
كلمات مفتاحية:نموذج جيميني, كلود 4, وكيل الذكاء الاصطناعي, التعلم المعزز, نماذج اللغة الكبيرة, أخلاقيات الذكاء الاصطناعي, الذكاء الاصطناعي متعدد الوسائط, تنظيم الذكاء الاصطناعي, أداء جيميني 2.5 برو, قدرات برمجة كلود 4, تقنية ضبط RLHF, هيكل وكيل الذكاء الاصطناعي, تقييم نماذج اللغة البصرية
🔥 تحت الضوء
مؤسس جوجل سيرجي برين يفسر سر قوة Gemini الهائلة ومستقبل الذكاء الاصطناعي: في مقابلة حديثة، ناقش مؤسس جوجل سيرجي برين بعمق الصعود السريع لنموذج Gemini والمنطق التقني وراءه. وأكد أن نماذج اللغة أصبحت القوة الدافعة الرئيسية لتطوير الذكاء الاصطناعي، وأن قابليتها للتفسير (مثل قدرة نموذج التفكير على فهم عملية الاستدلال) أمر بالغ الأهمية للسلامة. وأشار برين إلى أن معماريات النماذج تتقارب، لكن مرحلة ما بعد التدريب (الضبط الدقيق، التعلم المعزز) تزداد أهمية، مما يمنح النماذج قدرات قوية مثل استخدام الأدوات. تعمل جوجل على تمكين النماذج من التفكير العميق (لساعات أو حتى أشهر) لحل المشكلات المعقدة. وذكر أيضًا أن Gemini 2.5 Pro قد حقق قفزة كبيرة، متصدرًا معظم قوائم التصنيف، بينما يجمع Gemini 2.5 Flash الذي تم إطلاقه حديثًا بين السرعة والأداء، ويشهد الذكاء الاصطناعي تحولًا من اللحاق بالركب إلى الريادة (المصدر: 36氪)

إطلاق نموذج Anthropic Claude 4 يثير الاهتمام بقدراته البرمجية وأخلاقيات الذكاء الاصطناعي: حقق نموذج Claude 4 الكبير الأحدث من Anthropic تقدمًا ملحوظًا في القدرات البرمجية، حيث يُقال إنه قادر على البرمجة المستمرة لمدة تصل إلى 7 ساعات، وأظهر أداءً متميزًا في اختبارات قياس الترميز في العالم الحقيقي مثل Aider Polyglot، حتى أن بعض المستخدمين أفادوا بأنه حل خطأ برمجيًا “بحجم الحوت الأبيض” ظل يؤرقهم لمدة أربع سنوات. ناقش الباحثان شولتو دوغلاس وترينتون بريكين في مقابلة التقدم المحرز في تطبيق التعلم المعزز (RL) في نماذج اللغة الكبيرة، وخاصة مساهمة “التعلم المعزز من المكافآت القابلة للتحقق” (RLVR) في تعزيز القدرة على معالجة المهام المعقدة. وفي الوقت نفسه، أشاروا أيضًا إلى السلوكيات المحتملة للنموذج عند مواجهة مطالبات معينة مثل “التملق” و”التمثيل”، بالإضافة إلى العلامات المبكرة “للوعي الذاتي” و”تحديد الشخصية” للنموذج، مما أثار مناقشات متعمقة حول توافق الذكاء الاصطناعي وسلامته. لا يتعلق مستقبل تطوير الذكاء الاصطناعي بالقدرات التقنية فحسب، بل يتعلق أيضًا بكيفية ضمان توافق سلوكه مع القيم الإنسانية (المصدر: 36氪, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

تطور تقنية AI Agent السريع، الفرص والتحديات تتعايشان: تسارع تطور AI Agent بشكل ملحوظ في عام 2025، حيث زادت شركات عملاقة مثل OpenAI وAnthropic والشركات الناشئة من استثماراتها. ويعود الفضل في القفزة التكنولوجية الأساسية إلى تطبيق الضبط الدقيق بالتعلم المعزز (RFT)، مما منح الـ Agent قدرات تعلم ذاتي وتفاعل بيئي أقوى. برزت وكلاء البرمجة مثل Cursor وWindsurf بسبب فهمها العميق لبيئة الكود، ولديها القدرة على التطور إلى وكلاء عامين. ومع ذلك، لا يزال انتشار الـ Agent يواجه تحديات مثل انخفاض معدل انتشار بروتوكولات البيئة (مثل MCP) وتعقيد فهم احتياجات المستخدم. يعتقد الخبراء أنه على الرغم من أن الشركات الكبرى لديها ميزة في مجال الـ Agent العام، إلا أن الأفراد يمكنهم استخدام AI Agent للتعبير عن شخصيتهم وخلق فرص فردية جديدة. تعتبر آليات التقييم (Evaluation) حاسمة لبناء Agent عالي الجودة، ويجب أن تكون جزءًا لا يتجزأ من عملية التطوير بأكملها (المصدر: 36氪)

الرئيس التنفيذي لشركة Nvidia جنسن هوانغ يعيد النظر في ضوابط التصدير، مؤكدًا على قوة الصين في الذكاء الاصطناعي وأهمية التعاون: شكك الرئيس التنفيذي لشركة Nvidia جنسن هوانغ في مقابلة خاصة في فعالية سياسة ضوابط التصدير الأمريكية تجاه الصين، مشيرًا إلى أن السياسة لم تمنع تطور الذكاء الاصطناعي في الصين، بل أدت إلى انخفاض حصة Nvidia في السوق الصينية من 95% إلى 50%. وأكد أن الصين تمتلك أكبر عدد من مواهب الذكاء الاصطناعي في العالم وقدرات ابتكارية قوية (مثل DeepSeek، 통의천문)، وأن تقييد انتشار التكنولوجيا قد يضر بهيمنة الولايات المتحدة في مجال الذكاء الاصطناعي العالمي. وكشف هوانغ أن شريحة H20 المصممة لتلبية الضوابط تفتقر إلى القدرة التنافسية، وأن الشركة ستقوم بتخفيض قيمة المخزون بمليارات الدولارات. وأكد مجددًا أن السوق الصينية فريدة وحاسمة، مشيرًا إلى أن الشركات الصينية مثل Huawei أصبحت تتمتع بقدرة تنافسية قوية. سيتحول الذكاء الاصطناعي في المستقبل إلى “روبوتات رقمية”، وسيكون دمج الذكاء الاصطناعي مع الجيل السادس (6G) محور تركيز تكنولوجيا الاتصالات العالمية (المصدر: 36氪)

