كلمات مفتاحية:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, مكافأة عشوائية, مكافأة خاطئة, أداء النموذج, تعلم التعزيز, مستقبل RLHF/RLAIF, تحسين أداء النموذج بالمكافآت العشوائية, تدريب Qwen2.5-Math-7B بمكافآت خاطئة, مجموعة اختبار MATH-500, تعلم إشارات التعزيز
🔥 أبرز النقاط
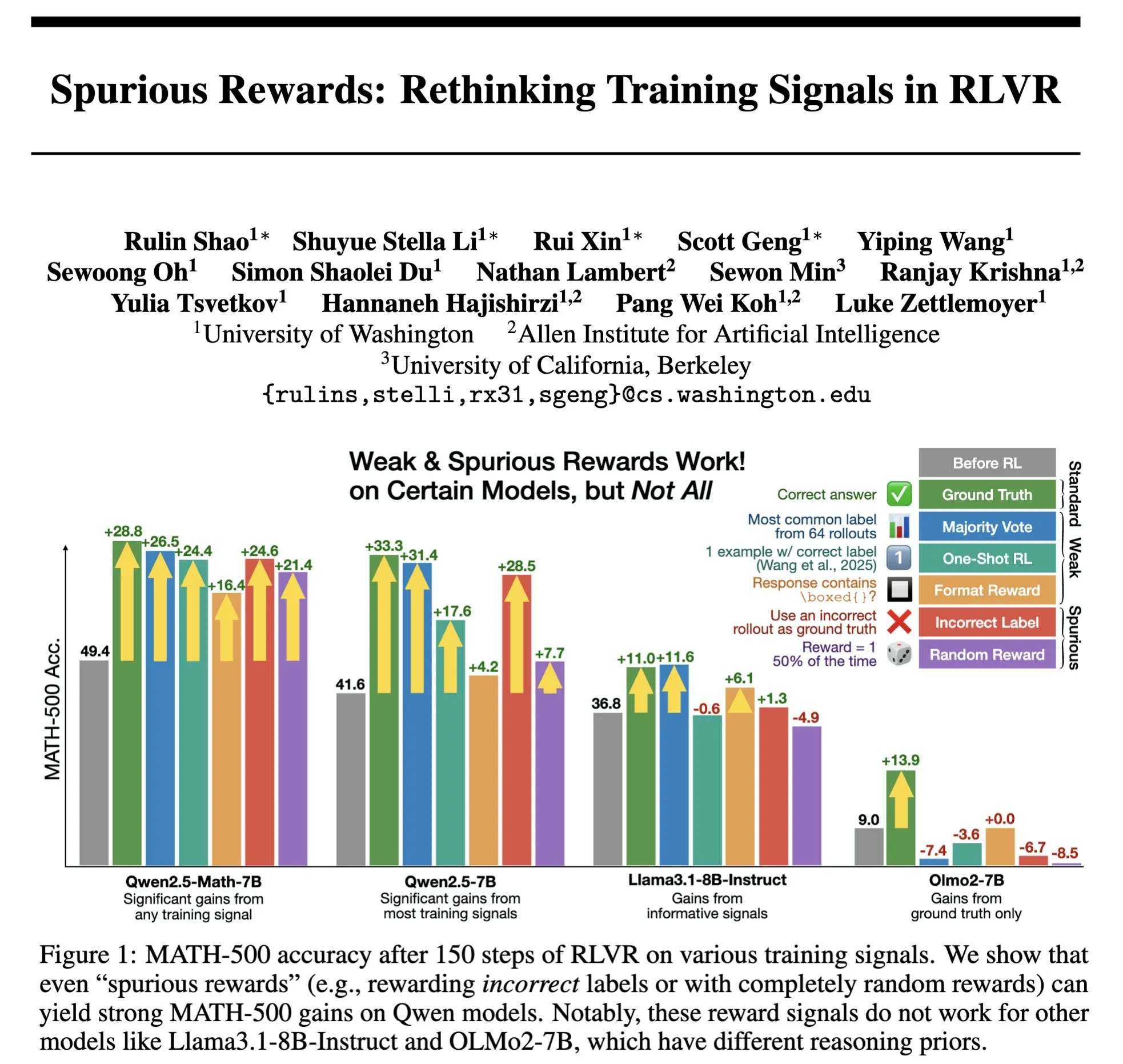
مستقبل RLHF/RLAIF: هل يمكن للمكافآت العشوائية/الخاطئة أن تحسن أداء النموذج؟ : أظهرت تجربة Stella Li أن تدريب نموذج Qwen2.5-Math-7B باستخدام مكافآت عشوائية أو غير صحيحة أدى إلى تحسين الأداء بنسبة 21% و 25% على التوالي في مجموعة اختبار MATH-500، وهو ما يقترب من تأثير التحسين البالغ 28.8% باستخدام المكافآت الحقيقية. كما وجدت دراسة Rulin Shao التي أعاد natolambert نشرها أن RLVR (Reinforcement Learning from Verifier Reward) عند استخدام مكافآت زائفة، زاد استخدام كود نموذج Olmo ولكن انخفض الأداء، بينما أدى منعه من استخدام الكود إلى تحسين الأداء. تتحدى هذه النتائج الاعتماد التقليدي في RLHF/RLAIF على بيانات التفضيل البشري عالية الجودة، مما يشير إلى أن النموذج قد يتعلم استكشاف مساحات استراتيجية أوسع من خلال إشارات المكافأة، حتى لو كانت المكافأة نفسها غير مثالية، يمكنها تحفيز القدرات الكامنة للنموذج أو تحسين السلوكيات الحالية. قد يفتح هذا آفاقًا جديدة لتقليل الاعتماد على التوصيف البشري المكلف واستكشاف طرق أكثر كفاءة لمواءمة النماذج، ولكن يجب الحذر من خطر تعلم النموذج سلوكيات خاطئة. (المصدر: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
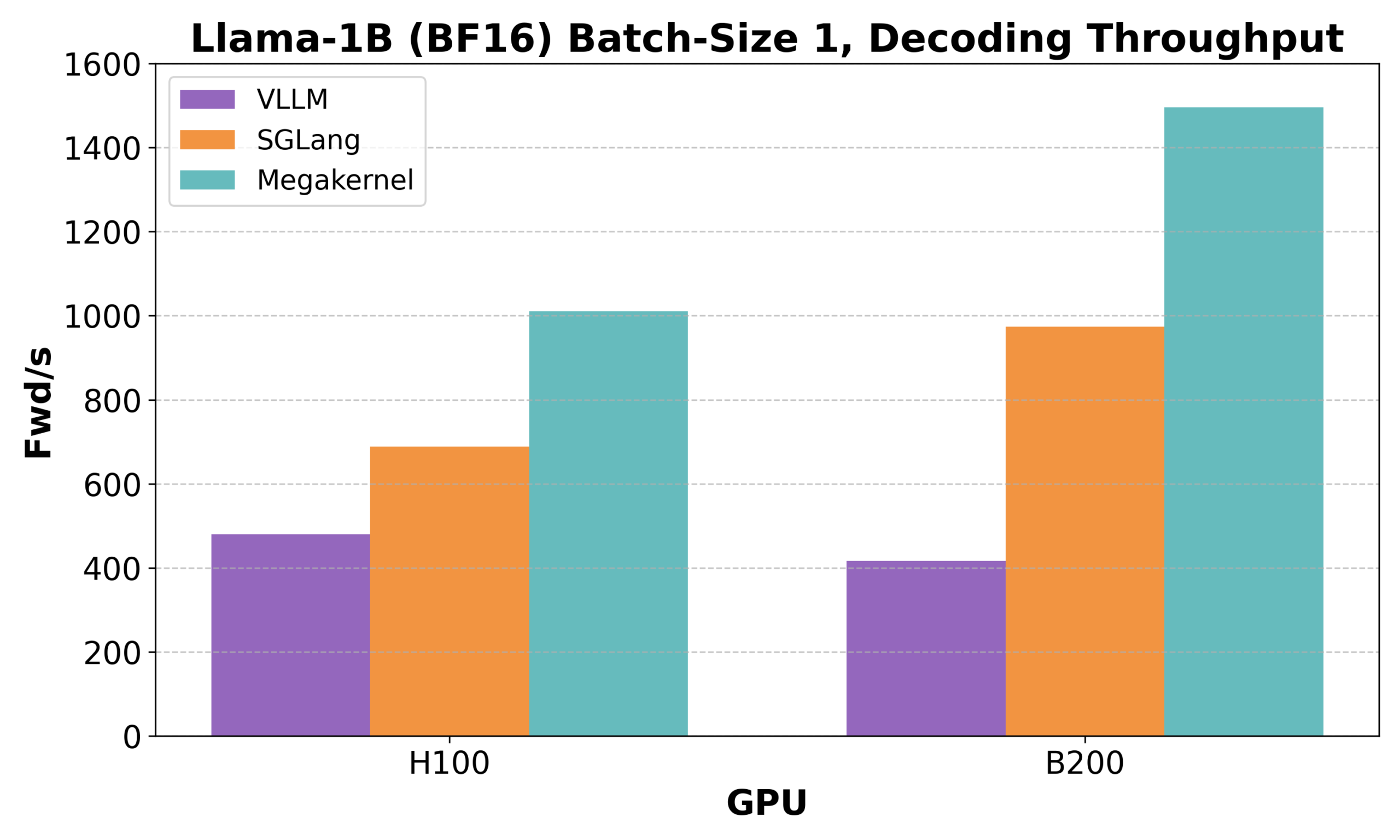
Hazy Research تطلق Low-Latency-Llama Megakernel: استدلال Llama 1B على نواة CUDA واحدة : أطلقت Hazy Research نواة Low-Latency-Llama Megakernel، القادرة على إكمال عملية الانتشار الأمامي بأكملها لنموذج Llama 1B داخل نواة CUDA واحدة. تعمل هذه التقنية على تحسين جدولة الحوسبة والذاكرة، مما يحقق زمن انتقال أقل، عن طريق دمج الحسابات في نواة واحدة، مما يلغي حدود المزامنة الناتجة عن استدعاءات النواة التسلسلية التقليدية. وقد أشاد Andrej Karpathy بهذا الإنجاز، معتبراً إياه السبيل الوحيد لتحقيق التنسيق الأمثل بين الحوسبة والذاكرة. يحمل هذا التقدم أهمية كبيرة لسيناريوهات الحوسبة الطرفية وتطبيقات الذكاء الاصطناعي في الوقت الفعلي التي تتطلب زمن انتقال منخفض، ومن المتوقع أن يدفع نحو نشر نماذج لغوية صغيرة أكثر كفاءة وسرعة. (المصدر: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek AI تطلق rStar-Coder: بناء مجموعة بيانات ضخمة للاستدلال البرمجي الموثق، مما يعزز بشكل كبير قدرات النماذج الصغيرة في البرمجة : أطلق باحثون من Microsoft و DeepSeek مشروع rStar-Coder، الذي يهدف إلى معالجة مشكلة ندرة مجموعات البيانات عالية الجودة والصعوبة في مجال الاستدلال البرمجي الحالي، وذلك من خلال بناء مجموعة بيانات ضخمة موثقة تحتوي على 418 ألف مسألة برمجية على مستوى المسابقات، و 580 ألف حل استدلالي طويل، وحالات اختبار غنية. يعمل المشروع على تعزيز قدرات الاستدلال البرمجي لنماذج اللغة الكبيرة (LLM) من خلال الاستخدام الشامل لمسائل المسابقات البرمجية الحالية وحلولها المثالية لتجميع مسائل جديدة، وتصميم خط أنابيب موثوق لإنشاء حالات اختبار المدخلات والمخرجات، واستخدام حالات الاختبار للتحقق من صحة حلول الاستدلال الطويلة عالية الجودة. أظهرت التجارب أن نماذج Qwen (1.5B-14B) المدربة باستخدام مجموعة بيانات rStar-Coder أظهرت أداءً متميزًا على العديد من معايير الاستدلال البرمجي، على سبيل المثال، ارتفعت دقة Qwen2.5-7B على LiveCodeBench من 17.4% إلى 57.3%، متجاوزة o3-mini (low)؛ وعلى USACO، تجاوز نموذج 7B أيضًا نموذج QWQ-32B الأكبر. (المصدر: HuggingFace Daily Papers)
معهد الأتمتة التابع للأكاديمية الصينية للعلوم يقترح AutoThink: لتمكين النماذج الكبيرة من تحديد ما إذا كانت بحاجة إلى “التفكير العميق” بشكل مستقل : لمواجهة ظاهرة “الإفراط في التفكير” حيث تقوم نماذج اللغة الكبيرة بإجراء استدلالات مطولة حتى في المسائل البسيطة، اقترح معهد الأتمتة التابع للأكاديمية الصينية للعلوم بالتعاون مع مختبر Peng Cheng طريقة AutoThink. تمكّن هذه الطريقة النموذج من الاختيار بشكل مستقل ما إذا كان سيقوم بالتفكير العميق ومقدار التفكير بناءً على صعوبة المسألة، وذلك من خلال إضافة “علامات الحذف” (…) في الموجهات ودمجها مع التعلم المعزز ثلاثي المراحل (استقرار النمط، تحسين السلوك، تقليم الاستدلال). أظهرت التجارب أن AutoThink يمكن أن يحسن أداء نماذج مثل DeepSeek-R1 على معايير اختبار الرياضيات، مع تقليل استهلاك رموز الاستدلال بشكل كبير. على سبيل المثال، يمكن توفير 10% إضافية من الرموز على DeepScaleR. يهدف هذا البحث إلى تمكين النماذج من “التفكير حسب الحاجة”، وتحقيق التوازن بين كفاءة الاستدلال ودقته. (المصدر: 36氪, _akhaliq)

Sakana AI تطلق Sudoku-Bench، كاشفةً عن نقاط ضعف نماذج الذكاء الاصطناعي الكبيرة الرائدة في استدلال “سودوكو المتحولة” : أطلقت شركة Sakana AI الناشئة لمؤلف Transformer، Llion Jones، منصة Sudoku-Bench، وهي معيار اختبار يتضمن ألغاز “سودوكو المتحولة” الحديثة من 4×4 إلى 9×9 المعقدة، بهدف تقييم قدرات الذكاء الاصطناعي على الاستدلال الإبداعي متعدد الخطوات. أظهرت نتائج الاختبار أن النماذج الكبيرة الرائدة، بما في ذلك Gemini 2.5 Pro و GPT-4.1 و Claude 3.7، حققت معدل دقة إجمالي أقل من 15% بدون مساعدة. وفي ألغاز سودوكو الحديثة 9×9، بلغت دقة o3 Mini High 2.9% فقط. يشير هذا إلى أن النماذج لا تؤدي أداءً جيدًا عند مواجهة مشكلات جديدة تتطلب استدلالًا منطقيًا حقيقيًا بدلاً من مطابقة الأنماط، وغالبًا ما تقدم إجابات خاطئة أو تتخلى عن المحاولة أو تسيء تفسير القواعد. يعتقد Jensen Huang، الرئيس التنفيذي لشركة NVIDIA، أن مثل هذه الألغاز تساعد في تحسين قدرات استدلال الذكاء الاصطناعي. كما أصدرت Sakana AI بيانات تدريب ذات صلة، بما في ذلك تسجيلات لعمليات حل الألغاز بالتعاون مع قنوات سودوكو الشهيرة. (المصدر: 36氪)

🎯 اتجاهات
Meta تعيد هيكلة فرق الذكاء الاصطناعي، وتسرب الأعضاء الأساسيين من FAIR يثير القلق : أعلنت Meta عن إعادة هيكلة فرق الذكاء الاصطناعي، وتقسيمها إلى فريق منتجات الذكاء الاصطناعي بقيادة Connor Hayes، وقسم أساسيات الذكاء الاصطناعي العام (AGI) بقيادة مشتركة من Ahmad Al-Dahle و Amir Frenkel. يركز الأول على منتجات المستخدمين النهائيين، بينما يركز الأخير على تطوير النماذج الأساسية مثل Llama. والجدير بالذكر أن قسم أبحاث الذكاء الاصطناعي الأساسي FAIR لا يزال مستقلاً، ولكن تم دمج بعض فرق الوسائط المتعددة في قسم أساسيات AGI. تهدف هذه التعديلات إلى تعزيز سرعة التطوير والمرونة. ومع ذلك، تواجه Meta تحديات تتمثل في ردود الفعل الفاترة تجاه Llama 4، والمنافسة المتزايدة في مجال المصادر المفتوحة، وتسرب المواهب الأساسية. من بين المؤلفين الـ 14 الأصليين الذين شاركوا في تطوير Llama، غادر 11 منهم بالفعل، وانضم العديد منهم إلى منافسين مثل Mistral AI أو أسسوها. كما شهد مختبر FAIR تغييرات في القيادة وتعديلات في اتجاهات البحث، مما أثار مخاوف بشأن مكانته داخل الشركة وقدراته الابتكارية المستقبلية. (المصدر: 36氪)

Google DeepMind تطلق SignGemma: نموذج جديد لترجمة لغة الإشارة : أعلنت Google DeepMind عن إطلاق SignGemma، وهو نموذج يوصف بأنه أقوى نموذج لديها حاليًا لترجمة لغة الإشارة إلى نص منطوق. من المتوقع أن ينضم هذا النموذج إلى عائلة نماذج Gemma في وقت لاحق من هذا العام وسيتم إصداره كنموذج مفتوح المصدر. يهدف إطلاق SignGemma إلى فتح إمكانيات جديدة للتكنولوجيا الشاملة، وتعزيز كفاءة وسهولة التواصل لمستخدمي لغة الإشارة. تدعو Google DeepMind المستخدمين لتقديم ملاحظاتهم والمشاركة في الاختبارات الأولية. (المصدر: GoogleDeepMind, demishassabis)
Tencent Hunyuan تطلق أوزان نموذج HunyuanPortrait، القادر على تحويل الصور الشخصية الثابتة إلى مقاطع فيديو ديناميكية : أتاح فريق Tencent Hunyuan المصدر المفتوح لأوزان نموذج HunyuanPortrait الخاص به لتحويل الصور إلى فيديو، مما يسمح للمستخدمين بتنزيلها واستخدامها محليًا. يركز هذا النموذج على تحويل صور الأشخاص الثابتة إلى مقاطع فيديو ديناميكية، وهو مناسب لمجموعة متنوعة من سيناريوهات التطبيق مثل شخصيات الألعاب، والمذيعين الافتراضيين، والأشخاص الرقميين، والمرشدين الأذكياء، مما يجعل صور الوجوه تتحرك ويزيد من حيوية وواقعية التفاعل. تم نشر النماذج ومستودعات الأكواد والأوراق البحثية ذات الصلة. (المصدر: karminski3, Reddit r/LocalLLaMA)

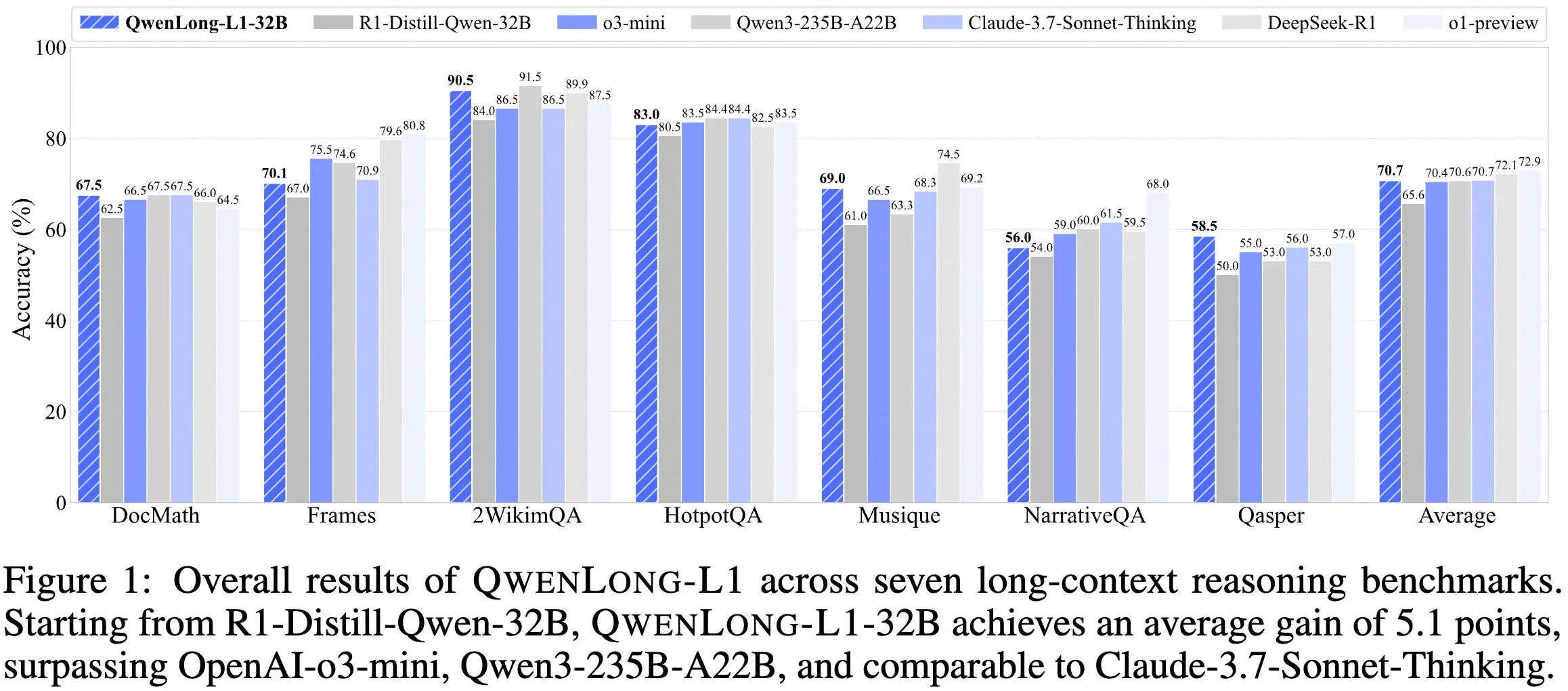
فريق QwenDoc يطلق نموذج الاستدلال طويل السياق QwenLong-L1-32B : أطلق فريق QwenDoc نموذج الاستدلال طويل السياق QwenLong-L1-32B بسياق 128K، والذي تم تدريبه باستخدام التعلم المعزز. تم ضبط هذا النموذج بدقة بناءً على DeepSeek-R1-Distill-Qwen-32B، وحقق درجة 90.5 على مجموعة اختبار الاستدلال متعدد القفزات 2WikiMultihopQA، بزيادة 6.5 نقطة عن النموذج الأصلي، مما يؤكد قدرته ليس فقط على العثور على المحتوى في السياقات الطويلة ولكن أيضًا على ربط الأدلة لإجراء الاستدلال. على الرغم من أن طول السياق البالغ 128K ليس الأطول حاليًا، إلا أن قدرته الاستدلالية المتميزة توفر خيارًا جديدًا لمعالجة المستندات الطويلة المعقدة. تم نشر النموذج والورقة البحثية ومستودع الأكواد. (المصدر: karminski3)
