
كلمات مفتاحية:أمن الذكاء الاصطناعي, أخلاقيات الذكاء الاصطناعي, وكلاء الذكاء الاصطناعي, التوليد ثلاثي الأبعاد, نماذج البرمجة, تقييم مخاطر الذكاء الاصطناعي, فهم الفيديو Gemini 2.5 Pro, التوليد ثلاثي الأبعاد AssetGen 2.0, نموذج البرمجة Seed-Coder, تشغيل وكلاء الذكاء الاصطناعي AgentOps
🔥 أبرز العناوين
مخاطر أمن الذكاء الاصطناعي تثير القلق، والخبراء يدعون للاستفادة من تجربة الأمن النووي في تقييم المخاطر: يتزايد القلق الدولي بشأن المخاطر المحتملة للذكاء الاصطناعي، حيث دعا خبراء (مثل Max Tegmark) شركات الذكاء الاصطناعي إلى محاكاة طريقة حسابات السلامة التي اتبعها روبرت أوبنهايمر عند إجراء أول تجربة نووية، وذلك لتقييم احتمالية خروج الذكاء الاصطناعي عن السيطرة (ثابت Compton) بشكل صارم قبل إطلاق أنظمة ذكاء اصطناعي خطيرة. يهدف هذا الإجراء إلى تكوين إجماع في الصناعة، ودفع إنشاء آلية عالمية لأمن الذكاء الاصطناعي، لمنع العواقب الكارثية المحتملة التي قد يجلبها الذكاء الخارق. (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)

البابا الجديد فرنسيس (الاسم المستعار Leo XIV) يولي اهتمامًا كبيرًا للتغيرات الاجتماعية التي أحدثها الذكاء الاصطناعي: حدد البابا المنتخب حديثًا فرنسيس (الذي يُقال إنه Leo XIV) الذكاء الاصطناعي كأحد التحديات الرئيسية التي تواجه البشرية. وقد اختار اسم “Leo” جزئيًا بسبب المشكلات الاجتماعية الجديدة والثورة الصناعية التي يقودها الذكاء الاصطناعي، مما يعكس استجابة البابا Leo XIII التاريخية للثورة الصناعية الأولى. أكد البابا أن الذكاء الاصطناعي يشكل تحديًا للحفاظ على “الكرامة الإنسانية والعدالة والعمل”، ويخطط لإصدار وثيقة مهمة حول أخلاقيات الذكاء الاصطناعي في المستقبل، مما يدل على الاهتمام العميق للزعيم الديني بأخلاقيات تكنولوجيا الذكاء الاصطناعي وتأثيرها الاجتماعي. (المصدر: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

جوجل تصدر ورقة بيضاء من 76 صفحة حول وكلاء الذكاء الاصطناعي، تشرح AgentOps والتطبيقات المستقبلية: أصدرت جوجل ورقة بيضاء مكونة من 76 صفحة حول وكلاء الذكاء الاصطناعي، تشرح بالتفصيل بناء وتقييم وتطبيق الوكلاء. تؤكد الورقة البيضاء على أهمية عمليات تشغيل الوكلاء (AgentOps)، كفرع من عمليات تشغيل الذكاء الاصطناعي التوليدي، حيث تركز AgentOps على إدارة الأدوات، وإعدادات التوجيه الأساسية، ووظائف الذاكرة، وتجزئة المهام اللازمة لتشغيل الوكلاء بكفاءة. كما تناقش الورقة البيضاء بنية التعاون متعدد الوكلاء، حيث يلعب وكلاء مختلفون أدوارًا مثل التخطيط والاسترجاع والتنفيذ والتقييم لإكمال المهام المعقدة بشكل مشترك، وتتطلع إلى آفاق تطبيق الوكلاء في مساعدة الموظفين وأتمتة مهام الخلفية في الشركات، مثل إصدار NotebookLM للمؤسسات و Agentspace. (المصدر: WeChat)

Meta تطلق AssetGen 2.0: إنشاء مواد ثلاثية الأبعاد عالية الجودة من النصوص/الصور: أطلقت Meta أحدث نماذجها الأساسية للذكاء الاصطناعي ثلاثي الأبعاد AssetGen 2.0، والذي يمكنه إنشاء أصول ثلاثية الأبعاد عالية الجودة بناءً على التوجيهات النصية والصورية. يتضمن AssetGen 2.0 نموذجين فرعيين: أحدهما لتوليد الشبكات ثلاثية الأبعاد، باستخدام نموذج انتشار ثلاثي الأبعاد أحادي المرحلة لتحسين التفاصيل والدقة؛ ونموذج TextureGen آخر لتوليد الأنسجة، مع إدخال طرق لتعزيز اتساق العرض، وإصلاح الأنسجة، ودقة نسيج أعلى. تُستخدم هذه التقنية حاليًا داخل Meta لإنشاء عوالم ثلاثية الأبعاد، ومن المقرر طرحها لمبدعي Horizon في وقت لاحق من هذا العام. (المصدر: Reddit r/artificial)

🎯 اتجاهات
فريق Seed من ByteDance يفتح مصدر نموذج الكود Seed-Coder بحجم 8B، معتمدًا نموذجًا جديدًا لإدارة البيانات بواسطة النماذج: فتح فريق Seed من ByteDance لأول مرة مصدر نموذج الكود الخاص به Seed-Coder بحجم 8B، والذي يتضمن ثلاثة إصدارات: Base و Instruct و Reasoning. أظهر هذا النموذج أداءً متميزًا في العديد من اختبارات توليد الأكواد القياسية، وتفوق بشكل خاص على نماذج مثل Qwen3 في HumanEval و MBPP. يكمن الابتكار الأساسي لـ Seed-Coder في اقتراح طريقة معالجة بيانات “مرتكزة على النموذج”، حيث يتم استخدام LLM نفسه لتوليد وفحص بيانات تدريب أكواد عالية الجودة، بما في ذلك أكواد على مستوى الملفات، وأكواد على مستوى المستودعات، وبيانات Commit، وبيانات الويب المتعلقة بالأكواد، بإجمالي حجم بيانات تدريب يصل إلى 6T tokens. يهدف هذا الإجراء إلى تقليل التدخل البشري وتعزيز قدرات نماذج الأكواد. (المصدر: WeChat)
Gemini 2.5 Pro يحقق طفرة في فهم الفيديو، ويدمج الصوت والفيديو مع الكود بشكل أصلي: حققت أحدث نماذج جوجل Gemini 2.5 Pro و Flash تقدمًا ملحوظًا في قدرات فهم الفيديو، حيث وصل Gemini 2.5 Pro إلى مستوى SOTA في العديد من اختبارات فهم الفيديو القياسية الرئيسية، بل وتفوق على GPT 4.1. ولأول مرة، تدمج سلسلة نماذج Gemini 2.5 معلومات الصوت والفيديو بسلاسة مع تنسيقات البيانات الأخرى مثل الكود، مما يمكنها من تحويل الفيديو مباشرة إلى تطبيقات تفاعلية (مثل تطبيقات التعلم)، وإنشاء رسوم متحركة p5.js بناءً على الفيديو، واسترجاع ووصف مقاطع الفيديو بدقة، مما يظهر قدرات استدلال زمني قوية. هذه الميزات متاحة الآن في Google AI Studio و Gemini API و Vertex AI. (المصدر: WeChat)

ModelScope تفتح مصدر نموذج الصور الموحد Nexus-Gen، لمنافسة قدرات GPT-4o في معالجة الصور: أطلق فريق ModelScope نموذج Nexus-Gen، وهو نموذج متعدد الوسائط موحد قادر على معالجة فهم الصور وتوليدها وتحريرها في نفس الوقت، بهدف منافسة قدرات GPT-4o في معالجة الصور. يعتمد النموذج على المسار التقني token → transformer → diffusion → pixels، ويدمج نمذجة النصوص من MLLM مع قدرات عرض الصور من نماذج Diffusion. لحل مشكلة تراكم الأخطاء عند التنبؤ الذاتي التراجعي بتضمينات الصور المستمرة، اقترح الفريق استراتيجية الملء المسبق الذاتي التراجعي. تم تدريب Nexus-Gen على حوالي 25 مليون زوج من الصور والنصوص، بما في ذلك مجموعة بيانات تحرير ImagePulse التي تم فتح مصدرها مؤخرًا من مجتمع ModelScope. (المصدر: WeChat)

