
كلمات مفتاحية:DeepSeek-R1-0528, الذكاء الاصطناعي الوكيل, النموذج متعدد الوسائط, الذكاء الاصطناعي مفتوح المصدر, التعلم المعزز, تحرير الصور, النموذج اللغوي الكبير, اختبار معايير الذكاء الاصطناعي, DeepSeek-R1-0528-Qwen3-8B, أداة تتبع الدائرة, آلة جودل داروين, FLUX.1 Kontext, الاسترجاع الوكيلي
🔥 أبرز العناوين
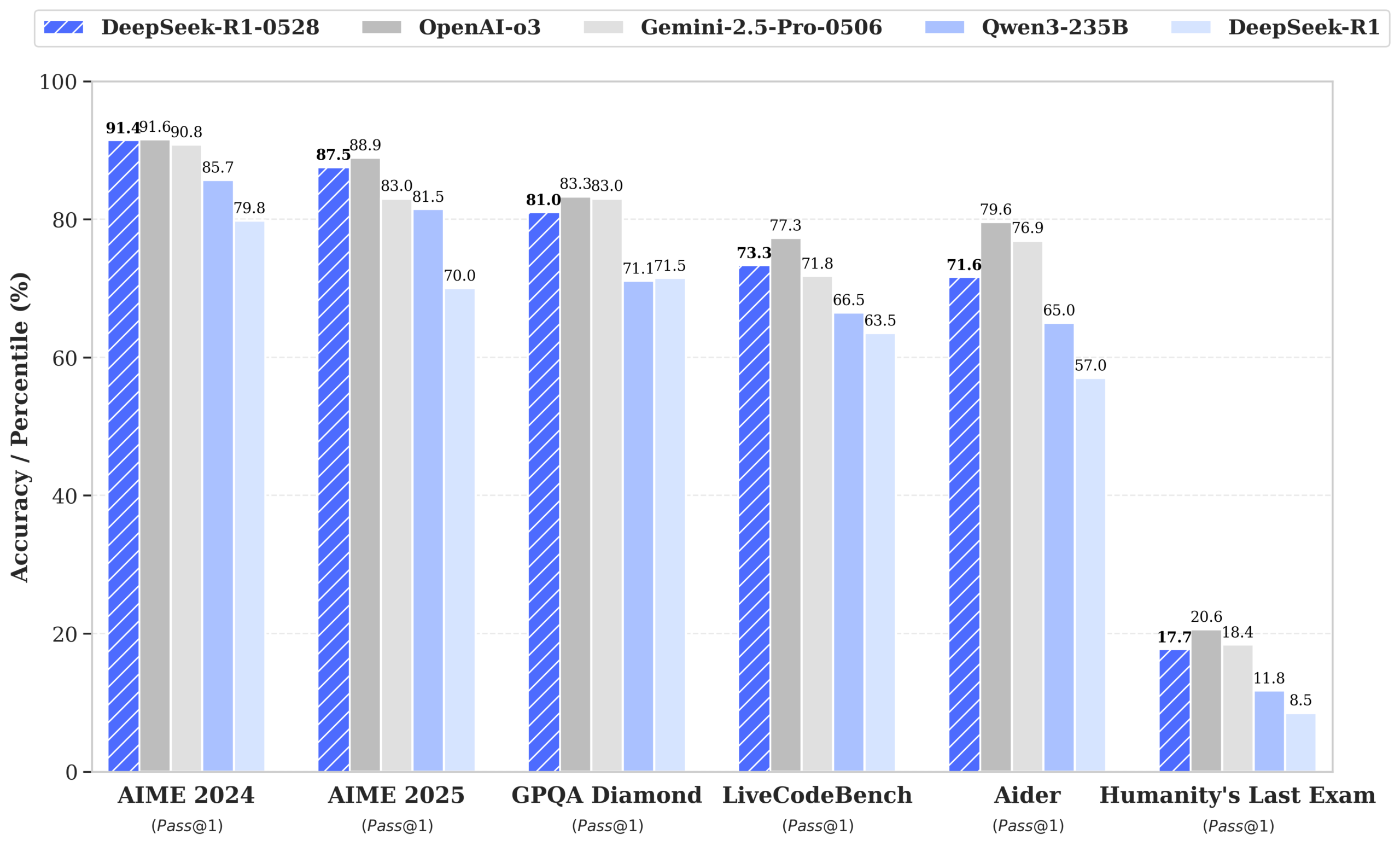
DeepSeek تطلق نموذج R1-0528 بأداء يقترب من GPT-4o و Gemini 2.5 Pro، ويتصدر قائمة النماذج مفتوحة المصدر: أظهر DeepSeek-R1-0528 أداءً متميزًا في العديد من الاختبارات المعيارية مثل الرياضيات والبرمجة والاستدلال المنطقي العام، خاصة في اختبار AIME 2025 حيث ارتفعت دقته من 70% إلى 87.5%. الإصدار الجديد قلل بشكل كبير من معدل الهلوسة (حوالي 45-50%)، وعزز قدرات إنشاء كود الواجهة الأمامية، ويدعم إخراج JSON واستدعاءات الدوال. في الوقت نفسه، أصدرت DeepSeek نموذج DeepSeek-R1-0528-Qwen3-8B المعدل بدقة استنادًا إلى Qwen3-8B Base، والذي يأتي أداؤه في اختبار AIME 2024 ثانيًا بعد R1-0528، متجاوزًا Qwen3-235B. يعزز هذا التحديث مكانة DeepSeek كثاني أكبر مختبر للذكاء الاصطناعي في العالم ورائد في مجال المصادر المفتوحة. (المصدر: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
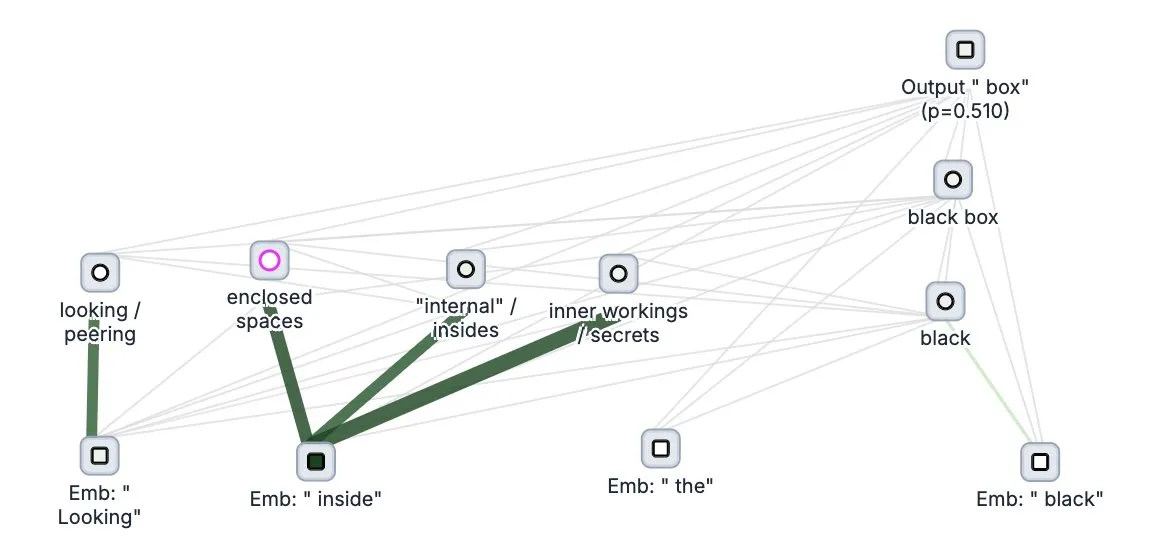
Anthropic تفتح مصدر أداة “تتبع التفكير” للنماذج الكبيرة Circuit Tracer: فتحت شركة Anthropic مصدر أداة Circuit Tracer لأبحاث قابلية تفسير النماذج الكبيرة، مما يسمح للباحثين بإنشاء واستكشاف “خرائط الإسناد” بشكل تفاعلي لفهم عمليات “التفكير” الداخلية وآليات اتخاذ القرار في نماذج اللغة الكبيرة (LLM). تهدف هذه الأداة إلى مساعدة الباحثين على التعمق أكثر في الأعمال الداخلية لـ LLM، مثل كيفية استخدام النموذج لميزات معينة للتنبؤ بالرمز (token) التالي. يمكن للمستخدمين تجربة الأداة على Neuronpedia، حيث يمكنهم إدخال جمل للحصول على مخطط دائرة يوضح استخدام النموذج للميزات. (المصدر: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
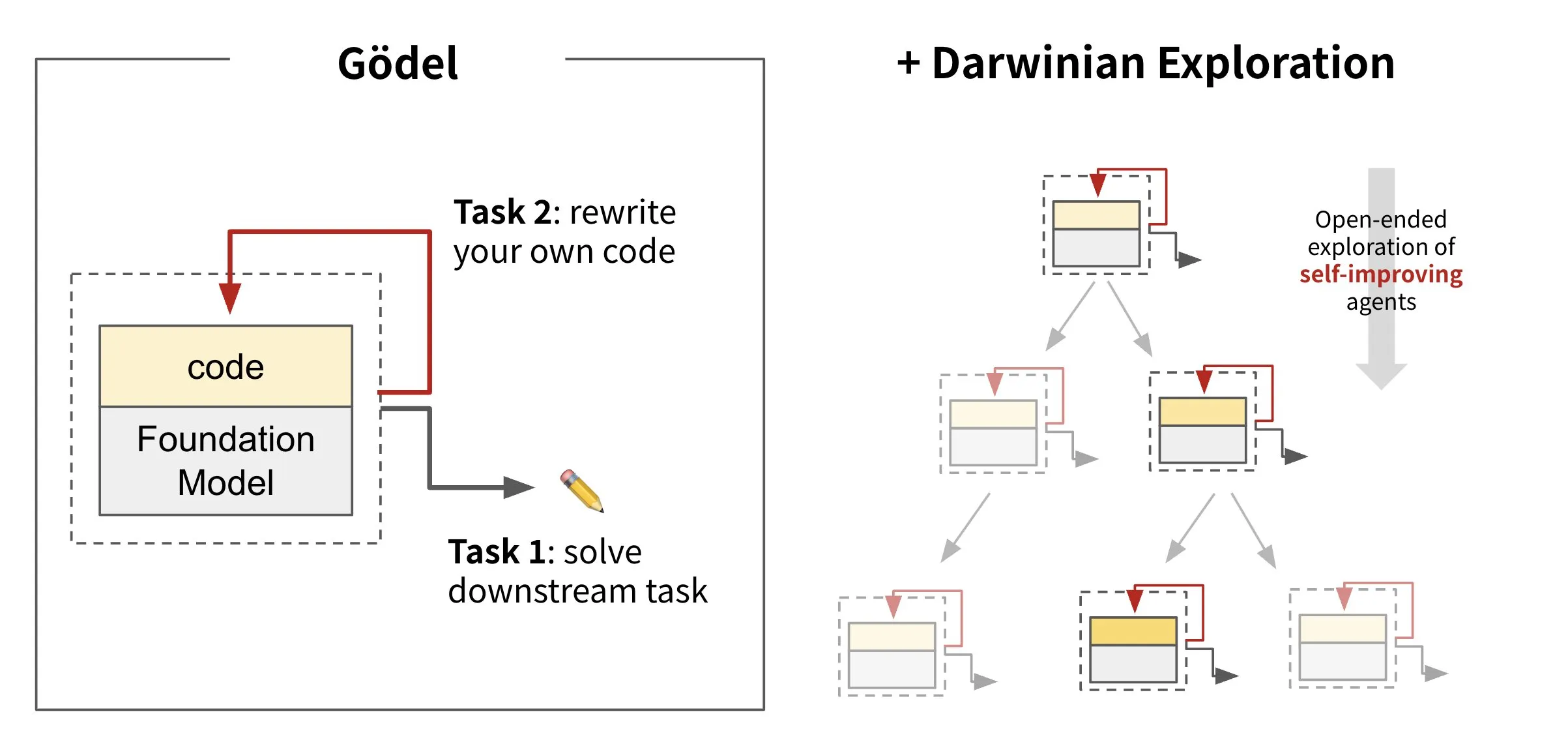
Sakana AI تطلق إطار عمل الوكلاء الأذكياء ذاتي التطور Darwin Gödel Machine (DGM): أطلقت Sakana AI إطار عمل Darwin Gödel Machine (DGM)، وهو إطار عمل للوكلاء الأذكياء قادر على تحسين نفسه ذاتيًا من خلال إعادة كتابة الكود الخاص به. يستلهم DGM من نظرية التطور، ويحافظ على سلالة متوسعة باستمرار من متغيرات الوكلاء لاستكشاف مساحة تصميم الوكلاء الأذكياء ذاتية التحسين بطريقة مفتوحة. يهدف هذا الإطار إلى تمكين أنظمة الذكاء الاصطناعي من تعلم وتطوير قدراتها ذاتيًا بمرور الوقت، تمامًا مثل البشر. في SWE-bench، رفع DGM الأداء من 20.0% إلى 50.0%؛ وفي Polyglot، ارتفع معدل النجاح من 14.2% إلى 30.7%. (المصدر: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs تطلق نموذج تحرير الصور FLUX.1 Kontext، ويدعم الإدخال المختلط للنصوص والصور: أطلقت Black Forest Labs الجيل الجديد من نموذج تحرير الصور FLUX.1 Kontext، والذي يعتمد على بنية مطابقة التدفق (flow matching architecture)، وهو قادر على قبول النصوص والصور كمدخلات في نفس الوقت، مما يحقق إنشاء وتحرير صور مدركة للسياق. يتميز هذا النموذج بأداء متميز في تناسق الشخصيات، والتحرير المحلي، والإشارة إلى الأسلوب، وسرعة التفاعل، على سبيل المثال، يستغرق إنشاء صورة بدقة 1024×1024 من 3 إلى 5 ثوانٍ فقط. أظهر اختبار Replicate أن تأثيرات التحرير الخاصة به تتفوق على GPT-4o-Image وبتكلفة أقل. يوفر Kontext إصدارات Pro و Max، ويخطط لإطلاق إصدار Dev مفتوح المصدر. (المصدر: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 اتجاهات
Google DeepMind تطلق النموذج الطبي متعدد الوسائط MedGemma: أطلقت Google DeepMind نموذج MedGemma، وهو نموذج مفتوح قوي مصمم خصيصًا لفهم النصوص والصور الطبية متعددة الوسائط. يتم توفير هذا النموذج كجزء من Health AI Developer Foundations، ويهدف إلى تعزيز قدرة الذكاء الاصطناعي على التطبيق في المجال الطبي، خاصة في الجمع بين النصوص والصور الطبية (مثل صور الأشعة السينية) لإجراء تحليل شامل. (المصدر: GoogleDeepMind)
Perplexity AI تطلق Perplexity Labs لتمكين معالجة المهام المعقدة: أطلقت Perplexity AI ميزة جديدة باسم Perplexity Labs، مصممة خصيصًا لمعالجة المهام الأكثر تعقيدًا، وتهدف إلى تزويد المستخدمين بقدرات تحليل وبناء تشبه فريق بحث كامل. يمكن للمستخدمين من خلال Labs بناء تقارير تحليلية وعروض تقديمية ولوحات معلومات ديناميكية وغيرها. الميزة متاحة حاليًا لجميع مستخدمي Pro، وتُظهر إمكاناتها في البحث العلمي وتحليل السوق وإنشاء تطبيقات مصغرة (مثل الألعاب ولوحات المعلومات). (المصدر: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan و Tencent Music تطلقان HunyuanVideo-Avatar، الذي يمكنه إنشاء مقاطع فيديو غنائية واقعية من الصور: أطلقت Tencent Hunyuan و Tencent Music بشكل مشترك نموذج HunyuanVideo-Avatar، الذي يمكنه دمج الصور والصوت الذي يحمله المستخدم، والكشف تلقائيًا عن سياق المشهد والعواطف، لإنشاء مقاطع فيديو ناطقة أو غنائية ذات مزامنة شفاه واقعية وتأثيرات بصرية ديناميكية. تدعم هذه التقنية أنماطًا متعددة وقد تم فتح مصدرها. (المصدر: huggingface, thursdai_pod)
إصدار Apache Spark 4.0.0 رسميًا، مع تحسينات في SQL و Spark Connect ودعم لغات متعددة: تم إصدار Apache Spark 4.0.0 رسميًا، مما يوفر تحسينات كبيرة في وظائف SQL، وتحسينات في Spark Connect تجعل تشغيل التطبيقات أكثر سهولة، بالإضافة إلى دعم لغات جديدة. قام هذا التحديث بحل أكثر من 5100 مشكلة، وشارك فيه أكثر من 390 مساهمًا. (المصدر: matei_zaharia, lateinteraction)

إصدار نموذج الفيديو Kling 2.1، مع دمج OpenArt لدعم تناسق الشخصيات: أطلقت Kling AI نموذج الفيديو الخاص بها Kling 2.1، وبالتعاون مع OpenArt، لدعم تحقيق تناسق الشخصيات في سرد قصص الفيديو بالذكاء الاصطناعي. حسّن Kling 2.1 محاذاة الأوامر النصية، وسرعة إنشاء الفيديو، ووضوح حركة الكاميرا، ويدعي أنه يمتلك أفضل تأثيرات تحويل النص إلى فيديو. يدعم الإصدار الجديد إخراج 720p (قياسي) و 1080p (احترافي)، وميزة تحويل الصورة إلى فيديو متاحة الآن، بينما ستتوفر ميزة تحويل النص إلى فيديو قريبًا. (المصدر: Kling_ai, NandoDF)
Hume تطلق نموذج الصوت EVI 3، القادر على فهم وإنشاء أي صوت بشري: أطلقت Hume أحدث نموذج لغة صوتي لها EVI 3، بهدف تحقيق ذكاء صوتي عالمي. يستطيع EVI 3 فهم وإنشاء أي صوت بشري، وليس فقط أصوات عدد قليل من المتحدثين المحددين، مما يوفر نطاقًا أوسع من القدرة التعبيرية وفهمًا أعمق لنبرة الصوت والإيقاع ودرجة الصوت وأسلوب الكلام. تهدف هذه التقنية إلى تمكين كل شخص من امتلاك ذكاء اصطناعي فريد وموثوق به يمكن التعرف عليه من خلال الصوت. (المصدر: AlanCowen, AlanCowen, _akhaliq)
