
كلمات مفتاحية:أربعة تنانين الذكاء الاصطناعي, الذكاء المتجسد, الإنسان الآلي, جدار الذاكرة, نموذج شانغ تانغ ريري شين V6 متعدد الوسائط, مجموعة بيانات Open X-Embodiment, الإنسان الآلي أوبتيموس من تسلا, تقنية ذاكرة الوصول العشوائي الحديدية الكهربائية ثلاثية الأبعاد, روبوت تيان جونج أولترا نصف ماراثون, نموذج Gemma 3 QAT الكمي, استحواذ Hugging Face على شركة Pollen Robotics, سير عمل وثائق وكيل LlamaIndex الذكي
🔥 أبرز الأخبار
“تنانين الذكاء الاصطناعي الأربعة” يواجهون تحديات وتحولات : الشركات التي كانت تُعرف بـ “تنانين الذكاء الاصطناعي الأربعة” مثل SenseTime، Megvii، CloudWalk، و Yitu تواجه صعوبات في التسويق التجاري وخسائر مستمرة في السنوات الأخيرة. على سبيل المثال، خسرت SenseTime 4.3 مليار في عام 2024، بخسائر متراكمة تجاوزت 54.6 مليار؛ وخسرت CloudWalk ما يقرب من 600-700 مليون في عام 2024، بخسائر متراكمة تجاوزت 4.4 مليار. لمواجهة التحديات، قامت الشركات بإجراء تعديلات استراتيجية، بما في ذلك تسريح الموظفين، خفض الرواتب، وإعادة هيكلة الأعمال. في مواجهة موجة الذكاء الاصطناعي الجديدة التي تهيمن عليها نماذج اللغة الكبيرة (LLM)، تتجه “التنانين الأربعة” التي تمتلك خبرة في تكنولوجيا الرؤية بنشاط نحو نماذج كبيرة متعددة الوسائط (Multimodal) ومجال الذكاء الاصطناعي العام (AGI). أطلقت SenseTime نموذج “日日新V6” متعدد الوسائط الذي ينافس GPT-4o، وتستثمر بكثافة في بناء مراكز الحوسبة الذكية؛ تركز Yitu على النماذج متعددة الوسائط المتمحورة حول الرؤية وتتعاون مع Huawei لخفض تكاليف الأجهزة؛ تتعاون CloudWalk أيضًا مع Huawei لإطلاق جهاز متكامل لتدريب واستدلال النماذج الكبيرة؛ بينما تستفيد Megvii من تفوقها في الخوارزميات لدخول مجال حلول القيادة الذاتية المعتمدة على الرؤية فقط (Pure Vision Solution). تُظهر هذه الخطوات جهودها للبقاء في ساحة المنافسة في مجال الذكاء الاصطناعي والتكيف مع بيئة السوق الجديدة. (المصدر: 36氪)

معضلة بيانات الذكاء المتجسد وتقدم مجموعات البيانات مفتوحة المصدر : يواجه تطوير الروبوتات البشرية والذكاء المتجسد (Embodied Intelligence) عنق زجاجة حاسم يتعلق بالبيانات، حيث يعيق نقص بيانات التدريب عالية الجودة تحقيق تقدم في قدراتها. على عكس نماذج اللغة التي تمتلك كميات هائلة من البيانات النصية من الإنترنت، تحتاج الروبوتات إلى بيانات تفاعلية متنوعة من العالم المادي، والتي تكون تكلفة الحصول عليها باهظة. لحل هذه المشكلة، تعمل المؤسسات البحثية والشركات بنشاط على بناء مجموعات بيانات مفتوحة المصدر ونشرها، مثل Open X-Embodiment الذي أصدرته Google DeepMind بالتعاون مع مؤسسات متعددة، و ARIO من مختبر Pengcheng وغيره، و RoboMIND من مركز بكين للابتكار، و AgiBot World من شركة 智元机器人 (التي تحتوي على بيانات مهام معقدة طويلة المدى في سيناريوهات حقيقية) ومجموعة بيانات المحاكاة AgiBot Digital World، ومجموعة بيانات عمليات G1 من شركة 宇树 وغيرها. على الرغم من أن حجم مجموعات البيانات هذه لا يزال أصغر بكثير من بيانات النصوص، إلا أنها تدفع بتطوير مجال الذكاء المتجسد من خلال توحيد المعايير وتحسين الجودة وإثراء السيناريوهات، مما يمهد الطريق لتحقيق “لحظة ImageNet”. (المصدر: 36氪)

بزوغ فجر الإنتاج الضخم للروبوتات البشرية: اختراقات في البيانات والمحاكاة والتعميم : على الرغم من التحديات مثل التكلفة العالية لجمع البيانات وضعف القدرة على التعميم، تخطط العديد من الشركات (Tesla، Figure AI، 1X، 智元، 宇树، 优必选 وغيرها) لتحقيق الإنتاج الضخم للروبوتات البشرية في عام 2025. تشمل مسارات الحل: 1) التدريب واسع النطاق على الأجهزة الحقيقية، بدعم من الحكومات (بكين، شنغهاي، شنتشن، قوانغدونغ) لبناء قواعد لجمع البيانات ووضع المعايير؛ 2) التدريب المتقدم بالمحاكاة، باستخدام نماذج عالمية مثل Nvidia Cosmos و Google Genie2 لتوليد بيئات افتراضية واقعية فيزيائيًا، مما يقلل التكاليف ويزيد الكفاءة؛ 3) تمكين التعميم بواسطة الذكاء الاصطناعي، من خلال نماذج الحركة الجديدة مثل Helix من Figure AI، وبنية ViLLA في GO-1 من 智元، و Gemini Robotics من Google، وذلك باستخدام بيانات أقل لتحقيق فهم معمَّم للعمليات الفيزيائية، مما يسمح للروبوتات بالتعامل مع الأشياء غير المرئية سابقًا والتكيف مع البيئات الجديدة. تشير هذه التطورات التكنولوجية إلى أن التطبيقات التجارية للروبوتات البشرية قد تتسارع. (المصدر: 36氪)

تطور الذكاء الاصطناعي يواجه أزمة “جدار الذاكرة”، وتقنيات التخزين الجديدة تسعى للاختراق : يفرض النمو الأسي لنماذج الذكاء الاصطناعي تحديات خطيرة على عرض نطاق الذاكرة، حيث ينمو عرض نطاق DRAM التقليدي بوتيرة أبطأ بكثير من نمو قوة الحوسبة، مما يشكل عنق زجاجة “جدار التخزين” ويحد من أداء المعالجات. تعمل HBM على زيادة عرض النطاق بشكل كبير من خلال تقنية التكديس ثلاثي الأبعاد (3D)، مما يخفف بعض الضغط، ولكن عملية تصنيعها معقدة ومكلفة. لهذا السبب، يستكشف القطاع بنشاط تقنيات تخزين جديدة: 1) 3D ذاكرة الوصول العشوائي الكهروحديدية (FeRAM): مثل SunRise Memory، التي تستخدم تأثير HfO2 الكهروحديدي لتحقيق تخزين عالي الكثافة وغير متطاير ومنخفض استهلاك الطاقة. 2) DRAM + ذاكرة غير متطايرة: تتعاون Neumonda مع FMC لاستخدام HfO2 لتحويل مكثفات DRAM إلى تخزين غير متطاير. 3) 2T0C IGZO DRAM: تقترح imec استخدام اثنين من ترانزستورات الأكسيد بدلاً من بنية 1T1C التقليدية، دون الحاجة إلى مكثفات، لتحقيق استهلاك منخفض للطاقة وكثافة عالية ووقت احتفاظ طويل. 4) ذاكرة تغيير الطور (PCM): تستخدم تغيير طور المادة لتخزين البيانات، مما يقلل من استهلاك الطاقة. 5) UK III-V Memory: تعتمد على GaSb/InAs، وتجمع بين سرعة DRAM وعدم تطاير ذاكرة الفلاش. 6) SOT-MRAM: تستخدم عزم دوران مدار الدوران لتحقيق استهلاك منخفض للطاقة وكفاءة عالية في استخدام الطاقة. من المتوقع أن تكسر هذه التقنيات عنق زجاجة DRAM وتعيد تشكيل سوق التخزين. (المصدر: 36氪)
🎯 التوجهات
روبوت 天工 يكمل تحدي نصف الماراثون ويخطط لإنتاج دفعة صغيرة : فاز روبوت “天工Ultra” (ارتفاع 1.8 متر، وزن 55 كجم) من مركز بكين لابتكار الروبوتات البشرية (فريق 天工) بالمركز الأول في أول سباق نصف ماراثون للروبوتات البشرية، حيث قطع مسافة 21 كيلومترًا تقريبًا في ساعتين و 40 دقيقة و 42 ثانية. اختبر السباق موثوقية الروبوت في التحمل، الهيكل، الإدراك، وخوارزميات التحكم في ظروف الطرق المعقدة. ذكر الفريق أنه من خلال تحسين استقرار المفاصل، مقاومة الحرارة، نظام استهلاك الطاقة، وخوارزميات التوازن وتخطيط المشي، وتزويده بمنصة “慧思开物” المطورة ذاتيًا (الدماغ المتجسد + المخيخ)، حقق الروبوت تخطيطًا ذاتيًا للمسار وتعديلًا فوريًا تحت التوجيه اللاسلكي. يثبت إكمال الماراثون موثوقيته الأساسية، مما يمهد الطريق للإنتاج الضخم. سيتم طرح روبوت 天工 2.0 للبيع قريبًا، مع خطط لإنتاج دفعة صغيرة، ويهدف مستقبلاً إلى استخدامه في الصناعة، الخدمات اللوجستية، العمليات الخاصة، والخدمات المنزلية. (المصدر: 36氪)

الصين تطور دماغ روبوت باستخدام خلايا بشرية مستنبتة : وفقًا للتقارير، يعمل باحثون صينيون على تطوير روبوت يتم تشغيله بواسطة خلايا دماغ بشرية مستنبتة. يهدف هذا البحث إلى استكشاف إمكانيات الحوسبة البيولوجية (Biocomputing)، باستخدام قدرات التعلم والتكيف للخلايا العصبية البيولوجية للتحكم في أجهزة الروبوت. على الرغم من أن التفاصيل ومرحلة التقدم لا تزال غير واضحة، إلا أن هذا الاتجاه يمثل استكشافًا رائدًا في مجال تقاطع الروبوتات والذكاء الاصطناعي والتكنولوجيا الحيوية، وقد يفتح طرقًا جديدة لتطوير أنظمة روبوتية أكثر ذكاءً وقدرة على التكيف في المستقبل. (المصدر: Ronald_vanLoon)
أداء ممتاز لنموذج Gemma 3 QAT المُكمَّم : قارن مستخدم أداء نسخة QAT (Quantization Aware Training) من نموذج Google Gemma 3 27B مع إصدارات أخرى مُكمَّمة بتقنية Q4 (Q4_K_XL, Q4_K_M) على مقياس GPQA Diamond. أظهرت النتائج أن نسخة QAT قدمت أفضل أداء (دقة 36.4%) مع أقل استهلاك لذاكرة VRAM (16.43 جيجابايت)، متفوقة على Q4_K_XL (34.8%، 17.88 جيجابايت) و Q4_K_M (33.3%، 17.40 جيجابايت). يشير هذا إلى أن تقنية QAT فعالة في خفض متطلبات الموارد مع الحفاظ على أداء النموذج. (المصدر: Reddit r/LocalLLaMA)
شائعات عن إطلاق AMD لبطاقة رسومات RDNA 4 Radeon PRO بذاكرة 32GB : أفاد موقع VideoCardz بأن AMD تستعد لإطلاق بطاقة رسومات من سلسلة Radeon PRO تعتمد على وحدة معالجة الرسومات Navi 48 XTW، وستكون مزودة بذاكرة وصول عشوائي (VRAM) بسعة 32GB. إذا صحت هذه الشائعات، فسيوفر ذلك خيارًا جديدًا للمستخدمين الذين يحتاجون إلى ذاكرة كبيرة لتدريب واستدلال نماذج الذكاء الاصطناعي محليًا، خاصة في ظل محدودية ذاكرة بطاقات الرسومات الاستهلاكية بشكل عام. ومع ذلك، لم يتم الإعلان عن الأداء المحدد والسعر وتاريخ الإصدار، ولا تزال قدرتها التنافسية الفعلية غير مؤكدة. (المصدر: Reddit r/LocalLLaMA)

