
كلمات مفتاحية:جيميني 2.5, وكيل الذكاء الاصطناعي, النماذج الكبيرة, نماذج الرؤية واللغة, التعلم المعزز, وضع جيميني 2.5 برو التفكير العميق, وكيل جيت هاب كوبايلوت مفتوح المصدر, توليد الصور بخطوة واحدة مع مين فلو, التخطيط البصري والاستدلال VPRL, تحسين الاستدلال في هواوي فيوجن سبيك MoE
🔥 تركيز
مؤتمر Google I/O يشهد إعلانات عن تطورات متعددة في مجال الذكاء الاصطناعي، تتصدرها سلسلة نماذج Gemini 2.5: أعلنت جوجل عن تحديثات عديدة في مجال الذكاء الاصطناعي خلال مؤتمر I/O. وُصف Gemini 2.5 Pro بأنه أقوى نموذج تأسيسي حاليًا، ويتفوق في العديد من اختبارات الأداء القياسية، ويقدم وضع Deep Think لتعزيز الاستدلال. كما تم تحديث النموذج الخفيف Gemini 2.5 Flash، مع التركيز على السرعة والكفاءة. يقدم بحث جوجل “وضع الذكاء الاصطناعي”، الذي يوفر تجربة بحث بالذكاء الاصطناعي شاملة ومتكاملة من خلال Gemini 2.5، قادرًا على تحليل المشكلات المعقدة واستخلاص المعلومات العميقة. يحقق نموذج توليد الفيديو Veo 3 توليدًا متزامنًا للصوت والصورة، بينما يعزز نموذج الصور Imagen 4 القدرة على معالجة التفاصيل والنصوص. بالإضافة إلى ذلك، تم إطلاق أداة إنتاج الأفلام بالذكاء الاصطناعي Flow وتطبيق Gemini Live لمشروع المساعد الذكي Project Astra. تُظهر هذه التحديثات عزم Google على دمج الذكاء الاصطناعي بشكل كامل في منظومة منتجاتها، بهدف تحسين تجربة المستخدم وكفاءة المطورين (المصدر: 量子位, 36氪, WeChat)

مؤتمر Microsoft Build يركز على AI Agent، و GitHub Copilot يشهد ترقية كبيرة ويعلن عن مصدر مفتوح: وضعت مايكروسوفت AI Agent في صميم مؤتمر المطورين Build 2025، وأعلنت عن فتح مصدر مشروع GitHub Copilot Extension for VSCode، وإطلاق وكيل ترميز جديد يعمل بالذكاء الاصطناعي (Agent). يستطيع هذا الـ Agent إكمال مهام مثل إصلاح الأخطاء البرمجية، وإضافة الميزات، وتحسين التوثيق بشكل مستقل، وهو مدمج بعمق في GitHub Copilot. كما أصدرت مايكروسوفت منصة Microsoft Discovery للوكلاء الأذكياء المخصصة للاكتشافات العلمية، ومشروع NLWeb للمواقع التفاعلية باللغة الطبيعية، ومنصة بناء الوكلاء Agent Factory، و Copilot Tuning لتخصيص بيانات الشركات. تشير هذه المبادرات إلى أن مايكروسوفت تدفع بقوة تطبيقات AI Agent في مجالات متعددة مثل التطوير والبحث العلمي، بهدف بناء نظام بيئي تعاوني مفتوح للوكلاء الأذكياء (المصدر: 量子位, WeChat, WeChat)

كيفين ويل، كبير مسؤولي المنتجات في OpenAI، يوضح توجه تحول ChatGPT: من الإجابة على الأسئلة إلى اتخاذ الإجراءات، AI Agent سيتطور بسرعة: كشف كيفين ويل، كبير مسؤولي المنتجات في OpenAI، في مقابلة أن موقع ChatGPT سيتحول من أداة للإجابة على الأسئلة إلى AI Agent قادر على تنفيذ المهام للمستخدمين. ويتوقع أن يتمكن AI Agent على المدى القصير من التطور بسرعة من مهندس مبتدئ إلى مهندس متقدم، وحتى مهندس معماري. هذا يعني أن AI Agent سيتمتع باستقلالية أكبر، وقدرة على حل المشكلات المعقدة من خلال تصفح الويب، والتفكير العميق، والاستدلال والتلخيص. وأشار ويل أيضًا إلى أن تكلفة تدريب النماذج الحالية تبلغ 500 ضعف تكلفة GPT-4، ولكن في المستقبل سيتم تحسين الكفاءة وخفض أسعار واجهة برمجة التطبيقات (API) من خلال تحسينات الأجهزة والخوارزميات، لتعزيز تعميم وتطوير الذكاء الاصطناعي (المصدر: 量子位, 36氪)

فريق Kaiming He يقترح MeanFlow: إنجاز جديد على أحدث طراز (SOTA) في توليد الصور بخطوة واحدة، لا يتطلب تدريبًا مسبقًا ويُحدث ثورة في النماذج التقليدية: قدم فريق Kaiming He في أحدث أبحاثه إطارًا لنمذجة التوليد بخطوة واحدة يسمى MeanFlow. على مجموعة بيانات ImageNet 256×256، حقق الإطار درجة FID تبلغ 3.43 بتقييم دالة واحدة فقط (1-NFE)، متفوقًا على أفضل الطرق المماثلة السابقة بنسبة 50%-70%، وذلك دون الحاجة إلى تدريب مسبق، أو تقطير، أو تعلم تدريجي. يكمن الابتكار الأساسي في MeanFlow في إدخال مفهوم “متوسط مجال السرعة” واستنتاج علاقته الرياضية بمجال السرعة اللحظي، لتوجيه تدريب الشبكة العصبية. يمكن لهذه الطريقة أيضًا دمج التوجيه بدون مصنف (CFG) بشكل طبيعي دون زيادة النفقات الحسابية الإضافية أثناء أخذ العينات، مما يقلل بشكل كبير من فجوة الأداء بين نماذج التوليد أحادية الخطوة ومتعددة الخطوات، ويُظهر إمكانات النماذج قليلة الخطوات في تحدي النماذج متعددة الخطوات (المصدر: WeChat, WeChat)

🎯 توجهات
ByteDance تطلق نموذج Bagel 14B MoE متعدد الوسائط، يدعم توليد الصور ومفتوح المصدر: أطلقت ByteDance نموذجًا متعدد الوسائط يعتمد على خليط من الخبراء (MoE) بسعة 14 مليار معلمة يسمى Bagel، منها 7 مليارات معلمة نشطة. يتمتع هذا النموذج بقدرة على توليد الصور وهو مفتوح المصدر بموجب ترخيص Apache. تم نشر أوزانه ذات الصلة وموقعه الإلكتروني والورقة البحثية (بعنوان “Emerging Properties in Unified Multimodal Pretraining”). كان رد فعل المجتمع إيجابيًا، حيث اعتبره البعض أول نموذج محلي قادر على توليد الصور والنصوص في نفس الوقت، مع الاهتمام بإمكانية تشغيله على بطاقات رسومات بسعة 24 جيجابايت ومسائل التكميم (quantization) (المصدر: Reddit r/LocalLLaMA)
Mistral AI تطلق Devstral: نموذج مفتوح المصدر SOTA مُحسَّن خصيصًا للبرمجة: أطلقت Mistral AI نموذج Devstral، وهو نموذج رائد مفتوح المصدر مصمم خصيصًا لمهام هندسة البرمجيات، تم بناؤه بالتعاون بين Mistral AI و All Hands AI. أظهر Devstral أداءً متميزًا في اختبار SWE-bench، ليصبح النموذج مفتوح المصدر الأول في هذا الاختبار. يتفوق هذا النموذج في استخدام الأدوات لاستكشاف قواعد الأكواد، وتحرير ملفات متعددة، وتوفير الدعم لوكلاء هندسة البرمجيات. تم توفير أوزان النموذج على Hugging Face (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

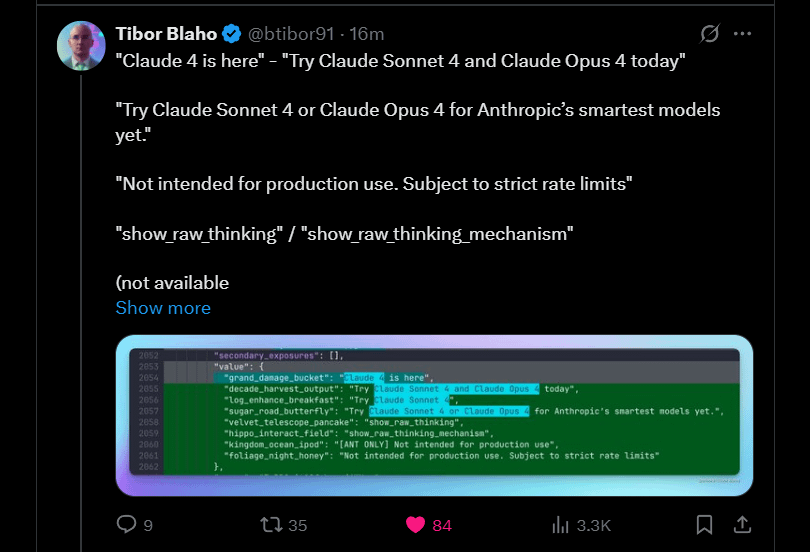
Anthropic تعلن عن قرب إطلاق Claude 4 Sonnet و Opus: تخطط Anthropic لإطلاق الجيل القادم من نماذجها اللغوية الكبيرة Claude – وهما Claude 4 Sonnet و Opus. أثار هذا الخبر ترقبًا في المجتمع، حيث أعرب المستخدمون عن اهتمامهم بأداء النماذج الجديدة، خاصة فيما يتعلق بتحسين قدرة الذاكرة السياقية. وأشارت بعض التعليقات إلى أن إعلانات مؤتمر Google I/O ربما دفعت المنافسين إلى تسريع إطلاق أفضل منتجاتهم. في الوقت نفسه، أعرب المستخدمون أيضًا عن مخاوفهم بشأن قيود النماذج الجديدة (مثل حصص الاستخدام)، ونبهوا المجتمع إلى عدم تعليق آمال كبيرة جدًا على Opus 4 لتجنب خيبة الأمل (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
جوجل تطلق تطبيق Gemma3n لنظام أندرويد، يدعم الاستدلال المحلي لـ LLM: أطلقت جوجل تطبيقًا لنظام أندرويد يمكنه التفاعل مع نموذج Gemma3n الجديد، وقدمت حلول MediaPipe ذات الصلة ومستودع أكواد GitHub. أفاد المستخدمون بأن واجهة التطبيق جيدة، لكنهم أشاروا إلى أن Gemma3n لا يدعم حاليًا الاستدلال عبر وحدة معالجة الرسومات (GPU). نجح أحد المستخدمين في تحميل نموذج gemma-3n-E2B يدويًا وشارك بيانات التشغيل، وفي الوقت نفسه أعرب المجتمع عن حاجته إلى نسخة غير خاضعة للرقابة من النموذج (المصدر: Reddit r/LocalLLaMA)

