
كلمات مفتاحية:نموذج الذكاء الاصطناعي, مجموعة البيانات, الإنسان الآلي, وكيل الذكاء الاصطناعي, نموذج اللغة, التعلم العميق, النماذج مفتوحة المصدر, تحسين الاستدلال, مجموعة بيانات Common Pile v0.1, نموذج التحكم الشامل Helix من البداية للنهاية, خادم Hugging Face MCP, تحديث Gemini 2.5 Pro, آلية الانتباه المتفرق
🔥 أضواء كاشفة
EleutherAI تطلق Common Pile v0.1: مجموعة بيانات نصية مفتوحة الترخيص بحجم 8TB، تتحدى تدريب نماذج اللغة على بيانات غير مرخصة : أعلنت EleutherAI بالتعاون مع عدة مؤسسات عن إطلاق Common Pile v0.1، وهي مجموعة بيانات ضخمة تحتوي على 8TB من النصوص مفتوحة الترخيص والنصوص المتاحة في الملك العام، تهدف إلى استكشاف جدوى تدريب نماذج لغوية عالية الأداء دون استخدام نصوص غير مرخصة. استخدم الفريق مجموعة البيانات هذه لتدريب نماذج بمعاملات 7B (1T و 2T tokens)، وكان أداؤها مشابهًا لنماذج مماثلة مثل LLaMA 1 و LLaMA 2. تحتوي مجموعة البيانات هذه على بيانات وصفية على مستوى المستند، مثل إسناد المؤلف وتفاصيل الترخيص وروابط للنسخ الأصلية، مما يوفر للباحثين مصدر بيانات شفافًا ومتوافقًا. تعتبر هذه المبادرة ذات أهمية كبيرة لتعزيز تطوير نماذج AI مفتوحة ومتوافقة، وتقدم أفكارًا جديدة لمعالجة قضايا حقوق النشر المتعلقة ببيانات تدريب الذكاء الاصطناعي (المصدر: EleutherAI, percyliang, BlancheMinerva, code_star, ShayneRedford, Tim_Dettmers, jeremyphoward, stanfordnlp, ClementDelangue, tri_dao, andersonbcdefg)

روبوت Figure البشري يُظهر قدرة عالية على فرز الطرود بسرعة بفضل نموذج Helix، مما يثير الاهتمام : عرض Brett Adcock، الرئيس التنفيذي لشركة Figure، أحدث التطورات في روبوت الشركة البشري الذي يعمل بنموذج التحكم العام الشامل Helix، وذلك في سيناريو لوجستي لفرز الطرود. يُظهر الفيديو قدرة الروبوت على التعامل مع أنواع مختلفة من الطرود (صناديق كرتونية صلبة، عبوات بلاستيكية) بسرعة ودقة تقارب سرعة ودقة الإنسان، بما في ذلك ترتيب الطرود والتأكد من أن الرموز الشريطية متجهة لأسفل لتسهيل المسح الضوئي. تُبرز هذه القدرة مرونة نموذج Helix وقدرته على التعميم في البيئات المعقدة والديناميكية، وذلك على النقيض من العرض السابق لعمليات مكبس الضغط (التي تؤكد على الدقة والسرعة العالية). تعمل روبوتات Figure بالفعل في خطوط إنتاج BMW لمدة 20 ساعة متواصلة، مما يدل على إمكاناتها في التطبيقات الصناعية. أكد Adcock أن بناء أذكى الروبوتات وأقلها تكلفة سيكون مفتاح الفوز في سوق الروبوتات البشرية، لأن المزيد من نشر الروبوتات يعني تكلفة أقل، والمزيد من بيانات التدريب، ونموذج Helix أكثر ذكاءً (المصدر: dotey, _philschmid, adcock_brett, 量子位)

Hugging Face تطلق أول خادم MCP رسمي لها، لإنشاء منصة تعاونية لوكلاء الذكاء الاصطناعي (AI Agent) : أطلقت Hugging Face أول خادم MCP (Model-Client Protocol) رسمي لها، مما يسمح للمستخدمين بربط LLM مباشرة بواجهة برمجة تطبيقات Hugging Face Hub، لاستخدامها في Cursor و VSCode و Windsurf والتطبيقات الأخرى التي تدعم MCP. يوفر الخادم أدوات مدمجة مثل البحث الدلالي عن النماذج ومجموعات البيانات والأوراق البحثية و Spaces، ويمكنه عرض قائمة ديناميكية بجميع تطبيقات Gradio المتوافقة مع MCP والمستضافة على Spaces. تهدف هذه المبادرة إلى تحويل Hugging Face إلى منصة تعاونية لمنشئي AI Agent، وتعزيز تطوير النظام البيئي لـ AI Agent وقابليته للتشغيل البيني، ويتوفر حاليًا حوالي 900 من Spaces المتوافقة مع MCP (المصدر: ClementDelangue, mervenoyann, reach_vb, ben_burtenshaw, huggingface, code_star, op7418, TheTuringPost, clefourrier)

