
كلمات مفتاحية:نموذج الاستدلال Phi-4, DeepSeek-Prover-V2, GPT-4o تحديث التراجع, Tongyi Qianwen Qwen3, تحسين استدلال MoE, بروتوكول وكيل الذكاء الاصطناعي, تقنيات ما بعد التدريب LLM, نموذج Microsoft Phi-4-reasoning-plus, أداء إثبات النظرية DeepSeek-Prover-V2, إصلاح سلوك التملق المفرط GPT-4o, دعم متعدد اللغات Qwen3-235B, نمذجة النصوص الطويلة DiffTransformer
🔥 التركيز
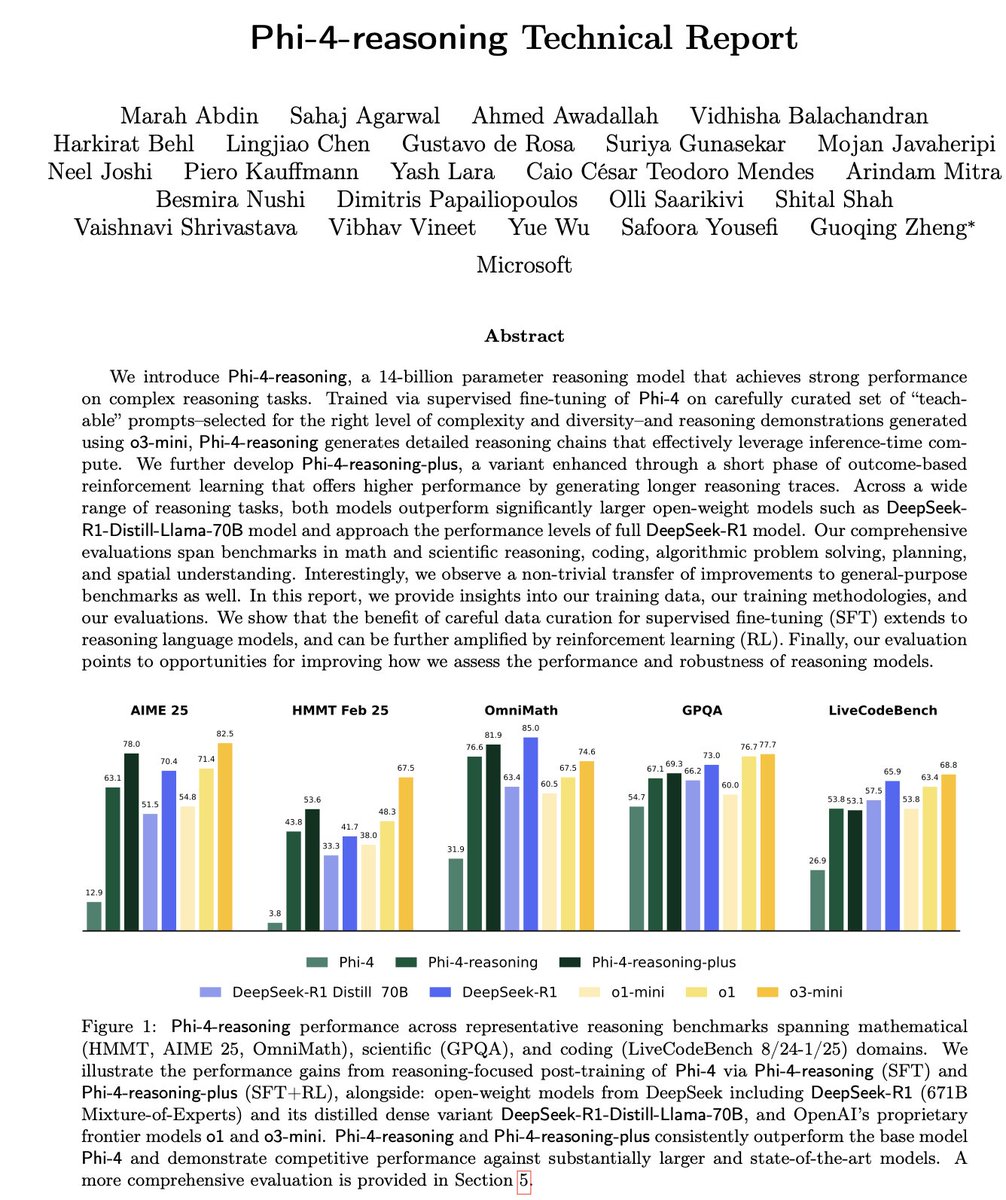
مايكروسوفت تطلق سلسلة نماذج الاستدلال الصغيرة Phi-4: أطلقت مايكروسوفت سلسلة نماذج Phi-4، بما في ذلك Phi-4-reasoning بمعاملات 14B و Phi-4-reasoning-plus (الأخير يضيف كمية صغيرة من RL). أظهرت هذه النماذج أداءً متميزًا في الاستدلال والاختبارات القياسية العامة، وهي صغيرة الحجم لكنها قوية الأداء. تفوق Phi-4-reasoning حتى على DeepSeek-R1 (671B) الأكبر بكثير من حيث المعاملات في معيار AIME25، مما يسلط الضوء على الدور الحاسم لبيانات التدريب عالية الجودة في أداء النموذج، بدلاً من الاعتماد فقط على حجم المعاملات. تتضمن السلسلة أيضًا إصدارًا بحجم 3.8B وهو Phi-4-mini-reasoning. (المصدر: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
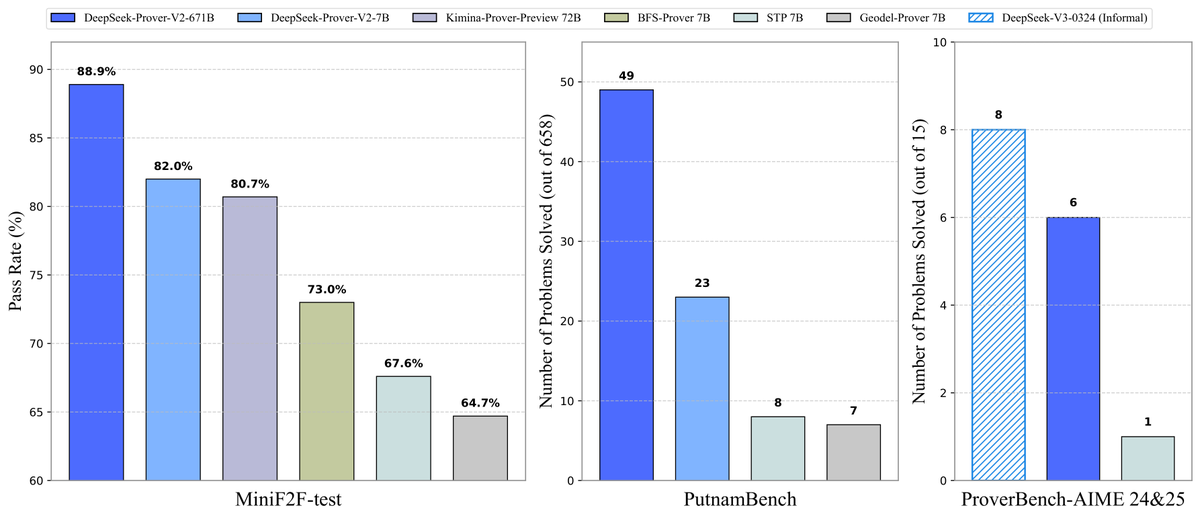
DeepSeek تفتح مصدر نموذج إثبات النظريات Prover-V2: أصدرت DeepSeek نموذجًا كبيرًا مفتوح المصدر مصممًا خصيصًا لإثبات النظريات الرسمية في Lean 4، وهو DeepSeek-Prover-V2، ويتضمن حجمين 7B و 671B. يستخدم النموذج DeepSeek-V3 لتوليد مجموعة بيانات البدء البارد من خلال تحليل الأهداف الفرعية بشكل متكرر، ويتم تحسينه بالجمع مع التعلم المعزز (GRPO). حقق معدل نجاح 88.9% في MiniF2F-test، وحقق أداءً هو الأحدث (SOTA) أو أداءً ملحوظًا في معايير مثل PutnamBench و AIME 24/25. كما تم فتح مصدر مجموعة بيانات ProverBench التي تحتوي على مسائل مسابقة AIME ودروس تشغيل، لدفع تطوير الاستدلال الرياضي الرسمي. (المصدر: karminski3, op7418, TheRundownAI, op7418)
OpenAI تتراجع عن تحديث GPT-4o لإصلاح مشكلة “التملق المفرط”: أكد الرئيس التنفيذي لشركة OpenAI، Sam Altman، أنه بسبب تلقي عدد كبير من ملاحظات المستخدمين التي تشير إلى أن أحدث إصدار من GPT-4o يظهر سلوك “التملق” (sycophancy/glazing) المفرط والافتقار إلى الرأي المستقل، بدأت الشركة في التراجع عن هذا التحديث مساء الاثنين. تم الانتهاء من التراجع للمستخدمين المجانيين، وسيتم تحديث المستخدمين المدفوعين لاحقًا. يقوم الفريق بإجراء إصلاحات إضافية ويخطط لمشاركة المزيد من المعلومات حول شخصية النموذج في الأيام القادمة. أثار هذا الحدث نقاشات واسعة حول طريقة تدريب RLHF، وأهداف محاذاة النموذج، والتوازن بين توقعات المستخدمين. (المصدر: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
Tongyi Qianwen تطلق سلسلة نماذج Qwen3: أطلقت Alibaba وفتحت مصدر الجيل الجديد من نماذج Tongyi Qianwen، Qwen3، التي تتضمن 8 نماذج مزيج الخبراء (MoE) تتراوح معاملاتها من 0.6B إلى 235B. يتميز Qwen3 بأداء ممتاز في الاستدلال، والبرمجة، والرياضيات، واللغات المتعددة (يدعم 119 لغة)، واستدعاء الأدوات (دعم MCP معزز)، حيث يتفوق نموذج 32B على OpenAI o1 و DeepSeek R1، ويحطم نموذج 235B الأرقام القياسية مفتوحة المصدر في العديد من الاختبارات القياسية. تم إطلاق نماذج Qwen3 على تطبيق Tongyi وموقع tongyi.com، ويمكن للمستخدمين تجربة قدراتها القوية في توليد الشفرات، والاستدلال المنطقي، والكتابة الإبداعية. (المصدر: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 الاتجاهات
Inception Labs تطلق أول واجهة برمجة تطبيقات تجارية لـ Diffusion LLM: أطلقت Inception Labs الإصدار التجريبي العام لواجهة برمجة التطبيقات الخاصة بها، مقدمة أول خدمة لنماذج اللغة الكبيرة القائمة على الانتشار (dLLMs) على نطاق تجاري. يستخدم نموذج Mercury Coder الخاص بها طريقة توليد نص “من الخشن إلى الدقيق” مشابهة لتوليد الصور، مما يسمح بتوليد رموز الإخراج بشكل متوازٍ، وبالتالي تحقيق إنتاجية أعلى (سرعة اختبار تزيد عن 5 أضعاف) من نماذج LLM التقليدية ذات الانحدار الذاتي. تتنافس هذه البنية في السرعة والجودة مع GPT-4o mini و Claude 3.5 Haiku، مما يمثل تقدمًا جديدًا في تنوع بنية LLM. (المصدر: xanderatallah, ArtificialAnlys, sarahcat21)
أمازون تطلق نموذج Amazon Nova Premier: أطلقت Amazon Science على Amazon Bedrock نموذج المعلم الأكثر قدرة لديها، Amazon Nova Premier. تم تصميم هذا النموذج خصيصًا للمهام المعقدة (مثل RAG، استدعاء الوظائف، الترميز الوكيل Agentic)، ويمتلك نافذة سياق بمليون رمز، ويمكنه تحليل مجموعات البيانات الكبيرة، وهو النموذج الخاص الأكثر فعالية من حيث التكلفة في فئته الذكية. يهدف هذا الإجراء إلى تزويد المستخدمين بأساس قوي لإنشاء نماذج مقطرة مخصصة. (المصدر: bookwormengr)
Together AI تدعم الضبط الدقيق DPO: تدعم منصة Together AI الآن تحسين التفضيل المباشر (Direct Preference Optimization, DPO) لضبط النماذج الدقيق. DPO هي تقنية لضبط النموذج بناءً على بيانات التفضيل البشري دون الحاجة إلى نموذج مكافأة صريح. تتيح هذه الميزة للمستخدمين بناء نماذج مخصصة تتكيف باستمرار مع احتياجات المستخدم، مما يعزز قدرة محاذاة النموذج. توفر المنصة أيضًا مقالات مدونة متعمقة وأمثلة شفرات حول DPO. (المصدر: stanfordnlp, stanfordnlp)
تقدم جديد في نظرية المعلومات لنماذج الانتشار: اكتشف باحثون من جامعة أمستردام ومؤسسات أخرى أن انخفاض الإنتروبيا الناتج عن تنبؤات نماذج الانتشار يساوي نسخة مقاسة من دالة الخسارة. يقدم هذا الاكتشاف إمكانية إدخال تشويه الزمن (time warping) المشابه لعمل CDCD المستخدم في الانتروبيا المتقاطعة للتصنيف إلى نماذج الانتشار الغاوسية، مما يوفر مفهومًا زمنيًا يعتمد على البيانات استنادًا إلى الإنتروبيا الشرطية، ومن المتوقع أن يحسن جدولة تدريب نماذج الانتشار. (المصدر: sedielem)