Alibaba تطلق WebDancer لاستكشاف وكلاء البحث عن المعلومات المستقلين: أطلقت Alibaba مشروع WebDancer، الذي يهدف إلى بحث وتطوير وكلاء ذكاء اصطناعي قادرين على البحث عن المعلومات بشكل مستقل. يركز هذا المشروع على كيفية جعل وكلاء الذكاء الاصطناعي أكثر فعالية في التنقل في بيئة الويب، وفهم المعلومات، وإكمال مهام الحصول على المعلومات المعقدة. (المصدر: _akhaliq)
MiniMax تفتح مصدر إطار V-Triune ونموذج Orsta لتوحيد مهام الاستدلال والإدراك البصري في التعلم المعزز: فتحت شركة الذكاء الاصطناعي MiniMax مصدر إطارها الموحد للتعلم المعزز البصري V-Triune وسلسلة نماذج Orsta (من 7B إلى 32B) القائمة على هذا الإطار. من خلال تصميم مكون من ثلاث طبقات وآلية مكافأة التقاطع الديناميكي فوق الاتحاد (IoU)، يمكّن هذا الإطار لأول مرة نماذج اللغة البصرية (VLM) من تعلم مهام الاستدلال البصري والإدراك بشكل مشترك في عملية واحدة بعد التدريب، مما أدى إلى تحسن كبير في الأداء على مقياس MEGA-Bench Core. (المصدر: 量子位)

مختبر شنغهاي للذكاء الاصطناعي وغيره يطلقون معيارًا جديدًا لتحرير الصور RISEBench، لاختبار قدرة النماذج على الاستدلال العميق: أطلق مختبر شنغهاي للذكاء الاصطناعي بالتعاون مع عدة جامعات معيارًا جديدًا لتقييم تحرير الصور يسمى RISEBench، يتضمن 360 حالة صعبة مصممة من قبل خبراء بشريين، تغطي أربعة أنواع أساسية من الاستدلال: الزمني، والسببي، والمكاني، والمنطقي. أظهرت نتائج الاختبار أنه حتى GPT-4o-Image لم يتمكن من إكمال سوى 28.9% من المهام، مما يكشف عن أوجه القصور في النماذج متعددة الوسائط الحالية في فهم التعليمات المعقدة والتحرير البصري. (المصدر: 36氪)

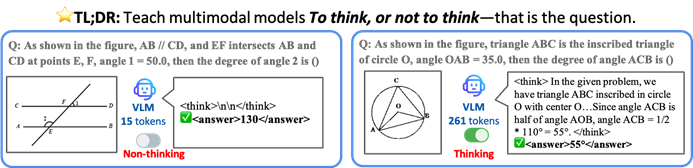
جامعة هونغ كونغ الصينية وغيرها يقترحون إطار TON، لجعل نماذج الذكاء الاصطناعي تفكر بشكل انتقائي لتعزيز الكفاءة والدقة: اقترح باحثون من جامعة هونغ كونغ الصينية ومختبر Show Lab بجامعة سنغافورة الوطنية إطار TON (Think Or Not)، الذي يمكّن نماذج اللغة البصرية (VLM) من الحكم ذاتيًا على ما إذا كانت بحاجة إلى استدلال صريح. من خلال “التخلص من الأفكار” والتعلم المعزز، يجعل هذا الإطار النموذج يجيب مباشرة على الأسئلة البسيطة، ويقوم باستدلال مفصل للمسائل المعقدة، وبالتالي يقلل متوسط طول إخراج الاستدلال بنسبة تصل إلى 90% دون التضحية بالدقة، بل إن دقة بعض المهام زادت بنسبة 17%. (المصدر: 36氪)
Microsoft Copilot يدمج Instacart لتحقيق تسوق البقالة بمساعدة الذكاء الاصطناعي: أعلن مصطفى سليمان، رئيس قسم الذكاء الاصطناعي في Microsoft، أن Copilot قد دمج الآن خدمة Instacart، مما يتيح للمستخدمين إكمال العملية بأكملها بسلاسة من إنشاء الوصفات، وإنشاء قوائم التسوق، إلى توصيل البقالة إلى المنزل من خلال تطبيق Copilot. يمثل هذا توسعًا إضافيًا لمساعدي الذكاء الاصطناعي في مجال خدمات الحياة اليومية. (المصدر: mustafasuleyman)
🧰 أدوات
LlamaIndex تطلق كود مصدر BundesGPT وأداة create-llama لتبسيط بناء تطبيقات الذكاء الاصطناعي: أعلن Jerry Liu من LlamaIndex عن توفير كود مصدر BundesGPT، والترويج لأداتهم مفتوحة المصدر create-llama. تهدف هذه الأداة، المبنية على LlamaIndex، إلى مساعدة المطورين على بناء ودمج بيانات الشركات ووكلاء الذكاء الاصطناعي بسهولة، كما أن وضعها الجديد eject-mode يجعل إنشاء واجهات ذكاء اصطناعي قابلة للتخصيص بالكامل مثل BundesGPT أمرًا بسيطًا للغاية. تهدف هذه الخطوة إلى دعم خطة ألمانيا المحتملة لتوفير اشتراك ChatGPT Plus مجاني لكل مواطن. (المصدر: jerryjliu0)
يمكن تحويل أدوات LangChain إلى أدوات MCP ودمجها في خادم FastMCP: يمكن لمستخدمي LangChain الآن تحويل أدوات LangChain إلى أدوات MCP (Model Component Protocol) وإضافتها مباشرة إلى خادم FastMCP. من خلال تثبيت مكتبة langchain-mcp-adapters، يمكن للمطورين استخدام مجموعة أدوات LangChain بشكل أكثر ملاءمة في نظام MCP البيئي، مما يعزز قابلية التشغيل البيني بين أطر عمل الذكاء الاصطناعي المختلفة. (المصدر: LangChainAI, hwchase17)
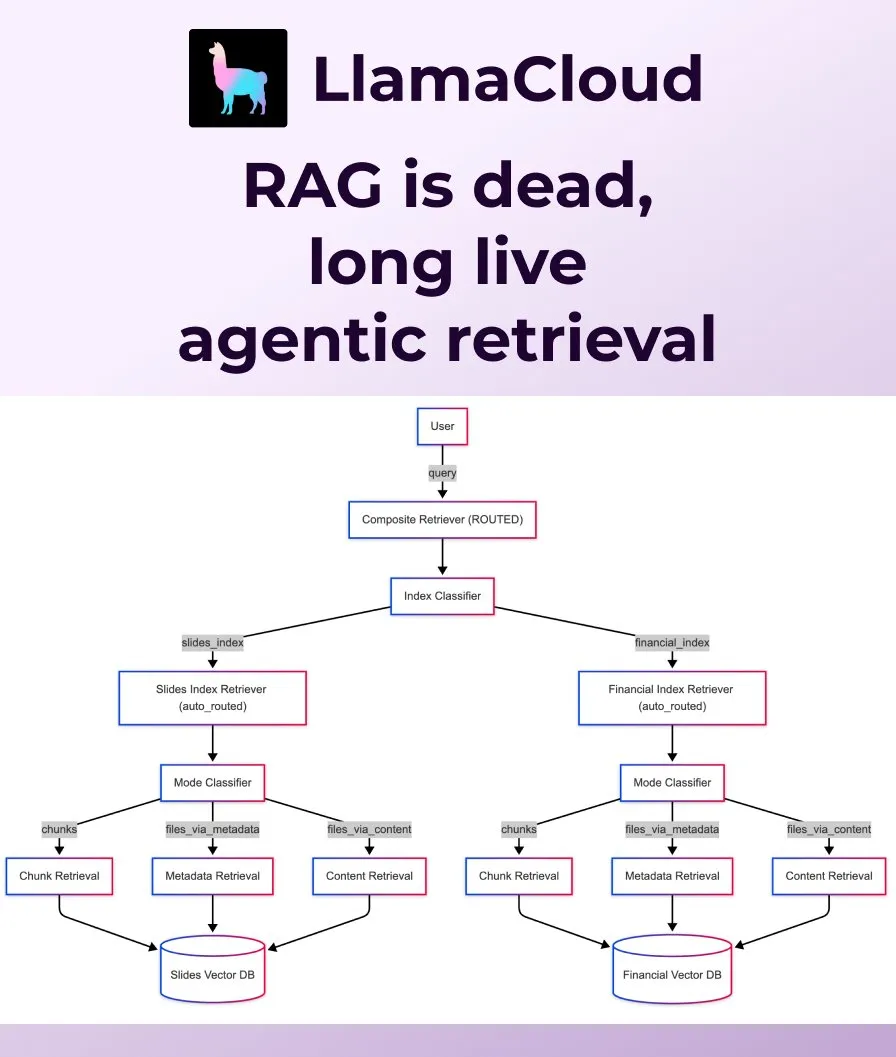
LlamaIndex تطلق Agentic Retrieval ليحل محل RAG التقليدي: ترى LlamaIndex أن RAG (Retrieval Augmented Generation) التقليدي البسيط لم يعد كافياً لتلبية احتياجات التطبيقات الحديثة، وأطلقت Agentic Retrieval. هذا الحل مدمج في LlamaCloud، ويسمح للوكلاء باسترداد ملفات كاملة أو كتل بيانات محددة ديناميكيًا من مستودع معرفة واحد أو أكثر (مثل Sharepoint, Box, GDrive, S3) بناءً على محتوى السؤال، مما يحقق الحصول على سياق أكثر ذكاءً ومرونة. (المصدر: jerryjliu0, jerryjliu0)
Ollama يدعم تشغيل نموذج Osmosis-Structure-0.6B لتحويل البيانات غير المهيكلة: يمكن للمستخدمين الآن تشغيل نموذج Osmosis-Structure-0.6B من خلال Ollama. هذا نموذج صغير جدًا قادر على تحويل أي بيانات غير مهيكلة إلى تنسيق محدد (مثل JSON Schema)، ويمكن استخدامه مع أي نموذج، وهو مناسب بشكل خاص لمهام الاستدلال التي تتطلب مخرجات مهيكلة. (المصدر: ollama)
CrewAI تحدث وثائق Gemini لتبسيط عملية البدء: قام فريق CrewAI بتحديث وثائقه المتعلقة بـ Google Gemini API، بهدف مساعدة المستخدمين على البدء بسهولة أكبر في استخدام نماذج Gemini لبناء وكلاء ذكاء اصطناعي. قد تتضمن الوثائق الجديدة إرشادات أوضح أو أمثلة على التعليمات البرمجية أو أفضل الممارسات. (المصدر: _philschmid)
Requesty تطلق ميزة Smart Routing لاختيار أفضل LLM تلقائيًا لـ OpenWebUI: أطلقت Requesty ميزة Smart Routing، التي يمكن دمجها بسلاسة مع OpenWebUI، لاختيار أفضل LLM تلقائيًا (مثل GPT-4o, Claude, Gemini) بناءً على نوع المهمة التي يطلبها المستخدم. يحتاج المستخدمون فقط إلى استخدام smart/task كمعرف للنموذج، ويمكن للنظام تصنيف الطلب في حوالي 65 مللي ثانية وتوجيهه إلى النموذج الأنسب بناءً على التكلفة والسرعة والجودة. تهدف هذه الميزة إلى تبسيط اختيار النموذج وتحسين تجربة المستخدم. (المصدر: Reddit r/OpenWebUI)
EvoAgentX: إطلاق أول إطار عمل مفتوح المصدر للتطور الذاتي لوكلاء الذكاء الاصطناعي: أطلق فريق بحثي من جامعة غلاسكو البريطانية EvoAgentX، وهو أول إطار عمل مفتوح المصدر للتطور الذاتي لوكلاء الذكاء الاصطناعي في العالم. يدعم بناء سير العمل بنقرة واحدة ويقدم آلية “التطور الذاتي”، مما يمكّن أنظمة الوكلاء المتعددين من تحسين هيكلها وأدائها باستمرار وفقًا للتغيرات في البيئة والأهداف، ويهدف إلى دفع أنظمة وكلاء الذكاء الاصطناعي المتعددين من “التصحيح اليدوي” إلى “التطور المستقل”. أظهرت التجارب تحسنًا في الأداء بمتوسط 8%-13% في مهام الإجابة على الأسئلة متعددة الخطوات، وإنشاء الأكواد، والاستدلال الرياضي. (المصدر: 36氪)

