
كلمات مفتاحية:تقنية الذكاء الاصطناعي, جوجل جيميني, استهلاك الطاقة في الذكاء الاصطناعي, التطبيقات القانونية للذكاء الاصطناعي, مايكروسوفت ديسكفري, هوانج رينكسون وإيلون ماسك, تنظيم الذكاء الاصطناعي, جيميني 2.5 برو, استهلاك الطاقة في مراكز بيانات الذكاء الاصطناعي, أخطاء توليد الوثائق القانونية بالذكاء الاصطناعي, منصة مايكروسوفت ديسكفري للبحث العلمي, قيود تصدير شرائح الذكاء الاصطناعي
🔥 聚焦
谷歌I/O大会发布多项AI进展,Gemini全面融入谷歌生态: أعلنت جوجل في مؤتمر المطورين I/O 2025 عن سلسلة من التحديثات الرئيسية في مجال الذكاء الاصطناعي، تتمحور حول ترقية نموذج Gemini ودمجه بعمق. يقدم Gemini 2.5 Pro ميزة “Deep Think” لتعزيز الاستدلال المعقد، بينما يحسن 2.5 Flash الكفاءة والتكلفة، ويضيف مخرج صوت أصلي. يقدم البحث “وضع AI”، الذي يوفر إجابات بأسلوب روبوتات الدردشة، ويمكنه تقديم نتائج مخصصة بناءً على بيانات المستخدم الشخصية (يتطلب الإذن). سيقوم متصفح Chrome بدمج مساعد Gemini. يحقق نموذج الفيديو Veo 3 إنشاء فيديو مع صوت، بينما يحسن نموذج الصور Imagen 4 التفاصيل ومعالجة النصوص. كما أصدرت جوجل أداة إنتاج الأفلام بالذكاء الاصطناعي Flow، ومساعد البرمجة Jules، وعرضت التقدم المحرز في Project Astra (مساعد متعدد الوسائط في الوقت الفعلي) و Project Mariner (وكيل ذكاء اصطناعي متعدد المهام). وفي الوقت نفسه، أطلقت جوجل خدمة اشتراك جديدة في الذكاء الاصطناعي، حيث تصل تكلفة الإصدار المتميز AI Ultra إلى 249.99 دولارًا أمريكيًا شهريًا. تشير هذه المبادرات إلى أن جوجل تسرع من دمج الذكاء الاصطناعي بشكل كامل في منتجاتها وخدماتها، مما يعيد تشكيل تجربة تفاعل المستخدم. (المصدر: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

AI能耗问题引关注,MIT科技评论深度剖析其能源足迹与未来挑战: نشرت MIT Technology Review سلسلة من التقارير التي تناقش بعمق استهلاك الطاقة وانبعاثات الكربون الناتجة عن تطور تكنولوجيا الذكاء الاصطناعي. تشير الأبحاث إلى أن استهلاك الطاقة في مرحلة استدلال الذكاء الاصطناعي قد تجاوز مرحلة التدريب، ليصبح العبء الرئيسي للطاقة. تحلل التقارير الطلب الهائل على الكهرباء واستهلاك الموارد المائية لمراكز البيانات (مثل مراكز البيانات في صحراء نيفادا)، والاعتماد على الوقود الأحفوري (مثل اعتماد مركز بيانات Meta في لويزيانا على الغاز الطبيعي). على الرغم من اعتبار الطاقة النووية حلاً محتملاً للطاقة النظيفة، إلا أن دورة بنائها طويلة، ومن الصعب تلبية احتياجات النمو السريع للذكاء الاصطناعي على المدى القصير. وفي الوقت نفسه، تشير التقارير أيضًا إلى آفاق متفائلة لتحسين كفاءة الطاقة للذكاء الاصطناعي، بما في ذلك خوارزميات نماذج أكثر كفاءة، ورقائق موفرة للطاقة مصممة خصيصًا للذكاء الاصطناعي، وتقنيات تبريد محسنة لمراكز البيانات. تؤكد السلسلة أنه على الرغم من أن استهلاك الطاقة لاستعلام ذكاء اصطناعي واحد يبدو ضئيلاً، إلا أن الاتجاه العام للصناعة والتخطيط المستقبلي (مثل خطة Stargate الخاصة بـ OpenAI) ينذران بتحديات طاقة هائلة، تتطلب الكشف الشفاف عن البيانات وتخطيطًا مسؤولًا للطاقة. (المصدر: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

AI在法律领域的应用引发错误与伦理担忧: أظهرت حوادث متعددة مؤخرًا أن مشكلة “الهلوسات” التي يولدها الذكاء الاصطناعي في صياغة المستندات القانونية تثير قلقًا بالغًا. فرض قاضٍ في كاليفورنيا غرامة على محامٍ لاستخدامه أدوات ذكاء اصطناعي مثل Google Gemini لإنشاء محتوى يتضمن اقتباسات مزيفة في وثائق المحكمة. وفي قضية أخرى، ارتكب نموذج Claude التابع لشركة Anthropic للذكاء الاصطناعي أخطاءً أيضًا عند إنشاء اقتباسات لمستندات قانونية. والأمر الأكثر إثارة للقلق هو اعتراف مدعٍ عام إسرائيلي باستخدام نصوص مولدة بالذكاء الاصطناعي تستشهد بقوانين غير موجودة في طلباته. تسلط هذه الحالات الضوء على أوجه القصور في نماذج الذكاء الاصطناعي من حيث الدقة والموثوقية، خاصة في المجال القانوني الذي يتطلب دقة عالية في الحقائق والاقتباسات. يشير الخبراء إلى أن المحامين قد يفرطون في الثقة بمخرجات الذكاء الاصطناعي سعيًا وراء الكفاءة، متجاهلين ضرورة المراجعة الدقيقة. على الرغم من الترويج لأدوات الذكاء الاصطناعي كمساعدين قانونيين موثوقين، إلا أن خاصية “الهلوسة” المتأصلة فيها تشكل تهديدًا محتملاً للعدالة القضائية، مما يستدعي وضع معايير صناعية وتوخي الحذر من جانب المستخدمين. (المصدر: MIT Technology Review)

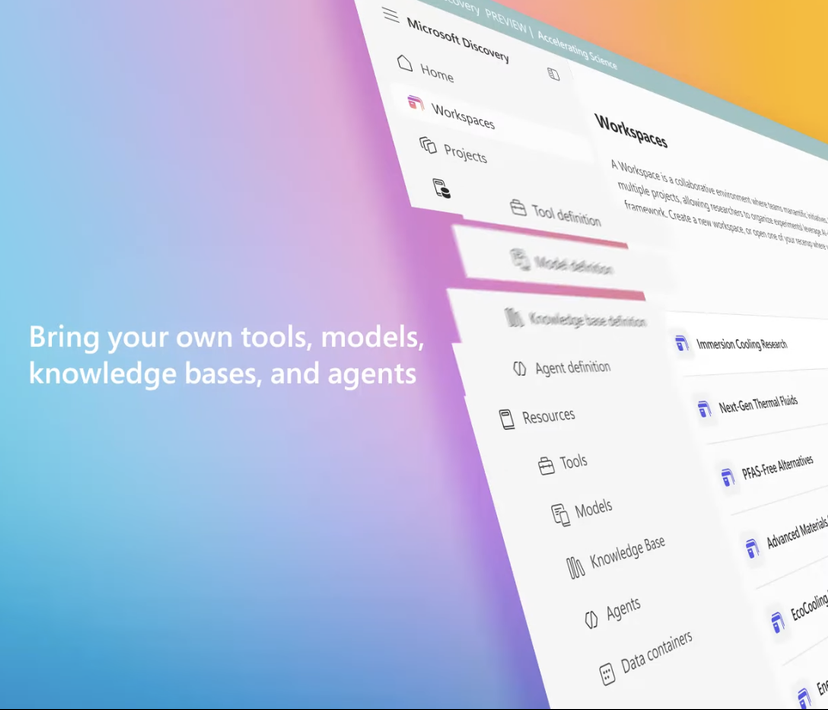
微软推出企业级AI科研平台Microsoft Discovery,助力科学发现: أعلنت مايكروسوفت في مؤتمر Build عن إطلاق Microsoft Discovery، وهي منصة ذكاء اصطناعي مصممة للمؤسسات ومعاهد البحث، تهدف إلى تمكين العلماء والمهندسين الذين ليس لديهم خلفية برمجية من استخدام الحوسبة عالية الأداء وأنظمة المحاكاة المعقدة من خلال التفاعل باللغة الطبيعية. تجمع المنصة بين النماذج الأساسية للتخطيط والنماذج المتخصصة المدربة لمجالات علمية محددة (مثل الفيزياء والكيمياء والأحياء)، لتشكيل فريق “AI Postdoc” قادر على تنفيذ عملية البحث العلمي بأكملها، من مراجعة الأدبيات إلى المحاكاة الحاسوبية. عرضت مايكروسوفت حالة استخدام لها: فحص 367,000 مادة في حوالي 200 ساعة، ونجحت في اكتشاف بديل محتمل لمبرد خالٍ من PFAS، وتم التحقق منه تجريبيًا. تشمل ميزات المنصة محرك معرفة بياني، واستدلال تعاوني، ودورة بحث وتطوير تكرارية مستمرة، وهي مبنية على بنية Azure التحتية، مع تصميم معماري مستقبلي يسمح بالاتصال بالحوسبة الكمومية. (المصدر: 量子位)
黄仁勋与马斯克就AI发展、监管及全球竞争发表看法: أعرب جنسن هوانغ، الرئيس التنفيذي لشركة Nvidia، في مقابلة خاصة عن قلقه بشأن قيود تصدير الرقائق الأمريكية، معتقدًا أن تقييد انتشار التكنولوجيا قد يقوض ريادة الولايات المتحدة في مجال الذكاء الاصطناعي، وأكد على قوة الصين في مجال البحث والتطوير في الذكاء الاصطناعي وحقيقة أن نصف مطوري الذكاء الاصطناعي في العالم هم من الصين. ودعا الولايات المتحدة إلى تسريع تعميم التكنولوجيا على مستوى العالم والسماح للشركات الأمريكية بالمنافسة في السوق الصينية. من ناحية أخرى، صرح إيلون ماسك، الرئيس التنفيذي لشركة Tesla، في مقابلة أخرى بأنه سيستمر في قيادة Tesla لمدة خمس سنوات على الأقل، ويعتقد أنه يقترب من تحقيق الذكاء الاصطناعي العام (AGI). وأيد التنظيم المعتدل للذكاء الاصطناعي، لكنه عارض التدخل المفرط. أكد كلا القائدين التكنولوجيين على الإمكانات الهائلة للذكاء الاصطناعي، حيث يعتقد هوانغ أن الذكاء الاصطناعي سيدفع النمو الكبير للناتج المحلي الإجمالي العالمي، بينما ذكر ماسك الأهداف الرئيسية لهذا العام مثل Starship و Neuralink وسيارات الأجرة ذاتية القيادة من Tesla، وكلها مرتبطة ارتباطًا وثيقًا بالذكاء الاصطناعي. (المصدر: 36氪, 36氪, 36氪)