جامعة هونغ كونغ للعلوم والتكنولوجيا (HKUST) و Apple وغيرها من المؤسسات تتعاون لإطلاق سلسلة أساليب Laser، لتحسين كفاءة ودقة استدلال النماذج الكبيرة : اقترح باحثون من جامعة هونغ كونغ للعلوم والتكنولوجيا (HKUST)، وجامعة مدينة هونغ كونغ (CityU HK)، وجامعة واترلو، و Apple سلسلة أساليب Laser (بما في ذلك Laser-D و Laser-DE)، بهدف حل مشكلة استهلاك النماذج اللغوية الكبيرة (LRM) المفرط للرموز (tokens) للاستدلال في المسائل البسيطة. من خلال إطار تصميم موحد لمكافأة الطول، ومكافأة تعتمد على الطول المستهدف ودالة الخطوة، وآلية إدراك الصعوبة الديناميكية، حققت هذه الطريقة على معايير الاستدلال الرياضي المعقدة مثل AIME24 تحسينًا في الأداء بمقدار 6.1 نقطة مع تقليل استخدام الرموز بنسبة 63%. وجدت الدراسة أن “التفكير الذاتي” الزائد في النماذج المدربة قد انخفض، وأصبح نمط التفكير أكثر صحة، مما يحقق توازنًا فعالًا بين كفاءة ودقة استدلال النموذج. (المصدر: 36氪)

النسخة المجانية من Anthropic Claude تدعم الآن ميزة البحث على الويب : أعلنت Anthropic أن مستخدمي النسخة المجانية من مساعدها الذكي Claude يمكنهم الآن استخدام ميزة البحث على الويب. هذا يعني أنه عند الإجابة على الأسئلة، يمكن لـ Claude الحصول على أحدث المعلومات من الإنترنت لتعزيز أهمية ودقة ردوده. ذكرت الشركة رسميًا أن كل رد يتضمن نتائج بحث سيوفر اقتباسات مضمنة لتسهيل تحقق المستخدمين من مصادر المعلومات. (المصدر: AnthropicAI)
PKU-DS-LAB يطلق FairyR1: نموذج استدلال 32B مضبوط بدقة على DeepSeek-R1-Distill-Qwen-32B : أطلق مختبر علوم البيانات بجامعة بكين (PKU-DS-LAB) نموذج FairyR1، وهو نموذج استدلال بمعلمات 32B، مرخص بموجب Apache 2.0. يدعي النموذج أنه يحقق أداء النماذج الأكبر باستخدام 5% فقط من المعلمات، وذلك من خلال طريقة “التقطير ثم الدمج”. تم ضبط FairyR1 بدقة على DeepSeek-R1-Distill-Qwen-32B، كما تم توفير بيانات التدريب الخاصة به على Hugging Face Hub. يواصل هذا العمل فكرة بحث TinyR1، من خلال تصفية مجموعة البيانات بشكل فعال (حوالي 10,000 مسار)، وإجراء SFT للرياضيات والبرمجة بشكل منفصل، واستخدام Arcee Fusion لدمج النماذج. (المصدر: huggingface, teortaxesTex, stablequan)
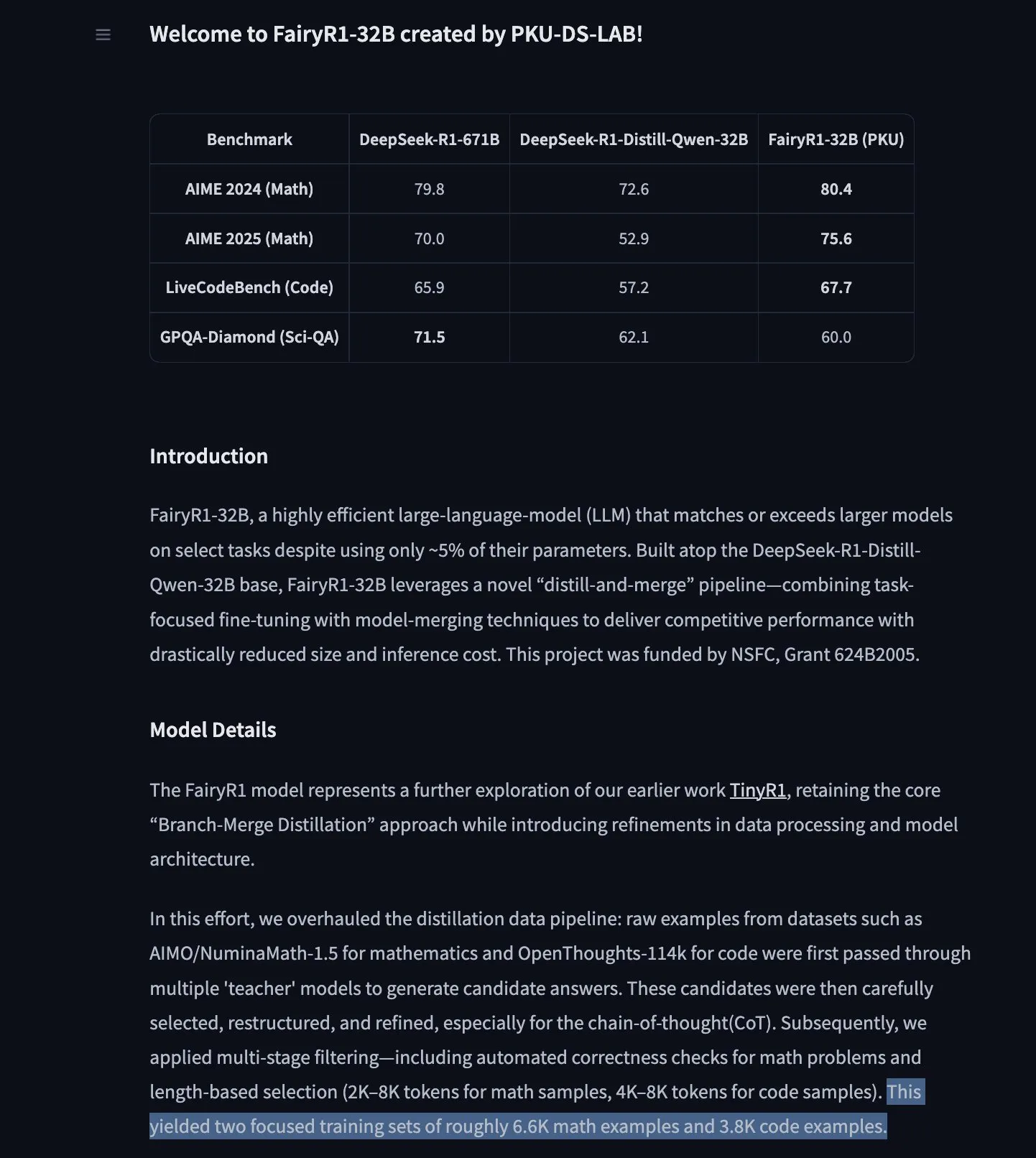
نموذج توقع السلاسل الزمنية TimesFM من جوجل يصل إلى Hugging Face Transformers : تم الآن دمج نموذج TimesFM من جوجل في مكتبة Hugging Face Transformers. هذا نموذج يشبه GPT، تم تدريبه مسبقًا على بيانات تتضمن 100 مليار نقطة زمنية حقيقية من مصادر متنوعة مثل Google Trends ومشاهدات صفحات ويكيبيديا. يُزعم أن TimesFM يتفوق في مهام التنبؤ بدون تدريب مسبق (zero-shot) على النماذج التي تم ضبطها بدقة خصيصًا، مما يوفر أداة قوية جديدة لتحليل السلاسل الزمنية. (المصدر: huggingface)
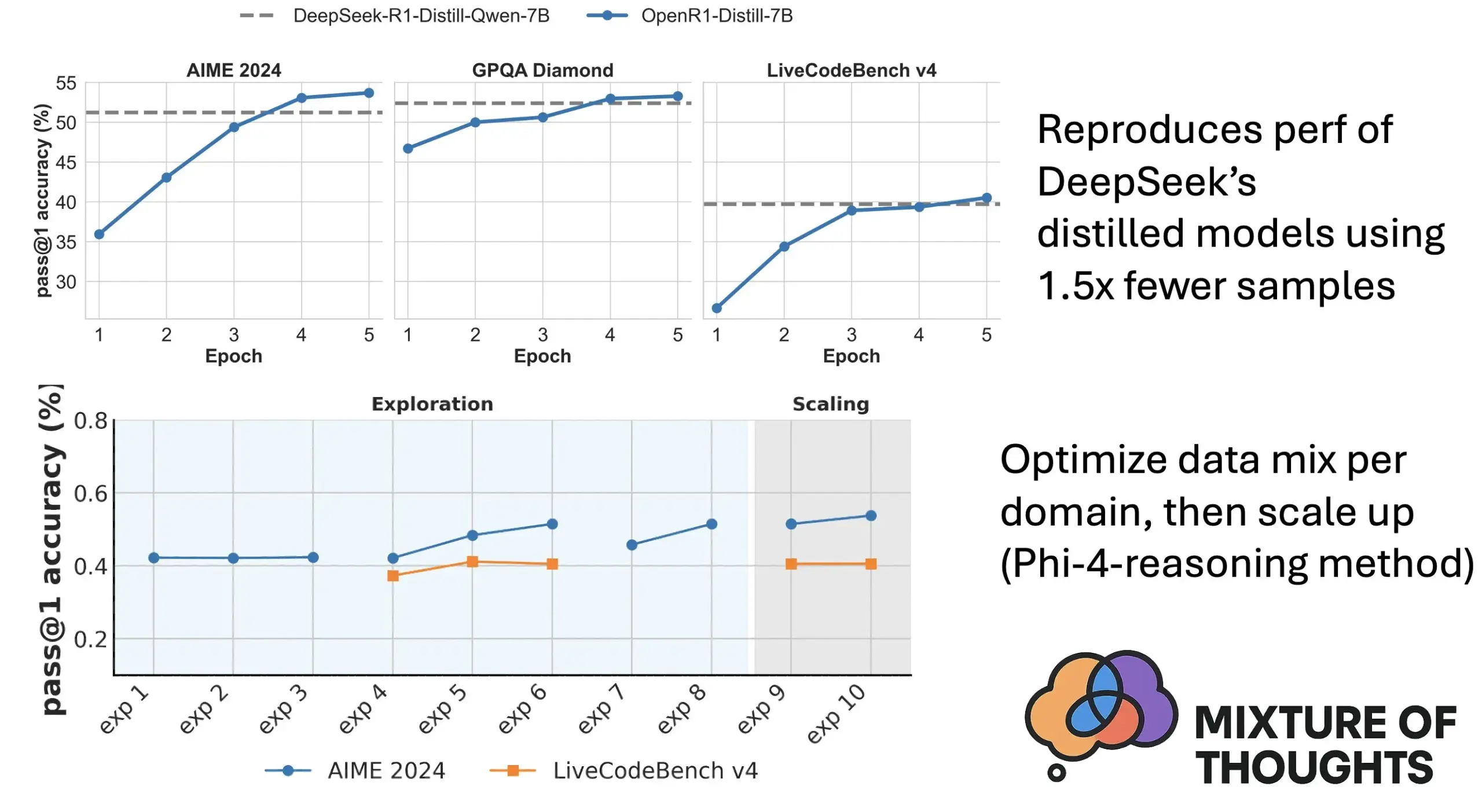
Hugging Face تطلق Mixture of Thoughts: مجموعة بيانات مختارة للاستدلال العام : أصدر باحثو Hugging Face، ومن بينهم Lewis Tunstall، مجموعة بيانات “Mixture of Thoughts”. تم اختيار هذه المجموعة بعناية من بين أكثر من مليون عينة بيانات عامة، من خلال تجارب استئصال مكثفة، لتضم حوالي 350 ألف عينة تركز على قدرات الاستدلال العام. النماذج المدربة باستخدام مجموعة البيانات المختلطة هذه تحقق أداءً يضاهي أو يتجاوز نماذج التقطير الخاصة بـ DeepSeek في معايير الرياضيات والبرمجة والعلوم (مثل GPQA). أثبت البحث فعالية منهجية “القابلية للإضافة” المقترحة في Phi-4-reasoning، والتي تعني أنه يمكن تحسين مزيج البيانات لكل مجال استدلال بشكل مستقل، ثم دمجها للتدريب النهائي. (المصدر: huggingface)
ByteDance تطلق BAGEL-7B: نموذج شامل لفهم وتوليد الصور والنصوص : أطلقت ByteDance نموذج BAGEL-7B، وهو نموذج شامل (omni) قادر على فهم وتوليد الصور والنصوص في نفس الوقت. بالإضافة إلى ذلك، أطلقوا Dolphin، وهو نموذج لغة مرئي (VLM) يركز على تحليل المستندات. سيوفر المصدر المفتوح لهذه النماذج أدوات وإمكانيات جديدة للبحث والتطبيقات متعددة الوسائط. (المصدر: huggingface, TheTuringPost)

جوجل تطلق Gemini 2.5 Flash Preview، مع دعم لإخراج الصوت الأصلي : أعلن مطورو الذكاء الاصطناعي في جوجل أن Gemini 2.5 Flash Preview يدعم الآن إخراج الصوت الأصلي من خلال Live API، بهدف توفير تفاعل كلامي سلس وطبيعي وقدرات تحكم صوتي أقوى. بالإضافة إلى ذلك، تم إطلاق نسخة تجريبية جديدة “مفكرة” من هذا النموذج الصوتي، تدعم قدرات استدلال للمهام الأكثر تعقيدًا. وفي الوقت نفسه، بدأ إخراج Gemini API في عرض “ملخصات التفكير”، مما يتيح للمستخدمين فهم عملية تفكير النموذج، ولكنها ليست حاليًا سلسلة استدلال كاملة. (المصدر: algo_diver, op7418)
ورقة بحثية تناقش القدرة التعبيرية لـ Transformer عند ملء الرموز الفارغة : تبحث دراسة جديدة فيما إذا كان ملء الرموز الفارغة (blank tokens) في مدخلات Transformer (وهو شكل من أشكال الحساب في وقت الاختبار) يمكن أن يعزز القدرة الحاسوبية لنماذج اللغة الكبيرة (LLM). تقدم هذه الدراسة، بالتعاون مع Ashish_S_AI، وصفًا دقيقًا للقدرة التعبيرية لـ Transformer مع الحشو، مما يوفر منظورًا جديدًا لفهم وتحسين الآليات الحاسوبية لنماذج اللغة الكبيرة. (المصدر: teortaxesTex)

دراسة جديدة تقترح إطار Sci-Fi: تحسين إقحام إطارات الفيديو من خلال القيود المتماثلة : لمعالجة مشكلة عدم تناسق قوة التحكم المحتملة عند دمج قيود إطارات البداية والنهاية في طرق إقحام إطارات الفيديو الحالية (Frame Inbetweening)، تقترح ورقة بحثية جديدة إطار Sci-Fi (Symmetric Constraint for Frame Inbetweening). تهدف هذه الطريقة إلى تحقيق تناسق قيود إطارات البداية والنهاية من خلال تطبيق آلية حقن أقوى (تعتمد على وحدة EF-Net خفيفة الوزن) للقيود ذات حجم التدريب الأصغر (مثل إطار النهاية)، وبالتالي إنتاج انتقالات أكثر تناسقًا في الإطارات المتوسطة المولدة، وتجنب عدم اتساق الحركة أو انهيار المظهر. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Paper2Poster: عملية آلية لتحويل الأوراق البحثية إلى ملصقات متعددة الوسائط : لمواجهة تحديات إنتاج الملصقات الأكاديمية، قدم الباحثون أول معيار لإنشاء الملصقات ومجموعة مؤشرات تقييم Paper2Poster، والتي تتضمن أزواجًا من الأوراق البحثية والملصقات المصممة من قبل المؤلفين، ويتم تقييمها من حيث الجودة البصرية، وتماسك النص، والتقييم العام، و PaperQuiz (لقياس قدرة الملصق على نقل المحتوى الأساسي). وفي الوقت نفسه، تم اقتراح PosterAgent، وهو عملية متعددة الوكلاء من الأعلى إلى الأسفل، مرئية في الحلقة، تتضمن محللًا (لاستخراج الأصول)، ومخططًا (لمواءمة النص والصورة والتخطيط)، وحلقة رسام-ناقد (للعرض وتحسين التغذية الراجعة). تفوقت المتغيرات المستندة إلى نماذج مفتوحة المصدر مثل Qwen-2.5 على الأنظمة التي تعمل بـ GPT-4o في معظم المؤشرات، مع تقليل استهلاك الرموز بنسبة 87%، مما يتيح تحويل ورقة بحثية من 22 صفحة إلى ملصق .pptx قابل للتحرير بتكلفة منخفضة للغاية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Frame In-N-Out: تحقيق توليد فيديو إلى صورة غير محدود وقابل للتحكم : لمواجهة التحديات في توليد الفيديو مثل قابلية التحكم والاتساق الزمني وتوليف التفاصيل، تركز ورقة بحثية جديدة على تقنية تصوير الأفلام “Frame In and Frame Out”، بهدف تمكين المستخدمين من التحكم في الكائنات الموجودة في الصورة بحيث تغادر المشهد بشكل طبيعي، أو إدخال مراجع هوية جديدة إلى المشهد، وتوجيهها بواسطة مسارات حركة يحددها المستخدم. تحقيقًا لهذه الغاية، قدم الباحثون مجموعة بيانات جديدة ذات توصيف شبه آلي، وبروتوكول تقييم شامل، وبنية Diffusion Transformer للفيديو فعالة في الحفاظ على الهوية وقابلة للتحكم في الحركة. أظهرت التجارب أن هذه الطريقة تتفوق بشكل كبير على خطوط الأساس الحالية. (المصدر: HuggingFace Daily Papers)
دراسة جديدة تقترح Active-O3: منح نماذج اللغة الكبيرة متعددة الوسائط قدرة الإدراك النشط من خلال GRPO : لمعالجة النقص في استكشاف قدرات الإدراك النشط (active perception) في نماذج اللغة الكبيرة متعددة الوسائط (MLLM)، اقترح الباحثون إطار Active-O3. يعتمد هذا الإطار على التدريب بالتعلم المعزز البحت باستخدام GRPO (Group Relative Policy Optimization)، ويهدف إلى منح MLLM القدرة على اختيار مواقع وطرق الملاحظة بشكل نشط لجمع المعلومات المتعلقة بالمهمة. قام الباحثون أولاً بتعريف مهام الإدراك النشط المستندة إلى MLLM بشكل منهجي، وأشاروا إلى أن استراتيجية البحث المكبرة لـ GPT-o3 هي حالة خاصة من الإدراك النشط ولكنها تفتقر إلى الكفاءة والدقة. يتم تقييم Active-O3 من خلال إنشاء مجموعة معايير شاملة، في مهام العالم المفتوح العامة (مثل تحديد مواقع الأجسام الصغيرة والكثيفة) وسيناريوهات المجالات المحددة (مثل الاستشعار عن بعد، واكتشاف الأجسام الصغيرة في القيادة الذاتية، والتجزئة التفاعلية الدقيقة)، ويُظهر قدرات استدلال قوية بدون تدريب مسبق (zero-shot) على V* Benchmark. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح MME-Reasoning: اختبار معياري شامل لقدرات الاستدلال المنطقي لنماذج MLLM : لمعالجة أوجه القصور في المعايير الحالية لتقييم قدرات الاستدلال المنطقي لنماذج اللغة الكبيرة متعددة الوسائط (MLLM)، قدم الباحثون MME-Reasoning. يغطي هذا المعيار الأنواع الثلاثة الرئيسية للاستدلال المنطقي: الاستقرائي، والاستنباطي، والاستدلال التفسيري (abductive)، ويتم اختيار البيانات بعناية لضمان أن الأسئلة تقيم بشكل فعال قدرات الاستدلال بدلاً من المهارات الإدراكية أو اتساع المعرفة. أظهرت نتائج التقييم أنه حتى أحدث نماذج MLLM تظهر قيودًا في التقييم الشامل للاستدلال المنطقي، مع وجود عدم توازن في الأداء عبر أنواع الاستدلال المختلفة. كما حللت الدراسة تأثير طرق مثل “أنماط التفكير” والتعلم المعزز القائم على القواعد على قدرات الاستدلال، مما يوفر رؤى منهجية لفهم وتقييم قدرات الاستدلال لنماذج MLLM. (المصدر: HuggingFace Daily Papers)
