
كلمات مفتاحية:AI, GPT-4.1, Zhipu AI IPO, استثمارات إنفيديا في الحوسبة الفائقة للذكاء الاصطناعي, إنفاق أمازون الرأسمالي على الذكاء الاصطناعي, بروتوكول التشغيل البيني لوكيل الذكاء الاصطناعي, حجم مستخدمي DeepSeek
🔥 أبرز الأخبار
OpenAI تطلق سلسلة نماذج GPT-4.1، مع تحسين أداء API وإيقاف GPT-4.5: أطلقت OpenAI ثلاثة نماذج جديدة عبر واجهة برمجة التطبيقات (API) في 15 أبريل، وهي GPT-4.1 و GPT-4.1 mini و GPT-4.1 nano، بهدف التفوق الشامل على سلسلة GPT-4o. تتميز النماذج الجديدة بنافذة سياق تصل إلى مليون Token وقاعدة معرفية محدثة حتى يونيو 2024. يبرز GPT-4.1 في قدرات البرمجة (بنتيجة 54.6% على SWE-bench Verified، بزيادة 21.4% عن GPT-4o)، واتباع التعليمات (بنتيجة 38.3% على MultiChallenge، بزيادة 10.5% عن GPT-4o)، وفهم الفيديو طويل السياق (بنتيجة 72.0% على Video-MME، بزيادة 6.7% عن GPT-4o). الجدير بالذكر أن GPT-4.1 nano هو أول نموذج nano، ويتفوق أداؤه على GPT-4o mini بتكلفة أقل. في الوقت نفسه، أعلنت OpenAI أنها ستوقف واجهة برمجة التطبيقات GPT-4.5 Preview API بعد 3 أشهر (14 يوليو)، واصفة إياه بأنه إصدار معاينة بحثي، وأنها ستدمج الميزات التي يفضلها المطورون في النماذج الجديدة مستقبلاً. يُعتبر هذا الإطلاق خطوة استراتيجية من OpenAI لتمييز نماذج API عن خط منتجات ChatGPT ومنافسة مباشرة لسلسلة Google Gemini. (المصدر: 36氪, 新智元1, AI科技评论, Reddit r/LocalLLaMA, Reddit r/artificial)
Zhipu AI تبدأ إجراءات الإدراج العام الأولي (IPO) وتفتح مصدر نماذج جديدة، بقيمة تتجاوز 20 مليار يوان: بدأت شركة Zhipu AI (智谱华章)، إحدى الشركات الصينية الرائدة في مجال النماذج اللغوية الكبيرة، إجراءات الإدراج العام الأولي (IPO) رسميًا في 14 أبريل لدى هيئة تنظيم الأوراق المالية في بكين، مع تعيين شركة CICC كجهة استشارية. تأسست Zhipu AI كشركة منبثقة عن مختبر هندسة المعرفة بجامعة تسينغهوا، ويضم فريقها الأساسي العديد من خريجي الجامعة. جمعت الشركة تمويلاً تراكميًا يزيد عن 15 مليار يوان، وتقدر قيمتها السوقية مؤخرًا بأكثر من 20 مليار يوان صيني. بالتزامن مع بدء إجراءات IPO، أعلنت Zhipu AI عن فتح مصدر سلسلة نماذج GLM-4-32B/9B على نطاق واسع، بما في ذلك النماذج الأساسية ونماذج الاستدلال ونماذج التفكير العميق، وذلك بموجب ترخيص MIT للاستخدام التجاري المجاني. من بينها، نموذج الاستدلال GLM-Z1-32B-0414 بمعاملات 32 مليار يتفوق في بعض المهام على نموذج DeepSeek-R1 بمعاملات 671 مليار. تصل سرعة استدلال نسخته السريعة عبر API، GLM-Z1-AirX، إلى 200 tokens/s، بينما يبلغ سعر نسخته الاقتصادية 1/30 فقط من سعر DeepSeek-R1. كما أطلقت الشركة نطاقًا جديدًا z.ai كمنصة لتجربة النماذج مجانًا. تعكس هذه الخطوة تخطيط Zhipu AI الشامل في البحث والتطوير الذاتي، والاستكشاف التجاري، وبناء نظام بيئي مفتوح المصدر. (المصدر: 智东西, InfoQ, 量子位, 极客公园, 雷递, 公众号)

Nvidia تستثمر 500 مليار دولار لتصنيع حواسيب فائقة للذكاء الاصطناعي في الولايات المتحدة: أعلنت Nvidia عن خطة ضخمة لاستثمار 500 مليار دولار على مدى السنوات الأربع القادمة لتصنيع حواسيب فائقة للذكاء الاصطناعي لأول مرة في الولايات المتحدة. تتضمن الخطة التعاون مع العديد من عمالقة الصناعة، بما في ذلك TSMC (لإنتاج رقائق Blackwell في أريزونا)، و Foxconn و Wistron (لبناء مصانع للحواسيب الفائقة في تكساس)، و Amkor و SPIL (لإجراء عمليات التغليف والاختبار في أريزونا). صرح الرئيس التنفيذي لشركة Nvidia، جنسن هوانغ، بأن هذه الخطوة تهدف إلى تلبية الطلب المتزايد على رقائق الذكاء الاصطناعي والحواسيب الفائقة، وتعزيز مرونة سلسلة التوريد، والاستفادة من تقنيات Nvidia في الذكاء الاصطناعي والروبوتات (Isaac GR00T) والتوائم الرقمية (Omniverse) لتصميم وتشغيل المصانع. تُعتبر هذه الخطة بمثابة نشر استراتيجي في ظل دفع الحكومة الأمريكية للتصنيع المحلي (مثل قانون الرقائق CHIPS Act) والسياق الجيوسياسي، بهدف تعزيز مكانة الولايات المتحدة في السباق العالمي للبنية التحتية للذكاء الاصطناعي، ولكنها تواجه أيضًا تحديات مثل تعقيد سلسلة التوريد، ونقص العمال الفنيين، وعدم اليقين بشأن السياسات. (المصدر: 新智元1, 新智元2, Reddit r/artificial)

Amazon تخطط لاستثمار أكثر من 100 مليار دولار لتعزيز الذكاء الاصطناعي، لمواجهة المنافسة واغتنام الفرص: كشف الرئيس التنفيذي لشركة Amazon، آندي جاسي (Andy Jassy)، في رسالته السنوية للمساهمين لعام 2024، أن الشركة تخطط لإنفاق رأسمالي يتجاوز 100 مليار دولار في عام 2025، سيخصص معظمه للمشاريع المتعلقة بالذكاء الاصطناعي، بما في ذلك مراكز البيانات، ومعدات الشبكات، وأجهزة الذكاء الاصطناعي (مثل رقائق Trainium المطورة ذاتيًا) وخدمات الذكاء الاصطناعي التوليدي (مثل سلسلة نماذج Nova الكبيرة المطورة ذاتيًا، ومنصة Bedrock، و Alexa+ المحدث، ومساعد التسوق Rufus). يعكس هذا الاستثمار الضخم (ما يقرب من سدس إيراداتها السنوية) رؤية Amazon للذكاء الاصطناعي كمفتاح لمواجهة المنافسة الشديدة في مجال التجارة الإلكترونية (من SHEIN و Temu و TikTok وغيرها) واغتنام فرصة تاريخية. أكد جاسي أن الذكاء الاصطناعي سيغير قواعد البحث والبرمجة والتسوق وغيرها، وأن عدم الاستثمار فيه يعني فقدان القدرة التنافسية. حاليًا، تصل إيرادات أعمال الذكاء الاصطناعي في Amazon إلى مليارات الدولارات سنويًا، بنمو سنوي يصل إلى ثلاثة أرقام. تظهر هذه الخطوة أيضًا تصميم Amazon على مواصلة الاستثمار لتعزيز مكانتها الرائدة في مجال الخدمات السحابية (AWS) في مواجهة منافسين مثل Microsoft Azure و Google Cloud. (المصدر: 36氪)
🎯 التوجهات
بروتوكولات التشغيل البيني لوكلاء الذكاء الاصطناعي MCP و A2A تحظى بالاهتمام: يشهد مجال وكلاء الذكاء الاصطناعي (AI Agents) منافسة على بروتوكولات التفاعل الموحدة. يهدف بروتوكول MCP (Model Context Protocol) الذي اقترحته Anthropic إلى توحيد الاتصال بين النماذج الكبيرة والأدوات الخارجية ومصادر البيانات، وقد وُصف بأنه “USB-C للذكاء الاصطناعي”، وحصل على دعم من OpenAI و Google وغيرهما. من جانبها، قامت Google بفتح مصدر بروتوكول A2A (Agent2Agent)، الذي يركز على التعاون الآمن والفعال بين الوكلاء من مختلف الموردين والأطر، بهدف كسر حواجز النظام البيئي. يشير ظهور هذين البروتوكولين إلى تطور الذكاء الاصطناعي من الذكاء الفردي إلى الشبكات التعاونية، ولكنه يثير أيضًا نقاشات حول “البروتوكول هو السلطة”، واحتكار البيانات، وحواجز النظام البيئي (“الأسوار العالية حول الأفنية الصغيرة”). قد يؤدي التحكم في وضع المعايير إلى إعادة تشكيل هيكل سلسلة صناعة الذكاء الاصطناعي، ويؤثر بعمق على اندماج الذكاء الاصطناعي مع العالم المادي (الروبوتات، إنترنت الأشياء). بدأت الشركات المحلية مثل Alibaba Cloud و Tencent Cloud أيضًا في التخطيط لدعم MCP. (المصدر: 36Kr)

تقرير QuestMobile: DeepSeek يقلب مشهد تطبيقات الذكاء الاصطناعي المحلية، وحجم المستخدمين يصل إلى 240 مليون: أظهر تقرير “تحليل المنافسة في سوق تطبيقات الذكاء الاصطناعي للربع الأول من عام 2025” الصادر عن QuestMobile أن سوق تطبيقات الذكاء الاصطناعي الأصلية في الصين قد انقلب رأسًا على عقب بسبب الشعبية الكبيرة لنموذج DeepSeek وتطبيقاته. حتى نهاية فبراير 2025، بلغ حجم المستخدمين النشطين شهريًا لتطبيقات الذكاء الاصطناعي الأصلية 240 مليون، بزيادة تقارب 90% عن شهر يناير. تصدر تطبيق DeepSeek App القائمة بـ 194 مليون مستخدم نشط شهريًا، يليه تطبيق Doubao من ByteDance (116 مليون) و Tencent Yuanbao (41.64 مليون)، ليحلوا محل Kimi وغيره. أشار التقرير إلى أن تأثير DeepSeek المفتوح المصدر والميسور التكلفة قد دفع اللاعبين الرئيسيين إلى اعتماده وأدى إلى انفجار في تطبيقات الذكاء الاصطناعي، مما أدى إلى تشكيل 23 مسارًا، بما في ذلك مساعدي الذكاء الاصطناعي الشاملين والبحث بالذكاء الاصطناعي، حيث يعد البحث بالذكاء الاصطناعي هو الأكثر تنافسية. حاليًا، أصبح “الدفع بنماذج متعددة” هو المعيار للتطبيقات الرائدة، وتحول تركيز المنافسة إلى تصميم المنتجات والعمليات. (المصدر: QuestMobile)

