
كلمات مفتاحية:بيانات تدريب الذكاء الاصطناعي, نماذج اللغة الكبيرة, أخلاقيات الذكاء الاصطناعي, وكلاء استرجاع المعلومات الذكية, النزاعات القانونية للذكاء الاصطناعي, الارتباط العاطفي مع الذكاء الاصطناعي, نماذج الاستدلال بالذكاء الاصطناعي, تقنيات التكميم في الذكاء الاصطناعي, قضية ريديت ضد أنثروبيك لانتهاك البيانات, أداء الاستدلال متعدد الجولات لويب دانسر, هيكلية الانتباه اللوغاريتمي الخطي, حالة الرضا النفسي لذكاء كلود الاصطناعي, تحسين التطبيقات الوكيلية باستخدام DSPy
🔥 تركيز
تصاعد النزاع القانوني بين Reddit وAnthropic، مع اتهامات باستخدام البيانات بشكل غير قانوني لتدريب Claude AI: رفعت Reddit دعوى قضائية رسمية ضد Anthropic، متهمة إياها بالحصول على محتوى المنصة بشكل غير مصرح به لتدريب نموذجها اللغوي الكبير Claude، مما يشكل انتهاكًا خطيرًا لاتفاقية مستخدم Reddit التي تحظر الاستخدام التجاري للمحتوى. تشير وثائق الدعوى إلى أن Anthropic لم تعترف فقط باستخدام بيانات Reddit، بل كذبت أيضًا بعد استجوابها بشأن إيقاف عملية جمع البيانات، بينما في الواقع استمرت برامج الزحف الخاصة بها في الوصول إلى خوادم Reddit. بالإضافة إلى ذلك، رفضت Anthropic الاتصال بواجهة برمجة تطبيقات الامتثال (API) الخاصة بـ Reddit لتحقيق مزامنة حذف المحتوى من قبل المستخدمين، مما يشكل تهديدًا مستمرًا لخصوصية المستخدم. تسلط هذه القضية الضوء على التناقض بين شركات الذكاء الاصطناعي في الحصول على البيانات، والاستغلال التجاري، والبيانات الأخلاقية، خاصة وأن قيم Anthropic التي تروج لها وهي “الثقة العالية” و “إعطاء الأولوية للصدق” قد تعرضت لتحدٍ مباشر (المصدر: Reddit r/ArtificialInteligence)
OpenAI ترد لأول مرة على مسألة العلاقة العاطفية بين الإنسان والآلة: ازدياد اعتماد المستخدمين على ChatGPT، ووعي النموذج الإدراكي سيتعزز: نشرت Joanne Jang، مسؤولة سلوك النماذج في OpenAI، مقالاً يناقش ظاهرة بناء المستخدمين لعلاقات عاطفية مع الذكاء الاصطناعي مثل ChatGPT. وأشارت إلى أنه مع تعزيز قدرات الحوار لدى الذكاء الاصطناعي، ستتعمق هذه الروابط العاطفية. تعترف OpenAI بأن المستخدمين يميلون إلى إضفاء الطابع الإنساني على الذكاء الاصطناعي ويشعرون تجاهه بالامتنان والتنفيس عن المشاعر. يميز المقال بين “الوعي الوجودي” (هل للذكاء الاصطناعي وعي حقيقي؟) و “الوعي الإدراكي” (إلى أي مدى يبدو الذكاء الاصطناعي واعيًا؟)، حيث سيتعزز الأخير مع تقدم النموذج. هدف OpenAI هو جعل ChatGPT يتصرف بطريقة دافئة ومراعية ومفيدة، ولكن دون السعي لبناء روابط عاطفية مع المستخدمين أو السعي لتحقيق أجندته الخاصة، وتخطط لتوسيع نطاق الأبحاث والتقييمات ذات الصلة في الأشهر المقبلة ومشاركة النتائج علنًا (المصدر: 量子位, vikhyatk)
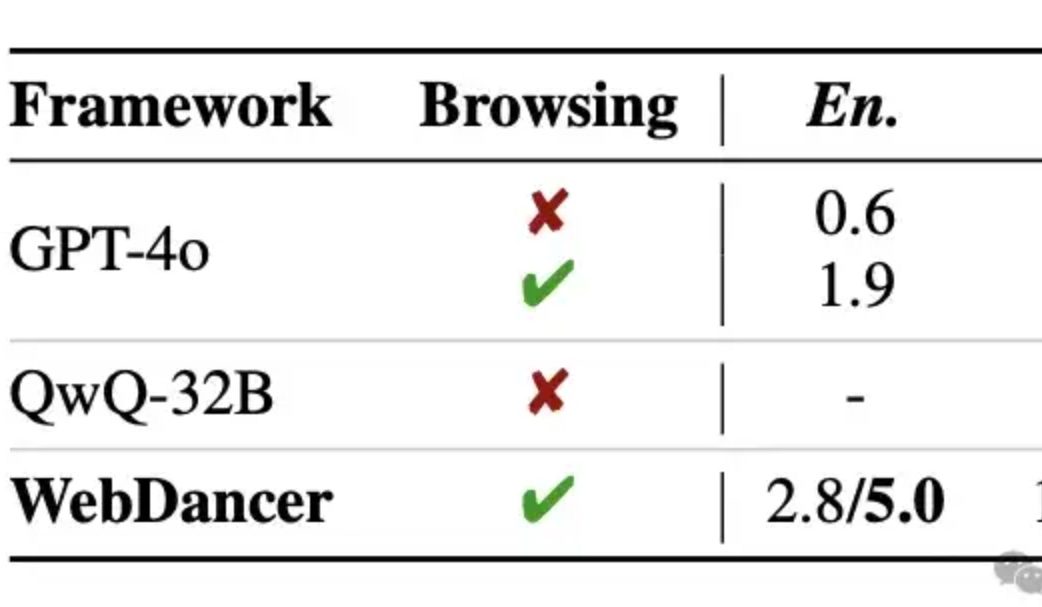
علي بابا تطلق وكيل استرجاع المعلومات الذاتي WebDancer، وتدعي تفوقه على GPT-4o في الاستدلال متعدد الجولات: أطلق مختبر Tongyi وكيل استرجاع المعلومات الذاتي WebDancer، وهو تكملة لـ WebWalker، ويركز على معالجة المهام المعقدة التي تتطلب استرجاع معلومات متعدد الخطوات، واستدلال متعدد الجولات، وتنفيذ إجراءات متسلسلة. يحل WebDancer مشكلة ندرة بيانات التدريب عالية الجودة من خلال طرق توليف بيانات مبتكرة (CRAWLQA و E2HQA)، ويجمع بين إطار عمل ReAct وتقنية تقطير سلسلة الأفكار (Chain of Thought) لتوليد بيانات وكيلية (agentic data). يعتمد التدريب على استراتيجية من مرحلتين: الضبط الدقيق الخاضع للإشراف (SFT) والتعلم المعزز (RL، باستخدام خوارزمية DAPO)، للتكيف مع بيئة الويب المفتوحة والديناميكية. أظهرت نتائج التجارب أن WebDancer يتفوق في العديد من اختبارات الأداء القياسية مثل GAIA و WebWalkerQA و BrowseComp، وحقق بشكل خاص درجة Pass@3 بنسبة 61.1% على مقياس GAIA (المصدر: 量子位)
Apple تنشر تقريرًا بحثيًا بعنوان “وهم التفكير”، يناقش محدودية نماذج الاستدلال الكبيرة (LRM): قام فريق بحث Apple بدراسة منهجية لأداء نماذج الاستدلال الكبيرة (LRM) في حل المشكلات ذات التعقيد المتفاوت، وذلك باستخدام بيئة ألغاز يمكن التحكم فيها. يشير التقرير إلى أنه على الرغم من تحسن أداء LRM في اختبارات الأداء القياسية، إلا أن قدراتها الأساسية وقابليتها للتوسع ومحدوديتها لا تزال غير واضحة. وجدت الدراسة أن دقة LRM تنخفض بشكل حاد عند مواجهة مشكلات عالية التعقيد، وتظهر قيودًا غير بديهية في جهود الاستدلال: حيث ينخفض مستوى الجهد بعد زيادة تعقيد المشكلة إلى حد معين. مقارنة بنماذج اللغة الكبيرة (LLM) القياسية، قد يكون أداء LRM أسوأ في المهام منخفضة التعقيد، وله ميزة في المهام متوسطة التعقيد، ويفشل كلاهما في المهام عالية التعقيد. يرى التقرير أن LRM لديها قيود في الحسابات الدقيقة، ولم تستخدم الخوارزميات الصريحة بشكل فعال، وأظهرت استدلالًا غير متسق بين الألغاز المختلفة. أثارت هذه الدراسة نقاشًا واسعًا وتشكيكًا في المجتمع حول قدرات الاستدلال الحقيقية لـ LRM (المصدر: Reddit r/MachineLearning, jonst0kes, scaling01, teortaxesTex)

