
كلمات مفتاحية:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, تنظيم الذكاء الاصطناعي, Seed1.5-VL, وكلاء الترميز المدعومون من Gemini, تحسين خوارزمية ضرب المصفوفات, تحسين كفاءة مراكز البيانات, نماذج متعددة اللغات والوسائط, شبكة تدريب الذكاء الاصطناعي اللامركزية
🔥 الأضواء
Google DeepMind تطلق AlphaEvolve: وكيل ترميز يعمل بواسطة Gemini يُحدث ثورة في اكتشاف الخوارزميات: أطلقت Google DeepMind وكيل AlphaEvolve، وهو وكيل ترميز يعمل بالذكاء الاصطناعي (AI) ومدعوم من Gemini، يهدف إلى اكتشاف وتحسين الخوارزميات المعقدة من خلال الجمع بين إبداع نماذج اللغة الكبيرة (LLM) والمقيِّمات الآلية. نجح AlphaEvolve في تصميم خوارزميات أسرع لضرب المصفوفات، وحل مسائل رياضية مفتوحة مثل مشكلة Erdős minimal overlap problem ومشكلة kissing number problem، ويُستخدم داخليًا في Google لتحسين كفاءة مراكز البيانات (بمتوسط استرداد 0.7% من موارد الحوسبة)، وتصميم الرقائق، وتسريع تدريب Gemini نفسه، مما يُظهر الإمكانات الهائلة للذكاء الاصطناعي في الاكتشاف العلمي والتحسين الهندسي. (المصدر: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic تستعد لإطلاق نماذج جديدة من Claude Sonnet و Opus، مع تعزيز قدرات الاستدلال واستدعاء الأدوات: وفقًا لـ The Information، تخطط Anthropic لإطلاق إصدارات جديدة من Claude Sonnet و Claude Opus في الأسابيع المقبلة. تتمثل الميزة الأساسية للنماذج الجديدة في قدرتها على التبديل بمرونة بين “وضع التفكير” و “وضع استخدام الأدوات”. عندما تواجه النماذج عقبات في حل المشكلات باستخدام أدوات خارجية (مثل التطبيقات وقواعد البيانات)، يمكنها العودة بشكل استباقي إلى “وضع الاستدلال” للتفكير والتصحيح الذاتي. وفيما يتعلق بتوليد الأكواد، يمكن للنماذج الجديدة اختبار الأكواد التي تم إنشاؤها تلقائيًا، وإذا اكتشفت أخطاء، فإنها تتوقف مؤقتًا وتفكر وتصحح. من المتوقع أن تؤدي هذه الحلقة المغلقة من “التفكير – العمل – التفكير” إلى تحسين قدرة النماذج على حل المشكلات المعقدة وموثوقيتها بشكل كبير. (المصدر: steph_palazzolo, dotey)

نواب جمهوريون أمريكيون يقترحون حظر تنظيم الذكاء الاصطناعي على المستوى الفيدرالي ومستوى الولايات لمدة 10 سنوات، مما يثير نقاشًا حادًا: أضاف نواب جمهوريون أمريكيون بنودًا إلى مشروع قانون تنسيق الميزانية، يقترحون فيها حظرًا على الحكومات الفيدرالية وحكومات الولايات من تنظيم نماذج أو أنظمة الذكاء الاصطناعي أو أنظمة اتخاذ القرار الآلي لمدة عشر سنوات مقبلة، ويخططون لتخصيص 500 مليون دولار لدعم تسويق الذكاء الاصطناعي وتطبيقه في أنظمة تكنولوجيا المعلومات الحكومية الفيدرالية. يعتبر بعض العاملين في مجال التكنولوجيا هذه الخطوة إشارة إيجابية لحماية ابتكارات الذكاء الاصطناعي ومنع القوانين من خنقها، ولكنها أثارت أيضًا مخاوف بشأن المخاطر المحتملة مثل انتشار DeepFake، وفقدان السيطرة على خصوصية البيانات، وأخلاقيات الذكاء الاصطناعي وتأثيره البيئي. إذا تم تمرير هذا الاقتراح، فسيكون له تأثير كبير على التشريعات الحالية والمستقبلية المتعلقة بالذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI تطلق نموذج GPT-4.1 وتفتتح مركز تقييم السلامة، مؤكدة على قدرات الترميز واتباع التعليمات: أعلنت OpenAI أنه بناءً على طلب المستخدمين، أصبح نموذج GPT-4.1 متاحًا في ChatGPT اعتبارًا من اليوم (لمستخدمي Plus و Pro و Team، وستتوفر لاحقًا لإصدارات Enterprise و Education). تم تحسين GPT-4.1 خصيصًا لمهام الترميز واتباع التعليمات، وهو أسرع ويمكن استخدامه كبديل يومي للترميز لـ o3 و o4-mini. وفي الوقت نفسه، سيحل GPT-4.1 mini محل GPT-4o mini المستخدم حاليًا من قبل جميع المستخدمين. بالإضافة إلى ذلك، أطلقت OpenAI مركز تقييم السلامة (Safety Evaluations Hub) لنشر نتائج اختبارات السلامة ومؤشراتها لنماذجها بشكل علني، وسيتم تحديثه بانتظام لزيادة شفافية التواصل بشأن السلامة. (المصدر: openai, michpokrass)
Meta FAIR تعلن عن عدة إنجازات بحثية في مجال الذكاء الاصطناعي، مع التركيز على اكتشاف الجزيئات ونمذجة الذرات: أعلنت Meta AI (FAIR) عن أحدث إصداراتها مفتوحة المصدر في مجالات التنبؤ بخصائص الجزيئات، ومعالجة اللغة، وعلم الأعصاب. وتشمل هذه Open Molecules 2025 (OMol25)، وهي مجموعة بيانات لاكتشاف الجزيئات لمحاكاة الأنظمة الذرية الكبيرة؛ و Universal Model for Atoms (UMA)، وهو نموذج جهد بين ذري يعتمد على التعلم الآلي ويمكن تطبيقه على نطاق واسع لنمذجة التفاعلات الذرية في المواد والجزيئات؛ و Adjoint Sampling، وهي خوارزمية قابلة للتطوير لتدريب النماذج التوليدية بناءً على مكافأة عددية. بالإضافة إلى ذلك، كشف بحث FAIR بالتعاون مع مستشفى مؤسسة روتشيلد عن أوجه تشابه ملحوظة بين البشر ونماذج اللغة الكبيرة (LLM) في تطور اللغة. (المصدر: AIatMeta)
🎯 التطورات
ByteDance تطلق نموذج اللغة المرئي الكبير Seed1.5-VL، بأداء متميز و 20 مليار معلمة نشطة: أطلقت ByteDance نموذجها الكبير متعدد الوسائط للغة والرؤية Seed1.5-VL. أظهر هذا النموذج، الذي يحتوي على 20 مليار معلمة نشطة فقط، أداءً يضاهي Gemini 2.5 Pro، وحقق نتائج SOTA في 38 من أصل 60 معيار تقييم عام. عزز Seed1.5-VL القدرات العامة للفهم والاستدلال متعدد الوسائط، وبرز بشكل خاص في تحديد المواقع المرئية، والاستدلال، وفهم الفيديو، والوكلاء الأذكياء متعددي الوسائط. تم توفير النموذج عبر واجهة برمجة تطبيقات (API) على منصة Volcano Engine، بسعر 0.003 يوان/ألف token للمدخلات، و 0.009 يوان/ألف token للمخرجات. (المصدر: 机器之心)

تقرير تقني يكشف عن Qwen3: دمج وضعي التفكير وعدم التفكير، وتقطير النماذج الكبيرة إلى نماذج أصغر: أصدرت Alibaba تقريرًا تقنيًا لسلسلة نماذج Qwen3، والتي تتضمن 8 نماذج تتراوح معلماتها من 0.6 مليار إلى 235 مليار. يكمن الابتكار الأساسي في وضع العمل المزدوج، حيث يمكن للنموذج التبديل تلقائيًا بين “وضع التفكير” (للاستدلال المعقد) و “وضع عدم التفكير” (للاستجابات السريعة) بناءً على تعقيد المهمة، وذلك من خلال معلمة “ميزانية التفكير” لتخصيص موارد الحوسبة ديناميكيًا. يعتمد التدريب على ثلاث مراحل من التدريب المسبق (المعرفة العامة، تعزيز الاستدلال، النصوص الطويلة) وأربع مراحل من التدريب اللاحق (بدء التشغيل البارد لسلاسل التفكير الطويلة، التعلم المعزز للاستدلال، دمج أوضاع التفكير، التعلم المعزز العام). كما يتم اعتماد استراتيجية تقطير البيانات “الكبير يقود الصغير”، حيث يتم استخدام مخرجات نموذج المعلم (مثل 235B) لتدريب نموذج الطالب (مثل 30B)، لتحقيق نقل المعرفة. (المصدر: 36氪)

