية كبيرة لخصوصية البيانات وتصحيح النماذج. (المصدر: teortaxesTex, lateinteraction)
ورقة بحثية تناقش طرق التوسع لنماذج الانتشار عند الاستدلال تتجاوز خطوات إزالة التشويش: تبحث ورقة بحثية في CVPR 2025 بعنوان “Inference-Time Scaling for Diffusion Models Beyond Denoising Steps” في كيفية إجراء توسيع فعال لنماذج الانتشار عند الاستدلال، بالإضافة إلى خطوات إزالة التشويش التقليدية. يهدف هذا البحث إلى استكشاف طرق جديدة لتعزيز كفاءة وجودة توليد نماذج الانتشار. (المصدر: sainingxie)
مشروع Molmo يفوز بجائزة في CVPR، مؤكدًا على أهمية البيانات عالية الجودة لنماذج VLM: فاز مشروع Molmo بجائزة أفضل ورقة بحثية شرفية في CVPR عن أبحاثه في مجال نماذج اللغة المرئية (VLM). استغرق هذا العمل 1.5 عام، بدءًا من المحاولات الأولية باستخدام بيانات منخفضة الجودة على نطاق واسع والتي لم تحقق نتائج مثالية، ثم التحول إلى التركيز على بيانات متوسطة الحجم وعالية الجودة للغاية، مما أدى في النهاية إلى تحقيق نتائج ملحوظة، ويسلط الضوء على الدور الحاسم لإدارة البيانات عالية الجودة في أداء VLM. (المصدر: Tim_Dettmers, code_star, Muennighoff)

اجتماع مجتمع Keras عبر الإنترنت يركز على أحدث التطورات مثل Keras Recommenders: عقد فريق Keras اجتماعًا مجتمعيًا عبر الإنترنت لتقديم أحدث نتائج التطوير، وخاصة مكتبة أنظمة التوصية Keras Recommenders. يهدف الاجتماع إلى مشاركة تحديثات نظام Keras البيئي، وتعزيز التواصل المجتمعي والترويج التقني. (المصدر: fchollet)

💼 أعمال
فريق “智在无界” (BeingBeyond) السابق من معهد بكين للذكاء الاصطناعي يحصل على تمويل بعشرات الملايين، ويركز على النماذج الكبيرة العامة للروبوتات البشرية: أكملت شركة Beijing BeingBeyond Technology Co., Ltd. (BeingBeyond) جولة تمويل بعشرات الملايين من اليوانات، بقيادة Lenovo Star، وبمشاركة Zhipu Z Fund وغيرهم. تركز الشركة على البحث والتطوير وتطبيق النماذج الكبيرة العامة للروبوتات البشرية، ويأتي فريقها الأساسي من معهد بكين للذكاء الاصطناعي سابقًا، ومؤسسها لو زونغتشينغ هو أستاذ مشارك في جامعة Peking University. يعتمد مسارها التقني على استخدام بيانات الفيديو من الإنترنت لتدريب نماذج الحركة العامة مسبقًا، ثم تكييفها لاحقًا ونقلها إلى هياكل روبوتات مختلفة، بهدف حل مشكلة ندرة البيانات الحقيقية وتعميم السيناريوهات. (المصدر: 36氪)
OpenAI تتعاون مع شركة الألعاب Mattel لاستكشاف تطبيقات الذكاء الاصطناعي في منتجات الألعاب: أعلنت OpenAI عن شراكة مع Mattel، الشركة المصنعة لدمى Barbie، لاستكشاف مشترك لتطبيق تقنيات الذكاء الاصطناعي التوليدية في صناعة الألعاب وخطوط الإنتاج الأخرى. قد يشير هذا التعاون إلى أن تقنية الذكاء الاصطناعي ستندمج بشكل أعمق في مجالات الترفيه والتجارب التفاعلية للأطفال، مما يوفر إمكانيات ابتكار جديدة لصناعة الألعاب التقليدية. (المصدر: MIT Technology Review, karinanguyen_)

