
كلمات مفتاحية:جيميني 2.5 برو, في برين, موديل تجزئة أي شيء 2, كيوين 3-تضمين, وكيل الذكاء الاصطناعي, وضع التفكير العميق لجيميني 2.5 برو, إطار في برين العام للدماغ المتمثل في الذكاء, تجزئة الصور والفيديو SAM 2, كيوين 3-تضمين مع سياق 32 ألف كلمة, فهم الوسائط المتعددة لوكيل الذكاء الاصطناعي
🔥 أبرز الأخبار
جوجل تعلن عن تطورات جديدة في مجال الذكاء الاصطناعي، ووضع Deep Think في Gemini 2.5 Pro يعزز قدرات الاستدلال المعقدة: في مؤتمر Google I/O، أعلنت جوجل عن وضع Deep Think لـ Gemini 2.5 Pro، والذي يهدف إلى تعزيز قدرة الذكاء الاصطناعي بشكل كبير على معالجة المشكلات المعقدة (مثل مسائل الرياضيات على مستوى USAMO) في الاستدلال. وفي الوقت نفسه، أطلقت جوجل أيضًا AlphaEvolve، وهو coding agent مدفوع بـ Gemini، يُستخدم لاكتشاف الخوارزميات، وقد حقق بالفعل نتائج في تصميم خوارزميات ضرب المصفوفات وحل المسائل الرياضية المفتوحة، ويُطبق لتحسين مراكز البيانات الداخلية لجوجل وتصميم الرقائق وكفاءة تدريب الذكاء الاصطناعي. بالإضافة إلى ذلك، تم إطلاق نموذج الفيديو Veo 3 ونموذج الصور Imagen 4 وأداة تحرير الفيديو FLOW، مما يُظهر التخطيط الشامل والتقدم السريع لجوجل في مجال الذكاء الاصطناعي متعدد الوسائط. (المصدر: OriolVinyalsML, demishassabis, demishassabis, op7418)
مختبر شنغهاي للذكاء الاصطناعي يشارك في إطلاق إطار عمل الدماغ المجسَّم العام VeBrain: أطلق مختبر شنغهاي للذكاء الاصطناعي بالتعاون مع عدة جهات إطار عمل VeBrain (Visual Embodied Brain)، وهو إطار عمل دماغ ذكاء اصطناعي مجسَّم عام يهدف إلى توحيد قدرات الإدراك البصري، والاستدلال المكاني، والتحكم في الروبوتات. يقوم هذا الإطار بتحويل مهام التحكم في الروبوت إلى مهام نصية مكانية ثنائية الأبعاد (2D) ضمن نماذج اللغة الكبيرة متعددة الوسائط (MLLM) (مثل اكتشاف النقاط الرئيسية وتحديد المهارات المجسَّمة)، ويقدم “محول الروبوت” (robot adapter) لتحقيق ربط دقيق وتحكم مغلق الحلقة من اتخاذ القرار النصي إلى الفعل الحقيقي. ولدعم تدريب النموذج، قام الفريق ببناء مجموعة بيانات VeBrain-600k، التي تحتوي على 600 ألف بيان تعليمي، تغطي ثلاث فئات من المهام: الفهم متعدد الوسائط، والاستدلال البصري المكاني، وعمليات الروبوت. وأظهرت الاختبارات أن VeBrain حقق مستوى SOTA في الفهم متعدد الوسائط، والاستدلال المكاني، والتحكم في الروبوتات الحقيقية (ذراع آلية وكلب آلي). (المصدر: 量子位)

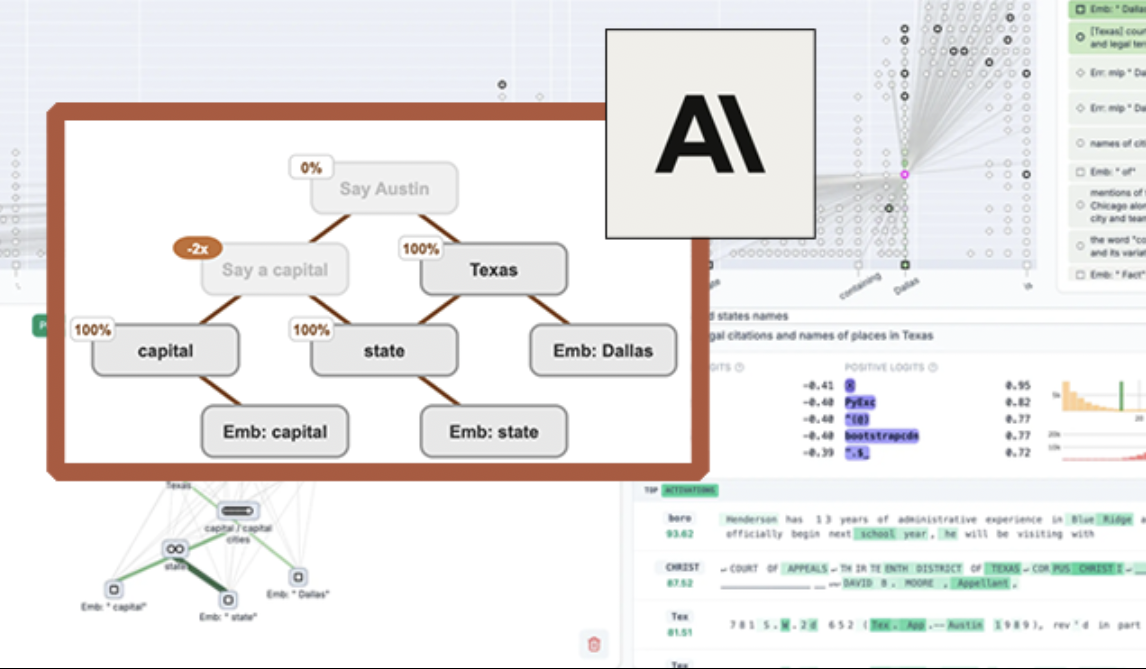
Anthropic تفتح مصدر أداة تصور نماذج اللغة الكبيرة “circuit tracing” لتعزيز قابلية تفسير النماذج: أطلقت Anthropic أداة مفتوحة المصدر باسم “circuit tracing” تهدف إلى مساعدة الباحثين على فهم آليات العمل الداخلية لنماذج اللغة الكبيرة (LLM). تقوم الأداة بإنشاء “attribution graphs” (مخططات الإسناد)، التي تصور العقد الفائقة الداخلية وعلاقاتها المتصلة عندما يعالج النموذج المعلومات، بشكل مشابه لمخططات الشبكات العصبية. يمكن للباحثين التحقق من وظائف كل عقدة عن طريق التدخل في قيم تنشيط العقد ومراقبة التغيرات في سلوك النموذج، لفك تشفير منطق اتخاذ القرار في نماذج اللغة الكبيرة. تدعم الأداة إنشاء مخططات الإسناد على النماذج مفتوحة المصدر الشائعة وتوفر واجهة أمامية تفاعلية Neuronpedia للتصور والتعليق والمشاركة. تهدف هذه الخطوة إلى دفع أبحاث قابلية تفسير الذكاء الاصطناعي، وتمكين مجتمع أوسع من استكشاف وفهم سلوك النماذج. (المصدر: 量子位, swyx)
Meta تطلق Segment Anything Model 2 (SAM 2) لتعزيز قدرات تجزئة الصور والفيديو: أطلق معهد Meta AI للأبحاث (FAIR) نموذج SAM 2، وهو ترقية لنموذجه الشهير Segment Anything Model. SAM 2 هو نموذج تأسيسي يركز على مهام التجزئة البصرية القابلة للتوجيه في الصور ومقاطع الفيديو، وهو قادر على تحديد وتجزئة كائنات أو مناطق معينة بدقة في صورة أو مقطع فيديو بناءً على توجيهات (مثل النقاط، المربعات، النصوص). النموذج مفتوح المصدر الآن، ويتبع ترخيص Apache، وهو متاح للباحثين والمطورين للاستخدام المجاني وبناء التطبيقات، مما يدفع عجلة التطور في مجال رؤية الحاسوب. (المصدر: AIatMeta)
🎯 التطورات
معهد أبحاث الذكاء الاصطناعي في بكين يفتح مصدر Video-XL-2، لتحقيق فهم الفيديو بآلاف الإطارات على بطاقة واحدة: أصدر معهد أبحاث الذكاء الاصطناعي في بكين (BAAI) بالتعاون مع جامعة شنغهاي جياو تونغ ومؤسسات أخرى الجيل الجديد من نموذج فهم الفيديو فائق الطول Video-XL-2. يُظهر هذا النموذج تحسينات كبيرة في الأداء وطول المعالجة والسرعة، حيث يمكن لبطاقة واحدة معالجة مدخلات فيديو تصل إلى عشرة آلاف إطار، وترميز 2048 إطارًا من الفيديو في 12 ثانية فقط. يعتمد Video-XL-2 على مُرمّز الرؤية SigLIP-SO400M، ووحدة تركيب الـ token الديناميكية (DTS)، ونموذج اللغة الكبير Qwen2.5-Instruct، ويحقق أداءً عاليًا من خلال التدريب التدريجي رباعي المراحل واستراتيجيات تحسين الكفاءة (مثل التعبئة المسبقة المجزأة وفك تشفير KV ثنائي الدقة). أظهر النموذج أداءً متميزًا في اختبارات MLVU و Video-MME وغيرها، وتم فتح مصدر أوزانه. (المصدر: 量子位)

