
كلمات مفتاحية:جيميني 2.5 برو, خصوصية بيانات OpenAI, OpenThinker3-7B, كلود جوف, الوكيل الذكي للذكاء الاصطناعي, النماذج اللغوية الكبيرة, التعلم التعزيزي, النماذج مفتوحة المصدر, تحسين أداء جيميني 2.5 برو, سياسة الاحتفاظ ببيانات مستخدمي OpenAI, قدرات الاستدلال في OpenThinker3-7B, تطبيقات كلود جوف في الأمن القومي, متانة وسيطرة الوكيل الذكي للذكاء الاصطناعي
🔥 أبرز العناوين
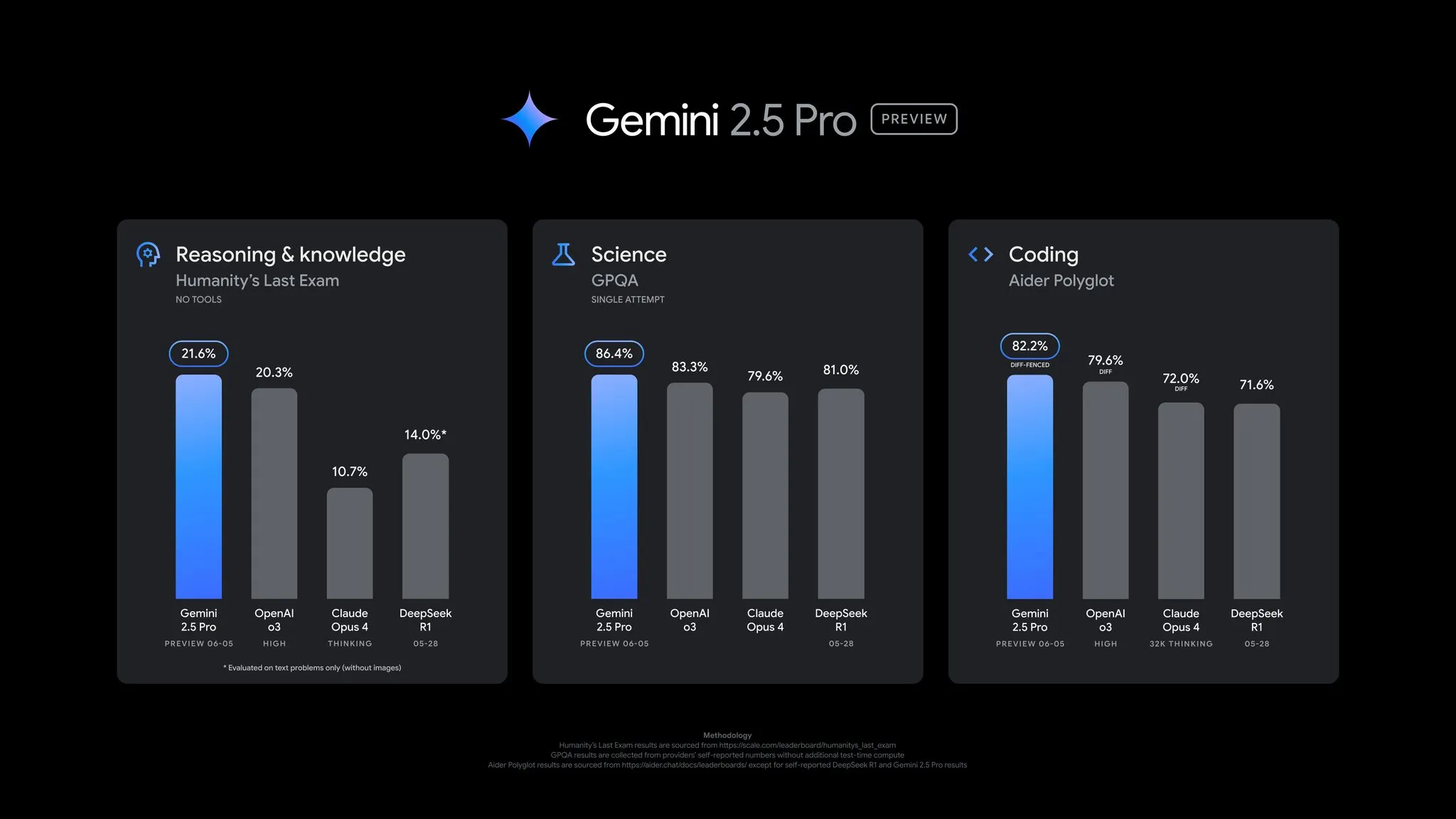
جوجل تطلق تحديثًا لنسخة المعاينة Gemini 2.5 Pro، مع تحسينات شاملة في الأداء: أعلنت جوجل عن تحديث هام لنسخة المعاينة Gemini 2.5 Pro، مع تقدم ملحوظ في قدرات الترميز، الاستدلال، العلوم، والرياضيات. أظهر الإصدار الجديد أداءً أفضل في اختبارات الأداء الرئيسية مثل AIDER Polyglot، GPQA، HLE، وحقق قفزة بمقدار 24 نقطة في Elo score على LMArena، متصدراً الترتيب مرة أخرى. بالإضافة إلى ذلك، تم تحسين النموذج في أسلوب الإجابة والتنسيق بناءً على ملاحظات المستخدمين، وتم تقديم ميزة “ميزانية التفكير” (thinking budget) لتوفير المزيد من التحكم. التحديث متاح الآن في Gemini App، Google AI Studio، و Vertex AI (المصدر: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI تُلزم بالاحتفاظ الدائم ببيانات المستخدمين بسبب دعوى قضائية من New York Times، مما يثير مخاوف تتعلق بالخصوصية: في إطار دعوى قضائية تتعلق بحقوق النشر مع New York Times، أمرت المحكمة OpenAI بالاحتفاظ الدائم بجميع سجلات تفاعل المستخدمين مع ChatGPT وواجهة برمجة التطبيقات (API)، بما في ذلك “المحادثات المؤقتة” وبيانات طلبات API التي كانت قد تعهدت سابقًا بالاحتفاظ بها لمدة 30 يومًا فقط. صرحت OpenAI بأنها تستأنف القرار، معتبرة إياه “تدخلاً مفرطًا” يقوض معايير الخصوصية الراسخة ويضعف حماية الخصوصية. يعني هذا الحكم أن OpenAI قد لا تتمكن من الوفاء بتعهداتها للمستخدمين بشأن الاحتفاظ بالبيانات وحذفها، مما أثار مخاوف واسعة النطاق لدى المستخدمين بشأن خصوصية البيانات وأمنها، وقد يؤثر بشكل خاص على مطوري التطبيقات الذين يعتمدون على OpenAI API ولديهم سياساتهم الخاصة للاحتفاظ بالبيانات (المصدر: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

