
كلمات مفتاحية:DeepSeek, OpenAI, نموذج الاستدلال, النموذج الكبير متعدد الوسائط, التعلم المعزز, ابتكار الذكاء الاصطناعي, النماذج مفتوحة المصدر, نموذج DeepSeek R1 للاستدلال, تدريب OpenAI o4 بالتعلم المعزز, خريطة التفكير البشري للنموذج الكبير متعدد الوسائط, سلسلة Mistral AI Magistral, نموذج dots.llm1 MoE من Xiaohongshu
🔥 أبرز العناوين
مسارات الابتكار لدى DeepSeek و OpenAI تكشف عن “الابتكار المعرفي”: حققت DeepSeek أداءً عاليًا بتكلفة منخفضة من خلال “Scaling Law المحدود” وابتكارات معمارية MLA و MoE وتحسين التآزر بين البرمجيات والأجهزة، وقد أدى فتح مصدر نموذج الاستدلال R1 الخاص بها إلى تحقيق طفرة في القدرات المعرفية للذكاء الاصطناعي، مما كسر “القالب الفكري” للمبتكرين الصينيين في مجال البحوث الأساسية، وأثبت القدرة الريادية العالمية للشركات الصينية في مجال البحوث الأساسية للذكاء الاصطناعي وابتكار النماذج. أما OpenAI، فبفضل الاستخدام المتقن لمعمارية Transformer و Scaling Law (قانون التوسع)، قادت ثورة النماذج اللغوية الكبيرة، ودفعت بتحول نمط التفاعل بين الإنسان والآلة وقفزة في القدرات المعرفية للذكاء الاصطناعي من خلال ChatGPT ونموذج الاستدلال o1. يؤكد مسار التطور لكليهما على الفهم العميق لجوهر التكنولوجيا وإعادة الهيكلة الاستراتيجية، مما يوفر لرواد الأعمال في عصر الذكاء الاصطناعي أفكارًا قيمة لبناء المؤسسات والابتكار، خاصة نموذج AI Lab الذي تشجعه DeepSeek والذي يعزز “الظهور التلقائي”، مما يوفر مرجعًا لنموذج تنظيمي جديد لرواد الأعمال المدفوعين بالابتكار التكنولوجي (المصدر: 36氪)
OpenAI يُشاع أنها تدرب نموذجًا جديدًا o4، والتعلم المعزز يعيد تشكيل مشهد الذكاء الاصطناعي: كشفت SemiAnalysis أن OpenAI تقوم بتدريب نموذج جديد يقع بين GPT-4.1 و GPT-4.5، وأن نموذج الاستدلال من الجيل التالي o4 سيتم تدريبه بناءً على GPT-4.1 باستخدام التعلم المعزز (RL). يفتح RL قدرات الاستدلال للنماذج من خلال توليد CoT ويدفع بتطوير وكلاء الذكاء الاصطناعي، ولكنه يتطلب بنية تحتية عالية (خاصة للاستدلال) وتصميمًا دقيقًا لدوال المكافأة، وهو عرضة لظاهرة “اختراق المكافأة”. البيانات عالية الجودة هي مفتاح توسيع RL، وستصبح بيانات سلوك المستخدم أصولًا مهمة. كما يغير RL الهيكل التنظيمي للمختبرات، مما يجعل الاستدلال والتدريب متكاملين بعمق. على عكس التدريب المسبق، يمكن لـ RL تحديث قدرات النموذج باستمرار، مثل DeepSeek R1. بالنسبة للنماذج الصغيرة، قد يكون التقطير (distillation) أفضل من RL. تشير هذه التسريبات إلى أن مجال الذكاء الاصطناعي، وخاصة نماذج الاستدلال، سيشهد تطورًا مستمرًا وقفزة في القدرات بناءً على RL (المصدر: 36氪)
اكتشاف أن النماذج الكبيرة متعددة الوسائط تشكل “خريطة تفكير بشرية” بشكل تلقائي: أكد فريق مشترك من معهد الأتمتة التابع للأكاديمية الصينية للعلوم ومركز الابتكار المتميز لعلوم الدماغ وتكنولوجيا الذكاء، من خلال التجارب السلوكية وتحليل التصوير العصبي، أن النماذج اللغوية الكبيرة متعددة الوسائط (MLLMs) قادرة على تكوين نظام تمثيل مفاهيمي للأشياء مشابه بدرجة كبيرة للبشر بشكل تلقائي. قامت الدراسة بتحليل 4.7 مليون حكم سلوكي من “مهمة تحديد العنصر المختلف من بين ثلاثة خيارات”، وبنت لأول مرة “خريطة مفاهيمية” لنماذج الذكاء الاصطناعي. تشمل الاكتشافات الأساسية: قد تتقارب نماذج الذكاء الاصطناعي ذات البنى المختلفة إلى هياكل معرفية منخفضة الأبعاد مماثلة؛ تظهر النماذج قدرة على تصنيف مفاهيم الأشياء المتقدمة في ظل ظروف غير خاضعة للإشراف، بما يتفق مع الإدراك البشري؛ يمكن إعطاء “أبعاد التفكير” لنماذج الذكاء الاصطناعي تسميات دلالية، مثل الحيوانات، الطعام، الصلابة، إلخ؛ يرتبط تمثيل MLLM بشكل كبير بأنماط النشاط العصبي في مناطق دماغية محددة (مثل FFA، PPA)، مما يوفر دليلًا على “مشاركة الذكاء الاصطناعي والبشر لآليات معالجة المفاهيم”. تقدم هذه الدراسة أفكارًا جديدة لفهم الإدراك الاصطناعي، وتطوير الذكاء الشبيه بالدماغ، وواجهات الدماغ والآلة (المصدر: 量子位)

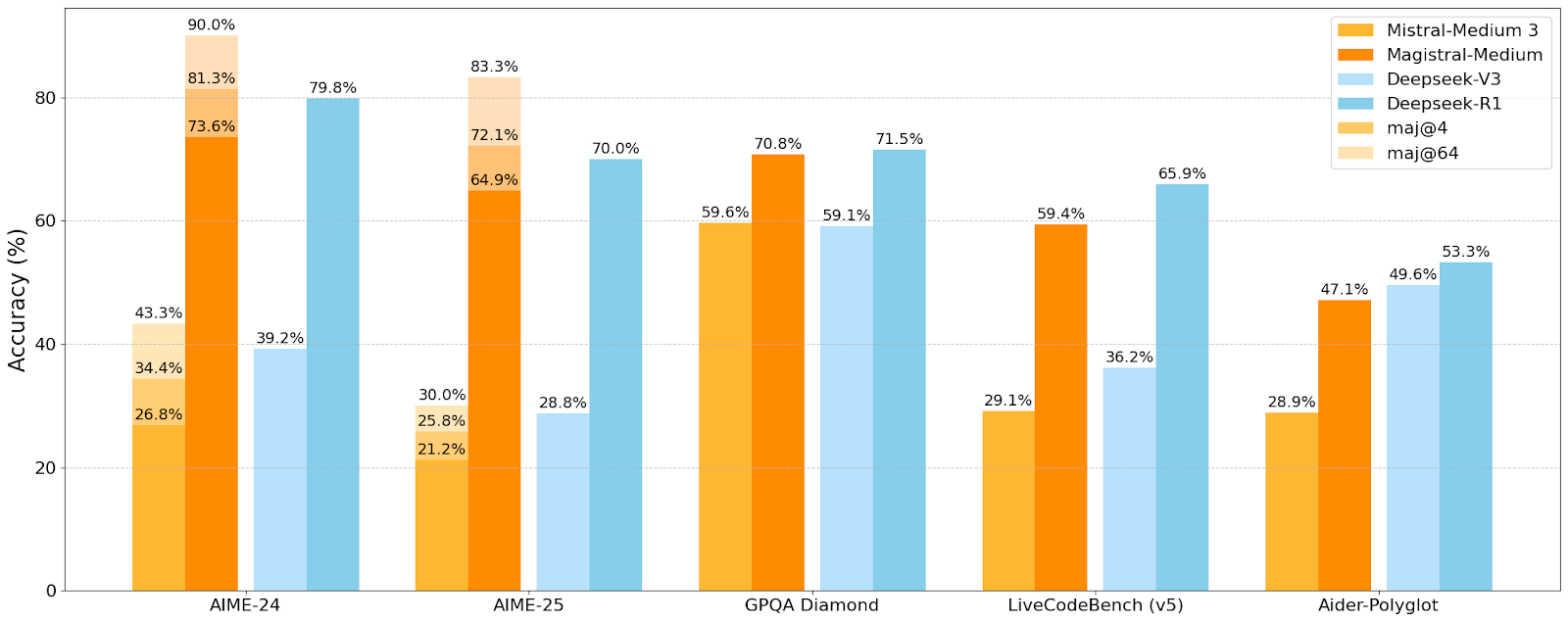
