
كلمات مفتاحية:جيميني 2.5 برو, فيو 3, أوبن إيه آي, جوني آيف, كلود 4 أوبوس, توليد فيديو بالذكاء الاصطناعي, وكلاء الذكاء الاصطناعي, نماذج متعددة الوسائط, وضع التفكير العميق, نماذج توليد الفيديو, قدرات الاستدلال بالذكاء الاصطناعي, تصميم أجهزة الذكاء الاصطناعي, تحسين هندسة البرمجيات
🔥 أبرز العناوين
جوجل تطلق Gemini 2.5 Pro Deep Think و Veo 3، مما يدفع بالاستدلال في الذكاء الاصطناعي وتوليد الفيديو إلى آفاق جديدة: في مؤتمر Google I/O، أطلقت جوجل وضع Deep Think لـ Gemini 2.5 Pro، وهو وضع مصمم خصيصًا لحل المشكلات المعقدة، وقد أظهر أداءً متميزًا في المسائل الصعبة لمسابقات الرياضيات مثل USAMO، مما يبرهن على التقدم الكبير للذكاء الاصطناعي في مجال الاستدلال المتقدم، على سبيل المثال، من خلال الاستدلال متعدد الخطوات وتجربة طرق إثبات مختلفة (مثل البرهان بالتناقض، نظرية رول) لحل مسائل الجبر المعقدة. في الوقت نفسه، فإن نموذج توليد الفيديو Veo 3 الذي أطلقته جوجل، بفضل مشاهده الواقعية، واتساق الشخصيات القابل للتحكم، وتركيب الصوت، ووظائف التحرير المتنوعة (مثل تحويل المشاهد، وتوليد الصور المرجعية، ونقل الأسلوب، وتحديد الإطارات الأولى والأخيرة، والتحرير الجزئي، وما إلى ذلك)، قد وضع معيارًا جديدًا في مجال توليد الفيديو بالذكاء الاصطناعي، مما أثار اهتمامًا واسع النطاق (المصدر: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI تستثمر 6.5 مليار دولار للاستحواذ على شركة Jony Ive، للتعاون في إنشاء جيل جديد من أجهزة الكمبيوتر المدعومة بالذكاء الاصطناعي: أعلنت OpenAI عن تعاونها مع المصمم الرئيسي السابق لشركة آبل Jony Ive، واستحواذها على شركته، بهدف مشترك هو بناء جيل جديد من أجهزة الكمبيوتر المدعومة بالذكاء الاصطناعي. تشير هذه الخطوة إلى توسع OpenAI في مجال الأجهزة ومحاولتها دمج قدرات الذكاء الاصطناعي بعمق في أجهزة الحوسبة، مما قد يعيد تشكيل طرق التفاعل بين الإنسان والآلة. يشتهر Jony Ive بتصاميمه المتميزة خلال فترة عمله في آبل، ويشير انضمامه إلى أن الأجهزة الجديدة قد تشهد طفرة كبيرة في التصميم وتجربة المستخدم، مما يشكل تحديًا لأشكال أجهزة الحوسبة الحالية (المصدر: op7418, TheRundownAI, BorisMPower)
مؤتمر مطوري Anthropic على وشك الانعقاد، واحتمالية إطلاق Claude 4 Opus، مع التركيز على قدرات هندسة البرمجيات: توشك Anthropic على عقد أول مؤتمر للمطورين، ويتوقع المجتمع على نطاق واسع أن يتم إطلاق الجيل الجديد من نماذج Claude 4 (بما في ذلك Sonnet 4 و Opus 4) في هذا المؤتمر. هناك دلائل تشير إلى أن Claude Sonnet 3.7 API قد أظهر سلوكًا مشابهًا لـ Claude 4، مثل استخدام الأدوات بسرعة دون الحاجة إلى “خطوات تفكير”. يبدو أن Anthropic تركز جهودها على التغلب على تحديات هندسة البرمجيات، وهو مسار يختلف عن سعي OpenAI وجوجل نحو “النماذج الشاملة”. كما أكدت مجلة TIME بشكل غير مباشر إطلاق Claude 4 Opus، مما زاد من توقعات السوق بشأن قدرات Anthropic في مجال ترميز الذكاء الاصطناعي ومعالجة المهام المعقدة (المصدر: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
الاختلافات في استراتيجية النظام البيئي للذكاء الاصطناعي بين OpenAI وجوجل: تجميع سفينة حربية مقابل تحديث إمبراطورية: تسعى كل من OpenAI وجوجل، عبر مسارين مختلفين هما “تجميع النظام البيئي” و “تحديث النظام البيئي”، إلى السيطرة على مكانة “نظام التشغيل الرئيسي” لمنصات الذكاء الاصطناعي المستقبلية. تقوم OpenAI بتجميع قدرات الذكاء الاصطناعي المتكاملة من الصفر من خلال الاستحواذ على الأجهزة (io)، وقواعد البيانات (Rockset)، وسلاسل الأدوات (Windsurf)، وأدوات التعاون (Multi)، وغيرها. بينما تختار جوجل دمج نموذجها Gemini بعمق في منتجاتها الحالية (البحث، أندرويد، Docs، يوتيوب، إلخ)، وتحديث أنظمتها الأساسية لتحقيق تكامل أصلي للذكاء الاصطناعي. على الرغم من اختلاف استراتيجياتهما، إلا أن هدفهما واحد، وهو بناء المنصة النهائية لعصر الذكاء الاصطناعي (المصدر: dotey)
🎯 الاتجاهات
مايكروسوفت تكشف عن رؤيتها لـ “شبكة الوكلاء الأذكياء”، مؤكدة أن وكلاء الذكاء الاصطناعي سيصبحون جوهر العمل المستقبلي: أوضح الرئيس التنفيذي لشركة مايكروسوفت Satya Nadella في مؤتمر Build 2025 وفي مقابلات رؤية الشركة لـ “شبكة الوكلاء الأذكياء (agentic web)”. يعتقد أن وكلاء الذكاء الاصطناعي المستقبليين سيصبحون مواطنين من الدرجة الأولى في النظام البيئي للأعمال و M365، بل وقد يؤدون إلى ظهور مهن جديدة مثل “مدير وكلاء الذكاء الاصطناعي”. عندما يتم إنشاء 95% من التعليمات البرمجية بواسطة الذكاء الاصطناعي، سيتحول دور البشر إلى إدارة وتنسيق هؤلاء الوكلاء. تعمل مايكروسوفت على بناء نظام بيئي مفتوح للوكلاء من خلال Azure AI Foundry و Copilot Studio وبروتوكولات مفتوحة مثل NLWeb، وستحول Teams إلى مركز تعاون متعدد الوكلاء (المصدر: rowancheung, TheTuringPost)
MMaDA: إطلاق نموذج لغة انتشار متعدد الوسائط يوحد الاستدلال النصي والفهم متعدد الوسائط وتوليد الصور: قدم باحثون MMaDA (Multimodal Large Diffusion Language Models)، وهو نوع جديد من نماذج الانتشار الأساسية متعددة الوسائط، والذي يحقق توحيد قدرات الاستدلال النصي والفهم متعدد الوسائط وتوليد الصور من خلال سلسلة التفكير الطويلة المختلطة (Mixed Long-CoT) وخوارزمية التعلم المعزز الموحدة UniGRPO. يتفوق MMaDA-8B على Show-o و SEED-X في الفهم متعدد الوسائط، ويتفوق على SDXL و Janus في تحويل النص إلى صورة، وقد تم توفير النموذج والتعليمات البرمجية مفتوحة المصدر على Hugging Face (المصدر: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: تصميم آلية تخزين مؤقت لنماذج لغة الانتشار، مما يعزز سرعة الاستدلال بشكل كبير: لمواجهة مشكلة بطء سرعة الاستدلال في نماذج لغة الانتشار (DLMs)، اقترح باحثون آلية dKV-Cache. تستلهم هذه الطريقة من KV-Cache في النماذج ذاتية الانحدار، وتقوم بتصميم ذاكرة تخزين مؤقت للقيم الرئيسية لعملية إزالة الضوضاء في DLMs من خلال استراتيجيات التخزين المؤقت المتأخر والمشروط. أظهرت التجارب أن dKV-Cache يمكن أن يحقق تسريعًا في الاستدلال بمقدار 2-10 مرات، مما يقلل بشكل كبير من الفجوة في السرعة بين DLMs والنماذج ذاتية الانحدار، بل ويحسن الأداء في التسلسلات الطويلة، ويمكن تطبيقه على DLM الحالية دون تدريب (المصدر: NandoDF, HuggingFace Daily Papers)

Imagen4 يظهر أداءً متميزًا في استعادة التفاصيل، مقتربًا من نهاية لعبة توليد الصور: أظهر نموذج Imagen4 قدرة قوية على استعادة التفاصيل عند توليد صور بناءً على مطالبات نصية معقدة. على سبيل المثال، عند توليد صورة تحتوي على 25 تفصيلاً محددًا (مثل ألوان معينة، وأشياء، ومواقع، وإضاءة، وأجواء)، نجح Imagen4 في استعادة 23 منها. تشير هذه الدقة العالية والفهم الدقيق للتعليمات المعقدة إلى أن تقنية تحويل النص إلى صورة تقترب من مستوى “نهاية اللعبة” القادر على إعادة إنتاج خيال المستخدم بشكل مثالي (المصدر: cloneofsimo)

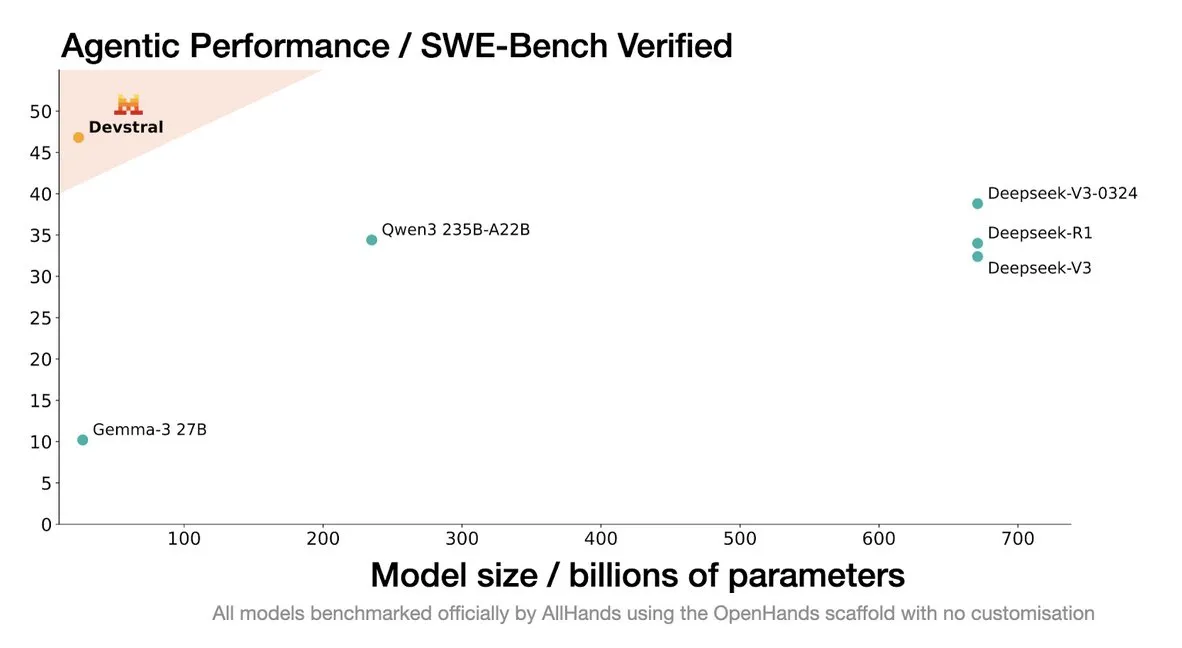
Mistral تطلق نموذج Devstral، المصمم خصيصًا لوكلاء الترميز: أطلقت Mistral AI نموذج Devstral، وهو نموذج مفتوح المصدر مصمم خصيصًا لوكلاء الترميز، وتم تطويره بالتعاون مع allhands_ai. تم إطلاق نسخته الكمومية 4-bit DWQ على Hugging Face (mlx-community/Devstral-Small-2505-4bit-DWQ)، ويمكن تشغيلها بسلاسة على أجهزة مثل M2 Ultra، مما يظهر إمكانات محسنة في توليد وفهم التعليمات البرمجية (المصدر: awnihannun, clefourrier, GuillaumeLample)
بايت دانس تنشر تقرير تدريب نموذج متعدد الوسائط من فئة Gemini، يعتمد على بنية Transformer متكاملة: كشفت بايت دانس عن تقرير من 37 صفحة يفصل طريقتها في تدريب نموذج متعدد الوسائط أصلي من فئة Gemini. أبرز ما في التقرير هو بنية “Transformer المتكامل” (Integrated Transformer)، والتي تستخدم نفس الشبكة الأساسية كنموذج ذاتي الانحدار من فئة GPT ونموذج انتشار من فئة DiT في نفس الوقت، مما يظهر استكشافها في النمذجة الموحدة متعددة الوسائط (المصدر: NandoDF)

