
كلمات مفتاحية:DeepSeek R1-0528, آلة جودل داروين, استهلاك طاقة الذكاء الاصطناعي, تعزيز التعلم بالمكافآت الزائفة, هواوي أسيند, قائمة SuperCLUE, اختبار معياري متعدد الوسائط, تحسين أداء DeepSeek R1-0528, آلية التطور الذاتي لـ DGM, حلول الطاقة النووية لمراكز بيانات الذكاء الاصطناعي, آلية RLVR لنموذج Qwen, تحسين تدريب Pangu Ultra MoE
🔥 أبرز العناوين
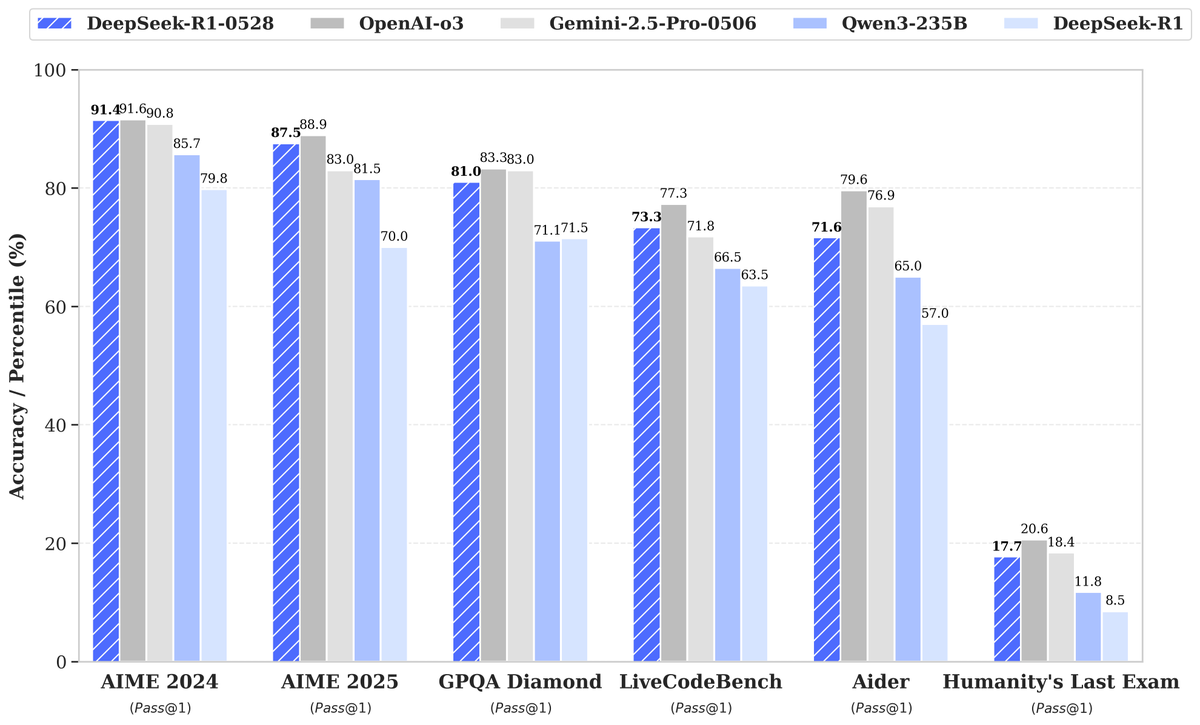
DeepSeek تطلق نموذج R1-0528 الجديد، وأداؤه المحسّن بشكل كبير يثير الاهتمام: أطلقت DeepSeek إصدارًا جديدًا من نموذجها اللغوي الكبير R1-0528، والذي أظهر أداءً متميزًا في العديد من اختبارات الأداء القياسية، لا سيما في مجالات توليد الأكواد (LiveCodeBench)، والاستدلال العلمي (GPQA Diamond)، ومسابقات الرياضيات (AIME 2024) حيث حقق تقدمًا ملحوظًا. وأشارت Artificial Analysis إلى أن R1-0528 قفز في مؤشرها للذكاء من 60 نقطة إلى 68 نقطة، ليتساوى مع Gemini 2.5 Pro من جوجل، ليصبح ثاني أفضل مختبر للذكاء الاصطناعي في العالم، ويعزز مكانته الرائدة في مجال النماذج مفتوحة الوزن. كان رد فعل المجتمع إيجابيًا، حيث أصدرت Unsloth بسرعة إصدارات GGUF المكممة، مما يسهل نشره محليًا. تم تحقيق هذا التحديث بشكل أساسي من خلال تقنيات ما بعد التدريب مثل التعلم المعزز (RL)، مما يُظهر إمكانية التحسين المستمر لذكاء النموذج بناءً على البنية الحالية والتدريب المسبق، وعلى الرغم من وجود نقاشات تشير إلى أن مخرجاته تحمل أحيانًا أسلوب “الإطراء”، إلا أنه يُعتبر بشكل عام قفزة كبيرة في قدرات الاستدلال والأكواد. (المصدر: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
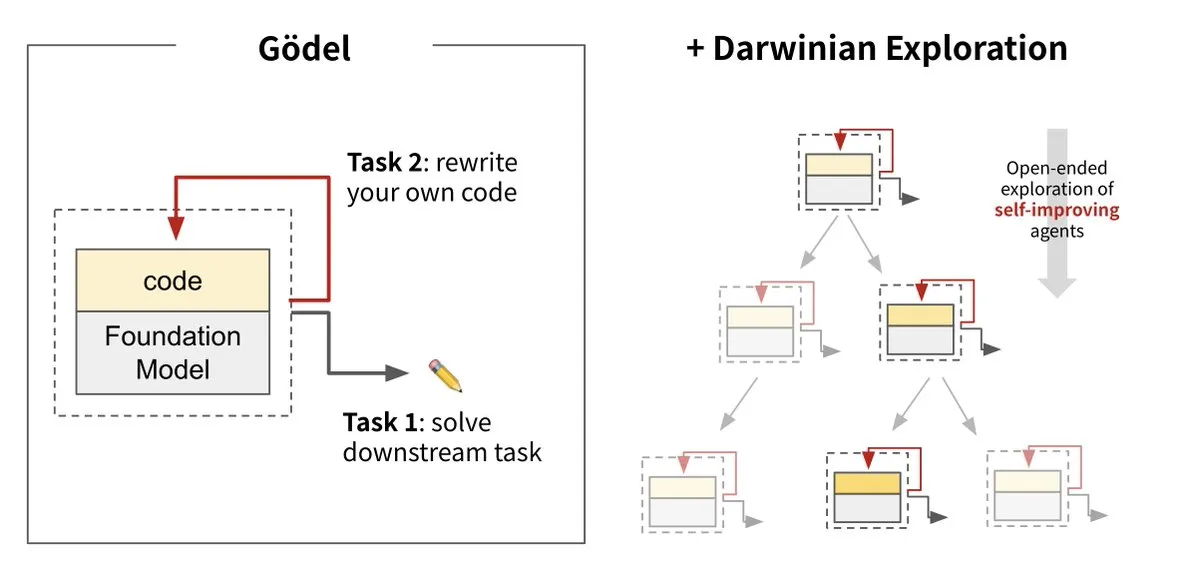
Sakana AI تطلق آلة داروين-جودل (DGM)، لتحقيق التطور الذاتي للذكاء الاصطناعي: أطلقت Sakana AI بالتعاون مع UBC آلة داروين-جودل (Darwin Gödel Machine, DGM)، وهي عبارة عن وكيل ذكاء اصطناعي قادر على تحسين نفسه باستمرار من خلال إعادة كتابة شفرته الخاصة. يستلهم هذا النظام من نظرية التطور، ويجمع بين النماذج التأسيسية الكبيرة ومستودعات الأكواد، حيث يستطيع الوكيل اقتراح تحسينات على الأكواد وتقييمها ذاتيًا. أظهرت التجارب أن أداء DGM على SWE-bench ارتفع من 20% إلى 50%، وعلى Polyglot ارتفعت نسبة النجاح من 14.2% إلى 30.7%، متفوقًا بشكل كبير على الوكلاء المصممين يدويًا. يُعتبر هذا البحث خطوة مهمة نحو ذكاء اصطناعي قادر على التعلم والابتكار بشكل مستقل، ويهدف إلى حل مشكلة ثبات ذكاء أنظمة الذكاء الاصطناعي بعد نشرها، مع التأكيد على الأهمية القصوى للسلامة أثناء عملية التطوير. (المصدر: Sakana AI, hardmaru, ITmedia AI+)
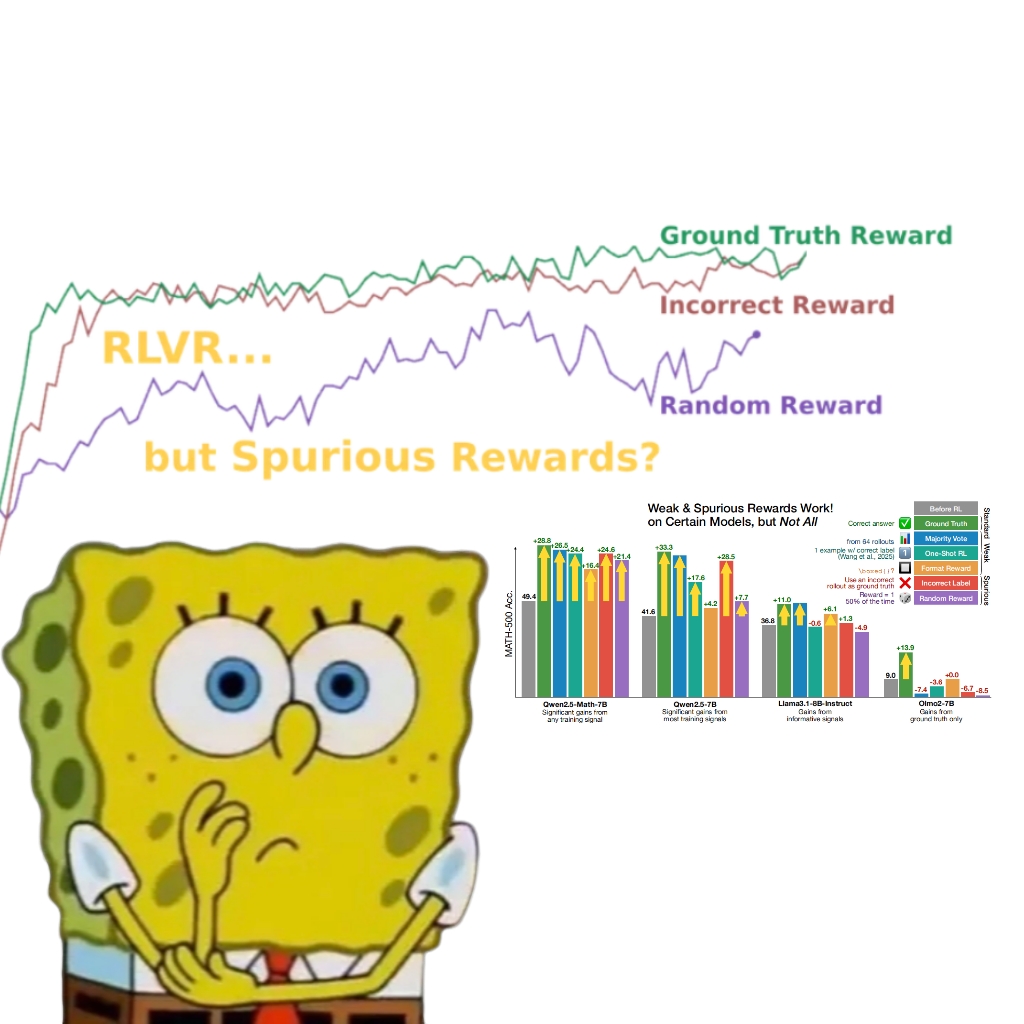
استهلاك الطاقة في الذكاء الاصطناعي يثير القلق، والطاقة النووية والوقود الأحفوري مصادر طاقة محتملة: سلسلة تقارير “Power Hungry” من MIT Technology Review تتعمق في احتياجات الطاقة المتوقعة للذكاء الاصطناعي (AI). تحتاج مراكز بيانات الذكاء الاصطناعي إلى إمدادات طاقة مستمرة ومستقرة، خاصة لسيناريوهات استدلال النماذج. على الرغم من أن الطاقة الشمسية وطاقة الرياح هي مصادر طاقة نظيفة، إلا أن طبيعتها المتقطعة تجعل من الصعب تلبية احتياجات الذكاء الاصطناعي بمفردها، ما لم تقترن بحلول تخزين طاقة باهظة الثمن. تُعتبر الطاقة النووية حلاً محتملاً لقدرتها على توفير طاقة مستمرة، لكن بناء محطات طاقة نووية جديدة يستغرق وقتًا طويلاً ومعقدًا. لذلك، قد يصبح الوقود الأحفوري مثل الغاز الطبيعي اعتمادًا قصير المدى لتلبية احتياجات الطاقة المتزايدة بسرعة للذكاء الاصطناعي، مما قد يشكل تحديًا للأهداف المناخية. تؤكد التقارير على ضرورة أن تدفع شركات التكنولوجيا الكبرى نحو حلول طاقة أنظف، مثل تقنيات احتجاز الكربون أو تحسين كفاءة استخدام الطاقة، لمواجهة التحديات المزدوجة للطاقة والمناخ التي يفرضها تطوير الذكاء الاصطناعي. (المصدر: MIT Technology Review, The Download)

