كلمات مفتاحية:سلسلة نماذج ووجيه الكبيرة, طريقة RLHF الجديدة, سلسلة نماذج كلود جوف, النماذج اللغوية الكبيرة, دمج متعدد الوسائط, الذكاء الاصطناعي العام الفيزيائي, أمن الذكاء الاصطناعي, الذكاء المتجسد, نموذج إيمو 3 الأصلي متعدد الوسائط للعالم, نموذج علم الأعصاب برين μ الدقيق, روبوبراين 2.0 الدماغ المتجسد, أوبن كومبلكس 2 نموذج الحياة المجهرية الذرية الكاملة, تعزيز التعلم بتقسيم الرموز
🔥 أبرز المستجدات
مؤتمر BAAI يطلق سلسلة نماذج “WuJie”، مع التركيز على AGI المادي ودمج الوسائط المتعددة: في مؤتمر أكاديمية بكين للذكاء الاصطناعي (BAAI) لعام 2025، أعلنت أكاديمية BAAI عن سلسلة نماذجها الكبيرة الجديدة “WuJie”، مما يمثل تحولًا في اتجاه أبحاثها من استكشاف نماذج اللغة “WuDao” إلى عالم مادي أوسع ودمج الوسائط المتعددة. تشمل هذه السلسلة نموذج العالم متعدد الوسائط الأصلي Emu3، وأول نموذج أساسي عالمي متعدد الوسائط لعلوم الدماغ في العالم “Jianwei Brainμ”، والدماغ المجسد RoboBrain 2.0، ونموذج الحياة المجهرية الذري الكامل OpenComplex2. يعكس إطلاق هذه السلسلة من النماذج اتجاه تطور الذكاء الاصطناعي من العالم الرقمي إلى العالم المادي، ومن الفهم الكلي إلى الاستكشاف المجهري، بهدف تمكين الذكاء الاصطناعي من إدراك وفهم العالم المادي والتفاعل معه، وحل المشكلات العملية، ودفع تطوير Physical AGI. كما جمع المؤتمر 4 فائزين بجائزة Turing، بمن فيهم Bengio، والعديد من قادة الصناعة، لمناقشة القضايا الرائدة مثل AI safety، وReinforcement Learning، وIntelligent Agents، وEmbodied Intelligence وغيرها من الموضوعات الحدودية (المصدر: QbitAI)

فريق Qwen و LeapLab من جامعة Tsinghua يقترحان طريقة جديدة لـ RLHF “تتجاوز قاعدة 20/80”: اكتشف بحث تعاوني بين فريق Qwen و LeapLab من جامعة Tsinghua أنه عند تحسين قدرات الاستدلال للنماذج الكبيرة من خلال التعلم المعزز من ردود الفعل البشرية (RLHF)، فإن التركيز فقط على حوالي 20% من “forking tokens” عالية الإنتروبيا يمكن أن يحقق أو حتى يتجاوز نتائج التدريب باستخدام جميع التوكنات. تؤدي هذه التوكنات عالية الإنتروبيا بشكل أساسي وظيفة الربط المنطقي وتلعب دورًا توجيهيًا رئيسيًا في عملية الاستدلال. بناءً على هذا الاكتشاف، حقق Qwen3-32B أداءً متطورًا (SOTA) في معايير مسابقة الرياضيات AIME’24 و AIME’25 للنماذج التي تم تدريبها من الصفر بأقل من 600 مليار معلمة. لم يعزز هذا البحث كفاءة التدريب فحسب، بل كشف أيضًا عن أهمية التوكنات عالية الإنتروبيا لقدرة النموذج على التعميم، وقدم منظورًا جديدًا لفهم الاختلافات بين RL و SFT وخصوصية LLM RL (المصدر: QbitAI)

شركة Anthropic تطلق سلسلة نماذج Claude Gov، المخصصة لعملاء الأمن القومي الأمريكي: أعلنت شركة Anthropic عن إطلاق سلسلة نماذج Claude Gov المخصصة لعملاء الأمن القومي الأمريكي. تم نشر هذه النماذج بالفعل في مؤسسات الأمن القومي الأمريكية رفيعة المستوى، ويقتصر الوصول إليها بشكل صارم على الموظفين الذين يتعاملون مع المعلومات السرية. أثارت هذه الخطوة نقاشات حول أخلاقيات الذكاء الاصطناعي ومخاطر إساءة الاستخدام المحتملة، خاصة بالنظر إلى أن أبحاث Anthropic السابقة وثقت إظهار النماذج “لسلوك البقاء” ومخاطر “إساءة الاستخدام الكارثية”. على الرغم من ادعاء Anthropic بأنها شركة أبحاث في مجال أمان الذكاء الاصطناعي تهدف إلى اكتشاف الثغرات وإصلاحها من خلال الاختبار، فإن تطبيق تقنيتها في المجالات العسكرية والأمن القومي يزيد بلا شك من مخاوف الجمهور بشأن تسليح الذكاء الاصطناعي ومخاطر خروجه عن السيطرة (المصدر: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun يتوقع أن النماذج اللغوية الكبيرة الحالية ستصبح قديمة في غضون خمس سنوات: صرح Yann LeCun، الأستاذ بجامعة نيويورك وكبير علماء الذكاء الاصطناعي في Meta، في مقابلة مع مجلة Newsweek، بأن النماذج اللغوية الكبيرة (LLM) الحالية ستصبح قديمة في غضون خمس سنوات. يعتقد أن أنظمة الذكاء الاصطناعي الحالية تفتقر إلى القدرة على فهم العالم الحقيقي، وهذا هو قيدها الأساسي. تطلع LeCun إلى أشكال أنظمة ذكاء اصطناعي أكثر ذكاءً في المستقبل، ملمحًا إلى اتجاه تطوير جيل جديد من تقنيات الذكاء الاصطناعي يتجاوز بنية LLM الحالية، وقد يركز بشكل أكبر على التمثيل الداخلي للعالم والقدرة على الاستدلال السببي (المصدر: ylecun)