Character.ai تطلق ميزة إنشاء الفيديو AvatarFX، مما يجعل شخصيات الصور متحركة وتفاعلية: أطلق تطبيق الرفقة بالذكاء الاصطناعي الرائد Character.ai (c.ai) ميزة AvatarFX، التي تسمح للمستخدمين بتحريك الشخصيات في الصور الثابتة (بما في ذلك الصور غير البشرية مثل الحيوانات الأليفة)، مما يجعلها قادرة على التحدث والغناء والتفاعل مع المستخدمين. تعتمد هذه الميزة على بنية DiT، وتؤكد على الدقة العالية والاتساق الزمني، وتحافظ على الاستقرار حتى في السيناريوهات المعقدة مثل الحوارات متعددة الشخصيات ذات التسلسل الطويل. ميزة AvatarFX متاحة حاليًا لجميع المستخدمين على نسخة الويب، وستتوفر قريبًا على التطبيق. وفي الوقت نفسه، أعلنت c.ai أيضًا عن ميزات جديدة مثل Scenes (مشاهد قصص تفاعلية)، و Imagine Animated Chat (سجلات دردشة متحركة)، و Stream (إنشاء قصص بين الشخصيات)، مما يزيد من إثراء تجربة الإبداع بالذكاء الاصطناعي. (المصدر: 量子位)

Nvidia تطلق نموذج اللغة المرئية Llama-3.1 Nemotron-Nano-VL-8B-V1: أصدرت Nvidia نموذجًا جديدًا للتحويل من الرؤية إلى نص باسم Llama-3.1-Nemotron-Nano-VL-8B-V1. يستطيع هذا النموذج معالجة مدخلات الصور والفيديو والنصوص، وإنشاء مخرجات نصية، ويمتلك درجة معينة من قدرات الاستدلال والتعرف على الصور. يعد إطلاق هذا النموذج دليلاً على استثمار Nvidia المستمر في مجال الذكاء الاصطناعي متعدد الوسائط. وفي الوقت نفسه، تشير مناقشات المجتمع إلى أن تخلي Llama-4 عن النماذج الأقل من 70B قد يوفر فرصًا لنماذج مثل Gemma3 و Qwen3 في سوق الضبط الدقيق. (المصدر: karminski3)
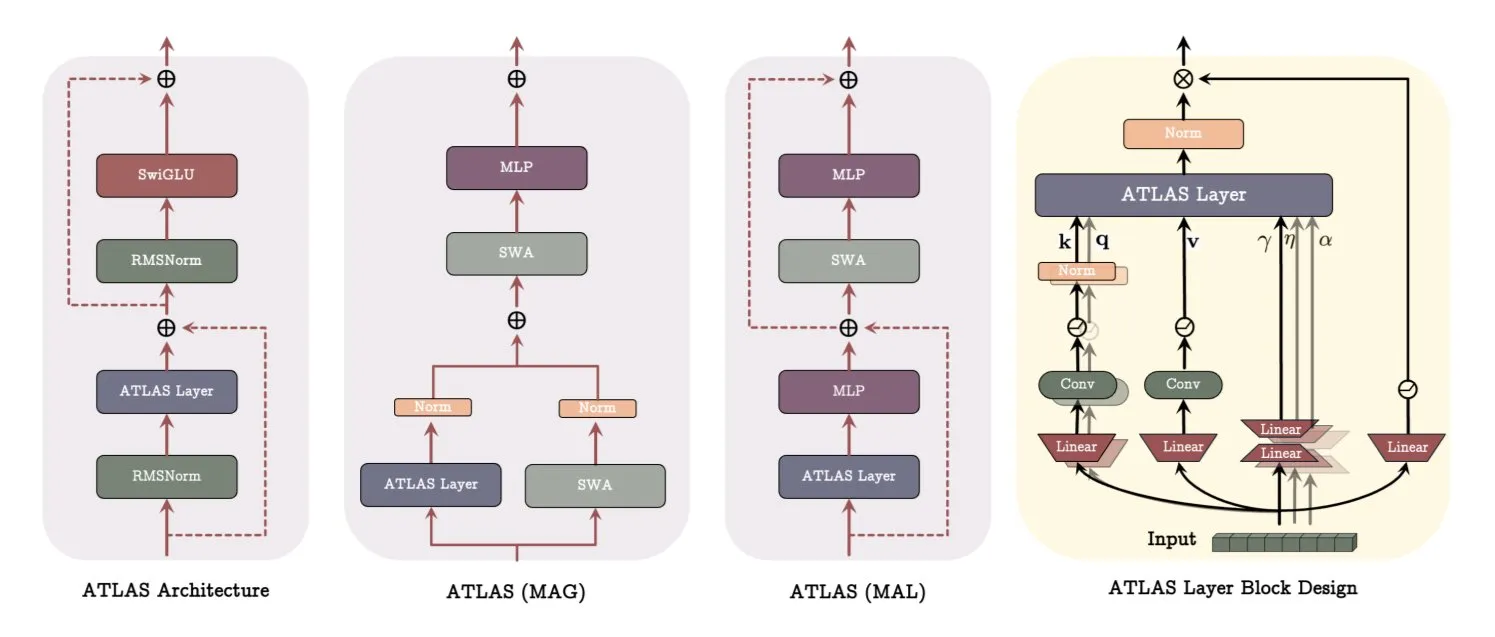
جوجل تنشر ورقة بحثية عن بنية ATLAS، وتُحدث ثورة في طرق تعلم النماذج وتذكرها: تقدم أحدث ورقة بحثية من جوجل بنية نموذجية جديدة تسمى ATLAS، تهدف إلى تحسين قدرات التعلم والتذكر للنماذج من خلال الذاكرة النشطة (قاعدة Omega لمعالجة أحدث c من الـ tokens) وإدارة سعة الذاكرة بشكل أذكى (تخطيطات الميزات متعددة الحدود والأسية). تستخدم ATLAS مُحسِّن Muon لتحديث الذاكرة بشكل أكثر فعالية، وتقدم تصميمات مثل DeepTransformers و Dot (Deep Omega Transformers)، لتحل محل الانتباه الثابت التقليدي بآليات قابلة للتعلم ومدفوعة بالذاكرة. يمثل هذا البحث خطوة نحو أنظمة ذكاء اصطناعي أكثر ذكاءً وإدراكًا للسياق، ومن المتوقع أن يعزز قدرة الذكاء الاصطناعي على معالجة واستخدام مجموعات البيانات الضخمة. (المصدر: TheTuringPost)
Qwen تطلق سلسلة نماذج Qwen3-Embedding، مما يعزز أداء التضمين بشكل كبير: أطلق فريق Qwen سلسلة نماذج Qwen3-Embedding الجديدة، والتي تشمل ثلاثة إصدارات: 0.6B، 4B، و 8B. تدعم هذه النماذج طول سياق يصل إلى 32 ألفًا و100 لغة، وحققت نتائج SOTA على MTEB (Massive Text Embedding Benchmark)، متفوقة على المركز الثاني في بعض المؤشرات بـ 10 نقاط. يمثل هذا التقدم طفرة أخرى مهمة في تقنية تضمين النصوص، ويوفر أساسًا أقوى لتطبيقات مثل البحث الدلالي و RAG. (المصدر: AymericRoucher, ClementDelangue)

