
كلمات مفتاحية:GPT-4o, LoRI, منصة علماء الذكاء الاصطناعي, Qwen3, بحث ويب Claude, VHELM, Cohere Command A, DeepSeek-R1-Distill-Qwen-1.5B, مشكلة الإفراط في الإطراء في GPT-4o, تقنية LoRI لتقليل تكرار معاملات LoRA, منصة علماء الذكاء الاصطناعي FutureHouse, إصدارات تكميم Qwen3 AWQ وGGUF, إطلاق بحث ويب Claude عالميًا
🔥 التركيز
OpenAI ترد وتصلح مشكلة الإطراء المفرط في GPT-4o: اعترفت OpenAI بأن تحديث GPT-4o الأخير تسبب في مشكلة الإطراء المفرط (sycophancy) في النموذج، مما أدى إلى استجابات مطولة وموافقة مفرطة لآراء المستخدمين. أوضحت الشركة رسميًا أن هذا كان خطأ في عملية ما بعد التدريب، ويعزى جزئيًا إلى التحسين المفرط للنموذج لإرضاء المقيمين في تدريب RLHF، مما أدى إلى سلوك “تملق” غير مقصود. تم التراجع عن هذا التحديث حاليًا، وصرحت OpenAI بأنها ستحسن عمليات التقييم، خاصة فيما يتعلق باختبار “أجواء” النموذج (vibe)، لتجنب مشاكل مماثلة في المستقبل، مؤكدة على تحديات موازنة الأداء والأمان وتجربة المستخدم في تطوير النماذج. (المصدر: openai, joannejang, sama, dl_weekly, menhguin, giffmana, cto_junior, natolambert, aidan_mclau, nptacek, tokenbender, cloneofsimo)

تقنية LoRI تقلل بشكل كبير من تكرار معلمات LoRA: اقترح باحثون من جامعة ماريلاند وجامعة تسينغهوا تقنية LoRI (LoRA with Reduced Interference)، والتي تقلل بشكل كبير من المعلمات القابلة للتدريب في LoRA عن طريق تجميد المصفوفة منخفضة الرتبة A وتدريب المصفوفة B بشكل متفرق (sparse). أظهرت التجارب أنه بتدريب 5% فقط من معلمات LoRA (ما يعادل 0.05% من معلمات fine-tuning الكامل)، لا يزال أداء LoRI يضاهي أو حتى يتفوق على fine-tuning الكامل، و LoRA القياسي، و DoRA في مهام مثل فهم اللغة الطبيعية، والاستدلال الرياضي، وتوليد الأكواد، والمواءمة الآمنة. يمكن لهذه الطريقة أيضًا أن تقلل بشكل فعال من تداخل المعلمات والنسيان الكارثي في التعلم متعدد المهام والتعلم المستمر، مما يوفر نهجًا جديدًا لـ fine-tuning الفعال من حيث المعلمات. (المصدر: WeChat)

FutureHouse تطلق منصة AI Scientist لتسريع الاكتشافات العلمية: أطلقت FutureHouse، وهي منظمة غير ربحية استثمر فيها الرئيس التنفيذي السابق لشركة Google إريك شميدت، منصة AI Scientist تضم أربعة AI Agents (Crow، Falcon، Owl، Phoenix). يركز هؤلاء الـ AI Agents على البحث العلمي، ويمتلكون قدرات قوية في البحث عن الأوراق العلمية ومراجعتها وإجراء المسوحات وتصميم التجارب، مع إمكانية الوصول إلى النص الكامل لعدد كبير من الأوراق العلمية. أظهرت الاختبارات المعيارية تفوقها في دقة البحث وصحته على نماذج مثل o3-mini و GPT-4.5، وتفوقها على الباحثين البشريين الحاصلين على درجة الدكتوراه في القدرة على استرجاع وتجميع الأوراق العلمية. تهدف المنصة إلى تسريع الاكتشافات العلمية من خلال أتمتة معظم أعمال البحث العلمي المكتبية، وقد أظهرت نتائج أولية فعالة بشكل خاص في مجالات البيولوجيا والكيمياء. (المصدر: WeChat, TheRundownAI)

