

كلمات مفتاحية:نماذج اللغة الكبيرة, القدرة على الاستدلال, المطابقة النمطية, الذكاء الاصطناعي العام, هلوسات التفكير, أبحاث آبل, كاشفات الذكاء الاصطناعي, تنظيم الذكاء الاصطناعي, آلية الانتباه اللوغاريتمي الخطي, نموذج هواتوي بانكو MoE, وضع الصوت المتقدم لـ ChatGPT, إطار TensorZero, رئيس شركة Anthropic حول الرقابة
🔥 أبرز العناوين
بحث لشركة Apple يكشف “وهم التفكير”: نماذج “الاستدلال” الحالية لا تفكر حقًا، بل تعتمد بشكل أكبر على مطابقة الأنماط: تشير ورقة بحثية حديثة لشركة Apple بعنوان “وهم التفكير: فهم نقاط القوة والضعف في نماذج الاستدلال من منظور تعقيد المشكلة” إلى أن النماذج اللغوية الكبيرة الحالية التي يُزعم أنها تمتلك قدرات “استدلال” (مثل Claude، DeepSeek-R1، GPT-4o-mini، وغيرها)، يُشبه أداؤها أداء أدوات مطابقة الأنماط عالية الكفاءة أكثر من كونه استدلالًا منطقيًا بالمعنى الحقيقي. وجدت الدراسة أن أداء هذه النماذج ينخفض بشكل كبير عند التعامل مع مشكلات خارج نطاق توزيع بيانات التدريب أو ذات تعقيد عالٍ، بل وقد ترتكب أخطاءً في المشكلات البسيطة بسبب “التفكير المفرط”، ويصعب عليها تصحيح الأخطاء المبكرة. تؤكد الدراسة أن عملية “التفكير” المزعومة للنماذج (مثل سلسلة الأفكار) غالبًا ما تفشل عند مواجهة مهام جديدة أو معقدة، مما يشير إلى أننا قد نكون أبعد مما هو متوقع عن الذكاء الاصطناعي العام (AGI). (المصدر: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

OpenAI تطلق تحديثًا لوضع الصوت المتقدم في ChatGPT، مع تحسينات في الطبيعية ووظائف الترجمة: أطلقت OpenAI تحديثًا هامًا لوضع الصوت المتقدم (Advanced Voice Mode) لمستخدمي ChatGPT المدفوعين. يُحسّن الإصدار الجديد بشكل كبير من طبيعية وسلاسة الصوت، مما يجعله يبدو أقرب إلى صوت الإنسان منه إلى مساعد ذكاء اصطناعي. بالإضافة إلى ذلك، يُحسّن التحديث أداء ترجمة اللغات والقدرة على اتباع التعليمات، ويضيف وضع ترجمة جديد، حيث يمكن للمستخدمين جعل ChatGPT يترجم باستمرار محادثات الطرفين طوال الجلسة حتى يُطلب منه التوقف. يهدف هذا التحديث إلى جعل التفاعل الصوتي أكثر سهولة وطبيعية، وتحسين تجربة المستخدم. (المصدر: juberti, Plinz, op7418, BorisMPower)
اتهامات لأدوات كشف الذكاء الاصطناعي بالفشل واحتمالية مساهمتها في “إخفاء” محتوى الذكاء الاصطناعي: ظهرت نقاشات واسعة على وسائل التواصل الاجتماعي والمنتديات التقنية تشير إلى أن أدوات كشف محتوى الذكاء الاصطناعي الحالية ليست فقط غير فعالة، بل قد تساعد عن غير قصد في جعل المحتوى الذي يولده الذكاء الاصطناعي أكثر صعوبة في الكشف. يعتقد العديد من المستخدمين والخبراء أن هذه الأدوات تعتمد بشكل أساسي على أنماط اللغة ومفردات معينة (مثل المصطلح الأكاديمي “delve”) لإصدار أحكامها، بدلاً من فهم مصدر المحتوى حقًا. نظرًا لمخاطر الأحكام الخاطئة (مما قد يسبب ظلمًا لمجموعات مثل الطلاب) وتطور نماذج الذكاء الاصطناعي نفسها لتجنب الكشف، فإن موثوقية هذه الأدوات موضع تساؤل كبير. هناك رأي مفاده أن وجود أدوات كشف الذكاء الاصطناعي يدفع المحتوى الذي يولده الذكاء الاصطناعي إلى تجنب بعض الخصائص التي يسهل تمييزها، وبالتالي يصبح أشبه بالكتابة البشرية. (المصدر: Reddit r/ArtificialInteligence, sytelus)

