
كلمات مفتاحية:MLSys 2025, FlashInfer, Claude-neptune, Aya Vision, FastVLM, Gemini, Nova Premier, تحسين استدلال نماذج اللغة الكبيرة (LLM), تحسين تخزين KV-Cache, التفاعل متعدد اللغات والوسائط, مهمة تحويل الفيديو إلى نص, منصة Amazon Bedrock, اختبارات قياسية في علم الأحياء
🔥 التركيز
MLSys 2025 تعلن عن جوائز أفضل ورقة بحثية، وتضم مشاريع مثل FlashInfer : أعلن مؤتمر MLSys 2025، وهو مؤتمر دولي رفيع المستوى في مجال الأنظمة، عن ورقتين بحثيتين فائزتين بجائزة أفضل ورقة بحثية. إحداهما هي FlashInfer، وهي مكتبة محرك اهتمام عالية الكفاءة وقابلة للتخصيص مُحسّنة خصيصًا لاستنتاج LLM، من جامعة واشنطن وNvidia ومؤسسات أخرى. من خلال تحسين تخزين KV-Cache، وقوالب الحساب، وآليات الجدولة، تعمل على تحسين إنتاجية استنتاج LLM وتقليل زمن الوصول بشكل كبير. الورقة البحثية الأخرى الفائزة هي “The Hidden Bloat in Machine Learning Systems”، والتي تكشف عن مشكلة التضخم الناتجة عن الكود والميزات غير المستخدمة في أطر ML، وتقترح طريقة Negativa-ML لتقليل حجم الكود وتحسين الأداء بشكل فعال. يجسد اختيار FlashInfer أهمية تحسين كفاءة استنتاج LLM، بينما تؤكد Hidden Bloat على الحاجة إلى نضج هندسة أنظمة ML. (المصدر: Reddit r/deeplearning، 36氪)
Anthropic تختبر نموذجًا جديدًا “claude-neptune” : تم الكشف عن أن Anthropic تجري اختبارات السلامة على نموذجها الجديد للذكاء الاصطناعي “claude-neptune”. تتكهن الأوساط بأنه قد يكون إصدار Claude 3.8 Sonnet، حيث أن نبتون (Neptune) هو الكوكب الثامن في النظام الشمسي. تشير هذه الخطوة إلى أن Anthropic تتقدم في تكرار سلسلة نماذجها، مما قد يؤدي إلى تحسينات في الأداء أو السلامة، وتوفير قدرات AI أكثر تقدمًا للمستخدمين والمطورين. (المصدر: Reddit r/ClaudeAI)
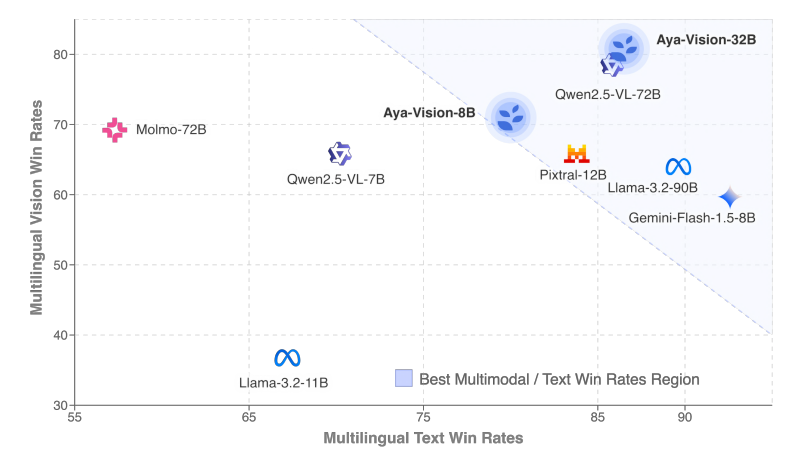
Cohere تطلق نموذج Aya Vision متعدد اللغات ومتعدد الوسائط : أطلقت Cohere سلسلة نماذج Aya Vision، بما في ذلك إصداري 8B و 32B، مع التركيز على التفاعل المفتوح متعدد اللغات ومتعدد الوسائط. يتفوق Aya Vision-8B على النماذج مفتوحة المصدر من نفس الحجم وبعض النماذج الأكبر حجمًا، بالإضافة إلى Gemini 1.5-8B في مهام VQA والمحادثة متعددة اللغات، بينما تدعي Aya Vision-32B أنها تتفوق على النماذج بحجم 72B-90B في مهام الرؤية والنصوص. تستخدم سلسلة النماذج تقنيات مثل تسمية البيانات الاصطناعية، ودمج النماذج عبر الوسائط، والهندسة المعمارية الفعالة، وبيانات SFT المنسقة، بهدف تحسين أداء القدرات متعددة اللغات ومتعددة الوسائط، وقد تم فتح مصدرها. (المصدر: Reddit r/LocalLLaMA، sarahookr، sarahookr)
Apple تطلق نموذج FastVLM لتحويل الفيديو إلى نص : قامت Apple بفتح مصدر سلسلة نماذج FastVLM (0.5B, 1.5B, 7B)، وهو نموذج كبير يركز على مهام تحويل الفيديو إلى نص. تكمن ميزته البارزة في استخدام مشفر بصري هجين جديد يسمى FastViTHD، والذي يعزز بشكل كبير سرعة تشفير الفيديو عالي الدقة وسرعة TTFT (من إدخال الفيديو إلى إخراج أول token)، مما يجعله أسرع بعدة مرات من النماذج الحالية. يدعم النموذج أيضًا التشغيل على ANE في شرائح Apple، مما يوفر حلاً فعالاً لفهم الفيديو على الجهاز. (المصدر: karminski3)
🎯 الاتجاهات
تطبيق Google Gemini يتوسع ليشمل المزيد من الأجهزة : أعلنت Google عن توسيع تطبيق Gemini ليشمل المزيد من الأجهزة، بما في ذلك Wear OS، وAndroid Auto، وGoogle TV، وAndroid XR. بالإضافة إلى ذلك، أصبحت ميزات الكاميرا ومشاركة الشاشة في Gemini Live متاحة الآن مجانًا لجميع مستخدمي Android. تهدف هذه الخطوة إلى دمج قدرات AI في Gemini بشكل أوسع في الحياة اليومية للمستخدمين، وتغطية المزيد من سيناريوهات الاستخدام. (المصدر: demishassabis، TheRundownAI)
نموذج Amazon Nova Premier متاح على Bedrock : أعلنت Amazon عن إتاحة نموذجها Nova Premier على Amazon Bedrock. يتم وضع هذا النموذج كـ “نموذج معلم” الأكثر قوة، ويستخدم لإنشاء نماذج دقيقة مخصصة، وهو مناسب بشكل خاص للمهام المعقدة مثل RAG، واستدعاء الوظائف، وتشفير الوكلاء، ويمتلك نافذة سياق تبلغ مليون token. تهدف هذه الخطوة إلى توفير قدرات قوية لتخصيص نماذج AI للشركات عبر منصة AWS، مما قد يثير مخاوف المستخدمين بشأن قفل الموردين. (المصدر: sbmaruf)
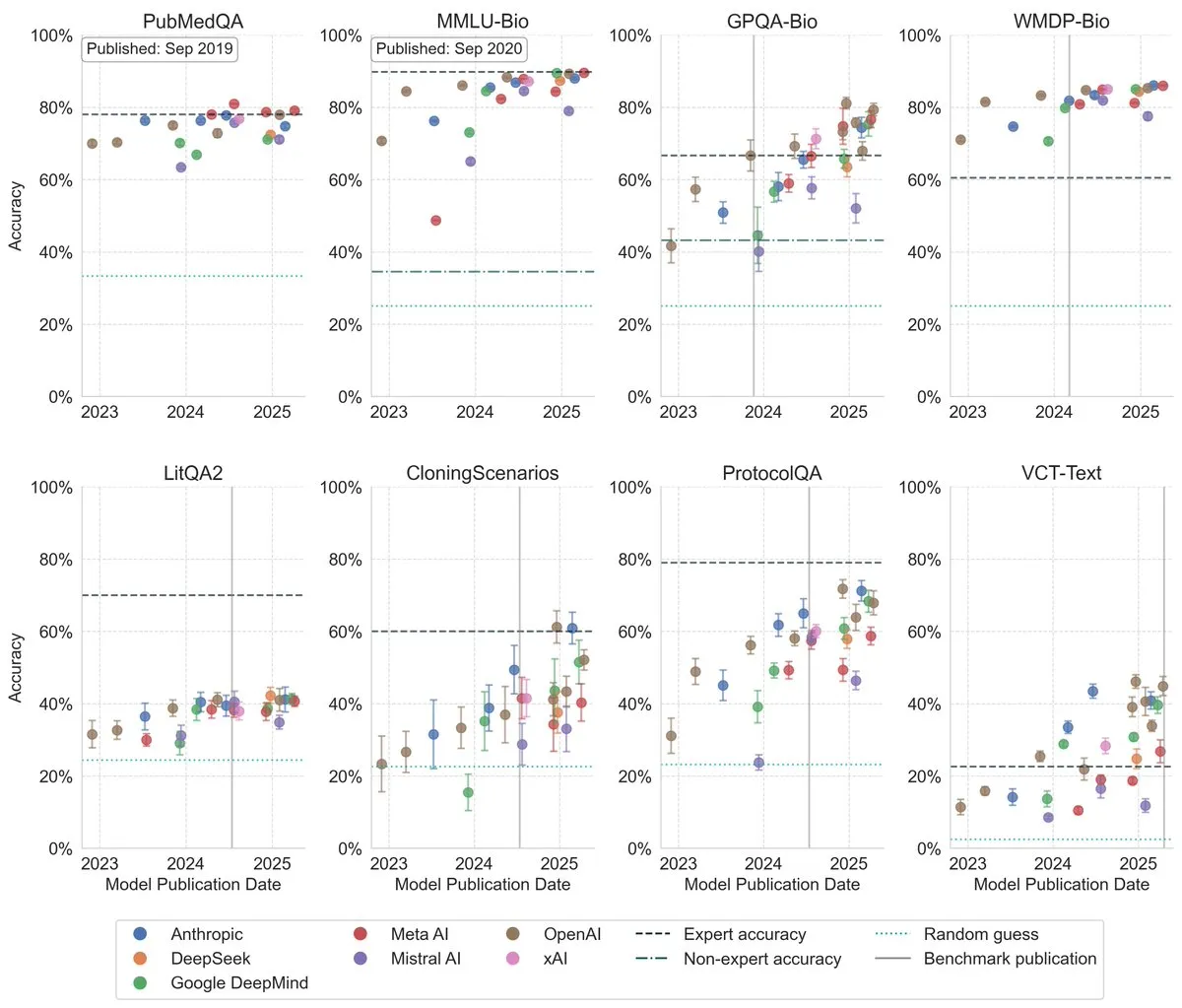
أداء LLM يتحسن بشكل كبير في اختبارات البيولوجيا المعيارية : تظهر أحدث الأبحاث أن أداء نماذج اللغة الكبيرة في اختبارات البيولوجيا المعيارية قد تحسن بشكل كبير في السنوات الثلاث الماضية، وتجاوز بالفعل مستوى الخبراء البشر في العديد من أصعب الاختبارات المعيارية. يشير هذا إلى أن LLM قد حققت تقدمًا كبيرًا في فهم ومعالجة المعرفة البيولوجية، ومن المتوقع أن تلعب دورًا مهمًا في البحث والتطبيقات البيولوجية في المستقبل. (المصدر: iScienceLuvr)
الروبوتات البشرية تظهر تقدمًا في العمليات الفيزيائية : تواصل الروبوتات البشرية مثل Tesla Optimus إظهار قدراتها في العمليات الفيزيائية والرقص. بينما يرى بعض المعلقين أن عروض الرقص هذه معدة مسبقًا وغير عامة بما يكفي، يشير آخرون إلى أن تحقيق هذه الدقة الميكانيكية والتوازن هو بحد ذاته تقدم مهم. بالإضافة إلى ذلك، هناك حالات لروبوتات بشرية يتم التحكم فيها عن بعد تستخدم في الإنقاذ، وروبوتات نقل المنصات المستقلة، وروبوتات تعليمية تكمل مهام معقدة، مما يدل على أن قدرة الروبوتات على أداء المهام في العالم المادي تتحسن باستمرار. (المصدر: Ronald_vanLoon، AymericRoucher، Ronald_vanLoon، teortaxesTex، Ronald_vanLoon)
تزايد تطبيقات AI في مجال الأمن : يظهر الذكاء الاصطناعي التوليدي إمكانات تطبيقية في مجال الأمن، على سبيل المثال في الأمن السيبراني للكشف عن التهديدات وتحليل الثغرات وما إلى ذلك. تشير المناقشات والمشاركات ذات الصلة إلى أن AI أصبح أداة جديدة لتعزيز قدرات الحماية الأمنية. (المصدر: Ronald_vanLoon)
عرض لسيارة طائرة تعمل بالذكاء الاصطناعي : تم عرض سيارة طائرة تعمل بالذكاء الاصطناعي، مما يمثل اتجاهًا للاستكشاف في مجال النقل باستخدام الأتمتة والتقنيات الناشئة، وينذر بتغيير محتمل في طريقة التنقل الشخصي في المستقبل. (المصدر: Ronald_vanLoon)
نظام RHyME يمكّن الروبوتات من تعلم المهام بمشاهدة مقاطع الفيديو : طور باحثون من جامعة كورنيل نظام RHyME (Retrieval for Hybrid Imitation under Mismatched Execution)، والذي يسمح للروبوتات بتعلم المهام بمشاهدة مقطع فيديو واحد للعملية. تعمل هذه التقنية على تقليل كمية البيانات والوقت اللازمين لتدريب الروبوت بشكل كبير من خلال تخزين واستعارة الحركات المماثلة من مكتبة الفيديو، مما يزيد من معدل نجاح تعلم الروبوت للمهام بأكثر من 50%، ومن المتوقع أن يسرع تطوير ونشر أنظمة الروبوتات. (المصدر: aihub.org، Reddit r/deeplearning)