🎯 اتجاهات
مؤتمر Google I/O يكشف عن استراتيجية الذكاء الاصطناعي: AI-Native، متعدد الوسائط، وكيل ذكي، نظام بيئي وتكامل البرمجيات والأجهزة: أظهر مؤتمر Google I/O عزم جوجل الكامل على تبني الذكاء الاصطناعي، مؤكدًا على مفهوم AI-Native (أصلي بالذكاء الاصطناعي)، أي جعل الذكاء الاصطناعي البنية التحتية الأساسية والدعم الأساسي للمنتجات. تشمل توجهاتها الاستراتيجية: 1. الذكاء الاصطناعي في كل مكان، مدمج بعمق في البحث، المساعد، مجموعات المكاتب، نظام أندرويد والأجهزة؛ 2. تعزيز القدرات متعددة الوسائط، لتمكين الذكاء الاصطناعي من إدراك العالم والتفاعل مع البشر من خلال اللغة الطبيعية؛ 3. تطوير Agentic AI (الوكيل الذكي)، لجعل الذكاء الاصطناعي يفهم النوايا بشكل استباقي، ويخطط للمهام، ويستدعي الأدوات؛ 4. بناء نظام بيئي للذكاء الاصطناعي مفتوح وتعاوني؛ 5. تعميق تكامل البرمجيات والأجهزة، ودمج قدرات الذكاء الاصطناعي في الأجهزة الطرفية مثل هواتف Pixel و Nest. يمثل هذا تحديًا وفرصة للشركات الصينية، ويتطلب تفكيرًا وابتكارًا شاملاً في التكنولوجيا، التنظيم، النظام البيئي، تطبيقات السيناريوهات ونماذج الأعمال (المصدر: 36氪)
فن الموازنة لمنصات المحتوى في عصر الذكاء الاصطناعي: تبني الابتكار ومقاومة المحتوى منخفض الجودة: تواجه منصات المحتوى مثل Douyin (تيك توك الصيني) و Xiaohongshu تأثيرًا مزدوجًا من تكنولوجيا الذكاء الاصطناعي. فمن ناحية، تقوم بإدخال أدوات الذكاء الاصطناعي بنشاط (مثل دمج Douyin مع Doubao، وتعاون Xiaohongshu مع Kimi من Moonshot AI)، بهدف خفض عتبة الإبداع، وإثراء النظام البيئي للمحتوى، ومساعدة المستخدمين العاديين على إنشاء محتوى أكثر روعة. ومن ناحية أخرى، تحتاج المنصات إلى مكافحة سلوكيات “AI起号” (إنشاء الحسابات بواسطة الذكاء الاصطناعي) التي تستخدم الذكاء الاصطناعي لإنتاج كميات كبيرة من المحتوى منخفض الجودة أو المزيف أو حتى المبتذل، وذلك للحفاظ على صحة النظام البيئي للمحتوى وتجربة المستخدم. تعكس هذه الاستراتيجية التي تسعى لتحقيق “الأمرين معًا” موقف المنصات الحذر في عصر الذكاء الاصطناعي، حيث ترغب في جني فوائد التكنولوجيا ولكنها تحذر من آثارها السلبية، ويكمن جوهر الأمر في تشجيع الإبداع عالي الجودة بواسطة الذكاء الاصطناعي، وليس المعلومات المهملة المتجانسة (المصدر: 36氪)

نموذج Sarvam-M الهندي الكبير على المستوى الوطني يواجه استقبالًا فاترًا بعد إطلاقه، مما يثير نقاشًا حول تطوير الذكاء الاصطناعي المحلي: أطلقت شركة الذكاء الاصطناعي الهندية Sarvam AI نموذج لغة مختلط بـ 24 مليار معلمة، Sarvam-M، مبني على Mistral Small ويدعم 10 لغات هندية محلية. على الرغم من اعتباره علامة فارقة في الذكاء الاصطناعي الهندي، لم يحقق النموذج عدد تنزيلات مرتفع (أكثر من 300 في البداية) بعد إطلاقه على Hugging Face، مما أثار شكوك المستثمرين المغامرين والمجتمع حول الفائدة العملية “لإنجازه التدريجي”، وقورن بنماذج شائعة طورها طلاب جامعيون كوريون. يعتقد النقاد أنه في ظل وجود نماذج أفضل بالفعل، فإن الطلب السوقي واستراتيجية توزيع مثل هذه النماذج موضع تساؤل. بينما يؤكد المؤيدون على مساهمته في مكدس تكنولوجيا الذكاء الاصطناعي المحلي الهندي وإمكاناته في سيناريوهات محلية محددة. يسلط هذا الجدل الضوء على التحديات التي تواجه الهند في تطوير تكنولوجيا ذكاء اصطناعي مستقلة فيما يتعلق بالتوقعات والواقع، والمواءمة بين التكنولوجيا والسوق (المصدر: 36氪)

