
كلمات مفتاحية:أوبن إيه آي, أو 3 برو, ميتا, مختبر الذكاء الفائق, ميسترال إيه آي, ماجيسترال, آي بي إم, الحاسوب الكمي, تسعير أو 3 برو, استثمار سكيل إيه آي, ماجيسترال-سمول-2506, الحاسوب الكمي ستارلينج, اختبار التطبيقات العسكرية للذكاء الاصطناعي
🔥 أبرز العناوين
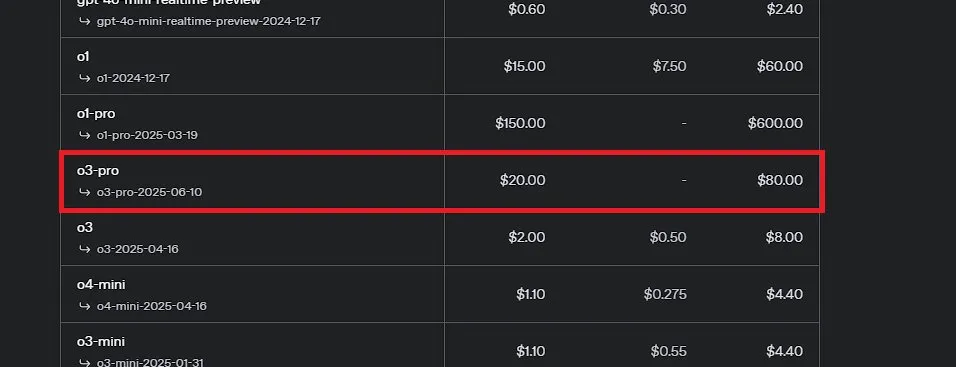
OpenAI تطلق o3-pro، الذي يوصف بأنه أقوى نموذج في تاريخها، وتخفض أسعار o3 بشكل كبير: أطلقت OpenAI رسميًا نموذجها الاستدلالي الأقوى حتى الآن o3-pro، وأتاحته لمستخدمي ChatGPT Pro و Team، كما تم إطلاق واجهة برمجة التطبيقات (API) بالتزامن مع ذلك. يتفوق o3-pro على النماذج السابقة في مجالات مثل العلوم والتعليم والبرمجة والأعمال والمساعدة في الكتابة، ويدعم أدوات متنوعة مثل البحث على الويب وتحليل الملفات والإدخال البصري وبرمجة Python. يبلغ سعر الإدخال 20 دولارًا أمريكيًا لكل مليون token، والإخراج 80 دولارًا أمريكيًا. وفي الوقت نفسه، تم تخفيض سعر نموذج o3 الأصلي بشكل كبير بنسبة 80%، ليصبح سعر الإدخال بعد التعديل 2 دولار أمريكي لكل مليون token، والإخراج 8 دولارات أمريكية، وهو ما يعادل سعر GPT-4o. قد تؤدي هذه الخطوة إلى إشعال حرب أسعار نماذج الذكاء الاصطناعي، ودفع التطبيقات العميقة للذكاء الاصطناعي في المجالات المهنية، ولكن o3-pro يعاني أيضًا من قيود مثل وقت الاستجابة الطويل وعدم دعم المحادثات المؤقتة حاليًا. (المصدر: OpenAI, sama, OpenAIDevs, scaling01, dotey)
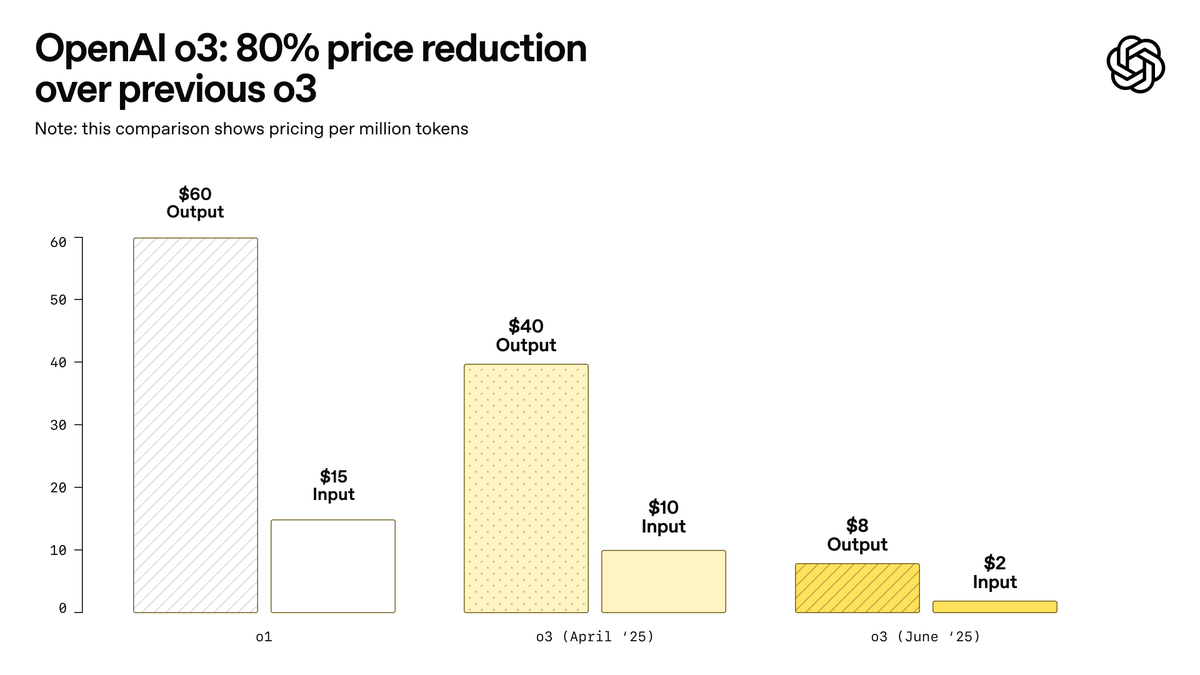
Meta تؤسس “مختبر الذكاء الفائق” وتستثمر بشكل ضخم في Scale AI، سعيًا لتعزيز قدرتها التنافسية في مجال الذكاء الاصطناعي: وفقًا لعدة مصادر بما في ذلك نيويورك تايمز، تقوم Meta Platforms بإعادة هيكلة قسم الذكاء الاصطناعي لديها، وتأسيس “مختبر الذكاء الفائق” الجديد، وتخطط لاستثمار أكثر من 14 مليار دولار أمريكي للاستحواذ على 49% من أسهم شركة Scale AI المتخصصة في توصيف البيانات. سينضم Alexandr Wang، المؤسس المشارك والرئيس التنفيذي لشركة Scale AI، إلى Meta لقيادة المختبر الجديد. تهدف هذه الخطوة إلى تسريع تطوير الذكاء الاصطناعي العام (AGI)، وتعزيز القدرة التنافسية الشاملة لشركة Meta في مجال الذكاء الاصطناعي، خاصة فيما يتعلق بمعالجة البيانات عالية الجودة واستقطاب أفضل المواهب. يمثل هذا تعديلاً كبيرًا في استراتيجية Meta للذكاء الاصطناعي، وقد يكون له تأثير عميق على المشهد التنافسي في الصناعة. (المصدر: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

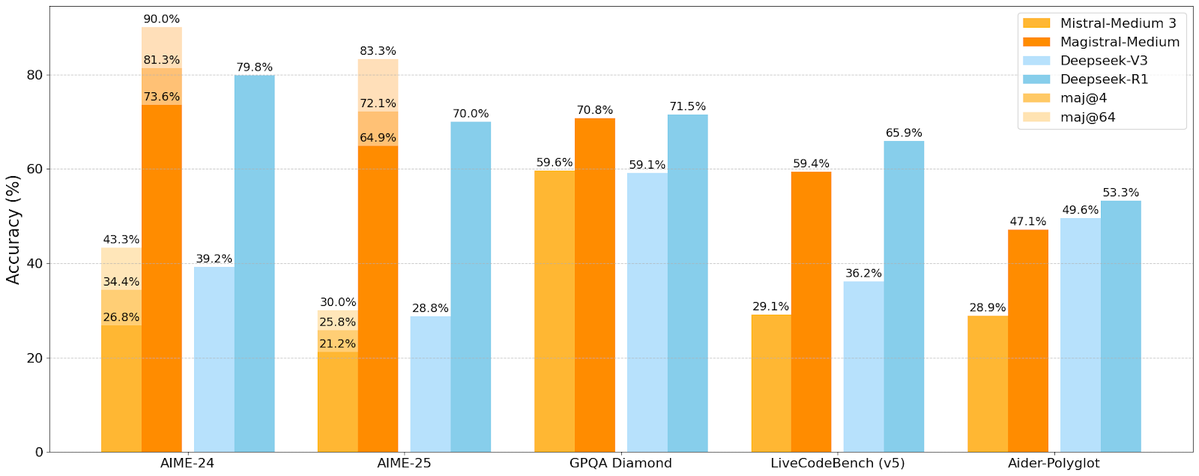
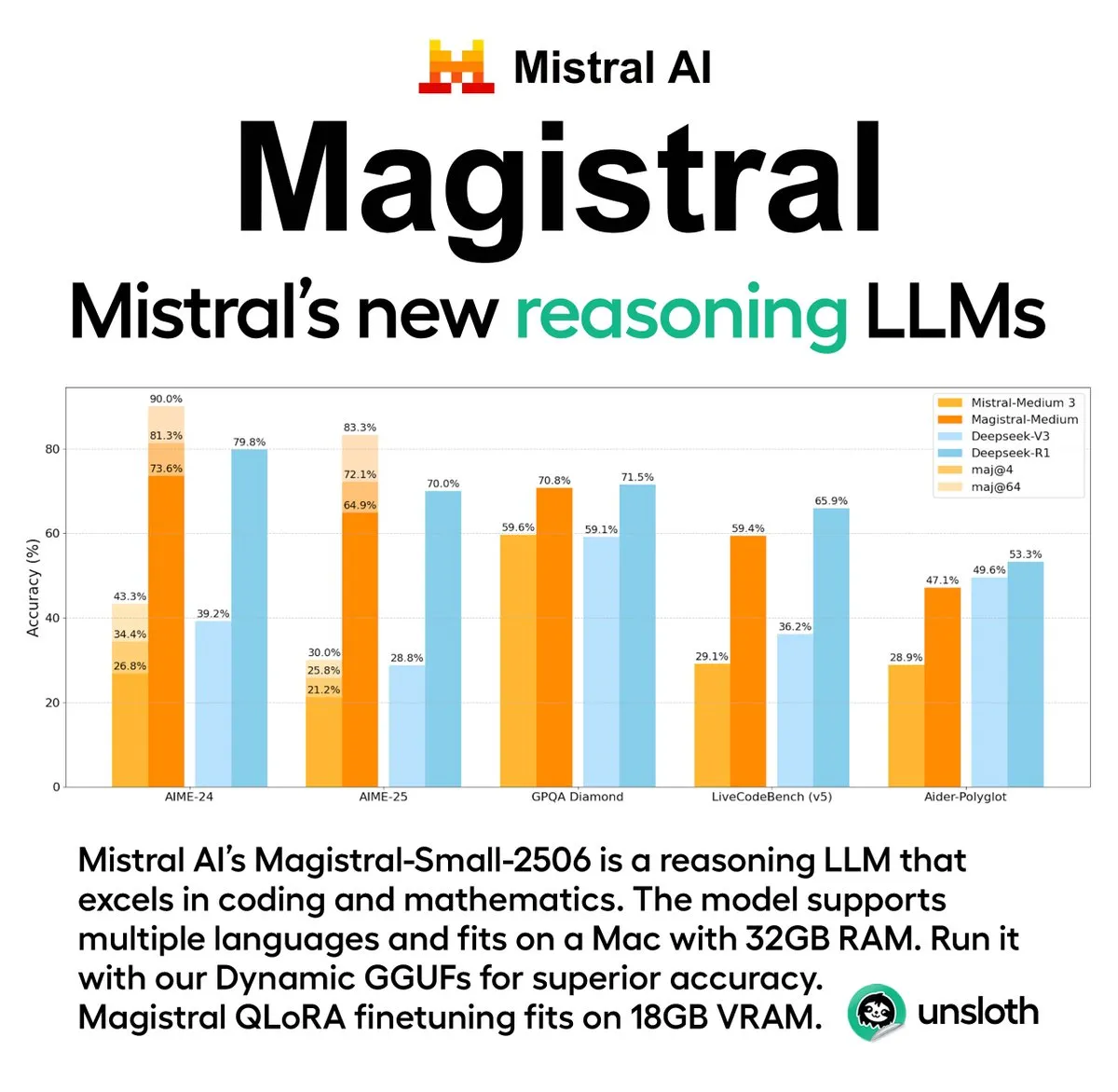
Mistral AI تطلق أول سلسلة نماذج استدلالية لها Magistral، تتضمن إصدارًا مفتوح المصدر: أطلقت شركة الذكاء الاصطناعي الفرنسية الناشئة Mistral AI أول سلسلة نماذج مصممة خصيصًا للاستدلال، Magistral. تتضمن السلسلة نموذجًا مغلق المصدر أكثر قوة على مستوى المؤسسات Magistral Medium ونموذجًا مفتوح المصدر بـ 24 مليار معامل Magistral Small (Magistral-Small-2506)، والذي تم إصداره بموجب ترخيص Apache 2.0. تتميز هذه النماذج بأداء متميز في الرياضيات والبرمجة والاستدلال متعدد اللغات، وتهدف إلى توفير قدرات استدلال أكثر شفافية وتخصصًا في مجالات معينة. يُقال إن سرعة استدلال Magistral Medium على منصة Le Chat أسرع 10 مرات من المنافسين، بينما يوفر Magistral Small للمجتمع خيارًا قويًا للتشغيل المحلي. (المصدر: Mistral AI, jxmnop, karminski3)
IBM تخطط لبناء حاسوب كمومي واسع النطاق متسامح مع الأخطاء Starling بحلول عام 2028: كشفت IBM عن خارطة طريقها لتطوير الحوسبة الكمومية، حيث تخطط لبناء حاسوب كمومي واسع النطاق متسامح مع الأخطاء باسم Starling بحلول عام 2028، وتتوقع إتاحته للمستخدمين عبر الخدمات السحابية في عام 2029. من المتوقع أن يحتوي نظام Starling على حوالي 100 وحدة و200 كيوبت منطقي، والهدف الأساسي هو تحقيق تصحيح فعال للأخطاء، وهو أحد أكبر التحديات التقنية التي تواجه مجال الحوسبة الكمومية حاليًا. ستستخدم الآلة أكواد التحقق من التكافؤ منخفضة الكثافة (LDPC) من IBM لتصحيح الأخطاء، وتهدف إلى تحقيق تشخيص الأخطاء في الوقت الفعلي. في حال نجاحها، ستكون هذه طفرة كبيرة في مجال الحوسبة الكمومية، وقد تسرع من تطبيقاتها في حل المشكلات المعقدة مثل علوم المواد وتطوير الأدوية. (المصدر: MIT Technology Review)

🎯 اتجاهات
تطورات Apple المتعلقة بالذكاء الاصطناعي في مؤتمر WWDC 2025 لم تبهر المطورين: أصدرت Apple تحديثات متعددة في مؤتمر WWDC 2025، بما في ذلك لغة تصميم “الزجاج السائل” الجديدة ودمج ChatGPT في Xcode 26. ومع ذلك، عبر مجتمع المطورين بشكل عام عن أن التقدم في مجال الذكاء الاصطناعي “لم يرقَ إلى مستوى التوقعات”. على الرغم من أن Apple أتاحت للمطورين لأول مرة نماذجها للذكاء الاصطناعي على الأجهزة، وأطلقت إطار عمل Foundation Models لتبسيط دمج وظائف الذكاء الاصطناعي، إلا أن تحديث Siri الجديد الذي طال انتظاره قد يتم تأجيله إلى العام المقبل. أشار المحلل Ming-Chi Kuo إلى أن استراتيجية Apple للذكاء الاصطناعي تحتل مركز الصدارة، ولكن لم تشهد اختراقات تقنية كبيرة، وأصبحت إدارة توقعات السوق أمرًا بالغ الأهمية. يبدو أن Apple تركز بشكل أكبر على تحسين واجهة المستخدم ووظائف نظام التشغيل، بدلاً من الابتكار الجذري في نماذج الذكاء الاصطناعي نفسها. (المصدر: MIT Technology Review, jonst0kes, rowancheung)