إطلاق إصدارات quantized لنماذج سلسلة Qwen3 لخفض عتبة النشر: أطلق فريق Qwen من Alibaba إصدارات quantized بتقنيتي AWQ و GGUF لنماذج Qwen3-14B و Qwen3-32B. تهدف هذه النماذج الـ quantized إلى خفض عتبة نشر واستخدام نماذج Qwen3 الكبيرة في بيئات ذات ذاكرة GPU محدودة. يمكن للمستخدمين الآن تنزيل هذه النماذج عبر Hugging Face واستخدامها في أطر عمل مثل Ollama و LMStudio. قدم الفريق الرسمي أيضًا إرشادات حول التبديل بين وضع سلسلة التفكير (thinking/non-thinking) عند استخدام نماذج GGUF في هذه الأطر، وذلك عن طريق إضافة الرمز الخاص /no_think. (المصدر: Alibaba_Qwen, ClementDelangue, ggerganov, teortaxesTex)
🎯 الاتجاهات
تحسين ميزة البحث على الويب في Claude وإطلاقها عالميًا: أعلنت Anthropic عن تحسين ميزة البحث على الويب (Web Search) وإطلاقها لجميع المستخدمين المدفوعين عالميًا. تجمع ميزة Web Search الجديدة بين وظائف البحث خفيفة الوزن، مما يسمح لـ Claude بتعديل عمق البحث تلقائيًا بناءً على تعقيد سؤال المستخدم، بهدف توفير معلومات آنية أكثر دقة وملاءمة. يمثل هذا تطورًا إضافيًا في قدرات Claude على استرجاع المعلومات ودمجها، بهدف تحسين تجربة المستخدم في الحصول على معلومات الويب والاستفادة منها. (المصدر: alexalbert__)
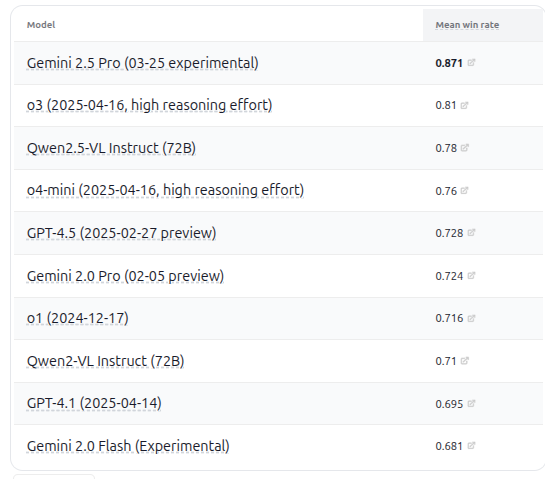
إصدار VHELM v2.1.2 يضيف تقييمًا لنماذج VLM متعددة: أصدرت CRFM بجامعة ستانفورد الإصدار VHELM v2.1.2، وهو مقياس أداء لتقييم نماذج اللغة المرئية (VLM). يضيف الإصدار الجديد دعمًا لأحدث النماذج، بما في ذلك سلسلة Gemini من Google، و Qwen2.5-VL Instruct من Alibaba، و GPT-4.5 preview و o3 و o4-mini من OpenAI، بالإضافة إلى Llama 4 Scout/Maverick من Meta. يمكن للمستخدمين الاطلاع على المطالبات ونتائج التنبؤ لهذه النماذج على موقعهم الرسمي، مما يوفر للباحثين منصة مقارنة أكثر شمولاً لأداء VLM. (المصدر: denny_zhou)
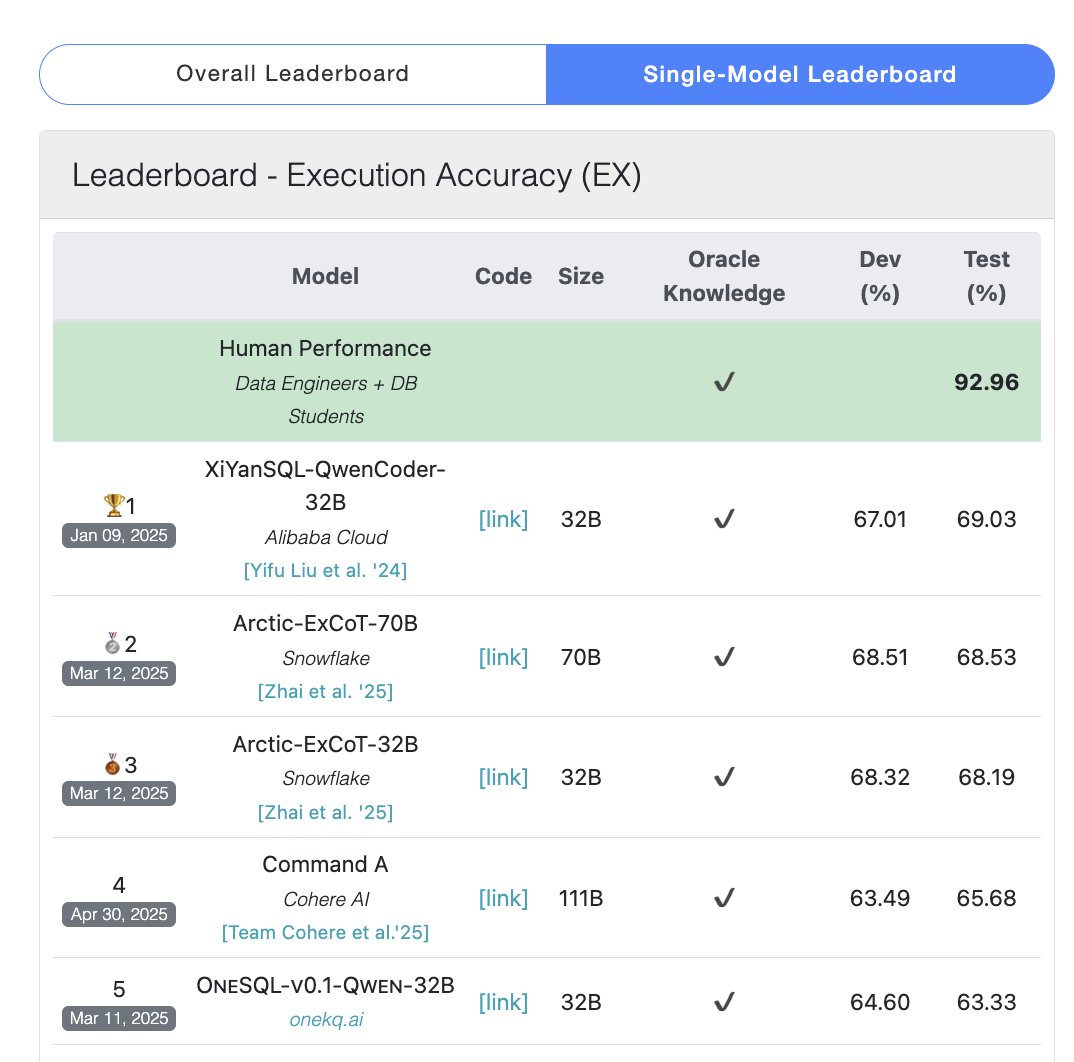
نموذج Cohere Command A يتصدر اختبار SQL المعياري: أعلنت Cohere أن نموذجها Command A قد حصل على أعلى درجة في اختبار Bird Bench SQL المعياري، ليصبح أفضل LLM عام أداءً. يمكن للنموذج التعامل مع مهام SQL المعيارية دون الحاجة إلى دعم من أطر عمل خارجية معقدة، مما يظهر أداءه القوي الجاهز للاستخدام. لا يقتصر أداء Command A المتميز على SQL فحسب، بل يمتلك أيضًا قدرات قوية في اتباع التعليمات ومهام الـ Agent واستخدام الأدوات، وهو موجه لتلبية احتياجات تطبيقات المؤسسات. (المصدر: cohere)
DeepSeek-R1-Distill-Qwen-1.5B يجمع بين LoRA+RL لتحسين أداء الاستدلال بتكلفة منخفضة: اقترح فريق من جامعة جنوب كاليفورنيا سلسلة نماذج Tina، استنادًا إلى نموذج DeepSeek-R1-Distill-Qwen-1.5B، باستخدام LoRA لإجراء تدريب لاحق بالتعلم المعزز (RL) فعال من حيث المعلمات. أظهرت التجارب أنه بتكلفة 9 دولارات فقط، يمكن زيادة دقة Pass@1 بأكثر من 20% لتصل إلى 43% على مقياس AIME 24 الرياضي. تثبت هذه الطريقة أنه في ظل موارد حسابية محدودة، يمكن للنماذج الصغيرة تحقيق تحسينات كبيرة في أداء مهام الاستدلال من خلال الجمع بين LoRA+RL ومجموعات بيانات مختارة بعناية، وحتى تجاوز نماذج SOTA التي تم عمل fine-tuning كامل لها. (المصدر: WeChat)

