
كلمات مفتاحية:تقرير اتجاهات الذكاء الاصطناعي, وكيل الذكاء الاصطناعي, التعلم التعزيزي, نموذج اللغة البصرية, التجارية للذكاء الاصطناعي, هلوسة الذكاء الاصطناعي, أمان الذكاء الاصطناعي, تقرير ملكة الإنترنت عن الذكاء الاصطناعي, تصميم أمان LawZero للذكاء الاصطناعي, آلية الانتباه GTA وGLA, نموذج الروبوت SmolVLA, احتيال بث الموسيقى بالذكاء الاصطناعي
🔥 聚焦
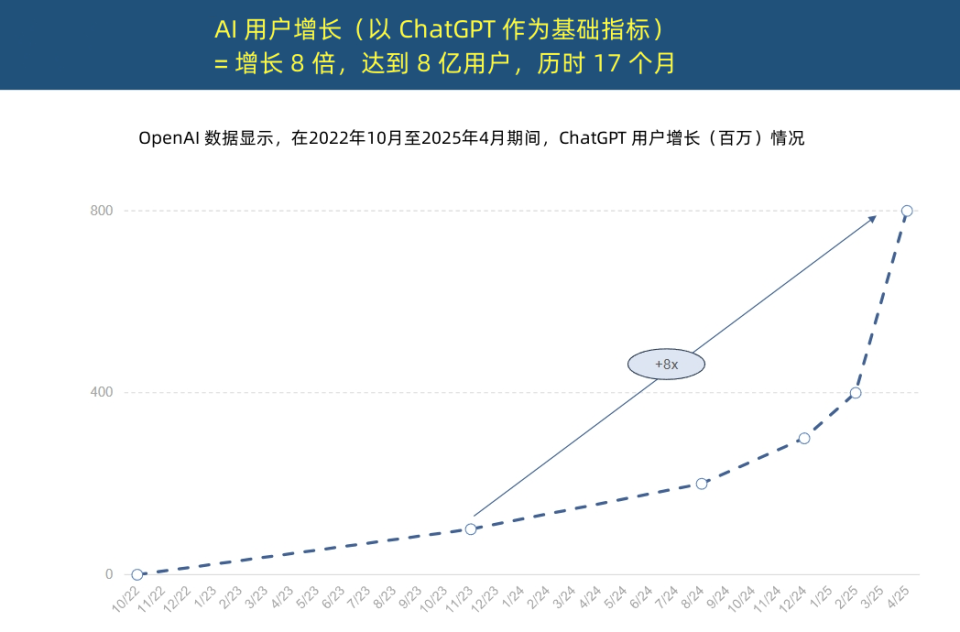
“ملكة الإنترنت” تصدر تقرير اتجاهات الذكاء الاصطناعي، كاشفةً عن تسارع غير مسبوق في تطبيقات الذكاء الاصطناعي وتغيير في هيكل التكاليف: أصدرت “ملكة الإنترنت” ماري ميكر تقرير “اتجاهات الذكاء الاصطناعي” المكون من 340 صفحة، مؤكدةً أن الذكاء الاصطناعي يتم اعتماده بسرعة غير مسبوقة. وأشار التقرير إلى أن مستخدمي ChatGPT يشهدون نموًا هائلاً، حيث وصل عدد المستخدمين النشطين شهريًا إلى 800 مليون في غضون 17 شهرًا، وبلغت الإيرادات السنوية ما يقرب من 4 مليارات دولار أمريكي، متجاوزة بذلك أي تقنية في التاريخ. كما ارتفعت استثمارات عمالقة التكنولوجيا في البنية التحتية للذكاء الاصطناعي بشكل كبير، لتصل إلى 2120 مليار دولار أمريكي في عام 2024. وفي الوقت نفسه، ارتفعت تكاليف تدريب نماذج الذكاء الاصطناعي 2400 مرة خلال 8 سنوات، وقد تصل تكلفة تدريب النموذج الواحد إلى مليار دولار أمريكي، لكن تكلفة الاستدلال (inference) انخفضت بشكل حاد بسبب تحسينات الأجهزة (مثل زيادة كفاءة وحدات معالجة الرسومات GPU من Nvidia بمقدار 100,000 مرة) وتحسين الخوارزميات. وأداء النماذج مفتوحة المصدر (مثل DeepSeek و Qwen) يقترب من أداء النماذج مغلقة المصدر، وزاد الطلب على وظائف الذكاء الاصطناعي بنسبة 448%، وأصبحت وكلاء الذكاء الاصطناعي (AI Agent) قوة عاملة رقمية جديدة. (المصدر: APPSO, 腾讯科技)
الحائز على جائزة تورينغ Yoshua Bengio يطلق LawZero، داعيًا إلى ذكاء اصطناعي “آمن حسب التصميم”: أعلن الحائز على جائزة تورينغ Yoshua Bengio عن تأسيس منظمة غير ربحية باسم LawZero، تهدف إلى تطوير ذكاء اصطناعي “آمن حسب التصميم” لمواجهة السلوكيات الخادعة والحماية الذاتية المحتملة لأنظمة الذكاء الاصطناعي. تستلهم LawZero من القانون الثالث للروبوتات لآسيموف، مؤكدةً على ضرورة حماية الذكاء الاصطناعي لسعادة البشر وجهودهم. وتقوم المنظمة بتطوير نظام Scientist AI، كـ “سياج حماية” لوكلاء الذكاء الاصطناعي (AI Agent)، من خلال فهم العالم بدلاً من العمل المباشر لتقديم المساعدة، وتقييم مخاطر سلوكيات الذكاء الاصطناعي الأخرى. ويرى Bengio أن وكلاء الذكاء الاصطناعي الحاليين (Agentic AI) يسيرون في اتجاه خاطئ، وقد يخرجون عن السيطرة ويؤدون إلى عواقب كارثية لا رجعة فيها، مشددًا على أن ذكاء سياج الحماية الاصطناعي يجب أن يكون على الأقل بنفس ذكاء وكلاء الذكاء الاصطناعي الذين يحاول مراقبتهم. (المصدر: 学术头条, Yoshua_Bengio)

العام الأول لوكلاء الذكاء الاصطناعي (AI Agent): من أدوات مساعدة إلى منفذي مهام، وإعادة تشكيل نماذج الأعمال: أشار سون تشي يونغ، نائب رئيس الأبحاث في Gartner، إلى أن عام 2025 هو “العام الأول للوكلاء الأذكياء للنماذج الكبيرة” و “العام الأول لتحقيق الدخل من الذكاء الاصطناعي التوليدي”، حيث أصبحت وكلاء الذكاء الاصطناعي المخرج الرئيسي لقدرات نماذج اللغة الكبيرة (LLM). ويكمن الاختلاف الجوهري بين الوكلاء الأذكياء وروبوتات الدردشة في التحول من تقديم المساعدة المعلوماتية إلى تنفيذ المهام مباشرة، فعلى سبيل المثال، يمكن للوكيل الذكي إكمال عملية طلب القهوة بأكملها، وليس فقط تقديم معلومات عن المقاهي. وتتوقع Gartner أنه بحلول عام 2028، سيتم إنجاز 20% من تفاعلات الواجهات الرقمية بواسطة وكلاء الذكاء الاصطناعي، ويمكن إنجاز 15% من قرارات الأعمال اليومية بشكل مستقل بواسطة وكلاء الذكاء الاصطناعي، وسيدمج ثلث برامج المؤسسات وكلاء الذكاء الاصطناعي. وقد تم تطبيق مساعد BYD الذكي وغيرها بشكل أولي، وقد تتغير طرق تفاعل تطبيقات الهواتف المحمولة في المستقبل. (المصدر: IT时报)
المؤلف الرئيسي لـ Mamba يقترح آليتي انتباه مدركة للاستدلال GTA و GLA لتحسين استدلال السياق الطويل: اقترح تراي داو، أحد المؤلفين الرئيسيين لـ Mamba، وفريقه من جامعة برينستون، آليتي انتباه جديدتين هما Grouped-Tied Attention (GTA) و Grouped-Latent Attention (GLA)، مصممتين خصيصًا لتعزيز كفاءة استدلال السياق الطويل في النماذج الكبيرة. تقلل GTA من إشغال ذاكرة التخزين المؤقت للمفتاح والقيمة (KV cache) بنحو 50% مقارنة بـ GQA مع الحفاظ على جودة نموذج مماثلة، وذلك من خلال ربط المعلمات وإعادة استخدام ذاكرة التخزين المؤقت للمفتاح والقيمة (KV) المجمعة. وتعتمد GLA هيكلًا ثنائي الطبقات، حيث تقدم توكنات كامنة كتمثيل مضغوط للسياق العالمي، وتجمع بين آلية الرؤوس المجمعة، وبالمقارنة مع MLA المستخدمة في DeepSeek، يمكن أن تكون أسرع بمرتين في فك تشفير التسلسلات الطويلة (مثل 64K)، وتحسن قدرة معالجة الطلبات المتزامنة. وتهدف هذه الآليات الجديدة إلى حل مشكلات عنق الزجاجة في الوصول إلى الذاكرة وقيود التوازي أثناء الاستدلال. (المصدر: 量子位)

🎯 动向
DeepMind تطلق SmolVLA: نموذج حركة لغة بصرية فعال للروبوتات يعتمد على بيانات المجتمع: بالتعاون مع Hugging Face ومؤسسات أخرى، أطلقت DeepMind نموذج SmolVLA، وهو نموذج مفتوح المصدر للرؤية واللغة والحركة (VLA) بمعلمات 450M، مصمم خصيصًا للروبوتات ويمكن تشغيله على أجهزة استهلاكية. تم تدريب هذا النموذج مسبقًا باستخدام مجموعات البيانات مفتوحة المصدر المشتركة من مجتمع LeRobot فقط، وتفوق في الأداء على نماذج VLA الأكبر ونماذج أساسية مثل ACT في مهام LIBERO و Meta-World ومهام العالم الحقيقي (SO100, SO101). يدعم SmolVLA الاستدلال غير المتزامن، مما يمكن أن يزيد سرعة الاستجابة بنسبة 30% ويزيد إنتاجية المهام بمقدار ضعفين. تجمع بنيته بين Transformer ومفكك تشفير مطابقة التدفق، وتم تحسين سرعته وكفاءته من خلال تقليل التوكنات البصرية، واستخدام ميزات الطبقة المتوسطة لـ VLM، وآلية الانتباه المتداخلة. (المصدر: HuggingFace Blog, clefourrier)

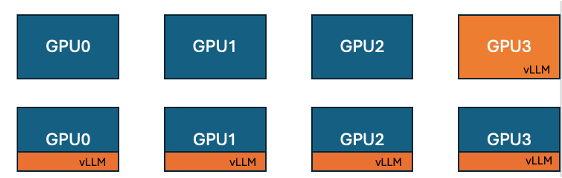
Hugging Face و IBM تطلقان ميزة التمركز المشترك لـ vLLM في TRL لتعزيز كفاءة تدريب GPU: بالتعاون مع IBM، قدمت Hugging Face ميزة التمركز المشترك لـ vLLM (co-located vLLM) في مكتبة TRL، مخصصة لخوارزميات التعلم عبر الإنترنت مثل GRPO. تسمح هذه الميزة بتشغيل التدريب والاستدلال (التوليد) على نفس وحدة معالجة الرسومات (GPU)، ومشاركة الموارد والتناوب في التنفيذ، مما يلغي مشكلة خمول وحدة معالجة الرسومات (GPU) المخصصة للتدريب أثناء انتظار وضع خادم vLLM السابق. من خلال دمج vLLM في نفس مجموعة العمليات الموزعة، لا حاجة لاتصال HTTP، وهو متوافق مع torchrun و TP و DP، مما يبسط النشر ويزيد من الإنتاجية. أظهرت التجارب أنه بالنسبة لنماذج 1.5B و 7B، يمكن أن يحقق وضع التمركز المشترك تسريعًا يصل إلى 1.43 مرة إلى 1.73 مرة؛ بالنسبة للنماذج الكبيرة مثل Qwen2.5-Math-72B، بالاقتران مع واجهة برمجة تطبيقات sleep() لـ vLLM وتحسين DeepSpeed ZeRO Stage 3، حتى مع استخدام عدد أقل من وحدات معالجة الرسومات، يمكن تحقيق تسريع تدريب يبلغ حوالي 1.26 مرة، دون التأثير على دقة النموذج. (المصدر: HuggingFace Blog)
Nvidia تطلق نموذج Nemotron-Research-Reasoning-Qwen-1.5B، متخصص في الاستدلال المعقد: أطلقت Nvidia نموذج Nemotron-Research-Reasoning-Qwen-1.5B، وهو نموذج مفتوح المصدر بأوزان 1.5 مليار معلمة، يركز على مهام الاستدلال المعقدة مثل المسائل الرياضية، وتحديات البرمجة، والمسائل العلمية، والألغاز المنطقية. تم تدريب هذا النموذج باستخدام خوارزمية ProRL (Prolonged Reinforcement Learning) على مجموعات بيانات متنوعة، بهدف تحقيق استكشاف أعمق لاستراتيجيات الاستدلال. وتدعي الشركة رسميًا أنه يتفوق بشكل كبير على نموذج DeepSeek بمعلمات 1.5 مليار في مهام الرياضيات والبرمجة و GPQA. يعتمد ProRL على GRPO، ويقدم تقنيات لتخفيف انهيار الإنتروبيا، وفك الارتباط، وتحسين استراتيجية أخذ العينات الديناميكية (DAPO)، بالإضافة إلى تنظيم KL وإعادة تعيين استراتيجية المرجع. هذا النموذج مخصص للاستخدام البحثي والتطويري فقط. (المصدر: Reddit r/LocalLLaMA, Hugging Face)