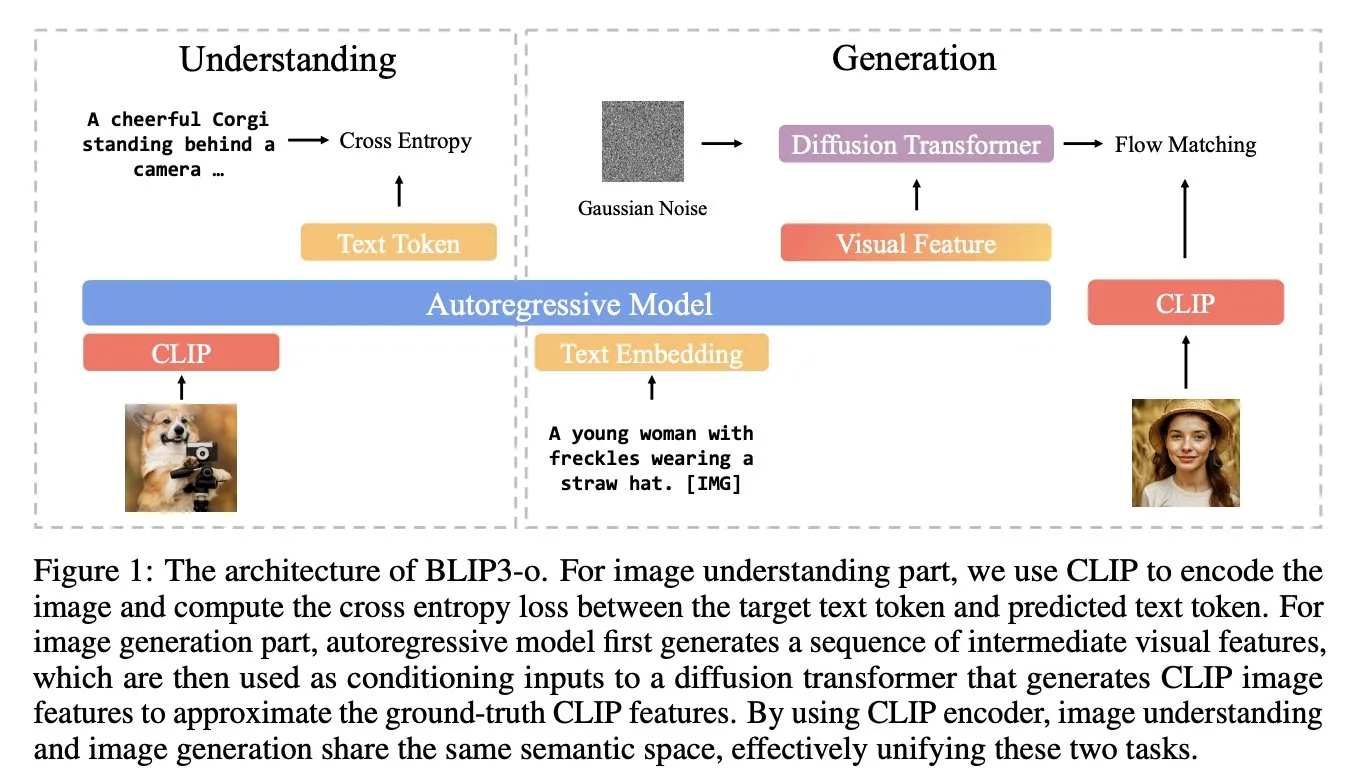
BLIP3-o: Salesforce تطلق سلسلة نماذج متعددة الوسائط موحدة ومفتوحة المصدر بالكامل، مما يفتح الباب أمام قدرات توليد صور من فئة GPT-4o: أطلق فريق أبحاث Salesforce سلسلة نماذج BLIP3-o، وهي مجموعة من النماذج متعددة الوسائط الموحدة والمفتوحة المصدر بالكامل، تهدف إلى محاولة فتح قدرات توليد صور مشابهة لـ GPT-4o. لم يقتصر المشروع على توفير النماذج مفتوحة المصدر فحسب، بل كشف أيضًا عن مجموعة بيانات تدريب مسبق تحتوي على 25 مليون بيان، مما يدفع بانفتاح أبحاث الوسائط المتعددة (المصدر: arankomatsuzaki)
جوجل تطلق نسخة معاينة Gemma 3n E4B، نموذج متعدد الوسائط مصمم للأجهزة منخفضة الموارد: أطلقت جوجل نموذج Gemma 3n E4B-it-litert-preview على Hugging Face. تم تصميم هذا النموذج لمعالجة مدخلات النصوص والصور ومقاطع الفيديو والصوت، وتوليد مخرجات نصية، ويدعم الإصدار الحالي مدخلات النصوص والمرئيات. يعتمد Gemma 3n على بنية Matformer المبتكرة، والتي تسمح بتضمين نماذج متعددة وتنشيط معلمات 2B أو 4B بشكل فعال، وهو مُحسَّن خصيصًا للتشغيل الفعال على الأجهزة منخفضة الموارد. تم تدريب النموذج على حوالي 11 تريليون رمز مميز من البيانات متعددة الوسائط، وتصل معرفته حتى يونيو 2024 (المصدر: Tim_Dettmers, Reddit r/LocalLLaMA)
دراسة تكشف عن ظاهرة المعرفة الخاصة باللغة (LSK) في النماذج الكبيرة: تستكشف دراسة جديدة ظاهرة “المعرفة الخاصة باللغة” (Language Specific Knowledge, LSK) الموجودة في نماذج اللغة، أي أن أداء النموذج في معالجة بعض الموضوعات أو المجالات قد يكون أفضل في لغة معينة غير الإنجليزية مقارنة بالإنجليزية. وجدت الدراسة أنه من خلال إجراء استدلال سلسلة التفكير بلغة معينة (حتى لو كانت لغة منخفضة الموارد)، يمكن تحسين أداء النموذج. يشير هذا إلى أن النصوص الخاصة بالثقافة تكون أكثر ثراءً في اللغة المقابلة، مما يجعل المعرفة المحددة قد توجد فقط في اللغات “الخبيرة”. صمم الباحثون طريقة LSKExtractor لقياس واستخدام هذه المعرفة الخاصة باللغة، وحققوا تحسنًا نسبيًا في متوسط الدقة بنسبة 10% عبر نماذج ومجموعات بيانات متعددة (المصدر: HuggingFace Daily Papers)
تأثيرات توليد الفيديو المذهلة لـ DeepMind Veo 3، تفاصيل واقعية تثير الاهتمام: أظهر نموذج توليد الفيديو Veo 3 من Google DeepMind قدرات قوية في توليد الفيديو، بما في ذلك تحويل المشاهد، والقيادة بالصور المرجعية، ونقل الأسلوب، واتساق الشخصيات، وتحديد الإطارات الأولى والأخيرة، وتكبير الفيديو، وإضافة الكائنات، والتحكم في الحركة. إن واقعية مقاطع الفيديو التي تم إنشاؤها وقدرتها على فهم التعليمات المعقدة جعلت المستخدمين يشيدون بالتطور السريع لتقنية توليد الفيديو بالذكاء الاصطناعي، حتى أن بعض المستخدمين استخدموها لإنتاج إعلانات تجارية تضاهي جودة الإنتاج الاحترافي (المصدر: demishassabis, , Reddit r/ChatGPT)
نموذج اللغة المرئية Moondream يطلق نسخة كمومية 4 بت، مما يقلل بشكل كبير من ذاكرة الوصول العشوائي للفيديو ويزيد السرعة: أصدر نموذج اللغة المرئية Moondream (VLM) نسخة كمومية 4 بت، مما أدى إلى تقليل استهلاك ذاكرة الوصول العشوائي للفيديو بنسبة 42% وزيادة سرعة الاستدلال بنسبة 34%، مع الحفاظ على دقة بنسبة 99.4%. هذا التحسين يجعل هذا النموذج الصغير والقوي VLM أسهل في النشر والاستخدام في مهام مثل اكتشاف الكائنات، وقد لقي ترحيبًا من المطورين (المصدر: Sentdex, vikhyatk)
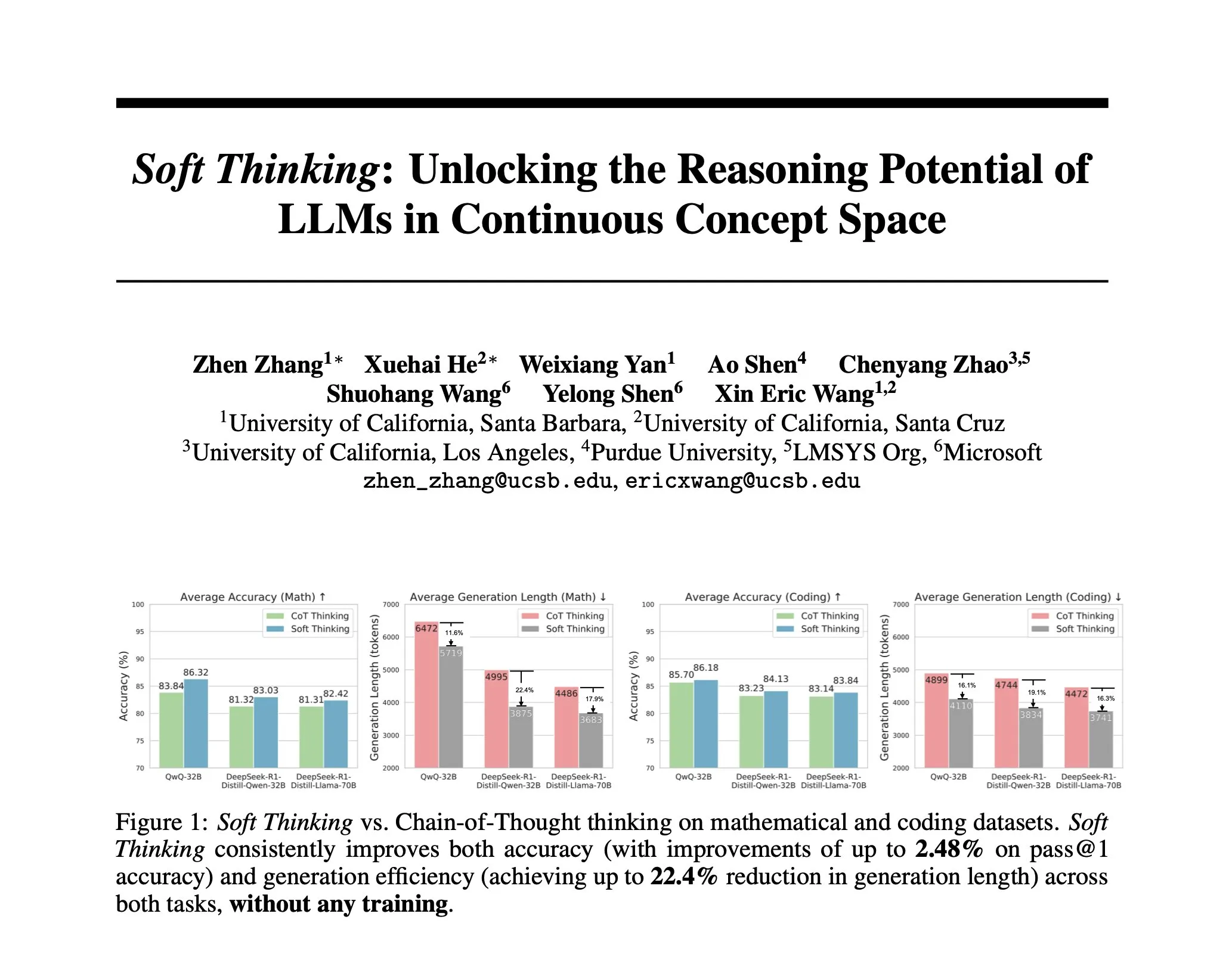
دراسة تقترح Soft Thinking: طريقة بدون تدريب لمحاكاة الاستدلال “الناعم” البشري: لجعل استدلال الذكاء الاصطناعي أقرب إلى التفكير البشري السلس، وغير مقيد بالرموز المنفصلة، اقترح باحثون طريقة Soft Thinking. لا تتطلب هذه الطريقة تدريبًا إضافيًا، فمن خلال توليد رموز مفاهيمية مستمرة ومجردة، يتم دمج هذه الرموز بسلاسة مع معانٍ متعددة من خلال مزيج من التضمينات المرجحة احتماليًا، وبالتالي تحقيق تمثيل أكثر ثراءً واستكشاف سلس لمسارات استدلال مختلفة. أظهرت التجارب أن هذه الطريقة تحسن الدقة في اختبارات الرياضيات والتعليمات البرمجية بنسبة تصل إلى 2.48% (pass@1)، مع تقليل استخدام الرموز بنسبة تصل إلى 22.4% (المصدر: arankomatsuzaki)
إطار عمل IA-T2I: استخدام الإنترنت لتعزيز قدرة نماذج تحويل النص إلى صورة على معالجة المعرفة غير المؤكدة: لمواجهة أوجه القصور في نماذج تحويل النص إلى صورة الحالية في معالجة المطالبات النصية التي تحتوي على معرفة غير مؤكدة (مثل الأحداث الحديثة والمفاهيم النادرة)، تم اقتراح إطار عمل IA-T2I (Internet-Augmented Text-to-Image Generation). يحدد هذا الإطار، من خلال وحدة استرجاع نشطة، ما إذا كانت هناك حاجة إلى صور مرجعية، ويستخدم وحدة اختيار صور هرمية لاختيار أنسب الصور من نتائج محرك البحث لتعزيز نموذج T2I، ويقوم بتقييم وتحسين الصور المولدة باستمرار من خلال آلية تفكير ذاتي. على مجموعة بيانات Img-Ref-T2I المصممة خصيصًا، تفوق IA-T2I على GPT-4o بحوالي 30% (تقييم بشري) (المصدر: HuggingFace Daily Papers)
MoI (Mixture of Inputs) يحسن جودة التوليد الذاتي الانحدار وقدرة الاستدلال: لحل مشكلة تجاهل معلومات توزيع الرموز في عملية التوليد الذاتي الانحدار القياسية، اقترح باحثون طريقة Mixture of Inputs (MoI). لا تتطلب هذه الطريقة تدريبًا إضافيًا، فبعد توليد رمز واحد، تقوم بخلط الرمز المنفصل الذي تم إنشاؤه مع توزيع الرموز الذي تم تجاهله سابقًا لإنشاء مدخل جديد. من خلال التقدير البايزي، يُنظر إلى توزيع الرموز على أنه سابق، ويُنظر إلى الرمز المُعاير على أنه ملاحظة، ويتم استخدام القيمة المتوقعة اللاحقة المستمرة لاستبدال المتجه التقليدي أحادي الترميز كمدخل جديد للنموذج. أدى MoI إلى تحسين مستمر لأداء نماذج متعددة مثل Qwen-32B و Nemotron-Super-49B في مهام الاستدلال الرياضي وتوليد التعليمات البرمجية والأسئلة والأجوبة على مستوى الدكتوراه (المصدر: HuggingFace Daily Papers)
ConvSearch-R1: تحسين إعادة كتابة الاستعلام في البحث الحواري من خلال التعلم المعزز: لمعالجة مشاكل الغموض والإغفال والإشارة في الاستعلامات المعتمدة على السياق في البحث الحواري، تم اقتراح إطار عمل ConvSearch-R1. يعتمد هذا الإطار لأول مرة على طريقة ذاتية الدفع، حيث يستخدم التعلم المعزز مباشرة إشارات الاسترجاع لتحسين إعادة كتابة الاستعلام، مما يلغي تمامًا الاعتماد على الإشراف الخارجي لإعادة الكتابة (مثل التسميات اليدوية أو النماذج الكبيرة). تتضمن طريقته المكونة من مرحلتين التسخين المسبق للاستراتيجية ذاتية الدفع والتعلم المعزز الموجه بالاسترجاع (باستخدام آلية مكافأة تحفيزية قائمة على الترتيب). أظهرت التجارب أن ConvSearch-R1 يتفوق بشكل كبير على طرق SOTA السابقة على مجموعتي بيانات TopiOCQA و QReCC (المصدر: HuggingFace Daily Papers)
إطار عمل ASRR يحقق استدلالًا تكيفيًا فعالًا لنماذج اللغة الكبيرة: لمواجهة مشكلة التكاليف الحسابية المفرطة الناتجة عن الاستدلال الزائد في النماذج الاستدلالية الكبيرة (LRMs) في المهام البسيطة، اقترح باحثون إطار عمل الاستدلال الذاتي التكيفي للاسترداد (Adaptive Self-Recovery Reasoning, ASRR). يكشف هذا الإطار عن “آلية الاسترداد الذاتي الداخلية” للنموذج (التي تكمل الاستدلال ضمنيًا في توليد الإجابات)، ويقمع الاستدلال غير الضروري، ويقدم تعديل مكافأة الطول المدرك للدقة، ويخصص جهد الاستدلال بشكل تكيفي وفقًا لصعوبة السؤال. أظهرت التجارب أن ASRR يمكن أن يقلل بشكل كبير من ميزانية الاستدلال ويزيد من معدل عدم الضرر على معايير السلامة مع خسارة أداء ضئيلة للغاية (المصدر: HuggingFace Daily Papers)
