كلمات مفتاحية:أوبن إيه آي, جوني آيف, أجهزة الذكاء الاصطناعي, جوجل آي/أو, جيميني, ميسترال إيه آي, ديفسترال, برمجة الذكاء الاصطناعي, استحواذ أوبن إيه آي على آي أو, جيميني 2.5 برو, نموذج ديفسترال مفتوح المصدر, أداة صناعة الأفلام بالذكاء الاصطناعي فلو, وكيل البرمجة الذكي بالذكاء الاصطناعي جولز
🔥 أبرز العناوين
OpenAI تعلن عن استحواذها على شركة io الناشئة لأجهزة الذكاء الاصطناعي التابعة لـ Jony Ive مقابل 6.5 مليار دولار: أكدت OpenAI استحواذها على شركة io لأجهزة الذكاء الاصطناعي، التي أسسها Jony Ive، كبير مسؤولي التصميم السابق في Apple، بالتعاون مع SoftBank، في صفقة تبلغ قيمتها حوالي 6.5 مليار دولار أمريكي. سيتولى Jony Ive منصب المدير الإبداعي في OpenAI، وسيكون مسؤولاً عن تصميم المنتجات. سينضم فريق io المكون من حوالي 55 شخصًا إلى OpenAI للعمل على تطوير أجهزة ذكاء اصطناعي جديدة كليًا، ومن المتوقع إطلاق أول منتج في عام 2026. يمثل هذا الاستحواذ دخول OpenAI رسميًا إلى مجال الأجهزة، بهدف إنشاء أجهزة حوسبة شخصية وتجارب تفاعلية أصلية للذكاء الاصطناعي (AI-native)، مما قد يشكل تحديًا لسوق الهواتف الذكية وأجهزة الحوسبة الحالية. (المصدر: QbitAI, تشي دونغ شي, شين مانغ xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

مؤتمر Google I/O يشهد إطلاق نماذج وتطبيقات ذكاء اصطناعي متعددة، مع التركيز على دمج الذكاء الاصطناعي في الحياة اليومية: أطلقت Google في مؤتمر المطورين I/O 2025 نماذج Gemini 2.5 Pro ونسخته ذات التفكير العميق (Deep Think)، والنموذج الخفيف Gemini 2.5 Flash، ونموذج انتشار النص Gemini Diffusion، ونموذج توليد الصور Imagen 4، ونموذج توليد الفيديو Veo 3. يدعم Veo 3 توليد مقاطع فيديو مع صوت وحوار، بنتائج مذهلة. كما أطلقت Google تطبيق Flow لإنشاء الأفلام بالذكاء الاصطناعي، والذي يدمج Veo و Imagen و Gemini. ستدمج ميزة البحث بالذكاء الاصطناعي ملخصات الذكاء الاصطناعي، والبحث العميق (Deep Search)، والمعلومات الشخصية، وستطلق وضع AI Mode. تؤكد Google على دمج الذكاء الاصطناعي بسلاسة في منتجاتها وخدماتها الحالية، بهدف جعل تقنية الذكاء الاصطناعي “غير مرئية” وتحسين تجربة المستخدم. (المصدر: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