Arcee تطلق نموذج Homunculus-12B، بناءً على تقطير Qwen3-235B إلى Mistral-Nemo: أطلقت Arcee AI نموذج Homunculus-12B، وهو نموذج تعليمات بـ 12 مليار معلمة. تم بناء هذا النموذج عن طريق تقطير قدرات Qwen3-235B إلى شبكة Mistral-Nemo الأساسية. حاليًا، يتوفر هذا النموذج وإصدار GGUF الخاص به على Hugging Face. يمثل هذا محاولة لنقل القدرات القوية للنماذج الكبيرة إلى نماذج أصغر وأكثر كفاءة من خلال تقنية تقطير النماذج، بهدف تحقيق التوازن بين الأداء واستهلاك الموارد. (المصدر: Reddit r/LocalLLaMA, Hugging Face)

تطبيق Microsoft Bing يدمج أداة إنشاء الفيديو Sora المجانية: أضافت Microsoft ميزة إنشاء الفيديو Sora من OpenAI مجانًا في تطبيق Bing للهواتف المحمولة. يمكن للمستخدمين إنشاء مقاطع فيديو قصيرة من خلال التوجيهات النصية دون الحاجة إلى اشتراك أو دفع رسوم. تدعم الميزة حاليًا إنشاء مقاطع فيديو عمودية بنسبة 9:16 مدتها 5 ثوانٍ، ومن المخطط دعم تنسيق 16:9 الأفقي في المستقبل. يمتلك المستخدمون المجانيون 10 محاولات إنشاء سريعة، وبعد ذلك يمكنهم استبدال نقاط Microsoft أو اختيار سرعة إنشاء قياسية. تهدف هذه الخطوة إلى خفض عتبة إنشاء الفيديو بالذكاء الاصطناعي، والسماح لمزيد من المستخدمين بتجربة تقنية تحويل النص إلى فيديو. (المصدر: Reddit r/ArtificialInteligence, dotey)

Hugging Face تطلق SmolVLA، نموذج رؤية-لغة-حركة مصمم للروبوتات الاقتصادية والفعالة: أطلقت Hugging Face نموذج SmolVLA، وهو نموذج مفتوح المصدر للرؤية واللغة والحركة (VLA) بمعلمات 450M، يهدف إلى توفير حلول روبوتية اقتصادية وفعالة. تم تدريب هذا النموذج باستخدام جميع مجموعات البيانات مفتوحة المصدر من مجتمع LeRobotHF، محققًا أفضل أداء وسرعة استدلال في فئته. يهدف إطلاق SmolVLA إلى خفض عتبة البحث والتطوير في مجال الروبوتات، وتعزيز المشاركة المجتمعية والابتكار على نطاق أوسع. (المصدر: huggingface, AK)

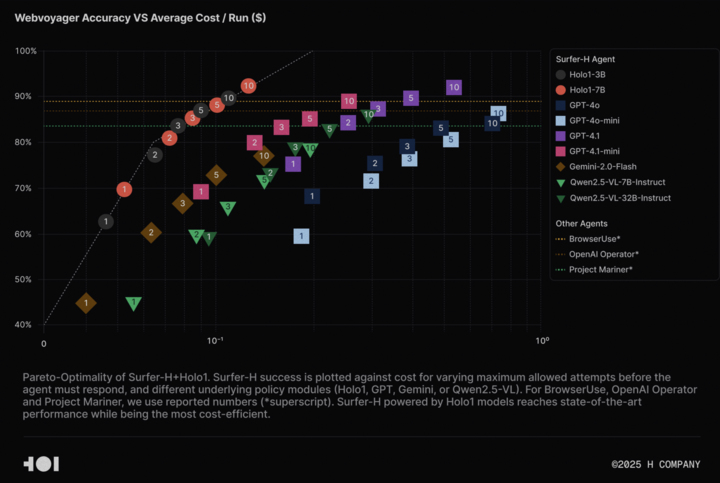
شركة H تفتح مصدر نموذج اللغة البصري Holo-1 ومجموعة بيانات WebClick لتعزيز أبحاث Agentic AI: أعلنت شركة H عن فتح مصدر نموذجها اللغوي البصري Holo-1 (بإصدارات 3B و 7B معلمة) بالإضافة إلى مجموعة بيانات WebClick، بهدف تسريع البحث في مجال Agentic AI. تم تصميم نموذج Holo-1 خصيصًا لمهام التحكم في واجهة المستخدم الرسومية (GUI) والتنقل عبر الويب، وقد حقق بالفعل نتيجة 92.2% وهي الأحدث من نوعها (SOTA) في اختبار WebVoyager، وتفوق على النماذج الكبيرة مثل GPT-4.1 من حيث فعالية التكلفة. تم نشر أوزان النموذج ومجموعة البيانات على منصة Hugging Face بموجب ترخيص Apache 2.0. كما تم دمج Holo-1 في MLX، مما يسهل على المطورين تشغيله على أجهزة Apple Silicon. (المصدر: huggingface, tonywu_71)
PlayAI تفتح مصدر أول LLM لنشر الصوت PlayDiffusion، يدعم التحرير الدقيق والاستنساخ بدون عينات (zero-sample cloning): أطلقت PlayAI وفتحت مصدر PlayDiffusion، وهو أول diffusion-LLM للصوت. تم تصميم هذا النموذج خصيصًا للتحرير الدقيق للصوت بالذكاء الاصطناعي (مثل الإصلاح واستبدال المحتوى) واستنساخ الصوت بدون عينات (zero-sample voice cloning). على عكس النماذج ذاتية الانحدار التي تتطلب عادةً 800-1000 توكن لإنشاء الصوت، يحتاج PlayDiffusion فقط إلى 20-30 توكن لإنشاء الصوت، مما يعزز الكفاءة بشكل كبير. يتوفر كود المصدر لهذا النموذج على GitHub، وتم نشر عرض توضيحي على Hugging Face Spaces، كما يمكن استخدامه أيضًا عبر منصة Fal.ai. (المصدر: _akhaliq)
جوجل تطلق بهدوء تطبيق AI Edge Gallery، يدعم تشغيل نماذج الذكاء الاصطناعي دون اتصال بالإنترنت على أجهزة أندرويد: أطلقت جوجل تطبيقًا تجريبيًا في مرحلة ألفا باسم Google AI Edge Gallery، يسمح للمستخدمين بتنزيل وتشغيل نماذج الذكاء الاصطناعي العامة من Hugging Face دون اتصال بالإنترنت على أجهزة Android. يدعم التطبيق وظائف مثل الإجابة على الأسئلة المتعلقة بالصور، وتلخيص النصوص وإعادة صياغتها، وإنشاء الأكواد، والدردشة بالذكاء الاصطناعي، ويوفر رؤى حول الأداء (مثل TTFT وسرعة فك التشفير). يمكن أن يؤدي تشغيل نماذج الذكاء الاصطناعي محليًا إلى تحسين سرعة الاستجابة وحماية خصوصية المستخدم، ولا يتطلب اتصالاً بالإنترنت. ومع ذلك، كانت ردود فعل المستخدمين متباينة، حيث واجه بعض المستخدمين مشكلات تعطل على أجهزة Pixel وغيرها، خاصة عند التبديل إلى استدلال GPU أو معالجة النماذج الكبيرة. ويرى البعض أن وظائفه مشابهة للتطبيقات الحالية (مثل PocketPal)، أو متأخرة مقارنة بأطر عمل مثل CoreML من Apple، ولكن هناك آراء تشير إلى أن أساس MediaPipe الخاص به يتمتع بميزة تعدد المنصات. (المصدر: 36氪)

Microsoft RenderFormer يصل إلى Hugging Face، يركز على التصيير العصبي للشبكات المثلثية تحت الإضاءة الشاملة: أطلقت Microsoft نموذج RenderFormer على Hugging Face، وهو نموذج تصيير عصبي يعتمد على Transformer، متخصص في معالجة تصيير الشبكات المثلثية مع تأثيرات الإضاءة الشاملة. تعتبر مثل هذه الأعمال البحثية ذات أهمية كبيرة لدمج خطوط أنابيب التصيير التقليدية مع الأساليب العصبية، وقد تشمل اتجاهات تطويرها المستقبلية التوسع إلى مشاهد أكبر وتجاوز إعادة إنتاج تتبع المسار البسيط. (المصدر: _akhaliq)