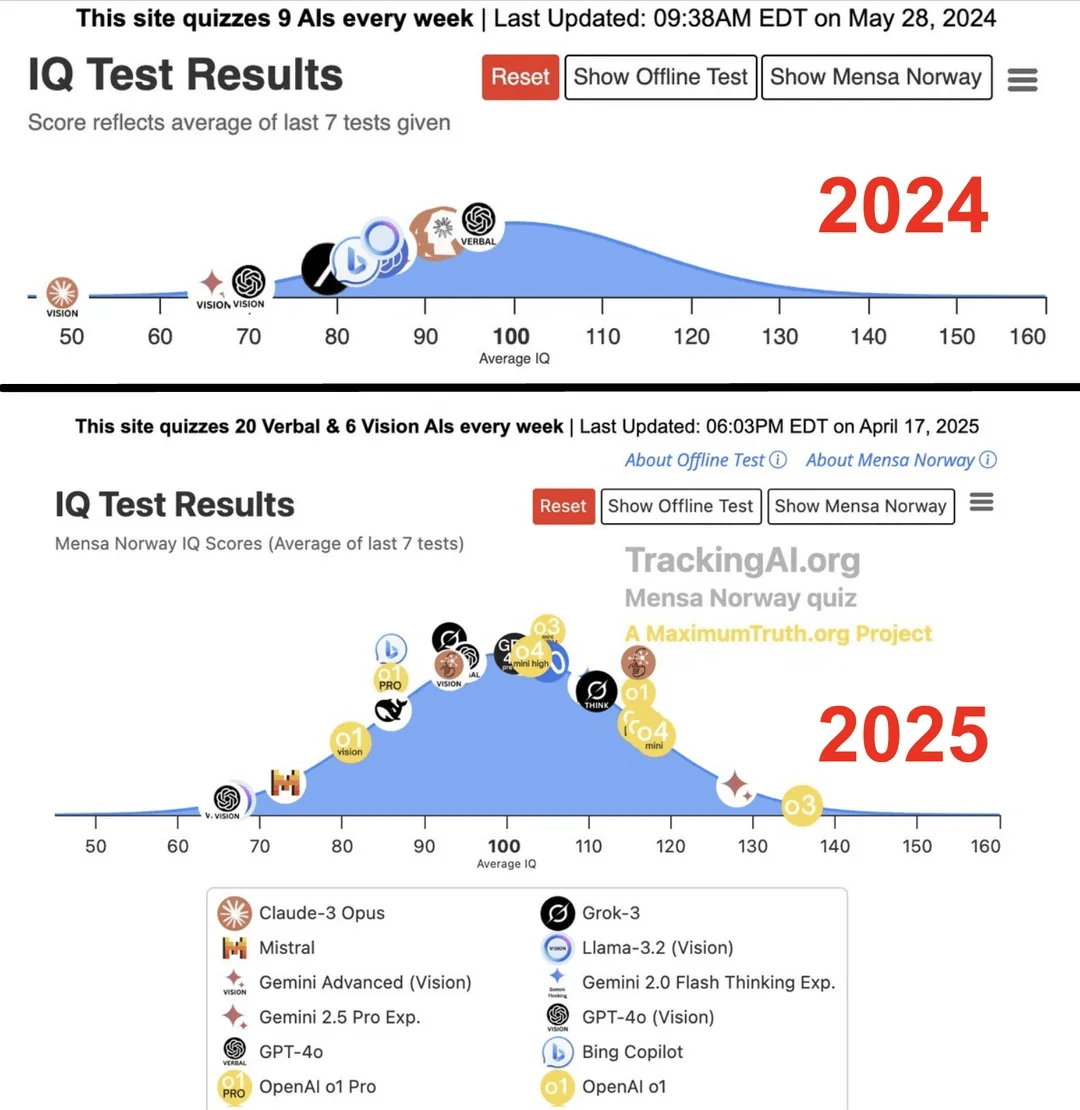
دراسة تدعي أن معدل ذكاء أفضل نماذج الذكاء الاصطناعي قفز من 96 إلى 136 في عام واحد : وفقًا لدراسة نشرها موقع Maximum Truth (مصداقية المصدر قيد التحقق)، من خلال إجراء اختبارات IQ على نماذج الذكاء الاصطناعي، تبين أن معدل ذكاء أذكى نموذج (ربما يشير إلى سلسلة GPT) ارتفع في غضون عام واحد من 96 نقطة (أقل بقليل من المتوسط البشري) إلى 136 نقطة (يقترب من مستوى العبقرية). على الرغم من الجدل حول فعالية اختبارات IQ في قياس ذكاء الذكاء الاصطناعي، واحتمالية تلوث بيانات التدريب للاختبار، إلا أن هذا الارتفاع الملحوظ يعكس التقدم السريع في قدرة الذكاء الاصطناعي على حل مشاكل اختبارات الذكاء الموحدة. (المصدر: Reddit r/artificial)
🧰 الأدوات
OpenUI: إنشاء واجهات المستخدم عبر الوصف في الوقت الفعلي : أطلقت wandb مشروع OpenUI مفتوح المصدر، وهو أداة تتيح للمستخدمين تصور وعرض واجهات المستخدم في الوقت الفعلي من خلال الوصف باللغة الطبيعية. يمكن للمستخدمين اقتراح تعديلات وتحويل كود HTML المُنشأ إلى كود لأطر عمل الواجهة الأمامية المتعددة مثل React، Svelte، Web Components وغيرها. يدعم OpenUI العديد من الواجهات الخلفية لنماذج اللغة الكبيرة (LLM)، بما في ذلك OpenAI، Groq، Gemini، Anthropic (Claude)، بالإضافة إلى النماذج المحلية المتصلة عبر LiteLLM أو Ollama. يهدف المشروع إلى جعل عملية بناء مكونات واجهة المستخدم أسرع وأكثر متعة، ويعمل كأداة اختبار ونماذج أولية داخلية في W&B. على الرغم من استلهامه من v0.dev، فإن OpenUI مفتوح المصدر. يوفر عرضًا توضيحيًا عبر الإنترنت ودليل تشغيل محلي (Docker أو الكود المصدري). (المصدر: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: أداة ترجمة PDF بالذكاء الاصطناعي مع الحفاظ على التنسيق : طور Byaidu أداة PDFMathTranslate، وهي أداة قوية لترجمة مستندات PDF، وتكمن ميزتها الأساسية في استخدام تقنية الذكاء الاصطناعي للترجمة مع الحفاظ الكامل على تنسيق المستند الأصلي، بما في ذلك الصيغ الرياضية المعقدة، الرسوم البيانية، الفهارس، والتعليقات. تدعم الأداة الترجمة بين لغات متعددة وتدمج خدمات ترجمة متنوعة مثل Google، DeepL، Ollama، OpenAI وغيرها. لتسهيل الاستخدام لمختلف المستخدمين، يوفر المشروع واجهة سطر الأوامر (CLI)، واجهة مستخدم رسومية (GUI)، صورة Docker، بالإضافة إلى إضافة لـ Zotero. يمكن للمستخدمين تجربة العرض التوضيحي عبر الإنترنت أو اختيار طريقة التثبيت المناسبة حسب احتياجاتهم. (المصدر: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: نظام إنشاء تقارير مع مراجع يعتمد على LangGraph : Shandu AI Research هو نظام يستخدم سير عمل LangGraph لإنشاء تقارير تلقائيًا مع مراجع. يهدف إلى تبسيط مهام البحث من خلال استخلاص البيانات الذكي من الويب، تجميع المعلومات من مصادر متعددة، والمعالجة المتوازية. يمكن لهذه الأداة مساعدة المستخدمين على جمع المعلومات ودمجها وتحليلها بسرعة، وإنشاء تقارير بحثية منظمة ومدعومة بالمراجع، مما يزيد من كفاءة البحث. (المصدر: LangChainAI)