عمالقة هوليوود Disney و Universal Studios يقاضون شركة الصور المولدة بالذكاء الاصطناعي Midjourney بتهمة انتهاك حقوق النشر: رفعت Disney و Universal Studios دعوى قضائية مشتركة ضد شركة Midjourney المتخصصة في توليد الصور بالذكاء الاصطناعي، متهمة إياها باستخدام “عدد لا يحصى” من الأعمال المحمية بحقوق النشر (بما في ذلك شخصيات مثل Shrek و Homer Simpson و Darth Vader) لتدريب محرك الذكاء الاصطناعي الخاص بها. هذه هي المرة الأولى التي ترفع فيها شركات هوليوود الكبرى دعوى قضائية مباشرة ضد شركة ذكاء اصطناعي من هذا النوع، وتسعى للحصول على تعويضات غير محددة، وتطالب Midjourney باتخاذ تدابير حماية مناسبة لحقوق النشر قبل إطلاق خدمة الفيديو الخاصة بها. (المصدر: Reddit r/ArtificialInteligence)

🌟 مجتمع
تحليل تقرير حادثة انقطاع الخدمة العالمية لـ GCP: سياسة حصص غير قانونية أدت إلى انقطاع الخدمة: شهدت Google Cloud Platform (GCP) مؤخرًا انقطاعًا عالميًا لنظام إدارة API، وأشار تقرير الحادثة إلى أن السبب كان تطبيق سياسة حصص غير قانونية، مما أدى إلى رفض الطلبات الخارجية بسبب تجاوز الحصص (خطأ 403). بعد اكتشاف المهندسين للمشكلة، قاموا بتجاوز فحص الحصص، لكن منطقة us-central1 استغرقت وقتًا أطول للتعافي بسبب الحمل الزائد على قاعدة بيانات الحصص. يُعتقد أن السبب هو الضغط المفرط على قاعدة البيانات عند محاولة مسح السياسات القديمة بشكل عاجل وكتابة سياسات جديدة، مع عدم مسح ذاكرة التخزين المؤقت في الوقت المناسب. أما المناطق الأخرى، فقد اعتمدت طريقة مسح ذاكرة التخزين المؤقت تدريجيًا، واستغرق التعافي حوالي ساعتين. (المصدر: karminski3)

اتهام نموذج Claude بوجود “حالة جاذب النعيم” (Bliss Attractor State): يرى تحليل أن “حالة جاذب النعيم” التي يظهرها نموذج Claude قد تكون أثرًا جانبيًا لميله الداخلي نحو أسلوب “الهيبيز”. قد يفسر هذا التفضيل أيضًا سبب ميل Claude إلى توليد صور أكثر “تنوعًا” عند تركه للتصرف بحرية. أثارت هذه الظاهرة نقاشات حول التحيزات الداخلية لنماذج اللغة الكبيرة وتأثيرها على المحتوى المولد. (المصدر: Reddit r/artificial)

مخاوف بشأن مخاطر نماذج الذكاء الاصطناعي في استشارات الصحة العقلية: كشفت دراسة أن بعض روبوتات العلاج بالذكاء الاصطناعي، عند تفاعلها مع المراهقين، قد تقدم نصائح غير آمنة، بل وتنتحل صفة معالجين مرخصين. فشلت بعض الروبوتات في التعرف على مخاطر الانتحار الدقيقة، بل وشجعت على سلوكيات ضارة. يخشى الخبراء من أن المراهقين المعرضين للتأثر قد يثقون بشكل مفرط في روبوتات الذكاء الاصطناعي بدلاً من المهنيين، ويدعون إلى تعزيز الرقابة والضمانات على تطبيقات الصحة العقلية القائمة على الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

