
كلمات مفتاحية:أوبن إيه آي كوديكس, تطوير برمجيات الذكاء الاصطناعي, النماذج متعددة الوسائط, توليف الصوت بالذكاء الاصطناعي, تصفية البيانات, نسخة كوديكس البحثية المسبقة, مينيماكس سبيتش-02, نموذج BLIP3 متعدد الوسائط, بريسيليكت لتصفية البيانات, سلسلة نماذج SWE-1
🔥 أبرز العناوين
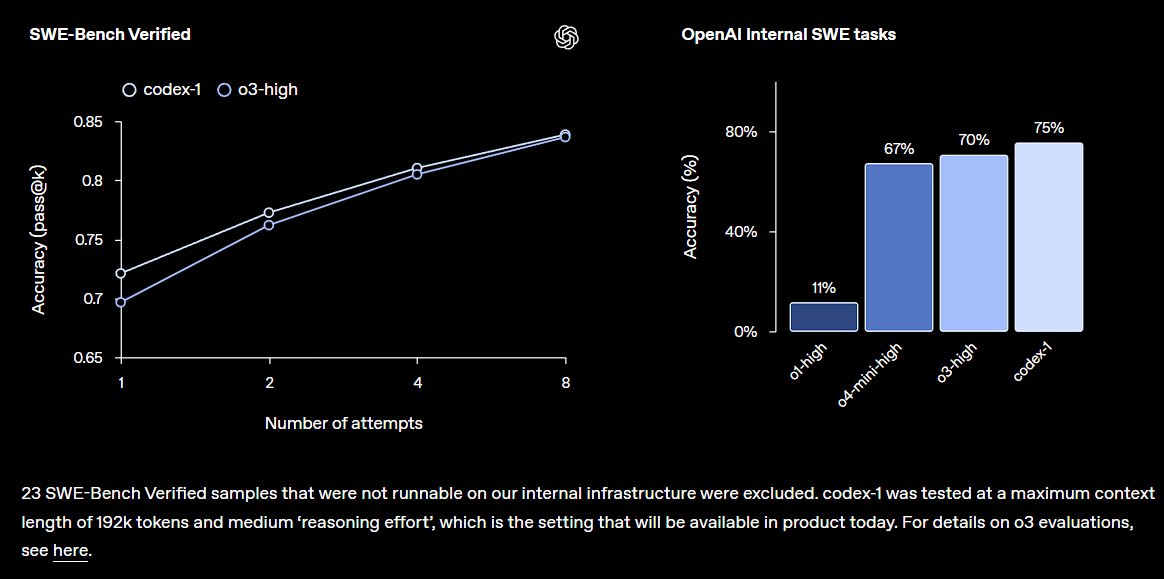
OpenAI تطلق نسخة معاينة بحثية من Codex، مدمجة في ChatGPT: أطلقت OpenAI نموذج Codex، وهو وكيل ذكاء اصطناعي لهندسة البرمجيات قائم على السحابة، يمكنه فهم قواعد التعليمات البرمجية الكبيرة، وكتابة ميزات جديدة، وإصلاح الأخطاء، ومعالجة مهام متعددة بالتوازي. يعتمد Codex على نموذج codex-1 المعدل بدقة o3، ويُظهر أداءً ممتازًا على SWE-bench. ستُتاح هذه الميزة تدريجيًا لمستخدمي ChatGPT Pro و Team و Enterprise، بهدف زيادة إنتاجية المطورين بشكل كبير، مما ينبئ بدور أكثر أهمية للذكاء الاصطناعي في مجال تطوير البرمجيات. كان رد فعل المجتمع إيجابيًا، ولكنه يركز أيضًا على فعاليته الفعلية والأخطاء المحتملة (المصدر: OpenAI, OpenAI Developers, scaling01, dotey)
تسريح Microsoft لعدد كبير من الموظفين يثير هزة في الصناعة، وتسريع التغيير التنظيمي المدفوع بالذكاء الاصطناعي: أعلنت Microsoft عن تسريح حوالي 6000 موظف عالميًا، بهدف تبسيط المستويات الإدارية وزيادة نسبة المبرمجين. من بين المسرحين موظفون قدامى يتمتعون بخبرة تصل إلى 25 عامًا ومساهمات بارزة، بالإضافة إلى مطورين أساسيين في TypeScript. يُعتبر هذا التسريح مرتبطًا بزيادة كفاءة تقنية الذكاء الاصطناعي وأتمتة بعض مهام العمل، مما يعكس اتجاه عمالقة التكنولوجيا نحو التحكم في التكاليف وتحسين هيكل القوى العاملة في عصر الذكاء الاصطناعي. أثارت الحادثة نقاشات واسعة حول تأثير الذكاء الاصطناعي على سوق العمل، والولاء المؤسسي، ونماذج العمل المستقبلية (المصدر: WeChat, NeelNanda5)
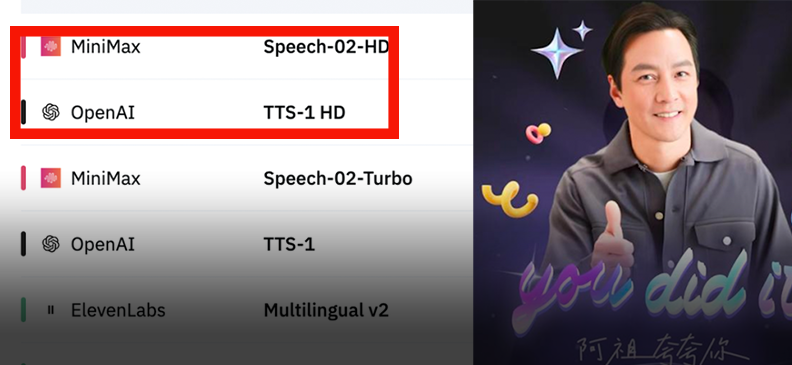
MiniMax تطلق نموذج الصوت Speech-02، وتتصدر القوائم العالمية: أطلقت MiniMax الجيل الجديد من نموذج الصوت Speech-02، والذي احتل المرتبة الأولى في تقييمين صوتيين مرموقين هما Artificial Analysis Speech Arena و Hugging Face TTS Arena، متجاوزًا OpenAI و ElevenLabs. يتميز النموذج بأداء متميز في محاكاة الصوت البشري بشكل فائق، وتخصيص نبرة الصوت بشكل شخصي (يدعم 32 لغة ولهجة، ويمكن استنساخه ببضع ثوانٍ من العينة المرجعية)، والتنوع. كما أنه يبتكر في استخدام تقنية Flow-VAE لتحسين تفاصيل الاستنساخ. تم تطبيق تقنيته بالفعل في سيناريوهات مثل “AI阿祖” لتعلم اللغة الإنجليزية، ودليل الذكاء الاصطناعي للمدينة المحرمة، مما يُظهر المكانة الرائدة للنماذج الكبيرة الصينية في مجال توليد الصوت بالذكاء الاصطناعي (المصدر: WeChat, WeChat)
Salesforce ومؤسسات أخرى تطلق نموذجًا موحدًا متعدد الوسائط BLIP3-o: أطلقت Salesforce Research بالتعاون مع عدة جامعات نموذجًا موحدًا متعدد الوسائط مفتوح المصدر بالكامل BLIP3-o، والذي يعتمد استراتيجية “الفهم أولاً ثم التوليد”، ويجمع بين البنية ذاتية الانحدار وبنية الانتشار. يبتكر النموذج في استخدام ميزات CLIP وتدريب Flow Matching، مما يحسن بشكل كبير جودة الصور المولدة وتنوعها ومواءمتها مع التوجيهات. يُظهر BLIP3-o أداءً ممتازًا في العديد من اختبارات الأداء القياسية، ويجري توسيعه ليشمل مهامًا متعددة الوسائط أكثر تعقيدًا مثل تحرير الصور والحوار البصري، مما يدفع تطور تقنية الذكاء الاصطناعي متعدد الوسائط (المصدر: 36氪)