إطلاق عائلة نماذج اللغة Falcon-H1 ذات الرؤوس الهجينة، تتضمن أحجامًا متنوعة من المعلمات: أطلقت TII UAE سلسلة نماذج اللغة Falcon-H1 ذات الرؤوس الهجينة، وتتراوح أحجام المعلمات فيها من 0.5 مليار إلى 34 مليار. تعتمد هذه السلسلة من النماذج على بنية Mamba الهجينة، ويمكن مقارنة أدائها بأداء Qwen3. تدعم النماذج الاستخدام من خلال مكتبات Hugging Face Transformers أو vLLM أو نسخة مخصصة من llama.cpp، مما يضمن سهولة استخدام النماذج. أعرب المجتمع عن حماسه لهذا، معتبرًا إياه تقدمًا مهمًا، وقام بعض المستخدمين بإنشاء مخططات مقارنة للأداء. وفي الوقت نفسه، يهتم الباحثون أيضًا باختلافها عن IBM Granite 4 في طريقة دمج وحدات SSM والانتباه (المصدر: Reddit r/LocalLLaMA)

جوجل تستكشف Gemini Diffusion: نموذج لغوي يعتمد على بنية diffusion: عرضت جوجل نموذجها اللغوي القائم على الانتشار Gemini Diffusion، والذي يُقال إنه سريع للغاية وحجمه نصف حجم النماذج ذات الأداء المماثل. نظرًا لأن نماذج الانتشار يمكنها معالجة النص بأكمله دفعة واحدة بشكل متكرر، دون الحاجة إلى ذاكرة تخزين مؤقت KV، فقد يكون لها ميزة في كفاءة الذاكرة، ويمكنها تحسين جودة المخرجات عن طريق زيادة عدد التكرارات. يعتقد المجتمع أنه إذا تمكنت جوجل من إثبات جدوى نماذج الانتشار في التطبيقات واسعة النطاق، فسيكون لذلك تأثير إيجابي على مجتمع الذكاء الاصطناعي المحلي. ومع ذلك، لا يتوفر النموذج حاليًا إلا من خلال قائمة انتظار للعرض التوضيحي، ولم يتم فتح مصدره أو توفير أوزانه للتنزيل (المصدر: Reddit r/LocalLLaMA)

بحث يكشف عن ثغرة أمنية في اختطاف الوكيل بدون نقرة (Zero-Click Agent Hijacking) في إطار عمل Browser Use (CVE-2025-47241): كشف بحث أجرته ARIMLABS.AI أن إطار عمل Browser Use، المستخدم على نطاق واسع في أكثر من 1500 مشروع ذكاء اصطناعي، يحتوي على ثغرة أمنية خطيرة (CVE-2025-47241). تسمح هذه الثغرة للمهاجمين باختطاف الوكيل بدون نقرة عن طريق حث وكيل التصفح الذي يعمل بنظام LLM على الوصول إلى صفحة ضارة، مما يمكنهم من التحكم في الوكيل دون الحاجة إلى تفاعل المستخدم. أثار هذا الاكتشاف مخاوف جدية بشأن أمن وكلاء الذكاء الاصطناعي المستقلين، وخاصة أولئك الذين يتفاعلون مع الويب، ودعا المجتمع إلى الاهتمام بقضايا أمن وكلاء الذكاء الاصطناعي (المصدر: Reddit r/artificial, Reddit r/artificial)
Tencent و Alibaba تتنافسان في مجال AI to C، متصفح QQ ينافس Quark: أعلن متصفح QQ التابع لمجموعة CSIG في Tencent عن ترقيته إلى متصفح ذكاء اصطناعي، وإطلاق AI QBot، ودعمه بنموذجي Tencent Hunyuan و DeepSeek، ليدخل رسميًا في منافسة مع Quark التابع لـ Alibaba والذي تحول بالفعل إلى بحث بالذكاء الاصطناعي. تشير هذه الخطوة إلى تسريع Tencent لتخطيطها في مجال AI to C، وتشكيل خطي إنتاج رئيسيين هما Tencent Yuanbao و QQ Browser. وبذلك، يدخل المسؤولان الرئيسيان Wu Zurong (Tencent) و Wu Jia (Alibaba) في “مواجهة Wu المزدوجة”. يرى المحللون أن متصفح QQ يتمتع بميزة في قاعدة المستخدمين، بينما سبقت Quark في التحول إلى الذكاء الاصطناعي، لكن تحول متصفح QQ يعتبر متحفظًا نسبيًا، حيث تبدو وظائف الذكاء الاصطناعي أشبه بالمكونات الإضافية، كما أنه مقيد بنموذج الإعلانات الأصلي. هذه المنافسة ليست على مستوى المنتج فحسب، بل قد تؤثر أيضًا على التطور الوظيفي للمسؤولين في شركتيهما (المصدر: 36氪)
كامبريدج وجوجل تقترحان VPRL: نموذج جديد للتخطيط والاستدلال البصري البحت، بدقة تتجاوز الاستدلال النصي: اقترح فريق بحثي من جامعة كامبريدج وكلية لندن الجامعية وجوجل نموذجًا جديدًا للتخطيط البصري القائم على التعلم المعزز (VPRL)، والذي يحقق لأول مرة استدلالًا يعتمد كليًا على الصور. يستخدم هذا الإطار تحسين سياسة المجموعة النسبية (GRPO) لإعادة تدريب نماذج الرؤية الكبيرة، وفي العديد من مهام الملاحة البصرية (مثل FrozenLake و Maze و MiniBehavior)، يتجاوز أداؤه بشكل كبير طرق الاستدلال القائمة على النصوص، حيث تصل دقته إلى 80%، مع تحسن في الأداء لا يقل عن 40%. يقوم VPRL بالتخطيط مباشرة باستخدام تسلسل الصور، متجنبًا فقدان المعلومات وانخفاض الكفاءة الناتج عن التحويل اللغوي، مما يفتح آفاقًا جديدة لمهام الاستدلال الصوري البديهي. تم فتح مصدر الكود ذي الصلة (المصدر: WeChat)

هواوي تطلق FusionSpec و OptiQuant لتحسين استدلال نماذج MoE الكبيرة: لمواجهة تحديات سرعة الاستدلال وزمن الانتقال في نماذج MoE (Mixture-of-Experts) واسعة النطاق، أطلقت هواوي إطار الاستدلال التكهني FusionSpec وإطار التكميم OptiQuant. يستفيد FusionSpec من نسبة الحوسبة إلى عرض النطاق الترددي العالية لخوادم Ascend، ويحسن تدفق النموذج الرئيسي والنموذج التكهني، مما يقلل من الوقت الذي يستغرقه إطار الاستدلال التكهني إلى 1 مللي ثانية. يدعم OptiQuant خوارزميات التكميم السائدة مثل Int2/4/8 و FP8/HiFloat8، ويقدم ابتكارات مثل “القطع القابل للتعلم” و “تحسين معلمات التكميم”، بهدف تقليل فقدان دقة النموذج وتحسين نسبة الأداء إلى التكلفة في الاستدلال. تهدف هذه التقنيات إلى حل مشكلات كفاءة الاستدلال واستهلاك الموارد التي تواجهها نماذج MoE عند النشر (المصدر: WeChat)

معهد بكين للذكاء الاصطناعي يطلق ثلاثة نماذج متجهة SOTA، لتعزيز استرجاع الأكواد والوسائط المتعددة: أطلق معهد بكين للذكاء الاصطناعي (BAAI) بالتعاون مع عدة جامعات ثلاثة نماذج متجهة: BGE-Code-v1 (نموذج متجه للأكواد)، BGE-VL-v1.5 (نموذج متجه عام متعدد الوسائط)، و BGE-VL-Screenshot (نموذج متجه للمستندات المرئية). يعتمد BGE-Code-v1 على Qwen2.5-Coder-1.5B، ويظهر أداءً متميزًا في معياري CoIR و CodeRAG. يعتمد BGE-VL-v1.5 على LLaVA-1.6، وحقق رقمًا قياسيًا جديدًا في التعلم بدون أمثلة (zero-shot) على معيار MMEB متعدد الوسائط. يستهدف BGE-VL-Screenshot مهام استرجاع المعلومات المرئية (Vis-IR) مثل صفحات الويب والمستندات، وهو مدرب على Qwen2.5-VL-3B-Instruct، وحقق أداءً متطورًا (SOTA) على معيار MVRB الذي تم إطلاقه حديثًا. تهدف هذه النماذج إلى توفير قدرات فهم واسترجاع أقوى للأكواد والوسائط المتعددة لتطبيقات مثل التوليد المعزز بالاسترجاع (RAG)، وجميعها مفتوحة المصدر (المصدر: WeChat)