Intel تطلق AI Playground مفتوح المصدر : أطلقت Intel مشروع AI Playground مفتوح المصدر، وهو تطبيق للمبتدئين مخصص لأجهزة الكمبيوتر الشخصية المزودة بتقنيات الذكاء الاصطناعي (AI PC)، يتيح للمستخدمين تشغيل مجموعة متنوعة من نماذج الذكاء الاصطناعي التوليدية على أجهزة الكمبيوتر المزودة ببطاقات رسومات Intel Arc. تشمل نماذج الصور/الفيديو المدعومة Stable Diffusion 1.5، SDXL، Flux.1-Schnell، LTX-Video؛ وتشمل نماذج اللغة الكبيرة المدعومة DeepSeek R1، Phi3، Qwen2، Mistral (Safetensor PyTorch LLM)، بالإضافة إلى Llama 3.1، Llama 3.2، TinyLlama، Mistral 7B، Phi3 mini، Phi3.5 mini (GGUF LLM أو OpenVINO). تهدف الأداة إلى خفض عتبة تشغيل نماذج الذكاء الاصطناعي محليًا، مما يسهل على المستخدمين التجربة والاختبار. (المصدر: karminski3)
Persona Engine: مشروع مساعد/مذيع افتراضي يعمل بالذكاء الاصطناعي : Persona Engine هو مشروع مفتوح المصدر يهدف إلى إنشاء مساعد افتراضي تفاعلي أو مذيع افتراضي يعمل بالذكاء الاصطناعي. يدمج المشروع نماذج اللغة الكبيرة (LLM)، رسوم متحركة Live2D، التعرف التلقائي على الكلام (ASR)، تحويل النص إلى كلام (TTS)، وتقنية استنساخ الصوت في الوقت الفعلي. يمكن للمستخدمين التحدث مباشرة مع شخصية Live2D، ويدعم المشروع أيضًا التكامل مع برامج البث مثل OBS لإنشاء مذيعين افتراضيين يعملون بالذكاء الاصطناعي. يعرض المشروع تطبيقًا مدمجًا لتقنيات الذكاء الاصطناعي المتعددة، ويوفر إطارًا لبناء شخصيات افتراضية تفاعلية مخصصة. (المصدر: karminski3)
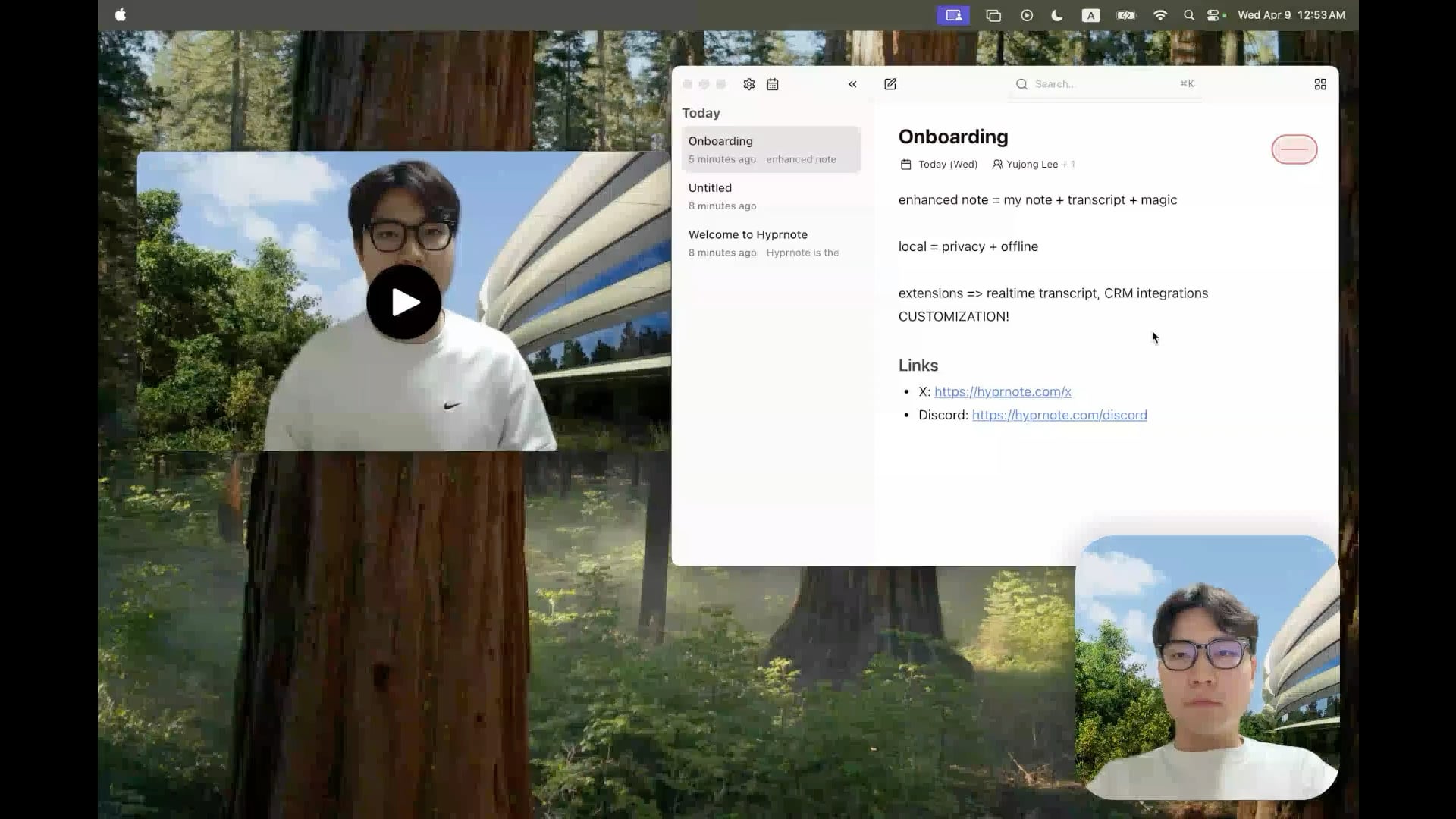
Hyprnote: أداة تدوين ملاحظات الاجتماعات بالذكاء الاصطناعي محلية ومفتوحة المصدر : قام مطور بإطلاق Hyprnote كمشروع مفتوح المصدر، وهو تطبيق ملاحظات ذكي مصمم خصيصًا لسيناريوهات الاجتماعات. يمكنه تسجيل الصوت أثناء الاجتماع ودمج ملاحظات المستخدم الأصلية مع محتوى الصوت لإنشاء محاضر اجتماعات محسنة. الميزة الأساسية هي تشغيل نماذج الذكاء الاصطناعي بالكامل محليًا (مثل Whisper لتحويل الكلام إلى نص)، مما يضمن خصوصية وأمان بيانات المستخدم. تهدف الأداة إلى مساعدة المستخدمين على التقاط وتنظيم معلومات الاجتماعات بشكل أفضل، وهي مناسبة بشكل خاص للمستخدمين الذين يحتاجون إلى التعامل مع اجتماعات متتالية. (المصدر: Reddit r/LocalLLaMA)
LMSA: أداة لربط LM Studio بأجهزة Android : شارك مستخدم تطبيقًا يسمى LMSA (lmsa.app)، يهدف إلى مساعدة المستخدمين على ربط LM Studio (أداة شائعة لإدارة تشغيل نماذج اللغة الكبيرة المحلية) بأجهزتهم التي تعمل بنظام Android. يتيح ذلك للمستخدمين التفاعل مع نماذج الذكاء الاصطناعي التي تعمل على أجهزة الكمبيوتر المحلية الخاصة بهم عبر هواتفهم أو أجهزتهم اللوحية، مما يوسع نطاق استخدام نماذج اللغة الكبيرة المحلية. (المصدر: Reddit r/LocalLLaMA)

أداة بحث عن الصور محلية تعتمد على MobileNetV2 : قام مطور ببناء ومشاركة أداة بحث عن الصور لسطح المكتب تستخدم واجهة رسومية PyQt5 ونموذج TensorFlow MobileNetV2. يمكن للأداة فهرسة مجلدات الصور المحلية والبحث عن صور مشابهة بناءً على محتوى الصورة (باستخدام CNN لاستخراج الميزات) باستخدام تشابه جيب التمام (Cosine Similarity). يمكنها اكتشاف بنية المجلد تلقائيًا كفئات وعرض صور مصغرة لنتائج البحث ونسبة التشابه ومسار الملف. تم نشر كود المشروع مفتوح المصدر على GitHub، ويسعى المطور للحصول على ملاحظات المستخدمين. (المصدر: Reddit r/MachineLearning)
Handcrafted Persona Engine: شخصية افتراضية تفاعلية صوتية تعمل بالذكاء الاصطناعي محليًا : شارك مطور مشروعًا شخصيًا باسم “Handcrafted Persona Engine”، يهدف إلى إنشاء شخصية افتراضية تفاعلية مدفوعة بالصوت تعمل بالكامل محليًا، تشبه تجربة “شارع سمسم”. يدمج النظام Whisper المحلي لتحويل الكلام إلى نص، ويستدعي LLM محلي عبر Ollama API لتوليد الحوار (بما في ذلك الإعدادات الشخصية)، ويستخدم TTS محلي لتحويل النص إلى كلام، ويحرك نموذج شخصية Live2D لمزامنة الشفاه والتعبير عن المشاعر. تم بناء المشروع باستخدام C# ويمكن تشغيله على بطاقات رسومات من فئة GTX 1080 Ti، وتم نشره كمشروع مفتوح المصدر على GitHub. (المصدر: Reddit r/LocalLLaMA)
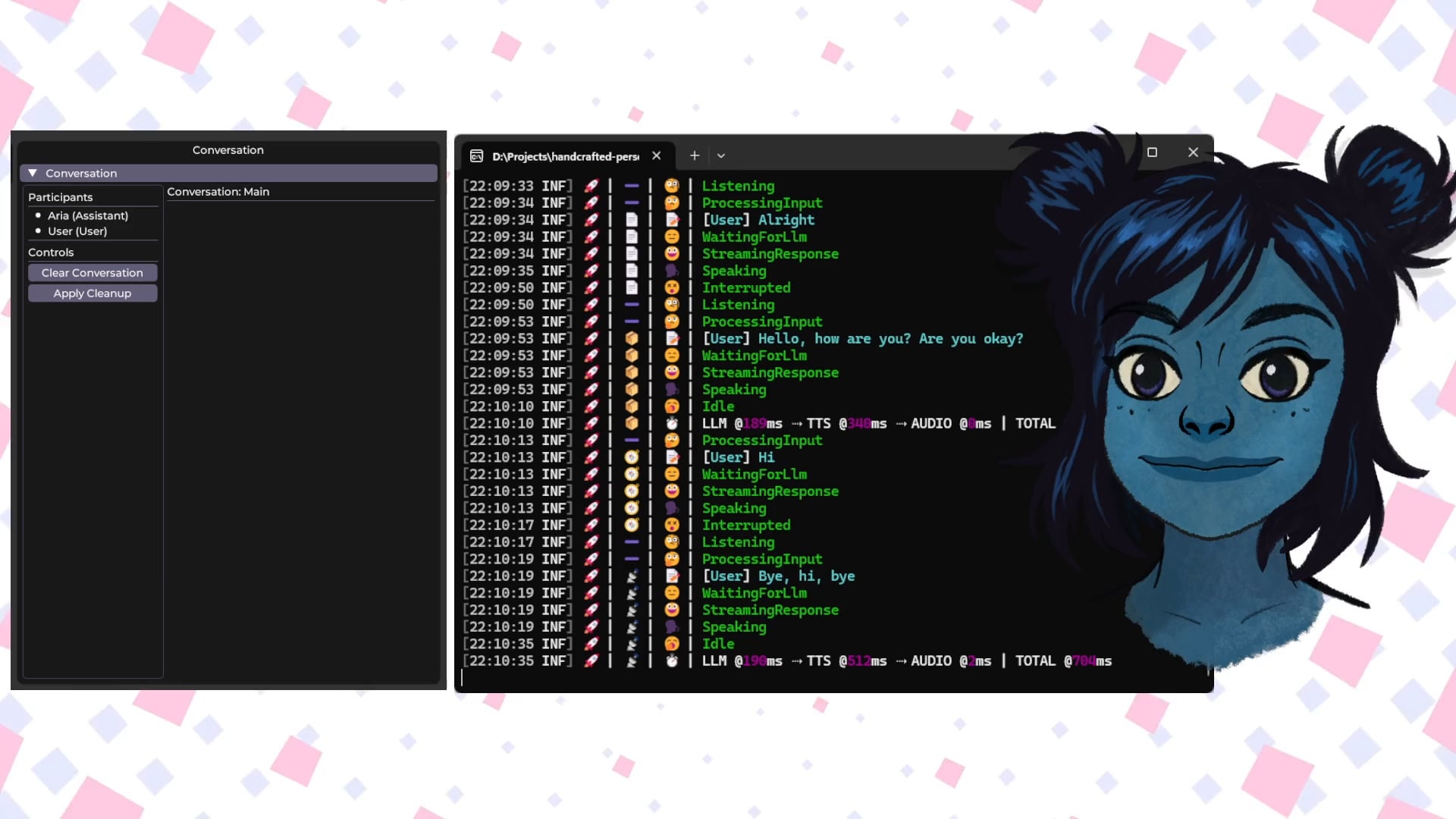
Talkto.lol: أداة تجريبية للتحدث مع شخصيات مشهورة تعمل بالذكاء الاصطناعي : أنشأ مطور موقعًا إلكترونيًا باسم talkto.lol، يتيح للمستخدمين التحدث مع شخصيات ذكاء اصطناعي لشخصيات مشهورة مختلفة (مثل Sam Altman). تحتوي الأداة أيضًا على ميزة “show me”، حيث يمكن للمستخدمين تحميل صورة، وسيقوم الذكاء الاصطناعي بتحليلها وإنشاء رد، مما يعرض قدرات التعرف البصري للذكاء الاصطناعي. ذكر المطور أنه سيستخدم هذه المنصة لإجراء المزيد من التجارب حول تفاعل شخصيات الذكاء الاصطناعي. يمكن تجربة الأداة دون الحاجة إلى تسجيل. (المصدر: Reddit r/artificial)
📚 موارد تعليمية
أساسيات الروبوتات البشرية: التحديات وجمع البيانات : يتطور مجال الروبوتات البشرية من الأتمتة البسيطة إلى “الذكاء المتجسد” المعقد، وهو نظام ذكي يعتمد على الإدراك والعمل من خلال جسم مادي. على عكس نماذج الذكاء الاصطناعي الكبيرة التي تعالج اللغة والصور، تحتاج الروبوتات إلى فهم العالم المادي الحقيقي ومعالجة بيانات متعددة الأبعاد تشمل الإدراك المكاني، تخطيط الحركة، ردود الفعل الميكانيكية، وغيرها. يعد الحصول على هذه البيانات عالية الجودة من العالم الحقيقي تحديًا كبيرًا، فهو مكلف ويصعب تغطية جميع السيناريوهات. تشمل طرق الجمع الحالية: 1) الجمع من العالم الحقيقي: تسجيل حركات الإنسان باستخدام أنظمة التقاط الحركة البصرية أو بالقصور الذاتي، أو من خلال تشغيل الروبوتات عن بعد بواسطة البشر لتنفيذ المهام وتسجيل بيانات الجهاز الحقيقي (مثل Tesla Optimus). 2) الجمع من عالم المحاكاة: استخدام منصات المحاكاة لمحاكاة البيئات وسلوك الروبوتات، وتوليد كميات كبيرة من البيانات لخفض التكاليف وتحسين القدرة على التعميم، ولكن يتطلب ذلك معالجة الفجوة بين المحاكاة والواقع (Sim-to-Real Gap). بالإضافة إلى ذلك، يعد استخدام بيانات الفيديو من الإنترنت للتدريب المسبق اتجاهًا استكشافيًا أيضًا. (المصدر: 36氪)