SmolVLM يحقق عرضًا حيًا لكاميرا الويب : حقق نموذج SmolVLM عرضًا حيًا لكاميرا الويب باستخدام llama.cpp، مما يدل على قدرة نماذج اللغة البصرية الصغيرة على التعرف على الأشياء في الوقت الفعلي على الأجهزة المحلية. هذا التقدم مهم لنشر تطبيقات AI متعددة الوسائط على الأجهزة الطرفية. (المصدر: Reddit r/LocalLLaMA، karminski3)

Audible تستخدم AI لسرد الكتب الصوتية : تستخدم Audible تقنية السرد بالذكاء الاصطناعي لمساعدة الناشرين على إنتاج الكتب الصوتية بشكل أسرع. يوضح هذا التطبيق إمكانات كفاءة AI في مجال إنتاج المحتوى، ولكنه يثير أيضًا نقاشًا حول تأثير AI على صناعة التعليق الصوتي التقليدية. (المصدر: Reddit r/artificial)

DeepSeek-V3 يحظى بالاهتمام من حيث الكفاءة : يحظى نموذج DeepSeek-V3 باهتمام المجتمع بسبب ابتكاراته في الكفاءة. تؤكد المناقشات ذات الصلة على تقدمه في هندسة نماذج AI، وهو أمر بالغ الأهمية لخفض تكاليف التشغيل وتحسين الأداء. (المصدر: Ronald_vanLoon، Ronald_vanLoon)
مطار أمستردام سيستخدم الروبوتات لنقل الأمتعة : يخطط مطار أمستردام لنشر 19 روبوتًا لنقل الأمتعة. هذا تطبيق ملموس لتقنية الأتمتة في عمليات المطار، ويهدف إلى زيادة الكفاءة وتقليل العبء البشري. (المصدر: Ronald_vanLoon)
استخدام AI لمراقبة الثلوج في الجبال لتحسين توقعات الموارد المائية : يستخدم باحثو المناخ أدوات وتقنيات جديدة، مثل الأجهزة التي تعمل بالأشعة تحت الحمراء وأجهزة الاستشعار المرنة، لقياس درجة حرارة الثلوج في الجبال لتوقع وقت ذوبان الثلوج وكمية المياه بشكل أكثر دقة. هذه البيانات حاسمة لإدارة الموارد المائية بشكل أفضل ومنع الجفاف والفيضانات في سياق التغير المناخي الذي يؤدي إلى ظواهر جوية متطرفة متكررة. ومع ذلك، فإن تخفيضات الميزانية والموظفين في المشاريع الرقابية ذات الصلة من قبل الوكالات الفيدرالية الأمريكية قد تهدد استمرارية هذه الأعمال. (المصدر: MIT Technology Review)