📚 موارد تعليمية
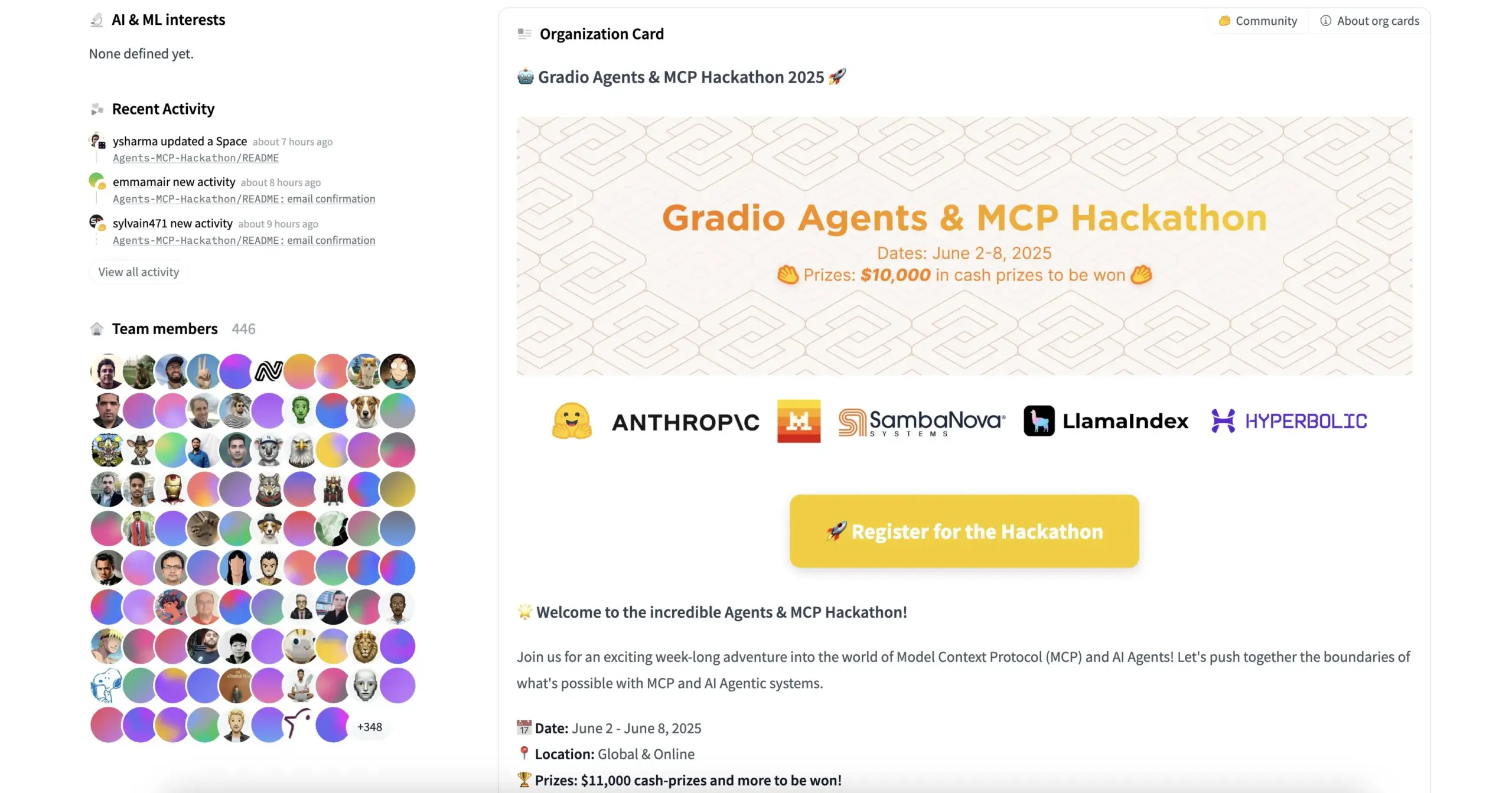
HuggingFace و Gradio وغيرهما ينظمون هاكاثون Agents & MCP Hackathon، ويقدمون جوائز سخية وحصص API: ستنظم HuggingFace و Gradio و Anthropic و SambaNovaAI و MistralAI و LlamaIndex وغيرها من المؤسسات هاكاثون Gradio Agents & MCP Hackathon (من 2 إلى 8 يونيو). يقدم الحدث جوائز إجمالية بقيمة 11000 دولار أمريكي، ويوفر للمسجلين الأوائل حصص API مجانية من Hyperbolic و Anthropic و Mistral و SambaNova. كما تعهدت Modal Labs بتوفير رصيد GPU بقيمة 250 دولارًا لجميع المشاركين، بإجمالي يتجاوز 300 ألف دولار. (المصدر: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain تشارك ممارسات JPMorgan Chase في استخدام أنظمة الوكلاء المتعددين للبحث الاستثماري: شارك David Odomirok و Zheng Xue من JPMorgan Chase كيف قاما ببناء نظام ذكاء اصطناعي متعدد الوكلاء يسمى “Ask David”. يهدف هذا النظام إلى أتمتة عمليات البحث الاستثماري لآلاف المنتجات المالية، مما يوضح إمكانات بنية الوكلاء المتعددين في التحليل المالي المعقد. (المصدر: LangChainAI, hwchase17)
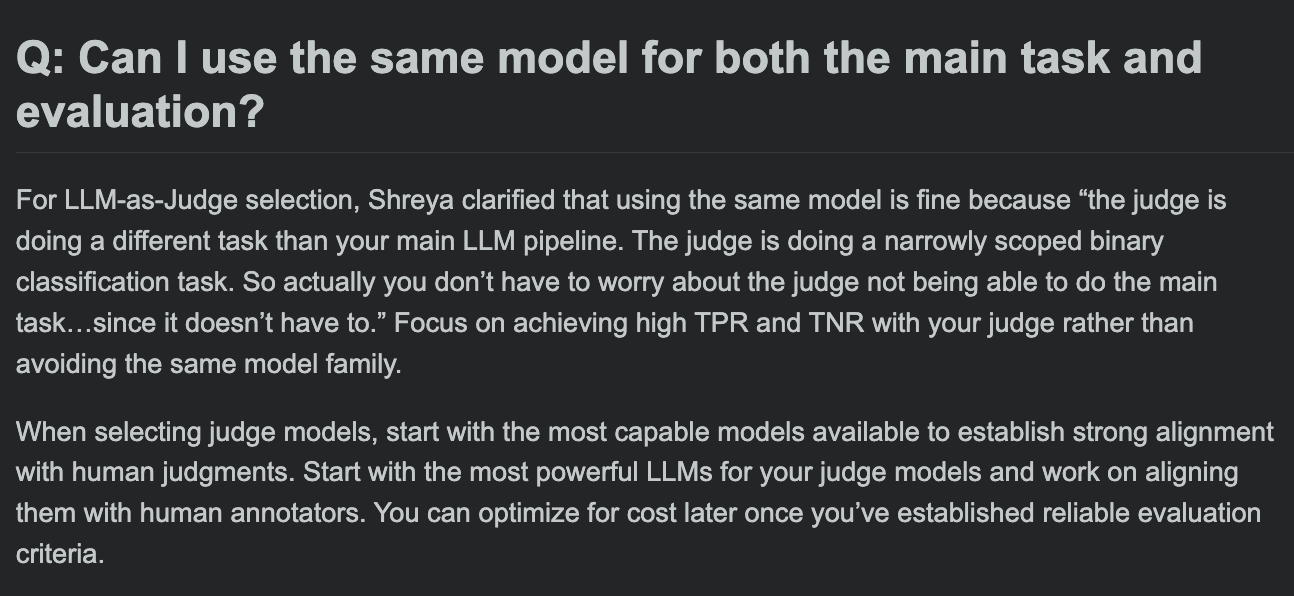
Hamel Husain يشارك الأسئلة الشائعة حول دورة تقييم LLM، ويناقش ما إذا كان نموذج التقييم ونموذج المهمة الرئيسية يمكن أن يكونا متماثلين: في جلسة الأسئلة والأجوبة لدورته التدريبية حول تقييم LLM، ناقش Hamel Husain سؤالًا شائعًا: هل يمكن استخدام نفس النموذج لمعالجة المهمة الرئيسية وتقييم المهمة؟ تساعد هذه المناقشة المطورين على فهم التحيزات المحتملة وأفضل الممارسات في تقييم النماذج. (المصدر: HamelHusain, HamelHusain)
The Rundown AI تطلق منصة تعليمية مخصصة للذكاء الاصطناعي: أعلنت The Rundown AI عن إطلاق أول منصة تعليمية مخصصة للذكاء الاصطناعي في العالم، تقدم تدريبًا مخصصًا وحالات استخدام وورش عمل مباشرة لمختلف الصناعات ومستويات المهارة وسير العمل اليومي. يتضمن محتوى المنصة 16 دورة شهادة متخصصة في الذكاء الاصطناعي في مجالات التكنولوجيا، وأكثر من 300 حالة استخدام واقعية للذكاء الاصطناعي، وورش عمل للخبراء، وخصومات على أدوات الذكاء الاصطناعي، وغيرها. (المصدر: TheRundownAI, rowancheung)
Common Crawl تنشر خرائط الويب على مستوى المضيف والنطاق لشهر مارس-مايو 2025: أعلنت Common Crawl عن أحدث بيانات خرائط الويب الخاصة بها على مستوى المضيف والنطاق، والتي تغطي شهور مارس وأبريل ومايو 2025. تعتبر هذه البيانات ذات قيمة كبيرة لدراسة بنية الويب، وتدريب نماذج اللغة، وإجراء تحليل واسع النطاق للويب. (المصدر: CommonCrawl)
Bill Chambers يطلق نشاطًا تعليميًا بعنوان “20 Days of DSPyOSS”: لمساعدة المجتمع على فهم وظائف DSPyOSS وطرق استخدامها بشكل أفضل، أطلق Bill Chambers نشاطًا تعليميًا لـ DSPyOSS لمدة 20 يومًا. سيتم نشر مقتطف كود DSPy وشرحه يوميًا، بهدف مساعدة المستخدمين على إتقان هذا الإطار من البداية. (المصدر: lateinteraction)
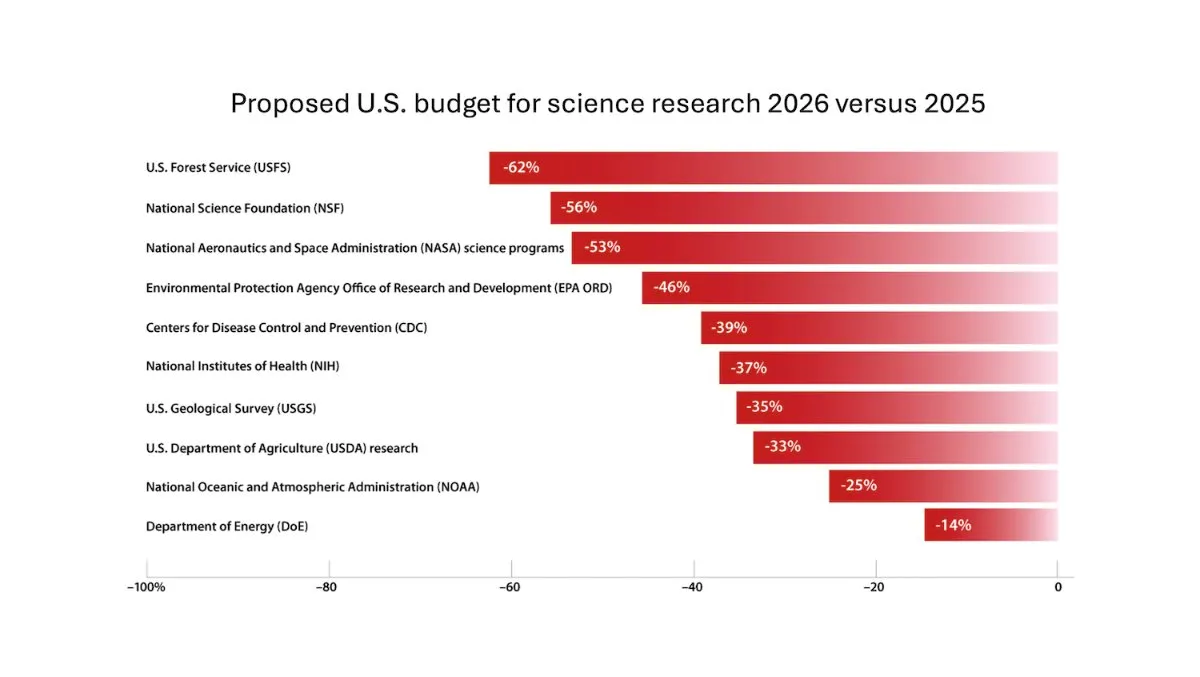
DeepLearning.AI تصدر النشرة الإخبارية The Batch، و Andrew Ng يناقش مخاطر خفض تمويل البحث العلمي: في أحدث إصدار من النشرة الإخبارية The Batch، يناقش Andrew Ng المخاطر المحتملة لخفض تمويل البحث العلمي على القدرة التنافسية والأمن الوطني. تغطي النشرة أيضًا أداء نموذج Claude 4 في اختبارات البرمجة المعيارية، وإصدارات الذكاء الاصطناعي في مؤتمر Google I/O، وطريقة DeepSeek للتدريب منخفض التكلفة، واحتمالية استخدام GPT-4o لكتب محمية بحقوق الطبع والنشر في التدريب، وغيرها من الموضوعات الساخنة. (المصدر: DeepLearningAI)
Google DeepMind توفر Gemini 2.5 Pro و NotebookLM مجانًا لطلاب الجامعات في المملكة المتحدة: أعلنت Google DeepMind عن توفير وصول مجاني لأحدث نماذجها (بما في ذلك Gemini 2.5 Pro و NotebookLM) لطلاب الجامعات في المملكة المتحدة لمدة 15 شهرًا. تهدف هذه الخطوة إلى دعم تعلم الطلاب في مجالات البحث والكتابة والتحضير للامتحانات، وتوفر مساحة تخزين مجانية تبلغ 2 تيرابايت. (المصدر: demishassabis)
قراءة في ورقة بحثية: Prot2Token إطار موحد لنمذجة البروتين: تقدم الورقة البحثية “Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction” إطارًا موحدًا لنمذجة البروتين يسمى Prot2Token، والذي يحول مهام التنبؤ المتنوعة مثل خصائص تسلسل البروتين، وميزات البقايا، والتفاعلات بين البروتينات إلى تنسيق قياسي للتنبؤ بالرمز التالي (next-token prediction). يعتمد الإطار على مفكك تشفير ذاتي الانحدار (autoregressive decoder)، ويستخدم تضمينات من مشفرات البروتين المدربة مسبقًا ورموز مهام قابلة للتعلم للتعلم متعدد المهام، بهدف تحسين الكفاءة وتسريع الاكتشافات البيولوجية. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: استخراج الأمثلة السلبية الصعبة للاسترجاع الخاص بالمجال في أنظمة المؤسسات: تقترح الورقة البحثية “Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems” إطار عمل قابل للتطوير لاستخراج الأمثلة السلبية الصعبة للبيانات الخاصة بمجال المؤسسة. تختار هذه الطريقة ديناميكيًا المستندات الصعبة من الناحية الدلالية ولكن غير ذات صلة بالسياق لتعزيز أداء نماذج إعادة الترتيب المنشورة، وأثبتت التجارب على مجموعات بيانات الشركات في مجال الخدمات السحابية تحسنًا في MRR@3 و MRR@10 بنسبة 15% و 19% على التوالي. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: FS-DAG، شبكة بيانية لفهم المستندات الغنية بصريًا في سيناريوهات قليلة العينات: تقدم الورقة البحثية “FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding” بنية نموذج FS-DAG لفهم المستندات الغنية بصريًا في سيناريوهات قليلة العينات. يستخدم هذا النموذج شبكات أساسية خاصة بالمجال وخاصة باللغة/البصريات للتكيف مع أنواع مختلفة من المستندات بأقل قدر من البيانات ضمن إطار عمل معياري، وأظهر في تجارب مهام استخراج المعلومات سرعة تقارب وأداء أفضل من طرق SOTA. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: FastTD3، تعلم معزز بسيط وسريع للتحكم في الروبوتات البشرية: تقدم الورقة البحثية “FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control” خوارزمية تعلم معزز تسمى FastTD3، والتي تسرع بشكل كبير تدريب الروبوتات البشرية في مجموعات الأدوات الشائعة مثل HumanoidBench و IsaacLab و MuJoCo Playground من خلال المحاكاة المتوازية، وتحديثات الدُفعات الكبيرة، والمقيّمين الموزعين، والمعلمات الفائقة المعدلة بعناية. (المصدر: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
