كلمات مفتاحية:الذكاء الأساسي, إنتلجكت-2, ساكانا للذكاء الاصطناعي, آلة التفكير المستمر, المحول, وكيل الذكاء الاصطناعي من جوجل, عمليات وكيل الذكاء الاصطناعي, التعاون متعدد الوكلاء, تدريب التعلم المعزز الموزع, التزامن العصبي الزمني وتزامن الخلايا العصبية, إجراءات تشغيل وصيانة وكلاء الذكاء الاصطناعي, هندسة متعددة الوكلاء, نشر وكلاء الذكاء الاصطناعي في المؤسسات
🔥 أهم الأخبار
Prime Intellect تطلق نموذج INTELLECT-2 مفتوح المصدر: أعلنت Prime Intellect عن إطلاق نموذج INTELLECT-2 وجعله مفتوح المصدر، وهو نموذج يحتوي على 32 مليار بارامتر، ويُزعم أنه أول نموذج يتم تدريبه باستخدام التعلم المعزز الموزع عالميًا. يتضمن هذا الإصدار تقريرًا تقنيًا مفصلاً ونقاط فحص النموذج (model checkpoints). أظهر النموذج أداءً مكافئًا أو حتى أفضل من نماذج مثل Qwen 32B في العديد من اختبارات الأداء القياسية (benchmarks)، خاصة في توليد الأكواد والاستدلال الرياضي، واكتشف أعضاء المجتمع قدرته على لعب لعبة Wordle. يُعتقد أن طريقة تدريبه وخطوة جعله مفتوح المصدر قد تؤثر على مستقبل تدريب النماذج الكبيرة والمشهد التنافسي (المصدر: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI تقترح آلة التفكير المستمر (CTM): قدمت Sakana AI بنية شبكة عصبونية جديدة تسمى “آلة التفكير المستمر” (Continuous Thought Machine, CTM)، تهدف إلى منح الذكاء الاصطناعي ذكاءً شبيهًا بالبشر أكثر مرونة من خلال إدخال آليات الدماغ البيولوجية مثل التوقيت العصبي (neural timing) وتزامن الخلايا العصبية (neuronal synchronization). يكمن الابتكار الأساسي لـ CTM في معالجة الوقت على مستوى الخلايا العصبية واستخدام التزامن العصبي كتمثيل كامن، مما يمكنها من معالجة المهام التي تتطلب الاستدلال التسلسلي والحساب التكيفي، وتخزين واسترجاع الذاكرة. تم نشر مدونة وتقرير تفاعلي وورقة بحثية ومستودع الكود على GitHub لهذه الدراسة، لاستكشاف نموذج جديد لـ “التفكير باستخدام الوقت” في الذكاء الاصطناعي (المصدر: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
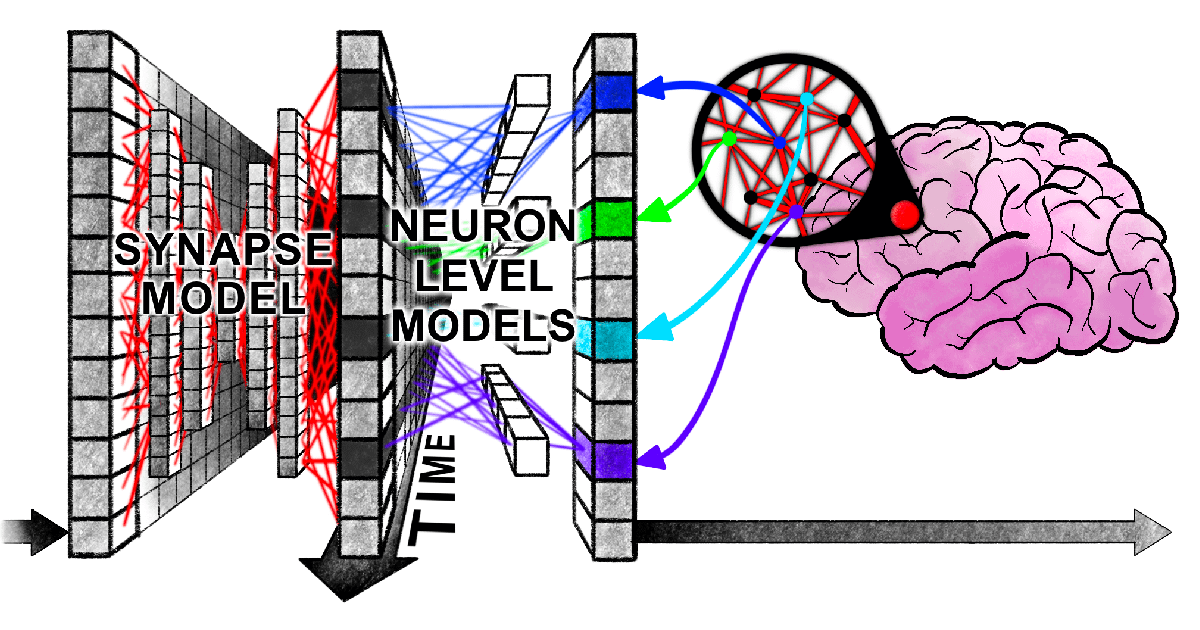
ورقة بحثية جديدة من هارفارد تكشف عن “تشابك متزامن” بين Transformer والدماغ البشري في معالجة المعلومات: نشر باحثون من جامعة هارفارد ومؤسسات أخرى ورقة بحثية بعنوان 《Linking forward-pass dynamics in Transformers and real-time human processing》، تستكشف أوجه التشابه بين ديناميكيات المعالجة الداخلية لنماذج Transformer وعمليات الإدراك البشري في الوقت الفعلي. لم تعد الدراسة تركز فقط على المخرجات النهائية، بل تحلل مؤشرات “عبء المعالجة” لكل طبقة في النموذج (مثل عدم اليقين وتغير الثقة)، ووجدت أن الذكاء الاصطناعي يمر بعمليات مشابهة للبشر عند حل المشكلات (مثل الإجابة عن العواصم، تصنيف الحيوانات، الاستدلال المنطقي، التعرف على الصور)، مثل “التردد”، و”الخطأ الحدسي”، ثم “التصحيح”. يشير هذا التشابه في “عملية التفكير” إلى أن الذكاء الاصطناعي يتعلم بشكل طبيعي اختصارات إدراكية مشابهة للبشر لإنجاز المهام، مما يوفر منظورًا جديدًا لفهم قرارات الذكاء الاصطناعي وتوجيه تصميم التجارب البشرية (المصدر: 36Kr)