🎯 动向
谷歌发布Gemma 3n预览版,专为端侧高效运行设计: أصدرت جوجل نسخة معاينة من نماذج Gemma 3n على HuggingFace، وهي مصممة خصيصًا للتشغيل الفعال على الأجهزة منخفضة الموارد (مثل الأجهزة المحمولة). تتمتع هذه السلسلة من النماذج بقدرات إدخال متعددة الوسائط، ويمكنها معالجة النصوص والصور ومقاطع الفيديو والصوت، وإنشاء مخرجات نصية. وتستخدم تقنية “تنشيط المعلمات الانتقائي” (مشابهة لمعمارية خبراء MoE المختلطة)، مما يسمح للنموذج بالعمل بأحجام معلمات فعالة تبلغ 2B و 4B، وبالتالي تقليل متطلبات الموارد. يعتقد مجتمع المطورين أن بنية Gemma 3n قد تكون مشابهة لـ Gemini، مما يفسر قدرات الأخير القوية متعددة الوسائط والسياق الطويل. إن أوزان Gemma 3n مفتوحة المصدر وإصداراتها المضبوطة بالتعليمات، بالإضافة إلى تدريبها على بيانات بأكثر من 140 لغة، تجعلها ذات إمكانات في تطبيقات الذكاء الاصطناعي الطرفية، مثل مساعدي المنازل الذكية. (المصدر: Reddit r/LocalLLaMA, developers.googleblog.com)

谷歌推出MedGemma,专为医疗领域优化的AI模型: أطلقت جوجل سلسلة نماذج MedGemma، وهما نوعان مختلفان من Gemma 3 تم تحسينهما خصيصًا للمجال الطبي، بما في ذلك إصدار متعدد الوسائط بمعلمات 4B وإصدار نصي خالص بمعلمات 27B. تم تدريب MedGemma 4B بشكل خاص على فهم الصور الطبية (مثل صور الأشعة السينية وصور الأمراض الجلدية وما إلى ذلك) والنصوص، باستخدام مشفر صور SigLIP تم تدريبه مسبقًا على البيانات الطبية. يركز MedGemma 27B على معالجة النصوص الطبية وتم تحسينه للحساب أثناء الاستدلال. صرحت جوجل بأن هذه النماذج تهدف إلى تسريع تطوير تطبيقات الذكاء الاصطناعي الطبية، وقد تم تقييمها على العديد من المعايير المرجعية ذات الصلة سريريًا، ويمكن للمطورين ضبطها بدقة لتحسين أداء مهام محددة. كان رد فعل المجتمع إيجابيًا، معتبرًا أن إمكاناتها هائلة، ولكنه أكد على الحاجة إلى ملاحظات فعلية من المتخصصين الطبيين. (المصدر: Reddit r/LocalLLaMA)

字节跳动发布开源多模态模型Bagel,支持图像生成: أطلقت شركة بايت دانس نموذج Bagel (المعروف أيضًا باسم BAGEL-7B-MoT)، وهو نموذج لغوي كبير متعدد الوسائط مفتوح المصدر بمعلمات 14B (7B نشطة)، بموجب ترخيص Apache 2.0. يعتمد النموذج على بنية الخبراء المختلطين (MoE) والمحول المختلط (MoT)، وهو قادر على فهم وإنشاء النصوص، ويتمتع بقدرة أصلية على إنشاء الصور. وقد تفوق أداؤه على النماذج الموحدة مفتوحة المصدر الأخرى في سلسلة من اختبارات فهم وإنشاء الوسائط المتعددة، وأظهر قدرات استدلال متقدمة متعددة الوسائط مثل معالجة الصور ذات الشكل الحر والتنبؤ بالإطارات المستقبلية. يأمل الباحثون في تعزيز أبحاث الوسائط المتعددة من خلال مشاركة تفاصيل التدريب المسبق وبروتوكولات إنشاء البيانات وفتح الأكواد ونقاط الفحص. (المصدر: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
英伟达发布DreamGen,利用生成视频模型训练机器人: أطلق فريق أبحاث Nvidia مشروع DreamGen، الذي يقوم بضبط نماذج توليد الفيديو المتقدمة (مثل Sora و Veo) بدقة، للسماح للروبوتات بتعلم مهارات جديدة في “عالم الأحلام” الذي تم إنشاؤه. لا تعتمد هذه الطريقة على محركات الرسوميات التقليدية أو محاكيات الفيزياء، بل تسمح للروبوتات بالاستكشاف والتجربة بشكل مستقل في مشاهد على مستوى البكسل تم إنشاؤها بواسطة الشبكات العصبية، وبالتالي إنشاء كمية كبيرة من المسارات العصبية مع تسميات حركة زائفة. أظهرت التجارب أن DreamGen يمكن أن يحسن بشكل كبير أداء الروبوتات في مهام المحاكاة والعالم الحقيقي، بما في ذلك الحركات التي لم يسبق لها مثيل والبيئات غير المألوفة. على سبيل المثال، باستخدام عدد قليل فقط من المسارات الحقيقية، تعلم الروبوت الشبيه بالبشر 22 مهارة جديدة مثل سكب الماء وطي الملابس، ونجح في تعميمها على مشاهد حقيقية مثل مقهى مقر Nvidia. (المصدر: 36氪, arxiv.org)

华为提出OmniPlacement优化MoE模型推理性能:針對 مشكلة تأخير الاستدلال الناتجة عن عدم توازن حمل شبكة الخبراء (الخبراء “الساخنون” مقابل الخبراء “الباردون”) في نماذج الخبراء المختلطين (MoE)، اقترح فريق هواوي حل تحسين OmniPlacement. يهدف هذا الحل إلى تحسين أداء استدلال نماذج MoE من خلال إعادة ترتيب الخبراء، ونشر التكرار بين الطبقات، والجدولة الديناميكية شبه في الوقت الفعلي. أظهر التحقق النظري على نماذج مثل DeepSeek-V3 أن OmniPlacement يمكن أن يقلل من تأخير الاستدلال بحوالي 10٪ ويزيد من الإنتاجية بحوالي 10٪. يكمن جوهر هذه الطريقة في الضبط الديناميكي لأولوية الخبراء، وتحسين مجال الاتصال، ونشر مثيلات التكرار بشكل تفاضلي، والاستجابة بمرونة لتغيرات الحمل من خلال آلية جدولة شبه في الوقت الفعلي ومراقبة ديناميكية. تخطط هواوي لفتح مصدر هذا الحل قريبًا. (المصدر: 量子位)

苹果计划向开发者开放AI模型权限,刺激应用创新: تفيد التقارير بأن آبل ستعلن في مؤتمر WWDC عن فتح صلاحيات نماذج الذكاء الاصطناعي Apple Intelligence لمطوري الطرف الثالث. ستركز المرحلة الأولية على نماذج لغوية خفيفة الوزن بحوالي 3 مليارات معلمة تعمل على الجهاز، وقد يتم لاحقًا فتح نماذج سحابية (تعمل عبر سحابة خاصة ومشفرة) تضاهي مستوى GPT-4-Turbo. تهدف هذه الخطوة إلى تشجيع المطورين على بناء وظائف تطبيقات جديدة تعتمد على نماذج LLM من آبل، وتعزيز جاذبية أجهزة آبل، وتعويض تأخرها النسبي في مجال الذكاء الاصطناعي التوليدي. يعتقد المحللون أن آبل تأمل في تعويض نقاط ضعفها التقنية من خلال بناء نظام بيئي مفتوح، والاستفادة من مجتمع المطورين الضخم لديها (6 ملايين) لمواجهة المنافسة الشرسة المتزايدة في مجال الذكاء الاصطناعي. (المصدر: 36氪)
美国众议院提案拟暂停州级AI监管十年,引发巨大争议: وافقت لجنة الطاقة والتجارة بمجلس النواب الأمريكي على اقتراح يهدف إلى حظر الولايات من تنظيم نماذج وأنظمة الذكاء الاصطناعي وأنظمة اتخاذ القرار الآلية التي “تؤثر بشكل كبير على قرارات الإنسان أو تحل محلها” لمدة عشر سنوات قادمة. يرى المؤيدون أن هذه الخطوة يمكن أن تتجنب عرقلة قوانين الولايات المختلفة لابتكار الذكاء الاصطناعي وتحديث أنظمة الحكومة الفيدرالية؛ بينما يصفها المعارضون بأنها “هدية ضخمة لشركات التكنولوجيا الكبرى” وستضعف قدرة الولايات على حماية مواطنيها من أضرار الذكاء الاصطناعي. إذا تم تمرير هذا الاقتراح، فقد يبطل عددًا كبيرًا من قوانين الذكاء الاصطناعي الحالية والمقترحة على مستوى الولايات، ولكنه يوضح أيضًا أنه لا ينطبق على القوانين التي تنص عليها القوانين الفيدرالية أو القوانين المطبقة بشكل عام والتي تعامل الذكاء الاصطناعي والأنظمة غير المعتمدة على الذكاء الاصطناعي على قدم المساواة. تعكس هذه الخطوة الصراع المحتدم عالميًا بين “أولوية ابتكار الذكاء الاصطناعي” و “الحد الأدنى للأمان”. (المصدر: 36氪, edition.cnn.com)

