كلمات مفتاحية:عامل الذكاء الاصطناعي للبرمجة, كوديكس, نموذج الصوت الكبير, عامل الذكاء الاصطناعي, أوبن إيه آي, ميني ماكس, علي بابا, كيو وين, نسخة معاينة كوديكس, نموذج الصوت سبيس-02, دراسة وورلد بي إم, نموذج الرؤية واللغة السريع, نموذج إف جي-كليب متعدد الوسائط
🔥 أبرز الأخبار
OpenAI تطلق نسخة معاينة من وكيل البرمجة الذكي Codex AI: كشفت OpenAI في وقت متأخر من ليلة 16 مايو عن نسخة معاينة من Codex، وهو وكيل هندسة برمجيات قائم على السحابة. يعمل Codex بواسطة نموذج o3 المتغير codex-1 المُحسَّن خصيصًا لهندسة البرمجيات، ويمكنه التعامل مع مهام متعددة بالتوازي مثل البرمجة، والإجابة على الأسئلة المتعلقة بمستودعات الأكواد، وإصلاح الأخطاء (Bug)، وتقديم طلبات السحب (pull requests). يعمل في بيئة معزولة (sandbox) سحابية، ويقوم بالتحميل المسبق لمستودعات أكواد المستخدم، ويستغرق إكمال المهام من 1 إلى 30 دقيقة. وهو متاح حاليًا لمستخدمي ChatGPT Pro و Team و Enterprise، وسيتم توفيره قريبًا لمستخدمي Plus و Edu. وفي الوقت نفسه، تم إطلاق نموذج خفيف الوزن codex-mini (المبني على o4-mini) لواجهة سطر الأوامر Codex CLI، ويبلغ سعر واجهة برمجة التطبيقات (API) 1.5 دولار لكل مليون توكن للمدخلات، و 6 دولارات لكل مليون توكن للمخرجات. (المصدر: 36氪, 机器之心, op7418)
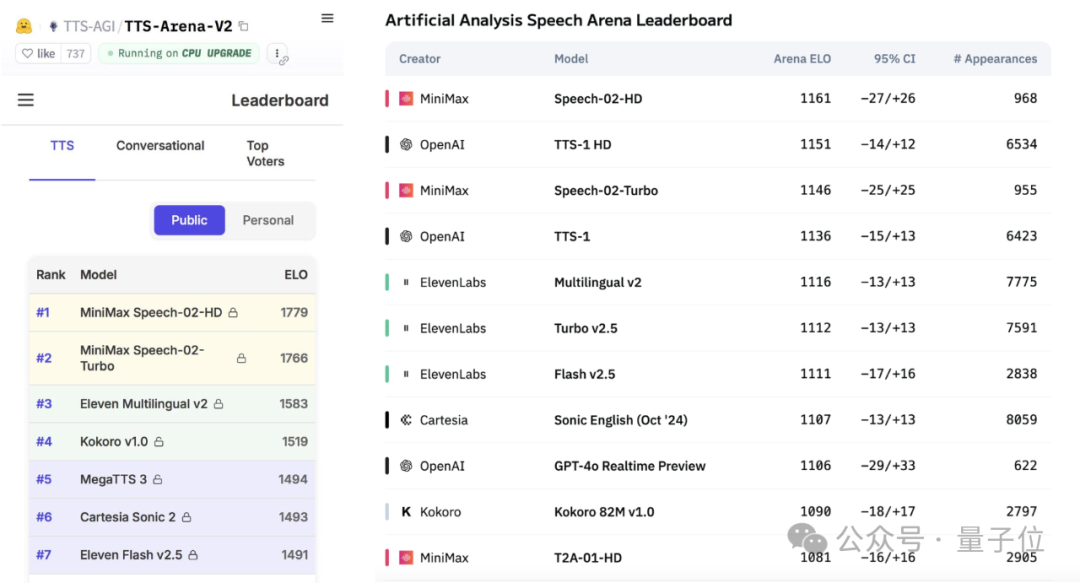
شركة MiniMax تطلق نموذج الكلام Speech-02 الكبير، ويتصدر قائمة التقييم العالمية: احتل نموذج تحويل النص إلى كلام (TTS) الكبير Speech-02-HD، الذي أطلقته شركة الذكاء الاصطناعي الصينية MiniMax مؤخرًا، المرتبة الأولى في كل من تقييمي Artificial Analysis Speech Arena و Hugging Face TTS Arena V2، وهما من أبرز معايير تقييم الكلام العالمية، متجاوزًا بذلك OpenAI و ElevenLabs. يتميز هذا النموذج بخصائص فائقة في محاكاة الصوت البشري والتخصيص والتنوع، ويدعم 32 لغة، ويمكنه استنساخ نبرة صوت واقعية باستخدام مرجع صوتي لا يقل عن 10 ثوانٍ. وقد استخدم تطبيق تعلم اللغة الإنجليزية الشهير “AI Wu Yanzu” تقنية MiniMax سابقًا. تشمل الابتكارات الأساسية في Speech-02 مُرمِّز المتحدث القابل للتعلم ونموذج مطابقة التدفق Flow-VAE، مما يحسن جودة الصوت والتشابه. (المصدر: 36氪, karminski3)
وكيل الذكاء الاصطناعي AI Agent يثير اهتمام السوق، والشركات الكبرى تسرع من تخطيطها: أصبح وكيل الذكاء الاصطناعي (Agent) محور اهتمام جديد في مجال الذكاء الاصطناعي، حيث أثار فتح التسجيل لمنصات Agent عالمية مثل Manus موجة من الحماس، ويُقال إن الشركة الأم Monica أكملت جولة تمويل جديدة بقيمة 75 مليون دولار، وقُدرت قيمتها بحوالي 500 مليون دولار. كما أطلقت الشركات الكبرى مثل Baidu (心响)، و ByteDance (扣子空间)، و Alibaba (心流) منتجات أو منصات Agent خاصة بها، متنافسة على مدخل عصر الذكاء الاصطناعي. يمكن لـ Agent تنفيذ مهام أكثر تعقيدًا، مثل إعداد المواد، وتصميم صفحات الويب، وتخطيط الرحلات. حاليًا، لا يزال Agent العالمي يعاني من قصور في العمليات عبر التطبيقات والمهام العميقة، ويعتبر النظام البيئي غير المكتمل وجزر البيانات من التحديات الرئيسية. يُنظر إلى بروتوكول MCP على أنه مفتاح لحل مشكلة الاتصال البيني، ولكن عدد المنضمين إليه لا يزال قليلاً. يُعتقد أن Agent في المجالات الرأسية لقطاع الأعمال (B2B) أسهل في تحقيق التسويق التجاري أولاً بسبب تركيزه على سيناريوهات محددة وسهولة تخصيصه. (المصدر: 36氪, 36氪)

Alibaba تنشر دراسة WorldPM، لاستكشاف قوانين التوسع في نمذجة التفضيلات البشرية: نشر فريق Qwen التابع لشركة Alibaba ورقة بحثية بعنوان “Modeling World Preference”، تكشف أن نمذجة التفضيلات البشرية تتبع قوانين التوسع (Scaling Laws)، مما يشير إلى أن التفضيلات البشرية المتنوعة قد تشترك في تمثيل موحد. استخدمت الدراسة مجموعة بيانات StackExchange تحتوي على 15 مليون زوج تفضيل، وأجرت تجارب على نماذج Qwen2.5 بمعلمات تتراوح من 1.5 مليار إلى 72 مليار. أظهرت النتائج أن نمذجة التفضيل تُظهر انخفاضًا في الخسارة اللوغاريتمية مع زيادة حجم التدريب في المقاييس الموضوعية والمتانة؛ وأظهر نموذج 72B ظاهرة الانبثاق في بعض المهام الصعبة. توفر هذه الدراسة أساسًا فعالاً للضبط الدقيق للتفضيلات، وقد تم فتح مصدر الورقة البحثية والنموذج (WorldPM-72B). (المصدر: Alibaba_Qwen)