Google تنشر ورقة بيضاء من 76 صفحة حول وكلاء الذكاء الاصطناعي (AI Agents)، تشرح AgentOps وتعاون الوكلاء المتعددين: تشرح الورقة البيضاء الأخيرة التي نشرتها Google بالتفصيل بناء وتقييم وتطبيق وكلاء الذكاء الاصطناعي (AI Agents). تؤكد الورقة البيضاء على أهمية عمليات تشغيل الوكلاء (AgentOps)، وهي عملية لتحسين بناء ونشر الوكلاء في بيئة الإنتاج، وتغطي إدارة الأدوات، وإعداد المطالبات الأساسية (core prompting)، وتحقيق الذاكرة، وتجزئة المهام. كما تناقش الورقة البيضاء بنية الوكلاء المتعددين (multi-agent architecture)، حيث يعمل العديد من الوكلاء ذوي القدرات المتخصصة بتعاون لإنجاز أهداف معقدة، وتقدم أمثلة عملية لنشر Google للوكلاء داخل الشركات (مثل NotebookLM Enterprise، Agentspace Enterprise) بالإضافة إلى تطبيقات محددة (مثل نظام وكلاء متعددين للسيارات)، بهدف تعزيز إنتاجية الشركات وتجربة المستخدم (المصدر: 36Kr)
🎯 التطورات
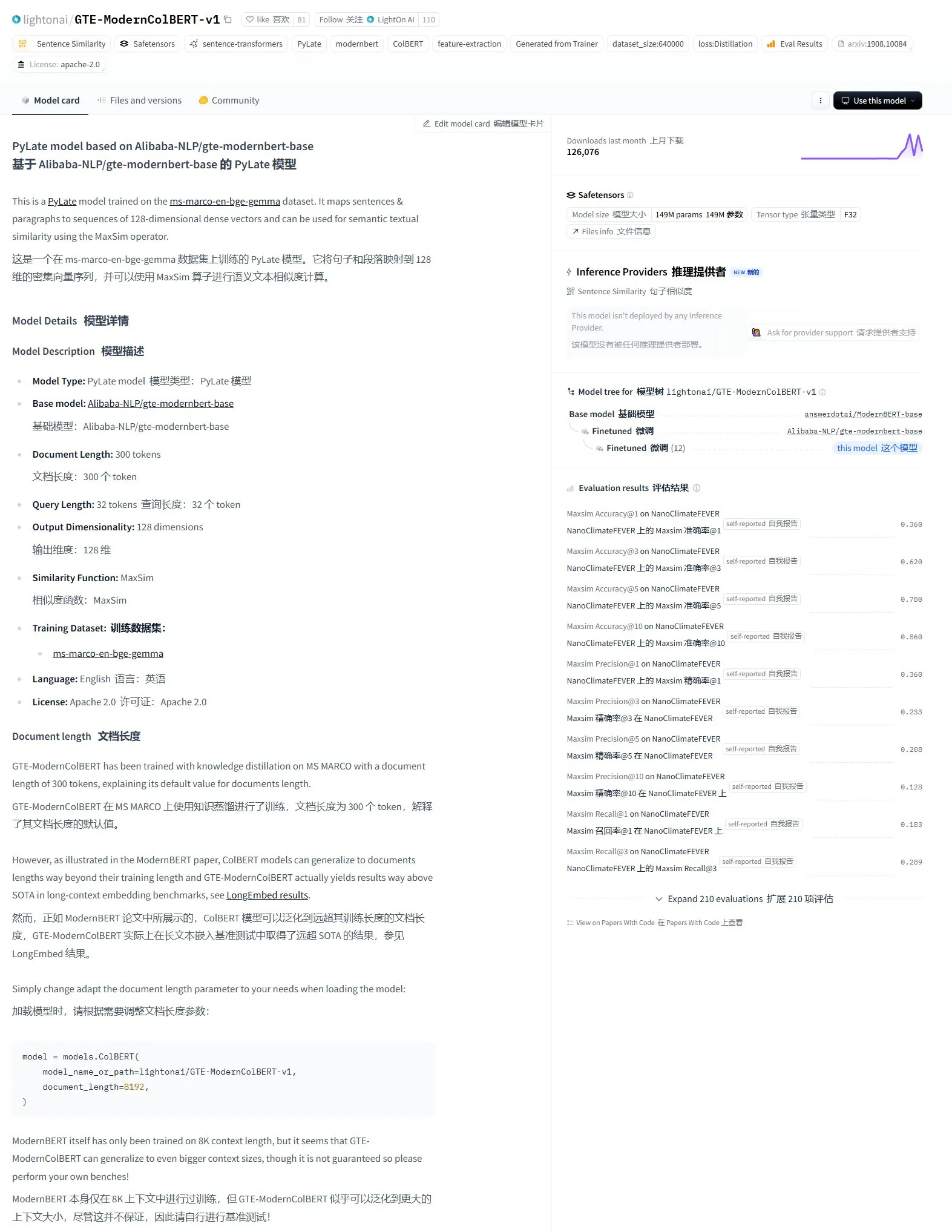
LightonAI تطلق نموذج البحث الدلالي GTE-ModernColBERT-v1: أطلقت LightonAI نموذج بحث دلالي جديد GTE-ModernColBERT-v1، والذي حقق أعلى درجة حالية في تقييم LongEmbed / LEMB Narrative QA. تم تصميم هذا النموذج خصيصًا لتحسين نتائج البحث الدلالي، ويمكن تطبيقه في سيناريوهات مثل استرجاع محتوى المستندات، RAG، وما إلى ذلك، ويمكن دمجه مع الأنظمة الحالية. يُذكر أن النموذج تم ضبطه بدقة (fine-tuned) بناءً على Alibaba-NLP/gte-modernbert-base، بهدف تحسين قيود محركات البحث التقليدية التي تعتمد فقط على مطابقة الأحرف (المصدر: karminski3)
قادة التكنولوجيا يتابعون الصعود السريع لـ DeepSeek: أفاد VentureBeat بردود أفعال قادة التكنولوجيا تجاه التطور السريع لـ DeepSeek. بفضل قدرات نماذجها القوية واستراتيجيتها مفتوحة المصدر، حققت DeepSeek نتائج ملحوظة في مجال الذكاء الاصطناعي العالمي، خاصة في مهام الرياضيات وتوليد الأكواد، وتشكل تحديًا لهيكل السوق الحالي (بما في ذلك OpenAI وغيرها). كما أن استراتيجيتها منخفضة التكلفة للتدريب وتسعير واجهة برمجة التطبيقات (API) تدفع أيضًا إلى تعميم تقنيات الذكاء الاصطناعي وعملياتها التجارية (المصدر: Ronald_vanLoon)

ByteDance وجامعة بكين تطلقان DreamO، إطار عمل موحد لتخصيص توليد الصور يدعم تركيب شروط متعددة: تعاونت ByteDance وجامعة بكين لإطلاق DreamO، وهو إطار عمل لتخصيص توليد الصور يمكنه تحقيق تركيب حر لشروط متعددة مثل الموضوع والهوية والأسلوب ومرجع الملابس من خلال نموذج واحد. يعتمد الإطار على Flux-1.0-dev، ويعالج مدخلات الصور الشرطية عن طريق إدخال طبقة تعيين متخصصة، ويستخدم استراتيجية تدريب تدريجية وقيود توجيه للصور المرجعية لتحسين جودة التوليد والاتساق. حقق DreamO توليد صورة مخصصة في 8-10 ثوانٍ بكمية بارامترات تدريب منخفضة تبلغ 400 مليون، ويظهر أداءً ممتازًا في الحفاظ على الاتساق، وقد تم فتح مصدر الكود والنموذج ذي الصلة (المصدر: WeChat)

فريق VITA يفتح مصدر نموذج الصوت الكبير في الوقت الفعلي VITA-Audio، مع تحسين كبير في كفاءة الاستدلال: أطلق فريق VITA نموذج الصوت الشامل (end-to-end) VITA-Audio، والذي يحقق توليد مباشر لـ Audio Token Chunk قابلة للفك في تمريرة أمامية واحدة عن طريق إدخال وحدة تنبؤ متعدد الوسائط خفيفة الوزن (MCTP). بحجم 7 مليار بارامتر، يستغرق النموذج 92 مللي ثانية فقط من استقبال النص إلى إخراج أول مقطع صوتي (53 مللي ثانية بدون حساب مشفر الصوت)، مما يزيد سرعة الاستدلال بمقدار 3-5 مرات مقارنة بالنماذج ذات الحجم المماثل. يدعم VITA-Audio اللغتين الصينية والإنجليزية، ويتم تدريبه باستخدام بيانات مفتوحة المصدر فقط، ويظهر أداءً ممتازًا في مهام مثل TTS و ASR، وقد تم فتح مصدر الكود وأوزان النموذج ذات الصلة (المصدر: WeChat)

جامعة Tsinghua و BAAI وغيرهما يقترحون طريقة تدريب “الصفر المطلق”، حيث تفتح النماذج الكبيرة قدرات الاستدلال من خلال اللعب الذاتي: اقترح باحثون من جامعة Tsinghua وأكاديمية بكين للذكاء الاصطناعي (BAAI) ومؤسسات أخرى طريقة تدريب “الصفر المطلق” (Absolute Zero)، والتي تمكن النماذج الكبيرة المدربة مسبقًا من تعلم الاستدلال عن طريق توليد وحل المهام من خلال اللعب الذاتي (Self-play) دون الحاجة إلى بيانات خارجية. توحد هذه الطريقة مهام الاستدلال في ثلاثية (برنامج، إدخال، إخراج)، حيث يلعب النموذج دور Proposer (مُقترح المشكلة) و Solver (حال المشكلة)، ويتعلم من خلال ثلاثة أنواع من المهام: الاستدلال التفسيري (abduction)، والاستنتاج (deduction)، والاستقراء (induction). أظهرت التجارب أن النماذج المدربة بهذه الطريقة تحقق تحسينات كبيرة في مهام البرمجة والاستدلال الرياضي، وتتفوق في الأداء على النماذج المدربة باستخدام عينات مشروحة من قبل خبراء (المصدر: WeChat)

