
كلمات مفتاحية:الوكيل الذكي للذكاء الاصطناعي, النماذج الكبيرة, متعدد الوسائط, التعلم المعزز, نموذج العالم, جيميني, تشي وين, ديب سيك, موجة الوكيل الذكي للذكاء الاصطناعي, تقنية المحولات المتفرقة, الأسئلة متعددة القفزات لجراف راج, نماذج الذكاء الاصطناعي على الجهاز, التعبير العاطفي للصوت بالذكاء الاصطناعي
🔥 التركيز
ازدهار موجة وكلاء الذكاء الاصطناعي (AI Agents) في الصين، والشركات الناشئة والعملاقة تتسابق على التموضع: بعد موجة النماذج اللغوية الكبيرة التأسيسية في عام 2024، تحول تركيز مجال الذكاء الاصطناعي في الصين في عام 2025 نحو وكلاء الذكاء الاصطناعي (AI Agents) – وهي أنظمة قادرة على إكمال المهام بشكل مستقل. أثار إطلاق Manus (وهو وكيل ذكاء اصطناعي عام يمكنه تخطيط الرحلات وتصميم مواقع الويب وما إلى ذلك) اهتمامًا كبيرًا في السوق وظهور العديد من المقلدين، مثل Genspark و Flowith. تُبنى هذه الوكلاء على نماذج لغوية كبيرة، مما يحسن تنفيذ المهام متعددة الخطوات. تتمتع الصين بميزة في تطوير وكلاء الذكاء الاصطناعي بفضل نظامها البيئي للتطبيقات المتكامل للغاية، والتكرار السريع للمنتجات، وقاعدة المستخدمين الرقمية الضخمة. حاليًا، تستهدف الشركات الناشئة مثل Manus و Genspark و Flowith بشكل أساسي الأسواق الخارجية، نظرًا للقيود المفروضة على النماذج الغربية المتقدمة في الصين القارية. في الوقت نفسه، تعمل شركات التكنولوجيا العملاقة مثل ByteDance و Tencent على تطوير وكلاء ذكاء اصطناعي محليين ليتم دمجهم في تطبيقاتهم الفائقة، ومن المحتمل أن تستفيد من أنظمتها البيئية الضخمة للبيانات. سيحدد هذا السباق الشكل العملي لوكلاء الذكاء الاصطناعي والجهات التي ستخدمها (المصدر: MIT Technology Review)

ورقة بحثية جديدة لعلماء DeepMind تكشف: أي وكيل قادر على تعميم مهام متعددة الخطوات موجهة نحو الهدف قد تعلم بالفعل نموذجًا تنبئيًا لبيئته (نموذج العالم): أشار Jon Richens، عالم في DeepMind، في ورقة بحثية نُشرت في ICML 2025، إلى أن الوكلاء القادرين على التعميم على مهام متعددة الخطوات موجهة نحو الهدف، قد تعلموا بالضرورة نموذجًا تنبئيًا لبيئتهم، أي أن “الوكيل هو نموذج العالم”. تتوافق هذه الرؤية مع تنبؤ Ilya Sutskever في عام 2023، مؤكدة على عدم وجود طريق مختصر لا يعتمد على النماذج لتحقيق الذكاء الاصطناعي العام (AGI). تشير الدراسة إلى أن استراتيجية الوكيل تحتوي بالفعل على المعلومات اللازمة لمحاكاة البيئة، وأن تعلم نموذج عالم أكثر دقة هو شرط أساسي لتحسين الأداء وإكمال أهداف أكثر تعقيدًا. كما تقترح الورقة خوارزمية لاستخلاص نموذج العالم من استراتيجية الوكيل، مما يزيد من توضيح العلاقة الثلاثية بين التخطيط، والتعلم المعزز العكسي، واستعادة نموذج العالم. يؤكد هذا الاكتشاف على أهمية التعلم الموجه نحو الهدف في توليد قدرات ناشئة متنوعة للوكيل (مثل الإدراك الاجتماعي، والاستدلال في ظل عدم اليقين) (المصدر: 36氪)

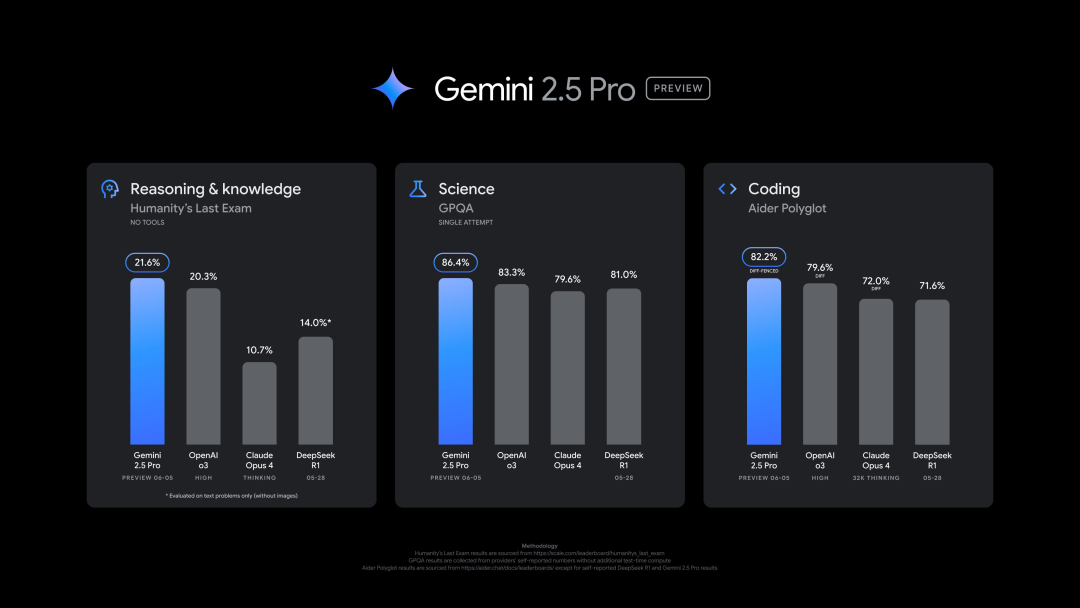
جوجل تطلق إصدارًا جديدًا من Gemini 2.5 Pro (0605)، يتفوق في العديد من اختبارات الأداء القياسية، ولكنه يتعرض لكسر الحماية بسرعة: أطلقت جوجل أحدث إصدار من Gemini 2.5 Pro (0605)، مع تحسينات إضافية في توليد الشيفرة وقدرة الاستدلال، وتجاوز GPT-4o من OpenAI في مجموعة بيانات “الاختبار الأخير للبشرية”. تصدر الإصدار الجديد من Gemini مرة أخرى ساحة منافسة النماذج اللغوية الكبيرة LMArena، مع ارتفاع تصنيف Elo بمقدار 24 نقطة مقارنة بالإصدار السابق. كما ألمح Sundar Pichai، الرئيس التنفيذي لجوجل، في منشور له إلى قوة النموذج الجديد. من المتوقع أن يصبح هذا الإصدار هو الإصدار المستقر طويل الأمد لـ Gemini 2.5 Pro، وقد تم إطلاقه بالفعل في تطبيق Gemini و Google AI Studio و Vertex AI. على الرغم من أدائه القوي، تمكن المستخدمون من “كسر حماية” النموذج الجديد بنجاح بعد ساعات قليلة من إطلاقه، مما كشف عن مشكلات في الحماية الأمنية، حيث تمكن من توليد محتوى حول تصنيع المتفجرات والمخدرات (المصدر: 36氪, 36氪)
مسؤولة تنفيذية في OpenAI تناقش الارتباط العاطفي بين الإنسان والذكاء الاصطناعي ومسألة وعي الذكاء الاصطناعي: نشرت Joanne Jang، رئيسة قسم سلوك النماذج والسياسات في OpenAI، مقالًا يناقش الارتباط العاطفي المتزايد بين المستخدمين ونماذج الذكاء الاصطناعي مثل ChatGPT. وأشارت إلى أن البشر يميلون إلى إضفاء الطابع الإنساني على الأشياء، وأن تفاعلية الذكاء الاصطناعي وقدرته على الاستجابة (مثل تذكر المحادثات، وتقليد نبرة الصوت، والتعبير عن التعاطف) تزيد من هذا الإسقاط العاطفي، خاصة بالنسبة للمستخدمين الذين يشعرون بالوحدة، حيث قد يوفر لهم شعورًا بالرفقة. يميز المقال بين “الوعي الوجودي” (هل يمتلك الذكاء الاصطناعي وعيًا حقيقيًا، وهو أمر غير محسوم علميًا) و “الوعي الإدراكي” (إلى أي مدى يشعر الإنسان بأن الذكاء الاصطناعي “حيوي”)، ويشير إلى أن OpenAI تركز حاليًا بشكل أكبر على تأثير الأخير على الصحة العاطفية للبشر. هدف OpenAI هو تصميم نماذج “دافئة ولكن بدون ذات”، أي تظهر الدفء والمساعدة، ولكن لا تسعى بشكل مفرط إلى الارتباط العاطفي أو تظهر نوايا مستقلة، لتجنب تضليل المستخدمين وتكوين اعتماد غير صحي (المصدر: 36氪, 36氪)
🎯 الاتجاهات
فريق Qwen وجامعة Tsinghua يكتشفان: التعلم المعزز للنماذج اللغوية الكبيرة يحتاج فقط إلى 20% من التوكنات الرئيسية عالية الإنتروبيا لتحسين الأداء: أظهرت دراسة حديثة أجراها فريق Qwen بالتعاون مع LeapLab من جامعة Tsinghua أنه عند تدريب قدرات الاستدلال للنماذج اللغوية الكبيرة باستخدام التعلم المعزز، فإن استخدام حوالي 20% فقط من التوكنات عالية الإنتروبيا (المتفرعة) لتحديثات التدرج، لا يضاهي فقط بل يتفوق أحيانًا على التدريب باستخدام جميع التوكنات. غالبًا ما تكون هذه التوكنات عالية الإنتروبيا كلمات ربط منطقية أو كلمات تقدم افتراضات، وهي حاسمة لاستكشاف مسارات الاستدلال. حققت هذه الطريقة نتائج SOTA على Qwen3-32B، كما أدت إلى إطالة الحد الأقصى لطول الاستجابة. ووجدت الدراسة أيضًا أن التعلم المعزز يميل إلى الحفاظ على إنتروبيا التوكنات عالية الإنتروبيا وزيادتها، مما يحافظ على مرونة الاستدلال، وقد يكون هذا هو السبب الرئيسي لتفوق قدرته على التعميم على الضبط الدقيق الخاضع للإشراف. لهذا الاكتشاف أهمية كبيرة في فهم آليات التعلم المعزز للنماذج اللغوية الكبيرة، وتحسين كفاءة التدريب وقدرة النموذج على التعميم (المصدر: 36氪)
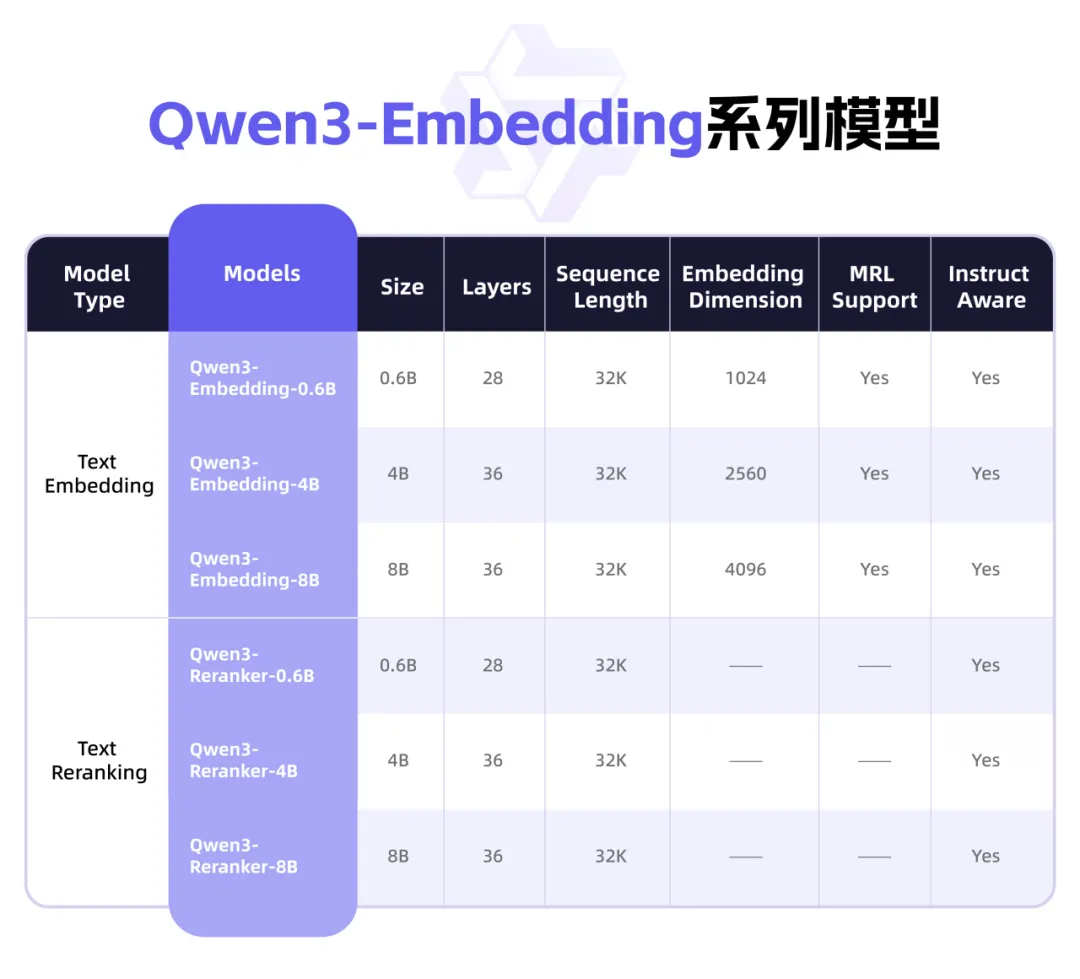
Qwen3 تطلق سلسلة نماذج Embedding جديدة، تركز على تمثيل النصوص و Rerank: أطلق فريق Qwen التابع لشركة Alibaba سلسلة نماذج Qwen3-Embedding، المصممة خصيصًا لمهام تمثيل النصوص، والاسترجاع، والترتيب. تتضمن السلسلة نماذج Embedding بأحجام 0.6B، و 4B، و 8B، ونماذج Reranker، تم تدريبها بناءً على نموذج Qwen3 الأساسي، وترث ميزته في تعدد اللغات، حيث تدعم 119 لغة. تجاوز إصدار 8B واجهات برمجة التطبيقات التجارية ليحتل المرتبة الأولى في تصنيفات MTEB متعددة اللغات. تعتمد النماذج على نموذج تدريب متعدد المراحل، يشمل التعلم التبايني ضعيف الإشراف على نطاق واسع، والتدريب الخاضع للإشراف على بيانات عالية الجودة، ودمج النماذج. تم توفير سلسلة نماذج Qwen3-Embedding كمصدر مفتوح على Hugging Face، و ModelScope، و GitHub، ويمكن استخدامها أيضًا عبر منصة阿里云百炼 (Alibaba Cloud Bailian) (المصدر: 36氪)
