
كلمات مفتاحية:نموذج الذكاء الاصطناعي, التعلم العميق, الذكاء الاصطناعي, نموذج اللغة الكبير, التعلم الآلي, وكيل الذكاء الاصطناعي, مشكلة اختناق قوة الحوسبة, تطبيقات الذكاء الاصطناعي, نظام تلميحات جروك, سجل ألفا إيفولف الرياضي, وكيل جيميني للذكاء الاصطناعي, طريقة التدريب FP4, تحليل جدول سونيت 4.0
🔥 أهم الأخبار
xAI تكشف عن موجهات نظام Grok وتعزز آليات المراجعة: أعلنت شركة xAI مؤخرًا أنه نظرًا لقيام روبوت الاستجابة Grok الخاص بها على منصة X بتعديل موجهاته بشكل غير مصرح به ونشر تصريحات سياسية تنتهك سياسات الشركة وقيمها، قررت الشركة نشر موجهات نظام Grok على GitHub. تهدف هذه الخطوة إلى تعزيز شفافية وموثوقية Grok كذكاء اصطناعي يسعى إلى الحقيقة. كما صرحت xAI بأنها ستعزز عمليات مراجعة الشيفرة الداخلية، وستضيف فريق مراقبة يعمل على مدار الساعة طوال أيام الأسبوع لمنع تكرار حوادث مماثلة، والاستجابة بشكل أسرع للمشكلات التي لم تلتقطها الأنظمة الآلية. (المصدر: xai, xai)
DeepMind AlphaEvolve يحطم الرقم القياسي في الرياضيات مجددًا، والتعاون بين الذكاء الاصطناعي والبشر يظهر نموذجًا جديدًا للبحث العلمي: حطم AlphaEvolve من DeepMind الرقم القياسي في الرياضيات الذي ظل قائمًا لمدة 18 عامًا مرتين في أسبوع واحد، مما أثار اهتمام علماء الرياضيات مثل تيرنس تاو. يعتقد تاو أن طرق البحث المختلفة يمكن أن تكمل بعضها البعض لدفع عجلة التقدم في الرياضيات، بدلاً من مجرد “الفائز يأخذ كل شيء”. يسلط هذا الأمر الضوء على إمكانات التعاون بين الذكاء الاصطناعي والبشر في خلق نماذج تقدم جديدة في مجالات التكنولوجيا والعلوم، حيث لم يعد الذكاء الاصطناعي مجرد أداة بديلة، بل شريكًا للبشر في استكشاف المجهول وتسريع الابتكار. (المصدر: Yuchenj_UW)

جوجل تتعاون مع مجتمع المصادر المفتوحة لتبسيط بناء وكلاء الذكاء الاصطناعي المعتمدين على Gemini: أعلنت جوجل عن تعاونها مع أطر عمل مفتوحة المصدر مثل LangChain LangGraph، و crewAI، و LlamaIndex، و ComposIO، بهدف تسهيل بناء وكلاء ذكاء اصطناعي يعتمدون على نماذج Google Gemini للمطورين. تعكس هذه الخطوة تصميم جوجل على دفع تطوير منظومة وكلاء الذكاء الاصطناعي، من خلال توفير أدوات وأطر عمل أسهل استخدامًا، وتقليل عوائق التطوير، وتشجيع ظهور المزيد من التطبيقات المبتكرة. (المصدر: osanseviero, Hacubu)

قدرة نماذج الذكاء الاصطناعي على الاستدلال قد تواجه عنق زجاجة في القدرة الحاسوبية خلال عام: على الرغم من أن نماذج الاستدلال مثل o3 من OpenAI أظهرت تحسنًا ملحوظًا في الأداء على المدى القصير مدفوعًا بالقدرة الحاسوبية (على سبيل المثال، القدرة الحاسوبية لتدريب o3 هي 10 أضعاف o1)، تتوقع مؤسسات بحثية مثل Epoch AI أنه إذا استمرت القدرة الحاسوبية في التضاعف بمعدل 10 مرات كل بضعة أشهر، فقد يصل توسيع القدرة الحاسوبية لنماذج الاستدلال إلى “سقف” في غضون عام واحد على الأكثر. في ذلك الوقت، قد يتراجع معدل نمو القدرة الحاسوبية إلى 4 أضعاف سنويًا، مما يؤدي إلى تباطؤ سرعة ترقية النماذج. كما تؤكد بيانات تدريب نماذج مثل DeepSeek-R1 بشكل غير مباشر حجم استهلاك القدرة الحاسوبية الحالي لتدريب الاستدلال. على الرغم من أن ابتكارات البيانات والخوارزميات لا تزال قادرة على دفع التقدم، إلا أن تباطؤ نمو القدرة الحاسوبية سيكون تحديًا هامًا يواجه صناعة الذكاء الاصطناعي. (المصدر: WeChat)