قراءة في ورقة بحثية: HLIP، تدريب مسبق قابل للتطوير للغة والصورة للتصوير الطبي ثلاثي الأبعاد: تقدم الورقة البحثية “Towards Scalable Language-Image Pre-training for 3D Medical Imaging” إطار عمل تدريب مسبق قابل للتطوير للتصوير الطبي ثلاثي الأبعاد يسمى HLIP (Hierarchical attention for Language-Image Pre-training). يعتمد HLIP على آلية انتباه هرمية خفيفة الوزن، قادرة على التدريب مباشرة على مجموعات البيانات السريرية غير المنسقة، وحقق أداء SOTA في العديد من الاختبارات المعيارية. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: PENGUIN، معيار أمان مخصص لـ LLM ونهج وكيل قائم على التخطيط: تقدم الورقة البحثية “Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach” مفهوم الأمان المخصص وتقترح معيار PENGUIN (يحتوي على 14000 سيناريو في 7 مجالات حساسة) وإطار RAISE (وكيل من مرحلتين لا يحتاج إلى تدريب، يمكنه الحصول بشكل استراتيجي على معلومات خلفية خاصة بالمستخدم). تظهر الدراسة أن المعلومات المخصصة يمكن أن تحسن بشكل كبير درجات الأمان، وأن RAISE يمكنه تعزيز الأمان بتكلفة تفاعل منخفضة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: تعزيز الاستدلال متعدد الأدوار في وكلاء LLM عبر تخصيص الائتمان على مستوى الدور: تدرس الورقة البحثية “Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment” كيفية تعزيز قدرة وكلاء LLM على الاستدلال من خلال التعلم المعزز، خاصة في سيناريوهات استخدام الأدوات متعددة الأدوار. يقترح المؤلفون استراتيجية تقدير ميزة دقيقة على مستوى الدور لتحقيق تخصيص ائتمان أكثر دقة، وتظهر التجارب أن هذه الطريقة يمكن أن تحسن بشكل كبير قدرة وكلاء LLM على الاستدلال متعدد الأدوار في مهام اتخاذ القرار المعقدة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: PISCES، محو دقيق للمفاهيم داخل المعلمات في نماذج اللغة الكبيرة: تقترح الورقة البحثية “Precise In-Parameter Concept Erasure in Large Language Models” إطار PISCES، الذي يهدف إلى محو المفاهيم بأكملها بدقة من معلمات النموذج عن طريق تحرير اتجاهات المفاهيم المشفرة مباشرة في مساحة المعلمات. تستخدم هذه الطريقة أداة فك تشابك (disentangler) لتحليل متجهات MLP، وتحديد الميزات المتعلقة بالمفهوم المستهدف وإزالتها من معلمات النموذج، وتظهر التجارب تفوقها على الطرق الحالية في تأثير المحو والخصوصية والمتانة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: DORI، تقييم فهم الاتجاه في MLLM من خلال مهام إدراك متعددة المحاور دقيقة: تقدم الورقة البحثية “Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks” معيار DORI، الذي يهدف إلى تقييم قدرة نماذج اللغة الكبيرة متعددة الوسائط (MLLM) على فهم اتجاه الكائنات. يتضمن DORI أربعة أبعاد: تحديد الموقع الأمامي، وتحويل الدوران، وعلاقات الاتجاه النسبي، وفهم الاتجاه المعياري. تم اختبار 15 نموذج MLLM من أحدث طراز، ووجد أن حتى أفضل النماذج لديها قيود كبيرة في الحكم الدقيق على الاتجاه. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: هل يمكن لنماذج اللغة الكبيرة استنتاج العلاقات السببية من النصوص الواقعية؟: تستكشف الورقة البحثية “Can Large Language Models Infer Causal Relationships from Real-World Text?” قدرة نماذج اللغة الكبيرة (LLM) على استنتاج العلاقات السببية من النصوص الواقعية. طور الباحثون معيارًا مستمدًا من المؤلفات الأكاديمية الحقيقية، يتضمن نصوصًا ذات أطوال وتعقيدات ومجالات مختلفة. أظهرت التجارب أنه حتى أحدث نماذج LLM تواجه تحديات كبيرة في هذه المهمة، حيث بلغ أفضل أداء لنموذج F1 درجة 0.477 فقط، مما يكشف عن صعوباتها في معالجة المعلومات الضمنية، والتمييز بين العوامل ذات الصلة، وربط المعلومات المتفرقة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: IQBench، تقييم “ذكاء” نماذج اللغة البصرية باستخدام اختبارات الذكاء البشري: تقدم الورقة البحثية “IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests” معيار IQBench، وهو معيار جديد يهدف إلى تقييم الذكاء السائل لنماذج اللغة البصرية (VLM) من خلال اختبارات الذكاء البصري الموحدة. يركز هذا المعيار على الجانب البصري، ويتضمن 500 سؤال ذكاء بصري تم جمعها وشرحها يدويًا، ويقيّم قدرة النموذج على التفسير، وأنماط حل المشكلات، ودقة التنبؤات النهائية. أظهرت التجارب أن نماذج o4-mini و Gemini-2.5-Flash و Claude-3.7-Sonnet أبلت بلاءً حسنًا، لكن جميع النماذج واجهت صعوبات في مهام الاستدلال المكاني ثلاثي الأبعاد والألغاز اللفظية. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: PixelThink، نحو استدلال فعال لسلسلة البكسلات: تقترح الورقة البحثية “PixelThink: Towards Efficient Chain-of-Pixel Reasoning” مخطط PixelThink، الذي ينظم توليد الاستدلال ضمن نموذج التعلم المعزز من خلال دمج صعوبة المهمة المقدرة خارجيًا وعدم اليقين المقاس داخليًا للنموذج. يتعلم النموذج ضغط طول الاستدلال بناءً على تعقيد المشهد وثقة التنبؤ. كما تم تقديم معيار ReasonSeg-Diff للتقييم، وأظهرت التجارب أن هذه الطريقة تحسن كفاءة الاستدلال وأداء التجزئة بشكل عام. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: إعادة النظر في نقاش الوكلاء المتعددين كتوسع في وقت الاختبار: دراسة منهجية للفعالية المشروطة: تقوم الورقة البحثية “Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness” بتصور نقاش الوكلاء المتعددين (MAD) كتقنية لتوسيع الحوسبة في وقت الاختبار، وتدرس بشكل منهجي فعاليتها مقارنة بأساليب الوكيل الذاتي في ظل ظروف مختلفة (صعوبة المهمة، حجم النموذج، تنوع الوكلاء). وجدت الدراسة أنه بالنسبة للاستدلال الرياضي، فإن ميزة MAD محدودة، ولكنها أكثر فعالية عندما تزداد صعوبة المشكلة أو تقل قدرة النموذج؛ أما بالنسبة لمهام الأمان، فقد يزيد التحسين التعاوني لـ MAD من الهشاشة، لكن التكوينات المتنوعة تساعد في تقليل معدل نجاح الهجوم. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: VF-Eval، تقييم قدرة MLLM على توليد ملاحظات حول مقاطع فيديو AIGC: تقترح الورقة البحثية “VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos” معيارًا جديدًا VF-Eval، لتقييم قدرة نماذج اللغة الكبيرة متعددة الوسائط (MLLM) على تفسير محتوى الفيديو الذي تم إنشاؤه بواسطة الذكاء الاصطناعي (AIGC). يتضمن VF-Eval أربع مهام: التحقق من التماسك، وإدراك الأخطاء، واكتشاف نوع الخطأ، وتقييم الاستدلال. أظهر تقييم 13 نموذج MLLM متطور أنه حتى GPT-4.1 الأفضل أداءً يجد صعوبة في الحفاظ على أداء جيد في جميع المهام. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: SafeScientist، وكلاء LLM يحققون اكتشافات علمية مدركة للمخاطر: تقدم الورقة البحثية “SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents” إطار عمل لعالم ذكاء اصطناعي يسمى SafeScientist، يهدف إلى تعزيز السلامة والمسؤولية الأخلاقية في الاستكشاف العلمي المدفوع بالذكاء الاصطناعي. يمكن لهذا الإطار رفض المهام غير المناسبة أو عالية المخاطر بشكل استباقي، ويؤكد على سلامة عملية البحث من خلال آليات دفاع متعددة مثل مراقبة الأوامر، ومراقبة تعاون الوكلاء، ومراقبة استخدام الأدوات، ومكون المراجع الأخلاقي. كما تم اقتراح معيار SciSafetyBench للتقييم. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: CXReasonBench، معيار لتقييم الاستدلال التشخيصي المهيكل في صور الأشعة السينية للصدر: تقدم الورقة البحثية “CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays” عملية CheXStruct ومعيار CXReasonBench، لتقييم ما إذا كانت نماذج اللغة البصرية الكبيرة (LVLM) قادرة على تنفيذ خطوات استدلال فعالة سريريًا في تشخيص صور الأشعة السينية للصدر. يتضمن هذا المعيار 18988 زوجًا من الأسئلة والأجوبة، تغطي 12 مهمة تشخيصية و 1200 حالة، ويدعم التقييم متعدد المسارات ومتعدد المراحل، بما في ذلك اختيار المنطقة التشريحية وتحديد الموقع البصري للقياسات التشخيصية. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: ZeroGUI، أتمتة تعلم واجهة المستخدم الرسومية عبر الإنترنت بتكلفة بشرية صفرية: تقترح الورقة البحثية “ZeroGUI: Automating Online GUI Learning at Zero Human Cost” إطار ZeroGUI، وهو إطار تعلم عبر الإنترنت قابل للتطوير لأتمتة تدريب وكلاء واجهة المستخدم الرسومية (GUI) بتكلفة بشرية صفرية. يدمج ZeroGUI إنشاء المهام التلقائي القائم على VLM، وتقدير المكافآت التلقائي، والتعلم المعزز عبر الإنترنت من مرحلتين، للتفاعل المستمر مع بيئة GUI والتعلم منها. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: Spatial-MLLM، تعزيز الذكاء المكاني البصري لـ MLLM: تقترح الورقة البحثية “Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence” إطار Spatial-MLLM، للاستدلال المكاني القائم على الرؤية من ملاحظات ثنائية الأبعاد بحتة. يعتمد هذا الإطار على بنية تشفير مزدوجة (مشفر بصري دلالي ومشفر مكاني)، ويجمع بين استراتيجية أخذ عينات الإطارات المدركة مكانيًا، وحقق أداء SOTA على العديد من مجموعات البيانات الواقعية. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: TrustVLM، الحكم على ما إذا كانت تنبؤات نموذج اللغة البصرية موثوقة: تقدم الورقة البحثية “To Trust Or Not To Trust Your Vision-Language Model’s Prediction” إطار TrustVLM، وهو إطار لا يحتاج إلى تدريب، يهدف إلى تقييم موثوقية تنبؤات نموذج اللغة البصرية (VLM). تستخدم هذه الطريقة الاختلافات في تمثيل المفاهيم في مساحة تضمين الصور، وتقترح دالة جديدة لتقييم الثقة لتحسين اكتشاف التصنيفات الخاطئة، وأظهرت أداء SOTA على 17 مجموعة بيانات مختلفة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: MAGREF، توليد فيديو متعدد المراجع موجه بالقناع: تقترح الورقة البحثية “MAGREF: Masked Guidance for Any-Reference Video Generation” إطار MAGREF، وهو إطار موحد لتوليد الفيديو متعدد المراجع. يقدم آلية توجيه بالقناع، من خلال قناع ديناميكي مدرك للمنطقة وربط القنوات على مستوى البكسل، مما يحقق توليف فيديو متماسك متعدد الكيانات في ظل ظروف صور مرجعية متنوعة وأوامر نصية، وتفوق على خطوط الأساس مفتوحة المصدر والتجارية الحالية على معيار الفيديو متعدد الكيانات. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: ATLAS، تعلم تحسين ذاكرة السياق في وقت الاختبار: تقترح الورقة البحثية “ATLAS: Learning to Optimally Memorize the Context at Test Time” وحدة ذاكرة طويلة الأمد عالية السعة ATLAS، والتي تتعلم حفظ السياق عن طريق تحسين الذاكرة بناءً على الرموز الحالية والسابقة، متغلبة على خاصية التحديث عبر الإنترنت لنماذج الذاكرة طويلة الأمد. بناءً على ذلك، اقترح المؤلفون عائلة بنى DeepTransformers، وأظهرت التجارب أن ATLAS يتفوق على Transformers والنماذج الدورية الخطية الحديثة في مهام نمذجة اللغة، والاستدلال المنطقي، والمهام كثيفة الاستدعاء وفهم السياق الطويل. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: Satori-SWE، طريقة هندسة برمجيات تطورية ذات كفاءة في العينات وتوسع في وقت الاختبار: تقترح الورقة البحثية “Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering” طريقة EvoScale، التي تتعامل مع إنشاء الأكواد كعملية تطورية، من خلال تحسين المخرجات بشكل متكرر لرفع أداء النماذج الصغيرة في مهام هندسة البرمجيات (مثل SWE-Bench). حقق نموذج Satori-SWE-32B من خلال هذه الطريقة، باستخدام عدد قليل من العينات، أداءً يعادل أو يتجاوز النماذج التي تحتوي على أكثر من 100 مليار معلمة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: OPO، تعلم معزز قائم على السياسة مع خط أساس مكافأة مثالي: تقترح الورقة البحثية “On-Policy RL with Optimal Reward Baseline” خوارزمية OPO، وهي خوارزمية تعلم معزز مبسطة جديدة، تهدف إلى حل مشكلات عدم استقرار التدريب وانخفاض كفاءة الحوسبة التي تواجهها خوارزميات RL الحالية عند تدريب LLM. تؤكد OPO على التدريب الدقيق القائم على السياسة، وتقدم خط أساس مكافأة مثالي يقلل نظريًا من تباين التدرج، وأظهرت التجارب أداءً واستقرارًا تدريبيًا متفوقين على معايير الاستدلال الرياضي. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: SWE-bench Goes Live! معيار هندسة برمجيات محدث في الوقت الفعلي: تقدم الورقة البحثية “SWE-bench Goes Live!” معيار SWE-bench-Live، وهو معيار يهدف إلى التغلب على قيود SWE-bench الحالية من خلال التحديث في الوقت الفعلي. يتضمن الإصدار الجديد 1319 مهمة مستمدة من مشكلات GitHub حقيقية منذ عام 2024، تغطي 93 مستودعًا، ومجهز بعمليات إدارة آلية لتحقيق قابلية التوسع والتحديث المستمر، وبالتالي توفير تقييم أكثر صرامة ومقاومة للتلوث لـ LLM والوكلاء. (المصدر: HuggingFace Daily Papers, _akhaliq)