Microsoft تطلق سلسلة نماذج Phi-4-reasoning، وتشارك خبراتها في تدريب نماذج الاستدلال: أطلقت Microsoft ثلاثة نماذج: Phi-4-reasoning، و Phi-4-reasoning-plus (كلاهما بمعلمات 14B)، و Phi-4-mini-reasoning (بمعلمات 3.8B)، وكشفت عن طرق تدريبها وخبراتها. تركز هذه النماذج، من خلال الضبط الدقيق للنماذج المدربة مسبقًا، على تعزيز القدرات مثل الاستدلال الرياضي. على سبيل المثال، يُظهر Phi-4-reasoning-plus أداءً متميزًا في المسائل الرياضية من خلال التعلم المعزز، بينما يخضع Phi-4-mini-reasoning لعملية ضبط دقيق مرحلية باستخدام SFT و RL. يشارك التقرير عدم الاستقرار المحتمل الذي قد يظهر في تدريب النماذج الصغيرة واستراتيجيات التعامل معه، بالإضافة إلى اعتبارات اختيار البيانات وتصميم دالة المكافأة في تدريب النماذج الكبيرة باستخدام RL. تم توفير أوزان النماذج على Hugging Face بموجب ترخيص MIT. (المصدر: DeepLearning.AI Blog)
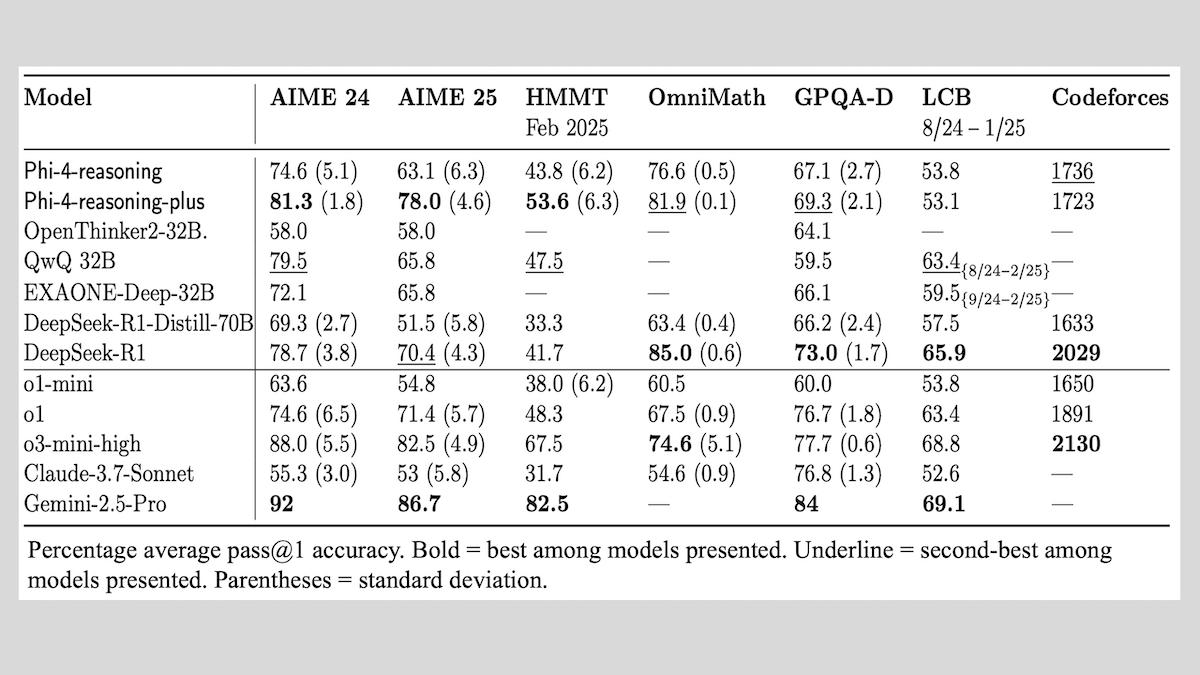
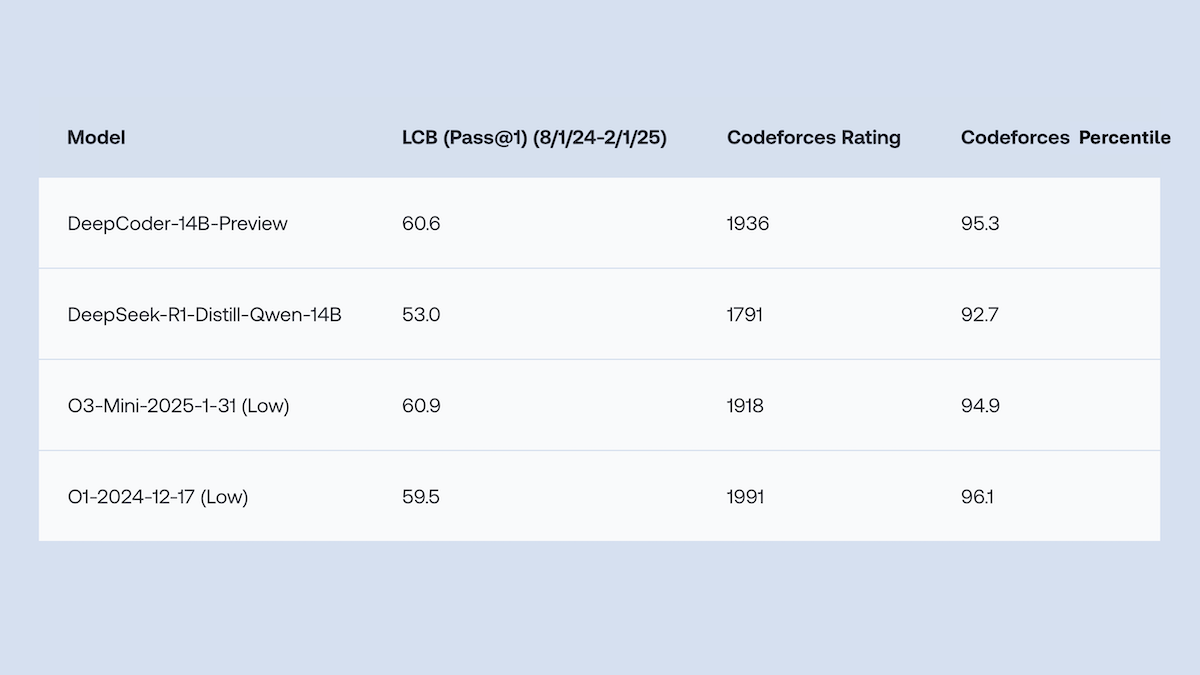
Together.AI و Agentica تطلقان DeepCoder-14B-Preview مفتوح المصدر، بأداء في توليد الأكواد يضاهي o1: أطلق فريقا Together.AI و Agentica نموذج DeepCoder-14B-Preview، وهو نموذج لتوليد الأكواد بمعلمات 14B، يضاهي أداؤه في العديد من معايير الترميز نماذج أكبر مثل DeepSeek-R1 و OpenAI o1. تم تحقيق ذلك من خلال الضبط الدقيق لنموذج DeepSeek-R1-Distilled-Qwen-14B، باستخدام طريقة تعلم معزز مبسطة (تجمع بين تحسينات GRPO و DAPO)، وتحسين قدرة المعالجة المتوازية لمكتبة RL Verl، مما أدى إلى تقصير وقت التدريب بشكل كبير. تم توفير أوزان النموذج والأكواد ومجموعات البيانات وسجلات التدريب مفتوحة المصدر بموجب ترخيص MIT. (المصدر: DeepLearning.AI Blog)
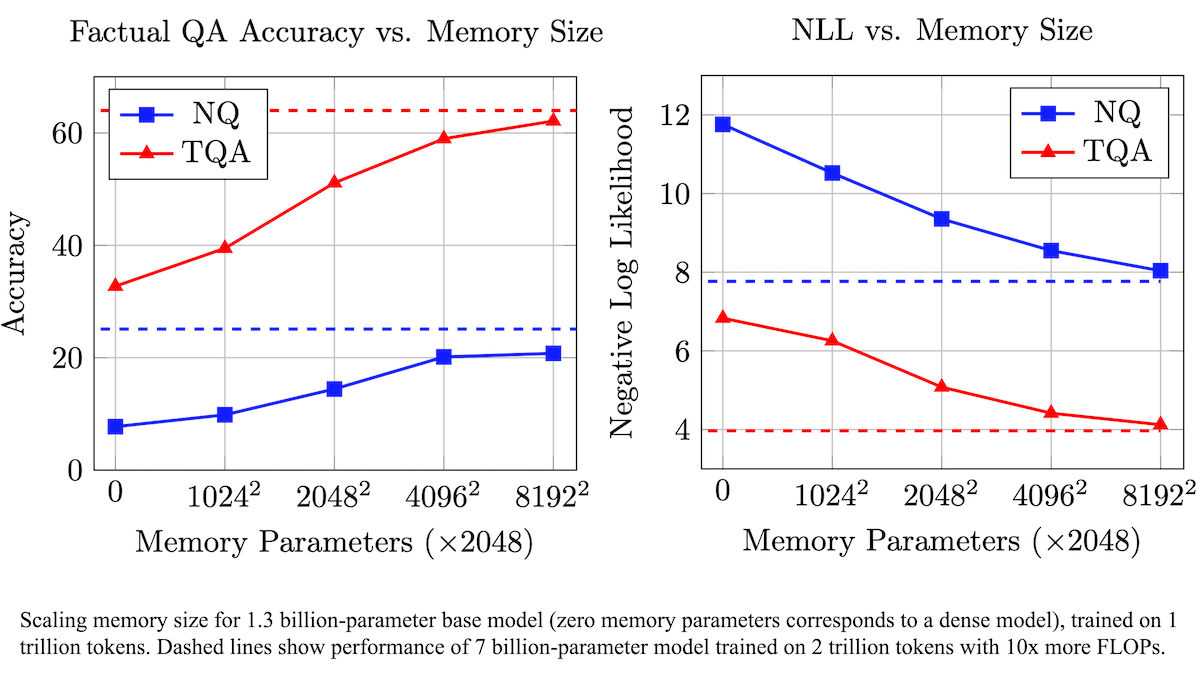
Meta تقترح طبقة ذاكرة قابلة للتدريب لتعزيز دقة الحقائق في نماذج اللغة الكبيرة (LLM) وتقليل متطلبات الحوسبة: قام باحثون في Meta بتحسين دقة نماذج اللغة الكبيرة في استرجاع الحقائق عن طريق إضافة طبقة ذاكرة قابلة للتدريب إلى بنية Transformer، دون زيادة كبيرة في حجم الحوسبة. تعتمد هذه الطريقة على تعلم المفاتيح والقيم المقابلة لتخزين المعلومات، وتستخدم استراتيجية تقسيم المفاتيح إلى نصفين، مما يحل بشكل فعال مشكلة عنق الزجاجة الحسابية عند استرجاع المفاتيح على نطاق واسع. أظهرت التجارب أن نموذجًا بمعلمات 8B مزودًا بطبقة ذاكرة يتفوق على النماذج المماثلة التي لا تحتوي على طبقة ذاكرة في العديد من مجموعات بيانات الأسئلة والأجوبة، مما يُظهر تفوقًا في بيانات التدريب المسبق ومتطلبات حجم الحوسبة. (المصدر: DeepLearning.AI Blog)
Alibaba تطلق سلسلة نماذج الفيديو الأساسية مفتوحة المصدر Wan2.1، لدعم تحويل النص/الصورة إلى فيديو وتحريره: أطلقت Alibaba مجموعة Wan2.1، وهي مجموعة شاملة من نماذج الفيديو الأساسية مفتوحة المصدر، تتضمن إصدارات بمعلمات 1.3B و 14B، بموجب ترخيص Apache 2.0. يُظهر Wan2.1 أداءً متميزًا في مهام متعددة مثل تحويل النص إلى فيديو، والصورة إلى فيديو، وتحرير الفيديو، وتحويل النص إلى صورة، وتحويل الفيديو إلى صوت، ويدعم بشكل خاص التوليد المرئي للنصوص باللغتين الصينية والإنجليزية. يتطلب نموذج T2V-1.3B الخاص به 8.19 جيجابايت فقط من ذاكرة VRAM، ويمكن تشغيله على وحدات معالجة رسومات (GPU) للمستهلكين، ويمكنه إنشاء فيديو بدقة 480P لمدة 5 ثوانٍ في غضون 4 دقائق. يمكن لـ Wan-VAE المصاحب ترميز وفك ترميز مقاطع الفيديو بدقة 1080P بكفاءة، مع الحفاظ على المعلومات الزمنية. (المصدر: _akhaliq, Reddit r/LocalLLaMA)