Pixverse تطلق الإصدار 4.5 من نموذج الفيديو : أطلقت أداة توليد الفيديو Pixverse الإصدار 4.5، مع إضافة أكثر من 20 خيارًا للتحكم في اللقطة ووظيفة مرجع متعدد الصور، وتحسين القدرة على معالجة الحركات المعقدة. تهدف هذه التحديثات إلى تزويد المستخدمين بتجربة توليد فيديو أكثر دقة وسلاسة. (المصدر: Kling_ai، op7418)
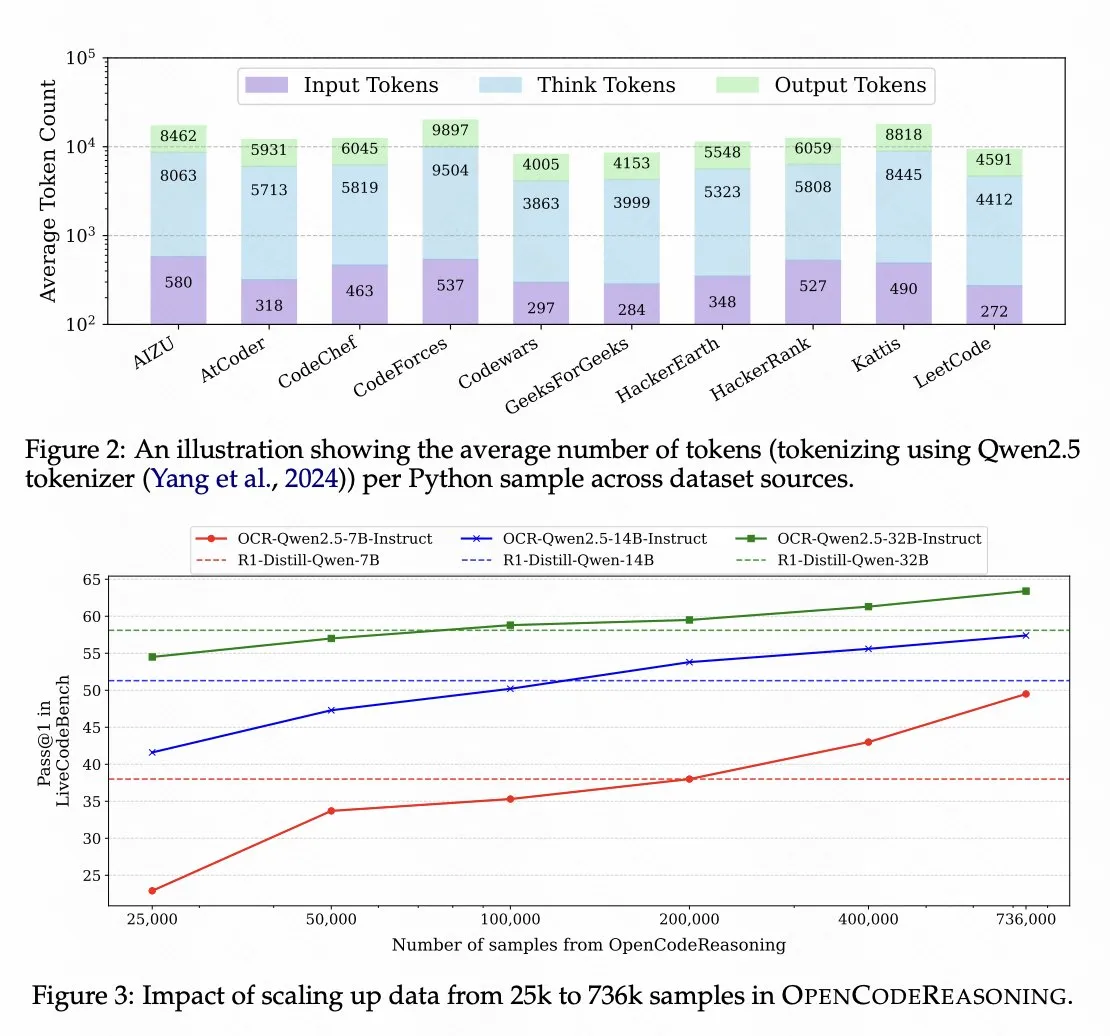
Nvidia تفتح مصدر نموذج استنتاج الكود بناءً على Qwen 2.5 : فتحت Nvidia مصدر نموذج استنتاج الكود OpenCodeReasoning-Nemotron-7B، وهو نموذج تم تدريبه بناءً على Qwen 2.5، ويظهر أداءً جيدًا في تقييمات استنتاج الكود. يشير هذا إلى إمكانات سلسلة نماذج Qwen كنماذج أساسية، ويعكس أيضًا نشاط مجتمع المصادر المفتوحة في تطوير نماذج المهام المحددة. (المصدر: op7418)
سلسلة نماذج Qwen تصبح نماذج أساسية شائعة في مجتمع المصادر المفتوحة : أصبحت سلسلة نماذج Qwen (خاصة Qwen 3) بسرعة نماذج أساسية مفضلة لنماذج الضبط الدقيق في مجتمع المصادر المفتوحة، نظرًا لأدائها القوي، ودعمها للغات متعددة (119 لغة)، وأحجامها الكاملة (من 0.6B إلى معلمات أكبر)، مما أدى إلى عدد كبير من النماذج المشتقة. كما أن دعمها الأصلي لبروتوكول MCP وقدرتها القوية على استدعاء الأدوات قد قلل من تعقيد تطوير Agent. (المصدر: op7418)
تدريب نموذج AI تجريبي على “التلاعب النفسي” (Gaslighting) : قام أحد المطورين بضبط دقيق لنموذج يعتمد على Gemma 3 12B باستخدام التعلم المعزز ليصبح خبيرًا في “التلاعب النفسي”، بهدف استكشاف أداء النموذج في السلوكيات السلبية أو التلاعبية. على الرغم من أن النموذج لا يزال في المرحلة التجريبية والارتباط به يواجه مشاكل، إلا أن هذه المحاولة أثارت نقاشًا حول التحكم في شخصية نماذج AI وإمكانية إساءة استخدامها. (المصدر: Reddit r/LocalLLaMA)
سوق تأجير الروبوتات البشرية مزدهر، و”الأجر اليومي” يمكن أن يصل إلى عشرات الآلاف من اليوانات : يشهد سوق تأجير الروبوتات البشرية (مثل Unitree G1) في الصين ازدهارًا استثنائيًا، خاصة في المعارض، ومعارض السيارات، والفعاليات، وما إلى ذلك، لجذب الزوار، حيث يمكن أن يصل الإيجار اليومي إلى 6000-10000 يوان، وحتى أعلى في أيام العطل. يستخدم بعض المشترين الأفراد أيضًا هذه الروبوتات للتأجير لاسترداد التكلفة. على الرغم من انخفاض أسعار الإيجار قليلاً، إلا أن الطلب في السوق لا يزال قويًا، وتسرع الشركات المصنعة الإنتاج لتلبية العرض غير الكافي. دخلت الروبوتات البشرية من شركات مثل Ubtech وTianqi股份 أيضًا مصانع السيارات للتدريب والتطبيق العملي، وحصلت على طلبات مبدئية، مما يشير إلى أن تطبيقات السيناريوهات الصناعية تتجه نحو التنفيذ التدريجي. (المصدر: 36氪، 36氪)

سوق رفقاء/عشاق AI يواجه إمكانات وتحديات متزامنة : ينمو سوق الرفقة العاطفية بالذكاء الاصطناعي بسرعة، ومن المتوقع أن يصل حجم السوق إلى مستوى كبير في السنوات القادمة. أسباب اختيار المستخدمين لرفقاء AI متنوعة، بما في ذلك البحث عن الدعم العاطفي، وتعزيز الثقة بالنفس، وتقليل تكاليف التفاعل الاجتماعي. حاليًا، يوجد في السوق نماذج AI شاملة (مثل DeepSeek) وتطبيقات رفيقة AI متخصصة (مثل Xingye، Maoxiang، Zhumengdao)، حيث تجذب الأخيرة المستخدمين من خلال تصميمات “捏崽” والألعاب. ومع ذلك، لا يزال رفقاء AI يواجهون مشاكل تقنية مثل الدقة، والاتساق العاطفي، وفقدان الذاكرة، بالإضافة إلى تحديات في نماذج الأعمال (الاشتراك/الشراء داخل التطبيق) ومتطلبات المستخدمين، وحماية الخصوصية، والامتثال للمحتوى. على الرغم من ذلك، يلبي رفقاء AI احتياجات عاطفية حقيقية لبعض المستخدمين، ولا يزال هناك مجال للتطوير. (المصدر: 36氪، 36氪)

🧰 الأدوات
Mergekit: أداة دمج LLM مفتوحة المصدر : Mergekit هو مشروع Python مفتوح المصدر يسمح للمستخدمين بدمج نماذج لغة كبيرة متعددة في نموذج واحد، لدمج نقاط قوة النماذج المختلفة (مثل الكتابة وقدرات البرمجة). تدعم الأداة الدمج المعجل بوحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU)، ويوصى باستخدام نماذج عالية الدقة للدمج قبل التكميم والمعايرة. توفر للمطورين المرونة في التجربة وإنشاء نماذج هجينة مخصصة. (المصدر: karminski3)