البنتاغون يخفض حجم مكتب اختبار وتقييم أنظمة أسلحة الذكاء الاصطناعي: أعلن وزير الدفاع الأمريكي Pete Hegseth عن تخفيض حجم مكتب مدير الاختبار والتقييم العملياتي (DOT&E) التابع لوزارة الدفاع إلى النصف، حيث تم تقليص عدد الموظفين من 94 إلى حوالي 45 موظفًا. هذا المكتب مسؤول عن اختبار وتقييم سلامة وفعالية الأسلحة وأنظمة الذكاء الاصطناعي، ويهدف هذا التعديل إلى “تقليل التضخم البيروقراطي والإنفاق المسرف، وزيادة الفتك”. أثارت هذه الخطوة مخاوف بشأن التأثير المحتمل على اختبار سلامة وفعالية تطبيقات الذكاء الاصطناعي العسكرية، خاصة في ظل سعي البنتاغون الحثيث لدمج تقنيات الذكاء الاصطناعي (بما في ذلك نماذج اللغة الكبيرة) في مختلف الأنظمة العسكرية. (المصدر: MIT Technology Review)

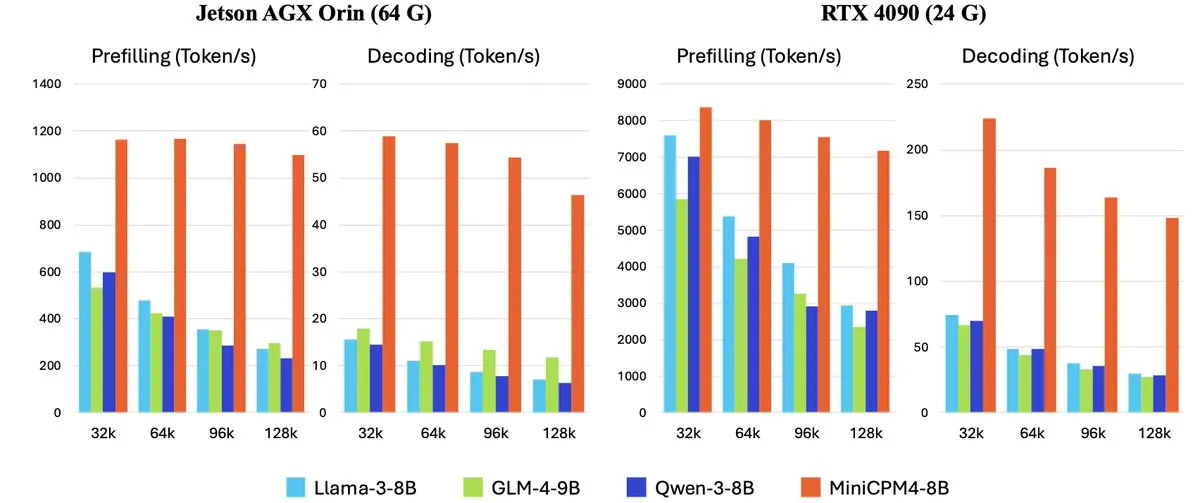
OpenBMB تطلق سلسلة نماذج لغوية كبيرة عالية الكفاءة للأجهزة الطرفية MiniCPM-4: أطلقت OpenBMB (ModelBest) سلسلة نماذج MiniCPM-4، المصممة خصيصًا للأجهزة الطرفية، بهدف تحقيق تشغيل فائق الكفاءة. تتضمن السلسلة MiniCPM4-0.5B، و MiniCPM4-8B (النموذج الرائد)، و BitCPM4 (نموذج تكميم 1-bit)، و MiniCPM4-Survey المخصص لإنشاء التقارير، ونموذج MiniCPM4-MCP المخصص لـ MCP. يشرح التقرير الفني بالتفصيل بنية النموذج عالية الكفاءة (مثل آلية الانتباه المتناثر القابلة للتدريب InfLLM v2)، وخوارزميات التعلم عالية الكفاءة (مثل Model Wind Tunnel 2.0)، وطرق معالجة بيانات التدريب عالية الجودة. هذه النماذج متاحة الآن للتنزيل على Hugging Face. (المصدر: _akhaliq, arankomatsuzaki, karminski3)
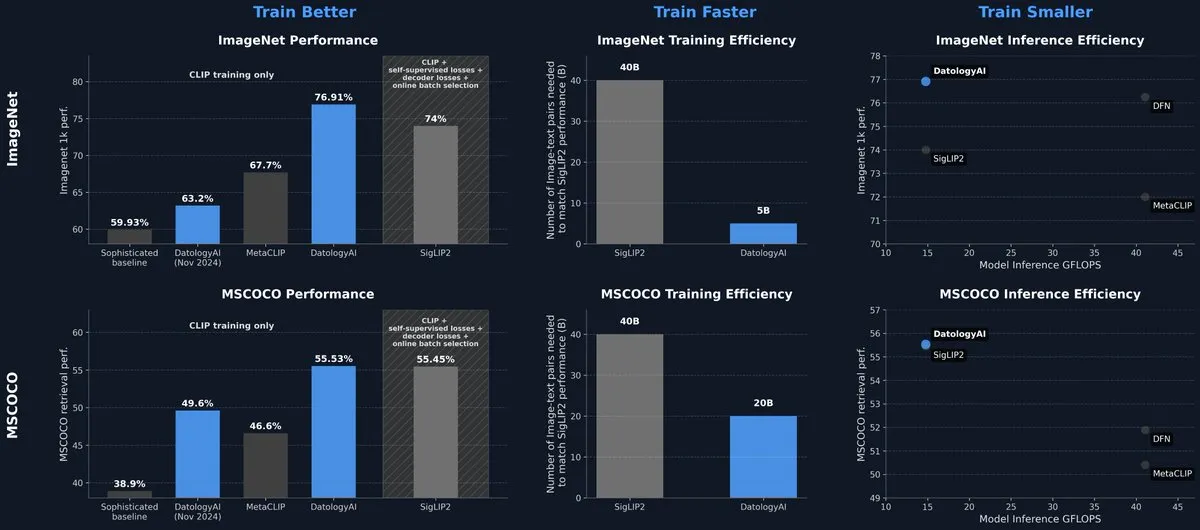
DatologyAI تطلق نموذج CLIP يصل إلى مستوى SOTA فقط من خلال إدارة البيانات: عرضت DatologyAI أحدث نتائج أبحاثها في مجال الوسائط المتعددة، حيث تمكنت من خلال الإدارة الدقيقة للبيانات (data curation) بدلاً من الابتكار في الخوارزميات أو البنية، من جعل نموذجها CLIP ViT-B/32 يحقق دقة 76.9% على ImageNet 1k، متجاوزًا نسبة 74% التي أبلغ عنها SigLIP2. أدت هذه الطريقة أيضًا إلى تحسين كفاءة التدريب بمقدار 8 أضعاف وتحسين كفاءة الاستدلال بمقدار ضعفين. تم إصدار النموذج بشكل عام، مما يسلط الضوء على الإمكانات الهائلة للبيانات عالية الجودة في تحسين أداء النماذج. (المصدر: code_star, andersonbcdefg)
Krea AI تطلق أول نموذج صور خاص بها Krea 1: أطلقت Krea AI أول نموذج صور لها Krea 1، والذي يتميز بأداء متميز في التحكم الجمالي وجودة الصورة، ويمتلك مخزونًا واسعًا من المعرفة الفنية، ويدعم مراجع الأنماط والتدريب المخصص. يهدف Krea 1 إلى تعزيز واقعية الصور، والقوام الدقيق، والتعبير الغني عن الأنماط. حاليًا، Krea 1 متاح للاختبار التجريبي المجاني، ويمكن للمستخدمين تجربة قدراته القوية في إنشاء الصور. (المصدر: _akhaliq, op7418)
NVIDIA تطلق نموذج روبوت بشري مفتوح المصدر قابل للتخصيص GR00T N1: أطلقت NVIDIA نموذج GR00T N1، وهو نموذج روبوت بشري مفتوح المصدر قابل للتخصيص. تهدف هذه الخطوة إلى دفع البحث والتطوير في مجال الروبوتات البشرية، وتوفير منصة مرنة للمطورين لبناء وتجربة تطبيقات روبوتية متنوعة. من المتوقع أن تجذب طبيعة GR00T N1 مفتوحة المصدر مشاركة مجتمعية أوسع، مما يسرع من تقدم تكنولوجيا الروبوتات البشرية. (المصدر: Ronald_vanLoon)
RoboBrain 2.0 تطلق نماذج روبوتية متعددة الوسائط 7B و 32B: أطلقت RoboBrain 2.0 نماذجها الروبوتية متعددة الوسائط بمعاملات 7B و 32B، بهدف تعزيز قدرات الروبوتات في الإدراك والتفكير وتنفيذ المهام. تدعم النماذج الجديدة الاستدلال التفاعلي، والتخطيط طويل المدى، وردود الفعل ذات الحلقة المغلقة، والإدراك المكاني الدقيق (توقع النقاط ومربعات الإحاطة)، والإدراك الزمني (تقدير المسارات المستقبلية)، واستدلال المشهد من خلال بناء وتحديث الذاكرة المهيكلة في الوقت الفعلي. من المتوقع أن تؤدي هذه التحسينات في القدرات إلى دفع مستوى التشغيل الذاتي واتخاذ القرار للروبوتات في البيئات المعقدة. (المصدر: Reddit r/LocalLLaMA)
Kling AI ستشارك أحدث أبحاث نماذج توليد الفيديو في CVPR 2025: سيقدم Pengfei Wan، مسؤول نماذج توليد الفيديو في Kling AI، عرضًا تقديميًا بعنوان “مقدمة عن Kling وأبحاثنا حول نماذج توليد الفيديو الأكثر قوة” في مؤتمر الرؤية الحاسوبية الرائد CVPR 2025. سيناقش مع خبراء من Google DeepMind ومؤسسات أخرى أحدث الاختراقات والتطورات المتطورة في تكنولوجيا توليد الفيديو. ستستعرض هذه المشاركة بعمق إنجازات Kling في دفع تطوير تكنولوجيا توليد الفيديو. (المصدر: Kling_ai)

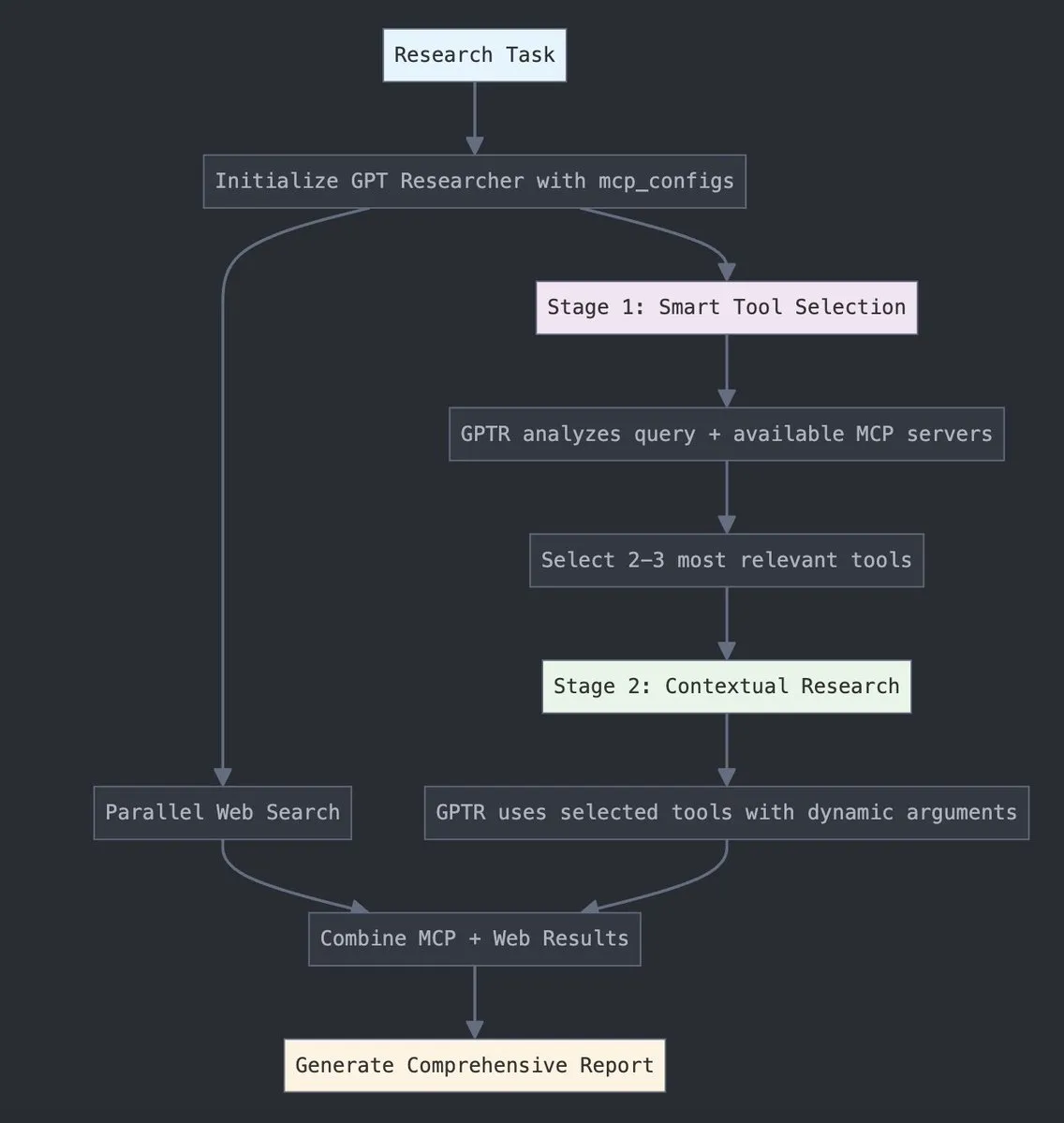
