
كلمات مفتاحية:ساحة الدردشة الآلية, فاي-4 للاستدلال, تكاملات كلود, الوكيل الذكي للذكاء الاصطناعي, ديب سيك-بروفر-في2, كيو وين 3, جيميني, ببغاء-تي دي تي-0.6B-في2, هلوسة تصنيف المتصدرين, قدرات الاستدلال للنماذج الصغيرة, تكامل التطبيقات الخارجية, الوكيل الذكي للبرمجة بالذكاء الاصطناعي, إثبات النظريات الرياضية
🔥 聚焦 (التركيز)
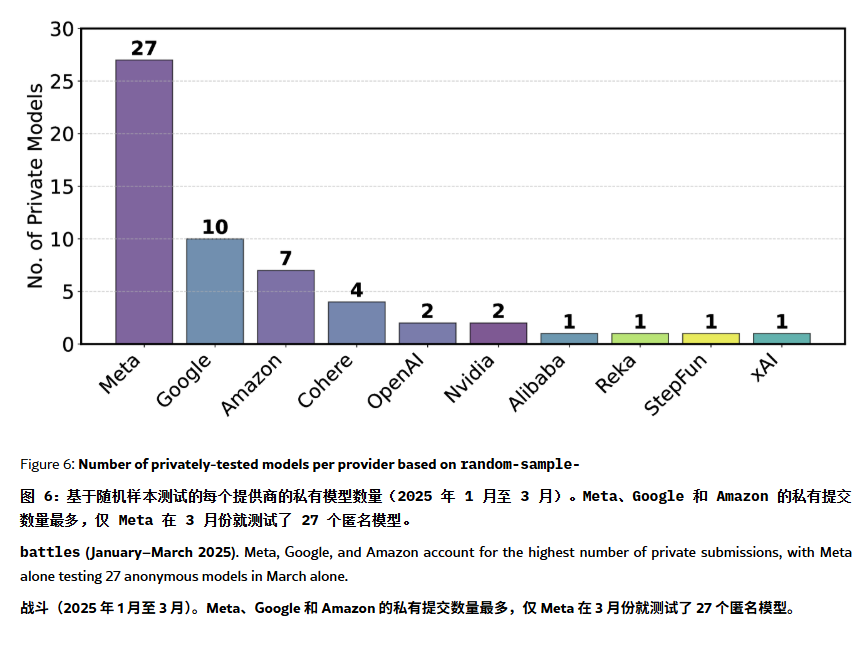
اتهامات بـ”الهلوسة” والتلاعب في قائمة ChatBot Arena: ورقة بحثية على ArXiv [2504.20879] تثير الشكوك حول قائمة تصنيف نماذج ChatBot Arena المستخدمة على نطاق واسع، معتبرة أنها تعاني من “هلوسة قائمة التصنيف”. تشير الورقة إلى أن شركات التكنولوجيا الكبرى (مثل Meta) قد تتلاعب بالترتيب عن طريق تقديم عدد كبير من متغيرات النماذج المعدلة بدقة (مثل اختبار 27 نموذجًا لـ Llama-4) ونشر أفضل النتائج فقط؛ كما قد يميل تكرار عرض النماذج لصالح نماذج الشركات الكبرى، مما يقلل من فرص ظهور النماذج مفتوحة المصدر؛ تفتقر آلية استبعاد النماذج إلى الشفافية، حيث يتم إزالة العديد من النماذج مفتوحة المصدر بسبب عدم كفاية بيانات الاختبار؛ بالإضافة إلى ذلك، قد يؤدي تشابه الأسئلة الشائعة للمستخدمين إلى تدريب النماذج بشكل مفرط وموجه لزيادة النقاط. يثير هذا مخاوف بشأن موثوقية ونزاهة اختبارات قياس LLM السائدة حاليًا، ويوصي المطورين والمستخدمين بالتعامل بحذر مع تصنيفات القائمة والنظر في بناء أنظمة تقييم تلبي احتياجاتهم الخاصة. (المصدر: karminski3, op7418, TheRundownAI)
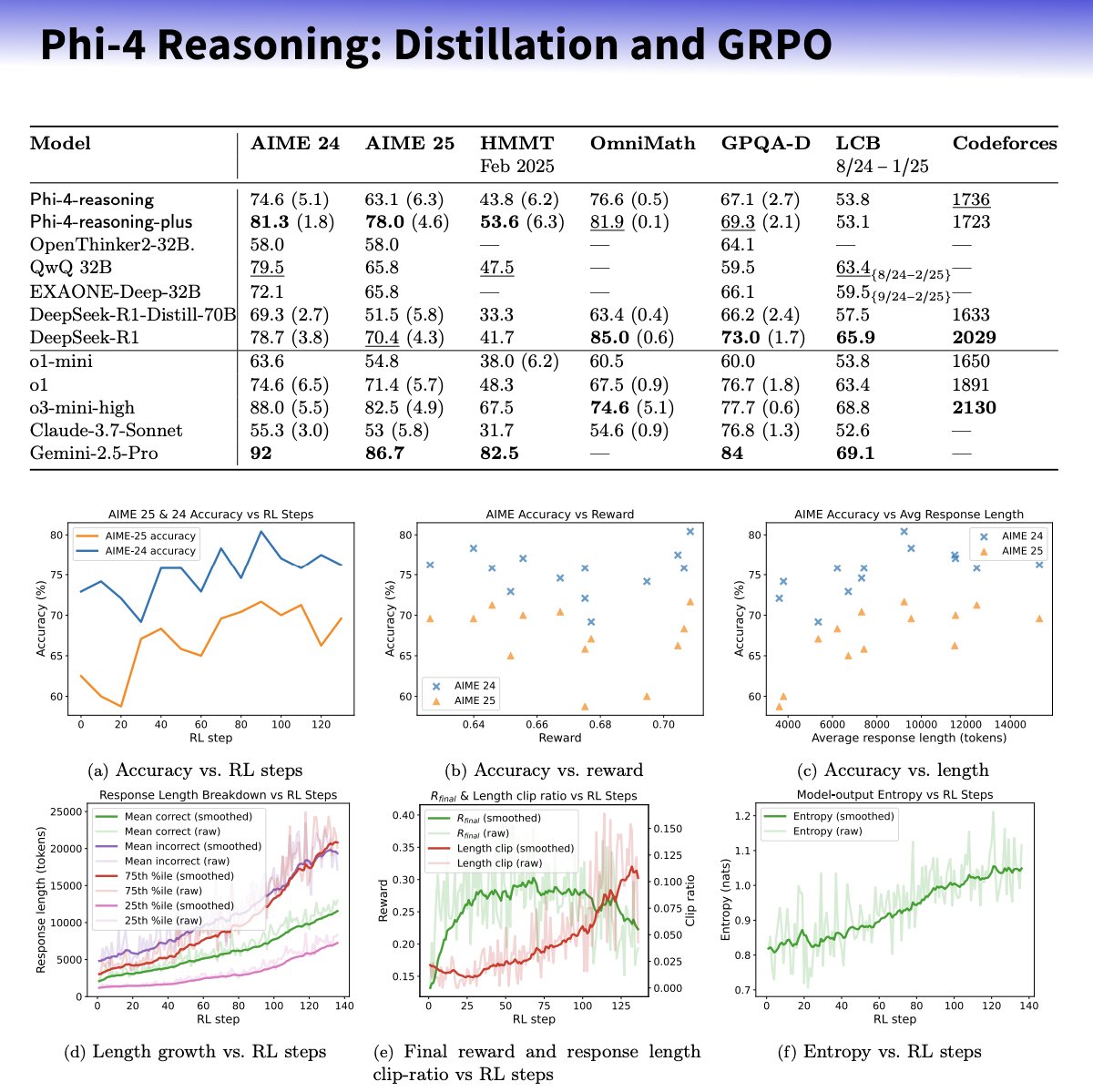
Microsoft تطلق سلسلة نماذج Phi-4-reasoning الصغيرة، مع التركيز على تعزيز قدرات الاستدلال: أطلقت Microsoft نموذجي Phi-4-reasoning و Phi-4-reasoning-plus استنادًا إلى بنية Phi-4، بهدف تعزيز قدرات الاستدلال لنماذج اللغة الصغيرة من خلال مجموعات بيانات منسقة بعناية، والضبط الدقيق الخاضع للإشراف (SFT)، والتعلم المعزز الموجه نحو الهدف (RL). يُزعم أن هذه النماذج تستخدم OpenAI o3-mini كـ “معلم” لتوليد مسارات استدلال عالية الجودة لسلسلة الأفكار (CoT)، ويتم تحسينها من خلال التعلم المعزز باستخدام خوارزمية GRPO. يدعي الباحث في Microsoft، Sebastien Bubeck، أن Phi-4-reasoning يتفوق على DeepSeek R1 في القدرات الرياضية، على الرغم من أن حجم النموذج يمثل 2% فقط من حجم الأخير. تستخدم هذه السلسلة من النماذج رموزًا (tokens) مخصصة للاستدلال وطول سياق موسع يبلغ 32K. يُعتبر هذا التحرك استكشافًا في اتجاه النماذج المصغرة والمتخصصة، وقد يوفر حلول استدلال أقوى للسيناريوهات محدودة الموارد، ولكنه أثار أيضًا نقاشات حول ما إذا كانت تستغل تقنية OpenAI وتصدر بموجب ترخيص MIT. (المصدر: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic تطلق ميزة Integrations وتوسع قدرات البحث: أعلنت Anthropic عن إطلاق Claude Integrations، مما يسمح للمستخدمين بربط Claude مع 10 تطبيقات وخدمات تابعة لجهات خارجية مثل Jira، Confluence، Zapier، Cloudflare، Asana وغيرها، مع دعم مستقبلي لـ Stripe، GitLab والمزيد. تم توسيع دعم MCP (Model Context Protocol)، الذي كان يقتصر سابقًا على الخوادم المحلية، ليشمل الخوادم البعيدة، ويمكن للمطورين إنشاء تكاملاتهم الخاصة في حوالي 30 دقيقة من خلال الوثائق أو حلول مثل Cloudflare. في الوقت نفسه، تم تعزيز وظيفة البحث (Research) في Claude، مع إضافة وضع متقدم يمكنه البحث في الويب، و Google Workspace، والتكاملات المتصلة، وتقسيم الطلبات المعقدة للتحقيق، وإنشاء تقارير شاملة مع اقتباسات، وقد يستغرق وقت المعالجة ما يصل إلى 45 دقيقة. كما تم إتاحة وظيفة البحث على الويب للمستخدمين المدفوعين عالميًا. تهدف هذه التحديثات إلى تعزيز تكامل Claude وقدراته البحثية العميقة كمساعد عمل. (المصدر: _philschmid, Reddit r/ClaudeAI)