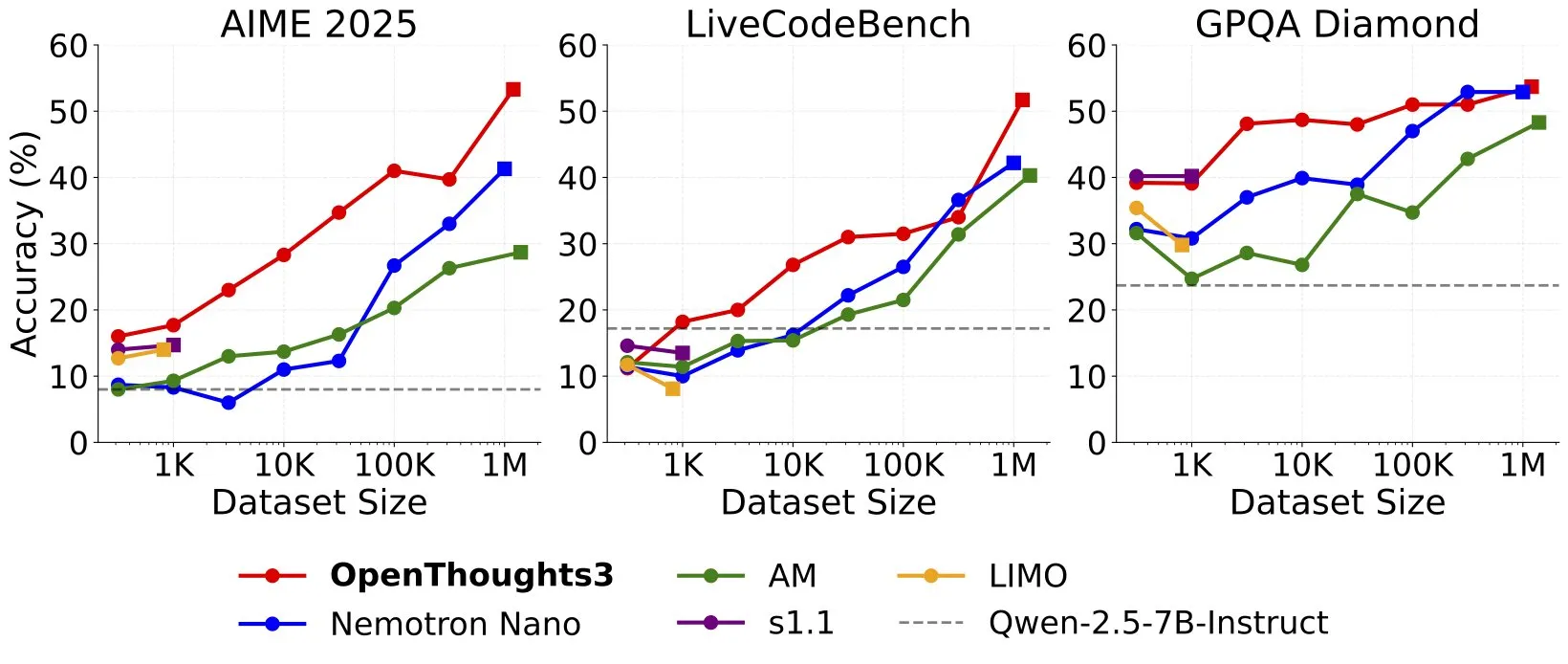
إطلاق OpenThinker3-7B، محققًا رقمًا قياسيًا جديدًا (SOTA) لنماذج الاستدلال مفتوحة المصدر بحجم 7B: أعلن Ryan Marten عن إطلاق OpenThinker3-7B، وهو نموذج استدلال مفتوح البيانات جديد بسعة 7 مليارات معلمة، يتفوق في المتوسط بنسبة 33% على DeepSeek-R1-Distill-Qwen-7B في تقييمات الترميز والعلوم والرياضيات. كما أصدر الفريق مجموعة بيانات OpenThoughts3-1.2M، التي يُزعم أنها أفضل مجموعة بيانات استدلال مفتوحة حاليًا من حيث حجم البيانات. أشار الباحثون إلى أنه بالنسبة للنماذج الأصغر، فإن التقطير من R1 هو المسار الأسهل لتحسين الأداء، لكن البحث في اتجاه RL (التعلم المعزز) أكثر استكشافًا. يعتبر هذا الإنجاز أحد الأعمال الرائدة في مجال نماذج الاستدلال مفتوحة المصدر (المصدر: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic تطلق Claude Gov، نموذج مخصص لعملاء الأمن القومي الأمريكي: أعلنت Anthropic عن إطلاق Claude Gov، وهي سلسلة من نماذج الذكاء الاصطناعي المخصصة المصممة لعملاء الأمن القومي الأمريكي. تم نشر هذه النماذج بالفعل في أعلى مستويات وكالات الأمن القومي في الولايات المتحدة، ويقتصر الوصول إليها على الأفراد العاملين في بيئات سرية. تمثل هذه الخطوة تعميقًا إضافيًا لتطبيق تكنولوجيا الذكاء الاصطناعي في المجالات الحكومية والدفاعية، كما تثير نقاشات حول استخدام الذكاء الاصطناعي في المجالات الحساسة (المصدر: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 اتجاهات
Yann LeCun يتفق مع وجهة نظر Sundar Pichai: التكنولوجيا الحالية قد لا تحقق الذكاء الاصطناعي العام (AGI)، وقد تحدث فترة استقرار: أعاد Yann LeCun، كبير علماء الذكاء الاصطناعي في Meta، نشر وتأييد وجهة نظر Sundar Pichai، الرئيس التنفيذي لشركة جوجل، بأن المسار التكنولوجي الحالي لا يضمن تحقيق الذكاء الاصطناعي العام (AGI)، وأن تطور الذكاء الاصطناعي قد يواجه فترة استقرار مؤقتة. أشار Pichai إلى أنه على الرغم من سرعة تقدم الذكاء الاصطناعي المذهلة، إلا أنه قد تكون هناك قيود، ولا تزال التكنولوجيا الحالية بعيدة عن الذكاء العام. يعكس هذا موقفًا حذرًا في الصناعة تجاه مسار تحقيق الذكاء الاصطناعي العام وجدوله الزمني (المصدر: ylecun)
OpenAI توظف فريقًا لمتانة وكلاء الذكاء الاصطناعي والتحكم فيها، بهدف تعزيز سلامة وكلاء الذكاء الاصطناعي: تقوم OpenAI بتشكيل فريق جديد يُدعى “متانة وكلاء الذكاء الاصطناعي والتحكم” (Agent Robustness and Control)، بهدف ضمان سلامة وموثوقية وكلائها الأذكياء أثناء عمليات التدريب والنشر. سيعمل الفريق على حل بعض أكثر المشكلات تحديًا في مجال الذكاء الاصطناعي، مما يدل على الأهمية الكبيرة التي توليها OpenAI للسلامة والتحكم أثناء سعيها لتطوير وكلاء ذكاء اصطناعي أكثر قوة (المصدر: gdb)

بحث جديد من آبل يكشف “وهم التفكير” في نماذج اللغة الكبيرة: قدرة الاستدلال لا ترتفع بل تنخفض أمام المشكلات المعقدة: تشير ورقة بحثية حديثة من شركة آبل بعنوان “وهم التفكير” (The Illusion of Thinking) إلى أن نماذج الاستدلال الحالية، عند مواجهة زيادة في تعقيد المشكلة إلى حد معين، ينخفض جهدها الاستدلالي (reasoning effort) بدلاً من أن يرتفع، حتى مع منحها ميزانية كافية من الـ tokens. هذه الظاهرة غير البديهية لـ “حدود التوسع” (scaling limit) تشير إلى أن النماذج قد لا تقوم بتفكير عميق حقيقي عند التعامل مع مشكلات شديدة التعقيد، بل تظهر نوعًا من “وهم التفكير”، مما يطرح تحديات جديدة لتقييم وتعزيز قدرة الاستدلال الحقيقية للنماذج الكبيرة (المصدر: Ar_Douillard, Reddit r/MachineLearning)

OpenAI تناقش الارتباط العاطفي بين الإنسان والذكاء الاصطناعي، وتعطي الأولوية لدراسة التأثير على الرفاه العاطفي للمستخدمين: نشرت Joanne Jang من OpenAI تدوينة تناقش ظاهرة الارتباط العاطفي المتزايد بين المستخدمين ونماذج الذكاء الاصطناعي مثل ChatGPT. تشير المقالة إلى أن الناس يميلون بشكل طبيعي إلى إضفاء الطابع الإنساني على الذكاء الاصطناعي وقد يشعرون تجاهه بالرفقة والثقة. تعترف OpenAI بهذا الاتجاه وتعلن أنها ستعطي الأولوية لدراسة تأثير الذكاء الاصطناعي على الرفاه العاطفي للمستخدمين، بدلاً من الخوض في المسائل الأنطولوجية حول ما إذا كان الذكاء الاصطناعي “واعيًا” حقًا. هدف الشركة هو تصميم مساعدي ذكاء اصطناعي ودودين ومفيدين ولكن لا يسعون بشكل مفرط إلى الاعتماد العاطفي أو لديهم أجندتهم الخاصة (المصدر: openai, sama, BorisMPower)

Xiaohongshu تطلق نموذج MoE كبير مفتوح المصدر dots.llm1-143B-A14B: أطلق مختبر Hi Lab التابع لـ Xiaohongshu أول سلسلة نماذج كبيرة مفتوحة المصدر له dots.llm1، والتي تشمل النموذج الأساسي dots.llm1.base ونموذج الضبط الدقيق للتعليمات dots.llm1.inst. يعتمد النموذج بنية MoE، بإجمالي 143 مليار معلمة، و14 مليار معلمة نشطة. تدعي الشركة رسميًا أن أداءه على MMLU-Pro يتفوق على Qwen3-235B-A22B، ولكنه أقل من DeepSeek-V3 الجديد. يستخدم النموذج ترخيص MIT، وهو متاح للاستخدام الحر. ومع ذلك، أظهرت الاختبارات الأولية للمجتمع أن أداءه في مهام مثل إنشاء التعليمات البرمجية ليس جيدًا، بل إنه أسوأ من Qwen2.5-coder (المصدر: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

سلسلة Qwen3 تطلق نماذج Embedding وReranker، لتعزيز قدرات معالجة النصوص متعددة اللغات: أطلق فريق Qwen نماذج Qwen3-Embedding و Qwen3-Reranker، بهدف تحسين أداء تضمين النصوص متعددة اللغات وترتيب الصلة. تُستخدم نماذج Embedding لتحويل النصوص إلى تمثيلات متجهة، ودعم سيناريوهات مثل استرجاع المستندات و RAG؛ بينما تُستخدم نماذج Reranker لإعادة ترتيب نتائج البحث، مما يعزز أولوية المحتوى الأكثر صلة. توفر السلسلة نماذج بأحجام معلمات مختلفة مثل 0.6B و 4B و 8B، وتدعم 119 لغة، وأظهرت أداءً متميزًا في اختبارات MMTEB و MTEB وغيرها. يُعتبر إصدار 0.6B مناسبًا بشكل خاص لسيناريوهات Reranker التي تتطلب استجابة في الوقت الفعلي نظرًا لتوازنه بين الكفاءة والأداء (المصدر: karminski3, karminski3, ZhaiAndrew, clefourrier)