تكنولوجيا الذكاء الاصطناعي تساعد في امتحانات القبول الجامعي الصينية لعام 2025، والعديد من المناطق تفعّل أنظمة التفتيش الذكية: اعتمدت امتحانات القبول الجامعي الصينية لعام 2025 على نطاق واسع أنظمة التفتيش الذكية بالذكاء الاصطناعي، حيث حققت قاعات الامتحانات في تيانجين، وجيانغشي، وهوبي، ويانغجيانغ في قوانغدونغ، وغيرها من المناطق تغطية كاملة للمراقبة بالذكاء الاصطناعي. تستخدم هذه الأنظمة كاميرات 4K، وتتبع الهيكل العظمي، والتعرف على الوجه، ومراقبة الصوت، وغيرها من التقنيات، للكشف في الوقت الفعلي عن سلوكيات الغش لدى الممتحنين، مثل الإجابة المبكرة، وتمرير الأشياء، والتحدث الجانبي، والانحراف غير الطبيعي للنظر، ويمكنها إصدار تحذيرات. تهدف هذه الخطوة إلى تعزيز نزاهة الامتحانات وضمان الانضباط في قاعات الامتحانات. يمثل تطبيق أنظمة المراقبة بالذكاء الاصطناعي دخول إدارة الامتحانات إلى عصر الذكاء، مما يحدث تغييرًا في طرق المراقبة التقليدية. (المصدر: 36氪)
إطلاق نموذج Gemma 3n لسطح المكتب، يدعم الأجهزة عبر المنصات وأجهزة إنترنت الأشياء (IoT): أطلقت جوجل نموذج Gemma 3n لسطح المكتب، ويتضمن إصدارات بمعاملات 2 مليار و 4 مليار، وهو مُحسَّن خصيصًا لأجهزة سطح المكتب (Mac/Windows/Linux) وأجهزة إنترنت الأشياء (IoT). يتم تشغيل النموذج بواسطة مكتبة LiteRT-LM الجديدة، ويهدف إلى توفير قدرات تشغيل محلية فعالة. يمكن للمطورين معاينة الموارد ذات الصلة والحصول عليها عبر Hugging Face و GitHub، مما يدفع قدمًا بتطبيق نماذج الذكاء الاصطناعي خفيفة الوزن على الأجهزة الطرفية. (المصدر: ClementDelangue, demishassabis)
🧰 أدوات
Yutori AI تطلق Scouts: وكيل ذكاء اصطناعي للمراقبة الفورية للشبكة: أطلقت Yutori AI، التي أسسها باحث سابق في Meta AI، منتج وكيل ذكاء اصطناعي يسمى Scouts. يستطيع Scouts مراقبة معلومات الإنترنت في الوقت الفعلي بناءً
على الموضوعات أو الكلمات الرئيسية التي يحددها المستخدم، وإخطار المستخدم عند ظهور محتوى ذي صلة. تهدف هذه الأداة إلى مساعدة المستخدمين على تصفية المحتوى القيم بالنسبة لهم من بين معلومات الشبكة الهائلة، مثل تتبع أخبار المجالات المحددة، واتجاهات السوق، وعروض المنتجات، وحتى الحجوزات النادرة. يمثل إطلاق Scouts تطورًا إضافيًا لأدوات الحصول على المعلومات المخصصة، مما يجعل الذكاء الاصطناعي “كشافًا” رقميًا للمستخدمين. (المصدر: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit تطلق ميزة جديدة: تحويل تصميمات Figma وغيرها إلى تطبيقات وظيفية بنقرة واحدة: أطلقت Replit ميزة Replit Import، التي تسمح للمستخدمين باستيراد التصميمات من منصات مثل Figma و Lovable و Bolt وتحويلها مباشرة إلى تطبيقات قابلة للتشغيل. تهدف هذه الميزة إلى خفض عتبة التطوير، وتمكين غير المبرمجين من تحويل أفكار التصميم بسرعة إلى واقع. تدعم Replit Import الحفاظ على دقة التصميم، وتتضمن فحصًا أمنيًا مدمجًا وإدارة المفاتيح، وبالاقتران مع Replit Agent وقواعد البيانات والمصادقة وخدمات الاستضافة، يمكن إنشاء تطبيقات متكاملة (full-stack). (المصدر: amasad, pirroh)
Hugging Face تطلق AISheets: دمج جداول البيانات مع آلاف نماذج الذكاء الاصطناعي: أعلن Thomas Wolf، المؤسس المشارك لـ Hugging Face، عن إطلاق منتج تجريبي يسمى AISheets، والذي يجمع بين سهولة استخدام جداول البيانات والقوة الهائلة لآلاف نماذج الذكاء الاصطناعي مفتوحة المصدر (خاصة LLM). يمكن للمستخدمين بناء وتحليل وأتمتة مهام معالجة البيانات في واجهة جداول بيانات مألوفة، والاستفادة من نماذج الذكاء الاصطناعي للحصول على رؤى حول البيانات وأتمتة المهام، بهدف توفير طريقة جديدة سريعة وبسيطة وقوية لتحليل البيانات. (المصدر: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex يدعم تحويل Agent إلى خادم MCP للتفاعل مع نماذج مثل Claude: أعلنت LlamaIndex عن دعم تحويل أي من وكلائها (Agent) إلى خادم بروتوكول سياق النموذج (MCP). من خلال أمثلة التعليمات البرمجية ومقاطع الفيديو، تم عرض كيفية نشر سير عمل FidelityFundExtraction المخصص (لاستخراج البيانات المهيكلة من ملفات PDF المعقدة) كخادم MCP واستدعائه من نموذج Claude. تهدف هذه الميزة إلى تعزيز مستوى ذكاء الأداة، وتسهيل التكامل مع عملاء MCP مثل Claude Desktop و Cursor، وتبسيط عملية ربط مهام سير العمل الحالية بنظام بيئي أوسع للذكاء الاصطناعي. (المصدر: jerryjliu0)
GPT Researcher يدمج بروتوكول سياق النموذج (MCP) من LangChain: يستخدم GPT Researcher الآن محول بروتوكول سياق النموذج (MCP) من LangChain لاختيار الأدوات الذكية وإجراء الأبحاث. يدمج هذا التكامل MCP بسلاسة مع وظائف البحث على الويب لتحقيق جمع شامل للبيانات. يمكن للمستخدمين الرجوع إلى وثائق التكامل ذات الصلة لفهم كيفية تكوين واستخدام هذه الميزة الجديدة، وبالتالي تعزيز كفاءة البحث وعمقه. (المصدر: hwchase17)