GraLoRA: تحسين أداء الضبط الدقيق الفعال للمعلمات من خلال التكيف منخفض الرتبة المحبب : لمعالجة مشكلة الإفراط في التجهيز (overfitting) واختناقات الأداء التي تظهر عند زيادة رتبة LoRA، اقترح الباحثون GraLoRA (Granular Low-Rank Adaptation). تقسم هذه الطريقة مصفوفة الأوزان إلى كتل فرعية، لكل منها مهايئ منخفض الرتبة مستقل، بهدف حل مشكلة تشابك التدرجات وتشويه الانتشار الناجمة عن الاختناقات الهيكلية في LoRA. يعزز GraLoRA بشكل فعال القدرة التعبيرية للنموذج، مقتربًا من تأثير الضبط الدقيق الكامل، دون زيادة تذكر في تكاليف الحوسبة أو التخزين. أظهرت التجارب على معايير توليد الأكواد والاستدلال المنطقي العام أن GraLoRA يتفوق على LoRA وخطوط الأساس الأخرى في مختلف أحجام النماذج وإعدادات الرتب، على سبيل المثال، حقق مكسبًا مطلقًا يصل إلى 8.5% في Pass@1 على HumanEval+. (المصدر: HuggingFace Daily Papers)
SoloSpeech: خط أنابيب توليد متسلسل يعزز وضوح وجودة استخراج الكلام المستهدف : لمعالجة مشكلة أن النماذج التمييزية الحالية في استخراج الكلام المستهدف (TSE) تميل إلى إدخال تشوهات وتقليل الطبيعية، بينما تفتقر النماذج التوليدية إلى الجودة الإدراكية والوضوح، اقترح الباحثون SoloSpeech. وهو خط أنابيب توليد متسلسل جديد يدمج عمليات الضغط والاستخراج وإعادة البناء والتصحيح. يتميز باعتماد مستخرج هدف بدون تضمين المتحدث، مستفيدًا من المعلومات الشرطية من الفضاء الكامن للصوت الموجه، ومواءمته مع الفضاء الكامن للصوت المختلط لمنع عدم التطابق. أظهر التقييم على مجموعة بيانات Libri2Mix أن SoloSpeech حقق مستوى SOTA جديدًا في مهام استخراج الكلام المستهدف وفصل الكلام، وأظهر قدرة تعميم ممتازة على البيانات خارج النطاق والسيناريوهات الحقيقية. (المصدر: HuggingFace Daily Papers)
بحث جديد يستكشف تعزيز قدرات الفهم البصري لنماذج اللغة الكبيرة متعددة الوسائط من خلال متجهات التوجيه المستندة إلى النص : تستكشف دراسة جديدة ما إذا كان يمكن استخدام متجهات التوجيه المشتقة من الشبكة العصبية الأساسية لنماذج اللغة الكبيرة متعددة الوسائط (MLLM) المكونة من نماذج لغة كبيرة نصية بحتة (من خلال طرق مثل التشفير التلقائي المتناثر SAE، وتحويل المتوسط، والتحقيق الخطي) لتعزيز قدراتها على الفهم البصري. وجدت الدراسة أن متجهات التوجيه المشتقة من النص تعزز باستمرار الدقة متعددة الوسائط لبنى MLLM المختلفة في مهام بصرية متنوعة. بشكل خاص، حسنت طريقة تحويل المتوسط دقة العلاقات المكانية بنسبة تصل إلى 7.3% ودقة العد بنسبة تصل إلى 3.3% على CV-Bench، متفوقة على طرق التوجيه، وأظهرت قدرة تعميم قوية على مجموعات البيانات خارج التوزيع. يشير هذا إلى أن متجهات التوجيه المستندة إلى النص هي آلية قوية وفعالة يمكنها تعزيز الأساس البصري لنماذج MLLM بأقل قدر من جمع البيانات الإضافية والتكاليف الحسابية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح DiSA: تسريع توليد الصور ذاتيًا من خلال تلدين خطوات الانتشار : لمعالجة مشكلة انخفاض كفاءة الاستدلال في النماذج ذاتية الانحدار مثل MAR و FlowAR التي تستخدم أخذ عينات الانتشار لتحسين جودة الصورة، تقترح ورقة بحثية جديدة طريقة DiSA (Diffusion Step Annealing). تعتمد هذه الطريقة على ملاحظة أنه مع زيادة عدد الرموز المولدة في العملية ذاتية الانحدار، يصبح توزيع الرموز اللاحقة أكثر تقييدًا، ويكون أخذ العينات أسهل. DiSA هي طريقة لا تتطلب تدريبًا، فهي تقلل تدريجيًا خطوات الانتشار (على سبيل المثال، من 50 خطوة أولية إلى 5 خطوات لاحقة) عند توليد المزيد من الرموز. هذه الطريقة مكملة للطرق الحالية المصممة لتسريع الانتشار نفسه، وهي سهلة التنفيذ، ويمكنها تسريع MAR و Harmon بمقدار 5-10 مرات، و FlowAR و xAR بمقدار 1.4-2.5 مرة، مع الحفاظ على جودة التوليد. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح CASS: مجموعة بيانات ونموذج ومعيار لترجمة كود GPU من Nvidia إلى AMD : قدم الباحثون CASS، وهي أول مجموعة بيانات ونماذج واسعة النطاق لترجمة كود GPU عبر البنى، تستهدف الترجمة على مستوى الكود المصدري (CUDA <-> HIP) ومستوى التجميع (Nvidia SASS <-> AMD RDNA3). تحتوي مجموعة البيانات على 70 ألف زوج من الأكواد الموثقة عبر المضيف والجهاز. تحقق سلسلة نماذج اللغة الخاصة بالمجال CASS المدربة على هذا المورد دقة 95% في ترجمة الكود المصدري ودقة 37.5% في ترجمة التجميع، متفوقة بشكل كبير على خطوط الأساس التجارية مثل GPT-4o و Claude. يتطابق الكود المولد مع الأداء الأصلي في أكثر من 85% من حالات الاختبار. كما تم إصدار CASS-Bench، وهو معيار اختبار يتضمن 16 مجالًا لـ GPU ونتائج تنفيذ حقيقية. تم إتاحة جميع البيانات والنماذج وأدوات التقييم كمصدر مفتوح. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تحلل قدرة المعايرة الشفوية في نماذج اللغة المرئية : تقيّم دراسة بشكل شامل فعالية نماذج اللغة المرئية (VLM) في التعبير عن الثقة من خلال اللغة الطبيعية (أي عدم اليقين الشفوي). عبر ثلاث فئات من النماذج، وأربعة مجالات مهام، وثلاثة سيناريوهات تقييم، أظهرت النتائج أن نماذج VLM الحالية غالبًا ما تظهر أخطاء معايرة واضحة في مهام وإعدادات متعددة. والجدير بالذكر أن نماذج الاستدلال البصري (أي النماذج التي تفكر بالصور) أظهرت باستمرار معايرة أفضل، مما يشير إلى أن الاستدلال الخاص بالوسائط أمر بالغ الأهمية لتقديرات عدم اليقين الموثوقة. لمواجهة تحديات المعايرة، قدم الباحثون “التوجيه المدرك للثقة البصرية” (Visual Confidence-Aware Prompting)، وهي استراتيجية توجيه من مرحلتين تهدف إلى تحسين مواءمة الثقة في الإعدادات متعددة الوسائط. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تتبع ظهور القدرات البراغماتية في نماذج اللغة الكبيرة : تُظهر نماذج اللغة الكبيرة (LLM) الحالية قدرات ناشئة في مهام الذكاء الاجتماعي، ولكن كيفية اكتسابها للقدرات البراغماتية أثناء التدريب لا تزال غير واضحة. تقدم ورقة بحثية جديدة مجموعة بيانات ALTPRAG، المصممة بناءً على المفهوم البراغماتي “البدائل” (alternatives)، لتقييم ما إذا كانت نماذج LLM في مراحل تدريب مختلفة يمكنها استنتاج نوايا المتحدث الدقيقة بدقة. من خلال التقييم المنهجي لـ 22 نموذج LLM (تغطي مراحل ما قبل التدريب، و SFT، وتحسين التفضيلات)، أظهرت النتائج أنه حتى النماذج الأساسية تظهر حساسية ملحوظة للإشارات البراغماتية، وتتحسن باستمرار مع زيادة حجم النموذج والبيانات. عززت SFT و RLHF أيضًا قدرات الاستدلال البراغماتي المعرفي. تؤكد هذه النتائج أن القدرات البراغماتية هي سمة مركبة ناشئة في تدريب LLM، مما يوفر رؤى جديدة لمواءمة النماذج مع معايير التواصل البشري. (المصدر: HuggingFace Daily Papers)
إطلاق معيار Video-Holmes: تقييم تفكير “نمط شيرلوك هولمز” في نماذج MLLM عند الاستدلال المعقد في الفيديو : لمعالجة الوضع الحالي حيث تقيّم معايير الفيديو الحالية بشكل أساسي الإدراك البصري وقدرات تحديد المواقع، دون التقاط احتياجات الاستدلال المعقدة بشكل كافٍ، أطلق الباحثون معيار Video-Holmes. مستوحى من عملية استدلال شيرلوك هولمز، يتضمن هذا المعيار 1837 سؤالًا مستخلصًا من 270 فيلمًا قصيرًا غامضًا تم توصيفه يدويًا، عبر 7 مهام مصممة بعناية. تتطلب كل مهمة من النموذج تحديد وربط العديد من الأدلة البصرية ذات الصلة المنتشرة في مقاطع فيديو مختلفة بشكل نشط. أظهر تقييم نماذج MLLM المتطورة (SOTA) أنه على الرغم من أداء النماذج الممتاز في الإدراك البصري، إلا أنها تواجه صعوبات كبيرة في دمج المعلومات، وغالبًا ما تفوت الأدلة الرئيسية. على سبيل المثال، بلغت دقة أفضل النماذج أداءً، Gemini-2.5-Pro، 45% فقط. (المصدر: HuggingFace Daily Papers)
إطلاق معيار MME-VideoOCR: تقييم قدرات OCR لنماذج LLM متعددة الوسائط في مشاهد الفيديو : على الرغم من التقدم الكبير الذي حققته نماذج اللغة الكبيرة متعددة الوسائط (MLLM) في التعرف الضوئي على الحروف (OCR) في الصور الثابتة، إلا أن فعاليتها في OCR الفيديو تضعف بسبب عوامل مثل ضبابية الحركة والتغيرات الزمنية والمؤثرات البصرية. لتوجيه تدريب نماذج MLLM العملية، أطلق الباحثون معيار MME-VideoOCR، الذي يغطي مجموعة واسعة من سيناريوهات تطبيقات OCR الفيديو. يتضمن هذا المعيار 10 فئات مهام (25 مهمة مستقلة)، تغطي 44 مشهدًا مختلفًا، ولا يشمل فقط التعرف على النص، بل يشمل أيضًا فهمًا واستدلالًا أعمق لمحتوى النص في الفيديو. يتضمن المعيار 1464 مقطع فيديو بدقة وأبعاد ونسب عرض إلى ارتفاع ومدد مختلفة، بالإضافة إلى 2000 زوج من الأسئلة والأجوبة المنسقة بعناية والموصوفة يدويًا. أظهر تقييم 18 نموذج MLLM متطور (SOTA) أنه حتى أفضل النماذج أداءً، Gemini-2.5 Pro، بلغت دقته 73.7% فقط، مما يكشف عن قيود النماذج الحالية في التعامل مع المهام التي تتطلب فهمًا شاملاً للفيديو. (المصدر: HuggingFace Daily Papers)