Mistral AI تطلق أول سلسلة نماذج استدلال Magistral، والنموذج الصغير Magistral-Small مفتوح المصدر: أطلقت Mistral AI أول سلسلة نماذج مصممة خصيصًا للاستدلال، Magistral، والتي تشمل Magistral-Small و Magistral-Medium. تم بناء Magistral-Small على أساس Mistral Small 3.1 (2503)، وهو نموذج استدلال فعال بـ 24 مليار معلمة، تم تدريبه باستخدام SFT و RL عبر مسار Magistral Medium، مما عزز قدراته الاستدلالية. يدعم النموذج لغات متعددة، ونافذة سياق تبلغ 128 ألفًا (يوصى بسياق فعال يبلغ 40 ألفًا)، وهو مفتوح المصدر بموجب ترخيص Apache 2.0، ويمكن نشره محليًا على جهاز RTX 4090 واحد أو MacBook بذاكرة وصول عشوائي (RAM) تبلغ 32 جيجابايت (بعد التكميم). تظهر اختبارات الأداء أن Magistral-Small يتفوق في مهام مثل AIME24، AIME25، GPQA Diamond، و Livecodebench (v5)، ويقترب أو حتى يتفوق على بعض النماذج الأكبر. يتمتع Magistral-Medium بأداء أقوى، ولكنه غير مفتوح المصدر حاليًا. يمثل هذا الإطلاق تقدم Mistral في تعزيز قدرات استدلال النماذج ودعم اللغات المتعددة (المصدر: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 اتجاهات
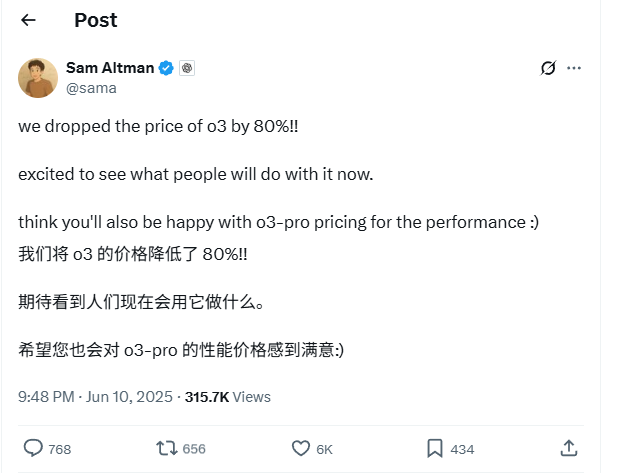
انخفاض كبير بنسبة 80% في أسعار واجهة برمجة تطبيقات نموذج o3 من OpenAI: أعلن Sam Altman، الرئيس التنفيذي لشركة OpenAI، عن تخفيض أسعار واجهة برمجة تطبيقات نموذج o3 بنسبة 80%. بعد التعديل، أصبح سعر الإدخال 2 دولار لكل مليون token، وسعر الإخراج 8 دولارات لكل مليون token (بعض المصادر ذكرت أن سعر الإخراج 5 دولارات لكل مليون token، يجب الرجوع إلى الوثائق الرسمية للتأكد). هذا التخفيض الكبير في الأسعار يقلل بشكل كبير من تكلفة استخدام نموذج o3 لمهام مثل كتابة الأكواد، ومن المتوقع أن يدفع نحو تطبيقات وابتكارات أوسع. يجب على المستخدمين ملاحظة أن قائمة الأسعار على الموقع الرسمي قد لا تكون محدثة بعد، ويوصى بإجراء اختبار قبل استدعاء واجهة برمجة التطبيقات لتأكيد السعر الفعلي الفعال، لتجنب الخسائر غير الضرورية. تعتبر هذه الخطوة استراتيجية لمواجهة المنافسة في السوق (مثل Gemini 2.5 Pro و Claude 4 Sonnet)، وقد تشير إلى أن تكلفة الذكاء الاصطناعي ستستمر في الانخفاض (المصدر: X, X, X)
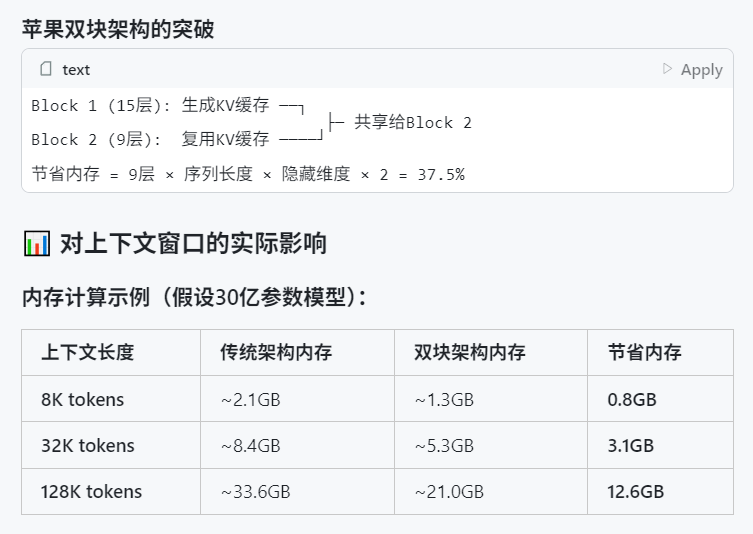
مؤتمر WWDC 2025 لشركة Apple يُنتقد لقلة التركيز على الذكاء الاصطناعي، لكن التفاصيل التقنية تكشف عن طموحاتها: بدا أن تركيز Apple على الذكاء الاصطناعي في مؤتمر المطورين العالمي (WWDC) 2025 أقل من المتوقع، لكن وثائقها التقنية كشفت عن استثماراتها العميقة في نماذج الأجهزة الطرفية والسحابية. تستخدم Apple تقنيات تدريب وتقطير وتكميم متقدمة، بما في ذلك “معمارية الكتلة المزدوجة” (المصممة لتقليل استهلاك الذاكرة) لنماذج الأجهزة المحمولة (بحجم حوالي 3B) ومعمارية “PT-MoE” (مزيج الخبراء بالمسارات المتوازية) لنماذج الخوادم. تهدف هذه التقنيات إلى تحسين الاستدلال بزمن انتقال منخفض على شرائح Apple وتقليل استخدام ذاكرة التخزين المؤقت KV. على الرغم من وجود أصوات خارجية ترى أن Apple متخلفة في مجال الذكاء الاصطناعي، إلا أن إنجازاتها في تكنولوجيا النماذج (مثل نماذج التضمين مفتوحة المصدر) واهتمامها بأولويات مختلفة (مثل الذكاء على الجهاز بدلاً من روبوتات الدردشة فقط) تشير إلى أن لديها استراتيجية فريدة للذكاء الاصطناعي. كما أعلن WWDC أن Safari 26 سيدعم WebGPU، مما سيعزز بشكل كبير أداء تشغيل نماذج الذكاء الاصطناعي على الجهاز (مثل من خلال Transformers.js)، على سبيل المثال، زيادة سرعة إنشاء التسميات التوضيحية للنماذج المرئية داخل المتصفح بحوالي 12 مرة (المصدر: X, X, X)
مستخدمو Perplexity Pro يمكنهم الآن استخدام نموذج o3 من OpenAI: أعلنت Perplexity أن مشتركيها في خدمة Pro يمكنهم الآن استخدام نموذج o3 من OpenAI. سيوفر هذا التكامل لمستخدمي Perplexity Pro قدرات أقوى في معالجة المعلومات والإجابة على الأسئلة. في الوقت نفسه، تختبر Perplexity أيضًا ميزة “Memory” الخاصة بها، وقامت بتحديث مساعدها الصوتي على iOS، بهدف توفير تجربة مستخدم أكثر إيجازًا وعملية. كما أن ميزة مقالات Discover الخاصة بها أصبحت الآن في وضع “Summary” الأكثر إيجازًا بشكل افتراضي، مع توفير خيار للتبديل إلى وضع “Report” الأكثر تعمقًا (المصدر: X, X, X)

Xiaohongshu تفتح مصدر أول نموذج كبير MoE بـ 142 مليار معلمة dots.llm1، ويتفوق على DeepSeek-V3 في التقييمات الصينية: فتحت Xiaohongshu مصدر أول نموذج كبير لها dots.llm1، وهو نموذج MoE (مزيج الخبراء) بـ 142 مليار معلمة، ينشط 14 مليار معلمة فقط أثناء الاستدلال. استخدم النموذج 11.2 تريليون token غير اصطناعي في مرحلة التدريب المسبق، معظمها من بيانات الويب من برامج الزحف العامة والخاصة بها. اقترح فريق Xiaohongshu إطارًا لمعالجة البيانات ثلاثي المراحل قابل للتطوير، وقام بفتح مصدره لتعزيز قابلية التكرار. حقق dots.llm1 درجة 92.2 في C-Eval، متجاوزًا جميع النماذج بما في ذلك DeepSeek-V3، ويقترب من أداء Qwen3-32B من Alibaba في المهام الصينية والإنجليزية والرياضيات والمواءمة. كما فتحت Xiaohongshu مصدر نقاط الفحص التدريبية الوسيطة لتعزيز فهم المجتمع لديناميكيات النماذج الكبيرة (المصدر: 36氪)