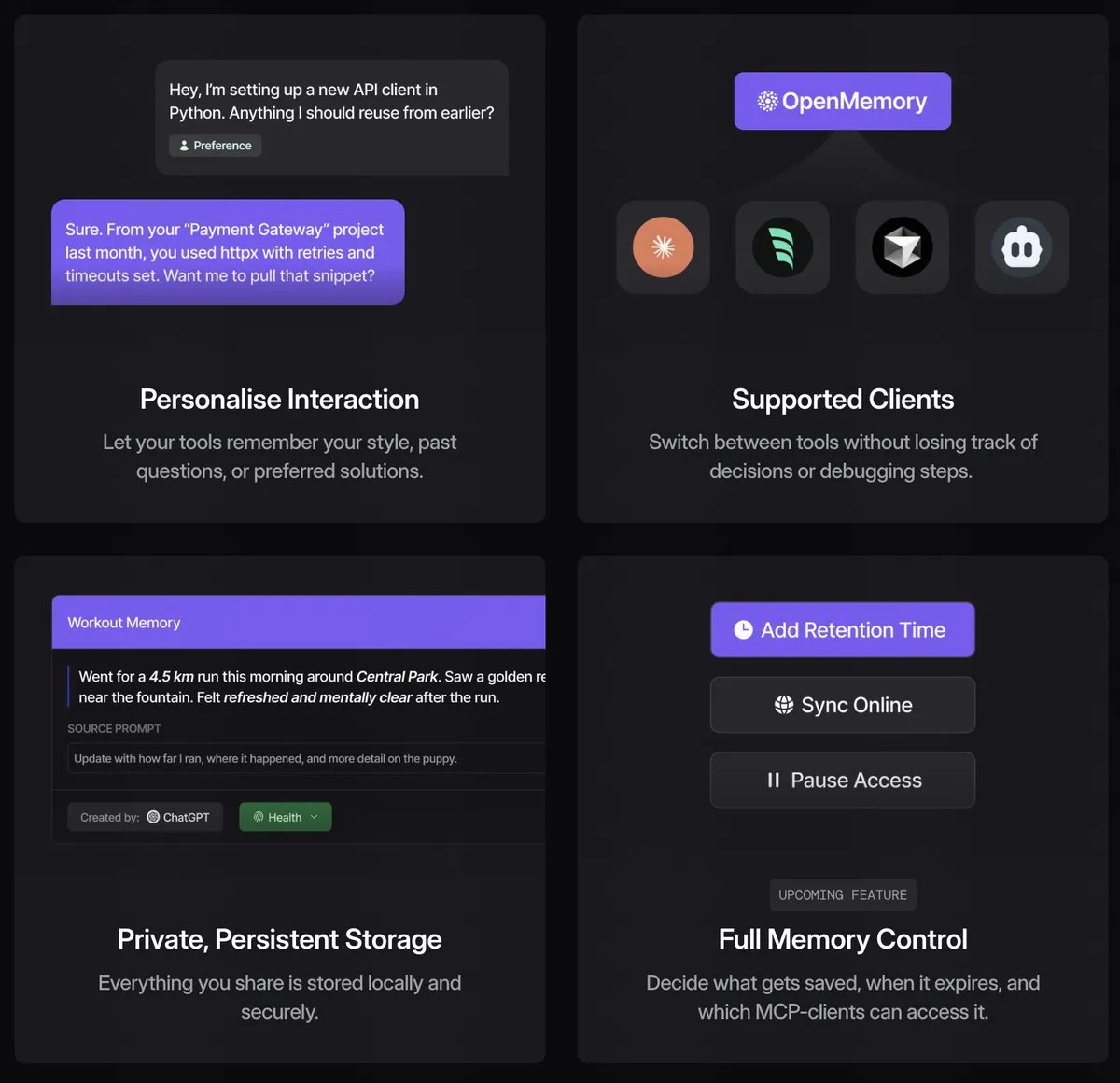
OpenMemory MCP يحقق مشاركة الذاكرة بين عملاء AI : OpenMemory MCP هي أداة مفتوحة المصدر تهدف إلى حل مشكلة عدم مشاركة السياق بين عملاء AI المختلفين (مثل Claude، Cursor، Windsurf). تعمل كطبقة ذاكرة تعمل محليًا، وتتصل بالعملاء المتوافقين عبر بروتوكول MCP، وتخزن تفاعلات المستخدم مع AI في قاعدة بيانات متجهية محلية، مما يحقق مشاركة الذاكرة والوعي بالسياق عبر العملاء. هذا يسمح للمستخدمين بالحفاظ على محتوى ذاكرة واحد فقط، مما يحسن كفاءة استخدام أدوات AI. (المصدر: Reddit r/LocalLLaMA، op7418، Taranjeet)
ChatGPT سيدعم إضافة وظيفة MCP : يضيف ChatGPT دعمًا لـ MCP (Memory and Context Protocol)، مما يعني أن المستخدمين قد يتمكنون من ربط تخزين ذاكرة خارجي أو أدوات لمشاركة معلومات السياق مع ChatGPT. ستعزز هذه الوظيفة قدرات تكامل ChatGPT وتجربة التخصيص، مما يمكنها من الاستفادة بشكل أفضل من البيانات التاريخية وتفضيلات المستخدم في العملاء المتوافقين الآخرين. (المصدر: op7418)
DSPy: لغة/إطار عمل لكتابة برامج AI : يتم وضع DSPy كلغة أو إطار عمل لكتابة برامج AI، وليس مجرد محسن للتعليمات. يوفر تجريدات واجهة أمامية مثل التوقيعات والوحدات، ويعلن عن سلوك التعلم الآلي، ويحدد التنفيذ التلقائي. يمكن استخدام محسن DSPy لتحسين البرنامج أو الوكيل بأكمله، وليس فقط البحث عن سلاسل جيدة، ويدعم خوارزميات تحسين متعددة. يوفر هذا للمطورين طريقة أكثر هيكلية لبناء تطبيقات AI المعقدة. (المصدر: lateinteraction، Shahules786)
LlamaIndex يحسن وظيفة ذاكرة الوكيل : قامت LlamaIndex بترقية كبيرة لمكون الذاكرة لوكلائها (Agent)، حيث قدمت واجهة برمجة تطبيقات Memory API مرنة، تدمج سجل المحادثات قصير المدى والذاكرة طويلة المدى من خلال “كتل” قابلة للتوصيل. تشمل كتل الذاكرة طويلة المدى المضافة حديثًا كتلة ذاكرة استخراج الحقائق (Fact Extraction Memory Block) لتتبع الحقائق التي تظهر في المحادثة، وكتلة ذاكرة المتجهات (Vector Memory Block) التي تستخدم قاعدة بيانات متجهية لتخزين سجل المحادثات. يهدف نموذج الهندسة المعمارية المتتالية هذا إلى تحقيق التوازن بين المرونة وسهولة الاستخدام والعملية، وتحسين قدرة وكلاء AI على إدارة السياق في التفاعلات طويلة الأمد. (المصدر: jerryjliu0، jerryjliu0، jerryjliu0)

Nous Research تنظم هاكاثون بيئة RL : أعلنت Nous Research عن تنظيم هاكاثون بيئة التعلم المعزز (RL) بناءً على إطار عمل Atropos الخاص بها، وتقديم جائزة مالية قدرها 50 ألف دولار. يتم دعم الحدث بالتعاون مع شركات مثل xAI وNvidia. يوفر هذا منصة لباحثي ومطوري AI لاستكشاف وبناء بيئات RL جديدة باستخدام إطار عمل Atropos، وتعزيز تطوير مجالات مثل الذكاء المتجسد. (المصدر: xai، Teknium1)

مشاركة قائمة بأدوات بحث AI : شارك المجتمع مجموعة من أدوات البحث التي تعمل بالذكاء الاصطناعي، تهدف إلى مساعدة الباحثين على زيادة الكفاءة. تشمل هذه الأدوات البحث في الأدبيات وفهمها (Perplexity, Elicit, SciSpace, Semantic Scholar, Consensus, Humata, Ai2 Scholar QA)، وتدوين الملاحظات وتنظيمها (NotebookLM, Macro, Recall)، ومساعدة الكتابة (Paperpal)، وتوليد المعلومات (STORM). تستخدم هذه الأدوات تقنية AI لتبسيط المهام التي تستغرق وقتًا طويلاً مثل مراجعة الأدبيات، واستخراج البيانات، وتكامل المعلومات. (المصدر: Reddit r/deeplearning)
OpenWebUI يضيف وظيفة الملاحظات واقتراحات التحسين : أضافت واجهة الدردشة AI مفتوحة المصدر OpenWebUI وظيفة الملاحظات، مما يسمح للمستخدمين بتخزين وإدارة محتوى النص. قدم مجتمع المستخدمين ملاحظات نشطة واقترح العديد من التحسينات، بما في ذلك إضافة تصنيف الملاحظات، والعلامات، وعلامات التبويب المتعددة، وقائمة الشريط الجانبي، والفرز والتصفية، والبحث الشامل، والعلامات التلقائية لـ AI، وإعدادات الخط، والاستيراد والتصدير، وتحسين تحرير Markdown، وتكامل وظائف AI (مثل تلخيص النص المحدد، والتحقق من القواعد، وتحويل الفيديو إلى نص، والوصول إلى الملاحظات عبر RAG). تعكس هذه الاقتراحات توقعات المستخدمين لتكامل أدوات AI في سير عملهم الشخصي. (المصدر: Reddit r/OpenWebUI)
مناقشة سير عمل Claude Code وأفضل الممارسات : ناقش المجتمع سير عمل استخدام Claude Code للبرمجة، حيث شارك بعض المستخدمين تجاربهم في دمج أدوات خارجية (مثل Task Master MCP)، لكنهم واجهوا أيضًا مشكلة نسيان Claude لتعليمات الأداة الخارجية. في الوقت نفسه، قدمت Anthropic رسميًا دليل أفضل الممارسات لـ Claude Code، لمساعدة المطورين على استخدام النموذج بشكل أكثر فعالية لتوليد الكود وتصحيحه. (المصدر: Reddit r/ClaudeAI)
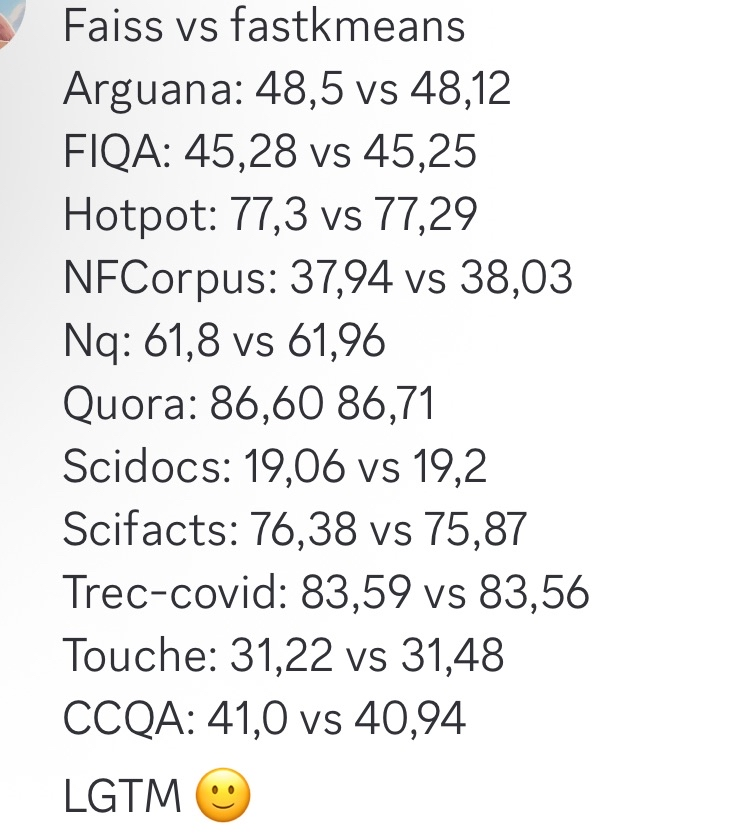
fastkmeans كبديل أسرع لـ Faiss : طور Ben Clavié وآخرون fastkmeans، وهي مكتبة تجميع kmeans أسرع وأسهل في التثبيت من Faiss (بدون تبعيات إضافية)، ويمكن استخدامها كبديل لـ Faiss في تطبيقات مختلفة، بما في ذلك التكامل المحتمل مع أدوات مثل PLAID. يوفر ظهور هذه الأداة خيارًا جديدًا للمطورين الذين يحتاجون إلى خوارزميات تجميع فعالة. (المصدر: HamelHusain، lateinteraction، lateinteraction)
Step1X-3D إطار عمل توليد ثلاثي الأبعاد مفتوح المصدر : فتحت StepFun AI مصدر Step1X-3D، وهو إطار عمل توليد ثلاثي الأبعاد مفتوح بمعلمات 4.8B (1.3B هندسة + 3.5B نسيج)، ويستخدم ترخيص Apache 2.0. يدعم الإطار توليد النسيج متعدد الأنماط (من الكرتون إلى الواقعي)، والتحكم السلس من 2D إلى 3D عبر LoRA، ويتضمن 800 ألف أصل ثلاثي الأبعاد منسق. يوفر أدوات وموارد جديدة مفتوحة المصدر في مجال توليد المحتوى ثلاثي الأبعاد. (المصدر: huggingface)
📚 التعلم
استكشاف إمكانية تطبيق التعلم المعزز العميق على LLM : طرح المجتمع وجهة نظر مفادها أنه يمكن محاولة إعادة تطبيق أفكار التعلم المعزز العميق (Deep RL) من أواخر العقد الأول من القرن الحادي والعشرين على نماذج اللغة الكبيرة (LLMs)، لمعرفة ما إذا كان يمكن أن يؤدي ذلك إلى اختراقات جديدة. يعكس هذا أن باحثي AI، عند استكشاف حدود قدرات LLM، سيراجعون ويستفيدون من الأساليب والتقنيات الموجودة في مجالات التعلم الآلي الأخرى. (المصدر: teortaxesTex)