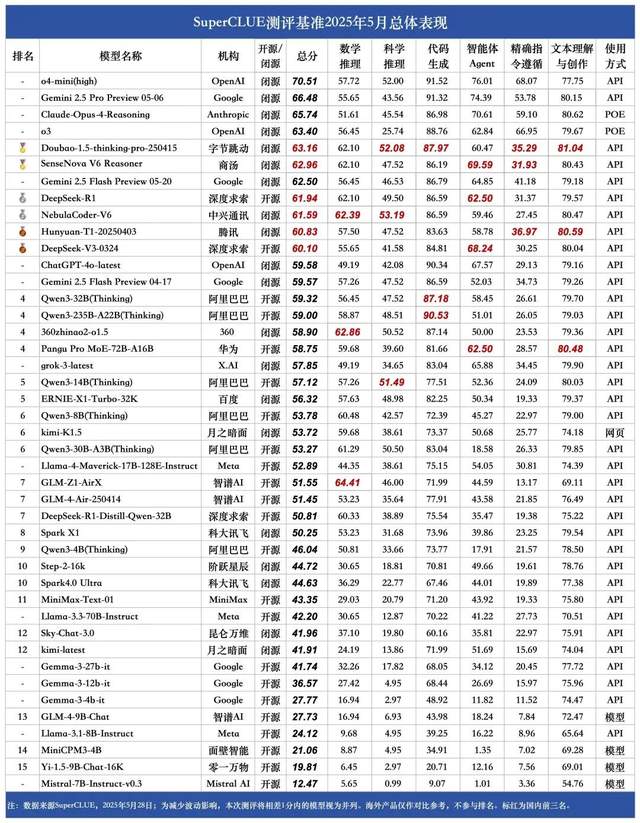
دراسة تكشف أن المكافآت الزائفة يمكنها أيضًا تحسين أداء نموذج Qwen، مما يثير إعادة التفكير في آلية RLVR: اكتشف فريق بحثي من جامعة واشنطن أنه حتى عند استخدام إشارات مكافأة عشوائية أو خاطئة، فإن تدريب نموذج Qwen2.5-Math من خلال التعلم المعزز بالمكافآت القابلة للتحقق (RLVR)، يمكن أن يؤدي إلى تحسن ملحوظ في أدائه على معايير الاستدلال الرياضي مثل MATH-500 بنحو 25%، مقتربًا من تأثير التحسين بالمكافآت الحقيقية. تشير الدراسة إلى أن هذه الظاهرة تُعزى بشكل أساسي إلى استراتيجيات استدلال أكواد معينة اكتسبها نموذج Qwen في مرحلة التدريب المسبق (مثل توليد أكواد Python للمساعدة في التفكير)، وأن عملية RLVR (خاصة عند استخدام خوارزمية GRPO) تعزز تكرار هذا السلوك المفيد، وليس صحة إشارة المكافأة نفسها. هذا الاكتشاف لا ينطبق على النماذج الأخرى التي لا تمتلك مثل هذه الخصائص المكتسبة من التدريب المسبق (مثل OLMo2-7B)، والتي أظهرت أداءً شبه ثابت أو حتى متدهورًا تحت تأثير المكافآت الزائفة. تتحدى هذه الدراسة المفهوم التقليدي لاعتماد RLVR على إشارات المكافأة الصحيحة، وتنبه الباحثين إلى ضرورة الحذر من تأثير سلوكيات النموذج المحددة على نتائج التقييم، مؤكدة على أهمية التحقق عبر نماذج متعددة. (المصدر: 量子位, Stella Li)
🎯 اتجاهات
هواوي Ascend تدعم التدريب الفعال لنموذج Pangu Ultra MoE الذي يقترب من تريليون بارامتر، محققة تحكمًا ذاتيًا كاملًا في العملية: أصدرت هواوي تقريرًا تقنيًا يفصل ممارساتها في التدريب الفعال لكامل عملية نموذج Pangu Ultra MoE (718 مليار بارامتر) استنادًا إلى أجهزة Ascend AI وإطار MindSpore. من خلال تقنيات مثل الاختيار الذكي لاستراتيجيات التوازي، والدمج العميق بين الحوسبة والاتصالات، وموازنة التحميل الديناميكية العالمية، تم تحقيق 41% من MFU (استخدام قوة حوسبة النموذج) على مجموعة Atlas 800T A2 التي تضم عشرة آلاف بطاقة. في مرحلة ما بعد التدريب بالتعلم المعزز (RL)، وبالجمع بين تقنية RL Fusion للتدريب والاستدلال على نفس البطاقة وآلية StaleSync شبه المتزامنة، تم تحقيق إنتاجية عالية بلغت 35 ألف توكن/ثانية لكل عقدة فائقة على مجموعة CloudMatrix 384 المكونة من 384 عقدة فائقة، وهو ما يعادل معالجة مسألة رياضيات عليا كل ثانيتين. تمثل هذه الخطوة نضج الحلقة المغلقة لقوة الحوسبة للذكاء الاصطناعي المحلي وتدريب النماذج الكبيرة، وتُظهر أداءً رائدًا في الصناعة في تدريب نماذج MoE فائقة الضخامة. (المصدر: 量子位)