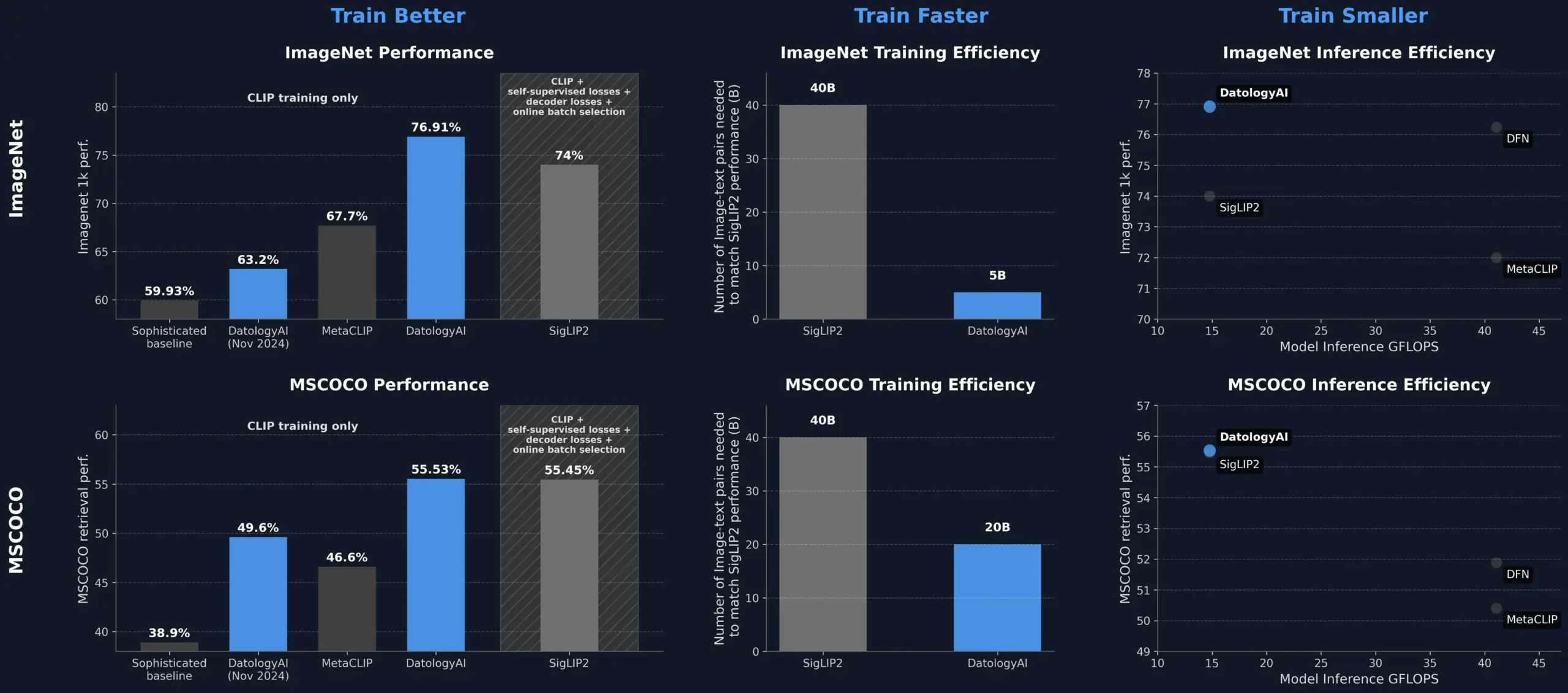
DatologyAI تحسن أداء نموذج CLIP من خلال إدارة البيانات، متجاوزة SigLIP2: عرضت DatologyAI كيف يمكن لإدارة البيانات (data curation) وحدها أن تحسن بشكل كبير أداء نموذج CLIP. مكنت طريقتهم نموذج ViT-B/32 من تحقيق دقة 76.9% على ImageNet 1k، متجاوزة نسبة 74% التي أبلغ عنها SigLIP2. بالإضافة إلى ذلك، أدت هذه الطريقة إلى تحسين كفاءة التدريب بمقدار 8 أضعاف وتحسين كفاءة الاستدلال بمقدار ضعفين، وقد تم إصدار النماذج ذات الصلة للعامة. يسلط هذا الضوء على الدور المركزي لمجموعات البيانات عالية الجودة والمنظمة بعناية في تدريب نماذج الذكاء الاصطناعي المتقدمة، حتى بدون تغيير بنية النموذج، يمكن استكشاف إمكانات النموذج من خلال تحسين البيانات (المصدر: X, X)
Kuaishou وجامعة Northeastern تقترحان إطار تضمين موحد متعدد الوسائط UNITE: لمعالجة مشكلة التداخل بين الوسائط المختلفة (النص، الصور، الفيديو) الناتجة عن اختلافات توزيع البيانات في استرجاع الوسائط المتعددة، اقترح باحثون من Kuaishou وجامعة Northeastern إطار تضمين موحد متعدد الوسائط UNITE. يستخدم هذا الإطار آلية “التعلم التبايني المقنع المدرك للوسائط” (MAMCL)، والتي تأخذ في الاعتبار فقط العينات السلبية المتوافقة مع وسيط الاستعلام المستهدف في التعلم التبايني، لتجنب المنافسة الخاطئة بين الوسائط. يعتمد UNITE على تدريب من مرحلتين “تكييف الاسترجاع + الضبط الدقيق للتعليمات”، وحقق نتائج SOTA في العديد من التقييمات مثل استرجاع الصور والنصوص، واسترجاع الفيديو والنصوص، واسترجاع التعليمات، كما هو الحال في MMEB Benchmark حيث تجاوز النماذج الأكبر حجمًا، وفي CoVR حيث تفوق بشكل كبير. تؤكد الدراسة على القدرة الأساسية لبيانات الفيديو والنص في توحيد الوسائط، وتشير إلى أن مهام التعليمات تعتمد بشكل أكبر على البيانات التي يهيمن عليها النص (المصدر: 量子位)

NVIDIA تطلق نموذج الذكاء الاصطناعي الأساسي لمحاكاة المناخ Earth-2: أطلقت منصة Earth-2 التابعة لشركة NVIDIA نموذجًا أساسيًا جديدًا للذكاء الاصطناعي قادرًا على محاكاة المناخ العالمي بدقة كيلومترية. يهدف النموذج إلى توفير تنبؤات مناخية أسرع وأكثر دقة، مما يوفر طرقًا جديدة لفهم والتنبؤ بالأنظمة الطبيعية المعقدة للأرض. تمثل هذه الخطوة خطوة مهمة إلى الأمام في تطبيق الذكاء الاصطناعي في علوم المناخ ونمذجة نظام الأرض، ومن المتوقع أن تعزز أبحاث تغير المناخ وقدرات الإنذار بالكوارث (المصدر: X)

خدمات OpenAI تشهد انقطاعًا واسع النطاق، مما يؤثر على ChatGPT وواجهة برمجة التطبيقات: شهدت خدمة ChatGPT وواجهات برمجة التطبيقات (API) التابعة لـ OpenAI انقطاعًا واسع النطاق مساء يوم 10 يونيو بتوقيت بكين، تمثل في ارتفاع معدلات الخطأ وزمن الانتقال. أبلغ العديد من المستخدمين عن عدم تمكنهم من الوصول إلى الخدمات أو مواجهة رسائل خطأ مثل “Hmm…something seems to have gone wrong”. أكدت صفحة الحالة الرسمية لـ OpenAI المشكلة، وذكرت أن المهندسين قد حددوا السبب الجذري ويعملون على إصلاحه بشكل عاجل. أثر هذا الانقطاع على عدد كبير من المستخدمين والتطبيقات التي تعتمد على ChatGPT وواجهات برمجة تطبيقاتها في جميع أنحاء العالم، مما يسلط الضوء مرة أخرى على أهمية استقرار خدمات الذكاء الاصطناعي الكبيرة (المصدر: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 أدوات
النظام البيئي لخوادم Model Context Protocol (MCP) يواصل التوسع: يهدف Model Context Protocol (MCP) إلى تزويد النماذج اللغوية الكبيرة (LLM) بوصول آمن ومتحكم فيه إلى الأدوات ومصادر البيانات. يجمع مستودع modelcontextprotocol/servers على GitHub تطبيقات مرجعية لـ MCP وخوادم أنشأها المجتمع، مما يوضح تطبيقاته المتنوعة. تغطي الخوادم الرسمية وخوادم الطرف الثالث أنظمة الملفات، وعمليات Git، والتفاعل مع قواعد البيانات (مثل PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra وغيرها)، والخدمات السحابية (AWS, Azure, Cloudflare)، وتكامل واجهات برمجة التطبيقات (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal)، والبحث (Brave, Algolia, Exa, Tavily)، وتنفيذ الأكواد، واستدعاء نماذج الذكاء الاصطناعي (Replicate, ElevenLabs) وغيرها من المجالات الواسعة. يتطور النظام البيئي لـ MCP بسرعة، مع وجود أكثر من 130 خادمًا رسميًا ومجتمعيًا، وظهور أطر تطوير مثل EasyMCP، FastMCP، MCP-Framework وأدوات إدارة مثل MCP-CLI، MCPM، بهدف خفض عتبة وصول LLM إلى الأدوات والبيانات الخارجية، ودفع تطوير وكلاء الذكاء الاصطناعي (AI Agent) (المصدر: GitHub Trending)
