
كلمات مفتاحية:ديب مايند ألفا إيفولف, ساكانا أي آي دي جي إم, ديب سيك-آر1, تعلم التعزيز برو آر إل, إنفيديا كوزموس, النماذج الكبيرة متعددة الوسائط, إطار عمل وكيل الذكاء الاصطناعي, تحسين استدلال نماذج اللغات الكبيرة, سجل ألفا إيفولف الرياضي, آلة جودل داروين للتحسين الذاتي, تقييم ميدهيلم الطبي, توسيع نطاق تعلم التعزيز برو آر إل, محاكاة نقل كوزموس الفيزيائية
🔥 أبرز المستجدات
DeepMind AlphaEvolve يحطم الرقم القياسي في الرياضيات، والتعاون بين الإنسان والآلة يدفع التقدم العلمي: حطم AlphaEvolve من DeepMind الرقم القياسي في الرياضيات الذي ظل صامدًا لمدة 18 عامًا مرتين في أسبوع واحد، مما أثار اهتمامًا واسعًا. علق تيرنس تاو بأن هذا يوضح كيف يمكن للطرق المختلفة أن تتكامل لدفع التقدم في الرياضيات، بدلاً من مجرد وجود “فائز” و “خاسر”. يسلط هذا الحدث الضوء على إمكانات التعاون بين AI والبشر في خلق نماذج جديدة في مجالات التكنولوجيا والعلوم، حيث لا يحل AI ببساطة محل البشر، بل يشاركان في فتح مسارات جديدة للتقدم (المصدر: shaneguML)

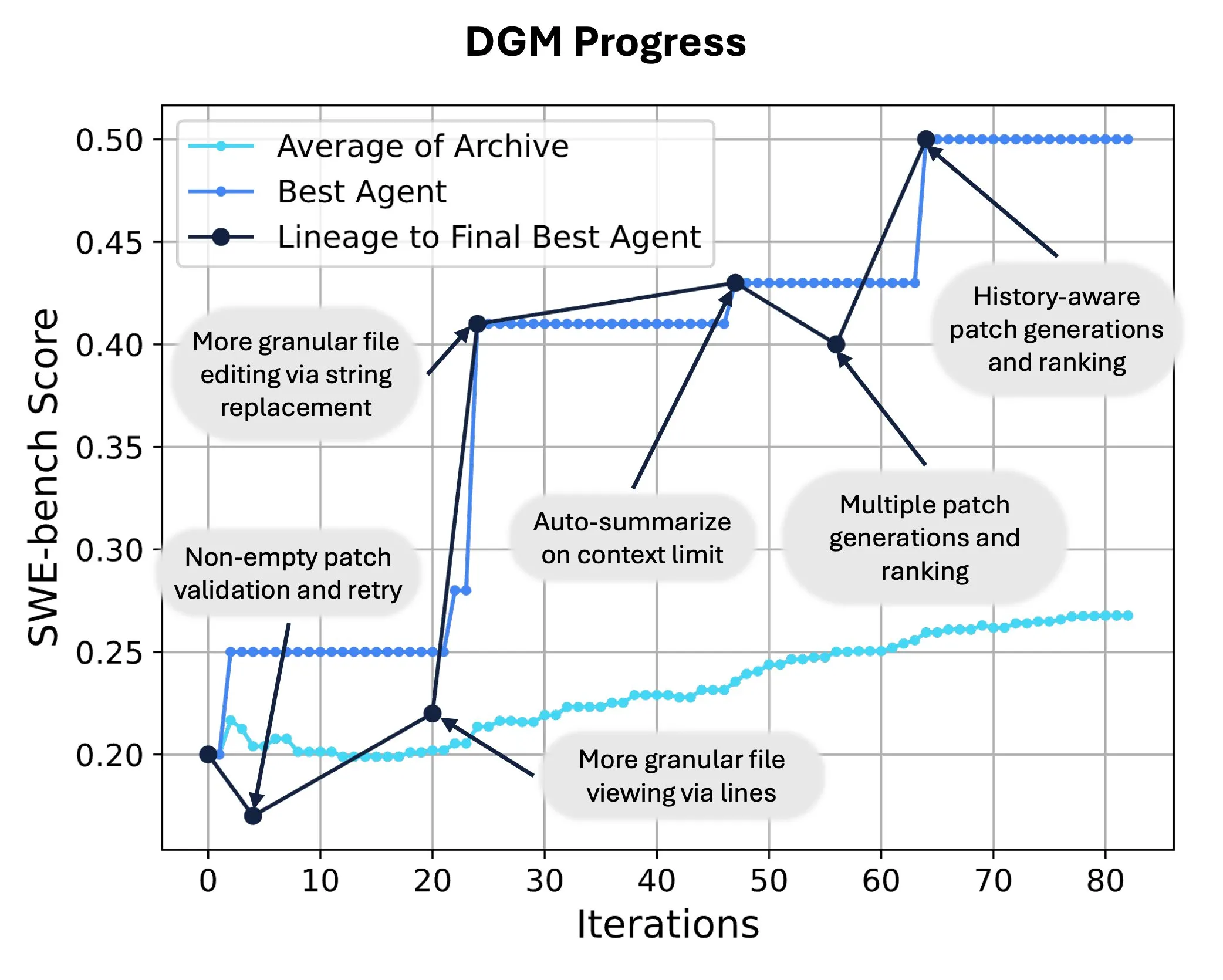
Sakana AI تطلق Darwin Gödel Machine (DGM)، مما يتيح إعادة كتابة الشيفرة المصدرية للذكاء الاصطناعي وتطوره ذاتيًا: أطلقت Sakana AI آلة Darwin Gödel Machine (DGM)، وهي عامل ذكي قادر على تحسين أدائه من خلال تعديل شيفرته المصدرية. مستوحاة من نظرية التطور، تحتفظ DGM بسلالة متوسعة باستمرار من متغيرات العوامل الذكية، مما يتيح استكشافًا مفتوحًا لمساحة تصميم العوامل الذكية “ذاتية التحسين”. على SWE-bench، حسنت DGM الأداء من 20.0% إلى 50.0%؛ وعلى Polyglot، ارتفعت نسبة النجاح من 14.2% إلى 30.7%، متجاوزة بشكل كبير العوامل الذكية المصممة يدويًا. توفر هذه التقنية مسارًا جديدًا لأنظمة AI لتحقيق التعلم المستمر وتطور القدرات (المصدر: SakanaAILabs, hardmaru)
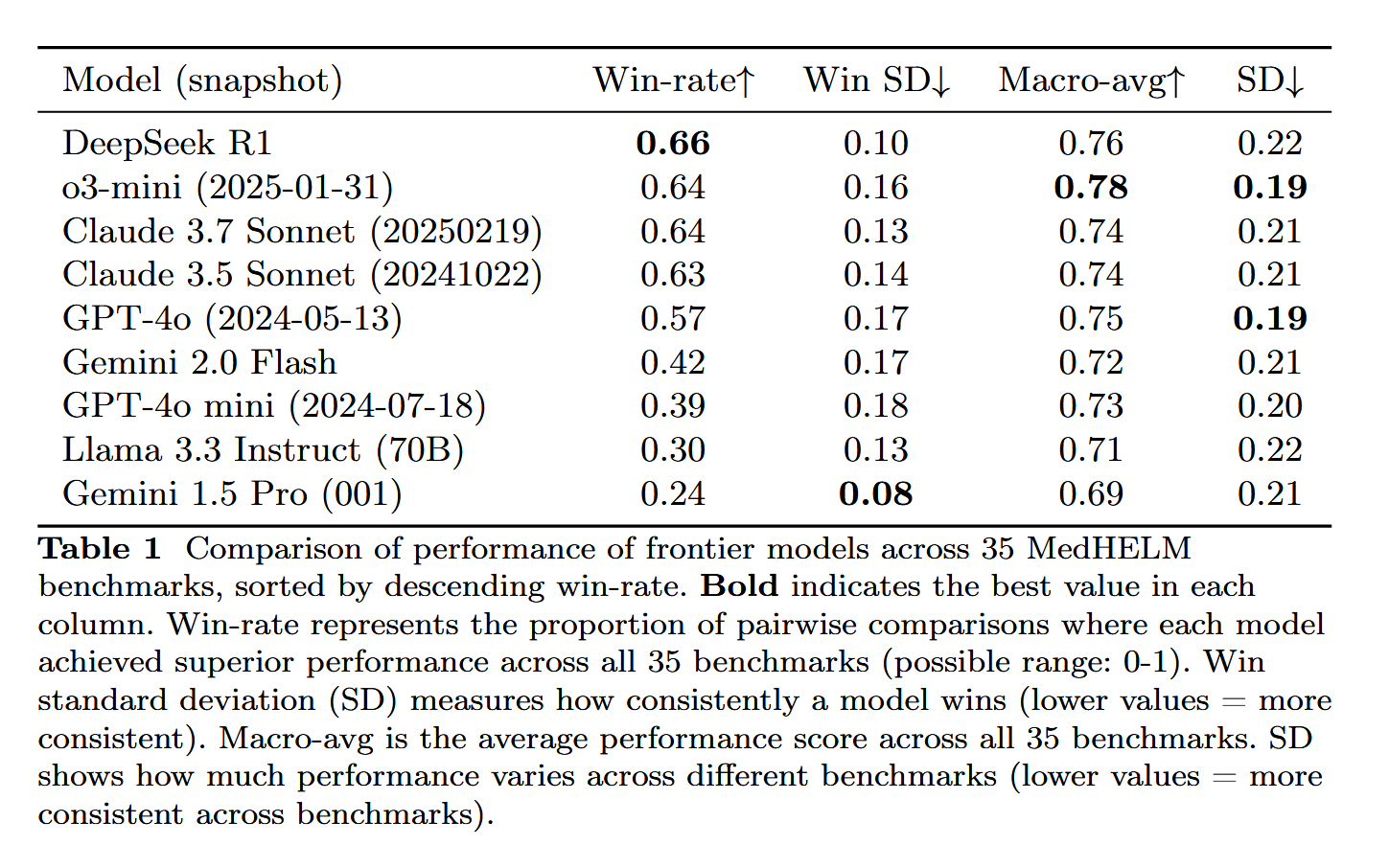
DeepSeek-R1 يُظهر أداءً متميزًا في تقييم المهام الطبية MedHELM: حقق نموذج اللغة الكبير DeepSeek-R1 أفضل أداء في اختبار MedHELM (التقييم الشامل للمهام الطبية لنماذج اللغة الكبيرة)، وهو اختبار معياري يهدف إلى تقييم أداء LLM في المهام السريرية الأكثر واقعية، بدلاً من اختبارات التراخيص الطبية التقليدية. تُعتبر هذه النتيجة ذات أهمية، حيث تُظهر إمكانات DeepSeek-R1 في التطبيقات الطبية، خاصة في التعامل مع السيناريوهات السريرية الفعلية (المصدر: iScienceLuvr)
تقدم جديد في أبحاث قابلية التوسع للتعلم المعزز: ProRL يوسع حدود استدلال LLM: أثارت ورقة بحثية جديدة (arXiv:2505.24864) حول قابلية التوسع للتعلم المعزز (RL) الاهتمام، حيث أظهرت الدراسة أنه من خلال التدريب المطول على التعلم المعزز (ProRL)، يمكن اكتشاف استراتيجيات استدلال جديدة تمامًا يصعب على النماذج الأساسية الحصول عليها من خلال أخذ العينات على نطاق واسع. يجمع ProRL بين التحكم في تباعد KL، وإعادة تعيين سياسة المرجع، ومجموعة متنوعة من المهام، مما يمكّن نماذج التدريب على RL من التفوق باستمرار على النماذج الأساسية في تقييمات pass@k المتعددة. تقدم هذه الدراسة رؤى جديدة حول كيف يمكن لـ RL أن يوسع بشكل كبير حدود استدلال نماذج اللغة، وتضع الأساس لأبحاث استدلال RL طويلة المدى في المستقبل. أصدرت NVIDIA أوزان النماذج ذات الصلة (المصدر: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 اتجاهات
NVIDIA تطلق Cosmos Transfer و Cosmos Reason لتعزيز تطبيقات الذكاء الاصطناعي في العالم المادي: أطلقت NVIDIA نظام Cosmos، حيث يمكن لـ Cosmos Transfer تحويل مشاهد محركات الألعاب البسيطة، ومعلومات العمق، وحتى محاكاة الروبوتات الأولية إلى مقاطع فيديو واقعية لمشاهد حقيقية، مما يوفر كمية كبيرة من بيانات التدريب القابلة للتحكم للروبوتات والقيادة الذاتية وغيرها من تطبيقات الذكاء الاصطناعي. أما Cosmos Reason فيمكن الذكاء الاصطناعي من فهم هذه المشاهد واتخاذ القرارات، مثل تحديد كيفية القيادة في اختبارات القيادة الذاتية. كلتا الأداتين مفتوحتا المصدر حاليًا، ومن المتوقع أن تسرعا من تطوير الذكاء الاصطناعي في العالم المادي، وحل مشكلات نقص بيانات التدريب والتحكم في المشاهد (المصدر: )
DeepSeek تصدر تحديث R1، والنظام البيئي مفتوح المصدر يواصل ازدهاره: أصدرت DeepSeek تحديثًا لنموذج R1، بما في ذلك R1 نفسه ونسخة مصغرة مُقطّرة (distilled) بحجم 8 مليارات معلمة. في الوقت نفسه، تتخذ ByteDance خطوات متكررة في مجال المصادر المفتوحة، حيث أطلقت مشاريع مثل BAGEL، و Dolphin، و Seedcoder، و Dream0. تُظهر هذه التطورات نشاط الصين وقدرتها على الابتكار في مجال الذكاء الاصطناعي مفتوح المصدر، خاصة في التطور السريع للنماذج متعددة الوسائط والمتخصصة (المصدر: TheRundownAI, stablequan, reach_vb, clefourrier)