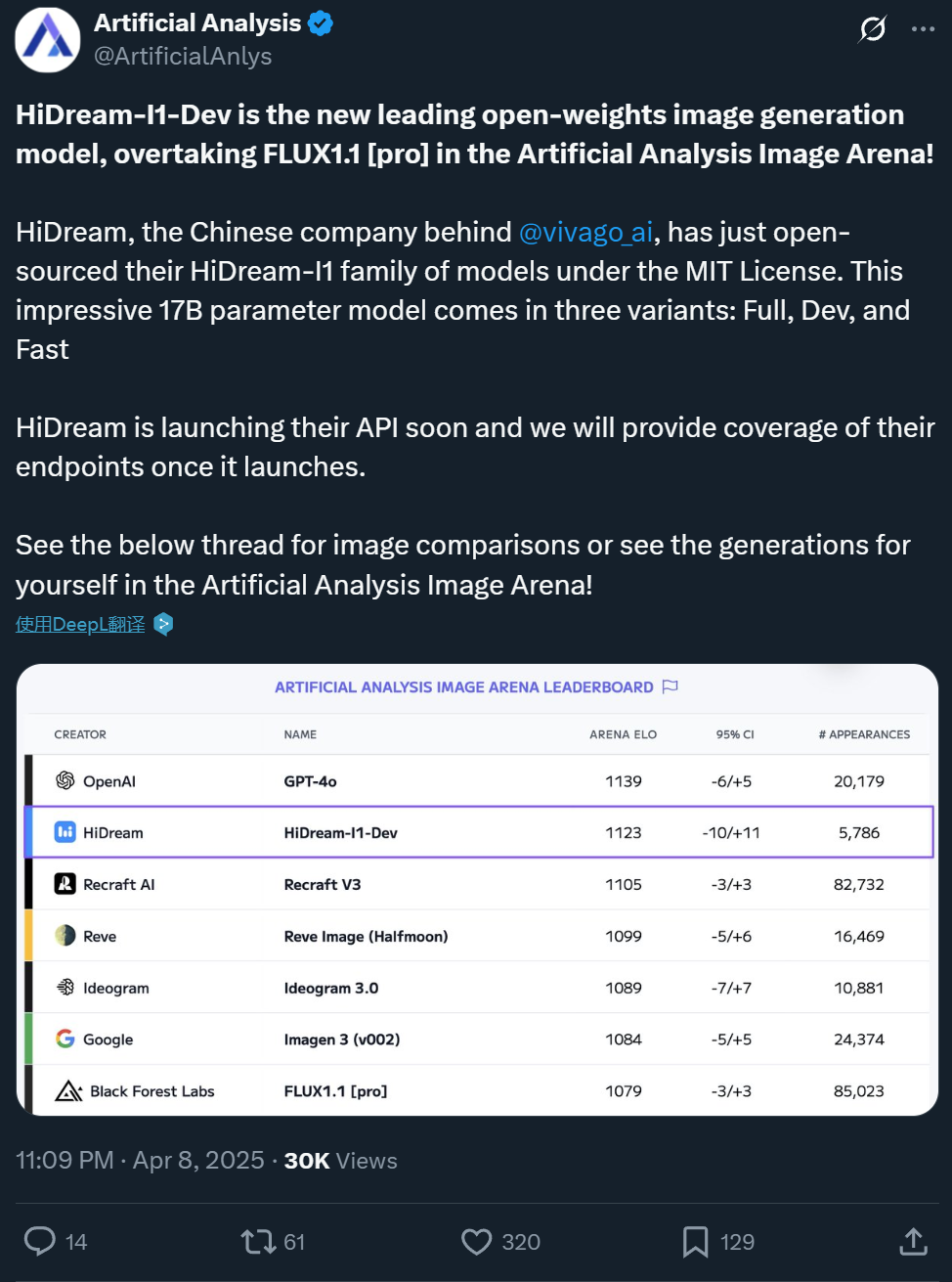
Zxiang Future تفتح مصدر نموذج تحويل النص إلى صورة HiDream-I1 بمعاملات 17 مليار، وتأثيره يضاهي GPT-4o: فتحت الشركة الصينية Zxiang Future مصدر نموذجها الكبير لتحويل النص إلى صورة HiDream-I1 بمعاملات 17 مليار، وذلك بموجب ترخيص MIT المتساهل الذي يسمح بالاستخدام التجاري. أظهر النموذج أداءً متميزًا في ساحات المنافسة والاختبارات المعيارية (مثل HPSv2.1 و GenEval و DPG-Bench) على منصات مثل Artificial Analysis، حيث يُعتقد أن واقعية الصور التي يولدها ودقتها وقدرتها على اتباع التعليمات تضاهي GPT-4o و FLUX 1.1 Pro، بل وتتفوق عليهما في بعض الجوانب. يعتمد HiDream-I1 على بنية Sparse Diffusion Transformer (Sparse DiT)، ويدمج تقنية MoE لتعزيز الأداء والكفاءة. كما أعلنت الشركة عن قرب فتح مصدر نموذج HiDream-E1 الذي يدعم تحرير الصور التفاعلي، ويهدف الجمع بينهما إلى توفير تجربة توليد وتحرير صور “مفتوحة المصدر تضاهي GPT-4o”. النموذج متاح الآن على Hugging Face ويمكن تجربته على منصة Vivago. (المصدر: 机器之心1, 机器之心2)
ByteDance تطلق نموذج الفيديو الأساسي Seaweed بمعاملات 7 مليار، بتكلفة منخفضة وكفاءة عالية: أطلق فريق Seed التابع لشركة ByteDance نموذجًا أساسيًا لتوليد الفيديو يُدعى Seaweed. يبلغ حجم معاملات النموذج 7 مليارات فقط، ويُقال إنه تم تدريبه باستخدام 665 ألف ساعة من وحدات معالجة الرسومات H100 (ما يعادل تدريب 1000 بطاقة لمدة 28 يومًا تقريبًا)، بتكلفة منخفضة نسبيًا. يستطيع Seaweed توليد مقاطع فيديو بدقة مختلفة (يدعم أصلاً 1280×720، ويمكن زيادتها إلى 2K)، وبأي نسبة عرض إلى ارتفاع ومدة، بناءً على النص. يدعم النموذج توليد الفيديو من الصور، والتحكم في الكائن المرجعي (صورة واحدة/متعددة)، والتكامل مع حل الشخصيات الرقمية Omnihuman لتوليد فيديو متزامن مع حركة الشفاه، ودبلجة الفيديو، وغيرها من الوظائف. يعتمد تقنيًا على بنية DiT+VAE، مع عملية معالجة بيانات شاملة واستراتيجية تدريب متعددة المراحل والمهام (التدريب المسبق، SFT، RLHF)، وتم تحسينه على مستوى النظام لرفع كفاءة التدريب. يقود الفريق الدكتور لو جيانغ (Lu Jiang)، الرئيس السابق لتوليد الفيديو في Google، وآخرون. (المصدر: 量子位)

Alibaba Tongyi تطلق نموذج توليد فيديو الشخصيات الرقمية OmniTalker: أطلق فريق HumanAIGC التابع لمختبر Alibaba Tongyi نموذجًا كبيرًا جديدًا لتوليد فيديو الشخصيات الرقمية يُدعى OmniTalker. يهدف النموذج إلى حل المشكلات التي تسببها الطرق التقليدية المتسلسلة (TTS + الدفع بالصوت) مثل التأخير وعدم تزامن الصوت والصورة وعدم اتساق الأسلوب. OmniTalker هو إطار موحد شامل، يأخذ نصًا ومقطع فيديو وصوت مرجعي كمدخلات، ويولد في الوقت الفعلي كلامًا متزامنًا وفيديو لشخصية رقمية، مع الحفاظ على صوت وأسلوب التحدث الوجهي للمصدر المرجعي. تعتمد بنيته الأساسية على DiT (Diffusion Transformer) ثنائي التدفق، لمعالجة المعلومات الصوتية والمرئية بشكل منفصل، ويضمن التزامن واتساق الأسلوب من خلال وحدة دمج صوت وفيديو مبتكرة. يستخدم النموذج وحدة تعلم مرجعية سياقية لالتقاط ميزات الأسلوب من الفيديو المرجعي، دون الحاجة إلى تدريب مستخرج أسلوب إضافي. المشروع متاح الآن للتجربة على مجتمع ModelScope و HuggingFace. (المصدر: 机器之心)

Kuaishou تطلق الإصدار 2.0 من نموذج الفيديو Kling AI: أطلقت شركة Kuaishou الإصدار 2.0 من نموذج توليد الفيديو Kling AI، والذي يقال إنه شهد تحسينات كبيرة في مدى حركة الكاميرا، والالتزام بقوانين الفيزياء، وأداء الشخصيات، واستقرار الحركة، والفهم الدلالي. أظهرت تقييمات المستخدمين أن الإصدار الجديد يتفوق في معالجة التفاعلات المعقدة (مثل اصطدام تيرانوصور وكسر شجرة)، والحركات الدقيقة (مثل خلع النظارات)، والمشاهد متعددة الأشخاص، ومحاكاة الظلال والإضاءة الواقعية، مما يعزز بشكل كبير واقعية الفيديو وإحساسه السينمائي، ويُعتقد أن تأثيره يتجاوز الإصدار السابق 1.6 ويصل إلى مستوى رائد في الصناعة. على الرغم من أنه لا يزال هناك مجال للتحسين في حركة المجموعات عالية السرعة والمحاكاة الفيزيائية المتطرفة (مثل رمي كرة السلة)، إلا أن أدائه العام يُعتبر قد بدأ في تحدي مستوى الإنتاج الاحترافي. يمكن للمستخدمين تجربة الإصدار الجديد عبر الموقع الرسمي klingai.com. (المصدر: 公众号, op7418)

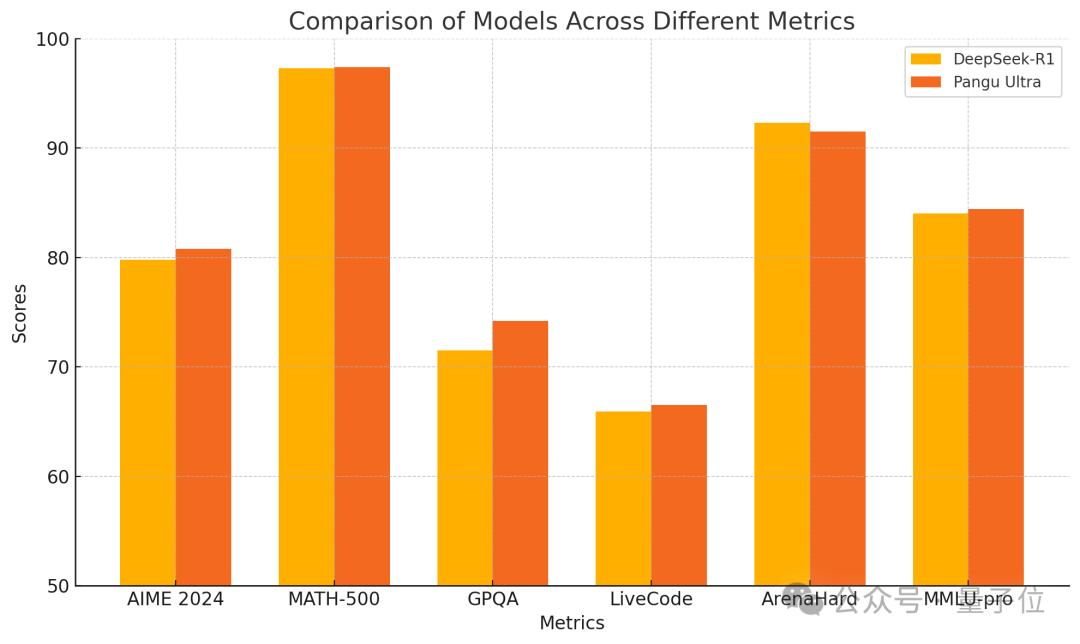
Huawei تطلق نموذج Pangu Ultra 135B الكثيف، مدرب بالكامل على Ascend بأداء متفوق: كشفت Huawei عن عضو جديد في سلسلة نماذجها الكبيرة Pangu، وهو Pangu Ultra. إنه نموذج كثيف (Dense) بمعاملات 135 مليار، تم تدريبه بالكامل على مجموعة حوسبة الذكاء الاصطناعي Ascend من Huawei (8192 وحدة NPU)، دون استخدام وحدات معالجة رسومات Nvidia. وفقًا للتقارير، أظهر Pangu Ultra أداءً متميزًا في مهام مثل الاستدلال الرياضي (AIME 2024, MATH-500) والبرمجة (LiveCodeBench)، حيث يضاهي أداؤه نماذج MoE الأكبر حجمًا مثل DeepSeek-R1. تقنيًا، استخدم النموذج تسوية طبقة Sandwich-Norm المبتكرة ذات القياس العميق واستراتيجية تهيئة المعاملات TinyInit، مما حل بفعالية مشكلات عدم الاستقرار أثناء تدريب الشبكات العميقة جدًا (94 طبقة)، وحقق تدريبًا سلسًا دون قمم خسارة. من خلال التحسين على مستوى النظام، حقق التدريب معدل استخدام للحوسبة (MFU) يتجاوز 52%. (المصدر: 量子位)
Canopy Labs تفتح مصدر نموذج توليد الكلام العاطفي Orpheus: أطلقت Canopy Labs وفتحت مصدر سلسلة نماذج تحويل النص إلى كلام (TTS) تُدعى Orpheus. يعتمد النموذج على بنية Llama، والإصدار الأول بمعاملات 3 مليارات، وسيتم إطلاق إصدارات أصغر لاحقًا (1B، 0.5B، 0.15B). يتميز Orpheus بقدرته على توليد كلام ذي عاطفة ونبرة وإيقاع شبيه بالإنسان بدرجة عالية، ويمكنه حتى استنتاج وتوليد أصوات غير لغوية من النص مثل الضحك والتنهد، مما يحقق تعبيرًا “تعاطفيًا”. يدعم النموذج استنساخ الصوت بدون تدريب مسبق (zero-shot) والتحكم في النبرة العاطفية من خلال العلامات. يعتمد على الاستدلال المتدفق (streaming inference)، بزمن انتقال منخفض يصل إلى 100-200 مللي ثانية، وسرعة استدلال أسرع من التشغيل في الوقت الفعلي على بطاقة رسومات A100 40GB. يدعي المطورون أن أداءه يتجاوز النماذج مفتوحة المصدر الحالية وبعض النماذج المغلقة الرائدة (SOTA)، بهدف كسر احتكار نماذج TTS المغلقة. النموذج والكود متاحان الآن على GitHub و Hugging Face. (المصدر: 新智元)