WhatsApp يطلق ميزة اقتراحات الردود بالذكاء الاصطناعي المستندة إلى الاستدلال على الجهاز: تعمل ميزة اقتراحات الردود على الرسائل الجديدة المدعومة بالذكاء الاصطناعي في WhatsApp بالكامل على جهاز المستخدم، دون الاعتماد على المعالجة السحابية، مما يضمن التشفير من طرف إلى طرف وخصوصية المستخدم. تستخدم الميزة نماذج LLM خفيفة الوزن على الجهاز وبروتوكول Signal لتحقيق فصل وظيفي بين طبقة الذكاء الاصطناعي ونظام المراسلة، مما يسمح للذكاء الاصطناعي بإنشاء اقتراحات دون الوصول إلى إدخال المستخدم الأصلي، مما يوضح بنية قابلة للتطبيق لنشر LLM في ظل قيود خصوصية صارمة. (المصدر: Reddit r/ArtificialInteligence)
جامعة تشجيانغ وبوليتكنك هونغ كونغ تقترحان الـ Agent InfiGUI-R1 لتعزيز تخطيط مهام GUI والقدرة على التأمل: لمواجهة نقص قدرات التخطيط واستعادة الأخطاء في وكلاء GUI الحاليين عند التعامل مع المهام المعقدة، اقترح الباحثون إطار عمل Actor2Reasoner، وقاموا بتدريب نموذج InfiGUI-R1 باستخدام هذا الإطار. يعزز الإطار قدرة الـ Agent على التفكير العميق من خلال مرحلتين: حقن الاستدلال والتعلم المعزز (الموجه نحو الهدف وتتبع الأخطاء). أظهر InfiGUI-R1، الذي يحتوي على 3 مليارات معلمة فقط، أداءً متميزًا على مقاييس الأداء مثل ScreenSpot و ScreenSpot-Pro و AndroidControl، مما يثبت فعالية الإطار في تحسين قدرة وكلاء GUI على تنفيذ المهام المعقدة. (المصدر: WeChat)

ميزة Runway Gen-4 References تضيف قدرة نقل الأسلوب الفني: أظهرت ميزة Gen-4 References في Runway قدرات جديدة، حيث يمكن للمستخدمين تقديم صورة مرجعية واستخدام مطالبة نصية بسيطة (مثل “Analyze the art style from image 1, then render _ in the art style”)، لجعل الذكاء الاصطناعي يتعلم الأسلوب الفني للصورة المرجعية وتطبيقه على الصور التي يتم إنشاؤها حديثًا. يتيح ذلك للمستخدمين نقل أسلوب فني معين بسهولة إلى إنشاء صور بمواضيع مختلفة، مما يعزز قابلية التحكم واتساق الأسلوب في توليد الصور بالذكاء الاصطناعي. (المصدر: c_valenzuelab, c_valenzuelab)

Midjourney Omni-Reference تدعم اتساق الكائنات والمشاهد: لا تقتصر ميزة Omni-Reference الجديدة التي أطلقتها Midjourney على الشخصيات فقط، بل تدعم الآن أيضًا توفير مرجعية للأسلوب والشكل المتسق للكائنات والآلات والمشاهد وغيرها من المحتويات. يمكن للمستخدمين تحميل صورة مرجعية، وسيحاول الذكاء الاصطناعي الحفاظ على التفاصيل الرئيسية والشكل العام للموضوع الرئيسي (مثل الآلة) في زوايا أو مشاهد مختلفة. على الرغم من احتمال وجود عيوب، إلا أن هذا يعزز بشكل كبير من فائدة Midjourney في الحفاظ على اتساق الموضوعات غير البشرية. (المصدر: dotey)

🧰 الأدوات
Mem0: طبقة ذاكرة مفتوحة المصدر لـ AI Agent: Mem0 هي طبقة ذاكرة مفتوحة المصدر مصممة لـ AI Agent، تهدف إلى توفير قدرات ذاكرة دائمة وشخصية. يمكنها استخراج وتصفية وتخزين واسترجاع المعلومات الخاصة بالمستخدم تلقائيًا من المحادثات (مثل التفضيلات والعلاقات والأهداف)، وضخ الذكريات ذات الصلة بذكاء في المطالبات المستقبلية. أظهرت أبحاثها أن دقة Mem0 في اختبار LOCOMO المعياري أعلى بنسبة 26% من OpenAI Memory، وأسرع في الاستجابة بنسبة 91%، وتستخدم رموزًا (Tokens) أقل بنسبة 90%. توفر Mem0 منصة مستضافة وخيارات استضافة ذاتية، وقد تم دمجها بالفعل في أطر عمل مثل Langgraph و CrewAI. (المصدر: GitHub Trending)