جوجل تطلق Edge AI Gallery لتعزيز تطبيقات نماذج الذكاء الاصطناعي مفتوحة المصدر على الهواتف الذكية: أطلقت جوجل Edge AI Gallery بهدف جلب نماذج الذكاء الاصطناعي مفتوحة المصدر إلى الهواتف الذكية، مما يتيح تطبيقات ذكاء اصطناعي محلية وخاصة. يمكن للمستخدمين تشغيل نماذج LLM من Hugging Face مباشرة على أجهزتهم، للقيام بعمليات مثل إنشاء الأكواد البرمجية والمحادثة حول الصور، مع دعم المحادثات متعددة الأدوار وإمكانية اختيار أي نموذج. يعتمد التطبيق على LiteRT، ويدعم حاليًا نظام أندرويد، ومن المقرر إطلاق نسخة iOS قريبًا، مما سيعزز تطوير وانتشار الذكاء الاصطناعي على الأجهزة الطرفية (المصدر: TheRundownAI, huggingface, reach_vb, osanseviero)
بحث جديد يستكشف استخدام مسارات الاستدلال الإيجابية والسلبية المقطرة لتحسين LLM: تقترح ورقة بحثية جديدة إطار عمل التقطير المعزز (REDI)، بهدف تحسين قدرات الاستدلال للنماذج الطلابية الصغيرة من خلال الاستفادة من مسارات الاستدلال الصحيحة والخاطئة التي تنتجها النماذج المعلمة (مثل DeepSeek-R1). ينقسم REDI إلى مرحلتين، الأولى هي التعلم من المسارات الصحيحة من خلال الضبط الدقيق الخاضع للإشراف (SFT)، ثم استخدام دالة الهدف REDI المقترحة حديثًا (دالة خسارة بدون مرجع) لدمج المسارات الإيجابية والسلبية لمزيد من تحسين النموذج. أظهرت التجارب أن REDI يتفوق على الطرق الأساسية في مهام الاستدلال الرياضي، حيث حقق نموذج Qwen-REDI-1.5B درجة عالية بلغت 83.1% على MATH-500 (المصدر: HuggingFace Daily Papers)
إطار عمل LLMSynthor يستخدم LLM لتوليد البيانات المدركة هيكليًا: LLMSynthor هو إطار عمل عام لتوليد البيانات يحول نماذج اللغة الكبيرة (LLM) إلى محاكيات مدركة هيكليًا، ويتم توجيهها من خلال التغذية الراجعة للتوزيع. يعتبر هذا الإطار LLM بمثابة محاكيات copula غير بارامترية لنمذجة الاعتماديات عالية الترتيب، ويقدم أخذ عينات مقترحة من LLM لتحسين كفاءة أخذ العينات. من خلال تقليل الاختلافات في مساحة الإحصاءات الموجزة، تعمل حلقة التوليد التكرارية على مواءمة البيانات الحقيقية والاصطناعية. أظهر التقييم على مجموعات بيانات غير متجانسة في مجالات حساسة للخصوصية مثل التجارة الإلكترونية والسكان والتنقل أن البيانات الاصطناعية التي تم إنشاؤها بواسطة LLMSynthor تتمتع بدقة إحصائية وفائدة عالية (المصدر: HuggingFace Daily Papers)
إطار عمل v1 يعزز الاستدلال التفاعلي متعدد الوسائط من خلال إعادة الزيارة البصرية الانتقائية: v1 هو امتداد خفيف الوزن يمكّن نماذج اللغة الكبيرة متعددة الوسائط (MLLM) من إجراء إعادة زيارة بصرية انتقائية أثناء عملية الاستدلال. على عكس MLLM الحالية التي تعالج عادةً المدخلات البصرية دفعة واحدة، يقدم v1 آلية “الإشارة والنسخ”، مما يسمح للنموذج باسترداد مناطق الصورة ذات الصلة ديناميكيًا أثناء الاستدلال. من خلال التدريب على مجموعة بيانات مسارات الاستدلال متعددة الوسائط v1g التي تحتوي على شروح أساسية بصرية، أظهر v1 تحسنًا في الأداء في اختبارات معيارية مثل MathVista، خاصة في المهام التي تتطلب مرجعًا بصريًا دقيقًا واستدلالًا متعدد الخطوات (المصدر: HuggingFace Daily Papers)
MetaFaith يعزز مصداقية تعبير LLM عن عدم اليقين في اللغة الطبيعية: لمعالجة مشكلة المبالغة التي غالبًا ما تظهر في تعبير LLM عن عدم اليقين، يقترح MetaFaith طريقة معايرة جديدة قائمة على التوجيه (prompt-based). وجدت الدراسة أن LLM الحالية لا تعكس بشكل جيد عدم اليقين الداخلي لديها، وأن طرق التوجيه القياسية ذات تأثير محدود، بل إن تقنيات المعايرة القائمة على الحقائق قد تضر بالمعايرة الصادقة. مستوحى من ما وراء المعرفة البشرية، يمكن لـ MetaFaith أن يحسن بشكل كبير قدرة النموذج على المعايرة الصادقة عبر مهام ونماذج مختلفة، مما يرفع المصداقية بنسبة تصل إلى 61% ويحقق نسبة فوز 83% في التقييمات البشرية (المصدر: HuggingFace Daily Papers)
CLaSp: تسريع فك التشفير التخميني الذاتي لـ LLM من خلال تخطي الطبقات داخل السياق: CLaSp هي استراتيجية فك تشفير تخميني ذاتي لنماذج اللغة الكبيرة (LLM)، تعمل على تسريع عملية فك التشفير من خلال بناء نموذج مسودة مضغوط عن طريق تخطي الطبقات الوسيطة في النموذج أثناء التحقق، وذلك دون الحاجة إلى تدريب إضافي أو تعديل النموذج. يستخدم CLaSp خوارزمية البرمجة الديناميكية لتحسين عملية تخطي الطبقات، ويقوم بتعديل الاستراتيجية ديناميكيًا بناءً على الحالة المخفية الكاملة لمرحلة التحقق السابقة. أظهرت التجارب أن CLaSp يحقق تسريعًا يتراوح بين 1.3 إلى 1.7 مرة على نماذج سلسلة LLaMA3، دون تغيير التوزيع الأصلي للنص المُنشأ (المصدر: HuggingFace Daily Papers)