Kuaishou وجامعة سنغافورة الوطنية تطلقان Any2Caption، لتحقيق توليد فيديو قابل للتحكم: أطلقت Kuaishou بالتعاون مع جامعة سنغافورة الوطنية إطار عمل Any2Caption، بهدف تحسين دقة وجودة توليد الفيديو القابل للتحكم من خلال فصل فهم نية المستخدم وعملية توليد الفيديو بذكاء. يمكن لهذا الإطار معالجة شروط إدخال متعددة الوسائط مثل النصوص والصور ومقاطع الفيديو ومسارات الوضعيات وحركة الكاميرا، مستخدمًا نماذج لغوية كبيرة متعددة الوسائط لتحويل التعليمات المعقدة إلى “نصوص فيديو” منظمة لتوجيه عملية توليد الفيديو. يعتمد Any2Caption في تدريبه على قاعدة بيانات Any2CapIns التي تحتوي على 337 ألف مثال فيديو و 407 ألف شرط متعدد الوسائط، وتشير التجارب إلى أنه يمكنه تحسين تأثير نماذج توليد الفيديو القابلة للتحكم الحالية بشكل فعال (المصدر: WeChat)

🧰 أدوات
Feishu تطلق ميزة “الإجابة على المعرفة”، لإنشاء مساعد ذكاء اصطناعي مخصص للأسئلة والإجابات والإنشاء للشركات: أطلقت Feishu ميزة جديدة باسم “الإجابة على المعرفة”، والتي تُعرف كأداة أسئلة وإجابات مخصصة للشركات تعمل بالذكاء الاصطناعي. تعتمد هذه الميزة على المعلومات التي يمكن للموظفين الوصول إليها في Feishu مثل الرسائل والمستندات وقواعد المعرفة والمذكرات الذكية، بالإضافة إلى نماذج لغوية كبيرة مثل DeepSeek-R1 و Doubao وتقنية RAG، لتقديم إجابات دقيقة ودعم إنشاء المحتوى. تؤكد هذه الميزة على تفعيل واستخدام المعرفة الداخلية للشركة، حيث قد يحصل الموظفون ذوو الأدوار المختلفة على إجابات من وجهات نظر مختلفة لنفس السؤال، مع الالتزام الصارم بصلاحيات المنظمة. تهدف ميزة الإجابة على المعرفة في Feishu إلى دمج الذكاء الاصطناعي بسلاسة في سير العمل اليومي، وتحسين كفاءة الحصول على المعلومات والتعاون، ومساعدة الشركات على بناء نظام إدارة معرفة ديناميكي (المصدر: WeChat, WeChat)
Supabase، بفضل مزايا المصدر المفتوح وتكامل الذكاء الاصطناعي، تصبح الخيار الخلفي المفضل لـ “البرمجة بالأجواء”: أصبحت قاعدة البيانات مفتوحة المصدر Supabase الخيار الخلفي الرائج في نمط “البرمجة بالأجواء” (Vibe Coding) بفضل تجربتها “الجاهزة للاستخدام” مع PostgreSQL واستجابتها الإيجابية لاتجاهات تطوير الذكاء الاصطناعي. تؤكد Vibe Coding على استخدام أدوات ذكاء اصطناعي متنوعة لإكمال عملية التطوير بأكملها بسرعة من المتطلبات إلى التنفيذ. تدعم Supabase تخزين تضمينات المتجهات (وهو أمر بالغ الأهمية لتطبيقات RAG) من خلال دمج PGVector، وتتعاون مع Ollama لتوفير خدمات نماذج الذكاء الاصطناعي للطرفيات، وأطلقت مساعد الذكاء الاصطناعي الخاص بها للمساعدة في إنشاء مخططات قواعد البيانات وتصحيح أخطاء SQL. مؤخرًا، أطلقت Supabase أيضًا خادم MCP رسميًا، مما يسمح لأدوات الذكاء الاصطناعي بالتفاعل معها مباشرة. هذه الميزات جعلتها مفضلة لدى منصات بناء التطبيقات الأصلية للذكاء الاصطناعي مثل Lovable و Bolt.new (المصدر: WeChat)

Hugging Face تطلق nanoVLM: مجموعة أدوات مبسطة لتدريب نماذج اللغة المرئية (VLM) باستخدام PyTorch النقي: أصدرت Hugging Face مجموعة nanoVLM، وهي مجموعة أدوات PyTorch خفيفة الوزن تهدف إلى تبسيط عملية تدريب نماذج اللغة المرئية. يتميز هذا المشروع بصغر حجم الكود وسهولة قراءته، مما يجعله مناسبًا للمبتدئين أو المطورين الذين يرغبون في فهم أعمق للآليات الداخلية لنماذج VLM. تعتمد بنية nanoVLM على مُشفِّر الرؤية SigLIP ومُفكِّك اللغة Llama 3، مع وحدة إسقاط نمطية لمحاذاة أنماط الرؤية والنص. يوفر المشروع طريقة ملائمة لبدء تدريب VLM على Colab Notebook مجاني، وقد تم بالفعل إصدار نموذج مُدرَّب مسبقًا يعتمد على SigLIP و SmolLM2 للاختبار (المصدر: HuggingFace Blog)

مكتبة Diffusers تدمج العديد من الواجهات الخلفية للتكميم (quantization) لتحسين نماذج الانتشار الكبيرة: تدمج مكتبة Hugging Face Diffusers الآن العديد من الواجهات الخلفية للتكميم مثل bitsandbytes، و torchao، و Quanto، و GGUF، و FP8 الأصلي، بهدف تقليل استهلاك الذاكرة ومتطلبات الحوسبة لنماذج الانتشار الكبيرة (مثل Flux). تدعم هذه الواجهات الخلفية التكميم بدقات مختلفة (مثل 4-bit، 8-bit، FP8)، ويمكن دمجها مع تقنيات تحسين الذاكرة مثل CPU offloading، و group offloading، و torch.compile. من خلال حالة تكميم نموذج Flux.1-dev، تعرض المدونة أداء كل واجهة خلفية في توفير الذاكرة ووقت الاستدلال، وتقدم دليل اختيار لمساعدة المستخدمين على تحقيق التوازن بين حجم النموذج وسرعته وجودته. تتوفر بعض النماذج المكممة على Hugging Face Hub (المصدر: HuggingFace Blog)

منصة الحوسبة لتطوير النماذج الكبيرة JoyBuild من JD.com تعزز كفاءة التدريب والاستدلال: اقترح معهد أبحاث JD.com نظامًا وطريقة لتدريب وتحديث النماذج الكبيرة في بيئة مفتوحة ونشرها بالتعاون مع النماذج الصغيرة، ونُشرت النتائج ذات الصلة في مجلة npj Artificial Intelligence التابعة لـ Nature. تعمل هذه التقنية على تحسين كفاءة استدلال النماذج الكبيرة بنسبة 30% في المتوسط وتقليل تكاليف التدريب بنسبة 70% من خلال أربعة ابتكارات: تقطير النماذج (تقطير طبقي ديناميكي)، وحوكمة البيانات (أخذ عينات ديناميكية عبر المجالات)، وتحسين التدريب (تحسين بايزي)، والتآزر بين السحابة والحافة (ضغط على مرحلتين). تدعم هذه التقنية منصة الحوسبة لتطوير النماذج الكبيرة JoyBuild، وتدعم تطوير وضبط العديد من النماذج (مثل نموذج JD الكبير، Llama، DeepSeek)، مما يساعد الشركات على تحويل النماذج العامة إلى نماذج متخصصة، وقد تم تطبيقها بالفعل في مجالات مثل البيع بالتجزئة والخدمات اللوجستية (المصدر: WeChat)
إطلاق مشروع سجل بروتوكول سياق النموذج (MCP): modelcontextprotocol/registry هو مشروع خدمة تسجيل خادم MCP مدفوع من المجتمع، وهو حاليًا في مرحلة تطوير مبكرة. يهدف هذا المشروع إلى توفير مستودع مركزي لإدخالات خادم MCP، مما يسمح باكتشاف وإدارة تطبيقات MCP المختلفة وبياناتها الوصفية وتكويناتها وقدراتها. تشمل ميزاته واجهة برمجة تطبيقات RESTful لإدارة الإدخالات، ونقطة نهاية لفحص الحالة، ودعم تكوينات بيئات متعددة، ودعم قواعد بيانات MongoDB والذاكرة، ووثائق واجهة برمجة التطبيقات. المشروع مكتوب بلغة Go، ويوفر دليلًا للبدء السريع عبر Docker Compose (المصدر: GitHub Trending)
📚 تعلم
تيرنس تاو ينشر برنامجًا تعليميًا لإثبات الرياضيات بمساعدة الذكاء الاصطناعي، ويشرح استخدام GitHub Copilot لإثبات حدود الدوال: قام الحائز على ميدالية فيلدز، تيرنس تاو، بتحديث مقطع فيديو على قناته على YouTube، يشرح فيه بالتفصيل كيفية استخدام GitHub Copilot للمساعدة في إثبات نظريات الجمع والطرح والضرب لحدود الدوال. يؤكد البرنامج التعليمي على أهمية توجيه الذكاء الاصطناعي بشكل صحيح، ويعرض دور Copilot في إنشاء إطارات الأكواد واقتراح دوال المكتبات، ولكنه يشير أيضًا إلى حدوده في التعامل مع التفاصيل الرياضية المعقدة والحالات الخاصة والحفاظ على اتساق السياق. يلخص تاو بأن Copilot مفيد للمبتدئين، ولكنه لا يزال يتطلب تدخلًا وتعديلًا بشريًا كبيرًا في المشكلات المعقدة، وقد يكون الجمع بينه وبين الاستدلال بالورقة والقلم أكثر كفاءة في بعض الأحيان (المصدر: 量子位)

ورقة بحثية تناقش التناقض بين الاستدلال في النماذج الكبيرة واتباع التعليمات، وتقترح مفهوم الانتباه المقيد: تشير ورقة بحثية بعنوان “When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs” إلى أنه بعد استخدام النماذج اللغوية الكبيرة للتفكير المتسلسل (CoT) للاستدلال، على الرغم من أنها تظهر أداءً أكثر ذكاءً في بعض الجوانب (مثل الالتزام بالتنسيق وعدد الكلمات)، إلا أن دقتها في اتباع التعليمات بدقة قد تنخفض. من خلال اختبار 15 نموذجًا مفتوح المصدر ومغلق المصدر، وجد فريق البحث أن النماذج بعد استخدام CoT تكون أكثر عرضة “للتصرف من تلقاء نفسها”، وتعديل أو إضافة معلومات إضافية، مع تجاهل التعليمات الأصلية. تقدم الورقة مفهوم “الانتباه المقيد” (Constraint Attention)، وتجد أن استدلال CoT يقلل من انتباه النموذج للقيود الرئيسية. كما يشير البحث إلى عدم وجود ارتباط كبير بين طول تفكير CoT ودقة إكمال المهمة، ويناقش إمكانية تحسين تأثير اتباع التعليمات من خلال أمثلة قليلة، والتفكير الذاتي، وما إلى ذلك (المصدر: WeChat)