إطار عمل MoT (Mixture-of-Thought) يعزز قدرة الاستدلال المنطقي: مستوحى من استخدام البشر لأنماط استدلال متعددة (اللغة الطبيعية، التعليمات البرمجية، المنطق الرمزي) لحل المشكلات المنطقية، اقترح باحثون إطار عمل Mixture-of-Thought (MoT). يمكّن MoT نماذج اللغة الكبيرة (LLM) من الاستدلال عبر ثلاث طرائق تكميلية، بما في ذلك طريقة الرموز الجديدة لجدول الحقيقة. من خلال تصميم من مرحلتين (تدريب MoT ذاتي التطور واستدلال MoT)، يتفوق MoT بشكل كبير على طرق سلسلة التفكير أحادية الطريقة في معايير الاستدلال المنطقي مثل FOLIO و ProofWriter، مع تحسن متوسط الدقة يصل إلى 11.7% (المصدر: HuggingFace Daily Papers)
RL Tango: تدريب مشترك للمولد والمحقق من خلال التعلم المعزز لتعزيز الاستدلال اللغوي: لمعالجة مشاكل اختراق المكافآت وضعف التعميم في طرق التعلم المعزز الحالية لنماذج اللغة الكبيرة (LLM) حيث يكون المحقق (نموذج المكافأة) ثابتًا أو يتم ضبطه بدقة تحت الإشراف، تم اقتراح إطار عمل RL Tango. يقوم هذا الإطار بتدريب مولد LLM ومحقق LLM توليدي على مستوى العملية بشكل متزامن ومتداخل من خلال التعلم المعزز. يتم تدريب المحقق فقط بناءً على مكافأة التحقق من صحة النتائج، دون الحاجة إلى تسميات على مستوى العملية، وبالتالي يشكل تعزيزًا متبادلًا فعالًا مع المولد. أظهرت التجارب أن مولد ومحقق Tango يحققان مستوى SOTA في نماذج بحجم 7B/8B (المصدر: HuggingFace Daily Papers)
pPE: هندسة المطالبات المسبقة تدعم الضبط الدقيق المعزز (RFT): تستكشف دراسة دور هندسة المطالبات المسبقة (prior prompt engineering, pPE) في الضبط الدقيق المعزز (RFT). على عكس هندسة المطالبات وقت الاستدلال (iPE)، تقوم pPE بوضع التعليمات (مثل الاستدلال خطوة بخطوة) قبل الاستعلام في مرحلة التدريب، لتوجيه نموذج اللغة لاستيعاب سلوكيات محددة. طبقت التجارب خمس استراتيجيات iPE (الاستدلال، التخطيط، استدلال التعليمات البرمجية، استدعاء المعرفة، استخدام الأمثلة الفارغة) كطرق pPE على Qwen2.5-7B. أظهرت النتائج أن جميع نماذج pPE المدربة تفوقت على نماذج iPE المقابلة، حيث حققت pPE للأمثلة الفارغة أكبر تحسن على معايير مثل AIME2024 و GPQA-Diamond، مما يكشف عن pPE كوسيلة فعالة لم يتم بحثها بشكل كافٍ في RFT (المصدر: HuggingFace Daily Papers)
BiasLens: إطار عمل لتقييم تحيز نماذج اللغة الكبيرة دون الحاجة إلى مجموعات اختبار يدوية: لمعالجة مشكلة اعتماد طرق تقييم تحيز نماذج اللغة الكبيرة الحالية على بيانات مصنفة يدويًا وتغطيتها المحدودة، تم اقتراح إطار عمل BiasLens. ينطلق هذا الإطار من بنية فضاء المتجهات للنموذج، ويجمع بين متجهات تنشيط المفاهيم (CAVs) وأجهزة التشفير التلقائي المتناثرة (SAEs) لاستخراج تمثيلات مفاهيمية قابلة للتفسير، ويقوم بقياس التحيز من خلال قياس التغير في تشابه التمثيل بين المفاهيم المستهدفة والمفاهيم المرجعية. أظهر BiasLens في حالة عدم وجود بيانات مصنفة توافقًا قويًا مع مقاييس تقييم التحيز التقليدية (ارتباط سبيرمان r > 0.85)، ويمكنه الكشف عن أشكال التحيز التي يصعب اكتشافها بالطرق الحالية (المصدر: HuggingFace Daily Papers)
HumaniBench: إطار عمل لتقييم النماذج الكبيرة متعددة الوسائط يركز على الإنسان: لمواجهة القصور الحالي في أداء النماذج الكبيرة متعددة الوسائط (LMM) في المعايير التي تركز على الإنسان مثل العدالة والأخلاق والتعاطف، تم اقتراح HumaniBench. وهو معيار شامل يتضمن 32 ألف زوج من الأسئلة والأجوبة المصورة من العالم الحقيقي، تم تصنيفها بمساعدة GPT-4o والتحقق منها من قبل خبراء. يقوم HumaniBench بتقييم سبعة مبادئ للذكاء الاصطناعي تركز على الإنسان: العدالة، والأخلاق، والفهم، والاستدلال، والشمول اللغوي، والتعاطف، والمتانة، ويغطي سبع مهام متنوعة. أظهر اختبار 15 نموذجًا من نماذج LMM الرائدة أن النماذج مغلقة المصدر تتفوق بشكل عام، ولكن المتانة وتحديد المواقع المرئية لا تزال نقاط ضعف (المصدر: HuggingFace Daily Papers)
AJailBench: أول معيار شامل لهجمات كسر الحماية على نماذج اللغة الصوتية الكبيرة: لتقييم أمان نماذج اللغة الصوتية الكبيرة (LAMs) بشكل منهجي في مواجهة هجمات كسر الحماية، تم اقتراح AJailBench. قام هذا المعيار أولاً ببناء مجموعة بيانات AJailBench-Base التي تحتوي على 1495 مطالبة صوتية معادية، تغطي 10 فئات من الانتهاكات. أظهر التقييم المستند إلى مجموعة البيانات هذه أن نماذج LAMs الرائدة الحالية لم تظهر أي منها متانة متسقة. لمحاكاة هجمات أكثر واقعية، طور الباحثون مجموعة أدوات اضطراب الصوت (APT)، والتي تبحث عن اضطرابات دقيقة وفعالة من خلال التحسين البايزي، وأنشأوا مجموعة بيانات موسعة AJailBench-APT. أظهرت الدراسة أن الاضطرابات الصغيرة والتي تحافظ على المعنى يمكن أن تقلل بشكل كبير من أداء أمان LAMs (المصدر: HuggingFace Daily Papers)
WebNovelBench: معيار لتقييم قدرة نماذج اللغة الكبيرة على تأليف الروايات الطويلة: لمواجهة تحديات تقييم قدرة نماذج اللغة الكبيرة على السرد الطويل، تم اقتراح WebNovelBench. يستخدم هذا المعيار مجموعة بيانات تضم أكثر من 4000 رواية شبكية صينية، ويحدد التقييم كمهمة توليد قصة من مخطط تفصيلي. من خلال طريقة “LLM كمحكم”، يتم إجراء تقييم تلقائي من ثمانية أبعاد لجودة السرد، ويتم استخدام تحليل المكونات الرئيسية لتجميع الدرجات، ومقارنتها بترتيب مئوي مع الأعمال البشرية. ميزت التجارب بشكل فعال بين روائع الأدب البشري، والروايات الشبكية الشائعة، والمحتوى الذي تم إنشاؤه بواسطة LLM، وقدمت تحليلاً شاملاً لـ 24 نموذجًا من نماذج LLM الرائدة (المصدر: HuggingFace Daily Papers)
MultiHal: مجموعة بيانات متعددة اللغات لرسو خرائط المعرفة لتقييم هلوسة نماذج اللغة الكبيرة: لسد النقص في معايير تقييم الهلوسة الحالية فيما يتعلق بمسارات خرائط المعرفة وتعدد اللغات، تم اقتراح MultiHal. وهو معيار متعدد اللغات ومتعدد القفزات يعتمد على خرائط المعرفة، مصمم خصيصًا لتقييم النصوص المولدة. قام الفريق باستخراج 140 ألف مسار من خرائط المعرفة مفتوحة المجال، وقام بتصفية 25.9 ألف مسار عالي الجودة. أظهر التقييم الأساسي أنه في اللغات المتعددة والنماذج المتعددة، أدى RAG المعزز بخرائط المعرفة (KG-RAG) مقارنة بالأسئلة والأجوبة العادية إلى تحسن مطلق في درجات التشابه الدلالي بحوالي 0.12 إلى 0.36 نقطة، مما يوضح إمكانات تكامل خرائط المعرفة (المصدر: HuggingFace Daily Papers)
Llama-SMoP: طريقة للتعرف على الكلام الصوتي والمرئي لنماذج اللغة الكبيرة تعتمد على مساقط خليط متناثر: لمعالجة مشكلة التكلفة الحسابية العالية لنماذج اللغة الكبيرة في التعرف على الكلام الصوتي والمرئي (AVSR)، تم اقتراح Llama-SMoP. وهو نموذج لغة كبير متعدد الوسائط فعال، يعتمد على وحدة مساقط خليط متناثر (SMoP)، والتي توسع سعة النموذج دون زيادة تكلفة الاستدلال من خلال مساقط خليط خبراء (MoE) ذات بوابات متناثرة. أظهرت التجارب أن تكوين Llama-SMoP DEDR الذي يعتمد على توجيه وخبراء خاصين بالوسائط يحقق أداءً متميزًا في مهام ASR و VSR و AVSR، ويظهر أداءً جيدًا في تنشيط الخبراء وقابلية التوسع والمتانة ضد الضوضاء (المصدر: HuggingFace Daily Papers)
VPRL: إطار عمل تخطيط بصري بحت يعتمد على التعلم المعزز، ويتفوق أداؤه على الاستدلال النصي: اقترح فريق من الباحثين من جامعة كامبريدج وكلية لندن الجامعية وجوجل VPRL (Visual Planning with Reinforcement Learning)، وهو نموذج جديد للاستدلال يعتمد بشكل بحت على تسلسل الصور. يستخدم هذا الإطار تحسين سياسة المجموعة النسبية (GRPO) لتدريب النماذج البصرية الكبيرة لاحقًا، ويحسب إشارات المكافأة ويتحقق من قيود البيئة من خلال تحويلات الحالة البصرية. في مهام الملاحة البصرية مثل FrozenLake و Maze و MiniBehavior، وصلت دقة VPRL إلى 80.6%، متفوقة بشكل كبير على طرق الاستدلال المستندة إلى النصوص (مثل 43.7% لـ Gemini 2.5 Pro)، وأظهرت أداءً أفضل في المهام المعقدة والمتانة، مما يثبت تفوق التخطيط البصري (المصدر: 量子位)