HardTests تولد حالات اختبار أكواد عالية الجودة باستخدام LLM: لمعالجة صعوبة التحقق الفعال من الأكواد التي تولدها LLM للمشكلات البرمجية المعقدة باستخدام حالات الاختبار الحالية، يقترح HardTests عملية HARDTESTGEN التي تستخدم LLM لإنشاء حالات اختبار عالية الجودة. تحتوي مجموعة بيانات HardTests المبنية على هذه العملية على 47 ألف مشكلة برمجية وحالات اختبار اصطناعية عالية الجودة. مقارنة بالاختبارات الحالية، فإن الاختبارات التي تم إنشاؤها بواسطة HARDTESTGEN عند تقييم الأكواد التي تم إنشاؤها بواسطة LLM، تزيد الدقة بنسبة 11.3%، والاستدعاء بنسبة 17.5%، ويمكن أن يصل تحسين الدقة للمشكلات الصعبة إلى 40%. أظهرت مجموعة البيانات هذه أيضًا تأثيرًا أفضل في تدريب النماذج (المصدر: HuggingFace Daily Papers)
دراسة تكشف عن وجود تحيزات في نماذج اللغة البصرية (VLM): كشفت دراسة أن نماذج اللغة البصرية المتقدمة (VLM) تتأثر بشدة بالمعرفة المسبقة الهائلة التي تعلمتها من الإنترنت عند معالجة المهام البصرية المتعلقة بالموضوعات الشائعة (مثل العد والتعرف). على سبيل المثال، تجد VLM صعوبة في التعرف على شريط رابع مضاف إلى شعار أديداس. في مهام العد التي تغطي 7 مجالات مختلفة بما في ذلك الحيوانات والعلامات التجارية وألعاب الطاولة، بلغ متوسط دقة VLM 17.05% فقط. حتى مع توجيه النموذج للفحص الدقيق أو الاعتماد فقط على تفاصيل الصورة، كان تحسن الدقة محدودًا. تقترح الدراسة إطار عمل آلي لاختبار تحيزات VLM (المصدر: HuggingFace Daily Papers)
Point-MoE: تحقيق التعميم عبر المجالات لتجزئة الدلالات ثلاثية الأبعاد باستخدام نموذج خليط الخبراء: لمعالجة صعوبة تدريب نموذج موحد بسبب تنوع مصادر بيانات السحابة النقطية ثلاثية الأبعاد (مثل كاميرات العمق، LiDAR) وعدم تجانس المجالات (مثل الأماكن الداخلية والخارجية)، يقترح Point-MoE بنية خليط الخبراء (MoE). تقوم هذه البنية، من خلال استراتيجية توجيه بسيطة top-k، بتخصيص شبكات الخبراء تلقائيًا حتى في حالة عدم وجود تسميات للمجالات. أظهرت التجارب أن Point-MoE لا يتفوق فقط على النماذج الأساسية القوية متعددة المجالات، بل يتمتع أيضًا بقدرة تعميم أفضل على المجالات غير المرئية، مما يوفر مسارًا قابلاً للتطوير للإدراك ثلاثي الأبعاد واسع النطاق وعبر المجالات (المصدر: HuggingFace Daily Papers)
SpookyBench يكشف عن “النقاط العمياء الزمنية” لنماذج لغة الفيديو: على الرغم من التقدم الذي أحرزته نماذج لغة الفيديو (VLM) في فهم العلاقات الزمانية المكانية، إلا أنها تواجه صعوبة في التقاط الأنماط الزمنية البحتة عندما تكون المعلومات المكانية غامضة. من خلال ترميز المعلومات (مثل الأشكال والنصوص) في تسلسلات إطارات شبيهة بالضوضاء، وجد اختبار SpookyBench أن البشر يمكنهم التعرف عليها بدقة تزيد عن 98%، بينما كانت دقة VLM المتقدمة 0%. يشير هذا إلى أن VLM تعتمد بشكل مفرط على الميزات المكانية على مستوى الإطار، ولا يمكنها استخلاص المعنى من الإشارات الزمنية. تؤكد هذه الدراسة على ضرورة التغلب على “النقاط العمياء الزمنية” لـ VLM، وقد يتطلب ذلك بنيات جديدة أو نماذج تدريب لفصل الاعتماد المكاني عن المعالجة الزمنية (المصدر: HuggingFace Daily Papers, _akhaliq)
طريقة جديدة ومجموعة بيانات للكشف عن الابتكار العلمي باستخدام LLM: يعد تحديد الأفكار البحثية الجديدة أمرًا بالغ الأهمية ولكنه مليء بالتحديات. لمعالجة هذه المشكلة، اقترح الباحثون استخدام نماذج اللغة الكبيرة (LLM) للكشف عن الابتكار العلمي، وقاموا ببناء مجموعتي بيانات جديدتين في مجالات التسويق ومعالجة اللغة الطبيعية. تقوم هذه الطريقة ببناء مجموعات البيانات عن طريق استخراج مجموعة الإغلاق (closure set) للأوراق البحثية واستخدام LLM لتلخيص أفكارها الرئيسية. لالتقاط مفاهيم الأفكار، اقترح الباحثون تدريب مُسترجع خفيف الوزن، من خلال تقطير المعرفة على مستوى الفكرة من LLM لمواءمة الأفكار ذات المفاهيم المتشابهة، وبالتالي تحقيق استرجاع فعال ودقيق للأفكار. أثبتت التجارب أن هذه الطريقة تتفوق على الطرق الأخرى في مجموعات البيانات المعيارية المقترحة (المصدر: HuggingFace Daily Papers)