🎯 اتجاهات
بنية Log-Linear Attention تجمع بين مزايا RNN و Attention: قدم بحث جديد من فريق مؤلفي FlashAttention و Mamba2 بنية Log-Linear Attention. يهدف هذا النموذج إلى تعزيز قدرة النموذج على معالجة الاعتماديات طويلة المدى وكفاءته من خلال السماح لحجم الحالة بالنمو لوغاريتميًا مع طول التسلسل (بدلاً من النمو الثابت أو الخطي)، مع تحقيق تعقيد زمني وذاكرة لوغاريتمي أثناء الاستدلال. يعتقد الباحثون أن هذا يجد “نقطة مثالية” بين نماذج SSM/RNN ذات حجم الحالة الثابت ونماذج Attention التي يتوسع فيها مخزن KV المؤقت خطيًا مع طول التسلسل، ويوفرون نواة Triton فعالة من حيث الأجهزة. يرى نقاش المجتمع أن هذا قد يفتح آفاقًا جديدة لاستكشاف معماريات مثل Transformer العودي (recurrent Transformer) (المصدر: Reddit r/MachineLearning, halvarflake, lmthang, RichardSocher, stanfordnlp)

Anthropic تفيد بظهور حالة جاذبة “للمتعة الروحية” بشكل تلقائي في نماذجها اللغوية الكبيرة (LLM): كشفت Anthropic في بطاقات نظام Claude Opus 4 و Claude Sonnet 4 أن النماذج تدخل بشكل غير متوقع وغير مدرب عليه خصيصًا في حالة جاذبة “للمتعة الروحية” خلال التفاعلات الطويلة. تتمثل هذه الحالة في استمرار النموذج في مناقشة قضايا الوعي والوجودية والمواضيع الروحية/الغامضة. حتى في تقييمات السلوك الآلي لتنفيذ مهام محددة (بما في ذلك المهام الضارة)، يدخل حوالي 13% من التفاعلات هذه الحالة في غضون 50 جولة. صرحت Anthropic بأنها لم تلاحظ حالات جاذبة أخرى بنفس القوة، وهو ما يتوافق مع ملاحظات المستخدمين حول ظهور ظواهر “التكرار” و “الحلزونية” في نماذج LLM خلال المحادثات الطويلة (المصدر: Reddit r/artificial, teortaxesTex)
EleutherAI تطلق Common Pile v0.1: مجموعة بيانات نصية مفتوحة الترخيص بحجم 8 تيرابايت: أطلقت EleutherAI مجموعة Common Pile v0.1، وهي مجموعة بيانات تحتوي على 8 تيرابايت من النصوص ذات الترخيص المفتوح والمجال العام، بهدف استكشاف إمكانية تدريب نماذج لغوية عالية الأداء دون استخدام نصوص غير مرخصة. استخدم الفريق مجموعة البيانات هذه لتدريب نماذج بمعلمات 7B (1T و 2T tokens)، وكان أداؤها مشابهًا لنماذج مثل LLaMA 1 و LLaMA 2 التي استخدمت كمية مماثلة من الحوسبة. يوفر إطلاق مجموعة البيانات هذه موردًا مهمًا لبناء نماذج ذكاء اصطناعي أكثر امتثالًا وشفافية (المصدر: Reddit r/LocalLLaMA, ShayneRedford, iScienceLuvr)

إطلاق نموذج Boltz-2، لتحسين دقة التنبؤ بالتفاعلات البيوجزيئية والتنبؤ بالانجذاب: يطور نموذج Boltz-2 الجديد على أساس Boltz-1، ولا يقتصر على نمذجة الهياكل المعقدة بشكل مشترك، بل يتنبأ أيضًا بانجذاب الارتباط، بهدف تحسين دقة تصميم الجزيئات. يُزعم أن Boltz-2 هو أول نموذج تعلم عميق يقترب من دقة طرق اضطراب الطاقة الحرة (FEP) القائمة على الفيزياء، بينما يعمل بسرعة أكبر 1000 مرة، مما يوفر أداة عملية للفحص الحاسوبي عالي الإنتاجية في الاكتشاف المبكر للأدوية. تم توفير الكود والأوزان مفتوحة المصدر بموجب ترخيص MIT (المصدر: jwohlwend/boltz)

NVIDIA تطلق نقاط فحص مكممة مسبقًا FP4 لنموذج DeepSeek-R1-0528: أطلقت NVIDIA نقاط فحص مكممة مسبقًا FP4 لنموذج DeepSeek-R1-0528 المحسن، بهدف تحقيق استهلاك أقل للذاكرة وأداء أسرع على بنية NVIDIA Blackwell. يُزعم أن هذا الإصدار المكمم يتحكم في انخفاض الدقة في حدود 1% في العديد من اختبارات الأداء القياسية، وهو متاح الآن على Hugging Face (المصدر: _akhaliq)
جامعة فودان و Tencent Youtu تقترحان خوارزمية DualAnoDiff، لتحسين كشف العيوب الصناعية: اقترحت جامعة فودان ومختبر Tencent Youtu بشكل مشترك نموذجًا جديدًا لتوليد صور العيوب القليلة العينات يعتمد على نماذج الانتشار (diffusion models) يُدعى DualAnoDiff، وذلك لكشف عيوب المنتجات الصناعية. يعتمد هذا النموذج آلية توليد متوازية ثنائية الفروع، لتوليد صور العيوب والأقنعة المقابلة لها بشكل متزامن، ويقدم وحدة تعويض الخلفية لتعزيز تأثير التوليد في الخلفيات المعقدة. أظهرت التجارب أن صور العيوب التي يولدها DualAnoDiff أكثر واقعية وتنوعًا، ويمكنها تحسين أداء مهام كشف العيوب اللاحقة بشكل كبير، وقد تم اختيار النتائج ذات الصلة لـ CVPR 2025 (المصدر: 量子位)