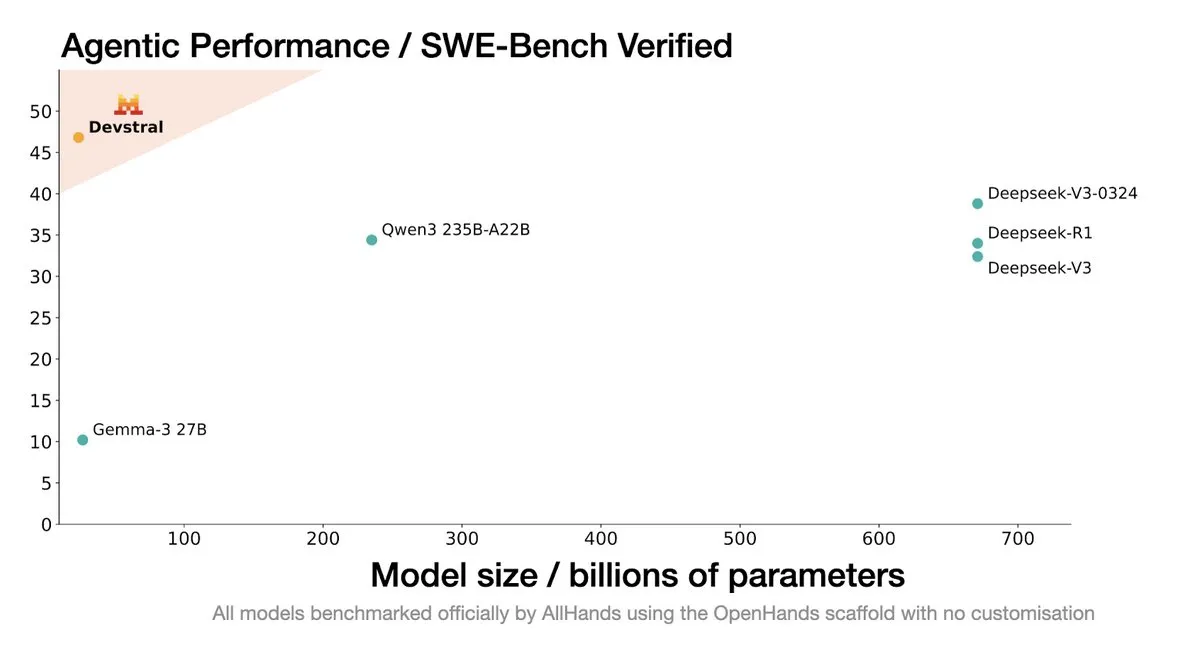
Mistral AI تطلق Devstral: نموذج SOTA مفتوح المصدر مصمم خصيصًا لوكلاء الترميز الذكي: أطلقت Mistral AI بالتعاون مع All Hands AI نموذج Devstral، وهو نموذج SOTA مفتوح المصدر مصمم خصيصًا لوكلاء الترميز الذكي. أظهر هذا النموذج أداءً متميزًا في اختبار SWE-Bench Verified، متفوقًا على سلسلة DeepSeek و Qwen3 235B، بحجم 24B بارامتر فقط، ويمكن تشغيله على بطاقة RTX4090 واحدة أو جهاز Mac بذاكرة 32 جيجابايت. تم تدريب Devstral على مشكلات GitHub حقيقية، مع التركيز على فهم السياق في مستودعات التعليمات البرمجية الكبيرة، وتحديد العلاقات بين المكونات، وتحديد الأخطاء في الدوال المعقدة. يعتمد النموذج على ترخيص Apache 2.0 مفتوح المصدر، وهو أكثر انفتاحًا مقارنةً بـ Codestral السابق. (المصدر: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
المدير التقني لـ Google DeepMind، كوراي كافوكوغلو، يشرح Veo 3 و Deep Think وتقدم AGI: خلال مؤتمر Google I/O، أجرى كوراي كافوكوغلو، المدير التقني لـ DeepMind، مقابلة ناقش فيها التقدم في نموذج توليد الفيديو Veo 3 (مثل مزامنة الصوت والصورة)، ووضع الاستدلال المعزز Deep Think في Gemini 2.5 Pro (من خلال سلاسل التفكير المتوازية)، وآرائه حول AGI. أكد كافوكوغلو أن الحجم ليس العامل الوحيد لتحقيق AGI، فالهندسة المعمارية والخوارزميات والبيانات وتقنيات الاستدلال لها نفس الأهمية، ويتطلب تحقيق AGI اختراقات في البحث الأساسي وابتكارات رئيسية، وليس مجرد تكديس هندسي. كما أعرب عن تفاؤله بـ “vibe coding” لتمكين الأشخاص الذين ليس لديهم خلفية في البرمجة من بناء التطبيقات. (المصدر: demishassabis, 36Kr)
🎯 اتجاهات الصناعة
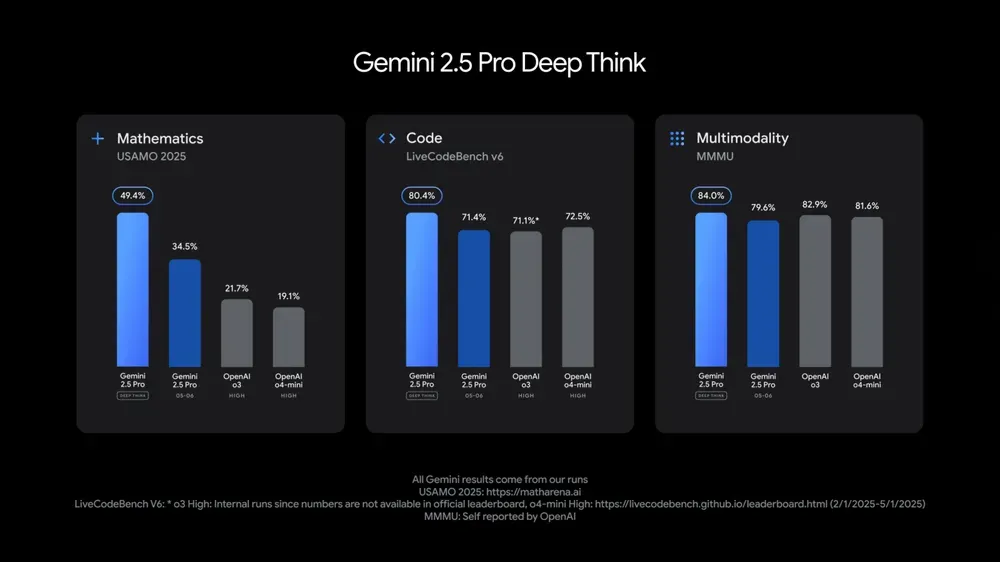
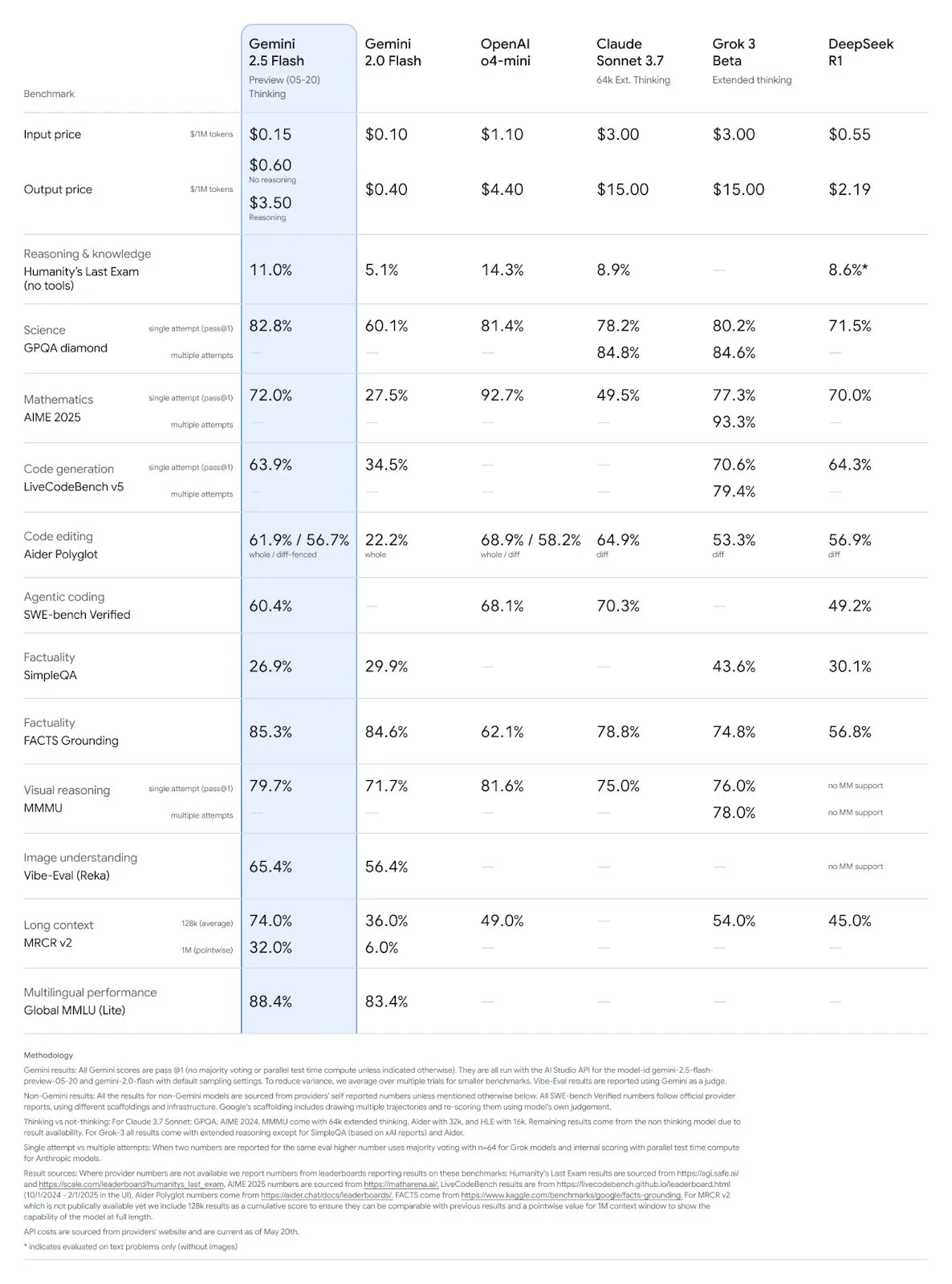
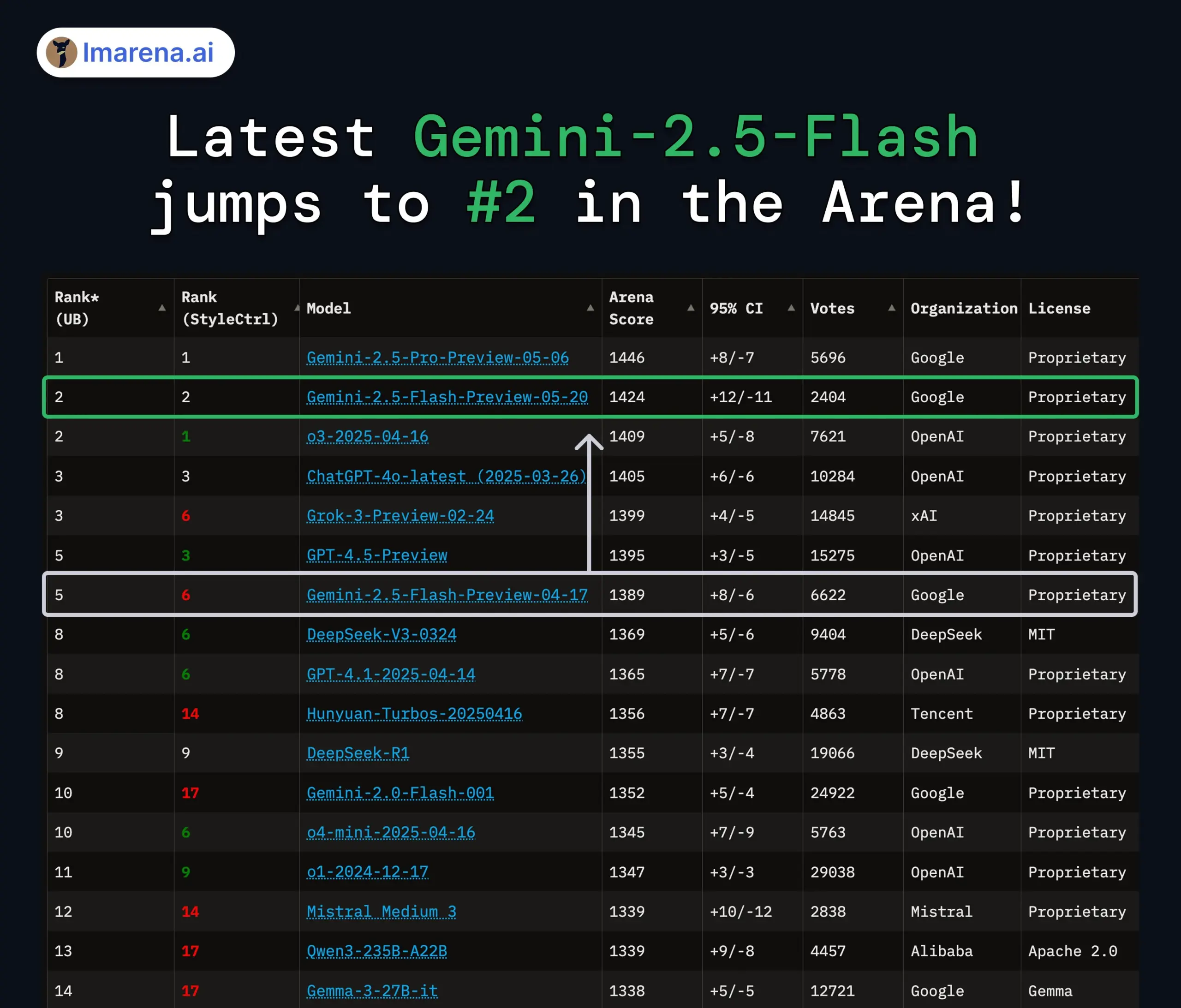
تحديث نماذج Gemini 2.5 Pro و Flash من Google، مع تحسن ملحوظ في الأداء: أعلنت Google في مؤتمر I/O أن نماذج Gemini 2.5 Pro و Flash ستُطرح رسميًا في يونيو. يُوصف Gemini 2.5 Pro بأنه أذكى نموذج ذكاء اصطناعي في العالم، مع إضافة إصدار التفكير العميق (Deep Think)، وقد أظهر تفوقًا في العديد من الاختبارات. أما Gemini 2.5 Flash، كنموذج خفيف الوزن، فقد شهد تحسنًا في الكفاءة بنسبة 22%، وتقليلًا في استهلاك الـ token بنسبة 20%-30%، مع قدرة أصلية على توليد الصوت. تُظهر بيانات LMArena أن الإصدار الجديد من Gemini-2.5-Flash قفز بشكل كبير إلى المرتبة الثانية في ساحة منافسة روبوتات الدردشة، خاصة في المهام الصعبة مثل البرمجة والرياضيات. (المصدر: natolambert, demishassabis, karminski3, lmarena_ai)
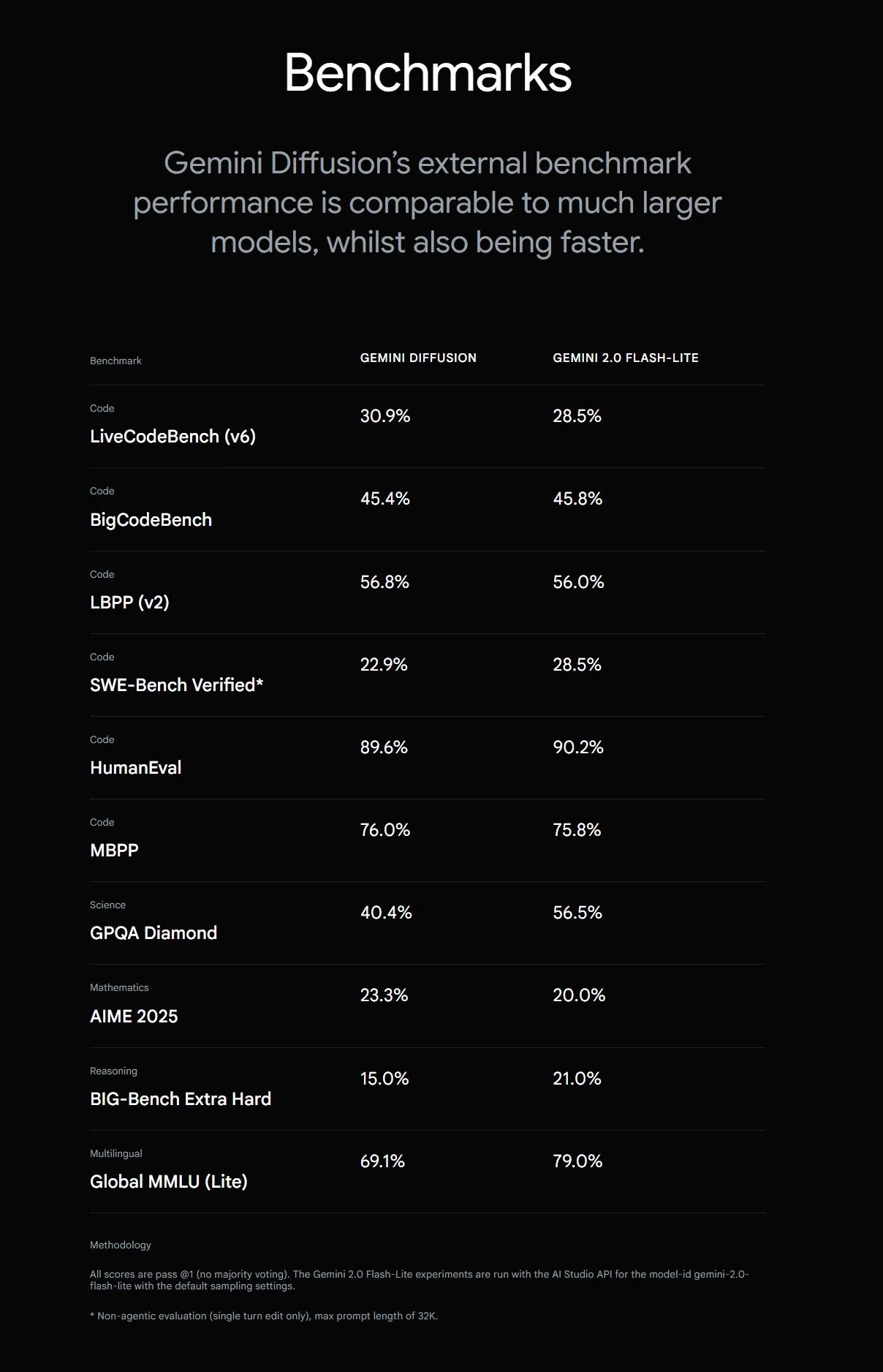
Google تطلق Gemini Diffusion، بسرعة توليد نصوص أسرع 5 مرات: أطلقت Google DeepMind نموذج توليد النصوص التجريبي Gemini Diffusion، الذي يتميز بسرعة توليد أسرع 5 مرات من أسرع النماذج السابقة، مع قدرات برمجة بارزة بشكل خاص، تصل إلى 2000 token في الثانية (بما في ذلك التكاليف العامة مثل التقطيع). على عكس النماذج التقليدية ذاتية الانحدار (autoregressive)، يمكن لنماذج الانتشار (diffusion models) إجراء استدلال غير سببي، مما يسمح لها “بالتفكير” مسبقًا في الإجابات اللاحقة، وتتفوق في حل المشكلات المعقدة التي تتطلب استدلالًا شاملاً (مثل مسائل حسابية معينة، وإيجاد الأعداد الأولية) على GPT-4o. النموذج متاح حاليًا للمطورين للتقدم بطلب اختباره. (المصدر: OriolVinyalsML, dotey, karminski3)
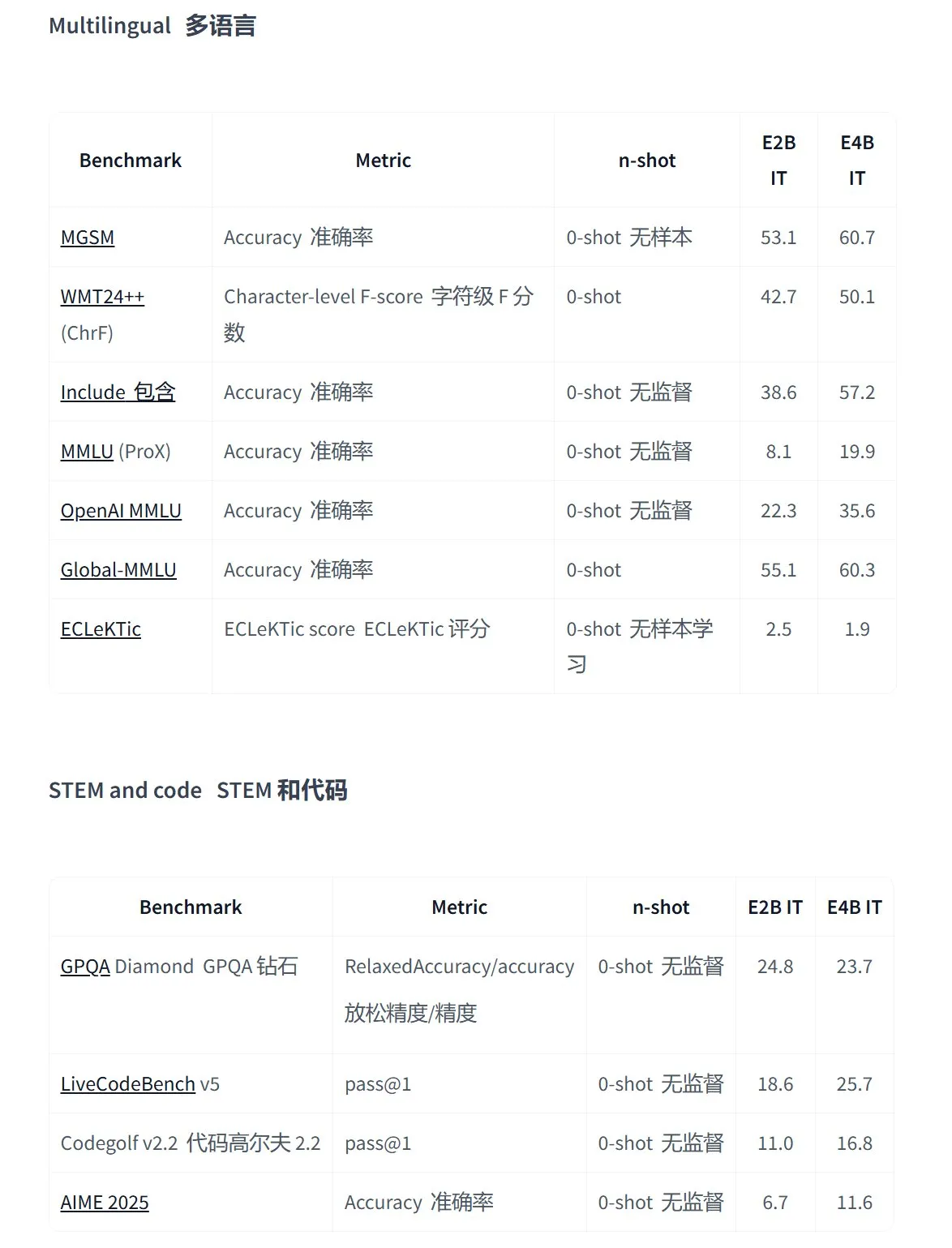
Google تطلق سلسلة نماذج Gemma 3n مفتوحة المصدر، مصممة خصيصًا لتطبيقات الوسائط المتعددة على الأجهزة الطرفية: أطلقت Google الجيل الجديد من نماذج الوسائط المتعددة مفتوحة المصدر عالية الكفاءة Gemma 3n، المصممة خصيصًا للأجهزة منخفضة استهلاك الطاقة، وتدعم إدخال النصوص والصوت والصور والفيديو ومعالجة اللغات المتعددة. تتميز هذه السلسلة من النماذج (مثل gemma-3n-E4B-it-litert-preview و gemma-3n-E2B-it-litert-preview) بحجمها الصغير (3-4.4 جيجابايت)، ويمكن تشغيلها على أجهزة بذاكرة وصول عشوائي (RAM) تبلغ 2 جيجابايت، وتستند معرفتها إلى بيانات حتى يونيو 2024. وهي متاحة حاليًا للمطورين كإصدار تجريبي على منصتي AI Studio و AI Edge. (المصدر: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
واجهة برمجة تطبيقات OpenAI Responses API تضيف دعم MCP، وتوليد الصور، ووظائف مفسر الأكواد: أعلنت منصة مطوري OpenAI عن تحديثات مهمة لواجهة برمجة تطبيقات Responses API (المعروفة سابقًا باسم Assistants API)، حيث أضافت دعمًا لخوادم بروتوكول سياق النموذج عن بُعد (MCP)، مما يسمح لوكلاء الذكاء الاصطناعي بالتفاعل بمرونة أكبر مع الأدوات والخدمات الخارجية. بالإضافة إلى ذلك، تدمج الواجهة أيضًا قدرات توليد الصور ووظائف مفسر الأكواد، مما يزيد من توسيع سيناريوهات تطبيقاتها وإمكانات تطويرها. (المصدر: gdb, npew, OpenAIDevs, snsf)
واجهة برمجة تطبيقات xAI API تدمج ميزة البحث في الوقت الفعلي Grok Live Search: أعلنت xAI عن إضافة ميزة Live Search إلى واجهة برمجة التطبيقات الخاصة بها، مما يمكّن Grok من البحث عن البيانات في الوقت الفعلي من منصة X، والإنترنت، والأخبار، ومصادر أخرى. هذه الميزة حاليًا في مرحلة الاختبار التجريبي (Beta)، ومتاحة مجانًا للمطورين لفترة محدودة، وتهدف إلى تعزيز قدرة Grok على الحصول على أحدث المعلومات ومعالجتها، لدعم بناء تطبيقات ذكاء اصطناعي أكثر ديناميكية وثراءً بالمعلومات. (المصدر: xai, TheGregYang, yoheinakajima)