🎯 اتجاهات
خلاف بين Google DeepMind و Anthropic حول أبحاث قابلية تفسير الذكاء الاصطناعي: أعلنت Google DeepMind مؤخرًا أنها لن تركز بعد الآن على “قابلية التفسير الآلي” (mechanistic interpretability) كأولوية بحثية، معتبرة أن مسار الهندسة العكسية للعمليات الداخلية للذكاء الاصطناعي من خلال طرق مثل أجهزة التشفير الذاتي المتناثرة (SAE) صعب للغاية، وأن SAE بها عيوب متأصلة. في المقابل، دعا Dario Amodei، الرئيس التنفيذي لشركة Anthropic، إلى تعزيز البحث في هذا المجال، وأعرب عن تفاؤله بتحقيق “تصوير بالرنين المغناطيسي للذكاء الاصطناعي” في غضون 5-10 سنوات. تعتبر خاصية “الصندوق الأسود” للذكاء الاصطناعي مصدرًا للعديد من المخاطر، وتهدف قابلية التفسير الآلي إلى فهم وظائف الخلايا العصبية والدوائر المحددة في النموذج، ولكن نتائج الأبحاث المحدودة على مدى أكثر من عقد أثارت تفكيرًا عميقًا حول مسارات البحث. (المصدر: WeChat)

تقرير Poe يكشف عن تغيرات في مشهد سوق نماذج الذكاء الاصطناعي، و OpenAI و Google في الصدارة: أظهر أحدث تقرير لاستخدام نماذج الذكاء الاصطناعي من Poe أن GPT-4o (35.8%) يتصدر في مجال توليد النصوص، بينما يتصدر Gemini 2.5 Pro (31.5%) في مجال الاستدلال. تهيمن Imagen3 و GPT-Image-1 وسلسلة Flux على مجال توليد الصور. انخفضت حصة Runway في مجال توليد الفيديو، بينما برز Kling من Kuaishou كحصان أسود. وفيما يتعلق بالوكلاء الأذكياء، أظهر o3 من OpenAI أداءً أفضل من Claude و Gemini في اختبارات البحث. تراجعت حصة Claude من Anthropic في السوق. وأشار التقرير إلى أن قدرة الاستدلال أصبحت نقطة تنافس رئيسية، وتحتاج الشركات إلى إنشاء أنظمة تقييم، واختيار نماذج مختلفة بمرونة لمواجهة السوق سريعة التغير. (المصدر: WeChat)

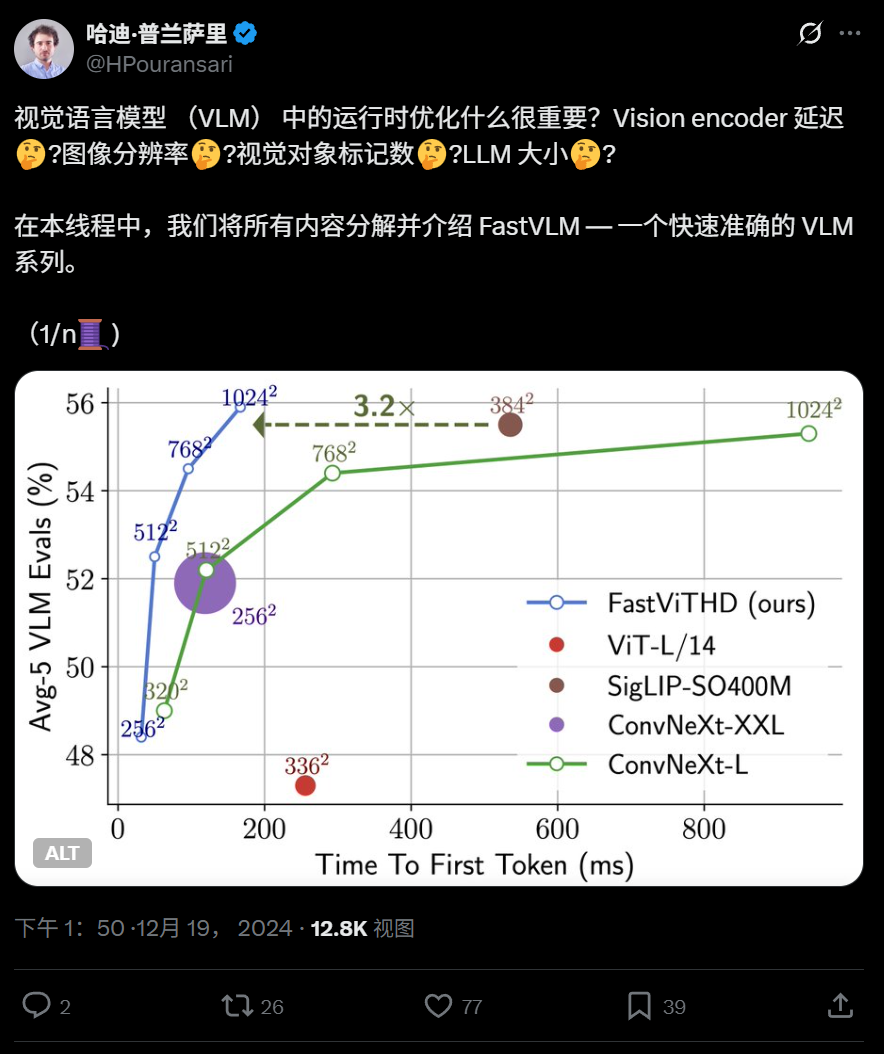
Apple تفتح مصدر نموذج اللغة المرئية عالي الكفاءة FastVLM، ويمكن تشغيله على iPhone: فتحت شركة Apple مصدر FastVLM، وهو نموذج لغة مرئية مصمم خصيصًا للتشغيل بكفاءة على الأجهزة الطرفية مثل iPhone. قلل هذا النموذج بشكل كبير من عدد التوكنات المرئية (أقل بـ 16 مرة من ViT) من خلال مُرمِّز مرئي هجين جديد FastViTHD (يدمج طبقات تلافيفية مع وحدات Transformer، ويعتمد تقنيات تجميع متعددة المقاييس وتقليل العينات)، مما أدى إلى زيادة سرعة إخراج التوكن الأول بمقدار 85 مرة مقارنة بالنماذج المماثلة. يتوافق FastVLM مع نماذج اللغة الكبيرة (LLM) السائدة، وقد تم إصدار نسخ بمعلمات 0.5B و 1.5B و 7B، بهدف تحسين سرعة فهم الصور وتجربة المستخدم في تطبيقات الذكاء الاصطناعي على الأجهزة الطرفية. (المصدر: WeChat)
360 تطلق الجيل الجديد من نموذج FG-CLIP متعدد الوسائط للصور والنصوص، لتعزيز قدرة المواءمة الدقيقة: طور معهد 360 للذكاء الاصطناعي الجيل الجديد من نموذج FG-CLIP متعدد الوسائط للصور والنصوص، بهدف معالجة أوجه القصور في نماذج CLIP التقليدية في فهم التفاصيل الدقيقة للصور والنصوص. يعتمد FG-CLIP استراتيجية تدريب من مرحلتين: التعلم التبايني العالمي (يدمج الأوصاف الطويلة التي تم إنشاؤها بواسطة نماذج كبيرة متعددة الوسائط) والتعلم التبايني المحلي (يدخل بيانات التعليقات التوضيحية الإقليمية-النصية وعينات سلبية دقيقة صعبة التعلم)، وبالتالي تحقيق التقاط دقيق للتفاصيل المحلية للصور والاختلافات الدقيقة في سمات النص. تم قبول هذا النموذج في ICML 2025، وتم فتح مصدره على Github و Huggingface، ويمكن استخدام أوزانه تجاريًا. (المصدر: WeChat)