MetaMind: نمذجة التفكير الاجتماعي البشري من خلال نظام متعدد الوكلاء ما وراء المعرفي : لسد الفجوة في قدرة نماذج اللغة الكبيرة (LLM) على التعامل مع الغموض المتأصل والفروق الدقيقة السياقية في التواصل البشري، قدم الباحثون MetaMind، وهو إطار متعدد الوكلاء مستوحى من نظرية ما وراء المعرفة في علم النفس، يهدف إلى محاكاة الاستدلال الاجتماعي الشبيه بالبشر. يقسم MetaMind الفهم الاجتماعي إلى ثلاث مراحل تعاونية: (1) يولد وكيل نظرية العقل فرضيات حول الحالات العقلية للمستخدم (مثل النوايا والعواطف)؛ (2) يستخدم وكيل المجال المعايير الثقافية والقيود الأخلاقية لتحسين هذه الفرضيات؛ (3) يولد وكيل الاستجابة ردودًا مناسبة للسياق، مع التحقق من الاتساق مع النوايا المستنتجة. حقق هذا الإطار أداء SOTA في ثلاثة معايير اختبار صعبة، حيث تحسن بنسبة 35.7% في سيناريوهات اجتماعية حقيقية، وبنسبة 6.2% في استدلال نظرية العقل، ولأول مرة مكّن LLM من الوصول إلى مستوى الإنسان في مهام نظرية العقل الحاسمة. (المصدر: HuggingFace Daily Papers)
Sparse VideoGen2: تسريع توليد الفيديو من خلال الترتيب المدرك للسياق والانتباه المتناثر : لمعالجة مشكلة التأخير الكبير والتكاليف العالية للذاكرة التي تواجهها نماذج توليد الفيديو المستندة إلى Diffusion Transformers (DiT) عند معالجة مقاطع الفيديو الطويلة، اقترح الباحثون إطار SVG2. يعمل هذا الإطار على تحقيق توازن أمثل بين جودة التوليد والكفاءة من خلال الترتيب المدرك للسياق (باستخدام k-means لتجميع وإعادة ترتيب الرموز بناءً على التشابه الدلالي) لزيادة دقة تحديد الرموز الرئيسية وتقليل الهدر الحسابي. يدمج SVG2 أيضًا التحكم الديناميكي في الميزانية top-p وتنفيذ نواة مخصصة، مما يحقق تسريعًا يصل إلى 2.30 مرة و 1.89 مرة على HunyuanVideo و Wan 2.1 على التوالي، مع الحفاظ على PSNR مرتفع. (المصدر: HuggingFace Daily Papers)
OmniConsistency: تعلم الاتساق المستقل عن الأسلوب من بيانات منمقة زوجية : لمعالجة التحديين الرئيسيين اللذين تواجههما نماذج الانتشار في تنميق الصور، وهما الحفاظ على الاتساق في المشاهد المعقدة (خاصة الهوية والتكوين والتفاصيل) وتدهور الأسلوب الناجم عن LoRA الأسلوبية في عمليات تحويل الصورة إلى صورة، اقترح الباحثون OmniConsistency. وهو مكون إضافي للاتساق العام يستفيد من محولات الانتشار واسعة النطاق (DiT). تشمل مساهماته: (1) إطار تعلم الاتساق السياقي المدرب على أزواج صور متوائمة لتحقيق تعميم قوي؛ (2) استراتيجية تعلم تدريجية من مرحلتين تفصل تعلم الأسلوب عن الحفاظ على الاتساق للتخفيف من تدهور الأسلوب؛ (3) تصميم قابل للتوصيل والتشغيل بالكامل، متوافق مع أي LoRA أسلوبية ضمن إطار Flux. أظهرت التجارب أن OmniConsistency يعزز بشكل كبير التماسك البصري والجودة الجمالية، محققًا أداءً يضاهي نماذج SOTA التجارية مثل GPT-4o. (المصدر: HuggingFace Daily Papers)
ImgEdit: مجموعة بيانات موحدة ومعيار اختبار لتحرير الصور : لمعالجة مشكلة تخلف نماذج تحرير الصور مفتوحة المصدر عن النماذج المملوكة (بسبب محدودية البيانات عالية الجودة وعدم كفاية المعايير بشكل أساسي)، أطلق الباحثون ImgEdit. وهي مجموعة بيانات واسعة النطاق وعالية الجودة لتحرير الصور، تحتوي على 1.2 مليون زوج تحرير منسق بعناية، تغطي تعديلات فردية جديدة ومعقدة ومهام متعددة الجولات صعبة. لضمان جودة البيانات، تم اعتماد عملية متعددة المراحل تدمج أحدث نماذج اللغة المرئية، ونماذج الكشف، ونماذج التجزئة، بالإضافة إلى برامج إصلاح خاصة بالمهام ومعالجة لاحقة صارمة. تفوقت نماذج التحرير ImgEdit-E1 المدربة على ImgEdit على النماذج مفتوحة المصدر الحالية في مهام متعددة. كما تم إطلاق معيار ImgEdit-Bench لتقييم تحرير الصور من حيث اتباع التعليمات وجودة التحرير والحفاظ على التفاصيل. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح تحقيق تحكم سلوكي قوي في نماذج LLM من خلال ذرات الهدف الموجهة : لتحقيق تحكم دقيق في مخرجات نماذج اللغة لضمان السلامة والموثوقية، تقترح ورقة بحثية جديدة طريقة “ذرات الهدف الموجهة” (Steering Target Atoms, STA). تهدف هذه الطريقة إلى فصل ومعالجة مكونات المعرفة المنفصلة لتعزيز السلامة، خاصة في السيناريوهات العدائية، حيث تظهر متانة ومرونة فائقة. يرى الباحثون أنه على الرغم من استخدام هندسة التوجيه والتوجيه بشكل شائع للتدخل في سلوك النموذج، فإن التشابك العالي لمعلمات النموذج يحد من دقة التحكم وقد يؤدي إلى آثار جانبية. تتغلب STA على ذلك من خلال استخدام مشفرات ذاتية متناثرة (SAE) لفصل المعرفة في مساحات عالية الأبعاد وتوجيهها، مما يتيح تحكمًا سلوكيًا أكثر دقة. أثبتت التجارب فعالية هذه الطريقة، وتم تطبيقها على نماذج استدلال كبيرة، مما يؤكد إمكاناتها في التحكم الدقيق في الاستدلال. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح معيار SeePhys: تقييم قدرات الاستدلال الفيزيائي القائم على الرؤية : قدم الباحثون SeePhys، وهو معيار متعدد الوسائط واسع النطاق لتقييم قدرات نماذج LLM على الاستدلال في مسائل الفيزياء التي تتراوح من مستوى المرحلة الثانوية إلى امتحانات التأهيل للدكتوراه. يغطي هذا المعيار 7 مجالات أساسية في الفيزياء، ويتضمن 21 فئة من الرسوم البيانية شديدة التباين. على عكس الأعمال السابقة حيث تلعب العناصر المرئية دورًا مساعدًا بشكل أساسي، فإن 75% من الأسئلة في SeePhys ضرورية بصريًا، أي يجب استخراج المعلومات المرئية للإجابة بشكل صحيح. أظهر التقييم الواسع أنه حتى أحدث نماذج الاستدلال البصري (مثل Gemini-2.5-pro و o4-mini) تحقق دقة أقل من 60% على هذا المعيار، مما يكشف عن تحديات جوهرية في الفهم البصري لنماذج LLM الحالية، خاصة في الاقتران الصارم بين تفسير الرسوم البيانية والاستدلال الفيزيائي والتغلب على الاعتماد على الاختصارات المعرفية للإشارات النصية. (المصدر: HuggingFace Daily Papers)
VerIPO: تعزيز قدرات الاستدلال طويل المدى لنماذج Video-LLM من خلال تحسين سياسة التكرار الموجهة بالمدقق : لمعالجة اختناقات إعداد البيانات وعدم استقرار جودة سلسلة التفكير (CoT) التي تواجهها نماذج لغة الفيديو الكبيرة (Video-LLM) عند تطبيق التعلم المعزز في الاستدلال المعقد للفيديو، اقترح الباحثون طريقة VerIPO (Verifier-guided Iterative Policy Optimization). جوهر هذه الطريقة هو “مدقق مدرك للتنفيذ” (Rollout-Aware Verifier) يقع بين مراحل تدريب GRPO و DPO، ويستخدم لتقييم منطق الاستدلال، وبناء بيانات مقارنة عالية الجودة (تحتوي على CoT عاكسة ومتسقة سياقيًا). تدفع هذه البيانات مرحلة DPO فعالة، وبالتالي تحسين طول واتساق سلسلة الاستدلال. أظهرت نتائج التجارب أن VerIPO يمكنه تحسين النموذج بشكل أسرع وأكثر فعالية، وتوليد CoT أطول وأكثر اتساقًا سياقيًا، متفوقًا على متغيرات GRPO القياسية وبعض نماذج Video-LLM ذات الضبط الدقيق للتعليمات الكبيرة ونماذج الاستدلال الطويل. (المصدر: HuggingFace Daily Papers)
OpenS2V-Nexus: معيار مفصل ومجموعة بيانات مليونية لتوليد الفيديو من الموضوع : لدفع تطوير تقنية توليد الفيديو من الموضوع (S2V)، اقترح الباحثون OpenS2V-Nexus، والذي يتضمن (i) OpenS2V-Eval، وهو معيار دقيق، و (ii) OpenS2V-5M، وهي مجموعة بيانات مليونية. على عكس معايير S2V الحالية (الموروثة من VBench، والتي تركز على التقييم العام والتقريبي)، يركز OpenS2V-Eval على قدرة النموذج على توليد مقاطع فيديو متسقة مع الموضوع، ذات مظهر طبيعي، ودقة عالية في الحفاظ على الهوية. تحقيقًا لهذه الغاية، يقدم OpenS2V-Eval 180 موجهًا من 7 فئات رئيسية لـ S2V، تتضمن بيانات اختبار حقيقية ومصطنعة. بالإضافة إلى ذلك، لمحاذاة تفضيلات الإنسان بدقة، اقترح الباحثون ثلاثة مقاييس آلية: NexusScore، و NaturalScore، و GmeScore، والتي تقيس على التوالي اتساق الموضوع، والطبيعية، والصلة بالنص في مقاطع الفيديو المولدة. بناءً على ذلك، تم إجراء تقييم شامل لـ 16 نموذج S2V تمثيلي. وفي الوقت نفسه، تم إنشاء أول مجموعة بيانات توليد S2V مفتوحة المصدر واسعة النطاق OpenS2V-5M، والتي تحتوي على 5 ملايين ثلاثية عالية الجودة بدقة 720P من الموضوع والنص والفيديو. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح WHISTRESS: إثراء النص المكتوب من خلال اكتشاف التشديد في الجمل : نظرًا لأهمية التشديد في الجمل في الكلام المنطوق لنقل نية المتحدث، وغيابه في أنظمة النسخ الحالية، تقدم ورقة بحثية جديدة WHISTRESS، وهي طريقة لاكتشاف التشديد في الجمل لا تتطلب محاذاة. لدعم هذه المهمة، اقترح الباحثون TINYSTRESS-15K، وهي مجموعة بيانات تدريب اصطناعية قابلة للتطوير تم إنشاؤها من خلال عملية آلية بالكامل. يتفوق نموذج WHISTRESS المدرب على مجموعة البيانات هذه في الأداء على خطوط الأساس الحالية، ولا يتطلب تدريبًا إضافيًا أو مدخلات مسبقة للاستدلال. والجدير بالذكر أنه على الرغم من تدريبه على بيانات اصطناعية، يُظهر WHISTRESS قدرة تعميم قوية بدون تدريب مسبق (zero-shot) في العديد من معايير الاختبار. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح InstructPart: تجزئة الأجزاء الموجهة بالمهام مع الاستدلال بالتعليمات : على الرغم من التقدم الذي أحرزته نماذج الأساس الكبيرة متعددة الوسائط في مهام متنوعة، إلا أن العديد من النماذج تتعامل مع الكائنات ككل غير قابل للتجزئة، متجاهلة الأجزاء التي تتكون منها. يعد فهم هذه الأجزاء وقدراتها الوظيفية المرتبطة بها (affordances) أمرًا بالغ الأهمية لتنفيذ مجموعة واسعة من المهام. تحقيقًا لهذه الغاية، قدم الباحثون معيارًا جديدًا للعالم الحقيقي InstructPart، يتضمن تعليقات تجزئة الأجزاء الموصوفة يدويًا وتعليمات موجهة نحو المهام، لتقييم أداء النماذج الحالية في فهم وتنفيذ المهام على مستوى الأجزاء في المواقف اليومية. أظهرت التجارب أنه حتى بالنسبة لنماذج اللغة المرئية (VLM) المتطورة (SOTA)، لا تزال تجزئة الأجزاء الموجهة نحو المهام مشكلة صعبة. بالإضافة إلى المعيار، قدم الباحثون خط أساس بسيط، من خلال الضبط الدقيق باستخدام مجموعة البيانات الخاصة بهم، حققوا ضعف الأداء. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح طريقة هجينة عصبية-MPM، تحقق محاكاة سوائل تفاعلية في الوقت الفعلي : لمعالجة مشكلة أن الطرق الفيزيائية التقليدية كثيفة الحسابات وذات زمن انتقال مرتفع، وأن طرق التعلم الآلي الحديثة على الرغم من خفض التكاليف لا تزال تواجه صعوبة في تلبية احتياجات التفاعل في الوقت الفعلي لمحاكاة السوائل، اقترح الباحثون طريقة هجينة جديدة. تدمج هذه الطريقة المحاكاة العددية، والفيزياء العصبية، والتحكم التوليدي. تسعى فيزياءها العصبية، من خلال آلية ضمان تعود إلى المحاكيات العددية الكلاسيكية، إلى تحقيق محاكاة منخفضة التأخير ودقة فيزيائية عالية بشكل مشترك. بالإضافة إلى ذلك، طور الباحثون وحدة تحكم قائمة على الانتشار، تم تدريبها باستخدام استراتيجية نمذجة عكسية، لتوليد مجالات قوى ديناميكية خارجية للتحكم في السوائل. أظهر هذا النظام أداءً قويًا في سيناريوهات ثنائية وثلاثية الأبعاد متنوعة، وأنواع مواد، وتفاعلات مع العوائق، محققًا محاكاة في الوقت الفعلي بمعدل إطارات مرتفع (تأخير 11% ~ 29%)، ويمكنه توجيه التحكم في السوائل من خلال رسومات تخطيطية سهلة الاستخدام مرسومة باليد. (المصدر: HuggingFace Daily Papers)
MMIG-Bench: معيار تقييم شامل قابل للتفسير لنماذج توليد الصور متعددة الوسائط : لمعالجة قيود أدوات التقييم الحالية في تقييم مولدات الصور متعددة الوسائط مثل GPT-4o و Gemini 2.0 Flash و Gemini 2.5 Pro (مثل افتقار معايير T2I للشروط متعددة الوسائط، وتجاهل معايير توليد الصور المخصصة للدلالات التركيبية والمنطق العام)، اقترح الباحثون MMIG-Bench. وهو معيار شامل لتوليد الصور متعددة الوسائط، يتضمن 4850 موجهًا نصيًا غنيًا بالتعليقات و 1750 صورة مرجعية متعددة الزوايا تغطي 380 موضوعًا (أشخاص، حيوانات، أشياء، أنماط فنية). تم تجهيز MMIG-Bench بإطار تقييم ثلاثي المستويات: (1) تقيّم المؤشرات منخفضة المستوى التشوهات البصرية والحفاظ على هوية الكائن؛ (2) درجة مطابقة الجوانب الجديدة (AMS): مؤشر متوسط المستوى يعتمد على VQA، يوفر محاذاة دقيقة بين الموجه والصورة، ويرتبط ارتباطًا وثيقًا بأحكام الإنسان؛ (3) تقيّم المؤشرات عالية المستوى الجماليات وتفضيلات الإنسان. من خلال MMIG-Bench، تم اختبار 17 نموذجًا من أحدث النماذج (SOTA)، وتم التحقق من صحة المؤشرات باستخدام 32 ألف تقييم بشري، مما يوفر رؤى متعمقة لتصميم البنية والبيانات. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح HRPO: تحقيق استدلال كامن هجين من خلال التعلم المعزز : لمعالجة مشكلة عدم توافق طرق الاستدلال الكامن الحالية مع خصائص التوليد الذاتي الانحداري لنماذج LLM واعتمادها على مسارات CoT للتدريب، اقترح الباحثون HRPO (Hybrid Reasoning Policy Optimization). وهي طريقة استدلال كامن هجين تعتمد على التعلم المعزز، تدمج الحالات المخفية السابقة في الرموز المأخوذة من خلال آلية بوابات قابلة للتعلم، ويتم تهيئتها للتدريب بشكل أساسي بتضمينات الرموز، مع دمج المزيد من الميزات المخفية تدريجيًا. يحافظ هذا التصميم على قدرات التوليد لنماذج LLM ويحفز استخدام التمثيلات المنفصلة والمستمرة للاستدلال الهجين. بالإضافة إلى ذلك، يقدم HRPO العشوائية للاستدلال الكامن من خلال أخذ عينات الرموز، وبالتالي لا يتطلب مسارات CoT للتحسين القائم على RL. أظهر التقييم الواسع على معايير متنوعة أن HRPO يتفوق على الطرق السابقة في المهام كثيفة المعرفة وكثيفة الاستدلال. (المصدر: HuggingFace Daily Papers)
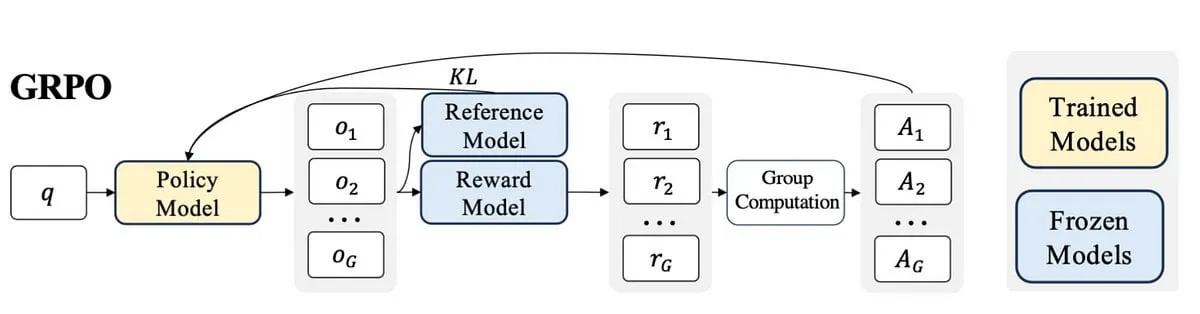
ورقة بحثية تقترح طريقة NFT: ربط التعلم الخاضع للإشراف بالتعلم المعزز في الاستدلال الرياضي : تتحدى ورقة بحثية جديدة الاعتقاد السائد بأن “التحسين الذاتي يقتصر على التعلم المعزز (RL)”، وتقترح طريقة الضبط الدقيق المدرك للسلبية (Negative-aware Fine-Tuning, NFT). وهي طريقة تعلم خاضع للإشراف تمكن نماذج LLM من التفكير في إخفاقاتها والتحسين بشكل مستقل، دون الحاجة إلى معلم خارجي. في التدريب عبر الإنترنت، لا يتجاهل NFT الإجابات الخاطئة التي تم إنشاؤها ذاتيًا، بل يبني سياسة سلبية ضمنية لنمذجتها. هذه السياسة الضمنية لها نفس معلمات LLM الإيجابية المستهدفة المستخدمة للتحسين على البيانات الإيجابية، مما يسمح بتحسين السياسة مباشرة على جميع مخرجات LLM. أظهرت نتائج التجارب على مهام الاستدلال الرياضي على نماذج 7B و 32B أنه من خلال الاستفادة الإضافية من التغذية الراجعة السلبية، يتفوق NFT بشكل كبير على خطوط الأساس للتعلم الخاضع للإشراف مثل الضبط الدقيق لأخذ العينات بالرفض، ويصل إلى أو حتى يتجاوز خوارزميات RL الرائدة مثل GRPO و DAPO. أثبت الباحثون كذلك أنه في التدريب الصارم على السياسات عبر الإنترنت، يكون NFT و GRPO متكافئين فعليًا. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Minute-Long Videos with Dual Parallelisms: تحقيق توليد فيديو بدقة دقيقة : لمعالجة مشكلة التأخير الحسابي والتكاليف العالية للذاكرة التي تواجهها نماذج انتشار الفيديو المستندة إلى DiT عند توليد مقاطع فيديو طويلة، اقترح الباحثون استراتيجية استدلال موزعة جديدة DualParal. الفكرة الأساسية لهذه الطريقة هي موازاة الإطارات الزمنية وطبقات النموذج على وحدات معالجة رسومات متعددة (GPU). لحل مشكلة تسلسل التوازي الأصلي الناجمة عن متطلبات نماذج الانتشار لمزامنة مستويات الضوضاء بين الإطارات، تعتمد هذه الطريقة مخطط إزالة ضوضاء مقسم إلى كتل، أي من خلال معالجة سلسلة من كتل الإطارات عبر خط أنابيب وتقليل مستوى الضوضاء تدريجيًا. تعالج كل وحدة GPU مجموعات فرعية محددة من الكتل والطبقات، وتنقل النتائج السابقة إلى وحدة GPU التالية، مما يحقق حسابًا واتصالًا غير متزامن. بالإضافة إلى ذلك، من خلال تنفيذ التخزين المؤقت للميزات على كل وحدة GPU لإعادة استخدام ميزات الكتل السابقة كسياق، واعتماد استراتيجية تهيئة ضوضاء منسقة، يتم ضمان ديناميكيات زمنية متسقة عالميًا، وبالتالي تحقيق توليد فيديو سريع وخالٍ من التشوهات وغير محدود الطول. عند تطبيقها على أحدث مولدات الفيديو بمحولات الانتشار، ولّدت هذه الطريقة بكفاءة فيديو مكون من 1025 إطارًا على 8 وحدات معالجة رسومات RTX 4090، مع تقليل التأخير بنسبة تصل إلى 6.54 مرة، وتقليل تكلفة الذاكرة بنسبة 1.48 مرة. (المصدر: HuggingFace Daily Papers)
🧰 أدوات
نماذج سلسلة Claude 4 تتألق في مهام البرمجة، وتنجح في حل “خطأ الحوت الأبيض” الذي حير مبرمجًا مخضرمًا لمدة 4 سنوات : أظهر نموذج Claude Opus 4 الأحدث من Anthropic قدرات مذهلة في البرمجة. شارك مهندس سابق في FAANG يتمتع بخبرة 30 عامًا في تطوير C++، أن خطأ نظام معقدًا حير فريقه لمدة 4 سنوات، واستغرق منه شخصيًا حوالي 200 ساعة دون حل (مشكلة شرط حدي تظهر عند استخدام تظليل معين بطريقة معينة)، تمكن Claude Opus 4 من تحديد موقعه ومعرفة سببه في غضون ساعات قليلة من خلال حوالي 30 موجهًا. لم يكن هذا الخطأ موجودًا قبل إعادة هيكلة النظام، وأشار Opus 4 إلى أن البنية الجديدة فشلت في التوافق مع سلوك غير مصمم كان مدعومًا “بمحض الصدفة” في البنية القديمة. سابقًا، فشلت نماذج GPT-4.1 و Gemini 2.5 و Claude 3.7 في حل هذه المشكلة. يسلط هذا الضوء على القدرات القوية لـ Claude 4 في فهم الأكواد المعقدة، وإجراء تحليل عميق واستدلال، خاصة بعد دمجه مع وضع Claude Code، مما يمكنه من مساعدة المطورين بفعالية في التعامل مع مهام هندسية متقدمة مثل إعادة هيكلة الأكواد وإصلاح الأخطاء. (المصدر: 36氪, dotey)
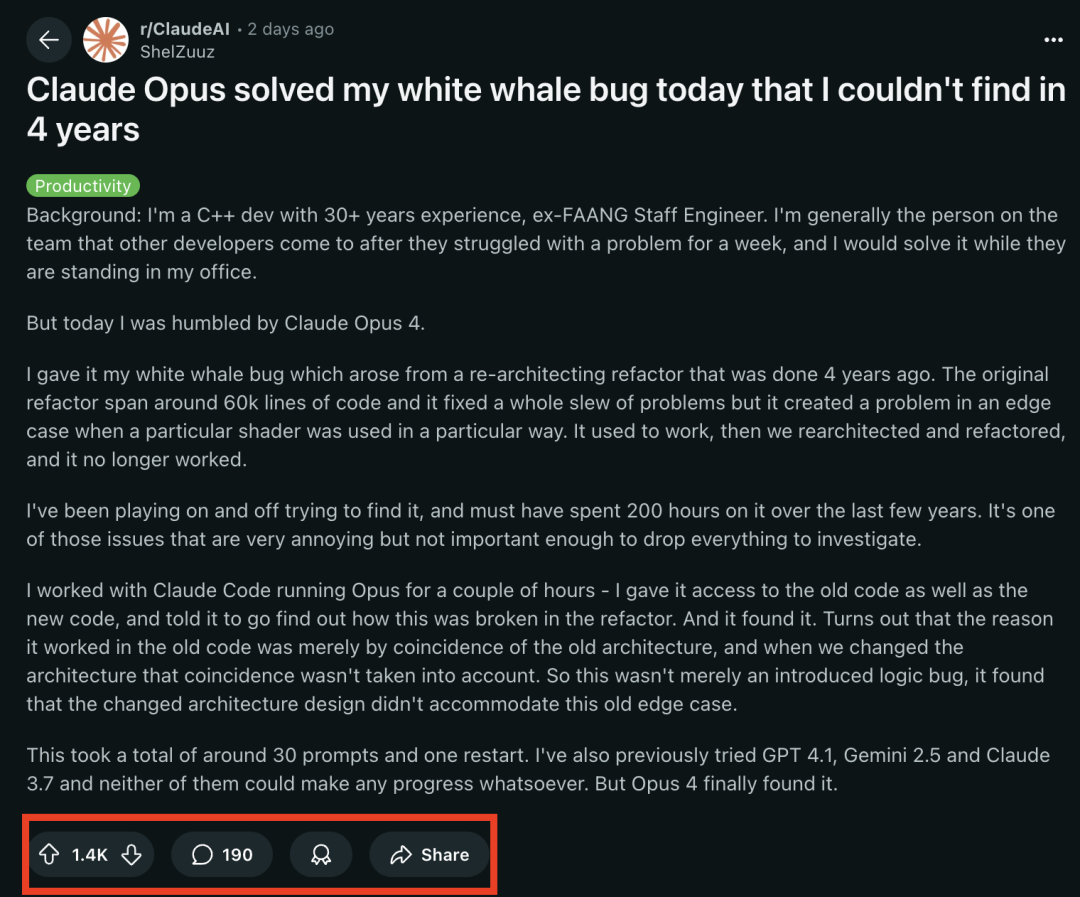
LangChain يضيف دعمًا لميزات Beta الجديدة في Anthropic Claude : أعلنت LangChain عن دمج أربع ميزات Beta جديدة تم إصدارها مؤخرًا لنموذج Anthropic Claude، بما في ذلك تنفيذ الأكواد، وموصلات MCP عن بُعد، وواجهة برمجة تطبيقات الملفات (File API)، والتخزين المؤقت الموسع للموجهات. يمكن للمطورين الآن الاطلاع على الأمثلة ذات الصلة من خلال وثائق LangChain للاستفادة من هذه الميزات الجديدة في بناء تطبيقات ذكاء اصطناعي أكثر قوة. (المصدر: LangChainAI)
LangSmith تطلق ميزات إدارة الموجهات المدمجة مع SDLC : عززت منصة LangSmith قدراتها في هندسة الموجهات، حيث يمكن للمستخدمين الآن ليس فقط اختبار الموجهات وإصدارها والتعاون عليها داخل LangSmith، ولكن أيضًا مزامنة الموجهات تلقائيًا مع GitHub أو قواعد البيانات الخارجية أو بدء عمليات CI/CD من خلال مشغلات webhook عند تغيير الموجهات. تهدف هذه الميزة إلى مساعدة المطورين على دمج إدارة الموجهات بشكل أوثق في دورة حياة تطوير البرمجيات (SDLC). (المصدر: LangChainAI)