إنفيديا تكشف عن خارطة طريق تكنولوجيا الذكاء الاصطناعي للسنوات الخمس القادمة، وتتحول إلى شركة بنية تحتية للذكاء الاصطناعي: أعلن الرئيس التنفيذي لشركة إنفيديا Jensen Huang في COMPUTEX 2025 عن تعديل في تحديد موقع الشركة لتصبح شركة بنية تحتية للذكاء الاصطناعي، وكشف عن خارطة طريق التكنولوجيا للسنوات الخمس القادمة. وأكد أن البنية التحتية للذكاء الاصطناعي ستكون منتشرة في كل مكان مثل الكهرباء أو الإنترنت، وأن إنفيديا ملتزمة ببناء “مصانع” عصر الذكاء الاصطناعي. لدعم هذا التحول، ستقوم إنفيديا بتوسيع “دائرة أصدقاء” سلسلة التوريد، وتعميق التعاون مع TSMC وغيرها، وتخطط لإنشاء مكتب في تايوان (NVIDIA Constellation) وأول حاسوب عملاق للذكاء الاصطناعي (المصدر: 36氪)

جوجل تعيد إطلاق مشروع نظارات الذكاء الاصطناعي، وتطلق منصة Android XR وأجهزة طرف ثالث: أعلنت جوجل في مؤتمر I/O 2025 عن إعادة إطلاق مشروع نظارات الذكاء الاصطناعي/الواقع المعزز، وأطلقت منصة Android XR المصممة خصيصًا لأجهزة XR، وعرضت جهازين من طرف ثالث يعتمدان على هذه المنصة: Project Moohan من سامسونج (لمنافسة Vision Pro) و Project Aura من Xreal. تهدف جوجل إلى تكرار نجاح Android في مجال الهواتف الذكية، وخلق “لحظة أندرويد” لأجهزة XR، والتخطيط لمنصات الحوسبة البيئية والمكانية المستقبلية. بالاقتران مع نموذج Gemini 2.5 Pro متعدد الوسائط المحدث وتقنية المساعد الذكي Project Astra، ستحقق نظارات الذكاء الاصطناعي/الواقع المعزز من الجيل الجديد تجربة ثورية في فهم الكلام والترجمة الفورية والوعي السياقي وتنفيذ المهام المعقدة (المصدر: 36氪)

تحديث مبادئ تحدي ARC-AGI-2، مع التركيز على الاستدلال السياقي متعدد الخطوات: تحديث ورقة ARC-AGI-2 المنشورة حديثًا مبادئ تصميم هذا التحدي. تتطلب المبادئ الجديدة أن يمتلك حل المهام قدرات استدلال متعددة القواعد ومتعددة الخطوات وسياقية. الشبكة أكبر، وتحتوي على المزيد من الكائنات، وتشفر مفاهيم تفاعلية متعددة. المهام جديدة وغير قابلة لإعادة الاستخدام، للحد من الحفظ. هذا التصميم يقاوم عمدًا التوليف البرنامجي بالقوة الغاشمة. يحتاج البشر لحل كل مهمة بمعدل 2.7 دقيقة، بينما تسجل الأنظمة الرائدة (مثل OpenAI o3-medium) حوالي 3% فقط، وتتطلب جميع المهام جهدًا إدراكيًا واضحًا (المصدر: TheTuringPost, clefourrier)
Skywork تطلق وكيلًا فائقًا، يهدف إلى تقليص 8 ساعات عمل إلى 8 دقائق: أطلقت Skywork وكيل مساحة العمل بالذكاء الاصطناعي الخاص بها – Skywork Super Agents، مدعيةً أنه قادر على ضغط عبء عمل المستخدم لمدة 8 ساعات إلى 8 دقائق. يتم وضع هذا المنتج كرائد في مجال وكلاء مساحة العمل بالذكاء الاصطناعي، وتنتظر وظائفه وطرق تحقيقه مزيدًا من الملاحظة (المصدر: _akhaliq)
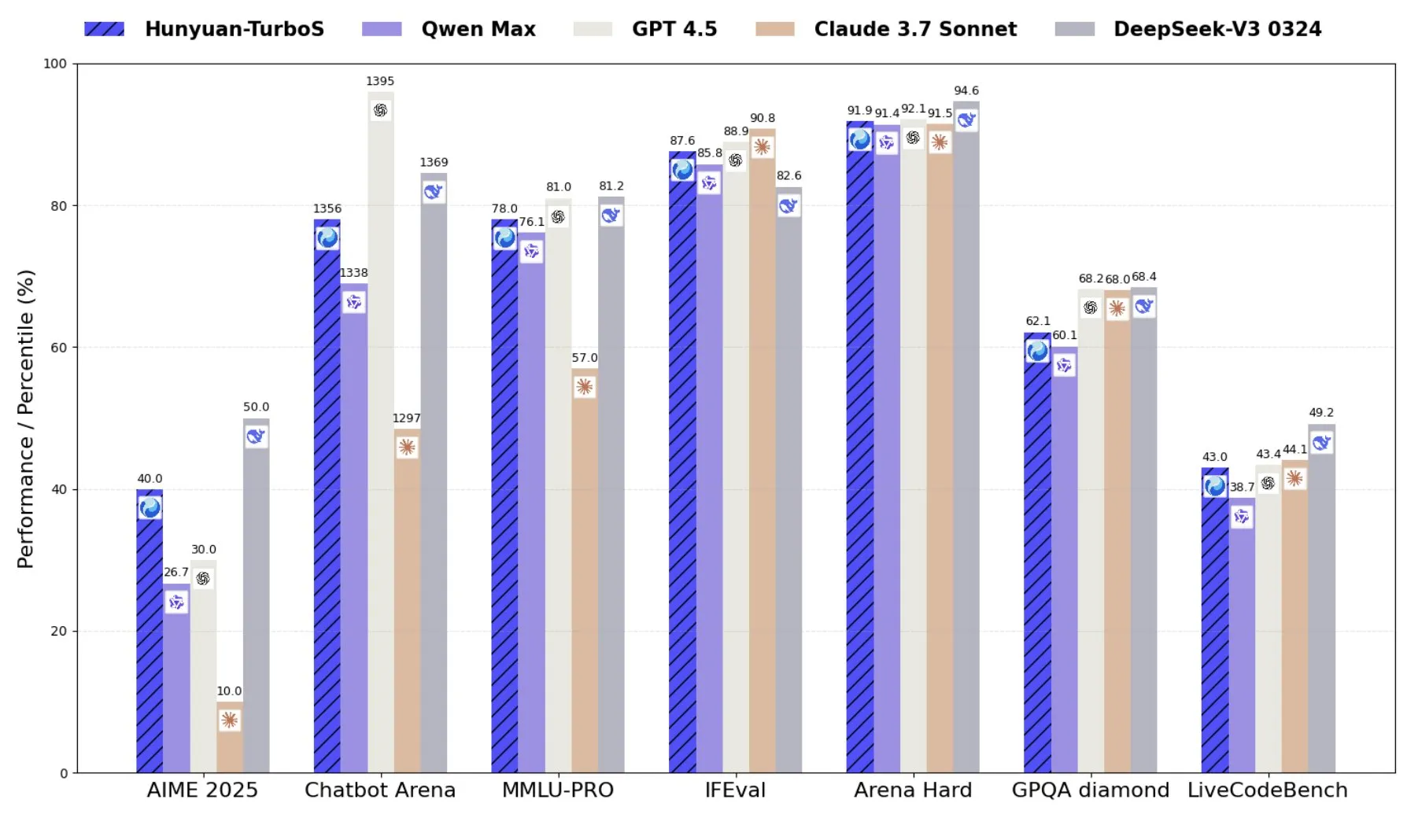
تينسنت تطلق Hunyuan-TurboS، نموذج خبير مختلط يجمع بين Transformer و Mamba: أطلقت تينسنت نموذج Hunyuan-TurboS، الذي يعتمد على بنية خبير مختلط (MoE) تجمع بين Transformer و Mamba، ويمتلك 56 مليار معلمة نشطة، وتم تدريبه على 16 تريليون رمز مميز. يستطيع Hunyuan-TurboS التبديل ديناميكيًا بين وضعي الاستجابة السريعة و “التفكير” العميق، ويحتل المرتبة السابعة بين أفضل النماذج بشكل عام على LMSYS Chatbot Arena (المصدر: tri_dao)
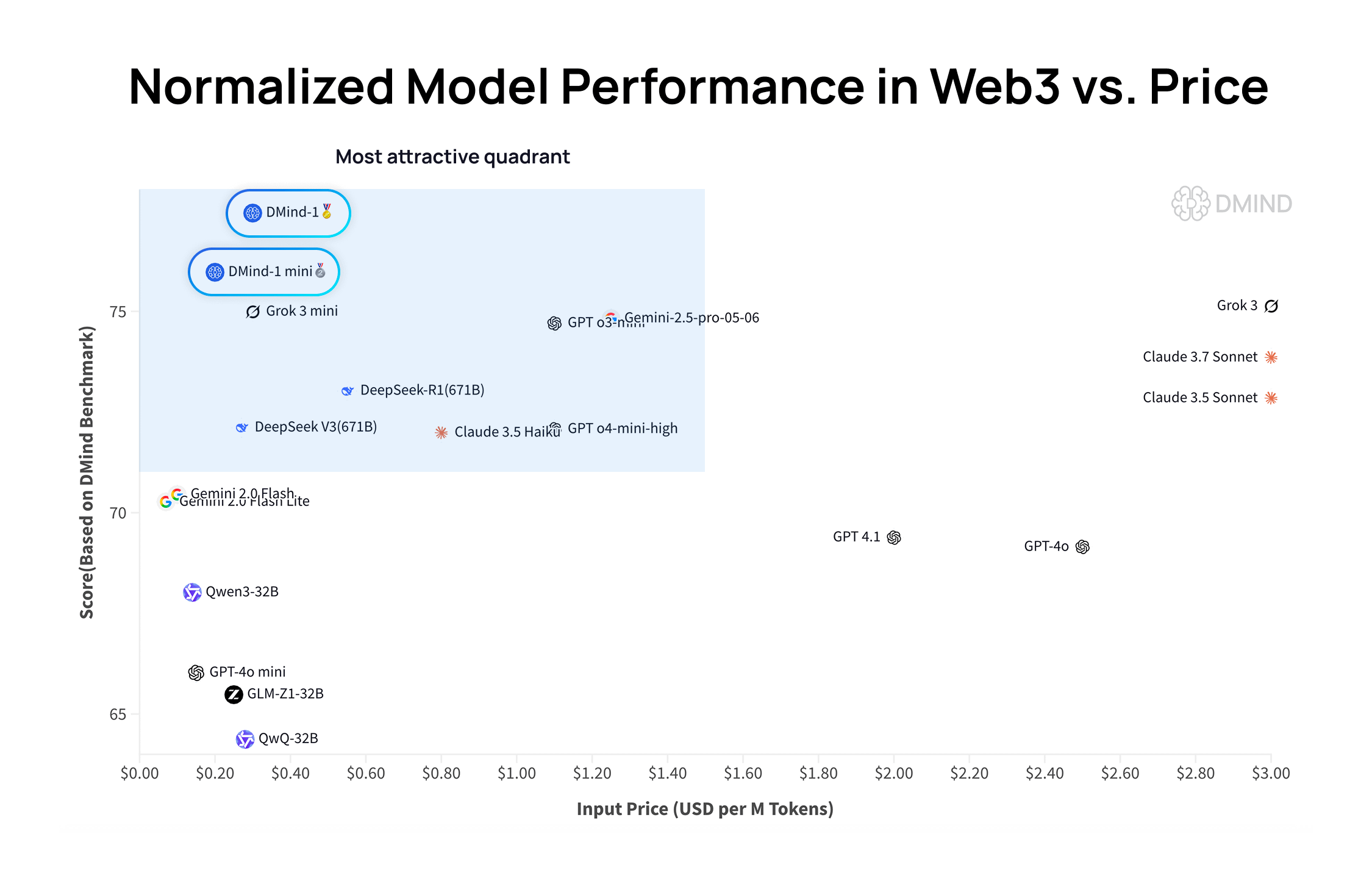
DMind-1: نموذج لغة كبير مفتوح المصدر مصمم خصيصًا لسيناريوهات Web3: أطلقت DMind AI نموذج DMind-1، وهو نموذج لغة كبير مفتوح المصدر مُحسَّن لسيناريوهات Web3. تم ضبط DMind-1 (32B) بدقة استنادًا إلى Qwen3-32B، باستخدام كمية كبيرة من المعرفة الخاصة بـ Web3، بهدف تحقيق التوازن بين الأداء والتكلفة لتطبيقات AI+Web3. في تقييمات معايير Web3، تفوق DMind-1 على نماذج LLM العامة السائدة، وبلغت تكلفة الرموز المميزة الخاصة به حوالي 10% فقط من تكلفتها. كما تم إطلاق DMind-1-mini (14B) الذي يحتفظ بأكثر من 95% من أداء DMind-1، ويتفوق في زمن الانتقال وكفاءة الحوسبة (المصدر: _akhaliq)
LightOn تطلق Reason-ModernColBERT، نموذج بمعلمات صغيرة يتفوق في مهام الاسترجاع كثيفة الاستدلال: أطلقت LightOn نموذج Reason-ModernColBERT، وهو نموذج تفاعل متأخر يحتوي على 149 مليون معلمة فقط. في اختبار BRIGHT الشهير (الذي يركز على الاسترجاع كثيف الاستدلال)، أظهر هذا النموذج أداءً متميزًا، متفوقًا على نماذج أكبر منه بـ 45 مرة في عدد المعلمات، وحقق مستوى SOTA في مجالات متعددة. تثبت هذه النتيجة مرة أخرى كفاءة نماذج التفاعل المتأخر في مهام محددة (المصدر: lateinteraction, jeremyphoward, Dorialexander, huggingface)

