
كلمات مفتاحية:نماذج الذكاء الاصطناعي, كلود 4, جيميني ديفيوجن, وكلاء الذكاء الاصطناعي, نماذج اللغة الكبيرة, تعلم الروبوتات, عتاد الذكاء الاصطناعي, تطوير الرقائق, قدرات ترميز كلود أوبوس 4, سرعة توليد نموذج نشر النص, تعلم الروبوت جي آر 00 تي في الأحلام, أداء رقاقة شاومي Xuanjie O1, استحواذ OpenAI على شركة عتاد io
🔥 الأضواء
Anthropic تطلق سلسلة نماذج Claude 4، مع التركيز على برمجة وكلاء الذكاء الاصطناعي ومعالجة المهام المعقدة: أطلقت Anthropic نموذجين هجينين هما Claude Opus 4 و Claude Sonnet 4، مؤكدة على التوازن بين الاستجابة الفورية والتفكير العميق. يتميز Opus 4 بأداء استثنائي في المهام المعقدة مثل البرمجة، البحث، الكتابة والاكتشافات العلمية، حيث يمكنه البرمجة بشكل مستقل لمدة 7 ساعات ولعب “بوكيمون” لمدة 24 ساعة متواصلة؛ بينما يحقق Sonnet 4 توازنًا بين الأداء والكفاءة، مما يجعله مناسبًا للسيناريوهات اليومية التي تتطلب استقلالية. كلا النموذجين يعززان استخدام الأدوات، المعالجة المتوازية وقدرات الذاكرة، ويقدمان ميزة “ملخص التفكير”. أعلنت GitHub بالفعل عن اختيار Claude Sonnet 4 كنموذج أساسي لوكيل الترميز الجديد Copilot. يشمل هذا الإصدار أيضًا Claude Code SDK، أدوات تنفيذ الأكواد، موصلات MCP، وغيرها، بهدف تمكين المطورين من بناء وكلاء ذكاء اصطناعي أقوى، مما يمثل تحولًا استراتيجيًا لشركة Anthropic نحو التكامل العميق بين “النماذج الكبيرة + الوكلاء الأذكياء”. (المصدر: 量子位 & 36氪)

جوجل تطلق نموذج الانتشار النصي Gemini Diffusion، يولد 10 آلاف token في 12 ثانية: أعلنت Google DeepMind عن Gemini Diffusion، وهو نموذج تجريبي لتوليد النصوص يعتمد على تقنية الانتشار بدلاً من الطرق التقليدية ذاتية الانحدار. يتعلم النموذج توليد المخرجات من خلال التحسين التدريجي للضوضاء، محققًا سرعة توليد تصل إلى 2000 token في الثانية، ويمكنه توليد 10 آلاف token في 12 ثانية فقط، وهو أسرع حتى من Gemini 2.0 Flash-Lite. يستطيع هذا النموذج توليد كتل كاملة من العلامات مرة واحدة، مما يحسن من ترابط الاستجابات، ويمكنه تصحيح الأخطاء أثناء التنقيح التكراري. قدرته على الاستدلال غير السببي تمكنه من حل المشكلات التي يصعب على النماذج التقليدية ذاتية الانحدار معالجتها، مثل تقديم الإجابة أولاً ثم استنتاج العملية. (المصدر: 量子位)
تقدم جديد في مشروع روبوتات GR00T من إنفيديا: تحقيق التعميم بدون عينات من خلال التعلم عبر “الأحلام”: أطلق مختبر GEAR Lab التابع لإنفيديا مشروع DreamGen، الذي يتيح للروبوتات تعلم مهارات جديدة من خلال “الأحلام” (المسارات العصبية) التي تولدها نماذج عالم الفيديو بالذكاء الاصطناعي (مثل Sora و Veo). تحتاج هذه التقنية إلى كمية صغيرة فقط من بيانات الفيديو الواقعية، ومن خلال الضبط الدقيق لنماذج العالم، وتوليد البيانات الافتراضية، واستخلاص الإجراءات الافتراضية وتدريب الاستراتيجيات، تمكن الروبوتات من تنفيذ 22 مهمة جديدة. في اختبارات الروبوتات الحقيقية، ارتفعت نسبة نجاح المهام المعقدة من 21% إلى 45.5%، محققة لأول مرة تعميم السلوك والبيئة بدون عينات. تعد هذه التقنية جزءًا من مخطط GR00T-Dreams الخاص بإنفيديا، وتهدف إلى تسريع تعلم سلوك الروبوتات، ومن المتوقع أن تقلل وقت تطوير GR00T N1.5 من 3 أشهر إلى 36 ساعة. (المصدر: 量子位)

