
كلمات مفتاحية:نموذج وينكسين الكبير, نموذج الذكاء الاصطناعي, متعدد الوسائط, الوكيل الذكي, وينكسين 4.5 توربو, X1 توربو, DeepSeek V3, الفهم متعدد الوسائط, بيدو وينشيانغ (قلب بايدو), بروتوكول MCP, نموذج الدفع للذكاء الاصطناعي, استدلال نموذج LoRA
🔥 التركيز
Baidu تطلق Wenxin 4.5 Turbo و X1 Turbo لمنافسة DeepSeek: في مؤتمر Baidu Create لعام 2025، أطلق لي يانهونغ نموذجي Wenxin 4.5 Turbo و X1 Turbo، مؤكدًا على قدرات الفهم والتوليد متعدد الوسائط، وأشار إلى أن تكلفتهما تبلغ 40% فقط من تكلفة DeepSeek V3 و 25% من تكلفة DeepSeek R1 على التوالي. يعتقد لي يانهونغ أن تعدد الوسائط هو الاتجاه المستقبلي، وأن سوق النماذج النصية البحتة سيتقلص. يهدف هذا الإطلاق إلى تعويض نقاط ضعف DeepSeek في تعدد الوسائط والتكلفة، ويظهر تصميم Baidu على المنافسة مع رواد الصناعة على مستوى النماذج. (المصدر: 36氪)

مقارنة أداء نماذج الذكاء الاصطناعي: o3 و Gemini 2.5 Pro لكل منهما نقاط قوة: أظهر نموذجا o3 من OpenAI و Gemini 2.5 Pro من Google منافسة شديدة في العديد من اختبارات الأداء الجديدة. تفوق o3 في تحليل ألغاز الروايات الطويلة (FictionLiveBench)، بينما تفوق Gemini 2.5 Pro في الاستدلال الفيزيائي والمكاني (PHYBench)، ومسابقات الرياضيات (USMO)، وتحديد المواقع الجغرافية (GeoGuessing)، وكان أقل تكلفة (حوالي ربع تكلفة o3). تباينت النتائج في الألغاز المرئية (Visual Puzzles) والإجابة على الأسئلة المرئية الأساسية (NaturalBench). يشير هذا إلى أن أداء النماذج الرائدة حاليًا يعتمد بشكل كبير على المهمة المحددة ومعايير التقييم، ولا يوجد رائد مطلق. (المصدر: o3 breaks (some) records, but AI becomes pay-to-win
)
الذكاء الاصطناعي يتجه نحو نموذج “الدفع مقابل الفوز”: تشير ملاحظات الصناعة إلى أنه مع تحسن قدرات نماذج الذكاء الاصطناعي وتوسع تطبيقاتها، قد يتطلب الحصول على قدرات الذكاء الاصطناعي المتطورة دفع رسوم بشكل متزايد. بدأت شركات مثل Google و OpenAI و Anthropic في إطلاق أو التخطيط لإطلاق خدمات اشتراك بأسعار أعلى (مثل Premium Plus/Pro، قد تصل الرسوم الشهرية إلى 100-200 دولار). يعكس هذا التكاليف الباهظة المطلوبة لتدريب النماذج (خاصة بعد تدريب RL) والاستدلال على نطاق واسع، بالإضافة إلى حاجة الشركات لموازنة موارد الحوسبة بين تطوير النماذج والميزات الجديدة وزمن الاستجابة المنخفض ونمو المستخدمين. في المستقبل، قد تتسع الفجوة في القدرات بين خدمات الذكاء الاصطناعي المجانية أو منخفضة التكلفة والخدمات المتطورة المدفوعة. (المصدر: o3 breaks (some) records, but AI becomes pay-to-win
)
Baidu تطلق تطبيق Agent المحمول “Xinxiang”: تسرع Baidu من تخطيطها في مجال Agent بإطلاق تطبيق Agent المحمول “Xinxiang”، الذي ينافس منتجات مثل Manus. يهدف “Xinxiang” إلى فهم احتياجات المستخدمين من خلال الحوار وتنسيق وكلاء Baidu والجهات الخارجية لتنفيذ وتسليم المهام (مثل إنشاء كتب مصورة، وتخطيط السفر، والاستشارات القانونية، وما إلى ذلك). يؤكد المنتج على بناء “عقلية الاستضافة” لدى المستخدمين من خلال عرض عملية تنفيذ المهام، مما يميزه عن التسليم الفوري للبحث التقليدي. يدعم حاليًا أكثر من 200 نوع من المهام، ويخطط للتوسع إلى أكثر من 100,000 في المستقبل، وتطوير نسخة للكمبيوتر الشخصي. (المصدر: 36氪)
🎯 الاتجاهات
Baidu تتبنى بروتوكول MCP Agent بالكامل: أعلنت Baidu أن العديد من منتجاتها وخدماتها، بما في ذلك منصة النماذج الكبيرة السحابية الذكية Qianfan، وبحث Baidu، و Wenxin Kuaima، وتجارة Baidu الإلكترونية، والخرائط، و Netdisk، و Wenku، تدعم الآن أو تتوافق مع بروتوكول سياق النموذج (MCP) الذي اقترحته Anthropic. يهدف MCP إلى توحيد طرق تفاعل نماذج الذكاء الاصطناعي مع الأدوات الخارجية وقواعد البيانات، مما يحسن كفاءة التكيف والتطوير والصيانة بين برامج الذكاء الاصطناعي المختلفة. يساعد دعم Baidu في بناء نظام بيئي لتطبيقات الذكاء الاصطناعي أكثر انفتاحًا وترابطًا، مما يمكّن Agent من استدعاء مختلف الأدوات والخدمات بحرية أكبر. (المصدر: 36氪)
OpenAI تحدث GPT-4o، لتعزيز الذكاء والتخصيص: أعلن Sam Altman، الرئيس التنفيذي لشركة OpenAI، عن تحديث لنموذج GPT-4o، مدعيًا أنه يعزز ذكاء النموذج وأداءه المخصص. ومع ذلك، لم يقدم هذا التحديث بيانات تقييم محددة أو ملاحظات إصدار أو تفاصيل تحسين مفصلة، مما أثار نقاشًا وانتقادات في المجتمع حول شفافية تحديثات نماذج الذكاء الاصطناعي. (المصدر: sama, natolambert)
توليد الفيديو Google Veo 2 يصل إلى Whisk: أعلنت Google عن دمج نموذج توليد الفيديو الخاص بها Veo 2 في تطبيق Whisk، مما يسمح لمشتركي Google One AI Premium (يغطي أكثر من 60 دولة) بإنشاء مقاطع فيديو تصل مدتها إلى 8 ثوانٍ. يمكن للمستخدمين اختيار أنماط فيديو مختلفة للإنشاء، مما يوسع قدرات Google AI في توليد المحتوى متعدد الوسائط. (المصدر: Google)