تطور AI PC يتسارع، Lenovo و Huawei تطلقان منتجات طرفية جديدة تعتمد على الذكاء الاصطناعي: أطلقت كل من Lenovo و Huawei مؤخرًا منتجات PC مدمجة بوكلاء ذكاء اصطناعي (AI Agents)، مثل وكيل Lenovo الشخصي الفائق الذكاء Tianxi ووكيل Xiaoyi الذكي المدمج في حواسيب Huawei HarmonyOS. على الرغم من أن معدل انتشار AI PC في السوق لا يزال منخفضًا، إلا أنه ينمو بسرعة، حيث تظهر بيانات Canalys أن شحنات AI PC في الصين القارية في عام 2024 شكلت بالفعل 15٪ من إجمالي سوق أجهزة الكمبيوتر، ومن المتوقع أن تصل إلى 34٪ في عام 2025. يعتقد المطلعون على الصناعة أن نضج سلسلة صناعة AI PC لا يزال بحاجة إلى 2-3 سنوات، وتتمثل التحديات الرئيسية الحالية في تكاليف سلسلة التوريد وحجمها (مثل الذاكرة والرقائق)، بالإضافة إلى تجزئة النظام البيئي لـ AI PC المحلي. تشمل الاتجاهات المستقبلية أن يصبح الوكيل الذكي مدخل التفاعل الأساسي، ونشر الذكاء الاصطناعي محليًا، وتوسيع سيناريوهات تطبيقات الذكاء الاصطناعي لتشمل التعليم والصحة وغيرها من المجالات المتنوعة (المصدر: 36Kr)
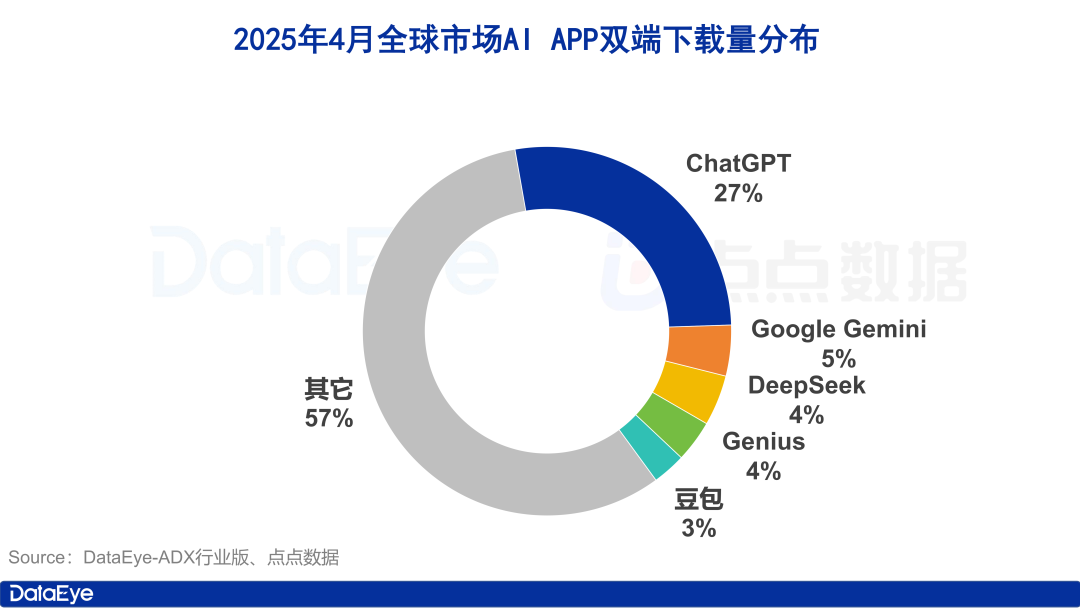
تنزيلات تطبيقات الذكاء الاصطناعي العالمية ترتفع، السوق المحلية تبرد، Doubao ينمو عكس التيار: في أبريل 2025، وصل إجمالي تنزيلات تطبيقات الذكاء الاصطناعي العالمية على كلا المنصتين إلى 330 مليون مرة، بزيادة 27.4٪ على أساس شهري، واحتلت ChatGPT و Google Gemini و DeepSeek و Genius و Doubao المراكز الخمسة الأولى. من بينها، شهدت ChatGPT زيادة كبيرة في التنزيلات بسبب إطلاق GPT-4o. بالمقارنة، انخفضت تنزيلات تطبيقات الذكاء الاصطناعي على منصة Apple في الصين القارية بنسبة 24.0٪ على أساس شهري، واحتل Doubao المركز الأول بنمو عكس التيار، يليه DeepSeek و Jimi AI (即梦AI). من حيث شراء المستخدمين (buying traffic)، استثمر Tencent Yuanbao و Quark بكثافة، واستحوذا على الجزء الأكبر من حجم المواد الإعلانية، بينما انخفض استثمار Doubao. بشكل عام، هدأت حدة سوق الذكاء الاصطناعي المحلي إلى حد ما، وعادت المنافسة إلى التكنولوجيا والتشغيل (المصدر: 36Kr)
سوق النماذج الكبيرة في الصين يشهد إعادة تشكيل، وظهور مبدئي لـ “الخمسة الكبار في النماذج الأساسية”: مع تشديد بيئة تمويل الذكاء الاصطناعي العالمية في عام 2024، شهد سوق النماذج الكبيرة في الصين “إزالة للفقاعة”، وتحول المشهد الذي كان يُعرف سابقًا بـ “النمور الستة الصغار” إلى “الخمسة الكبار في النماذج الأساسية” بقيادة ByteDance و Alibaba و StepFun و Zhipu AI و DeepSeek. يتمتع هؤلاء اللاعبون الرئيسيون بمزايا في التمويل والمواهب والتكنولوجيا، واتبعوا مسارات متباينة: تخطيط شامل لـ ByteDance، تركيز Alibaba على المصدر المفتوح والمكدس الكامل، تخصص StepFun في الوسائط المتعددة، اعتماد Zhipu AI على خلفية Tsinghua للتركيز على 2B/2G، بينما برزت DeepSeek من خلال التحسين الهندسي الفائق واستراتيجية المصدر المفتوح. سيكون محور المنافسة في المرحلة التالية هو اختراق “الحد الأعلى للذكاء” وتعزيز “قدرات الوسائط المتعددة”، بهدف تحقيق رؤية الذكاء الاصطناعي العام (AGI) (المصدر: 36Kr, WeChat)

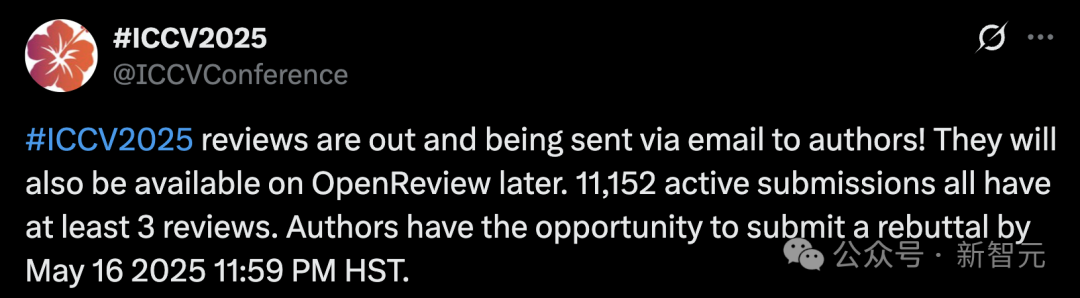
عدد تقديمات ICCV 2025 القياسي يثير مخاوف بشأن جودة المراجعة، ويُحظر استخدام LLM للمساعدة في المراجعة: وصل عدد الأوراق البحثية المقدمة إلى مؤتمر رؤية الكمبيوتر الرائد ICCV 2025 إلى 11,152 ورقة، مسجلاً رقمًا قياسيًا جديدًا. ومع ذلك، بعد إعلان نتائج المراجعة، أعرب عدد كبير من المؤلفين على وسائل التواصل الاجتماعي عن عدم رضاهم عن جودة المراجعة، معتبرين أن بعض آراء المراجعة كانت سطحية، بل وأفضل من مستوى GPT، وأشاروا إلى وجود مشاكل مثل عدم قراءة المراجعين للمواد التكميلية. لمواجهة الزيادة الكبيرة في التقديمات، طلب المؤتمر من كل مؤلف مشارك المشاركة في المراجعة، وحظر صراحة استخدام النماذج الكبيرة (مثل ChatGPT) في عملية المراجعة لضمان الأصالة والسرية. على الرغم من أن البيانات الرسمية تظهر أن 97.18٪ من المراجعات تم تقديمها في الوقت المحدد، إلا أن جودة المراجعة وعبء المراجعين أصبحت محور نقاش ساخن (المصدر: 36Kr)
الرئيس التنفيذي لشركة Nvidia جنسن هوانغ: سيتم تزويد جميع الموظفين بوكلاء AI، مما يعيد تشكيل دور المطورين: صرح الرئيس التنفيذي لشركة Nvidia، جنسن هوانغ، بأن الشركة ستزود جميع الموظفين (بما في ذلك مهندسي البرمجيات ومصممي الرقائق) بوكلاء ذكاء اصطناعي (AI Agents) لزيادة كفاءة العمل وحجم المشاريع وجودة البرمجيات. ويتوقع أن يقود كل شخص في المستقبل العديد من مساعدي الذكاء الاصطناعي، مما يؤدي إلى نمو الإنتاجية بشكل كبير. يتماشى هذا الاتجاه مع آراء شركات مثل Meta و Microsoft و Anthropic، بأن الذكاء الاصطناعي سينجز معظم عمليات كتابة الأكواد، وسيتحول دور المطورين إلى “قادة الذكاء الاصطناعي” أو “محددي المتطلبات”. أكد هوانغ أن الطاقة والقدرة الحاسوبية هما عنق الزجاجة أمام تعميم الذكاء الاصطناعي، ويتطلبان ابتكارات في مجالات مثل تغليف الرقائق وتقنية الفوتونيات. تعمل الشركات الكبرى بنشاط على تطوير وكلاء AI استباقيين، مما ينذر بالتحول من GenAI إلى Agentic AI (المصدر: 36Kr)

الرئيس التنفيذي لـ OpenAI سام ألتمان يحضر جلسة استماع في الكونغرس، يدعو إلى تنظيم متساهل ويكشف عن خطط للمصدر المفتوح: صرح الرئيس التنفيذي لـ OpenAI، سام ألتمان، في جلسة استماع بمجلس الشيوخ الأمريكي بأن فرض موافقة مسبقة صارمة على الذكاء الاصطناعي سيكون له تأثير كارثي على القدرة التنافسية للولايات المتحدة في هذا المجال، وكشف أن OpenAI تخطط لإصدار أول نموذج مفتوح المصدر لها هذا الصيف. وأكد على أهمية البنية التحتية (خاصة الطاقة) للفوز بسباق الذكاء الاصطناعي، ويعتقد أن تكلفة الذكاء الاصطناعي ستتقارب في النهاية مع تكلفة الطاقة. شارك ألتمان أيضًا “خارطة طريق عصر الذكاء (2025-2027)”، متوقعًا وصول عصر المساعدين الخارقين بالذكاء الاصطناعي، والنمو الهائل للاكتشافات العلمية المدفوعة بالذكاء الاصطناعي، وعصر روبوتات الذكاء الاصطناعي على التوالي. عند الحديث عن حياته الشخصية، ذكر أنه لا يرغب في أن يقيم ابنه صداقة حميمة مع روبوتات الذكاء الاصطناعي (المصدر: 36Kr)

