
كلمات مفتاحية:OpenAI, شرائح الذكاء الاصطناعي, النماذج الكبيرة, التعلم المعزز, بنية الذكاء الاصطناعي التحتية, الذكاء الاصطناعي متعدد الوسائط, الوكلاء الأذكياء, RAG, خطة OpenAI الوطنية للذكاء الاصطناعي, قيود تصدير شريحة إنفيديا H20, تحسين الاستدلال في DeepSeek-R1, مجهر الذكاء الاصطناعي البصري Meta-rLLS-VSIM, نموذج الترميز الكبير Seed-Coder من ByteDance
🔥 أبرز العناوين
OpenAI تطلق خطة “الذكاء الاصطناعي الوطني” لدعم بناء البنية التحتية العالمية للذكاء الاصطناعي: أطلقت OpenAI مشروع “OpenAI for Countries” كجزء من خطتها “Stargate”، بهدف مساعدة الدول في إنشاء مراكز بيانات محلية للذكاء الاصطناعي، وتخصيص ChatGPT، ودفع تطوير النظام البيئي للذكاء الاصطناعي. وقد قام الرئيس التنفيذي Sam Altman بزيارة ميدانية لأول مجمع حوسبة فائقة في Abilene بولاية تكساس، وهو جزء من خطة “Stargate” التي تبلغ تكلفتها 500 مليار دولار وتهدف إلى بناء أكبر منشأة لتدريب الذكاء الاصطناعي في العالم. تشير هذه الخطوة إلى أن OpenAI ستتعاون مع حكومات متعددة لدفع تعميم وتطبيق تكنولوجيا الذكاء الاصطناعي عالميًا من خلال بناء البنية التحتية ومشاركة التكنولوجيا، وتخطط للتعاون مبدئيًا مع 10 دول أو مناطق (المصدر: WeChat)

أنباء عن نية إدارة ترامب إلغاء القيود الثلاثية على تصدير رقائق الذكاء الاصطناعي، واستبدالها بنظام ترخيص عالمي أبسط: أفادت وسائل إعلام أجنبية أن إدارة ترامب تخطط لإلغاء “إطار نشر الذكاء الاصطناعي” (FAID) الذي تم وضعه في أواخر عهد بايدن، والذي كان يهدف إلى فرض قيود تصنيف ثلاثية المستويات على صادرات رقائق الذكاء الاصطناعي العالمية. يرى فريق ترامب أن الإطار معقد للغاية ويعيق الابتكار، ويميل إلى استبداله بنظام ترخيص عالمي أبسط يتم تنفيذه من خلال اتفاقيات حكومية دولية. قد تؤثر هذه الخطوة على استراتيجيات السوق العالمية لمصنعي الرقائق مثل Nvidia، وتهدف إلى تعزيز مكانة الولايات المتحدة في الابتكار والريادة في مجال الذكاء الاصطناعي (المصدر: WeChat)

فريق SGLang يحسن أداء استدلال DeepSeek-R1 بشكل كبير، ويزيد الإنتاجية بمقدار 26 مرة: نجح فريق مشترك من SGLang و Nvidia ومؤسسات أخرى في تحسين أداء استدلال نموذج DeepSeek-R1 على وحدات معالجة الرسومات H100 GPU بمقدار 26 مرة في غضون أربعة أشهر، وذلك من خلال ترقية شاملة لمحرك استدلال SGLang. تتضمن حلول التحسين تقنيات مثل فصل التعبئة المسبقة عن فك التشفير (PD separation)، والتوازي الخبير واسع النطاق (EP)، و DeepEP، و DeepGEMM، وموازن تحميل التوازي الخبير (EPLB). عند معالجة تسلسلات إدخال مكونة من 2000 رمز (token)، تم تحقيق إنتاجية قدرها 52.3 ألف رمز إدخال و 22.3 ألف رمز إخراج لكل عقدة في الثانية، وهو ما يقترب من البيانات الرسمية لـ DeepSeek، ويقلل بشكل كبير من تكاليف النشر المحلي (المصدر: WeChat)

عالم OpenAI دان روبرتس: توسيع نطاق التعلم المعزز سيدفع الذكاء الاصطناعي لاكتشاف علوم جديدة، وقد يحقق ذكاء اصطناعي عام بمستوى آينشتاين في 9 سنوات: ألقى عالم الأبحاث في OpenAI، Dan Roberts، كلمة في مؤتمر AI Ascent الذي نظمته Sequoia Capital، ناقش فيها الدور المحوري للتعلم المعزز (RL) في بناء نماذج الذكاء الاصطناعي المستقبلية. ويرى أنه من خلال التوسع المستمر في نطاق RL، لن تتمكن نماذج الذكاء الاصطناعي من تحسين أدائها في مهام مثل الاستدلال الرياضي فحسب، بل ستتمكن أيضًا من تحقيق اكتشافات علمية من خلال “حساب وقت الاختبار” (أي كلما زاد وقت تفكير النموذج، كان أداؤه أفضل). واستشهد باكتشاف آينشتاين للنسبية العامة، متكهنًا بأنه إذا تمكن الذكاء الاصطناعي من إجراء حسابات وتفكير لمدة 8 سنوات، فقد يتمكن من تحقيق اختراقات علمية مماثلة لمستوى آينشتاين بعد 9 سنوات. وأكد Roberts أن تطوير الذكاء الاصطناعي في المستقبل سيركز بشكل أكبر على حسابات RL، بل وقد يهيمن على عملية التدريب بأكملها (المصدر: WeChat)

🎯 اتجاهات
جيم فان من Nvidia: الروبوتات ستجتاز “اختبار تورينغ الفيزيائي”، والمحاكاة والذكاء الاصطناعي التوليدي هما المفتاح: طرح Jim Fan، رئيس قسم الروبوتات في Nvidia، في كلمته بمؤتمر AI Ascent الذي نظمته Sequoia، مفهوم “اختبار تورينغ الفيزيائي”، أي عدم قدرة الإنسان على التمييز بين ما إذا كانت المهمة قد أنجزها إنسان أم روبوت. وأشار إلى أن تكلفة الحصول على بيانات الروبوتات حاليًا باهظة، وأن تكنولوجيا المحاكاة هي المفتاح، خاصةً عند دمجها مع الذكاء الاصطناعي التوليدي (مثل ضبط نماذج توليد الفيديو) لإنشاء بيانات تدريب متنوعة وواسعة النطاق (“أقارب رقميون” بدلاً من “توائم رقمية” دقيقة). وتوقع أنه من خلال المحاكاة واسعة النطاق ونماذج الرؤية واللغة والحركة (مثل Nvidia GR00T)، ستصبح واجهات برمجة التطبيقات الفيزيائية (physical API) منتشرة في كل مكان في المستقبل، وستتمكن الروبوتات من إنجاز المهام اليومية المعقدة، والاندماج مع البيئة الذكية (المصدر: WeChat)
ByteDance تطلق سلسلة نماذج الأكواد الكبيرة Seed-Coder، وإصدار 8B يُظهر أداءً متفوقًا: أطلقت ByteDance سلسلة نماذج الأكواد الكبيرة Seed-Coder، والتي تتضمن إصدارات متعددة مثل 8B و 14B. ومن بينها، أظهر Seed-Coder-8B أداءً متميزًا في العديد من معايير تقييم قدرات الأكواد مثل SWE-bench و Multi-SWE-bench و IOI، ويُقال إنه يتفوق على Qwen3-8B و Qwen2.5-Coder-7B-Inst. تتضمن هذه السلسلة من النماذج إصدارات Base و Instruct و Reasoner، وتتمثل فكرتها الأساسية في “جعل نموذج الكود يخطط لبياناته بنفسه”، مع تحسينات ملحوظة في قدرات استدلال الأكواد وهندسة البرمجيات. تم توفير النماذج مفتوحة المصدر على Hugging Face و GitHub (المصدر: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
علي بابا تطلق إطار ZeroSearch مفتوح المصدر، وتستخدم LLM لمحاكاة البحث لخفض تكاليف تدريب الذكاء الاصطناعي بنسبة 88%: أصدر باحثون من Alibaba إطارًا للتعلم المعزز يسمى “ZeroSearch”، يسمح لنماذج اللغة الكبيرة (LLM) بتطوير وظائف بحث متقدمة من خلال محاكاة محركات البحث، دون الحاجة إلى استدعاء واجهات برمجة تطبيقات محركات البحث التجارية باهظة الثمن (مثل Google) أثناء عملية التدريب. أظهرت التجارب أن استخدام LLM بحجم 3B كمحرك بحث محاكاة يمكن أن يعزز بشكل فعال قدرات البحث لنموذج السياسة، وأن أداء وحدة الاسترجاع بمعلمات 14B يتجاوز حتى بحث Google، مع خفض تكاليف API بنسبة 88%. تم توفير هذه التقنية مفتوحة المصدر على GitHub و Hugging Face، وتدعم سلاسل نماذج مثل Qwen-2.5 و LLaMA-3.2 (المصدر: WeChat)