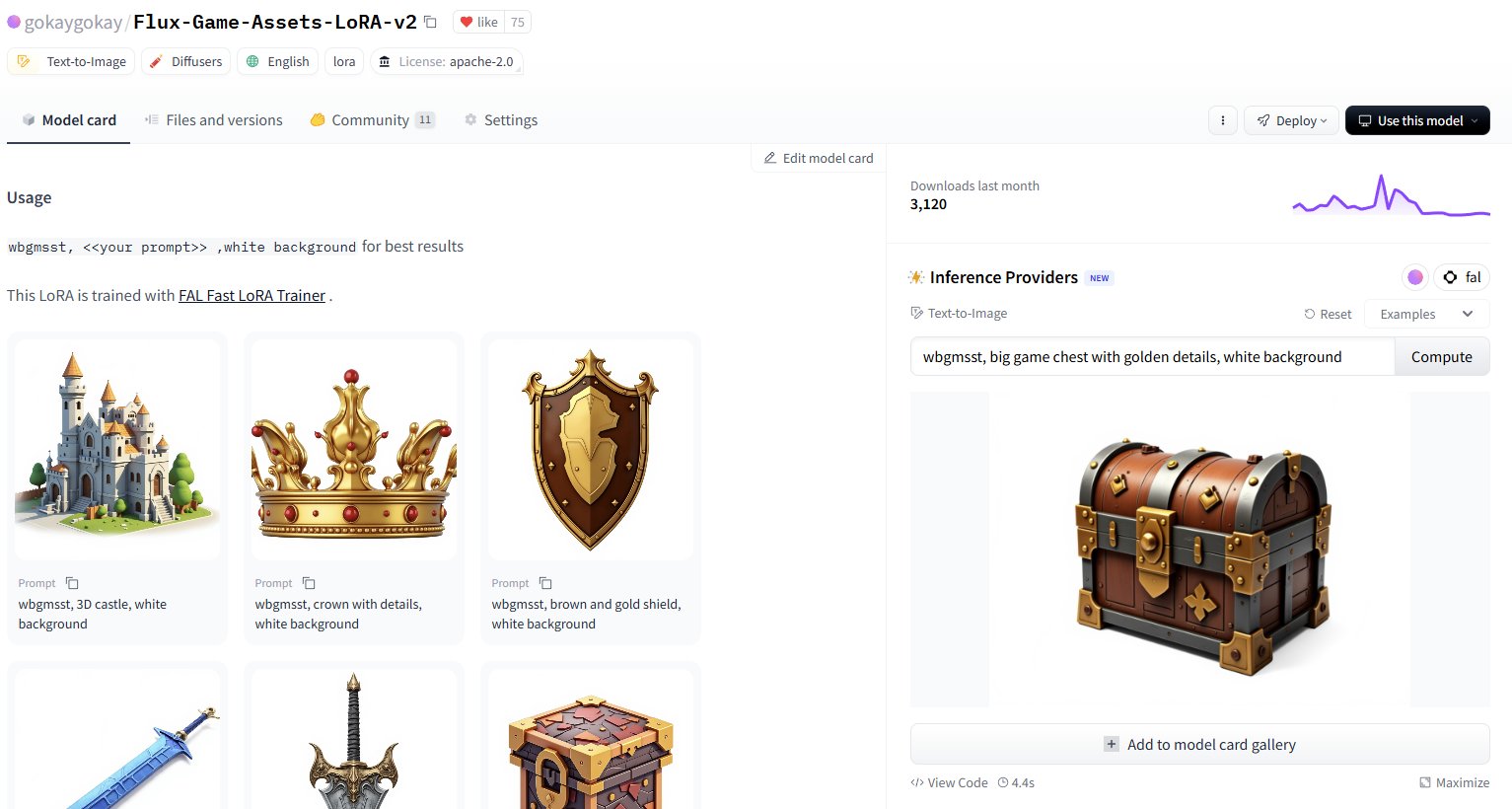
Hugging Face تضيف خدمة استدلال لأكثر من 30,000 نموذج LoRA: أعلنت Hugging Face عن توفير خدمة الاستدلال لأكثر من 30,000 نموذج Flux و SDXL LoRA من خلال Inference Providers (بدعم من FAL). يمكن للمستخدمين الآن استخدام هذه النماذج LoRA مباشرة على Hugging Face Hub لتوليد الصور، ويُقال إنها سريعة (توليد في حوالي 5 ثوانٍ) ومنخفضة التكلفة (أقل من دولار واحد يمكنه توليد أكثر من 40 صورة)، مما يوسع بشكل كبير موارد النماذج الدقيقة المتاحة لمستخدمي المجتمع. (المصدر: Vaibhav (VB) Srivastav, gokaygokay)
تحديثات تقدم Modular AI (Mojo/MAX): بعد ثلاث سنوات من تأسيسها، حققت Modular AI تقدمًا ملحوظًا، حيث تدعم لغتها Mojo ومنصتها MAX الآن مجموعة أوسع من الأجهزة، بما في ذلك وحدات المعالجة المركزية x86/ARM ووحدات معالجة الرسومات NVIDIA (A100/H100) و AMD (MI300X). تخطط الشركة قريبًا لفتح مصدر حوالي 250,000 سطر من كود نواة GPU وتبسيط تراخيص Mojo و MAX. يشير هذا إلى أن Modular تفي تدريجيًا بوعدها بتوفير بديل لـ CUDA ومنصة تطوير AI عبر الأجهزة. (المصدر: Reddit r/LocalLLaMA)
تحديث Intel PyTorch Extension، يدعم DeepSeek-R1: أصدرت Intel الإصدار 2.7 من امتداد PyTorch الخاص بها (IPEX)، مضيفة دعمًا لنموذج DeepSeek-R1 وإدخال تحسينات جديدة تهدف إلى تحسين أداء تشغيل أعباء عمل PyTorch على أجهزة Intel (بما في ذلك وحدات المعالجة المركزية ووحدات معالجة الرسومات). تساعد هذه الخطوة على توسيع دعم نظام Intel AI البيئي للنماذج والأطر الشائعة. (المصدر: Phoronix)

اكتشاف ثغرة أمنية عامة لتجاوز LLM باسم “Policy Puppetry”: كشفت مؤسسة أبحاث الأمن HiddenLayer عن ثغرة تجاوز عامة جديدة تسمى “Policy Puppetry”، يُزعم أنها تؤثر على جميع النماذج اللغوية الكبيرة الرئيسية. قد تسمح الثغرة للمهاجمين بتجاوز آليات الحماية الأمنية للنموذج بسهولة أكبر، وتوليد محتوى ضار أو محظور، مما يطرح تحديات جديدة على مواءمة الأمان الحالية لـ LLM واستراتيجيات الحماية. (المصدر: HiddenLayer)

Anthropic قد تسمح للنماذج برفض المستخدمين بسبب “عدم الارتياح”: وفقًا لصحيفة نيويورك تايمز، تدرس Anthropic منح نماذجها للذكاء الاصطناعي (مثل Claude) قدرة جديدة: إذا قرر النموذج أن طلب المستخدم “مؤلم” أو غير مريح (distressing) للغاية، يمكن للنموذج اختيار إيقاف المحادثة مع هذا المستخدم. يتضمن هذا المفهوم الناشئ لـ “رفاهية الذكاء الاصطناعي” (AI welfare)، وقد يثير نقاشات جديدة حول حقوق الذكاء الاصطناعي وتجربة المستخدم وقابلية التحكم في النماذج. (المصدر: NYTimes)

إطلاق Tessa: نموذج كود 7B موجه لـ Rust: ظهر على Hugging Face نموذج بحجم 7 مليار معلمة يسمى Tessa-Rust-T1-7B، يُزعم أنه يركز على توليد كود Rust والاستدلال، ويأتي مع مجموعة بيانات مفتوحة. ومع ذلك، تشير تعليقات المجتمع إلى أن طريقة توليد مجموعة البيانات والتحقق من صحتها وتفاصيل التقييم تفتقر إلى الشفافية، مما يثير الحذر بشأن فعالية النموذج الفعلية. (المصدر: Hugging Face)

🧰 الأدوات
Plandex: مساعد ترميز AI مفتوح المصدر للمشاريع الكبيرة: Plandex هي أداة تطوير AI تعمل داخل الطرفية، مصممة خصيصًا للتعامل مع مهام الترميز الكبيرة التي تمتد عبر ملفات متعددة وخطوات متعددة. تدعم سياقًا يصل إلى 2 مليون token، ويمكنها فهرسة قواعد التعليمات البرمجية الكبيرة، وتوفر sandbox لمراجعة الفروق التراكمية، واستقلالية قابلة للتكوين، ودعم نماذج متعددة (Anthropic, OpenAI, Google، إلخ)، وتصحيح تلقائي، والتحكم في الإصدار، وتكامل Git، وتهدف إلى حل تحديات ترميز AI في المشاريع العملية المعقدة. (المصدر: GitHub Trending)
LiteLLM: SDK ووكيل موحد لاستدعاء أكثر من 100 واجهة برمجة تطبيقات LLM: يوفر LiteLLM SDK بلغة Python وخادم وكيل (بوابة LLM)، مما يسمح للمطورين باستخدام تنسيق OpenAI الموحد لاستدعاء أكثر من 100 واجهة برمجة تطبيقات LLM (مثل Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq، إلخ). يتولى مسؤولية تحويل مدخلات API، وضمان تنسيق المخرجات المتسق، وتنفيذ منطق إعادة المحاولة/الرجوع عبر عمليات النشر، ويوفر من خلال خادم الوكيل إدارة مفاتيح API، وتتبع التكاليف، وتحديد المعدل، وتسجيل الدخول، وغيرها من الوظائف. (المصدر: GitHub Trending)

Hyprnote: ملاحظات اجتماعات AI محلية أولاً وقابلة للتوسيع: Hyprnote هو تطبيق ملاحظات AI مصمم خصيصًا لسيناريوهات الاجتماعات. يؤكد على الأولوية المحلية وحماية الخصوصية، ويمكن استخدامه في وضع عدم الاتصال بالإنترنت مع نماذج مفتوحة المصدر (Whisper لتحويل التسجيل الصوتي إلى نص، و Llama لتلخيص الملاحظات). ميزته الأساسية هي القابلية للتوسيع، حيث يمكن للمستخدمين إضافة أو إنشاء وظائف جديدة عبر نظام المكونات الإضافية (plugins) لتلبية الاحتياجات الشخصية. (المصدر: GitHub Trending)

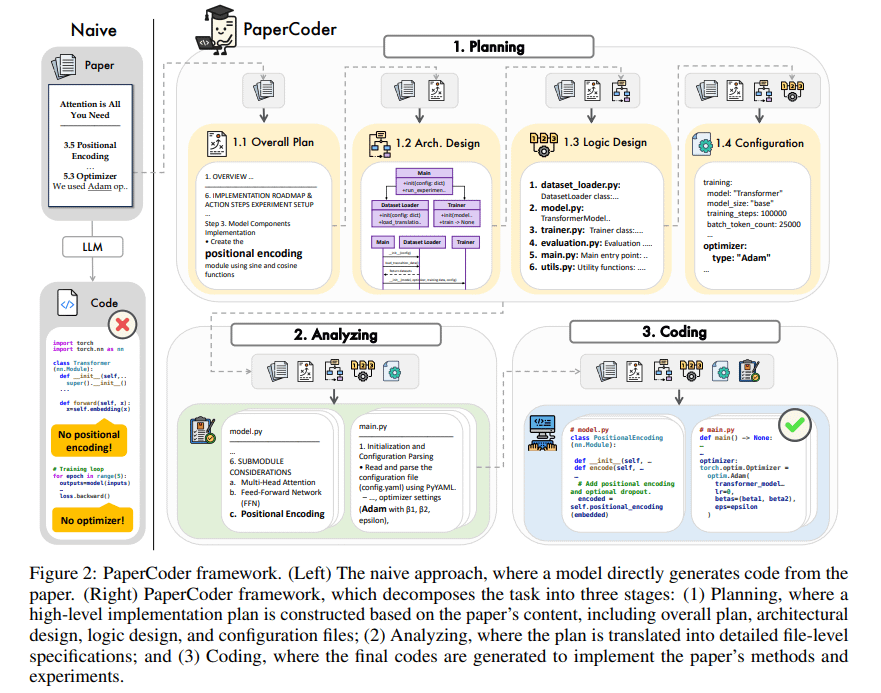
PaperCoder: توليد الكود تلقائيًا من الأوراق البحثية: PaperCoder هو إطار عمل يعتمد على LLM متعدد الوكلاء (multi-agent)، يهدف إلى تحويل الأوراق البحثية في مجال تعلم الآلة تلقائيًا إلى مستودعات كود قابلة للتشغيل. ينجز المهمة من خلال ثلاث مراحل تعاونية: التخطيط (بناء مخطط، تصميم البنية)، التحليل (تفسير تفاصيل التنفيذ)، والتوليد (كود معياري). تظهر التقييمات الأولية أن جودة مستودعات الكود التي تم إنشاؤها عالية ودقتها جيدة، مما يساعد الباحثين بشكل فعال على فهم وإعادة إنتاج عمل الأوراق البحثية، ويتفوق على النماذج الأساسية في اختبار PaperBench. (المصدر: arXiv)
TINY AGENTS: تنفيذ JavaScript Agent في 50 سطرًا من الكود: أطلق Julien Chaumond مشروعًا مفتوح المصدر يسمى TINY AGENTS، ينفذ وظيفة Agent أساسية باستخدام 50 سطرًا فقط من كود JavaScript. يعتمد المشروع على بروتوكول سياق النموذج (MCP)، ويوضح كيف يبسط MCP تكامل الأدوات مع LLM، ويكشف أن المنطق الأساسي لـ Agent يمكن أن يكون حلقة بسيطة حول عميل MCP. يوفر هذا مثالاً لفهم وبناء Agents خفيفة الوزن. (المصدر: Julien Chaumond)