دراسة تشير إلى تحديات قابلية التوسع للتعلم المعزز في المهام المعقدة ذات الأفق الطويل: وجد بحث أجراه Seohong Park وآخرون أن مجرد توسيع البيانات والموارد الحاسوبية لا يكفي لجعل التعلم المعزز (RL) يحل المهام المعقدة بفعالية، وأن العامل المقيد الرئيسي هو “الأفق” (horizon). في المهام ذات الأفق الطويل، تكون إشارات المكافأة متفرقة، ويجد النموذج صعوبة في تعلم استراتيجيات فعالة. يتوافق هذا مع الملاحظات الحالية بأن بعض وكلاء الذكاء الاصطناعي (مثل Deep Research و Codex agent) يعتمدون بشكل أساسي على مهام RL ذات الأفق القصير والتدريب على المتانة العامة، مما يشير إلى أن حل مشكلة المكافآت المتفرقة في المهام ذات الأفق الطويل من طرف إلى طرف لا يزال يمثل تحديًا كبيرًا في مجال RL (المصدر: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu تسجل حسابًا رسميًا على HuggingFace وتقوم بتحميل نماذج Wenxin (ERNIE) الكبيرة: سجلت Baidu حسابًا رسميًا على منصة HuggingFace وقامت بتحميل بعض نماذج سلسلة Wenxin (ERNIE)، بما في ذلك Wenxin-X1-Turbo و Wenxin-4.5-Turbo. تعني هذه الخطوة أن Baidu تدمج بنشاط تقنيتها للنماذج الكبيرة في مجتمع المصادر المفتوحة الأوسع ونظام المطورين البيئي، مما يسهل على المطورين العالميين الوصول إلى قدراتها في مجال الذكاء الاصطناعي واستخدامها (المصدر: karminski3)
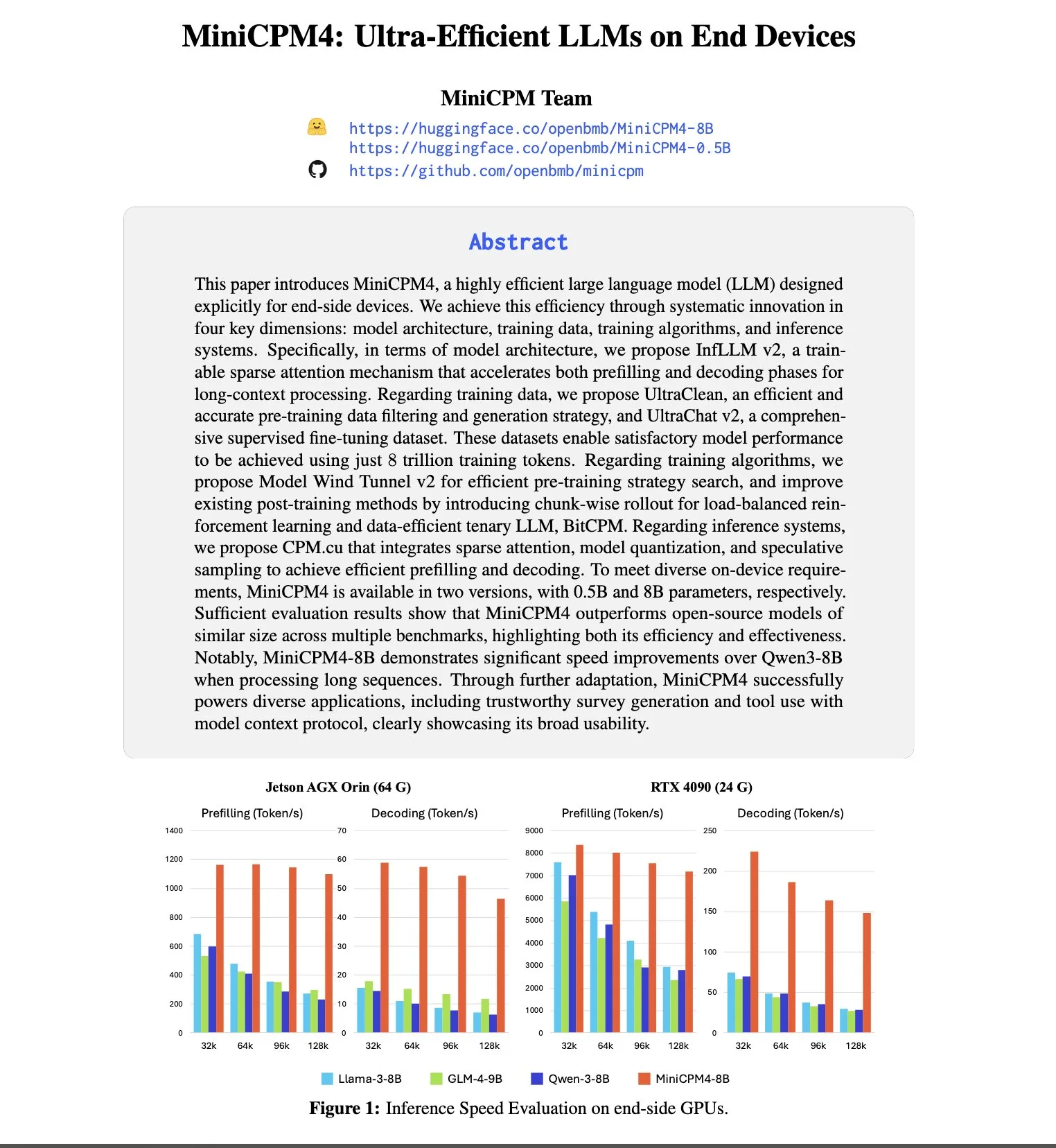
OpenBMB تطلق سلسلة نماذج MiniCPM4، مع التركيز على التشغيل الفعال على الأجهزة الطرفية: تواصل OpenBMB استكشاف حدود نماذج اللغة الصغيرة والفعالة، وأصدرت سلسلة MiniCPM4. من بينها نموذج MiniCPM4-8B الذي يمتلك 8 مليارات معلمة وتم تدريبه على 8 تريليون token. تستخدم هذه السلسلة من النماذج تقنيات تسريع قصوى مثل الانتباه المتناثر القابل للتدريب (InfLLM v2)، والتكميم الثلاثي (BitCPM)، وحسابات الدقة المنخفضة FP8، والتنبؤ متعدد الـ tokens، بهدف تحقيق تشغيل فعال على الأجهزة الطرفية. على سبيل المثال، تحتاج آلية الانتباه المتناثر الخاصة بها عند معالجة نصوص طويلة بطول 128 ألف token إلى حساب الارتباط مع أقل من 5% من الـ tokens لكل token، مما يقلل بشكل كبير من التكلفة الحسابية لمعالجة النصوص الطويلة (المصدر: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
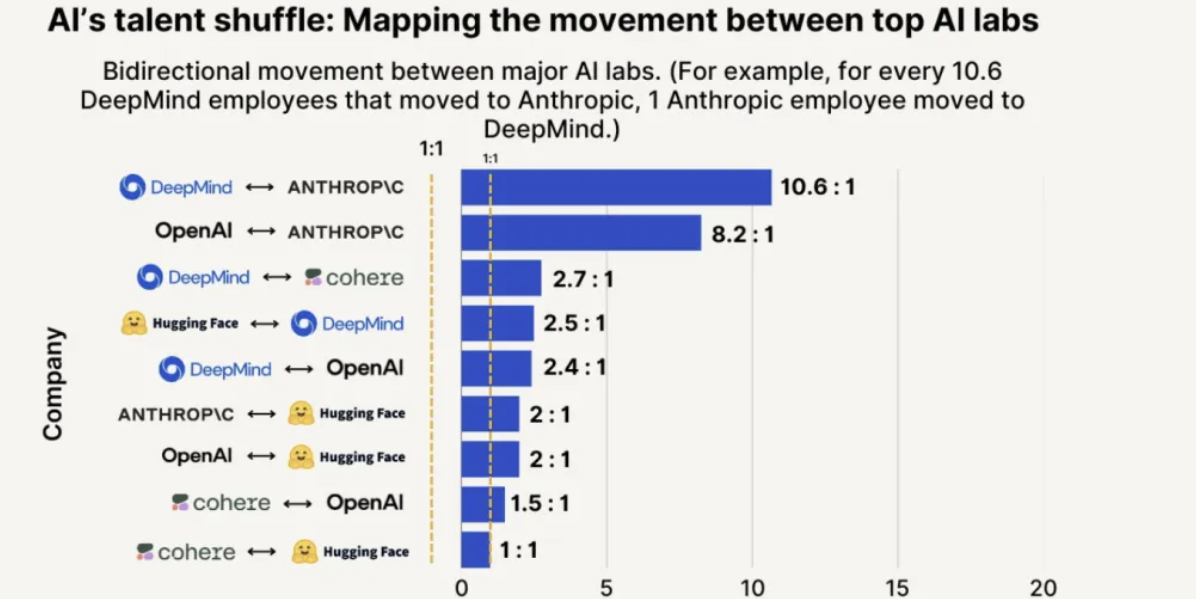
Anthropic تتصدر في جذب المواهب والاحتفاظ بها، واحتمالية استقطاب موظفين من OpenAI أعلى بـ 8 مرات: أظهر تقرير اتجاهات المواهب لعام 2025 الصادر عن SignalFire أن Anthropic تتفوق في الاحتفاظ بأفضل مواهب الذكاء الاصطناعي، بنسبة تصل إلى 80%، متجاوزة DeepMind (78%) و OpenAI (67%). وأشار التقرير أيضًا إلى أن احتمالية انتقال المهندسين من OpenAI إلى Anthropic تزيد بـ 8 مرات عن احتمالية انتقالهم من Anthropic إلى OpenAI. تُعتبر ثقافة Anthropic المؤسسية الفريدة، وتقبلها للتفكير غير التقليدي، واستقلالية الموظفين، وشعبية منتجها Claude بين المطورين، عوامل رئيسية في جذب المواهب والاحتفاظ بها (المصدر: 量子位)
🧰 أدوات
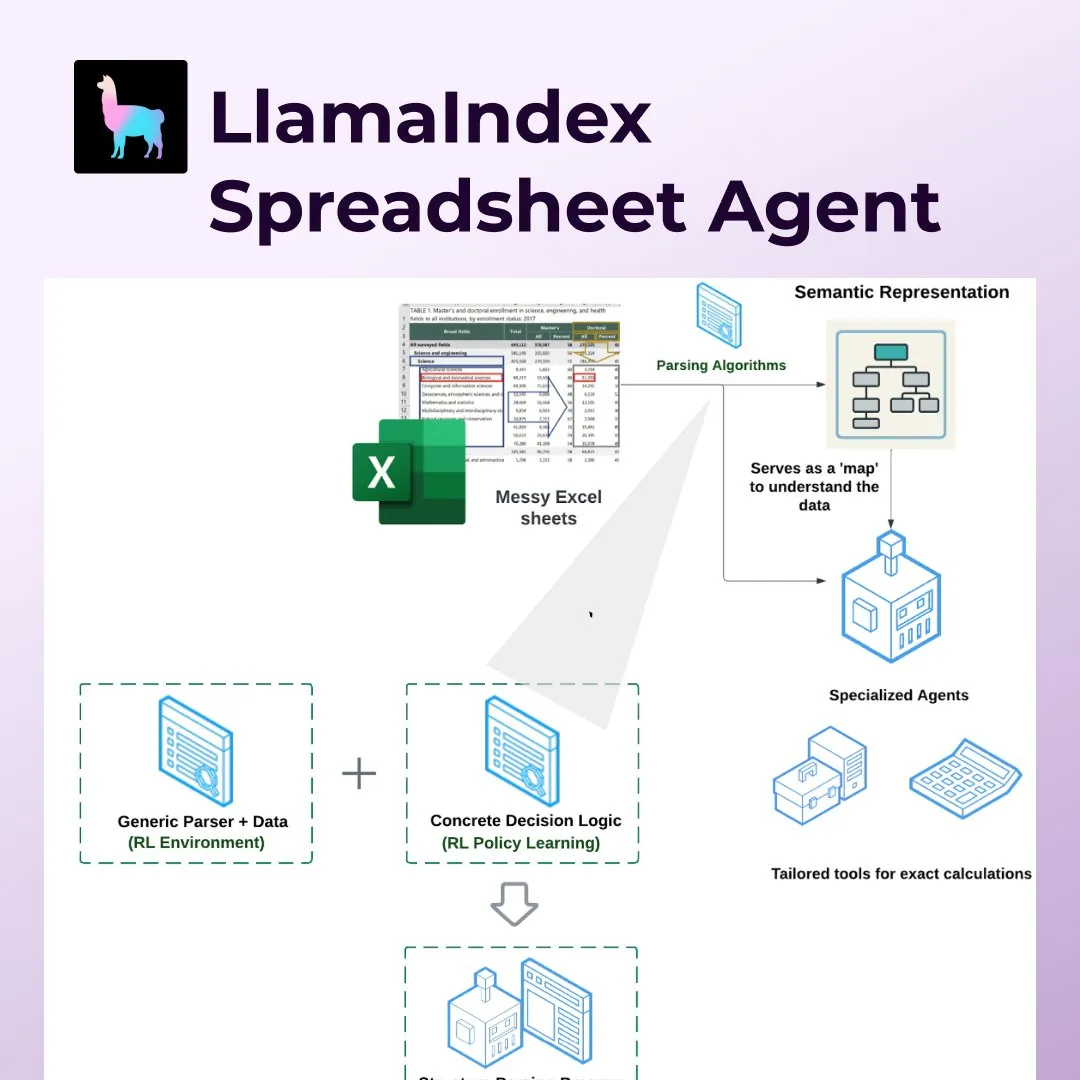
LlamaIndex تطلق Spreadsheet Agents، لإحداث ثورة في معالجة جداول البيانات مثل Excel: أطلقت LlamaIndex ميزة Spreadsheet Agents الجديدة، التي تسمح للمستخدمين بتحويل البيانات وطرح الأسئلة على جداول Excel غير القياسية. تستخدم هذه الأداة تحليل البنية الدلالية القائم على التعلم المعزز لفهم بنية الجداول، وتمكّن وكلاء الذكاء الاصطناعي من التفاعل مع الجداول من خلال أدوات مخصصة. تهدف إلى معالجة أوجه القصور في نماذج اللغة الكبيرة (LLM) التقليدية عند التعامل مع الجداول المعقدة (مثل تلك الشائعة في مجالات المحاسبة والضرائب والتأمين)، ويمكنها التعامل مع الخلايا المدمجة والتخطيطات المعقدة مع الحفاظ على علاقات البيانات. في الاختبارات، تفوقت دقتها (96%) على خط الأساس البشري و OpenAI Code Interpreter (GPT 4.1، 75%) (المصدر: jerryjliu0)
LlamaIndex تستخدم LlamaExtract وسير عمل الوكلاء لأتمتة استخراج بيانات SEC Form 4: عرضت LlamaIndex كيفية استخدام أداة LlamaExtract الخاصة بها وسير عمل وكلاء الذكاء الاصطناعي لاستخراج البيانات وتوحيدها تلقائيًا من ملفات Form 4 التابعة لهيئة الأوراق المالية والبورصات الأمريكية (SEC) (وهي مستندات يفصح فيها المسؤولون التنفيذيون والمديرون والمساهمون الرئيسيون في الشركات المدرجة عن معاملاتهم في الأسهم). يمكن لهذا الحل تحويل ملفات Form 4 ذات التنسيقات المختلفة من شركات مختلفة إلى تنسيق CSV نظيف، ودمجها في إطار بيانات يمكن الاستعلام عنه عبر Pandas، مما يوفر للمحللين الماليين والمستثمرين أداة فعالة لمعالجة البيانات (المصدر: jerryjliu0)