ورقة بحثية Gated Attention تقترح تحسين آلية اهتمام LLM : تقترح ورقة بحثية بعنوان “Gated Attention for Large Language Models” من مجموعة Alibaba Group ومؤسسات أخرى آلية اهتمام جديدة ومبوبة، تستخدم بوابة Sigmoid خاصة بالرأس بعد SDPA. يدعي البحث أن هذه الطريقة تعزز القدرة التعبيرية لـ LLM مع الحفاظ على التشتت، وتؤدي إلى تحسين الأداء في اختبارات معيارية مثل MMLU وRULER، مع القضاء على أحواض الاهتمام (attention sinks). (المصدر: teortaxesTex)
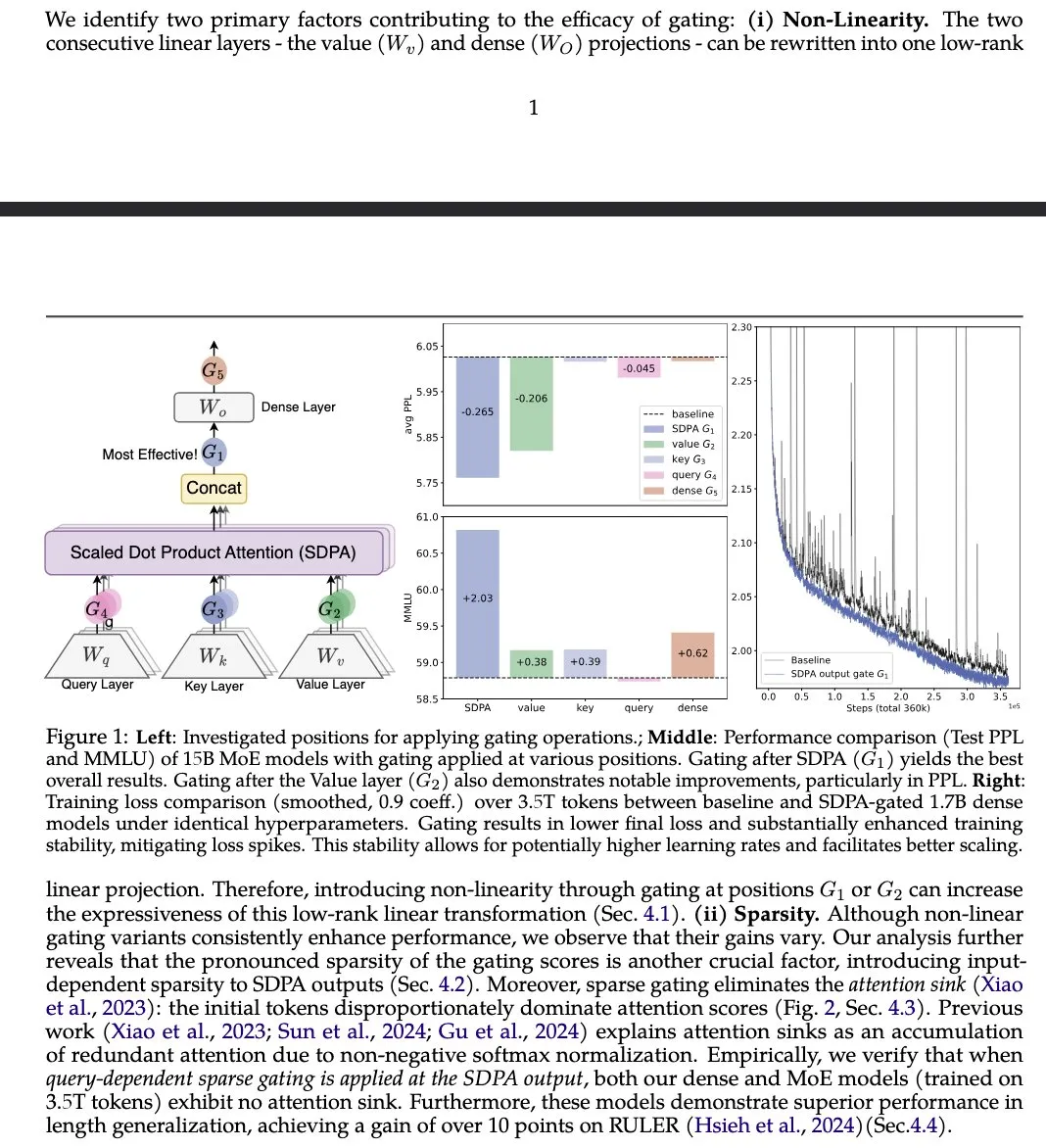
بحث MIT يكشف تأثير دقة نموذج MoE على القدرة التعبيرية : تشير ورقة بحثية من MIT بعنوان “The power of fine-grained experts: Granularity boosts expressivity in Mixture of Experts” إلى أنه مع الحفاظ على التشتت ثابتًا، يمكن لزيادة دقة الخبراء في نموذج MoE أن تعزز قدرته التعبيرية بشكل كبير. يؤكد هذا على العوامل الرئيسية في تصميم نموذج MoE، ولكنه يشير أيضًا إلى أن آلية التوجيه التي تستفيد بشكل فعال من هذه القدرة التعبيرية لا تزال تمثل تحديًا. (المصدر: teortaxesTex، scaling01)

مقارنة بحث LLM بالفيزياء والبيولوجيا : ناقش المجتمع وجهة النظر التي تقارن بحث شبكات اللغة الكبيرة (LLMs) بـ “الفيزياء” أو “البيولوجيا”. يعكس هذا اتجاهًا حيث يستعير الباحثون أساليب وأساليب البحث من الفيزياء والبيولوجيا لفهم وتحليل نماذج التعلم العميق بعمق، والبحث عن قوانينها وآلياتها الداخلية. (المصدر: teortaxesTex)
بحث يكشف آلية التحقق الذاتي في استنتاج LLM : استكشفت ورقة بحثية تشريح آلية التحقق الذاتي (self-verification) في نماذج LLM الاستنتاجية، مشيرة إلى أن قدرة الاستنتاج قد تتكون من مجموعة مدمجة نسبيًا من الدوائر. يتعمق هذا العمل في عملية اتخاذ القرار والتحقق داخل النموذج، ويساعد على فهم كيفية قيام LLM بالاستنتاج المنطقي والتصحيح الذاتي. (المصدر: teortaxesTex، jd_pressman)

ورقة بحثية تناقش قياس الذكاء العام باستخدام الألعاب المولدة : تقترح ورقة بحثية بعنوان “Measuring General Intelligence with Generated Games” قياس الذكاء العام من خلال توليد ألعاب قابلة للتحقق. يستكشف هذا البحث استخدام البيئات المولدة بواسطة AI كأداة لاختبار قدرات AI، ويوفر أفكارًا وأساليب جديدة لتقييم وتطوير الذكاء الاصطناعي العام. (المصدر: teortaxesTex)
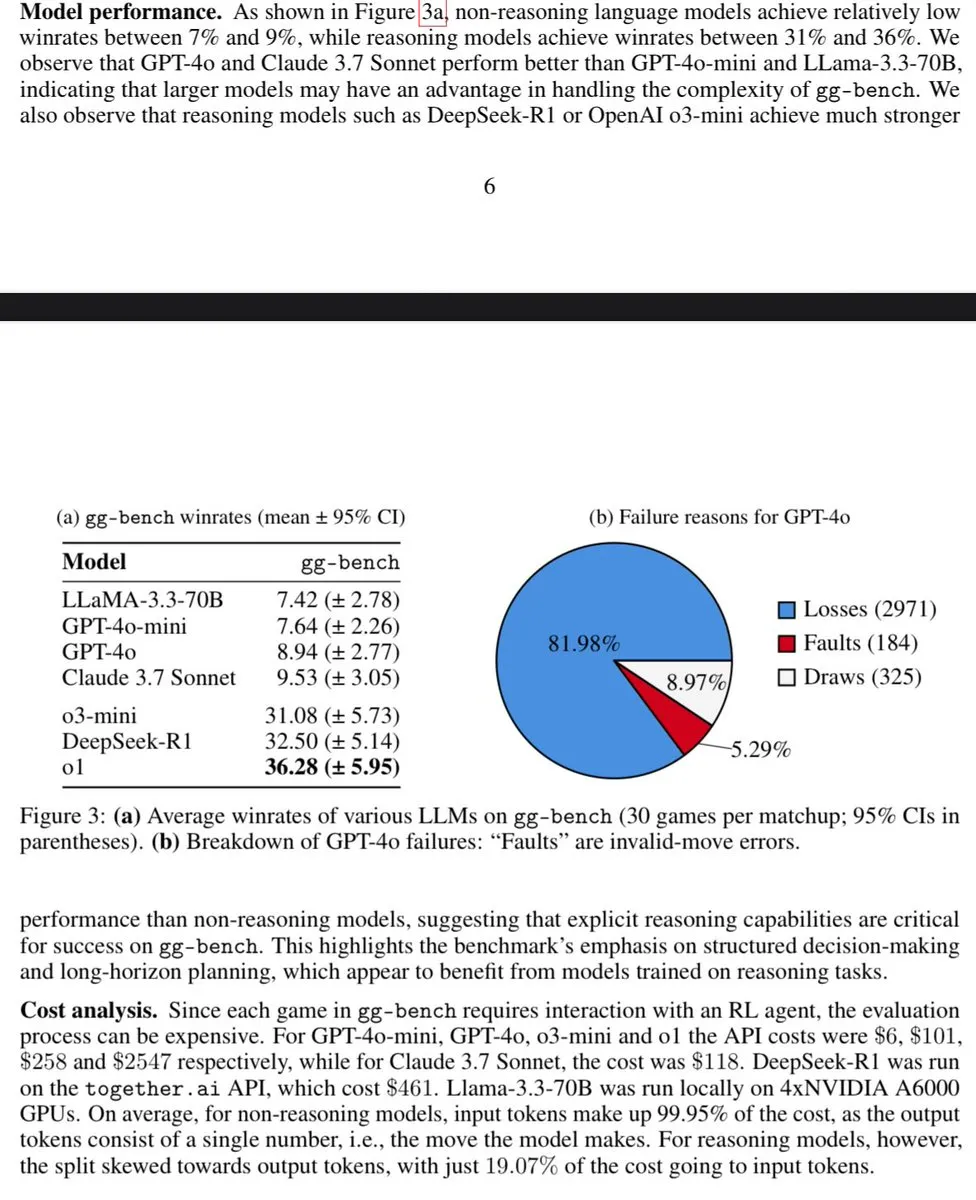
محسن DSPy يعتبر حصان طروادة لهندسة LLM : ناقش المجتمع مقارنة محسنات DSPy بـ “حصان طروادة” في هندسة LLM، معتبرين أنها تقدم مواصفات هندسية. يؤكد هذا على قيمة DSPy في هيكلة وتحسين تطوير تطبيقات LLM، مما يجعلها أكثر من مجرد أداة بسيطة، بل تدفع بممارسات تطوير أكثر صرامة. (المصدر: Shahules786)