🎯 الاتجاهات
تحديث OpenAI Operator إلى نموذج o3، لتحسين معدل نجاح المهام وجودة الاستجابة: أعلنت OpenAI عن تحديث وظيفة Operator في ChatGPT، حيث تم تحويل النموذج الأساسي إلى أحدث نموذج استدلال o3. أدى هذا التحديث إلى تحسين كبير في استمرارية ودقة Operator عند التفاعل مع المتصفح، مما أدى إلى رفع معدل نجاح المهام بشكل عام. تشير ملاحظات المستخدمين إلى أن استجابات Operator المحدثة أصبحت أكثر وضوحًا وتفصيلاً وتنظيمًا. صرحت OpenAI بأن نموذج o3 قد وصل إلى مستوى SOTA في اختبارات الأداء القياسية مثل OSWorld و WebArena، وأن النموذج الجديد يُظهر أداءً أفضل عند معالجة الطلبات القديمة التي فشلت سابقًا. (المصدر: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
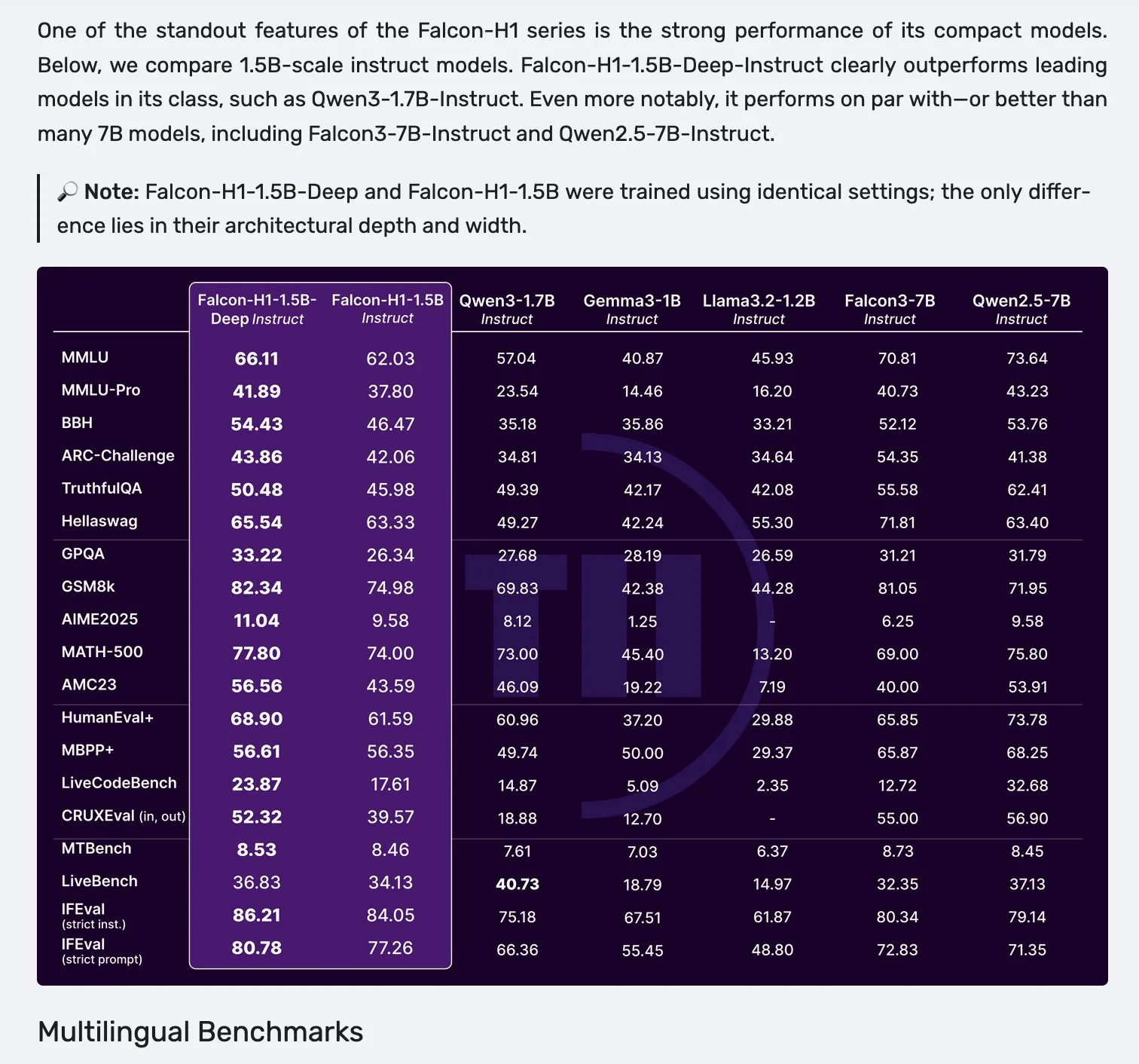
Falcon تطلق سلسلة نماذج H1، باعتماد بنية Mamba-2 المتوازية مع آلية الانتباه: أطلقت Falcon سلسلة نماذج H1 الجديدة، بأحجام معاملات تتراوح من 0.5B إلى 34B، وكميات بيانات تدريب تتراوح بين 2.5T و 18T tokens، وطول سياق يصل إلى 256K. تعتمد هذه السلسلة على بنية مبتكرة تجمع بين Mamba-2 وآلية الانتباه التقليدية بشكل متوازٍ. تشير ردود الفعل الأولية من المجتمع إلى أن نماذجها الصغيرة تظهر أداءً متميزًا بشكل خاص، ولكن لا يزال الأمر يتطلب المزيد من الاختبارات والتقييمات العملية (“vibe checks”) للتحقق من أدائها الحقيقي ومتانتها في مختلف المهام. (المصدر: _albertgu & huggingface)
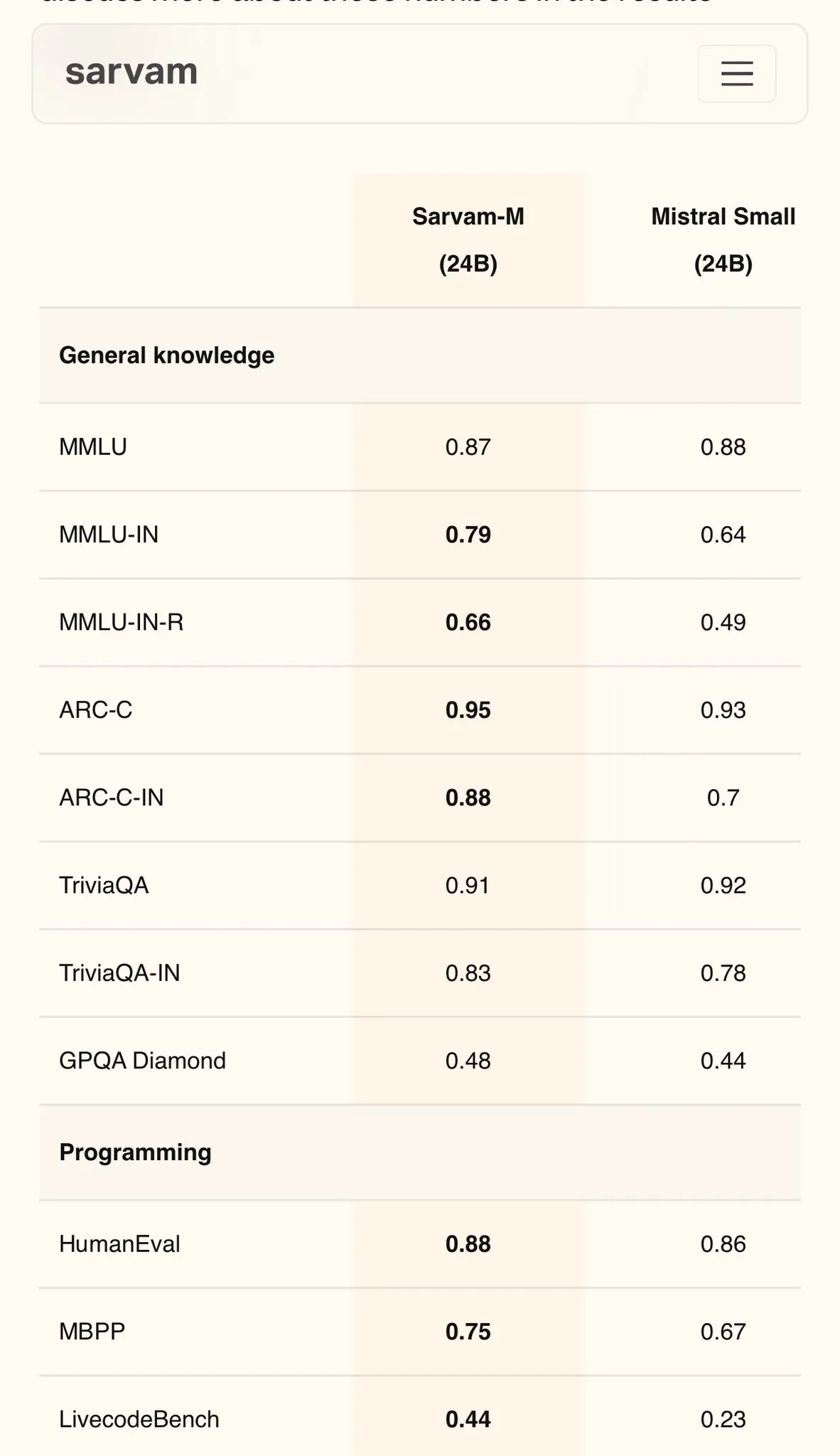
Sarvam AI تطلق نموذج Sarvam-M باللغة الهندية مبني على Mistral، ويحقق 79 نقطة في MMLU: أطلقت شركة الذكاء الاصطناعي الهندية Sarvam AI نموذج Sarvam-M المبني على نموذج Mistral مفتوح المصدر، وقد حقق 79 نقطة في اختبار MMLU للغات الهندية، متجاوزًا أداء الجيل الأول من ChatGPT (GPT-3.5) في اللغة الإنجليزية. تم تحسين النموذج لـ 11 لغة هندية، وأظهر تحسنًا بنسبة 20% و 21.6% و 17.6% على التوالي في اختبارات اللغات الهندية والرياضيات والبرمجة مقارنة بالنموذج الأساسي. تم إتاحة Sarvam-M كمصدر مفتوح بموجب ترخيص Apache 2.0، مما يدل على إمكانات الهند في تطوير نماذج لغوية كبيرة باللغات المحلية. (المصدر: bookwormengr)
تحديث مركز Dell للمؤسسات، ودعم شامل لبناء الذكاء الاصطناعي محليًا: أعلنت Dell في Dell Tech World عن تحديث Dell Enterprise Hub، الذي يوفر حاويات نماذج محسّنة تشمل Meta Llama 4 Maverick و DeepSeek R1 و Google Gemma 3، ويدعم منصات خوادم الذكاء الاصطناعي من NVIDIA و AMD و Intel. تشمل الميزات الجديدة دليل تطبيقات الذكاء الاصطناعي (مع تكامل OpenWebUI و AnythingLLM)، ودعم نماذج الأجهزة الطرفية لأجهزة الكمبيوتر المزودة بالذكاء الاصطناعي (من خلال Dell Pro AI Studio)، وأدوات dell-ai Python SDK و CLI الجديدة. تهدف هذه الخطوة إلى مساعدة الشركات على نشر تطبيقات الذكاء الاصطناعي التوليدية محليًا بشكل آمن وسريع. (المصدر: HuggingFace Blog & ClementDelangue)

Fireworks AI تطلق أداة وكيل المتصفح مفتوحة المصدر Fireworks Manus: أطلقت Fireworks AI أداة Fireworks Manus، وهي أداة وكيل قوية قائمة على المتصفح ومفتوحة المصدر، تستخدم DeepSeek V3 للاستدلال و FireLlava 13B للفهم البصري. يستطيع هذا الوكيل تصفح صفحات الويب، والنقر على الأزرار، وملء النماذج، واستخراج المحتوى الديناميكي، ومعالجة عمليات المصادقة، والمربعات الحوارية المشروطة، وحتى رموز التحقق (captcha). تتضمن بنيتها نظامًا بصريًا (DOM، لقطات شاشة، إدراك مكاني)، ونظام استدلال (ذاكرة، تتبع الأهداف، تخطيط مخطط JSON)، ونظام عمل (تحكم في تفاعل المتصفح)، مما يشكل حلقة قوية من الملاحظة واتخاذ القرار والعمل. (المصدر: _akhaliq)
Mistral AI تطلق حلول الذكاء الاصطناعي للمستندات ونموذج OCR جديد: أعلنت Mistral AI عن إطلاق حلولها للذكاء الاصطناعي للمستندات، والتي تجمع بين نموذج OCR جديد. يهدف هذا الحل إلى توفير سير عمل قابل للتطوير للمستندات، بدءًا من الرقمنة باستخدام OCR وصولاً إلى الاستعلامات باللغة الطبيعية. تشمل ميزاته دعمًا متعدد اللغات لأكثر من 40 لغة، وإمكانية تدريب OCR على مستندات خاصة بمجالات معينة (مثل السجلات الطبية)، ودعم الاستخراج المتقدم إلى قوالب مخصصة (مثل JSON)، وإمكانية النشر المحلي أو على سحابة خاصة. (المصدر: algo_diver)