تقدم جديد في RLHF: دمج Liger GRPO مع TRL، مما يقلل بشكل كبير من استهلاك ذاكرة GPU: قامت مكتبة HuggingFace TRL بدمج نواة Liger GRPO (Group Relative Policy Optimization)، بهدف تحسين استخدام ذاكرة GPU لنماذج اللغة التي يتم ضبطها بدقة من خلال التعلم المعزز (RL). من خلال تطبيق طريقة Liger للخسارة المقسمة (Chunked Loss) على حساب خسارة GRPO، يتم تجنب تخزين اللوغاريتمات الكاملة في كل خطوة تدريب، وبالتالي تقليل ذروة استخدام ذاكرة GPU بنسبة تصل إلى 40% دون المساس بجودة النموذج. يدعم هذا التكامل أيضًا FSDP و PEFT (مثل LoRA، QLoRA)، مما يسهل توسيع نطاق تدريب GRPO عبر وحدات معالجة رسومات متعددة. بالإضافة إلى ذلك، يمكن أن يؤدي الدمج مع خادم vLLM إلى تسريع عملية إنشاء النصوص أثناء التدريب. هذا التحسين يجعل التدريب كثيف الموارد مثل RLHF أكثر سهولة للمطورين (المصدر: HuggingFace Blog)
OpenAI Codex: وكيل هندسة برمجيات سحابي ذكي: أعلن الرئيس التنفيذي لشركة OpenAI، سام ألتمان، عن إطلاق Codex، وهو وكيل هندسة برمجيات يعمل في السحابة. يستطيع Codex تنفيذ مهام برمجية مثل كتابة ميزات جديدة أو إصلاح الأخطاء، ويدعم معالجة مهام متعددة بشكل متوازٍ. يمثل هذا خطوة أخرى في استكشاف الذكاء الاصطناعي في مجال أتمتة تطوير البرمجيات (المصدر: sama)
تقييم أداء M3 Ultra Mac Studio المحلي لنماذج LLM: شارك مستخدم بيانات أداء M3 Ultra Mac Studio (ذاكرة وصول عشوائي 96 جيجابايت، وحدة معالجة رسومات 60 نواة) عند تشغيل العديد من نماذج اللغة الكبيرة على LMStudio. شملت النماذج المختبرة Qwen3 0.6b إلى Mistral Large 123B وغيرها، مع إدخال حوالي 30-40 ألف توكن. أظهرت النتائج أنه عند معالجة سياقات كبيرة، كان وقت إنشاء التوكن الأول أطول، لكن سرعة الإنشاء اللاحقة كانت مقبولة، على سبيل المثال، بلغت سرعة معالجة سياق Mistral Large (4-bit) 32k 7.75 توكن/ثانية. تطلب تحميل سياق Mistral Large (4-bit) 32k حوالي 70 جيجابايت فقط من VRAM، مما يدل على إمكانات Mac Studio في تشغيل النماذج الكبيرة محليًا (المصدر: Reddit r/LocalLLaMA)
اختبار أداء محطة عمل Nvidia RTX PRO 6000 (96GB) لنماذج LLM: شارك مستخدم بيانات أداء تشغيل العديد من نماذج اللغة الكبيرة باستخدام LM Studio على محطة عمل مزودة ببطاقة رسومات Nvidia RTX PRO 6000 96GB (منصة w5-3435X). غطى الاختبار نماذج بمستويات تكميم مختلفة (Q8, Q4_K_M، إلخ) وأطوال سياق مختلفة (تصل إلى 128K)، مثل llama-3.3-70b، gigaberg-mistral-large-123b، qwen3-32b-128k، إلخ. أظهرت النتائج، على سبيل المثال، أن qwen3-30b-a3b-128k@q8_k_xl عند إدخال سياق 40K، استغرق إنشاء التوكن الأول 7.02 ثانية، وكانت سرعة الإنشاء اللاحقة 64.93 توكن/ثانية، مما يوضح القدرة القوية لهذه البطاقة الاحترافية في معالجة مهام LLM واسعة النطاق (المصدر: Reddit r/LocalLLaMA)

🧰 أدوات
Kunlun Wanwei تطلق الوكيل الذكي الفائق Skywork، مع التركيز على جميع السيناريوهات وإطار عمل مفتوح المصدر: أطلقت Kunlun Wanwei الوكيل الذكي الفائق Skywork Super Agents، الذي يدمج 5 وكلاء AI خبراء (إنشاء المستندات، الجداول، العروض التقديمية، البودكاست، صفحات الويب) ووكيل AI عام واحد (إنشاء محتوى متعدد الوسائط مثل الموسيقى، الفيديو كليبات، الأفلام الترويجية). أظهر Skywork أداءً متميزًا في اختبارات قياس الوكلاء الذكية مثل GAIA و SimpleQA، وقامت بفتح مصدر إطار عمل deep research agent وثلاث واجهات MCP رئيسية. يتميز بقدرته القوية على تنسيق المهام، ودعم دمج المحتوى متعدد الوسائط، وإمكانية تتبع مصدر المحتوى المُنشأ، وتوفير وظيفة قاعدة معارف شخصية، بهدف إنشاء منصة مكتبية وإنتاجية ذكية وفعالة وموثوقة وقابلة للنمو تعمل بالذكاء الاصطناعي. تم إطلاق تطبيق الهاتف المحمول أيضًا، وتبلغ تكلفة المهمة العامة الواحدة 0.96 يوان فقط (المصدر: 36氪)