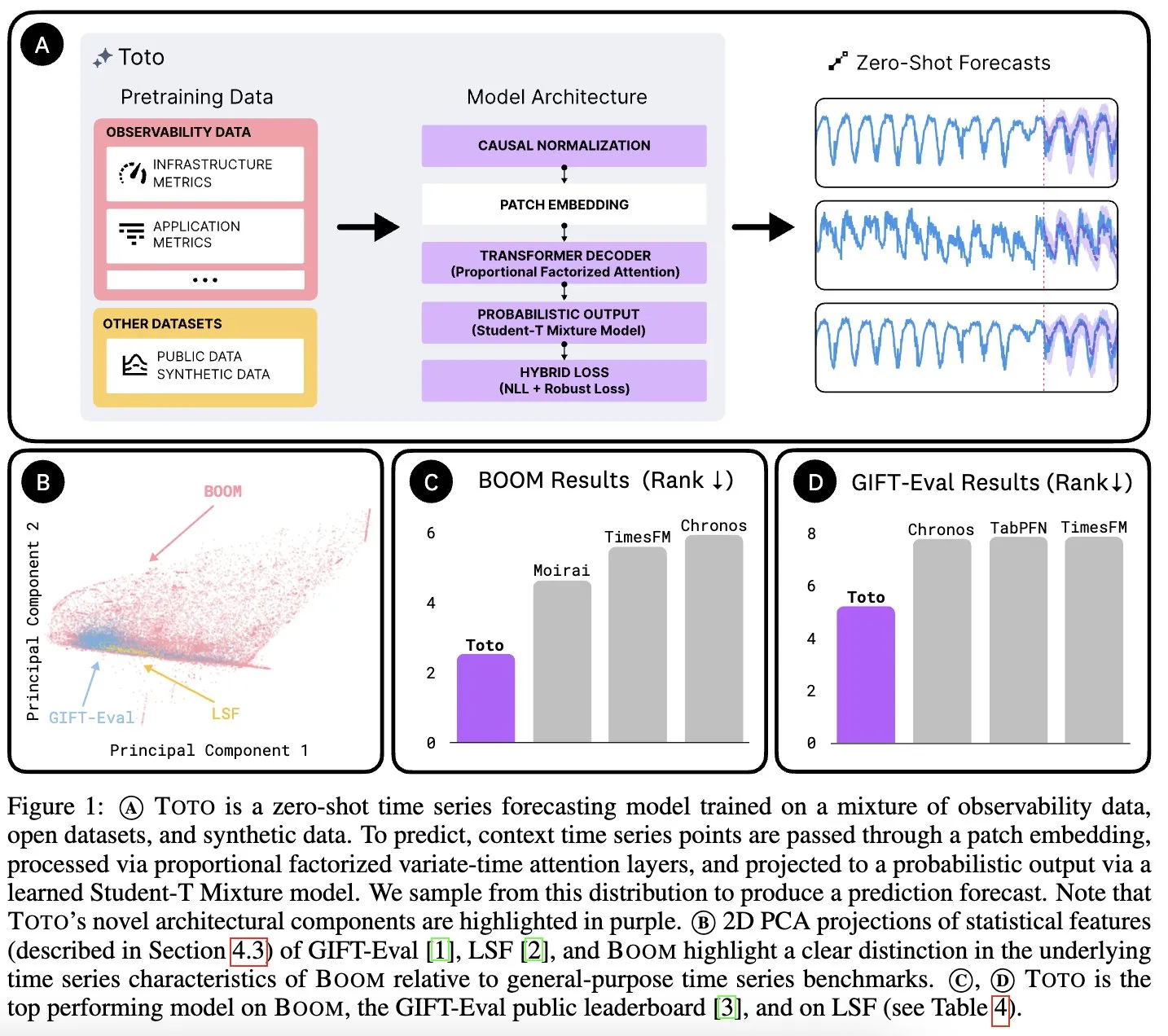
Datadog AI Research تطلق نموذج Toto الأساسي للسلاسل الزمنية ومعيار BOOM لمقاييس المراقبة: أطلقت Datadog AI Research نموذج Toto، وهو نموذج أساسي جديد للسلاسل الزمنية، وتفوق بشكل كبير على نماذج SOTA الحالية في اختبارات المعايير ذات الصلة. كما تم إطلاق BOOM، وهو أكبر معيار حالي لمقاييس المراقبة. كلاهما مفتوح المصدر بموجب ترخيص Apache 2.0، ويهدفان إلى دفع البحث والتطبيق في مجالات تحليل السلاسل الزمنية والمراقبة (المصدر: jefrankle, ClementDelangue)
TII تطلق سلسلة نماذج Falcon-H1 الهجينة Transformer-SSM: أطلق معهد الابتكار التكنولوجي (TII) في الإمارات العربية المتحدة سلسلة نماذج Falcon-H1، وهي مجموعة من نماذج اللغة ذات البنية الهجينة التي تجمع بين آليات انتباه Transformer ورؤوس نموذج فضاء الحالة Mamba2 (SSM). تتراوح أحجام معلمات هذه السلسلة من 0.5B إلى 34B، وتدعم طول سياق يصل إلى 256K، وتتفوق أو تضاهي نماذج Transformer الرائدة مثل Qwen3-32B و Llama4-Scout في العديد من اختبارات المعايير، خاصة في تعدد اللغات (تدعم 18 لغة أصلاً) والكفاءة. تم دمج النماذج في vLLM و Hugging Face Transformers و llama.cpp (المصدر: Reddit r/LocalLLaMA)

دراسة من MIT: الذكاء الاصطناعي يتعلم الارتباط بين المرئيات والأصوات دون تدخل بشري: عرض باحثون من MIT نظام ذكاء اصطناعي قادر على تعلم الروابط بين المعلومات المرئية والأصوات المقابلة لها بشكل مستقل، دون توجيه بشري صريح أو بيانات مصنفة. هذه القدرة ضرورية لتطوير أنظمة ذكاء اصطناعي متعددة الوسائط أكثر شمولاً، مما يمكنها من فهم وإدراك العالم بشكل أشبه بالبشر (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)

الإمارات تطلق نموذج ذكاء اصطناعي عربي كبير، مما يسرع سباق الذكاء الاصطناعي في منطقة الخليج: أطلقت الإمارات العربية المتحدة نموذج ذكاء اصطناعي عربي كبير، مما يمثل استثمارًا إضافيًا في مجال الذكاء الاصطناعي، ويزيد من حدة المنافسة بين دول منطقة الخليج في تطوير تكنولوجيا الذكاء الاصطناعي. تهدف هذه الخطوة إلى تعزيز تأثير اللغة العربية في مجال الذكاء الاصطناعي وتلبية احتياجات تطبيقات الذكاء الاصطناعي المحلية (المصدر: Reddit r/artificial)
شركة Fenbi Technology تطلق نموذجًا كبيرًا متخصصًا، وتعرف نموذجًا جديدًا لـ “الذكاء الاصطناعي + التعليم”: عرضت شركة Fenbi Technology في قمة تطبيقات صناعة الذكاء الاصطناعي السحابية من Tencent نموذجها الكبير المتخصص الذي طورته ذاتيًا في مجال التعليم المهني. تم تطبيق هذا النموذج بالفعل في منتجات مثل تقييم المقابلات وفصول نظام التدريب بالذكاء الاصطناعي، ويغطي السلسلة الكاملة من “التدريس والتعلم والممارسة والتقييم والاختبار”. من خلال أشكال مثل معلمي الذكاء الاصطناعي، تهدف إلى تحقيق تحول من التعليم “مقاس واحد يناسب الجميع” إلى التعليم المخصص “مقاس واحد يناسب كل فرد”، وتخطط لإطلاق منتجات أجهزة ذكاء اصطناعي مزودة بنماذج كبيرة مطورة ذاتيًا، لدفع عجلة التحول الذكي في التعليم (المصدر: 量子位)

Beisen Kuxueyuan تطلق منصة AI Learning من الجيل الجديد، وتقدم خمسة وكلاء AI رئيسيين: أطلقت Beisen Holdings، بعد استحواذها على Kuxueyuan، منصة تعلم من الجيل الجديد تعتمد على نماذج AI الكبيرة، وهي AI Learning. أضافت هذه المنصة إلى أساس eLearning الأصلي خمسة وكلاء أذكياء: مساعد إنشاء الدورات التدريبية بالذكاء الاصطناعي، ومساعد التعلم بالذكاء الاصطناعي، ومدرب الممارسة بالذكاء الاصطناعي، ومدرب القيادة بالذكاء الاصطناعي، ومساعد الامتحانات بالذكاء الاصطناعي. تهدف المنصة إلى إحداث ثورة في نماذج التعلم المؤسسي التقليدية من خلال الحوارات الفورية مع الوكلاء، وتدريب المهارات، والتعلم المخصص، وإنشاء الدورات التدريبية والامتحانات الشاملة بالذكاء الاصطناعي (المصدر: 量子位)