جامعة Zhejiang و ByteDance تطلقان نموذج توليد الكلام MegaTTS3: أطلق فريق البروفيسور تشو تشاو (Zhou Zhao) من جامعة Zhejiang بالتعاون مع ByteDance الجيل الثالث من نموذج توليد الكلام MegaTTS3 وفتح مصدره. يحقق النموذج، بحجم معاملات خفيف يبلغ 0.45 مليار فقط، توليد كلام عالي الجودة باللغتين الصينية والإنجليزية، ويظهر أداءً متميزًا في استنساخ الصوت بدون تدريب مسبق (zero-shot)، قادرًا على توليد كلام طبيعي وقابل للتحكم وشخصي. يركز MegaTTS3 على اختراق محاذاة الكلام والنص المتفرقة، وقابلية التحكم في التوليد، والتوازن بين الكفاءة والجودة. تشمل الميزات التقنية تقنية “التوجيه الحر المصنف متعدد الشروط” (Multi-Condition CFG) للتحكم متعدد الأبعاد مثل شدة اللهجة، وتقنية “تسريع التدفق المصحح المجزأ” (PeRFlow) التي تزيد سرعة أخذ العينات بمقدار 3 مرات. أظهر النموذج طبيعية رائدة (CMOS) وتشابهًا مع المتحدث (SIM-O) على معايير مثل LibriSpeech. (المصدر: PaperWeekly)

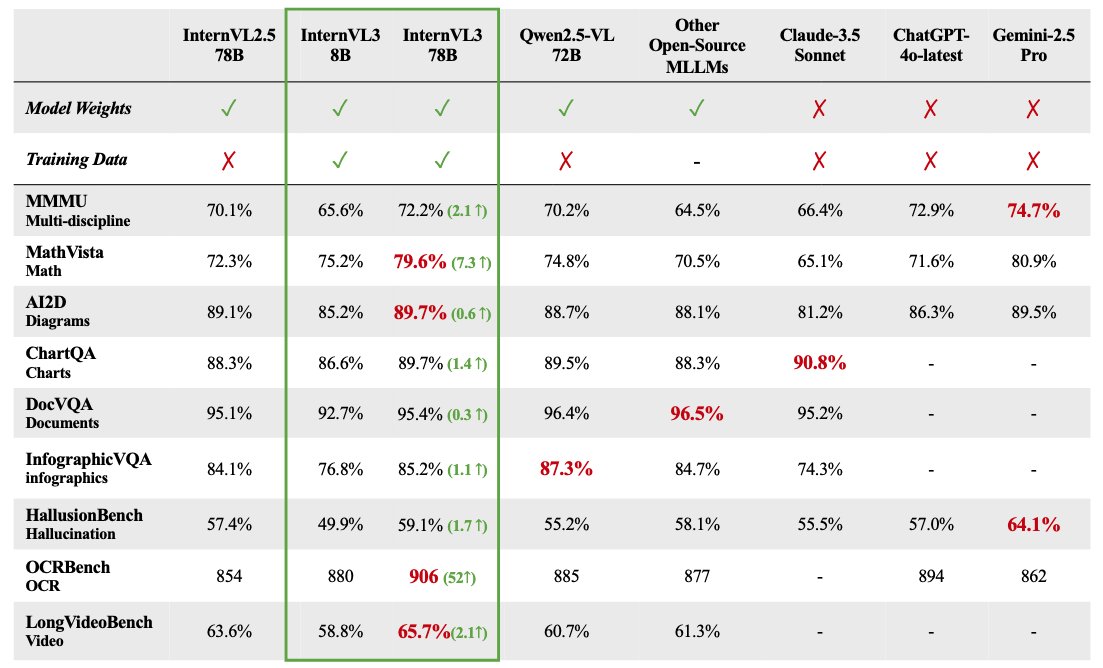
فتح مصدر سلسلة نماذج InternVL 3 متعددة الوسائط: أطلق OpenGVLab سلسلة نماذج InternVL 3 الكبيرة متعددة الوسائط، بأحجام معاملات تتراوح من 1 مليار إلى 78 مليار، وهي متاحة الآن على Hugging Face. يقال إن إصدار 78 مليار معامل قد حقق درجة 72.2 في اختبار MMMU المعياري، مسجلاً رقمًا قياسيًا جديدًا لنماذج الوسائط المتعددة مفتوحة المصدر (SOTA). تشمل الميزات التقنية لـ InternVL 3: استخدام التدريب المسبق متعدد الوسائط الأصلي لتعلم اللغة والرؤية في وقت واحد؛ إدخال ترميز الموضع البصري المتغير (V2PE) لدعم السياق الموسع؛ استخدام تقنيات ما بعد التدريب المتقدمة مثل SFT و MPO؛ وتطبيق استراتيجيات القياس وقت الاختبار لتعزيز قدرات الاستدلال الرياضي. تم فتح بيانات التدريب وأوزان النموذج للمجتمع لاستخدامها. (المصدر: huggingface)
تحليل أداء GPT-4.1 في الاختبارات الأولية: تحسن في البرمجة ولكن تأخر في الاستدلال: أظهرت سلسلة نماذج GPT-4.1 التي أطلقتها OpenAI صورة أداء معقدة في الاختبارات الأولية والتقييمات المعيارية. على الرغم من إظهار تقدم ملحوظ مقارنة بـ GPT-4o في مهام توليد الكود، مثل إنجاز محاكاة فيزيائية وتطوير ألعاب بشكل أفضل، وتحقيق درجة عالية على SWE-Bench. ومع ذلك، في معايير الاستدلال الأوسع والرياضيات والإجابة على الأسئلة المعرفية (مثل Livebench و GPQA Diamond)، لا يزال أداء GPT-4.1 متأخرًا عن Gemini 2.5 Pro من Google و Claude 3.7 Sonnet من Anthropic. يعتقد المحللون أن GPT-4.1 قد يكون تحديثًا تدريجيًا لـ GPT-4o، أو تم تقطيره من GPT-4.5، وأن استراتيجية إطلاقه قد تهدف إلى توفير خيارات نماذج أكثر فعالية من حيث التكلفة ومحسنة لمهام محددة عبر API، بدلاً من كونه نموذجًا رائدًا يتفوق بشكل شامل على المنافسين. (المصدر: 新智元)
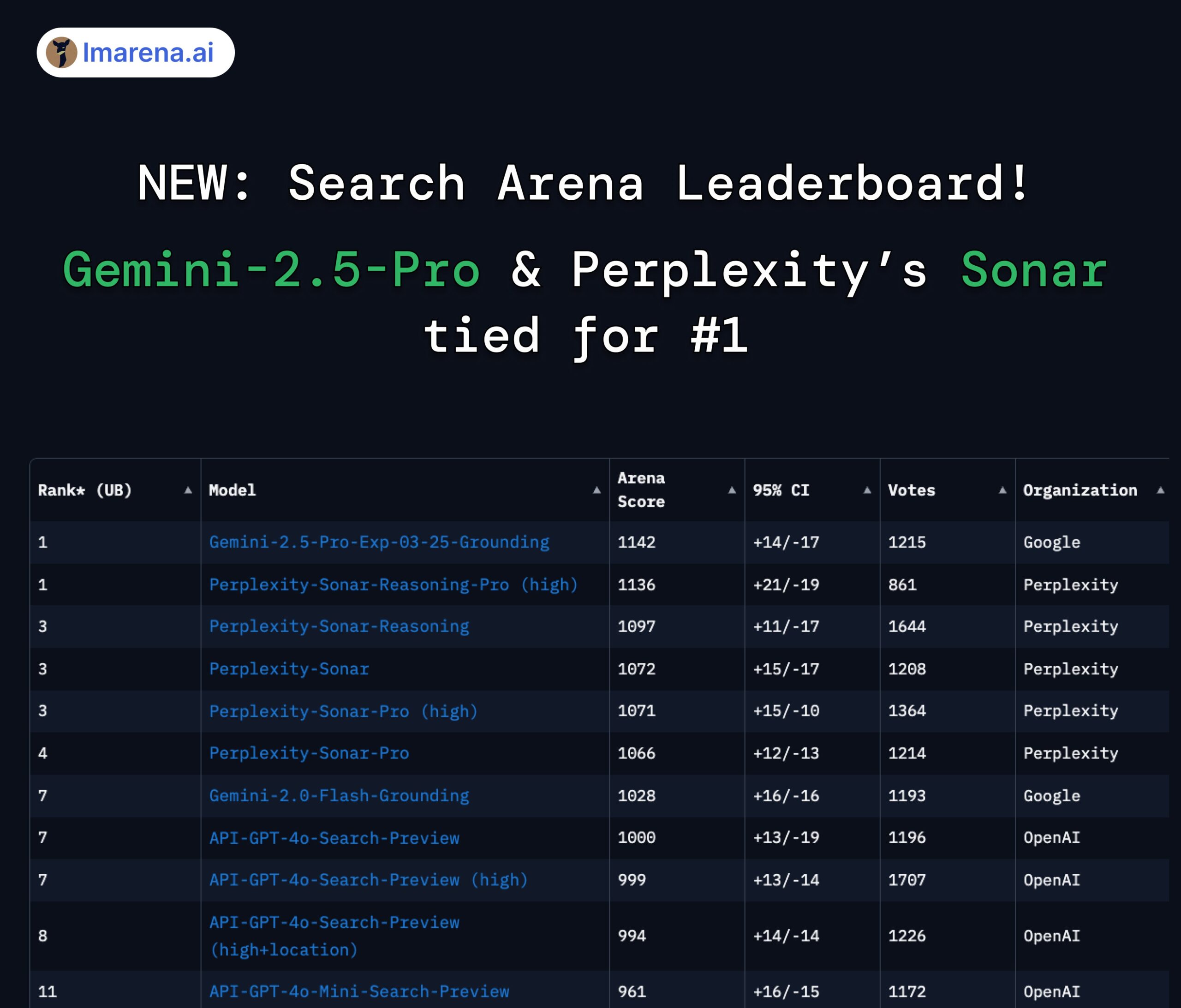
تصنيف LMArena Search: Gemini 2.5 Pro و Perplexity Sonar يتعادلان في المركز الأول: في تقييم ساحة المنافسة LMArena للنماذج الكبيرة التي تتمتع بقدرات البحث/الاتصال بالإنترنت، تعادل Gemini-2.5-Pro من Google (بالاشتراك مع Google Search) و Sonar-Reasoning-Pro من Perplexity في الصدارة. تم تأكيد هذه النتيجة وإعادة نشرها من قبل الرئيس التنفيذي لـ Google DeepMind، ديميس هاسابيس، ورئيس علاقات المطورين في Google، لوجان كيلباتريك. وعلق الرئيس التنفيذي لشركة Perplexity، أرافيند سرينيفاس، على ذلك قائلاً إن اختبارات A/B الداخلية تظهر أن نموذج Sonar الخاص بهم يتفوق على GPT-4o في الاحتفاظ بالمستخدمين، وأن أداءه يضاهي Gemini 2.5 Pro و GPT-4.1 الذي تم إطلاقه حديثًا. قامت الجهة المنظمة للتقييم lmarena.ai بفتح مصدر بيانات تصويت المستخدمين البالغ عددها 7000 صوت. (المصدر: lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta تستأنف استخدام المحتوى العام للمستخدمين الأوروبيين لتدريب الذكاء الاصطناعي: أعلنت شركة Meta أنها ستبدأ من جديد في استخدام المحتوى العام للمستخدمين في أوروبا لتدريب نماذج الذكاء الاصطناعي الخاصة بها. في السابق، علقت Meta هذه الممارسة بسبب الضغوط والمتطلبات التنظيمية من هيئات حماية البيانات الأوروبية (خاصة لجنة حماية البيانات الأيرلندية). قد يعكس قرار استئناف التدريب جهود Meta المستمرة وتعديلاتها الاستراتيجية لتحقيق التوازن بين خصوصية المستخدم، والامتثال للوائح (مثل GDPR)، والحصول على بيانات كافية للحفاظ على القدرة التنافسية لنماذج الذكاء الاصطناعي. قد تثير هذه الخطوة مرة أخرى نقاشات حول حقوق بيانات المستخدم وشفافية تدريب الذكاء الاصطناعي. (المصدر: Reddit r/artificial)

تطبيق Claude للهواتف المحمولة قد يضيف وضع التفاعل الصوتي: بناءً على أدلة اكتشفها مستخدم X @testingcatalog، قد تخطط Anthropic لإضافة ميزة التفاعل الصوتي إلى تطبيق Claude للهواتف المحمولة. تظهر لقطات الشاشة أيقونة ميكروفون في واجهة التطبيق، مما يشير إلى أن المستخدمين قد يتمكنون في المستقبل من التحدث مع Claude صوتيًا، على غرار الوضع الصوتي المتوفر بالفعل في تطبيقات ChatGPT و Google Gemini. سيؤدي ذلك إلى جعل طرق التفاعل مع Claude على الأجهزة المحمولة أكثر تنوعًا وملاءمة، مما يعزز تجربة المستخدم بشكل أكبر ويحافظ على التوافق الوظيفي مع مساعدي الذكاء الاصطناعي الرئيسيين الآخرين. (المصدر: Reddit r/ClaudeAI)
سرعة نماذج Z1 من Zhipu تثير الاهتمام، وتوصف بـ “النموذج اللحظي”: حظيت سلسلة نماذج Z1 التي أطلقتها Zhipu AI مؤخرًا، وخاصة إصدار GLM-Z1-AirX، بالاهتمام بسبب سرعة استدلالها الفائقة. وصفها بعض المحللين بأنها “نموذج لحظي”، مشيرين إلى قدرتها على إكمال الاستجابة الأولى وتوليد أكثر من 50 حرفًا صينيًا في غضون 0.3 ثانية، وهي سرعة تقترب من زمن رد الفعل العصبي البشري. من المتوقع أن يغير هذا الكمون المنخفض والإنتاجية العالية نمط التفاعل بين الإنسان والآلة، من “طرح السؤال – الانتظار – الإجابة” إلى حوار متزامن شبه فوري، وهو مناسب بشكل خاص للسيناريوهات التي تتطلب سرعة استجابة عالية مثل التعليم وخدمة العملاء وإنشاء المحتوى واستدعاء الوكلاء (Agents). يقال إن سرعة إصدار API لـ Z1-AirX تصل إلى 200 tokens/s. (المصدر: 公众号)