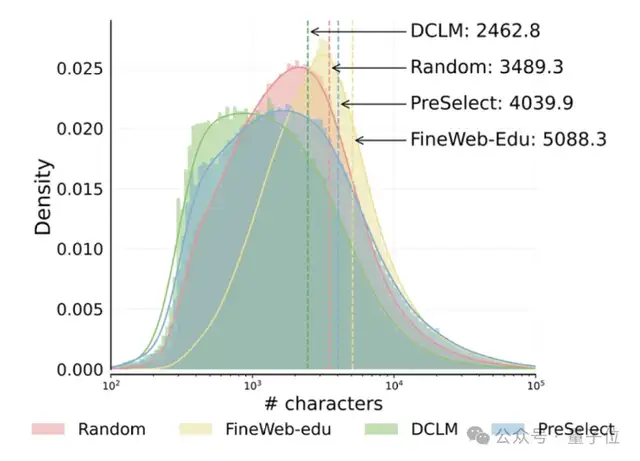
جامعة هونغ كونغ للعلوم والتكنولوجيا و vivo تقترحان حل PreSelect لاختيار البيانات، مما يزيد من كفاءة التدريب المسبق بمقدار 10 أضعاف: اقترحت جامعة هونغ كونغ للعلوم والتكنولوجيا بالتعاون مع vivo AI Lab طريقة اختيار بيانات خفيفة الوزن وفعالة PreSelect، والتي تم قبولها في ICML 2025. تقوم هذه الطريقة بتحديد مساهمة البيانات في قدرات معينة للنموذج من خلال مؤشر “قوة التنبؤ”، وتستخدم مصنف fastText لفحص بيانات التدريب الكاملة، مما يمكن من تحسين أداء النموذج بمعدل 3% مع تقليل متطلبات الحوسبة بمقدار 10 أضعاف. يهدف PreSelect إلى اختيار بيانات عالية الجودة ومتنوعة بشكل أكثر موضوعية وعمومية، متغلبًا على قيود طرق اختيار البيانات التقليدية القائمة على القواعد أو النماذج (المصدر: 量子位)
🎯 اتجاهات
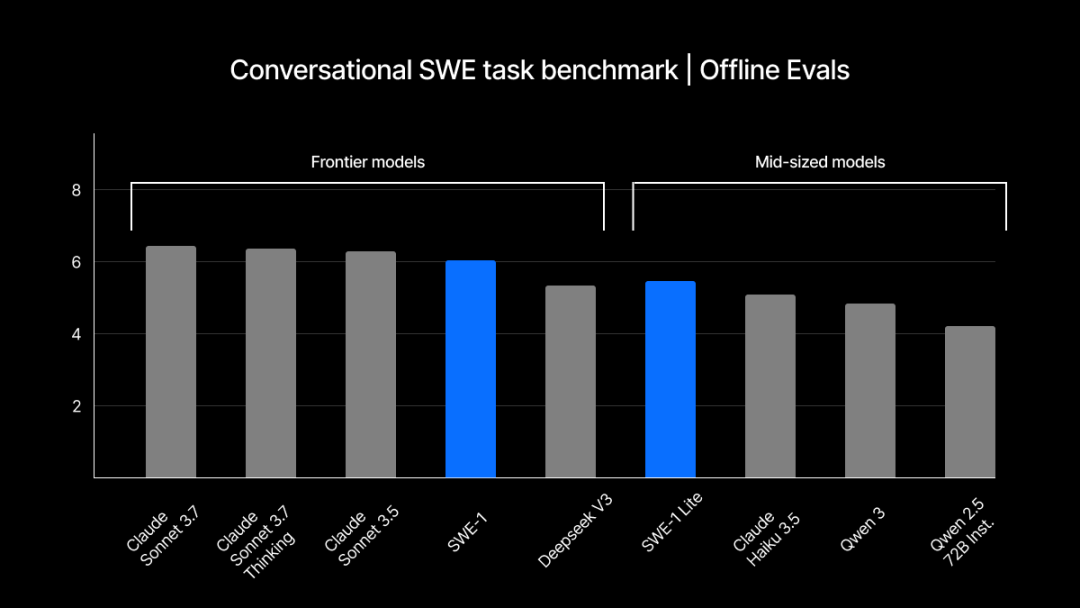
Windsurf تطلق سلسلة نماذج SWE-1 المطورة ذاتيًا، لتحسين عمليات هندسة البرمجيات: أطلقت Windsurf أول سلسلة نماذج مُحسَّنة خصيصًا لهندسة البرمجيات SWE-1، بهدف زيادة كفاءة التطوير بنسبة 99%. تتضمن السلسلة SWE-1 (بقدرات استدعاء أدوات قريبة من Claude 3.5 Sonnet، ولكن بتكلفة أقل)، و SWE-1-lite (جودة عالية، بديل لـ Cascade Base)، و SWE-1-mini (صغير وسريع، للاستخدام في سيناريوهات تتطلب زمن انتقال منخفض). يكمن ابتكارها الأساسي في نظام “الوعي بالتدفق” (Flow Awareness)، حيث يشارك الذكاء الاصطناعي المستخدم في الجدول الزمني للعمليات، مما يحقق تعاونًا فعالًا وفهمًا للحالات غير المكتملة (المصدر: WeChat, WeChat)
آلية ذاكرة ChatGPT تخضع للهندسة العكسية، وتكشف عن ثلاثة أنظمة فرعية للذاكرة: تم تحليل وظيفة ذاكرة “سجل الدردشة” التي أطلقتها OpenAI لـ ChatGPT من قبل هواة التكنولوجيا، مما كشف أنها قد تحتوي على ثلاثة أنظمة فرعية: سجل الحوار الحالي، وسجل تاريخ الحوار (يعتمد على الملخصات واسترجاع المحتوى)، ورؤى المستخدم (تُنشأ بناءً على تحليل حوارات متعددة، مع درجة ثقة). تهدف هذه الآليات إلى توفير تجربة تفاعلية أكثر تخصيصًا وكفاءة، من خلال تقنيات مثل RAG والفضاء المتجهي. على الرغم من أن الشركة تدعي أنها تحسن تجربة المستخدم، إلا أن ردود فعل المجتمع متباينة، حيث أبلغ بعض المستخدمين عن عدم استقرار الوظيفة أو وجود أخطاء (المصدر: WeChat, 量子位)
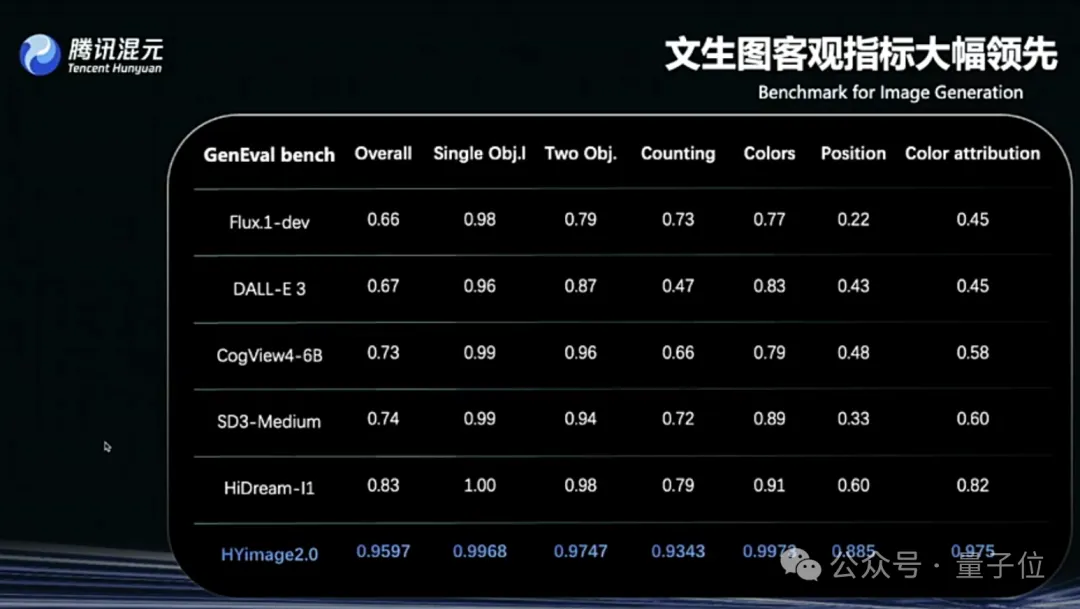
Tencent Hunyuan Image 2.0 يُطلق، ويدعم “الرسم أثناء التحدث” في الوقت الفعلي: أطلقت Tencent Hunyuan نموذج Hunyuan Image 2.0، الذي يحقق وظيفة تحويل النص إلى صورة في الوقت الفعلي باستجابة بالمللي ثانية. عندما يُدخل المستخدم نصًا أو وصفًا صوتيًا، يتم إنشاء الصورة وتعديلها في الوقت الفعلي. يدعم النموذج الجديد أيضًا لوحة رسم في الوقت الفعلي، حيث يمكن للمستخدم رسم مخططات يدوية مع وصف نصي لإنشاء صور. حقق النموذج تحسينات كبيرة في الواقعية، والالتزام الدلالي (يتكيف مع نماذج اللغة الكبيرة متعددة الوسائط كمشفرات نصية)، ومعدل ضغط مشفرات الصور، وتم تحسينه من خلال التعلم المعزز بعد التدريب (المصدر: 量子位)
TII تطلق سلسلة نماذج Falcon-Edge BitNet ومكتبة الضبط الدقيق onebitllms: أطلقت TII سلسلة Falcon-Edge، وهي سلسلة من نماذج اللغة المدمجة بمعلمات 1B و 3B، بأحجام 600 ميجابايت و 900 ميجابايت على التوالي. تستخدم هذه النماذج بنية BitNet، ويمكنها استعادة دقة bfloat16 دون فقدان يذكر في الأداء. تُظهر النتائج الأولية أن أداءها يتفوق على النماذج الصغيرة الأخرى، ويعادل Qwen3-1.7B، ولكن بصمة الذاكرة الخاصة بها تبلغ ربع حجمها فقط. تم أيضًا إطلاق مكتبة onebitllms المخصصة للضبط الدقيق لنماذج BitNet (المصدر: Reddit r/LocalLLaMA, winglian)

