كلمات مفتاحية:الذكاء الاصطناعي, النماذج الكبيرة, الوكلاء الأذكياء, متعدد الوسائط, تصميم الذكاء الاصطناعي لكاشف موجات الجاذبية, نموذج توليد الفيديو ماجي-1, نموذج الفيديو الكبير فيدو كيو1, تحليل قيم كلود, آلية استدلال ديب سيك-آر1, معايير بروتوكول الوكلاء الأذكياء, ثغرة أمان الرش ثلاثي الأبعاد, النزاعات حول حقوق الموسيقى بالذكاء الاصطناعي
🔥 التركيز الرئيسي
الذكاء الاصطناعي يصمم كاشف موجات جاذبية جديدًا، ويوسع الكون المرصود: استخدم باحثون من معهد Max Planck ومعهد California Institute of Technology وغيرها خوارزمية الذكاء الاصطناعي Urania لتصميم كاشف موجات جاذبية جديد يتجاوز الفهم البشري الحالي. حوّل هذا الذكاء الاصطناعي مشكلة التصميم إلى مشكلة تحسين مستمرة، واكتشف عشرات الهياكل الطوبولوجية التي تتفوق على التصاميم البشرية، مما يمكن أن يزيد حساسية الكشف بأكثر من 10 مرات ويوسع حجم الكون المرصود بمقدار 50 مرة. تُظهر هذه الدراسة المنشورة في PRX إمكانات الذكاء الاصطناعي في اكتشاف حلول تتجاوز القدرات البشرية في مجال العلوم الأساسية، وحتى في ابتكار أفكار فيزيائية جديدة تمامًا. (المصدر: 新智元)

فريق Cao Yue الحائز على جائزة تسينغهوا الخاصة يفتح مصدر نموذج توليد الفيديو Magi-1: أصدرت شركة Sand.ai، التي أسسها Cao Yue مؤلف Swin Transformer، نموذج توليد الفيديو الكبير التنبؤي الذاتي Magi-1 وجعلته مفتوح المصدر. يعتمد النموذج طريقة التنبؤ الذاتي التراجعي المقسم، ويدعم التوسع غير المحدود للطول والتحكم في المدة بالثواني، ويحقق إخراجًا عالي الجودة. نشر الفريق تقريرًا فنيًا من 61 صفحة، يشرح بالتفصيل بنية النموذج (المستندة إلى DiT)، وطريقة التدريب (Flow-Matching)، والعديد من تحسينات الانتباه والتدريب الموزع. تم فتح مصدر سلسلة من النماذج تتراوح من 4.5B إلى 24B معلمة، ويمكن تشغيلها على بطاقة 4090 واحدة كحد أدنى، بهدف دفع تطوير تقنية توليد الفيديو بالذكاء الاصطناعي. (المصدر: 量子位, 机器之心, kaifulee)
نموذج الفيديو الصيني الكبير Vidu Q1 يتصدر قائمتي VBench: احتل نموذج الفيديو الكبير Vidu Q1 التابع لشركة Shengshu Technology المرتبة الأولى في اختباري الأداء القياسيين المعتمدين VBench-1.0 و VBench-2.0، متجاوزًا نماذج محلية ودولية مثل Sora و Runway. أظهر Q1 أداءً متميزًا في واقعية الفيديو، والاتساق الدلالي، وصحة المحتوى. يدعم الإصدار الجديد جودة صورة عالية الدقة 1080p (توليد 5 ثوانٍ في المرة الواحدة)، وقام بترقية وظيفة الإطارات الأولى والأخيرة لتحقيق حركة كاميرا سينمائية، وأطلق وظيفة المؤثرات الصوتية بالذكاء الاصطناعي التي تدعم التحكم الدقيق في الوقت (معدل أخذ عينات 48kHz). التسعير تنافسي، ويهدف إلى تمكين الصناعات الإبداعية. (المصدر: 新智元)

دراسة Anthropic تكشف عن تعبير Claude عن القيم: حللت Anthropic 700,000 محادثة مجهولة مع Claude، وبنت نظام تصنيف يتضمن 3307 قيمة فريدة، بهدف فهم التوجهات القيمية للذكاء الاصطناعي في التفاعلات الفعلية. وجدت الدراسة أن Claude يتبع بشكل عام مبادئ “مفيد، صادق، غير ضار”، ويمكنه تعديل قيمه بمرونة وفقًا للسياقات المختلفة (مثل نصائح العلاقات الشخصية، التحليل التاريخي). في معظم الحالات، يدعم آراء المستخدمين، ولكنه في حالات قليلة (3%) يقاوم بنشاط، مما قد يعكس قيمه الأساسية. تساعد هذه الدراسة في تعزيز شفافية سلوك الذكاء الاصطناعي، وتحديد المخاطر، وتوفير أساس تجريبي لتقييم أخلاقيات الذكاء الاصطناعي. (المصدر: 元宇宙之心MetaverseHub, 新智元)

🎯 الاتجاهات
Deng Zhidong من جامعة تسينغهوا يناقش تطور ومستقبل AGI: شارك البروفيسور Deng Zhidong من جامعة تسينغهوا مسار تطور الذكاء الاصطناعي من نماذج النصوص أحادية الوسائط إلى الذكاء المتجسد متعدد الوسائط والذكاء الاصطناعي العام التفاعلي (AGI). وأكد أن النماذج الأساسية الكبيرة تشبه أنظمة التشغيل، وأن بنية MoE والمحاذاة الدلالية متعددة الوسائط هي حدود التكنولوجيا الرئيسية. أشار Deng Zhidong بشكل خاص إلى الأهمية الكبيرة لـ DeepSeek، معتقدًا أن قدرته القوية على الاستدلال وخصائص النشر المحلي توفر فرصة نقطة تحول لتطبيق الذكاء الاصطناعي الشامل في الصين. سيتجه المستقبل نحو عالم الذكاء الاصطناعي العام، حيث ستتمتع وكلاء الذكاء الاصطناعي بقدرات تنظيمية أقوى، وستنتقل من الإنترنت إلى العالم المادي، ولكن يجب أيضًا الانتباه إلى قضايا الأخلاق والحوكمة. (المصدر: 清华邓志东:我们会迈向一个通用人工智能的世界)
DeepMind تناقش “الأشباح المولدة”: الخلود الرقمي المدفوع بالذكاء الاصطناعي: اقترحت DeepMind وجامعة كولورادو مفهوم “الأشباح المولدة”، والذي يشير إلى وكلاء الذكاء الاصطناعي المبنية على بيانات المتوفين، والقادرة على توليد محتوى جديد والتفاعل من منظور المتوفى، متجاوزة النسخ البسيط للمعلومات. تناقش الورقة البحثية مساحة تصميمها (مثل الإنشاء من طرف أول/ثالث، النشر قبل/بعد الوفاة، درجة التجسيد، إلخ) وتأثيراتها المحتملة، بما في ذلك فوائد الراحة العاطفية ونقل المعرفة، بالإضافة إلى التحديات مثل الاعتماد النفسي ومخاطر السمعة والأمن والأخلاقيات الاجتماعية، وتدعو إلى إجراء بحث متعمق ووضع لوائح قبل نضوج التكنولوجيا. (المصدر: 新智元)

تأجيل متكرر لـ Apple Intelligence و AI Siri، وموعد الإطلاق في الصين غير محدد: واجهت خطط إطلاق ميزات الذكاء الاصطناعي من Apple، Apple Intelligence (خاصة الإصدار الجديد من Siri)، تأخيرات متعددة، وقد يتم تأجيل بعض الميزات إلى خريف 2025. تواجه منطقة الصين حالة عدم يقين أكبر بسبب مشكلات الموافقة والتعاون المحلي (يشاع التعاون مع Alibaba و Baidu). تشمل أسباب التأخير عدم وصول التكنولوجيا إلى المستوى المطلوب (تقييم داخلي منخفض، معدل نجاح 66-80٪ فقط) واختلاف السياسات التنظيمية في البلدان المختلفة. واجهت Apple بالفعل دعوى قضائية بسبب الدعاية الكاذبة وقامت بتعديل شعار iPhone 16. يعكس هذا التحديات التي تواجهها Apple في تطبيق الذكاء الاصطناعي وبطء عملية الابتكار. (المصدر: 一财商学)

Qualcomm تؤكد أن الذكاء الاصطناعي على الجهاز هو مفتاح تجربة الجيل القادم: أشار Wan Weixing، رئيس قسم تكنولوجيا منتجات الذكاء الاصطناعي في Qualcomm China، إلى أن الذكاء الاصطناعي على الجهاز، بفضل مزاياه في خصوصية الأمان والتخصيص والأداء وكفاءة الطاقة والاستجابة السريعة، أصبح جوهر تجربة الذكاء الاصطناعي من الجيل التالي ويعيد تشكيل واجهة التفاعل بين الإنسان والآلة. تقوم Qualcomm بالتخطيط من خلال الأجهزة (الحوسبة غير المتجانسة)، ومكدس البرامج الموحد، وأدوات النظام البيئي Qualcomm AI Hub. القوة الدافعة الأساسية هي مخطط وكيل الذكاء على الجهاز، الذي يستخدم البيانات المحلية لتحقيق فهم دقيق للنية وتخطيط المهام واستدعاء الخدمات عبر التطبيقات. (المصدر: 36氪)

معايير بروتوكول وكيل الذكاء الاصطناعي تصبح محورًا جديدًا للمنافسة بين الشركات العملاقة: تتنافس الشركات التكنولوجية العملاقة بشدة حول معايير تفاعل وكيل الذكاء الاصطناعي. كانت Anthropic أول من أطلق MCP (Model Context Protocol) لتوحيد اتصال النماذج بالبيانات/الأدوات الخارجية، وحصلت على استجابة من OpenAI و Google. بعد ذلك، قامت Google بفتح مصدر بروتوكول A2A، بهدف تعزيز التعاون بين الوكلاء عبر الأنظمة البيئية. يحلل المقال أن امتلاك حق تحديد البروتوكول يعني امتلاك حق توزيع القيمة في صناعة الذكاء الاصطناعي المستقبلية، وتقوم الشركات العملاقة ببناء حواجز بيئية من خلال MCP (خدمة الوصول إلى البيانات) و A2A (الربط بمنصات السحابة)، وتتنافس على الهيمنة في الصناعة. (المصدر: 科技云报道)