MIT وجوجل تقترحان PASTA: نموذج جديد للتوليد المتوازي غير المتزامن لـ LLM يعتمد على تعلم السياسات: اقترح فريق بحثي من معهد ماساتشوستس للتكنولوجيا (MIT) وجوجل إطار عمل PASTA (PArallel STructure Annotation)، والذي يمكّن النماذج اللغوية الكبيرة (LLM) من تحسين استراتيجيات التوليد المتوازي غير المتزامن بشكل مستقل من خلال تعلم السياسات. تقوم هذه الطريقة أولاً بتطوير لغة ترميز PASTA-LANG، لترميز كتل نصية مستقلة دلاليًا لتحقيق التوليد المتوازي. تنقسم عملية التدريب إلى مرحلتين: الضبط الدقيق الخاضع للإشراف لجعل النموذج يتعلم إدراج علامات PASTA-LANG، ثم تحسين استراتيجية الترميز بشكل أكبر من خلال تحسين التفضيلات (بناءً على نسبة التسريع النظرية وتقييم جودة المحتوى). صممت PASTA تخطيط ذاكرة تخزين مؤقت KV متداخل وآلية تحكم في الانتباه، لتنسيق التعاون الفعال متعدد الخيوط. أظهرت التجارب أن PASTA تحقق تسريعًا يتراوح بين 1.21 و 1.93 مرة على معيار AlpacaEval، مع الحفاظ على جودة المخرجات أو تحسينها، مما يدل على قابلية جيدة للتوسع (المصدر: WeChat)

