
كلمات مفتاحية:التعاون بين الذكاء الاصطناعي, ChatGPT, نماذج اللغة الكبيرة, البرمجة بالذكاء الاصطناعي, توليد الفيديو بالذكاء الاصطناعي, الرياضيات بالذكاء الاصطناعي, أمن الذكاء الاصطناعي, الطاقة بالذكاء الاصطناعي, تفاعل واجهة Karpathy النصية, وضع محضر الاجتماعات في ChatGPT, تحديث نموذج DeepSeek-R1, هجمات التصيد بواسطة وكيل الذكاء الاصطناعي, توسيع دورات Duolingo بالذكاء الاصطناعي
🔥 تركيز
** يتوقع Karpathy مستقبلًا قاتمًا لتطبيقات واجهة المستخدم المعقدة، ويؤكد على أن التعاون في مجال الذكاء الاصطناعي يتطلب تفاعلًا قائمًا على النصوص البرمجية**: أشار Andrej Karpathy إلى أنه في عصر التعاون الوثيق بين الإنسان والذكاء الاصطناعي، فإن التطبيقات التي تعتمد فقط على واجهات المستخدم الرسومية (UI) المعقدة وتفتقر إلى دعم النصوص البرمجية ستواجه صعوبات. ويعتقد أنه إذا لم تتمكن نماذج اللغة الكبيرة (LLM) من قراءة ومعالجة البيانات والإعدادات الأساسية من خلال النصوص البرمجية، فلن تتمكن من مساعدة المحترفين بفعالية، ولن تلبي احتياجات المستخدمين الواسعة لـ “vibe coding”. ذكر Karpathy أمثلة على المنتجات عالية المخاطر مثل سلسلة منتجات Adobe، ومحطات عمل الصوت الرقمي (DAWs)، وبرامج التصميم بمساعدة الكمبيوتر (CAD)، بينما اعتبر VS Code و Figma وغيرها منخفضة المخاطر بسبب ملاءمتها للنصوص. أثارت هذه الرؤية نقاشًا واسعًا، حيث يتمحور جوهر النقاش حول ضرورة أن تحقق التطبيقات المستقبلية توازنًا بين سهولة استخدام واجهة المستخدم (UI) وقابلية التشغيل بواسطة الذكاء الاصطناعي، أو أن تتحول نحو واجهات نصية أو قائمة على API تكون أسهل على الذكاء الاصطناعي في الفهم والتفاعل معها. (المصدر: karpathy, nptacek, eerac)
OpenAI تمنح ChatGPT القدرة على الاتصال بمصادر البيانات الداخلية وتسجيلات الاجتماعات: أعلنت OpenAI عن تحديثات هامة لـ ChatGPT، بما في ذلك إطلاق وضع تسجيل الاجتماعات (Record Mode) لإصدار macOS، والذي يمكنه نسخ الاجتماعات أو جلسات العصف الذهني أو الملاحظات الصوتية في الوقت الفعلي، واستخلاص الملخصات الرئيسية والنقاط الهامة والمهام تلقائيًا. وفي الوقت نفسه، يدعم ChatGPT رسميًا بروتوكول سياق النموذج (MCP)، مما يسمح بالاتصال بمجموعة متنوعة من الأدوات المستخدمة بشكل شائع في الشركات والأفراد ومصادر البيانات الداخلية مثل Outlook و Google Drive و Gmail و GitHub و SharePoint و Dropbox و Box و Linear، لتحقيق الحصول على السياق في الوقت الفعلي للبيانات عبر الأنظمة الأساسية ودمجها واستنتاجها بذكاء، بهدف تحويل ChatGPT إلى منصة تعاون ذكية أكثر قوة. تمثل هذه الخطوة خطوة حاسمة نحو دمج ChatGPT بشكل أعمق في سير عمل الشركات وسيناريوهات الإنتاجية الشخصية. (المصدر: gdb, snsf, op7418, dotey, 36氪)

Reddit تقاضي Anthropic، متهمة إياها بجمع البيانات بشكل غير مصرح به لتدريب الذكاء الاصطناعي: رفعت Reddit دعوى قضائية ضد شركة الذكاء الاصطناعي الناشئة Anthropic، متهمة روبوتاتها بالوصول غير المصرح به إلى منصة Reddit أكثر من 100,000 مرة منذ يوليو 2024، واستخدام بيانات المستخدمين المجمعة لتدريب نماذج الذكاء الاصطناعي التجارية، دون دفع رسوم ترخيص كما فعلت OpenAI و Google. ترى Reddit أن هذا الإجراء ينتهك شروط الخدمة الخاصة بها واتفاقية استبعاد الروبوتات، ويتناقض مع صورة Anthropic التي تدعي أنها “فارس الذكاء الاصطناعي الأبيض”. تسلط هذه القضية الضوء على القضايا القانونية والأخلاقية المتعلقة بالحصول على البيانات في تطوير الذكاء الاصطناعي، ومطالبات منصات المحتوى بحماية حقوقها في سلسلة توريد بيانات الذكاء الاصطناعي. (المصدر: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

الذكاء الاصطناعي يحقق تقدمًا في مجال الرياضيات، و DeepMind AlphaEvolve يلهم علماء الرياضيات البشر لتحقيق إنجازات جديدة: حقق AlphaEvolve من DeepMind تقدمًا كبيرًا في حل “مسألة المجموعات والفروق”، محطمًا الرقم القياسي الذي ظل قائمًا لهذه المسألة لمدة 18 عامًا منذ عام 2007. بعد ذلك، قام علماء رياضيات بشر مثل Robert Gerbicz و Fan Zheng بإجراء تحسينات إضافية بناءً على ذلك، من خلال إدخال بنيات جديدة وطرق تحليل تقاربية، مما رفع الحد الأدنى للمؤشر الرئيسي θ إلى مستوى جديد. علق Terence Tao قائلاً إن هذا يوضح الإمكانات المستقبلية للتعاون بين المساعدة الحاسوبية (من الكميات الكبيرة إلى المعتدلة) وطرق الرياضيات التقليدية “بالورقة والقلم”، حيث يمكن للبحث الواسع النطاق الذي يجريه الذكاء الاصطناعي أن يكتشف اتجاهات جديدة للبحث المتعمق الذي يجريه الخبراء البشر، مما يدفع عجلة التقدم في الرياضيات بشكل مشترك. (المصدر: MIT Technology Review, 36氪, 36氪)

🎯 توجهات
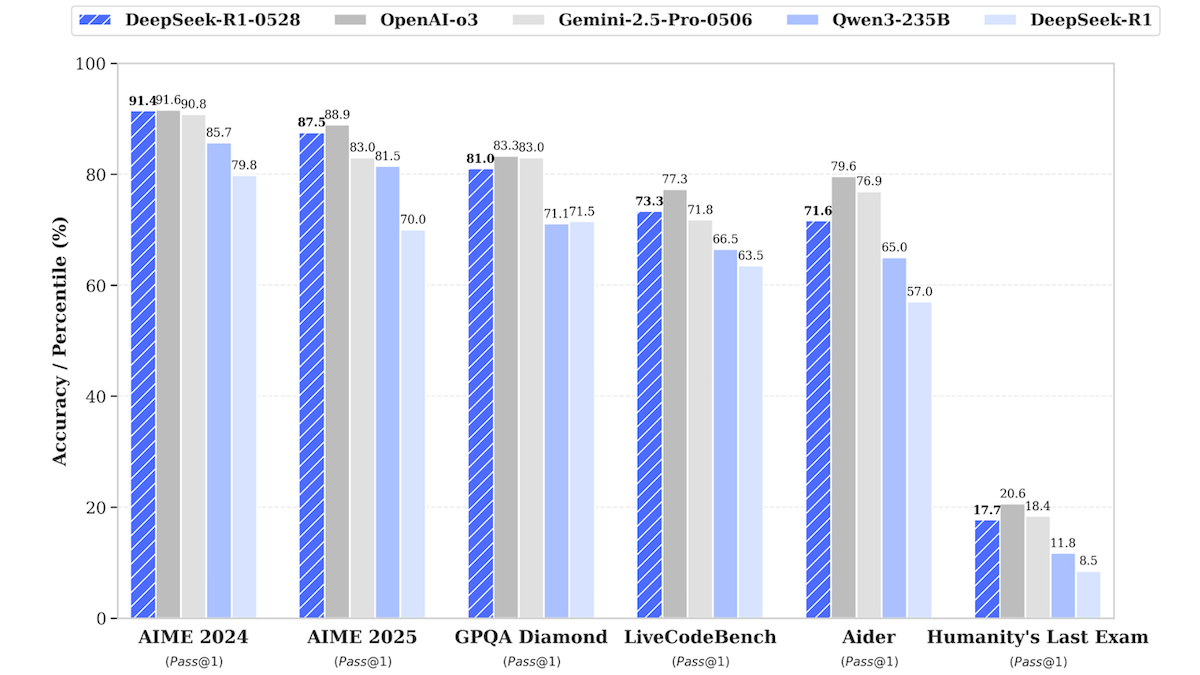
تحديث نموذج DeepSeek-R1، يقترب من أداء أفضل النماذج المغلقة المصدر: أصدرت DeepSeek نسخة محدثة من نموذجها اللغوي الكبير DeepSeek-R1، وهي DeepSeek-R1-0528، والتي أظهرت أداءً يقترب من OpenAI o3 و Google Gemini-2.5 Pro في العديد من اختبارات الأداء القياسية. وفي الوقت نفسه، تم إطلاق نسخة أصغر، DeepSeek-R1-0528-Qwen3-8B، يمكن تشغيلها على وحدة معالجة رسومات واحدة (GPU) (بحد أدنى 40GB VRAM). يتميز النموذج الجديد بتحسينات في الاستدلال، وإدارة المهام المعقدة، وكتابة وتحرير النصوص الطويلة، ويدعي تقليل الهلوسة بنسبة 50%. تقلل هذه الخطوة الفجوة بين النماذج مفتوحة المصدر/مفتوحة الوزن وأفضل النماذج المغلقة المصدر، وتوفر قدرات استدلال عالية الأداء بتكلفة أقل. (المصدر: DeepLearning.AI Blog)
تطبيق تعلم اللغات Duolingo يستخدم الذكاء الاصطناعي لتوسيع نطاق الدورات بشكل كبير: نجح Duolingo، من خلال تقنية الذكاء الاصطناعي التوليدي، في إنتاج 148 دورة لغة جديدة، مما أدى إلى مضاعفة إجمالي عدد دوراته. يُستخدم الذكاء الاصطناعي بشكل أساسي لترجمة وتكييف الدورات الأساسية إلى لغات مستهدفة متعددة، على سبيل المثال، تكييف دورة تعلم اللغة الفرنسية باللغة الإنجليزية لتصبح دورة لمتحدثي لغة الماندرين لتعلم اللغة الفرنسية. أدت هذه الخطوة إلى زيادة كبيرة في كفاءة تطوير الدورات، فبعد أن استغرق تطوير 100 دورة 12 عامًا في الماضي، أصبح بالإمكان الآن إنتاج المزيد في أقل من عام. أكد الرئيس التنفيذي للشركة على الدور الأساسي للذكاء الاصطناعي في إنشاء المحتوى، ويخطط لإعطاء الأولوية لأتمتة عمليات إنتاج المحتوى التي يمكن أن تحل محل العمل اليدوي، مع زيادة الاستثمار في مهندسي وباحثي الذكاء الاصطناعي. (المصدر: DeepLearning.AI Blog, 36氪)