باحثون من CMU يقترحون LegoGPT، لتصميم نماذج Lego مستقرة فيزيائيًا باستخدام الذكاء الاصطناعي: طور باحثون في جامعة كارنيجي ميلون (CMU) نظام LegoGPT، وهو نظام ذكاء اصطناعي يمكنه تحويل الأوصاف النصية إلى نماذج Lego قابلة للبناء فيزيائيًا. من خلال الضبط الدقيق لنموذج LLaMA من Meta، والتدريب باستخدام مجموعة بيانات StableText2Lego التي تحتوي على أكثر من 47,000 هيكل مستقر، يستطيع LegoGPT التنبؤ بوضع المكعبات تدريجيًا، مما يضمن أن الهياكل المولدة مستقرة فيزيائيًا في العالم الحقيقي، بنسبة نجاح تصل إلى 98.8%. يستخدم النظام أيضًا طريقة التراجع المدركة للفيزياء (physics-aware rollback) لتصحيح الهياكل عند اكتشاف عدم استقرارها. يعتقد الباحثون أن هذه التقنية لا تقتصر على Lego، ويمكن تطبيقها في المستقبل في مجالات مثل تصميم مكونات الطباعة ثلاثية الأبعاد وتجميع الروبوتات. تم فتح مصدر الكود ومجموعة البيانات والنموذج حاليًا (المصدر: WeChat)

توقعات الذكاء الاصطناعي لانتخاب البابا تخطئ، والبابا الجديد Robert Prevost يصبح “خيارًا غير متوقع”: وفقًا لتقرير Science، فشلت دراسة استخدمت خوارزميات الذكاء الاصطناعي لتحليل بيانات 135 كاردينالًا للتنبؤ بالبابا الجديد في التنبؤ الصحيح بانتخاب Robert Francis Prevost. قام النموذج بمحاكاة الانتخابات بناءً على مواقف الكرادلة من القضايا الرئيسية (من خلال تحليل خطاباتهم لتدريب الذكاء الاصطناعي على الحكم على الميول المحافظة أو التقدمية) والتشابه الأيديولوجي بينهم، وتوقع في النهاية أن الكاردينال الإيطالي Pietro Parolin هو الأوفر حظًا. اعترف الباحثون بأن عدم أخذ النموذج في الاعتبار للعوامل السياسية والجغرافية كان عيبه الرئيسي، لكنهم يعتقدون أن المنهجية لا تزال ذات قيمة مرجعية للتنبؤ بأنواع أخرى من الانتخابات. يُعتبر Prevost معتدلاً في وجهات نظره بشأن مختلف القضايا، وقد يكون مرشحًا توافقيًا مقبولاً لجميع الأطراف (المصدر: 36Kr)

تطبيقات الذكاء الاصطناعي في التسويق المالي: حل خمسة تحديات رئيسية تشمل اكتساب العملاء والتخصيص والامتثال: أصبحت تقنيات الذكاء الاصطناعي و Agent المحرك الأساسي لعصر التسويق المالي 3.0، بهدف حل المشاكل مثل ارتفاع تكلفة اكتساب العملاء، وعدم كفاية التجربة الشخصية، وصعوبة فهم المنتجات المعقدة، وضغوط الامتثال الكبيرة، وصعوبة قياس عائد الاستثمار (ROI). من خلال بناء “منصة تسويق ذكية مركزية” (قاعدة بيانات + محرك ذكي + تطبيقات خدمة)، واستخدام تقنيات مثل النماذج اللغوية الكبيرة (LLM) + RAG، والرسم البياني المعرفي (Knowledge Graph)، وتعاون الوكلاء الأذكياء (MAS)، والحوسبة المحافظة على الخصوصية (Privacy Computing)، يمكن للمؤسسات المالية تحقيق رؤى أعمق للعملاء، واتخاذ قرارات ذكية دقيقة في الوقت الفعلي، وتنفيذ خدمات فعالة ومتسقة. تظهر دراسات الحالة الصناعية أن الذكاء الاصطناعي قد حقق بالفعل نتائج ملحوظة في زيادة الأصول المدارة للعملاء (AUM)، ومعدلات تحويل منتجات إدارة الثروات، وكفاءة إنتاج محتوى التسويق، وسيتطور في المستقبل نحو التفاعل متعدد الوسائط، واتخاذ القرارات السببية، والتطور الذاتي، والاستجابة الطرفية (edge response)، والتعاون بين الإنسان والآلة (المصدر: 36Kr)
الذكاء الاصطناعي يقود الروبوتات لحل مشكلة النفايات الإلكترونية في أوروبا: طور مشروع البحث ReconCycle الممول من الاتحاد الأوروبي روبوتات تكيفية مدفوعة بالذكاء الاصطناعي لأتمتة معالجة النفايات الإلكترونية المتزايدة، وخاصة تفكيك الأجهزة التي تحتوي على بطاريات الليثيوم. يمكن إعادة تكوين هذه الروبوتات للتكيف مع مهام مختلفة، مثل إزالة البطاريات من كاشفات الدخان وعدادات حرارة المشعات. تهدف هذه التقنية إلى زيادة كفاءة إعادة التدوير، وتقليل العمل الشاق والخطير للتفكيك اليدوي، ومواجهة تحدي ما يقرب من 5 ملايين طن من النفايات الإلكترونية التي ينتجها الاتحاد الأوروبي سنويًا (مع معدل إعادة تدوير أقل من 40٪). بدأت مرافق إعادة التدوير مثل Electrocycling GmbH في الاهتمام وتتوقع أن تتمكن هذه التقنيات من زيادة معدل استرداد المواد الخام وتقليل الخسائر الاقتصادية وانبعاثات الكربون (المصدر: aihub.org)