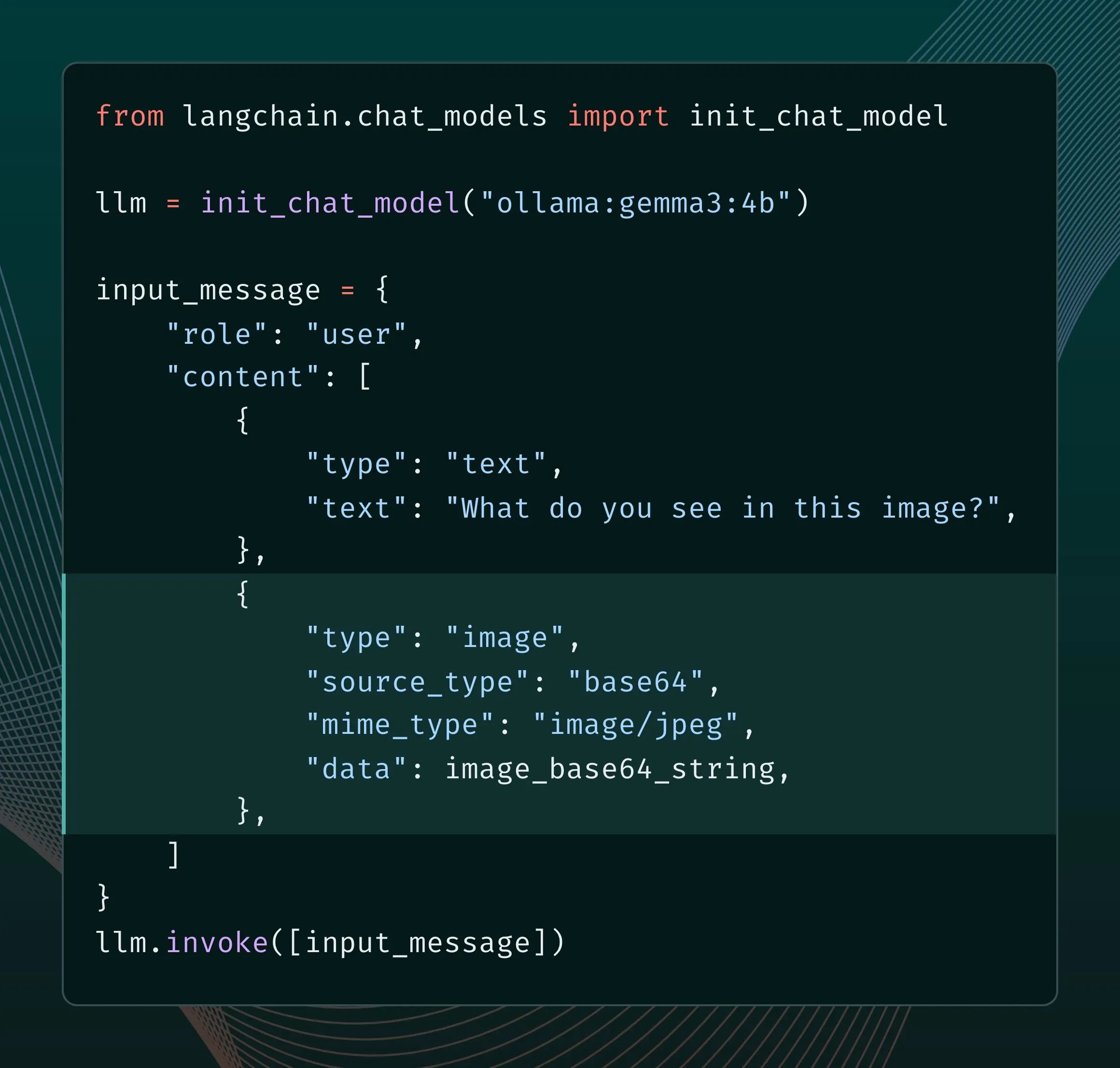
محرك Ollama الجديد يعزز دعم الوسائط المتعددة: قامت Ollama بتحديث محركها لتوفير دعم أصلي للنماذج متعددة الوسائط، مما يسمح بتحسينات خاصة بالنماذج وتحسين إدارة الذاكرة. يمكن للمستخدمين تجربة نماذج متعددة الوسائط مثل Llama 4 و Gemma 3 من خلال تكامل LangChain. أصدر مطورو Google AI أيضًا دليلًا لاستخدام Ollama و Gemma 3 لاستدعاء الدوال، لتحقيق وظائف مثل البحث في الوقت الفعلي (المصدر: LangChainAI, ollama)
Grok يضيف ميزة التحكم في نسبة العرض إلى الارتفاع لتوليد الصور: يسمح نموذج Grok من xAI الآن للمستخدمين بتحديد نسبة العرض إلى الارتفاع المطلوبة عند إنشاء الصور، مما يوفر مرونة وتحكمًا أكبر في إنشاء الصور (المصدر: grok)
تحديثات Google AI Studio، تتضمن صفحة وسائط مُنشأة جديدة ولوحة معلومات للاستخدام: أجرت منصة ai.studio من Google سلسلة من التحديثات، بما في ذلك تصميم جديد لصفحة الهبوط، ولوحة معلومات مدمجة للاستخدام، وصفحة وسائط مُنشأة (gen media) جديدة، مما ينبئ بإمكانية وجود المزيد من الإصدارات ذات الصلة في مؤتمر I/O القادم (المصدر: matvelloso)
LatitudeGames تطلق نموذجًا جديدًا Harbinger-24B (New Wayfarer): أطلقت LatitudeGames نموذجًا جديدًا باسم Harbinger-24B على Hugging Face، يحمل الاسم الرمزي New Wayfarer. أبدى المجتمع اهتمامًا بهذا الأمر، وناقش سبب عدم اختيار ضبط دقيق لنماذج أخرى مثل Qwen3 32B أو Llama 4 Scout (المصدر: Reddit r/LocalLLaMA)