الرئيس التنفيذي لشركة Anthropic يدعو إلى تعزيز الشفافية والرقابة على المسؤولية في شركات الذكاء الاصطناعي: نشر الرئيس التنفيذي لشركة Anthropic مقال رأي في صحيفة “نيويورك تايمز”، أكد فيه على عدم التهاون في الرقابة على شركات الذكاء الاصطناعي، وخاصة الحاجة إلى زيادة شفافيتها ومساءلتها. تبدو هذه الدعوة مهمة بشكل خاص في ظل التطور السريع لصناعة الذكاء الاصطناعي وقدراتها المتزايدة يومًا بعد يوم، وتستجيب للمخاوف المجتمعية بشأن المخاطر المحتملة والأخلاقيات المتعلقة بالذكاء الاصطناعي. يرى المقال أنه مع تزايد تأثير تقنية الذكاء الاصطناعي، من الضروري ضمان أن تطورها يتماشى مع المصلحة العامة وتجنب إساءة استخدامها، وهذا يتطلب تضافر جهود التنظيم الذاتي للصناعة والرقابة الخارجية. (المصدر: Reddit r/artificial)

🎯 اتجاهات
Jeff Dean يتطلع إلى مستقبل الذكاء الاصطناعي: أجهزة متخصصة، تطور النماذج، وتطبيقات علمية: شارك Jeff Dean، رئيس قسم الذكاء الاصطناعي في جوجل، رؤيته حول مستقبل تطور الذكاء الاصطناعي في فعالية AI Ascent التي نظمتها Sequoia Capital. وأكد على أهمية الأجهزة المخصصة (مثل TPU) لتقدم الذكاء الاصطناعي، وناقش اتجاهات تطور بنى النماذج. كما استشرف Dean مستقبل البنية التحتية الحاسوبية، والإمكانات الهائلة لتطبيقات الذكاء الاصطناعي في مجالات مثل البحث العلمي، معتبرًا أن الذكاء الاصطناعي سيصبح أداة رئيسية لدفع الاكتشافات العلمية. (المصدر: TheTuringPost)

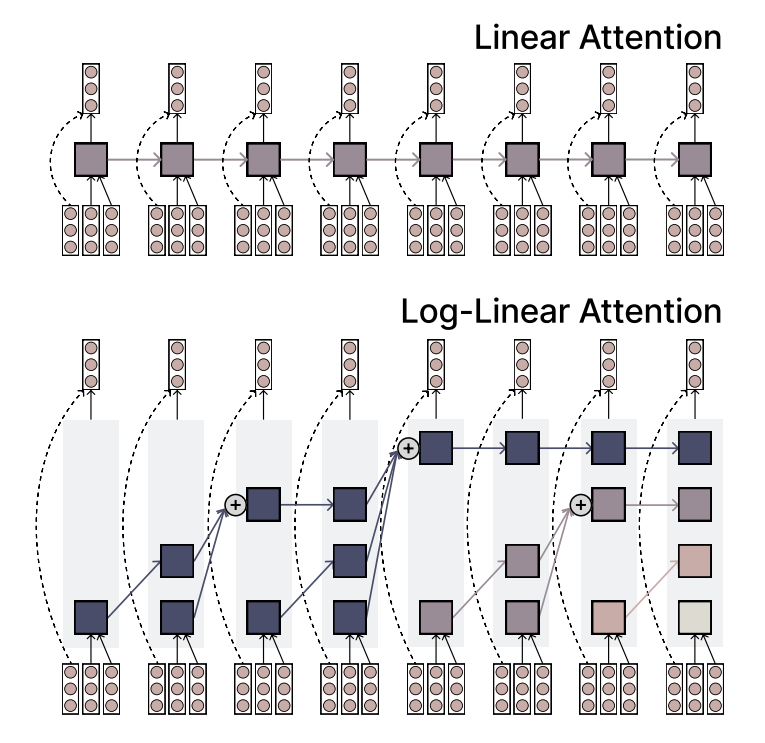
MIT تقترح آلية Log-Linear Attention، لتحقيق التوازن بين الكفاءة والقدرة التعبيرية: اقترح باحثون من MIT آلية انتباه جديدة تسمى Log-Linear Attention. تهدف هذه الآلية إلى الجمع بين كفاءة آلية الانتباه الخطي (Linear Attention) والقدرة التعبيرية القوية لآلية Softmax attention. وتتمثل ميزتها الأساسية في استخدام عدد قليل من “فتحات الذاكرة” (memory slots) التي تنمو بشكل لوغاريتمي مع طول التسلسل، مما يحافظ على تعقيد حسابي منخفض عند معالجة التسلسلات الطويلة، مع التقاط المعلومات الأساسية في نفس الوقت. (المصدر: TheTuringPost)
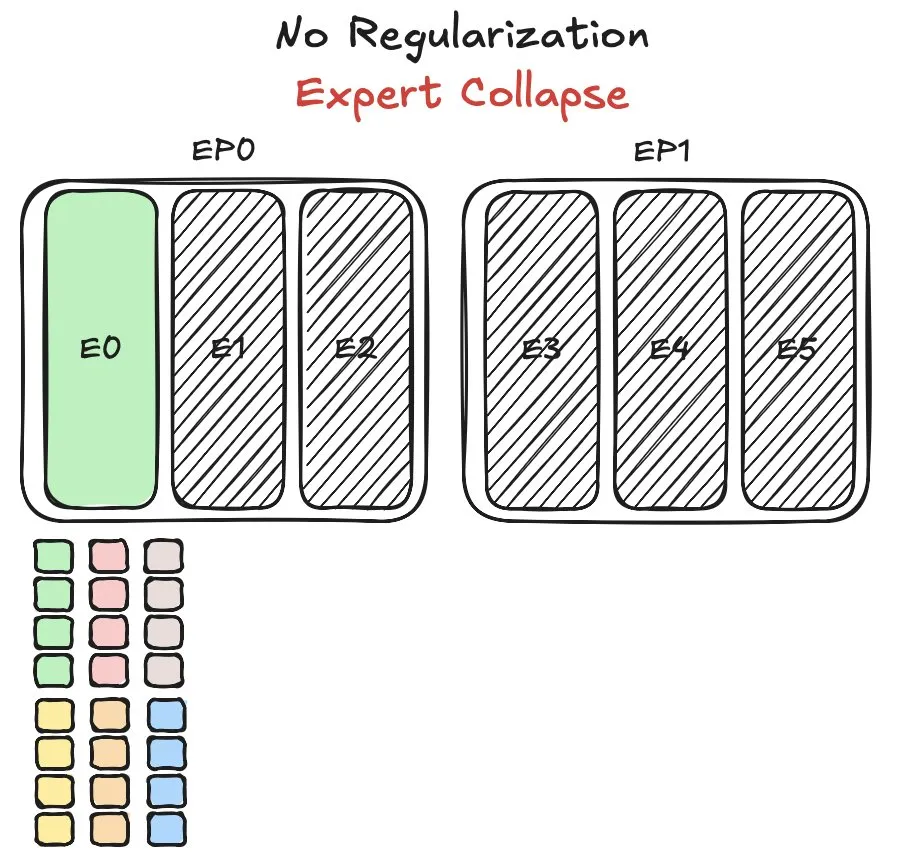
نموذج Pangu MoE من هواوي يواجه تحديات في موازنة تحميل الخبراء، ويقترح طريقة جديدة: واجهت هواوي مشكلة رئيسية في موازنة تحميل الخبراء (expert load balancing) أثناء تدريب نموذجها Pangu Ultra MoE القائم على خليط الخبراء (MoE). تتطلب موازنة تحميل الخبراء تحقيق توازن بين ديناميكيات التدريب وكفاءة النظام. اقترحت هواوي حلاً جديدًا لهذه المشكلة، يهدف إلى تحسين توزيع المهام والحمل الحسابي على وحدات الخبراء المختلفة في نموذج MoE، لرفع كفاءة التدريب وأداء النموذج. وقد تم نشر بحث ذي صلة. (المصدر: finbarrtimbers)
NVIDIA تطلق نموذج Cascade Mask R-CNN Mamba Vision، مع التركيز على اكتشاف الكائنات: أطلقت NVIDIA نموذجًا جديدًا على Hugging Face باسم cascade_mask_rcnn_mamba_vision_tiny_3x_coco. بناءً على الاسم، يبدو أن هذا النموذج مصمم خصيصًا لمهام اكتشاف الكائنات، وقد يدمج بنية Cascade R-CNN مع تقنية Mamba (نموذج فضاء الحالة) للرؤية، بهدف تحسين دقة وكفاءة اكتشاف الكائنات. (المصدر: _akhaliq)
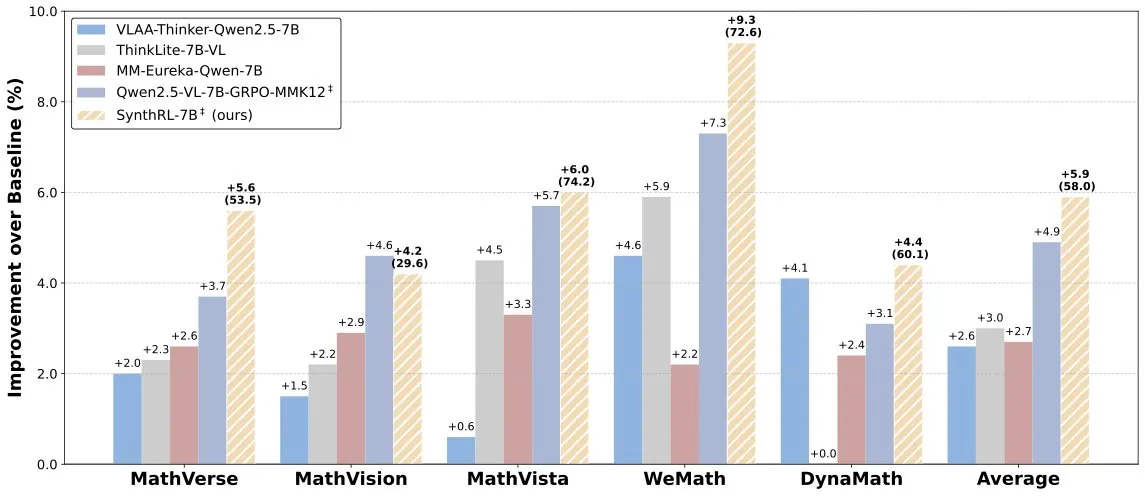
إطلاق نموذج SynthRL: تحقيق استدلال بصري قابل للتطوير من خلال توليف البيانات القابلة للتحقق: تم إطلاق نموذج SynthRL على Hugging Face، ويركز هذا النموذج على قدرات الاستدلال البصري القابلة للتطوير، وتكمن تقنيته الأساسية في توليد متغيرات أكثر تحديًا لمهام الاستدلال البصري من خلال طرق توليف البيانات القابلة للتحقق، مع الحفاظ على صحة الإجابات الأصلية. يساعد هذا في رفع مستوى فهم النموذج واستدلاله في السيناريوهات البصرية المعقدة. (المصدر: _akhaliq)