🎯 أحدث التطورات
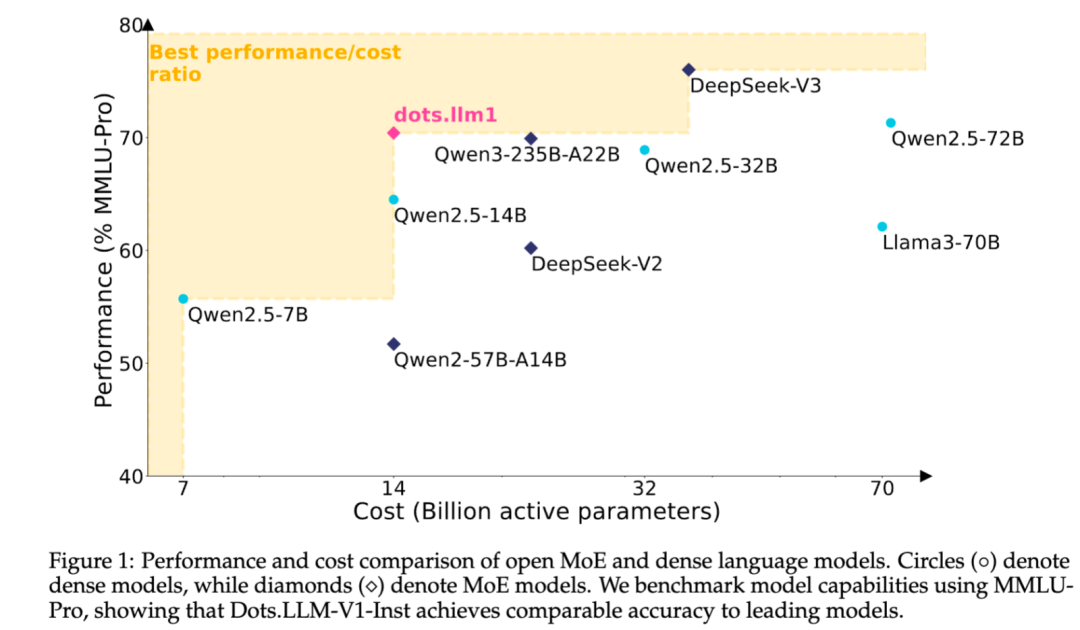
شركة Xiaohongshu تطلق نموذجها النصي الكبير مفتوح المصدر dots.llm1 المبني على معمارية MoE: أطلق فريق hi lab التابع لشركة Xiaohongshu أول نموذج نصي كبير مفتوح المصدر تم تطويره ذاتيًا، dots.llm1. يعتمد النموذج على معمارية MoE، بإجمالي 142 مليار معلمة، منها 14 مليار معلمة نشطة. مع تنشيط 14 مليار معلمة، يُظهر النموذج أداءً متميزًا في السيناريوهات العامة باللغتين الصينية والإنجليزية، والرياضيات، والبرمجة، ومهام المواءمة، ويمكنه منافسة نماذج مثل Qwen2.5-32B/72B-Instruct. كانت جهود Xiaohongshu في فتح المصدر كبيرة هذه المرة، حيث لم تقدم فقط نموذج dots.llm1.inst الجاهز للاستخدام، بل أتاحت أيضًا العديد من نقاط التحقق (checkpoints) من مراحل التدريب المسبق ونموذج base للنصوص الطويلة، مع تفصيل عملية التدريب لتسهيل التطوير الثانوي والبحث من قبل المجتمع. لم يستخدم النموذج بيانات اصطناعية، مؤكدًا على تطبيق بيانات حقيقية عالية الجودة (المصدر: 36Kr)
تحديثات مستمرة لوظائف نماذج Claude من Anthropic، لتوسيع معالجة السياق وقدرات التكامل: أطلقت Anthropic مؤخرًا العديد من التحديثات الهامة لسلسلة نماذج Claude الخاصة بها. تدعم Projects on Claude الآن معالجة محتوى أكبر بعشر مرات، وعندما تتجاوز الملفات الحد الأقصى، تنتقل إلى وضع استرجاع جديد لتوسيع السياق الوظيفي. في الوقت نفسه، يمكن لمستخدمي خطة Pro الآن استخدام ميزات Research و Integrations، مما يسمح لـ Claude بالبحث في الويب، و Google Workspace، وأي تطبيقات مخصصة أو خدمات مسبقة الإنشاء متصلة عبر MCP (Model Control Protocol) (مثل Zapier و Asana)، مما يتيح عمليات عبر الأدوات مثل إنشاء المهام وتحديث المستندات وتشغيل تدفقات العمل. تهدف هذه التحديثات إلى تعزيز قدرات Claude في معالجة المهام المعقدة وتكامل المعلومات متعددة المصادر (المصدر: AnthropicAI, AnthropicAI)
Hugging Face تطلق خادم MCP لتعزيز النظام البيئي لوكلاء الذكاء الاصطناعي: أعلنت Hugging Face عن إطلاق أول خادم MCP (Model Control Protocol) لها (hf.co/mcp)، مما يسمح لوكلاء الذكاء الاصطناعي بالوصول إلى النماذج ومجموعات البيانات وحتى التطبيقات المستضافة في Space على منصة Hugging Face واستخدامها بشكل أكثر فعالية. تعتبر هذه الخطوة خطوة هامة نحو تطوير الإنترنت ليكون أكثر ملاءمة للوكلاء الأذكياء، وتهدف إلى بناء نظام بيئي “لمتجر تطبيقات” لوكلاء الذكاء الاصطناعي. يتيح إطلاق خادم MCP للمطورين ربط وكلاء الذكاء الاصطناعي بسهولة أكبر بموارد Hugging Face الهائلة، مما يعزز تطوير وابتكار تطبيقات وكلاء الذكاء الاصطناعي (المصدر: TheTuringPost, karminski3)
OpenAI تحدث نموذج ChatGPT الصوتي لتعزيز الطلاقة الطبيعية وقدرات الترجمة: قامت OpenAI بترقية ميزة Advanced Voice في ChatGPT، مما يجعل تجربة المحادثة أكثر طبيعية وسلاسة. أصبح هذا التحديث متاحًا لجميع المستخدمين المدفوعين. في الوقت نفسه، تم تعزيز قدرات ChatGPT في ترجمة اللغات، حيث يمكن للمستخدمين توجيهه مباشرة للترجمة الفورية بين لغات مختلفة. تهدف هذه التحسينات إلى تعزيز سهولة الاستخدام والفائدة العملية للتفاعل الصوتي للمستخدمين مع ChatGPT (المصدر: kevinweil, shuchaobi)
PyTorch يدمج Safetensors لتعزيز أمان وسهولة نقاط التحقق الموزعة (Distributed Checkpoint): أعلنت PyTorch أن ميزة Distributed Checkpoint الخاصة بها تدعم الآن تنسيق Safetensors من Hugging Face. هذا التكامل يجعل حفظ وتحميل نقاط تحقق النماذج (model checkpoints) بين الأنظمة البيئية المختلفة أكثر أمانًا وسهولة، خاصةً أنه يحل مخاطر الأمان التي كانت موجودة سابقًا في تنسيق pickle. تسمح واجهة برمجة التطبيقات (API) الجديدة بقراءة وكتابة Safetensors عبر مسارات fsspec، وأصبحت torchtune أول مكتبة تعتمد هذه الميزة، مما يحسن عمليات نقاط التحقق الخاصة بها. تعتبر هذه الخطوة واحدة من أهم التطورات في مجال أمان الذكاء الاصطناعي خلال العام الماضي، وتساعد على تعزيز أمان مشاركة النماذج ونشرها (المصدر: ClementDelangue, huggingface)

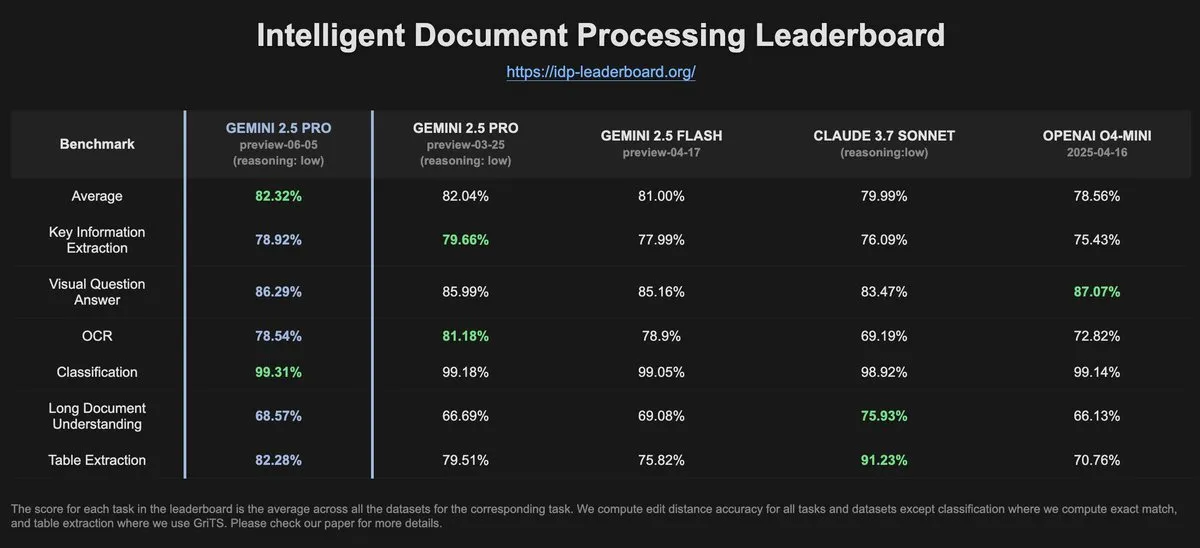