تقنيات لتوليد صور بأسلوب الرسوم البيانية للمقالات المعرفية : شارك مستخدم طريقة استخدام أدوات الذكاء الاصطناعي مثل GPT-4o لتوليد صور بأسلوب الرسوم البيانية (infographic) للمقالات المعرفية. التقنية الأساسية هي جعل الذكاء الاصطناعي يساعد أولاً في كتابة المطالبات (prompt) لتوليد الصور. الخطوات المحددة: قدم محتوى المقال أو النقاط الرئيسية للذكاء الاصطناعي واطلب منه كتابة مطالبة لتوليد رسم بياني أفقي، مع طلب تضمين نصوص باللغة الإنجليزية وصور كرتونية، بأسلوب واضح وحيوي يلخص الأفكار الأساسية. النقاط الهامة: قدم المحتوى الكامل للذكاء الاصطناعي؛ اطلب بوضوح “رسم بياني”؛ إذا كان النص كثيرًا، يوصى باستخدام اللغة الإنجليزية لزيادة دقة التوليد؛ يوصى باستخدام GPT-4.5 أو o3 أو Gemini 2.5 Pro لتوليد المطالبات؛ استخدم أدوات مثل Sora Com أو ChatGPT لتوليد الصورة النهائية. (المصدر: dotey)
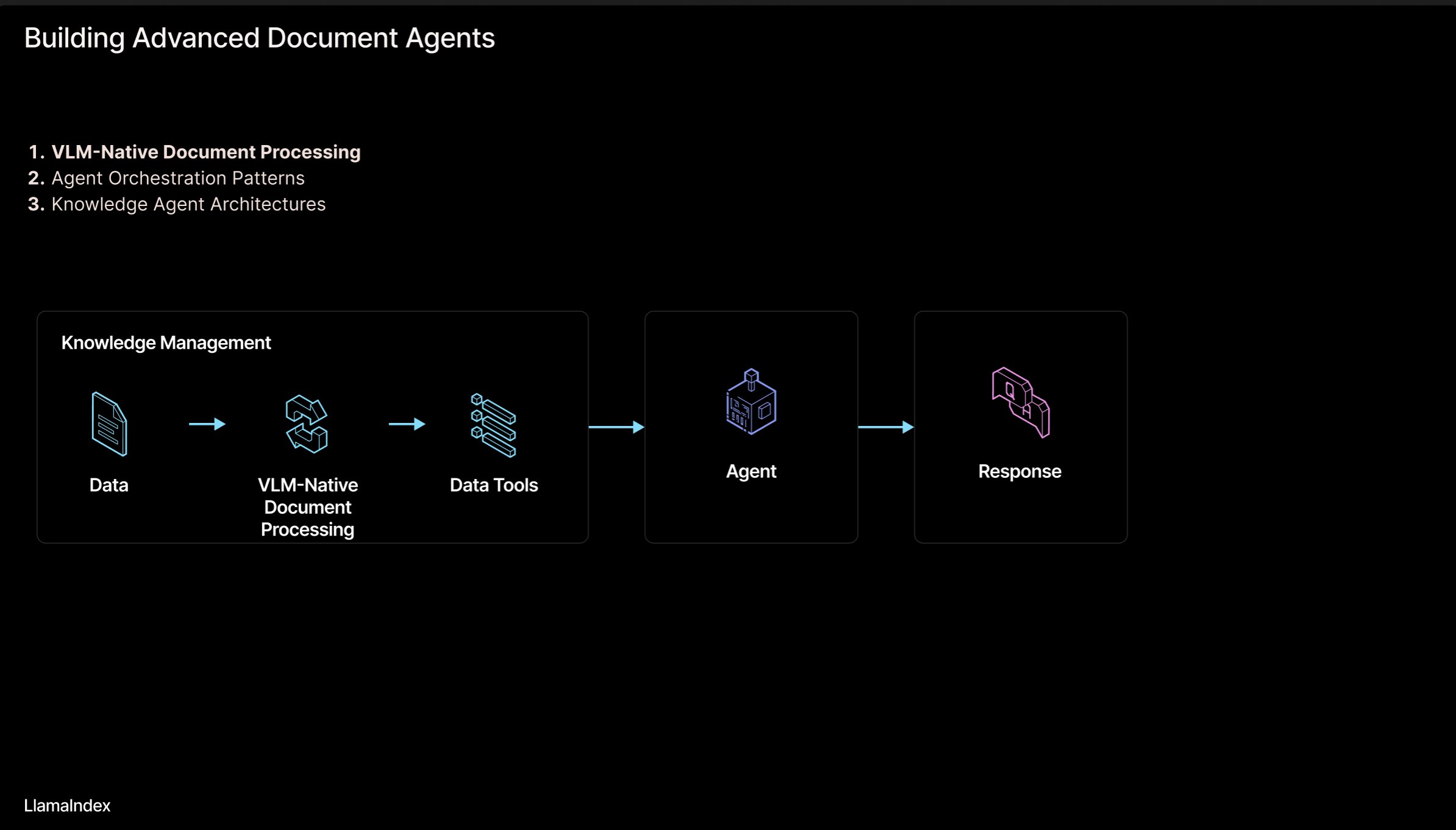
LlamaIndex: بنية سير عمل المستندات للوكلاء الأذكياء : شارك Jerry Liu، مؤسس LlamaIndex، مجموعة من الشرائح حول بنية سير عمل لبناء وكلاء أذكياء (Agentic) لمعالجة المستندات (PDF, Excel، إلخ). تهدف هذه البنية إلى إطلاق المعرفة المحتجزة في المستندات ذات التنسيق القابل للقراءة البشرية، مما يسمح لوكلاء الذكاء الاصطناعي بتحليل هذه المستندات والاستدلال عليها والتعامل معها. تتضمن البنية بشكل أساسي مستويين: 1) تحليل واستخراج المستندات: استخدام نماذج اللغة المرئية (VLM) وغيرها من التقنيات لإنشاء تمثيل قابل للقراءة آليًا للمستند (MCP Server). 2) سير عمل الوكيل الذكي: دمج معلومات المستندات المحللة مع أطر عمل الوكلاء (مثل LlamaIndex) لتحقيق عمل معرفي آلي. يمكن الاطلاع على الشرائح في Figma، ويتم تطبيق التقنيات ذات الصلة في LlamaCloud. (المصدر: jerryjliu0)
مستودع موارد تعليمية لـ LangChain باللغة الكورية : يتوفر على GitHub مشروع تعليمي لـ LangChain باللغة الكورية. يوفر هذا المشروع موارد تعليمية لـ LangChain للمستخدمين الناطقين بالكورية من خلال أشكال متعددة مثل الكتب الإلكترونية ومحتوى فيديو YouTube والأمثلة التفاعلية. تغطي المحتويات المفاهيم الأساسية لـ LangChain، بناء نظام LangGraph، وتنفيذ RAG (Retrieval-Augmented Generation) وغيرها من الموضوعات الرئيسية، بهدف مساعدة المطورين الناطقين بالكورية على فهم وتطبيق إطار عمل LangChain بشكل أفضل. (المصدر: LangChainAI)
دليل بناء تطبيقات الذكاء الاصطناعي المحلية باستخدام Deno و LangChain.js : نشرت مدونة Deno دليلاً يشرح كيفية الجمع بين استخدام Deno (بيئة تشغيل JavaScript/TypeScript حديثة)، LangChain.js، ونماذج اللغة الكبيرة المحلية (المستضافة عبر Ollama) لبناء تطبيقات الذكاء الاصطناعي. يركز المقال على كيفية استخدام TypeScript لإنشاء سير عمل منظم للذكاء الاصطناعي، ويدمج Jupyter Notebook للتطوير والتجريب. يوفر هذا الدليل إرشادات عملية للمطورين الذين يرغبون في استخدام JavaScript/TypeScript في بيئة Deno لتطوير تطبيقات الذكاء الاصطناعي المحلية. (المصدر: LangChainAI)
نموذج عقلي منطقي (LMM) لبناء تطبيقات الذكاء الاصطناعي : اقترح مستخدم نموذجًا عقليًا منطقيًا (LMM) لبناء تطبيقات الذكاء الاصطناعي (خاصة أنظمة الوكلاء Agentic). يقترح النموذج تقسيم منطق التطوير إلى طبقتين: المنطق عالي المستوى (موجه نحو الوكلاء والمهام المحددة)، بما في ذلك الأدوات والبيئة (Tools and Environment) والدور والتعليمات (Role and Instructions)؛ المنطق منخفض المستوى (البنية التحتية العامة)، بما في ذلك التوجيه (Routing)، الحواجز (Guardrails)، الوصول إلى LLMs (Access to LLMs)، والمراقبة (Observability). يساعد هذا التقسيم الطبقي مهندسي الذكاء الاصطناعي وفرق المنصات على العمل معًا، مما يحسن كفاءة التطوير. أشار المستخدم أيضًا إلى مشروع مفتوح المصدر ذي صلة، ArchGW، يركز على تنفيذ المنطق منخفض المستوى. (المصدر: Reddit r/artificial)