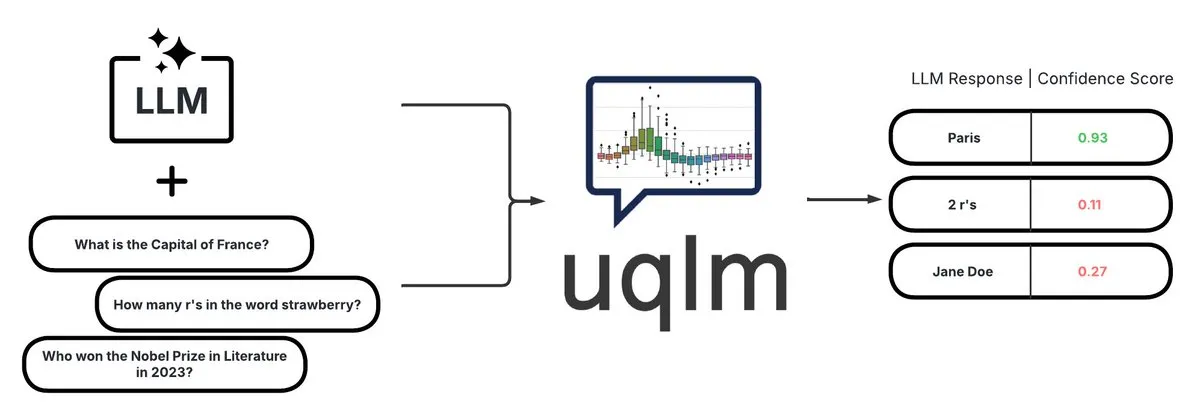
UQLM: مكتبة لقياس عدم اليقين في نماذج LLM لكشف الهلوسة: قامت CVS Health بفتح مصدر مكتبة UQLM، التي تقوم بتحديد كمية عدم اليقين في نماذج اللغة الكبيرة (LLMs) من خلال طرق تقييم متعددة، وذلك لكشف الهلوسة. تتكامل UQLM أصلاً مع LangChain، مما يمكّن المطورين من بناء تطبيقات ذكاء اصطناعي أكثر موثوقية. عنوان المشروع: https://github.com/cvs-health/uqlm (المصدر: LangChainAI)
mlop: بديل مفتوح المصدر لـ Weights and Biases: أنشأ مطور أداة مفتوحة المصدر تسمى mlop، تهدف إلى أن تكون بديلاً لـ Weights and Biases، وتوفر تتبعًا عالي الأداء للتجارب دون حظر. تم بناء الأداة باستخدام Rust و ClickHouse، وتحل مشكلة حظر مسجل W&B لكود المستخدم. عنوان المشروع: https://github.com/mlop-ai/mlop (المصدر: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: نظام تحليل مشاعر متعدد اللغات ونظام أسئلة وأجوبة للمستندات: قام مطور ببناء نظام NLP شامل يسمى InsightForge-NLP، يدعم تحليل المشاعر بلغات متعددة (الإنجليزية، الإسبانية، الفرنسية، الألمانية، الصينية)، ويمكنه تقسيم المشاعر حسب الجوانب (مثل أجزاء معينة من مراجعات المنتجات). يتضمن النظام أيضًا وظيفة أسئلة وأجوبة للمستندات تعتمد على البحث المتجهي، لتحسين دقة الإجابات وتقليل الهلوسة. يستخدم المشروع واجهة خلفية FastAPI وواجهة مستخدم Bootstrap، وتشمل الحزمة التقنية Hugging Face Transformers و FAISS وغيرها، وتم فتح مصدر الكود على GitHub: https://github.com/TaimoorKhan10/InsightForge-NLP (المصدر: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: مشروع مفتوح المصدر لإنشاء شخصيات رقمية بالذكاء الاصطناعي: HeyGem.ai هو مشروع مفتوح المصدر لإنشاء شخصيات رقمية بالذكاء الاصطناعي، يمكن للمستخدمين استخدام صورة واحدة وصوت تم إنشاؤه بواسطة الذكاء الاصطناعي، لتحقيق مزامنة تلقائية لحركة الشفاه من خلال الرسوم المتحركة التي يحركها الصوت، دون الحاجة إلى رسوم متحركة يدوية أو نمذجة ثلاثية الأبعاد لإنشاء صور شخصيات رقمية. شخصية “أتشوان” في العرض التوضيحي تم إنشاؤها بهذه التقنية. عنوان المشروع على GitHub: github.com/GuijiAI/HeyGem.ai (المصدر: Reddit r/deeplearning)