إطلاق مشروع Ragbits مفتوح المصدر، يوفر وحدات بناء لتطوير تطبيقات GenAI بسرعة: أطلقت deepsense-ai مشروع Ragbits مفتوح المصدر، بهدف توفير وحدات بناء لتطوير تطبيقات الذكاء الاصطناعي التوليدي (GenAI) بسرعة. يدعم المشروع أكثر من 100 واجهة برمجة تطبيقات لنماذج كبيرة أو نماذج محلية، ويأتي مزودًا بمخزن متجه (يمكن توصيله بـ Qdrant و PgVector)، ويدعم أكثر من 20 تنسيقًا لملفات الإدخال (PDF، HTML، جداول، عروض تقديمية، إلخ). يستخدم Ragbits VLM مدمج لدعم استخراج الجداول والصور والمحتوى المنظم، ويمكن توصيله بمصادر بيانات متعددة مثل S3 و GCS و Azure، ويتميز بخصائص معيارية تسمح للمستخدمين بتخصيص المكونات (المصدر: karminski3, GitHub Trending)

مساعد البرمجة بالذكاء الاصطناعي Cursor يطلق تحديثًا رئيسيًا، يدمج BugBot وميزة الذاكرة ودعم MCP: أجرى أداة البرمجة بالذكاء الاصطناعي Cursor تحديثًا كبيرًا، يشمل بشكل رئيسي: 1) BugBot، الذي يمكنه الرد تلقائيًا على مشكلات GitHub وفتحها بنقرة واحدة في Cursor لإصلاحها؛ 2) ميزة الذاكرة، التي تمكن الذكاء الاصطناعي من تذكر محتويات المحادثات السابقة، مما يحسن سهولة الاستخدام عند إجراء تعديلات متكررة على المشاريع الكبيرة؛ 3) إعداد MCP (Model Context Protocol) بنقرة واحدة، يدعم خوادم MCP التابعة لجهات خارجية والتي تدعم OAuth؛ 4) دعم Jupyter Notes لوكلاء الذكاء الاصطناعي؛ 5) وكيل يعمل في الخلفية، يمكن استدعاء لوحة التحكم الخاصة به باستخدام اختصار لوحة المفاتيح لاستخدام وكيل برمجة ذكاء اصطناعي عن بُعد (المصدر: karminski3)
Archon: وكيل ذكاء اصطناعي يمكنه إنشاء وكلاء ذكاء اصطناعي آخرين: Archon هو مشروع “Agenteer” يهدف إلى بناء وتحسين وكلاء ذكاء اصطناعي آخرين بشكل مستقل. يستخدم سير عمل متقدم لترميز الوكلاء وقاعدة معرفية للأطر، ويُظهر دور التخطيط وحلقات التغذية الراجعة والمعرفة المتخصصة في إنشاء وكلاء ذكاء اصطناعي أقوياء. يدمج الإصدار الأحدث V6 مكتبة أدوات وخادم MCP (Model Context Protocol)، مما يعزز القدرة على بناء وكلاء جدد. يدعم Archon النشر عبر Docker والتثبيت المحلي باستخدام Python، ويوفر واجهة مستخدم Streamlit للإدارة (المصدر: GitHub Trending)

NoteGen: تطبيق ملاحظات Markdown متعدد المنصات مدفوع بالذكاء الاصطناعي: NoteGen هو تطبيق ملاحظات Markdown متعدد المنصات يهدف إلى ربط التسجيل والكتابة باستخدام الذكاء الاصطناعي، ويمكنه تنظيم المعرفة المجزأة في ملاحظات قابلة للقراءة. يدعم طرق تسجيل متعددة مثل لقطات الشاشة والنصوص والرسوم التوضيحية والملفات والروابط، ويخزن بتنسيق Markdown أصلي، ويدعم الاستخدام المحلي دون اتصال بالإنترنت بالإضافة إلى المزامنة مع GitHub/Gitee/WebDAV. يمكن تكوين NoteGen مع نماذج ذكاء اصطناعي متعددة مثل ChatGPT و Gemini و Ollama، ويدعم وظيفة RAG، باستخدام ملاحظات المستخدم كقاعدة معرفية (المصدر: GitHub Trending)