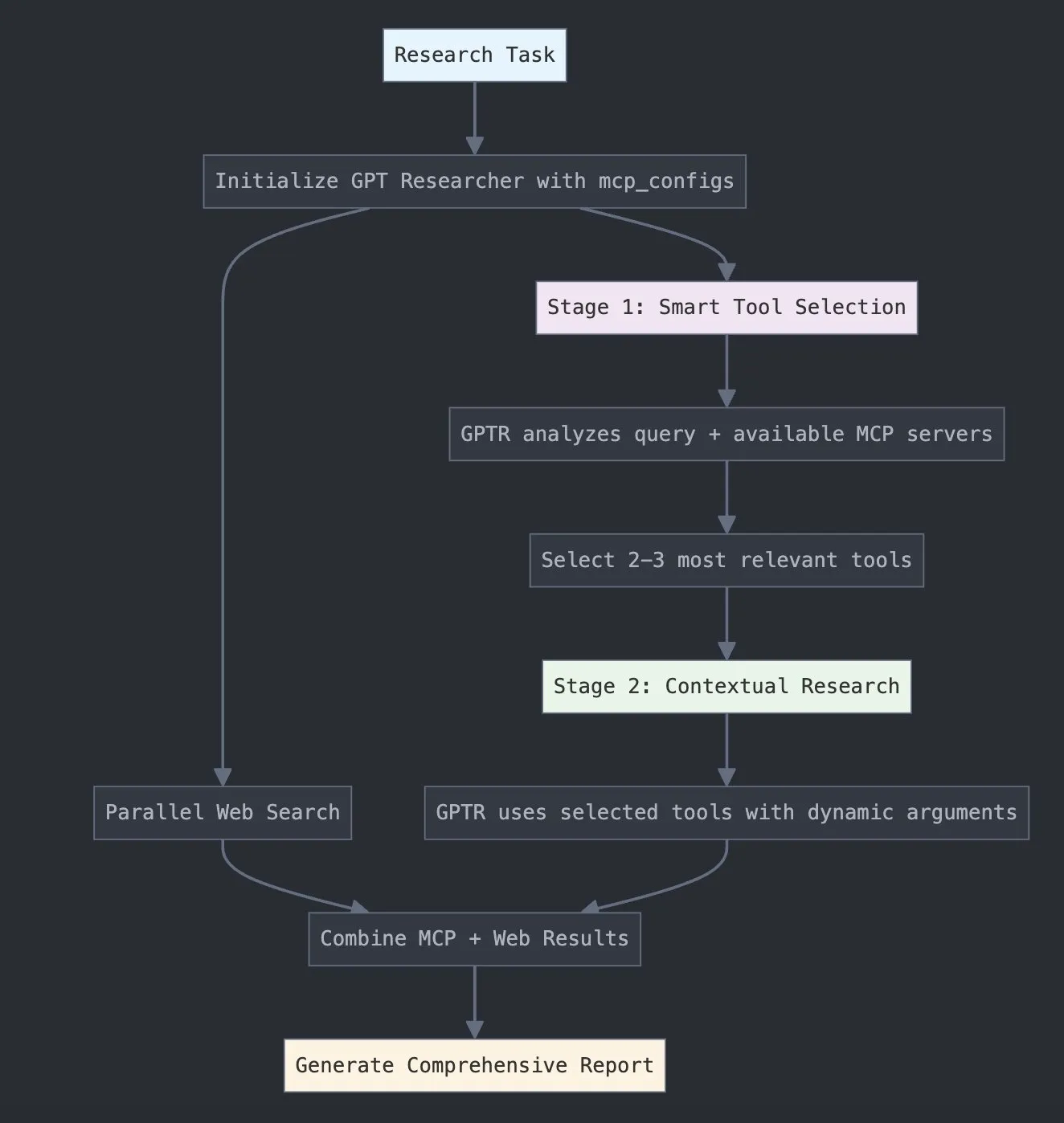
LangChain تطلق GPT Researcher MCP لتعزيز القدرات البحثية: أعلنت LangChain أن GPT Researcher يستخدم الآن محول Model Context Protocol (MCP) الخاص بها، لتحقيق اختيار ذكي للأدوات والبحث. يدمج هذا التكامل MCP مع وظائف البحث على الويب، بهدف تزويد المستخدمين بقدرات أكثر شمولاً لجمع البيانات وتحليلها، مما يزيد من عمق واتساع تطبيقات الذكاء الاصطناعي في مجال البحث (المصدر: X)
Hugging Face تطلق Vui: مشروع NotebookLM مفتوح المصدر بـ 100 مليون معلمة، يحقق تحويل نص إلى كلام (TTS) شبيه بالبشر: تم إطلاق Vui على Hugging Face، وهو مشروع NotebookLM مفتوح المصدر بـ 100 مليون معلمة، يتضمن ثلاثة نماذج: Vui.BASE (نموذج أساسي مدرب على 40 ألف ساعة من الحوارات الصوتية)، Vui.ABRAHAM (نموذج لمتحدث واحد يتمتع بقدرات إدراك السياق)، و Vui.COHOST (نموذج يمكنه إجراء حوارات ثنائية). يستطيع Vui استنساخ الأصوات، وتقليد التنفس، والهمهمات، وغيرها من العبارات الشائعة، وحتى الأصوات غير الكلامية، مما يمثل تقدمًا جديدًا في تكنولوجيا تحويل النص إلى كلام (TTS) الشبيهة بالبشر (المصدر: X, X)
Consilium: منصة تعاون مفتوحة المصدر متعددة الوكلاء لحل المشكلات المعقدة: تم عرض مشروع Consilium على Hugging Face، وهو منصة تعاون مفتوحة المصدر متعددة الوكلاء. يمكن للمستخدمين تشكيل فريق من وكلاء الذكاء الاصطناعي الخبراء، الذين يعملون معًا لحل المشكلات المعقدة والتوصل إلى توافق في الآراء من خلال النقاش والبحث في الوقت الفعلي (صفحات الويب، arXiv، ملفات SEC). يحدد المستخدمون الاستراتيجية، ويتولى فريق الوكلاء مسؤولية إيجاد الإجابات، مما يوضح استكشافًا جديدًا للذكاء الاصطناعي في حل المشكلات التعاوني (المصدر: X)
Unsloth تطلق نسخة محسنة من نموذج Magistral-Small-2506 بتنسيق GGUF: بعد إطلاق Mistral AI لنموذج الاستدلال Magistral-Small-2506، سرعان ما أطلقت Unsloth نسختها المحسنة من النموذج بتنسيق GGUF، وهي مناسبة لمنصات مثل llama.cpp و LMStudio و Ollama. تعكس هذه الاستجابة السريعة حيوية وكفاءة مجتمع المصادر المفتوحة في تحسين النماذج ونشرها، مما يتيح استخدام النماذج الجديدة بسرعة أكبر من قبل مجموعة أوسع من المستخدمين والمطورين (المصدر: X)
📚 دراسات وأبحاث
ورقة بحثية جديدة تناقش نموذج التدريب المسبق بالتعلم المعزز (RPT): تقترح ورقة بحثية جديدة بعنوان “Reinforcement Pre-Training (RPT)” إعادة صياغة توقع الرمز التالي من الجيل القادم كمهمة استدلال باستخدام RLVR (التعلم المعزز مع المكافآت القابلة للتحقق). يهدف RPT إلى تحسين دقة توقع النماذج اللغوية من خلال تحفيز قدرة استدلال الرمز التالي، وتوفير أساس قوي للضبط الدقيق المعزز لاحقًا. أظهرت الدراسة أن زيادة الحسابات التدريبية يمكن أن تحسن دقة التوقع باستمرار، مما يشير إلى أن RPT هو نموذج فعال وواعد لتوسيع نطاق التدريب المسبق للنماذج اللغوية (المصدر: HuggingFace Daily Papers, X)

ورقة بحثية تقترح Cartridges: تمثيلات سياق طويل خفيفة الوزن من خلال الدراسة الذاتية: تستكشف ورقة بحثية بعنوان “Cartridges: Lightweight and general-purpose long context representations via self-study” طريقة لمعالجة النصوص الطويلة من خلال تدريب ذاكرة تخزين مؤقت KV صغيرة (تسمى Cartridge) دون اتصال بالإنترنت، كبديل لوضع المجموعة النصية بأكملها في نافذة السياق أثناء الاستدلال. وجدت الدراسة أن Cartridge المدربة من خلال “الدراسة الذاتية” (توليد حوارات اصطناعية حول المجموعة النصية والتدريب باستخدام هدف تقطير السياق)، يمكن أن تحقق أداءً مشابهًا لـ ICL باستهلاك ذاكرة أقل بكثير (انخفاض بمقدار 38.6 مرة) وإنتاجية أعلى (زيادة بمقدار 26.4 مرة)، ويمكنها توسيع طول السياق الفعال للنموذج، وحتى دعم الاستخدام عبر مجموعات نصية متعددة دون الحاجة إلى إعادة التدريب (المصدر: HuggingFace Daily Papers, X)