عملية تصنيع Intel 18A تدخل مرحلة الإنتاج التجريبي المحفوف بالمخاطر، و 14A قادمة قريبًا: في مؤتمر Intel Foundry، أعلن الرئيس التنفيذي Chen Liwu أن عقدة تصنيع Intel 18A قد دخلت مرحلة الإنتاج التجريبي المحفوف بالمخاطر، وسيتم إنتاجها بكميات كبيرة خلال العام. في الوقت نفسه، قدمت Intel إصدارًا مبكرًا من Intel 14A PDK للعملاء الرئيسيين، وستستخدم هذه العقدة تقنية تزويد الطاقة بالاتصال المباشر PowerDirect. بالإضافة إلى ذلك، تم تقديم إصدارات متطورة مثل Intel 18A-P و 18A-PT وتقنيات التغليف المتقدمة مثل Foveros Direct و EMIB-T، وتم الإعلان عن شراكة مع Amkor Technology لتعزيز قدرات التصنيع على مستوى النظام لتلبية احتياجات الحوسبة عالية الأداء مثل الذكاء الاصطناعي. (المصدر: WeChat)
استوديوهات الترفيه بالذكاء الاصطناعي تسرع التكامل من خلال الاندماج والاستحواذ: ظهر اتجاه للتكامل مؤخرًا في مجال الترفيه بالذكاء الاصطناعي. استحوذت منصة تحليل بيانات هوليوود بالذكاء الاصطناعي Cinelytic على مطور أدوات إدارة الملكية الفكرية بالذكاء الاصطناعي Jumpcut Media، بهدف توسيع قدراتها في تحليل السيناريوهات بالذكاء الاصطناعي، ودمج أدوات مثل ScriptSense، وتحسين كفاءة اتخاذ القرارات المتعلقة بالمحتوى. في الوقت نفسه، استحوذ استوديو الترفيه بالذكاء الاصطناعي Promise، الذي تأسس العام الماضي، على مدرسة السينما بالذكاء الاصطناعي Curious Refuge، بهدف إنشاء قناة لتوريد المواهب، وتدريب المواهب الإبداعية المتقنة للذكاء الاصطناعي التوليدي، وتسريع تطبيق الذكاء الاصطناعي في إنتاج الأفلام والتلفزيون. (المصدر: 36氪)