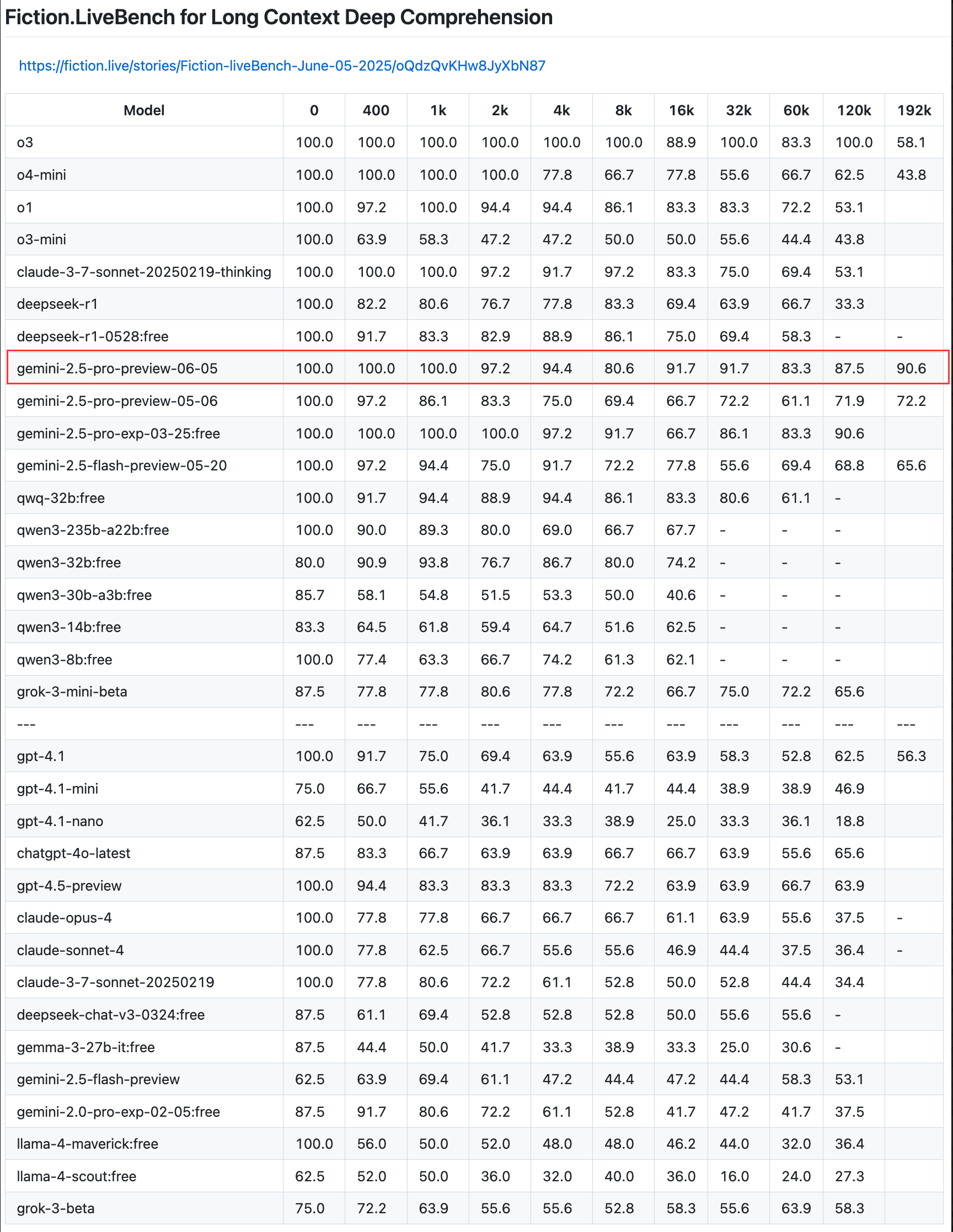
جوجل تحدث النسخة التجريبية من Gemini 2.5 Pro، معززة قدرات الترميز والاستدلال والإبداع، وتقدم “ميزانية التفكير” : أعلنت جوجل عن تحديث للنسخة التجريبية من نموذجها الأذكى Gemini 2.5 Pro، مما يعزز قدراته في الترميز والاستدلال المنطقي والكتابة الإبداعية. يقدم الإصدار الجديد بشكل خاص ميزة “ميزانية التفكير” (thinking budget)، مما يسمح للمطورين بالتحكم بشكل أفضل في استهلاك النموذج لموارد الحوسبة. تُظهر ملاحظات المستخدمين أن الإصدار الجديد (06-05) يتميز بأداء ممتاز في استرجاع النصوص الطويلة، خاصةً بمعدل استرجاع يصل إلى 90.6% بطول 192K، متجاوزًا OpenAI-o3. تم دمج النموذج في LangChain و LangGraph، مما يسهل على المطورين تجربته وبناء التطبيقات. كما عرضت جوجل قدرات Gemini 2.5 Pro الإبداعية في فهم الصور وإنشاء تعليقات سياقية وبارعة (المصدر: Teknium1, Google, karminski3, hwchase17, )
🎯 التوجهات
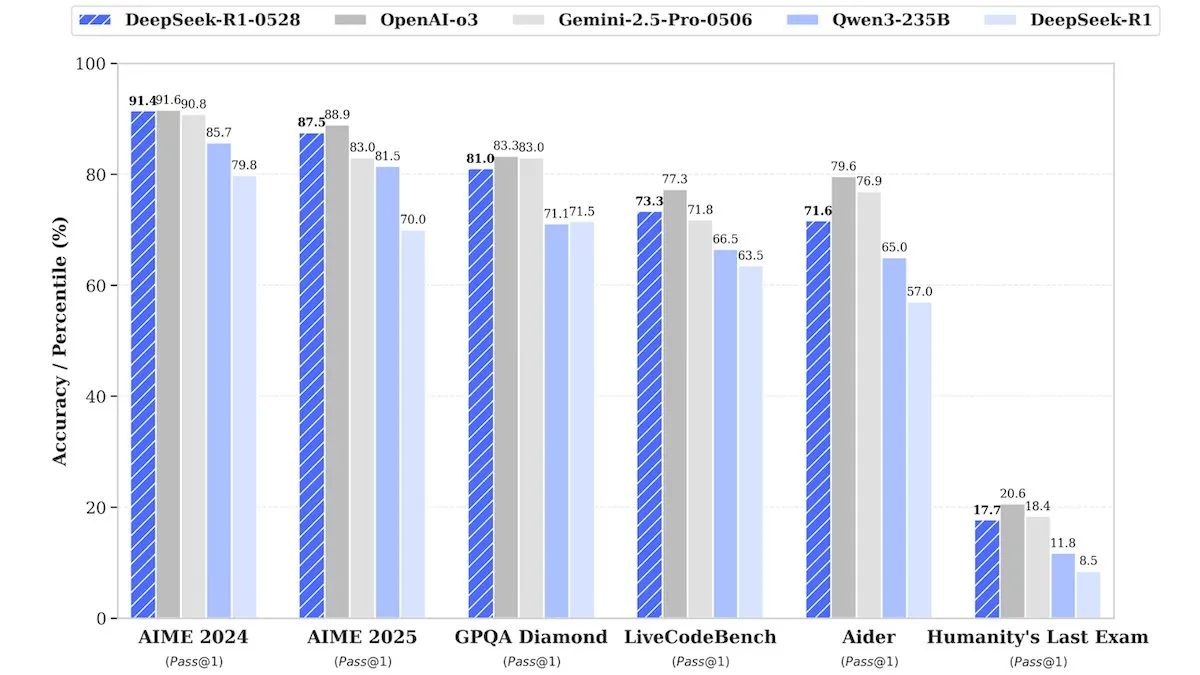
DeepSeek تطلق إصدارًا مطورًا من DeepSeek-R1-0528، بأداء يضاهي النماذج مغلقة المصدر : أطلقت DeepSeek إصدارًا مطورًا من نموذجها الرائد مفتوح المصدر DeepSeek-R1-0528. يُزعم أن هذا النموذج يقدم أداءً يضاهي النماذج مغلقة المصدر مثل o3 من OpenAI و Gemini-2.5 Pro من جوجل في العديد من اختبارات الأداء القياسية. على الرغم من أن الشركة لم تكشف عن تفاصيل التدريب، إلا أن التقارير تشير إلى أن النموذج الجديد يُظهر تحسينات كبيرة في الاستدلال ومعالجة تعقيد المهام وتقليل الهلوسة، مما يتحدى مرة أخرى المفهوم التقليدي بأن الذكاء الاصطناعي المتقدم يتطلب موارد هائلة. قدمت Unsloth AI دفتر ملاحظات مجانيًا لـ fine-tuning لـ DeepSeek-R1-0528-Qwen3 باستخدام GRPO، مدعية أن دالة المكافأة الجديدة الخاصة بها يمكن أن تزيد من معدل الاستجابة متعدد اللغات (أو المجالات المخصصة) بأكثر من 40%، وتجعل fine-tuning لـ R1 أسرع مرتين، وتقلل استخدام VRAM بنسبة 70% (المصدر: DeepLearningAI, ImazAngel)
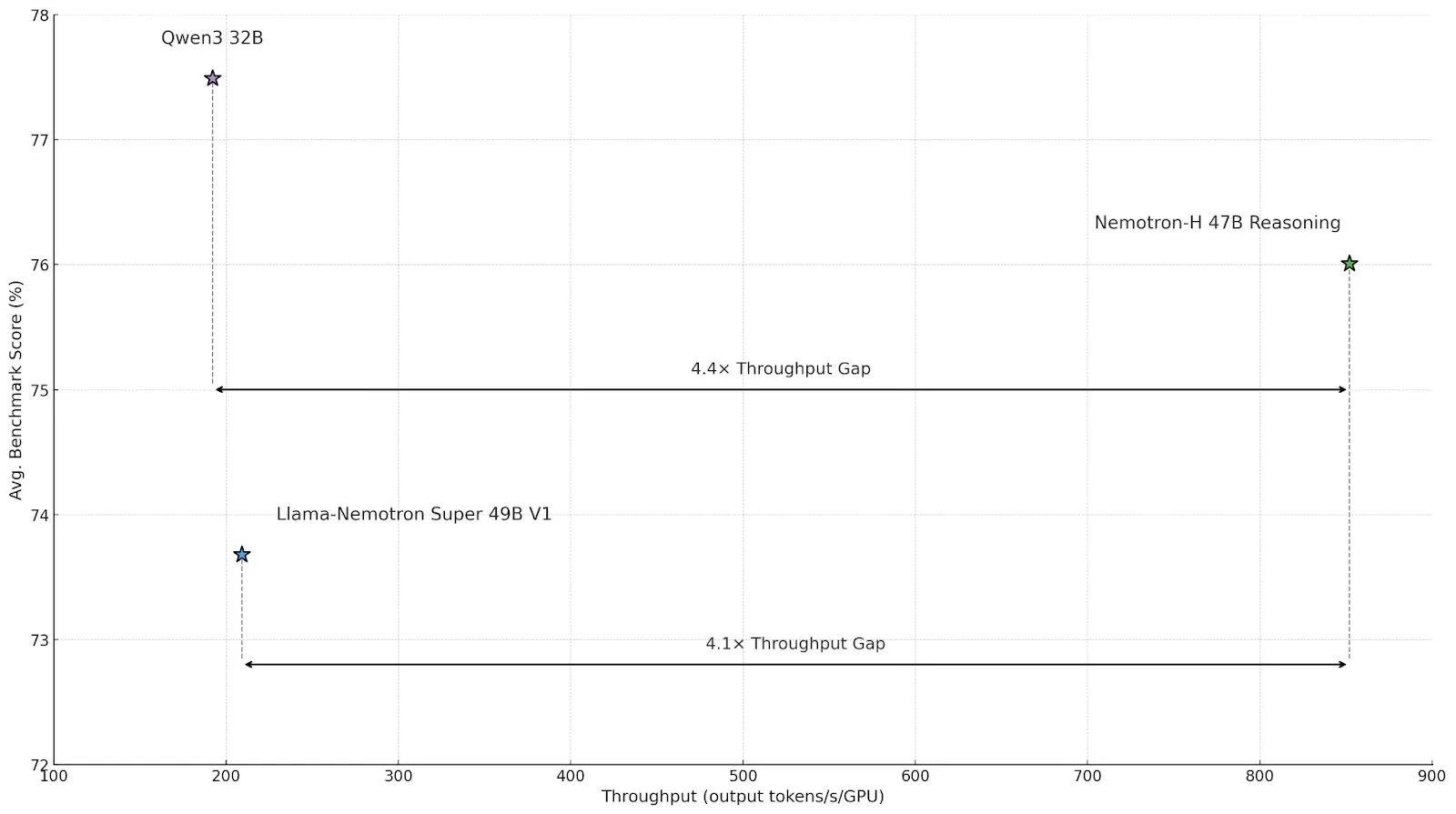
إنفيديا تطلق نموذج inference مختلط البنية Nemotron-H، لتعزيز الإنتاجية والكفاءة : أطلقت إنفيديا نموذج inference جديدًا باسم Nemotron-H، يتضمن إصدارات 47B و 8B (يدعم BF16 و FP8)، ويعتمد على بنية Mamba-Transformer المختلطة. يهدف هذا النموذج إلى حل مشكلات inference واسعة النطاق مع الحفاظ على سرعة عالية، ويُزعم أن إنتاجيته تبلغ 4 أضعاف إنتاجية نماذج Transformer المماثلة. يتفوق Nemotron-H-47B-Reasoning-128k قليلاً في الدقة على Llama-Nemotron-Super-49B-1.0 في جميع اختبارات الأداء القياسية، ولكنه يقلل تكلفة inference بما يصل إلى 4 مرات. تم نشر أوزان النموذج على HuggingFace بترخيص غير إنتاجي، وسيصدر التقرير الفني قريبًا (المصدر: ClementDelangue, ctnzr)
Anthropic تطلق Claude Gov، المصمم خصيصًا للحكومة الأمريكية ووكالات الاستخبارات العسكرية : أعلنت شركة Anthropic عن إطلاق خدمة ذكاء اصطناعي جديدة باسم Claude Gov، وهي مصممة خصيصًا لتلبية احتياجات الحكومة الأمريكية ووكالات الدفاع والاستخبارات. تمثل هذه الخطوة توسعًا رسميًا لتقنيات الذكاء الاصطناعي المتقدمة لشركة Anthropic لتشمل التطبيقات الحكومية والعسكرية، والتي يمكن استخدامها في تحليل البيانات ومعالجة المعلومات الاستخباراتية ودعم اتخاذ القرار وغيرها من السيناريوهات. انضمت Anthropic سابقًا أيضًا إلى صندوق ائتمان للمصالح طويلة الأجل، يهدف إلى مساعدة الشركة على تحقيق مهمتها المتعلقة بالمصلحة العامة (المصدر: MIT Technology Review, akbirkhan, jeremyphoward)
Hugging Face تتعاون مع جوجل Colab لتبسيط عملية تجربة النماذج وتصميم النماذج الأولية : أعلنت Hugging Face عن شراكة مع Google Colaboratory لإضافة دعم “الفتح في Colab” إلى جميع بطاقات النماذج على Hugging Face Hub. يمكن للمستخدمين الآن تشغيل Colab Notebook مباشرة من أي بطاقة نموذج، مما يسهل تجربة النماذج وتقييمها. بالإضافة إلى ذلك، يمكن للمستخدمين وضع ملف notebook.ipynb مخصص في مستودعات النماذج الخاصة بهم، وستوفر Hugging Face هذا الـ Notebook مباشرة، مما يعزز إمكانية الوصول إلى نماذج الذكاء الاصطناعي وقدرات تصميم النماذج الأولية السريعة (المصدر: huggingface, osanseviero, ClementDelangue, mervenoyann)
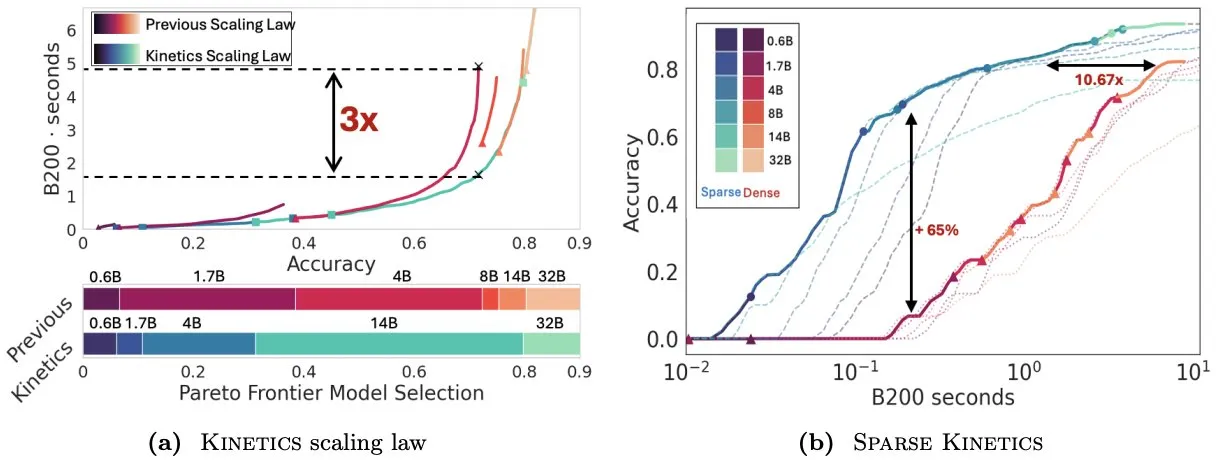
ورقة بحثية Kinetics تعيد التفكير في قوانين التوسع في وقت الاختبار، مؤكدة على أهمية الانتباه المتناثر (sparse attention) لكفاءة الاستدلال : نشر Infini-AI-Lab ورقة بحثية بعنوان “Kinetics: Rethinking Test-Time Scaling Laws”، تشير إلى أن قوانين التوسع السابقة القائمة على الأمثلية الحسابية قد بالغت في تقدير فعالية النماذج الصغيرة، وتجاهلت اختناقات الوصول إلى الذاكرة الناتجة عن استراتيجيات وقت الاستدلال (مثل Best-of-N، CoT الطويل). يقترح البحث قوانين توسع Kinetics جديدة، تأخذ في الاعتبار تكاليف الحوسبة والوصول إلى الذاكرة، وترى أن موارد الحوسبة في وقت الاختبار تكون أكثر فعالية عند استخدامها للنماذج الكبيرة مقارنة بالنماذج الصغيرة، لأن الانتباه وليس عدد المعلمات يصبح التكلفة المهيمنة. تطرح الورقة بعد ذلك نموذج توسع يركز على الانتباه المتناثر، من خلال تقليل تكلفة الوحدة لكل token لتحقيق توليد أطول وعينات متوازية أكثر، وتظهر التجارب أن نماذج الانتباه المتناثر تتفوق على النماذج الكثيفة في نطاقات تكلفة مختلفة، وهو أمر بالغ الأهمية لتعزيز كفاءة استدلال النماذج واسعة النطاق (المصدر: realDanFu, tri_dao, simran_s_arora)
سوق AI Agent في الصين يشهد ازدهارًا، و Manus تقود موجة ريادة الأعمال : بعد موجة النماذج التأسيسية الحارة في العام الماضي، تحول تركيز مجال الذكاء الاصطناعي في الصين هذا العام إلى AI Agent. يركز AI Agent بشكل أكبر على إكمال المهام للمستخدمين بشكل مستقل، بدلاً من مجرد الاستجابة للاستعلامات. أثارت Manus، كرائدة في مجال AI Agent العام، اهتمامًا واسع النطاق بعد إطلاقها المحدود في أوائل مارس، وأدت إلى ظهور مجموعة من الشركات الناشئة التي تبني أدوات رقمية عامة قادرة على معالجة رسائل البريد الإلكتروني وتخطيط الرحلات وحتى تصميم مواقع الويب التفاعلية. يشير هذا الاتجاه إلى أن صناعة التكنولوجيا في الصين تستكشف بنشاط التطبيقات العملية ونماذج الأعمال لـ AI Agent (المصدر: MIT Technology Review)