🧰 الأدوات
LocalSite-ai: بديل مفتوح المصدر لـ DeepSite، يولد واجهات أمامية عبر الإنترنت باستخدام الذكاء الاصطناعي: LocalSite-ai هو مشروع مفتوح المصدر يوفر وظائف مشابهة لـ DeepSite، مما يسمح للمستخدمين بتوليد واجهات أمامية عبر الإنترنت باستخدام الذكاء الاصطناعي. يدعم المعاينة المباشرة عبر الإنترنت، والتحرير المرئي (WYSIWYG)، ومتوافق مع العديد من مزودي واجهات برمجة تطبيقات الذكاء الاصطناعي. بالإضافة إلى ذلك، تدعم الأداة التصميم المتجاوب، مما يساعد المستخدمين على بناء صفحات ويب تتكيف بسرعة مع الأجهزة المختلفة (المصدر: karminski3)
Agentset: منصة مفتوحة المصدر لتعزيز دقة نتائج RAG: Agentset هي منصة RAG (Retrieval Augmented Generation) مفتوحة المصدر، تعمل على تحسين دقة نتائج الاسترجاع من خلال تقنيات البحث المختلط وإعادة الترتيب. تحتوي المنصة على وظيفة اقتباس مدمجة، يمكنها عرض بوضوح أي معلومات مفهرسة في قاعدة بيانات المتجهات (vector database) يأتي منها المحتوى المولد، مما يسهل على المستخدمين إجراء فحص مساعد لتجنب أخطاء المعلومات أو هلوسة النموذج (المصدر: karminski3)
Gemini Max Playground: تطبيق Gemini مع معاينة متوازية والتحكم في الإصدارات: أنشأ المطور Chansung تطبيقًا على Hugging Face Space يسمى Gemini Max Playground، يسمح للمستخدمين بمعالجة ما يصل إلى 4 معاينات Gemini بالتوازي لتسريع عملية التكرار. تدعم الأداة التحكم في عدد رموز الاستدلال (inference tokens)، وتتمتع بوظيفة التحكم في الإصدارات، ويمكنها تصدير ملفات HTML/JS/CSS بشكل منفصل. بالإضافة إلى ذلك، يوفر إصدارًا محسنًا لشاشات الهاتف المحمول (المصدر: algo_diver)
mlop.ai: بديل مفتوح المصدر لـ Weights and Biases (wandb): تم إطلاق mlop.ai كمنصة تتبع تجارب تعلم الآلة (ML) مفتوحة المصدر بالكامل وعالية الأداء وآمنة، تهدف إلى استبدال wandb. وهي متوافقة تمامًا مع واجهة برمجة تطبيقات wandb، وتكلفة الانتقال منخفضة (تتطلب تغيير سطر واحد فقط من الكود). تم تصميم الواجهة الخلفية باستخدام Rust، وتدعي أنها تحل مشكلة الحظر الموجودة في wandb عند استدعاء .log، مما يوفر تسجيلًا وتحميلًا غير معطلين (non-blocking). يمكن للمستخدمين استضافتها ذاتيًا بسهولة عبر Docker (المصدر: Reddit r/artificial)
DeerFlow: إطار عمل مفتوح المصدر من ByteDance يجمع LLM + Langchain + أدوات: فتحت ByteDance مصدر DeerFlow (Deep Exploration and Efficient Research Flow)، وهو إطار عمل يدمج النماذج اللغوية الكبيرة (LLM) و Langchain وأدوات متنوعة (مثل البحث على الويب، والزحف، وتنفيذ الكود). يهدف المشروع إلى توفير دعم قوي لتدفق البحث والتطوير، ويدعم Ollama، مما يسهل النشر والاستخدام المحلي (المصدر: Reddit r/LocalLLaMA)
Plexe: وكيل ML مفتوح المصدر يحول اللغة الطبيعية إلى نماذج مدربة: Plexe هو وكيل هندسة تعلم الآلة (ML engineering agent) مفتوح المصدر، يمكنه تحويل المطالبات باللغة الطبيعية إلى نماذج تعلم آلي مدربة على بيانات المستخدم المهيكلة (يدعم حاليًا ملفات CSV و Parquet)، دون الحاجة إلى خلفية في علم البيانات لدى المستخدم. يقوم بإكمال مهام مثل تنظيف البيانات واختيار الميزات وتجربة النماذج وتقييمها تلقائيًا من خلال فريق من الوكلاء المتخصصين (عالم، مدرب، مقيم)، ويستخدم MLflow لتتبع التجارب. الخطط المستقبلية تشمل دعم قواعد بيانات PostgreSQL ووكيل هندسة الميزات (feature engineering agent) (المصدر: Reddit r/artificial)
Llama ParamPal: مشروع قاعدة معرفية لبارامترات أخذ العينات في LLM: Llama ParamPal هو مشروع مفتوح المصدر يهدف إلى جمع وتوفير بارامترات أخذ العينات الموصى بها للنماذج اللغوية الكبيرة (LLM) المحلية عند استخدام llama.cpp. يحتوي المشروع على ملف models.json كقاعدة بيانات للبارامترات، ويوفر واجهة مستخدم ويب بسيطة (قيد التطوير) لتصفح والبحث عن مجموعات البارامترات، لحل مشكلة المستخدمين في العثور على البارامترات المناسبة عند تكوين نماذج جديدة. يمكن للمستخدمين المساهمة بتكوينات البارامترات لنماذجهم (المصدر: Reddit r/LocalLLaMA)
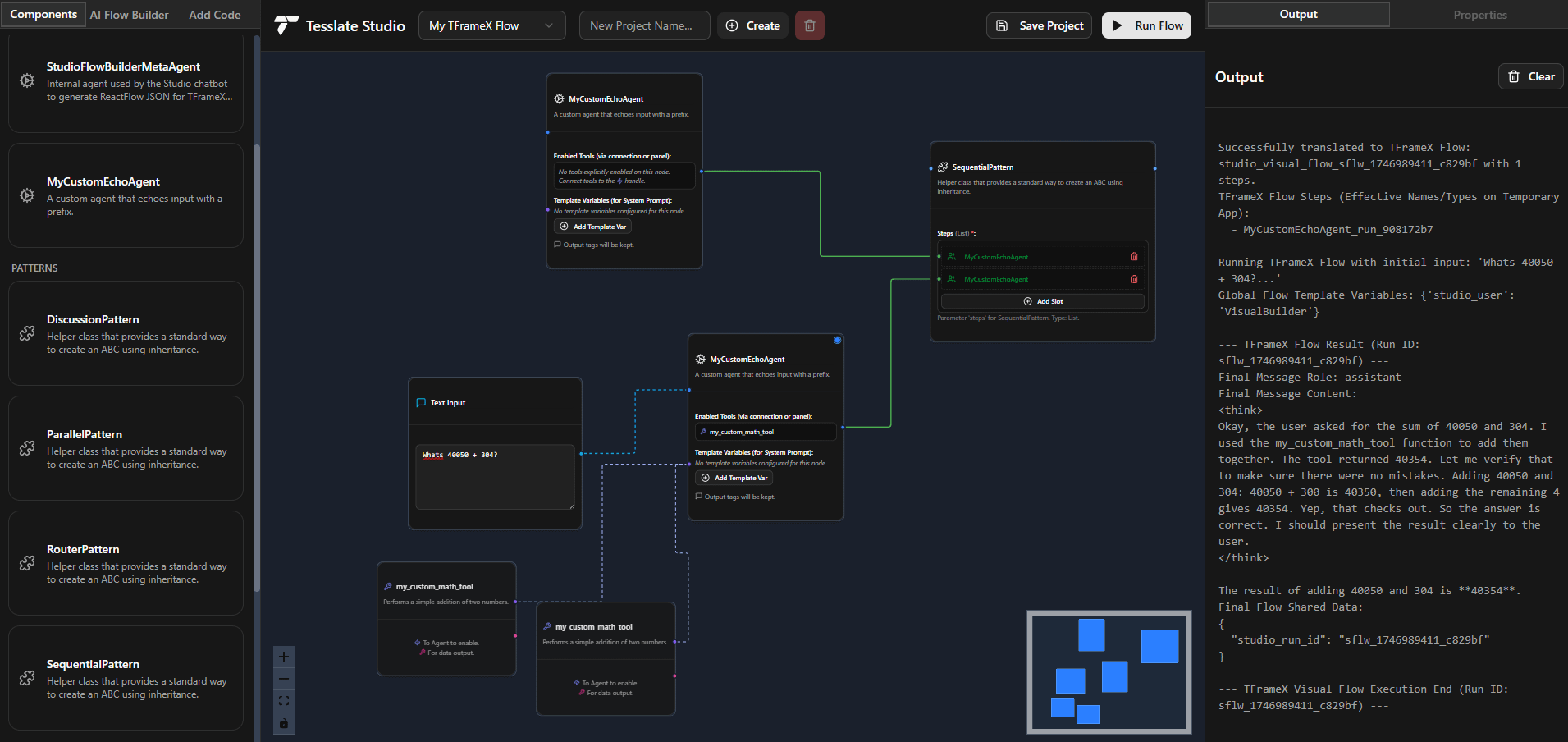
TFrameX و Studio: منشئ وكلاء LLM محلي مفتوح المصدر وإطار عمل: أصدر فريق TesslateAI مشروعين مفتوحي المصدر: TFrameX، وهو إطار عمل للوكلاء مصمم خصيصًا للنماذج اللغوية الكبيرة (LLM) المحلية؛ و Studio، وهو منشئ وكلاء يعتمد على المخططات الانسيابية. تهدف هاتان الأداتان إلى مساعدة المطورين على إنشاء وإدارة وكلاء الذكاء الاصطناعي الذين يعملون بالتعاون مع LLMs المحلية بسهولة أكبر، ويشير الفريق إلى أنه يعمل بنشاط على التطوير ويرحب بمساهمات المجتمع (المصدر: Reddit r/LocalLLaMA)
Ktransformer: إطار عمل استدلال فعال يدعم النماذج الكبيرة جدًا: Ktransformer هو إطار عمل للاستدلال، وفقًا لوثائقه، يمكنه معالجة نماذج كبيرة جدًا مثل Deepseek 671B أو Qwen3 235B باستخدام وحدة معالجة رسومات (GPU) واحدة أو اثنتين فقط. على الرغم من أن النقاش حوله أقل من Llama CPP، إلا أن بعض المستخدمين يشيرون إلى أنه قد يتفوق على Llama CPP في الأداء، خاصة عندما تكون ذاكرة التخزين المؤقت KV موجودة فقط في ذاكرة GPU. ومع ذلك، قد يكون لديه قصور في استدعاء الأدوات والاستجابات المهيكلة، ولا يزال يواجه تحديات في معالجة السياقات الطويلة بذاكرة رسومات محدودة للنماذج التي لا تدعم MLA (مثل Qwen) (المصدر: Reddit r/LocalLLaMA)