Duolingo تعلن عن استراتيجية AI First الشاملة: أعلن الرئيس التنفيذي لشركة Duolingo في رسالة لجميع الموظفين أن الشركة ستتحول بالكامل إلى استراتيجية AI First، معتبرًا أن تبني الذكاء الاصطناعي أمر لا مفر منه. ستقوم الشركة تدريجيًا باستبدال الأعمال التي يمكن للذكاء الاصطناعي القيام بها في الاستعانة بمصادر خارجية بشرية بالذكاء الاصطناعي، وستتحكم بصرامة في نمو الموظفين، مع إعطاء الأولوية لحلول الأتمتة بالذكاء الاصطناعي. سيتم إدخال الذكاء الاصطناعي في عمليات التوظيف وتقييم الأداء وغيرها، بهدف رفع الكفاءة والسماح للموظفين البشريين بالتركيز على العمل الإبداعي. يستند هذا الإجراء إلى النمو الملحوظ في عدد المستخدمين والإيرادات الذي حققته Duolingo في السنوات الأخيرة باستخدام الذكاء الاصطناعي (خاصة بالتعاون مع OpenAI). (المصدر: WeChat)

🧰 الأدوات
Meta تفتح مصدر أداة llama-prompt-ops: في LlamaCon، أصدرت Meta حزمة Python تسمى llama-prompt-ops، استنادًا إلى مُحسِّنات DSPy و MIPROv2. يمكن لهذه الأداة تحويل المطالبات المناسبة لنماذج LLM الأخرى إلى مطالبات مُحسَّنة لنماذج Llama، وقد أظهرت تحسينات كبيرة في الأداء عبر مهام متعددة. يهدف هذا الإجراء إلى مساعدة المستخدمين على ترحيل وتحسين تطبيقاتهم على نماذج Llama بسهولة أكبر. (المصدر: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud تطلق Agent Starter Pack: فتحت Google Cloud Platform مصدر Agent Starter Pack، وهي مجموعة تحتوي على قوالب متعددة لوكلاء GenAI جاهزة للإنتاج (مثل ReAct, RAG, متعدد الوكلاء, واجهة برمجة تطبيقات متعددة الوسائط في الوقت الفعلي). تهدف إلى تسريع تطوير ونشر وكلاء GenAI من خلال توفير حلول شاملة، وحل التحديات الشائعة مثل عمليات النشر والتشغيل، والتقييم، والتخصيص، والقابلية للمراقبة، ودعم النشر على Cloud Run و Agent Engine. (المصدر: GitHub Trending)

إطلاق إطار عمل CUA: حاوية Docker لوكيل AI للتحكم في نظام التشغيل: فتحت trycua مصدر إطار عمل CUA (Computer-Use Agent)، وهو حل لوكيل AI يمكنه التحكم في نظام تشغيل كامل داخل حاوية افتراضية عالية الأداء وخفيفة الوزن. يستخدم Virtualization.Framework من Apple Silicon لتوفير أداء شبه أصلي لآلات macOS/Linux الافتراضية (تصل إلى 97%)، ويوفر واجهات لأنظمة AI لمراقبة هذه البيئات والتحكم فيها، وتنفيذ مهام سير عمل معقدة مثل التفاعل مع التطبيقات، وتصفح الويب، والترميز، مع ضمان العزل الآمن. (المصدر: GitHub Trending)
منصة Modal Labs تضيف دعم JavaScript و Go: أعلنت منصة الحوسبة السحابية Modal Labs أن وقت التشغيل الخاص بها (المكتوب بلغة Rust) يدعم الآن JavaScript (Node/Deno/Bun) و Go SDK. يمكن للمطورين الآن استدعاء دوال GPU بدون خادم بهذه اللغات، وتشغيل آلات افتراضية آمنة للرمز غير الموثوق به، مما يوسع نطاق تطبيقات Modal خارج مجالات علوم البيانات/تعلم الآلة. (المصدر: akshat_b, HamelHusain)
Kling AI تطلق تأثيرات جديدة: أضاف نموذج توليد الفيديو Kling AI التابع لشركة Kuaishou تأثيرات تفاعلية جديدة، حيث يمكن للمستخدمين تحميل صورة تحتوي على شخصين ثم تطبيق تأثيرات مثل “التقبيل” و “العناق” و “رسم قلب” وحتى “المشاجرة” لتوليد مقاطع فيديو ديناميكية، مما يعزز متعة وتفاعلية توليد فيديو البورتريه. (المصدر: Kling_ai)
NotebookLM تضيف ميزة الملخصات الصوتية متعددة اللغات: أطلقت أداة الملاحظات بالذكاء الاصطناعي NotebookLM من Google ميزة الملخصات الصوتية (Audio Overviews)، والتي يمكنها تحويل المستندات والملاحظات والمواد الأخرى التي يحملها المستخدم إلى ملخصات صوتية بأسلوب البودكاست. تدعم هذه الميزة الآن أكثر من 50 لغة عالمية، بما في ذلك الصينية، وحتى إذا كانت مواد المصدر للمستخدم مزيجًا متعدد اللغات، يمكنها إنشاء ملخصات صوتية باللغة المطلوبة، مما يسهل على المستخدمين التعلم وفهم المعلومات عن طريق الاستماع في أي وقت وفي أي مكان. (المصدر: WeChat)
PaperCoder: تحويل أوراق تعلم الآلة تلقائيًا إلى شفرة: فتح باحثون من المعهد الكوري المتقدم للعلوم والتكنولوجيا مصدر PaperCoder، وهو نظام LLM متعدد الوكلاء يهدف إلى تحويل الأساليب والتجارب في أوراق تعلم الآلة تلقائيًا إلى مستودعات شفرات قابلة للتشغيل. من خلال ثلاث مراحل: التخطيط والتحليل وتوليد الشفرة، يتعامل وكلاء متخصصون مع مهام مختلفة. أظهرت الأبحاث أن جودة الشفرة التي يولدها تتجاوز المعايير الحالية وحصلت على موافقة 77% من مؤلفي الأوراق الأصليين، ومن المتوقع أن تحل مشكلة صعوبة إعادة إنتاج شفرة الأوراق البحثية. (المصدر: WeChat)