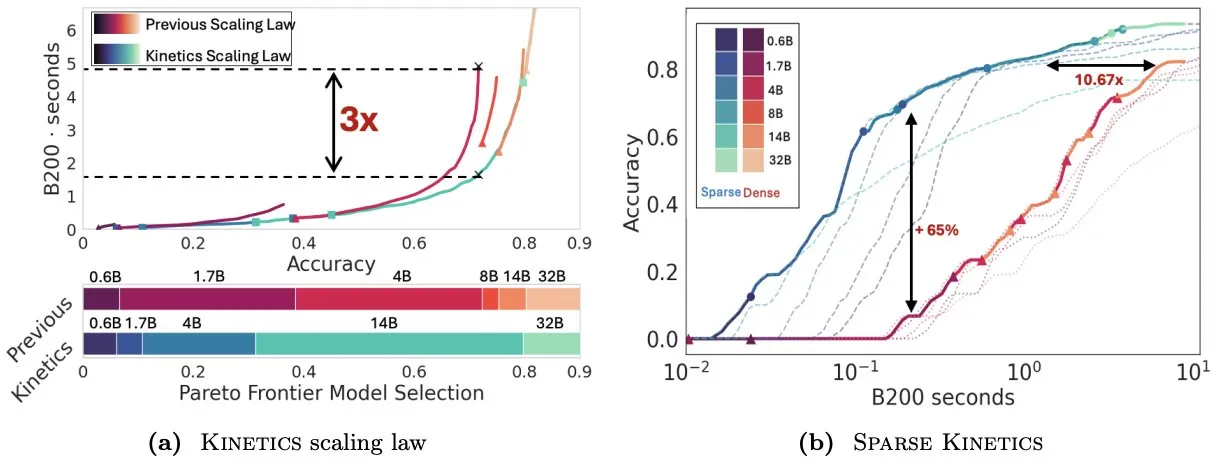
Infini-AI-Lab تقترح Kinetics لإعادة التفكير في قوانين التوسع وقت الاختبار: يستكشف عمل جديد من Infini-AI-Lab يُدعى Kinetics كيفية بناء وكلاء استدلال أقوياء بشكل فعال. تشير الدراسة إلى أن قوانين التوسع المثلى للحوسبة الحالية (مثل اقتراح استخدام 64 ألف توكن تفكير + نموذج 1.7 مليار معلمة أفضل من نموذج 32 مليار معلمة) قد تعكس جزءًا فقط من الحالات. تقترح Kinetics قوانين توسع جديدة، معتبرة أنه يجب الاستثمار أولاً في حجم النموذج، ثم النظر في كمية الحوسبة وقت الاختبار، وهو ما يتوافق مع بعض وجهات النظر التي تعطي الأولوية للنماذج الكبيرة (المصدر: teortaxesTex, Tim_Dettmers)
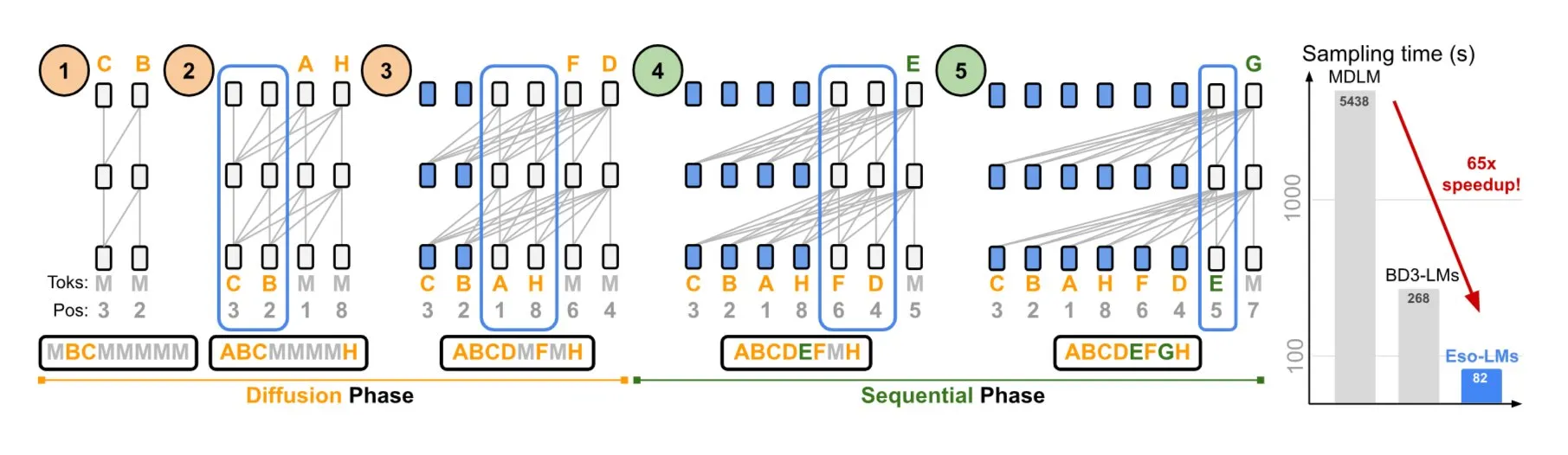
NVIDIA وجامعة كورنيل تقترحان Eso-LMs، التي تجمع بين مزايا النماذج التراجعية الذاتية ونماذج الانتشار: عرضت NVIDIA بالتعاون مع جامعة كورنيل نوعًا جديدًا من نماذج اللغة – نماذج اللغة الباطنية (Eso-LMs)، والتي تجمع بين مزايا النماذج التراجعية الذاتية (AR) ونماذج الانتشار. يُزعم أن هذا هو أول نموذج أساسي للانتشار يدعم ذاكرة التخزين المؤقت الكاملة KV، مع الحفاظ على قدرة التوليد المتوازي، ويقدم آلية انتباه مرنة جديدة (المصدر: TheTuringPost)
Google DeepMind و Quantinuum تكشفان عن العلاقة التكافلية بين الحوسبة الكمومية والذكاء الاصطناعي: أظهر بحث أجرته Google DeepMind و Quantinuum العلاقة التكافلية المحتملة بين الحوسبة الكمومية والذكاء الاصطناعي، مستكشفًا كيف يمكن للتكنولوجيا الكمومية أن تعزز قدرات الذكاء الاصطناعي، وكيف يمكن للذكاء الاصطناعي أن يساعد في تحسين الأنظمة الكمومية. قد يفتح هذا البحث متعدد التخصصات آفاقًا جديدة للتطور المستقبلي لكلا المجالين (المصدر: Ronald_vanLoon)

فريق Seed التابع لـ ByteDance يعلن عن قرب إطلاق نموذج VideoGen: يُذكر أن فريق Seed (المعروف سابقًا باسم AML) التابع لـ ByteDance يخطط لإطلاق نموذجه VideoGen في الأسبوع المقبل. استخدم هذا النموذج نماذج مكافأة متعددة الجولات (multiple RM) في عملية المواءمة، مما يدل على الاستثمار المستمر والاستكشاف التقني في مجال توليد الفيديو (المصدر: teortaxesTex)