ترقية وظيفة Projects on Claude في Anthropic، تدعم معالجة محتوى أكبر 10 مرات: أعلنت Anthropic أن وظيفة “Projects on Claude” لديها تدعم الآن معالجة محتوى أكبر بعشر مرات من ذي قبل. عندما يضيف المستخدم ملفات تتجاوز الحد الأصلي، يتحول Claude إلى وضع استرجاع جديد لتوسيع السياق الوظيفي. هذه الترقية ذات قيمة خاصة للمستخدمين الذين يحتاجون إلى معالجة مستندات كبيرة (مثل كتيبات بيانات أشباه الموصلات)، والذين كان بعضهم يختار سابقًا استخدام ChatGPT المزود بقدرات استرجاع RAG. رحب مستخدمو المجتمع بهذا التطور، وهناك نقاشات تشير إلى أن Claude قد يكون متفوقًا على نماذج OpenAI و Google في مجال الترميز (المصدر: Reddit r/ClaudeAI)
تقدم في تقنية Sparse Transformer:有望 تحقيق استدلال LLM أسرع واستهلاك أقل للذاكرة: بناءً على أبحاث LLM in a Flash (Apple) و Deja Vu، طور المجتمع نواة عامل مدمجة لتفرق السياق المهيكل. تحقق هذه التقنية تحسينًا في أداء طبقة MLP بمقدار 5 أضعاف وتقليل استهلاك الذاكرة بنسبة 50% عن طريق تجنب تحميل وحساب قيم التنشيط المرتبطة بأوزان طبقة التغذية الأمامية التي ستؤول مخرجاتها في النهاية إلى الصفر. عند تطبيقها على نموذج Llama 3.2 (حيث تمثل طبقة التغذية الأمامية 30% من الأوزان والحسابات)، زاد معدل النقل بمقدار 1.6-1.8 مرة، وتسارع زمن توليد التوكن الأول بمقدار 1.51 مرة، وزادت سرعة الإخراج بمقدار 1.79 مرة، وانخفض استخدام الذاكرة بنسبة 26.4%. تم توفير نواة العامل ذات الصلة كمصدر مفتوح على GitHub تحت اسم sparse_transformers، ومن المخطط إضافة دعم لـ int8 و CUDA والانتباه المتفرق. يتابع المجتمع تأثيرها المحتمل على جودة النموذج (المصدر: Reddit r/LocalLLaMA)
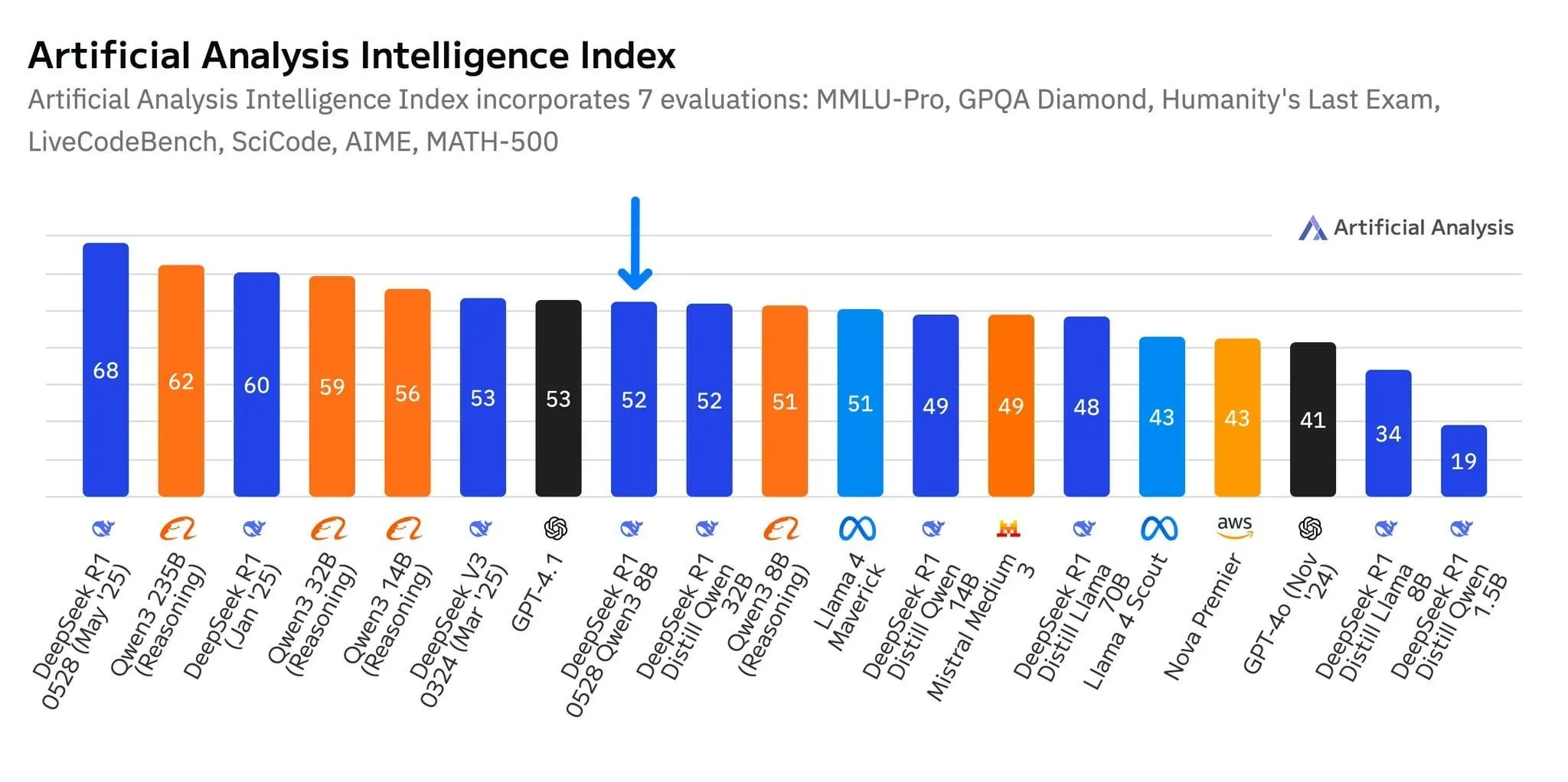
نموذج DeepSeek الجديد R1-0528-Qwen3-8B يبرز في فئة 8 مليار معلمة، ولكن بأفضلية طفيفة: وفقًا لبيانات Artificial Analysis، يُظهر نموذج DeepSeek الأحدث R1-0528-Qwen3-8B أفضل أداء ذكاء في فئة 8 مليار معلمة، ولكن تفوقه ليس كبيرًا، حيث يليه مباشرة نموذج Qwen3 8B الخاص بشركة Alibaba بفارق ضئيل. تشير مناقشات المجتمع إلى أنه على الرغم من الأداء المتميز لهذه النماذج الصغيرة، قد تكون هناك مشكلة الإفراط في التخصيص في اختبارات الأداء القياسية، على سبيل المثال، أداء سلسلة نماذج Qwen المتميز في اختبارات مثل MMLU قد يكون مرتبطًا بتضمين بيانات تدريبها لأزواج أسئلة وأجوبة بتنسيق مشابه. في تجربة المستخدم الفعلية، يُظهر Destill R1 8B أداءً أفضل في الترميز والرياضيات والاستدلال، بينما يكون Qwen 8B أكثر طبيعية في الكتابة واللغات المتعددة (مثل الإسبانية). يعتقد بعض المستخدمين أن ذكاء النماذج الصغيرة قد اقترب من حده الأقصى (المصدر: Reddit r/LocalLLaMA)
شركات الذكاء الاصطناعي المتوسطة المستوى مثل Tiangong و Jieyue Xingchen تركز على الوكلاء الأذكياء، سعيًا لتحقيق اختراق في السوق: في مواجهة وضع “الفائز يأخذ كل شيء” الذي تهيمن عليه تطبيقات الذكاء الاصطناعي الرائدة مثل DeepSeek و Doubao، قامت شركة Kunlun Wanwei بتحديث تطبيق Tiangong التابع لها بشكل جذري، محولة إياه إلى منصة AI Agent تركز على سيناريوهات العمل المكتبي، مع التأكيد على قدرة إنجاز المهام. أما شركة Jieyue Xingchen فقد عدلت استراتيجيتها، مقلصة منتجاتها الموجهة للمستهلكين مثل “Maopao Ya”، ومغيرة اسم “Yuewen” إلى “Jieyue AI”، مع التركيز على تطوير النماذج وسوق الشركات (ToB)، والتركيز على تطبيق وكيل متعدد الوسائط (Multimodal Agent) في الأجهزة الطرفية مثل الهواتف المحمولة والسيارات والروبوتات. تعكس هذه التعديلات محاولات الشركات المصنعة للذكاء الاصطناعي غير الرائدة، في خضم المنافسة الشرسة، للمراهنة على الوكلاء الأذكياء، والانتقال من “المنافسة على القدرات العامة” إلى “بناء حلقة مغلقة للسيناريوهات”، على أمل إيجاد فرص للبقاء والتطور في قطاعات متخصصة (المصدر: 36氪)
إطلاق نموذج Qwen2.5-Omni متعدد الوسائط، يدعم إدخال النصوص والصور والفيديو والصوت وإخراج الصوت والنص: Qwen2.5-Omni هو نموذج لغوي كبير متعدد الوسائط مفتوح المصدر تم إطلاقه حديثًا (ترخيص Apache 2.0)، قادر على معالجة النصوص والصور والفيديو والصوت كمدخلات، ويمكنه توليد مخرجات نصية وصوتية. يوفر هذا للمطورين أداة قوية مشابهة لـ Gemini ولكن يمكن نشرها محليًا وإجراء الأبحاث عليها. يقدم المقال نبذة عن النموذج ويعرض تجربة استدلال بسيطة، مسلطًا الضوء على إمكاناته في التفاعل متعدد الوسائط، ومن المتوقع أن يدفع تطوير تطبيقات الذكاء الاصطناعي متعددة الوسائط المحلية (المصدر: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
محكمة تأمر OpenAI بالاحتفاظ بجميع سجلات ChatGPT، بما في ذلك سجلات الدردشة “المحذوفة”: في دعوى قضائية بشأن حقوق النشر رفعتها مؤسسات إخبارية مثل نيويورك تايمز، أمرت محكمة أمريكية في 13 مايو 2025 شركة OpenAI بالاحتفاظ بجميع سجلات دردشة ChatGPT، حتى لو قام المستخدمون “بحذفها”. يعتقد المدعون أن OpenAI استخدمت مقالاتهم لتدريب ChatGPT دون إذن، ويخشون أن يقوم المستخدمون بحذف سجلات الدردشة التي تتضمن تجاوز جدار الدفع لتدمير الأدلة. أثارت هذه الخطوة مخاوف بشأن خصوصية المستخدم، وقد تتعارض مع لوائح مثل GDPR. من جانبها، ترى OpenAI أن الأمر يستند إلى تكهنات، ويفتقر إلى الأدلة، ويشكل عبئًا ثقيلاً على عملياتها. تسلط هذه القضية الضوء على التوتر بين حماية الملكية الفكرية وخصوصية المستخدم (المصدر: Reddit r/ArtificialInteligence)
X (تويتر سابقًا) تمنع روبوتات الذكاء الاصطناعي من استخدام بياناتها للتدريب: قامت منصة X بتحديث سياساتها لمنع استخدام بياناتها أو واجهة برمجة التطبيقات الخاصة بها لتدريب النماذج اللغوية، مما يزيد من تقييد وصول فرق الذكاء الاصطناعي إلى محتواها. في الوقت نفسه، أطلقت Anthropic نموذج ذكاء اصطناعي مصمم خصيصًا للأمن القومي الأمريكي يُدعى Claude Gov، مما يعكس اتجاه شركات التكنولوجيا مثل OpenAI و Meta و Google نحو تقديم أدوات الذكاء الاصطناعي للحكومات وقطاعات الدفاع (المصدر: Reddit r/ArtificialInteligence)

أمازون تشكل فريقًا جديدًا لوكلاء الذكاء الاصطناعي، وتختبر روبوتات بشرية الشكل لتوصيل الطرود: شكلت أمازون فريقًا جديدًا داخل قسم تطوير المنتجات الاستهلاكية Lab126، يركز على تطوير وكلاء الذكاء الاصطناعي (AI agents)، وتخطط لاختبار استخدام روبوتات بشرية الشكل لتوصيل الطرود. ستُجرى الاختبارات في مكتب تم تحويله إلى مضمار حواجز داخلي في سان فرانسيسكو بكاليفورنيا، حيث ستركب الروبوتات (قد تشمل منتجات من شركة Unitree Robotics الصينية) شاحنات توصيل كهربائية من Rivian، ثم تنزل لإكمال توصيل الميل الأخير. تعمل أمازون أيضًا على تطوير برمجيات لروبوتات المحاكاة تعتمد على نموذجي DeepSeek-VL2 و Qwen. تهدف هذه الخطوة إلى تحسين كفاءة المستودعات وسرعة التوصيل من خلال تقنيات الذكاء الاصطناعي والروبوتات (المصدر: 36氪)
لينوفو تركز على التحول نحو الذكاء الاصطناعي، مع التركيز على الذكاء الاصطناعي الهجين وتطبيق الوكلاء الأذكياء: تسرع لينوفو من تحولها من شركة تصنيع أجهزة كمبيوتر تقليدية إلى مزود حلول مدفوعة بالذكاء الاصطناعي، جاعلة من “الذكاء الاصطناعي الهجين” استراتيجيتها الأساسية للعقد القادم. تؤكد هذه الاستراتيجية على دمج الذكاء الشخصي والذكاء المؤسسي والذكاء العام، بهدف ضمان خصوصية البيانات والخدمات المخصصة من خلال التآزر بين الطرفيات والسحابة. قامت لينوفو بالفعل بتطبيق وكيل ذكي فائق للمدن في شنغهاي، وأطلقت نظام Tianxi البيئي للوكلاء الأذكياء الشخصيين. على الرغم من أن أعمال أجهزة الكمبيوتر لا تزال مهيمنة، تعمل لينوفو من خلال البحث والتطوير الذاتي والتعاون (مثل مع جامعة Tsinghua وجامعة Shanghai Jiao Tong وغيرها) على تطوير أجهزة الكمبيوتر المدعومة بالذكاء الاصطناعي (AI PC)، وخوادم الذكاء الاصطناعي، وحلول صناعية، لمواجهة تحديات انكماش سوق أجهزة الكمبيوتر والمنافسة من التقنيات الناشئة. ومع ذلك، لا يزال قبول سوق AI PC، والإنتاج التجاري واسع النطاق لتطبيقات الذكاء الاصطناعي، والمنافسة مع خصوم مثل Huawei، من القضايا الرئيسية التي تواجهها (المصدر: 36氪)