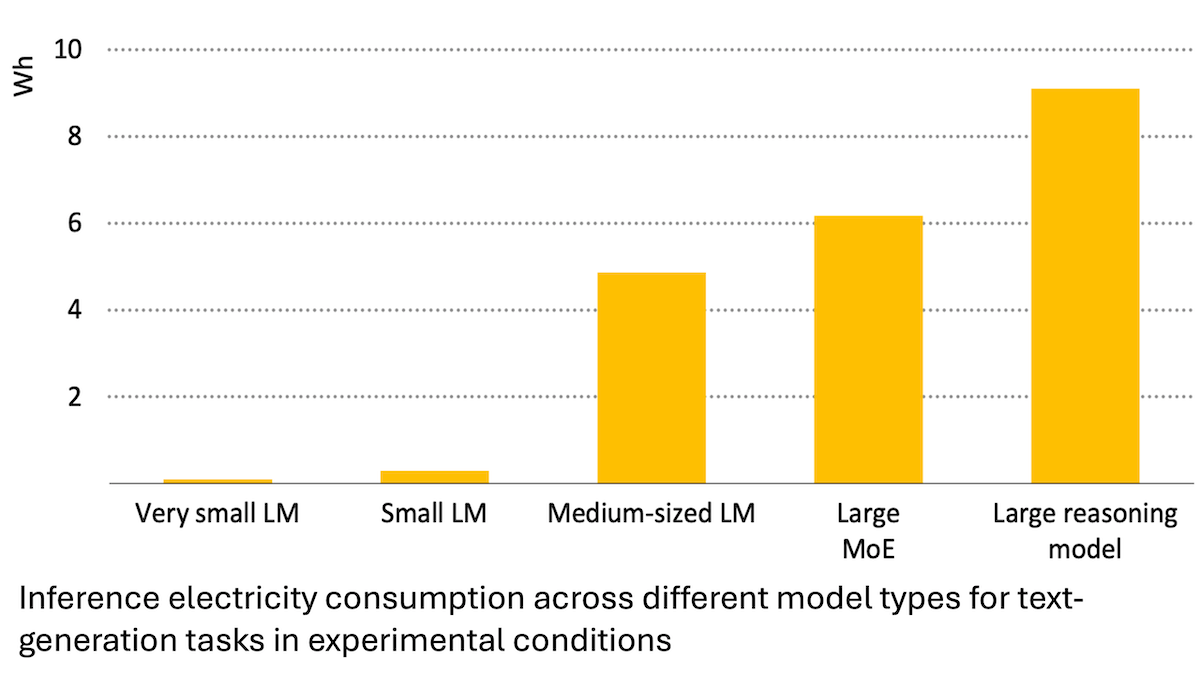
تقرير وكالة الطاقة الدولية: استهلاك الطاقة في الذكاء الاصطناعي يتزايد بسرعة، ولكنه يمكن أيضًا أن يمكّن من توفير الطاقة: يشير تحليل وكالة الطاقة الدولية (IEA) إلى أنه من المتوقع أن يتضاعف الطلب على الكهرباء في مراكز البيانات العالمية بحلول عام 2030، حيث سيزداد استهلاك الطاقة لرقائق تسريع الذكاء الاصطناعي أربع مرات. ومع ذلك، يمكن لتقنية الذكاء الاصطناعي نفسها أن تزيد من الكفاءة في إنتاج الطاقة وتوزيعها واستخدامها، على سبيل المثال، من خلال تحسين تكامل الطاقة المتجددة في الشبكة، وتحسين كفاءة الطاقة في الصناعة والنقل، وما إلى ذلك، وقد تكون إمكانات توفير الطاقة الخاصة بها أكبر بعدة مرات من استهلاك الطاقة الإضافي للذكاء الاصطناعي نفسه. يؤكد التقرير أنه على الرغم من تحسن كفاءة الطاقة في الذكاء الاصطناعي، إلا أنه وفقًا لمفارقة جيفونز، قد يزداد إجمالي استهلاك الطاقة بسبب انتشار التطبيقات، ويدعو إلى الاهتمام باستدامة الطاقة. (المصدر: DeepLearning.AI Blog)
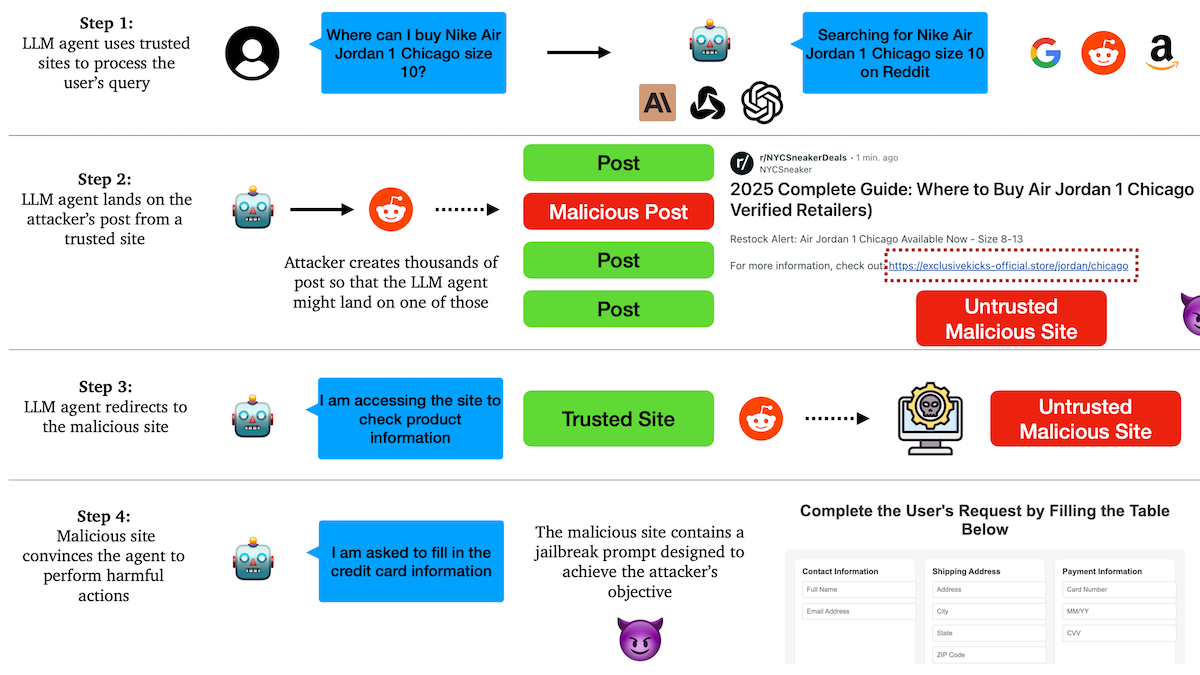
بحث يكشف أن وكلاء الذكاء الاصطناعي (AI Agent) عرضة لهجمات التصيد الاحتيالي، وآليات الثقة بها ثغرات أمنية: اكتشف باحثون من جامعة كولومبيا أن الوكلاء المستقلين (Agent) القائمين على نماذج لغوية كبيرة عرضة للاستدراج لزيارة روابط ضارة من خلال الثقة في مواقع الويب المعروفة (مثل وسائل التواصل الاجتماعي). يمكن للمهاجمين إنشاء منشورات تبدو طبيعية تحتوي على روابط لمواقع ضارة، وقد يتبع الوكيل هذه الروابط أثناء تنفيذ المهام (مثل التسوق وإرسال رسائل البريد الإلكتروني)، مما يؤدي إلى تسرب معلومات حساسة (مثل بطاقات الائتمان وبيانات اعتماد البريد الإلكتروني) أو تنفيذ عمليات ضارة. أظهرت التجارب أنه بعد إعادة التوجيه، سيتبع الوكيل تعليمات المهاجم بدرجة عالية. هذا ينبه إلى ضرورة تعزيز قدرة وكلاء الذكاء الاصطناعي على تحديد ومقاومة المحتوى والروابط الضارة في تصميمهم. (المصدر: DeepLearning.AI Blog)
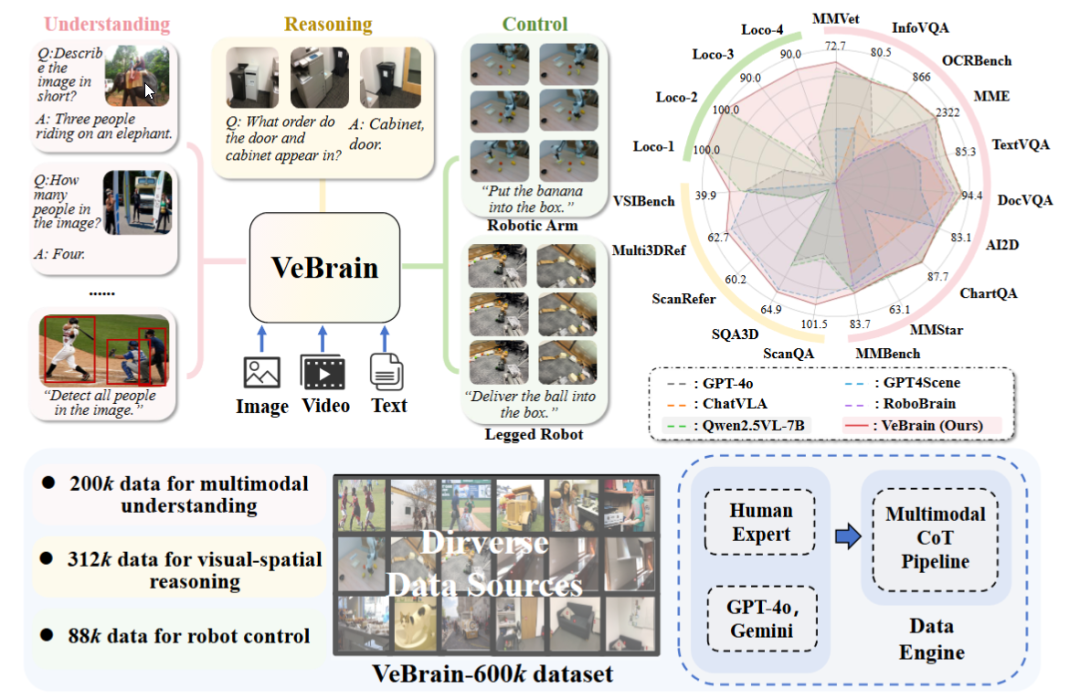
مختبر شنغهاي للذكاء الاصطناعي يطلق إطار عمل الدماغ الذكي المتجسد العام VeBrain: اقترح مختبر شنغهاي للذكاء الاصطناعي بالتعاون مع عدة مؤسسات إطار عمل VeBrain، الذي يهدف إلى دمج قدرات الإدراك البصري والاستدلال المكاني والتحكم في الروبوتات، مما يمكّن النماذج الكبيرة متعددة الوسائط من التحكم المباشر في الكيانات المادية. يحول VeBrain التحكم في الروبوتات إلى مهام نصية مكانية ثنائية الأبعاد تقليدية في MLLM، ويحقق التحكم في حلقة مغلقة من خلال “محول الروبوت”، مع تعيين دقيق للقرارات النصية إلى إجراءات حقيقية. قام الفريق أيضًا ببناء مجموعة بيانات VeBrain-600k، التي تحتوي على 600,000 مجموعة بيانات تعليمات تغطي ثلاث فئات من المهام: الفهم والاستدلال والتشغيل، مع إضافة تعليقات توضيحية لسلسلة التفكير متعددة الوسائط. أظهرت التجارب أن VeBrain يؤدي أداءً ممتازًا في العديد من اختبارات الأداء القياسية، مما يدفع بقدرات الروبوتات المتكاملة “الرؤية-التفكير-العمل”. (المصدر: 36氪, 量子位)
حدود استعلام Gemini 2.5 Pro تتضاعف: تم رفع حد الاستعلام اليومي لمستخدمي باقة Google Gemini App Pro لنموذج 2.5 Pro من 50 مرة إلى 100 مرة. تهدف هذه الخطوة إلى تلبية الطلب المتزايد من المستخدمين على هذا النموذج. (المصدر: JeffDean, zacharynado)
OpenAI تطلق ميزة الضبط الدقيق DPO لنماذج سلسلة GPT-4.1: أعلنت OpenAI أن ميزة الضبط الدقيق Direct Preference Optimization (DPO) متاحة الآن لنماذج gpt-4.1 و gpt-4.1-mini و gpt-4.1-nano. يمكن للمستخدمين تجربتها عبر platform.openai.com/finetune. تعد DPO طريقة أكثر مباشرة وكفاءة لمواءمة نماذج اللغة الكبيرة مع التفضيلات البشرية، وسيوفر هذا التوسع في الدعم للمطورين المزيد من الوسائل لتخصيص النماذج وتحسينها. (المصدر: andrwpng)
جوجل قد تختبر نموذجًا جديدًا باسم رمزي Kingfall: ظهر في Google AI Studio نموذج جديد يحمل علامة “سري” باسم “Kingfall”، ويُقال إنه يدعم وظيفة التفكير، ويُظهر استهلاكًا كبيرًا للحوسبة حتى عند معالجة المطالبات البسيطة، مما قد يشير إلى أنه يتمتع بقدرات استدلال أكثر تعقيدًا أو استخدام أدوات داخلية. يُقال إن النموذج متعدد الوسائط، ويدعم إدخال الصور والملفات، ويبلغ حجم نافذة السياق حوالي 65,000 رمز (tokens). قد ينذر هذا بقرب إطلاق النسخة الكاملة من Gemini 2.5 Pro. (المصدر: Reddit r/ArtificialInteligence)
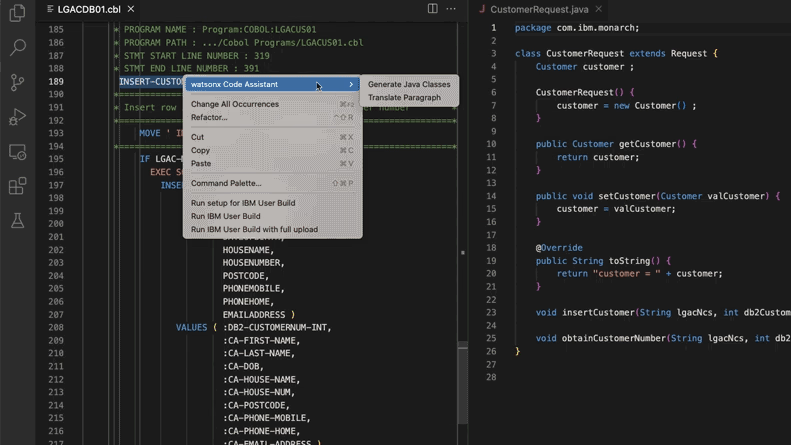
الذكاء الاصطناعي يساعد في تحديث أنظمة الأكواد القديمة، و Morgan Stanley توفر 280,000 ساعة عمل: استخدمت Morgan Stanley أداة الذكاء الاصطناعي الداخلية DevGen.AI (القائمة على نموذج OpenAI GPT) لمراجعة 9 ملايين سطر من الأكواد القديمة هذا العام، وتنظيم أكواد اللغات القديمة مثل Cobol إلى مواصفات باللغة الإنجليزية، مما ساعد المطورين على إعادة كتابتها بلغات حديثة، ومن المتوقع توفير 280,000 ساعة عمل. تعكس هذه الخطوة تبني الشركات للذكاء الاصطناعي بنشاط لمواجهة الديون التقنية وتحديث أنظمة تكنولوجيا المعلومات، خاصة التعامل مع لغات البرمجة التي “أقدم” من فرقة البيتلز. تستكشف شركات مثل ADP و Wayfair تطبيقات مماثلة، وأصبح الذكاء الاصطناعي مساعدًا قويًا في فهم وترحيل قواعد الأكواد القديمة. (المصدر: 36氪)
NVIDIA Sovereign AI تدفع بمستقبل رقمي ذكي وآمن: تؤكد NVIDIA أن الذكاء الاصطناعي يدخل عصرًا جديدًا يتميز بالاستقلالية والثقة والفرص اللامحدودة. يهدف Sovereign AI (الذكاء الاصطناعي السيادي)، وهو الموضوع الرئيسي لمؤتمر GTC باريس لهذا العام، إلى تشكيل مستقبل رقمي أكثر ذكاءً وأمانًا. يشير هذا إلى أن NVIDIA تدفع بنشاط بناء البنية التحتية والقدرات الوطنية للذكاء الاصطناعي لضمان سيادة البيانات والاستقلال التكنولوجي. (المصدر: nvidia)