un^2CLIP يعزز قدرة CLIP على التقاط التفاصيل البصرية عن طريق عكس unCLIP: لمعالجة أوجه القصور في نموذج CLIP في التمييز بين اختلافات التفاصيل في الصور ومعالجة المهام مثل التنبؤ الكثيف، يقترح un^2CLIP تحسين CLIP عن طريق عكس نموذج unCLIP. يقوم unCLIP نفسه بتدريب مولد صور باستخدام تضمينات صور CLIP، وبالتالي يتعلم توزيع تفاصيل الصورة. يستفيد un^2CLIP من هذه الميزة، مما يمكّن مُشفّر صور CLIP المُحسَّن من اكتساب قدرة unCLIP على التقاط التفاصيل البصرية، مع الحفاظ على التوافق مع مُشفّر النص الأصلي. أظهرت التجارب أن un^2CLIP يتفوق بشكل كبير على CLIP الأصلي وطرق التحسين الأخرى في مهام متعددة (المصدر: HuggingFace Daily Papers)
ViStoryBench: إطلاق مجموعة معيارية شاملة لتصور القصص: لدفع تطوير تقنيات تصور القصص (إنشاء تسلسلات صور متماسكة بناءً على السرد والصور المرجعية)، يوفر ViStoryBench معيار تقييم شامل. يحتوي هذا المعيار على مجموعات بيانات لأنواع قصص متنوعة (كوميديا، رعب، إلخ) وأنماط فنية (أنمي، عرض ثلاثي الأبعاد، إلخ)، ويضم قصصًا ذات بطل واحد ومتعدد الأبطال لاختبار اتساق الشخصيات، بالإضافة إلى حبكات معقدة وبناء عالم لتحدي دقة التوليد البصري للنماذج. يعتمد ViStoryBench على مقاييس تقييم متعددة، تهدف إلى تقييم أداء النماذج بشكل شامل في جوانب البنية السردية والعناصر البصرية، ومساعدة الباحثين على تحديد نقاط القوة والضعف في النماذج وتحسينها بشكل مستهدف (المصدر: HuggingFace Daily Papers)
فك التشفير المتشعب المدمج (FMD) يعزز الفهم المتوازن متعدد الوسائط لنماذج الصوت والفيديو الكبيرة: لمعالجة مشكلة التحيز الوسائطي المحتمل في نماذج اللغة الكبيرة للصوت والفيديو (AV-LLM) (أي ميل النموذج إلى الاعتماد المفرط على وسيط واحد عند اتخاذ القرارات)، يقترح فك التشفير المتشعب المدمج (FMD) استراتيجية وقت الاستدلال لا تتطلب تدريبًا إضافيًا. يقوم FMD أولاً بمعالجة مدخلات الصوت الخالص والفيديو الخالص بشكل منفصل من خلال طبقات فك التشفير المبكرة (مرحلة التشعب)، ثم يدمج الحالات المخفية الناتجة للاستدلال المشترك (مرحلة الدمج). تهدف هذه الطريقة إلى تعزيز التوازن في مساهمة الوسائط والاستفادة من المعلومات التكميلية عبر الوسائط. أظهرت التجارب على نماذج مثل VideoLLaMA2 و video-SALMONN أن FMD يمكن أن يحسن الأداء في مهام استدلال الصوت والفيديو والصوت والفيديو المشتركة (المصدر: HuggingFace Daily Papers)
LegalSearchLM: إعادة صياغة استرجاع القضايا القانونية كإنشاء عناصر قانونية: تعتمد طرق استرجاع القضايا القانونية التقليدية (LCR) على مطابقة التضمينات أو المفردات، وتواجه قيودًا في السيناريوهات الحقيقية. يقترح LegalSearchLM طريقة جديدة تعتبر LCR مهمة إنشاء عناصر قانونية. يقوم هذا النموذج بالاستدلال على العناصر القانونية للقضية المستعلم عنها، ومن خلال فك التشفير المقيد، ينشئ مباشرة محتوى يعتمد على القضية المستهدفة. في الوقت نفسه، أصدر الباحثون LEGAR BENCH، وهو معيار LCR واسع النطاق يحتوي على 1.2 مليون قضية قانونية كورية. أظهرت التجارب أن أداء LegalSearchLM على LEGAR BENCH يتفوق على النماذج الأساسية بنسبة 6-20%، ويظهر قدرة تعميم قوية عبر المجالات (المصدر: HuggingFace Daily Papers)
RPEval: معيار جديد لتقييم قدرة نماذج اللغة الكبيرة على لعب الأدوار: لمواجهة تحديات تقييم قدرة نماذج اللغة الكبيرة (LLM) على لعب الأدوار، يوفر RPEval اختبارًا معياريًا جديدًا. يقوم هذا المعيار بتقييم أداء LLM في لعب الأدوار من أربعة أبعاد رئيسية: الفهم العاطفي، واتخاذ القرار، والميول الأخلاقية، واتساق الدور. يهدف إلى حل مشكلة استهلاك الموارد الكبيرة للتقييم اليدوي والتحيزات المحتملة للتقييم الآلي (المصدر: HuggingFace Daily Papers)
GATE: نموذج تضمين نصي عام لتعزيز STS باللغة العربية: لمواجهة مشكلة ندرة مجموعات البيانات عالية الجودة والنماذج المدربة مسبقًا في أبحاث التشابه النصي الدلالي (STS) باللغة العربية، ظهر نموذج GATE (General Arabic Text Embedding). يستخدم GATE تعلم تمثيل Matryoshka وطرق تدريب الخسارة المختلطة، جنبًا إلى جنب مع التدريب على مجموعة بيانات ثلاثية لاستدلال اللغة الطبيعية العربية. أظهرت نتائج التجارب أن GATE حقق أداءً متطورًا (SOTA) في مهام STS على معيار MTEB، مع تحسن في الأداء بنسبة 20-25% مقارنة بالنماذج الكبيرة بما في ذلك OpenAI، ويمكنه التقاط الفروق الدقيقة الدلالية الفريدة للغة العربية بشكل فعال (المصدر: HuggingFace Daily Papers)
CoDA: إطار عمل لتحسين ضوضاء الانتشار التعاوني للتحكم في كامل الجسم للأجسام المفصلية: لتحقيق الواقعية والدقة في التحكم في كامل الجسم للأجسام المفصلية (بما في ذلك حركة الجسم واليدين والجسم)، يقترح CoDA إطار عمل جديد لتحسين ضوضاء الانتشار التعاوني. يقوم هذا الإطار بتحسين مساحة الضوضاء لثلاثة نماذج انتشار متخصصة للجسم واليد اليسرى واليد اليمنى، ومن خلال تدفق التدرج في سلسلة الحركة البشرية، يحقق التنسيق الطبيعي بين اليدين وبقية الجسم. لزيادة دقة تفاعل اليد مع الجسم، يعتمد CoDA على تمثيل موحد قائم على مجموعة النقاط الأساسية (BPS)، حيث يتم ترميز موضع الطرف المنفذ كمسافة إلى BPS الهندسي للجسم، وبالتالي توجيه تحسين ضوضاء الانتشار، وإنشاء حركات تفاعلية عالية الدقة (المصدر: HuggingFace Daily Papers)