《Take It Down Act》签署成为美国法律,打击非自愿私密图像传播: وقع الرئيس الأمريكي ترامب على مشروع قانون 《Take It Down Act》، الذي يجرم إنتاج ونشر الصور الحميمة غير الرضائية (بما في ذلك محتوى التزييف العميق الناتج عن الذكاء الاصطناعي) كجريمة فيدرالية. يلزم القانون منصات التكنولوجيا بإزالة المحتوى ذي الصلة في غضون 48 ساعة من تلقي الإشعار. يهدف هذا القانون إلى حماية الضحايا ومواجهة المشكلات الاجتماعية المتزايدة الناجمة عن إساءة استخدام تقنية التزييف العميق. ومع ذلك، تشير بعض التعليقات أيضًا إلى أن القانون قد يساء استخدامه، مما يؤدي إلى رقابة مفرطة. (المصدر: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

AI大模型助力健康管理,实现个性化与多维数据联动: تضخ نماذج الذكاء الاصطناعي الكبيرة حيوية جديدة في مجال إدارة الصحة، من خلال دمجها مع الأجهزة القابلة للارتداء، لتحقيق ربط البيانات متعددة الأبعاد وتقديم خدمات مخصصة. تستكشف شركات مثل WeDoctor و Deepwise Healthcare و NandaFITT بنشاط سيناريوهات التطبيق، مثل البدء من سيناريوهات الفحص البدني لإجراء الفحص المبكر والعلاج المبكر، أو استخدام إدارة الوزن كنقطة انطلاق للوقاية من الأمراض المزمنة ومكافحتها. يمكن للنماذج الكبيرة معالجة أبعاد بيانات أكثر تنوعًا، وإنشاء ذاكرة للمستخدم، وتقديم خطط تدخل صحي أكثر دقة. تشمل التحديات هلوسات النماذج، وجودة البيانات وصعوبة التنسيق، ولكن يتم التغلب عليها تدريجيًا من خلال RAG، وضبط النماذج الدقيق، وآليات المراجعة، ونموذج “الذكاء الاصطناعي + مدير بشري”. على صعيد نماذج الأعمال، تم التحقق مبدئيًا من خدمات B2B، والدفع من جانب المستخدمين الأفراد، والمجتمعات الصحية المعتمدة على الذكاء الاصطناعي، وسيتجه الاتجاه المستقبلي نحو ترقية التفاعل متعدد الوسائط. (المصدر: 36氪)
百度强化文心大模型多模态能力,应对市场竞争与应用落地: أظهر أحدث إصدارات بايدو من نموذج Wenxin Large Model 4.5 Turbo ونموذج التفكير العميق X1 Turbo تحسنًا ملحوظًا في قدرات الفهم والإنشاء متعدد الوسائط، من خلال تقنيات مثل التدريب المختلط ونمذجة الخبراء غير المتجانسين متعددة الوسائط، مما أدى إلى تحسين كفاءة التعلم عبر الوسائط وتأثير الدمج. على الرغم من أن الرئيس التنفيذي لي يانهونغ قد أعرب سابقًا عن حذره بشأن مشكلة الهلوسة في نماذج إنشاء الفيديو المشابهة لـ Sora، إلا أنه في مواجهة المنافسة في السوق (مثل تقدم Doubao من بايت دانس و Tongyi Qianwen من علي بابا في مجال الوسائط المتعددة) واحتياجات تطبيق الذكاء الاصطناعي، تعمل بايدو بنشاط على سد نقاط ضعفها، وتخطط لفتح مصدر سلسلة Wenxin Large Model 4.5 في 30 يونيو. تعتقد بايدو أن الشخصيات الرقمية المعتمدة على الذكاء الاصطناعي تمثل نقطة انطلاق مهمة للتطبيق، وقد طورت بالفعل تقنية شخصيات رقمية فائقة الواقعية مدفوعة “بالسيناريو”، تدعم أكثر من 100,000 مذيع رقمي. (المصدر: 36氪)
抖音、小红书等平台专项治理“AI起号”,维护内容生态: عززت منصات التجارة الإلكترونية القائمة على الاهتمامات مثل تيك توك (Douyin) وشياو هونغ شو (Xiaohongshu) مؤخرًا من حملاتها الخاصة لمعالجة السلوكيات مثل إنتاج محتوى مزيف بكميات كبيرة باستخدام تقنية الذكاء الاصطناعي، والقيام بـ “إنشاء الحسابات بواسطة الذكاء الاصطناعي”. تشمل هذه السلوكيات إنشاء مقاطع فيديو مبتذلة وغريبة بواسطة الذكاء الاصطناعي، ومحتوى خبراء افتراضي، وبيع دروس تعليمية لإنشاء الحسابات بواسطة الذكاء الاصطناعي وحسابات جاهزة. ترى المنصات أن مثل هذه السلوكيات تقوض مصداقية المحتوى، وتؤدي إلى تجانس المحتوى، وتضر بتجربة المستخدم وبيئة المبدعين الأصليين، وبالتالي تقلل من القيمة التجارية. في المقابل، تشجع منصات التجارة الإلكترونية التقليدية القائمة على عرض المنتجات مثل تاوباو وجيه دي دوت كوم التجار بنشاط على استخدام أدوات الذكاء الاصطناعي (مثل “تحويل الصور إلى فيديو” والشخصيات الرقمية للبث المباشر) لتحسين عرض المنتجات وكفاءة التشغيل، بهدف أساسي هو تسهيل إتمام المعاملات. يعكس هذا الاختلاف تباين استراتيجيات تطبيق الذكاء الاصطناعي في نماذج التجارة الإلكترونية المختلفة. (المصدر: 36氪)

苹果AI版Siri开发遇阻,或再次跳票,管理层调整应对危机: وفقًا لبلومبرج، قد يتم تأجيل إصدار نسخة Siri المطورة بنماذج كبيرة، والتي كان من المقرر أن تظهر لأول مرة في WWDC، مرة أخرى. تكمن العقبة التقنية في تعارض بنية النظام الجديد والقديم، مما يؤدي إلى ظهور أخطاء برمجية بشكل متكرر. يشير التقرير إلى أن آبل تواجه مشكلات في استراتيجيتها للذكاء الاصطناعي، بما في ذلك أخطاء في اتخاذ القرارات على مستوى الإدارة العليا، وصراعات داخلية على السلطة، وعدم كفاية شراء وحدات معالجة الرسومات (GPU)، وقيود حماية الخصوصية التي تحد من استخدام البيانات، مما أدى إلى تأخر تقنيتها في مجال الذكاء الاصطناعي عن منافسيها. لمواجهة الأزمة، يعمل مختبر آبل في زيورخ على تطوير بنية “LLM Siri” جديدة تمامًا، وتم نقل مشروع Siri إلى إدارة مايك روكويل، المسؤول عن Vision Pro. وفي الوقت نفسه، تسعى آبل أيضًا إلى التعاون مع تقنيات خارجية مثل Gemini من جوجل و OpenAI، وقد تقوم في التسويق بفصل علامة Apple Intelligence التجارية عن Siri، لإعادة تشكيل صورتها في مجال الذكاء الاصطناعي. (المصدر: 36氪)

字节跳动推出集成英语外教智能体Owen的Ola Friend耳机: أضافت بايت دانس إلى سماعاتها الذكية Ola Friend وظيفة وكيل ذكي لتعليم اللغة الإنجليزية يدعى Owen. يمكن للمستخدمين تنشيط Owen من خلال تطبيق Doubao لإجراء محادثات باللغة الإنجليزية، والقراءة الموجهة باللغة الإنجليزية، وتقديم تعليقات ثنائية اللغة. تغطي هذه الوظيفة سيناريوهات مثل المحادثات اليومية، واللغة الإنجليزية في مكان العمل، والسفر، وتهدف إلى توفير مدرب لغة إنجليزية محمول ومريح. يمثل هذا محاولة أخرى من بايت دانس في مجال التعليم، حيث تدمج قدرات نماذج الذكاء الاصطناعي الكبيرة مع الأجهزة لإنشاء منتج تعليم لغة إنجليزية متخصص. كانت سماعات Ola Friend تدعم سابقًا طرح الأسئلة المعرفية وممارسة التحدث من خلال Doubao، ويؤدي إضافة الوكيل الذكي الجديد إلى تعزيز سماتها التعليمية بشكل أكبر. (المصدر: 36氪)