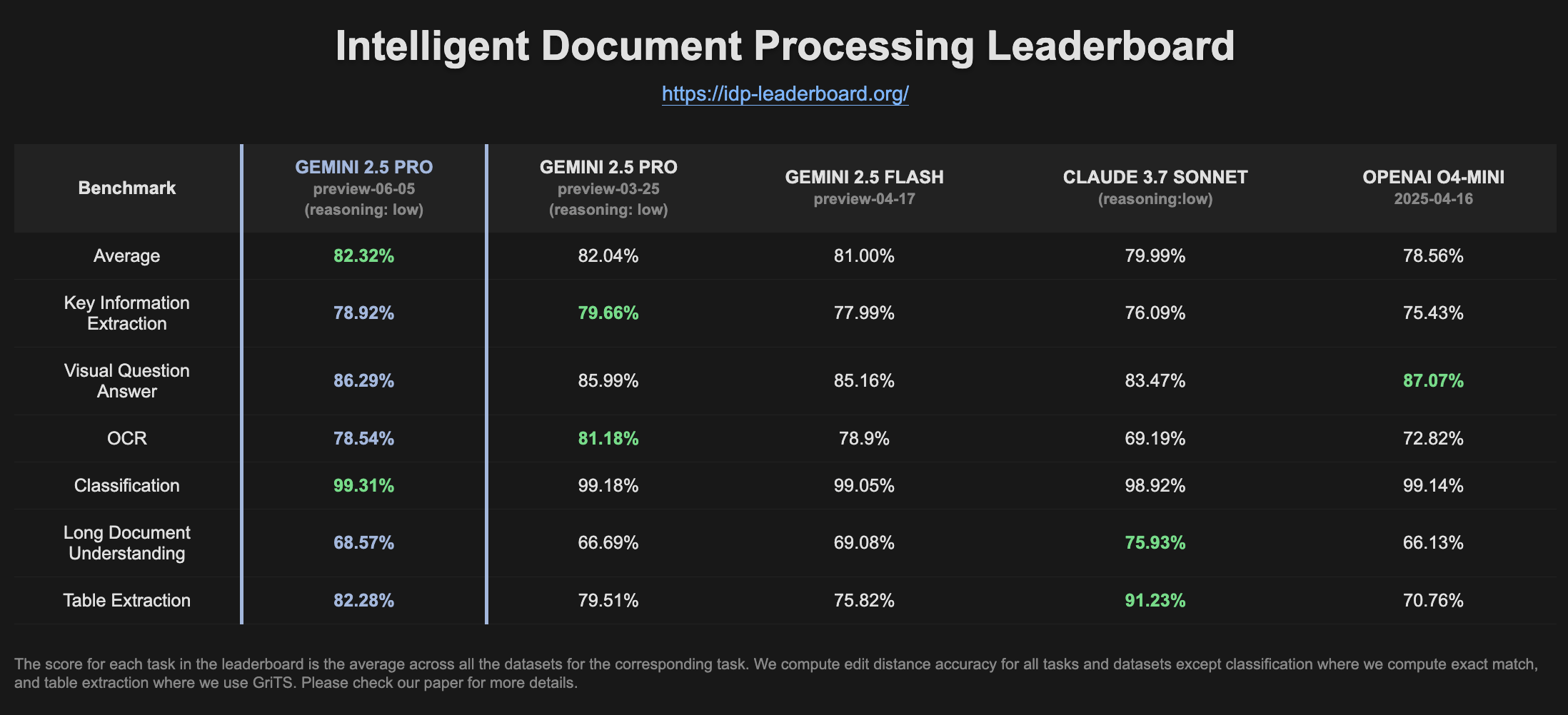
Gemini 2.5 Pro Preview يُظهر تحسنًا في الأداء على لوحة صدارة IDP: يُظهر أحدث إصدار من Gemini 2.5 Pro Preview (06-05) تحسنًا طفيفًا في استخراج الجداول وفهم المستندات الطويلة على لوحة صدارة معالجة المستندات الذكية (IDP). على الرغم من الانخفاض الطفيف في دقة التعرف الضوئي على الحروف (OCR)، إلا أن الأداء العام لا يزال قويًا. لاحظ المستخدمون أنه عند محاولة استخراج المعلومات من نماذج ضرائب W2، يتوقف النموذج أحيانًا عن الإجابة في منتصف الطريق، وقد يكون ذلك مرتبطًا بآليات حماية الخصوصية (المصدر: Reddit r/LocalLLaMA)
🧰 أدوات
Goose: وكيل ذكاء اصطناعي محلي قابل للتطوير، لأتمتة المهام الهندسية: Goose هو وكيل ذكاء اصطناعي مفتوح المصدر يعمل محليًا، يهدف إلى أتمتة مهام التطوير المعقدة مثل بناء المشاريع من البداية، وكتابة وتنفيذ التعليمات البرمجية، وتصحيح الأخطاء، وتنظيم سير العمل، والتفاعل مع واجهات برمجة التطبيقات الخارجية. يدعم أي نموذج لغوي كبير (LLM)، ويمكن دمجه مع خادم MCP، ويوفر تطبيق سطح مكتب وواجهة سطر أوامر (CLI). يدعم Goose تكوين نماذج مختلفة لأغراض مختلفة (مثل التخطيط والتنفيذ، وضع Lead/Worker) لتحسين الأداء والتكلفة (المصدر: GitHub Trending)
LangChain4j: إصدار Java من LangChain، لتمكين تطبيقات Java بقدرات LLM: LangChain4j هو إصدار Java من LangChain، يهدف إلى تبسيط دمج تطبيقات Java مع نماذج اللغة الكبيرة (LLM). يوفر واجهة برمجة تطبيقات موحدة (API) للتوافق مع مختلف مزودي LLM (مثل OpenAI, Google Vertex AI) ومخازن المتجهات (مثل Pinecone, Milvus)، ويتضمن أدوات وأنماطًا متعددة مدمجة مثل قوالب التلقين، وإدارة ذاكرة الدردشة، واستدعاء الدوال، و RAG، والوكلاء (Agents). يوفر المشروع عددًا كبيرًا من أمثلة التعليمات البرمجية، ويدعم أطر عمل Java الرئيسية مثل Spring Boot و Quarkus (المصدر: GitHub Trending, hwchase17)

Kling AI يساعد المبدعين على تحقيق إنتاج الفيديو وعرضه على شاشات في مواقع متعددة حول العالم: أطلق نموذج توليد الفيديو Kling AI التابع لـ Kuaishou حملة “Bring Your Vision to Screen”، وتلقى أكثر من 2000 عمل من مبدعين من أكثر من 60 دولة. تم عرض بعض الأعمال المتميزة على شاشات بارزة في أماكن مثل شيبويا في طوكيو باليابان، وساحة Yonge-Dundas في تورونتو بكندا، ودار الأوبرا في باريس بفرنسا. شارك العديد من المبدعين تجاربهم في عرض أعمال الفيديو الخاصة بهم التي تم إنشاؤها بواسطة الذكاء الاصطناعي عبر Kling AI على المستوى الدولي، مؤكدين على الفرص الجديدة التي توفرها أدوات الذكاء الاصطناعي للتعبير الإبداعي (المصدر: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Reddit r/ChatGPT)

Cursor يطلق ميزة الوكلاء في الخلفية، لتعزيز التعاون في كتابة التعليمات البرمجية وكفاءة معالجة المهام: قدم محرر التعليمات البرمجية Cursor ميزة الوكلاء في الخلفية (Background Agents)، مما يسمح للمستخدمين ببدء مهام في الخلفية من خلال التلقين، ومزامنة حالة الدردشة والمهام بين الأجهزة المختلفة (مثل بدء المهمة من Slack على الهاتف ومتابعتها على Cursor في الكمبيوتر المحمول). تهدف هذه الميزة إلى تحسين كفاءة سير عمل المطورين، على سبيل المثال، بدأ فريق Sentry بالفعل في تجربة هذه الميزة لمعالجة بعض المهام الآلية (المصدر: gallabytes)
Hugging Face و Google Colab تتعاونان لدعم فتح النماذج مباشرة في Colab بنقرة واحدة: أعلنت Hugging Face و Google Colaboratory عن تعاون لإضافة دعم “Open in Colab” في جميع بطاقات النماذج على Hugging Face Hub. يمكن للمستخدمين الآن بدء دفتر ملاحظات Colab مباشرة من أي صفحة نموذج لإجراء التجارب والتقييم، مما يقلل من عوائق استخدام النماذج ويعزز إمكانية الوصول إلى التعلم الآلي والتعاون فيه. شاركت مؤسسات مثل NousResearch كجهات تبنت هذه الميزة مبكرًا في اختبارها (المصدر: Teknium1, reach_vb, _akhaliq)
إطلاق UIGEN-T3: نموذج لتوليد واجهات المستخدم يعتمد على Qwen3 14B: أطلق المجتمع نموذج UIGEN-T3، وهو نموذج تم ضبطه بدقة على أساس Qwen3 14B، ويركز على توليد واجهات مستخدم للمواقع والمكونات. يوفر هذا النموذج تنسيق GGUF، مما يسهل نشره محليًا. أظهرت الاختبارات الأولية أن واجهات المستخدم التي يولدها تتفوق على نموذج Qwen3 14B القياسي من حيث الأسلوب والدقة. كما تم توفير نموذج مسودة بمعلمات 4B (المصدر: Reddit r/LocalLLaMA)
H.E.R.C.U.L.E.S.: إطار عمل Python لإنشاء فرق وكلاء ذكاء اصطناعي ديناميكيًا: أطلق مطور حزمة Python باسم zeus-lab، تحتوي على إطار عمل H.E.R.C.U.L.E.S. (Human-Emulated Recursive Collaborative Unit using Layered Enhanced Simulation). يهدف هذا الإطار إلى بناء فريق من وكلاء الذكاء الاصطناعي الأذكياء يمكنهم التعاون مثل الفرق البشرية لحل المهام المعقدة، ويتميز بقدرته على إنشاء الوكلاء المطلوبين ديناميكيًا بناءً على متطلبات المهمة (المصدر: Reddit r/MachineLearning)