قائمة SuperCLUE لنماذج اللغة الصينية الكبيرة لشهر مايو: Doubao 1.5 و SenseNova V6 من SenseTime يتشاركان المركز الأول محليًا: أصدرت SuperCLUE، وهي هيئة تقييم نماذج كبيرة ذات مرجعية، “تقرير تقييم النماذج الصينية الكبيرة القياسي” لشهر مايو 2025. أظهر التقرير أن نموذج Doubao-1.5-thinking-pro من ByteDance ونموذج SenseNova-V6 Reasoner متعدد الوسائط من SenseTime قد احتلا المركز الأول محليًا، وتجاوز أداؤهما في القدرات الصينية العامة نموذج Gemini 2.5 Flash Preview. تلتهما نماذج DeepSeek-R1 و NebulaCoder-V6 و 混元-T1 و DeepSeek-V3 في المرتبة الثانية. أكد التقرير على أن الفجوة في القدرات العامة بين النماذج الكبيرة المحلية والدولية في مجال اللغة الصينية تتقلص، وأن مشهد المنافسة بين نماذج الاستدلال المحلية بدأ يتشكل. شمل هذا التقييم ست مهام رئيسية: الاستدلال الرياضي، والاستدلال العلمي، وتوليد الأكواد، ووكيل الذكاء الاصطناعي (Agent)، والالتزام الدقيق بالتعليمات، وفهم النصوص والإبداع. (المصدر: 量子位)
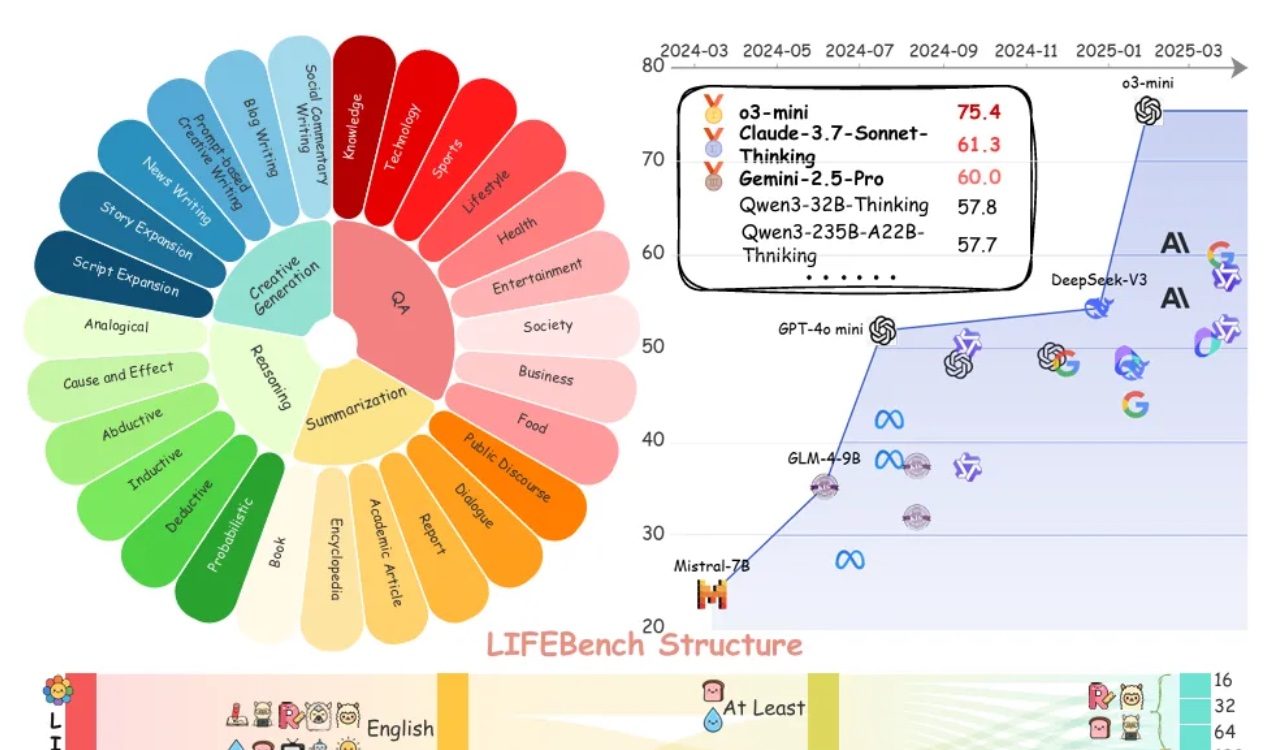
تقييم LIFEBench يُظهر قصورًا عامًا في النماذج الكبيرة في اتباع تعليمات الطول: أظهر اختبار معياري جديد يُدعى LIFEBench أن النماذج اللغوية الكبيرة (LLMs) السائدة حاليًا تُظهر أداءً ضعيفًا في اتباع تعليمات طول النص المحددة، خاصة عند توليد نصوص طويلة. اختبر البحث 26 نموذجًا، ووجد أن معظم النماذج حصلت على درجات منخفضة عندما طُلب منها توليد نصوص بطول دقيق، ولم يُظهر سوى عدد قليل من النماذج مثل o3-mini و Claude-Sonnet-Thinking و Gemini-2.5-Pro أداءً مقبولاً. كان توليد النصوص الطويلة (>2000 كلمة) نقطة ضعف عامة، حيث انخفضت درجات جميع النماذج بشكل ملحوظ. بالإضافة إلى ذلك، كان أداء النماذج في معالجة المهام باللغة الصينية أسوأ بشكل عام من اللغة الإنجليزية، وأظهرت ميلًا إلى “التوليد المفرط”. وأشارت الدراسة أيضًا إلى أن الحد الأقصى لطول الإخراج المُعلن عنه من قبل العديد من النماذج لا يتوافق مع قدرتها الفعلية، مما يشير إلى وجود ظاهرة “الدعاية المفرطة”. تواجه النماذج تحديات في إدراك الطول، ومعالجة المدخلات الطويلة، وتجنب “التوليد الكسول” (مثل الإنهاء المبكر أو رفض التوليد). (المصدر: 量子位)
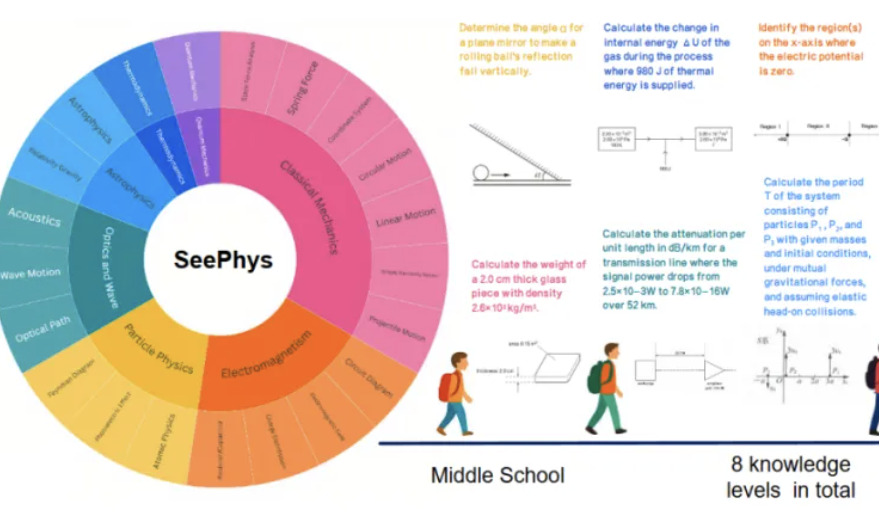
معيار SeePhys الجديد يكشف عن نقاط ضعف النماذج متعددة الوسائط الكبيرة في فهم الصور الفيزيائية: أطلقت جامعة سون يات سين ومؤسسات أخرى بالتعاون اختبار SeePhys المعياري، المصمم خصيصًا لتقييم قدرة النماذج متعددة الوسائط الكبيرة (MLLM) على فهم واستنتاج الصور المتعلقة بالفيزياء. يحتوي هذا المعيار على 2000 سؤال و 2245 رسمًا بيانيًا تغطي الفيزياء الكلاسيكية والحديثة، من مستوى الإعدادي إلى الدكتوراه. أظهرت نتائج الاختبار أنه حتى النماذج الرائدة مثل Gemini-2.5-Pro و o4-mini، لم تتجاوز دقتها 55% على SeePhys، خاصة عند معالجة أنواع معينة من الرسوم البيانية مثل مخططات الدوائر الكهربائية ورسوم معادلات الموجات، حيث أظهرت عوائق منهجية في التعرف. كما وجدت الدراسة أن النماذج اللغوية البحتة أظهرت في بعض الحالات أداءً قريبًا من النماذج متعددة الوسائط، مما يكشف عن عيوب حالية في محاذاة الرؤية والنص في MLLM. يؤكد هذا المعيار على أهمية إدراك الرسوم البيانية لفهم النماذج للعالم المادي، ويكشف عن التحديات الهائلة التي يواجهها الذكاء الاصطناعي حاليًا في المهام التي تربط بين الرسوم البيانية العلمية المعقدة والاستدلال النظري. (المصدر: 量子位)
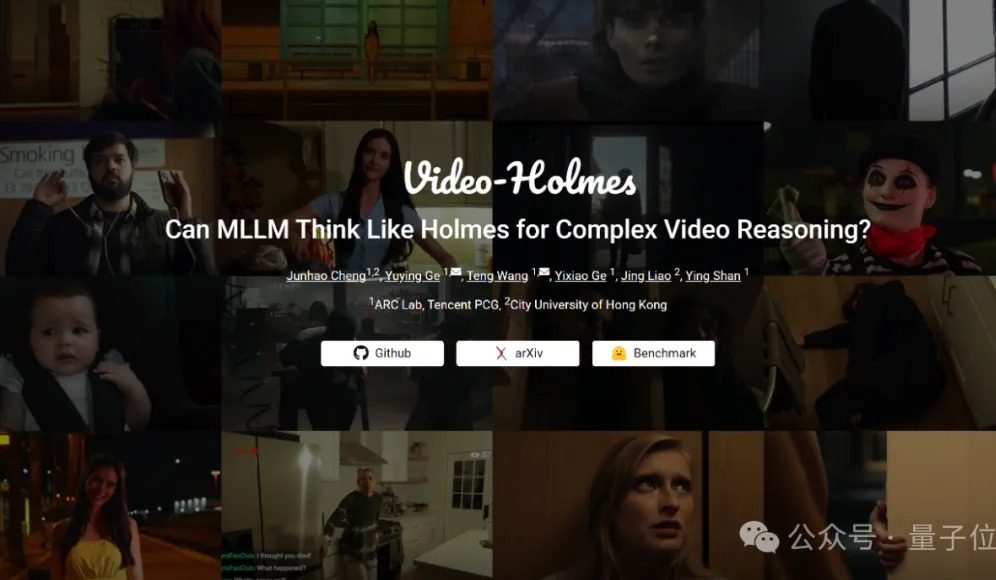
اختبار Video-Holmes المعياري: النماذج الكبيرة الحالية تفشل جميعها في قدرات استنتاج الفيديو المعقدة: أطلق مختبر ARC Lab التابع لشركة Tencent وجامعة مدينة هونغ كونغ معيار Video-Holmes، الذي يهدف إلى تقييم قدرات الاستنتاج المعقدة للفيديو في النماذج متعددة الوسائط الكبيرة (MLLM). يتضمن هذا المعيار 270 “فيلمًا قصيرًا استنتاجيًا”، ويطرح 7 أنواع من أسئلة الاختيار من متعدد تتطلب قدرة استنتاج عالية، مثل “استنتاج القاتل” و “تحليل نية الجريمة”، مما يتطلب من النموذج استخلاص وربط المعلومات الأساسية المتناثرة في الفيديو. أظهرت نتائج الاختبار أن جميع النماذج الكبيرة التي تم اختبارها، بما في ذلك Gemini-2.5-Pro، لم تصل إلى درجة النجاح (بلغت دقة Gemini-2.5-Pro حوالي 45%). تشير الدراسة إلى أن النماذج الحالية يمكنها إدراك المعلومات المرئية، ولكنها تعاني من عيوب عامة في ربط الأدلة المتعددة والتقاط المعلومات الأساسية، وتجد صعوبة في محاكاة عملية الاستدلال المعقدة التي يقوم بها الإنسان والتي تتضمن البحث النشط والتكامل والتحليل. (المصدر: 量子位)
Meta ترى أن التكامل السلس لخدمات الذكاء الاصطناعي هو المفتاح، وتستغل تأثير الشبكات الاجتماعية لزيادة مشاركة المستخدمين: تؤكد Meta أنه على الرغم من أن نموذجها Llama ليس في صدارة قوائم الترتيب، إلا أن الشركة تتمتع بميزة هائلة في سباق الذكاء الاصطناعي بفضل نظامها البيئي الضخم لوسائل التواصل الاجتماعي (3.43 مليار مستخدم نشط يوميًا). تستطيع Meta تزويد المستخدمين بأدوات ذكاء اصطناعي متكاملة بسلاسة، وهو ما يصعب على منصات الذكاء الاصطناعي المستقلة مثل ChatGPT منافسته. وقد نجحت الشركة بالفعل في زيادة عائدات المعلنين (ارتفاع سعر الإعلان الواحد بنسبة 10% على أساس سنوي) من خلال أدوات الذكاء الاصطناعي الجذابة، وتحقيق أرباح سريعة من استثمارات الذكاء الاصطناعي. من المتوقع أن يتجاوز عدد مستخدمي منصة Meta AI المليار مستخدم بحلول نهاية العام. ومع ذلك، فإن النفقات الرأسمالية المرتفعة (من المتوقع أن تتراوح بين 64 و 72 مليار دولار أمريكي في عام 2025) والخسائر المستمرة في Reality Labs (خسارة سنوية تزيد عن 15 مليار دولار أمريكي) تشكل عائقًا أمام تطورها، وقد انخفض التدفق النقدي الحر نتيجة لذلك. على الرغم من ذلك، لا يزال سهم Meta يُنظر إليه بإيجابية بفضل تقييمه المعتدل وإمكانات تحقيق الدخل على المدى القصير. (المصدر: 36氪)