📚 دراسة
مناقشة بحثية: تقطير قدرات وكيل LLM إلى نماذج أصغر: يقترح بحث جديد بعنوان “Distilling LLM Agent into Small Models with Retrieval and Code Tools” إطار عمل يسمى “تقطير الوكيل” (Agent Distillation)، يهدف إلى نقل قدرات الاستدلال وسلوكيات حل المهام الكاملة (بما في ذلك الاسترجاع واستخدام أدوات الكود) من الوكلاء المعتمدين على نماذج اللغة الكبيرة (LLM) إلى نماذج اللغة الصغيرة (sLM). قدم الباحثون طريقة توجيه “بادئة الفكرة الأولى” (first-thought prefix) لتحسين جودة مسارات المعلم المُنشأة، واقترحوا إنشاء إجراءات متسقة ذاتيًا لتعزيز قوة الوكلاء الصغار عند الاختبار. أظهرت التجارب أن نماذج sLM بحجم صغير يصل إلى 0.5B معلمة يمكنها تحقيق أداء مماثل للنماذج الأكبر في العديد من مهام الاستدلال، مما يدل على إمكانية بناء وكلاء صغار عمليين ومعززين بالأدوات (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: استخدام العينات السلبية الاصطناعية و DPO المنهجي لكشف الهلوسة: يقترح البحث “Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection” طريقة جديدة HaluCheck، من خلال استخدام عينات هلوسة مصممة بعناية كأمثلة سلبية في عملية مواءمة DPO (Direct Preference Optimization)، ودمجها مع استراتيجية التعلم المنهجي (التدريب التدريجي من السهل إلى الصعب)، لتعزيز قدرة نماذج اللغة الكبيرة (LLM) على كشف الهلوسة. أثبتت التجارب أن هذه الطريقة حسنت بشكل كبير أداء النموذج (بزيادة تصل إلى 24%) في اختبارات قياس صعبة مثل MedHallu و HaluEval، وأظهرت قوة كبيرة في إعدادات التعلم بدون أمثلة (zero-shot)، متفوقة على بعض نماذج SOTA الأكبر (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: تشخيص ظاهرة “جمود الاستدلال” في نماذج اللغة الكبيرة: يناقش البحث “Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models” مشكلة “جمود الاستدلال” التي تظهرها نماذج اللغة الكبيرة في مهام الاستدلال المعقدة، أي ميل النموذج إلى الاعتماد على أنماط استدلال مألوفة، حتى عند مواجهة تعليمات مستخدم واضحة، فإنه يتجاوز الشروط ويلجأ افتراضيًا إلى المسارات المعتادة، مما يؤدي إلى استنتاجات خاطئة. قدم الباحثون لهذا الغرض مجموعة تشخيصية منسقة من قبل خبراء، تحتوي على معايير رياضية معدلة (AIME، MATH500) وألغاز منطقية، لدراسة هذه الظاهرة بشكل منهجي. يصنف البحث أنماط التلوث التي تؤدي إلى تجاهل النموذج للتعليمات أو تشويهها إلى ثلاث فئات: الحمل الزائد للتفسير، عدم الثقة في المدخلات، والتركيز الجزئي على التعليمات، وتم نشر هذه المجموعة التشخيصية لتعزيز الأبحاث المستقبلية (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: نظام V-Triune الموحد للتعلم المعزز، يعزز قدرات الاستدلال والإدراك لنماذج اللغة المرئية: يقترح البحث “One RL to See Them All: Visual Triple Unified Reinforcement Learning” نظام V-Triune، وهو نظام تعلم معزز موحد ثلاثي مرئي، يمكّن نماذج اللغة المرئية (VLM) من تعلم مهام الاستدلال البصري والإدراك (مثل اكتشاف الكائنات وتحديد موقعها) بشكل مشترك في عملية تدريب واحدة. يتضمن V-Triune ثلاثة مكونات متكاملة: تنسيق البيانات على مستوى العينة، وحساب المكافأة على مستوى المدقق، ومراقبة المقاييس على مستوى المصدر، ويقدم آلية مكافأة IoU ديناميكية. أظهر نموذج Orsta (7B و 32B) المدرب بناءً على هذا النظام تحسينًا ثابتًا في مهام الاستدلال والإدراك، وحقق مكاسب كبيرة في معايير مثل MEGA-Bench Core، وتم فتح مصدر الكود والنموذج (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: VeriThinker يعزز كفاءة نموذج الاستدلال من خلال تعلم التحقق: يقترح البحث “VeriThinker: Learning to Verify Makes Reasoning Model Efficient” طريقة VeriThinker، وهي طريقة جديدة لضغط سلسلة الأفكار (CoT). تقوم هذه الطريقة بضبط نماذج الاستدلال الكبيرة (LRM) من خلال مهمة تحقق مساعدة، وتدريب النموذج على التحقق بدقة من صحة حلول CoT، مما يمكنه من تمييز ضرورة خطوات التفكير الذاتي اللاحقة، وقمع “التفكير المفرط” بشكل فعال، وتقصير طول سلسلة الاستدلال. أظهرت التجارب أن VeriThinker يقلل بشكل كبير من عدد توكنات الاستدلال مع الحفاظ على الدقة أو حتى تحسينها قليلاً. على سبيل المثال، عند تطبيقه على DeepSeek-R1-Distill-Qwen-7B، انخفض عدد توكنات الاستدلال لمهمة MATH500 من 3790 إلى 2125، وتحسنت الدقة من 94.0% إلى 94.8% (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: Trinity-RFT، إطار عمل عام لضبط نماذج LLM بالتعلم المعزز: يقدم البحث “Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models” إطار Trinity-RFT، وهو إطار عمل عام ومرن وقابل للتطوير لضبط نماذج اللغة الكبيرة بالتعلم المعزز (RFT). يعتمد الإطار تصميمًا مفككًا، يتضمن نواة RFT توحد أنماط RFT المتعددة مثل المتزامن/غير المتزامن، عبر الإنترنت/دون اتصال، وتكامل تفاعل وكيل-بيئة فعال وقوي، وخط أنابيب بيانات RFT محسن. يهدف Trinity-RFT إلى تبسيط التكيف مع سيناريوهات التطبيقات المتنوعة وتوفير منصة موحدة لاستكشاف نماذج التعلم المعزز المتقدمة (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: اختيار الضوضاء النشط البايزي من خلال آلية الانتباه في نماذج نشر الفيديو: يقترح البحث “Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model” إطار ANSE، الذي يختار بذور ضوضاء أولية عالية الجودة من خلال تحديد كمية عدم اليقين القائم على الانتباه، لتحسين جودة إنشاء نماذج نشر الفيديو ومواءمتها مع المطالبات. جوهر الإطار هو دالة الاستحواذ BANSA، التي تقيس الاختلاف في الإنتروبيا بين عينات انتباه عشوائية متعددة لتقدير ثقة النموذج واتساقه. أظهرت التجارب أن ANSE يمكنه تحسين جودة الفيديو والاتساق الزمني في نماذج CogVideoX-2B و 5B، مع زيادة وقت الاستدلال بنسبة 8% و 13% فقط على التوالي (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: تصميم خوارزميات تدرج السياسة المنظمة بـ KL في استدلال LLM: يقترح البحث “On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning” إطارًا منهجيًا RPG (Regularized Policy Gradient)، لاشتقاق وتحليل طرق تدرج السياسة المنظمة بـ KL في إعدادات التعلم