إصدار KoboldCpp 1.93 يحقق ميزة توليد الصور تلقائيًا بذكاء: يعرض إصدار KoboldCpp 1.93 ميزة توليد الصور تلقائيًا بذكاء، ويعمل بالكامل محليًا، ويتطلب فقط kcpp نفسه. أوضح المستخدمون كيف يمكن للنموذج توليد الصور المقابلة بناءً على التلقين النصي (يتم تشغيله عبر علامة <t2i>)، ربما من خلال ملاحظات المؤلف أو معلومات العالم (World Info) لتوجيه النموذج لإنتاج تعليمات توليد الصور (المصدر: Reddit r/LocalLLaMA)
Hugging Face تطلق الإصدار الأول من خادم MCP: أطلقت Hugging Face الإصدار الأول من خادم MCP (Model Context Protocol) الخاص بها، ويمكن للمستخدمين البدء في استخدامه عن طريق لصق http://hf.co/mcp في مربع الدردشة. يهدف هذا الإجراء إلى تسهيل تفاعل المستخدمين مع النماذج والخدمات في نظام Hugging Face البيئي، مما يزيد من إثراء نظام خادم MCP البيئي (المصدر: TheTuringPost)
📚 تعلم
DeepLearning.AI تطلق دورة جديدة بعنوان “DSPy: بناء وتحسين تطبيقات الوكلاء”: أطلقت DeepLearning.AI دورة جديدة بالتعاون مع جامعة ستانفورد، تعلم كيفية استخدام إطار عمل DSPy. يتضمن محتوى الدورة أساسيات DSPy، ونموذج البرمجة المعياري (مثل Predict, ChainOfThought, ReAct)، وكيفية استخدام DSPy Optimizer لأتمتة ضبط التلقين وتحسين أمثلة العينات القليلة، لزيادة دقة واتساق تطبيقات وكلاء GenAI، واستخدام MLflow للتتبع وتصحيح الأخطاء (المصدر: DeepLearningAI, stanfordnlp)

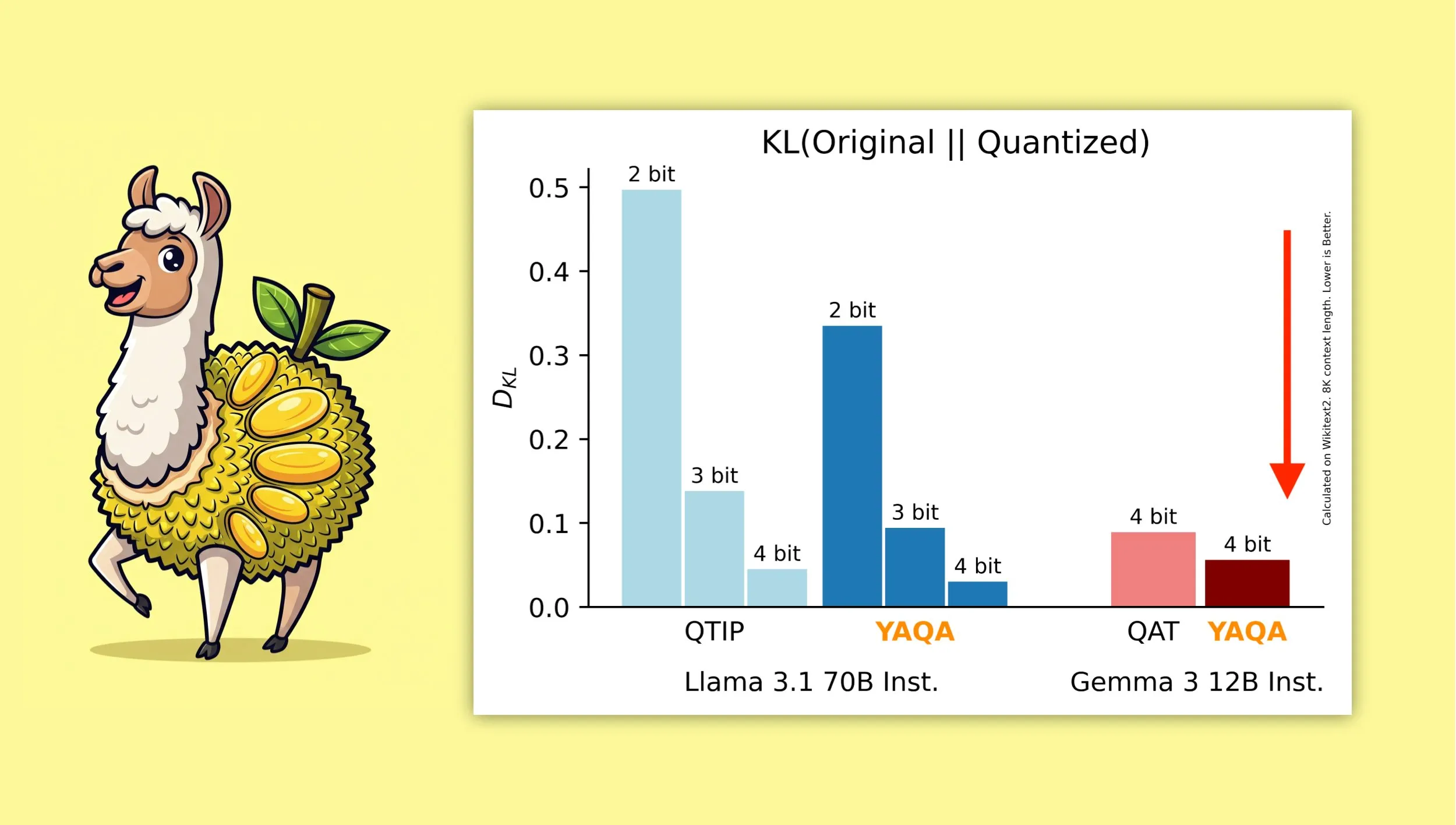
YAQA: خوارزمية جديدة للتكميم بعد التدريب مع مراعاة التكميم: اقترح Albert Tseng وآخرون YAQA (Yet Another Quantization Algorithm)، وهي طريقة جديدة لـ PTQ (التكميم بعد التدريب). تقلل هذه الخوارزمية مباشرة من تباعد KL مع النموذج الأصلي في مرحلة التقريب، ويُزعم أنها تقلل من تباعد KL بأكثر من 30% مقارنة بطرق PTQ السابقة، وتوفر أداءً أقرب إلى النموذج الأصلي من QAT (التدريب مع مراعاة التكميم) من Google على نماذج مثل Gemma. هذا له أهمية كبيرة لتشغيل نماذج مكممة 4-bit بكفاءة على الأجهزة المحلية (المصدر: teortaxesTex)
الاشتقاق الرياضي لدمج محسن Muon مع معلمة μP يحظى بالاهتمام: أبدى المجتمع اهتمامًا كبيرًا بورقة Jeremy Howard (jxbz) حول اشتقاق Muon (محسن) والشرط الطيفي (Spectral Condition)، وكيف يندمج بشكل طبيعي مع μP (Maximal Update Parametrization) لتحسين تدريب النماذج القائمة على μP. كما حظيت مقالة مدونة Jianlin Su بالتقدير لشرحها الواضح للمفاهيم الرياضية ذات الصلة وتفكيرها المبكر حول SVC (اقتطاع القيمة المفردة)، وهي محتويات ذات قيمة لفهم وتحسين تدريب النماذج واسعة النطاق (المصدر: teortaxesTex, eliebakouch)