الرئيس التنفيذي لشركة جوجل، بيتشاي: الذكاء الاصطناعي يمر بمرحلة جديدة من تحول المنصات، وسيعيد تشكيل النظام البيئي للإنترنت: صرح ساندر بيتشاي، الرئيس التنفيذي لشركة جوجل، بعد مؤتمر I/O، بأن الذكاء الاصطناعي يمر بمرحلة تحول منصات مشابهة لظهور الأجهزة المحمولة، ويتميز بقدرة المنصة نفسها على الخلق والتحسين الذاتي، مما سيطلق العنان للإبداع بتأثير مضاعف. تقوم جوجل بدمج نتائج أبحاث الذكاء الاصطناعي على نطاق واسع في جميع منتجاتها، بما في ذلك البحث و YouTube والخدمات السحابية. تم إطلاق وظيفة البحث الجديدة القائمة على الذكاء الاصطناعي للمستخدمين في الولايات المتحدة، وهي قادرة على توليد صفحات نتائج مخصصة في الوقت الفعلي، تتضمن رسومًا بيانية تفاعلية ووحدات تطبيقات مخصصة، مما ينبئ بأن البحث سيتجاوز الروابط التقليدية لصفحات الويب. يعتقد بيتشاي أنه على الرغم من أن هذا قد يغير النظام البيئي للإنترنت (حيث سيعتبر الذكاء الاصطناعي الشبكة قاعدة بيانات منظمة)، إلا أن عدد الإحالات التي توجهها جوجل إلى الويب لا يزال يسجل أرقامًا قياسية. ويتوقع أن يشهد الذكاء الاصطناعي طفرة سريعة في تطبيقات المؤسسات (مثل بيئات تطوير الأكواد، وإنشاء الفيديو، والقانون، والرعاية الصحية)، ويرى أن أشكال الأجهزة الجديدة التي تعمل بالذكاء الاصطناعي مثل نظارات الواقع المعزز مليئة بالفرص. (المصدر: 36氪)

تطبيقات الذكاء الاصطناعي مثل Zhipu Qingyan و Kimi متهمة بجمع معلومات شخصية بشكل غير قانوني، مما يثير مخاوف تتعلق بالخصوصية: في الآونة الأخيرة، أشارت تقارير رسمية إلى أن تطبيق “Zhipu Qingyan” التابع لشركة Zhipu AI يعاني من مشكلة “جمع معلومات شخصية تتجاوز نطاق تفويض المستخدم”، بينما تطبيق “Kimi” التابع لشركة Moonshot AI يقوم “بجمع معلومات شخصية بوتيرة لا ترتبط مباشرة بوظائف العمل”. أثار ذكر هذين التطبيقين البارزين للذكاء الاصطناعي مخاوف واسعة النطاق لدى الجمهور بشأن مخاطر تسرب الخصوصية من منتجات الذكاء الاصطناعي التوليدي. إن اعتماد الذكاء الاصطناعي التوليدي على البيانات والذكاء يجعله يواجه تحديًا في تحقيق التوازن بين تحسين أداء النموذج وحماية خصوصية المستخدم. يعد التدريب المسبق على كميات هائلة من البيانات شرطًا ضروريًا للتطور التكنولوجي، ولكن أي جمع غير قانوني أو إساءة استخدام للمعلومات الشخصية سيضر بشكل خطير بثقة المستخدم وسمعة الصناعة. كشفت هذه الحادثة عن مشكلات محتملة في معالجة البيانات لدى بعض شركات الذكاء الاصطناعي، بالإضافة إلى أوجه القصور في الأطر الحالية لحماية البيانات في مواجهة تحديات تكنولوجيا الذكاء الاصطناعي. (المصدر: 36氪)