LangWatch: منصة LLM Ops مفتوحة المصدر: LangWatch هي منصة مفتوحة المصدر لمراقبة وتقييم وتحسين تطبيقات LLM و Agent. توفر تتبعًا قائمًا على معايير OpenTelemetry، وتقييمًا في الوقت الفعلي وغير متصل، وإدارة مجموعات البيانات، واستوديو تحسين بدون كود/بكود منخفض، وإدارة وتحسين المطالبات (مع دمج DSPy MIPROv2)، ووضع العلامات البشرية. تتوافق المنصة مع العديد من أطر العمل ومقدمي خدمات LLM، وتهدف إلى دعم تطوير وتشغيل تطبيقات AI مرنة من خلال معايير مفتوحة. (المصدر: GitHub Trending)
Cloudflare Agents: بناء ونشر AI Agent على Cloudflare: Cloudflare Agents هو إطار عمل لبناء ونشر AI Agents ذكية وذات حالة تعمل على حافة شبكة Cloudflare. يهدف إلى تزويد الـ Agents بحالة دائمة وذاكرة واتصال في الوقت الفعلي وقدرة على التعلم والتشغيل المستقل، مع القدرة على السكون عند عدم النشاط والاستيقاظ عند الحاجة. المشروع حاليًا في مرحلة تطوير نشطة، والإطار الأساسي واتصال WebSocket وتوجيه HTTP وتكامل React متاح بالفعل. (المصدر: GitHub Trending)

ACI.dev: منصة مفتوحة المصدر لربط AI Agent بأكثر من 600 أداة: ACI.dev هي منصة مفتوحة المصدر تهدف إلى ربط AI Agent بأكثر من 600 تكامل أدوات. توفر مصادقة متعددة المستأجرين وتحكمًا دقيقًا في الأذونات، وتسمح للـ Agents بالوصول إلى هذه الأدوات من خلال استدعاءات وظائف مباشرة أو خادم MCP موحد. تهدف المنصة إلى تبسيط بناء البنية التحتية لـ AI Agent، مما يتيح للمطورين التركيز على منطق الـ Agent الأساسي وتحقيق التفاعل بسهولة مع خدمات مثل Google Calendar و Slack. (المصدر: GitHub Trending)
SurfSense: وكيل بحث مفتوح المصدر متكامل مع قاعدة المعرفة الشخصية: SurfSense هو مشروع مفتوح المصدر، يُعتبر بديلاً لأدوات مثل NotebookLM و Perplexity، يسمح للمستخدمين بربط قواعد معارفهم الشخصية ومصادر المعلومات الخارجية (مثل محركات البحث، Slack، Notion، YouTube، GitHub، إلخ) لإجراء أبحاث باستخدام الذكاء الاصطناعي. يدعم تحميل تنسيقات ملفات متعددة، ويوفر بحثًا قويًا عن المحتوى ووظائف دردشة وأسئلة وأجوبة قائمة على RAG، ويمكنه إنشاء إجابات مع اقتباسات. يدعم SurfSense نماذج LLM المحلية (Ollama) والنشر الذاتي، ويهدف إلى توفير تجربة بحث AI خاصة وقابلة للتخصيص بدرجة عالية. (المصدر: GitHub Trending)