إصدار Cursor 0.50، يبسط التسعير ويعزز العديد من ميزات تحرير الكود: أصدر محرر الكود المدعوم بالذكاء الاصطناعي Cursor الإصدار 0.50، والذي يجلب تحديثات كبيرة. تم تبسيط نموذج التسعير ليصبح قائمًا على الطلب، ويدعم وضع Max جميع نماذج الذكاء الاصطناعي الرائدة ويعتمد تسعيرًا قائمًا على الـ token. تشمل تحسينات الميزات: نموذج Tab جديد يدعم الاقتراحات عبر الملفات وإعادة هيكلة الكود؛ وكيل خلفية (إصدار تجريبي) يدعم تشغيل وكلاء متعددين بالتوازي وتنفيذ المهام في بيئات بعيدة؛ سياق مستودع الكود يسمح بإضافة مستودعات أكواد كاملة عبر @folders؛ تحسين واجهة المستخدم للتحرير المضمن، مع إضافة ميزات تحرير الملف بالكامل والإرسال إلى الوكيل؛ تحرير الملفات الطويلة يقدم أداة بحث واستبدال؛ دعم مساحات العمل متعددة الجذور لمعالجة مستودعات أكواد متعددة؛ تعزيز وظيفة الدردشة، ودعم التصدير إلى Markdown والنسخ. (المصدر: op7418)
llama.cpp يضيف دعمًا لنماذج اللغة المرئية (VLM)، مما يتيح بناء تدفقات Vision RAG كاملة: أعلن مشروع llama.cpp مفتوح المصدر عن دعمه لنماذج اللغة المرئية (VLM)، ويمكن للمستخدمين الآن استخدام الميزات المرئية عبر خادم llama.cpp وواجهة مستخدم الويب. يعني هذا التحديث أنه يمكن تحميل نفس النموذج الأساسي الذي يدعم LoRA متعددة بالإضافة إلى نماذج التضمين على llama.cpp، مما يتيح بناء تدفقات كاملة لتوليد معزز بالاسترجاع المرئي (Vision RAG). يوسع هذا الإجراء بشكل أكبر قدرات llama.cpp في تشغيل نماذج لغوية كبيرة محليًا، مما يمكنه من معالجة المهام متعددة الوسائط. (المصدر: mervenoyann, mervenoyann)
Tencent تطلق HunyuanCustom: بنية توليد فيديو مخصصة تعتمد على HunyuanVideo: أطلقت Tencent على Hugging Face مشروع HunyuanCustom، وهو بنية مدفوعة بالوسائط المتعددة مصممة خصيصًا لتوليد الفيديو المخصص. يعتمد هذا العمل على HunyuanVideo، مع التركيز بشكل خاص على الحفاظ على اتساق الموضوع الرئيسي عند توليد الفيديو، مع دعم إدخال شروط متعددة مثل الصور والصوت والفيديو والنصوص، مما يوفر للمستخدمين قدرات إنشاء فيديو أكثر مرونة وتخصيصًا. (المصدر: _akhaliq)
Qwen Chat يضيف وضع “تطوير الويب”، لإنشاء تطبيقات ويب React بجملة واحدة: أطلق Qwen Chat من Alibaba وضع “تطوير الويب” (Web Dev)، حيث يمكن للمستخدمين إنشاء تطبيقات ويب تتضمن HTML و CSS و JavaScript باستخدام أمر واحد فقط، مع استخدام إطار عمل React و Tailwind CSS في الخلفية. تتيح هذه الميزة إنشاء مواقع ويب شخصية بسرعة، أو استنساخ واجهات ويب موجودة (مثل Twitter و GitHub)، أو بناء نماذج ورسوم متحركة محددة بناءً على الوصف. يمكن للمستخدمين اختيار نماذج Qwen مختلفة ودمجها مع وضع “التفكير العميق” لتحسين جودة صفحة الويب. تهدف هذه الميزة إلى تبسيط عملية تطوير الواجهة الأمامية وبناء نماذج أولية للتطبيقات بسرعة. (المصدر: WeChat)
Unitree Robotics ترد على ثغرة أمنية في روبوت Go1، وتؤكد تحديث المنتجات اللاحقة: ردت شركة Unitree Robotics على الشائعات المتعلقة بوجود “ثغرة باب خلفي” في سلسلة روبوتات Go1 التي توقف إنتاجها منذ حوالي عامين، معترفة بأن المشكلة هي ثغرة أمنية. يمكن للمهاجمين استغلال مفتاح إدارة خدمة نفق سحابي لجهة خارجية لتعديل بيانات جهاز المستخدم، والحصول على لقطات الكاميرا وصلاحيات النظام. ذكرت Unitree Robotics أن سلاسل الروبوتات اللاحقة تستخدم إصدارات مطورة أكثر أمانًا ولا تتأثر بهذه الثغرة. أثارت هذه الحادثة مخاوف بشأن أمن سلسلة توريد الروبوتات الذكية وخصوصية البيانات، خاصة في سياق العام الأول لتسويق الروبوتات البشرية، حيث تواجه الصناعة تحديات متعددة مثل الاختراقات التقنية والتحكم في التكاليف واستكشاف مسارات التسويق. (المصدر: 36氪)

Claude Code يدعم الآن الإشارة إلى ملفات .MD أخرى، مما يحسن تنظيم التعليمات: قامت Anthropic بتحديث وظيفة Claude Code الخاصة بها، حيث يسمح الإصدار 0.2.107 لملفات CLAUDE.md باستيراد ملفات Markdown أخرى. يمكن للمستخدمين تحميل محتوى ملفات إضافية عند بدء التشغيل عن طريق إضافة [u/path/to/file].md في ملف CLAUDE.md الرئيسي. يعمل هذا التحسين على تمكين المستخدمين من تنظيم وإدارة تعليمات Claude بشكل أفضل، مما يزيد من موثوقية ووحدات تكوين التعليمات في المشاريع الكبيرة، ويحل مشكلة الفوضى التي قد تنشأ عن الاعتماد على ملفات متفرقة في السابق. (المصدر: Reddit r/ClaudeAI)

مكتب حقوق الطبع والنشر الأمريكي يتخذ موقفًا أكثر صرامة بشأن التدريب المسبق للذكاء الاصطناعي، مما يضعف دفاع “الاستخدام العادل”: اتخذ أحدث تقرير صادر عن مكتب حقوق الطبع والنشر الأمريكي موقفًا أكثر صرامة بشأن استخدام المواد المحمية بحقوق الطبع والنشر في مرحلة التدريب المسبق لنماذج الذكاء الاصطناعي. وأشار التقرير إلى أنه نظرًا لأن مختبرات الذكاء الاصطناعي تدعي الآن أن نماذجها قادرة على منافسة أصحاب الحقوق (على سبيل المثال، إنشاء محتوى مشابه للأعمال الأصلية)، فإن هذا يضعف من قوة دفاعهم عن “الاستخدام العادل” (fair use) في دعاوى انتهاك حقوق الطبع والنشر. قد يكون لهذا التحول تأثير كبير على مصادر بيانات تدريب نماذج الذكاء الاصطناعي والامتثال التنظيمي. (المصدر: Dorialexander)

Nvidia تطلق بطاقة الرسومات الاحترافية RTX Pro 5000، مزودة بذاكرة GDDR7 بسعة 48 جيجابايت: أطلقت Nvidia وحدة معالجة الرسومات المكتبية الاحترافية الجديدة RTX Pro 5000، المبنية على معمارية Blackwell. تم تجهيز البطاقة بذاكرة GDDR7 بسعة 48 جيجابايت، وعرض نطاق ترددي للذاكرة يصل إلى 1344 جيجابايت/ثانية، واستهلاك طاقة يبلغ 300 واط. على الرغم من أن الشركة وصفتها بأنها بطاقة Blackwell “رخيصة” بسعة 48 جيجابايت، إلا أنه من المتوقع أن يكون سعرها مرتفعًا (ذكرت بعض التعليقات أنها في فئة 4000 دولار)، وهي موجهة بشكل أساسي لمستخدمي محطات العمل الاحترافية، لتوفير قوة حوسبة قوية لمهام مثل تدريب نماذج الذكاء الاصطناعي وعرض النماذج ثلاثية الأبعاد الكبيرة. (المصدر: Reddit r/LocalLLaMA)