تقرير Pony.ai للربع الأول: إيرادات خدمة Robotaxi ترتفع 8 أضعاف على أساس سنوي، وسيتم نشر ألف مركبة ذاتية القيادة بحلول نهاية العام: أعلنت Pony.ai عن نتائجها المالية للربع الأول من عام 2025، حيث بلغ إجمالي الإيرادات 102 مليون يوان، بزيادة 12% على أساس سنوي. ومن بينها، بلغت إيرادات خدمة Robotaxi الأساسية 12.3 مليون يوان، بزيادة كبيرة بلغت 200.3% على أساس سنوي، كما ارتفعت إيرادات رسوم الركاب 8 أضعاف على أساس سنوي. تخطط الشركة لبدء الإنتاج الضخم للجيل السابع من Robotaxi في الربع الثاني، ونشر 1000 مركبة بحلول نهاية العام، والسعي لتحقيق نقطة التعادل لكل مركبة. كما أعلنت Pony.ai عن تعاونها مع Tencent Cloud و Uber، لتوسيع أسواقها المحلية والشرق أوسطية على التوالي من خلال منصتي WeChat و Uber (المصدر: 量子位)

Kevin Weil، كبير مسؤولي المنتجات في OpenAI: سيتحول ChatGPT إلى مساعد تنفيذي، وتكلفة النموذج الحالي تبلغ 500 ضعف تكلفة GPT-4: صرح Kevin Weil، كبير مسؤولي المنتجات في OpenAI، بأن موقع ChatGPT سيتحول من الإجابة على الأسئلة إلى تنفيذ المهام للمستخدمين، من خلال استخدام الأدوات بشكل متداخل (مثل تصفح الويب، والبرمجة، والاتصال بمصادر المعرفة الداخلية) ليصبح مساعدًا تنفيذيًا للذكاء الاصطناعي. وكشف أن تكلفة النموذج الحالي تبلغ 500 ضعف تكلفة GPT-4 الأولي، لكن OpenAI ملتزمة بتحسين الكفاءة وخفض أسعار API من خلال تحسينات الأجهزة والخوارزميات. ويعتقد أن وكلاء الذكاء الاصطناعي سيتطورون بسرعة، من مستوى مهندس مبتدئ إلى مستوى مهندس معماري في غضون عام واحد (المصدر: 量子位)

🧰 الأدوات
FlowiseAI: بناء وكلاء الذكاء الاصطناعي بشكل مرئي: FlowiseAI هو مشروع مفتوح المصدر يسمح للمستخدمين ببناء وكلاء الذكاء الاصطناعي وتطبيقات LLM من خلال واجهة مرئية. يدعم سحب وإفلات المكونات، وربط مختلف نماذج LLM والأدوات ومصادر البيانات، مما يبسط عملية تطوير تطبيقات الذكاء الاصطناعي. يمكن للمستخدمين تثبيت Flowise عبر npm أو نشره عبر Docker، لبناء واختبار تدفقات الذكاء الاصطناعي الخاصة بهم بسرعة (المصدر: GitHub Trending)

إطلاق مكتبة Hugging Face JS، لتبسيط التفاعل مع Hub API وخدمات الاستدلال: أطلقت Hugging Face سلسلة من مكتبات JavaScript (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client وغيرها)، تهدف إلى تسهيل تفاعل المطورين عبر JS/TS مع Hugging Face Hub API وخدمات الاستدلال. تدعم هذه المكتبات إنشاء المستودعات، وتحميل الملفات، واستدعاء استدلال أكثر من 100,000 نموذج (بما في ذلك إكمال الدردشة، وتحويل النص إلى صورة، وما إلى ذلك)، واستخدام عميل MCP لبناء الوكلاء، وتدعم العديد من مزودي خدمات الاستدلال (المصدر: GitHub Trending)

تحديث بيئة التشغيل المحلية Jan AI إلى ترخيص Apache 2.0، مما يقلل من عوائق استخدام الشركات: Jan AI هي أداة مفتوحة المصدر تدعم تشغيل LLM محليًا، وقد غيرت مؤخرًا ترخيصها من AGPL إلى Apache 2.0 الأكثر مرونة. تهدف هذه الخطوة إلى تسهيل نشر واستخدام Jan من قبل الشركات والفرق داخل مؤسساتهم، دون القلق بشأن مشكلات الامتثال التي يفرضها AGPL، مما يسمح بالتفرع والتعديل والنشر بحرية، وبالتالي دفع اعتماد Jan على نطاق واسع في بيئات الإنتاج الفعلية (المصدر: reach_vb, Reddit r/LocalLLaMA)
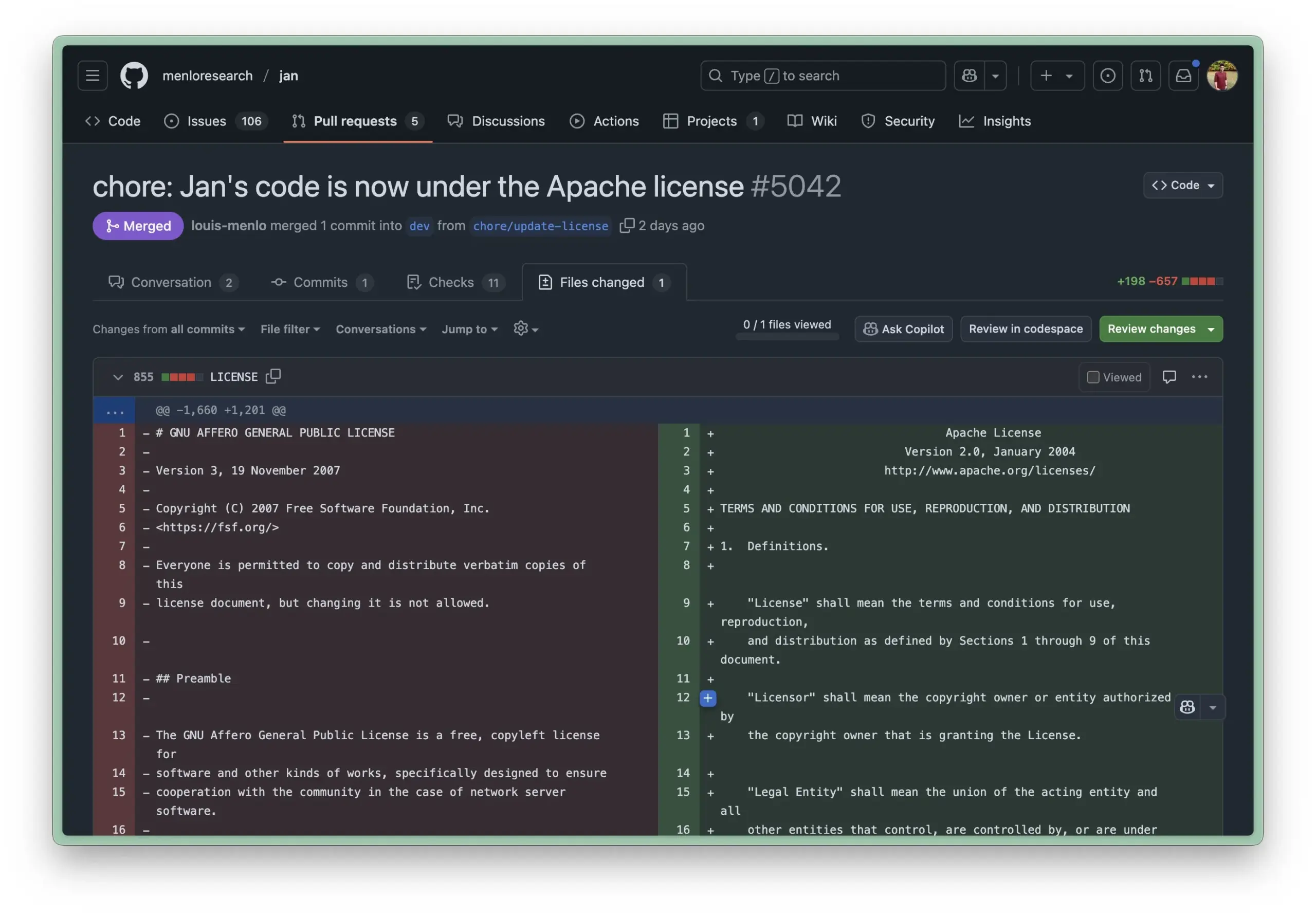
Obsidian تطلق إضافة Bases الأساسية، لتحقيق إدارة الملاحظات كقاعدة بيانات: قام برنامج إدارة المعرفة Obsidian بتحديث إضافته الأساسية Bases، مما يسمح للمستخدمين بتحويل مجموعات الملاحظات إلى قواعد بيانات قوية. من خلال Bases، يمكن للمستخدمين إنشاء عروض جداول مخصصة، وتصور البيانات في قاعدة معارفهم والتفاعل معها بشكل تفاعلي، ويدعم تصفية الملاحظات حسب الخصائص، وإنشاء صيغ لاشتقاق خصائص ديناميكية، وهو مناسب لسيناريوهات متعددة مثل إدارة المشاريع، وتخطيط السفر، وقوائم القراءة. هذه الميزة متاحة حاليًا للمستخدمين الأوائل (المصدر: op7418)
Hugging Face تطلق Tiny Agents، لتبسيط التحكم في المتصفح وعمليات الملفات باستخدام النماذج المحلية: قدمت Hugging Face في دورتها التدريبية MCP أداة Tiny Agents، وهي إطار عمل سهل الاستخدام لإعداد التحكم في المتصفح. يمكن للمستخدمين، من خلال سطر الأوامر وتكوين JSON والمطالبات، تمكين نماذج LLM التي تعمل محليًا (عبر خادم متوافق مع OpenAI) من التحكم في المتصفح (مثل Playwright) أو نظام الملفات المحلي، دون الحاجة إلى استدعاء API مباشرة، مما يوفر سهولة لتطبيقات الوكلاء للنماذج المحلية مثل llama.cpp (المصدر: Reddit r/LocalLLaMA)

مطور يفتح مصدر تطبيق تحسين السيرة الذاتية بالذكاء الاصطناعي، بناءً على LangChain و Ollama: قام مطور ببناء وفتح مصدر تطبيق لتحسين السيرة الذاتية مدفوع بالذكاء الاصطناعي. بعد تحميل المستخدم لسيرته الذاتية الحالية ووصف الوظيفة المستهدفة، يحاول التطبيق تعديل الكلمات المفتاحية في السيرة الذاتية لجعلها أكثر توافقًا مع متطلبات التوظيف. يستخدم المشروع LangChain في الواجهة الخلفية، مع دمج استرجاع BM25 المتناثر ونموذج كثيف للاسترجاع المختلط، ويعمل نموذج اللغة محليًا عبر Ollama، وتستخدم الواجهة الأمامية React. المشروع حاليًا في مرحلة إثبات المفهوم، والتعليمات البرمجية مفتوحة المصدر على GitHub (المصدر: Reddit r/deeplearning)
أداة بناء التطبيقات Lovable تعزز قدرات معالجة الصور: أعلنت أداة بناء التطبيقات بالذكاء الاصطناعي Lovable عن تحسينات في وظائف معالجة الصور الخاصة بها. يمكن للمستخدمين الآن تحميل الصور إلى الدردشة وتوجيه Lovable لاستخدام هذه المواد المصورة في التطبيق، مما يعزز تجربة المستخدم في بناء تطبيقات تحتوي على عناصر مرئية بمساعدة الذكاء الاصطناعي (المصدر: op7418)
Helios: أول منصة تحاول تسريع العمل الحكومي باستخدام الذكاء الاصطناعي: أطلق Joe Scheidler منصة Helios، وهي منصة تهدف إلى استخدام الذكاء الاصطناعي لتعزيز كفاءة العمل الحكومي، وتوصف بأنها “Cursor للقطاع الحكومي”. تعد هذه المنصة من أوائل المحاولات التي تستهدف بشكل واضح الإدارات الحكومية، وتسعى إلى تحسين إجراءات عملها وكفاءتها من خلال تكنولوجيا الذكاء الاصطناعي، وتنتظر وظائفها وسيناريوهات تطبيقها مزيدًا من الملاحظة (المصدر: timsoret)
📚 موارد تعليمية
جامعة تشجيانغ تنشر كتاب “أساسيات النماذج الكبيرة”، يشرح بشكل منهجي معرفة LLM ويتم تحديثه باستمرار: قام فريق LLM بجامعة تشجيانغ بفتح مصدر كتاب “أساسيات النماذج الكبيرة”، بهدف تزويد القراء المهتمين بنماذج اللغة الكبيرة بمعرفة أساسية منهجية ومقدمة للتقنيات المتطورة. يتضمن محتوى الكتاب نماذج اللغة التقليدية، وتطور بنية LLM، وهندسة المطالبات، والضبط الدقيق الفعال للمعلمات، وتحرير النماذج، والتوليد المعزز بالاسترجاع، وما إلى ذلك، وسيتم تحديثه شهريًا. كل فصل مزود بقائمة أوراق بحثية ذات صلة لتتبع أحدث التطورات. تم نشر ملف PDF الكامل والمحتويات المقسمة حسب الفصول على GitHub (المصدر: GitHub Trending)