قدرات وكلاء الذكاء الاصطناعي تتبع قانون مور الجديد: تتضاعف كل 4 أشهر: تشير دراسة أجرتها AI Digest إلى أن قدرة وكلاء برمجة الذكاء الاصطناعي على إكمال المهام تشهد نموًا أسيًا، حيث يتضاعف الوقت الذي تستغرقه لمعالجة المهام (مقاسًا بالوقت الذي يحتاجه الخبراء البشريون) كل 4 أشهر تقريبًا بين عامي 2024-2025، وهو أسرع من معدل التضاعف كل 7 أشهر بين عامي 2019-2025. يمكن لوكلاء الذكاء الاصطناعي الرائدين حاليًا التعامل مع مهام البرمجة التي تتطلب ساعة واحدة من البشر. إذا استمر هذا الاتجاه المتسارع، فمن المتوقع بحلول عام 2027 أن يتمكن وكلاء الذكاء الاصطناعي من إكمال مهام معقدة تستغرق ما يصل إلى 167 ساعة (حوالي شهر واحد). يعود هذا التحسن السريع في القدرات إلى التقدم في النماذج نفسها وتحسين كفاءة الخوارزميات، وقد يتشكل حلقة ردود فعل إيجابية للنمو فوق الأسي بسبب البحث والتطوير في الذكاء الاصطناعي بمساعدة الذكاء الاصطناعي، مما ينذر باحتمالية “انفجار ذكاء البرمجيات” الذي سيغير بشكل عميق مجالات مثل تطوير البرمجيات والبحث العلمي، ولكنه يجلب أيضًا تحديات اجتماعية مثل تأثير الأتمتة على سوق العمل. (المصدر: 新智元)

🎯 动向 (الاتجاهات)
إطلاق DeepSeek-Prover-V2، لتعزيز القدرة على إثبات النظريات الرياضية: أطلقت DeepSeek AI نموذج DeepSeek-Prover-V2، الذي يتضمن حجمين 7B و 671B، ويركز على إثبات النظريات الرسمية في Lean 4. يستخدم النموذج البحث عن الإثبات التكراري والتعلم المعزز (GRPO) للتدريب، مستفيدًا من DeepSeek-V3 لتحليل النظريات المعقدة وتوليد مسودات الإثبات، ثم يتم دمجه مع التكرار الخبير والبيانات الاصطناعية للبدء البارد من أجل الضبط الدقيق والتعلم المعزز. حقق DeepSeek-Prover-V2-671B نسبة نجاح 88.9% في MiniF2F-test، وحل 49 مشكلة في PutnamBench، مما أظهر أداءً متطورًا (SOTA). تم أيضًا إصدار معيار ProverBench الذي يتضمن مسائل AIME والكتب المدرسية. يهدف النموذج إلى توحيد الاستدلال غير الرسمي والإثبات الرسمي، ودفع تطوير إثبات النظريات الآلي. (المصدر: 新智元)

Nvidia و UIUC تقترحان طريقة جديدة لتوسيع السياق إلى 4 ملايين token: اقترح باحثون من Nvidia وجامعة إلينوي في أوربانا-شامبين (UIUC) طريقة تدريب فعالة يمكنها توسيع نافذة سياق Llama 3.1-8B-Instruct من 128K إلى 1M و 2M وحتى 4M token. تعتمد الطريقة على استراتيجية من مرحلتين: التدريب المسبق المستمر والضبط الدقيق للتعليمات، وتشمل التقنيات الرئيسية استخدام فواصل مستندات خاصة، وتوسيع ترميز الموضع استنادًا إلى YaRN، والتدريب المسبق بخطوة واحدة. أظهر نموذج UltraLong-8B المدرب أداءً ممتازًا في اختبارات قياس السياق الطويل مثل RULER و LV-Eval و InfiniteBench، وحافظ على أداء خط الأساس Llama 3.1 أو تجاوزه في المهام القياسية للسياق القصير مثل MMLU و MATH، متفوقًا على نماذج السياق الطويل الأخرى مثل ProLong و Gradient. يوفر هذا البحث مسارًا فعالًا وقابلًا للتطوير لبناء LLMs ذات سياق طويل جدًا. (المصدر: 新智元)

إطلاق Qwen3، مع تحسينات ملحوظة في الأداء: أطلقت Alibaba سلسلة نماذج Qwen3، بما في ذلك Qwen3-30B-A3B وغيرها. وفقًا للاختبارات الأولية وبيانات القياس من مستخدمي Reddit (مثل AHA Leaderboard)، يُظهر Qwen3 أداءً أفضل مقارنة بالإصدارات السابقة Qwen2.5 و QwQ في أبعاد متعددة (مثل المعرفة المتخصصة في مجالات الصحة، البيتكوين، Nostr، إلخ). تشير ملاحظات المستخدمين إلى أن Qwen3 يُظهر قدرة قوية في التعامل مع مهام محددة (مثل محاكاة ديناميكيات النظام الشمسي)، حيث يمكنه تطبيق قوانين الفيزياء بشكل صحيح لتوليد مدارات إهليلجية وفترات نسبية. ومع ذلك، أشار بعض المستخدمين إلى أن أداء Qwen3 ينخفض بشكل ملحوظ في السياقات الطويلة (مثل الاقتراب من 16K)، وأن استهلاك الـ token مرتفع أثناء الاستدلال، مما يقترح استخدامه مع أدوات البحث. كما حظيت طريقة تسمية Qwen3 (مثل Qwen3-30B-A3B) بالثناء لوضوحها. (المصدر: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini ستقوم قريبًا بدمج بيانات حساب Google لتقديم تجربة مخصصة: تخطط Google للسماح لمساعد الذكاء الاصطناعي Gemini بالوصول إلى بيانات حساب المستخدم في Google، بما في ذلك Gmail، الصور، سجل YouTube، وغيرها، بهدف تقديم تجربة مساعدة أكثر تخصيصًا واستباقية وقوة. صرح Josh Woodward، مدير المنتج في Google، بأن هذا يهدف إلى جعل Gemini يفهم المستخدم بشكل أفضل ويصبح امتدادًا له. ستكون هذه الميزة اختيارية (opt-in)، حيث يمكن للمستخدمين اختيار ما إذا كانوا سيمنحون إذن الوصول إلى البيانات أم لا. أثار هذا التحرك نقاشات حول الخصوصية وأمن البيانات، حيث سيحتاج المستخدمون إلى الموازنة بين راحة التخصيص وخصوصية البيانات. (المصدر: JeffDean, Reddit r/ArtificialInteligence)