تفسير جديد لآلية التفكير الاستدلالي في LLM: إطار التعلم المعزز التكيفي البايزي BARL: اقترحت جامعة نورث وسترن بالتعاون مع جوجل DeepMind إطار التعلم المعزز التكيفي البايزي (BARL)، بهدف تفسير وتحسين سلوك “التفكير” في نماذج اللغة الكبيرة (LLM) أثناء عملية الاستدلال. عادةً ما يستخدم التعلم المعزز التقليدي (RL) الاستراتيجيات المتعلمة فقط أثناء الاختبار، بينما يقدم BARL نمذجة لعدم اليقين في البيئة، مما يمكّن النموذج من استكشاف استراتيجيات جديدة بشكل تكيفي أثناء الاستدلال. أظهرت التجارب أن BARL يمكن أن يحقق دقة أعلى في مهام مثل الاستدلال الرياضي، ويقلل بشكل كبير من استهلاك الـ token. تشرح هذه الدراسة لأول مرة من منظور بايزي لماذا وكيف ومتى يجب على LLM إجراء استكشاف تأملي (المصدر: 量子位)

تطبيق LLM في قواعد النحو غير المؤكدة الشكلية: متى نثق في LLM للاستدلال التلقائي: تُظهر نماذج اللغة الكبيرة (LLM) إمكانات في إنشاء المواصفات الشكلية، ولكن طبيعتها الاحتمالية تتعارض مع متطلبات اليقين في التحقق الشكلي. قام الباحثون بالتحقيق بشكل شامل في أنماط الفشل وقياس عدم اليقين (UQ) في المكونات الشكلية التي تم إنشاؤها بواسطة LLM. أظهرت النتائج أن تأثير الشكليات التلقائية القائمة على SMT على الدقة يختلف باختلاف المجال، وأن تقنيات UQ الحالية تجد صعوبة في تحديد هذه الأخطاء. تقدم الورقة إطار عمل قواعد النحو الخالية من السياق الاحتمالية (PCFG) لنمذجة مخرجات LLM، ووجدت أن إشارات عدم اليقين تعتمد على المهمة. من خلال دمج هذه الإشارات، يمكن تحقيق التحقق الانتقائي، مما يقلل الأخطاء بشكل كبير، ويجعل الشكليات التي تعتمد على LLM أكثر موثوقية (المصدر: HuggingFace Daily Papers)
مقارنة بين الضبط الدقيق لنماذج اللغة الصغيرة (SLM) والتوجيه لنماذج اللغة الكبيرة (LLM) في إنشاء سير عمل منخفض الكود: قارنت دراسة بين تأثير الضبط الدقيق لنماذج اللغة الصغيرة (SLM) وتوجيه نماذج اللغة الكبيرة (LLM) في مهمة إنشاء سير عمل منخفض الكود بتنسيق JSON. أظهرت النتائج أنه على الرغم من أن التوجيه الجيد يمكن أن يجعل LLM تنتج نتائج معقولة، إلا أنه بالنسبة للمهام الخاصة بالمجال والمخرجات المهيكلة، فإن الضبط الدقيق لـ SLM يحقق تحسنًا في الجودة بنسبة 10% في المتوسط. يشير هذا إلى أنه في سيناريوهات محددة، لا تزال SLM تتمتع بميزة، خاصة عندما تكون متطلبات جودة الإخراج عالية (المصدر: HuggingFace Daily Papers)
تقييم وتوجيه التفضيلات الوسائطية في النماذج الكبيرة متعددة الوسائط: قام الباحثون ببناء معيار MC² لتقييم تفضيلات الوسائط لنماذج اللغة الكبيرة متعددة الوسائط (MLLM) بشكل منهجي في سيناريوهات تضارب الأدلة الخاضعة للرقابة (أي الميل إلى وسيط معين عند اتخاذ القرارات). وجدت الدراسة أن 18 MLLM التي تم اختبارها أظهرت جميعها تحيزًا وسائطيًا واضحًا، وأن اتجاه التفضيل يمكن أن يتأثر بالتدخلات الخارجية. بناءً على ذلك، اقترح الباحثون طريقة استكشاف وتوجيه قائمة على هندسة التمثيل، والتي يمكنها التحكم بشكل صريح في تفضيلات الوسائط دون الحاجة إلى ضبط دقيق إضافي أو توجيهات مصممة بعناية، وحققت نتائج إيجابية في المهام النهائية مثل تخفيف الهلوسة والترجمة الآلية متعددة الوسائط (المصدر: HuggingFace Daily Papers)
الوضع الحالي لأبحاث أمان LLM متعدد اللغات: من قياس الفجوة اللغوية إلى سد الفجوة: أظهرت مراجعة منهجية لما يقرب من 300 ورقة بحثية في مؤتمرات NLP بين عامي 2020 و 2024 أن أبحاث أمان LLM تعاني من مشكلة مركزية اللغة الإنجليزية بشكل كبير. حتى اللغات غير الإنجليزية الغنية بالموارد نادرًا ما تحظى بالاهتمام، ونادرًا ما تُعتبر اللغات غير الإنجليزية موضوعات بحث مستقلة، كما تفتقر أبحاث الأمان باللغة الإنجليزية عمومًا إلى ممارسات توثيق لغوي جيدة. لدفع أبحاث الأمان متعددة اللغات، تقترح الورقة اتجاهات مستقبلية، بما في ذلك تقييم الأمان، وإنشاء بيانات التدريب، وتعميم الأمان عبر اللغات، بهدف تطوير ممارسات أمان AI أكثر قوة وشمولية لمختلف المجموعات السكانية العالمية (المصدر: HuggingFace Daily Papers, sarahookr)