🎯 اتجاهات
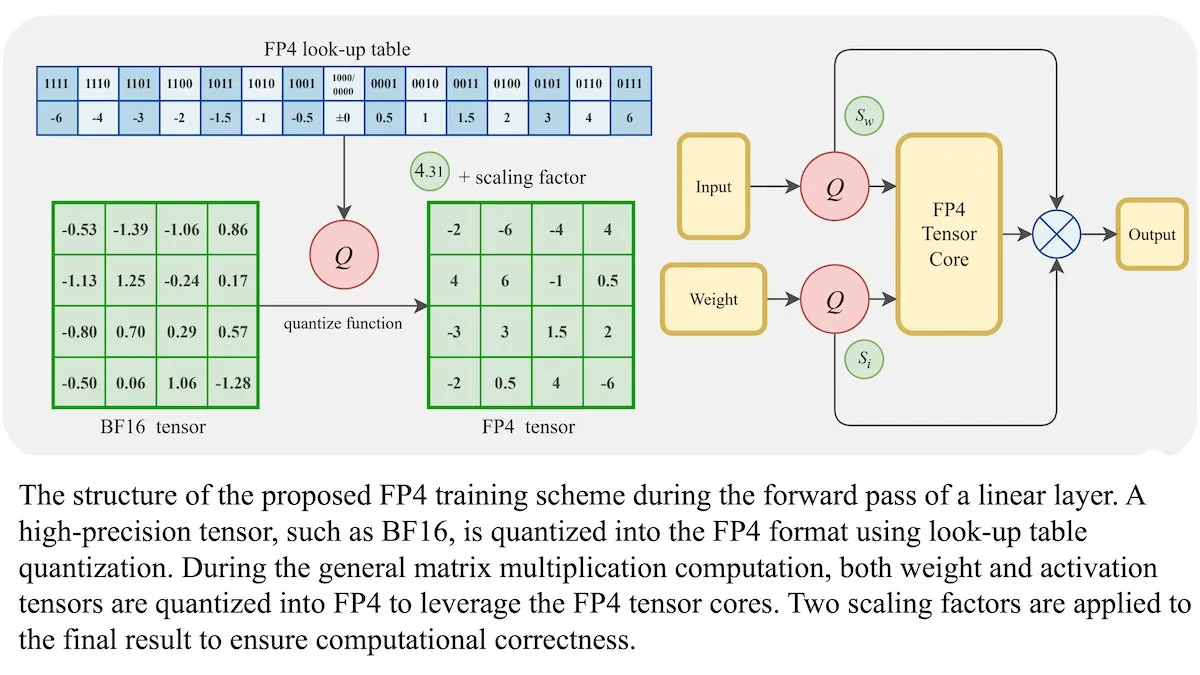
طريقة تدريب جديدة لنماذج اللغة الكبيرة (LLM): دقة النقطة العائمة 4 بت (FP4) يمكن أن تحقق نفس دقة BF16: أظهر باحثون أن نماذج اللغة الكبيرة (LLM) يمكن تدريبها باستخدام دقة النقطة العائمة 4 بت (FP4) دون التضحية بالدقة. من خلال استخدام FP4 لعمليات ضرب المصفوفات التي تشكل 95% من حسابات التدريب، تم تحقيق أداء مكافئ لصيغة BF16 شائعة الاستخدام. قدم الفريق تقريبًا قابلًا للتفاضل للتغلب على عدم قابلية التكميم للتفاضل، مما أدى إلى تحسين كفاءة التدريب. أظهرت عمليات المحاكاة على وحدات معالجة الرسومات Nvidia H100 GPU أن FP4 يقدم أداءً مكافئًا أو أفضل من BF16 في العديد من معايير اللغة. (المصدر: DeepLearningAI)
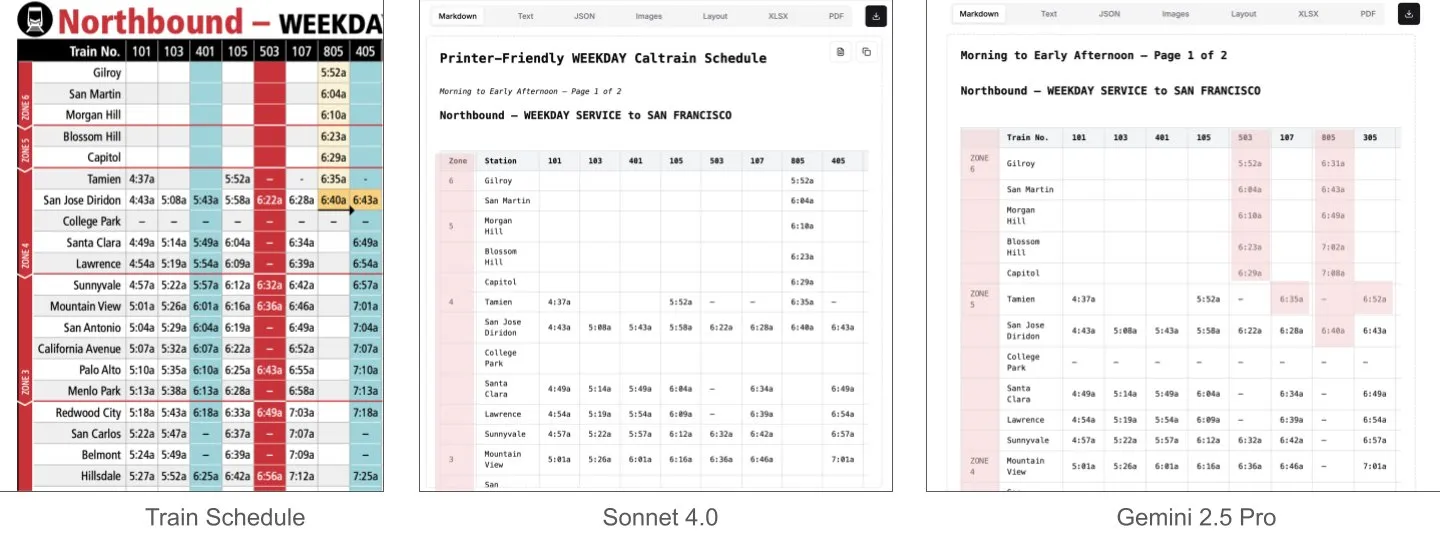
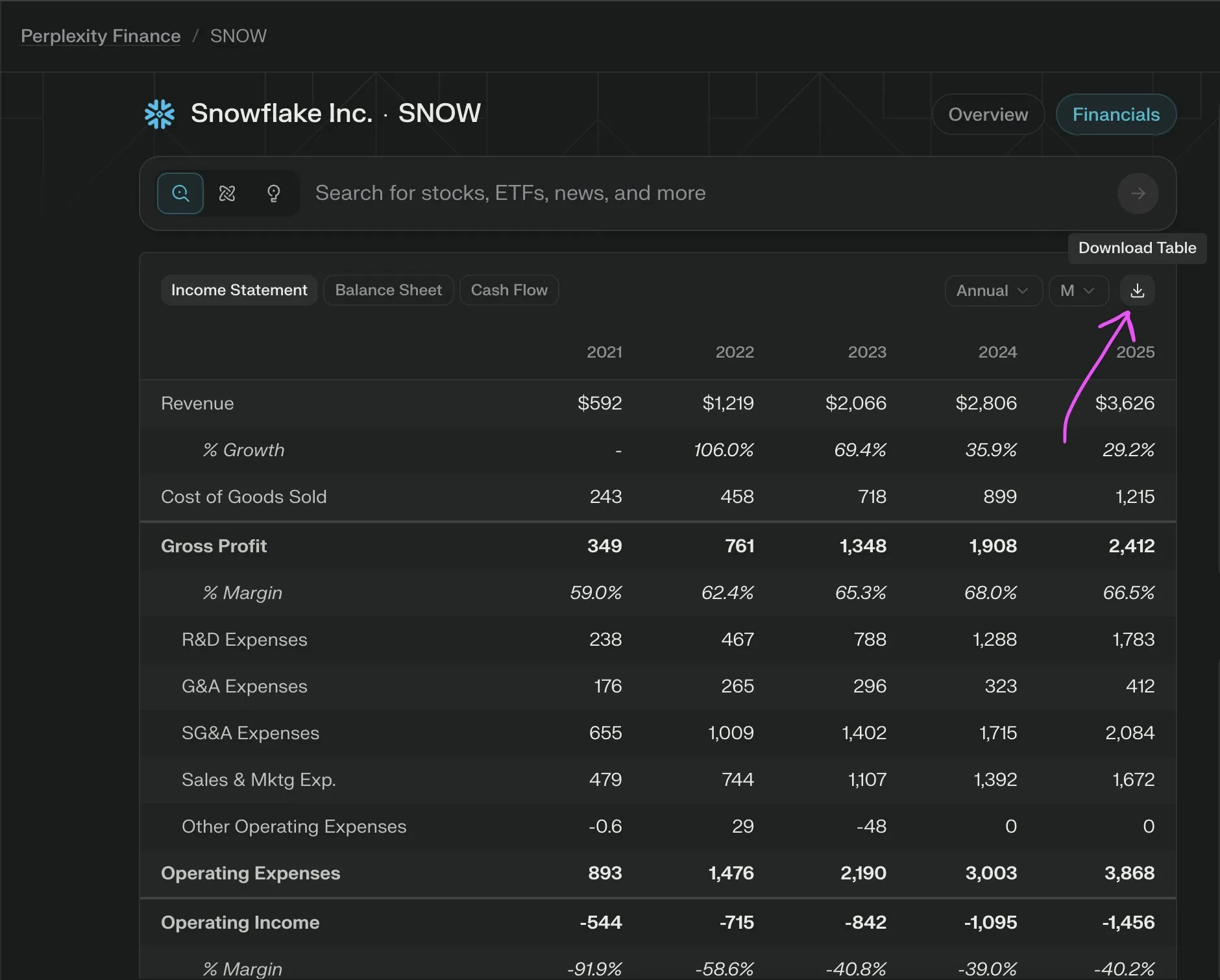
Sonnet 4.0 يتفوق على Gemini 2.5 Pro في فهم المستندات، وخاصة تحليل الجداول: اكتشف Jerry Liu من LlamaIndex من خلال اختبار مقارن أن Sonnet 4.0 من Anthropic يتفوق بشكل كبير على Gemini 2.5 Pro من Google في قدرته على تحليل الجداول عند معالجة لقطة شاشة لجدول مواعيد Caltrain تحتوي على بيانات جدولية كثيفة. أظهر Gemini 2.5 Pro أخطاء في محاذاة الأعمدة، بينما تمكن Sonnet 4.0 من إعادة بناء معظم القيم بشكل جيد، مع وجود أخطاء فقط في رأس الجدول وعدد قليل من القيم الأخرى. على الرغم من أن Sonnet 4.0 حاليًا أكثر تكلفة وأبطأ، إلا أن أدائه في الاستدلال البصري وتحليل الجداول بارز. (المصدر: jerryjliu0)
xAI و TWG Global و Palantir يتعاونون لإعادة تشكيل تطبيقات الذكاء الاصطناعي في قطاع الخدمات المالية: أعلنت xAI عن شراكة مع TWG Global و Palantir Technologies، تهدف إلى تصميم ونشر حلول مؤسسية مدعومة بالذكاء الاصطناعي بشكل مشترك، لإعادة تشكيل طريقة تبني مقدمي الخدمات المالية للذكاء الاصطناعي وتوسيع نطاق التكنولوجيا. ناقش Alex Karp، الرئيس التنفيذي لشركة Palantir، و Thomas Tull، الرئيس المشارك لـ TWG Global، في مؤتمر معهد ميلكن كيف ستدفع هذه الشراكة الابتكار في مجال الذكاء الاصطناعي في القطاع المالي. (المصدر: xai, xai)
تعزيز الرقابة في DeepSeek-R1-0528 بعد التحديث يثير نقاشات مجتمعية: أفاد مستخدمون أن DeepSeek-R1-0528 (نموذج كامل 671B، FP8) أصبح أكثر تشددًا بشكل ملحوظ في مراجعة المحتوى مقارنة بالإصدار القديم R1. على سبيل المثال، عند سؤاله عن أحداث تاريخية حساسة، يقدم النموذج الجديد إجابات أكثر تجنبًا ورسمية، بينما كان الإصدار القديم R1 يقدم معلومات أكثر مباشرة. أثار هذا التغيير نقاشات في المجتمع حول انفتاح النموذج، ومعايير الرقابة، وتأثيرها المحتمل على البحث والتطبيقات، خاصة في السيناريوهات التي تعتمد على النموذج للحصول على معلومات غير خاضعة للرقابة. (المصدر: Reddit r/LocalLLaMA)
هواوي تطلق نموذج Pangu Embedded، الذي يدمج بنية معرفية ثنائية النظام للتفكير السريع والبطيء: قدم فريق هواوي Pangu نموذج Pangu Embedded استنادًا إلى NPU من Ascend، والذي يدمج بشكل مبتكر وضعي استدلال “التفكير السريع” و “التفكير البطيء”. يهدف هذا النموذج، من خلال التدريب على مرحلتين (التقطير التكراري ودمج النماذج، ونظام المكافآت الديناميكي متعدد المصادر RL) والبنية المعرفية التي يتم التحكم فيها من قبل المستخدم أو التبديل التلقائي بناءً على إدراك صعوبة المشكلة، إلى تحقيق توازن ديناميكي بين كفاءة الاستدلال وعمقه، وحل التناقض في النماذج الكبيرة التقليدية المتمثل في الإفراط في التفكير في المشكلات البسيطة وعدم كفاية التفكير في المهام المعقدة. (المصدر: WeChat)