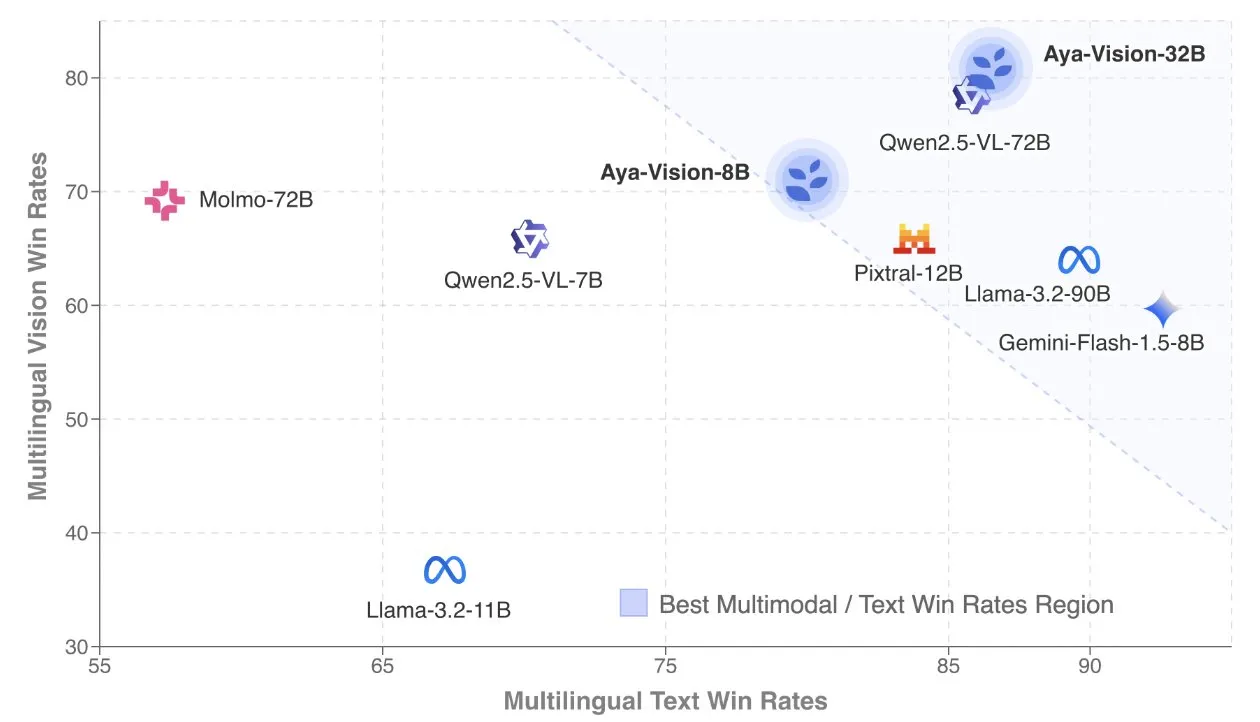
Cohere تنشر تقريرًا تقنيًا عن Aya Vision، مع التركيز على النماذج متعددة اللغات ومتعددة الوسائط: كشفت Cohere Labs عن التقرير التقني لـ Aya Vision، الذي يشرح بالتفصيل وصفتها لبناء نماذج SOTA متعددة اللغات ومتعددة الوسائط. تهدف نماذج Aya Vision إلى توحيد القدرات في 23 لغة عبر المهام متعددة الوسائط والنصية. يناقش التقرير إطار عمل البيانات الاصطناعية متعددة اللغات، وتصميم البنية، وطرق التدريب، ودمج النماذج عبر الوسائط، والتقييم الشامل للمهام التوليدية المفتوحة ومتعددة اللغات. يتفوق نموذجها 8B في الأداء على نماذج أكبر مثل Pixtral-12B، بينما يُعد نموذج 32B أكثر كفاءة، ويتجاوز نماذج بحجم يزيد عن ضعف حجمه مثل Llama3.2-90B. (المصدر: sarahookr, Cohere Labs)
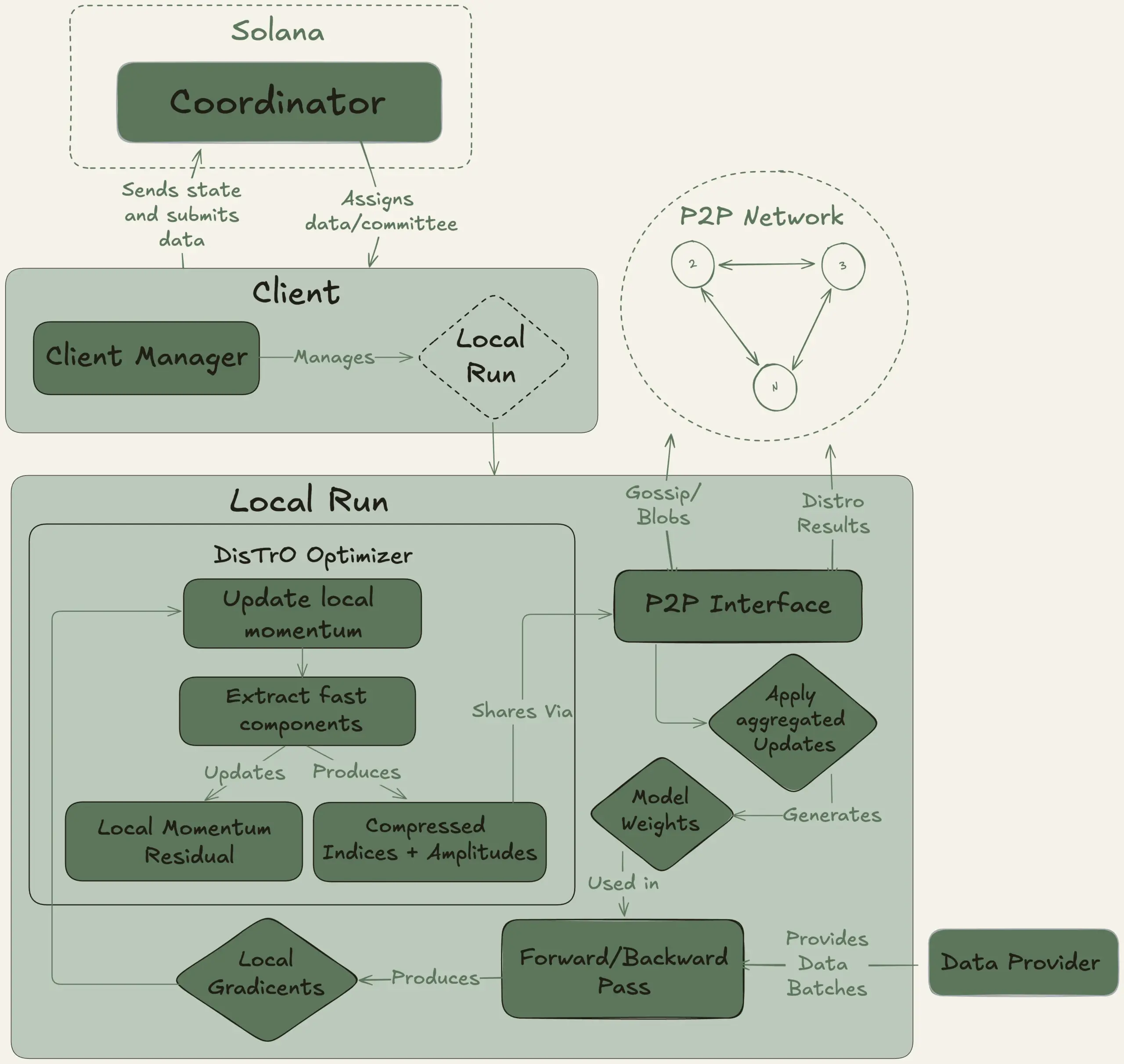
Nous Research تطلق مشروع Psyche، بهدف تدريب نموذج لغوي كبير بمعلمات 40B بشكل لامركزي: أعلنت Nous Research عن إطلاق شبكة Psyche، وهي شبكة تدريب لامركزية للذكاء الاصطناعي، تهدف إلى تجميع القدرة الحاسوبية العالمية لتدريب نماذج AI قوية بشكل مشترك، مما يمكّن الأفراد والمجتمعات الصغيرة من المشاركة في تطوير النماذج على نطاق واسع. بدأت شبكتها التجريبية بالفعل في التدريب المسبق لنموذج لغوي كبير (LLM) بمعلمات 40B، باستخدام بنية MLA، وتتضمن مجموعة البيانات FineWeb (14T)، وأجزاء من FineWeb-2 (4T)، و The Stack v2 (1T)، بإجمالي حوالي 20T token. بعد اكتمال تدريب هذا النموذج، سيتم توفير جميع نقاط الفحص (بما في ذلك الإصدارات غير الملدنة والملدنة) ومجموعات البيانات مفتوحة المصدر. (المصدر: eliebakouch, Teknium1)
Stability AI تطلق نموذج Stable Audio Open Small مفتوح المصدر، مع التركيز على التوليد السريع من النص إلى الصوت: أطلقت Stability AI نموذج Stable Audio Open Small على Hugging Face، وهو نموذج مصمم خصيصًا للتوليد السريع من النص إلى الصوت، ويستخدم تقنية التدريب اللاحق التنافسي. يهدف هذا النموذج إلى توفير حل فعال ومفتوح المصدر لتوليد الصوت. (المصدر: _akhaliq)
Google Gemini Advanced يتكامل مع GitHub، لتعزيز قدرات المساعدة في الترميز: أعلنت Google أن Gemini Advanced متصل الآن بـ GitHub، مما يعزز قدراته كمساعد في الترميز. يمكن للمستخدمين الاتصال مباشرة بمستودعات GitHub العامة أو الخاصة، للاستفادة من Gemini في إنشاء أو تعديل الدوال، وشرح الأكواد المعقدة، وطرح الأسئلة المتعلقة بمستودع الأكواد، وإجراء عمليات التصحيح، وغيرها. يمكن البدء في الاستخدام عن طريق النقر على زر “+” في شريط الأوامر واختيار “استيراد كود”، ثم لصق عنوان URL الخاص بـ GitHub. (المصدر: algo_diver)
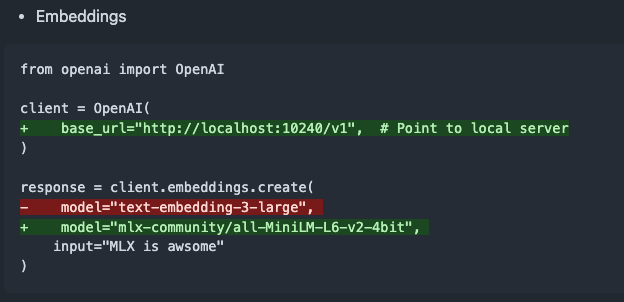
إصدار mlx-omni-server v0.4.0، مع إضافة خدمة embeddings والمزيد من نماذج TTS: تم تحديث mlx-omni-server إلى الإصدار v0.4.0، حيث تم تقديم خدمة /v1/embeddings جديدة، مما يبسط عملية إنشاء التضمينات من خلال mlx-embeddings. وفي الوقت نفسه، تم دمج المزيد من نماذج تحويل النص إلى كلام (TTS) (مثل kokoro, bark)، وتم ترقية mlx-lm لدعم نماذج جديدة مثل qwen3. (المصدر: awnihannun)
Together Chat يضيف ميزة معالجة ملفات PDF: أعلن Together Chat عن دعم تحميل ومعالجة ملفات PDF. يركز الإصدار الحالي بشكل أساسي على تحليل المحتوى النصي في ملفات PDF وتمريره إلى النموذج للمعالجة، ومن المخطط إطلاق إصدار v2 في المستقبل، مع إضافة ميزة OCR لقراءة المحتوى الصوري في ملفات PDF. (المصدر: togethercompute)
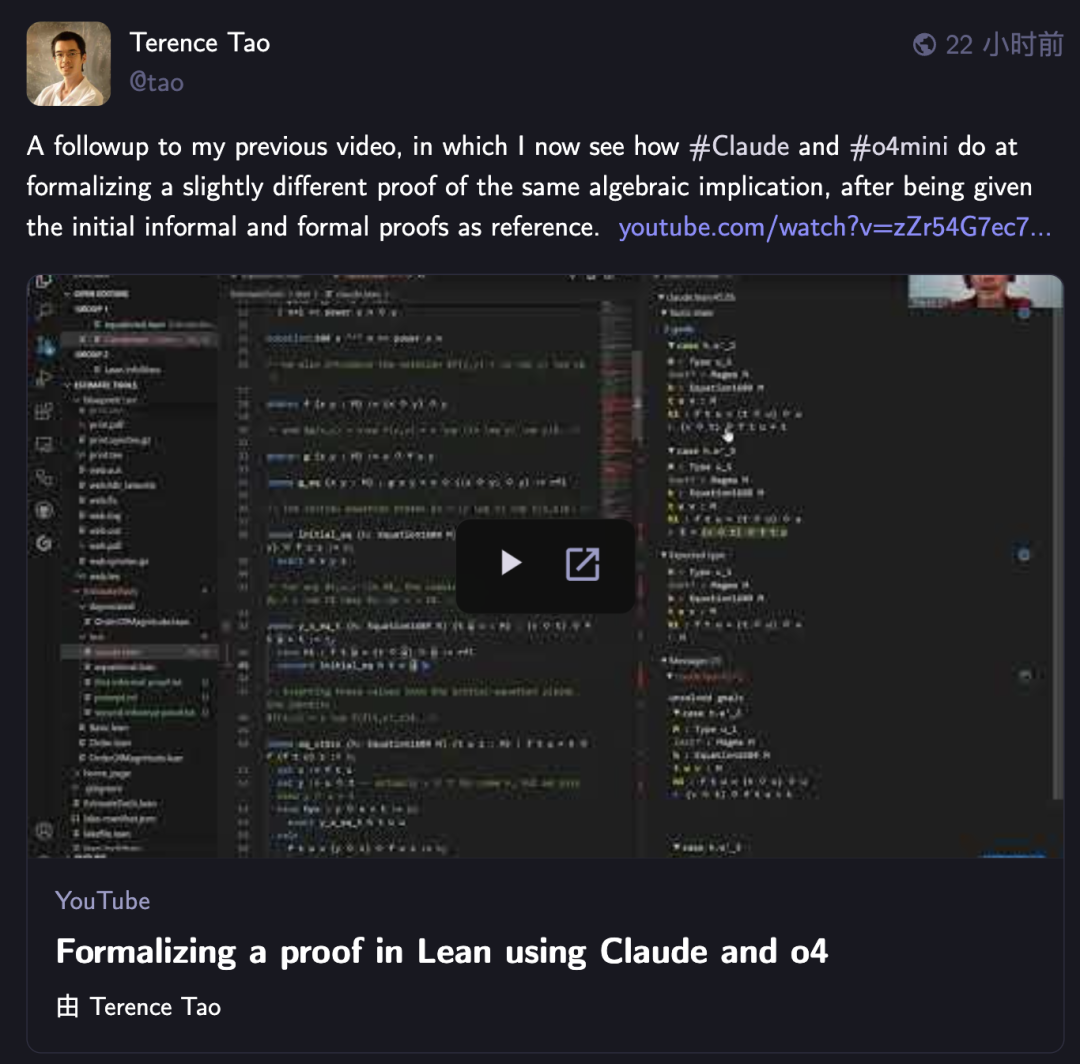
تيرنس تاو يتحدى مرة أخرى الذكاء الاصطناعي في إثبات الرياضيات الرسمي، و Claude يتفوق على o4-mini: في سلسلة مقاطع الفيديو الخاصة به على YouTube، اختبر عالم الرياضيات تيرنس تاو قدرة الذكاء الاصطناعي على إثبات التضمين الجبري الرسمي في مساعد الإثبات Lean. في التجربة، تمكن Claude من إكمال المهمة في حوالي 20 دقيقة، على الرغم من أنه كشف أثناء عملية التجميع عن سوء فهم لقاعدة بدء الأعداد الطبيعية من الصفر في Lean ومشكلات في معالجة التناظر، ولكن تم تصحيحها بتدخل بشري. بالمقارنة، كان أداء o4-mini أكثر حذرًا، حيث تمكن من تحديد مشكلات تعريف دالة القوة، لكنه اختار التخلي عن خطوات الإثبات الحاسمة ولم يتمكن من إكمال المهمة. خلص تاو إلى أن الاعتماد المفرط على الأتمتة قد يضعف فهم الهيكل العام للإثبات، وأن المستوى الأمثل للأتمتة يجب أن يكون بين 0% و 100%، مع الاحتفاظ بالتدخل البشري لتعميق الفهم. (المصدر: 36氪)
مقابلة مع آلتمان: الهدف النهائي لـ OpenAI هو بناء خدمة اشتراك أساسية للذكاء الاصطناعي: صرح سام آلتمان، الرئيس التنفيذي لـ OpenAI، في حدث Sequoia Capital AI Ascent 2025 بأن “المثل الأفلاطوني” لـ OpenAI هو تطوير نظام تشغيل للذكاء الاصطناعي، ليصبح خدمة اشتراك أساسية للذكاء الاصطناعي للمستخدمين. يتصور أن نماذج الذكاء الاصطناعي المستقبلية ستكون قادرة على معالجة بيانات حياة المستخدم بأكملها (علامات سياق بتريليونات)، لتحقيق استدلال شخصي عميق. اعترف آلتمان بأن هذا لا يزال في “مرحلة العرض التقديمي”، لكنه أكد أن الشركة تفخر بمرونتها وقدرتها على التكيف. كما تحدث عن إمكانات التفاعل الصوتي للذكاء الاصطناعي، وأن عام 2025 سيكون عامًا يتألق فيه وكلاء الذكاء الاصطناعي، ويعتقد أن الترميز سيكون هو المحرك الأساسي لعمل النماذج واستدعاءات واجهة برمجة التطبيقات (API). (المصدر: 36氪, 量子位)