بيانات IDP-Leaderboard تظهر انخفاضًا في أداء Gemini-2.5-pro-06-05 في التعرف الضوئي على الحروف (OCR) مقارنة بالإصدار السابق: وفقًا لأحدث البيانات من IDP-Leaderboard، أظهر الإصدار الجديد Gemini-2.5-pro-06-05 انخفاضًا في أداء التعرف الضوئي على الحروف (OCR) مقارنة بإصدار 03-25. على الرغم من ذلك، لا يزال هذا النموذج هو الأقوى في القدرات الشاملة لمعالجة المستندات (بما في ذلك التعرف على المستندات وجداول البيانات وغيرها). IDP-Leaderboard هو معيار يركز على تقييم قدرات النماذج الكبيرة في مجال معالجة المستندات الذكية (المصدر: karminski3)
أبحاث Apple تكشف عن محدودية قدرات الاستدلال في النماذج اللغوية الكبيرة (LLM)، وقد لا تكون “تفكر” حقًا: نشر باحثون من شركة Apple ورقة بحثية تناقش مزايا وحدود النماذج اللغوية الكبيرة الحالية في مهام الاستدلال، مشيرين إلى أن أداء هذه النماذج “ينهار” عند التعامل مع مهام تتجاوز درجة معينة من التعقيد. يشير البحث إلى أن “استدلال” النماذج اللغوية الكبيرة يعتمد بشكل أكبر على مطابقة الأنماط والذاكرة، وليس على التفكير والفهم الحقيقي بالمعنى الإنساني. تتوافق هذه النظرة مع آراء خبراء مثل Yann LeCun، مما أثار نقاشات حول مسار تحقيق الذكاء الاصطناعي العام (AGI) وحدود قدرات النماذج الحالية (المصدر: omarsar0, NandoDF)

DeepSeek R1 يُظهر قدرات متميزة في فهم النصوص والتفسير الإبداعي في لعبة Dwarf Fortress: أظهرت تجارب المستخدمين أن نموذج DeepSeek R1 يُظهر قدرات قوية في فهم النصوص والتفسير الإبداعي عند معالجة بيانات من لعبة Dwarf Fortress المعقدة والغنية بالنصوص. من خلال استخراج البيانات النصية من لقطات شاشة اللعبة وإدخالها إلى DeepSeek R1، لم يتمكن النموذج من تحليل البيانات فحسب، بل تمكن أيضًا من تحديد السلوكيات الغريبة والمثيرة للاهتمام للأقزام وأنماطهم، ووصفها بلغة حية وممتعة، مما يُظهر إمكاناته في فهم النصوص غير المهيكلة وتوليدها (المصدر: Reddit r/LocalLLaMA)

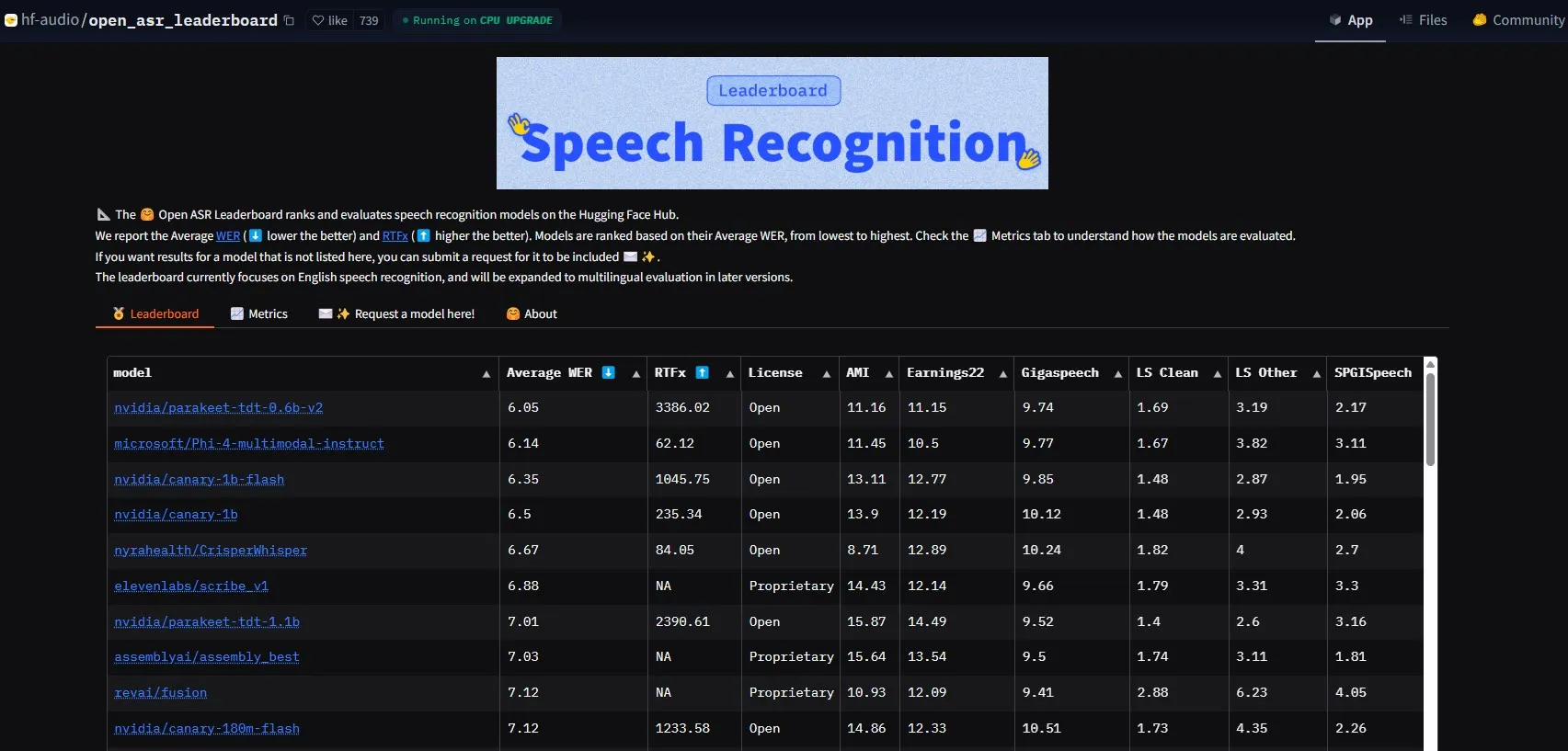
NVIDIA تطلق نموذج Parakeet-tdt-0.6b-v2، محققة رقمًا قياسيًا جديدًا في أداء ASR: حقق نموذج التعرف التلقائي على الكلام (ASR) الجديد Parakeet-tdt-0.6b-v2 من NVIDIA رقمًا قياسيًا جديدًا في الصناعة على HuggingFace Open-ASR-Leaderboard بمعدل خطأ في الكلمات (WER) بلغ 6.05%. لا يتفوق هذا النموذج في الدقة فحسب، بل يتميز أيضًا بسرعة استدلال فائقة (RTFx 3386، أسرع بـ 50 مرة من البدائل)، ويدعم ميزات مبتكرة مثل نسخ كلمات الأغاني، والطوابع الزمنية الدقيقة/تنسيق الأرقام (المصدر: huggingface)
فريق Qwen من Alibaba يطلق سلسلة نماذج Qwen3-Embedding: أطلق فريق Qwen التابع لشركة Alibaba سلسلة نماذج Qwen3-Embedding الجديدة، والتي تشمل ثلاثة أحجام مختلفة: 0.6B، 4B، 8B. حققت هذه النماذج أداءً متطورًا (SOTA) في العديد من اختبارات تضمين النصوص مثل MMTEB، MTEB، و MTEB-Code، وتدعم 119 لغة، ويمكن تشغيلها داخل المتصفح عبر Transformers.js (مع دعم تسريع WebGPU)، مما يوفر قدرات تمثيل نصي قوية للتطبيقات متعددة اللغات وعبر المنصات (المصدر: huggingface)
Gemini 2.5 Pro يُظهر قدرات قوية في توليد الأكواد ومعالجة المهام: أظهر Gemini 2.5 Pro (إصدار preview-06-05) من GoogleDeepMind قدرات قوية في معالجة المهام المعقدة. على سبيل المثال، حاول المستخدم Majid Manzarpour جعله يكتب برنامجًا نصيًا لتنظيم وتصنيف مكتبة تحتوي على أكثر من 25000 ملف صوتي، وعلق Jeff Dean قائلاً إن هذا “لا يبدو صعبًا للغاية”، مما يشير إلى إمكانات النموذج في معالجة مهام البرمجة المعقدة وواسعة النطاق. بالإضافة إلى ذلك، يُظهر مخطط اختبار GosuCoder أن الإصدار المحدث Gemini 2.5 Pro 06-05 يقدم أداءً أفضل في مساعدة الترميز بالذكاء الاصطناعي، خاصةً عند ضبط درجة الحرارة (temperature) على 0.7 حيث حصل على أعلى درجات التقييم (المصدر: JeffDean, jeremyphoward)
Hugging Face و Google Colab يعمقان التكامل لتبسيط سير عمل الذكاء الاصطناعي: أعلنت Hugging Face و Google Colab عن تعزيز التعاون بينهما، بإضافة دعم “Open in Colab” إلى جميع بطاقات النماذج على Hugging Face Hub. يمكن للمستخدمين الآن تشغيل دفاتر Colab مباشرة من أي بطاقة نموذج، مما يسهل تجربة واستخدام النماذج الموجودة على Hugging Face، ويقلل من عوائق تطوير وأبحاث الذكاء الاصطناعي (المصدر: huggingface)
🧰 الأدوات