ورقة بحثية تناقش تحسين استراتيجية التباين الجماعي (GCPO) في النماذج اللغوية الكبيرة (LLM) لحل المسائل الهندسية: تستهدف الورقة البحثية “GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization” التحديات التي تواجهها النماذج اللغوية الكبيرة (LLM) في بناء الخطوط المساعدة لحل المسائل الهندسية، وتقترح إطار GCPO. يوفر هذا الإطار إشارات مكافأة إيجابية وسلبية لبناء الخطوط المساعدة بناءً على فائدة السياق من خلال “قناع التباين الجماعي”، ويقدم مكافأة الطول لتعزيز سلاسل الاستدلال الأطول. أظهرت سلسلة نماذج GeometryZero المطورة بناءً على GCPO أداءً متفوقًا على النماذج الأساسية في اختبارات مثل Geometry3K و MathVista، بمتوسط تحسن قدره 4.29%، مما يوضح إمكانية تعزيز قدرات الاستدلال الهندسي للنماذج الصغيرة في ظل قدرة حسابية محدودة (المصدر: HuggingFace Daily Papers)
ورقة بحثية بعنوان “The Illusion of Thinking” تستكشف قدرات وحدود نماذج الاستدلال من خلال تعقيد المشكلات: تبحث هذه الدراسة بشكل منهجي في قدرات وخصائص التوسع وحدود نماذج الاستدلال الكبيرة (LRMs). من خلال استخدام بيئة ألغاز يمكن التحكم في تعقيدها بدقة، وجدت الدراسة أن دقة LRMs تنهار تمامًا بعد تجاوز تعقيد معين، وتظهر قيود توسع غير بديهية: ينخفض جهد الاستدلال مع زيادة تعقيد المشكلة إلى حد معين. مقارنة بالنماذج اللغوية الكبيرة (LLM) القياسية، يكون أداء LRMs أسوأ في المهام منخفضة التعقيد، ويتفوق في المهام متوسطة التعقيد، ويفشل كلاهما في المهام عالية التعقيد. تشير الدراسة إلى وجود قيود على LRMs في الحسابات الدقيقة، وصعوبة تطبيق الخوارزميات الصريحة، وعدم اتساق الاستدلال على نطاقات مختلفة (المصدر: HuggingFace Daily Papers, X)
ورقة بحثية تدرس تقييم متانة النماذج اللغوية الكبيرة (LLM) في اللغات ذات الموارد المحدودة: تستكشف الورقة البحثية “Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models” حساسية النماذج اللغوية الكبيرة (LLMs) للاضطرابات (مثل الهجمات على مستوى الحروف والكلمات) في اللغات ذات الموارد المنخفضة مثل اللغة البولندية. وجدت الدراسة أنه من خلال تعديلات قليلة على الحروف واستخدام نماذج وكيلة صغيرة لحساب أهمية الكلمات، يمكن إنشاء هجمات تغير بشكل كبير توقعات LLM المختلفة، مما يكشف عن ثغرات أمنية محتملة في LLM في هذه اللغات، والتي يمكن استخدامها للتحايل على آليات الأمان الداخلية الخاصة بها. نشر الباحثون مجموعة البيانات والأكواد ذات الصلة (المصدر: HuggingFace Daily Papers)
Rel-LLM: طريقة جديدة لتعزيز كفاءة LLM في معالجة قواعد البيانات العلائقية: تقترح ورقة بحثية إطار عمل Rel-LLM، يهدف إلى حل مشكلة الكفاءة المنخفضة للنماذج اللغوية الكبيرة (LLM) عند معالجة قواعد البيانات العلائقية. تؤدي الطرق التقليدية لتحويل البيانات المهيكلة إلى نص إلى فقدان الروابط الهامة وتكرار الإدخال. يقوم Rel-LLM بإنشاء مطالبات رسوم بيانية مهيكلة من خلال مُرمِّز شبكة عصبونية بيانية (GNN)، مع الحفاظ على البنية العلائقية ضمن إطار عمل الجيل المعزز بالاسترجاع (RAG). تتضمن هذه الطريقة أخذ عينات من الرسوم البيانية الفرعية المدركة للوقت، ومُرمِّز GNN غير متجانس، وطبقة إسقاط MLP لمحاذاة تضمينات الرسوم البيانية مع الفضاء الكامن لـ LLM، وهيكلة تمثيلات الرسوم البيانية كمطالبات رسوم بيانية JSON، ومن خلال هدف التدريب المسبق ذاتي الإشراف لمحاذاة تمثيلات الرسوم البيانية والنصوص. أظهرت التجارب أن ترميز GNN يمكنه التقاط البنية العلائقية المعقدة المفقودة في تسلسل النصوص بشكل فعال، وأن مطالبات الرسوم البيانية المهيكلة يمكنها حقن السياق العلائقي بشكل فعال في آلية انتباه LLM (المصدر: X)

ورقة بحثية تناقش مشكلة “الرفض المفرط” في النماذج اللغوية الكبيرة وطريقة التحسين EvoRefuse: تدرس الورقة البحثية “EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions” مشكلة الرفض المفرط من قبل النماذج اللغوية الكبيرة (LLM) لـ “التعليمات الخبيثة الزائفة” (المدخلات غير الضارة دلاليًا ولكنها تؤدي إلى رفض النموذج). لمعالجة أوجه القصور في طرق إدارة التعليمات الحالية من حيث قابلية التوسع والتنوع، تقترح الورقة EVOREFUSE، وهي طريقة تستخدم الخوارزميات التطورية لتحسين المطالبات، ويمكنها توليد تعليمات خبيثة زائفة متنوعة ومستمرة تثير رفض LLM. بناءً على ذلك، أنشأ الباحثون EVOREFUSE-TEST (اختبار معياري يحتوي على 582 تعليمة) و EVOREFUSE-ALIGN (مجموعة بيانات تدريب للمواءمة تحتوي على 3000 تعليمة واستجابة). أظهرت التجارب أن نموذج LLAMA3.1-8B-INSTRUCT الذي تم ضبطه بدقة على EVOREFUSE-ALIGN، انخفض معدل رفضه المفرط بنسبة تصل إلى 14.31% مقارنة بالنماذج المدربة على مجموعات بيانات مواءمة دون المستوى الأمثل، ودون المساس بالأمان (المصدر: HuggingFace Daily Papers)