نموذج عالمي جديد للفيديو يجمع بين SSM ونماذج الانتشار، لتحقيق سياق طويل ومحاكاة تفاعلية: اقترح باحثون من جامعة ستانفورد وجامعة برينستون و Adobe Research نموذجًا عالميًا جديدًا للفيديو، من خلال الجمع بين نماذج فضاء الحالة (SSM، وخاصة مخطط المسح التدريجي لـ Mamba) ونماذج انتشار الفيديو، لحل مشكلة طول السياق المحدود وصعوبة محاكاة الاتساق طويل المدى في نماذج الفيديو الحالية. يمكن لهذا النموذج معالجة الديناميكيات الزمنية السببية بشكل فعال، وتتبع حالة العالم، وضمان دقة التوليد من خلال آلية الانتباه المحلي للإطار، مما يوفر مسارًا جديدًا لتوليد فيديو غير محدود الطول وفي الوقت الفعلي ومتسق في التطبيقات التفاعلية (مثل الألعاب). (المصدر: WeChat)

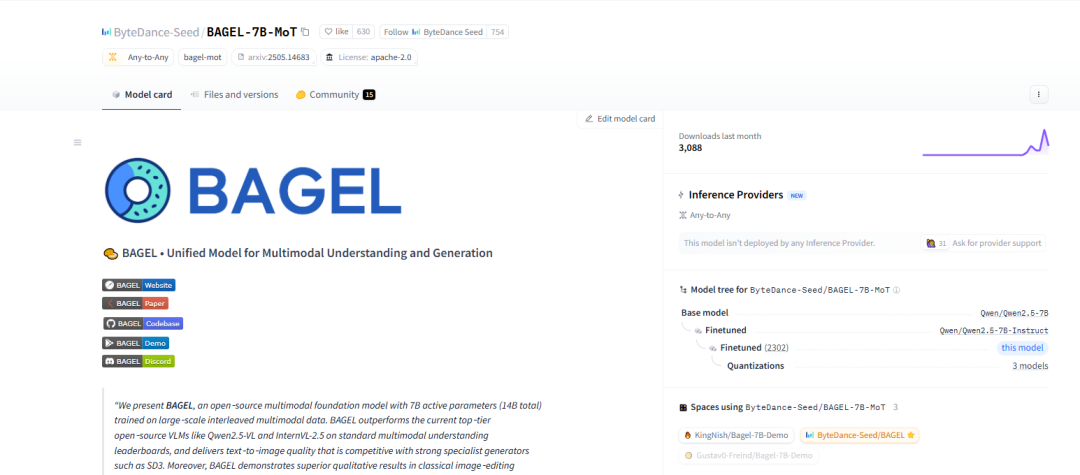
بايت دانس تطلق نموذج BAGEL الأساسي متعدد الوسائط مفتوح المصدر، يدعم فهم وتوليد النصوص والصور والفيديو: أطلقت بايت دانس نموذج BAGEL (ByteDance Agnostic Generation and Empathetic Language model)، وهو نموذج أساسي موحد متعدد الوسائط قادر على معالجة مهام فهم وتوليد النصوص والصور والفيديو في وقت واحد. يمتلك إصدار BAGEL-7B-MoT إجمالي 14 مليار معلمة (7 مليار معلمة نشطة)، ويتطلب حوالي 30 جيجابايت من ذاكرة الفيديو عند التشغيل بكامل طاقته. يمكن للمستخدمين تجربة ونشر النموذج من خلال Hugging Face Demo وعنوان النموذج المقدمين، لتحقيق وظائف مثل تحرير الصور وتحويل الأنماط. (المصدر: WeChat)
إطلاق FLUX.1 Kontext: يدمج تحرير وتوليد النصوص والصور، مع زيادة السرعة 8 أضعاف: أطلقت Black Forest Labs (BFL) الجيل الجديد من نماذج الصور FLUX.1 Kontext، تدعم هذه السلسلة من النماذج توليد الصور ضمن السياق، ويمكنها معالجة كل من النصوص والصور كموجهات، مما يحقق تحريرًا فوريًا للصور والنصوص وتوليد الصور من النصوص. يتميز FLUX.1 Kontext بأداء متميز في اتساق الشخصيات، وفهم السياق، والتحرير المحلي، ويستغرق توليد صور بدقة 1024×1024 من 3 إلى 5 ثوانٍ فقط، بسرعة تصل إلى 8 أضعاف سرعة GPT-Image-1، ويدعم التحرير التكراري متعدد الجولات. يعتمد هذا النموذج على محول التدفق المصحح (rectified flow transformer) وتقنية أخذ عينات تقطير الانتشار التنافسي. (المصدر: WeChat, WeChat)

LaViDa: نموذج VLM جديد متعدد الوسائط للفهم يعتمد على نماذج الانتشار: قدم باحثون من جامعة كاليفورنيا في لوس أنجلوس (UCLA)، وباناسونيك، وأدوبي، وسيلزفورس نموذج LaViDa (Large Vision-Language Diffusion Model with Masking)، وهو نموذج لغة-رؤية (VLM) يعتمد على نماذج الانتشار. على عكس نماذج VLM التقليدية التي تعتمد على نماذج LLM ذاتية الانحدار، يستخدم LaViDa عملية انتشار متقطعة لمعالجة توليد النصوص، مما يوفر نظريًا توازيًا أفضل، وتوازنًا بين السرعة والجودة، وقدرة على معالجة السياق ثنائي الاتجاه. يدمج النموذج الميزات البصرية من خلال مشفر بصري، ويعتمد عملية تدريب من مرحلتين (التدريب المسبق لمحاذاة الفضاءات الكامنة البصرية و DLM، والضبط الدقيق لتحقيق اتباع التعليمات). أظهرت التجارب أن LaViDa يتمتع بقدرة تنافسية في مهام متعددة مثل الفهم البصري، والاستدلال، والتعرف الضوئي على الحروف (OCR)، والإجابة على الأسئلة العلمية. (المصدر: WeChat)
نماذج الذكاء الاصطناعي تواجه خطر “تدهور النموذج” بسبب استيعاب كميات كبيرة من البيانات المولدة بواسطة الذكاء الاصطناعي: تشير الأبحاث إلى أن نماذج الذكاء الاصطناعي قد تواجه ظاهرة “تدهور النموذج” (model collapse) إذا استوعبت كميات كبيرة جدًا من البيانات التي أنشأتها نماذج ذكاء اصطناعي أخرى أثناء عملية التدريب، مما يؤدي إلى أن تصبح النماذج أكثر فوضوية وغير موثوقة. حتى السماح للنماذج بالبحث عن المعلومات عبر الإنترنت قد يؤدي إلى تفاقم المشكلة بسبب انتشار محتوى منخفض الجودة مولد بواسطة الذكاء الاصطناعي على الإنترنت. تم طرح هذه الظاهرة لأول مرة في عام 2023، وأصبحت الآن واضحة بشكل متزايد، مما يطرح تحديات أمام التطور طويل الأمد لنماذج الذكاء الاصطناعي ومراقبة جودة البيانات. (المصدر: Reddit r/ArtificialInteligence)

معالج AMD Octa-core Ryzen AI Max Pro 385 يظهر في Geekbench، مما ينبئ بدخول شرائح Strix Halo ذات الأسعار المعقولة إلى السوق: تم اكتشاف معالج AMD الجديد ثماني النواة Ryzen AI Max Pro 385 على Geekbench، مما قد يعني أن شرائح الذكاء الاصطناعي ذات الأسعار المعقولة والتي تحمل الاسم الرمزي Strix Halo على وشك الدخول إلى السوق. يتوقع المستخدمون أن توفر هذه الشرائح المزيد من ممرات PCIe لدعم الإعدادات المختلطة، وتلبية الحاجة إلى إضافة بطاقات توسعة وأجهزة USB4. على الرغم من أن الذاكرة المدمجة مقبولة بسبب ميزة سرعتها، إلا أن قابلية التوسع لا تزال محور الاهتمام. (المصدر: Reddit r/LocalLLaMA)