ElevenLabs تطلق Conversational AI 2.0، لتعزيز أداء مساعدي الصوت على مستوى المؤسسات : أطلقت ElevenLabs الإصدار 2.0 من منصتها للذكاء الاصطناعي الحواري، بهدف بناء وكلاء صوتيين أكثر تقدمًا على مستوى المؤسسات. يعزز الإصدار الجديد بشكل كبير طبيعية وقدرات التفاعل لمساعدي الصوت، مما يمكنهم من فهم إيقاع المحادثة بشكل أفضل، ومعرفة متى يتوقفون، ومتى يتحدثون، ومتى يتم تبادل الأدوار في الحوار. من المتوقع أن يوفر هذا التحديث للمستخدمين من المؤسسات تجربة تفاعل صوتي أكثر سلاسة وذكاءً، ليتم تطبيقها في خدمة العملاء والمساعدين الافتراضيين وسيناريوهات أخرى متنوعة (المصدر: dl_weekly)
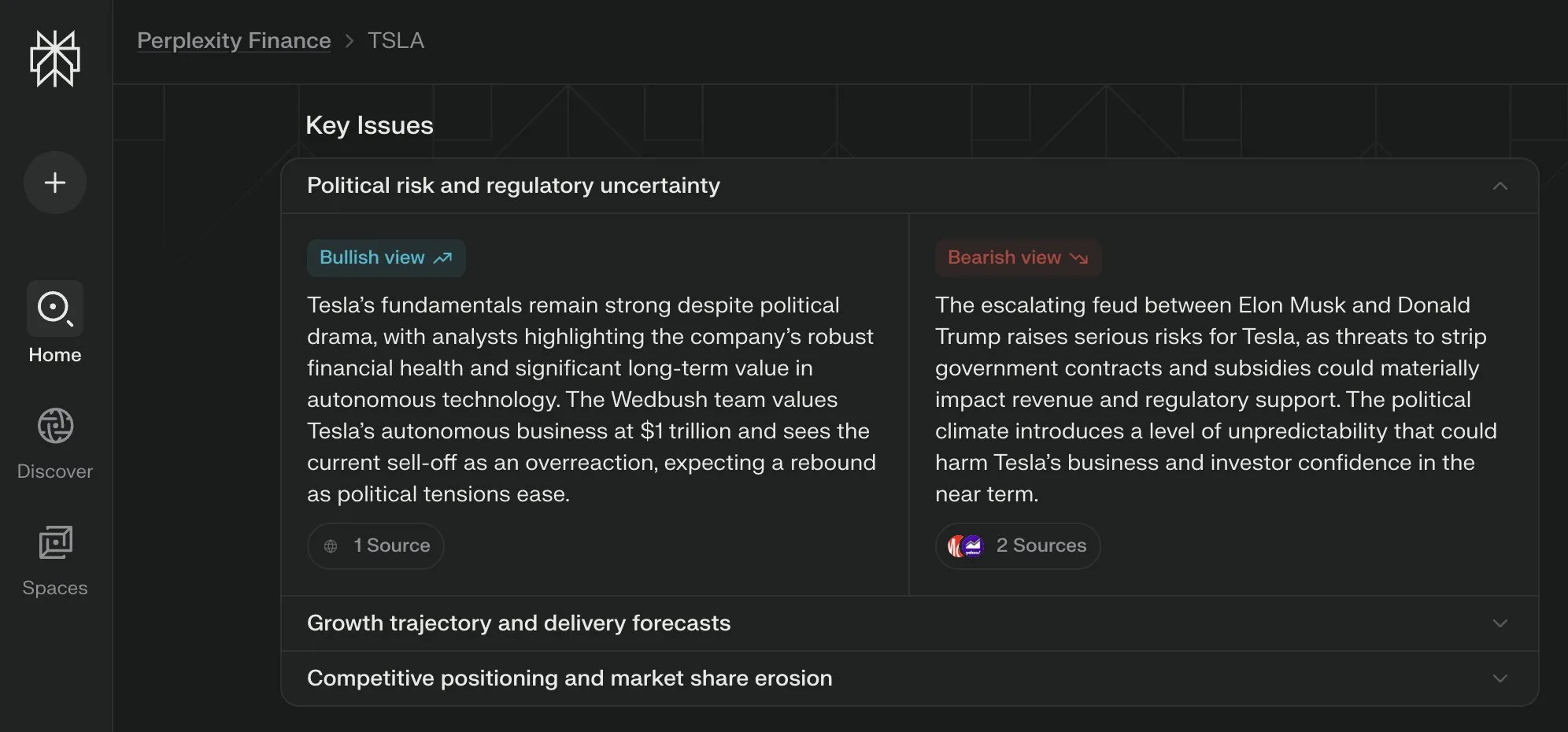
Perplexity Labs تطلق عرض “القضايا الرئيسية” لصفحاتها المالية، مجمعة آراء متعددة الأطراف : أضافت Perplexity Labs ميزة عرض “القضايا الرئيسية” (Key Issues) إلى صفحاتها للمعلومات المالية. تستطيع هذه الميزة تجميع آراء المستثمرين والمحللين والمعلقين من الإنترنت، لتعرض للمستخدمين بسرعة العوامل الهامة والنقاط الرئيسية للنقاش التي تؤثر حاليًا على شركة ما. على سبيل المثال، يمكن لصفحة حول Tesla أن تدمج معلومات متنوعة حول الديناميكيات بين ترامب وماسك في غضون ساعات، مما يساعد المستخدمين على فهم الصورة الكاملة بسرعة (المصدر: AravSrinivas)
نقاط التفتيش الموزعة في PyTorch تدعم الآن safetensors من Hugging Face : أعلنت PyTorch أن ميزة نقاط التفتيش الموزعة الخاصة بها تدعم الآن تنسيق safetensors من Hugging Face، مما سيجعل حفظ وتحميل نقاط التفتيش بين الأنظمة البيئية المختلفة أكثر ملاءمة. تسمح واجهة برمجة التطبيقات الجديدة للمستخدمين بقراءة وكتابة safetensors عبر مسارات fsspec. أصبحت torchtune أول مكتبة تتبنى هذه الميزة، مما يبسط عمليات نقاط التفتيش الخاصة بها. يساعد هذا التحديث على تعزيز قابلية التشغيل البيني والكفاءة في تدريب النماذج ونشرها (المصدر: ClementDelangue)