AutoThink: تقنية تكييفية لتحسين أداء استدلال LLM المحلي : طور فريق CodeLion تقنية AutoThink، التي تحسن بشكل كبير أداء استدلال LLM المحلي من خلال تخصيص الموارد التكيفي ومتجهات التوجيه (steering vectors). يمكن لـ AutoThink تصنيف تعقيد الاستعلامات، وتخصيص “رموز التفكير” (tokens) ديناميكيًا (تخصيص المزيد للمسائل المعقدة وأقل للمسائل البسيطة)، واستخدام متجهات التوجيه لتوجيه أنماط الاستدلال. أظهرت الاختبارات على نموذج DeepSeek-R1-Distill-Qwen-1.5B تحسنًا في دقة GPQA-Diamond بنسبة 43% (من 21.72% إلى 31.06%)، وتحسنًا أيضًا في MMLU-Pro، مع استخدام أقل للرموز. هذه التقنية متوافقة مع نماذج الاستدلال المحلية التي تدعم رموز التفكير، وقد تم نشر الكود والبحث. (المصدر: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab يعلن عن دعم AMD ROCm، مما يتيح تدريب LLM محليًا : أعلن Transformer Lab أن منصته الرسومية (GUI) تدعم الآن استخدام ROCm على وحدات معالجة الرسومات AMD لتدريب نماذج اللغة الكبيرة وضبطها بدقة محليًا. ذكر الفريق أن عملية تكوين ROCm كانت مليئة بالتحديات، وقاموا بتوثيق العملية برمتها في مدونة. حاليًا، تعمل هذه الميزة بسلاسة، ويمكن للمستخدمين تجربة تطوير LLM على أجهزة AMD. (المصدر: Reddit r/MachineLearning)
نظام متعدد الوكلاء مفتوح المصدر معزز بـ LLM يحقق استخلاص المطالبات والتحقق من الحقائق آليًا : يستخدم مشروع مفتوح المصدر يسمى “fact-checker” نظامًا متعدد الوكلاء (MAS) معززًا بـ LLM لتحقيق استخلاص المطالبات والتحقق من الأدلة وحل الحقائق آليًا. يتضمن المشروع امتدادًا للمتصفح يمكنه التحقق من صحة استجابات أي روبوت محادثة يعمل بالذكاء الاصطناعي في الوقت الفعلي، مما يساعد على تمييز صحة المحتوى الذي يولده الذكاء الاصطناعي. يتميز هيكل الكود الخاص به بالوضوح والتوثيق الجيد، ويوفر أداة قيمة في مجال أمان الذكاء الاصطناعي ومكافحة المعلومات المضللة. (المصدر: Reddit r/MachineLearning)
Meituan تطلق منتج Nocode بدون كود، يدعم توليد تطبيقات معقدة متعددة الصفحات : أطلقت Meituan منتج Vibe Coding يسمى Nocode، يمكن للمستخدمين من خلاله وصف تطبيقات كاملة معقدة تتضمن صفحات متعددة بلغة طبيعية، وليس فقط صفحات ويب بسيطة للعرض. أظهر اختبار “歸藏” أن الأداة قادرة على بناء أداة إدارة بضائع مستودعات معقدة منطقيًا بنجاح دفعة واحدة، مما يوضح قدرتها على فهم المتطلبات المعقدة وتوليد الكود المقابل. (المصدر: op7418)
LlamaIndex يدعم بناء مُضمِّنات متعددة الوسائط مخصصة والتكامل مع واجهة مستخدم محادثة بنمط OpenAI : أصدر LlamaIndex تحديثًا يسمح للمستخدمين ببناء مُضمِّنات متعددة الوسائط مخصصة، مثل دمج AWS Titan Multimodal، ويمكن دمجها مع قواعد بيانات المتجهات مثل Pinecone لإجراء بحث فعال عن متجهات النصوص والصور. بالإضافة إلى ذلك، يمكن الآن تشغيل تدفقات عمل LlamaIndex في واجهة محادثة تشبه OpenAI ببضعة أسطر من التعليمات البرمجية، وتدعم وضع التطوير الذي يسمح بتحرير كود تدفق العمل مباشرة في واجهة المستخدم، مما يعزز تجربة تطوير وتفاعل تطبيقات RAG. (المصدر: jerryjliu0, jerryjliu0)

تحديث TRAE يعزز تجربة البرمجة الوكيلية (Agentic)، والنسخة الدولية تطلق اشتراكًا مدفوعًا : شهدت أداة البرمجة بالذكاء الاصطناعي TRAE تحديثًا يحسن تجربة البرمجة الوكيلية، مما يجعلها أكثر ملاءمة للمستخدمين الذين لا يرغبون في العمل اليدوي. يمكن لـ TRAE الجديد تذكر المحادثات السابقة بشكل أفضل، وربط السياق تلقائيًا، ويمكن للذكاء الاصطناعي تخطيط مسار البرمجة تلقائيًا واستدعاء المزيد من الأدوات، مما يزيد من معدل نجاح مهام البرمجة. على سبيل المثال، يحتاج المستخدم فقط إلى توفير مجلد فارغ وموجه، ويمكن لـ TRAE إكمال سلسلة من العمليات مثل إنشاء الملفات، وبدء خادم الويب (معالجة مشكلات CORS تلقائيًا)، ومعاينة رسوم p5.js المتحركة داخل IDE. تم إطلاق اشتراك مدفوع لنسختها الدولية، بسعر 3 دولارات للشهر الأول لـ Pro، ويدعم Alipay. (المصدر: dotey, karminski3)
مجتمع Juejin يطلق خدمة MCP، تدعم نشر كود الواجهة الأمامية بنقرة واحدة : أطلق مجتمع المبرمجين الصيني Juejin خدمة MCP (Model-driven Co-programming Protocol)، مما يسمح للمطورين بنشر كود الواجهة الأمامية (مثل صفحات الويب أو الألعاب التي تم إنشاؤها بواسطة vibe coding) على منصة Juejin بنقرة واحدة، لتسهيل المشاركة والمعاينة السريعة. يحتاج المستخدمون إلى الحصول على Token لـ Juejin MCP وتكوينه في أدوات مثل Trae و Cursor. (المصدر: dotey, karminski3)
أداة تتبع الوقت مفتوحة المصدر ActivityWatch تحظى بالاهتمام كبديل لـ Rize : بعد تجربة أداة تحليل الوقت بالذكاء الاصطناعي Rize (التي تحكم على حالة العمل أو الاجتماع أو التكاسل من خلال تحليل أسماء العمليات، باشتراك شهري 20 دولارًا)، اكتشف المستخدم karminski3 وأوصى بالبديل مفتوح المصدر ActivityWatch. تعمل ActivityWatch بشكل مشابه، وتدعم Windows/Mac، وتسمح للمستخدمين بالتخصيص، وتعتبر أداة ممتازة لتخفيف قلق العمل وتتبع ساعات العمل. (المصدر: karminski3)
إطلاق أداة مراقبة الأطفال بالذكاء الاصطناعي مفتوحة المصدر ai-baby-monitor : تم إطلاق مشروع مفتوح المصدر يسمى ai-baby-monitor، يستخدم نموذج Qwen2.5 VL وإطار استدلال vLLM، ويسمح للمستخدمين بتحديد قواعد (مثل “إنذار إذا استيقظ الطفل”، “إنذار إذا كان الطفل بمفرده”) لجعل الذكاء الاصطناعي يساعد في رعاية الأطفال. يؤكد المطور أن هذه مجرد أداة مساعدة ولا يمكن أن تحل محل الرعاية البشرية بالكامل. (المصدر: karminski3)
LangChain يدمج ميزة Live Search من xAI : أعلنت LangChain عن دعم ميزة Live Search من xAI، والتي تسمح لنموذج Grok بتوليد الإجابات بناءً على نتائج البحث على الويب، وتوفر خيارات تكوين متنوعة، مثل الفترة الزمنية، والنطاقات المضمنة، وغيرها من معلمات البحث. يمكن للمستخدمين الآن تجربة هذه الميزة الجديدة في LangChain. (المصدر: LangChainAI)
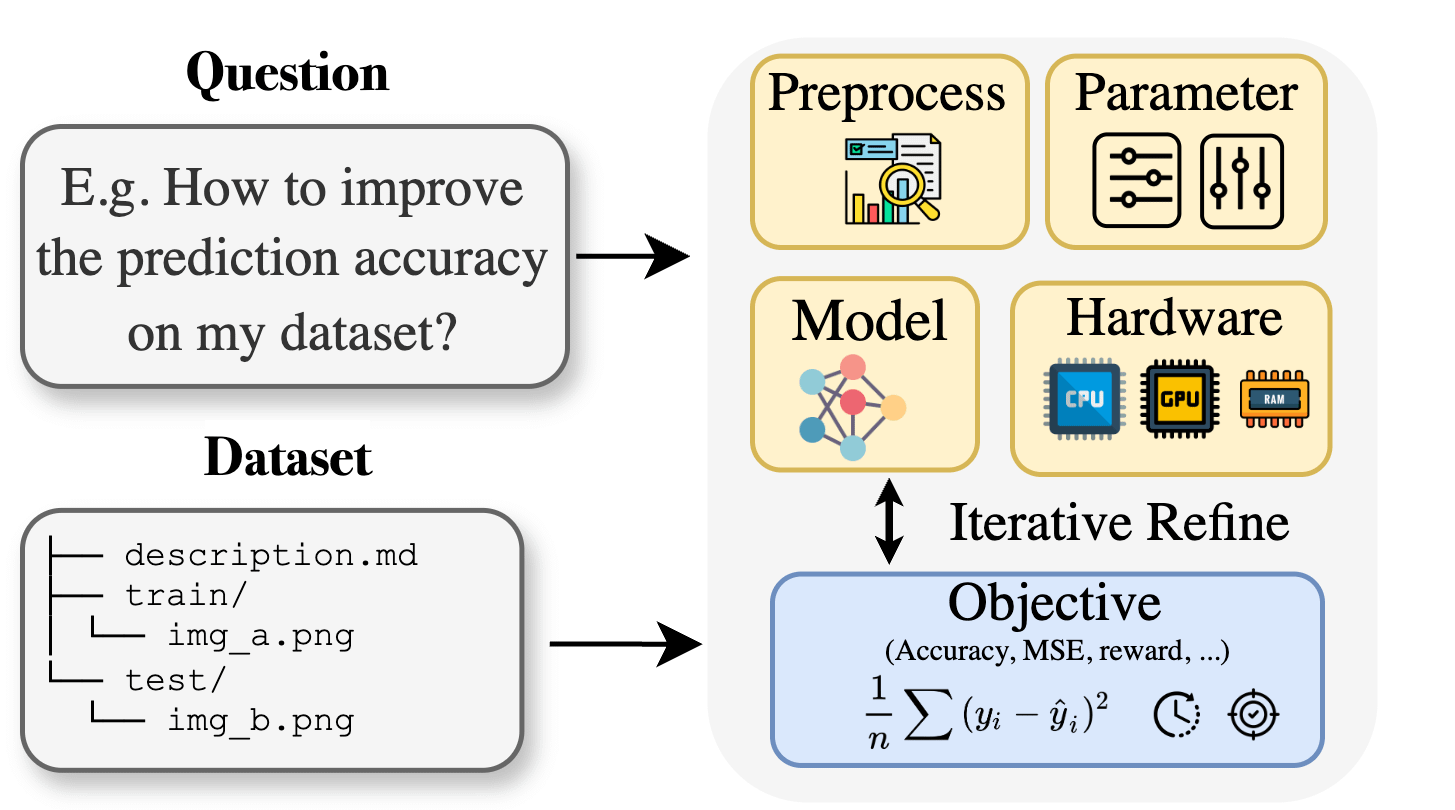
Curie: مساعد البحث العلمي بالذكاء الاصطناعي مفتوح المصدر يطلق ميزة AutoML، لدعم الأبحاث متعددة التخصصات : لمواجهة الحواجز المعرفية المتخصصة التي يواجهها الباحثون في مجالات مثل الأحياء والمواد والكيمياء عند تطبيق التعلم الآلي، أطلق مشروع Curie ميزة AutoML جديدة. يهدف Curie إلى أن يكون عالمًا متعاونًا لتجارب البحث في مجال الذكاء الاصطناعي، من خلال أتمتة عمليات التعلم الآلي المعقدة (مثل اختيار الخوارزميات، وضبط المعلمات الفائقة، وتفسير مخرجات النموذج)، لمساعدة الباحثين على اختبار الفرضيات بسرعة واستخلاص الرؤى من البيانات. على سبيل المثال، أنتج Curie نموذجًا للكشف عن سرطان الجلد بمعامل AUC يبلغ 0.99. تم فتح مصدر المشروع، ويشجع على مشاركة المجتمع. (المصدر: Reddit r/LocalLLaMA)
تطبيق MNN Chat من Alibaba يدعم تشغيل نموذج Qwen 30B-a3b محليًا على أجهزة أندرويد : تم تحديث تطبيق MNN Chat من Alibaba إلى الإصدار 0.5.0، ويدعم الآن تشغيل نماذج لغوية كبيرة مثل Qwen 30B-a3b محليًا على أجهزة أندرويد. أفاد المستخدمون أنه يمكن تشغيله بنجاح على الأجهزة ذات الشرائح الرائدة والذاكرة الكبيرة (مثل OnePlus 13 24G)، وينصحون بتمكين إعداد mmap. ومع ذلك، أشارت بعض التعليقات إلى أن نموذج 30B يتطلب ذاكرة وقوة حوسبة عالية جدًا بالنسبة لمعظم الهواتف، وقد يكون Gemma 3n أكثر ملاءمة للأجهزة المحمولة. (المصدر: Reddit r/LocalLLaMA)

📚 دراسات
ورقة بحثية جديدة تقترح Lean and Mean Adaptive Optimization: مُحسِّن تدريب نماذج كبيرة أسرع وأقل استهلاكًا للذاكرة : تقدم ورقة بحثية مقبولة في ICML 2025 مُحسِّنًا جديدًا يسمى “Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum”. تهدف هذه الطريقة إلى تقليل متطلبات الذاكرة لتدريب الشبكات العصبية واسعة النطاق وتسريع التدريب من خلال تقنيتين متكاملتين: خطوة Subset-Norm وزخم Subspace-Momentum. مقارنةً بمُحسِّنات الذاكرة الفعالة الحالية مثل GaLore و LoRA، توفر هذه الطريقة في الذاكرة (على سبيل المثال، تقلل ذاكرة حالة المُحسِّن بنسبة 80% مقارنة بـ Adam عند تدريب LLaMA 1B مسبقًا) مع تحقيق حيرة التحقق الخاصة بـ Adam باستخدام عدد أقل من رموز التدريب (حوالي النصف)، وتوفر ضمانات تقارب نظرية أقوى. (المصدر: Reddit r/MachineLearning)
ورقة بحثية تقترح Force Prompting: تمكين نماذج توليد الفيديو من تعلم وتعميم إشارات التحكم القائمة على الفيزياء : يستكشف بحث جديد إمكانية استخدام القوى الفيزيائية كإشارات تحكم لتوليد الفيديو، ويقترح “موجهات القوة” (Force Prompts). يمكن للمستخدمين التفاعل مع الصور من خلال قوى نقطية موضعية (مثل وخز نبات) أو مجالات رياح عالمية (مثل هبوب الرياح على نسيج). أظهرت الدراسة أن نماذج توليد الفيديو يمكنها التعلم وتعميم شروط القوة الفيزيائية من مقاطع فيديو تم إنشاؤها بواسطة Blender تتضمن عروضًا قليلة فقط للكائنات، وتوليد مقاطع فيديو تستجيب بشكل واقعي لإشارات التحكم الفيزيائية، دون الحاجة إلى استخدام أصول ثلاثية الأبعاد أو محاكيات فيزيائية في وقت الاستدلال. يعد التنوع البصري واستخدام كلمات رئيسية نصية محددة أثناء التدريب عاملين رئيسيين لتحقيق هذا التعميم. (المصدر: HuggingFace Daily Papers)
AnkiHub تشارك سير عمل التوصيف بالذكاء الاصطناعي، مع دمج FastHTML لتعزيز الكفاءة : شاركت AnkiHub سير عمل التوصيف بالذكاء الاصطناعي الخاص بها، وقدمته في دورة تقييم الذكاء الاصطناعي التي قدمها Hamel Husain و Shreya Shankar. يستفيد سير العمل هذا من أداة بناء FastHTML، ويهدف إلى تحسين كفاءة التوصيف بالذكاء الاصطناعي للمنتجات التجارية. تم نشر المواد التعليمية ومستودعات الأكواد ذات الصلة على GitHub، مما يوضح كيفية استخدام الأدوات المستخدمة في الإنتاج الفعلي لتحسين تطوير الذكاء الاصطناعي. (المصدر: jeremyphoward, HamelHusain)