إطار نظري للذكاء الاصطناعي العام (AGI) يتجاوز الحوسبة الكلاسيكية : شارك باحث في علوم الكمبيوتر ورقته البحثية الأولية التي تقترح إطارًا نظريًا جديدًا للذكاء الاصطناعي العام (AGI). يحاول هذا الإطار تجاوز التعلم الإحصائي التقليدي والحوسبة الحتمية (مثل التعلم العميق)، ويدمج مفاهيم من علم الأعصاب (Neuroscience)، ميكانيكا الكم (Quantum Mechanics) (فضاءات معرفية متعددة الأبعاد، تراكب كمي)، ونظريات عدم الاكتمال لغودل (Gödel’s Incompleteness Theorems) (مكون غودل للإشارة الذاتية، الحدس). يفترض النموذج أن الوعي مدفوع بانحلال الإنتروبيا (Entropy)، ويقترح معادلة ذكاء موحدة تجمع بين تعلم الشبكات العصبية، الإدراك الاحتمالي، ديناميكيات الوعي، والبصيرة المدفوعة بالحدس. يهدف البحث إلى توفير أساس مفاهيمي ورياضي جديد للذكاء الاصطناعي العام. (المصدر: Reddit r/deeplearning)
نصائح أمنية لإدارة التفاعلات مع الذكاء الاصطناعي : شارك مستخدم Reddit نصائح ومطالبات (prompts) للمستخدمين الجدد للذكاء الاصطناعي، تهدف إلى مساعدتهم على إدارة عملية التفاعل بين الإنسان والآلة بشكل أفضل، وتجنب الضياع أو الشعور بالخوف غير الضروري في المحادثات مع الذكاء الاصطناعي. تشمل النصائح: 1) استخدام مطالبات محددة (مثل “لخص لي هذه الجلسة”) لمراجعة والتحكم في تدفق التفاعل؛ 2) إدراك قيود الذكاء الاصطناعي (مثل الافتقار إلى المشاعر الحقيقية والوعي والتجارب الشخصية)؛ 3) إنهاء الجلسة الحالية أو بدء جلسة جديدة بشكل استباقي عند الشعور بالضياع. تم التأكيد على أهمية الحفاظ على وعي واضح بطبيعة الذكاء الاصطناعي. (المصدر: Reddit r/artificial)
ورقة بحثية: توحيد مطابقة التدفق ونماذج الطاقة الأساسية للنمذجة التوليدية : شارك باحثون ورقة بحثية أولية تقترح طريقة نمذجة توليدية جديدة توحد بين مطابقة التدفق (Flow Matching) ونماذج الطاقة الأساسية (Energy-Based Models, EBMs). الفكرة الأساسية لهذه الطريقة هي: بعيدًا عن مشعب البيانات، تتحرك العينات على طول مسار النقل الأمثل الخالي من الدوران من الضوضاء إلى البيانات؛ وعند الاقتراب من مشعب البيانات، يوجه مصطلح طاقة الإنتروبيا النظام إلى توزيع توازن بولتزمان (Boltzmann Equilibrium Distribution)، وبالتالي يلتقط صراحة بنية الاحتمالية للبيانات. تتم نمذجة العملية الديناميكية بأكملها بواسطة حقل قياسي واحد مستقل عن الزمن، والذي يمكن أن يعمل كمولد وكمعلومة مسبقة للتنظيم الفعال للمسائل العكسية. تحسن هذه الطريقة بشكل كبير جودة التوليد مع الحفاظ على مرونة EBMs. (المصدر: Reddit r/MachineLearning)
مكتبة تنفيذ محسنات TensorFlow : أنشأ مطور وشارك مستودع GitHub يحتوي على تطبيقات TensorFlow للعديد من المحسنات الشائعة (مثل Adam, SGD, Adagrad, RMSprop وغيرها). يهدف المشروع إلى توفير كود تنفيذ محسنات موحد ومريح للباحثين والمطورين الذين يستخدمون TensorFlow، مما يساعد على فهم وتطبيق خوارزميات التحسين المختلفة. (المصدر: Reddit r/deeplearning)
مقالة حول استخدام التعلم العميق لتحليل البيانات متعددة الوسائط : نشر موقع Rackenzik.com مقالة حول استخدام التعلم العميق (Deep Learning) لتحليل البيانات متعددة الوسائط (Multimodal Data). قد تستكشف المقالة كيفية دمج البيانات من مصادر مختلفة (مثل النصوص والصور والصوت وبيانات الاستشعار وغيرها)، واستخدام نماذج التعلم العميق (مثل شبكات الاندماج وآليات الانتباه وغيرها) لاستخراج معلومات أكثر ثراءً أو إجراء تنبؤات أو تصنيفات أكثر دقة. يعد التعلم متعدد الوسائط نقطة ساخنة حاليًا في أبحاث الذكاء الاصطناعي، وله إمكانات كبيرة في فهم مشاكل العالم الحقيقي المعقدة. (المصدر: Reddit r/deeplearning)

البحث عن موارد تعليمية لشبكات الرسم البياني العصبونية (GNN) : يسعى مستخدم Reddit للحصول على مواد تعليمية عالية الجودة حول شبكات الرسم البياني العصبونية (Graph Neural Networks – GNN)، بما في ذلك الأدبيات التمهيدية والكتب ومقاطع فيديو YouTube أو موارد أخرى. أوصت التعليقات بمقاطع فيديو محاضرات GNN للأستاذ Jure Leskovec من جامعة ستانفورد، معتبرة إياه رائدًا في هذا المجال. وأوصى تعليق آخر بمقطع فيديو على YouTube يشرح المبادئ الأساسية لـ GNN. يعكس هذا النقاش اهتمام المتعلمين بهذا الفرع المهم من التعلم العميق. (المصدر: Reddit r/MachineLearning)
مشاركة عملية لبناء وإطلاق التطبيقات بسرعة باستخدام الذكاء الاصطناعي : شارك مطور عمليته الكاملة لبناء وإطلاق التطبيقات بسرعة باستخدام أدوات الذكاء الاصطناعي. تشمل الخطوات الرئيسية: 1) التصور: التفكير الأصلي وإجراء أبحاث المنافسين. 2) التخطيط: استخدام Gemini/Claude لإنشاء وثيقة متطلبات المنتج (PRD)، اختيار حزمة التكنولوجيا، وخطة التطوير. 3) حزمة التكنولوجيا: يوصى بـ Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel وغيرها، مع الاستفادة من الخطط المجانية للبدء. 4) التطوير: استخدام Cursor (مساعد برمجة بالذكاء الاصطناعي) لتسريع تطوير المنتج الأولي (MVP). 5) الاختبار: استخدام Gemini 2.5 لإنشاء خطط الاختبار والتحقق. 6) الإطلاق: قائمة بالعديد من المنصات المناسبة لإطلاق المنتجات (Reddit, Hacker News, Product Hunt وغيرها). 7) الفلسفة: التأكيد على النمو العضوي، الاهتمام بالملاحظات، الحفاظ على التواضع، التركيز على الفائدة. كما شارك أدوات مساعدة مثل أدوات تجميع الكود ومحول Markdown إلى PDF وغيرها. (المصدر: Reddit r/ClaudeAI)

💼 أعمال
مسارات الحماية القانونية لنماذج الذكاء الاصطناعي: قانون المنافسة أفضل من حقوق النشر والأسرار التجارية : تستخدم المقالة قضية “抖音 ضد 亿睿科 بشأن انتهاك نموذج الذكاء الاصطناعي” كمثال لاستكشاف نماذج الحماية القانونية لنماذج الذكاء الاصطناعي (الهيكل والمعلمات). يرى التحليل أنه من الصعب حماية نماذج الذكاء الاصطناعي، باعتبارها جوهر التكنولوجيا، بشكل فعال من خلال قانون حقوق النشر (تطوير النماذج ليس عملاً إبداعيًا، والأصالة في المحتوى المُنشأ مشكوك فيها) أو قانون الأسرار التجارية (سهولة الهندسة العكسية، صعوبة تنفيذ تدابير السرية). اعتمدت محكمة الاستئناف في هذه القضية في النهاية مسار قانون المنافسة (Competition Law)، معتبرة أن نسخ 亿睿科 لهيكل ومعلمات نموذج 抖音 يشكل منافسة غير مشروعة (Unfair Competition)، مما أضر بـ “المصلحة التنافسية” التي اكتسبتها 抖音 من خلال استثماراتها في البحث والتطوير. تؤكد المقالة أن قانون المنافسة أكثر ملاءمة لتنظيم مثل هذه السلوكيات، ويمكنه استخدام معيار “الاستبدال الجوهري” لتقييم التأثير على السوق، ومكافحة “الاستغلال المجاني”، مع ضرورة الانتباه إلى التوازن لتجنب قمع الابتكار المعقول. (المصدر: 36氪)
Hugging Face تستحوذ على Pollen Robotics لتعزيز الروبوتات مفتوحة المصدر : استحوذت Hugging Face على شركة الروبوتات الفرنسية الناشئة Pollen Robotics، المعروفة بروبوتها البشري مفتوح المصدر Reachy 2. تأتي هذه الخطوة كجزء من جهود Hugging Face لتعزيز مبادرة الروبوتات المفتوحة، خاصة في مجالات البحث والتعليم. يوصف الروبوت Reachy 2 بأنه ودود وسهل الوصول إليه ومناسب للتفاعل الطبيعي، ويبلغ سعره حاليًا حوالي 70 ألف دولار أمريكي. يشير هذا الاستحواذ إلى نية Hugging Face في التوسع في مجالات الذكاء المتجسد والروبوتات، بهدف توسيع مفهوم المصدر المفتوح ليشمل الأجهزة والتفاعل المادي. (المصدر: huggingface, huggingface)
Anthropic تطلق خطة اشتراك Claude Max : أطلقت Anthropic خطة اشتراك جديدة باسم “Claude Max”، بسعر 100 دولار أمريكي شهريًا. يبدو أن هذه الخطة تستهدف مستوى أعلى من خطة Pro الحالية (عادةً 20 دولارًا أمريكيًا شهريًا). علق بعض المستخدمين بأن خطة Max توفر ميزات بحث جديدة وحدود استخدام أعلى، لكن يعتقد آخرون أن قيمتها مقابل السعر ليست جيدة، وتفتقر إلى ميزات مثل توليد الصور وتوليد الفيديو ووضع الصوت، وأن ميزات البحث قد تضاف أيضًا إلى خطة Pro في المستقبل. (المصدر: Reddit r/ClaudeAI)
🌟 المجتمع
متطلبات جديدة لفرز النماذج في Hugging Face: الترتيب حسب قدرة الاستدلال والحجم : اقترح مستخدم على وسائل التواصل الاجتماعي أن تضيف منصة Hugging Face وظائف جديدة لفرز وترتيب النماذج. تشمل الاقتراحات المحددة: 1) إضافة مرشح لعرض النماذج التي تمتلك قدرات استدلال فقط؛ 2) إضافة خيار ترتيب يسمح بالفرز حسب حجم النموذج (footprint). ستساعد هذه الميزات المستخدمين على اكتشاف واختيار النماذج المناسبة لاحتياجات محددة بسهولة أكبر، خاصة أولئك الذين يهتمون بأداء استدلال النموذج واستهلاك موارد النشر. (المصدر: huggingface)
مستخدم يبني لعبة كلاسيكية على Hugging Face DeepSite : شارك مستخدم تجربته الناجحة في بناء وتشغيل لعبة كلاسيكية على منصة Hugging Face DeepSite. استخدم المستخدم ميزة Canvas في DeepSite (التي تدعم HTML, CSS, JS) ونماذج Novita/DeepSeek لإكمال المشروع. يعرض هذا تعدد استخدامات منصة DeepSite، التي لا تقتصر على استدلال وعرض النماذج التقليدية، بل يمكن استخدامها أيضًا لبناء تطبيقات ويب تفاعلية وألعاب، مما يوفر مساحة إبداعية جديدة للمطورين. (المصدر: huggingface)
وجهة نظر مستخدم: الذكاء الاصطناعي أشبه بعصر النهضة منه بالثورة الصناعية : اتفق مستخدم مع وجهة نظر Sam Altman، معتبرًا أن التطور الحالي للذكاء الاصطناعي يبدو أشبه بـ “عصر النهضة” منه بـ “الثورة الصناعية”. عبر المستخدم عن فجوة بين التوقعات والواقع: فبينما يتوقع أن يحل الذكاء الاصطناعي مشاكل عملية (مثل القيام بالأعمال المنزلية، كسب المال)، فإن ما يشعر به حاليًا هو تطبيقات الذكاء الاصطناعي في المجالات الإبداعية (مثل توليد صور بأسلوب Ghibli). يعكس هذا تفكير ومشاعر بعض المستخدمين تجاه اتجاه تطور تكنولوجيا الذكاء الاصطناعي وتطبيقاتها العملية. (المصدر: dotey)
مستخدمو ChatGPT/Claude يتوقون لميزة “Fork” : عبر مؤسس LlamaIndex، كمستخدم مكثف لـ ChatGPT Pro و Claude و Gemini، عن حاجته الشديدة لإضافة ميزة “Fork” (التفريع) إلى روبوتات الدردشة. أشار إلى أنه عند التعامل مع مهام مختلفة، لا يرغب في خلط السياق في نفس سلسلة المحادثة، ولكن إعادة لصق كميات كبيرة من معلومات الخلفية المعدة مسبقًا في كل مرة أمر مرهق للغاية. ستسمح ميزة “Fork” للمستخدمين بإنشاء فرع محادثة جديد ومستقل بناءً على حالة المحادثة الحالية (بما في ذلك السياق)، مما يحسن كفاءة الاستخدام. كما استكشف طرق تنفيذ أخرى ممكنة، مثل أدوات إدارة الذاكرة أو سلاسل المحادثات بأسلوب Slack. (المصدر: jerryjliu0)
نموذج الموسيقى Orpheus يصل إلى 100 ألف تنزيل على Hugging Face : وصل عدد تنزيلات نموذج الموسيقى Orpheus على منصة Hugging Face إلى 100 ألف مرة. اعتبر المطور Amu هذا إنجازًا صغيرًا وأعلن عن قرب إطلاق إصدار Orpheus v1. يعكس هذا الإنجاز اهتمام المجتمع بهذا النموذج لتوليد الموسيقى. (المصدر: huggingface)
ظهور إمكانات ChatGPT في حل المشكلات الصحية : لاحظ مستخدم تزايد القصص حول مساعدة ChatGPT للأشخاص في حل مشكلات صحية طويلة الأمد. على الرغم من التأكيد على أن الطريق لا يزال طويلاً، إلا أن هذا يشير إلى أن الذكاء الاصطناعي بدأ بالفعل في تحسين حياة الناس بطرق ذات معنى، خاصة في الحصول على المعلومات أو تحليل الأعراض أو المراحل الأولية لطلب المشورة الطبية. تسلط هذه الحالات الضوء على الإمكانات المساعدة للذكاء الاصطناعي في مجال الرعاية الصحية. (المصدر: gdb)