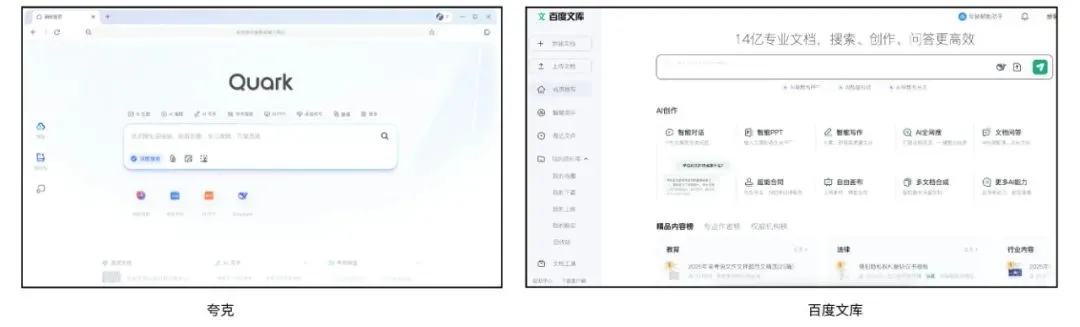
夸克与百度文库竞逐AI超级应用,整合搜索、工具与内容服务: تتحول Quark التابعة لشركة علي بابا و Baidu Wenku التابعة لشركة بايدو إلى تطبيقات “بوابة فائقة” تتمحور حول الذكاء الاصطناعي، حيث تدمج الحوار المعتمد على الذكاء الاصطناعي، والبحث العميق، وأدوات الذكاء الاصطناعي (مثل الكتابة، وإنشاء عروض PowerPoint، ومساعد الصحة، وما إلى ذلك)، بالإضافة إلى خدمات التخزين السحابي والمستندات، بهدف أن تصبح بوابة ذكاء اصطناعي شاملة للمستخدمين الأفراد. بفضل البحث الخالي من الإعلانات وقاعدة المستخدمين الشباب، وصل عدد مستخدمي Quark النشطين شهريًا إلى 149 مليونًا، وحققت أرباحًا من خلال نظام العضوية. تعتمد Baidu Wenku على مواردها الضخمة من المستندات وقاعدة المستخدمين المدفوعين، وأطلقت “Cangzhou OS” لدمج AI Agent، وتعزيز سلسلة القيمة الكاملة لإنشاء المحتوى واستهلاكه. يواجه كلاهما تحديات تتمثل في تجانس الوظائف، وتضخم التطبيقات، وكيفية تحقيق التوازن بين الاحتياجات العامة والخدمات المتخصصة. (المصدر: 36氪)
智谱清言、Kimi等35款App因违规收集个人信息被通报: أصدر المركز الوطني للإبلاغ عن معلومات الأمن السيبراني والمعلوماتي إشعارًا يفيد بأن تطبيق Zhipu Qingyan (الإصدار 2.9.6) بسبب “الجمع الفعلي لمعلومات شخصية تتجاوز نطاق تفويض المستخدم”، وتطبيق Kimi (الإصدار 2.0.8) بسبب “الجمع الفعلي لمعلومات شخصية لا علاقة مباشرة لها بوظائف العمل”، بالإضافة إلى 33 تطبيقًا آخر، تم إدراجهم ضمن التطبيقات التي تجمع وتستخدم المعلومات الشخصية بشكل غير قانوني وغير نظامي. تم تطوير هذين التطبيقين الشهيرين للذكاء الاصطناعي من قبل فرق ذات خلفية من جامعة تسينغهوا، وحصلا مؤخرًا على تمويل كبير واهتمام في السوق. شملت فترة الكشف المذكورة في هذا الإشعار الفترة من 16 أبريل إلى 15 مايو 2025، مما يسلط الضوء على تحديات الامتثال للبيانات التي تواجهها تطبيقات الذكاء الاصطناعي في خضم تطورها السريع. (المصدر: 36氪)
🧰 工具
OpenEvolve:DeepMind AlphaEvolve的开源实现,用LLM进化代码库: قام المطورون بفتح مصدر مشروع OpenEvolve، وهو تطبيق لنظام AlphaEvolve من Google DeepMind. يقوم إطار عمل OpenEvolve بتطوير مستودعات الأكواد بأكملها من خلال عملية تكرارية لنماذج LLM (إنشاء الأكواد، التقييم، الاختيار)، لاكتشاف خوارزميات جديدة أو تحسين الخوارزميات الحالية. وهو يدعم أي LLM متوافق مع OpenAI API، ويمكنه دمج نماذج متعددة (مثل مجموعة Gemini-Flash-2.0 و Claude-Sonnet-3.7)، ويدعم التحسين متعدد الأهداف والتقييم الموزع. نجح المشروع في إعادة إنتاج حالات تكديس الدوائر وتقليل الدوال المذكورة في ورقة AlphaEvolve، مما يدل على القدرة على التطور من طرق بسيطة إلى خوارزميات تحسين معقدة (مثل scipy.minimize والتلدين المحاكى). (المصدر: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

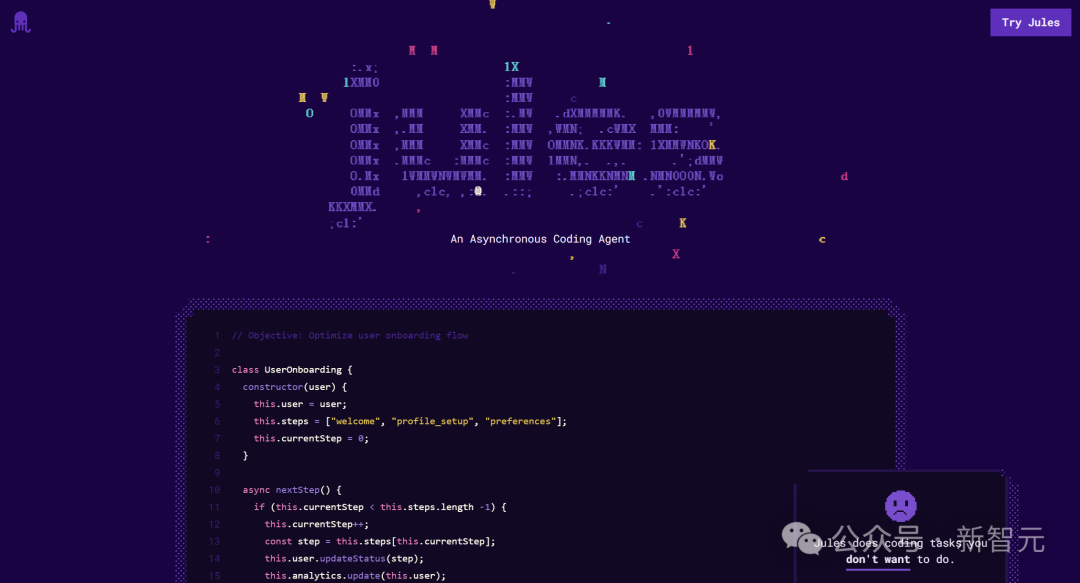
谷歌推出AI编程智能体Jules,支持自动化代码任务: أطلقت جوجل وكيل البرمجة الذكي Jules، وهو حاليًا في مرحلة الاختبار العالمي، ويمكن للمستخدمين تنفيذ 5 مهام مجانًا يوميًا. يعتمد Jules على نموذج Gemini 2.5 Pro متعدد الوسائط، وهو قادر على فهم مستودعات الأكواد المعقدة، وتنفيذ مهام مثل إصلاح الأخطاء، وتحديث الإصدارات، وكتابة الاختبارات، وتنفيذ وظائف جديدة، ويدعم Python و JavaScript. يمكنه الاتصال بـ GitHub لإنشاء طلبات السحب (PR)، والتحقق من الكود في أجهزة افتراضية سحابية، وتقديم خطط تنفيذ مفصلة للمطورين لمراجعتها وتعديلها. يهدف Jules إلى الاندماج بعمق في سير عمل المطورين، وتحسين كفاءة البرمجة، وسيتم إطلاق وظيفة Codecast (ملخص صوتي لنشاط مستودع الأكواد) وإصدار للمؤسسات في المستقبل. (المصدر: 36氪)
飞书上线“飞书知识问答”,打造企业专属AI问答工具: ستطلق Feishu قريبًا منتج ذكاء اصطناعي جديدًا باسم “Feishu Knowledge Q&A”، والذي يتم وضعه كأداة أسئلة وأجوبة بالذكاء الاصطناعي مخصصة للمؤسسات تعتمد على معرفة المؤسسة. يمكن للمستخدمين استدعاؤها من الشريط الجانبي لـ Feishu لطرح أسئلة حول العمل. يمكن للأداة الوصول إلى جميع رسائل Feishu والمستندات وقواعد المعرفة والملفات وما إلى ذلك ضمن نطاق صلاحيات المستخدم، وتقديم إجابات دقيقة مباشرة بناءً على هذا “السياق”. تتوافق إدارة الصلاحيات الخاصة بها مع نظام صلاحيات Feishu نفسه، مما يضمن أمن المعلومات. حاليًا، أكمل المنتج اختبارًا داخليًا لعشرات الآلاف من المستخدمين، وتم إطلاق نسخة الويب (ask.feishu.cn)، والتي تدعم تحميل البيانات الشخصية واستدعاء نماذج DeepSeek أو Doubao لطرح الأسئلة. تتماشى هذه الخطوة مع اتجاه دمج قواعد معارف المؤسسات مع الذكاء الاصطناعي، وتهدف إلى تحسين كفاءة العمل وقدرات إدارة المعرفة. (المصدر: 36氪)
Manus:AI智能体平台开放注册,母公司获高额融资: أعلنت منصة الوكلاء الأذكياء Manus عن فتح التسجيل للمستخدمين في الخارج، وإلغاء قائمة الانتظار، وتوفير مهام مجانية يوميًا. تستطيع Manus، من خلال تقنية “الاستدلال التعاوني متعدد النماذج بهيكلية هجينة”، تنفيذ مهام مثل إنشاء عروض PowerPoint تلقائيًا وتنظيم الفواتير. وقد أكملت الشركة الأم Butterfly Effect مؤخرًا جولة تمويل بقيمة 75 مليون دولار، بتقييم يصل إلى 3.6 مليار دولار. يُعتبر نجاح Manus تجسيدًا لـ “سرعة التكرار الصينية × عقلية المنتج في وادي السيليكون”، حيث يتم تنسيق وكلاء التخطيط والتنفيذ والتحقق، لتحقيق قفزة للذكاء الاصطناعي من “تقديم الاقتراحات” إلى “التنفيذ المغلق الحلقة”. (المصدر: 36氪)