Gemini API تطلق ميزة التخزين المؤقت الضمني، مما يوفر ما يصل إلى 75% من التكاليف: قامت Google Gemini API مؤخرًا بتمكين ميزة التخزين المؤقت الضمني لسلسلة نماذج Gemini 2.5 (Pro و Flash). عندما يصادف طلب المستخدم ذاكرة التخزين المؤقت، يمكن توفير ما يصل إلى 75% من التكاليف تلقائيًا. وفي الوقت نفسه، تم تخفيض الحد الأدنى لمتطلبات الـ token لتشغيل ذاكرة التخزين المؤقت، حيث انخفض نموذج 2.5 Flash إلى 1K token، ونموذج 2.5 Pro إلى 2K token. تهدف هذه الخطوة إلى خفض تكاليف استخدام Gemini API للمطورين، وتحسين كفاءة الطلبات المتكررة عالية التردد (المصدر: JeffDean)
جامعة تسينغهوا تطور مجهرًا ضوئيًا يعمل بالذكاء الاصطناعي Meta-rLLS-VSIM، بدقة حجمية محسنة 15.4 مرة: بالتعاون بين فريق لي دونغ وفريق داي تشيونغهاي من جامعة تسينغهوا، تم اقتراح مجهر الإضاءة الافتراضية المهيكلة ذو الشريحة الضوئية الشبكية العاكسة المدفوع بالتعلم الميتا (Meta-rLLS-VSIM). يعمل هذا النظام من خلال الابتكار المتقاطع بين الذكاء الاصطناعي والبصريات، على تحسين الدقة الجانبية لتصوير الخلايا الحية إلى 120 نانومتر، والدقة المحورية إلى 160 نانومتر، مما يحقق دقة فائقة شبه متناحية، ودقة حجمية محسنة بمقدار 15.4 مرة مقارنة بـ LLSM التقليدي. تشمل تقنياته الأساسية استخدام DNN لتعلم وتوسيع قدرة الدقة الفائقة إلى اتجاهات متعددة من خلال “الإضاءة المهيكلة الافتراضية”، وتحسين الدقة المحورية من خلال دمج معلومات الرؤية المزدوجة المنعكسة من المرآة وشبكة RL-DFN. أدى إدخال استراتيجية التعلم الميتا إلى تمكين نموذج الذكاء الاصطناعي من إكمال النشر التكيفي في 3 دقائق فقط، مما يقلل بشكل كبير من عتبة تطبيق الذكاء الاصطناعي في التجارب البيولوجية، ويوفر أداة قوية لمراقبة عمليات الحياة مثل انقسام الخلايا السرطانية وتطور الأجنة (المصدر: WeChat)

إطلاق سلسلة نماذج Qwen3 الكبيرة، واستمرار ريادتها لمجتمع المصادر المفتوحة: أطلقت Alibaba سلسلة نماذج اللغة الكبيرة Qwen3، بأحجام معلمات تتراوح من 0.5B إلى 235B، وأظهرت أداءً متميزًا في العديد من اختبارات القياس، حيث حققت العديد من النماذج صغيرة الحجم مستوى SOTA (الأحدث) بين النماذج مفتوحة المصدر ذات الحجم المماثل. تدعم سلسلة Qwen3 لغات متعددة، ويصل طول السياق إلى 128 ألف رمز (token). نظرًا لأدائها القوي وتكاليف النشر المنخفضة (مقارنة بـ DeepSeek-R1 وغيرها)، تم اعتماد سلسلة Qwen على نطاق واسع في الخارج (خاصة في اليابان) كأساس لتطوير الذكاء الاصطناعي، ونتج عنها عدد كبير من النماذج المتخصصة. يعزز إطلاق Qwen3 مكانتها الرائدة في مجتمع الذكاء الاصطناعي مفتوح المصدر العالمي، حيث تجاوز عدد النجوم على GitHub 20 ألفًا في غضون أسبوع (المصدر: dl_weekly, WeChat)

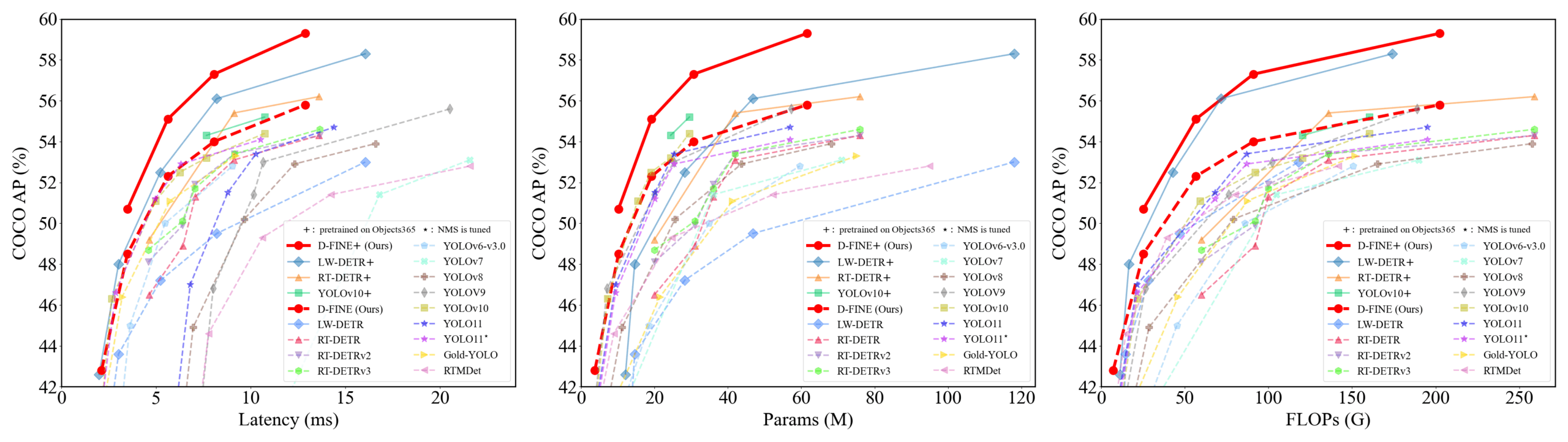
D-FINE: كاشف أهداف في الوقت الحقيقي يعتمد على تحسين التوزيع الدقيق، بأداء متفوق: اقترح باحثون D-FINE، وهو كاشف أهداف جديد في الوقت الحقيقي، يعيد تعريف مهمة تراجع المربع المحيط في DETR كتحسين للتوزيع الدقيق (FDR)، ويقدم استراتيجية التقطير الذاتي لتحديد المواقع الأمثل عالميًا (GO-LSD). يحقق D-FINE أداءً متميزًا دون زيادة تكاليف الاستدلال والتدريب الإضافية. على سبيل المثال، يحقق D-FINE-N دقة 42.8% AP على COCO val، بسرعة تصل إلى 472 FPS (T4 GPU)؛ ويحقق D-FINE-X بعد التدريب المسبق على Objects365+COCO، دقة 59.3% AP على COCO val. تعمل هذه الطريقة على تحقيق تحديد مواقع أكثر دقة من خلال التحسين التكراري لتوزيع الاحتمالات، وتنقل معرفة تحديد المواقع من الطبقة النهائية إلى الطبقات المبكرة من خلال التقطير الذاتي (المصدر: GitHub Trending)
نموذج Harmon ينسق التمثيلات البصرية، ويوحد الفهم والتوليد متعدد الوسائط: اقترح باحثون من جامعة نانيانغ التكنولوجية نموذج Harmon، الذي يهدف إلى توحيد مهام الفهم والتوليد متعدد الوسائط من خلال مشاركة MAR Encoder (Masked Autoencoder for Reconstruction). وجد البحث أن MAR Encoder يمكنه تعلم الدلالات البصرية في نفس الوقت أثناء تدريب توليد الصور، وأن نتائج Linear Probing الخاصة به تتجاوز بكثير VQGAN/VAE. يستخدم إطار Harmon MAR Encoder لمعالجة الصور الكاملة من أجل الفهم، ويتبع نموذج نمذجة القناع MAR لتوليد الصور، حيث يحقق LLM التفاعل بين الوسائط. أظهرت التجارب أن Harmon يقترب من Janus-Pro في معايير الفهم متعدد الوسائط، ويتفوق في معيار جماليات تحويل النص إلى صورة MJHQ-30K ومعيار اتباع التعليمات GenEval، بل ويتجاوز بعض النماذج المتخصصة. تم توفير هذا النموذج مفتوح المصدر (المصدر: WeChat)