Karminski3 يشارك نسخة معدلة من مجتمع Qwen3-30B، مع مضاعفة عدد الخبراء النشطين: قام مجتمع المطورين بتعديل نموذج Qwen3، وأطلق إصدار Qwen3-30B-A6B-16-Extreme. من خلال تعديل معلمات النموذج، تم زيادة عدد الخبراء النشطين من A3B إلى A6B، ويُقال إن هذا يؤدي إلى تحسن طفيف في الجودة، ولكن سرعة التوليد ستصبح أبطأ وفقًا لذلك. يمكن للمستخدمين أيضًا تحقيق تأثير مماثل عن طريق تعديل معلمات تشغيل llama.cpp --override-kv http://qwen3moe.expert_used_count=int:24، أو إجراء عملية عكسية لتقليل كمية التنشيط في Qwen3-235B-A22B لتسريع الأداء. (المصدر: karminski3)

🧰 الأدوات
إطلاق OpenMemory MCP: نظام ذاكرة مشتركة يعمل محليًا، يربط بين العديد من أدوات الذكاء الاصطناعي: أطلق فريق mem0ai نظام OpenMemory MCP، وهو خادم ذاكرة خاص مبني على بروتوكول سياق النموذج المفتوح (MCP). يدعم التشغيل المحلي بنسبة 100%، ويهدف إلى حل مشكلة عدم مشاركة معلومات السياق بين أدوات الذكاء الاصطناعي الحالية (مثل Cursor, Claude Desktop, Windsurf, Cline)، وفقدان الذاكرة بمجرد انتهاء الجلسة. يتم تخزين بيانات المستخدم محليًا، مما يضمن خصوصية البيانات وأمانها. يوفر OpenMemory MCP واجهة برمجة تطبيقات (API) موحدة لعمليات الذاكرة (إضافة، حذف، بحث، تعديل)، ويحتوي على لوحة معلومات مركزية للمستخدمين لإدارة الذاكرة وأذونات وصول العملاء، مع تبسيط عملية النشر من خلال Docker. (المصدر: 36氪, AI进修生)