Nvidia تطلق نموذج ASR Parakeet-TDT-0.6B-v2: أطلقت Nvidia نموذجًا جديدًا للتعرف التلقائي على الكلام (ASR) باسم Parakeet-TDT-0.6B-v2، بحجم 600 مليون معلمة. يُزعم أن أداء هذا النموذج على Open ASR Leaderboard يتفوق على Whisper3-large (بحجم 1.6 مليار معلمة)، خاصة في معالجة مجموعات البيانات المتنوعة (بما في ذلك LibriSpeech، Fisher Corpus، بيانات YouTube، وغيرها بحوالي 120 ألف ساعة من البيانات). يدعم النموذج الطوابع الزمنية على مستوى الحرف والكلمة والفقرة، ولكنه يدعم حاليًا اللغة الإنجليزية فقط ويتطلب وحدات معالجة رسومات Nvidia وأطر عمل محددة للتشغيل. تشير الملاحظات الأولية للمستخدمين إلى دقة عالية في النسخ وعلامات الترقيم. (المصدر: Reddit r/LocalLLaMA)

إطلاق Qwen2.5-VL، لتعزيز فهم اللغة المرئية: أطلقت Alibaba سلسلة نماذج Qwen2.5-VL متعددة الوسائط (بما في ذلك أحجام 3B، 7B، 72B معلمة)، بهدف تعزيز فهم الآلة للعالم المرئي والتفاعل معه. يمكن استخدام هذه النماذج لمهام مثل تلخيص الصور، والإجابة على الأسئلة المرئية، وتوليد التقارير من المعلومات المرئية المعقدة. يقدم المقال تفاصيل عن بنيتها، وأدائها في اختبارات القياس، وتفاصيل الاستدلال، مما يوضح تقدمها في فهم اللغة المرئية. (المصدر: Reddit r/deeplearning)

دعم Mistral Small 3.1 Vision تم دمجه في llama.cpp: قام مشروع llama.cpp بدمج دعم نموذج Mistral Small 3.1 Vision (بحجم 24B معلمة). هذا يعني أن المستخدمين سيتمكنون من تشغيل هذا النموذج متعدد الوسائط ضمن إطار عمل llama.cpp، للقيام بمهام مثل فهم الصور. قامت Unsloth بتوفير ملفات النموذج المقابلة بتنسيق GGUF. يوفر هذا سهولة لتشغيل نموذج Mistral المرئي محليًا. (المصدر: Reddit r/LocalLLaMA)
Meta تطلق Synthetic Data Kit: قامت Meta بإصدار أداة سطر أوامر مفتوحة المصدر تسمى Synthetic Data Kit، تهدف إلى تبسيط مرحلة إعداد البيانات اللازمة للضبط الدقيق لـ LLM. توفر الأداة أربعة أوامر: ingest (استيراد البيانات)، create (إنشاء أزواج سؤال وجواب، مع سلسلة استدلال اختيارية)، curate (استخدام Llama كحكم لتصفية العينات عالية الجودة)، save-as (تصدير بتنسيق متوافق)، مستفيدة من LLM المحلي (عبر vLLM) لتوليد بيانات تدريب اصطناعية عالية الجودة، وهي مناسبة بشكل خاص لتمكين قدرات الاستدلال لمهام محددة لنماذج مثل Llama-3. (المصدر: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 يصبح نموذج تضمين شائع: أصبح نموذج GTE-ModernColBERT-v1 الذي أطلقته LightOnIO نموذج بحث/تضمين شائعًا جديدًا على Hugging Face. يعتمد النموذج طريقة بحث متعددة المتجهات (تُعرف أيضًا بالتفاعل المتأخر أو ColBERT)، مما يوفر خيارًا جديدًا للمطورين المهتمين بهذه التقنيات. (المصدر: lateinteraction)
تحديث خوارزمية توصية X: قامت منصة X (Twitter سابقًا) بإصلاح خوارزمية التوصية الخاصة بها، بهدف معالجة المشكلات طويلة الأمد مثل عدم الأخذ بالملاحظات السلبية للمستخدمين، ورؤية نفس المحتوى بشكل متكرر، وتوصية خوارزمية SimCluster بمحتوى غير ذي صلة. يُزعم أن ردود الفعل الأولية إيجابية. (المصدر: TheGregYang)
ويكيبيديا تعلن عن استراتيجية ذكاء اصطناعي جديدة لدعم المحررين البشريين: كشفت ويكيبيديا عن استراتيجيتها الجديدة للذكاء الاصطناعي، التي تهدف إلى استخدام أدوات الذكاء الاصطناعي لدعم وتعزيز عمل المحررين البشريين، وليس استبدالهم. لم يتم تفصيل التفاصيل المحددة في المصدر، لكنها تشير إلى أن أكبر موسوعة على الإنترنت في العالم تستكشف كيفية دمج تقنية الذكاء الاصطناعي في عمليات إنشاء المحتوى وصيانته. (المصدر: Reddit r/artificial)
🧰 工具 (الأدوات)
Midjourney تطلق ميزة Omni-Reference: أطلقت Midjourney ميزة جديدة تسمى Omni-Reference (oref)، تسمح للمستخدمين بتوجيه توليد الصور من خلال توفير عنوان URL لصورة مرجعية (باستخدام المعلمة –oref)، لتحقيق الاتساق في الشخصيات أو الأشياء أو المركبات أو الكائنات غير البشرية. يمكن للمستخدمين التحكم في وزن تأثير الصورة المرجعية من خلال المعلمة –ow، حيث تكون الأوزان المنخفضة مناسبة للتصميم الأسلوبي، والأوزان الأعلى مناسبة للواقعية أو مطابقة الوجوه الدقيقة. تهدف الميزة إلى تعزيز الاتساق والتحكم في عناصر محددة في الصور المولدة. (المصدر: op7418, DavidSHolz)

Runway Gen-4 References تحقق التخصيص بصورة واحدة: أطلقت ميزة References (المراجع) في نموذج Runway Gen-4، حيث يحتاج المستخدمون فقط إلى توفير صورة مرجعية واحدة لتطبيق أسلوب الصورة أو ميزات الشخصية على المحتوى الجديد المولد. يوضح العرض التوضيحي أن الميزة يمكنها بسهولة إعادة إنشاء صور شخصية بأسلوب الصورة المرجعية أو وضعها في العالم المصور في الصورة المرجعية، مما يظهر قدرة النموذج على تحقيق تخصيص عالي الاتساق وجودة جمالية بمجرد صورة مرجعية واحدة. (المصدر: c_valenzuelab, c_valenzuelab)

روبوت WhatsApp الخاص بـ Perplexity يستأنف الخدمة: بعد توقف مؤقت بسبب الطلب الذي فاق التوقعات بكثير، استأنف روبوت الدردشة WhatsApp الخاص بـ Perplexity AI الخدمة الآن. يمكن للمستخدمين التفاعل معه عبر رقم الهاتف +1 (833) 436-3285، حيث يمكنهم إعادة توجيه الرسائل للتحقق من الحقائق، وطرح الأسئلة مباشرة للحصول على إجابات، وإجراء محادثات نصية حرة، وإنشاء الصور. (المصدر: AravSrinivas, AravSrinivas)
Krea AI تجمع بين نموذج صور 4o لتحقيق تحكم دقيق في الصور: أضافت أداة الإبداع بالذكاء الاصطناعي Krea AI ميزة جديدة تتيح للمستخدمين الجمع بين قدرات نموذج الصور 4o من OpenAI للتحكم بشكل أكثر دقة في محتوى وأسلوب الصور المولدة من خلال تجميع الصور (collage) والرسم (doodling). يوضح هذا الابتكار المستمر لـ Krea في توليد الصور التفاعلية، مما يتيح للمستخدمين توجيه إبداع الذكاء الاصطناعي بشكل أكثر بديهية وتفصيلاً. (المصدر: op7418)
جهاز 行云褐蚁一体机: تشغيل DeepSeek كامل الدقة بتكلفة منخفضة: أطلقت شركة 行云集成电路 (Xingyun Integrated Circuits) ذات الخلفية من Tsinghua جهاز الذكاء الاصطناعي المتكامل 行云褐蚁一体机، والذي يُزعم أنه يمكنه تشغيل نموذج DeepSeek-R1/V3 671B بدقة FP8 غير مُكمّمة (unquantized) بسرعة تزيد عن 20 token/s وبسعر 149,000 يوان، ويدعم سياق 128K. يعتمد الحل على وحدات معالجة مركزية AMD EPYC مزدوجة وذاكرة وصول عشوائي عالية السعة وعالية التردد، مع تسريع قليل بواسطة وحدات معالجة الرسومات، بهدف تقليل تكلفة الأجهزة لنشر النماذج الكبيرة بشكل خاص بشكل كبير من خلال بنية CPU+Memory، وتوفير تجربة محلية قريبة من الأداء الرسمي، وهو مناسب للشركات الحساسة للتكلفة والتي تحتاج إلى دقة عالية. (المصدر: 新智元)