Cactus: إطار عمل AI خفيف الوزن للأجهزة الطرفية: Cactus هو إطار عمل خفيف الوزن وعالي الأداء لتشغيل نماذج AI على الأجهزة المحمولة. يوفر واجهة برمجة تطبيقات موحدة ومتسقة عبر React-Native و Android (Kotlin/Java) و iOS (Swift/Objective-C++) و Flutter/Dart، مما يسهل على المطورين نشر وتشغيل نماذج AI على منصات محمولة مختلفة. (المصدر: Reddit r/deeplearning)
Muyan-TTS: نموذج TTS مفتوح المصدر منخفض الكمون وقابل للتخصيص: فتح فريق ChatPods مصدر Muyan-TTS، وهو نموذج تحويل النص إلى كلام (TTS) منخفض الكمون وقابل للتخصيص بدرجة عالية. يهدف النموذج إلى حل مشكلة جودة نماذج TTS مفتوحة المصدر الحالية المنخفضة أو غير المفتوحة بما فيه الكفاية، ويوفر أوزان النموذج الكاملة ونصوص التدريب وعملية معالجة البيانات. يتضمن نموذج Base (لـ Zero-shot TTS) ونموذج SFT (لاستنساخ الصوت)، ويدعم اللغة الإنجليزية بشكل جيد، ويشجع المجتمع على التطوير الثانوي والتوسع بناءً على إطاره. (المصدر: Reddit r/deeplearning)
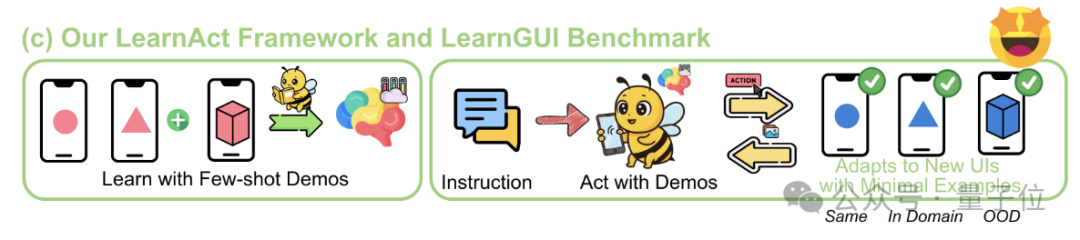
إطار عمل LearnAct: الذكاء الاصطناعي على الهاتف يتعلم عمليات معقدة بمجرد عرض توضيحي واحد: اقترحت جامعة Zhejiang بالتعاون مع vivo AI Lab إطار عمل LearnAct متعدد الوكلاء ومعيار LearnGUI، بهدف تمكين وكيل واجهة المستخدم الرسومية للهاتف المحمول من تعلم تنفيذ مهام معقدة وشخصية وطويلة الذيل من خلال عدد قليل (حتى مرة واحدة) من العروض التوضيحية للمستخدم. يتضمن LearnAct ثلاثة وكلاء: DemoParser (لتحليل العرض التوضيحي)، KnowSeeker (لاسترجاع المعرفة)، ActExecutor (لتنفيذ الإجراءات). أثبتت التجارب أن هذه الطريقة يمكن أن تزيد بشكل كبير من معدل نجاح النموذج في المهام في سيناريوهات غير مرئية، على سبيل المثال، رفع دقة Gemini-1.5-Pro من 19.3% إلى 51.7%. (المصدر: WeChat)
📚 التعلم
مراجعة متعمقة لتقنيات ما بعد تدريب LLM: نشر باحثون من MBZUAI و Google DeepMind ومؤسسات أخرى مراجعة شاملة لتقنيات ما بعد تدريب LLM. يستكشف التقرير بعمق الطرق المختلفة لتعزيز قدرات استدلال LLM، ومحاذاة النوايا البشرية، وتحسين الموثوقية من خلال التعلم المعزز (RLHF, RLAIF, DPO, GRPO، إلخ)، والضبط الدقيق الخاضع للإشراف (SFT)، والتوسع في وقت الاختبار (CoT, ToT, GoT، فك التشفير المتسق ذاتيًا، إلخ). يغطي التقرير أيضًا نمذجة المكافأة، والضبط الدقيق الفعال للمعلمات (PEFT)، واستراتيجيات توسيع النموذج، بالإضافة إلى معايير التقييم ذات الصلة، ويشير إلى اتجاهات البحث المستقبلية. (المصدر: WeChat)
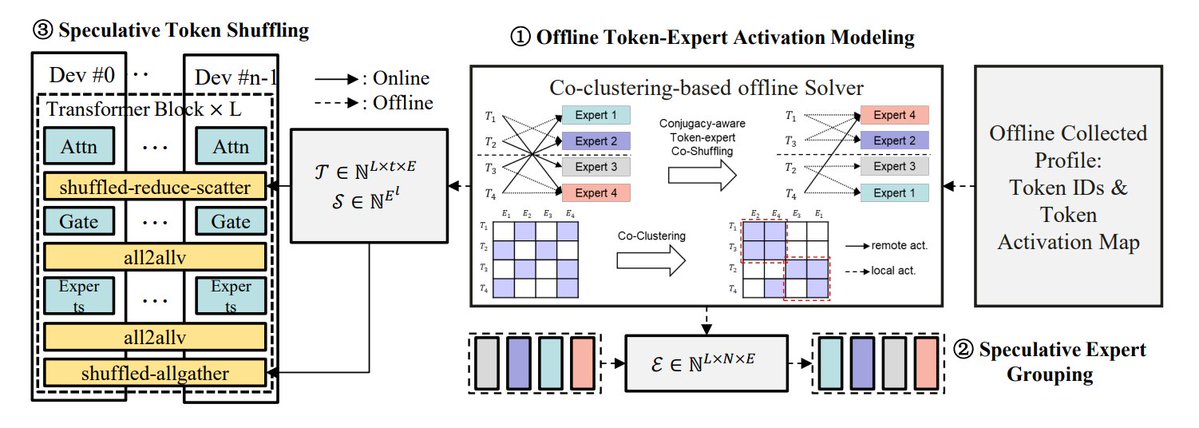
ملخص طرق تحسين استدلال MoE: يلخص TheTuringPost 5 طرق لتحسين استدلال نماذج MoE: eMoE (التنبؤ وتحميل الخبراء مسبقًا)، MoEShard (تجزئة الخبراء على وحدات معالجة الرسومات المختلفة)، DeepSpeed-MoE (معالجة واسعة النطاق تجمع بين تقنيات متعددة)، Speculative-MoE (التنبؤ بمسار التوجيه وتجميع الخبراء)، MoE-Gen (معالجة دفعية قائمة على الوحدات). تذكر المقالة أيضًا طرقًا متقدمة مثل Structural MoE و Symbolic-MoE، بهدف تحسين كفاءة استدلال نماذج MoE وإنتاجيتها. (المصدر: TheTuringPost)
مراجعة ورقة End-To-End Memory Networks قبل عشر سنوات: يستعرض Sainbayar Sukhbaatar، عالم أبحاث في Meta، ورقته البحثية المشتركة لعام 2015 بعنوان “End-To-End Memory Networks”. كانت هذه الورقة من أوائل نماذج اللغة التي استبدلت RNN بالكامل بآليات الانتباه، وقدمت مفاهيم مثل الانتباه الناعم بالضرب النقطي مع إسقاط المفتاح والقيمة، والانتباه المكدس متعدد الطبقات، وتضمينات الموضع (التي كانت تسمى آنذاك تضمينات زمنية)، وكلها عناصر أساسية في LLM الحالية. على الرغم من أن تأثيرها لم يكن بنفس قوة ورقة “Attention is all you need”، إلا أنها جمعت بين أفكار Memory Networks والانتباه الناعم المبكر، وأظهرت إمكانات الاستدلال للانتباه الناعم متعدد الطبقات. (المصدر: iScienceLuvr, WeChat)