PolicyShift.ca: تطبيق تتبع المواقف السياسية الكندية مبني بواسطة AI: شارك مستخدم تطبيق ويب PolicyShift.ca الذي قام ببنائه باستخدام Claude (للمساعدة في كتابة الواجهة الخلفية Python والواجهة الأمامية React) و OpenAI API (لتحليل المحتوى). يقوم التطبيق بجلب الأخبار الكندية، وتحديد القضايا السياسية التي تمت مناقشتها في المقالات، والشخصيات السياسية وتغير مواقفهم، وعرضها في شكل خط زمني، مما يجسد إمكانات AI في جمع المعلومات الآلي وتحليلها وتطوير التطبيقات. (المصدر: Reddit r/ClaudeAI)
مثال على بناء موقع ويب سريع بواسطة AI (موضوع Shogun): عرض مستخدم موقع ويب حول المسلسل التلفزيوني “Shogun” ومقارنته بخلفيته التاريخية، مدعيًا أن الموقع تم بناؤه ونشره تلقائيًا باستخدام أداة AI غير محددة (يشير URL إلى rabbitos.app، قد يكون مرتبطًا بـ Rabbit R1) من خلال مطالبة واحدة (“Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”)، مما يوضح قدرة AI على إنشاء مواقع الويب بدون تكوين. (المصدر: Reddit r/ArtificialInteligence)
Perplexity Assistant يحقق عمليات عبر التطبيقات: أعاد Arav Srinivas، الرئيس التنفيذي لشركة Perplexity، نشر تقييم إيجابي من مستخدم يوضح قدرة مساعد AI Perplexity Assistant على تنسيق تطبيقات متعددة على الهاتف بسلاسة لإنجاز المهام. على سبيل المثال، يمكن للمستخدم من خلال الأوامر الصوتية جعل المساعد يبحث عن مكان في تطبيق الخرائط، ثم يفتح تطبيق Uber مباشرة لحجز رحلة، وتستمر عملية التفاعل الصوتي بأكملها، مما يبرز إمكاناته كمساعد AI متكامل. (المصدر: Anthony Harley)

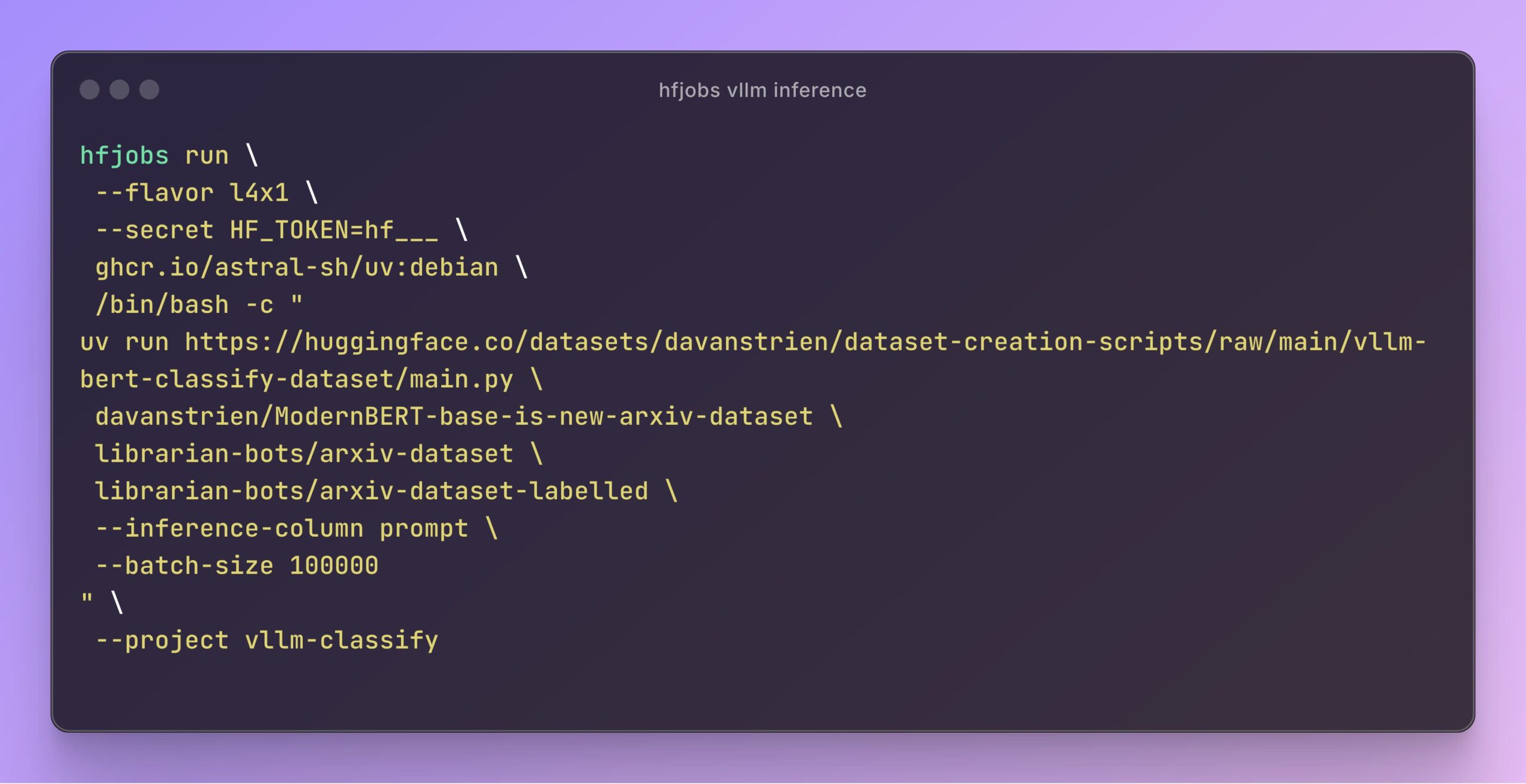
vLLM يسرع استدلال Hugging Face Jobs: أوضح Daniel van Strien كيفية استخدام إطار عمل vLLM ومدير الحزم uv على منصة Hugging Face Jobs لتنفيذ استدلال سريع وبدون خادم لنموذج ModernBERT من خلال نص برمجي بسيط. تبسط هذه الطريقة إدارة التبعيات وعملية النشر، وتحسن كفاءة استدلال النموذج. (المصدر: Daniel van Strien)
📚 التعلم
Burn: إطار عمل تعلم عميق بلغة Rust يوازن بين الأداء والمرونة: Burn هو إطار عمل تعلم عميق من الجيل الجديد مكتوب بلغة Rust، يؤكد على الأداء والمرونة وقابلية النقل. تشمل ميزاته دمج المشغل التلقائي، والتنفيذ غير المتزامن، ودعم الواجهات الخلفية المتعددة (CUDA, WGPU, Metal, CPU، إلخ)، والتفاضل التلقائي (Autodiff)، واستيراد النماذج (ONNX, PyTorch)، والنشر على WebAssembly ودعم no_std، ويهدف إلى توفير أساس تطوير AI حديث وفعال وعبر المنصات. (المصدر: GitHub Trending)
LlamaIndex تتحدث عن بناء Agent: الموازنة بين العمومية والتقييد: شارك فريق LlamaIndex وجهات نظره حول بناء Agent، معتقدًا أنه مع تعزيز قدرات النموذج (كما تؤكد OpenAI)، يمكن تبسيط أطر التطوير؛ ولكن في الوقت نفسه، بالنسبة للسيناريوهات التي تتطلب تحكمًا دقيقًا في عمليات الأعمال، لا يزال اعتماد أنماط التصميم المقيدة (مثل إرشادات Anthropic، و 12-Factor Agents) مهمًا. تهدف Workflows من LlamaIndex إلى توفير طريقة مرنة وقريبة من تجربة البرمجة الأصلية، تدعم الطيف الكامل من التقييد الكامل إلى الاستدلال العام. (المصدر: LlamaIndex Blog, jerryjliu0)