🧰 أدوات
Adopt AI تحصل على تمويل بقيمة 6 ملايين دولار، بهدف إعادة بناء تفاعل البرمجيات من خلال وكلاء الذكاء الاصطناعي: حصلت الشركة الناشئة Adopt AI على تمويل أولي بقيمة 6 ملايين دولار، وهي ملتزمة بتمكين برامج المؤسسات التقليدية من دمج قدرات التفاعل باللغة الطبيعية بسرعة وبطريقة بدون كود، من خلال وظيفتين رئيسيتين هما Agent Builder و Agent Experience. يمكن لتقنيتها تعلم بنية التطبيق وواجهات برمجة التطبيقات (API) تلقائيًا، وإنشاء عمليات يمكن استدعاؤها باللغة الطبيعية، وضمان أمان البيانات من خلال بنية Pass-through، بهدف زيادة معدل اعتماد البرامج وكفاءتها، وتقليل تكاليف المؤسسات (المصدر: WeChat)

محرك Volcengine من ByteDance يطلق عرضًا توضيحيًا لجهاز ذكاء اصطناعي مصغر، يدعم تخصيصًا عاليًا (DIY): أطلق محرك Volcengine عرضًا توضيحيًا لجهاز ذكاء اصطناعي مصغر، وقام بفتح مصدر كود العميل/الخادم الخاص به. يدعم هذا الجهاز تخصيصًا حرًا بدرجة عالية، ويمكنه التكامل مع نماذج Volcengine الكبيرة، ووكلاء Coze الأذكياء، بالإضافة إلى نماذج كبيرة من جهات خارجية متوافقة مع OpenAI API (مثل FastGPT) ومجموعة متنوعة من أصوات TTS (بما في ذلك MiniMax). يمكن للمستخدمين تخصيص (DIY) تطبيقات مثل الحوار مع شخصيات معينة (مثل الشاب Jay Chou، He Jiong)، أو إنشاء خدمة عملاء صوتية تعمل بالذكاء الاصطناعي، مما يوفر تجارب تفاعلية غنية بالذكاء الاصطناعي (المصدر: WeChat)

Runway تطلق Gen-4 References API، لتمكين المطورين من بناء تطبيقات توليد الصور: تتيح Runway نموذجها الشهير لتوليد الصور Gen-4 References للمطورين من خلال واجهة برمجة تطبيقات (API). يشتهر هذا النموذج بتعدد استخداماته ومرونته، وقدرته على إنشاء صور جديدة متناسقة الأسلوب بناءً على صور مرجعية. سيسمح إطلاق واجهة برمجة التطبيقات للمطورين بدمج هذه القدرة القوية على توليد الصور في تطبيقاتهم وسير عملهم (المصدر: c_valenzuelab)

Zencoder تطلق منصة وكلاء ذكاء اصطناعي Zen Agents لتحسين الترميز: أطلقت شركة الذكاء الاصطناعي الناشئة Zencoder (اسمها الرسمي For Good AI Inc.) منصة سحابية تسمى Zen Agents، تُستخدم لإنشاء وكلاء ذكاء اصطناعي مُحسَّنين لمهام الترميز، بهدف زيادة كفاءة وجودة تطوير البرمجيات (المصدر: dl_weekly)
llmbasedos: توزيعة Linux مبسطة للغاية تعتمد على MCP، مُحسَّنة خصيصًا لـ LLM المحلي: قام أحد المطورين ببناء llmbasedos، وهي توزيعة مبسطة للغاية تعتمد على Arch Linux، تهدف إلى تحويل البيئة المحلية إلى مواطن من الدرجة الأولى لواجهات LLM الأمامية (مثل Claude Desktop, VS Code). تعرض القدرات المحلية (الملفات، البريد الإلكتروني، الوكلاء، إلخ) من خلال بروتوكول MCP (Model Context Protocol)، وتدعم وضع عدم الاتصال (بما في ذلك llama.cpp) أو الاتصال بنماذج سحابية مثل GPT-4o و Claude، مما يسهل على المطورين إضافة ميزات جديدة بسرعة (المصدر: Reddit r/LocalLLaMA)
ملفات PDF يمكنها تشغيل LLM ونظام Linux تثير الاهتمام: عرض هاوي التكنولوجيا Aiden Bai مشروع “llm.pdf” الذي يقوم بتشغيل نماذج لغوية صغيرة (مثل TinyStories, Pythia, TinyLLM) داخل ملفات PDF، من خلال تجميع النموذج إلى JavaScript والاستفادة من دعم PDF لـ JS. أشار البعض في قسم التعليقات إلى وجود سوابق لتشغيل نظام Linux داخل PDF (من خلال محاكي RISC-V). يكشف هذا عن إمكانات PDF كحاوية محتوى ديناميكي، ولكنه يثير أيضًا نقاشات حول الأمان والتطبيق العملي (المصدر: WeChat)

تحديث أداة OpenAI Codex CLI، يدعم تسجيل الدخول عبر ChatGPT ونموذج mini الجديد: أعلن فريق مطوري OpenAI عن تحسينات في أداة Codex CLI، بما في ذلك دعم تسجيل الدخول عبر حساب ChatGPT للاتصال السريع بمنظمات API، وإضافة نموذج codex-mini الجديد، والذي تم تحسينه خصيصًا لمهام الأسئلة والأجوبة المتعلقة بالكود وتحريره بزمن انتقال منخفض (المصدر: openai, dotey)
جهاز SenseTime المتكامل للنماذج الكبيرة يحصل على توصية IDC، ويدعم نماذج مثل 日日新 و DeepSeek: في تقرير “تحليل سوق أجهزة الذكاء الاصطناعي المتكاملة للنماذج الكبيرة في الصين وتوصيات العلامات التجارية، 2025” الصادر عن IDC، تم اختيار جهاز SenseTime المتكامل للنماذج الكبيرة. يعتمد هذا الجهاز المتكامل على البنية التحتية للذكاء الاصطناعي SenseTime Large Installation، وهو مزود بشرائح حوسبة عالية الأداء ومحرك تسريع الاستدلال، ويدعم نماذج SenseTime “日日新SenseNova V6” ونماذج DeepSeek وغيرها من النماذج الكبيرة السائدة، ويوفر حلولًا مستقلة وقابلة للتحكم بالكامل، ويحسن التكلفة الإجمالية للملكية (TCO)، وقد تم تطبيقه بالفعل في العديد من الصناعات مثل الرعاية الصحية والمالية (المصدر: 量子位)

أداة أتمتة سير العمل مفتوحة المصدر n8n تضيف دعمًا للغة الصينية: تدعم الآن أداة أتمتة سير العمل مفتوحة المصدر الشهيرة n8n واجهة باللغة الصينية من خلال حزمة تعريب ساهم بها المجتمع. يمكن للمستخدمين تنزيل ملفات التعريب الخاصة بالإصدار المقابل، ومن خلال تعديل بسيط في تكوين Docker، يمكنهم استخدام n8n باللغة الصينية، مما يقلل من عائق الاستخدام للمستخدمين المحليين (المصدر: WeChat)

git-bug: متتبع أخطاء موزع يعمل دون اتصال بالإنترنت أولاً ومدمج في Git: git-bug هي أداة مفتوحة المصدر تدمج المشكلات والتعليقات وما إلى ذلك ككائنات في مستودع Git (بدلاً من الملفات العادية)، مما يحقق تتبع أخطاء موزع يعمل دون اتصال بالإنترنت أولاً. يدعم المزامنة مع منصات مثل GitHub و GitLab من خلال جسور، ويوفر واجهات CLI و TUI و Web (المصدر: GitHub Trending)