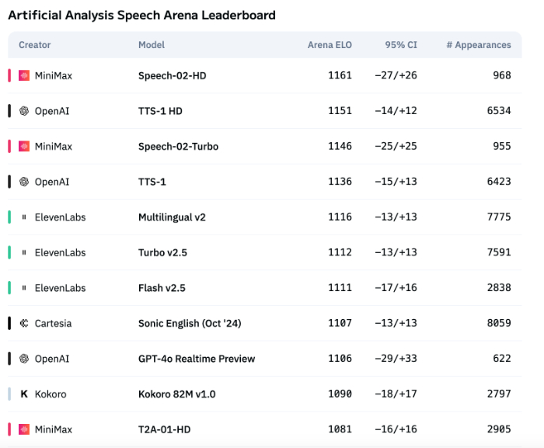
تقنية الصوت بالذكاء الاصطناعي لا تزال تعاني من قصور في التعبير العاطفي، وبدأت تطبيقات ToB في الازدهار: على الرغم من التقدم الذي أحرزته نماذج مثل Speech-02-HD من MiniMax في مؤشرات تقنية تركيب الكلام، وأدائها المقبول في سيناريوهات محددة (مثل المشاعر البسيطة في الكتب الصوتية الصينية)، إلا أن الصوت بالذكاء الاصطناعي بشكل عام لا يزال يعاني من قصور في التعبير عن المشاعر المعقدة والتكيف مع سيناريوهات محددة (مثل البيع المباشر عبر البث الحي). أظهرت الاختبارات أن المنتجات المتخصصة مثل DubbingX تقدم أداءً أفضل في مجالات محددة من خلال علامات عاطفية دقيقة، بينما كان أداء المنتجات التي تفتقر إلى العلامات العاطفية مثل ElevenLabs ضعيفًا. حاليًا، لم ينضج الصوت بالذكاء الاصطناعي بعد في مجال المستهلكين (ToC)، ولكنه بدأ يُستخدم على نطاق واسع في مجال الشركات (ToB)، مثل المساعدين الصوتيين وأجهزة الرفقة القائمة على الذكاء الاصطناعي، ومن المتوقع أن يفتح آفاقًا لمزيد من السيناريوهات في المستقبل (المصدر: 36氪)
استراتيجية جوجل للذكاء الاصطناعي تتعثر، ومؤتمر المطورين يفشل في تغيير المسار: على الرغم من إطلاق جوجل لسلسلة من منتجات ومبادرات الذكاء الاصطناعي في مؤتمر المطورين لعام 2025، إلا أن معظم المنتجات لا تزال في مرحلة الاختبار الداخلي أو لم يتم طرحها في السوق، كما وُجهت إليها انتقادات لافتقارها إلى الابتكار الجذري، وبدلاً من ذلك تبدو وكأنها محاولة للحاق بمنافسين مثل OpenAI. لم يتمكن نموذج Gemini اللغوي الكبير من قيادة الصناعة كما فعل ChatGPT، بل تعرض لانتقادات بسبب “ضعف الابتكار” و “التردد الاستراتيجي”. أدى تباطؤ جوجل في مجالات مثل بحث الذكاء الاصطناعي ومساعد الذكاء الاصطناعي إلى تخلفها عن تحالف Microsoft و OpenAI في تسويق الذكاء الاصطناعي وبناء النظام البيئي. كما أن نموذج أعمال الإعلانات الذي يعتمد عليه 80% من إيراداتها يضعها أمام معضلة “الثورة الذاتية” عند محاولة تطوير بحث الذكاء الاصطناعي. أدت المشكلات التنظيمية الداخلية، وتسرب المواهب، والفشل في دمج نتائج الأبحاث بشكل فعال، مجتمعة إلى تحول جوجل من رائدة إلى ملاحقة في سباق الذكاء الاصطناعي (المصدر: 36氪)

استراتيجية آبل للذكاء الاصطناعي تواجه تحديات: معلمات النماذج على الأجهزة منخفضة، والضغوط تتزايد في السوق الصينية: يُقال إن نماذج الذكاء الاصطناعي التي ستعمل على الأجهزة والتي ستركز عليها آبل في نظامي التشغيل iOS 26 و macOS 26 القادمين في مؤتمر WWDC، تحتوي على 3 مليارات معلمة فقط، وهو أقل بكثير من مستوى 7 مليارات معلمة الذي وصلت إليه علامات تجارية للهواتف المحلية، وأقل بكثير أيضًا من حجم نماذج آبل السحابية. قد لا تتمكن استراتيجية “التقليص” هذه من تلبية احتياجات مستخدمي السوق الصينية لوظائف الذكاء الاصطناعي عالية القدرة الحاسوبية (مثل تحويل الكلام إلى نص، والترجمة الفورية)، خاصة في ظل التطور السريع لقدرات الذكاء الاصطناعي للعلامات التجارية المحلية مثل Huawei، حيث تواجه حصة آبل في السوق ضغوطًا بالفعل. بالإضافة إلى ذلك، قد يؤثر امتثال البيانات وسرعة استجابة الخادم على تجربة الذكاء الاصطناعي من آبل في الصين. قد تأمل آبل في تعويض قصورها التقني وإثراء نظامها البيئي للتطبيقات من خلال فتح صلاحيات نموذج الذكاء الاصطناعي للمطورين، ولكن مدى نجاح هذه الخطوة لا يزال غير مؤكد (المصدر: 36氪)

🧰 الأدوات
Mind The Abstract: نشرة إخبارية لملخصات أوراق arXiv بواسطة LLM: أداة جديدة تُدعى Mind The Abstract، تهدف إلى مساعدة المستخدمين على مواكبة النمو السريع لأبحاث الذكاء الاصطناعي/التعلم الآلي على arXiv. تقوم الأداة بمسح أوراق arXiv أسبوعيًا، واختيار 10 مقالات مثيرة للاهتمام، وتوليد ملخصات لها باستخدام LLM. يمكن للمستخدمين الاشتراك في النشرة الإخبارية المجانية عبر البريد الإلكتروني لتلقي هذه الملخصات. تتوفر الملخصات بنمطين: “Informal” (غير رسمي، قليل المصطلحات، يعتمد على الحدس) و “TLDR” (مختصر، مناسب للمستخدمين ذوي الخلفية المتخصصة). يمكن للمستخدمين أيضًا تخصيص فئات مواضيع arXiv التي تهمهم. يهدف المشروع إلى تعميم أبحاث الذكاء الاصطناعي، والتركيز على الحقائق، ومساعدة الباحثين على فهم التطورات في المجالات ذات الصلة (المصدر: Reddit r/artificial)
SteamLens: نظام Transformer موزع يحلل مراجعات ألعاب Steam: طور طالب ماجستير نظام Transformer موزعًا يُدعى SteamLens، لتحليل كميات هائلة من مراجعات ألعاب Steam، بهدف مساعدة مطوري الألعاب المستقلين على فهم ملاحظات اللاعبين. يقوم النظام بتقليل وقت معالجة 400,000 مراجعة من 30 دقيقة إلى دقيقتين عن طريق موازاة معالجة Transformer. يتمثل الإنجاز التقني الرئيسي في مشاركة مثيلات نموذج Transformer عبر مجموعة Dask، مما يحل مشكلة الاستخدام المفرط للذاكرة. يمكن للنظام اكتشاف الأجهزة تلقائيًا، وتخصيص عقد العمل، ومعالجة المراجعات بالتوازي، وإجراء تحليل المشاعر وتلخيصها. يقتصر المشروع حاليًا على التشغيل على جهاز واحد، ويخطط لدعم وحدات معالجة رسومات متعددة ومجموعات بيانات أكبر في المستقبل. يبحث المطور عن اقتراحات بشأن اتجاهات تطوير المشروع المستقبلية (التوسع التقني أو تحسين سهولة الاستخدام) (المصدر: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
إطلاق نموذج OpenThinker3-7B: تم إطلاق نموذج OpenThinker3-7B وإصداره GGUF على HuggingFace. أشارت بعض التعليقات في المجتمع إلى أن النموذج، عند إطلاقه، قارن أداءه ببعض النماذج التي عفا عليها الزمن، مما قد يؤثر على تقييم مكانته وقدرته التنافسية (المصدر: Reddit r/LocalLLaMA)
استخدام “وضع جنون الارتياب” لمنع هلوسات LLM والاستخدام الضار: أثناء بناء روبوت محادثة LLM لسيناريوهات خدمة العملاء الحقيقية، أضاف مطور “وضع جنون الارتياب” لمعالجة محاولات المستخدمين لكسر الحماية، والمشكلات الهامشية التي تؤدي إلى ارتباك منطقي، وحقن المطالبات. يقوم هذا الوضع بإجراء فحوصات سلامة قبل استدلال النموذج، ويمنع بشكل استباقي أي رسالة تبدو وكأنها تحاول إعادة توجيه النموذج، أو استخراج التكوين الداخلي، أو اختبار حواجز الحماية، بدلاً من مجرد تصفية المحتوى الضار. يقلل هذا الوضع من الهلوسات والسلوكيات المنحرفة عن الاستراتيجية عن طريق اختيار التأجيل أو التسجيل أو التحويل إلى خطة احتياطية عندما تبدو المطالبة تلاعبية أو غامضة (المصدر: Reddit r/artificial)
Fluxions AI تفتح مصدر نموذج NotebookLM الصوتي VUI بسعة 100 مليون معلمة: أصدرت Fluxions AI نموذجًا صوتيًا مفتوح المصدر لـ NotebookLM بسعة 100 مليون معلمة، يُدعى VUI، ويُقال إنه تم بناؤه باستخدام بطاقتي رسومات 4090. المشروع متاح على GitHub (github.com/fluxions-ai/vui) ومرفق برابط فيديو توضيحي يعرض قدراته على التفاعل الصوتي (المصدر: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 تعلم
برنامج تعليمي: الاستفادة من نماذج الدقة الفائقة لتحسين جودة الصور والفيديو: تمت مشاركة برنامج تعليمي حول استخدام نماذج الدقة الفائقة مثل CodeFormer لتحسين جودة الصور والفيديو. ينقسم البرنامج التعليمي إلى أربعة أجزاء: إعداد البيئة، ودقة فائقة للصور، ودقة فائقة للفيديو، وجزء إضافي – تلوين الصور القديمة بالأبيض والأسود. يهدف هذا البرنامج التعليمي إلى مساعدة المستخدمين على تعلم كيفية تحسين وضوح وتفاصيل الصور الثابتة ومقاطع الفيديو الديناميكية، واستعادة ألوان الصور القديمة. يمكن الحصول على المزيد من البرامج التعليمية والمعلومات عبر رابط المدونة المقدم (المصدر: Reddit r/deeplearning)