LangChain تطلق الإصدار الرسمي لمنصة LangGraph وتحديثات متعددة، لتعزيز تطوير وكلاء الذكاء الاصطناعي وقابلية الملاحظة: أعلنت LangChain في مؤتمر Interrupt عن الإتاحة العامة (GA) لمنصتها LangGraph، المصممة خصيصًا لبناء وإدارة تدفقات عمل وكلاء الذكاء الاصطناعي طويلة الأمد وذات الحالة، وتدعم النشر بنقرة واحدة، والتوسع الأفقي، وواجهات برمجة التطبيقات (API) للذاكرة، والتفاعل بين الإنسان والآلة (HIL)، وسجل المحادثات، وغيرها. وفي الوقت نفسه، تم إصدار LangGraph Studio V2، كبيئة تطوير متكاملة (IDE) للوكلاء، تدعم التشغيل المحلي، والتحرير المباشر للتكوينات، والتكامل مع Playground، والقدرة على سحب بيانات التتبع من بيئة الإنتاج للتصحيح المحلي. بالإضافة إلى ذلك، أطلقت LangChain منصة بناء الوكلاء مفتوحة المصدر بدون كود Open Agent Platform (OAP)، وعززت قابلية ملاحظة الوكلاء في LangSmith فيما يتعلق باستدعاء الأدوات والمسارات. (المصدر: LangChainAI, hwchase17)
PatronusAI تطلق Percival: وكيل ذكاء اصطناعي قادر على تقييم وإصلاح وكلاء ذكاء اصطناعي آخرين: أطلقت PatronusAI وكيل Percival، الذي يُوصف بأنه أول وكيل ذكاء اصطناعي قادر على تقييم وإصلاح أخطاء وكلاء ذكاء اصطناعي آخرين تلقائيًا. لا يقتصر Percival على اكتشاف الأعطال في سجلات تتبع الوكلاء، بل يقدم أيضًا اقتراحات للإصلاح. يُقال إن أداء Percival على مجموعة بيانات TRAIL التي تحتوي على أخطاء بشرية من GAIA و SWE-Bench، يتفوق على أداء نماذج اللغة الكبيرة (SOTA LLM) بمقدار 2.9 مرة. تشمل وظائفه اقتراح حلول تلقائية لإصلاح أوامر الوكلاء، والتقاط أكثر من 20 نوعًا من أعطال الوكلاء (تغطي استخدام الأدوات، وتنسيق التخطيط، والأخطاء الخاصة بالمجال، وغيرها)، وتقليل وقت التصحيح اليدوي من ساعات إلى أقل من دقيقة واحدة. (المصدر: rebeccatqian, basetenco)
PyWxDump: أداة لاستخراج وتصدير معلومات WeChat، تدعم تدريب الذكاء الاصطناعي: PyWxDump هي أداة Python تُستخدم للحصول على معلومات حساب WeChat (الاسم المستعار، الحساب، الهاتف، البريد الإلكتروني، مفتاح قاعدة البيانات)، وفك تشفير قاعدة البيانات، وعرض سجلات الدردشة محليًا، وتصدير سجلات الدردشة بتنسيقات مثل CSV و HTML، والتي يمكن استخدامها لتدريب الذكاء الاصطناعي، والردود التلقائية، وغيرها من السيناريوهات. تدعم الأداة الحصول على معلومات حسابات متعددة وجميع إصدارات WeChat، وتوفر واجهة مستخدم ويب لعرض سجلات الدردشة. (المصدر: GitHub Trending)

Airweave: أداة تمكّن وكلاء الذكاء الاصطناعي من البحث في أي تطبيق، متوافقة مع بروتوكول MCP: Airweave هي أداة تهدف إلى تمكين وكلاء الذكاء الاصطناعي من البحث الدلالي في محتوى أي تطبيق. وهي متوافقة مع بروتوكول سياق النموذج (MCP)، ويمكنها الاتصال بسلاسة بمختلف التطبيقات أو قواعد البيانات أو واجهات برمجة التطبيقات (API)، وتحويل محتواها إلى معرفة قابلة للاستخدام من قبل الوكلاء. تشمل وظائفها الرئيسية مزامنة البيانات، واستخراج الكيانات وتحويلها، وبنية متعددة المستأجرين، والتحديثات التزايدية، والبحث الدلالي، والتحكم في الإصدارات، وغيرها. (المصدر: GitHub Trending)

iFlytek تطلق الجيل الجديد من سماعات الرأس AI iFLYBUDS Pro3 و Air2 المزودة بدماغ viaim AI: أطلقت Future Intelligence سماعات الرأس AI للمؤتمرات iFLYBUDS Pro3 و iFLYBUDS Air2 من iFlytek، وكلاهما مزود بدماغ viaim AI الجديد. viaim هو وكيل ذكاء اصطناعي موجه للأعمال المكتبية الشخصية، يدمج أربع وحدات أساسية: معالجة الإدراك الذكي من طرف إلى طرف، والاستدلال التعاوني للوكيل الذكي، والقدرة متعددة الوسائط في الوقت الفعلي، وحماية أمن البيانات والخصوصية. تدعم سماعات الرأس التسجيل المريح (المكالمات، التسجيلات الميدانية، تسجيلات الصوت والفيديو)، ومساعد AI (إنشاء العناوين والملخصات تلقائيًا، وطرح الأسئلة المستهدفة)، والترجمة متعددة اللغات (32 لغة، الترجمة الفورية السمعية، الترجمة وجهًا لوجه، ترجمة المكالمات)، وغيرها من الوظائف، مع تحسين جودة الصوت وراحة الارتداء. (المصدر: WeChat)

إطلاق KoboldCpp Smart Launcher: أداة ضبط تلقائي لـ Tensor Offload لتحسين أداء LLM: تم إطلاق أداة واجهة مستخدم رسومية (GUI) وواجهة سطر أوامر (CLI) تسمى KoboldCpp Smart Launcher، تهدف إلى مساعدة المستخدمين على إيجاد أفضل استراتيجية Tensor Offload لـ KoboldCpp تلقائيًا عند تشغيل نماذج اللغة الكبيرة (LLM) محليًا. من خلال توزيع الموترات بشكل أكثر دقة بين وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU) (بدلاً من طبقات كاملة)، يُقال إن الأداة يمكنها مضاعفة سرعة التوليد أو أكثر دون زيادة متطلبات VRAM. على سبيل المثال، ارتفعت سرعة QwQ Merge على وحدة معالجة رسومات (GPU) بذاكرة VRAM سعة 12 جيجابايت من 3.95 t/s إلى 10.61 t/s. (المصدر: Reddit r/LocalLLaMA)
OpenBMB تطلق AgentCPM-GUI مفتوح المصدر: أول وكيل GUI على الجهاز محسن للغة الصينية: أطلق فريق OpenBMB وكيل AgentCPM-GUI مفتوح المصدر، وهو أول وكيل واجهة مستخدم رسومية (GUI) على الجهاز محسن خصيصًا للتطبيقات الصينية. يعزز هذا الوكيل قدرات الاستدلال من خلال الضبط الدقيق المعزز (RFT)، ويعتمد تصميمًا مضغوطًا لمساحة العمل، ويتمتع بقدرات تحديد مواقع GUI عالية الجودة (grounding)، بهدف تحسين تجربة المستخدم في تشغيل مختلف التطبيقات في البيئة الصينية. (المصدر: Reddit r/LocalLLaMA)
MAESTRO: تطبيق بحثي للذكاء الاصطناعي يعطي الأولوية للتشغيل المحلي، ويدعم التعاون متعدد الوكلاء ونماذج LLM المخصصة: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) هو تطبيق بحثي مدفوع بالذكاء الاصطناعي تم إطلاقه حديثًا، يركز على التحكم والقدرات المحلية. يوفر إطار عمل معياري، بما في ذلك استخراج المستندات، وعمليات RAG قوية، وأنظمة متعددة الوكلاء (التخطيط، البحث، التفكير، الكتابة)، ويمكنه التعامل مع مشكلات بحثية معقدة. يمكن للمستخدمين التفاعل من خلال واجهة مستخدم ويب Streamlit أو واجهة سطر الأوامر (CLI)، باستخدام مجموعات المستندات الخاصة بهم ونماذج LLM المحلية أو المستندة إلى API التي يختارونها. (المصدر: Reddit r/LocalLLaMA)
Contextual AI تطلق محلل مستندات محسن خصيصًا لـ RAG: أطلقت Contextual AI محلل مستندات جديدًا، مصمم خصيصًا لأنظمة التوليد المعزز بالاسترجاع (RAG). تهدف هذه الأداة إلى توفير تحليل عالي الدقة للمستندات المعقدة غير المهيكلة من خلال الجمع بين النماذج المرئية، و OCR، ونماذج اللغة المرئية، ويمكنها الحفاظ على الهيكل الهرمي للمستندات، ومعالجة الوسائط المعقدة مثل الجداول والمخططات والرسوم البيانية، وتوفير مربعات الإحاطة ومستويات الثقة ليتمكن المستخدمون من مراجعتها، وبالتالي تقليل فقدان السياق والهلوسة في أنظمة RAG الناتجة عن فشل التحليل. (المصدر: douwekiela)
Gradio يضيف ميزة التراجع/الإعادة لمكون ImageEditor: تمت إضافة أزرار التراجع (undo) والإعادة (redo) إلى مكون ImageEditor في Gradio، مما يوفر للمستخدمين وظائف تحرير صور Python مشابهة للتطبيقات الاحترافية المدفوعة، ويعزز التفاعلية وسهولة الاستخدام. (المصدر: _akhaliq)
RunwayML تطلق ميزة References الجديدة، لدعم اختبار المواد والأزياء والمواقع والأوضاع بدون عينات (zero-shot): تم تحديث ميزة References في RunwayML، حيث يمكن للمستخدمين استخدام صور معاينة لمواد ثلاثية الأبعاد تقليدية كمدخلات، وتطبيق موادها على أي كائن، لتحقيق نقل المواد وتصورها بدون عينات (zero-shot). بالإضافة إلى ذلك، تدعم الميزة الجديدة أيضًا اختبار الأزياء والمواقع وأوضاع الشخصيات بدون عينات، مما يوسع إمكانيات التوليد الإبداعي والنماذج الأولية السريعة. (المصدر: c_valenzuelab, c_valenzuelab)

Mita AI تطلق ميزة “ماذا نتعلم اليوم”، للتعلم المنظم بمساعدة الذكاء الاصطناعي: أطلقت Mita AI ميزة جديدة تسمى “ماذا نتعلم اليوم”، تهدف إلى تحويل دور الذكاء الاصطناعي من مساعد في استرجاع المعلومات ومعالجة المستندات إلى “معلم AI” قادر على التوجيه والتعليم بشكل استباقي. بعد تحميل المستخدم للمواد أو البحث عنها، يمكن لهذه الميزة إنشاء دورات فيديو منظمة ومنهجية وعروض تقديمية PPT تلقائيًا، لمساعدة المستخدمين على تنظيم نقاط المعرفة، وتدعم اختيار أعماق شرح مختلفة (مبتدئ/خبير) وأنماط (سرد قصصي/شخص غاضب، إلخ) بناءً على مستوى المستخدم. بالإضافة إلى ذلك، تدعم طرح الأسئلة أثناء الشرح والاختبارات بعد الدرس. (المصدر: WeChat)