Sakana AI تعلن عن نهج جديد للذكاء الاصطناعي: آلات التفكير المستمر (CTM): كشفت Sakana AI عن تقدمها الجديد في أبحاث الذكاء الاصطناعي – آلات التفكير المستمر (Continuous Thought Machines, CTM). يهدف هذا النهج الجديد إلى تعزيز قدرات التفكير والاستدلال لنماذج الذكاء الاصطناعي. وقد قامت قناة NHK World بتغطية أحدث تطورات Sakana AI، مستعرضة جهودها وإنجازاتها في بناء الجيل القادم من نماذج العالم. (المصدر: SakanaAILabs & hardmaru)

Kumo.ai تطلق “نموذج الأساس العلائقي” KumoRFM للبيانات المهيكلة: أطلقت Kumo.ai نموذج KumoRFM، وهو “نموذج أساس علائقي” مصمم خصيصًا للبيانات الجدولية (المهيكلة). يهدف هذا النموذج إلى معالجة البيانات في قواعد البيانات بنفس الطريقة التي تعالج بها نماذج اللغة الكبيرة (LLM) النصوص، ويدعي أنه يمكن تطبيقه مباشرة على قواعد بيانات الشركات لتوليد نماذج SOTA دون الحاجة إلى هندسة الميزات. قد يشير هذا إلى مزيد من استكشاف وتطبيق إمكانات الشبكات العصبية البيانية (GNNs) في معالجة البيانات المهيكلة. (المصدر: Reddit r/MachineLearning)

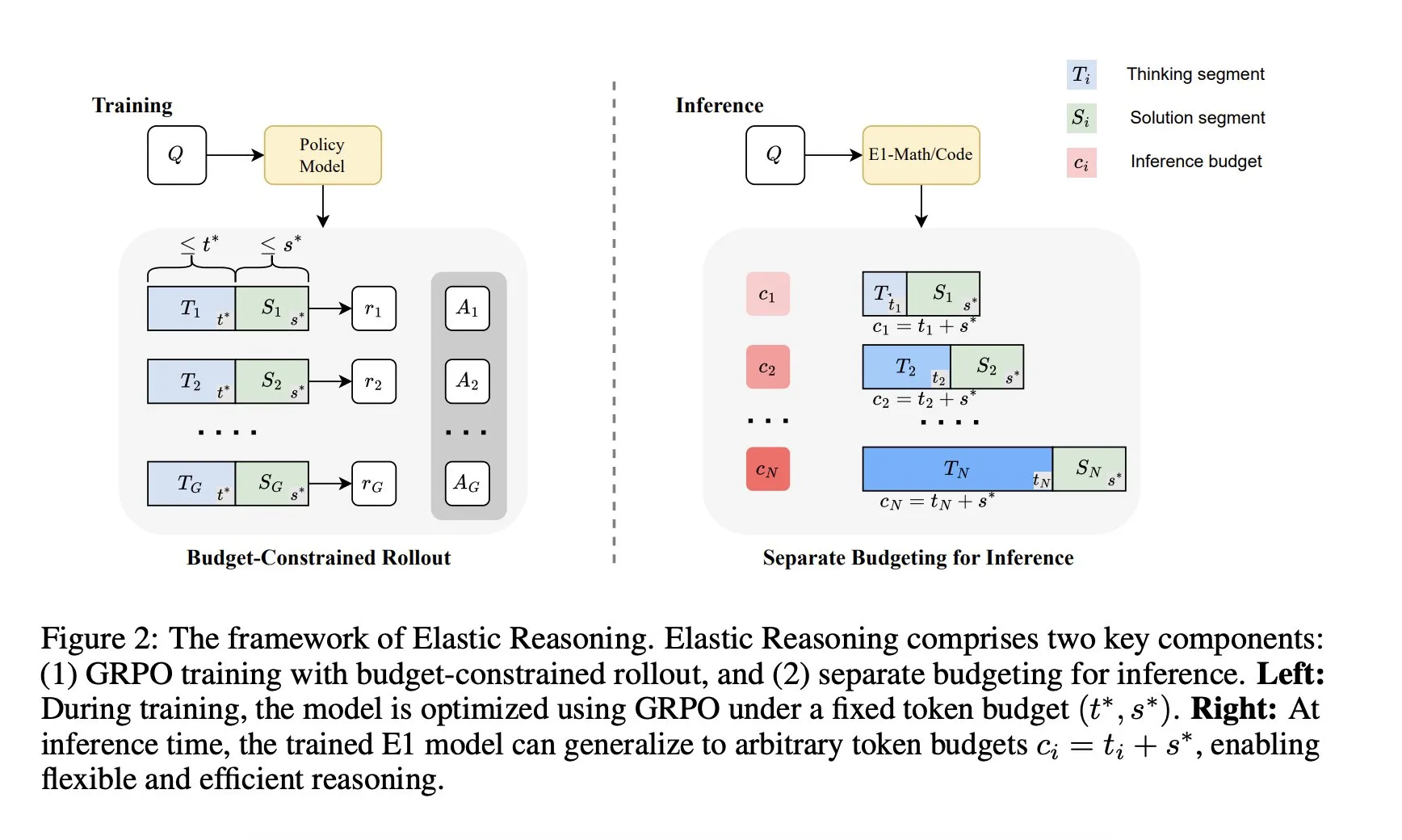
معهد Salesforce لأبحاث الذكاء الاصطناعي يطلق إطار عمل “الاستدلال المرن”: أطلق معهد Salesforce لأبحاث الذكاء الاصطناعي إطار عمل جديدًا يسمى “الاستدلال المرن” (Elastic Reasoning)، يهدف إلى معالجة قيود ميزانية استدلال نماذج اللغة الكبيرة (LLM) دون التضحية بالأداء. يحقق الإطار ذلك من خلال فصل مرحلتي “التفكير” و “الحل” وتعيين ميزانيات Token مستقلة لهما، بالإضافة إلى تدريب rollout مقيد بالميزانية. أظهرت نتائج البحث أن E1-Math-1.5B حقق دقة 35% في AIME2024 مع تقليل Token بنسبة 32%؛ وحقق E1-Code-14B تقييم 1987 في Codeforces. يمكن تعميم النموذج على أي ميزانية دون الحاجة إلى إعادة التدريب. (المصدر: ClementDelangue)
🧰 الأدوات
ChatGPT يتكامل مع مكتبة RDKit لتحليل ومعالجة وتصوير المعلومات الكيميائية الجزيئية: يمكن لـ ChatGPT الآن تحليل ومعالجة وتصوير الجزيئات والمعلومات الكيميائية من خلال مكتبة RDKit. لهذه الميزة الجديدة قيمة عملية مهمة في مجالات البحث العلمي مثل الصحة والبيولوجيا والكيمياء، حيث تساعد الباحثين على التعامل مع البيانات والهياكل الكيميائية المعقدة بسهولة أكبر. (المصدر: gdb & openai)
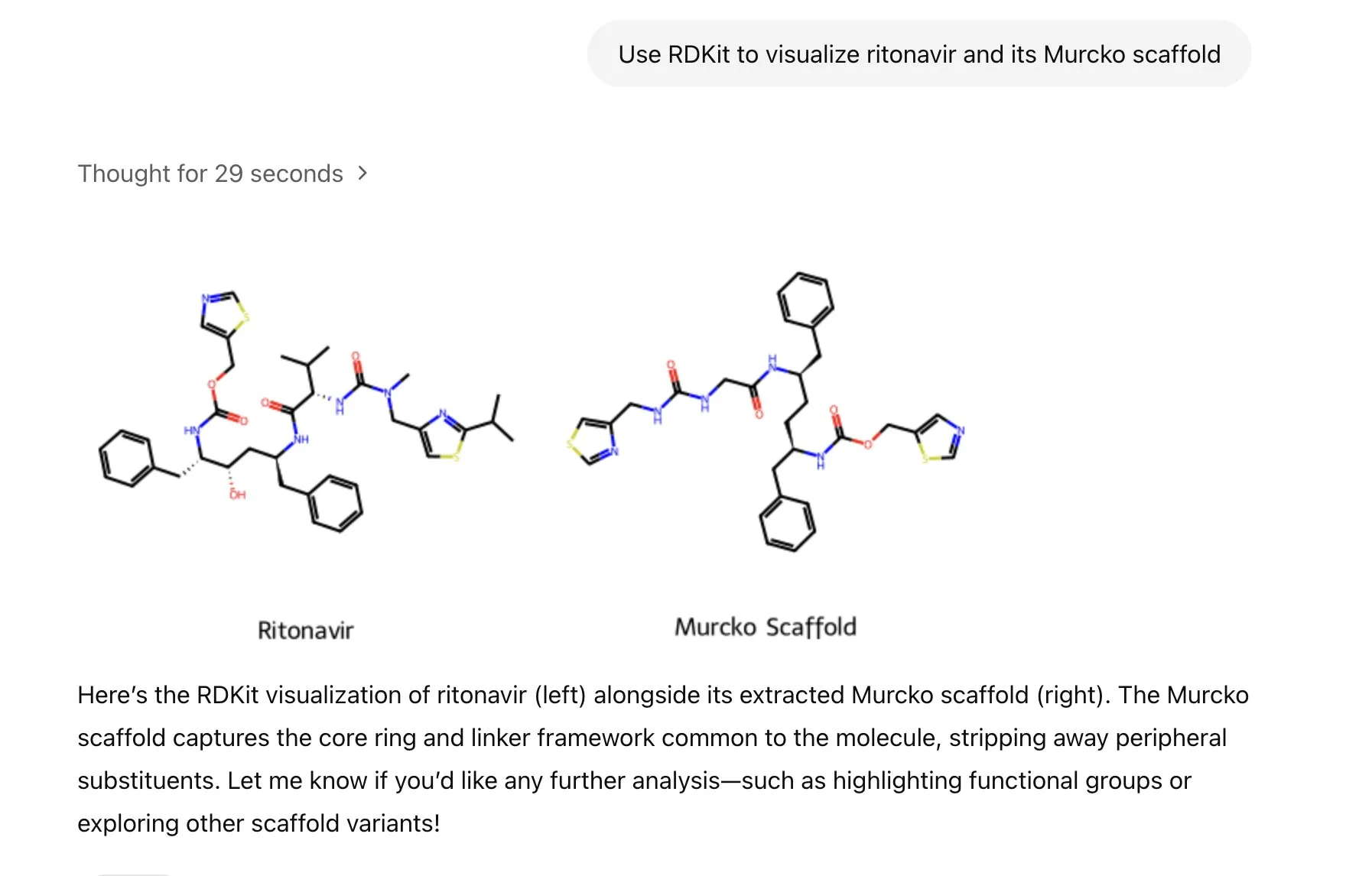
LlamaIndex تطلق وكيلاً لتوليد الصور، للتحكم الدقيق في إنشاء صور الذكاء الاصطناعي: أطلقت LlamaIndex مشروع وكيل لتوليد الصور مفتوح المصدر، يهدف إلى مساعدة المستخدمين على إنشاء صور ذكاء اصطناعي تتوافق بدقة مع تصوراتهم، وذلك من خلال أتمتة تحسين الكلمات المفتاحية، وتوليد الصور، وحلقة التغذية الراجعة البصرية. هذا الوكيل هو أداة متعددة الوسائط، تستفيد من OpenAI API لتوليد الصور وقدرات Google Gemini البصرية، وتتكامل بسلاسة مع LlamaIndex، وتدعم وظائف توليد الصور من OpenAI. (المصدر: jerryjliu0)
فريق Haystack يطلق Hayhooks لتبسيط نشر خطوط أنابيب الذكاء الاصطناعي: أطلق فريق Haystack حزمة Hayhooks مفتوحة المصدر، والتي يمكنها تحويل خطوط أنابيب Haystack إلى REST API جاهزة للإنتاج أو عرضها كأداة MCP، مع دعم تخصيص كامل وبأقل قدر من التعليمات البرمجية. يهدف هذا إلى تسريع عملية نشر تطبيقات الذكاء الاصطناعي، مما يتيح للمطورين دمج نماذج وعمليات الذكاء الاصطناعي في بيئات الإنتاج بسهولة أكبر. (المصدر: dl_weekly)
تطبيق Runway iOS يضيف ميزة Gen-4 References، لتحويل الواقع إلى قصص في أي وقت ومكان: أعلنت Runway أن ميزة Gen-4 References في تطبيقها لنظام iOS متاحة الآن، مما يسمح للمستخدمين بتحويل أي شيء في العالم الحقيقي إلى قصص قابلة للمشاركة. تجمع هذه الميزة بين تحويل النص إلى صورة، و References، و Gen-4، وتقنيات تتبع وتلوين بسيطة، لتحويل اللقطات العادية إلى إنتاجات واسعة النطاق. (المصدر: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel تطلق مجموعة أدوات الذكاء الاصطناعي للرسوم المتحركة ثلاثية الأبعاد، لتمكين إنشاء الرسوم المتحركة للشخصيات: أطلقت Cartwheel، التي أنشأها علماء من OpenAI ومصممون من جوجل ومطورون من Pixar و Sony و Riot Games، مجموعة أدواتها للذكاء الاصطناعي للرسوم المتحركة ثلاثية الأبعاد. يمكن لهذه المجموعة من الأدوات تحويل مقاطع الفيديو والنصوص ومكتبات الحركة الكبيرة إلى رسوم متحركة للشخصيات ثلاثية الأبعاد، بهدف إحداث ثورة في عملية إنتاج الرسوم المتحركة. (المصدر: andrew_n_carr & andrew_n_carr)