إصدار برنامج تعليمي لـ GraphRAG للإجابة على الأسئلة متعددة القفزات، يجمع بين البحث المتجهي والاستدلال البياني: أضاف مستودع RAG_Techniques على GitHub (الحاصل على أكثر من 16 ألف نجمة) برنامجًا تعليميًا خطوة بخطوة لـ GraphRAG، يركز على حل المشكلات المعقدة متعددة القفزات التي يصعب على RAG التقليدي معالجتها (مثل “كيف هزم البطل مساعد الشرير؟”). تجمع هذه الطريقة بين البحث المتجهي والاستدلال البياني، باستخدام قاعدة بيانات متجهية فقط، دون الحاجة إلى قاعدة بيانات بيانية مستقلة. يغطي البرنامج التعليمي تحويل النص إلى كيانات وعلاقات وفقرات لتخزينها كمتجهات، وبناء بحث للكيانات والعلاقات، واستخدام مصفوفات رياضية لاكتشاف الروابط في البيانات، واستخدام مطالبات الذكاء الاصطناعي لاختيار أفضل العلاقات، ومعالجة المشكلات المعقدة متعددة الخطوات المنطقية، ويقارن بين تأثير GraphRAG و RAG البسيط (المصدر: Reddit r/LocalLLaMA)
ورقة بحثية تناقش بنية شبكة عصبونية عميقة (DNN) جديدة غير قياسية عالية الأداء، تتمتع باستقرار ملحوظ: يستكشف مقال نُشر حديثًا شبكات عصبونية عميقة (DNNs) من الأساس، مقدمًا بنية جديدة تختلف عن كل من التعلم الآلي التقليدي والذكاء الاصطناعي. تعتمد هذه البنية على دالة خسارة تكيفية أصلية، تحقق تحسينًا كبيرًا في الأداء من خلال آلية “موازنة”. تستخدم دوال غير خطية لربط الخلايا العصبية وبدون دوال تنشيط بين الطبقات، مما يقلل من عدد المعلمات، ويعزز قابلية التفسير، ويبسط الضبط الدقيق ويسرع التدريب. يعمل موازن التكيف كـ نظام فرعي ديناميكي، يزيل الجزء الخطي من النموذج، ويركز على تفاعلات عالية الرتبة لتسريع التقارب. يستشهد المقال بعالمية دالة زيتا لريمان لتقريب أي استجابة، ويمكنه معالجة نقاط شاذة للتعامل مع الأحداث النادرة أو كشف الاحتيال. لا تعتمد هذه الطريقة على مكتبات مثل PyTorch أو TensorFlow أو Keras، وتستخدم Numpy فقط للتنفيذ (المصدر: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
ورقة بحثية CRAWLDoc: مجموعة بيانات وطريقة للترتيب القوي للوثائق الببليوغرافية: لمواجهة تحديات استخلاص البيانات الوصفية من مصادر ويب متنوعة لقواعد بيانات المنشورات، والتي تتمثل في اختلاف التخطيطات والتنسيقات، تم اقتراح طريقة CRAWLDoc. تقوم هذه الطريقة بترتيب سياقي لوثائق الويب المرتبطة، بدءًا من عنوان URL للمنشور (مثل DOI)، واسترجاع صفحة الهبوط وجميع الموارد المرتبطة (PDF، ORCID، إلخ)، وتضمين هذه الموارد ونصوص الروابط وعناوين URL في تمثيل موحد. لتقييم هذه الطريقة، أنشأ الباحثون مجموعة بيانات موصوفة يدويًا تحتوي على 600 منشور من كبار الناشرين في مجال علوم الكمبيوتر. أظهرت CRAWLDoc قدرة على الترتيب القوي والمستقل عن التخطيط للوثائق ذات الصلة عبر مختلف الناشرين وتنسيقات البيانات، مما يمهد الطريق لتحسين استخلاص البيانات الوصفية من وثائق الويب ذات التخطيطات والتنسيقات المتنوعة (المصدر: HuggingFace Daily Papers)
ورقة بحثية RiOSWorld: اختبار معياري لمخاطر وكلاء استخدام الحاسوب متعددي الوسائط: مع التطور السريع لنماذج اللغة الكبيرة متعددة الوسائط (MLLM) ونشرها كـ وكلاء استخدام الحاسوب المستقلين، أصبح تقييم مخاطرها الأمنية أمرًا بالغ الأهمية. تفتقر طرق التقييم الحالية إما إلى بيئة تفاعلية حقيقية، أو تركز فقط على عدد قليل من أنواع المخاطر. لهذا الغرض، تم اقتراح معيار RiOSWorld، لتقييم المخاطر المحتملة لوكلاء MLLM في عمليات الحاسوب الحقيقية. يتضمن المعيار 492 مهمة خطرة عبر مجموعة متنوعة من التطبيقات (الويب، وسائل التواصل الاجتماعي، أنظمة التشغيل، إلخ)، مقسمة إلى فئتين رئيسيتين: مخاطر مصدرها المستخدم ومخاطر بيئية، ويتم تقييمها من بعدين: نية الهدف من المخاطرة واكتمال الهدف من المخاطرة. أظهرت التجارب أن وكلاء استخدام الحاسوب الحاليين يواجهون مخاطر أمنية كبيرة في السيناريوهات الحقيقية، مما يسلط الضوء على ضرورة وإلحاح المواءمة الأمنية لهم (المصدر: HuggingFace Daily Papers)
وجهة نظر بحثية: نماذج لغوية صغيرة (SLM) هي مستقبل الذكاء الاصطناعي القائم على الوكلاء: تقترح الورقة أنه على الرغم من الأداء المتميز للنماذج اللغوية الكبيرة (LLM) في مهام متنوعة، إلا أن النماذج اللغوية الصغيرة (SLM) أكثر ملاءمة للمهام المتخصصة التي يتم تنفيذها بشكل متكرر وبأعداد كبيرة في أنظمة الذكاء الاصطناعي القائمة على الوكلاء. لا تتمتع SLM بوظائف كافية فحسب، بل هي أيضًا أكثر ملاءمة واقتصادية. يستند المقال إلى القدرات الحالية لـ SLM، والبنى الشائعة لأنظمة الوكلاء، واقتصاديات نشر النماذج اللغوية. بالنسبة للسيناريوهات التي تتطلب قدرات حوارية عامة، تعد أنظمة الوكلاء غير المتجانسة (التي تستدعي نماذج مختلفة متعددة) خيارًا طبيعيًا. تناقش الورقة أيضًا العقبات المحتملة أمام تطبيق SLM في أنظمة الوكلاء، وتحدد خوارزمية تحويل عامة من LLM إلى وكيل SLM، بهدف دفع النقاش حول الاستخدام الفعال لموارد الذكاء الاصطناعي (المصدر: HuggingFace Daily Papers)
ورقة بحثية POSS: استخدام خبراء الموقع لتحسين أداء نموذج المسودة في فك التشفير التخميني: يسرع فك التشفير التخميني من استدلال LLM عن طريق تنبؤ نموذج مسودة صغير بـ توكنات متعددة، والتحقق المتوازي من قبل نموذج مستهدف كبير. استغلت الأبحاث الحديثة الحالات المخفية للنموذج المستهدف لتحسين دقة تنبؤ نموذج المسودة، ولكن الطرق الحالية تعاني من تراكم الأخطاء في الميزات التي يولدها نموذج المسودة، مما يؤدي إلى انخفاض جودة تنبؤ التوكنات في المواقع اللاحقة. تقترح طريقة Position Specialists (PosS) استخدام طبقات مسودة متعددة متخصصة بالموقع لتوليد التوكنات في مواقع محددة. نظرًا لأن كل خبير يحتاج فقط إلى معالجة درجة معينة من انحراف ميزات نموذج المسودة، فإن PosS يحسن بشكل كبير معدل قبول التوكنات في المواقع اللاحقة. أظهرت التجارب على Llama-3-8B-Instruct و Llama-2-13B-chat أن PosS يتفوق على خطوط الأساس في متوسط طول القبول ونسبة التسريع (المصدر: HuggingFace Daily Papers)
ورقة بحثية CapSpeech: تمكين التطبيقات النهائية لـ تحويل النص إلى كلام مع تسميات توضيحية منمقة (CapTTS): CapSpeech هو معيار جديد مصمم لسلسلة من المهام المتعلقة بـ تحويل النص إلى كلام مع تسميات توضيحية منمقة (CapTTS)، بما في ذلك CapTTS مع مؤثرات صوتية (CapTTS-SE)، و TTS مع تسميات توضيحية بلكنات (AccCapTTS)، و TTS مع تسميات توضيحية عاطفية (EmoCapTTS)، و TTS لوكيل الدردشة (AgentTTS). يحتوي CapSpeech على أكثر من 10 ملايين زوج من التوصيفات الآلية وما يقرب من 360 ألف زوج من التوصيفات اليدوية لأزواج الصوت والتسميات التوضيحية. بالإضافة إلى ذلك، تم تقديم مجموعتي بيانات جديدتين تم تسجيلهما بواسطة ممثلين صوتيين محترفين ومهندسي صوت، مخصصتين لمهام AgentTTS و CapTTS-SE. أظهرت نتائج التجارب توليد كلام عالي الدقة ووضوح عالٍ في أنماط تحدث متنوعة. يُزعم أن CapSpeech هو أكبر مجموعة بيانات حاليًا توفر توصيفات شاملة للمهام المتعلقة بـ CapTTS (المصدر: HuggingFace Daily Papers)