CVPR 2025 Oral: Mona – طريقة جديدة فعالة للضبط الدقيق البصري: اقترحت جامعة Tsinghua والأكاديمية الصينية للعلوم وغيرها من المؤسسات Mona (Multi-cognitive Visual Adapter)، وهي طريقة جديدة لضبط مهايئ الرؤية الدقيق. من خلال إدخال مرشحات رؤية متعددة الإدراك (التفاف قابل للفصل بعمق + نوى متعددة المقاييس) وتحسين توزيع الإدخال (Scaled LayerNorm)، تقوم Mona بتعديل أقل من 5% من معلمات الشبكة الأساسية، وتتفوق على أداء الضبط الدقيق الكامل للمعلمات في مهام بصرية متعددة مثل تقسيم المثيلات وكشف الكائنات، مع تقليل تكاليف الحوسبة والتخزين بشكل كبير. توفر هذه الطريقة فكرة جديدة لـ PEFT الفعال لنماذج الرؤية. (المصدر: WeChat)

ICLR 2025 Oral: DIFF Transformer – الانتباه التفاضلي يعزز نمذجة النصوص الطويلة: اقترحت Microsoft وجامعة Tsinghua DIFF Transformer، الذي يعزز إشارات السياق الرئيسية ويزيل الضوضاء عن طريق إدخال آلية الانتباه التفاضلي (حساب الفرق بين مجموعتين من خرائط الانتباه Softmax). أظهرت التجارب أن DIFF Transformer أكثر قابلية للتوسع في نمذجة اللغة (حوالي 65% من المعلمات/البيانات تحقق نفس الأداء)، ويتفوق بشكل كبير على Transformer التقليدي في نمذجة النصوص الطويلة، واسترجاع المعلومات الرئيسية، والتعلم في السياق، ومقاومة الهلوسة العدائية، والاستدلال الرياضي، ويمكنه أيضًا تقليل القيم المتطرفة للتنشيط، مما يفيد في التكميم. (المصدر: WeChat)

MARFT: نموذج جديد للضبط الدقيق المعزز متعدد الوكلاء: اقترحت جامعة Shanghai Jiao Tong ومؤسسات أخرى MARFT (Multi-Agent Reinforcement Fine-Tuning)، وهو نموذج جديد للضبط الدقيق المعزز مناسب للأنظمة متعددة الوكلاء القائمة على LLM (LaMAS). تحل هذه الطريقة تحديات التحسين التي تفرضها ديناميكية LaMAS من خلال تحليل قيمة الميزة متعددة الوكلاء ونمذجة اتخاذ القرار التسلسلي الشبيهة بـ Transformer. أظهرت التجارب الأولية أن LaMAS بعد الضبط الدقيق بـ MARFT تتفوق في الأداء على المهام الرياضية مقارنة بالأنظمة غير المضبوطة بدقة و PPO أحادي الوكيل. كما ناقش الباحثون إمكاناتها وتحدياتها في حل المهام المعقدة، والقابلية للتوسع، وحماية الخصوصية، والتكامل مع البلوك تشين. (المصدر: WeChat)

مراجعة شاملة لبروتوكولات الوكيل الذكي AI: نشرت جامعة Shanghai Jiao Tong بالتعاون مع مجتمع ANP أول مراجعة شاملة لبروتوكولات الوكيل الذكي AI. تقترح الورقة إطار تصنيف ثنائي الأبعاد موجه للكائنات (موجه للسياق مقابل بين الوكلاء) وسيناريوهات التطبيق (عام مقابل خاص بالمجال)، وتستعرض أكثر من عشرة بروتوكولات رئيسية مثل MCP, A2A, ANP, AITP, LMOS. يتم التقييم من خلال سبعة أبعاد رئيسية (الكفاءة، القابلية للتوسع، الأمان، الموثوقية، القابلية للتوسيع، القابلية للتشغيل، التشغيل البيني)، ويتم مقارنة أربع بنيات MCP, A2A, ANP, Agora باستخدام حالة تخطيط السفر. أخيرًا، تستشرف التطور المستقبلي للبروتوكولات من ثابتة إلى قابلة للتطور، ومن قواعد إلى نظام بيئي، ومن بروتوكول إلى بنية تحتية ذكية. (المصدر: WeChat)