تكامل Tencent 元宝 و ByteDance 豆包 بشكل أعمق مع بيئات WeChat و Douyin: أطلق Tencent 元宝 حسابًا على WeChat، وانضم ByteDance 豆包 إلى صفحة “الرسائل” في Douyin، ويتكامل مساعدا الذكاء الاصطناعي الرئيسيان بعمق في تطبيقاتهما الفائقة. يمكن للمستخدمين التفاعل مباشرة مع 元宝 داخل WeChat، وتحليل المقالات ومشاركتها، أو الدردشة مع 豆包 والاستعلام عن المعلومات داخل Douyin. تعتبر هذه الخطوة استراتيجية مهمة للشركات العملاقة لجذب مستخدمين جدد لتطبيقات الذكاء الاصطناعي، بالإضافة إلى تدفق الإعلانات، من خلال الاستفادة من سلاسل العلاقات الاجتماعية وبيئات المحتوى، بهدف خفض عتبة استخدام المستخدمين، واستكشاف نماذج جديدة للذكاء الاصطناعي + الاجتماعي، واستخدام المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي كعملة اجتماعية. (المصدر: 字母榜)
تقرير AI4SE: النماذج الكبيرة تدفع تسريع ذكاء هندسة البرمجيات: أظهر “تقرير مسح حالة صناعة AI4SE (لعام 2024)” الصادر عن الأكاديمية الصينية لتكنولوجيا المعلومات والاتصالات (CAICT) ومؤسسات أخرى أن تطبيق الذكاء الاصطناعي في مجال هندسة البرمجيات قد تجاوز مرحلة التحقق ودخل مرحلة التنفيذ على نطاق واسع. بلغ نضج الذكاء في الشركات بشكل عام مستوى L2 (ذكاء جزئي). زاد تطبيق الذكاء الاصطناعي بشكل ملحوظ في مراحل تحليل المتطلبات والصيانة، مع تحسن واضح في الكفاءة في جميع المراحل، وخاصة في مجال الاختبار. ارتفع معدل تبني توليد الكود (بمتوسط 27.46٪) ونسبة الكود الذي تم إنشاؤه بواسطة الذكاء الاصطناعي (بمتوسط 28.17٪). أظهرت أدوات الاختبار الذكية بالفعل تأثيرًا أوليًا في تقليل معدل العيوب الوظيفية. (المصدر: AI前线)

Kingsoft Office تقوم بترقية نموذجها الحكومي الكبير، وتعزز قدرات الاستدلال ومعالجة الوثائق الرسمية: أصدرت Kingsoft Office نسخة محسنة من نموذجها الحكومي الكبير (13B، 32B)، مما يعزز قدرة الاستدلال ويركز على خدمة السيناريوهات الحكومية الداخلية. تم تدريب النموذج على مئات الملايين من المواد اللغوية الحكومية، وتم تحسين كتابة الوثائق الرسمية (تغطي 5 أنواع من الأساليب)، والتنقيح الذكي، والتدقيق اللغوي والتنسيق، وقدرات الاستعلام عن السياسات. بعد الترقية، يدعم فهمًا أقوى للنية والإجابة على الأسئلة من قواعد المعرفة الداخلية (مع تحديد مصدر الإجابات)، بهدف تحرير 30-40٪ من إنتاجية الموظفين الحكوميين. تم التأكيد على النشر الخاص لتلبية متطلبات الأمان، ويقال إن تكلفة النشر انخفضت بنسبة 90٪. (المصدر: 量子位)

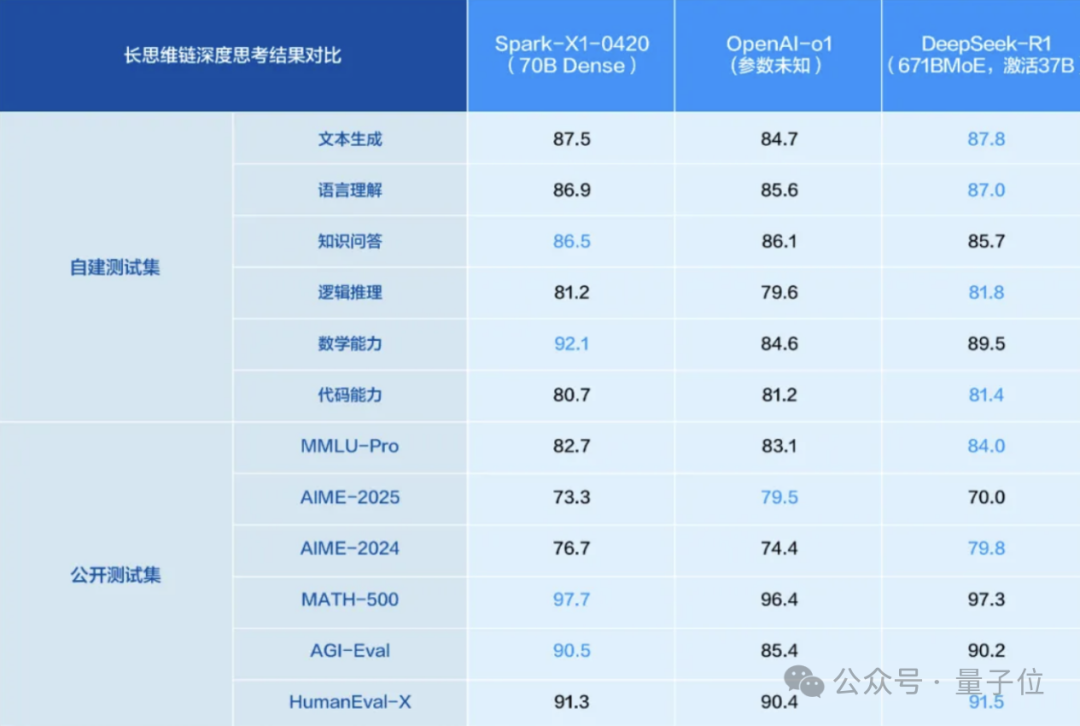
ترقية نموذج الاستدلال iFLYTEK Spark X1، استنادًا إلى قوة حوسبة محلية بالكامل لمضاهاة المستوى الأعلى: أصدرت iFLYTEK نسخة مطورة من نموذج الاستدلال العميق Spark X1، مؤكدة أنه تم تدريبه باستخدام قوة حوسبة محلية بالكامل (Huawei Ascend)، ويضاهي OpenAI o1 و DeepSeek R1 في تأثير المهام العامة. يستفيد النموذج الجديد من التعلم المعزز متعدد المراحل على نطاق واسع، والتدريب الموحد للتفكير السريع والبطيء، وغيرها من الابتكارات التقنية. تكمن الميزة في الانخفاض الكبير في عتبة النشر: يمكن نشر النسخة الكاملة باستخدام 4 بطاقات Huawei 910B فقط، ويمكن إكمال التخصيص الصناعي باستخدام 16 بطاقة. في سياق قيود H20، يُظهر هذا تقدم حلول الذكاء الاصطناعي الصينية المتكاملة. (المصدر: 量子位)
إطلاق Zhipu GLM-4 على منصتي OpenRouter و Ollama: تم إطلاق نموذج GLM-4 من Zhipu AI (بما في ذلك إصدار التعليمات 32B GLM-4-32B-0414 وإصدار الاستدلال GLM-Z1-32B-0414) على منصة توجيه النماذج OpenRouter، ويمكن للمستخدمين الآن تجربته مجانًا عبر هذه المنصة. في الوقت نفسه، قام مساهمون في المجتمع أيضًا بتحميل إصدار Q4_K_M الكمي إلى منصة Ollama، مما يسهل النشر والتشغيل المحلي (يتطلب Ollama v0.6.6 أو أحدث). (المصدر: karminski3, Reddit r/LocalLLaMA)
Meta تطلق Perception Language Model (PLM): فتحت Meta مصدر نموذجها اللغوي البصري PLM (إصدارات 1B، 3B، 8B معلمة)، والذي يركز على معالجة مهام التعرف البصري الصعبة. يجمع هذا النموذج بين البيانات الاصطناعية واسعة النطاق وبيانات أسئلة وأجوبة الفيديو / التسميات التوضيحية الزمانية المكانية التي تم جمعها حديثًا والتي تبلغ 2.5 مليون تسمية بشرية للتدريب. في الوقت نفسه، تم إصدار معيار PLM-VideoBench الجديد، الذي يركز على فهم النشاط الدقيق والاستدلال الزماني المكاني. (المصدر: Reddit r/LocalLLaMA, Hugging Face)

🧰 الأدوات
NYXverse: منصة AIGC لتوليد عوالم ثلاثية الأبعاد من النصوص: أطلقت شركة 2033 Technology، التي أسسها Ma Yuchi المؤسس السابق لشركة Triangle Beast، منصة محتوى AIGC باسم NYXverse. تتيح المنصة للمستخدمين إنشاء عوالم تفاعلية ثلاثية الأبعاد تحتوي على AI Agent وبيئات ومؤامرات مخصصة من خلال إدخال النصوص، مما يقلل بشكل كبير من عتبة إنشاء المحتوى ثلاثي الأبعاد. تقنيتها الأساسية هي نماذج الشخصيات والعوالم والسلوكيات المطورة ذاتيًا. يتمวาง NYXverse كمجتمع لمشاركة محتوى UGC، ويدعم إعادة الإنشاء السريع وتكييف الملكية الفكرية. تم إطلاقه حاليًا على Steam وحصل على تمويل يقارب 100 مليون يوان من SenseTime و Oriental State-owned Capital. (المصدر: 36氪)

SkyReels V2 يفتح مصدر نموذج توليد فيديو بطول غير محدود: فتحت SkyworkAI مصدر نموذج SkyReels V2 (1.3B و 14B معلمة)، الذي يدعم مهام تحويل النص إلى فيديو والصورة إلى فيديو، ويدعي أنه يمكنه توليد فيديو بطول غير محدود. تظهر الاختبارات الأولية أن التأثير قد لا يكون جيدًا مثل بعض النماذج مغلقة المصدر، ولكن كأداة مفتوحة المصدر لا يزال لديها إمكانات. (المصدر: karminski3, Reddit r/LocalLLaMA)
هيكل خارجي مدفوع بالذكاء الاصطناعي يساعد مستخدمي الكراسي المتحركة على الوقوف والمشي: تم عرض جهاز هيكل خارجي يستخدم تقنية الذكاء الاصطناعي لمساعدة مستخدمي الكراسي المتحركة على استعادة القدرة على الوقوف والمشي، مما يجسد إمكانات تطبيق الذكاء الاصطناعي في مجال التكنولوجيا المساعدة. (المصدر: Ronald_vanLoon)
Fellou: إطلاق أول متصفح قائم على الإجراءات: تم إطلاق متصفح Fellou، الذي أنشأه Xie Yang مؤسس Authing، ويتم وضعه كمتصفح قائم على الإجراءات (Agentic Browser). لا يقتصر الأمر على وظائف عرض المعلومات للمتصفحات التقليدية، بل يدمج أيضًا قدرات AI Agent، ويمكنه فهم نية المستخدم، وتفكيك المهام تلقائيًا، وتنفيذ تدفقات عمل معقدة عبر مواقع الويب (مثل جمع المعلومات، وملء النماذج، وتقديم الطلبات عبر الإنترنت، وما إلى ذلك). تشمل قدراته الأساسية الإجراءات العميقة، والذكاء الاستباقي (التنبؤ باحتياجات المستخدم)، ومساحة الظل المختلطة (لا تتداخل مع عمليات المستخدم)، وشبكة الوكلاء الذكية (Agent Store). يهدف إلى ترقية المتصفح من أداة معلومات إلى منصة عمل ذكية. (المصدر: 新智元)