Tesslate تطلق سلسلة نماذج توليد واجهة المستخدم UIGEN-T3، تدعم أحجامًا متعددة: أطلق فريق Tesslate سلسلة نماذج توليد واجهة المستخدم UIGEN-T3، والتي تتضمن أحجام معاملات متعددة مثل 32B و 14B و 8B و 4B. تم تصميم هذه النماذج خصيصًا لتوليد مكونات واجهة المستخدم (مثل مسارات التنقل والأزرار والبطاقات) وكود الواجهة الأمامية الكامل (مثل صفحات تسجيل الدخول ولوحات المعلومات وواجهات الدردشة)، وتدعم Tailwind CSS. النماذج متوفرة على Hugging Face، وتهدف إلى مساعدة المطورين على بناء واجهات المستخدم بسرعة. أفاد المطورون أن التكميم القياسي يقلل بشكل كبير من جودة النموذج، ويوصى بتشغيله تحت BF16 أو FP8 للحصول على أفضل النتائج. (المصدر: Reddit r/LocalLLaMA)
إطلاق نموذج Doubao للبودكاست، لإنشاء بودكاست ذكاء اصطناعي شبيه بالبشر بنقرة واحدة: أطلقت Volcano Engine نموذج Doubao للبودكاست، والذي يمكنه إنشاء بودكاست بأسلوب حوار شبيه بالبشر بدرجة عالية بسرعة بناءً على النص الذي يدخله المستخدم (مثل رابط مقال أو Prompt). الصوت الذي يولده النموذج قريب من صوت الإنسان من حيث النبرة والتوقفات والتعبيرات العامية، بل ويمكنه إجراء مناقشات ذات وجهة نظر بناءً على المحتوى. تعتمد هذه التقنية على نموذج الصوت الفوري من طرف إلى طرف لفريق تكنولوجيا الصوت في ByteDance، مما يحقق فهمًا واستدلالًا مباشرًا على مستوى النمط الصوتي. حاليًا، تم إطلاق هذه الميزة على إصدار الكمبيوتر الشخصي من Doubao ومساحة Kouzi، بهدف خفض عتبة إنشاء المحتوى الصوتي وتوفير طريقة فعالة وشخصية للحصول على المعلومات. (المصدر: 量子位)

Unsloth AI توفر إصدار GGUF مُكمَّم من Magistral-Small-2506:針對 Mistral AI 新發布的 Magistral-Small-2506 推理模型،提供了 Unsloth AI إصدار GGUF مُكمَّم. هذا يتيح للمستخدمين تشغيل هذا النموذج ذي الـ 24 مليار معامل محليًا، على سبيل المثال، على جهاز بذاكرة وصول عشوائي (RAM) تبلغ 32 جيجابايت فقط. تخفض هذه الخطوة متطلبات الأجهزة لنماذج الاستدلال عالية الأداء، مما يسهل على نطاق أوسع من المطورين والباحثين تجربة واستخدام نموذج Magistral في بيئاتهم المحلية. (المصدر: ImazAngel)
📚 تعلم
تحليل تقني معمق لبناء مساعد الرؤية LLaVA-1.5: نشر LearnOpenCV مقالًا تحليليًا تقنيًا معمقًا حول بنية LLaVA-1.5. يشرح المقال بالتفصيل كيف يبني LLaVA-1.5 مساعد رؤية ذكاء اصطناعي متطور، بما في ذلك تقنيته الرائدة لضبط التعليمات المرئية (Visual Instruction Tuning) ومجموعة البيانات مفتوحة المصدر التي غيرت مجال الذكاء الاصطناعي متعدد الوسائط. يعتبر هذا الدليل مرجعًا مهمًا لمهندسي وباحثي الذكاء الاصطناعي/التعلم الآلي لفهم مبادئ عمل نماذج اللغة الكبيرة متعددة الوسائط وطرق تدريبها. (المصدر: LearnOpenCV)
إصدار دليل تمهيدي لتعلم الآلة للبروتينات: شاركت DL Weekly دليلاً شاملاً للمبتدئين حول تعلم الآلة للبروتينات. يغطي الدليل أنواع البيانات الأساسية المتعلقة بالبروتينات، ونماذج التعلم العميق، والطرق الحسابية، والمفاهيم البيولوجية الأساسية، بهدف مساعدة الباحثين والمطورين المهتمين بهذا المجال متعدد التخصصات على البدء بسرعة. (المصدر: dl_weekly)
Qdrant تتعاون مع DataTalksClub لإطلاق دورة مجانية حول RAG والبحث عن المتجهات: أعلنت Qdrant عن تعاونها مع DataTalksClub لتقديم دورة مجانية عبر الإنترنت لمدة 10 أسابيع. يتضمن محتوى الدورة التوليد المعزز بالاسترجاع (RAG)، والبحث عن المتجهات، والبحث المختلط، وطرق التقييم، ويتضمن مشروعًا عمليًا متكاملاً. سيقوم خبيرا Qdrant، Kacper Łukawski و Daniel Wanderung، بالتدريس شخصيًا، بهدف مساعدة المتعلمين على اكتساب المهارات العملية لبناء تطبيقات ذكاء اصطناعي متقدمة. (المصدر: qdrant_engine)
بودكاست Weaviate يناقش الإخراج المهيكل لـ LLM وفك التشفير المقيد: استضاف بودكاست Weaviate في أحدث حلقاته Will Kurt و Cameron Pfiffer من dottxt.ai، لمناقشة مشكلة الإخراج المهيكل لنماذج اللغة الكبيرة (LLM) مع المضيف Connor Shorten. ناقش البرنامج بعمق كيفية ضمان أن تولد LLM نتائج موثوقة وقابلة للتنبؤ (مثل JSON صالح، ورسائل بريد إلكتروني، وتغريدات، وما إلى ذلك) من خلال تقنية فك التشفير المقيد، وليس مجرد التحقق البسيط من تنسيق JSON. كما قدموا أداة Outlines مفتوحة المصدر وتطبيقاتها في حالات استخدام الذكاء الاصطناعي الفعلية، وتطلعوا إلى تأثير هذه التقنية على أنظمة الذكاء الاصطناعي المستقبلية. (المصدر: bobvanluijt)
ورقة بحثية في ACL2025NLP بعنوان SynthesizeMe!: توليد مطالبات مخصصة من تفاعلات المستخدم: تقترح ورقة بحثية بعنوان “SynthesizeMe!” في مؤتمر ACL 2025 NLP طريقة جديدة لإنشاء نماذج مستخدم مخصصة باللغة الطبيعية من خلال تحليل تفاعلات المستخدم مع الذكاء الاصطناعي (بما في ذلك ردود الفعل الضمنية والصريحة). تقوم الطريقة أولاً بإنشاء والتحقق من صحة عمليات الاستدلال التي تشرح تفضيلات المستخدم، ثم تستخلص منها صورًا شخصية مركبة للمستخدم، وتصفي تفاعلات المستخدم السابقة الغنية بالمعلومات، وأخيرًا تبني مطالبات مخصصة لمستخدم معين، بهدف تعزيز نمذجة المكافآت المخصصة واستجابة LLM. كما أعادت DSPy نشرها وذكرت أنها حالة استخدام ممتازة لـ dspy.MIPROv2. (المصدر: lateinteraction, stanfordnlp)