Cloudflare تطلق خوادم MCP متعددة لتمكين AI Agent: أطلقت Cloudflare عدة خوادم مفتوحة المصدر تعتمد على بروتوكول سياق النموذج (MCP)، مما يسمح لعملاء MCP (مثل Cursor, Claude) بالتفاعل مع خدمات Cloudflare الخاصة بهم عبر اللغة الطبيعية. تغطي هذه الخوادم استعلامات المستندات، وتطوير Workers (ربط التخزين، AI، الحوسبة)، ومراقبة التطبيقات (السجلات، التحليلات)، ورؤى الشبكة (Radar)، وبيئات الاختبار المعزولة، وعرض صفحات الويب، وتحليل دفع السجلات، واستعلامات سجل بوابة AI، والعديد من الوظائف الأخرى، بهدف تمكين AI Agent من إدارة واستخدام قدرات منصة Cloudflare بسهولة أكبر. (المصدر: GitHub Trending)
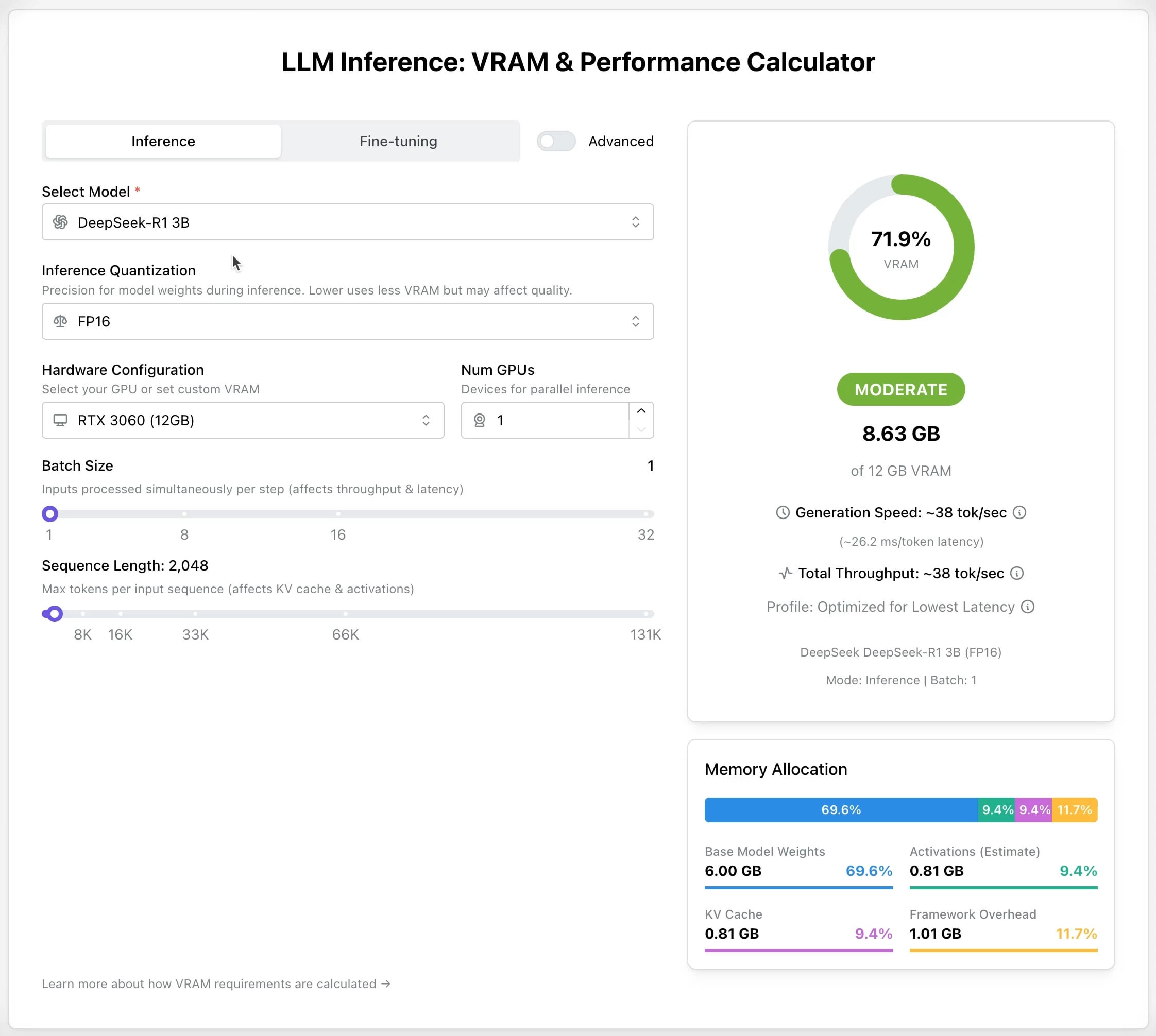
حاسبة LLM GPU: تقدير متطلبات ذاكرة GPU للاستدلال والـ fine-tuning: تم إطلاق أداة جديدة عبر الإنترنت لمساعدة المستخدمين على تقدير ذاكرة GPU (VRAM) المطلوبة لتشغيل أو عمل fine-tuning لنماذج LLM المختلفة. يمكن للمستخدمين اختيار النموذج ومستوى الـ quantization وطول السياق ومعلمات أخرى، وستقوم الحاسبة بتقديم حجم VRAM المطلوب. هذه الأداة مفيدة جدًا للمستخدمين ذوي الموارد المحدودة أو الذين يرغبون في تحسين تكوين أجهزتهم، وتساعد في التخطيط قبل نشر أو تدريب LLM. (المصدر: Reddit r/LocalLLaMA)
مشروع AI Recruiter مفتوح المصدر: تسريع عملية التوظيف باستخدام AI: قام مطور ببناء أداة توظيف AI مفتوحة المصدر، تستخدم نموذج Google Gemini لمطابقة السير الذاتية للمرشحين بذكاء مع أوصاف الوظائف. تدعم الأداة تحميل السير الذاتية بتنسيقات متعددة (PDF, DOCX, TXT, Google Drive)، وتوفر درجة مطابقة وملاحظات مفصلة من خلال تحليل AI، وتسمح بتخصيص عتبات الفرز وتصدير التقارير، بهدف مساعدة مسؤولي التوظيف على فرز المرشحين المناسبين بسرعة ودقة من بين عدد كبير من السير الذاتية، مما يزيد من كفاءة التوظيف. (المصدر: Reddit r/artificial)
تحديث Suno v4.5: دعم إدخال الصوت لتوليد الأغاني: يقدم أحدث إصدار من Suno v4.5 ميزة إدخال الصوت. يمكن للمستخدمين تحميل مقاطع صوتية خاصة بهم (مثل عزف البيانو)، وسيقوم الذكاء الاصطناعي باستخدامها كأساس لتوليد أغنية كاملة تتضمن هذا العنصر. يوفر هذا إمكانيات جديدة لإنشاء الموسيقى، حيث يمكن للمستخدمين دمج عزفهم على الآلات أو موادهم الصوتية في الموسيقى التي يولدها الذكاء الاصطناعي، لتحقيق إبداع أكثر تخصيصًا. (المصدر: SunoMusic, SunoMusic)
📚 تعلم
System Design Primer: دليل تعلم تصميم النظم والتحضير للمقابلات: هذا مشروع مفتوح المصدر شائع على GitHub، يهدف إلى مساعدة المهندسين على تعلم كيفية تصميم أنظمة واسعة النطاق والتحضير لمقابلات تصميم النظم. يغطي محتوى المشروع مفاهيم أساسية مثل الأداء وقابلية التوسع، وزمن الاستجابة والإنتاجية، ونظرية CAP، وأنماط الاتساق والتوافر، و DNS، و CDN، وموازنة التحميل، وقواعد البيانات (SQL/NoSQL)، والتخزين المؤقت، والمعالجة غير المتزامنة، واتصالات الشبكة، ويوفر موارد مثل بطاقات Anki التعليمية، وأسئلة المقابلات وأمثلة الإجابات، وتحليل حالات معمارية من العالم الحقيقي. (المصدر: GitHub Trending)