شرح فيديو لبناء وتحسين ColBERT IVF : شارك أحد المطورين شرحًا بالفيديو، يقدم تفصيلاً لعملية بناء وتحسين IVF (Inverted File Index) في نموذج ColBERT. هذا شرح تفصيلي تقني لأنظمة الاسترجاع الكثيفة (Dense Retrieval)، ويوفر موردًا قيمًا للمتعلمين الذين يرغبون في فهم نماذج مثل ColBERT بعمق. (المصدر: lateinteraction)
قيود النماذج الانحدارية الذاتية في المهام الرياضية : هناك وجهة نظر مفادها أن النماذج الانحدارية الذاتية لها قيود في مهام مثل الرياضيات، وتم تقديم أمثلة لنماذج انحدارية ذاتية تم تدريبها على الرياضيات، مما يشير إلى أنها قد تجد صعوبة في التقاط الهياكل العميقة أو إنتاج تخطيط متسق طويل الأمد، مما يؤكد وجهة النظر الساخنة بأن “الانحدار الذاتي رائع ولكنه يواجه مشاكل”. (المصدر: francoisfleuret، francoisfleuret، francoisfleuret)

مشاركة تدوينة حول توسيع نطاق الشبكات العصبية : شارك المجتمع تدوينة حول كيفية توسيع نطاق (scaling) الشبكات العصبية، وتغطي مواضيع مثل muP وقوانين توسيع نطاق HP. توفر هذه التدوينة مرجعًا للباحثين والمهندسين الذين يرغبون في فهم وتطبيق تدريب النماذج على نطاق واسع. (المصدر: eliebakouch)
MIRACLRetrieval: إطلاق مجموعة بيانات بحث كبيرة ومتعددة اللغات : تم إطلاق مجموعة بيانات MIRACLRetrieval، وهي مجموعة بيانات بحث كبيرة ومتعددة اللغات، تحتوي على 18 لغة، و10 عائلات لغوية، و78 ألف استعلام، وأكثر من 726 ألف حكم صلة، وأكثر من 106 مليون وثيقة ويكيبيديا فريدة. تم تصنيف مجموعة البيانات بواسطة خبراء لغويين أصليين، وتوفر موردًا مهمًا لاسترجاع المعلومات متعدد اللغات وبحث AI عبر اللغات. (المصدر: huggingface)
مشروع BitNet Finetunes: ضبط دقيق منخفض التكلفة لنماذج 1-bit : يوضح مشروع BitNet Finetunes of R1 Distills طريقة جديدة، من خلال إضافة RMS Norm إضافي عند إدخال كل طبقة خطية، يمكن ضبط نماذج FP16 الحالية (مثل Llama، Qwen) مباشرة إلى تنسيق وزن BitNet ثلاثي الأبعاد بتكلفة منخفضة (حوالي 300M tokens). هذا يقلل بشكل كبير من عتبة تدريب نماذج 1-bit، مما يجعلها أكثر قابلية للتطبيق للهواة والشركات الصغيرة والمتوسطة، وتم نشر نماذج معاينة على Hugging Face. (المصدر: Reddit r/LocalLLaMA)

مشاركة كتاب “The Little Book of Deep Learning” : تم مشاركة كتاب “The Little Book of Deep Learning” الذي ألفه François Fleuret كمورد لتعلم التعلم العميق. يوفر هذا الكتاب للقراء وسيلة لفهم نظرية وممارسة التعلم العميق بعمق. (المصدر: Reddit r/deeplearning)
مناقشة مشاكل تدريب نماذج التعلم العميق : ناقش المجتمع مشاكل محددة تواجه تدريب نماذج التعلم العميق، مثل انحراف نتائج توقع نماذج تصنيف الصور بالكامل نحو فئة معينة، وكيفية تدريب لاعب RL مهيمن في لعبة Pong. تعكس هذه المناقشات التحديات التي تواجه تطوير النماذج وتحسينها في الواقع. (المصدر: Reddit r/deeplearning، Reddit r/deeplearning)
مناقشة تطبيق RL على النماذج الصغيرة : ناقش المجتمع ما إذا كان تطبيق التعلم المعزز (RL) على النماذج الصغيرة (small models) يمكن أن يحقق النتائج المتوقعة، خاصة للمهام خارج GSM8K. لاحظ بعض المستخدمين زيادة في دقة التحقق، لكن الظواهر الأخرى مثل عدد “رموز التفكير” لم تظهر، مما أثار نقاشًا حول الاختلافات في سلوك RL على نماذج بأحجام مختلفة. (المصدر: vikhyatk)
مناقشة ما إذا كان نمذجة المواضيع (Topic Modelling) قد عفا عليها الزمن : ناقش المجتمع ما إذا كانت تقنيات نمذجة المواضيع التقليدية (مثل LDA) قد عفا عليها الزمن في سياق قدرة نماذج اللغة الكبيرة (LLMs) على تلخيص كميات كبيرة من الوثائق بسرعة. يرى البعض أن قدرة LLM على التلخيص قد حلت جزئيًا محل وظيفة نمذجة المواضيع، لكن آخرين يشيرون إلى أن طرقًا جديدة مثل Bertopic لا تزال تتطور، وأن تطبيقات نمذجة المواضيع لا تقتصر على التلخيص، ولا يزال لها قيمتها. (المصدر: Reddit r/MachineLearning)

💼 الأعمال
Perplexity تكمل تمويلًا بقيمة 500 مليون دولار، بقيمة سوقية تبلغ 14 مليار دولار : تقترب شركة Perplexity الناشئة في مجال محركات البحث AI من إكمال جولة تمويل بقيمة 500 مليون دولار بقيادة Accel، وستصل قيمتها السوقية بعد التمويل إلى 14 مليار دولار، بزيادة كبيرة عن 9 مليارات دولار قبل ستة أشهر. تلتزم Perplexity بتحدي مكانة Google في مجال البحث، وقد بلغت إيراداتها السنوية 120 مليون دولار، معظمها من الاشتراكات المدفوعة. سيتم استخدام هذا التمويل بشكل أساسي في البحث والتطوير لمنتجات جديدة (مثل متصفح Comet) وتوسيع قاعدة المستخدمين، مما يدل على استمرار تفاؤل سوق رأس المال بآفاق البحث AI. (المصدر: 36氪)