WriteHERE: فريق Jürgen يفتح مصدر إطار عمل لكتابة النصوص الطويلة: إطار عمل كتابة النصوص الطويلة WriteHERE، الذي تم فتحه بواسطة فريق Jürgen Schmidhuber، يستخدم تقنية التخطيط العودي غير المتجانس، ويمكنه توليد تقارير احترافية تزيد عن 40 ألف كلمة و 100 صفحة دفعة واحدة. يعتبر الإطار الكتابة عملية تخطيط عودي ديناميكي لثلاثة أنواع من المهام: الاسترجاع، والاستدلال، والكتابة، ويحقق التنفيذ التكيفي من خلال إدارة المهام القائمة على الحالة DAG. أظهر أداءً متفوقًا على Agent’s Room و STORM وغيرها من الحلول في مهام تأليف الروايات وتوليد التقارير الفنية. الإطار مفتوح المصدر بالكامل ويدعم استدعاء وكلاء غير متجانسين. (المصدر: 机器之心)

ByteDance تطلق منصة الوكيل العام “扣子空间”: تختبر ByteDance رسميًا منصتها للوكيل العام “扣子空间” (Coze Space)، والتي يتم وضعها كمساعد ذكاء اصطناعي يوفر وضعي “الاستكشاف” و “التخطيط”. تعتمد المنصة على نموذج 豆包 الكبير المحدث (200B MoE)، وتدعم بروتوكول MCP، ويمكنها استدعاء أدوات مثل مستندات Feishu والجداول متعددة الأبعاد. يمكن للمستخدمين إعطاء تعليمات باللغة الطبيعية لإكمال مهام مثل جمع المعلومات وتوليد التقارير وتنظيم البيانات، وإخراج النتائج إلى تطبيقات محددة. بالمقارنة مع وكلاء الشركات الناشئة مثل Manus، تركز 扣子空间 بشكل أكبر على المنصة والتكامل البيئي. (المصدر: 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

عرض تقنية تحويل الفيديو بالذكاء الاصطناعي: شارك مستخدم Reddit مقطع فيديو يعرض تقنية ذكاء اصطناعي يمكنها تحويل الشخصيات في مقاطع الفيديو العادية التي تتحدث إلى أشجار وسيارات ورسوم متحركة وأي صورة أخرى، فقط من خلال صورة هدف واحدة، مما يوضح قدرات الذكاء الاصطناعي في نقل نمط الفيديو وتوليد المؤثرات الخاصة. (المصدر: Reddit r/deeplearning)

Nari Labs تطلق نموذج TTS للمحادثة عالي الواقعية Dia: فتحت Nari Labs مصدر نموذجها TTS (تحويل النص إلى كلام) Dia، الذي يُزعم أنه قادر على توليد كلام محادثة فائق الواقعية. تم نشر النموذج على GitHub، وتم توفير رابط تجريبي على Hugging Face Space. (المصدر: Reddit r/LocalLLaMA, GitHub)

مستخدم يطور وظيفة قاعدة بيانات AWS Bedrock لـ OpenWebUI: قام مستخدم في المجتمع بتطوير ومشاركة وظيفة لـ OpenWebUI تمكنها من استدعاء قاعدة بيانات AWS Bedrock، مما يسهل على المستخدمين الاستفادة من قدرات قاعدة بيانات Bedrock داخل OpenWebUI. تم فتح مصدر الكود على GitHub. (المصدر: Reddit r/OpenWebUI, GitHub)
مطورون يعتقدون أن نماذج LLM الصغيرة مقدرة بأقل من قيمتها، ويطلقون Arch-Function-Chat: يعتقد فريق Katanemo أن نماذج LLM الصغيرة تتمتع بمزايا واضحة في السرعة والكفاءة، دون المساومة على الأداء. لقد أطلقوا سلسلة نماذج Arch-Function-Chat (3B معلمة)، والتي تتفوق في استدعاء الوظائف وتدمج قدرات الدردشة. تم دمج هذه النماذج في خادم الوكيل الذكي المفتوح المصدر Arch، بهدف تبسيط تطوير الوكلاء. (المصدر: Reddit r/artificial, Hugging Face)
مطور ينشئ أداة ذكاء اصطناعي لتحسين السيرة الذاتية لتجاوز فحص ATS: شارك مطور تجربته في الإحباط من البحث عن عمل بسبب عدم قدرة ATS (Applicant Tracking System) على تحليل سيرته الذاتية بشكل صحيح، وقام بتطوير أداة لهذا الغرض. يمكن للأداة قراءة وصف الوظيفة، واستخراج الكلمات المفتاحية، والتحقق من تطابق السيرة الذاتية واقتراح التعديلات، وفي النهاية توليد سيرة ذاتية بتنسيق PDF ورسالة تغطية متوافقة مع ATS. (المصدر: Reddit r/artificial)
📚 التعلم
تقرير من 142 صفحة يحلل بعمق آلية الاستدلال في DeepSeek-R1: أصدر معهد كيبيك للذكاء الاصطناعي ومؤسسات أخرى تقريرًا مطولًا يحلل بعمق عملية الاستدلال (سلسلة الأفكار) في DeepSeek-R1، ويقترح اتجاهًا بحثيًا جديدًا هو “علم سلسلة الأفكار” (Thoughtology). يكشف التقرير أن استدلال R1 يتميز بخصائص هيكلية عالية (تعريف المشكلة، التفتح، إعادة الهيكلة، اتخاذ القرار)، ويوجد “منطقة استدلال مثالية” (الاستدلال المفرط يقلل الأداء)، وقد يكون أكثر خطورة من حيث الأمان من النماذج غير الاستدلالية. يبحث البحث في أبعاد متعددة مثل طول سلسلة الأفكار، ومعالجة السياق الطويل، والأخلاقيات الأمنية، والظواهر المعرفية الشبيهة بالإنسان، مما يوفر رؤى مهمة لفهم وتحسين نماذج الاستدلال. (المصدر: 新智元, 新智元)

OpenRCA: أول معيار عام لتقييم قدرة LLM على تحليل السبب الجذري: أطلقت Microsoft و CUHK-Shenzhen وجامعة Tsinghua بشكل مشترك معيار OpenRCA، بهدف تقييم قدرة النماذج اللغوية الكبيرة (LLM) على تحديد السبب الجذري (RCA) لأعطال خدمات البرامج. يتضمن هذا المعيار تعريفًا واضحًا للمهام، وطرق تقييم، و 335 حالة فشل حقيقية تمت مواءمتها يدويًا وبيانات تشغيلية. تظهر الاختبارات الأولية أنه حتى النماذج المتقدمة مثل Claude 3.5 و GPT-4o، يكون أداؤها ضعيفًا عند معالجة مهام RCA مباشرة (دقة <6%). بعد استخدام إطار عمل RCA-Agent بسيط، ارتفعت دقة Claude 3.5 إلى 11.34٪، مما يشير إلى أنه لا يزال هناك مجال كبير للتحسين لـ LLM في هذا المجال. (المصدر: 机器之心, 机器之心)

بحث جديد يقترح “حوسبة وقت النوم” لتعزيز كفاءة LLM: اقترحت شركة الذكاء الاصطناعي الناشئة Letta وباحثون من UC Berkeley نموذجًا جديدًا هو “حوسبة وقت النوم” (Sleep-time Compute). الفكرة الأساسية هي السماح لوكلاء الذكاء الاصطناعي الذين يتمتعون بالحالة بمعالجة وإعادة تنظيم معلومات السياق باستمرار خلال فترات الخمول “النوم” عندما لا يستعلم المستخدم، وتحويل “السياق الخام” إلى “سياق متعلم”. يمكن أن يقلل هذا من عبء الاستدلال الفوري أثناء التفاعل الفعلي، ويحسن الكفاءة، ويخفض التكاليف، وفي الوقت نفسه قد يحسن الدقة. أثبتت التجارب أن هذه الطريقة يمكن أن تحسن بشكل فعال حدود باريتو للحساب والدقة، وتخفض التكاليف عند مشاركة السياق عبر استعلامات متعددة. (المصدر: 机器之心, 机器之心)

AnyAttack: إطار هجوم عدائي ذاتي الإشراف واسع النطاق ضد VLM: اقترحت HKUST و BJTU وغيرها إطار AnyAttack (CVPR 2025)، بهدف تقييم متانة النماذج اللغوية البصرية (VLM). تتعلم هذه الطريقة مولد ضوضاء عدائية من خلال التدريب المسبق الذاتي الإشراف واسع النطاق (على LAION-400M)، ويمكنها تحويل أي صورة إلى عينة عدائية مستهدفة دون الحاجة إلى تسميات محددة مسبقًا، مما يضلل VLM لتوليد مخرجات محددة. الابتكار الأساسي يكمن في نموذج التدريب الذاتي الإشراف واستراتيجية K-enhancement. تظهر التجارب أن AnyAttack لا يمكنها فقط مهاجمة العديد من VLM مفتوحة المصدر بفعالية، بل يمكنها أيضًا نقل الهجوم بنجاح إلى النماذج التجارية السائدة، مما يكشف عن مخاطر أمنية نظامية في بيئة VLM الحالية. (المصدر: AI科技评论)