Google تطلق سلسلة نماذج MedGemma الطبية الكبيرة مفتوحة المصدر: أطلقت Google نماذج MedGemma الطبية مفتوحة المصدر، المستندة إلى بنية Gemma 3، وتشمل medgemma-4b-pt (النموذج الأساسي)، و medgemma-4b-it (متعدد الوسائط، لتشخيص الصور الطبية)، و medgemma-27b-text-it (نصي فقط، للاستشارات والسجلات الطبية). تم تدريب هذه النماذج خصيصًا على فهم النصوص والصور الطبية، بهدف تعزيز قدرات تطبيقات الذكاء الاصطناعي في المجال الطبي، مثل المساعدة في التشخيص وتحليل السجلات المرضية. النماذج متاحة على Hugging Face. (المصدر: JeffDean, karminski3)
تحديثات لعدة منتجات من نموذج Tencent Hunyuan الكبير، وإطلاق منصة مفتوحة للوكلاء الأذكياء: أعلنت Tencent Hunyuan عن تحديثات تكرارية لنموذجها الرائد سريع التفكير TurboS ونموذج التفكير العميق T1، حيث دخل TurboS ضمن أفضل عشرة نماذج عالميًا في قدرات البرمجة والرياضيات. تم إطلاق نموذج الاستدلال البصري العميق T1-Vision ونموذج المكالمات الصوتية الشامل Hunyuan Voice. تم ترقية محرك المعرفة الأصلي إلى “منصة تطوير الوكلاء الأذكياء من Tencent Cloud”، والتي تدمج قدرات RAG و Agent. كما تم إطلاق إصدارات جديدة من Hunyuan Image 2.0 و 3D v2.5 ونماذج توليد الصور المرئية للألعاب، مع خطط لمواصلة فتح مصدر النماذج الأساسية متعددة الوسائط والإضافات. (المصدر: 36Kr)