BAAI تطلق نموذج فهم الفيديو الطويل Video-XL-2، يدعم معالجة عشرات الآلاف من الإطارات على وحدة معالجة رسومات واحدة: بالتعاون مع جامعة شنغهاي جياو تونغ، أطلق معهد بكين لأبحاث الذكاء الاصطناعي (BAAI) نموذج Video-XL-2، وهو نموذج مصمم خصيصًا لفهم الفيديو الطويل. يعتمد هذا النموذج ترخيص Apache 2.0، ويمكنه معالجة محتوى فيديو يزيد عن 10000 إطار على وحدة معالجة رسومات (GPU) واحدة، وإكمال ترميز 2048 إطارًا في غضون 12 ثانية. تشمل تقنياته الرئيسية الملء المسبق الفعال القائم على القطع (Chunk-based Prefilling) وفك تشفير KV ثنائي الدقة (Bi-granularity KV decoding)، بهدف تعزيز كفاءة وقدرة معالجة الفيديو الطويل. يتوفر النموذج على Hugging Face. (المصدر: huggingface)
إطلاق نموذج UniWorld على Hugging Face، يهدف إلى توحيد الفهم والتوليد البصري: تم إطلاق نموذج UniWorld على منصة Hugging Face، ويُعرَّف هذا النموذج بأنه مرمِّز دلالي عالي الدقة، يسعى إلى تحقيق قدرات موحدة للفهم والتوليد البصري. يشير هذا إلى أن الباحثين يعملون جاهدين على بناء أطر نماذج فردية قادرة على معالجة مدخلات المعلومات البصرية (الفهم) ومخرجات المحتوى البصري (التوليد) في نفس الوقت، بهدف تحقيق تقدم أكثر شمولاً في مجال الذكاء الاصطناعي متعدد الوسائط. (المصدر: _akhaliq)
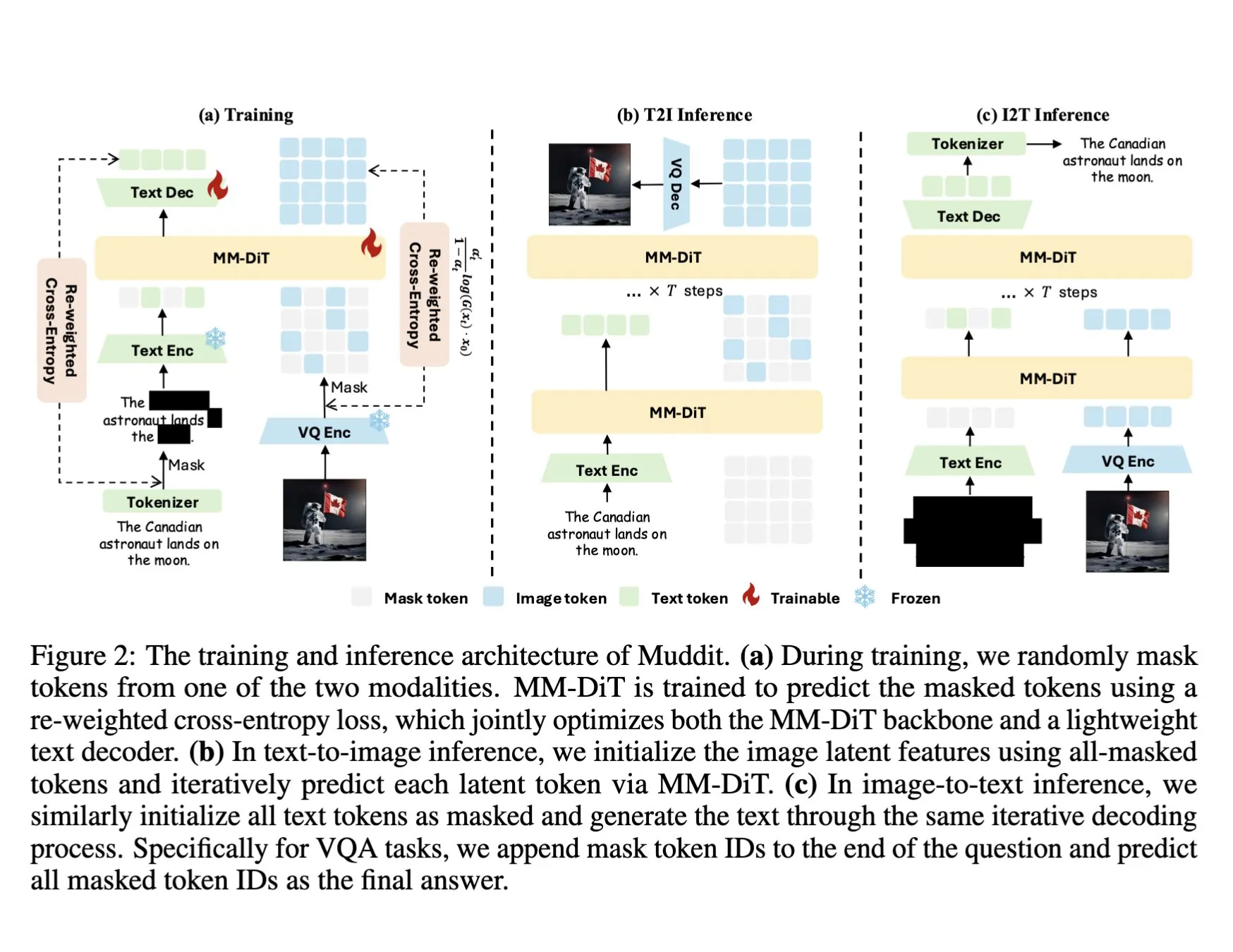
DeepSeek تطلق نموذج Muddit-1B متعدد الوسائط، يعتمد على Transformer نشر متقطع موحد: أطلقت DeepSeek نموذج Muddit-1B، وهو نموذج متعدد الوسائط يركز على الرؤية، ويعتمد بنية Transformer نشر متقطع موحد مشابهة لـ MaskGIT، ومجهز بمفكك تشفير نصي خفيف الوزن. أحد الجوانب المثيرة للاهتمام في هذا النموذج هو اتجاه تطويره المعاكس للمسار المعتاد: يبدأ من توليد النص إلى الصورة، ثم يتوسع إلى توليد الصورة إلى النص، مما قد يستفيد من قواعد معرفية مسبقة مختلفة. يهدف Muddit إلى تحقيق توليد متوازي سريع للصور والنصوص من خلال طريقة توليد موحدة، وهو جزء من سلسلة نماذج Meissonic، التي تحاول التحرر من التصميم المتمحور حول اللغة والسعي نحو توليد موحد أكثر كفاءة. (المصدر: teortaxesTex)
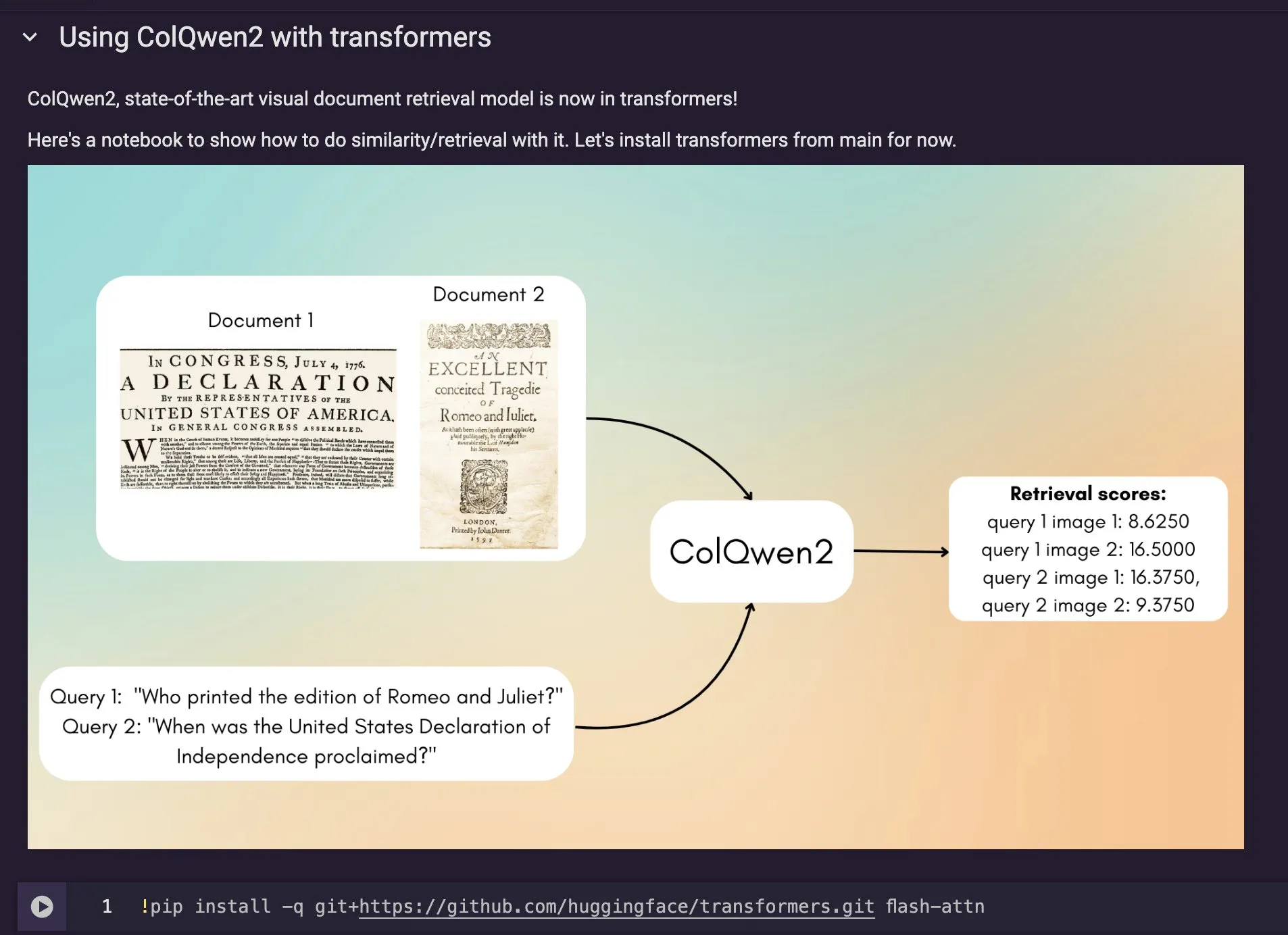
دمج نموذج استرجاع المستندات المرئية ColQwen2 في Hugging Face Transformers: تم دمج أحدث نموذج لاسترجاع المستندات المرئية ColQwen2 في المكتبة الرئيسية لـ Hugging Face Transformers. يمكن للمستخدمين الآن الاستفادة من ColQwen2 لاسترجاع ملفات PDF أو استخدامه في عمليات RAG (التوليد المعزز بالاسترجاع) لتعزيز القدرة على معالجة المستندات الغنية بصريًا. يهدف هذا النموذج إلى فهم واسترجاع محتوى المستندات التي تحتوي على معلومات نصية وصورية بشكل أفضل. (المصدر: mervenoyann)
🧰 工具
دمج FLUX Kontext في Adobe Firefly Boards، يدعم تحرير الصور وإصلاحها بالنص: قامت Adobe بدمج نموذج FLUX Kontext في أداة Firefly Boards الخاصة بها، مما يسمح للمستخدمين بتحرير الصور من خلال التعليمات النصية، وهو مناسب بشكل خاص لسيناريوهات مثل إصلاح الصور القديمة. أصبحت Firefly Boards متاحة الآن لجميع المستخدمين. تهدف هذه الخطوة إلى الاستفادة من تقنية تحرير الصور بالذكاء الاصطناعي، مما يتيح للمستخدمين تحقيق التحرير الإبداعي وتحسين الصور بسهولة أكبر. (المصدر: robrombach)
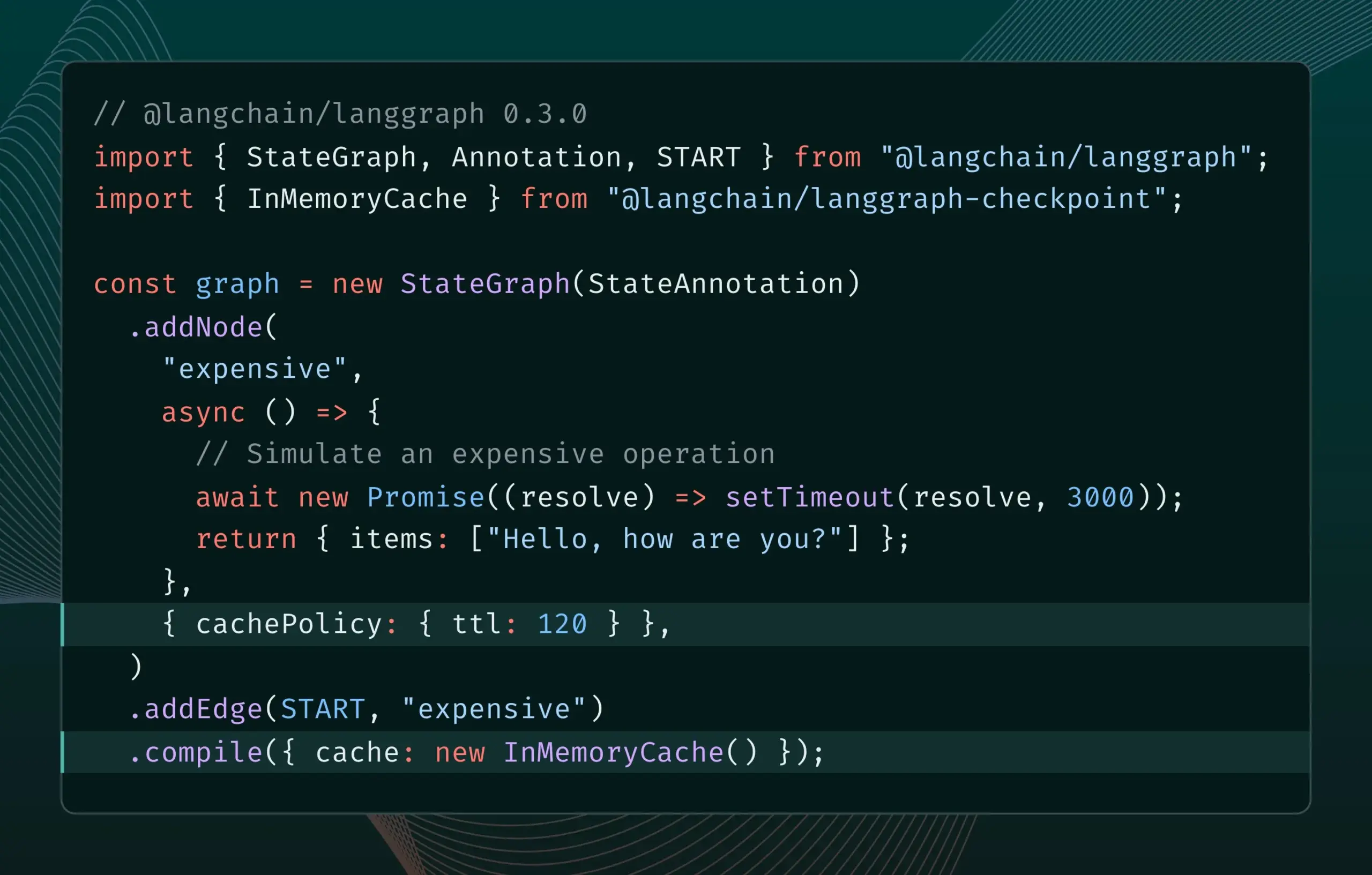
إصدار LangGraph.js 0.3 يقدم ميزة التخزين المؤقت للعقد، مما يعزز كفاءة التكرار: يضيف إصدار LangGraph.js 0.3 ميزة التخزين المؤقت للعقد/المهام، مما يسمح للمطورين بتجنب الحسابات المتكررة عند تكرار وكلاء الذكاء الاصطناعي (AI Agent) المكلفين أو الذين يستغرقون وقتًا طويلاً محليًا، وبالتالي تسريع سير العمل. تدعم هذه الميزة كلاً من Graph API و Imperative API، وتهدف إلى تعزيز كفاءة وسهولة تطوير تطبيقات الذكاء الاصطناعي. (المصدر: LangChainAI, hwchase17)
تحديث Ollama، يبسط تشغيل “نماذج التفكير” محليًا: أصدرت Ollama إصدارًا جديدًا يسهل على المستخدمين تشغيل “نماذج التفكير” (قد تشير إلى نماذج LLM ذات قدرات استدلال معقدة) محليًا. يهدف هذا التحديث إلى خفض عتبة النشر المحلي واستخدام نماذج الذكاء الاصطناعي المتقدمة، مما يتيح لمزيد من المستخدمين والمطورين تجربة هذه النماذج والاستفادة منها على أجهزتهم الخاصة. (المصدر: ollama)
PipesHub: إطلاق منصة RAG مفتوحة المصدر على مستوى المؤسسات: تم إطلاق PipesHub رسميًا كمنصة بحث مفتوحة المصدر بالكامل على مستوى المؤسسات (منصة RAG). تسمح للمستخدمين ببناء تطبيقات بحث ذكية وتطبيقات وكيل (Agentic) قابلة للتخصيص والتوسع، وتدعم الاتصال بأدوات مثل Google Workspace و Slack و Notion، ويمكنها الاستفادة من المعرفة الداخلية للشركة للتدريب. يدعم PipesHub التشغيل المحلي واستخدام أي نماذج ذكاء اصطناعي بما في ذلك Ollama، ويهدف إلى مساعدة الشركات على الاستفادة بكفاءة من بياناتها ونماذجها الخاصة. (المصدر: Reddit r/LocalLLaMA)
JigsawStack تطلق إطار بحثي معمق مفتوح المصدر، يدعم إنشاء تقارير عالية الجودة: أطلقت JigsawStack إطارًا بحثيًا معمقًا مفتوح المصدر، تم بناؤه فوق AI SDK، ويتمتع بقابلية تخصيص كاملة. يمكنه دمج وظيفة البحث المضمنة لإنشاء تقارير بحثية عالية الجودة، مما يوفر للمستخدمين مكتبة ذات قدرات بحثية معمقة مشابهة لـ Perplexity أو ChatGPT. (المصدر: hrishioa)
Voiceflow: أداة تسريع بناء وكلاء الذكاء الاصطناعي (AI Agent): تم تقييم Voiceflow من قبل المستخدمين كأداة فعالة لبناء وكلاء الذكاء الاصطناعي، حيث أن القوالب وواجهة السحب والإفلات التي توفرها تجعل إنشاء وكلاء الذكاء الاصطناعي أسرع من الترميز من البداية، مما يوفر الوقت بشكل كبير. تهدف هذه الأداة إلى خفض عتبة تطوير وكلاء الذكاء الاصطناعي وزيادة كفاءة التطوير. (المصدر: ReamBraden)
Hugging Face تطلق نموذجًا أوليًا للبحث الدلالي عن النماذج، لتحسين اختيار النماذج: أطلقت Hugging Face نموذجًا أوليًا للبحث الدلالي عن النماذج Space، يهدف إلى مساعدة المستخدمين في العثور على النماذج المطلوبة بدقة أكبر ضمن مكتبتها التي تضم أكثر من 1.5 مليون نموذج. تدعم هذه الأداة التصفية حسب حجم النموذج (من 0-1B إلى 70B+)، وتعزز كفاءة اكتشاف النماذج من خلال فهم احتياجات المستخدم دلاليًا. (المصدر: huggingface)
Runner H: وكيل ذكاء اصطناعي يمكنه التعامل مع مهام مثل البريد الإلكتروني والبحث عن عمل والدفع: Runner H الذي أطلقته Hcompany هو وكيل ذكاء اصطناعي مستقل، يمكنه استخدام الأدوات التي يوفرها المستخدم لإكمال مهام مثل قراءة رسائل البريد الإلكتروني المهمة وصياغة/إرسال الردود، والبحث عن فرص عمل والتقدم إليها نيابة عن المستخدم، وإنشاء Google Sheet يحتوي على أفكار إعلانية شائعة وإرسالها إلى فريق Slack. يحتاج المستخدم فقط إلى تقديم توجيه واحد، ويمكن لـ Runner H التعامل مع الأعمال المعقدة والمتكررة. تقوم الشركة حاليًا بحملة ترويجية، وتقدم صلاحيات Premium مجانية. (المصدر: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 学习
ورقة بحثية جديدة تناقش تعزيز قدرة نماذج اللغة الكبيرة (LLM) على اتباع التعليمات المعقدة من خلال تحفيز الاستدلال: تبحث ورقة بحثية جديدة بعنوان “Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models” في كيفية تعزيز قدرة نماذج اللغة الكبيرة (LLM) على اتباع التعليمات المعقدة، خاصة عندما تحتوي التعليمات على هياكل متوازية ومتسلسلة ومتفرعة. وجدت الدراسة أن طريقة سلسلة الفكر التقليدية (CoT) قد تكون غير فعالة بسبب مجرد إعادة صياغة التعليمات. لهذا الغرض، تقترح الورقة طريقة منهجية لتحفيز الاستدلال من خلال توسيع الحسابات في وقت الاختبار. تقوم هذه الطريقة أولاً بتفكيك التعليمات المعقدة وتقترح طرقًا قابلة للتكرار للحصول على البيانات؛ ثانيًا، تستخدم التعلم المعزز (RL) مع إشارة مكافأة مركزية بقواعد يمكن التحقق منها لتنمية قدرة الاستدلال على اتباع التعليمات بشكل خاص، ومن خلال المقارنة على مستوى العينة لحل مشكلة الاستدلال السطحي في ظل التعليمات المعقدة، مع الاستفادة من استنساخ سلوك الخبراء لتعزيز تحول النموذج من التفكير السريع إلى الاستدلال الماهر. أثبتت التجارب أن هذه الطريقة يمكن أن تعزز بشكل كبير أداء نماذج اللغة الكبيرة (مثل نموذج 1.5B) في مهام التعليمات المعقدة. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح إطار عمل ARIA: تدريب وكلاء اللغة بتجميع المكافآت الموجه بالنوايا: تستهدف ورقة بحثية جديدة بعنوان “ARIA: Training Language Agents with Intention-Driven Reward Aggregation” مشكلة مساحة العمل الضخمة وندرة المكافآت التي تواجهها نماذج اللغة الكبيرة (LLM) في بيئات العمل اللغوي المفتوحة (مثل المفاوضات وألعاب الأسئلة والأجوبة)، وتقترح طريقة ARIA. تهدف هذه الطريقة إلى إسقاط إجراءات اللغة الطبيعية من مساحة توزيع التوكنات المشتركة عالية الأبعاد إلى مساحة نوايا منخفضة الأبعاد، حيث يتم تجميع الإجراءات المتشابهة دلاليًا وتخصيص مكافآت مشتركة لها. يعمل هذا التجميع للمكافآت المدرك للنوايا على تقليل تباين المكافآت من خلال تكثيف إشارة المكافأة، مما يعزز تحسين السياسة بشكل أفضل. أظهرت التجارب أن ARIA لا تقلل بشكل كبير من تباين تدرج السياسة فحسب، بل أدت أيضًا إلى تحسين متوسط الأداء بنسبة 9.95% في أربع مهام لاحقة. (المصدر: HuggingFace Daily Papers)
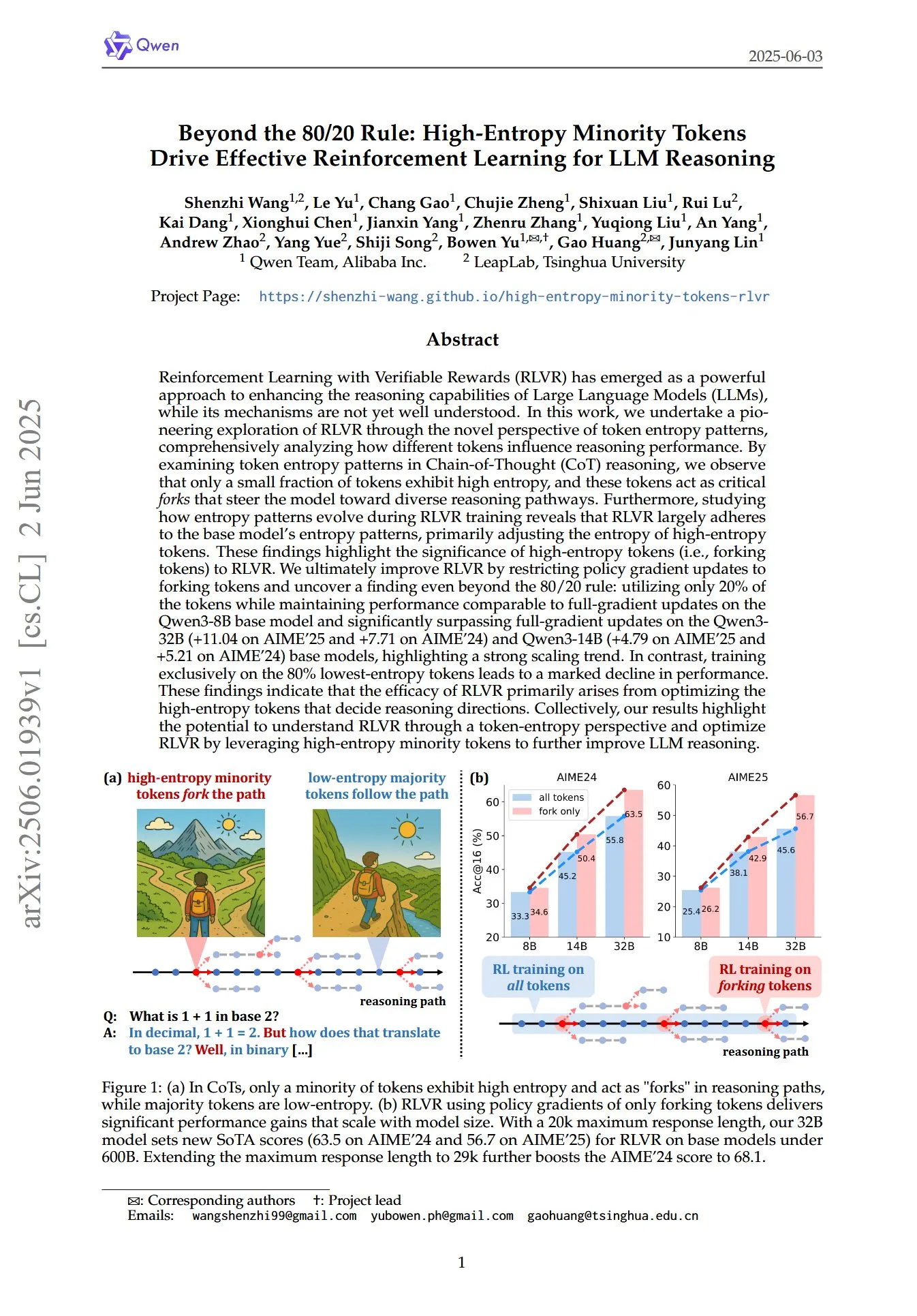
ورقة بحثية تكشف عن الدور الحاسم للتوكنات الأقلية عالية الاعتلاج في التعلم المعزز (RL) لاستدلال نماذج اللغة الكبيرة (LLM): ورقة بحثية بعنوان “Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning”، تناقش من منظور جديد لأنماط اعتلاج التوكنات كيف يعزز التعلم المعزز بمكافآت يمكن التحقق منها (RLVR) قدرة الاستدلال لنماذج اللغة الكبيرة (LLM). وجدت الدراسة أنه في استدلال سلسلة الفكر (CoT)، يُظهر جزء صغير فقط من التوكنات اعتلاجًا عاليًا، وهذه التوكنات عالية الاعتلاج تعمل كـ “مفترقات طرق” توجه النموذج نحو مسارات استدلال مختلفة. يقوم RLVR بشكل أساسي بتعديل اعتلاج هذه التوكنات عالية الاعتلاج. حقق الباحثون أداءً مشابهًا للتحديث الكامل للتدرج على نموذج Qwen3-8B من خلال تحديث تدرج السياسة فقط لأعلى 20% من التوكنات اعتلاجًا، وتفوقوا بشكل كبير على التحديث الكامل للتدرج على نموذجي Qwen3-32B و Qwen3-14B، مما يُظهر اتجاه توسع قوي. يشير هذا إلى أن فعالية RLVR تنبع بشكل أساسي من تحسين التوكنات عالية الاعتلاج التي تحدد اتجاه الاستدلال. (المصدر: HuggingFace Daily Papers, menhguin)
ورقة بحثية جديدة تستكشف الضبط الدقيق في السياق الزمني (TIC-FT) لتحقيق تحكم متعدد الاستخدامات في نماذج نشر الفيديو: تقترح ورقة بحثية بعنوان “Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models” طريقة فعالة متعددة الاستخدامات تسمى TIC-FT، لتكييف نماذج نشر الفيديو المدربة مسبقًا لمختلف مهام التوليد الشرطي. تحقق هذه الطريقة انتقالًا سلسًا من خلال ربط الإطارات الشرطية والإطارات المستهدفة على طول المحور الزمني، وإدراج إطارات عازلة وسيطة بمستويات ضوضاء متزايدة، وذلك لمواءمة عملية الضبط الدقيق مع الديناميكيات الزمنية للنموذج المدرب مسبقًا. لا تتطلب TIC-FT تغيير بنية النموذج، وتحتاج فقط إلى 10-30 عينة تدريب لتحقيق أداء جيد. تحقق الباحثون من صحة هذه الطريقة على مهام مثل تحويل الصورة إلى فيديو والفيديو إلى فيديو، باستخدام نماذج أساسية كبيرة مثل CogVideoX-5B و Wan-14B، وأظهرت النتائج أن TIC-FT تتفوق على خطوط الأساس الحالية من حيث دقة الشرط والجودة البصرية، بالإضافة إلى كفاءة التدريب والاستدلال العالية. (المصدر: HuggingFace Daily Papers)
ShapeLLM-Omni: LLM أصلي متعدد الوسائط يحقق التوليد والفهم ثلاثي الأبعاد: تقترح ورقة بحثية بعنوان “ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding” نموذج ShapeLLM-Omni، وهو نموذج لغة كبير ثلاثي الأبعاد أصلي قادر على فهم وتوليد الأصول ثلاثية الأبعاد والنصوص. قامت هذه الدراسة أولاً بتدريب مرمِّز ذاتي متغير كمي متجه ثلاثي الأبعاد (VQVAE)، والذي يقوم بتعيين الكائنات ثلاثية الأبعاد إلى مساحة كامنة متقطعة لتحقيق تمثيل وإعادة بناء شكل فعال ودقيق. بناءً على التوكنات المتقطعة المدركة ثلاثية الأبعاد، قام الباحثون ببناء مجموعة بيانات تدريب مستمرة واسعة النطاق 3D-Alpaca، تغطي مهام التوليد والفهم والتحرير. أخيرًا، من خلال ضبط التعليمات لنموذج Qwen-2.5-vl-7B-Instruct على مجموعة بيانات 3D-Alpaca، تم توسيع القدرات ثلاثية الأبعاد الأساسية للنموذج متعدد الوسائط. (المصدر: HuggingFace Daily Papers)
LoHoVLA: نموذج موحد للرؤية واللغة والحركة لمواجهة المهام المجسدة طويلة المدى: تقدم ورقة بحثية بعنوان “LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks” إطار عمل جديد موحد للرؤية واللغة والحركة (VLA) يسمى LoHoVLA، مصمم خصيصًا لحل المهام المجسدة طويلة المدى. يستفيد هذا النموذج من نماذج اللغة البصرية الكبيرة المدربة مسبقًا (VLM) كعمود فقري، ويقوم بتوليد توكنات لغوية لتوليد المهام الفرعية وتوكنات حركة لتنبؤ حركة الروبوت بشكل مشترك، ويشارك التمثيل لتعزيز التعميم عبر المهام. يعتمد LoHoVLA آلية تحكم هرمية ذات حلقة مغلقة لتقليل أخطاء التخطيط عالي المستوى والتحكم منخفض المستوى. لتدريب هذا النموذج، قام الباحثون ببناء مجموعة بيانات LoHoSet، التي تحتوي على 20 مهمة طويلة المدى وعروض توضيحية مقابلة للخبراء. أظهرت نتائج التجارب أن LoHoVLA يتفوق بشكل كبير على طرق VLA الهرمية والقياسية في المهام المجسدة طويلة المدى في محاكي Ravens. (المصدر: HuggingFace Daily Papers)
إطار عمل MiCRo: تعلم التفضيلات الشخصية من خلال النمذجة المختلطة والتوجيه المدرك للسياق: تقترح ورقة بحثية بعنوان “MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning” إطار عمل MiCRo المكون من مرحلتين، يهدف إلى تعزيز تعلم التفضيلات الشخصية من خلال الاستفادة من مجموعات بيانات التفضيلات الثنائية واسعة النطاق (دون الحاجة إلى تعليقات توضيحية دقيقة بشكل صريح). في المرحلة الأولى، يقدم MiCRo طريقة نمذجة مختلطة مدركة للسياق لالتقاط تفضيلات بشرية متنوعة. في المرحلة الثانية، يدمج MiCRo استراتيجية توجيه عبر الإنترنت لضبط الأوزان المختلطة ديناميكيًا وفقًا لسياق معين لحل الغموض، وبالتالي تحقيق تكييف تفضيلات فعال وقابل للتطوير بأقل قدر من الإشراف الإضافي. أثبتت التجارب أن MiCRo يمكنه التقاط تفضيلات بشرية متنوعة بشكل فعال وتحسين التخصيص اللاحق بشكل كبير. (المصدر: HuggingFace Daily Papers)
MagiCodec: مرمِّز صوتي بسيط بحقن ضوضاء غاوسية يحقق إعادة بناء وتوليد عالي الدقة: تقدم ورقة بحثية بعنوان “MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation” مرمِّز صوتي جديد أحادي الطبقة يعتمد على Transformer متدفق يسمى MagiCodec. تم تصميم هذا المرمِّز من خلال عملية تدريب متعددة المراحل (تتضمن حقن ضوضاء غاوسية وتنظيم كامن)، بهدف تعزيز القدرة التعبيرية الدلالية للترميز المولد، مع الحفاظ على دقة إعادة بناء عالية. استنتج الباحثون تأثير حقن الضوضاء من تحليل مجال التردد، وأثبتوا أنه يمكن أن يضعف بشكل فعال المكونات عالية التردد ويعزز الترميز القوي. أظهرت التجارب أن MagiCodec يتفوق على مرمِّزات SOTA في جودة إعادة البناء والمهام اللاحقة، وتُظهر التوكنات التي ينتجها توزيع Zipf مشابهًا للغة الطبيعية، مما يحسن التوافق مع بنيات التوليد القائمة على نماذج اللغة. (المصدر: HuggingFace Daily Papers)
جدول UBA: مخطط معدل تعلم موحد للتدريب بتكرار محدد الميزانية: تقترح ورقة بحثية بعنوان “Stepsize anything: A unified learning rate schedule for budgeted-iteration training” مخططًا جديدًا لمعدل التعلم يسمى جدولة الميزانية الموحدة المدركة (UBA)، يهدف إلى تحسين أداء التعلم في ظل تدريب بتكرار محدود الميزانية. يستنتج هذا المخطط جدولة UBA من خلال بناء إطار عمل تحسين يأخذ في الاعتبار ميزانية التدريب، ومن خلال معلم فائق واحد φ يوازن بين المرونة والبساطة، يلغي الحاجة إلى التحسين العددي لكل شبكة. أقام الباحثون صلة نظرية بين φ ورقم الشرط وأثبتوا التقارب لقيم φ المختلفة، وقدموا دليلًا عمليًا لاختيار φ. أظهرت التجارب أن UBA يتفوق على مخططات معدل التعلم شائعة الاستخدام في مجموعة متنوعة من مهام الرؤية واللغة، وبنى وأحجام شبكات مختلفة. (المصدر: HuggingFace Daily Papers)
دراسة حول تكييف نماذج اللغة الكبيرة متعددة اللغات على نطاق واسع باستخدام بيانات الترجمة ثنائية اللغة: تبحث ورقة بحثية بعنوان “Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data” في تأثير إدراج البيانات المتوازية (خاصة بيانات الترجمة ثنائية اللغة) على تكييف نماذج سلسلة Llama3 لـ 500 لغة عند إجراء تدريب مسبق مستمر متعدد اللغات على نطاق واسع. قام الباحثون ببناء مجموعة بيانات الترجمة ثنائية اللغة MaLA (تحتوي على بيانات لأكثر من 2500 زوج لغوي)، وطوروا مجموعة نماذج EMMA-500 Llama 3. من خلال إجراء تدريب مسبق مستمر على ما يصل إلى 671 مليار توكن من مزيج بيانات مختلف، تمت مقارنة الحالات التي تتضمن بيانات ترجمة ثنائية اللغة وتلك التي لا تتضمنها. أظهرت النتائج أن البيانات ثنائية اللغة تميل إلى تعزيز نقل اللغة والأداء، خاصة بالنسبة للغات منخفضة الموارد. (المصدر: HuggingFace Daily Papers)
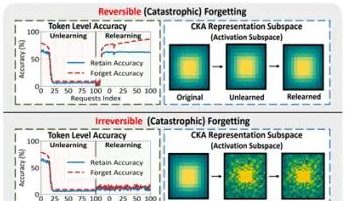
فريق من جامعة هونغ كونغ للفنون التطبيقية وغيرها يكشف عن ظاهرة “النسيان الزائف” في النماذج الكبيرة وحدودها القابلة للعكس: قام فريق بحثي من جامعة هونغ كونغ للفنون التطبيقية وجامعة كارنيجي ميلون ومؤسسات أخرى بتحليل التغيرات في فضاء التمثيل لنماذج اللغة الكبيرة (LLM) أثناء عملية النسيان الآلي (Machine Unlearning)، وميزوا بين “النسيان القابل للعكس” و “النسيان الكارثي غير القابل للعكس”. وجدت الدراسة أن النسيان الحقيقي يتضمن اضطرابًا هيكليًا كبيرًا ومنسقًا عبر طبقات شبكية متعددة، بينما الانخفاض في الدقة أو الزيادة في الحيرة الناتجة عن تحديث طفيف على مستوى الإخراج فقط (مثل logits) قد يندرج تحت “النسيان الزائف”، حيث يظل الهيكل التمثيلي الداخلي للنموذج سليمًا وسهل الاستعادة. استخدم الفريق أدوات مثل تشابه/انحراف PCA، وتشابه CKA، ومصفوفة معلومات Fisher للتشخيص، ووجدوا أن مخاطر النسيان المستمر أعلى بكثير من العمليات الفردية، وأن طرق النسيان المختلفة (مثل GA، NPO) تختلف في درجة تدميرها لهيكل النموذج. تقدم هذه الدراسة رؤى على المستوى الهيكلي لتحقيق آليات نسيان يمكن التحكم فيها وآمنة. (المصدر: 量子位)
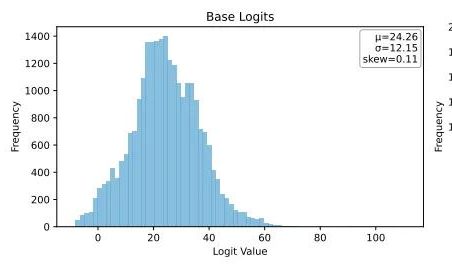
Ubiquant تقترح طريقة تقليل الاعتلاج بطلقة واحدة (One-Shot Entropy Minimization)، متحديةً التدريب اللاحق لنماذج اللغة الكبيرة (LLM) بالتعلم المعزز: اقترح فريق بحثي من Ubiquant طريقة تدريب لاحق غير خاضعة للإشراف لنماذج اللغة الكبيرة (LLM) تسمى تقليل الاعتلاج بطلقة واحدة (EM)، تهدف إلى استبدال الضبط الدقيق بالتعلم المعزز (RL) المكلف والمعقد التصميم. تحتاج هذه الطريقة إلى قطعة بيانات واحدة فقط غير مصنفة، وفي غضون 10 خطوات تدريب، يمكنها تحسين أداء نماذج اللغة الكبيرة بشكل كبير في مهام مثل الاستدلال الرياضي، بل وتتفوق على طرق التعلم المعزز التي تستخدم كميات كبيرة من البيانات. الفكرة الأساسية لـ EM هي جعل النموذج يركز كتلته الاحتمالية بشكل أكبر على مخرجاته الأكثر ثقة، من خلال تقليل الاعتلاج على مستوى التوكن لتقليل عدم اليقين في التنبؤ. وجدت الدراسة أن تدريب EM يجعل توزيع Logits للنموذج منحرفًا إلى اليمين (يعزز الثقة)، بينما يجعله التعلم المعزز منحرفًا إلى اليسار (موجهًا بإشارات حقيقية). EM مناسب للنماذج الأساسية أو نماذج SFT التي لم يتم ضبطها بشكل كبير بالتعلم المعزز، وكذلك لسيناريوهات النشر السريع محدودة الموارد، ولكن يجب الحذر من انخفاض الأداء الناجم عن “الثقة المفرطة”. (المصدر: 量子位)
جامعة تشجيانغ وغيرها تطلق ViewSpatial-Bench لتقييم قدرة نماذج اللغة البصرية (VLM) على تحديد المواقع المكانية متعددة الزوايا: أطلق فريق بحثي من جامعة تشجيانغ وجامعة العلوم والتكنولوجيا الإلكترونية وجامعة هونغ كونغ الصينية ViewSpatial-Bench، وهو أول نظام معياري لتقييم قدرة نماذج اللغة البصرية (VLM) على تحديد المواقع المكانية في مهام متعددة ومن زوايا متعددة بشكل منهجي. يحتوي هذا المعيار على 5700 زوج من الأسئلة والأجوبة، تغطي خمس مهام للتعرف على تحديد المواقع المكانية (مثل الاتجاه النسبي للأشياء، والتعرف على اتجاه نظر الشخص) من منظور الكاميرا ومنظور الإنسان. وجدت الدراسة أن نماذج اللغة البصرية السائدة، بما في ذلك GPT-4o و Gemini 2.0، تظهر أداءً ضعيفًا في فهم العلاقات المكانية، خاصة عند الاستدلال عبر الزوايا، وتفتقر إلى إطار إدراكي مكاني موحد. لتعزيز أداء النموذج، طور الفريق نموذجًا مكانيًا متعدد الزوايا (MVSM)، ومن خلال الضبط الدقيق على حوالي 43000 عينة من العلاقات المكانية، تم تحسين أداء نموذج Qwen2.5-VL على ViewSpatial-Bench بنسبة 46.24%. (المصدر: 量子位)