مايكروسوفت تطلق Bing Video Creator، المعتمد على نموذج Sora من OpenAI ومتاح مجانًا: أطلقت مايكروسوفت أداة Bing Video Creator ضمن تطبيق Bing الخاص بها. تعتمد هذه الميزة على نموذج Sora من OpenAI، وتسمح للمستخدمين بإنشاء مقاطع فيديو مجانًا من خلال التوجيهات النصية. هذه هي المرة الأولى التي يتم فيها إتاحة نموذج Sora على نطاق واسع للجمهور مجانًا. على الرغم من كونه مجانيًا، إلا أن هناك قيودًا حالية على الميزات، مثل أن طول الفيديو يقتصر على 5 ثوانٍ، وبنسبة 9:16، وسرعة الإنشاء بطيئة نسبيًا. تشير ملاحظات المستخدمين إلى وجود فجوة في أدائه مقارنة بنماذج الفيديو SOTA الحالية (مثل Keling و Veo3)، مما أثار نقاشات حول سرعة تطور تقنية Sora واستراتيجية منتجات مايكروسوفت. (المصدر: 36氪)
OpenAI تطلق العديد من الميزات على مستوى المؤسسات لتعزيز التكامل في مكان العمل: أصدرت OpenAI سلسلة من الميزات الجديدة الموجهة لمستخدمي المؤسسات، بما في ذلك توفير موصلات مخصصة لتطبيقات مثل Google Drive، بالإضافة إلى تمكين تسجيل الاجتماعات ونسخها وتلخيصها في ChatGPT، ودعم SSO (تسجيل الدخول الموحد) والتسعير القائم على النقاط لإصدار المؤسسات. تهدف هذه التحديثات إلى دمج ChatGPT بشكل أعمق في سير عمل المؤسسات، وتعزيز كفاءة العمل المكتبي. (المصدر: TheRundownAI, EdwardSun0909)
Hugging Face تطلق نموذج الروبوت الفعال SmolVLA، الذي يمكن تشغيله على MacBook: أطلقت Hugging Face نموذج روبوت يسمى SmolVLA، يتميز بكفاءته العالية للغاية، حتى أنه يمكن تشغيله على جهاز MacBook. بعد الضبط الدقيق على كمية صغيرة من بيانات العرض (مثل 31)، يمكن للنموذج أن يصل إلى أو يتجاوز أداء خطوط الأساس أحادية المهمة في مهام محددة (مثل عمليات Koch Arm)، مما يدل على إمكاناته في نشر الذكاء الاصطناعي للروبوتات في بيئات محدودة الموارد. (المصدر: mervenoyann, sytelus)
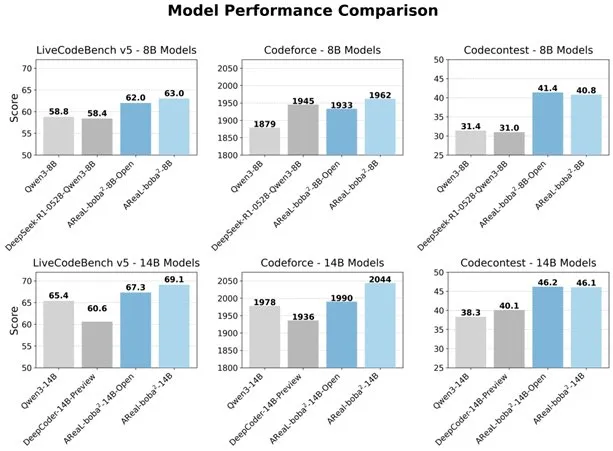
علي بابا تفتح مصدر نظام التعلم المعزز غير المتزامن بالكامل AReaL-boba²، لتعزيز قدرات نماذج اللغة الكبيرة في البرمجة: فتح فريق Qwen التابع لشركة علي بابا مصدر نظام التعلم المعزز غير المتزامن بالكامل AReaL-boba²، المصمم خصيصًا لنماذج اللغة الكبيرة (LLM)، وحقق نتائج SOTA في التعلم المعزز للبرمجة على Qwen3-14B. من خلال التصميم التعاوني للنظام والخوارزمية، حقق النظام تسريعًا في التدريب بمقدار 2.77 مرة، وحصل على 69.1 نقطة على LiveCodeBench، ويدعم التعلم المعزز متعدد الجولات. (المصدر: _akhaliq)
DuckDB تطلق إضافة DuckLake، لدمج بحيرات البيانات وتنسيقات الكتالوج: أصدرت DuckDB إضافة DuckLake، وهي تنسيق مفتوح المصدر لبحيرة البيانات الموحدة يعتمد على SQL و Parquet. تقوم DuckLake بتخزين البيانات الوصفية في قاعدة بيانات الكتالوج، والبيانات في ملفات Parquet. من خلال هذه الإضافة، يمكن لـ DuckDB قراءة وكتابة البيانات مباشرة في DuckLake، ودعم إنشاء الجداول وتعديلها والاستعلام عنها والسفر عبر الزمن وتطور المخططات، بهدف تبسيط بناء وإدارة بحيرات البيانات. (المصدر: GitHub Trending)
إصدار Model Context Protocol (MCP) Ruby SDK: أصدر Model Context Protocol (MCP) حزمة تطوير البرمجيات (SDK) الرسمية لـ Ruby، والتي يتم صيانتها بالتعاون مع Shopify، وتستخدم لتنفيذ خوادم MCP. يهدف MCP إلى توفير طريقة موحدة لنماذج الذكاء الاصطناعي (خاصة الـ Agents) لاكتشاف واستدعاء الأدوات، والوصول إلى الموارد، وتنفيذ التوجيهات المحددة مسبقًا. تدعم حزمة SDK هذه JSON-RPC 2.0، وتوفر وظائف أساسية مثل تسجيل الأدوات، وإدارة التوجيهات، والوصول إلى الموارد، مما يسهل على المطورين بناء تطبيقات ذكاء اصطناعي متوافقة مع مواصفات MCP. (المصدر: GitHub Trending)
تقنية الذكاء الاصطناعي تساعد بطاريات الزنك على تحقيق كفاءة 99.8% وعمر تشغيل يصل إلى 4300 ساعة: من خلال التحسين بواسطة الذكاء الاصطناعي، حققت بطاريات الزنك من الجيل الجديد كفاءة كولومبية بنسبة 99.8% وعمر تشغيل يصل إلى 4300 ساعة. إن تطبيق الذكاء الاصطناعي في مجال علوم المواد، وخاصة في تصميم البطاريات والتنبؤ بأدائها، يدفع عجلة التقدم في تكنولوجيا تخزين الطاقة، ومن المتوقع أن يوفر حلول طاقة أكثر كفاءة واستدامة لمجالات مثل السيارات الكهربائية والأجهزة الإلكترونية المحمولة. (المصدر: Ronald_vanLoon)