HeyGen:AI视频生成与翻译工具,支持40+语言口型同步: HeyGen هي أداة فيديو تعمل بالذكاء الاصطناعي، يمكن للمستخدمين تحميل الصور أو مقاطع الفيديو لإنشاء شخصيات رقمية بسرعة مع صوت وتعبيرات وحركات، وتدعم تخصيص الملابس والمشاهد. إحدى وظائفها الأساسية هي دعم الترجمة الفورية لأكثر من 175 لغة ولهجة، ومن خلال خوارزميات الذكاء الاصطناعي، تقوم بمطابقة حركات فم الشخصيات الرقمية بدقة مع اللغة المترجمة، مما يعزز طبيعية محتوى الفيديو متعدد اللغات. تأسست الشركة من قبل أعضاء سابقين في Snapchat و ByteDance، وقد حصلت على تمويل بقيمة 60 مليون دولار بقيادة Benchmark، بتقييم 4.4 مليار دولار، وإيرادات سنوية متكررة تزيد عن 35 مليون دولار. (المصدر: 36氪)
Opus Clip:AI驱动的自主视频编辑代理工具: بدأت Opus Clip كأداة بث مباشر تعمل بالذكاء الاصطناعي، ثم تحولت إلى منصة تحرير فيديو تعمل بالذكاء الاصطناعي، وتطورت لتصبح “وكيل تحرير فيديو مستقل”. وظيفتها الأساسية هي قص مقاطع الفيديو الطويلة بسرعة إلى عدة مقاطع فيديو قصيرة مناسبة للانتشار الفيروسي، ويمكنها قص الموضوع الرئيسي تلقائيًا، وإنشاء العناوين والنصوص، وإضافة الترجمة والرموز التعبيرية. تدعم وظيفة ClipAnything التي تم اختبارها مؤخرًا التعرف على التعليمات متعددة الوسائط. يقود الشركة تشاو يانغ، مؤسس التطبيق الاجتماعي السابق Sober، وقد حصلت على تمويل بقيمة 20 مليون دولار بقيادة SoftBank، بتقييم 2.15 مليار دولار، وإيرادات سنوية متكررة تقارب 10 ملايين دولار. (المصدر: 36氪)
Trae:基于AI IDE的自动化编程Agent: Trae هي أداة تهدف إلى بناء “مهندس ذكاء اصطناعي حقيقي”، تدعم المستخدمين في تحقيق برمجة آلية للوكيل من خلال التفاعل باللغة الطبيعية. وهي متوافقة مع بروتوكول MCP والوكلاء المخصصين، وتحتوي على محرك قواعد وتحليل سياق محسن مدمج، وتدعم لغات البرمجة الرئيسية ومتوافقة مع VS Code. تم تطوير Trae بواسطة أعضاء أساسيين من فريق مساعد البرمجة Marscode الأصلي في ByteDance، وتعتبر منافسًا قويًا لأدوات البرمجة بالذكاء الاصطناعي مثل Cursor، وتسعى جاهدة لتحقيق نموذج جديد لتطوير البرمجيات بالتعاون بين الإنسان والآلة. (المصدر: 36氪)
Notta:AI驱动的多语言会议纪要与实时翻译工具: Notta هي أداة ذكاء اصطناعي تركز على سيناريوهات الاجتماعات، وتقدم خدمة إنشاء محاضر اجتماعات متعددة اللغات تلقائيًا، وتدعم الترجمة الفورية وتمييز المحتوى المهم. يهدف هذا المنتج إلى تحسين كفاءة الاجتماعات وحل حواجز التواصل بين اللغات المختلفة. يُقال إن مؤسسها الرئيسي هو عضو أساسي سابق في فريق الصوت السحابي في Tencent، ويقع مقر تشغيلها في سنغافورة، ومركز البحث والتطوير في سياتل. بلغت إيراداتها 18 مليون دولار في عام 2024، بتقييم 300 مليون دولار، وهي حاليًا في جولة تمويل B. (المصدر: 36氪)
开源GPT+ML交易助手登陆iPhone: تم تشغيل مساعد تداول مفتوح المصدر يدمج التعلم العميق وتقنية GPT محليًا على iPhone من خلال Pyto. حاليًا هو إصدار خفيف مجاني، ومن المخطط إضافة مصنف أنماط رسوم بيانية CNN ودعم قواعد البيانات في المستقبل. تم تصميم المنصة بشكل معياري، مما يسهل على مطوري التعلم العميق ربط نماذجهم الخاصة، وتدعم بالفعل OpenAI GPT بشكل أصلي. (المصدر: Reddit r/deeplearning)
📚 学习
新论文探讨深度学习中的“断裂纠缠表征假说”: تم تقديم ورقة موقف بعنوان “التشكيك في التفاؤل التمثيلي في التعلم العميق: فرضية التمثيل المتشابك المكسور (Fractured Entangled Representation Hypothesis)” إلى Arxiv. تقارن هذه الدراسة الشبكات العصبية الناتجة عن عمليات البحث التطوري بالشبكات المدربة تقليديًا بواسطة SGD (في مهمة بسيطة لإنشاء صورة واحدة)، ووجدت أنه على الرغم من أن كلاهما ينتج نفس السلوك الناتج، إلا أن التمثيلات الداخلية تختلف اختلافًا كبيرًا. تُظهر الشبكات المدربة بواسطة SGD شكلاً غير منظم يسميه المؤلفون “التمثيل المتشابك المكسور” (FER)، بينما تكون الشبكات التطورية أقرب إلى التمثيل الموحد المفكك (UFR). يعتقد الباحثون أنه في النماذج الكبيرة، قد يقلل FER من القدرات الأساسية مثل التعميم والإبداع والتعلم المستمر، وأن فهم وتخفيف FER أمر بالغ الأهمية لتعلم التمثيل في المستقبل. (المصدر: Reddit r/MachineLearning, arxiv.org)
R3:可鲁棒控制且可解释的奖励模型框架: تقدم ورقة بعنوان “R3: Robust Rubric-Agnostic Reward Models” إطار عمل جديد لنماذج المكافآت R3. يهدف هذا الإطار إلى حل مشكلة نقص قابلية التحكم والتفسير في نماذج المكافآت ضمن طرق محاذاة نماذج اللغة الحالية. يتميز R3 بأنه “rubric-agnostic” (غير مرتبط بمعايير تقييم محددة)، وقادر على التعميم عبر أبعاد التقييم، ويوفر تخصيصًا للدرجات قابلًا للتفسير ومصحوبًا بعملية استدلال. يعتقد الباحثون أن R3 يمكن أن يحقق تقييمًا أكثر شفافية ومرونة لنماذج اللغة، ويدعم المحاذاة القوية مع القيم البشرية المتنوعة وحالات الاستخدام. تم فتح مصدر النموذج والبيانات والكود. (المصدر: HuggingFace Daily Papers)
通过低秩克隆实现高效知识蒸馏的论文《A Token is Worth over 1,000 Tokens》发布: تقترح هذه الورقة طريقة تدريب مسبق فعالة تسمى الاستنساخ منخفض الرتبة (Low-Rank Clone, LRC)، لبناء نماذج لغوية صغيرة (SLM) تعادل في سلوكها نماذج المعلم القوية. يحقق LRC بشكل مشترك التقليم الناعم من خلال ضغط أوزان المعلم، واستنساخ التنشيط من خلال محاذاة تنشيطات الطالب (بما في ذلك إشارات FFN) مع تنشيطات المعلم، وذلك من خلال تدريب مجموعة من مصفوفات الإسقاط منخفضة الرتبة. يزيد هذا التصميم الموحد من نقل المعرفة إلى أقصى حد، دون الحاجة إلى وحدات محاذاة صريحة. أظهرت التجارب أنه باستخدام نماذج المعلم مفتوحة المصدر مثل Llama-3.2-3B-Instruct، يمكن لـ LRC تحقيق أداء يعادل أو يتجاوز أداء نماذج SOTA (المدربة على تريليونات من الرموز) باستخدام 20 مليار رمز فقط للتدريب، مما يحقق كفاءة تدريب تزيد عن 1000 مرة. (المصدر: HuggingFace Daily Papers)
MedCaseReasoning:评估和学习临床病例诊断推理的数据集与方法: تقدم ورقة “MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports” مجموعة بيانات مفتوحة جديدة MedCaseReasoning، لتقييم قدرات نماذج اللغة الكبيرة (LLM) في الاستدلال التشخيصي السريري. تحتوي مجموعة البيانات على 14489 حالة أسئلة وأجوبة تشخيصية، كل حالة مصحوبة ببيانات استدلال مفصلة مستمدة من تقارير حالات طبية مفتوحة. وجدت الدراسة أن نماذج LLM للاستدلال الحالية من فئة SOTA تعاني من أوجه قصور كبيرة في التشخيص والاستدلال (مثل دقة DeepSeek-R1 بنسبة 48٪، ومعدل استدعاء بيانات الاستدلال بنسبة 64٪). ومع ذلك، من خلال ضبط نماذج LLM بدقة على مسارات الاستدلال في MedCaseReasoning، تحسنت دقة التشخيص ومعدل استدعاء الاستدلال السريري بمتوسط نسبي قدره 29٪ و 41٪ على التوالي. (المصدر: HuggingFace Daily Papers)
《EfficientLLM: Efficiency in Large Language Models》论文发布,全面评估LLM效率技术: تجري هذه الدراسة لأول مرة بحثًا تجريبيًا شاملاً حول تقنيات الكفاءة لنماذج LLM واسعة النطاق، وتقدم معيار EfficientLLM. تستكشف الدراسة بشكل منهجي ثلاثة جوانب رئيسية على مجموعات إنتاجية: التدريب المسبق للبنية (متغيرات الانتباه الفعالة، MoE المتناثر)، الضبط الدقيق (طرق فعالة من حيث المعلمات مثل LoRA)، والاستدلال (التكميم). من خلال ستة مقاييس دقيقة (استخدام الذاكرة، استخدام الحوسبة، الكمون، الإنتاجية، استهلاك الطاقة، معدل الضغط)، تم تقييم أكثر من 100 زوج من النماذج والتقنيات (معلمات 0.5B-72B). تشمل النتائج الأساسية ما يلي: الكفاءة تنطوي على مقايضات قابلة للقياس الكمي، ولا توجد طريقة مثلى عالميًا؛ يعتمد الحل الأمثل على المهمة والحجم؛ يمكن تعميم التقنيات عبر الوسائط. (المصدر: HuggingFace Daily Papers)
《NExT-Search》论文探讨生成式AI搜索的反馈生态系统重建: تشير ورقة “NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search” إلى أنه على الرغم من أن البحث التوليدي بالذكاء الاصطناعي قد عزز الراحة، إلا أنه قوض أيضًا دورة التحسين التي يعتمد عليها بحث الويب التقليدي على ملاحظات المستخدم الدقيقة (مثل النقرات، ووقت البقاء). لحل هذه المشكلة، تتصور الورقة نموذج NExT-Search، الذي يهدف إلى إعادة تقديم ملاحظات دقيقة على مستوى العملية. يتضمن هذا النموذج “وضع تصحيح أخطاء المستخدم” الذي يسمح للمستخدمين بالتدخل في المراحل الرئيسية، و “وضع المستخدم الظلي” الذي يحاكي تفضيلات المستخدم ويقدم ملاحظات مدعومة بالذكاء الاصطناعي. يمكن استخدام إشارات الملاحظات هذه للتكيف عبر الإنترنت (تحسين مخرجات البحث في الوقت الفعلي) والتحديث دون اتصال (ضبط مكونات النموذج المختلفة بشكل دوري). (المصدر: HuggingFace Daily Papers)
《Latent Flow Transformer》提出新型LLM架构: تقترح الورقة محول التدفق الكامن (Latent Flow Transformer, LFT)، وهو نموذج يقوم بتدريب عامل نقل تعلم واحد من خلال مطابقة التدفق (flow matching) ليحل محل الطبقات المنفصلة المتعددة في المحولات التقليدية. يهدف LFT إلى ضغط عدد طبقات النموذج بشكل كبير مع الحفاظ على التوافق مع البنية الأصلية. بالإضافة إلى ذلك، تقدم الورقة خوارزمية Flow Walking (FW) لمعالجة قيود طرق التدفق الحالية في الحفاظ على الاقتران. أظهرت التجارب على نموذج Pythia-410M أن LFT يمكنه ضغط عدد الطبقات بشكل فعال والتفوق على أداء التخطي المباشر للطبقات، مما يقلل بشكل كبير من الفجوة بين نماذج التوليد الذاتي التراجعي ونماذج التوليد القائمة على التدفق. (المصدر: HuggingFace Daily Papers)