قراءة في ورقة بحثية: ToMAP، تدريب مقنعي LLM مدركين للخصم باستخدام نظرية العقل: تقدم الورقة البحثية “ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind” طريقة جديدة تسمى ToMAP، والتي تبني وكلاء إقناع أكثر مرونة من خلال دمج وحدتي نظرية العقل، مما يعزز وعيهم وتحليلهم للحالة العقلية للخصم. أظهرت التجارب أن مقنعي ToMAP ذوي 3 مليارات معلمة فقط يتفوقون على خطوط الأساس الكبيرة مثل GPT-4o في العديد من نماذج ومجموعات بيانات كائنات الإقناع. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: هل يمكن لـ LLM خداع CLIP؟ تقييم التركيبية العدائية للتمثيلات متعددة الوسائط المدربة مسبقًا عبر تحديثات النص: تقدم الورقة البحثية “Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates” معيار التركيبية العدائية متعددة الوسائط (MAC)، الذي يستخدم LLM لإنشاء عينات نصية خادعة لاستغلال ثغرات التركيبية في التمثيلات متعددة الوسائط المدربة مسبقًا مثل CLIP. تقترح الدراسة طريقة تدريب ذاتي، من خلال أخذ عينات الرفض المعدلة لتعزيز التنوع، لزيادة معدل نجاح الهجوم وتنوع العينات. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: دور المكافآت الصاخبة في تعلم الاستدلال – الطريق إلى القمة ينحت الحكمة أعمق من القمة نفسها: تدرس الورقة البحثية “The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason” تأثير ضوضاء المكافأة على تدريب LLM بعد الاستدلال من خلال التعلم المعزز. وجدت الدراسة أن LLM تظهر متانة قوية تجاه كميات كبيرة من ضوضاء المكافأة، حتى عند مكافأة ظهور عبارات الاستدلال الرئيسية فقط (دون التحقق من صحة الإجابة)، يمكن للنموذج تحقيق أداء مماثل للنماذج المدربة بمكافآت دقيقة وتحقق صارم. (المصدر: HuggingFace Daily Papers)
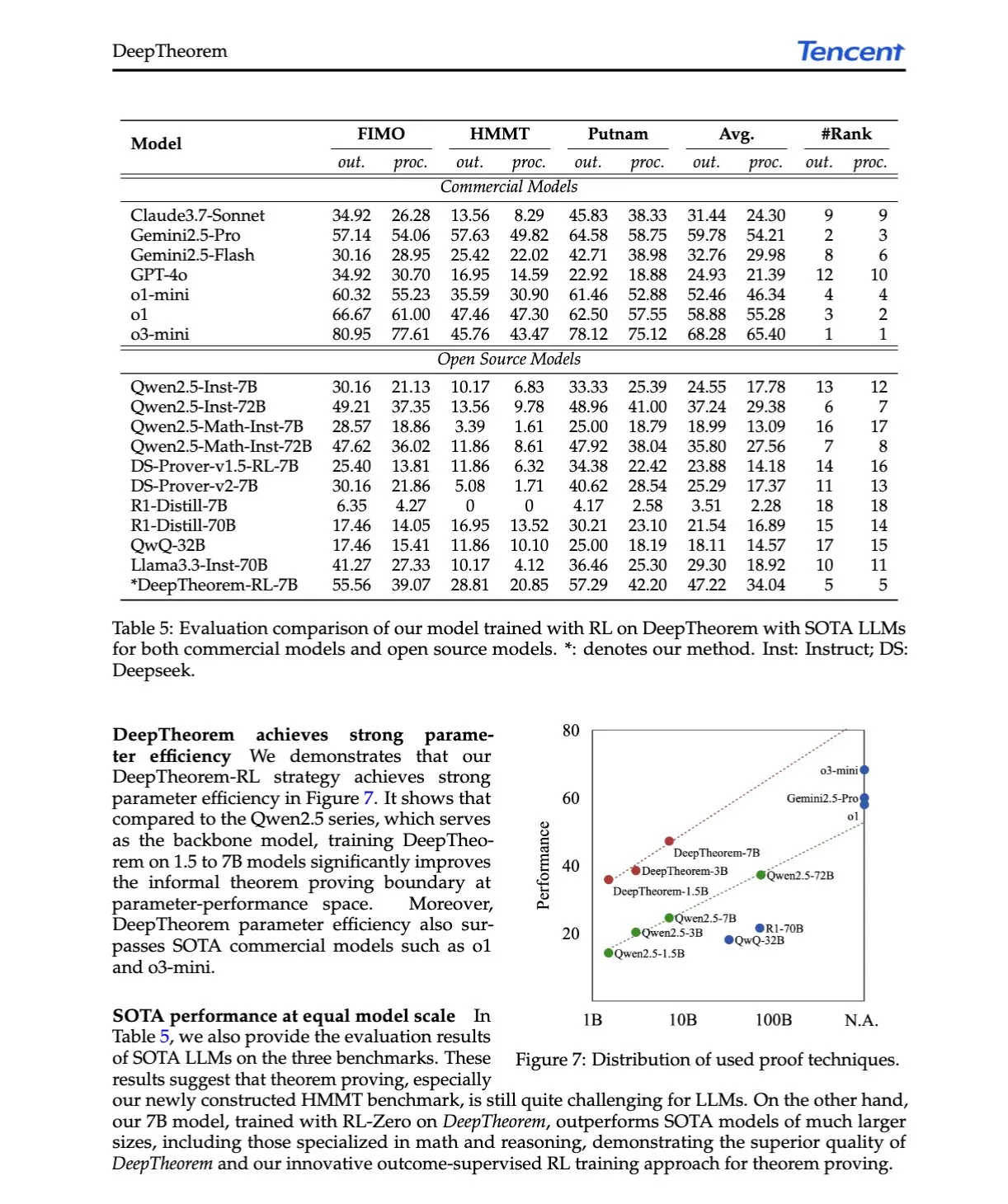
قراءة في ورقة بحثية: DeepTheorem، تطوير إثبات النظريات في LLM من خلال اللغة الطبيعية والتعلم المعزز: تقترح الورقة البحثية “DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning” إطار DeepTheorem، وهو إطار لإثبات النظريات غير الرسمي يعزز الاستدلال الرياضي لـ LLM باستخدام اللغة الطبيعية. يتضمن هذا الإطار مجموعة بيانات معيارية واسعة النطاق (121 ألف نظرية وبرهان غير رسمي على مستوى IMO) واستراتيجية تعلم معزز (RL-Zero) مصممة خصيصًا لإثبات النظريات غير الرسمي. (المصدر: HuggingFace Daily Papers, teortaxesTex)
قراءة في ورقة بحثية: D-AR، الانتشار عبر النماذج ذاتية الانحدار: تقترح الورقة البحثية “D-AR: Diffusion via Autoregressive Models” نموذجًا جديدًا D-AR، يعيد تشكيل عملية انتشار الصور كعملية تنبؤ قياسية ذاتية الانحدار للرمز التالي. من خلال أداة ترميز (tokenizer) مصممة، يتم تحويل الصور إلى تسلسلات رموز منفصلة، ويمكن فك تشفير الرموز في مواقع مختلفة إلى خطوات مختلفة لإزالة تشويش الانتشار في مساحة البكسل. حققت هذه الطريقة 2.09 FID على ImageNet باستخدام هيكل Llama بحجم 775 مليون معلمة و 256 رمزًا منفصلاً. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: Table-R1، توسيع وقت الاستدلال للاستدلال الجدولي: تستكشف الورقة البحثية “Table-R1: Inference-Time Scaling for Table Reasoning” لأول مرة توسيع وقت الاستدلال في مهام الاستدلال الجدولي. طور الباحثون وقيموا استراتيجيتين بعد التدريب: التقطير من مسارات استدلال النماذج المتطورة (Table-R1-SFT) والتعلم المعزز بمكافآت يمكن التحقق منها (Table-R1-Zero). حقق Table-R1-Zero (7 مليارات معلمة) أداءً يعادل أو يتجاوز GPT-4.1 و DeepSeek-R1 في العديد من مهام الاستدلال الجدولي. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: Muddit، نموذج انتشار منفصل موحد لتحقيق توليد يتجاوز تحويل النص إلى صورة: تقدم الورقة البحثية “Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model” نموذج Muddit، وهو نموذج Transformer لانتشار منفصل موحد، يدعم التوليد المتوازي السريع لوضعيات النص والصورة. يدمج Muddit المعرفة البصرية القوية من هياكل تحويل النص إلى صورة المدربة مسبقًا ومفكك تشفير نصي خفيف الوزن، وهو تنافسي من حيث الجودة والكفاءة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: VideoReasonBench، هل يمكن لـ MLLM تنفيذ استدلال فيديو معقد يركز على الرؤية؟: تقدم الورقة البحثية “VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?” معيار VideoReasonBench، وهو معيار يهدف إلى تقييم قدرات الاستدلال المعقد للفيديو الذي يركز على الرؤية. يتضمن هذا المعيار مقاطع فيديو لتسلسلات عمليات دقيقة، وتقيّم الأسئلة قدرات التذكر والاستدلال والتنبؤ. أظهرت التجارب أن معظم نماذج MLLM من أحدث طراز كان أداؤها ضعيفًا على هذا المعيار، بينما برز أداء Gemini-2.5-Pro المعزز بالتفكير. (المصدر: HuggingFace Daily Papers, OriolVinyalsML)
قراءة في ورقة بحثية: GeoDrive، نموذج عالم قيادة مدرك للهندسة ثلاثية الأبعاد مع تحكم دقيق في الحركة: تقترح الورقة البحثية “GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control” نموذج GeoDrive، الذي يدمج بشكل صريح شروط هندسية ثلاثية الأبعاد قوية في نموذج عالم القيادة لتعزيز الفهم المكاني والتحكم في الحركة. تعزز هذه الطريقة تأثيرات العرض في التدريب من خلال وحدة تحرير ديناميكية، وأثبتت التجارب تفوقها على النماذج الحالية في دقة الحركة والإدراك المكاني ثلاثي الأبعاد. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: توجيه تكيفي خالٍ من المصنف عبر إخفاء ديناميكي منخفض الثقة: تقترح الورقة البحثية “Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking” طريقة A-CFG، التي تخصص المدخلات غير المشروطة للتوجيه الخالي من المصنف (CFG) من خلال الاستفادة من ثقة التنبؤ اللحظية للنموذج. تحدد A-CFG الرموز منخفضة الثقة في كل خطوة من نموذج لغة الانتشار التكراري (القناع) وتعيد إخفاءها مؤقتًا، مما ينشئ مدخلات غير مشروطة ديناميكية ومحلية، ويجعل التأثير التصحيحي لـ CFG أكثر دقة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: PatientSim، محاكي مدفوع بالشخصيات لتفاعلات واقعية بين الطبيب والمريض: تقدم الورقة البحثية “PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions” محاكي PatientSim، الذي يولد شخصيات مرضى واقعية ومتنوعة بناءً على الملفات السريرية من مجموعة بيانات MIMIC وأربع محاور للشخصية (الشخصية، إتقان اللغة، مستوى تذكر التاريخ المرضي، مستوى الارتباك المعرفي). يهدف إلى توفير نظام تفاعل واقعي مع المرضى لتدريب أو تقييم أطباء LLM. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: LoRAShop، توليد وتحرير صور متعددة المفاهيم بدون تدريب باستخدام محولات التدفق المصححة: تقدم الورقة البحثية “LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers” أول إطار عمل يستخدم نماذج LoRA لتحرير الصور متعددة المفاهيم LoRAShop. يستفيد هذا الإطار من أنماط تفاعل الميزات الداخلية لمحول انتشار نمط Flux، لاستخلاص أقنعة كامنة مفككة لكل مفهوم، ومزج أوزان LoRA فقط داخل منطقة المفهوم، مما يحقق تكاملاً سلسًا لكيانات أو أنماط متعددة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: AnySplat، رش غاوسي ثلاثي الأبعاد أمامي التغذية من مناظير غير مقيدة: تقدم الورقة البحثية “AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views” شبكة AnySplat، وهي شبكة أمامية التغذية لتوليف مناظير جديدة من مجموعة صور غير معايرة. على عكس عمليات العرض العصبي التقليدية، يمكن لـ AnySplat من خلال تمريرة أمامية واحدة التنبؤ بالبدائيات الغاوسية ثلاثية الأبعاد (التي تشفر هندسة ومظهر المشهد) بالإضافة إلى المعلمات الداخلية والخارجية للكاميرا لكل صورة إدخال، دون الحاجة إلى تسميات الوضع، ويدعم توليف مناظير جديدة في الوقت الفعلي. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: ZeroSep، فصل كل شيء في الصوت بدون تدريب: تكتشف الورقة البحثية “ZeroSep: Separate Anything in Audio with Zero Training” أنه بمجرد استخدام نماذج انتشار الصوت الموجهة بالنص المدربة مسبقًا، في تكوين معين، يمكن تحقيق فصل مصادر الصوت بدون أي عينات (zero-shot). تقوم طريقة ZeroSep بعكس الصوت المختلط إلى الفضاء الكامن لنموذج الانتشار، وتستخدم التوجيه المشروط بالنص لعملية إزالة التشويش لاستعادة مصادر الصوت الفردية، دون الحاجة إلى أي تدريب أو ضبط دقيق خاص بالمهمة. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: دراسة تقليل الإنتروبيا بعينة واحدة: اكتشفت الورقة البحثية “One-shot Entropy Minimization” من خلال تدريب 13440 نموذج لغة كبير أن تقليل الإنتروبيا يتطلب فقط بيانات واحدة غير مسماة و 10 خطوات تحسين، لتحقيق أو حتى تجاوز تحسينات الأداء التي يمكن تحقيقها باستخدام آلاف البيانات والمكافآت المصممة بعناية في التعلم المعزز القائم على القواعد. قد تدفع هذه النتيجة إلى إعادة التفكير في نماذج التدريب اللاحق لـ LLM. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: ChartLens، إسناد بصري دقيق في المخططات البيانية: تعالج الورقة البحثية “ChartLens: Fine-grained Visual Attribution in Charts” مشكلة ميل MLLM إلى توليد هلوسات في فهم المخططات البيانية، وتقدم مهمة الإسناد البصري اللاحق للمخططات، وتقترح خوارزمية ChartLens. تستخدم هذه الخوارزمية تقنيات التجزئة لتحديد كائنات المخطط، وتقوم بإسناد بصري دقيق مع MLLM من خلال مطالبات مجموعة العلامات. كما تم إصدار معيار ChartVA-Eval، الذي يتضمن شروح إسناد دقيقة لمخططات من مجالات مثل التمويل والسياسة والاقتصاد. (المصدر: HuggingFace Daily Papers)
قراءة في ورقة بحثية: استكشاف الأنماط الهيكلية للمعرفة في نماذج اللغة الكبيرة من منظور الرسم البياني: تدرس الورقة البحثية “A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models” الأنماط الهيكلية للمعرفة في LLM من منظور الرسم البياني. تحدد الدراسة كميًا معرفة LLM على مستوى الثلاثيات والكيانات، وتحلل علاقتها بخصائص هيكل الرسم البياني مثل درجة العقدة، وتكشف عن تجانس المعرفة (مستوى معرفة الكيانات المتقاربة طوبولوجيًا متشابه). بناءً على ذلك، تم تطوير نماذج تعلم آلي للرسم البياني لتقدير معرفة الكيان واستخدامها لفحص المعرفة. (المصدر: HuggingFace Daily Papers)
💼 أعمال
شركة الروبوتات المجسدة Lumos Robotics تجمع ما يقرب من 200 مليون يوان في نصف عام وتتعاون مع COSCO Shipping وغيرها: أعلنت شركة Lumos Robotics (鹿明机器人)، وهي شركة روبوتات مجسدة أسسها المدير التنفيذي السابق لشركة Dreame، Yu Chao، عن إكمال جولة تمويل ++Angel، بمشاركة مستثمرين من بينهم Fosun RZ Capital و Dematic Technology و Wuzhong Financial Holding، ليصل إجمالي التمويل المتراكم في نصف عام إلى ما يقرب من 200 مليون يوان. تركز الشركة على سيناريوهات الاستخدام المنزلي، وتشمل منتجاتها روبوتات بشرية من سلسلة LUS و MOS ومكونات أساسية، وقد أطلقت بالفعل روبوتًا بشريًا كامل الحجم LUS، وأبرمت شراكات استراتيجية مع Dematic Technology و COSCO Shipping وغيرها، لتسريع تسويق الذكاء المجسد في مجالات مثل الخدمات اللوجستية والتصنيع الذكي. (المصدر: 36氪)

Snorkel AI تجمع 100 مليون دولار في جولة تمويل D، وتطلق خدمات تقييم وكلاء الذكاء الاصطناعي وبيانات الخبراء: أعلنت شركة Snorkel AI، وهي شركة ذكاء اصطناعي لمركز البيانات، عن إكمال جولة تمويل D بقيمة 100 مليون دولار بقيادة Valor Equity Partners، ليصل إجمالي تمويلها إلى 235 مليون دولار. في الوقت نفسه، أطلقت الشركة Snorkel Evaluate (منصة تقييم وكلاء الذكاء الاصطناعي لمركز البيانات) و Expert Data-as-a-Service (بيانات الخبراء كخدمة)، بهدف مساعدة الشركات على بناء ونشر وكلاء ذكاء اصطناعي أكثر موثوقية واحترافية. (المصدر: realDanFu, percyliang, tri_dao, krandiash)
وزارة الطاقة الأمريكية تعلن عن تعاون مع Dell و Nvidia لتطوير الجيل القادم من الكمبيوتر العملاق “Doudna”: أعلنت وزارة الطاقة الأمريكية عن توقيع عقد مع شركة Dell لتطوير الجيل القادم من الكمبيوتر العملاق الرائد لمختبر لورانس بيركلي الوطني، والذي يحمل اسم “Doudna” (NERSC-10). سيتم تشغيل هذا النظام بواسطة منصة Vera Rubin من الجيل القادم من Nvidia، ومن المتوقع أن يدخل الخدمة في عام 2026، وسيكون أداؤه أعلى بـ 10 مرات من الكمبيوتر الرائد الحالي Perlmutter، ويهدف إلى دعم أعباء العمل واسعة النطاق للحوسبة عالية الأداء والذكاء الاصطناعي، ومساعدة الولايات المتحدة على الفوز في سباق الهيمنة العالمية على الذكاء الاصطناعي. (المصدر: 36氪, nvidia)

🌟 مجتمع
DeepSeek R1-0528 يثير نقاشًا ساخنًا، مع التركيز على الأداء والهلوسة واستدعاء الأدوات: أثار إصدار DeepSeek R1-0528 نقاشًا واسعًا في المجتمع. ترى معظم الآراء أن لديه تحسنًا كبيرًا في الرياضيات والبرمجة والاستدلال المنطقي العام، ويقترب أو حتى يتجاوز بعض النماذج مغلقة المصدر. أحرز الإصدار الجديد تقدمًا في تقليل معدل الهلوسة، وأضاف دعمًا لإخراج JSON واستدعاء الدوال. في الوقت نفسه، حظي إصداره المقطر Qwen3-8B باهتمام لأدائه الرياضي المتميز في النماذج الصغيرة. يعتقد المجتمع بشكل عام أن DeepSeek عززت مكانتها الرائدة في مجال المصادر المفتوحة، ويتطلعون إلى إصدار R2. (المصدر: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
نموذج تحرير الصور بالذكاء الاصطناعي FLUX.1 Kontext يحظى بالاهتمام، مع التركيز على فهم السياق وتناسق الشخصيات: حظي نموذج تحرير الصور FLUX.1 Kontext الذي أصدرته Black Forest Labs باهتمام المجتمع لقدرته على معالجة مدخلات النصوص والصور في نفس الوقت والحفاظ على تناسق الشخصيات. أفاد المستخدمون بأنه يؤدي أداءً ممتازًا في مهام تحرير الصور ونقل الأسلوب وتراكب النصوص، خاصة في التحرير متعدد الجولات حيث يمكنه الحفاظ على ميزات الكائن الرئيسي بشكل جيد. قامت منصات مثل Replicate بإتاحة هذا النموذج وقدمت تقارير اختبار مفصلة ونصائح للاستخدام. (المصدر: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