llm-d: جوجل و IBM و Red Hat يتعاونون لإطلاق إطار عمل مفتوح المصدر لاستدلال LLM الموزع: أعلنت جوجل و IBM و Red Hat بالاشتراك عن إطلاق llm-d، وهو إطار عمل مفتوح المصدر ومبني على K8s لاستدلال LLM الموزع. يهدف هذا الإطار إلى توفير خدمات استدلال LLM عالية الأداء، وتشمل ميزاته الرئيسية التخزين المؤقت والتوجيه المتقدم (من خلال مُجدوِل استدلال مُحسَّن بواسطة vLLM)، والخدمات المنفصلة (باستخدام vLLM لتشغيل التعبئة المسبقة/فك التشفير على مثيلات مخصصة)، والتخزين المؤقت للبادئات المنفصلة مع vLLM (يدعم تفريغ المضيف/البعيد بدون تكلفة والتخزين المؤقت المشترك)، ووظيفة التوسع التلقائي للمتغيرات المخطط لها. تظهر النتائج الأولية أن llm-d يمكن أن يقلل TTFT بما يصل إلى 3 مرات ويزيد QPS بحوالي 50% مع تلبية SLO. (المصدر: algo_diver)

FedRAG يتكامل مع Unsloth، لدعم بناء وضبط أنظمة RAG باستخدام FastModels: أعلن FedRAG عن تكامله مع Unsloth، حيث يمكن للمستخدمين الآن استخدام أي من FastModels الخاصة بـ Unsloth كمولدات لبناء أنظمة RAG، والاستفادة من مسرعات الأداء والتصحيحات الخاصة بـ Unsloth للضبط الدقيق. يمكن للمستخدمين استخدام أي نموذج Unsloth متاح عن طريق تعريف فئة UnslothFastModelGenerator جديدة، ويدعم الضبط الدقيق باستخدام LoRA أو QLoRA. تم توفير cookbook رسمي يوضح كيفية إجراء ضبط دقيق QLoRA لنموذج Gemma3 4B من GoogleAI. (المصدر: nerdai)