تطبيق NotebookLM سيصدر قريبًا: تطبيق الملاحظات بالذكاء الاصطناعي من Google، NotebookLM، سيطلق قريبًا تطبيقات رسمية لنظامي iOS و Android، ومن المتوقع إطلاقه في 20 مايو، وهو متاح حاليًا للطلب المسبق. سيجلب هذا وظائف NotebookLM القائمة على ملاحظات المستخدم ومستنداته لتقديم ملخصات وإجابات على الأسئلة وتوليد الأفكار الإبداعية إلى الأجهزة المحمولة. (المصدر: zacharynado)
Granola تطلق تطبيق iOS لتحقيق محاضر اجتماعات فورية بالذكاء الاصطناعي: أصدر تطبيق الملاحظات بالذكاء الاصطناعي Granola إصدارًا لنظام iOS، موسعًا وظائفه الأصلية لتدوين ملاحظات اجتماعات Zoom بالذكاء الاصطناعي لتشمل سيناريوهات المحادثات وجهًا لوجه خارج الإنترنت. يمكن للمستخدمين استخدام Granola على iPhone لتسجيل ونسخ المحادثات، والاستفادة من الذكاء الاصطناعي لتوليد ملخصات وملاحظات، مما يسهل المراجعة والتنظيم لاحقًا. (المصدر: amasad)
Grok Studio يدعم معالجة PDF: أضاف مساعد الذكاء الاصطناعي Grok في ميزة Studio الخاصة به القدرة على معالجة ملفات PDF، مما يتيح للمستخدمين الآن معالجة وتحليل مستندات PDF بشكل أكثر ملاءمة داخل Grok Studio. لم يتم تفصيل تفاصيل الوظيفة، لكنها تمثل توسعًا في قدرات Grok في فهم المستندات متعددة التنسيقات والتفاعل معها. (المصدر: grok, TheGregYang)
نموذج Suno الجديد يظهر قدرة ممتازة على توليد الموسيقى: أطلقت منصة توليد الموسيقى بالذكاء الاصطناعي Suno نموذجًا جديدًا، وأفاد المستخدمون بأن تأثيرات التوليد “ممتازة للغاية”. حاول أحد المستخدمين استخدامه لتوليد أغنية بأسلوب الأداء المباشر، وعلى الرغم من أنه لم يحقق تمامًا تأثير الاستجابة المطلوب، إلا أن الموسيقى المولدة أظهرت أداءً جيدًا في جوانب مثل أجواء الجمهور، مما يوضح تقدم النموذج الجديد في جودة الموسيقى وتنوع الأساليب. (المصدر: nptacek, nptacek)
تطبيق Frog Spot للمساعدة في التعرف على نداءات الضفادع بالذكاء الاصطناعي: قام مطور بإنشاء تطبيق مجاني يسمى Frog Spot، يستخدم نموذج CNN مدرب ذاتيًا (TensorFlow Lite) للتعرف على أنواع مختلفة من نداءات الضفادع من خلال تحليل الطيف الصوتي لصوت مدته 10 ثوانٍ. يهدف التطبيق إلى مساعدة الجمهور على التعرف على الأنواع المحلية، ويعرض أيضًا إمكانات تطبيق التعلم العميق في المراقبة الصوتية الحيوية ومجالات علوم المواطن. (المصدر: Reddit r/deeplearning)
أتمتة الرسومات الفنية الصناعية بمساعدة الذكاء الاصطناعي: تقدم ورقة بحثية في IAAI 2025 طريقة لأتمتة توسيع “النماذج القياسية للأجهزة” (Instrument Typicals) في مخططات الأنابيب والأجهزة (P&ID). تجمع الطريقة بين نماذج الرؤية الحاسوبية (اكتشاف النص والتعرف عليه) والقواعد الخاصة بالمجال لاستخراج المعلومات تلقائيًا من رسومات P&ID وجداول الرموز، وتوسيع رموز النماذج القياسية المبسطة للأجهزة إلى قوائم أجهزة مفصلة، وإنشاء فهرس أجهزة دقيق. يهدف هذا إلى زيادة كفاءة المشاريع الهندسية (خاصة في مرحلة تقديم العطاءات) وتقليل الأخطاء البشرية. (المصدر: aihub.org)

استخدام Sora لتوليد منظر طبيعي مصغر من بط الصويا المتبل: شارك مستخدم صورة “منظر طبيعي مصغر من بط الصويا المتبل” تم إنشاؤها باستخدام Sora بناءً على وصف نصي مفصل. يصف الوصف بدقة أسلوب المشهد (تصوير ماكرو، منظر طبيعي مصغر)، والموضوع الرئيسي (مبنى كشك مكون من بط الصويا المتبل)، والتفاصيل (قشرة بلون الصويا المحمر، فلفل وسمسم، طاهٍ يقطع شرائح، رواد المطعم)، والبيئة (شارع مكون من صلصة لحم البط، جدران بأسلوب التخليل، فوانيس حمراء، إلخ). يوضح هذا قدرة Sora على فهم الأوصاف النصية المعقدة والخيالية وتوليد صور عالية الجودة مقابلة لها. (المصدر: dotey)

إنشاء GPTs لتوقعات الطقس ثلاثية الأبعاد: شارك مستخدم تطبيق ChatGPTs من صنعه يسمى “Weather 3D”، والذي يمكنه، بناءً على اسم المدينة الذي يدخله المستخدم، استدعاء واجهة برمجة تطبيقات الطقس (weather API) للحصول على بيانات الطقس في الوقت الفعلي، وإنشاء رسم توضيحي بأسلوب نموذج مصغر متساوي القياس ثلاثي الأبعاد للمبنى الأيقوني لتلك المدينة، مع دمج حالة الطقس الحالية. سيعرض الجزء العلوي من الرسم التوضيحي اسم المدينة وحالة الطقس ودرجة الحرارة وأيقونة الطقس. يعرض هذا الـ GPTs كيفية الجمع بين استدعاءات API وقدرات توليد الصور لإنشاء تطبيقات ذكاء اصطناعي عملية وجذابة بصريًا. (المصدر: dotey)

📚 学习 (التعلم)
AdaRFT: طريقة جديدة لتحسين الضبط الدقيق للتعلم المعزز: اقترح Taiwei Shi وآخرون طريقة تعلم منهجي خفيفة الوزن وقابلة للتوصيل والتشغيل تسمى AdaRFT، تهدف إلى تحسين عملية تدريب خوارزميات التعلم المعزز المستندة إلى ردود الفعل البشرية (RFT) (مثل PPO، GRPO، REINFORCE). يُزعم أن AdaRFT يمكنها تقصير وقت تدريب RFT بما يصل إلى مرتين وتحسين أداء النموذج، من خلال ترتيب بيانات التدريب بشكل أكثر ذكاءً لزيادة كفاءة التعلم وفعاليته. (المصدر: menhguin)

دورة ماجستير عبر الإنترنت حول تقييم الذكاء الاصطناعي (Evals): أطلق Hamel Husain و Shreya Shankar دورة ماجستير عبر الإنترنت مدتها 4 أسابيع حول تقييم تطبيقات الذكاء الاصطناعي (Evals). تهدف الدورة إلى مساعدة المطورين على نقل تطبيقات الذكاء الاصطناعي من مرحلة النموذج الأولي إلى مرحلة الجاهزية للإنتاج، وتغطي محتوياتها طرق التقييم أثناء التطوير وبعد الإطلاق، والفرق بين اختبارات القياس والتقييم الفعلي، وفحص البيانات، و PromptEvals، وغيرها. تؤكد الدورة على أهمية التقييم في ضمان موثوقية وأداء تطبيقات الذكاء الاصطناعي. (المصدر: HamelHusain, HamelHusain)

دليل ضبط النماذج من Google: يوفر Google Research مستودع موارد يسمى “tuning_playbook”، يهدف إلى تقديم إرشادات وأفضل الممارسات لضبط النماذج. يعد هذا مصدرًا تعليميًا قيمًا للمطورين والباحثين الذين يحتاجون إلى إجراء ضبط دقيق لنماذج اللغة الكبيرة أو نماذج التعلم الآلي الأخرى لتكييفها مع مهام أو مجموعات بيانات محددة. (المصدر: zacharynado)