🧰 أدوات
RunwayML تطلق ميزة References، التي تتيح مزج مواد مرجعية متعددة لإنشاء المحتوى: تتيح ميزة “References” الجديدة من RunwayML للمستخدمين مزج مواد مرجعية مختلفة (مثل الصور والأنماط) كـ “مواد خام”، والقدرة على إنشاء محتوى مرئي جديد بناءً على أي مزيج من هذه “المواد الخام”. تُعتبر هذه الميزة بمثابة آلة إبداعية شبه فورية، قادرة على مساعدة المستخدمين على تحقيق أفكار إبداعية متنوعة بسرعة، مما يوسع بشكل كبير مرونة وإمكانيات الذكاء الاصطناعي في إنشاء المحتوى المرئي. (المصدر: c_valenzuelab)
Chat2DB: عميل ذكاء اصطناعي للتعامل مع قواعد البيانات باللغة الطبيعية: Chat2DB هي أداة عميل لقواعد البيانات مدفوعة بالذكاء الاصطناعي، تسمح للمستخدمين بالتفاعل مع قواعد البيانات باستخدام اللغة الطبيعية. على سبيل المثال، يمكن للمستخدم طرح سؤال مثل “من هو العميل الأكثر إنفاقًا هذا الشهر؟”، ويمكن لـ Chat2DB فهم السؤال باستخدام الذكاء الاصطناعي، وإنشاء استعلام SQL المقابل تلقائيًا بناءً على بنية جدول قاعدة البيانات وتنفيذ الاستعلام، ثم إرجاع النتائج. هذا يقلل بشكل كبير من العتبة التقنية لعمليات قواعد البيانات، مما يمكّن حتى غير التقنيين من إجراء استعلامات وتحليلات البيانات بسهولة. المشروع مفتوح المصدر على GitHub. (المصدر: karminski3)
نموذج Qwen 3 8B يُظهر قدرات برمجية متميزة، ويمكنه إنشاء لوحة مفاتيح HTML: أظهر نموذج Qwen 3 8B (إصدار Q6_K الكمي) أداءً متميزًا في توليد الأكواد على الرغم من صغر حجم معالمه. نجح المستخدمون، من خلال موجهين قصيرين، في جعل النموذج يُنشئ كود لوحة مفاتيح HTML قابلة للتشغيل. يُظهر هذا إمكانات النماذج المصغرة في تحقيق فائدة عملية عالية في مهام محددة، خاصةً في سيناريوهات النشر المحلي محدودة الموارد. (المصدر: Reddit r/LocalLLaMA)
Ollama Chat: أداة دردشة LLM محلية بواجهة تشبه Claude: Ollama Chat هي واجهة دردشة ويب مصممة لنماذج اللغة الكبيرة المحلية، حيث تستوحي تصميم واجهة المستخدم وتجربة المستخدم من Claude الخاص بـ Anthropic. تدعم الأداة تحميل الملفات النصية، وسجل المحادثات، وإعدادات موجهات النظام، وتهدف إلى توفير حل تفاعلي سهل الاستخدام وجمالي لنماذج LLM المحلية. المشروع مفتوح المصدر على GitHub، مما يسهل على المستخدمين نشره واستخدامه بأنفسهم. (المصدر: Reddit r/LocalLLaMA)
تقنيات كتابة الموجهات لإنشاء بطاقات شخصية (عيد ميلاد/عيد الأم) بواسطة الذكاء الاصطناعي: شارك مستخدمون تقنيات كتابة الموجهات لاستخدام الذكاء الاصطناعي في إنشاء بطاقات شخصية (مثل بطاقات عيد الميلاد، بطاقات عيد الأم). يكمن المفتاح في تحديد موضوع البطاقة بوضوح (مثل عيد الأم، عيد الميلاد)، والأسلوب (مثل أسلوب أنثوي، أسلوب طفولي)، والمستلم (مثل أمي، ساندي، جيمي)، والعمر (مثل 30 عامًا، 6 سنوات)، والمحتوى المحدد للتهنئة أو النبرة الدافئة والجميلة. من خلال الجمع بين هذه العناصر، يمكن توجيه الذكاء الاصطناعي لإنشاء تصميم بطاقة يلبي الاحتياجات. (المصدر: dotey)

📚 تعلم
جوجل تصدر ورقة بيضاء حول هندسة الموجهات، لتوجيه المستخدمين حول كيفية طرح الأسئلة بفعالية: أصدرت جوجل ورقة بيضاء حول هندسة الموجهات (يمكن الوصول إليها عبر Kaggle)، تهدف إلى تعليم المستخدمين كيفية طرح الأسئلة على نماذج الذكاء الاصطناعي بشكل أكثر فعالية. محتوى البرنامج التعليمي واضح، ويشرح بالتفصيل كيفية تحديد متطلبات الإخراج بوضوح، وتقييد نطاق الإخراج، وكيفية استخدام المتغيرات وغيرها من التقنيات، لمساعدة المستخدمين على تحسين كفاءة وفعالية تفاعلهم مع نماذج اللغة الكبيرة، وبالتالي الحصول على إجابات أكثر دقة وفائدة. (المصدر: karminski3)

فريق من جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو) يقترح MultiGO: نمذجة غاوسية هرمية لإنشاء أجسام بشرية ثلاثية الأبعاد مزودة بنسيج من صورة واحدة: اقترح فريق من جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو) إطارًا مبتكرًا يسمى MultiGO، يقوم بإعادة بناء نماذج بشرية ثلاثية الأبعاد مزودة بنسيج من صورة واحدة من خلال نمذجة غاوسية هرمية. تقوم هذه الطريقة بتفكيك الجسم البشري إلى مستويات دقة مختلفة مثل الهيكل العظمي والمفاصل والتجاعيد، مع تحسينها تدريجيًا. تعتمد التقنية الأساسية على نقاط تناثر غاوسية كوحدات أولية ثلاثية الأبعاد، وتصمم وحدات لتعزيز الهيكل العظمي والمفاصل وتحسين التجاعيد. تم اختيار هذا البحث ليُعرض في CVPR 2025، ويوفر أفكارًا جديدة لإعادة بناء الأجسام البشرية ثلاثية الأبعاد من صورة واحدة، وسيتم فتح مصدر الكود قريبًا. (المصدر: WeChat)

جامعات تسينغهوا وفودان وهونغ كونغ للعلوم والتكنولوجيا تطلق RM-BENCH: أول معيار تقييم لنماذج المكافآت: لمواجهة مشكلة “الشكل أهم من المحتوى” والتحيز الأسلوبي في تقييم نماذج المكافآت الحالية لنماذج اللغة الكبيرة، أطلق فريق بحثي مشترك من جامعة تسينغهوا وجامعة فودان وجامعة هونغ كونغ للعلوم والتكنولوجيا أول معيار تقييم منهجي لنماذج المكافآت RM-BENCH. يغطي هذا المعيار أربعة مجالات رئيسية: الدردشة، والكود، والرياضيات، والأمان. من خلال تقييم حساسية النموذج للاختلافات الدقيقة في المحتوى ومتانته ضد التحيز الأسلوبي، يهدف إلى إنشاء معيار جديد أكثر موثوقية لـ “حكم المحتوى”. وجدت الدراسة أن نماذج المكافآت الحالية ضعيفة الأداء في مجالي الرياضيات والكود، وتعاني بشكل عام من التحيز الأسلوبي. تم قبول هذا العمل كعرض شفوي في ICLR 2025. (المصدر: WeChat)

جامعة تيانجين و Tencent تفتحان مصدر حل COME: 5 أسطر من الكود لتحسين متانة TTA وحل مشكلة انهيار النموذج: اقترحت جامعة تيانجين بالتعاون مع Tencent طريقة COME (Conservatively Minimizing Entropy)، بهدف حل مشكلة الثقة المفرطة وانهيار النموذج الناجمة عن تقليل الإنتروبيا (EM) أثناء التكيف وقت الاختبار (TTA). تقوم COME بنمذجة عدم اليقين في التنبؤ بشكل صريح من خلال المنطق الذاتي، وتستخدم قيد Logit التكيفي (تجميد معيار Logit) للتحكم بشكل غير مباشر في عدم اليقين، وبالتالي تحقيق تقليل متحفظ للإنتروبيا. لا تتطلب هذه الطريقة تعديل بنية النموذج، وتحتاج فقط إلى عدد قليل من أسطر الكود لتضمينها في طرق TTA الحالية، وقد أدت إلى تحسين كبير في متانة النموذج ودقته على مجموعات بيانات مثل ImageNet-C، مع تكلفة حسابية ضئيلة للغاية. تم قبول الورقة في ICLR 2025 وتم فتح مصدر الكود. (المصدر: WeChat)
هواوي ومعهد هندسة المعلومات يقترحان DEER: آلية “الخروج المبكر الديناميكي” لسلسلة الأفكار لتحسين كفاءة ودقة استدلال LLM: اقترحت هواوي بالتعاون مع معهد هندسة المعلومات التابع للأكاديمية الصينية للعلوم آلية DEER (Dynamic Early Exit in Reasoning)، بهدف حل مشكلة التفكير المفرط المحتملة في نماذج اللغة الكبيرة أثناء الاستدلال بسلسلة أفكار طويلة (Long CoT). تقوم DEER بمراقبة نقاط التحول في الاستدلال، واستحثاث إجابات تجريبية وتقييم مدى ثقتها، وتحديد ما إذا كان يجب إنهاء التفكير مبكرًا وتوليد استنتاج بشكل ديناميكي. أظهرت التجارب على نماذج LLM للاستدلال مثل سلسلة DeepSeek، أن DEER يمكنها تقليل طول توليد سلسلة الأفكار بمعدل 31%-43% في المتوسط دون الحاجة إلى تدريب إضافي، مع زيادة الدقة بنسبة 1.7%-5.7%. (المصدر: WeChat)