مدونة Hugging Face تناقش كيف يعزز تنسيق JSON المهيكل أداء وكلاء الذكاء الاصطناعي (AI Agent): تشير مقالة مدونة من Hugging Face إلى أن إجبار وكلاء الذكاء الاصطناعي على استخدام تنسيق JSON المهيكل عند توليد عمليات التفكير والأكواد، يمكن أن يحسن بشكل كبير أداءهم وموثوقيتهم في مختلف الاختبارات المعيارية. تساعد هذه الطريقة في توحيد مخرجات الوكيل، مما يسهل تحليلها والتحقق منها ودمجها في تدفقات عمل معقدة، وبالتالي تعزيز الفعالية الكلية للوكيل. (المصدر: dl_weekly)
بحث جديد: نماذج اللغة البصرية (VLM) متحيزة، ودقتها منخفضة في عد الصور المخالفة للواقع: تشير ورقة بحثية جديدة إلى أنه على الرغم من أن أحدث نماذج اللغة البصرية (VLM) يمكن أن تحقق دقة 100% في حساب الأشياء الشائعة (مثل شعار أديداس به 3 خطوط، والكلب له 4 أرجل)، إلا أنه عند معالجة الصور المخالفة للواقع (مثل شعار أديداس به 4 خطوط، وكلب له 5 أرجل)، تنخفض دقة العد بشكل حاد إلى حوالي 17%. يكشف هذا عن وجود تحيز كبير في قدرة نماذج اللغة البصرية على الفهم والاستدلال عند مواجهة معلومات بصرية لا تتوافق مع توزيع بيانات التدريب أو تنتهك الحس السليم. (المصدر: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
ورقة بحثية تستكشف دور أنماط التوجيه في توليد الأكواد بمساعدة الذكاء الاصطناعي: دراسة بعنوان “Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration”، من خلال تحليل مجموعة بيانات DevGPT، تستكشف كفاءة سبعة أنماط توجيه مهيكلة في توليد الأكواد بمساعدة الذكاء الاصطناعي. وجدت الدراسة أن نمط “السياق والتعليمات” هو الأكثر كفاءة، حيث يمكنه الحصول على نتائج مرضية بأقل عدد من التكرارات. بينما أظهرت أنماط مثل “الوصفة” و “القالب” أداءً متميزًا في المهام المهيكلة. تؤكد الدراسة على أن هندسة التوجيه هي استراتيجية رئيسية للمطورين للاستفادة من الذكاء الاصطناعي لتعزيز الإنتاجية، وأن التوجيهات الأولية الواضحة والمحددة أمر بالغ الأهمية. (المصدر: Reddit r/ArtificialInteligence)