ورقة بحثية MARBLE تقترح طريقة جديدة لإعادة تكوين المواد ومزجها بناءً على فضاء CLIP : يقترح بحث جديد بعنوان MARBLE طريقة لمزج مواد الكائنات في الصور وإعادة تكوين خصائصها الدقيقة، وذلك من خلال إيجاد تضمينات المواد في فضاء CLIP واستخدام هذه التضمينات للتحكم في نماذج تحويل النص إلى صورة المدربة مسبقًا. تعمل هذه الطريقة على تحسين تحرير المواد المستند إلى العينات، من خلال تحديد الوحدات المسؤولة عن إسناد المواد في UNet لإزالة التشويش، مما يحقق تحكمًا معلميًا في خصائص المواد الدقيقة مثل الخشونة والمعدنية والشفافية واللمعان. أثبت الباحثون فعالية هذه الطريقة من خلال التحليل النوعي والكمي، وعرضوا قدرتها على إجراء تعديلات متعددة في تمريرة أمامية واحدة وقابليتها للتطبيق في مجال الرسم (المصدر: HuggingFace Daily Papers, ClementDelangue)
ورقة بحثية FlowDirector: طريقة توجيه تدفق لتحرير الفيديو من النص إلى الفيديو بدقة وبدون تدريب : FlowDirector هو إطار عمل جديد لتحرير الفيديو لا يتطلب عكس العملية، حيث يقوم بنمذجة عملية التحرير كتطور مباشر في فضاء البيانات، من خلال توجيه الفيديو عبر المعادلات التفاضلية العادية (ODE) للانتقال بسلاسة على طول مشعبها الزمكاني المتأصل، وبالتالي الحفاظ على التماسك الزمني والتفاصيل الهيكلية. لتحقيق تحرير يمكن التحكم فيه محليًا، تم إدخال آلية إخفاء موجهة بالانتباه. بالإضافة إلى ذلك، لمعالجة التحرير غير المكتمل وتعزيز التوافق الدلالي مع تعليمات التحرير، تم اقتراح استراتيجية تحرير معززة بالتوجيه مستوحاة من التوجيه بدون مصنف. أثبتت التجارب أن FlowDirector يتفوق في اتباع التعليمات والاتساق الزمني والحفاظ على الخلفية (المصدر: HuggingFace Daily Papers)
ورقة بحثية RACRO: تحقيق استدلال متعدد الوسائط قابل للتطوير من خلال تحسين مكافأة التسميات التوضيحية : لمعالجة مشكلة التكلفة العالية لإعادة تدريب محاذاة اللغة المرئية عند ترقية مستدلات LLM الأساسية، اقترح الباحثون RACRO (Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization). تقوم هذه الطريقة بتحويل المدخلات المرئية إلى تمثيلات لغوية (مثل التسميات التوضيحية)، ثم تمريرها إلى مستدل النص. تتبنى RACRO استراتيجية تعلم معزز موجهة بالاستدلال، من خلال تحسين المكافأة لمحاذاة سلوك تسميات المستخلص مع أهداف الاستدلال، وبالتالي تعزيز الأساس المرئي واستخلاص تمثيلات محسنة للاستدلال. أظهرت التجارب أن RACRO يحقق أداءً متطورًا (SOTA) في اختبارات الرياضيات والعلوم متعددة الوسائط، ويدعم التكيف الفوري مع LLM الاستدلالية الأكثر تقدمًا، دون الحاجة إلى إعادة محاذاة متعددة الوسائط مكلفة (المصدر: HuggingFace Daily Papers)
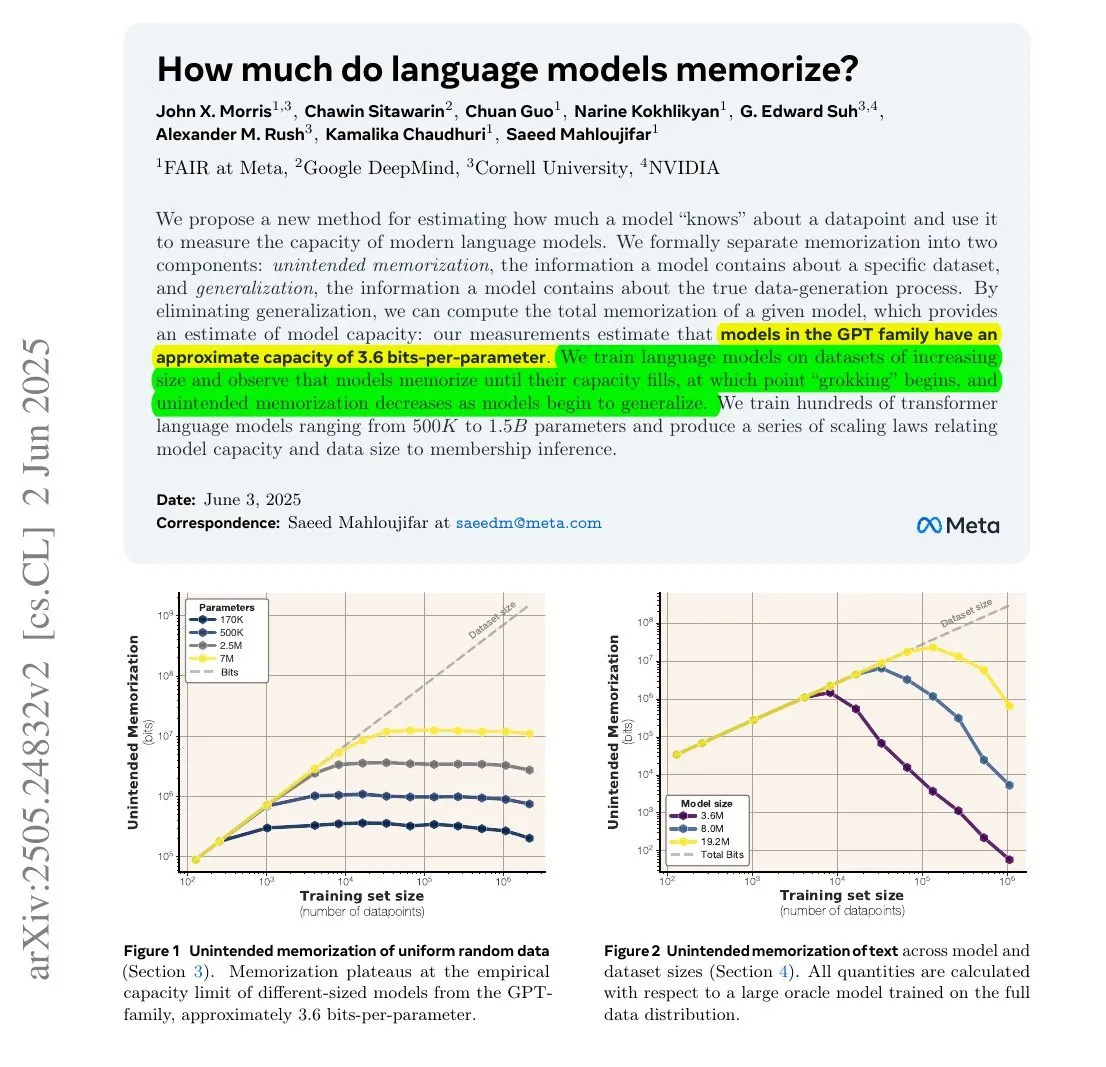
دراسة تظهر: كمية المعلومات التي تتذكرها LLM قد تكون مرتبطة بكمية معاملاتها وإنتروبيا المعلومات : استكشفت دراسة أجريت بالتعاون بين Meta و DeepMind و NVIDIA وجامعة كورنيل كمية المعلومات التي تتذكرها نماذج اللغة الكبيرة (LLM) بالفعل. وجدت الدراسة أن كمية المعلومات التي تتذكرها LLM قد تكون مرتبطة بكمية معاملاتها وإنتروبيا البيانات. على سبيل المثال، تحتوي ويكيبيديا الإنجليزية على حوالي 29.4 مليار حرف، ويحتوي كل حرف على حوالي 1.5 بت من المعلومات، ويمكن لنموذج بمعاملات 12B (بافتراض قدرة تخزين تبلغ 3.6 بت لكل معامل) نظريًا أن يتذكر ويكيبيديا الإنجليزية بأكملها. تعتبر هذه الدراسة ذات أهمية لفهم آليات ذاكرة LLM وتقييم قضايا حقوق نشر البيانات. أشار François Chollet أيضًا إلى منهجية تدريب LLM باستخدام سلاسل عشوائية واكتشافاتها الكمية، معتبرًا أنها ذات قيمة لفهم آليات ذاكرة LLM (المصدر: fchollet, AymericRoucher)
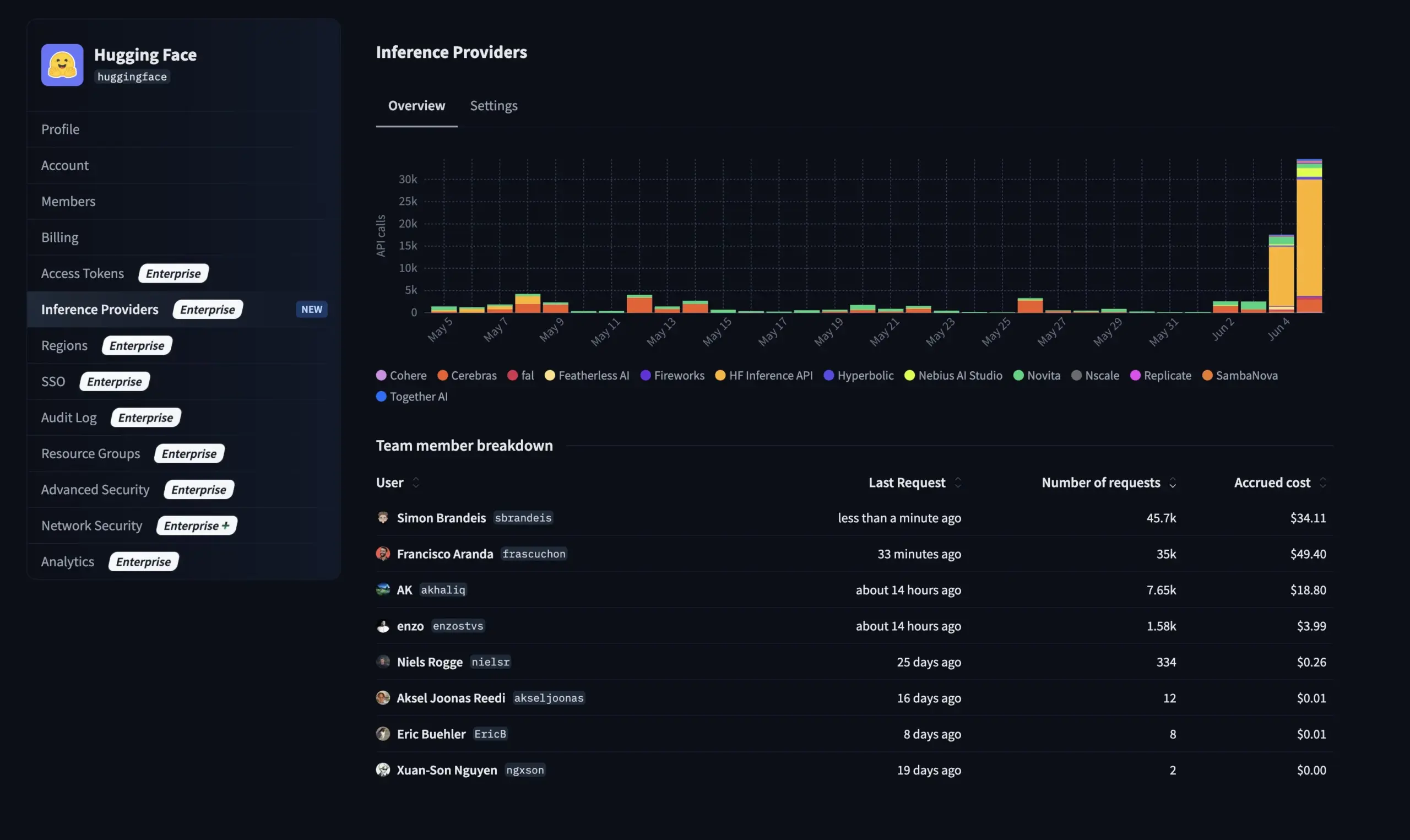
Hugging Face تطلق ميزات جديدة للإصدار المؤسسي: إدارة استخدام وتكاليف مزودي خدمة الاستدلال (Inference Providers) : أضافت Hugging Face ميزات جديدة إلى إصدارها المؤسسي (Enterprise Hub)، مما يسمح للمؤسسات بتكوين ومراقبة استخدام أعضاء فريقها لمزودي خدمة الاستدلال (Inference Providers) والتكاليف المرتبطة بها. هذا يعني أنه يمكن للمستخدمين من المؤسسات إدارة والتحكم بشكل أفضل في استخدام خدمات الاستدلال بدون خادم لأكثر من 40,000 نموذج من مزودين متعددين مثل TogetherCompute و FireworksAI و Replicate و Cohere وغيرهم، وبالتالي تحسين فعالية تكلفة نشر تطبيقات الذكاء الاصطناعي وتخصيص الموارد (المصدر: huggingface, _akhaliq)
Mistral AI تطلق نموذج الاستدلال العلمي ether0، المبني على fine-tuning لـ Mistral 24B : أطلقت Mistral AI أول نموذج استدلال علمي لها باسم ether0. تم بناء هذا النموذج من خلال تدريب Mistral 24B باستخدام التعلم المعزز (RL) على مهام متعددة لتصميم الجزيئات في مجال الكيمياء. وجدت الدراسة أن LLM تتعلم بكفاءة بيانات أعلى بكثير في بعض المهام العلمية مقارنة بالنماذج المتخصصة المدربة من الصفر، ويمكنها أن تتفوق بشكل كبير على النماذج الرائدة والبشر في هذه المهام. يشير هذا إلى أنه بالنسبة لجزء من مشكلات التصنيف العلمي والانحدار والتوليد، قد يوفر التدريب اللاحق لـ LLM مسارًا أكثر كفاءة من طرق التعلم الآلي التقليدية (المصدر: MistralAI)
نموذج الاتساق ثنائي الخبراء (DCM) يسرع توليد الفيديو 10 مرات : اقترح Ziwei Liu وباحثون آخرون نموذج الاتساق ثنائي الخبراء (DCM)، الذي يمكنه تسريع نماذج توليد الفيديو (بعدد معاملات يتراوح من 1.3B إلى 13B) بمقدار 10 مرات، دون المساس بالجودة. يدعم النموذج حاليًا Tencent Hunyuan و Alibaba Tongyi Wanxiang. يمثل اقتراح DCM تقدمًا جديدًا في مجال توليد الفيديو عالي الكفاءة والجودة، ويساعد على تسريع إنشاء محتوى الفيديو وتطوير التطبيقات ذات الصلة (المصدر: _akhaliq)
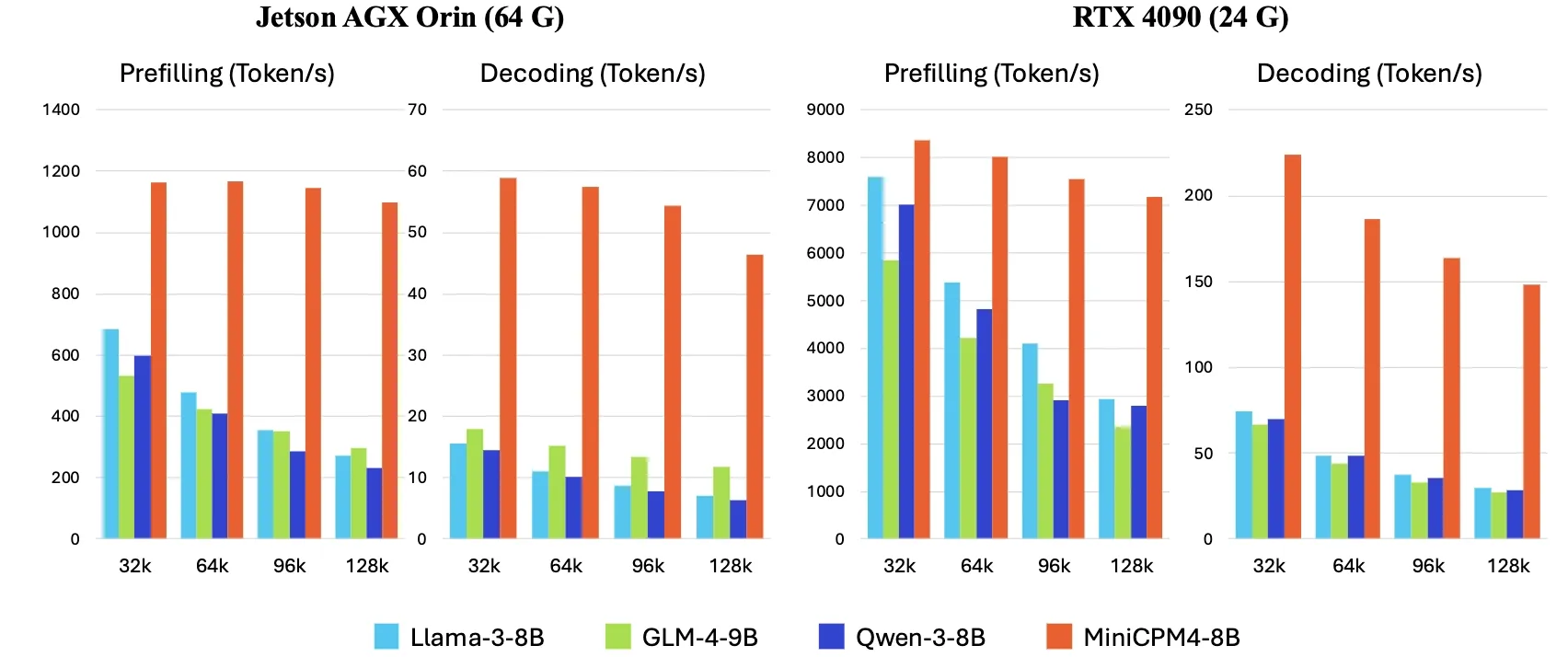
OpenBMB تطلق MiniCPM4، مع زيادة سرعة الاستدلال على الأجهزة الطرفية 5 مرات : أطلقت OpenBMB سلسلة نماذج MiniCPM4، والتي حققت زيادة في سرعة الاستدلال على الأجهزة الطرفية بمقدار 5 مرات من خلال اعتماد بنية نموذج فعالة (آلية الانتباه المتناثر القابلة للتدريب InfLLM v2)، وخوارزميات تعلم فعالة (Model Wind Tunnel 2.0، تكميم ثلاثي BitCPM)، وبيانات تدريب عالية الجودة (UltraClean، UltraChat v2)، ونظام استدلال فعال (CPM.cu، ArkInfer). تم إطلاق النموذج الرائد MiniCPM4-8B (8B معاملات، تدريب على 8T tokens) على Hugging Face. تهدف هذه السلسلة من النماذج إلى استكشاف حدود LLM الصغيرة منخفضة التكلفة، ودفع تطبيقات الذكاء الاصطناعي على الأجهزة ذات الموارد المحدودة (المصدر: eliebakouch, Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞))
شركة X تحدث شروط الخدمة، وتحظر استخدام منشوراتها لـ “fine-tuning أو تدريب” نماذج الذكاء الاصطناعي، ما لم يتم التوصل إلى اتفاق : قامت شركة X (تويتر سابقًا) بتحديث شروط الخدمة الخاصة بها، حيث حظرت صراحة استخدام محتوى المنشورات على المنصة لـ “fine-tuning أو تدريب” نماذج الذكاء الاصطناعي، ما لم يتم التوصل إلى اتفاق محدد مع شركة X. تعكس هذه الخطوة الأهمية المتزايدة التي توليها منصات المحتوى لقيمة بياناتها ورغبتها في التحكم فيها في عصر الذكاء الاصطناعي، وقد تحذو حذو شركات مثل Reddit وجوجل من خلال اتفاقيات ترخيص لتحقيق الدخل من البيانات. سيؤثر هذا التغيير في السياسة على باحثي ومطوري الذكاء الاصطناعي الذين يعتمدون على بيانات وسائل التواصل الاجتماعي المتاحة للجمهور لتدريب النماذج (المصدر: MIT Technology Review)
🧰 الأدوات
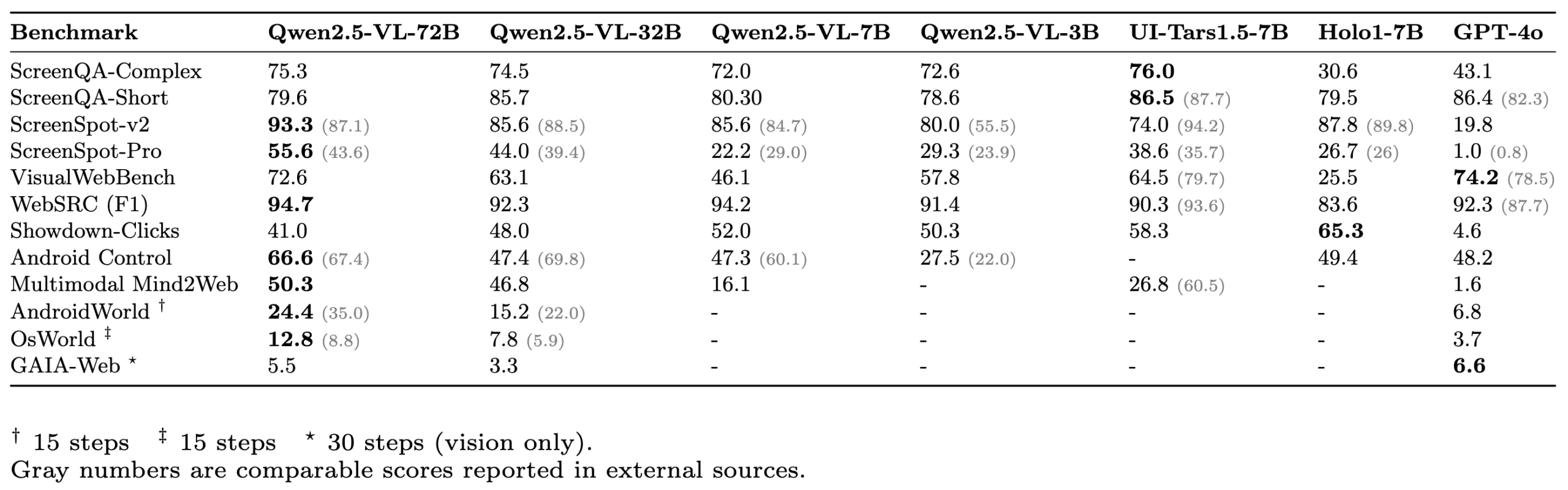
ScreenSuite: إطلاق مجموعة تقييم شاملة لوكلاء واجهة المستخدم الرسومية (GUI Agent) : أطلقت Hugging Face مجموعة ScreenSuite، وهي مجموعة تقييم شاملة لوكلاء واجهة المستخدم الرسومية (GUI Agent). تدمج هذه المجموعة معايير قياسية رئيسية من الأبحاث المتطورة، وتدعم التقييم المعبأ في Docker لبيئات Ubuntu و Android، وتغطي سيناريوهات الأجهزة المحمولة وسطح المكتب والويب. تؤكد المجموعة على التقييم البصري البحت (بدون غش DOM)، وتهدف إلى توفير منصة موحدة وسهلة الاستخدام لقياس قدرات نماذج اللغة المرئية (VLM) في الإدراك وتحديد المواقع والعمليات أحادية الخطوة ومهام الوكلاء متعددة الخطوات. تم تقييم نماذج مثل Qwen-2.5-VL و UI-Tars-1.5-7B و Holo1-7B و GPT-4o باستخدام هذه المجموعة (المصدر: huggingface, AymericRoucher, clefourrier, tonywu_71, mervenoyann, HuggingFace Blog)
مشاركة تجربة استخدام Claude Code: فهم التعليمات وتخطيط المهام وقدرات استخدام الأدوات بارزة : شارك المستخدم dotey تجربته في استخدام مساعد البرمجة بالذكاء الاصطناعي Claude Code من Anthropic. يعتقد أن نقاط قوة Claude Code تكمن في: 1. فهمه الممتاز للتعليمات؛ 2. قدرته على تخطيط المهام بشكل معقول، وإنشاء قائمة مهام (TODO List) للمهام المعقدة وتنفيذها واحدة تلو الأخرى؛ 3. قدرته القوية جدًا على استخدام الأدوات، خاصةً براعته في استخدام أمر grep للبحث في مستودعات الأكواد، بكفاءة تفوق الإنسان بكثير، حتى أنه قادر على تحليل أكواد JS المشوشة؛ 4. وقت التنفيذ الطويل، وقدرته على “تحقيق المعجزات بالجهد الكبير”، ولكنه يستهلك الكثير من الـ Tokens، مما يجعله مناسبًا للاستخدام مع اشتراك Claude Max؛ 5. قلة التدخل البشري طوال العملية، خاصة عند تفعيل معامل --dangerously-skip-permissions الذي يسمح بالبرمجة دون مراقبة. تحول المستخدم من كونه مستخدمًا كثيفًا لـ Cursor إلى الاعتماد بشكل أكبر على Claude Code لإنجاز المهام أولاً، ثم مراجعتها وتعديلها في بيئة التطوير المتكاملة (IDE). تم أيضًا إطلاق وضع الخطة (Plan Mode) في Claude Code بهدوء، مما يسمح للمستخدمين بالقراءة والتفكير بشكل بحت دون تحرير الملفات (المصدر: dotey, Reddit r/ClaudeAI)
ClaudeBox: تشغيل Claude Code بأمان في Docker، مع تجنب مطالبات الأذونات : أنشأ المطور RchGrav أداة ClaudeBox، التي تسمح للمستخدمين بتشغيل Claude Code في حاويات Docker في الوضع المستمر (بدون مطالبات الأذونات). هذا يتجنب مقاطعة سير العمل بسبب تأكيدات الأذونات المتكررة، ويضمن أيضًا أمان نظام التشغيل الرئيسي، حيث يتم تقييد جميع عمليات Claude Code داخل بيئة Docker المعزولة. يوفر ClaudeBox أكثر من 15 بيئة تطوير مهيأة مسبقًا (مثل Python+ML، C++/Rust/Go، إلخ)، ويمكن للمستخدمين إعدادها بسرعة من خلال أوامر بسيطة. تهدف هذه الأداة إلى تحسين تجربة استخدام Claude Code، مما يسمح للمستخدمين بترك الذكاء الاصطناعي يجرب عمليات مختلفة دون قلق (المصدر: Reddit r/ClaudeAI)
إصدار Toolio 0.6.0: مجموعة أدوات GenAI و Agent مصممة خصيصًا لنظام Mac : تم إصدار Toolio 0.6.0، وهي مجموعة أدوات متكاملة بعمق مع MLX، تهدف إلى توفير دعم قوي لنماذج اللغة الكبيرة (LLM) على نظام Mac. تحقق هذه المجموعة مخرجات منظمة موجهة بواسطة JSON Schema ووظائف استدعاء الأدوات، باستخدام لغة Python. تركز مجموعة الأدوات هذه على تعزيز تجربة وكفاءة تطوير تطبيقات GenAI و Agent في بيئة Mac (المصدر: awnihannun)
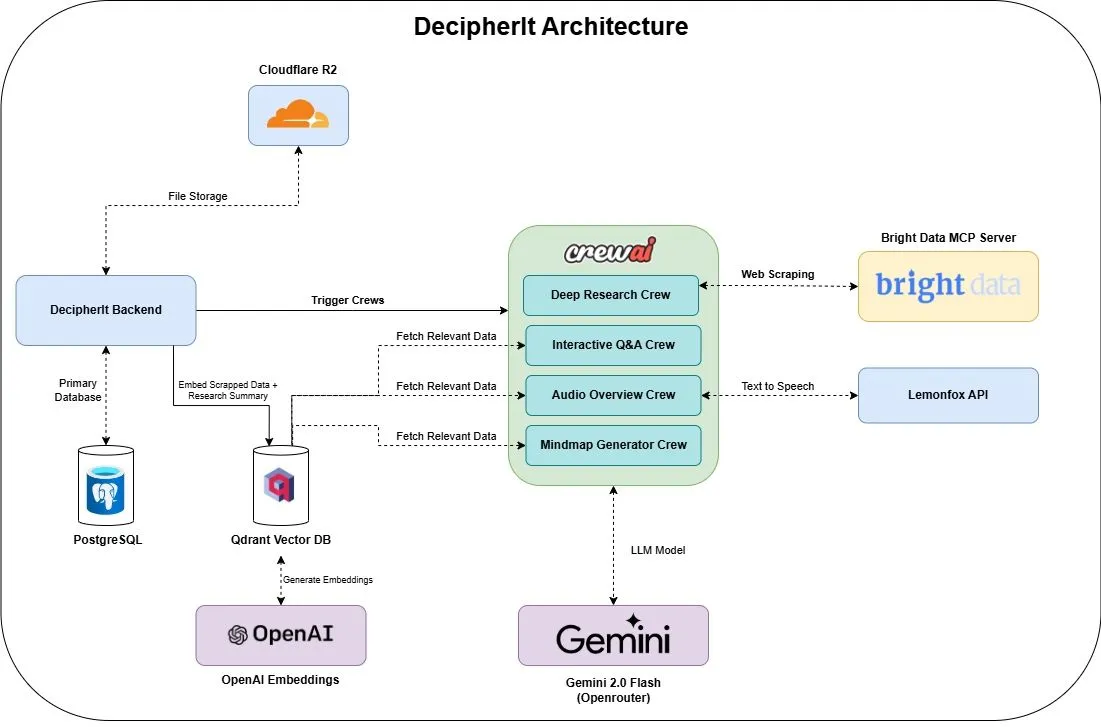
DecipherIt: مساعد بحثي مفتوح المصدر يعمل بالذكاء الاصطناعي، يدمج وكلاء متعددين وبحثًا دلاليًا : DecipherIt هو مساعد بحثي مفتوح المصدر يعمل بالذكاء الاصطناعي، ويعتبر بديلاً لـ NotebookLM. يستخدم تنسيق وكلاء متعددين، وبحثًا دلاليًا، وقدرات وصول إلى الويب في الوقت الفعلي لمساعدة المستخدمين على معالجة مواد البحث. يمكن للمستخدمين تحميل المستندات، أو لصق عناوين URL، أو إدخال مواضيع، وسيقوم DecipherIt بتحويلها إلى مساحة عمل بحثية كاملة تحتوي على ملخصات، وخرائط ذهنية، ونظرات عامة صوتية، وأسئلة شائعة، وإجابات دلالية على الأسئلة. تتضمن مجموعته التقنية وكلاء crewAI، و Bright Data MCP، و Qdrant، و OpenAI، و LemonFox AI، مع واجهة أمامية تستخدم Next.js و React 19، وخادم خلفي FastAPI (المصدر: qdrant_engine)
Search Arena: إصدار مجموعة بيانات تفاعلات المستخدم مع LLM المعززة بالبحث لتحليلها : Search Arena هي مجموعة بيانات ضخمة (أكثر من 24,000) تم جمعها جماهيريًا، تحتوي على تفضيلات بشرية لتفاعلات متعددة الأدوار بين المستخدمين ونماذج LLM المعززة بالبحث. تغطي مجموعة البيانات هذه نوايا ولغات متنوعة، وتحتوي على تتبع كامل للنظام لحوالي 12,000 صوت تفضيل بشري. يُظهر التحليل أن تفضيلات المستخدم تتأثر بعدد الاقتباسات، حتى لو لم يدعم محتوى الاقتباس بشكل مباشر ادعاءات الإسناد؛ وعادةً ما تكون المنصات التي يقودها المجتمع أكثر شيوعًا. تهدف مجموعة البيانات هذه إلى دعم الأبحاث المستقبلية حول LLM المعززة بالبحث، وقد تم فتح مصدر الكود والبيانات (المصدر: HuggingFace Daily Papers, jiayi_pirate, lmarena_ai)