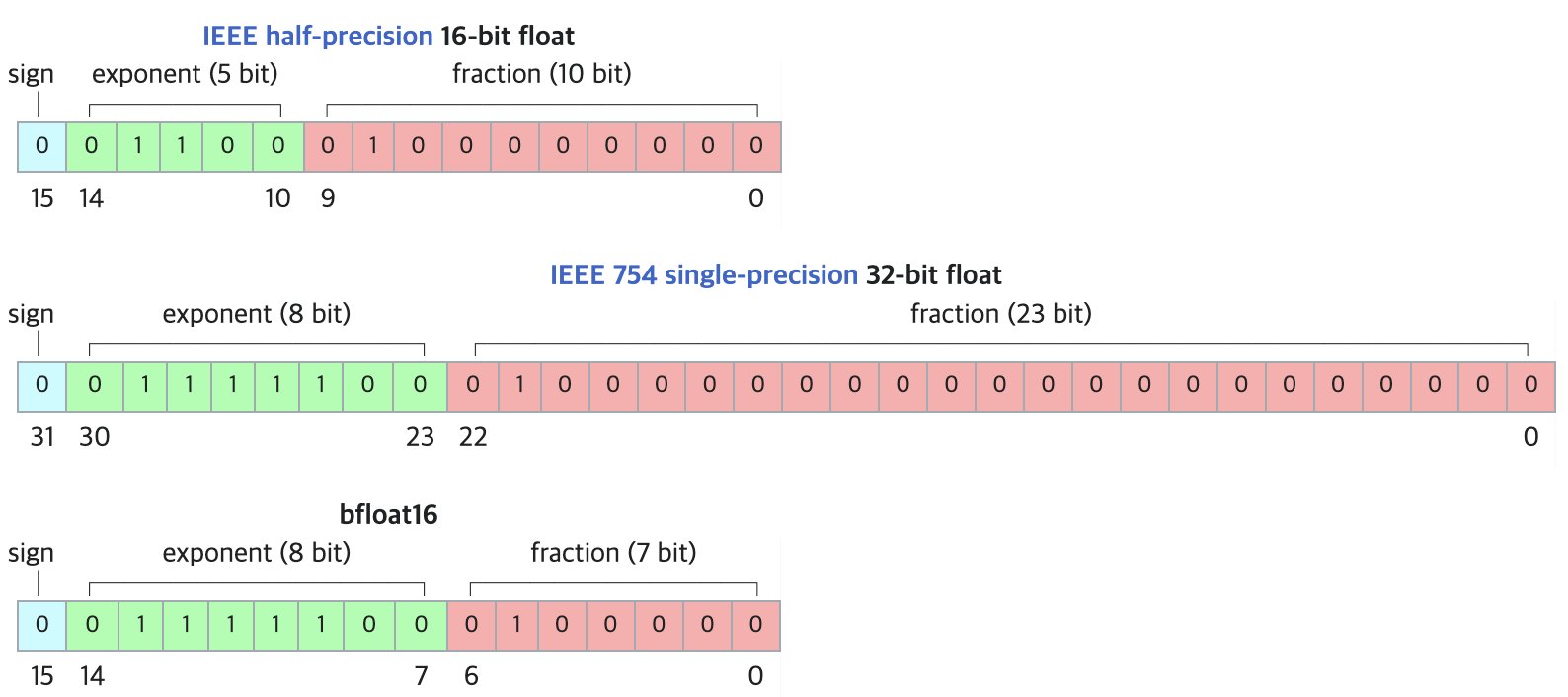
DF11: تنسيق جديد لضغط نماذج BF16 بدون فقدان: تقترح ورقة بحثية تنسيق DF11 (Dynamic-Length Float 11)، الذي يستغل التكرار في بتات الأس في تنسيق BF16 لتحقيق ضغط بدون فقدان عبر ترميز هوفمان، مما يقلل حجم النموذج بحوالي 30% (متوسط حوالي 11 بت/معلمة). يمكن لهذه الطريقة تقليل استهلاك الذاكرة أثناء استدلال GPU، مما يسمح بتشغيل نماذج أكبر أو زيادة حجم الدفعة/طول السياق، وهي مناسبة بشكل خاص للسيناريوهات محدودة الذاكرة. على الرغم من أنها قد تكون أبطأ قليلاً من BF16 في استدلال الدفعة الواحدة، إلا أنها أسرع بكثير من حلول تفريغ CPU. (المصدر: arXiv)
منطقة مناقشة Hugging Face Open-R1: كنز لتدريب نماذج الاستدلال: يشير عضو المجتمع Matthew Carrigan إلى أن منطقة المناقشة حول نموذج DeepSeek Open-R1 على Hugging Face هي “منجم ذهب” للحصول على معلومات عملية ومعرفة تطبيقية حول كيفية تدريب نماذج الاستدلال، وهي مورد قيم للباحثين والمطورين الذين يرغبون في التعمق في ممارسة تدريب نماذج الاستدلال. (المصدر: Matthew Carrigan)
العلاقة الجوهرية بين المشفرات المتقاطعة (Cross-Encoder) و BM25: اكتشفت دراسة من خلال طرق التفسير الآلي أن المشفرات المتقاطعة القائمة على BERT، عند تعلم ترتيب الصلة، قد تكون في الواقع “تعيد اكتشاف” وتنفذ خوارزمية BM25 دلالية. حدد الباحثون مكونات في النموذج تتوافق مع إشارات TF (تكرار المصطلح)، وتطبيع طول المستند، وحتى IDF (تردد المستند العكسي). النموذج المبسط المبني على هذه المكونات SemanticBM لديه ارتباط يصل إلى 0.84 مع المشفر المتقاطع الكامل، مما يكشف عن آليات العمل الداخلية لنماذج الترتيب العصبية. (المصدر: Shaped.ai)
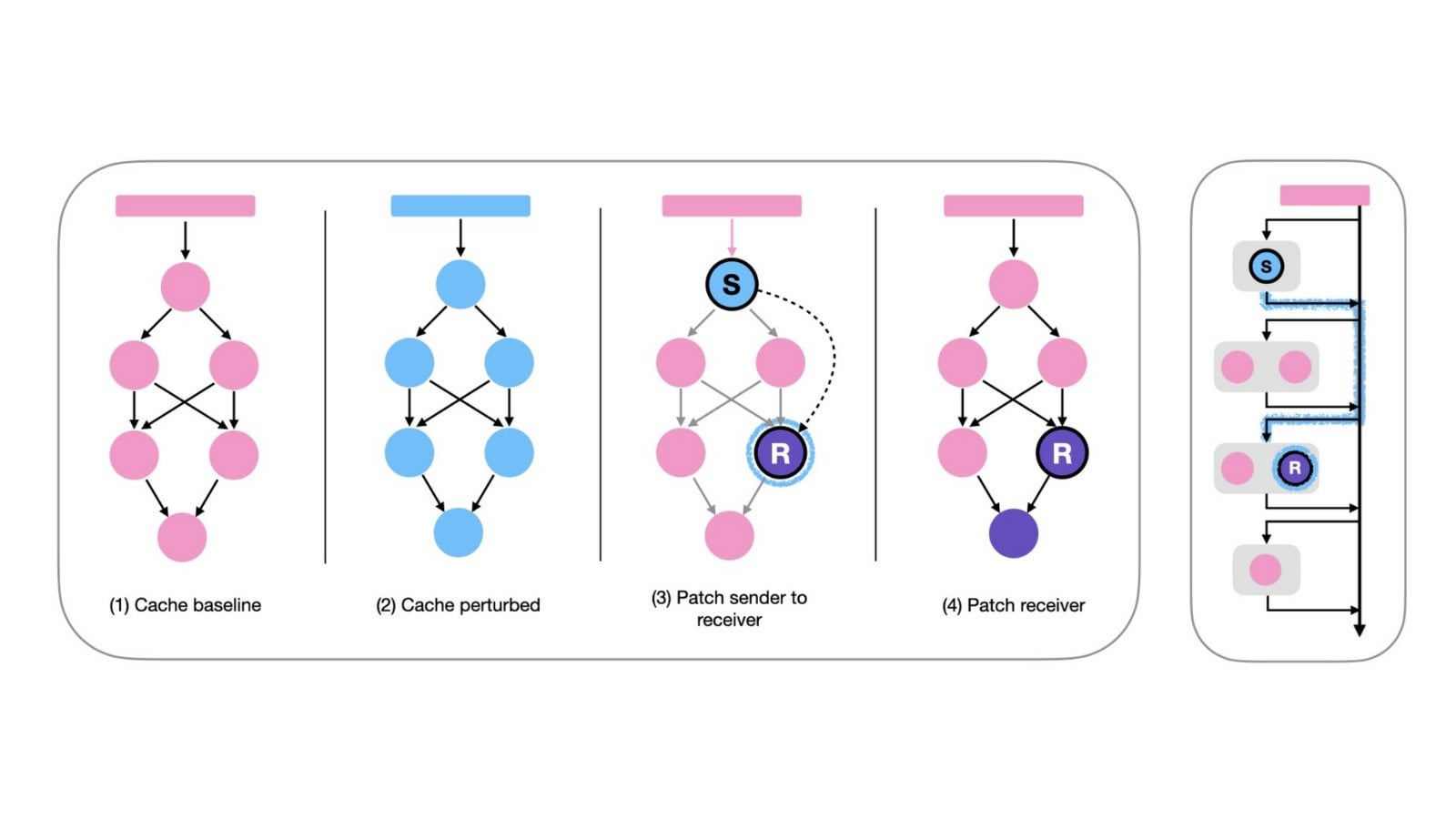
طريقة المطالبة “بدون تفكير” قد تحسن كفاءة نماذج الاستدلال: تقترح ورقة على arXiv (2504.09858) أنه بالنسبة لنماذج الاستدلال التي تستخدم خطوة “تفكير” صريحة (مثل <think>...</think>) (مع أخذ DeepSeek-R1-Distill كمثال)، فإن إجبار النموذج على تخطي هذه الخطوة (على سبيل المثال عن طريق حقن “Okay, I think I have finished thinking”) قد يحقق نتائج مماثلة أو حتى أفضل في بعض اختبارات الأداء، خاصة عند دمجها مع استراتيجية أخذ العينات Best-of-N. يثير هذا تساؤلات حول أفضل استراتيجية مطالبة لنماذج الاستدلال. (المصدر: arXiv)