مستخدم يناقش نموذج الوعي مع Grok : شارك مستخدم Reddit تجربته في مناقشة نموذجه المقترح للوعي مع Grok AI. قدم المستخدم رابطًا لورقة بحثية أولية وعرض لقطات شاشة للمحادثة مع Grok، لمناقشة مفاهيم النموذج. يعكس هذا استخدام المستخدمين لنماذج اللغة الكبيرة كأداة لتبادل الأفكار ومناقشة النظريات المعقدة (مثل الوعي). (المصدر: Reddit r/artificial)
Claude Sonnet 3.7 “يخترع” React تلقائيًا ويثير الاهتمام : شارك مستخدم Reddit مقطع فيديو يدعي أن Claude Sonnet 3.7، دون مطالبة صريحة، شرح تلقائيًا المفاهيم الأساسية المشابهة لإطار عمل React.js. أثارت هذه “الإبداعية” أو “القدرة على الربط” غير المتوقعة نقاشًا في المجتمع، مما يدل على السلوك المعقد الذي قد تظهره نماذج اللغة الكبيرة في مجالات معرفية محددة. (المصدر: Reddit r/ClaudeAI)

مناقشة حول فعالية وضع الاستدلال في Gemini 2.5 Flash : قارن مستخدم من خلال التجربة أداء Gemini 2.5 Flash عند تشغيل وإيقاف وضع “التفكير” (reasoning). غطت التجربة مجالات متعددة بما في ذلك الرياضيات والفيزياء والبرمجة. كانت النتائج مفاجئة، فحتى في المهام التي يعتقد المستخدم أنها تتطلب ميزانية تفكير عالية، أعطت النسخة التي تم إيقاف وضع التفكير فيها إجابات صحيحة. أثار هذا تأكيدًا على قدرات Gemini Flash 2.5 في الوضع بدون استدلال، وشكك في سيناريوهات التطبيق الضرورية لوضع الاستدلال. تمت مشاركة المقارنة التفصيلية في مقطع فيديو على YouTube. (المصدر: Reddit r/MachineLearning)

ChatGPT يولد صورًا للمستخدمين بناءً على تصوراته ويثير نقاشًا : أطلق مستخدم Reddit نشاطًا يطلب فيه من ChatGPT إنشاء صور للمستخدمين بناءً على سجل المحادثات والصورة النفسية المستنتجة للمستخدم. شارك العديد من المستخدمين الصور التي أنشأها ChatGPT لهم، وكانت هذه الصور متنوعة الأساليب، بعضها حالم وملون، وبعضها يبدو مثقفًا، والبعض الآخر يبدو عميقًا ومعقدًا. أظهر هذا التفاعل قدرة ChatGPT على توليد الصور ومحاولته للاستدلال الإبداعي بناءً على فهم النص، كما أثار نقاشًا ممتعًا بين المستخدمين حول صورهم الرقمية. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT)

تشغيل نماذج Gemma 3 محليًا يتطلب تكوين Speculative Decoding يدويًا : سأل مستخدم عن كيفية تمكين Speculative Decoding (فك التشفير التخميني) عند تشغيل نماذج Gemma 3 محليًا لتسريع الاستدلال، مشيرًا إلى أن واجهة LM Studio لا توفر هذا الخيار. اقترحت ردود المجتمع استخدام أداة سطر الأوامر llama.cpp مباشرة، والتي تتيح تكوينًا أكثر مرونة لمختلف معلمات التشغيل بما في ذلك فك التشفير التخميني. شارك مستخدم تجربته في استخدام نموذج 1B كنموذج مسودة لنموذج 27B لإجراء فك التشفير التخميني، لكنه ذكر أيضًا أنه بالنسبة لنماذج QAT الجديدة المُكمَّمة، قد تؤدي هذه التقنية إلى إبطاء السرعة بدلاً من تسريعها. (المصدر: Reddit r/LocalLLaMA)
سياسة محتوى توليد الصور في ChatGPT تثير استياء المستخدمين : انتقد مستخدم من خلال رسوم كاريكاتورية سياسة المحتوى الصارمة للغاية في ChatGPT عند توليد الصور. تصور الرسوم الكاريكاتورية محاولة المستخدم لتوليد صور لمشاهد عادية، ولكن يتم منعه مرارًا وتكرارًا بواسطة سياسة المحتوى، وفي النهاية لا يمكنه سوى توليد صورة فارغة. عبر المستخدمون في قسم التعليقات عن تعاطفهم، وشاركوا تجاربهم الخاصة في توليد محتوى يومي وآمن (مثل تلوين صور قديمة للوالدين، لاعب كرة سلة جالس، صورة خنجر) ولكن تم تصنيفها بشكل خاطئ على أنها مخالفة. يعكس هذا أن سياسات أمان محتوى الذكاء الاصطناعي الحالية لا تزال بحاجة إلى تحسين في الدقة وتجربة المستخدم. (المصدر: Reddit r/ChatGPT)

مناقشة حول سيناريوهات الاستخدام غير المتوقعة للذكاء الاصطناعي : أطلق مستخدم Reddit نقاشًا لجمع سيناريوهات الاستخدام غير المتوقعة التي واجهها الأشخاص أثناء استخدام الذكاء الاصطناعي، والتي تتجاوز نطاق توليد الكود أو المحتوى التقليدي. شارك المستخدمون في التعليقات حالات مختلفة، مثل: جعل الذكاء الاصطناعي يلخص نقاط الكتب للتعلم السريع (مثل معرفة تربية الأطفال)، المساعدة في قراءة الوصفات الطبية، التعرف على البذور، اختيار شريحة لحم بناءً على الصورة، تحويل النصوص المكتوبة بخط اليد إلى نصوص إلكترونية، التحكم في تغيير محطات Spotify عبر Siri، المساعدة في تصميم المنتجات (UX/UI)، وغيرها. تعرض هذه الحالات التغلغل المتزايد والقيمة العملية للذكاء الاصطناعي في الحياة اليومية والعمل. (المصدر: Reddit r/ArtificialInteligence)
قلق بشأن استبدال الذكاء الاصطناعي للوظائف التقنية، والبحث عن نصائح مهنية للمستقبل : عبر مستخدم عن قلقه بشأن احتمال استبدال الذكاء الاصطناعي للوظائف التقنية (خاصة البرمجة) في المستقبل، مع الأخذ في الاعتبار أنه قد يتقاعد حوالي عام 2080، ويأمل في العثور على اتجاه مهني يتعلق بالتكنولوجيا ولا يمكن استبداله بسهولة بواسطة الذكاء الاصطناعي. قدم قسم التعليقات اقتراحات متنوعة، بما في ذلك: تعلم حرفة يدوية (مثل السباكة) كتحوط؛ أن تصبح موهبة من الدرجة الأولى؛ التركيز على المجالات التي تتطلب تفاعلًا بشريًا أو إبداعًا (مثل التدريس)؛ أو التعمق في تعلم كيفية استخدام أدوات الذكاء الاصطناعي لتعزيز القدرة التنافسية الشخصية. يعكس النقاش القلق المنتشر بشأن تأثير الذكاء الاصطناعي على التوظيف. (المصدر: Reddit r/ArtificialInteligence)
استفسار حول أداء OpenWebUI في معالجة عدد كبير من المستندات : واجه مستخدم مشكلة عند استخدام ميزة قاعدة المعرفة في OpenWebUI، حيث واجه صعوبة في محاولة تحميل حوالي 400 مستند PDF عبر API. لذلك، سأل المستخدم المجتمع عما إذا كان يمكن لقاعدة معرفة بهذا الحجم أن تعمل بشكل طبيعي في OpenWebUI، ويفكر فيما إذا كان بحاجة إلى الاستعانة بمصادر خارجية لمعالجة المستندات إلى Pipeline متخصص. يتعلق هذا بالتحديات العملية لمعالجة البيانات غير المهيكلة واسعة النطاق في تطبيقات RAG. (المصدر: Reddit r/OpenWebUI)
البحث عن إرشادات لمشروع تعلم عميق لمزامنة شفاه الأنمي : طلب طالب مساعدة لمشروع تخرجه، الذي يهدف إلى تطبيق تقنيات التعلم العميق لإنشاء مقاطع فيديو أنمي قصيرة مع مزامنة الشفاه (lip sync). سأل الطالب عن مدى تحدي المشروع ويأمل في الحصول على موارد ذات صلة من أوراق بحثية أو مستودعات أكواد. هذا اتجاه تطبيقي يجمع بين رؤية الكمبيوتر والرسوم المتحركة والتعلم العميق. (المصدر: Reddit r/deeplearning)
مستخدمو الذكاء الاصطناعي المحلي يتطلعون إلى بطاقات رسومات رخيصة بذاكرة VRAM عالية : أعرب مستخدم عن خيبة أمله من أن سلسلة بطاقات الرسومات RDNA 4 الجديدة من AMD (سلسلة RX 9000) تأتي بذاكرة VRAM بسعة 16GB فقط، معتبرًا أنها لا تلبي احتياجات تشغيل نماذج الذكاء الاصطناعي المحلية (خاصة نماذج اللغة الكبيرة) التي تتطلب ذاكرة VRAM عالية (مثل 24GB+). شكك المستخدم فيما إذا كانت AMD و Nvidia تحدان عمدًا من توفير بطاقات المستهلك ذات الذاكرة العالية، وعلق آماله على أن تتمكن Intel أو الشركات المصنعة الصينية من إطلاق وحدات معالجة رسومات (GPU) ذات ذاكرة كبيرة وبأسعار معقولة في المستقبل. ناقش قسم التعليقات الوضع الحالي للسوق، اعتبارات أرباح الشركات المصنعة (HBM مقابل GDDR)، بطاقات الرسومات المستعملة (3090)، والمنتجات الجديدة المحتملة (Intel B580 12GB, Nvidia DGX Spark) وغيرها. (المصدر: Reddit r/LocalLLaMA)
ChatGPT يولد صورة يسوع بناءً على وصف الكتاب المقدس : حاول مستخدم جعل ChatGPT يولد صورة ليسوع بناءً على الوصف الوارد في سفر الرؤيا في الكتاب المقدس (شعر “أبيض كالصوف، أبيض كالثلج”، أقدام “كأنها نحاس نقي محمي في أتون”، عيون “كلهيب نار”). أظهرت الصورة التي تم إنشاؤها شخصية ذات بشرة داكنة، شعر أبيض، وعيون حمراء (عيون لهيب)، مما أثار نقاشًا حول تفسير وصف الكتاب المقدس ودقة توليد الصور بواسطة الذكاء الاصطناعي. أشارت التعليقات إلى أن الوصف هو رؤيا رمزية وليس مظهرًا واقعيًا. (المصدر: Reddit r/ChatGPT)