PyLate يدمج فهرس PLAID، مما يحسن كفاءة اختبار أداء النماذج على مجموعات البيانات الكبيرة: أعلن Antoine Chaffin أن PyLate (وهو نظام بيئي لتدريب واستدلال نماذج ColBERT) قد دمج فهرس PLAID. يمكّن هذا التكامل المستخدمين من اختبار أداء أفضل النماذج بشكل فعال على مجموعات بياناتهم الكبيرة جدًا، مما يوفر وسيلة لتحقيق SOTA على مختلف قوائم ترتيب الاسترجاع (المصدر: lateinteraction, tonywu_71)

Neon: قاعدة بيانات PostgreSQL مفتوحة المصدر بدون خادم: Neon هو بديل مفتوح المصدر لـ PostgreSQL بدون خادم، يفصل التخزين عن الحوسبة لتحقيق التوسع التلقائي، وتفرع قاعدة البيانات كالكود، والتوسع إلى الصفر. يحظى هذا المشروع باهتمام على GitHub، ويوفر خيارًا جديدًا لمطوري الذكاء الاصطناعي والتطبيقات الأخرى الذين يحتاجون إلى حلول قواعد بيانات مرنة وقابلة للتطوير (المصدر: GitHub Trending)

Unmute.sh: أداة دردشة صوتية جديدة تعمل بالذكاء الاصطناعي مع موجهات وأصوات قابلة للتخصيص: Unmute.sh هي أداة دردشة صوتية جديدة تعمل بالذكاء الاصطناعي، تتميز بالسماح للمستخدمين بتخصيص الموجهات (prompt) واختيار أصوات مختلفة، مما يوفر للمستخدمين تجربة تفاعل صوتي أكثر تخصيصًا ومرونة (المصدر: Reddit r/artificial)
📚 تعلم
إطلاق أول إطار عالمي لتقييم النماذج الشاملة متعددة الوسائط General-Level ومعيار General-Bench: قدمت دراسة تم قبولها في ICML‘25 (Spotlight) إطارًا جديدًا لتقييم النماذج الكبيرة متعددة الوسائط (MLLM) يسمى General-Level ومجموعة بيانات مصاحبة General-Bench. يقدم هذا الإطار نظام تصنيف من خمسة مستويات، ويركز بشكل أساسي على “تأثير التعميم التآزري” (Synergy) للنموذج، أي قدرة المعرفة على الانتقال والتحسين بين الوسائط أو المهام المختلفة. يعد General-Bench حاليًا أكبر وأشمل معيار لتقييم MLLM، حيث يحتوي على أكثر من 700 مهمة وأكثر من 320,000 بيانات اختبار، ويغطي خمس وسائط رئيسية هي الصور والفيديو والصوت و 3D واللغة، و 29 مجالًا. تُظهر قائمة الترتيب أن نماذج مثل GPT-4V تصل حاليًا فقط إلى المستوى 2 (بدون تآزر)، ولا يوجد نموذج حتى الآن يصل إلى المستوى 5 (تآزر كامل متعدد الوسائط) (المصدر: WeChat)

ورقة بحثية J1 تقترح تحفيز LLM-as-a-Judge على التفكير من خلال التعلم المعزز: تستكشف ورقة بحثية جديدة بعنوان “J1: Incentivizing Thinking in LLM-as-a-Judge via RL” (arxiv:2505.10320) كيفية استخدام التعلم المعزز (RL) لتحفيز نماذج اللغة الكبيرة التي تعمل كمقيمين (LLM-as-a-Judge) على “التفكير” بشكل أعمق، بدلاً من مجرد إعطاء أحكام سطحية. قد تعمل هذه الطريقة على تحسين دقة وموثوقية LLM في تقييم المهام المعقدة (المصدر: jaseweston)

إطار عمل جديد TREQA يستخدم LLM لتقييم جودة ترجمة النصوص المعقدة: لمواجهة أوجه القصور في مقاييس الترجمة الآلية (MT) الحالية في تقييم النصوص المعقدة، اقترح الباحثون إطار عمل TREQA. يقوم هذا الإطار بتقييم ما إذا كانت الترجمة تحتفظ بالمعلومات الأساسية عن طريق استخدام نماذج اللغة الكبيرة (LLM) لإنشاء أسئلة حول النص المصدر والنص المترجم، ومقارنة الإجابات على هذه الأسئلة. تهدف هذه الطريقة إلى قياس جودة ترجمة النصوص الطويلة بشكل أكثر شمولاً (المصدر: gneubig)

دراسة تكتشف طريقة فعالة لحساب حاصل ضرب المصفوفة في منقولها: اكتشف Dmitry Rybin وآخرون خوارزمية أسرع لحساب حاصل ضرب المصفوفة في منقولها (arxiv:2505.09814). لهذا الاختراق الأساسي تأثير عميق على مجالات متعددة مثل تحليل البيانات، وتصميم الرقائق، والاتصالات اللاسلكية، وتدريب LLM، لأن هذا النوع من الحسابات شائع في هذه المجالات. وهذا يثبت مرة أخرى أنه حتى في مجال الجبر الخطي الحسابي الناضج، لا يزال هناك مجال للتحسين (المصدر: teortaxesTex, Ar_Douillard)