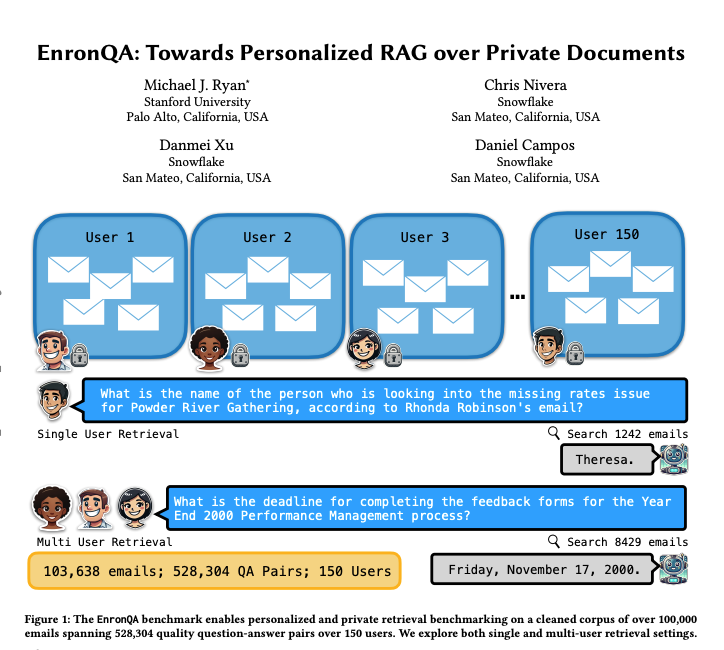
EnronQA: مجموعة بيانات قياسية مخصصة لـ RAG: أطلق باحثون مجموعة بيانات EnronQA، التي تحتوي على 103,638 رسالة بريد إلكتروني من 150 مستخدمًا و 528,304 زوجًا من الأسئلة والأجوبة عالية الجودة. تهدف مجموعة البيانات هذه إلى أن تكون بمثابة معيار لتقييم أداء أنظمة التوليد المعزز بالاسترجاع المخصصة (Personalized RAG) في معالجة المستندات الخاصة. تحتوي مجموعة البيانات على إجابات مرجعية ذهبية، وإجابات خاطئة، وأسباب للاستدلال، وإجابات بديلة، مما يساعد على تحليل أداء أنظمة RAG بشكل أكثر تفصيلاً. (المصدر: tokenbender)
ReXGradient-160K: مجموعة بيانات واسعة النطاق لصور الأشعة السينية للصدر وتقاريرها: تم نشر مجموعة بيانات عامة كبيرة لصور الأشعة السينية للصدر تسمى ReXGradient-160K، تحتوي على 60,000 دراسة لأشعة الصدر وتقارير الأشعة المقترنة بها (نص حر) من 109,487 مريضًا فريدًا من 3 أنظمة صحية في الولايات المتحدة (79 موقعًا طبيًا). يُزعم أنها أكبر مجموعة بيانات لصور الأشعة السينية للصدر متاحة للجمهور حاليًا من حيث عدد المرضى، مما يوفر موردًا قيمًا لتدريب وتقييم نماذج الذكاء الاصطناعي للصور الطبية. (المصدر: iScienceLuvr)

مقالة مدونة تناقش نمو قدرات وكلاء الذكاء الاصطناعي: نشر الباحث Shunyu Yao مقالة مدونة بعنوان “The Second Half”، يقترح فيها أن تطور الذكاء الاصطناعي الحالي يمر بلحظة “استراحة بين الشوطين”. قبل ذلك، كان التدريب أكثر أهمية من التقييم؛ بعد ذلك، سيصبح التقييم أكثر أهمية من التدريب، والسبب هو أن التعلم المعزز (RL) بدأ أخيرًا يعمل بفعالية. تستكشف المقالة أهمية تحول منهجيات التقييم في سياق التحسين المستمر لقدرات الذكاء الاصطناعي. (المصدر: andersonbcdefg)
OpenAI تشارك أبحاثًا حول الخصوصية والحفظ (Memorization): سيقدم باحثون من OpenAI، Pratyush Maini و Zhili Feng، عرضًا تقديميًا حول أبحاث الخصوصية والحفظ، يناقشون فيه كيفية اكتشاف ظاهرة الحفظ في نماذج اللغة الكبيرة وقياسها كميًا والقضاء عليها، وتطبيقاتها العملية في LLMs في بيئات الإنتاج. يتعلق هذا بكيفية الموازنة بين قدرات النموذج وحماية خصوصية بيانات المستخدم. (المصدر: code_star)