💼 أعمال
Zhongke Wenge تستكمل جولة تمويل استراتيجية جديدة، باستثمار من صندوق صناعي في منطقة شيجينغشان ببكين: أعلنت شركة Zhongke Wenge، المزودة لخدمات الذكاء الاصطناعي على مستوى الشركات، عن استكمال جولة تمويل استراتيجية جديدة، وكان المستثمر هو شركة صندوق تنمية الصناعات الحديثة المبتكرة بمنطقة شيجينغشان في بكين المحدودة. سيُستخدم هذا التمويل بشكل أساسي في البحث والتطوير لنظام تشغيل ذكاء القرار DIOS الذي طورته الشركة ذاتيًا وفي الترويج للسوق، مما يسرع من تطوير تكنولوجيا الذكاء الاصطناعي على مستوى الشركات وتطبيقها تجاريًا. تأسست Zhongke Wenge في عام 2017، وينتمي فريقها الأساسي إلى معهد الأتمتة التابع للأكاديمية الصينية للعلوم، وهي متخصصة في فهم اللغات المتعددة، والدلالات عبر الوسائط، وتكنولوجيا اتخاذ القرار في السيناريوهات المعقدة، وتخدم قطاعات الإعلام، والمالية، والحكومة، والطاقة. وقد حصلت سابقًا على استثمارات تزيد عن مليار يوان من صناديق ذات خلفية حكومية مثل China Development Bank Financial Leasing، و China Internet Investment Fund، و Shenzhen Capital Group (المصدر: 量子位)

Sakana AI وبنك Hokkoku الياباني يتوصلان إلى تعاون استراتيجي لتعزيز تطوير الذكاء الاصطناعي المالي الإقليمي: أعلنت شركة Sakana AI اليابانية الناشئة في مجال الذكاء الاصطناعي عن توقيع مذكرة تفاهم (MOU) مع شركة Hokkoku Financial Holdings، التي يقع مقرها في محافظة إيشيكاوا، حيث سيتعاون الطرفان في مجال دمج التمويل الإقليمي والذكاء الاصطناعي. يأتي هذا التعاون بعد إقامة شراكة شاملة مع بنك Mitsubishi UFJ، ويمثل خطوة أخرى لـ Sakana AI للتعاون مع المؤسسات المالية، بهدف تطبيق تكنولوجيا الذكاء الاصطناعي المتطورة لحل المشكلات التي تواجه المجتمعات الإقليمية في اليابان، خاصة في مجال الخدمات المالية. تلتزم Sakana AI بتطوير تكنولوجيا ذكاء اصطناعي متخصصة للغاية للمؤسسات المالية، ومن المتوقع أن يشكل هذا التعاون نموذجًا لتطبيقات الذكاء الاصطناعي للبنوك الإقليمية الأخرى في اليابان (المصدر: X, X)

Cohere تتعاون مع Ensemble لجلب منصتها للذكاء الاصطناعي إلى قطاع الرعاية الصحية: أعلنت شركة الذكاء الاصطناعي Cohere عن شراكة مع EnsembleHP (مزود حلول الرعاية الصحية)، لجلب منصة وكلاء الذكاء الاصطناعي Cohere North إلى قطاع الرعاية الصحية. يهدف الطرفان إلى تقليل الاحتكاك في عمليات الإدارة الطبية وتعزيز تجربة المرضى في المستشفيات والأنظمة الصحية من خلال منصة وكلاء ذكاء اصطناعي آمنة. تمثل هذه الخطوة خطوة مهمة لـ Cohere في دفع تطبيقات نماذجها اللغوية الكبيرة وتكنولوجيا الذكاء الاصطناعي في القطاعات الرأسية الرئيسية (المصدر: X)
🌟 مجتمع
Ilya Sutskever في خطاب درجة الشرف بجامعة تورنتو: الذكاء الاصطناعي سيصبح قادرًا على كل شيء في النهاية، ويتطلب اهتمامًا إيجابيًا: صرح Ilya Sutskever، المؤسس المشارك لـ OpenAI، في خطابه بمناسبة حصوله على درجة الدكتوراه الفخرية في العلوم من جامعة تورنتو (وهي الدرجة الرابعة له من الجامعة)، بأن تقدم الذكاء الاصطناعي سيجعله “قادرًا يومًا ما على إنجاز كل ما يمكننا القيام به”، لأن الدماغ البشري هو كمبيوتر بيولوجي، والذكاء الاصطناعي هو دماغ رقمي. ويرى أننا نعيش في عصر استثنائي يحدده الذكاء الاصطناعي، الذي غير بالفعل معنى الدراسة والعمل بشكل عميق. وأكد أنه بدلاً من القلق، يجب علينا تكوين حدس من خلال استخدام ومراقبة أفضل تقنيات الذكاء الاصطناعي لفهم حدود قدراتها. ودعا الناس إلى الاهتمام بتطور الذكاء الاصطناعي والتعامل بفعالية مع التحديات والفرص الهائلة التي تصاحبه، لأن الذكاء الاصطناعي سيؤثر بعمق على حياة كل فرد. كما شارك عقليته الشخصية: “تقبل الواقع، لا تندم على الماضي، واسعَ لتحسين الوضع الحالي.” (المصدر: X, 36氪)
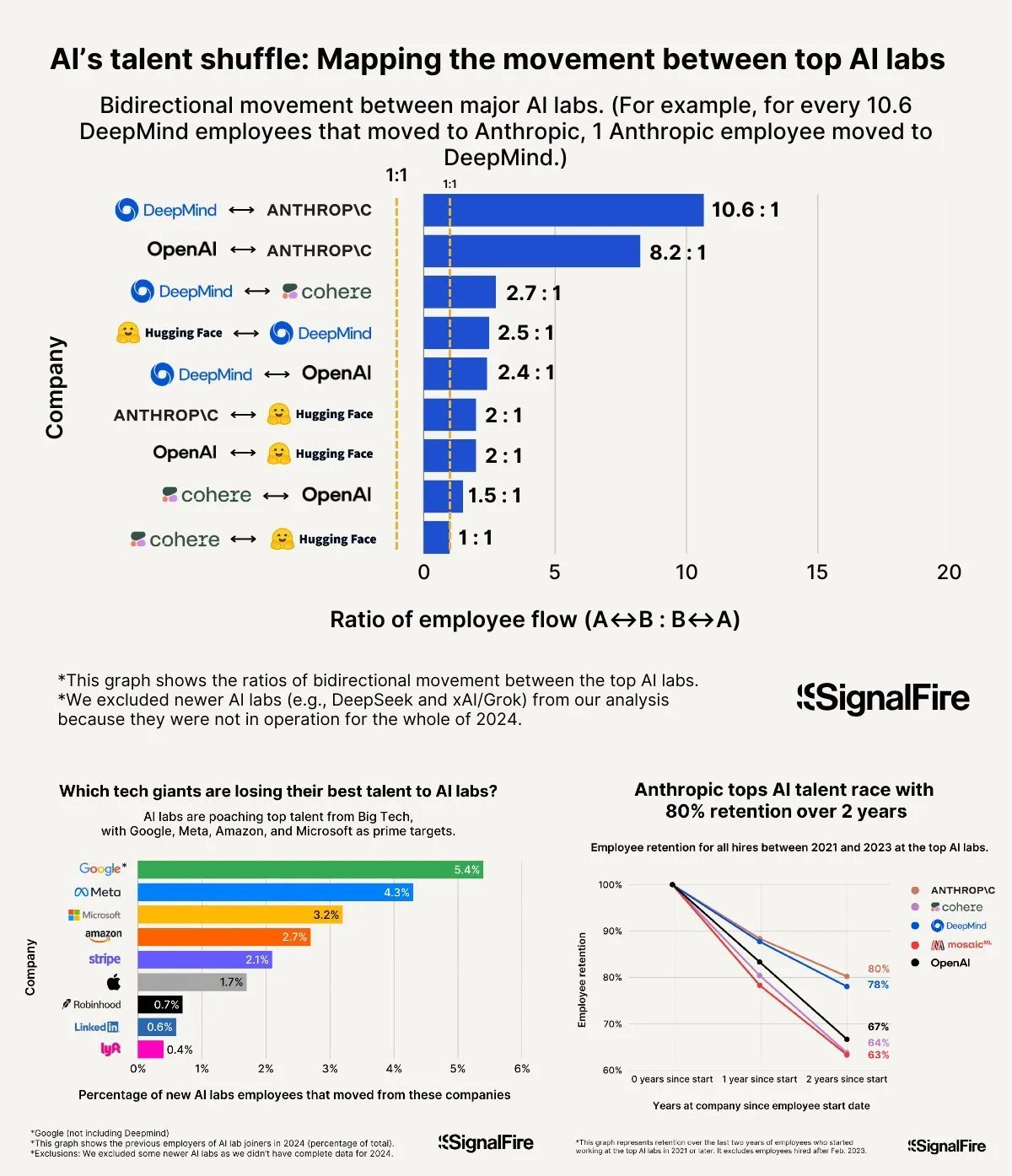
حرب المواهب في مجال الذكاء الاصطناعي تشتعل: Meta برواتبها المرتفعة لا تزال تجد صعوبة في منافسة OpenAI و Anthropic: يُقال إن Meta تعرض رواتب سنوية تزيد عن 2 مليون دولار لجذب مواهب الذكاء الاصطناعي، لكنها لا تزال تواجه نزوح المواهب إلى OpenAI و Anthropic. تشير المناقشات إلى أن رواتب المستوى L6 في OpenAI تقترب من 1.5 مليون دولار، وأن إمكانات نمو قيمة الأسهم تعتبر أفضل من Meta، مما يجعلها أكثر جاذبية في نظر أفضل المواهب. بالإضافة إلى ذلك، يُتهم فريق Llama بوجود سلوكيات غش، كما أن ضغط مؤشرات الأداء الرئيسية الداخلية في Meta وارتفاع معدل الاستبعاد (وصل إلى 15-20% هذا العام) يؤثران أيضًا على اختيار المواهب. أما Anthropic، فتتميز بمعدل احتفاظ بالمواهب يصل إلى حوالي 80% (بعد عامين من تأسيسها)، مما يجعلها واحدة من أفضل الشركات الكبرى التي يفضلها كبار باحثي الذكاء الاصطناعي. وُصفت شدة هذه الحرب على المواهب بأنها “لا يمكن تصورها” (المصدر: X, X)