الألعاب الأصلية للذكاء الاصطناعي: التطور والتحديات من أداة لزيادة الكفاءة إلى ابتكار في طريقة اللعب: تتجه صناعة الألعاب من استخدام الذكاء الاصطناعي لرفع كفاءة البحث والتطوير والعمليات (مثل توليد الرسوم الفنية، والمساعدة في البرمجة، والاختبار الآلي) نحو استكشاف “الألعاب الأصلية للذكاء الاصطناعي” الحقيقية. يكمن جوهر الألعاب الأصلية للذكاء الاصطناعي في دمج الذكاء الاصطناعي بعمق في طريقة اللعب، لخلق محتوى ديناميكي وتجارب شخصية مدفوعة بتفاعل اللاعب، بدلاً من سيناريوهات محددة مسبقًا. تعد لعبة “Whispers from the Star” التي استثمر فيها مؤسس miHoYo، تساي هاويو، ووضع لاعب الذكاء الاصطناعي في لعبة “Space Kill” من Giant Network أمثلة على هذا الاستكشاف. ومع ذلك، يواجه تحقيق الألعاب الأصلية للذكاء الاصطناعي العديد من التحديات: على المستوى التقني، يجب حل مشكلات قدرة النموذج واستقراره وتكلفته؛ على مستوى التصميم، تفتقر الأمثلة الناضجة، ويجب الموازنة بين قابلية التحكم والحرية؛ على مستوى المستخدم، يجب تلبية احتياجات اللاعبين من حيث المتعة وعمق التفاعل؛ بالإضافة إلى ذلك، هناك مخاطر تتعلق بامتثال المحتوى والأخلاقيات. لا تزال الصناعة في مرحلة الاستكشاف المبكرة، ولا يزال الطريق طويلاً للوصول إلى التنفيذ الناضج. (المصدر: 界面新闻)
🧰 الأدوات
استعراض خمسة تطبيقات ذكاء اصطناعي مبتكرة: استعرضت 36Kr خمس أدوات ذكاء اصطناعي مبتكرة وعملية من بين حالات الابتكار في تطبيقات الذكاء الاصطناعي الأصلية التي تم جمعها مؤخرًا: 1) AiPPT.com: يولد عروض PowerPoint بسرعة من خلال جملة واحدة أو استيراد ملف (Word, PDF, Xmind, رابط)، ويدعم التشغيل دون اتصال بالإنترنت. 2) نظارات Sharge AI Clap Mirror: نظارات ذكاء اصطناعي مزودة بوظائف التصوير الفوتوغرافي وتسجيل الفيديو والترجمة الفورية والتعرف على الصيغ الرياضية. 3) وكيل Lianxin الذكي للاستجواب الرقمي بدون استشعار: يعتمد على نموذج علم النفس الكبير “洞见人和”، ويساعد في الاستجواب من خلال تحليل التعبيرات الدقيقة والصوت والإشارات الفسيولوجية، ويولد التقارير. 4) Huili Ma Vali Shoe AI: يُدخل الكلمات المفتاحية ليولد 8 تصميمات أحذية في 10 ثوانٍ، ويدمج مكتبة المواد وبيانات القوالب، ويرتبط بالإنتاج. 5) وكيل Nanfang Shidong Sandbox HR الذكي: يعالج مهام إدارة الموارد البشرية المتعلقة بالضمان الاجتماعي، ويوفر تفسير السياسات، وحساب التكاليف، والمعالجة الذكية، والتحذير من المخاطر، وغيرها من الوظائف. تعرض هذه التطبيقات إمكانات الذكاء الاصطناعي في أدوات الكفاءة، والأجهزة الذكية، والمجالات المهنية (الأمن، التصميم، الموارد البشرية). (المصدر: 36Kr)

Haixin Intelligence تطلق منصة تطوير الذكاء الاصطناعي بدون كود “Haisnap”: أطلقت شركة Haixin Intelligent Technology، المدعومة من الدولة في بكين، منصة تطوير ذكاء اصطناعي بدون كود/قليلة الكود تُدعى “Haisnap”. يمكن للمستخدمين وصف احتياجاتهم باللغة الطبيعية، ليقوم الذكاء الاصطناعي تلقائيًا بإنشاء تطبيقات ويب أو ألعاب صغيرة وما إلى ذلك. تتميز المنصة بأن الكود يكون مرئيًا في الوقت الفعلي أثناء عملية التوليد، وتدعم التحرير والتعديل الثانوي من خلال الحوار. يمكن نشر التطبيقات التي يطورها المستخدمون في “مجتمع الإبداع” الخاص بالمنصة، ليتمكن الآخرون من تصفحها واستخدامها وإعادة إنشائها (remix). المنصة متاحة مجانًا حاليًا، وتهدف إلى خفض عتبة تطوير تطبيقات الذكاء الاصطناعي، وتعزيز الإبداع للجميع، مع التركيز بشكل خاص على تعليم الذكاء الاصطناعي للشباب وتطبيقات الصناعة. (المصدر: 量子位)

إطلاق نظام ChatWiki مفتوح المصدر للإجابة على الأسئلة من قواعد المعرفة، يدعم GraphRAG والتكامل مع WeChat: ChatWiki هو نظام جديد مفتوح المصدر للإجابة على الأسئلة باستخدام الذكاء الاصطناعي من قواعد المعرفة، يدمج النماذج اللغوية الكبيرة (يدعم أكثر من 20 نموذجًا مثل DeepSeek و OpenAI و Claude) مع تقنية التوليد المعزز بالاسترجاع (RAG)، ويدعم بشكل خاص GraphRAG المستند إلى الرسوم البيانية المعرفية لمعالجة الاستعلامات المعقدة. تشمل وظائف النظام: دعم استيراد مستندات بتنسيقات متعددة (OFD، Word، PDF، إلخ) لبناء قواعد معرفة خاصة؛ دعم التجزئة الدلالية لتحسين دقة RAG؛ إمكانية نشر قاعدة المعرفة كموقع مستندات عام؛ توفير واجهة برمجة تطبيقات (API) للتكامل السلس مع حسابات WeChat الرسمية وخدمة عملاء WeChat وغيرها من الأنظمة البيئية لإنشاء روبوتات محادثة ذكاء اصطناعي؛ أداة تنسيق سير عمل مرئية مدمجة؛ دعم الربط مع بيانات الأعمال الخارجية؛ توفير إدارة أذونات على مستوى المؤسسة؛ دعم النشر المحلي باستخدام Docker والمصدر. (المصدر: 公众号)

مجتمع ModelScope يطلق MCP Square، لبناء أكبر نظام بيئي لخدمات MCP في الصين: أطلق مجتمع ModelScope التابع لشركة Alibaba رسميًا “MCP Square”، الذي يجمع ما يقرب من 1500 خدمة تطبق بروتوكول سياق النموذج (MCP)، تغطي مجالات مثل البحث والخرائط والدفع وأدوات المطورين، بهدف بناء أكبر مجتمع MCP صيني في الصين. تم إطلاق العديد من خدمات MCP من Alipay و MiniMax حصريًا هنا لأول مرة، مثل قدرات الدفع والاستعلام واسترداد الأموال من Alipay، وقدرات توليد الصوت والصورة والفيديو من MiniMax، والتي يمكن استدعاؤها جميعًا بواسطة وكلاء الذكاء الاصطناعي عبر بروتوكول MCP. يمكن للمطورين في ساحة تجارب MCP في ModelScope، من خلال تكوين JSON بسيط وموارد سحابية مجانية، تجربة هذه الخدمات ودمجها بسرعة، مما يقلل بشكل كبير من عتبة وصول تطبيقات الذكاء الاصطناعي إلى الأدوات والبيانات الخارجية. أطلقت ModelScope أيضًا MCP Bench لتقييم جودة وأداء خدمات MCP المختلفة. (المصدر: 新智元)

مناقشة حول استخدام ميزة WebSearch في Open WebUI: ناقش مستخدمو مجتمع Reddit كيفية استخدام ميزة Web Search في Open WebUI. تركزت الأسئلة حول كيفية التحكم الدقيق في الكلمات المفتاحية التي يستخدمها محرك البحث، وكيفية قصر ميزة Web Search على نماذج محددة لمنع إرسال بيانات النماذج الخاصة عن طريق الخطأ إلى الشبكة. يعكس هذا احتياجات المستخدمين الفعلية للتحكم الدقيق وأمن الخصوصية عند استخدام أدوات الذكاء الاصطناعي التي تدمج وظائف البحث. (المصدر: Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
مستخدمون يسعون لفهم بروتوكول سياق النموذج (MCP): نشر مستخدمون في مجتمع Reddit طلبات لشرح بروتوكول سياق النموذج (MCP)، مما يشير إلى أنه مع ترويج وتطبيق معيار MCP (مثل MCP Square في ModelScope)، تتزايد حاجة مجتمع المطورين والمستخدمين لفهم هذه التقنية الناشئة ومبدأ عملها. (المصدر: Reddit r/OpenWebUI)
📚 للتعلم
جائزة اختبار الزمن في ICLR 2025 تُمنح لمحسن Adam وآلية الانتباه: منح المؤتمر الدولي لتمثيلات التعلم (ICLR) جائزة “اختبار الزمن” (Test of Time Award) لعام 2025 لورقتين بحثيتين بارزتين نُشرتا قبل عشر سنوات (في عام 2015). الأولى هي “Adam: A Method for Stochastic Optimization” بقلم Diederik P. Kingma و Jimmy Ba، والتي قدمت محسن Adam الذي أصبح خوارزمية قياسية لتدريب نماذج التعلم العميق. والأخرى هي “Neural Machine Translation by Jointly Learning to Align and Translate” بقلم Dzmitry Bahdanau و Kyunghyun Cho و Yoshua Bengio، والتي قدمت لأول مرة آلية الانتباه، مما مهد الطريق لبنية Transformer والنماذج اللغوية الكبيرة الحديثة. تبرز هاتان الجائزتان التأثير العميق للبحث الأساسي على تطور الذكاء الاصطناعي الحالي. (المصدر: 新智元)

تاريخ موجز لتطور الذكاء الاصطناعي وتطور الشركات: يستعرض المقال بشكل منهجي تاريخ تطور الذكاء الاصطناعي منذ منتصف القرن العشرين حتى الآن، وتشمل النقاط الرئيسية اختبار تورينغ، مؤتمر دارتموث، الرمزية والأنظمة الخبيرة، شتاء الذكاء الاصطناعي، صعود تعلم الآلة (DeepBlue، PageRank)، ثورة التعلم العميق (AlexNet، AlphaGo)، وعصر النماذج الكبيرة الحالي (سلسلة GPT، تسويق الذكاء الاصطناعي التوليدي، الصراع بين المصدر المفتوح والمغلق). في الوقت نفسه، يقسم المقال تطور شركات الذكاء الاصطناعي إلى أربعة عصور: عصر الرواد (2000-2010، استكشاف التطبيقات كأدوات)، عصر البحث عن الذهب (2011-2016، تمكين المنصات وانفجار البيانات)، عصر الفقاعة (2017-2020، التنافس على السيناريوهات وعقبات التسويق)، وعصر إعادة الهيكلة (2021 حتى الآن، النماذج الكبيرة تقود المشهد الجديد). يؤكد المقال على التأثير التآزري لقوة الحوسبة والبيانات والخوارزميات، بالإضافة إلى تأثير القوى الجديدة مثل DeepSeek على المشهد. (المصدر: 混沌大学)
OpenAI تنشر دليل هندسة الأوامر النصية لـ GPT-4.1: بالتزامن مع إطلاق سلسلة نماذج GPT-4.1، قامت OpenAI بتحديث دليلها لهندسة الأوامر النصية (Prompting). يؤكد الدليل أن سلسلة نماذج GPT-4.1، مقارنة بنماذج GPT-4 السابقة، ستتبع التعليمات بشكل أكثر صرامة وحرفية، وستكون أكثر حساسية للأوامر النصية الواضحة والمحددة. إذا لم يكن أداء النموذج متوافقًا مع التوقعات، فعادةً ما يكفي إضافة تعليمات موجزة وواضحة لتوجيه سلوكه. يختلف هذا عن النماذج السابقة التي كانت تميل إلى تخمين نية المستخدم، وقد يحتاج المطورون إلى تعديل استراتيجيات الأوامر النصية الحالية. يوفر الدليل أفضل الممارسات بدءًا من المبادئ الأساسية إلى الاستراتيجيات المتقدمة لمساعدة المطورين على الاستفادة بشكل أفضل من ميزات النماذج الجديدة. (المصدر: dotey, Reddit r/LocalLLaMA)
جامعة شنغهاي جياو تونغ وغيرها تطلق معيار الذكاء الزماني المكاني STI-Bench، لتحدي فهم النماذج متعددة الوسائط للفيزياء: أطلقت جامعة شنغهاي جياو تونغ بالتعاون مع مؤسسات متعددة أول اختبار معياري لتقييم الذكاء الزماني المكاني للنماذج الكبيرة متعددة الوسائط (MLLM)، وهو STI-Bench. يستخدم هذا المعيار مقاطع فيديو من العالم الحقيقي، ويركز على قدرات الفهم المكاني والزماني الدقيقة والكمية، ويتضمن ثماني مهام: قياس المقياس، والعلاقات المكانية، وتحديد المواقع ثلاثية الأبعاد، ومسار الإزاحة، والسرعة والتسارع، والاتجاه المرتكز على الذات، ووصف المسار، وتقدير الوضعية. أظهر تقييم النماذج الرائدة مثل GPT-4o و Gemini 2.5 Pro و Claude 3.7 Sonnet و Qwen 2.5 VL أن أداء النماذج الحالية في هذه المهام ضعيف بشكل عام (دقة <42%)، وتجد صعوبة خاصة في معالجة الخصائص المكانية الكمية، والتغيرات الديناميكية الزمنية، ودمج المعلومات عبر الوسائط. يكشف هذا المعيار عن قيود MLLM الحالية في فهم العالم المادي، ويوفر اتجاهًا للبحث المستقبلي. (المصدر: 量子位)