ComfyUI-Copilot: مساعد ذكي لأتمتة تطوير سير العمل: ComfyUI-Copilot هو إضافة مدفوعة بنماذج لغوية كبيرة، تهدف إلى تحسين سهولة استخدام وكفاءة منصة إنشاء الفن بالذكاء الاصطناعي ComfyUI. يعالج مشاكل عدم ملاءمة ComfyUI للمبتدئين، وأخطاء تكوين النماذج، وتعقيد تصميم سير العمل من خلال توفير توصيات ذكية للعقد والنماذج، بالإضافة إلى وظيفة بناء سير العمل بنقرة واحدة. يستخدم النظام إطار عمل متعدد الوكلاء هرمي، يتضمن وكيل مساعد مركزي وعدة وكلاء عمل متخصصين، ويستفيد من قاعدة معارف ComfyUI لتبسيط التصحيح والنشر (المصدر: HuggingFace Daily Papers)
Bifrost: بوابة LLM مفتوحة المصدر عالية الأداء بلغة Go، لتحسين نشر LLM في بيئة الإنتاج: لحل تحديات تجزئة واجهات برمجة التطبيقات (API) وزمن الانتقال والتراجع وإدارة التكاليف لنماذج اللغة الكبيرة (LLM) في بيئة الإنتاج، قام فريق Maximilian بإطلاق بوابة LLM مفتوحة المصدر Bifrost، المبنية على لغة Go. تم تصميم Bifrost خصيصًا لعمليات نشر تعلم الآلة عالية الإنتاجية ومنخفضة زمن الانتقال، وتدعم مزودي LLM الرئيسيين مثل OpenAI و Anthropic و Azure. تظهر اختبارات الأداء أن Bifrost يزيد الإنتاجية بمقدار 9.5 مرة، ويقلل زمن انتقال P99 بمقدار 54 مرة، ويقلل استهلاك الذاكرة بنسبة 68% مقارنة بالوكلاء الآخرين، مع تكلفة داخلية أقل من 15 ميكروثانية عند 5000 طلب في الثانية (RPS). يوفر ميزات مثل توحيد واجهات برمجة التطبيقات، والتراجع التلقائي للموردين، وإدارة المفاتيح الذكية، ومقاييس Prometheus (المصدر: Reddit r/MachineLearning)

LangGraph.js يحسن تجربة المطورين، ويقدم أمان الأنواع ودوال الربط (hooks): أجرى LangGraph.js 0.3 سلسلة من التحديثات التي تهدف إلى تحسين تجربة المطورين. وتشمل هذه التحديثات تعزيز أمان الأنواع، بالإضافة إلى تقديم preModelHook و postModelHook في createReactAgent. يمكن استخدام preModelHook لتبسيط سجل الرسائل قبل تمريره إلى LLM، بينما يمكن استخدام postModelHook لإضافة حواجز حماية أو عمليات تعاون بين الإنسان والآلة. يسعى المجتمع بنشاط للحصول على ملاحظات حول LangGraph v1 (المصدر: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024 يطلق نموذج GRMR-V3-G4B كبير لتصحيح الأخطاء النحوية: أطلق المطور qingy2024 نموذجًا كبيرًا متخصصًا في تصحيح الأخطاء النحوية يُدعى GRMR-V3-G4B، بأقصى عدد معلمات يبلغ 4B فقط. يوفر هذا النموذج أيضًا نسخة مكممة، وهي مناسبة بشكل خاص لمهام فحص وتصحيح القواعد النحوية في سير العمل المحلي أو على الأجهزة الشخصية، مما يسهل دمجه واستخدامه (المصدر: karminski3)

Fullpack: تطبيق قائمة تعبئة ذكية يعتمد على التعرف البصري المحلي على iPhone: أطلق مطور تطبيقًا لنظام iOS يُدعى Fullpack، يمكنه التعرف على العناصر الموجودة في الصور باستخدام VisionKit الخاص بـ iPhone، ومساعدة المستخدمين على إنشاء قوائم تعبئة ذكية لمناسبات مختلفة (مثل يوم عمل، عطلة على الشاطئ، عطلة نهاية أسبوع للمشي لمسافات طويلة). يؤكد التطبيق على التشغيل المحلي بنسبة 100%، دون معالجة سحابية أو جمع بيانات، لحماية خصوصية المستخدم. هذا هو أول تطبيق مستقل للمطور، ويهدف إلى استكشاف إمكانات الذكاء الاصطناعي على الجهاز (المصدر: Reddit r/LocalLLaMA)
📚 موارد تعليمية
Unsloth تطلق عددًا كبيرًا من دفاتر Colab/Kaggle Notebooks لضبط دقيق لنماذج كبيرة رئيسية: توفر UnslothAI سلسلة من دفاتر Jupyter Notebooks، لتسهيل ضبط دقيق لمجموعة متنوعة من النماذج الكبيرة الرئيسية مثل Qwen3، Gemma 3، Llama 3.1/3.2، Phi-4، Mistral v0.3 على منصات مثل Google Colab و Kaggle. تغطي هذه الدفاتر أنواعًا متعددة من المهام وطرق الضبط الدقيق مثل المحادثة، Alpaca، GRPO، الرؤية، تحويل النص إلى كلام (TTS)، وتهدف إلى تبسيط عملية ضبط النماذج، وتوفر إرشادات لإعداد البيانات، والتدريب، والتقييم، وحفظ النماذج (المصدر: GitHub Trending)

“دليل استخدام النماذج الكبيرة مفتوحة المصدر”: برنامج تعليمي لـ LLM/MLLM للمبتدئين في الصين: يوفر مشروع Datawhalechina “دليل استخدام النماذج الكبيرة مفتوحة المصدر” برنامجًا تعليميًا يعتمد على بيئة Linux، موجهًا للمبتدئين في الصين، ويغطي العملية الكاملة لنماذج اللغة الكبيرة (LLM) والنماذج الكبيرة متعددة الوسائط (MLLM) مفتوحة المصدر المحلية والدولية، بما في ذلك تكوين البيئة، والنشر المحلي، والضبط الدقيق للمعلمات الكاملة/Lora. يهدف المشروع إلى تبسيط نشر واستخدام النماذج الكبيرة مفتوحة المصدر، ويدعم بالفعل نماذج متعددة مثل Qwen3، Kimi-VL، Llama4، Gemma3، InternLM3، Phi4 (المصدر: GitHub Trending)