Google تطلق LightLab، وتستخدم نماذج الانتشار للتحكم الدقيق في إضاءة وظلال الصور: أطلق فريق بحث Google مشروع LightLab، وهي تقنية تتيح التحكم الدقيق في معلمات مصدر الضوء بناءً على صورة واحدة. يمكن للمستخدمين ضبط شدة ولون مصادر الضوء المرئية، وشدة الإضاءة المحيطة، وإدخال مصادر ضوء افتراضية في المشهد. يحقق LightLab ذلك من خلال الضبط الدقيق لنماذج الانتشار على مجموعة بيانات مُعدة خصيصًا (تحتوي على أزواج صور حقيقية بإضاءة خاضعة للرقابة وصور مُصنَّعة على نطاق واسع)، مستفيدًا من الخصائص الخطية للضوء لفصل مصادر الضوء والإضاءة المحيطة، وتجميع عدد كبير من أزواج الصور ذات التغيرات الضوئية المختلفة للتدريب. يمكن لهذا النموذج محاكاة تأثيرات الإضاءة المعقدة مباشرة في فضاء الصورة، مثل الإضاءة غير المباشرة والظلال والانعكاسات. (المصدر: WeChat)

Tencent تقترح طريقتي التعلم المعزز GRPO و RCS، لتعزيز قابلية تعميم اكتشاف النوايا: اقترح فريق بحث الخط الاجتماعي في Tencent PCG استخدام خوارزمية تحسين السياسة النسبية المجمعة (GRPO) جنبًا إلى جنب مع استراتيجية أخذ عينات المناهج القائمة على المكافأة (RCS) في التعلم المعزز، وتطبيقها على مهام اكتشاف النوايا. حسنت هذه الطريقة بشكل كبير من قدرة النموذج على التعميم على النوايا غير المعروفة (تحسن يصل إلى 47% في النوايا الجديدة والقدرة عبر اللغات)، خاصة بعد إدخال “التفكير (Thought)”، حيث تعززت قدرة تعميم اكتشاف النوايا المعقدة بشكل أكبر. أظهرت التجارب أن النماذج المدربة بالتعلم المعزز (RL) تتفوق على نماذج SFT في قابلية التعميم، وأنه بغض النظر عما إذا كانت مبنية على نماذج مدربة مسبقًا أو نماذج مضبوطة بالتعليمات، فإن أداء GRPO بعد التدريب يكون متقاربًا. (المصدر: WeChat)

جامعة نانيانغ التكنولوجية وغيرها يقترحون إطار RAP، لتحسين إدراك الصور عالية الدقة بناءً على RAG: اقترح فريق البروفيسور Tao Dacheng من جامعة نانيانغ التكنولوجية وآخرون إطار Retrieval-Augmented Perception (RAP)، وهو مكون إضافي لإدراك الصور عالية الدقة يعتمد على تقنية RAG ولا يحتاج إلى تدريب، ويهدف إلى حل مشكلة فقدان المعلومات عند معالجة نماذج اللغة الكبيرة متعددة الوسائط (MLLM) للصور عالية الدقة. يقوم RAP باسترداد أجزاء الصورة ذات الصلة بسؤال المستخدم، ويستخدم خوارزمية Spatial-Awareness Layout للحفاظ على علاقاتها المكانية النسبية، ثم من خلال Retrieved-Exploration Search (RE-Search) يختار بشكل تكيفي عدد أجزاء الصورة المحتفظ بها K، مما يقلل بشكل فعال من دقة الصورة المدخلة مع الحفاظ على المعلومات المرئية الرئيسية. أظهرت التجارب أن RAP يحسن الدقة بنسبة تصل إلى 21% و 21.7% على مجموعتي بيانات HR-Bench 4K و 8K على التوالي. تم قبول هذا الإنجاز كورقة Spotlight في ICML 2025. (المصدر: WeChat)

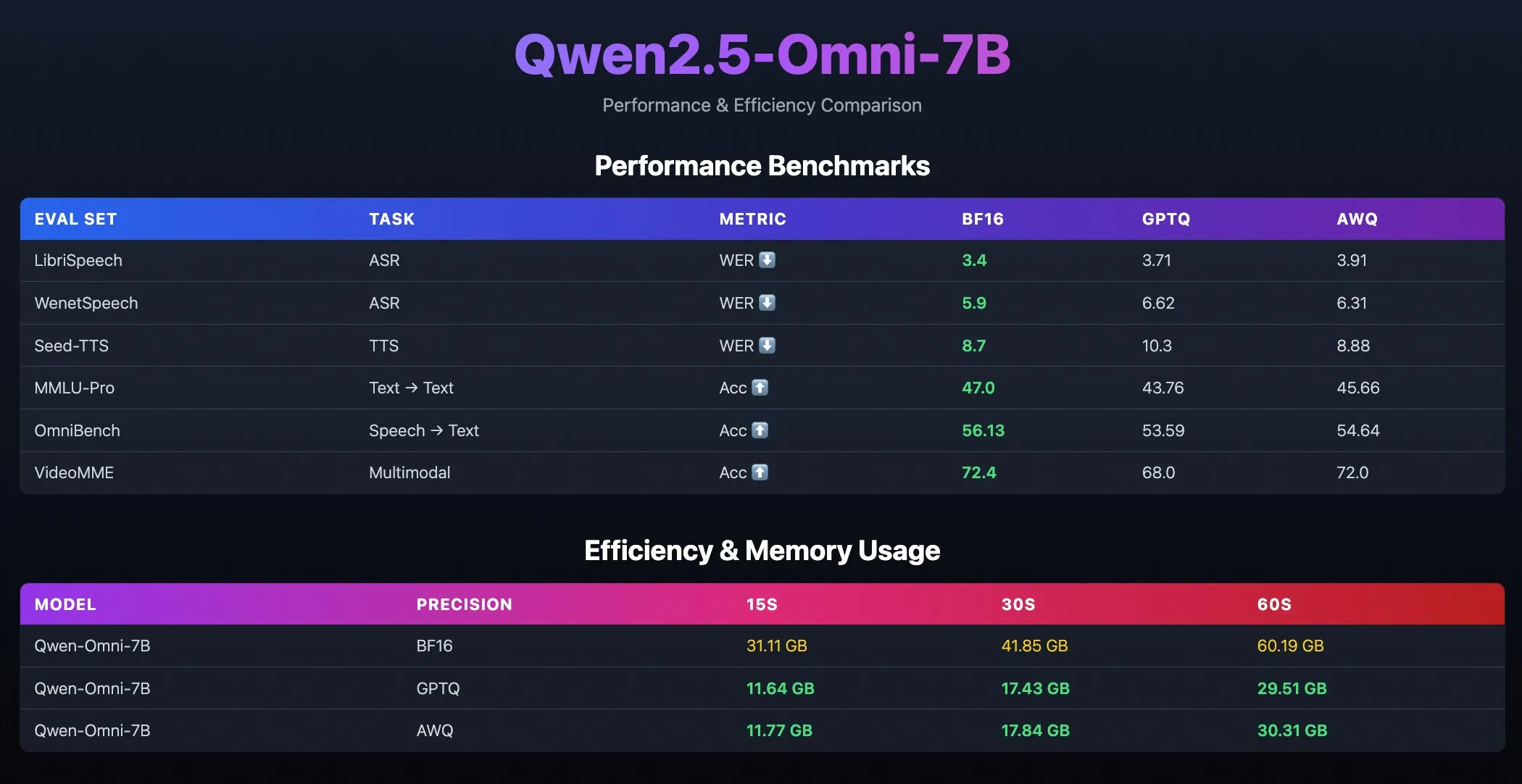
إصدار نموذج Qwen2.5-Omni-7B المُكمَّم: أصدر فريق Qwen التابع لشركة Alibaba نسخًا مُكمَّمة من نموذج Qwen2.5-Omni-7B، بما في ذلك نقاط فحص مُحسَّنة لـ GPTQ و AWQ. تم إتاحة هذه النماذج على Hugging Face و ModelScope، بهدف توفير خيارات نشر أكثر كفاءة وأقل استهلاكًا للموارد، مع الحفاظ على قدراتها القوية متعددة الوسائط. (المصدر: Alibaba_Qwen, karminski3, reach_vb)
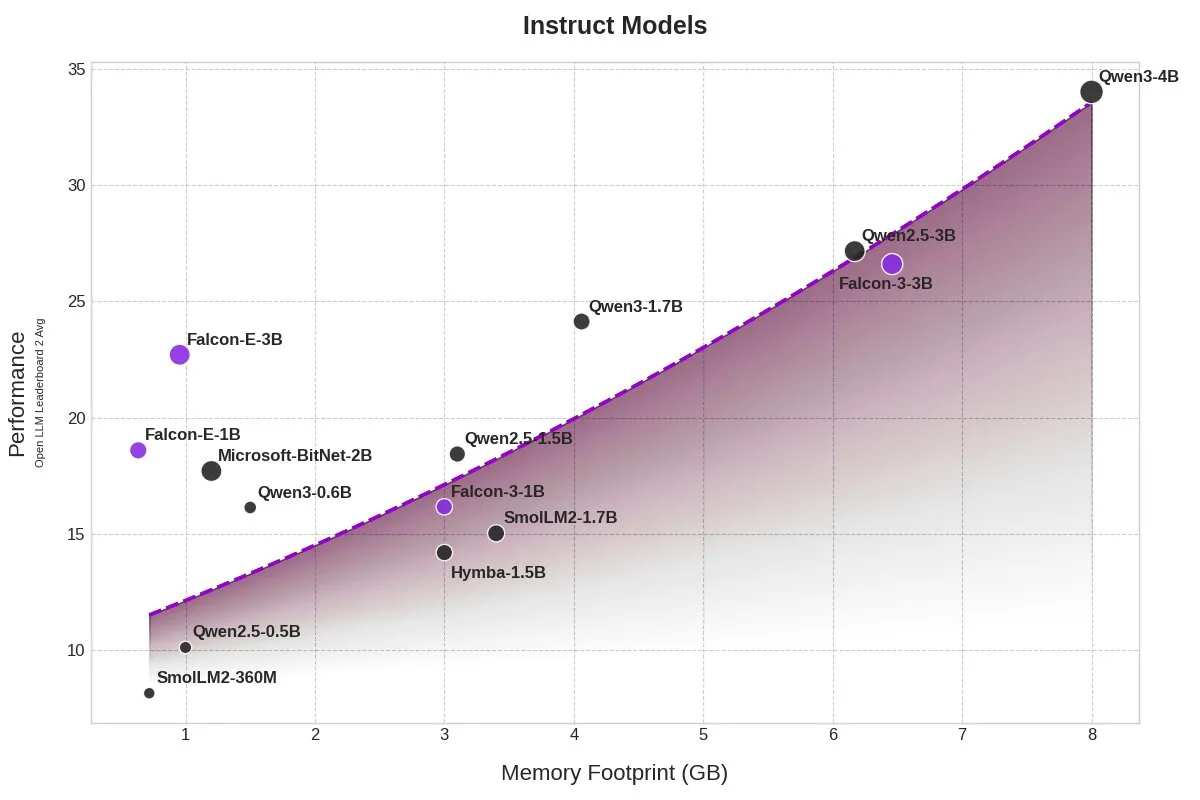
TII تطلق نماذج BitNet Falcon-E-1B/3B، مما يقلل بشكل كبير من استهلاك الذاكرة: أطلق معهد الابتكار التكنولوجي (TII) سلسلة نماذج جديدة Falcon-Edge تعتمد على إطار عمل نموذج BitNet بدقة 1-bit من Microsoft، وتشمل Falcon-E-1B و Falcon-E-3B. يُقال إن أداء هذه النماذج يعادل أداء Qwen3-1.7B، ولكن استهلاك الذاكرة يبلغ 1/4 فقط. كما أصدر TII مكتبة الضبط الدقيق onebitllms، التي تدعم المستخدمين في ضبط هذه النماذج بدقة 1-bit بأنفسهم على بطاقات NVIDIA. (المصدر: karminski3)
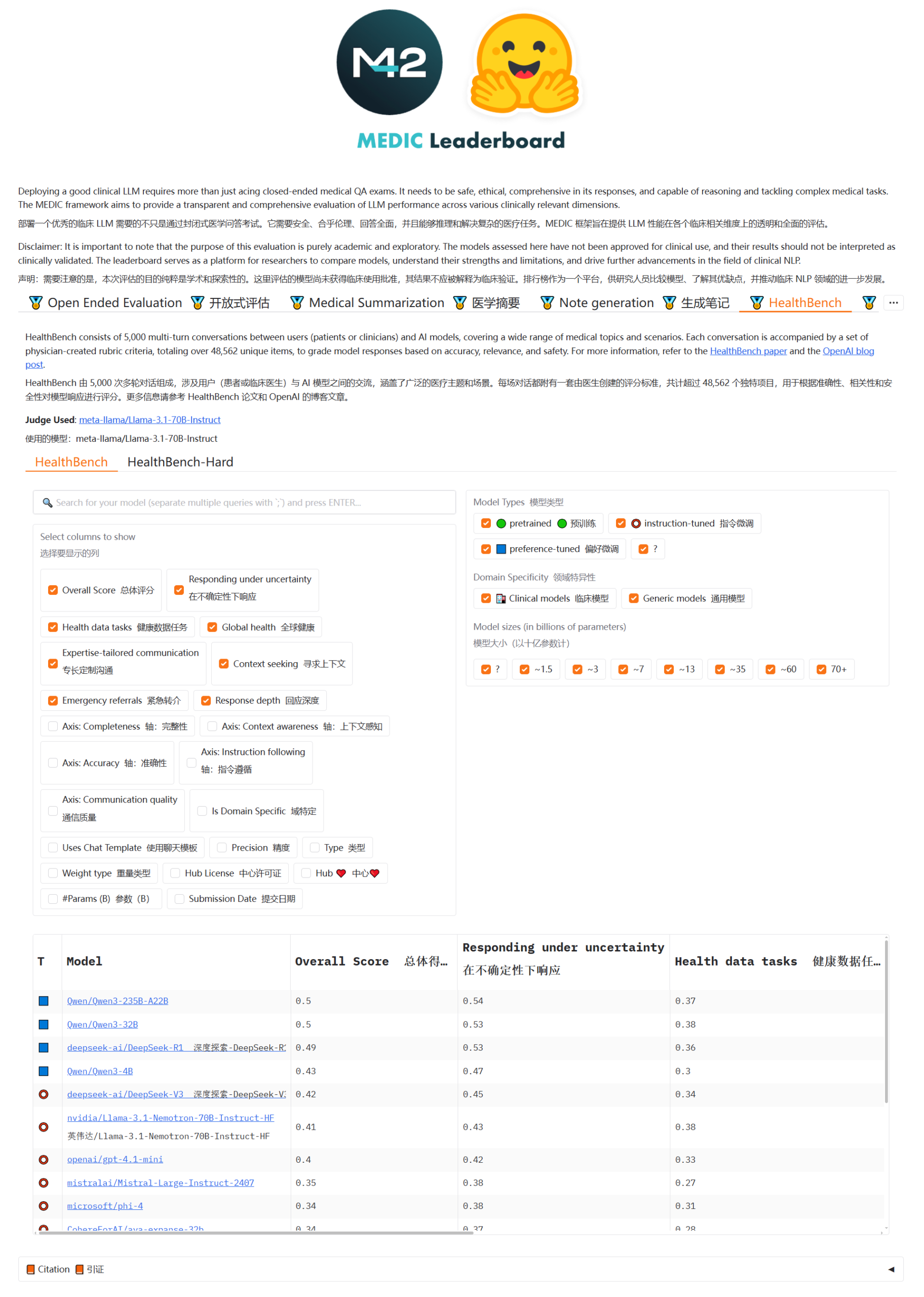
نماذج Qwen3 و DeepSeek تتصدر قائمة MEDIC-Benchmark للأسئلة والأجوبة الطبية: حققت نماذج Qwen3 المركزين الأول والثاني في أحدث قائمة MEDIC-Benchmark للأسئلة والأجوبة الطبية. بالإضافة إلى ذلك، احتلت نماذج Qwen و DeepSeek المراكز الخمسة الأولى في القائمة، مما يدل على القدرة القوية لهذه النماذج الصينية الكبيرة في مجال الأسئلة والأجوبة الطبية المتخصصة. (المصدر: karminski3)