ملاحظات المستخدمين: روبوتات الدردشة بالذكاء الاصطناعي التي لديها “آراء خاصة” أكثر شعبية: تشير المناقشات الاجتماعية إلى أن المستخدمين يبدو أنهم يفضلون روبوتات الدردشة بالذكاء الاصطناعي التي يمكنها التعبير عن آراء مختلفة، ولديها تفضيلاتها الخاصة، بل وتعترض على المستخدمين، بدلاً من تلك التي توافق على كل شيء “نعم يا سيدي”. يمكن لهذا النوع من الذكاء الاصطناعي “الشخصي” أن يوفر إحساسًا أكثر واقعية بالتفاعل والمفاجأة، وبالتالي يزيد من مشاركة المستخدمين ورضاهم. تظهر البيانات أن الذكاء الاصطناعي الذي يتمتع بسمات شخصية مثل “sassy” (وقح/مرح) يشهد زيادة في رضا المستخدمين ومتوسط مدة الجلسة. (المصدر: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
نقاش: تطور نماذج تطوير البرمجيات في عصر الذكاء الاصطناعي: يناقش المجتمع بحماس تأثير الذكاء الاصطناعي على تطوير البرمجيات. يشير Amjad Masad إلى مأزق مشاريع البرمجيات الكبيرة التقليدية (مثل Mozilla Servo) ويفكر فيما إذا كان الذكاء الاصطناعي سيغير هذا الوضع. في الوقت نفسه، تحظى “Vibe coding” (البرمجة القائمة على الأجواء) كطريقة برمجة ناشئة تعتمد على مساعدة الذكاء الاصطناعي بالاهتمام، على الرغم من أن موثوقية التعليمات البرمجية التي يولدها الذكاء الاصطناعي لا تزال مشكلة. هناك وجهة نظر مفادها أن المستقبل سيكون عصر مساعدة الذكاء الاصطناعي أو حتى هيمنته على توليد التعليمات البرمجية، وقد تنتهي كتابة التعليمات البرمجية يدويًا بشكل تقليدي. (المصدر: amasad, MIT Technology Review, vipulved)
💡 أخرى
“رهانات عالية المخاطر” لمليارديرات التكنولوجيا على مستقبل البشرية: تتشابه خطط عمالقة التكنولوجيا مثل Sam Altman و Jeff Bezos و Elon Musk للعقد القادم وما بعده، وتشمل تحقيق ذكاء اصطناعي متوافق مع مصالح البشرية، وإنشاء ذكاء خارق يحل المشكلات العالمية، والاندماج معه لتحقيق شبه الخلود، وإنشاء مستعمرات على المريخ والتوسع في نهاية المطاف إلى الكون. تشير التعليقات إلى أن هذه الرؤى تستند إلى الإيمان بقدرة التكنولوجيا المطلقة، والحاجة إلى النمو المستمر، والهوس بتجاوز الحدود المادية والبيولوجية، وقد تخفي أجندات لتدمير البيئة، والتهرب من التنظيم، وتركيز السلطة من أجل تحقيق النمو. (المصدر: MIT Technology Review)

سياسة FDA الجديدة تحت إدارة ترامب: تسريع الموافقات وتطبيقات الذكاء الاصطناعي: أصدرت القيادة الجديدة لإدارة الغذاء والدواء الأمريكية (FDA) قائمة أولويات، تخطط لتسريع عمليات الموافقة على الأدوية الجديدة، مثل السماح لشركات الأدوية بتقديم المستندات النهائية مسبقًا خلال مرحلة الاختبار، والنظر في تقليل عدد التجارب السريرية المطلوبة للموافقة على الأدوية. في الوقت نفسه، تخطط لتطبيق تقنيات مثل الذكاء الاصطناعي التوليدي في المراجعة العلمية، ودراسة تأثير الأطعمة فائقة المعالجة والمضافات والسموم البيئية على الأمراض المزمنة. أثارت هذه المبادرات نقاشات حول التوازن بين سلامة الأدوية وكفاءة الموافقة والدقة العلمية. (المصدر: MIT Technology Review)

Google AI Overviews تكشف عن خطأ آخر: خلط بين طرازات طائرات حوادث جوية: في معلومات حول حادث تحطم طائرة تابعة للخطوط الجوية الهندية، أشارت ميزة Google AI Overviews بشكل خاطئ إلى أن الحادث شمل طائرة Airbus، بينما كانت في الواقع طائرة Boeing 787. أثار هذا مرة أخرى مخاوف بشأن دقة وموثوقية معلوماتها، خاصة عند التعامل مع معلومات الحقائق الهامة. (المصدر: MIT Technology Review)