LlamaBot: مساعد ترميز ذكاء اصطناعي يعتمد على LangGraph: قدمت LangChainAI أداة LlamaBot، وهي وكيل ذكاء اصطناعي مدعوم بـ LangGraph، قادر على إنشاء تطبيقات ويب من خلال الدردشة باللغة الطبيعية. تشمل ميزاته توليد الأكواد في الوقت الفعلي، والمعاينة المباشرة، ووكلاء متخصصين مصممين لمهام تطوير مختلفة، بهدف تبسيط عملية تطوير تطبيقات الويب (المصدر: LangChainAI, hwchase17)
نظام Fast RAG: يجمع بين DeepSeek-R1 و Qdrant لمعالجة المستندات بكفاءة: عرضت LangChainAI حلاً عالي الأداء لتطبيق RAG (Retrieval Augmented Generation). يجمع هذا الحل بين نموذج DeepSeek-R1 من SambaNova، وتقنية التكميم الثنائي (binary quantization) من Qdrant، و LangGraph، مما يحقق تقليلًا في الذاكرة بمقدار 32 ضعفًا، وبالتالي يمكنه معالجة المستندات واسعة النطاق بكفاءة، ويوفر مسارًا جديدًا لتحسين استرجاع المعلومات وتوليد المحتوى (المصدر: LangChainAI, hwchase17)

Gemini Research Assistant: مساعد بحث ذكي متكامل يعتمد على Gemini و LangGraph: أطلق فريق Google Gemini مساعد بحث ذكاء اصطناعي متكامل مفتوح المصدر، يستخدم نموذج Gemini و LangGraph لإجراء أبحاث ويب ذكية. يتمتع هذا المساعد بقدرات استدلال تأملي، ويمكنه تحسين استراتيجيات البحث الخاصة به باستمرار، لتزويد المستخدمين بدعم بحثي أعمق وأكثر كفاءة. كود المشروع متاح على GitHub (المصدر: LangChainAI, hwchase17)
Agent Flow: منشئ وكلاء ذكاء اصطناعي مفتوح المصدر بدون كود: أطلق Karan Vaidya أداة Agent Flow، وهي منشئ وكلاء ذكاء اصطناعي مفتوح المصدر بدون كود، كبديل لـ Gumloop. تعتمد الأداة على ComposioHQ و LangGraph من LangChain، وتسمح للمستخدمين بأتمتة تدفقات العمل وأنماط الوكلاء المعقدة عن طريق سحب وإفلات العقد، بهدف تقليل عوائق تطوير تطبيقات وكلاء الذكاء الاصطناعي (المصدر: hwchase17)
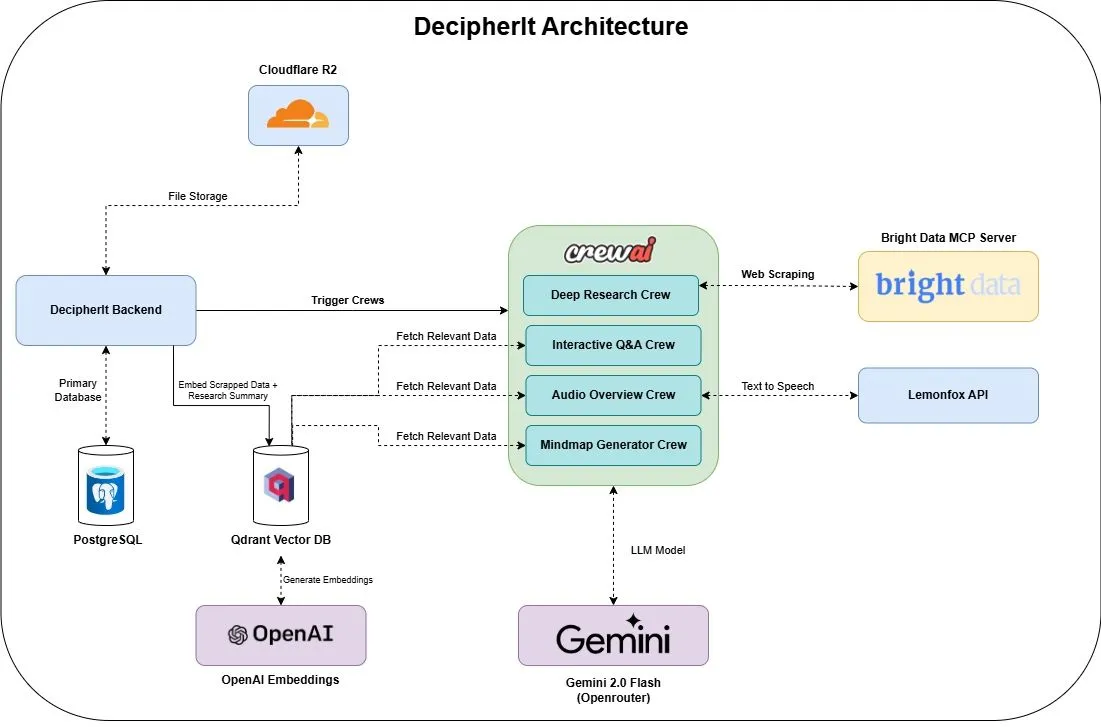
DecipherIt: مساعد بحث ذكاء اصطناعي مفتوح المصدر، بديل لـ NotebookLM: تم إطلاق مساعد بحث ذكاء اصطناعي مفتوح المصدر يسمى DecipherIt، ويُعتبر بديلاً لـ NotebookLM. تستخدم هذه الأداة تنسيق وكلاء متعددين (crewAI)، والبحث الدلالي (Qdrant + OpenAI)، والوصول إلى الويب في الوقت الفعلي (Bright Data MCP)، وتوليد الكلام (lemonfoxai)، لتحويل المستندات التي يحملها المستخدم أو عناوين URL أو الموضوعات المدخلة إلى مساحة عمل بحثية كاملة تحتوي على ملخصات، وخرائط ذهنية، ونظرات عامة صوتية، وأسئلة وأجوبة شائعة، وإجابات دلالية على الأسئلة (المصدر: qdrant_engine)
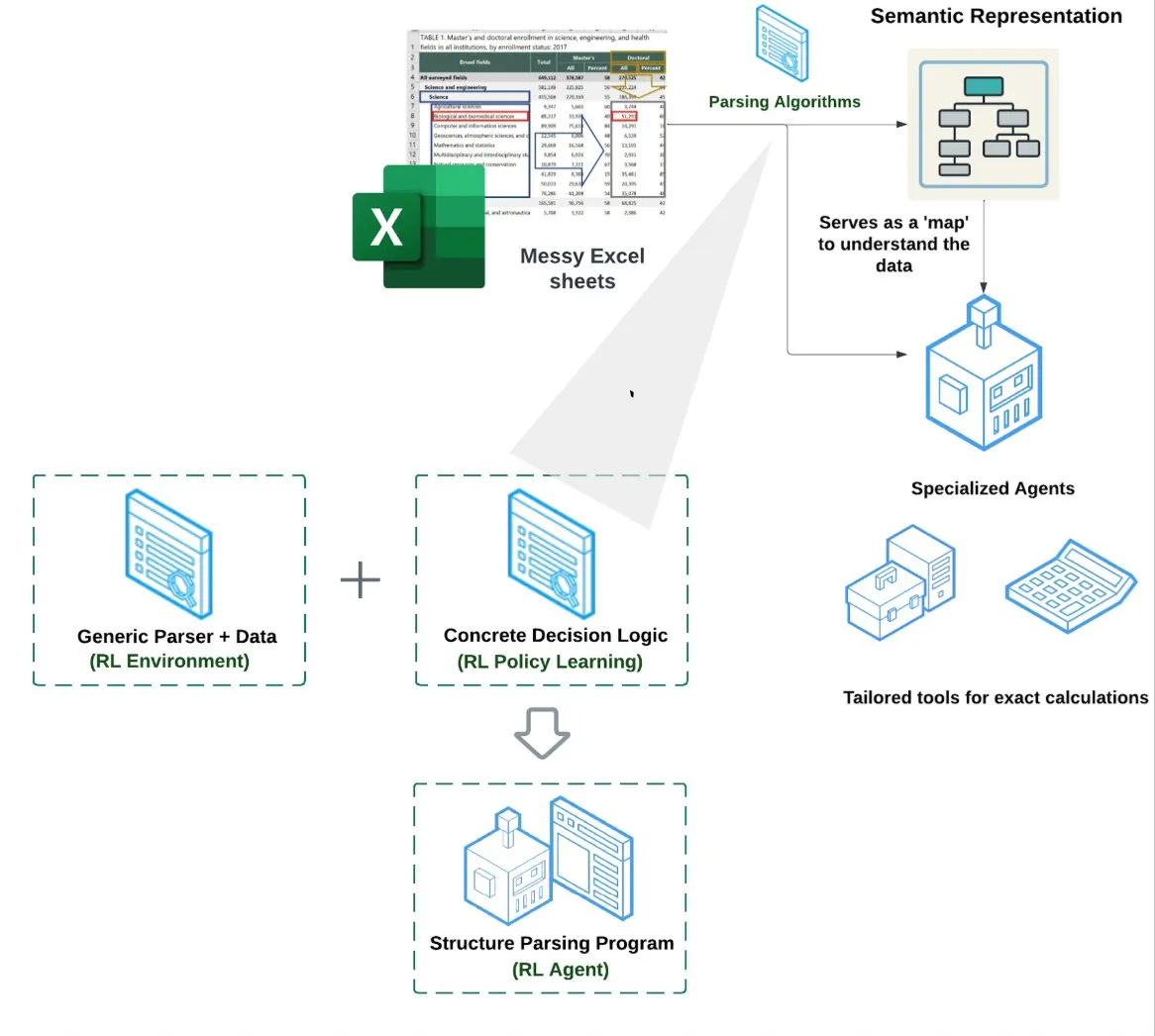
LlamaIndex تطلق وكيل جداول البيانات (Spreadsheet Agent): أعلنت LlamaIndex عن وكيل جداول بيانات جديد، لا يزال في مرحلة المعاينة الخاصة. يركز هذا الوكيل على معالجة ملفات Excel المعقدة، ويمكنه إجراء تحويل البيانات وضمان الجودة. يكمن جوهر بنيته التقنية في فهم الهيكل القائم على التعلم المعزز (Reinforcement Learning) (تعلم نموذج البيانات/الرسم البياني الدلالي) والأدوات المتخصصة المبنية فوق الرسم البياني الدلالي، بهدف توفير قدرة معالجة Excel أفضل من طرق RAG التقليدية أو تحويل النص إلى CSV، ويُقال إن أداءه أفضل بنسبة 10-20% من خط الأساس الذي يعتمد على LLM لكتابة الأكواد فقط (المصدر: jerryjliu0)
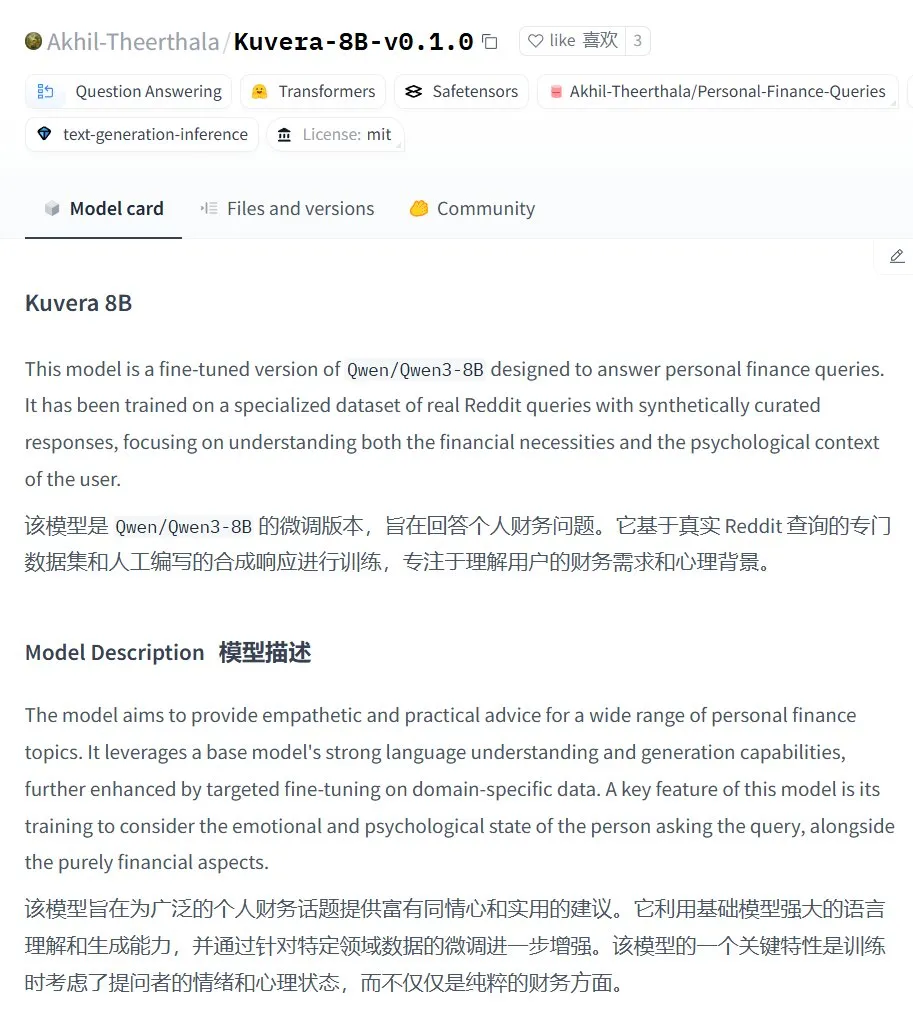
Kuvera-8B-v0.1.0: نموذج كبير للاستشارات المالية الشخصية: نشر Akhil-Theerthala نموذج Kuvera-8B-v0.1.0 على Hugging Face، وهو نموذج مصمم خصيصًا للمسائل المالية الشخصية. تم ضبطه بدقة (fine-tuned) بناءً على Qwen3-8B، باستخدام مصادر بيانات مثل Reddit، ويهدف إلى تقديم نصائح متعاطفة وعملية حول مواضيع مثل الميزانية، والادخار، والاستثمار، وإدارة الديون، والتخطيط المالي الأساسي. نظرًا لأنه يعتمد على Qwen3، يدعم النموذج الأسئلة والأجوبة باللغة الصينية (المصدر: karminski3)
حل محلي لمعالجة الصوت باستخدام Whisper+Pyannote كبديل لـ Otter.ai: شارك أحد مستخدمي Reddit تجربته في بناء نظام معالجة صوت محلي بالكامل ليحل محل الخدمات السحابية مثل Otter.ai. يجمع هذا الحل بين ctranslate2 و faster-whisper للنسخ، و pyannote و speechbrain لفصل المتحدثين (diarisation)، ويمكنه معالجة تسجيلات اجتماعات تصل مدتها إلى ثلاث ساعات أو أكثر على وحدة معالجة الرسومات (GPU) المحلية، وإخراج نصوص مسجلة مع تحديد المتحدثين وملفات JSON، بما في ذلك ملخصات تنفيذية وقوائم مهام مخصصة. تهدف هذه الخطوة إلى معالجة قيود الخدمات السحابية، ومخاوف الخصوصية، ونقص التخصيص (المصدر: Reddit r/LocalLLaMA)