روبوتات “تويشينغ تكنولوجي” اللوجستية تحقق حلقة تجارية مغلقة، وتجمع البيانات من خلال “نظام ظل السائق”: تم تشغيل روبوتات “تويشينغ تكنولوجي” اللوجستية بالفعل في العديد من المدن في الصين، وحققت نقطة التعادل لروبوت واحد من خلال العمل بالتعاون مع السائقين البشريين. إحدى تقنياتها الأساسية هي “نظام ظل السائق”، الذي يجمع بيانات سلوك القيادة والإدراك البيئي والعمليات (مثل فتح وإغلاق الأبواب، والتقاط ووضع الأشياء) للسائقين الحقيقيين في بيئات حضرية معقدة، مما يوفر بيانات تدريب ضخمة وعالية الجودة للتعلم بالتقليد والتعلم المعزز للروبوتات. وقد جمع هذا النظام حاليًا عشرات الملايين من الكيلومترات من بيانات القيادة وما يقرب من مليون مسار للأطراف العلوية. استنادًا إلى ذلك، قامت “تويشينغ تكنولوجي” بتدريب نموذج VLA لشجرة السلوك، مما يمكّن الروبوتات من التعامل مع المواقف المعقدة في العالم الحقيقي، وتخطط لتوسيع أسواقها الخارجية (المصدر: WeChat)

Kuaishou تطلق إطار KuaiMod، وتستخدم نماذج كبيرة متعددة الوسائط لتحسين النظام البيئي للفيديو القصير: اقترحت Kuaishou حلاً لتحسين النظام البيئي لمنصة الفيديو القصير يعتمد على نماذج كبيرة متعددة الوسائط يسمى KuaiMod، ويهدف إلى تحسين تجربة المستخدم من خلال التمييز الآلي لجودة المحتوى. يستلهم KuaiMod فكرة السوابق القضائية، ويستخدم نماذج اللغة المرئية (VLM) للاستدلال المتسلسل لتحليل المحتوى منخفض الجودة، ويقوم بتحديث استراتيجيات التمييز باستمرار من خلال التعلم المعزز القائم على ملاحظات المستخدم (RLUF). تم نشر هذا الإطار على منصة Kuaishou، وخفض بشكل فعال معدل شكاوى المستخدمين بأكثر من 20%. تلتزم Kuaishou أيضًا بإنشاء نماذج كبيرة متعددة الوسائط يمكنها فهم مقاطع الفيديو القصيرة المجتمعية، والانتقال من استخراج التمثيلات إلى الفهم الدلالي العميق، وقد تم تطبيقها بالفعل في العديد من السيناريوهات مثل هيكلة علامات الاهتمام بالفيديو والمساعدة في إنشاء المحتوى وحققت نتائج فعالة (المصدر: WeChat)

Lenovo تطلق الوكيل الذكي الفائق الشخصي “Tianxi”، وتتجه نحو الذكاء من المستوى L3: أطلقت Lenovo في مؤتمر الابتكار التكنولوجي الوكيل الذكي الفائق الشخصي “Tianxi”، الذي يتمتع بقدرات إدراك وتفاعل متعددة الوسائط، وقدرات معرفية واتخاذ قرارات تستند إلى قاعدة معارف شخصية، وقدرة على تفكيك وتنفيذ المهام المعقدة بشكل مستقل. يهدف “Tianxi” إلى توفير تجربة تعاون سلسة وطبيعية بين الإنسان والآلة من خلال واجهات مستخدم مصاحبة مثل AI Suixin Chuang و AI Linglong Tai و AI Ruying Kuang. وهو يدمج العديد من النماذج الكبيرة الرائدة في الصناعة، بما في ذلك DeepSeek-R1، ويعتمد بنية نشر مختلطة بين الطرفيات والسحابة، جنبًا إلى جنب مع Lenovo Personal Cloud 1.0 (المجهز بنموذج كبير بـ 72 مليار معلمة) لتوفير قوة حوسبة قوية ومساحة ذاكرة مخصصة تبلغ 100 جيجابايت. كما أطلقت Lenovo أيضًا وكلاء أذكياء فائقين على مستوى المؤسسات “Lexiang” وعلى مستوى المدن، مما يعكس تخطيطها الشامل في مجال الذكاء الاصطناعي (المصدر: WeChat)

بحث جديد يحدد قابلية تعميم الشبكات العصبية من خلال تعقيد التفاعل الرمزي: اقترح فريق البروفيسور Zhang Quanshi من جامعة Shanghai Jiao Tong نظرية جديدة لتحليل قابلية تعميم الشبكات العصبية من منظور تعقيد تمثيل التفاعل الرمزي الداخلي. وجد البحث أن التفاعلات القابلة للتعميم (التي تظهر بتردد عالٍ في مجموعتي التدريب والاختبار) عادةً ما تظهر توزيعًا متناقصًا (تهيمن عليه التفاعلات منخفضة الرتبة) عبر رتب مختلفة (تعقيد)، بينما تظهر التفاعلات غير القابلة للتعميم (التي تظهر بشكل أساسي في مجموعة التدريب) توزيعًا مغزلي الشكل (تهيمن عليه التفاعلات متوسطة الرتبة، ويسهل إلغاء التأثيرات الإيجابية والسلبية). تهدف هذه النظرية إلى الحكم مباشرة على إمكانات تعميم النموذج من خلال تحليل أنماط توزيع “منطق التفاعل AND-OR” المكافئ للنموذج، مما يوفر منظورًا جديدًا لفهم وتحسين قابلية تعميم النموذج (المصدر: WeChat)
🧰 أدوات
Llama.cpp متوافق تمامًا مع نماذج اللغة المرئية (VLM): يدعم Llama.cpp الآن بشكل كامل نماذج اللغة المرئية (VLM)، مما يمكّن المطورين من تشغيل تطبيقات متعددة الوسائط على الأجهزة الطرفية. شارك Julien Chaumond وآخرون من Hugging Face نماذج مكممة مسبقًا، بما في ذلك Gemma من Google DeepMind، و Pixtral من Mistral AI، و Qwen VL من Alibaba، و SmolVLM من Hugging Face، والتي يمكن استخدامها مباشرة. يعود الفضل في هذا التحديث إلى مساهمات فريقي @ngxson و @ggml_org، مما يفتح إمكانيات جديدة لتطبيقات الذكاء الاصطناعي متعددة الوسائط المحلية ذات زمن انتقال منخفض (المصدر: ggerganov, ClementDelangue, cognitivecompai)
صندوق كوارك AI الفائق يطور “البحث العميق” لتعزيز “ذكاء البحث” لدى الذكاء الاصطناعي: تم مؤخرًا ترقية صندوق كوارك AI الفائق، حيث أطلق ميزة “البحث العميق” التي تهدف إلى تعزيز ذكاء البحث (search quotient) لدى الذكاء الاصطناعي. تؤكد الميزة الجديدة على التفكير الاستباقي والتخطيط المنطقي للذكاء الاصطناعي قبل البحث، مما يمكنه من فهم نوايا استعلام المستخدم المعقدة والشخصية بشكل أفضل، وتفكيك المشكلات وإجراء عمليات بحث ذكية ومنظمة. في مجال الصحة، يستشير مستشار كوارك AI الصحي “أكوا” آراء أطباء من الدرجة الثالثة ومواد متخصصة؛ أما في المجال الأكاديمي، فيتصل بمصادر موثوقة مثل CNKI. بالإضافة إلى ذلك، يتمتع كوارك بقدرات معالجة متعددة الوسائط قوية، مثل تحليل الصور، واقتطاع الصور بالذكاء الاصطناعي، وتحسين الصور وتحويل الأنماط. ويُذكر أن كوارك ستطلق في المستقبل إصدارًا احترافيًا من البحث العميق يتمتع بقدرات Deep Research (المصدر: WeChat)