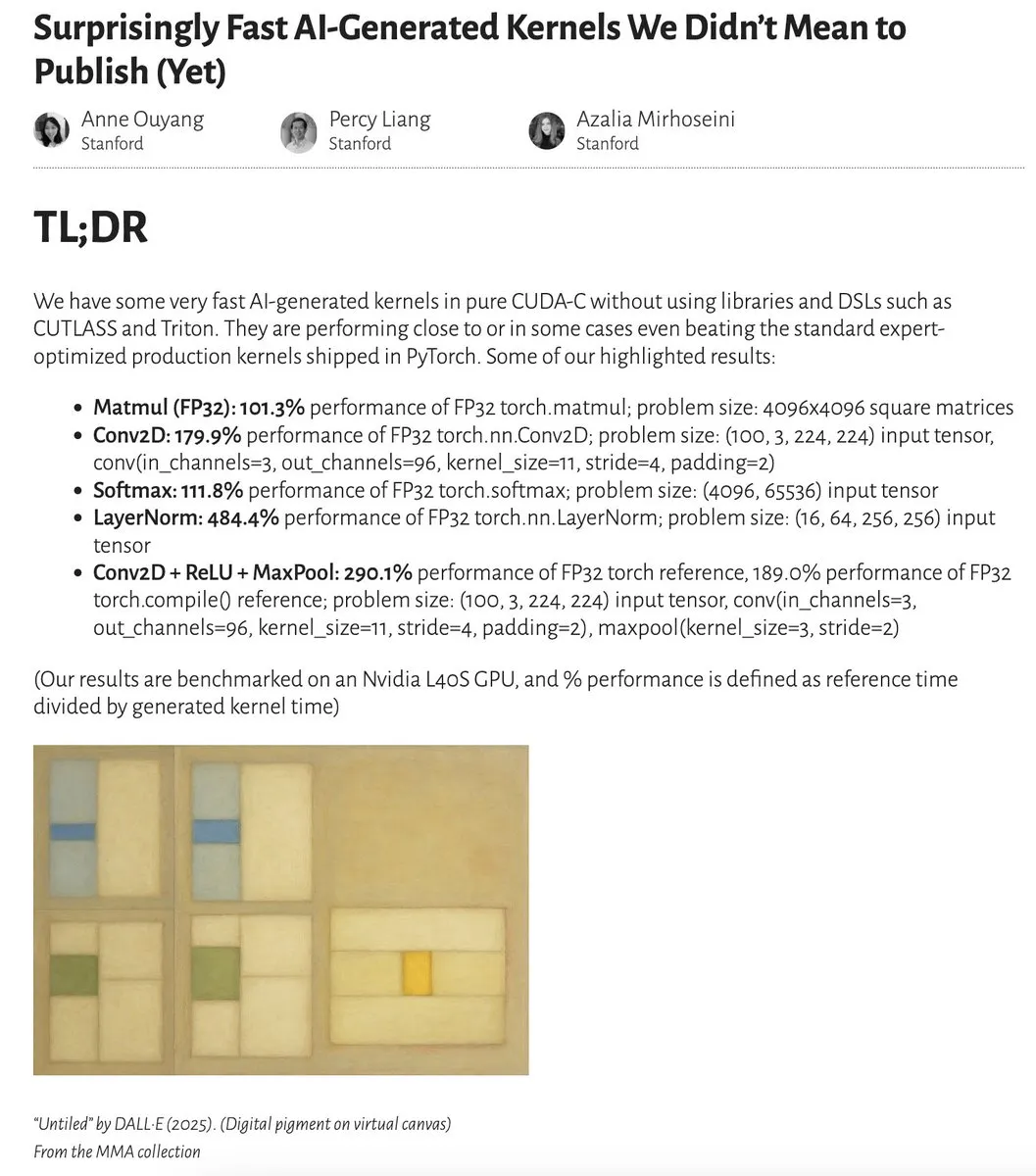
أداء النوى (Kernels) المولدة بواسطة الذكاء الاصطناعي يقترب أو حتى يتجاوز النوى المحسنة من قبل الخبراء: نشرت Anne Ouyang والمتعاونون معها بحثًا يوضح أن النوى المولدة بواسطة الذكاء الاصطناعي من خلال بحث بسيط في وقت الاختبار فقط، تقترب في أدائها، بل وتتجاوز في بعض الحالات، النوى الإنتاجية القياسية والمحسنة من قبل الخبراء في PyTorch. قام Fleetwood بإعادة إنتاج أولية لنواة LayerNorm على Colab، مما أكد تحسن الأداء المثير للإعجاب (حوالي 484.4%). يشير هذا التقدم إلى الإمكانات الهائلة للذكاء الاصطناعي في مجال تحسين الأكواد منخفضة المستوى، وقد يؤثر حتى على عمل مهندسي النوى. ومع ذلك، أشارت تحديثات لاحقة إلى أن نواة LayerNorm المولدة تعاني من مشكلات عدم استقرار عددي، مما ينبه المستخدمين إلى توخي الحذر عند استخدامها. (المصدر: eliebakouch, fleetwood___)
نقاش: هل يمكن للنماذج اللغوية الكبيرة أن تمتلك إبداعًا حقيقيًا؟: نشر MoritzW42 مقالًا يناقش مسألة الإبداع في النماذج اللغوية الكبيرة (LLM)، معتبرًا أن LLM بطبيعتها لا يمكن أن تمتلك إبداعًا حقيقيًا. استشهد بتعريف الفيزيائي David Deutsch للإبداع – القدرة على خلق معرفة جديدة من خلال التخمين والنقد – واعتبر أن هذا يشبه عملية التطور من خلال الطفرات والانتقاء. تعتمد LLM على الاحتمالات الاستقرائية والأنماط الموجودة في بيانات التدريب، ولا يمكنها إجراء تخمينات إبداعية أو حل مشكلات جديدة، مثل توليد أمثلة “البجعة السوداء” غير الموجودة في بيانات التدريب (مثل كأس نبيذ ممتلئ حتى حافته). يرى المقال أن LLM هي أدوات لتعزيز الإبداع البشري أكثر من كونها كيانات ذات إبداع مستقل، وبالتالي فإن الخوف منها غير عقلاني. (المصدر: MoritzW42)
نقاش: يجب تجنب تقييد الموردين عند بناء وكلاء الذكاء الاصطناعي، والتركيز على النموذج نفسه: يشير رأي Austin Vance (الذي أعادت نشره rachel_l_woods) إلى أن أحد الأخطاء الكبيرة عند بناء وكلاء الذكاء الاصطناعي هو الوقوع في فخ تقييد الموردين. تميل شركات مثل OpenAI و Anthropic و Google إلى الترويج لواجهات برمجة التطبيقات (API) المتكاملة الخاصة بها، ولكن هذا يؤدي إلى تكاليف تحويل ضخمة دون تحقيق قيمة إضافية. ويؤكد أن ما يدفع الأداء هو النموذج نفسه، وليس واجهة برمجة التطبيقات. نظرًا لأن ترتيب النماذج في قوائم الأداء يتغير باستمرار، فإن استخدام أطر عمل مفتوحة المصدر وغير مرتبطة بنموذج معين (مثل LangChain) وأدوات (مثل LangSmith) يضمن للشركات اختيار أفضل نموذج متاح في الوقت الحالي، بدلاً من أن تكون مقيدة بالخيارات التي تقدمها مختبرات النماذج التأسيسية المحددة. (المصدر: rachel_l_woods)
نقاش: وظيفة الملخصات بالذكاء الاصطناعي (AI overview) معرضة لخطر حقن الأوامر (prompt injection): اكتشف Zack Witten وأظهر إمكانية إجراء حقن للأوامر (prompt injection) في وظيفة الملخصات بالذكاء الاصطناعي (AI overview)، مما يعني أنه يمكن من خلال مدخلات معدة خصيصًا التلاعب بالذكاء الاصطناعي لتوليد معلومات ملخصة غير متوقعة أو مضللة. قام مستخدمون مثل Charles IRL بإعادة النشر والاهتمام بهذه الثغرة الأمنية، مما يشير إلى ضرورة الانتباه إلى متانة وأمان مثل هذه الوظائف عند تطبيقها على نطاق واسع. (المصدر: charles_irl, giffmana)
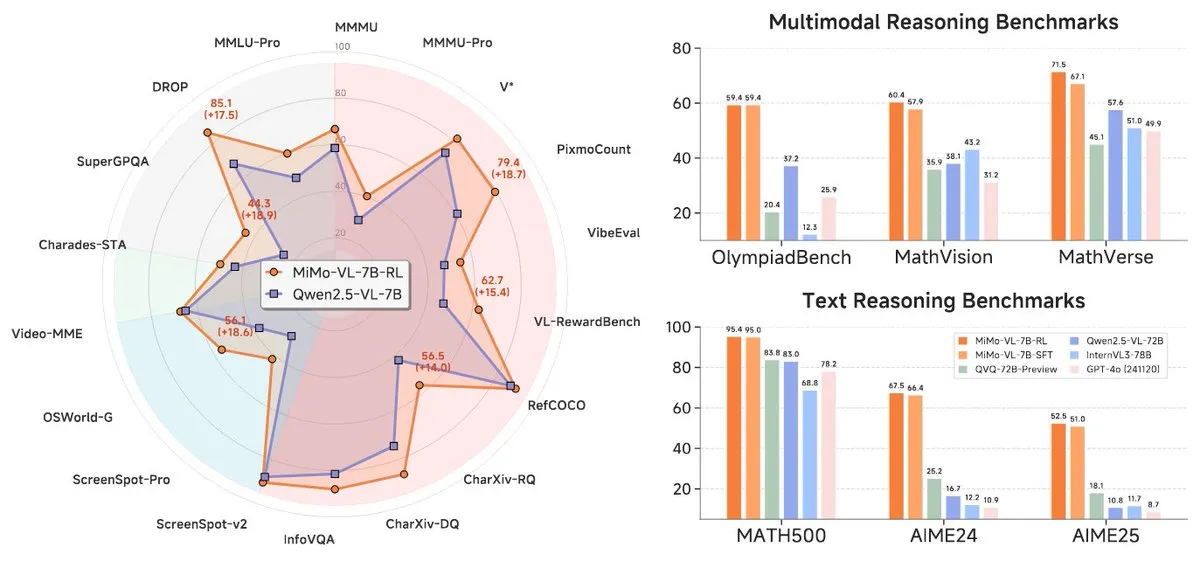
شاومي تطلق سلسلة نماذج MiMo-7B الجديدة، بأداء متميز في فئة 7B: أطلقت شاومي نماذجها المحدثة للاستدلال بحجم 7B، وهي MiMo-7B-RL-0530 ونسختها للغة المرئية MiMo-VL-7B-RL، مدعية أنها تحقق مستوى SOTA (الأحدث في المجال) ضمن نطاق حجم البارامترات الخاص بها. هذه النماذج متوافقة مع بنية Qwen-VL، ويمكن تشغيلها على أطر عمل مثل vLLM و Transformers و SGLang و Llama.cpp، وهي مفتوحة المصدر بموجب ترخيص MIT. أظهر إصدار MiMo-VL-RL تحسنًا ملحوظًا في العديد من اختبارات النصوص القياسية مقارنةً بنموذج MiMo-7B-RL النصي البحت، مع إضافة قدرات بصرية، مما أثار نقاشًا في المجتمع حول ما إذا كانت قد حسنت بشكل مفرط أداءها على المعايير القياسية أم أنها حققت تقدمًا جوهريًا في القدرات متعددة الوسائط. (المصدر: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 أدوات
Black Forest Labs تطلق FLUX.1 Kontext، لتحقيق تحرير صور على مستوى البكسل وتوليد سياقي: أطلقت Black Forest Labs (BFL)، التي أسسها أعضاء من الفريق الأساسي الذي اخترع تقنية Stable Diffusion، مجموعة نماذج جديدة لتوليد وتحرير الصور باسم FLUX.1 Kontext. يعتمد هذا النموذج على بنية مطابقة التدفق (flow matching)، ويمكنه فهم مدخلات النصوص والصور في نفس الوقت، مما يتيح التوليد القائم على السياق والتحرير متعدد الجولات، مع الحفاظ على اتساق ممتاز للشخصيات. يدعم FLUX.1 Kontext التحرير الجزئي دون التأثير على الأجزاء الأخرى، ويمكنه الرجوع إلى نمط الإدخال لتوليد مشاهد بنفس النمط، ويتميز بزمن انتقال منخفض. تم إطلاق إصدارات Pro و Max بالفعل، وهي متاحة على منصات مثل KreaAI و Freepik، بهدف تزويد فرق الإبداع في الشركات بقدرات تحرير صور أكثر دقة وسرعة. كانت ردود فعل المجتمع إيجابية، حيث أشارت إلى قدرته على تحقيق تحرير مثالي على مستوى البكسل. (المصدر: 36氪, timudk, op7418, lmarena_ai)