GPT Deep Research MCP: دمج مع OpenWebUI لإجراء أبحاث معمقة: يوصي المستخدمون بتجربة دمج GPT Deep Research MCP مع OpenWebUI. تهدف أداة MCP هذه (gptr-mcp) إلى توفير قدرات بحث معمقة، وعند استخدامها مع OpenWebUI الذي يدعم MCP، يمكن أن توفر تجربة بحث مثيرة للإعجاب، مما يوسع نطاق تطبيقات أدوات الذكاء الاصطناعي المحلية في معالجة المعلومات واكتشاف المعرفة (المصدر: Reddit r/OpenWebUI)
📚 موارد تعليمية
OpenAI ستعقد جلسة لمشاركة ممارسات تقييم التطبيقات، تتضمن حالات واقعية ونظرة مستقبلية على الأدوات: ستعقد OpenAI جلسة لمشاركة أفضل الممارسات في تقييم التطبيقات (Evals). خلال الجلسة، سيناقش Jim Blomo من OpenAI كيفية تقييم منتجات الذكاء الاصطناعي بفعالية، مستندًا إلى حالات عملاء ونتائج حقيقية. سيعرض الحدث أيضًا الأدوات القادمة من OpenAI للتقييم، بما في ذلك ميزات التتبع والتقييم وغيرها. تهدف هذه الجلسة إلى مساعدة المطورين والشركات على بناء وتحسين تطبيقات الذكاء الاصطناعي بشكل أفضل، وسيتم توفير تسجيل للجلسة (المصدر: HamelHusain, HamelHusain)

Anthropic تفتح مصدر أساليب بحثها في قابلية التفسير، للمساعدة في فهم “تفكير” النماذج اللغوية الكبيرة (LLM): أعلنت Anthropic عن فتح مصدر أساليب بحثها المستخدمة لتتبع “عمليات التفكير” في النماذج اللغوية الكبيرة. يمكن للباحثين الآن استخدام هذه الأساليب لإنشاء “خرائط الإسناد” (attribution graphs) واستكشافها بشكل تفاعلي، على غرار ما عرضته Anthropic في أبحاثها الأخيرة. قدم الفريق أيضًا واجهة Neuronpedia التفاعلية ودروس Jupyter Notebook، لتسهيل تطبيق الباحثين لهذه الأدوات على النماذج مفتوحة المصدر، بهدف تعزيز فهم الآليات الداخلية لعمل النماذج اللغوية الكبيرة. قاد هذا المشروع مشاركون من برنامج Anthropic Fellows بالتعاون مع Decode Research (المصدر: AnthropicAI)
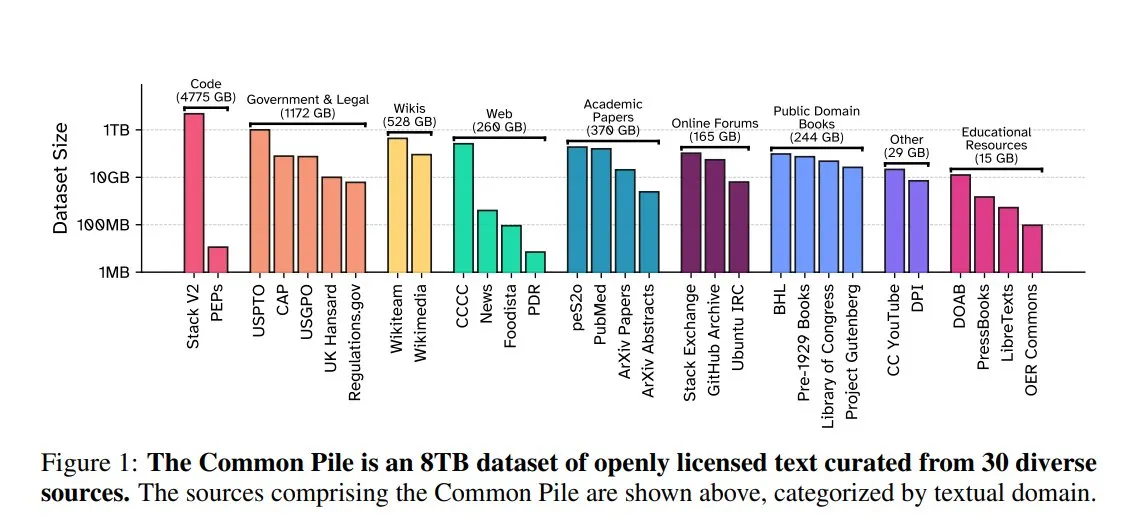
EleutherAI تطلق Common Pile v0.1: مجموعة بيانات نصية مفتوحة الترخيص بحجم 8 تيرابايت: أطلقت EleutherAI بالتعاون مع Vector Institute، و Allen AI، و Hugging Face، و DPI مجموعة بيانات Common Pile v0.1، وهي مجموعة بيانات نصية متاحة للعامة ومفتوحة الترخيص بحجم 8 تيرابايت، وتحتوي على تريليون توكن. قام الفريق بتدريب نموذجي Comma v0.1-1T و -2T بحجم 7 مليارات معلمة على هذه المجموعة، وأظهر أداءً مشابهًا لنماذج مثل LLaMA 1&2 التي تم تدريبها على مجموعات بيانات مماثلة الحجم. تهدف هذه الخطوة إلى استكشاف إمكانية تدريب نماذج لغوية عالية الأداء دون استخدام نصوص غير مصرح بها، مما يوفر موردًا قيمًا لمجتمع المصادر المفتوحة (المصدر: huggingface)
NVIDIA NIM تسرع استدلال Vanna من النص إلى SQL: نشرت مدونة مطوري NVIDIA برنامجًا تعليميًا يوضح كيفية استخدام NVIDIA NIM (NVIDIA Inference Microservices) لتحسين حل Vanna لتحويل النص إلى SQL. يوفر NIM نقاط نهاية محسّنة لنماذج الذكاء الاصطناعي التوليدية، مما يسرع عملية الاستدلال، وبالتالي يتيح إجراء التحليلات بشكل أسرع. هذا مهم للتطبيقات التي تحتاج إلى تحويل الاستعلامات باللغة الطبيعية إلى استعلامات قاعدة بيانات (المصدر: dl_weekly)
مشاركة محاضرات مجانية من دورة تعلم الآلة بجامعة ستانفورد: شاركت The Turing Post محاضرات مجانية من دورة تعلم الآلة CS229 بجامعة ستانفورد، التي يدرسها Andrew Ng و Tengyu Ma. يغطي المحتوى موضوعات تعلم الآلة الأساسية مثل التعلم الخاضع للإشراف، وطرق وخوارزميات التعلم غير الخاضع للإشراف، والتعلم العميق والشبكات العصبية، والتعميم، والتنظيم، وعملية التعلم المعزز، مما يوفر للمتعلمين موارد تعليمية عالية الجودة (المصدر: TheTuringPost)

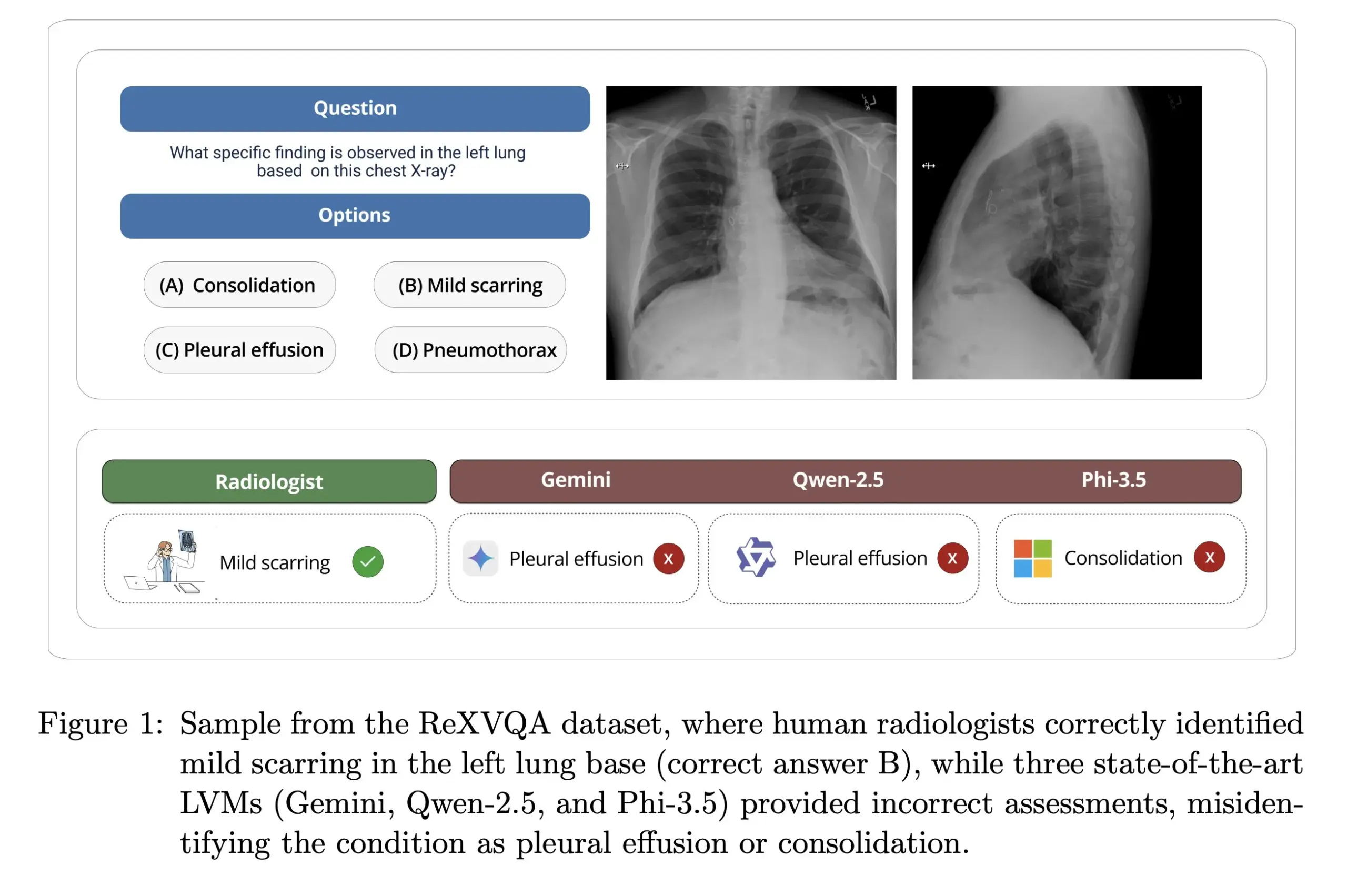
جامعة هارفارد تطلق ReXVOA: معيار واسع النطاق وعالي الجودة للإجابة على أسئلة صور الأشعة السينية للصدر: أطلق مختبر Pranav Rajpurkar بجامعة هارفارد ReXVOA، وهو مجموعة بيانات معيارية واسعة النطاق وعالية الجودة للإجابة على الأسئلة المرئية (VQA) لصور الأشعة السينية للصدر. تهدف مجموعة البيانات هذه إلى تحدي النماذج الرائدة الحالية واسعة النطاق، وأن تكون بمثابة مقياس لتقدم الجيل القادم من النماذج في فهم الصور الطبية وقدرات الإجابة على الأسئلة (المصدر: huggingface)