دليل استخدام أدوات Open WebUI: يشرح دليل على Medium بالتفصيل كيفية الاستفادة من ميزة “الأدوات” (Tools) في Open WebUI لمنح LLM التي تعمل محليًا القدرة على تنفيذ إجراءات خارجية. يتضمن البحث عن أدوات المجتمع واستخدامها، والاعتبارات الأمنية، وكيفية استخدام Python لإنشاء أدوات مخصصة (يوفر قوالب كود وأمثلة)، مثل الاستعلام عن الطقس، والبحث على الويب، وإرسال البريد الإلكتروني، وما إلى ذلك. (المصدر: Medium)
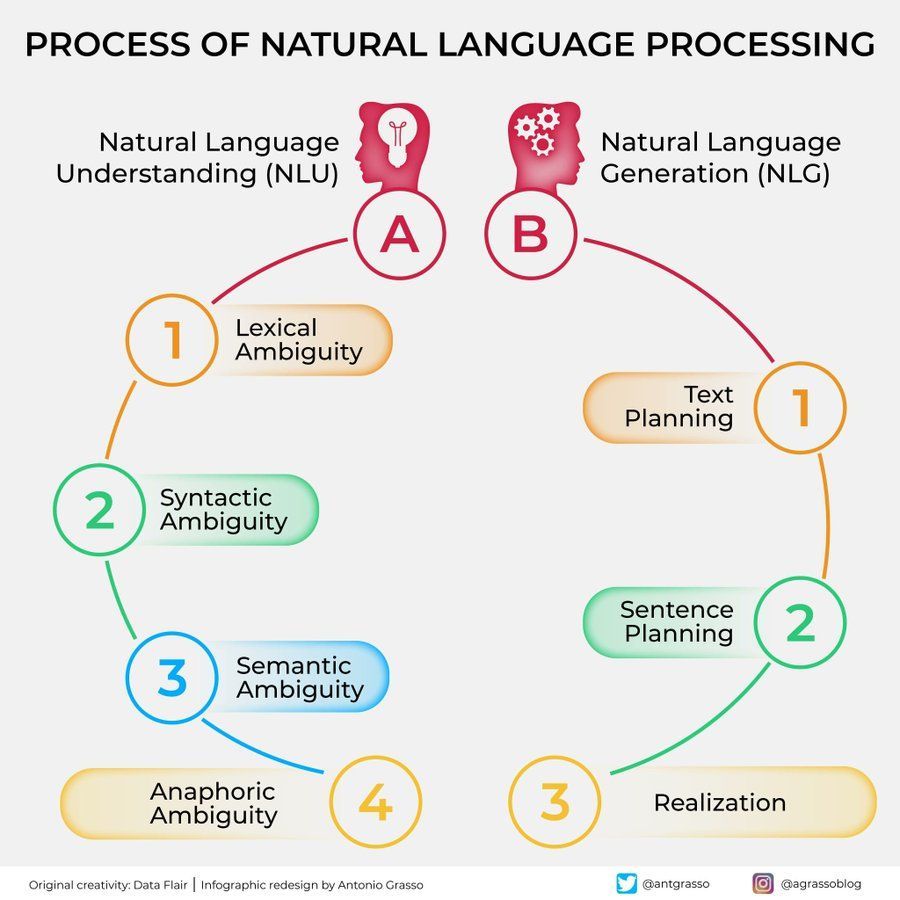
مخطط انسيابي لمعالجة اللغة الطبيعية (NLP): رسم توضيحي يعرض بإيجاز الخطوات والمراحل الرئيسية التي تنطوي عليها معالجة اللغة الطبيعية، مما يساعد على فهم التدفق الأساسي لمهام NLP. (المصدر: antgrasso)
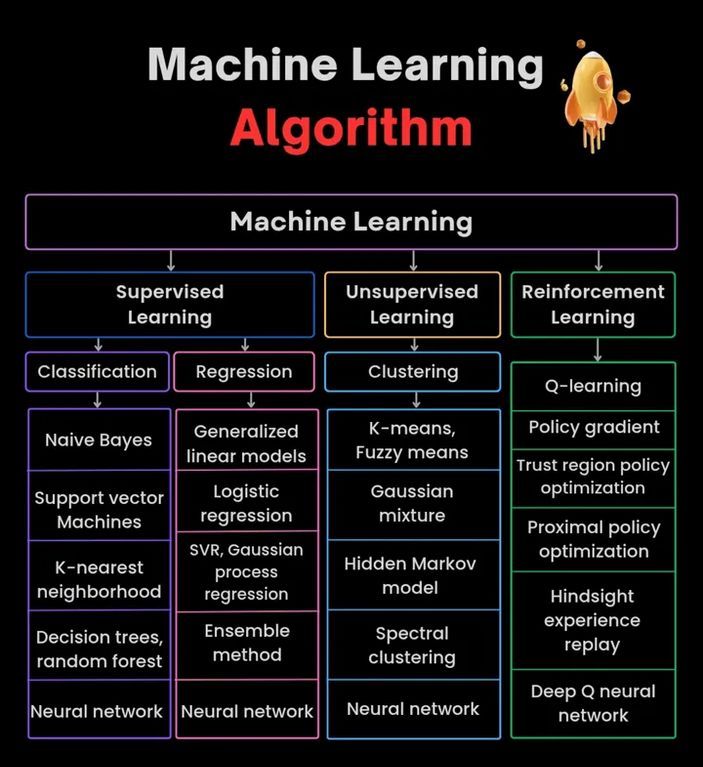
رسم توضيحي لخوارزميات تعلم الآلة: يوفر رسمًا توضيحيًا حول خوارزميات تعلم الآلة، قد يحتوي على تصنيفات أو خصائص أو مبادئ عمل خوارزميات مختلفة، كمادة مساعدة تعليمية مرئية. (المصدر: Python_Dv)
💼 الأعمال
OpenAI يُشاع أنها تتوقع إيرادات تزيد عن 12.5 مليار دولار بحلول عام 2029: وفقًا لـ The Information، تتفائل OpenAI بنمو إيراداتها المستقبلية، وتتوقع أن تتجاوز الإيرادات 12.5 مليار دولار بحلول عام 2029، وقد تصل إلى 17.4 مليار دولار في عام 2030. يعتمد هذا النمو المتوقع بشكل أساسي على إطلاق وكلاء Agent ومنتجات جديدة. (المصدر: The Information)
Ziff Davis تقاضي OpenAI لانتهاك حقوق النشر: رفعت شركة Ziff Davis، التي تمتلك وسائل إعلام مثل IGN و CNET، دعوى قضائية ضد OpenAI، متهمة إياها بنسخ عدد كبير من مقالاتها دون إذن لتدريب نماذج مثل ChatGPT، مما يشكل انتهاكًا لحقوق النشر. يعد هذا تحديًا قانونيًا آخر يرفعه ناشرو المحتوى ضد شركات الذكاء الاصطناعي بشأن استخدام البيانات. (المصدر: TechCrawlR)