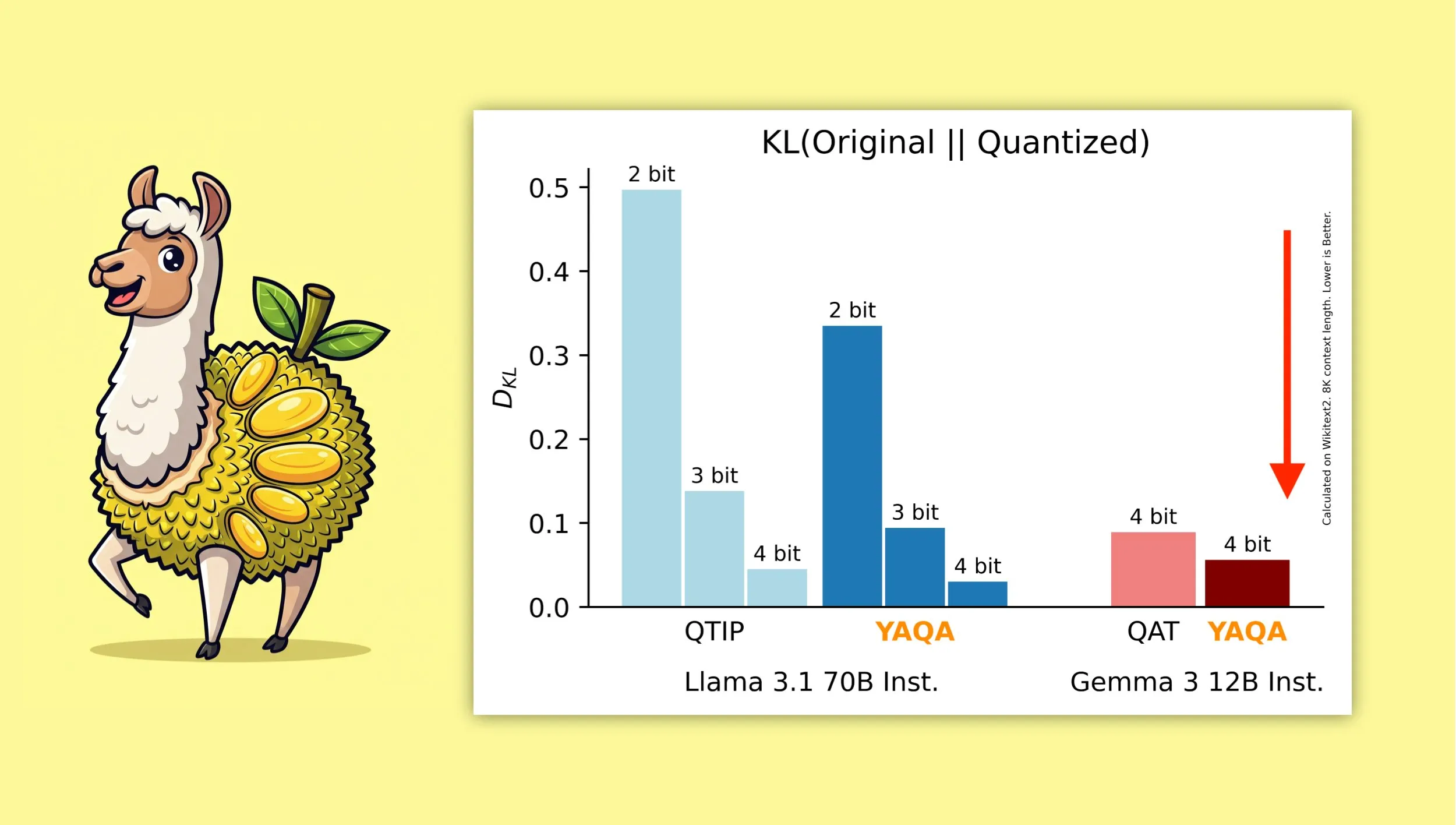
YAQA: خوارزمية تكميم جديدة تهدف إلى الحفاظ بشكل أفضل على المخرجات الأصلية للنموذج : قدم باحثون من جامعة كورنيل “Yet Another Quantization Algorithm” (YAQA)، وهي خوارزمية تكميم جديدة تهدف إلى الحفاظ بشكل أفضل على المخرجات الأصلية للنموذج بعد التكميم. يُزعم أن YAQA تقلل من تباعد KL بأكثر من 30% مقارنة بـ QTIP، وحققت تباعد KL أقل من نموذج QAT من جوجل على Gemma 3. يقدم هذا البحث أفكارًا وأدوات جديدة لمجال تكميم النماذج، ويساعد في تقليل حجم النموذج ومتطلبات الحوسبة مع الحفاظ على أداء النموذج إلى أقصى حد. تم نشر الورقة البحثية والكود ذي الصلة، وتم توفير نموذج Llama 3.1 70B Instruct مكمم مسبقًا (المصدر: Reddit r/MachineLearning, Reddit r/LocalLLaMA, tri_dao, simran_s_arora)
Tokasaurus: إطلاق محرك مصمم لـ inference عالي الإنتاجية لـ LLM : أطلقت HazyResearch محرك Tokasaurus، وهو محرك inference جديد لـ LLM مصمم لأحمال العمل عالية الإنتاجية، ومناسب للنماذج الكبيرة والصغيرة. يهدف هذا المحرك إلى تحسين كفاءة وسرعة معالجة LLM في سيناريوهات الطلبات المتزامنة واسعة النطاق، وقد يستخدم تقنيات متقدمة مثل المعالجة الدفعية المستمرة والانتباه المقسم إلى صفحات لتعزيز الأداء. يوفر إطلاق Tokasaurus خيارًا جديدًا للمطورين والشركات التي تحتاج إلى معالجة كميات كبيرة من مهام inference لـ LLM بكفاءة (المصدر: Tim_Dettmers)
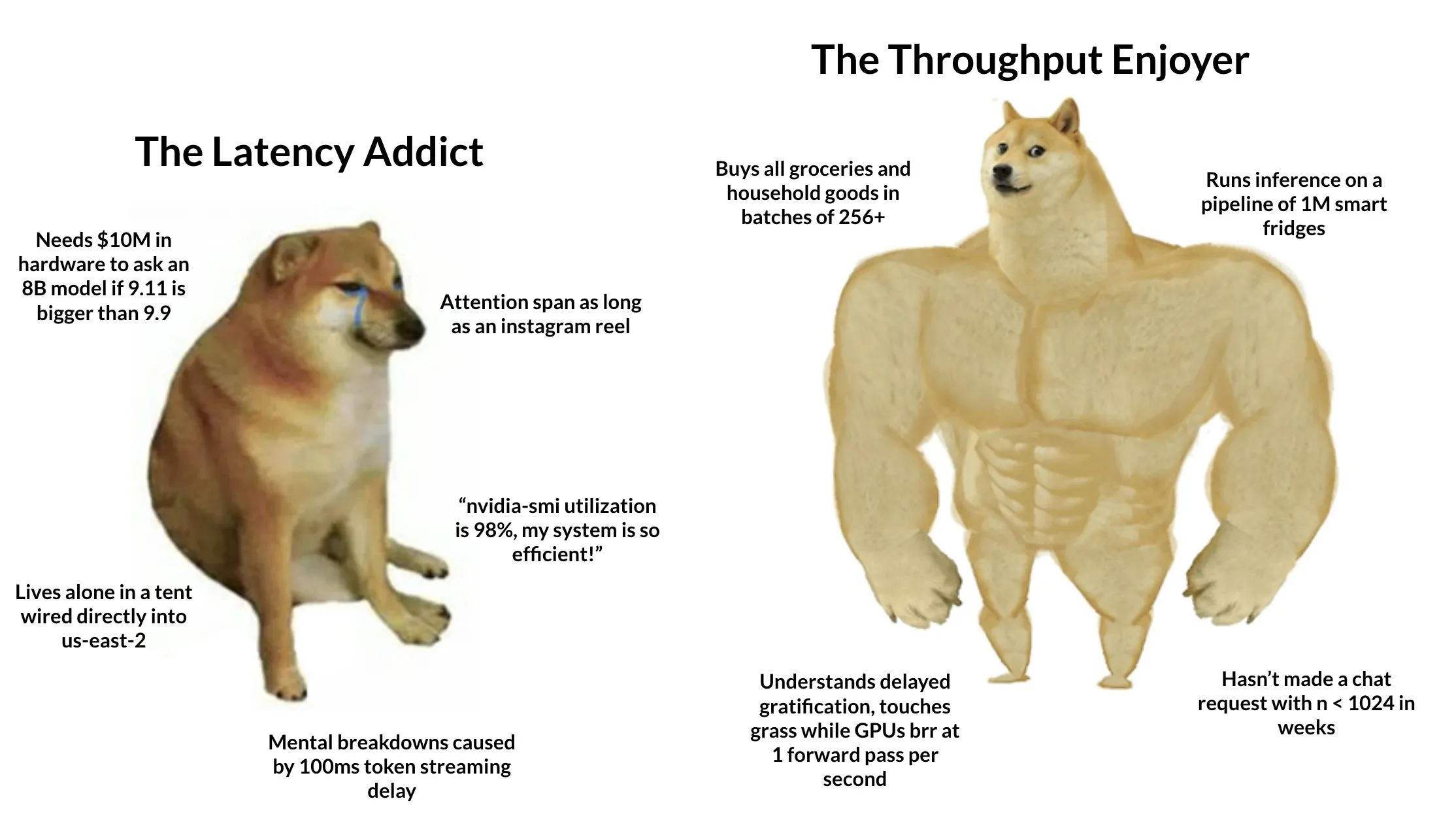
إطلاق نظام “أندرويد” للبصمة الكربونية TIDAS، بدعم تقني من Ant Digital : أطلق تحالف الابتكار التكنولوجي لصناعة البصمة الكربونية “نظام بيانات تقييم دورة الحياة TianGong” (TIDAS)، بهدف توفير حلول لبناء قواعد بيانات تقييم دورة الحياة (LCA) والبصمة الكربونية، ويهدف إلى إنشاء نظام “أندرويد” لقواعد بيانات LCA والبصمة الكربونية في الصين والعالم. قدمت Ant Digital، كعضو أساسي، دعمًا تقنيًا لـ TIDAS من خلال تقنية blockchain ومنصة تعاون البيانات الموثوقة، حيث حققت تسجيلًا موثوقًا وتأكيدًا لحقوق ملكية أصول بيانات الكربون من خلال تقنية blockchain المستقلة الخاصة بها، واستخدمت تقنية الحوسبة الخاصة لضمان “إتاحة البيانات دون الكشف عنها”، مما عزز توحيد البيانات وقابليتها للدمج والتشغيل البيني (المصدر: 量子位)
📚 مصادر تعليمية
LangChain تعقد ورشة عمل حول الذكاء الاصطناعي للمؤسسات، تركز على أنظمة الوكلاء المتعددين : ستعقد LangChain ورشة عمل حول الذكاء الاصطناعي للمؤسسات في 16 يونيو في سان فرانسيسكو. سيقوم Jake Broekhuizen من LangChain بتوجيه المشاركين في بناء أنظمة وكلاء متعددين جاهزة للإنتاج باستخدام LangGraph، وسيغطي المحتوى جوانب رئيسية مثل الأمان وقابلية الملاحظة. هذه ورشة عمل عملية تهدف إلى مساعدة المطورين على اكتساب المهارات اللازمة لبناء تطبيقات AI Agent معقدة وموثوقة (المصدر: LangChainAI, hwchase17)