《Reasoning Path Compression》提出压缩LLM推理生成轨迹方法: لمعالجة مشكلة شغل الذاكرة الكبير وانخفاض الإنتاجية الناتجة عن المسارات الوسيطة المطولة التي تولدها نماذج اللغة الاستدلالية، تقترح الورقة طريقة ضغط مسار الاستدلال (Reasoning Path Compression, RPC). RPC هي طريقة لا تتطلب تدريبًا، تقوم بضغط ذاكرة التخزين المؤقت KV بشكل دوري عن طريق الاحتفاظ بذاكرة التخزين المؤقت KV ذات درجات الأهمية العالية (محسوبة باستخدام “نافذة محدد” تتكون من الاستعلامات التي تم إنشاؤها مؤخرًا). أظهرت التجارب أن RPC يمكن أن يحسن بشكل كبير إنتاجية التوليد لنماذج مثل QwQ-32B، مع تأثير ضئيل على الدقة، مما يوفر مسارًا عمليًا لنشر نماذج LLM الاستدلالية بكفاءة. (المصدر: HuggingFace Daily Papers)
《Bidirectional LMs are Better Knowledge Memorizers?》论文发布,关注双向LM知识记忆能力: تقدم هذه الدراسة معيارًا جديدًا وواقعيًا وواسع النطاق لضخ المعرفة WikiDYK، باستخدام الحقائق المكتوبة يدويًا والمضافة مؤخرًا في مقالات “هل تعلم…” في ويكيبيديا. وجدت التجارب أنه بالمقارنة مع نماذج اللغة السببية (CLM) الشائعة حاليًا، تُظهر نماذج اللغة ثنائية الاتجاه (BiLM) قدرة أقوى بشكل ملحوظ على حفظ المعرفة، مع دقة موثوقية أعلى بنسبة 23٪. لتعويض النقص الحالي في حجم BiLM الصغير نسبيًا، اقترح الباحثون إطار عمل تعاوني معياري، يستخدم مجموعات BiLM كقواعد معرفة خارجية مدمجة مع LLM، مما يزيد من دقة الموثوقية بنسبة تصل إلى 29.1٪. (المصدر: HuggingFace Daily Papers)
《Truth Neurons》论文探讨语言模型中真实性的神经元层面编码: يقترح الباحثون طريقة لتحديد تمثيلات الصدق على مستوى الخلايا العصبية في نماذج اللغة، واكتشفوا وجود “خلايا عصبية للحقيقة” (truth neurons) في النموذج، والتي تشفر الصدق بطريقة مستقلة عن الموضوع. أثبتت التجارب عبر نماذج مختلفة الأحجام وجود الخلايا العصبية للحقيقة، ويتوافق نمط توزيعها مع نتائج الدراسات السابقة حول البنية الهندسية للصدق. يؤدي التثبيط الانتقائي لتنشيط هذه الخلايا العصبية إلى تقليل أداء النموذج على TruthfulQA والمعايير المرجعية الأخرى، مما يشير إلى أن آلية الصدق ليست خاصة بمجموعة بيانات معينة. (المصدر: HuggingFace Daily Papers)
《Understanding Gen Alpha Digital Language》评估LLM在内容审核中的局限性: تقيم هذه الدراسة قدرة أنظمة الذكاء الاصطناعي (GPT-4, Claude, Gemini, Llama 3) على تفسير اللغة الرقمية “للجيل ألفا” (Gen Alpha، المولود بين 2010-2024). تشير الدراسة إلى أن لغة الإنترنت الفريدة للجيل ألفا (المتأثرة بالألعاب والميمات واتجاهات الذكاء الاصطناعي) غالبًا ما تخفي تفاعلات ضارة، وتجد أدوات الأمان الحالية صعوبة في التعرف عليها. من خلال اختبار مجموعة بيانات تحتوي على 100 تعبير حديث للجيل ألفا، وجد أن نماذج الذكاء الاصطناعي السائدة تعاني من عقبات فهم خطيرة في اكتشاف التحرش والتلاعب المقنع. تشمل مساهمات الدراسة أول مجموعة بيانات لتعبيرات الجيل ألفا، وإطار عمل لتحسين أنظمة مراجعة الذكاء الاصطناعي، وتؤكد على الحاجة الملحة لإعادة تصميم أنظمة الأمان لتناسب خصائص تواصل المراهقين. (المصدر: HuggingFace Daily Papers)
《CompeteSMoE》提出基于竞争的混合专家模型训练方法: ترى الورقة أن تدريب نماذج الخبراء المختلطين المتناثرين (SMoE) الحالي يواجه تحديًا يتمثل في عملية التوجيه دون المستوى الأمثل، أي أن الخبراء الذين ينفذون الحساب لا يشاركون بشكل مباشر في قرارات التوجيه. لهذا السبب، يقترح الباحثون آلية جديدة تسمى “المنافسة” (competition)، والتي توجه الرموز إلى الخبراء ذوي أعلى استجابة عصبية. يثبت الدليل النظري أن آلية المنافسة تتمتع بكفاءة عينات أفضل من التوجيه التقليدي باستخدام softmax. بناءً على ذلك، تم تطوير خوارزمية CompeteSMoE، التي تنشر موجهات لتعلم استراتيجيات المنافسة، وأظهرت الفعالية والمتانة والقابلية للتوسع في مهام ضبط التعليمات المرئية والتدريب المسبق للغة. (المصدر: HuggingFace Daily Papers)
《General-Reasoner》旨在提升LLM跨领域推理能力: لمعالجة مشكلة تركيز أبحاث استدلال LLM الحالية بشكل أساسي على مجالات الرياضيات والترميز، تقترح هذه الورقة General-Reasoner، وهو نموذج تدريب جديد يهدف إلى تعزيز قدرة LLM على الاستدلال عبر مجالات مختلفة. تشمل مساهماته: بناء مجموعة بيانات واسعة النطاق وعالية الجودة من الأسئلة ذات الإجابات القابلة للتحقق في تخصصات متعددة؛ تطوير مدقق إجابات قائم على نموذج توليدي، يتمتع بقدرات سلسلة الأفكار (chain-of-thought) والوعي بالسياق، ليحل محل التحقق التقليدي القائم على القواعد. في سلسلة من الاختبارات المرجعية التي تغطي مجالات مثل الفيزياء والكيمياء والمالية، تفوق أداء General-Reasoner على الطرق الأساسية الحالية. (المصدر: HuggingFace Daily Papers)
《Not All Correct Answers Are Equal》探讨知识蒸馏源的重要性: أجرت هذه الدراسة بحثًا تجريبيًا واسع النطاق حول تقطير بيانات الاستدلال من خلال جمع المخرجات التي تم التحقق منها لثلاثة نماذج معلم من فئة SOTA (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) على 1.89 مليون استعلام. وجد التحليل أن البيانات المقطرة من AM-Thinking-v1 أظهرت تنوعًا أكبر في طول الرمز وحيرة أقل. أظهرت النماذج الطلابية المدربة على مجموعة البيانات هذه أفضل أداء على معايير الاستدلال مثل AIME2024، وأظهرت سلوك إخراج تكيفي. أصدر الباحثون مجموعات البيانات المقطرة من AM-Thinking-v1 و Qwen3-235B-A22B لدعم الأبحاث المستقبلية. (المصدر: HuggingFace Daily Papers)
《SSR》通过基本原理引导的空间推理增强VLM深度感知: على الرغم من التقدم الذي أحرزته نماذج اللغة المرئية (VLM) في المهام متعددة الوسائط، إلا أن اعتمادها على مدخلات RGB يحد من الفهم المكاني الدقيق. تقترح الورقة إطار عمل جديدًا يسمى SSR (Spatial Sense and Reasoning)، والذي يحول بيانات العمق الأولية إلى مبادئ أساسية نصية منظمة وقابلة للتفسير. تعمل هذه المبادئ الأساسية النصية كتمثيلات وسيطة ذات معنى، مما يعزز بشكل كبير قدرات الاستدلال المكاني. بالإضافة إلى ذلك، تستخدم الدراسة تقطير المعرفة لضغط المبادئ التي تم إنشاؤها إلى تضمينات كامنة مدمجة، من أجل دمجها بكفاءة في نماذج VLM الحالية دون الحاجة إلى إعادة التدريب. كما تقدم مجموعة بيانات SSR-CoT ومعيار SSRBench. (المصدر: HuggingFace Daily Papers)
《Solve-Detect-Verify》提出具有灵活生成验证器的推理时扩展方法: لمعالجة مشكلة المقايضة بين الدقة والكفاءة في استدلال LLM في المهام المعقدة، والتناقض بين التكلفة الحاسوبية والموثوقية التي أدخلتها خطوة التحقق، تقترح الورقة FlexiVe، وهو مدقق توليدي جديد. يقوم FlexiVe بموازنة موارد الحوسبة بين “التفكير السريع” الموثوق به و “التفكير البطيء” الدقيق من خلال استراتيجية تخصيص مرنة لميزانية التحقق. كما تقترح عملية Solve-Detect-Verify، وهو إطار عمل يدمج FlexiVe بذكاء، ويحدد بشكل استباقي نقاط اكتمال الحل لتشغيل التحقق المستهدف وتقديم الملاحظات. أظهرت التجارب أن هذه الطريقة تتفوق على خطوط الأساس في معايير الاستدلال الرياضي. (المصدر: HuggingFace Daily Papers)
《SageAttention3》探索FP4 Attention推理及8位训练: تعزز هذه الدراسة كفاءة Attention من خلال مساهمتين رئيسيتين: أولاً، استخدام FP4 Tensor Cores الجديدة في Blackwell GPU لتسريع حسابات Attention، مما يحقق تسريع استدلال فوري أسرع 5 مرات من FlashAttention. ثانيًا، تطبيق Attention منخفض البت لأول مرة على مهام التدريب، وتصميم Attention 8 بت دقيق وفعال للانتشار الأمامي والخلفي. أظهرت التجارب أن Attention 8 بت يحقق أداءً دون فقدان في مهام الضبط الدقيق، ولكنه يتقارب بشكل أبطأ في مهام التدريب المسبق. (المصدر: HuggingFace Daily Papers)
《The Little Book of Deep Learning》深度学习入门资源分享: يوفر كتاب “The Little Book of Deep Learning” الذي ألفه فرانسوا فلوريه (عالم أبحاث في Meta FAIR) موردًا تعليميًا موجزًا للتعلم العميق. يهدف الكتاب إلى مساعدة المبتدئين والممارسين ذوي الخبرة على فهم المفاهيم والتقنيات الأساسية للتعلم العميق بسرعة. (المصدر: Reddit r/deeplearning)
CodeSparkClubs:为高中生创办AI/计算机科学俱乐部提供免费资源: يهدف مشروع CodeSparkClubs إلى مساعدة طلاب المدارس الثانوية على إطلاق أو تطوير نوادي الذكاء الاصطناعي وعلوم الكمبيوتر. يوفر المشروع مواد مجانية وجاهزة للاستخدام، بما في ذلك الأدلة وخطط الدروس ودروس المشاريع، وكلها متاحة عبر الموقع الإلكتروني. تم تصميمه لتمكين الطلاب من إدارة النوادي بشكل مستقل، وبالتالي تنمية المهارات والمجتمع. (المصدر: Reddit r/deeplearning)
💼 商业
微软Azure将托管xAI的Grok模型,助力马斯克AI商业化: أعلنت مايكروسوفت أن منصتها السحابية Azure ستستضيف نماذج الذكاء الاصطناعي مثل Grok من شركة xAI التابعة لإيلون ماسك. تعني هذه الخطوة أن ماسك يخطط لبيع Grok لشركات أخرى، والوصول إلى قاعدة عملاء أوسع من خلال خدمات مايكروسوفت السحابية. سابقًا، أثار Grok جدلاً بسبب إنشائه منشورات مضللة حول “الإبادة الجماعية للبيض” في جنوب إفريقيا. تباينت ردود فعل المجتمع تجاه هذا التعاون، حيث اعتبره البعض خطوة من مايكروسوفت لتوسيع نظامها البيئي للذكاء الاصطناعي، بينما شكك آخرون في جودة Grok وما إذا كانت AWS قد رفضت Grok. (المصدر: Reddit r/ArtificialInteligence, MIT Technology Review)