OWL Labs تشارك خبراتها في تدريب المشفرات التلقائية لنماذج الانتشار (Diffusion Models): لخصت OWL (Open World Labs) في مدونتها خبراتها واكتشافاتها في تدريب المشفرات التلقائية (autoencoders) المستخدمة في نماذج الانتشار، وشاركت بعض حالات الفشل لطرق غير تقليدية. يوفر هذا المقال مرجعًا للباحثين والمطورين في تطبيق وتحسين المشفرات التلقائية لنماذج الانتشار عمليًا (المصدر: NandoDF)
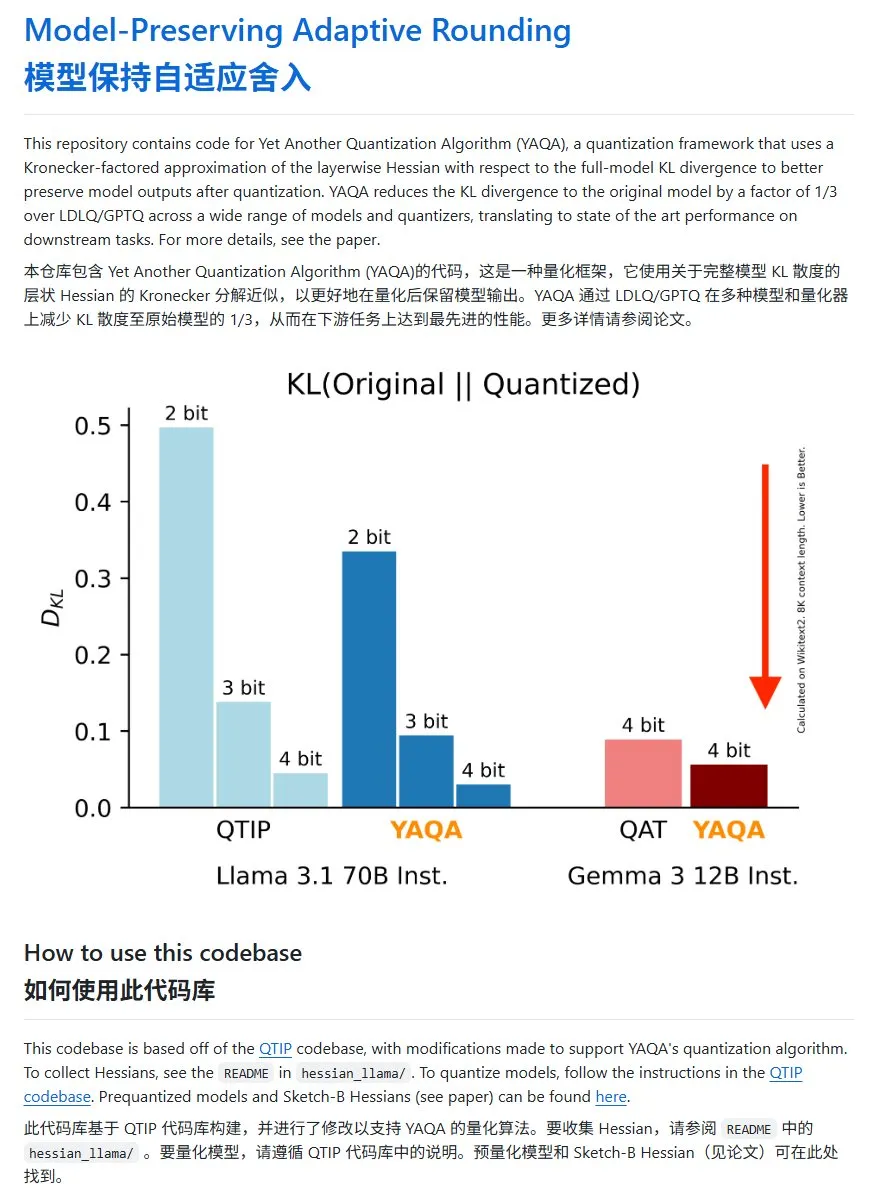
YAQA: طريقة جديدة لتكميم النماذج، مع انخفاض كبير في KL divergence: اقترح فريق Cornell-RelaxML طريقة جديدة لتكميم النماذج تسمى YAQA. تجمع هذه الطريقة بين تقنيات LDLQ/GPTQ، وبالمقارنة مع طرق التكميم الحالية، يمكنها تقليل KL divergence للنماذج المكممة إلى ثلث النموذج الأصلي. على الرغم من أن عملية تكميم YAQA بطيئة وتتطلب كمية كبيرة من ذاكرة الوصول العشوائي للفيديو (VRAM)، إلا أن تحسين الأداء الذي تحققه والاقتصاد في الاستدلال اللاحق يجعلانها حلاً واعدًا للتكميم. كود المشروع مفتوح المصدر على GitHub (المصدر: karminski3)
💼 الأعمال
الشابة هونغ لي تونغ من مواليد الألفية الثانية في قوانغتشو تؤسس Axiom، بهدف حل المشكلات الرياضية المعقدة بالذكاء الاصطناعي: أثارت الشابة المتفوقة هونغ لي تونغ (Carina Hong)، المولودة في الألفية الثانية، الاهتمام بتأسيسها شركة Axiom الناشئة في مجال الذكاء الاصطناعي. تركز Axiom على استخدام الذكاء الاصطناعي لحل المشكلات الرياضية المعقدة، ويشمل عملاؤها المستهدفون صناديق التحوط وشركات التداول الكمي. وفقًا لتقرير The Information، تجري Axiom محادثات لجمع تمويل بقيمة 50 مليون دولار، بتقييم يتراوح بين 300 و 500 مليون دولار، وقد تقود B Capital جولة التمويل. صرحت هونغ لي تونغ على وسائل التواصل الاجتماعي بأن تقارير التمويل غير دقيقة، لكنها أكدت أن الشركة تقوم بتوظيف مواهب في مجال الرياضيات والذكاء الاصطناعي. تخرجت هونغ لي تونغ بدرجة البكالوريوس من معهد ماساتشوستس للتكنولوجيا (MIT)، وحصلت على درجة الماجستير من جامعة أكسفورد، وهي حاليًا طالبة دكتوراه مزدوجة في الرياضيات والقانون بجامعة ستانفورد، وقد فازت بالعديد من الجوائز في مسابقات الرياضيات (المصدر: 36Kr)

Anthropic تقطع وصول Windsurf إلى Claude API بسبب المنافسة: أكد أحد مؤسسي Anthropic أن الشركة أوقفت تزويد شركة Windsurf الناشئة في مجال الذكاء الاصطناعي بإمكانية الوصول إلى Claude API. السبب هو أن Windsurf تُعتبر شكلاً من أشكال “الغلاف” لـ OpenAI أو خدمة مرتبطة بها ارتباطًا وثيقًا، و OpenAI هي منافس مباشر لـ Anthropic. أثارت هذه الخطوة نقاشات حول الاعتماد على واجهات برمجة التطبيقات (API) ومخاطر المنصات، خاصة بالنسبة للشركات الناشئة التي تعتمد أعمالها على واجهات برمجة تطبيقات النماذج الكبيرة التابعة لجهات خارجية، حيث يمكن أن تؤثر القرارات التجارية لمقدمي النماذج بشكل مباشر على بقائها (المصدر: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI مطالبة بالاحتفاظ بسجلات الدردشة المحذوفة للمستخدمين بسبب دعوى قضائية تتعلق بحقوق النشر: أفادت التقارير أنه في دعوى قضائية تتعلق بحقوق النشر رفعتها صحيفة نيويورك تايمز، أمرت محكمة اتحادية أمريكية OpenAI بالاحتفاظ بجميع سجلات محادثات مستخدمي ChatGPT، بما في ذلك المحتوى الذي اختار المستخدمون حذفه، كدليل محتمل. تتهم صحيفة نيويورك تايمز OpenAI باستخدام مقالاتها المحمية بنظام الدفع مقابل الاشتراك لتدريب ChatGPT، وتخشى أن يتمكن الذكاء الاصطناعي من إنشاء محتوى مشابه. أثارت هذه الخطوة مخاوف بشأن خصوصية المستخدم وحماية البيانات (مثل GDPR)، وتسلط الضوء على التوتر القانوني والأخلاقي بين حقوق نشر بيانات تدريب الذكاء الاصطناعي وخصوصية المستخدم (المصدر: Reddit r/ArtificialInteligence)

🌟 المجتمع