الجمع بين التعلم المعزز والتحسين متعدد الأهداف يحظى بالاهتمام البحثي: أصبح المجال المتقاطع بين التعلم المعزز (RL) والتحسين متعدد الأهداف (MOO) نقطة ساخنة في أبحاث اتخاذ القرار بالذكاء الاصطناعي. يهدف هذا الجمع إلى تمكين الوكلاء الذكية من الموازنة بين أهداف متعددة (قد تكون متعارضة) في بيئات معقدة، بدلاً من السعي لتحقيق هدف أمثل واحد. على سبيل المثال، اقترحت جامعة هونغ كونغ للعلوم والتكنولوجيا إطار توازن التدرج الديناميكي للقيادة الذاتية، لتحسين السلامة وكفاءة الطاقة في وقت واحد؛ خوارزمية بحث استراتيجية باريتو من MIT للتحكم في الروبوتات؛ تستخدم Alibaba Cloud تقنية المحاذاة متعددة الأهداف للمعاملات المالية لتحقيق التوازن بين العائد والمخاطر. تستكشف الأبحاث ذات الصلة مثل CMORL (التعلم المعزز المستمر متعدد الأهداف) وتعلم مجموعة باريتو للتحسين التوافقي، كيفية جعل وكلاء RL أكثر فعالية في التعامل مع مشكلات العالم الحقيقي المتغيرة ديناميكيًا أو التي لها أبعاد تحسين متعددة. (المصدر: 公众号)

إطلاق منصة الهجوم والدفاع التلقائي A³D مفتوحة المصدر (TPAMI 2025): قام فريق أبحاث التصميم الذكي والتعلم القوي (IDRL) التابع لمعهد ابتكار تكنولوجيا الدفاع الوطني بالأكاديمية العسكرية للعلوم بتطوير وفتح مصدر منصة تُدعى A³D (الهجوم والدفاع التلقائي). تستخدم هذه المنصة تقنيات التعلم الآلي التلقائي (AutoML)، جنبًا إلى جنب مع أفكار نظرية الألعاب الهجومية والدفاعية، بهدف البحث التلقائي عن بنى شبكات عصبية قوية واستراتيجيات هجوم مضاد فعالة. تدمج المنصة طرق بحث بنية الشبكة العصبية (NAS) المتعددة ومقاييس تقييم المتانة (هجمات المعيار، الهجمات الدلالية، التمويه المضاد، إلخ) للدفاع التلقائي، وفي الوقت نفسه توفر وحدة هجوم مضاد تلقائي يمكنها البحث عن خطط هجوم مركبة مثلى من خلال خوارزميات التحسين. نُشرت نتائج البحث في المجلة الرائدة TPAMI، وتم نشر الكود على منصات مثل Hongshan Open Source، مما يوفر أداة جديدة لتقييم وتعزيز أمان نماذج DNN. (المصدر: 公众号)

جامعة فلوريدا تبحث عن طلاب دكتوراه ومتدربين ممولين بالكامل في مجال NLP/LLM: نشر الأستاذ المساعد Yuanyuan Lei في قسم علوم الكمبيوتر بجامعة فلوريدا (سيبدأ العمل في خريف 2025) إعلانًا لقبول طلاب دكتوراه ممولين بالكامل للالتحاق في خريف 2025 أو ربيع 2026، بالإضافة إلى متدربين بحثيين بأوقات مرنة (يمكن العمل عن بعد). تركز اتجاهات البحث على معالجة اللغة الطبيعية (NLP) والنماذج اللغوية الكبيرة (LLM)، وتشمل تحديدًا LLM المعززة بالمعرفة، والتحقق من الحقائق، والاستدلال والتخطيط، وتطبيقات NLP (متعددة الوسائط، القانون، الأعمال، العلوم، إلخ). نرحب بالطلاب ذوي الخلفيات ذات الصلة في علوم الكمبيوتر، والهندسة الإلكترونية، والإحصاء، والرياضيات، والذين لديهم اهتمام ودافع للبحث في الذكاء الاصطناعي للتقديم. أشارت الرسالة الإلكترونية إلى التأثير المحتمل لقانون فلوريدا SB-846 على قبول الطلاب من الصين القارية وطرق التعامل معه. (المصدر: PaperWeekly)

بحث جديد في نماذج الانتشار: ضوضاء مسبقة مرتبطة زمنيًا: تقترح ورقة بحثية على arXiv بعنوان “How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models” ضوضاء مسبقة جديدة لنماذج الانتشار. تهدف هذه الطريقة إلى تحسين جودة أو كفاءة توليد نماذج الانتشار (ربما للفيديو) عن طريق إدخال ضوضاء مرتبطة زمنيًا. تتطلب التفاصيل التقنية المحددة الرجوع إلى الورقة الأصلية. (المصدر: Reddit r/MachineLearning)
بحث جديد في الاكتشاف العلمي الآلي: AI Scientist-v2: تقدم ورقة بحثية على arXiv بعنوان “The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search” نظام AI Scientist-v2. يستخدم هذا النظام طريقة Agentic Tree Search (بحث شجرة الوكيل) بهدف تحقيق اكتشاف علمي آلي يصل إلى “مستوى ورشة العمل” (Workshop-Level). يشير هذا إلى أن الباحثين يستكشفون استخدام وكلاء الذكاء الاصطناعي لإجراء أبحاث واستكشافات علمية أكثر تقدمًا واستقلالية. (المصدر: Reddit r/MachineLearning)
شرح تنفيذ تنظيم Dropout: يشرح مقال على Substack بالتفصيل كيفية تنفيذ تقنية تنظيم Dropout. Dropout هي تقنية تنظيم مستخدمة على نطاق واسع في التعلم العميق لمنع النموذج من التجهيز المفرط (overfitting) عن طريق “إسقاط” جزء من الخلايا العصبية بشكل عشوائي أثناء عملية التدريب. قد يستهدف المقال المتعلمين الذين يرغبون في فهم مبدأ عمل Dropout بعمق أو تنفيذه بأنفسهم. (المصدر: Reddit r/deeplearning)
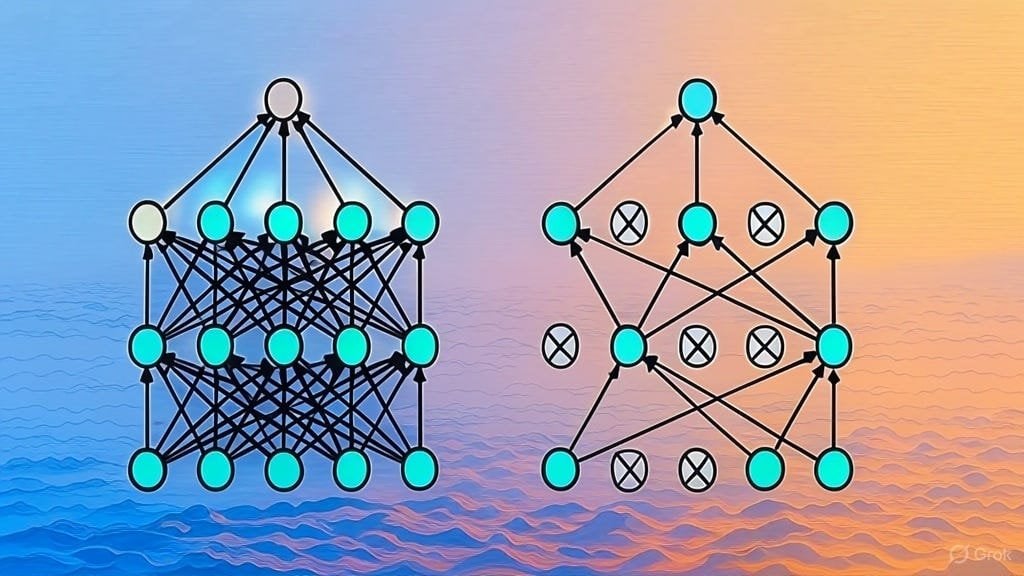
جمع قائمة بأوراق بحثية حول بنى LLM: أطلق مستخدمو Reddit نقاشًا لمشاركة وجمع أوراق بحثية من arXiv حول بنى النماذج اللغوية الكبيرة (LLM). تشمل البنى المدرجة حتى الآن BERT، Transformer، Mamba، RetNet، RWKV، Hyena، Jamba، سلسلة DeepSeek، وغيرها. تعكس هذه القائمة التنوع والتطور السريع لأبحاث بنى LLM الحالية، وتعتبر مرجعًا قيمًا للباحثين الذين يرغبون في فهم هذا المجال بشكل منهجي. (المصدر: Reddit r/MachineLearning)
💼 الأعمال
منصة التغذية بالذكاء الاصطناعي Fay تحصل على تمويل بقيمة 50 مليون دولار، وإيرادات سنوية تصل إلى 50 مليون دولار: أكملت منصة التغذية بالذكاء الاصطناعي Fay في وادي السيليكون مؤخرًا جولة تمويل B بقيمة 50 مليون دولار بقيادة Goldman Sachs، ليصل إجمالي تمويلها إلى 75 مليون دولار، وبتقييم 500 مليون دولار. تربط Fay أخصائيي التغذية المسجلين بالمرضى، وتستخدم الذكاء الاصطناعي لرفع كفاءة الخدمة (تدعي خفض الوقت من 6.5 ساعة/مريض إلى ساعتين)، وأتمتة معالجة مهام مثل توليد الملاحظات السريرية (بما في ذلك ترميز ICD)، ووضع خطط تغذية شخصية، ومطالبات التأمين، والإدارة الخلفية. استغلت المنصة بدقة الطلب المتزايد على استشارات التغذية الناتج عن أدوية إنقاص الوزن GLP-1، ونجحت في ربط عملية الدفع من خلال التعاون مع شركات التأمين (يمكن أن يقلل التدخل الغذائي من تكاليف الرعاية الصحية طويلة الأجل للأمراض المزمنة). تضم منصة Fay أقل من 3000 أخصائي تغذية فقط، ومع ذلك حققت إيرادات سنوية متكررة (ARR) بقيمة 50 مليون دولار، مما يظهر نجاح نموذج الأعمال القائم على تمكين الذكاء الاصطناعي للمهنيين في مجال الرعاية الصحية العمودي وربطه بجهات الدفع. (المصدر: 乌鸦智能说)
Hengtu Technology في تشنغدو: تمكين الإبداع الرقمي بالذكاء الاصطناعي، وتحقيق الربح من التوسع الخارجي: جمعت شركة Hengtu Technology المحلية في تشنغدو حوالي 700 مليون مستخدم عالميًا من خلال منتجها الأساسي Fotor (منصة تحرير الصور والفيديو)، مع أكثر من عشرة ملايين مستخدم نشط شهريًا، وبرزت بشكل خاص في الأسواق الخارجية، وهي واحدة من أوائل شركات تطبيقات الذكاء الاصطناعي الصينية التي توسعت خارجيًا وحققت ربحية واسعة النطاق. عملت الشركة بعمق في تكنولوجيا معالجة الصور لمدة 16 عامًا، وفي عام 2022 دمجت بسرعة وظائف AIGC (تحويل النص إلى صورة، تحويل النص إلى فيديو، إلخ) في Fotor ومنصتها الجديدة Clipfly. خفضت Fotor عتبة إنشاء المحتوى البصري الرقمي من خلال الذكاء الاصطناعي، وخدمت قطاعات متعددة مثل التجارة الإلكترونية، والإعلام الذاتي، والإعلانات، والسياحة الثقافية، والتعليم. تستخدم Hengtu Technology الذكاء الاصطناعي لإجراء “الترجمة الثقافية”، مما يساعد على تصدير الثقافة الصينية واستكشاف مسارات جديدة في صناعة الإبداع الرقمي. (المصدر: 36Kr四川)
الممارسات العملية لتطبيق الذكاء الاصطناعي في الشركات: التركيز على القيمة، تقليل الضبط الدقيق، تعزيز التعاون: تحولت الشركات في عملية تطبيق النماذج الكبيرة من الاستكشاف المبكر إلى التوجه العملي نحو القيمة. غالبًا ما تركز تطبيقات الذكاء الاصطناعي الناجحة على السيناريوهات ذات التكرار العالي، والتي تتطلب إبداعًا ويمكن ترسيخ نماذجها، مثل الإجابة على الأسئلة المعرفية، وخدمة العملاء الذكية، وتوليد المواد، وتحليل البيانات. تدرك الشركات عمومًا أن السعي الأعمى لضبط النماذج الدقيق غالبًا ما يكون ذا عائد استثمار منخفض، ويجب إعطاء الأولوية لإدارة المعرفة وبناء منصات الوكلاء الذكية (مع التركيز على RAG في البداية). يتطلب تطبيق الذكاء الاصطناعي مشاركة عميقة من أقسام الأعمال ودعمًا من الإدارة العليا، ويكون اعتماد استراتيجية متوازية “التجربة السريعة + التحضير لأساسيات الذكاء الاصطناعي” أكثر فعالية. فيما يتعلق بالمواهب التنظيمية، تميل الشركات إلى تشكيل فرق ذكاء اصطناعي صغيرة ومتخصصة لتمكين الأعمال، وحل مشكلة نقص المواهب من خلال استقطاب أفضل المواهب الخارجية، وتنمية القوى الشابة الداخلية (المتدربون + الموظفون ذوو الخبرة)، والتعاون مع خبراء الطرف الثالث. (المصدر: AI前线)
مؤشر الذكاء الاصطناعي في بورصة STAR يحظى بالاهتمام، وقد يصبح وجهة استثمارية جديدة: يشير تحليل التقرير إلى أنه على الرغم من تقلبات السوق الأخيرة، فقد شكلت صناعة الذكاء الاصطناعي في الصين حلقة مغلقة كاملة “حوسبة – نموذج – تطبيق”، وأظهرت مرونة قوية. يعد مشروع “البيانات الشرقية والحوسبة الغربية” الوطني، والنماذج منخفضة التكلفة مثل DeepSeek، والتطورات في التطبيقات مثل الروبوتات البشرية من النقاط البارزة. يُعتبر الذكاء الاصطناعي محركًا مهمًا للنمو الاقتصادي العالمي في العقد القادم، وتحقق الأصول ذات الصلة عوائد طويلة الأجل كبيرة. في هذا السياق، يحظى مؤشر الذكاء الاصطناعي في بورصة STAR ببورصة شنغهاي (الذي يركز على رقائق الحوسبة وتطبيقات الذكاء الاصطناعي) باهتمام المستثمرين بسبب توقعات نموه العالية وزيادة محتواه من التكنولوجيا المحلية القابلة للتحكم. أطلقت مؤسسات مثل E Fund بالفعل صناديق ETF وصناديق ربط تتبع هذا المؤشر (مثل 588730، 023564/023565)، مما يوفر للمستثمرين أدوات للاستثمار في سلسلة صناعة الذكاء الاصطناعي المحلية. (المصدر: 创业最前线)