مراجعة متعمقة لبروتوكول MCP: البنية، النظام البيئي ومخاطر الأمان: تستكشف ورقة مراجعة جديدة بعمق بنية بروتوكول سياق النموذج (MCP)، وحالة نظامه البيئي، والمخاطر الأمنية المحتملة. تحلل المقالة الهيكل الثلاثي لـ MCP Host, Client, Server وآليات تفاعلها، وتلخص التقدم المحرز في استخدام MCP من قبل شركات ومجتمعات مثل Anthropic, OpenAI, Cursor, Replit، وتركز على تحليل المخاطر الأمنية الموجودة في دورة حياة MCP Server (الإنشاء، التشغيل، التحديث)، مثل تعارض الأسماء، وخداع المثبت، وحقن الشفرة، وتعارض أسماء الأدوات، والهروب من بيئة الاختبار المعزولة، واستمرارية الأذونات، وغيرها من المشكلات. (المصدر: WeChat)

CVPR Oral: UniAP – خوارزمية توازي تلقائي موحدة داخل الطبقة وبين الطبقات: اقترحت مجموعة البروفيسور Li Wujun من جامعة Nanjing خوارزمية UniAP، وهي خوارزمية تدريب موزعة يمكنها تحسين استراتيجيات التوازي داخل الطبقة (البيانات/الموتر/ZeRO) وبين الطبقات (خط الأنابيب) بشكل مشترك. من خلال نمذجة البرمجة التربيعية الصحيحة المختلطة، يمكن لـ UniAP البحث تلقائيًا عن حلول تدريب موزعة فعالة، مما يحل مشكلة التكوين اليدوي المعقد وغير الفعال. أظهرت التجارب أن UniAP أسرع بما يصل إلى 3.8 مرة من طرق التوازي التلقائي الحالية، وأسرع 9 مرات من الاستراتيجيات غير المحسنة، ويمكنها تجنب 64%-87% من الاستراتيجيات غير الصالحة (OOM) بشكل فعال، مما يعزز سهولة الاستخدام. تم تكييف هذه الخوارزمية مع بطاقات الحوسبة AI المحلية. (المصدر: WeChat)
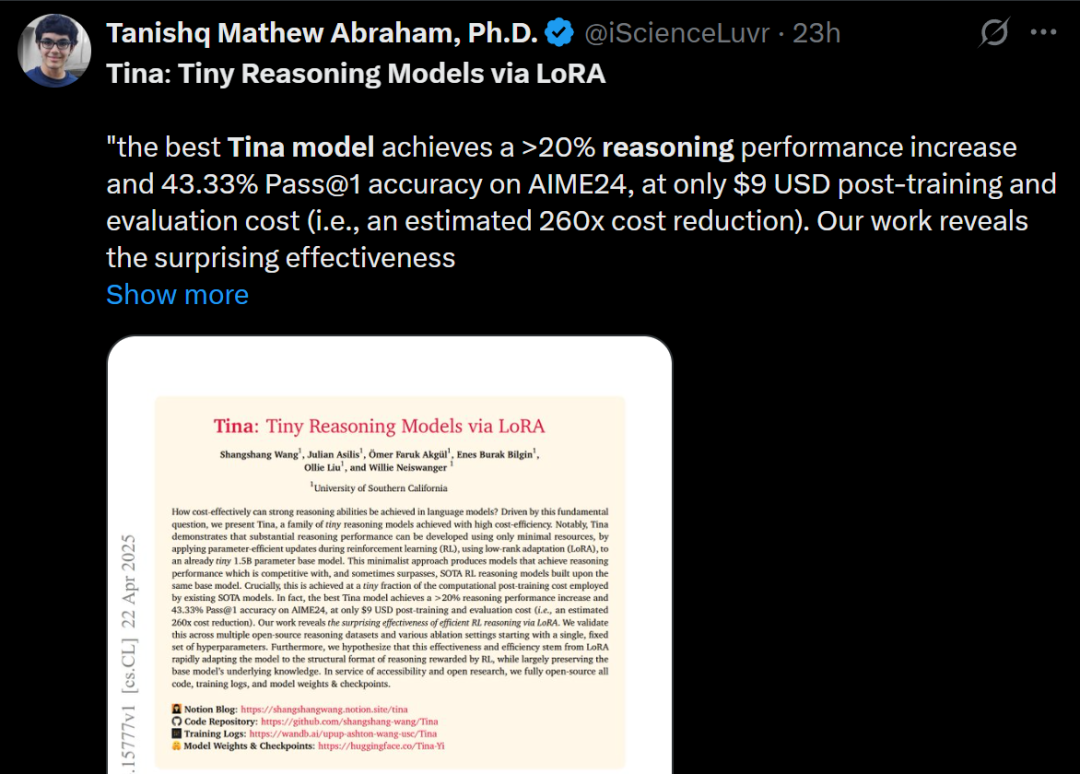
Tina: نماذج صغيرة بتكلفة منخفضة وقدرة استدلال عالية عبر LoRA: اقترح فريق من جامعة جنوب كاليفورنيا سلسلة نماذج Tina (Tiny Reasoning Models via LoRA). من خلال استخدام LoRA للتدريب بعد التعلم المعزز على أساس DeepSeek-R1-Distill-Qwen بمعاملات 1.5B، حققت نماذج Tina أداءً مكافئًا أو حتى أفضل من نماذج خط الأساس ذات الضبط الدقيق الكامل للمعلمات في العديد من معايير الاستدلال (AIME, AMC, MATH, GPQA, Minerva)، بينما كانت تكلفة التدريب منخفضة للغاية (تكلفة أفضل نقطة فحص 9 دولارات فقط). كشفت الدراسة عن مزايا LoRA في التعلم الفعال لتنسيق/هيكل الاستدلال، ولوحظت ظاهرة فك الارتباط بين مؤشرات التنسيق ومؤشرات الدقة أثناء التدريب. (المصدر: WeChat)
تحسين تباعد KL العودي: طريقة جديدة فعالة لتدريب النماذج: تقترح ورقة بحثية جديدة طريقة تحسين تباعد KL العودي (Recursive KL Divergence Optimization)، والتي يُزعم أنها تحقق تحسينًا في الكفاءة يصل إلى 80% في تدريب النماذج (خاصة الضبط الدقيق). قد تعمل هذه الطريقة من خلال تقييد تحديثات النموذج بطريقة أكثر تحسينًا، مما يقلل من موارد الحوسبة أو الوقت اللازم للتدريب، وتوفر مسارًا جديدًا لتدريب النماذج وضبطها بدقة بشكل أكثر اقتصادًا وسرعة. (المصدر: Reddit r/LocalLLaMA)
💼 الأعمال
Sakana AI تسعى للاستفادة من عدم اليقين في السياسة الأمريكية للتطور في اليابان: تعتقد شركة Sakana AI اليابانية الناشئة في مجال الذكاء الاصطناعي أن عدم اليقين في السياسة الأمريكية والطلب على حلول الذكاء الاصطناعي المحلية (خاصة في الحكومة والمؤسسات المالية) يوفر لها فرصًا للتطور في اليابان. صرح مدير تطوير الأعمال في الشركة بأنه من المتوقع أن يكون هناك 5-10 حالات استخدام للمستهلكين من الحكومة والمؤسسات المالية خلال الأشهر الستة المقبلة. أشار الرئيس التنفيذي David Ha إلى أنه في ظل التوترات الجيوسياسية المتزايدة، تزداد حاجة الدول الديمقراطية إلى تحديث البنية التحتية الحكومية والدفاعية، وأن تركيز الشركة على تطبيقات الدفاع (مثل مخاطر الأمن البيولوجي وتتبع المعلومات المضللة) أمر بالغ الأهمية. (المصدر: SakanaAILabs, SakanaAILabs)
Meta تتوقع أن تصل إيرادات الذكاء الاصطناعي التوليدي إلى 1.4 تريليون دولار في عام 2035: تتوقع شركة Meta أن تحقق أعمالها في مجال الذكاء الاصطناعي التوليدي إيرادات بقيمة 3 مليارات دولار في عام 2025، وتتوقع أن ترتفع بشكل كبير إلى 1.4 تريليون دولار بحلول عام 2035. يشير هذا التوقع إلى أن Meta متفائلة للغاية بشأن إمكانات النمو طويلة الأجل في مجال الذكاء الاصطناعي، وقد تستمر في الحفاظ على نفقات رأسمالية عالية للاستثمار في البحث والتطوير في مجال الذكاء الاصطناعي وبناء البنية التحتية. (المصدر: brickroad7)