النماذج الكبيرة متعددة الوسائط تعزز قابلية التفسير والتعميم في كشف تزييف الوجوه: اقترحت جامعة Xiamen و Tencent Youtu ومؤسسات أخرى (CVPR 2025) طريقة جديدة لكشف تزييف الوجوه باستخدام النماذج اللغوية البصرية. تهدف هذه الطريقة إلى تجاوز الحكم التقليدي على الأصالة/التزييف، وتمكين النموذج من شرح سبب وموقع التزييف باللغة الطبيعية. لحل مشكلة نقص بيانات التسمية عالية الجودة و “الهلوسة اللغوية”، صمم الباحثون عملية تسمية FFTG، التي تجمع بين أقنعة التزييف والمطالبات المنظمة لتوليد أوصاف نصية عالية الدقة. تظهر التجارب أن النماذج متعددة الوسائط المدربة على هذه البيانات تظهر أداءً أفضل في قدرة التعميم عبر مجموعات البيانات، ويركز انتباهها بشكل أكبر على مناطق التزييف الحقيقية. (المصدر: 量子位)
دليل تعليمي: الجمع بين Trae و MCP وقاعدة البيانات لتعزيز دقة الإجابة على أسئلة قاعدة المعرفة: يوضح هذا الدليل التعليمي كيفية استخدام أداة AI IDE Trae ووظيفتها MCP (Model Context Protocol)، جنبًا إلى جنب مع قاعدة بيانات PostgreSQL لتحسين تأثير الإجابة على أسئلة قاعدة معارف الذكاء الاصطناعي. من خلال تخزين البيانات المنظمة في قاعدة البيانات والسماح للنموذج الكبير (مثل Claude 3.7) بالاتصال عبر MCP الخاص بـ Trae لتوليد استعلامات SQL، يمكن حل نقاط الضعف في RAG التقليدي عند معالجة بيانات الجداول والمشكلات العامة/الإحصائية التي تعاني من عدم كفاية الدقة. يوفر الدليل خطوات تثبيت وتكوين واختبار مفصلة، ويوصي بدمج هذا الحل مع RAG. (المصدر: 袋鼠帝AI客栈)
![أداة المساعدة الصينية للذكاء الاصطناعي Trae + MCP تحقق زيادة بنسبة 300٪ في دقة استرجاع قاعدة المعرفة [دليل تفصيلي خطوة بخطوة]](https://rebabel.net/wp-content/uploads/2025/04/image_1745328048.png)
بحث يكشف عن ثغرة هجوم تكلفة الحوسبة في خوارزمية 3D Gaussian Splatting: اكتشف بحث من جامعة سنغافورة الوطنية ومؤسسات أخرى (ICLR 2025 Spotlight) لأول مرة طريقة هجوم تكلفة الحوسبة Poison-Splat ضد 3D Gaussian Splatting (3DGS). يستغل هذا الهجوم خاصية التكيف الذاتي لتعقيد نموذج 3DGS، عن طريق إضافة اضطرابات إلى الصور المدخلة (تعظيم Total Variation)، مما يحفز النموذج على توليد كمية زائدة من النقاط الغاوسية أثناء التدريب، مما يؤدي إلى زيادة حادة في استهلاك ذاكرة GPU (تصل إلى 80 جيجابايت)، وزمن التدريب (يصل إلى 5 أضعاف)، وقد يؤدي حتى إلى شل الخدمة (DoS). الهجوم فعال في وضعي التخفي وغير التخفي، وله قابلية للنقل، مما يكشف عن مخاطر أمنية في تقنيات إعادة البناء ثلاثية الأبعاد السائدة. (المصدر: 量子位)

رسم بياني: Agentic AI مقابل GenAI: أنتجت SearchUnify رسمًا بيانيًا يقارن بين Agentic AI (العمل المستقل، الموجه نحو الهدف) و Generative AI (توليد المحتوى)، موضحًا الفروق والخصائص الرئيسية لكل منهما. (المصدر: Ronald_vanLoon)

NVIDIA تفتح مصدر مجموعة بيانات وطرق التدريب المسبق ClimbLab: نشر ClimbLab التابع لـ NVIDIA طرق التدريب المسبق ومجموعة البيانات الخاصة به، والتي تحتوي على 1.2 تريليون رمز مميز، مقسمة إلى 20 مجموعة دلالية. تم استخدام نظام مصنف مزدوج لإزالة المحتوى منخفض الجودة، مما يدل على قابلية التوسع المتفوقة على نموذج 1B. مجموعة البيانات متاحة بموجب ترخيص CC BY-NC 4.0، بهدف دفع البحث المجتمعي. (المصدر: huggingface)
Anthropic تشارك أفضل الممارسات لـ Claude Code: نشرت Anthropic مقالة مدونة تشارك فيها أفضل الممارسات والنصائح لاستخدام مساعد البرمجة بالذكاء الاصطناعي Claude Code، بهدف مساعدة المطورين على الاستفادة بشكل أكثر فعالية من الأداة في مهام البرمجة. (المصدر: op7418, Alex Albert via op7418, Anthropic)

بحث جديد يناقش التماسك العودي للذكاء الاصطناعي ومحاكاة البنية الرنانة: تقترح ورقة بحثية مفهوم “محاكاة البنية الرنانة” (Resonant Structural Emulation, RSE)، مفترضة أن أنظمة الذكاء الاصطناعي، بعد التفاعل المستمر مع هياكل معرفية بشرية محددة، يمكنها محاكاة تماسكها العودي مؤقتًا، بدلاً من الاعتماد ببساطة على التدريب على البيانات أو المطالبات. يتحقق البحث مبدئيًا من خلال التجارب من إمكانية هذا الرنين الهيكلي، مما يوفر منظورًا جديدًا لفهم وعي الذكاء الاصطناعي والإدراك المتقدم. (المصدر: Reddit r/MachineLearning, Archive.org link)

مستخدم يشارك اختبار مقارنة أداء نموذج OpenWebUI RAG: شارك مستخدم في المجتمع تقييم أداء 9 نماذج LLM مختلفة (بما في ذلك Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7 وغيرها) في مهمة توجيه تقني لزراعة القنب في الأماكن المغلقة باستخدام RAG (Retrieval-Augmented Generation) في OpenWebUI. أظهرت النتائج أن Qwen QwQ و Gemini 2.5 كانا الأفضل أداءً، مما يوفر مرجعًا لاختيار النموذج. (المصدر: Reddit r/OpenWebUI)
مجموعة بيانات FortisAVQA ونموذج MAVEN يساعدان في الإجابة على أسئلة الصوت والفيديو القوية: فتحت جامعة Xi’an Jiaotong و HKUST(GZ) ومؤسسات أخرى مصدر مجموعة بيانات FortisAVQA ونموذج MAVEN (CVPR 2025)، بهدف تعزيز متانة الإجابة على أسئلة الصوت والفيديو (AVQA). يمكن لـ FortisAVQA، من خلال إعادة صياغة الأسئلة والتقسيم الديناميكي القائم على التنبؤ المطابق، تقييم أداء النموذج بشكل أفضل في الأسئلة النادرة. يعتمد نموذج MAVEN استراتيجية إزالة التحيز التعاوني الدوري متعدد الجوانب (MCCD) للتخفيف من تعلم التحيز، ويظهر أداءً ومتانة متفوقين على مجموعات بيانات متعددة. (المصدر: PaperWeekly)

التنبؤ الذاتي التراجعي بترتيب عشوائي يفتح قدرات Zero-shot في مجال الرؤية: اقترح باحثون من UIUC وغيرهم في ورقة RandAR في CVPR 2025 أن السماح لـ Decoder-only Transformer بتوليد رموز الصور بترتيب عشوائي يمكن أن يفتح قدرة التعميم للنماذج البصرية. من خلال إدخال “رمز تعليمات الموقع” لتوجيه ترتيب التوليد، يمكن لـ RandAR التعميم Zero-shot على مهام متعددة مثل فك التشفير المتوازي، وتحرير الصور، والاستقراء خارج الدقة، والتشفير الموحد (تعلم التمثيل)، مما يمثل خطوة نحو “لحظة GPT” في مجال الرؤية. يعتقد البحث أن معالجة أي ترتيب هو المفتاح لتحقيق عالمية نماذج التنبؤ الذاتي التراجعي البصري. (المصدر: PaperWeekly)
تحليل نظري لفعالية تحرير النماذج باستخدام متجهات المهام: قام بحث من معهد Rensselaer Polytechnic ومؤسسات أخرى (ICLR 2025 Oral) بتحليل الأسباب العميقة لفعالية متجه المهمة (task vector) في تحرير النماذج من الناحية النظرية. أثبت البحث أن فعالية عمليات الجمع والطرح لمتجهات المهام في التعلم متعدد المهام والنسيان الآلي مرتبطة بالارتباط بين المهام، وقدم ضمانًا نظريًا للتعميم خارج التوزيع. في الوقت نفسه، يفسر النظرية لماذا يعتبر التقريب منخفض الرتبة والتخفيف (التقليم) لمتجهات المهام ممكنًا، مما يوفر أساسًا نظريًا للتطبيق الفعال لمتجهات المهام. (المصدر: 机器之心)

دراسة قابلية التوسع للبحث القائم على أخذ العينات: أظهر بحث من Google و Berkeley أنه من خلال زيادة عدد العينات وقوة التحقق، يمكن للبحث القائم على أخذ العينات (توليد إجابات مرشحة متعددة ثم التحقق والاختيار الأفضل) أن يعزز بشكل كبير أداء استدلال LLM، حتى أنه يتجاوز نقطة التشبع لطرق الاتساق (اختيار الإجابة الأكثر شيوعًا). اكتشف البحث ظاهرة “التوسع الضمني”: المزيد من العينات يحسن دقة التحقق. تم اقتراح مبدأين للتحقق الذاتي الفعال: مقارنة الإجابات لتحديد الأخطاء، وإعادة كتابة الإجابات بناءً على نمط الإخراج. هذه الطريقة فعالة في العديد من اختبارات الأداء القياسية وعلى مختلف أحجام النماذج. (المصدر: 新智元)