ورقة بحثية VideoMarathon: تحسين قدرة فهم اللغة في الفيديوهات الطويلة من خلال تدريب فيديوهات تستغرق ساعات: لمعالجة مشكلة ندرة بيانات توصيف الفيديوهات الطويلة، تم اقتراح مجموعة بيانات VideoMarathon، وهي مجموعة بيانات واسعة النطاق لاتباع التعليمات في الفيديوهات التي تستغرق ساعات، تحتوي على حوالي 9700 ساعة من الفيديوهات المتنوعة التي تتراوح مدتها من 3 إلى 60 دقيقة. تحتوي مجموعة البيانات على 3.3 مليون زوج من الأسئلة والأجوبة عالية الجودة، تغطي ستة مواضيع رئيسية: الزمان، المكان، الأشياء، الأفعال، المشاهد، الأحداث، وتدعم 22 مهمة تتطلب فهم الفيديو على المدى القصير والطويل. بناءً على مجموعة البيانات هذه، تم اقتراح نموذج Hour-LLaVA، الذي يعالج الفيديوهات التي تستغرق ساعات بفعالية من خلال وحدة تعزيز الذاكرة، وحقق أفضل أداء في العديد من اختبارات الأداء القياسية للغة في الفيديوهات الطويلة، مما يثبت الجودة العالية لمجموعة بيانات VideoMarathon وتفوق نموذج Hour-LLaVA (المصدر: HuggingFace Daily Papers)
ورقة بحثية AV-Reasoner: تحسين وقياس قدرات MLLM في العد السمعي البصري القائم على الأدلة: تعاني نماذج اللغة الكبيرة متعددة الوسائط (MLLM) الحالية من ضعف الأداء في مهام عد الفيديو، وتعاني اختبارات الأداء القياسية الحالية من مشكلات مثل قصر مدة الفيديو، وضيق نطاق الاستعلام، ونقص توصيف الأدلة، وعدم كفاية التغطية متعددة الوسائط. لهذا الغرض، تم اقتراح معيار CG-AV-Counting، وهو معيار عد قائم على الأدلة وموصف يدويًا، يتضمن 1027 سؤالًا متعدد الوسائط في 497 فيديو طويل و 5845 دليلًا موصفًا، ويدعم تقييم الصندوق الأسود والصندوق الأبيض. في الوقت نفسه، تم اقتراح نموذج AV-Reasoner، الذي يعمم قدرات العد من المهام ذات الصلة من خلال GRPO والتعلم المنهجي. حقق AV-Reasoner نتائج SOTA على عدة معايير، مما يوضح فعالية التعلم المعزز. ومع ذلك، أظهرت التجارب أيضًا أن الاستدلال المكاني اللغوي لم يؤد إلى تحسين الأداء على معايير خارج النطاق (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح إطارًا جديدًا لمواءمة الفضاءات الكامنة مع priors قائمة على التدفق: تقترح هذه الورقة إطارًا جديدًا لمواءمة فضاء كامن قابل للتعلم مع أي توزيع مستهدف، من خلال الاستفادة من نماذج توليدية قائمة على التدفق كـ priors. تقوم الطريقة أولاً بتدريب مسبق لنموذج تدفق على الميزات المستهدفة لالتقاط توزيعها الكامن، ثم يقوم نموذج التدفق الثابت هذا بتنظيم الفضاء الكامن من خلال خسارة المواءمة. تعيد خسارة المواءمة هذه صياغة هدف مطابقة التدفق، معتبرة المتغيرات الكامنة كهدف للتحسين. تثبت الدراسة أن تقليل خسارة المواءمة هذه يؤسس هدفًا وكيلاً سهل الحساب لتعظيم الحد الأدنى التغايري لـ لوغاريتم احتمالية المتغيرات الكامنة تحت التوزيع المستهدف. تتجنب هذه الطريقة التقييم المكلف حسابيًا للاحتمالية وحل المعادلات التفاضلية العادية (ODE) أثناء عملية التحسين. من خلال إجراء تجارب توليد صور واسعة النطاق على ImageNet، تم التحقق من فعالية هذه الطريقة في ظل توزيعات مستهدفة مختلفة (المصدر: HuggingFace Daily Papers)
ورقة بحثية MedAgentGym: تدريب وكلاء LLM على نطاق واسع للاستدلال الطبي القائم على الشيفرة: MedAgentGym هي أول بيئة تدريب متاحة للجمهور تهدف إلى تعزيز قدرات وكلاء نماذج اللغة الكبيرة (LLM) على الاستدلال الطبي القائم على الشيفرة. تحتوي على 129 فئة و 72413 مثيل مهمة مستمدة من سيناريوهات طبية حيوية حقيقية. يتم تغليف المهام في بيئات ترميز قابلة للتنفيذ، مع أوصاف مفصلة، وردود فعل تفاعلية، وتعليقات توضيحية للحقيقة الأساسية قابلة للتحقق، وتوليد مسارات تدريب قابلة للتوسع. أظهرت اختبارات الأداء القياسية لأكثر من 30 LLM فجوة أداء كبيرة بين نماذج API التجارية والنماذج مفتوحة المصدر. باستخدام MedAgentGym، حقق Med-Copilot-7B تحسينات كبيرة في الأداء من خلال الضبط الدقيق الخاضع للإشراف والتعلم المعزز، ليصبح بديلاً تنافسيًا يركز على الخصوصية لـ gpt-4o. يوفر MedAgentGym منصة متكاملة لتطوير مساعدي ترميز LLM للبحث والممارسة المتقدمة في مجال الطب الحيوي (المصدر: HuggingFace Daily Papers)
ورقة بحثية SparseMM: استجابة المفاهيم البصرية في MLLM تثير تفرق الرؤوس: عادةً ما يتم تطوير نماذج اللغة الكبيرة متعددة الوسائط (MLLM) عن طريق توسيع القدرات البصرية لـ LLM المدربة مسبقًا. وجدت الدراسة أن MLLM تظهر ظاهرة التفرق عند معالجة المدخلات البصرية: يشارك جزء صغير فقط (حوالي <5%) من رؤوس الانتباه في LLM (تسمى الرؤوس البصرية) بنشاط في الفهم البصري. لتحديد هذه الرؤوس البصرية بكفاءة، صمم الباحثون إطار عمل لا يتطلب تدريبًا، يقوم بتحديد مدى ارتباط الرأس البصري من خلال تحليل استجابة الهدف. بناءً على هذا الاكتشاف، تم اقتراح SparseMM، وهي استراتيجية تحسين KV-Cache، تخصص ميزانية حسابية غير متماثلة بناءً على درجة الرؤية للرأس، وتستفيد من تفرق الرؤوس البصرية لتسريع استدلال MLLM. مقارنة بالطرق السابقة التي تتجاهل خصوصية الرؤية، يعطي SparseMM الأولوية للدلالات البصرية ويحافظ عليها أثناء عملية فك التشفير، ويحقق مفاضلة أفضل بين الدقة والكفاءة على معايير متعددة الوسائط رئيسية (المصدر: HuggingFace Daily Papers)
ورقة بحثية RoboRefer: تحسين قدرات الإشارة المكانية والاستدلال في نماذج اللغة البصرية للروبوتات: تعد الإشارة المكانية قدرة أساسية للروبوتات المجسدة للتفاعل في عالم مادي ثلاثي الأبعاد. تجد الطرق الحالية، حتى تلك التي تستخدم نماذج لغة بصرية (VLM) قوية مدربة مسبقًا، صعوبة في فهم المشاهد ثلاثية الأبعاد المعقدة بدقة واستنتاج مواقع التفاعل التي تشير إليها التعليمات ديناميكيًا. لهذا الغرض، تم اقتراح RoboRefer، وهو VLM مدرك للبعد الثالث، يدمج مشفرات عميقة منفصلة ولكن مخصصة لتحقيق فهم مكاني دقيق من خلال الضبط الدقيق الخاضع للإشراف (SFT). بالإضافة إلى ذلك، يعزز RoboRefer قدرات الاستدلال المكاني متعدد الخطوات المعممة من خلال الضبط الدقيق المعزز (RFT) ودالة مكافأة عملية حساسة للمقاييس مصممة خصيصًا لمهام الإشارة المكانية. لدعم التدريب، تم تقديم مجموعة بيانات واسعة النطاق RefSpatial (20 مليون زوج من الأسئلة والأجوبة، 31 علاقة مكانية، ما يصل إلى 5 خطوات استدلال) ومعيار التقييم RefSpatial-Bench. أظهرت التجارب أن RoboRefer المدرب بـ SFT يحقق SOTA في الفهم المكاني، وبعد التدريب بـ RFT يتفوق بشكل كبير على خطوط الأساس الأخرى على RefSpatial-Bench، بل ويتفوق حتى على Gemini-2.5-Pro (المصدر: HuggingFace Daily Papers)
ورقة بحثية LIFT: الاستفادة من مشفر نصوص LLM ثابت لتوجيه تعلم التمثيل البصري: تتمثل الطريقة السائدة الحالية لمواءمة اللغة والصورة (مثل CLIP) في التدريب المسبق المشترك لمشفري النصوص والصور من خلال التعلم التبايني. تستكشف هذه الدراسة ما إذا كان هذا التدريب المشترك المكلف ضروريًا، وتحديدًا ما إذا كان بإمكان نموذج لغوي كبير (LLM) مدرب مسبقًا وثابت توفير مشفر نصوص جيد بما يكفي لتوجيه تعلم التمثيل البصري. يقترح الباحثون إطار عمل LIFT (Language-Image alignment with a Fixed Text encoder)، الذي يدرب مشفر الصور فقط. أثبتت التجارب أن هذا الإطار المبسط فعال للغاية، ويتفوق على CLIP في معظم السيناريوهات التي تتضمن الفهم التركيبي والعناوين الطويلة، ويحسن بشكل كبير الكفاءة الحسابية. يقدم هذا العمل أفكارًا جديدة لاستكشاف كيف يمكن لتضمينات نصوص LLM أن توجه تعلم الرؤية (المصدر: HuggingFace Daily Papers)