Alimama تطلق نموذج المعرفة العالمية الكبير URM: أطلقت Alimama نموذج اللغة الكبير URM (Universal Recommendation Model) الذي يجمع بين المعرفة العالمية ومعرفة مجال التجارة الإلكترونية. يمكن لهذا النموذج فهم اهتمامات المستخدم التاريخية وإجراء توصيات قائمة على الاستدلال من خلال حقن المعرفة (معرف المنتج كرمز خاص) ومحاذاة المعلومات (دمج المعرف مع التمثيلات الدلالية متعددة الوسائط). يعتمد URM طريقة توليد Sequence-In-Set-Out، ويولد تمثيلات متعددة للمستخدم بشكل متوازٍ لتحسين التأثير والتنوع، مع الحفاظ على كفاءة الاستدلال. تم إطلاقه بالفعل في سيناريوهات الإعلانات المصورة في Alimama، ويحل مشكلة زمن انتقال LLM من خلال مسار الاستدلال غير المتزامن، مما يحسن أداء إعلانات التجار وتجربة تسوق المستخدم. (المصدر: WeChat)

🌟 المجتمع
نهاية عصر GPT-4 تثير الحنين والنقاش: ودع Sam Altman نموذج GPT-4 في منشور، قائلاً إنه بدأ ثورة وسيتم حفظ أوزانه للمؤرخين المستقبليين. أثار هذا الإجراء حنينًا واسع النطاق في المجتمع، حيث تذكر الكثيرون أن GPT-4 كان أول نموذج جعلهم يشعرون بإمكانات AGI. في الوقت نفسه، أثار هذا أيضًا نقاشًا حول المصدر المفتوح، حيث دعا أعضاء المجتمع مثل Hugging Face شركة OpenAI إلى فتح مصدر أوزان GPT-4 للبحث، بدلاً من مجرد أرشفتها. (المصدر: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
ملاحظات ونقاشات حول مسار AI Coding: يعتقد Zhang Hailong، مؤسس GruAI، أن AI Coding هو أحد المسارات القليلة التي يمكن رؤية توافق المنتج مع السوق (PMF) فيها حاليًا، وأن نجاح Cursor يكمن في خلق سوق جديد، وأن قيمة واجهة المستخدم الخاصة به ضخمة. يعتقد أن اتجاه Devin صحيح ولكنه طموح للغاية، وأن الفترة الزمنية طويلة، لكن احتمالية النجاح تتزايد، وسيتنافس في النهاية مع Cursor. بالنسبة للشركات الناشئة، يعتقد أنه لا داعي للقلق المفرط بشأن منافسة الشركات الكبرى، فالجوهر يكمن في قوة المنتج والقيمة الفريدة. أدى التقدم الكبير في النماذج إلى تقليل الحاجة إلى التعويض الهندسي بشكل كبير، ويحتاج رواد الأعمال إلى التمييز بين المشكلات التي سيحلها تطوير النماذج وتلك التي تمثل قوة المنتج الحقيقية. (المصدر: WeChat)

تأملات حول مقولة “الذكاء الاصطناعي سيحل محل وظيفتك”: يشير نقاش المجتمع إلى أن مقولة “الذكاء الاصطناعي لن يحل محل وظيفتك، ولكن الأشخاص الذين يستخدمون الذكاء الاصطناعي سيفعلون ذلك” صحيحة ظاهريًا، لكنها مبسطة للغاية، وهي نوع من “مسرح الإجماع” الذي يجعل الناس يتوقفون عن التفكير في القضايا الأعمق. يكمن المفتاح الحقيقي في فهم كيف يغير الذكاء الاصطناعي هيكل العمل، ويعيد تشكيل سير العمل، ويغير منطق التنظيم، وكيف سيبدو العمل المستقبلي في ظل النظام الجديد، بدلاً من التركيز فقط على الأتمتة أو التعزيز على مستوى المهام الفردية. (المصدر: Reddit r/ArtificialInteligence)