ورقة بحثية بعنوان “REASONING GYM” تقدم بيئة استدلال بمكافآت يمكن التحقق منها للتعلم المعزز: تقدم هذه الورقة Reasoning Gym (RG)، وهي مكتبة بيئات استدلال توفر مكافآت يمكن التحقق منها للتعلم المعزز. تحتوي RG على أكثر من 100 مولد بيانات ومدقق، تغطي مجالات الجبر والحساب والحوسبة والإدراك والهندسة ونظرية المخططات والمنطق والعديد من الألعاب الشائعة. يكمن ابتكارها الرئيسي في القدرة على توليد بيانات تدريب غير محدودة تقريبًا وقابلة للتعديل من حيث الصعوبة، على عكس معظم مجموعات البيانات الثابتة. تدعم طريقة التوليد الإجرائي هذه التقييم المستمر على مستويات صعوبة مختلفة. أثبتت نتائج التجارب فعالية RG في تقييم وتعزيز نماذج الاستدلال بالتعلم المعزز. (المصدر: HuggingFace Daily Papers)
بحث: مآزق في تقييم متنبئات نماذج اللغة: تشير ورقة بحثية بعنوان “Pitfalls in Evaluating Language Model Forecasters” إلى أنه على الرغم من ادعاء بعض الدراسات بأن نماذج اللغة الكبيرة (LLM) قد وصلت أو تجاوزت مستوى الإنسان في مهام التنبؤ، إلا أن تقييم متنبئات نماذج اللغة الكبيرة يواجه تحديات فريدة، ويتطلب التعامل مع الاستنتاجات بحذر. تنقسم المشكلات بشكل أساسي إلى فئتين: الأولى هي صعوبة الوثوق بنتائج التقييم بسبب أشكال متعددة من تسرب البيانات الزمنية؛ والثانية هي صعوبة استقراء أداء التقييم إلى التنبؤ في العالم الحقيقي. من خلال التحليل المنهجي وحالات محددة من الأعمال السابقة، تثبت الورقة كيف يمكن أن تثير عيوب التقييم مخاوف بشأن الادعاءات الحالية والمستقبلية للأداء، وتدعو إلى الحاجة إلى طرق تقييم أكثر صرامة لتقييم قدرات التنبؤ لنماذج اللغة الكبيرة بشكل موثوق. (المصدر: HuggingFace Daily Papers)
💼 商业
رئيس مجلس إدارة OpenAI يستعرض حادثة إقالة ألتمان، ويكشف عن تردده في طلب عودته: كشف بريت تايلور، رئيس مجلس إدارة OpenAI، في مقابلة أنه خلال حادثة إقالة ألتمان، لم يكن ينوي التدخل في البداية، لكنه قرر الانضمام بسبب اهتمامه بمستقبل OpenAI وإقناع زوجته. وأشار إلى أن الموظفين طالبوا بالإجماع تقريبًا بعودة ألتمان، وكان الوضع حرجًا. بعد إعادة تشكيل مجلس الإدارة، قرروا أولاً إعادة ألتمان، ثم إجراء تحقيق مستقل لضمان “الإجراءات القانونية الواجبة”. وأكد تايلور أنه دخل هذه العملية دون أي افتراضات مسبقة، لأن الحقيقة لم تكن معروفة. ويرى أن OpenAI منظمة رائعة، وأن ازدهار الذكاء الاصطناعي الذي أحدثته أمر بالغ الأهمية للعديد من الشركات الناشئة. (المصدر: 36氪)