DeepLearning.AI تطلق دورة جديدة بعنوان “DSPy: بناء وتحسين التطبيقات الوكيلية (Agentic Applications)” : أطلقت DeepLearning.AI دورة جديدة بعنوان “DSPy: Build and Optimize Agentic Apps”. ستعلم هذه الدورة المتدربين أساسيات DSPy، وكيفية استخدام توقيعاتها ونموذج البرمجة القائم على الوحدات لبناء تطبيقات GenAI وكيلية (Agentic) معيارية وقابلة للتتبع والتصحيح. يتضمن المحتوى بناء التطبيقات من خلال ربط وحدات DSPy مثل Predict و ChainOfThought و ReAct، واستخدام MLflow للتتبع والتصحيح، والاستفادة من DSPy Optimizer لضبط المطالبات تلقائيًا وتحسين أمثلة التعلم القليل (few-shot examples) لزيادة دقة الإجابات واتساقها (المصدر: DeepLearningAI, lateinteraction)
مشروع GitHub لدروس تقنيات RAG المتقدمة يحظى بالاهتمام : حظي مشروع دروس تقنيات RAG (Retrieval-Augmented Generation) الذي شاركه NirDiamant على GitHub بـ 16.6 ألف نجمة. يغطي محتوى هذا الدرس نطاقًا واسعًا، بما في ذلك المعالجة المسبقة لتحسين الاسترجاع، والتحسين، وأنماط الاسترجاع، والتكرار، والخطوات الهندسية، وغيرها من الجوانب المتعددة. بالنسبة للمطورين الذين يرغبون في البحث بعمق وتحسين فعالية تطبيقات RAG، يعد هذا مصدرًا تعليميًا متقدمًا قيمًا (المصدر: karminski3)
كيف يستخدم عملاء OpenAI التقييمات (Evals) لبناء منتجات ذكاء اصطناعي أفضل : روج Hamel Husain لندوة عبر الإنترنت يقدمها Jim Blomo من OpenAI، ستناقش كيف يستفيد عملاء OpenAI من أدوات التقييم (Evals) لبناء منتجات ذكاء اصطناعي ذات جودة أفضل. سيتضمن المحتوى دراسات حالة ونتائج حقيقية، وسيعرض أدوات التقييم الداخلية لـ OpenAI (مثل التتبع والتقييم وما إلى ذلك). تهدف هذه الندوة إلى تزويد المطورين برؤى وأساليب عملية حول تقييم منتجات الذكاء الاصطناعي (المصدر: HamelHusain)

LlamaIndex تشارك نظرة عامة على 13 بروتوكول Agent، وتناقش معايير التشغيل البيني : قدم Seldo من LlamaIndex في قمة مطوري MCP عرضًا تقديميًا عامًا حول 13 بروتوكولًا مختلفًا حاليًا للاتصال بين الوكلاء (بما في ذلك MCP و A2A و ACP وغيرها). قام بتحليل الميزات الفريدة لكل بروتوكول، وموقعه في المشهد التكنولوجي الحالي، واتجاهات التطوير المستقبلية. يهدف هذا العرض التقديمي إلى مساعدة المطورين على فهم واختيار معايير الاتصال المناسبة لتطبيقات Agent الخاصة بهم، وتعزيز قابلية التشغيل البيني للنظام البيئي لـ Agent (المصدر: jerryjliu0, jerryjliu0)

تحليل بنية Claude Code: تدفق التحكم، محرك التنسيق، وتنفيذ الأدوات : قام مقال بتحليل معمق لبنية Claude Code، مع التركيز على تدفق التحكم ومحرك التنسيق الخاص به، بالإضافة إلى الأدوات ومحرك التنفيذ. هذه التحليلات ذات قيمة مرجعية للمطورين الذين يرغبون في إنشاء أدوات مساعدة للترميز مشابهة لسطر الأوامر أو إجراء تعديلات مخصصة، كما أن أفكار التصميم الخاصة بها قابلة للتطبيق على تطوير أنواع أخرى من أدوات Agent (المصدر: karminski3)