🧰 الأدوات
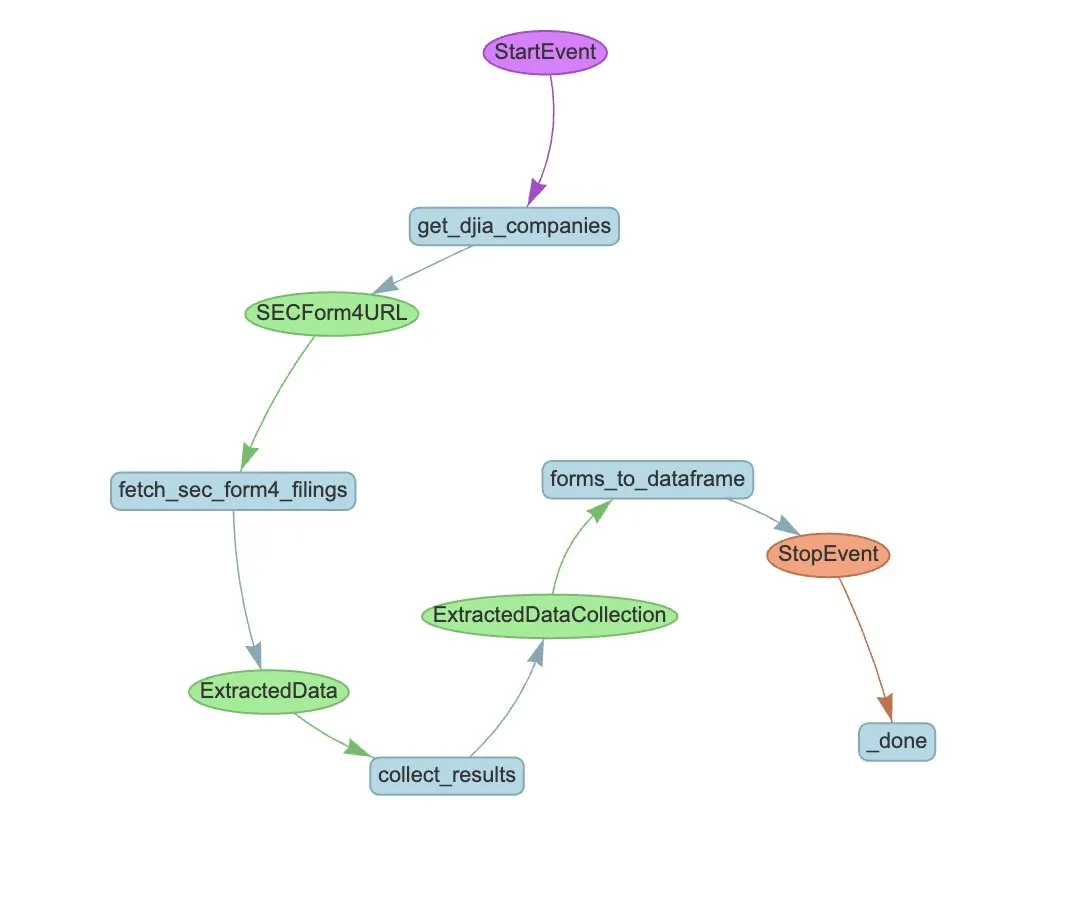
LlamaIndex تطلق LlamaExtract وسير عمل Agent لأتمتة استخراج بيانات نماذج SEC Form 4: عرضت LlamaIndex كيفية استخدام LlamaExtract وسير عمل Agent لأتمتة استخراج المعلومات المهيكلة من ملفات SEC Form 4. يعتبر SEC Form 4 وثيقة مهمة يفصح فيها المسؤولون التنفيذيون والمديرون والمساهمون الرئيسيون في الشركات المدرجة عن معاملاتهم في الأسهم. من خلال بناء وكيل استخراج وسير عمل قابل للتطوير، يمكن معالجة إقرارات Form 4 لجميع الشركات المدرجة في مؤشر داو جونز الصناعي بكفاءة، مما يعزز شفافية السوق وكفاءة تحليل البيانات. (المصدر: jerryjliu0)
Cognee: أداة مفتوحة المصدر لتزويد AI Agents بذاكرة ديناميكية: Cognee هو مشروع مفتوح المصدر يهدف إلى تزويد AI Agents بقدرات ذاكرة ديناميكية، ويدعي أنه يمكن دمجه بخمسة أسطر فقط من التعليمات البرمجية. يقوم ببناء خطوط أنابيب ECL (Extract, Cognify, Load) قابلة للتطوير والنمذجة، لمساعدة الـ Agents على الاتصال واسترجاع المحادثات السابقة والمستندات والصور ونسخ التسجيلات الصوتية، ليحل محل أنظمة RAG التقليدية، ويقلل من صعوبة وتكلفة التطوير، ويدعم معالجة وتحميل البيانات من أكثر من 30 مصدر بيانات. (المصدر: GitHub Trending)
Claude Code متاح الآن لمستخدمي Pro، وتم إطلاق نسخة مجتمعية من GitHub Action: أصبح مساعد البرمجة بالذكاء الاصطناعي Claude Code من Anthropic متاحًا لمشتركي Pro، ويمكن للمستخدمين استخدامه من خلال ملحقات JetBrains IDE وغيرها. كما أطلق مطورو المجتمع نسخة فرعية (fork) من Claude Code GitHub Action، مما يسمح للمستخدمين المدفوعين باستدعاء Claude Code مباشرة في GitHub Issues أو PRs، والاستفادة من حصص اشتراكهم لإكمال مهام مثل مراجعة التعليمات البرمجية والإجابة على الأسئلة، دون الحاجة إلى دفع رسوم API إضافية. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
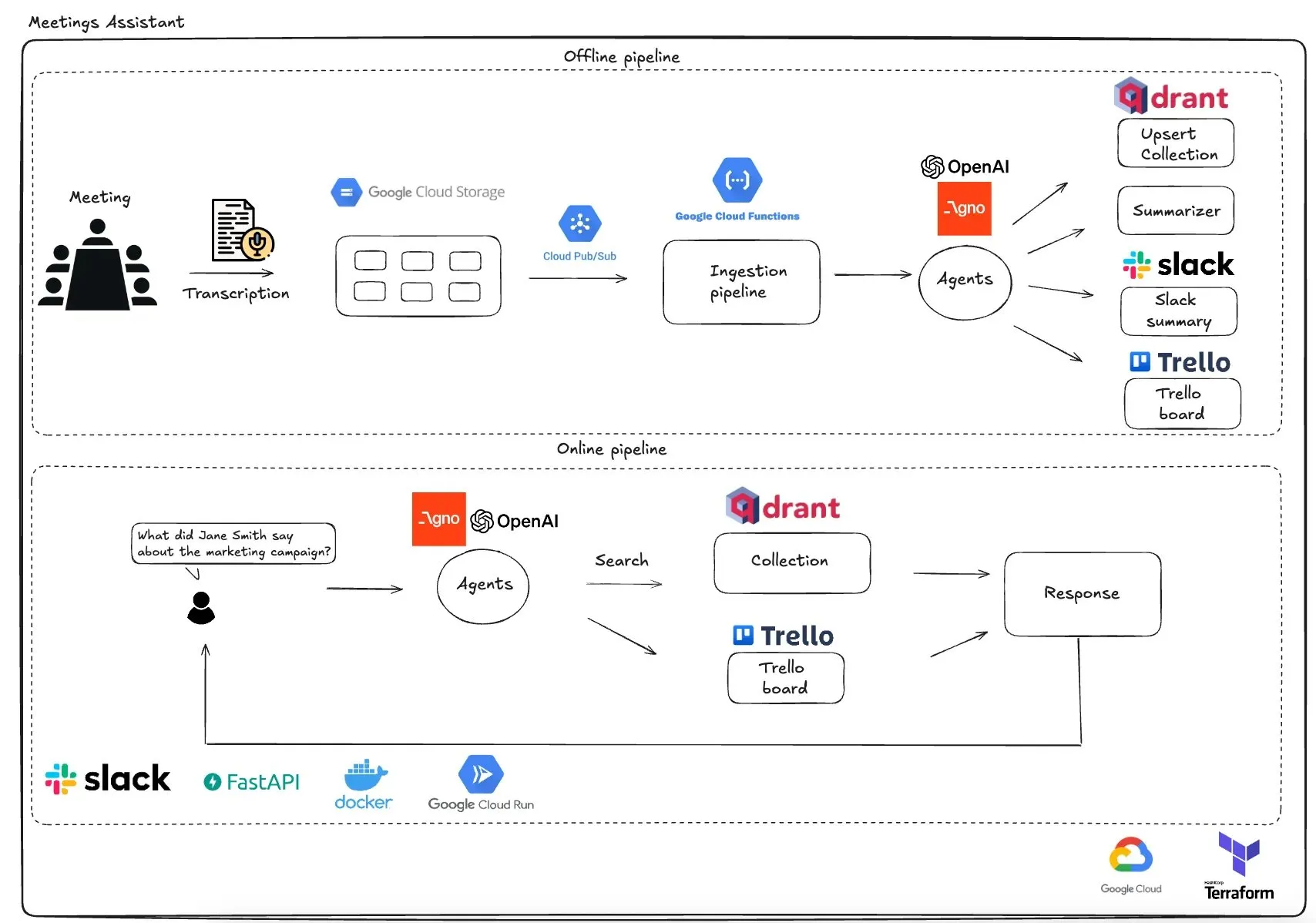
Qdrant تطلق مساعد اجتماعات متعدد الـ Agents يعتمد على GCP: عرضت Qdrant نظام مساعد اجتماعات متعدد الـ Agents لا يعتمد على خوادم بشكل كامل. يستطيع هذا النظام نسخ محتوى الاجتماعات، واستخدام LLM agents للتلخيص، وتخزين معلومات السياق في قاعدة بيانات Qdrant vector، ومزامنة المهام مع Trello، وتسليم النتائج النهائية مباشرة في Slack. يستفيد هذا النظام من AgnoAgi لتنسيق الـ Agents، و FastAPI الذي يعمل على Cloud Run، ويستخدم OpenAI للتضمين والاستدلال. (المصدر: qdrant_engine)
مايكروسوفت تطلق GUI-Actor، لتحقيق تحديد عناصر واجهة المستخدم الرسومية بدون إحداثيات: أطلقت مايكروسوفت على Hugging Face أداة GUI-Actor، وهي طريقة لتحديد عناصر واجهة المستخدم الرسومية (GUI) بدون الحاجة إلى إحداثيات. تسمح هذه الطريقة لـ AI agents بالإشارة مباشرة إلى الكتل المرئية الأصلية (visual patches) من خلال token خاص يسمى <actor>، بدلاً من الاعتماد على توقع الإحداثيات المستند إلى النص، بهدف تعزيز دقة ومتانة عمليات GUI agents. (المصدر: _akhaliq)