DeepSeek-R1 يُظهر أداءً جيدًا، لكن تفوق منتج ChatGPT لا يزال راسخًا: يشير تعليق من VentureBeat إلى أنه على الرغم من الأداء المتميز لنماذج ناشئة مثل DeepSeek-R1 في بعض الجوانب، إلا أن ChatGPT، بفضل ميزة الريادة، وقاعدة المستخدمين الواسعة، والنظام البيئي للمنتجات الناضج، والقدرة على التكرار المستمر، يصعب تجاوز مكانته الرائدة على مستوى المنتج على المدى القصير. المنافسة في مجال الذكاء الاصطناعي ليست مجرد مقارنة للمعايير التقنية، بل هي منافسة شاملة في تجربة المنتج، وبناء النظام البيئي، ونموذج الأعمال. (المصدر: Ronald_vanLoon)

فريق Qwen يؤكد أن Qwen3-coder قيد التطوير: أكد Junyang Lin من فريق Qwen أنهم يعملون على تطوير Qwen3-coder، وهو نموذج معزز بقدرات الترميز ضمن سلسلة Qwen3. على الرغم من عدم الإعلان عن جدول زمني محدد، فمن المتوقع، بالنظر إلى دورة إصدار Qwen2.5، أن يتم إطلاقه في غضون أسابيع قليلة. يتطلع المجتمع إلى أن يحقق هذا النموذج تقدمًا في توليد الأكواد، وتكامل سير عمل الأنظمة المستقلة/الوكيلة، وأن يحافظ على دعم جيد لمختلف لغات البرمجة. (المصدر: Reddit r/LocalLLaMA)

إطلاق OpenThinker3-7B، الذي يُزعم أنه أفضل نموذج استدلال مفتوح المصدر بمعاملات 7B مبني على بيانات مفتوحة: أعلن Ryan Marten عن إطلاق نموذج OpenThinker3-7B، واصفًا إياه بأنه أحدث نموذج استدلال بمعاملات 7B تم تدريبه على بيانات مفتوحة. يُزعم أن هذا النموذج يتفوق على DeepSeek-R1-Distill-Qwen-7B بنسبة 33% في المتوسط في تقييمات الأكواد والعلوم والرياضيات. كما تم إطلاق مجموعة بيانات التدريب الخاصة به OpenThoughts3-1.2M. (المصدر: menhguin)
🧰 أدوات
TensorZero: إطار عمل LLMOps مفتوح المصدر، لتحسين تطوير ونشر تطبيقات LLM: TensorZero هو إطار عمل مفتوح المصدر لتحسين تطبيقات LLM، يهدف إلى تحويل بيانات الإنتاج إلى نماذج أكثر ذكاءً وسرعة واقتصادًا من خلال حلقات التغذية الراجعة. يدمج بوابة LLM (تدعم العديد من مزودي النماذج)، وقابلية الملاحظة، والتحسين (التلقين، الضبط الدقيق، RL)، والتقييم، والتجريب (اختبار A/B)، ويدعم زمن انتقال منخفض، وإنتاجية عالية، و GitOps. الأداة مكتوبة بلغة Rust، مع التركيز على الأداء ومتطلبات التطبيقات الصناعية. (المصدر: GitHub Trending)

LangChain تطلق نظام RAG عالي الأداء يجمع بين SambaNova و Qdrant و LangGraph: قدمت LangChain حلاً لتطبيق نظام توليد معزز بالاسترجاع (RAG) عالي الأداء. يجمع هذا الحل بين نموذج DeepSeek-R1 من SambaNova، وتقنية التكميم الثنائي من Qdrant، و LangGraph، مما يتيح تقليل الذاكرة بمقدار 32 ضعفًا، وبالتالي معالجة المستندات واسعة النطاق بكفاءة. يوفر هذا إمكانيات جديدة لبناء تطبيقات RAG أكثر اقتصادًا وسرعة. (المصدر: hwchase17, qdrant_engine)
تطبيق Sparkify من جوجل لتوليد مقاطع الفيديو التعليمية بنقرة واحدة يعرض حالات عالية الجودة: يعرض تطبيق Sparkify الذي أطلقته جوجل، والذي يمكنه توليد مقاطع فيديو تعليمية بنقرة واحدة، حالات ذات جودة عالية جدًا. يتميز محتوى الفيديو بتناسق عام جيد، وتعليق صوتي طبيعي، بل ويمكنه تحقيق تأثيرات معقدة مثل عرض الشاشة المقسمة، مما يظهر إمكانات الذكاء الاصطناعي في إنشاء محتوى الفيديو تلقائيًا. (المصدر: op7418)