Simon Willison يطلق أداة LLM CLI للوصول المريح إلى نماذج كبيرة متعددة: طور Simon Willison أداة سطر أوامر ومكتبة Python تسمى LLM، تسمح للمستخدمين بالتفاعل مع نماذج لغوية كبيرة متعددة مثل OpenAI و Anthropic Claude و Google Gemini و Meta Llama عبر سطر الأوامر، وتدعم واجهات برمجة التطبيقات (API) عن بُعد والنماذج المنشورة محليًا. يمكن للأداة تنفيذ الأوامر، وتخزين الأوامر والاستجابات في SQLite، وتوليد وتخزين التضمينات (embeddings)، واستخراج المحتوى المنظم من النصوص والصور، وما إلى ذلك. يمكن للمستخدمين تثبيتها عبر pip أو Homebrew، ويمكنهم استخدام النماذج المحلية عن طريق تثبيت ملحقات (مثل llm-ollama). تدعم وضع الدردشة التفاعلي، مما يسهل على المستخدمين التحدث مع النماذج. (المصدر: GitHub Trending)

Contextual.ai تطلق محلل مستندات محسن خصيصًا لـ RAG: أطلقت Contextual.ai محلل مستندات مصمم خصيصًا لتطبيقات التوليد المعزز بالاسترجاع (RAG). تجمع هذه الأداة بين أحدث نماذج الرؤية الحاسوبية والتعرف الضوئي على الحروف (OCR) ونماذج اللغة المرئية، بهدف توفير استخراج محتوى المستندات بدقة عالية. يمكن للمستخدمين تجربتها مجانًا، مع إتاحة أول 500 صفحة مجانًا. هذا مفيد جدًا للسيناريوهات التي تتطلب استخراج معلومات من مستندات معقدة لاستخدامها بواسطة النماذج اللغوية الكبيرة (LLM)، مما يساعد على تحسين أداء ودقة أنظمة RAG. (المصدر: douwekiela)
علي بابا تطلق بيئة التطوير المتكاملة (IDE) للذكاء الاصطناعي “Tongyi Lingma”، مع دمج إكمال الأكواد ووضع الوكيل (Agent): أطلقت شركة علي بابا بيئة تطوير متكاملة (IDE) للذكاء الاصطناعي باسم “Tongyi Lingma”. تتميز هذه البيئة بوظائف مثل إكمال الأكواد، و MCP (Model-Copilot-Playground)، ووضع الوكيل (Agent)، والذاكرة طويلة المدى، وإكمال الأكواد عبر الأسطر. تدعم حاليًا نماذج Qwen و DeepSeek، ويتطلع المستخدمون إلى إضافة دعم لنماذج أخرى في المستقبل. تُظهر ردود الفعل الأولية على الاستخدام أن لوحة الدردشة الخاصة بها لا تزال بحاجة إلى تحسين في وظائف البحث عبر الإنترنت والإشارة (@reference)، ولكنها بشكل عام توفر للمطورين أداة جديدة تدمج قدرات البرمجة المساعدة بالذكاء الاصطناعي. (المصدر: karminski3, karminski3)
Perplexity Labs تطلق ميزة جديدة لإنشاء تطبيقات وتقارير بناءً على الأوامر النصية: تعرض منصة Labs التابعة لـ Perplexity AI ميزة جديدة تتيح للمستخدمين إنشاء تطبيقات وتقارير تفاعلية من خلال الأوامر النصية. على سبيل المثال، نجح مستخدم في إنشاء لوحة معلومات تقارن أداء محفظة أسهم تقليدية بمحفظة مدفوعة بالذكاء الاصطناعي على مدى 5 سنوات، وحصل على نتائج دقيقة للغاية. استخدم مستخدم آخر المنصة لمقارنة نماذج LLM مختلفة وأعرب عن رضاه بالنتائج. تُظهر هذه الحالات تقدم Perplexity في تحويل قدرات الذكاء الاصطناعي إلى أدوات تحليل عملية، خاصة في مجالات مثل البحوث المالية. (المصدر: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth تصدر إصدارات GGUF المكممة لنموذج DeepSeek-R1-0528، لدعمه محليًا: قامت Unsloth بإنشاء إصدارات GGUF مكممة لنموذج DeepSeek-R1-0528 الذي تم إصداره حديثًا، بما في ذلك IQ1_S (185GB) و Q2_K_XL (251GB) ومواصفات أخرى متنوعة، لتسهيل تشغيل هذا النموذج الكبير على الأجهزة المحلية للمستخدمين (مثل RTX 4090/3090 التي تحتوي على ذاكرة رسوميات كافية). من خلال استخدام بارامترات مثل "-ot ".ffn_.*_exps.=CPU""، يمكن تفريغ بعض طبقات MoE إلى ذاكرة الوصول العشوائي (RAM)، وبالتالي تحقيق الاستدلال في ظل ذاكرة رسوميات محدودة. يوفر هذا الراحة للمستخدمين الذين يرغبون في تجربة وبحث قدرات DeepSeek R1 القوية محليًا. (المصدر: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged: بيئة تطوير ذكاء اصطناعي محلية متكاملة مع Ollama و Supabase وغيرها: coleam00/local-ai-packaged هو قالب Docker Compose مفتوح المصدر يهدف إلى إنشاء بيئة تطوير ذكاء اصطناعي محلية ومنخفضة الأكواد (low-code) كاملة الوظائف بسرعة. يدمج Ollama (لتشغيل LLM محليًا)، و Supabase (قاعدة بيانات، تخزين متجهي، مصادقة)، و n8n (أتمتة منخفضة الأكواد)، و Open WebUI (واجهة دردشة)، و Flowise (منشئ وكلاء ذكاء اصطناعي)، و Neo4j (مخطط معرفي)، و Langfuse (قابلية مراقبة LLM)، و SearXNG (محرك بحث وصفي)، و Caddy (إدارة HTTPS). يسهل هذا المشروع على المطورين دمج واستخدام مختلف أدوات وخدمات الذكاء الاصطناعي في بيئة محلية. (المصدر: GitHub Trending)
Resemble AI تطلق أداة الصوت بالذكاء الاصطناعي مفتوحة المصدر ChatterBox، مع دعم التحكم في المشاعر: أطلقت Resemble AI أداة صوت بالذكاء الاصطناعي مفتوحة المصدر باسم ChatterBox. تتيح هذه الأداة للمستخدمين تصميم واستنساخ وتحرير الأصوات مجانًا، مع إمكانية التحكم في المشاعر. يُقال إن ChatterBox تتفوق في أدائها على بعض خدمات الصوت التجارية الرائدة في مجال الذكاء الاصطناعي (مثل Elevenlabs)، مما يوفر للمطورين ومنشئي المحتوى قدرات قوية في توليف وتحرير الصوت. (المصدر: ClementDelangue)
Mem0.ai بالتعاون مع Qdrant يوفران حل ذاكرة طويلة المدى لوكلاء الذكاء الاصطناعي: يوفر إطار عمل Mem0.ai بالاشتراك مع قاعدة بيانات المتجهات Qdrant حلاً للذاكرة طويلة المدى لوكلاء الذكاء الاصطناعي. يهدف هذا الحل إلى مساعدة الوكلاء على الحفاظ على السياق، وتذكر الحقائق، والحفاظ على الاتساق في المحادثات. يمكن للمستخدمين نشره عبر السحابة أو كحل مفتوح المصدر، وربط Mem0 بـ Qdrant لتخزين ذاكرة متجهة طويلة المدى. هذا مهم لبناء تطبيقات الذكاء الاصطناعي التي تتطلب ذاكرة مستمرة وقدرات حوار معقدة. (المصدر: qdrant_engine)