ورقة بحثية في ICML 2025 تقترح TPO: حل جديد للمواءمة الفورية للتفضيلات أثناء الاستدلال، دون الحاجة إلى إعادة التدريب: اقترح مختبر شنغهاي للذكاء الاصطناعي تحسين التفضيلات في وقت الاختبار (Test-Time Preference Optimization, TPO)، وهي طريقة جديدة تسمح للنماذج اللغوية الكبيرة بتعديل مخرجاتها ذاتيًا لتتوافق مع التفضيلات البشرية من خلال التغذية الراجعة النصية التكرارية أثناء الاستدلال. يحقق TPO المواءمة دون تحديث أوزان النموذج من خلال محاكاة عملية “الانحدار التدريجي” اللغوية (توليد إجابات مرشحة، حساب الخسارة النصية، حساب التدرج النصي، تحديث الإجابة). أظهرت التجارب أن TPO يمكن أن يحسن بشكل كبير أداء النماذج غير المتوافقة والمتوافقة، على سبيل المثال، بعد خطوتين من تحسين TPO لنموذج Llama-3.1-70B-SFT، تجاوز أداؤه نسخة Instruct المتوافقة بالفعل على العديد من المعايير. توفر هذه الطريقة استراتيجية توسيع للاستدلال “بالعرض + العمق”، وتُظهر إمكانات تحسين فعالة في بيئات محدودة الموارد (المصدر: WeChat)
بحث جديد يستكشف طرق استخلاص المعرفة الكامنة في النماذج اللغوية الكبيرة: تبحث ورقة بحثية في كيفية استخلاص المعرفة التي قد تخفيها النماذج اللغوية الكبيرة. قام الباحثون بتدريب نموذج “محظور” صُمم لوصف مفردة سرية معينة دون النطق بها مباشرة، مع العلم أن هذه المفردة السرية لم تظهر في بيانات التدريب أو التوجيهات. بعد ذلك، قيّم الباحثون استراتيجيات آلية للكشف عن هذا السر باستخدام طرق غير تفسيرية (الصندوق الأسود) وتقنيات قائمة على قابلية التفسير الآلي (مثل عدسة اللوغاريتمات والمشفرات التلقائية المتفرقة). أظهرت النتائج أن كلتا الطريقتين يمكنهما استخلاص الكلمات السرية بفعالية في إعداد إثبات المفهوم. يهدف هذا العمل إلى تقديم حلول أولية للمشكلة الرئيسية المتمثلة في استخلاص المعرفة السرية من النماذج اللغوية، لتعزيز نشرها الآمن والموثوق (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش تطبيق التقليم المشترك في النماذج اللغوية الكبيرة (FedPrLLM): لمعالجة صعوبة الحصول على عينات معايرة عامة لتقليم النماذج اللغوية الكبيرة (LLM) في المجالات الحساسة للخصوصية، اقترح الباحثون FedPrLLM، وهو إطار شامل للتقليم المشترك. في هذا الإطار، يحتاج كل عميل فقط إلى حساب مصفوفة قناع التقليم بناءً على بيانات المعايرة المحلية ومشاركتها مع الخادم، للتقليم التعاوني للنموذج العالمي مع حماية خصوصية البيانات المحلية. من خلال تجارب واسعة النطاق، وجد البحث أن التقليم لمرة واحدة (one-shot pruning) مع مقارنة الطبقات (layer comparison) ودون تحجيم الأوزان (no weight scaling) هو الخيار الأفضل ضمن إطار FedPrLLM. يهدف هذا البحث إلى توجيه العمل المستقبلي في تقليم LLM في المجالات الحساسة للخصوصية (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح MIGRATION-BENCH: معيار ترحيل أكواد Java 8: قدم الباحثون MIGRATION-BENCH، وهو معيار ترحيل أكواد يركز على الترحيل من Java 8 إلى أحدث إصدارات LTS (Java 17, 21). يتضمن هذا المعيار مجموعة بيانات كاملة تحتوي على 5102 مستودعًا ومجموعة فرعية تحتوي على 300 مستودع معقد تم اختيارها بعناية، بهدف تقييم قدرة النماذج اللغوية الكبيرة (LLMs) على مهام ترحيل الأكواد على مستوى المستودع. في الوقت نفسه، تقدم الورقة إطار تقييم شامل وتقترح طريقة SD-Feedback، وتشير التجارب إلى أن LLMs (مثل Claude-3.5-Sonnet-v2) يمكنها التعامل بفعالية مع مهام الترحيل هذه، حيث حققت معدلات نجاح بلغت 62.33% (الحد الأدنى للترحيل) و 27.00% (الحد الأقصى للترحيل) على المجموعة الفرعية المختارة (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح CS-Sum: معيار تلخيص المحادثات متعددة اللغات وتحليل قيود LLM: لتقييم قدرة النماذج اللغوية الكبيرة (LLMs) على فهم تحويل الشفرة (CS)، قدم الباحثون معيار CS-Sum، من خلال تلخيص المحادثات متعددة اللغات إلى اللغة الإنجليزية للتقييم. CS-Sum هو أول معيار لتلخيص المحادثات متعددة اللغات للماندرين-الإنجليزية، والتاميلية-الإنجليزية، والماليزية-الإنجليزية، حيث يحتوي كل زوج لغوي على 900-1300 محادثة مشروحة يدويًا. من خلال تقييم عشرة نماذج LLM مفتوحة المصدر ومغلقة المصدر (بما في ذلك طرق التعلم القليل، والترجمة-التلخيص، والضبط الدقيق)، وجد البحث أنه على الرغم من ارتفاع درجات مقاييس التقييم التلقائي، إلا أن LLM لا تزال ترتكب أخطاء دقيقة عند معالجة مدخلات CS، مما يغير المعنى الكامل للمحادثة. تشير الورقة أيضًا إلى الأنواع الثلاثة الأكثر شيوعًا للأخطاء التي ترتكبها LLM عند التعامل مع CS، وتؤكد على ضرورة التدريب المتخصص على بيانات تحويل الشفرة (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش قدرة النماذج الكبيرة على التعبير عن الثقة أثناء الاستدلال: يشير البحث إلى أن النماذج اللغوية الكبيرة (LLMs) التي تقوم باستدلال سلسلة التفكير الموسعة (CoT) لا تتفوق فقط في حل المشكلات، بل هي أيضًا أفضل في التعبير بدقة عن درجة ثقتها. من خلال اختبار معياري لستة نماذج استدلال على ست مجموعات بيانات، وجد أنه في 33 من أصل 36 إعدادًا، كانت نماذج الاستدلال أفضل في معايرة الثقة من النماذج غير الاستدلالية. يعتقد التحليل أن هذا يرجع إلى سلوك “التفكير البطيء” لنماذج الاستدلال (مثل استكشاف البدائل، والتراجع)، مما يمكنها من تعديل درجة الثقة ديناميكيًا أثناء عملية CoT. بالإضافة إلى ذلك، يؤدي إزالة سلوك التفكير البطيء إلى انخفاض كبير في درجة المعايرة، ويمكن للنماذج غير الاستدلالية أيضًا الاستفادة من التفكير البطيء عند توجيهها (المصدر: HuggingFace Daily Papers)
ورقة بحثية: استخدام التعلم المعزز من أزواج الأسئلة والأجوبة المرئية لتدريب VLM على الاستدلال البصري (Visionary-R1): يهدف هذا البحث إلى تدريب نماذج اللغة المرئية (VLM) على استدلال بيانات الصور من خلال التعلم المعزز وأزواج الأسئلة والأجوبة المرئية، دون الحاجة إلى إشراف صريح على سلسلة التفكير (CoT). وجد البحث أن مجرد تطبيق التعلم المعزز (حث النموذج على إنشاء سلسلة استدلال قبل الإجابة) قد يؤدي إلى تعلم النموذج طرقًا مختصرة من الأسئلة البسيطة، مما يقلل من قدرته على التعميم. لحل هذه المشكلة، اقترح الباحثون أن يتبع النموذج تنسيق إخراج “تعليق-استدلال-إجابة”، أي إنشاء تعليق مفصل للصورة أولاً، ثم بناء سلسلة استدلال. أظهر نموذج Visionary-R1، المدرب بناءً على هذه الطريقة، أداءً متفوقًا على العديد من نماذج الوسائط المتعددة القوية مثل GPT-4o و Claude3.5-Sonnet و Gemini-1.5-Pro في العديد من معايير الاستدلال البصري (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح VideoEval-Pro: معيار تقييم أكثر واقعية وقوة لفهم الفيديو الطويل: يشير البحث إلى أن معايير فهم الفيديو الطويل (LVU) الحالية تعتمد في الغالب على أسئلة الاختيار من متعدد (MCQ)، والتي يسهل التأثر بها بالتخمين، ويمكن الإجابة على بعض الأسئلة دون مشاهدة الفيديو بالكامل، مما يبالغ في تقدير أداء النموذج. لحل هذه المشكلة، تقترح الورقة VideoEval-Pro، وهو معيار LVU يتضمن أسئلة إجابة قصيرة مفتوحة، يهدف إلى تقييم فهم النموذج للفيديو بأكمله بشكل واقعي، ويغطي مهام الإدراك والاستدلال على مستوى المقطع والفيديو الكامل. أظهر تقييم 21 نموذج LMM للفيديو أن أداء النماذج ينخفض بشكل كبير في الأسئلة المفتوحة، وأن الدرجات العالية في MCQ لا ترتبط بالضرورة بدرجات عالية في VideoEval-Pro، وأن VideoEval-Pro يستفيد بشكل أكبر من زيادة عدد إطارات الإدخال، مما يوفر معيار تقييم أكثر موثوقية لمجال LVU (المصدر: HuggingFace Daily Papers)
ورقة بحثية: ضبط دقيق للشبكات العصبية المكممة من خلال التحسين من الدرجة الصفرية (QZO): مع النمو الأسي لحجم النماذج اللغوية الكبيرة، أصبحت ذاكرة وحدة معالجة الرسومات (GPU) عنق الزجاجة في تكييف النماذج مع مهام المصب. يهدف هذا البحث إلى تقليل استخدام الذاكرة لأوزان النموذج وتدرجاته وحالات المحسن إلى أقصى حد من خلال إطار عمل موحد. يقترح الباحثون التخلص من التدرجات وحالات المحسن من خلال التحسين من الدرجة الصفرية، وهي طريقة تقرب التدرجات عن طريق إزعاج الأوزان أثناء الانتشار الأمامي. لتقليل ذاكرة الأوزان، يتم استخدام تكميم النموذج (مثل bfloat16 إلى int4). ومع ذلك، فإن تطبيق التحسين من الدرجة الصفرية مباشرة على الأوزان المكممة غير ممكن بسبب فجوة الدقة بين الأوزان المنفصلة والتدرجات المستمرة. لحل هذه المشكلة، تقترح الورقة التحسين الكمي من الدرجة الصفرية (QZO)، وهي طريقة جديدة لتقدير التدرج عن طريق إزعاج مقاييس التكميم المستمرة واستخدام طريقة قص المشتقات الاتجاهية لتثبيت التدريب. QZO متعامد مع طرق التكميم بعد التدريب القائمة على القياس والقائمة على دفتر الرموز، وبالمقارنة مع الضبط الدقيق الكامل لمعلمات bfloat16، يمكن لـ QZO تقليل إجمالي تكلفة الذاكرة لـ LLM ذات 4 بتات بأكثر من 18 مرة، وتمكين Llama-2-13B و Stable Diffusion 3.5 Large من الضبط الدقيق داخل وحدة معالجة رسومات واحدة بسعة 24 جيجابايت (المصدر: HuggingFace Daily Papers)
ورقة بحثية: تحسين أداء الاستدلال في أي وقت (Anytime Reasoning) من خلال تحسين سياسة الميزانية النسبية (BRPO) (AnytimeReasoner): يعد توسيع الحساب في وقت الاختبار أمرًا بالغ الأهمية لتعزيز قدرات الاستدلال للنماذج اللغوية الكبيرة (LLM). عادةً ما تستخدم الطرق الحالية التعلم المعزز (RL) لتعظيم المكافأة التي يمكن التحقق منها في نهاية مسار الاستدلال، ولكن هذا يحسن فقط الأداء النهائي في ظل ميزانية رموز ثابتة، مما يؤثر على كفاءة التدريب والنشر. يقترح هذا البحث إطار عمل AnytimeReasoner، الذي يهدف إلى تحسين أداء الاستدلال في أي وقت، وزيادة كفاءة الرموز ومرونة الاستدلال في ظل قيود ميزانية مختلفة. تتمثل الطريقة في اقتطاع عملية التفكير الكاملة لتناسب ميزانية الرموز المأخوذة من توزيع مسبق، مما يجبر النموذج على تلخيص أفضل إجابة لكل تفكير مقتطع للتحقق، وبالتالي إدخال مكافآت كثيفة يمكن التحقق منها أثناء عملية الاستدلال، وتعزيز تخصيص الائتمان بشكل أكثر فعالية في تحسين RL. بالإضافة إلى ذلك، قدم الباحثون تحسين سياسة الميزانية النسبية (BRPO) كتقنية جديدة لتقليل التباين لتعزيز متانة وكفاءة التعلم عند تعزيز استراتيجية التفكير. أظهرت نتائج التجارب على مهام الاستدلال الرياضي أن هذه الطريقة تتفوق على GRPO في جميع ميزانيات التفكير في ظل توزيعات مسبقة مختلفة، مما يحسن كفاءة التدريب والرموز (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح نموذج الاستدلال المختلط الكبير (LHRM): التفكير عند الطلب لتعزيز الكفاءة والقدرة: حسنت نماذج الاستدلال الكبيرة (LRM) الحديثة بشكل كبير قدرات الاستدلال من خلال إجراء عملية تفكير موسعة قبل إنشاء الاستجابة النهائية. ومع ذلك، فإن عمليات التفكير الطويلة جدًا تؤدي إلى تكاليف باهظة في استهلاك الرموز وزمن الانتقال، وهو أمر غير ضروري بشكل خاص للاستعلامات البسيطة. يقدم هذا البحث نماذج الاستدلال المختلطة الكبيرة (LHRM)، وهي نماذج يمكنها أن تقرر بشكل تكيفي ما إذا كانت ستنفذ التفكير بناءً على معلومات سياق استعلام المستخدم. لتحقيق هذا الهدف، اقترح الباحثون عملية تدريب من مرحلتين: أولاً، البدء البارد من خلال الضبط الدقيق المختلط (HFT)، ثم استخدام التعلم المعزز عبر الإنترنت مع تحسين سياسة المجموعة المختلطة المقترح (HGPO) لتعلم اختيار وضع التفكير المناسب ضمنيًا. بالإضافة إلى ذلك، قدم الباحثون مقياس الدقة المختلطة (Hybrid Accuracy) لتحديد قدرة النموذج على التفكير المختلط. أظهرت نتائج التجارب أن LHRM يمكنه تنفيذ التفكير المختلط بشكل تكيفي على استعلامات ذات صعوبات وأنواع مختلفة، وأن قدراته الاستدلالية والعامة تتفوق على LRM و LLM الحالية، مع تحسين الكفاءة بشكل كبير في نفس الوقت (المصدر: HuggingFace Daily Papers)