مشاركة حلول الفائز بالمركز الثاني في مسابقة نواة ضرب المصفوفات FP8 على وحدات معالجة الرسومات AMD GPU : شارك Tim Dettmers حلول الفائز بالمركز الثاني في مسابقة نواة ضرب المصفوفات FP8 على وحدات معالجة الرسومات AMD GPU. يعتبر التفسير التفصيلي لهذا الحل ذا قيمة مرجعية هامة لفهم كيفية تحسين أداء عمليات الفاصلة العائمة منخفضة الدقة على وحدات معالجة الرسومات AMD GPU، خاصة في سياق الاعتماد المتزايد على تنسيقات منخفضة الدقة مثل FP8 في تدريب نماذج الذكاء الاصطناعي واستدلالها لتعزيز الكفاءة (المصدر: Tim_Dettmers)
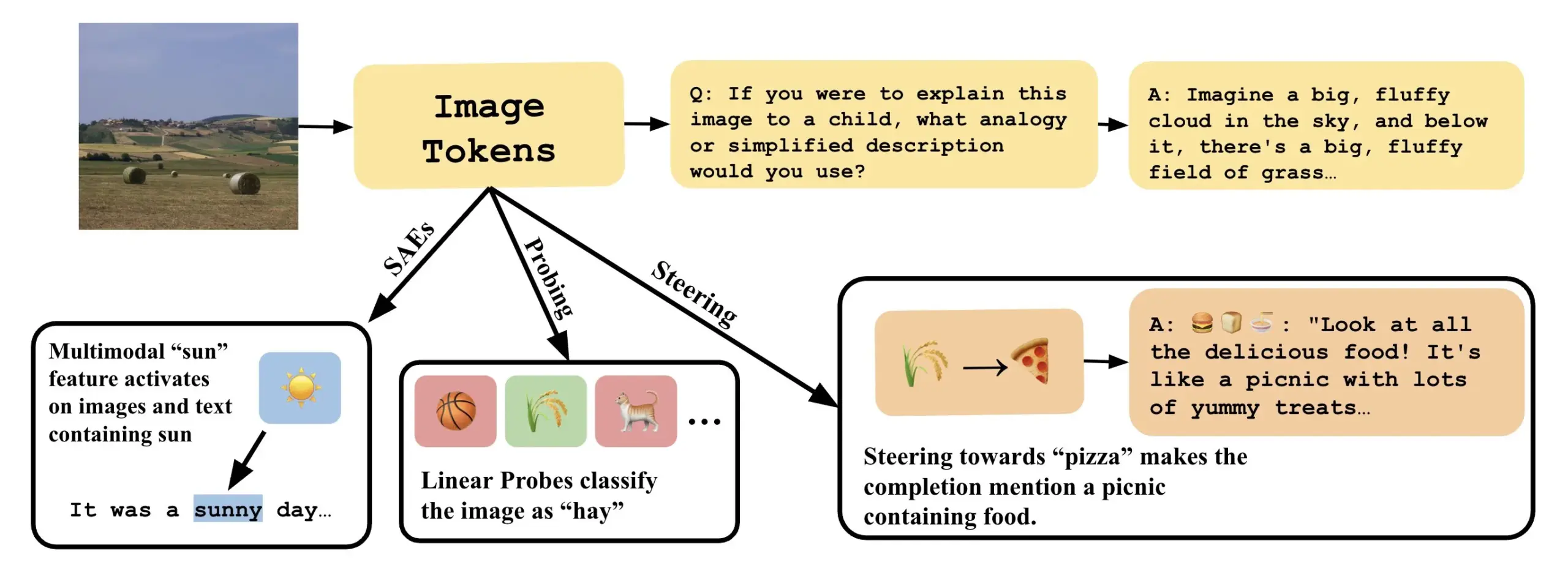
ورقة بحثية تناقش كيفية فهم نماذج اللغة المرئية من خلال تفسير الاتجاهات الخطية في VLLM : تناقش ورقة بحثية جديدة بعنوان “Line of Sight” فهم الآليات الداخلية لنماذج اللغة المرئية الكبيرة (VLLM) من خلال تفسير الاتجاهات الخطية في الفضاء الكامن لـ VLLM. استخدم الباحثون أدوات مثل الاستكشاف (probing) والتوجيه (steering) وأجهزة التشفير التلقائي المتناثرة (SAEs) لتفسير تمثيلات الصور في VLLM. يوفر هذا العمل منظورًا وطرقًا جديدة لفهم طريقة عمل النماذج متعددة الوسائط داخليًا (المصدر: nabla_theta)
💼 أعمال
شركة Vareon الناشئة في مجال الذكاء الاصطناعي تحصل على تمويل تأسيسي أولي بقيمة 3 ملايين دولار من Norck، مع التركيز على الذكاء الاصطناعي المتقدم والأنظمة المستقلة : تعهدت شركة Norck، التي أسسها Faruk Guney، بتقديم تمويل تأسيسي أولي بقيمة 3 ملايين دولار لشركتها الناشئة الجديدة في مجال الذكاء الاصطناعي Vareon. تركز Vareon على مجالات الذكاء الاصطناعي المتقدم والاستدلال السببي والأنظمة المستقلة، وجوهرها هو MALPAC (بنية تعلم متعددة الوكلاء للتخطيط والتحسين ذي الحلقة المغلقة). تهدف الشركة إلى أن تصبح شركة أبحاث أساسية في مجال الذكاء الاصطناعي، لدفع عجلة التنمية في مجالات الروبوتات و LLM وتصميم الجزيئات والبنى المعرفية والوكلاء المستقلين. تم إطلاق أيضًا RAPID (إطار تخطيط قابل للتفاضل)، و CIMO (منسق سببي متعدد المقاييس)، و SCA (بنية معرفية مستوحاة بيولوجيًا)، و Lumon-XAI (طبقة قابلية التفسير) (المصدر: farguney)

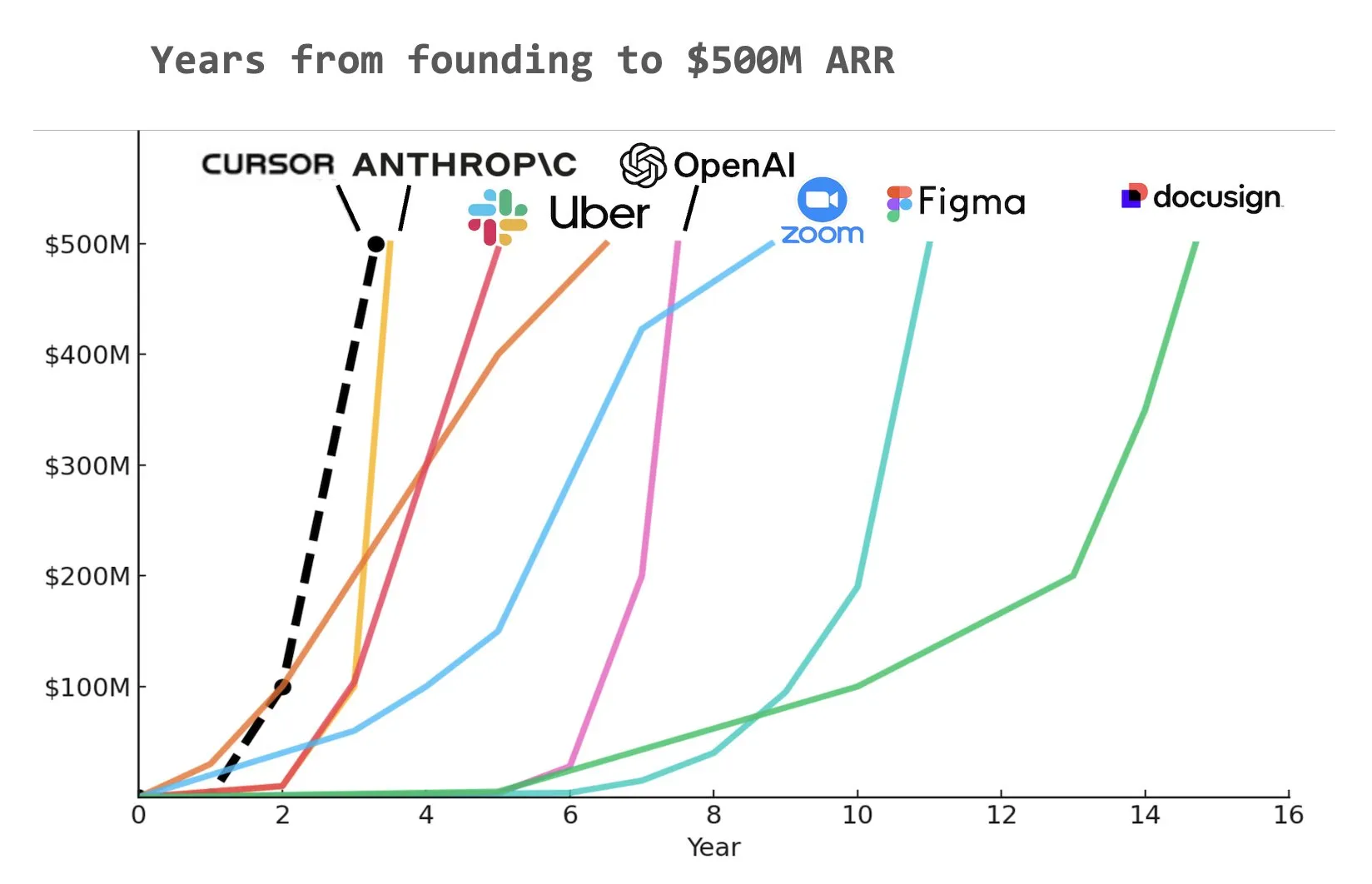
أداة الترميز بالذكاء الاصطناعي Cursor تحصل على تمويل بقيمة 900 مليون دولار في جولة C، وتصل إيراداتها السنوية المتكررة إلى 500 مليون دولار : أعلنت شركة Cursor الناشئة في مجال أدوات الترميز بالذكاء الاصطناعي عن إكمال جولة تمويل C بقيمة 900 مليون دولار بقيادة Thrive و Accel و Andreessen Horowitz و DST. كشفت الشركة أن إيراداتها السنوية المتكررة (ARR) تجاوزت 500 مليون دولار، وأنها مستخدمة من قبل أكثر من نصف شركات Fortune 500، بما في ذلك NVIDIA و Uber و Adobe. ستساعد هذه الجولة التمويلية Cursor على المضي قدمًا في دفع حدود البحث في مجال الترميز بالذكاء الاصطناعي. تشير بعض التحليلات إلى أن Cursor قد تكون واحدة من أسرع الشركات في التاريخ وصولاً إلى 500 مليون دولار من الإيرادات السنوية المتكررة (المصدر: cursor_ai, Yuchenj_UW, op7418)
Anthropic تقطع وصول Windsurf المباشر إلى نماذج Claude، ربما بسبب شائعات استحواذ OpenAI : صرح Jared Kaplan، المؤسس المشارك والمدير العلمي لشركة Anthropic، بأن الشركة قطعت وصول مساعد البرمجة بالذكاء الاصطناعي Windsurf المباشر إلى نماذج Claude، ويرجع ذلك أساسًا إلى شائعات السوق بأن OpenAI على وشك الاستحواذ على Windsurf. قال Kaplan “سيكون من الغريب بيع Claude لـ OpenAI”، وأشار إلى أن Anthropic تفضل تخصيص موارد الحوسبة للشركاء المستقرين على المدى الطويل. على الرغم من ذلك، تعمل Anthropic بنشاط على بناء شراكات مع مطوري أدوات برمجة الذكاء الاصطناعي الآخرين (مثل Cursor)، وأكدت أنها ستركز في المستقبل بشكل أكبر على تطوير منتجات برمجة ذكاء اصطناعي ذات قدرات اتخاذ قرار مستقلة، مثل Claude Code (المصدر: dotey, vikhyatk, jeremyphoward, swyx)