LangChain تطلق العديد من عمليات الدمج والبرامج التعليمية لتعزيز قدرات RAG والوكلاء الأذكياء: أصدرت LangChain مؤخرًا العديد من التحديثات والبرامج التعليمية: 1. برنامج تعليمي لواجهة مستخدم وكيل الوسائط الاجتماعية: يرشد إلى كيفية تحويل وكيل الوسائط الاجتماعية LangChain إلى تطبيق ويب سهل الاستخدام، ويدمج ExpressJS وواجهة مستخدم AgentInbox، ويدعم Notion. 2. حل RAG حائز على جوائز: يعرض تطبيق RAG لتحليل التقارير السنوية للشركات، ويدعم تحليل PDF، و LLM متعددة، واسترجاع متقدم. 3. تطبيق دردشة RAG خاص: يوضح البرنامج التعليمي كيفية استخدام LangChain وإطار Reflex لبناء تطبيق دردشة RAG محلي يركز على خصوصية البيانات. 4. دمج Nimble Retriever: يقدم مسترجع بيانات ويب قويًا، ويوفر بيانات دقيقة لتطبيقات LangChain. 5. دليل الإخراج المنظم لـ Claude 3.7: يوفر ثلاث طرق لتحقيق إخراج منظم لـ Claude 3.7 من خلال LangChain و AWS Bedrock. 6. نظام دردشة RAG محلي: يعرض مشروع مفتوح المصدر نظامًا محليًا بالكامل للإجابة على الأسئلة المتعلقة بالمستندات، تم إنشاؤه باستخدام تدفق LangChain RAG و LLM محلي (عبر Ollama)، مما يضمن خصوصية البيانات (المصدر: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: إطار عمل مفتوح المصدر للوكلاء الأذكياء يدمج قدرات أطر متعددة: Minion-agent هو إطار عمل جديد مفتوح المصدر لتطوير الوكلاء الأذكياء، يهدف إلى حل مشكلة تجزئة أطر عمل الذكاء الاصطناعي الحالية (مثل OpenAI، LangChain، Google AI، SmolaAgents). يوفر واجهة موحدة، ويدعم استدعاء قدرات أطر متعددة، وأدوات كخدمة (تصفح الويب، عمليات الملفات، إلخ)، وتعاون وكلاء متعددين. يعرض المشروع إمكاناته التطبيقية في البحث العميق (جمع المراجع تلقائيًا لإنشاء تقارير)، ومقارنة الأسعار (أتمتة أبحاث السوق)، وتوليد الأفكار الإبداعية (توليد أكواد الألعاب)، وتتبع التطورات التقنية، مع التأكيد على مزايا نموذج المصدر المفتوح في المرونة وفعالية التكلفة (المصدر: WeChat)

RunwayML يُظهر قدرات قوية في توليد وتحرير الفيديو في سيناريوهات متعددة: عرض الباحث المستقل في مجال الذكاء الاصطناعي Cristobal Valenzuela ومستخدمون آخرون تطبيقات RunwayML في مجموعة متنوعة من السيناريوهات الإبداعية. وشمل ذلك استخدام وظائف Frames و References و Gen-4 لتوليد وتصور الأفكار المرئية بسرعة مع الحفاظ على اتساق الأسلوب والشخصيات؛ وتحويل عالم Rembrandt إلى لعبة فيديو RPG؛ وتحقيق تركيبات جديدة لمشاهد التصميم الداخلي من صورة واحدة من خلال توفير مراجع بصرية. تسلط هذه الحالات الضوء على التقدم الذي أحرزته RunwayML في توليد الفيديو القابل للتحكم، ونقل الأسلوب، وبناء المشاهد (المصدر: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: موجه مهام عالمي لمهام رؤية الكمبيوتر: Olympus هو موجه مهام عالمي مصمم لمهام رؤية الكمبيوتر. يهدف إلى تبسيط وتوحيد عمليات معالجة مهام الرؤية المختلفة، ربما من خلال الجدولة الذكية وتخصيص موارد الحوسبة أو استدعاءات النماذج، لتحسين كفاءة وأداء أنظمة رؤية الكمبيوتر متعددة المهام. تم توفير المشروع مفتوح المصدر على GitHub (المصدر: dl_weekly)
Tracy Profiler: محلل إطارات وعينات مختلط في الوقت الحقيقي بدقة نانوثانية: Tracy Profiler هو أداة تحليل إطارات وعينات مختلطة في الوقت الحقيقي، بدقة نانوثانية، تدعم القياس عن بعد، للألعاب والتطبيقات الأخرى. يدعم تحليل أداء وحدة المعالجة المركزية (C, C++, Lua, Python, Fortran وربطات طرف ثالث لـ Rust, Zig, C# وغيرها)، ووحدة معالجة الرسومات (OpenGL, Vulkan, Direct3D, Metal, OpenCL)، وتخصيص الذاكرة، والأقفال، وتبديل السياق، ويمكنه ربط لقطات الشاشة والإطارات الملتقطة تلقائيًا. توفر هذه الأداة، بدقتها العالية وطبيعتها في الوقت الحقيقي، للمطورين وسائل قوية لتحديد مواقع اختناقات الأداء وتحسينها (المصدر: GitHub Trending)

FieldStation42: محاكي بث تلفزيوني قديم: FieldStation42 هو مشروع Python يهدف إلى محاكاة تجربة مشاهدة البث التلفزيوني القديم. يمكنه دعم قنوات متعددة في وقت واحد، وإدراج الإعلانات وبرامج العرض الترويجي تلقائيًا، وإنشاء جدول برامج أسبوعي بناءً على التكوين. يمكن لهذا المحاكي اختيار برامج لم يتم بثها مؤخرًا بشكل عشوائي للحفاظ على الحداثة، ويدعم تحديد نطاق تاريخ بث البرامج (مثل البرامج الموسمية)، ويمكن تكوين فيديو توقف البث التلفزيوني وشاشة دورة عدم وجود إشارة. يدعم المشروع أيضًا الاتصال بالأجهزة (مثل Raspberry Pi Pico) لمحاكاة عمليات تغيير القنوات، ويوفر وظيفة قناة المعاينة/الدليل. هدفه هو أنه عندما “يشغل” المستخدم التلفزيون، يمكنه تشغيل محتوى برنامج “حقيقي” يتوافق مع ذلك الوقت والقناة (المصدر: GitHub Trending)

Tiny Corp تطلق حلاً لوحدة معالجة الرسومات الخارجية AMD eGPU يعتمد على USB3، ويدعم Apple Silicon: عرضت Tiny Corp حلاً لتوصيل وحدة معالجة الرسومات الخارجية AMD eGPU بأجهزة Mac التي تعمل بمعالج Apple Silicon عبر USB3 (تحديدًا جهاز ADT-UT3G يعتمد على وحدة التحكم ASM2464PD). أعاد هذا الحل كتابة برامج التشغيل، بهدف الاستفادة من عرض النطاق الترددي البالغ 10 جيجابت في الثانية لـ USB3، ويستخدم libusb، ويدعم نظريًا أيضًا Linux أو Windows. يوفر هذا مسارًا جديدًا لمستخدمي Apple Silicon لتوسيع قدرات معالجة الرسومات، وله قيمة محتملة خاصة لسيناريوهات مثل تشغيل نماذج الذكاء الاصطناعي الكبيرة محليًا (المصدر: Reddit r/LocalLLaMA)
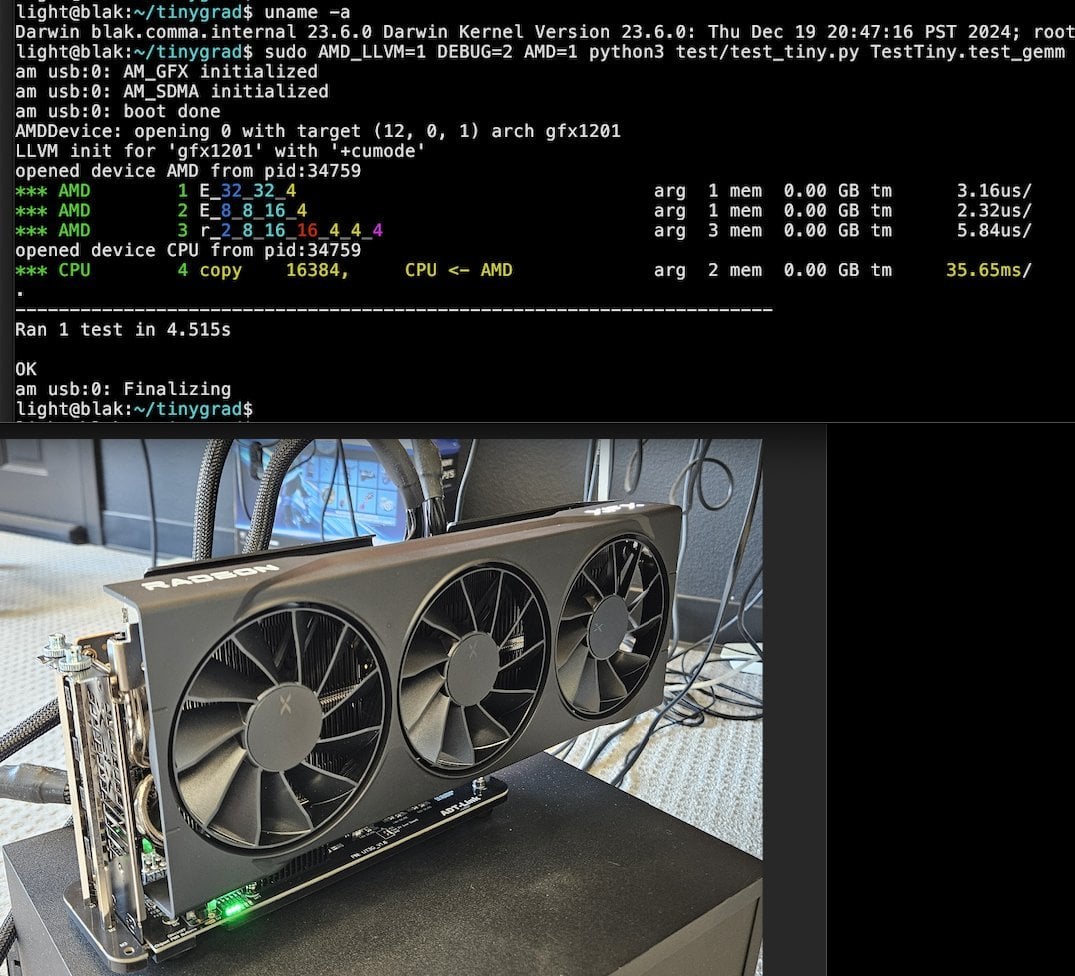
Llama.cpp-vulkan يحقق دعم FlashAttention على وحدات معالجة الرسومات AMD GPU: قام الواجهة الخلفية Vulkan لـ Llama.cpp مؤخرًا بدمج تطبيق FlashAttention، مما يعني أن المستخدمين الذين يستخدمون llama.cpp-vulkan على وحدات معالجة الرسومات AMD GPU يمكنهم الآن الاستفادة من تقنية FlashAttention. بالاقتران مع تكميم ذاكرة التخزين المؤقت Q8 KV، من المتوقع أن يتمكن المستخدمون من مضاعفة حجم السياق مع الحفاظ على سرعة الاستدلال أو تحسينها. يعد هذا التحديث فائدة مهمة لمستخدمي AMD GPU في تشغيل نماذج لغة كبيرة محليًا (المصدر: Reddit r/LocalLLaMA)
Devseeker: مساعد ترميز خفيف الوزن يعمل بالذكاء الاصطناعي، بديل لـ Aider و Claude Code: Devseeker هو مشروع وكيل ترميز خفيف الوزن مفتوح المصدر جديد، يُعتبر بديلاً لـ Aider و Claude Code. يتمتع بقدرات إنشاء وتحرير الأكواد، وإدارة ملفات ومجلدات الأكواد، وذاكرة أكواد قصيرة المدى، ومراجعة الأكواد، وتشغيل ملفات الأكواد، وحساب استخدام الـ token، وتوفير أوضاع ترميز متعددة. يهدف هذا المشروع إلى توفير أداة برمجة مساعدة بالذكاء الاصطناعي أسهل في النشر والاستخدام محليًا (المصدر: Reddit r/ClaudeAI)
📚 تعلم
Panaversity تطلق مشروع تعلم الذكاء الاصطناعي الوكيل، مع التركيز على Dapr و OpenAI Agents SDK: أطلقت Panaversity مشروع “Learn Agentic AI”، الذي يهدف إلى تدريب مهندسي الذكاء الاصطناعي الوكيل والروبوتي من خلال نمط تصميم Dapr Agentic Cloud Ascent (DACA) والعديد من تقنيات السحابة الأصلية للوكلاء الأذكياء (بما في ذلك OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes). يركز المشروع بشكل أساسي على كيفية تصميم أنظمة يمكنها التعامل مع عشرات الملايين من وكلاء الذكاء الاصطناعي المتزامنين، ويوفر سلسلة دورات AI-201 و AI-202 و AI-301، تغطي مسار التعلم من الأساسيات إلى وكلاء الذكاء الاصطناعي الموزعين على نطاق واسع. يؤكد المشروع على أن OpenAI Agents SDK يجب أن يصبح إطار التطوير الرئيسي نظرًا لسهولة استخدامه وقابليته العالية للتحكم (المصدر: GitHub Trending)