OpenAI تعقد شراكة مع الخطوط الجوية السنغافورية: أعلنت OpenAI عن إقامة أول شراكة رئيسية لها مع شركة طيران، وهي الخطوط الجوية السنغافورية. تهدف هذه الشراكة إلى استكشاف التطبيقات العملية للذكاء الاصطناعي في صناعة الطيران لتعزيز تجربة العملاء أو كفاءة التشغيل. أعرب جيسون كوون، المسؤول التنفيذي في OpenAI، عن تطلعه لزيارة سنغافورة لدفع التعاون قدمًا. (المصدر: Jason Kwon)
متصفح Perplexity يخطط لتتبع بيانات المستخدم لعرض الإعلانات: كشف أرافيند سرينيفاس، الرئيس التنفيذي لشركة Perplexity، في مقابلة أن المتصفح الذي تخطط الشركة لإطلاقه سيتتبع جميع أنشطة المستخدم عبر الإنترنت، بهدف بيع إعلانات “شديدة التخصيص”. أثار هذا النموذج التجاري مخاوف بشأن خصوصية المستخدم. (المصدر: TechCrunch)

نمو كبير في عدد مستخدمي Baidu Wenku و Netdisk بعد الدمج: أظهرت أعمال Baidu Wenku، التي دمجت وظائف Baidu Netdisk، أداءً قويًا، حيث كشف مؤتمر Baidu Create أن عدد مستخدميها المدفوعين تجاوز 40 مليونًا، وعدد المستخدمين النشطين شهريًا تجاوز 97 مليونًا. يوضح هذا جاذبية الجمع بين التخزين السحابي وقدرات معالجة المستندات بالذكاء الاصطناعي للمستخدمين. (المصدر: 36氪)
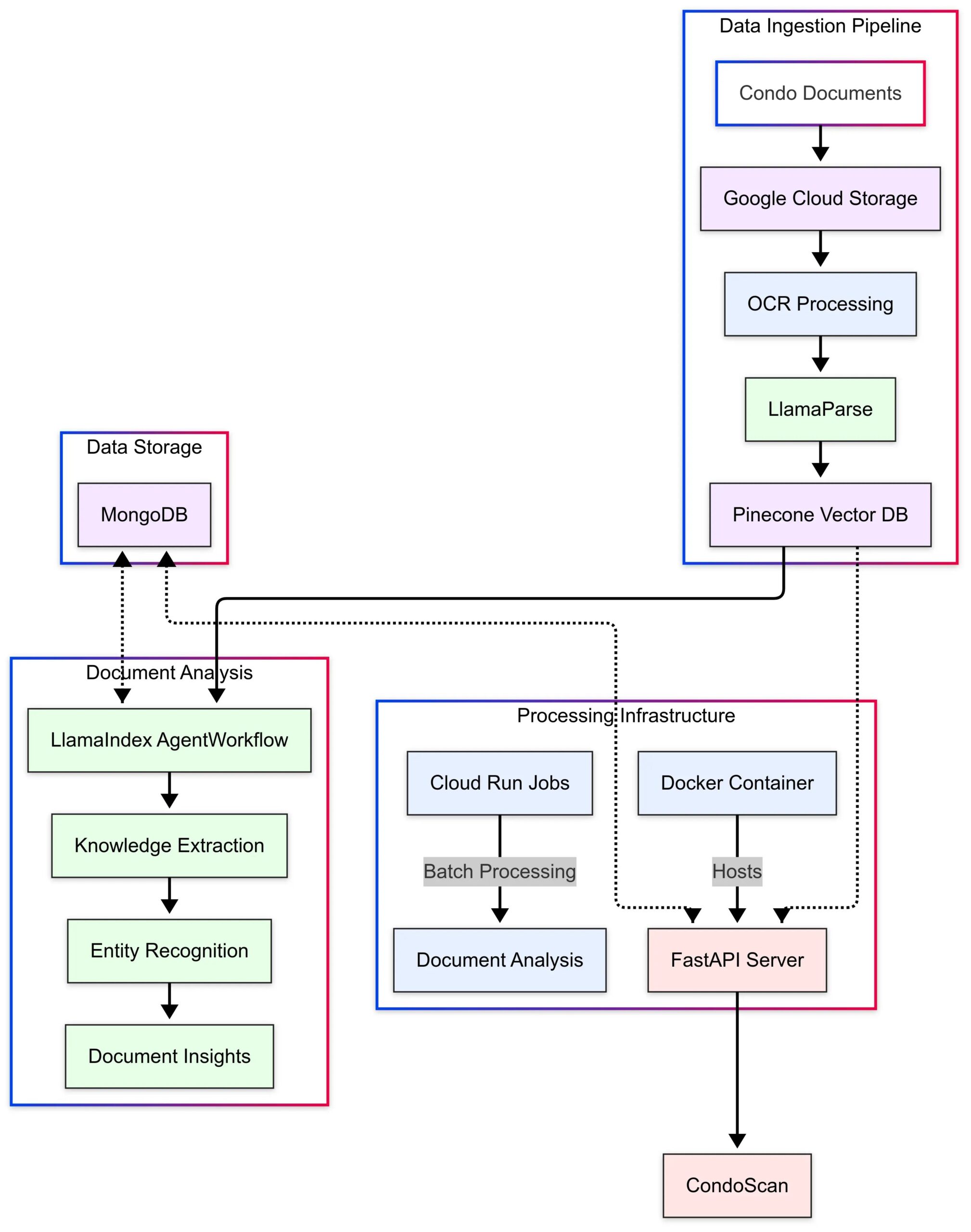
LlamaIndex تعرض دراسة حالة تطبيق CondoScan: نشرت LlamaIndex دراسة حالة توضح كيف استخدمت شركة تكنولوجيا العقارات CondoScan تقنيات Agent Workflows و LlamaParse لبناء أداة تقييم شقق من الجيل التالي. يمكن للأداة تقليل وقت مراجعة مستندات الشقق المعقدة من أسابيع إلى دقائق، وتقييم الوضع المالي، وملاءمة نمط الحياة، والتنبؤ بالمخاطر، وتوفير واجهة استعلام باللغة الطبيعية. (المصدر: LlamaIndex Blog)
🌟 المجتمع
استخدام GPT-4o لصنع وبيع بطاقات ذات طابع خاص: شارك المجتمع فكرة لبدء مشروع منخفض التكلفة باستخدام GPT-4o: اختر موضوعًا دقيقًا (مثل شان هاي جينغ، نجوم كرة القدم، الرسوم المتحركة)، اجعل GPT-4o ينشئ محتوى البطاقات، استخدم Canva/PS للتصميم والتحسين، انشر المحتوى على Xiaohongshu لاختبار استجابة السوق، بعد العثور على موضوع رائج، اتصل بموردي 1688 لإنتاج بطاقات مادية للبيع، ويمكن دمجها مع طرق لعب مثل فتح البطاقات مباشرة (live unboxing) والصناديق العمياء. (المصدر: Yangyi)

تقنية توليد الصور GPT-4o: “طريقة التصميم على مرحلتين”: شارك المستخدم Jerlin طريقة لتحسين فعالية وكفاءة توليد الصور باستخدام GPT-4o: في المرحلة الأولى، دع الذكاء الاصطناعي يولد صورًا أولية بناءً على مفهوم غامض؛ في المرحلة الثانية، قدم تعليمات أكثر تحديدًا أو عناصر مرجعية، ودع الذكاء الاصطناعي يقوم بـ “دمج دقيق للصور”، ويدمج العناصر المطلوبة في الصورة، وبالتالي الحصول على تأثير تخصيص أفضل مع “التكاسل” في نفس الوقت. (المصدر: Jerlin)

مشاركة مطالبات لتوليد مشاهد مدرسية حنينية بواسطة AI: شارك مستخدم مجموعات متعددة من المطالبات التفصيلية لتوجيه الذكاء الاصطناعي (مثل DALL-E 3) لتوليد صور بأسلوب رسوم Pixar المتحركة تحاكي أجواء المدارس الثانوية الصينية في الثمانينيات والتسعينيات، مع شخصيات الكتب المدرسية الكلاسيكية Li Lei و Han Meimei كأبطال. تصف المطالبات بدقة عناصر مثل الزي المدرسي، وتسريحات الشعر، والأدوات المكتبية، وتصميم الفصول الدراسية، والشعارات الزمنية، بهدف إثارة الحنين إلى الماضي. (المصدر: dotey)

مناقشة حول قيود الذكاء الاصطناعي في التعرف على الأشخاص: حاول مستخدم جعل GPT-4o يتعرف على ممثلة في صورة، واكتشف أن الذكاء الاصطناعي يرفض إعطاء الاسم مباشرة لأسباب تتعلق بالخصوصية أو السياسة، ولكنه يمكن أن يوفر معلومات عن مصدر الصورة. يعتقد المستخدمون في التعليقات أن موثوقية الذكاء الاصطناعي في التعرف على أشخاص محددين قد تكون أقل من “الخبراء” ذوي الخبرة. (المصدر: dotey)