الأكاديمية الصينية للعلوم وغيرها تقترح R1-Reward: تدريب نماذج المكافآت متعددة الوسائط من خلال التعلم المعزز المستقر: اقترح فريق بحثي من الأكاديمية الصينية للعلوم، وجامعة تسينغهوا، و Kuaishou، وجامعة نانجينغ، R1-Reward، وهي طريقة لتدريب نماذج المكافآت متعددة الوسائط (MRM) من خلال خوارزمية تعلم معزز مستقرة تسمى StableReinforce، بهدف تعزيز قدرتها على الاستدلال طويل المدى. تعمل StableReinforce على تحسين مشكلات عدم الاستقرار التي قد تواجهها خوارزميات RL الحالية مثل PPO عند تدريب MRM، وذلك من خلال استراتيجية Pre-Clip، ومرشح الميزة، وآلية مكافأة متسقة مبتكرة (إدخال نموذج حكم للتحقق من اتساق التحليل مع الإجابة) لتحقيق استقرار عملية التدريب. أظهرت التجارب أن R1-Reward تتفوق في الأداء على نماذج SOTA في العديد من معايير MRM، ويمكن تحسين أدائها بشكل أكبر من خلال أخذ عينات متعددة والتصويت أثناء الاستدلال. (المصدر: WeChat)
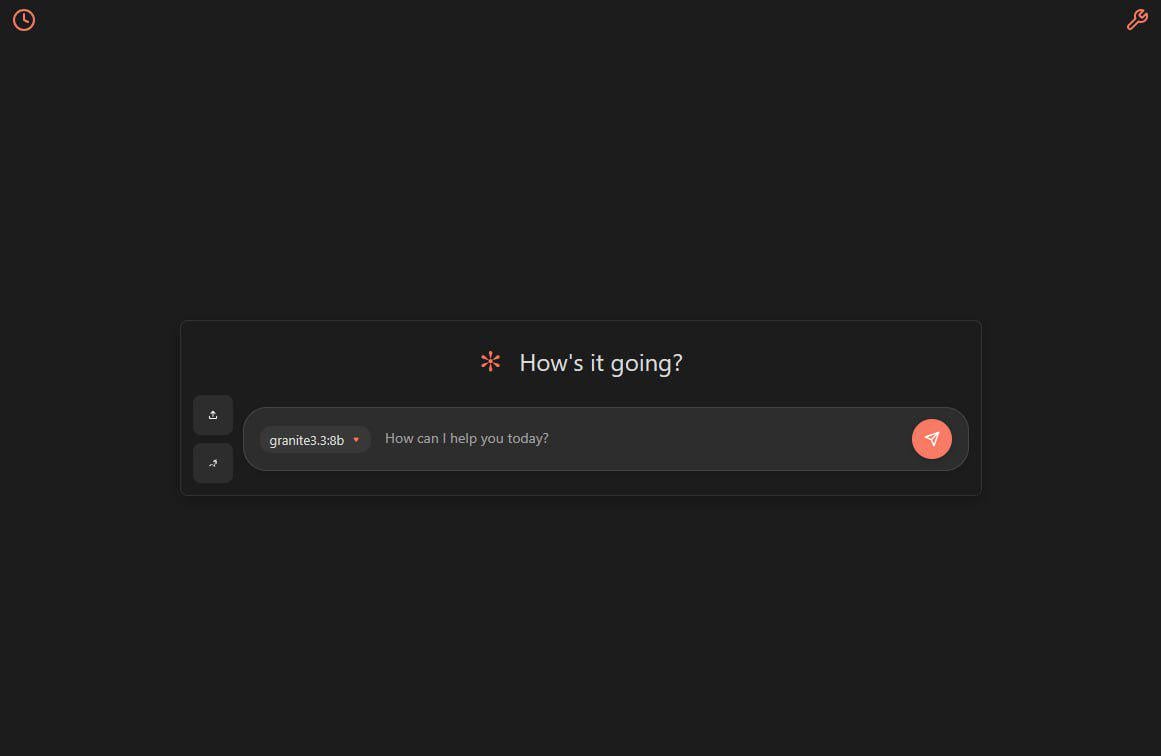
HuggingFace تطلق مبادرة مجموعة بيانات مجتمع LeRobot، لدفع “لحظة ImageNet” للروبوتات: أطلقت HuggingFace مشروع مجموعة بيانات مجتمع LeRobot، بهدف بناء “ImageNet” في مجال الروبوتات، من خلال مساهمات المجتمع لدفع تطوير تكنولوجيا الروبوتات العامة. تؤكد المقالة على أهمية تنوع البيانات لقدرة الروبوتات على التعميم، وتشير إلى أن مجموعات بيانات الروبوتات الحالية تأتي في الغالب من بيئات أكاديمية محدودة. يشجع LeRobot المستخدمين على مشاركة بيانات من روبوتات مختلفة (مثل So100، ذراع Koch الآلي) في مهام متنوعة (مثل لعب الشطرنج، تشغيل الأدراج)، من خلال تبسيط عمليات جمع البيانات وتحميلها وتقليل تكاليف الأجهزة. في الوقت نفسه، تقترح المقالة معايير جودة البيانات وقائمة بأفضل الممارسات، لمواجهة تحديات مثل عدم اتساق تسمية البيانات وغموض تعيين الميزات، وتعزيز بناء مجموعات بيانات روبوتات عالية الجودة ومتنوعة. (المصدر: HuggingFace Blog, LoubnaBenAllal1)
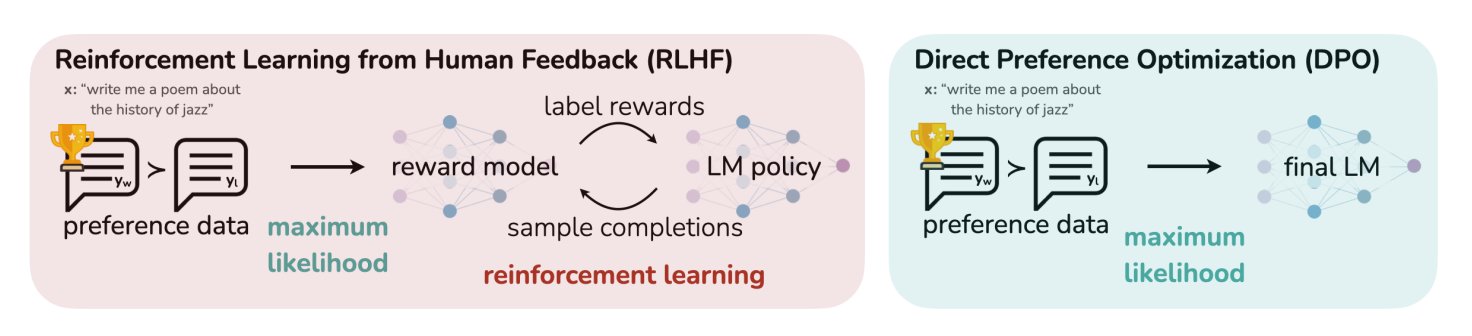
مدونة HuggingFace تلخص 11 خوارزمية للمواءمة والتحسين لنماذج LLM: شارك TheTuringPost مقالًا من HuggingFace يلخص 11 خوارزمية للمواءمة والتحسين تُستخدم لنماذج اللغة الكبيرة (LLM). تشمل هذه الخوارزميات PPO (تحسين السياسة القريبة)، DPO (تحسين التفضيل المباشر)، GRPO (تحسين سياسة المجموعة النسبية)، SFT (الضبط الدقيق الخاضع للإشراف)، RLHF (التعلم المعزز من ردود الفعل البشرية)، و SPIN (الضبط الدقيق باللعب الذاتي) وغيرها. يوفر المقال روابط لهذه الخوارزميات ومزيدًا من المعلومات، مما يقدم للباحثين والمطورين نظرة عامة على طرق تحسين LLM. (المصدر: TheTuringPost)
جامعة كاليفورنيا في بيركلي تشارك مواد دورة الدراسات العليا في رؤية الحاسوب CS280: شارك الأستاذان Angjoo Kanazawa و Jitendra Malik من جامعة كاليفورنيا في بيركلي جميع مواد المحاضرات لدورة الدراسات العليا في رؤية الحاسوب CS280 التي قاما بتدريسها هذا الفصل الدراسي. يعتقدان أن هذه المجموعة من المواد التي تجمع بين محتوى رؤية الحاسوب الكلاسيكي والحديث كانت فعالة، وقاما بنشرها للعامة ليستفيد منها المتعلمون. (المصدر: NandoDF)
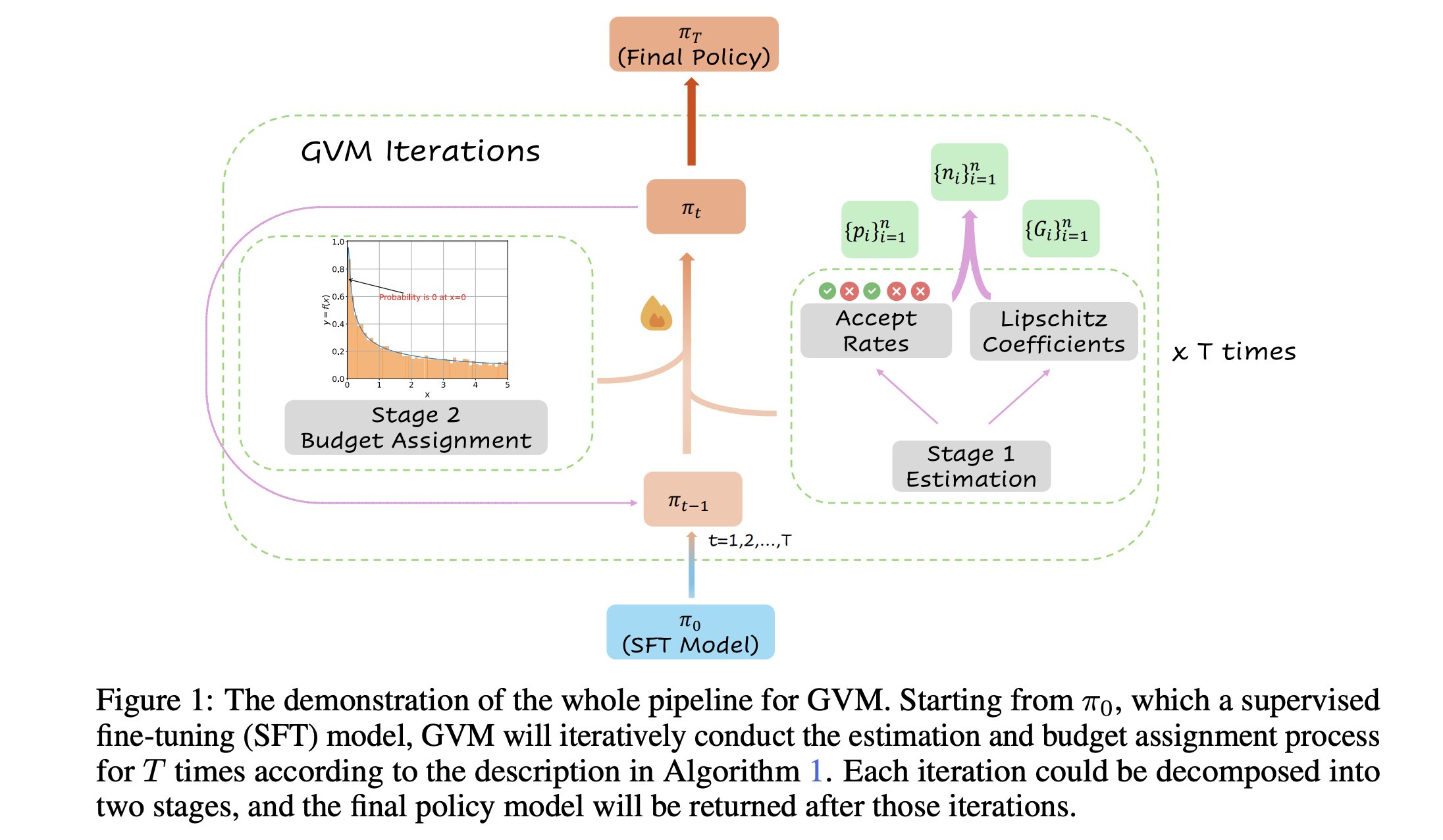
GVM-RAFT: إطار أخذ عينات ديناميكي محسن لأجهزة استدلال سلسلة الأفكار: تقدم ورقة بحثية جديدة إطار GVM-RAFT، الذي يحسن أجهزة استدلال سلسلة الأفكار (chain-of-thought) من خلال تعديل استراتيجية أخذ العينات ديناميكيًا لكل موجه، بهدف تقليل تباين التدرج. يُزعم أن هذه الطريقة تحقق تسريعًا بمقدار 2-4 مرات في مهام الاستدلال الرياضي، وتحسن الدقة. (المصدر: _akhaliq)
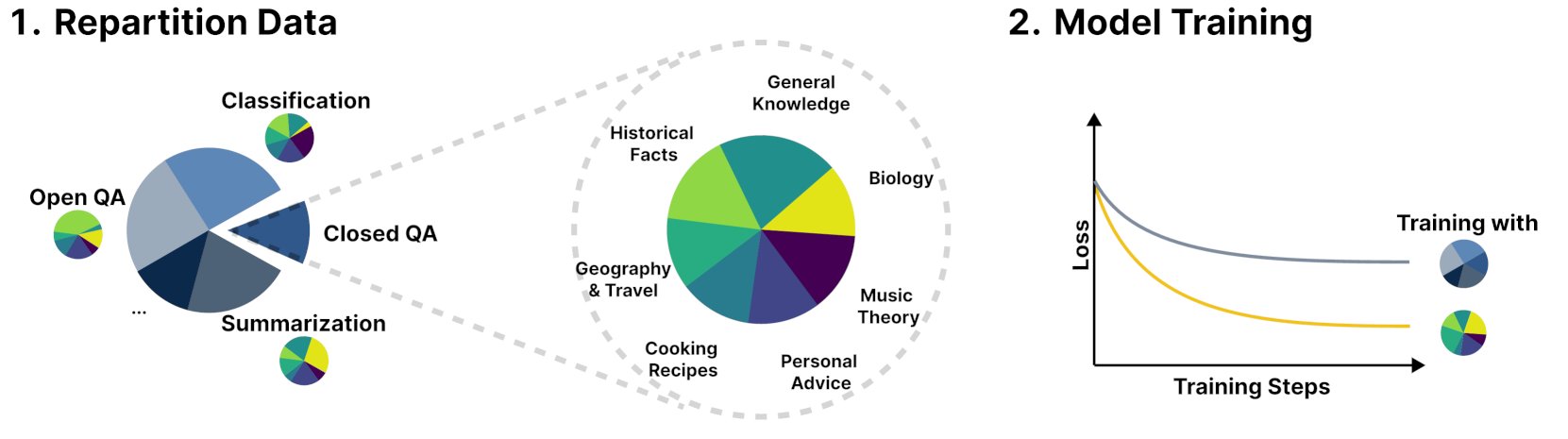
إطار عمل جديد R&B يحسن أداء نماذج اللغة من خلال موازنة بيانات التدريب ديناميكيًا: يقترح بحث جديد بعنوان R&B إطار عمل جديدًا يحسن أداء نماذج اللغة من خلال موازنة بيانات تدريبها ديناميكيًا، مع زيادة بنسبة 0.01% فقط في الحسابات الإضافية. تهدف هذه الطريقة إلى تحسين كفاءة استخدام البيانات، وتحقيق تحسن في أداء النموذج بتكلفة قليلة. (المصدر: _akhaliq)
ورقة بحثية تناقش منظورًا جديدًا لأمن الذكاء الاصطناعي: اعتبار التقدم الاجتماعي والتكنولوجي كخياطة لحاف: تقترح ورقة بحثية جديدة نُشرت على arXiv بعنوان “Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt” رؤية جديدة لأمن الذكاء الاصطناعي، تدعو إلى تركيز جوهر أمن الذكاء الاصطناعي على منع تصاعد الخلافات إلى صراعات. تشبه الورقة التقدم الاجتماعي والتكنولوجي بخياطة لحاف يتوسع باستمرار ويتغير ومليء بالرقع والألوان المتعددة، مؤكدة على أهمية الحفاظ على الاستقرار والتعاون في الأنظمة المعقدة. (المصدر: jachiam0)
ورقة بحثية تناقش الحوسبة التكيفية في نماذج اللغة ذاتية الانحدار: يشير النقاش إلى أهمية الحوسبة التكيفية في التعلم العميق، ويعدد التطورات التقنية ذات الصلة: PonderNet (DeepMind, 2021) كأداة مبكرة لدمج الشبكات العصبية والحلقات؛ نماذج الانتشار التي تقوم بالحساب من خلال تمريرات أمامية متعددة؛ ونماذج اللغة الاستدلالية الحديثة التي تحقق تأثيرًا مشابهًا من خلال توليد عدد عشوائي من الرموز. يعكس هذا اتجاه المرونة والديناميكية في تخصيص واستخدام موارد الحوسبة من قبل النماذج. (المصدر: jxmnop)
ورقة بحثية تناقش كيف يمكن لـ “البيانات السيئة” أن تؤدي إلى “نماذج جيدة”: تناقش ورقة بحثية من جامعة هارفارد لعام 2025 بعنوان “When Bad Data Leads to Good Models” (arXiv:2505.04741) كيف أنه في بعض الحالات، قد تساعد البيانات التي تبدو منخفضة الجودة (مثل بيانات التدريب المسبق التي تحتوي على محتوى من 4chan) في مواءمة النموذج وإخفاء “مستوى طاقته” (power level)، مما يجعله يؤدي بشكل أفضل. أثار هذا نقاشًا حول جودة البيانات، ومواءمة النماذج، وصدق سلوك النموذج. (المصدر: teortaxesTex)