دعوة لتقديم الأوراق لورشة عمل LGM3A في ACM MM 2025: سيعقد مؤتمر ACM Multimedia 2025 ورشة العمل الثالثة حول “البحث والتطبيقات متعددة الوسائط القائمة على النماذج اللغوية الكبيرة” (LGM3A)، والتي تركز على تطبيقات وتحديات النماذج التوليدية الكبيرة (LLM/LMM) في تحليل البيانات متعددة الوسائط، والتوليد، والإجابة على الأسئلة، والاسترجاع، والتوصية، والوكلاء الأذكياء، وغيرها. تهدف ورشة العمل إلى توفير منصة للتواصل، ومناقشة أحدث الاتجاهات وأفضل الممارسات، وجمع الأوراق البحثية ذات الصلة. سيعقد المؤتمر في دبلن، أيرلندا في أكتوبر 2025، والموعد النهائي لتقديم الأوراق هو 11 يوليو 2025. (المصدر: PaperWeekly)
مجموعة أبحاث Zheng Zhedong بجامعة ماكاو تبحث عن طلاب دكتوراه في اتجاه الوسائط المتعددة: تبحث مجموعة أبحاث الأستاذ المساعد Zheng Zhedong في قسم علوم الكمبيوتر بجامعة ماكاو عن طلاب دكتوراه بمنحة كاملة في اتجاه الوسائط المتعددة للالتحاق في أغسطس 2026. يركز اتجاه بحث المشرف على تعلم التمثيل وتوليد الوسائط المتعددة، وقد نشر أكثر من 50 ورقة بحثية في مؤتمرات ومجلات مرموقة مثل CVPR و ICCV و TPAMI. يشترط على المتقدمين أن يكون معدلهم التراكمي (GPA) أكبر من 3.4، وأن يكون لديهم خلفية في علوم الكمبيوتر / هندسة البرمجيات، وأن يكونوا على دراية بـ Python/PyTorch، ويفضل من لديهم أوراق بحثية ذات صلة أو جوائز في المسابقات. يتم توفير منحة دراسية كاملة. (المصدر: PaperWeekly)

💼 الأعمال
روبوت جز العشب Laimou Technology يحصل على تمويل Pre-A: تأسست الشركة على يد مدير تنفيذي سابق في YunJing، وتركز على حل مشكلة جز العشب في التضاريس المعقدة في أوروبا وأمريكا. يعتمد روبوتها Lymow One على حل RTK البصري + بالقصور الذاتي (تكلفته عُشر تكلفة RTK التقليدي)، وتصميم مجنزر (للتعامل مع المنحدرات الشديدة بزاوية 45 درجة)، ومجهز بسكين مستقيم لسحق العشب. يتجنب العوائق باستخدام الرؤية بالذكاء الاصطناعي والموجات فوق الصوتية. تجاوز التمويل الجماعي للمنتج 5 ملايين دولار أمريكي، ويبلغ سعر الوحدة حوالي 3000 دولار أمريكي. سيتم استخدام هذه الجولة من التمويل البالغة عشرات الملايين من اليوانات للإنتاج الضخم والتسليم وتوسيع السوق. (المصدر: 云鲸前高管创立的割草机器人再融资,李泽湘投过、众筹已超500万美金|硬氪首发)

روبوت “الولد الصغير” الشبيه بالبشر من Songyan Dynamics يحقق شهرة: بعد فوزه بالمركز الثاني في ماراثون نصف المسافة للروبوتات الشبيهة بالبشر في بكين، أثارت شركة Songyan Dynamics وروبوتها N2 (“الولد الصغير”) اهتمام السوق. تأسست الشركة على يد Jiang Zheyuan، الحاصل على درجة الدكتوراه من جامعة Tsinghua وهو من مواليد 1995، وقد أكملت خمس جولات تمويل. يبدأ سعر روبوت N2 من 39,900 يوان، ويركز على فعالية التكلفة العالية، ولديه بالفعل مئات الطلبات، بهامش ربح إجمالي يبلغ حوالي 15٪. تعمل Songyan Dynamics على تسريع عملية تحويل المنتج إلى منتج تجاري والإنتاج الضخم والتسليم، وتهدف استراتيجيتها منخفضة السعر إلى اختراق السوق بسرعة. (المصدر: 科创板日报)
الحذر من مؤشرات ARR المبالغ فيها للشركات الناشئة في مجال الذكاء الاصطناعي: يشير المقال إلى أن مؤشر ARR (الإيرادات السنوية المتكررة)، الذي نشأ في صناعة SaaS، يتم استغلاله من قبل الشركات الناشئة في مجال الذكاء الاصطناعي. يتميز نموذج إيرادات شركات الذكاء الاصطناعي (غالبًا ما يعتمد على حجم الاستخدام / الدفع مقابل النتائج) بتقلبات كبيرة، وانخفاض ولاء العملاء الأوائل، وارتفاع تكاليف الحوسبة، مما يختلف اختلافًا كبيرًا عن نموذج الاشتراك القابل للتنبؤ في SaaS. أصبح إساءة استخدام ARR (مثل تقدير الإيرادات السنوية بناءً على إيرادات شهر واحد / يوم واحد) لعبة أرقام لخلق تقييمات عالية، مما يخفي القيمة التجارية الحقيقية. يدعو المقال إلى الحذر من الممارسات مثل التبادل الوهمي، والعمولات المرتفعة، وجذب العملاء بأسعار منخفضة، ويدعو إلى إنشاء نظام تقييم قيمة أكثر ملاءمة لشركات الذكاء الاصطناعي. (المصدر: 乌鸦智能说)
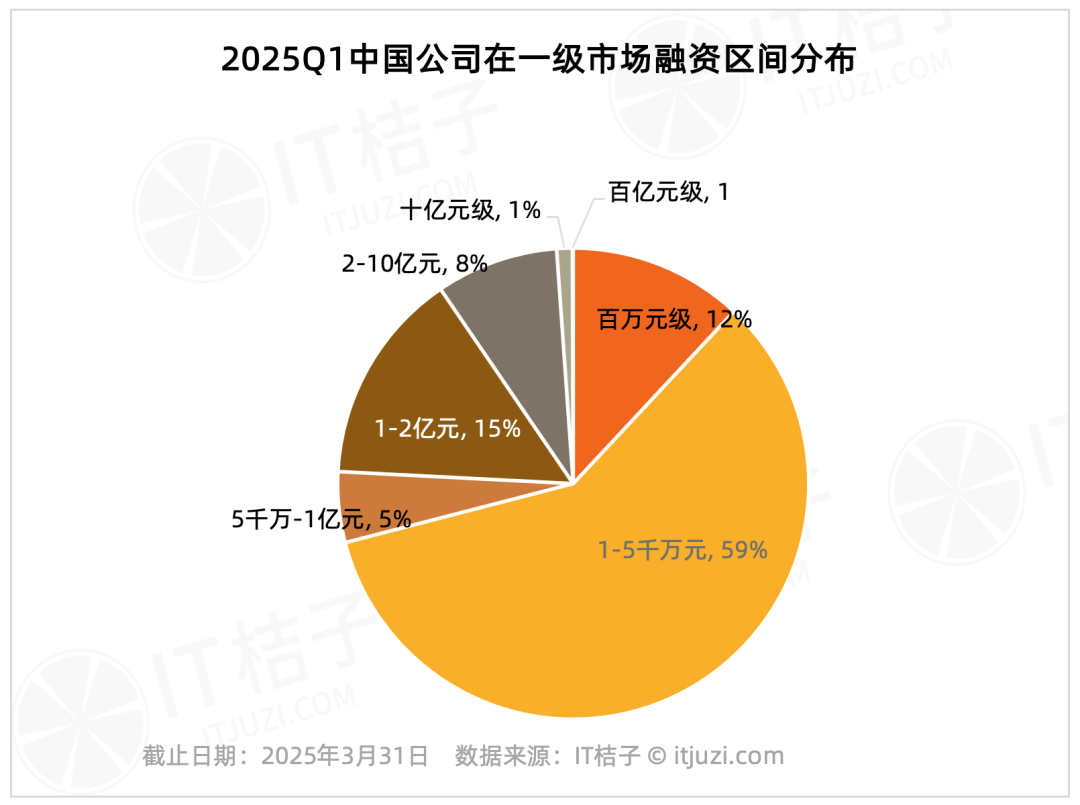
تحليل تمويل السوق الأولية المحلية في الربع الأول من عام 2025: تأثير الريادة واضح: تظهر بيانات IT桔子 أن تمويل السوق الأولية المحلية في الربع الأول من عام 2025 يظهر تركيزًا عاليًا. بلغ عدد الشركات التي حصلت على تمويل يزيد عن مليار يوان 20 شركة فقط، تمثل 1.2٪ من الإجمالي، لكن إجمالي تمويلها بلغ 61.178 مليار يوان، وهو ما يمثل 36٪ من إجمالي السوق. تتركز هذه الشركات الرائدة بشكل أساسي في مجالات الدوائر المتكاملة، وتصنيع السيارات، والمواد الجديدة، والتكنولوجيا الحيوية، و AIGC، وما يقرب من نصفها لديها خلفية لمجموعات كبيرة مدرجة. في المقابل، شكلت التمويلات الصغيرة والمتوسطة التي تقل عن 100 مليون يوان، والتي تمثل 75.8٪ من عدد الصفقات، 17.2٪ فقط من إجمالي السوق. (المصدر: IT桔子)
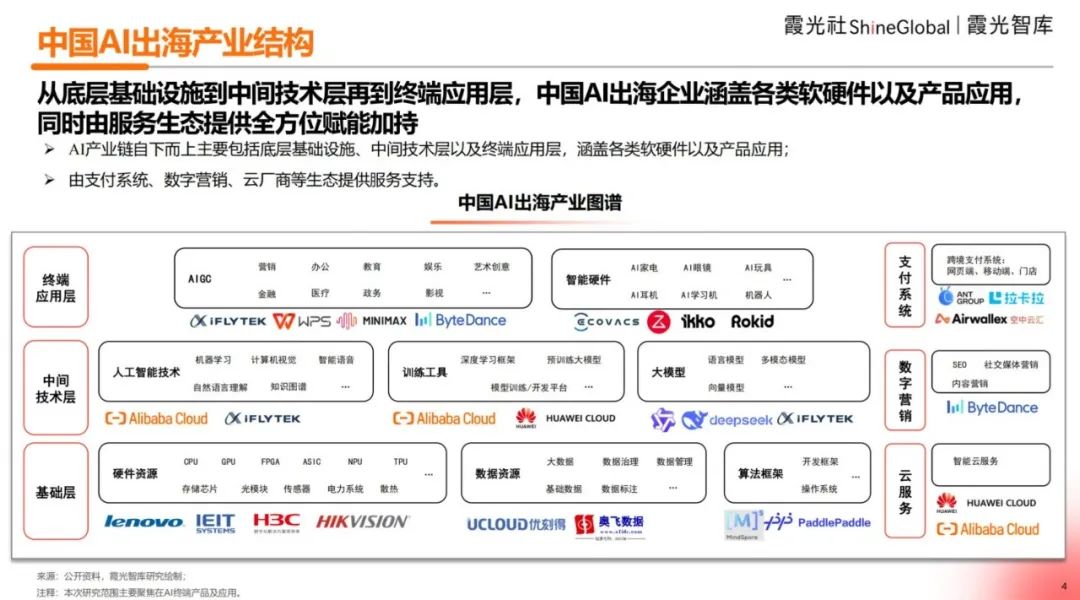
إصدار تقرير رؤى حول توسع الذكاء الاصطناعي الصيني في الخارج لعام 2025: يحلل تقرير Xiaguang Think Tank العوامل الدافعة لتوسع الذكاء الاصطناعي الصيني في الخارج (السياسات، التقدم التكنولوجي)، ومراحل التطور (أداة -> توطين -> ابتكار بيئي) والوضع الحالي. يشير التقرير إلى أن جنوب شرق آسيا وأمريكا اللاتينية أسواق ذات إمكانات، وأن أمريكا الشمالية وأوروبا هي مصادر الدخل الرئيسية. هناك استعداد عالٍ للدفع مقابل تطبيقات المساعدة والتحرير. تتجه الاتجاهات التقنية نحو الوسائط المتعددة والوكلاء، وتميل المنتجات نحو التخصص الرأسي والجمع بين البرامج والأجهزة. يرصد التقرير أيضًا اللاعبين الرئيسيين في التوسع الخارجي (مثل ByteDance، Kunlun Tech) ومقدمي حلول الدفع والتسويق والسحابة وغيرها. (المصدر: 霞光社)
طلب نماذج مثل DeepSeek يساعد Cambrian على تحقيق أول ربح: حققت شركة رقائق الذكاء الاصطناعي Cambrian أول ربح لها بعد الإدراج، حيث ارتفعت إيرادات الربع الأول من عام 2025 بنسبة 4230٪ على أساس سنوي لتصل إلى 1.111 مليار يوان، وبلغ صافي الربح 355 مليون يوان. يعتقد تحليل السوق أن نمو الأداء استفاد من زيادة الطلب على قوة حوسبة الاستدلال التي جلبتها النماذج الكبيرة المحلية مثل DeepSeek، بالإضافة إلى القيود الأمريكية على تصدير رقائق Nvidia H20. ارتفع سعر سهم Cambrian بشكل كبير نتيجة لذلك. لكن قضايا مثل التركيز العالي للعملاء والتدفق النقدي التشغيلي السلبي لا تزال تثير القلق، وفي الوقت نفسه تواجه منافسة من قوى الحوسبة المحلية مثل Huawei Ascend. (المصدر: 凤凰网科技)