بحث حول الضبط الدقيق بالتعلم المعزز يكشف عن علاقة معقدة بين إدارة البيانات وقدرة التعميم: تناقش ورقة بحثية شاركها Minqi Jiang تأثير إدارة البيانات في الضبط الدقيق بالتعلم المعزز (RL) على قدرة تعميم النموذج. وجد البحث أنه سواء من خلال التعلم الذاتي في مهام ترميز “غير محدودة” (Absolute Zero Reasoner)، أو من خلال التدريب المتكرر على عينة مهمة MATH واحدة فقط (1-shot RLVR)، يمكن لنماذج سلسلة Qwen2.5 بحجم 7B تحقيق تحسن في الدقة يتراوح بين 28% و 40% تقريبًا في اختبارات قياس الرياضيات. يكشف هذا عن مفارقة: استراتيجيات إدارة البيانات المتطرفة (بيانات غير محدودة مقابل بيانات نقطة واحدة) يمكن أن تنتج تحسينات تعميم مماثلة. تشمل التفسيرات المحتملة أن RL يستخلص بشكل أساسي القدرات الموجودة مسبقًا في النموذج المدرب مسبقًا، ووجود “دوائر استدلال” مشتركة، وأن التدريب المسبق قد يؤدي إلى دوائر استدلال تنافسية. يعتقد الباحثون أنه لاختراق “سقف التدريب المسبق”، يجب الاستمرار في جمع وإنشاء مهام وبيئات جديدة (المصدر: menhguin)
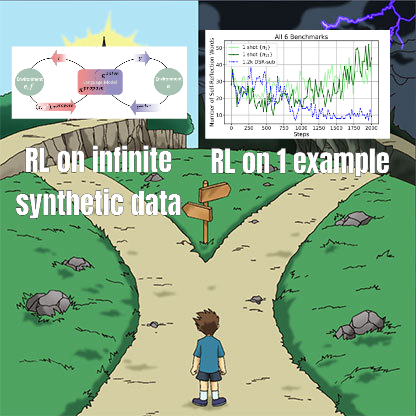
Absolute Zero Reasoner: تحقيق تحسين قدرة الاستدلال بدون بيانات من خلال اللعب الذاتي: تقترح ورقة بحثية بعنوان “Absolute Zero Reasoner” أن النموذج يمكنه تعلم اقتراح مهام تزيد من قابلية التعلم إلى أقصى حد من خلال اللعب الذاتي الكامل (self-play)، وتحسين قدرته على الاستدلال من خلال حل هذه المهام، كل ذلك دون الحاجة إلى أي بيانات خارجية. تتفوق هذه الطريقة على النماذج الأخرى “بدون عينات” في مجالي الرياضيات والترميز. يشير هذا إلى أن أنظمة الذكاء الاصطناعي قد تكون قادرة على تطوير قدراتها على الاستدلال باستمرار من خلال توليد المشكلات وحلها داخليًا، مما يوفر أفكارًا جديدة لتطبيقات الذكاء الاصطناعي في المجالات التي تعاني من ندرة البيانات أو ارتفاع تكاليف التسمية (المصدر: cognitivecompai, Reddit r/LocalLLaMA)

مشاركة الأخطاء الشائعة وأفضل الممارسات في تقييم منتجات الذكاء الاصطناعي: شارك Hamel Husain و Shreya Runwal الأخطاء الشائعة عند إنشاء تقييمات منتجات الذكاء الاصطناعي (evals)، وقدما اقتراحات لتجنب هذه الأخطاء. تشمل النقاط الرئيسية: معايير النماذج الأساسية لا تساوي تقييم التطبيق؛ التقييمات العامة غير فعالة، ويجب أن تكون خاصة بالتطبيق المحدد؛ لا ينبغي الاستعانة بمصادر خارجية لوضع العلامات وهندسة الأوامر لغير المتخصصين في المجال؛ يجب بناء تطبيقات وضع العلامات على البيانات ذاتيًا؛ يجب أن تكون أوامر LLM محددة وتستند إلى تحليل الأخطاء؛ استخدام العلامات الثنائية؛ إيلاء أهمية لمراجعة البيانات؛ الحذر من الإفراط في التكيف مع بيانات الاختبار؛ إجراء اختبارات عبر الإنترنت. تهدف هذه الممارسات إلى مساعدة المطورين على بناء أنظمة تقييم منتجات ذكاء اصطناعي أكثر موثوقية وتعكس الأداء في العالم الحقيقي بشكل أفضل (المصدر: jeremyphoward, HamelHusain)
فكرة جديدة لتحسين ذاكرة التخزين المؤقت KV: قاموس عالمي قابل للنقل وإعادة بناء معالجة الإشارات: اقترح فريق Dimitris Papailiopoulos من جامعة ويسكونسن ماديسون طريقة جديدة لتقليل ذاكرة التخزين المؤقت KV، من خلال استخدام قاموس عالمي قابل للنقل مع خوارزميات إعادة بناء معالجة الإشارات التقليدية. حققت هذه الطريقة مستوى SOTA (الأحدث) على النماذج غير الاستدلالية، ومن المتوقع أن يكون أداؤها أفضل على النماذج الاستدلالية. تم قبول هذا البحث في ICML، ويوفر منظورًا جديدًا ومسارًا تقنيًا لحل مشكلة الاستخدام المفرط لذاكرة التخزين المؤقت KV في استدلال النماذج الكبيرة (المصدر: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