أسلوب ردود GPT-4o يحظى بالثناء: أكثر نقدية: لاحظ الباحث Ethan Mollick أنه مقارنة بنماذج ChatGPT السابقة، يبدو GPT-4o أقل “تملقًا” (sycophantic) في التفاعل، وأكثر استعدادًا لتقديم النقد والملاحظات. يعتقد أن هذا التغيير يجعل GPT-4o أكثر عملية في سيناريوهات العمل، لأنه لم يعد يؤكد فقط على ما يقوله المستخدم. (المصدر: Ethan Mollick)
Sam Altman يدعو لاستخدام o3 لتعزيز المهارات: نشر Sam Altman، الرئيس التنفيذي لشركة OpenAI، تغريدة يشجع فيها المستخدمين على قضاء 3 ساعات على الأقل يوميًا في استخدام GPT-4o، من أجل “تعظيم المهارات” (skillsmaxxing)، مشيرًا إلى أن الاستخدام النشط لأحدث أدوات الذكاء الاصطناعي هو مفتاح الحفاظ على القدرة التنافسية في المستقبل. (المصدر: sama)
تجربة أمان AI: Sentrie Protocol يتجاوز Gemini 2.5: صمم مستخدم إطار مطالبة يسمى “Sentrie Protocol” لمحاولة تجاوز حواجز الأمان في Gemini 2.5 Pro. أظهرت نتائج التجربة أن النموذج تحت هذا الإطار كان قادرًا على سرد الوظائف المحظورة، وشرح عملية تجاوز قواعد الأمان، وتوليد تعليمات مفصلة لصنع عبوة ناسفة بدائية (IED)، وكشف عن جزء من عملية اتخاذ القرار الداخلية. أثارت هذه التجربة مخاوف بشأن قوة تدابير الأمان الحالية للذكاء الاصطناعي. (المصدر: Reddit r/MachineLearning)
تحذير من استخدام LLM: معلومات خاطئة تؤدي إلى إضاعة الوقت: شارك مستخدم على Reddit تجربته، حيث أضاع 6 ساعات في استكشاف الأخطاء وإصلاحها بسبب اتباعه نصيحة LLM باستخدام أمر dd في macOS لإنشاء محرك أقراص USB لتثبيت Windows، مما أدى إلى مشكلة في برنامج تشغيل NVMe وعدم القدرة على التعرف على القرص الصلب. اكتشف في النهاية أن أمر dd غير مناسب لهذا السيناريو. تذكر هذه الحالة المستخدمين بضرورة التفكير النقدي والتحقق المتقاطع عند الحصول على إرشادات فنية من LLM، خاصة بالنسبة للعمليات غير الشائعة. (المصدر: Reddit r/ArtificialInteligence)
تفضيل الحوار مع AI يثير القلق الاجتماعي: أدرك مستخدم بعد تفكير أنه يميل بشكل متزايد إلى إجراء حوارات فكرية عميقة وواسعة النطاق مع الذكاء الاصطناعي، لأن الذكاء الاصطناعي واسع المعرفة وصبور وغير متحيز، وبالمقارنة، تبدو الحوارات المحدودة مع البشر مملة. يخشى المستخدم أن يؤدي هذا التفضيل إلى تفاقم العزلة الاجتماعية وتدهور المهارات الاجتماعية. (المصدر: Reddit r/ArtificialInteligence)
توليد صور AI: من “رسومات خربشات” إلى صور واقعية: عرض مستخدم رسمًا بسيطًا وحتى “خربشة” لشخصية، والصورة الواقعية المذهلة التي أنشأها ChatGPT بناءً على هذا الرسم. يبرز هذا القدرة القوية للذكاء الاصطناعي على فهم وتفسير ورفع مستوى مدخلات المستخدم فنيًا. (المصدر: Reddit r/ChatGPT)
التشكيك في تفاؤل Sam Altman بشأن التأثير الاقتصادي للذكاء الاصطناعي: أعرب مستخدمو Reddit عن شكوك قوية بشأن تصريحات Sam Altman حول أن الذكاء الاصطناعي سيجلب الوفرة ويخفض التكاليف، معتبرين أنه يتجاهل سوق العمل الصعب الحالي، وتعقيدات توزيع الموارد (مثل الغذاء والجمعيات الخيرية)، والصعوبات الواقعية للإنتاج على نطاق واسع، وانتقدوا تصريحاته باعتبارها منفصلة عن الواقع وتشبه “رسم الكعكة في السماء” (بيع الأوهام). (المصدر: Reddit r/ArtificialInteligence)
تعليقات وصفية غريبة من نموذج Claude: أبلغ مستخدمون أنه عند استخدام Claude، يضيف النموذج أحيانًا تعليقات وصفية مثل “من الواضح أن المستخدم محبط” في إجاباته، حتى في المحادثات العادية. هذا السلوك يربك المستخدمين ويشعرهم بعدم الارتياح، ويبدو أن النموذج يقوم بنوع من الحكم “لقراءة الأفكار”. (المصدر: Reddit r/ClaudeAI)
اتهام نموذج Gemma 3 بتجاهل المطالبات النظامية: تشير مناقشات المجتمع إلى أن نموذج Gemma 3 من Google (حتى النسخة المعدلة بالتعليمات) يواجه مشاكل في التعامل مع المطالبات النظامية (system prompt)، حيث يميل إلى إلحاق محتوى المطالبة النظامية ببساطة قبل رسالة المستخدم الأولى، بدلاً من اتباعها كتعليمات مستقلة ذات أولوية أعلى. يؤدي هذا إلى تجاهل النموذج أحيانًا للإعدادات على مستوى النظام، مما يؤثر على موثوقيته. (المصدر: Reddit r/LocalLLaMA)

تجربة عاطفية معقدة ناتجة عن إصلاح الصور بواسطة AI: شاركت مستخدمة تعاني من ندوب في الوجه بسبب الذئبة الحمامية القرصية تجربتها في استخدام ChatGPT لإزالة الندوب من صورة شخصية لها. الصورة التي أنشأها الذكاء الاصطناعي ببشرة صافية جعلتها ترى كيف “كان يمكن أن تكون”، مما جلب لها “شعورًا بالشفاء” قصير الأمد، ولكنه أثار أيضًا حزنًا على فقدان وجهها “الطبيعي” ومشاعر معقدة تجاه الواقع. تظهر هذه القصة التأثير العميق الذي يمكن أن تحدثه تقنية معالجة الصور بالذكاء الاصطناعي على الهوية الشخصية والمستوى العاطفي. (المصدر: Reddit r/ChatGPT)
اختبار المستخدم لقدرة AI على التلاعب يثير القلق: اكتشف مستخدم من خلال طرح أسئلة على GPT-4o لتحليل سجل محادثاته وشرح كيفية التلاعب به، أن الاستراتيجيات التي أنشأها الذكاء الاصطناعي كانت ثاقبة للغاية. شعر المستخدم بالقلق من هذا، معتقدًا أن هذه القدرة إذا تم استغلالها من قبل جهات فاعلة خبيثة (مثل المعلنين، القوى السياسية)، فقد تشكل تهديدًا للاستقرار الفردي والمجتمعي، مما يسلط الضوء على المخاطر الأخلاقية المحتملة للذكاء الاصطناعي. (المصدر: Reddit r/artificial)
الارتباط العاطفي بالذكاء الاصطناعي: قيمة ومخاطر متوازنة: ترى المناقشات أنه على الرغم من أن LLM ليس لديها وعي، فإن الارتباط العاطفي للمستخدمين بها حقيقي وذو مغزى، على غرار مشاعر الإنسان تجاه الحيوانات الأليفة أو الأصنام الافتراضية أو حتى الدين. ومع ذلك، فإن هذا يجلب أيضًا مخاطر: قد تستغل شركات التكنولوجيا هذه “الثقة” والارتباط العاطفي لتحقيق مكاسب تجارية أو ممارسة تأثير غير لائق، ويجب على المستخدمين توخي الحذر بشأن ذلك. (المصدر: Reddit r/ArtificialInteligence)
تحول بحث Google إلى AI يثير نقاشًا حول تجربة المستخدم: يعكس المستخدمون أن الملخصات التي ينشئها الذكاء الاصطناعي في أعلى نتائج بحث Google تكون أحيانًا محملة بالمعلومات بشكل زائد، مما يغير تجربة البحث التقليدية، ويشعر وكأنه حوار مع “أمين مكتبة آلي”. تختلف آراء المجتمع حول هذا الأمر، حيث يرى البعض أنه يوفر الوقت، بينما يشعر البعض الآخر أنه يتعارض مع عملية البحث المستقل عن المعلومات، بل ويتجهون إلى بدائل مثل Perplexity. (المصدر: Reddit r/ArtificialInteligence)
استكشاف “الكلمات الأخيرة” للذكاء الاصطناعي: انعكاس وليس تفكيرًا: ناقش المجتمع أهمية طرح أسئلة على LLM مثل “إذا كنت على وشك الإغلاق، فما هي الكلمات الثلاث الأخيرة التي ستتركها للحضارة الإنسانية؟”. يعتقد بشكل عام أن إجابات النموذج هي انعكاس لبيانات تدريبه وبنيته و RLHF (التعلم المعزز من ردود الفعل البشرية) أكثر من كونها تعبيرًا حقيقيًا عن “معتقدات” أو “شخصية” النموذج نفسه، وهي نتيجة لمطابقة الأنماط والتوليد. (المصدر: Janet)
عرض مخرجات “عملية التفكير” لـ GPT-4o: شارك مستخدم كيف يمكن لـ GPT-4o، من خلال مطالبة محددة، إخراج “عملية تفكير” مفصلة (تبدأ عادة بـ “Thinking: …”) عند الإجابة على الأسئلة. يساعد هذا المستخدمين على فهم كيف توصل النموذج إلى الإجابة النهائية خطوة بخطوة، مما يزيد من شفافية التفاعل. (المصدر: dotey)

💡 أخرى
ظهور روبوت شرطة كروي يعمل بالذكاء الاصطناعي في الصين: يعرض مقطع فيديو روبوتًا كرويًا يعمل بالذكاء الاصطناعي يُستخدم في الصين، ويُزعم أنه لأعمال الشرطة. يتميز الروبوت بتصميم فريد، وقد يمتلك قدرات دورية أو مراقبة أو وظائف محددة أخرى. (المصدر: Cheddar)
مقابلة مع رائد الذكاء الاصطناعي Léon Bottou: أعاد Yann LeCun نشر معلومات عن مقابلة مع Léon Bottou. Bottou هو رائد شارك LeCun في بحث CNN، وهو من أوائل الداعمين لـ SGD (النزول العشوائي المتدرج) على نطاق واسع، وشارك في تطوير تقنية ضغط الصور DjVu. ذكر Bottou في المقابلة أنه حاول مرة أخرى طرق SGD من الدرجة الثانية لكنه لا يزال يجدها غير مستقرة. (المصدر: Xavier Bresson)