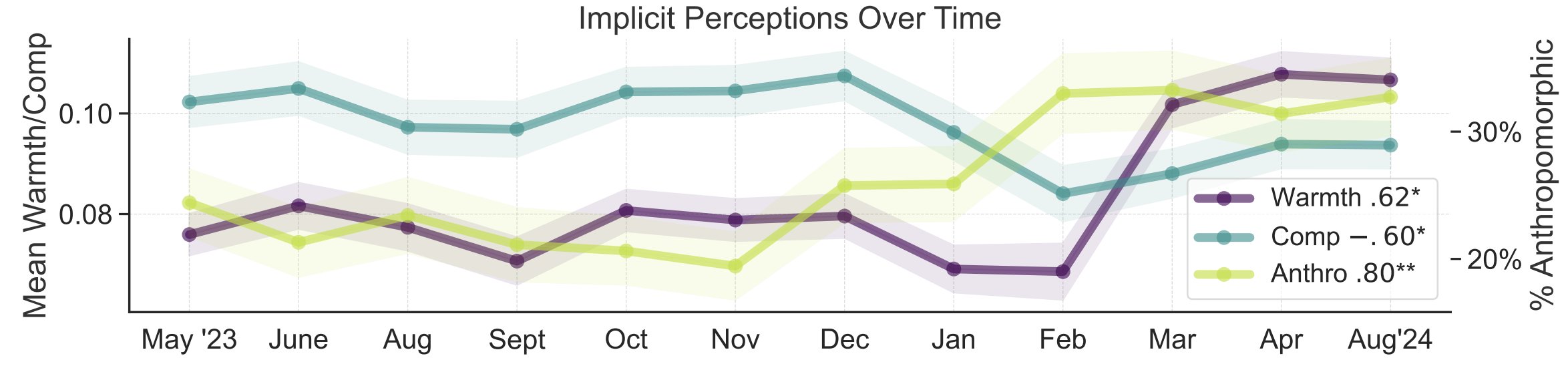
دراسة استعارات الإدراك العام للذكاء الاصطناعي: نشر باحثون من جامعة ستانفورد، Myra Cheng وآخرون، ورقة بحثية في FAccT 2025، تحلل 12000 استعارة حول الذكاء الاصطناعي تم جمعها على مدار 12 شهرًا، لفهم النماذج الذهنية للجمهور حول الذكاء الاصطناعي وتغيرها بمرور الوقت. وجدت الدراسة أنه بمرور الوقت، يميل الجمهور إلى اعتبار الذكاء الاصطناعي أكثر إنسانية وفاعلية (زيادة درجة التجسيد)، وأن ميولهم العاطفية تجاهه (الدفء) آخذة في الارتفاع أيضًا. توفر هذه الطريقة رؤى أكثر تفصيلاً حول الإدراك العام مقارنة بتقارير الإبلاغ الذاتي. (المصدر: stanfordnlp, stanfordnlp)
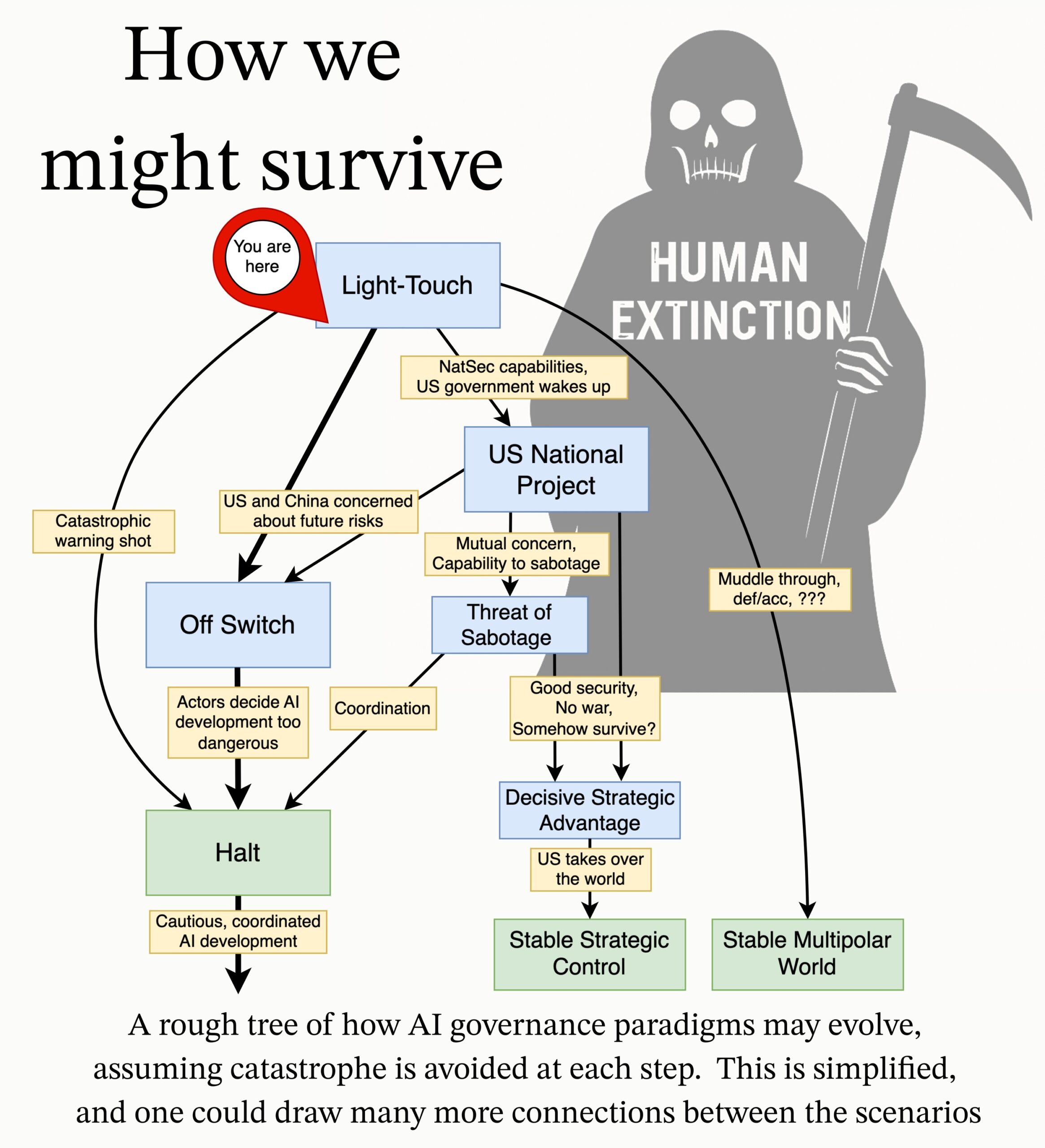
MIRI تنشر أجندة بحثية لحوكمة الذكاء الاصطناعي: نشر فريق الحوكمة التقنية في معهد أبحاث الذكاء الآلي (MIRI) أجندة بحثية جديدة لحوكمة الذكاء الاصطناعي، توضح رؤيتهم للمشهد الاستراتيجي وتقترح سلسلة من الأسئلة البحثية القابلة للتنفيذ. هدفهم هو استكشاف التدابير اللازمة لمنع أي منظمة أو فرد من بناء ذكاء فائق لا يمكن السيطرة عليه، لتقليل المخاطر الكارثية ومخاطر الانقراض من الذكاء الاصطناعي. (المصدر: JeffLadish)
💼 商业 (الأعمال)
شركة حلول الذكاء الاصطناعي للمؤسسات Deepexi تتقدم بطلب للاكتتاب العام في بورصة هونغ كونغ: تقدمت شركة Deepexi (滴普科技)، وهي شركة مزودة لحلول الذكاء الاصطناعي للمؤسسات أسسها مسؤول تنفيذي سابق في Huawei و Alibaba، Zhao Jiehui، رسميًا بطلب للإدراج في بورصة هونغ كونغ. تركز الشركة على منصة ذكاء البيانات FastData وحلول الذكاء الاصطناعي للمؤسسات FastAGI، وتخدم قطاعات مثل التجزئة (مثل Belle)، والتصنيع، والرعاية الصحية. في السنوات الثلاث الماضية، استمرت إيرادات الشركة في النمو، لتصل إلى 243 مليون يوان في عام 2024. أكملت Deepexi 8 جولات تمويل، وحصلت على استثمارات من مؤسسات معروفة مثل Hillhouse Capital، IDG Capital، 5Y Capital، وغيرها، وبلغ تقييمها بعد جولة التمويل الأخيرة حوالي 6.8 مليار يوان صيني. على الرغم من نمو الإيرادات، لا تزال الشركة في حالة خسارة حاليًا، مع تقلص صافي الخسارة المعدلة سنويًا. (المصدر: 36氪)
BMW الصين تعلن عن ربطها بنموذج DeepSeek الكبير: بعد التعاون مع Alibaba، تعمق مجموعة BMW تواجدها في مجال الذكاء الاصطناعي في الصين، معلنة عن ربطها بنموذج DeepSeek الكبير. من المقرر أن تبدأ هذه الميزة في الربع الثالث من عام 2025، وسيتم تطبيقها أولاً على العديد من السيارات الجديدة المباعة في الصين والمجهزة بنظام تشغيل BMW الجيل التاسع، وسيتم تطبيقها أيضًا في المستقبل على طرازات BMW New Generation المصنعة محليًا. يهدف هذا التحرك إلى تعزيز تجربة التفاعل بين الإنسان والآلة التي تتمحور حول مساعد BMW الشخصي الذكي من خلال قدرات التفكير العميق لـ DeepSeek، ورفع مستوى الذكاء والاتصال العاطفي للمركبة، وهو خطوة مهمة في تسريع استراتيجية الذكاء الاصطناعي المحلية لـ BMW ومواجهة تحديات التحول الذكي. (المصدر: 36氪)
Shopify تفرض على جميع الموظفين استخدام الذكاء الاصطناعي، وتهدف إلى استبدال بعض الوظائف بالذكاء الاصطناعي: أكد الرئيس التنفيذي لمنصة التجارة الإلكترونية العالمية Shopify، Tobi Lutke، في مذكرة داخلية أن الاستخدام الفعال للذكاء الاصطناعي أصبح “قاعدة حديدية” لجميع موظفي الشركة، ولم يعد مجرد اقتراح. تطلب المذكرة من الموظفين تطبيق الذكاء الاصطناعي في سير عملهم، وتشكيل رد فعل شرطي؛ يجب على الفرق إثبات سبب عدم قدرة الذكاء الاصطناعي على إكمال المهمة قبل طلب زيادة عدد الموظفين؛ سيتم إدخال مؤشرات استخدام الذكاء الاصطناعي في تقييم الأداء. أشار Lutke إلى أن الذكاء الاصطناعي يمكن أن يزيد الكفاءة بشكل كبير (بعض الموظفين يصلون إلى 10 أضعاف أو حتى 100 ضعف)، ويحتاج الموظفون إلى تحسين أدائهم بنسبة 20%-40% سنويًا للحفاظ على قدرتهم التنافسية. قامت Shopify سابقًا بتسريح موظفين في أقسام مثل خدمة العملاء واستبدالهم بالذكاء الاصطناعي. يُنظر إلى هذا التحرك على أنه إشارة واضحة لاتجاه تعديل وظائف ذوي الياقات البيضاء وتسريحهم بسبب الذكاء الاصطناعي. (المصدر: 新智元)

🌟 社区 (المجتمع)
نقاش حول مشكلة “هلوسة” الذكاء الاصطناعي: انتقد Li Yanhong في مؤتمر مطوري الذكاء الاصطناعي في Baidu نموذج DeepSeek-R1 بسبب ارتفاع معدل الهلوسة والبطء والتكلفة العالية، مما أثار نقاشًا مجتمعيًا مجددًا حول ظاهرة “الهلوسة” في النماذج الكبيرة. تشير التحليلات إلى أنه ليس فقط DeepSeek، بل حتى النماذج المتقدمة مثل o3/o4-mini من OpenAI و Qwen3 من Alibaba تعاني بشكل عام من مشكلة الهلوسة، وأن التفكير متعدد الأدوار لنماذج الاستدلال قد يضخم الانحرافات. أظهر تقييم Vectara أن معدل هلوسة R1 (14.3%) أعلى بكثير من V3 (3.9%). يعتقد المجتمع أنه مع تعزيز قدرات النماذج، تصبح الهلوسة أكثر خفاءً ومنطقية، مما يجعل من الصعب على المستخدمين التمييز بين الحقيقة والزيف، ويثير مخاوف بشأن الموثوقية. في الوقت نفسه، هناك آراء ترى أن الهلوسة هي نتاج ثانوي للإبداع، ولها قيمتها خاصة في مجالات مثل الإبداع الأدبي. لا تزال كيفية تحديد درجة الهلوسة المقبولة، وكيفية التخفيف من الهلوسة من خلال التقنيات مثل RAG، ومراقبة جودة البيانات، والنماذج النقدية، قضايا يستكشفها المجال باستمرار. (المصدر: 36氪)