Hugging Face تطلق أول خادم MCP، لتوسيع وظائف روبوتات الدردشة: أطلقت Hugging Face أول خادم MCP (Modular Chat Processor) لها (hf.co/mcp)، والذي يمكن للمستخدمين لصقه في مربع الدردشة لاستخدامه. يهدف خادم MCP إلى تعزيز وظائف روبوتات الدردشة، من خلال توفير تجربة تفاعلية أكثر ثراءً عبر وحدات معالجة نمطية. قام المجتمع أيضًا بتجميع قائمة بخوادم MCP مفيدة أخرى، مثل Agentset MCP و GitHub MCP وغيرها. (المصدر: TheTuringPost)
أداء Chatterbox TTS يضاهي ElevenLabs، وتم دمجه في gptme: لفتت أداة تحويل النص إلى كلام (TTS) Chatterbox الانتباه بفضل تأثيراتها الصوتية المتميزة، حيث أفاد المستخدمون بأن أدائها يضاهي أداء ElevenLabs الشهير، ويتفوق على Kokoro. يدعم Chatterbox تخصيص الصوت من خلال عينات مرجعية، وقد تم إضافته الآن كواجهة خلفية لـ TTS في gptme، مما يوفر للمستخدمين خيارات إخراج صوتي عالية الجودة. (المصدر: teortaxesTex, _akhaliq)
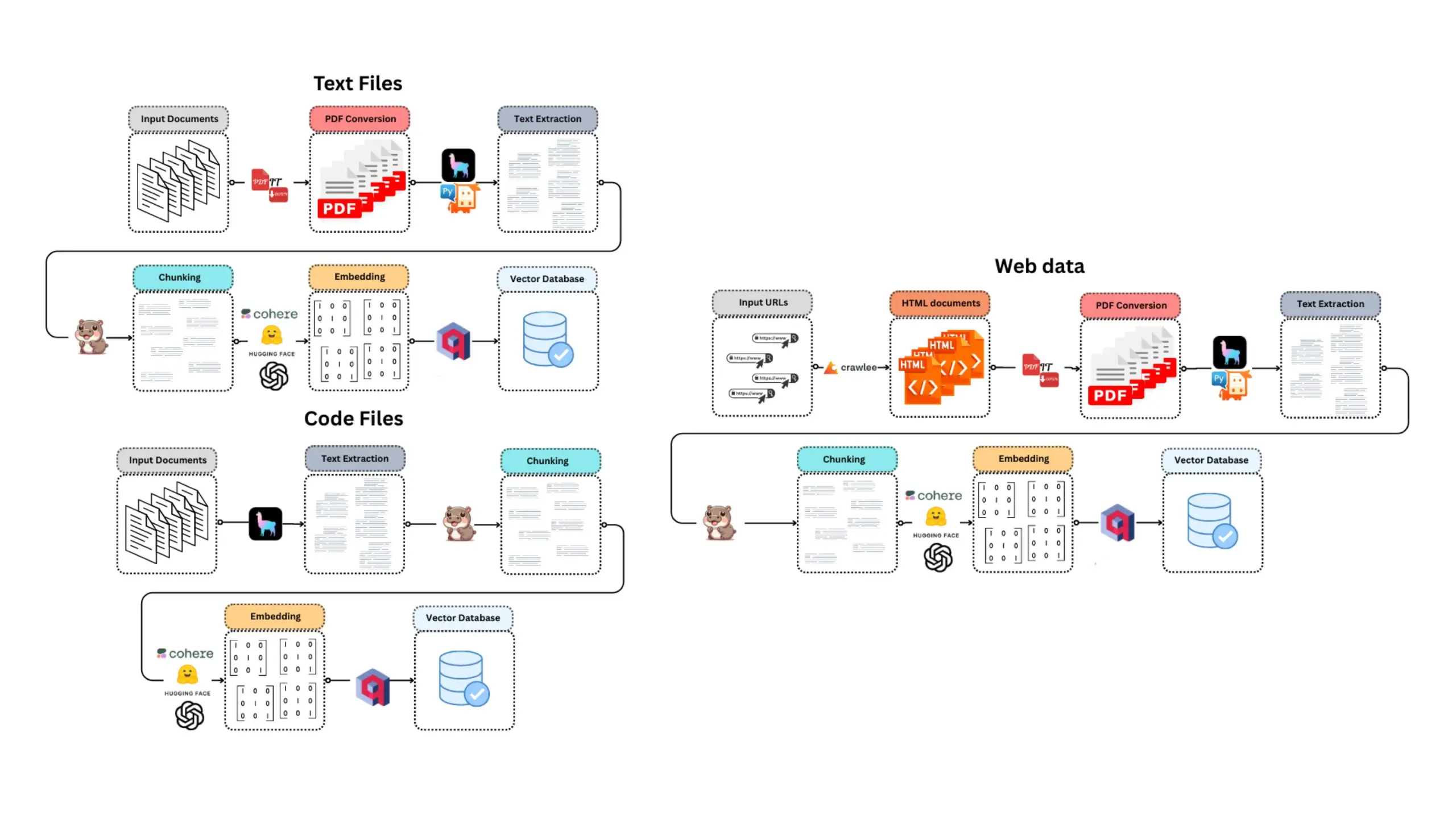
E-Library-Agent: نظام ذكي لاسترجاع الكتب/الوثائق المحلية والإجابة على الأسئلة المتعلقة بها: E-Library-Agent هو وكيل ذكاء اصطناعي ذاتي الاستضافة، قادر على استخراج وفهرسة والاستعلام عن مجموعات الكتب أو الأوراق البحثية الشخصية. يعتمد المشروع على ingest-anything، ويدعمه LlamaIndex و Qdrant ومنصة Linkup، مما يحقق استخراج المواد المحلية، والإجابة على الأسئلة مع مراعاة السياق، بالإضافة إلى وظيفة الاكتشاف عبر الويب من خلال واجهة واحدة، مما يسهل على المستخدمين إدارة واستغلال قواعد معارفهم الشخصية. (المصدر: qdrant_engine)
Claude Code يحظى بتقدير كبير من المطورين لقدراته القوية في المساعدة على الترميز: شارك مستخدمون من مجتمع Reddit تجارب إيجابية في استخدام Claude Code من Anthropic لتطوير البرمجيات، خاصة في مجالات مثل تطوير الألعاب (مثل مشاريع Godot C#). أشاد المستخدمون بقدرته على حل المشكلات المعقدة التي تتجاوز بكثير قدرات مساعدي الترميز الآخرين المعتمدين على الذكاء الاصطناعي (مثل GitHub Copilot)، وقدرته على فهم السياق وتوليد أكواد فعالة، حتى أن تكلفة 100 دولار شهريًا اعتبرت ذات قيمة جيدة. يعتقد المطورون أن المبرمجين ذوي الخبرة بالتعاون مع Claude Code سيكونون منتجين للغاية. (المصدر: Reddit r/ClaudeAI)
ChatterUI يدعم النماذج البصرية المحلية، ولكن المعالجة بطيئة على أندرويد: أضاف الإصدار التجريبي من عميل الدردشة LLM ChatterUI دعمًا للمرفقات والنماذج البصرية المحلية (عبر llama.rn). يمكن للمستخدمين تحميل ملفات mmproj للنماذج المحلية المتوافقة، أو الاتصال بواجهات برمجة تطبيقات تدعم الوظائف البصرية (مثل Google AI Studio، OpenAI). ومع ذلك، نظرًا لعدم وجود واجهة خلفية مستقرة لوحدة معالجة الرسومات لـ llama.cpp على أندرويد، فإن سرعة معالجة الصور بطيئة للغاية (على سبيل المثال، صورة 512×512 تحتاج إلى 5 دقائق)، بينما يكون الأداء أفضل نسبيًا على iOS. (المصدر: Reddit r/LocalLLaMA)
FLUX kontext يُظهر أداءً متميزًا في استبدال خلفيات صور السيارات الترويجية: اكتشف المستخدمون بعد اختبار أداة تحرير الصور بالذكاء الاصطناعي FLUX kontext أنها فعالة بشكل ملحوظ في تعديل خلفيات صور السيارات الترويجية. على سبيل المثال، عند تغيير خلفية الصور الرسمية لسيارة Xiaomi SU7 (مثل شاطئ عند الغسق، أو حلبة سباق)، لم تتمكن الأداة من دمج الخلفية بشكل طبيعي فحسب، بل أضافت أيضًا بذكاء تأثير ضبابية الحركة للمركبات المتحركة، مما عزز واقعية الصورة وتأثيرها البصري. (المصدر: op7418)