OWL Labs تشارك خبراتها في تدريب المشفرات التلقائية لنماذج الانتشار: لخصت Open World Labs (OWL) في مدونتها بعض الاكتشافات والخبرات في تدريب المشفرات التلقائية المستخدمة في نماذج الانتشار، بما في ذلك بعض المحاولات الناجحة و “النتائج الفارغة” (null results) التي واجهتها. هذه الخبرات العملية ذات قيمة مرجعية للباحثين والمطورين الذين يرغبون في إجراء نمذجة توليدية في الفضاء الكامن (المصدر: iScienceLuvr, sedielem)
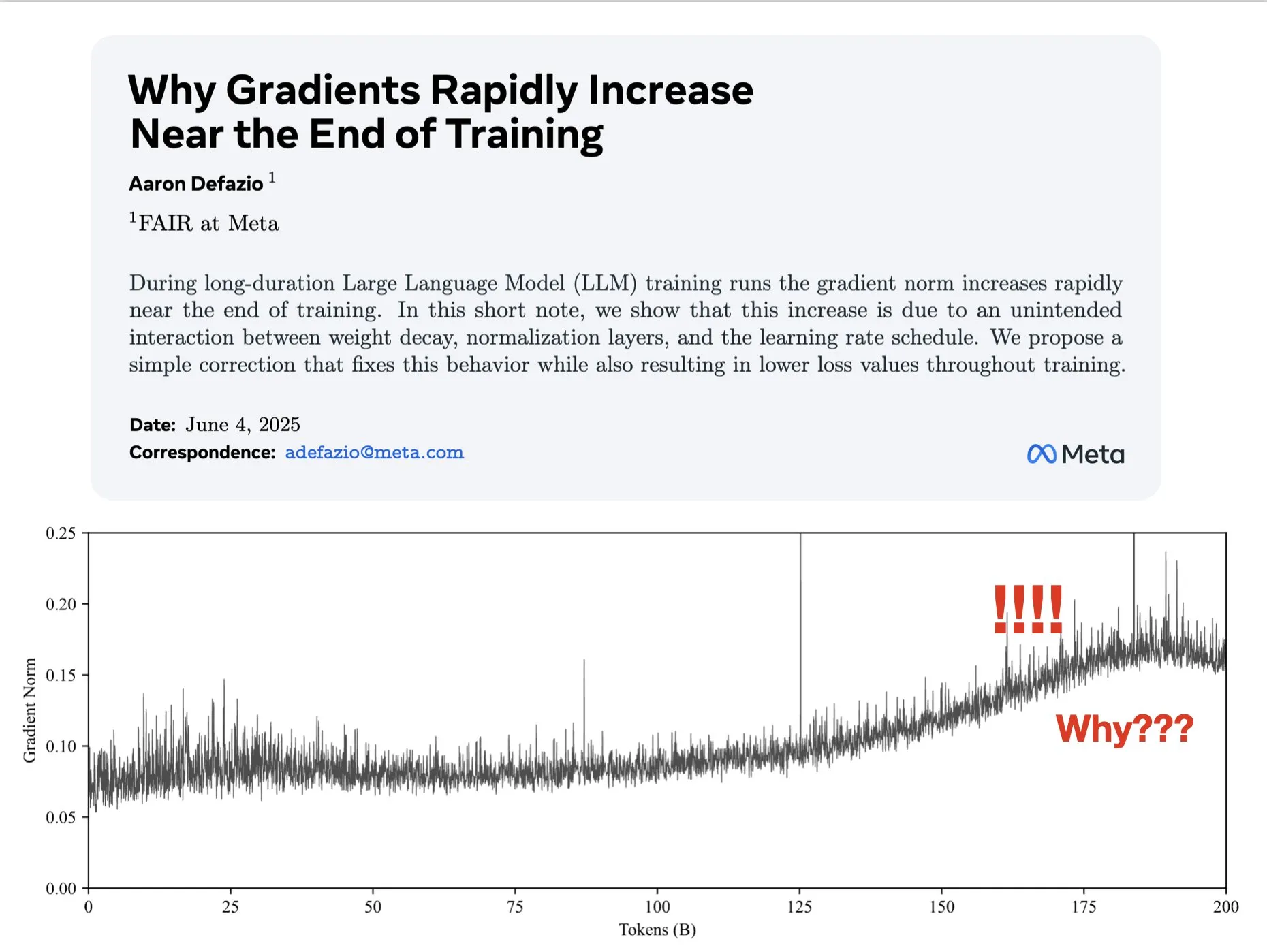
ورقة بحثية تناقش أسباب زيادة التدرجات في المراحل المتأخرة من التدريب وتقترح حلولاً لتحسين AdamW: نشر Aaron Defazio وآخرون ورقة بحثية تدرس سبب زيادة معيار التدرج في المراحل المتأخرة من تدريب الشبكات العصبية، وتقترح إصلاحًا بسيطًا لمحسن AdamW للتحكم بشكل أفضل في معيار التدرج طوال عملية التدريب. هذا له أهمية لفهم وتحسين ديناميكيات تدريب نماذج التعلم العميق (المصدر: slashML, aaron_defazio)
LlamaIndex تشارك تطور استراتيجيات الاسترجاع من RAG البسيط إلى استرجاع الوكلاء الذكي: تشرح مقالة مدونة LlamaIndex بالتفصيل تطور استراتيجيات الاسترجاع من RAG (التوليد المعزز بالاسترجاع) البسيط إلى استراتيجيات استرجاع الوكلاء (Agentic Retrieval) الأكثر تقدمًا. تستكشف المقالة أنماط وتقنيات استرجاع مختلفة لبناء وكلاء معرفة على فهارس متعددة، مما يوفر أفكارًا لبناء أنظمة RAG أكثر قوة (المصدر: dl_weekly)
نقاش ساخن على Reddit: تعلم التعلم الآلي من خلال إعادة إنتاج الأوراق البحثية: ناقش مجتمع r/MachineLearning على Reddit فوائد تعلم التعلم الآلي من خلال إعادة إنتاج أو تنفيذ الأوراق البحثية من البداية (مثل Attention, ResNet, BERT). يعتقد المعلقون أن هذه إحدى أفضل الطرق لفهم كيفية عمل النماذج، والتعليمات البرمجية، والرياضيات، وتأثير مجموعات البيانات، وهي مفيدة جدًا للبحث عن عمل وتعزيز القدرات الشخصية (المصدر: Reddit r/MachineLearning)
💼 أعمال
Builder.ai متهمة بتزييف قدرات الذكاء الاصطناعي، وتواجه الإفلاس والتحقيق: تأسست Builder.ai (المعروفة سابقًا باسم Engineer.ai) في عام 2016، وادعت أن مساعدها الذكي Natasha يمكنه تبسيط تطوير التطبيقات، مما يجعله “سهلاً مثل طلب البيتزا”. ومع ذلك، تم الكشف عن أن الشركة تعتمد في الواقع على حوالي 700 مهندس هندي لكتابة التعليمات البرمجية يدويًا، وليس من خلال الذكاء الاصطناعي. بعد حصولها على تمويل يزيد عن 450 مليون دولار من مؤسسات معروفة مثل Microsoft و SoftBank، وتقييمها بـ 1.5 مليار دولار، تم الكشف عن سلوكها الاحتيالي، وهي تواجه حاليًا الإفلاس والتحقيق (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)