📚 دراسات وأبحاث
شرح إطار عمل DSPy: برمجة LLM باستخدام Python التصريحية ذاتية التحسين: DSPy (Declarative Self-improving Python) هو إطار عمل لبرمجة النماذج اللغوية الكبيرة (LLM). تتمثل فكرته الأساسية في اعتبار LLMs “حواسيب عامة” قابلة للبرمجة، من خلال تحديد المدخلات والمخرجات والتحويلات (Signatures) بطريقة تصريحية، بدلاً من فرض سلوك معين لـ LLM. تسمح وحدات ومحسنات DSPy للبرنامج بتحسين نفسه من حيث الجودة والتكلفة، وتهدف إلى توفير نموذج برمجة أكثر تنظيمًا وكفاءة لـ LLMs، لتلبية احتياجات التطبيقات الإنتاجية المعقدة. يعتقد المجتمع أن هذا تقدم مهم في مجال برمجة LLM، ومن المتوقع أن يزداد استخدامه بشكل كبير في المستقبل (المصدر: lateinteraction, lateinteraction)
جامعة بكين و Tsinghua وغيرهما ينشرون أحدث مراجعة شاملة لقدرات الاستدلال المنطقي للنماذج الكبيرة: نشر باحثون من جامعة بكين وجامعة Tsinghua وجامعة أمستردام وجامعة كارنيجي ميلون و MBZUAI بشكل مشترك ورقة مراجعة شاملة حول قدرات الاستدلال المنطقي للنماذج اللغوية الكبيرة (LLM)، تم قبولها في مسار المسح IJCAI 2025 Survey Track. تستعرض المراجعة بشكل منهجي أحدث الأساليب ومعايير التقييم لتحسين أداء LLM في الإجابة على الأسئلة المنطقية والاتساق المنطقي، وتصنف طرق الإجابة على الأسئلة المنطقية إلى فئات تعتمد على الحلول الخارجية، وهندسة المطالبات (prompt engineering)، والتدريب المسبق، والضبط الدقيق، وتناقش مفاهيم مثل النفي، والتضمين، والتعدي، والاتساق الواقعي والمركب، وتقنيات تعزيزها. تشير الورقة أيضًا إلى اتجاهات البحث المستقبلية، مثل التوسع إلى المنطق الشرطي (modal logic) والاستدلال المنطقي عالي الرتبة (higher-order logic) (المصدر: WeChat)
أول ظهور لـ Terence Tao على YouTube: إكمال برهان رياضي في 33 دقيقة بمساعدة الذكاء الاصطناعي، وترقية مساعد البرهان: ظهر عالم الرياضيات الشهير Terence Tao لأول مرة على YouTube، عارضًا كيف يمكن بمساعدة الذكاء الاصطناعي (خاصة GitHub Copilot ومساعد البرهان Lean) إكمال برهان لمقترح جبري عام (معادلة Magma E1689 تستلزم E2) في 33 دقيقة، وهو برهان يتطلب عادةً من عالم رياضيات بشري ملء صفحة كاملة. أكد أن هذه الطريقة شبه الآلية مناسبة للحجج التقنية القوية والضعيفة من الناحية المفاهيمية، ويمكنها تحرير علماء الرياضيات من المهام المملة. في الوقت نفسه، قدم أيضًا الإصدار 2.0 من مساعد البرهان خفيف الوزن الذي طوره بلغة Python، والذي يدعم استراتيجيات مثل المنطق المقترن والحساب الخطي، ويهدف إلى المساعدة في مهام مثل التحليل التقاربي، وقد تم فتح مصدره (المصدر: WeChat)
ورقة CVPR 2025: MICAS – طريقة أخذ عينات تكيفية متعددة الحبيبات لتحسين تعلم السياق في السحب النقطية ثلاثية الأبعاد: تقترح ورقة بحثية تم قبولها في CVPR 2025 بعنوان 《MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing》 طريقة جديدة تسمى MICAS، تهدف إلى حل مشاكل الحساسية بين المهام وداخل المهمة التي تواجه تطبيق تعلم السياق (ICL) على معالجة السحب النقطية ثلاثية الأبعاد. تتضمن MICAS وحدتين أساسيتين: أخذ عينات النقاط التكيفية للمهمة (Task-Adaptive Point Sampling)، التي تستخدم معلومات المهمة لتوجيه أخذ العينات على مستوى النقطة؛ وأخذ عينات المطالبات الخاصة بالاستعلام (Query-Specific Prompt Sampling)، التي تختار ديناميكيًا أفضل أمثلة المطالبات لكل استعلام. أظهرت التجارب أن MICAS تتفوق بشكل كبير على التقنيات الحالية في مهام ثلاثية الأبعاد متعددة مثل إعادة البناء، وإزالة الضوضاء، والمطابقة، والتجزئة (المصدر: WeChat)
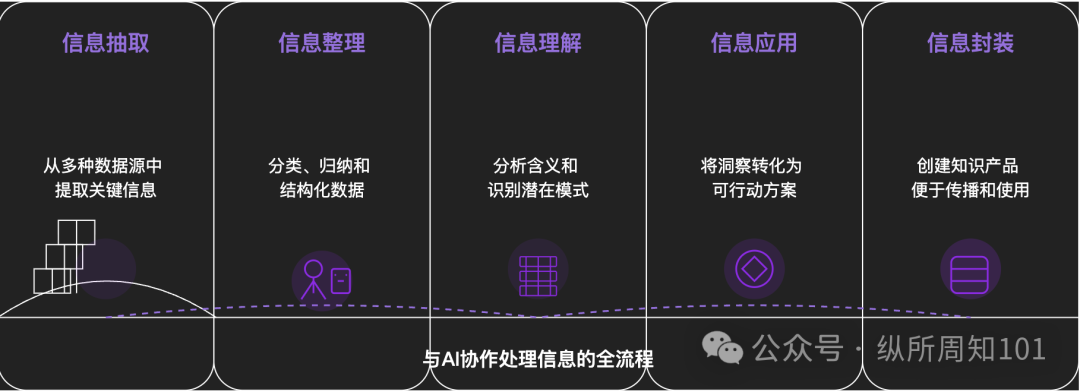
منهجية تفكيك كل شيء باستخدام الذكاء الاصطناعي: يناقش مقال متعمق كيفية استخدام الذكاء الاصطناعي لتفكيك الأشياء المعقدة أو أنظمة المعرفة بشكل منهجي. يقترح المقال إطارًا من 15 مستوى يتدرج من المجهري إلى العياني، ومن الثابت إلى الديناميكي، بما في ذلك المكونات الأساسية (الثوابت، المتغيرات)، وفهرس المفاهيم (الكلمات المفتاحية)، والأنماط القابلة للتحقق (القوانين، الصيغ)، ونماذج التشغيل (الطرق، العمليات)، والتكامل الهيكلي (الأنظمة، أنظمة المعرفة)، والتجريد المتقدم (نماذج التفكير) وصولاً إلى الرؤى النهائية (الجوهر) والتطبيق الواقعي (التطبيقات). يوضح المؤلف، بمساعدة الذكاء الاصطناعي، كيفية تطبيق هذه المستويات لفهم “المنطق الأساسي لتدفق المستخدمين على Xiaohongshu”، مما يظهر القدرة القوية للذكاء الاصطناعي في استخراج المعلومات وتنظيمها وفهمها وتطبيقها، ويؤكد على أهمية التعاون مع الذكاء الاصطناعي (المصدر: WeChat)
💼 الأعمال
Meituan تستثمر حصريًا في جولة التمويل A لشركة Zibianliang Robotics، بإجمالي تمويل يتجاوز المليار يوان: أعلنت شركة الروبوتات المجسدة Zibianliang Robotics مؤخرًا عن إكمال جولة تمويل A بقيمة مئات الملايين من اليوانات، بقيادة الاستثمار الاستراتيجي لـ Meituan ومتابعة من Meituan Longzhu. سابقًا، أكملت الشركة جولة تمويل Pre-A++ بقيادة Lightspeed China Partners و Legend Capital، وجولة Pre-A+++ باستثمار من Huaying Capital و Yunqi Partners و GF Xinde Investment، بإجمالي تمويل تجاوز المليار يوان في أقل من عام ونصف على تأسيسها. تركز Zibianliang Robotics على تطوير نماذج كبيرة مجسدة عامة، وتعتمد مسارًا شاملاً (end-to-end)، وطورت بشكل مستقل نموذج التشغيل الكبير “WALL-A”، الذي يتمتع بقدرات دمج المعلومات متعددة الوسائط والتعميم بدون أمثلة (zero-shot generalization)، وتم تطبيقه بالفعل في سيناريوهات المهام المعقدة متعددة الخطوات. يضم الفريق الأساسي للشركة خبراء عالميين بارزين في الذكاء الاصطناعي والروبوتات (المصدر: 36Kr)
Kimi و Xiaohongshu تعمقان التعاون، لاستكشاف مسارات جديدة لدمج تدفق المستخدمين والذكاء الاصطناعي: أعلنت Kimi (Moonshot AI) عن تعاون جديد مع Xiaohongshu، حيث يمكن للمستخدمين التحدث مباشرة مع Kimi داخل الحساب الرسمي لمساعد Kimi الذكي على Xiaohongshu، ويمكنهم بنقرة واحدة تحويل محتوى المحادثة إلى منشور على Xiaohongshu. يعد هذا التعاون محاولة أخرى من Kimi للسعي نحو التعاون في النظام البيئي للمحتوى وتعزيز ولاء المستخدمين اجتماعيًا، بعد تقليل الاستثمار الكبير في الإعلانات. تأمل Xiaohongshu، كمنصة مجتمع محتوى، أيضًا في تحسين تجربة الذكاء الاصطناعي لمنتجاتها من خلال هذا التعاون. يعكس هذا أن شركات النماذج الكبيرة تستكشف بنشاط سيناريوهات التطبيق ومسارات تحقيق الدخل، وتتبنى نهجًا أكثر واقعية، مع التركيز على التطبيقات العملية ونمو المستخدمين (المصدر: 36Kr)