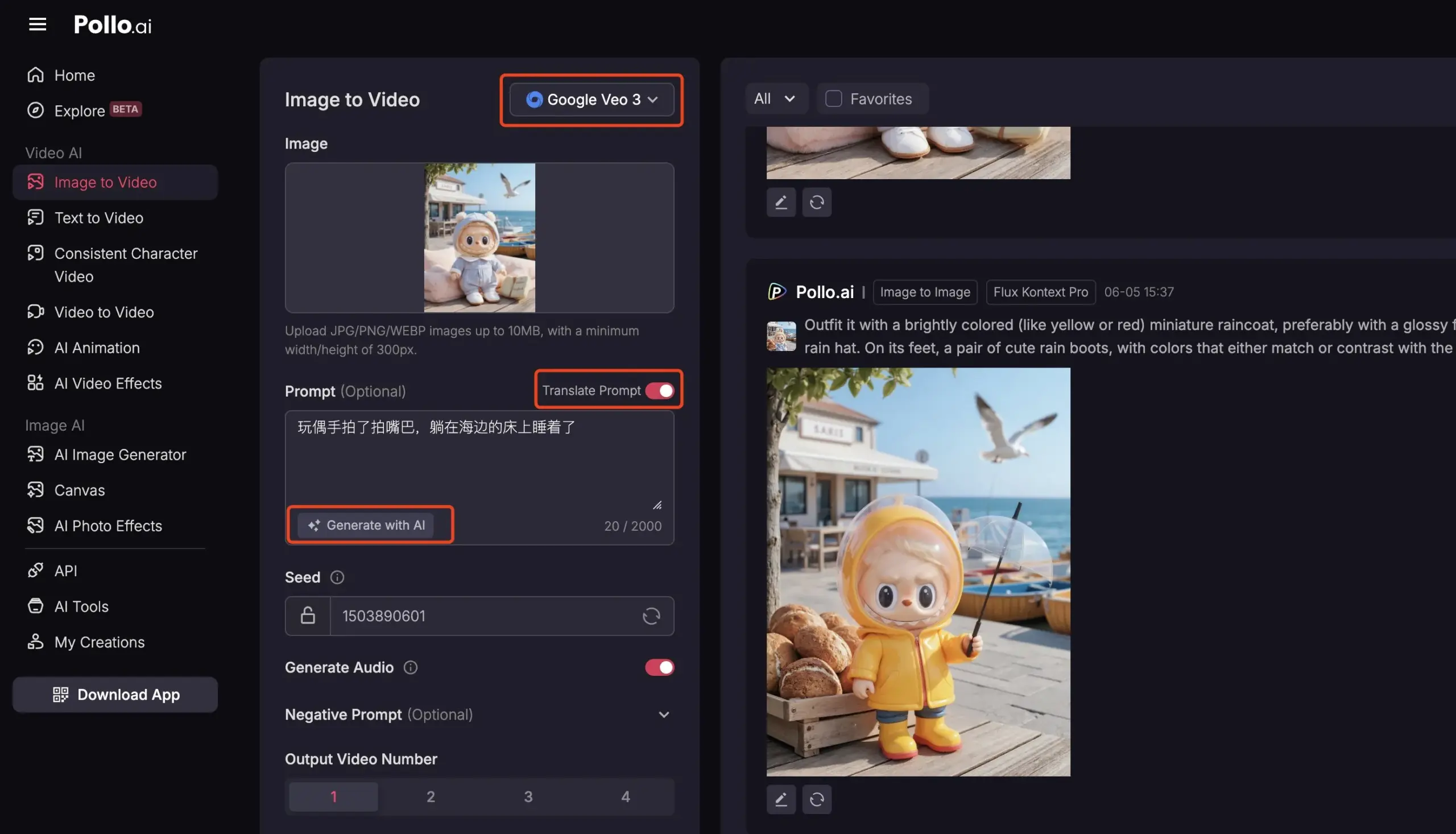
Pollo AI تدمج Veo3 و FLUX Kontext لتقديم خدمات فيديو شاملة بالذكاء الاصطناعي: شهدت منصة أدوات الذكاء الاصطناعي Pollo AI تحديثات متكررة مؤخرًا، حيث دمجت نموذج إنشاء الفيديو Veo3 من جوجل وميزة تحرير الصور FLUX Kontext. يمكن للمستخدمين على هذه المنصة استخدام FLUX Kontext لتعديل الصور ثم إرسالها مباشرة إلى Veo3 لإنشاء مقاطع فيديو. توفر المنصة أيضًا واجهة برمجة تطبيقات (API)، تدعم الوصول مرة واحدة إلى العديد من نماذج الفيديو الكبيرة السائدة في السوق، وتتضمن وظائف مساعدة مدمجة مثل إنشاء توجيهات الذكاء الاصطناعي والترجمة متعددة اللغات، بهدف تعزيز سهولة وكفاءة إنشاء الفيديو بالذكاء الاصطناعي. (المصدر: op7418)
📚 دراسات وأبحاث
تحليل معمق لـ Meta-Learning: تعليم الذكاء الاصطناعي كيف يتعلم: Meta-Learning (التعلم الميتا)، المعروف أيضًا باسم “تعلم كيف تتعلم”، تتمثل فكرته الأساسية في تدريب النماذج لتكون قادرة على التكيف بسرعة مع المهام الجديدة، حتى مع وجود عدد قليل فقط من العينات. تتضمن هذه العملية عادةً نموذجين: المتعلم الأساسي (base-learner) الذي يتكيف بسرعة مع مهام محددة (مثل تصنيف الصور بعدد قليل من العينات) في حلقة تعلم داخلية، والمتعلم الميتا (meta-learner) الذي يدير ويحدث معلمات أو استراتيجيات المتعلم الأساسي في حلقة تعلم خارجية، لتعزيز قدرته على حل المهام الجديدة. بعد اكتمال التدريب، يستخدم المتعلم الأساسي المعرفة التي اكتسبها المتعلم الميتا للتهيئة الأولية. (المصدر: TheTuringPost, TheTuringPost)