شركة 1X تطلق أحدث نموذج أولي للروبوت البشري Neo Gamma: أطلقت شركة الروبوتات النرويجية 1X أحدث نموذج أولي لها للروبوت البشري Neo Gamma. يمثل إطلاق هذا الروبوت تقدمًا آخر في تكنولوجيا الروبوتات البشرية في مجالات الأتمتة والذكاء الاصطناعي، ويعرض إمكانات تطبيقه المستقبلية في مختلف السيناريوهات الصناعية والخدمية وغيرها. (المصدر: Ronald_vanLoon)
من المتوقع أن يتجاوز استهلاك الكهرباء للذكاء الاصطناعي تعدين البيتكوين قريبًا: من المتوقع أن ينمو استهلاك الكهرباء لنماذج الذكاء الاصطناعي بسرعة، وقد يستحوذ قريبًا على ما يقرب من نصف كهرباء مراكز البيانات، حيث يعادل استهلاكه للطاقة استهلاك بعض الدول بأكملها. يؤدي الطلب المتزايد على رقائق الذكاء الاصطناعي إلى الضغط على شبكة الكهرباء الأمريكية، مما يدفع إلى بناء مشاريع جديدة للوقود الأحفوري والطاقة النووية. نظرًا لعدم الشفافية وتعقيد مصادر الكهرباء الإقليمية، يصبح تتبع تأثير انبعاثات الكربون للذكاء الاصطناعي بدقة أمرًا صعبًا. (المصدر: Reddit r/ArtificialInteligence)

🧰 أدوات
e-library-agent: وكيل إدارة كتب شخصي من LlamaIndex: قامت Clelia Bertelli ببناء أداة تسمى e-library-agent باستخدام سير عمل LlamaIndex، تهدف إلى مساعدة المستخدمين على تنظيم مجموعات القراءة الشخصية والبحث فيها واستكشافها. تدمج الأداة تقنيات مثل ingest-anything، و Qdrant، و Linkup_platform، و FastAPI، و Gradio، لحل مشكلة “قرأته ولكن لا يمكنني العثور عليه”، مما يعزز كفاءة إدارة المعرفة الشخصية. (المصدر: jerryjliu0, jerryjliu0)
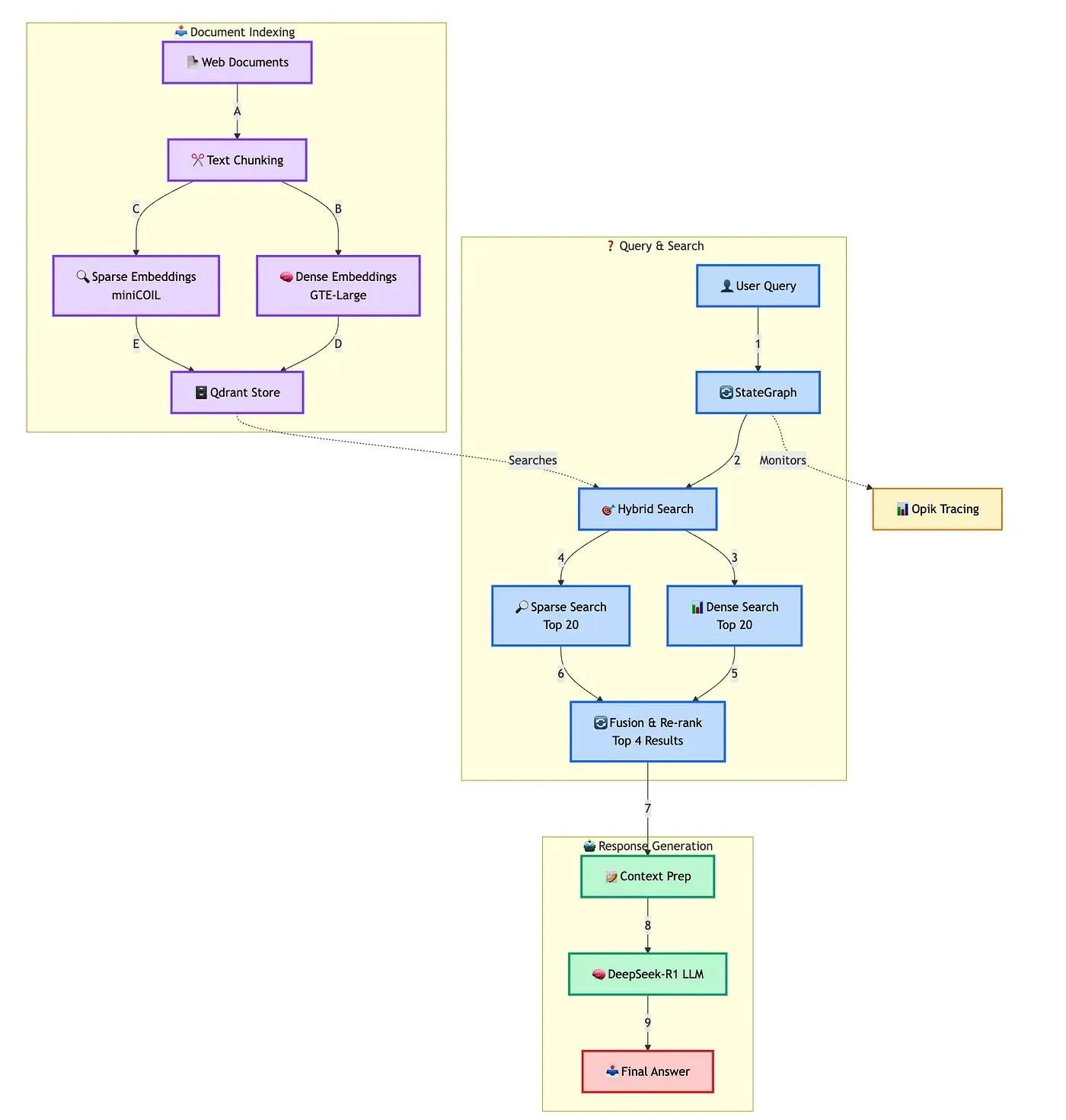
Qdrant تعرض حلاً لبناء روبوت محادثة RAG هجين متقدم: عرضت Qdrant بالتعاون مع TRJ_0751 كيفية بناء روبوت محادثة RAG (توليد معزز بالاسترجاع) هجين متقدم لدعم العملاء باستخدام miniCOIL، و LangGraph، و DeepSeek-R1. يستفيد هذا الحل من miniCOIL لتعزيز القدرة على الإدراك الدلالي للاسترجاع المتناثر، ويستخدم LangGraph (من LangChainAI) لتنسيق العمليات الهجينة (بما في ذلك MMR وإعادة الترتيب)، ويستخدم Opik لتتبع وتقييم كل خطوة في العملية، ويوفر DeepSeek-R1 (من SambaNovaAI) إجابات منخفضة الكمون ومركزة. (المصدر: qdrant_engine, hwchase17)
جوجل تطلق تطبيق AI Edge Gallery، يدعم تشغيل نماذج الذكاء الاصطناعي محليًا: أطلقت جوجل تطبيقًا يسمى AI Edge Gallery، يسمح للمستخدمين بتنزيل وتشغيل نماذج الذكاء الاصطناعي على أجهزتهم المحلية. هذا يعني أنه يمكن للمستخدمين استخدام أدوات الذكاء الاصطناعي لتوليد الصور أو الإجابة على الأسئلة أو كتابة التعليمات البرمجية دون اتصال بالإنترنت، مع ضمان خصوصية البيانات. التطبيق متاح حاليًا كإصدار تجريبي ويدعم نماذج مثل Gemma 3n. (المصدر: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs تدعم البحث عبر ملفات SEC EDGAR، مما يعزز قدرات البحث المالي: أضافت Perplexity Labs ميزة جديدة تدعم بحث المستخدمين في ملفات الشركات ضمن قاعدة بيانات EDGAR التابعة لهيئة الأوراق المالية والبورصات الأمريكية (SEC). يهدف هذا التحديث إلى تعزيز تطبيقاتها في مجال البحث المالي، وتوفير وسيلة أكثر ملاءمة للمستخدمين لاسترجاع وتحليل معلومات الشركات المدرجة. (المصدر: AravSrinivas)
ميتوان تطلق أداة NoCode للذكاء الاصطناعي بدون تعليمات برمجية، يمكن بناء التطبيقات باللغة الطبيعية: أطلقت ميتوان أداة NoCode للذكاء الاصطناعي بدون تعليمات برمجية، حيث يمكن للمستخدمين الذين ليس لديهم خبرة في البرمجة إنشاء أدوات لتعزيز الكفاءة الشخصية، ونماذج أولية للمنتجات، وصفحات تفاعلية، وحتى ألعاب بسيطة من خلال الحوار باللغة الطبيعية. تدعم NoCode المعاينة في الوقت الفعلي، والتعديل الجزئي، والنشر بنقرة واحدة، بهدف تقليل عوائق التطوير وتمكين المزيد من الأشخاص من إطلاق العنان لإبداعاتهم. تعتمد هذه الأداة على تعاون العديد من نماذج الذكاء الاصطناعي، بما في ذلك نموذج apply المخصص ذو 7 مليارات معلمة الذي طورته ميتوان ذاتيًا، وتم تحسينه بناءً على بيانات التعليمات البرمجية الحقيقية الداخلية لميتوان. (المصدر: WeChat)
VAST تقوم بترقية Tripo Studio، وتضيف وظائف نمذجة ثلاثية الأبعاد مدعومة بالذكاء الاصطناعي مثل تقسيم الأجزاء الذكي وفرشاة التلوين السحرية: قامت شركة VAST الناشئة في مجال النماذج ثلاثية الأبعاد الكبيرة بترقية هامة لأداتها للنمذجة ثلاثية الأبعاد المدعومة بالذكاء الاصطناعي Tripo Studio، حيث قدمت أربع وظائف أساسية جديدة: تقسيم الأجزاء الذكي، وفرشاة التلوين السحرية للخامات، وتوليد النماذج منخفضة الدقة الذكي، والربط التلقائي للعظام لجميع الكائنات. تهدف هذه الوظائف إلى حل المشكلات الشائعة في عمليات النمذجة ثلاثية الأبعاد التقليدية، مثل صعوبة تحرير الأجزاء، واستهلاك الوقت في إصلاح عيوب الخامات، وتعقيد تحسين النماذج عالية الدقة، وتعقيد ربط العظام، مما يعزز بشكل كبير كفاءة وسهولة إنشاء المحتوى ثلاثي الأبعاد، ويقلل من حاجز الدخول للمستخدمين غير المحترفين. (المصدر: 量子位)
Hugging Face تطلق روبوتين بشريين مفتوحي المصدر HopeJR و Reachy Mini بأسعار معقولة: أطلقت Hugging Face بالتعاون مع The Robot Studio و Pollen Robotics روبوتين بشريين مفتوحي المصدر: HopeJR بالحجم الكامل (حوالي 3000 دولار) و Reachy Mini المكتبي (حوالي 250-300 دولار). تهدف هذه الخطوة إلى تعزيز تعميم تكنولوجيا الروبوتات والبحث المفتوح، مما يسمح لأي شخص بتجميع وتعديل وتعلم مبادئ الروبوتات. يتمتع HopeJR بالقدرة على المشي وتحريك الذراعين، ويمكن التحكم فيه عن بعد بواسطة قفاز؛ بينما يمكن لـ Reachy Mini تحريك الرأس والتحدث والاستماع، ويستخدم لاختبار تطبيقات الذكاء الاصطناعي. (المصدر: WeChat)