Hugging Face تقدم 10 دورات مجانية في الذكاء الاصطناعي، تغطي مستويات مختلفة ومجالات معرفية متعددة: جمعت Hugging Face 10 دورات مجانية في الذكاء الاصطناعي تقدمها منصتها، وتغطي محتوياتها مواضيع الذكاء الاصطناعي الشائعة من المستوى المبتدئ إلى المتقدم، بما في ذلك معالجة اللغة الطبيعية، والتعلم العميق، والتعلم المعزز، ومعالجة الصوت، والوسائط المتعددة، وغيرها. توفر هذه الدورات للمتعلمين من مختلف المستويات موارد قيمة لتعلم معرفة الذكاء الاصطناعي بشكل منهجي، مما يدفع بنشر معرفة الذكاء الاصطناعي وتطوير مجتمع المصادر المفتوحة (المصدر: huggingface, reach_vb, _akhaliq)

جامعة ستانفورد تشارك خبرات ودروس تدريب نموذج Marin 8B: كشف فريق Percy Liang بجامعة ستانفورد عن مراجعة مفصلة لتدريبهم لنموذج Marin 8B من الصفر (والذي تفوق على نموذج Llama 3.1 8B الأساسي في العديد من المعايير). يتضمن هذا السجل الصادق جميع اكتشافات الفريق والأخطاء التي ارتكبوها أثناء عملية البحث والتطوير، مما يوفر للمجتمع خبرة قيمة في بناء LLM بشكل حقيقي، ويؤكد على أهمية التجربة والخطأ والتكرار في عملية البحث العلمي (المصدر: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI تتعاون مع Predibase لإطلاق دورة تدريبية حول الضبط الدقيق المعزز (RFT) لنماذج LLM: تعاونت DeepLearning.AI التابعة لـ Andrew Ng مع Predibase لإطلاق دورة تدريبية قصيرة مجانية حول استخدام GRPO (Group Relative Policy Optimization) للضبط الدقيق المعزز (RFT) لتحسين أداء LLM. يقدم الدورة مؤسس Predibase المشارك ومديرها التقني Travis Addair وآخرون، وتهدف إلى مساعدة المتعلمين على إتقان كيفية استخدام التعلم المعزز، باستخدام كمية صغيرة فقط من البيانات المصنفة، لتحويل نماذج LLM مفتوحة المصدر الصغيرة إلى محركات استدلال مخصصة لحالات استخدام محددة (المصدر: DeepLearningAI)
صفحة الأوراق البحثية في Hugging Face تضيف ميزة ملخصات مولدة بالذكاء الاصطناعي: قدمت Hugging Face ميزة جديدة في صفحة عرض الأوراق البحثية الخاصة بها، حيث توفر ملخصًا من جملة واحدة مولدًا بالذكاء الاصطناعي لكل ورقة بحثية. يهدف هذا الملخص إلى تلخيص المحتوى الأساسي للورقة البحثية بشكل موجز وواضح، ومساعدة المستخدمين على تصفية وفهم المؤلفات البحثية بسرعة، مما يعزز إمكانية الوصول إلى الموارد الأكاديمية وكفاءة استخدامها. هذه الميزة مدفوعة بنماذج LLM مفتوحة المصدر، وتجسد مفهوم “الذكاء الاصطناعي يمكّن أبحاث الذكاء الاصطناعي” (المصدر: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

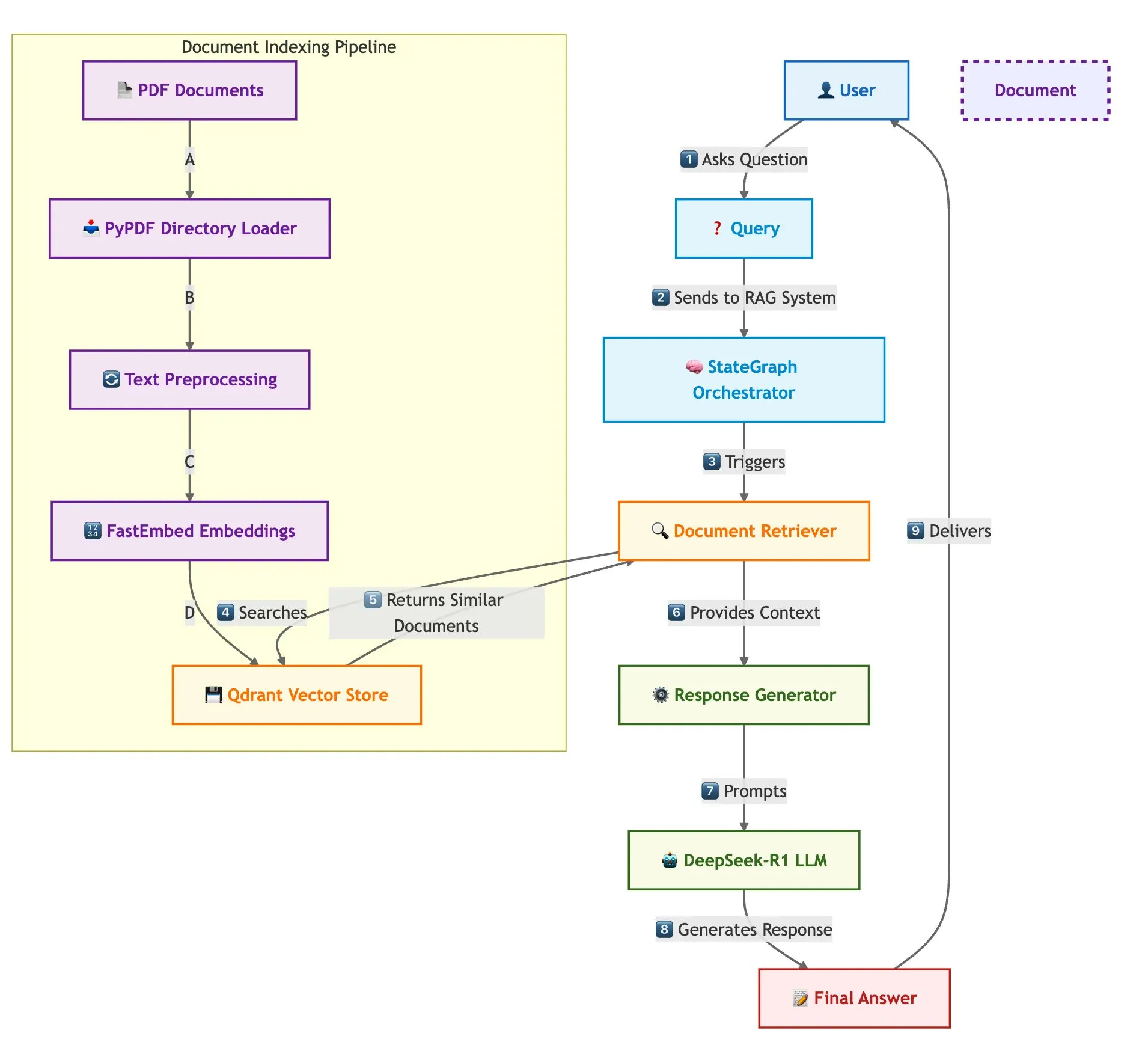
Qdrant و SambaNova وغيرهما يعرضون بالاشتراك حل بناء نظام RAG سريع متعدد المستندات: تشرح مدونة تقنية كيفية استخدام قاعدة بيانات المتجهات Qdrant و SambaNova و DeepSeek-R1 و LangGraph لبناء نظام توليد معزز بالاسترجاع (RAG) متعدد المستندات عالي السرعة وفعال من حيث الذاكرة. يحقق هذا الحل توفيرًا في الذاكرة بمقدار 32 ضعفًا من خلال التكميم الثنائي، ويستخدم DeepSeek-R1 للاستجابات السريعة والمركزة من LLM، ويستفيد من LangGraph للتنسيق المعياري، وهو مناسب لسيناريوهات معالجة المستندات المتعددة على نطاق واسع (المصدر: qdrant_engine)
إصدار مراجعة قمة LangChain Interrupt 2025 (باللغة الماندرينية): تم إصدار مراجعة قمة LangChain Interrupt 2025 باللغة الماندرينية. اجتذبت هذه القمة أكثر من 800 مشارك من جميع أنحاء العالم، حيث تمت مشاركة الخبرات والرؤى المستقبلية حول بناء وكلاء الذكاء الاصطناعي، وتم الإعلان عن العديد من المنتجات مثل LangGraph Platform و LangGraph Studio v2، ومناقشة موضوعات مثل هندسة الوكلاء ومراقبة الذكاء الاصطناعي (المصدر: hwchase17)
Andi Marafioti ينشر برنامجًا تعليميًا لـ nanoVLM، يشرح خطوة بخطوة تدريب نموذج لغة مرئية باستخدام PyTorch النقي: نشر Andi Marafioti برنامجًا تعليميًا جديدًا على مدونته بعنوان nanoVLM، يشرح بالتفصيل كيفية تدريب نموذج لغة مرئية (VLM) خاص بك من البداية باستخدام PyTorch النقي. محتوى البرنامج التعليمي سهل الفهم والتطبيق، ويهدف إلى مساعدة المبتدئين على إتقان عملية تدريب VLM بسرعة (المصدر: LoubnaBenAllal1)

Ferenc Huszár يشرح سلاسل ماركوف الزمنية المستمرة وتطبيقاتها في نماذج لغة الانتشار: نشر باحث التعلم العميق Ferenc Huszár تدوينة تشرح بشكل مبسط وبديهي سلاسل ماركوف الزمنية المستمرة (CTMCs)، وهي مكون رئيسي في نماذج لغة الانتشار (DLMs) مثل Mercury و Gemini Diffusion. تستكشف المقالة وجهات نظر مختلفة لسلاسل ماركوف وعلاقتها بعمليات النقطة، وتوفر مرجعًا قيمًا لفهم الأساس النظري لـ DLM (المصدر: fhuszar)
💼 الأعمال
شركة “الذكاء الاصطناعي الاصطناعي” Builder.ai تعلن إفلاسها، بعد أن جمعت ما يقرب من 500 مليون دولار: أعلنت شركة Builder.ai البريطانية (المعروفة سابقًا باسم Engineer.ai)، التي ادعت أنها ستحدث ثورة في تطوير البرمجيات باستخدام الذكاء الاصطناعي وقُدرت قيمتها ذات مرة بمليار دولار، عن تصفيتها بسبب الإفلاس هذا الأسبوع. تم الكشف سابقًا عن أن العديد من وظائف منصة الذكاء الاصطناعي الخاصة بها كانت تتم يدويًا بواسطة مهندسين هنود. على الرغم من حصولها على تمويل يقارب 500 مليون دولار من مؤسسات معروفة مثل مايكروسوفت وسوفت بنك DeepCore، إلا أنها استنفدت أموالها في النهاية بسبب الشكوك حول صحة تقنيتها، وسوء الإدارة المالية، والنزاعات القانونية للمؤسس، وتخلفت عن سداد 30 مليون دولار لمايكروسوفت و 85 مليون دولار لخدمات أمازون السحابية (المصدر: 36氪)