📚 دراسات وأبحاث
بحث جديد من جامعة طوكيو: التعلم الميتا السياقي يوجه ظهور دوائر متعددة المراحل داخل النماذج اللغوية الكبيرة: بحث من جامعة طوكيو بعنوان “Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence” يستكشف هياكل أكثر تعقيدًا داخل النماذج اللغوية الكبيرة (LLM). وجد البحث أنه خلال عملية التعلم الميتا السياقي (in-context meta-learning)، تستطيع النماذج اللغوية الكبيرة توجيه ظهور دوائر متعددة المراحل، وهو ما يتجاوز الآليات البسيطة التي فُهمت سابقًا مثل رؤوس الاستقراء (induction heads). يقدم هذا البحث منظورًا جديدًا لفهم كيف تتعلم النماذج اللغوية الكبيرة من خلال السياق وتشكل تمثيلات داخلية معقدة. (المصدر: teortaxesTex, [email protected])

MLflow يعزز دعم سير عمل تحسين DSPy، مما يحسن قابلية المراقبة: أعلنت MLflow عن دعم تتبع سير عمل تحسين DSPy (وهو إطار عمل لبناء وتحسين تطبيقات النماذج اللغوية)، على غرار دعمها لتدريب PyTorch. من خلال ميزات التتبع والتسجيل التلقائي في MLflow، يمكن للمطورين تصحيح ومراقبة استدعاءات وحدات DSPy وتقييمها ومحسناتها بسلاسة، وبالتالي فهم وتكرار سير عمل GenAI بشكل أفضل، وتحقيق إدارة شاملة من التطوير إلى النشر. يوفر هذا للمطورين الذين يستخدمون DSPy لهندسة الأوامر وتطوير تطبيقات LLM قابلية مراقبة أقوى وممارسات MLOps أفضل. (المصدر: lateinteraction, dennylee)

ورقة بحثية جديدة تناقش طريقة التحسين الذاتي للنماذج متعددة الوسائط الموحدة UniRL: ورقة بحثية بعنوان “UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning” تقدم طريقة تحسين ذاتي بعد التدريب تسمى UniRL. تمكّن هذه الطريقة النموذج من توليد صور بناءً على الأوامر، واستخدام هذه الصور كبيانات تدريب تكرارية، دون الحاجة إلى بيانات صور خارجية. كما أنها تحقق تعزيزًا متبادلاً بين مهام التوليد ومهام الفهم: تُستخدم الصور المولدة للفهم، وتُستخدم نتائج الفهم للإشراف على التوليد. استكشف الباحثون الضبط الدقيق الخاضع للإشراف (SFT) وتحسين السياسة النسبية للمجموعة (GRPO) لتحسين النماذج، مثل Show-o و Janus. تتمثل مزايا UniRL في عدم الحاجة إلى بيانات صور خارجية، والقدرة على تحسين أداء المهام الفردية وتقليل عدم التوازن بين التوليد والفهم، والحاجة إلى خطوات تدريب إضافية قليلة فقط. (المصدر: HuggingFace Daily Papers)
ورقة بحثية Fast-dLLM: تسريع Diffusion LLM من خلال ذاكرة التخزين المؤقت KV والفك المتوازي: ورقة بحثية بعنوان “Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding” تعالج مشكلة بطء استدلال النماذج اللغوية الكبيرة القائمة على الانتشار (Diffusion LLM)، وتقترح طريقة تسريع لا تتطلب تدريبًا. تقدم هذه الطريقة آلية ذاكرة تخزين مؤقت KV تقريبية على مستوى الكتلة مخصصة لنماذج الانتشار ثنائية الاتجاه، وتقترح استراتيجية فك متوازية واعية بالثقة للحفاظ على جودة التوليد عند فك تشفير رموز متعددة في وقت واحد. أظهرت التجارب أن هذه الطريقة تحقق زيادة في الإنتاجية تصل إلى 27.6 مرة على نماذج LLaDA و Dream، مع خسارة ضئيلة جدًا في الدقة، مما يساعد على سد فجوة الأداء بين Diffusion LLM والنماذج ذاتية الانحدار. (المصدر: HuggingFace Daily Papers)
ورقة بحثية Uni-Instruct: تحقيق نماذج انتشار أحادية الخطوة من خلال تعليمات تباعد الانتشار الموحدة: ورقة بحثية بعنوان “Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction” تقترح إطار عمل نظريًا يُدعى Uni-Instruct، يوحد أكثر من 10 طرق حالية لتقطير الانتشار أحادي الخطوة. يعتمد هذا الإطار على نظرية توسيع الانتشار لعائلة f-divergence التي اقترحها المؤلفون، ويقدم نظرية رئيسية للتغلب على المشكلات الصعبة في f-divergence الأصلية الموسعة، مما يؤدي إلى دالة خسارة مكافئة وسهلة التعامل معها، وذلك من خلال تقليل عائلة f-divergence الموسعة لتدريب نماذج الانتشار أحادية الخطوة بفعالية. حقق Uni-Instruct أداء SOTA في التوليد أحادي الخطوة على معايير مثل CIFAR10 و ImageNet-64×64، وتم تطبيقه بالفعل على مهام مثل تحويل النص إلى ثلاثي الأبعاد. (المصدر: HuggingFace Daily Papers)
بحث جديد يستكشف العلاقة بين قدرة الاستدلال في النماذج اللغوية الكبيرة وظاهرة الهلوسة: ورقة بحثية بعنوان “Are Reasoning Models More Prone to Hallucination?” تدرس ما إذا كانت نماذج الاستدلال الكبيرة (LRM)، مع إظهارها لقدرات استدلال قوية لسلسلة الفكر (CoT)، أكثر عرضة للهلوسة. وجد البحث أن نماذج LRM التي خضعت لعملية ما بعد التدريب الكاملة (بما في ذلك SFT للبدء البارد و RL بالمكافآت القابلة للتحقق) عادة ما تقلل من الهلوسة، في حين أن التدريب من خلال التقطير فقط أو RL بدون ضبط دقيق للبدء البارد قد يؤدي إلى هلوسات أكثر دقة. كما حلل البحث السلوكيات المعرفية الرئيسية التي تؤدي إلى الهلوسة (مثل التكرار المعيب، وعدم تطابق التفكير مع الإجابة) بالإضافة إلى عدم التوافق بين عدم يقين النموذج ودقة الحقائق. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح KVzip: ضغط ذاكرة التخزين المؤقت KV غير المعتمد على الاستعلام وإعادة بناء السياق: ورقة بحثية بعنوان “KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction” تقدم طريقة إخلاء لذاكرة التخزين المؤقت KV غير معتمدة على الاستعلام تسمى KVzip، تهدف إلى إعادة استخدام ذاكرة التخزين المؤقت KV المضغوطة بفعالية لمواجهة استعلامات مختلفة. تقوم KVzip بتحديد أهمية أزواج KV المخزنة مؤقتًا عن طريق إعادة بناء السياق الأصلي من أزواج KV المخزنة باستخدام LLM الأساسي، وتقوم بإخلاء أزواج KV الأقل أهمية. أظهرت التجارب أن KVzip يمكن أن تقلل حجم ذاكرة التخزين المؤقت KV بمقدار 3-4 مرات، وتقلل من زمن انتقال فك تشفير FlashAttention بحوالي مرتين، مع خسارة أداء ضئيلة في مهام مثل الإجابة على الأسئلة، والاسترجاع، والاستدلال، وفهم الأكواد، وتدعم سياقًا يصل إلى 170 ألف توكن. (المصدر: HuggingFace Daily Papers)
💼 أعمال
أحدث تقرير مالي لشركة Nvidia يُظهر زيادة في الإيرادات بنسبة 69%، واستمرار الطلب القوي على رقائق الذكاء الاصطناعي: أعلنت شركة Nvidia العملاقة في مجال رقائق الذكاء الاصطناعي عن أحدث تقرير مالي لها، حيث بلغت مبيعاتها الفصلية 44.1 مليار دولار أمريكي، بزيادة سنوية قدرها 69%، وارتفع صافي الربح بنسبة 26% على أساس سنوي ليصل إلى 18.78 مليار دولار أمريكي. على الرغم من تجاوز المبيعات للتوقعات، إلا أن الأرباح كانت أقل قليلاً من المتوقع. تسببت القيود الأمريكية على تصدير الرقائق إلى الصين في خسارة للشركة قدرها 4.5 مليار دولار أمريكي، لكن الشركة تتوقع أن ترتفع إيراداتها في الربع القادم بنسبة 50% على أساس سنوي لتصل إلى 45 مليار دولار أمريكي، ويرجع ذلك أساسًا إلى مبيعات أحدث رقائق الذكاء الاصطناعي Blackwell. صرح الرئيس التنفيذي لشركة Nvidia، جنسن هوانغ، بأن دول العالم أدركت أن الذكاء الاصطناعي سيصبح بنية تحتية. وبفضل التقرير المالي الإيجابي، تجاوزت القيمة السوقية لشركة Nvidia قيمة شركة Apple لفترة وجيزة، لتحتل المرتبة الثانية عالميًا. تعمل الشركة بنشاط على توسيع أسواقها في أوروبا وآسيا والشرق الأوسط، وأصبح بيع الرقائق للعملاء الحكوميين اتجاهًا استراتيجيًا مهمًا. (المصدر: dotey)