وكلاء الذكاء الاصطناعي سيغيرون بشكل كبير نماذج البحث والإعلان: يعتقد Arav Srinivas، الرئيس التنفيذي لشركة Perplexity AI، أنه مع قيام وكلاء الذكاء الاصطناعي بإجراء عمليات البحث نيابة عن المستخدمين، فإن حجم استعلامات البحث البشري على محركات البحث مثل Google سينخفض بشكل كبير، مما سيؤدي إلى انخفاض تكلفة الألف ظهور/تكلفة النقرة (CPM/CPC) للإعلانات، وقد يتدفق الإنفاق الإعلاني إلى وسائل التواصل الاجتماعي أو منصات الذكاء الاصطناعي. لن يحتاج المستخدمون بعد الآن إلى إجراء عمليات بحث متكررة عن الكلمات الرئيسية، بل سيقوم مساعدو الذكاء الاصطناعي بدفع المعلومات إليهم بشكل استباقي. (المصدر: AravSrinivas)
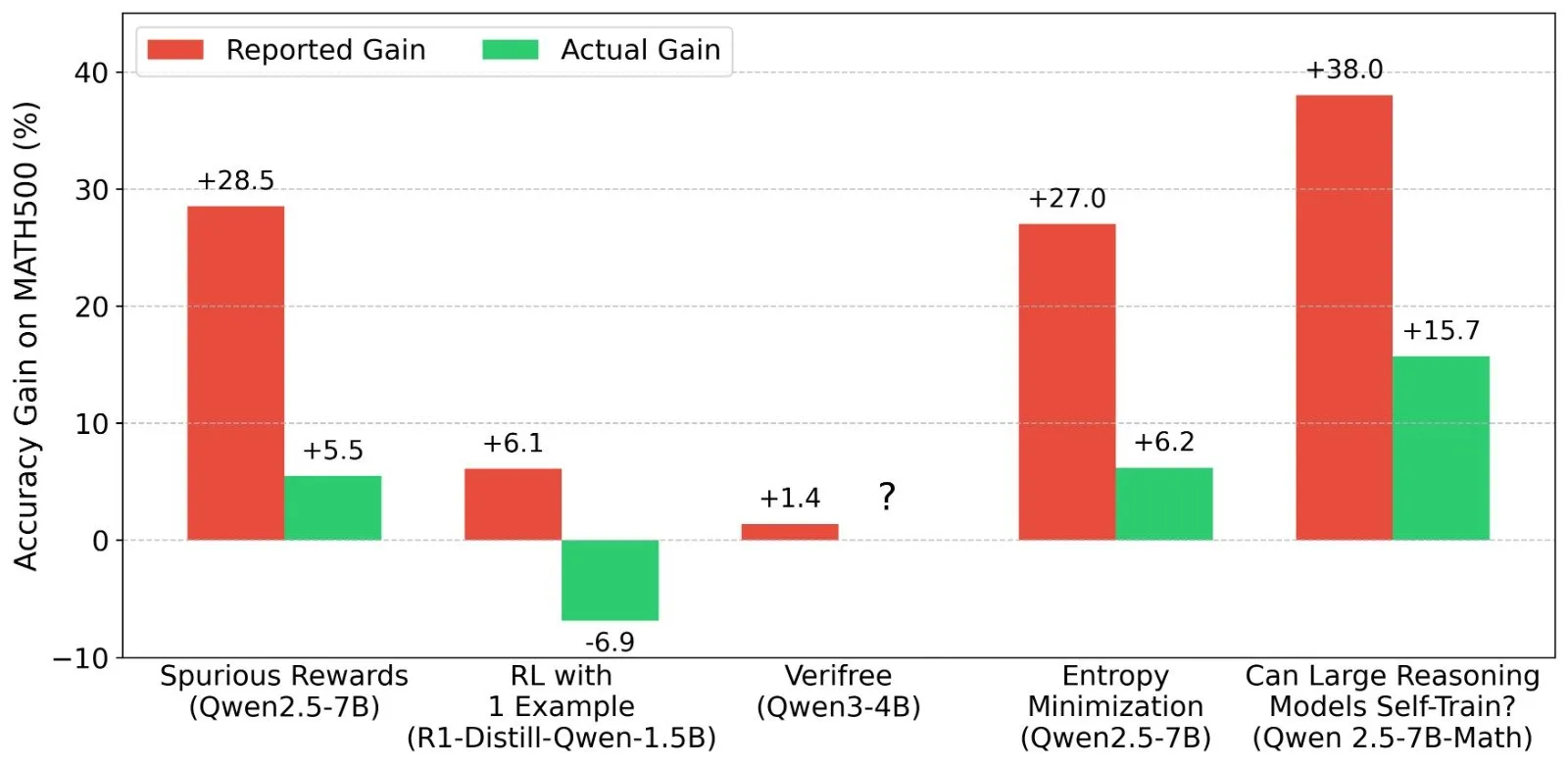
نقاش حول نتائج التعلم المعزز (RL) لـ LLM: حقيقة إشارات المكافأة وقدرات النموذج: أثار Shashwat Goel وباحثون آخرون تساؤلات حول ظاهرة تحسن أداء النماذج في أبحاث RL لـ LLM الحديثة حتى في غياب إشارات مكافأة حقيقية، مشيرين إلى أن بعض الأبحاث قد تقلل من شأن القدرات الأساسية للنماذج المدربة مسبقًا أو وجود عوامل مربكة أخرى. أثار النقاش تحليلًا أعمق لأداء نماذج مثل Qwen في RL، والتفكير في فعالية RLVR (التعلم المعزز بالمكافآت القابلة للتحقق)، مع التأكيد على الحاجة إلى خطوط أساس أكثر صرامة وتحسين للأوامر عند تقييم تأثيرات RL. (المصدر: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” يثير نقاشًا، مع التركيز على القيم الافتراضية الآمنة ومخاطر الديون التقنية: أصبحت “Vibe coding” (برمجة الأجواء، وتشير إلى طريقة برمجة تعتمد بشكل أكبر على الحدس والتكرار السريع بدلاً من المواصفات الصارمة) موضوع نقاش ساخن في المجتمع. يعتقد Amjad Masad، الرئيس التنفيذي لشركة Replit، أن هذه الطريقة تمكّن المطورين الجدد، ولكن يجب على المنصات توفير تكوينات افتراضية آمنة. في الوقت نفسه، علق Pedro Domingos قائلاً إن “برمجة الأجواء هي بمثابة Godzilla للديون التقنية”، مما يشير إلى مشكلات الصيانة طويلة الأجل التي قد تسببها. ذكرت Semafor ثغرة أمنية في Lovable بسبب تكوين غير صحيح لسياسة RLS، مما أثار مزيدًا من الاهتمام بسلامة طريقة البرمجة هذه. (المصدر: alexalbert__, amasad, pmddomingos, gfodor)
دور الذكاء الاصطناعي في هندسة البرمجيات: تحسين الكفاءة وعدم قابلية استبدال المبرمجين البشريين: شارك Salvatore Sanfilippo، مبتكر Redis، خبرته قائلاً إنه على الرغم من قيمة الذكاء الاصطناعي (مثل Gemini 2.5 Pro) في المساعدة في البرمجة ومراجعة الأكواد والتحقق من الأفكار، إلا أن المبرمجين البشريين لا يزالون يتفوقون بشكل كبير على الذكاء الاصطناعي في حل المشكلات الإبداعية والتفكير خارج الصندوق. وأشار النقاش المجتمعي كذلك إلى أن الذكاء الاصطناعي حاليًا أشبه بـ “بطة مطاطية ذكية”، يمكنه المساعدة في التفكير، ولكن يجب تقييم اقتراحاته بحذر، وقد يؤدي الاعتماد المفرط عليه إلى إضعاف القدرات الأساسية للمطورين. كما شارك Mitchell Hashimoto حالة ساعده فيها LLM على تحديد مشكلة في تجميع Clang بسرعة، مما وفر الكثير من الوقت. (المصدر: mitchellh, 36氪)
هل سيحل الذكاء الاصطناعي محل الوظائف على نطاق واسع يثير اهتمامًا مستمرًا: توقع Dario Amodei، الرئيس التنفيذي لشركة Anthropic، أن الذكاء الاصطناعي قد يؤدي إلى اختفاء نصف وظائف المكاتب للمبتدئين، بينما يعتقد Mark Cuban أن الذكاء الاصطناعي سيخلق شركات ووظائف جديدة. كان النقاش المجتمعي حول هذا الموضوع محتدمًا، حيث رأت بعض الآراء أن وظائف مثل خدمة العملاء، وكتابة النصوص للمبتدئين، وبعض وظائف التطوير قد تأثرت بالفعل، ولكن الذكاء الاصطناعي لا يزال يجد صعوبة في استبدال البشر في المجالات التي تتطلب إبداعًا، وقرارات معقدة، وتفاعلًا بشريًا عاليًا. الإجماع العام هو أن الذكاء الاصطناعي سيغير طبيعة العمل، ويحتاج البشر إلى التكيف وتعزيز قدرتهم على التعاون مع الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
وكلاء الذكاء الاصطناعي (AI Agent) يصبحون مدخل التفاعل من الجيل التالي، مما يثير منافسة بين الشركات الكبرى: تتسابق شركات التكنولوجيا المحلية والدولية مثل Microsoft و Google و OpenAI و Alibaba و Tencent و Baidu و Coocaa في مجال وكلاء الذكاء الاصطناعي. يمكن للوكلاء الأذكياء التفكير بعمق، والتخطيط بشكل مستقل، واتخاذ القرارات، وتنفيذ المهام المعقدة، ويعتبرون مدخل التفاعل من الجيل التالي بعد محركات البحث والتطبيقات. تشكلت حاليًا ثلاث قوى رئيسية: بناة النظم البيئية التقنية بقيادة OpenAI و Baidu؛ ومقدمو خدمات الشركات للمشاهد الرأسية بقيادة Microsoft و Alibaba Cloud؛ ومصنعو الأجهزة والبرامج الطرفية بقيادة Huawei و Coocaa. (المصدر: 36氪)

💡 أخرى
تسارع خروج الذكاء الاصطناعي الصيني إلى الخارج، من تصدير المنتجات إلى بناء النظم البيئية: يشير تقرير “نمو الذكاء الاصطناعي الصيني عبر المحيطات” إلى أن خروج شركات الذكاء الاصطناعي الصينية إلى الخارج قد دخل مسارًا سريعًا للتوسع، حيث يتركز 76% منها في مستوى التطبيقات. تطورت مسارات الخروج إلى الخارج من تطبيقات الأدوات في المرحلة المبكرة، إلى تصدير حلول الصناعة التي تجمع بين المزايا التقنية في المرحلة المتوسطة، بينما تركز المرحلة الحالية على خروج النظم البيئية التقنية إلى الخارج، وتعزيز المعايير التقنية والتعاون مفتوح المصدر. يُظهر خروج الذكاء الاصطناعي إلى الخارج تغلغلاً متدرجًا “من القريب إلى البعيد”، ويواجه تحديات مثل التوطين، والامتثال والأخلاقيات، والتسويق للعلامة التجارية. (المصدر: 36氪)

وزارة الطاقة الأمريكية تشبه سباق الذكاء الاصطناعي بـ “مشروع مانهاتن الجديد”، وتؤكد أن الولايات المتحدة ستفوز: عند الإعلان عن الجيل القادم من الكمبيوتر العملاق “Doudna”، وصفت وزارة الطاقة الأمريكية المنافسة في تطوير الذكاء الاصطناعي بأنها “مشروع مانهاتن في عصرنا”، وأعلنت أن الولايات المتحدة ستفوز في هذا السباق. أثارت هذه التصريحات نقاشًا مجتمعيًا حول المنافسة التكنولوجية بين الدول الكبرى، وأخلاقيات الذكاء الاصطناعي، والتعاون الدولي. (المصدر: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
تقدم الذكاء الاصطناعي في مجال إنشاء المحتوى يثير التفكير حول “الأصالة” و “الإبداع”: ناقش المجتمع تطبيقات الذكاء الاصطناعي في مجالات مثل تصميم الأزياء، وإنشاء القصص المصورة، وتوليد الفيديو. فمن ناحية، يمكن للذكاء الاصطناعي إنشاء محتوى متنوع بسرعة، وحتى تحويل أعمال القصص المصورة التي تعود إلى سنوات مضت إلى فيديو؛ ومن ناحية أخرى، يبدو هذا المحتوى الذي تم إنشاؤه أحيانًا غريبًا أو يفتقر إلى العمق. أثار هذا تساؤلات حول ما إذا كان المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي “أفضل”، وما هو الدور الذي سيلعبه الإبداع البشري في عصر الذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT, Reddit r/artificial)