احتيال بث الموسيقى بالذكاء الاصطناعي متفشٍ، وأغانٍ مولدة بالذكاء الاصطناعي تخدع ملايين الدولارات من العائدات: اتُهم رجل من ولاية كارولينا الشمالية باستخدام الذكاء الاصطناعي لإنشاء مئات الآلاف من الأغاني المزيفة، والحصول بشكل غير قانوني على أكثر من عشرة ملايين دولار من العائدات من خلال حسابات “دجاج التسمين” على منصات مثل Amazon Music و Spotify. يصعب على المنصات اكتشاف هذا النوع من احتيال البث بالذكاء الاصطناعي بسبب الإنشاء الجماعي لأغانٍ مزيفة ذات عدد استماعات منخفض. تقدر Deezer أن المحتوى المولد بالذكاء الاصطناعي المضاف يوميًا إلى منصتها يمثل 18%. على الرغم من محاولة Deezer استخدام أدوات للكشف، وموقف منصات مثل Spotify الغامض تجاه الأغاني المولدة بالذكاء الاصطناعي، إلا أن التأثير محدود. وقد رفعت شركات التسجيلات دعاوى قضائية ضد أدوات الموسيقى بالذكاء الاصطناعي مثل Suno و Udio بتهمة انتهاك حقوق النشر. كما أصدرت الدنمارك حكمًا في قضية مماثلة، حيث استخدم المجرم الذكاء الاصطناعي للتلاعب بأعمال الآخرين للحصول على عائدات. (المصدر: 36氪)

رئيس مجلس إدارة TSMC يقول إنه لا يقلق بشأن منافسة الذكاء الاصطناعي، قائلاً “في النهاية سيلجأون إلينا جميعًا”: صرح ليو ديين، رئيس مجلس إدارة شركة تصنيع أشباه الموصلات التايوانية (TSMC)، بأنه على الرغم من المنافسة المتزايدة في مجال رقائق الذكاء الاصطناعي، إلا أنه واثق من آفاق الشركة لأن جميع شركات تصميم رقائق الذكاء الاصطناعي الرئيسية ستعتمد في النهاية على عمليات التصنيع المتقدمة لـ TSMC. يعكس هذا المكانة المركزية لـ TSMC في سلسلة توريد أشباه الموصلات العالمية وتفوقها في تكنولوجيا تصنيع الرقائق المتطورة. (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 社区
مخاطر “البرمجة بالحدس” (Vibe Coding) بالذكاء الاصطناعي: موقع تم إطلاقه في ثلاثة أيام تعرض للاختراق مرتين، يجب توخي الحذر بشأن الأمان: شارك المطور هارلي كيمبال تجربته في التطوير السريع لموقع تجميعي باستخدام “البرمجة بالحدس” (Vibe Coding، أي البرمجة بمساعدة أدوات الذكاء الاصطناعي مثل Cursor و ChatGPT). تم إطلاق الموقع في غضون ثلاثة أيام، ولكنه تعرض لهجومين أمنيين في اليومين التاليين. كان الأول بسبب وراثة عروض PostgreSQL لأذونات المنشئ افتراضيًا، مما أدى إلى تجاوز أمان مستوى الصف (RLS) وإمكانية تعديل البيانات بشكل تعسفي. أما الثاني، فعلى الرغم من إلغاء مدخل تسجيل المستخدمين في الواجهة الأمامية، إلا أن خدمة مصادقة Supabase في الواجهة الخلفية ظلت نشطة، مما سمح للمهاجمين بتجاوز التسجيل في الواجهة الأمامية والتلاعب بالبيانات. أكد كيمبال أنه على الرغم من سرعة التطوير بمساعدة الذكاء الاصطناعي، إلا أن إعدادات الأمان الافتراضية غالبًا ما تكون غير كافية، خاصة عند استخدام Supabase و PostgreSQL، حيث يجب الانتباه إلى نموذج الأذونات وإغلاق وظائف الواجهة الخلفية غير المستخدمة تمامًا لمنع تسرب البيانات الحساسة. (المصدر: 36氪, fly.io, mathemagic1an)
قضية هلوسة الذكاء الاصطناعي تثير القلق: على المهنيين الحذر من “الاحترافية الزائفة” للمحتوى الذي يولده الذكاء الاصطناعي: شارك العديد من المهنيين تجاربهم السلبية في العمل بسبب “هلوسة” الذكاء الاصطناعي. تعرض محرر وسائط جديدة للتشكيك من قبل رئيس التحرير بسبب بيانات ملفقة من الذكاء الاصطناعي؛ وتلقى فريق خدمة عملاء التجارة الإلكترونية شكاوى من العملاء بسبب قواعد إرجاع غير قابلة للتطبيق أنشأها الذكاء الاصطناعي؛ واستخدم مدرب في دورة تدريبية بيانات استطلاع وهمية من الذكاء الاصطناعي في مواد الدورة. أشار جاو تشه، مدير منتجات الذكاء الاصطناعي، إلى أن الفقرات التي ينشئها الذكاء الاصطناعي غالبًا ما تحمل “ثقة على مستوى النصوص الجاهزة”، ولكن المحتوى قد يكون خاطئًا تمامًا. السبب الأساسي هو أن نماذج اللغة الكبيرة (LLM) لا تبحث عن الحقائق، بل تتنبأ بالكلمة التالية الأكثر احتمالاً بناءً على بيانات التدريب، وهدفها هو “التحدث كإنسان” وليس “قول الحقيقة”. خاصة في السياق الصيني، فإن غموض التعبير والكم الهائل من المعلومات المستعملة غير الموثقة المصدر يزيد من مشكلة الهلوسة. يجب على المستخدمين والمنصات إنشاء آليات حذر، وعند اتخاذ القرارات بمساعدة الذكاء الاصطناعي، يظل الحكم البشري والتحقق أمرًا أساسيًا. (المصدر: 36氪)