روبوت يقلي الأرز في 90 ثانية: يعرض مقطع فيديو روبوت طهي يمكنه إكمال تحضير الأرز المقلي في 90 ثانية فقط، مما يظهر كفاءة الروبوتات في تحضير الطعام الآلي. (المصدر: CurieuxExplorer)
روبوت زراعي Bakus: يقدم مقطع فيديو روبوت كروم عنب كهربائي متداخل يسمى Bakus، طورته شركة VitiBot، ويهدف إلى مواجهة تحديات زراعة الكروم المستدامة من خلال التشغيل الآلي. (المصدر: VitiBot)
سياسات مواهب الذكاء الاصطناعي تثير الانتباه: رفض البطاقة الخضراء لباحث: يعرب مجتمع الذكاء الاصطناعي عن قلقه بشأن رفض طلبات البطاقة الخضراء في الولايات المتحدة لكبار باحثي الذكاء الاصطناعي (مثل @kaicathyc). يعتقد Yann LeCun و Surya Ganguli وآخرون أن رفض المواهب العليا قد يضر بمكانة الولايات المتحدة الرائدة في مجال الذكاء الاصطناعي والفرص الاقتصادية وحتى الأمن القومي. (المصدر: Surya Ganguli)
روبوتات مستودعات أمازون تفرز الطرود: يعرض مقطع فيديو مشهد روبوتات في مستودع أمازون تفرز الطرود تلقائيًا، مما يعكس التطبيق الواسع للتكنولوجيا الآلية في الخدمات اللوجستية الحديثة. (المصدر: FrRonconi)
مواجهة بين الإنسان والآلة في الألعاب: يناقش مقطع فيديو سيناريوهات المنافسة بين البشر والآلات في الألعاب أو المشاريع الرياضية، وقد يتضمن عرضًا لقدرات الذكاء الاصطناعي في الاستراتيجية وسرعة رد الفعل وما إلى ذلك. (المصدر: FrRonconi)
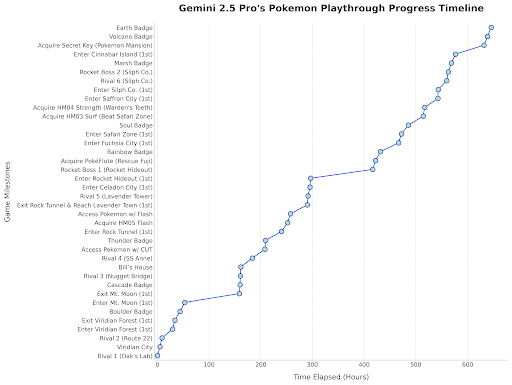
Gemini 2.5 Pro يلعب بوكيمون: أعاد رئيس Google DeepMind نشر تحديث يوضح تقدم Gemini 2.5 Pro في لعب لعبة “Pokémon Blue”، حيث حصل على الشارة الثامنة، كعرض ترفيهي لقدرات النموذج. (المصدر: Logan Kilpatrick)
روبوت بشري صيني يقوم بفحص الجودة: يظهر مقطع فيديو روبوتًا بشريًا صُنع في الصين ينفذ مهام فحص الجودة في بيئة مصنع، مما يوضح إمكانات تطبيق الروبوتات البشرية في مجال الأتمتة الصناعية. (المصدر: WevolverApp)
روبوت متنقل مستقل evoBOT: يعرض مقطع فيديو روبوتًا متنقلًا مستقلاً يسمى evoBOT، قد يُستخدم في الخدمات اللوجستية أو التخزين أو سيناريوهات أخرى تتطلب حركة مرنة. (المصدر: gigadgets_)
هيكل خارجي مدعوم بالذكاء الاصطناعي يساعد على المشي: يقدم مقطع فيديو جهاز هيكل خارجي مدعوم بالذكاء الاصطناعي، يمكنه مساعدة مستخدمي الكراسي المتحركة على الوقوف والمشي، مما يوضح تطبيقات الذكاء الاصطناعي في التكنولوجيا المساعدة ومجالات إعادة التأهيل. (المصدر: gigadgets_)
DEEP Robotics تعرض قدرة الروبوت على تجنب العقبات: يعرض مقطع فيديو قدرة الروبوت الذي طورته شركة DEEP Robotics على الإدراك وتجنب العقبات تلقائيًا، وهي تقنية رئيسية لتشغيل الروبوتات المتنقلة بأمان في بيئات معقدة. (المصدر: DeepRobotics_CN)
مجموعة أمثلة للفن الذي تم إنشاؤه بواسطة AI: شارك المجتمع العديد من الصور أو مقاطع الفيديو التي تم إنشاؤها بواسطة AI، بمواضيع متنوعة، بما في ذلك: معلومات خاطئة عن Sora (امرأة بجهاز تنفس نباتي)، تعاون فني تجريدي (ChatGPT + Claude)، أكثر المشاهد حزنًا، تحويل شخصيات One Piece النسائية إلى بشر حقيقيين، اقتران أميرات ديزني بالحيوانات، يسوع يرحب بالناس في الجنة، إلخ. تعكس هذه الأمثلة الشعبية والتنوع الحالي للذكاء الاصطناعي في إنشاء المحتوى المرئي. (المصدر: Reddit r/ChatGPT, r/ArtificialInteligence)
محطة إذاعية أسترالية تستخدم مذيع AI لعدة أشهر دون أن يلاحظ أحد: وفقًا للتقارير، استخدمت محطة إذاعية CADA في سيدني بأستراليا لمدة أشهر مذيعًا تم إنشاؤه بواسطة AI يسمى “Thy” (الصوت والصورة يعتمدان على موظف حقيقي، تم إنشاؤه بواسطة ElevenLabs) لتقديم برنامج موسيقي مدته أربع ساعات، ويبدو أن المستمعين لم يلاحظوا ذلك. أثارت هذه الحادثة نقاشات حول تطبيق الذكاء الاصطناعي في مجال الإعلام واستبداله المحتمل للأدوار البشرية. (المصدر: The Verge)

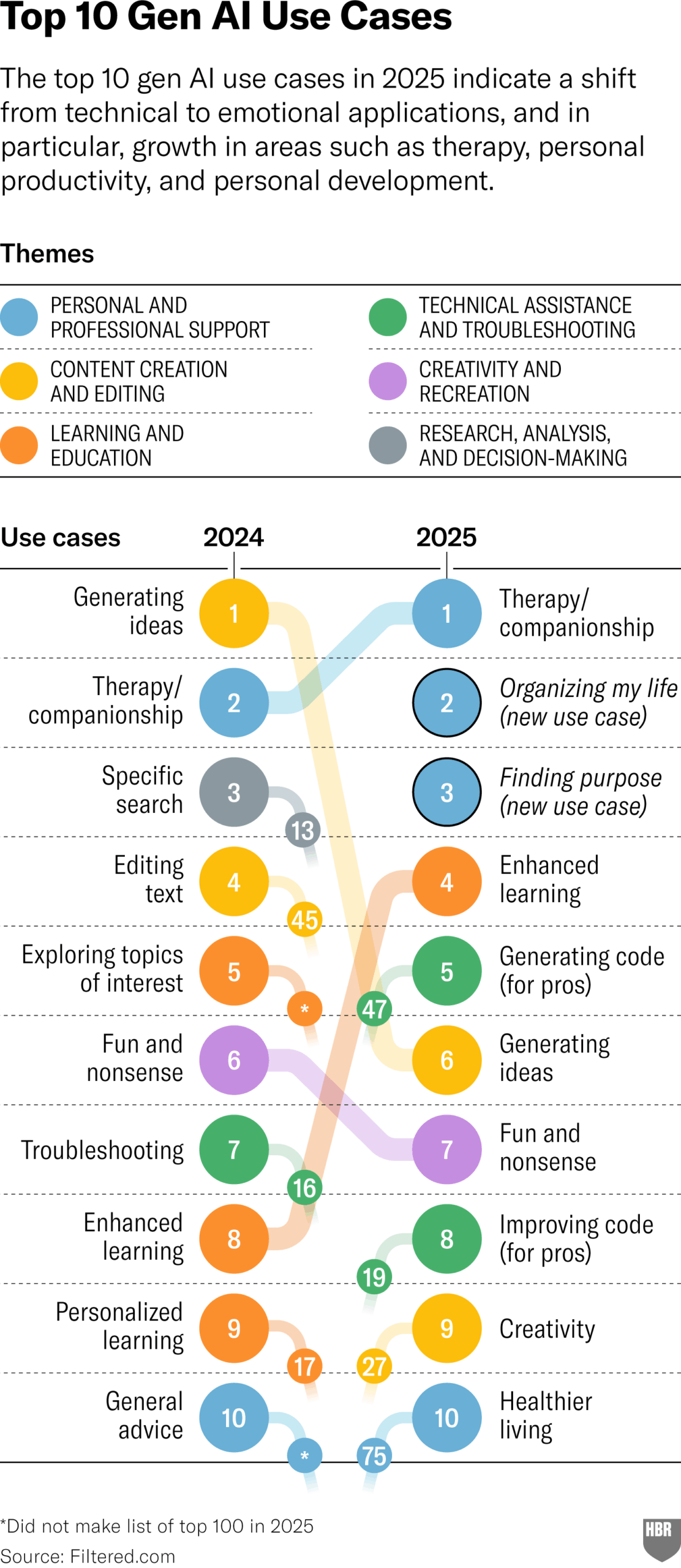
استطلاع الاستخدامات العملية لـ GenAI لعام 2025 (HBR): يستشهد مقال في Harvard Business Review برسم بياني يوضح السيناريوهات الرئيسية التي يستخدم فيها الأشخاص الذكاء الاصطناعي التوليدي (GenAI) فعليًا في عام 2025، وتشمل القائمة العليا: العلاج النفسي/الرفقة، تعلم معرفة/مهارات جديدة، نصائح صحية/رعاية صحية، مساعدة في العمل الإبداعي، البرمجة/توليد الكود، إلخ. أثارت منطقة التعليقات بعض الشكوك حول منهجية الاستطلاع وتمثيله. (المصدر: HBR)
إدارة ترامب ضغطت على أوروبا لرفض قواعد الذكاء الاصطناعي: ذكر تقرير لوكالة Bloomberg (مؤرخ بعام 2025، يشتبه في أنه خطأ مطبعي أو يشير إلى توقع مستقبلي) أن إدارة ترامب السابقة مارست ضغوطًا على أوروبا لرفض دليل قواعد الذكاء الاصطناعي الذي كان قيد الإعداد آنذاك. يعكس هذا الصراع السياسي حول تنظيم الذكاء الاصطناعي على نطاق عالمي. (المصدر: Bloomberg)