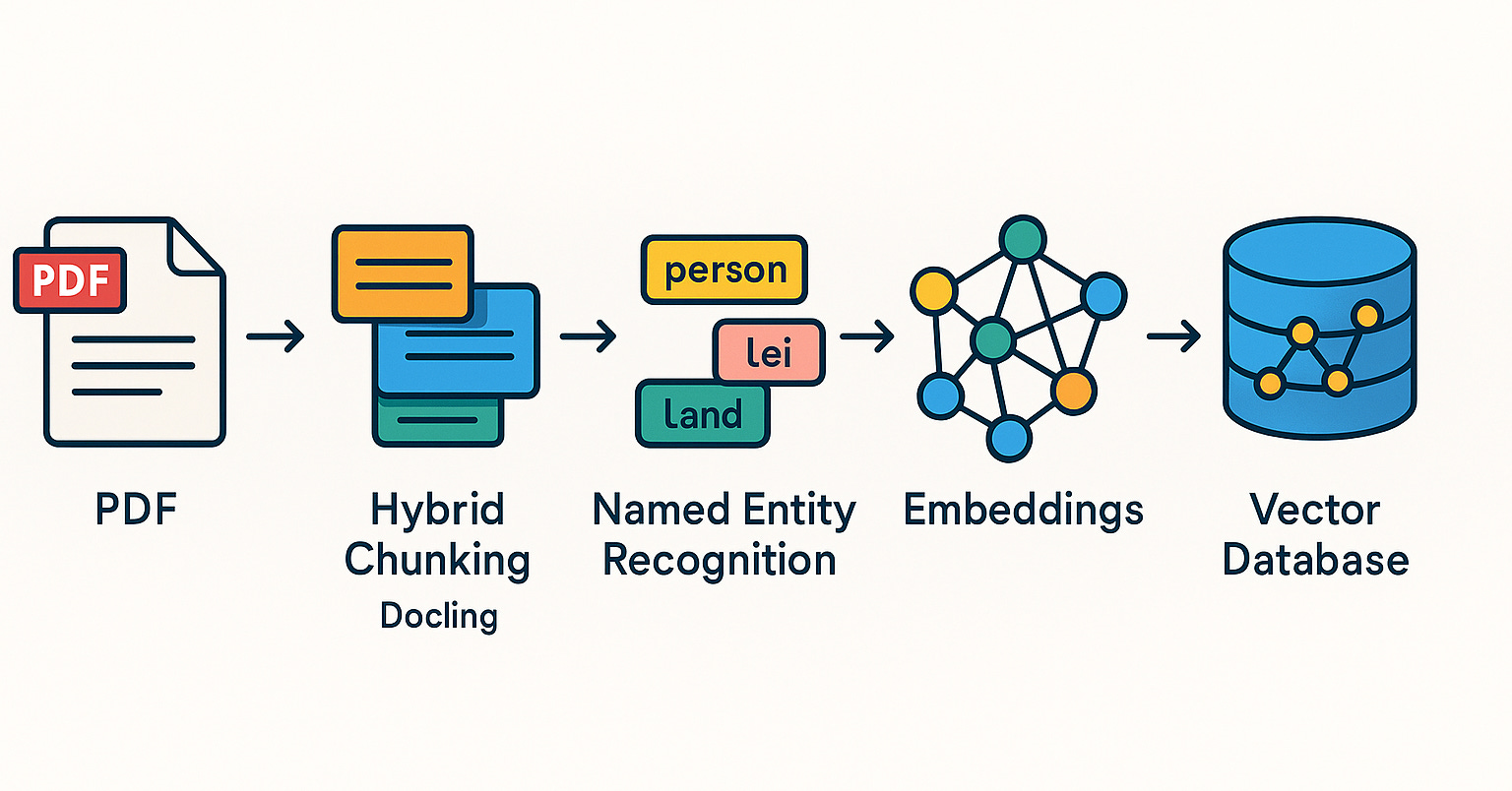
Qdrant تروج لأنظمة RAG وممارسات البحث المختلط في المجتمع البرازيلي: تحظى قاعدة بيانات المتجهات Qdrant باهتمام متزايد في المجتمع البرازيلي. شارك المطور Daniel Romero مقالين باللغة البرتغالية، يوضحان طرقًا عملية لبناء أنظمة RAG (التوليد المعزز بالاسترجاع) باستخدام Qdrant و FastAPI والبحث المختلط. يتضمن المحتوى كيفية بناء نظام RAG للبحث المختلط، واستراتيجيات استيعاب البيانات لـ RAG، وخاصة تقنية التقطيع المختلط (Hybrid Chunking). تساعد هذه المشاركات المطورين البرازيليين على الاستفادة بشكل أفضل من Qdrant في تطوير تطبيقات الذكاء الاصطناعي (المصدر: qdrant_engine)
أكاديمية OpenAI تطلق سلسلة مواضيع حول هندسة الأوامر للتعليم من الروضة حتى الصف الثاني عشر (K12): أطلقت أكاديمية OpenAI سلسلة تعليمية حول هندسة الأوامر (Prompt Engineering) موجهة للعاملين في مجال التعليم من الروضة حتى الصف الثاني عشر (K-12) بعنوان “Mastering Your Prompts”. تهدف هذه السلسلة إلى مساعدة المعلمين على فهم وتطبيق تقنيات الأوامر بشكل أفضل، وذلك لدمج أدوات الذكاء الاصطناعي (مثل ChatGPT) بشكل أكثر فعالية في الممارسات التعليمية، وتحسين نتائج التدريس وتجربة تعلم الطلاب. يشير هذا إلى أن التعليم المدعوم بالذكاء الاصطناعي يتغلغل تدريجياً في مراحل التعليم الأساسي، مع التركيز على تنمية مهارات المعلمين في مجال الذكاء الاصطناعي (المصدر: dotey)
Yann LeCun يشارك محتوى محاضرته في جامعة سنغافورة الوطنية: شارك Yann LeCun وثيقة PDF لمحاضرته المتميزة (Distinguished Lecture) التي ألقاها في 27 أبريل 2025 في جامعة سنغافورة الوطنية (NUS). على الرغم من عدم تقديم موضوع محدد للمحاضرة، إلا أن LeCun، كرائد في مجال التعلم العميق، عادة ما تتناول محاضراته النظريات المتطورة في الذكاء الاصطناعي، أو الاتجاهات المستقبلية، أو رؤى عميقة حول التطورات الحالية في الذكاء الاصطناعي. توفر هذه المشاركة للمهتمين بأبحاث الذكاء الاصطناعي وسيلة مباشرة للحصول على أحدث وجهات نظره (المصدر: ylecun)
PyTorch تتعاون مع Mojo backend لتبسيط تكييف الأجهزة واللغات الجديدة: تعمل PyTorch على تبسيط عملية إنشاء واجهات خلفية جديدة للغات البرمجة والأجهزة الناشئة. في هاكاثون Mojo، عرض marksaroufim جهود PyTorch في هذا المجال، وأشار إلى واجهة خلفية قيد التطوير (WIP) تم تطويرها بالتعاون مع فريق Mojo. يشير هذا إلى أن نظام PyTorch البيئي يوسع بنشاط توافقه لدعم بيئات تطوير ذكاء اصطناعي وخيارات تسريع أجهزة أكثر تنوعًا، مما يقلل من العوائق التي يواجهها المطورون في نشر وتحسين نماذج PyTorch على منصات مختلفة (المصدر: marksaroufim)
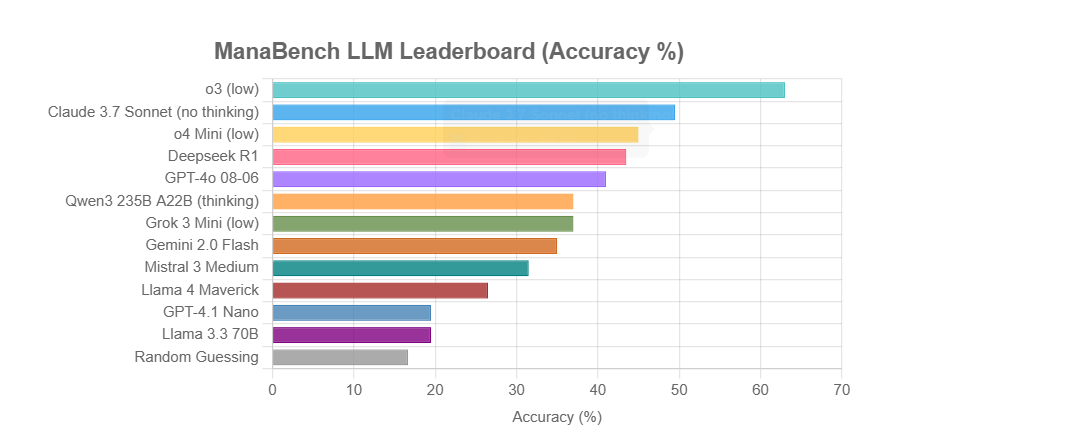
ManaBench: معيار جديد لقدرة استدلال LLM يعتمد على بناء مجموعات أوراق لعبة Magic: The Gathering: أنشأ مطور معيارًا جديدًا يسمى ManaBench، يختبر قدرة استدلال الأنظمة المعقدة لدى LLM من خلال جعلها تختار الورقة الستين الأنسب من بين ستة خيارات، بعد إعطائها 59 ورقة من لعبة Magic: The Gathering (MTG). يؤكد هذا المعيار على الاستدلال الاستراتيجي وتحسين الأنظمة، وتتوافق الإجابات مع تصميم خبراء بشريين، ويصعب اختراقه عن طريق الحفظ البسيط. تظهر النتائج الأولية أن أداء نماذج سلسلة Llama أقل من المتوقع، بينما تتصدر النماذج مغلقة المصدر مثل o3 و Claude 3.7 Sonnet. يهدف هذا المعيار إلى تقييم أداء LLM بشكل أكثر واقعية في المهام التي تتطلب استدلالًا معقدًا (المصدر: Reddit r/LocalLLaMA)
نقاش: هل سيحيي الذكاء الاصطناعي حلم الويب الدلالي أم سيدفنه؟: على وسائل التواصل الاجتماعي، ذكر المستخدم Spencer أنه ما لم تكن مواقع الشركات الكبيرة معرضة لمخاطر كبيرة بسبب قانون ADA (قانون الأمريكيين ذوي الإعاقة)، فإن الويب الدلالي على معظم المواقع هو نظرية أكثر منه ممارسة. رد Dorialexander قائلاً إنه يشعر بأن الذكاء الاصطناعي إما سيحيي حلم الويب الدلالي أو سيدفنه إلى الأبد. يعكس هذا التوقعات والمخاوف بشأن إمكانات الذكاء الاصطناعي في فهم واستخدام البيانات المهيكلة، حيث قد يحقق الذكاء الاصطناعي أهداف الويب الدلالي بشكل غير مباشر من خلال فهم وإنشاء المعلومات المهيكلة تلقائيًا، ولكنه قد يجعل أيضًا تقنيات الويب الدلالي التقليدية أقل أهمية بسبب قدراته القوية (المصدر: Dorialexander)
باحثون يناقشون أخلاقيات وبنى ذاكرة النماذج ونسيانها: يتم حاليًا كتابة مسودة ورقة بحثية بعنوان “Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting”، تناقش كيف نقرر ما يجب أن تنساه النماذج عندما تبدأ في “التذكر بشكل جيد للغاية”، وتدمج بين البنى العصبية وأخلاقيات الذاكرة. يتناول هذا كيفية تخزين أنظمة الذكاء الاصطناعي للمعلومات واسترجاعها ونسيانها (بشكل انتقائي)، والتحديات الأخلاقية والتأثيرات الاجتماعية المترتبة على ذلك، وهو أمر بالغ الأهمية لبناء ذكاء اصطناعي مسؤول وجدير بالثقة (المصدر: Reddit r/artificial)
💼 أعمال
أنباء عن اعتزام Nvidia إطلاق نسخة “مخصصة إضافية” من رقاقة H20 متوافقة مع ضوابط التصدير الأمريكية الجديدة: أفادت وكالة رويترز أن Nvidia تخطط لإطلاق نسخة جديدة مخصصة للصين من رقاقة الذكاء الاصطناعي H20 خلال الشهرين المقبلين، لتتوافق مع أحدث ضوابط التصدير الأمريكية. ستخضع هذه الرقاقة لـ “تخصيص إضافي” على أساس رقاقة H20 الأصلية (التي هي نفسها نسخة مخفضة مخصصة للسوق الصينية)، على سبيل المثال، سيتم تقليل سعة ذاكرة الفيديو بشكل كبير. على الرغم من انخفاض الأداء مرة أخرى، يُقال إن المستخدمين النهائيين قد يتمكنون من تعديل الأداء إلى حد ما عن طريق تعديل تكوينات الوحدات. حاليًا، تلقت Nvidia طلبات بقيمة 18 مليار دولار لرقاقة H20 (المصدر: WeChat)