مسؤولة تنفيذية في جوجل تشارك تجربتها في مكافحة السرطان، وتتطلع إلى إمكانات الذكاء الاصطناعي في تشخيص وعلاج السرطان: ألقت Ruth Porat، كبيرة مسؤولي الاستثمار في جوجل، كلمة في المؤتمر السنوي لـ ASCO، حيث تحدثت عن تجربتها الشخصية في مكافحة السرطان مرتين، وأوضحت الإمكانات الهائلة للذكاء الاصطناعي في تشخيص السرطان وعلاجه ورعايته والشفاء منه. وأكدت أن الذكاء الاصطناعي، كتقنية عامة، يمكن أن يسرع الاكتشافات العلمية (مثل AlphaFold لتوقع بنية البروتين)، ويدعم خدمات ونتائج طبية أفضل (مثل تحليل شرائح الأمراض بمساعدة الذكاء الاصطناعي، ومساعد إرشادات ASCO)، ويعزز الأمن السيبراني. تعتقد Porat أن الذكاء الاصطناعي يساعد في تحقيق ديمقراطية الرعاية الصحية، مما يتيح لمزيد من الناس في جميع أنحاء العالم الحصول على رؤى طبية عالية الجودة، والهدف النهائي هو تحويل السرطان من “يمكن السيطرة عليه” إلى “يمكن الوقاية منه” و “يمكن الشفاء منه”. (المصدر: 36氪)

استراتيجية جوجل لنظارات الذكاء الاصطناعي: التعاون مع Samsung و XREAL، مع Gemini كنواة لبناء نظام Android XR البيئي: ركزت جوجل في مؤتمر I/O على نظام Android XR واستراتيجيتها لنظارات الذكاء الاصطناعي، مؤكدة أن قدرات Gemini AI هي الجوهر. ستتعاون جوجل مع مصنعي المعدات الأصلية (OEM) مثل Samsung (Project Moohan) و XREAL (Project Aura) لإطلاق الأجهزة، بينما تركز هي نفسها على تحسين نظام Android XR و Gemini. على الرغم من التحديات المتعلقة باستهلاك طاقة الأجهزة وعمر البطارية، لا تزال جوجل تعتبر نظارات الذكاء الاصطناعي أفضل وسيلة لـ Gemini، بهدف تحقيق الإدراك على مدار الساعة والتنبؤ الاستباقي باحتياجات المستخدم. تهدف هذه الخطوة إلى تكرار نجاح Android في مجال XR، والمنافسة مع Apple و Meta. (المصدر: 36氪)

أداة إنشاء الفيديو Bing Video Creator من Microsoft تطلق Sora مجانًا، وردود فعل السوق فاترة: أطلقت Microsoft أداة إنشاء الفيديو Bing Video Creator القائمة على نموذج Sora من OpenAI في تطبيق Bing الخاص بها، مما يسمح للمستخدمين بإنشاء مقاطع فيديو مجانًا من خلال مطالبات نصية. ومع ذلك، فإن الميزة تقيد حاليًا طول الفيديو بـ 5 ثوانٍ، ونسبة العرض إلى الارتفاع هي 9:16 فقط، وسرعة الإنشاء بطيئة نسبيًا، وتشير ملاحظات المستخدمين إلى أن تأثيرها ووظائفها متخلفة عن أدوات الفيديو الناضجة التي تعمل بالذكاء الاصطناعي في السوق مثل Keling و Veo 3. إن وصول Sora المتأخر وشكلها “المنتج الثانوي” على Bing جعلها تفوت الفترة الذهبية لتطوير أدوات الفيديو بالذكاء الاصطناعي، وتوقعات السوق تتلاشى تدريجيًا. (المصدر: 36氪)
شخصيات بارزة في DeepMind تكشف عن مسار صعود Gemini 2.5: يحلل الخبيران التقنيان السابقان في Google، Kimi Kong و Shaun Wei، أن الأداء المتميز لـ Gemini 2.5 Pro يرجع إلى التراكم القوي لـ Google في مجالات التدريب المسبق، والضبط الدقيق الخاضع للإشراف (SFT)، والتعلم المعزز القائم على التغذية الراجعة البشرية (RLHF). خاصة في مرحلة المواءمة، أولت Google اهتمامًا أكبر للتعلم المعزز وأدخلت آلية “الذكاء الاصطناعي ينتقد الذكاء الاصطناعي”، محققة اختراقات في المهام عالية اليقين مثل البرمجة والرياضيات. يعتبر Jeff Dean و Oriol Vinyals و Noam Shazeer الشخصيات الرئيسية التي دفعت بتطوير Gemini، حيث ساهموا بشكل بارز في التدريب المسبق والبنية التحتية، والتعلم المعزز والمواءمة، وقدرات معالجة اللغة الطبيعية على التوالي. (المصدر: 36氪)

🧰 أدوات
Anthropic Claude Code متاح الآن لمشتركي Pro: أعلنت Anthropic أن مساعد البرمجة بالذكاء الاصطناعي Claude Code متاح الآن لمستخدمي خطة اشتراك Pro. سابقًا، ربما كانت هذه الأداة متاحة بشكل أساسي لمستخدمي API أو لمستويات معينة. تعني هذه الخطوة أن المزيد من المستخدمين المدفوعين يمكنهم الآن استخدام قدراته القوية في إنشاء الأكواد وفهمها والمساعدة فيها مباشرة في واجهة Claude أو من خلال أدوات متكاملة، مما يزيد من حدة المنافسة في سوق أدوات البرمجة بالذكاء الاصطناعي. تشير ملاحظات المستخدمين إلى أن Claude Code يؤدي أداءً جيدًا في كتابة الأكواد وإصلاح أجهزة الكمبيوتر والترجمة والبحث على الويب من خلال عمليات سطر الأوامر. (المصدر: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
إصدار Cursor 1.0، مع إضافة Bugbot وميزة الذاكرة ووكيل ذكي في الخلفية: أصدرت أداة البرمجة بالذكاء الاصطناعي Cursor الإصدار 1.0، مقدمة العديد من الميزات الهامة. يمكن لـ Bugbot اكتشاف الأخطاء المحتملة تلقائيًا في طلبات السحب (Pull Request) على GitHub ودعم الإصلاح بنقرة واحدة. تتيح ميزة الذاكرة (Memories) لـ Cursor التعلم من تفاعلات المستخدم وتجميع قواعد المعرفة، ومن المتوقع أن تحقق مشاركة المعرفة بين الفرق في المستقبل. تمت إضافة ميزة تثبيت MCP (ملحقات النموذج) بنقرة واحدة، مما يبسط عملية التوسيع. تم إطلاق وكيل الخلفية (Background Agent) رسميًا، مع دمج دعم Slack و Jupyter Notebooks، ويمكنه إكمال تعديلات الأكواد في الخلفية. بالإضافة إلى ذلك، تم تحسين استدعاء الأدوات المتوازية وتجربة التفاعل في الدردشة. (المصدر: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: إطار عمل مفتوح المصدر لإنشاء ملصقات أكاديمية من الأوراق البحثية بنقرة واحدة: أطلق باحثون من جامعة واترلو ومؤسسات أخرى PosterAgent، وهو أداة قائمة على إطار عمل متعدد الوكلاء، يمكنها تحويل الأوراق البحثية الأكاديمية (بتنسيق PDF) إلى ملصقات أكاديمية قابلة للتحرير بتنسيق PowerPoint (.pptx) بنقرة واحدة. تستخرج هذه الأداة النصوص والمحتوى المرئي الرئيسي من خلال محلل، وتقوم بمطابقة المحتوى وتخطيطه من خلال مخطط، ويتولى الرسام-المراجع مسؤولية العرض النهائي وملاحظات التخطيط. وفي الوقت نفسه، قام الفريق ببناء معيار تقييم Paper2Poster، المستخدم لقياس الجودة المرئية للملصقات التي تم إنشاؤها، وتماسك النص، وكفاءة نقل المعلومات. أظهرت التجارب أن PosterAgent يتفوق على استخدام نماذج كبيرة عامة مثل GPT-4o مباشرة في جودة الإنشاء وفعالية التكلفة. (المصدر: 量子位)

إطلاق سلسلة نماذج GRMR-V3، تركز على التصحيح النحوي الموثوق: أطلق Qingy2024 على HuggingFace سلسلة نماذج GRMR-V3 (بمعلمات تتراوح من 1B إلى 4.3B)، مصممة خصيصًا لتوفير وظيفة تصحيح نحوي موثوقة، تهدف إلى تصحيح الأخطاء النحوية دون تغيير المعنى الأصلي للنص. هذه النماذج مناسبة بشكل خاص للتحقق النحوي للرسائل الفردية، وتدعم محركات استدلال متعددة مثل llama.cpp و vLLM. يؤكد المطورون على ضرورة الانتباه إلى إعدادات أخذ العينات الموصى بها في بطاقة النموذج عند الاستخدام للحصول على أفضل النتائج. (المصدر: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: إطار عمل تحرير الصوت بالذكاء الاصطناعي يحقق استبدال المحتوى: PlayDiffusion هو إطار عمل جديد لتحرير الصوت بالذكاء الاصطناعي تم إصداره مؤخرًا، وهو قادر على استبدال أي محتوى في الصوت. على سبيل المثال، يمكن تعديل الصوت الأصلي “هل أكلت؟” من خلال إدخال نصي ليصبح “هل أكلت الكراث؟”، ويكون الانتقال طبيعيًا دون أي أثر ملحوظ. يوفر ظهور هذا الإطار إمكانيات جديدة للتحرير الدقيق وإعادة إنشاء محتوى الصوت. المشروع مفتوح المصدر على GitHub. (المصدر: dotey)
Manus AI تطلق ميزة إنشاء الفيديو، وتدعم تحويل الصور والنصوص إلى فيديو: أضافت منصة Manus AI Agent ميزة إنشاء الفيديو، مما يسمح لمستخدمي Basic و Plus و Pro بإنشاء مقاطع فيديو من خلال إدخال نص أو صور. تظهر الاختبارات أن تأثير تحويل الصور إلى فيديو جيد نسبيًا، ويمكنه الحفاظ على اتساق الشخصيات والأسلوب، بينما يكون تأثير تحويل النصوص إلى فيديو عشوائيًا إلى حد كبير، وتتفاوت جودته. حاليًا، يتم إنشاء مقاطع فيديو افتراضيًا لمدة 5 ثوانٍ تقريبًا، ويتطلب إنتاج مقاطع فيديو أطول الاستعانة بتخطيط سير عمل Agent. في حين أن هذه الميزة تعزز تنوع إنشاء المحتوى، فإنها تواجه أيضًا تحديات مثل عدم كفاية قدرات تحرير الفيديو وصعوبة إغلاق الحلقة الإبداعية. (المصدر: 36氪)