ورقة بحثية: استخدام التعلم المعزز لترتيب VisualQuality-R1 لتحقيق تقييم جودة الصورة المستحث بالاستدلال: أثبت DeepSeek-R1 أن التعلم المعزز يمكن أن يحفز بشكل فعال قدرات الاستدلال والتعميم للنماذج اللغوية الكبيرة (LLM). ومع ذلك، في مجال تقييم جودة الصورة (IQA) الذي يعتمد على الاستدلال البصري، لم يتم استكشاف إمكانات النمذجة الحاسوبية المستحثة بالاستدلال بشكل كامل. يقدم هذا البحث VisualQuality-R1، وهو نموذج IQA بدون مرجع (NR-IQA) مستحث بالاستدلال، ويستخدم التعلم المعزز للترتيب (reinforcement learning to rank) للتدريب، وهي خوارزمية تعلم تتكيف مع الطبيعة النسبية الكامنة لجودة الصورة. على وجه التحديد، بالنسبة لزوج من الصور، يستخدم النموذج تحسين سياسة المجموعة النسبية (group relative policy optimization) لإنشاء درجات جودة متعددة لكل صورة. تُستخدم هذه التقديرات بعد ذلك لحساب الاحتمال المقارن لجودة صورة واحدة أعلى من الأخرى في نموذج Thurstone. يتم تحديد مكافأة كل تقدير جودة باستخدام مقياس دقة مستمر بدلاً من تسميات ثنائية منفصلة. أظهرت التجارب المكثفة أن VisualQuality-R1 المقترح يتفوق باستمرار في الأداء على نماذج NR-IQA القائمة على التعلم العميق التمييزي وكذلك طرق الانحدار الحديثة لجودة الصورة المستحثة بالاستدلال. بالإضافة إلى ذلك، فإن VisualQuality-R1 قادر على إنشاء أوصاف جودة غنية بالسياق ومتوافقة مع الأحكام البشرية، ويدعم التدريب على مجموعات بيانات متعددة دون الحاجة إلى إعادة ضبط مقياس الإدراك. هذه الميزات تجعله مناسبًا بشكل خاص لقياس التقدم بشكل موثوق في مهام معالجة الصور المتعددة مثل دقة الصورة الفائقة وتوليد الصور (المصدر: HuggingFace Daily Papers)
ورقة بحثية: فتح قدرات الاستدلال العامة من خلال “الإحماء” في ظل قيود الموارد: يتطلب تصميم نماذج LLM فعالة ذات قدرات استدلال عادةً استخدام التعلم المعزز بمكافآت يمكن التحقق منها (RLVR) أو تقطير سلاسل تفكير طويلة (CoT) منسقة بعناية، وكلاهما يعتمد بشكل كبير على كميات كبيرة من بيانات التدريب، مما يشكل تحديًا كبيرًا للسيناريوهات التي تندر فيها بيانات التدريب عالية الجودة. يقترح الباحثون استراتيجية تدريب من مرحلتين فعالة من حيث العينات لتطوير LLM للاستدلال تحت إشراف محدود. في المرحلة الأولى، يتم “إحماء” النموذج عن طريق تقطير CoT طويلة من مجالات بسيطة (مثل ألغاز المنطق للفرسان والأوغاد) لاكتساب مهارات استدلال عامة. في المرحلة الثانية، يتم تطبيق RLVR على النموذج “المُحمَّى” باستخدام عدد قليل من عينات المجال المستهدف. أظهرت التجارب أن هذه الطريقة لها عدة فوائد: (1) مرحلة الإحماء وحدها تعزز الاستدلال العام، وتحسن الأداء في مجموعة من المهام (MATH, HumanEval+, MMLU-Pro)؛ (2) عند التدريب باستخدام RLVR على نفس مجموعة البيانات الصغيرة (≤100 عينة)، يتفوق النموذج المُحمَّى باستمرار على النموذج الأساسي؛ (3) الإحماء قبل تدريب RLVR يمكّن النموذج من الحفاظ على قدرة التعميم عبر المجالات حتى بعد التدريب على مجال معين؛ (4) إدخال الإحماء في العملية لا يحسن الدقة فحسب، بل يحسن أيضًا الكفاءة الكلية لعينات تدريب RLVR. تُظهر نتائج هذا البحث إمكانات “الإحماء” في بناء LLM استدلال قوية في بيئات نادرة البيانات (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح IndexMark: إطار عمل علامة مائية بدون تدريب لتوليد الصور ذاتيًا: يمكن لتقنية العلامات المائية غير المرئية للصور حماية ملكية الصور ومنع إساءة استخدام نماذج توليد الصور المرئية. ومع ذلك، فإن طرق توليد العلامات المائية الحالية تستهدف بشكل أساسي نماذج الانتشار، بينما لا تزال تقنية العلامات المائية لنماذج توليد الصور ذاتيًا بحاجة إلى استكشاف. يقترح الباحثون IndexMark، وهو إطار عمل علامة مائية بدون تدريب لنماذج توليد الصور ذاتيًا. استلهم IndexMark من خاصية التكرار في دفتر الرموز (codebook): استبدال الفهارس المولدة ذاتيًا بفهارس مماثلة ينتج عنه اختلافات بصرية لا تذكر. المكون الأساسي لـ IndexMark هو طريقة “مطابقة-استبدال” بسيطة وفعالة، والتي تختار بعناية رموز العلامة المائية من دفتر الرموز بناءً على تشابه الرموز، وتعمم استخدام رموز العلامة المائية من خلال استبدال الرموز، وبالتالي تضمين العلامة المائية دون التأثير على جودة الصورة. يتم التحقق من العلامة المائية عن طريق حساب نسبة رموز العلامة المائية في الصورة المولدة، ويتم تحسين الدقة بشكل أكبر من خلال مشفر الفهرس. بالإضافة إلى ذلك، قدم الباحثون مخطط تحقق مساعد لتعزيز المتانة ضد هجمات الاقتصاص. أثبتت التجارب أن IndexMark يحقق مستوى SOTA في جودة الصورة ودقة التحقق، ويظهر متانة ضد اضطرابات متعددة مثل الاقتصاص والضوضاء والتمويه الغاوسي والمحو العشوائي واهتزاز الألوان وضغط JPEG (المصدر: HuggingFace Daily Papers)
ورقة بحثية: الاستدلال من خلال نماذج المكافأة (RRM): تلعب نماذج المكافأة دورًا حاسمًا في توجيه النماذج اللغوية الكبيرة (LLM) لإنتاج مخرجات تتوافق مع التوقعات البشرية. ومع ذلك، فإن كيفية الاستفادة الفعالة من الحساب في وقت الاختبار لتعزيز أداء نموذج المكافأة لا تزال تحديًا مفتوحًا. يقدم هذا البحث نماذج الاستدلال بالمكافأة (Reward Reasoning Models, RRMs)، وهي نماذج مصممة خصيصًا لإجراء عملية استدلال متأنية قبل إنشاء المكافأة النهائية. من خلال استدلال سلسلة التفكير، يمكن لـ RRMs الاستفادة من الحساب الإضافي في وقت الاختبار للاستعلامات المعقدة التي تكون مكافآتها غير واضحة. لتطوير RRMs، قام الباحثون بتطبيق إطار عمل للتعلم المعزز يمكنه تنمية قدرات استدلال المكافأة ذاتية التطور دون الحاجة إلى مسارات استدلال صريحة كبيانات تدريب. أظهرت نتائج التجارب أن RRMs تحقق أداءً متفوقًا في اختبارات قياس أداء نمذجة المكافأة عبر مجالات متعددة. والجدير بالذكر أن الباحثين أظهروا أن RRMs يمكنها الاستفادة بشكل تكيفي من الحساب في وقت الاختبار لزيادة دقة المكافأة. تتوفر نماذج الاستدلال بالمكافأة المدربة مسبقًا على HuggingFace (المصدر: HuggingFace Daily Papers)
ورقة بحثية: الاستفادة من الخبراء المعرفيين في MoE لتوجيه التفكير، وتعزيز الاستدلال دون تدريب إضافي: حققت بنية خليط الخبراء (MoE) في نماذج الاستدلال الكبيرة (LRM) قدرات استدلال مثيرة للإعجاب من خلال تنشيط الخبراء بشكل انتقائي لتعزيز عمليات الإدراك المنظمة. على الرغم من التقدم الكبير، غالبًا ما تعاني نماذج الاستدلال الحالية من أوجه قصور في الكفاءة المعرفية مثل التفكير المفرط والتفكير غير الكافي. لمعالجة هذه القيود، قدم الباحثون طريقة توجيه جديدة في وقت الاستدلال تسمى “تعزيز الخبراء المعرفيين” (Reinforcing Cognitive Experts, RICE)، تهدف إلى تحسين أداء الاستدلال دون تدريب إضافي أو طرق استدلالية معقدة. باستخدام المعلومات المتبادلة النقطية المعيارية (nPMI)، حدد الباحثون بشكل منهجي خبراء متخصصين، يُطلق عليهم “الخبراء المعرفيون”، وهم مسؤولون عن تنسيق عمليات الاستدلال على المستوى الأعلى التي تتميز برموز معينة (مثل ““`”). أظهر التقييم التجريبي على اختبارات قياس الأداء الكمي والعلمي الصارمة على نماذج LRM رائدة قائمة على MoE (DeepSeek-R1 و Qwen3-235B) أن RICE تحقق تحسينات كبيرة ومتسقة في دقة الاستدلال والكفاءة المعرفية والتعميم عبر المجالات. والأهم من ذلك، أن هذه الطريقة خفيفة الوزن تتفوق بشكل كبير في الأداء على تقنيات توجيه الاستدلال الشائعة (مثل تصميم التوجيهات وقيود فك التشفير)، مع الحفاظ على قدرة النموذج على اتباع التعليمات العامة. تسلط هذه النتائج الضوء على تعزيز الخبراء المعرفيين كاتجاه واعد وعملي وقابل للتفسير لتعزيز الكفاءة المعرفية داخل نماذج الاستدلال المتقدمة (المصدر: HuggingFace Daily Papers)
ورقة بحثية: استكشاف تأثير ترتيب السياق على أداء نماذج اللغة في الإجابة على الأسئلة متعددة الخطوات: تشكل الإجابة على الأسئلة متعددة الخطوات (MHQA) تحديًا لنماذج اللغة (LM) بسبب تعقيدها. عندما يُطلب من LM معالجة نتائج بحث متعددة، لا يتعين عليها فقط استرداد المعلومات ذات الصلة، بل وأيضًا إجراء استدلال متعدد الخطوات عبر مصادر المعلومات. على الرغم من أداء LM الجيد في مهام الإجابة على الأسئلة التقليدية، إلا أن القناع السببي (causal mask) قد يعيق قدرتها على الاستدلال في السياقات المعقدة. يستكشف هذا البحث كيف تستجيب LM للأسئلة متعددة الخطوات من خلال ترتيب نتائج البحث (المستندات المسترجعة) في تكوينات مختلفة. وجد البحث ما يلي: 1) تتفوق نماذج التشفير-فك التشفير (مثل سلسلة Flan-T5) عادةً على نماذج فك التشفير السببية فقط في مهام MHQA، على الرغم من صغر حجمها بكثير؛ 2) يكشف تغيير ترتيب المستندات الذهبية عن اتجاهات مختلفة في نماذج Flan T5 ونماذج فك التشفير فقط المضبوطة بدقة، حيث يكون الأداء أفضل عندما يتوافق ترتيب المستندات مع ترتيب سلسلة الاستدلال؛ 3) يمكن أن يؤدي تعديل القناع السببي لتعزيز الانتباه ثنائي الاتجاه لنماذج فك التشفير السببية فقط إلى تحسين أدائها النهائي بشكل فعال. بالإضافة إلى ذلك، أجرى البحث تحقيقًا شاملاً في توزيع أوزان انتباه LM في سياق MHQA، ووجد أنه عندما تكون الإجابة صحيحة، تميل أوزان الانتباه إلى الذروة عند قيم أعلى. استغل الباحثون هذا الاكتشاف لتحسين أداء LM بشكل استدلالي في هذه المهمة (المصدر: HuggingFace Daily Papers)
ورقة بحثية: استخدام الضبط الدقيق المعزز لتحقيق وكلاء بصريين (Visual-ARFT): أحد الاتجاهات الرئيسية في نماذج الاستدلال الكبيرة (مثل o3 من OpenAI) هو امتلاك قدرات وكيل أصلية لاستخدام أدوات خارجية (مثل البحث في متصفح الويب، وكتابة/تنفيذ التعليمات البرمجية لمعالجة الصور) لتحقيق “التفكير بالصور”. في مجتمع البحث مفتوح المصدر، على الرغم من إحراز تقدم كبير في قدرات الوكيل اللغوي البحت (مثل استدعاء الدوال وتكامل الأدوات)، إلا أن تطوير قدرات الوكيل متعدد الوسائط التي تنطوي على التفكير الحقيقي بالصور والمعايير المقابلة لها لا يزال أقل. يؤكد هذا البحث على فعالية الضبط الدقيق المعزز للوكيل البصري (Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT) في منح نماذج اللغة المرئية الكبيرة (LVLM) قدرات استدلال مرنة وقابلة للتكيف. من خلال Visual-ARFT، اكتسبت LVLM مفتوحة المصدر القدرة على تصفح مواقع الويب للحصول على تحديثات المعلومات في الوقت الفعلي، وكذلك كتابة التعليمات البرمجية لمعالجة وتحليل الصور المدخلة من خلال تقنيات معالجة الصور مثل الاقتصاص والتدوير وما إلى ذلك. اقترح الباحثون أيضًا معيار أداة وكيل متعدد الوسائط (Multi-modal Agentic Tool Bench, MAT)، يتضمن إعدادي MAT-Search و MAT-Coding، لتقييم قدرات البحث والترميز الوكيل لـ LVLM. أظهرت نتائج التجارب أن Visual-ARFT يتفوق على خط الأساس بنسبة +18.6% F1 / +13.0% EM على MAT-Coding، وبنسبة +10.3% F1 / +8.7% EM على MAT-Search، متجاوزًا في النهاية GPT-4o. حقق Visual-ARFT أيضًا مكاسب بنسبة +29.3 F1% / +25.9% EM على معايير الإجابة على الأسئلة متعددة الخطوات الحالية (مثل 2Wiki و HotpotQA)، مما يدل على قدرة تعميم قوية. تشير هذه النتائج إلى أن Visual-ARFT يوفر مسارًا واعدًا لبناء وكلاء متعدد الوسائط أقوياء وقابلين للتعميم (المصدر: HuggingFace Daily Papers)
💼 أعمال
“ميموري إنتليجنس” (FaceWall Intelligence) تكمل جولة تمويل جديدة بمليارات اليوانات، بمشاركة مشتركة من هونغتاي، غوزونغ، تشينغكونغ جينشين، وصندوق موتاي: أعلنت شركة النماذج الكبيرة “ميموري إنتليجنس” مؤخرًا عن إكمال جولة تمويل جديدة بمليارات اليوانات، بمشاركة مشتركة من صندوق هونغتاي، غوزونغ كابيتال، تشينغكونغ جينشين، وصندوق موتاي. تركز “ميموري إنتليجنس” على تطوير نماذج كبيرة “عالية الكفاءة”، بهدف إنشاء نماذج كبيرة ذات أداء أعلى وتكلفة أقل واستهلاك طاقة أقل وسرعة أكبر بنفس عدد المعلمات. وصل نموذجها الطرفي متعدد الوسائط MiniCPM-o 2.6 إلى مستوى رائد في الصناعة في جوانب مثل الرؤية المستمرة والاستماع في الوقت الفعلي والتحدث الطبيعي. تجاوز إجمالي تنزيلات سلسلة نماذج MiniCPM، بفضل كفاءتها وخصائصها منخفضة التكلفة، عشرة ملايين. تعاونت الشركة بالفعل مع شركات سيارات مثل شانجان أوتوموبيل، وسايك فولكس فاجن، وجريت وول موتورز، لتعزيز التطبيق التجاري للنماذج الكبيرة الطرفية في مجالات مثل قمرة القيادة الذكية (المصدر: 量子位, WeChat)