قراءة في ورقة بحثية بعنوان “A Controllable Examination for Long-Context Language Models”: تستهدف هذه الورقة البحثية القيود المفروضة على أطر تقييم نماذج اللغة ذات السياق الطويل (LCLM) الحالية (تعقيد مهام العالم الحقيقي وصعوبة حلها، وسهولة تأثرها بتلوث البيانات؛ والمهام الاصطناعية مثل NIAH التي تفتقر إلى ترابط السياق)، وتقترح ثلاثة خصائص يجب أن يتمتع بها إطار التقييم المثالي: سياق سلس، وإعدادات قابلة للتحكم، وتقييم سليم. وتقدم LongBioBench، وهو معيار جديد يستخدم السير الذاتية التي تم إنشاؤها يدويًا كبيئة خاضعة للرقابة، لتقييم LCLM من أبعاد الفهم والاستدلال والموثوقية. أظهرت التجارب أن معظم النماذج لا تزال تعاني من قصور في الفهم الدلالي، والاستدلال الأولي، والموثوقية في السياقات الطويلة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية بعنوان “Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning”: مستوحاة من قدرات الاستدلال الفائقة لـ Deepseek-R1 في المهام النصية المعقدة، تستكشف هذه الدراسة كيفية تعزيز قدرات الاستدلال المعقدة لنماذج اللغة الكبيرة متعددة الوسائط (MLLM) من خلال تحسين البدء البارد (cold start) والتعلم المعزز المرحلي (RL). وجدت الدراسة أن التهيئة الفعالة للبدء البارد ضرورية لتعزيز استدلال MLLM، وأن التهيئة باستخدام بيانات نصية مختارة بعناية فقط يمكن أن تتفوق على العديد من النماذج الحالية. يواجه تطبيق GRPO القياسي على التعلم المعزز متعدد الوسائط مشكلة ركود التدرج، بينما يمكن لتدريب التعلم المعزز النصي اللاحق أن يعزز الاستدلال متعدد الوسائط بشكل أكبر. بناءً على هذه النتائج، قدم الباحثون ReVisual-R1، الذي حقق نتائج SOTA على العديد من المعايير الصعبة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية بعنوان “Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem”: تقترح هذه الدراسة طريقة فعالة لإطلاق إمكانات الاستدلال لنماذج اللغة الكبيرة المدربة مسبقًا (LLM): الضبط الدقيق النقدي لمشكلة واحدة (Critique Fine-Tuning, CFT). من خلال جمع حلول متعددة تم إنشاؤها بواسطة النموذج لمشكلة واحدة، واستخدام LLM مُعلِّم لتقديم انتقادات مفصلة، يتم بناء بيانات نقدية للضبط الدقيق. أظهرت التجارب أنه بعد إجراء CFT لمشكلة واحدة على نماذج سلسلة Qwen و Llama، تم تحقيق تحسينات كبيرة في الأداء في العديد من مهام الاستدلال، على سبيل المثال، حقق Qwen-Math-7B-CFT تحسنًا متوسطًا بنسبة 15-16% في معايير الرياضيات والاستدلال المنطقي، بتكلفة حسابية أقل بكثير من التعلم المعزز. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية بعنوان “SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation”: لمعالجة مشكلة محدودية تغطية معايير معالجة SVG (Scalable Vector Graphics) الحالية، وافتقارها إلى تصنيف التعقيد، وتجزئة نماذج التقييم، ظهر SVGenius. وهو معيار شامل يتضمن 2377 استعلامًا، يغطي ثلاثة أبعاد: الفهم والتحرير والإنشاء، مبني على بيانات حقيقية من 24 مجال تطبيق، وتم تصنيفه بشكل منهجي حسب التعقيد. من خلال 8 فئات مهام و 18 مؤشرًا، تم تقييم 22 نموذجًا سائدًا، مما كشف عن قيود النماذج الحالية في معالجة SVG المعقدة، وأشار إلى أن التدريب المعزز بالاستدلال أكثر فعالية من مجرد توسيع النطاق. (المصدر: HuggingFace Daily Papers)
إصدار سجل تحديثات Hugging Face Hub: أصدر Hugging Face Hub أحدث سجل تحديثات له، ويمكن للمستخدمين الاطلاع عليه لمعرفة الميزات الجديدة للمنصة، وتحديثات مكتبة النماذج، وتوسيع مجموعات البيانات، وتحسينات سلسلة الأدوات، وغيرها من المستجدات. يساعد هذا مستخدمي المجتمع على الاطلاع والاستفادة من أحدث الموارد والقدرات في نظام Hugging Face البيئي. (المصدر: huggingface, _akhaliq)
Maxime Labonne ومؤلفون آخرون يفتحون مصدر عدد كبير من LLM Notebooks: قام Maxime Labonne، مؤلف دليل مهندس نماذج اللغة الكبيرة (LLM Engineer Handbook)، و Iustin Paul بفتح مصدر سلسلة من Jupyter Notebooks المتعلقة بنماذج اللغة الكبيرة. هذه الـ Notebooks غنية بالمحتوى، ولا تتضمن فقط تقنيات الضبط الدقيق الأساسية، بل تغطي أيضًا موضوعات متقدمة مثل التقييم التلقائي، والدمج الكسول (lazy merges)، وبناء نماذج خليط الخبراء (frankenMoEs)، وتقنيات إلغاء الرقابة، مما يوفر موارد عملية قيمة لمطوري وباحثي نماذج اللغة الكبيرة. (المصدر: maximelabonne)
DeepLearningAI تصدر النشرة الأسبوعية The Batch، وتناقش كيف يقوم AI Fund بتنمية بناة الذكاء الاصطناعي: شارك Andrew Ng في أحدث إصدار من نشرته الأسبوعية The Batch، خبرات واستراتيجيات AI Fund في تنمية مواهب وبناة الذكاء الاصطناعي. يغطي هذا العدد أيضًا موضوعات ساخنة مثل أداء نموذج DeepSeek الجديد مفتوح المصدر الذي ينافس أفضل نماذج اللغة الكبيرة، واستخدام Duolingo للذكاء الاصطناعي لتوسيع دورات اللغة، والمقايضات المتعلقة باستهلاك الطاقة في الذكاء الاصطناعي، والتضليل المحتمل لـ AI Agents بواسطة الروابط الخبيثة. (المصدر: DeepLearningAI)