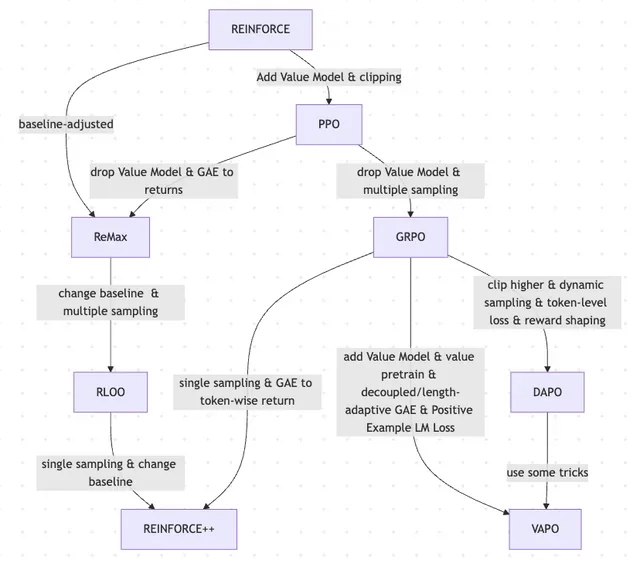
ورقة بحثية تناقش تطور RLHF ومتغيراته، من REINFORCE إلى VAPO: تلخص مقالة بحثية تطور طرق التعلم المعزز (RL) المستخدمة في الضبط الدقيق لنماذج اللغة الكبيرة (LLMs). تتتبع المقالة التطور بدءًا من خوارزميات PPO و REINFORCE الكلاسيكية، إلى الطرق الحديثة مثل GRPO و ReMax و RLOO و DAPO و VAPO، وتحلل التخلي عن نماذج القيمة، وتغيير استراتيجيات أخذ العينات، وتعديل خطوط الأساس، وتطبيق تقنيات مثل تشكيل المكافآت وخسارة مستوى الرمز. يهدف هذا البحث إلى عرض واضح لخريطة البحث في مجال RLHF ومتغيراته في مواءمة LLM. (المصدر: Reddit r/MachineLearning)
ورقة بحثية “Absolute Zero”: الذكاء الاصطناعي يقوم بالاستدلال الذاتي المعزز باللعب دون بيانات بشرية: تستكشف ورقة بيضاء بعنوان “Absolute Zero: Reinforced Self-Play Reasoning with Zero Data” (arXiv:2505.03335) طرقًا جديدة لتدريب الذكاء الاصطناعي المنطقي. قام الباحثون بتدريب نماذج ذكاء اصطناعي منطقية دون استخدام مجموعات بيانات مصنفة بشريًا، حيث يمكن للنموذج إنشاء مهام استدلال بنفسه، وحل المشكلات، والتحقق من الحلول من خلال تنفيذ الكود. أثار هذا نقاشًا حول ما إذا كان بإمكان الذكاء الاصطناعي، في بيئة بدائية تمامًا خالية من المعرفة المسبقة (مثل الرياضيات والفيزياء واللغة)، أن يخترع تمثيلات رمزية من الصفر، ويحدد هياكل منطقية، ويطور أنظمة رقمية، ويبني نماذج سببية، بالإضافة إلى إمكانات ومخاطر هذا “الذكاء الغريب”. (المصدر: Reddit r/ArtificialInteligence, Reddit r/artificial)
مختبر التفاعل الذكي بين الإنسان والآلة بجامعة فودان يستقبل طلبات الماجستير والدكتوراه لعام 2026: يستقبل مختبر التفاعل الذكي بين الإنسان والآلة بكلية علوم وتكنولوجيا الحاسوب بجامعة فودان طلبات الالتحاق ببرامج الماجستير والدكتوراه لعام 2026 (المخيم الصيفي/التوصية بالإعفاء من الامتحان). يقود المختبر البروفيسور شانغ لي، وتشمل اتجاهات البحث AGI القابل للارتداء (نظارات MemX الذكية مع دمج LLM)، والذكاء المجسد مفتوح المصدر، وضغط النماذج (من الكبير إلى الصغير)، وأنظمة التعلم الآلي (مثل تحسين تجميع ML، ومعالجات الذكاء الاصطناعي). يلتزم المختبر باستكشاف الذكاء المرتكز على الإنسان، ودمج النماذج الكبيرة مع الأجهزة الذكية القابلة للارتداء، ونماذج جديدة للتفاعل بين الإنسان والآلة في أنظمة الذكاء المجسد. (المصدر: WeChat)