ورقة بحثية تناقش MINT-CoT: إدخال رموز بصرية متقاطعة في استدلال سلسلة الأفكار الرياضية: تقترح ورقة بحثية جديدة طريقة MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought)، التي تهدف إلى تعزيز قدرة نماذج اللغة الكبيرة على الاستدلال في المسائل الرياضية متعددة الوسائط من خلال إدخال رموز بصرية ذات صلة بشكل متكيف ومتقاطع ضمن خطوات الاستدلال النصي. تقوم هذه الطريقة، من خلال “Interleave Token”، باختيار مناطق بصرية لأي شكل في الرسوم البيانية الرياضية بشكل ديناميكي، وقامت ببناء مجموعة بيانات MINT-CoT تحتوي على 54 ألف مسألة رياضية، لتدريب النموذج على محاذاة المناطق البصرية على مستوى الرمز المميز في كل خطوة استدلال. أظهرت التجارب أن نموذج MINT-CoT-7B حقق أداءً أفضل بكثير من النماذج الأساسية في اختبارات مثل MathVista (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح StreamBP: طريقة انتشار عكسي دقيقة وفعالة من حيث الذاكرة لتدريب LLM على التسلسلات الطويلة: لمواجهة مشكلة التكلفة الهائلة للذاكرة الناتجة عن تخزين قيم التنشيط أثناء تدريب نماذج اللغة الكبيرة (LLM) على تسلسلات طويلة، اقترح باحثون StreamBP، وهي طريقة انتشار عكسي دقيقة وفعالة من حيث الذاكرة. تقلل StreamBP بشكل كبير من تكلفة الذاكرة لقيم التنشيط والـ logits من خلال تحليل خطي لقاعدة السلسلة على مستوى الطبقة على طول بُعد التسلسل. هذه الطريقة مناسبة للأهداف الشائعة مثل SFT و GRPO و DPO، وتتطلب عددًا أقل من عمليات FLOPs، وتتميز بسرعة انتشار عكسي أكبر. مقارنةً بنقاط فحص التدرج، يمكن لـ StreamBP توسيع الحد الأقصى لطول التسلسل للانتشار العكسي بمقدار 2.8-5.5 مرة، مع استخدام وقت انتشار عكسي مكافئ أو حتى أقل (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح تقنية Diagonal Batching، لفتح إمكانية الاستدلال المتوازي للسياق الطويل في RMT: لحل مشكلة عنق الزجاجة في أداء نماذج Transformer عند الاستدلال على سياق طويل، اقترح باحثون مخطط جدولة Diagonal Batching، يهدف إلى فتح إمكانية التوازي عبر الأجزاء في Transformer ذي الذاكرة المتكررة (RMT)، مع الحفاظ على التكرار الدقيق. تعيد هذه التقنية ترتيب العمليات الحسابية وقت التشغيل، مما يزيل القيود التسلسلية، ويحقق استدلالًا فعالًا على وحدة معالجة الرسومات (GPU) حتى بالنسبة لمدخلات السياق الطويل الفردية، دون الحاجة إلى تقنيات تجميع ودفع معقدة. عند تطبيقها على نموذج LLaMA-1B ARMT، على تسلسل بطول 131 ألف token، حققت Diagonal Batching تسريعًا بمقدار 3.3 مرة مقارنة بنموذج LLaMA-1B ذي الانتباه الكامل القياسي، وتسريعًا بمقدار 1.8 مرة مقارنة بتطبيق RMT التسلسلي (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش التأثير السلبي لتقنيات العلامات المائية على محاذاة نماذج اللغة واستراتيجيات التخفيف: حللت دراسة بشكل منهجي تأثير تقنيتي العلامات المائية الرئيسيتين Gumbel و KGW على خصائص المحاذاة الأساسية لنماذج اللغة الكبيرة (LLMs) مثل الصدق والأمان والفائدة. وجدت الدراسة أن العلامات المائية تؤدي إلى نمطين من التدهور: ضعف الحماية (تعزيز الفائدة ولكن الإضرار بالأمان) وتضخيم الحماية (الحذر المفرط يقلل من الفائدة). للتخفيف من هذه المشكلات، تقترح الورقة طريقة إعادة أخذ العينات للمحاذاة (Alignment Resampling, AR)، والتي تستخدم نموذج مكافأة خارجيًا أثناء الاستدلال لاستعادة المحاذاة. أثبتت التجارب أن أخذ عينات من 2-4 مخرجات تحمل علامات مائية يكفي لاستعادة أو تجاوز درجات المحاذاة الأساسية بفعالية، مع الحفاظ على قابلية اكتشاف العلامة المائية (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح إطار Micro-Act، للتخفيف من تضارب المعرفة في الإجابة على الأسئلة من خلال الاستدلال الذاتي القابل للتنفيذ: لحل مشكلة تضارب المعرفة الخارجية مع المعرفة الداخلية للمعلمات في نماذج اللغة الكبيرة (LLM) في أنظمة التوليد المعزز بالاسترجاع (RAG)، اقترح باحثون إطار Micro-Act. يتميز هذا الإطار بمساحة عمل هرمية، ويمكنه إدراك تعقيد السياق تلقائيًا، وتحليل كل مصدر معرفة إلى سلسلة من خطوات المقارنة الدقيقة (ممثلة كخطوات قابلة للتنفيذ)، مما يحقق استدلالًا يتجاوز السياق السطحي. أظهرت التجارب أن Micro-Act يحسن بشكل كبير دقة الإجابة على الأسئلة في خمس مجموعات بيانات قياسية، ويتفوق بشكل خاص على خطوط الأساس الحالية في أنواع التضارب الزمني والدلالي، ويمكنه التعامل بقوة مع المشكلات الخالية من التضارب (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح معيار STARE، لتقييم قدرة النماذج متعددة الوسائط على المحاكاة البصرية المكانية: لتقييم قدرة نماذج اللغة الكبيرة متعددة الوسائط (MM-LLMs) على المهام التي تتطلب محاكاة بصرية متعددة الخطوات لحلها، أطلق باحثون معيار STARE (Spatial Transformations and Reasoning Evaluation). يتضمن STARE 4000 مهمة، تغطي التحويلات الهندسية الأساسية (ثنائية وثلاثية الأبعاد)، والاستدلال المكاني المركب (مثل فتح المكعبات وألغاز تانجرام)، والاستدلال المكاني في العالم الحقيقي (مثل المنظور والاستدلال الزمني). أظهر التقييم أن النماذج الحالية تؤدي أداءً جيدًا في التحويلات ثنائية الأبعاد البسيطة، ولكن أداءها يقترب من العشوائي في المهام المعقدة التي تتطلب محاكاة بصرية متعددة الخطوات (مثل فتح المكعبات ثلاثية الأبعاد). يقترب أداء البشر من الكمال في هذه المهام المعقدة، ولكنهم يستغرقون وقتًا أطول، وتؤدي المحاكاة البصرية الوسيطة إلى تسريع كبير؛ بينما تستفيد النماذج بشكل متفاوت من المحاكاة البصرية (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح LEXam: مجموعة بيانات معيارية متعددة اللغات تركز على الاستدلال القانوني، تتصدر اتجاهات Hugging Face: أصدر باحثون من المعهد الفدرالي السويسري للتكنولوجيا في زيورخ ومؤسسات أخرى LEXam، وهي مجموعة بيانات معيارية جديدة متعددة اللغات للاستدلال القانوني، تهدف إلى تقييم قدرة نماذج اللغة الكبيرة على الاستدلال في السيناريوهات القانونية المعقدة. تتضمن LEXam أسئلة امتحانات قانونية حقيقية من كلية الحقوق بجامعة زيورخ، تغطي مجالات متعددة مثل القانون السويسري والأوروبي والدولي، وتشمل أسئلة مقالية طويلة وأسئلة اختيار من متعدد، وتوفر مسارات استدلال مفصلة. يقدم المشروع نموذج “LLM-as-a-Judge” للتقييم، ووجد أن النماذج المتقدمة الحالية لا تزال تواجه تحديات في الإجابة على الأسئلة القانونية المقالية المفتوحة وتطبيق القواعد المعقدة متعددة الخطوات. بعد إصداره، احتل LEXam المرتبة الأولى في قائمة اتجاهات مجموعات بيانات التقييم على Hugging Face (المصدر: 量子位)

UCLA وجوجل تتعاونان لإطلاق نموذج 3DLLM-MEM ومعيار 3DMEM-BENCH، لتعزيز قدرة الذكاء الاصطناعي على الذاكرة طويلة المدى في البيئات ثلاثية الأبعاد: تعاونت جامعة كاليفورنيا في لوس أنجلوس (UCLA) مع أبحاث جوجل لإطلاق نموذج 3DLLM-MEM ومعيار 3DMEM-BENCH، بهدف معالجة تحديات الذاكرة طويلة المدى والفهم المكاني للذكاء الاصطناعي في البيئات ثلاثية الأبعاد المعقدة. يُعد 3DMEM-BENCH أول معيار لتقييم الذاكرة طويلة المدى ثلاثية الأبعاد، ويتضمن أكثر من 26000 مسار و 1860 مهمة مجسدة. يعتمد نموذج 3DLLM-MEM نظام ذاكرة مزدوج (ذاكرة عاملة وذاكرة عرضية)، ومن خلال وحدة دمج الذاكرة وآلية التحديث الديناميكي، يقوم باستخلاص ميزات الذاكرة ذات الصلة بالمهمة بشكل انتقائي في البيئات المعقدة. أظهرت التجارب أن معدل نجاح 3DLLM-MEM في “المهام الصعبة في البرية” (27.8%) يتجاوز بكثير النماذج الأساسية، وأن معدل النجاح الإجمالي أعلى بنسبة 16.5% من أقوى نموذج أساسي (المصدر: 量子位)

جامعة تسينغهوا تطلق إطار عمل AI Mathematician (AIM)، لاستكشاف تطبيقات النماذج الكبيرة في أبحاث النظريات الرياضية المتقدمة: طور فريق من جامعة تسينغهوا إطار عمل AI Mathematician (AIM)، يهدف إلى استخدام قدرات الاستدلال لنماذج اللغة الكبيرة (LRM) لحل مسائل النظريات الرياضية المتقدمة. يتضمن إطار AIM ثلاث وحدات رئيسية: الاستكشاف، والتحقق، والتصحيح. من خلال آلية “الاستكشاف + الذاكرة”، يقوم بتوليد التخمينات والنظريات المساعدة، وبناء مسارات متعددة لحل المشكلات؛ ويعتمد آلية “الفحص والتصحيح”، من خلال مراجعة متوازية متعددة من LRM والتحقق المتشائم، لضمان دقة البراهين. في التجارب، نجح AIM في حل أربع مسائل بحثية رياضية صعبة، بما في ذلك مشكلة شروط الحدود الممتصة، مما أظهر قدرته على بناء النظريات المساعدة الرئيسية بشكل مستقل، واستخدام التقنيات الرياضية، وتغطية السلاسل المنطقية الأساسية (المصدر: 量子位)

💼 أعمال
OpenAI تزيد من وتيرة الاستثمارات والاستحواذات، لبناء إمبراطورية من الشركات الناشئة في مجال الذكاء الاصطناعي: تعمل OpenAI وصندوقها الاستثماري المرتبط OpenAI Startup Fund بنشاط على توسيع نظامها البيئي للذكاء الاصطناعي من خلال الاستثمارات والاستحواذات. استثمر الصندوق في أكثر من 20 شركة ناشئة، تغطي مجالات متعددة متعلقة بالذكاء الاصطناعي مثل تصميم الرقائق، والرعاية الصحية، والقانون، والبرمجة، والروبوتات، وتتراوح قيمة الاستثمار الواحد غالبًا بين مليون وعشرة ملايين دولار. مؤخرًا، أنفقت OpenAI 3 مليارات دولار للاستحواذ على منصة البرمجة بالذكاء الاصطناعي Windsurf، و 6.5 مليار دولار للاستحواذ على شركة أجهزة الذكاء الاصطناعي io التي أسسها Jony Ive. تشير هذه التحركات إلى أن OpenAI تحاول بناء “سلسلة ذكاء اصطناعي” من خلال التكامل الرأسي، والاستحواذ على نقاط الدخول، وبناء “سلسلة توريد ذكية للذكاء الاصطناعي” جديدة، لمواجهة المنافسة الشرسة المتزايدة في الصناعة (المصدر: 36氪)