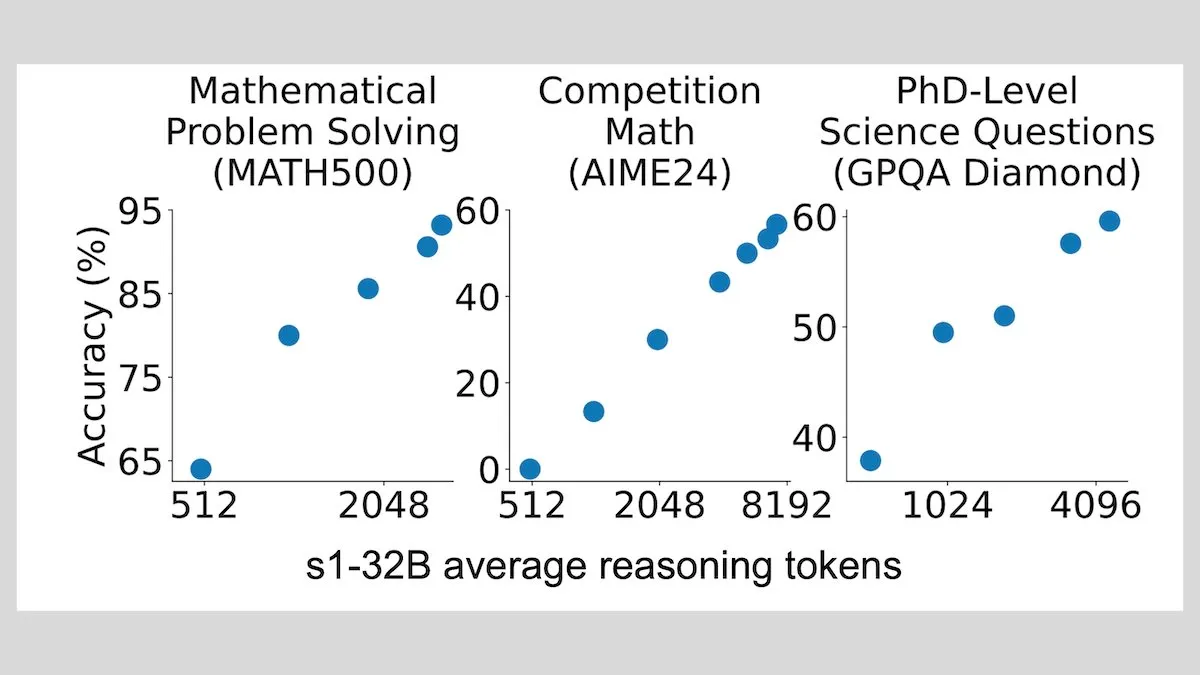
DeepLearningAI: الضبط الدقيق بكمية صغيرة من العينات يمكن أن يحسن بشكل كبير قدرة LLM على الاستدلال: أظهرت الأبحاث أن الضبط الدقيق لنماذج اللغة الكبيرة باستخدام 1000 عينة فقط يمكن أن يحسن بشكل كبير قدرتها على الاستدلال. قام نموذجهم التجريبي s1 بتوسيع عملية الاستدلال عن طريق إلحاق كلمة “Wait” أثناء الاستدلال، وحقق أداءً جيدًا في اختبارات الأداء القياسية مثل AIME و MATH 500. تشير هذه الطريقة منخفضة الموارد إلى أنه يمكن تعليم الاستدلال المتقدم بكمية صغيرة من البيانات دون الحاجة إلى التعلم المعزز (المصدر: DeepLearningAI)
Hugging Face تطلق دورة MCP مجانية، للمساعدة في بناء تطبيقات ذكاء اصطناعي غنية السياق: أطلقت Hugging Face بالتعاون مع Anthropic دورة مجانية بعنوان “MCP: Build Rich-Context AI Apps with Anthropic”. تهدف الدورة إلى مساعدة المطورين على فهم بنية MCP (Model Context Protocol)، وتعلم كيفية بناء ونشر خوادم MCP والتطبيقات المتوافقة، وبالتالي تبسيط تكامل تطبيقات الذكاء الاصطناعي مع الأدوات ومصادر البيانات. سجل أكثر من 3000 طالب حتى الآن (المصدر: DeepLearningAI, huggingface, ClementDelangue)
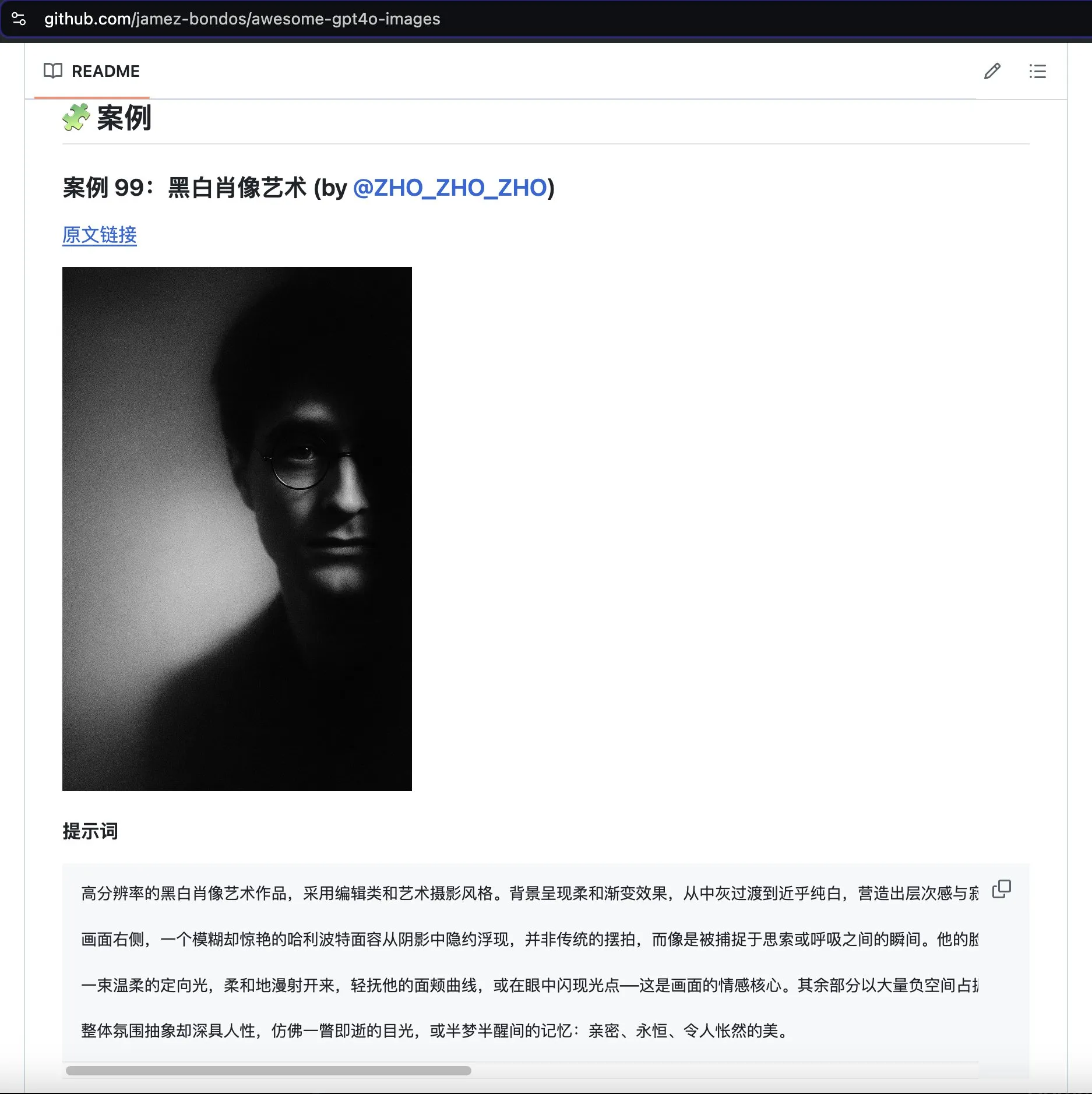
مشروع awesome-gpt4o-images يجمع حالات استخدام رائعة لتوليد الصور بواسطة GPT-4o: حصل مشروع GitHub awesome-gpt4o-images الذي أنشأه Jamez Bondos على أكثر من 5700 نجمة في غضون 33 يومًا. يجمع هذا المشروع ويعرض حالات استخدام ممتازة للصور التي تم إنشاؤها باستخدام GPT-4o والموجهات المستخدمة، ويحتوي حاليًا على ما يقرب من مائة حالة استخدام، ويخطط لمواصلة التحديث بعد التنظيم والتحقق، مما يوفر لمجتمع AIGC موردًا إبداعيًا قيمًا (المصدر: dotey)
Yann LeCun يشارك عرضًا تقديميًا حول التعلم الذاتي تحت الإشراف (SSL): شارك Yann LeCun محتوى عرضه التقديمي حول التعلم الذاتي تحت الإشراف (SSL). يعد SSL نموذجًا مهمًا للتعلم الآلي، يهدف إلى تمكين النماذج من تعلم تمثيلات فعالة من البيانات غير المصنفة، وهو ذو أهمية كبيرة لتقليل الاعتماد على البيانات المصنفة على نطاق واسع وتحسين قدرة النماذج على التعميم (المصدر: ylecun)
منتدى أبحاث Hugging Face يصبح موردًا ممتازًا لاختيار أبحاث الذكاء الاصطناعي: يوصي Dwarkesh Patel بمنتدى أبحاث Hugging Face، معتبرًا إياه موردًا ممتازًا لاختيار أفضل أبحاث الذكاء الاصطناعي من الشهر الماضي. توفر هذه المنصة للباحثين قناة مريحة لاكتشاف ومناقشة أحدث التطورات البحثية في مجال الذكاء الاصطناعي (المصدر: dwarkesh_sp, huggingface)
إعلان نتائج قبول ACL 2025، واختيار عدة أوراق بحثية لفريق AIB الدولي في Alibaba: أعلن مؤتمر معالجة اللغة الطبيعية المرموق ACL 2025 عن نتائج القبول، حيث سجل عدد الطلبات هذا العام رقمًا قياسيًا جديدًا، وكانت المنافسة شديدة. تم قبول عدة أوراق بحثية لفريق AI Business الدولي في Alibaba، وحظيت بعض النتائج مثل Marco-o1 V2 و Marco-Bench-IF و HD-NDEs (المعادلات التفاضلية العصبية لاكتشاف الهلوسة) بتقييم عالٍ وتم قبولها كأوراق بحثية رئيسية في المؤتمر. يعكس هذا الاستثمار المستمر لـ Alibaba International في مجال الذكاء الاصطناعي وتنمية المواهب التي بدأت تؤتي ثمارها (المصدر: 量子位)