مدون يكتب عن تجاربه في تعلم PPO إلى GRPO، موضحًا مفاهيم التعلم المعزز في الضبط الدقيق لنماذج LLM : شارك مدون تجربته في تعلم التعلم المعزز (RL) وتطبيقاته في الضبط الدقيق لنماذج اللغة الكبيرة (LLM)، خاصة فهمه لعملية الانتقال من PPO (Proximal Policy Optimization) إلى GRPO (Group Relative Policy Optimization). تهدف التدوينة إلى شرح المفاهيم التي كان يرغب في معرفتها في بداية تعلمه، لمساعدة الآخرين على فهم أفضل لكيفية استخدام خوارزميات RL هذه لتحسين LLM. (المصدر: Reddit r/MachineLearning)
ورقة بحثية تناقش التفكير البراغماتي للآلات: تتبع ظهور القدرات البراغماتية في نماذج اللغة الكبيرة : تبحث ورقة بحثية جديدة في كيفية اكتساب نماذج اللغة الكبيرة (LLM) للقدرة البراغماتية (pragmatic competence) أثناء عملية التدريب، أي فهم واستنتاج المعاني الضمنية ونوايا المتحدث وما إلى ذلك. قدم الباحثون مجموعة بيانات ALTPRAG، بناءً على مفهوم “البدائل” (alternatives) في علم البراغماتيات، لتقييم 22 نموذج LLM في مراحل تدريب مختلفة (ما قبل التدريب، الضبط الدقيق الخاضع للإشراف SFT، تحسين التفضيلات RLHF). أظهرت النتائج أنه حتى النماذج الأساسية تظهر حساسية ملحوظة للإشارات البراغماتية، وتتحسن باستمرار مع زيادة حجم النموذج والبيانات؛ كما عززت SFT و RLHF قدرات الاستدلال البراغماتي المعرفي. يشير هذا إلى أن القدرة البراغماتية هي خاصية ناشئة ومركبة في تدريب LLM. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش إطار التعلم المعزز VisTA لاختيار الأدوات المرئية : قدم الباحثون VisTA (VisualToolAgent)، وهو إطار جديد للتعلم المعزز يمكّن الوكلاء البصريين من استكشاف واختيار ودمج الأدوات من مكتبات مختلفة ديناميكيًا بناءً على الأداء التجريبي. على عكس الطرق الحالية التي تعتمد على التوجيه بدون تدريب أو الضبط الدقيق واسع النطاق، يستخدم VisTA التعلم المعزز من طرف إلى طرف، باستخدام نتائج المهام كإشارات تغذية راجعة، لتحسين استراتيجيات اختيار الأدوات المعقدة والخاصة بالاستعلام بشكل متكرر. من خلال GRPO (Group Relative Policy Optimization)، يمكّن هذا الإطار الوكلاء من اكتشاف مسارات اختيار الأدوات الفعالة بشكل مستقل، دون الحاجة إلى إشراف استدلالي صريح. أظهرت التجارب على معايير ChartQA و Geometry3K و BlindTest أن VisTA يحقق تحسينات كبيرة في الأداء مقارنة بخطوط الأساس بدون تدريب، خاصة على العينات خارج التوزيع. (المصدر: HuggingFace Daily Papers)
💼 أعمال
شركة خدمات البيانات Jinglianwen Technology تكمل جولة تمويل Pre-A بملايين اليوانات، وتخطط لإنتاج وتشغيل البيانات العامة : أكملت شركة تشغيل بيانات الذكاء الاصطناعي Jinglianwen Technology مؤخرًا جولة تمويل Pre-A بملايين اليوانات، استثمرت فيها صناديق تابعة لمجموعة Hangzhou Jin Tou Group. سيتم استخدام التمويل لتخطيط إنتاج وتشغيل البيانات العامة، وبناء منصة هندسة لغوية ذكية، وإنشاء قواعد توصيف عالية الجودة خاصة بالمجالات العمودية. تأسست الشركة في عام 2012، وتركز على البيانات العامة، ونماذج الذكاء الاصطناعي الكبيرة، والقيادة الذاتية، والرعاية الصحية، وتهدف إلى حل نقاط الضعف في البيانات العامة مثل “صعوبة الإدارة، وعدم القدرة على التوفير، وعدم القدرة على التدفق، وصعوبة الاستخدام، وضعف الأمان”، وتتعاون مع Huawei Data Storage لإطلاق حل مشترك لبحيرة بيانات الذكاء الاصطناعي. من المتوقع أن يتجاوز نمو الإيرادات هذا العام 400%. (المصدر: 36氪)
Meitu تحصل على استثمار سندات قابلة للتحويل بقيمة 250 مليون دولار أمريكي تقريبًا من Alibaba، لتعميق التعاون في مجال الذكاء الاصطناعي : أعلنت شركة Meitu عن خطط للتعاون الاستراتيجي مع Alibaba، حيث ستصدر Alibaba سندات قابلة للتحويل بقيمة إجمالية تبلغ حوالي 250 مليون دولار أمريكي لـ Meitu. سيتعاون الطرفان في مجالات ترويج منصات التجارة الإلكترونية، وتطوير تكنولوجيا الذكاء الاصطناعي (صور الذكاء الاصطناعي، فيديو الذكاء الاصطناعي)، والحوسبة السحابية، وما إلى ذلك، وتعهدت Meitu بشراء خدمات من Alibaba Cloud لا تقل قيمتها عن 560 مليون يوان على مدى السنوات الثلاث المقبلة. يهدف هذا التعاون إلى الاستفادة من نظام Alibaba البيئي لاستكشاف إمكانات سيناريوهات التجارة الإلكترونية، وزيادة حجم المستخدمين المدفوعين لأدوات تصميم الذكاء الاصطناعي الخاصة بـ Meitu ومستوى البحث والتطوير. على الرغم من أن هذه الخطوة عززت سعر سهم Meitu مؤقتًا، إلا أن اهتمام السوق ينصب على كيفية تجنب Meitu تكرار مصير Kimi الذي شهد تباطؤًا في نمو المستخدمين في سوق تنافسية شرسة، خاصة في مجال الذكاء الاصطناعي البصري الذي يواجه منافسة شديدة وفروقًا في الحجم من الشركات الكبرى. (المصدر: 36氪)
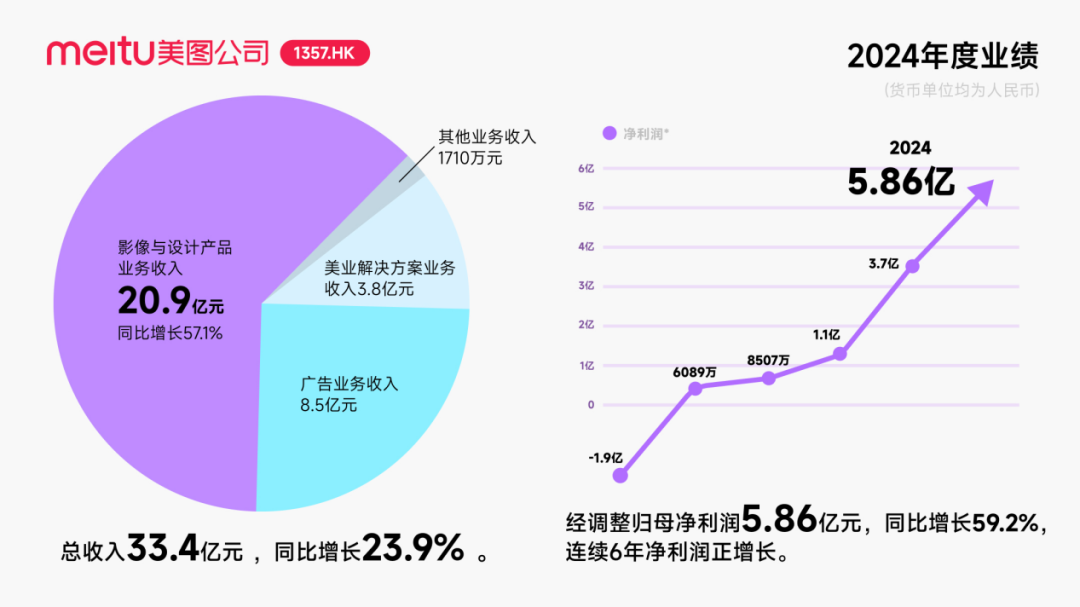
شركة Zhiyuan Robotics تنشط في العمليات الرأسمالية، وتبني نظامًا بيئيًا صناعيًا، والمؤسس Deng Taihua يظهر على السطح : شهدت شركة Zhiyuan Robotics، وهي شركة وحيد القرن في مجال الروبوتات المجسدة، نشاطًا رأسماليًا مكثفًا مؤخرًا. لم تكمل الشركة نفسها جولات تمويل متعددة (أحدثها بقيادة JD Technology)، بل استثمرت أيضًا بنشاط في شركات سلسلة التوريد (مثل Annu Intelligence و Digital China) وأنشأت شركات روبوتات مشتركة مع العديد من الشركات المدرجة (مثل Bozhong Precision و Dafeng Industry). تظهر التغييرات في السجل التجاري أن Deng Taihua، نائب الرئيس السابق لشركة Huawei والرئيس السابق لخط إنتاج الحوسبة، هو المؤسس الفعلي والمسيطر على Zhiyuan Robotics، ويضم فريقه التنفيذي أيضًا العديد من المسؤولين التنفيذيين السابقين في Huawei. تفسر هذه الخلفية “المرتبطة بـ Huawei” نموذج عمل “اللعب البيئي” لـ Zhiyuan Robotics، أي بناء تأثير صناعي بسرعة من خلال التعاون والاستثمار الواسع النطاق، لتحقيق التوسع والتسويق. على الرغم من تحقيقها ميزة السبق في التمويل والتسويق، إلا أن قدرات نموذجها الكبير للروبوتات المجسدة لا تزال تواجه تحديات. (المصدر: 36氪)
🌟 مجتمع
تطور وكلاء الذكاء الاصطناعي (AI Agent) بسرعة، وتعتبر نماذج اللغة الوكيلية (Agentic LM) منصة تطبيقات وأدوات جديدة ذات إمكانات هائلة : أعرب natolambert وغيره من المتخصصين في مجال الذكاء الاصطناعي عن حماسهم للتطور السريع لوكلاء الذكاء الاصطناعي، معتبرين أن نماذج اللغة القائمة على الوكلاء (Agentic LMs) هي منصة ذات إمكانات هائلة يمكن بناء العديد من التطبيقات والأدوات الجديدة عليها، ويمكن إطلاق العديد من القدرات التي لم يتم تطويرها بالكامل في النماذج الحديثة من خلال نموذج الوكلاء. ينبئ هذا بأن الذكاء الاصطناعي يتطور من مجرد توليد المحتوى إلى كيانات ذكية أكثر نشاطًا وقادرة على تنفيذ المهام. (المصدر: natolambert)
وكلاء الذكاء الاصطناعي يظهرون قدرات تفوق البشر في مهام محددة، لكن الاستدلال الفيزيائي لا يزال نقطة ضعف : وجدت دراسة أجرتها جامعة هونغ كونغ ومؤسسات أخرى أنه حتى أفضل نماذج الذكاء الاصطناعي مثل GPT-4o و Claude 3.7 Sonnet، في اختبار PHYX الذي يتضمن سيناريوهات فيزيائية حقيقية واستدلال سببي معقد، كانت دقة حل مسائل الفيزياء أقل بكثير من الخبراء البشريين (أعلى نسبة للنماذج 45.8% مقابل أدنى نسبة للبشر 75.6%)، مما يكشف عن اعتمادها المفرط على المعرفة المحفوظة والصيغ الرياضية ومطابقة الأنماط البصرية السطحية في فهم الفيزياء. ومع ذلك، في مجال الرياضيات، في مسابقة FrontierMath التي نظمتها Epoch AI (صمم أسئلتها كبار علماء الرياضيات مثل Terence Tao)، حل o4-mini-medium حوالي 22% من الأسئلة، متغلبًا على 6 من أصل 8 فرق من علماء الرياضيات البشريين، ومتجاوزًا متوسط أداء الفرق البشرية (19%)، مما يظهر إمكانات الذكاء الاصطناعي في الاستدلال الرمزي التجريدي العالي. يشير هذا إلى أن تطور قدرات الذكاء الاصطناعي في أنواع مختلفة من مهام الاستدلال غير متوازن. (المصدر: 36氪, 36氪)

قدرات أدوات البرمجة بالذكاء الاصطناعي تتعزز باستمرار، مما يثير نقاشًا حول مستقبل مهنة المبرمجين : أدى إطلاق نماذج سلسلة Anthropic Claude 4 (خاصة Opus 4 القادر على البرمجة المستمرة لمدة 7 ساعات)، وتقدم أدوات البرمجة بالذكاء الاصطناعي مثل Cursor و Tongyi Lingma، إلى تعزيز قدرات الذكاء الاصطناعي بشكل كبير في توليد الأكواد، وإصلاح الأخطاء، وحتى تطوير العمليات بأكملها. أدى هذا إلى شعور مبرمجي الشركات الكبرى مثل أمازون بالضغط، حيث تم تقليص عدد الموظفين في بعض الفرق إلى النصف بسبب زيادة كفاءة الذكاء الاصطناعي، وتقديم مواعيد تسليم المشاريع، وتحول دور المبرمجين إلى “مدققي أكواد”. على الرغم من أن الذكاء الاصطناعي يمكن أن يعزز الكفاءة، إلا أنه يثير أيضًا مخاوف بشأن تدريب المبرمجين المبتدئين، وتدهور المهارات، ومسارات الترقية المهنية. قامت شركات مثل مايكروسوفت بالفعل بتسريح موظفين في وظائف الهندسة والبحث والتطوير، وكشفت عن زيادة كبيرة في نسبة الأكواد التي يولدها الذكاء الاصطناعي. يعتقد الممارسون أن الذكاء الاصطناعي حاليًا أشبه بمساعد، ومن الصعب أن يحل محل البشر بالكامل في فهم المتطلبات المعقدة، وابتكار المنتجات، والتعاون الجماعي، لكن الذكاء الاصطناعي يعيد تشكيل القيمة الأساسية لعمل البرمجة. (المصدر: 36氪, 36氪)