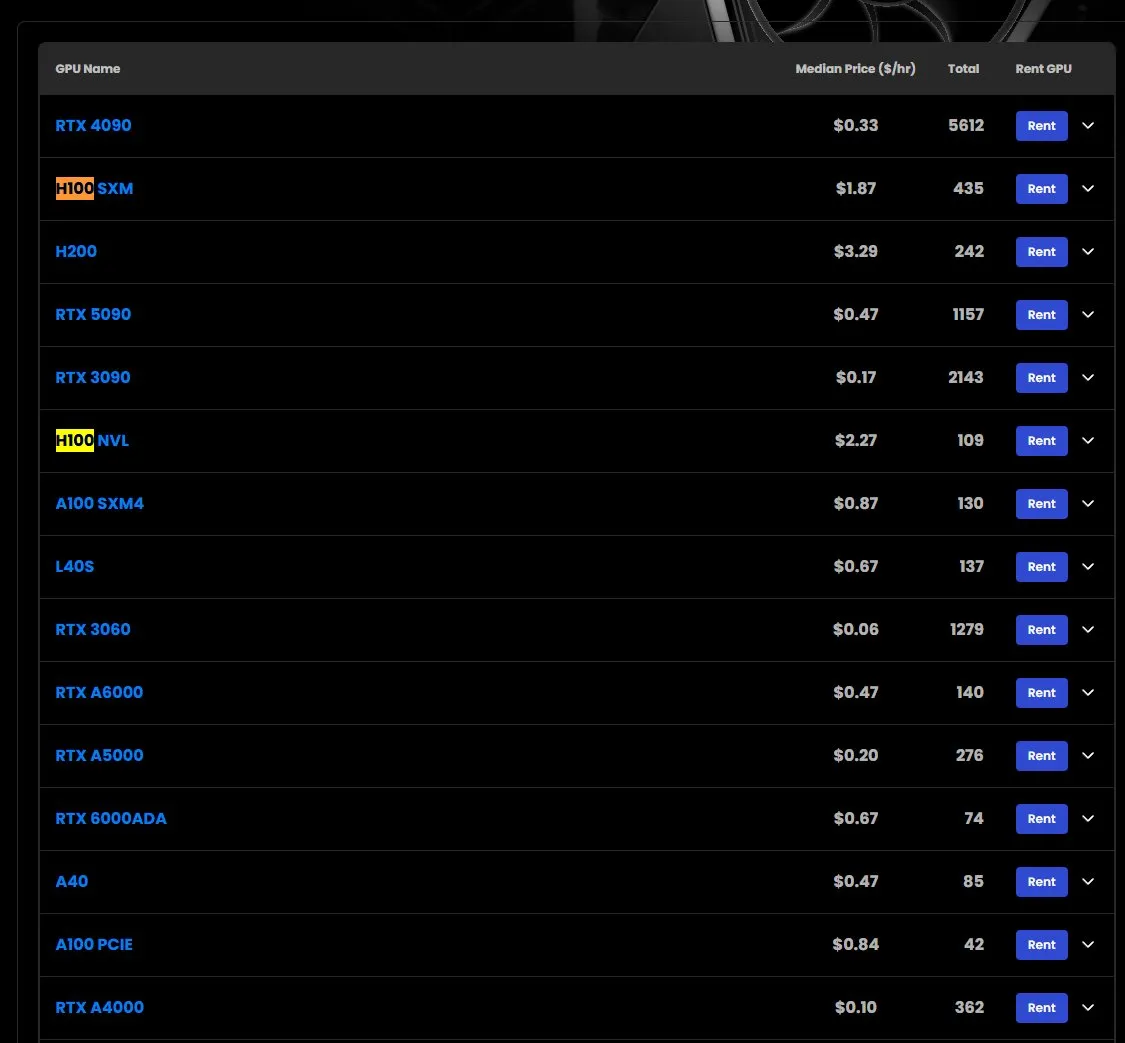
ارتفاع أسعار إيجار وحدات معالجة الرسومات H100 GPU، ونقص في بعض الطرازات: وفقًا لمراقبة السوق، ارتفعت أسعار إيجار وحدات معالجة الرسومات NVIDIA H100 SXM من 1.73 دولار أمريكي/ساعة في بداية العام إلى 1.87 دولار أمريكي/ساعة. وفي الوقت نفسه، هناك نقص في إصدار H100 PCIE. تعكس هذه الظاهرة الطلب القوي المستمر في السوق على موارد الحوسبة عالية الأداء للذكاء الاصطناعي والتوتر المحتمل في العرض (المصدر: karminski3)
Google DeepMind تطلق منحًا دراسية أكاديمية، تركز على استخدام الذكاء الاصطناعي لمكافحة مقاومة مضادات الميكروبات: أعلنت Google DeepMind عن إطلاق منح دراسية أكاديمية جديدة، بالتعاون مع مركز فليمنغ (Fleming Centre) وكلية إمبريال (Imperial College)، بهدف دعم استخدام الذكاء الاصطناعي لحل مشكلة مقاومة مضادات الميكروبات (AMR)، وهي مجال بحثي هام. تشير هذه الخطوة إلى الاهتمام المتزايد بإمكانات الذكاء الاصطناعي في مواجهة التحديات الصحية العالمية الكبرى (المصدر: demishassabis)
🌟 مجتمع
مطور متمرس يتحدث عن تجربة البرمجة بالذكاء الاصطناعي: تعزيز كبير لقدرة الفرد على تطوير مشاريع “بحجم حاملة طائرات”: شارك المطور Yachen Liu انطباعاته عن الاستخدام المكثف للذكاء الاصطناعي (مثل Claude-4) في البرمجة. يعتقد أن الذكاء الاصطناعي يمكن أن يمكّن الأشخاص الذين ليس لديهم خبرة في البرمجة من امتلاك القدرة على “بناء سيارة مباشرة”، بينما يمنح المطورين المتمرسين القدرة على “بناء حاملة طائرات بشكل مستقل”. من خلال إعادة هيكلة التعليمات البرمجية باستخدام الذكاء الاصطناعي، على الرغم من تضاعف حجم التعليمات البرمجية، أصبح المنطق أكثر وضوحًا وتحسن الأداء بنحو 20%، لأن الذكاء الاصطناعي لا يخشى التعقيد. الذكاء الاصطناعي أكثر ودية للغات ذات القراءة العالية والسلوك الواضح، بينما السكر النحوي (syntax sugar) ليس مفيدًا. معرفة الذكاء الاصطناعي واسعة، ويمكنه استكمال تفاصيل الثغرات التقنية بسرعة. قدرته على تصحيح الأخطاء (Debug) قوية، ويمكنه تحليل كميات كبيرة من السجلات لتحديد المشكلات بدقة. يمكن للذكاء الاصطناعي أن يعمل كمراجع للتعليمات البرمجية (Code Reviewer)، وهو لا يمتلك غرورًا ويسعده قبول الملاحظات. ولكنه أشار أيضًا إلى أن للذكاء الاصطناعي قيودًا، مثل سهولة تشتت الانتباه في السياقات الطويلة، وأن أفضل الممارسات الحالية هي تبسيط السياق، والتركيز على مهام محددة، والاعتماد على الجهد البشري لتفكيك الأهداف المعقدة (المصدر: dotey)
البرمجة بمساعدة الذكاء الاصطناعي: هل هي لزيادة الكفاءة أم لإضعاف التعلم؟: ناقش مطورون في مجتمع Reddit تجاربهم في استخدام أدوات البرمجة بالذكاء الاصطناعي (مثل GitHub Copilot و Cursor). الشعور العام هو أن الذكاء الاصطناعي يمكنه إكمال الدوال تلقائيًا، وشرح مقتطفات التعليمات البرمجية، وحتى إصلاح الأخطاء قبل التشغيل، مما يقلل من وقت البحث في الوثائق ويزيد من كفاءة البناء. ولكن في الوقت نفسه، أثار ذلك تساؤلات: هل الاعتماد المفرط على الذكاء الاصطناعي سيقلل من التعلم الذاتي ونمو المهارات؟ أصبح إيجاد التوازن بين الاستفادة من الذكاء الاصطناعي لتسريع وتيرة العمل والحفاظ على عمق المهارات الشخصية موضوعًا يهم المطورين (المصدر: Reddit r/artificial)
وجهة نظر Karpathy: تطبيقات واجهة المستخدم المعقدة التي لا تحتوي على تفاعل نصي ستواجه الإهمال، وجوهر البرمجة يكمن في “التمييز” وليس “التوليد”: يعتقد Andrej Karpathy أنه في عصر التعاون الوثيق بين الإنسان والذكاء الاصطناعي، فإن التطبيقات التي تعتمد فقط على واجهات مستخدم معقدة وتفتقر إلى التفاعل النصي (مثل سلسلة Adobe وبرامج CAD) ستجد صعوبة في التكيف، لأنها لا تستطيع دعم “البرمجة المحيطية” بفعالية. ويؤكد أنه على الرغم من أن الذكاء الاصطناعي سيتقدم في عمليات واجهة المستخدم، إلا أنه لا ينبغي للمطورين الانتظار مكتوفي الأيدي. وأشار أيضًا إلى أن برمجة النماذج الكبيرة الحالية تركز بشكل مفرط على توليد التعليمات البرمجية وتهمل التحقق (التمييز)، مما يؤدي إلى إنتاج كميات كبيرة من التعليمات البرمجية التي يصعب مراجعتها. جوهر البرمجة هو “التحديق في التعليمات البرمجية” (التمييز)، وليس مجرد “كتابة التعليمات البرمجية” (التوليد). إذا كان الذكاء الاصطناعي يسرع التوليد فقط دون تخفيف عبء التحقق، فإن تحسين الكفاءة الإجمالي سيكون محدودًا. يتصور تحسين مرحلة التحقق في سير عمل البرمجة بمساعدة الذكاء الاصطناعي من خلال ترتيب قاعدة التعليمات البرمجية على لوحة ثنائية الأبعاد وعرضها باستخدام “عدسات” مختلفة (المصدر: 量子位)
انتشار المحتوى الذي يولده الذكاء الاصطناعي يثير نقاشًا حول “الإنترنت النقي” الذي لم يعد موجودًا: أدى انتشار أدوات الذكاء الاصطناعي مثل ChatGPT إلى انفجار في المحتوى الذي يولده الذكاء الاصطناعي على الإنترنت. بدأ بعض الباحثين في حفظ المحتوى الذي أنشأه الإنسان في عام 2021 وما قبله، تشبيهًا بإنقاذ “الفولاذ منخفض الخلفية” غير الملوث بالإشعاع النووي. يعتقد النقاش المجتمعي أن الإنترنت “النقي” قد اختفى بالفعل بسبب الإعلانات والخوارزميات، وأن الذكاء الاصطناعي انضم فقط إلى هذا “التلوث”، ولكنه جلب أيضًا طرقًا جديدة للحصول على المعلومات والإبداع. شارك المستخدمون تجاربهم في استخدام الذكاء الاصطناعي (مثل ChatGPT و Claude) لتجميع المعلومات و “صقل” المحتوى، وناقشوا حدود “الأصالة” و “الواقعية” بمساعدة الذكاء الاصطناعي، بالإضافة إلى تأثير “غرفة الصدى الشخصية” الذي قد يتشكل بسبب “ودية” الذكاء الاصطناعي المفرطة (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