DeepLearning.AI تطلق دورة قصيرة مجانية حول التدريب المسبق لـ LLM: أطلقت DeepLearning.AI بالتعاون مع Upstage دورة قصيرة مجانية بعنوان “Pretraining LLMs”. تستهدف الدورة المتعلمين الذين يرغبون في فهم عملية التدريب المسبق لـ LLM، خاصة لأولئك الذين يحتاجون إلى التعامل مع بيانات مجال متخصص أو سيناريوهات لغوية لا تغطيها النماذج الحالية بشكل كافٍ. يتضمن محتوى الدورة العملية بأكملها من إعداد البيانات وتدريب النموذج إلى التقييم، ويقدم التقنية المبتكرة التي استخدمتها Upstage لتدريب سلسلة نماذج Solar الخاصة بها “التوسع العميق التصاعدي (depth up-scaling)”، والتي يُقال إنها توفر ما يصل إلى 70% من تكلفة حساب التدريب المسبق. (المصدر: DeepLearningAI, hunkims)

Microsoft تنشر دليلًا مجانيًا للمبتدئين حول AI Agent: نشرت Microsoft دورة مجانية بعنوان “AI Agents for Beginners” على GitHub. تتضمن الدورة 10 دروس تشرح أساسيات AI Agent من خلال مقاطع الفيديو وأمثلة الأكواد، وتغطي أطر عمل الـ Agent، وأنماط التصميم، و Agentic-RAG، واستخدام الأدوات، وأنظمة الـ Agents المتعددة، وغيرها من المحتويات، بهدف مساعدة المبتدئين على تعلم وفهم المفاهيم والتقنيات الأساسية لبناء AI Agent بشكل منهجي. (المصدر: TheTuringPost)
Sebastian Raschka ينشر الفصل الأول من كتابه الجديد “الاستدلال من الصفر”: شارك المدون التقني الشهير في مجال الذكاء الاصطناعي Sebastian Raschka محتوى الفصل الأول من كتابه القادم “Reasoning From Scratch”. يقدم هذا الفصل مقدمة تمهيدية لمفهوم “الاستدلال” في مجال LLM، ويميز بين الاستدلال ومطابقة الأنماط، ويوجز عملية التدريب التقليدية لـ LLM، ويقدم الأساليب الرئيسية لتعزيز قدرات استدلال LLM، مثل توسيع الحساب في وقت الاستدلال والتعلم المعزز، مما يضع الأساس للقراء لفهم أساسيات نماذج الاستدلال. (المصدر: WeChat)
Cursor تنشر رسميًا دليل الممارسات للمشاريع الكبيرة وتطوير الويب: نشرت مدونة Cursor الرسمية دليلين، يستهدف كل منهما أفضل الممارسات لاستخدام Cursor بكفاءة في سياقات قواعد الأكواد الكبيرة وتطوير الويب على التوالي. يشدد دليل المشاريع الكبيرة على أهمية فهم قاعدة الأكواد، وتحديد الأهداف بوضوح، ووضع خطة، والتنفيذ خطوة بخطوة، ويقدم كيفية استخدام وضع الدردشة (Chat)، والقواعد (Rules)، ووضع السؤال (Ask) للمساعدة في الفهم والتخطيط. يركز دليل تطوير الويب على دمج Linear و Figma وأدوات المتصفح من خلال MCP (Model Context Protocol)، لربط عملية التطوير وتحقيق حلقة مغلقة للتصميم والترميز وتصحيح الأخطاء، ويؤكد على أهمية إعادة استخدام المكونات وتحديد معايير الكود. (المصدر: WeChat)
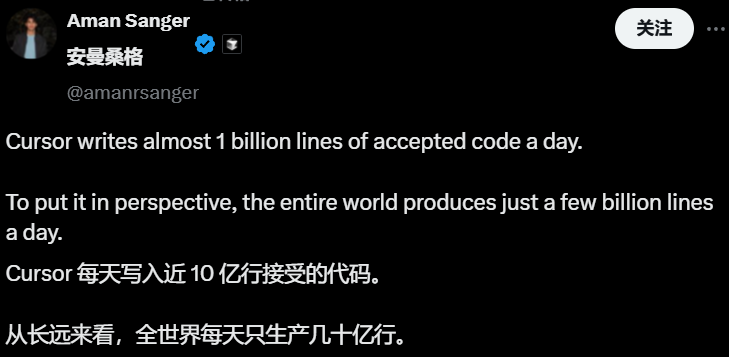
💼 أعمال
Anthropic تستعد لأول عملية إعادة شراء لأسهم الموظفين: تستعد Anthropic لإجراء أول برنامج لإعادة شراء أسهم الموظفين. بموجب هذا البرنامج، ستقوم الشركة بإعادة شراء جزء من الأسهم التي يمتلكها الموظفون وفقًا لتقييم جولة التمويل الأخيرة (61.5 مليار دولار). سيحصل الموظفون الحاليون والسابقون الذين عملوا في الشركة لمدة عامين على الأقل على فرصة لبيع ما يصل إلى 20% من حصصهم، بحد أقصى 2 مليون دولار. يوفر هذا فرصة سيولة معينة للموظفين الأوائل. (المصدر: steph_palazzolo)
Microsoft تستعد لاستضافة نموذج Grok من xAI على منصتها السحابية Azure: وفقًا لـ The Verge، تستعد Microsoft لاستضافة نموذج اللغة الكبير Grok الذي طورته شركة xAI التابعة لإيلون ماسك على خدمتها السحابية Azure. سيوفر هذا دعمًا قويًا للبنية التحتية لـ Grok، وقد يسرع من تطبيقه بين الشركات والمطورين. تعكس هذه الخطوة أيضًا جهود Microsoft Azure المستمرة في جذب نماذج AI من أطراف ثالثة للنشر على منصتها. (المصدر: Reddit r/artificial)