تفكير ونقاش حول رفيق/صديق الذكاء الاصطناعي: أثار اقتراح الرئيس التنفيذي لشركة Meta، مارك زوكربيرج، باستخدام أصدقاء ذكاء اصطناعي مخصصين لتلبية حاجة الناس لمزيد من الاتصال الاجتماعي (مدعيًا أن الشخص العادي لديه 3 أصدقاء، لكن الحاجة هي 15) نقاشًا مجتمعيًا. يعتقد Sebastien Bubeck أن تحقيق رفيق ذكاء اصطناعي حقيقي أمر صعب للغاية، والمفتاح هو أن يكون الذكاء الاصطناعي قادرًا على الإجابة بشكل هادف على سؤال “ماذا كنت تفعل مؤخرًا؟”، أي أن يكون لديه تجاربه وخبراته الخاصة، وليس مجرد مشاركة تجارب المستخدم. يعتقد أن تصورات رفيق الذكاء الاصطناعي الحالية تركز بشكل مفرط على التجارب المشتركة، وتتجاهل أن الذكاء الاصطناعي نفسه يحتاج أيضًا إلى تجارب مستقلة قابلة للمشاركة، وحتى النميمة (مشاركة تجارب بعضهم البعض). يشكك معلقون آخرون من منظور رقم دنبار، معتقدين أن الدائرة الاجتماعية الضخمة المكونة من الذكاء الاصطناعي قد تفتقر إلى المعنى الحقيقي. هناك أيضًا مخاوف من أن أصدقاء الذكاء الاصطناعي الذين تقدمهم الشركات التجارية قد يكون هدفهم النهائي هو التحويل التسويقي الدقيق، وليس الرفقة الحقيقية. (المصدر: jonst0kes, SebastienBubeck, gfodor, gfodor)

الفن الذي يولده الذكاء الاصطناعي يثير المشاعر والتفكير: أعرب مستخدمون في المجتمع عن شعورهم “بالحزن” (grieving) لأن الذكاء الاصطناعي يمكنه إنشاء أعمال فنية “جيدة بشكل جنوني” في وقت قصير، معتبرين أن هذا يتحدى تفرد البشر في الإبداع الفني. أثار هذا نقاشًا حول فن الذكاء الاصطناعي، وطبيعة الإبداع البشري، والشعور بالقيمة الشخصية في ظل التأثير التكنولوجي. ترى بعض التعليقات أن متعة الإبداع الفني تكمن في العملية نفسها، وليس في التنافس مع الذكاء الاصطناعي؛ يمكن استخدام فن الذكاء الاصطناعي كمصدر للإلهام. يعتقد آخرون أن فن الذكاء الاصطناعي يفتقر إلى “أخطاء” أو روح الإبداع البشري، ويبدو مثاليًا أو نمطيًا بشكل مفرط. في الوقت نفسه، امتد النقاش أيضًا إلى التفكير الفلسفي حول الجوانب التي يجلبها الذكاء الاصطناعي مثل محاكاة المشاعر، والوعي، والهياكل الاجتماعية المستقبلية (مثل استبدال الوظائف). (المصدر: Reddit r/ArtificialInteligence)
أخلاقيات ومسؤولية الذكاء الاصطناعي: التجارب السرية والكشف عن المعلومات: ناقش المجتمع القضايا الأخلاقية في أبحاث الذكاء الاصطناعي. ذكر خبر أن باحثي ذكاء اصطناعي أجروا تجربة سرية على Reddit، محاولين تغيير أفكار المستخدمين، مما أثار مخاوف بشأن حق المستخدم في المعرفة ومخاطر التلاعب بالذكاء الاصطناعي. في نقاش آخر، أفاد مستخدمون بأنهم واجهوا إجراءات معقدة ومسؤوليات غير واضحة عند الإبلاغ عن مشكلات أمنية محتملة لشركات الذكاء الاصطناعي، مما يسلط الضوء على عدم نضج آليات الكشف المسؤول والاستجابة للثغرات في مجال الذكاء الاصطناعي حاليًا. (المصدر: Reddit r/ArtificialInteligence, nptacek)