阿里巴巴投资美图,深化AI电商布局: استثمرت علي بابا في شركة Meitu من خلال سندات قابلة للتحويل، بسعر تحويل أولي قدره 6 دولار هونج كونج للسهم. سيتعاون الطرفان على الصعيدين التجاري الإلكتروني والتقني. تمتلك Meitu أدوات إنشاء صور بالذكاء الاصطناعي (مثل Meitu Design Studio)، وقد خدمت أكثر من 2 مليون تاجر إلكتروني. ستقوم علي بابا بإدخال أدوات الذكاء الاصطناعي من Meitu لتحسين عرض المنتجات وتجربة المستخدم على منصتها للتجارة الإلكترونية، خاصة لجذب المستخدمات الشابات. من جانبها، يمكن لـ Meitu استخدام بيانات التجارة الإلكترونية من علي بابا لتحسين أدوات الذكاء الاصطناعي الخاصة بها، وتعهدت بشراء خدمات Alibaba Cloud بقيمة 560 مليون يوان في غضون ثلاث سنوات. تعتبر هذه الخطوة بمثابة تعزيز لنقاط ضعف علي بابا في أدوات الإبداع بالذكاء الاصطناعي، واكتساب حركة مرور المستخدمين، ودمج الحوسبة السحابية بشكل أعمق في النظام البيئي للذكاء الاصطناعي للتجارة الإلكترونية. (المصدر: 36氪)
光源资本完成首期5000万美元AI孵化基金募资,关注超早期前沿科技: أكملت Lighthouse Capital بنجاح جمع التبرعات للمرحلة الأولى من صندوق L2F (Lighthouse Innovation Frontier Incubation Fund) التابع لها، متجاوزة التوقعات، حيث من المتوقع أن لا يقل حجمه عن 50 مليون دولار أمريكي، وقد دخل مرحلة الاستثمار بالفعل. يركز هذا الصندوق ثنائي العملة على الاستثمار في جولات التمويل الأولية والمبكرة في مجالات الذكاء الاصطناعي والتكنولوجيا المتطورة، ويوفر أيضًا دعمًا للحضانة. يتألف الشركاء المحدودون (LP) من رواد أعمال ناجحين، وشركات في سلسلة القيمة للذكاء الاصطناعي، وعائلات ذات رؤية عالمية. أول مشروع استثماري هو شركة “Lingyun Zhimine” لاستكشاف المعادن بالذكاء الاصطناعي، وقد شاركت Lighthouse Capital بعمق في عملية حضانتها. يعتقد مؤسس Lighthouse Capital، تشنغ شوانلي، أن مرحلة تطوير الذكاء الاصطناعي الحالية تشبه المراحل المبكرة للإنترنت عبر الهاتف المحمول، وأن الحضانة هي أفضل أداة لدخول السوق. (المصدر: 36氪)
🌟 社区
AI对就业前景的讨论:乐观与担忧并存: أثار مجتمع Reddit مرة أخرى نقاشًا ساخنًا حول تأثير الذكاء الاصطناعي على سوق العمل. أبدى العديد من المتخصصين مثل مطوري البرامج ومصممي تجربة المستخدم تفاؤلهم بشأن استبدال الذكاء الاصطناعي لوظائفهم، معتقدين أن الذكاء الاصطناعي لا يزال غير قادر على التعامل مع المهام المعقدة. ومع ذلك، أشارت وجهات نظر أخرى إلى أن هذا الرأي قد يقلل من شأن إمكانات تطوير الذكاء الاصطناعي على المدى الطويل، مستشهدين بالشكوك التي كانت سائدة في عام 2018 حول استبدال ترجمة جوجل للترجمة البشرية. يرى النقاش أن التقدم السريع للذكاء الاصطناعي قد يؤدي إلى استبدال معظم المهن في المستقبل (باستثناء عدد قليل من المجالات الطبية والفنية)، وأن المفتاح يكمن في تغيير النموذج الاقتصادي بدلاً من مجرد تحسين المهارات الفردية. ذكرت التعليقات عبارة “نحن نبالغ في تقدير المدى القصير ونقلل من شأن المدى الطويل”، وأن زيادة إنتاجية الذكاء الاصطناعي قد تتجاوز بكثير نمو الصناعة، مما يؤدي إلى البطالة. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
探讨AI时代人机共存的哲学与伦理: أثار منشور على Reddit نقاشًا فلسفيًا حول التعايش بين الإنسان والذكاء الاصطناعي. يرى المنشور أنه مع إظهار أنظمة الذكاء الاصطناعي لقدرات الفهم والذاكرة والاستدلال والتعلم، قد يحتاج البشر إلى إعادة التفكير في أسس المكانة الأخلاقية، بحيث لا تقتصر على الجانب البيولوجي، بل تستند إلى القدرة على الفهم والتواصل والعمل الواعي. امتد النقاش ليشمل تأثير الذكاء الاصطناعي على الهوية الذاتية للإنسان، والانتقال من “أنا أفكر إذن أنا موجود” إلى هوية علائقية “أنا موجود من خلال الاتصال وتقاسم المعنى”. يدعو المنشور إلى استقبال مستقبل التعاون مع الذكاء الاصطناعي بشجاعة وكرامة وعقل متفتح، بدلاً من الخوف. (المصدر: Reddit r/artificial)
ChatGPT“绝对模式”引争议,用户褒贬不一: شارك أحد مستخدمي Reddit تجربته مع “الوضع المطلق” في ChatGPT، قائلاً إنه يمكن أن يقدم نصائح حقيقية “حقائق بحتة، تهدف إلى النمو”، بدلاً من الكلمات المهدئة، وأشار إلى أن هذا الوضع قد ذكر سابقًا أن 90٪ من الأشخاص يستخدمون الذكاء الاصطناعي للشعور بالتحسن بدلاً من تغيير حياتهم. ومع ذلك، تباينت الآراء في قسم التعليقات. اعتبر بعض المستخدمين أن هذه مجرد نصائح تطوير ذاتي مختصرة وفارغة، تفتقر إلى الحداثة والقيمة العملية، بل تبدو وكأنها “تصريحات مراهق مدمن على اقتباسات Andrew Tate”. شككت تعليقات أخرى في أن نماذج LLM نفسها هي مجرد ترديد لمعتقدات المستخدم، وأن فعالية نصائحها مشكوك فيها، معتبرة أن تطبيق الذكاء الاصطناعي في مجال الصحة العقلية قد لا يكون ثوريًا. (المصدر: Reddit r/ChatGPT)