ورقة بحثية جديدة تناقش مراقبة وتسريع نماذج LLM بتقنية التوسع وقت الاختبار (Test-Time Scaling): تركز ورقة بحثية جديدة على تقنية التوسع وقت الاختبار التي تتبناها نماذج مثل o3 و DeepSeek-R1، والتي تسمح لـ LLM بإجراء المزيد من الاستدلال قبل الإجابة، ولكن غالبًا ما لا يتمكن المستخدمون من معرفة تقدمها الداخلي أو التحكم فيه. يقترح الباحثون كشف “الساعة” الداخلية لـ LLM، ويعرضون كيفية مراقبة عملية الاستدلال الخاصة بها و “تسريعها” لتسريعها. يوفر هذا رؤى جديدة لفهم وتحسين كفاءة نماذج الاستدلال الكبيرة. (المصدر: arankomatsuzaki)

ورقة بحثية تقترح CARTRIDGES: ضغط ذاكرة التخزين المؤقت KV لنماذج LLM ذات السياق الطويل من خلال التعلم الذاتي دون اتصال بالإنترنت: اقترح باحثون من HazyResearch بجامعة ستانفورد طريقة جديدة تسمى CARTRIDGES، تهدف إلى حل مشكلة شغل ذاكرة التخزين المؤقت KV لمساحة كبيرة من الذاكرة في نماذج LLM ذات السياق الطويل. تستخدم هذه الطريقة آلية تدريب وقت الاختبار “للتعلم الذاتي” لتدريب ذاكرة تخزين مؤقت KV أصغر (تسمى cartridge) لتخزين معلومات المستندات دون اتصال بالإنترنت، وبالتالي تقليل ذاكرة التخزين المؤقت بمعدل 39 مرة وزيادة ذروة الإنتاجية بمقدار 26 مرة مع الحفاظ على أداء المهمة. يمكن إعادة استخدام هذا الـ cartridge المدرب مرة واحدة من قبل طلبات مستخدمين مختلفين، مما يوفر نهجًا جديدًا لتحسين معالجة السياق الطويل. (المصدر: gallabytes, simran_s_arora, stanfordnlp)

ورقة بحثية جديدة Grafting: تحقيق تحرير بنية Transformer للانتشار المدرب مسبقًا بتكلفة منخفضة: اقترح باحثون من جامعة ستانفورد طريقة جديدة تسمى Grafting، لتحرير بنية نماذج Transformer للانتشار المدربة مسبقًا. تسمح هذه التقنية باستبدال آليات الانتباه وغيرها في النموذج بوحدات حسابية أولية جديدة بتكلفة حسابية لا تتجاوز 2% من تكلفة التدريب المسبق، مما يتيح تصميمًا مخصصًا لبنية النموذج بميزانية حسابية صغيرة. هذا له أهمية كبيرة لاستكشاف بنيات نماذج جديدة وتحسين كفاءة النماذج الحالية. (المصدر: realDanFu, togethercompute)
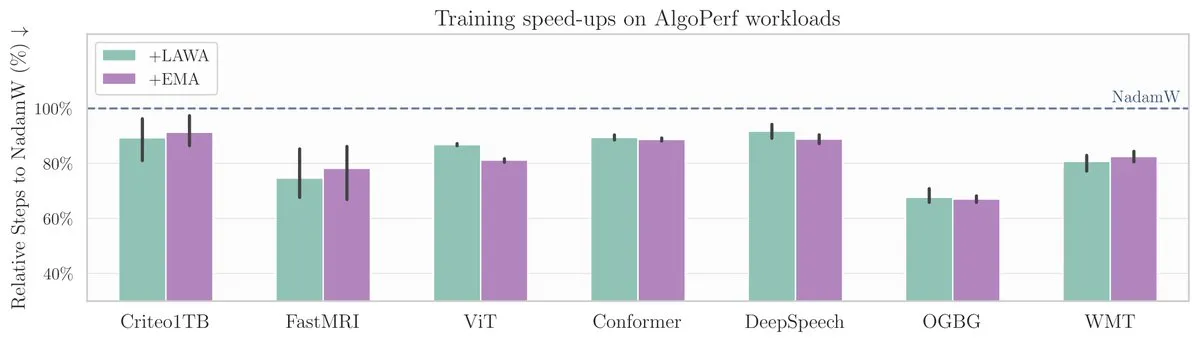
ورقة بحثية جديدة في ICML: طريقة متوسط نقاط الفحص تسرع تدريب النماذج على معيار AlgoPerf: تبحث ورقة بحثية جديدة في ICML في تطبيق طريقة متوسط نقاط الفحص (Averaging Checkpoints) الكلاسيكية في تحسين سرعة وأداء تدريب نماذج التعلم الآلي. اختبر الباحثون هذه الطريقة على AlgoPerf، وهو معيار منظم ومتنوع لخوارزميات التحسين، وناقشوا فوائدها العملية في مهام مختلفة، مما يوفر مرجعًا عمليًا لتسريع تدريب النماذج. (المصدر: aaron_defazio)
أداة تفسير مرئية لـ Transformer مفتوحة المصدر: قدمت DL Weekly أداة مرئية تفاعلية تهدف إلى مساعدة المستخدمين على فهم مبادئ عمل النماذج القائمة على بنية Transformer (مثل GPT). تقوم الأداة بتفكيك الآليات الداخلية للنموذج بطريقة مرئية، مما يجعل المفاهيم المعقدة أسهل في الفهم، وهي مناسبة للمتعلمين والباحثين المهتمين بنماذج Transformer. المشروع مفتوح المصدر على GitHub. (المصدر: dl_weekly)
جامعة تشجيانغ تقترح InftyThink: تحقيق استدلال بعمق لا نهائي من خلال التجزئة والتلخيص: اقترح فريق بحثي من جامعة تشجيانغ بالتعاون مع جامعة بكين نموذجًا جديدًا لاستدلال النماذج الكبيرة يسمى InftyThink. تقوم هذه الطريقة بتقسيم الاستدلال الطويل إلى عدة أجزاء قصيرة، وإدخال ملخصات بين الأجزاء لربط السياق، وبالتالي تحقيق استدلال بعمق لا نهائي نظريًا، مع الحفاظ على إنتاجية توليد عالية. لا تعتمد هذه الطريقة على تعديل بنية النموذج، ومن خلال إعادة بناء بيانات التدريب لتنسيق استدلال متعدد الأدوار، فهي متوافقة مع عمليات التدريب المسبق والضبط الدقيق الحالية. أظهرت التجارب أن InftyThink يمكن أن يحسن بشكل كبير أداء النموذج على معايير مثل AIME24 ويزيد من إنتاجية التوليد. (المصدر: 量子位)

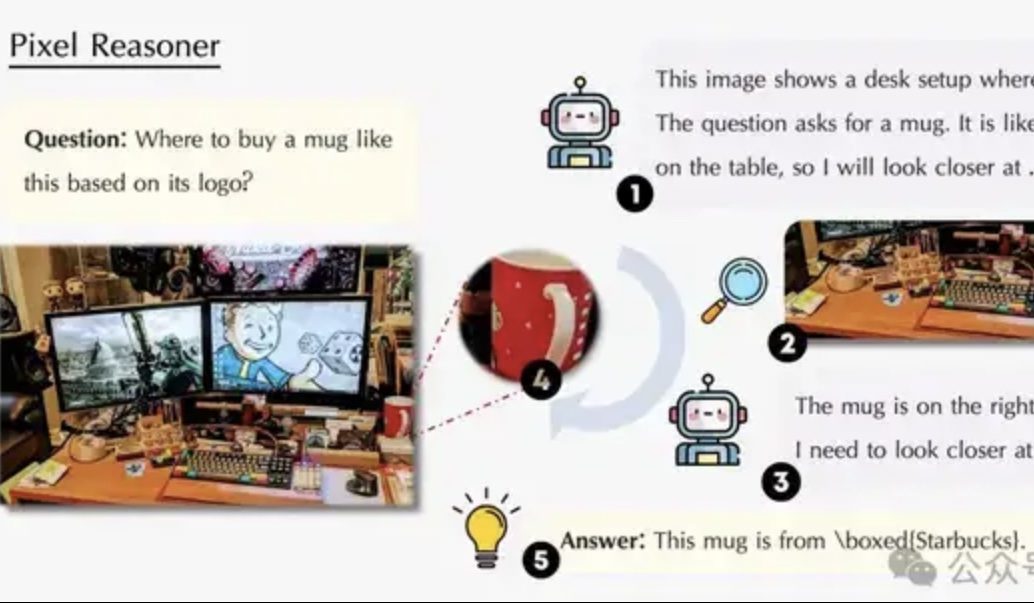
ورقة بحثية تناقش الاستدلال في فضاء البكسل: جعل نماذج VLM “تستخدم العين والعقل معًا” مثل البشر: اقترح فريق بحثي من جامعة واترلو وجامعة هونغ كونغ للعلوم والتكنولوجيا وجامعة العلوم والتكنولوجيا الصينية نموذج “الاستدلال في فضاء البكسل” (Pixel-Space Reasoning)، والذي يمكّن نماذج اللغة المرئية (VLM) من العمل والاستدلال مباشرة على مستوى البكسل، مثل التكبير البصري والعلامات الزمانية المكانية، بدلاً من الاعتماد على رموز النص كوسيط. من خلال خطة تعلم معزز تعتمد على تحفيز الفضول الداخلي وتحفيز الصحة الخارجية، تم التغلب على “الخمول المعرفي” للنماذج. أظهر Pixel-Reasoner المبني على Qwen2.5-VL-7B أداءً متميزًا على العديد من المعايير مثل V*Bench، حيث تجاوز أداء نموذج 7B أداء GPT-4o. (المصدر: 量子位)
DeepLearning.AI تطلق الدورة الخامسة من شهادة احتراف تحليل البيانات: سرد القصص بالبيانات: أطلقت DeepLearning.AI الدورة الخامسة من شهادتها الاحترافية في تحليل البيانات، وموضوعها “سرد القصص بالبيانات”. تعلم الدورة كيفية اختيار الوسيط المناسب (لوحات المعلومات، المذكرات، العروض التقديمية) لتقديم الرؤى، واستخدام Tableau لتصميم لوحات معلومات تفاعلية، ومواءمة الاكتشافات مع أهداف العمل والتواصل الفعال، بالإضافة إلى إرشادات البحث عن عمل. تؤكد على أهمية سرد القصص بالبيانات في تعزيز أداء الأعمال ونقل الرؤى بفعالية. (المصدر: DeepLearningAI)