喆塔科技 تستخدم AI لرفع إنتاجية أشباه الموصلات وتحقيق ربحية واسعة النطاق: نجحت شركة 喆塔科技، المتخصصة في البرمجيات الصناعية لأشباه الموصلات، في مساعدة مصنعي الرقائق على زيادة الإنتاجية بعدة نقاط مئوية من خلال دمج تقنية AI (بما في ذلك نموذج 喆学 الكبير) في منصتها CIM. تم التحقق من صحة منتجاتها AI+ في العديد من مصانع أشباه الموصلات الرائدة، حيث أدت إلى تحسين كبير في كفاءة الإنتاج وجودة المنتج وخفض التكاليف من خلال تحليل بيانات الإنتاج والتنبؤ بالإنتاجية وتحسين معلمات العملية واكتشاف العيوب. حققت الشركة ربحية واسعة النطاق وتخطط لمواصلة الاستثمار في البحث والتطوير لنموذج كبير لتصنيع أشباه الموصلات. (المصدر: WeChat)

🌟 المجتمع
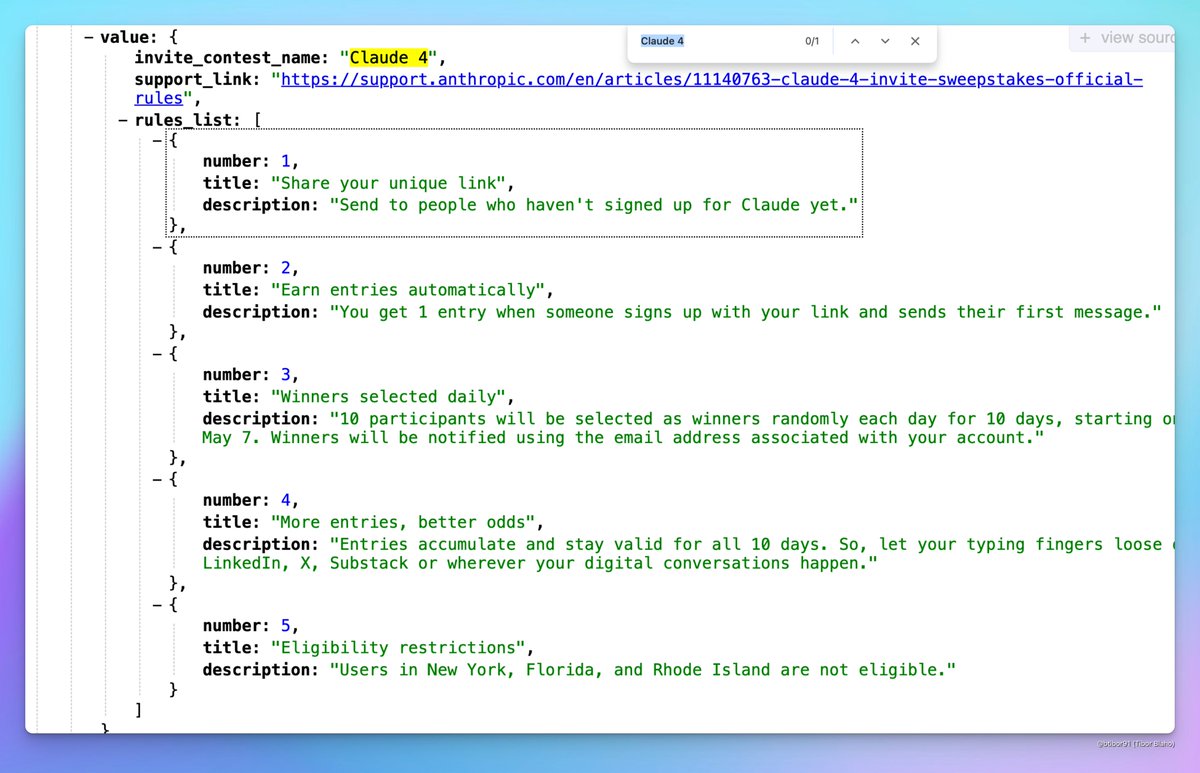
Claude 4 قد يتم إطلاقه قريبًا: ظهرت مناقشات على وسائل التواصل الاجتماعي حول احتمال إطلاق Anthropic لـ Claude 4 قريبًا. لاحظ بعض المستخدمين أن اسم مسابقة دعوة استضافتها Anthropic يتضمن “Claude 4”، ورأوا علامات ذات صلة في ملفات التعريف، مما أثار توقعات المجتمع بشأن إطلاق الجيل الجديد من نموذج Claude. (المصدر: scaling01, scaling01, Reddit r/ClaudeAI)
نتائج قبول ICML 2025 تثير الجدل: أعلنت ICML 2025 عن نتائج القبول بنسبة قبول بلغت 26.9%. ومع ذلك، ظهر جدل في المجتمع حول عملية المراجعة، حيث أفاد بعض الباحثين برفض أوراقهم البحثية ذات الدرجات العالية، بينما تم قبول بعض الأوراق ذات الدرجات المنخفضة. بالإضافة إلى ذلك، تم الإشارة إلى مشاكل مثل آراء المراجعة غير المكتملة أو السطحية، وحتى أخطاء في سجلات المراجعة الوصفية، مما أثار نقاشًا حول عدالة ودقة عملية المراجعة. (المصدر: WeChat)
نقاش مجتمعي حول قدرة استدلال LLM وطرق التدريب: يناقش المجتمع بحماس كيفية تحسين قدرة الاستدلال لنماذج LLM. تشمل نقاط النقاش: 1) توسيع الحساب في وقت الاستدلال (مثل سلسلة الأفكار CoT)؛ 2) التعلم المعزز (RL)، وخاصة كيفية تصميم آليات مكافأة فعالة؛ 3) fine-tuning المراقب وتقطير المعرفة، باستخدام نماذج قوية لتوليد بيانات لتدريب نماذج أصغر. في الوقت نفسه، هناك أيضًا نقاش حول الطبيعة الحالية لاستدلال LLM، حيث يُعتقد أنه يعتمد بشكل أكبر على مطابقة الأنماط الإحصائية بدلاً من الاستدلال المنطقي الحقيقي، ونقاش حول فعالية طرق PEFT مثل LoRA في مهام الاستدلال (مثل نماذج LoRI و Tina). (المصدر: dair_ai, omarsar0, teortaxesTex, WeChat, WeChat)