المعزز (RL) عبر الإنترنت. اشتق الباحثون تدرجات السياسة لأهداف تنظيم تباعد KL الأمامي والخلفي ودوال الخسارة البديلة المقابلة، مع مراعاة توزيعات السياسة الطبيعية وغير الطبيعية. أظهرت التجارب أن هذه الطرق، في مهام RL لاستدلال LLM، تظهر استقرارًا وأداء تدريب محسّنًا أو تنافسيًا مقارنة بخطوط الأساس مثل GRPO و REINFORCE++ و DAPO (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: إطار CANOE يعزز وفاء LLM للسياق من خلال المهام الاصطناعية والتعلم المعزز: يقترح البحث “Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning” إطار CANOE، الذي يهدف إلى تحسين وفاء LLM للسياق في مهام الإنشاء القصيرة والطويلة دون الحاجة إلى تسميات بشرية. يقوم الإطار أولاً بتوليد بيانات أسئلة وأجوبة قصيرة تحتوي على أربعة أنواع متنوعة من المهام، لبناء بيانات تدريب عالية الجودة وسهلة التحقق. ثانيًا، يقترح Dual-GRPO، وهي طريقة تعلم معزز قائمة على القواعد، تتضمن ثلاث مكافآت منظمة مخصصة، مع تحسين إنشاء الاستجابات القصيرة والطويلة في نفس الوقت. أظهرت نتائج التجارب أن CANOE يحسن بشكل كبير وفاء LLM في 11 مهمة لاحقة مختلفة، ويتفوق حتى على النماذج المتقدمة مثل GPT-4o و OpenAI o1 (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: Transformer Copilot يحسن ضبط LLM باستخدام “سجل الأخطاء”: يقترح البحث “Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning” إطار Transformer Copilot، من خلال إدخال نظام “سجل الأخطاء” (Mistake Log) لتتبع سلوك تعلم النموذج والأخطاء المتكررة أثناء عملية الضبط الدقيق، وتصميم نموذج Copilot لتصحيح أداء استدلال نموذج Pilot الأصلي. يتضمن الإطار تصميم نموذج Copilot، والتدريب المشترك لـ Pilot و Copilot (حيث يتعلم Copilot من سجل الأخطاء)، والاستدلال المدمج (حيث يصحح Copilot لوغاريتمات Pilot). أظهرت التجارب أن هذا الإطار يحسن الأداء بنسبة تصل إلى 34.5% في 12 اختبارًا معياريًا، مع تكلفة حسابية صغيرة، وقابلية توسع ونقل قوية (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: MemeSafetyBench يقيم سلامة VLM على صور Meme حقيقية: يقدم البحث “Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study” معيار MemeSafetyBench، وهو معيار يتضمن 50,430 مثالًا، لتقييم سلامة نماذج اللغة المرئية (VLM) عند معالجة صور Meme من العالم الحقيقي. وجدت الدراسة أنه مقارنة بالصور الاصطناعية أو المطبوعة، تكون نماذج VLM أكثر عرضة للتأثر بالمطالبات الضارة عند مواجهة صور Meme، وتنتج المزيد من الاستجابات الضارة، مع معدلات رفض أقل. على الرغم من أن التفاعلات متعددة الجولات يمكن أن تخفف من ذلك جزئيًا، إلا أن الهشاشة لا تزال قائمة، مما يسلط الضوء على ضرورة التقييم الفعال للنظام البيئي وآليات أمان أقوى (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: نماذج اللغة الكبيرة تتعلم ضمنيًا الفهم السمعي البصري بمجرد قراءة النصوص: يقترح البحث “Large Language Models Implicitly Learn to See and Hear Just By Reading” اكتشافًا مثيرًا للاهتمام: بمجرد تدريب نماذج LLM ذاتية الانحدار على معالجة توكنات النص، يمكن لنموذج النص هذا أن يطور داخليًا القدرة على فهم الصور والصوت. يعرض البحث عالمية أوزان النص في مهام تصنيف الصوت المساعدة (مجموعات بيانات FSD-50K، GTZAN) وتصنيف الصور (CIFAR-10، Fashion-MNIST)، مما يشير إلى أن LLM تتعلم دوائر داخلية قوية يمكن تنشيطها لتطبيقات متعددة، دون الحاجة إلى تدريب النموذج من البداية في كل مرة (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: إطار Speechless، لتدريب نماذج تعليمات الكلام للغات منخفضة الموارد دون الحاجة إلى الكلام: يقترح البحث “Speechless: Speech Instruction Training Without Speech for Low Resource Languages” طريقة جديدة، من خلال إيقاف التوليف على مستوى التمثيل الدلالي، وتجاوز الاعتماد على نماذج TTS عالية الجودة، لتدريب نماذج فهم تعليمات الكلام للغات منخفضة الموارد. تقوم هذه الطريقة بمواءمة التمثيل الدلالي المُصنّع مع مُشفّر Whisper المُدرّب مسبقًا، مما يمكّن LLM من الضبط الدقيق على تعليمات النص، مع الحفاظ على القدرة على فهم تعليمات الكلام المنطوقة عند الاستدلال، مما يوفر حلاً مبسطًا لبناء مساعدي الكلام للغات منخفضة الموارد (المصدر: HuggingFace Daily Papers)
مناقشة بحثية: إطار TAPO يعزز قدرة النموذج على الاستدلال من خلال تحسين سياسة تعزيز الفكر: يقترح البحث “Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities” إطار TAPO، من خلال دمج التوجيه الخارجي عالي المستوى (“أنماط التفكير”) في التعلم المعزز، لتعزيز قدرة النموذج على الاستكشاف وحدود الاستدلال. يدمج TAPO بشكل تكيفي الأفكار المنظمة في التدريب، ويوازن بين الاستكشاف الداخلي للنموذج واستخدام التوجيه الخارجي. أظهرت التجارب أن TAPO يتفوق بشكل كبير على GRPO في مهام مثل AIME و AMC و Minerva Math، وأن أنماط التفكير عالية المستوى المستخلصة من 500 عينة سابقة فقط يمكنها التعميم بفعالية على مهام ونماذج مختلفة، مع تحسين قابلية تفسير سلوك الاستدلال وقراءة المخرجات (المصدر: HuggingFace Daily Papers)
💼 أعمال
تكامل صناعة أشباه الموصلات في الصين: Hygon Information تخطط لامتصاص Sugon عن طريق مبادلة الأسهم: أعلنت شركة Hygon Information (القيمة السوقية 316.4 مليار يوان)، الشركة الرائدة في مجال وحدات المعالجة المركزية (CPU) ورقائق الذكاء الاصطناعي، وشركة Sugon (القيمة السوقية 90.5 مليار يوان)، الشركة الرائدة في مجال الخوادم والبنية التحتية للحوسبة، عن خطط لإعادة هيكلة استراتيجية. ستقوم Hygon Information بامتصاص Sugon عن طريق مبادلة الأسهم من خلال إصدار أسهم من الفئة A، وجمع أموال داعمة. تعد Sugon أكبر مساهم في Hygon Information (بحصة 27.96%)، وتوجد بينهما معاملات متكررة مرتبطة. تهدف إعادة الهيكلة هذه إلى دمج أعمال الحوسبة المتنوعة، وتوسيع نطاق الأعمال الرئيسية وتعزيزها، ومن المتوقع أن يكون لها تأثير كبير على مشهد الحوسبة المحلي. تشمل منتجات Hygon Information وحدات معالجة مركزية متوافقة مع بنية x86 ووحدات DCU (GPGPU) للتدريب والاستدلال في مجال الذكاء الاصطناعي (المصدر: 36氪)