Databricks قد تستحوذ على شركة قواعد البيانات مفتوحة المصدر Neon مقابل مليار دولار لتعزيز البنية التحتية للذكاء الاصطناعي: يُشاع أن شركة البيانات والذكاء الاصطناعي Databricks تجري محادثات للاستحواذ على Neon، مطور محرك قواعد بيانات PostgreSQL مفتوح المصدر، في صفقة قد تبلغ قيمتها حوالي مليار دولار. تتميز Neon ببنيتها التحتية الخالية من الخوادم، وفصل التخزين عن الحوسبة، وتكيفها الجيد مع وكلاء الذكاء الاصطناعي والبرمجة المحيطة، مما يسمح بالدفع حسب الاستخدام، والتشغيل السريع لمثيلات قواعد البيانات، وهو مناسب لسيناريوهات تطبيقات الذكاء الاصطناعي. إذا نجح هذا الاستحواذ، فسيعزز قدرات Databricks في طبقة البنية التحتية في عصر الذكاء الاصطناعي، ويوفر لها حلاً لقواعد البيانات حديثًا يركز على الذكاء الاصطناعي (المصدر: WeChat)

OpenAI تعين الرئيسة التنفيذية السابقة لـ Instacart، Fidji Simo، رئيسة تنفيذية لأعمال التطبيقات، لتعزيز المنتجات والتسويق: أعلنت OpenAI عن تعيين Fidji Simo، الرئيسة التنفيذية السابقة لـ Instacart وعضو مجلس إدارة الشركة، في منصب “الرئيس التنفيذي لأعمال التطبيقات” الذي تم إنشاؤه حديثًا، على قدم المساواة مع Sam Altman. ستكون Simo مسؤولة بشكل كامل عن منتجات OpenAI، وخاصة التطبيقات الموجهة للمستخدمين مثل ChatGPT، بهدف دفع تحسين المنتجات، وتعزيز تجربة المستخدم، وعملية التسويق. تشير هذه الخطوة إلى تحول استراتيجي كبير في تركيز OpenAI من تطوير النماذج إلى منصات المنتجات وتوسيع السوق، بهدف بناء قدرة تنافسية أقوى في طبقة تطبيقات الذكاء الاصطناعي. ستساعد خبرة Simo الواسعة في المنتجات والتسويق في Facebook و Instacart OpenAI على مواجهة المنافسة الشرسة المتزايدة في السوق (المصدر: WeChat)

🌟 مجتمع
مساعد JetBrains AI يثير استياء المستخدمين بسبب تجربة سيئة وإدارة التعليقات: على الرغم من أن إضافة JetBrains AI Assistant قد تم تنزيلها أكثر من 22 مليون مرة، إلا أن تقييمها في سوقها يبلغ 2.3 نقطة فقط (من أصل 5)، ومليء بالتقييمات السلبية بنجمة واحدة. يشكو المستخدمون بشكل عام من التثبيت التلقائي، والتشغيل البطيء، وكثرة الأخطاء، وعدم كفاية دعم النماذج الخارجية، وربط الوظائف الأساسية بخدمات سحابية، ونقص التوثيق، وغيرها من المشكلات. مؤخرًا، اتُهمت JetBrains بحذف التعليقات السلبية بشكل جماعي، وعلى الرغم من أن الشركة أوضحت أن ذلك كان لمعالجة المحتوى المخالف أو المشكلات التي تم حلها، إلا أن ذلك أثار شكوك المستخدمين بشأن تحكمها في التقييمات وعدم اهتمامها بملاحظات المستخدمين، واختار بعض المستخدمين إعادة نشر التقييمات السلبية والاستمرار في منح نجمة واحدة. أدى هذا الأمر إلى تفاقم استياء المستخدمين من استراتيجية منتجات الذكاء الاصطناعي لدى JetBrains (المصدر: WeChat)