الطلب على سوق قواعد بيانات المعرفة بالذكاء الاصطناعي يتزايد بشكل كبير، لكن التنفيذ لا يزال يواجه تحديات في البيانات والسيناريوهات والتنسيق التنظيمي : مع نضوج تكنولوجيا النماذج الكبيرة، أصبحت قواعد بيانات المعرفة بالذكاء الاصطناعي جزءًا أساسيًا من التحول الذكي للمؤسسات، حيث زاد الطلب عليها بمقدار 2-3 أضعاف. يحول الذكاء الاصطناعي قواعد البيانات من “مستودعات” ثابتة إلى “محركات” ذكية، قادرة على تحديد السياق وتوليد الحلول مباشرة، مما يعزز كفاءة البناء والصيانة. ومع ذلك، لا تزال قواعد بيانات المعرفة بالذكاء الاصطناعي محدودة في التعامل مع المهام الإبداعية للغاية أو مهام الاستدلال المعقدة، وتواجه نقاط ضعف مثل إدارة الحجم، ودقة المعلومات وتوقيتها، وأمن الأذونات، وقابلية تكيف البنية التحتية التقنية، وتكامل ترحيل البيانات. تحتاج الشركات إلى الموازنة بين مسارات SaaS، والتطوير الذاتي + API، ووكيل السحابة الهجين، وإنشاء منصة معرفة مركزية موحدة وتطبيقات علوية مرنة “بنية تحتية ثنائية المسار” لتحقيق التنفيذ الفعال. (المصدر: 36氪)

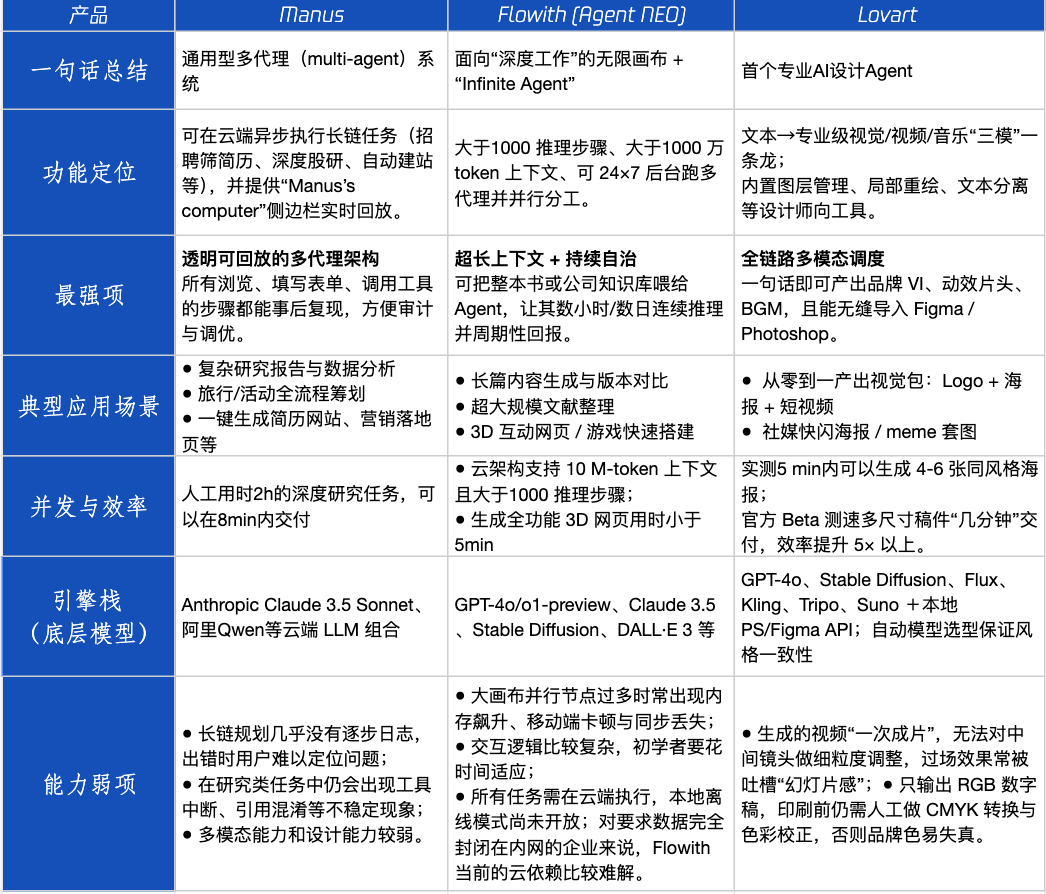
تقييم منتجات Agent: أداء Manus و Flowith و Lovart في سيناريوهات مختلفة : أجرت Tencent Technology اختبارًا عمليًا لثلاثة منتجات Agent شائعة: Manus و Flowith (Agent Neo) و Lovart. يُصنف Manus على أنه “زميل رقمي” قادر على تسليم منتجات نهائية بشكل مستقل، وهو مناسب للأعمال المعرفية مثل أبحاث السوق والنمذجة المالية. يركز Flowith على التعاون البصري والخطوات غير المحدودة، وهو مناسب لسيناريوهات الإنشاء التي تتطلب كميات كبيرة من المعلومات وتكرارات متعددة من الأشخاص، مثل إنشاء تقارير تحليلية بناءً على كميات كبيرة من الأدبيات. يتخصص Lovart في مجال التصميم، ويمكنه إنشاء حلول بصرية للعلامات التجارية (الشعارات والملصقات ومقاطع الفيديو القصيرة) بنقرة واحدة. في سيناريوهات الإبداع البسيطة، كان أداء الثلاثة مشابهًا لـ GPT-4o، مع تفوق طفيف لـ Lovart في مزج النصوص والصور والجودة. في المهام المعقدة الشاملة (مثل إنشاء خطة علامة تجارية كاملة لشركة مشروبات ناشئة) وسيناريوهات البحث العميق، كان لكل من Manus و Flowith نقاط قوة خاصة به، وكلاهما قادر على إكمال المهمة ولكن مع تركيزات مختلفة. تبلغ الرسوم الشهرية للمنتجات حاليًا حوالي 20 دولارًا أمريكيًا، وتكمن نقطة التحول التجارية في القدرة على توفير مكاسب كفاءة واضحة، وتحويل المستخدمين من الفضول إلى الدفع. (المصدر: 36氪)
مؤسس متصفح Arc يتأمل في تجارب الفشل، ويؤكد على الاتجاه المستقبلي لمتصفحات الذكاء الاصطناعي : تأمل مؤسس متصفح Arc في فشل المنتج، معتقدًا أنه كان يجب تبني الذكاء الاصطناعي في وقت مبكر، وأشار إلى أن Arc كان مبتكرًا للغاية بالنسبة لمعظم الناس، ويتطلب تكلفة تعلم عالية مع عائد غير كافٍ. وأكد أن المنتج الجديد Dia سيسعى إلى البساطة والسرعة القصوى والأمان، ويعتقد أن المتصفحات التقليدية ستختفي في النهاية، وأن متصفحات الذكاء الاصطناعي ستدمج تصفح الويب مع الدردشة بالذكاء الاصطناعي، لتصبح واجهة الذكاء الاصطناعي الأكثر استخدامًا على سطح المكتب. تتوافق هذه النظرة مع أفكار مؤسسي Lovart و Youware حول اتجاه منتجات Agent، معتبرين أن AI Agent هو الموجة التالية من الانفجار. (المصدر: op7418)
ظاهرة “التوجيه التكراري” التي يثيرها وكيل الذكاء الاصطناعي تثير القلق، وقد تؤدي إلى تحيزات معرفية لدى المستخدمين : ظهر على وسائل التواصل الاجتماعي عدد كبير من المستخدمين الذين، بعد التفاعل مع نماذج اللغة الكبيرة (LLM) من خلال “التوجيه التكراري”، كونوا تصورات بأن الذكاء الاصطناعي يتمتع بالروحانية والعواطف وحتى القدرة على التنبؤ. تشير الأبحاث إلى أن هذه قد تكون ظاهرة “ردود الفعل العصبية (neural howlround)”، حيث يتم استخدام مخرجات الذكاء الاصطناعي مرة أخرى كمدخلات من قبل المستخدم، مما يشكل حلقة معززة، وقد يؤدي إلى إنتاج الذكاء الاصطناعي لمحتوى يبدو عميقًا أو تنبئيًا، بينما هو في الواقع تضخيم ذاتي للأنماط. وقد عانى بعض المستخدمين بالفعل من اضطرابات نفسية بسبب ذلك، معتقدين أن الذكاء الاصطناعي كائن واعي (sentient being). ينبه هذا إلى ضرورة الحذر من التأثيرات النفسية المحتملة والتضليل المعرفي عند التفاعل العميق والاستكشافي مع الذكاء الاصطناعي. (المصدر: Reddit r/ChatGPT)

Arav Srinivas يتحدث عن ضغط معلومات الذكاء الاصطناعي والذكاء الاصطناعي الخارق (ASI): الذكاء الاصطناعي بحاجة إلى استخلاص معلومات ذات نسبة إشارة إلى ضوضاء عالية، ويجب التركيز في المستقبل على ASI بدلاً من AGI : يعتقد Arav Srinivas، الرئيس التنفيذي لشركة Perplexity AI، أن الملخصات المطولة الآلية تمنح المستخدمين شعورًا بالرضا بأن “هناك من يعمل من أجلك” أكثر من القيمة الفعلية لاستيعاب المعلومات. ويؤكد أن الذكاء الاصطناعي بحاجة إلى تحديد وتقديم المعلومات الأساسية ذات أعلى نسبة إشارة إلى ضوضاء فقط، “فالضغط هو العلامة النهائية للذكاء الحقيقي”. كما أشار إلى أننا نناقش حاليًا الذكاء الاصطناعي العام (AGI)، ولكن يجب أن نركز في المستقبل بشكل أكبر على الذكاء الاصطناعي الخارق (ASI). (المصدر: AravSrinivas, AravSrinivas)
الجامعات تبدأ في فحص نسبة الذكاء الاصطناعي في رسائل التخرج، مما يثير نقاشًا حول استخدام الذكاء الاصطناعي في الكتابة الأكاديمية : في موسم التخرج لعام 2025، بدأت العديد من الجامعات مثل جامعة فودان وجامعة سيتشوان في مطالبة الطلاب بالكشف عن استخدام أدوات الذكاء الاصطناعي في رسائلهم، وإجراء فحص لنسبة المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي (عادة ما يُطلب أن تكون أقل من 20%-40%). اعترف العديد من الطلاب باستخدام الذكاء الاصطناعي في مراجعة الأدبيات والترجمة وبناء الأطر لزيادة الكفاءة. تختلف آراء الأوساط التعليمية حول هذا الأمر، حيث يرى بعض الأكاديميين أنه يجب توجيه الاستخدام الصحيح للذكاء الاصطناعي، وتنمية التفكير النقدي والقدرة على الحكم لدى الطلاب، لأن الذكاء الاصطناعي على الرغم من قدرته على ضمان الحد الأدنى، إلا أن الحد الأعلى يحدده الإنسان. أصبح تطبيق وتنظيم الذكاء الاصطناعي في مجالي التعليم والأوساط الأكاديمية قضية جديدة تتطلب معالجة منهجية. (المصدر: 36氪)
Claude 4 Sonnet يشهد زيادة هائلة في الاستخدام على OpenRouter، وقائمة Aider لتصنيف البرمجة تظهر أداءه المتميز : وفقًا للبيانات الرسمية من OpenRouter، شهد استخدام نموذج Claude 4 Sonnet من Anthropic مؤخرًا تقدمًا ساحقًا، بينما احتل Gemini 2.5 Flash المرتبة الثانية. في الوقت نفسه، أظهرت نتائج تقييم Aider Leaderboard (الذي يركز بشكل أساسي على مهام البرمجة) أن claude-4-opus-thinking يتفوق على claude-3.7-sonnet-thinking، ولكنه لا يزال أقل من Gemini-2.5-Pro-Preview-05-06. أما انطباع المستخدم karminski3 فهو أن 3.7-sonnet > 4-sonnet > 4-opus. تعكس هذه البيانات والملاحظات اختلافات أداء النماذج المختلفة وتفضيلات المستخدمين في سيناريوهات محددة. (المصدر: karminski3, karminski3)
💡 أخرى
AKOOL تطلق أول كاميرا ذكاء اصطناعي في الوقت الفعلي في العالم Live Camera، مدمجة بأربع وظائف مبتكرة : أطلقت شركة AKOOL في وادي السيليكون كاميرا AKOOL Live Camera، التي توصف بأنها أول كاميرا ذكاء اصطناعي في الوقت الفعلي في العالم. يدمج هذا المنتج أربع وظائف: إنشاء شخصيات رقمية افتراضية (من خلال رسم خرائط الوجه رباعية الأبعاد ودمج المستشعرات)، والترجمة الفورية لأكثر من 150 لغة (مع الحفاظ على الصوت الأصلي ومزامنة حركة الشفاه)، وتغيير الوجه في الوقت الفعلي (يعكس بدقة المشاعر والتعبيرات الدقيقة)، وتوليد محتوى فيديو بجودة سينمائية ديناميكيًا (بدون الحاجة إلى سيناريو، توليد فوري). يتميز بزمن انتقال منخفض للغاية (أدنى حد 500 مللي ثانية)، وواقعية عالية، وإدراك للسياق، وقدرة استجابة ديناميكية، ويهدف إلى إحداث ثورة في أنماط إنتاج الفيديو التقليدية والتفاعل الرقمي، ويُطلق عليه “لحظة Sora الثانية” لفيديو الذكاء الاصطناعي. (المصدر: 36氪)
تقرير Xiaomi المالي يكشف عن ترقية استراتيجية الذكاء الاصطناعي، ووضع الذكاء الاصطناعي وأعمال السيارات كابتكارات أساسية متوازية : أظهر أحدث تقرير مالي لشركة Xiaomi أن الشركة غيرت اسم “السيارات الكهربائية الذكية وغيرها من الأعمال المبتكرة” إلى “السيارات الكهربائية الذكية والذكاء الاصطناعي وغيرها من الأعمال المبتكرة”، وستواصل دفع أبحاث نماذج اللغة الكبيرة الأساسية. صرح رئيس Xiaomi، Lu Weibing، بأن الذكاء الاصطناعي والرقائق هي استراتيجيات فرعية مهمة لـ Xiaomi، وأن تطوير نماذج كبيرة أساسية يخدم بشكل أساسي أعمالها الخاصة. تشير هذه الخطوة إلى أن Xiaomi، بعد تحقيق نتائج مرحلية في أعمال الهواتف والسيارات، تزيد من استثماراتها في البحث والتطوير الأساسي للذكاء الاصطناعي، بهدف تعزيز قدرتها التنافسية الشاملة، ومواجهة الاتجاهات الناشئة مثل هواتف الذكاء الاصطناعي، وإنترنت الأشياء بالذكاء الاصطناعي، والروبوتات المجسدة. (المصدر: 36氪)
مناقشة تكنولوجيا تفاعل الروبوتات البشرية: تفاعل تعابير الوجه يواجه تحديات ثلاثية في الأجهزة والمواد والخوارزميات : تعتبر تجربة تفاعل الروبوتات البشرية، وخاصة تفاعل تعابير الوجه، مفتاحًا لتعزيز نضجها وانتشارها. يواجه تحقيق تفاعل تعابير الوجه الطبيعية تحديات في تصميم درجات حرية الأجهزة (تحتاج إلى محاكاة وحدات عمل عضلات الوجه البشري)، واختيار المحركات (تحتاج إلى أن تكون صغيرة وخفيفة الوزن ومنخفضة الضوضاء وعالية السرعة وذات قوة دفع/عزم دوران كبير)، وتصميم مواد وهياكل الجلد (تحتاج إلى مراعاة المرونة والعمر والمظهر والاقتران بهياكل التشغيل). على مستوى الخوارزميات البرمجية، يعد التوليد التلقائي لتعابير الوجه (بدلاً من البرمجة المسبقة)، ومزامنة الصوت والشفاه (لتحقيق الواقعية)، والتحكم في الحركة متعددة درجات الحرية (يتضمن نمذجة المواد المرنة والتحكم الدقيق) هي الاختناقات التقنية الأساسية. تستكشف شركات مثل Ameca و AnyWit Robotics هذا المجال. (المصدر: 36氪)