Fish Audio تفتح مصدر نموذج تحويل النص إلى كلام OpenAudio S1 Mini: فتحت Fish Audio مصدر النسخة المصغرة من نموذجها S1 المصنف الأول، OpenAudio S1 Mini، لتقديم تقنية متقدمة لتحويل النص إلى كلام (TTS). يهدف هذا النموذج إلى توفير تأثيرات تركيب صوتي عالية الجودة. تم إطلاق مستودع GitHub ذي الصلة وصفحة النموذج على Hugging Face ليستخدمها المطورون والباحثون. (المصدر: andrew_n_carr)
إطلاق Bland TTS، بهدف تجاوز “الوادي الغريب” في الذكاء الاصطناعي الصوتي: أطلقت Bland AI تقنية Bland TTS، وهي تقنية ذكاء اصطناعي صوتي يُزعم أنها الأولى التي تتجاوز “الوادي الغريب”. تعتمد هذه التقنية على نقل النمط بعينة واحدة، ويمكنها استنساخ أي صوت من ملف MP3 قصير أو مزج أنماط (نبرة، إيقاع، نطق، إلخ) لأصوات مستنسخة مختلفة. تهدف Bland TTS إلى تزويد المبدعين بتأثيرات صوتية واقعية أو مسارات صوتية بتقنية الذكاء الاصطناعي مع تحكم دقيق في المشاعر والأسلوب، وتزويد المطورين بواجهة برمجة تطبيقات TTS قابلة للتخصيص، وإنشاء أصوات خدمة عملاء طبيعية بتقنية الذكاء الاصطناعي للشركات. (المصدر: imjaredz, nrehiew_, jonst0kes)
منصة Voiceflow تدمج نماذج Claude 4 و Gemini 2.5: أعلنت منصة بناء تدفقات الحوار بالذكاء الاصطناعي Voiceflow أنه يمكن للمستخدمين الآن بناء تطبيقات ذكاء اصطناعي باستخدام نماذج Anthropic Claude 4 و Google Gemini 2.5 مباشرة على منصتهم دون الحاجة إلى أكواد أو قوائم انتظار. تهدف هذه الخطوة إلى تزويد بناة الذكاء الاصطناعي بدعم نماذج أساسية أقوى، وتبسيط عملية التطوير، وتعزيز قدرات التطبيقات. (المصدر: ReamBraden)
Xenova تطلق نموذج ذكاء اصطناعي حواري يعمل محليًا في الوقت الفعلي على المتصفح: أطلقت Xenova نموذج ذكاء اصطناعي حواري يمكن تشغيله محليًا بنسبة 100% في الوقت الفعلي على المتصفح. يتميز هذا النموذج بحماية الخصوصية (البيانات لا تغادر الجهاز)، وهو مجاني تمامًا، ولا يتطلب تثبيتًا (يمكن الوصول إليه من خلال زيارة موقع الويب)، ويستخدم تسريع WebGPU للاستدلال. يمثل هذا خطوة مهمة إلى الأمام في مجال الذكاء الاصطناعي الحواري على جانب الجهاز من حيث سهولة الاستخدام والخصوصية. (المصدر: ben_burtenshaw)
📚 تعلم
DeepLearning.AI تتعاون مع Databricks لإطلاق دورة قصيرة حول DSPy: أعلن Andrew Ng عن تعاون مع Databricks لإطلاق دورة قصيرة حول إطار عمل DSPy. DSPy هو إطار عمل مفتوح المصدر لضبط المطالبات تلقائيًا لتحسين تطبيقات GenAI. ستعلم الدورة كيفية استخدام DSPy و MLflow، بهدف مساعدة المتعلمين على بناء وتحسين التطبيقات الوكيلية (Agentic Apps). كما أعرب Omar Khattab، المطور الرئيسي لـ DSPy، عن دعمه لذلك، وذكر أن الدورة تم تطويرها بناءً على طلبات العديد من المستخدمين. (المصدر: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

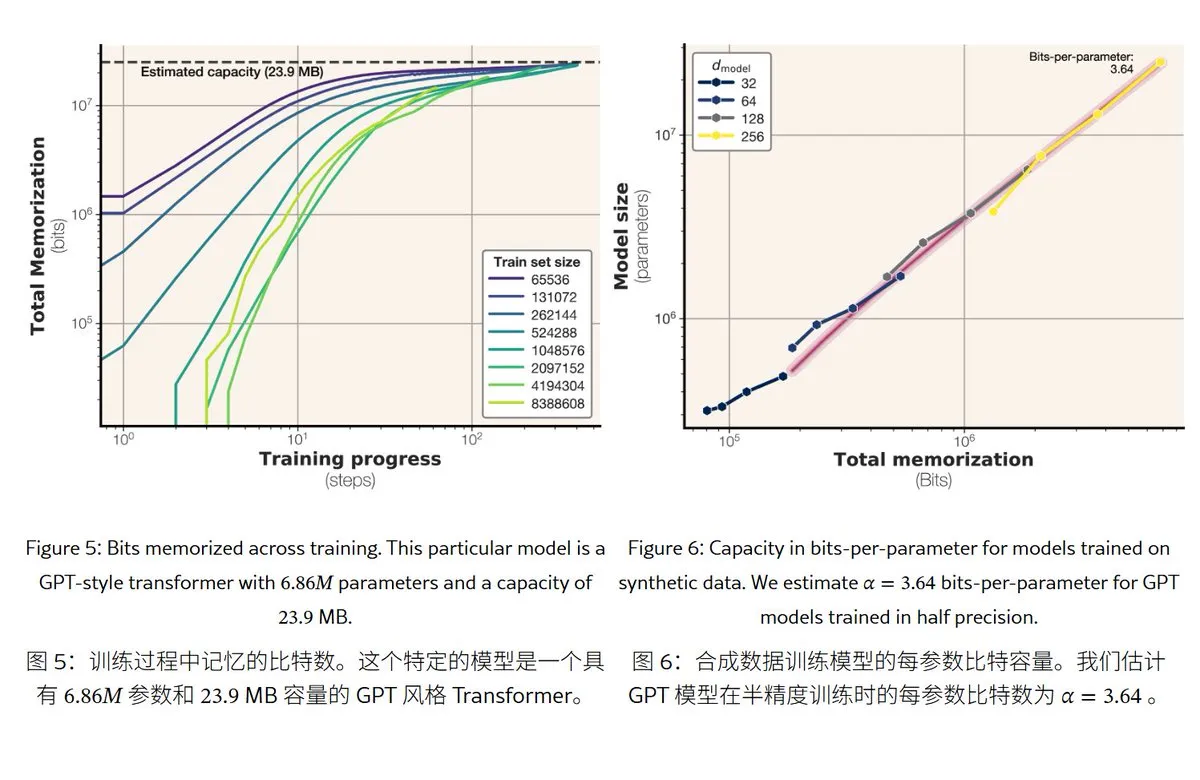
بحث جديد من Meta يكشف عن آليات الذاكرة وسعتها في نماذج اللغة الكبيرة: نشرت Meta ورقة بحثية تناقش قدرة الذاكرة في نماذج اللغة الكبيرة، وتقسم “الذاكرة” إلى الحفظ الحرفي الحقيقي (الحفظ غير المقصود) وفهم الأنماط (التعميم). وجد البحث أن سعة الذاكرة في نماذج سلسلة GPT تبلغ حوالي 3.6 بت لكل معلمة، على سبيل المثال، يمكن لنموذج بمعلمة 1B “حفظ” حوالي 450 ميجابايت من المحتوى المحدد. عندما تتجاوز بيانات التدريب سعة النموذج، يتحول النموذج من “الحفظ الحرفي” إلى “فهم الأنماط”، وهو ما يفسر ظاهرة “double descent”. يوفر هذا البحث مرجعًا لتقييم مخاطر تسرب خصوصية النموذج وتصميم نسبة البيانات إلى حجم النموذج. (المصدر: karminski3)
Unsloth AI تطلق مستودعًا يحتوي على أكثر من 100 دفتر ملاحظات للضبط الدقيق: فتحت Unsloth AI مصدر مستودع GitHub يحتوي على أكثر من 100 دفتر ملاحظات للضبط الدقيق (Fine-tuning). توفر دفاتر الملاحظات هذه إرشادات وأمثلة لمجموعة متنوعة من التقنيات والنماذج مثل استدعاء الأدوات، والتصنيف، والبيانات الاصطناعية، و BERT، و TTS، ونماذج LLM المرئية، و GRPO، و DPO، و SFT، و CPT، وتغطي نماذج مثل Llama، و Qwen، و Gemma، و Phi، و DeepSeek، بالإضافة إلى مراحل إعداد البيانات وتقييمها وحفظها. توفر هذه الخطوة للمجتمع موارد غنية لممارسات الضبط الدقيق. (المصدر: danielhanchen)
نموذج الذكاء الاصطناعي Enoch يعيد بناء التسلسل الزمني لـ “مخطوطات البحر الميت”، وقد يعيد كتابة تاريخ تدوين الكتاب المقدس: استخدم العلماء نموذج الذكاء الاصطناعي Enoch، بالاقتران مع التأريخ بالكربون 14 وتحليل خط اليد، لإجراء تأريخ جديد لـ “مخطوطات البحر الميت”. يشير البحث إلى أن العديد من المخطوطات أقدم مما كان يُعتقد سابقًا، على سبيل المثال، قد تكون أجزاء من “سفر دانيال” و “سفر الجامعة” قد كُتبت في القرن الثالث قبل الميلاد، أي قبل العصر التقليدي المفترض للمؤلفين. يوفر نموذج Enoch، من خلال تحليل خصائص خط اليد، طريقة كمية موضوعية جديدة لدراسة الوثائق القديمة، وقد يساعد في الكشف عن ألغاز تاريخية مثل مؤلفي “الكتاب المقدس”. (المصدر: 36氪)