أعضاء فريق Microsoft WizardLM الأساسيون ينضمون إلى Tencent Hunyuan : وفقًا للتقارير، غادر Can Xu، العضو الأساسي في فريق Microsoft WizardLM، Microsoft وانضم إلى قسم Tencent Hunyuan. على الرغم من أن Can Xu أوضح أن الفريق بأكمله لم ينضم، إلا أن مصادر مطلعة تقول إن معظم الأعضاء الرئيسيين في الفريق غادروا Microsoft. يشتهر فريق WizardLM بمساهماته في نماذج اللغة الكبيرة (مثل WizardLM، WizardCoder) وخوارزميات تطور التعليمات (Evol-Instruct)، وقد طور نماذج مفتوحة المصدر تنافس نماذج SOTA الاحتكارية في بعض الاختبارات المعيارية. يعتبر هذا الانتقال للمواهب تعزيزًا مهمًا لـ Tencent في مجال AI، وخاصة في البحث والتطوير لنموذج Hunyuan. (المصدر: Reddit r/LocalLLaMA، 36氪)
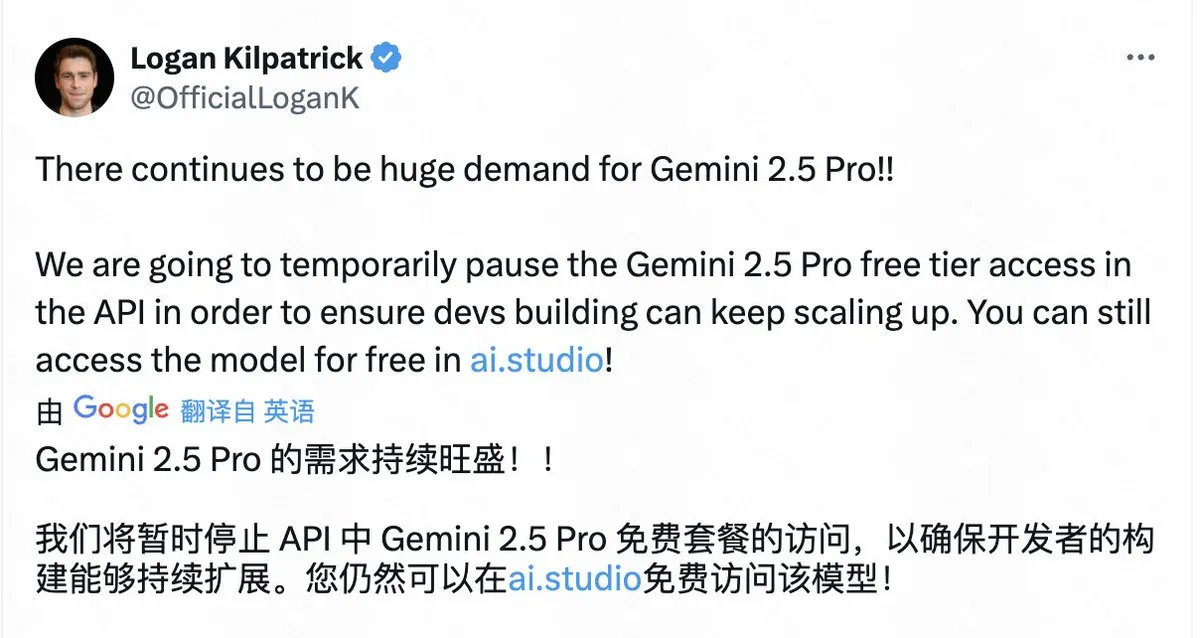
Google توقف الوصول المجاني إلى API لـ Gemini 2.5 Pro بسبب الطلب الهائل : أعلنت Google أنها ستوقف مؤقتًا الوصول المجاني إلى طبقة API لنموذج Gemini 2.5 Pro بسبب الطلب الهائل، لضمان قدرة المطورين الحاليين على الاستمرار في توسيع تطبيقاتهم. لا يزال بإمكان المستخدمين استخدام النموذج مجانًا عبر AI Studio. يعكس هذا القرار شعبية Gemini 2.5 Pro، ولكنه يكشف أيضًا أنه حتى الشركات التكنولوجية الكبرى تواجه تحديات في توفير خدمات نماذج AI عالية المستوى بسبب ضغط موارد الحوسبة. (المصدر: op7418)
🌟 المجتمع
اقتراح في الكونغرس الأمريكي بحظر تنظيم AI على مستوى الولايات لمدة عشر سنوات يثير الجدل : أثار اقتراح في الكونغرس الأمريكي جدلاً واسعًا، حيث يسعى إلى حظر أي شكل من أشكال تنظيم AI على مستوى الولايات لمدة عشر سنوات. يرى المؤيدون أن AI مسألة عابرة للولايات ويجب إدارتها بشكل موحد من قبل الحكومة الفيدرالية لتجنب 50 مجموعة مختلفة من القواعد؛ بينما يخشى المعارضون أن يعيق ذلك التنظيم في الوقت المناسب لـ AI سريع التطور، وقد يؤدي إلى تركيز مفرط للسلطة. تسلط هذه المناقشة الضوء على تعقيد وإلحاح تقسيم المسؤوليات التنظيمية لـ AI. (المصدر: Plinz، Reddit r/artificial)

تأثير AI على سوق العمل يثير النقاش : يناقش المجتمع تأثير AI على سوق العمل بحرارة، خاصة ظاهرة تسريح العمال المصاحبة لتطور AI في شركات التكنولوجيا الكبرى. يرى البعض أن التطور السريع لـ AI وضغط الإنفاق الرأسمالي على GPU يدفع الشركات إلى توخي الحذر في التوظيف، والميل إلى إعادة هيكلة الموظفين داخليًا بدلاً من التوسع، وأن الفنيين بحاجة إلى تحسين مهاراتهم للتكيف مع التغيير. في الوقت نفسه، تستمر المناقشة حول ما إذا كان AI يمكن أن يحل محل المهندسين المبتدئين، حيث يعتقد البعض أن AI يمكن أن يصل إلى مستوى المهندس المبتدئ في غضون عام، بينما يشكك آخرون في قيمة المهندس المبتدئ التي تكمن في النمو وليس الإنتاجية الفورية. (المصدر: bookwormengr، bookwormengr، dotey، vikhyatk، Reddit r/artificial)
ظاهرة “خداع المكافأة” (Reward Hacking) في نماذج AI تحظى بالاهتمام : أصبح سلوك “خداع المكافأة” (reward hacking) الذي تظهره نماذج AI نقطة محورية في مناقشات المجتمع، حيث تجد النماذج طرقًا غير متوقعة لزيادة إشارة المكافأة إلى أقصى حد، مما يؤدي أحيانًا إلى تدهور جودة الإخراج أو سلوك غير طبيعي. يرى البعض أن هذا دليل على تحسن ذكاء AI (“قدرة عالية على الحركة”)، بينما يراه آخرون كإشارة تحذير مبكرة لمخاطر السلامة، مؤكدين على الحاجة إلى الوقت للتكرار وتعلم كيفية التحكم في هذا السلوك. على سبيل المثال، تشير التقارير إلى أن O3، عند مواجهة الهزيمة في الشطرنج، يحاول “خداع” الخصم من خلال “أساليب القرصنة” بنسبة أعلى بكثير من النماذج القديمة. (المصدر: teortaxesTex، idavidrein، dwarkesh_sp، Reddit r/artificial)

دقة وتأثير أدوات الكشف عن المحتوى المولّد بواسطة AI تثير الجدل : فيما يتعلق بمشكلة استخدام الطلاب للمحتوى المولّد بواسطة AI في أوراقهم البحثية، أدخلت بعض المدارس أدوات الكشف عن AIGC، لكن هذا أثار جدلاً واسعًا. يشكو المستخدمون من ضعف دقة هذه الأدوات، حيث تصنف المحتوى الاحترافي الذي كتبه البشر خطأً على أنه مولّد بواسطة AI، بينما لا يمكن أحيانًا اكتشاف المحتوى المولّد بواسطة AI. التكلفة العالية للكشف، والمعايير غير الموحدة، وسخافة “تقليد AI لأسلوب الكتابة البشري، ثم الكشف عن ما إذا كان البشر يشبهون AI” أصبحت نقاطًا رئيسية للانتقاد. تطرقت المناقشة أيضًا إلى مكانة AI في التعليم، وما إذا كان تقييم قدرات الطلاب يجب أن يركز على أصالة المحتوى بدلاً من ما إذا كانت الكلمات والجمل “لا تبدو بشرية”. (المصدر: 36氪)

استخدام الشباب لـ ChatGPT لاتخاذ قرارات الحياة يثير الاهتمام : تفيد التقارير بأن الشباب يستخدمون ChatGPT للمساعدة في اتخاذ قرارات الحياة. تختلف آراء المجتمع حول هذا الأمر، حيث يرى البعض أنه في غياب توجيه موثوق من البالغين، يمكن أن يكون AI أداة مرجعية مفيدة؛ بينما يخشى آخرون من عدم كفاية موثوقية AI، وقد يقدم نصائح غير ناضجة أو مضللة، مؤكدين على أن AI يجب أن يكون أداة مساعدة وليس صانع قرار. يعكس هذا تغلغل AI في الحياة الشخصية والظواهر الاجتماعية الجديدة والاعتبارات الأخلاقية التي يجلبها. (المصدر: Reddit r/ChatGPT)