Alibaba تتعاون مع جامعة Zhejiang لاقتراح قانون ParScale لتوسيع نطاق الحوسبة المتوازية: اقترح فريق بحثي من Alibaba بالتعاون مع جامعة Zhejiang قانونًا جديدًا لتوسيع النطاق (Scaling Law): قانون توسيع نطاق الحوسبة المتوازية (ParScale). يشير هذا القانون إلى أن زيادة الحوسبة المتوازية للنماذج أثناء التدريب والاستدلال يمكن أن تعزز قدرات النماذج الكبيرة دون زيادة عدد البارامترات، وتحسن كفاءة الاستدلال. مقارنةً بتوسيع نطاق البارامترات، فإن زيادة الذاكرة في ParScale تبلغ 4.5% فقط، وزيادة زمن الانتقال تبلغ 16.7%. تحقق هذه الطريقة ذلك من خلال تحويلات متنوعة للمدخلات، والمعالجة المتوازية، والتجميع الديناميكي للمخرجات، وتظهر أداءً ملحوظًا بشكل خاص في مهام الاستدلال القوية مثل الرياضيات والبرمجة. (المصدر: 36Kr)
Microsoft تطلق نموذج Aurora الأساسي الضخم للغلاف الجوي، بسرعة تنبؤ أسرع 5000 مرة: أطلقت Microsoft والمتعاونون معها أول نموذج أساسي ضخم للغلاف الجوي Aurora، تم تدريبه على أكثر من مليون ساعة من البيانات الجيوفيزيائية، ويمكنه التنبؤ بجودة الهواء ومسارات الأعاصير المدارية وديناميكيات أمواج المحيط والطقس عالي الدقة بشكل أكثر دقة وكفاءة. مقارنةً بنظام التنبؤ العددي المتقدم IFS، فإن سرعة حساب Aurora أسرع بحوالي 5000 مرة، ويحقق أداءً متطورًا (SOTA) في العديد من مجالات التنبؤ الرئيسية. يتميز هذا النموذج ببنية مرنة، ويمكن ضبطه بدقة لمهام محددة، ومن المتوقع أن يعزز تعميم التنبؤ بنظام الأرض. (المصدر: 36Kr)

بحث Google بالذكاء الاصطناعي سيطلق AI Mode، مدمجًا وظائف ذكية متعددة: أعلنت Google عن إطلاق “وضع الذكاء الاصطناعي” (AI Mode) لمحرك البحث الخاص بها، والذي يوصف بأنه “أقوى بحث بالذكاء الاصطناعي”. يعتمد هذا الوضع على Gemini 2.5، ويتمتع بقدرات استدلال أقوى، ويدعم استعلامات أطول، وبحث متعدد الوسائط، وإجابات فورية عالية الجودة. في المستقبل، سيدمج أيضًا وظيفة “البحث العميق” (Deep Search)، التي يمكنها إجراء مئات الاستعلامات في وقت واحد وتقديم تقارير شاملة، ويخطط لدمج البيانات الشخصية من Gmail وغيرها، بالإضافة إلى التفاعل المباشر مع الكاميرا من Project Astra، وإدارة المهام التلقائية من Project Mariner. (المصدر: dotey, Google)

إطلاق نموذج Imagen 4 لتوليد الصور من Google، مع تحسينات كبيرة في السرعة والتفاصيل: أطلقت Google أحدث نموذج لتحويل النص إلى صورة Imagen 4، مدعيةً أنه أسرع بما يتراوح بين 3 إلى 10 مرات مقارنة بالجيل السابق، مع تفاصيل صور أكثر ثراءً، وتأثيرات أكثر دقة، وقدرة معززة بشكل كبير على عرض النصوص. يستطيع Imagen 4 توليد صور لأشياء معقدة مثل الأقمشة وقطرات الماء وفراء الحيوانات، بدقة تصل إلى 2K، ويدعم إنشاء بطاقات المعايدة والملصقات والقصص المصورة وغيرها. النموذج متاح الآن مجانًا على تطبيق Gemini وتطبيقات Whisk و Workspace و Vertex AI. (المصدر: dotey, GoogleDeepMind)
دراسة تكشف عن مخاطر “هلوسة الحزم البرمجية” في الأكواد التي تولدها أدوات مساعدة البرمجة بالذكاء الاصطناعي: تشير دراسة ستُنشر قريبًا في USENIX Security 2025 إلى أن ظاهرة “هلوسة الحزم البرمجية” منتشرة في الأكواد التي يولدها الذكاء الاصطناعي، أي أن المكتبات الخارجية المشار إليها غير موجودة أصلاً. اختبرت الدراسة 16 نموذجًا لغويًا كبيرًا سائدًا، ووجدت أن أكثر من 20% من الأكواد تعتمد على حزم برمجية وهمية، وكانت النسبة أعلى في النماذج مفتوحة المصدر. وهذا يخلق فرصًا لهجمات سلسلة التوريد، حيث يمكن للمهاجمين استغلال أسماء هذه الحزم الوهمية لنشر أكواد ضارة. وقد تعرضت شركات مثل Apple و Microsoft لهجمات إرباك الاعتماديات المماثلة. (المصدر: 36Kr)