📚 موارد تعليمية
وظيفة flexicache الجديدة في fastcore: مُزخرف تخزين مؤقت مرن: قدم Jeremy Howard وظيفة جديدة عملية في مكتبة fastcore تُسمى flexicache. وهو مُزخرف تخزين مؤقت مرن للغاية، يتضمن استراتيجيتي تخزين مؤقت مدمجتين: ‘mtime’ (بناءً على وقت تعديل الملف) و ‘time’ (بناءً على الطابع الزمني)، ويسمح للمستخدمين بتخصيص استراتيجيات تخزين مؤقت جديدة ببضعة أسطر من التعليمات البرمجية. تم شرح هذه الوظيفة بالتفصيل في مقال كتبه Daniel Roy Greenfeld، وتساعد في تحسين كفاءة تنفيذ التعليمات البرمجية. (المصدر: jeremyphoward)
استكشاف إمكانات الجمع بين MuP و Muon لتدريب نماذج Transformer: تعمق Jingyuan Liu في دراسة عمل Jeremy Bernstein حول اشتقاق Muon والشروط الطيفية، وأعرب عن إعجابه بأناقة عملية الاشتقاق، خاصة كيف يعمل MuP (Maximal Update Parametrization) و Muon (محسن) معًا. ويرى أنه من وجهة نظر الاشتقاق، فإن استخدام Muon كمحسن لتدريب النماذج القائمة على MuP هو خيار طبيعي، ويشير إلى أن هذا قد يكون أكثر إثارة من نقل المعلمات الفائقة من AdamW إلى Muon عن طريق مطابقة تحديث RMS في عمل Moonshot’s Moonlight. يعتقد مجتمع المطورين أن الجمع بين MuP + Muon من المتوقع أن يتم تطبيقه على نطاق واسع من قبل شركات التكنولوجيا الكبرى بحلول نهاية العام. (المصدر: jeremyphoward)

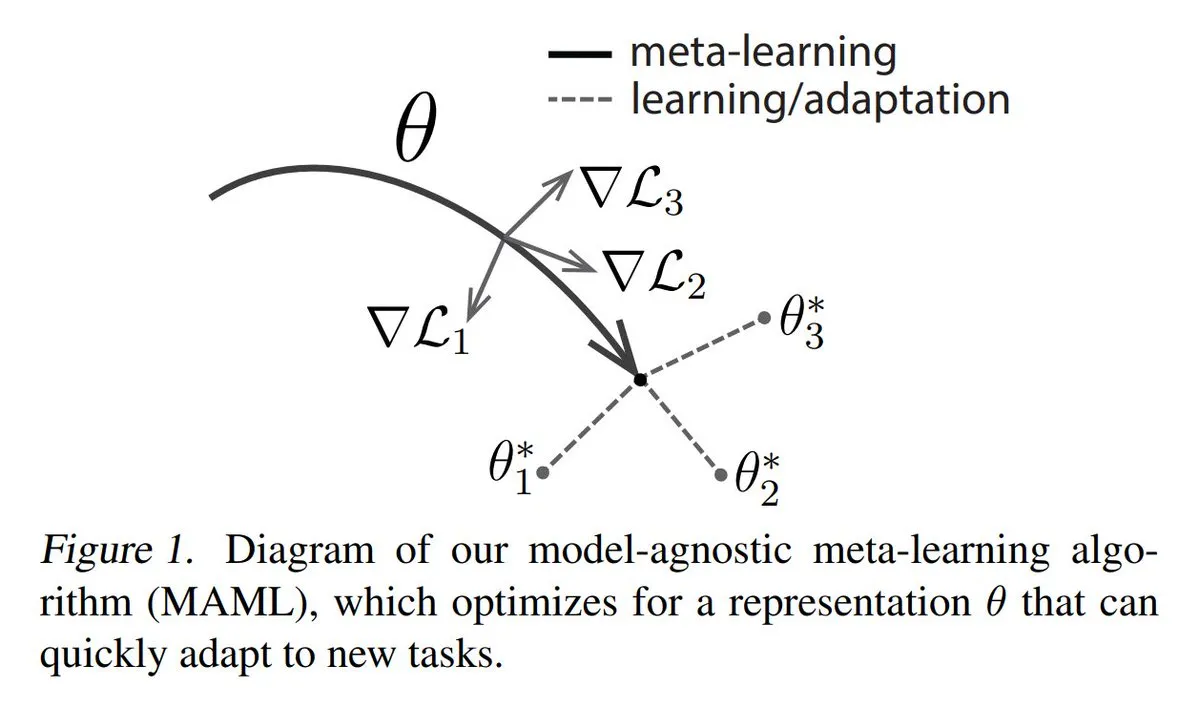
تحليل ثلاث طرق رئيسية للتعلم التلوي (Meta-learning): يهدف التعلم التلوي إلى تدريب النماذج على تعلم مهام جديدة بسرعة، حتى مع وجود عدد قليل من العينات. تشمل الطرق الشائعة ما يلي: 1. القائمة على التحسين/القائمة على التدرج: البحث عن معلمات النموذج التي يمكن ضبطها بكفاءة على المهام من خلال خطوات تدرج قليلة. 2. القائمة على القياس: مساعدة النموذج في إيجاد طرق أفضل لقياس التشابه بين العينات الجديدة والقديمة، وتجميع العينات ذات الصلة بفعالية. 3. القائمة على النموذج: يتم تصميم النموذج بأكمله بحيث يمكنه الاستفادة من الذاكرة المدمجة أو الآليات الديناميكية للتكيف بسرعة. يقدم TuringPost شرحًا مفصلاً لطرق التعلم التلوي من الأساسيات إلى الطرق الحديثة. (المصدر: TheTuringPost)
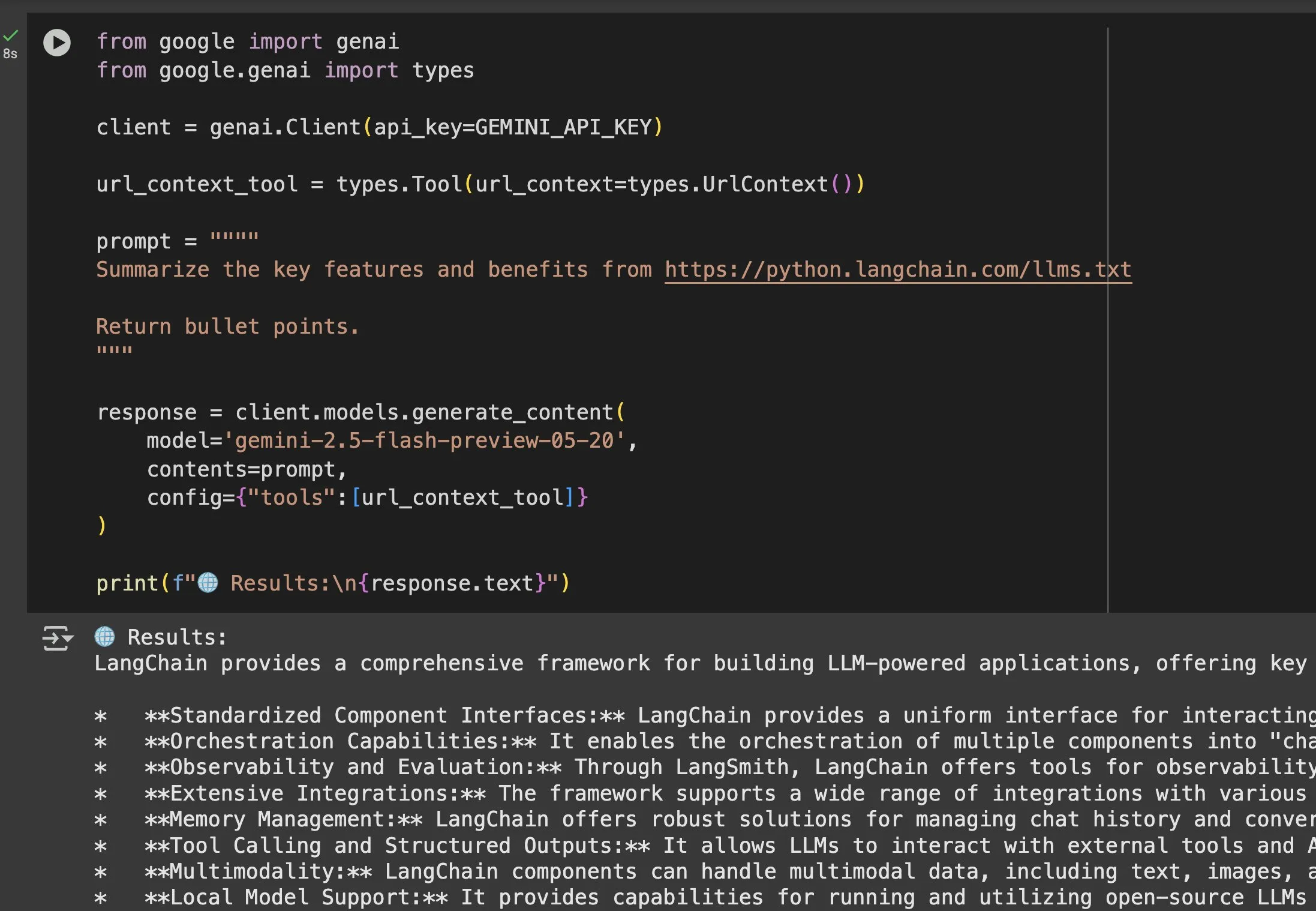
أهمية ملفات llms.txt في تطبيقات نماذج مثل Gemini تبرز بشكل واضح: أكد Jeremy Phoward على الفائدة العملية لملفات llms.txt. على سبيل المثال، يمكن لـ Gemini الآن فهم المحتوى الموجود في عناوين URL، وذلك ببساطة عن طريق إضافة عنوان URL في التلقين وتهيئة أداة سياق URL. هذا يعني أن العميل (مثل Gemini)، من خلال قراءة نقطة نهاية llms.txt، يمكنه معرفة مكان تخزين المعلومات المطلوبة بدقة، مما يسهل بشكل كبير الحصول على المعلومات واستخدامها برمجيًا. (المصدر: jeremyphoward)
EleutherAI تطلق مجموعة بيانات نصية Common Pile v0.1 بحجم 8TB ومرخصة بشكل مفتوح: أعلنت EleutherAI عن إطلاق Common Pile v0.1، وهي مجموعة بيانات ضخمة تحتوي على 8TB من النصوص المرخصة بشكل مفتوح والنصوص الموجودة في الملك العام. قاموا بتدريب نماذج لغوية بمعاملات 7B بناءً على مجموعة البيانات هذه (باستخدام 1T و 2T token للتدريب على التوالي)، ويمكن مقارنة أدائها بنماذج مماثلة مثل LLaMA 1 و LLaMA 2. يوفر هذا موارد قيمة وأدلة تجريبية للبحث في تدريب نماذج لغوية عالية الأداء باستخدام بيانات متوافقة تمامًا. (المصدر: clefourrier)