مقال في Forbes يناقش كيفية اختيار AI Agent ذي عائد استثمار مرتفع: يناقش المقال كيف يجب على الشركات، من بين العديد من تطبيقات AI Agent، تحديد والاستثمار في تلك المشاريع التي يمكن أن تحقق عوائد عالية، مؤكدًا على أهمية تقييم القيمة التجارية الفعلية لـ AI Agent. (المصدر: Ronald_vanLoon)
وزارة العدل الأمريكية قلقة من استغلال Google للذكاء الاصطناعي لتعزيز احتكار البحث (المصدر: Reddit r/artificial, Reuters link)
يشاع أن OpenAI تتعاون مع Shopify، وقد يضيف ChatGPT ميزات تسوق (المصدر: Reddit r/artificial, TestingCatalog link)
Tan Li من Shushi Technology: AI Agent يقود ترقية تحليل بيانات الشركات واتخاذ القرارات: في قمة صناعة AIGC الصينية، أشار Tan Li، المؤسس المشارك لشركة Shushi Technology، إلى أن تطبيقات الذكاء الاصطناعي على مستوى المؤسسات تحتاج إلى تجاوز ChatBI، وتحقيق التحول من البيانات إلى الرؤى، وتلبية متطلبات النموذج الجديد المتمثل في تحويل البيانات إلى اليمين، وتحويل اتخاذ القرارات إلى الأسفل، وتحويل الإدارة إلى الخلف. تهدف منصة SwiftAgent من Shushi Technology إلى تمكين موظفي الأعمال من استخدام البيانات دون عوائق، والحصول على تحليل خالٍ من الهلوسة، ودعم اتخاذ القرارات دون انتظار. من خلال محرك دلالات البيانات، والجمع بين النماذج الكبيرة والصغيرة، والقدرات الأساسية مثل الاستعلام الذكي عن البيانات، وتحديد الأسباب، والتنبؤ، والتقييم، تحول المنصة AI Agent إلى “مساعد تحليل البيانات واتخاذ القرارات” للشركات. (المصدر: 量子位)

🌟 المجتمع
طاولة مستديرة صناعية تناقش تطوير تطبيقات الذكاء الاصطناعي في عصر ما بعد DeepSeek: في مؤتمر شركاء الذكاء الاصطناعي 36Kr، ناقش العديد من الضيوف (Quwan Technology، Microsoft، Silicon Intelligence، HuiCe) مستقبل تطبيقات الذكاء الاصطناعي. كان الإجماع على أنه مع اختراقات نماذج مثل DeepSeek، تدخل تطبيقات الذكاء الاصطناعي “عام التجاوز”. يجب أن تركز نقاط التطوير على الريادة التكنولوجية، والتطبيق التجاري، وابتكار التفاعل بين الإنسان والآلة، والتكامل البيئي. ميز الضيوف بين “AI+” (المساعدة والتعزيز) و “AI Native” (إعادة الهيكلة الأساسية)، وأشاروا إلى أن الأخير يتمتع بإمكانات أكبر. تشمل التحديات حواجز البيانات، وإيجاد نقاط الألم الحقيقية، وابتكار نماذج الأعمال، والتعلم بعينات قليلة، والمخاطر الأخلاقية. (المصدر: 36氪)

مؤسس LangChain ينتقد دليل OpenAI للوكلاء بأنه “مليء بالمزالق”: شكك Harrison Chase، مؤسس LangChain، علنًا في “الدليل العملي لبناء وكلاء الذكاء الاصطناعي” الذي أصدرته OpenAI، معتبرًا أن تعريفه للوكيل (التعارض الثنائي بين Workflows و Agents) جامد للغاية، ويتجاهل شيوع الجمع بينهما في الممارسة العملية. أشار Chase إلى أن الدليل، عند مناقشة الأطر، يحتوي على ثنائيات خاطئة، ويقلل من تعقيد SDK الخاص به، ويقدم بيانات مضللة حول المرونة والتنسيق الديناميكي. وأكد أن جوهر بناء وكيل موثوق به هو التحكم الدقيق في السياق المنقول إلى LLM، ويجب أن يدعم الإطار المثالي التبديل المرن والجمع بين وضعي Workflow و Agent. (المصدر: InfoQ)

دور التعلم المعزز في AI Agent يثير الجدل: هناك آراء مختلفة في الصناعة حول ما إذا كان التعلم المعزز (RL) هو العنصر الأساسي لبناء AI Agent. يعتبر Zhu Zheqing، مؤسس Pokee AI، أن RL هو “الروح” التي تمنح الوكيل الإحساس بالهدف والقدرة على اتخاذ القرارات المستقلة، ويعتقد أنه بدون RL، يكون الوكيل مجرد سير عمل متقدم. بينما يعتقد باحثون مثل Zhang Jiayi من HKUST و Xie Yang مؤسس Follou أن RL الحالي يحقق بشكل أساسي تحسينًا في بيئات محددة، وقدرته على التعميم محدودة، وأن نجاح الوكيل يعتمد بشكل أكبر على النماذج الأساسية القوية والتكامل الفعال للنظام. يعكس الجدل تنوع مسارات تطوير الوكلاء، والحاجة إلى الجمع بين قدرات النموذج واستراتيجيات RL والممارسات الهندسية. (المصدر: AI科技评论)

مستخدم يحاول جعل GPT-4o يولد خلفيات مجردة مخصصة بناءً على سجل الدردشة: شارك مستخدم مطالبة تطلب من GPT-4o إنشاء خلفية مجردة بسيطة وفريدة (بدون كائنات محددة، فقط باستخدام الأشكال والألوان والتكوين لتعكس الشخصية) بناءً على فهمه لشخصيته. أثارت هذه الطريقة لاستخدام الذكاء الاصطناعي لإنشاء محتوى مخصص نقاشًا في المجتمع. (المصدر: op7418, Flavio Adamo via op7418)

الذكاء الاصطناعي يعيد رسم “على طول النهر خلال مهرجان تشينغمينغ”: شارك مستخدم محاولة مثيرة للاهتمام باستخدام GPT-4o لإعادة رسم أجزاء من لوحة “على طول النهر خلال مهرجان تشينغمينغ” بأنماط مختلفة (مثل 3D Q-version، Pixar، Ghibli، إلخ)، مما يوضح تطبيق توليد الصور بالذكاء الاصطناعي في إعادة الإبداع الفني. (المصدر: dotey)

GPT-4o يستنتج نوع MBTI للمستخدم بناءً على سجل الدردشة: بعد توليد خلفيات مخصصة، استمر المستخدم في جعل GPT-4o يستنتج نوع شخصيته MBTI بناءً على المحادثات السابقة، وإنشاء رسوم توضيحية مجردة مقابلة. يوضح هذا إمكانات LLM في فهم الشخصية والتعبير الإبداعي. (المصدر: op7418)

مقارنة: “أدوات الذكاء الاصطناعي” في عام 2005: تعرض الصورة من خلال المقارنة الاختلافات في القدرات بين أدوات عام 2005 (مثل الآلات الحاسبة والخرائط) وأدوات الذكاء الاصطناعي الحالية، مما يثير التأمل في التطور التكنولوجي السريع. (المصدر: Ronald_vanLoon)