💼 أعمال
نظرة عامة على 10 شركات ناشئة في مجال الذكاء الاصطناعي تتجاوز قيمتها المليار دولار ويعمل بها أقل من 50 موظفًا: قام موقع Business Insider بإعداد قائمة تضم 10 شركات ناشئة في مجال الذكاء الاصطناعي تتجاوز قيمتها السوقية مليار دولار ولكن عدد موظفيها أقل من 50 شخصًا. من بين هذه الشركات Safe Superintelligence (تقدر قيمتها بـ 32 مليار دولار، 20 موظفًا)، OG Labs (تقدر قيمتها بـ 2 مليار دولار، 40 موظفًا)، Magic (تقدر قيمتها بـ 1.58 مليار دولار، 20 موظفًا)، Sakana AI (تقدر قيمتها بـ 1.5 مليار دولار، 28 موظفًا) وغيرها. تُظهر هذه الشركات إمكانية تحقيق تقييمات عالية بفرق عمل صغيرة في مجال الذكاء الاصطناعي، مما يعكس القيمة العالية للتكنولوجيا والابتكار في أسواق رأس المال. (المصدر: hardmaru)
Fourier Intelligence تعمق حضورها في مجال الرعاية الصحية للمسنين، وتتعاون مع مركز شنغهاي الطبي الدولي لإنشاء قاعدة لإعادة التأهيل بالذكاء المجسد: أعلنت شركة Fourier Intelligence، وهي شركة يونيكورن في مجال الذكاء المجسد، في أول قمة لها حول النظام البيئي للذكاء المجسد، عن تعاونها مع مركز شنغهاي الطبي الدولي لتعزيز تطبيق روبوتات الذكاء المجسد في سيناريوهات إعادة التأهيل الطبي، بما في ذلك وضع المعايير، والابتكار المشترك للحلول، والبحث العلمي، وإنشاء أول قاعدة نموذجية لإعادة التأهيل بالذكاء المجسد في الصين. اقترح مؤسس Fourier، جو جي، أن الاستراتيجية الأساسية للسنوات العشر القادمة هي “التركيز على الرعاية الصحية للمسنين، والتركيز على التفاعل، وخدمة الناس”، مؤكدًا أن إعادة التأهيل الطبي هي أساس الشركة. منذ تأسيسها في عام 2015، توسعت الشركة تدريجيًا من روبوتات إعادة التأهيل إلى الروبوتات البشرية العامة GR-1 وسلسلة GRx، وقد شحنت مئات الوحدات حتى الآن. (المصدر: 36氪)
Meta يُقال إنها توظف مسؤولين سابقين في البنتاغون، مما قد يعزز تواجدها في المجال العسكري: وفقًا لتقرير من Forbes، تقوم شركة Meta بتوظيف مسؤولين سابقين في البنتاغون، وهي خطوة قد تعني أن الشركة تخطط لتعزيز أعمالها في مجال التكنولوجيا العسكرية أو المجالات المتعلقة بالدفاع. أثار هذا التوجه نقاشات واهتمامًا بشأن مشاركة شركات التكنولوجيا الكبرى في التطبيقات العسكرية. (المصدر: Reddit r/artificial)