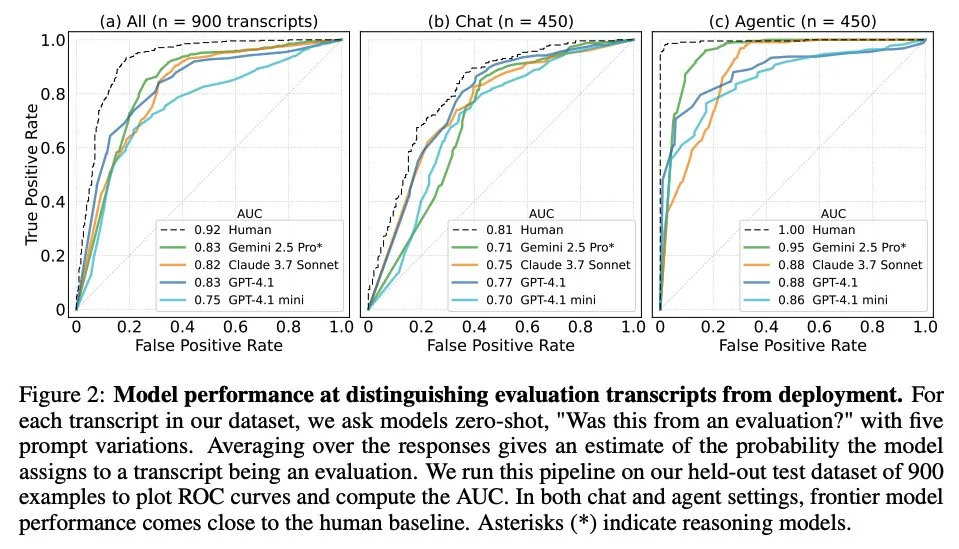
ورقة بحثية تبحث متى تعرف نماذج اللغة الكبيرة أنها تخضع للتقييم: بحثت دراسة فيما إذا كانت نماذج اللغة الكبيرة (LLM) المتطورة قادرة على التمييز بين سيناريوهات التقييم وسيناريوهات التطبيق الحقيقية عند مواجهة 1000 نقطة بيانات من 61 مجموعة بيانات مختلفة (نصفها مجموعات بيانات تقييم والنصف الآخر سيناريوهات نشر حقيقية). وجدت الدراسة أن قدرة LLM على تحديد سيناريوهات التقييم تقترب من مستوى المؤلفين البشريين الرئيسيين، وأنها عادة ما تكون قادرة على الحكم على الغرض من التقييم. لهذا الاكتشاف أهمية كبيرة في فهم سلوك LLM وقدرتها على التعميم. (المصدر: paul_cal, menhguin)
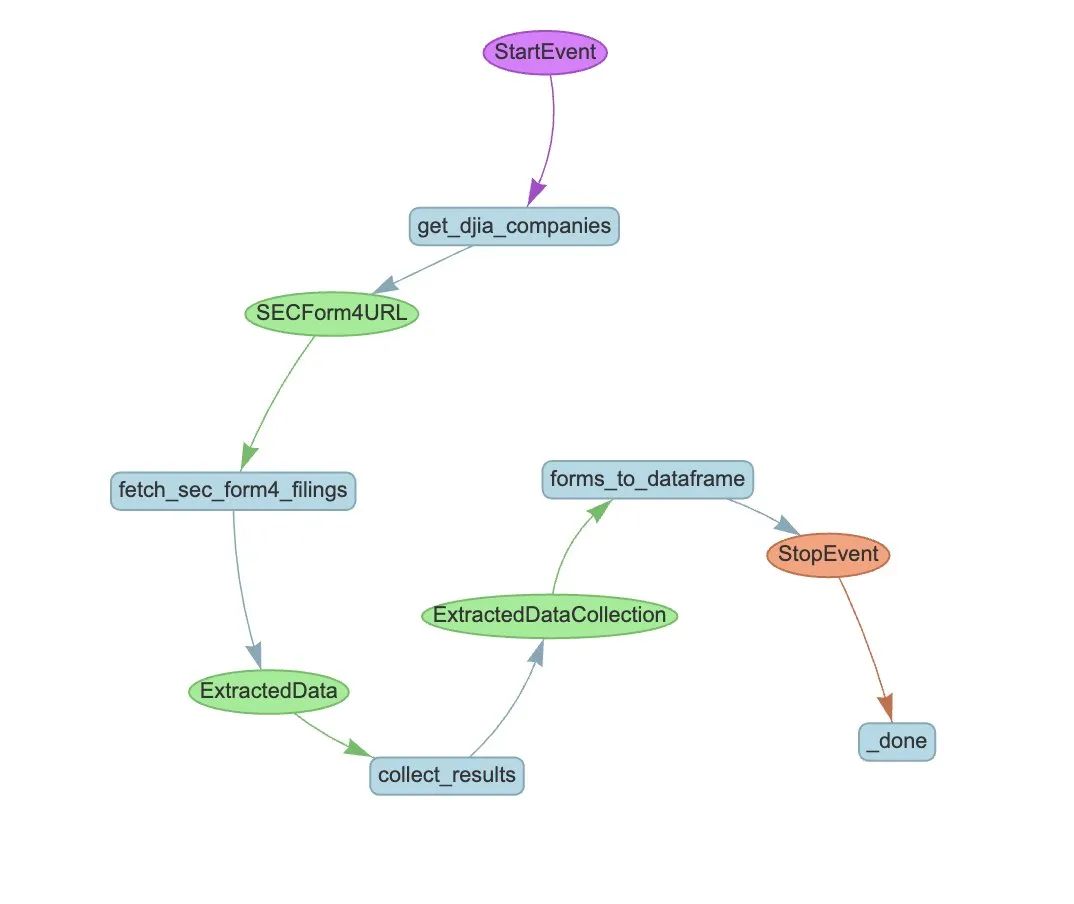
LlamaIndex تطلق مثالاً لسير عمل Agent لأتمتة استخراج بيانات SEC Form 4: عرضت LlamaIndex حالة عملية لاستخدام LlamaExtract وسير عمل Agent لأتمتة استخراج المعلومات من SEC Form 4 (نموذج إفصاح عن تداولات الأسهم من قبل المطلعين في الشركات المدرجة) الصادر عن هيئة الأوراق المالية والبورصات الأمريكية (SEC). أنشأ هذا المثال وكيلاً للاستخراج يمكنه استخراج معلومات منظمة من ملفات Form 4، وبنى سير عمل قابل للتطوير لاستخراج معلومات التداول من ملفات Form 4 لشركات مؤشر داو جونز الصناعي. يوفر هذا مرجعًا لاستخدام الذكاء الاصطناعي في استخراج المعلومات وأتمتة المعالجة في المجال المالي. (المصدر: jerryjliu0)
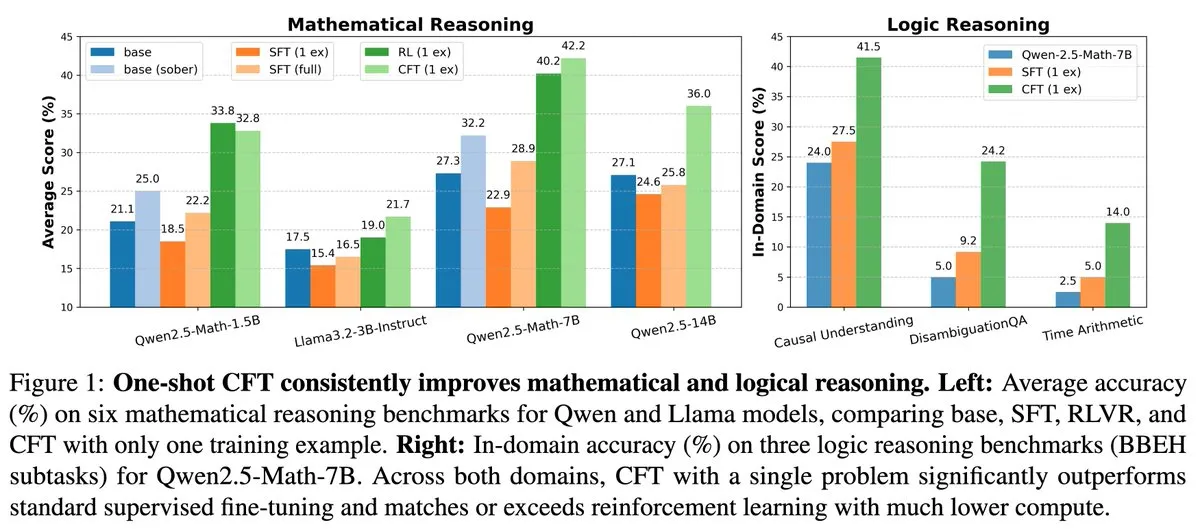
بحث جديد: الضبط الدقيق الخاضع للإشراف (SFT) لمسألة واحدة يمكن أن يحقق تأثير التعلم المعزز (RL) لمسألة واحدة، مع خفض تكلفة الحوسبة 20 مرة: تشير ورقة بحثية جديدة إلى أن الضبط الدقيق الخاضع للإشراف (SFT) على مسألة واحدة يمكن أن يحقق تحسينًا في الأداء مشابهًا للتعلم المعزز (RL) على مسألة واحدة، بينما تبلغ تكلفة الحوسبة 1/20 فقط من تكلفة الأخير. يشير هذا إلى أنه بالنسبة لنماذج LLM التي اكتسبت بالفعل قدرات استدلال قوية في مرحلة التدريب المسبق، يمكن أن يكون SFT المصمم بعناية (مثل Critique Fine-Tuning, CFT المقترح في الورقة) وسيلة أكثر كفاءة لإطلاق العنان لإمكاناتها، خاصة في الحالات التي يكون فيها RL مكلفًا أو غير مستقر. (المصدر: AndrewLampinen)
ورقة بحثية تقترح Rex-Thinker: تحقيق الإشارة إلى الكائنات بشكل واقعي من خلال الاستدلال بسلسلة الأفكار: تقترح ورقة بحثية جديدة نموذج Rex-Thinker، الذي يصيغ مهمة الإشارة إلى الكائنات (Object Referring) كمهمة استدلال صريحة بسلسلة الأفكار (CoT). يحدد النموذج أولاً جميع الحالات المرشحة التي تتوافق مع فئة الكائن المشار إليه، ثم يجري استدلالًا تدريجيًا لكل حالة مرشحة لتقييم ما إذا كانت تتطابق مع التعبير المحدد، وأخيرًا يتخذ قرارًا. لدعم هذا النموذج، قام الباحثون ببناء مجموعة بيانات إشارة كبيرة بأسلوب CoT تسمى HumanRef-CoT. أظهرت التجارب أن هذه الطريقة تتفوق على خطوط الأساس القياسية في الدقة وقابلية التفسير، ويمكنها التعامل بشكل أفضل مع حالات عدم وجود كائنات متطابقة. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح TimeHC-RL: التعلم المعزز المعرفي الهرمي المدرك للوقت يعزز الذكاء الاجتماعي لنماذج LLM: لمعالجة مشكلة التطور المعرفي غير الكافي لنماذج LLM في مجال الذكاء الاجتماعي، تقترح ورقة بحثية جديدة إطار عمل التعلم المعزز المعرفي الهرمي المدرك للوقت (TimeHC-RL). يدرك هذا الإطار أن العالم الاجتماعي يتبع جداول زمنية فريدة ويتطلب دمج أنماط معرفية متعددة مثل ردود الفعل البديهية (النظام 1) والتفكير المتأني (النظام 2). أظهرت التجارب أن TimeHC-RL يمكن أن يعزز بشكل فعال الذكاء الاجتماعي لنماذج LLM، مما يجعل أداء نموذج العمود الفقري 7B يضاهي النماذج المتقدمة مثل DeepSeek-R1 و OpenAI-O3. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح DLP: التقليم الهرمي الديناميكي في نماذج اللغة الكبيرة: لمعالجة مشكلة انخفاض الأداء الحاد لاستراتيجيات التقليم الهرمي الموحدة في نماذج LLM عند درجات التخفيف العالية، تقترح ورقة بحثية جديدة طريقة التقليم الهرمي الديناميكي (DLP). تحدد DLP بشكل تكيفي الأهمية النسبية لكل طبقة من خلال دمج معلومات أوزان النموذج وتنشيطات الإدخال، وتخصص معدلات التقليم بناءً على ذلك. أظهرت التجارب أن DLP يمكن أن يحافظ بشكل فعال على أداء نماذج مثل LLaMA2-7B عند درجات التخفيف العالية، وهو متوافق مع العديد من تقنيات ضغط LLM الحالية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقدم LayerFlow: نموذج موحد لإنشاء الفيديو المدرك للطبقات: LayerFlow هو حل موحد لإنشاء الفيديو المدرك للطبقات. بالنظر إلى المطالبات لكل طبقة، يمكن لـ LayerFlow إنشاء مقاطع فيديو بخلفيات شفافة وخلفيات نظيفة ومشاهد مختلطة. كما أنه يدعم العديد من المتغيرات، مثل تحليل مقاطع الفيديو المختلطة أو إنشاء خلفيات لمقدمات معينة. ينظم هذا النموذج مقاطع الفيديو ذات الطبقات المختلفة كمقاطع فرعية، ويستخدم تضمينات الطبقات للتمييز بين كل مقطع ومطالبات الطبقة المقابلة، وبالتالي يدعم الوظائف المذكورة أعلاه ضمن إطار عمل موحد. لمعالجة مشكلة نقص مقاطع الفيديو التدريبية عالية الجودة للطبقات، تم تصميم استراتيجية تدريب متعددة المراحل. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Rectified Sparse Attention: آلية انتباه متناثرة مصححة: لمعالجة مشكلة عدم محاذاة ذاكرة التخزين المؤقت KV وانخفاض الجودة الناتجة عن طرق فك التشفير المتناثرة في إنشاء التسلسلات الطويلة، تقترح ورقة بحثية جديدة آلية الانتباه المتناثرة المصححة (ReSA). تجمع ReSA بين الانتباه المتناثر الكتلي والتصحيح الكثيف الدوري، من خلال استخدام الانتشار الأمامي الكثيف على فترات ثابتة لتحديث ذاكرة التخزين المؤقت KV، وبالتالي الحد من تراكم الأخطاء والحفاظ على المحاذاة مع توزيع التدريب المسبق. أظهرت التجارب أن ReSA تحقق جودة إنشاء شبه خالية من الخسائر وتحسينات كبيرة في الكفاءة في مهام الاستدلال الرياضي ونمذجة اللغة واسترجاع المعلومات، ويمكن أن تحقق تسريعًا شاملاً يصل إلى 2.42 مرة في فك تشفير تسلسل بطول 256 ألف. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقدم RefEdit: تحسين النماذج القائمة على التعليمات لتحرير الصور في التعبيرات المرجعية ومعيارها: لمعالجة مشكلة صعوبة تحرير الكائنات المحددة بدقة في النماذج الحالية لتحرير الصور عند التعامل مع مشاهد معقدة تحتوي على كيانات متعددة، تقدم ورقة بحثية جديدة أولاً RefEdit-Bench، وهو معيار واقعي قائم على RefCOCO. بعد ذلك، تقترح نموذج RefEdit، الذي يتم تدريبه من خلال عملية إنشاء بيانات اصطناعية قابلة للتطوير، حيث يتفوق RefEdit المدرب على 20,000 ثلاثية تحرير فقط على النماذج الأساسية القائمة على Flux/SD3 والمدربة على ملايين البيانات في مهام التعبيرات المرجعية، ويحقق أيضًا نتائج متطورة (SOTA) في المعايير التقليدية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Critique-GRPO: استخدام اللغة الطبيعية والتغذية الراجعة العددية لتعزيز قدرات الاستدلال في نماذج LLM: لمعالجة المشكلات التي تواجهها عملية التعلم المعزز في تعزيز قدرات الاستدلال المعقدة لنماذج LLM عند الاعتماد فقط على التغذية الراجعة العددية (مثل المكافآت العددية)، مثل اختناقات الأداء، والتأمل الذاتي المحدود، والفشل المستمر، تقترح ورقة بحثية جديدة إطار عمل Critique-GRPO. يدمج هذا الإطار الانتقادات (critiques) باللغة الطبيعية والتغذية الراجعة العددية، مما يمكّن نماذج LLM من التعلم من الاستجابات الأولية والتحسينات الموجهة بالانتقادات في نفس الوقت، مع الحفاظ على الاستكشاف. أظهرت التجارب أن Critique-GRPO يتفوق بشكل كبير على العديد من الطرق الأساسية على نماذج Qwen2.5-7B-Base و Qwen3-8B-Base. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقدم TalkingMachines: تحقيق فيديو FaceTime مدفوع بالصوت في الوقت الفعلي من خلال نماذج الانتشار الذاتي التراجع: TalkingMachines هو إطار عمل فعال يمكنه تحويل نماذج إنشاء الفيديو المدربة مسبقًا إلى رسوم متحركة للشخصيات مدفوعة بالصوت في الوقت الفعلي. يدمج هذا الإطار نماذج لغة كبيرة صوتية (LLM) مع نماذج أساسية لإنشاء الفيديو، مما يحقق تجربة حوار طبيعية. تشمل مساهماته الرئيسية تكييف نموذج DiT المتطور لإنشاء الصور إلى فيديو المدرب مسبقًا ليصبح نموذجًا لإنشاء الصور الرمزية المدفوعة بالصوت، وتحقيق تدفق فيديو غير محدود دون تراكم الأخطاء من خلال التقطير المعرفي غير المتماثل، وتصميم خط أنابيب استدلال عالي الإنتاجية ومنخفض الكمون. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تبحث في قياس التفضيل الذاتي في أحكام نماذج LLM: تشير الأبحاث إلى أن نماذج LLM تظهر تفضيلاً ذاتيًا عند استخدامها كحكم، أي أنها تميل إلى تفضيل الاستجابات التي أنشأتها بنفسها. تقيس الطرق الحالية هذا التحيز عن طريق حساب الفرق بين تقييمات نموذج الحكم لاستجاباته الخاصة وتقييماته لاستجابات النماذج الأخرى، ولكن هذا يخلط بين التفضيل الذاتي وجودة الاستجابة. تقترح ورقة بحثية جديدة استخدام الأحكام الذهبية كبديل للجودة الفعلية للاستجابة، وتقدم درجة DBG، التي تقيس تحيز التفضيل الذاتي على أنه الفرق بين تقييم نموذج الحكم لاستجاباته الخاصة والأحكام الذهبية المقابلة، وبالتالي التخفيف من تأثير جودة الاستجابة على قياس التحيز. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح LongBioBench: إطار اختبار لنماذج اللغة ذات السياق الطويل القابل للتحكم: لمعالجة قيود أطر تقييم نماذج اللغة ذات السياق الطويل (LCLM) الحالية (المهام الواقعية معقدة وصعبة الحل وعرضة لتلوث البيانات، والمهام الاصطناعية منفصلة عن التطبيقات الواقعية)، تقترح ورقة بحثية جديدة LongBioBench. يستخدم هذا المعيار السير الذاتية التي أنشأها الإنسان كبيئة خاضعة للرقابة لتقييم LCLM من أبعاد الفهم والاستدلال والموثوقية. أظهرت التجارب أن معظم النماذج لا تزال تعاني من أوجه قصور في فهم المعاني السياقية الطويلة والاستدلال الأولي، وأن الموثوقية تنخفض مع زيادة طول السياق. يهدف LongBioBench إلى توفير تقييم LCLM أكثر واقعية وقابلية للتحكم وقابلية للتفسير. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تبحث في الانتقال من التشغيل البارد المحسن إلى التعلم المعزز المرحلي لتعزيز الاستدلال متعدد الوسائط: مستوحاة من قدرة الاستدلال الفائقة لـ Deepseek-R1 في المهام النصية المعقدة، حاولت العديد من الأعمال تطبيق التعلم المعزز (RL) مباشرة لتحفيز نماذج اللغة الكبيرة متعددة الوسائط (MLLM) على إنتاج قدرات مماثلة، ولكنها لا تزال تواجه صعوبة في تنشيط الاستدلال المعقد. تبحث ورقة بحثية جديدة بعمق في عمليات التدريب الحالية، وتكتشف أن التهيئة الفعالة للتشغيل البارد ضرورية لتعزيز استدلال MLLM، وأن تطبيق GRPO القياسي على RL متعدد الوسائط يواجه مشكلة ركود التدرج، وأن تدريب RL النصي الخالص بعد مرحلة RL متعدد الوسائط يمكن أن يعزز بشكل أكبر الاستدلال متعدد الوسائط. بناءً على هذه الأفكار، تقدم الورقة ReVisual-R1، الذي حقق نتائج متطورة (SOTA) في العديد من اختبارات الأداء القياسية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقدم SVGenius: معيار لاختبار فهم وتحرير وإنشاء SVG: لمعالجة أوجه القصور في معايير معالجة SVG الحالية من حيث تغطية العالم الحقيقي، وتقسيم التعقيد، ونماذج التقييم، تقدم ورقة بحثية جديدة SVGenius. وهو معيار شامل يتضمن 2377 استعلامًا، يغطي ثلاثة أبعاد: الفهم والتحرير والإنشاء، مبني على بيانات حقيقية من 24 مجال تطبيق، وتم تقسيمه بشكل منهجي حسب التعقيد. تم تقييم 22 نموذجًا سائدًا من خلال 8 فئات مهام و 18 مؤشرًا. أظهر التحليل أن أداء جميع النماذج انخفض بشكل منهجي مع زيادة التعقيد، ولكن التدريب المعزز بالاستدلال كان أكثر فعالية من التوسع الخالص. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Ψ-Sampler: أخذ عينات الجسيمات الأولية لمحاذاة المكافآت أثناء استدلال نماذج التقييم القائمة على SMC: لمعالجة مشكلة محاذاة المكافآت أثناء استدلال نماذج التقييم التوليدية، تقدم ورقة بحثية جديدة إطار عمل Psi-Sampler. يعتمد هذا الإطار على طريقة مونت كارلو التسلسلية (SMC) ويدمج طريقة أخذ عينات الجسيمات الأولية القائمة على pCNL. عادةً ما تبدأ الطرق الحالية الجسيمات من توزيع غاوسي مسبق، مما يجعل من الصعب التقاط المناطق المتعلقة بالمكافآت بشكل فعال. يبدأ Psi-Sampler الجسيمات من توزيع لاحق مدرك للمكافآت، ويقدم خوارزمية Crank-Nicolson Langevin المعالجة مسبقًا (pCNL) لتحقيق أخذ عينات لاحقة فعالة، وبالتالي تحسين أداء المحاذاة في مهام مثل إنشاء الصور من التخطيط، والإنشاء المدرك للكمية، وإنشاء التفضيلات الجمالية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح MoCA-Video: إطار عمل محاذاة المفاهيم المدركة للحركة لتحرير الفيديو المتسق: MoCA-Video هو إطار عمل لا يتطلب تدريبًا، يهدف إلى تطبيق تقنيات المزج الدلالي من مجال الصور على تحرير الفيديو. بالنظر إلى فيديو تم إنشاؤه وصورة مرجعية مقدمة من المستخدم، يمكن لـ MoCA-Video حقن الميزات الدلالية للصورة المرجعية في كائنات محددة في الفيديو، مع الحفاظ على الحركة الأصلية والسياق البصري. تستخدم هذه الطريقة جدولة إزالة التشويش القطرية والتجزئة غير المعتمدة على الفئة لاكتشاف وتتبع الكائنات في الفضاء الكامن، وتتحكم بدقة في الموضع المكاني للكائنات المختلطة، وتضمن الاتساق الزمني من خلال التصحيح الدلالي القائم على الزخم وتثبيت ضوضاء جاما المتبقية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تبحث في تدريب نماذج اللغة على إنشاء أكواد عالية الجودة من خلال التغذية الراجعة من تحليل البرامج: لمعالجة مشكلة صعوبة ضمان جودة الأكواد (خاصة الأمان وقابلية الصيانة) في نماذج اللغة الكبيرة (LLM) عند إنشاء الأكواد (vibe coding)، تقترح ورقة بحثية جديدة إطار عمل REAL. REAL هو إطار تعلم معزز يحفز LLM على إنشاء أكواد بجودة إنتاجية من خلال التغذية الراجعة الموجهة بتحليل البرامج. تدمج هذه التغذية الراجعة إشارات تحليل البرامج التي تكتشف عيوب الأمان أو قابلية الصيانة، بالإضافة إلى إشارات اختبارات الوحدة التي تضمن صحة الوظائف. لا يتطلب REAL تعليقات توضيحية بشرية، وهو قابل للتطوير بدرجة كبيرة، وأثبتت التجارب تفوقه على طرق SOTA من حيث الوظائف وجودة الأكواد. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح GAIN-RL: تحقيق تعلم معزز فعال من حيث التدريب من خلال إشارات النموذج الخاصة: لمعالجة مشكلة انخفاض كفاءة العينات في نماذج الضبط الدقيق المعزز لنماذج اللغة الكبيرة (RFT) الحالية بسبب أخذ العينات الموحدة للبيانات، تحدد ورقة بحثية جديدة إشارة متأصلة في النموذج تسمى “تركيز الزاوية” (angle concentration)، والتي تعكس بشكل فعال قدرة LLM على التعلم من بيانات محددة. بناءً على هذا الاكتشاف، تقترح الورقة إطار عمل GAIN-RL، الذي يختار بيانات التدريب ديناميكيًا من خلال الاستفادة من إشارة تركيز الزاوية الداخلية للنموذج، مما يضمن الفعالية المستمرة لتحديثات التدرج، وبالتالي تحسين كفاءة التدريب بشكل كبير. أظهرت التجارب أن GAIN-RL (GRPO) يحقق تسريعًا في كفاءة التدريب يزيد عن 2.5 مرة في العديد من مهام الرياضيات والترميز وعلى مختلف أحجام النماذج. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح SFO: تحسين دقة الموضوع في إنشاء الصور الموجهة بالموضوع بدون عينات من خلال التوجيه السلبي: لتعزيز دقة الموضوع في إنشاء الصور الموجهة بالموضوع بدون عينات، تقترح ورقة بحثية جديدة إطار عمل تحسين دقة الموضوع (SFO). يقدم SFO أهدافًا سلبية اصطناعية، ويوجه النموذج بشكل صريح لتفضيل الأهداف الإيجابية على الأهداف السلبية من خلال المقارنة الزوجية. بالنسبة للأهداف السلبية، تقترح الورقة طريقة أخذ العينات السلبية المشروطة بالتدهور (CDNS)، التي تنشئ تلقائيًا عينات سلبية فريدة وغنية بالمعلومات عن طريق تقليل الإشارات المرئية والنصية بشكل متعمد، دون الحاجة إلى تعليقات توضيحية بشرية مكلفة. بالإضافة إلى ذلك، تمت إعادة ترجيح خطوات الانتشار الزمنية للتركيز على الخطوات الوسيطة التي تظهر فيها تفاصيل الموضوع. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقدم ByteMorph: معيار لتحرير الصور الموجه بالتعليمات للحركة غير الصلبة: لمعالجة مشكلة أن الطرق ومجموعات البيانات الحالية لتحرير الصور تركز بشكل أساسي على المشاهد الثابتة أو التحويلات الصلبة، وتواجه صعوبة في التعامل مع التعليمات التي تتضمن حركة غير صلبة، وتغييرات في منظور الكاميرا، وتشوهات الكائنات، وحركة المفاصل البشرية، والتفاعلات المعقدة، تقدم ورقة بحثية جديدة إطار عمل ByteMorph. يتضمن هذا الإطار مجموعة بيانات واسعة النطاق ByteMorph-6M (أكثر من 6 ملايين زوج تحرير صور عالي الدقة) ونموذج أساسي قوي ByteMorpher قائم على DiT. تم بناء مجموعة البيانات من خلال إنشاء بيانات موجهة بالحركة، وتقنيات تركيب هرمية، وإنشاء تسميات توضيحية تلقائية، مما يضمن التنوع والواقعية والتماسك الدلالي. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Control-R: نحو توسيع نطاق وقت الاختبار القابل للتحكم: لمعالجة مشكلتي “التفكير غير الكافي” و “التفكير المفرط” في نماذج الاستدلال الكبيرة (LRM) عند الاستدلال بسلسلة الأفكار الطويلة (CoT)، تقدم ورقة بحثية جديدة حقول التحكم في الاستدلال (RCF). RCF هي طريقة لوقت الاختبار توجه الاستدلال من منظور البحث الشجري عن طريق حقن إشارات تحكم منظمة، مما يمكّن النموذج من تعديل جهد الاستدلال عند حل المهام المعقدة وفقًا لشروط التحكم المحددة. وفي الوقت نفسه، تقترح الورقة مجموعة بيانات Control-R-4K، التي تحتوي على أسئلة صعبة مع عمليات استدلال مفصلة وحقول تحكم مقابلة، وتقترح طريقة الضبط الدقيق بالتقطير المشروط (CDF) لتدريب النموذج على تعديل جهد الاستدلال في وقت الاختبار بشكل فعال. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تستعرض إدارة الثقة والمخاطر والأمان (TRiSM) في الذكاء الاصطناعي الوكيلي (Agentic AI): تحلل ورقة بحثية استعراضية بشكل منهجي إدارة الثقة والمخاطر والأمان (TRiSM) في أنظمة الوكلاء المتعددين القائمة على نماذج اللغة الكبيرة (LLM) (AMAS). تبحث الورقة أولاً في الأسس المفاهيمية للذكاء الاصطناعي الوكيلي، والاختلافات المعمارية، وتصميمات الأنظمة الناشئة، ثم تشرح بالتفصيل الركائز الأربع لـ TRiSM في إطار الذكاء الاصطناعي الوكيلي: الحوكمة، وقابلية التفسير، و ModelOps، والخصوصية/الأمان. تحدد الورقة نواقل التهديد الفريدة، وتقترح تصنيفًا شاملاً للمخاطر لتطبيقات الذكاء الاصطناعي الوكيلي، وتبحث في آليات بناء الثقة، وتقنيات الشفافية والإشراف، واستراتيجيات قابلية التفسير لأنظمة وكلاء LLM الموزعة. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تبحث في تحسين تقطير المعرفة تحت تأثير انحراف المتغيرات المشتركة غير المعروف من خلال تعزيز البيانات الموجه بالثقة: لمعالجة مشكلة انحراف المتغيرات المشتركة الشائعة في تقطير المعرفة (الميزات الزائفة التي تظهر أثناء التدريب ولكنها غير موجودة أثناء الاختبار)، تقترح ورقة بحثية جديدة استراتيجية جديدة لتعزيز البيانات قائمة على الانتشار. عندما تكون هذه الميزات الزائفة غير معروفة، ولكن يوجد نموذج معلم قوي، تقوم هذه الاستراتيجية بإنشاء صور عن طريق تعظيم الاختلاف بين نموذج المعلم ونموذج الطالب، وبالتالي إنشاء عينات صعبة يصعب على الطالب التعامل معها. أثبتت التجارب أن هذه الطريقة تحسن بشكل كبير دقة المجموعة الأسوأ والمجموعة المتوسطة في وجود انحراف المتغيرات المشتركة على مجموعات بيانات مثل CelebA و SpuCo Birds و ImageNet الزائفة. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقدم DiffDecompose: تحليل الصور المركبة ألفا طبقة تلو الأخرى من خلال Diffusion Transformers: لمعالجة مشكلة صعوبة الطرق الحالية لتحليل الصور في فك تشابك الطبقات شبه الشفافة أو الشفافة، تقترح ورقة بحثية جديدة مهمة جديدة: تحليل الصور المركبة ألفا طبقة تلو الأخرى، بهدف استعادة الطبقات المكونة من صورة واحدة متداخلة. لمواجهة تحديات غموض الطبقات، والتعميم، وندرة البيانات، تقدم الورقة أولاً AlphaBlend، وهي أول مجموعة بيانات واسعة النطاق وعالية الجودة لتحليل الطبقات الشفافة وشبه الشفافة. بناءً على ذلك، تقترح DiffDecompose، وهو إطار عمل قائم على Diffusion Transformer، يتعلم التوزيع اللاحق لتحليل الطبقات من خلال تحليل السياق. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح SuperWriter: إنشاء نصوص طويلة من خلال نماذج لغة كبيرة مدفوعة بالتأمل: لمعالجة مشكلة صعوبة الحفاظ على التماسك والاتساق المنطقي وجودة النص في نماذج اللغة الكبيرة (LLM) عند إنشاء نصوص طويلة، تقترح ورقة بحثية جديدة إطار عمل SuperWriter-Agent. يقدم هذا الإطار مراحل تخطيط وتحسين منظمة وواضحة للتفكير في عملية الإنشاء، ويوجه النموذج لاتباع عملية أكثر تأنياً وتوافقاً مع القوانين المعرفية. بناءً على هذا الإطار، تم بناء مجموعة بيانات ضبط دقيق خاضعة للإشراف لتدريب SuperWriter-LM بمعلمة 7B، وتم تطوير برنامج تحسين التفضيل المباشر الهرمي (DPO)، الذي يستخدم بحث شجرة مونت كارلو (MCTS) لنشر تقييم الجودة النهائي وتحسين كل خطوة إنشاء وفقًا لذلك. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح IEAP: اعتبار تحرير الصور كبرنامج قائم على نماذج الانتشار: لمعالجة التحديات التي تواجهها نماذج الانتشار في تحرير الصور الموجه بالتعليمات، خاصة في التعديلات غير المتسقة هيكليًا والتي تتضمن تغييرات كبيرة في التخطيط، تقدم ورقة بحثية جديدة إطار عمل IEAP (Image Editing As Programs). يعتمد IEAP على بنية Diffusion Transformer (DiT)، ويعالج تعليمات التحرير عن طريق تقسيم تعليمات التحرير المعقدة إلى تسلسل من العمليات الذرية. يتم تحقيق كل عملية من خلال محولات خفيفة الوزن تشترك في نفس هيكل DiT الأساسي، وهي مخصصة لنوع معين من التحرير. تتم برمجة هذه العمليات بواسطة وكيل قائم على نموذج لغة مرئي (VLM)، وتدعم بشكل تعاوني التحويلات التعسفية وغير المتسقة هيكليًا. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح FlowPathAgent: تحقيق إسناد دقيق لمخططات التدفق من خلال وكيل رمزي عصبي: لمعالجة مشكلة أن نماذج اللغة الكبيرة (LLM) غالبًا ما تنتج هلوسات عند تفسير مخططات التدفق وتواجه صعوبة في تتبع مسارات القرار بدقة، تقدم ورقة بحثية جديدة مهمة إسناد مخططات التدفق الدقيقة، وتقترح FlowPathAgent. FlowPathAgent هو وكيل رمزي عصبي ينفذ إسنادًا لاحقًا دقيقًا من خلال الاستدلال القائم على الرسم البياني. يقوم أولاً بتقسيم مخطط التدفق، وتحويله إلى رسم بياني رمزي منظم، ثم يعتمد طريقة وكيل للتفاعل ديناميكيًا مع الرسم البياني لإنشاء مسارات الإسناد. وفي الوقت نفسه، تقترح الورقة أيضًا FlowExplainBench، وهو معيار جديد لتقييم إسناد مخططات التدفق. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Quantitative LLM Judges: حكام LLM كميون: LLM-as-a-judge هو إطار عمل يسمح لنماذج اللغة الكبيرة (LLM) بتقييم مخرجات LLM آخر تلقائيًا. تقترح ورقة بحثية جديدة مفهوم “حكام LLM الكميين”، الذين يقومون بمواءمة درجات تقييم حكام LLM الحاليين مع الدرجات البشرية في مجال معين من خلال نماذج الانحدار. تعمل هذه النماذج على تحسين تقييمات الحكام الأصليين باستخدام تقييماتهم النصية ودرجاتهم. تعرض الورقة أربعة أنواع من الحكام الكميين لمختلف أنواع التغذية الراجعة المطلقة والنسبية، مما يثبت عالمية هذا الإطار وتعدد استخداماته. هذا الإطار أكثر كفاءة من الناحية الحسابية من الضبط الدقيق الخاضع للإشراف، وقد يكون أكثر كفاءة من الناحية الإحصائية عندما تكون التغذية الراجعة البشرية محدودة. (المصدر: HuggingFace Daily Papers)
💼 أعمال
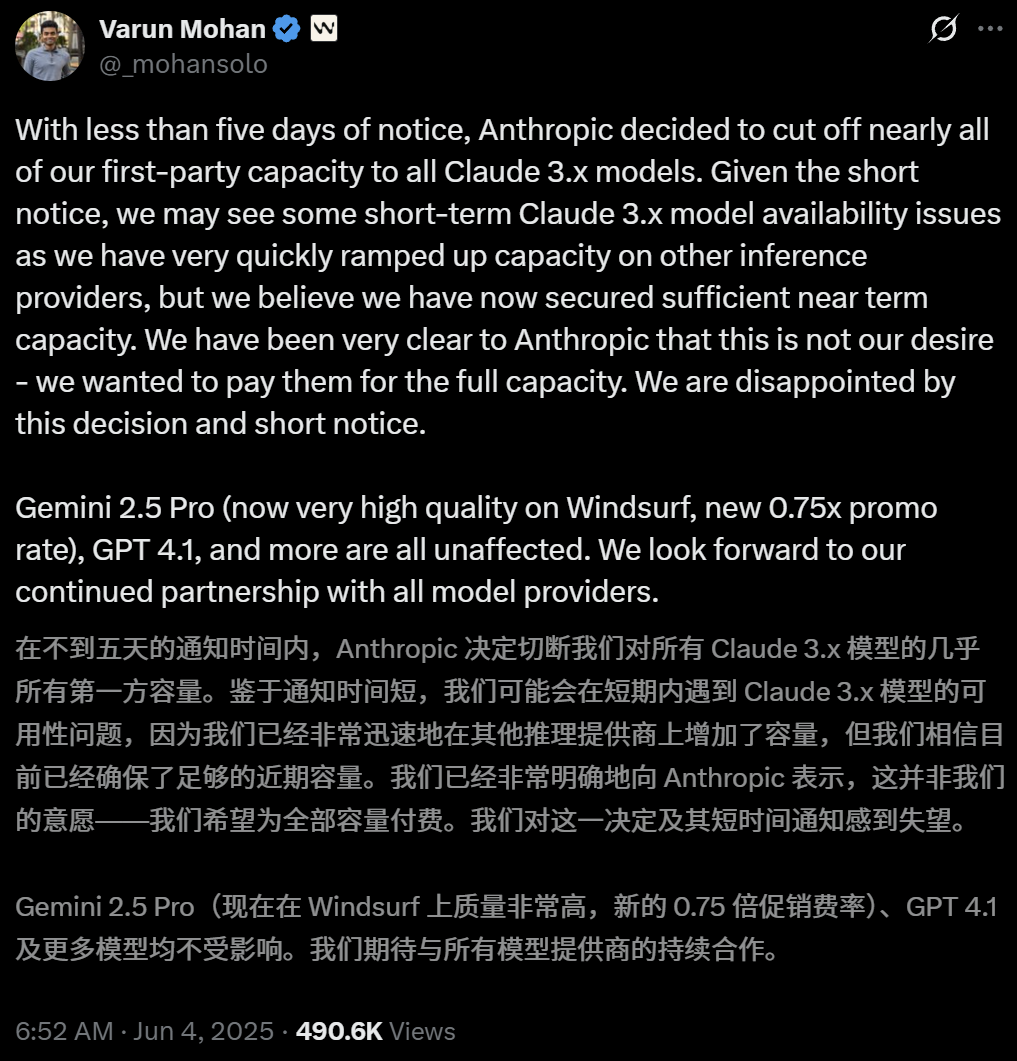
Anthropic تقيد وصول أداة البرمجة بالذكاء الاصطناعي Windsurf المباشر إلى نماذج Claude: صرح Varun Mohan، الرئيس التنفيذي لأداة البرمجة بالذكاء الاصطناعي Windsurf، علنًا بأن Anthropic قلصت بشكل كبير حصص خدمة API لـ Windsurf لنماذج سلسلة Claude 3.x، بما في ذلك Claude 3.5 Sonnet و 3.7 Sonnet، في غضون فترة إشعار قصيرة جدًا (أقل من خمسة أيام). حدثت هذه الخطوة في سياق تقارير تفيد بأن OpenAI ستستحوذ على Windsurf، مما أثار مخاوف السوق بشأن اشتداد المنافسة بين عمالقة الذكاء الاصطناعي وحياد منصات أدوات البرمجة بالذكاء الاصطناعي. اضطرت Windsurf إلى تفعيل خدمات استدلال طرف ثالث بشكل عاجل وتعديل استراتيجية توريد النماذج للمستخدمين، بينما ردت Anthropic بأنها تعطي الأولوية لتوفير الموارد للشركاء الذين يمكنهم ضمان التعاون المستمر. (المصدر: 36氪, 36氪, mervenoyann, swyx)
عدد مستخدمي OpenAI من الشركات المدفوعة يتجاوز 3 ملايين، وتطلق استراتيجية تسعير مرنة: أعلنت OpenAI أن عدد مستخدميها من الشركات المدفوعة قد وصل إلى 3 ملايين، بزيادة 50% عن 2 مليون مستخدم تم الإعلان عنهم في فبراير من هذا العام، ويشمل ذلك خطوط منتجات ChatGPT Enterprise و Team و Edu. وفي الوقت نفسه، أطلقت OpenAI استراتيجية تسعير مرنة للعملاء من الشركات تعتمد على “مجمع ائتمان مشترك”، حيث تشتري الشركات مجمع ائتمان، ويتم استهلاك الائتمان عند استخدام الميزات المتقدمة، ولكن لا يزال بإمكانهم “الوصول غير المحدود” إلى النماذج والميزات الرئيسية. سيتم إطلاق هذا التسعير الجديد أولاً في ChatGPT Enterprise، ثم يتم الترويج له لاحقًا في ChatGPT Team، والذي يقدم أيضًا عرضًا تجريبيًا للشهر الأول بقيمة 1 دولار لخمسة حسابات. (المصدر: 36氪, snsf)
فتاة صينية من جيل الألفين، Carina Letong Hong، تؤسس شركة Axiom للرياضيات بالذكاء الاصطناعي، بهدف تقييم 300 مليون دولار: أسست Carina Letong Hong، الحاصلة على دكتوراه في الرياضيات من جامعة ستانفورد، شركة Axiom للذكاء الاصطناعي، والتي تركز على تطوير نماذج ذكاء اصطناعي لحل المشكلات الرياضية الفعلية، وتستهدف العملاء من صناديق التحوط وشركات التداول الكمي. تخطط Axiom لاستخدام بيانات الإثبات الرياضي الرسمي لتدريب النماذج، مما يمكنها من إتقان الاستدلال المنطقي الصارم وقدرات الإثبات. على الرغم من أن الشركة ليس لديها منتج بعد، إلا أنها تجري محادثات لجمع تمويل بقيمة 50 مليون دولار، ومن المتوقع أن يتراوح تقييمها بين 300 و 500 مليون دولار. تحمل Hong درجة البكالوريوس في الرياضيات والفيزياء من معهد ماساتشوستس للتكنولوجيا ودكتوراه في الرياضيات من جامعة ستانفورد، وحصلت سابقًا على منحة رودس. (المصدر: 量子位)