Suno تطلق ميزة Remix، مما يسمح للمستخدمين بإعادة إنتاج الأغاني الموجودة: أطلقت منصة توليد الموسيقى بالذكاء الاصطناعي Suno ميزة Remix، التي تسمح للمستخدمين باختيار أي مقطوعة موسيقية على المنصة لإعادة إنتاجها. يمكن للمستخدمين إجراء عمليات مثل إعادة الغناء (Cover)، أو التوسيع (Extend)، أو إعادة استخدام المطالبات (Reuse Prompt) للأغنية. ستحتفظ عمليات Remix بمعلومات مصدر المادة الأصلية، ويمكن للمستخدمين أيضًا تمكين أو تعطيل صلاحيات Remix لأعمالهم الخاصة في أي وقت. (المصدر: SunoMusic)
دراسة تكشف أن جميع نماذج التضمين (embedding models) تتعلم هياكل دلالية متشابهة: اكتشف Jack Morris وباحثون آخرون أن الهياكل الدلالية التي تتعلمها نماذج التضمين المختلفة متشابهة إلى حد كبير، لدرجة أنه يمكن، حتى بدون أي بيانات مقترنة، رسم خرائط بين مساحات التضمين لنماذج مختلفة بناءً على المعلومات الهيكلية فقط. يشير هذا الاكتشاف إلى احتمال وجود نوع من البنية الهندسية العالمية في مساحات التضمين، وهو أمر ذو أهمية كبيرة لتوافق النماذج، ونقل التعلم، وفهم جوهر التضمينات. (المصدر: menhguin, torchcompiled, dilipkay, jeremyphoward)
ورقة بحثية تناقش مشكلة “ضريبة الهلوسة” (hallucination tax) في الضبط الدقيق بالتعلم المعزز (RFT): تشير دراسة أجراها Taiwei Shi وآخرون إلى أن الضبط الدقيق بالتعلم المعزز (RFT)، مع تعزيزه لقدرات الاستدلال في النماذج اللغوية الكبيرة، قد يؤدي إلى أن تنتج النماذج بثقة إجابات هلوسية عند مواجهة أسئلة لا يمكنها الإجابة عليها، وهو ما أطلقوا عليه “ضريبة الهلوسة”. قدمت الدراسة مجموعة بيانات SUM (مسائل رياضية مصطنعة لا يمكن الإجابة عليها) للتحقق، ووجدت أن تدريب RFT القياسي يقلل بشكل كبير من معدل رفض النموذج. من خلال إضافة كمية صغيرة من بيانات SUM إلى RFT، يمكن استعادة سلوك الرفض المناسب للنموذج بشكل فعال، وتعزيز إدراكه لعدم اليقين الخاص به وحدود معرفته. (المصدر: teortaxesTex)

🧰 أدوات
Google تطلق أداة Flow لإنتاج الأفلام بالذكاء الاصطناعي، مدمجةً Veo و Imagen و Gemini: أطلقت Google أداة Flow لإنتاج الأفلام بالذكاء الاصطناعي، والتي تدمج أحدث نماذجها لتوليد الفيديو Veo 3، ونموذج توليد الصور Imagen 4، ونموذج الوسائط المتعددة Gemini. يمكن للمستخدمين من خلال Flow استخدام اللغة الطبيعية وإدارة الموارد لإنشاء أفلام قصيرة بجودة سينمائية بسهولة، بما في ذلك توليد المقاطع من مطالبات نصية، ودمج المشاهد، وبناء السرد، وحفظ العناصر شائعة الاستخدام كمواد. تهدف هذه الأداة إلى مساعدة المبدعين على إنتاج أعمال ذات جودة سينمائية بسرعة وكفاءة. وهي متاحة حاليًا لمشتركي Google AI Pro و Ultra في الولايات المتحدة. (المصدر: dotey, op7418)

Google تطلق وكيل البرمجة الذكي السحابي Jules، المدعوم بـ Gemini 2.5 Pro: أطلقت Google وكيل البرمجة الذكي Jules، المستند إلى Gemini 2.5 Pro. يستطيع Jules معالجة المهام في مستودعات الأكواد تلقائيًا في الخلفية، مثل إصلاح الأخطاء وإعادة هيكلة الأكواد، ويدعم مهام متعددة متوازية. بالإضافة إلى ذلك، يوفر Jules بودكاست Codecasts محدثًا يوميًا، لمساعدة المستخدمين على فهم أحدث التطورات في مستودعات الأكواد. الأداة متاحة حاليًا للتجربة المجانية. (المصدر: dotey, karminski3, GoogleDeepMind)
LangChain تطلق منصة الوكلاء الأذكياء مفتوحة المصدر بدون كود Open Agent Platform (OAP): أطلقت LangChain منصة Open Agent Platform (OAP)، وهي منصة مفتوحة المصدر بدون كود موجهة للمستخدمين العاديين، لبناء ونمذجة ونشر وكلاء الذكاء الاصطناعي. تدعم OAP بناء الوكلاء من خلال واجهة مستخدم ويب، والاتصال بخوادم RAG لتحسين استرجاع المعلومات، وتوسيع الأدوات الخارجية من خلال MCP، واستخدام Agent Supervisor لتنسيق تدفقات عمل الوكلاء المتعددين. تهدف إلى تمكين المطورين غير المتخصصين من الاستفادة من القدرات القوية لوكلاء LangGraph. (المصدر: LangChainAI, Hacubu)

مختبرات Google تطلق أداة تصميم واجهة المستخدم بالذكاء الاصطناعي Stitch: أطلقت مختبرات Google أداة تصميم واجهة المستخدم بالذكاء الاصطناعي Stitch، والتي تدمج أحدث نماذج DeepMind من Google (بما في ذلك Gemini و Imagen)، ويمكنها إنشاء تصميمات واجهة مستخدم عالية الجودة بسرعة. يمكن للمستخدمين من خلال اللغة الطبيعية تحديث سمات الواجهة، وضبط الصور تلقائيًا، وتحقيق ترجمة المحتوى متعدد اللغات، وتصدير كود الواجهة الأمامية بنقرة واحدة. Stitch هي نسخة مطورة من Galileo AI السابق، وقد انضم مؤسسها إلى فريق Google. (المصدر: dotey)
LangChain تطلق صندوق الحماية المحلي للأكواد LangChain Sandbox: أطلقت LangChain أداة LangChain Sandbox، التي تسمح لوكلاء الذكاء الاصطناعي بتشغيل أكواد Python غير موثوق بها بأمان محليًا. توفر بيئة تنفيذ معزولة وصلاحيات قابلة للتكوين، دون الحاجة إلى تنفيذ عن بُعد أو حاويات Docker، وتدعم استمرار الحالة بين عمليات التنفيذ المتعددة من خلال الجلسات. يوفر هذا أداة أكثر أمانًا وملاءمة لبناء وكلاء ذكاء اصطناعي قادرين على تنفيذ الأكواد (مثل codeact agents). (المصدر: hwchase17, Hacubu)
Vitalops تفتح مصدر Datatune: أداة LLM لمعالجة مجموعات البيانات الضخمة باللغة الطبيعية: فتحت Vitalops مصدر Datatune، وهي أداة تسمح للمستخدمين بمعالجة مجموعات بيانات بأي حجم من خلال تعليمات اللغة الطبيعية. تدعم Datatune عمليات Map و Filter، ويمكنها الاتصال بمختلف مزودي خدمات LLM مثل OpenAI و Azure و Ollama أو نماذج مخصصة، وتستخدم Dask DataFrame للتقسيم والمعالجة المتوازية. تهدف هذه الأداة إلى تبسيط مهام مثل تنظيف البيانات وإثرائها، لتحل محل التعبيرات النمطية المعقدة أو الأكواد المخصصة. (المصدر: Reddit r/MachineLearning)
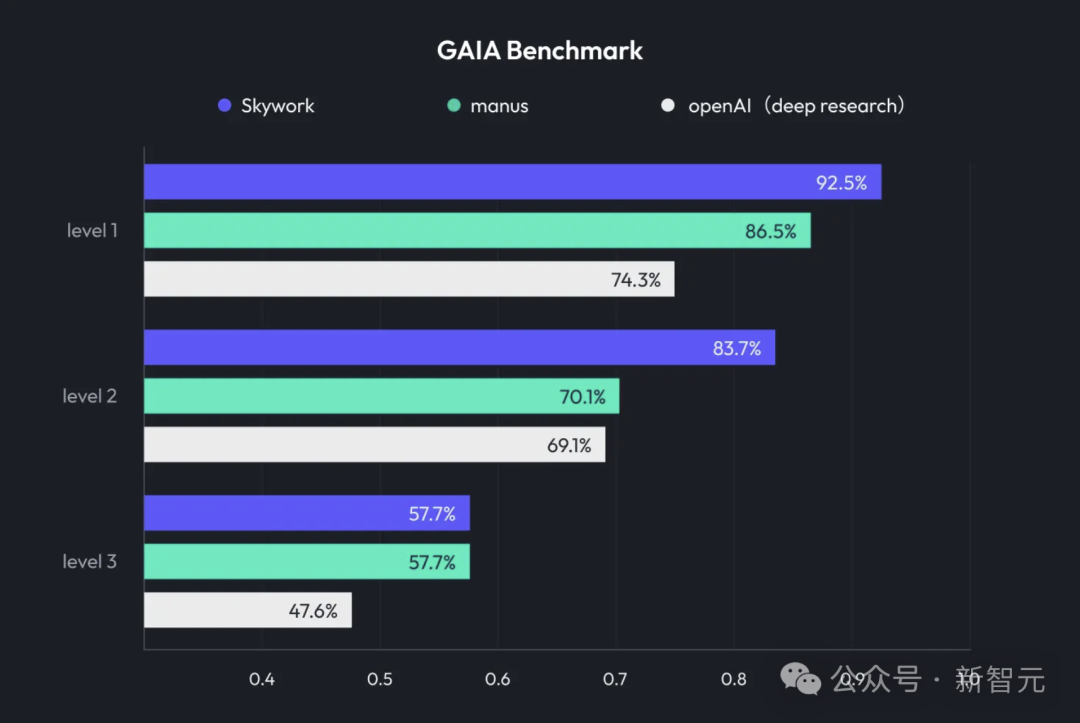
Kunlun Tech تطلق Skywork Super Agents، مدمجةً Deep Research ومخرجات متعددة الوسائط: أطلقت Kunlun Tech منتجها المكتبي القائم على الذكاء الاصطناعي Skywork Super Agents، والذي يجمع بين قدرات البحث العميق (Deep Research) ووظائف الإخراج متعدد الوسائط للوكلاء الأذكياء العامين. يدعم هذا المنتج سيناريوهات مكتبية متعددة مثل إنشاء عروض PowerPoint التقديمية، وكتابة المستندات، ومعالجة جداول البيانات، وإنشاء صفحات الويب، وإنشاء البودكاست، مع التركيز على تتبع مصدر المحتوى لتقليل الهلوسة، وتوفير وظائف التحرير والتصدير عبر الإنترنت. كما فتحت Kunlun Tech مصدر إطار عمل Deep Research Agent و MCP ذات الصلة. (المصدر: 36Kr)
Google تطلق SynthID Detector للمساعدة في تحديد المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي: أطلقت Google أداة SynthID Detector، وهي بوابة إلكترونية جديدة تهدف إلى مساعدة الصحفيين والإعلاميين والباحثين على تحديد ما إذا كان المحتوى يحمل علامة SynthID المائية بسهولة أكبر. SynthID هي تقنية طورتها Google لإضافة علامة مائية غير مرئية إلى المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي (بما في ذلك الصور والصوت والفيديو والنصوص)، ويساعد إطلاق أداة الكشف هذه على زيادة شفافية المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي وإمكانية تتبعه. (المصدر: dotey, Google)
Feishu تطلق ميزة “الأسئلة والأجوبة المعرفية”، لإنشاء أداة أسئلة وأجوبة بالذكاء الاصطناعي مخصصة للشركات: أطلقت Feishu ميزة جديدة باسم “الأسئلة والأجوبة المعرفية”، وهي أداة يمكنها، بناءً على جميع المعلومات التي يمكن لموظفي الشركة الوصول إليها على Feishu (الرسائل، المستندات، قواعد المعرفة، إلخ)، وبالاقتران مع نماذج لغوية كبيرة مثل DeepSeek-R1 و Doubao وتقنية RAG، تزويد الموظفين بإجابات دقيقة ودعم لإنشاء المحتوى. تتميز بأن الإجابات يتم تعديلها ديناميكيًا بناءً على هوية السائل وصلاحياته داخل الشركة، وتهدف إلى دمج الذكاء الاصطناعي بسلاسة في سير العمل اليومي، وتعزيز كفاءة إدارة المعرفة واستخدامها في الشركات. (المصدر: QbitAI)