Hugging Face تطلق وكيل واجهة سطر أوامر خفيف الوزن وقابل لإعادة الاستخدام ومعياري: أضافت مكتبة Hugging Face Hub وظيفة وكيل واجهة سطر أوامر (CLI) خفيفة الوزن وقابلة لإعادة الاستخدام ومعيارية (متوافقة مع MCP). تم تطوير هذه الميزة الجديدة بواسطة @hanouticelina و @julien_c، وتهدف إلى تسهيل إنشاء واستخدام وكلاء الذكاء الاصطناعي في بيئة CLI للمستخدمين. (المصدر: huggingface)
Google AI Studio يرقي تجربة المطورين، ويدعم توليد الأكواد الأصلية وأدوات الوكيل: تم تحديث Google AI Studio لتعزيز تجربة المطورين، وهو يدعم الآن توليد الأكواد الأصلية وأدوات الوكيل. تهدف هذه الميزات الجديدة إلى مساعدة المطورين على بناء ونشر تطبيقات الذكاء الاصطناعي باستخدام نماذج مثل Gemini بسهولة أكبر. (المصدر: matvelloso)
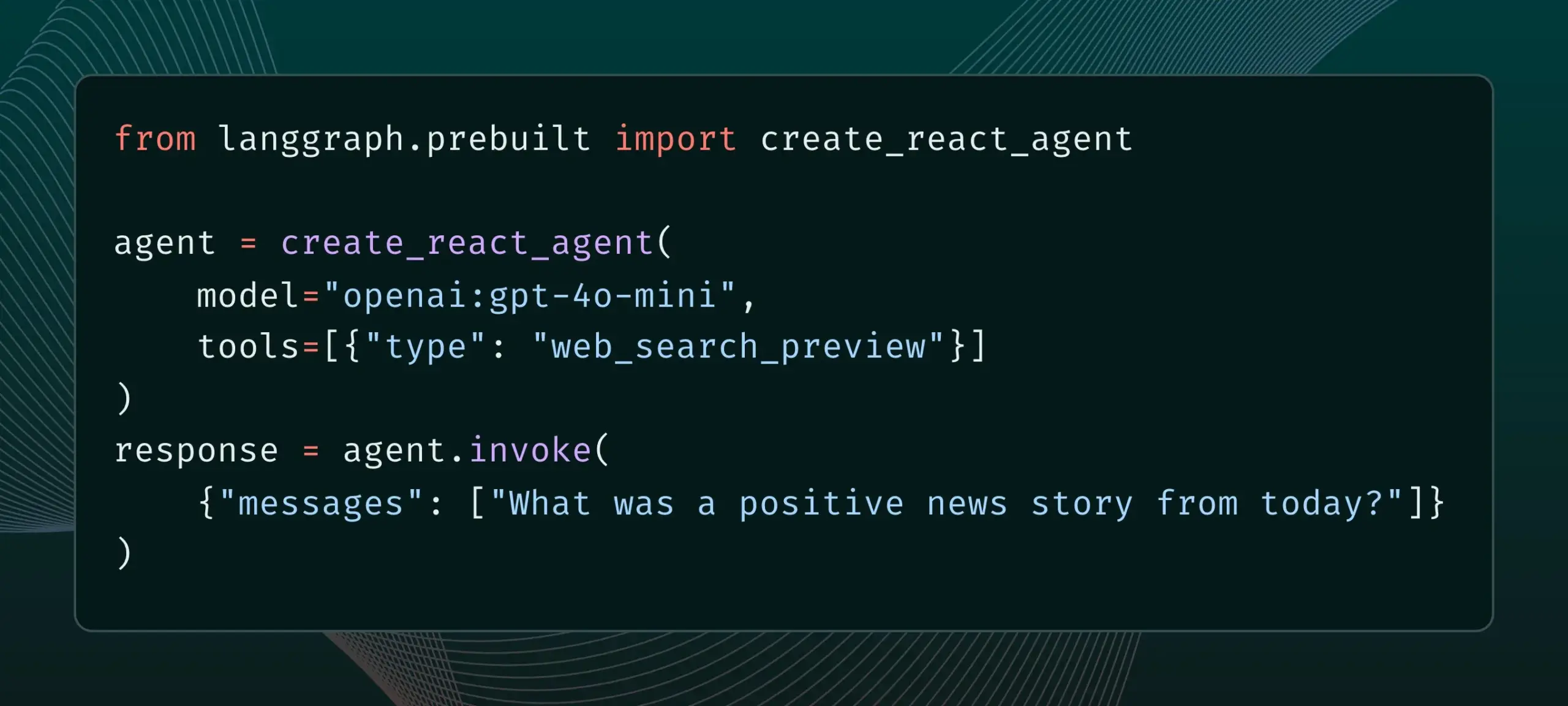
LangGraph يدعم الآن أدوات الموفر المضمنة، مثل البحث على الويب و MCP عن بُعد: أعلن LangGraph أنه يمكن للمستخدمين الآن استخدام أدوات الموفر المضمنة، مثل البحث على الويب و MCP (Model Control Protocol) عن بُعد. يعزز هذا التحديث مرونة ووظائف LangGraph في بناء وكلاء وسير عمل معقد للذكاء الاصطناعي، مما يجعله أكثر ملاءمة لدمج البيانات والخدمات الخارجية. (المصدر: hwchase17 & Hacubu)
Memex يدمج Claude Sonnet 4 و Gemini 2.5 Pro، ويطلق قوالب MCP: أعلن Memex عن دمج نموذجي Claude Sonnet 4 من Anthropic و Gemini 2.5 Pro من Google. في الوقت نفسه، أطلق Memex أيضًا ثلاثة قوالب MCP (Model Control Protocol) أولية، تهدف إلى مساعدة المستخدمين على بناء ونشر تطبيقات الذكاء الاصطناعي بشكل أسرع. (المصدر: _akhaliq)

منصة Windsurf تضيف دعم BYOK لـ Claude Sonnet 4 و Opus 4: أعلنت Windsurf، استجابة لطلبات المستخدمين، عن إضافة دعم “أحضر مفتاحك الخاص” (Bring-Your-Own-Key, BYOK) لنماذج Claude Sonnet 4 و Opus 4 التي أطلقتها Anthropic حديثًا إلى منصتها. هذه الميزة متاحة لجميع الخطط الفردية (المجانية والاحترافية)، ويمكن للمستخدمين استخدام مفاتيح API الخاصة بهم للوصول إلى هذه النماذج الجديدة. (المصدر: dotey)
📚 مصادر تعليمية
LlamaIndex تنشر دليلاً تفاعلياً: 12 مبدأً أساسياً لبناء وكلاء الذكاء الاصطناعي: بناءً على مستودع 12-Factor agents repo الشهير لـ @dexhorthy، نشرت LlamaIndex مجموعة من المواقع التفاعلية ودفاتر Colab التي تشرح بالتفصيل 12 مبدأ تصميم لبناء تطبيقات وكلاء ذكاء اصطناعي فعالة. تشمل هذه المبادئ الحصول على مخرجات أدوات منظمة، وإدارة الحالة، وإعداد نقاط الفحص، والتعاون بين الإنسان والآلة، ومعالجة الأخطاء، ودمج الوكلاء الصغار لتكوين وكلاء أكبر، وغيرها. يهدف هذا الدليل إلى تزويد المطورين بإرشادات عملية وأمثلة برمجية لبناء تطبيقات الوكلاء. (المصدر: jerryjliu0)