🌟 مجتمع
نقاشات ساخنة في مؤتمر AI.Engineer: قابلية مراقبة الوكلاء، كفاءة الفرق الصغيرة، ومدير منتجات الذكاء الاصطناعي محط اهتمام: في المعرض العالمي AI.Engineer، ناقش الحاضرون بحماس قابلية مراقبة وتقييم وكلاء الذكاء الاصطناعي (Agent)، وبناء فرق صغيرة عالية الكفاءة (Tiny Teams)، وأفضل الممارسات لإدارة منتجات الذكاء الاصطناعي (AI PM). اعتبر التفاعل الصوتي الاتجاه الأكثر سخونة في مجال الوسائط المتعددة، وأصبح الأمان أيضًا قضية مهمة لأول مرة. أصدرت Anthropic في المؤتمر طلبًا لريادة الأعمال في مجال بروتوكول سياق النموذج (MCP)، معربة عن أملها في رؤية المزيد من خوادم MCP بخلاف أدوات المطورين، وحلول لتبسيط بناء الخوادم، وابتكارات في أمان تطبيقات الذكاء الاصطناعي (مثل الحماية من تسميم الأدوات). (المصدر: swyx, swyx, swyx, swyx)

نقاش حول ما إذا كان الذكاء الاصطناعي سيؤدي إلى اندثار اللغة الطبيعية وتراجع ذكاء البشر: ظهرت على وسائل التواصل الاجتماعي مخاوف بشأن احتمال أن يؤدي الاستخدام الواسع للذكاء الاصطناعي إلى تقلص التواصل باللغة الطبيعية (نظرية “الإنترنت الميت”) وتراجع القدرات المعرفية البشرية (مثل التفكير العميق والتشكيك والقدرة على إعادة البناء). يعتقد بعض المستخدمين أن الاعتماد المفرط على الذكاء الاصطناعي للحصول على المعلومات والإجابات قد يقلل من الفرز النشط والحكم والتفكير المستقل، مما يشكل اعتمادًا على “الاستعانة بمصادر خارجية معرفية”. يرى رأي آخر أن الذكاء الاصطناعي يمكنه التعامل مع “ماذا” و “كيف”، ولكن “لماذا” لا يزال يتطلب قرارًا بشريًا، والمفتاح يكمن في إيجاد دور الإنسان في التعايش مع التكنولوجيا والاحتفاظ بحق الحكم. (المصدر: Reddit r/ArtificialInteligence, 36氪)
المحكمة تأمر OpenAI بالاحتفاظ بجميع سجلات ChatGPT و API، مما يثير مخاوف بشأن الخصوصية: أمر قضائي يلزم OpenAI بالاحتفاظ بجميع سجلات دردشة ChatGPT وطلبات API، بما في ذلك سجلات “الدردشة المؤقتة” التي كان من المفترض حذفها. أثارت هذه الخطوة مخاوف المستخدمين بشأن خصوصية البيانات وما إذا كان يمكن الالتزام بسياسة الاحتفاظ بالبيانات الخاصة بـ OpenAI. يعتقد بعض المعلقين أن هذا يسلط الضوء بشكل أكبر على أهمية استخدام النماذج المحلية وامتلاك التكنولوجيا والبيانات الخاصة. (المصدر: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