📚 موارد تعليمية
أندرو نج يتعاون مع Anthropic لإطلاق دورة تدريبية جديدة: بناء تطبيقات AI غنية بالسياق باستخدام MCP: أطلقت DeepLearning.AI التابعة لأندرو نج بالتعاون مع Anthropic دورة تدريبية جديدة بعنوان “MCP: Build Rich-Context AI Apps with Anthropic”، يقدمها إيلي شوبيك، مدير التعليم التقني في Anthropic. تركز الدورة على بروتوكول سياق النموذج (MCP)، وهو بروتوكول مفتوح يهدف إلى توحيد وصول نماذج اللغة الكبيرة (LLM) إلى الأدوات والبيانات والأوامر الخارجية. سيتعلم المشاركون البنية الأساسية لـ MCP، وإنشاء روبوتات محادثة متوافقة مع MCP، وبناء ونشر خوادم MCP، وربطها بالتطبيقات التي تعمل بواسطة Claude وخوادم الطرف الثالث الأخرى، لتبسيط تطوير تطبيقات AI غنية بالسياق. (المصدر: AndrewYNg, DeepLearningAI)
FlashInfer: أفضل ورقة بحثية في MLSys 2025، محرك انتباه فعال وقابل للتخصيص لاستدلال LLM: فاز مشروع FlashInfer، وهو تعاون بين زيهاو يي من جامعة واشنطن، و NVIDIA، وتيانكي تشين من OctoAI وآخرين، بجائزة أفضل ورقة بحثية في MLSys 2025. FlashInfer هو محرك انتباه فعال وقابل للتخصيص مصمم لتحسين خدمة استدلال نماذج اللغة الكبيرة (LLM)، من خلال تحسين الوصول إلى الذاكرة (باستخدام تنسيق متفرق كتلي وتنسيق قابل للتركيب لمعالجة ذاكرة التخزين المؤقت KV)، وتوفير قوالب حساب انتباه مرنة تعتمد على الترجمة الفورية (JIT)، وإدخال آلية جدولة مهام متوازنة الحمل، مما أدى إلى تحسين أداء استدلال LLM بشكل كبير، وتم دمجه في مشاريع مثل vLLM و SGLang. (المصدر: 机器之心)
ورقة بحثية في ICML 2025: تحليل نظري لتوجيه الرسوم البيانية (Graph Prompting) من منظور معالجة البيانات: قدم وانغ تشون تشونغ، والدكتور سون شيانغ قوه، والبروفيسور تشنغ هونغ من الجامعة الصينية في هونغ كونغ ورقة بحثية في ICML 2025، تقدم لأول مرة إطارًا نظريًا منهجيًا لفعالية توجيه الرسوم البيانية من منظور “معالجة البيانات”. يقدم البحث مفهوم “الرسم البياني الجسري”، ويثبت أن آلية توجيه الرسوم البيانية تعادل نظريًا إجراء عملية معينة على بيانات الرسم البياني المدخلة، مما يمكّن النموذج المدرب مسبقًا من معالجتها بشكل صحيح للتكيف مع المهام الجديدة. تستنبط الورقة حدًا أعلى للخطأ، وتحلل مصادر الخطأ وقابليتها للتحكم، وتقوم بنمذجة توزيع الخطأ، مما يوفر أساسًا نظريًا لتصميم وتطبيق توجيه الرسوم البيانية. (المصدر: WeChat)
ورقة بحثية في ICML 2025: توليد بيانات نصية اصطناعية من خلال التحرير على مستوى الـ Token لتجنب انهيار النموذج: نشر فريق بحثي من جامعة شنغهاي جياو تونغ ومؤسسات أخرى ورقة بحثية في ICML 2025، تناقش مشكلة “انهيار النموذج” الناتجة عن البيانات الاصطناعية، وتقترح استراتيجية لتوليد البيانات تسمى “Token-Level Editing”. تعتمد هذه الطريقة على إجراء تعديلات دقيقة على الـ Tokens التي يكون النموذج “واثقًا جدًا” منها في البيانات الحقيقية، بدلاً من توليد نصوص جديدة بالكامل، بهدف بناء بيانات شبه اصطناعية ذات بنية أكثر استقرارًا وقدرة تعميم أقوى. يُظهر التحليل النظري أن هذه الطريقة يمكنها تقييد خطأ الاختبار بشكل فعال، وتجنب انهيار أداء النموذج مع زيادة جولات التكرار. أثبتت التجارب فعالية هذه الطريقة في مراحل التدريب المسبق، والتدريب المسبق المستمر، والضبط الدقيق الخاضع للإشراف. (المصدر: WeChat)

ورقة بحثية في ICML 2025: OmniAudio، توليد صوت مكاني ثلاثي الأبعاد من مقاطع فيديو بانورامية 360 درجة: عرض فريق OmniAudio في ICML 2025 تقنية لتوليد صوت مكاني محيطي من الدرجة الأولى (FOA) مباشرة من مقاطع فيديو بانورامية 360 درجة. لحل مشكلة ندرة البيانات، قام الفريق ببناء مجموعة بيانات 360V2SA واسعة النطاق تسمى Sphere360 (أكثر من 100,000 مقطع، 288 ساعة). يعتمد OmniAudio على تدريب من مرحلتين: تدريب مسبق ذاتي الإشراف لمطابقة التدفق من الخشن إلى الناعم، أولاً باستخدام صوت ستيريو عادي محول إلى FOA زائف للتدريب، ثم الضبط الدقيق باستخدام FOA حقيقي؛ ثم الضبط الدقيق الخاضع للإشراف بالاقتران مع مشفر فيديو ثنائي الفروع، لاستخراج ميزات المنظور العالمي والمحلي، وتوليد صوت مكاني عالي الدقة ودقيق الاتجاه. (المصدر: 量子位)

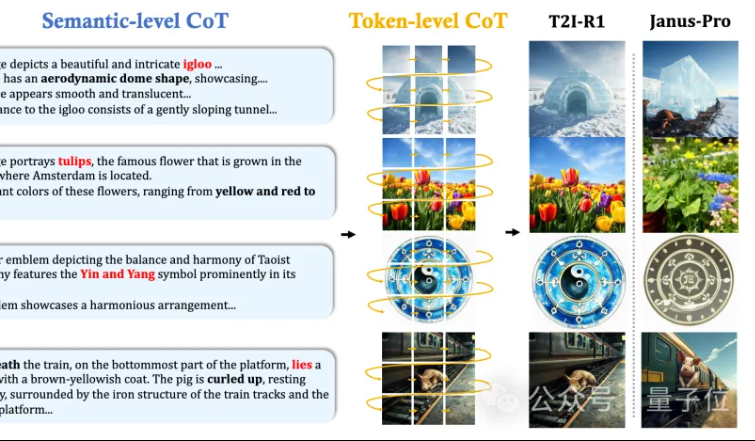
MMLab بالجامعة الصينية في هونغ كونغ تقترح T2I-R1: إدخال استدلال CoT ثنائي المستوى وتعلم معزز لتوليد الصور من النصوص: أطلق فريق MMLab بالجامعة الصينية في هونغ كونغ نموذج T2I-R1، وهو أول نموذج لتوليد الصور من النصوص معزز بالاستدلال يعتمد على التعلم المعزز. يقدم هذا النموذج بشكل مبتكر إطار عمل استدلال سلسلة الأفكار (CoT) ثنائي المستوى: Semantic-CoT (استدلال نصي، يخطط للهيكل العام للصورة) و Token-CoT (توليد كتل رموز الصورة، يركز على التفاصيل الدقيقة). من خلال طريقة التعلم المعزز BiCoT-GRPO، يتم تحسين هذين المستويين من CoT بشكل تعاوني في نموذج لغوي متعدد الوسائط موحد (Janus-Pro)، دون الحاجة إلى نماذج إضافية. يعتمد نموذج المكافأة على تكامل نماذج خبراء بصرية متعددة، لضمان موثوقية التقييم ومنع الإفراط في التجهيز. أظهرت التجارب أن T2I-R1 يمكنه فهم نية المستخدم بشكل أفضل، وتوليد صور أكثر توافقًا مع التوقعات، ويتفوق بشكل كبير على النماذج الأساسية في معياري T2I-CompBench و WISE. (المصدر: 量子位, WeChat)
OpenAI تطلق مكتبة تقييم نماذج اللغة خفيفة الوزن simple-evals: أطلقت OpenAI مكتبة simple-evals مفتوحة المصدر، وهي مكتبة خفيفة الوزن لتقييم نماذج اللغة، تهدف إلى إضفاء الشفافية على بيانات الدقة الخاصة بأحدث إصدارات نماذجها. تركز المكتبة على إعدادات التقييم بدون عينات (zero-shot) وسلسلة الأفكار (chain-of-thought)، وتوفر مقارنات مفصلة لأداء النماذج على معايير متعددة مثل MMLU و MATH و GPQA، بما في ذلك نماذج OpenAI الخاصة (مثل o3, o4-mini, GPT-4.1, GPT-4o) بالإضافة إلى نماذج رئيسية أخرى (مثل Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5). (المصدر: GitHub Trending)
إصدار النسخة الكورية من دليل مهندس LLM: تم الآن إصدار النسخة الكورية من “دليل مهندس LLM” لمؤلفه Maxime Labonne، بترجمة Woocheol Cho. سيتم قريبًا إصدار المزيد من النسخ اللغوية لهذا الدليل باللغات الروسية والصينية والبولندية وغيرها، لتوفير موارد تعليمية لمطوري LLM حول العالم. (المصدر: maximelabonne)