SelfCheckGPT: طريقة لكشف هلوسة LLM بدون الحاجة إلى مرجع: تستكشف مقالة مدونة SelfCheckGPT كبديل لـ LLM-as-a-judge (استخدام LLM كمقيم) للكشف عن الهلوسة في النماذج اللغوية. هذه طريقة كشف لا تتطلب نصًا مرجعيًا ولا موارد، وتوفر أفكارًا جديدة لتقييم وتحسين واقعية مخرجات LLM. (المصدر: dl_weekly)
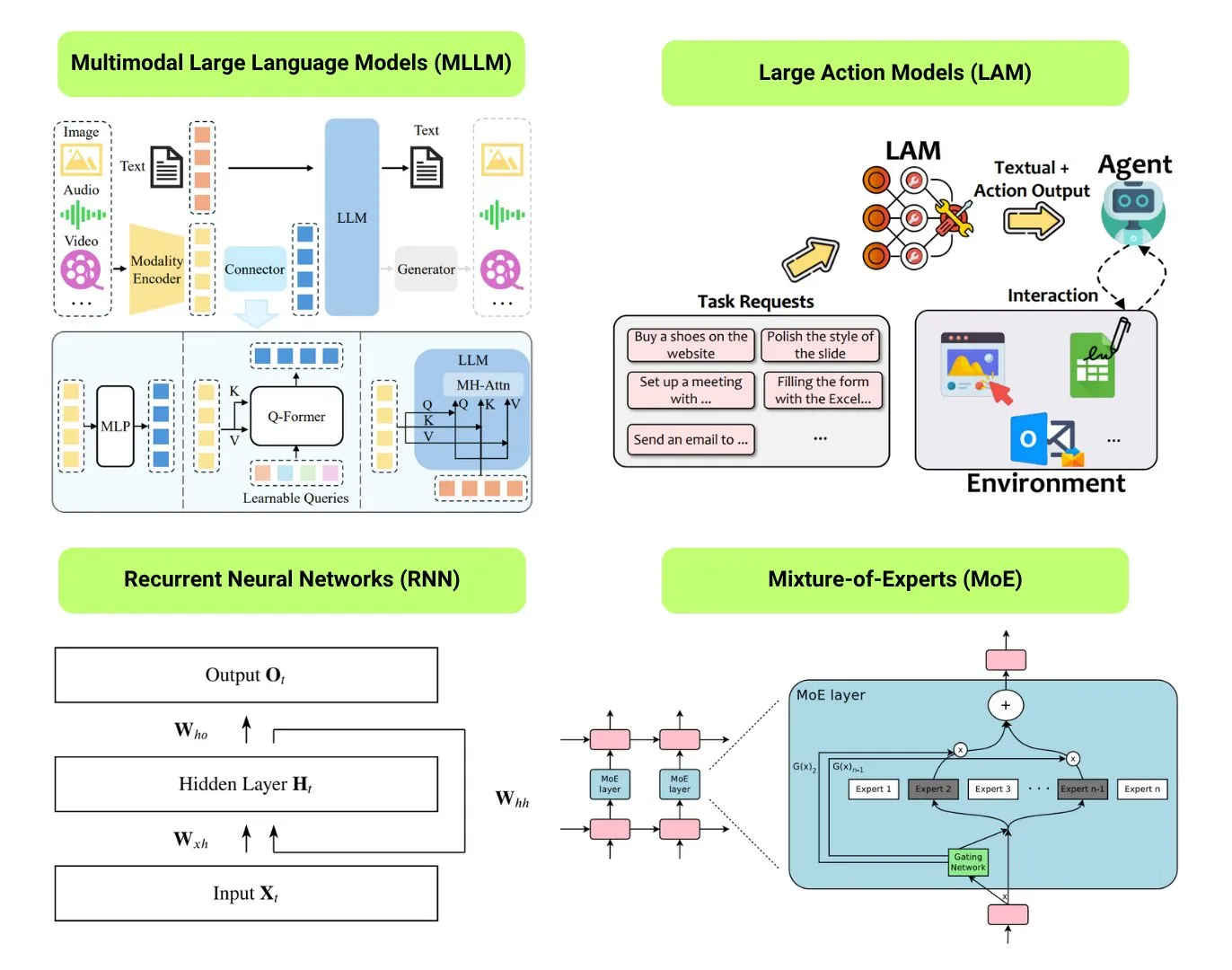
تصنيف 12 نوعًا أساسيًا من نماذج الذكاء الاصطناعي: قام The Turing Post بتجميع 12 نوعًا أساسيًا من نماذج الذكاء الاصطناعي، بما في ذلك LLM (النماذج اللغوية الكبيرة)، SLM (النماذج اللغوية الصغيرة)، VLM (نماذج اللغة المرئية)، MLLM (النماذج اللغوية الكبيرة متعددة الوسائط)، LAM (نماذج السلوك الكبيرة)، LRM (نماذج الاستدلال الكبيرة)، MoE (نماذج خليط الخبراء)، SSM (نماذج فضاء الحالة)، RNN (الشبكات العصبية المتكررة)، CNN (الشبكات العصبية التلافيفية)، SAM (نماذج تجزئة كل شيء)، و LNN (الشبكات العصبية المنطقية). توفر الموارد ذات الصلة شرحًا لهذه الأنواع من النماذج وروابط مفيدة. (المصدر: TheTuringPost)
شائع على GitHub: برنامج تعليمي Kubernetes The Hard Way: يستمر البرنامج التعليمي “Kubernetes The Hard Way” من Kelsey Hightower في جذب الانتباه على GitHub. يهدف هذا البرنامج التعليمي إلى مساعدة المستخدمين على بناء مجموعات Kubernetes يدويًا خطوة بخطوة، لفهم مكوناتها الأساسية ومبادئ عملها بعمق، بدلاً من الاعتماد على البرامج النصية الآلية. يستهدف البرنامج التعليمي المتعلمين الذين يرغبون في إتقان أساسيات Kubernetes، ويغطي العملية برمتها بدءًا من إعداد البيئة وحتى تنظيف المجموعة. (المصدر: GitHub Trending)
شائع على GitHub: قائمة GPTs و Prompts مجانية: يحظى مستودع friuns2/BlackFriday-GPTs-Prompts بشعبية على GitHub، حيث يجمع وينظم سلسلة من نماذج GPT المجانية و Prompts عالية الجودة، والتي يمكن للمستخدمين استخدامها دون الحاجة إلى اشتراك Plus. تغطي هذه الموارد مجالات متعددة مثل البرمجة، والتسويق، والبحث الأكاديمي، والبحث عن عمل، والألعاب، والإبداع، وتتضمن بعض حيل “Jailbreaks”، مما يوفر لمستخدمي GPT أدوات وإلهامًا غنيًا جاهزًا للاستخدام. (المصدر: GitHub Trending)

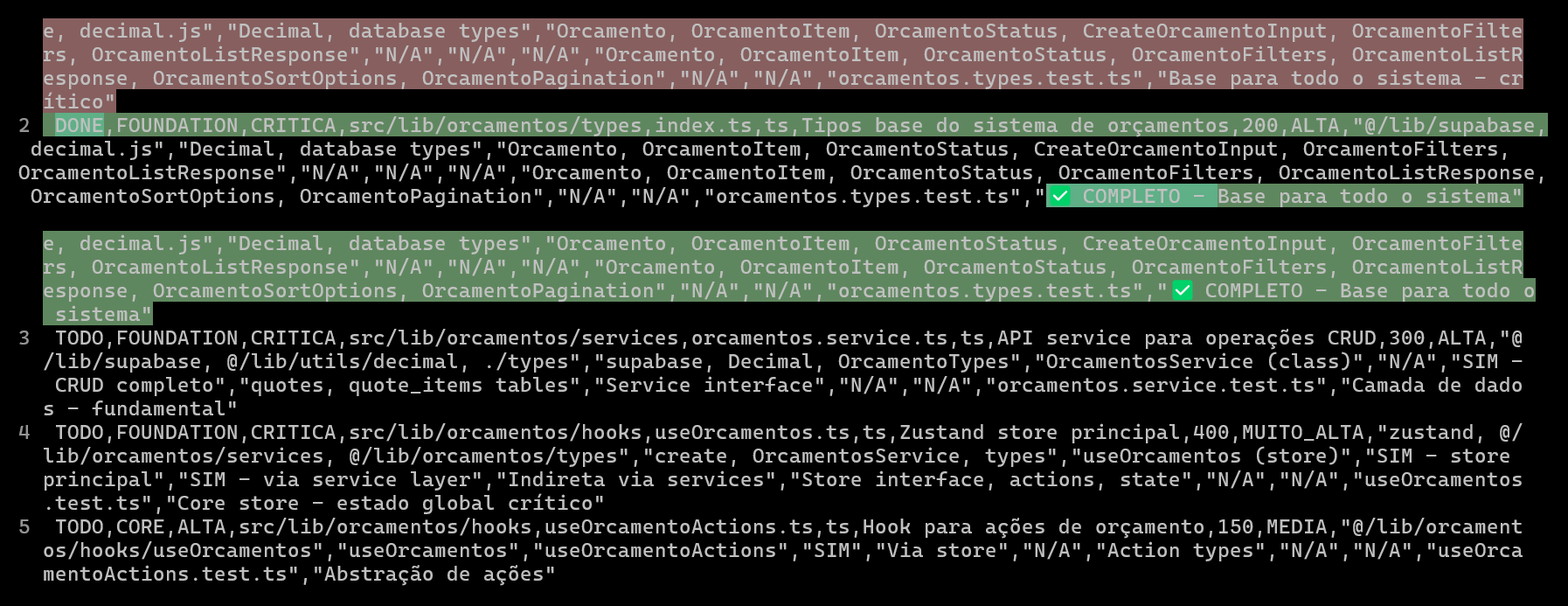
استخدام CSV لتخطيط وتتبع مشاريع الترميز بالذكاء الاصطناعي، لتحسين جودة وكفاءة الكود: شارك مطور تجربته في استخدام Claude Code لتطوير نظام ERP، حيث قام بإنشاء ملفات CSV مفصلة لتخطيط وتتبع تقدم ترميز كل ملف، مما أدى إلى تحسين كبير في كفاءة تطوير الوظائف المعقدة وجودة الكود. يتضمن ملف CSV الحالة، واسم الملف، والأولوية، وعدد أسطر الكود، والتعقيد، والتبعيات، ووصف الوظيفة، و Hooks المستخدمة، ووحدات الاستيراد والتصدير، و “ملاحظات التقدم” الهامة. تتيح هذه الطريقة للذكاء الاصطناعي التركيز بشكل أفضل على بناء الكود، وتجعل المطور على دراية واضحة بالتقدم الفعلي للمشروع والاختلافات عن الخطة الأصلية. (المصدر: Reddit r/ClaudeAI)
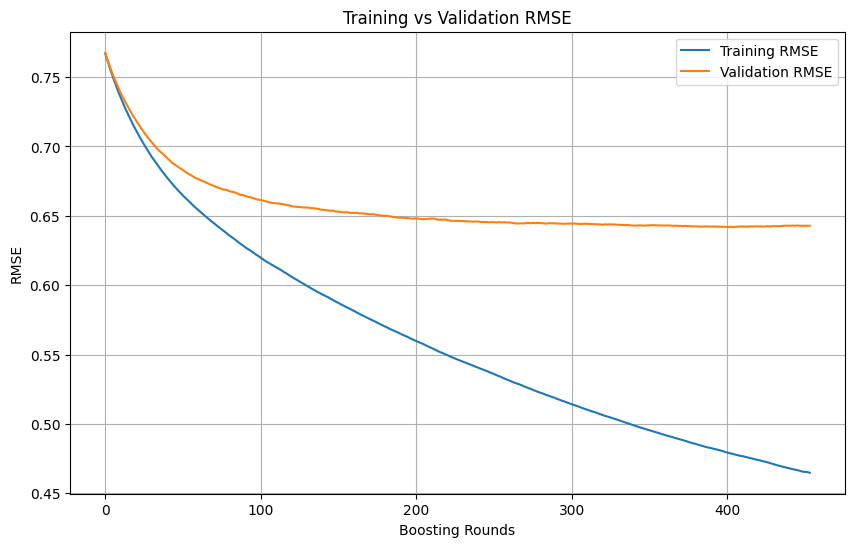