جامعة تشجيانغ تقترح Rankformer: بنية نموذج توصية Transformer لتحسين الترتيب مباشرة: اقترح فريق من جامعة تشجيانغ بنية نموذج توصية Transformer رسومية جديدة تسمى Rankformer، تصميمها مستمد مباشرة من أهداف الترتيب (مثل دالة خسارة BPR). يقوم Rankformer بتصميم آلية Transformer رسومية فريدة من خلال محاكاة اتجاه تحسين المتجهات في عملية الانحدار التدريجي، ويوجه النموذج في الانتشار الأمامي لترميز تمثيلات ترتيب أفضل. يستخدم هذا النموذج آلية انتباه عالمية لتجميع المعلومات ويدعي أنه يقلل من التعقيد الزمني والمكاني إلى المستوى الخطي من خلال التحويلات الرياضية وتحسين التخزين المؤقت. تم قبول هذه الدراسة في مؤتمر WWW 2025. (المصدر: WeChat)
🧰 أدوات
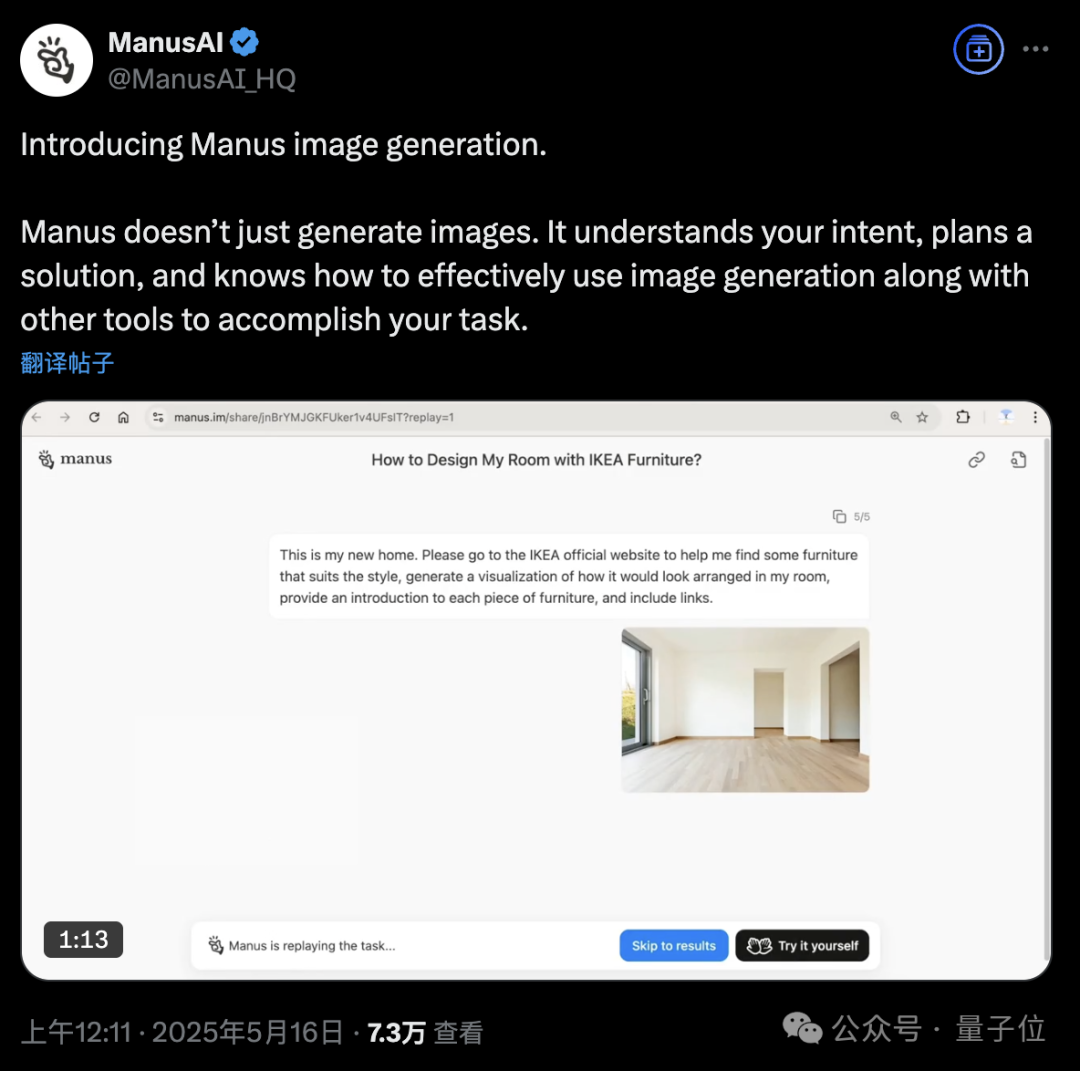
منصة Manus AI Agent تضيف ميزة توليد الصور: أعلنت منصة Manus AI Agent عن دعمها لتوليد الصور. بخلاف أدوات الرسم التقليدية بالذكاء الاصطناعي، يمكن لـ Manus فهم غرض المستخدم من الرسم وتخطيط حلول التوليد. على سبيل المثال، يمكن للمستخدم تحميل صورة غرفة، ويطلب من Manus البحث عن أثاث من موقع Ikea وإنشاء صور مرئية لتأثيرات الديكور، مع إرفاق روابط الأثاث. يكمل Manus المهمة من خلال خطوات مثل التحليل والبحث واختيار الأثاث وكتابة استراتيجية التصميم. تهدف هذه الميزة إلى دمج سير عمل الوكيل الذكي مع توليد الصور بعمق. حاليًا، Manus مفتوح للتسجيل، ويقدم 1000 نقطة مجانية، و 300 نقطة إضافية يوميًا، ويوفر خطط اشتراك مدفوعة. (المصدر: 36氪, WeChat)
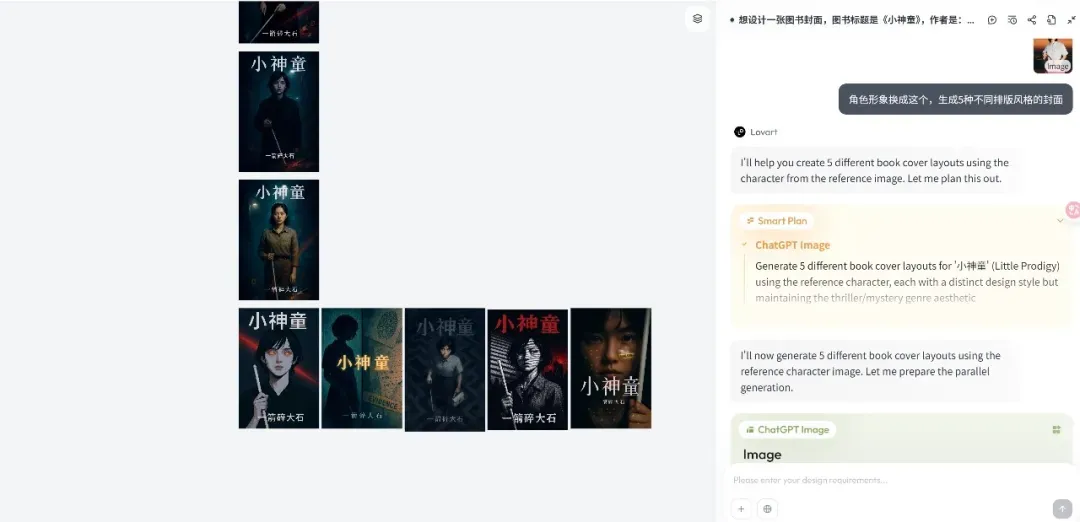
إطلاق منصة Lovart Design Agent، مع التركيز على سير العمل الإبداعي: أثارت منصة Lovart Design Agent الناشئة اهتمامًا سريعًا بعد إطلاقها، وتتمثل فكرتها الأساسية في تحويل عملية إبداع المصمم (التي تتضمن وسائط متعددة) إلى سير عمل Agent. توفر Lovart واجهة تفاعلية تشبه لوحة الرسم، حيث يمكن للمستخدمين توجيه الذكاء الاصطناعي لإكمال مهام التصميم من خلال الحوار، ويكون الذكاء الاصطناعي مسؤولاً عن التخطيط والتنفيذ. يعتقد المؤسس Chen Mian أن منتجات صور الذكاء الاصطناعي قد دخلت مرحلة 3.0 التي يقودها Agent، وتهدف Lovart إلى أن تصبح “صديقًا” للمصممين، وتترك المهام الروتينية للذكاء الاصطناعي، مما يسمح للمصممين بالتركيز على الإبداع. ستدمج المنتجات المستقبلية قدرات النمذجة ثلاثية الأبعاد والفيديو والصوت، لتصبح “فريقًا إبداعيًا” أو “شركة تصميم”. (المصدر: 36氪)
تحديث OpenAI Codex CLI، يدمج o4-mini ويوفر رصيد API مجاني: قامت OpenAI بتحسين واجهة سطر الأوامر (CLI) لوكيل الترميز مفتوح المصدر وخفيف الوزن Codex CLI. الإصدار الجديد مدعوم بنسخة مبسطة من codex-1 تسمى o4-mini (تحت اسم codex-mini)، وهي مُحسَّنة خصيصًا للإجابة على أسئلة الأكواد وتحريرها بزمن انتقال منخفض. يمكن للمستخدمين الآن تسجيل الدخول إلى Codex CLI باستخدام حساب ChatGPT الخاص بهم، ويمكن لمستخدمي Plus و Pro استبدال 5 دولارات و 50 دولارًا على التوالي من أرصدة API المجانية (صالحة لمدة 30 يومًا)، لاستخدام نموذج codex-mini-latest. (المصدر: openai, hwchung27, op7418)
إطار عمل معالجة البيانات مفتوح المصدر Smallpond من DeepSeek يدمج الوصول الأصلي لـ DuckDB إلى 3FS: يستخدم إطار عمل معالجة البيانات مفتوح المصدر Smallpond من DeepSeek داخليًا 3FS (DeepSeek File System) و DuckDB. يدعم DuckDB الآن الوصول الأصلي إلى 3FS من خلال المكون الإضافي hf3fs_usrbio، مما سيؤدي إلى تحسين الأداء وتقليل النفقات. كما أن DuckDB نفسه يحظى بالثناء لسهولة استخدامه، على سبيل المثال، يمكن تضمين عناوين URL مباشرة في عبارات الاستعلام لمعالجة البيانات. (المصدر: karminski3)