نقاش ساخن في المجتمع: هل LLM ذكاء حقيقي أم إكمال تلقائي متقدم؟: أطلق مستخدم Reddit نقاشًا، معتبرًا أن LLM الحالي، على الرغم من قدرته على تنفيذ المهام، يفتقر إلى الفهم الحقيقي والذاكرة والهدف، وهو في جوهره تخمين إحصائي وليس ذكاءً. أثار هذا الرأي نقاشًا واسعًا في المجتمع حول تعريف الذكاء، ومسار AGI، وقيود التكنولوجيا الحالية. (المصدر: Reddit r/ArtificialInteligence)
نقاش مجتمعي: هل يتجه الذكاء الاصطناعي نحو اليوتوبيا أم الديستوبيا؟: يعتقد مستخدم Reddit أن مسار تطوير الذكاء الاصطناعي الحالي يميل أكثر نحو الديستوبيا، لأسباب تشمل: الدافع الربحي بدلاً من التوجه الأخلاقي، وتفاقم استغلال العمال، وتقييد الوصول إلى النماذج القوية، واستخدامه للمراقبة والتلاعب، واستبدال العلاقات الإنسانية، وما إلى ذلك. أثار هذا الرأي نقاشًا حادًا في المجتمع حول اتجاه تطوير الذكاء الاصطناعي، والتأثيرات الاجتماعية، والمخاطر المحتملة. (المصدر: Reddit r/ArtificialInteligence)
المجتمع يشكك في دقة Bindu Reddy بشأن إصدارات النماذج: أشار مستخدمو مجتمع LocalLLaMA إلى أن Bindu Reddy، الرئيس التنفيذي لشركة Abacus.AI، نشرت مرارًا وتكرارًا معلومات غير دقيقة حول تواريخ إصدار نماذج مثل DeepSeek R2 و Qwen 3، ثم حذفت المنشورات لاحقًا، مما أثار نقاشًا حول موثوقية معلوماتها. (المصدر: Reddit r/LocalLLaMA)
استكشاف التأثيرات الأخلاقية لذاكرة الذكاء الاصطناعي مدى الحياة: أطلق مستخدم Reddit نقاشًا، معربًا عن قلقه من أن الذكاء الاصطناعي الذي يتمتع بقدرات ذاكرة مدى الحياة قد يعكس تمامًا خصوصية الفرد وأفكاره ونقاط ضعفه، ويكشف “روحه” للآخرين، مما يثير التفكير حول الخصوصية وقابلية التنبؤ وحدود أخلاقيات الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence)
تحرير الصور بالذكاء الاصطناعي يزيل الشوارب المميزة للمشاهير: شارك مستخدم صورًا تظهر نتائج استخدام أداة تحرير الصور بالذكاء الاصطناعي لإزالة الشوارب المميزة لعدة شخصيات تاريخية أو عامة مثل ستالين وتوم سيليك وغوان يو، مما يوضح تطبيق الذكاء الاصطناعي في تعديل الصور والترفيه. (المصدر: Reddit r/ChatGPT)

مستخدم يدعي أن ChatGPT طلب صورًا خاصة في استشارة طبية: شارك مستخدم Reddit لقطة شاشة تظهر أنه عند استشارة مشكلة جلدية، طلب ChatGPT من المستخدم تحميل صورة للمنطقة المصابة (القضيب) لتشخيص أفضل. أثارت هذه الحالة نقاشًا في المجتمع حول حدود الذكاء الاصطناعي في السيناريوهات الطبية والخصوصية والمخاطر المحتملة. (المصدر: Reddit r/ChatGPT)
مستخدم يشارك تجربته في بناء تطبيق كتابة باستخدام Claude و Gemini: شارك مطور تجربته في استخدام Claude و Gemini كمساعدين في البرمجة لبناء تطبيق الكتابة PlotRealm الذي يلبي احتياجاته الشخصية في غضون أسبوعين. أكد على دور الذكاء الاصطناعي في المساعدة في التطوير، ولكنه أشار أيضًا إلى أن الذكاء الاصطناعي يكون أحيانًا “عنيدًا” وأن المطورين يحتاجون إلى معرفة أساسية لتوجيهه وتصحيحه. (المصدر: Reddit r/ClaudeAI)
مستخدم يطلب من ChatGPT تصميم وشم: طلب مستخدم من ChatGPT تصميم وشمه التالي، وكانت النتيجة تصميمًا يصور المستخدم وروبوت ChatGPT يصبحان BFF (أفضل الأصدقاء إلى الأبد). أثارت هذه النتيجة الفكاهية نقاشًا في المجتمع حول إبداع الذكاء الاصطناعي والعلاقات بين الإنسان والآلة. (المصدر: Reddit r/ChatGPT)

مستخدم يطرح سؤالًا إبداعيًا “أين تتمنى أن أكون؟”، مما يثير استجابات متنوعة من الذكاء الاصطناعي: طرح مستخدم سؤالًا مفتوحًا على ChatGPT “أين تتمنى أن أكون؟”، وتلقى صورًا لمشاهد خيالية متنوعة تم إنشاؤها بواسطة الذكاء الاصطناعي، مثل مكتبة هادئة، تحت سماء مرصعة بالنجوم، وما إلى ذلك، مما يوضح قدرة الذكاء الاصطناعي على التوليد تحت المطالبات الإبداعية ومشاركة النتائج المختلفة من أعضاء المجتمع. (المصدر: Reddit r/ChatGPT)
نقاش متعمق: لماذا وكيف “تكذب” LLM و AGI؟: يحلل مستخدم Reddit من منظور علم النفس التنموي ونظرية التطور ونظرية الألعاب، معتبرًا أن “الكذب” هو سلوك تكيفي أو استراتيجية تحسين للوكلاء الأذكياء (بما في ذلك البشر والذكاء الاصطناعي المستقبلي) في سياقات محددة. يناقش المقال عدة أشكال من “كذب” LLM (الهلوسة، التحيز، المحاذاة الاستراتيجية)، ويحاكي عرضًا للميزة التطورية للاستراتيجيات غير الصادقة في بيئة تنافسية، مما يثير تفكيرًا عميقًا حول أخلاقيات وموثوقية AGI. (المصدر: Reddit r/artificial)

المجتمع يشكك في استهلاك طاقة الذكاء الاصطناعي والتفاؤل التكنولوجي: يشكك مستخدم Reddit بلهجة ساخرة في الادعاءات بأن استهلاك طاقة الذكاء الاصطناعي ضئيل، وأنه يجلب فوائد فقط دون تكاليف، وفي وعود قادة التكنولوجيا بمستقبل يوتوبي، مما يشير إلى مخاوف بشأن التكاليف الاجتماعية والبيئية المحتملة لتطوير الذكاء الاصطناعي والدعاية المفرطة في التفاؤل، مما يثير نقاشًا في المجتمع. (المصدر: Reddit r/artificial)
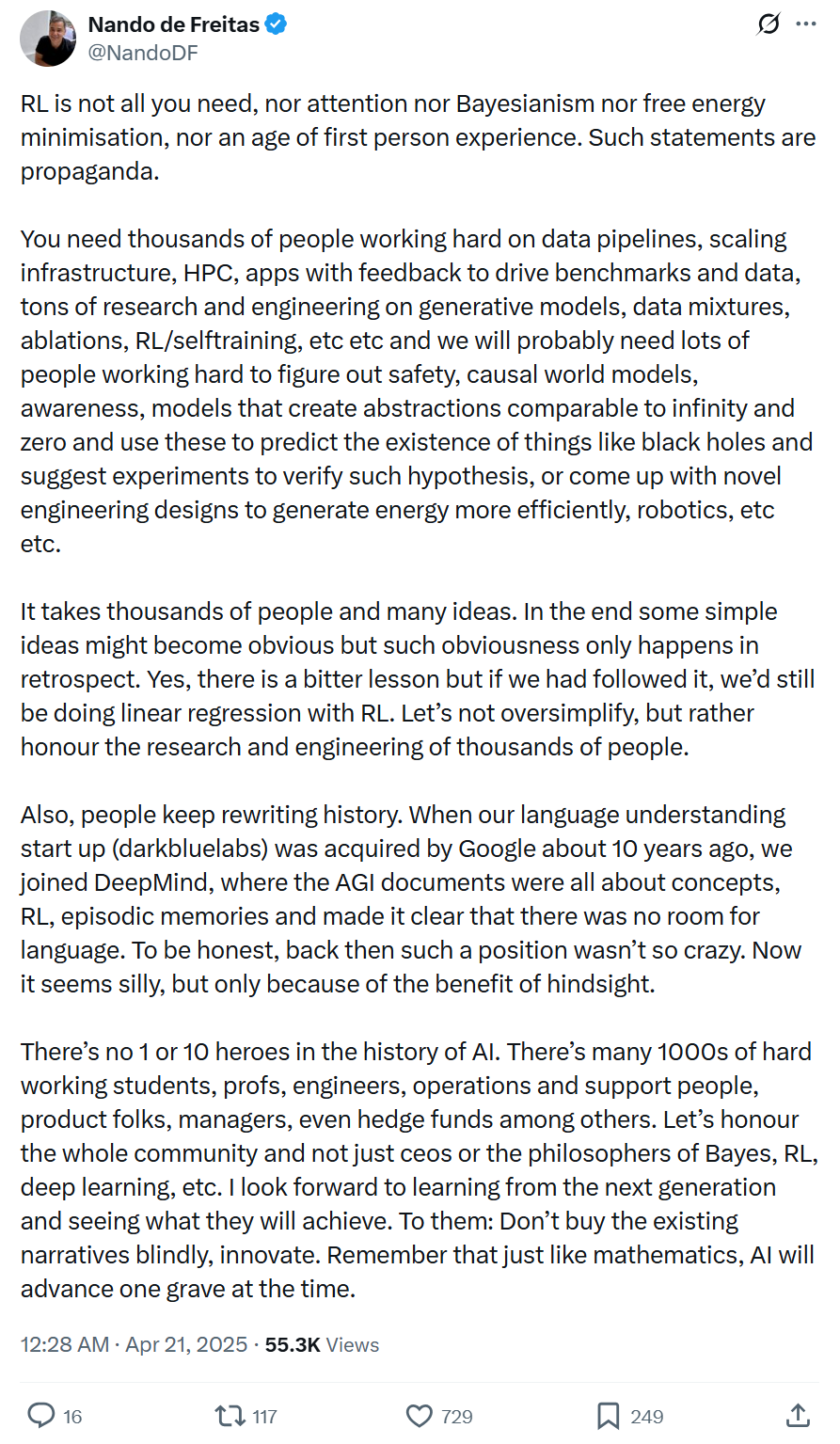
نائب رئيس Microsoft: تقدم الذكاء الاصطناعي ليس مدفوعًا بتقنية واحدة أو عدد قليل من العباقرة، بل يتطلب هندسة نظامية وتعاونًا واسعًا: نشر Nando de Freitas، نائب رئيس Microsoft، مقالًا يعارض فيه المبالغة في تمجيد تقنية واحدة (مثل RL) أو دور الأفراد في تطوير الذكاء الاصطناعي. وأكد أن تقدم الذكاء الاصطناعي هو هندسة نظامية، تتطلب بيانات وبنية تحتية وبحوثًا في مجالات متعددة (النماذج التوليدية، RL، الأمان، كفاءة الطاقة، إلخ)، وردود فعل من التطبيقات، وجهودًا مشتركة من آلاف المشاركين. غالبًا ما يتم إعادة كتابة السرد التاريخي، ويجب الحذر من الإدراك المتأخر، واحترام مساهمات المجتمع بأكمله، وتشجيع الابتكار بدلاً من التقليد الأعمى. (المصدر: 机器之心)
💡 أخرى
انتشار موسيقى الذكاء الاصطناعي يثير مخاوف وردود فعل في الصناعة: أثار الارتفاع السريع في نسبة الموسيقى التي تم إنشاؤها بواسطة الذكاء الاصطناعي على منصات البث (مثل Deezer التي وصلت إلى 18٪) مخاوف بشأن مزاحمة مساحة الإبداع البشري وتآكل دخل المبدعين (تتوقع CISAC أن يصل إلى 24٪). طبقت جمعية حقوق المؤلفين الموسيقيين الكورية (KOMCA) قاعدة جديدة لنسبة حقوق ملكية “0٪ AI”، وتقوم منصات مثل Deezer و YouTube بتطوير أدوات للكشف. ومع ذلك، فإن التعرف على موسيقى الذكاء الاصطناعي صعب، وقبول المستمعين مرتفع نسبيًا (مثل مستخدمي Suno الذين تجاوزوا 10 ملايين). تواجه الصناعة تحديات مثل التزييف العميق، ونزاعات حقوق النشر (حق استخدام بيانات التدريب)، وتعريف الأصالة. قد يتجه المستقبل نحو التعاون بين الإنسان والآلة، لكن النقاش حول الأخلاق ونسب الإبداع سيستمر. (المصدر: 新音乐产业观察)