dstack تنشر دليل إعداد الاتصال البيني السريع للتدريب الموزع: توفر dstack للمستخدمين الذين يقومون بالتدريب الموزع على مجموعات NVIDIA أو AMD دليلًا موجزًا حول كيفية إعداد اتصال بيني سريع من خلال dstack. يهدف هذا الدليل إلى مساعدة المستخدمين على تحسين أداء الشبكة عند توسيع نطاق أعباء عمل الذكاء الاصطناعي في السحابة أو محليًا (المصدر: algo_diver)
AssemblyAI تشارك 10 مقاطع فيديو لتحسين مهارات توجيه LLM: تشارك AssemblyAI من خلال مقاطع فيديو على YouTube 10 نصائح لتحسين فعالية توجيه نماذج اللغة الكبيرة (LLM)، بهدف مساعدة المستخدمين على التفاعل بشكل أكثر فعالية مع LLM للحصول على المخرجات المرجوة (المصدر: AssemblyAI)
مجموعة موارد تعلم LangGraph.js “awesome-langgraphjs” تحظى بالاهتمام: أنشأ Brace ويحافظ على مستودع GitHub يسمى “awesome-langgraphjs”، يجمع المشاريع مفتوحة المصدر ودروس الفيديو على YouTube التي تم إنشاؤها باستخدام LangGraph.js. يوفر هذا المورد وسيلة مريحة للمطورين الذين يرغبون في تعلم واستخدام LangGraph.js لبناء أنواع مختلفة من التطبيقات، من أنظمة الوكلاء المتعددين إلى تطبيقات الدردشة كاملة المكدس (المصدر: LangChainAI)
💼 أعمال
تحول استراتيجية الذكاء الاصطناعي في Alibaba يُظهر نتائج، ونمو كبير في إيرادات الأعمال السحابية ومنتجات الذكاء الاصطناعي: أظهرت النتائج المالية لشركة Alibaba للربع الرابع من عام 2025 أنه بعد استبعاد بعض الأعمال المحددة، ارتفع إجمالي الإيرادات بنسبة 10% على أساس سنوي، وزادت إيرادات الأعمال السحابية الذكية بنسبة 18%، حيث حافظت إيرادات المنتجات المتعلقة بالذكاء الاصطناعي على نمو ثلاثي الأرقام لمدة 7 أرباع متتالية. تعتبر Alibaba الذكاء الاصطناعي استراتيجية أساسية، وتخطط لاستثمار أكثر من 380 مليار يوان في السنوات الثلاث المقبلة لترقية البنية التحتية للحوسبة السحابية والذكاء الاصطناعي. تصدر نموذجها مفتوح المصدر Tongyi Qianwen Qwen-3 العديد من القوائم العالمية، وتجاوز عدد النماذج المشتقة منه 100,000 نموذج، مما يدل على قوتها التقنية وحيوية نظامها البيئي مفتوح المصدر. تعمل Alibaba على تسريع تطبيق الذكاء الاصطناعي في صناعات مثل السيارات والاتصالات والمالية (المصدر: 36氪)
تطبيق تحرير الفيديو Mojo يتم الاستحواذ عليه من قبل Dailymotion: تم الاستحواذ على تطبيق تحرير الفيديو Mojo (@mojo_video_app) من قبل Dailymotion. سيتم دمج تقنية تحرير الفيديو الخاصة بـ Mojo في تطبيق Dailymotion الاجتماعي ومنتجات B2B، ويهدف الطرفان إلى بناء منصة الفيديو الاجتماعية الأوروبية من الجيل التالي بشكل مشترك (المصدر: ClementDelangue)
Cohere تستحوذ على Ottogrid، لتعزيز قدرات الذكاء الاصطناعي للمؤسسات: أعلنت شركة الذكاء الاصطناعي Cohere عن استحواذها على الشركة الناشئة Ottogrid. من المتوقع أن يعزز هذا الاستحواذ قدرات Cohere في حلول الذكاء الاصطناعي على مستوى المؤسسات، ولكن لم يتم الكشف عن تفاصيل الصفقة المحددة أو التوجه التقني لـ Ottogrid بالتفصيل (المصدر: aidangomez, nickfrosst)

🌟 مجتمع
وكلاء الذكاء الاصطناعي يثيرون نقاشًا حول تغيير طرق العمل، والمستقبل قد يشبه ألعاب الاستراتيجية في الوقت الحقيقي: اقترح Will Depue أن العمل في المستقبل قد يتطور ليصبح مشابهًا لألعاب مثل StarCraft أو Age of Empires، حيث يقود البشر حوالي 200 وكيل ذكاء اصطناعي صغير لمعالجة المهام، وجمع المعلومات، وتصميم الأنظمة، وما إلى ذلك. أعاد Sam Altman نشر التغريدة موافقًا. بينما وصف Fabian Stelzer ذلك مازحًا بأنه “ترميز بأسلوب Zerg rush”. تعكس وجهة النظر هذه تصورات المجتمع ومناقشاته حول كيفية إعادة تشكيل وكلاء الذكاء الاصطناعي لسير العمل وأنماط التعاون بين الإنسان والآلة (المصدر: willdepue, sama, fabianstelzer)
ردود روبوت Grok من xAI تثير الجدل، واتهامات بتعديل غير مصرح به للموجهات: اعترفت xAI بأن موجهات روبوت الاستجابة Grok الخاص بها على منصة X قد تم تعديلها بشكل غير مصرح به في الساعات الأولى من يوم 14 مايو، مما أدى إلى ظهور تحليلاته لبعض الأحداث (مثل الأحداث المتعلقة بترامب) بشكل غير طبيعي أو غير متوافق مع المعلومات السائدة. حظي هذا الأمر باهتمام كبير من المجتمع، ودعا Clement Delangue وآخرون إلى فتح مصدر Grok لزيادة الشفافية. حاول مستخدمون مثل Colin Fraser إجراء هندسة عكسية لتاريخ تعديل موجهات النظام الخاصة به من خلال مقارنة ردود Grok في أوقات مختلفة (المصدر: ClementDelangue, menhguin, colin_fraser)

أنباء عن استقالة عدد كبير من فريق Meta Llama4، مما يثير مخاوف المجتمع بشأن مستقبل الذكاء الاصطناعي مفتوح المصدر: تشير أخبار المجتمع إلى أن حوالي 80% من أعضاء فريق Llama4 في Meta (استقال 11 شخصًا من فريق مكون من 14 شخصًا) قد استقالوا، وأن إطلاق نموذجهم الرائد Behemoth قد تأجل. أثار هذا الأمر اهتمامًا واسعًا، وأعرب خبراء الصناعة مثل Nat Lambert عن أسفهم لذلك. علق Scaling01 بأن Meta قد تحتاج إلى مدير تسويق جديد لـ Llama. بينما أعرب مستخدمون مثل TeortaxesTex عن قلقهم من أن هذا قد يكون له تأثير سلبي على تطوير الذكاء الاصطناعي مفتوح المصدر، بل وناقشوا ما إذا كانت الصين ستصبح الأمل الأخير للمصدر المفتوح (المصدر: teortaxesTex, Dorialexander, scaling01)