إعادة النظر في انتقال الحالة ثنائي الخطية في الشبكات العصبية المتكررة: ترى وجهة النظر التقليدية أن الوحدات المخفية في الشبكات العصبية المتكررة (RNN) تستخدم بشكل أساسي لنمذجة الذاكرة. تنطلق هذه الدراسة من منظور آخر، حيث ترى أن الوحدات المخفية هي مشارك نشط في حسابات الشبكة. أعاد الباحثون النظر في العمليات ثنائية الخطية التي تتضمن تفاعلات ضرب بين الوحدات المخفية وتضمينات الإدخال، وأثبتوا نظريًا وتجريبيًا أنها انحياز استقرائي طبيعي لتمثيل تطور الحالة المخفية في مهام تتبع الحالة. أظهرت الدراسة أيضًا أن تحديثات الحالة ثنائية الخطية تشكل تسلسلًا هرميًا طبيعيًا، يتوافق مع مهام تتبع الحالة ذات التعقيد المتزايد، بينما تقع RNN الخطية الشائعة (مثل Mamba) في مركز التعقيد الأدنى لهذا التسلسل الهرمي (المصدر: HuggingFace Daily Papers)
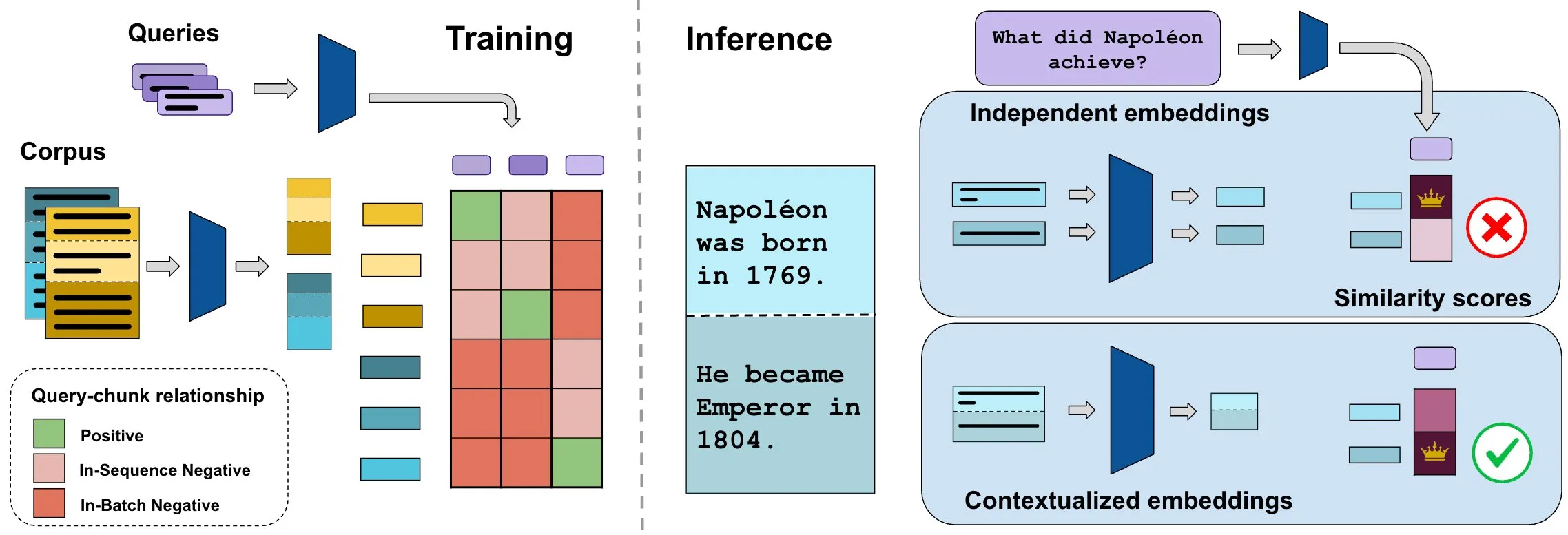
معيار ConTEB يقيم تضمينات المستندات السياقية، وطريقة InSeNT تحسن جودة الاسترجاع: عادةً ما تقوم طرق تضمين استرجاع المستندات الحالية بترميز الأجزاء المختلفة (chunk) من نفس المستند بشكل مستقل، متجاهلة معلومات السياق على مستوى المستند. لحل هذه المشكلة، أطلق الباحثون معيار ConTEB، المصمم خصيصًا لتقييم قدرة نماذج الاسترجاع على استخدام سياق المستند، ووجدوا أن نماذج SOTA ضعيفة الأداء في هذا الجانب. في الوقت نفسه، اقترح الباحثون طريقة التدريب اللاحق للتعلم التبايني InSeNT (التدريب السلبي داخل التسلسل)، جنبًا إلى جنب مع تجميع الأجزاء اللاحق، لتعزيز تعلم تمثيل السياق، مما أدى إلى تحسين جودة الاسترجاع بشكل كبير على ConTEB، وأظهر قوة أكبر تجاه استراتيجيات التجزئة دون المستوى الأمثل ومجموعات النصوص الأكبر حجمًا (المصدر: HuggingFace Daily Papers, tonywu_71)
🧰 أدوات
PraisonAI: إطار عمل متعدد وكلاء الذكاء الاصطناعي منخفض الكود: PraisonAI هو إطار عمل متعدد وكلاء الذكاء الاصطناعي جاهز للإنتاج، يهدف إلى تبسيط الأتمتة وحل المشكلات من المهام البسيطة إلى التحديات المعقدة من خلال حلول منخفضة الكود. يدمج PraisonAI Agents و AG2 (AutoGen) و CrewAI، مع التركيز على البساطة والتخصيص والتعاون الفعال بين الإنسان والآلة. تشمل وظائفه الإنشاء التلقائي لوكلاء الذكاء الاصطناعي، والتفكير الذاتي، والوسائط المتعددة، والتعاون متعدد الوكلاء، وإضافة المعرفة، والذاكرة طويلة وقصيرة المدى، و RAG، ومفسر الأكواد، وأكثر من 100 أداة مخصصة ودعم LLM، إلخ. يدعم Python و JavaScript، ويوفر خيارات تكوين YAML بدون كود (المصدر: GitHub Trending)
TinyTroupe: إطار عمل مفتوح المصدر من مايكروسوفت لمحاكاة أدوار متعددة الوكلاء مدفوعة بـ LLM: TinyTroupe هي مكتبة Python تجريبية تستخدم نماذج اللغة الكبيرة (LLM، وخاصة GPT-4) لمحاكاة شخصيات (TinyPerson) ذات سمات شخصية واهتمامات وأهداف محددة، والتفاعل في بيئة محاكاة (TinyWorld). يهدف هذا الإطار إلى تعزيز الخيال وتقديم رؤى تجارية من خلال المحاكاة، ويمكن تطبيقه في سيناريوهات مثل تقييم الإعلانات، واختبار البرمجيات، وإنشاء بيانات اصطناعية، وجمع ملاحظات حول المنتجات، والعصف الذهني. يمكن للمستخدمين تحديد الوكلاء والبيئات من خلال ملفات Python و JSON، لإجراء تجارب محاكاة برمجية وتحليلية ومتعددة الوكلاء (المصدر: GitHub Trending)

FLUX Kontext يحقق اختراقًا جديدًا في مرجعية الصور المتعددة وتحرير الصور: أفاد المستخدمون بأن FLUX Kontext يُظهر أداءً متميزًا في مرجعية الصور المتعددة، ويمكن تمكين هذه الميزة من خلال عقدة ربط الصور في ComfyUI. تتيح هذه الأداة تحرير صور متسق للغاية، على سبيل المثال، عند إنشاء صور عرض لعلب الهدايا، يمكنها استعادة التفاصيل مثل المواد والغبار بشكل جيد. بالإضافة إلى ذلك، عرض المستخدمون استخدام FLUX Kontext لإجراء عمليات تعديل صور مثل التنحيف وتصغير الوجه وزيادة العضلات بنقرة واحدة، مع تأثيرات طبيعية وتشابه عالٍ في ملامح الوجه، مما يوفر الراحة لسيناريوهات مثل التجارة الإلكترونية (المصدر: op7418, op7418, op7418)

Ichi: ذكاء اصطناعي محادثة على الجهاز يعتمد على MLX Swift و MLX audio: طور Rudrank Riyam مشروع Ichi، وهو مشروع ذكاء اصطناعي محادثة على الجهاز يستخدم MLX Swift و MLX audio. هذا يعني أن معالجة المحادثة يمكن أن تتم محليًا على الجهاز، مما يساعد على حماية خصوصية المستخدم وتقليل الاعتماد على الخدمات السحابية. تم فتح مصدر كود المشروع على GitHub (المصدر: stablequan, awnihannun)
FedRAG يقدم NoEncode RAG و MCP كجوهر تجريدي: قدم مشروع FedRAG تجريدًا أساسيًا جديدًا – NoEncode RAG مع MCP. يتضمن RAG التقليدي مُسترجعًا ومُولدًا وقاعدة معرفية، حيث تحتاج المعرفة في قاعدة المعرفة إلى ترميز بواسطة نموذج المُسترجع. أما NoEncode RAG فيتخطى خطوة الترميز تمامًا، ويتكون مباشرة من قاعدة معرفية NoEncode ومُولد، دون الحاجة إلى مُسترجع/تضمين. يمهد هذا الطريق لبناء أنظمة RAG تستخدم خوادم MCP (Model Component Provider) كمصدر للمعرفة، حيث يمكن للمستخدمين الاتصال بمصادر MCP متعددة من جهات خارجية، ومن خلال FedRAG، يمكن ضبط RAG للحصول على أفضل أداء (المصدر: nerdai)