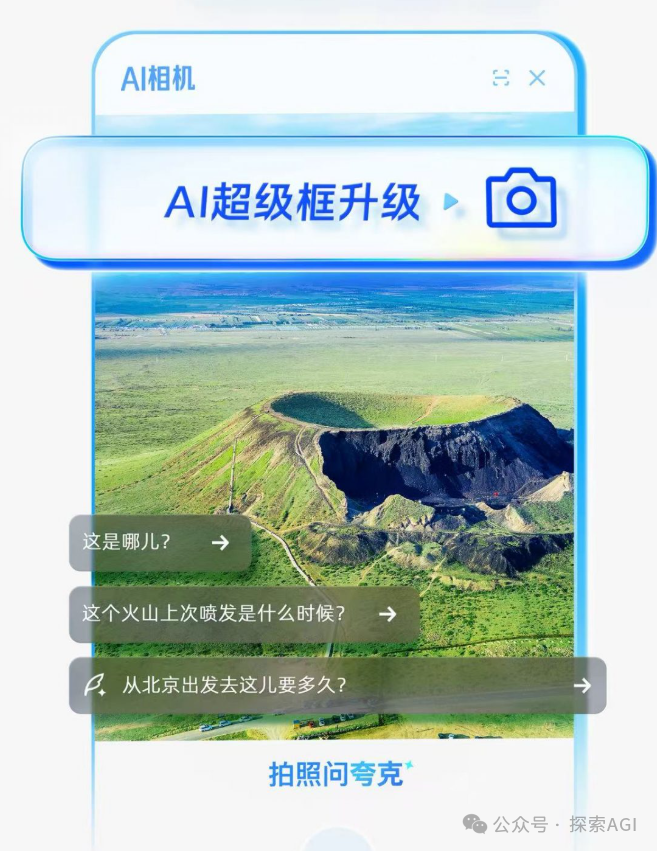
مدخل جديد لتفاعل وكلاء الذكاء الاصطناعي مع العالم المادي: الكاميرا: يرى النقاش أن وظائف مثل “اسأل بالصورة” في Quark تمثل اتجاهًا جديدًا لتفاعل تطبيقات الذكاء الاصطناعي. من خلال كاميرا الهاتف المحمول، هذا المستشعر المنتشر، جنبًا إلى جنب مع الفهم متعدد الوسائط وقدرات الوكيل (Agent)، يمكن للذكاء الاصطناعي فهم العالم المادي بشكل أفضل، واتخاذ القرارات بشكل مستقل واستدعاء القدرات لإكمال المهام بناءً على احتياجات المستخدم الضمنية أو الصريحة (مثل التعرف على الأشياء، والترجمة، ومقارنة الأسعار، والمساعدة في الواجبات المنزلية، ومعالجة الفواتير، وما إلى ذلك). هذا يحول الكاميرا من أداة إدخال معلومات بسيطة إلى محور يربط العالم المادي بالذكاء الرقمي، ويحقق “إنجاز المهمة” (Get it Done). (المصدر: WeChat)
💡 أخرى
الذكاء الاصطناعي والبحث العلمي: ترى وجهات نظر المجتمع أن الذكاء الاصطناعي أصبح تدريجيًا “الرياضيات” الجديدة للبحث العلمي، مما يعني أن الذكاء الاصطناعي سيصبح، مثل الرياضيات، أداة ولغة أساسية لدفع الاكتشاف العلمي والفهم. (المصدر: shuchaobi)

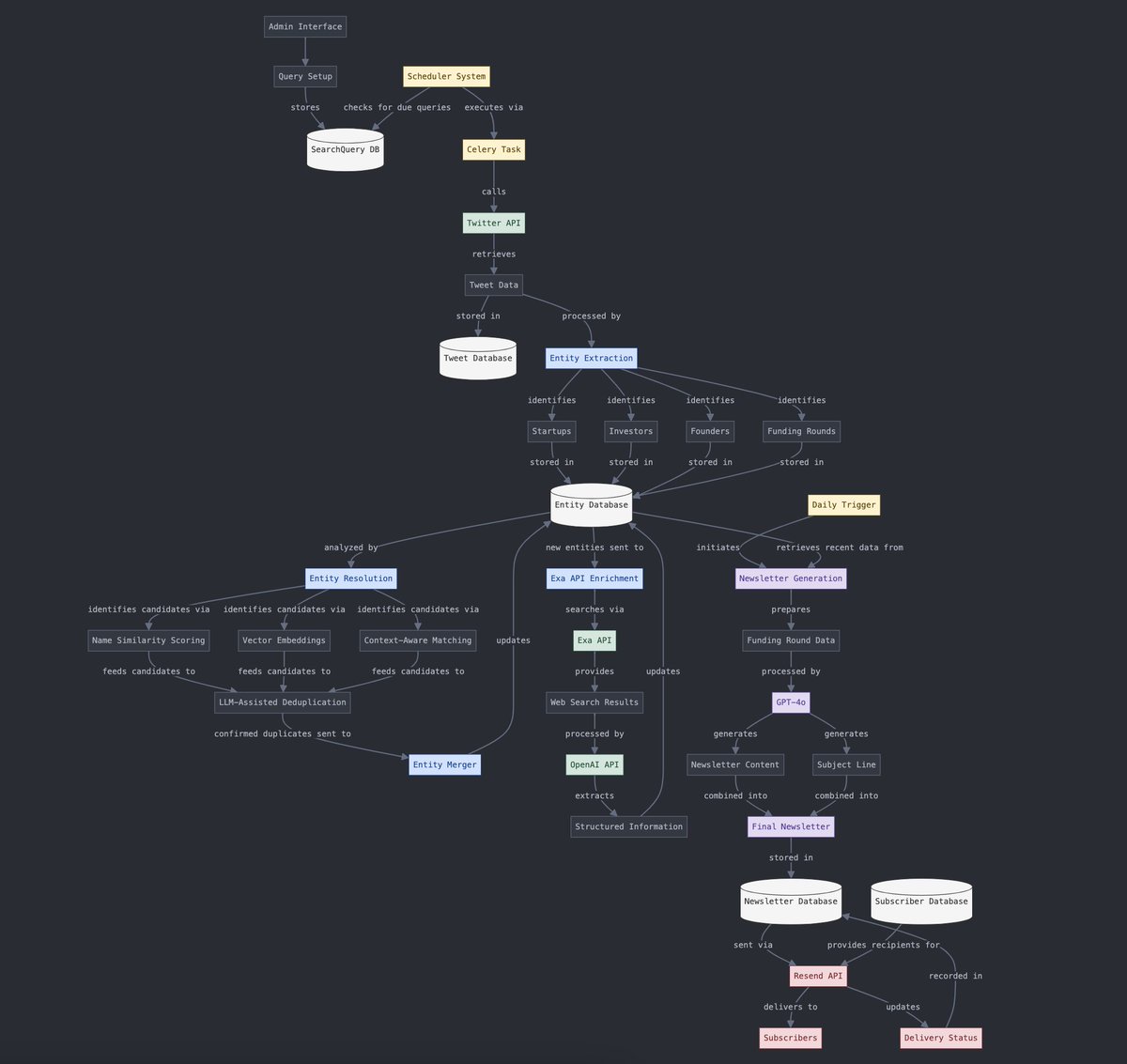
تحويل البيانات المهيكلة وغير المهيكلة: يعرض Yohei Nakajima استخدام الذكاء الاصطناعي لتحويل بيانات التغريدات غير المهيكلة إلى بيانات مهيكلة، ليتم بعد ذلك تحويلها مرة أخرى إلى نشرة إخبارية يومية غير مهيكلة، مما يعكس تطبيق الذكاء الاصطناعي في عمليات معالجة المعلومات وتوليد المحتوى. (المصدر: yoheinakajima)
مستقبل دمج الذكاء الاصطناعي والواقع الافتراضي (VR): يتطلع نقاش المجتمع إلى إمكانات دمج الذكاء الاصطناعي والواقع الافتراضي، متخيلًا أنه قد يكون من الممكن في المستقبل توليد كائنات ثلاثية الأبعاد والتلاعب بها مباشرة في “مساحة اللوحة البيضاء” في الواقع الافتراضي باستخدام اللغة الطبيعية أو الأفكار، لتحقيق الإبداع المدفوع بالإدراك. تعتبر Meta لاعبًا رئيسيًا في دفع هذا الاتجاه. (المصدر: Reddit r/ArtificialInteligence)