💼 أعمال
Reddit تقاضي Anthropic، متهمة إياها باستخدام بيانات المستخدمين دون ترخيص لتدريب الذكاء الاصطناعي: رفعت Reddit دعوى قضائية ضد شركة الذكاء الاصطناعي Anthropic، متهمة إياها باستخدام روبوتات آلية لجمع محتوى Reddit دون إذن، لاستخدامه في تدريب نماذج الذكاء الاصطناعي الخاصة بها (مثل Claude)، مما يشكل خرقًا للعقد ومنافسة غير مشروعة. تسلط هذه القضية الضوء على الجدل الحالي حول شرعية جمع البيانات وتدريب النماذج في تطوير الذكاء الاصطناعي، وتعكس أيضًا الاهتمام المتزايد لمنصات المحتوى بحماية قيمة بياناتها. (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

أمازون تخطط لاستثمار 10 مليارات دولار في بناء مركز بيانات للذكاء الاصطناعي في ولاية كارولينا الشمالية: أعلنت أمازون أنها ستستثمر 10 مليارات دولار في بناء مركز بيانات جديد في ولاية كارولينا الشمالية، لدعم احتياجات أعمالها المتزايدة في مجال الذكاء الاصطناعي. تعكس هذه الخطوة الاستثمار المستمر من قبل شركات التكنولوجيا الكبرى في البنية التحتية للذكاء الاصطناعي، بهدف تلبية متطلبات الحوسبة والتخزين واسعة النطاق اللازمة لتدريب نماذج الذكاء الاصطناعي واستدلالها. (المصدر: Reddit r/artificial)

Anthropic تقلص وصول Windsurf.ai إلى واجهة برمجة تطبيقات نموذج Claude، مما يثير مخاوف بشأن مخاطر المنصة: كشفت منصة تطوير تطبيقات الذكاء الاصطناعي Windsurf.ai أن Anthropic قلصت بشكل كبير من قدرة وصولها إلى واجهة برمجة تطبيقات نماذج Claude 3.x و Claude 4، وذلك بإشعار مسبق يقل عن 5 أيام. أجبرت هذه الخطوة Windsurf.ai على البحث بشكل عاجل عن موردين خارجيين لضمان خدمة المستخدمين المدفوعين، وتوفير خيار BYOK (أحضر مفتاحك الخاص) للمستخدمين المجانيين ومستخدمي Pro. زادت هذه الحادثة من مخاوف المطورين بشأن مخاطر منصات مزودي نماذج الذكاء الاصطناعي، أي أن مزودي النماذج قد يقومون بتعديل سياسات الخدمة في أي وقت، أو حتى الدخول في منافسة مع التطبيقات النهائية. (المصدر: swyx, scaling01, mervenoyann)
🌟 المجتمع
مؤتمر مهندسي الذكاء الاصطناعي (@aiDotEngineer) يثير نقاشًا واسعًا، ويركز على تصميم الـ Agents وريادة الأعمال في مجال الذكاء الاصطناعي: أصبح مؤتمر مهندسي الذكاء الاصطناعي (@aiDotEngineer) الذي عقد في سان فرانسيسكو محور نقاش ساخن في المجتمع. شاركت LlamaIndex أنماط تصميم Agents فعالة في بيئات الإنتاج؛ وقدمت Anthropic في المؤتمر “قائمة احتياجات” للشركات الناشئة، مع التركيز على تطبيقات خوادم MCP في مجالات جديدة، وتبسيط بناء الخوادم، وأمن تطبيقات الذكاء الاصطناعي (مثل تسميم الأدوات)؛ وعرضت Graphite أداة مراجعة التعليمات البرمجية المدفوعة بالذكاء الاصطناعي. كما ناقش المؤتمر تحديات البحث الأساسي التي تواجه توسيع نطاق نماذج GPT من الجيل التالي وغيرها من القضايا. (المصدر: swyx, swyx, swyx, iScienceLuvr)

انضمام الباحث Rohan Anil إلى Anthropic يثير الاهتمام: أعلن الباحث Rohan Anil عن انضمامه إلى فريق Anthropic، وهو خبر أثار اهتمامًا ونقاشًا واسعًا في مجتمع الذكاء الاصطناعي. أعرب العديد من المتخصصين والمتابعين في هذا المجال عن تهانيهم، ويتطلعون إلى مساهماته الجديدة في أعمال أبحاث Anthropic. يعكس هذا أيضًا التأثير المحتمل لحركة أفضل مواهب الذكاء الاصطناعي على هيكل الصناعة. (المصدر: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
المحكمة تطالب OpenAI بالاحتفاظ بجميع سجلات ChatGPT، مما يثير نقاشًا حول سياسات الاحتفاظ بالبيانات: أفادت التقارير أن المحكمة طالبت OpenAI بالاحتفاظ بجميع سجلات ChatGPT، بما في ذلك “المحادثات المؤقتة” وطلبات API التي كان من المفترض حذفها. أثار هذا الخبر نقاشًا في المجتمع حول سياسات الاحتفاظ بالبيانات، خاصة بالنسبة للتطبيقات التي تستخدم واجهة برمجة تطبيقات OpenAI، حيث قد يعني ذلك أن سياسات الاحتفاظ بالبيانات الخاصة بها لن يتم الالتزام بها بالكامل، مما يفرض تحديات جديدة على خصوصية المستخدم وإدارة البيانات. يُنصح المستخدمون بإعطاء الأولوية لاستخدام النماذج المحلية قدر الإمكان لحماية البيانات. (المصدر: code_star, TomLikesRobots)