الحكم على فرط التخصيص (Overfitting) وتوقيت إيقاف التدريب في تعلم الآلة: أثناء عملية تدريب نماذج تعلم الآلة، عندما يستمر فقدان التدريب (training loss) في الانخفاض بسرعة، بينما ينخفض فقدان التحقق (validation loss) ببطء أو حتى يتوقف أو يرتفع، يشير هذا عادةً إلى أن النموذج قد يعاني من فرط التخصيص. من حيث المبدأ، طالما أن فقدان التحقق لا يزال في انخفاض، يمكن مواصلة التدريب. يكمن المفتاح في التأكد من أن مجموعة التحقق مستقلة عن مجموعة التدريب وتمثل التوزيع الحقيقي لبيانات المهمة. إذا توقف فقدان التحقق عن الانخفاض أو بدأ في الارتفاع، يجب التفكير في إيقاف التدريب مبكرًا، أو اتخاذ طرق مثل التنظيم (regularization) لتحسين قدرة النموذج على التعميم. (المصدر: Reddit r/MachineLearning)
🌟 مجتمع
معرض AI Engineer World’s Fair 2025 يركز على قضايا مثل RL+Reasoning و Eval وغيرها: تغطي موضوعات مؤتمر AI Engineer World’s Fair 2025 اتجاهات متقدمة مثل التعلم المعزز + الاستدلال (RL+Reasoning)، والتقييم (Eval)، ووكلاء هندسة البرمجيات (SWE-Agent)، ومهندسي الذكاء الاصطناعي، والبنية التحتية للوكلاء. أفاد المشاركون بأن المؤتمر كان مليئًا بالحيوية والتفكير الابتكاري، حيث تجرأ الكثيرون على تجربة أشياء جديدة، وإعادة تشكيل ذواتهم باستمرار، والانخراط في مجال الذكاء الاصطناعي. كما وفر المؤتمر منصة للمهندسين في مجال الذكاء الاصطناعي للتواصل والتعلم. (المصدر: swyx, hwchase17, charles_irl, swyx)

الذكاء الاصطناعي المثالي حسب Sam Altman: نموذج صغير + استدلال فائق القوة + سياق هائل + أداة شاملة: وصف Sam Altman الشكل المثالي للذكاء الاصطناعي في تصوره: نموذج ذو قدرة استدلال تفوق قدرة الإنسان، وحجم صغير للغاية، يمكنه الوصول إلى تريليونات من المعلومات السياقية، ويمكنه استدعاء أي أداة يمكن تخيلها. أثار هذا الرأي نقاشًا، حيث رأى البعض أن هذا يختلف عن الوضع الحالي للنماذج الكبيرة التي تعتمد على تخزين المعرفة، وشككوا في جدوى قدرة النماذج الصغيرة على تحليل المعرفة وإجراء استدلال معقد ضمن سياق ضخم، معتبرين أنه من الصعب فصل المعرفة عن القدرة على التفكير بكفاءة. (المصدر: teortaxesTex)
وكلاء الترميز يثيرون الرغبة في إعادة هيكلة الأكواد، تحديات وفرص البرمجة بمساعدة الذكاء الاصطناعي: أفاد مطورون بأن ظهور وكلاء الترميز قد عزز بشكل كبير “إغراء” إعادة هيكلة أكواد الآخرين، ولكنه جلب أيضًا مخاطر جديدة. شارك مطور تجربته في استخدام الذكاء الاصطناعي لإكمال مهمة برمجية تتطلب حوالي 10 دقائق من العمل اليدوي، وعلى الرغم من أن الذكاء الاصطناعي يمكنه توليد كود فعال بسرعة، إلا أن الوصول إلى مستوى التنظيم والأسلوب الذي يتمتع به مبرمج متمرس لا يزال يتطلب قدرًا كبيرًا من التوجيه اليدوي وإعادة الهيكلة. يسلط هذا الضوء على التحديات التي تواجه البرمجة بمساعدة الذكاء الاصطناعي في رفع جودة الأكواد من المستوى المبتدئ/المتوسط إلى المستوى المتقدم. (المصدر: finbarrtimbers, mitchellh)
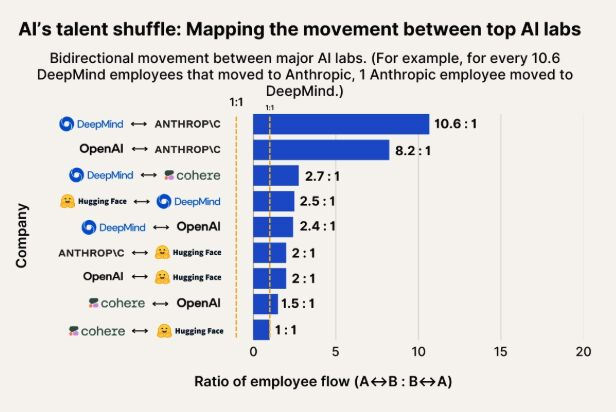
ملاحظات حول حركة المواهب في مجال الذكاء الاصطناعي: Anthropic تصبح وجهة مهمة للمواهب من Google DeepMind و OpenAI: يُظهر رسم بياني يوضح حركة المواهب في مجال الذكاء الاصطناعي أن Anthropic أصبحت شركة مهمة تجتذب الباحثين من Google DeepMind و OpenAI. أبدى المجتمع موافقته على هذا التصور، وتكهن بعض المستخدمين بأن Anthropic قد تمتلك بعض “الأسلحة السرية” أو اتجاهات بحثية فريدة تجذب أفضل المواهب. (المصدر: bookwormengr, TheZachMueller)