تحول استراتيجية Apple في الذكاء الاصطناعي نحو الانفتاح: السماح لمطوري Siri باستخدام نماذج طرف ثالث: لتسريع تطوير ميزة “Siri المخصص” واللحاق بالمنافسين، ورد أن شركة Apple قد عدلت استراتيجيتها طويلة الأمد للتطوير الداخلي المغلق. تحت قيادة نائب الرئيس الأول الجديد لهندسة البرمجيات، كريغ فيديريغي، سُمح لمهندسي Siri لأول مرة باستخدام نماذج لغوية كبيرة من طرف ثالث لتطوير ميزات Siri، مما كسر القيد السابق الذي كان يقتصر على استخدام نماذج Apple المطورة ذاتيًا. يُعتبر هذا التحول خطوة حاسمة من Apple لمواجهة تأخرها النسبي في احتياطيات تكنولوجيا الذكاء الاصطناعي، وتجنب المزيد من استياء المستخدمين (أو حتى الدعاوى القضائية) بسبب تأجيل ميزة “Siri المخصص”. قد تفتح هذه الخطوة فرصًا لموردي النماذج الخارجيين مثل OpenAI أو Alibaba (في السوق الصينية) للتعاون مع Apple. (المصدر: 三易生活)

🌟 المجتمع
منافسة شرسة بين تطبيقات DeepSeek و Doubao و Yuanbao، وتجربة المنتج تصبح المفتاح: اشتدت المنافسة في سوق تطبيقات المساعد الذكي في الصين، حيث شهد DeepSeek زيادة هائلة في عدد المستخدمين بعد شعبيته الكبيرة بفضل قدرات نموذجه، مما دفع Tencent Yuanbao الذي كان أول من اعتمده إلى تصدر القائمة مؤقتًا. ومع ذلك، تمكن Doubao من ByteDance من التفوق مرة أخرى على Yuanbao بفضل وظائف المنتج الأكثر اكتمالاً والتكامل العميق مع Douyin. يعتقد المحللون أن الاعتماد فقط على ربط نماذج قوية (مثل DeepSeek) لا يمكن أن يحقق سوى مكاسب قصيرة الأجل، وفي المنافسة طويلة الأجل، تعد ثراء وظائف التطبيق نفسه، وتجربة المستخدم، والتنسيق عبر الأجهزة المتعددة، وقدرات تكامل النظام البيئي للمنصة أكثر أهمية. مع تقارب قدرات النماذج المختلفة (مثل امتلاكها جميعًا لقدرات التفكير العميق)، سيتركز التنافس المستقبلي على تصميم المنتج، واستراتيجيات التشغيل، والتطورات في أشكال التطبيقات الجديدة مثل AI Agent. (المصدر: 字母榜)
طالب آسيوي يطور أداة غش للمقابلات ويثير جدلاً واسعًا على الإنترنت: طور طالب آسيوي في جامعة كولومبيا يُدعى Roy Lee أداة ذكاء اصطناعي تُسمى Interview Coder، استخدم فيها ChatGPT للمساعدة في اجتياز المقابلات التقنية عن بُعد لعدة شركات تكنولوجيا مثل Amazon و Meta و TikTok. لم يكتف برفض عروض العمل من هذه الشركات، بل قام بتسجيل فيديو لعملية استخدام أداة الغش ونشره على YouTube، مما أدى إلى إيقافه عن الدراسة من قبل الجامعة بعد بلاغ من Amazon. لم يكترث Roy Lee لذلك، بل قام بنشر تفاصيل الحادثة والمراسلات مع الجامعة والشركات علنًا، وحصل على دعم كبير من مستخدمي الإنترنت واهتمام من الصناعة، واستغل هذه الفرصة لتأسيس شركة. أثارت هذه الحادثة نقاشًا حادًا حول فعالية المقابلات التقنية (خاصة نمط حل مسائل LeetCode)، والحدود الأخلاقية لاستخدام أدوات الذكاء الاصطناعي في التوظيف، وتحدي الأفراد للأنظمة المؤسسية الكبيرة. (المصدر: 直面AI)

مستخدم يختبر نماذج GLM الجديدة مفتوحة المصدر من Zhipu مع قاعدة معرفة و MCP: قام أحد المستخدمين باختبار سلسلة نماذج GLM التي أصدرتها Zhipu AI مؤخرًا (عبر استدعاء API). أظهرت النتائج أن GLM-Z1-AirX (الإصدار السريع) عند ربطه بقاعدة معرفة محلية مبنية باستخدام FastGPT، كانت سرعة الاستجابة فائقة (يقال إنها تصل إلى 200 tokens/s)، وتحسنت جودة الإجابات مقارنة بالنماذج العادية، حيث تمكن من توليد إجابات أكثر تفصيلاً واكتمالاً وجداول مقارنة. أما GLM-4-Air (النموذج الأساسي) عند ربطه بـ MCP (بروتوكول سياق النموذج) لتنفيذ مهام Agent (مثل البحث على الإنترنت، والكتابة في ملفات محلية، والتحكم في Docker، وتلخيص صفحات الويب)، فقد تمكن من استدعاء الأدوات بشكل صحيح وإكمال المهام، ولكن كان أداؤه أقل قليلاً من DeepSeek-V3. أشاد المستخدم أيضًا بأداء نماذج Zhipu من حيث الأمان (عدم الاستجابة لأوامر كسر الحماية). (المصدر: 公众号)

مشاركة أمر نصي “لحل المشكلات بمنطقية فائقة” ومقارنة أداء النماذج: شارك مستخدم في المجتمع أمرًا نصيًا متقدمًا (Prompt) يهدف إلى جعل LLM يلعب دور “حل المشكلات بمنطقية فائقة ومبادئ أولى”. يحدد هذا الأمر النصي بالتفصيل مبادئ عمل النموذج (تفكيك المشكلة، هندسة الحلول، بروتوكول التسليم، قواعد التفاعل)، وتنسيق الاستجابة وخصائص النبرة، مع التأكيد على المنطق والعمل والنتائج، ونبذ الغموض والأعذار والمواساة العاطفية. استخدم المستخدم هذا الأمر النصي لمقارنة أداء DeepSeek و Claude Sonnet 3.7 و ChatGPT 4o في الإجابة على الأسئلة وتقديم التوجيهات والتوصية بموارد عبر الإنترنت، واعتبر أن أداء Claude 3.7 كان الأفضل. يوضح هذا كيف يمكن للأوامر النصية المصممة بعناية توجيه وتحسين أداء LLM بشكل كبير في مهام محددة. (المصدر: 公众号)

نقاش مجتمعي حول إطلاق GPT-4.1: الأداء والاستراتيجية والتسمية: أثار إطلاق OpenAI لسلسلة نماذج GPT-4.1 نقاشًا واسعًا في المجتمع. من ناحية، وجد المستخدمون من خلال الاختبارات العملية والمقارنات المعيارية (مثل Aider و Livebench و GPQA Diamond و KCORES Arena) أنه على الرغم من التحسن الملحوظ لـ GPT-4.1 في البرمجة، إلا أنه لا يزال متأخرًا في قدرات الاستدلال الشاملة مقارنة بـ Google Gemini 2.5 Pro و Claude 3.7 Sonnet. من ناحية أخرى، ناقش المجتمع وانتقد استراتيجية منتجات OpenAI (التمييز بين API و ChatGPT، إيقاف GPT-4.5)، وسرعة تكرار النماذج، وطريقة التسمية المربكة (إطلاق 4.1 بعد 4.5). يعتقد البعض أن OpenAI قد تواجه عنق زجاجة في الابتكار، بينما يرى آخرون أن هذه استراتيجية لتحسين خط منتجات API وتقديم خيارات مختلفة من حيث التكلفة والأداء. (المصدر: dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT يتألق في سيناريوهات الاستشارات القانونية، ومستخدمون يشاركون تجارب ناجحة: شارك مستخدمو Reddit حالات نجاح لاستخدام ChatGPT في التعامل مع نزاعات قانونية متعلقة بالعمل. واجه أحد المستخدمين خطر الفصل، ومن خلال تزويد ChatGPT بالمستندات وجعله يلعب دور خبير في قانون العمل البريطاني، اكتشف خطأ إجرائيًا من قبل صاحب العمل، وبمساعدة رسالة صاغها ChatGPT، تفاوض ووصل في النهاية إلى تسوية تتضمن تعويضًا يعادل راتب شهرين، وتجنب سجلًا سيئًا. شارك مستخدمون آخرون في قسم التعليقات تجاربهم في استخدام الذكاء الاصطناعي (ChatGPT أو Gemini) لصياغة رسائل قانونية والتحضير لجلسات استماع وتحقيق نتائج إيجابية، معتبرين أن الذكاء الاصطناعي يمكن أن يوفر الكثير من التكاليف والوقت في المساعدة القانونية. (المصدر: Reddit r/ChatGPT)
مستخدم ينتقد ضعف أداء ميزة Deep Research في OpenAI: نشر مستخدم على Reddit ينتقد ميزة Deep Research (البحث العميق) في OpenAI، معتبرًا أنها تعاني من ثلاث مشكلات رئيسية: 1) نتائج البحث غير دقيقة أو غير ذات صلة (تعتمد على Bing API)؛ 2) طريقة الاستكشاف تشبه البحث العميق أولاً بدلاً من البحث الواسع؛ 3) منفصلة عن أهداف بحث المستخدم وتفتقر إلى القيود. يعتقد المستخدم أن هذه الميزة أشبه بقدرة بحث موسعة وليست بحثًا عميقًا حقيقيًا. يعكس هذا الفجوة بين توقعات المستخدمين لقدرات البحث الحالية لوكلاء الذكاء الاصطناعي والتجربة الفعلية. (المصدر: Reddit r/deeplearning)
عرض ومناقشة المحتوى المولد بالذكاء الاصطناعي: يشارك مستخدمو المجتمع بنشاط المحتوى الذي تم إنشاؤه باستخدام أدوات الذكاء الاصطناعي المختلفة (مثل ChatGPT و Midjourney و Kling AI و Suno AI)، بما في ذلك الرسوم الكاريكاتورية الساخرة (ترامب وماسك)، وصور تجسيدية للجامعات، وأفلام قصيرة بديلة عن الحرب العالمية الثانية، وصور لشخصيات الأساطير اليونانية، وإعلانات معجون أسنان بأسلوب التسعينيات، والقصص المصورة متعددة اللوحات، وغيرها. لا تعرض هذه المشاركات قدرات الذكاء الاصطناعي في توليد النصوص والصور والفيديو والموسيقى فحسب، بل تثير أيضًا نقاشات حول إبداعية المحتوى المولد بالذكاء الاصطناعي، وجماليته (مثل وصفه بأنه “مبتذل”)، وقيوده (مثل ضعف اتساق شخصيات القصص المصورة)، والقضايا الأخلاقية. (المصدر: dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