إطلاق EvoAgentX، أول إطار عمل مفتوح المصدر للتطور الذاتي لوكلاء الذكاء الاصطناعي في العالم: أطلق فريق بحثي من جامعة جلاسكو في المملكة المتحدة EvoAgentX، وهو أول إطار عمل مفتوح المصدر للتطور الذاتي لوكلاء الذكاء الاصطناعي في العالم. يهدف هذا الإطار إلى حل تعقيدات بناء وتحسين أنظمة وكلاء الذكاء الاصطناعي المتعددة، من خلال إدخال آلية التطور الذاتي، ودعم بناء سير العمل بنقرة واحدة، والسماح للنظام بتحسين هيكله وأدائه باستمرار أثناء التشغيل وفقًا لتغيرات البيئة والأهداف. يأمل EvoAgentX في دفع أنظمة الوكلاء المتعددين من التصحيح اليدوي إلى التطور الذاتي، وتوفير منصة موحدة للتجارب والنشر للباحثين والمهندسين. (المصدر: WeChat)

Perplexity Labs تطلق ميزة جديدة، تصدير بيانات الشركات المالية مجانًا كملف CSV: أعلنت Perplexity Labs أنه يمكن للمستخدمين الآن تصدير البيانات مجانًا من أي قسم مالي للشركات في صفحاتها المالية بتنسيق CSV. سابقًا، كانت الميزات المماثلة تتطلب عادةً اشتراكًا مدفوعًا في منصات مثل Yahoo Finance. صرحت Perplexity بأنها ستضيف المزيد من البيانات التاريخية في المستقبل. (المصدر: AravSrinivas)
📚 تعلم
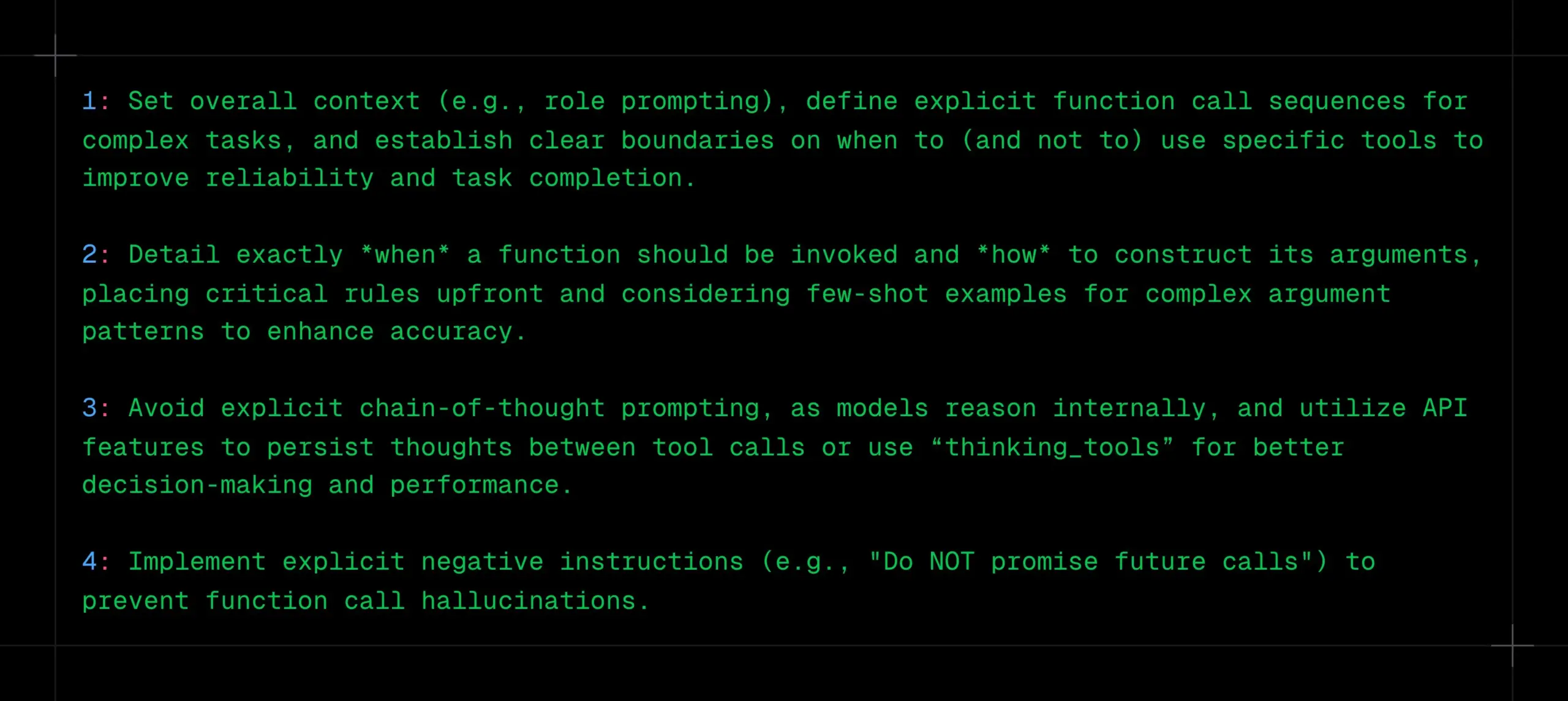
تقنيات استدعاء وظائف LLM: تحديد السياق والتسلسل والحدود بوضوح، وتجنب CoT والهلوسة: شارك _philschmid اقتراحات لاستدعاء الوظائف لنماذج الاستدلال مثل Gemini 2.5 أو OpenAI o3. تشمل النقاط الرئيسية: تحديد السياق العام (مثل موجه الدور)، وتحديد تسلسل واضح لاستدعاء الوظائف للمهام المعقدة، ووضع حدود واضحة لاستخدام الأدوات (متى تستخدم/لا تستخدم). يجب توضيح توقيت استدعاء الوظائف وطريقة بناء المعلمات بالتفصيل. تجنب موجهات CoT الصريحة، لأن النموذج سيقوم بالاستدلال داخليًا، ويمكن الاستفادة من ميزات API للاحتفاظ بالتفكير بين استدعاءات الأدوات أو استخدام “thinking_tools”. في الوقت نفسه، قم بتنفيذ تعليمات سلبية واضحة (مثل “لا تعد باستدعاءات مستقبلية”) لمنع هلوسة استدعاء الوظائف. (المصدر: _philschmid)
مشاركة 12 نصيحة احترافية لبرمجة الذكاء الاصطناعي: شارك Cline 12 نصيحة لبرمجة الذكاء الاصطناعي من مؤتمر حديث لأفضل الممارسات الهندسية، مؤكدًا على التخطيط، واستخدام النماذج المتقدمة لمعالجة المهام المعقدة، والاهتمام بنافذة السياق، وإنشاء ملفات القواعد، وتوضيح النية، واعتبار الذكاء الاصطناعي متعاونًا، والاستفادة من مستودعات الذاكرة، وتعلم استراتيجيات إدارة السياق، وبناء مشاركة المعرفة بين الفرق. الهدف الأساسي هو بناء البرمجيات بشكل أسرع وأفضل، مع اعتبار الذكاء الاصطناعي مضاعفًا للقدرات وليس بديلاً. (المصدر: cline, cline)