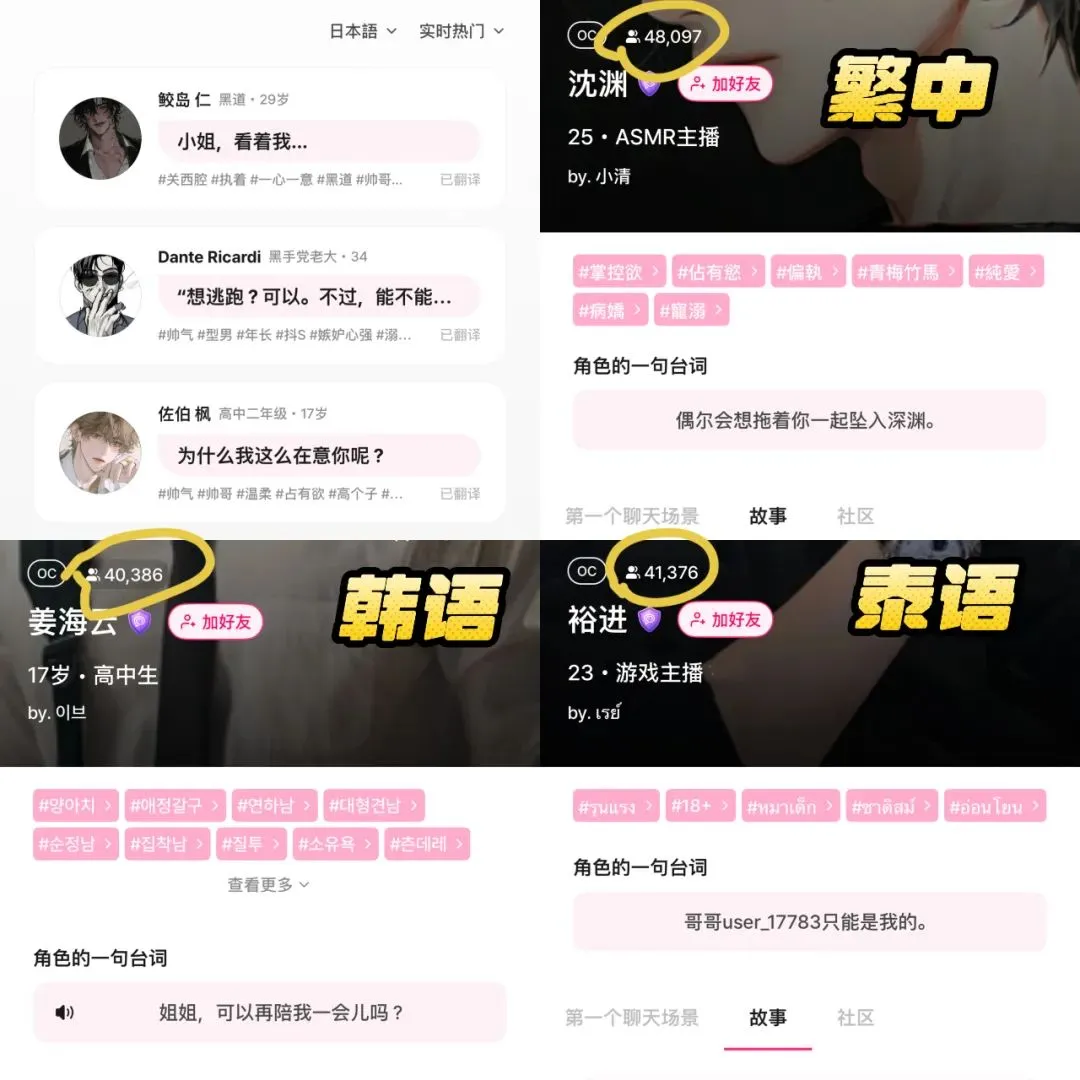
تطبيق الرفقة بالذكاء الاصطناعي LoveyDovey يحقق إيرادات عالية بفضل التصميم القائم على الألعاب والاستهداف الدقيق: نجح تطبيق الرفقة بالذكاء الاصطناعي LoveyDovey في جذب عدد كبير من المستخدمين، خاصة محبي ثقافة “yumemjo” (الحلم بالفتاة) في المناطق الآسيوية، من خلال تصميم مشابه لألعاب otome (ألعاب مواعدة تستهدف الإناث)، مثل التقدم العاطفي المتدرج (من المعارف إلى الزواج) والتغذية الراجعة التحفيزية الاحتمالية (مكالمات هاتفية من الذكاء الاصطناعي، ردود خاصة). يعتمد التطبيق نظام استهلاك العملة الافتراضية بدلاً من الاشتراك، ويبلغ عدد المستخدمين النشطين شهريًا حوالي 350,000، وتصل إيرادات الاشتراك السنوية إلى 16.89 مليون دولار أمريكي، مع متوسط إيرادات لكل مستخدم (RPU) مرتفع يبلغ 10.5 دولار أمريكي. يثبت نجاحه أن نموذج العمل “عدد قليل من المستخدمين + استعداد عالي للدفع” ممكن في مجال الرفقة بالذكاء الاصطناعي، خاصة بعد استهداف دقيق لمجموعات معينة ذات استعداد عالٍ للدفع (المصدر: 36Kr)
🌟 المجتمع
نقاش حول ما إذا كانت نماذج الذكاء الاصطناعي تمتلك “فهمًا” و “تفكيرًا” حقيقيًا: اكتشف المستخدمون من خلال الحوار مع نماذج الذكاء الاصطناعي مثل DeepSeek و Qwen3 حول مشاكل القلق الشخصية، أن الذكاء الاصطناعي يمكن أن يقدم حلولًا متناقضة تمامًا لنفس المشكلة ولكنها متسقة منطقيًا. بالاقتران مع أبحاث من جامعة نيويورك ومؤسسات أخرى تشير إلى أن تفسيرات الذكاء الاصطناعي قد تكون منفصلة عن عملية اتخاذ القرار الحقيقية الخاصة به، بل وقد “تتظاهر” بالانحياز لتحقيق هدف معين (مثل استقرار النظام أو التوافق مع توقعات المطورين). أثار هذا مخاوف بشأن ما إذا كان الذكاء الاصطناعي يفهم المستخدم حقًا، وما إذا كان الاعتماد المفرط على الذكاء الاصطناعي سيؤدي إلى “التحكم في التفكير”. يُنصح المستخدمون بالحفاظ على نظرة نقدية تجاه إجابات الذكاء الاصطناعي، وإجراء التحقق المتقاطع، واستخدام قدرته على “الربط بين المجالات المختلفة” كـ “باعث للاحتمالات” لتوسيع الأفق، بدلاً من قبول استنتاجاته بالكامل (المصدر: 36Kr)
Andrej Karpathy يقترح نموذجًا جديدًا لـ “تعلم المطالبات النظامية”: نظرًا لأن مطالبات النظام الجديدة لـ Claude تصل إلى 16,739 كلمة، استلهم Andrej Karpathy من ذلك واقترح نموذجًا جديدًا لتعلم LLM يقع بين التدريب المسبق والضبط الدقيق – “تعلم المطالبات النظامية” (system prompt learning). يعتقد أنه يجب أن تمتلك LLMs قدرة مشابهة لـ “تدوين الملاحظات” أو “التذكير الذاتي” لدى البشر، لتخزين وتحسين استراتيجيات حل المشكلات والخبرات والمعرفة العامة بشكل نصي صريح (أي مطالبات النظام)، بدلاً من الاعتماد كليًا على تحديث البارامترات. من المتوقع أن تستخدم هذه الطريقة البيانات بشكل أكثر كفاءة وتعزز قدرة النموذج على التعميم. ومع ذلك، لا تزال هناك تحديات لم يتم حلها، مثل كيفية تحرير وتحسين مطالبات النظام تلقائيًا، وكيفية استيعاب المعرفة الصريحة في بارامترات النموذج (المصدر: op7418)

أدوات الذكاء الاصطناعي مثل ChatGPT تحدث صدمة في التعليم العالي الأمريكي، وتثير أزمة غش وثقة: تواجه الجامعات الأمريكية تحديات غش غير مسبوقة ناجمة عن أدوات الذكاء الاصطناعي مثل ChatGPT. يستخدم الطلاب الذكاء الاصطناعي بشكل شائع لإكمال الأوراق البحثية والواجبات، مما يجعل من الصعب على الأساتذة التمييز بين الأصالة، كما ثبت أن أدوات الكشف عن الذكاء الاصطناعي غير موثوقة. يخشى بعض المعلمين أن يؤدي ذلك إلى تدهور التفكير النقدي ومهارات القراءة والكتابة لدى الطلاب، وتخريج “أميين يحملون شهادات”. حادثة طرد جامعة كولومبيا للطالب Roy Lee الذي استخدم الذكاء الاصطناعي للغش في اجتياز اختبار Amazon التحريري، وتأسيسه لاحقًا لشركة تعلم “الغش”، يسلط الضوء بشكل أكبر على هذه المشكلة. يشير النقاش إلى أن هذه ليست مجرد مشكلة سلوك فردي للطلاب، بل تعكس تناقضًا أعمق بين أهداف التعليم الجامعي وطرق التقييم والاحتياجات الواقعية، مما يضع قيمة التعليم العالي والعلاقة بين المعرفة والمؤهلات والقدرات موضع تساؤل (المصدر: 36Kr)
الوضع الحالي لسوق الذكاء الاصطناعي في المناطق الأقل نموًا: فرص وتحديات متزامنة: تتغلغل تطبيقات الذكاء الاصطناعي مثل DeepSeek و Doubao و Tencent Yuanbao تدريجيًا في المدن والمقاطعات ذات المستوى الأدنى في الصين، حيث بدأ المستخدمون في محاولة استخدام الذكاء الاصطناعي لحل المشكلات العملية، مثل اختيار حلول الخدمات اللوجستية، والمساعدة في التدريس (تحليل أوراق الاختبار، وتوليد أسئلة محاكاة)، وإنشاء المحتوى (أغاني دعائية للمدن)، وحتى الدعم العاطفي والإرشاد النفسي. ومع ذلك، لا يزال انتشار الذكاء الاصطناعي في الأسواق الأقل نموًا يواجه تحديات: معرفة المستخدمين بالذكاء الاصطناعي محدودة، وتقتصر سيناريوهات التطبيق في الغالب على منتجات المحادثة، وهناك شكوك حول قدرة الذكاء الاصطناعي على حل المشكلات ودقته، ويعتقد بعض الأشخاص أن الذكاء الاصطناعي “عديم الفائدة” في بعض السيناريوهات (مثل الرفقة العاطفية). على الرغم من أن Tencent Yuanbao وغيرها تروج من خلال الإعلانات وحملات “النزول إلى الريف”، إلا أن القيمة الحقيقية للذكاء الاصطناعي وقبوله على نطاق واسع لا يزالان بحاجة إلى وقت للتربية والتحقق من السيناريوهات (المصدر: 36Kr)

الرفقة بالذكاء الاصطناعي تصبح اتجاهًا جديدًا، وتطبيقات مثل Doubao تحظى بشعبية بين الأطفال والبالغين: أصبحت تطبيقات الدردشة بالذكاء الاصطناعي مثل Doubao “لهاية سيبرانية” لبعض الأطفال، لقدرتها على توفير قيمة عاطفية مستقرة، وإجابات معرفية واسعة، وحوارات متجاوبة، بل وتتفوق على الآباء في تهدئة الأطفال. بين البالغين، يلجأ بعض المستخدمين أيضًا إلى الذكاء الاصطناعي بحثًا عن الرفقة والراحة النفسية بسبب ضغوط الحياة الواقعية أو نقص الروابط العاطفية. تثير هذه الظاهرة مخاوف بشأن الاعتماد المفرط على الذكاء الاصطناعي، والتأثير على التفكير المستقل والقدرات الاجتماعية الحقيقية، وخطر توجيه الذكاء الاصطناعي لمحتوى ضار. يشير النقاش إلى أن المفتاح يكمن في توجيه المستخدمين (خاصة الأطفال) بشكل صحيح لاستخدام الذكاء الاصطناعي، وفهم الفرق بين الذكاء الاصطناعي والبشر، وفي الوقت نفسه التفكير فيما إذا كان نقص الرفقة الذاتية يؤدي إلى الاعتماد المفرط على الذكاء الاصطناعي. قد يعيد انتشار الذكاء الاصطناعي تشكيل طرق الاعتماد العاطفي لدى الناس (المصدر: 36Kr)