ورقة بحثية تناقش تأثير تضارب المعرفة على نماذج اللغة الكبيرة: تقيّم ورقة بحثية جديدة بشكل منهجي سلوك نماذج اللغة الكبيرة (LLM) عند مواجهة تضارب بين مدخلات السياق والمعرفة المعيارية (أي “الذاكرة” الداخلية للنموذج). وجدت الدراسة أن تضارب المعرفة له تأثير ضئيل على المهام التي لا تعتمد على استخدام المعرفة؛ عندما يتوافق السياق مع المعرفة المعيارية، يكون أداء النموذج أفضل؛ حتى عند توجيهها، لا تستطيع النماذج قمع معرفتها الداخلية بالكامل؛ تقديم أسباب تشرح التضارب يزيد من اعتماد النموذج على السياق. تثير هذه النتائج تساؤلات حول فعالية التقييم القائم على النموذج، وتؤكد على ضرورة مراعاة مشكلة تضارب المعرفة عند نشر نماذج LLM. (المصدر: HuggingFace Daily Papers)
ورقة بحثية CyberV: إطار سيبراني للتوسع وقت الاختبار في فهم الفيديو: لمعالجة مشكلات متطلبات الحوسبة والمتانة والدقة التي تواجهها نماذج اللغة الكبيرة متعددة الوسائط (MLLM) عند معالجة مقاطع الفيديو الطويلة أو المعقدة، اقترح الباحثون إطار CyberV. مستوحى من مبادئ السيبرانية، يعيد هذا الإطار تصميم MLLM للفيديو كنظام تكيفي، يتضمن نظام استدلال MLLM، وأجهزة استشعار، ووحدة تحكم. تراقب أجهزة الاستشعار عملية النموذج الأمامية وتجمع التفسيرات الوسيطة (مثل انحراف الانتباه)، وتقرر وحدة التحكم متى وكيف يتم تشغيل التصحيح الذاتي وتوليد التغذية الراجعة. يعزز إطار التوسع التكيفي وقت الاختبار هذا نماذج MLLM الحالية دون الحاجة إلى إعادة التدريب، وأظهرت التجارب أنه يحسن بشكل كبير أداء نماذج مثل Qwen2.5-VL-7B على معايير مثل VideoMMMU. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح LoRMA: التكيف المضاعف منخفض الرتبة للضبط الدقيق الفعال لمعاملات LLM: لمعالجة مشكلات انهيار التمثيل وعدم توازن تحميل الخبراء الموجودة في طرق الضبط الدقيق الفعال للمعاملات (PEFT) الحالية القائمة على LoRA و MoE، اقترح الباحثون التكيف المضاعف منخفض الرتبة (LoRMA). تحول هذه الطريقة طريقة تحديث خبراء محولات PEFT من الجمع إلى تحويلات ضرب مصفوفة أكثر ثراءً، من خلال عمليات إعادة ترتيب فعالة وإدخال استراتيجيات تضخيم الرتبة لمواجهة التعقيد الحسابي وعنق الزجاجة في الرتبة. أثبتت التجارب أن طريقة MoA (مزيج المحولات) غير المتجانسة تتفوق على طريقة MoE-LoRA المتجانسة في الأداء وكفاءة المعاملات. (المصدر: Reddit r/MachineLearning)
ورقة بحثية تقترح FlashDMoE: تنفيذ MoE موزع سريع على نواة واحدة: قدم الباحثون FlashDMoE، وهو أول نظام يدمج بالكامل الانتشار الأمامي لخليط الخبراء الموزع (MoE) في نواة CUDA واحدة. من خلال كتابة طبقة الدمج من البداية باستخدام CUDA النقي، حقق FlashDMoE زيادة تصل إلى 9 أضعاف في استخدام وحدة معالجة الرسومات (GPU)، وتقليل زمن الانتقال بمقدار 6 أضعاف، وتحسين كفاءة التوسع الضعيف بمقدار 4 أضعاف. يوفر هذا العمل رؤى جديدة وتنفيذًا لتحسين كفاءة استدلال نماذج MoE واسعة النطاق. (المصدر: Reddit r/MachineLearning)
💼 أعمال
xAI و Polymarket تتعاونان لدمج توقعات السوق مع تحليلات Grok: أعلنت شركة الذكاء الاصطناعي xAI التابعة لـ Elon Musk عن شراكة مع منصة أسواق التنبؤ اللامركزية Polymarket. تهدف هذه الشراكة إلى دمج بيانات توقعات السوق من Polymarket مع بيانات X (تويتر سابقًا) وقدرات تحليل Grok AI، لإنشاء “محرك حقائق صارم” للكشف عن العوامل التي تشكل العالم. صرحت xAI بأن هذه مجرد بداية للتعاون، وسيكون هناك المزيد من محتوى التعاون في المستقبل. (المصدر: xai)
شركة رقائق استدلال الذكاء الاصطناعي Groq تحصل على التزام استثماري سعودي بقيمة 1.5 مليار دولار، وتركز على استراتيجية التكامل الرأسي: أعلنت شركة رقائق استدلال الذكاء الاصطناعي Groq عن حصولها على التزام استثماري من المملكة العربية السعودية بقيمة 1.5 مليار دولار أمريكي، لتوسيع نطاق تسليم بنيتها التحتية لاستدلال الذكاء الاصطناعي القائمة على LPU (وحدة معالجة اللغة) محليًا. أسس Groq أحد مخترعي TPU، Jonathan Ross، وتركز على حوسبة استدلال الذكاء الاصطناعي، وتستخدم شريحة LPU الخاصة بها بنية خط أنابيب قابلة للبرمجة، حيث يتم دمج الذاكرة ووحدات الحوسبة على نفس الشريحة، مما يعزز بشكل كبير سرعة الوصول إلى البيانات وكفاءة الطاقة. لا تبيع Groq الرقائق فحسب، بل توفر أيضًا مجموعات GroqRack (سحابة خاصة / مركز حوسبة الذكاء الاصطناعي) ومنصة GroqCloud السحابية (Tokens-as-a-Service)، وتدعم نماذج مفتوحة المصدر رئيسية مثل Llama و DeepSeek و Qwen. كما طورت الشركة نظام الذكاء الاصطناعي المركب Compound، لتعزيز قيمة سحابة استدلال الذكاء الاصطناعي. (المصدر: 36氪)