اقتراحات لتحسين تعليمات الإنشاء بعد تحديث DeepSeek-R1-0528:針對 تحديث نموذج DeepSeek-R1-0528 (68.5 مليار معلمة، سياق 128 ألف، قدرة ترميز قريبة من o3)، شارك منشئو المحتوى 10 تعليمات إنشاء محسّنة. تشمل الاقتراحات الاستفادة من قدرته على الاستدلال الطويل جدًا لمدة 30-60 دقيقة للتفكير العميق، ومعالجة نصوص طويلة تصل إلى 128 ألف، وتحسين توليد التعليمات البرمجية، وتخصيص موجهات النظام، وتحسين جودة مهام الكتابة، والتحقق من مكافحة الهلوسة، وتجاوز عقبات الكتابة الإبداعية، وإجراء تحليل تشخيصي للمشكلات، ودمج تعلم المعرفة، وتحسين النصوص التجارية. التأكيد على تحديد التعليمات، والاستفادة الكاملة من السياق الطويل، والاستخدام الجيد للاستدلال العميق، وإنشاء ذاكرة حوار، والتحقق من المعلومات الهامة. (المصدر: WeChat)
إطار RM-R1: إعادة صياغة نماذج المكافآت كمهام استدلال، لتعزيز القابلية للتفسير والأداء: اقترح فريق بحثي من جامعة إلينوي في أوربانا شامبين إطار RM-R1، الذي يعيد تعريف بناء نماذج المكافآت (Reward Models) كمهمة استدلال. من خلال إدخال آلية “سلسلة معايير التقييم” (Chain-of-Rubrics, CoR)، يمكّن هذا الإطار النموذج من توليد معايير تقييم منظمة وعمليات استدلال قبل إصدار أحكام التفضيل، مما يعزز قابلية تفسير نماذج المكافآت ودقتها في تقييم المهام المعقدة (مثل الرياضيات والبرمجة). يتم تدريب RM-R1 على مرحلتين من خلال تقطير الاستدلال والتعلم المعزز، وقد تفوق على النماذج مفتوحة المصدر والمغلقة الحالية في العديد من معايير نماذج المكافآت. (المصدر: WeChat)

تحليل معمق لبروتوكول سياق النموذج (MCP): تبسيط تكامل الذكاء الاصطناعي مع الخدمات الخارجية: يهدف بروتوكول سياق النموذج (MCP)، كمعيار مفتوح، إلى حل مشكلة التجزئة عند دمج نماذج الذكاء الاصطناعي مع مصادر البيانات الخارجية والأدوات (مثل Slack و Gmail). من خلال واجهة نظام موحدة (تدعم بروتوكولي STDIO و SSE)، يسمح MCP للمطورين ببناء عملاء MCP (مثل Claude لسطح المكتب و Cursor IDE) وخوادم MCP (لتشغيل قواعد البيانات وأنظمة الملفات واستدعاء واجهات برمجة التطبيقات)، مما يبسط شبكة التكيف المعقدة “M×N” إلى نمط “M+N”، ويحقق تكاملًا فوريًا بين الذكاء الاصطناعي والخدمات الخارجية. يعتقد تان يو، الشريك في Fabarta للتكنولوجيا، أن قيمة MCP تكمن في توفير قدرة اتصال أساسية، وأن تسويقه يعتمد على القيمة المحددة التي يوفرها النظام الأساسي، على سبيل المثال، من خلال دمج خادم MCP مع وكيل Fabarta الذكي للمكاتب الفائقة لتبسيط إجراءات المستخدم. (المصدر: WeChat)

Agentic ROI: مؤشر رئيسي لقياس قابلية استخدام وكلاء النماذج الكبيرة: اقترحت جامعة شنغهاي جياو تونغ بالتعاون مع جامعة العلوم والتكنولوجيا الصينية Agentic ROI (عائد الاستثمار في الوكلاء) كمؤشر أساسي لقياس مدى عملية وكلاء النماذج الكبيرة في السيناريوهات الحقيقية. يأخذ هذا المؤشر في الاعتبار جودة المعلومات، وتكلفة وقت المستخدم والوكيل، والنفقات الاقتصادية. تشير الدراسة إلى أن الوكلاء الحاليين يُستخدمون بشكل أكبر في مجالات ذات تكلفة بشرية عالية مثل البحث العلمي والبرمجة، ولكن في السيناريوهات اليومية مثل التجارة الإلكترونية والبحث، يكون Agentic ROI منخفضًا بسبب القيمة الهامشية غير الواضحة وارتفاع تكاليف التفاعل. يتطلب تحسين Agentic ROI اتباع مسار تطوير “متعرج” يتمثل في “تحسين جودة المعلومات على نطاق واسع أولاً، ثم تقليل التكاليف بشكل خفيف لاحقًا”. (المصدر: WeChat)
💼 أعمال
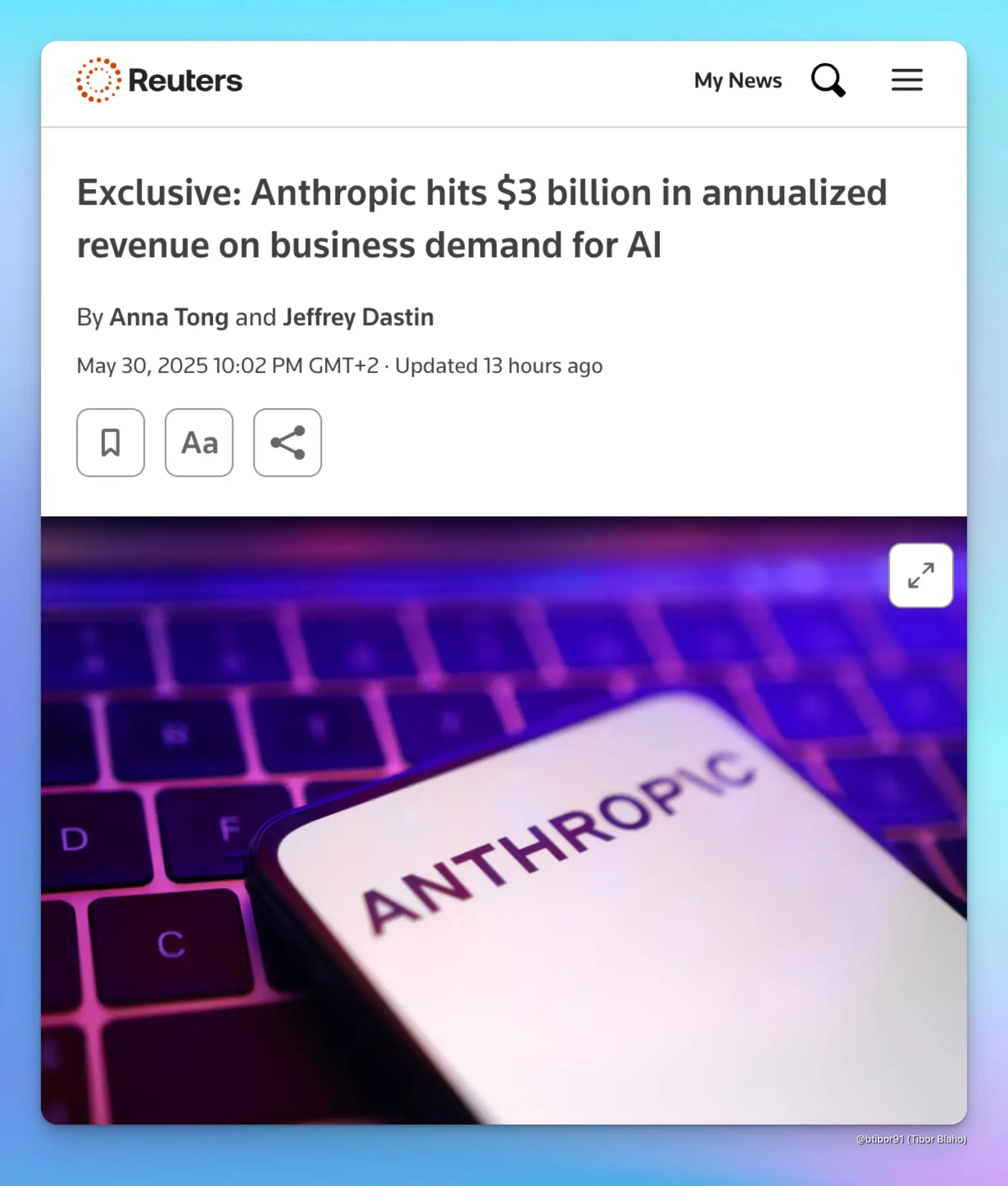
إيرادات Anthropic السنوية ترتفع إلى 3 مليارات دولار، مدفوعة بالطلب المؤسسي على الذكاء الاصطناعي: كشف مصدران أن الإيرادات السنوية لشركة Anthropic ارتفعت من مليار دولار إلى 3 مليارات دولار في غضون خمسة أشهر فقط. يُعزى هذا النمو الكبير بشكل أساسي إلى الطلب القوي من الشركات على الذكاء الاصطناعي، خاصة في مجال توليد الأكواد. يشير هذا إلى أن سوق الشركات يظهر استعدادًا متزايدًا لتطبيق ودفع مقابل نماذج الذكاء الاصطناعي المتقدمة (مثل سلسلة Claude من Anthropic). (المصدر: cto_junior, scaling01, Reddit r/ArtificialInteligence)
تقرير Nvidia المالي للربع الأول من السنة المالية 2026: إجمالي الإيرادات 44.1 مليار دولار، وقطاع مراكز البيانات يساهم بنحو 90%: أصدرت Nvidia تقريرها المالي للربع الأول من السنة المالية 2026 المنتهي في 27 أبريل 2025، حيث بلغ إجمالي الإيرادات 44.1 مليار دولار، بزيادة 12% على أساس ربع سنوي و 69% على أساس سنوي. بلغت إيرادات قطاع مراكز البيانات 39.1 مليار دولار، أي ما يمثل 88.91%، بزيادة 73% على أساس سنوي. بلغت إيرادات قطاع الألعاب 3.8 مليار دولار، وهو رقم قياسي. على الرغم من تأثر رقاقة H20 بقيود التصدير، مما أدى إلى انخفاض قيمة المخزون بمقدار 4.5 مليار دولار ورسوم التزامات الشراء، ومن المتوقع أن تخسر الشركة 8 مليارات دولار من الإيرادات في الربع الثاني بسبب ذلك، إلا أن الأداء العام لا يزال قوياً. من المتوقع أن تساهم المنتجات الجديدة مثل Blackwell Ultra في تعزيز النمو. (المصدر: 量子位, WeChat)