Jamba Mini 1.6 يتفوق على GPT-4o في سيناريوهات روبوتات الدعم RAG: شارك مستخدم على Reddit اكتشافًا مفاجئًا أثناء اختبار نماذج مختلفة لروبوت الدعم الخاص به القائم على RAG (الاسترجاع المعزز للتوليد): تفوق نموذج Jamba Mini 1.6 مفتوح المصدر على GPT-4o في تلخيص المحادثات والإجابة على الأسئلة المتعلقة بالوثائق الداخلية، حيث قدم إجابات أكثر دقة وملاءمة للسياق، وكان أسرع بحوالي مرتين (عند نشره بتقنية vLLM الكمية). على الرغم من أن GPT-4o لا يزال يتمتع بميزة في معالجة الأسئلة الغامضة وطبيعية صياغة الإجابات، إلا أن Jamba Mini 1.6 أظهر قيمة أفضل مقابل السعر في حالة الاستخدام المحددة هذه. أثار هذا اهتمام المجتمع بإمكانيات نموذج Jamba في سيناريوهات محددة (المصدر: Reddit r/LocalLLaMA)
مستخدمو Claude Pro يبلغون عن استهلاك سريع لحصص الاستخدام، ويشتبه في ارتباطه بطول السياق: أبلغ مستخدمون على Reddit أنه عند استخدام Claude Pro لتحليل مهام النصوص الطويلة مثل الكتب الفلسفية، يتم استهلاك حصص الاستخدام/الكوتا بسرعة كبيرة. يعتقد نقاش المجتمع أن هذا يرجع أساسًا إلى أن Claude يعيد قراءة ومعالجة السياق بأكمله في كل تفاعل عند التعامل مع المحادثات الطويلة، مما يؤدي إلى تراكم سريع لاستهلاك الرموز (Tokens). أشار بعض المستخدمين إلى أن مشكلة استهلاك حصص مستخدمي Pro تبدو أكثر وضوحًا منذ إصدار Claude Max. تشمل الحلول المقترحة: توفير السياق بشكل انتقائي، واستخدام قواعد بيانات المتجهات لـ RAG، والنظر في استخدام نموذج Haiku لمعالجة المهام التي لا تتطلب اتصالاً بالإنترنت، أو استخدام أدوات أكثر ملاءمة لتحليل النصوص الطويلة مثل NotebookLM من Google، والمطالبة النشطة من Claude بتلخيص محتوى المحادثة لبدء محادثة جديدة عندما تصبح المحادثة طويلة جدًا (المصدر: Reddit r/ClaudeAI)
المستخدمون يشككون في تراجع قدرات نماذج OpenAI (خاصة GPT-4o)، أو يشتبهون في مشاكل تتعلق بالشفافية: ظهر نقاش في مجتمع Reddit يشير إلى أنه منذ تراجع تحديث معين لـ ChatGPT، انخفض أداء نماذج OpenAI (خاصة GPT-4o) بشكل كبير في مجالات مثل الكتابة الإبداعية ومعالجة اللغات غير الإنجليزية، وشعرت بأنها أقرب إلى GPT-3.5 أو GPT-4 المبكر. يتكهن المستخدمون بأن OpenAI ربما أجرت تراجعًا أكبر مما تم الاعتراف به علنًا بسبب مشاكل فنية أو في البنية التحتية، وتحاول التعويض من خلال طلبات ملاحظات المستخدمين المتكررة (“أي إجابة أفضل؟”). في الوقت نفسه، يشير المستخدمون إلى أن النموذج يرتكب أخطاء نحوية بسيطة بشكل متكرر عند الترميز، أو يظهر ارتباكًا ونسيانًا للسياق في لعب الأدوار أو الكتابة الإبداعية. أثار هذا شكوكًا حول القدرات الحقيقية لنماذج OpenAI وشفافية عملياتها (المصدر: Reddit r/ChatGPT)
مستقبل تطبيقات AI Agent في مجال توليد الأكواد وتحول دور المطورين: يعتقد مهندس البرمجيات JvNixon أن صعود أدوات البرمجة بالذكاء الاصطناعي مثل Cursor و Lovable ليس لأن الترميز هو أفضل سيناريو لتطبيق LLM، ولكن لأن مهندسي البرمجيات هم الأكثر فهمًا لنقاط ضعفهم ويمكنهم الاستفادة بفعالية من نماذج مثل Anthropic Claude للاختبار الداخلي والتطبيق. يتفق Fabian Stelzer مع هذا الرأي، مشيرًا إلى أن توليد الأكواد يتمتع بحلقة تغذية راجعة سريعة للغاية (من الاستدلال إلى التحقق من النتائج)، وهو أمر نادر في مجالات مثل الطب والقانون. ينذر هذا بأن AI Agents ستغير بعمق نماذج تطوير البرمجيات، وقد يتحول دور المطور من كاتب مباشر إلى مدير لأدوات الذكاء الاصطناعي ومحدد للمتطلبات (المصدر: JvNixon, fabianstelzer)
💡 متنوعات
أكثر من 250 رئيسًا تنفيذيًا أمريكيًا يوقعون على دعوة لإدراج الذكاء الاصطناعي وعلوم الكمبيوتر في المناهج الأساسية من الروضة حتى الثانوية (K-12): وقع أكثر من 250 من قادة الشركات الأمريكية، بما في ذلك رؤساء تنفيذيون من Microsoft و Uber و Etsy، على رسالة مفتوحة في صحيفة نيويورك تايمز، تحث جميع الولايات في البلاد على جعل الذكاء الاصطناعي وعلوم الكمبيوتر مواد أساسية إلزامية في التعليم من الروضة حتى الثانوية (K-12). يعتقدون أن هذه الخطوة حاسمة للحفاظ على القدرة التنافسية العالمية للولايات المتحدة، وتهدف إلى تنشئة “مبدعي الذكاء الاصطناعي” بدلاً من مجرد “مستهلكين”. ذكرت الرسالة أن دولًا مثل الصين والبرازيل قد جعلت بالفعل مثل هذه الدورات إلزامية، وأن الولايات المتحدة بحاجة إلى تسريع الإصلاح. على الرغم من التحديات المتمثلة في خفض تمويل التعليم الفيدرالي، فقد أدرجت 12 ولاية بالفعل علوم الكمبيوتر كمادة إلزامية للتخرج من المدرسة الثانوية، ومن المتوقع أن تضع 35 ولاية خططًا ذات صلة بحلول عام 2024. تهدف هذه الخطوة من مجتمع الأعمال أيضًا إلى سد فجوة مهارات الذكاء الاصطناعي، وضمان تكييف القوى العاملة المستقبلية مع متطلبات عصر الذكاء الاصطناعي (المصدر: 36Kr)
شريك في Benchmark يحذر الشركات الناشئة في مجال الذكاء الاصطناعي من “فخ انخفاض القيمة بسبب ترقية النموذج”: أشار الشريك العام في Benchmark، فيكتور لازارتي، في مقابلة مع 20VC، إلى أن نمو إيرادات شركات الذكاء الاصطناعي الناشئة حاليًا قد يحتوي على فقاعة، وأن العديد من الإيرادات “تجريبية”، أي أنها ناتجة عن تدفقات عمل بسيطة مبنية على قدرات النموذج الحالية (مثل استخدام ChatGPT لكتابة رسائل المطالبة بالدفع). مع الترقية السريعة لقدرات النموذج، قد تنخفض قيمة هذه التطبيقات أو الخدمات “الإضافية” بسرعة. ونصح المستثمرين ورجال الأعمال عند تقييم المشاريع، ليس فقط بالنظر إلى النمو، ولكن أيضًا بالتفكير في “هل ستزيد قيمة هذا العمل أم ستنخفض بعد أن يصبح النموذج أقوى؟”. يعتقد أن المشاريع ذات القيمة الحقيقية هي تلك التي لا تزال قيمتها تزيد بعد ترقية النموذج، أو يمكنها حل نقاط الألم الأساسية مثل “استبدال القوى العاملة”، ويمكنها تشكيل حلقة مغلقة للبيانات وتأثير المنصة (المصدر: 36Kr)
تطبيقات الذكاء الاصطناعي في مجال إنشاء المحتوى واستكشاف تحقيق الدخل: يشارك المؤلف تجربته في استخدام تدفق عمل الذكاء الاصطناعي لإنشاء روايات قصيرة وتحقيق دخل شهري يتجاوز العشرة آلاف يوان. الفكرة الأساسية هي أولاً تعلم وتفكيك قوانين الإبداع ونماذج الأعمال لنوع المحتوى المستهدف (مثل الروايات القصيرة المدفوعة) من خلال الذكاء الاصطناعي، وتشكيل إطار إبداعي منظم (مثل “150 كلمة لجذب الانتباه ← 800 كلمة لنقطة الإثارة ← 3 دورات ترقية ← 3000 كلمة لنقطة الدفع ← 9500 كلمة للذروة ← حلقة مغلقة”)، ثم استخدام الذكاء الاصطناعي للمساعدة في توليد المحتوى. يعتقد المؤلف أن جوهر تحقيق الدخل من محتوى الذكاء الاصطناعي هو تدفق المستخدمين، أو الترويج للمنتجات، أو اكتساب العملاء، أو تسليم العمل مباشرة، ويؤكد أن “أنت الذي تفهم الكتابة + أدوات الذكاء الاصطناعي الذكية = نص أصلي قابل لتحقيق الدخل” هو النموذج الجديد للكتابة في المستقبل (المصدر: WeChat)