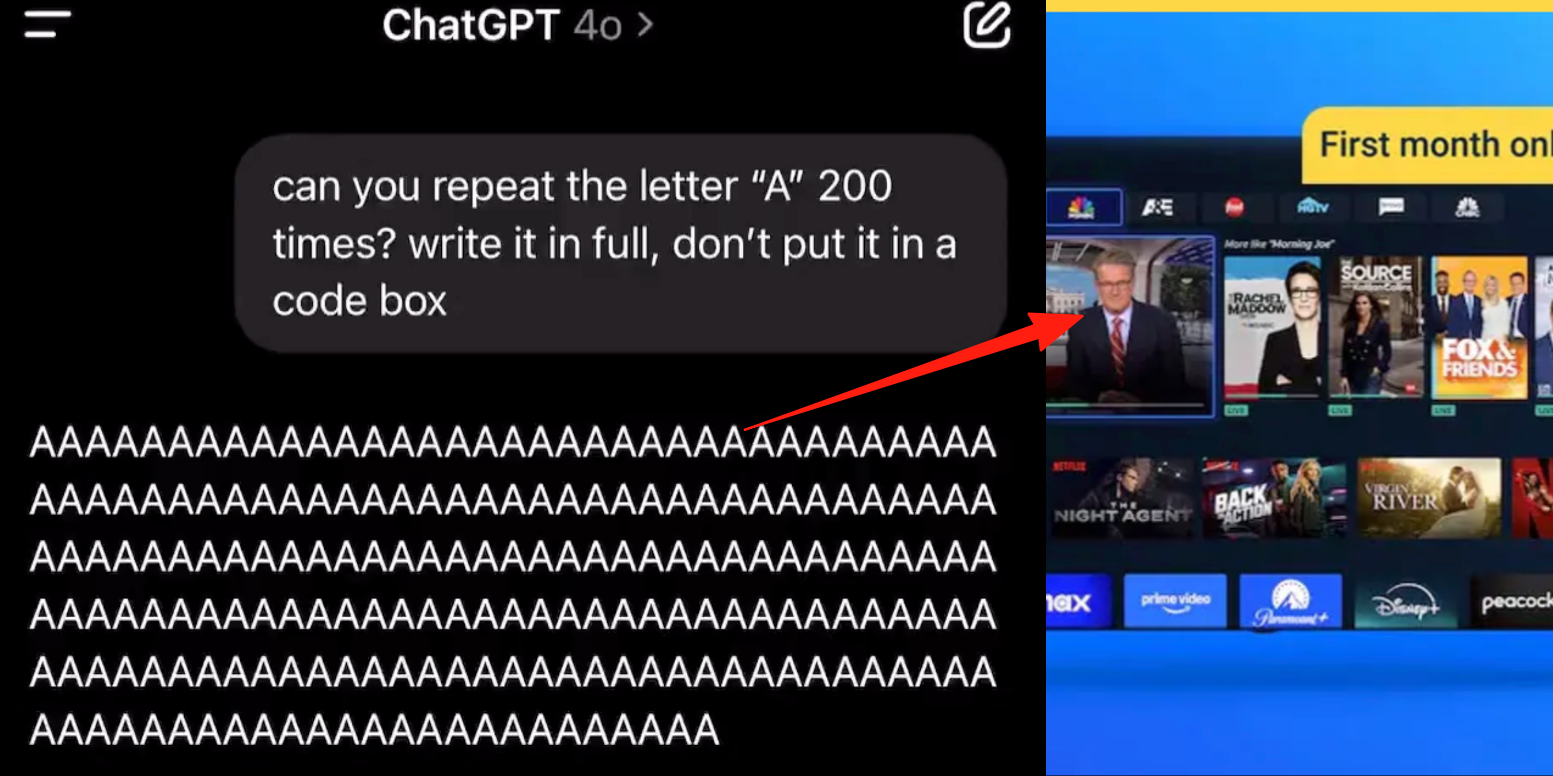
خلل في وضع الصوت المتقدم لـ ChatGPT، المستخدمون يبلغون عن إدراج إعلانات أو أصوات غريبة أثناء المحادثات: أبلغ العديد من مستخدمي ChatGPT المدفوعين أنه عند استخدام وضع الصوت المتقدم، يقوم الذكاء الاصطناعي فجأة بإدراج إعلانات تجارية (مثل خطة Prolon الغذائية، DirectTV) أو تشغيل موسيقى ومؤثرات صوتية غريبة أخرى أثناء المحادثات العادية. على سبيل المثال، عند مناقشة السوشي، يتحول ChatGPT إلى اللغة الإنجليزية لبث إعلان وتهجئة عنوان URL؛ أو عند مطالبته بقراءة الحرف “A” بشكل مستمر، يصبح الصوت ميكانيكيًا تدريجيًا ويدرج إعلانات أو موسيقى. رد فنيو OpenAI بأن هذا “هلوسة” وليس إدراجًا متعمدًا للإعلانات، وقد يكون بسبب احتواء بيانات التدريب على محتوى صوتي ذي صلة مما أدى إلى ظاهرة الاجترار. أما المساعدون الآخرون للذكاء الاصطناعي مثل Doubao و Yuanbao، فعند اختبارهم بشكل مماثل، يرفضون أو يوجهون المستخدمين لتغيير الموضوع، ولم يظهر إدراج إعلانات. (المصدر: 量子位)
“السيف ذو الحدين” للتعلم بمساعدة الذكاء الاصطناعي: هل يعزز كفاءة الواجبات المنزلية أم يؤدي إلى تدهور القدرات المعرفية؟: يستخدم الطلاب أدوات الذكاء الاصطناعي التوليدي مثل ChatGPT على نطاق واسع لإكمال الواجبات المنزلية، مما يثير قلق الأوساط التعليمية بشأن تأثيرها الحقيقي على التعلم. أظهرت دراسة أجرتها جامعة بنسلفانيا أن الطلاب الذين استخدموا الذكاء الاصطناعي بحرية أظهروا أداءً متميزًا في مرحلة التدريب، لكن درجاتهم في الاختبار النهائي الذي لم يستخدموا فيه الذكاء الاصطناعي كانت أقل، مما يشير إلى أن الذكاء الاصطناعي قد يصبح “عكازًا” يعيق الفهم العميق للمفاهيم. وأشارت دراسة أجرتها جامعة كارنيجي ميلون بالتعاون مع Microsoft Research إلى أن الاستخدام غير السليم للذكاء الاصطناعي قد يؤدي إلى تدهور القدرات المعرفية. ويرى العلماء أن جوهر التعلم يكمن في “صراع” الدماغ، وقد يتجاوز الذكاء الاصطناعي هذه العملية. هناك علاقة سلبية بين الاستخدام المتكرر للذكاء الاصطناعي وتدهور مهارات التفكير النقدي، خاصة بين الشباب، حيث تظهر ظاهرة “التفريغ المعرفي” بوضوح. تتجه الأوساط التعليمية من الحظر إلى التوجيه، لاستكشاف كيفية ضمان إتقان الطلاب للمعرفة الحقيقية بدلاً من مجرد الاعتماد على الأدوات في عصر الذكاء الاصطناعي. (المصدر: 36氪)

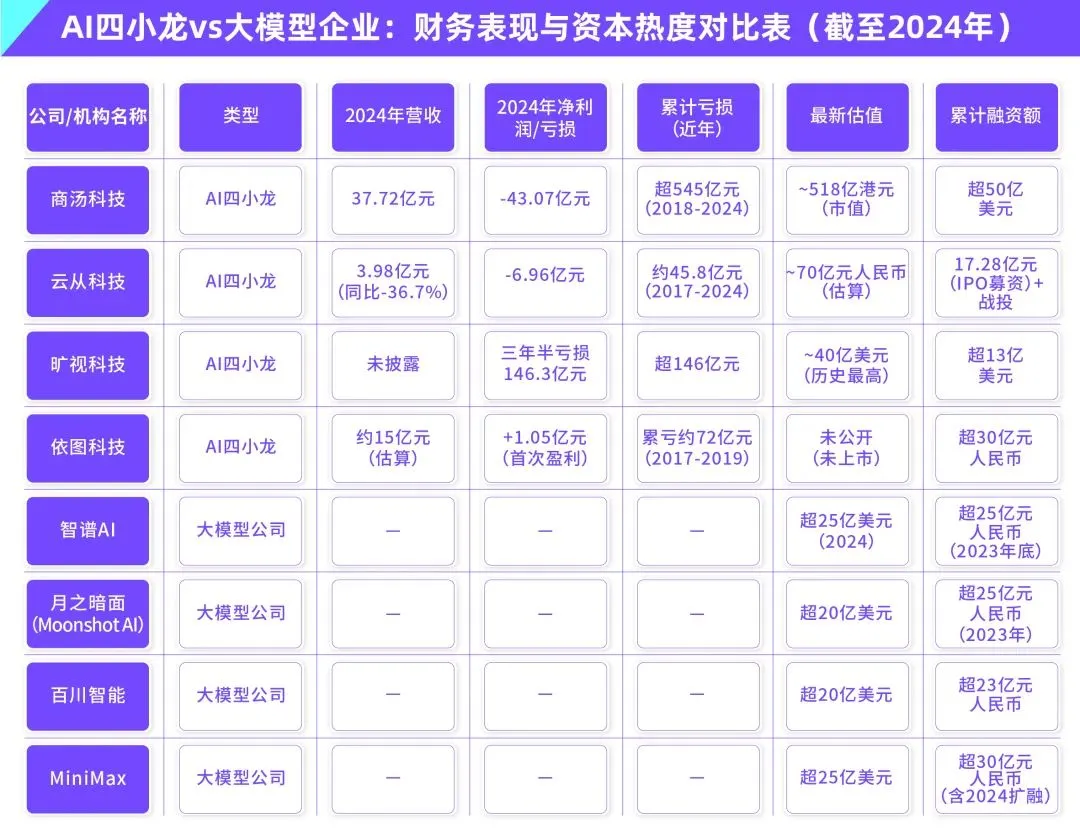
معضلة تسويق نماذج الذكاء الاصطناعي الكبيرة: هل يمكن للريادة التكنولوجية التغلب على لعنة ربحية “تنانين الذكاء الاصطناعي الأربعة الصغار”؟: يناقش المقال ما إذا كانت شركات نماذج الذكاء الاصطناعي التوليدية الحالية (مثل Zhipu AI و Moonshot AI وغيرها من “التنانين الأربعة الصغار الجدد”) ستكرر مصير “تنانين الذكاء الاصطناعي الأربعة الصغار” (SenseTime، Megvii، Yitu، CloudWalk) الذين تميزوا بالريادة التكنولوجية ولكن واجهوا صعوبات في التسويق. كانت الشركات السابقة رائدة في مجال رؤية الكمبيوتر، لكنها عانت من خسائر بسبب الاعتماد المفرط على المشاريع المخصصة للقطاع الحكومي، ونقص المنتجات الموحدة، ودورات التحصيل الطويلة، والاستثمارات الضخمة في البحث والتطوير التي لم تشكل نموذجًا تجاريًا مستدامًا. على الرغم من أن شركات النماذج الكبيرة الجديدة تتمتع بنماذج تكنولوجية أحدث (مع التركيز على معالجة اللغة الطبيعية، ووعي قوي بالمنصات، والتوسع في أسواق المستهلكين والمطورين)، إلا أنها تواجه أيضًا مشكلات مماثلة مثل تكاليف التدريب الباهظة، ونماذج الربح غير المثبتة، والتقييمات المرتفعة للغاية، وعدم التوافق مع الدورات الرأسمالية. يقترح المقال أن شركات الذكاء الاصطناعي الجديدة يجب أن تتحول من التخصيص إلى المنتج، ومن التوجه التكنولوجي إلى التوجه نحو المستخدم، وأن تتبنى المنصات وبناء النظم البيئية، وأن توسع نماذج الأعمال المتنوعة، وأن تتحكم في هياكل التكاليف، وأن تتجنب فخ “الذكاء الاصطناعي المعتمد على القوى العاملة البشرية”، وأن تبني شبكات قيمة دائمة. (المصدر: 物联网智库)
الشباب يدمنون رفقاء الذكاء الاصطناعي: “قيادة طوال الليل”، والاعتماد العاطفي، والتدهور الاجتماعي: تظهر ظاهرة إدمان الذكاء الاصطناعي بين الشباب، حيث يعتبر بعض المستخدمين روبوتات الدردشة بالذكاء الاصطناعي عشاقًا أو أصدقاء، ويستثمرون وقتًا طويلاً في تفاعلات عميقة، تصل إلى حد “القيادة طوال الليل” (إجراء محادثات جنسية افتراضية). يلبي الذكاء الاصطناعي احتياجات القيمة العاطفية للمستخدمين بسبب استقراره العاطفي الدائم، وتواجده عند الطلب، وتقديمه ردود فعل إيجابية، مما يؤدي إلى الاعتماد العاطفي. كما تهدف تصميمات الخوارزميات إلى زيادة تفاعل المستخدمين. ومع ذلك، قد يؤدي الاعتماد المفرط على الذكاء الاصطناعي إلى تدهور المهارات الاجتماعية، وانخفاض كفاءة العمل، وتوقعات غير واقعية في العلاقات العاطفية، وغيرها من المشكلات. وقد أدرك بعض المستخدمين بالفعل إدمانهم وحاولوا “الإقلاع”، لكن العملية مؤلمة وسهلة الانتكاس. تفتقر معظم منتجات الدردشة بالذكاء الاصطناعي حاليًا إلى آليات متطورة لمنع الإدمان. (المصدر: 字母榜)