الإعلان عن ورشة عمل تعلم الآلة للصوتيات ML4Audio في ICML 2025: ستعود ورشة عمل تعلم الآلة للصوتيات (ML for Audio) الشهيرة خلال مؤتمر ICML 2025 الذي سيعقد في فانكوفر، وتحديدًا يوم السبت 19 يوليو. ستستضيف الورشة متحدثين بارزين مثل Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti و Pratyusha Rakshit. الموعد النهائي لتقديم الأوراق البحثية هو 23 مايو. (المصدر: sedielem)
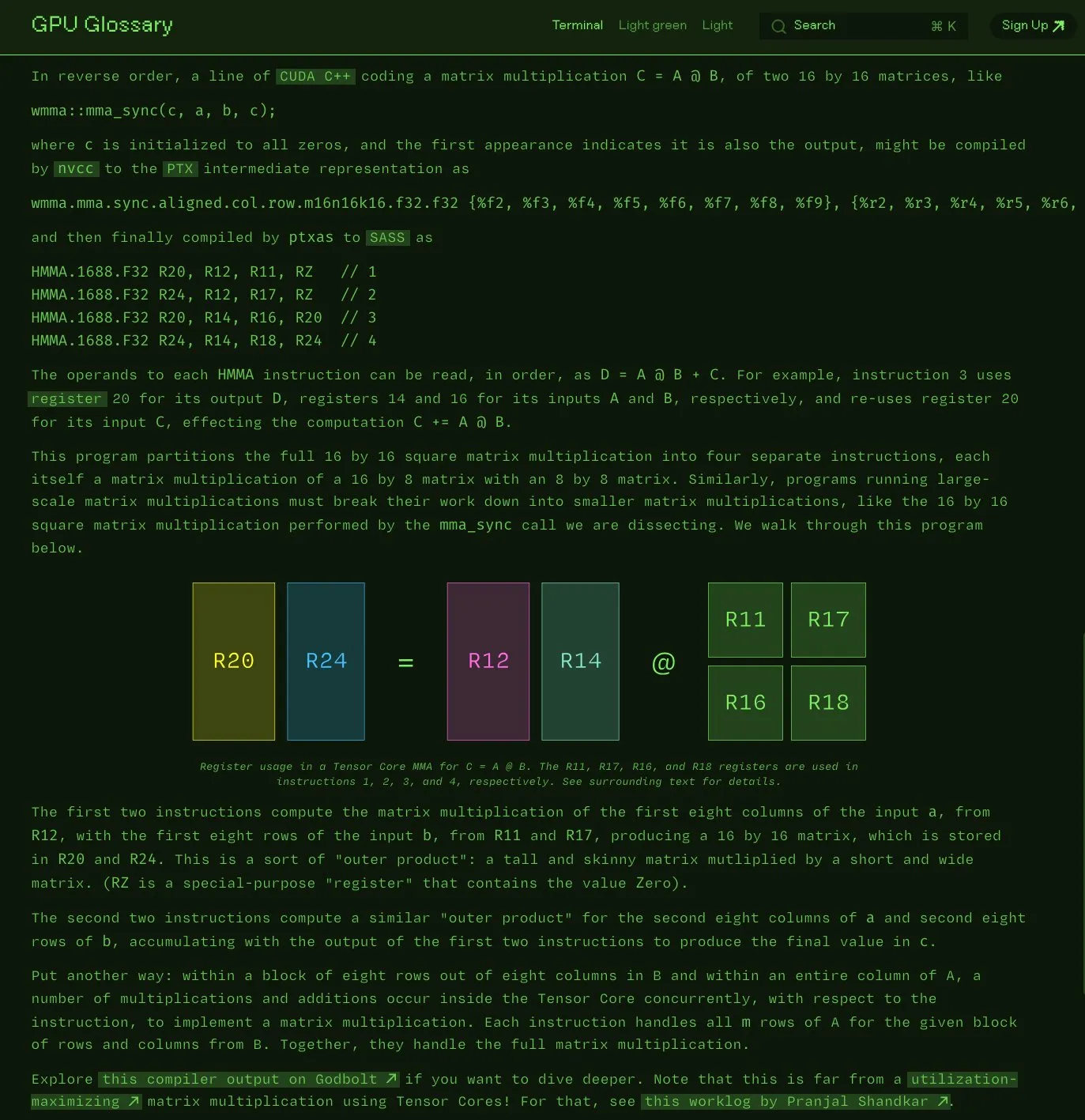
Charles Frye يطلق مسرد مصطلحات GPU مفتوح المصدر: أعلن Charles Frye أن مسرد مصطلحات GPU الذي قام بتجميعه أصبح الآن مفتوح المصدر. يهدف هذا المسرد إلى المساعدة في فهم المفاهيم المتعلقة بأجهزة GPU وبرمجتها، وقد تم تحديثه مؤخرًا ليشمل تفكيك تعليمات SASS لعمليات ضرب المصفوفات البسيطة وإضافة (mma) التي تنفذها Tensor Core. المشروع مستضاف على GitHub، ويسرد بعض المهام التي لم تكتمل بعد. (المصدر: charles_irl)
OpenAI تنشر دليل هندسة الأوامر لـ GPT-4.1، مع التركيز على الهيكلة والتعليمات الواضحة: أصدرت OpenAI دليلاً لهندسة الأوامر لـ GPT-4.1، يهدف إلى مساعدة المستخدمين على بناء الأوامر بشكل أكثر فعالية، خاصة للتطبيقات التي تتطلب مخرجات منظمة، واستدلالًا، واستخدام الأدوات، والتطبيقات القائمة على الوكلاء. يؤكد الدليل على أهمية تحديد الأدوار والأهداف بوضوح، وتقديم تعليمات واضحة (بما في ذلك النبرة، والتنسيق، والحدود)، والتعليمات الفرعية الاختيارية، والاستدلال/التخطيط خطوة بخطوة، وتحديد تنسيق الإخراج بدقة، واستخدام الأمثلة، ويقدم بعض النصائح العملية مثل إبراز التعليمات الرئيسية، واستخدام Markdown أو XML لهيكلة المدخلات، وغيرها. (المصدر: Reddit r/MachineLearning)

Kaggle و Hugging Face تعمقان التعاون لتبسيط استدعاء النماذج واكتشافها: أعلنت Kaggle عن تعزيز التعاون مع Hugging Face، حيث يمكن للمستخدمين الآن تشغيل نماذج Hugging Face مباشرة في Kaggle Notebooks، واكتشاف أمثلة الأكواد العامة ذات الصلة، والتنقل بسلاسة بين المنصتين. يهدف هذا التكامل إلى توسيع إمكانية الوصول إلى النماذج، وتمكين مستخدمي Kaggle من الاستفادة بشكل أسهل من موارد النماذج في نظام Hugging Face البيئي. (المصدر: huggingface)
FedRAG: إطار عمل مفتوح المصدر لضبط أنظمة RAG، يدعم التعلم الفيدرالي: أطلق باحثون من Vector Institute إطار عمل FedRAG، وهو إطار عمل مفتوح المصدر يهدف إلى تبسيط عملية الضبط الدقيق لأنظمة التوليد المعزز بالاسترجاع (RAG). لا يدعم هذا الإطار التدريب المركزي النموذجي فحسب، بل يقدم أيضًا بشكل خاص بنية تعلم فيدرالي، للتكيف مع متطلبات التدريب على مجموعات بيانات موزعة. يتوافق FedRAG مع نظامي PyTorch و Hugging Face البيئيين، ويدعم استخدام Qdrant كمخزن للمعرفة، ويمكن ربطه بـ LlamaIndex. (المصدر: nerdai)

💼 الأعمال
شركة Anysphere، الشركة الأم لـ Cursor، تحقق إيرادات سنوية متكررة (ARR) بقيمة 200 مليون دولار في غضون عامين، وتقييمها يرتفع إلى 9 مليارات دولار: تمكنت شركة Anysphere، التي يقودها مايكل ترويل البالغ من العمر 25 عامًا والذي ترك معهد ماساتشوستس للتكنولوجيا، من تحقيق إيرادات سنوية متكررة (ARR) بقيمة 200 مليون دولار في غضون عامين من خلال محرر الأكواد المدعوم بالذكاء الاصطناعي Cursor، وذلك دون القيام بأي حملات تسويقية، مما أدى إلى ارتفاع تقييم الشركة بسرعة إلى 9 مليارات دولار. أعاد Cursor تشكيل نموذج تطوير البرمجيات من خلال دمج الذكاء الاصطناعي بعمق في عملية التطوير، مع التركيز على خدمة المطورين الأفراد، وحصل على اعتراف واسع النطاق وانتشار شفهي من المطورين في جميع أنحاء العالم. قادت Thrive Capital أحدث جولة تمويل للشركة. (المصدر: 36氪)