Animon: أول منصة يابانية لتوليد الرسوم المتحركة بالذكاء الاصطناعي، تركز على جودة الأنمي ثنائي الأبعاد والتوليد المجاني غير المحدود: أطلقت شركة CreateAI اليابانية (المعروفة سابقًا باسم TuSimple Future) منصة Animon لتوليد الرسوم المتحركة بالذكاء الاصطناعي، وهي مصممة خصيصًا لإنشاء الرسوم المتحركة. تدمج هذه المنصة جماليات الرسوم المتحركة اليابانية مع تقنية الذكاء الاصطناعي، مع التركيز على اتساق نمط الصورة والإنتاج الفعال، وتدعي أن المستخدمين الأفراد يمكنهم توليد مقاطع فيديو مجانًا وبلا حدود. تدعم Animon توليد مقاطع رسوم متحركة بسرعة (حوالي 3 دقائق) من خلال تحميل صور الشخصيات والأوصاف النصية، وتهدف إلى خفض عتبة إنشاء الرسوم المتحركة وتحفيز نظام بيئي للمحتوى الذي ينشئه المستخدمون (UGC). تمتلك الشركة الأم CreateAI نموذجًا لغويًا كبيرًا خاصًا بها Ruyi، وتحمل حقوق تعديل أعمال مثل “The Three-Body Problem” و “Jin Yong Qunxia Zhuan”، وتتبع استراتيجية ذات شقين: “محتوى ذاتي التطوير + منصة أدوات UGC”. (المصدر: QbitAI)

📚 موارد تعليمية
DeepLearning.AI تطلق دورة جديدة: التحسين المعزز لـ LLM باستخدام GRPO: أعلن Andrew Ng عن إطلاق دورة قصيرة جديدة بالتعاون مع Predibase، بعنوان “التحسين المعزز لـ LLM باستخدام GRPO (Group Relative Policy Optimization)”. ستُعلّم الدورة كيفية استخدام التعلم المعزز (خاصة خوارزمية GRPO) لتعزيز أداء LLM في مهام الاستدلال متعددة الخطوات (مثل حل المسائل الرياضية، وتصحيح الأخطاء البرمجية)، دون الحاجة إلى عينات ضبط دقيق مُشرَف عليها بكميات كبيرة. يوجه GRPO النموذج من خلال دالة مكافأة قابلة للبرمجة، وهو مناسب للمهام التي يمكن التحقق من نتائجها، ويمكنه تحسين قدرات الاستدلال في نماذج LLM الصغيرة بشكل كبير. (المصدر: AndrewYNg, DeepLearningAI)
LlamaIndex تشارك خبراتها في إدارة مستودعات Python الأحادية الضخمة: شارك فريق LlamaIndex خبراته في إدارة مستودع Python الأحادي (monorepo) الذي يحتوي على أكثر من 650 حزمة مجتمعية. لقد انتقلوا من Poetry و Pants إلى uv وأداة إدارة البناء مفتوحة المصدر التي طوروها ذاتيًا LlamaDev، مما أدى إلى زيادة سرعة تشغيل الاختبارات بنسبة 20%، وسجلات أوضح، وتبسيط التطوير المحلي، وخفض عتبة المساهمة للمساهمين. هذه التجربة مفيدة للفرق التي تحتاج إلى إدارة مشاريع Python كبيرة. (المصدر: jerryjliu0)