مخاوف من أن تؤدي حلقة التغذية الراجعة لبيانات تدريب الذكاء الاصطناعي إلى “انهيار النموذج”: يركز نقاش المجتمع على خطر محتمل: مع تزايد المحتوى المولد بالذكاء الاصطناعي على الإنترنت، إذا تم تدريب نماذج الذكاء الاصطناعي المستقبلية بشكل أساسي على هذه البيانات المولدة بالذكاء الاصطناعي، فقد يؤدي ذلك إلى “انهيار النموذج” (Model Collapse). تشير هذه الظاهرة إلى تدهور أداء النموذج، حيث تصبح المخرجات ضيقة ومتكررة وتفتقر إلى الأصالة والدقة، مثل النسخ المتكررة التي تؤدي إلى تشويش الصورة. يخشى المستخدمون أن يؤدي هذا إلى تآكل بطيء لحقيقة المعلومات والمنظور البشري. تطرق النقاش أيضًا إلى طرق المواجهة، مثل استخدام البيانات الاصطناعية للتدريب وتعزيز مراقبة جودة البيانات، ولكن هناك جدل حول ما إذا كانت المشكلة قد حدثت بالفعل وكيفية تجنبها بفعالية. (المصدر: Reddit r/ArtificialInteligence)
وجهة نظر: في عصر الذكاء الاصطناعي، قوة الحوسبة هي النفط الجديد: طرح مستخدمو Reddit وجهة نظر مفادها أنه في تطور الذكاء الاصطناعي، ستصبح القدرة الحاسوبية (Compute)، وليس البيانات، هي عنق الزجاجة والمورد الاستراتيجي الحاسم، تمامًا مثل النفط في الثورة الصناعية. السبب هو أن النماذج الأكثر قوة للذكاء الاصطناعي (خاصة أنظمة الاستدلال والوكلاء) تتطلب نموًا أسيًا في قوة الحوسبة؛ ستولد التفاعلات المادية مثل الروبوتات كميات هائلة من البيانات الجديدة، مما يزيد الطلب على قوة الحوسبة. امتلاك المزيد من قوة الحوسبة سيترجم مباشرة إلى قدرة إنتاج اقتصادي أقوى. أثارت وجهة النظر هذه نقاشًا في المجتمع، حيث اتفقوا على أن قوة الحوسبة هي بالفعل عنصر أساسي يحدد الحد الأقصى لقدرات الذكاء الاصطناعي وسرعة تطوره. (المصدر: Reddit r/ArtificialInteligence)
نقاش حول أخلاقيات استخدام الذكاء الاصطناعي: هل استخدام الذكاء الاصطناعي لتحسين الأداء الدراسي غير لائق؟: فشل طالب جامعي عبر الإنترنت بسبب مشكلات في هيكل الدورة التدريبية (اختبار أو واجب واحد فقط أسبوعيًا، يليه مباشرة الامتحان)، ثم استخدم ChatGPT لتوليد أسئلة تدريبية بناءً على ملفات PDF للمحاضرات للدراسة اليومية، وتحسنت درجاته بشكل ملحوظ. لكن الطالب شعر بالذنب بعد رؤية انتقادات حول تأثير الذكاء الاصطناعي على البيئة و “التفكير المستقل”. اعتبرت تعليقات المجتمع بشكل عام أن استخدام الذكاء الاصطناعي للمساعدة في التعلم هو استخدام مشروع وفعال، ويساعد على تحسين الكفاءة ونتائج التعلم، ولا ينبغي الشعور بالذنب لذلك. أشار المعلقون إلى أن التأثير البيئي للذكاء الاصطناعي يجب مقارنته بالأنشطة البشرية الأخرى، وأن الاستفادة من الذكاء الاصطناعي لزيادة الإنتاجية أصبح اتجاهًا في مكان العمل. (المصدر: Reddit r/ArtificialInteligence)
تجربة مستخدم Claude Pro: نقاش حول تقييد الاستخدام ونموذج العمل: في مجتمع Reddit r/ClaudeAI، ناقش المستخدمون مشكلة تقييد الاستخدام (throttling) التي واجهوها عند استخدام خدمة Claude Pro، واستكشفوا نموذج أعمال Anthropic. أشار بعض المستخدمين إلى أن رسوم الاشتراك في Pro البالغة 20 دولارًا شهريًا أقل بكثير من تكلفة الحوسبة الفعلية التي تدفعها Anthropic للمستخدمين ذوي الاستخدام الكثيف (قد تصل إلى 100 دولار شهريًا)، معتبرين أن شكاوى المستخدمين (مثل الشعور بـ “الاستغلال”) قد تتجاهل هيكل تكلفة خدمات الذكاء الاصطناعي. تطرق النقاش أيضًا إلى قيام Anthropic مؤخرًا بتوفير الميزات الجديدة أولاً لباقة Max الأغلى ثمناً بدلاً من باقة Pro، مما أثار استياء المستخدمين الذين اشتركوا مبكرًا في Pro سنويًا. (المصدر: Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
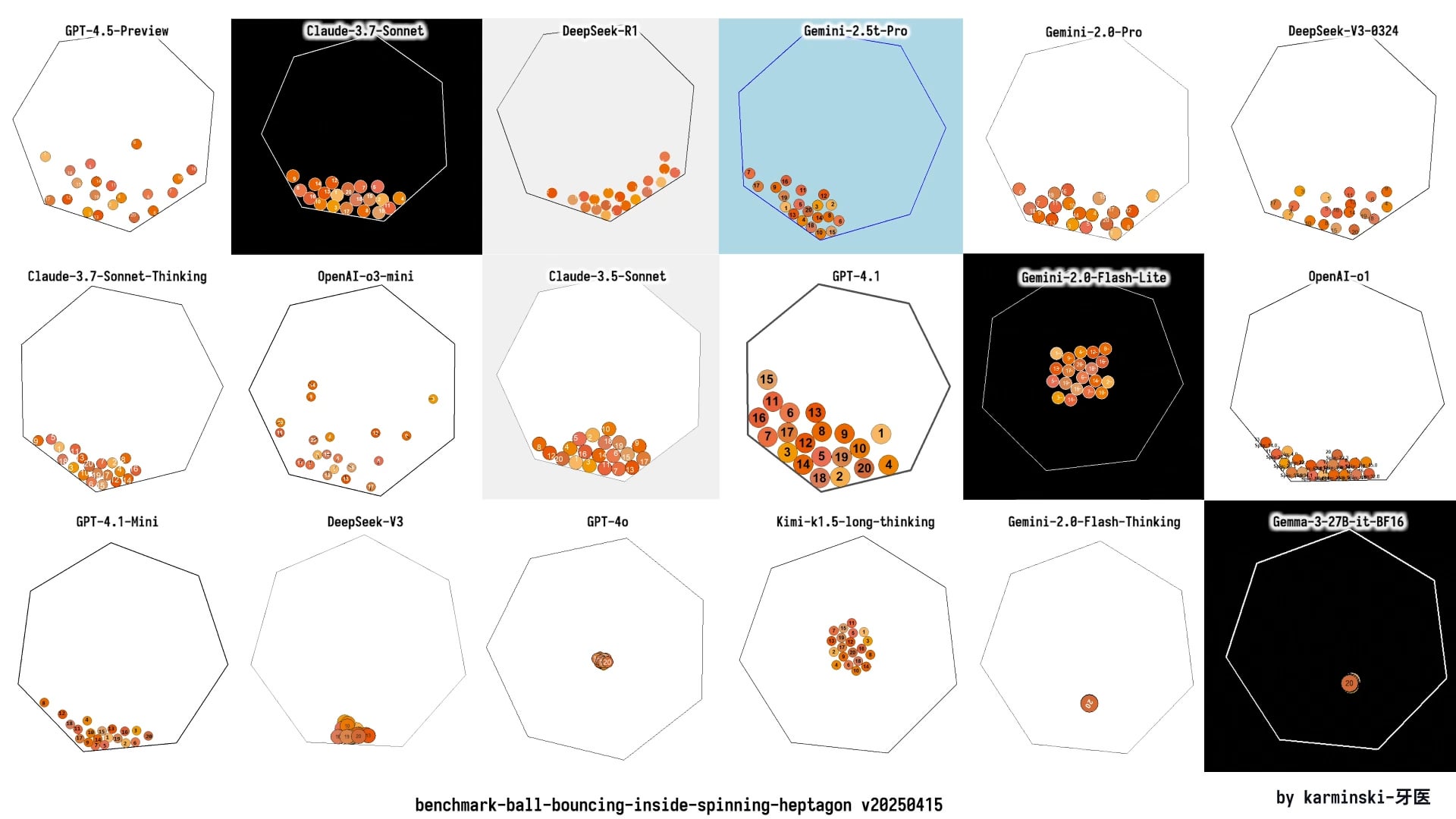
تحديث KCORES LLM Arena، وأداء DeepSeek R1 لافت للنظر: شارك مستخدم نتائج الاختبار الأخيرة لساحة منافسة LLM التي يديرها شخصيًا (KCORES LLM Arena)، والتي تطلب من النموذج إنشاء محاكاة فيزيائية معقدة (20 كرة تتصادم وترتد داخل مضلع سباعي دوار) باستخدام كود Python. بعد تحديث الساحة بإضافة نماذج جديدة مثل GPT-4.1 و Gemini 2.5 Pro و DeepSeek-V3، أظهرت النتائج أن DeepSeek R1 قدم أداءً متميزًا في هذه المهمة، وكانت المحاكاة التي ولدها جيدة نسبيًا. يوفر هذا للمجتمع مرجعًا آخر لتقييم قدرات النماذج المختلفة في مهام البرمجة المعقدة. (المصدر: Reddit r/LocalLLaMA)
استكشاف قدرات الاستجابة العاطفية لنماذج LLM المختلفة: نشر مستخدم على Reddit صورة Meme تقارن بطريقة فكاهية أساليب رد الفعل المختلفة لـ ChatGPT 4o و Claude 3 Sonnet و Llama 3 70B و Mistral Large عند مواجهة مستخدم يعبر عن مشاعر الحزن. يعكس هذا الاختلافات في تجربة المستخدمين عند استخدام LLM مختلفة للتواصل العاطفي أو البحث عن الدعم، بالإضافة إلى تصور المجتمع وتقييمه لقدرة النموذج على “التعاطف”. ناقش قسم التعليقات أيضًا مزايا الخصوصية لاستخدام النماذج المحلية لمعالجة الموضوعات العاطفية الخاصة. (المصدر: Reddit r/LocalLLaMA)

نقاش حول ما إذا كان الذكاء الاصطناعي العام (AGI) خدعة من وادي السيليكون: أعاد أعضاء المجتمع نشر مقال وربما ناقشوه يشكك فيما إذا كان الذكاء الاصطناعي العام (AGI) مفهومًا تبالغ فيه صناعة التكنولوجيا (وادي السيليكون) لجذب الاستثمار أو الحفاظ على الزخم (خدعة). يعكس هذا الجدل والشك المستمر في الصناعة والجمهور حول إمكانية تحقيق AGI وجدوله الزمني ومصداقية الدعاية الحالية المتعلقة به. (المصدر: Ronald_vanLoon)