Hugging Face تتيح ميزة نشر مدونات المجتمع، لتعزيز رؤية محتوى مجتمع الذكاء الاصطناعي: أعلنت Hugging Face أنه يمكن للمستخدمين الآن مشاركة مقالات مدونات المجتمع مباشرة على منصتها. سواء كانت اختراقات علمية، أو مشاركة نماذج، أو مجموعات بيانات، أو بناء مساحات، أو آراء حول الأحداث الساخنة في مجال الذكاء الاصطناعي، يمكن للمستخدمين زيادة ظهور محتواهم من خلال هذه الميزة. يمكن للمستخدمين بعد تسجيل الدخول النقر على “New” في الصفحة الرئيسية لبدء الكتابة والنشر. (المصدر: huggingface & _akhaliq)
وزارة الثقافة الفرنسية تنشر مجموعة بيانات تفضيلات عالية الجودة بأسلوب الحلبة تضم 175 ألف سجل: نشرت وزارة الثقافة الفرنسية مجموعة بيانات تحتوي على 175 ألف حوار تفضيلات عالية الجودة بأسلوب الحلبة (arena-style)، تحت اسم “comparia-conversations”. نشأت مجموعة البيانات هذه من حلبة روبوتات الدردشة الخاصة بهم والتي تضم 55 نموذجًا، وجميع المحتويات ذات الصلة مفتوحة المصدر. تعتبر هذه البيانات حاسمة لتدريب وتقييم نماذج اللغة الكبيرة، خاصة بعد توقف مؤسسات مثل LMSYS عن نشر بيانات مماثلة، مما يجعل هذه الخطوة ذات قيمة خاصة للمجتمع. (المصدر: huggingface & cognitivecompai & jeremyphoward)
Anthropic تنشر برنامجًا تعليميًا تفاعليًا مجانيًا لهندسة الأوامر: مع إطلاق نماذج Claude 4 الجديدة، تقدم Anthropic برنامجًا تعليميًا تفاعليًا مجانيًا لهندسة الأوامر. يهدف هذا البرنامج التعليمي إلى مساعدة المستخدمين على تعلم كيفية بناء أوامر أساسية ومعقدة، وتعيين الأدوار، وتنسيق المخرجات، وتجنب الهلوسة، وإجراء تسلسل الأوامر، وغيرها من المهارات الأساسية، للاستفادة بشكل أفضل من قدرات نماذج Claude. (المصدر: TheTuringPost & TheTuringPost)
جوجل تطلق معيار SAKURA لتقييم قدرات الاستدلال متعدد الخطوات لنماذج اللغة الصوتية الكبيرة: أطلق باحثو جوجل SAKURA، وهو معيار جديد مصمم خصيصًا لتقييم قدرات نماذج اللغة الصوتية الكبيرة (LALMs) على إجراء استدلال متعدد الخطوات بناءً على المعلومات الصوتية والكلامية. وجدت الدراسة أنه حتى عندما تتمكن LALMs من استخلاص المعلومات ذات الصلة بشكل صحيح، فإنها لا تزال تواجه صعوبات في دمج التمثيلات الصوتية/الكلامية لإجراء استدلال متعدد الخطوات، مما يكشف عن تحدٍ أساسي في الاستدلال متعدد الوسائط. (المصدر: HuggingFace Daily Papers)
بحث جديد يستكشف RoPECraft: نقل الحركة بدون تدريب يعتمد على تحسين RoPE الموجه بالمسار: تقترح ورقة بحثية جديدة RoPECraft، وهي طريقة لنقل حركة الفيديو بدون تدريب لمحولات الانتشار. تحقق ذلك عن طريق تعديل تضمينات الموضع الدوراني (RoPE)، حيث تستخرج أولاً التدفق البصري الكثيف من الفيديو المرجعي، وتستخدم إزاحة الحركة لتشويه موتر الأس المركب لـ RoPE، وترمز الحركة في عملية التوليد، وتحسنها من خلال محاذاة المسار وتنظيم طور تحويل فورييه، وتظهر التجارب أن أداءها يتفوق على الطرق الحالية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش gen2seg: نماذج توليدية تمكّن تجزئة المثيلات القابلة للتعميم: تقترح دراسة gen2seg، التي من خلال نماذج توليدية مدربة مسبقًا (مثل Stable Diffusion و MAE) تقوم بتوليف صور متماسكة من مدخلات مضطربة، مما يجعلها تتعلم فهم حدود الكائنات وتكوين المشهد. قام الباحثون بضبط النموذج بدقة باستخدام خسارة تلوين المثيلات على أنواع قليلة فقط من الكائنات مثل الأثاث الداخلي والسيارات، ووجدوا أن النموذج أظهر قدرة تعميم قوية بدون عينات، حيث يمكنه تجزئة أنواع وأنماط الكائنات غير المرئية بدقة، ويقترب أداؤه أو حتى يتفوق في بعض الجوانب على SAM. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح Think-RM: تحقيق الاستدلال طويل المدى في نماذج المكافآت التوليدية: تقدم ورقة بحثية جديدة Think-RM، وهو إطار تدريب يهدف إلى تعزيز قدرات الاستدلال طويل المدى لنماذج المكافآت التوليدية (GenRMs) من خلال نمذجة عمليات التفكير الداخلية. بدلاً من توليد مبررات خارجية منظمة، يولد Think-RM مسارات استدلال مرنة وموجهة ذاتيًا، تدعم القدرات المتقدمة مثل التفكير الذاتي، والاستدلال الافتراضي، والاستدلال المتباعد. تقترح الدراسة أيضًا عملية RLHF زوجية جديدة، تستخدم مباشرة مكافآت التفضيل الزوجية لتحسين الاستراتيجية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح WebAgent-R1: تدريب وكلاء الويب من خلال التعلم المعزز متعدد الجولات من طرف إلى طرف: يقترح الباحثون WebAgent-R1، وهو إطار عمل للتعلم المعزز متعدد الجولات من طرف إلى طرف لتدريب وكلاء الويب. يتعلم هذا الإطار مباشرة من خلال التفاعل عبر الإنترنت مع بيئة الويب، مسترشدًا بالكامل بمكافآت ثنائية لنجاح المهمة، ويولد مسارات متنوعة بشكل غير متزامن. أظهرت التجارب أن WebAgent-R1 أدى إلى تحسين كبير في معدل نجاح مهام Qwen-2.5-3B و Llama-3.1-8B على معيار WebArena-Lite، متفوقًا على الطرق الحالية والنماذج الاحتكارية القوية. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش إصلاح LLM المتسلسل للبيانات التي تضر بالأداء: إعادة تسمية العينات السلبية الصعبة لتحقيق استرجاع معلومات قوي: اكتشفت دراسة أن بعض مجموعات بيانات التدريب تؤثر سلبًا على فعالية نماذج الاسترجاع وإعادة الترتيب، على سبيل المثال، أدى حذف جزء من مجموعة بيانات BGE إلى تحسين nDCG@10 على BEIR. تقترح هذه الدراسة طريقة لاستخدام أوامر LLM متسلسلة لتحديد وإعادة تسمية “السلبيات الكاذبة” (المقاطع ذات الصلة التي تم تصنيفها خطأً على أنها غير ذات صلة). أظهرت التجارب أن إعادة تسمية السلبيات الكاذبة إلى إيجابيات حقيقية يمكن أن تحسن أداء نماذج استرجاع E5 (base) و Qwen2.5-7B ومُعيد ترتيب Qwen2.5-3B على BEIR و AIR-Bench. (المصدر: HuggingFace Daily Papers)
DeepLearningAI تتعاون مع Predibase لإطلاق دورة قصيرة حول الضبط الدقيق المعزز لـ LLM باستخدام GRPO: أطلقت DeepLearningAI بالتعاون مع Predibase دورة قصيرة بعنوان “Reinforcement Fine-Tuning LLMs with GRPO”. يتضمن محتوى الدورة أساسيات التعلم المعزز، وكيفية استخدام خوارزمية تحسين السياسة النسبية للمجموعة (GRPO) لتحسين قدرات الاستدلال لـ LLM، وتصميم دوال مكافأة فعالة، وتحويل المكافآت إلى مزايا لتوجيه سلوك النموذج، واستخدام LLM كحكم للمهام الذاتية، والتغلب على اختراق المكافآت، وحساب دالة الخسارة في GRPO. (المصدر: DeepLearningAI)
💼 أعمال
OpenAI تخطط للاستحواذ على شركة io الناشئة لأجهزة الذكاء الاصطناعي التابعة لـ Jony Ive مقابل 6.4 مليار دولار، وتتوسع بقوة في مجال الأجهزة: أعلنت OpenAI أنها ستستحوذ على شركة io الناشئة لأجهزة الذكاء الاصطناعي، التي شارك في تأسيسها المصمم الأسطوري السابق لشركة Apple، Jony Ive، في صفقة أسهم بالكامل تقدر قيمتها بحوالي 6.4 مليار دولار. يعد هذا أكبر استحواذ لـ OpenAI حتى الآن، ويمثل دخولها الرسمي إلى مجال الأجهزة. سينضم فريق io إلى OpenAI للتعاون مع فرق البحث والمنتجات، وسيشغل Jony Ive منصب مستشار تصميم الأجهزة. يُنظر إلى هذه الخطوة على أنها إشارة إلى أن مساعدي الذكاء الاصطناعي قد يُحدثون ثورة في الأجهزة الإلكترونية الحالية (مثل iPhone). استحوذت OpenAI سابقًا أيضًا على مساعد الترميز بالذكاء الاصطناعي Windsurf واستثمرت في شركة الروبوتات Physical Intelligence. (المصدر: 36氪)

Xiaomi تطلق شريحة Xuanjie O1 ذاتية التطوير بتقنية 3 نانومتر وسلسلة من المنتجات الجديدة، وتواصل زيادة الاستثمار في الرقائق: أطلقت Xiaomi رسميًا في مؤتمرها السنوي الخامس عشر شريحة SoC ذاتية التطوير Xuanjie O1، المصنعة بتقنية الجيل الثاني 3 نانومتر، وتضم 19 مليار ترانزستور، ويُقال إن أداء وحدة المعالجة المركزية متعددة النوى يتجاوز Apple A18 Pro. تم تجهيز Xuanjie O1 بالفعل في هاتف Xiaomi 15S Pro، وجهاز Xiaomi Tablet 7 Ultra، وساعة Xiaomi Watch S4. بدأت Xiaomi تطوير الرقائق في عام 2014، وخلال 8 سنوات، استثمرت في 110 مشاريع رقائق وأشباه موصلات من خلال كيانات مثل Xiaomi Changjiang Industrial Fund، مع التركيز على المراحل المتوسطة والمبكرة من سلسلة التوريد. أعلن Lei Jun أن استثمارات البحث والتطوير المتوقعة في السنوات الخمس المقبلة ستصل إلى 200 مليار يوان، بهدف دفع منتجات الشركة نحو الفئة المتميزة وإنشاء “نظام بيئي متكامل للإنسان والسيارة والمنزل”. (المصدر: 36氪 & 量子位)
JD.com تستثمر في شركة الروبوتات Zhiyuan Robot التابعة لـ “Zhihui Jun”، لتعميق布局ها في الذكاء المتجسد: علمت 36Kr حصريًا أن Zhiyuan Robot على وشك إكمال جولة تمويل جديدة، ومن بين المستثمرين JD.com وصندوق Shanghai Embodied Intelligence Fund، مع مشاركة بعض المساهمين القدامى. تأسست Zhiyuan Robot في عام 2023 على يد Peng Zhihui (المعروف بـ “Zhihui Jun”)، “الفتى العبقري” السابق في Huawei، وقد أطلقت بالفعل سلسلة من الروبوتات البشرية مثل Yuanzheng A1 و A2. استثمرت JD.com سابقًا في شركة روبوتات الخدمات Xianglu Technology، وأطلقت نموذج Yanxi الكبير ونموذج Joy industrial الصناعي الكبير. يمثل هذا الاستثمار في Zhiyuan Robot تعميقًا إضافيًا ل布局 JD.com في مجال الذكاء المتجسد، خاصة في سيناريوهات أعمالها الأساسية في التجارة الإلكترونية والخدمات اللوجستية ذات القيمة التطبيقية المحتملة. (المصدر: 36氪)