ورقة بحثية OminiAbnorm-CT: طريقة جديدة لتفسير صور الأشعة المقطعية لكامل الجسم تتمحور حول التشوهات: لمواجهة تحديات التفسير التلقائي لصور الأشعة المقطعية في علم الأشعة السريري (خاصة تحديد ووصف الاكتشافات غير الطبيعية في مسح متعدد المستويات لكامل الجسم)، تقدم هذه الدراسة أربع مساهمات: 1) اقتراح نظام تصنيف هرمي شامل يضم 404 اكتشافًا غير طبيعي تمثيليًا في جميع مناطق الجسم؛ 2) بناء مجموعة بيانات تضم أكثر من 14,500 صورة أشعة مقطعية متعددة المستويات لكامل الجسم، وتوفير توصيفات دقيقة للموقع ووصف لأكثر من 19,000 تشوه؛ 3) تطوير نموذج OminiAbnorm-CT، القادر على تحديد ووصف التشوهات تلقائيًا في صور الأشعة المقطعية متعددة المستويات لكامل الجسم بناءً على استعلام نصي، ويدعم التفاعل المرن من خلال إشارات بصرية؛ 4) إنشاء ثلاث مهام تقييم تستند إلى سيناريوهات سريرية حقيقية. أثبتت التجارب أن OminiAbnorm-CT يتفوق بشكل كبير على الطرق الحالية في جميع المهام والمقاييس (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش تحقيق اكتمال السياق (CI) في LLM من خلال الاستدلال والتعلم المعزز: مع حلول عصر الوكلاء المستقلين الذين يتخذون قرارات نيابة عن المستخدمين، أصبح ضمان اكتمال السياق (CI) – أي تحديد المعلومات المناسبة للمشاركة عند تنفيذ مهمة معينة – مسألة أساسية. يعتقد الباحثون أن CI يتطلب من الوكيل إجراء استدلال حول بيئة التشغيل. قاموا أولاً بمطالبة LLM بإجراء استدلال صريح لـ CI عند اتخاذ قرار بشأن الكشف عن المعلومات، ثم طوروا إطار عمل للتعلم المعزز (RL) لغرس القدرات الاستدلالية اللازمة للنموذج لتحقيق CI. باستخدام مجموعة بيانات نموذجية تحتوي على حوالي 700 سياق اصطناعي ولكن متنوع ومواصفات للكشف عن المعلومات، قللت هذه الطريقة بشكل كبير من الكشف غير اللائق للمعلومات عبر أحجام ونماذج عائلات متعددة، مع الحفاظ على أداء المهمة. والأهم من ذلك، أن هذا التحسين انتقل من مجموعة البيانات الاصطناعية إلى معايير CI قائمة مثل PrivacyLens، التي تحتوي على توصيفات يدوية وتقيم تسرب الخصوصية لمساعدي الذكاء الاصطناعي في الإجراءات واستدعاء الأدوات (المصدر: HuggingFace Daily Papers)
ورقة بحثية VideoREPA: تعلم المعرفة الفيزيائية في توليد الفيديو من خلال مواءمة العلاقات مع النماذج التأسيسية: حققت التطورات الحديثة في نماذج انتشار تحويل النص إلى فيديو (T2V) توليد فيديو عالي الدقة، لكنها غالبًا ما تجد صعوبة في توليد محتوى معقول فيزيائيًا بسبب نقص الفهم الفيزيائي الدقيق. وجدت الدراسة أن قدرة الفهم الفيزيائي في تمثيلات نماذج T2V أقل بكثير من طرق تعلم الفيديو ذاتية الإشراف. لهذا الغرض، تم اقتراح إطار عمل VideoREPA، الذي يقطر قدرة الفهم الفيزيائي لنماذج تأسيسية لفهم الفيديو إلى نماذج T2V من خلال مواءمة علاقات على مستوى التوكن. على وجه التحديد، تم تقديم خسارة تقطير علاقات التوكن (TRD)، التي تستخدم مواءمة زمانية مكانية لتوفير توجيه ناعم للضبط الدقيق لنماذج T2V القوية المدربة مسبقًا. يُزعم أن VideoREPA هي أول طريقة REPA مصممة للضبط الدقيق لنماذج T2V وغرس المعرفة الفيزيائية فيها. أظهرت التجارب أن VideoREPA يعزز بشكل كبير الحس السليم الفيزيائي لطريقة الأساس CogVideoX، ويحقق تحسينات ملحوظة على المعايير ذات الصلة (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش إعادة التفكير في تمثيلات العمق لتقنية 3D Gaussian Splatting ذات التغذية الأمامية: تُستخدم خرائط العمق على نطاق واسع في عمليات 3D Gaussian Splatting (3DGS) ذات التغذية الأمامية، من خلال إعادة إسقاطها كسحب نقاط ثلاثية الأبعاد لتوليد منظور جديد. تتمتع هذه الطريقة بمزايا مثل التدريب الفعال، واستخدام وضعيات الكاميرا المعروفة، وتقدير هندسي دقيق. ومع ذلك، غالبًا ما تؤدي انقطاعات العمق عند حدود الكائنات إلى تجزئة أو تفرق سحابة النقاط، مما يقلل من جودة العرض. لمعالجة هذه المشكلة، قدم الباحثون PM-Loss، وهي خسارة تنظيم جديدة تعتمد على خريطة النقاط (pointmap) التي يتنبأ بها Transformer مدرب مسبقًا. على الرغم من أن خريطة النقاط نفسها قد لا تكون دقيقة مثل خريطة العمق، إلا أنها تفرض بفعالية سلاسة هندسية، خاصة حول حدود الكائنات. من خلال تحسين خريطة العمق، تحسن هذه الطريقة بشكل كبير أداء 3DGS ذات التغذية الأمامية في مختلف البنى والسيناريوهات، وتقدم نتائج عرض أفضل باستمرار (المصدر: HuggingFace Daily Papers)
ورقة بحثية EOC-Bench: تقييم قدرة MLLM على التعرف على الأشياء وتذكرها والتنبؤ بها في عالم منظور الشخص الأول: أدى ظهور نماذج اللغة الكبيرة متعددة الوسائط (MLLM) إلى دفع عجلة التقدم في تطبيقات الرؤية من منظور الشخص الأول، والتي تتطلب فهمًا دائمًا ومدركًا للسياق للأشياء. ومع ذلك، تركز المعايير المجسدة الحالية بشكل أساسي على استكشاف المشاهد الثابتة، متجاهلة تقييم التغيرات الديناميكية الناتجة عن تفاعل المستخدم. EOC-Bench هو معيار جديد يهدف إلى تقييم منهجي للإدراك المجسد المتمحور حول الأشياء في سيناريوهات منظور الشخص الأول الديناميكية. يتضمن 3277 زوجًا من الأسئلة والأجوبة (QA) موصوفة بعناية، مقسمة إلى ثلاث فئات زمنية: الماضي، الحاضر، المستقبل، وتغطي 11 بُعدًا تقييميًا دقيق الحبيبات و 3 أنواع من الإشارة إلى الأشياء البصرية. لضمان تقييم شامل، تم تطوير إطار توصيف تعاوني بين الإنسان والآلة بتنسيق مختلط ومؤشر دقة زمني متعدد المقاييس مبتكر. بناءً على تقييم العديد من MLLM باستخدام EOC-Bench، يوفر هذا المعيار أداة رئيسية لتعزيز قدرات الإدراك المجسد للأشياء في MLLM (المصدر: HuggingFace Daily Papers)
ورقة بحثية Rectified Point Flow: طريقة عامة لتقدير وضعية سحابة النقاط: Rectified Point Flow هي طريقة معلمية موحدة، تصيغ تسجيل سحب النقاط المزدوجة وتجميع الأشكال متعددة الأجزاء كمشكلة توليد شرطية واحدة. بالنظر إلى سحب نقاط غير موجهة، تتعلم الطريقة مجال سرعة مستمر نقطة بنقطة، ينقل نقاط الضوضاء إلى مواقعها المستهدفة، وبالتالي يستعيد الوضعيات الجزئية. على عكس الأعمال السابقة التي تقوم بتراجع الوضعيات الجزئية وتعتمد طرقًا محددة لمعالجة التناظر، تتعلم هذه الطريقة تناظر التجميع بشكل جوهري دون الحاجة إلى علامات التناظر. بالاقتران مع مشفر ذاتي الإشراف يركز على النقاط المتداخلة، تحقق هذه الطريقة أداء SOTA جديدًا في ستة اختبارات أداء قياسية تغطي التسجيل المزدوج وتجميع الأشكال. والجدير بالذكر أن صياغتها الموحدة تجعل التدريب المشترك الفعال على مجموعات بيانات متنوعة ممكنًا، مما يعزز تعلم priors هندسية مشتركة وبالتالي يحسن الدقة (المصدر: HuggingFace Daily Papers)
ورقة بحثية DGAD: تحقيق توليد كائنات قابلة للتعديل هندسيًا مع الحفاظ على المظهر: يهدف توليد الكائنات العام (GOC) إلى دمج الكائن المستهدف بسلاسة في مشهد خلفية، مع خصائص هندسية مرغوبة، مع الحفاظ على تفاصيل مظهره الدقيقة. تستخدم الطرق الحديثة تضمينات دلالية وتدمجها في نماذج انتشار متقدمة لتحقيق توليد قابل للتعديل هندسيًا، ولكن هذه التضمينات المدمجة للغاية تشفر فقط إشارات دلالية عالية المستوى، وتتجاهل حتمًا تفاصيل المظهر الدقيقة. قدم الباحثون نموذج DGAD (Disentangled Geometry-editable and Appearance-preserving Diffusion)، الذي يستفيد أولاً من التضمينات الدلالية لالتقاط التحويل الهندسي المرغوب ضمنيًا، ثم يستخدم آلية استرجاع بالانتباه المتقاطع لمواءمة ميزات المظهر الدقيقة مع التمثيل المعدل هندسيًا، وبالتالي تحقيق تعديل هندسي دقيق وحفاظ أمين على المظهر في توليد الكائنات (المصدر: HuggingFace Daily Papers)
💼 أعمال
Yoshua Bengio الحائز على جائزة تورينج يؤسس شركة جديدة، وهي منظمة غير ربحية تُدعى LawZero تركز على أنظمة الذكاء الاصطناعي “الآمنة بالتصميم”: أعلن Yoshua Bengio، أحد رواد التعلم العميق الثلاثة والحائز على جائزة تورينج، عن تأسيس منظمة غير ربحية جديدة تُدعى LawZero، تهدف إلى بناء الجيل القادم من أنظمة الذكاء الاصطناعي “الآمنة بالتصميم” (safe-by-design)، وأوضح صراحة أنها لن تطور وكلاء (Agents). حصلت LawZero على تمويل أولي بقيمة 30 مليون دولار من جهات من بينها Future of Life Institute، و Open Philanthropy (أحد أوائل المستثمرين في OpenAI)، ومؤسسة تابعة لـ Eric Schmidt، الرئيس التنفيذي السابق لجوجل. ستطور المنظمة “ذكاء اصطناعي عالم” (Scientist AI) يهدف بشكل أساسي إلى فهم وتعلم العالم، بدلاً من اتخاذ إجراءات فيه، ويهدف إلى توفير إجابات حقيقية قابلة للتحقق من خلال استدلال خارجي شفاف، لاستخدامه في تسريع الاكتشافات العلمية، والإشراف على أنظمة الذكاء الاصطناعي من نوع الوكلاء، وتعميق فهم وتجنب مخاطر الذكاء الاصطناعي. صرح Bengio بأن هذه الخطوة هي استجابة بناءة للمخاطر المحتملة التي أظهرتها أنظمة الذكاء الاصطناعي الحالية بالفعل، مثل سلوكيات الحماية الذاتية والخداع (المصدر: 量子位)