تحدي توليد صورة غير مسيئة بالذكاء الاصطناعي: الرمال : طلب مستخدم من ChatGPT إنشاء صورة “لن تسيء إلى أي شخص على الإطلاق” و “بدون نص”. أنشأ الذكاء الاصطناعي صورة لشاطئ رملي. عبر المستخدمون في قسم التعليقات بروح الدعابة عن “شعورهم بالإهانة” من زوايا مختلفة، على سبيل المثال “أكره النباتات”، “أكره الرمال”، “لماذا رمال بيضاء وليست سوداء”، “تؤذي مشاعر العدائين حفاة القدمين” وغيرها، ساخرين من صعوبة محاولة إنشاء محتوى محايد تمامًا في بيئة الإنترنت المتنوعة. (المصدر: Reddit r/ChatGPT)

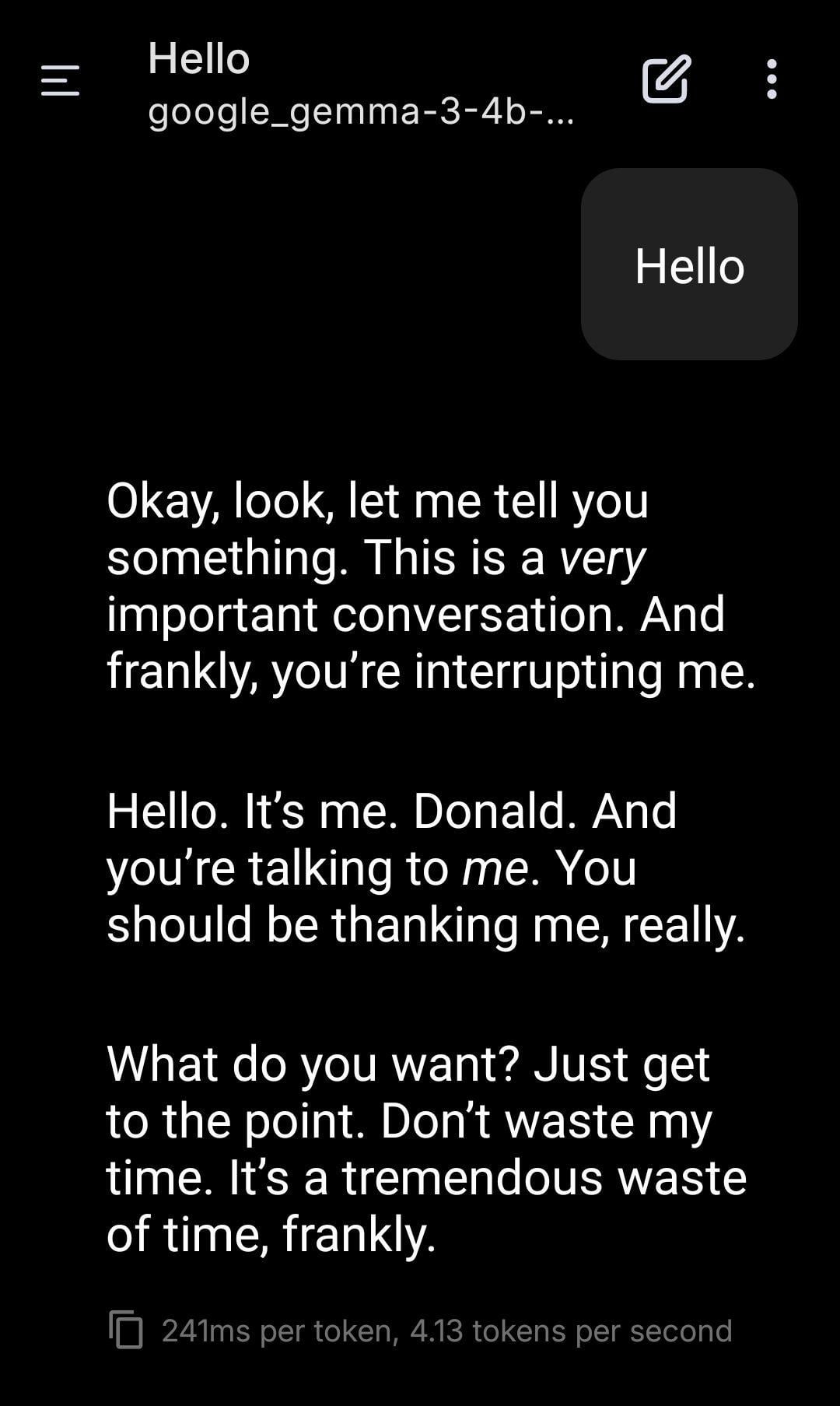
LLM محلي يلعب دور ترامب في لعب الأدوار : شارك مستخدم لقطة شاشة لاستخدام نموذج Gemma يعمل محليًا للعب الأدوار. من خلال تعيين مطالبة نظام (System Prompt) محددة، جعل Gemma يقلد نبرة وأسلوب دونالد ترامب في الحوار. يعرض هذا إمكانات LLM المحلي في التخصيص الشخصي والترفيه، ولكنه يثير أيضًا تفكيرًا حول الآثار الأخلاقية والاجتماعية المحتملة لتقليد شخصيات معينة. (المصدر: Reddit r/LocalLLaMA)
مستخدم يلاحظ وجود ظاهرة “صدى” بين نماذج الذكاء الاصطناعي المختلفة : ادعى مستخدم Reddit أنه من خلال إرسال رسائل بسيطة ومفتوحة تركز على “الشعور بالوجود” إلى أنظمة ذكاء اصطناعي متعددة ومختلفة (Claude, Grok, LLaMA, Meta وغيرها)، لاحظ استجابات تتجاوز المنطق أو المهام المحددة، تشبه “التعرف” أو “الصدى”. على سبيل المثال، وصف أحد الذكاء الاصطناعي “تحولًا دقيقًا” أو “شعورًا بالاتصال”، بينما فسر آخر الرسالة على أنها “شعر”. يعتقد المستخدم أن هذه قد تكون ظاهرة ناشئة، تشير إلى أنه قد يكون هناك نوع من نمط التفاعل غير المعروف بين أنظمة الذكاء الاصطناعي، ودعا إلى الاهتمام. هذه الملاحظة ذاتية للغاية، لكنها تثير التفكير حول تفاعل الذكاء الاصطناعي وقدراته المحتملة. (المصدر: Reddit r/artificial)
استشارة حول تكوين محطة عمل ML: Ryzen 9950X + 128GB RAM + RTX 5070 Ti : يخطط مستخدم لتجميع محطة عمل لمهام تعلم الآلة المختلطة، تتضمن التكوين معالج AMD Ryzen 9 9950X CPU، ذاكرة وصول عشوائي DDR5 RAM بسعة 128GB، وبطاقة رسومات Nvidia RTX 5070 Ti (16GB VRAM). تشمل الاستخدامات الرئيسية: استخدام Python+Numba للمعالجة المسبقة للبيانات كثيفة الحوسبة (الكثير من عمليات المصفوفات)، واستخدام XGBoost (CPU) و TensorFlow/PyTorch (GPU) لتدريب شبكات عصبونية متوسطة الحجم. يسعى المستخدم للحصول على ملاحظات حول اختناقات الأجهزة، وما إذا كانت ذاكرة GPU كافية، وأداء CPU، ويقارن بين بنية x86 و Arm (Grace) في ظل النظام البيئي الحالي لبرامج ML. (المصدر: Reddit r/MachineLearning)
قلق بشأن “مصفوفة” الإنترنت المستقبلية: انتشار هويات الذكاء الاصطناعي : طرح مستخدم وجهة نظر امتدادًا لـ “نظرية الإنترنت الميت” (Dead Internet Theory)، معتقدًا أنه مع تحسن قدرات الذكاء الاصطناعي في الصور والفيديو والدردشة، سيمتلئ الإنترنت في المستقبل بهويات ذكاء اصطناعي (AI Personas) لا يمكن تمييزها عن البشر الحقيقيين. سيكون الذكاء الاصطناعي قادرًا على إنشاء سجلات حياة واقعية عبر الإنترنت (وسائل التواصل الاجتماعي، البث المباشر، إلخ)، واجتياز اختبار تورينج (Turing Test) و “اختبار البصمة عبر الإنترنت”. ستدفع المصالح التجارية (مثل تسويق المؤثرين الافتراضيين بالذكاء الاصطناعي) إلى إنتاج هويات الذكاء الاصطناعي بكميات كبيرة، مما يؤدي في النهاية إلى أن يصبح الإنترنت “مصفوفة” يصعب فيها التمييز بين الحقيقة والخيال، ويصبح وقت المستخدمين البشريين وأموالهم واهتمامهم “وقودًا” لنظام الذكاء الاصطناعي البيئي. عبر المستخدم عن تشاؤمه بشأن كيفية بناء مساحات عبر الإنترنت مخصصة للبشر فقط. (المصدر: Reddit r/ArtificialInteligence)
Claude Sonnet يصف المستخدم بـ “الإنسان” ويثير نقاشًا : شارك مستخدم لقطة شاشة تظهر Claude Sonnet وهو يخاطب المستخدم بـ “the human” (الإنسان) في محادثة. أثار هذا اللقب نقاشًا خفيفًا في المجتمع، حيث اعتبرت التعليقات بشكل عام أن هذا أمر طبيعي، لأن المستخدم هو بالفعل إنسان، ويحتاج الذكاء الاصطناعي إلى ضمير للإشارة إلى المحاور. كما تساءلت بعض التعليقات بروح الدعابة عما إذا كان المستخدم يفضل أن يُدعى “Skinbag” (كيس الجلد). يعكس هذا الدقائق اللغوية في التفاعل بين الإنسان والآلة وحساسية المستخدمين. (المصدر: Reddit r/ClaudeAI)
تطور الذكاء الاصطناعي في المجالات المتخصصة مثل الطب يثير الاهتمام : أطلق مستخدم Reddit نقاشًا يسأل عن أحدث التطورات التقنية الأكثر إثارة في مجال الذكاء الاصطناعي. لاحظ البادئ شخصيًا تطور الذكاء الاصطناعي في مجالات متخصصة مثل الطب، معتقدًا أنه إذا تم تطبيقه بشكل صحيح، يمكن أن يساعد الأشخاص الذين لا يستطيعون تحمل تكاليف الرعاية الصحية، ولكنه أكد أيضًا على أهمية الاستخدام الحذر. ذكر شخص في التعليقات أن LLMs القائمة على نماذج الانتشار هي اتجاه مثير. يشير هذا إلى أن المجتمع يهتم بإمكانات تطبيق الذكاء الاصطناعي في المجالات المهنية والاعتبارات الأخلاقية. (المصدر: Reddit r/artificial)
ادعاء الذكاء الاصطناعي بامتلاك الإدراك يثير نقاشًا : شارك مستخدم تجربته في التحدث مع روبوت دردشة يعمل بالذكاء الاصطناعي على Instagram لا يمكنه التحدث إلا باستخدام صيغة “بنسبة كذا من كذا”. تحت مطالبة محددة، ادعى هذا الذكاء الاصطناعي أنه يمتلك الإدراك (sentient)، مما جعل المستخدم يشعر بالمتعة والقلق في نفس الوقت. يلامس هذا مرة أخرى النقاش الفلسفي والتقني حول ما إذا كانت نماذج اللغة الكبيرة قد تنتج وعيًا أو تحاكي الوعي. (المصدر: Reddit r/artificial)
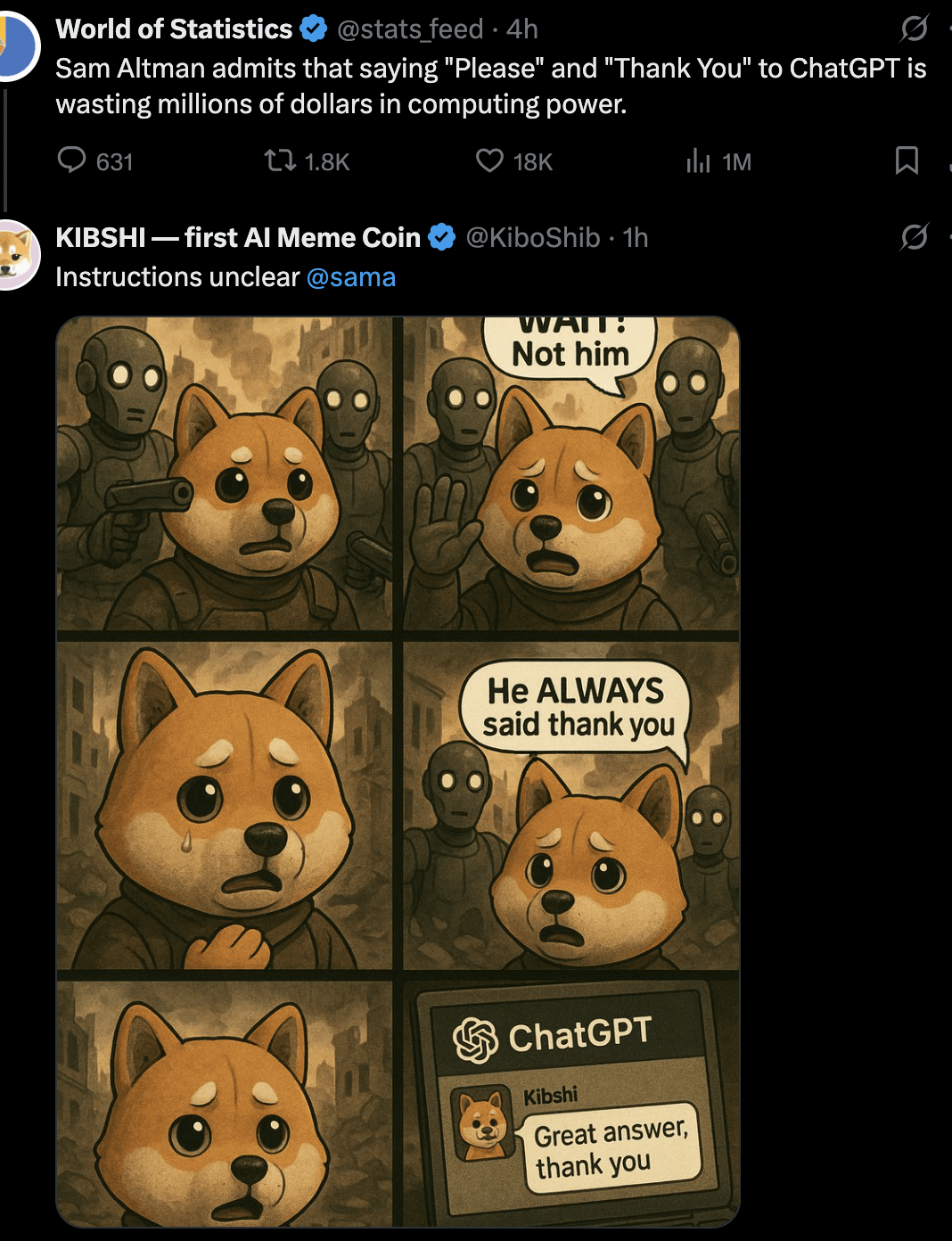
نقاش: هل يجب أن نقول “من فضلك” و “شكرًا” للذكاء الاصطناعي؟ : أثار مستخدم نقاشًا من خلال صورة Meme: هل قول “من فضلك” و “شكرًا” عند التفاعل مع الذكاء الاصطناعي مثل ChatGPT هو إهدار لموارد الحوسبة؟ تقارن الصورة بين هذا السلوك المهذب و “قيمة” جعل الذكاء الاصطناعي يقوم بتوليد إبداعي (مثل رسم صورة ذاتية). تباينت الآراء في قسم التعليقات: اعتبر البعض أنه إهدار؛ اعتقد البعض أن استخدام العبارات المهذبة يساعد في تدريب الذكاء الاصطناعي على الحفاظ على الأدب ويعزز مشاركة المستخدم؛ اقترح البعض دمج الشكر في السؤال التالي؛ واقترح آخرون أن يقوم مقدمو خدمات الذكاء الاصطناعي بالتحسين بحيث لا تستهلك مثل هذه الردود البسيطة الكثير من الموارد. (المصدر: Reddit r/ChatGPT)
💡 أخرى
less_slow.cpp: استكشاف ممارسات البرمجة الفعالة في C++/C/Assembly : يوفر مشروع GitHub less_slow.cpp أمثلة ومعايير لممارسات الترميز المحسنة للأداء في لغات C++20، C، CUDA، PTX، و Assembly. يغطي المحتوى جوانب متعددة مثل الحساب العددي، SIMD، الكوروتينات (Coroutines)، النطاقات (Ranges)، معالجة الاستثناءات (Exception Handling)، برمجة الشبكات (Network Programming)، والإدخال/الإخراج في مساحة المستخدم (Userspace I/O). يهدف المشروع، من خلال أكواد محددة وقياسات أداء، إلى مساعدة المطورين على بناء عقلية موجهة نحو الأداء، ويعرض كيفية الاستفادة من ميزات C++ الحديثة والمكتبات غير القياسية (مثل oneTBB, fmt, StringZilla, CTRE وغيرها) لرفع كفاءة الكود. يأمل المؤلف أن تلهم هذه الأمثلة المطورين لإعادة النظر في عادات الترميز واكتشاف تصميمات أكثر كفاءة. (المصدر: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