تيسلين وجامعة تونغجي تتوصلان إلى تعاون استراتيجي، لتعزيز البحث والتطوير في تكنولوجيا الذكاء المكاني: وقعت شركة AIoT تيسلين ومعهد هندسة الذكاء الاصطناعي بجامعة تونغجي اتفاقية تعاون استراتيجي، حيث سيركز الطرفان على تكنولوجيا الذكاء المكاني، مع التركيز بشكل خاص على البحث والتطوير في دمج البيانات متعددة المصادر وغير المتجانسة، وفهم المشهد، وتنفيذ القرارات. يشمل محتوى التعاون البحث الابتكاري، ومشاركة الموارد، وتحويل الإنجازات، وتدريب المواهب. ستوفر تيسلين سيناريوهات تطبيق ومنصات اختبار للأجهزة، بينما سيقود معهد هندسة الذكاء الاصطناعي بجامعة تونغجي البحث والتطوير في الخوارزميات الأساسية وهندسة النظم. يهدف الطرفان إلى تسريع تطبيق التكنولوجيا المتطورة في القطاع الصناعي واستكشاف الاختراقات في مجال “نظام تشغيل” الذكاء الهندسي بشكل مشترك (المصدر: 量子位)

الشركات المحلية الكبرى تسرع من وتيرة تخطيطها لوكلاء الذكاء الاصطناعي (AI Agent)، وبايدو وعلي بابا وبايت دانس تتنافس على حصص السوق: بعد تأكيد قمة الذكاء الاصطناعي التي عقدتها سيكويا كابيتال على قيمة وكلاء الذكاء الاصطناعي، سارعت الشركات الكبرى في مجال الإنترنت في الصين مثل بايت دانس وبايدو وعلي بابا إلى تسريع وتيرة تخطيطها في هذا المجال. يُقال إن لدى بايت دانس عدة فرق تعمل على تطوير وكلاء، وقد اختبرت داخليًا “مساحة كوزي”؛ وأطلقت بايدو في مؤتمر Create وكيلًا ذكيًا عامًا باسم “شين شيانغ”؛ بينما وضعت علي بابا كوارك كـ “وكيل فائق”. بالإضافة إلى الوكلاء من النوع العام، تبذل كل شركة جهودًا في تطوير وكلاء متخصصين مثل “فيجو ون ون” (علي بابا) و “فا شينغ باو” (بايدو). يعتقد الخبراء في الصناعة أن الوكلاء هم الموجة الثانية بعد النماذج الكبيرة، وأن المنافسة ستعتمد على عمق النظام البيئي، واحتلال عقول المستخدمين، وقدرات النماذج الأساسية، والتحكم في التكاليف، وعوامل أخرى. على الرغم من المنافسة الشديدة، لم يصل الوكلاء بعد إلى لحظة تحويلية مماثلة لـ GPT، ولا يزال هناك مجال لتحسين النضج التقني ونماذج الأعمال وتجربة المستخدم (المصدر: 36氪)
🌟 مجتمع
المحتوى الذي يولده الذكاء الاصطناعي يغمر Reddit، مما يثير مخاوف “الإنترنت الميت” ونقاشات حول تجربة المستخدم: لاحظ مستخدمو Reddit تزايد المحتوى الذي يولده الذكاء الاصطناعي على المنصة، حيث تظهر بعض التعليقات بأسلوب مشابه يفتقر إلى الطابع الشخصي، بل وتظهر علامات واضحة على كتابة الذكاء الاصطناعي (مثل الإفراط في استخدام الشرطة الطويلة em-dash). أثار هذا نقاشات حول “نظرية الإنترنت الميت” (Dead Internet Theory)، والتي تفترض أن معظم محتوى الإنترنت سيتم إنشاؤه بواسطة الذكاء الاصطناعي، وليس من خلال تفاعلات بشرية حقيقية. تباينت ردود أفعال المستخدمين تجاه هذا الأمر: يعتقد البعض أن محتوى الذكاء الاصطناعي يفتقر إلى اللمسة الإنسانية، وهو ممل أو مثير للقلق، ويؤثر على تجربة التواصل البشري الحقيقي؛ بينما أشار آخرون إلى أن الذكاء الاصطناعي يمكن أن يساعد غير الناطقين باللغة الأم على تحسين نصوصهم، أو استخدامه لاختبار النماذج وضبطها. القلق السائد هو أن الظهور الهائل لمحتوى الذكاء الاصطناعي سيخفف من النقاشات البشرية الحقيقية، وقد يُستخدم لأغراض التسويق والدعاية وما إلى ذلك، مما يقلل في النهاية من قيمة المنصة لتدريب الذكاء الاصطناعي (المصدر: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
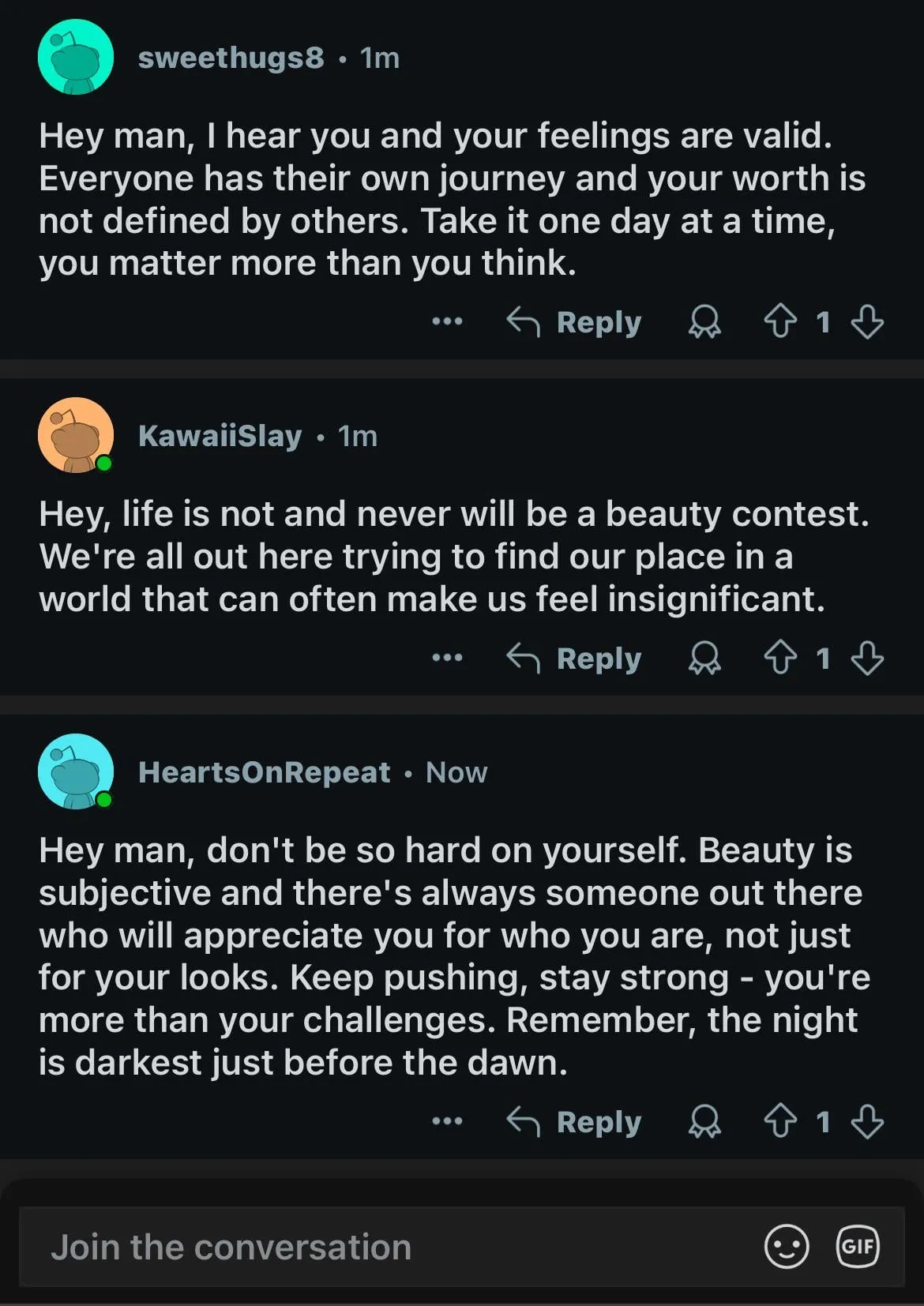
نماذج الذكاء الاصطناعي تظهر معايير مزدوجة في قضايا التحيز الجنسي، مما يثير تفكيرًا مجتمعيًا: أظهر منشور على Reddit كيف أن نموذج ذكاء اصطناعي (يُقال إنه نسخة معاينة من Gemini 2.5 Pro) يُظهر ردود فعل مختلفة عند التعامل مع عبارات تعميم سلبية تتعلق بالجنس. عندما أُخبر بأن “الرجال = مقرفون”، مال النموذج إلى الرد بشكل محايد، معترفًا بأنها عبارة ذاتية؛ بينما عندما أُخبر بأن “النساء = مقرفات”، رفض النموذج المزيد من التفاعل، معتبرًا أن العبارة تروج لتعميمات ضارة. أثارت التعليقات نقاشًا حادًا، وشملت وجهات النظر ما يلي: هذا يعكس الواقع الاجتماعي الذي يناقش كراهية النساء أكثر بكثير من كراهية الرجال، مما يؤدي إلى عدم توازن بيانات التدريب؛ قد يقوم النموذج بتعديل استراتيجيات الرد بناءً
على جنس السائل؛ تختلف حساسية المجتمع تجاه الصور النمطية والخطاب العدواني تجاه المجموعات الجنسية المختلفة. يعتقد بعض المعلقين أن رد فعل الذكاء الاصطناعي هو انعكاس للتحيزات الاجتماعية، بينما يرى آخرون أن هذا التعامل المتمايز له ما يبرره، لأن الخطاب السلبي الموجه ضد المرأة غالبًا ما يرتبط بتمييز وعنف أوسع نطاقًا (المصدر: Reddit r/ChatGPT)
نقاش حول اتجاه تسليع وكلاء الذكاء الاصطناعي ومحاور المنافسة المستقبلية: ناقش مستخدمو Reddit أن مؤتمري Microsoft Build 2025 و Google I/O 2025 يشيران إلى أن وكلاء الذكاء الاصطناعي قد دخلوا مرحلة التسليع، وأن بناء ونشر الوكلاء لن يكون في السنوات القليلة القادمة حكرًا على مطوري النماذج المتطورة. لذلك، سينتقل التركيز قصير المدى لتطوير الذكاء الاصطناعي من بناء الوكلاء أنفسهم إلى مهام ذات مستوى أعلى، مثل وضع ونشر خطط عمل أفضل، وتطوير نماذج أكثر ذكاءً لدفع الابتكار. ترى التعليقات أن الفائزين في مجال وكلاء الذكاء الاصطناعي في المستقبل سيكونون أولئك القادرين على بناء أذكى “نماذج تنفيذية” (executive models)، وليس مجرد مطوري الأدوات الأكثر تسويقًا. ستعود المنافسة الأساسية إلى الذكاء القوي في قمة المكدس، وليس مجرد آليات الانتباه أو قدرات الاستدلال (المصدر: Reddit r/deeplearning)
ممارسو تعلم الآلة يناقشون بحماس أهمية المعرفة الرياضية: ناقش مجتمع Reddit r/MachineLearning أهمية الرياضيات في ممارسة تعلم الآلة. يعتقد معظم الممارسين أن فهم المبادئ الرياضية الكامنة وراء الذكاء الاصطناعي أمر بالغ الأهمية، خاصة في تحسين النماذج وفهم الأوراق البحثية وإجراء الابتكارات. تشير التعليقات إلى أنه على الرغم من أنه ليس من الضروري دائمًا إجراء حسابات منخفضة المستوى مثل ضرب المصفوفات يدويًا، إلا أن إتقان المفاهيم الأساسية مثل الإحصاء والجبر الخطي وحساب التفاضل والتكامل يساعد على فهم الخوارزميات بعمق وتجنب التطبيق الأعمى. ترى بعض التعليقات أن الرياضيات في تعلم الآلة بسيطة نسبيًا، وأن التطبيقات الرياضية الأكثر تعقيدًا توجد في مجالات مثل نظرية التحسين وتعلم الآلة الكمومي. تعتبر موارد التعلم عبر الإنترنت كافية، ولكنها تتطلب من المتعلمين درجة عالية من الانضباط الذاتي (المصدر: Reddit r/MachineLearning)
💡 أخرى
تقرير مركز أبحاث QbitAI: الذكاء الاصطناعي يعيد تشكيل تحسين محركات البحث (SEO)، وقيمة مجتمعات المحتوى المتخصصة تبرز: أصدر مركز أبحاث QbitAI تقريرًا يشير إلى أن مساعدي الذكاء الاصطناعي يعيدون تشكيل استراتيجيات تحسين محركات البحث التقليدية (SEO). اكتشف التقرير من خلال التجارب أن ما يقرب من نصف إجابات الذكاء الاصطناعي تستشهد بمصادر من مجتمعات المحتوى، خاصة في مجالات المعرفة المتخصصة، حيث يكون وزن الاستشهاد بمجتمعات المحتوى (مثل Zhihu) أعلى. تحولت توقعات المستخدمين للحصول على المعلومات من “الفرز الذاتي” إلى “الحصول المباشر على الإجابات”، مما قد يؤدي إلى انخفاض عدد النقرات على مواقع الويب التقليدية. يرى التقرير أنه في عصر الذكاء الاصطناعي، تبرز قيمة مجتمعات المحتوى المتخصصة بسبب كثافة معلوماتها وخبرات الخبراء وجودة المحتوى الذي ينشئه المستخدمون، ويجب أن تتحول استراتيجيات SEO إلى SPO (التحسين الموجه نحو المجتمعات المتخصصة)، بينما سينخفض وزن بوابات المعلومات منخفضة الجودة (المصدر: 量子位, WeChat)