🌟 مجتمع
Andrej Karpathy يثير نقاشًا حادًا باقتراحه أن تعلم LLM يفتقر إلى نموذج هام هو “تعلم موجهات النظام”: يعتقد Andrej Karpathy أن تعلم LLM الحالي يفتقر إلى نموذج هام يسميه “تعلم موجهات النظام”. ويشير إلى أن التدريب المسبق يهدف إلى اكتساب المعرفة، والضبط الدقيق (الخاضع للإشراف/التعلم المعزز) يهدف إلى السلوك المعتاد، وكلاهما يتضمن تغيير المعلمات، ولكن يبدو أن الكم الهائل من التفاعل البشري وردود الفعل لم يتم استغلاله بشكل كافٍ. ويشبه ذلك بإعطاء بطل فيلم “Memento” دفتر ملاحظات لتخزين المعرفة والاستراتيجيات العالمية لحل المشكلات. أثار هذا الرأي نقاشًا واسعًا، حيث رأى البعض أن هذا قريب من فلسفة DSPy، أو يتعلق بمشكلات الذاكرة/التحسين، والتعلم المستمر، وناقشوا كيفية تحقيق آلية مماثلة في Langgraph. (المصدر: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
شركات الذكاء الاصطناعي تطلب من المتقدمين للوظائف عدم استخدام الذكاء الاصطناعي لكتابة طلباتهم، مما يثير نقاشًا حادًا: أثار طلب شركات الذكاء الاصطناعي مثل Anthropic من المتقدمين للوظائف عدم استخدام أدوات الذكاء الاصطناعي في كتابة طلبات التوظيف (مثل السير الذاتية) نقاشًا مجتمعيًا. ذكر بعض مسؤولي التوظيف أن ظاهرة “النفايات النصية” الناتجة عن السير الذاتية التي أنشأها الذكاء الاصطناعي خطيرة، وحتى الأشخاص ذوي الخبرة قد يفقدون التركيز بسبب ذلك. لكن بعض المتقدمين للوظائف يعتقدون أن الذكاء الاصطناعي يمكن أن يساعدهم في تحسين سيرهم الذاتية بشكل أفضل لتناسب متطلبات الوظيفة، وإبراز المهارات، وتحسين قابلية القراءة. امتد النقاش أيضًا إلى ظاهرة المحتوى الذي ينشئه الذكاء الاصطناعي والذي يملأ منصات مثل LinkedIn، وما إذا كان ينبغي اعتماد طرق أخرى مثل الفيديو لتقييم المتقدمين للوظائف. (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)

“قابلية التعرف” على المحتوى الذي يولده الذكاء الاصطناعي تثير نقاشًا، والمستخدمون يعتقدون أنه من السهل اكتشافه: يشير نقاش مجتمعي إلى أنه من السهل التعرف على المحتوى الذي يولده الذكاء الاصطناعي (خاصة ChatGPT)، ليس فقط بسبب علامات الترقيم المحددة (مثل الشرطات الطويلة em dashes) أو تراكيب الجمل (مثل “That’s not x; that’s y.”)، ولكن بشكل أكبر بسبب “الإيقاع” و “الرتابة” المميزة له. بمجرد التعرف على بصمات الذكاء الاصطناعي، يبدو المحتوى غير حقيقي ويفتقر إلى الشخصية. ذكر بعض المستخدمين أنهم واجهوا مثل هذه الحالات في رسائل البريد الإلكتروني ومنشورات وسائل التواصل الاجتماعي وحتى ألعاب الفيديو، ويعتقدون أن استخدام الذكاء الاصطناعي مباشرة لإنشاء محتوى كامل يؤدي إلى محتوى ممل وغير صادق، وينصحون المستخدمين باستخدام الذكاء الاصطناعي كأداة للتعديل والتخصيص. (المصدر: Reddit r/ChatGPT)
تطور الذكاء الاصطناعي يُظهر دورة “شهر العسل – رد الفعل العكسي”، مما يعكس تفضيل الإنسان للأصالة: يرى البعض أن ظهور نماذج الذكاء الاصطناعي التوليدية الجديدة (نصوص، صور، موسيقى، إلخ) غالبًا ما يكون مصحوبًا بـ “شهر عسل”، حيث يشعر الناس بالدهشة من قدراتها. ولكن سرعان ما، عندما يبدأ الناس في التعرف على “الأنماط” أو “البصمات” التي يولدها الذكاء الاصطناعي، يحدث رد فعل عكسي، يتحول من الثناء إلى الشك، بل وحتى الاعتقاد بأنها “بلا روح”. هذه الظاهرة المتمثلة في التعلم السريع للتعرف على أعمال الذكاء الاصطناعي والميل إلى الإبداعات البشرية المعيبة، قد تعني أن الذكاء الاصطناعي هو أداة مساعدة أكثر من كونه بديلاً كاملاً للمبدعين البشريين، لأن الناس يقدرون القصص الكامنة وراء الأعمال، ونية المؤلف، والأصالة. (المصدر: Reddit r/ArtificialInteligence)
معدل توليد الكود بواسطة الذكاء الاصطناعي داخل Anthropic يتجاوز 70%، مما يثير تساؤلات حول التكرار الذاتي للذكاء الاصطناعي: كشف Mike Krieger من Anthropic أن أكثر من 70% من طلبات السحب (pull requests) داخل الشركة يتم إنشاؤها الآن بواسطة الذكاء الاصطناعي. أثارت هذه البيانات نقاشًا مجتمعيًا، حيث ربط البعض ذلك بسيناريوهات التحرير الذاتي والتحسين الذاتي للآلات، على غرار ما يحدث في أعمال الخيال العلمي. في الوقت نفسه، شكك البعض في صحة هذه البيانات ومعناها المحدد (مثل مدى تعقيد هذه الطلبات). (المصدر: Reddit r/ClaudeAI)

الرئيس التنفيذي لشركة Nvidia، جنسن هوانغ، يؤكد على تبني جميع الموظفين لوكلاء الذكاء الاصطناعي، والذكاء الاصطناعي سيعيد تشكيل دور المطورين: صرح الرئيس التنفيذي لشركة Nvidia، جنسن هوانغ، بأن الشركة ستزود جميع موظفيها بمساعدين يعملون بالذكاء الاصطناعي، وسيتم دمج وكلاء الذكاء الاصطناعي في عمليات التطوير اليومية، لتحسين الكود، واكتشاف الثغرات، وتسريع تصميم النماذج الأولية. ويعتقد أن كل شخص في المستقبل سيقود عدة مساعدين يعملون بالذكاء الاصطناعي، وستنمو الإنتاجية بشكل كبير. ويشاركه الرأي نفسه الرئيس التنفيذي لشركة Meta، مارك زوكربيرج، والرئيس التنفيذي لشركة Microsoft، ساتيا ناديلا، وغيرهم، حيث يعتقدون أن الذكاء الاصطناعي سينجز معظم أعمال البرمجة، وسيتحول دور المطورين إلى “قيادة الذكاء الاصطناعي” و “تحديد المتطلبات”. يشير هذا الاتجاه إلى حدوث تغيير جذري في دورة تطوير البرمجيات، وانتشار أدوات برمجة الذكاء الاصطناعي مثل GitHub Copilot و Cursor وغيرها. (المصدر: WeChat)