شركة الروبوتات التفاعلية البشرية “Digital China” في شنتشن تكمل جولة تمويل ملاك+ بعشرات الملايين من اليوانات: أكملت شركة Digital China (Shenzhen) Technology Co., Ltd. مؤخرًا جولة تمويل ملاك+ بعشرات الملايين من اليوانات، باستثمار حصري من Tongchuang Weiye. تركز الشركة على الاستخدام التجاري واسع النطاق لروبوتات AGI، وتشمل منتجاتها الأساسية الروبوت الشبيه بالبشر “Xialan”، والروبوت البشري العام “Xiaqi”، وسلسلة روبوتات IP “Xingxingxia”. يتميز روبوت “Xialan” بتقنية المحاكاة الحيوية الدقيقة كنواة له، ويمكنه تقليد معظم تعابير الوجه البشري، ويمتلك قدرات تفاعلية متعددة الوسائط. حصلت الشركة على طلبات بمئات الملايين من اليوانات، ويشمل عملاؤها كبار مصنعي تكنولوجيا المعلومات والاتصالات (ICT) وشبكات الكهرباء المحلية. (المصدر: 36氪)

🌟 مجتمع
Sam Altman ينشر تدوينة بعنوان “التفرد اللطيف”، يناقش الثورة التدريجية للذكاء الاصطناعي ومستقبله: نشر Sam Altman، الرئيس التنفيذي لـ OpenAI، تدوينة يرى فيها أن التفرد التكنولوجي يحدث بطريقة أكثر سلاسة و “لطفًا” مما كان متوقعًا، وهو عملية تدريجية مستمرة ومتسارعة بشكل كبير. يتوقع أن وكلاء الذكاء الاصطناعي القادرين على إكمال الأعمال الذهنية المعقدة (مثل البرمجة) بشكل مستقل في عام 2025 سيعيدون تشكيل صناعة البرمجيات، وفي عام 2026 قد تظهر أنظمة قادرة على اكتشاف رؤى علمية جديدة تمامًا، وفي عام 2027 قد تظهر روبوتات قادرة على إكمال المهام في العالم الحقيقي. يؤكد Altman أن حل مشكلة مواءمة الذكاء الاصطناعي وضمان تعميم التكنولوجيا هما مفتاح مستقبل مزدهر. كما كشف أن أول نموذج أوزان مفتوح المصدر لـ OpenAI سيتم تأجيله حتى أواخر الصيف، لأن فريق البحث حقق “نتائج مذهلة غير متوقعة”. (المصدر: dotey, scaling01, sama)
نقاش مجتمعي حاد حول OpenAI o3-pro: أداء قوي ولكن تكلفة باهظة، وتخفيض سعر o3 يثير ردود فعل متسلسلة: أصبح إطلاق OpenAI o3-pro وتسعيره المرتفع (80 دولارًا أمريكيًا للإخراج لكل مليون token) محور نقاش مجتمعي. يعترف المستخدمون عمومًا بقدراته القوية في مهام الاستدلال المعقد والبرمجة، لكنهم يعربون أيضًا عن قلقهم بشأن سرعة استجابته وتكلفته، حيث سخر بعض المستخدمين من أن تحية بسيطة مثل “Hi” قد تكلف 80 دولارًا أمريكيًا. في الوقت نفسه، يُنظر إلى التخفيض الكبير في سعر نموذج o3 بنسبة 80% على أنه قد يؤدي إلى حرب أسعار نماذج الذكاء الاصطناعي، مستهدفًا GPT-4o وغيره من المنافسين. هناك جدل في المجتمع حول ما إذا كان أداء o3 قد “تراجع ذكاؤه” بعد تخفيض السعر. أعلنت OpenAI لاحقًا عن مضاعفة حصة استخدام o3 لمستخدمي ChatGPT Plus، استجابة لطلبات المستخدمين. (المصدر: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
رواتب Meta المرتفعة لاستقطاب المواهب والاستثمار في تنظيم الذكاء الاصطناعي يثيران نقاشًا حادًا: أثارت حزم الرواتب المرتفعة التي تقدمها Meta لباحثي الذكاء الاصطناعي (يقال إنها تصل إلى تسعة أرقام بالدولار الأمريكي) نقاشًا مجتمعيًا. أشار Nat Lambert إلى أن مثل هذه الرواتب قد تمول مؤسسة بحثية كاملة بحجم AI2، مما يشير إلى التكلفة الباهظة للمواهب المتميزة. بالاقتران مع تأسيس Meta لـ “مختبر الذكاء الفائق” واستثمارها الضخم في Scale AI، يعتقد المجتمع عمومًا أن Meta لا تدخر وسعًا لإعادة تشكيل قدرتها التنافسية في مجال الذكاء الاصطناعي، ولكنها تهتم أيضًا بقضايا السياسة الداخلية والكفاءة. يشير محتوى ChinaTalk الذي أعادت Helen Toner نشره إلى أن خطوة Meta هذه تهدف إلى كسر المشاكل السياسية والغطرسة داخل المنظمة. (المصدر: natolambert, natolambert)
نمط واجهة المستخدم الجديد “Liquid Glass” من Apple في WWDC يثير نقاشًا حول التصميم وسهولة الاستخدام: أثار نمط تصميم واجهة المستخدم الجديد “Liquid Glass” الذي قدمته Apple في WWDC 2025 نقاشًا واسعًا في مجتمعات المطورين والمصممين. ترى بعض الآراء أن تأثيره البصري مبتكر، ويعكس استكشاف Apple لتصميم الواجهات ثلاثية الأبعاد. ومع ذلك، أشار خبراء مخضرمون مثل ID_AA_Carmack (John Carmack) إلى أن واجهات المستخدم شبه الشفافة عادة ما تواجه مشكلات في سهولة الاستخدام، حيث يسهل أن تسبب تشتتًا بصريًا وتباينًا منخفضًا، مما يؤثر على القراءة والتشغيل، وأشاروا إلى أن Windows و Mac قد جربا تصميمات مماثلة في الماضي ولكن تم تعديلها في النهاية بسبب مشكلات سهولة الاستخدام. أصبحت تجربة المستخدم (UX) ذات أولوية على التأثير البصري لواجهة المستخدم (UI) محور النقاش. (المصدر: gfodor, ID_AA_Carmack, ReamBraden, dotey)
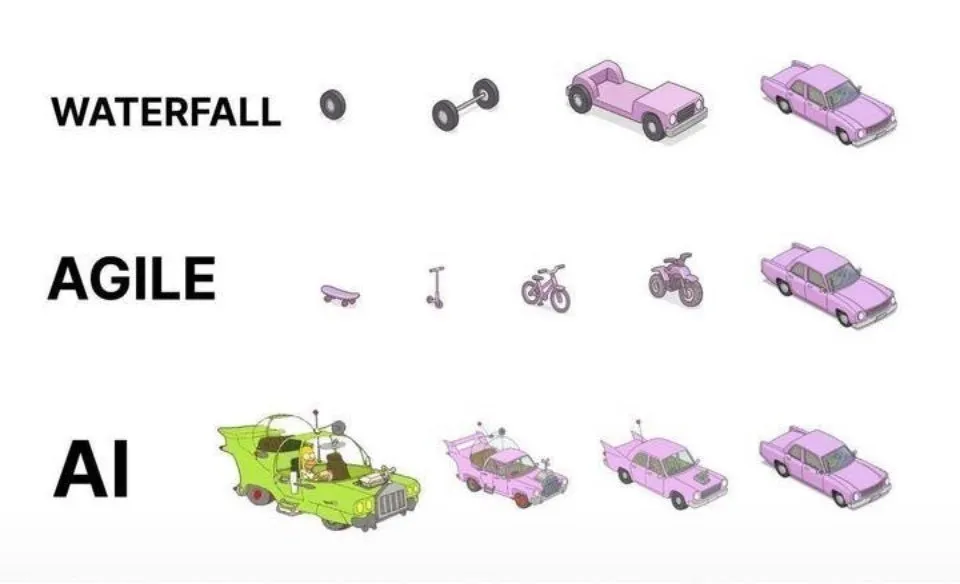
ممارسات البرمجة بمساعدة الذكاء الاصطناعي: التكرار السريع أفضل من التوليد لمرة واحدة: على وسائل التواصل الاجتماعي، عبر dotey عن رأيه بشأن أفضل الممارسات لاستخدام الذكاء الاصطناعي (مثل Claude Code) في البرمجة. يرى أنه لا ينبغي اعتماد طريقة تقديم المتطلبات الكاملة مرة واحدة ليقوم الذكاء الاصطناعي بتوليد منتج نصف مكتمل ضخم (نموذج الشلال) أو توليد منتج غير مكتمل أولاً ثم تحسينه (على غرار النمط الثالث في الصورة)، لأن هذا يجعل من الصعب التحكم في الجودة ويصعب صيانته لاحقًا. يدعو إلى اعتماد نموذج التكرار السريع (على غرار النمط الأول في الصورة)، حيث يتم تقسيم المشاريع الكبيرة (مثل أنظمة ERP) إلى عدة إصدارات صغيرة يمكن تشغيلها بثبات بشكل مستقل، ويتم تطويرها بشكل متكرر، مما يضمن اكتمال وظائف كل إصدار وقابليته للتحكم، وهذا يتوافق مع أفضل الممارسات التقليدية في هندسة البرمجيات. (المصدر: dotey)