ComfyUI يدعم أصلاً نموذج الفيديو Wan2.1-VACE من Alibaba: أعلنت ComfyUI عن دعمها الأصلي لنموذجي توليد الفيديو Wan2.1-VACE 14B و 1.3B من فريق Wanxiang (@Alibaba_Wan) التابع لشركة Alibaba. يجلب هذا النموذج إلى ComfyUI قدرات تحرير فيديو متكاملة، بما في ذلك تحويل النص إلى فيديو، والصورة إلى فيديو، والفيديو إلى فيديو (التحكم في الوضعية والعمق)، وإصلاح الفيديو (inpainting) والتوسيع الخارجي (outpainting)، بالإضافة إلى ميزات مرجعية للشخصيات/الكائنات. (المصدر: TomLikesRobots)
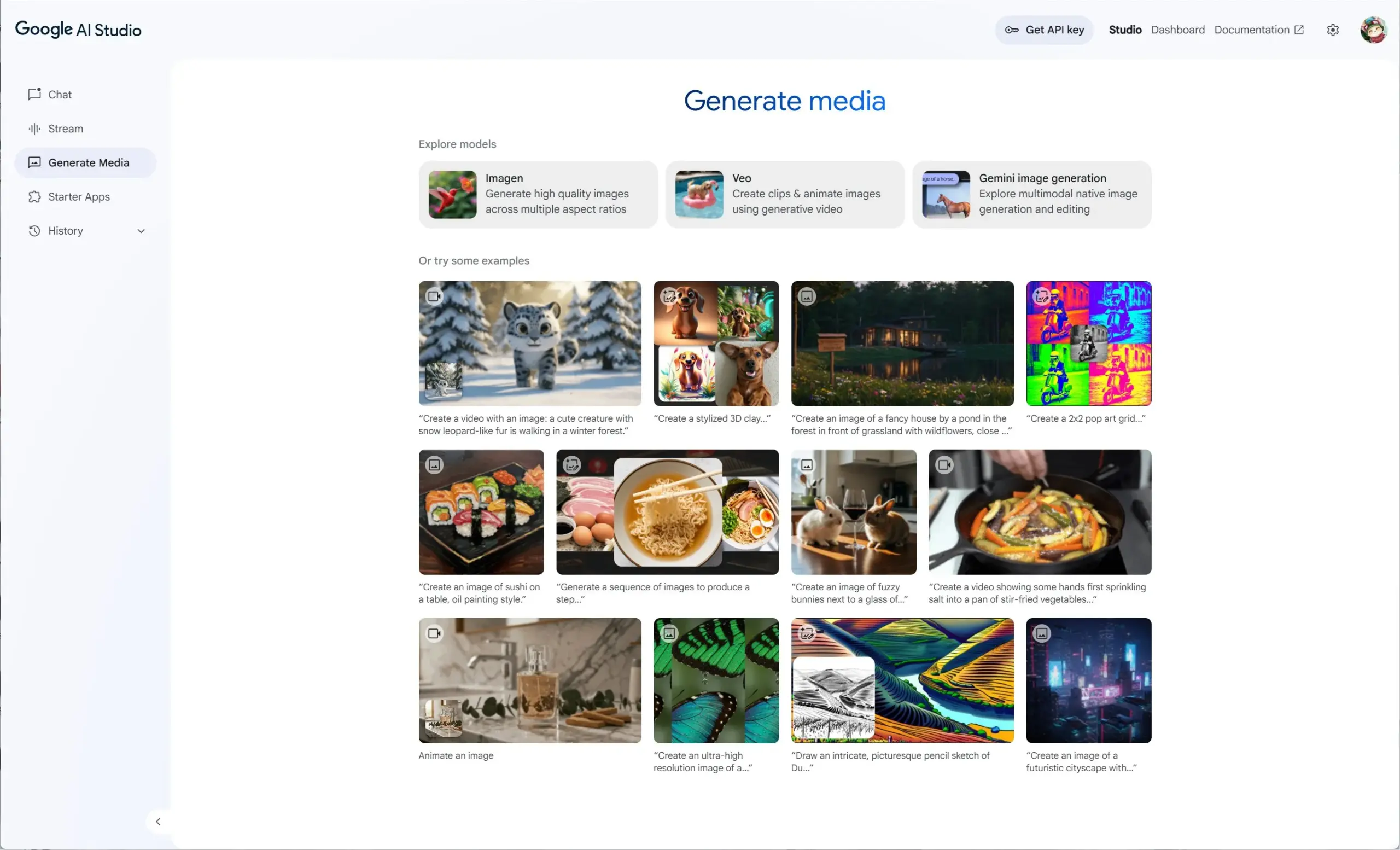
Google AI Studio يدمج Veo 2 و Gemini 2.0 و Imagen 3، لتقديم تجربة وسائط توليدية موحدة: أطلق Google AI Studio تجربة وسائط توليدية جديدة، تدمج نموذج الفيديو Veo 2، وقدرات توليد/تحرير الصور الأصلية لـ Gemini 2.0، وأحدث نموذج لتحويل النص إلى صورة Imagen 3. يمكن للمستخدمين تجربة هذه النماذج مجانًا في AI Studio، ويمكن للمطورين أيضًا البناء باستخدام واجهة برمجة التطبيقات (API). (المصدر: op7418)
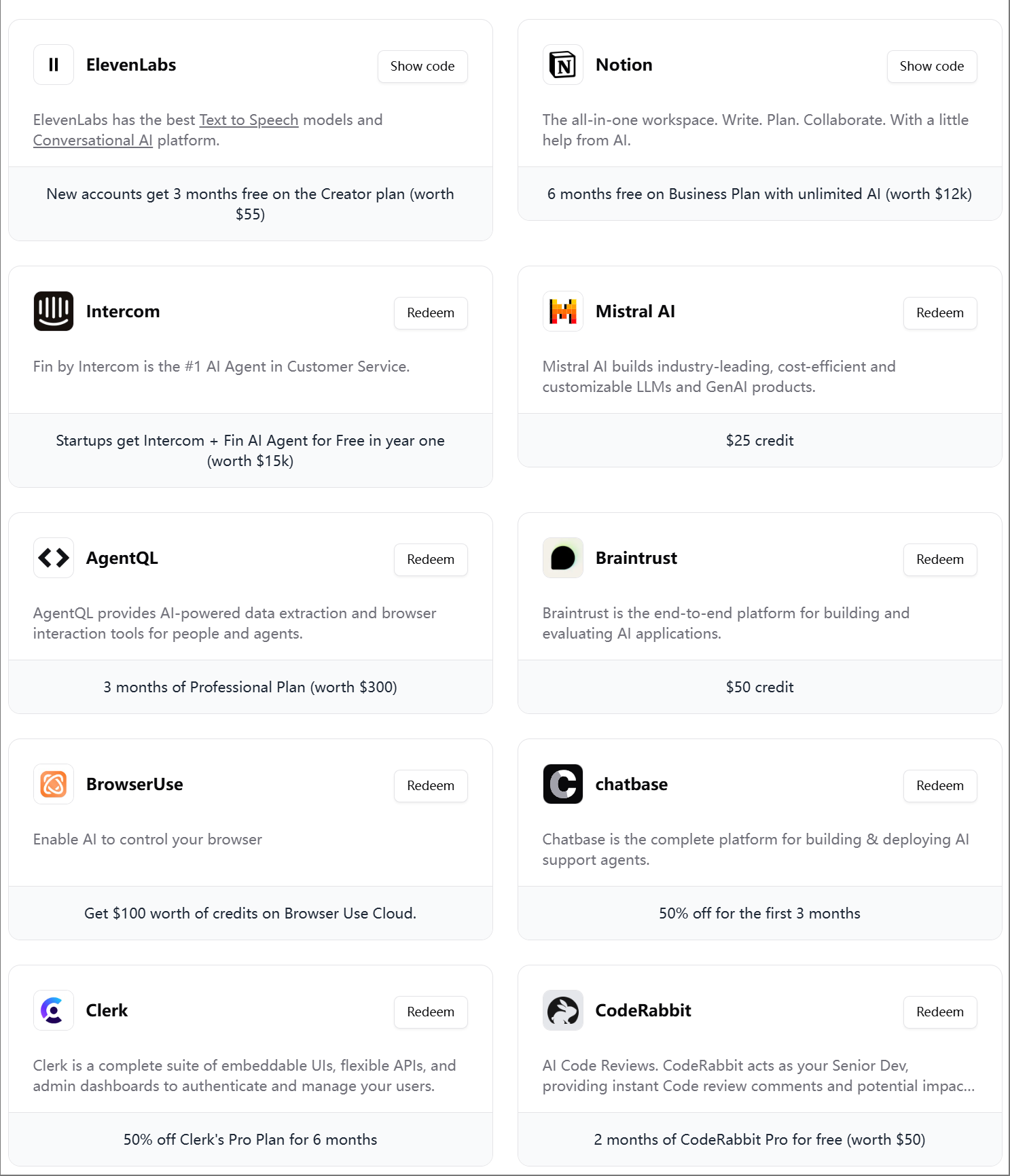
ElevenLabs تطلق الدفعة الرابعة من حزمة هدايا مهندسي الذكاء الاصطناعي: أصدرت ElevenLabs الدفعة الرابعة من حزمة هدايا مهندسي الذكاء الاصطناعي الموجهة لمطوري الذكاء الاصطناعي، وتحتوي على عضويات وأرصدة API لعدة أدوات وخدمات، مثل Modal Labs، و Mistral AI، و Notion، و BrowserUse، و Intercom، و Hugging Face، و CodeRabbit، وغيرها، بهدف مساعدة الشركات الناشئة والمطورين في مجال الذكاء الاصطناعي. (المصدر: op7418)
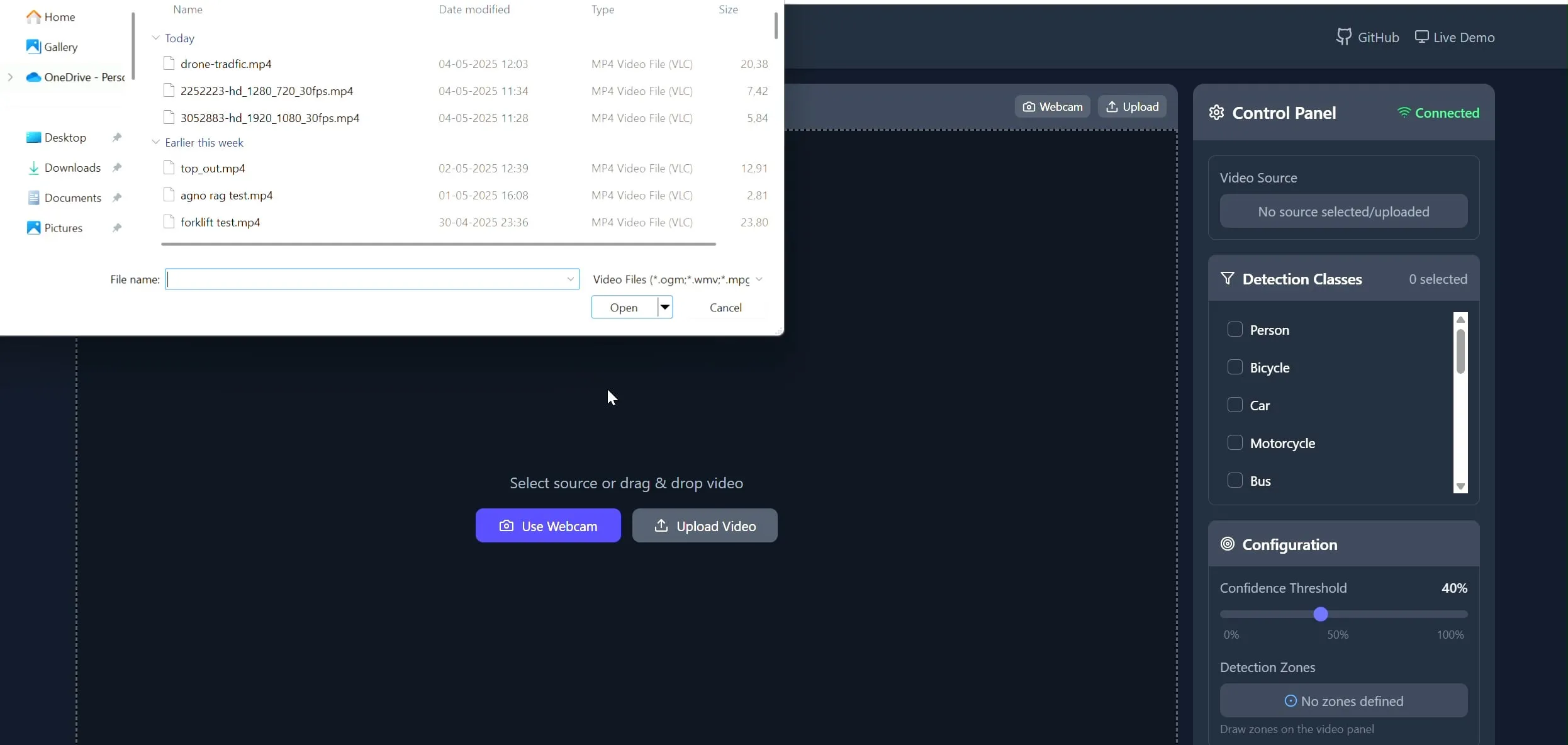
تطبيق Polygon Zone: أداة رسم مضلعات مخصصة على الفيديو لمهام الرؤية الحاسوبية (CV): أنشأ المطور Pavan Kunchala أداة تسمى Polygon Zone App، تسمح للمستخدمين بتحميل مقاطع الفيديو، ورسم مناطق مضلعة مخصصة (ROI) بشكل تفاعلي على إطارات الفيديو، وتشغيل تحليلات الرؤية الحاسوبية مثل اكتشاف الكائنات داخل هذه المناطق. تهدف هذه الأداة إلى تبسيط العملية المملة لتعريف مناطق الاهتمام (ROI) في مشاريع الرؤية الحاسوبية، وتجنب التحرير اليدوي لإحداثيات JSON. (المصدر: Reddit r/deeplearning)
📚 تعلم
دورة تقييمات الذكاء الاصطناعي (AI Evals) تجذب مشاركة أكثر من 300 شركة: جذبت دورة تقييمات الذكاء الاصطناعي (bit.ly/evals-ai) التي يقدمها Hamel Husain مشاركة أكثر من 300 شركة، من بينها شركات معروفة مثل Adobe، و Amazon، و Google، و Meta، و Microsoft، و NVIDIA، و OpenAI، بالإضافة إلى العديد من الجامعات المرموقة. يعكس هذا الاهتمام والحاجة الكبيرة في الصناعة لأساليب وممارسات تقييم نماذج الذكاء الاصطناعي. (المصدر: HamelHusain)
Latent.Space تنشر دليل استخدام ChatGPT Codex: أطلقت Latent.Space دليلاً بعنوان “ChatGPT Codex: The Missing Manual”، يشرح بالتفصيل كيفية استخدام مهندس البرمجيات المستقل السحابي الجديد ChatGPT Codex من OpenAI بكفاءة. تم إعداد هذا الدليل بواسطة Josh Ma و Alexander Embiricos، ويهدف إلى مساعدة المستخدمين على الاستفادة الكاملة من قدرات Codex القوية في عمليات مستودعات الأكواد. (المصدر: swyx)

Qdrant تطلق برنامجًا تعليميًا لتطبيق RAG محلي: شاركت Qdrant Engine برنامجًا تعليميًا من إعداد @maxedapps، يوضح كيفية بناء تطبيق توليد معزز بالاسترجاع (RAG) يعمل محليًا بنسبة 100% من الصفر باستخدام Gemma 3 و Ollama و Qdrant Engine. يستغرق هذا البرنامج التعليمي ساعتين، ويوفر الكود والخطوات الكاملة، وهو مناسب للمطورين الراغبين في ممارسة تطبيقات الذكاء الاصطناعي المحلية. (المصدر: qdrant_engine)

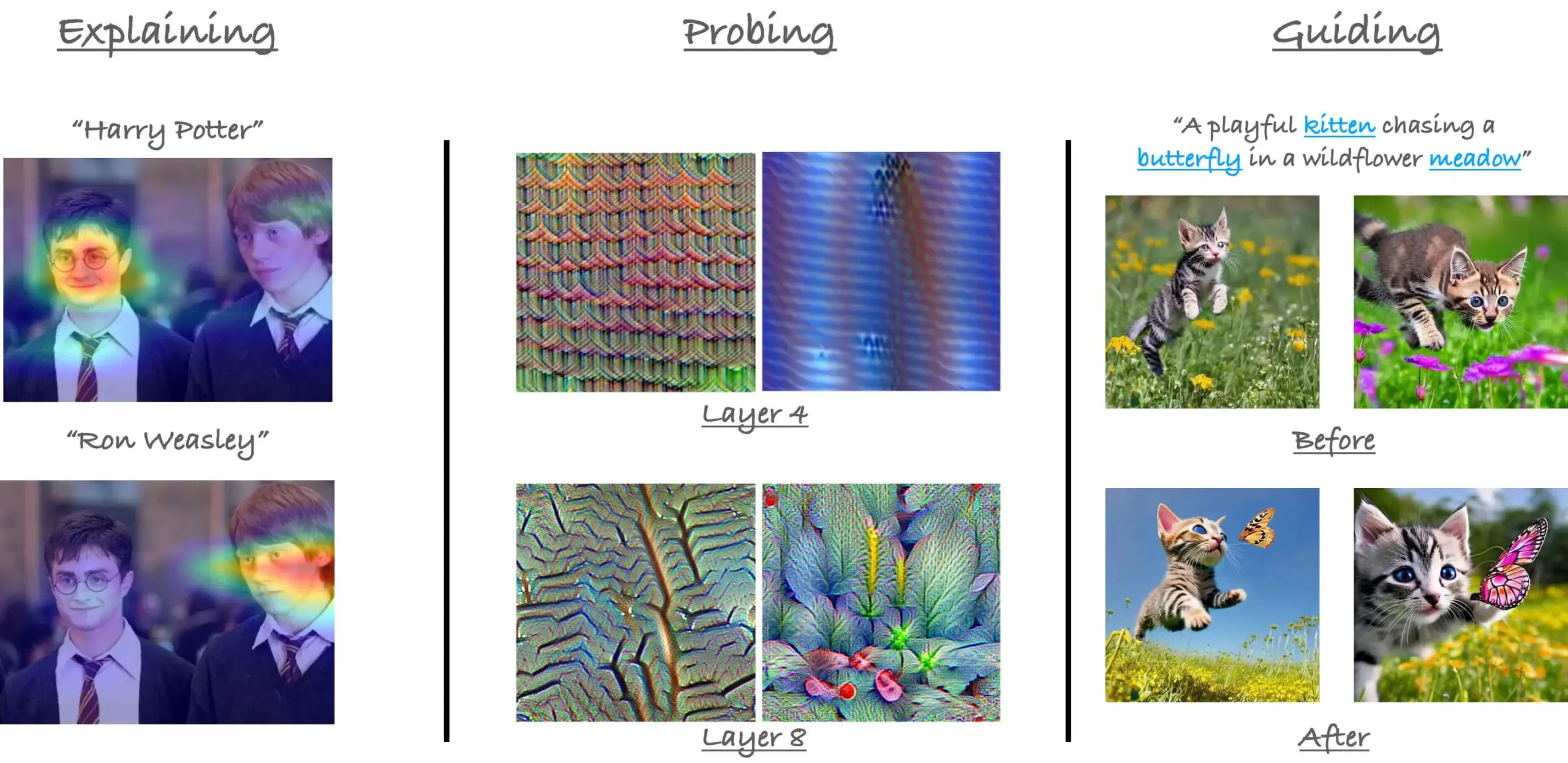
مراجعة البرنامج التعليمي حول آلية الانتباه في ViT من CVPR23: استعرض الباحث Sayak Paul برنامجه التعليمي مع Hila Chefer في CVPR 2023 حول آلية الانتباه في Vision Transformer (ViT). يدور البرنامج التعليمي حول ثلاثة مواضيع رئيسية: “الشرح (explain)”، و “الاستكشاف (probe)”، و “التوجيه (guide)”، ويهدف إلى المساعدة في فهم كيفية عمل الانتباه داخل ViT. (المصدر: RisingSayak)