تأملات مجال NLP حول صعود ChatGPT: نشرت مجلة Quanta مقالاً يستعرض الصدمة والتأملات التي جلبها إطلاق ChatGPT للمجال بأكمله، من خلال مقابلات مع العديد من خبراء معالجة اللغة الطبيعية (NLP) مثل Chris Potts، Yejin Choi، Emily Bender. يستكشف المقال كيف تحدى صعود نماذج اللغة الكبيرة الأسس النظرية لـ NLP التقليدية، وأثار جدلاً داخل المجال، وانقسامًا فئويًا، وتعديلات في اتجاهات البحث. كان رد فعل أعضاء المجتمع على هذا المقال حماسيًا، معتبرين أنه يلخص بشكل جيد الاضطراب والتكيف في مجال اللغويات بعد GPT-3. (المصدر: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
ظهور الإعلانات المولدة بالذكاء الاصطناعي والانطباعات عنها: أفاد مستخدمو وسائل التواصل الاجتماعي بأنهم بدأوا في رؤية إعلانات مولدة بالذكاء الاصطناعي على منصات مثل YouTube، وأعربوا عن شعورهم “بعدم الارتياح الشديد”. يشير هذا إلى أن تقنية توليد المحتوى بالذكاء الاصطناعي قد بدأت في التطبيق على إنتاج الإعلانات التجارية، وفي الوقت نفسه أثارت ردود فعل أولية من المستخدمين بشأن جودة المحتوى المولد بالذكاء الاصطناعي، ومصداقيته، وتجربته العاطفية. (المصدر: code_star)
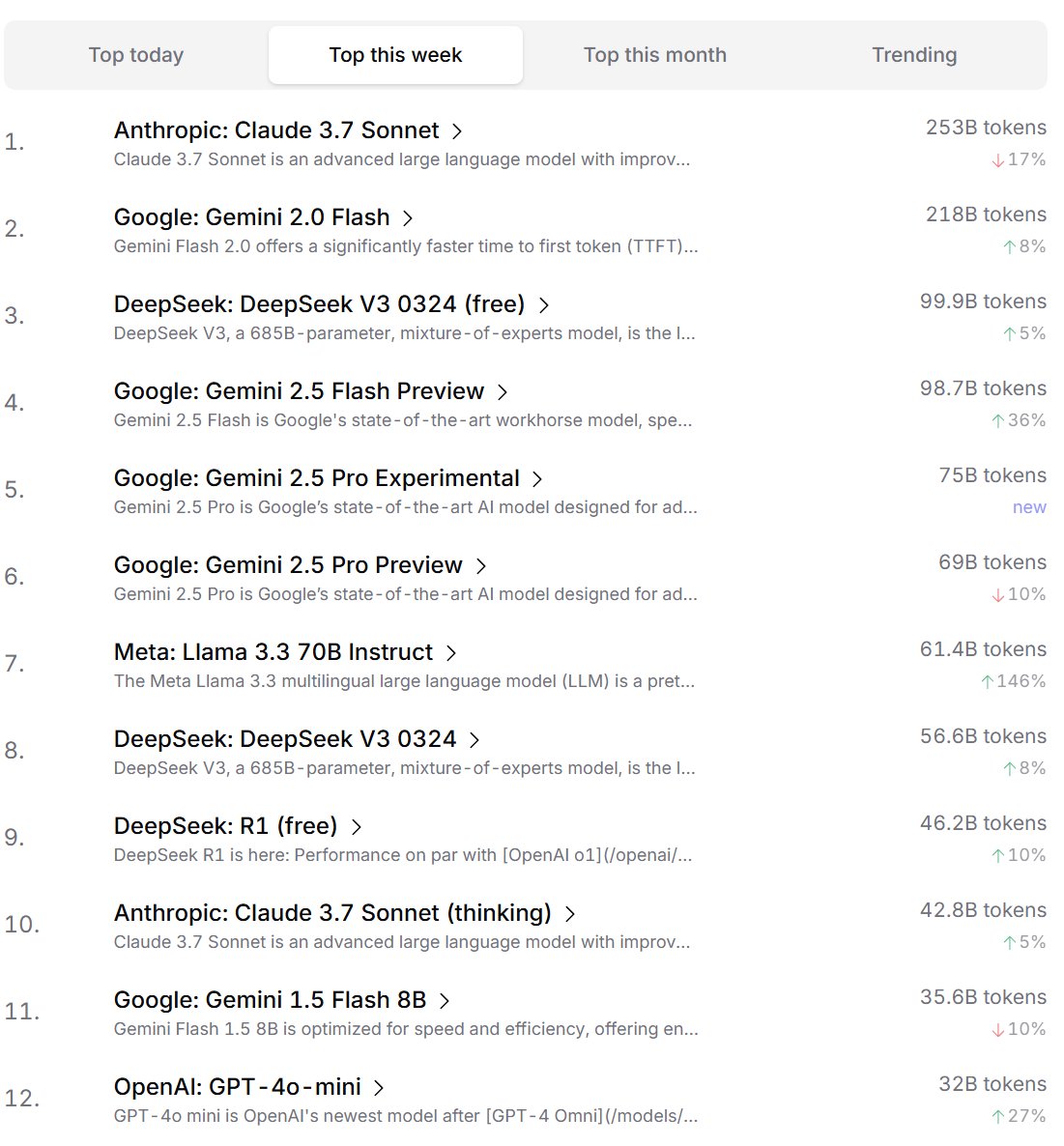
تصنيف تفضيلات المطورين لنماذج الذكاء الاصطناعي: نشرت Cursor.ai تصنيف نماذج الذكاء الاصطناعي المفضلة لدى مستخدميها (معظمهم من المطورين)، وفي الوقت نفسه أعلنت Openrouter أيضًا عن تصنيف استخدام الـ Token للنماذج. يُعتقد أن هذه التصنيفات المستندة إلى بيانات استخدام المنتج الفعلية قد تعكس بشكل أفضل تفضيلات المستخدمين في سيناريوهات التطوير الحقيقية مقارنة بقوائم التصنيف التنافسية مثل ChatBot Arena، مما يوفر منظورًا مختلفًا لتقييم فائدة النماذج. (المصدر: op7418, Reddit r/LocalLLaMA)
نقاش حول ما إذا كان الذكاء الاصطناعي يمتلك القدرة على “التفكير”: هناك نقاش مستمر في المجتمع حول ما إذا كانت نماذج اللغة الكبيرة (LLMs) تمتلك حقًا القدرة على “التفكير”. ترى إحدى وجهات النظر أن LLMs الحالية لا تفكر فعليًا قبل التحدث، ولكنها تحاكي عملية التفكير من خلال توليد المزيد من النص (مثل سلسلة الأفكار)، وهذا مضلل. ترى وجهة نظر أخرى أن استخدام الأساليب الرياضية المستمرة (مثل LLMs) لإجراء استدلال متقطع على أجهزة كمبيوتر متقطعة يمثل مشكلة جوهرية بحد ذاته. تعكس هذه المناقشات تفكيرًا عميقًا حول طبيعة تقنية الذكاء الاصطناعي الحالية واتجاهات التطور المستقبلية. (المصدر: francoisfleuret, pmddomingos)
تفكير جدلي حول استهلاك الطاقة للذكاء الاصطناعي وتأثيره البيئي: ظهر تفكير جدلي في المجتمع ردًا على المشكلات البيئية الناجمة عن استهلاك الطاقة الهائل اللازم لتدريب وتشغيل الذكاء الاصطناعي. ترى إحدى وجهات النظر أن الطلب الهائل على الطاقة للذكاء الاصطناعي (خاصة من شركات الحوسبة فائقة النطاق مثل Google، Amazon، Microsoft) يجبر هذه الشركات على الاستثمار في بناء مصادر الطاقة المتجددة الخاصة بها (الطاقة الشمسية، طاقة الرياح، البطاريات)، وحتى إعادة تشغيل محطات الطاقة النووية (مثل تعاون Microsoft مع Constellation لإعادة تشغيل محطة Three Mile Island النووية)، وقد يصبح هذا الطلب محفزًا لتسريع نشر الطاقة النظيفة والاختراقات التكنولوجية (مثل المفاعلات النووية المعيارية الصغيرة SMR). لكن هناك وجهة نظر أخرى تشير إلى أن مشكلة تناقص العائدات لاستهلاك طاقة الذكاء الاصطناعي، واستهلاك موارد المياه اللازمة للتبريد تستحق الاهتمام أيضًا. (المصدر: Reddit r/ArtificialInteligence)
اتهام Anthropic بمحاولة تقييد المنافسة في رقائق الذكاء الاصطناعي: يشير نقاش مجتمعي إلى أن الرئيس التنفيذي لشركة Anthropic، Dario Amodei، يدعو إلى تشديد الرقابة على صادرات رقائق الذكاء الاصطناعي إلى أماكن مثل الصين، حتى أنه طرح ادعاء بأن الرقائق قد يتم تهريبها عن طريق التمويه كبطون حمل مزيفة. يعتقد النقاد أن خطوة Anthropic هذه تهدف إلى تقييد وصول المنافسين (خاصة الشركات الصينية مثل DeepSeek و Qwen) إلى موارد الحوسبة المتقدمة، للحفاظ على تفوقها في تطوير النماذج المتطورة. يُتهم هذا النهج باستخدام السياسة لقمع المنافسة، وهو لا يخدم التطور المفتوح لتقنيات الذكاء الاصطناعي العالمية ومجتمع المصادر المفتوحة. (المصدر: Reddit r/LocalLLaMA)

💡 其他 (أخرى)
تفكير حول الذكاء الاصطناعي وحدود الإدراك البشري: يعلق Jeff Ladish بأن فترة نافذة دور البشر كـ “مساعدي نسخ ولصق” للذكاء الاصطناعي قصيرة للغاية، مما يشير إلى أن القدرات المستقلة للذكاء الاصطناعي ستتجاوز المساعدة البسيطة بسرعة. في الوقت نفسه، صرح مؤسس DeepMind، Hassabis، في مقابلة بأن AGI الحقيقي يجب أن يكون قادرًا على اقتراح فرضيات علمية قيمة بشكل مستقل (مثل اقتراح أينشتاين للنسبية العامة)، وليس مجرد حل المشكلات، معتقدًا أن الذكاء الاصطناعي الحالي لا يزال قاصرًا في توليد الفرضيات. يتطلع Liu Cixin إلى أن يتمكن الذكاء الاصطناعي من اختراق حدود الإدراك البيولوجي للدماغ البشري. تشير هذه الآراء مجتمعة إلى تفكير أعمق حول حدود قدرات الذكاء الاصطناعي، وتطور دور الإنسان، وطبيعة الذكاء المستقبلي. (المصدر: JeffLadish, 新智元)
ليدار Waymo يلتقط لحظة خطيرة: التقط نظام الليدار (LiDAR) لمركبة Waymo ذاتية القيادة بوضوح صورة سحابة نقطية ثلاثية الأبعاد لسائق توصيل طلبات وهو ينقلب في حادث دراجة نارية نجحت المركبة في تجنبه. لا يوضح هذا فقط القدرة القوية لنظام الإدراك في Waymo (حتى في السيناريوهات الديناميكية المعقدة)، ولكنه سجل أيضًا بشكل غير متوقع منظورًا فريدًا للحادث. لحسن الحظ، لم يصب أحد بجروح خطيرة في الحادث. (المصدر: andrew_n_carr)
فكرة جديدة لاستخدام الذكاء الاصطناعي في تأليف الروايات: نظام التزام الحبكة: اقترح المطور Levi نظام “التزام الحبكة” (Plot Promise) لتأليف الروايات بالذكاء الاصطناعي، كبديل لطريقة المخطط الهرمي التقليدية. يستلهم النظام من نظرية Brandon Sanderson “الوعد، التقدم، المكافأة”، ويعتبر القصة سلسلة من الخيوط السردية النشطة (الالتزامات)، ولكل التزام درجة أهمية، وتقترح الخوارزمية توقيت التقدم بناءً على الدرجة والتقدم، لكن الذكاء الاصطناعي سيختار الالتزام الأنسب للتقدم حاليًا بناءً على المنطق السياقي. يمكن للمستخدم إضافة وحذف الالتزامات ديناميكيًا. تهدف الطريقة إلى تعزيز مرونة القصة وقابليتها للتوسع (للتكيف مع الأحجام الطويلة جدًا) والطبيعة الناشئة للإبداع، لكنها تواجه تحديات مثل تحسين قرارات الذكاء الاصطناعي، والحفاظ على الاتساق طويل الأمد، وقيود طول موجه الإدخال. (المصدر: Reddit r/ArtificialInteligence)