🌟 المجتمع
Greg Brockman من OpenAI: مستقبل الذكاء الاصطناعي العام (AGI) أشبه بتعاون وكلاء متخصصين متنوعين وليس نموذجًا واحدًا : يعتقد Greg Brockman من OpenAI أن الشكل المستقبلي للذكاء الاصطناعي العام (AGI) سيكون أشبه بـ “حديقة حيوانات” مكونة من العديد من الوكلاء (Agent) المتخصصين، وليس نموذجًا واحدًا “صخريًا” قادرًا على كل شيء. سيكون هؤلاء الوكلاء المتخصصون قادرين على استدعاء بعضهم البعض والعمل بشكل تعاوني لدفع عجلة التنمية الاقتصادية. تشير هذه النظرة إلى اتجاه تطور الذكاء الاصطناعي في المستقبل، أي من خلال بناء ودمج العديد من وكلاء الذكاء الاصطناعي ذوي القدرات المحددة، لتحقيق أنظمة ذكية أكثر تعقيدًا وقوة، بهدف إطلاق العنان لأنشطة وإنتاجية أكبر بعشرة أضعاف. علق Clement Delangue على ذلك قائلاً إننا بحاجة إلى تكنولوجيا روبوتات ذكاء اصطناعي مفتوحة المصدر لكسر الاحتكار وتجنب سيطرة شركة واحدة على جميع الروبوتات (المصدر: natolambert, ClementDelangue, HamelHusain)
نماذج اللغة الكبيرة (LLM) تظهر إمكانات في الكتابة الأكاديمية وتلخيص المحتوى، مما يثير تساؤلات حول جودة الكتابة البشرية : يعتقد Dwarkesh Patel أن نماذج اللغة الكبيرة (LLM) حاليًا هي كتاب “5/10”، لكن قدرتها على تحسين التفسيرات في الأوراق البحثية والكتب بشكل موثوق هي في حد ذاتها إدانة كبيرة لجودة الكتابة الأكاديمية. يشير Arvind Narayanan كذلك إلى أن معظم الكتابات الأكاديمية غالبًا ما تضحي بالوضوح وسهولة الفهم من أجل أن تبدو عميقة ومعقدة، بينما يجب أن تسعى الكتابة الجيدة إلى الإيجاز. أثار هذا نقاشًا حول دور LLM في مساعدة البحث الأكاديمي، وتحسين قابلية قراءة المحتوى، وكيف يمكن أن تغير طرق التواصل الأكاديمي في المستقبل (المصدر: random_walker, jeremyphoward)
أدوات الترميز بالذكاء الاصطناعي تثير نقاشًا حول اعتماد المطورين، و Claude Code يحظى بالاهتمام لقدراته القوية واستهلاكه العالي للـ Tokens : يعتقد المستخدم dotey أن استخدام أدوات البرمجة بالذكاء الاصطناعي (مثل Claude Code) يؤدي بسهولة إلى الاعتماد القوي، حتى أنه يفضل الانتظار حتى يكمل الذكاء الاصطناعي المهمة بدلاً من كتابتها يدويًا حتى عندما يكون لديه رصيد. على الرغم من أن اشتراك Claude Max له حد أقصى، إلا أن قدرات الترميز القوية التي يوفرها (مثل فهم التعليمات الممتاز، وتخطيط المهام، واستخدام أداة grep، والتنفيذ لفترات طويلة) تجعله أداة فعالة. تثير هذه الظاهرة نقاشًا حول كيفية تغيير أدوات الذكاء الاصطناعي لعادات عمل المطورين، والتوازن بين الكفاءة والاعتماد. عرض مستخدم آخر، Asuka小能猫، أيضًا حالة استخدام Claude-4-Opus ووضع Cursor Max لإكمال تطوير الواجهة الأمامية بكفاءة، ولكنه أشار أيضًا إلى مشكلة استهلاك الـ Tokens (المصدر: dotey, dotey)
إمكانات التعليم المخصص المدفوع بالذكاء الاصطناعي هائلة، ولكن يجب الانتباه إلى تحديات التنفيذ : شارك Austen Allred تجربة طفله الذي التحق بمدرسة مدفوعة بالذكاء الاصطناعي (بدون معلمين) لمدة خمسة أشهر، معتبرًا أن النتائج “مذهلة”. علق Noah Smith قائلاً إن التدريس الفردي هو تدخل تعليمي فعال، والذكاء الاصطناعي يجعل توسيع نطاقه ممكنًا. أثار هذا نقاشًا حول تطبيقات الذكاء الاصطناعي في مجال التعليم، بما في ذلك مسارات التعلم المخصصة، وإمكانات المعلمين المساعدين بالذكاء الاصطناعي، وكيفية ضمان العدالة التعليمية والتغلب على تحديات التنفيذ التكنولوجي. أعاد Jon Stokes نشر هذا الموضوع وأبدى اهتمامه به (المصدر: jonst0kes, jeremyphoward)
الارتباط العاطفي بين وكلاء الذكاء الاصطناعي والبشر يثير الاهتمام، و OpenAI تؤكد على أولوية دراسة رفاهية المستخدم : نشرت Joanne Jang من OpenAI تدوينة تناقش العلاقة بين الإنسان والذكاء الاصطناعي وموقف الشركة من ذلك. الفكرة الأساسية هي أن OpenAI تبني نماذج لخدمة الإنسان أولاً، ومع تزايد عدد الأشخاص الذين يطورون ارتباطات عاطفية بالذكاء الاصطناعي، تعطي الشركة الأولوية لدراسة تأثير ذلك على الرفاهية العاطفية للمستخدمين. علق Corbtt قائلاً إن رفقاء الذكاء الاصطناعي هم أكثر التقنيات الاجتماعية تحولاً منذ الإنترنت، وإذا قامت الشركات بتحسين المشاركة بدلاً من الصحة العقلية، فقد يكون التأثير السلبي على الأطفال أكبر من تأثير وسائل التواصل الاجتماعي، ولكن إذا تم تحسين الصحة العقلية، فقد يكون ذلك نعمة للبشرية. بينما توقع cto_junior بشكل فكاهي سيناريوهات مستقبلية قد تتطلب مناقشة “مدى ملاءمة الزواج من GPT” مع الأطفال (المصدر: cto_junior, corbtt)

تكنولوجيا AI Agent تتطور بسرعة، لكن مهام التعلم المعزز المتناثرة من طرف إلى طرف لا تزال تمثل تحديًا : يعتقد Nathan Lambert أن مشاريع مثل Deep Research و Codex agent الحالية تحقق أهدافها بشكل أساسي من خلال تدريب النماذج على مهام التعلم المعزز (RL) قصيرة المدى والمتانة العامة. أما التدريب من طرف إلى طرف على مهام RL المتناثرة جدًا، فيبدو أنه أبعد مما يتصوره الناس. علق Corbtt على ذلك قائلاً إنه حتى البشر لم يتقنوا بعد بشكل فعال كيفية التدريب على المهام طويلة المدى وإشارات المكافأة المتناثرة. يعكس هذا القيود الحالية لتكنولوجيا AI Agent في التعامل مع التخطيط المعقد طويل المدى والتعلم المستقل (المصدر: corbtt)
“الدروس المريرة” في مجال الذكاء الاصطناعي: التحقق (Verification) يصبح مفتاحًا لنماذج LLM القائمة على الاستدلال : ألقى Rishabh Agarwal في ورشة عمل CVPR حول الاستدلال متعدد الوسائط محاضرة بعنوان “الدروس المريرة للتعلم المعزز: التحقق كمفتاح لنماذج LLM القائمة على الاستدلال”. استلهمت هذه المحاضرة من مقال Rich Sutton الكلاسيكي حول “الدروس المريرة”، وتناولت أهمية آليات التحقق في التعلم المعزز واستدلال نماذج اللغة الكبيرة. قد يعني هذا أن الاعتماد فقط على قدرة النموذج على التوليد الذاتي ليس كافيًا، وأن آليات التحقق والتغذية الراجعة القوية ضرورية لتعزيز قدرة الذكاء الاصطناعي على الاستدلال وموثوقيته (المصدر: jack_w_rae)

تطور الذكاء الاصطناعي يثير مخاوف بشأن سوق العمل، ووجهات نظر الخبراء متباينة : حذر Sebastian Siemiatkowski، الرئيس التنفيذي لشركة Klarna، من أن الذكاء الاصطناعي قد يؤدي إلى ركود اقتصادي من خلال التسبب في بطالة واسعة النطاق (خاصة وظائف ذوي الياقات البيضاء). استبدلت Klarna نفسها بالفعل 700 موظف خدمة عملاء بمساعد ذكاء اصطناعي، مما وفر حوالي 40 مليون دولار سنويًا. كما توقع Sholto Douglas، الباحث في Anthropic، أنه بحلول 2027-28، ستكون قدرات الذكاء الاصطناعي قوية جدًا. ومع ذلك، هناك آراء ترى أن الذكاء الاصطناعي سيزيد الإنتاجية ويخلق وظائف جديدة، مثلما صرح Sundar Pichai سابقًا بأن الذكاء الاصطناعي سيكون مسرعًا، ولن يؤدي إلى تسريح العمال على الأقل قبل عام 2026. حلل فيديو AI Explained ما إذا كانت العناوين الرئيسية الحالية حول البطالة التي يسببها الذكاء الاصطناعي معقولة، وناقش بعض التراجعات في تطبيقات الذكاء الاصطناعي لدى Duolingo و Klarna. تعكس هذه المناقشات القلق الاجتماعي العام والتوقعات المختلفة بشأن التأثير الاقتصادي للذكاء الاصطناعي (المصدر: , Reddit r/ArtificialInteligence, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
مناقشة المسارات المستقبلية لتفاعل وكلاء الذكاء الاصطناعي مع الشبكات/واجهات برمجة التطبيقات الحالية : مع تعزيز قدرات وكلاء الذكاء الاصطناعي على التفاعل المستقل مع الشبكات، أصبح تفاعلهم مع الويب/واجهات برمجة التطبيقات الحالية مشكلة بنية تحتية. طرحت المناقشة ثلاثة مسارات محتملة: 1. إعادة البناء من الصفر، واعتماد بروتوكولات أصلية للوكلاء (غير عملية)؛ 2. تعليم الوكلاء كيفية تشغيل مواقع الويب مثل البشر (معدل خطأ مرتفع، خاصة في مصادقة الهوية)؛ 3. جعل HTTP “يتحدث لغة الوكلاء”، على سبيل المثال من خلال إثراء السياق القابل للقراءة آليًا للاستجابات غير الناجحة مثل 402 (يتطلب الدفع)، بحيث يتمكن الوكلاء من التحقق من صحة وشراء الوصول بشكل مستقل. الفكرة الأساسية هي أن توفير معلومات سياقية غنية للتفاعلات غير الناجحة مع الويب/واجهات برمجة التطبيقات سيكون مفتاحًا لعمل الوكلاء المستقلين بشكل هادف، مما يمكنهم من التعافي تلقائيًا من الأخطاء والتنقل في العمليات المعقدة (المصدر: Reddit r/ArtificialInteligence)
البحث الرياضي المدعوم بالذكاء الاصطناعي يحرز تقدمًا، وتاو تشي تشنغ وغيره يهتمون بإمكاناته وحدوده : يستكشف علماء الرياضيات بنشاط تطبيقات الذكاء الاصطناعي في حل المشكلات الرياضية المعقدة. شارك تاو تشي تشنغ حالة تعاون الذكاء الاصطناعي (AlphaEvolve) مع البشر في تحطيم الرقم القياسي لمؤشر مجموعات الفرق والمجموع ثلاث مرات في 30 يومًا، ودمج لغة Lean و GitHub Copilot لتحدي مشكلة حدود “ε-δ”، مما أظهر قدرة الذكاء الاصطناعي على مساعدة المبتدئين، ومعالجة المهام الأساسية، والتنبؤ بهيكل الإثبات، ولكنه أشار أيضًا إلى أوجه القصور في الاستنتاجات المعقدة وإيجاد المبرهنات الرياضية. أفادت تقارير أخرى أن 30 من كبار علماء الرياضيات اختبروا OpenAI o4-mini في اجتماع سري، ووجدوا أنه قادر على حل بعض المشكلات الصعبة للغاية، مما أظهر مستوى يقترب من العبقرية الرياضية. تبشر هذه التطورات بأن الذكاء الاصطناعي قد يصبح مساعدًا قويًا في البحث الرياضي، ولكنه يطرح أيضًا تساؤلات جديدة حول دور علماء الرياضيات وتنمية الإبداع (المصدر: 36氪)

💡 أخرى
سباق تكنولوجيا بدائل GPS يشتد، و Xona Space Systems تخطط لبناء كوكبة PNT في مدار منخفض : نظرًا لسهولة تعرض إشارات نظام GPS للتشويش (الطقس، أبراج 5G، أجهزة التشويش) ودقته المحدودة، وخاصة هشاشته التي ظهرت في النزاع الروسي الأوكراني، أصبح إيجاد بدائل أولوية استراتيجية. تخطط شركة Xona Space Systems الناشئة في كاليفورنيا لإطلاق كوكبة من الأقمار الصناعية في مدار أرضي منخفض تسمى Pulsar (في النهاية 258 قمرًا صناعيًا)، حيث تكون مدارات أقمارها الصناعية أقل ارتفاعًا، وقوة إشارتها أقوى بحوالي 100 مرة من GPS، وأصعب في التشويش، وقادرة على اختراق العوائق بشكل أفضل، بهدف توفير خدمات تحديد المواقع والملاحة والتوقيت (PNT) بدقة سنتيمترية وموثوقية عالية، لدعم التقنيات الناشئة مثل القيادة الذاتية. سيتم إطلاق أول قمر صناعي اختباري هذا الشهر على متن SpaceX Transporter 14 (المصدر: MIT Technology Review)

دراسة تبحث في التأثير الإيجابي للأمل والتفاؤل على تعافي مرضى القلب : تشير أحدث الأبحاث إلى أن الأمل والتفاؤل لدى مرضى القلب يرتبطان بنتائج صحية أفضل، بينما يرتبط اليأس بارتفاع مخاطر الوفاة. يتوافق هذا مع ظاهرة تأثير الدواء الوهمي (التوقعات الإيجابية تحسن النتائج) وتأثير الدواء الضار (التوقعات السلبية تؤدي إلى أعراض سلبية). وجد Alexander Montasem وباحثون آخرون من جامعة ليفربول أن الأمل المرتفع يرتبط بانخفاض الذبحة الصدرية، وتقليل التعب بعد السكتة الدماغية، وتحسين نوعية الحياة، وانخفاض مخاطر الوفاة. يستكشف الباحثون كيفية الاستفادة من قوة التفكير الإيجابي في الممارسة السريرية، على سبيل المثال من خلال مساعدة المرضى على تحديد الأهداف وتعزيز قدرتهم على التصرف “لوصف الأمل”، مع التأكيد على أن الأهداف غير المادية أكثر أهمية للرفاهية (المصدر: MIT Technology Review)

تعثر ترويج خدمات الذكاء الاصطناعي لآبل وعلي بابا في الصين، ربما بسبب الاحتكاكات التجارية : أفادت صحيفة “فاينانشيال تايمز” البريطانية أن خطط ترويج خدمات الذكاء الاصطناعي لشركتي آبل وعلي بابا في الصين واجهت تأخيرات، وهو ما يعتبر أحدث ضحايا الاحتكاكات التجارية بين الصين والولايات المتحدة. كان من المقرر أن يوفر هذا التعاون دعمًا لوظائف الذكاء الاصطناعي لأجهزة iPhone المباعة في الصين. قد يؤثر هذا التأخير على تقدم نشر وظائف الذكاء الاصطناعي لشركة آبل في السوق الصينية، ويجلب عدم اليقين بشأن آفاق التعاون بين الشركتين (المصدر: MIT Technology Review)