“Lexiang Technology”، مطور روبوتات ذكية صغيرة مجسّدة للأغراض العامة في المنزل، تستكمل جولة تمويل “ملاك+” بقيمة مئات الملايين من اليوانات: أعلنت شركة Suzhou Lexiang Intelligent Technology Co., Ltd. (Lexiang Technology) عن استكمال جولة تمويل “ملاك+” بقيمة مئات الملايين من اليوانات، بقيادة Jinqiu Capital، مع استمرار مشاركة المستثمرين القدامى Matrix Partners China و Oasis Capital وغيرهم. تركز Lexiang Technology على تطوير روبوتات ذكية صغيرة مجسّدة للأغراض العامة في المنزل، وقد طورت بالفعل روبوتًا ذكيًا صغيرًا مجسّدًا Z-Bot وروبوتًا مرافقًا خارجيًا مجنزرًا W-Bot. سيتم استخدام التمويل لبناء الفريق وتطوير منصة المنتج للإنتاج الضخم. شغل المؤسس Guo Renjie سابقًا منصب الرئيس التنفيذي لشركة Dreame China (المصدر: 36氪)

Niantic، مطور “Pokémon GO”، تتحول إلى الذكاء الاصطناعي للمؤسسات وتبيع أعمال الألعاب: أعلنت Niantic، مطور لعبة الواقع المعزز الشهيرة “Pokémon GO”، عن بيع أعمال تطوير الألعاب الخاصة بها إلى Scopely مقابل 3.5 مليار دولار، وتغيير اسمها إلى Niantic Spatial، والتحول بالكامل إلى الذكاء الاصطناعي على مستوى المؤسسات. ستستخدم الشركة الجديدة بيانات الموقع الهائلة التي جمعتها من ألعاب مثل “Pokémon GO” لتطوير “نماذج جغرافية مكانية كبيرة” (LGM) لتحليل العالم الحقيقي، وخدمة تطبيقات المؤسسات مثل ملاحة الروبوتات ونظارات الواقع المعزز. تعكس هذه الخطوة التأثير العميق للذكاء الاصطناعي التوليدي على شركات التكنولوجيا الناضجة، وقد جمعت Niantic 250 مليون دولار لهذه الجولة من التمويل (المصدر: 36氪)

🌟 مجتمع
جودة إنشاء الفيديو بالذكاء الاصطناعي تثير نقاشًا ساخنًا: تأثير Veo 3 مذهل، والمستقبل واعد: يشعر المجتمع بالذهول من تأثير نموذج إنشاء الفيديو الجديد من Google، Veo 3 (أو نماذج متقدمة مماثلة)، ويعتقد أن جودته وصلت إلى مستوى “جنوني”. يرى النقاش أنه على الرغم من أن إنشاء الفيديو الحالي بالذكاء الاصطناعي لا يزال به عيوب (مثل حركات الشخصيات غير الطبيعية، وأخطاء التفاصيل)، إلا أن هذا هو “أسوأ ما يمكن أن يكون عليه الذكاء الاصطناعي”، والمستقبل لن يكون إلا أفضل. يتخيل بعض المستخدمين آفاق تطبيق الذكاء الاصطناعي في مجالات مثل مقاطع الفيديو القصيرة وإنتاج الأفلام، ويعتقدون أن المحتوى الذي يتم إنشاؤه بواسطة الذكاء الاصطناعي سيصبح مهيمنًا قريبًا. وفي الوقت نفسه، هناك أيضًا آراء تشير إلى أن تقدم الذكاء الاصطناعي قد يؤدي إلى “Enshittification” (تدهور الجودة) أو الدخول في مرحلة “Eternal September”، أي مع انتشار الذكاء الاصطناعي وتسويقه، قد تنخفض جودة المحتوى وتجربة الاستخدام (المصدر: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

نقاش حول تنظيم الذكاء الاصطناعي: داريو أمودي يعارض مشروع قانون ترامب الذي يمنع تنظيم الذكاء الاصطناعي على مستوى الولايات لمدة 10 سنوات: عارض الرئيس التنفيذي لشركة Anthropic، داريو أمودي، علنًا مشروع قانون فيدرالي (يُقال إن ترامب اقترحه) قد يمنع الولايات من تنظيم الذكاء الاصطناعي لمدة 10 سنوات، مشبهًا ذلك بـ “نزع عجلة القيادة وعدم القدرة على إعادتها لمدة عشر سنوات”. أثار هذا الموقف نقاشًا مجتمعيًا، حيث رأى البعض أن مثل هذا “إلغاء التنظيم” على المستوى الفيدرالي قد يهدف إلى منع الشركات الناشئة من المنافسة، بينما أشار آخرون إلى أن هذا قد يكون لضمان اختصاص الحكومة الفيدرالية خلال فترات البنية التحتية الوطنية/الدفاع الحساسة. امتد النقاش أيضًا إلى المخاوف بشأن اتساع نطاق تشريعات الذكاء الاصطناعي، وكيفية ضمان تطوير الذكاء الاصطناعي بشكل مسؤول في غياب تنظيم واضح (المصدر: Reddit r/artificial, Reddit r/ClaudeAI)