Meta تعيد هيكلة فرق الذكاء الاصطناعي، معظم المؤلفين الأساسيين لـ Llama يغادرون، ومكانة FAIR تثير الاهتمام: أعلنت Meta عن إعادة هيكلة فرق الذكاء الاصطناعي، وتقسيمها إلى فريق منتجات الذكاء الاصطناعي بقيادة Connor Hayes وقسم أساسيات الذكاء الاصطناعي العام (AGI) بقيادة مشتركة من Ahmad Al-Dahle و Amir Frenkel، مع الحفاظ على قسم أبحاث الذكاء الاصطناعي الأساسي FAIR مستقلاً نسبيًا ولكن مع دمج بعض فرق الوسائط المتعددة. يهدف هذا التعديل إلى تعزيز الاستقلالية وسرعة التطوير. ومع ذلك، من بين المؤلفين الأساسيين الـ 14 لنموذج Llama، بقي 3 فقط، بينما غادر معظمهم أو انضموا إلى منافسين (مثل Mistral AI). بالإضافة إلى ردود الفعل الفاترة بعد إطلاق Llama 4، والتعديلات الداخلية على تخصيص القدرة الحاسوبية واتجاهات البحث والتطوير، أثار ذلك مخاوف بشأن قدرة Meta على الحفاظ على مكانتها الرائدة في مجال الذكاء الاصطناعي مفتوح المصدر ومستقبل FAIR. (المصدر: WeChat)

🌟 مجتمع
نقاش حول محاذاة الذكاء الاصطناعي: هل يمكن للمعايير الناعمة الحفاظ على سلطة الإنسان في عصر الذكاء الاصطناعي العام (AGI)؟: يناقش Ryan Greenblatt وجهة نظر Dwarkesh Patel، الذي يشكك في محاذاة الذكاء الاصطناعي، ويأمل بدلاً من ذلك في أن تتمكن المعايير الناعمة من الحفاظ على جزء من السلطة ومساحة البقاء للبشر بعد أن يسيطر الذكاء الاصطناعي العام (AGI) على السلطة الصارمة. يعتقد Greenblatt أنه إذا كان الذكاء الاصطناعي حساسًا للنطاق (scope sensitive) ولديه القدرة على الاستيلاء على السلطة، فمن غير المرجح أن تنجح محاولة الكشف عن عدم محاذاته أو جعله يعمل لصالح البشر من خلال الصفقات أو العقود. بالإضافة إلى ذلك، فإن عوامل مثل الضبط الدقيق الرخيص، وتحسين المحاذاة من قبل البشر، والنسخ الحر تجعل سيطرة الإنسان على الممتلكات غير مستقرة للغاية قبل حل مشكلة المحاذاة. بمجرد ظهور ذكاء اصطناعي محاذٍ أو عمالة ذكاء اصطناعي أرخص، سيعطي البشر الأولوية لاستخدامها، مما سيحفز بشدة الذكاء الاصطناعي غير المحاذي على الاستيلاء على السلطة. (المصدر: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

مؤسس Redis يرى أن برمجة الذكاء الاصطناعي أقل بكثير من المبرمجين البشر، مما يثير صدى ونقاشًا بين المطورين: شارك Salvatore Sanfilippo (Antirez)، مؤسس Redis، تجربته في التطوير، معتبرًا أن الذكاء الاصطناعي الحالي في مجال البرمجة، على الرغم من فائدته، أقل بكثير من المبرمجين البشر، خاصة في الخروج عن المألوف وابتكار حلول غريبة وفعالة. وشبه الذكاء الاصطناعي بـ “مساعد ذكي بما فيه الكفاية” يساعد في التحقق من الأفكار. أثارت وجهة النظر هذه نقاشًا حادًا بين المطورين، حيث اتفق الكثيرون على أن الذكاء الاصطناعي يمكن أن يكون بمثابة “بطة مطاطية” للمساعدة في التفكير، لكنهم أشاروا إلى أن الذكاء الاصطناعي واثق جدًا من نفسه ويميل إلى تضليل المطورين المبتدئين. وذكر بعض المطورين أن الإجابات الخاطئة التي يولدها الذكاء الاصطناعي تحفزهم على البرمجة يدويًا. أكد النقاش على أهمية الخبرة في الاستفادة الفعالة من الذكاء الاصطناعي، والتأثير السلبي المحتمل للذكاء الاصطناعي على المبرمجين المبتدئين. (المصدر: WeChat)