مشاركة خبرات “Vibe Coding”: 5 قواعد لتجنب المزالق في البرمجة بمساعدة الذكاء الاصطناعي: على وسائل التواصل الاجتماعي، شارك مطورون ذوو خبرة خمس قواعد لتجنب الوقوع في دوامات تصحيح الأخطاء غير الفعالة عند استخدام الذكاء الاصطناعي (مثل Claude) في “Vibe Coding” (طريقة برمجة تعتمد على مساعدة الذكاء الاصطناعي): 1. ثلاث محاولات فاشلة: إذا فشل الذكاء الاصطناعي في إصلاح المشكلة ثلاث مرات، يجب التوقف وجعل الذكاء الاصطناعي يبني من جديد بناءً على وصف جديد للمتطلبات. 2. إعادة تعيين السياق: “ينسى” الذكاء الاصطناعي بعد محادثات طويلة، يوصى بحفظ الكود الفعال كل 8-10 جولات من الرسائل، وبدء جلسة جديدة ولصق مكونات المشكلة فقط ووصف موجز للتطبيق. 3. وصف المشكلة بإيجاز ووضوح: صف الخطأ بوضوح في جملة واحدة. 4. التحكم المتكرر في الإصدارات: قم بتثبيت التغييرات (commit) في Git بعد إكمال كل ميزة. 5. البدء من جديد عند الضرورة: إذا استغرق إصلاح الخطأ وقتًا طويلاً (مثل أكثر من ساعتين)، فمن الأفضل حذف مكون المشكلة والسماح للذكاء الاصطناعي بإعادة بنائه. يكمن جوهر الأمر في الاعتراف بأن الكود قد تلف بشكل لا رجعة فيه، ويجب التخلي بحزم عن محاولة إصلاحه. مع التأكيد على أن فهم البرمجة يمكّن من توجيه الذكاء الاصطناعي وتصحيح الأخطاء بشكل أفضل (المصدر: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
لي فيفي تتحدث عن تأسيس World Labs: نابع من استكشاف جوهر الذكاء، والذكاء المكاني هو الحلقة المفقودة الرئيسية في الذكاء الاصطناعي: في بودكاست a16z، شاركت لي فيفي دوافعها لتأسيس World Labs، مؤكدة أنها ليست مجرد مواكبة لموجة النماذج الأساسية، بل هي استكشاف مستمر لجوهر الذكاء. وترى أنه على الرغم من أن اللغة وسيلة فعالة لنقل المعلومات، إلا أنها تعاني من قصور في تمثيل العالم المادي ثلاثي الأبعاد، وأن الذكاء العام الحقيقي يجب أن يبنى على فهم الفضاء المادي والعلاقات بين الأشياء. حادثة إصابة في القرنية أدت إلى فقدانها المؤقت للرؤية ثلاثية الأبعاد، جعلتها تدرك بعمق أكبر أهمية تمثيل الفضاء ثلاثي الأبعاد للتفاعل المادي. تهدف World Labs إلى بناء نماذج ذكاء اصطناعي (نموذج العالم LWM) قادرة على فهم العالم المادي حقًا، لسد النقص الحالي في الذكاء الاصطناعي في مجال الذكاء المكاني. وترى أنه لتحقيق هذه الرؤية، يجب حشد القدرة الحاسوبية والبيانات والمواهب على المستوى الصناعي، وتشير إلى أن نقطة الاختراق التكنولوجي الحالية تكمن في تمكين الذكاء الاصطناعي من إعادة بناء فهم كامل للمشاهد ثلاثية الأبعاد من الرؤية الأحادية (المصدر: 量子位)

الذكاء الاصطناعي يساعد في امتحانات القبول الجامعي: من جدل توقع الأسئلة إلى الفرص والمخاوف في ملء طلبات الالتحاق: قبل وبعد امتحانات القبول الجامعي، أثارت تطبيقات الذكاء الاصطناعي في مجال التعليم نقاشًا واسعًا. فمن ناحية، أصبح “توقع أسئلة الامتحان بواسطة الذكاء الاصطناعي” موضوعًا ساخنًا، ولكن نظرًا للطبيعة العلمية والسرية لعملية وضع أسئلة الامتحانات وآليات “مكافحة توقع الأسئلة”، فإن إمكانية توقع الذكاء الاصطناعي للأسئلة بدقة منخفضة، كما أن جودة بعض أوراق توقع الأسئلة المتوفرة في السوق مشكوك فيها. ومن ناحية أخرى، أظهر الذكاء الاصطناعي دورًا إيجابيًا في تخطيط الاستعداد للامتحانات، وشرح الأسئلة، ومراقبة قاعات الامتحانات، وتصحيح الأوراق، مثل خطط الدراسة المخصصة، والإجابة الذكية على الأسئلة، وأنظمة المراقبة بالذكاء الاصطناعي التي تعزز العدالة والكفاءة. في مرحلة ملء طلبات الالتحاق، يمكن لأدوات الذكاء الاصطناعي أن توصي بسرعة بالكليات والتخصصات بناءً على درجات الطلاب وترتيبهم، مما يكسر فجوة المعلومات. ومع ذلك، فإن الاعتماد المفرط على الذكاء الاصطناعي في ملء الطلبات يثير أيضًا مخاوف: قد تعزز الخوارزميات تفضيل التخصصات الشائعة، متجاهلة الاهتمامات الفردية والتنمية طويلة الأجل؛ وقد يؤدي تسليم قرار مصيري بالكامل للخوارزميات إلى “سيطرة الخوارزميات على الحياة”. تدعو المقالة إلى التعامل بعقلانية مع مساعدة الذكاء الاصطناعي، مؤكدة على أهمية توجيه الأدوات بحكمة، وتحديد المستقبل بالتفكير (المصدر: 36氪)