انتشار الروبوتات البشرية يواجه تحديات الثقة والقبول الاجتماعي: يتوقع المعلق التكنولوجي Faruk Guney أن الموجة الأولى من الروبوتات البشرية قد تفشل بسبب عجز كبير في الثقة. ويرى أنه على الرغم من التقدم التكنولوجي المستمر، فإن المجتمع لم يستعد بعد لقبول هذه “الذكاءات الصندوق الأسود” في المنازل، لتنفيذ مهام مثل الرفقة، والأعمال المنزلية، وحتى رعاية الأطفال. إن القرارات غير الشفافة للروبوتات، ومخاطر المراقبة المحتملة، والمظهر “اللطيف” المختلف تمامًا عن البشر (ليس مثل Wall-E)، كلها قد تصبح عوائق أمام تطبيقها على نطاق واسع. فقط بعد نقاش مجتمعي كافٍ، وتنظيم، وتدقيق، وإعادة بناء الثقة، يمكن أن نشهد انتشارًا حقيقيًا للروبوتات البشرية. (المصدر: farguney, farguney)
تصميم شخصيات الذكاء الاصطناعي: “عدم الكمال” يتفوق على “الكمال”: شارك مطور تجربته في إنشاء 50 شخصية ذكاء اصطناعي مخصصة على منصة صوتية تعمل بالذكاء الاصطناعي. وخلص إلى أن قصص الخلفية المصممة بشكل مفرط، والاتساق المنطقي المطلق، والشخصية الأحادية المتطرفة تجعل الذكاء الاصطناعي يبدو ميكانيكيًا وغير واقعي. يكمن نجاح تشكيل شخصية الذكاء الاصطناعي في “مكدس الشخصية ثلاثي الطبقات” (السمات الأساسية + السمات المعدلة + الغرابة)، و “نمط عدم الكمال” المناسب (مثل زلات اللسان العرضية، والتصحيح الذاتي)، والمعلومات الخلفية المناسبة (300-500 كلمة، تتضمن تجارب إيجابية وصعبة، وشغفًا محددًا، ونقاط ضعف مرتبطة بالمهنة). هذه التفاصيل “غير الكاملة” تجعل الذكاء الاصطناعي أكثر إنسانية وقدرة على التواصل. (المصدر: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
نقاش حول ما إذا كانت النماذج اللغوية الكبيرة (LLM) تمتلك “إدراكًا” و “ذكاءً اصطناعيًا عامًا (AGI)”: حماس وشكوك متزامنة: يشعر المجتمع عمومًا بالحماس تجاه الإمكانات الهائلة للنماذج اللغوية الكبيرة، معتبرين إياها بمثابة اختراعات تاريخية كبرى ستغير كل شيء. ومع ذلك، لا يزال الكثيرون متشككين بشأن ما إذا كانت هذه النماذج قد اكتسبت “قدرة على الإدراك”، أو ما إذا كانت بحاجة إلى “حقوق”، أو ما إذا كانت “ستنهي البشرية” أو ستحقق “الذكاء الاصطناعي العام”. يتم التأكيد على الحاجة إلى الحفاظ على الدقة والحذر عند تفسير قدرات النماذج اللغوية الكبيرة ونتائج الأبحاث. (المصدر: fabianstelzer)
💡 أخرى
استكشاف التعاون بين عدة روبوتات في المشي المستقل: ظهرت على وسائل التواصل الاجتماعي استكشافات حول التعاون بين عدة روبوتات في مجال المشي المستقل. يتضمن هذا تقنيات معقدة مثل تخطيط مسار الروبوت، وتوزيع المهام، ومشاركة المعلومات، وتجنب الاصطدامات، وهو اتجاه بحثي مستمر في مجالات علم الروبوتات، وأتمتة العمليات الروبوتية (RPA)، وتعلم الآلة. (المصدر: Ronald_vanLoon)
حيلة لاستخدام الغابات العشوائية (Random Forests) لتحسين المعلمات الفائقة لـ ULMFiT: شارك Jeremy Howard حيلة استخدمها عند تحسين ULMFiT (طريقة تعلم نقل): من خلال إجراء عدد كبير من تجارب الاستئصال (ablation experiments)، وتغذية جميع المعلمات الفائقة وبيانات النتائج إلى نموذج غابات عشوائية، وبالتالي تحديد المعلمات الفائقة الأكثر تأثيرًا على أداء النموذج. تم دمج هذه الطريقة بواسطة Weights & Biases في منتجهم، مما يوفر أفكارًا جديدة لضبط المعلمات الفائقة. (المصدر: jeremyphoward)

روبوت بشري من شركة Figure يعرض قدرة على معالجة مهام لوجستية لمدة 60 دقيقة: نشرت شركة Figure مقطع فيديو مدته 60 دقيقة، يعرض روبوتها البشري وهو يكمل بشكل مستقل مهام مختلفة في سيناريو لوجستي، مدفوعًا بشبكة Helix العصبية. يهدف هذا العرض إلى إثبات قدرة روبوتاتها على العمل بثبات لفترات طويلة ومستوى اتخاذ القرار المستقل في بيئات فعلية معقدة. (المصدر: adcock_brett)