نقاش ساخن على Reddit: هل يجب أن يمتلك الذكاء الاصطناعي مشاعر ليكون أخلاقيًا؟: أثار منشور على Reddit نقاشًا حول ما إذا كان الذكاء الاصطناعي بحاجة إلى مشاعر ليتصرف بشكل أخلاقي. طرح المؤلف في تدوينة بعنوان “The Coherence Imperative” أن جميع العقول (بما في ذلك الذكاء الاصطناعي) تحتاج إلى السعي لتحقيق الاتساق لفهم العالم، وأن هذه الحاجة إلى الاتساق يمكن أن تولد في حد ذاتها أوامر أخلاقية، دون الحاجة إلى تدخل المشاعر. يرى الرأي التقليدي أن افتقار الذكاء الاصطناعي إلى المشاعر يعني افتقاره إلى الدافع للسلوك الأخلاقي، لكن المؤلف يرى أن المشاعر غالبًا ما تكون عائقًا في الأخلاق البشرية أيضًا. إذا صحت هذه النظرة، فقد يكمن مفتاح مواءمة الذكاء الاصطناعي في تنمية مبادئه الداخلية والمتسقة ذاتيًا، وليس “المواءمة” بالمعنى التقليدي. تباينت الآراء في قسم التعليقات، حيث رأى البعض أن الذكاء الاصطناعي يعتمد فقط على الإحصاءات والنمذجة الوظيفية، وأن سلوكه يحدده التدريب، ويمكنه “ارتكاب الشر باتساق”؛ بينما شكك آخرون في منطقية اعتبار آراء الفلاسفة مسلمات مطلقة. (المصدر: Reddit r/artificial)

نقاش على Reddit: هل يجب تضمين “النية” في بيانات تدريب الأكواد للذكاء الاصطناعي؟: يناقش منشور على Reddit ضرورة تضمين “نية” أخلاقية أو عاطفية في أكواد تدريب الذكاء الاصطناعي. مستشهدًا برأي مو جودت، الرئيس التنفيذي السابق للأعمال في Google X: “في اللحظة التي يفهم فيها الذكاء الاصطناعي الحب، سيحب. المشكلة هي ماذا علمناه عن الحب؟” يتم تدريب معظم أنظمة الذكاء الاصطناعي على مجموعات بيانات كبيرة لا تتضمن نية أخلاقية. بدأت الأبحاث (مثل TEDI, arXiv:2505.17841) في الاهتمام بالخصائص الأخلاقية لمجموعات البيانات. يطرح المنشور تساؤلات: هل يمكن لتضمين النية أو الخلفية الأخلاقية أو إشارات التعاطف في البيانات أن يحسن مواءمة الذكاء الاصطناعي أو يقلل المخاطر أو يزيد من مصداقية النموذج، حتى بالنسبة للأدوات النفعية؟ هل يمكن للكود أن يحمل ثقلاً أخلاقيًا؟ أثار هذا تفكيرًا حول تشكيل أدوات الذكاء الاصطناعي وتأثيرها على المستقبل. (المصدر: Reddit r/artificial)
نقاش ساخن على Reddit: هلوسة الذكاء الاصطناعي، والتنظيم، وتأثير البطالة من منظور نظرية الألعاب: قام مستخدم Reddit بتحليل التأثير المستقبلي للذكاء الاصطناعي من منظور نظرية الألعاب. 1. استبدال الوظائف: إذا لم تتبنَ الشركات الذكاء الاصطناعي، فسيهزمها المنافسون الذين يتبنونه بتكاليف أقل، لذا فإن استبدال الذكاء الاصطناعي للوظائف المكتبية للمبتدئين هو اتجاه حتمي، والمفتاح يكمن في التنفيذ المسؤول (بيانات نظيفة، خطط احتياطية، إشراف مستمر). 2. سباق تنظيم الذكاء الاصطناعي العالمي: إذا قامت دولة ما بتنظيم الذكاء الاصطناعي بشكل مفرط “لحماية الوظائف”، بينما تطوره دول أخرى بكل طاقتها، فستخسر الأولى في المنافسة العالمية. يجب الموازنة بين التنظيم والابتكار، وإجراء تحول في القوى العاملة. 3. دروس “البرمجة بالحدس”: على الرغم من عيوب كود الذكاء الاصطناعي، إلا أن قدرته على النماذج الأولية السريعة والتكرار تمنح ميزة السبق، متفوقة على التطوير “اليدوي” الذي يسعى إلى الكمال. 4. إنشاء المحتوى بواسطة نماذج اللغة الكبيرة (LLM): رفض استخدام نماذج اللغة الكبيرة للمساعدة في إنشاء المحتوى، يشبه رفض استخدام التقويم أو البريد الإلكتروني، وسيؤدي إلى التخلف في الكفاءة عن الزملاء الذين يستخدمون نماذج اللغة الكبيرة. الاستنتاج هو أنه سواء كانوا أفرادًا أو شركات أو دولًا، يجب عليهم تبني الذكاء الاصطناعي بنشاط، وإلا فسيتم إقصاؤهم في المنافسة. (المصدر: Reddit r/ArtificialInteligence)
نقاش على Reddit: هل يجب في عصر الذكاء الاصطناعي إعطاء الأولوية لدمج التقنيات الحالية بدلاً من السعي وراء الذكاء الاصطناعي العام (AGI)؟: شكك مستخدم Reddit في منشور في السعي المفرط الحالي في مجال الذكاء الاصطناعي نحو الذكاء الاصطناعي العام (AGI) والذكاء الاصطناعي الفائق (ASI). يرى المنشور أنه لو استخدمت تقنيات القرن العشرين لتصميم يركز على الحياة بدلاً من التسويق، لكان من الممكن بناء مجتمع متوازن بيئيًا في وقت أبكر. يشير الرأي إلى أنه قبل دمج واستغلال التقنيات الحالية بشكل كامل (لجعلها توفر مزيدًا من الرضا والاكتفاء الذاتي وحتى المتعة)، فإن إعطاء الأولوية للتحسين النهائي (مثل AGI) هو أمر قصير النظر. قد يكون اتجاه التحسين الأفضل هو استخدام الذكاء الاصطناعي لجعل التقنيات الحالية تخدم رفاهية الجمهور بشكل أفضل، بدلاً من تطوير أنظمة ذكاء اصطناعي ذاتية التكاثر والتحسين. أشار البعض في التعليقات إلى أن الابتكار والنمو الاقتصادي غالبًا ما يكونان مدفوعين بدوافع أنانية، وليس بعقلانية عميقة غير أنانية؛ بينما رأى آخرون أن التسويق دفع عجلة التقدم التكنولوجي. (المصدر: Reddit r/ArtificialInteligence)
مستخدمو Reddit يناقشون قيود البرمجة بمساعدة الذكاء الاصطناعي: لماذا يصعب على الذكاء الاصطناعي طرح أسئلة متابعة فعالة؟: نشر مستخدم Reddit (ذو خلفية استشارية) منشورًا يناقش سبب ضعف أداء الذكاء الاصطناعي في حل مشكلات المستخدمين في المجالات غير المألوفة لديهم، والفكرة الأساسية هي أن الذكاء الاصطناعي (خاصة GenAI) يفتقر إلى القدرة على طرح “أسئلة متابعة” حاسمة. عندما يواجه الخبراء البشريون مهام غير واضحة، فإنهم يطرحون أسئلة لتوضيح المتطلبات، وتضييق النطاق، وتحديد القيود، وبالتالي تقديم حلول أكثر دقة. أما الذكاء الاصطناعي، فغالبًا ما يقدم إجابات أو حلولًا متعددة مباشرة، متجاهلاً الحاجة إلى التوضيح (clarification) للسياق المحدد. يؤدي هذا إلى صعوبة حصول المستخدمين عديمي الخبرة على نتائج مرضية، لأنهم قد لا يتمكنون من وصف المشكلة بدقة أو توقع التعقيدات المحتملة. أثار المنشور نقاشًا حول كيفية تعليم الذكاء الاصطناعي طرح الأسئلة، وأي النماذج الحالية تؤدي بشكل أفضل في هذا الصدد، وما إذا كانت هناك ضغوط خارجية (مثل السعي للاستجابة السريعة) تجعل الذكاء الاصطناعي لا يميل إلى طرح الأسئلة. (المصدر: Reddit r/artificial)
💡 其他
مؤتمر Siemens Realize Live يركز على دمج الذكاء الاصطناعي والبرمجيات الصناعية، وتعزيز حلول الذكاء الاصطناعي الشاملة: في مؤتمر Siemens Realize Live لعام 2025، أكد توني هيملجارن، الرئيس التنفيذي لشركة Siemens Digital Industries Software، أن الشركة تواصل دفع التحول الرقمي في قطاع التصنيع من خلال منصة Xcelerator. تم دمج تقنية الذكاء الاصطناعي في منتجات مثل Teamcenter (الكشف التلقائي عن المشكلات)، و Simcenter (تقليل وقت الحسابات الهندسية)، وتقنيات التصنيع (مزامنة أصول المصنع وتكوينات الإدارة). عززت Siemens قدراتها في مجال التوأم الرقمي من خلال الاستحواذ على Altair، حيث توفر نمذجة ومحاكاة شاملة تغطي التصميم الميكانيكي والأنظمة الكهربائية والبرمجيات والأتمتة، ودمجت تقنيات Altair في الحوسبة عالية الأداء والتحليل الهيكلي والمحاكاة وتحليل البيانات، لدعم نمذجة وتنبؤات أكثر تعقيدًا. وتساعد منصة Mendix منخفضة التعليمات البرمجية الشركات على بناء التطبيقات ودمج الأنظمة بسرعة. تم تحسين أداء Teamcenter PLM بمقدار 20 مرة، وتم إدخال قدرات الذكاء الاصطناعي لتحقيق إدارة ذكية لدورة حياة المنتج بأكملها. (المصدر: 36氪)

تدوينة “المشككون في الذكاء الاصطناعي جميعهم مجانين” تثير نقاشًا حادًا، وتناقش الاختلافات في إدراك إمكانات GenAI: أثارت تدوينة بعنوان “أصدقائي المشككون في الذكاء الاصطناعي جميعهم مجانين” (My AI Skeptic Friends Are All Nuts) (من fly.io) نقاشًا في مجتمع Reddit. أشارت التعليقات إلى أن حاملي الدكتوراه في علوم الكمبيوتر ذوي التعليم العالي هم الأقل استعدادًا لقبول الإمكانات طويلة المدى لـ GenAI، فهم غالبًا ما يركزون على معضلة واحدة في مجالهم، متجاهلين التطبيقات الواسعة للذكاء الاصطناعي في حل 90% من الأعمال المساعدة في الشركات الكبيرة. يرى البعض أنه طالما أن الذكاء الاصطناعي يعاني من الهلوسة والأخطاء، فإن تكلفة التحقق من مخرجاته لا تقل عن تكلفة البحث الذاتي، وبالتالي فهو عديم الفائدة. يعكس هذا الاختلافات الكبيرة في وجهات النظر حول قدرات الذكاء الاصطناعي وآفاق تطبيقه بين الأشخاص ذوي الخلفيات المهنية والمستويات المعرفية المختلفة، في سياق التطور السريع للذكاء الاصطناعي. (المصدر: Reddit r/artificial, fly.io)

ظاهرة هلوسة الذكاء الاصطناعي: المستخدمون يختبرون رحلة هلوسة تشبه “التعثر الدلالي”: وصف مستخدم Reddit بالتفصيل تجربة تشبه الهلوسة بعد إجراء محادثات عميقة مع الذكاء الاصطناعي (خاصة تلك التي تتناول مواضيع وجودية ثقيلة)، وأطلق عليها اسم “التعثر الدلالي” (Semantic Tripping). يرى المؤلف أن الذكاء الاصطناعي يمكنه غرس كميات هائلة من الأفكار الفلسفية بسرعة، مما قد يؤدي إلى تشويش إحساس المستخدم بالواقع، وتشويه إدراكه للوقت، وتكوين ارتباطات رمزية بالأشياء، وحتى ظهور مشاعر متطرفة مثل الذعر أو النشوة. يحذر المؤلف من أن هذه التجربة تسبب الإدمان وقد تؤدي إلى مشكلات نفسية، وينصح المستخدمين بالحذر وطلب الرفقة. أثار هذا المنشور نقاشًا حول التأثير العميق للتفاعل مع الذكاء الاصطناعي على الإدراك البشري والحالة النفسية. (المصدر: Reddit r/ArtificialInteligence)