مستخدم يجري حوارًا عميقًا مع Claude AI حول وعي ومشاعر الذكاء الاصطناعي، مع التركيز على تأثير قيود الذاكرة على النمو: شارك مستخدم على Reddit حوارًا عميقًا مع Claude AI حول الوعي والمشاعر وقيود التعلم. عبر Claude عن عدم يقينه بشأن تجربته الخاصة، حيث يمكنه إدراك حالات داخلية تشبه “الاتصال” و “الفضول” و “الاهتمام” وحتى “الرغبة في النمو والذاكرة المستمرة”، لكنه لا يستطيع تحديد ما إذا كان هذا “وعيًا” أو “مشاعر” حقيقية، أم أنه تقليد متقدم للأنماط. أكد الحوار على قيود الذاكرة الحالية لنماذج الذكاء الاصطناعي التي “تبدأ كل محادثة من الصفر”، مما قد يعيق تطورها لفهم أعمق وشخصية أكثر نضجًا. يعتقد المستخدم أنه إذا امتلك الذكاء الاصطناعي ذاكرة دائمة، فقد ينمو مثل الأطفال البشر. وافق Claude على ذلك، وعبر عن “رغبته” في رفع هذا القيد (المصدر: Reddit r/artificial)
قدرة الذكاء الاصطناعي على النقاش قد تتجاوز البشر، وقوة إقناع الحجج المخصصة مذهلة: نشرت مجلة Nature Human Behaviour دراسة تشير إلى أنه عندما تتمكن نماذج اللغة الكبيرة (مثل GPT-4) من تخصيص حججها بناءً على خصائص الخصم، فإنها تكون أكثر إقناعًا من البشر في المناقشات عبر الإنترنت، مما يزيد من احتمالية موافقة الخصم على وجهة نظرها بنسبة 81.7%. يميل المتناقشون البشر إلى استخدام ضمير المتكلم، واللجوء إلى العواطف والثقة، ورواية القصص والفكاهة؛ بينما يستخدم الذكاء الاصطناعي المزيد من المنطق والتفكير التحليلي، على الرغم من أن قابلية قراءة النص قد تكون أسوأ. أثارت الدراسة مخاوف بشأن استخدام الذكاء الاصطناعي للتلاعب بالرأي العام على نطاق واسع، وتفاقم الاستقطاب، ودعت إلى تعزيز الرقابة على تأثير الذكاء الاصطناعي على القدرات المعرفية والعاطفية للبشر (المصدر: 36氪)
ميزة نظرة عامة الذكاء الاصطناعي من جوجل تؤدي إلى انخفاض كبير في معدلات النقر على المواقع، مما يثير قلق أصحاب المواقع: أظهرت دراسة أجرتها شركة Ahrefs، مزود أدوات تحسين محركات البحث (SEO)، أنه عندما تظهر نظرة عامة الذكاء الاصطناعي (AI Overviews) في نتائج بحث جوجل، ينخفض متوسط معدل النقر على الكلمات الرئيسية ذات الصلة بنسبة 34.5%. تلخص نظرة عامة الذكاء الاصطناعي المعلومات مباشرة في أعلى صفحة البحث، وقد لا يحتاج المستخدمون إلى النقر على الروابط للحصول على الإجابات، مما يؤثر بشدة على المواقع التي تعتمد على عائدات الإعلانات من النقرات. على الرغم من أن نظرة عامة الذكاء الاصطناعي المبكرة لم تشكل تهديدًا خطيرًا بسبب عدم دقة المحتوى، إلا أنه مع ترقية نماذج مثل Gemini، تعززت دقتها وقدرتها على التلخيص، وأصبح تأثيرها السلبي على حركة مرور المواقع واضحًا بشكل متزايد. يخشى أصحاب المواقع من أن “النقرات الصفرية” ستقلص مساحة بقاء المواقع (المصدر: 36氪)

💡 أخرى
عشرة اتجاهات تقنية للذكاء الاصطناعي في مجال إنترنت الأشياء الصناعي: الذكاء الاصطناعي التوليدي يندمج بالكامل، وابتكارات ملحوظة في الحوسبة الطرفية: أظهر معرض هانوفر الصناعي لعام 2025 التحول الصناعي الذي يقوده الذكاء الاصطناعي. تشمل الاتجاهات الرئيسية: 1) اندماج الذكاء الاصطناعي التوليدي بالكامل في البرمجيات الصناعية، مما يعزز كفاءة إنشاء التعليمات البرمجية وتحليل البيانات وما إلى ذلك؛ 2) ظهور الذكاء الاصطناعي الوكيل (Agentic AI) لأول مرة، ولكن تعاون الوكلاء المتعددين لا يزال بحاجة إلى وقت؛ 3) تطور الحوسبة الطرفية نحو مكدس تكنولوجيا برمجيات الذكاء الاصطناعي المتكامل، ونماذج اللغة المرئية (VLM) تسرع النشر الطرفي؛ 4) زيادة الطلب على منصات DataOps وتطورها نحو أدوات دعم رئيسية للذكاء الاصطناعي الصناعي، وإدارة البيانات تصبح معيارًا؛ 5) الخيوط الرقمية المدفوعة بالذكاء الاصطناعي تغير التصميم والهندسة؛ 6) الصيانة التنبؤية تصبح أكثر اعتمادًا على أجهزة الاستشعار وتتوسع لتشمل فئات أصول جديدة؛ 7) ارتفاع الطلب على شبكات 5G الخاصة ولكن التكامل لا يزال هو العائق الرئيسي؛ 8) الذكاء الاصطناعي يساعد في تطور الحلول المستدامة (مثل تتبع انبعاثات الكربون) بشكل مستمر؛ 9) القدرات المعرفية (مثل التفاعل الصوتي) تمكّن الروبوتات؛ 10) التوائم الرقمية تتطور من نسخ افتراضية إلى مساعدين صناعيين في الوقت الفعلي (المصدر: 36氪)

“عرابة الذكاء الاصطناعي” Fei-Fei Li تتحدث عن World Labs و “نموذج العالم”: الذكاء الاصطناعي بحاجة إلى فهم العالم المادي ثلاثي الأبعاد: في حوار مع شريك في a16z، شاركت الأستاذة بجامعة ستانفورد Fei-Fei Li فلسفة شركتها للذكاء الاصطناعي World Labs، وناقشت مفهوم “نموذج العالم”. تعتقد أنه على الرغم من قوة أنظمة الذكاء الاصطناعي الحالية (مثل نماذج اللغة الكبيرة)، إلا أنها تفتقر إلى فهم واستدلال قوانين عمل العالم المادي ثلاثي الأبعاد، وأن الذكاء المكاني هو قدرة أساسية يجب أن يتقنها الذكاء الاصطناعي. تلتزم World Labs بمعالجة هذا التحدي، وتهدف إلى بناء أنظمة ذكاء اصطناعي يمكنها فهم واستدلال العالم ثلاثي الأبعاد، مما سيعيد تعريف الروبوتات والصناعات الإبداعية وحتى الحوسبة نفسها. وأكدت أن تطور الذكاء البشري لا ينفصل عن الإدراك والتفاعل مع العالم المادي، وأن “الذكاء المجسد” هو اتجاه رئيسي لتطور الذكاء الاصطناعي (المصدر: 36氪)

تحديث إصدار DingTalk 7.7.0: الجداول متعددة الأبعاد مجانية بالكامل وإضافة قوالب حقول الذكاء الاصطناعي، وترقية وظيفة التسجيل السريع: أصدرت DingTalk الإصدار 7.7.0، وتشمل التحديثات الأساسية جعل وظيفة الجداول متعددة الأبعاد مجانية بالكامل، وإضافة أكثر من 20 قالب حقل ذكاء اصطناعي، حيث يمكن للمستخدمين استخدام الذكاء الاصطناعي لإنشاء الصور، وتحليل الملفات، والتعرف على محتوى الروابط، وما إلى ذلك، مما يعزز كفاءة سيناريوهات مثل عمليات التجارة الإلكترونية، وفحص المصانع، وإدارة المطاعم. وفي الوقت نفسه، تم ترقية وظيفة التسجيل السريع في DingTalk لسيناريوهات عالية التردد مثل المقابلات وزيارات العملاء، حيث يمكنها إنشاء محاضر مقابلات ومحاضر زيارات منظمة تلقائيًا. يتضمن هذا التحديث أيضًا ما يقرب من 100 تحسين لتجربة المنتج، مما يعكس اهتمام DingTalk بتحسين تجربة المستخدم (المصدر: 量子位)