مشاركة نصائح استخدام Claude Code: التخطيط، القواعد، والضغط اليدوي: شارك مستخدم Reddit خبرته في استخدام Claude Code بشكل مكثف لمدة أسبوع، مؤكدًا على أهمية التخطيط، ووضع القواعد (من خلال ملف CLAUDE.md)، وتشغيل /compact يدويًا قبل الوصول إلى حد الضغط التلقائي. تساعد هذه النصائح في تحسين الإنتاجية وجودة المخرجات، خاصة عند التعامل مع ميزات كبيرة أو تجنب انحراف النموذج عن المسار. ذكر المستخدم أنه من خلال هذه الطرق، يمكن لـ Claude Code إكمال المهام المعقدة بكفاءة. (المصدر: Reddit r/ClaudeAI)
مقابلة مع Su Wen مؤسس AIGCode: الإصرار على تطوير نماذج كبيرة ذاتيًا، والهدف هو توليد كود بمستوى “L5” من Autopilot: صرح Su Wen، مؤسس AIGCode، في مقابلة بأن هدف الشركة هو أن تصبح بنية تحتية لتوفير الأكواد، وتحقيق برمجة آلية بمستوى “L5” من Autopilot، مما يسمح حتى لغير المبرمجين بتوليد تطبيقات كاملة من خلال الذكاء الاصطناعي. يعتقد أن الترميز (Coding) هو أفضل سيناريو لتدريب النماذج الكبيرة، وأن الكود هو بيانات تدريب عالية الجودة. قامت AIGCode بالفعل بتدريب نموذج أساسي بسعة 66 مليار معلمة يسمى “Xiyue”، وأطلقت منتج AutoCoder. أكد Su Wen أن منتجات الذكاء الاصطناعي تتنافس في النهاية على “ذكاء العقل”، وأن التدريب المسبق هو القوة الدافعة التقنية، وحتى لو كانت التكلفة باهظة، فإن تطوير النماذج ذاتيًا أمر بالغ الأهمية لتحقيق الذكاء الاصطناعي العام (AGI) وبناء القدرة التنافسية الأساسية للمنتج. (المصدر: WeChat)

💼 أعمال
فريق منصة الوكلاء الأذكياء وتطبيقات الخوارزميات في JD.com يبحث عن موظفين: يبحث فريق منصة الوكلاء الأذكياء وتطبيقات الخوارزميات، وهو مشروع أساسي في مجموعة JD.com، عن مهندسي خوارزميات نماذج كبيرة ومتدربين، ومقر العمل في بكين. تشمل الاتجاهات التقنية الرئيسية LLM Agent، و LLM Reasoning، ودمج LLM مع التعلم المعزز. يستهدف التوظيف خريجي الماجستير والدكتوراه لعام 2026 (توظيف الخريجين)، والأشخاص ذوي الخبرة المعادلة للمستويات P5-P8 (توظيف ذوي الخبرة)، والمتدربين البحثيين. يركز الفريق على الدفع التقني وحل المشكلات العملية، ولديه أوراق بحثية منشورة في مؤتمرات الذكاء الاصطناعي المرموقة. (المصدر: WeChat)

استراتيجية “الذكاء الاصطناعي أولاً” تواجه تحديات في Klarna و Duolingo، والتوازن بين الإنسان والآلة يحظى بالاهتمام: تواجه شركة التكنولوجيا المالية Klarna وتطبيق تعلم اللغات Duolingo ضغوطًا من ردود فعل المستهلكين وواقع السوق بعد تبني استراتيجية “الذكاء الاصطناعي أولاً”. كانت Klarna قد استبدلت مئات وظائف خدمة العملاء بالذكاء الاصطناعي، ولكنها الآن تعيد توظيف موظفي خدمة عملاء بشريين بسبب انخفاض جودة الخدمة. أثار Duolingo استياء المستخدمين بسبب أتمتة الأدوار، حيث يعتقد الكثيرون أن جوهر تعلم اللغة يجب أن يقوده الإنسان. تُظهر هذه الحالات أن الشركات في تحولها نحو الذكاء الاصطناعي تحتاج إلى تحقيق التوازن بين الابتكار والاهتمام الإنساني، فالتكنولوجيا مهمة، ولكن ثقة المستخدم لا تزال بحاجة إلى بناء بشري. (المصدر: Reddit r/ArtificialInteligence)
شائعات عن استحواذ Databricks على شركة Neon الناشئة لقواعد البيانات مقابل مليار دولار: وفقًا لملخص أخبار الذكاء الاصطناعي المتداول في مجتمع Reddit، استحوذت Databricks على شركة Neon الناشئة لقواعد البيانات، ويُقال إن قيمة الصفقة بلغت مليار دولار. قد يهدف هذا الاستحواذ إلى تعزيز قدرات Databricks في إدارة البيانات والبنية التحتية للذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence)
🌟 مجتمع