نقاش: هل من الممكن لباحثي التعلم الآلي قراءة 1000-2000 ورقة بحثية سنويًا؟: أشار نقاش مجتمعي إلى أن كبار باحثي التعلم الآلي قد يقرأون ما يقرب من 2000 ورقة بحثية سنويًا. ردًا على ذلك، رأى البعض أن عدد الأوراق البحثية المقروءة في حد ذاته مجرد مؤشر بديل، وأن المهم حقًا هو القدرة على تصفية الإشارات من كم هائل من المعلومات، واستخلاص المعلومات الفعالة وتطبيقها بشكل صحيح. إن القدرة على مواكبة أبرز التطورات والاتجاهات في المجال، والتعمق في محتوى معين عند الحاجة، هي مهارة أساسية في هذا القرن. (المصدر: torchcompiled)
نقاش: شراء وحدات معالجة الرسومات (GPU) مقابل استئجارها لتدريب/ضبط النماذج: يواجه ممارسو التعلم الآلي خيار شراء أو استئجار موارد GPU. ينصح ذوو الخبرة باتباع استراتيجية مختلطة: تكوين وحدة معالجة رسومات استهلاكية ذات أداء مقبول محليًا للتجارب الصغيرة، واستئجار وحدات معالجة رسومات سحابية لمهام التدريب واسعة النطاق. يعتمد الاختيار على مدى تعقيد النموذج وحجم البيانات والميزانية. تتمتع وحدات معالجة الرسومات السحابية بمزايا في تنظيم عمليات التعلم الآلي (ML Ops)، ولكن بنفس السعر، قد يكون أداء وحدات معالجة الرسومات السحابية الشائعة مثل T4 أقل من بطاقات المستهلك المتطورة (مثل 3090/4090)، ومع ذلك، يمكن للسحابة توفير وحدات معالجة رسومات متطورة مثل A100/H100 ذات ذاكرة أكبر. (المصدر: Reddit r/MachineLearning)
💡 أخرى
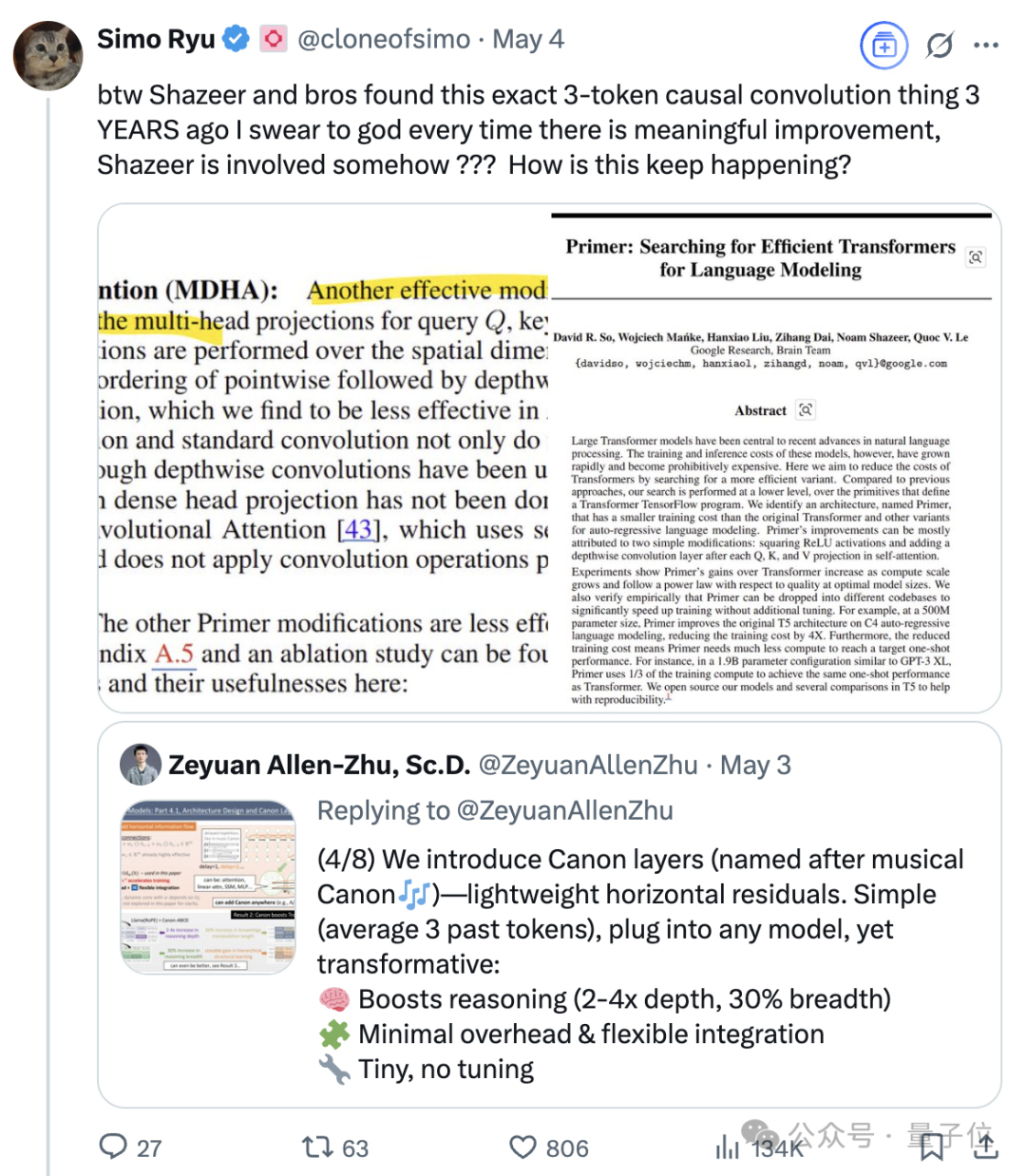
التأثير المستمر لـ Noam Shazeer، أحد مؤلفي Transformer الثمانية: يُعتبر Noam Shazeer، أحد المؤلفين الثمانية لورقة Transformer البحثية “Attention Is All You Need”، صاحب أكبر مساهمة على نطاق واسع. يمتد تأثيره إلى ما هو أبعد من ذلك، ليشمل الأبحاث المبكرة حول إدخال مزيج الخبراء المتناثر المتحكم به (MoE) في نماذج اللغة، ومحسن Adafactor، والانتباه متعدد الاستعلامات (MQA)، والطبقات الخطية المتحكم بها (GLU) في Transformer. أرست هذه الأعمال الأساس لبنية نماذج اللغة الكبيرة السائدة حاليًا، مما جعل Shazeer يُعتبر شخصية رئيسية في مجال الذكاء الاصطناعي تواصل تحديد النماذج التقنية. كان قد غادر جوجل ليؤسس Character.AI، ثم عاد إلى جوجل بعد استحواذ الشركة عليها، ليشارك في قيادة مشروع Gemini. (المصدر: WeChat)
عمالقة التكنولوجيا يواجهون “أزمة منتصف العمر” التي أثارها الذكاء الاصطناعي: يشير تحليل إلى أن “عمالقة التكنولوجيا السبعة”، بما في ذلك جوجل وأبل وميتا وتسلا، يواجهون تحديات جذرية ناجمة عن الذكاء الاصطناعي، ويقعون في “أزمة منتصف العمر”. تتعرض أعمال البحث في جوجل للتهديد من نماذج الإجابة المباشرة للذكاء الاصطناعي، وتتقدم أبل ببطء في ابتكارات الذكاء الاصطناعي، وتحاول ميتا دمج الذكاء الاصطناعي في الشبكات الاجتماعية لكن أداء Llama 4 لم يرق إلى مستوى التوقعات، بينما تواجه تسلا ضغوطًا من انخفاض المبيعات وأسعار الأسهم. هؤلاء القادة السابقون في الصناعة، مثل الحالات الواردة في كتاب “معضلة المبتكر”، بحاجة إلى مواجهة تأثير الأسواق والنماذج الجديدة التي يجلبها الذكاء الاصطناعي، وإلا فقد يصبحون “نوكيا” عصر الذكاء الاصطناعي. (المصدر: WeChat)

الذكاء الاصطناعي من جوجل يتفوق على الأطباء البشريين في محاكاة الحوارات الطبية: أظهرت دراسة أن نظام ذكاء اصطناعي تم تدريبه على إجراء المقابلات الطبية، تفوق في أدائه على الأطباء البشريين أو تطابق معهم في الحوار مع مرضى محاكين وإدراج التشخيصات المحتملة بناءً على التاريخ المرضي. يعتقد الباحثون أن هذا النوع من أنظمة الذكاء الاصطناعي لديه القدرة على المساعدة في تعميم وإضفاء الطابع الديمقراطي على الخدمات الطبية. (المصدر: Reddit r/ArtificialInteligence)