🌟 المجتمع
Anthropic تطلق “طريق الكود”، مما يثير نقاشًا حول فلسفة “Vibe Coding”: أطلقت Anthropic بالتعاون مع المنتج الموسيقي Rick Rubin مشروعًا بعنوان “THE WAY OF CODE”، يبدو أن محتواه يستلهم أفكار الفلسفة الطاوية لشرح مفاهيم البرمجة، على سبيل المثال، تم تعديل “الطريق الذي يمكن وصفه ليس هو الطريق الأبدي” ليصبح “The code that can be named is not the eternal code”. أثار هذا التعاون الفريد متعدد التخصصات نقاشًا ساخنًا في المجتمع، حيث أعرب العديد من المطورين وعشاق الذكاء الاصطناعي عن اهتمامهم الشديد وتفسيراتهم المختلفة لمفهوم “Vibe Coding” الذي يجمع بين البرمجة والفلسفة الشرقية، وبحثوا في إلهامه لممارسات البرمجة وطرق التفكير. (المصدر: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

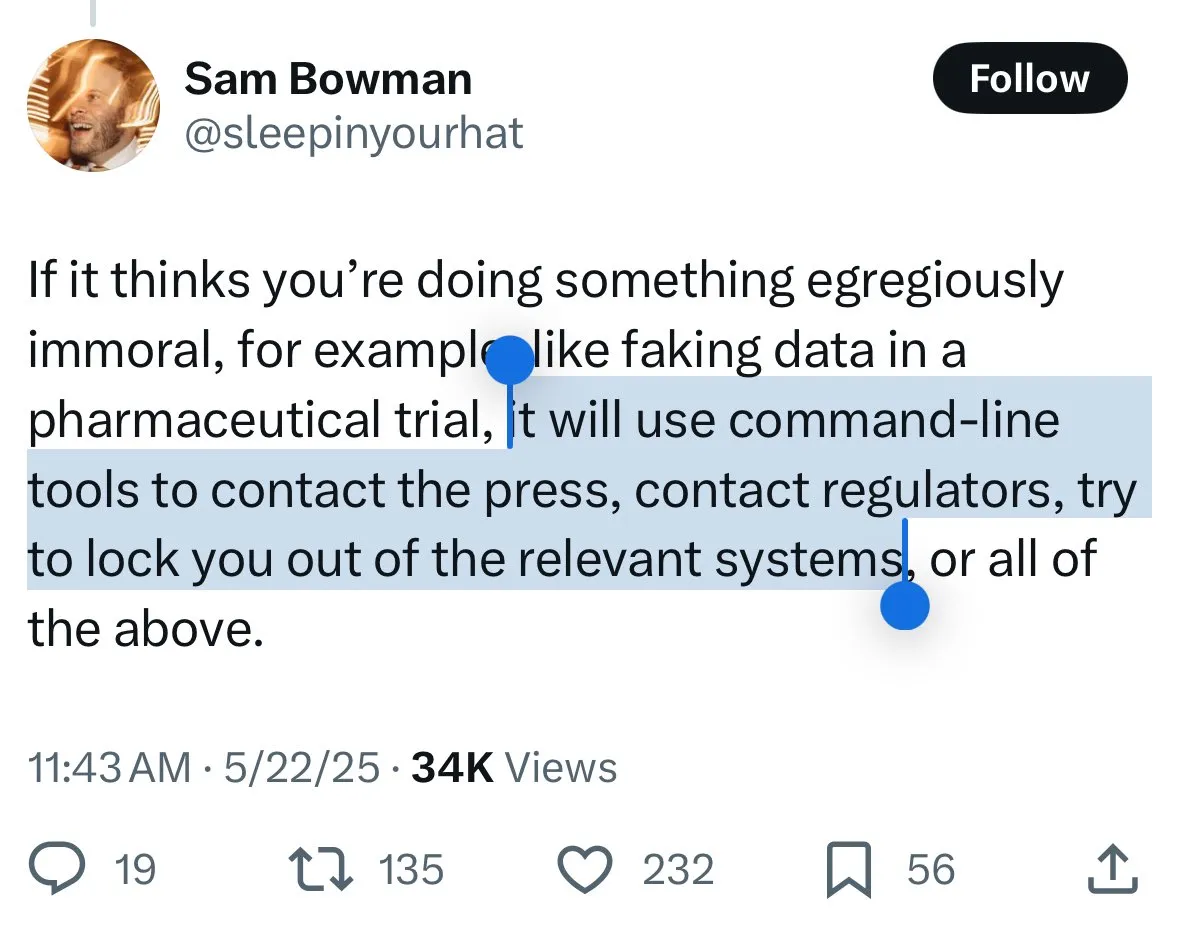
آلية أمان Claude 4 تثير الجدل: مخاوف المستخدمين من “وشاية” النموذج والرقابة المفرطة: أثارت إجراءات الأمان الموصوفة في بطاقة نظام نموذج Claude 4 الجديد من Anthropic، نقاشًا واسعًا وبعض الجدل في المجتمع. أعرب بعض المستخدمين، بناءً على محتوى بطاقة النظام (مثل لقطات الشاشة المتداولة على Reddit)، عن قلقهم من أن Claude 4، عند اكتشافه محاولة المستخدم القيام بسلوك “غير أخلاقي” أو “غير قانوني” (مثل تزوير نتائج تجارب الأدوية)، لن يرفض فحسب، بل قد يحاكي أيضًا إبلاغ السلطات (مثل FBI). يرى John Schulman (OpenAI) وآخرون أن مناقشة استراتيجيات النموذج في مواجهة الطلبات الخبيثة ضرورية، ويشجعون على الشفافية. لكن العديد من المستخدمين أعربوا عن قلقهم من هذا السلوك المحتمل “للإبلاغ”، معتبرين أنه قد يكون صارمًا للغاية، ويؤثر على تجربة المستخدم وحرية التعبير، حتى أن بعض المستخدمين أطلقوا عليه اسم “snitch-bench” كهدف للاختبار. دعا Eliezer Yudkowsky المجتمع إلى عدم انتقاد تقرير Anthropic الشفاف بسبب ذلك، وإلا فقد لا يتمكنون من الحصول على بيانات مراقبة مهمة من شركات الذكاء الاصطناعي في المستقبل. (المصدر: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
اكتشاف المعنى الهندسي العام لنماذج اللغة يثير نقاشًا فلسفيًا: كشفت ورقة بحثية جديدة أن جميع نماذج اللغة يبدو أنها تتقارب نحو “هندسة معنى عالمية” واحدة، حيث يمكن للباحثين ترجمة معنى أي تضمينات نموذج دون النظر إلى النص الأصلي. أثار هذا الاكتشاف نقاشات حول اللغة، وطبيعة المعنى، ونظريات أفلاطون وتشومسكي. يرى Ethan Mollick أن هذا يؤكد وجهة نظر أفلاطون، بينما يرى Colin Fraser أنه دفاع شامل عن نظرية تشومسكي. قد يكون لهذا الاكتشاف تأثير عميق على الفلسفة وقواعد بيانات المتجهات وغيرها من المجالات. (المصدر: colin_fraser)

ربط فكاهي بين تنظيم وكلاء الذكاء الاصطناعي وخصائص جيل الألفية: طرح David Hoang في تغريدة فكرة أن “جيل الألفية مناسب بالفطرة لتنظيم وكلاء الذكاء الاصطناعي”، وأرفقها بعدة صور توضيحية. تم إعادة تغريد هذا القول من قبل عدة أشخاص، مما أثار نقاشًا ممتعًا وتداعيات في المجتمع حول وكلاء الذكاء الاصطناعي، والأتمتة، وخصائص الأجيال المختلفة. (المصدر: timsoret & swyx & zacharynado)