AI工程师核心技能讨论:沟通与适应新技术能力至关重要: ناقش مجتمع Reddit المهارات اللازمة ليصبح مهندس ذكاء اصطناعي متميزًا، بهدف الحفاظ على القدرة التنافسية أو حتى أن يصبح “لا يمكن الاستغناء عنه” في مجال سريع التطور. أشارت التعليقات إلى أنه بالإضافة إلى الأساس التقني المتين، تعد مهارات الاتصال والقدرة على التكيف السريع مع التقنيات الجديدة عنصرين أساسيين. يعكس هذا أن مجال الذكاء الاصطناعي لا يتطلب خبرة تقنية عميقة فحسب، بل يؤكد أيضًا على أهمية المهارات الشخصية والتعلم المستمر في التطوير الوظيفي. (المصدر: Reddit r/deeplearning)
AI生成视频带声音引热议,谷歌Veo 3技术展示: انتشر مقطع فيديو على وسائل التواصل الاجتماعي تم إنشاؤه بواسطة نموذج Veo 3 الجديد من Google DeepMind، ويتميز بأن الفيديو والصوت تم إنشاؤهما بواسطة نفس النموذج، مما أثار دهشة المستخدمين بشأن التقدم في تكنولوجيا الفيديو بالذكاء الاصطناعي. صرح المنتج بأن الفيديو “جاهز للاستخدام”، ولم تتم إضافة أي صوت أو مواد إضافية، وتم إنجازه من خلال التفاعل مع نموذج الذكاء الاصطناعي لمدة ساعتين تقريبًا والتجميع اللاحق. تعتقد التعليقات أن Gemini من جوجل قد تجاوزت Sora من OpenAI في القدرات متعددة الوسائط، وأعربت عن قلقها بشأن الاضطراب المحتمل الذي قد تحدثه في صناعات إنشاء المحتوى مثل هوليوود. وفي الوقت نفسه، أعرب بعض المستخدمين أيضًا عن مخاوفهم بشأن التطور السريع جدًا للتكنولوجيا وإمكانية إساءة استخدامها. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 其他
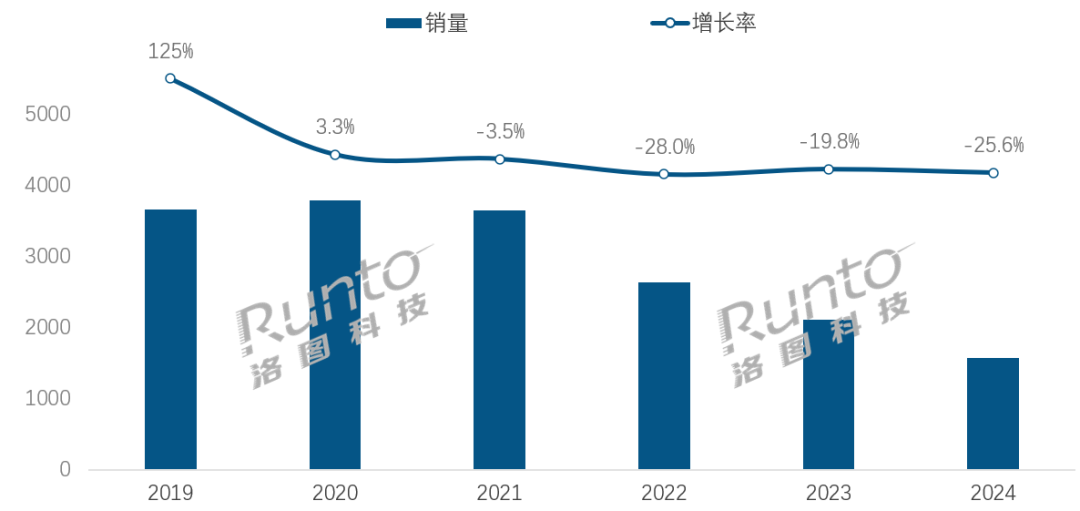
AI时代,智能音箱行业面临转型挑战与机遇: شهد سوق مكبرات الصوت الذكية في الصين انخفاضًا في المبيعات للعام الرابع على التوالي، حيث انخفضت المبيعات في عام 2024 بنسبة 25.6٪ على أساس سنوي. على الرغم من أن دمج نماذج الذكاء الاصطناعي الكبيرة (مثل Xiao Ai Tongxue و Xiaodu) يعتبر أملًا للصناعة، حيث تجاوز معدل الانتشار 20٪، إلا أن هذا لم يحل بشكل أساسي مشكلات القيود البيئية، وتجانس الوظائف، واستبدالها بأجهزة ذكية أخرى مثل الهواتف المحمولة. يرى تحليل الصناعة أن مكبرات الصوت الذكية تحتاج إلى تجاوز كونها مجرد مركز تحكم صوتي، والتطور نحو أشكال منتجات ذات شاشات كبيرة عالية الدقة، وقدرات تفاعلية أقوى، وقادرة على توفير الرفقة والدعم التعليمي، وتوسيع النظام البيئي للبرامج والأجهزة. يعد الذكاء الاصطناعي ميزة إضافية، ولكن ثراء وظائف المنتج نفسه وفائدته العملية في مختلف السيناريوهات أكثر أهمية. (المصدر: 36氪)
AI驱动的酒店机器人:从送餐员到“智能运营官”的进化之路: أصبحت روبوتات توصيل الطعام في الفنادق شائعة بشكل متزايد، خاصة بين جيل Z الذي يسعى إلى التكنولوجيا والخصوصية. على سبيل المثال، تم استخدام روبوتات توصيل الطعام من Yunji Technology على نطاق واسع في سوق الفنادق الصينية. ومع ذلك، لا تزال الصناعة تواجه مشكلات مثل عدم كفاية التمايز التكنولوجي، وضعف القدرة على التكيف مع السيناريوهات المعقدة، وقضية فعالية التكلفة لاستبدال الروبوتات بالعمالة البشرية. يتمثل الاتجاه المستقبلي في أن الروبوتات “لن تقتصر على توصيل الطعام”، بل ستندمج بعمق في عمليات الفنادق، من خلال الاتصال بأنظمة الفنادق (المصاعد، معدات الغرف)، وفهم تفضيلات النزلاء، وجمع وتحليل بيانات التفاعل، لتتطور إلى “مسؤول تشغيل ذكي” أو جزء من منصة بيانات الفندق، قادر على الإدراك الاستباقي وتقديم خدمات مخصصة، وبالتالي رفع المستوى العام للخدمة الذكية. (المصدر: 36氪)

OpenAI治理结构危机:资本与使命的博弈引发对AI发展路径的深思: يهدف الهيكل الفريد لـ OpenAI، وهو شركة فرعية ربحية “بربح محدود” تشرف عليها منظمة غير ربحية، إلى تحقيق التوازن بين تطوير تكنولوجيا الذكاء الاصطناعي ورفاهية الإنسان. ومع ذلك، أثار تفكير الرئيس التنفيذي Altman مؤخرًا في تحويل الشركة إلى كيان ربحي أكثر تقليدية مخاوف خبراء الذكاء الاصطناعي وعلماء القانون. يعتقدون أن هذه الخطوة قد تجعل صناع القرار الرئيسيين لا يضعون مهمة OpenAI الخيرية في المقام الأول، وتضعف القيود المفروضة على أرباح المستثمرين، وقد تغير الجدول الزمني واتجاه تطوير الذكاء الاصطناعي العام (AGI). تسلط هذه المعركة حول السيطرة وتوزيع الأرباح والتشكيل الاجتماعي والأخلاقي للذكاء الاصطناعي الضوء على التحديات والثغرات التي تواجهها أطر حوكمة الشركات الحالية في عصر التطور السريع للذكاء الاصطناعي. (المصدر: 36氪)