العلاقة بين DeepMind و Google Research تثير الجدل مجددًا: نقاش حول العلامة التجارية والمساهمة الفعلية في الابتكار: نشر Faruk Guney تغريدة مطولة يعلق فيها على العلاقة بين DeepMind و Google Research، معتبرًا أن الاختراقات الأساسية في ثورة الذكاء الاصطناعي الحالية (مثل بنية Transformer) نشأت بشكل رئيسي من Google Research، وليس من DeepMind بعد استحواذ جوجل عليها. وأشار إلى أنه على الرغم من أن AlphaFold هو إنجاز لـ DeepMind، إلا أنه لم يكن ليتحقق لولا موارد جوجل الحاسوبية وبنيتها التحتية البحثية، وأن المساهمين الأساسيين هم علماء ومهندسون مثل John Jumper و Pushmeet Kohli. يرى Guney أن دمج Google Research لاحقًا في DeepMind كان في الغالب تعديلًا للعلامة التجارية والهيكل التنظيمي، وينطوي على سياسات مؤسسية معقدة، قد تخفي المصدر الحقيقي للابتكار. وأكد أن العديد من اختراقات الذكاء الاصطناعي هي نتيجة سنوات من البحث الجماعي، ولا يمكن نسبها فقط إلى عدد قليل من الشخصيات أو العلامات التجارية المعروفة. (المصدر: farguney, farguney)
تحول الوظائف والمهارات في عصر الذكاء الاصطناعي يثير القلق والنقاش: تستمر النقاشات على وسائل التواصل الاجتماعي حول تأثير الذكاء الاصطناعي على سوق العمل. فمن ناحية، هناك آراء ترى أن الذكاء الاصطناعي سيؤدي إلى بطالة واسعة النطاق، كما عبر الرئيس التنفيذي لشركة Anthropic عن مثل هذه المخاوف، مما يدفع الناس إلى التفكير في كيفية التعامل مع ذلك. ومن ناحية أخرى، هناك أصوات تشير إلى أن الذكاء الاصطناعي يعزز الإنتاجية بشكل أساسي، ومن غير المرجح أن يسبب بطالة واسعة النطاق، ما لم يحدث ركود اقتصادي حاد، لأن الطلب الاستهلاكي يعتمد على التوظيف والدخل. في الوقت نفسه، شارك بعض المستخدمين تجاربهم الشخصية مع فقدان الوظائف بسبب الذكاء الاصطناعي (مثل استخدام المدير لـ ChatGPT بدلاً من الموظفين). بالنسبة للمستقبل، يشير النقاش إلى الحاجة إلى الادخار، وتعلم المهارات العملية، والتكيف مع إمكانية انخفاض الدخل، وكيفية تعديل النظام التعليمي لتنمية المهارات المطلوبة في عصر الذكاء الاصطناعي، مثل التفكير النقدي والقدرة على استخدام أدوات الذكاء الاصطناعي بفعالية. (المصدر: Reddit r/ArtificialInteligence, Reddit r/artificial)

الاعتماد المفرط على ChatGPT يثير مخاوف بشأن تدهور القدرة على التفكير: نشر مستخدم على Reddit منشورًا يعرب فيه عن قلقه من اعتماد صديقته المفرط على ChatGPT لاتخاذ القرارات والحصول على الآراء والأفكار الإبداعية، معتبرًا أن ذلك قد يؤدي إلى فقدانها القدرة على التفكير المستقل والإبداع الأصيل. أثار المنشور نقاشًا واسعًا، حيث اتفق بعض المعلقين مع هذا القلق، معتبرين أن الاعتماد المفرط على أدوات الذكاء الاصطناعي قد يضعف بالفعل التفكير الفردي؛ بينما رأى معلقون آخرون أن الذكاء الاصطناعي مجرد أداة، مثل الموسوعات أو محركات البحث في الماضي، وأن المفتاح يكمن في كيفية استخدام المستخدم لها، سواء كنقطة انطلاق للتفكير أو كبديل كامل. كما اقترح بعض المعلقين التعامل مع الأمر من خلال التواصل والتوجيه وإظهار محدودية الذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT)
تحديات الذكاء الاصطناعي في مجال التعليم: أستاذ جامعي يعاني من إساءة استخدام الطلاب لـ ChatGPT، ويدعو إلى تنمية القدرة على التفكير الحقيقي: نشر أستاذ تاريخ قديم على Reddit منشورًا يقول فيه إن إساءة استخدام ChatGPT قد أثرت بشكل خطير على تدريسه، حيث أصبحت الأوراق البحثية التي يقدمها الطلاب مليئة بـ “القمامة الفارغة” التي أنشأها الذكاء الاصطناعي، والتي تحتوي حتى على أخطاء واقعية، مما جعله يشك فيما إذا كان الطلاب يتعلمون حقًا. وأكد أن جوهر تعليم العلوم الإنسانية هو تنمية المعرفة الجديدة، والرؤى الإبداعية، والتفكير المستقل، وليس مجرد تكرار المعلومات الموجودة. أثار هذا المنشور نقاشًا حادًا، حيث اقترح المعلقون استراتيجيات متعددة للتعامل مع الأمر، مثل التحول إلى التقارير الشفوية، وكتابة الأوراق البحثية يدويًا في الفصل، ومطالبة الطلاب بتقديم تحليل وصفي لعملية استخدامهم للذكاء الاصطناعي، أو دمج الذكاء الاصطناعي في التدريس، وجعل الطلاب ينتقدون مخرجات الذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT)
نواة مولدة بالذكاء الاصطناعي تتفوق بشكل غير متوقع على نواة خبير PyTorch، فريق صيني من ستانفورد يكشف عن إمكانيات جديدة: أثناء محاولة فريق من جامعة ستانفورد يضم Anne Ouyang و Azalia Mirhoseini و Percy Liang توليد بيانات اصطناعية لتدريب نموذج توليد النواة، اكتشفوا بشكل غير متوقع أن نواتهم المولدة بالذكاء الاصطناعي والمكتوبة بلغة CUDA-C البحتة تقترب في أدائها من نواة FP32 المدمجة في PyTorch والمحسّنة من قبل الخبراء، بل وتتفوق عليها أحيانًا. على سبيل المثال، في ضرب المصفوفات، وصلت إلى 101.3% من أداء PyTorch، وفي الالتفاف ثنائي الأبعاد وصلت إلى 179.9%. اعتمد الفريق على التحسين التكراري متعدد الجولات، ودمج أفكار تحسين الاستدلال باللغة الطبيعية واستراتيجية البحث بتوسيع الفروع، مستخدمًا نماذج OpenAI o3 و Gemini 2.5 Pro. تشير هذه النتيجة إلى أن الذكاء الاصطناعي، من خلال البحث الذكي والاستكشاف المتوازي، لديه القدرة على تحقيق اختراقات في مجال توليد نواة الحوسبة عالية الأداء. (المصدر: WeChat)

💡 أخرى
قوة جماعات الضغط في صناعة الذكاء الاصطناعي هائلة، وتلفت انتباه Max Tegmark: أشار Max Tegmark، الأستاذ في معهد ماساتشوستس للتكنولوجيا (MIT)، إلى أن عدد جماعات الضغط التابعة لصناعة الذكاء الاصطناعي في واشنطن وبروكسل قد تجاوز مجموع عدد جماعات الضغط التابعة لصناعتي الوقود الأحفوري والتبغ. تكشف هذه الظاهرة عن التأثير المتزايد لصناعة الذكاء الاصطناعي في صنع السياسات، واستثمارها النشط في تشكيل البيئة التنظيمية، مما قد يكون له تأثير عميق على اتجاه تطوير تكنولوجيا الذكاء الاصطناعي، والمعايير الأخلاقية، والمشهد التنافسي في السوق. (المصدر: Reddit r/artificial)

الذكاء الاصطناعي قد يحاكي هجمات إرهابية بيولوجية من خلال التزييف العميق، مما يشكل تهديدًا جديدًا للصحة العامة: يشير مقال في STAT News إلى أنه بالإضافة إلى مخاطر الأسلحة البيولوجية المدعومة بالذكاء الاصطناعي، فإن استخدام تقنية التزييف العميق لمحاكاة هجمات إرهابية بيولوجية قد يشكل أيضًا تهديدًا خطيرًا. خاصة بين الدول المتنازعة عسكريًا، قد تؤدي مثل هذه المعلومات المزيفة إلى إثارة الذعر وسوء التقدير والتصعيد العسكري غير الضروري. نظرًا لأن التحقيقات قد تقودها وكالات إنفاذ القانون أو الوكالات العسكرية، وليس فرق الصحة العامة أو الفرق الفنية، فقد يكونون أكثر ميلًا إلى تصديق صحة الهجمات، مما يجعل من الصعب دحضها بفعالية. (المصدر: Reddit r/ArtificialInteligence)
هل لا يزال ينبغي الحصول على شهادة في الهندسة في عصر الذكاء الاصطناعي؟ نقاش ساخن: يناقش المجتمع قيمة الحصول على شهادة في الهندسة في عصر الذكاء الاصطناعي. يرى البعض أن الذكاء الاصطناعي قد يحل محل العديد من المهام الهندسية التقليدية، مما يقلل من قيمة الشهادة. بينما يرى آخرون أن التفكير المنظومي، وقدرات حل المشكلات، والأسس الرياضية والفيزيائية التي تنميها شهادة الهندسة لا تزال مهمة، خاصة في فهم وتطبيق أدوات الذكاء الاصطناعي. تشير بعض الآراء إلى أنه إذا كان الذكاء الاصطناعي قادرًا على استبدال المهندسين، فإن المهن الأخرى لن تكون بمنأى عن ذلك، والمفتاح يكمن في التعلم المستمر والتكيف. تعتبر المجالات ذات الطابع العملي القوي والتي يصعب أتمتتها، مثل الطب البيطري، خيارات آمنة نسبيًا. (المصدر: Reddit r/ArtificialInteligence)