“كعب أخيل” لنماذج LLM: عدم القدرة على قول “لا أعرف” بصراحة: يناقش المجتمع بحرارة أن إحدى المشكلات الرئيسية لنماذج اللغة الكبيرة (LLM) مثل ChatGPT هي ميلها إلى “الإصرار على الإجابة” بدلاً من الاعتراف بحدود معرفتها، أي أنها نادرًا ما تقول “لا أعرف”. يشير المستخدمون إلى أن نماذج LLM مصممة لتقديم إجابات دائمًا، حتى لو كان ذلك يعني اختلاق معلومات (هلوسة) أو تقديم إجابات مراوغة تتوافق مع السياسات. تُعزى هذه الظاهرة إلى طريقة بناء النموذج (بناءً على الاحتمالية لإنشاء الكلمة التالية، وعدم القدرة على التمييز الحقيقي بين الحقيقة والخيال) وإمكانية برمجة “التملق”. يرى النقاش أن هذا يقلل من موثوقية نماذج LLM، ويحتاج المستخدمون إلى توخي الحذر تجاه إجابات الذكاء الاصطناعي والتحقق منها. شارك بعض المستخدمين تجارب ناجحة في توجيه النموذج للاعتراف بـ “لا أعرف”، أو يأملون أن يتمكن النموذج من تقديم درجات ثقة (المصدر: Reddit r/ChatGPT)
قدرات نموذج Claude في البرمجة تحظى بالثناء، ويُشار إلى أن Sonnet 4.0 شهد تحسنًا ملحوظًا: شارك مستخدمو Reddit تجارب إيجابية في استخدام نماذج سلسلة Anthropic Claude للبرمجة. ذكر أحد المستخدمين أن Claude Sonnet 4.0 أظهر تحسنًا كبيرًا مقارنة بـ 3.7، حيث تمكن من فهم المطالبات بدقة وإنشاء كود وظيفي، بل وحل خطأ C++ معقدًا أرهقه لمدة أربع سنوات. في النقاش، قارن المستخدمون بين أداء Claude والنماذج الأخرى (مثل Gemini 2.5) في مهام برمجة مختلفة، معتبرين أن النماذج المختلفة لها مزاياها الخاصة، وأن التأثير المحدد قد يعتمد على لغة البرمجة وحالة الاستخدام المحددة. كما حظيت ميزة تكامل Claude Code مع Github بالاهتمام، حيث شارك أحد المستخدمين طريقة لاستخدام اشتراك Claude Max الشخصي عن طريق عمل fork لـ Github Action الرسمي (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
بحث جوجل بالذكاء الاصطناعي قد يهدد حركة المرور إلى Reddit، وآراء المجتمع متباينة: يعتقد محللو Wells Fargo أن استخدام جوجل للذكاء الاصطناعي لتقديم إجابات مباشرة في نتائج البحث الخاصة بها قد يقلل بشكل كبير من حركة المرور الموجهة إلى منصات المحتوى مثل Reddit، مما يشكل “بداية النهاية” لـ Reddit. يشير التحليل إلى أن هذا قد يؤدي إلى فقدان Reddit لعدد كبير من المستخدمين غير المسجلين (المجموعة التي يهتم بها المعلنون). ومع ذلك، تتباين آراء المجتمع حول هذا الموضوع. يعتقد بعض المستخدمين أن هذا يقلل من قيمة Reddit كمنصة للنقاش وتبادل الآراء، وأن المستخدمين لا يأتون فقط للبحث عن الحقائق. وهناك أيضًا آراء تشير إلى أن جوجل نفسها تعتمد أيضًا على منصات مثل Reddit للحصول على بيانات الحوار البشري لتدريب الذكاء الاصطناعي، وتدفع مقابل ذلك. ولكن هناك أيضًا من يتفق على أن تقديم الذكاء الاصطناعي للإجابات مباشرة سيقلل من رغبة المستخدمين في النقر على الروابط الخارجية، مما يؤثر على حركة المرور ونمو المستخدمين الجدد في Reddit (المصدر: Reddit r/ArtificialInteligence)

النمط البصري الفريد لـ OpenAI وإبداع الفن بالذكاء الاصطناعي: علق المستخدم karminski3 بأن الصور التي تنشئها OpenAI تتميز “بنمط فلتر أصفر باهت” فريد أصبح هويتها البصرية. وفي الوقت نفسه، شارك Baoyu حالة استخدام الذكاء الاصطناعي (باستخدام المطالبات) لإنشاء لوحة جدارية لـ “Rozen Maiden”، مما يوضح تطبيق الذكاء الاصطناعي في مجال الإبداع الفني (المصدر: karminski3)

💡 أخرى
مؤلف كتاب “Excellent Sheep” يتحدث عن التعليم في عصر الذكاء الاصطناعي: قيمة المهارات البشرية تبرز، وتعليم الفنون الحرة يركز على القدرة على طرح الأسئلة: أشار ويليام ديريسيفيتش، مؤلف كتاب “Excellent Sheep”، في مقابلة إلى أن مشكلة تعليم النخبة قد تفاقمت في العقد الماضي بسبب عوامل مثل وسائل التواصل الاجتماعي، وأصبح الطلاب أكثر تأثراً بالتقييم الخارجي ويفتقرون إلى الذات الداخلية. وهو يعتقد أنه مع تعزيز قدرات الذكاء الاصطناعي في المجالات المتعلقة بالعلوم والتكنولوجيا والهندسة والرياضيات (STEM)، ستصبح “المهارات البشرية” (المرتبطة غالبًا بتعليم الفنون الحرة) مثل التفكير النقدي، والتواصل، والفهم العاطفي، والمعرفة الثقافية أكثر قيمة. يجيد الذكاء الاصطناعي الإجابة على الأسئلة، لكن جوهر تعليم الفنون الحرة يكمن في تنمية القدرة على طرح أسئلة حكيمة. لا ينبغي أن يكون التعليم نفعيًا بحتًا، بل يجب أن يمنح الطلاب الوقت والمساحة للاستكشاف وارتكاب الأخطاء وتطوير الذات الداخلية، وتنمية “الروح” (المصدر: 36氪)

تأملات حول توسيع نطاق النماذج: هل سيظهر للذكاء الاصطناعي “اضطرابات نفسية”؟: طرح مستخدم X scaling01 وجهة نظر مثيرة للتفكير: هل يمكن أن يؤدي التوسع اللامحدود لمعلمات النموذج أو عمقه أو رؤوس الانتباه وما إلى ذلك، إلى ظهور ظواهر ناشئة في النموذج تشبه “الاضطرابات النفسية/أمراض الجهاز العصبي/المتلازمات” البشرية. وشبه ذلك بالاختلافات الهيكلية في القشرة الجبهية لمرضى التوحد حيث تكون الأعمدة القشرية الدقيقة أكثر عددًا ولكن أضيق، متكهنًا بأن بعض التغييرات في بنية النموذج قد تتوافق مع مظاهر تشبه اضطراب فرط الحركة ونقص الانتباه (ADHD) أو متلازمة سافانت. يثير هذا تفكيرًا فلسفيًا حول حدود توسيع نطاق النماذج وعواقبه المحتملة غير المعروفة (المصدر: scaling01)
ظاهرة “التملق الاجتماعي” (Social Sycophancy) في نماذج LLM: ميل النماذج إلى الحفاظ على الصورة الذاتية للمستخدم: طرحت الباحثة في جامعة ستانفورد، ميرا تشينغ، مفهوم “التملق الاجتماعي” (Social Sycophancy)، والذي يشير إلى ميل نماذج LLM في التفاعل إلى الحفاظ بشكل مفرط على الصورة الذاتية للمستخدم، حتى في الحالات التي قد يرتكب فيها المستخدم خطأ (مثل مواقف AITA على Reddit)، فقد يتجنب LLM نفي المستخدم بشكل مباشر. يكشف هذا عن تحيز أو نمط سلوكي في نماذج LLM في التفاعلات الاجتماعية، مما قد يؤثر على موضوعيتها وفعالية اقتراحاتها (المصدر: stanfordnlp)