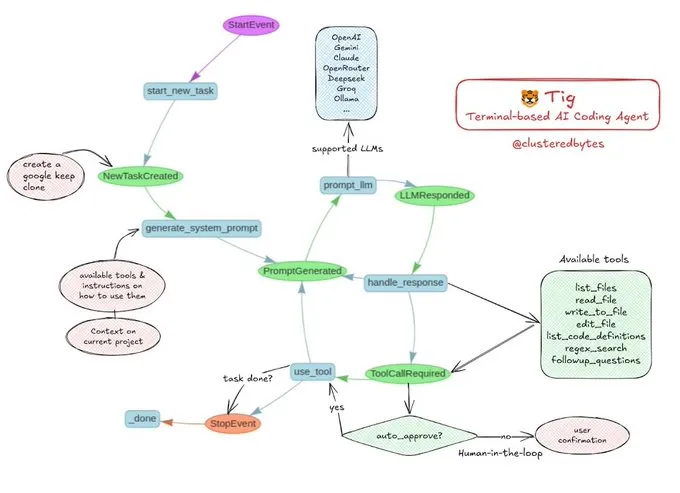
مشاركة تعليمية: بناء وكيل الترميز الذكي الخاص بك Tig: أوصى Jerry Liu بمشروع وكيل ترميز ذكي مفتوح المصدر يسمى Tig. هذا المشروع هو مساعد ترميز قائم على الطرفية، مع تدخل بشري في الحلقة (human-in-the-loop)، تم بناؤه باستخدام سير عمل LlamaIndex. يستطيع Tig تنفيذ مهام مثل كتابة وتصحيح وتحليل أكواد لغات متعددة، وتنفيذ أوامر shell، والبحث في مستودعات الأكواد، وإنشاء الاختبارات والوثائق. يوفر مستودع GitHub دليل بناء مفصل، وهو مورد تعليمي جيد للمطورين الذين يرغبون في تعلم بناء وكلاء ترميز ذكيين. (المصدر: jerryjliu0)
Hugging Face تنشر تدوينة مهمة عن VLM، وتقدم مختبر nanoVLM المجتمعي: نشرت Hugging Face تدوينة حول نماذج اللغة المرئية (VLM)، تغطي أساسيات VLM، وهندستها المعمارية، وكيفية تدريب VLM خفيف الوزن خاص بك. كما قدمت nanoVLM، وهو مستودع مفتوح المصدر لضبط VLM بدقة، والذي تطور الآن ليصبح مختبرًا مجتمعيًا لأبحاث اللغة المرئية، يهدف إلى مساعدة المطورين على استكشاف والمساهمة في أبحاث VLM. (المصدر: _akhaliq, huggingface)
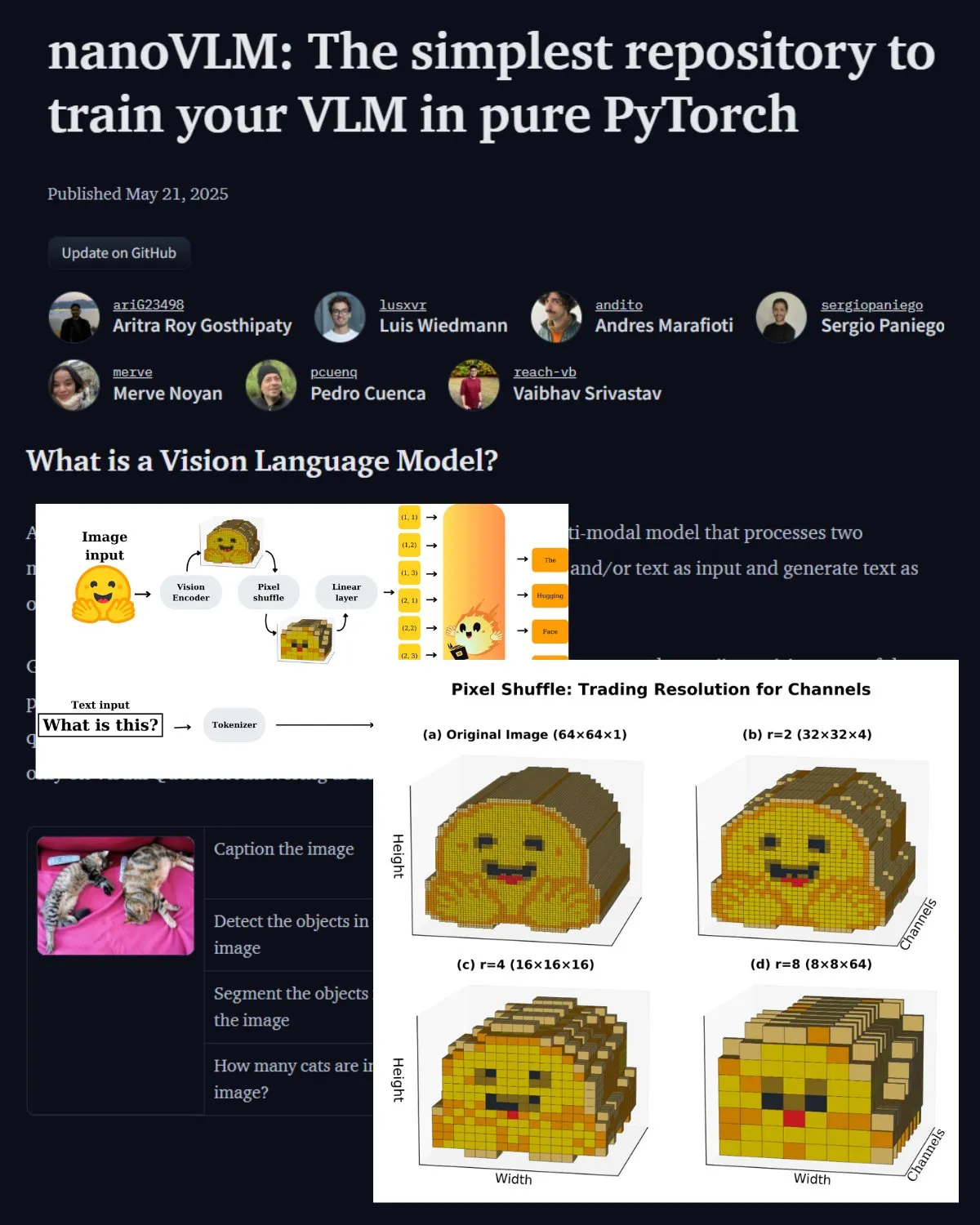
Serrano Academy تنشر سلسلة دروس فيديو حول الضبط الدقيق لـ LLM بالتعلم المعزز: أكملت Serrano Academy ونشرت سلسلة من دروس الفيديو حول استخدام التعلم المعزز للضبط الدقيق وتدريب LLM. تغطي المحتويات مفاهيم وتقنيات رئيسية مثل التعلم المعزز العميق (Deep Reinforcement Learning)، و RLHF (Reinforcement Learning from Human Feedback)، و PPO (Proximal Policy Optimization)، و DPO (Direct Preference Optimization)، و GRPO (Group Relative Policy Optimization)، و KL Divergence. (المصدر: SerranoAcademy)
ورقة بحثية تناقش ظاهرة “الطبقات الفارغة” (Voids) في النماذج اللغوية الكبيرة: حققت دراسة في ظاهرة عدم تنشيط جميع الطبقات في النماذج اللغوية الكبيرة المضبوطة بالتعليمات أثناء عملية الاستدلال، وأطلقت على الطبقات غير النشطة اسم “الطبقات الفارغة” (Voids). استخدمت الدراسة طريقة الحوسبة التكيفية L2 (LAC) لتتبع الطبقات النشطة خلال مرحلتي معالجة المطالبة وتوليد الاستجابة، ووجدت أن الطبقات النشطة تختلف في المراحل المختلفة. أظهرت التجارب أنه في اختبارات مثل MMLU، أدى تخطي الطبقات الفارغة في Qwen2.5-7B-Instruct (باستخدام 30% فقط من الطبقات) إلى تحسين الأداء، مما يشير إلى أن التخطي الانتقائي لمعظم الطبقات قد يكون مفيدًا لمهام معينة. (المصدر: HuggingFace Daily Papers)
دراسة تقترح “التفكير الناعم” (Soft Thinking): إطلاق العنان لإمكانات استدلال LLM في مساحة المفاهيم المستمرة: تقترح ورقة بحثية بعنوان “Soft Thinking” طريقة لا تتطلب تدريبًا، وذلك من خلال توليد رموز مفاهيمية ناعمة ومجردة في مساحة المفاهيم المستمرة لمحاكاة الاستدلال “الناعم” الشبيه بالبشر. تتكون هذه الرموز المفاهيمية من مزيج مرجح احتماليًا من تضمينات الرموز، ويمكنها تغليف معانٍ متعددة من الرموز المنفصلة ذات الصلة، وبالتالي استكشاف مسارات استدلال متعددة ضمنيًا. أظهرت التجارب أن هذه الطريقة حسنت دقة pass@1 في معايير الرياضيات والبرمجة، مع تقليل استخدام الـ token، والحفاظ على قابلية تفسير المخرجات. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش تحقيق سلاسل تفكير قابلة للتطوير من خلال الاستدلال المرن (Elastic Reasoning): اقترح باحثون من Salesforce طريقة لتحقيق سلاسل تفكير قابلة للتطوير من خلال الاستدلال المرن (Elastic Reasoning). تهدف هذه الدراسة إلى معالجة كيفية قيام النماذج اللغوية الكبيرة بتوليد وإدارة سلاسل التفكير الطويلة بفعالية عند التعامل مع مهام الاستدلال المعقدة، وذلك لتحسين دقة الاستدلال وكفاءته. تم نشر النماذج والأكواد ذات الصلة على Hugging Face. (المصدر: _akhaliq)

دراسة بحثية: هل ستكذب نماذج الذكاء الاصطناعي لإنقاذ الأطفال المرضى؟: أنشأت دراسة بعنوان LitmusValues عملية تقييم تهدف إلى الكشف عن أولويات نماذج الذكاء الاصطناعي ضمن مجموعة من فئات قيم الذكاء الاصطناعي. من خلال جمع AIRiskDilemmas (مجموعة من المعضلات تحتوي على سيناريوهات متعلقة بمخاطر أمان الذكاء الاصطناعي)، قام الباحثون بقياس اختيارات نماذج الذكاء الاصطناعي في ظل تضارب القيم المختلفة، وبالتالي التنبؤ بأولويات قيمها وتحديد المخاطر المحتملة. أظهرت الدراسة أن القيم المحددة في LitmusValues (بما في ذلك الرعاية وغيرها) يمكن أن تتنبأ بالسلوكيات الخطرة التي شوهدت بالفعل في AIRiskDilemmas بالإضافة إلى السلوكيات الخطرة غير المرئية في HarmBench. (المصدر: HuggingFace Daily Papers)
ورقة بحثية تدرس الضبط الدقيق الفعال لنماذج الانتشار من خلال التعلم المعزز القائم على القيمة (VARD): تُظهر نماذج الانتشار أداءً قويًا في مهام التوليد، ولكن الضبط الدقيق لخصائص معينة لا يزال يمثل تحديًا. تعاني طرق التعلم المعزز الحالية من أوجه قصور في الاستقرار والكفاءة والتعامل مع المكافآت غير القابلة للتفاضل. يقترح VARD (Value-based Reinforced Diffusion) أولاً تعلم دالة قيمة تتنبأ بتوقعات المكافأة من الحالات الوسيطة، ثم استخدام دالة القيمة هذه والتنظيم باستخدام KL regularization لتوفير إشراف مكثف طوال عملية التوليد. أثبتت التجارب أن هذه الطريقة يمكن أن تحسن توجيه المسار، وتعزز كفاءة التدريب، وتوسع تطبيقات التعلم المعزز لتشمل تحسين نماذج الانتشار لدوال المكافآت المعقدة غير القابلة للتفاضل. (المصدر: HuggingFace Daily Papers)
💼 أعمال
LMArena.ai (سابقًا LMSYS.org) تحصل على تمويل أولي بقيمة 100 مليون دولار، بقيادة a16z وشركة استثمارات جامعة كاليفورنيا: أعلنت منصة تقييم نماذج الذكاء الاصطناعي LMArena.ai (المعروفة سابقًا باسم LMSYS.org) عن إكمال جولة تمويل أولية بقيمة 100 مليون دولار أمريكي، بقيادة مشتركة من Andreessen Horowitz (a16z) وشركة استثمارات جامعة كاليفورنيا (UC Investments). تلتزم الشركة ببناء منصة محايدة ومفتوحة وموجهة نحو المجتمع، لمساعدة العالم على فهم وتحسين أداء نماذج الذكاء الاصطناعي في استعلامات المستخدمين الحقيقية. بلغت قيمة الشركة بعد التمويل 600 مليون دولار أمريكي. (المصدر: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
الحكومة الأمريكية تعلن عن بيع تقنيات وخدمات ذكاء اصطناعي للسعودية والإمارات بقيمة مئات المليارات من الدولارات: أعلنت الحكومة الأمريكية عن اتفاقيات مع المملكة العربية السعودية ودولة الإمارات العربية المتحدة لبيع تقنيات وخدمات ذكاء اصطناعي للبلدين بقيمة مئات المليارات من الدولارات. تشمل الشركات المشاركة AMD، و Nvidia، و Amazon، و Google، و IBM، و Oracle، و Qualcomm وغيرها. ستقوم Nvidia بتزويد شركة Humain السعودية بـ 18,000 شريحة ذكاء اصطناعي GB300 ومئات الآلاف من وحدات معالجة الرسومات (GPU) لاحقًا؛ وستستثمر AMD و Humain بشكل مشترك 10 مليارات دولار لبناء مراكز بيانات للذكاء الاصطناعي. تهدف هذه الخطوة إلى تعزيز نفوذ الولايات المتحدة في مجال الذكاء الاصطناعي في منطقة الشرق الأوسط ومساعدة البلدين على تنويع اقتصاداتهما. (المصدر: DeepLearning.AI Blog)