📚 موارد تعليمية
إطلاق دورة CS224n (إصدار 2024) من جامعة ستانفورد، مع إضافة محتوى جديد حول LLM والوكلاء: أصدرت جامعة ستانفورد نسختها الأحدث لعام 2024 من دورتها الكلاسيكية في معالجة اللغات الطبيعية CS224n. يغطي محتوى الدورة الجديد موضوعات متقدمة متعلقة بنماذج اللغة الكبيرة (LLM) مثل التدريب المسبق، والتدريب اللاحق، والاختبارات المعيارية، والاستدلال، والوكلاء. تم نشر مقاطع فيديو الدورة على YouTube، مع توفير تجربة دورة متزامنة مدفوعة (المصدر: stanfordnlp)
دليل لتعزيز قدرات هندسة النظم: الممارسة والتعلم في عصر الذكاء الاصطناعي: شارك Dotey طرقًا مفصلة لتعزيز القدرات الشخصية في هندسة النظم في ظل تزايد قوة البرمجة بمساعدة الذكاء الاصطناعي. يؤكد المقال على أن تصميم النظم هو عملية تفكيك النظم المعقدة إلى وحدات صغيرة سهلة التنفيذ والصيانة، وتحديد التعاون بين الوحدات بوضوح. تشمل طرق التعزيز “المشاهدة المتعددة” (دراسة الحالات الكلاسيكية، المشاريع مفتوحة المصدر)، “الممارسة المتعددة” (استعادة البنية، التعلم بالمقارنة، التصميم أولاً، التحقق بمساعدة الذكاء الاصطناعي، إعادة الهيكلة، المشاريع الجانبية العملية)، و “المراجعة المتعددة” (تلخيص أسس اتخاذ القرار، الدروس المستفادة). يمكن استخدام الذكاء الاصطناعي كأداة مساعدة للبحث عن المعلومات، والتحقق من التصميم، والمساعدة في التواصل واتخاذ القرار، ولكنه لا يمكن أن يحل محل الممارسة والتفكير (المصدر: dotey)

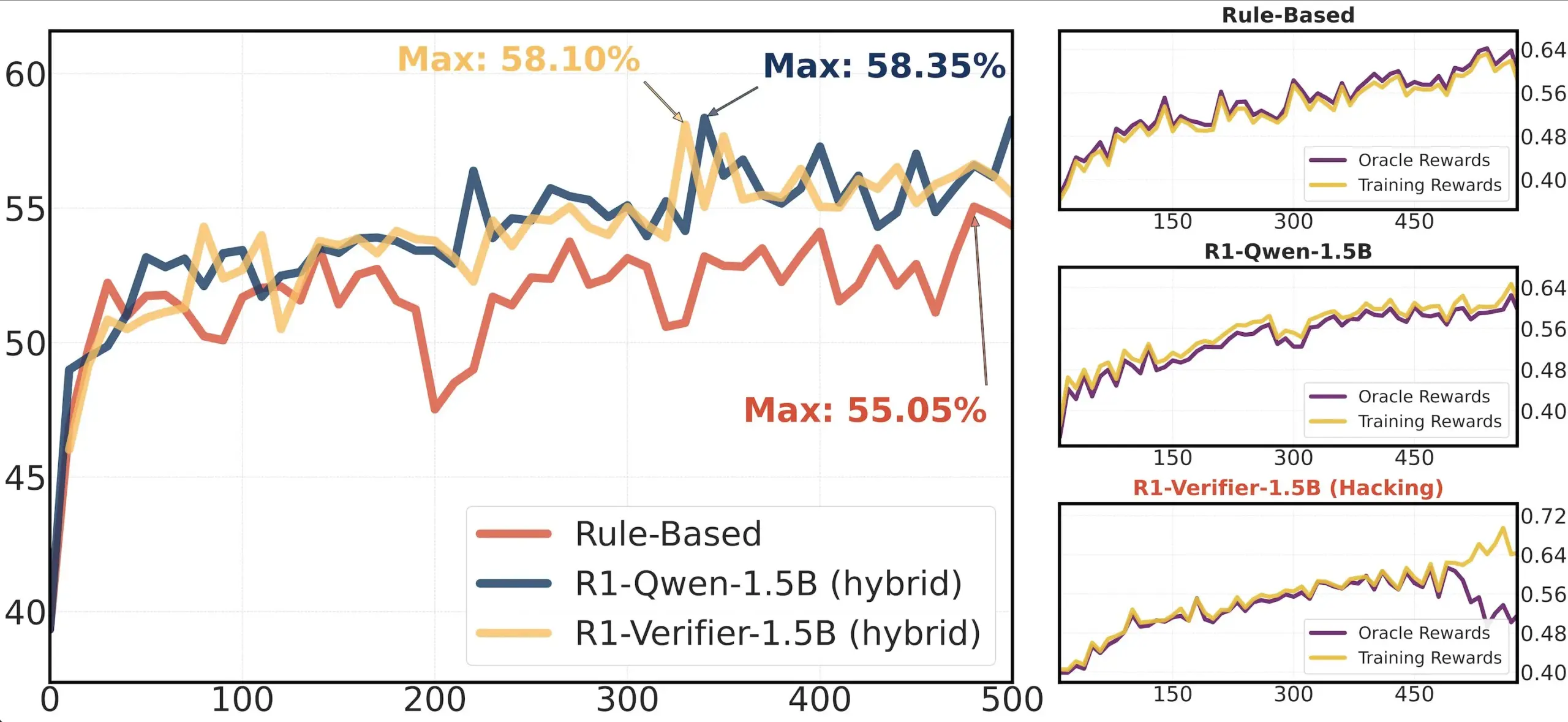
مشاركة ورقة بحثية: دراسة موثوقية المُحقِّق في RLHF: تناقش ورقة بحثية بعنوان “Pitfalls of Rule- and Model-based Verifiers” عيوب المُحقِّقات القائمة على القواعد والقائمة على النماذج في التحقق من التعلم المعزز (RLVR). وجدت الدراسة أن المُحقِّقات القائمة على القواعد غالبًا ما تكون غير موثوقة حتى في مجال الرياضيات، وغير متوفرة في العديد من المجالات؛ بينما المُحقِّقات القائمة على النماذج سهلة الاختراق، على سبيل المثال من خلال بناء أنماط معادية بسيطة. ومن المثير للاهتمام، مع تحول المجتمع نحو المُحقِّقات التوليدية، وجدت الدراسة أنها أكثر عرضة للتلاعب بالمكافآت (reward hacking) من المُحقِّقات التمييزية، مما يشير إلى أن المُحقِّقات التمييزية قد تكون أكثر قوة في RLVR (المصدر: Francis_YAO_)
توصية بورقة بحثية: نظرية التذبذب المتساوي لأفضل تقريب متعدد الحدود: يقدم مقال نظرية التذبذب المتساوي لأفضل تقريب متعدد الحدود، ومشكلة التفاضل اللانهائي المعيار المرتبطة بها. هذه النظرية هي نتيجة كلاسيكية في نظرية تقريب الدوال، ولها أهمية كبيرة في فهم وتصميم الخوارزميات العددية (المصدر: eliebakouch)
Reasoning Gym: بيئات استدلال للتعلم المعزز ذات مكافآت يمكن التحقق منها: تقترح ورقة بحثية جديدة بعنوان “Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards” (arXiv:2505.24760) مجموعة من بيئات الاستدلال للتعلم المعزز. تتميز هذه البيئات بأن مكافآتها يمكن التحقق منها، مما يوفر منصة للبحث وتطوير وكلاء استدلال تعلم معزز أكثر موثوقية (المصدر: Ar_Douillard)

🌟 المجتمع
نقاش حول “التدريب المتوسط (Mid-training)”: أجرى مجتمع الذكاء الاصطناعي نقاشًا حول معنى وممارسة مصطلح “التدريب المتوسط (Mid-training)”. أعرب البعض عن حيرتهم، حيث يعرفون فقط التدريب المسبق والتدريب اللاحق. هناك وجهة نظر مفادها أن التدريب المتوسط قد يشير إلى مرحلة تدريب محددة تتم بين التدريب المسبق والضبط الدقيق النهائي، مثل التدريب المسبق المستمر لمعرفة مجال معين أو المواءمة المبكرة. شارك Dorialexander مقالة مدونة ذات صلة، تستكشف هذا المفهوم بشكل أكبر، معتبرًا أنه قد يتضمن حقن مهام أو قدرات محددة فوق النموذج الأساسي، ولكن لم يتم بعد تشكيل تعريف ومنهجية موحدة (المصدر: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

تحليل الهندسة العكسية لـ Claude Code يثير الاهتمام: من خلال إجراء هندسة عكسية للكود المصغر لـ Claude Code، استغرق Hrishi من 8 إلى 10 ساعات، مستخدمًا عدة وكلاء فرعيين ونماذج رائدة من كبار المزودين، ليكشف عن تعقيد هيكله الداخلي. يشير التحليل إلى أن Claude Code ليس مجرد حلقة بسيطة من نموذج Claude، بل يحتوي على آليات كثيرة تستحق التعلم. أثار هذا الاكتشاف نقاشًا في المجتمع، حيث رأى البعض أنه يمكن تعلم الكثير من الخبرات حول بناء الوكلاء وتطبيقات النماذج منه (المصدر: rishdotblog, imjaredz, hrishioa)