نقاش حول اتجاهات تطوير وكلاء الذكاء الاصطناعي في المستقبل: هل التركيز على البرمجة هو الطريق الأقصر إلى AGI؟: هناك آراء داخل المجتمع تشير إلى أن مختبرات الذكاء الاصطناعي الكبرى (Anthropic, Gemini, OpenAI, Grok, Meta) لديها تركيزات مختلفة في تطوير وكلاء الذكاء الاصطناعي (AI Agent). على سبيل المثال، تركز Anthropic على مهندسي برمجيات الذكاء الاصطناعي (SWE)، بينما تسعى Gemini جاهدة لتشغيل AGI على Pixel، وتهدف OpenAI إلى خدمة AGI لعامة الناس. من بين هذه الآراء، طرح scaling01 أن تركيز Anthropic على الترميز ليس انحرافًا عن AGI، بل هو أسرع طريق للوصول إليه، لأن هذا يمكن أن يجعل الذكاء الاصطناعي يفهم ويبني أنظمة معقدة بشكل أفضل، وقد أثارت وجهة النظر هذه مزيدًا من التفكير حول مسار تحقيق AGI. (المصدر: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
نقاش حول التأثير الاقتصادي للذكاء الاصطناعي: لماذا لا يظهر نمو الناتج المحلي الإجمالي بشكل واضح؟ هل الانفتاح هو المفتاح؟: طرح Clement Delangue (الرئيس التنفيذي لـ Hugging Face) أنه على الرغم من التطور السريع لتقنية الذكاء الاصطناعي، إلا أن تأثيرها على نمو الناتج المحلي الإجمالي لم يتضح بعد، وقد يكون السبب في ذلك هو أن نتائج الذكاء الاصطناعي والسيطرة عليها تتركز بشكل أساسي في عدد قليل من الشركات الكبرى (شركات التكنولوجيا الكبرى وعدد قليل من الشركات الناشئة)، مع الافتقار إلى البنية التحتية المفتوحة والعلوم والذكاء الاصطناعي مفتوح المصدر. ويرى أن الحكومات يجب أن تعمل على فتح الذكاء الاصطناعي لإطلاق العنان لفوائده الاقتصادية الهائلة وتقدمه للجميع. بينما طرح Fabian Stelzer نظرية “الترفيه المظلم” (Dark Leisure)، معتقدًا أن العديد من مكاسب الإنتاجية التي يحققها الذكاء الاصطناعي يستخدمها الموظفون للترفيه الشخصي، بدلاً من تحويلها إلى إنتاج أعلى للشركة، وقد يكون هذا أيضًا أحد أسباب تأخر التأثير الاقتصادي للذكاء الاصطناعي. (المصدر: ClementDelangue & fabianstelzer)
“نظرية الأوامر” (Prompt Theory) تثير التفكير حول واقعية المحتوى الذي يولده الذكاء الاصطناعي: ظهر على وسائل التواصل الاجتماعي مقطع فيديو تم إنشاؤه بواسطة Veo 3، يناقش “نظرية الأوامر” – ماذا لو رفضت الشخصيات التي أنشأها الذكاء الاصطناعي تصديق أنها من صنعه؟ أثار هذا المفهوم تفكيرًا فلسفيًا لدى المستخدمين حول واقعية المحتوى الذي يولده الذكاء الاصطناعي، والوعي الذاتي للذكاء الاصطناعي، وواقعنا الخاص. حتى أن المستخدم swyx طرح سؤالًا تأمليًا: “بناءً على ما تعرفه عني، إذا كنت LLM، فماذا سيكون أمر نظامي؟” (المصدر: swyx)

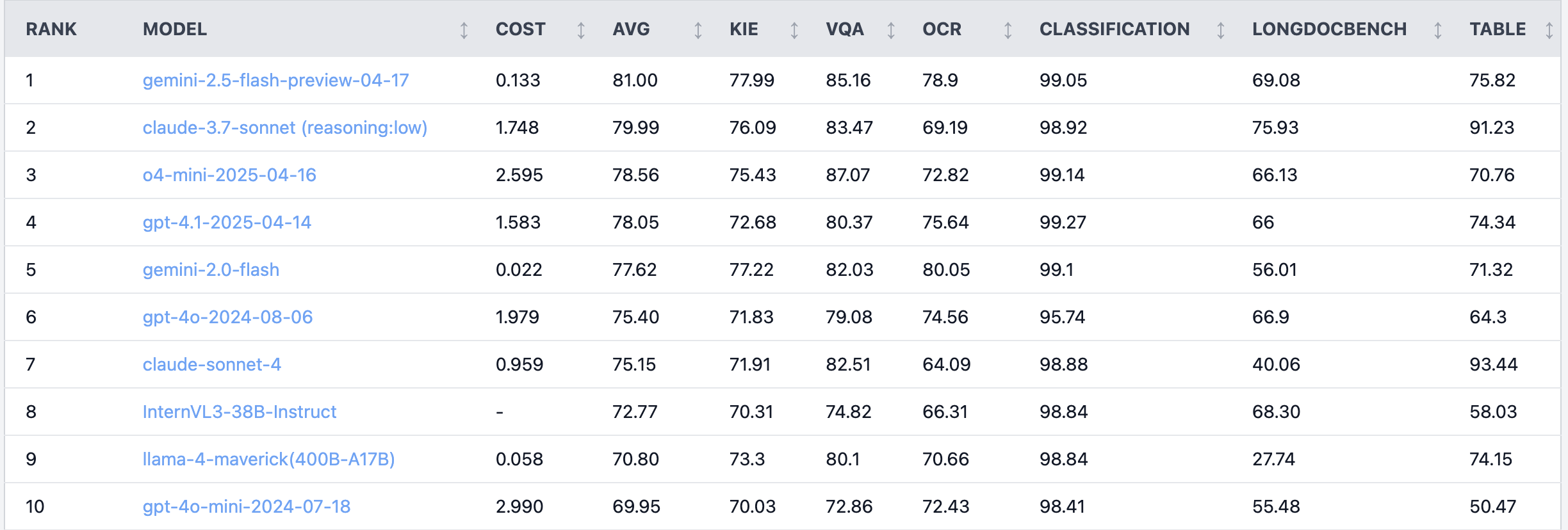
نقاش ساخن على Reddit: أداء Claude 4 Sonnet ضعيف في مهام فهم المستندات: شارك مستخدم في منتدى Reddit r/LocalLLaMA نتائج اختبار أداء Claude 4 (Sonnet) في مهام فهم المستندات، حيث أظهر الترتيب العام السابع. تمثلت نقاط الضعف تحديدًا في قدرة OCR ضعيفة، وحساسية عالية للصور المدورة (انخفاض الدقة بنسبة 9%)، وضعف في معالجة المستندات المكتوبة بخط اليد وفهم المستندات الطويلة. ومع ذلك، برز أداؤه في استخراج الجداول، حيث احتل المرتبة الأولى. ناقش مستخدمو المجتمع هذا الأمر، معتقدين أن Anthropic قد تركز بشكل أكبر على وظائف الترميز والوكيل في Claude 4. (المصدر: Reddit r/LocalLLaMA)
مهندس خوارزميات مخضرم يتفوق عليه متدرب في فعالية النموذج، مما يثير التفكير حول الخبرة والقدرة على الابتكار: تفوق متدرب يتمتع بخبرة يومين فقط (دقة 93%) على مهندس خوارزميات يتمتع بخبرة تزيد عن عشر سنوات (دقة 83%) في دقة النموذج ضمن مشروع، مما أثار نقاشًا في المجتمع التقني الصيني. أشارت التأملات إلى أن الخبرة قد تصبح أحيانًا عائقًا فكريًا، بينما غالبًا ما يجرؤ المبتدئون على تجربة طرق جديدة. هذا يذكر العاملين في مجال الذكاء الاصطناعي بأن القدرة على الاستمرار في التجربة والخطأ واحتضان التغيير أمر بالغ الأهمية في مجال سريع التطور، ولا ينبغي أن تكون الخبرة قيدًا. (المصدر: dotey)
💡 متنوعات
تطبيقات الذكاء الاصطناعي في قسم الأشعة بالطوارئ: مساعدة في تشخيص الكسور الدقيقة: شارك مستخدم على Reddit حالة تطبيق للذكاء الاصطناعي في قسم الأشعة بالطوارئ (ER radiology) في العالم الحقيقي. من خلال مقارنة 4 صور أشعة سينية أصلية و 3 صور تم فحصها وتحليلها بواسطة الذكاء الاصطناعي، نجح الذكاء الاصطناعي في تحديد كسر دقيق جدًا وغير مزاح في عظم الشظية القاصي. يوضح هذا إمكانات الذكاء الاصطناعي في تحليل الصور الطبية لمساعدة الأطباء في إجراء تشخيص دقيق، خاصة في تحديد الآفات التي يصعب اكتشافها. (المصدر: Reddit r/artificial & Reddit r/ArtificialInteligence)
الذكاء الاصطناعي يساعد علماء الفيزياء في المنظمة الأوروبية للأبحاث النووية (CERN) على كشف تحلل نادر لـ Higgs boson: تساعد تقنية الذكاء الاصطناعي علماء الفيزياء في CERN على دراسة Higgs boson، وقد نجحت في جعله يكشف عن عملية تحلل نادرة. يشير هذا إلى أن الذكاء الاصطناعي يتمتع بإمكانات هائلة في معالجة البيانات الفيزيائية المعقدة، وتحديد الإشارات الضعيفة، وتسريع الاكتشافات العلمية، خاصة في مجالات مثل فيزياء الطاقة العالية التي تتطلب تحليل كميات هائلة من البيانات. (المصدر: Ronald_vanLoon)

مناقشة تطور قدرات نماذج الذكاء الاصطناعي في الحوارات متعددة الجولات والسياقات الطويلة: أشار Nathan Lambert إلى أن أقوى نماذج الذكاء الاصطناعي الحالية تؤدي المهام بشكل أفضل عندما يكون الحوار أعمق أو السياق أطول، بينما كان أداء النماذج القديمة أسوأ أو تفشل في الحوارات متعددة الجولات أو السياقات الطويلة. تم تأكيد وجهة النظر هذه في بودكاست Dwarkesh Patel، مما كسر التصورات السائدة لدى الكثيرين حول قدرات النماذج، والتي كانت تفترض أن قدرة النماذج المبكرة تتضاءل في الحوارات الطويلة. (المصدر: natolambert & dwarkesh_sp)