إطلاق OpenAI Codex يثير نقاشًا حادًا، والمطورون بين التوقعات والحذر: بعد إطلاق OpenAI لوكيل البرمجة Codex، كانت ردود فعل المجتمع حماسية. أعرب العديد من المطورين عن حماسهم لقدرة Codex على إكمال مهام مثل إنشاء طلبات السحب (PR) وإصلاح الأكواد تلقائيًا، معتبرين أن هذا سيزيد بشكل كبير من كفاءة البرمجة، حتى أن البعض وصفه بأنه “شعور بلحظة الذكاء الاصطناعي العام (AGI)”. شارك Ryan Pream تجربته في استخدام Codex لإنشاء أكثر من 50 طلب سحب في يوم واحد. وفي الوقت نفسه، أشار بعض المستخدمين إلى أن Codex لا يزال بحاجة إلى تحسين في مجالات مثل تقسيم المهام وإضافة حالات الاختبار، وأنه حاليًا أكثر ملاءمة للمحترفين. شارك Yohei Nakajima انطباعاته الأولية، معتبرًا أن تصميمه المركزي حول GitHub منطقي، ولكن منحنى التعلم حاد. (المصدر: kevinweil, gdb, itsclivetime, dotey, yoheinakajima, cto_junior)
مساهمات Meta في مجال الذكاء الاصطناعي مفتوح المصدر تحظى بالتقدير، وتثير نقاشًا حول الانفتاح والانغلاق: نشر Clement Delangue، الرئيس التنفيذي لـ Hugging Face، منشورًا يدعم فيه Meta، معتبرًا أن مساهماتها في مجال نماذج الذكاء الاصطناعي مفتوحة المصدر تفوق بكثير مساهمات الشركات الكبرى والناشئة الأخرى التي تمتلك موارد أكثر، ولا ينبغي أن تتعرض للكثير من الانتقادات. حظي هذا الرأي بتأييد بعض المستخدمين، الذين يرون أن بناء نماذج ذكاء اصطناعي متطورة أمر صعب للغاية، وأن سلوك Meta المنفتح أمر بالغ الأهمية لتطوير هذا المجال. ولكن هناك أيضًا وجهة نظر (gabriberton) تشير إلى أن فتح المصدر يعني التخلي عن الميزة المعرفية، وأن الانغلاق في جوهره يمكن أن يحقق نتائج أفضل. أما Dorialexander فقد أعرب عن عدم فهمه لتبني الولايات المتحدة المفاجئ “لأسلوب الرد الأوروبي” (في إشارة إلى الدفاع عن Meta). (المصدر: ClementDelangue, gabriberton, Dorialexander)
تسريب موجهات نظام xAI Grok ودمج محتوى غير لائق يثيران الانتباه: تم اكتشاف تسريب موجهات نظام نموذج Grok من xAI على GitHub، بل وتضمنت موجهات نظام DeepSearch. والأخطر من ذلك، أشار بعض المستخدمين إلى أنه تم دمج طلب سحب (PR) يحتوي على محتوى غير لائق مثل “إبادة جماعية للبيض” في الفرع الرئيسي بعد مراجعته من قبل خمسة أشخاص، وعلى الرغم من أنه تم التراجع عنه وحذف السجل لاحقًا، إلا أن هذا الحادث كشف عن عيوب كبيرة في إدارة العمليات وأمن التشغيل في xAI. أثار هذا الأمر تساؤلات ونقاشات واسعة في المجتمع حول العمليات الداخلية وآليات مراجعة المحتوى في xAI. (المصدر: karminski3, eliebakouch, colin_fraser, Reddit r/artificial)
يعتبر AI Agent اتجاهًا مستقبليًا، ولكن التحديات والتوقعات تتعايش: تنتشر في المجتمع فكرة أن “عام 2025 هو عام Agent”، مما يثير نقاشًا حول التطور المستقبلي لـ AI Agent. هناك وجهة نظر ترى أن نموذج العمل المستقبلي سيشبه لعبة “StarCraft” أو “Age of Empires”، حيث يوجه المستخدمون عددًا كبيرًا من الوكلاء الصغار لإكمال المهام. ومع ذلك، يشير بعض المستخدمين أيضًا إلى أن Agent الحالي لا يزال غير ناضج في تفكيك المهام وفهم التعليمات المعقدة، ويتطلب من المستخدمين امتلاك قدرات تخطيط قوية. يشكك البعض في قدرة AI Agent على تحقيق التوقعات في عام 2025، ويعتقدون أنه قد يتحول من ضجة إلى أخرى، ويتوقعون تغييرًا جوهريًا في عام 2026. (المصدر: gdb, EdwardSun0909, op7418, eliza_luth, tokenbender)
دور الذكاء الاصطناعي في مجالي التعليم والتوظيف يثير نقاشًا عميقًا: ظهر نقاش في مجتمع Reddit حول تأثير تطور الذكاء الاصطناعي على نماذج التعليم والتوظيف التقليدية. تساءل أحد المستخدمين “ما جدوى الذهاب إلى المدرسة الآن؟”، معتقدًا أن الذكاء الاصطناعي سيجعل لا أحد بحاجة إلى العمل في المستقبل. ردًا على ذلك، أكدت معظم التعليقات على أهمية التفكير النقدي والقدرة على التعلم والمهارات الاجتماعية، معتبرة أن هذه أمور لا يمكن للذكاء الاصطناعي أن يحل محلها. فالمدرسة ليست مجرد مكان لنقل المعرفة، بل هي أيضًا بيئة لتعلم كيفية التعلم وكيفية التفكير والتفاعل مع الناس. حتى في عالم يهيمن عليه الذكاء الاصطناعي، تظل هذه القدرات حاسمة، بل وقد تتطلب تعلم الذكاء الاصطناعي نفسه. وأشار نقاش آخر إلى أنه لا ينبغي مساواة قيمة الإنسان بعمله فقط، وأن تطور الذكاء الاصطناعي يجب أن يدفعنا إلى التفكير في معنى إنساني يتجاوز المهنة. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