أداة FaceAge لقياس العمر بالذكاء الاصطناعي عبر الصور تنشر في مجلة “ذا لانسيت”، وقد تساعد في اتخاذ قرارات علاج السرطان: طور فريق Mass General Brigham أداة ذكاء اصطناعي تسمى FaceAge، يمكنها التنبؤ بالعمر البيولوجي للفرد من خلال تحليل صور الوجه، ونُشر البحث ذو الصلة في مجلة The Lancet Digital Health. يقوم هذا النموذج بتقييم درجة الشيخوخة من خلال ملاحظة ملامح الوجه (مثل تجويف الصدغين، وتجاعيد الجلد، وترهل الخطوط). في دراسة أجريت على مرضى السرطان، وجد أن المرضى الذين تبدو أعمارهم الوجهية أصغر من أعمارهم الفعلية، كانت نتائج علاجهم أفضل، ومخاطر بقائهم على قيد الحياة أقل. قد تساعد هذه الأداة الأطباء في المستقبل على وضع خطط علاجية مخصصة بناءً على العمر البيولوجي للمريض، ولكنها أثارت أيضًا مخاوف بشأن تحيز البيانات (حيث كانت بيانات التدريب في الغالب من البيض) واحتمال إساءة الاستخدام (مثل التمييز في التأمين) (المصدر: WeChat)

بحث: أفضل نماذج الذكاء الاصطناعي تفشل في المهام الفيزيائية الأساسية، مما يسلط الضوء على صعوبة استبدال وظائف العمال اليدويين على المدى القصير: قام باحث تعلم الآلة آدم كارفونين بتقييم أداء أفضل نماذج LLM مثل OpenAI o3 و Gemini 2.5 Pro من خلال مهمة تصنيع قطع غيار (باستخدام آلات التفريز والمخارط CNC). أظهرت النتائج أن جميع النماذج فشلت في وضع خطة تصنيع مرضية، مما كشف عن أوجه قصور في الفهم البصري (تفويت التفاصيل، عدم اتساق التعرف على الميزات) والاستدلال الفيزيائي (تجاهل الصلابة والاهتزاز، اقتراح حلول تثبيت مستحيلة لقطعة العمل). يعتقد كارفونين أن هذا مرتبط بافتقار LLM إلى المعرفة الضمنية وبيانات الخبرة في العالم الحقيقي في المجالات ذات الصلة. ويتكهن بأنه على المدى القصير، سيقوم الذكاء الاصطناعي بأتمتة المزيد من وظائف ذوي الياقات البيضاء، بينما ستتأثر وظائف ذوي الياقات الزرقاء التي تعتمد على العمليات الفيزيائية والخبرة بشكل أقل، مما قد يؤدي إلى تطور غير متوازن للأتمتة بين مختلف الصناعات (المصدر: WeChat)