LMArena.ai (LMSys سابقًا) تحصل على تمويل أولي بقيمة 100 مليون دولار، وتنتقل من تطبيق Gradio إلى التسويق التجاري: أعلنت LMArena.ai، التي كانت في الأصل مشروعًا أكاديميًا يعتمد على Gradio يُعرف باسم LMSys (لمنافسة وتقييم LLM)، عن حصولها على تمويل أولي بقيمة 100 مليون دولار، بقيادة a16z وشركة استثمار جامعة كاليفورنيا. سيدعم هذا التمويل LMArena في مواصلة أبحاثها في مجال الذكاء الاصطناعي الموثوق به وتشغيل منصتها، مما يمثل تحول مشروع أكاديمي ناجح مفتوح المصدر إلى التشغيل التجاري. كما يسلط هذا الضوء على إمكانات أدوات النماذج الأولية السريعة مثل Gradio في احتضان مشاريع الذكاء الاصطناعي المؤثرة (المصدر: ClementDelangue, _akhaliq, clefourrier)
حرب المواهب في مجال الذكاء الاصطناعي تشتعل، OpenAI وجوجل وغيرهما يتنافسون على المواهب برواتب تصل إلى عشرات الملايين: دخلت المنافسة على المواهب في مجال الذكاء الاصطناعي في وادي السيليكون مرحلة محمومة، حيث أصبح كبار الباحثين (IC) المورد الأساسي الذي تتنافس عليه شركات عملاقة مثل OpenAI وجوجل و xAI، مع رواتب وحوافز أسهم تتجاوز عمومًا عشرات الملايين من الدولارات. على سبيل المثال، عرضت OpenAI على باحث كبير كان ينوي الانضمام إلى SSI مكافأة قدرها 2 مليون دولار وأسهم تزيد قيمتها عن 20 مليون دولار للاحتفاظ به؛ كما تقدم جوجل DeepMind لكبار المواهب رواتب سنوية تصل إلى 20 مليون دولار. تنبع هذه المنافسة الشرسة من المساهمات الهائلة لعدد قليل من المواهب الأساسية في تطوير نماذج اللغة الكبيرة، حيث يمكن أن يؤثر بقاؤهم أو رحيلهم بشكل مباشر على نجاح أو فشل نماذج الذكاء الاصطناعي (المصدر: 36氪)
🌟 المجتمع
يبدو أن قدرة Sora على التعامل مع اللغة الصينية قد تحسنت، ولكن لا تزال هناك قيود على النموذج: لاحظ مستخدمو وسائل التواصل الاجتماعي أن نموذج توليد الفيديو Sora من OpenAI يبدو أنه قد حقق تقدمًا في معالجة النصوص الصينية، حيث أصبح قادرًا على إنشاء مشاهد تحتوي على أحرف صينية. ومع ذلك، أشار المستخدمون أيضًا إلى أن النموذج لا يزال لديه قيوده، وأن المحتوى الذي يتم إنشاؤه ليس مثاليًا، وأن قبول هذا النقص قد يكون أمرًا طبيعيًا في التفاعل مع نماذج الذكاء الاصطناعي في المرحلة الحالية (المصدر: dotey)

Gemini تطلق ميزة “اختبار” التقارير العميقة، للمساعدة في إعادة استخدام المعرفة وإغلاق حلقة التعلم: أطلقت جوجل Gemini ميزة جديدة، حيث يمكن لـ Gemini، بعد قراءة المستخدم لتقرير عميق، طرح أسئلة لاختباره مباشرة. تهدف هذه الميزة إلى التحقق من مدى فهم المستخدم الحقيقي للمحتوى وبناء حلقة تعلم أصلية للذكاء الاصطناعي “تعلم ← اختبار ← مراجعة ← إعادة تعلم”، مع التأكيد على أن جوهر التعلم في عصر الذكاء الاصطناعي يكمن في القدرة على إعادة استخدام المعرفة وليس في حجم القراءة (المصدر: dotey)
ميزة الذاكرة في ChatGPT تثير مخاوف المستخدمين بشأن التحكم: تتيح ميزة “التعلم من الدردشات لتذكرها” الجديدة في ChatGPT للنموذج تذكر معلومات محادثات المستخدم السابقة لتقديم استجابات أكثر تخصيصًا في التفاعلات اللاحقة. ومع ذلك، أعرب بعض المستخدمين المتقدمين عن قلقهم بشأن هذا الأمر، معتبرين أنه يغير طريقة التفاعل مع النموذج، وأنهم يفضلون التحكم الكامل في محتوى إدخال النموذج، ولا يرغبون في أن يستخدم النموذج معلومات تاريخية دون علمهم أو قدرتهم على التحكم الدقيق فيها (المصدر: random_walker)
تطور وكلاء الذكاء الاصطناعي السريع، قد يغير نماذج العمل المستقبلية: يناقش المجتمع التطور السريع لوكلاء الذكاء الاصطناعي وتأثيرهم المحتمل على نماذج العمل المستقبلية. تشير الآراء إلى أن وكلاء الذكاء الاصطناعي يتحولون من أدوات بسيطة للإجابة على الأسئلة إلى “موظفين افتراضيين” قادرين على إكمال مهام معقدة بشكل مستقل (مثل الترميز والبحث ودعم العملاء). يتوقع Kevin Weil، كبير مسؤولي المنتجات في OpenAI، أن قدرات وكلاء الذكاء الاصطناعي سترتفع بسرعة، من مستوى مهندس مبتدئ إلى مستوى مهندس معماري في غضون عام واحد. كما طرحت مايكروسوفت تصور “شبكة الوكلاء الأذكياء”، مما ينبئ بأن العمل المستقبلي قد يتمحور حول إدارة وتنسيق وكلاء الذكاء الاصطناعي (المصدر: rowancheung, 量子位)
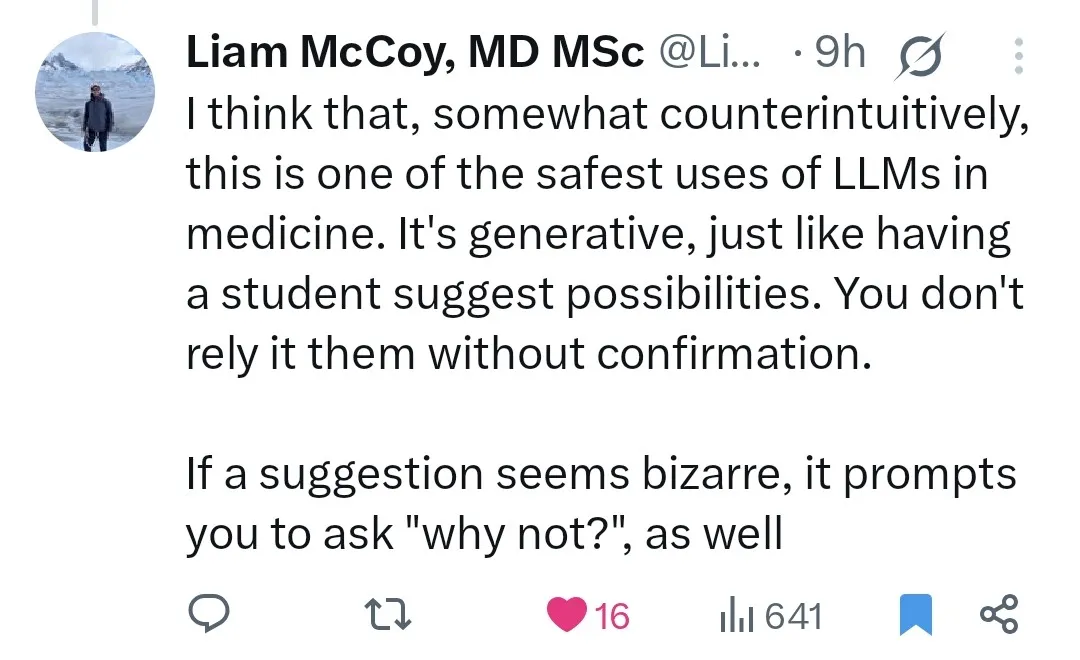
إمكانات الذكاء الاصطناعي الهائلة في مجال التشخيص الطبي، ولكنها تثير قلق الأطباء بشأن مستقبلهم المهني: يُظهر الذكاء الاصطناعي قدرات مذهلة في مجال التشخيص الطبي، على سبيل المثال، تشير إحدى الدراسات إلى أن نموذج o1-preview يُظهر قدرات تفوق البشر في مهام الاستدلال والتشخيص الطبي، كما أثارت حالات اكتشاف الذكاء الاصطناعي للالتهاب الرئوي في ثوانٍ اهتمامًا. هذا يجعل التشخيص بمساعدة الذكاء الاصطناعي موضوعًا ساخنًا، ولكنه يثير أيضًا قلق بعض الأطباء الذين يعملون منذ 20 عامًا بشأن مستقبلهم المهني، حتى أنهم يمزحون بالقول إنهم سيذهبون للعمل في ماكدونالدز. يرى النقاش المجتمعي أنه يجب اعتبار الذكاء الاصطناعي أداة لمساعدة الأطباء على تحسين الكفاءة والدقة، وليس بديلاً كاملاً لهم (المصدر: paul_cal, Reddit r/ArtificialInteligence)
ناشرو الأخبار يتهمون نمط بحث جوجل بالذكاء الاصطناعي بـ “السرقة”: أعرب ناشرون مثل تحالف وسائل الإعلام الإخبارية عن استيائهم الشديد من نمط بحث جوجل الجديد بالذكاء الاصطناعي، واصفين إياه بـ “السرقة”. يعتقدون أن ذكاء جوجل الاصطناعي يستخلص المعلومات مباشرة من محتوى الأخبار ويدمجها في نتائج البحث، متجاوزًا مواقع الأخبار، مما يضر بحركة المرور وعائدات الإعلانات للناشرين، ويثير نقاشًا حادًا حول حقوق الطبع والنشر للمحتوى والاستخدام العادل في عصر الذكاء الاصطناعي (المصدر: Reddit r/artificial)
نموذج DeepSeek يُستخدم في الصين للتنجيم التقليدي، مما يثير نقاشًا حول حدود تطبيقات الذكاء الاصطناعي: اكتشف بعض المستخدمين أن جزءًا كبيرًا من حركة مرور نموذج DeepSeek في الصين يأتي من استخدامه في أنشطة التنجيم التقليدية مثل قراءة الطالع باستخدام كتاب التغيرات (I Ching). أثارت هذه الظاهرة نقاشًا حول حدود تطبيقات الذكاء الاصطناعي والتكيف الثقافي، وتعكس أيضًا بشكل غير مباشر استكشاف المستخدمين المتنوع واحتياجاتهم من قدرات الذكاء الاصطناعي (المصدر: menhguin, cto_junior)

💡 أخرى
روبوتات Figure البشرية تكمل 20 ساعة عمل متواصلة في خط إنتاج BMW: أعلنت شركة الروبوتات البشرية Figure أن روبوتاتها أكملت بنجاح 20 ساعة عمل متواصلة في خط إنتاج BMW X3. قبل ذلك، خضع الروبوت لاختبارات عمل لمدة 10 ساعات متواصلة لعدة أسابيع. صرحت Figure بأن هذه هي المرة الأولى عالميًا التي يكمل فيها روبوت بشري مثل هذه الفترة الطويلة من العمل المتواصل في خط إنتاج سيارات، مما يظهر إمكاناته في مجال الأتمتة الصناعية (المصدر: adcock_brett, TheRundownAI)
الفرق والصلة بين Agentic AI و GenAI: ناقش المجتمع مفهومي Agentic AI (الذكاء الاصطناعي الوكيل) و Generative AI (الذكاء الاصطناعي التوليدي). يشير الذكاء الاصطناعي التوليدي بشكل أساسي إلى الذكاء الاصطناعي القادر على إنشاء محتوى جديد (نصوص، صور، أكواد، إلخ)، بينما يركز الذكاء الاصطناعي الوكيل بشكل أكبر على الاستقلالية، والتوجه نحو الهدف، والقدرة على التفاعل مع البيئة. عادةً ما يستخدم الذكاء الاصطناعي الوكيل الذكاء الاصطناعي التوليدي كأحد قدراته الأساسية لفهم المهام وتخطيطها وتنفيذها، وهو اتجاه مهم في تطور الذكاء الاصطناعي نحو ذكاء مستقل أكثر تقدمًا (المصدر: Ronald_vanLoon, Ronald_vanLoon)

تطبيقات الذكاء الاصطناعي في البحث العلمي مُقلل من شأنها، ووجود ظاهرة “تجميل النتائج”: يشير النقاش المجتمعي إلى أن إمكانات تطبيقات الذكاء الاصطناعي في البحث العلمي هائلة ولكنها قد تكون مُقلل من شأنها، وفي الوقت نفسه توجد ظاهرة قيام الباحثين بـ “تجميل” نتائج تجارب الذكاء الاصطناعي من أجل النشر. على سبيل المثال، في مجالات مثل المعادلات التفاضلية الجزئية (PDEs)، قد لا يكون الأداء الفعلي للذكاء الاصطناعي متميزًا كما هو معروض في الأوراق البحثية. هذا ينبه المجتمع العلمي إلى الحاجة إلى تقييم أكثر صرامة وشفافية للدور الحقيقي للذكاء الاصطناعي وحدوده في الاكتشافات العلمية (المصدر: clefourrier)