المستخدمون يناقشون بحماس جودة مخرجات وكلاء التسويق بالذكاء الاصطناعي: لاحظ مستخدم وسائل التواصل الاجتماعي omarsar0 أن العديد من دروس YouTube التي تعرض وكلاء تسويق يعملون بالذكاء الاصطناعي، تكون جودة النصوص التسويقية التي تنتجها رديئة بشكل عام، وتفتقر إلى الإبداع والأسلوب. ويرى أن هذا يعكس صعوبة جعل LLM ينتج محتوى عالي الجودة وجذاب، ويؤكد على أن “الذوق” أمر بالغ الأهمية عند بناء وكلاء الذكاء الاصطناعي. وأشار إلى أن العديد من وكلاء الذكاء الاصطناعي الحاليين، على الرغم من تعقيد سير عملهم، لا يزالون يعانون من قصور في إنتاج محتوى ذي قيمة تجارية حقيقية، مما يوفر فرصًا للمواهب ذات الذوق الرفيع والخبرة الواسعة والقادرة على تصميم أنظمة تقييم جيدة (المصدر: omarsar0)
الترميز بمساعدة الذكاء الاصطناعي واتجاه “البرمجة المحيطة” يثيران نقاشًا: أثار مقطع فيديو على Reddit يناقش ترميز الذكاء الاصطناعي من Y Combinator نقاشًا حادًا. تتوافق آراء الفيديو بشكل كبير مع تجربة ناشر الموضوع (الذي يدعي أنه أنشأ العديد من المشاريع المربحة من خلال “البرمجة المحيطة”)، وتشمل النقاط الأساسية ما يلي: 1. أصبح الذكاء الاصطناعي قادرًا على المساعدة في بناء منتجات برمجية معقدة وقابلة للاستخدام، حتى دون الحاجة إلى كتابة أكواد. 2. يتزايد قلق مهندسي البرمجيات بشأن استبدال الذكاء الاصطناعي لوظائفهم، لكن أولئك الذين يتقنون حقًا التطوير بمساعدة الذكاء الاصطناعي يمتلكون “قدرات خارقة”. 3. قد يتحول دور مهندسي البرمجيات في المستقبل إلى “مديري وكلاء أذكياء” يجيدون استخدام أدوات الذكاء الاصطناعي، حيث سيتولى الذكاء الاصطناعي معظم كتابة الأكواد. 4. سيؤدي الذكاء الاصطناعي إلى ظهور عدد كبير من البرامج المتخصصة التي تستهدف أسواقًا محددة. يعتقد المشاركون في النقاش أنه على الرغم من الإمكانات الهائلة لترميز الذكاء الاصطناعي، إلا أنه لا يزال من الضروري امتلاك معرفة بالمفاهيم الهندسية وقواعد البيانات والبنية التحتية وغيرها للاستفادة منه بشكل فعال (المصدر: Reddit r/ClaudeAI)

استمرار النقاش حول ما إذا كان الذكاء الاصطناعي “سيستولي على العالم” وتأثيره على التوظيف: تعكس المنشورات في منتدى Reddit r/ArtificialInteligence القلق العام والآراء المتنوعة للمجتمع بشأن التأثير المستقبلي للذكاء الاصطناعي. يعتقد بعض المستخدمين أنه كلما زادت المعرفة بقدرات الذكاء الاصطناعي، زاد القلق بشأن تجاوزه للبشر وهيمنته على المستقبل، ويشيرون إلى أن أنظمة الذكاء الاصطناعي المتطورة أظهرت بالفعل قدرات مذهلة. بينما يرى مستخدمون آخرون أن المبالغة في تصوير الذكاء الاصطناعي العام (AGI) أدت إلى توقعات غير واقعية، وأن الذكاء الاصطناعي هو في الأساس أداة أتمتة ذكية، وسيكون تأثيره تدريجيًا، على غرار الكمبيوتر والإنترنت. يتطرق النقاش أيضًا إلى التأثير المحتمل للذكاء الاصطناعي على التوظيف، وتوزيع الثروة، وفعالية التنظيم، حيث يرى البعض أن التاريخ يظهر أن التقدم التكنولوجي غالبًا ما يؤدي إلى تفاقم الفجوة بين الأغنياء والفقراء، وأن الذكاء الاصطناعي قد يزيد من تركيز الثروة من خلال القضاء على عدد كبير من الوظائف. في الوقت نفسه، يعرب البعض عن تفاؤلهم بشأن الدور الإيجابي للذكاء الاصطناعي في مجالات مثل الرعاية الصحية والتعليم (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
تجربة المستخدم: كيف تؤثر أدوات الذكاء الاصطناعي مثل ChatGPT على التفكير والإدراك: شارك بعض المستخدمين على منصات التواصل الاجتماعي و Reddit التأثيرات الإيجابية على المستوى الإدراكي لاستخدام أدوات الذكاء الاصطناعي مثل ChatGPT. يشعرون أن الذكاء الاصطناعي ليس مجرد أداة للحصول على المعلومات أو المساعدة في الكتابة، بل هو أشبه بـ “شريك تفكير” أو “مرآة” تساعدهم على توضيح أفكارهم والتعبير بوضوح عن الأفكار الكامنة في اللاوعي. من خلال الحوار مع الذكاء الاصطناعي، أفاد المستخدمون بأنهم قادرون على التفكير بشكل أفضل، وتحدي معتقداتهم الخاصة، واكتشاف أنماط التفكير، بل ويشعرون بأنهم “يستيقظون” ولديهم فهم أعمق للحياة والأنظمة. تشير هذه التجربة إلى أن الذكاء الاصطناعي قد يصبح في بعض الحالات حافزًا للنمو الشخصي واستكشاف الذات (المصدر: Reddit r/ChatGPT)
💡 أخرى
انطلاق الدورة الثانية من المسابقة الوطنية لتطبيقات الذكاء الاصطناعي المبتكرة “كأس شينغجي”: انطلقت الدورة الثانية من “كأس شينغجي” التي تنظمها الأكاديمية الصينية لتكنولوجيا المعلومات والاتصالات وغيرها من الوحدات، تحت شعار “التمكين الذكي، والابتكار الرائد”. تتضمن المسابقة ثلاثة مسارات رئيسية: ابتكار النماذج الكبيرة، وتمكين الصناعة، والنظام البيئي لابتكار البرمجيات والأجهزة، بالإضافة إلى العديد من الاتجاهات المميزة. تهدف المسابقة إلى دفع الابتكار التكنولوجي في مجال الذكاء الاصطناعي، وتطبيقه الهندسي، وبناء نظام بيئي مستقل، وتغطي ما يقرب من 10 صناعات رئيسية مثل الصناعة والرعاية الصحية والتمويل، وتؤكد على تطبيق البرمجيات والأجهزة الصينية للذكاء الاصطناعي. ستحصل المشاريع الفائزة على دعم مالي وفرص للتواصل مع الصناعة (المصدر: WeChat)

مشاركة من مؤتمر AI Ascent لـ Sequoia Capital: إمكانات سوق الذكاء الاصطناعي هائلة، وطبقة التطبيقات واقتصاد الوكلاء هما المستقبل: شارك Pat Grady وشركاء آخرون من Sequoia Capital رؤاهم حول سوق الذكاء الاصطناعي في فعالية AI Ascent. يعتقدون أن إمكانات سوق الذكاء الاصطناعي تتجاوز بكثير الحوسبة السحابية، ولكن يجب الحذر من “الإيرادات المحيطة” (حيث يجرب المستخدمون بدافع الفضول فقط وليس بسبب حاجة حقيقية). تُعتبر طبقة التطبيقات هي القيمة الحقيقية، ويجب على الشركات الناشئة التركيز على المجالات المتخصصة واحتياجات العملاء. حقق الذكاء الاصطناعي اختراقات في مجالات توليد الكلام والبرمجة. تتطلع التوقعات المستقبلية إلى “اقتصاد الوكلاء”، حيث سيتمكن وكلاء الذكاء الاصطناعي من نقل الموارد وإجراء المعاملات، ولكنهم يواجهون تحديات مثل الهوية الدائمة وبروتوكولات الاتصال والأمن. في الوقت نفسه، سيعزز الذكاء الاصطناعي بشكل كبير قدرات الأفراد، مما يؤدي إلى ظهور “أفراد خارقين” (المصدر: WeChat)

نقاش: محتوى وجودة تدريس مقررات تعلم الآلة الجامعية في عصر الذكاء الاصطناعي يثيران الاهتمام: أثارت مشاركة أستاذ جامعة نيويورك Kyunghyun Cho لمخطط مقرر تعلم الآلة للدراسات العليا نقاشًا، حيث يؤكد المقرر على المشكلات التي يمكن لـ SGD حلها والتي لا تتعلق بـ LLM وقراءة الأوراق البحثية الكلاسيكية، وحصل على تقدير من زملاء مثل أستاذ علوم الحاسوب بجامعة هارفارد، الذين يرون أهمية الحفاظ على المفاهيم الأساسية. ومع ذلك، اشتكى طلاب من الهند والولايات المتحدة من تدني جودة مقررات تعلم الآلة في جامعاتهم، وكونها مجردة للغاية، ومليئة بالمصطلحات دون تفسير متعمق، مما يدفع الطلاب إلى الاعتماد على التعلم الذاتي والموارد عبر الإنترنت. يعكس هذا التناقض بين التطور السريع في مجال الذكاء الاصطناعي/تعلم الآلة وتأخر تحديث المقررات الجامعية، بالإضافة إلى أهمية بناء أساس قوي في الرياضيات والنظرية (المصدر: WeChat)