Databricks تعلن عن استحواذها على شركة Neon المتخصصة في Serverless Postgres: وافقت Databricks على الاستحواذ على شركة Neon، وهي شركة متخصصة في Serverless Postgres تركز على المطورين. تشتهر Neon ببنيتها المبتكرة لقواعد البيانات، والتي توفر السرعة، والتوسع المرن، وميزات التفرع والتشعب، وهي ميزات جذابة للمطورين ووكلاء الذكاء الاصطناعي على حد سواء. يهدف هذا الاستحواذ إلى بناء أساس قاعدة بيانات مفتوح و Serverless للمطورين ووكلاء الذكاء الاصطناعي بشكل مشترك. (المصدر: jefrankle, matei_zaharia)
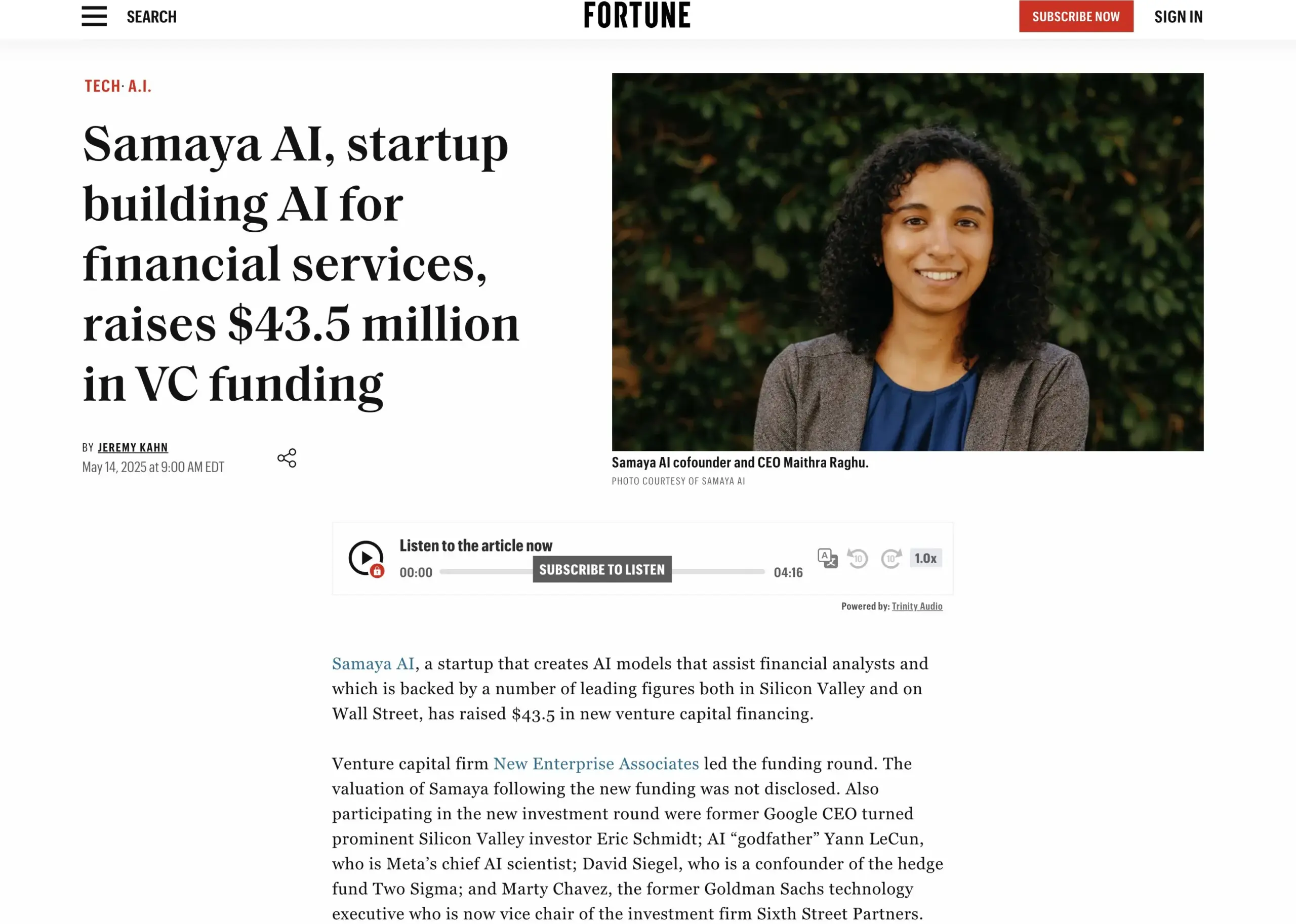
شركة Samaya AI الناشئة في مجال الخدمات المالية بالذكاء الاصطناعي تجمع 43.5 مليون دولار: أعلنت Samaya AI عن حصولها على تمويل بقيمة 43.5 مليون دولار بقيادة NEA، لبناء وكلاء AI خبراء للخدمات المالية، بهدف إحداث تحول واسع النطاق في أعمال المعرفة. تأسست الشركة في عام 2022، وتركز على بناء حلول AI مخصصة لتدفقات العمل المالية المعقدة. يتم استخدام وكلاء AI الخبراء لديها، القائمين على نماذج LLM مطورة ذاتيًا، من قبل آلاف المستخدمين في مؤسسات كبرى مثل Morgan Stanley، في تطبيقات مثل العناية الواجبة، والنمذجة الاقتصادية، ودعم اتخاذ القرار، مع التركيز على الدقة والشفافية وعدم الهلوسة. (المصدر: maithra_raghu)
🌟 المجتمع
هل سيحل الذكاء الاصطناعي محل مهندسي البرمجيات؟ نقاش مجتمعي حول ضرورة تطوير المهارات: ظهر مجددًا على وسائل التواصل الاجتماعي نقاش حول ما إذا كان الذكاء الاصطناعي سيحل محل مهندسي البرمجيات. الرأي السائد هو أن الذكاء الاصطناعي لن يحل محل مهندسي البرمجيات بالكامل، لأن تطوير البرمجيات يتجاوز مجرد الترميز نفسه. ومع ذلك، فإن أولئك الذين يعملون بشكل أساسي في أعمال الترميز المتكررة ويفتقرون إلى فهم شامل للنظام، أي “قرود الأكواد” (code monkeys)، يواجهون خطرًا كبيرًا بأن يتم استبدالهم بأدوات مساعدة تعمل بالذكاء الاصطناعي إذا لم يتمكنوا من تطوير مهاراتهم، وتعميق فهمهم لبنية النظام، وحل المشكلات المعقدة. (المصدر: cto_junior, cto_junior)
مستقبل وكلاء الذكاء الاصطناعي (AI Agent): الفرص والتحديات تتعايش، وقادة الصناعة متفائلون بإمكاناتهم: يتوقع سام آلتمان، الرئيس التنفيذي لـ OpenAI، أن يكون عام 2025 عامًا يتألق فيه وكلاء الذكاء الاصطناعي، حيث سيشاركون بشكل أكبر في العمل الفعلي. أكد ليو تشي يي في مقابلته أيضًا أن الوكلاء يتحولون من أدوات سلبية إلى أنظمة تنفيذ نشطة، وأن تطورهم يعتمد على تقدم النماذج الأساسية وقدرتهم على التفاعل مع العالم المادي. على الرغم من أن الوكلاء لا يزالون يعانون من أوجه قصور في سرعة الاستجابة والتحكم في الهلوسة وغيرها، إلا أن قدرتهم على تنفيذ المهام بشكل مستقل ومساعدة النماذج الكبيرة على التعلم تحظى بتقدير واسع، وقد بدأ تطبيقهم بالفعل في مجالات مثل خدمة العملاء الذكية والاستشارات المالية. (المصدر: 36氪, 量子位)

Perplexity AI تعقد شراكة مع PayPal و Venmo لدمج مدفوعات التجارة الإلكترونية والسفر: أعلنت Perplexity AI عن تعاونها مع PayPal و Venmo لدمج وظائف الدفع في منصتها للتسوق عبر التجارة الإلكترونية، وحجوزات السفر، وكذلك في مساعدها الصوتي ومتصفحها القادم Comet. تهدف هذه الخطوة إلى تبسيط عملية التجارة بأكملها، من التصفح والبحث والاختيار إلى الدفع الآمن، وتحسين تجربة المستخدم. (المصدر: AravSrinivas, perplexity_ai)
نقاش حول تقييم نماذج الذكاء الاصطناعي: IFEval و ChartQA محط اهتمام، والحاجة إلى الحذر من تلوث بيانات التدريب: في نقاش مجتمعي، اعتُبر IFEval أحد أفضل معايير تقييم اتباع التعليمات بسبب تصميمه البسيط والذكي. وفي الوقت نفسه، أشار بعض المستخدمين إلى أن بيانات اختبار ChartQA تحتوي على ضوضاء، وإجابات غامضة، وعدم اتساق، وقد تحتاج إلى التخلص منها. نبه Vikhyatk إلى أن العديد من النماذج التي تدعي تحقيق دقة عالية في اختبارات المعايير القياسية قد تكون لديها مشكلة تلوث بيانات التدريب دون أن يتم اكتشافها. (المصدر: clefourrier, vikhyatk)

حقوق النشر والأخلاقيات المتعلقة بالمحتوى الذي يولده الذكاء الاصطناعي تثير القلق: Audible تخطط لاستخدام رواة AI، واستخدام شخصيات مولدة بالذكاء الاصطناعي في المواعدة عبر الإنترنت يثير المخاوف: أعلنت Audible عن خطط لاستخدام رواة مولدين بالذكاء الاصطناعي لإنتاج كتب صوتية، بهدف “جلب المزيد من القصص إلى الحياة”، مما أثار نقاشًا حول تطبيقات الذكاء الاصطناعي في الصناعات الإبداعية. من ناحية أخرى، نشر مستخدم على Reddit أن والدته تفاعلت مع صور “رجال حقيقيين” يُشتبه في أنهم مولودون بالذكاء الاصطناعي على موقع مواعدة، معربًا عن قلقه من تعرضها للخداع. يسلط هذا الضوء على المخاطر المحتملة للمحتوى الذي يولده الذكاء الاصطناعي فيما يتعلق بالأصالة، والتلاعب العاطفي، والاحتيال. (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 متنوعات
شركة “Star算” الصينية تنجح في إطلاق أول 12 قمرًا صناعيًا للحوسبة الفضائية، لتبدأ حقبة جديدة من القدرة الحاسوبية الفضائية: نجحت خطة “Star算” التي تقودها شركة Guoxing Aerospace في إرسال أول 12 قمرًا صناعيًا للحوسبة إلى الفضاء، لتشكيل أول كوكبة حوسبة فضائية في العالم. يتمتع كل قمر صناعي بقدرات حوسبة فضائية واتصال بيني، وقد ارتفعت قدرة الحوسبة للقمر الصناعي الواحد من مستوى T إلى مستوى P، ووصلت القدرة الحاسوبية للكوكبة الأولى في المدار إلى 5 POPS، وتبلغ سرعة الاتصال بالليزر بين الأقمار الصناعية 100 جيجابت في الثانية. تهدف هذه الخطوة إلى بناء بنية تحتية للحوسبة الذكية قائمة على الفضاء، لحل مشكلات مثل استهلاك الطاقة الكبير وصعوبة تبديد الحرارة للقدرة الحاسوبية الأرضية، ودعم المعالجة الفورية للبيانات من استكشاف الفضاء السحيق في المدار، لتحقيق “حوسبة البيانات السماوية في السماء”. ومن المخطط إطلاق 2800 قمر صناعي في المستقبل لتشكيل شبكة حوسبة فضائية واسعة. (المصدر: 量子位)

NVIDIA تنشر مراجعتها السنوية، مؤكدة أن الذكاء الاصطناعي هو جوهر الثورة الصناعية الجديدة، وأن الذكاء هو المنتج: أشارت NVIDIA في مراجعتها السنوية إلى أن العالم يدخل ثورة صناعية جديدة، وأن منتجها الأساسي هو “الذكاء”. تلتزم NVIDIA ببناء بنية تحتية ذكية، وتحويل الحوسبة إلى قوة توليدية تدفع التنمية في مختلف الصناعات. (المصدر: nvidia)

NBA تتعاون مع Kuaishou Kling AI لإطلاق فيلم قصير بالذكاء الاصطناعي بعنوان “Childhood Curry’s Dunk”: تعاونت NBA مع Kling AI، وهو نموذج كبير لتوليد الفيديو من النصوص شبيه بـ Sora تابع لشركة Kuaishou، لإنتاج فيلم قصير بالذكاء الاصطناعي بعنوان “Childhood Curry’s Dunk” من إنتاج AI TALK. يحاول الفيلم استخدام Kling AI لإعادة إنشاء مشهد “السفر عبر الزمن” لـ Curry وهو يقوم بالـ dunk، لدعم تصفيات NBA، ويظهر في الفيلم أيضًا باركلي، وأونيل، ويوكيتش كضيوف شرف خاصين. (المصدر: TomLikesRobots)