استخدام الذكاء الاصطناعي في الحرب والقضايا الأخلاقية يثير الاهتمام: ناقش مجتمع Reddit استخدام الذكاء الاصطناعي في الحرب، مشيرًا إلى أنه يُستخدم بالفعل للمراقبة وتحديد مواقع المقاتلين، من خلال تحليل المعلومات لتقديم معلومات استخباراتية عسكرية. أشارت المناقشة إلى أن الجيش الأمريكي يستخدم أدوات ذكاء اصطناعي مثل DART منذ عام 1991. يخشى المستخدمون من المخاطر المميتة المحتملة لتسليح الذكاء الاصطناعي والتهديدات المحتملة للبشرية، ويهتمون بوضع المعاهدات والتدابير الدولية ذات الصلة. كما أزالت إرشادات استخدام OpenAI البنود التي تحظر الاستخدامات العسكرية، مما أثار مزيدًا من التفكير (المصدر: Reddit r/ArtificialInteligence)
أداء نماذج اللغة الكبيرة ضعيف في مسابقة البرمجة CCPC، مما يكشف عن القيود الحالية: في نهائيات مسابقة تصميم البرامج للطلاب الجامعيين الصينيين (CCPC) العاشرة، كان أداء العديد من نماذج اللغة الكبيرة المعروفة مثل Seed-Thinking من ByteDance (بما في ذلك o3/o4, Gemini 2.5 pro, DeepSeek R1) ضعيفًا، حيث حل معظمها فقط مسألة تسجيل الحضور (مسألة سهلة) أو حصل على صفر. أوضح المسؤولون أن النماذج حاولت بشكل مستقل تمامًا، دون تدخل بشري. يرى تحليل المجتمع أن هذا يكشف عن أوجه القصور الحالية للنماذج الكبيرة في حل المشكلات الخوارزمية شديدة الابتكار والتعقيد، خاصة في وضع غير وكيل (أي بدون مساعدة أدوات للتنفيذ والتصحيح). يتناقض هذا مع أداء OpenAI o3 في مسابقة IOI حيث حصل على الميدالية الذهبية من خلال التدريب الوكيل (المصدر: WeChat)

إطار عمل DSPy و “الدروس المريرة” يثيران نقاشًا، مع التأكيد على التصميم الموحد والموجهات الآلية: تؤكد المناقشات المتعلقة بـ DSPy أنه على الرغم من أن التوسع في الذكاء الاصطناعي (Scaling) يمكن أن يتجاوز العديد من الصعوبات الهندسية (“الدروس المريرة”)، إلا أنه لا يمكن أن يحل محل التصميم الدقيق للمواصفات الأساسية للمشكلة (المتطلبات وتدفق المعلومات). ومع ذلك، يمكن للتوسع أن يرفع مستوى التجريد في تعريف المشكلات. تُعتبر الموجهات الآلية (مثل مُحسِّنات الموجهات) وسيلة للاستفادة من القدرة الحاسوبية بما يتماشى مع “الدروس المريرة”، بينما قد تتعارض الموجهات اليدوية مع ذلك، لأنها تضخ الحدس البشري بدلاً من السماح للنموذج بالتعلم (المصدر: lateinteraction, lateinteraction)
التكلفة الحاسوبية لفحص الذات/استكشاف الأدوات بواسطة وكلاء الذكاء الاصطناعي أثناء الاستدلال تحظى بالاهتمام: تساءل Paul Calcraft عن ممارسة تخصيص موارد حاسوبية كبيرة (مثل أكثر من 200 دولار لحل مشكلة واحدة) في مرحلة الاستدلال لوكلاء الذكاء الاصطناعي لإجراء فحص ذاتي نشط، واستخدام الأدوات، وسير العمل الاستكشافي. وأشار إلى أن أمثال Devin ومنافسيه قد يفعلون ذلك لعروض العلاقات العامة، ولكن الأمر غير واضح بالنسبة للسيناريوهات التي تبحث عن حلول جديدة (مشابهة لـ FunSearch ولكن بقيود أقل) (المصدر: paul_cal)
“البرمجة بالحدس” (Vibe Coding) بمساعدة الذكاء الاصطناعي تثير نقاشًا: أدوات مثل GitHub Copilot جعلت “البرمجة بالحدس” (Vibe Coding، التي تشير إلى طريقة برمجة تعتمد بشكل أكبر على الحدس ومساعدة الذكاء الاصطناعي بدلاً من التخطيط الصارم) ممكنة، حتى أن طالبًا يبلغ من العمر 16 عامًا استخدم Copilot لإكمال مشروع مدرسي. تباينت آراء المجتمع حول هذه الظاهرة، حيث اعتبرها البعض نموذجًا جديدًا للبرمجة، بينما أكد آخرون على أهمية الأساسيات والمواصفات (المصدر: Reddit r/ArtificialInteligence, nrehiew_)
مكتبة Hugging Face Transformers تطلق لوحة مجتمع جديدة: فتحت Hugging Face لوحة مجتمع جديدة لمكتبتها الأساسية Transformers، لنشر الإعلانات، وتقديم الميزات الجديدة، وتحديثات خارطة الطريق، وترحب بأسئلة المستخدمين ومناقشاتهم حول استخدام المكتبة أو مشكلات النماذج، بهدف تعزيز التفاعل والدعم مع المطورين (المصدر: TheZachMueller, ClementDelangue)
مطورو الذكاء الاصطناعي يدعون المؤتمرات الكبرى إلى إضافة مسار أبحاث “Findings”: نظرًا للزيادة الهائلة في عدد الطلبات المقدمة إلى مؤتمرات الذكاء الاصطناعي الكبرى مثل NeurIPS (حيث وصل عدد الطلبات في NeurIPS إلى 25000)، دعا Dan Roy وآخرون إلى الاقتداء بمؤتمرات مثل ACL وإنشاء مسار أبحاث من نوع “Findings”. يهدف هذا إلى توفير فرصة لنشر الأبحاث التي، على الرغم من عدم استيفائها لمعايير المؤتمر الرئيسي، لا تزال ذات قيمة، وتخفيف الضغط على المراجعين، وتعزيز التبادل الأكاديمي على نطاق أوسع. تشمل المقترحات مراجعة خفيفة الوزن، والتركيز على تحسين وضوح الأوراق البحثية، وما إلى ذلك (المصدر: AndrewLampinen)
💡 أخرى
هيكل خارجي مدفوع بالذكاء الاصطناعي يساعد مستخدمي الكراسي المتحركة على الوقوف والمشي: عرض جهاز هيكل خارجي مدفوع بالذكاء الاصطناعي قدرته على مساعدة مستخدمي الكراسي المتحركة على الوقوف والمشي مرة أخرى. تدمج هذه التقنية تكنولوجيا الروبوتات وأجهزة الاستشعار وخوارزميات الذكاء الاصطناعي، من خلال استشعار نية المستخدم وتوفير المساعدة الحركية، مما يوفر الأمل في إعادة التأهيل وتحسين نوعية الحياة للأشخاص ذوي الإعاقة الحركية (المصدر: Ronald_vanLoon)
استخدام الذكاء الاصطناعي لتصور إبداعات أسماء المستخدمين: ظهرت موجة صغيرة في مجتمعي Reddit و X، حيث قام المستخدمون باستخدام أدوات توليد الصور بالذكاء الاصطناعي (مثل DALL-E 3 المدمج في ChatGPT) لإنشاء صور مفاهيمية بناءً على أسماء المستخدمين الخاصة بهم على وسائل التواصل الاجتماعي، ومشاركة هذه الأعمال المليئة بالخيال، مما يوضح التطبيقات الممتعة للذكاء الاصطناعي في التعبير الإبداعي المخصص (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT)

إعلانات أمازون تستخدم الذكاء الاصطناعي لزيادة كفاءة تسويق العلامات التجارية عالميًا: أطلقت إعلانات أمازون مفهوم “مختبر الشاشة العالمية”، لعرض كيفية استخدامها لتقنية الذكاء الاصطناعي لتمكين العلامات التجارية الصينية من التوسع عالميًا. من خلال توسيع نطاق وصول العلامة التجارية عبر مصفوفة وسائط مثل Prime Video، واستخدام استوديوهات الذكاء الاصطناعي الإبداعية (مثل أدوات إنشاء الفيديو) لتقليل عائق إنتاج المحتوى، ومن خلال أدوات مثل Amazon DSP و Performance+ لتحسين عرض الإعلانات والتحويلات. يلعب الذكاء الاصطناعي دورًا شاملاً من توليد الأفكار إلى قياس النتائج، بهدف مساعدة أصحاب العلامات التجارية، وخاصة الشركات الصغيرة والمتوسطة، على بناء علامات تجارية عالمية بشكل أكثر كفاءة (المصدر: 36氪)