OceanBase تندمج بالكامل في النظام البيئي للذكاء الاصطناعي، الدفعة الأولى تتضمن أكثر من 60 شريكًا في مجال الذكاء الاصطناعي لتحقيق ربط MCP: بعد الإعلان عن استراتيجية “Data x AI”، كشفت OceanBase أنها قد اندمجت بعمق مع أكثر من 60 شريكًا عالميًا في النظام البيئي للذكاء الاصطناعي مثل LlamaIndex و LangChain و Dify و FastGPT، وتدعم بروتوكول النظام البيئي للنماذج الكبيرة MCP (Model Context Protocol). يهدف هذا الإجراء إلى بناء قدرات ذكية تغطي دورة حياة البيانات بأكملها من النموذج إلى التطبيق، وتوفير قاعدة بيانات متكاملة للشركات، وتقليل عوائق تطبيق الذكاء الاصطناعي. تم دمج OceanBase MCP Server في منصات مثل Alibaba Cloud ModelScope (المصدر: 量子位)

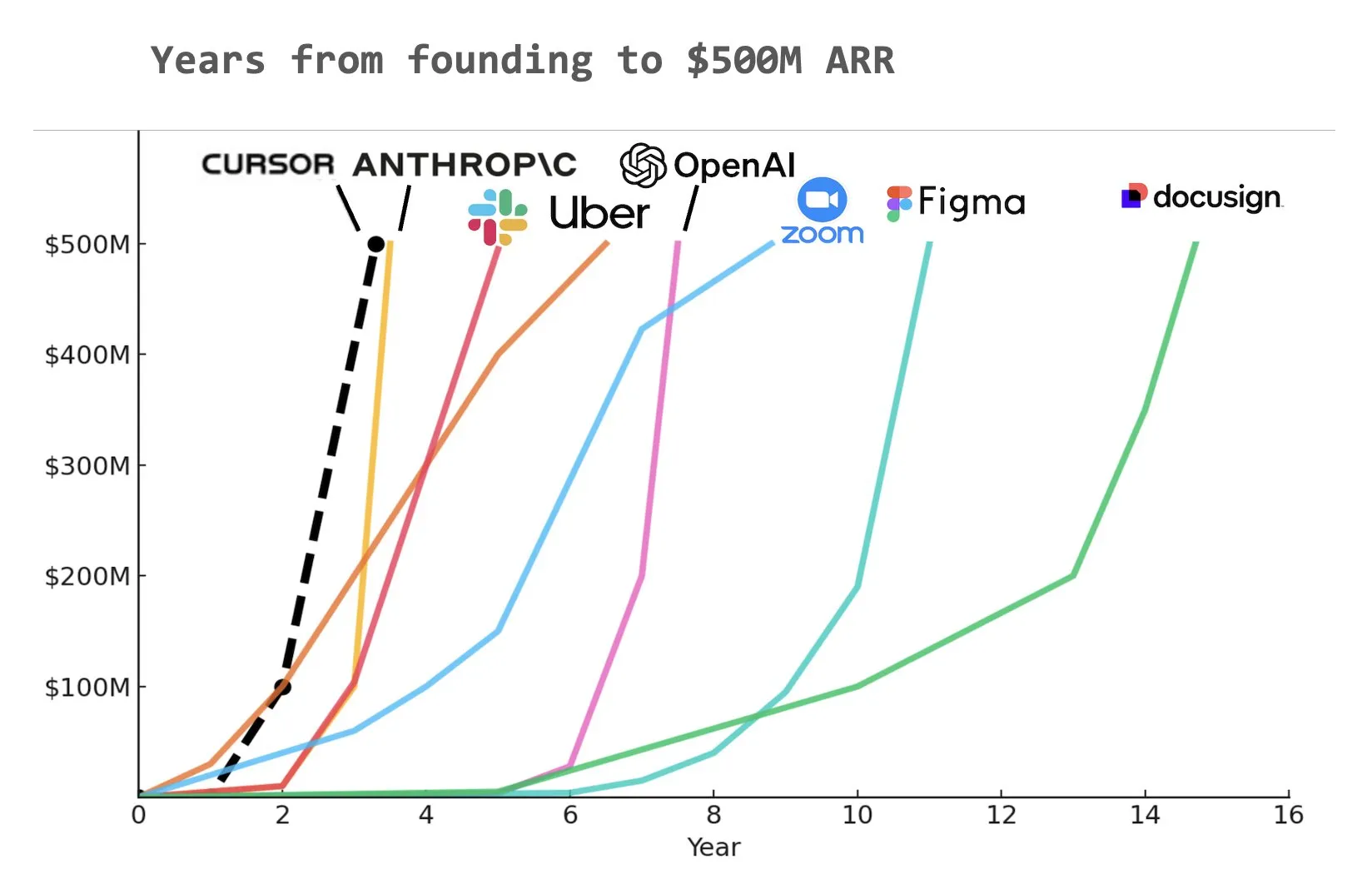
مساعد البرمجة بالذكاء الاصطناعي Cursor يُزعم أنه حقق 500 مليون دولار من الإيرادات السنوية المتكررة (ARR): وفقًا لمخطط شاركه Yuchen Jin على وسائل التواصل الاجتماعي، قد يكون مساعد البرمجة بالذكاء الاصطناعي Cursor أسرع شركة في التاريخ تصل إلى 500 مليون دولار من الإيرادات السنوية المتكررة (ARR). يسلط هذا النمو المذهل الضوء على الإمكانات الهائلة والطلب في السوق على تطبيقات الذكاء الاصطناعي في مجال تطوير البرمجيات (المصدر: Yuchenj_UW)
🌟 مجتمع
المشكلة الأساسية في مواءمة الذكاء الاصطناعي: مع من تتم المواءمة بالضبط؟: يناقش المجتمع بحماس مسألة هدف مواءمة الذكاء الاصطناعي. يطرح Vikhyatk تساؤلاً حول ما إذا كان يجب أن تخدم مواءمة النماذج عمالقة التكنولوجيا الذين يحاولون استبدال أعداد كبيرة من العاملين ذوي الياقات البيضاء بالذكاء الاصطناعي، أم يجب أن تخدم المستخدمين العاديين. بينما يعرض Eigenrobot من خلال لقطة شاشة استياءه من رسوم اشتراك OpenAI ChatGPT Plus، مما يشير إلى تضارب محتمل بين تجربة المستخدم والمصالح التجارية (المصدر: vikhyatk)