انتشار المحتوى الناتج عن الذكاء الاصطناعي وظاهرة “AI Slop” تثير القلق: يتزايد المحتوى الناتج عن الذكاء الاصطناعي منخفض الجودة والذي يسعى لجذب الانتباه (يُعرف بـ “AI Slop”) على وسائل التواصل الاجتماعي، بدءًا من المنشورات التي أنشأها الذكاء الاصطناعي على Reddit إلى صور الذكاء الاصطناعي مثل “يسوع الجمبري” على Facebook، مما يثير قلق المستخدمين بشأن جودة المعلومات وتدهور بيئة الإنترنت. عادةً ما يتم إنشاء هذا المحتوى بثمن بخس بواسطة روبوتات أو باحثين عن التفاعل، بهدف الحصول على الإعجابات والمشاركات من خلال “طُعم المشاركة”. تشير الأبحاث إلى أن جزءًا كبيرًا من حركة المرور على الإنترنت يتكون بالفعل من “روبوتات سيئة” تنشر معلومات مضللة وتسرق البيانات. لا تؤثر هذه الظاهرة على تجربة المستخدم فحسب، بل تشكل أيضًا تهديدًا للديمقراطية والاتصال السياسي، وفي الوقت نفسه قد تلوث بيانات تدريب نماذج الذكاء الاصطناعي المستقبلية. (المصدر: aihub.org)

نقاش حول تكلفة نماذج اللغة الكبيرة: Gemini يتمتع بفعالية تكلفة عالية، وتكلفة برمجة Claude 4 تثير الاهتمام: تشير مناقشات المجتمع إلى أن تكلفة استخدام نماذج اللغة الكبيرة الحالية تختلف بشكل كبير. على سبيل المثال، تبلغ تكلفة استخدام Gemini لمعالجة مستند تأمين كامل وطرح عدد كبير من الأسئلة حوالي 0.01 دولار أمريكي فقط، مما يدل على فعالية تكلفة عالية. في المقابل، على الرغم من أن نموذج Claude 4 يقدم أداءً متميزًا في مهام مثل البرمجة، إلا أن تكلفة استخدامه في الوضع الأقصى (max mode) على منصات مثل Cursor.ai مرتفعة، مما يدفع المستخدمين إلى التحول إلى خيارات أكثر فعالية من حيث التكلفة مثل Google Gemini 2.5 Pro. (المصدر: finbarrtimbers, Teknium1)
AI Agents تواجه تحديات في حل CAPTCHA (التحقق البشري الآلي) في سيناريوهات الويب الحقيقية: أطلق فريق MetaAgentX منصة Open CaptchaWorld، التي تركز على تقييم قدرة الـ Agents التفاعلية متعددة الوسائط على حل CAPTCHA. أظهرت الاختبارات أنه حتى نماذج SOTA مثل GPT-4o، عند معالجة 20 نوعًا من رموز التحقق التفاعلية في بيئات الويب الحقيقية، لم تتجاوز نسبة نجاحها 5%-40%، وهو أقل بكثير من متوسط نسبة نجاح البشر البالغة 93.3%. يشير هذا إلى أن AI Agents الحالية لا تزال تعاني من اختناقات في الفهم البصري، والتخطيط متعدد الخطوات، وتتبع الحالة، والتفاعل الدقيق، مما يجعل رموز التحقق عقبة رئيسية أمام نشرها العملي. (المصدر: 量子位)

سوق تدريب AI Agents يشهد رواجًا، وجودة الدورات وآفاق التوظيف تثير الاهتمام: مع ظهور مفهوم AI Agents، ظهرت أيضًا الدورات التدريبية ذات الصلة بأعداد كبيرة. تدعي بعض مؤسسات التدريب أنها تقدم توجيهًا شاملاً من المستوى المبتدئ إلى التوظيف، بل وتعد “بضمان التوظيف”، وتتراوح الرسوم الدراسية من بضع مئات من اليوانات إلى عشرات الآلاف. ومع ذلك، فإن جودة الدورات التدريبية في السوق متفاوتة، ويُتهم بعضها بتقديم محتوى سطحي وتسويق مفرط، بل ويشبه دورات الذكاء الاصطناعي السريعة التي تهدف إلى “جني الأموال”. يبدي المتدربون والمراقبون حذرًا تجاه الفعالية الفعلية لهذه الدورات، ومؤهلات المدربين، ومصداقية وعود “ضمان التوظيف”، ويخشون أن تصبح “طلبًا زائفًا” آخر في الفترة الانتقالية لتطور الذكاء الاصطناعي. (المصدر: 36氪)

💡 أخبار أخرى
تطورات تطبيقات الذكاء الاصطناعي في مجال الروبوتات: يد ذات إحساس باللمس، وروبوت برمائي، وكلب روبوتي للإطفاء: تدفع تقنية الذكاء الاصطناعي حدود قدرات الروبوتات. طور باحثون يدًا ميكانيكية ذات قدرة على الإحساس باللمس، مما يمكنها من التفاعل بشكل أفضل مع البيئة. عرضت Copperstone HELIX Neptune روبوتًا برمائيًا مدفوعًا بالذكاء الاصطناعي، قادرًا على العمل في تضاريس مختلفة. أما الصين فقد أطلقت كلبًا روبوتيًا للإطفاء قادرًا على ضخ المياه لمسافة 60 مترًا، وتسلق السلالم، وبث عمليات الإنقاذ مباشرة. تُظهر هذه التطورات إمكانات الذكاء الاصطناعي في تعزيز قدرات الروبوتات على الإدراك واتخاذ القرار وتنفيذ المهام المعقدة. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

نقاش حول المقارنة بين AI Agents والذكاء الاصطناعي التوليدي: ظهر في المجتمع نقاش حول الفروق والروابط بين AI Agents (الذكاء الاصطناعي القائم على الوكلاء) والذكاء الاصطناعي التوليدي (Generative AI). يركز الذكاء الاصطناعي التوليدي بشكل أساسي على إنشاء المحتوى، بينما يركز AI Agents بشكل أكبر على اتخاذ القرارات المستقلة وتنفيذ المهام بناءً على الإدراك والتخطيط والعمل. يساعد فهم الفروق بينهما على فهم اتجاهات تطور تكنولوجيا الذكاء الاصطناعي وسيناريوهات تطبيقها بشكل أفضل. (المصدر: Ronald_vanLoon, Ronald_vanLoon)
استكشاف تحديات الذكاء الاصطناعي في أتمتة العمليات التنظيمية المعقدة: حقق الذكاء الاصطناعي تقدمًا في أتمتة أو مساعدة مهام محددة، ولكنه يواجه تعقيدًا هائلاً في استبدال العمالة البشرية أو الفرق لتحقيق تحول اقتصادي أوسع نطاقًا. توجد في العديد من المنظمات عمليات غير موثقة بشكل واضح ولكنها حاسمة، وهذه العمليات عالية المخاطر ولكنها تحدث بشكل متقطع، وقد تكون أصبحت روتينية لدرجة أن أسبابها قد نُسيت. يصعب على AI agents تعلم هذا النوع من المعرفة الضمنية من خلال التجربة والخطأ، نظرًا لتكلفتها الباهظة وفرص التعلم المحدودة. يتطلب هذا نماذج تقنية جديدة، وليس مجرد تعلم آلي بسيط. (المصدر: random_walker)