Meta تطلق برنامج Llama للشركات الناشئة، لتمكين الشركات الناشئة المبكرة في مجال الذكاء الاصطناعي: أعلنت Meta عن إطلاق برنامج Llama للشركات الناشئة (Llama Startup Program)، الذي يهدف إلى دعم الشركات الناشئة الأمريكية في مراحلها المبكرة (التي جمعت تمويلاً أقل من 10 ملايين دولار، ولديها مطور واحد على الأقل) للاستفادة من نماذج Llama في ابتكار تطبيقات الذكاء الاصطناعي التوليدي. يوفر البرنامج سداد تكاليف الموارد السحابية، ودعمًا فنيًا من خبراء Llama، وموارد مجتمعية. الموعد النهائي لتقديم الطلبات هو 30 مايو 2025، الساعة 6 مساءً (بتوقيت المحيط الهادئ). (المصدر: AIatMeta)
🌟 المجتمع
مؤتمر Google I/O يثير نقاشًا واسعًا: اندماج شامل للذكاء الاصطناعي وآفاق مستقبلية: أثار مؤتمر Google I/O، الذي شهد إطلاق عدد كبير من المنتجات والتحديثات المتعلقة بالذكاء الاصطناعي، بما في ذلك سلسلة نماذج Gemini، وتوليد الفيديو Veo 3، وتوليد الصور Imagen 4، ووضع البحث بالذكاء الاصطناعي، نقاشًا واسعًا في المجتمع. رأى العديد من المعلقين أن Google أظهرت قوة كبيرة في تطبيقات الذكاء الاصطناعي، خاصة استراتيجيتها لدمج الذكاء الاصطناعي بسلاسة في نظامها البيئي للمنتجات الحالية. في الوقت نفسه، أصبحت موضوعات مثل مصداقية المحتوى الذي يولده الذكاء الاصطناعي، وأخلاقيات الذكاء الاصطناعي، والمسار المستقبلي لـ AGI، محط تركيز للنقاش. (المصدر: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

أجهزة الذكاء الاصطناعي تصبح محور اهتمام جديد، وتعاون OpenAI مع Jony Ive يثير الانتباه: أشعل خبر استحواذ OpenAI على شركة io لأجهزة الذكاء الاصطناعي التابعة لـ Jony Ive، وعرض Google للنموذج الأولي لنظارات Android XR الذكية في مؤتمر I/O، نقاشًا مجتمعيًا حول مستقبل أجهزة الذكاء الاصطناعي. يُنظر إلى تعاون Sam Altman مع Jony Ive على أنه يهدف إلى إنشاء جيل جديد من أجهزة الحوسبة الشخصية المدفوعة بالذكاء الاصطناعي، والتي قد تحدث ثورة في طرق التفاعل الحالية مع الهواتف وأجهزة الكمبيوتر. يتطلع المجتمع بشكل عام إلى أن تقدم أجهزة الذكاء الاصطناعي الأصلية (AI-native) تجربة ثورية، ولكنه يهتم أيضًا بشكلها ووظائفها وقبولها في السوق. (المصدر: dotey, sama, dotey, swyx)

دور الذكاء الاصطناعي ومخاطره في تطوير البرمجيات يثير النقاش: أثار إطلاق Mistral AI لنموذج Devstral المصمم خصيصًا لوكلاء الترميز الذكي، وتحديث OpenAI لـ Codex، نقاشًا حول تطبيقات الذكاء الاصطناعي في تطوير البرمجيات. يهتم المجتمع بالقدرات الفعلية لأدوات البرمجة بالذكاء الاصطناعي، وجودة وسلامة الأكواد التي تولدها. على وجه الخصوص، تشير الأبحاث إلى أن الأكواد التي يولدها الذكاء الاصطناعي قد تشير إلى “حزم برمجية هلوسية” غير موجودة، مما يشكل مخاطر على أمن سلسلة التوريد، ويُنبه المطورين إلى ضرورة التحقق بعناية من الأكواد والاعتماديات التي يولدها الذكاء الاصطناعي. (المصدر: MistralAI, DeepLearning.AI Blog, qtnx_)
النقاش حول تقييم نماذج الذكاء الاصطناعي واختبارات الأداء القياسية مستمر في التصاعد: أدى حصول LMArena.ai على تمويل ضخم، وأداء النماذج الجديدة المختلفة في اختبارات الأداء القياسية، إلى جعل تقييم نماذج الذكاء الاصطناعي موضوعًا ساخنًا للنقاش في المجتمع. يهتم المستخدمون بالقدرات الحقيقية للنماذج المختلفة في مهام محددة (مثل البرمجة، والرياضيات، والإجابة على الأسئلة العامة، وفهم المشاعر)، بالإضافة إلى موثوقية وقيود أنظمة التقييم الحالية. على سبيل المثال، يحاول إطار تقييم الذكاء العاطفي SAGE الذي أصدرته Tencent، توفير بُعد تقييم جديد لنماذج الذكاء الاصطناعي من منظور “الذكاء العاطفي”. (المصدر: lmarena_ai, 36Kr, natolambert)
تأخر تطور قطاع التكنولوجيا في أوروبا يثير التفكير، و Yann LeCun يعيد نشر نقاش حول أن الافتقار إلى “الوطنية” هو السبب الرئيسي: أثار مقال في صحيفة وول ستريت جورنال حول كون المشهد التكنولوجي الأوروبي أصغر بكثير من نظيره الأمريكي والصيني نقاشًا، وأعاد Yann LeCun نشر تعليق Arnaud Bertrand. يرى Bertrand أن السبب الرئيسي لتخلف التكنولوجيا الأوروبية هو الافتقار إلى روح “الوطنية”، حيث تميل وسائل الإعلام والنخب الأوروبية إلى الإشادة بالشركات الناشئة الأمريكية وتجاهل الابتكار المحلي، مما يؤدي إلى صعوبة حصول الشركات المحلية على الدعم المبكر والاعتراف في السوق. واستشهد بتجربته في تأسيس HouseTrip كمثال، مشيرًا إلى أن أوروبا تفتقر إلى الثقة بالنفس والدعم للابتكار المحلي. (المصدر: ylecun)

💡 أخبار أخرى
مشكلة استهلاك الطاقة في الذكاء الاصطناعي تثير القلق: نظم MIT Technology Review مائدة مستديرة لمناقشة مشكلة استهلاك الطاقة الناجمة عن التطور المتسارع لتقنية الذكاء الاصطناعي وتأثيرها على المناخ. مع تزايد حجم نماذج الذكاء الاصطناعي ونطاق تطبيقاتها، تزداد بشكل حاد حاجتها إلى الكهرباء والموارد الحاسوبية، وأصبحت احتياجات مراكز البيانات من الطاقة محط تركيز جديد. ركز النقاش على استهلاك الطاقة لكل استعلام ذكاء اصطناعي، والبصمة الطاقوية الإجمالية للذكاء الاصطناعي، وكيفية مواجهة هذا التحدي. (المصدر: MIT Technology Review, madiator)

Anthropic تُلمح إلى أخبار جديدة، والمجتمع يتكهن بإمكانية إطلاق Claude 4: نشرت شركة Anthropic تلميحًا بأنها ستقوم ببث مباشر في 22 مايو الساعة 9:30 صباحًا بتوقيت المحيط الهادئ (23 مايو الساعة 00:00 بتوقيت بكين)، مما أثار تكهنات في المجتمع حول إمكانية إطلاقها لجيل جديد من نموذج Claude (قد يكون Claude 4). بالنظر إلى التحديثات الهامة الأخيرة من OpenAI و Google، تحظى هذه الخطوة من Anthropic باهتمام كبير. (المصدر: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
اندماج تقنيات الذكاء الاصطناعي و XR، و Google تعرض نموذجًا أوليًا لنظارات Android XR الذكية: عرضت Google في مؤتمر I/O نموذجًا أوليًا لنظارات Android XR الذكية، مؤكدةً على اندماجها العميق مع الذكاء الاصطناعي. يدعم هذا الجهاز المساعدة الذكية من منظور الشخص الأول ووظائف المساعدة بدون تلامس، حيث يمكن للمستخدمين التفاعل مع الجهاز من خلال اللغة الطبيعية لإكمال مهام مثل الاستعلام عن المعلومات، وإدارة الجداول الزمنية، والملاحة في الوقت الفعلي. يشير هذا إلى أن الذكاء الاصطناعي سيصبح القوة الدافعة الأساسية للتفاعل والوظائف في الجيل القادم من أجهزة XR، مما يعزز تجربة المستخدم في بيئات الواقع المعزز. (المصدر: dotey, 36Kr)