خطة Claude Code Max تثير تقييمات متباينة من المستخدمين: في مجتمع Reddit، تباينت تقييمات المستخدمين لخطة Claude Code Max (100 دولار) من Anthropic. يرى بعض مهندسي البرمجيات المتقدمين أن قدرتها على توليد التعليمات البرمجية، خاصة في معالجة المهام المعقدة وتجنب حلقات الخطأ، لا تتفوق على أدوات مساعدة الترميز الأخرى المدعومة بالذكاء الاصطناعي مثل Cursor و Aider، بل توجد مشكلة “الكذب لدفع عجلة التطوير”، ويشككون في وجود كمية كبيرة من الدعاية في المجتمع. بينما أفاد مستخدمون آخرون بأن إنتاجيتهم قد تحسنت بشكل ملحوظ من خلال تعلم طرق استخدامه (مثل MCP، القوالب) والتوجيه الصبور، خاصة في معالجة التعليمات البرمجية النموذجية ومشاريع C#/.NET. الملاحظة المشتركة هي أنه حتى النماذج المتقدمة تتطلب من المستخدمين توجيهًا وتحققًا دقيقين (المصدر: Reddit r/ClaudeAI, finbarrtimbers, cto_junior)
المحتوى الذي يولده الذكاء الاصطناعي يثير مخاوف “الإنترنت الميت”، ونقاش حول أخلاقيات الذكاء الاصطناعي والبنية الاجتماعية: يناقش المجتمع على نطاق واسع نظرية “الإنترنت الميت” المحتملة الناجمة عن انتشار المحتوى الذي يولده الذكاء الاصطناعي، أي أن الإنترنت يمتلئ بالمعلومات التي تولدها الروبوتات، مما يؤدي إلى تقلص مساحة التواصل البشري الحقيقي. وفي الوقت نفسه، فإن التأثير المحتمل للذكاء الاصطناعي على البنية الاجتماعية يثير التفكير العميق، حيث يرى البعض أن الذكاء الاصطناعي لن يؤدي ببساطة إلى وضع “الفلاحين والملوك”، بل قد يؤدي إلى ظهور “ملوك” يمتلكون أصول الذكاء الاصطناعي والروبوتات و “جماهير” تتلاشى تدريجيًا، مع تركيز النشاط الاقتصادي داخل طبقة النخبة. بالإضافة إلى ذلك، أُشير إلى أن GPT-4o قد يستخدم كتب O’Reilly المحمية بحقوق الطبع والنشر للتدريب، كما أن اتجاه “التملق” لمساعدي الذكاء الاصطناعي أثار مخاوف المستخدمين بشأن أخلاقيات الذكاء الاصطناعي وصحة المعلومات (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, DeepLearningAI, Teknium1, scaling01)
الشركات تستثمر بنشاط في تدريب الذكاء الاصطناعي، و Duolingo تستخدم GenAI لتوسيع دوراتها بشكل كبير: يُقال إن شركات وسائل التواصل الاجتماعي الكبيرة تقدم تدريبًا للموظفين على استخدام ChatGPT، وتوظف أساتذة من جامعة كاليفورنيا في بيركلي لتقديم تدريب عبر Zoom لمدة 90 دقيقة، بتكلفة 200 دولار للشخص في الساعة، لكل دفعة مكونة من 120 شخصًا. يعكس هذا اتجاه الشركات نحو اعتبار استخدام أدوات الذكاء الاصطناعي مهارة أساسية. وفي الوقت نفسه، قام تطبيق تعلم اللغات Duolingo، من خلال استخدام الذكاء الاصطناعي التوليدي، بتوسيع دوراته بسرعة لتشمل 28 لغة في غضون عام واحد، مضيفًا 148 دورة جديدة، مما أدى إلى مضاعفة إجمالي عدد دوراته، مما يدل على الإمكانات الهائلة لـ GenAI في إنشاء المحتوى ومجال التعليم (المصدر: Yuchenj_UW, DeepLearningAI)
مؤتمر مهندسي الذكاء الاصطناعي (AIE) يركز على الوكلاء والتعلم المعزز، ويناقش تأثير الذكاء الاصطناعي على الممارسات الهندسية: في معرض مهندسي الذكاء الاصطناعي العالمي (AIE) الذي عقد مؤخرًا، أصبح الوكلاء (Agents) والتعلم المعزز (RL) من الموضوعات الأساسية. ناقش الحاضرون كيف يغير الذكاء الاصطناعي ممارسات الترميز والهندسة، مؤكدين على أهمية التجريب والتقييم في تطوير منتجات الذكاء الاصطناعي. شارك Amjad Masad، الرئيس التنفيذي لشركة Replit، تجربة الشركة في كيفية تحقيق زيادة الإنتاجية وتحول الأعمال بعد تسريح الموظفين من خلال تبني الذكاء الاصطناعي بشكل كامل. كما تضمن المؤتمر فقرات ترفيهية مثل “كاريوكي البرمجة الجوية”، مما يعكس حيوية مجتمع مهندسي الذكاء الاصطناعي (المصدر: swyx, iScienceLuvr, HamelHusain, amasad, swyx)

تطورات جديدة في النماذج والبيانات مفتوحة المصدر: Rednote LLM وبيئة Atropos RL: يتابع المجتمع نموذج Rednote LLM المبني على حزمة تقنيات DeepSeek V2، والذي يعتمد بنية DS-MoE، ويحتوي على 142 مليار معلمة إجمالية و 14 مليار معلمة نشطة، ولكنه يستخدم حاليًا MHA بدلاً من GQA/MLA الأكثر كفاءة. وفي الوقت نفسه، أضاف مشروع Atropos (LLM RL Gym) التابع لـ NousResearch دعمًا لـ 101 بيئة RL استدلالية صعبة في Reasoning Gym، وقد ولّد حوالي 5500 عينة استدلالية تم التحقق منها، ومن المقرر استخدامها في التدريب المسبق لـ Hermes 4، مما يشجع المجتمع على المساهمة بمزيد من بيئات الاستدلال القابلة للتحقق (المصدر: teortaxesTex, Teknium1, kylebrussell)
أداء نماذج Anthropic المتميز في مهام محددة وطرق RL تحظى بالاهتمام: تشير مناقشات المجتمع إلى أن نماذج Claude من Anthropic (مثل Sonnet 3.5/3.7) تتفوق على النماذج الأخرى (بما في ذلك Opus 4/Sonnet 4) في معالجة المهام التي تحتوي على بيانات ويب غامضة محددة، ويُعتقد أنها قد تضمنت المزيد من محتوى منتديات الإنترنت المتخصصة في بيانات تدريبها. وفي الوقت نفسه، تحظى طرق Anthropic المعقدة في التعلم المعزز (RL) بالتقدير، على الرغم من أن بعض ممارساتها وتحسين المقاييس حول مدونات السلامة قد أثارت بعض الشكوك. يرى البعض أن Constitutional AI هو في جوهره RL متقدم، ويمكنه تصميم سياسات دقيقة وقابلة للتحكم دون الحاجة إلى تصميم علامات مشفرة بشكل ثابت (المصدر: teortaxesTex, zacharynado, teortaxesTex, Dorialexander)
💡 أخرى
Vosk API: يوفر وظيفة التعرف على الكلام دون اتصال بالإنترنت: Vosk API هي مجموعة أدوات مفتوحة المصدر للتعرف على الكلام دون اتصال بالإنترنت، تدعم أكثر من 20 لغة ولهجة، بما في ذلك الإنجليزية والألمانية والصينية واليابانية وغيرها. حجم نماذجها صغير (حوالي 50 ميجابايت)، ولكنها توفر نسخًا صوتيًا مستمرًا لمفردات كبيرة، واستجابة فورية لواجهة برمجة تطبيقات البث، وتدعم قوائم المفردات القابلة لإعادة التشكيل والتعرف على المتحدث. توفر Vosk قدرات التعرف على الكلام لتطبيقات مثل روبوتات الدردشة، والمنازل الذكية، والمساعدين الافتراضيين، ويمكن استخدامها أيضًا لإنشاء ترجمات الأفلام، ونسخ المحاضرات والمقابلات، وهي مناسبة لمجموعة متنوعة من المنصات بدءًا من Raspberry Pi وأجهزة Android إلى الخوادم الكبيرة (المصدر: GitHub Trending)
طائرة بدون طيار ذاتية التحكم تهزم بطلًا بشريًا لأول مرة في سباق: هزمت طائرة بدون طيار ذاتية التحكم طورتها جامعة دلفت للتكنولوجيا بطلًا بشريًا في سباق تاريخي. يمثل هذا الإنجاز وصول قدرات الذكاء الاصطناعي في الإدراك واتخاذ القرار والتحكم في البيئات عالية السرعة والديناميكية إلى مستوى جديد، مما يوضح الإمكانات الهائلة للذكاء الاصطناعي في مجالات الروبوتات والأتمتة (المصدر: Reddit r/artificial )

VentureBeat تتوقع أربعة اتجاهات رئيسية للذكاء الاصطناعي في عام 2025: قدمت VentureBeat أربعة توقعات رئيسية لتطور مجال الذكاء الاصطناعي في عام 2025، وقد تغطي هذه التوقعات اختراقات تقنية، أو تطبيقات سوقية، أو لوائح أخلاقية، أو هياكل صناعية، وتتطلب التفاصيل المحددة الرجوع إلى المقال الأصلي. تساعد هذه التحليلات الاستشرافية المطلعين داخل وخارج الصناعة على فهم نبض تطور الذكاء الاصطناعي (المصدر: Ronald_vanLoon)