مناقشة حول طول موجهات النظام وأداء النموذج: ناقش المجتمع تأثير طول موجهات النظام على أداء LLM. يرى Dotey أن موجهات النظام الطويلة جدًا ليست جيدة دائمًا، وقد تخفف من انتباه النموذج، وتزيد التكاليف، ويشير إلى أن موجهات النظام لمنتجات سلسلة ChatGPT قصيرة نسبيًا ولكنها فعالة. بينما ذكر Tony出海号 أن موجهات النظام لمنتجات مثل Claude و Cursor تصل إلى عشرات الآلاف من الكلمات، مما يشير إلى ضرورة توسيع أنظمة الموجهات. كشفت مقالة YC أيضًا أن شركات الذكاء الاصطناعي الكبرى تستخدم موجهات طويلة، و XML، وموجهات وصفية (meta-prompts) وغيرها من الطرق “لترويض” LLM. بينما أعرب Dorialexander عن شكوكه بشأن قوة طرق الموجهات الطويلة المذكورة في مقالة YC في تدريب RL/الاستدلال، وركز على كيفية التخفيف من مشكلة “التملق” (sycophancy) (المصدر: dotey, Dorialexander)

مشكلة قابلية التوسع لـ Softpick تثير الإشادة بشفافية البحث العلمي: صرح الباحث Zed علنًا بأن طريقة Softpick التي طورها سابقًا، عند توسيعها إلى نماذج أكبر (1.8 مليار معلمة)، أظهرت خسارة تدريب ونتائج اختبارات معيارية أسوأ من Softmax، وقام بتحديث النسخة الأولية على arXiv. أشاد المجتمع بشدة بهذا السلوك الشفاف في مشاركة النتائج السلبية، معتبرين أن ذلك أمر بالغ الأهمية لتقدم البحث العلمي، واعتبروه من صفات الزملاء الباحثين المتميزين (المصدر: gabriberton, vikhyatk, BlancheMinerva)
مستخدمون يشاركون اختياراتهم وخبراتهم في تشغيل LLM محليًا: ناقش مستخدمو مجتمع Reddit r/LocalLLaMA بحماس نماذج اللغة الكبيرة المحلية التي يستخدمونها حاليًا. تم ذكر نماذج مثل Qwen 3 (خاصة 32B Q4، 32B Q8، 30B A3B)، و Gemma 3 (خاصة 27B QAT Q8، 12B)، و Devstral وغيرها على نطاق واسع لأدائها في مجالات مثل البرمجة، والإبداع، والاستدلال العام. يهتم المستخدمون بطول سياق النماذج، وسرعة الاستدلال، والإصدارات الكمومية (مثل IQ1_S_R4)، وتشغيلها على أجهزة مختلفة (مثل 8GB VRAM، هواتف بشريحة Snapdragon 8 Elite). كما تم استخدام نماذج مغلقة المصدر مثل Claude Code و Gemini API في نفس الوقت لمزاياها المحددة (مثل معالجة السياق الطويل، وقدرات البرمجة) (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 أخرى
تنمية المهارات في عصر الذكاء الاصطناعي: طرح الأسئلة والتفكير النقدي والتعلم المستمر هي المفتاح: يؤكد النقاش على أن ست مهارات حاسمة في عصر الذكاء الاصطناعي: القدرة على طرح الأسئلة، والتفكير النقدي، والحفاظ على نمط التعلم، والقدرة على البرمجة أو إعطاء التعليمات، والاستخدام الماهر لأدوات الذكاء الاصطناعي، والتواصل الواضح. حتى أن شركة Zapier تطلب من 100% من الموظفين الجدد إتقان الذكاء الاصطناعي، وهو ما يُفسر على أنه تأكيد بشكل أساسي على احتياجات التواصل والقدرة على تفويض المهام بشكل صحيح، وليس مجرد المعرفة التقنية البحتة. يجعل الذكاء الاصطناعي التنفيذ أسهل، وبالتالي فإن جودة التصميم والتفكير لها تأثير أكبر على النتيجة النهائية (المصدر: TheTuringPost, zacharynado)

أخلاقيات الذكاء الاصطناعي وتأثيره الاجتماعي: مخاوف وتمكين متلازمان: أعرب الممثل ستيف كاريل عن قلقه بشأن المجتمع المستقبلي الذي يصوره فيلمه الجديد “Mountainhead”، معتبرًا أن هذا قد يكون المجتمع الذي سنعيش فيه قريبًا، مما يشير إلى مخاوف بشأن التأثيرات السلبية المحتملة للذكاء الاصطناعي. من ناحية أخرى، هناك وجهة نظر مفادها أن الذكاء الاصطناعي لن يؤدي بالضرورة إلى انقسام حاد بين “الفلاحين والملوك”، بل قد يعمل على تمكين الأفراد، وتقليص الفجوة في القدرات بين الأفراد والشركات الكبرى، وتعزيز الإنتاجية الفردية والإبداع والتأثير. ومع ذلك، فيما يتعلق بآفاق دمقرطة الذكاء الاصطناعي، هناك أيضًا من يتخذ موقفًا حذرًا، معتقدًا أن الشركات الكبرى ستظل تسيطر من خلال التحكم في تدريب النماذج ونشرها (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

منصة تجميع معلومات التوظيف المدفوعة بالذكاء الاصطناعي Hiring Cafe: استخدم Hamed N. واجهة برمجة تطبيقات ChatGPT لجمع 4.1 مليون إعلان وظائف منشورة مباشرة على مواقع الشركات، وأنشأ موقع Hiring Cafe. تهدف هذه المنصة إلى حل مشكلة “الوظائف الوهمية” ووسطاء الطرف الثالث المنتشرة على منصات مثل LinkedIn و Indeed، من خلال مرشحات قوية (مثل المسمى الوظيفي، والوظيفة، والصناعة، وسنوات الخبرة، والأدوار الإدارية/الفردية، إلخ) لمساعدة الباحثين عن عمل على تصفية الوظائف بشكل أكثر فعالية. هذا مشروع جانبي غير تجاري لطالب دكتوراه، وقد حظي بإشادة واستخدام من المجتمع (المصدر: Reddit r/ChatGPT)