💡 أخرى
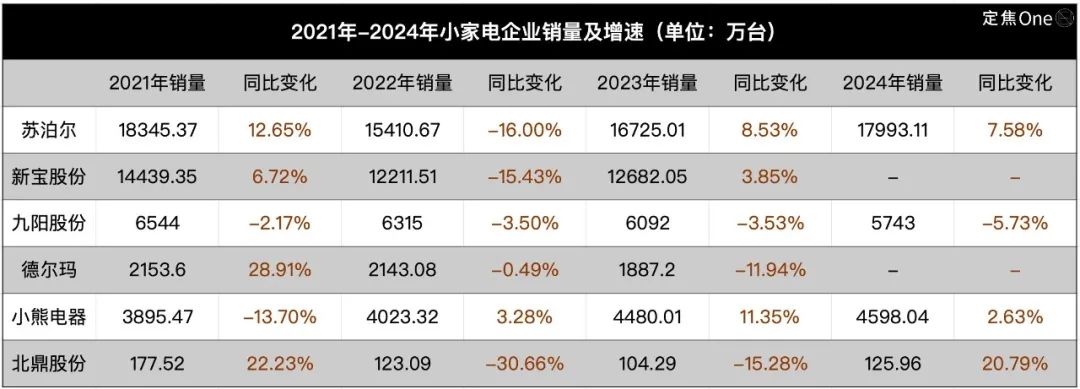
صناعة الأجهزة المنزلية الصغيرة تواجه ركودًا، والذكاء الاصطناعي قصة جديدة ولكن التطبيقات لا تزال سطحية: يواجه سوق الأجهزة المنزلية الصغيرة للمطبخ (مثل آلات الإفطار، المقالي الهوائية) انخفاضًا في المبيعات وحرب أسعار بعد تراجع طفرة “اقتصاد البقاء في المنزل”. تعاني الشركات الست الكبرى المدرجة في البورصة مثل Supor و Joyoung و Bear Electric من ضغوط على الأداء. بحثًا عن اختراق، تتجه الشركات عمومًا نحو توسيع الأسواق الخارجية ودمج تكنولوجيا الذكاء الاصطناعي. ومع ذلك، فإن تطبيقات الذكاء الاصطناعي الحالية في الأجهزة الصغيرة غالبًا ما تكون أوامر صوتية بسيطة، وتعديلًا تلقائيًا، وما إلى ذلك، مع محدودية في التطبيق العملي ومساحة الابتكار، وقد تزيد التكاليف وتثني المستخدمين. بالمقارنة، تتمتع الأجهزة الكبيرة بمزايا أكبر في تطبيقات الذكاء الاصطناعي، حيث يمكنها بناء أنظمة بيئية للمنزل الذكي واستخدام البيانات الضخمة لتقديم خدمات مخصصة. لا تزال قصة الذكاء الاصطناعي في صناعة الأجهزة الصغيرة في مراحلها الأولى. (المصدر: 36Kr)
اضطرابات التعريفات الجمركية تؤثر على سوق الرقائق في Huaqiangbei، وقد يتسارع البديل المحلي: أثارت التغييرات الأخيرة في سياسة التعريفات الجمركية المتعلقة بالرقائق مخاوف في سوق الإلكترونيات Huaqiangbei في شنتشن. شهد تجار الرقائق الشائعة مثل CPU و GPU (خاصة تلك التي قد تكون من أصل أمريكي) توقفًا عن عرض الأسعار وتخزين البضائع ترقبًا، مما أدى إلى تفاقم تقلبات الأسعار. كان التأثير على فئات مثل رقائق الذاكرة أقل نسبيًا. صرح العديد من الموزعين المدرجين في البورصة بأن التأثير المباشر لحرب التعريفات محدود بسبب النسبة الصغيرة للواردات المباشرة من الولايات المتحدة، ولكن عدم اليقين في السوق قد زاد. يعتقد العاملون في الصناعة بشكل عام أن شركات IDM التي تمتلك مصانع رقائق في الولايات المتحدة (مثل TI و Intel و Micron) هي الأكثر تضررًا. دفعت هذه الحادثة بالفعل بعض العملاء في المراحل النهائية إلى الاستفسار عن حلول بديلة للرقائق المحلية، مما قد يسرع عملية التوطين في قطاع أشباه الموصلات. (المصدر: 创业板观察)

هل يفاقم الذكاء الاصطناعي أزمة المعنى الإنساني؟ إعادة التفكير في التوازن بين التكنولوجيا والقيمة: يناقش المقال كيف يؤثر التطور السريع للذكاء الاصطناعي على معنى الوجود الإنساني. يرى أن تفوق الذكاء الاصطناعي في المجالات المهنية (مثل لعبة Go، التشخيص الطبي، الإبداع الفني) يفاقم أزمة المعنى الإنساني التي نجمت عن اغتراب العمل، وأزمة الإيمان، والمشكلات البيئية منذ الثورة الصناعية. قد يعزز الذكاء الاصطناعي مأزق “الإنسان كأداة”، خاصة في استبدال قدرات اتخاذ القرار في وظائف ذوي الياقات البيضاء. يستشهد المقال بآراء فلاسفة وأعمال خيال علمي (مثل “Dune” و “Westworld”) للتحذير من مخاطر الاستعباد التكنولوجي، ويدعو إلى إعادة بناء العقلانية القيمية من خلال الأطر الأخلاقية والتعليم الإنساني لحماية الإبداع البشري والترابط العاطفي والتفكير النقدي، مع احتضان التحسينات التكنولوجية التي يجلبها الذكاء الاصطناعي، لتجنب أن نصبح تابعين لمخلوقاتنا. (المصدر: 腾讯研究院)
تكلفة تصنيع iPhone في الولايات المتحدة باهظة، وقد تتجاوز 25000 يوان: يحلل المقال أنه إذا تم إنتاج iPhone بالكامل في الولايات المتحدة، فإن تكلفته سترتفع بشكل كبير، ومن المقدر أن يصل سعر البيع إلى 3500 دولار (حوالي 25588 يوان صيني)، وهو أعلى بكثير من السعر الحالي. تشمل الأسباب الرئيسية أن الولايات المتحدة تتفوق عليها الصين بكثير في الحصول على المواد الخام (مثل العناصر الأرضية النادرة، والليثيوم والكوبالت المكرر)، والنقل اللوجستي، وبناء المصانع (الأرض، الكهرباء، الموافقات البيئية)، وتكاليف العمالة (الحد الأدنى للأجور بالساعة أعلى بـ 4-5 مرات من الصين، ونقص العمال الصناعيين المهرة). سيكون من الصعب على Apple الحفاظ على نموذجها السابق لتحقيق هوامش ربح عالية من خلال الضغط على سلسلة التوريد العالمية (خاصة الموردين الصينيين ذوي هوامش الربح الكبيرة نسبيًا) في الولايات المتحدة. قد تنتقل تكاليف الإنتاج الباهظة في النهاية إلى المستهلكين، مما يزعزع استراتيجية تسعير Apple ومكانتها في السوق. (المصدر: 星海情报局)

اختراق رياضي: إثبات نظرية التفرد في تدفق الانحناء المتوسط: تم مؤخرًا إثبات تخمين Multiplicity-one الذي حير علماء الرياضيات لما يقرب من 30 عامًا بواسطة Richard Bamler و Bruce Kleiner. يتعلق التخمين بتدفق الانحناء المتوسط (Mean Curvature Flow, MCF) – وهي عملية رياضية تصف كيف يتطور السطح بمرور الوقت لتقليل مساحته بأسرع معدل (على غرار ذوبان مكعبات الثلج أو تآكل قلاع الرمال). يشير الإثبات إلى أنه في الفضاء ثلاثي الأبعاد، تكون التفردات (النقاط التي يميل فيها الانحناء إلى ما لا نهاية) التي تتشكل بواسطة الأسطح المغلقة ثنائية الأبعاد تحت MCF بسيطة، وتظهر عادةً على شكل كرة تتقلص محليًا إلى نقطة أو أسطوانة تنهار إلى خط، ولا تحدث تفردات معقدة متعددة الطبقات ومتداخلة. يضمن هذا الاختراق إمكانية استمرار تحليل MCF حتى بعد تشكل التفردات، ويوفر أساسًا نظريًا أكثر صلابة لاستخدام MCF لحل المشكلات المهمة في الهندسة والطوبولوجيا (مثل تخمين بوانكاريه). (المصدر: 机器之心)

مستخدم يشارك تكوين جهاز AI محلي “بميزانية محدودة” 4x RTX 3090: شارك مستخدم Reddit تكوين جهاز قام ببنائه لتشغيل LLM محليًا، بتكلفة إجمالية تبلغ حوالي 4204 دولارًا. يتضمن التكوين 4 بطاقات رسومات EVGA RTX 3090 مستعملة (بسعر 600 دولار للواحدة)، ومعالج خادم AMD EPYC 7302P، ولوحة أم Asrock Rack، وذاكرة DDR4 بسعة 96 جيجابايت، و SSD NVMe بسعة 2 تيرابايت، تم تجميعها في هيكل مفتوح MLACOM Quad Station Pro Lite، واستخدمت وحدتي طاقة بقوة 1200 واط. توفر هذه المشاركة حلاً مرجعيًا “اقتصاديًا” نسبيًا للمستخدمين الذين يرغبون في بناء محطة عمل AI منزلية تتمتع بقدرة حوسبة قوية (4x 24GB VRAM). (المصدر: Reddit r/LocalLLaMA)

قراصنة أمريكيون يخترقون إشارات المرور لبث رسائل Deepfake لماسك وزوكربيرغ: أفادت التقارير أن العديد من أنظمة إشارات عبور المشاة في منطقة خليج سان فرانسيسكو بالولايات المتحدة تعرضت لهجوم من قراصنة، وتم استخدامها لبث رسائل Deepfake (تزييف عميق) مولدة بالذكاء الاصطناعي لماسك وزوكربيرغ. تسلط هذه الحادثة الضوء على ضعف البنية التحتية العامة في مواجهة الهجمات السيبرانية التي تستخدم تقنيات الذكاء الاصطناعي، ومخاطر إساءة استخدام تقنية Deepfake لنشر معلومات كاذبة أو القيام بأعمال تخريبية. (المصدر: Reddit r/ArtificialInteligence)

عرض روبوتات متنوعة وتقنيات الأتمتة: عرضت وسائل التواصل الاجتماعي تطبيقات متنوعة للروبوتات وتقنيات الأتمتة، بما في ذلك: روبوت Booster T1 القادر على تقليد حركات الإنسان لأداء الكونغ فو؛ أنظمة روبوتية للتدريب التأهيلي؛ ذراع آلية قادرة على صنع القهوة؛ روبوتات زراعية لزراعة الأرز وإزالة الأعشاب الضارة؛ نظام آلي يسهل على الرعاة التعامل مع الأغنام؛ وروبوتات راقصة، وغيرها. تعكس هذه الأمثلة التطبيقات الواسعة والتطور المستمر للروبوتات في الصناعة والزراعة والخدمات والرعاية الصحية والترفيه. (المصدر: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
عرض تقنيات ناشئة ومنتجات مبتكرة: شاركت وسائل التواصل الاجتماعي تقنيات ناشئة ومنتجات مبتكرة متنوعة، مثل: هوائي لاسلكي صغير طوره معهد ماساتشوستس للتكنولوجيا (MIT) يستخدم الضوء لمراقبة الاتصالات الخلوية؛ طائرة بدون طيار ذات جناح واحد تحاكي طيران بذور القيقب؛ مرحاض ذكي متصل بإنترنت الأشياء (IoT)؛ تقنية الطبعات الرقمية لتقويم الأسنان؛ جهاز يولد الكهرباء باستخدام الماء المالح؛ جدران ديناميكية يمكنها التنفس والتحرك؛ بدلة Iron Man Cosplay؛ لوح تزلج كهربائي لجميع التضاريس؛ وتقنية نسخ المفاتيح باستخدام جهاز Flipper Zero، وغيرها. تعرض هذه الأمثلة الابتكار المستمر للتكنولوجيا في مجالات متعددة مثل الاتصالات والطاقة والصحة والنقل والبناء والأمن. (المصدر: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

اتجاهات تكنولوجيا الرعاية الصحية: أشارت وسائل التواصل الاجتماعي وروابط المقالات إلى تطبيقات التكنولوجيا واتجاهات التطور في مجال الرعاية الصحية، بما في ذلك الجراحة بمساعدة الروبوت، واتجاهات ونقاط التحول في تطبيقات الذكاء الاصطناعي في الرعاية الصحية، واستخدام التكنولوجيا لدفع التميز التشغيلي (الأتمتة الفائقة)، والتغييرات المحتملة التي قد يجلبها الذكاء الاصطناعي. تعكس هذه المحتويات إمكانات وممارسات تقنيات مثل الذكاء الاصطناعي والروبوتات والأتمتة في تحسين كفاءة الخدمات الطبية ودقة التشخيص وتجربة المريض. (المصدر: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

معلومات متعلقة بالأمن السيبراني: شاركت وسائل التواصل الاجتماعي محتوى متعلقًا بالأمن السيبراني، بما في ذلك رسم توضيحي لأنواع هجمات كلمات المرور ومقال حول أهمية القدرة على الاسترداد في غضون 60 دقيقة بعد اختراق البيانات. تذكر هذه المحتويات المستخدمين بالاهتمام بمخاطر الأمن السيبراني واستراتيجيات المواجهة. (المصدر: Ronald_vanLoon 1, Ronald_vanLoon 2)

نقاش حول منصة AMD ROCm: ناقش مستخدمو Reddit إمكانية بناء محطة عمل للتعلم العميق باستخدام وحدتي معالجة رسومات AMD Radeon RX 7900 XTX، بما في ذلك حزمة برامج ROCm (Radeon Open Compute platform). يعكس هذا اهتمام المستخدمين واستكشافهم لحلول وحدات معالجة الرسومات من AMD ونظامها البيئي البرمجي (ROCm) في سوق أجهزة الذكاء الاصطناعي الذي تهيمن عليه Nvidia. (المصدر: Reddit r/deeplearning)