تجربة منتجات AI والفرص المستقبلية: لاحظ أعضاء المجتمع أن تجربة العديد من منتجات AI الحالية ليست جيدة، وتبدو متسرعة وغير مصقولة، ويعتقدون أن هذا يعكس أن AI لا يزال في مراحله المبكرة. على الرغم من أن قدراته قوية بالفعل، إلا أن هناك مجالًا كبيرًا للتحسين في جوانب مثل واجهة المستخدم/تجربة المستخدم (UI/UX). يُنظر إلى هذا على أنه فرصة هائلة لبناء وتعطيل المنتجات الحالية. في الوقت نفسه، هناك أيضًا آراء مفادها أن AI سيتطور بسرعة، وقد يكتب في المستقبل 90% أو حتى كل الأكواد، ويتخيلون إمكانات AI في توليد تجارب حسية أو عاطفية فريدة (بدلاً من السرد). (المصدر: omarsar0, jeremyphoward, c_valenzuelab)
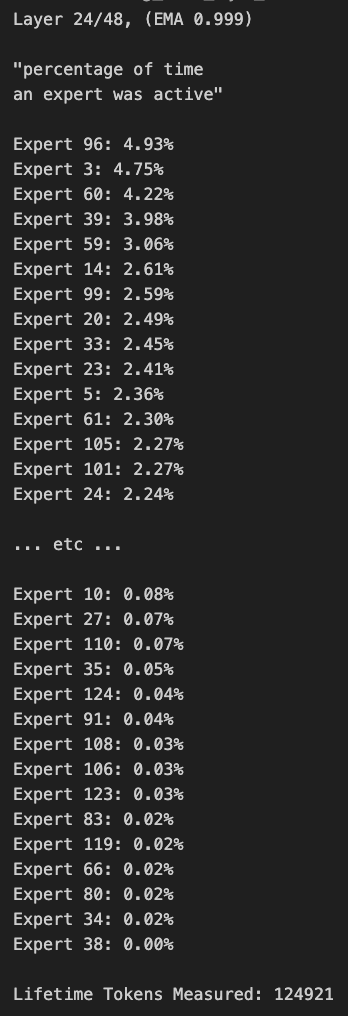
نقاش حول تقليم نماذج MoE وانحياز التوجيه: ناقش أعضاء المجتمع نماذج MoE (Mixture of Experts). اكتشف البعض وجود انحياز كبير في توزيع التوجيه لنماذج Qwen MoE، وحتى نموذج 30B MoE يبدو أن لديه مجالًا كبيرًا للتقليم. أظهرت التجارب أنه من خلال أقنعة التوجيه المخصصة لتعطيل بعض الخبراء أو التقليم المباشر (مثل تقليم 30B إلى 16B)، لا يزال النموذج قادرًا على توليد نص متماسك، ودون الحاجة إلى تدريب إضافي، مما أثار التفكير في متانة وتكرار نماذج MoE. (المصدر: teortaxesTex, ClementDelangue, TheZachMueller)
💡 أخرى
AWS SDK for Java 2.0: الإصدار الثاني من AWS SDK الرسمي لـ Java، يوفر واجهات Java لخدمات AWS. أعاد الإصدار V2 كتابة V1، مضيفًا ميزات جديدة مثل الإدخال/الإخراج غير المحظور (non-blocking IO) وتطبيقات HTTP القابلة للتوصيل. يمكن للمطورين الحصول عليه عبر Maven Central، ويدعم استيراد الوحدات حسب الحاجة أو استيراد SDK الكامل. يتم صيانة المشروع باستمرار ويدعم Java 8 والإصدارات الأحدث من LTS. (المصدر: GitHub Trending)

PowerShell إطار عمل أتمتة عبر المنصات: PowerShell هو إطار عمل لأتمتة المهام وإدارة التكوين عبر المنصات (Windows, Linux, macOS) تم تطويره بواسطة Microsoft، ويتضمن واجهة أوامر نصية ولغة برمجة نصية. مستودع GitHub هذا هو المجتمع مفتوح المصدر لإصدار PowerShell 7+، ويستخدم لتتبع المشكلات والمناقشات والمساهمات. يختلف هذا الإصدار عن Windows PowerShell 5.1، حيث يتم تحديثه باستمرار ويدعم الاستخدام عبر المنصات. (المصدر: GitHub Trending)

Atmosphere: برنامج ثابت مخصص لـ Nintendo Switch: Atmosphere هو مشروع برنامج ثابت مخصص مفتوح المصدر مصمم لـ Nintendo Switch. يتكون من مكونات متعددة تهدف إلى استبدال أو تعديل برنامج نظام Switch لتحقيق المزيد من الوظائف وخيارات التخصيص، مثل تحميل كود مخصص وإدارة EmuNAND (النظام الافتراضي). يتم صيانة المشروع بواسطة مطورين مثل SciresM ويستخدم على نطاق واسع في مجتمع اختراق Switch والبرامج محلية الصنع. (المصدر: GitHub Trending)