Mustafa Suleyman: تكنولوجيا الذكاء الاصطناعي تتطور من الثبات والتوحيد إلى الديناميكية والتخصيص: علق Mustafa Suleyman، المؤسس المشارك لـ Inflection AI و DeepMind سابقًا، قائلاً إن التكنولوجيا التقليدية عادة ما تكون ثابتة وموحدة و “مقاس واحد يناسب الجميع”، بينما تظهر تكنولوجيا الذكاء الاصطناعي الحالية خصائص ديناميكية وشخصية وناشئة. يرى أن هذا يعني أن التكنولوجيا تتحول من تقديم نتائج متكررة واحدة إلى استكشاف مسارات لا حصر لها من الاحتمالات، مؤكدًا على الإمكانات الهائلة للذكاء الاصطناعي في الخدمات المخصصة والتطبيقات الإبداعية. (المصدر: mustafasuleyman)
Perplexity AI تواجه مشكلات في البنية التحتية، والرئيس التنفيذي يوضح: رد Arav Srinivas، الرئيس التنفيذي لـ Perplexity AI، على وسائل التواصل الاجتماعي على أسئلة المستخدمين بشأن عدم استقرار الخدمة، قائلاً إنه بسبب مشكلات في البنية التحتية، اضطروا إلى تفعيل تجربة مستخدم متدهورة (degraded UX) لبعض حركة المرور. وأكد أن بيانات المستخدمين (مثل library أو threads) لم تُفقد، وبمجرد استقرار النظام، ستعود جميع الوظائف إلى طبيعتها. يعكس هذا التحديات التي تواجهها خدمات الذكاء الاصطناعي في عملية التطور السريع فيما يتعلق باستقرار البنية التحتية وقابليتها للتوسع. (المصدر: AravSrinivas)
Sergey Levine يناقش الاختلافات في التعلم بين نماذج اللغة ونماذج الفيديو: طرح Sergey Levine، الأستاذ بجامعة كاليفورنيا في بيركلي، في مقاله “نماذج اللغة في كهف أفلاطون” سؤالًا عميقًا: لماذا تتعلم نماذج اللغة الكثير من التنبؤ بالكلمة التالية، بينما تتعلم نماذج الفيديو القليل نسبيًا من التنبؤ بالإطار التالي؟ يرى أن نماذج LLM اكتسبت قدرات استدلال قوية من خلال تعلم “ظلال” المعرفة البشرية (البيانات النصية)، وهذا أشبه بـ “الهندسة العكسية” للإدراك البشري، وليس استكشافًا حقيقيًا مستقلًا للعالم المادي. تراقب نماذج الفيديو العالم المادي مباشرة، لكنها حاليًا أقل قدرة على الاستدلال المعقد من نماذج LLM. يقترح أن الهدف طويل المدى للذكاء الاصطناعي يجب أن يكون تجاوز الاعتماد على “ظلال” المعرفة البشرية، والتفاعل مباشرة مع العالم المادي من خلال أجهزة الاستشعار، لتحقيق الاستكشاف المستقل. (المصدر: 36氪)
💡 أخرى
نقاش حول أخلاقيات ووعي الذكاء الاصطناعي: هل يمكن للذكاء الاصطناعي أن يمتلك وعيًا حقيقيًا؟: تهتم MIT Technology Review بالقضية المعقدة لوعي الذكاء الاصطناعي. يشير المقال إلى أن وعي الذكاء الاصطناعي ليس مجرد لغز فكري، بل هو أيضًا قضية ذات وزن أخلاقي. قد يؤدي الحكم الخاطئ على وعي الذكاء الاصطناعي إلى استعباد غير مقصود لذكاء اصطناعي واعٍ، أو التضحية برفاهية الإنسان من أجل آلات غير واعية. لقد أحرز مجتمع البحث تقدمًا في فهم طبيعة الوعي، وقد توفر هذه النتائج إرشادات لاستكشاف الوعي الاصطناعي والتعامل معه. يثير هذا تفكيرًا عميقًا حول حقوق الذكاء الاصطناعي ومسؤولياته والعلاقات بين الإنسان والآلة. (المصدر: MIT Technology Review)
الحائز على جائزة تورينغ Joseph Sifakis: الذكاء الاصطناعي الحالي ليس ذكاءً حقيقيًا، ويجب الحذر من الخلط بين المعرفة والمعلومات: أشار Joseph Sifakis، الحائز على جائزة تورينغ، في كتابه ومقابلاته إلى أن الفهم الحالي للمجتمع للذكاء الاصطناعي يعاني من انحراف، حيث يخلط بين تراكم المعلومات والإبداع الحكيم، ويغالي في تقدير “ذكاء” الآلات. يرى أنه لا يوجد حتى الآن نظام ذكي حقيقي، وأن التأثير الفعلي للذكاء الاصطناعي على الصناعة ضئيل للغاية. يفتقر الذكاء الاصطناعي إلى فهم الحس السليم، و “ذكاؤه” هو نتاج نماذج إحصائية، ويصعب عليه الموازنة بين القيمة والمخاطر في السياقات الاجتماعية المعقدة. يؤكد أن جوهر التعليم هو تنمية التفكير النقدي والإبداع، وليس نقل المعرفة، ويدعو إلى وضع معايير عالمية لتطبيقات الذكاء الاصطناعي، وتحديد حدود المسؤولية، لجعل الذكاء الاصطناعي شريكًا يعزز قدرات الإنسان وليس بديلاً له. (المصدر: 36氪)
إعادة هيكلة صناعة الإعلان في عصر الذكاء الاصطناعي: تحول من توليد الأفكار الإبداعية إلى الاستهداف المخصص: عرض مؤتمر Google I/O 2025 كيف يعيد الذكاء الاصطناعي هيكلة صناعة الإعلان بعمق. تشمل الاتجاهات: 1) أتمتة الإبداع المدفوعة بالذكاء الاصطناعي، حيث يمكن للذكاء الاصطناعي توليد كل شيء من الصور إلى نصوص الفيديو، مثل أدوات Veo 3 و Imagen 4 و Flow التي تخفض عتبة إنشاء محتوى عالي الجودة. 2) تحول نموذج التخصيص من “ألف وجه لألف شخص” إلى “ألف وجه لشخص واحد”، حيث يمكن لوكلاء الذكاء الاصطناعي فهم احتياجات المستخدم بشكل استباقي وتسهيل المعاملات. 3) طمس الحدود بين الإعلانات والمحتوى، حيث يتم دمج الإعلانات مباشرة في نتائج البحث التي يولدها الذكاء الاصطناعي، لتصبح جزءًا من المعلومات. يحتاج أصحاب العلامات التجارية إلى بناء وكلاء أذكياء خاصين بهم، وتقديم خدمات موجهة للذكاء الاصطناعي، والالتزام باستراتيجية طويلة الأجل “للتكامل بين العلامة التجارية والأداء” للتكيف مع التغيير. (المصدر: 36氪)