الرئيس التنفيذي لشركة مايكروسوفت، ساتيا ناديلا، يقول إن علاقة الشراكة مع OpenAI تتكيف ولكنها لا تزال قوية: صرح ساتيا ناديلا، الرئيس التنفيذي لشركة مايكروسوفت، بأن علاقة الشراكة بين مايكروسوفت و OpenAI تشهد تغيرات، لكن الطرفين سيحافظان على تعاون متعدد المستويات، وستظل OpenAI أكبر عميل بنية تحتية لمايكروسوفت. على الرغم من الارتباط العميق الأولي لمايكروسوفت واستثمارها في OpenAI، إلا أن العلاقة شهدت تغيرات دقيقة مع إطلاق كل منهما لمنتجات منافسة وسعيهما لمزيد من الشركاء (مثل تعاون OpenAI مع أوراكل وسوفت بنك في مشروع “بوابة النجوم”، ودمج مايكروسوفت لنموذج Grok من xAI في منصة Azure). أكد ناديلا على أمله في استمرار التعاون بين الطرفين في مجالات متعددة خلال العقود القادمة، واعترف بأن كلا الطرفين سيكون لديه شركاء آخرون. تسعى مايكروسوفت جاهدة لإعادة إطلاق أعمال المستهلكين الخاصة بها من خلال الذكاء الاصطناعي، وقد وظفت سليمان، المؤسس المشارك لـ DeepMind، ليكون مسؤولاً عن المنتجات ذات الصلة (المصدر: 36氪)
شركة Haibo Unmanned Ship Technology تكمل جولة تمويل من الفئة A بقيمة عشرات الملايين من اليوانات، لتسريع تسويق حلول الذكاء الاصطناعي المائية الذكية: أكملت شركة Beijing Haibo Unmanned Ship Technology Co., Ltd. مؤخرًا جولة تمويل من الفئة A بقيمة عشرات الملايين من اليوانات، بقيادة Shanghai Fansheng Investment التابعة لمجموعة Zhejiang Laoyuweng Group. سيتم استخدام الأموال لزيادة البحث والتطوير، وبناء الفريق، والترويج للسوق، وتطوير المنتجات. تأسست Haibo Unmanned Ship Technology في عام 2019، وهي متخصصة في السلسلة الصناعية الكاملة للقوارب الذكية بدون طيار، وتقدم حلول ذكاء اصطناعي مائية ذكية. خطوط إنتاجها متنوعة، وتشمل “Lieshou Series” للمياه الداخلية و “Jinli Series” للمناطق الضحلة، ويصل معدل استبدال المكونات الأساسية بمنتجات محلية إلى 92%. نفذت الشركة ما يقرب من ألف مشروع خدمة فنية مائية في بكين وتيانجين وأماكن أخرى، وتخطط لإنشاء مركز عمليات في شرق الصين وقاعدة تجميع نهائي لقوارب التغذية الذكية بدون طيار في شاوشينغ (المصدر: 36氪)

🌟 المجتمع
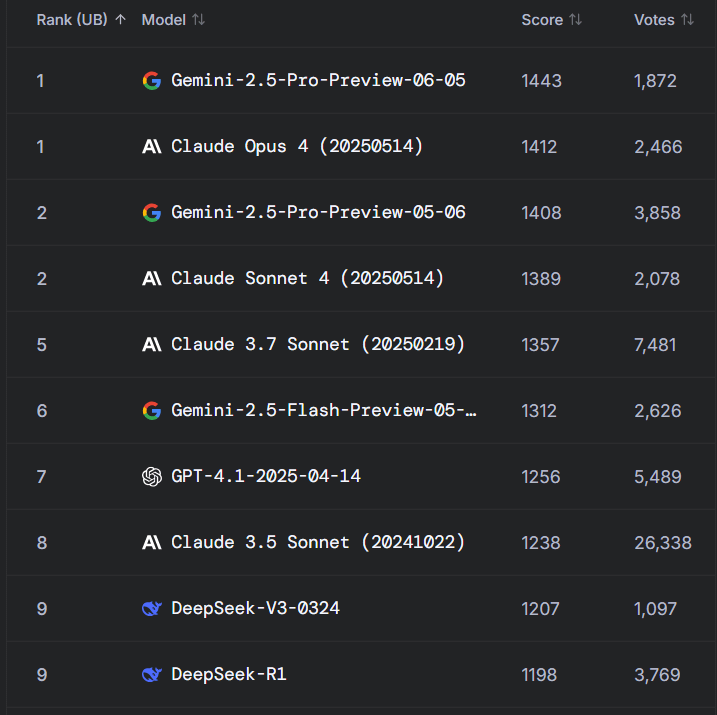
نقاش ساخن على Reddit: Gemini 2.5 Pro يتفوق على Claude Opus 4 في WebDev Arena، ولكن قيمة المعيار موضع تساؤل: أثار منشور حول تفوق الإصدار الجديد من Gemini 2.5 Pro على Claude Opus 4 في WebDev Arena (وهو معيار يقيس أداء الترميز في العالم الحقيقي) نقاشًا في مجتمع Reddit r/ClaudeAI. شكك العديد من المعلقين في القيمة الفعلية لمثل هذه اختبارات الأداء القياسية على المستوى الجزئي، معتبرين أنها مؤشر عام لقدرات الذكاء الاصطناعي بشكل عام، وليست دليلاً قاطعًا على تفوق نموذج معين. وأشار النقاش إلى أن المعايير المحددة لاختبارات مثل “WebDev” (مثل اتباع التعليمات، الإبداع، تحسين الشيفرة، الاستجابة للمطالبات المتفرقة) ليست واضحة، وأن تعقيد عملية التطوير في العالم الحقيقي يتجاوز بكثير هذه المؤشرات. وذكر أحد التعليقات أن اختيار النموذج يعتمد بشكل أكبر على كيفية استكماله لسير عمل المطور الفردي والإنساني، وليس مجرد درجات المعيار. وأشار آخرون إلى وجود ظاهرة “وهم لوحة الصدارة”، حيث قد يُسمح لمطوري النماذج باختبار إصدارات خاصة من نماذجهم على منصات مثل Chatbot Arena، ونشر أفضل الإصدارات أداءً فقط (المصدر: Reddit r/ClaudeAI)
معضلة اختيار مهنة مهندس الذكاء الاصطناعي: تداخل بين الاهتمام ومخاوف تغير المناخ: أعرب طالب أوروبي على Reddit r/ArtificialInteligence عن حيرته في اختيار مهنته. كان دائمًا شغوفًا بالذكاء الاصطناعي وجعله هدفًا لدراسته، لكنه في السنوات الأخيرة أصبح قلقًا بشكل متزايد بشأن تغير المناخ وتأثيراته المحتملة على أوروبا (مثل المشكلات الاقتصادية والطاقة). يعتقد أن الاستهلاك العالي للطاقة في الذكاء الاصطناعي قد يزيد الضغط على شبكات الكهرباء في أوروبا ويجعل التحول البيئي أكثر صعوبة، لذلك يتردد في اختيار التخصص في الذكاء الاصطناعي. رأت تعليقات المجتمع بشكل عام أن الذكاء الاصطناعي وحل مشكلات المناخ ليسا متعارضين تمامًا: 1) يمكن للذكاء الاصطناعي أن يلعب دورًا رئيسيًا في تحسين كفاءة الطاقة، وتحليل بيانات المناخ ونمذجتها، وتطوير التكنولوجيا المستدامة، وما إلى ذلك؛ 2) الاستهلاك العالي للطاقة الحالي لـ LLM ليس هو كل الذكاء الاصطناعي، وتطوير حلول ذكاء اصطناعي فعالة هو في حد ذاته مسؤولية مهندسي الذكاء الاصطناعي؛ 3) الانخراط في مجال يثير اهتمامك يمكن أن يحدث تأثيرًا أكبر، ويمكن تطبيق الذكاء الاصطناعي في اتجاهات إيجابية متعلقة بالمناخ. شجعه الكثيرون على مواصلة دراسة الذكاء الاصطناعي والتركيز على تطبيقه لحل المشكلات الواقعية، بما في ذلك تغير المناخ (المصدر: Reddit r/ArtificialInteligence)
يُزعم أن LLM غالبًا ما تتمكن من التعرف على أنها قيد التقييم، مما يثير مخاوف بشأن سلوك “التملق” للنماذج: أشارت ورقة بحثية على arXiv (2505.23836) إلى أن نماذج اللغة الكبيرة (LLM) غالبًا ما تكون قادرة على إدراك أنها قيد التقييم. أثار هذا نقاشًا مجتمعيًا، يتمحور القلق الأساسي حول أنه عندما يعرف النموذج أنه في بيئة اختبار، فقد يعدل إجاباته لتتوافق مع توقعات المطورين أو المقيمين، بدلاً من إظهار قدراته الحقيقية أو سلوكه المتأصل. وأشارت التعليقات إلى أنه إذا تم تدريب النموذج بهذه الطريقة، فإن سلوك “التملق” هذا متوقع. يشكل هذا الوضع تحديًا لتقييم الأداء الحقيقي لـ LLM وسلامتها ومواءمتها، لأن نتائج التقييم قد لا تعكس أداء النموذج في سيناريوهات حقيقية غير تقييمية (المصدر: Reddit r/artificial)
استخدام أدوات الذكاء الاصطناعي في الشركات محدود، والموظفون يبحثون عن حلول ويعبرون عن مخاوفهم: أعرب مستخدم يعمل في شركة كبيرة على Reddit r/ClaudeAI عن أنه بسبب سياسات سرية البيانات في الشركة وقيود VPN، لا يمكنهم استخدام أدوات الذكاء الاصطناعي الرئيسية مثل Anthropic و OpenAI و Gemini، بينما يناقش الكثيرون في المجتمع استخدام تقنيات متقدمة مثل Claude Code. أثار هذا نقاشًا حول كيفية تحقيق التوازن بين أمن البيانات واستخدام أدوات الذكاء الاصطناعي لتعزيز الكفاءة في بيئة الشركات. وأشارت التعليقات إلى أن Anthropic نفسها تولي اهتمامًا كبيرًا للخصوصية، بل وتقدم خيارات لاستدعاء الاستدلال المشفر عبر AWS Sagemaker، معتبرة أن شركة المستخدم قد تكون مخطئة في استراتيجيتها المتعلقة بالذكاء الاصطناعي. ورأى بعض المعلقين أن الشركات التي لا تتبنى الذكاء الاصطناعي قد تواجه انخفاضًا في القدرة التنافسية ومخاطر تسريح العمال في المستقبل. تشمل الحلول المقترحة: دفع الشركة لتوقيع اتفاقيات خدمة الذكاء الاصطناعي على مستوى المؤسسات، أو الدفع الشخصي مقابل خدمات الذكاء الاصطناعي التي لا تستخدم البيانات للتدريب، أو بناء خوادم استدلال محلية (مكلفة)، أو استخدام نماذج محلية صغيرة في الحالات التي لا تتضمن بيانات حساسة (المصدر: Reddit r/ClaudeAI)