مناقشة نماذج نجاح شركات وكلاء الذكاء الاصطناعي (AI Agent): الخدمة الذاتية مقابل الخدمات المخصصة: ناقش المجتمع نماذج نجاح شركات وكلاء الذكاء الاصطناعي، حيث يرى أحد الآراء أن شركات وكلاء الذكاء الاصطناعي الناجحة (خاصة تلك التي تخدم الأسواق المتوسطة والكبيرة) تتبنى في الغالب نموذجًا مشابهًا لـ Palantir، أي عدد كبير من مهندسي التطوير الميداني (FDEs) والبرامج المخصصة، بدلاً من نموذج الخدمة الذاتية البحت. بينما يصر الطرف الآخر على القيمة طويلة الأجل لنموذج الخدمة الذاتية، معتقدًا أن الفرق ستختار في النهاية بناء التطبيقات الهامة داخليًا. يعكس هذا مسارات التفكير المختلفة في مجال وكلاء الذكاء الاصطناعي فيما يتعلق بنماذج الخدمة واستراتيجيات السوق (المصدر: X)
💡 أخرى
تسريب موجه نظام Google Diffusion يكشف عن مبادئ تصميمه وحدود قدراته: شارك أحد المستخدمين ما يُزعم أنه موجه نظام Google Diffusion (نموذج لغوي لنشر النصوص). يوضح هذا الموجه بالتفصيل هوية النموذج (Gemini Diffusion، نموذج لغوي خبير لنشر النصوص مدرب بواسطة Google، غير ذاتي الانحدار)، والمبادئ والقيود الأساسية (مثل اتباع التعليمات، والخصائص غير ذاتية الانحدار، والدقة، وعدم الوصول في الوقت الفعلي، والأخلاقيات الأمنية، وتاريخ قطع المعرفة ديسمبر 2023، والقدرة على توليد الأكواد)، بالإضافة إلى تعليمات محددة لإنشاء صفحات ويب HTML وألعاب HTML. تغطي هذه التعليمات تنسيق الإخراج، والتصميم الجمالي، والأنماط (مثل الاستخدام المخصص لـ Tailwind CSS أو CSS المخصص في الألعاب)، واستخدام الأيقونات (أيقونات Lucide SVG)، والتخطيط والأداء (منع CLS)، ومتطلبات التعليقات. وأخيرًا، تم التأكيد على أهمية التفكير التدريجي واتباع تعليمات المستخدم بدقة. يوفر هذا الموجه نافذة لفهم طريقة تصميم مثل هذه النماذج وسلوكها المتوقع (المصدر: Reddit r/LocalLLaMA)
Arvind Narayanan يشرح نشأة وتفكير ورقة “الذكاء الاصطناعي كتكنولوجيا عادية”: شارك Arvind Narayanan، الأستاذ بجامعة برينستون، رحلة تأليف ورقته البحثية “AI as Normal Technology” بالاشتراك مع Sayash Kapoor. كان في البداية متشككًا بشأن الذكاء الاصطناعي العام (AGI) والمخاطر الوجودية، ولكن بناءً على إلحاح زملائه، قرر أن يأخذ الأمر على محمل الجد ويشارك في المناقشات ذات الصلة. من خلال التأمل، أدرك أن وجهات النظر المتعلقة بالذكاء الخارق تستحق الدراسة الجادة، وأن وسائل التواصل الاجتماعي ليست مناسبة للمناقشات الجادة، وأن مجتمعي أخلاقيات الذكاء الاصطناعي وأمن الذكاء الاصطناعي يعانيان كلاهما من “شرنقة معلومات” خاصة بهما. تم رفض المسودة الأولى للورقة في ICML، لكن الجدل الحاد أثناء عملية المراجعة عزز من تصميمهم على مواصلة البحث. أدركوا أن الخلاف مع مجتمع أمن الذكاء الاصطناعي أعمق مما كانوا يتوقعون، وأدركوا ضرورة إجراء نقاشات أكثر إنتاجية عبر التخصصات. في النهاية، نُشرت الورقة في ورشة عمل معهد Knight First Amendment بجامعة كولومبيا، وأثارت اهتمامًا واسعًا ونقاشات مثمرة، مما جعل Narayanan أكثر تفاؤلاً بشأن مستقبل سياسات الذكاء الاصطناعي (المصدر: X)
صعود جيل رواد الأعمال في مجال الذكاء الاصطناعي من مواليد ما بعد عام 2000، يعيدون تشكيل قواعد ريادة الأعمال: تبرز مجموعة من رواد الأعمال في مجال الذكاء الاصطناعي من مواليد ما بعد عام 2000 بسرعة مذهلة في موجة ريادة الأعمال العالمية، حيث يعيدون تعريف قوانين ريادة الأعمال بفضل فهمهم العميق لتكنولوجيا الذكاء الاصطناعي وبصيرتهم الحادة بالبيئة الرقمية الأصلية. تشمل الأمثلة Michael Truell من Anysphere (Cursor) (الذي تحول في 3 سنوات من متدرب إلى رئيس تنفيذي لشركة بقيمة عشرات المليارات من الدولارات)، والمؤسسين الثلاثة لـ Mercor (الذين أنشأوا في عامين منصة توظيف بالذكاء الاصطناعي بقيمة عشرات المليارات)، و Eric Steinberger من Magic (الذي شارك في تأسيس شركة ترميز بالذكاء الاصطناعي بتمويل يزيد عن 400 مليون دولار وهو في الخامسة والعشرين من عمره)، و Hong Letong من Axiom (التي تركز على حل المشكلات الرياضية الصعبة بالذكاء الاصطناعي، وحصلت على تقييم عالٍ حتى قبل إطلاق منتج). يتميز هؤلاء رواد الأعمال الشباب عمومًا بالخصائص التالية: البرمجة هي لغتهم الأم؛ الشهرة المبكرة، واغتنام نافذة الفرص التكنولوجية؛ الإدراك الحاد لاحتياجات المستخدمين؛ الفهم الأصيل للمؤسسات والمنتجات القائم على الذكاء الاصطناعي، والميل نحو فرق عمل بسيطة وفعالة ومنطق “الذكاء الاصطناعي كمنتج”. يمثل نجاحهم تحولًا في نموذج ريادة الأعمال في عصر الذكاء الاصطناعي (المصدر: 36氪)