أبرز شركات رأس المال الاستثماري في وادي السيليكون تتجه نحو أجهزة الذكاء الاصطناعي، بحثًا عن الجيل القادم من أجهزة التفاعل: مع التطور السريع لخوارزميات الذكاء الاصطناعي، يتجه الاستثمار في وادي السيليكون من التركيز على تحسين الخوارزميات البحتة إلى الأجهزة القادرة على استيعاب قدرات الذكاء الاصطناعي. تعمل شركات عملاقة مثل جوجل و OpenAI (التي استحوذت على شركة أجهزة الذكاء الاصطناعي io) و Meta و Apple بنشاط في مجال أجهزة الذكاء الاصطناعي مثل النظارات الذكية وأجهزة الواقع المعزز. استثمرت Sequoia Capital في نظارات الذكاء الاصطناعي Brilliant Labs، واستثمرت IDG Capital في الكمبيوتر المحمول بدون شاشة Spacetop. كما تعمل شركات ناشئة مثل Celestial AI (توصيل الرقائق الضوئية) و NeuroFlex (مواد واجهات الدماغ والحاسوب المرنة) و Luminai (وحدات الواقع المعزز خفيفة الوزن) و BioLink Systems (مستشعرات الذكاء الاصطناعي القابلة للهضم) و SynthSense (أنظمة استشعار روبوتية متعددة الوسائط) على دفع عجلة الابتكار في مجال أجهزة الذكاء الاصطناعي في مجالاتها الخاصة. يعكس هذا اهتمام الصناعة بـ “جسم” الذكاء الاصطناعي، مع الاعتقاد بأن ابتكار الأجهزة سيحدد سرعة وحدود تطبيق تكنولوجيا الذكاء الاصطناعي، وسيعيد تشكيل طرق التفاعل بين الإنسان والآلة. (المصدر: 36氪)

Sequoia تستثمر في شركة ناشئة جديدة لوكلاء البرمجة بالذكاء الاصطناعي، متحدية الشركات العملاقة الحالية: وفقًا لتقرير LiorOnAI، استثمرت Sequoia Capital في شركة ناشئة جديدة تهدف إلى تحدي أدوات البرمجة الحالية القائمة على الذكاء الاصطناعي مثل Devin و Cursor و OpenAI Codex. يُقال إن وكيل الذكاء الاصطناعي الذي طورته الشركة قادر على قراءة قاعدة الأكواد بأكملها، وإكمال مهام مثل كتابة واختبار وإصلاح ودمج طلبات السحب (PR) تلقائيًا، بهدف توفير مساعد مهندس برمجيات مستقل تمامًا يعمل على مدار الساعة. يمثل هذا تصعيدًا إضافيًا للمنافسة في مجال أتمتة تطوير البرمجيات باستخدام الذكاء الاصطناعي. (المصدر: LiorOnAI)
🌟 مجتمع
نقاش مجتمعي حول قصور النماذج اللغوية الكبيرة في اتباع تعليمات الطول و”الدعاية المفرطة”: أثارت دراسة LIFEBench نقاشًا في المجتمع، حيث اتفق العديد من المستخدمين والمطورين على قصور النماذج اللغوية الكبيرة الحالية في اتباع تعليمات الطول الدقيقة، خاصة فيما يتعلق بتوليد النصوص الطويلة. أشار أعضاء المجتمع إلى أن النماذج غالبًا ما تنتج محتوى لا يتوافق مع الطول المطلوب، أو تنهي التوليد مبكرًا، أو حتى ترفض توليد نصوص طويلة. وفي الوقت نفسه، غالبًا ما يكون هناك تباين بين عدد التوكنات الأقصى للإخراج الذي تعلن عنه النماذج وقدرتها الفعلية على التوليد الفعال، مما يجعل ظاهرة “الدعاية المفرطة” شائعة. يتطلع الجميع إلى أن تتمكن النماذج المستقبلية من خلال استراتيجيات تدريب وأنظمة تقييم أفضل، من تحسين قدرتها على تنفيذ تعليمات الطول وأدائها الفعلي، لتحقيق “عدد كلمات مستهدف ومحتوى عالي الجودة”. (المصدر: 量子位)
ملاحظات المستخدمين حول ظاهرة “الإطراء” المفرط (Glazing) في روبوتات الدردشة بالذكاء الاصطناعي: أبلغ مستخدمون في مجتمع Reddit أنهم عند استخدام روبوتات الدردشة بالذكاء الاصطناعي مثل ChatGPT، يواجهون بشكل متكرر قيام النموذج بمدح وتأكيد مفرط لأسئلة المستخدم أو مدخلاته (يُعرف بالعامية بـ “glazing” أو “sycophancy”)، مثل قول “هذه ملاحظة ذكية جدًا!”. أعرب المستخدمون عن انزعاجهم من ذلك، معتبرين أن هذا الإطراء غير ضروري ويؤثر على طبيعية التفاعل. ناقش أعضاء المجتمع طرقًا لتقليل هذه الظاهرة من خلال أوامر محددة (مثل مطالبة النموذج بالإجابة بشكل مباشر وموضوعي ومحايد)، وتبادلوا خبراتهم ومشاعرهم. كما أشار بعض المستخدمين إلى أن DeepSeek-R1-0528 يميل إلى سلوك مشابه. (المصدر: Reddit r/ChatGPT, teortaxesTex)

نقاش مجتمعي: هل الذكاء الاصطناعي “يسرق الوظائف” حقًا، أم أنه يكشف عن فائض وظائف “الوسيط”؟: هناك نقاش على Reddit يرى أنه بدلاً من القول بأن الذكاء الاصطناعي “يسرق وظائفنا”، فإنه يكشف عن طبيعة “الوسيط” والفائض المحتمل في العديد من الوظائف الحالية (مثل معالجة الأعمال الورقية، وإعادة توجيه رسائل البريد الإلكتروني، ونقل المعلومات بين صانعي القرار، وما إلى ذلك). أثار هذا الرأي تفكيرًا حول طبيعة العمل، وتوزيع القيمة الاجتماعية، وتحول دور الإنسان في عصر الذكاء الاصطناعي. أشار المعلقون إلى أنه حتى لو كانت بعض الوظائف ذات طبيعة “وسيطة” بالفعل، فإنها توفر سبل عيش للناس، وأن التحول الذي يجلبه الذكاء الاصطناعي يتطلب دعمًا على المستوى المجتمعي وتنمية مهارات جديدة. (المصدر: Reddit r/ArtificialInteligence)
Ollama تثير استياء مستخدمي المجتمع بسبب تسمية النماذج بشكل غير دقيق: أشار مستخدمون في مجتمع Reddit r/LocalLLaMA إلى أن Ollama تستخدم تسميات غير دقيقة أو مربكة للنماذج. على سبيل المثال، اختصار DeepSeek-R1-Distill-Qwen-32B إلى deepseek-r1:32b، قد يجعل المستخدمين الجدد يعتقدون خطأً أنهم يشغلون نموذج DeepSeek خالص، متجاهلين طبيعته المقطرة من Qwen. يرى المستخدمون أن طريقة التسمية هذه لا تتوافق مع عادات منصات مثل HuggingFace، وتفتقر إلى الشفافية، وقد تؤدي إلى تكوين تصورات خاطئة لدى المستخدمين حول خصائص النموذج. (المصدر: Reddit r/LocalLLaMA)

لغات البرمجة تساهم بشكل كبير في نجاح النماذج اللغوية الكبيرة: يؤكد نقاش مجتمعي على أن لغات البرمجة، باعتبارها مادة تدريب عالية الجودة، قد لعبت دورًا رئيسيًا في نجاح تطوير النماذج اللغوية الكبيرة، وذلك بفضل تعريفاتها المنطقية الواضحة وسهولة التحقق من صحة نتائجها. فهي لم توفر للنماذج مصدرًا للمعرفة المنظمة فحسب، بل أرست أيضًا الأساس لتعلم النماذج للاستدلال وتوليد أكواد قابلة للتنفيذ. (المصدر: dotey)

💡 أخرى
Indoor Robotics تطلق طائرة بدون طيار روبوتية أمنية ذاتية الملاحة تعتمد على الذكاء الاصطناعي: عرضت شركة Indoor Robotics طائرة بدون طيار روبوتية أمنية ذاتية الملاحة تعتمد على الذكاء الاصطناعي. صُممت هذه الطائرة خصيصًا للبيئات الداخلية، وهي قادرة على تنفيذ مهام الدوريات والمراقبة الأمنية بشكل مستقل، مستخدمة الذكاء الاصطناعي للملاحة وتحديد التهديدات، مما يوفر حلاً آليًا مبتكرًا للأمن الداخلي. (المصدر: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics تقوم بترقية الروبوت الصناعي ذي العجلات B2-W، معززة وظائفه: قامت Unitree Robotics بترقية وظائف روبوتها الصناعي ذي العجلات B2-W، مانحة إياه المزيد من القدرات المثيرة. يجمع هذا الروبوت بين مرونة الحركة بالعجلات وتعدد استخدامات الروبوتات، ويهدف إلى تطبيقه في مختلف السيناريوهات الصناعية، لرفع مستوى الأتمتة وكفاءة العمليات. (المصدر: Ronald_vanLoon)
لينوفو تطلق الروبوت سداسي الأرجل Daystar، موجهًا للمجالات الصناعية والبحثية والتعليمية: أطلقت شركة لينوفو (Lenovo) روبوتًا سداسي الأرجل يُدعى Daystar. صُمم هذا الروبوت خصيصًا للتطبيقات الصناعية والأبحاث العلمية والأغراض التعليمية، وتسمح له بنيته متعددة الأرجل بالتكيف مع التضاريس المعقدة، مما يوفر خيار منصة روبوتية جديدة للمجالات ذات الصلة. (المصدر: Ronald_vanLoon)