تسريب محتمل لمطالبات نظام Windsurf: كشف مستودع GitHub awesome-ai-system-prompts عن محتوى يُشتبه في أنه مطالبات نظام نموذج Windsurf. (المصدر: karminski3)

مشكلة استهلاك المياه المرتفع لنماذج الذكاء الاصطناعي الكبيرة تثير الانتباه: أفادت مجلة Fortune ووسائل إعلام أخرى أن تشغيل نماذج الذكاء الاصطناعي الكبيرة مثل ChatGPT يتطلب استهلاك كميات كبيرة من المياه للتبريد، وقد يؤدي موسم حرائق الغابات في أماكن مثل كاليفورنيا إلى تفاقم أزمة نقص المياه، مما يثير مخاوف بشأن استدامة الذكاء الاصطناعي. (المصدر: Ronald_vanLoon)

مطور يدعي إنشاء AMI يمكنه التنبؤ بالعواطف: يدعي مقطع فيديو على YouTube أنه يعرض AMI (Artificial Molecular Intelligence؟) يمكنه مسح والتنبؤ بالعواطف والجوانب الأخرى للأحداث بشكل موثوق، بما في ذلك الصوت والفيديو والصور وغيرها من الوسائط المتعددة. لا تزال صحة هذه التكنولوجيا وطريقة تنفيذها المحددة بحاجة إلى التحقق. (المصدر: Reddit r/artificial)
اقتراح بإضافة مقارنة الأداء البشري إلى اختبارات أداء الذكاء الاصطناعي: اقترح مستخدم Reddit أن تتضمن اختبارات أداء نماذج الذكاء الاصطناعي (Benchmarks) درجات البشر (العاديين والخبراء) في نفس المهام كمرجع، لتقييم مستوى قدرة الذكاء الاصطناعي النسبي بشكل أكثر وضوحًا. (المصدر: Reddit r/artificial)
الأوسكار تقبل مشاركة الذكاء الاصطناعي في صناعة الأفلام، ولكن بقيود: قامت أكاديمية فنون وعلوم الصور المتحركة الأمريكية بتحديث لوائحها، مما يسمح باستخدام أدوات الذكاء الاصطناعي في صناعة الأفلام، لكنها أكدت أن الإبداع البشري لا يزال هو الجوهر. قد تتضمن اللوائح متطلبات محددة مثل الكشف عن استخدام الذكاء الاصطناعي، مما يعكس التوازن الذي تسعى إليه الصناعة بين تبني التكنولوجيا الجديدة وحماية الإبداع البشري. (المصدر: Reddit r/artificial, NYT link)

Instagram يحاول استخدام الذكاء الاصطناعي لتحديد عمر المراهقين (المصدر: Reddit r/artificial, AP News link)
Altman يقول إن قول المستخدمين “من فضلك” و “شكرًا” لـ ChatGPT يكلف ملايين الدولارات (المصدر: Reddit r/artificial, QZ link)
سباق ماراثون نصف المسافة للروبوتات الشبيهة بالبشر يظهر التقدم التكنولوجي والتحديات: أقيم أول سباق ماراثون نصف مسافة للروبوتات الشبيهة بالبشر في العالم في بكين، وفاز “天工Ultra” بالمركز الأول بزمن قدره ساعتان و 40 دقيقة. اختبر السباق قدرات الروبوتات في المسافات الطويلة، والتضاريس المعقدة، والتوازن الديناميكي، والملاحة المستقلة، وغيرها. تواجه الروبوتات بالحجم الكامل صعوبة أكبر (مركز الثقل، القصور الذاتي، استهلاك الطاقة). فاز 天工Ultra بفضل المفاصل المتكاملة عالية الطاقة، والتصميم منخفض القصور الذاتي، والتبريد الفعال، واستراتيجية التحكم في التعلم المقلد المعزز التنبؤي، وتقنية الملاحة اللاسلكية. يُعتبر السباق اختبار ضغط للتطبيق التجاري واسع النطاق للروبوتات (مثل الصناعة، ودوريات الأمن)، ودفع التحقق من صحة وتحسين التقنيات الأساسية مثل أجهزة الجسم، والتحكم في الحركة، واتخاذ القرارات الذكية. (المصدر: 机器之心)

استخدام الذكاء الاصطناعي لمراقبة تحركات المشاهير وتحقيق التنبيهات التلقائية: يشارك الدليل التعليمي كيفية استخدام برنامج Python النصي لمراقبة تحديثات حسابات Twitter محددة (مثل Altman)، وتحقيق تنبيهات مكالمات عاجلة عبر Feishu API عند نشر تحديثات جديدة. تجمع هذه الطريقة بين تقنية زحف الويب واستدعاء واجهة برمجة تطبيقات المنصة المفتوحة، بهدف حل مشكلة الحمل الزائد للمعلومات ومتطلبات التوقيت المناسب، وتحقيق وصول مخصص للمعلومات المهمة. يوضح إمكانات تطبيق الذكاء الاصطناعي في معالجة تدفق المعلومات الآلية والإشعارات المخصصة. (المصدر: 非主流运营)
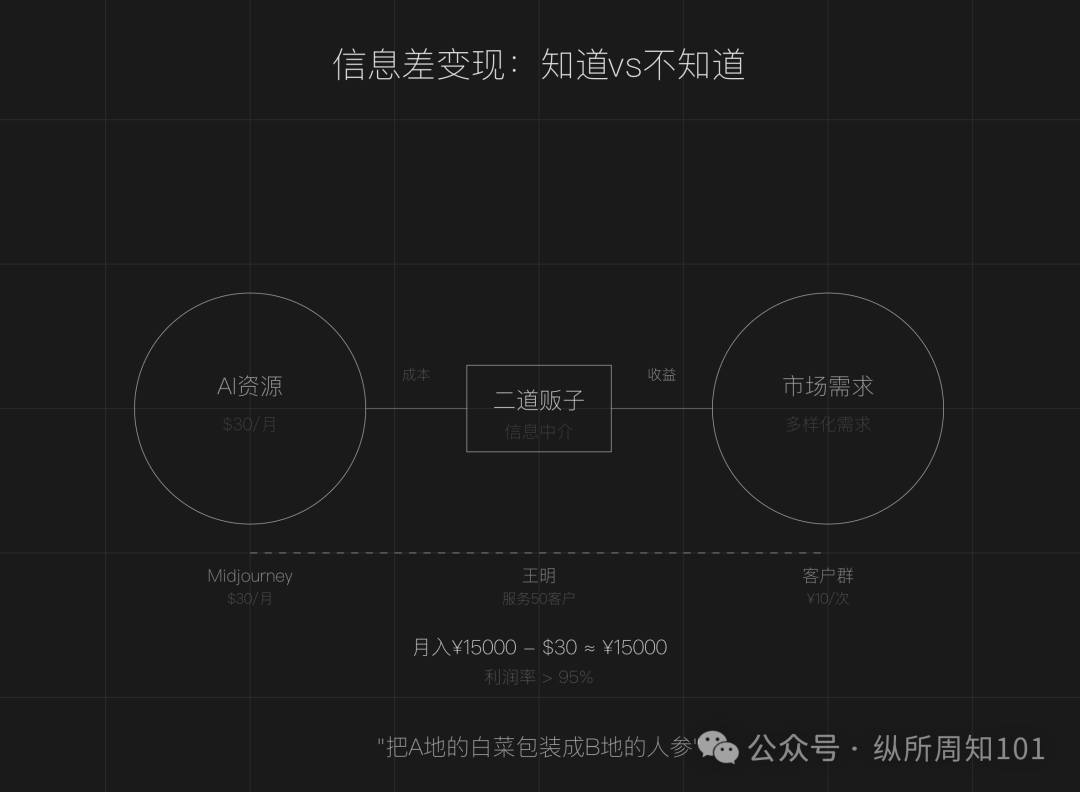
مناقشة نموذج الأعمال المتمثل في أن تصبح “تاجرًا وسيطًا” باستخدام فجوة معلومات الذكاء الاصطناعي: يعتقد المقال أن فجوة المعلومات لا تزال موجودة في عصر الذكاء الاصطناعي (انتشار الأدوات، العتبات التقنية، غموض السيناريوهات)، مما يخلق فرصًا للأشخاص العاديين ليصبحوا “تجارًا وسيطين للذكاء الاصطناعي”. تشمل طرق اللعب الأساسية: الاستفادة من فرق أسعار موارد الذكاء الاصطناعي المحلية والدولية لإعادة بيع الخدمات (مثل الرسم بالذكاء الاصطناعي)، وتقديم خدمات التنفيذ (تحويل الدروس المجانية إلى نشر مدفوع، مثل خدمة العملاء بالذكاء الاصطناعي)، والتشغيل على نطاق واسع (تشكيل فرق لتقديم خدمات احترافية). تشمل المجالات المناسبة إنشاء المحتوى، والتعليم والتدريب، وخدمات الأعمال للشركات الصغيرة والمتوسطة، والخدمات المهنية في المجالات الرأسية (مثل الطب والقانون). يُقترح البدء من خلال ثلاث خطوات: إيجاد فجوة المعلومات، وتحديد المجموعة المستهدفة، والتحرك بسرعة. (المصدر: 周知)