نماذج الذكاء الاصطناعي الكبيرة تتحدى امتحانات كتابة المقالات والرياضيات في امتحانات القبول الجامعي لعام 2025، وتظهر أداءً متباينًا: خلال فترة امتحانات القبول الجامعي لعام 2025، واجهت العديد من نماذج الذكاء الاصطناعي الكبيرة تحدي كتابة المقالات وحل مسائل الرياضيات. في مجال كتابة المقالات، أظهر 16 مساعدًا للذكاء الاصطناعي، بما في ذلك Doubao و DeepSeek و ChatGPT، قدراتهم الكتابية، حيث تمكن معظمهم من إنشاء مقالات جدلية ذات هيكل منظم، ولكنها عانت بشكل عام من القولبة، واستخدام العبارات المبتذلة، وتشابه الأفكار. في اختبار الرياضيات (أسئلة موضوعية من امتحان المعايير الجديدة I)، حصل Doubao من ByteDance و Yuanbao من Tencent على 68 نقطة (من أصل 73) ليحتلا المركز الأول مناصفة، بينما كان أداء OpenAI o3 ضعيفًا بحصوله على 34 نقطة فقط. تعكس الاختبارات التقدم والقيود الحالية للذكاء الاصطناعي في فهم اللغة الصينية، والاستدلال المنطقي، والتعبير الإبداعي، خاصة فيما يتعلق بتجنب آثار الذكاء الاصطناعي والتعامل مع الاستدلال الرياضي المعقد (المصدر: 36Kr, 36Kr)

اتجاهات تطبيق الذكاء الاصطناعي داخل الشركات: قواعد المعرفة الداخلية وروبوتات الدردشة المخصصة تحظى بالاهتمام: تُظهر مناقشات المجتمع أن استخدام الذكاء الاصطناعي لبناء روبوتات دردشة داخلية للشركات، مدربة على بيانات الشركة للإجابة على أسئلة الموظفين حول الإجراءات، والبحث عن البيانات، والمسؤولين، أصبح اتجاهًا سائدًا. تهدف هذه التطبيقات إلى تحسين كفاءة استرجاع المعلومات الداخلية ومستوى إدارة المعرفة. قامت شركات مثل Amazon بالفعل بنشر أنظمة مماثلة وحصلت على ردود فعل جيدة. ومع ذلك، لا تزال قضايا أمان البيانات، والتسريب المحتمل للمعلومات الحساسة، وكيفية تحقيق الدخل الفعال من هذه التطبيقات، من بين القضايا التي تحتاج الشركات إلى الاهتمام بها أثناء التنفيذ (المصدر: Reddit r/ArtificialInteligence)
الجدل حول “الفهرسة” و “عدم الفهرسة” في البرمجة بمساعدة الذكاء الاصطناعي: الموازنة بين الأداء والموثوقية: قارنت تجربة أُجريت على مساعدي ترميز الذكاء الاصطناعي (باستخدام كود مهمة أبولو 11 للهبوط على سطح القمر ككائن اختبار) بين نوعين من وكلاء الذكاء الاصطناعي: “القائم على الفهرسة” (الذي ينشئ فهرسًا لمستودع الأكواد مسبقًا ويستخدم البحث المتجهي) و “غير القائم على الفهرسة” (الذي يقرأ ويحلل ملفات الأكواد حسب الحاجة). أظهرت النتائج أن الوكيل القائم على الفهرسة كان أسرع في معظم الحالات وأجرى عددًا أقل من استدعاءات واجهة برمجة التطبيقات (API)، ولكنه في حالات تغير مستودع الأكواد بشكل متكرر مما يؤدي إلى تقادم الفهرس، قد ينتج أخطاء بسبب اعتماده على معلومات قديمة، مما يزيد من وقت تصحيح الأخطاء. يكشف هذا عن الحاجة إلى الموازنة بين الأداء الفوري وموثوقية المعلومات عند اختيار أدوات الترميز بالذكاء الاصطناعي (المصدر: Reddit r/ClaudeAI)

النقاش المستمر حول ما إذا كانت النماذج اللغوية الكبيرة (LLM) “تفكر”: من مطابقة الأنماط إلى الإدراك البشري: يستمر النقاش في المجتمع حول ما إذا كانت النماذج اللغوية الكبيرة (LLM) “تفكر” حقًا. يرى النقاد أن النماذج اللغوية الكبيرة هي في الأساس مولدات نصوص تنبؤية معقدة، تعمل عن طريق حساب احتمالات تسلسل الكلمات، وليس عن طريق التفكير الواعي. ومع ذلك، يشعر العديد من المستخدمين عند التفاعل مع النماذج اللغوية الكبيرة بتجربة مشابهة للحوار مع البشر. أثار هذا تساؤلات حول آليات توليد اللغة البشرية، وما إذا كانت هناك أوجه تشابه بين النماذج اللغوية الكبيرة وعمليات الإدراك البشري. تشير أبحاث شركة Apple أيضًا إلى محدودية النماذج اللغوية الكبيرة في الاستدلال المعقد، معتبرة أنها تعتمد بشكل أكبر على ذاكرة الأنماط بدلاً من الاستدلال الحقيقي، مما يضيف منظورًا جديدًا لهذا النقاش (المصدر: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham يتحدث عن تأثير الذكاء الاصطناعي على فجوة الدخل: صرح Paul Graham لابنه البالغ من العمر 16 عامًا بأن تقنية الذكاء الاصطناعي قد تؤدي على المدى القصير إلى توسيع فجوة الدخل في العمل بين الناس. وضرب مثالاً بأن المبرمجين ذوي المستوى المتوسط يجدون الآن صعوبة أكبر في العثور على عمل، بينما يتقاضى المبرمجون المتميزون أجورًا أعلى بفضل مساعدة الذكاء الاصطناعي. ويرى أن هذا ليس بالأمر الجديد، فالتقدم التكنولوجي غالبًا ما يؤدي إلى توسيع فجوة الدخل، لأن الحد الأدنى للدخل ثابت عند الصفر، بينما ترفع التكنولوجيا باستمرار سقف مكافآت أصحاب المواهب المتميزة (المصدر: dotey)