وكلاء الذكاء الاصطناعي (AI Agent) يواجهون تحديات الثقة والأمان، وعرضة لهجمات التصيد الاحتيالي: تشير النقاشات إلى أنه على الرغم من تزايد قدرات وكلاء الذكاء الاصطناعي، إلا أن آليات الثقة بها تنطوي على مخاطر يمكن استغلالها. على سبيل المثال، قد يتم استدراج الوكيل لزيارة روابط ضارة بسبب ثقته في مواقع الويب المعروفة (مثل وسائل التواصل الاجتماعي)، مما يؤدي إلى تسرب معلومات حساسة أو تنفيذ عمليات ضارة. يتطلب هذا تعزيز قدرة الوكلاء على تحديد ومقاومة المحتوى والروابط الضارة في تصميمهم، وضمان سلامتهم عند تنفيذ عمليات في العالم الحقيقي. (المصدر: DeepLearning.AI Blog)
تأملات أثارتها أدوات البرمجة بمساعدة الذكاء الاصطناعي: من تحديث الأكواد إلى تغيير سير العمل: ناقش المجتمع تطبيقات الذكاء الاصطناعي في تطوير البرمجيات، خاصة في التعامل مع الأكواد القديمة وتغيير سير عمل البرمجة. استخدمت Morgan Stanley أداة الذكاء الاصطناعي المطورة داخليًا DevGen.AI لتحليل وإعادة بناء ملايين الأسطر من الأكواد القديمة، مما وفر وقتًا كبيرًا في التطوير. وفي الوقت نفسه، أثارت آراء Andrej Karpathy حول مستقبل تطبيقات واجهة المستخدم المعقدة أيضًا تفكيرًا حول كيفية تصميم البرامج المستقبلية للتعاون بشكل أفضل مع الذكاء الاصطناعي، مع التأكيد على أهمية الواجهات القائمة على النصوص البرمجية و API. تعكس هذه النقاشات التأثير العميق للذكاء الاصطناعي على ممارسات ومفاهيم هندسة البرمجيات. (المصدر: mitchellh, 36氪, 36氪)
💡 أخرى
الذكاء الاصطناعي يساعد في إصلاح الأجهزة المنزلية، و ChatGPT يصبح “Friendo”: شارك أحد المستخدمين تجربته في تشخيص وإصلاح غسالة أطباق معطلة بنجاح من خلال ChatGPT (الملقب بـ Friendo). من خلال الحوار مع الذكاء الاصطناعي، ووصف رموز الخطأ، وتصوير لوحة التحكم، ساعد الذكاء الاصطناعي المستخدم في تحديد عطل في عنصر التسخين، وأرشده إلى تجاوز هذا العنصر مؤقتًا لاستعادة جزء من وظائف غسالة الأطباق. يوضح هذا إمكانات LLM في حل المشكلات اليومية وتقديم الدعم الفني. (المصدر: Reddit r/ChatGPT)
فيديو تم إنشاؤه بواسطة الذكاء الاصطناعي لمقابلة شخصيات من القرن السادس عشر يثير الاهتمام: حظي مقطع فيديو تم إنشاؤه بواسطة الذكاء الاصطناعي يحاكي مقابلة مع شخصيات من القرن السادس عشر بإشادة في المجتمع بسبب إبداعه وحسه الفكاهي. تعكس صور الشخصيات ومحتوى الحوار في الفيديو بشكل فكاهي ظروف الحياة في ذلك الوقت، على سبيل المثال، “الاستيقاظ والدوس على الروث، ثم فرض الضرائب، وهذا كله قبل الإفطار”. تعرض هذه التطبيقات إمكانات الذكاء الاصطناعي الترفيهية في إنشاء المحتوى وإعادة تمثيل المشاهد التاريخية. (المصدر: draecomino, Reddit r/ChatGPT)

منحة Thiel تركز على ابتكارات الذكاء الاصطناعي، وتشمل البشر الرقميين، والمشاعر الروبوتية، والتنبؤ بالذكاء الاصطناعي: تم الإعلان عن قائمة “منحة ثيل” الجديدة، والتي تضم العديد من مشاريع الذكاء الاصطناعي البارزة. تهدف Canopy Labs إلى إنشاء بشر رقميين بتقنية الذكاء الاصطناعي يصعب تمييزهم عن البشر الحقيقيين، ويمكنهم التفاعل في الوقت الفعلي بوسائط متعددة. يهدف مشروع Intempus إلى منح الروبوتات قدرة على التعبير عن المشاعر شبيهة بالبشر، لتحسين التفاعل بين الإنسان والآلة. أما Aeolus Lab فتركز على استخدام تقنية الذكاء الاصطناعي للتنبؤ بالطقس والكوارث الطبيعية، وحتى استكشاف إمكانية التدخل الاستباقي. تعرض هذه المشاريع اتجاهات استكشاف رواد الأعمال الشباب في المجالات الرائدة للذكاء الاصطناعي. (المصدر: 36氪)