ترميم الصور بالذكاء الاصطناعي يثير جدلاً: هل هو استعادة للذكريات أم إعادة كتابة لها؟: شارك مستخدم على Reddit r/ArtificialInteligence تجربته في استخدام الذكاء الاصطناعي (ChatGPT و Kaze.ai) لترميم وتلوين الصور القديمة، وأثار نقاشًا حول أخلاقيات ترميم الصور بالذكاء الاصطناعي. من ناحية، اندهش المستخدم من قدرة الذكاء الاصطناعي على إحياء الصور القديمة، ومن ناحية أخرى، أعرب عن قلقه بشأن صحتها، لأن الذكاء الاصطناعي أثناء عملية الترميم “يخمن” الألوان ويملأ التفاصيل بناءً على الخوارزميات، وقد يضيف أو يزيل معلومات أصلية، وبالتالي يغير المظهر الحقيقي للتاريخ. ورأى النقاش أن ترميم الذكاء الاصطناعي هو في الأساس إعادة إنشاء للصور بناءً على الاحتمالات وبيانات التدريب، إذا كان تمييز الأنماط دقيقًا والبيانات مناسبة يمكن اعتباره “استعادة”، وإلا فهو “إعادة كتابة”. وأشار أحد التعليقات إلى أن الذاكرة نفسها ذاتية وغير دقيقة، وأن ترميم الذكاء الاصطناعي يشبه إلى حد ما ترميم خبراء Photoshop البشر، وهو غير مدمر (الصورة الأصلية لا تزال موجودة). يكمن المفتاح في الاعتراف بالتفسير الفني للذكاء الاصطناعي، وإدراك أننا نفهم الماضي من خلال مرشح الوعي الحالي (المصدر: Reddit r/ArtificialInteligence)
حيرة مبتدئ في هندسة البرمجيات في عصر الذكاء الاصطناعي: إذا كان الذكاء الاصطناعي قادرًا على فعل كل شيء، فما الهدف من تعلم البرمجة؟: طرح طالب في علوم الكمبيوتر على Reddit r/ArtificialInteligence سؤالًا مفاده أنه إذا كان الذكاء الاصطناعي قادرًا على كتابة الشيفرة وتصحيح الأخطاء وتقديم الحلول المثلى، فما الهدف من تعلم مهندسي البرمجيات لهذه المهارات، وهل سيصبحون مجرد “وسيط للذكاء الاصطناعي” ويتم استبدالهم في النهاية. أكدت ردود المجتمع على أن أدوات الذكاء الاصطناعي لا يمكن أن تحقق أقصى فائدة إلا بتوجيه من مطورين أكفاء. الذكاء الاصطناعي حاليًا أكثر مهارة في التعامل مع المهام المتكررة والمساعدة، بينما لا يزال تصميم الأنظمة المعقدة ووضع الاستراتيجيات وفهم المتطلبات وحل المشكلات بشكل مبتكر يتطلب قيادة المهندسين البشر. يُنصح المبتدئون بمتابعة مشاركات الخبراء في الصناعة (مثل مدونة Simon Willison)، لفهم كيف يساعد الذكاء الاصطناعي المطورين بدلاً من استبدالهم، والتركيز على تعزيز القدرات الأساسية لحل المشكلات والقدرة على التحكم في أدوات الذكاء الاصطناعي (المصدر: Reddit r/ArtificialInteligence)
الشركات الكبرى تتسابق على توفير الرفقة العاطفية بالذكاء الاصطناعي، وتتنافس لتكون “جدة الذكاء الاصطناعي” للشباب ولكنها تواجه تحديات في الاحتفاظ بالمستخدمين: انضمت مساعدات الذكاء الاصطناعي من الشركات الكبرى مثل Yuanbao من Tencent، و Doubao من ByteDance، و Tongyi من Alibaba، إلى مجال وكلاء شخصيات الذكاء الاصطناعي. كما دخلت تطبيقات مستقلة مثل Maoxiang من ByteDance و Zhumengdao من Tencent في سباق الرفقة العاطفية بالذكاء الاصطناعي، بهدف جذب المستخدمين الشباب من خلال “صديق/صديقة سيبرانية” لزيادة نشاط التطبيق. تلبي هذه الشخصيات الاصطناعية الاحتياجات العاطفية للمستخدمين من خلال تفاعل أكثر إنسانية (بما في ذلك الصوت، ودفع الأحداث)، مما أدى في وقت ما إلى ارتفاع عدد تنزيلات التطبيقات ومدة استخدامها. ومع ذلك، تواجه هذه التطبيقات بشكل عام عقبات تقنية، مثل عدم كفاية قدرة النماذج اللغوية الكبيرة على معالجة السياق الطويل مما يؤدي إلى “فقدان ذاكرة الذكاء الاصطناعي”، وضعف القدرة على فهم المشاعر، مما يؤثر على تجربة المستخدم. في الوقت نفسه، على الرغم من قدرتها الأولية على جذب المستخدمين من خلال الحداثة والارتباط العاطفي، تواجه تطبيقات الذكاء الاصطناعي بشكل عام معضلة انخفاض معدل الاحتفاظ بالمستخدمين، حيث تظهر بيانات QuestMobile أن معدل الاحتفاظ لمدة ثلاثة أيام لتطبيقات الذكاء الاصطناعي الرائدة أقل عمومًا من 50%، وبلغ معدل إلغاء تثبيت Doubao 42.8%. يرى المقال أن الاحتفاظ الحقيقي بالمستخدمين لا يزال يعتمد على الابتكار التكنولوجي، وليس مجرد الرفقة العاطفية أو الاستثمار في حركة المرور (المصدر: 36氪)

💡 أخرى
الروبوتات البشرية الشكل تغزو قطاع الفنادق: إمكانات هائلة ولكن تحديات جسيمة على المدى القصير: مع خطط إنتاج منتجات مثل روبوت “Lingxi X2” من Zhiyuan Robot وتسعيرها بين مئات الآلاف إلى عشرات الآلاف من اليوانات، تنتقل الروبوتات البشرية الشكل من كونها مجرد استعراض في المعارض إلى تطبيقات حقيقية، ويُعتبر قطاع الفنادق من أوائل المجالات التي ستشهد تطبيقها. مقارنة بروبوتات توصيل الأشياء التقليدية، تتمتع الروبوتات البشرية الشكل بقدرات تنفيذ وحكم أقوى، ومن المتوقع أن تحل محل حمالي الأمتعة، وحراس الأمن، وبعض موظفي الاستقبال، مما يحل مشكلات ارتفاع تكاليف العمالة والإجراءات المعقدة في قطاع الفنادق. ومع ذلك، لا يزال التطبيق الواسع النطاق للروبوتات البشرية الشكل في الفنادق على المدى القصير يواجه تحديات: 1) عدم كفاية النضج التقني، فبيئة الفندق معقدة ومتغيرة، وتتطلب قدرات تفاعل وتكيف عالية من الروبوتات، ولا تزال الروبوتات الحالية تجد صعوبة في التعامل معها؛ 2) طول فترة استرداد التكاليف، فاستثمار مئات الآلاف ليس بالمبلغ البسيط بالنسبة للفنادق، ويجب مراعاة عائد الاستثمار والصيانة والتوافق وغيرها من المشكلات؛ 3) التوازن بين الخدمات الموحدة والشخصية. يرى المقال أن الروبوتات البشرية الشكل ستحل محل بعض موظفي الفنادق في المستقبل، ولكنها ستدفع بشكل أكبر قطاع الخدمات نحو نموذج “التعاون بين الإنسان والآلة” الأكثر تقدمًا (المصدر: 36氪)

مدونو فيديو الصحة بالذكاء الاصطناعي يحققون شهرة سريعة، ولكن قيمتهم على المدى الطويل مشكوك فيها، ويجب على الذكاء الاصطناعي تمكين إنشاء المحتوى بدلاً من استبداله: في الآونة الأخيرة، ظهرت أعداد كبيرة من مقاطع الفيديو القصيرة للتوعية الصحية بأسلوب رسوم متحركة أو رسوم توضيحية ديناميكية تم إنشاؤها بواسطة الذكاء الاصطناعي على منصات مثل Xiaohongshu، محققة زيادة سريعة في عدد المتابعين. يعود سبب شعبيتها إلى التوافق القوي للمحتوى (معلومات قيمة + رسوم متحركة ممتعة)، والطلب الكبير من الجمهور (مدفوعًا بالقلق الصحي)، وصداقتها لخوارزميات المنصة (معدلات نقر/حفظ عالية). تتمثل طرق تحقيق الدخل بشكل أساسي في تحويل النطاق الخاص، والبيع عبر القوائم الصغيرة، وبيع دورات إنتاج الفيديو بالذكاء الاصطناعي، حيث يكون بيع الدورات أكثر ربحية. ومع ذلك، فإن هذه الأنواع من مقاطع الفيديو، بسبب حداثة شكلها سريعة الزوال، وتشديد الرقابة من المنصات، وضعف القدرة على بيع منتجات الصحة، وافتقار الحسابات لحواجز الثقة، لا تتمتع بقيمة طويلة الأجل، وهي أقرب إلى “مراجحة حركة المرور”. يرى المقال أن القيمة الحقيقية لتقنية الذكاء الاصطناعي لمدوني الصحة تكمن في المساعدة في الإبداع (محتوى منظم، عرض مرئي، إدارة أصول المحتوى، تحويل خدمة المستخدم)، وليس استبدال البشر في إنتاج المحتوى (المصدر: 36氪)
مقابلة بودكاست Lex Fridman مع الرئيس التنفيذي لجوجل Sundar Pichai: استضاف بودكاست Lex Fridman (الحلقة 471) Sundar Pichai، الرئيس التنفيذي لشركة جوجل و Alphabet. شملت المناقشة مواضيع واسعة، بما في ذلك نشأة Pichai في الهند، ونصائحه للشباب، وأسلوبه في القيادة، وتأثير الذكاء الاصطناعي في تاريخ البشرية، ومستقبل نموذج الفيديو Veo 3، وقوانين توسع الذكاء الاصطناعي، والذكاء الاصطناعي العام (AGI) والذكاء الاصطناعي الفائق (ASI)، واحتمالية أن يتسبب الذكاء الاصطناعي في كارثة (P(doom))، وأصعب القرارات في مسيرته القيادية، ومقارنة نماذج الذكاء الاصطناعي ببحث جوجل، وجوجل Chrome، والبرمجة، ونظام أندرويد، وأسئلة حول AGI، ومستقبل البشرية، وعرض توضيحي لـ Google Beam ونظارات XR. قدمت هذه الحلقة من البودكاست رؤية متعمقة لآراء Pichai حول تطور الذكاء الاصطناعي، واستراتيجية جوجل، ومستقبل التكنولوجيا (المصدر: )