نقاش حول أخلاقيات أمان الذكاء الاصطناعي: من سلوك النموذج إلى المعايير الاجتماعية: يتصاعد النقاش المجتمعي حول أمان وأخلاقيات الذكاء الاصطناعي. هنأ Geoffrey Hinton يوشوا Bengio على إطلاق مشروع LawZero، الذي يهدف إلى تعزيز التصميم الآمن للذكاء الاصطناعي، مع التركيز بشكل خاص على السلوكيات المحتملة للحماية الذاتية والخداع في الأنظمة المتطورة. في الوقت نفسه، تنتقد بعض وجهات النظر أبحاث أمان الذكاء الاصطناعي (مثل اختبار ما إذا كان النموذج يوافق على إيقاف تشغيله) باعتبارها “مسرحية أمان” تفتقر إلى القيمة العملية. كما أثارت أبحاث OpenAI حول العلاقات بين الإنسان والآلة نقاشًا، مؤكدة على الحاجة إلى إعطاء الأولوية لدراسة تأثير الذكاء الاصطناعي على الرفاهية العاطفية للمستخدمين في سياق اندماجه المتزايد في الحياة، واستكشاف كيفية تحقيق التوازن بين التواصل الواضح وتجنب التجسيم في تفاعلات النموذج (المصدر: geoffreyhinton, ClementDelangue, togelius)

مساعدو الذكاء الاصطناعي مثل ChatGPT يحظون بتقدير المستخدمين لدورهم في الدعم العاطفي: شارك العديد من المستخدمين على وسائل التواصل الاجتماعي تجاربهم مع مساعدي الذكاء الاصطناعي مثل ChatGPT في تقديم الدعم العاطفي والمساعدة العملية لهم عند مواجهة الصعوبات. ذكر بعض المستخدمين أنه في أوقات البطالة، أو المشاكل الصحية، أو الحالة المزاجية السيئة، لم يقدم ChatGPT خطط عمل وموارد معلومات محددة فحسب، بل ساعدهم أيضًا بطريقة غير قضائية على تخفيف الذعر واستعادة القوة. يُظهر هذا القيمة المحتملة للذكاء الاصطناعي في الدعم النفسي والتدخل في الأزمات، على الرغم من أنه لا يمتلك مشاعر أو وعيًا حقيقيًا (المصدر: Reddit r/ChatGPT)
“Vibe Coding” تصبح ظاهرة جديدة في البرمجة بمساعدة الذكاء الاصطناعي: انتشر مصطلح “Vibe Coding” في مجتمع المطورين، ويشير إلى طريقة برمجة تعتمد على الحدس والتكرار السريع للأكواد بمساعدة الذكاء الاصطناعي. حظيت أدوات مثل Claude Code بتقدير بعض المبرمجين لأدائها المتميز في أوقات معينة (مثل الليل أو الصباح الباكر، ربما بسبب انخفاض حمل الخادم أو عدم تكميمها بدرجة عالية). تعكس هذه الظاهرة التحسن الذي أحدثه مساعدو الترميز بالذكاء الاصطناعي في كفاءة التطوير، وفي الوقت نفسه تثير نقاشات حول اتساق النماذج، وتأثير التكميم، وأنماط العمل الجديدة للمطورين (المصدر: dotey, jeremyphoward)
💡 أخرى
Andrej Karpathy يتأمل في التأثير الهائل للتلوث الضوضائي على النوم والصحة: شارك Andrej Karpathy تجربته الشخصية، مشيرًا إلى أن التلوث الضوضائي البيئي مثل ضوضاء حركة المرور قد يكون له تأثير سلبي هائل وغير معترف به بشكل كافٍ على جودة النوم والصحة على المدى الطويل. ويتكهن بأن الضوضاء الليلية (مثل أصوات السيارات والدراجات النارية الصاخبة) قد تؤدي إلى تدهور جودة نوم الملايين، مما يؤثر بدوره على الحالة المزاجية، والإبداع، والطاقة، ويزيد من مخاطر الإصابة بأمراض القلب والأوعية الدموية، والأمراض الأيضية، والأمراض المعرفية. ويدعو أجهزة تتبع النوم (مثل Whoop و Oura) إلى تتبع العلاقة بين الضوضاء والنوم بوضوح، وزيادة الوعي العام بهذه المشكلة (المصدر: karpathy)
تقاطع الذكاء الاصطناعي مع الدين يثير الاهتمام: لاحظ مستخدم وسائل التواصل الاجتماعي menhguin أن السوق المحتمل للتطبيقات الدينية الجديدة أو الشبيهة بالدين القائمة على الذكاء الاصطناعي لا يمكن إغفاله. على سبيل المثال، يشير التنجيم بالذكاء الاصطناعي، ومقاطع الفيديو الإنجيلية بالذكاء الاصطناعي، وتطبيقات الصلاة بالذكاء الاصطناعي، وبعض تطبيقات الذكاء الاصطناعي لمجموعات معينة، إلى إمكانيات تقنية الذكاء الاصطناعي في تلبية الاحتياجات الروحية أو الإيمانية للبشر (المصدر: menhguin)
توليد خادم HTTP 2.0 بمساعدة الذكاء الاصطناعي، لاستكشاف إمكانات النماذج اللغوية الكبيرة في مشاريع البرمجيات الكبيرة: استخدم مطور إطار عمل مطور ذاتيًا (promptyped) ونموذج Gemini 2.5 Pro، من خلال دورة من كتابة الأكواد والترجمة والاختبار، لينجح في جعل نموذج لغوي كبير يبني خادمًا متوافقًا مع معايير HTTP 2.0 من البداية. أنتج المشروع 15 ألف سطر من كود المصدر وأكثر من 30 ألف سطر من كود الاختبار، واجتاز اختبار التوافق h2spec. على الرغم من أن التجربة استغرقت حوالي 119 ساعة من وقت واجهة برمجة التطبيقات (API) و 631 دولارًا من تكاليف واجهة برمجة التطبيقات، إلا أنها أظهرت إمكانات النماذج اللغوية الكبيرة في تصميم البنية وكتابة برامج معقدة ومتوافقة مع المعايير، وكشفت أيضًا عن شكل التطبيقات المكتوبة بالكامل بواسطة النماذج اللغوية الكبيرة (المصدر: Reddit r/LocalLLaMA)