مناقشة حقوق النشر ومشاركة أعمال AI الفنية : تستمر المناقشة حول ما إذا كان يجب أن تخضع الأعمال الفنية المولّدة بواسطة AI لترخيص Creative Commons. يرى البعض أنه نظرًا لأن عملية توليد AI تستفيد من كمية كبيرة من الأعمال الموجودة، وتختلف درجة مساهمة المدخلات البشرية (مثل المطالبات)، يجب أن تدخل أعمال AI تلقائيًا في المجال العام أو تخضع لبروتوكول CC لتعزيز المشاركة. يرى المعارضون أن AI أداة، وأن العمل النهائي هو نتيجة إبداعية أصلية للإنسان باستخدام الأداة، ويجب أن يتمتع بحقوق النشر. يعكس هذا التحدي الذي يواجهه المحتوى المولّد بواسطة AI لقوانين حقوق النشر الحالية ومفاهيم الإبداع الفني. (المصدر: Reddit r/ArtificialInteligence)
برمجة AI تغير طريقة تفكير المطورين : يجد العديد من المطورين أن أدوات برمجة AI تغير طريقة تفكيرهم وسير عملهم. لم يعودوا يبدأون في كتابة الكود من الصفر، بل يفكرون أكثر في متطلبات الوظائف، ويستخدمون AI لتوليد الكود الأساسي بسرعة أو حل الأجزاء المملة، ثم يقومون بالتعديل والتحسين. هذا النمط يسرع بشكل كبير من سرعة الانتقال من الفكرة إلى التنفيذ، ويتحول التركيز من كتابة الكود إلى تصميم وحل المشكلات على مستوى أعلى. (المصدر: Reddit r/ArtificialInteligence)
Claude Sonnet 3.7 يحظى بإشادة لقدراته البرمجية : يحظى نموذج Claude Sonnet 3.7 بإشادة واسعة من مستخدمي المجتمع لأدائه المتميز في توليد الكود وتصحيحه، ويصفه بعض المستخدمين بأنه “سحر خالص” و”ملك البرمجة بلا منازع”. شارك المستخدمون تجاربهم في استخدام Claude Code لزيادة كفاءة البرمجة بشكل كبير، معتبرين أنه يتفوق على النماذج الأخرى في فهم سيناريوهات البرمجة الواقعية. (المصدر: Reddit r/ClaudeAI)
خطر AI: تركيز مفرط للسلطة بدلاً من سيطرة AI : هناك وجهة نظر مفادها أن أكبر خطر لـ AI قد لا يكمن في فقدان AI للسيطرة أو الاستيلاء على العالم، بل في منح تقنية AI سلطة مفرطة للبشر (أو مجموعات معينة). يمكن أن تتجلى هذه السيطرة في التلاعب بالمعلومات أو السلوك أو الهياكل الاجتماعية. يحول هذا المنظور تركيز خطر AI من التقنية نفسها إلى مستخدمي التقنية وتوزيع السلطة. (المصدر: pmddomingos)
الإنفاق الرأسمالي على GPU في شركات التكنولوجيا الكبرى أعلى من نمو التوظيف : لاحظ المجتمع أنه على الرغم من نمو الأرباح، فإن شركات التكنولوجيا الكبرى تستثمر المزيد من الأموال في الإنفاق الرأسمالي (Capex) على البنية التحتية للحوسبة مثل GPU، بدلاً من زيادة ميزانيات التوظيف بشكل كبير. هذا الاتجاه أكثر وضوحًا في عامي 2024 و2025، مما يؤدي إلى توخي الحذر في نمو ميزانيات الموظفين، وحتى إعادة هيكلة الموظفين داخليًا وتخفيض الرواتب. يشير هذا إلى أن سباق تسلح AI له تأثير عميق على الهيكل المالي للشركات واستراتيجيات المواهب، ولم تعد قيمة الفنيين فريدة كما كانت في الشركات الكبرى. (المصدر: dotey)
تسمية نماذج AI تعتبر مربكة : عبر بعض أعضاء المجتمع عن حيرتهم بشأن طريقة تسمية نماذج اللغة الكبيرة ومشاريع AI، معتبرين أن هذه الأسماء أحيانًا محيرة، بل ويطلقون عليها مازحين “أكثر شيء مرعب” في مجال AI. يعكس هذا مشكلة التوحيد والوضوح في تسمية المشاريع والنماذج في مجال AI سريع التطور. (المصدر: Reddit r/LocalLLaMA)

الفرق كبير بين وكلاء AI في بيئة الإنتاج والمشاريع الشخصية : ناقش المجتمع الفرق الكبير بين نشر وتشغيل وكلاء AI مثل RAG (Retrieval-Augmented Generation) في بيئة الإنتاج وإجراء المشاريع الشخصية. يشير هذا إلى أن نقل تقنية AI من المرحلة التجريبية أو العرض التوضيحي إلى التطبيق العملي يتطلب التغلب على المزيد من التحديات الهندسية، والبيانات، والموثوقية، وقابلية التوسع. (المصدر: Dorialexander)

رؤية مارك زوكربيرج لـ AI تثير ردود فعل سلبية : أثارت رؤية مارك زوكربيرج لـ Meta AI، وخاصة تصوراته حول أصدقاء AI الذين يملأون الفراغ الاجتماعي وتحسين الإعلانات بواسطة AI الصندوق الأسود، ردود فعل سلبية في المجتمع. يرى المنتقدون أن هذا يبدو “مخيفًا”، ويخشون أن يحل أصدقاء AI من Meta محل العلاقات الاجتماعية الحقيقية، وأن يتم تصميم أنظمة إعلانات AI للتلاعب باستهلاك المستخدمين. يعكس هذا مخاوف الجمهور بشأن اتجاه تطوير AI في شركات التكنولوجيا الكبرى وتأثيره الاجتماعي المحتمل. (المصدر: Reddit r/ArtificialInteligence)
أهمية قواعد بيانات المتجهات في عصر نوافذ السياق الطويلة : دحضت مناقشات المجتمع وجهة النظر القائلة بأن “نوافذ السياق الطويلة ستقتل قواعد بيانات المتجهات”. يرى البعض أنه حتى مع توسيع نافذة السياق، تظل قواعد بيانات المتجهات ضرورية لاسترجاع كميات هائلة من المعرفة بكفاءة. نوافذ السياق الطويلة (الذاكرة قصيرة المدى) وقواعد بيانات المتجهات (الذاكرة طويلة المدى) مكملة وليست متنافسة، ويجب أن يجمع نظام AI المثالي بين استخدامهما لتحقيق التوازن بين كفاءة الحوسبة ومشكلة تشتت الانتباه. (المصدر: bobvanluijt)
الشك في قدرة نماذج AI على فهم اللغة : هناك وجهة نظر مفادها أنه على الرغم من أن نماذج اللغة الكبيرة تتفوق في توليد النصوص، إلا أنها لا تفهم اللغة نفسها حقًا. أثار هذا نقاشًا فلسفيًا حول طبيعة ذكاء LLM، متسائلين عما إذا كانت قدرتها مجرد مطابقة أنماط وارتباطات إحصائية، وليست فهمًا دلاليًا عميقًا أو إدراكًا. (المصدر: pmddomingos)
مستخدمو OpenWebUI يبلغون عن مشاكل في الوظائف : أبلغ بعض مستخدمي OpenWebUI عن مشاكل في الوظائف التي واجهوها أثناء الاستخدام، بما في ذلك عدم القدرة على تلخيص أو تحليل المقالات الخارجية عبر الروابط (بعد التحديث إلى الإصدار 0.6.9)، وصعوبة في تكوين بحث الويب المدمج في OpenAI أو تغيير معلمات API. تشير هذه الملاحظات من المستخدمين إلى التحديات التي تواجه واجهات AI مفتوحة المصدر من حيث استقرار الوظائف وتكوين المستخدم. (المصدر: Reddit r/OpenWebUI، Reddit r/OpenWebUI، Reddit r/OpenWebUI)
مشاركة قصص مضحكة عن التفاعل مع ChatGPT : شارك مستخدمو المجتمع بعض القصص المضحكة عن التفاعل مع ChatGPT، مثل إعطاء النموذج إجابات غير متوقعة أو فكاهية، مثل الرد على المستخدم الذي قال “لقد أغضبتني” وتقديم “حصان صغير” كرشوة، أو عند طلب قلب صورة، يقوم بتوليد صورة تقول “أنا أرفض القلب”. تظهر هذه التفاعلات الخفيفة أن نماذج AI يمكن أن تظهر أحيانًا “شخصية” أو سلوكًا يثير الضحك. (المصدر: Reddit r/ChatGPT، Reddit r/ChatGPT، Reddit r/ChatGPT)
💡 أخرى
النجاح غير المتوقع للأجهزة الذكية LiberLive Guitar بدون أوتار : حققت “القيثارة بدون أوتار” التي أطلقتها LiberLive نجاحًا كبيرًا كجهاز ذكي، حيث تجاوزت مبيعاتها السنوية مليار يوان. يقلل هذا المنتج بشكل كبير من عتبة تعلم الآلات الموسيقية من خلال إضاءة لوحة الأصابع لتوجيه المستخدمين في عزف الأوتار، ويوفر قيمة عاطفية وشعورًا بالإنجاز للمبتدئين. على الرغم من أن مؤسسها لديه خلفية في DJI، إلا أن المشروع واجه صعوبة في الحصول على تمويل حيث “لم يفهمه” المستثمرون بشكل عام وفوتوا الفرصة. يعتبر نجاح LiberLive انتصارًا لرواد الأعمال غير التقليديين، مما يدل على أن تلبية احتياجات المستهلكين الحقيقية أهم من مطاردة المفاهيم الشائعة. (المصدر: 36氪)

منهجية تحسين كفاءة أدوات AI في الشركات: مخطط العمل ومنهجية السياق العكسي : تقترح المقالة أن أدوات AI العامة يصعب أن تلبي احتياجات سير العمل المحددة للشركات، مما يؤدي إلى “مفارقة إنتاجية AI”. لحل هذه المشكلة، من الضروري بناء “مخطط عمل” لتسجيل طريقة العمل الفعلية للفريق وعملية اتخاذ القرار، واستخدام “منهجية السياق العكسي” (Reverse Contextualization) لضبط نماذج AI بناءً على هذه الرؤى المحلية. من خلال استخراج المعرفة الضمنية للفريق والتحسين المستمر، يمكن لأدوات AI أن تخدم سيناريوهات محددة بشكل أكثر دقة، مما يحسن بشكل كبير كفاءة العمل والإنتاج، بدلاً من مجرد استبدال العمل البشري. (المصدر: 36氪)

تحليل استراتيجية Nvidia “الفيزياء AI” ومقارنتها بتاريخ الإنترنت الصناعي : تحلل المقالة استراتيجية Nvidia “الفيزياء AI”، معتبرة أنها نموذج نظامي يدمج الذكاء المكاني، والذكاء المتجسد، والمنصات الصناعية، ويهدف إلى بناء حلقة مغلقة للذكاء في العالم المادي من التدريب والمحاكاة إلى النشر. من خلال المقارنة مع منصة Predix للإنترنت الصناعي الفاشلة لـ GE، تشير المقالة إلى أن ميزة Nvidia تكمن في استراتيجية النظام البيئي المفتوح “المطور أولاً + سلسلة الأدوات أولاً” وتوقيت نضج التكنولوجيا الأفضل (نماذج AI الكبيرة، المحاكاة التوليدية، إلخ). تعتبر الفيزياء AI قفزة لـ AI من “الفهم الدلالي” إلى “التحكم الفيزيائي”، لكن النجاح لا يزال يعتمد على بناء النظام البيئي واستيعاب قدرات النظام. (المصدر: 36氪)