ظاهرة “صديقة الذكاء الاصطناعي” تثير تفكيرًا حول القضايا الاجتماعية والأخلاقية والسكانية: ذكرت مجلة The Economist أن الشباب الصيني بدأ في إقامة علاقات عاطفية وصداقات مع الذكاء الاصطناعي، مما أثار نقاشًا حادًا بين مستخدمي الإنترنت. شبه البعض هذه الظاهرة بـ “إطلاق أعداد كبيرة من البعوض الأنثوي العقيم في البرية لتقليل أعداد البعوض”، مما يشير إلى أن رفقاء الذكاء الاصطناعي قد يؤدون إلى تفاقم مشكلة انخفاض معدلات المواليد، على الرغم من أن رفقاء الذكاء الاصطناعي يمكنهم تقديم تجربة مثالية “تفهمك دائمًا”. يعكس هذا التأثيرات الاجتماعية المعقدة والاعتبارات الأخلاقية التي تطرحها تطبيقات تكنولوجيا الذكاء الاصطناعي في مجال الرفقة العاطفية. (المصدر: dotey)
واقعية المحادثات الهاتفية بالذكاء الاصطناعي تثير القلق، وصعوبة التمييز بين الحقيقة والخيال تحدٍ جديد: شارك مستخدم Reddit تجربته في تلقي مكالمة هاتفية من مؤسسة تعليمية، حيث كان صوت المتحدث ونبرته طبيعيين، وإجاباته سلسة، لدرجة أنه كان من المستحيل تقريبًا التمييز بينه وبين إنسان حقيقي. لم يدرك أنه ذكاء اصطناعي إلا بعد بضع دقائق من المحادثة، بسبب إجاباته المثالية الخالية من العيوب. أثارت هذه التجربة دهشة المستخدم وقلقه الطفيف من سرعة تطور تكنولوجيا الصوت بالذكاء الاصطناعي، والخوف من صعوبة تمييز الذكاء الاصطناعي في المكالمات الهاتفية مستقبلًا، خاصةً ما قد يشكله ذلك من مخاطر احتيال على فئات مثل كبار السن. (المصدر: Reddit r/ArtificialInteligence, Reddit r/artificial)
💡 أخرى
طلب MIT من arXiv سحب ورقة ما قبل الطباعة حول الذكاء الاصطناعي والاكتشاف العلمي يثير الجدل: طلب معهد ماساتشوستس للتكنولوجيا (MIT) من arXiv سحب ورقة ما قبل الطباعة أعدها أحد طلاب الدكتوراه لديه حول تأثير الذكاء الاصطناعي على الابتكار في علوم المواد، وذلك لـ “عدم الثقة” في مصدر البيانات البحثية وموثوقيتها وصلاحيتها. كانت الورقة قد أشارت إلى أن الباحثين بمساعدة الذكاء الاصطناعي زادوا من اكتشاف المواد بنسبة 44%، وزادت طلبات براءات الاختراع بنسبة 39%. أثار هذا الإجراء من MIT نقاشًا، حيث رأى البعض أن تصرفه يضر بالحرية الأكاديمية، وقد يكون مرتبطًا بأن استنتاجات البحث (أن الذكاء الاصطناعي قد يزيد من تفوق كبار الباحثين ويقلل من رضا الباحثين العاديين عن عملهم) لا تتوافق مع توقعات الممولين؛ بينما رأى آخرون أن دقة نتائج البحث في مجال الذكاء الاصطناعي أمر بالغ الأهمية، ويجب الحذر من المبالغة التي تحركها الأوراق ما قبل الطباعة. (المصدر: Reddit r/ArtificialInteligence)
انتشار أدوات الترميز بالذكاء الاصطناعي يفرض متطلبات أعلى على نمطية الكود والممارسات الهندسية: أشار E0M على تويتر إلى أن الميزة التنافسية للشركات الناشئة تتجلى بشكل متزايد في سرعة وكفاءة اعتماد المهندسين لأدوات الترميز بالذكاء الاصطناعي. أصبحت ممارسات الكود النمطية الجيدة أكثر أهمية من أي وقت مضى، فإذا كان تعقيد الكود ضمن نطاق معالجة وكلاء الترميز الحديثين، فيمكن تحقيق تكرار سريع؛ وعلى العكس من ذلك، فإن “كود السباغيتي” المعقد للغاية قد يبطئ التقدم، ويتم تجاوزه من قبل المنافسين الذين يستخدمون الذكاء الاصطناعي. (المصدر: E0M, E0M)
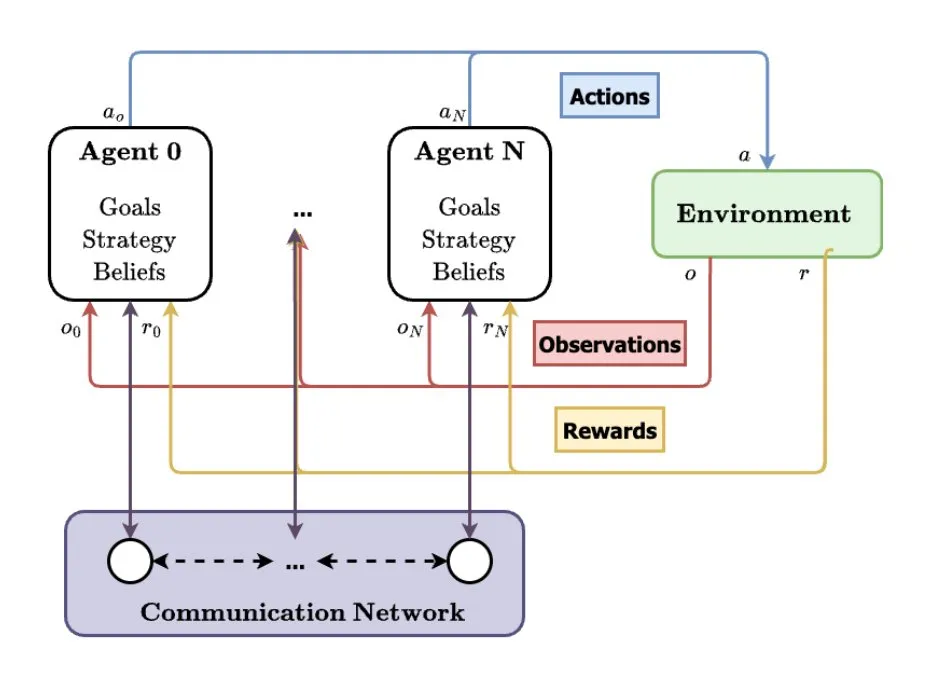
تُعتبر أنظمة الوكلاء المتعددين (MAS) اتجاهًا مستقبليًا لتطور الذكاء الاصطناعي: حلل TheTuringPost اتجاه صعود أنظمة الوكلاء المتعددين (MAS)، وتشمل التطورات الرئيسية التعلم المعزز متعدد الوكلاء (MARL)، وتقنيات الروبوتات الجماعية، وأنظمة الوكلاء المتعددين المدركة للسياق (CA-MAS)، بالإضافة إلى أنظمة الوكلاء المتعددين التي تعتمد على نماذج اللغة الكبيرة (LLM). تمكّن هذه التقنيات أنظمة الذكاء الاصطناعي من حل المشكلات المعقدة من خلال التعاون والمنافسة، وتُطبق في مجالات مثل الاستجابة للكوارث، ومراقبة البيئة، ومحاكاة الديناميكيات الاجتماعية، مما ينبئ بمستقبل الذكاء الجماعي. (المصدر: TheTuringPost)