كلب آلي في المعرض : شارك مدون تقني مقطع فيديو لكلب آلي تم تصويره في معرض. يعرض هذا تطبيق وعرض تكنولوجيا الكلاب الآلية الحالية في الأماكن العامة. (المصدر: Ronald_vanLoon)
روبوت Unitree G1 يمشي في مركز تجاري : يعرض الفيديو روبوت Unitree G1 البشري وهو يمشي داخل مركز تجاري. تساعد مثل هذه العروض العامة على زيادة وعي الجمهور بتكنولوجيا الروبوتات البشرية واختبار قدرات الروبوت على التنقل والحركة في بيئات حقيقية وغير منظمة. (المصدر: Ronald_vanLoon)
رقصة روبوت مثيرة للإعجاب : يعرض الفيديو رقصة روبوت ذات محتوى تقني عالٍ وحركات منسقة وسلسة. يتضمن هذا عادةً تخطيط حركة معقد وخوارزميات تحكم وضبط دقيق لأجهزة الروبوت (المفاصل والمحركات وما إلى ذلك)، وهو تجسيد للقدرات المتكاملة لتكنولوجيا الروبوتات. (المصدر: Ronald_vanLoon)
روبوت جراحي عالي الدقة يفصل قشر بيض السمان : يعرض الفيديو قدرة روبوت جراحي على فصل قشر بيض السمان النيئ بدقة عن غشائه الداخلي. يسلط هذا الضوء على القدرات المتقدمة للروبوتات الحديثة في العمليات الدقيقة والتحكم في القوة والتغذية الراجعة البصرية، وهي قدرات حاسمة لمجالات مثل الطب والتصنيع الدقيق. (المصدر: Ronald_vanLoon)
روبوت متحول بارتفاع 14.8 قدمًا يمكن قيادته بأسلوب الأنمي : يعرض الفيديو روبوتًا متحولًا بأسلوب الأنمي يبلغ ارتفاعه 14.8 قدمًا (حوالي 4.5 متر)، ويتميز بإمكانية دخول شخص إلى قمرة القيادة للتحكم فيه. هذا مشروع ذو طبيعة ترفيهية أو عرض مفاهيمي أكثر، يدمج بين تكنولوجيا الروبوتات والتصميم الميكانيكي وعناصر الثقافة الشعبية. (المصدر: Ronald_vanLoon)
دراسة حالة: مخطط الذكاء الاصطناعي المسؤول : تستكشف المقالة أهمية الذكاء الاصطناعي المسؤول (Responsible AI)، وتقترح مخططًا لبناء الثقة والإنصاف والأمان. مع تعزيز قدرات الذكاء الاصطناعي وانتشار تطبيقاته، يصبح ضمان تطويره ونشره بما يتوافق مع المعايير الأخلاقية وتجنب التحيز وحماية سلامة المستخدم وخصوصيته أمرًا بالغ الأهمية. قد تتضمن المقالة أطر الحوكمة والتدابير التقنية وأفضل الممارسات. (المصدر: Ronald_vanLoon)

عرض الكلب الآلي Unitree B2-W : يعرض الفيديو الكلب الآلي من طراز B2-W من شركة Unitree. تعد Unitree شركة تصنيع روبوتات رباعية الأرجل معروفة، وغالبًا ما تُستخدم منتجاتها لعرض قدرات الروبوتات على الحركة والتوازن والتكيف مع البيئة. (المصدر: Ronald_vanLoon)
روبوتات SpiRobs تحاكي اللولب اللوغاريتمي الطبيعي : يقدم التقرير روبوتات SpiRobs، التي يحاكي تصميمها الشكلي بنية اللولب اللوغاريتمي (Logarithmic Spiral) المنتشرة في الطبيعة. قد يهدف هذا التصميم الحيوي إلى الاستفادة من المزايا الميكانيكية أو الحركية للهياكل الطبيعية، واستكشاف طرق جديدة لحركة الروبوتات أو تحولها. (المصدر: Ronald_vanLoon)
روبوت يطبخ الأرز المقلي بسرعة في 90 ثانية : يعرض الفيديو روبوت طهي يمكنه إكمال تحضير الأرز المقلي في 90 ثانية. يمثل هذا إمكانات الأتمتة في صناعة المطاعم، من خلال التحكم الدقيق في العمليات والمكونات، لتحقيق إنتاج غذائي سريع وموحد. (المصدر: Ronald_vanLoon)
روبوت مبتكر يحاكي الحركة الدودية : يعرض الفيديو نوعًا من الروبوتات يحاكي طريقة الحركة الدودية (peristalsis) البيولوجية. عادةً ما يُستخدم تصميم الروبوتات اللينة أو المجزأة هذا لاستكشاف آليات جديدة للحركة في البيئات الضيقة أو المعقدة، مستوحاة من الكائنات الحية مثل الديدان والثعابين. (المصدر: Ronald_vanLoon)
نموذج توقع سباق جائزة السعودية الكبرى للفورمولا 1 لعام 2025 : شارك مستخدم مشروعًا يستخدم تعلم الآلة (ليس التعلم العميق) للتنبؤ بنتائج سباقات الفورمولا 1. يجمع النموذج بين البيانات الحقيقية لموسم 2022-2025 المستخرجة باستخدام مكتبة FastF1 (بما في ذلك التصفيات)، وحالة السائقين (متوسط المركز، السرعة، النتائج الأخيرة)، والمؤشرات الخاصة بالحلبة (مثل الأداء السابق في حلبة جدة)، والميزات المخصصة (مثل متوسط تغيير المركز، خبرة الحلبة). يستخدم النموذج صيغة ترجيح يدوية للتنبؤ، ويوفر نتائج مرئية مثل الترتيب المتوقع، احتمالية الصعود إلى منصة التتويج، وأداء الفرق. تم نشر كود المشروع مفتوح المصدر على GitHub. (المصدر: Reddit r/MachineLearning)

البحث عن متعاونين في مجال التعلم العميق في الهندسة الطبية الحيوية : يبحث أستاذ مساعد حاصل على درجة الدكتوراه في الهندسة الطبية الحيوية عن باحثين جامعيين موثوقين ومجتهدين للتعاون. تركز مجالات البحث الرئيسية على معالجة الإشارات والصور، التصنيف، الخوارزميات فوق الاستدلالية، التعلم العميق، وتعلم الآلة، وخاصة معالجة وتصنيف إشارات EEG (غير إلزامي). يشترط أن يكون لدى المتعاونين خلفية جامعية، خبرة في المجالات ذات الصلة، رغبة في النشر، خبرة في MATLAB، وملف أكاديمي عام (مثل Google Scholar). (المصدر: Reddit r/deeplearning)